Moderna Salesforce-integreringar måste ha stöd för mycket mer än enkelt datautbyte. De förväntas driva kundupplevelser i realtid, koordinera åtgärder i flera system och fungera tillförlitligt på företagsnivå—samtidigt som de uppfyller strikta krav på säkerhet och efterlevnad. Att välja rätt integreringsmetod är därför ett kritiskt arkitektoniskt beslut, inte en implementeringsdetalj. Överväg ett vanligt företagsscenario. En kund slutför ett köp i en mobilapp, vilket utlöser en kontroll av rätt till ett personligt erbjudande i realtid. Samtidigt måste transaktionsdata registreras i ett ERP-system, kundattribut uppdateras i Salesforce och analyser strömmas till en datasjö—utan att introducera latens, dataduplicering eller efterlevnadsrisk. Scenarion som detta är nu typiska i moderna Salesforce-miljöer, där Salesforce sällan fungerar isolerat och måste integreras sömlöst med ett bredare ekosystem av program och dataplattformar. Denna guide finns för att hjälpa arkitekter och utvecklare utforma dessa integreringar med tydlighet och förtroende. Istället för att fokusera på implementeringar från punkt till punkt presenterar den en uppsättning beprövade integreringsmönster som hanterar återkommande företagsscenarion—som processorkestrering, datasynkronisering och åtkomst till data i realtid. Varje mönster betonar arkitektoniskt syfte, kompromisser och utförandemodeller, vilket låter team fatta välgrundade designbeslut som skalar och varar. I detta dokument hittar du:
- Integreringsmönster som representerar vanliga företagsarketyper över processer, data och virtuella åtkomstscenarion
- Ett ramverk för mönsterval för att hjälpa till att identifiera rätt tillvägagångssätt baserat på integrationssyfte och utförandetidpunkt
- Praktisk vägledning om skalbarhet, motståndskraft, styrning och säkerhetsöverväganden
- Rekommenderade metoder hämtade från verkliga Salesforce- och Data 360-implementeringar Målet med detta dokument är att tillhandahålla ett gemensamt arkitektoniskt språk för integrering, vilket hjälper team utforma lösningar som balanserar prestanda, flexibilitet och Trust samtidigt som de följer företagets data och styrningsstrategier.
Detta dokument är till för designers och arkitekter som behöver integrera data från andra program i sin verksamhet med Salesforce Data 360 (tidigare Data Cloud). Detta innehåll är en destillation av många framgångsrika implementeringar av Salesforces arkitekter och partners. För att bekanta dig med integreringsfunktioner och alternativ som är tillgängliga för storskalig användning av Data 360, läs avsnitten Mönstersammanfattning och Guide för att välja mönster nedan. Arkitekter och utvecklare bör överväga dessa mönsterdetaljer och rekommenderade metoder under design- och implementeringsfasen av datainteraktionsprojekt i Data 360. Om de implementeras korrekt låter dessa mönster dig komma till produktion så snabbt som möjligt och ha den mest stabila, skalbara och underhållsfria uppsättningen applikationer som möjligt. Salesforces egna konsultarkitekter använder dessa mönster som referenspunkter under arkitektgranskningar och underhåller och förbättrar dem aktivt. Som med alla mönster täcker detta innehåll de flesta integreringsscenarion, men inte alla. Salesforce tillåter integrering av användargränssnitt (UI),-mashups, till exempel, men sådan integrering ligger utanför detta dokuments omfattning.
Varje integreringsmönster följer en enhetlig struktur. Detta ger enhetlighet i informationen i varje mönster och gör det även enklare att jämföra mönster.
- Namn: Mönsteridentifieraren som även indikerar vilken typ av integrering som finns i mönstret.
- Sammanhang: Det övergripande integreringsscenario som mönstret hanterar. Sammanhang ger information om vad användare försöker åstadkomma och hur programmet beter sig för att stödja kraven.
- Problem: Uttryckt som en fråga är detta scenariot som mönstret är utformat för att lösa. Läs denna sektion för att förstå om mönstret är lämpligt för ditt integreringsscenario.
- Krafter: De begränsningar och omständigheter som gör det angivna scenariot svårt att lösa.
- Lösning: Det rekommenderade sättet att lösa integreringsscenariot.
- Skiss: Ett UML-sekvensdiagram som visar dig hur lösningen hanterar scenariot.
- Resultat: Förklarar detaljerna om hur du tillämpar lösningen på ditt integreringsscenario och hur den löser de krafter som är associerade med det scenariot. Denna sektion innehåller även nya utmaningar som kan uppstå som ett resultat av att tillämpa mönstret.
- Sidofält: Ytterligare sektioner relaterade till mönstret som innehåller viktiga tekniska problem, variationer av mönstret, mönsterspecifika problem och så vidare.
- Exempel: Ett verkligt scenario som beskriver hur designmönstret används i ett verkligt Salesforce-scenario. Exemplet förklarar integreringsmålen och hur man implementerar mönstret för att uppnå dessa mål.
Använd denna tabell som en innehållsförteckning för de integreringsmönster som finns i detta dokument.
| Mönsternivå1 | Mönsternivå2 | Pattern | Secenario |
|---|---|---|---|
| Mönster för dataintag -- Datainkommande | Mönster för satsintag | Massera dataintag från molnlagring | Data tas in från ett företags molnlagringskälla som Amazon S3, Azure Blob eller Google Cloud Storage till Data 360 i form av stora satser med rådata (t.ex. transaktioner eller produktloggar). |
| Massera dataintag från Salesforce Clouds | Data 360 tar emot CRM-data i bunt från flera Salesforce-organisationer (t.ex. Sales Cloud, Service Cloud) för att bygga sammanslagna kundprofiler. | ||
| Intagsmönster för streaming och realtid | Händelsedrivet intag via Ingestion API ---Streaming | Data 360 prenumererar på slutpunkter för strömmande intag som får kontinuerliga händelsebelastningar (t.ex. inköpshändelser, IoT-telemetri) från företagssystem för profiluppdateringar i realtid. | |
| Intag av realtidsbeteende på webb och mobil | Data 360 samlar in och bearbetar beteendedata för webbplatser och mobilappar i realtid genom SDK för att förbättra engagemangsmått och personanpassningsmodeller. | ||
| Nära realtidssynkronisering av CRM via streaming | Data 360 tar emot CRM-datauppdateringar (t.ex. ändringar av kontakter, kundcase, säljprojekt) i nearReal-Time via händelseströmmar för att upprätthålla en kontinuerligt synkroniserad Customer 360. | ||
| Händelseströmintag från molnmeddelandeplattformar – Kinesis och MSK | Data 360 använder strömmande data direkt från molnhändelseplattformar som AWS Kinesis eller Kafka (MSK) för att bearbeta högfrekventa operativa händelser eller IoT-händelser. | ||
| Noll kopieringsmönster – Inkommande och utgående | Inkommande nollkopiering --Externa plattformar till Data 360 | Data 360 frågar externa datauppsättningar (t.ex. Snowflake, BigQuery) på begäran genom Zero Copy Ingestion, utan att fysiskt flytta data till Salesforce. | |
| Utgående nollkopiering - Data 360 till externa plattformar | Externa system som Databricks eller Tableau får åtkomst till utökade segment och insikter i Data 360 via utgående Zero Copy-anslutningar utan datareplikering. | ||
| Samlad dataplattform för flera organisationer med Data Cloud One | Data Cloud One slår samman flera Salesforce-organisationer och externa datakällor under en delad metadata- och semantisk modell, vilket ger en enhetlig Customer 360 utan dubbletter. | ||
| Dataaktiveringsmönster – Utgående data | Batchaktiveringsmönster | Segmentaktivering till marknadsförings- och reklamplattformar | Data 360 aktiverar utvalda kundsegment direkt i Marketing Cloud, Meta, Google Ads eller andra annonsplattformar för personlig kampanjleverans |
| Dataexport till molnlagring | Data 360 exporterar sammanslagna eller filtrerade datauppsättningar (t.ex. kundposter med samtycke) som CSV- eller Parquet-filer till företagets molnlagring för analys eller efterlevnadsarkivering. | ||
| På begäran API-baserad aktivering | Egen programintegrering via Connect API | Externa program åberopar Data 360 Connect API inReal-Time för att hämta eller utlösa personliga åtgärder (t.ex. kontroll av lojalitetssaldo eller skapande av AI-erbjudanden) baserat på aktuella kunddata.Skräddarsydda webb- eller mobilprogram hämtar harmoniserade Data 360-insikter säkert via Connect REST API för att visas i företags- eller partnergränssnitt. | |
| Fullständig kundprofilhämtning via Data Graph API | Ett system hämtar en kunds sammanslagna profil med hjälp av Data Graph API och returnerar en förkopplad JSON-representation i realtid av den fullständiga 360°-vyn för beslut eller personanpassning. | ||
| Åtgärder för realtidsdata | Åtgärd för realtidsdata Förvandlar kundsignaler till omedelbara åtgärder | Data 360 upptäcker och bearbetar en livehändelse (t.ex. samtyckesuppdatering, inköpsutlösare) och åberopar omedelbart ett anslutet system eller Salesforce-flöde för åtgärd längre ner.En kundaktivitetssignal (t.ex. upptäckt risk för bortfall) i Data 360 utlöser en direkt realtidsåtgärd — som att uppdatera CRM, åberopa Einstein betyg eller starta en lagringsresa. |
Integreringsmönstren i detta dokument klassificeras i tre kategorier: data-, process- och visuella integreringar.
Dataintegreringsmönster i Data 360 hanterar förflyttning och synkronisering av data mellan system för att säkerställa att både Data 360 och externa plattformar har enhetlig, snabb och pålitlig information. Dessa mönster hanterar vanligtvis storskaliga dataflöden med hög volym och förlitar sig på styrda pipelines som tillämpar schemakonsekvens, härkomstspårning och överordnade regler.
- Mönster för satsintag representerar det grundläggande lagret av introduktioner av företagsdata. Massintag av data från molnlagringstjänster som AWS S3, Azure Blob eller Google Cloud Storage gör att stora historiska datauppsättningar kan läsas in periodiskt i Data 360 för identitetslösning, segmentering och analys. På samma sätt använder massintag från Salesforce Clouds—som Sales, Service eller Marketing Cloud—inbyggda anslutare och dataströmmar för att föra in CRM-data i det enhetliga datalagret, vilket säkerställer harmonisering och kontinuitet i alla engagemangssystem.
- Intagsmönster för streaming och realtid utökar detta genom att samla in händelsedata med hög hastighet. Händelsedrivet intag via Ingestion API låter externa system kontinuerligt strömma kundaktivitet till Data 360. Intag av webb- och mobilbeteende i realtid samlar in klickström och interaktionsdata direkt från digitala beröringspunkter för att driva omedelbar personanpassning. CRM-synkronisering nästan i realtid genom Streaming API säkerställer att kundattribut och samtyckesuppdateringar återspeglas snabbt i alla system. Intag av händelseströmmar från meddelandeplattformar som Amazon Kinesis eller Confluent MSK har stöd för kontinuerliga pipelines med hög genomströmning och anpassar Data 360 till företagets händelsearkitektur.
- Enhetlig flerorganisationsdataplattform med Data Cloud One exemplifierar ytterligare dataintegrering, vilket ger en sammanslagen miljö för att slå samman data från flera Salesforce-organisationer och externa källor under ett gemensamt styrlager och semantiskt lager. Detta gör att organisationer kan uppnå enhetlighet i data i hela företaget, delade datamodeller och skalbara analyser.
- I aktiveringsfasen följer satsaktiveringsmönster samma dataintegreringsprincip. Segment som valts ut i Data 360 exporteras i schemalagda jobb till marknadsförings- och reklamplattformar längre ner—som Marketing Cloud, Meta Ads eller Google Ads—där de utlöser kampanjkörning. På samma sätt kan datauppsättningar exporteras till molnlagringsmål för att driva externa analyser och pipelines för datavetenskap. I alla dessa användningsfall fungerar Data 360 som sanningskälla för synkroniserade och utvalda kunddata.
Processintegreringsmönster i Data 360 involverar att utlösa eller orkestrera verksamhetsprocesser över system i nearReal-Time. Dessa mönster låter Data 360 aktivt delta i företagsflöden, vilket möjliggör sammanhangssvar och dynamisk dataaktivering.
- På-begäran API-baserad aktivering aktiverar engagemangsscenarion i realtid. Genom Connect API kan egna program fråga eller aktivera kundprofiler direkt från Data 360 som en del av operativa processer—till exempel att en agentkonsol hämtar sammanslagna profilinsikter under en kundinteraktion. Fullständig kundprofilhämtning via datagraf API har stöd för sammansatta program och mikrotjänster som förlitar sig på API-driven åtkomst till kundens fullständiga enhetsgraf, vilket möjliggör dynamiska upplevelser utan förfasade segment.
- Dataåtgärder i realtid driver detta integreringssätt ytterligare genom att aktivera omedelbar respons. När en kundsignal—som ett köp, formulärinskickning eller tröskelhändelse—upptäcks kan Data 360 utlösa åtgärder som att uppdatera en CRM-post, åberopa en extern webhook eller starta ett personligt erbjudandeflöde. Dessa mönster förkroppsligar verklig processorkestrering och överbryggar Kundintelligens i realtid med automatiserad operativ körning.
Virtuella integreringsmönster i Data 360 möjliggör liveåtkomst till externa eller sammanslagna datakällor utan att fysiskt kopiera eller duplicera data. Dessa är viktiga för företag som behöver styrd, uppdaterad information vid sökfrågor och samtidigt minimera dataflyttning.
- Inkommande nollkopieringsdatafederation (Externa plattformar-till-Data 360) låter externa system—som datalager eller datasjöar—dela datauppsättningar med Data 360 genom säkra, styrda anslutningar (t.ex. Snowflake-säker datadelning). Detta säkerställer att Data 360 kan komma åt och hantera externa data virtuellt, vilket bevarar färskhet och eliminerar onödig replikering.
- Utgående nollkopieringsdatadelning (Data 360-till-externa plattformar) gör att Data 360 kan exponera utvalda datauppsättningar för extern användning, som AI-modeller, verksamhetsinformation eller avancerade analyser, genom säkra datafederations- och livefrågemekanismer. Att välja den bästa integreringsstrategin för ditt system är inte trivialt. Det finns många aspekter att tänka på och många verktyg som kan användas, där vissa verktyg är mer lämpliga än andra för vissa uppgifter. Varje mönster hanterar specifika kritiska områden, inklusive kapaciteten för vart och ett av systemen, datavolym, felhantering och transaktionalitet.
När du väljer ett integreringsmönster, börja med att svara på två grundläggande frågor som formar den övergripande designen och beteendet för integreringen. Vad integrerar du? — Process, data eller virtuell åtkomst Denna dimension definierar det primära syftet med integreringen.
- Processintegreringar fokuserar på att orkestrera verksamhetsflöden och koordinera åtgärder mellan system.
- Dataintegreringar fokuserar på att synkronisera, berika eller sprida data mellan system.
- Virtuella integreringar fokuserar på åtkomst till externa data i Real-Time utan att kopiera eller bevara dem i Salesforce eller Data 360. Att förstå detta syfte hjälper till att avgöra nivån av orkestrering, dataflyttning och koppling som krävs mellan system.
- Hur behöver den köras? — Synkron eller asynkron metod definierar integreringens utförandemodell.
- Synkrona integreringar är i realtid och blockerande, där anroparen förväntar sig ett omedelbart svar—används ofta för användardrivna scenarion eller valideringsscenarion.
- Asynkrona integreringar är icke-blockerande och frånkopplade, utformade för att hantera skala, processer som körs länge, försök och stora datavolymer. Tillsammans ger dessa två dimensioner – integreringssyfte och utförandetiming – ett tydligt och enhetligt ramverk för att välja rätt integreringsmönster samtidigt som de balanserar användarupplevelse, skalbarhet och operativ motståndskraft. Obs! En integrering kan kräva en extern mellanprogramvara eller integreringslösning (till exempel Enterprise Service Bus) beroende på vilka aspekter som gäller för ditt integreringsscenario.
Denna tabell listar mönstren och deras nyckelaspekter för att hjälpa dig avgöra vilket mönster som passar dina krav bäst när din integrering är från Salesforce till ett annat system
| Typ | Timing | Utgående överväganden |
|---|---|---|
| Dataintegrering | Asynchronous | Segmentaktivering till marknadsförings- och reklamplattformar |
| Process/dataintegrering | Synkron | Egen programintegrering via Connect API Fullständig kundprofilhämtning via Data Graph API |
| Dataintegrering | Synkron | Åtgärd för realtidsdata Förvandlar kundsignaler till omedelbara åtgärder |
| Virtuell integrering (med nollkopiering) | Asynchronous | Utgående nollkopiering - Data 360 till externa plattformar |
| Virtuell integrering | Asynchronous | Samlad dataplattform för flera organisationer med Data Cloud One |
Denna tabell listar mönstren och deras nyckelaspekter för att hjälpa dig avgöra vilket mönster som passar dina krav bäst när din integrering är från ett annat system till Salesforce.
| Typ | Timing | Inkommande överväganden |
|---|---|---|
| Dataintegrering | Asynchronous | Massera dataintag från molnlagring Massera dataintag från Salesforce Clouds |
| Dataintegrering | Asynchronous | Händelseströmintag från molnmeddelandeplattformar – Kinesis och MSK Nära realtidssynkronisering av CRM via streaming |
| Processintegrering | Synkron | Händelsedrivet intag via Ingestion API ---Streaming Intag av realtidsbeteende på webb och mobil |
| Virtuell integrering | Asynchronous | Inkommande nollkopiering --Externa plattformar till Data 360 |
Denna tabell listar några nyckeltermer relaterade till middleware och deras definitioner med avseende på dessa mönster.
| Term | Definition |
|---|---|
| Händelsehantering | Händelsehantering refererar till att ta emot, dirigera och svara på identifierbara förekomster från ett källsystem eller program. Middleware hanterar händelser genom att identifiera målslutpunkten, vidarebefordra händelsen och utlösa den nödvändiga verksamhetsåtgärden (t.ex. loggning, försök eller aktivering av tjänster längre ner). I Data 360-arkitekturer är händelsehantering viktigt för dataintag i realtid, aktiveringsutlösare och publicerings-/prenumerationsmönster. Händelser kan komma från externa system (Kafka, AWS Kinesis) eller Salesforce Platform-händelser och dirigeras av middleware eller Data 360-händelsebussen för omedelbar bearbetning. |
| Protokollkonvertering | Protokollkonvertering tillåter kommunikation mellan system som använder olika datatransportstandarder. Middleware översätter egna eller äldre protokoll (som AMQP, MQTT, FTP) till Data 360-protokoll som stöds (REST, gRPC eller HTTPS). Detta säkerställer driftskompatibilitet mellan heterogena system. Eftersom Data 360 inte hanterar protokollkonvertering inbyggt tillhandahåller middleware anpassningslagret, vilket kapslar in eller transformerar meddelanden till ett format som Data 360 API och anslutare kan tolka. |
| Översättning och transformation | Översättning och transformation säkerställer interoperabilitet genom att mappa ett dataformat eller schema till ett annat. Middleware utför dessa transformationer för att anpassa olika databelastningar (CSV, XML, JSON) till Data 360-datamodellobjekt (DMO) och sammanslagna datalagerobjekt (UDLO). Detta inkluderar rengöring, berikning och tillämpning av semantisk eller ontologibaserad mappning innan intag. Salesforce erbjuder transformationsverktyg som Dataförberedelserecept, men komplexa transformationer (särskilt för semantisk harmonisering) hanteras bäst i mellanprogramvara. |
| Köer och buffring | Köer och buffring förlitar sig på asynkrona meddelanden som skickas för att säkerställa motståndskraftig, frånkopplad kommunikation. Middleware-plattformar (t.ex. MuleSoft, Kafka eller Azure Event Hub) tillhandahåller beständiga köer som tillfälligt lagrar data när Data 360 eller system längre ner är upptagna eller inte kan nås. Detta förhindrar dataförlust och har stöd för intag eller aktiveringsförsök nästan i realtid. Data 360 har stöd för strömmande intag och flödesbaserade utgående meddelanden, men hållbart köande och garanterad leverans hanteras vanligtvis av mellanprogramvara. |
| Synkrona transportprotokoll | Synkrona transportprotokoll innefattar blockering, begäran/svar i realtid. Avsändaren väntar på ett svar innan de fortsätter. I Data 360 används dessa för API-baserade aktiveringar på begäran, anrikning i realtid eller profilsökningar, där svar krävs omedelbart. Middleware säkerställer anslutningstillförlitlighet och hanterar försök eller reservhantering för synkrona Data 360 API-anrop. |
| Asynkrona transportprotokoll | Asynkrona transportprotokoll har stöd för icke-blockerande, frånkopplad kommunikation där avsändaren fortsätter bearbeta utan att vänta på ett svar. Middleware hanterar asynkrona flöden för batchaktiveringar, strömmande intag och händelsedriven aktivering. Detta ger hög genomströmning och motståndskraft — viktigt för händelseströmning och dataintagsmönster nästan i realtid i Data 360. |
| Medlingsdirigering | Medlingsdirigering definierar komplexa meddelandeflöden mellan system, vilket säkerställer att rätt data eller händelse når rätt konsument. Middleware fungerar som medlare och hanterar dirigeringslogik baserat på regler, sidhuvuden, innehåll eller händelsetyp. I Data 360-integreringar säkerställer medling att händelser och profiluppdateringar från flera system dirigeras korrekt till API:n för dataintag, aktiveringsslutpunkter eller externa konsumenter. Detta förenklar orkestrering och har stöd för datasynkronisering i flera system. |
| Processkoreografi och serviceorkestrering | Processkoreografi och orkestrering koordinerar processer med flera system. Koreografi har stöd för autonoma, asynkrona händelsedrivna flöden, där system agerar baserat på delade regler utan en central kontroll. Orkestrering är ett centralt hanterat flöde som dirigerar serviceutförande. I Data 360-arkitekturer hanterar middleware orkestrering för intag och aktivering mellan system, medan Salesforce-flöden eller flöden hanterar lätta koreografier inom plattformen. Komplex orkestrering, som kräver transaktionskoordination eller tillståndshantering, rekommenderas i mellanlager. |
| Transaktionalitet (kryptering, signering, pålitlig leverans, transaktionshantering) | Transaktionalitet säkerställer atomära, konsekventa, isolerade och hållbara (ACID) operationer i alla system. Salesforce och Data 360 är transaktioner inom sina gränser men har inte stöd för distribuerade transaktioner över externa system. Middleware hanterar global transaktionskontroll, inklusive kryptering, meddelandesignering, återställning, kompensation och pålitlig leverans. För verksamhetskritiska dataflöden (t.ex. ekonomiska uppdateringar eller samtyckesuppdateringar) säkerställer middleware fullständig integritet och återställning över Data 360 och externa system. |
| Dirigering | Dirigering specificerar det kontrollerade flödet av meddelanden eller data mellan komponenter. Den kan baseras på sidhuvuden, innehållstyp, prioritet eller regler. Middleware hanterar dirigeringslogik för händelser och aktiveringar som involverar Data 360, till exempel att dirigera utökade målgruppssegment till olika system längre ner (annonsplattformar, lagerbyggnader, CRM-appar). Även om dirigering kan implementeras i Salesforce (Apex, flöden) föredras middleware-dirigering för skalbarhet, flexibilitet och styrning. |
| Extrahera, transformera och läs in (ETL) | ETL innefattar att extrahera data från källsystem, transformera dem till ett enhetligt schema och läsa in dem till ett mål (som Data 360). Middleware- eller ETL-verktyg hanterar dessa operationer innan dataintag. Data 360 kan ta emot ETL-utdata via API:n, anslutare eller pipelines för massintag, och har även stöd för datainsamling (CDC) för synkronisering nästan i realtid. Middleware ETL-processer är viktiga för att integrera äldre system och säkerställa datakvalitet innan sammanslagning i Data 360. |
| Lång pollning | Lång pollning (kometprogrammering) är en metod för att upprätthålla öppen kommunikation mellan system för uppdateringar i realtid. Klienten skickar en begäran och servern håller den tills en händelse inträffar och svarar sedan och öppnar en ny anslutning igen. Salesforce använder detta i protokollen Streaming API och CometD/Bayeux för händelsedriven datasynkronisering. Middleware kan prenumerera på dessa händelser och vidarebefordra dem till Data 360 för intag eller aktiveringsutlösare i realtid, vilket säkerställer minimal latens mellan företagssystem. |
Dataintag är det första och mest kritiska steget i Salesforce Data 360s datalivscykel. Det är hur rådata från flera externa system—CRM, ERP, webb, mobil eller API från tredje part—kommer in i plattformen och blir en del av en enhetlig kundvy. Rätt intagsmönster beror på vad verksamheten behöver:
- Datavolym — hur mycket data som rör sig samtidigt
- Latens — hur färska data måste vara
- Källsystemkapacitet – hur systemet kan ansluta och leverera data Data 360 har stöd för flera intagslägen för att uppfylla dessa behov: batch för laddningar med hög volym, streaming för uppdateringar nästan i realtid, händelsebaserad för transaktionell omedelbarhet och Zero Copy-intag för direkt åtkomst till externa data utan att fysiskt flytta dem. Tillsammans säkerställer dessa mönster att varje kundsignal—oavsett om det är en köphändelse, en klickströmlogg eller en lojalitetsuppdatering—flödar till Data 360 effektivt, säkert och inom rätt tidsram för att driva betrodda analyser och AI-drivna upplevelser.
Mönster för satsintag är ryggraden i storskalig dataintroduktion i Data 360. De är optimerade för scenarion där data bearbetas i bunt — vanligtvis på schemalagd eller periodisk basis — istället för kontinuerligt. Dessa mönster passar bäst för:
- Historiska datainläsningar för att initiera plattformen med befintliga företagsposter
- Regelbunden synkronisering med postsystem som ERP, datalager eller egna databaser
- Använd kundcase där färskhet i realtid inte är avgörande, men där enhetlighet, fullständighet och granskningsbarhet är avgörande Satsintag erbjuder förutsägbar prestanda och enkelhet i verksamheten, vilket gör det till ett pålitligt val för företag som hanterar terabyte av strukturerade eller semistrukturerade data. Data 360 tillhandahåller en uppsättning produktionsklara, allmänt tillgängliga anslutare som har inbyggt stöd för batchintag. Dessa anslutare effektiviserar integreringskonfigurationen, minskar egen ETL-utveckling och säkerställer datakvalitet och säkerhet i varje import. Tabellen nedan lyfter fram de vanligaste anslutarna som används för batchintag i företagsskala.
Sammanhang
Detta mönster är utformat för företagsscenarion som involverar att ta in stora volymer strukturerade data—som CSV- eller Parquet-filer—och ostrukturerade tillgångar från centraliserade datasjöar eller schemalagda filsläpp. Datakällor inkluderar vanligtvis molnlagringsplattformar som Amazon S3, Google Cloud Storage (GCS) och Microsoft Azure Blob Storage, där filer levereras regelbundet som en del av uppströmsdatapipeline eller batchexporter.
Problem
Hur kan en organisation etablera en tillförlitlig, säker process med hög genomströmning för att ta in massiva filbaserade datauppsättningar från sin primära molnlagringsplattform till Data 360 enligt ett förutsägbart, återkommande schema – utan att göra avkall på styrning, skalbarhet eller prestanda?
Krafter
Att ta in massiva filbaserade datauppsättningar i Data 360 är inte en enkel dataöverföring — det är en arkitektonisk utmaning som formats av skala, styrning och plattformsbegränsningar.
Datavolym och skala : Data 360-intagsanslutare är optimerade för pålitlighet och styrning, inte godtycklig massgenomströmning. Till exempel har Amazon S3-anslutaren stöd för upp till 100 miljoner rader eller 50 GB per objekt, beroende på vilken gräns som nås först. För företag med historiska datauppsättningar som körs in i miljarder poster blir denna gräns en viktig begränsning i utformningen. En metod med en fil, lyft-och-skift blir snabbt ogenomförbar, vilket kräver intelligent datapartitionering, uppdelning och orkestrering för att uppnå skala utan att uppnå anslutargränser.
Schemadefinition och underhåll : Data 360 kräver uttryckliga schemadefinitioner för varje intagspipeline för att säkerställa semantisk och strukturell integritet. Vid S3-intag måste en csv-fil definiera kolumnrubriker och en enskild representativ datarad. Denna fil fungerar som det kanoniska kontraktet mellan källsystemet, dvs molnlagring och Data 360. Alla feljusteringar — i fältnamn, datatyper eller kodning — kan orsaka intagsfel eller tyst datakorruption. Att upprätthålla denna schemafil i versionshantering och tillämpa validering genom arbetsflöden för CI/CD eller datastyrning blir en rekommenderad metod för produktionsmiljöer.
Strikta namnkonventioner : Data 360 tillämpar strikta namngivningsregler för objekt och fält för att upprätthålla enhetlighet i metadatagrafen.
- Objektnamn måste börja med en bokstav och kan endast innehålla bokstäver, siffror eller understreck.
- Fältnamn måste följa samma mönster. Filer som bryter mot dessa konventioner — till exempel fält som innehåller blanksteg, specialtecken eller symboler som inte stöds — kommer att misslyckas med schemavalidering under intag. Företag måste implementera hygienprocesser innan intag för att rengöra och normalisera inkommande filstrukturer.
Autentisering och säkerhetsstatus : Varje anslutning till extern lagring måste följa säkerhetsstandarder och efterlevnadsstandarder av företagsklass.
- Autentisering hanteras vanligtvis genom AWS Access/Secret Keys eller autentisering med federerad identitetsleverantör (IdP).
- IAM-roller måste vara begränsade för att tillämpa minsta privilegium och endast tillåta läsåtkomst till de specificerade lagringssökvägarna.
- För säker åtkomst måste utgående IP-adresser läggas till direkt på källsystemets tillåtelselista. Dessa lagerkontroller säkerställer att varje filöverföring sker inom en granskningsbar omkrets med noll Trust och balanserar efterlevnad av företagets krav med den flexibilitet som krävs för storskaligt intag.
Lösning
Denna tabell innehåller lösningar på detta integreringsproblem.
| Lösning | Anpassa | Kommentarer |
|---|---|---|
| Använd inbyggda molnlagringsanslutare (Amazon S3, Google Cloud Storage, Azure Blob Storage) | Bästa | Detta är det rekommenderade och mest pålitliga mönstret för storskaligt, återkommande filbaserat intag i Data 360\. Inbyggda anslutare tillhandahåller hanterad autentisering, schemamappning och säker dataförflyttning direkt till Data 360:s Data Lake Objects (DLO). Idealisk för schemalagda batchinläsningar där latensen inte är viktig (till exempel schemaläggning varje timme eller dag). |
| Hantera stora datauppsättningar (utanför anslutargränser) | Bäst med förbehandling | Varje anslutare tillämpar intagsgränser (till exempel S3: 100 miljoner rader eller 50 GB per objekt). För större datauppsättningar, implementera ett ETL-förbearbetningssteg för att partitionera data i mindre filer/mappar som hamnar under dessa trösklar. Konfigurera sedan flera dataströmmar för att ta in varje partition parallellt och använd tilläggsnoden i en satsdatatransformation) inom Data 360 för att återkombinera partitionerna till en enhetlig datauppsättning. |
| Säkerhet och styrning | Bästa | Alla anslutare har stöd för säker autentisering via molnbaserade metoder (IAM-roller, servicekonton eller åtkomstnycklar). För extra kontroll, begränsa åtkomsten till Data 360 IP-intervall via molnleverantörens tillåtelselista. Dataöverföring sker över krypterade kanaler, med filer lagrade i ett tillfälligt, säkert fasningslager under intag. |
| När du inte ska använda | Suboptimal | Detta mönster är inte optimalt för:
|
Skiss
Detta diagram illustrerar sekvensen av steg för att ta in data från molnlagring till Data 360
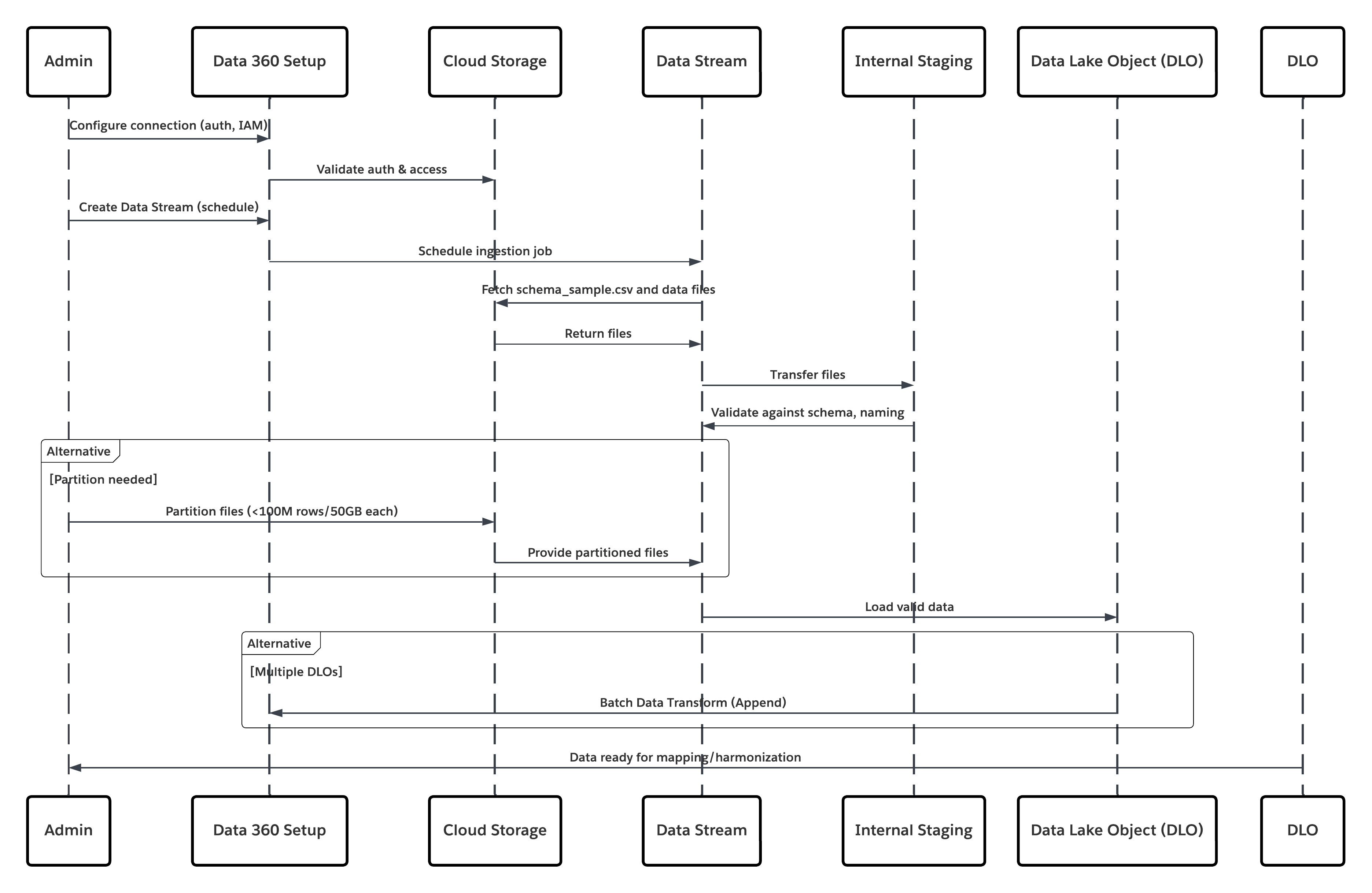
I detta scenario:
- Administratör konfigurerar en anslutning till molnlagring via gränssnittet Data 360 Setup (ange autentisering, hinkdetaljer, IAM-roller och vitlista).
- Gränssnittet för Data Cloud-konfiguration autentiseras med molnlagringsplattformen och bekräftar inloggningsuppgifter och åtkomst.
- Administratör skapar en dataström i Data 360, länkar dataströmmen till objektet/mappen i molnlagring och definierar intagsschemat.
- Vid schemautlösare begär dataströmmar källfiler (t.ex. CSV, Parkett) från molnlagringsplattformen.
- Cloud Storage Platform levererar filer, inklusive den obligatoriska giltiga schema_sample.csv och andra datafiler som följer namnkonventioner.
- Dataström överför filer till den interna fasningsmiljön i Data 360.
- Data 360-pipeline bearbetar filerna: Använder schemadefinitionen från schema_sample.csv Validerar struktur, fältnamn och delar upp belastningen om den överstiger intagströsklar (100 miljoner rader/50 GB per fil). Om stora filer upptäcks utförs ett förbearbetningspartitioneringssteg (meddelas administratören för nästa körning) externt.
- Poster importeras från faser till ett datasjöobjekt (DLO).
- Om det behövs och data partitioneras, använd tilläggsnoden i en batch datatransformering för att kombinera flera DLO.
- Data 360 loggar framgång/misslyckande, uppdaterar status för övervakning och signalerar att data är redo för mappning, harmonisering och sammanslagning.
Resultat
Tillämpningen av detta mönster möjliggör säkert, schemalagt och storskaligt intag av strukturerade eller ostrukturerade filer från företagets molnlagringsplattformar till Data 360. Processen är automatiserad, skalbar och motståndskraftig — och levererar rådata till datasjöobjekt (DLO) som fungerar som grunden för harmonisering och mappning till Customer 360 Data Model.
Intagsmekanismer
Intagsmekanismen beror på anslutaren och schemaläggningsstrategin som definieras i Data 360.
| Intagsmekanism | Beskrivning |
|---|---|
| Inbyggd molnlagringsanslutare (Amazon S3, GCS, Azure) | Rekommenderas för direkt intag av filer i CSV- eller Parkettformat från företagets molndatasjö. Dessa anslutare har stöd för inkrementella och fullständiga uppdateringsscheman. Till exempel kan en bank konfigurera en daglig synkronisering av kundtransaktionsfiler från en S3-hink till ett DLO. |
| Strategi för partitionerad fil | För mycket stora datauppsättningar (utöver 100 miljoner rader eller 50 GB per objekt) partitioneras data i mindre logiska uppsättningar (t.ex. efter månad eller region). Varje partition hanteras som en separat dataström och återkombineras senare med hjälp av en batch-datatransformering med en tilläggsnod. |
| Automatiserad schemalagd synkronisering | Data 360 tillhandahåller en deklarativ schemaläggare (timvis, dagligen eller egen kadens) som utlöser intagsjobb automatiskt, vilket säkerställer att data är färska utan manuella ingripanden. |
Felhantering och återställning
Felhantering och återställning är viktigt för att säkerställa pålitlighet vid intag med hög volym.
- Feldetektering: Varje dataströmkörning loggar intagsfel (t.ex. schemafel, filkorruption eller namnbrott) i Data 360 Monitoring. Administratörer kan granska och bearbeta misslyckade satser igen.
- Återställningsmekanism: Data 360 upprätthåller kontrollpunkter för att säkerställa att misslyckade satser inte korrupterar tidigare intag. Försök kan konfigureras igen efter att källproblem har korrigerats (t.ex. CSV med felaktigt format).
- Schemavalidering: Filen schema_sample.csv definierar datatyper och struktur. Alla ändringar utlöser validering för att undvika tyst schemadrift över körningar.
Att tänka på vad gäller Idempotent design
Intag är idempotent till sin design — att bearbeta samma fil igen resulterar inte i dubbletter av poster. Nyckelstrategier inkluderar:
- Filavtryck: Data 360 beräknar kontrollsummor för att identifiera och hoppa över tidigare bearbetade filer.
- Transaktionellt intag: Data fasas och överlämnas endast till DLO efter framgångsrik bearbetning av alla poster.
- Tillägg vs. Ersätt: Beroende på verksamhetslogik kan strömmar lägga till eller helt ersätta mål-DLO, vilket säkerställer deterministiska resultat och förhindrar delvis överlappning av data.
Att tänka på vad gäller säkerhet
Säkerhet är en integrerad del av pipelinen för intag, från autentisering till kryptering och åtkomstkontroll.
- Auktorisering och auktorisering: Anslutare använder Salesforces ramverk för säker integrering och använder autentiseringsuppgifter och externa inloggningsuppgifter för autentisering utan att avslöja hemligheter.
- Kryptering: Data krypteras under överföring (TLS 1.2+) och i vila (AES-256).
- Nätverkskontroller: Källlagringssystem (t.ex. S3-hinkar) måste tillåta Data 360 IP-adresser.
- Efterlevnadsanpassning: Stöder företagets dataskyddsramverk som GDPR, HIPAA och FFIEC-riktlinjer när de paras ihop med kundhanterade nycklar (CMK).
- Granskningsbarhet: Varje intagsjobb och inloggningsuppgifter loggas för spårbarhet och efterlevnadsrapportering.
Sidofält
Aktualitet
Tidsaspekten beror på intagsschemat och datavolymen.
- Stora företagsdatauppsättningar (100M+ rader) kan kräva partitionering för parallellt intag.
- Typisk latens för intag varierar från minuter till några timmar, beroende på filstorlek och transformationskomplexitet.
- För intag nästan i realtid kan Data 360-streaming eller API-baserade anslutare komplettera den filbaserade modellen.
Datavolymer
- Bäst lämpad för periodiskt satsintag med hög volym.
- Varje objekt som bearbetas genom S3-anslutaren har stöd för upp till 100 miljoner rader eller 50 GB per fil.
- För system i petabyteskala, använd datapartitionering och orkestrering med flera strömmar.
Stöd för slutpunktskapacitet och standarder
Kapaciteten och standardsupporten för slutpunkten beror på vilken lösning du väljer.
| Anslutartyp | Slutpunktskrav |
|---|---|
| Amazon S3-anslutare | S3-hink med lämplig IAM-policy och schema\_sample.csv-fil som definierar schemat. |
| Google Cloud-lagringsanslutare | Inloggningsuppgifter för servicekonton och hinkåtkomst med enhetliga namnkonventioner. |
| Azure Storage-anslutare | Åtkomst till nyckel eller SAS-tokenbaserad autentisering; blob eller mappstruktur måste följa Data 360-konventioner. |
Delstatshantering
Status spåras genom dataströmmar och deras senaste framgångsrika tidsstämpel för körning.
- Data 360 upprätthåller automatiskt synkroniseringslägen och förskjutningar, vilket säkerställer att endast nya eller ändrade filer bearbetas vid efterföljande körningar.
- Vid integrering med externa ETL-verktyg rekommenderas unika filidentifierare (t.ex. UUID eller tidsstämplar) för att undvika dubbletter.
Komplexa integreringsscenarion
I avancerade företagsarkitekturer kan detta mönster integreras med:
- Middleware ETL-pipelines (t.ex. Informatica, MuleSoft): för att orkestrera förbearbetning, validering och filpartitionering innan överföring till Data 360.
- AI/ML-arbetsflöden: bearbetade DLO-data kan publiceras via DMO till modellinlärningsmiljöer eller RAG-index genom Data 360-aktiveringsmål.
- Transaktionssystem: harmoniserade DMO kan utlösa uppdateringar längre ner i Salesforce CRM eller externa system via dataåtgärder eller plattformshändelser.
Exempel
En global finansinstitution lagrar kund- och transaktionsdata i en AWS S3-datasjö, där partitionerade parkettfiler skapas varje natt efter region (som USA, EU och APAC). Dataarkitekturteamet konfigurerar flera dataströmmar i Data 360, var och en ansluten till en regional mapp, med en delad schema_sample.csv som säkerställer enhetliga sidhuvuden och datatyper över alla partitioner. Scheman för nattligt intag läser automatiskt in data till DLO, varefter batchdatatransformationer lägger till alla regionala partitioner till ett enhetligt Customer_Transactions_DLO. Denna harmoniserade datauppsättning mappas sedan till Customer 360 Data Model, vilket möjliggör analyser och AI-aktivering längre ner. Tillvägagångssättet levererar automatiserat och pålitligt intag från den befintliga datasjön, tillämpar stark autentisering och kryptering i enlighet med företagets IT-policyer och ger en skalbar, modulär grund som stöder framtida expansion och schemautveckling.
Sammanhang
Ett primärt och kritiskt användningsfall för Data 360 är att slå samman kunddata i Salesforces ekosystem. Detta mönster täcker inbyggt intagande av data från Salesforces kärnplattformar — Sales Cloud och Service Cloud (gemensamt Salesforce CRM) och Marketing Cloud-engagemang. Källor inkluderar standardobjekt och egna CRM-objekt (t.ex. Konto, Kontakt, Kundcase, Säljprojekt) och Marketing Cloud-engagemangstillägg som innehåller engagemangshändelser, e-postutskick och spårningsdata.
Problem
Hur kan en organisation effektivt och tillförlitligt ta in standardobjekt och egna CRM-objekt och Marketing Cloud-engagemangsdatatillägg i Data 360 så att data kan användas för att bygga sammanslagna kundprofiler (identitetslösning, Customer 360), samtidigt som prestanda, styrning och minimala störningar av källsystem bibehålls?
Krafter
Inbyggda anslutare förenklar jobbet, men flera operativa och arkitektoniska krafter måste hanteras:
- Omfattande källbehörigheter: En dedikerad anslutande användare (integreringskonto) måste ha lämpliga läsbehörigheter på objekt- och fältnivå. Att inte tilldela de behörighetsuppsättningar som behövs (till exempel en färdigbyggd behörighetsuppsättning för Data 360-anslutare) är en vanlig orsak till intagsfel.
- Datauppdateringslägen och kostnad: Anslutare har stöd för fullständiga och delta/inkrementella uppdateringslägen. Fullständiga uppdateringar är tyngre för prestanda och krediter; deltaextraheringar minskar belastningen men är beroende av pålitlig ändringsspårning i källsystemet.
- Mappning av eget schema och fält: CRM-instanser innehåller ofta egna objekt/fält. Korrekt schemamappning och hantering av egna fält (namn, typer) krävs för att undvika mappningsfel eller semantisk drift.
- Starta datapaket vs. Egen mappning: Startdatapaket accelererar introduktion genom att förmarkera typiska objekt/fält, men starkt anpassade organisationer behöver skräddarsydda strömdefinitioner.
- Gränser för genomströmning och API: Källorganisationens API-gränser och Marketing Cloud-extraheringsresultat begränsar hur aggressivt du kan schemalägga uppdateringar.
- Datahygien- och namnkonventioner: Källfältnamn, nullbeteende och datatyper måste normaliseras innan intag för att förhindra mappningsproblem längre ner.
- Säkerhet och minsta privilegium: Anslutaren förlitar sig på säker autentisering och måste respektera IAM-mönster med minst privilegier, granskningsbarhet och nätverkskontroller.
Lösning
Denna tabell innehåller lösningar på detta integreringsproblem.
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| Lösningsanpassning | Bästa | Använd den inbyggda Salesforce CRM-anslutaren och Marketing Cloud-engagemangsanslutaren i Data 360\. Börja med startdatapaket för standardanvändningsfall och snabba på introduktioner. Använd manuell strömanpassning för skräddarsydda eller domänspecifika datamodeller. |
| Hantera mycket anpassade CRM-instanser | Bäst med Mapping Workshop | Behandla startpaket som en baslinje och genomför en mappningsworkshop för att identifiera: Egna objekt och relationer. Formelfält eller beräknade fält. Hanterade pakettillägg. För tunga formelfält, beräkna värden i en ETL från försteg eller inuti Data 360-transformationer för att minimera API-belastning på källorganisationer. |
| När du inte ska använda | Suboptimala scenarion | Undvik detta mönster om: Du behöver händelseintag med hög frekvens eller i realtid (använd istället Streaming-anslutare, Plattformshändelser eller Nollkopieringsfederation). Källorganisationen har begränsad API-kapacitet och kan inte upprätthålla schemalagda extraheringar utan begränsning eller köfördröjningar. |
| Säkerhet och styrning | Obligatoriska kontroller | Principen om minsta behörighet - Använd en dedikerad integreringsanvändare med minimal läsåtkomst. Använd aldrig organisationsomfattande administratörer. Autentisering — Använd OAuth 2.0 och anslutna appar, rotera klienthemligheter regelbundet och övervaka användningen av uppdateringstoken. Granskning och spårbarhet — Logga alla körningar av intag, schemaändringar och anslutarhändelser. Vidarebefordra loggar till SIEM eller efterlevnadssystem för granskningsberedskap. Dataklassificering — Tillämpa PII/PHI-taggning och attributbaserad åtkomstkontroll (ABAC) med CEDAR-policyer direkt efter intag för att tillämpa maskering, samtycke och efterlevnad längre ner. |
Skiss
Detta diagram illustrerar sekvensen av steg för att ta in data från molnlagring till Data 360
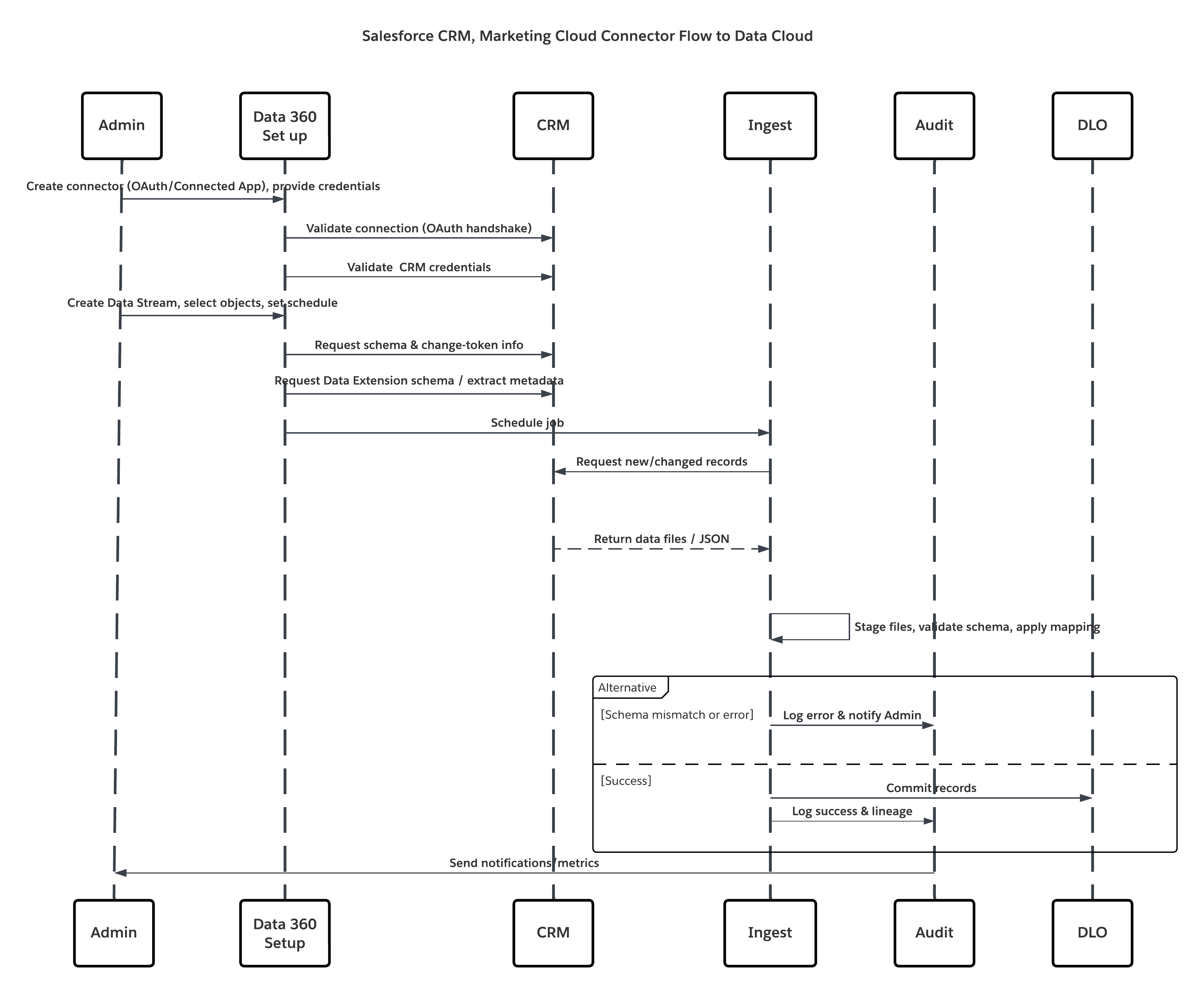
I detta scenario:
- Administratörsprovisionerar integreringsanvändare och tilldelar behörighetsuppsättningar för anslutare till källorganisationer.
- Administratör konfigurerar anslutare i Data 360-inställningarna (ansluter till Salesforce CRM och Marketing Cloud via OAuth/ansluten app).
- Administratören skapar dataströmmar som väljer objekt och datatillägg, väljer fullständig uppdatering eller deltauppdatering och anger scheman.
- Vid schemalagd körning begär Data 360 schema- och deltatokens från källan/källorna.
- Källsystem returnerar poster (delta eller full belastning). Marketing Cloud kan leverera extraheringar; CRM kan returnera JSON/Query-resultat.
- Data 360 fasar filer i sitt interna säkra fasningsområde och validerar mot mappat schema.
- Om validering misslyckas loggas fel i intag, administratör varnas och åtaganden stoppas. Om validering lyckas överlämnar Data 360 poster atomiskt till mål-DLO.
- Övervaknings- och granskningsloggar uppdateras med härkomst, körlängd, radantal och användning av inloggningsuppgifter. Varningar utfärdade till administratörer om trösklar eller fel utlöstes.
Resultat
Huvuddata för kundrelationer och marknadsföringsengagemang tas in i Data 360 som Datasjöobjekt (DLO). Detta ger:
- Samlad datauppsättning som innehåller profiler, kundcase, säljprojekt och e-post/engagemangsmått.
- Stiftelse för identitetslösning och konstruktion av sammanslagna individuella profiler.
- Operativ beredskap för harmonisering, berikning, AI-modellering och aktivering längre ner, samtidigt som styrning och granskning bevaras.
Intagsmekanismer
Intagsmekanismen beror på anslutaren och schemaläggningsstrategin som definieras i Data 360.
| Mekanism | När man ska använda |
|---|---|
| Salesforce CRM-anslutare (inbyggd) | Bäst för standard/egna CRM-objekt; har stöd för fullständig uppdatering och deltauppdatering. |
| Anslutare för Marketing Cloud-engagemang (inbyggt) | Bäst för datatillägg, utskick och spårningsextraheringar; har stöd för fullständiga/delta-lägen. |
| Startdatapaket | Påskynda introduktion för vanliga försäljnings-/service-/marknadsföringsobjekt. |
| Egna strömmar + förbehandling | Använd när komplexa transformationer eller tung schemanormalisering krävs. |
Felhantering och återställning
Felhantering och återställning är viktigt för att säkerställa pålitlighet vid intag med hög volym.
- Loggar per körning: Varje dataströmkörning ger detaljer om framgång/misslyckande och fel på radnivå.
- Försök och kontrollpunkter: Misslyckade körningar kan försökas igen efter att ha åtgärdat käll- eller schemaproblem; Data 360 använder fasning och atomär commit semantik.
- Varningar: Konfigurera varningar för schemadrift, upprepade fel eller deltasekvensluckor.
Att tänka på vad gäller Idempotent design
Intag är idempotent till sin design — om samma sak bearbetas igen resulterar det inte i dubbletter av poster. Nyckelstrategier inkluderar:
- Ändringsdetektering: Deltaextraheringar förlitar sig på ändringsindikatorer för källsystemet (LastModifiedDate / datainsamling av systemändringar). Kontrollera att källan har pålitliga tidsstämplar/flaggor.
- Deduplicering: Använd unika verksamhetsnycklar (t.ex. Contact.ExternalId) för att avdupera eller infoga i DLO.
- Transaktionellt åtagande: Poster fasas och överlämnas endast när batchbearbetning slutförs framgångsrikt.
Att tänka på vad gäller säkerhet
Säkerhet är en integrerad del av pipelinen för intag, från autentisering till kryptering och åtkomstkontroll.
- Auktorisering och auktorisering: Anslutare använder Salesforces ramverk för säker integrering och använder autentiseringsuppgifter och externa inloggningsuppgifter för autentisering utan att avslöja hemligheter.
- Kryptering: Data krypteras under överföring (TLS 1.2+) och i vila (AES-256).
- Nätverkskontroller: Källlagringssystem (t.ex. S3-hinkar) måste tillåta Data 360 IP-adresser.
- Efterlevnadsanpassning: Stöder företagets dataskyddsramverk som GDPR, HIPAA och FFIEC-riktlinjer när de paras ihop med kundhanterade nycklar (CMK).
- Granskningsbarhet: Varje intagsjobb och inloggningsuppgifter loggas för spårbarhet och efterlevnadsrapportering
Sidofält
Aktualitet
Tidsaspekten beror på intagsschemat och datavolymen.
- Idealisk kadens beror på verksamhetsbehov — varje timme för marknadsföringsutlösare nästan i realtid, varje natt för stora avstämningar.
- Delta-lägen minskar belastning och kostnad. Fullständiga uppdateringar är tyngre och används för inledande laddningar eller större schemaändringar.
Datavolymer
- CRM-anslutare är optimerade för datauppsättningar med transaktion och mellanvolym (miljoner poster).
- För extremt stora historiska volymer, överväg fasad ETL att partitionera och läsa in i faser.
Stöd för slutpunktskapacitet och standarder
Kapaciteten och standardsupporten för slutpunkten beror på vilken lösning du väljer.
| Anslutare | Slutpunktskrav |
|---|---|
| Salesforce CRM-anslutare | Källorganisationen måste tillåta en ansluten app, OAuth-tokens och en dedikerad integreringsanvändare med läsbehörigheter. |
| Marketing Cloud-anslutare | Marketing Cloud API-inloggningsuppgifter eller installerat paket; Datatillägg måste exponera data via Extraheringar/API. |
Delstatshantering
- Anslutarstatus: Dataströmmar behåller de senaste lyckade synkroniseringstidsstämplarna och deltaförskjutningarna.
- Huvudnyckelstrategi: Föredrar enhetliga verksamhetsidentifierare (externa ID:n) så att avstämning och infogningar längre ner är deterministiska.
Komplexa integreringsscenarion
I avancerade företagsarkitekturer kan detta mönster integreras med:
- Hybridtopologier: Kombinera CRM-intag med streaming (plattformshändelser) för uppdateringar nästan i realtid.
- Orkestrering av mellanprogram: Använd MuleSoft- eller ETL-verktyg när komplex orkestrering, berikning eller förintag av transformation krävs.
- Aktiveringsfeedbackloopar: Harmoniserade DMO kan utlösa uppdateringar av källsystem längre ner via dataåtgärder eller plattforms-API (försiktigt med SoD-kontroller).
Exempel
En multinationell återförsäljare slår samman mått för Konton, Kontakter, Kundcase, Säljprojekt och Marketing Cloud-engagemang i Data 360 för att skapa en enhetlig kundvy. Startdatapaketet inleder kärnobjekten Försäljning och Service, medan teamet utökar modellen med egna fält som Loyalty_Membershipc och Customer_Tierc för att samla in lojalitetssammanhang. CRM-dataströmmar körs varje timme i deltaläge, och Marketing Cloud-engagemang synkroniseras dagligen med deltaextraheringar för engagemangshändelser. Dessa datauppsättningar bearbetas genom DLO och identitetslösning, vilket resulterar i en enhetlig kundprofil som kombinerar CRM- och engagemangssignaler för att driva personanpassning och AI-modeller längre ner.
Dessa mönster är byggda för scenarion där millisekunder är viktiga — när kundinteraktioner, transaktioner eller signaler måste utlösa omedelbar insikt eller åtgärd. De går utöver traditionellt, schemalagt batchintag för att aktivera händelsedrivet dataflöde, där information bearbetas i samma ögonblick som den skapas. I Salesforce Data 360-ekosystemet är “realtid” inte ett enskilt läge — det är en kontinuerlig uppsättning latensmodeller. I ena änden ligger synkronisering nästan i realtid, där uppdateringar från postsystem (som CRM eller ERP) återspeglas i Data 360 inom några sekunder eller minuter. I den andra änden finns sann händelseinsamling i realtid, där beteendesignaler på klientsidan — som klick, inköp eller mobilinteraktioner — tas in och aktiveras på millisekunder. För arkitekter är skillnaden mer än semantisk. Den definierar hur pipelines utformas, hur API åberopas och hur beslut fattas längre ner. Att välja rätt mönster — oavsett om det är synkronisering nästan i realtid eller intag av händelseströmmar — säkerställer att systemet uppfyller verksamhetens mål för latens samtidigt som dataintegritet, skalbarhet och styrning bibehålls.
Sammanhang
Detta mönster låter alla externa system — som ett eget program, en IoT-plattform (Internet-of-Things), ett POS-system (point-of-sale) eller en tredjepartstjänst — pusha händelsedata till Data 360 programmatiskt nästan i realtid när diskreta händelser inträffar.
Problem
Hur kan en utvecklare pålitligt skicka enskilda poster eller små asynkrona satser av händelser från ett externt program till Data 360 med låg latens så att data snabbt är tillgängliga för bearbetning, segmentering och aktivering?
Krafter
Detta mönster ger låg latens och bättre utvecklarkontroll men introducerar flera tekniska begränsningar och operativa beroenden:
- Utvecklarberoende: Kräver utvecklarinsatser för att implementera autentiserade REST API-klienter och fel-/försökslogik — det är inte en peka-och-klicka-anslutare.
- Strikt schema vid skrivning: Ingestion API tillämpar schema-on-write. Ett exakt schema måste definieras och laddas upp till anslutarkonfigurationen; alla nyttolaster måste överensstämma exakt eller avvisas.
- Dubbla interaktionslägen: Samma anslutare har stöd för både streaming (JSON) för uppdateringar post för post med låg latens och massuppdatering (CSV) för större periodiska synkroniseringar — arkitekter måste välja efter användningsfall.
- Autentisering och säkerhet: Samtal måste autentiseras via en Salesforce Connected App med OAuth 2.0 (t.ex. JWT-bärarflöde för server-till-server). Tokenhantering, rotation och omfattningar med minst behörighet är obligatoriska.
- Operativ synlighet: Utvecklare och plattformsteam måste implementera övervakning för svarskoder, försök, köer med döda bokstäver och varningar om schemadrift.
- Krav på graf i realtid: För sann direktaktivering (direkt segmentering, DMO-mappning i realtid) måste måldatamodellobjektet (DMO) vara en del av datagrafen i realtid, annars går händelser igenom en pipeline med något högre latens.
Lösning
Denna tabell innehåller lösningar på detta integreringsproblem.
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| Lösningsanpassning | Bäst för insamling av händelser med låg latens | Använd Data 360 Ingestion API (streaming JSON) för att pusha enskilda händelser eller mikrosatser. Konfigurera Ingestion API-anslutaren med ett strikt OAS 3.0-schema (.yaml). Använd massintag av CSV för större, mer sällan förekommande synkroniseringar. |
| Hantera schemaändringar | Strikt/hanterat | Schemaändringar bryts: uppdatera OAS .yaml, versionshantera anslutaren och utför kontrakttester. Implementera migrering av rullande scheman om producenter inte kan ändra samtidigt. |
| När du inte ska använda | Suboptimal | Inte idealiskt om förbehandling behövs ( ex: deduplicering, garanterad order etc. ) , eller för extremt stora masslaster (använd inbyggda massanslutare eller batch-ETL ). Om källan inte kan skapa schemagiltiga belastningar eller inte kan autentisera säkert, använd alternativa intagsmetoder. |
| Säkerhet och styrning | Obligatoriskt | Använd OAuth 2.0 med omfattningar med minst behörighet, rotera nycklar, loggtokenanvändning. Tillämpa TLS 1.2+, validera klient-IP:er om det behövs och säkerställ PII-taggning av nyttolast. Alla händelser måste innehålla metadata om härkomst (källa, tidsstämpel, schemaversion, idempotensnyckel). |
Skiss
Detta diagram illustrerar sekvensen av steg för att ta in data från Ingestion API till Data 360
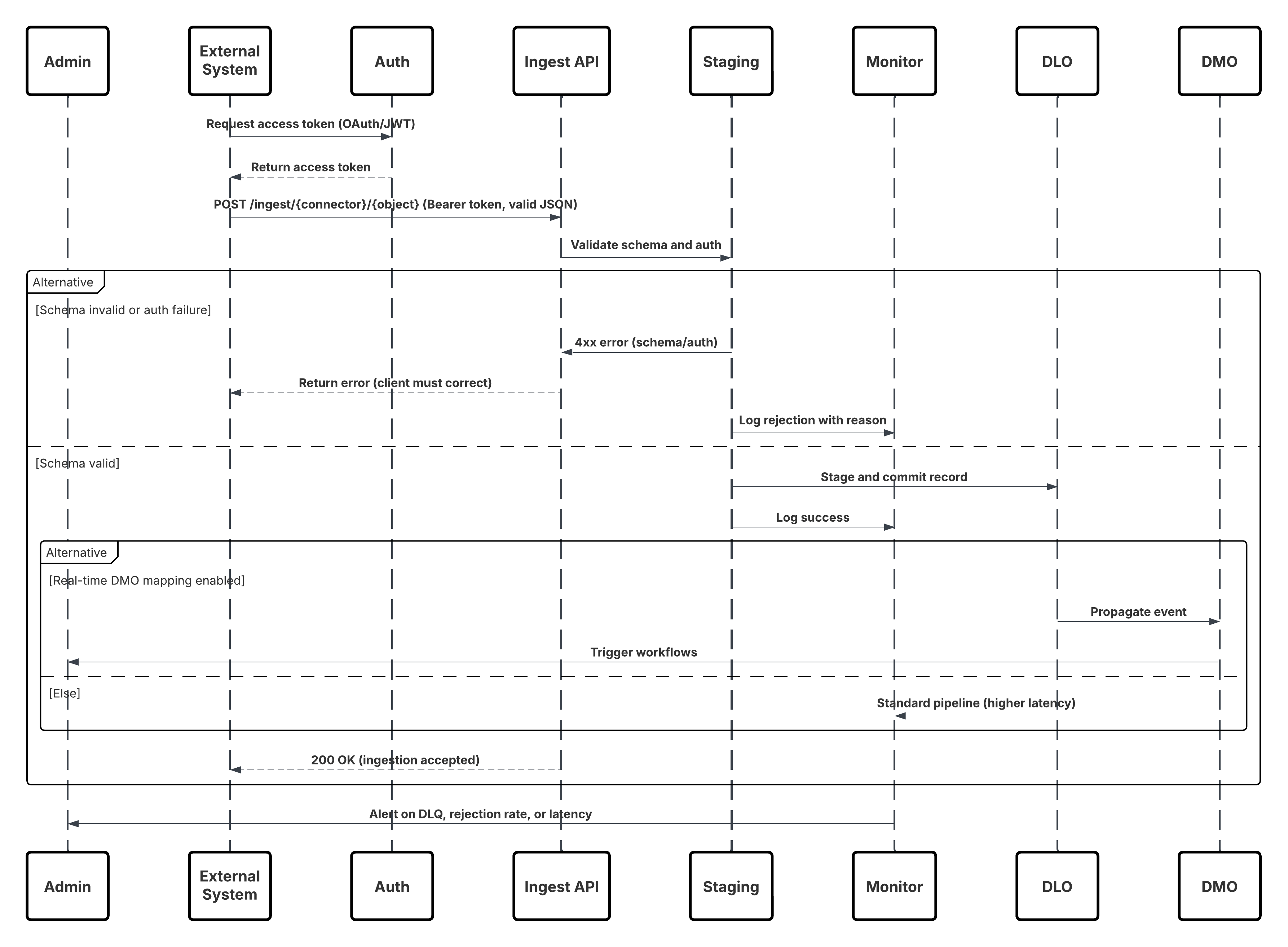
I detta scenario:
- Externt system begär autentisering via OAuth/JWT från Autentiseringsserver.
- Autentiseringsserver returnerar åtkomsttoken till externt system.
- Externt system skickar POST-begäran för dataintag till Data 360 Ingestion API med auktorisering och JSON-belastning.
- Ingestion API validerar begärandeschema och autentisering via modulen Faser och validering.
- Vid schema/autentiseringsfel:
- Fel returnerades till Externt system.
- Avvisande loggat för övervakning och varning.
- Vid framgångsrik validering:
- Poster fasade och överlämnade till Data Lake Object (DLO).
- Framgång loggad för övervakning.
- Om aktiverat propageras data till realtidsdatagraf (DMO) som utlöser arbetsflöden längre ner.
- Annars bearbetas data via standard batch eller pipeline med högre latens.
- Ingestion API bekräftar framgång för externt system.
- Bevakningskomponenter varnar administratörer om köer med döda bokstäver, avvisanderesultat eller latensproblem.
Resultat
Externa händelsedata tas in i Data 360 DLO med låg latens. När mål-DMO är en del av realtidsgrafen är data tillgängliga för direkt segmentering, agentflöden, AI-modeller och operativ aktivering. Detta möjliggör snabba verksamhetssvar på händelser som kommer från ett anslutet system.
Intagsmekanismer
Intagsmekanismen beror på anslutaren och schemaläggningsstrategin som definieras i Data 360.
| Mekanism | När man ska använda |
|---|---|
| Streaming JSON (Ingestion API) | Enskilda händelser, mikrosatser, beteendehändelser, klickströmmar, IoT-telemetri — när låg latens krävs. |
| Bulk CSV (Bulkläge för Intags-API) | Större, periodiska uppladdningar där latenskraven har minskat. |
| Edge / Mellanprogramvara | Använd när du behöver validering, transformation, berikning eller begränsning av hastighet innan du pushar till Ingestion API. |
Felhantering och återställning
- Omedelbara (synkroniserings)fel: 4xx-svar för schema-/autentiseringsfel — klienten måste fixa payload eller token och försöka igen.
- Övergående (asynkrona) fel: 5xx-svar — klientförsök med exponentiell backoff och jitter.
- Kö med död bokstav (DLQ): Ihållande fel landar i DLQ för manuell inspektion och repris.
- Övervakar: Följ schemaavvisandefrekvens, autentiseringsfel, latenspercentiler och DLQ-eftersläpning. Varning om trösklar.
Att tänka på vad gäller Idempotent design
- Idempotensnyckel: Varje händelse ska innehålla en unik idempotensnyckel/meddelande-ID.
- Infoga strategi: Använd företagsnycklar (ExternalId) för att undvika dubbletter vid repriser.
- Dedupfönster: Arkitekten bör definiera dedupliceringsfönster och lagring för spårning av idempotens.
Att tänka på vad gäller säkerhet
Säkerhet är en integrerad del av pipelinen för intag, från autentisering till kryptering och åtkomstkontroll.
- Autentisering: OAuth 2.0 (JWT Bearer) rekommenderas för server-till-server. Begränsa omfattningar till endast intag.
- Kryptering: TLS 1.2+ för transport; Data 360 tillämpar kryptering vid vila.
- Minsta privilegium: Inloggningsuppgifter för den anslutna appen har minimala rättigheter; rotera hemligheter och instrumentåtkomstloggar.
- Betalningsstyrning: Inkludera flaggor för samtycke/konsumtion i händelsemetadata; tillämpa ABAC/CEDAR-policyer direkt efter intag.
- IP-kontroller / Privat anslutning: Begränsa åtkomst via tillåtelselistor eller använd Privat anslutning för privata nätverk om det behövs.
Sidofält
Aktualitet
Tidsaspekten beror på intagsschemat och datavolymen. Streaming JSON ger latens under sekund till sekund beroende på bearbetning och grafkonfiguration. Bulk-CSV är minuter till timmar. Välj baserat på verksamhets-SLA.
Datavolymer
Individuella händelsestorlekar ska vara små (< några KB). För producenter med hög genomströmning, överväg att batcha hos producenten eller använda en streamingbuffert (Kafka/Kinesis) innan du anropar API.
Delstatshantering
- Schemaversioner: Bibehåll schemaversionen i händelsemetadata och använd versionshantering för anslutare när du uppdaterar OAS-kontrakt.
- Anslutarförskjutningar: Data 360-handtag överlämnar semantik; producenter bör spåra nycklar för bristande makt och senaste lyckade sekvens för säker repris.
Komplexa integreringsscenarion
I avancerade företagsarkitekturer kan detta mönster integreras med:
- Kantvalideringslager: Använd middleware för att översätta heterogena producentformat till det obligatoriska OAS-kontraktet, utföra begränsning av hastighet och förbereda.
- Hybridarkitekturer: Kombinera Ingestion API för händelser och Anslutare för massavstämning.
- Agentaktivering: Händelser som mappas till DMO i realtid kan utlösa Agentforces arbetsflöden och Einstein modeller för automatiserade beslut.
Exempel
En butikskedja strömmar inköpshändelser (POS) till Data 360 inReal-Time för att driva direkt kundengagemang. Varje butik kör en lättviktig serverkomponent som samlar in transaktioner, berikar dem med plats- och enhetsmetadata och publicerar JSON-händelser säkert med JWT Bearer OAuth med idempotensnycklar för att förhindra dubbletter. En administratör definierar händelsestrukturen genom att ladda upp ett OAS-schema för försäljning och konfigurera Ingestion API-anslutaren. Inkommande händelser tas in i pos_sale DLO, mappas till Sale DMO och läggs till i realtidsgrafen. På så sätt upptäcks inköp med högt värde direkt, vilket utlöser VIP-flöden i Agentforce och uppdaterar kundsegmentering för att driva personanpassning i realtid.
Sammanhang
Detta mönster möjliggör insamling av detaljerade användarinteraktionsdata med hög volym—som sidvisningar, knappklick, produktvisningar och videouppspelningar—från webbplatser och mobilappar i trueReal-Time. Den är grundläggande för att leverera direkt personanpassning, där varje digital interaktion dynamiskt kan påverka användarupplevelsen och driva engagemang.
Problem
Hur kan ett företag samla in och bearbeta en kontinuerlig ström av beteendehändelser från digitala fastigheter—som sträcker sig över miljontals användarinteraktioner per minut—och göra dessa data omedelbart tillgängliga i Data 360 för att driva segmentering, personanpassning och aktivering i realtid?
Krafter
Detta användningsfall introducerar flera designutmaningar som kräver en syftesbyggd intagsarkitektur med låg latens:
- Extrem genomströmning : Webbplatser eller mobilappar med hög trafik kan avge miljontals händelser per minut. Intagslagret måste skalas horisontellt för att hantera denna volym utan händelseförlust eller mottryck, vilket säkerställer en jämn latens vid toppbelastning.
- Instrumentering på klientsidan : Till skillnad från serverdrivna integreringar beror detta mönster på SDK:er på klientsidan. En JavaScript-beacon (Salesforce Interactions SDK) måste vara inbäddad på varje sida, eller en inbyggd SDK integrerad i mobilappar. Detta kräver robust klientdistribuering, versionshantering och händelseschemastyrning.
- Bearbetar händelser med låg latens : Användaråtgärder—som "lägg i varukorg" eller "videospel"—måste nå Data 360 inom några sekunder, vilket möjliggör aktivering i realtid och sammanhangssvar (t.ex. riktade erbjudanden, personliga rekommendationer).
- Harmonisering och identitetslösning av uppgifter : Insamlade händelser inkluderar ofta anonyma identifierare (cookies, enhets-ID:n, sessionstokens). För att driva användningsfall för Customer 360 måste dessa mappas till kända profiler via Data 360:s identitetslösning och harmoniseras med Customer 360 Data Model.
Lösning
Den rekommenderade metoden är att använda Salesforce Marketing Cloud Personalization Connector – en inbyggd, fullständigt hanterad pipeline utformad för beteendeintag med hög genomströmning.
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| SDK-baserad händelseinsamling | Bästa | Distribuera Salesforce Interactions SDK (webb) eller inbyggd SDK (mobil). Dessa lättviktiga bibliotek samlar in och serialiserar användarinteraktioner i realtid och bifogar metadata (sessions-ID, tidsstämpel, sammanhang). |
| Streamingpipeline för händelse | Bästa | Händelser skickas till Marketing Cloud Personalizations händelsestreamingtjänst över säker HTTPS. Detta lager är horisontellt skalbart och optimerat för överföring med låg latens (<2s). |
| Data 360-integrering | Bästa | Data 360:s personanpassningsanslutare prenumererar på streamingkanalen och tar in varje händelse i ett Data Lake Object (DLO) i nearReal-Time. |
| Datamodellmappning | Bästa praxis | Det intagna DLO mappas till Customer 360 Data Model Objects (DMO). Detta aktiverar länkning av anonyma och kända användare genom Identitetslösning. |
| Aktivering av graf i realtid | Valfritt/rekommenderas | Inkludera mappade DMO i realtidsgrafen för omedelbar segmentering och utlös personliga åtgärder via Einstein eller Agentforces arbetsflöden. |
| När du inte ska använda | Suboptimal | Detta mönster är inte idealiskt när: Källdata är webbklient och händelser (använd Ingestion API istället). Organisationen har inte kontroll över webb-/mobilklienter. Spårning av beteende i realtid krävs inte (använd batchintag). |
| Hantera schemaändringar | Hanterad utveckling | Händelsescheman utvecklas i takt med att nya interaktioner läggs till. SDK:er ska versionera händelsedefinitioner. Bakåtkompatibla ändringar (att lägga till valfria fält) är säkra; att bryta ändringar kräver omkonfigurering av anslutare och kontrakttest. |
Skiss
Detta diagram illustrerar sekvensen av steg för att ta in data från mobil- och webbkanaler till Data 360
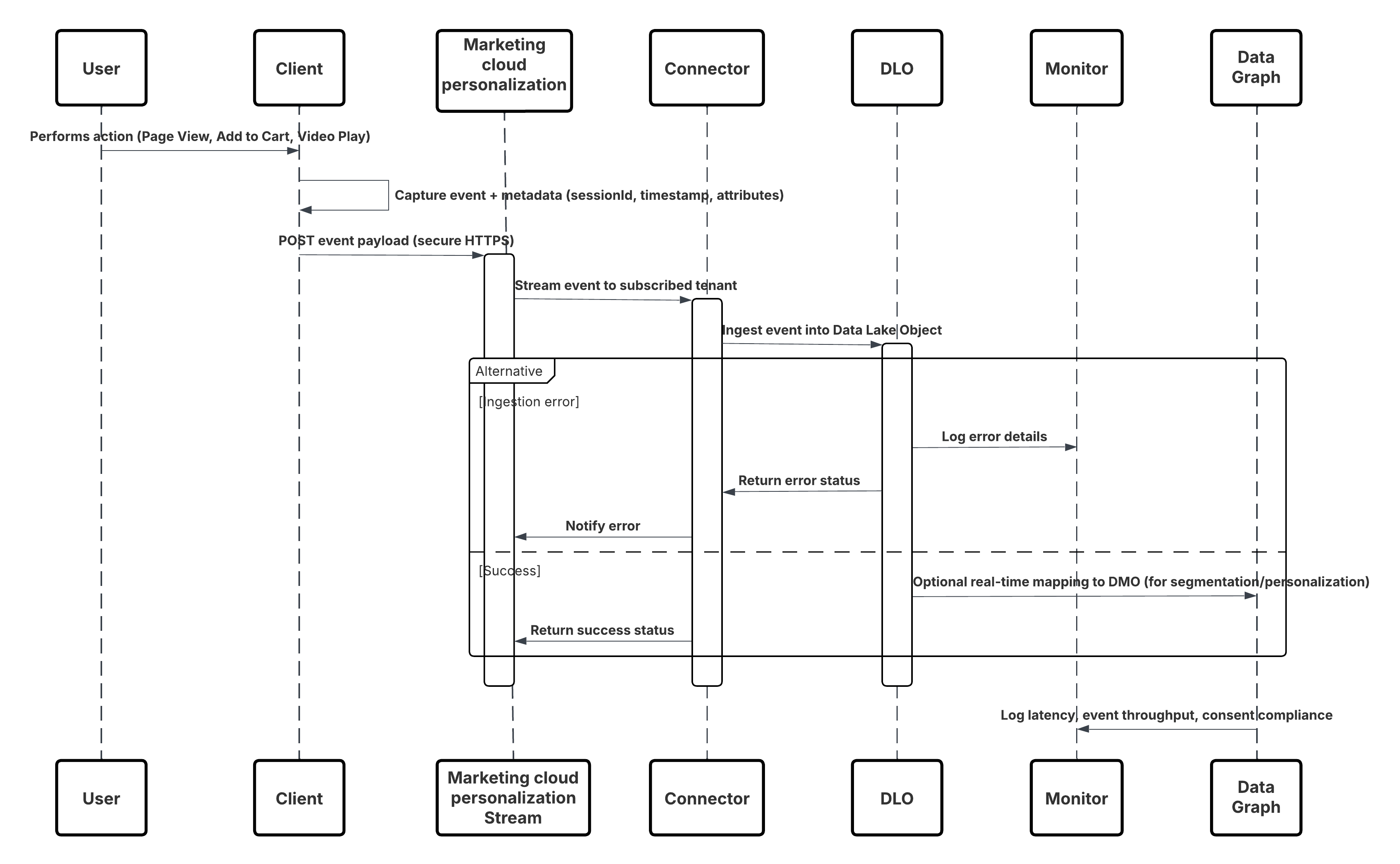
I detta scenario:
- Distribuera SDK i webb- eller mobilkanaler (insamling av användarinteraktion).
- Konfigurera SDK med arrendator-ID, miljö och samtyckeskontroller.
- Strömma insamlade JSON-händelser (metadata + attribut) till Marketing Clouds slutpunkt för streaming.
- I Inställningar för Data 360, skapa och konfigurera Personanpassningsanslutaren för arrendatorn.
- Ta in händelser i ett DLO och mappa DLO → DMO inuti Data 360.
- Aktivera DMO i realtidsgrafen för omedelbar aktivering.
- Övervaka latens, schemaefterlevnad, samtyckesflagg, genomströmning, felfrekvenser.
- Distribuera till produktion och övervaka kontinuerligt.
Resultat
En kontinuerlig ström med låg latens av beteendehändelser flödar från digitala kanaler till Data 360. Inom några sekunder blir varje användaråtgärd tillgänglig för segmentering i realtid, prediktiva modeller eller utlöst personanpassning, vilket möjliggör verkligt anpassningsbara kundupplevelser.
Intagsmekanismer
Intagsmekanismen beror på anslutaren och schemaläggningsstrategin som definieras i Data 360.
| Mekanism | När man ska använda |
|---|---|
| Interactions SDK (webb) | Insamling i realtid från webbläsare och SPA. |
| Mobile SDK | Insamling i realtid från inbyggda mobilappar. |
| Personanpassningsanslutare | Hanterad prenumeration mellan Marketing Cloud och Data 360\. |
| Mappning av graf i realtid | Aktiverar omedelbar aktivering i segmentation, Einstein och Journeys. |
Felhantering och återställning
- Skiktad feltolerans: Implementera validerings- och försöksmekanismer i flera nivåer — klient-SDK hanterar tillfälliga fel med exponentiell backoff, medan intagslagret använder hållbara köer och pipelines som går att spela upp igen för att förhindra dataförlust.
- Schema- och datastyrning: Versionera och validera händelsescheman kontinuerligt. Ogiltiga eller växande händelser dirigeras till en kö för Schemaavvisande eller Död bokstav för säker prioritering och repris.
- Idempotens och deduplicering: Använd stabila händelseidentifierare och infoga semantik för att garantera exakt bearbetning även under försök eller repriser.
- Automatisering av övervakning och återställning: Kontinuerlig övervakning av genomströmning, latens och felfrekvenser utlöser automatiserade återställningsflöden — vilket säkerställer låg latens, pålitlig leverans och enhetliga resultat för personanpassning i realtid.
Att tänka på vad gäller Idempotent design
- Varje händelse måste ha en unik idempotensnyckel eller meddelande-ID så att dubbletter av inskickningar kan avdupliceras längre ner.
- Använd verksamhetsnycklar (t.ex. sessionID + eventTimestamp + userID) där det är lämpligt för att identifiera dubbletter.
- Definiera ett dedupliceringsfönster (t.ex. 24 timmar) där dubbletthändelser ignoreras eller filtreras.
- Använd strategier för att infoga uppåt vid behov (t.ex. uppdatera räknare eller flaggor istället för att infoga dubbletter).
Att tänka på vad gäller säkerhet
Säkerhet är en integrerad del av pipelinen för intag, från autentisering till kryptering och åtkomstkontroll.
- Transportkryptering: TLS 1.2+ för alla SDK → streamingtjänstanslutningar.
- Datakryptering vid vila i Data 360 och marknadsföringsström.
- SDK respekterar användares samtyckesflagg (GDPR/CCPA) och förhindrar spårning om samtycke nekas.
- Auktorisering av SDK-trafik: se till att endast godkända arrendatorer/klienter kan strömma händelser.
- Metadata: varje händelse måste innehålla käll-ID, tidsstämpel, schemaversion, sessions-ID, idempotensnyckel.
- Åtkomst med minst behörighet: SDK-slutpunkter och -anslutare begränsade till händelseintagsomfång; rotera inloggningsuppgifter regelbundet.
- Dataklassificering: Annotera PII i händelse av belastning, tillämpa policyer direkt efter intag
Sidofält
Aktualitet
- Tidsaspekten beror på slutanvändarens aktivitet och konfigurationen för händelsestreaming.
- Händelser som samlats in via Salesforce Interactions SDK och levererats genom Marketing Cloud-personaliseringsströmmen uppnår vanligtvis latens på under- till ~2 sekunder innan de blir tillgängliga i Data 360-realtidsgrafen.
- Detta möjliggör nästan omedelbar segmentering, personanpassning och aktivering inom aktiva användarsessioner.
Datavolymer
Individuella beteendehändelser (t.ex. klicka, visa, lägg till i varukorg) är lätta — i allmänhet 1–5 KB per belastning. För storskaliga digitala fastigheter, förvänta dig tusentals till miljoner händelser per minut. För att säkerställa genomströmning och motståndskraft:
- Använd SDK:s inbyggda mekanismer för batchning och försök igen för sidor med hög trafik.
- Hantering av avlastningsskurar till Marketing Clouds buffertlager för streaming.
- Övervaka genomströmning och felförhållanden för intag med hjälp av instrumentpanelen för anslutarmått.
Delstatshantering
Varje händelse innehåller metadata för status- och versionshantering:
- Schemaversioner: Bädda in schemaversionen i varje händelse; versionera personanpassningsanslutaren när du uppdaterar schemat.
- Reprishantering: Händelser som misslyckas på grund av tillfälliga nätverksproblem försöks automatiskt av SDK med exponentiell backoff.
- Idempotensnycklar: Unika identifierare (sessionId + eventType + tidsstämpel) säkerställer att repriserade händelser inte skapar dubbletter i Data 360.
- Kompensationshantering: Data 360 följer framgångsrika åtaganden; alla obearbetade händelser placeras i kö igen av anslutaren tills de intas.
Komplexa integreringsscenarion
Detta mönster integreras sömlöst i avancerade företagsarkitekturer:
- Kantberikningslager: Lägg till mellanprogramvara (t.ex. omvänd proxy eller serverlös funktion) för att infoga ytterligare sammanhang — som geo, enhetstyp eller kampanjmetadata — innan händelser når Marketing Cloud.
- Hybrid(Streaming + Batch): Använd Marketing Cloud-anslutaren för realtidsströmmar och kombinera den med batch-ETL-jobb (t.ex. orderdata) för avstämning längre ner.
- Agentaktivering: Händelser mappade till DMO i realtid kan utlösa Einstein Personanpassning, Agentforce eller AI-drivna beslut för att anpassa den digitala upplevelsen i ögonblicket.
- Styrning av flera arrendatorer: Använd samtyckesflagg och arrendatorbaserade metadata för att tillämpa sekretess och efterlevnad i miljöer med flera varumärken eller regioner.
Exempel
Ett globalt e-handelsföretag levererar personliga produktrekommendationer och dynamiskt innehåll till kunder medan de aktivt surfar på www.retailx.com, ett React-baserat program på en sida. Med Salesforce Interactions SDK på klientsidan samlar webbplatsen in sidvisningar, produktklick, varukorgsåtgärder och videointeraktioner i Real-Time. Dessa händelser flödar genom händelseströmmen Marketing Cloud Personalization och anslutaren Personanpassning till Data 360 DLO, där de modelleras till DMO och införlivas i realtidsgrafen. Denna arkitektur gör beteendesignaler direkt tillgängliga för segmentering, Einstein driven personanpassning och Agentforce aktivering, vilket möjliggör responsiva kundupplevelser under sessionen
Sammanhang
För många affärskritiska processer är det viktigt att hålla Data 360 perfekt i linje med de senaste uppdateringarna i CRM-kärnsystem. Kundtjänst-, försäljnings- och marknadsföringsteam är beroende av uppdaterad information för att driva beslut, utlösa resor och aktivera automatisering. Detta mönster ger en mekanism för att synkronisera ändringar av viktiga Salesforce CRM-objekt—som Kontakt, Konto och Kundcase—till Data 360 med minimal fördröjning, utan ineffektiviteten eller latensen av frekvent batchomröstning.
Problem
Hur kan Data 360 upprätthålla ett nästan perfekt synkroniserat läge med viktiga Salesforce CRM-objekt, vilket säkerställer att analyser, segmentering och AI-driven aktivering längre ner alltid fungerar med de mest aktuella data som finns tillgängliga?
Krafter
Detta mönster introducerar flera tekniska begränsningar och arkitektoniska överväganden:
- Händelsedriven arkitektur : Synkronisering måste vara reaktiv—drivs av ändringshändelser i CRM-källorganisationen istället för periodiska batchjobb.
- Stöd för selektiva objekt : Inte alla Salesforces standardobjekt och egna objekt har stöd för streaming i realtid. Arkitekter måste referera objektlistan som stöds under designen för att undvika luckor.
- Åtkomst och behörigheter : Att aktivera streaming kräver att integreringsanvändaren i källorganisationen tilldelas systembehörigheten "Aktivera behörigheter för CRM-streaming".
- Datafräschhet vs. Bearbetningskostnad : Synkronisering nästan i realtid förbättrar responsen, men överdriven händelsegenomströmning kan kräva horisontell skalning och robusta mekanismer för felåterställning.
- Integrering av lager för säkerhet och förtroende : Alla händelsedata måste följa Salesforces Trust- och säkerhetsramverk – krypterade under överföring, validerade för schemaefterlevnad och bearbetade inom organisationens Trust.
Lösning
Den rekommenderade metoden är att använda Salesforce CRM-anslutaren med Streaming (Ändra datainsamling) aktiverat. När du skapar en dataström för ett CRM-objekt som stöds (t.ex. Kontakt) kan administratörer växla mellan alternativet "Aktivera streaming". Salesforces plattform för datainsamling (CDC) publicerar ett ChangeEvent-meddelande varje gång en post skapas, uppdateras, tas bort eller inte tas bort i källorganisationen för CRM. Data 360 CRM-anslutaren prenumererar på dessa CDC-händelser och tillämpar motsvarande ändringar av det mappade Data Lake-objektet (DLO) i Data 360 nästan i realtid. Detta säkerställer kontinuerlig synkronisering mellan CRM och Data 360 med minimalt manuellt ingripande.
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| CDC-baserad streaminganslutare | Bästa | Ursprunglig Salesforce-mekanism; fullständigt hanterad och integrerad med plattformshändelseinfrastruktur. |
| Eventprenumeration och -leverans | Bästa | Anslutaren prenumererar på ChangeEvent-kanaler (t.ex. /data/ContactChangeEvent) via hållbara repris-ID:n. |
| Datamappning och schemautveckling | Bästa praxis | Mappa strömmade belastningar till motsvarande DLO. Hantera schemaversioner i metadata för att förhindra intagsavbrott. |
| Återställning av repris och fel | Rekommenderad | Använd repris-ID och idempotensnycklar för att undvika dubbletter och återställa från tillfälliga fel. |
| Hybridläge (Streaming + Batch) | Valfritt | För objekt som inte stöds eller inledande massinläsning, använd batchintag i kombination med CDC-streaming. |
| När du inte ska använda | Suboptimal | Detta mönster kan vara inte optimalt om: Källobjektet är inte CDC-aktiverat. Användningsfallet kräver inga uppdateringar i realtid (batch är tillräckligt). Nätverksutträde från källorganisationen begränsas eller händelsegränser överskrids. |
Skiss
Detta diagram illustrerar sekvensen av steg för att ta in data från CRM till Data 360 i nearReal-Time
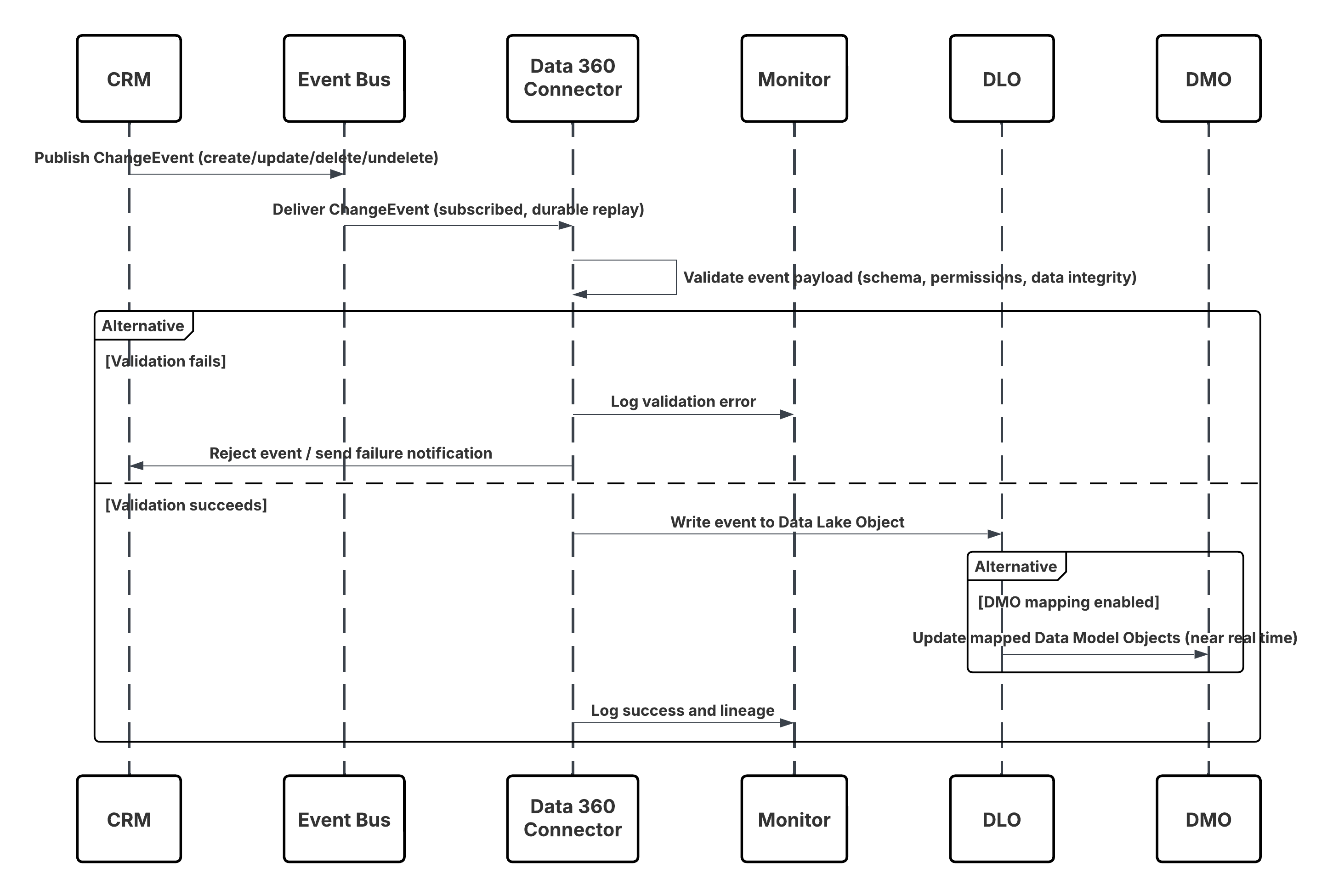
I detta scenario:
- Ändring inträffar i Salesforce CRM (skapa/uppdatera/ta bort/ångra).
- CDC publicerar en ChangeEvent till den interna Salesforce-händelsebussen.
- Data 360 CRM-anslutaren prenumererar på händelsebussen med en hållbar reprismarkör.
- Händelsebelastning valideras för schema, behörigheter och dataintegritet.
- Data 360 skriver den validerade händelsen till det mappade Data Lake-objektet (DLO).
- Om detta är aktiverat uppdateras mappade datamodellobjekt (DMO) i nearReal-Time, vilket driver segmentering och aktivering.
Resultat
Data 360 upprätthåller en kontinuerligt synkroniserad spegel av viktiga CRM-data. Detta aktiverar:
- Utlösare i realtid (t.ex. Journey öppnas när ett kundcase skapas).
- Uppdaterad segmentering (t.ex. flytta kunder till segmentet "Guld" vid ändring av kontostatus).
- Mer korrekta analyser och personanpassning baserat på live CRM-sammanhang.
Intagsmekanismer
Intagsmekanismen för detta mönster hanteras inbyggt genom Salesforce CRM-anslutaren med aktiverad datainsamling (CDC). Data 360 fungerar som en prenumerant på CDC-händelseströmmen, vilket säkerställer pålitlig synkronisering med låg latens mellan källorganisationen för CRM och Data 360.
| Mekanism | När man ska använda |
|---|---|
| Streaming via CDC (Föredragen) | För alla Salesforces standardobjekt och egna objekt som stöds där synkronisering nästan i realtid krävs. |
| Hybridläge (CDC + Batch) | För objekt som ännu inte är CDC-aktiverade eller där inledande historisk inläsning krävs. |
| Reprisprenumerationsläge | För återsynkronisering efter nedtid eller distribuering. |
| Felisoleringsläge | För test- och valideringsmiljöer. |
Felhantering och återställning
- Automatisk felåterställning: CRM-anslutaren försöker automatiskt tillfälliga nätverks- eller plattformsfel med exponentiell backoff och dirigerar bestående fel till Dead-Letter-kön (DLQ) för repris.
- Schema- och autentiseringsresiliens: Schemafelmatchningar placeras i karantän i kön Schemaavvisande för administratörsgranskning, medan autentiserings- eller behörighetsfel utlöser kontrollerade försök och varningar genom Data 360-övervakning.
- Garanterad händelsekontinuitet: Varaktiga ReplayID:n säkerställer ingen händelseförlust under nedtid för anslutaren. Missade händelser hydreras genom reprisfönster eller batch-omsynkroniseringsjobb.
- Dataintegritet och ordning: Inbyggd idempotens (RecordID + SequenceNumber) förhindrar dubbletter och ChangeEventHeader.sequenceNumber bevarar korrekt händelseordning för varje CRM-post.
Att tänka på vad gäller Idempotent design
- Händelseunikitet: Varje CDC-händelse har ett ReplayID och ChangeEventHeader.entityName för deterministisk deduplicering.
- Infoga strategi: Implementera UPSERT-logik baserat på post-ID för att säkerställa att upprepade händelser inte skapar dubbletter.
- Reprishantering: Använd anslutarens reprismarkör för att återuppta från den senaste förskjutningen i händelse av tillfälliga fel.
- **Schemautveckling: **Upprätthåll en schemaversion i händelsemetadata och uppdatera DLO-mappningar när CRM-schemat ändras.
Att tänka på vad gäller säkerhet
Säkerhet är en integrerad del av pipelinen för intag, från autentisering till kryptering och åtkomstkontroll.
- Encryption and Trust : Alla händelser överförs med TLS 1.2+ och lagras krypterade i vila i Data 360.
- Åtkomstkontroll: Endast autentiserade anslutare med lämpliga integreringsbehörigheter kan prenumerera på CDC-kanaler.
- Schemavalidering: Varje händelsebelastning valideras mot DLO-schemat innan intag.
- Samtyckespropagering: Metadata för samtycke och dataklassificering flödar längre ner med varje händelse för att bevara sekretess och efterlevnad (GDPR, CCPA).
- Operativ styrning: Händelser loggas, granskas och övervakas för repris, schemaavvisande och genomströmningsavvikelser via Data 360 Trust Layer.
Sidofält
Aktualitet
- CDC-händelser bearbetas nästan i realtid—vanligtvis inom några sekunder efter ändringen i CRM.
- Latens kan variera beroende på händelsevolym och anslutargenomströmning, men Data 360 garanterar tillgänglighet under minuter för objekt som stöds.
Datavolymer
- Varje händelsebelastning är lätt (~1–5 KB).
- För objekt med hög ändringsfrekvens som Kundcase eller Kontakt, se till att genomströmningsgränserna stämmer överens med Salesforce CDC-händelseallokeringar.
Delstatshantering
Varje händelse innehåller metadata för status- och versionshantering:
- Repris-ID: Används för sekventiell händelseåterställning.
- Schemaversioner: Hantera versionsmetadata för att hantera kontraktändringar.
- Idempotensnycklar: Deduplicera repriser över försök.
- Kompensationsförpliktelse: Data 360 behåller överlämningsläget efter varje framgångsrik sats av händelser.
Komplexa integreringsscenarion
Detta mönster integreras sömlöst i avancerade företagsarkitekturer:
- Hybrid(Streaming + Batch): Använd CDC för deltauppdateringar och massjobb för fullständiga uppdateringar.
- Streaming mellan organisationer: Flera källorganisationer kan strömma till samma Data 360-arrendator, sammanslagna via DMO-mappningar.
- Agentaktivering: Objektuppdateringar i realtid utlöser automatiseringar med Einstein eller Agentforce.
- Händelsedirigering: Middleware (t.ex. MuleSoft eller Event Relay) kan berika eller dirigera CDC-meddelanden innan intag.
Exempel
En global bank vill säkerställa att ändringar av kunddata i Salesforce Sales Cloud omedelbart återspeglas i Data 360.När en kontakts adress uppdateras i Sales Cloud publicerar mekanismen för datainsamling av ändringsdata en ContactChangeEvent.Data 360 CRM-anslutaren konsumerar denna händelse, tillämpar uppdateringen av Kund-DLO och uppdaterar automatiskt alla associerade Customer 360. Detta utlöser en Einstein Next Best Action för att verifiera den nya adressen—slutföra feedbackloopen inom några sekunder efter den ursprungliga CRM-ändringen.
Sammanhang
Moderna digitala företag förlitar sig på händelsestreamingplattformar i realtid som Amazon Kinesis-dataströmmar och Amazon MSK (hanterad strömning för Apache Kafka) för att samla in kontinuerliga dataflöden från distribuerade program, IoT-enheter och transaktionssystem. Data 360 möjliggör direkt intag från dessa plattformar genom inbyggda anslutare från första part — vilket eliminerar behovet av egna ETL- eller middleware-baserade lösningar. Detta mönster är utformat för dataintag med hög genomströmning och låg latens, vilket driver insikter nästan i realtid, personanpassning och AI-driven aktivering.
Problem
Hur kan ett företag säkert och effektivt ansluta Data 360 till AWS Kinesis- eller AWS MSK Kafka-ämnen för att kontinuerligt ta in strukturerade händelse- och profildata, vilket säkerställer schemaefterlevnad, skalbarhet och styrning?
Krafter
Detta mönster introducerar flera arkitektoniska och operativa överväganden:
- Inbyggd anslutartillgänglighet: Salesforce tillhandahåller allmänt tillgängliga inbyggda anslutare för både Amazon Kinesis och Amazon MSK. Dessa anslutare erbjuder stöd från första part och eliminerar behovet av egna API-baserade pipelines.
- Autentisering och säkerhet: Varje anslutare kräver AWS-nivåautentisering.
- För Kinesis använder detta AWS-åtkomstnyckel och hemlig nyckel, som styrs av IAM-policyer.
- För MSK kan autentisering konfigureras via åtkomstnyckel/hemlig eller OpenID Connect (OIDC).
- Schemadefinition: Data 360 kräver ett schema för att tolka streamingbelastningen. För Kinesis laddas schemafilen upp under anslutningskonfigurationen och definierar händelsestruktur och fältmappningar.
- Konfigurationskälla:
- Kinesis-anslutaren prenumererar på ett specifikt Kinesis Stream-namn.
- MSK-anslutare prenumererar på ett Kafka-ämne inom MSK-klustret.
- Nätverksåtkomst: För säkra miljöer kan anslutare konfigureras med PrivateLink- eller VPC-dirigering, vilket säkerställer att inga data korsar det offentliga internet.
- Operativ styrning: Streaminggenomströmning, schemavalidering och autentiseringshändelser övervakas inom Data 360 Trust Layer, vilket säkerställer efterlevnad och spårbarhet.
Lösning
Lösningen använder de inbyggda Amazon Kinesis- eller Amazon MSK-anslutarna i Data 360.
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| Inbyggd Kinesis-anslutare | Bästa | Förstapartsintegrering med AWS Kinesis; har stöd för kontinuerligt intag med hög genomströmning. |
| Inbyggd MSK-anslutare | Bästa | Hanterat Kafka-intag med OIDC och nyckelbaserad autentisering. |
| Schemamappning och validering | Bästa praxis | Uppladdningsschema (.json/.avro) definierar händelsestruktur; upprätthåller enhetlighet under intag. |
| IAM-konfiguration | Rekommenderad | Tilldela IAM-roll med minst behörighet med skrivskyddad åtkomst till mål för Kinesis-ström eller MSK-ämne. |
| Dirigering av privat nätverk | Valfritt | Konfigurera PrivateLink/VPC-slutpunkter för säker, intern dirigering. |
| Hybridmönster(Streaming + Batch) | Valfritt | Använd streaming för deltan och batchintag för återfyllning eller historiska inläsningar. |
| Felisoleringsläge | Rekommenderad | Avvisande av dirigeringsschema och tillfälliga fel till DLQ för repris |
Skiss
Detta diagram illustrerar sekvensen av steg för att ta in data från händelseplattformar som Kafka och Kinesis i Data 360 i nearReal-Time
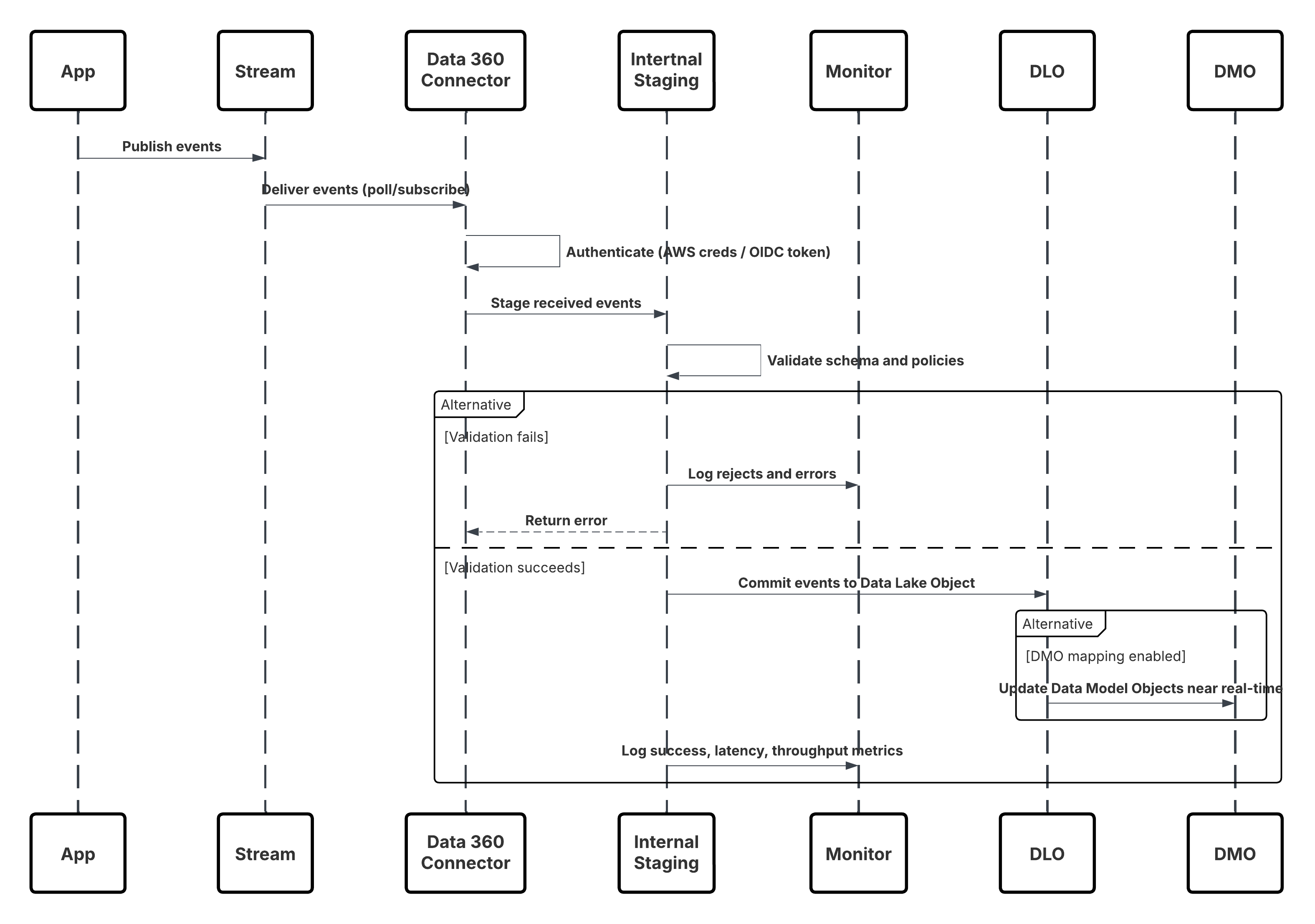
I detta scenario:
- Program eller enheter publicerar händelser till Kinesis Stream eller MSK-ämne.
- Data 360-anslutare autentiseras med AWS-inloggningsuppgifter eller OIDC-token.
- Connector röstar eller prenumererar kontinuerligt på strömmen.
- Händelser fasas, valideras för schema och policy och överlämnas sedan till Data Lake Object (DLO).
- Om de mappas uppdateras datamodellobjekt (DMO) nästan i realtid för aktivering.
- Bevakningslager följer mått, schemaavvisande och latens.
Resultat
Kontinuerligt intag med låg latens av strukturerade data direkt från AWS Kinesis eller MSK till Data 360. Data är omedelbart tillgängliga för:
- Identitetslösning
- Realtidssegmentering
- Einstein AI-aktivering
- Agentforce-driven Triggers Utesluter beroendet av batch-ETL, vilket möjliggör strömbaserade arkitekturer i linje med företagets händelsedrivna design.
Intagsmekanismer
| Mekanism | När man ska använda |
|---|---|
| Kinesis-anslutare (föredragen) | För AWS-inbyggda streamingkällor som kräver kontinuerligt intag av strukturerade data med hög volym. |
| MSK-anslutare | För organisationer som kör händelsepipeline på Kafka-kompatibla plattformar. |
| Hybrid(Streaming + Batch) | För inkrementellt händelseintag kombinerat med periodisk massbelastning. |
Felhantering och återställning
- Automatiska försök: Anslutare försöker igen tillfälliga nätverks- eller plattformsfel med exponentiell backoff.
- Schemaavvisande: Ogiltiga payloads dirigeras till schemaavvisandekön för administratörsgranskning.
- DLQ-repris: Ihållande fel samlas in i köer med döda bokstäver för ombearbetning.
- Idempotenskontroll: Händelsenycklar eller sekvensnummer säkerställer avduplicering och ordnat intag.
- Bevaka integrering: Alla fel, försök och genomströmningsmått visas i instrumentpaneler för Data 360-övervakning.
Att tänka på vad gäller Idempotent design
- Unikitet och spårning av händelser: Varje händelse tilldelas en deterministisk unik nyckel (t.ex. PartitionKey + SequenceNumber för Kinesis eller Ämne + Partition + Förskjutning för MSK) för att säkerställa exakt intag en gång.
- Kontrollpunkt för anslutare: Data 360-anslutare behåller den senast bearbetade förskjutningen eller sekvensnumret för att återuppta intaget säkert efter fel eller omstarter.
- Deduplicering och UPSERT-logik: Under DLO-överlämningar upptäcks och hoppas dubbletter över; giltiga poster infogas med den unika nyckeln för att upprätthålla enhetlighet.
- Repris- och återställningskontroll: Misslyckade eller försenade händelser spelas upp igen från lagrade förskjutningar genom köer med döda bokstäver och repris, vilket säkerställer pålitlig återställning utan dubbletter.
Att tänka på vad gäller säkerhet
Säkerhet är en integrerad del av pipelinen för intag, från autentisering till kryptering och åtkomstkontroll.
- Autentisering: Säkert utbyte av inloggningsuppgifter med AWS IAM-policyer eller OIDC.
- Kryptering: Data krypterade under överföring (TLS 1.2+) och i vila (AES-256) inom Data 360.
- Åtkomstkontroll: Roller med minst behörighet tillämpas; anslutare begränsade till specifika strömmar/ämnen.
- Styrning: Metadata för härkomst och klassificering som tillämpas för varje post för fullständig spårbarhet.
- Nätverkssäkerhet: Distribuera om du vill inom privata undernät med AWS PrivateLink.
Sidofält
Aktualitet
- Bearbetar nästan i realtid: CDC- och streaminganslutare bearbetar händelser inom några sekunder efter källändringar, vilket vanligtvis säkerställer att data är färska under en minut.
- Deterministisk latens: Fördröjning från början till slut beror på källgenomströmning, händelsebuntning och nätverksvillkor, men Data 360 garanterar förutsägbar latens för servicenivåavtalsdrivna objekt som stöds.
- Elastisk skalning: Intagspipeline skalas automatiskt under hög händelsevolym, vilket bevarar aktualitet även under datatoppar.
- Operativ synlighet: Att bevaka instrumentpaneler exponerar händelseförsening, överlämnar tidsstämplar och reprisstatus för latensgaranti och felsökning.
Datavolymer
- Lätta belastningar: Enskilda CDC- eller streaminghändelser är kompakta (1–5 KB typisk storlek), optimerade för uppdateringar med hög frekvens.
- Objekt med hög ändring: För flyktiga enheter (t.ex. Kundcase, Kontakt, Order) måste arkitekter säkerställa CDC-allokeringar och händelsegenomströmning i enlighet med förväntade uppdateringsresultat.
- Parallella strömmar: Data 360 har stöd för intag av flera strömmar för horisontell skalning över stora objektvolymer eller flera källorganisationer.
- Baktryckshantering: Inbyggda strypmekanismer bibehåller stabiliteten vid intag under belastning utan att tappa händelser.
Delstatshantering
Varje händelse innehåller metadata för status- och versionshantering:
- Repris- och förskjutningsspårning: Varje händelse bär metadata för Repris-ID och sekvens, vilket möjliggör beställd leverans och kontrollpunktsbaserad återställning.
- Schemaversioner: Versionstaggar i händelsesidhuvuden säkerställer bakåtkompatibel bearbetning när källscheman utvecklas.
- Idempotensnycklar: Varje händelse innehåller en unik transaktions- eller överlämningsnyckel som låter Data 360 avduplicera repriser och försök på ett säkert sätt.
- Atomiskt åtagande: Intagspipeline markerar endast förskjutningar som slutförda när åtaganden längre ner till DLO lyckas, vilket säkerställer enhetlighet.
Komplexa integreringsscenarion
Detta mönster integreras sömlöst i avancerade företagsarkitekturer:
- Hybridintag: Kombinera CDC för inkrementella deltan med massdataströmmar för fullständiga uppdateringar, med bibehållen fräschör och fullständighet.
- Streaming mellan organisationer: Flera CRM- eller ERP-organisationer kan publicera till samma Data 360-arrendator, sammanslagna genom DMO-mappning och ontologianpassning.
- Händelseförbättring: Middleware (t.ex. MuleSoft, Event Relay) kan berika, filtrera eller dirigera strömmande data innan de når Data 360.
- AI och agentaktivering: Uppdateringar i realtid utlöser automatisering längre ner, som Einstein förutsägelser eller Agentforce svar, inom några sekunder efter den ursprungliga händelsen.
Exempel
Ett globalt detaljhandelsföretag använder AWS Kinesis för att strömma data om försäljningsställen och webbinteraktioner.Data 360:s Kinesis-anslutare autentiseras via IAM-inloggningsuppgifter och tar kontinuerligt in händelser i ett transaktions-DLO.Varje post schemavalideras, berikas med metadata och propageras omedelbart till Kund-DMO.Inom några sekunder uppdaterar Einstein AI-modeller kundsegment och Agentforce utlöser rekommendationer om nästa bästa erbjudande i realtid – vilket ger en fullständigt händelsedriven personanpassningsloop.
Zero Copy är mer än en integreringsmetod — det är en grundläggande förändring i hur företagsdata rör sig, eller snarare inte rör sig. Tidigare krävde dataintegrering kopiering av stora volymer poster genom ETL-pipeline, vilket skapade överflödiga datalagringar, synkroniseringsfördröjningar och styrningsutmaningar. Zero copy eliminerar allt detta. I denna modell ansluter Data 360 direkt till externa dataplattformar som Snowflake och Databricks och läser och aktiverar data på plats på ett säkert sätt – utan att någonsin flytta eller duplicera dem. Resultatet är en sömlös bro mellan ditt företags datasjöhus och Salesforces ekosystem, vilket ger direkt åtkomst, lägre operativ overhead och starkare datastyrning.
Funktioner för inkommande nollkopiering låter Data 360 fråga och harmonisera externa data vid källan — som kundprofiler, transaktioner eller produktdata — som lagras i Snowflake eller Databricks. Istället för att ta in filer etablerar Data 360 en säker, metadatamedveten anslutning som använder befintliga schemadefinitioner och säkerhetspolicyer i den externa lagerbyggnaden.
- Direkt federation: Data 360 läser data på plats genom säkra, optimerade sökfrågor utan replikering.
- Samlad styrning: Data förblir under källsystemets ramverk för säkerhet, åtkomstkontroll och efterlevnad.
- Operativ effektivitet: Eliminerar ETL-overhead och lagringsduplicering, vilket minskar kostnader och komplexitet.
- Beredskap i realtid: Aktiverar harmonisering på begäran — i samma ögonblick som data uppdateras i Snowflake är de omedelbart tillgängliga för aktivering i Data 360.
Sammanhang
Moderna datadrivna företag hanterar petabyte av kund-, transaktions- och telemetridata inom molnskaliga datasjöhusplattformar som Snowflake och Databricks. Dessa miljöer fungerar som den enskilda källan för analys, AI och efterlevnad. Data 360 introducerar Zero CopyData Federation, vilket låter Data 360 direkt fråga och använda externa datauppsättningar på plats – utan att kopiera, transformera eller lagra överflödiga data. Detta mönster ger organisationer möjlighet att utöka Customer 360 till sin befintliga infrastruktur för datalager eller sjöbodar – och uppnå en sammanslagning och aktivering i realtid utan dubbletter, latens och kompromisser vad gäller styrning.
Problem
Hur kan företag använda rika datauppsättningar som redan är utvalda i Snowflake, Databricks eller öppna sjöformat som Apache Iceberg — för segmentering, identitetslösning och aktivering i Data 360 — utan kostnaden, latensen och styrningen över ETL-pipeline eller fysisk dataflyttning?
Krafter
Detta mönster introducerar flera överväganden vad gäller arkitektur, säkerhet och prestanda:
Nätverk och säkerhet
- Data 360 måste etablera en säker, privat anslutning till det externa lagerhuset eller sjöhuset.
- Konfigureras vanligtvis med Salesforce Private Connect eller PrivateLink/VPC Peering, vilket säkerställer att trafik aldrig lämnar kundens kontrollerade nätverk.
- Externa system måste tillåtelselista Data 360 IP-adresser och tillämpa TLS 1.2+-kryptering.
Autentisering och åtkomstkontroll
- Stöder nyckelparautentisering, OAuth 2.0 eller identitetsleverantörsbaserad (IdP) Trust Delegering (Data 360 fungerar som en betrodd klient)
- Rollbaserad åtkomstkontroll (RBAC) i det externa systemet tillämpar minst behörighetsåtkomst för körning av sökfrågor.
Prestanda- och beräkningsberoende
- Sökfrågefederation trycker ner SQL-körning till Snowflake eller Databricks och använder deras beräkningskluster.
- Prestanda och kostnadsskala med extern sökfrågebelastning — segmenteringslatens och kostnad är knutna till extern beräkningskonfiguration.
Utvecklade standarder: Filfederation
- En nästa generations modell, Filfederation, använder öppna tabellformat som Apache Iceberg eller Delta Lake, vilket gör att Data 360 kan läsas direkt från objektlagring (t.ex. Amazon S3, Azure ADLS, Google Cloud Storage).
- Genom att kringgå källberäkningslagret minskar filfederation drastiskt latens och kostnad för lästunga analytiska arbetsbelastningar samtidigt som schemats integritet bibehålls.
Styrning och efterlevnad
- Data lämnar aldrig källplattformen — efterlevnad, kryptering och lagringspolicyer tillämpas fortfarande vid ursprunget.
- Alla metadata, härkomst och samtyckesattribut propageras till Data 360s Trust Layer för att säkerställa spårbarhet från början till slut.
Lösning
Den rekommenderade metoden är att använda inbyggda Zero Copy-anslutare för Snowflake, Databricks eller Filfederation i Data 360.
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| Snowflake Zero Copy-anslutare | Bästa | Inbyggd integrering från första part; etablerar livefrågefederation via Snowflakes API för datadelning eller externa tabeller. |
| Databricks Zero Copy-anslutare | Bästa | Stöder direkt liveåtkomst till tabeller/vyer i Delta Lake; pushdown-frågor körs i Databricks runtime. |
| Filfederation (Apache Iceberg / Delta / Parkett) | Ny bästa praxis | Data 360 läser direkt öppna tabellformat från objektlagring utan externt beräkningsberoende. Idealisk för massiva datauppsättningar. |
| Konfiguration av privat nätverk | Rekommenderas | Använd Salesforce Private Connect eller VPC peering för säker nätverksnivåfederation. |
| Hantering av autentisering och nycklar | Bästa praxis | Implementera säker nyckelbaserad eller OAuth-baserad autentisering med periodisk rotation och valvhantering. |
| Schemaregistrering | Obligatoriskt | Data 360 hämtar externt schema och mappar det till ett externt datasjöobjekt (Externt DLO). |
| Styrda metadata | Rekommenderas | Alla externa DLO ärver klassificering, samtycke och härstamningsmetadata för efterlevnadssynlighet. |
Skiss
Följande diagram illustrerar hur du konfigurerar en nollkopieringsanslutning och skapar externa DLO i Data 360.
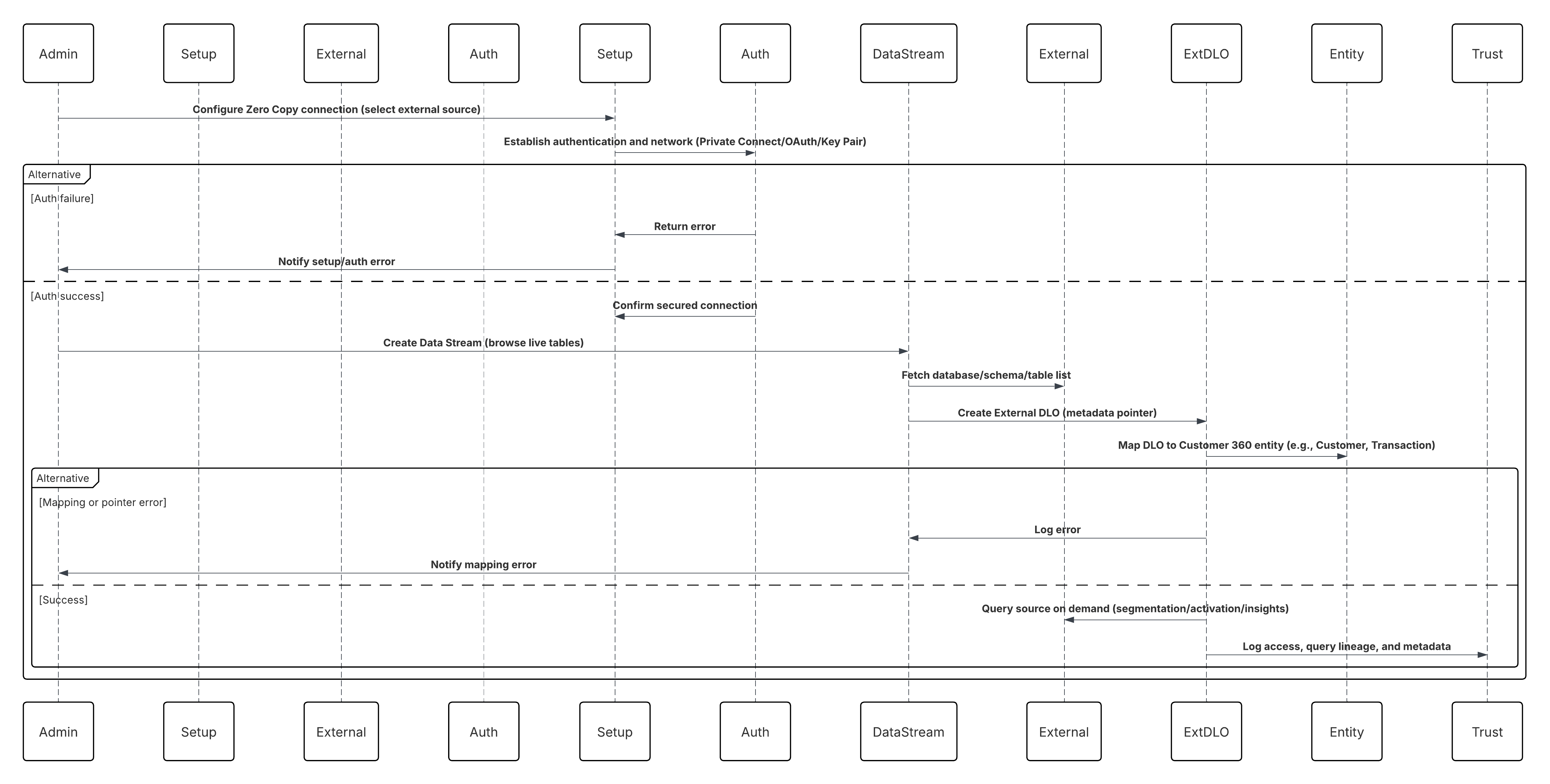
I detta scenario:
- Administratör konfigurerar en Zero Copy-anslutning i Data 360-inställningarna (Snowflake, Databricks eller Filfederation).
- Säker autentisering och nätverksdirigering etableras (Privat anslutning / OAuth / Nyckelpar).
- Administratör skapar en dataström som väljer den externa källan — bläddrar i livedatabaser, scheman och tabeller.
- Istället för att kopiera data skapar Data 360 ett externt DLO (Datasjöobjekt) — en metadatapekare som refererar till livetabellen eller Iceberg-filen.
- Externa DLO mappas till Customer 360 enheter (t.ex. Kund, Transaktion, Produkt).
- Data 360 frågar källan som finns under segmentering, aktivering eller insiktsberäkning.
- All åtkomst, härkomst och metadata granskas inom Data 360 Trust Layer.
Resultat
- Externa data finns kvar i Snowflake, Databricks eller S3 — ingen ETL, ingen duplicering, ingen ytterligare lagring.
- Data 360 får åtkomst i realtid till data i företagsskala för identitetslösning, beräknade insikter och aktivering.
- Organisationer behåller fullständig kontroll under sina befintliga ramverk för styrning, kryptering och efterlevnad.
- Detta mönster möjliggör en äkta Zero Copy-arkitektur — som kombinerar prestandan för lokal åtkomst med styrningen av sammanslagen lagring.
Anropsmekanismer
Anropsmekanismen beror på vilken lösning som valts för att implementera detta mönster.
| Mekanism | När man ska använda |
|---|---|
| Snowflake Federation (Föredragen) | För live, högpresterande sökfrågefederation med styrd datalagring för företag. |
| Databricksfederation | För sammanslagna analys- och sjöhusmiljöer med Delta- eller Parkettstödda datauppsättningar. |
| Filfederation (Apache Iceberg / Delta Lake) | För storskaliga datauppsättningar i objektlagring där beräkningsfrigörande och kostnadsoptimering är nyckeln. |
| Hybridläge (nollkopiering + intag) | När historiska data behöver engångsintag men livedata nås via Zero Copy. |
Felhantering och återställning
- Automatisk avstängning av försök och sökfrågor: Tillfälliga anslutnings- eller sökfrågetimeouter testas automatiskt med exponentiell backoff.
- Isolering av schemafelmatchning: Ändringar i källschema (t.ex. nya kolumner) loggas i kön Schemaavvisande. Administratörer kan mappa om eller uppdatera schemametadata.
- Autentiseringsfel: Om inloggningsuppgifter löper ut försöker Data 360 ansluta med lagrade uppdateringstokens eller nyckelrotationspolicyer.
- Beräkna tillgänglighetsdetektering: Om Snowflake- eller Databricks-kluster pausas avbryter Data 360 federationsjobb och försöker igen när beräkningen återupptas.
- Bevaka integrering: Alla anslutningshälsa, sökfrågelatens och härkomstmetadata synliga i instrumentpaneler för Data 360-övervakning.
Att tänka på vad gäller Idempotent design
- Frågedeterminism: Sammanslagna sökfrågor använder konsekvent ögonblicksbildsemantik för att säkerställa stabila, repeterbara läsningar under segmentering eller aktivering.
- Extern DLO-version: Varje sammanslagen sökfråga innehåller metadata om scheman och tidsstämplar för härkomstspårning.
- Offsetfri åtkomst: Eftersom Zero Copy är skrivskyddat förlitar det sig inte på händelseförskjutningar — enhetlighet upprätthålls via det externa systemets ACID-garantier (Snowflake/Delta Lake).
- Schemadrifthantering: Upprätthåll versionerade schemamappningar i Data 360; uppdatera externa DLO-metadata om källutvecklingen.
Att tänka på vad gäller säkerhet
Säkerheten är integrerad i hela federationsmodellen — vilket säkerställer att Trust eller efterlevnad inte kompromissar.
- Kryptering: Alla datautbyten använder TLS 1.2+; externa lager krypterar vid vila med AES-256.
- Åtkomstkontroll: Externa tabeller nås genom roller med minst behörighet med skrivskyddade behörigheter.
- Nätverksisolering: Privat anslutning eller VPC-rutter förhindrar exponering för offentliga slutpunkter.
- Styrt dataflöde: Metadata för härkomst, samtycke och klassificering flödar till Data 360 Trust Layer för policytillämpning.
- Granskningsbarhet: Varje sammanslagen sökfråga och schemaåtkomsthändelse loggas för spårbarhet av efterlevnad (GDPR, CCPA, HIPAA).
Sidofält
Aktualitet
- Sökfrågor körs live mot den externa lagerbyggnaden eller lagringen, vilket säkerställer synlighet i realtid för den senaste datastatusen.
- Segmenterings- eller aktiveringskörningar återspeglar aktuella ändringar i Snowflake-, Databricks- eller S3-stödda Iceberg-tabeller.
- Sökfrågelatens beror på prestandanivån i källsystemet — vanligtvis sekunder till tiotals sekunder per sökfråga.
- Idealisk för analytiska och AI-arbetsbelastningar som kräver "färsk, inte kopierad" dataåtkomst.
Datavolymer
- Stöder datauppsättningar i petabyteskala som lagras inbyggt i Snowflake eller Databricks utan replikering.
- Data 360 hämtar endast resultat — inte rådatauppsättningar — vilket minimerar nätverks- och beräkningskostnader.
- Filfederation optimerar stora analytiska skanningar genom partitionsbeskärning och kolumnär pushdown.
- Skalar linjärt med lagerberäkningskapacitet och Data 360:s sammanslagna frågeorkestreringslager.
Delstatshantering
- Externa DLO behåller metadata för anslutning, schema och version i Data 360.
- Schemautveckling hanteras automatiskt genom metadatauppdateringscykler.
- Sökfrågehärkomst inkluderar tidsstämplar, användaridentitet och utförandemått för spårbarhet.
- Inget intag eller förskjutningar bibehålls — enhetlighet ärvs från den externa källans ACID-garantier.
Komplexa integreringsscenarion
- Hybridläge: Kombinera Zero Copy (för livefederation) med intag (för historiska datauppsättningar).
- Åtkomst till korslager: Data 360 kan federeras från flera Snowflake- eller Databricks-arrendatorer inom en organisation.
- AI/BI-interoperabilitet: Externa system (t.ex. SageMaker, Tableau, Power BI) kan fråga Data 360:s utökade profiler via omvänd nollkopia.
- Filfederationens tillägg: Företag som börjar använda öppna sjöformat (Isberg/Delta) kan slå samman strukturerade och ostrukturerade data under en sammanslagen modell.
Exempel
Ett globalt finansföretag lagrar alla transaktions- och interaktionsdata i Snowflake, samtidigt som det behåller kundattribut och marknadsföringshändelser i Data 360. Med Zero Copy Data Federation ansluter Data 360 säkert till Snowflake via Privat anslutning.När ett segmenteringsjobb körs, t.ex. "Kunder med >10 000 SEK spenderar under de senaste 30 dagarna, trycker Data 360 ner sökfrågan till Snowflake, hämtar aggregerade resultat och aktiverar dessa profiler direkt i Journey Builder. Ingen replikering eller ETL behövs. Detta exempel använder sammanslagen intelligens i realtid som är sammanslagen över företagets dataekosystem.
Utgående nollkopia utökar samma princip omvänt. Istället för att exportera eller kopiera datauppsättningar från Data 360 kan externa system som Snowflake fråga Data 360 direkt och behandla dem som en sammanslagen källa för utökad Kundintelligens.
- Omvänd federation: Externa Analytics- eller AI-plattformar kan komma åt Data 360:s sammanslagna profildata utan att extrahera dem.
- Dataaktivering vid källan: Verksamhetsteam kan använda insikter där data redan finns — oavsett om det gäller AI-modellering, rapporter eller kundanpassning.
- Latensfri interoperabilitet: Inga batchexporter eller synkroniseringsjobb; insikter flödar direkt mellan plattformar.
- Konsekvent semantik: Eftersom båda systemen delar samma ontologi och schemamappningar bevaras sammanhang och mening i alla ekosystem. Zero copy omdefinierar rollen för Data 360 från ett datalager till ett semantiskt aktiveringslager. Det gör att organisationer kan hålla data exakt där de hör hemma – i styrda, högpresterande lagerbyggnader – och samtidigt låsa upp deras fulla värde innanför Salesforces Trust. Detta mönster överensstämmer med moderna datanät och inbyggda AI-arkitekturer: data förblir decentraliserade, men intelligens blir enhetlig. Arkitekter kan nu bygga aktiveringspipelines som är snabbare, smidigare och mer kompatibla — ingen kopiering krävs.
Sammanhang
Moderna företag arbetar i allt större utsträckning i dataekosystem med flera plattformar, där Salesforce Data 360 driver sammanslagna kundprofiler och aktivering, medan datalager för företag som Snowflake eller Databricks fungerar som analytiska ryggrader för datavetenskap, maskininlärning och BI-arbetsbelastningar. Salesforce Data 360:s kapacitet för utgående delning med noll kopia överbryggar sömlöst dessa miljöer — vilket ger styrd, säker åtkomst i realtid till harmoniserade Data 360-data direkt i Snowflake eller Databricks, utan replikering eller ETL. Detta låter analytiker och dataforskare fråga, visualisera och modellera på samma live, betrodda data som driver marknadsföring, försäljning och serviceaktivering.
Problem
Hur kan ett företag säkert och effektivt exponera Data 360:s sammanslagna kundprofiler och beräknade mått (t.ex. Livstidsvärde, Kundbortfallrisk) för externa analyssystem — utan att kopiera data, bryta styrningen eller införa latens genom traditionella omvända ETL-pipeline?
Krafter
Detta mönster introducerar flera överväganden vad gäller arkitektur, styrning och drift:
- Styrd säkerhet: Åtkomst till Data 360-data måste vara kontrollerad, detaljerad och granskningsbar. Zero Copy-delning använder uttrycklig objektnivååtkomst, vilket säkerställer att endast godkända datamodellobjekt (DMO) och beräknade insiktsobjekt (CIO) är tillgängliga för utsedda konsumenter.
- Explicit objektval: Administratörer väljer delningsbara data genom en datadelning och väljer uttryckligen vilka objekt som ska visas. Detta upprätthåller styrningen och minimerar riskexponeringen.
- Bilateral konfiguration: Både Data 360 och det externa lagerutrymmet behöver konfigureras. Data 360 definierar datadelningsmålet (Snowflake/Databricks), medan det mottagande systemet måste acceptera och instansiera delningen.
- Frågefederationsmodell: När den har accepterats frågar den externa plattformen live, styrda Data 360-data via sammanslagna vyer, vilket eliminerar extraheringsjobb eller manuella uppdateringscykler.
- Utveckling av öppna standarder: Framväxande metoder som Filfederation använder öppna tabellformat (t.ex. Apache Iceberg) för att aktivera skrivskyddad åtkomst i lagringslagret – vilket förbättrar skalbarhet, prestanda och interoperabilitet mellan flera molnarkitekturer.
Lösning
Lösningen använder Salesforce Data 360:s inbyggda Zero Copy-delning med dataplattformar som Snowflake eller Databricks.
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| Skapande av datadelning | Bästa | Administratör skapar en datadelning i Data 360 och lägger till valda DMO och CIO:er (t.ex. Sammanslagen individ, Kundhälsobetyg). |
| Målkonfiguration | Bästa | Skapa ett datadelningsmål som specificerar Snowflake- eller Databricks-kontoidentifierare och autentiseringsparametrar. |
| Dela publicering | Bästa praxis | Länka datadelningen till datadelningsmålet för att publicera säkert. |
| Lagergodkännande | Obligatoriskt | Den externa administratören accepterar delningen och materialiserar delade objekt som skrivskyddade vyer/tabeller i lagerbyggnaden. |
| Granulär åtkomstkontroll | Rekommenderas | Tillämpa objekt- och rollbaserade behörigheter inom Data 360; anpassa till rollbaserad åtkomstkontroll på lagernivå. |
| Åtkomst till sammanslagen sökfråga | Bästa | Analytiker frågar delade data live via standard-SQL; slår samman med inbyggda lagerdata för analyser längre ner och ML. |
| Filfederations-alternativ | Valfritt | För stora datauppsättningar, använd Apache Iceberg-baserad federation för direkta S3- eller Delta Lake-läsningar utan beräkningsberoende. |
Skiss
Följande diagram illustrerar ett anrop från Salesforce Data 360 till en extern dataplattform.
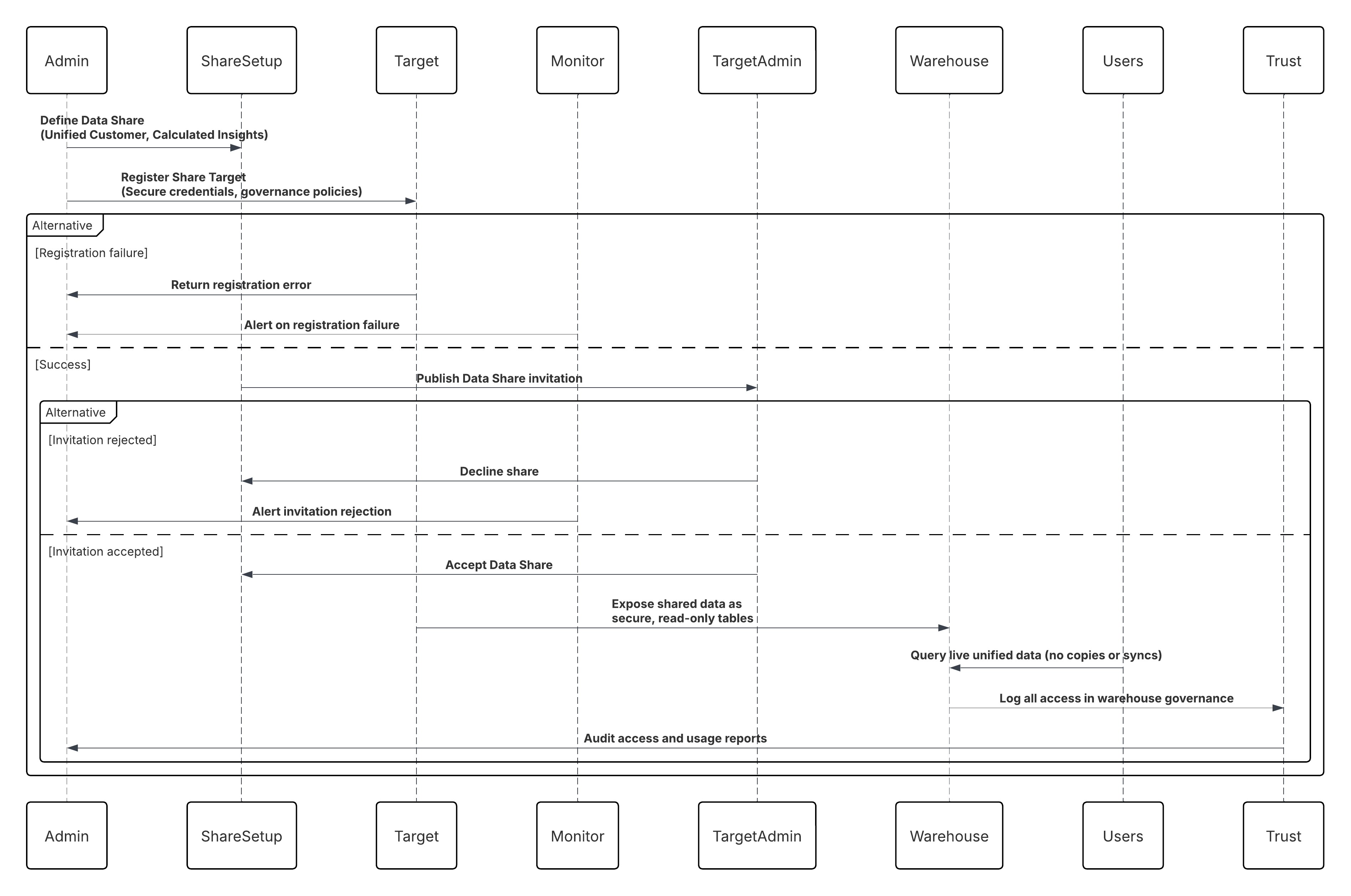
I detta scenario:
- Data 360-administratör definierar en datadelning inklusive objekten Sammanslagen kund och Beräknad insikt.
- Ett datadelningsmål (Snowflake- eller Databricks-konto) registreras med säkra inloggningsuppgifter och styrande policyer.
- Data 360 publicerar delningen; Snowflake/Databricks-administratörer accepterar den.
- Delade data visas som säkra, skrivskyddade tabeller i lagerbyggnaden.
- Analytiker, BI-verktyg eller ML-pipelines frågar live, enhetliga kunddata utan att kopiera eller synkronisera.
- All åtkomst granskas inom Data 360 Trust Layer och lagerstyrningsloggar.
Resultat
- Externa lagerbyggnader får sökbar åtkomst till harmoniserade Data 360-data i realtid.
- Utesluter omvända ETL-pipelines, vilket minskar den operativa bördan och latensen.
- Aktiverar AI/ML-utbildning, prediktiva modeller och avancerad BI direkt på sammanslagna data.
- Bibehåller noll dubbletter, stark styrning och inbyggd åtkomstkontroll.
- Slutför loopen Zero Copy i två riktningar, där inkommande federation och utgående delning samexisterar under en enda styrmodell.
Anropsmekanismer
Anropsmekanismen beror på vilken lösning som valts för att implementera detta mönster.
| Mekanism | När man ska använda |
|---|---|
| Snowflake-säker datadelning (föredragen) | Använd när ditt företags lager är Snowflake och du behöver live, styrd åtkomst till harmoniserade Data 360-datauppsättningar utan dataflyttning eller duplicering. Idealisk för analyser, AI och efterlevnadsdrivna arbetsbelastningar som kräver delning med noll latens och inbyggd härstamning. |
| Dela databricksdelta | Används när konsumenter längre ner arbetar i Databricks- eller Delta Lake-miljöer och kräver skrivskyddad åtkomst i realtid till sammanslagna eller aktiverade datauppsättningar via det öppna Delta Sharing-protokollet. |
| Extern tabelldelning (Apache Iceberg / Parkett) | Använd vid underhåll av arkitekturer i öppet format i objektlagring (S3, ADLS eller GCS) och som behöver interoperabel, billig delning mellan analytiska motorer som Athena, BigQuery eller Snowflake-on-Iceberg. |
| Data Share API (Programmatisk åtkomst) | Använd när egna appar eller mellanprogram (t.ex. MuleSoft) måste upptäcka, prenumerera eller konsumera delade datauppsättningar säkert via API:n, med händelsebaserade uppdateringsnotiser och finjusterad åtkomstkontroll. |
| Hybriddelning (noll kopia + utgående delning) | Använd vid implementering av utbytesmönster i två riktningar — använd Zero Copy för inkommande data och Utgående datadelning för att publicera insikter, vilket säkerställer semantisk och styrningsmässig enhetlighet över företagets dataplan. |
Felhantering och återställning
- Anslutningsförsök: Automatiserade försök för tillfälliga anslutnings- eller autentiseringsfel mellan Data 360 och lager.
- Dela validering: Ogiltiga eller oauktoriserade delningskonfigurationer placeras i karantän i en administratörsgranskningskö.
- Synkronisera hälsoövervakning: Data 360 lyfter fram livedelningsstatus, sökfrågelatens och åtkomstloggar via instrumentpaneler för övervakning.
- Åtkomståterkallande: Administratörer kan återkalla delningar direkt och inaktivera åtkomst i båda ändar utan restdatakopior.
- Styrd granskningslogg: Alla ändringar av konfiguration och åtkomst loggas för verifiering av efterlevnad.
Att tänka på vad gäller Idempotent design
- Konsekvent delningsidentifiering: Varje par av datadelning och datadelningsmål har en unik identifierare som säkerställer exakt styrning och åtkomstspårning.
- Oföränderliga vyer: Delade dataobjekt är skrivskyddade; konsumenter kan inte mutera status, vilket säkerställer deterministiska resultat och efterlevnad.
- Atomisk delnings livscykel: Dela publicering, återkallande och uppdateringar är kärnåtgärder — antingen helt slutförda eller tillbakadragna.
- Repriskonsekvens: När Data 360-data uppdateras returnerar sökfrågor på lagersidan alltid den senaste enhetliga ögonblicksbilden, vilket eliminerar gamla läsningar.
Att tänka på vad gäller säkerhet
Säkerhet stöder varje aspekt av nollkopieringsdelning:
- Autentisering: Mutual Trust etableras med OAuth 2.0, utbyte av privata nycklar eller identitetsfederation (OIDC).
- Kryptering: Data krypterade under överföring (TLS 1.2+) och i vila (AES-256).
- Åtkomstkontroll: Objektnivåbehörigheter tillämpar åtkomst med minst behörighet, styrd av Data 360 Trust Layer.
- Nätverkssäkerhet: Datautbyte sker genom privata nätverkslänkar som Salesforce Private Connect eller Secure Data Exchange API.
- Metadata för styrning: Varje delat objekt bär attribut för härkomst, klassificering och samtycke för fullständig spårbarhet och regelefterlevnad.
Sidofält
Aktualitet
- Tillgänglighet i realtid: Delade data återspeglar det senaste läget för Data 360 utan replikeringsfördröjningar.
- Sökfrågans färskhet: Ändringar i DMO eller CIO propageras direkt till delade lagervyer.
- Prestandaelasticitet: Pushdown för sökfrågor anpassas dynamiskt till lagerberäkningsresurser.
- Övervakar: Liveinstrumentpaneler exponerar delade latens- och sökfrågeprestandamått för verksamhetssäkerhet.
Datavolymer
- Skalbar delning: Stöder detaljerad datadelning på objektnivå eller fullständig domän beroende på analytiska behov.
- Optimerad sökfrågeprestanda: Snowflake/Databricks cachar delade data intelligent för att minimera latens.
- Lagringseffektivitet: Noll dubbletter eliminerar överflödiga lagringskostnader.
- Alternativ för filfederation: För datauppsättningar i petabyteskala kringgår direkt Iceberg-baserad delning beräkning och snabbar på åtkomst.
Delstatshantering
- Schemautveckling: Versionsstyrda scheman säkerställer kompatibilitet när Data 360-modellen utvecklas.
- Åtkomststatusspårning: Aktiva/inaktiva delningslägen som upprätthålls inom Data 360 för livscykelstyrning.
- Metadatasynkronisering: Uppdateringar av delade objektdefinitioner återspeglas automatiskt i lagerbyggnadskataloger längre ner.
- Oföränderlig statlig garanti: Lagerbyggnadsvyer representerar alltid ett enhetligt läge för Data 360-data vid en viss tidpunkt.
Komplexa integreringsscenarion
- Hybridläge: Kombinera Zero Copy (för livefederation) med intag (för historiska datauppsättningar).
- Åtkomst till korslager: Data 360 kan federeras från flera Snowflake- eller Databricks-arrendatorer inom en organisation.
- AI/BI-interoperabilitet: Externa system (t.ex. SageMaker, Tableau, Power BI) kan fråga Data 360:s utökade profiler via omvänd nollkopia.
- Filfederationens tillägg: Företag som börjar använda öppna sjöformat (Isberg/Delta) kan slå samman strukturerade och ostrukturerade data under en sammanslagen modell.
Exempel
Korsmolnanalys låter organisationer kombinera styrd Salesforce Data 360-data med inbyggda datauppsättningar på plattformar som Snowflake och Databricks för att leverera en fullständig, 360-graders analytisk vy. Genom åtkomst för flera arrendatorer kan olika affärsenheter säkert konsumera utvalda och policystyrda databitar via separata delningar utan att duplicera data. Dataforskare kan sedan utföra sammanslagen AI och maskininlärning genom att utbilda modeller direkt på sammanslagna kundprofiler inom Snowflake ML- eller Databricks MLflow-miljöer. Genom hela denna process säkerställer inbyggd härkomst, styrning och granskningsfunktioner att all dataåtkomst och användning fortsätter att uppfylla företagspolicyer och regelkrav som GDPR och HIPAA.
Data Cloud One låter organisationer med flera Salesforce-organisationer (till exempel på grund av affärsenheter, regioner, produktlinjer eller förvärv) dela en enda, central Data 360-instans. Denna organisation fungerar som "hemorganisation", medan andra organisationer, som kallas "följeslagare", kan komma åt och agera på dessa sammanslagna data — med minimal ansträngning, ingen egen kod och fullständiga styrningskontroller.
Sammanhang
Företag driver ofta mer än en Salesforce-organisation (till exempel en för försäljning, en för service, en för marknadsföring eller specifika regioner). Varje organisation kan ha sina egna data, konfigurationer och processer. Innan Data Cloud One behövde varje organisation antingen sin egen Data 360-konfiguration eller komplex egen kod för att dela data mellan organisationer. Data Cloud One förenklar detta genom att tillåta en enskild "hemorganisation" med Data 360 och flera "följeslagare" som ansluter via lågkodskonfiguration och metadatadelning.
Problem
Hur kan en verksamhet möjliggöra en konsekvent användning av sammanslagna Customer 360 — intagna, harmoniserade och hanterade av hemorganisationens Data 360 — i alla sina Salesforce-organisationer (så att försäljning, marknadsföring, service etc. alla använder samma underliggande data), samtidigt som dubbelarbete, egen kodning, separata Data 360-instanser per organisation och styrningsluckor undviks?
Krafter
Detta mönster introducerar flera överväganden vad gäller arkitektur, säkerhet och prestanda:
- Komplexitet i flera organisationer: Varje affärsenhets organisation kan ha olika data, egna objekt, säkerhet och processer—att upprätthålla enhetliga enhetliga vyer är svårt.
- Duplicering & kostnad: Att köra en separat Data 360-instans per organisation innebär extra konfiguration, extra styrning, extra licensiering och risk för datasilos.
- Kontroller för styrning och datadelning: Du måste bestämma vilka data varje medföljande organisation kan se och agera efter – du kan inte bara dela "allt" utan styrningsrisk.
- Konfigurationshastighet: Marknadsförings-, försäljnings- eller serviceteam kan inte vänta veckor på egen kod för att göra korsorganisationsdata tillgängliga—de behöver klickkonfigurationslösningar.
- Datalagring, regionala överväganden: Om hemorganisationer och medföljande organisationer finns i olika regioner kan det finnas juridiska eller lagstadgade begränsningar för var data lagras och hur de delas.
Lösning
Följande tabell innehåller olika lösningar på detta integreringsproblem.
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| Startorganisationsprovisionering | Bästa | Utse en Salesforce-organisation som den hemorganisation där Data 360 provisioneras; detta blir det centrala dataarkivet och styrningsnavet. |
| Kompanjonorganisationsanslutning | Bästa | Konfigurera Companion-anslutningar från hemorganisationen till en eller flera Companion-organisationer via Data Cloud One-appen — ingen egen kod krävs. |
| Datautrymmesdefinition | Bästa praxis | Definiera datautrymmen inom hemorganisationen för att logiskt segmentera data (t.ex. Butik, Service, Marknadsföring) och isolera åtkomstgränser. |
| Datautrymmesdelning | Bästa | Dela uttryckligen utvalda datautrymmen från hemorganisationen till kompanjonsorganisationer, vilket säkerställer styrd, rollbaserad synlighet för sammanslagna data. |
| Åtkomstkonfiguration | Obligatoriskt | I Companion-organisationer, aktivera appen Data Cloud One och tilldela användarbehörigheter för åtkomst till profiler, insikter och segment. |
| Styrning och policykontroll | Rekommenderas | Centralisera alla konfigurationer för intag, identitetslösning och Trust i hemorganisationen och upprätthåll en heltäckande styrning. |
| Synkronisering av flera organisationer | Bästa | Dataändringar och beräknade insikter i hemorganisationen återspeglas i Realtid i alla partnerorganisationer genom hanterade synkroniseringspipelines. |
| Alternativ för hybriddistribuering | Valfritt | För stora företag kan flera följeslagare ansluta till en enskild hemorganisation samtidigt som de behåller lokala sammanhang och efterlevnadsgränser. |
Skiss
Följande diagram illustrerar händelseförloppet i detta mönster, där Salesforce är huvuddata.
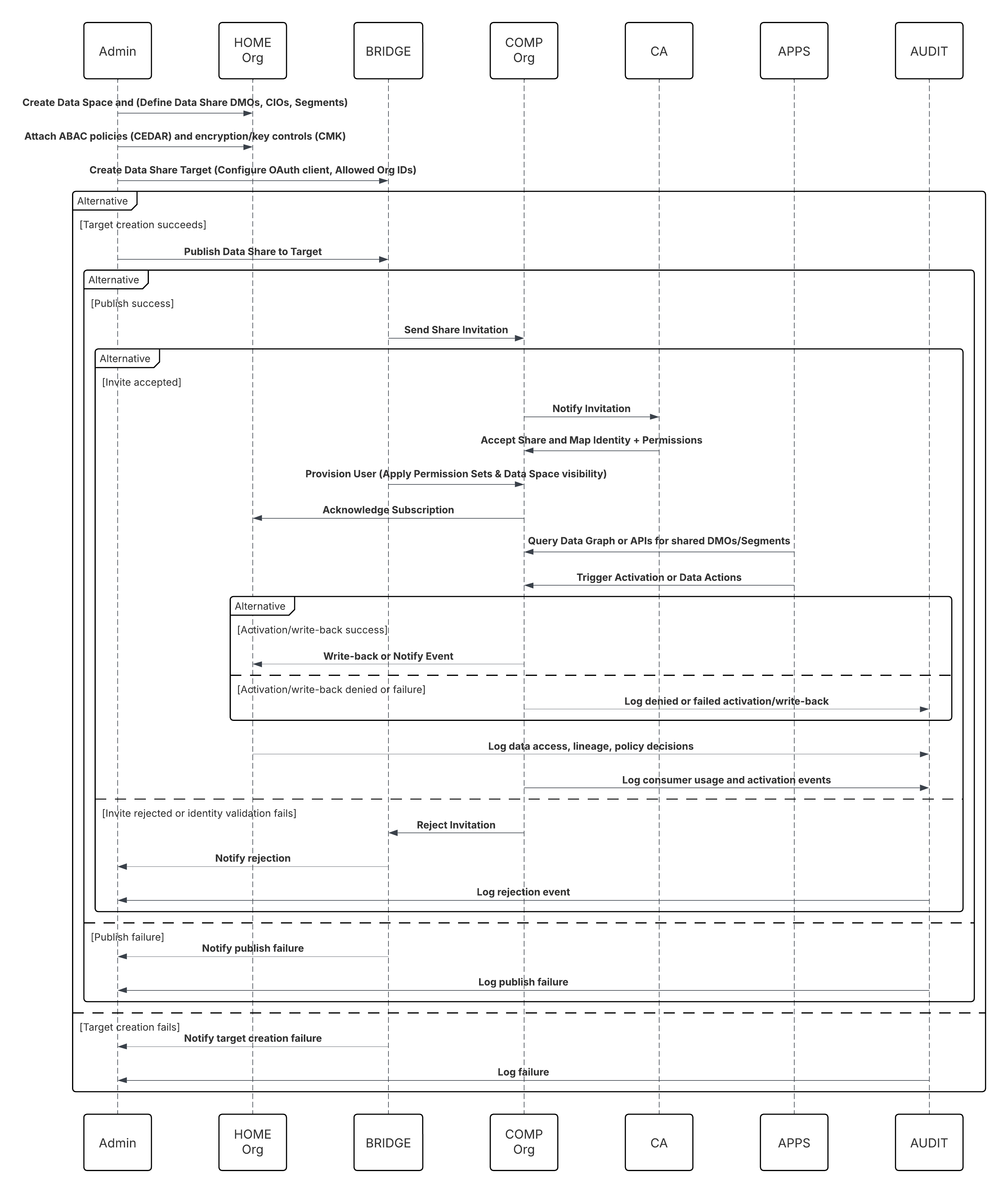
I detta scenario:
- Startadministratör: skapa datautrymme och definiera datadelning (välj DMO/CIO, segment).
- Hemadministratör: Skapa datadelningsmål för följeslagare och konfigurera Trust (OAuth-klient, tillåtna organisations-ID:n).
- Hemadministratör: publicera Datadelning till mål, bifoga ABAC-policyer (CEDAR) och kryptering/nyckelkontroller (CMK om det behövs).
- Companion Org Admin: tar emot inbjudan, validerar identitetsmappning och accepterar delning.
- Kompanjonsorganisation: Data Cloud One Bridge provisionerar en Data Cloud One-användare och tillämpar synlighet för behörighetsuppsättningar och datautrymme.
- Appar för följeslagare (flöden / Einstein / Apex): Fråga en datagraf eller anropa Data Cloud One API för att läsa delade DMO eller segment.
- Aktivering: Följeslagare utlöser aktivering eller skriver tillbaka via dataåtgärder (om tillåtet).
Resultat
- En enda källa för kunddata (Customer 360) i alla anslutna organisationer – inga överflödiga Data 360-instanser.
- En snabbare tid att värdera. Medföljande organisationer kan komma åt sammanslagna data och Data 360-drivna funktioner på bara några minuter, inte veckor med egen kodning.
- Styrd datadelning. Endast godkända datautrymmen delas, vilket bevarar säkerhet och styrning samtidigt som verksamheten är smidig.
- Verksamhetsfunktioner (försäljning, service, marknadsföring) arbetar på samma enhetliga datagrund, vilket möjliggör enhetliga mått, aktivering och insikter i hela företaget.
Anropsmekanismer
Anropsmekanismen beror på vilken lösning som valts för att implementera detta mönster.
| Mekanism | När man ska använda |
|---|---|
| Inbyggd delning för Data Cloud One (rekommenderas) | Använd när flera Salesforce-organisationer (försäljnings-, service- eller branschmoln) behöver åtkomst i realtid till sammanslagna kunddata direkt från Data 360\. Detta eliminerar replikering och aktiverar åtkomst utan latens till gyllene poster, segment och beräknade insikter. |
| Dela organisation-till-organisation via Data Cloud One-brygga | Används när flera affärsenheter eller dotterbolag arbetar i separata Salesforce-organisationer men behöver delad åtkomst till gemensamma kunddata och segment från en central Data 360-instans. Idealisk för företag med flera organisationer som upprätthåller oberoende operativsystem. |
| Einstein 1 Platform Query APIs | Används när Salesforce-appar, -flöden eller Einstein Copilot måste fråga eller aktivera Data 360-data programmatiskt. Aktiverar hämtning i realtid av sammanslagna profiler, mått eller aktiveringsresultat till andra Salesforce-program utan batchexporter. |
| Aktivering till Salesforce-kanaler | Använd när Data 360-data (segment, insikter eller attribut) måste aktiveras i Marketing Cloud, Service Cloud eller Commerce Cloud för personanpassning, kampanjkörning eller agenthjälpupplevelser. |
| Åtkomst till datagraf (semantiskt sökfrågelager) | Använd när du behöver åtkomst på semantisk nivå till den sammanslagna datamodellen via Salesforce Data Graph — med stöd för Copilot, AI-flöden och korsmolnanalyser i Real-Time, utan manuella sammanslagningar eller transformationer. |
Felhantering och återställning
- Motståndskraft för korssynkronisering: Data Cloud One försöker automatiskt utföra misslyckade synkroniseringsjobb mellan hem- och följeslagarorganisationer med exponentiell backoff för tillfälliga nätverks- eller plattformsfel.
- Delvis satsisolering: Misslyckade postsatser placeras i karantän i en kö för Försök igen inom hemorganisationen tills avstämningen lyckas, vilket förhindrar datadivergens.
- Styrning av schemaavvisande: Schema- eller mappningsfel dirigeras till kön Schemaavvisande för administratörsgranskning och korrigering.
- Repris och återuppta kontinuitet: Varje synkroniseringsjobb behåller förskjutningskontrollpunkter så att replikering kan återupptas från den senaste lyckade överlämningen utan duplicering.
- Integrerad övervakning: Alla fel, försök och återställningsmått samlas in i instrumentpanelen Trust Layer Monitoring Dashboard för synlighet och servicenivåavtalsgaranti.
Att tänka på vad gäller Idempotent design
- Deterministiska Idempotensnycklar: Varje synkroniseringshändelse har en unik nyckel (organisations-ID + post-ID + versionsnummer) för att garantera exakt en gångs bearbetning.
- Reprissäkerhet: Dubbletter eller repriserade händelser filtreras vid överlämningstid, vilket säkerställer enhetliga uppdateringar av DMO och CIO längre ner.
- Atomär förpliktelsesemantik: Följeslagare markerar data som utförda endast efter framgångsrika skrivningar längre ner, vilket bevarar transaktionsintegriteten mellan organisationer.
- Konfliktlösning: Uppdateringar med flera källor följer senaste-write-wins eller policydriven kopplingslogik, vilket upprätthåller härkomst och enhetlighet.
- Kontrollpunktsbeständighet: Synkroniseringsjobb behåller senast bearbetade förskjutningar och status inom Trust Layer för säker återställning och repris.
Att tänka på vad gäller säkerhet
- Stark autentisering: Anslutningar mellan hem- och följeslagarorganisationer använder ömsesidig OAuth 2.0 med automatiskt roterade tokens som hanteras via anslutna appar.
- Granulär auktorisering: Companion-organisationer kan endast komma åt specifika datautrymmen, DMO eller CIO:er som uttryckligen delas genom styrda datadelningspolicyer.
- Kryptering överallt: Data krypteras under överföring (TLS 1.2+) och i vila (AES-256) över både hem- och följeslagarorganisationer.
- Principen om lägsta privilegium: Integreringsanvändare är begränsade till endast de objekt som behövs; inga administrativa behörigheter eller systemnivåbehörigheter propageras.
- Synlighet för revision och efterlevnad: Alla synkroniseringshändelser, schemaändringar, uppdateringar av inloggningsuppgifter och åtkomstbeviljanden loggas i Data 360 Trust Layer för fullständig spårbarhet.
- Isolering av privat nätverk: Tillvalet Salesforce Private Connect eller Privat länk säkerställer att datareplikering endast sker över säkra, interna kanaler.
Sidofält
Aktualitet
- Synkronisering mellan hem- och följeslagarorganisationer sker nästan i realtid, vanligtvis inom några sekunder efter en dataändring i källorganisationen.
- Zero Copy-arkitekturen säkerställer att delade data är direkt sökbara i alla deltagande organisationer — inga replikeringar eller batchfördröjningar.
- Aktiverings- och segmenteringsjobb återspeglar automatiskt de senaste uppdateringarna från alla anslutna organisationer, vilket bibehåller operativ fräschör.
- End-to-end-latens är deterministisk och styrs av Data Cloud Ones orkestreringspipeline, vilket säkerställer enhetlig aktualitet mellan organisationer även under belastning.
Datavolymer
- Utformad för datasynkronisering i hyperskala mellan regioner och affärsenheter med flera klienter — med kapacitet att hantera miljarder poster per organisation.
- Data refereras, inte dupliceras, vilket minskar lagringsavtryck samtidigt som global sökfråga bibehålls.
- Streamingdelta och metadatakomprimering optimerar bandbredd och överlägg för objekt med hög ändringsfrekvens (t.ex. Kontakt, Order).
- Skalar horisontellt över flera följeslagarorganisationer med adaptiv belastningsbalansering och orkestrering genom Trust Layer.
Delstatshantering
- Varje synkroniserad datauppsättning behåller metadatahärkomst, version och organisationsägandesammanhang för att säkerställa spårbarhet från början till slut.
- Kontrollpunktsbeständighet samlar in senast synkroniserade förskjutningar mellan organisationer, vilket möjliggör återställning utan dubbletter.
- Schemaversioner och semantisk anpassning mellan organisationer styrs automatiskt av Trust Layers.
- Inga manuella statusåterställningar krävs — synkroniseringsstatus upprätthålls genom Data Cloud One Orchestration Service.
Komplexa integreringsscenarion
- Korsorganisationsfederation: Aktiverar sömlösa sökfrågor och aktiveringar för flera Data 360-arrendatorer eller -regioner under en enhetlig styrmodell.
- Hybridsynkronisering: Kombinerar replikering nästan i realtid för transaktionsuppdateringar med schemalagd synkronisering för mass- eller arkivdata.
- Styrelseformer med flera regioner: Stöder geografiskt distribuerad datadelning med respekt för gränser för vistelseort, samtycke och efterlevnad.
- AI och automatiseringsaktivering: Synkroniserade data driver direkt Einstein AI, Agentforce eller egna ML-modeller mellan organisationer – vilket möjliggör korsorganisationsintelligens i realtid.
Exempel
En global butiksorganisation har tre Salesforce-organisationer: en för Konsumenthandel, en för Premiumvarumärken och en för Internationella marknader. De provisionerar Data 360 i konsumentorganisationen (vilket gör den till hemorganisationen). Med Data Cloud One konfigurerar de följeslagare till Premiumvarumärken och internationella marknadsorganisationer. De delar endast lämpliga datautrymmen (t.ex. "Customer 360 – Butiksprofiler" och "Customer 360 – Premiumprofiler") med varje tillhörande organisation. I organisationen Premiumvarumärken kan marknadsföringsteam se sammanslagna kundprofiler, bygga segment baserat på beräknade insikter (t.ex. livstidsvärde för premiumkunder) och utlösa marknadsföringsautomatiseringar — allt drivet av hemorganisationens Data 360-instans, utan egen kodning eller dataduplicering.
Dataaktivering är platsen där värdet i Salesforce Data 360 verkligen kommer till liv. Det är processen att ta de sammanslagna, berikade och styrda data som finns inuti plattformen och få den att fungera i hela verksamheten. I praktiken innebär detta att säkert leverera utvalda segment, beräknade insikter och sammanhangsattribut från Data 360 till de system som engagerar kunder — oavsett om det är marknadsföringsautomatisering, servicekonsoler, säljaktivering, analyser eller AI-modeller. Ur ett tekniskt perspektiv definierar aktiveringsmönster hur dessa data rör sig: vilka kanaler som utlöses, vilka transformationer eller mappningar som inträffar och hur policyer tillämpas längs vägen. Dessa mönster handlar inte bara om att exportera data — de handlar om att orkestrera policymedvetna dataflöden i realtid som driver mätbara verksamhetsresultat. Varje aktiveringsrutt förvandlar Customer 360 till en operativ tillgång i realtid — som driver personanpassning, prediktiva beslut och kontinuerlig inlärning över varje beröringspunkt.
Batchaktivering är fortfarande den mest använda och operativt beprövade metoden för att exportera data från Data 360. Den arbetar på en schemalagd kadens — publicerar fördefinierade målgruppssegment eller attributuppsättningar till plattformar längre ner i kedjan med jämna mellanrum. Detta mönster passar perfekt för arbetsflöden för marknadsföring och engagemang som förlitar sig på enhetliga målgruppsleveranser med hög volym istället för omedelbara uppdateringar. Typiska användningsfall inkluderar att driva e-postresor, direktreklamkampanjer eller målgruppsuppladdningar till digitala annonsnätverk. Varje aktiveringskörning extraherar det kvalificerade segmentet från Data 360:s enhetliga profilgraf, tillämpar policyer för styrning och samtycke och överför utdata till målsystemet på ett säkert sätt. Arkitektoniskt sett ger batchaktivering en förutsägbar, granskningsbar och kostnadseffektiv metod för datadistribution — som balanserar operativ enkelhet med pålitlighet i företagsklass. Det är ryggraden i storskaligt kampanjutförande, där rätt data, levererade i tid och under kontroll, driver mätbar verksamhetspåverkan.
Sammanhang
Moderna marknadsförare arbetar i flera engagemangskanaler—e-post, reklam, mobil och webb—var och en kräver exakta, snabba och personliga kundmålgrupper. Data 360 fungerar som en enhetlig grund för dessa målgrupper och kombinerar kunddata från alla system till rika, användbara segment. Batchaktivering är det vanligaste aktiveringsmönstret som används för att exportera dessa segment från Data 360 till marknadsförings- eller reklamplattformar längre ner. Typiska destinationer inkluderar Marketing Cloud-engagemang, Google Ads, Meta egna målgrupper eller LinkedIn-annonser, där kampanjer kan utföras direkt mot dessa utvalda målgrupper.
Problem
Hur kan ett marknadsföringsteam ta en exakt definierad målgrupp — byggd med sammanslagna och utökade data i Data 360 — och göra den tillgänglig i externa marknadsförings- eller annonssystem för aktivering? Tänk till exempel på segmentet: "Kunder med högt värde som inte har köpt under de senaste 90 dagarna men som nyligen har engagerat sig på webbplatsen." Marknadsförare måste säkerställa att denna målgrupp överförs korrekt, berikas med relevanta attribut (t.ex. lojalitetsnivå, region eller förutsagt CLV) och uppdateras regelbundet för att upprätthålla kampanjens relevans och effektivitet.
Krafter
Flera tekniska och operativa faktorer formar mönstret för batchaktivering:
- Identitetsmappning: Korrekt målgruppsleverans kräver att mappa Data 360:s enhetliga individuella ID till motsvarande identifierare i destinationssystemet—till exempel en prenumerantnyckel i Marketing Cloud eller ett hashat e-postmeddelande för digitala annonsplattformar. Detta säkerställer exakt matchning och eliminerar målfel.
- Attributval och -förbättring: Marknadsförare måste gå utöver ID:n och inkludera ytterligare profildata—som förnamn, lojalitetsstatus, CLV eller andra personanpassade attribut—för att aktivera personanpassning och analyser längre ner.
- Målplattformskonfiguration: Varje destination måste registreras i Data 360 som ett aktiveringsmål, inklusive anslutningsdetaljer, autentisering och datafältmappningar. Denna engångskonfiguration definierar säker anslutning och styr vilka system som kan ta emot aktiverade data.
- Styrning och efterlevnad: Dataaktivering måste följa samtyckesmetadata, sekretesspolicyer (t.ex. GDPR eller CCPA) och marknadsföringsbehörigheter som lagras i den enhetliga profilen. Samtyckesmedveten aktivering säkerställer att data endast används i auktoriserade syften.
- Schemaläggning och prestanda: Aktiveringar schemaläggs ofta dagligen eller varje timme för att hålla målgrupper längre ner aktuella. Systemet måste effektivt hantera stora volymer och inkrementella uppdateringar utan duplicering eller dataförlust.
Lösning
Processen för satsaktivering i Data 360 följer ett guidat arbetsflöde som minimerar teknisk friktion för marknadsförare samtidigt som styrning och skalbarhet bibehålls:
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| Skapa segment | Bästa | En marknadsförare eller analytiker bygger ett segment på den visuella segmenteringsarbetsytan genom att tillämpa filter över ett datamodellobjekt (DMO) eller ett beräknat insiktsobjekt (CIO). Detta definierar målgruppen för aktivering. |
| Aktiveringsinställningar | Bästa | Användaren skapar en aktivering och väljer det segment de just byggt som källa. Detta definierar vilken målgrupp Data 360 kommer att exportera till system längre ner. |
| Val av aktiveringsmål | Bästa praxis | Marknadsföraren väljer ett förkonfigurerat aktiveringsmål (t.ex. Marketing Cloud, Google Ads, LinkedIn Ads). Varje mål registreras i Data 360 med autentiseringsuppgifter och fältmappningar. |
| Payload-definition | Obligatoriskt | Marknadsföraren definierar payload genom att välja kontaktidentifierare (t.ex. e-post, mobil, hashade ID) och välja ytterligare profilattribut (t.ex. förnamn, lojalitetsnivå eller CLV) för berikning i destinationssystemet. |
| Schemaläggning och frekvens | Rekommenderas | Aktiveringar kan schemaläggas att köras en gång eller på en återkommande basis (t.ex. dagligen eller veckovis). Schemaläggning säkerställer att målgrupper längre ner förblir synkroniserade och aktuella. |
| Utförande och export | Bästa | När aktiveringsjobbet körs frågar Data 360 segmentet, samlar in de valda attributen, tillämpar samtyckesfilter och exporterar data till målplattformen. För Marketing Cloud resulterar detta vanligtvis i att ett delat datatillägg skapas eller uppdateras. |
| Styrning och efterlevnad | Obligatoriskt | Trust Layer tillämpar schemavalidering, samtyckesmetadata och policykontroller för att säkerställa efterlevnad av dataskydds- och marknadsföringsföreskrifter (t.ex. GDPR, CCPA). |
| Övervakning och granskning | Bästa praxis | Varje aktiveringskörning följs med mått för framgång/misslyckande, utförandeloggar och härkomstsynlighet i instrumentpanelen Trust Layer Monitoring, vilket möjliggör transparens i verksamheten och servicenivåavtalsgaranti. |
Skiss
Här är sammanfattningen av stegen:
- Byggsegment: En marknadsförare eller analytiker skapar ett segment med ett visuellt segmenteringsverktyg och kombinerar filter över alla sammanslagna dataobjekt.
- Skapa aktivering: De väljer segmentet som källa och väljer en förkonfigurerad destination (som Marketing Cloud eller Google Ads).
- Definiera belastning: Kontaktidentifieraren och andra profilattribut väljs för målgruppsexport och rapportering.
- Schemalägg leverans: Aktiveringen är schemalagd att köras en gång eller på en återkommande basis, vilket håller målgruppen i destinationen uppdaterad.
- Utförande: Vid utlösare frågar Data 360 segmentet, bygger nyttolasten, tillämpar filter för samtycke och pushar resultatet till destinationssystemet.
Resultat
- Riktade, förbättrade målgruppssegment från Data 360 görs tillgängliga direkt i marknadsförings- och reklamplattformar längre ner.
- Målgrupper uppdateras och synkroniseras automatiskt med de senaste enhetliga kunddata, vilket upprätthåller kampanjrelevans i realtid.
- Marknadsförare kan använda dessa aktiverade målgrupper som inmatningskällor för Marketing Cloud-resor, e-postkampanjer eller egna målgrupper i digitala annonsplattformar som Google Ads, Meta eller LinkedIn Ads.
- Varje aktiveringskörning upprätthåller en från början till slut-härkomst, vilket säkerställer efterlevnad, spårbarhet och enhetlighet mellan Data 360 och externa system.
- Affärsanvändare kan leverera mycket personliga, datadrivna upplevelser som drivs av en fullständig och betrodd Customer 360.
Anropsmekanismer
Anropsmekanismen beror på destinationsplattformen och aktiveringsmålets konfiguration.
| Mekanism | När man ska använda |
|---|---|
| Aktivering av Marketing Cloud-engagemang (rekommenderas) | Använd när du utför e-post- eller flerkanalsresor som kräver dynamiska segment, personliga attribut och uppdateringar i realtid i Marketing Cloud. Data 360 exporteras direkt till delade datatillägg för kampanjaktivering. |
| Aktivering av annonsplattform (Google Ads, LinkedIn Ads, Meta Ads) | Använd vid aktivering av Data 360-segment som egna målgrupper i reklamplattformar för ommål eller liknande modeller. Stöder hashade identifierare och samtyckesmedveten leverans. |
| CRM-aktivering (försäljning eller Service Cloud) | Använd vid delning av utökade kunddata, insikter eller benägenhet till CRM-användare för personliga säljengagemang eller serviceinteraktioner. Data görs tillgängliga som utökade poster eller insikter via dataåtgärder eller sammanslagna profilkomponenter. |
| Extern aktivering via MuleSoft eller API | Använd när aktivering behöver nå icke-Salesforce-system som lojalitet, e-handel eller datalager från tredje part. MuleSoft eller Data 360 Activation API säkerställer säker, policystyrd leverans med händelsebaserade uppdateringsalternativ. |
| Hybridaktivering (sats + händelseutlöst) | Använd när du kombinerar schemalagda batchaktiveringar med händelsebaserade utlösare — aktivera "alltid på"-anpassning för tidskänsliga kampanjer som till exempel varningar om övergiven varukorg eller riskbortfall. |
Felhantering och återställning
- Felisolering på jobbnivå: Varje aktiveringskörning körs som ett distinkt, spårbart jobb i Data 360-orkestreringslagret. Misslyckade körningar placeras automatiskt i karantän utan att påverka andra aktiveringar eller segmentdefinitioner.
- Delvis återställning av sats: Om vissa poster inte kan exporteras (t.ex. på grund av felaktiga identifierare eller API-hastighetsgränser) försöker systemet använda inkrementella deltaköer med exponentiell backoff och parallell återställning.
- Fel vid schemavalidering: När utgående belastningsattribut inte längre matchar målschemat (t.ex. ett borttaget attribut eller ett fält som bytt namn), dirigerar jobbet posterna till kön Schemaavvisande för administratörsgranskning.
- Repris och återuppta support: Varje aktiveringsjobb upprätthåller en kontrollpunktstoken och samlar in den senaste framgångsrika batchen. Vid återställning återupptas bearbetningen från kontrollpunkten, vilket säkerställer ingen dubblering eller dataförlust.
- Omfattande övervakning: Alla aktiveringshändelser, försök och leveransmått loggas i Trust Layer Monitoring, vilket möjliggör spårning av servicenivåavtal, analys av grundorsak och automatiserad varning via Event Monitoring API.
Att tänka på vad gäller Idempotent design
- Deterministiska aktiveringsnycklar: Varje aktiveringskörning använder en sammansatt idempotensnyckel—som kombinerar segment-ID, aktiverings-ID och målsystem-ID—för att garantera exakt en leverans.
- Reprisdetektering: Data 360-aktiveringstjänsten inspekterar inkommande belastningar mot tidigare jobbhashar för att upptäcka och förhindra repriser.
- Atomiska exportåtaganden: Payloads överlämnas till målsystemet endast efter framgångsrik bekräftelse av skrivning, vilket förhindrar delvisa uppdateringar eller dubbelräkning.
- Konsekvent identitetslösning: Eftersom aktiveringar är beroende av sammanslagna ID:n (t.ex. Sammanslagna individer) är repriser eller försök alltid inriktade på samma gyllene post, vilket upprätthåller semantisk enhetlighet.
- Aktiveringslägets varaktighet: Orkestreringslagret behåller metadata för aktiveringsstatus—tidsstämplar, statuskoder och sekvenstokens—för deterministisk ombearbetning om det behövs.
Att tänka på vad gäller säkerhet
- Stark autentisering: Varje aktiveringsmål (t.ex. Marketing Cloud, Ads eller CRM) använder OAuth 2.0 med tokenrotation och arrendatorspecifik omfattning för att förhindra oauktoriserad dataexport.
- Styrning på attributnivå: Endast godkända attribut från den enhetliga profilen är berättigade till aktivering, tillämpade av datadelningspolicyer och aktiveringsmallar.
- Kryptering vid överföring och vila: Alla payloads krypteras med TLS 1.2+ under överföring och AES-256 i vila inom både Data 360 och målplattformen.
- Samtycke och policytillämpning: Aktiveringsjobb respekterar samtyckesobjekt och datapolicyer som lagras i Data 360:s Trust Layer. Poster utan giltiga samtyckesmetadata utesluts automatiskt från export.
- Loggning av granskning och efterlevnad: Varje aktiveringskörning samlar in vem som initierade den, vilka data som skickades och till vilken destination—vilket möjliggör fullständiga regelgranskningskedjor (GDPR, CCPA) inom instrumentpanelen Trust Layer.
- Minsta behörighetsåtkomst: Integreringsanvändare för varje mål är begränsade till aktiveringsspecifika omfång—inga administrativa behörigheter eller skrivåtkomst till orelaterade system.
Sidofält
Aktualitet
- Utformad för schemalagda batchexporter eller batchexporter nästan i realtid (latens minuter till timmar).
- Stöder tidsfönsteruppdateringar i linje med kampanjkalendrar.
- Aktiveringsjobb kan ordnas med databeredskapsmarkörer för att säkerställa att data är färska.
- Passar bäst för icke-interaktiva aktiveringsscenarion där dataprecision överväger omedelbarhet.
Datavolymer
- Hanterar storskaliga datauppsättningar (miljoner poster per körning).
- Skalar horisontellt genom segmentpartitionering och parallella exportkanaler.
- Använder bitbaserad batchning för att undvika timeout och optimera genomströmning.
- Idealisk för datapipelines i företagsklass där det är viktigt att data är fullständiga.
Delstatshantering
- Bibehåller objekt för aktiveringsstatus som registrerar jobb-ID:n, tidsstämplar och sekvenstokens.
- Använder kontrollpunkter för omstart och felåterställning.
- Versionerade segmentdefinitioner säkerställer reproducerbarhet över aktiveringscykler.
- Aktiverar spårbarhet mellan källsegment, DMO-attribut och målbelastningar.
Komplexa integreringsscenarion
- Integreras sömlöst med Salesforce CRM, Marketing Cloud och externa system genom färdigbyggda anslutare.
- Stöder aktiveringar med flera mål och distribuerar data samtidigt till olika destinationer (t.ex. CRM + Ads).
- Kan utlösa sammansatta arbetsflöden — t.ex. batchexport följt av API-anrop längre ner eller AI-betyg.
- Hanterar schemautveckling smidigt genom styrlagret för datamodeller.
Exempel
Ett globalt varumärke vill återengagera inaktiva kunder från de senaste 90 dagarna. Med hjälp av Data 360 definierar dataarkitekten ett segment för "Vilande shoppare" berikat med inköpshistorik, lojalitetsnivå och samtyckesmetadata. Batchaktiveringsjobbet körs varje natt och pushar detta segment till Marketing Cloud-engagemang för att utlösa en personlig e-postkampanj "Vi saknar dig" och till Ad Studio för ommål. Jobbet använder idempotent leverans, vilket säkerställer att ingen dubblering sker över försök, och alla händelser loggas i Trust Layer för granskningsefterlevnad.
Sammanhang
Företag behöver ofta en styrd mekanism för att exportera sammanslagna eller segmenterade data från Salesforce Data 360 till ett standardfilformat (t.ex. CSV eller Parkett) för arkivering, efterlevnad eller integrering längre ner. Detta mönster aktiverar export av Data 360-till-moln-lagring—låter betrodda kunddata flöda säkert till företagets datasjöar eller analyspipelines som värdas på Amazon S3, Azure Blob eller Google Cloud Storage (GCS). Typiska användningsfall inkluderar:
- Periodisk arkivering av samtyckesgivna kunddatauppsättningar för lagstadgad lagring.
- Exportera utvalda segment för icke-Salesforce Analytics-arbetsbelastningar (t.ex. Tableau, Databricks eller Power BI).
- Aktivera externa maskininlärningsmodeller som kräver strukturerade CSV- eller Parkettfiler som indata.
Problem
Hur kan en organisation exportera ett utvalt segment eller datauppsättning från Data 360 till en molnlagringshink (t.ex. Amazon S3)—på ett styrt, säkert och automatiserat sätt—med bibehållen schemaintegritet och efterlevnadskontroll? Till exempel kan ett efterlevnadsteam behöva: "Extrahera alla aktiva kunder i EU-regionen med giltigt samtycke och exportera data veckovis till en S3-plats för extern granskning och rapportering." Detta kräver en repeterbar och policymedveten exportpipeline som säkerställer rätt filformat, åtkomstbehörigheter och leveransschema – utan manuella ingripanden eller okontrollerad dataflyttning.
Krafter
Flera operativa och arkitektoniska faktorer styr detta exportmönster:
- Autentisering och auktorisering: Exporter måste respektera molnleverantörens IAM-modell (t.ex. AWS IAM-roller eller Azure Service Principals) för att säkerställa att endast auktoriserade system kan skriva till målhinken.
- Schemajustering: Det utgående schemat måste matcha målsystemets förväntade struktur och format (CSV, Parquet eller JSON).
- Datasekretess och samtycke: Exporterade datauppsättningar måste filtrera bort poster som inte har giltiga samtyckesmetadata.
- Schemaläggning och färskhet: Många exporter är periodiska (dagligen, veckovis eller månadsvis) och måste överensstämma med företagets datauppdateringscykler.
- Styrning och övervakning: Varje export måste kunna granskas med fullständig härkomstsynlighet, vilket säkerställer efterlevnad av datalagring och lagstadgade mandat (t.ex. GDPR, CCPA).
Lösning
Mönstret Filexportaktivering återanvänder samma säkra molnlagringsanslutare som används för intag men är konfigurerade för datautmatning. Administratörer registrerar först molnlagringsplattformen (t.ex. Amazon S3, Azure Blob Storage eller GCS) som ett aktiveringsmål i Data 360. Sedan konfigurerar och kör användare ett aktiveringsarbetsflöde för att exportera önskat segment till den utsedda fillagringsvägen.
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| Segmentval | Bästa | Analytiker väljer en befintlig segment- eller sökfrågedefinition i Data 360\. Segmentet avgör vilka poster och attribut som exporteras. |
| Aktiveringsinställningar | Bästa | Användare skapar en ny aktivering och väljer segmentet som källa och molnlagringsmålet (t.ex. S3) som destination. |
| Konfiguration av aktiveringsmål | Obligatoriskt | Administratörer förkonfigurerar målet med inloggningsuppgifter, IAM-roller och utdatasökväg. Format som stöds inkluderar CSV, Parkett och JSON. |
| Payload-definition | Bästa praxis | Definiera exportschemat genom att välja de attribut som behövs (t.ex. ID, Namn, E-post, Region, Samtyckesflagga). Systemet tillämpar styrning på attributnivå. |
| Schemaläggning och frekvens | Rekommenderas | Exporter kan schemaläggas att köras på en definierad kadens (dagligen, veckovis, månadsvis) eller utlösas manuellt efter behov. |
| Utförande & leverans | Bästa | Vid körning frågar Data 360 segmentet, kompilerar exportfilen, krypterar den och skriver den till den konfigurerade hinken/mappen med molnleverantörens API. |
| Styrning och efterlevnad | Obligatoriskt | Data 360s Trust Layer säkerställer att alla exporter följer samtyckespolicyer, schemavalidering och efterlevnadsfilter. |
| Övervakning och granskning | Bästa praxis | Varje export spåras i instrumentpanelen Trust Layer Monitoring med status, utförandeloggar och härkomstmetadata. |
Skiss
Här är sammanfattningen av stegen.
- Välj segment: En analytiker eller datasteward väljer det sammanslagna segmentet att exportera.
- Skapa aktivering: De skapar ett nytt aktiveringsjobb och väljer det registrerade molnlagringsmålet.
- Definiera belastning: Specificera exportschema, attributlista och filformat (t.ex. CSV).
- Schemalägg export: Välj ett engångsschema eller återkommande schema.
- Kör jobb: Data 360 skapar och levererar filen säkert till den utsedda hinkvägen.
- Övervaka och verifiera: Resultat och loggar granskas i Trust Layer för validering och efterlevnad.
Resultat
- Riktade, förbättrade målgruppssegment från Data 360 görs tillgängliga direkt i marknadsförings- och reklamplattformar längre ner.
- Målgrupper uppdateras och synkroniseras automatiskt med de senaste enhetliga kunddata, vilket upprätthåller kampanjrelevans i realtid.
- Marknadsförare kan använda dessa aktiverade målgrupper som inmatningskällor för Marketing Cloud-resor, e-postkampanjer eller egna målgrupper i digitala annonsplattformar som Google Ads, Meta eller LinkedIn Ads.
- Varje aktiveringskörning upprätthåller en från början till slut-härkomst, vilket säkerställer efterlevnad, spårbarhet och enhetlighet mellan Data 360 och externa system.
- Affärsanvändare kan leverera mycket personliga, datadrivna upplevelser som drivs av en fullständig och betrodd Customer 360.
Anropsmekanismer
Anropsmekanismen beror på målmolnets lagringsplattform och aktiveringskonfiguration.
| Mekanism | När man ska använda |
|---|---|
| Aktivering av Amazon S3 | Använd när din företagsdatasjö värdas på AWS. Data 360 skriver direkt till en S3-hink med IAM-roller eller tillfälliga inloggningsuppgifter, vilket säkerställer säker och skalbar export. |
| Aktivering av Azure Blob-lagring | Använd när din organisation arbetar med Microsoft Azure. Data 360 använder SAS-tokens eller serviceprinciper för att skriva krypterade filer till Blob-behållare. |
| Aktivering av Google Cloud Storage (GCS) | Använd när dina datavetenskap- eller Analytics-arbetsbelastningar körs med GCP. Data 360 använder OAuth-inloggningsuppgifter för att exportera filer till GCS-hinkar i CSV- eller Parkettformat. |
| SFTP eller extern filgateway | Använd när regelsystem eller äldre system kräver säker filleverans via SFTP-slutpunkter eller företagshanterade filöverföringsplattformar. |
| Hybridexport (fil + API) | Använd när ett program längre ner behöver både filbaserad export för analys och en API-utlösare för arbetsflödesorkestrering (t.ex. MuleSoft-flöde). |
Felhantering och återställning
- Jobbnivåisolering: Varje export körs som ett diskret jobb. Misslyckade jobb placeras i karantän och testas oberoende.
- Delvis filförsök: Om vissa satser inte kan laddas upp (t.ex. på grund av nätverksavbrott) försöker systemet göra samma sak med exponentiell backoff.
- Hantering av schemafelmatchning: Alla schemadrifter eller fältfel dirigerar poster till kön Schemaavvisande för granskning.
- Kontrollpunkt och återuppta: Exportjobb behåller metadata för kontrollpunkter, vilket möjliggör återupptagande från den senaste lyckade skrivningen utan dubbletter.
- Integrerad övervakning: Misslyckanden och försök loggas i instrumentpanelen Trust Layer för synlighet och efterlevnad av servicenivåavtal.
Att tänka på vad gäller Idempotent design
- Deterministiska exportnycklar: Varje exportjobb innehåller ett unikt ID som består av segment-ID + mål-ID + tidsstämpel.
- Reprissäkerhet: Dubbletter av jobbkörningar upptäcks med hjälp av jobbhashar och hoppas över för att förhindra överflödig export.
- Atomisk skrivgaranti: Data 360 överlämnar endast filer till målhinken efter fullständigt slutförande och validering av kontrollsumma.
- Konsekvent schemaversion: Exportdefinitioner är versionsstyrda för att säkerställa enhetlighet i scheman över körningar.
- Kontrollpunktsbeständighet: Exportjobb kvarstår i läget för deterministisk återställning och ombearbetning om det behövs
Att tänka på vad gäller säkerhet
- Stark autentisering: Cloud-anslutare använder OAuth 2.0, IAM-roller eller serviceprinciper för autentiserade skrivningar.
- Kryptering överallt: Data krypteras både under överföring (TLS 1.2+) och i vila (AES-256).
- Samtyckesmedveten export: Endast poster med giltigt samtycke exporteras och tillämpas av Trust Layer-policyer.
- Principen om minsta privilegium: Exportera användare och servicekonton är begränsade till deras utsedda lagringssökvägar.
- Omfattande granskningsloggning: Varje export registrerar metadata inklusive initiator, schema, destination och tidsstämplar för efterlevnadsrapportering.
Sidofält
Aktualitet
- Utformad för omedelbar, händelsedriven aktivering med latens under en sekund.
- Idealisk för scenarion som kräver omedelbar personanpassning, rekommendation eller beslut.
- Fungerar i streamingläge — utlösare aktiveras så fort kvalificerande dataändringar inträffar i Data 360.
- Säkerställer kontinuerlig respons utan att behöva vänta på batchscheman eller segmentomberäkning.
Datavolymer
- Hanterar storskaliga datauppsättningar (miljoner poster per körning).
- Skalar horisontellt genom segmentpartitionering och parallella exportkanaler.
- Använder bitbaserad batchning för att undvika timeout och optimera genomströmning.
- Idealisk för datapipelines i företagsklass där det är viktigt att data är fullständiga.
Delstatshantering
- Varje händelseåtgärd behåller sin egen händelsetoken och repris-ID för idempotent bearbetning.
- Stöder att kontrollpunkten fortsätter från den senaste överlämnade händelsen i händelse av tillfälligt fel.
- Inkluderar inbyggd dedupliceringslogik och reprisfönster för att säkerställa exakt aktiveringssemantik.
- Åtgärdsresultat (framgång/misslyckande) loggas i Realtid och visas genom instrumentpanelen Trust Layer observerbarhet.
Komplexa integreringsscenarion
- Integreras direkt med Salesforce-flöden, Einstein 1-plattformshändelser eller externa webhooks för omedelbara svarskedjor.
- Kan utlösa automatiseringar längre ner — t.ex. direkta CRM-postuppdateringar, AI-betyg eller Marketing Cloud-meddelanden.
- Stöder komponerbar orkestrering: händelseutlösare kan anropa Data 360-åtgärder, Apex åberopningar eller externa API:er.
- Utformad för agentiska och anpassningsbara företagsmönster där sammanhangsberoende svar måste inträffa direkt.
Exempel
Ett globalt detaljhandelsföretag behöver leverera en veckovis export av sitt segment "Aktiva lojalitetsmedlemmar" för analys i Databricks. Data 360-administratören konfigurerar Amazon S3 som ett aktiveringsmål och schemalägger en veckovis CSV-export till s3://enterprise-analytics/loyalty/weekly_exports/. Exportjobbet körs varje söndag och skapar en samtyckesfil med 2M+-poster. Alla händelser, schemadefinitioner och härkomst registreras i instrumentpanelen Trust Layer, vilket säkerställer transparens, granskningsbarhet och efterlevnad.
API-baserad aktivering på begäran är en händelsedriven metod i realtid för att göra Data 360-insikter användbara i samma ögonblick som de behövs — utan att behöva vänta på batchjobb eller schemalagda exporter. Istället för att publicera färdigbyggda segment på en fast kadens låter detta mönster externa system, Salesforce-appar eller AI-agenter anropa Data 360 API direkt för att hämta eller aktivera specifika målgruppsbitar, kundattribut eller insikter på begäran. Detta mönster är utformat för interaktiva, utlösarbaserade upplevelser — som när en användare loggar in i en portal, en agent öppnar en kundpost eller en AI-copilot inleder en Next Best Action-fråga. Istället för att förlita sig på förberäknade exporter frågar eller aktiverar systemet dynamiskt de mest aktuella, styrda data från Data 360 inReal-Time. Den viktigaste fördelen är omedelbarhet och precision:
- Varje API-anrop får åtkomst till den senaste Kundintelligensen i Data 360:s sammanslagna, samtyckesmedvetna profilgraf.
- Aktiveringar är idempotenta och granskningsbara och uppfyller kraven för Enterprise Trust och efterlevnad.
- Integreringar kan utlösas direkt från Salesforce-flöden, Apex eller externa system via Einstein 1 Platform APIs, Connect APIs eller Activation APIs. Detta tillvägagångssätt har stöd för användningsfall där latens och personanpassning är viktigast — till exempel:
- Utlösa ett personligt produkterbjudande under ett servicesamtal.
- Skapa dynamiska kampanjmålgrupper baserat på beteendehändelser live.
- Mata in beslut i realtid i AI- eller ML-modeller som fungerar vid tidpunkten för engagemang.
Sammanhang
Företag behöver ofta lyfta fram harmoniserade Data 360-insikter i realtid i egna program — som interna webbportaler, mobilappar eller webbupplevelser som visas för partners. Detta mönster låter utvecklare bygga säkra, användargränssnittscentrerade lösningar som konsumerar och visar sammanslagna kunddata tillsammans med Salesforce CRM och andra sammanhangssystem, allt genom styrd och API-baserad åtkomst. Typiska användningsfall inkluderar:
- Bädda in Data 360-insikter i interna instrumentpaneler eller mobilappar för anställda.
- Skapa partner- eller återförsäljarportaler med synlighet för kunder och transaktioner.
- Integrera Data 360-data i webbprogram eller upplevelselager från tredje part.
- Visar personliga rekommendationer i realtid som drivs av Data 360 och Einstein 1.
Problem
Hur kan en utvecklare bygga ett eget, användargränssnittfokuserat program som säkert öppnar och visar harmoniserade Data 360-data, ofta tillsammans med andra Salesforce-datakällor – utan att duplicera eller exportera känslig information? Till exempel kan ett företag behöva bygga en kundportal som visar sammanslagna kundprofiler, interaktioner och beräknade insikter från Data 360. Detta kräver ett enda, säkert och effektivt API-lager som kan driva frontendupplevelsen, hantera autentisering och säkerställa styrning — samtidigt som komplexiteten hos Data 360:s interna datamodell abstraheras bort.
Krafter
Flera arkitektoniska och operativa överväganden påverkar detta mönster:
- Användargränssnittscenteråtkomst : Det primära målet är att lyfta fram data i egna frontendupplevelser (webb eller mobil), inte att utföra batchextrahering eller backendsynkroniseringar.
- Säker gateway : Den valda API:n måste fungera som en säker och skalbar inkörsport för autentiserade program och användare och tillämpa åtkomstkontroller i företagsklass.
- Sammanslaget datasammanhang : Program ska sömlöst kunna kombinera Data 360-data (t.ex. sammanslagna profiler, beräknade insikter) med CRM-, ERP- eller egna objektdata.
- Utvecklarens enkelhet : API:n ska returnera presentationsklara belastningar som minimerar backendbearbetning eller schemamappning i klientlagret.
- Styrning och observerbarhet : All åtkomst ska flöda genom betrodda, granskningsbara kanaler med tydlig härkomst, autentisering och policytillämpning.
Lösning
Lösningen är att använda Salesforce Connect REST API som den primära integreringsgateway för att bygga egna, datadrivna program ovanpå Data 360. Connect API ger RESTful åtkomst till Salesforce-data — inklusive Data 360:s harmoniserade profiler, segment och beräknade insikter — i svarsformat optimerade för användning i användargränssnittet (JSON-baserade, lätta och mobilvänliga). Utvecklare autentiserar genom en ansluten app, hämtar OAuth 2.0-tokens och anropar Connect API-resurser som /query, /Chatter eller /data för att lyfta fram enhetliga data direkt i sina programgränssnitt. Bakom kulisserna fungerar Connect API som transportgrunden för andra API:n — som Query API, Data Graph API och Einstein 1 Platform API:n — vilket låter utvecklare kombinera flera datakällor under ett enhetligt åtkomstmönster.
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| Autentisering och appregistrering | Obligatoriskt | Skapa en ansluten app i Salesforce för OAuth 2.0-baserad autentisering. Konfigurera omfattningar för Data 360 API-åtkomst. |
| Dataåtkomst (profiler, segment, insikter) | Bästa | Använd Connect API-slutpunkter (/services/data/vXX.X/connect) för att fråga harmoniserade Data 360-data, enhetliga profiler och beräknade insikter. |
| Användargränssnittintegrering | Bästa | Frontend-appar (React, Angular, iOS, Android) anropar Connect API för att återge Data 360-data i instrumentpaneler, portaler eller mobilgränssnitt. |
| Fråga om datagraf | Rekommenderad | Kombinera Connect API med Data Graph API för sökfrågor på semantisk nivå som förenklar komplexa sammanslagningar och relationer. |
| Realtidsuppdatering | Valfritt | Använd Connect API med WebSocket eller streamingtillägg för livedatauppdateringar. |
| Säkerhet och styrning | Obligatoriskt | Tillämpa datasynlighet med OAuth-omfång, Data 360-policyer och granskningsramverket Trust Layer. |
Skiss
Här är sammanfattningen av stegen.
- Registrera ansluten app — Definiera OAuth-omfång och API-behörigheter för extern appautentisering.
- Hämta åtkomsttoken — Den externa appen utför OAuth 2.0-autentisering för att ta emot en token för Data 360-åtkomst.
- Åberopa Connect API — Appen gör REST API-anrop för att hämta sammanslagna profil-, segment- eller insiktsdata.
- Återge data i användargränssnitt — Svar tolkas och presenteras för användare i en varumärkt portal eller ett mobilgränssnitt.
- Hantera fel och uppdateringstokens — Appar implementerar återförsökslogik och automatisk tokenuppdatering för sessionskontinuitet.
- Åtkomsten Övervaka och granska – Alla API-anrop loggas i Trust Layer för synlighet och efterlevnad.
Resultat
Utvecklare kan skapa säkra, anpassade varumärkta program som är tätt integrerade med Data 360. Dessa appar kan:
- Visa harmoniserade kundprofiler och insikter i Realtid.
- Visa Data 360-data tillsammans med CRM eller egna objekt genom enhetliga API:n.
- Använd enhetlig autentisering, auktorisering och granskningskontroller via Trust Layer.
- Ge företagsanvändare eller partners sömlös, styrd åtkomst till betrodd Kundintelligens mellan upplevelser.
Anropsmekanismer
Anropsmekanismen beror på målmolnets lagringsplattform och aktiveringskonfiguration.
| Mekanism | När man ska använda |
|---|---|
| Connect REST API (Föredragen) | Använd när du bygger webb-, mobil- eller tredjepartsappar som kräver åtkomst i realtid till Data 360-data i ett användargränssnittsvänligt JSON-format. |
| Datagraf-API | Använd när appen behöver utföra sökfrågor på semantisk nivå över flera objekt (t.ex. Kund → Transaktioner → Kampanjer). |
| Query API | Använd när du utför SOQL-liknande sökfrågor för att hämta harmoniserade datauppsättningar med hög precision. |
| Einstein 1 Platform APIs | Använd vid integrering av AI-drivna insikter eller copilot-genererade rekommendationer i egna användargränssnitt. |
| MuleSoft- eller Apex Gateway-omslag | Använd när ytterligare orkestrering, cachning eller policytillämpning krävs mellan appen och Connect API. |
Felhantering och återställning
- Begär strypning: Backar automatiskt och försöker API-anrop under hastighetsgränser.
- Schemadriftskydd: Använder GraphQL-schemaversioner eller REST-metadataupptäckt för att anpassa till schemaändringar.
- Hantering av tokenutgång – Program uppdaterar OAuth-tokens automatiskt för att undvika sessionsavbrott.
- API-felisolering – Misslyckade API-anrop loggas och försöks igen utan att påverka samtidiga sessioner.
- Trust Layer Observability – API success/failability rates och åtkomstloggar visas i instrumentpanelen Trust Layer.
Att tänka på vad gäller Idempotent design
- ID:n för deterministiska begäranden: Varje API-begäran innehåller ett korrelations-ID för reprissäker bearbetning.
- Cachevalideringssidhuvuden: Sidhuvudena ETag och Senast ändrad förhindrar överflödiga datahämtningar.
- Atomiska läsoperationer: Connect API säkerställer att varje svar återspeglar en enhetlig ögonblicksbild av sammanslagna data.
- Reprisskydd – Dubbletter av API-anrop filtreras med hjälp av begärandesignaturer och tidsstämplar.
Säkerhetsöverväganden
- OAuth 2.0-autentisering: Alla API-anrop använder säkra, kortlivade OAuth-åtkomsttokens via anslutna appar.
- Minsta behörighetsåtkomst: API-omfång är begränsade till endast nödvändiga objekt och fält.
- Kryptering överallt: TLS 1.2+ är under överföring, AES-256-kryptering vid vila för cachade eller lagrade svar.
- Samtyckesmedveten dataåtkomst: Data 360 säkerställer att alla hämtade poster följer policyer för samtycke och styrning.
- Omfattande granskningsloggning: Varje API-interaktion registreras med metadata för användare, appar och tidsstämplar i Trust Layer.
Sidofält
Aktualitet
- Utformad för API-åtkomst i realtid med låg latens.
- Idealisk för interaktiva program som kräver omedelbar dataåtergivning.
- Stöder nästan omedelbara sökfrågesvarstider via cachade och indexerade Data 360-källor.
- Inget beroende av batchscheman eller asynkrona aktiveringscykler.
Datavolymer
- Optimerad för interaktiva användningsfall som hämtar små till medelstora datauppsättningar (t.ex. profiler, insikter eller senaste transaktioner).
- Hanterar paginerade resultat smidigt genom markörbaserad paginering.
- Inte avsedd för massexporter med hög volym — använd mönster för batch- eller filexport för stora datauppsättningar.
Delstatshantering
- Program upprätthåller ett lätt sessionsläge med OAuth-tokens och lokal cache.
- Connect API har stöd för villkorliga begäranden och delvis uppdatering för effektivitet.
- API-svar inkluderar versionsmarkörer för enhetlighet i scheman mellan utgåvor.
Komplexa integreringsscenarion
- Kombinera Connect API med Data Graph API för semantiska sökfrågor över flera domäner.
- Integrera med Einstein 1 Copilot eller AI API för prediktiva konversationsupplevelser.
- Använd tillsammans med Experience Cloud eller Lightning Web Components för utveckling av hybridgränssnitt.
- Utöka via MuleSoft för att orkestrera dataförbättring eller externa systemsökningar i Real-Time.
Exempel
Ett multinationellt försäkringsbolag bygger en självbetjäningsportal som låter försäkringstagare se sina sammanslagna profiler, senaste anspråk och personliga erbjudanden. Den frontendbaserade appen eact autentiseras via OAuth 2.0 och hämtar data med Connect REST API och Data Graph API. Alla data visas i realtid, samtyckesmedvetna och styrs genom Data 360 Trust layer. Utvecklare bevakar API-anrop och granskningsloggar direkt i Salesforce, vilket säkerställer fullständig efterlevnad och observerbarhet.
Sammanhang
Företag behöver i allt högre grad omedelbar åtkomst till en fullständig kundprofil för beslutssystem i realtid — som servicekonsoler, rekommendationsmotorer eller personanpassningsplattformar. Detta mönster låter program hämta förberäknade, enhetliga vyer av en kunds data i nearReal-Time med hjälp av Data 360:s Data Graph API, vilket ger sekundsnabba svarstider för interaktiva upplevelser. Typiska användningsfall inkluderar:
- Visa en 360-graders kundvy i en Kundtjänst eller Sales Console.
- Drivkraft för AI-baserade rekommendationer för "Next Best Action" eller "Next Best Offer".
- Leverera hyperpersonliga webb- eller mobilupplevelser vid sidinläsning.
- Stöd för beslut under sessionen i agent- eller självbetjäningsmiljöer.
Problem
Hur kan ett program hämta en fullständig, förberäknad, enhetlig kundvy direkt istället för att utföra långsamma flerobjektsfrågor vid runtime? Till exempel måste en webbpersonaliseringsmotor läsa in hela kundsammanhanget (demografi, inställningar, transaktioner och beräknade insikter) inom millisekunder för att välja ett personligt erbjudande. Traditionella relationsfrågor kan kräva flera sammanslagningar och resultera i oacceptabel latens. Detta kräver en API som levererar denormaliserade, färdiga profildata, som kan hämtas via en enda nyckelsökning — som kombinerar hastighet, fullständighet och styrning.
Krafter
Flera operativa faktorer och prestandafaktorer påverkar detta mönster:
- Hastighet: Svarstiden måste vara nearReal-Time. API måste returnera en fullständig profil inom millisekunder för att stödja synkrona interaktioner.
- Fullständighet: Svaret måste inkludera alla relevanta attribut, relationer och beräknade insikter — helst i en enda belastning.
- Sökeffektivitet: Profiler ska kunna hämtas via identifierare som customerId, contactKey eller e-post, vilket eliminerar flerstegsfrågor.
- Datafräschhet vs. Latens: Vissa användningsfall föredrar förberäknade (cachade) data för hastighet, andra behöver livedata och accepterar högre latens.
- Styrning och säkerhet: Åtkomst måste fortsätta styras genom Salesforce Trust Layer-policyer och säkerställa efterlevnad av datasynlighet och samtyckesregler.
Lösning
Lösningen är att använda Salesforce Data Graph API för att hämta förberäknade, denormaliserade kundvisningar som lagras som datagrafposter. En datagraf är en materialiserad semantisk vy som kombinerar flera datamodellobjekt (DMO) — som Individuell, Transaktion och ProductInterest — till en enda skrivskyddad post, ofta representerad som en JSON-blob. Utvecklare kan använda REST-slutpunkter som: GET /api/v1/dataGraph/{dataGraphEntityName}/{id} för att hämta en fullständig post med dess unika identifierare. För dynamiska scenarion har API stöd för en live=true-parameter som kringgår det materialiserade cacheminnet och utför en sökfråga i realtid över Data 360, vilket ger minimal latens för de senaste data. Detta låter utvecklare välja mellan omedelbara (cachade) och aktuella (live) profilhämtningar beroende på verksamhetsbehov.
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| Datagrafdefinition | Obligatoriskt | Arkitekter definierar en datagraf som kombinerar flera DMO till en enda semantisk enhet (t.ex. UnifiedCustomerProfile). |
| Återhämtning av profilsökning | Bästa | Program anropar GET /api/v1/dataGraph/{entity}/{id} för att hämta fullständiga, denormaliserade profiler med unikt ID eller nyckel. |
| Liveparameteranvändning | Valfritt | Lägg till ?live=true för att tvinga fram nya beräkningar istället för cachad hämtning; lämpligt för beslut med högt värde. |
| Autentisering | Obligatoriskt | Använd OAuth 2.0 via anslutna appar för att autentisera API-anrop säkert. |
| Svarstolkning | Bästa praxis | Program tolkar JSON-svaret direkt i sitt användargränssnitt eller beslutsmotor. Inga ytterligare sammanslagningar krävs. |
| Cachestrategi | Rekommenderad | Implementera kortsiktig lokal cachning (t.ex. i minnet eller CDN) för upprepade profilsökningar. |
| Övervakning och iakttagbarhet | Obligatoriskt | Använd Trust Layer-instrumentpaneler för att övervaka sökfrågeprestanda, svarstider och policyefterlevnad. |
Skiss
Här är sammanfattningen av implementeringsflödet:
- Definiera datagraf — Dataarkitekter skapar en datagraf som modellerar en enhetlig kundvy över flera DMO.
- Registrera ansluten app — Utvecklare konfigurerar OAuth-inloggningsuppgifter för säker API-åtkomst.
- Åberopa Data Graph API — Programmet utfärdar en GET-begäran med namnet på datagrafen och post-ID.
- Processsvar — API returnerar en fullständig JSON-representation av kundprofilen.
- Återge eller agera — Den konsumerande appen (gränssnitt eller motor) använder sammanslagna data för personanpassning, rekommendationer eller serviceåtgärder.
- Övervaka och finjustera – Prestandamått och åtkomstloggar granskas genom observerbarhetskonsolen Trust Layer.
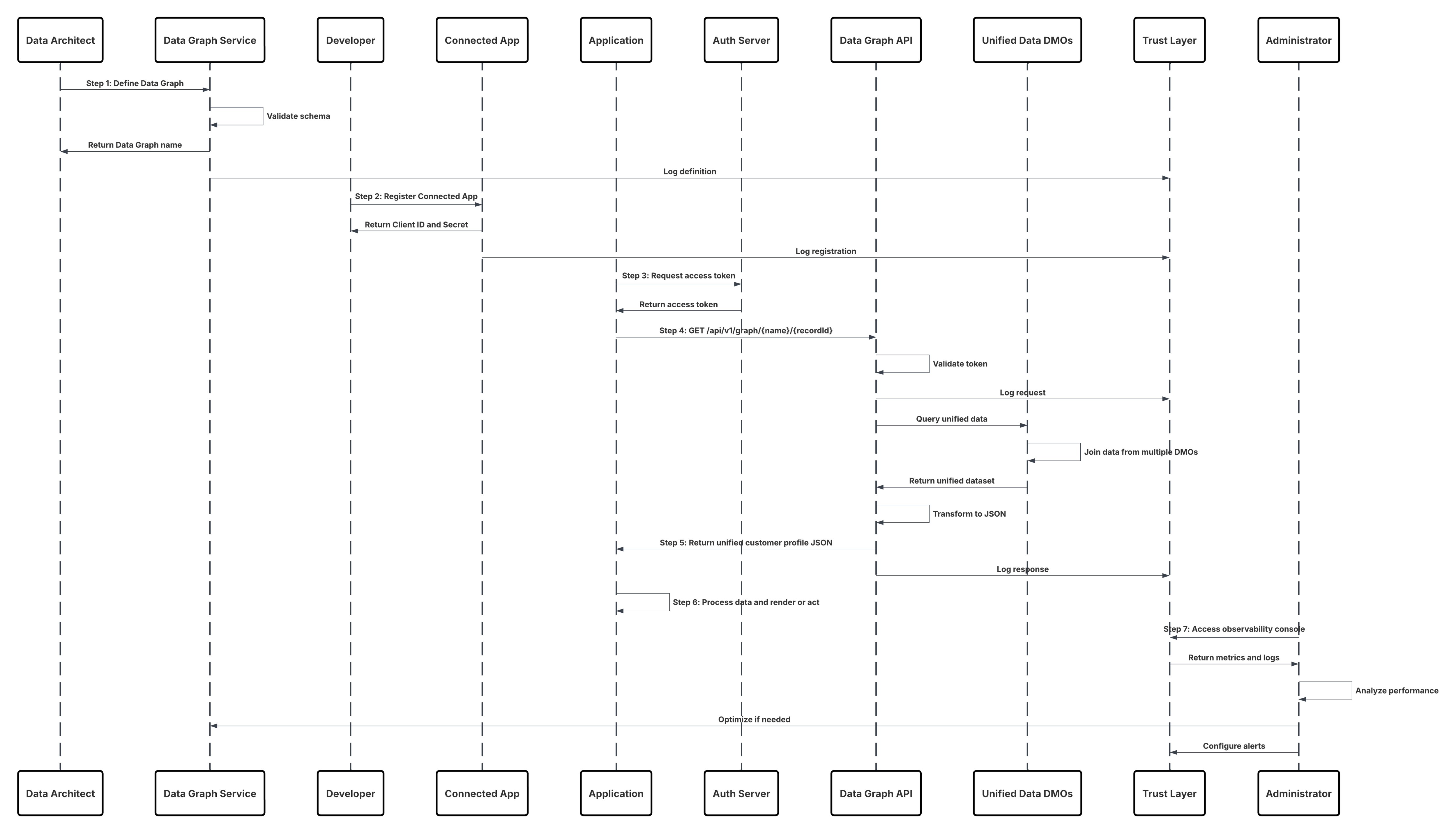
Resultat
Applikationer kan nu hämta en fullständig, förkopplad kundprofil direkt och driva interaktioner i realtid som personanpassning, service och beslutsautomatisering. Detta mönster säkerställer:
- Svarstider på undersekunder för direktbeslut.
- Konsekvent, styrd datahämtning i linje med den semantiska modellen Data 360.
- Förenklad programlogik — inga sammanslagningar, ingen schemaavstämning.
- Spårbar och efterlevnadsåtkomst via Trust Layer för granskning och observerbarhet.
Anropsmekanismer
Anropsmekanismen beror på målmolnets lagringsplattform och aktiveringskonfiguration.
| Mekanism | När man ska använda |
|---|---|
| Datagraf-API (föredragen) | Använd för att hämta fullständiga, förmaterialiserade profiler direkt med ID eller nyckel. |
| Data Graph API med live=true | Använd för användningsfall med högt värde (t.ex. bedrägeriupptäckt, liveerbjudanden) där de senaste data behövs, med något högre latens. |
| Connect API (Fallback) | Använd för sammansatta appscenarion som kombinerar datagrafhämtningar med andra Salesforce-data. |
| Query API | Använd vid konstruktion av ad hoc-frågor eller analytiska läsningar istället för direkt profilhämtning. |
| MuleSoft API-proxy | Använd vid dirigering av datagrafanrop genom företagsgateways eller när ytterligare orkestrering/policytillämpning krävs. |
Felhantering och återställning
- Graceful Fallbacks – Om livefrågor misslyckas eller överskrider timeout-trösklar, återgå automatiskt till cachade datagrafhämtningar.
- Timeouthantering – Implementera logik för återförsök och brytare för API-anrop under hög belastning.
- Ogiltig ID-hantering – Returnerar standardsvar på 404 Hittades inte för obefintliga profilnycklar; hanteras smidigt i användargränssnittet.
- Validering av schemaversion – Validera metadata för datagrafversioner för att förhindra felaktiga matchningar när schemat utvecklas.
- Integrering av observerbarhet – Logga alla fel, försök och latenser i Trust Layer-instrumentpaneler för övervakning av servicenivåavtal.
Att tänka på vad gäller Idempotent design
- Deterministiska nycklar – Varje profilhämtning använder ett stabilt ID (t.ex. IndividualId) för att säkerställa förutsägbara, reprissäkra sökfrågor.
- Konsekvens i cache – Använd sidhuvudena ETag eller Senast ändrad för villkorlig hämtning och cachevalidering.
- Atomhämtning – Varje API-svar representerar en enhetlig ögonblicksbild av den materialiserade datagrafposten.
- Reprisskydd – Se till att klientprogram upptäcker dubbletter via korrelations-ID och tidsstämplar.
Att tänka på vad gäller säkerhet
- Stark autentisering – OAuth 2.0 via anslutna appar upprätthåller säker, tokenbaserad åtkomst.
- Samtyckesmedveten hämtning – Endast samtyckesattribut returneras. Samtyckesfilter tillämpas automatiskt av Trust Layer.
- Fältnivåstyrning – Åtkomst till attribut styrs via metadata och policydefinitioner i Data 360.
- Kryptering vid överföring och vila – Alla svar krypteras med TLS 1.2+ och AES-256.
- Granskning och spårbarhet – Varje profilhämtningshändelse loggas med identifierare, tidsstämplar och policysammanhang.
Sidofält
Aktualitet
- Utformad för omedelbar hämtning.
- Stöder livefrågor för uppdaterade data med något högre latens (undersekund).
- Optimerad för synkrona beslut och interaktiva applikationer.
- Utesluter behovet av försatsaktivering eller segmentomberäkning.
Datavolymer
- Idealisk för enskilda postsökningar eller små uppsättningar (tiotals till hundratals) per begäran.
- Inte optimerad för masshämtning i stor skala; använd API:n för batch eller sökfrågor för läsning med hög volym.
- Använder horisontellt skalbar cachning och förmaterialisering för hastighet.
Delstatshantering
- Bibehåller lätt, lägeslös åtkomst; varje begäran är oberoende.
- Har stöd för att cacha sidhuvuden för att hämta dem säkert.
- Program kan upprätthålla lokal cache eller kortsiktig sessionslagring för att minska upprepade sökningar.
Komplexa integreringsscenarion
- Integreras sömlöst med Einstein 1, Connect API och MuleSoft för sammansatta dataupplevelser.
- Kan driva agentsystem (t.ex. andrepilot- eller AI-resonemangsmotorer) som kräver omedelbar kontextuell medvetenhet.
- Kombineras med dataåtgärder för utlösare i realtid vid hämtning eller lägesändring.
- Aktiverar personalisering i stor skala utan att kompromissa med prestanda eller styrning.
Exempel
En global e-handelsplattform använder Data 360:s Data Graph API för att hämta sammanslagna kundprofiler i realtid för sin rekommendationsmotor. När en användare loggar in åberopar programmet Datagrafslutpunkten för att hämta UnifiedCustomerProfile för den kunden och returnerar demografiska attribut, beteendesignaler och beräknade insikter som en enskild JSON-belastning. Personanpassningsmotorn använder detta svar inom millisekunder för att avgöra och visa "Nästa bästa erbjudande" under den aktiva sessionen. Alla begäranden styrs och loggas genom ** Trust Layer**, vilket säkerställer fullständig synlighet, policytillämpning och efterlevnad i hela interaktionen.
Dataåtgärder i realtid aktiverar direkt aktivering av kunddata i samma ögonblick som de ändras i Data 360. Istället för att vänta på schemalagda batchexporter pushar dessa åtgärder uppdateringar, insikter eller utlösare direkt till Salesforce eller externa system på några millisekunder. När en kunds status, samtycke eller engagemangsmått uppdateras i Data 360 kan den signalen omedelbart driva personliga erbjudanden, utlösa Service Cloud-automatiseringar eller uppdatera lojalitetsnivåer — vilket säkerställer att varje kundupplevelse återspeglar den senaste, enhetliga sanningen. Detta mönster är idealiskt för mycket effektiva, latenskänsliga användningsfall som personliga webbupplevelser, varningar om upptäckt av bedrägerier, rekommendationer om nästa åtgärd eller CRM-uppdateringar i realtid. Det minskar avståndet mellan datainsikt och verksamhetsåtgärder och förvandlar sammanslagna data till information i realtid.
Sammanhang
Moderna digitala upplevelser och operativa arbetsflöden kräver omedelbara, kontextuella åtgärder i samma ögonblick som en händelse inträffar — till exempel att uppdatera en kundpost under en Checkout, justera lager när en retur skannas eller leverera ett personligt erbjudande i samma ögonblick som en användare lämnar en varukorg. Med dataåtgärder i realtid kan system åberopa, berika och agera på sammanslagna Data 360-profiler och beräknade insikter med latens under sekunder och möjliggöra interaktiv personanpassning, operativ automatisering och direktbeslut.
Problem
Hur kan program, användargränssnittinteraktionsflöden eller mellanprogramvara anropa Data 360 vid runtime för att läsa, beräkna eller uppdatera en enskild enhetlig profil eller för att utlösa en åtgärd (t.ex. skicka ett erbjudande, uppdatera CRM, starta ett arbetsflöde) med låg latens, stark enhetlighet och styrningskontroller — utan att behöva vänta på schemalagda batchjobb eller tungviktspipeline?
Krafter
Flera tekniska, operativa och styrande krafter formar detta mönster:
- Lågt latenskrav: Samtal måste slutföras på undersekunder till några sekunder för att bevara en bra UX eller för att uppfylla operativa servicenivåavtal.
- Lösning av deterministisk identitet: Begäranden måste lösas till rätt enhetlig individprofil (gyllene post) tillförlitligt och snabbt.
- Finkornig auktorisering: Realtidssamtal måste tillämpa attributnivåpolicyer och samtyckeskontroller vid begäran.
- Payload Minimalism: Realtidsbelastningar ska vara små och fokuserade (enskild profil eller liten attributuppsättning) för att minska latens och kostnad.
- Utvecklarupplevelse: API måste vara utvecklarvänligt (REST/gRPC/GraphQL), med tydliga scheman och stabila kontrakt för produktionsanvändning.
- Granskning och spårbarhet: Varje åtgärd i realtid måste loggas med härkomst, användaridentitet och policybeslut för efterlevnad.
Lösning
Den rekommenderade lösningen är att använda Data 360:s gränssnitt för realtidsdataåtgärder (API:er + SDK:er) kombinerat med kantcachning och minimala beräkningstransformationer vid behov. Integreringar åberopar en slutpunkt för dataåtgärder för att läsa eller skriva profilattribut, beräkna insikter eller inleda orkestreringar. Policykontroller i realtid (CEDAR) och dynamisk maskering tillämpas vid policytillämpningspunkten innan någon nyttolast returneras eller åtgärd utförs.
| Lösningsområde | Anpassa | Kommentarer / Implementeringsdetaljer |
|---|---|---|
| Åtgärd för realtidsdata | Bästa | Visa slutpunkt för läs-/skrivutlösare för enskilda poster och åtgärdsutlösare. Autentisera via OAuth/JWT. |
| Identitetslösning | Obligatoriskt | Lös inkommande identifierare (e-post, externalId, cookie) till Sammanslaget individuellt ID direkt. Använd en deterministisk lösare med cache. |
| Policytillämpning (CEDAR) | Bästa praxis | Utvärdera samtyckes-, ABAC- och maskeringspolicyer vid begäran; avvisa eller maskera fält per policybeslut. |
| Kant-/cachelager | Rekommenderas | Använd korta TTL-cacher för profilfragment och beräknade insikter för att minska latens; ogiltigförklara ändringshändelser. |
| Lättviktstransformationer | Rekommenderas | Tillämpa enkla berikningar eller beräknade fält i åtgärdsvägen; tunga transformationer ska beräknas i förväg. |
| Åtgärdsorkestrering | Bästa | Stöd för synkrona åtgärder i ett steg (t.ex. returerbjudandetoken) och asynkrona orkestreringar (kö \+ webhook) för komplexa flöden. |
| Observerbarhet och spårning | Obligatoriskt | Logga begäran/svar, policybeslut och härkomst till Trust Layer/ SIEM för granskning och felsökning. |
| Begränsning och begränsning av taxa | Obligatoriskt | Tillämpa klientmål och eleganta försämringsstrategier för stunder med hög trafik. |
Skiss
Här är sammanfattningen av stegen.
- Klient (UI / middleware / POS) skickar autentiserade begäranden om dataåtgärd med identifierare och åtgärdstyp.
- API Gateway validerar token, begränsningsgränser och vidarebefordring till Data 360 Action Service.
- Åtgärdstjänst löser identifierare → Sammanslaget individuellt ID (snabb cache för sökväg; reserv till grafsökning).
- Policytillämpning (PDP) utvärderar CEDAR-policyer med hjälp av attribut från PIP och begäransammanhang.
- Om det tillåts läser Åtgärdstjänst eventuella profilattribut/insikter och utför ljustransformationer.
- Åtgärdstjänst returnerar svar synkront (t.ex. erbjudandetoken, uppdaterat attribut) eller asynkron orkestrering i köer och returnerar bekräftelse.
- Alla händelser, beslut och belastningar loggas till Trust Layer och vidarebefordras om du vill till SIEM.
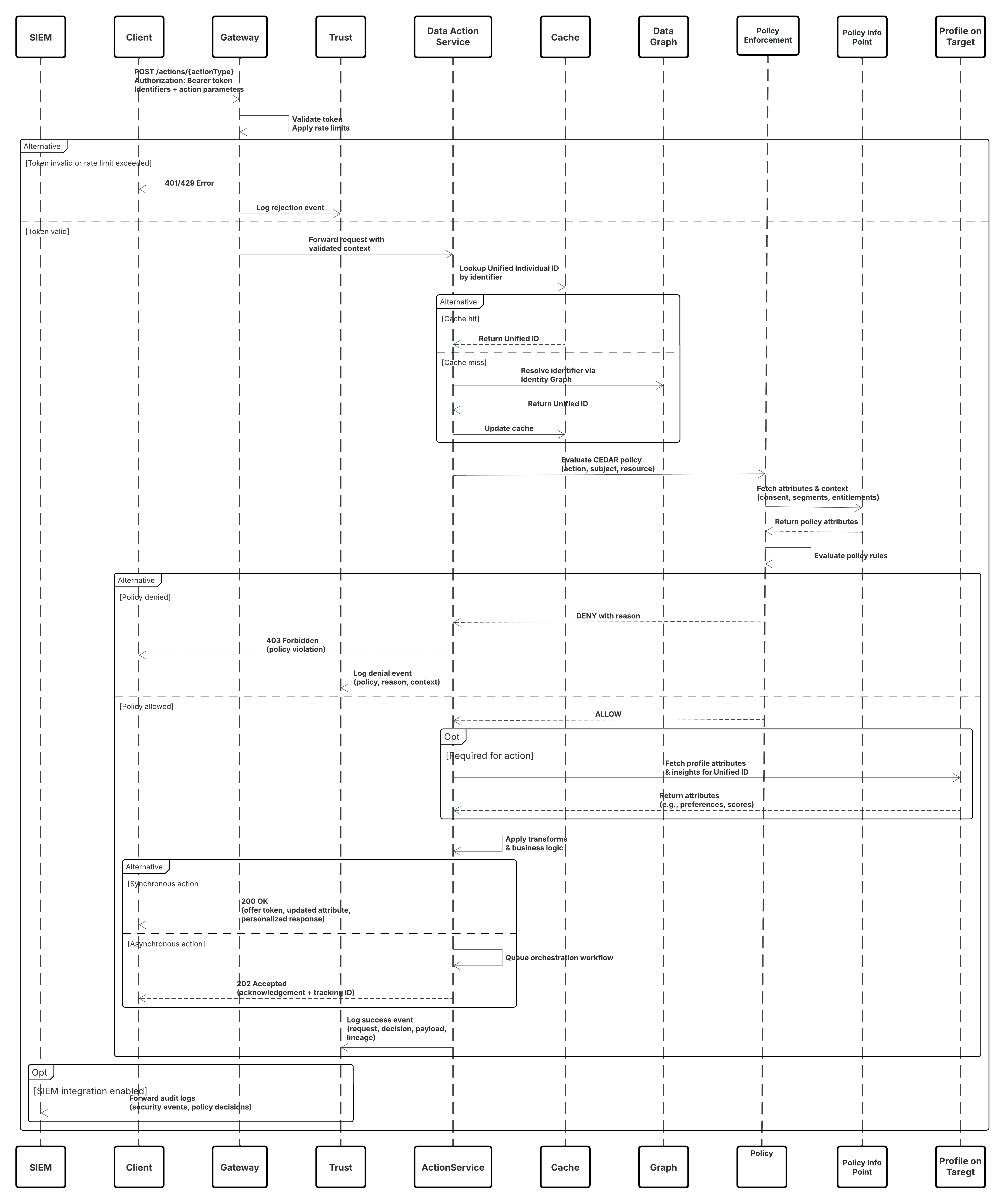
Resultat
- Program får omedelbar, policystyrd åtkomst till sammanslagna profilläsningar/-skrivningar och åtgärdsutlösare med latens under sekunden till sekunden.
- Personanpassning i realtid, beslut och operativa arbetsflöden (t.ex. erbjudanden, agenthjälp, lageruppdateringar) aktiveras utan batchfördröjningar.
- Alla åtgärder går att granska, är samtyckesmedvetna och tillämpar maskering på attributnivå för att upprätthålla sekretess och efterlevnad.
Anropsmekanismer
Anropsmekanismen beror på destinationsplattformen och aktiveringsmålets konfiguration.
| Mekanism | När man ska använda |
|---|---|
| RESTful Data Actions API | Föredragen för webb-/mobilappar och mellanprogram som behöver synkrona profilläsningar eller åtgärdssvar. |
| gRPC / Binär RPC | Använd för företagstjänster med ultralåg latens eller interna mikrotjänster med beständiga anslutningar. |
| Enskilda GraphQL-postfrågor | Använd när klienter behöver flexibla fältval och vill minimera belastningar. |
| Händelseutlösta webhooks | Använd för asynkrona arbetsflöden där åtgärden utlöser processer längre ner (t.ex. starta en resa). |
| Plattformshändelser / PubSub | Använd för utflyttningsscenarion där flera system måste reagera på en enskild åtgärdshändelse. |
| Edge SDK (client libs) | Använd för klienter med låg latens som cachar profilfragment och endast anropar Data Actions API vid behov. |
Felhantering och återställning
- Synkrona fel: Returnera strukturerade felkoder med mänskligt läsbara meddelanden och idempotenstokens.
- Övergående försök: Klienter ska försöka igen idempotenta begäranden med exponentiell backback för 429/5xx-svar.
- Hantering av policynekande: Avvisande returnerar tydliga orsakskoder; känsliga data returneras aldrig om policyn misslyckas.
- Asynkrona orkestreringsfel: Orkestreringsjobb flyttas till DLQ och kan spelas upp igen. En jobbstatus-API låter klienter rösta eller ta emot callbacks.
- Reservstrategier: Om identitetslösning misslyckas, returnera ett deterministiskt fel och om du vill en föreslagen åtgärd (t.ex. kräva externalId).
Att tänka på vad gäller Idempotent design
- Idempotensnyckel: Klienter tillhandahåller en idempotensnyckel (UUID + klientnamnutrymme) för ignoreringsåtgärder.
- Deterministiska nycklar: Använd sammansatta nycklar (UnifiedIndividualId + ActionType + TimestampWindow) för att upptäcka dubbletter.
- Säkra försök: Utforma åtgärder för att vara toleranta mot sidoeffekter eller för att utföra infogningar istället för blindinfogningar.
- Reprisskydd: Behåll bearbetade idempotensnycklar och TTL:a dem efter affärsfönstret för att undvika repriser.
- Statslöshet: Håll synkrona åtgärder lägeslösa där så är möjligt; behåll minimalt läge för asynkrona arbetsflöden.
Att tänka på vad gäller säkerhet
- Autentisering: OAuth 2.0 (JWT Bearer eller mTLS för servicekonton); kortlivade tokens och uppdateringsrotation.
- Godkännande: Policybeslutspunkt tillämpar attributbaserad åtkomstkontroll (CEDAR) och samtyckeskontroller per begäran.
- Transport- och lagringskryptering: TLS 1.2+ är under överföring; AES-256 i vila för cachade fragment eller granskningsloggar.
- Minsta privilegium: API-klienter begränsade till minimala behörigheter; roller separerade för läs vs skriv vs orkestrering.
- Dataminimering: Returnera endast begärda och samtyckta attribut; tillämpa dynamisk maskering för PII/PHI.
- Nätverkskontroller: Om du vill kan du kräva samtal från privata nätverk (Privat anslutning, IP-tillåtelselistor) för högriskåtgärder.
- Revision och övervakning: Logga metadata för begäranden, policybeslut, begärandeidentitet och svarshashar till Trust Layer och SIEM.
Sidofält
Aktualitet
- Utformad för genomsnittliga latenser i intervallet under sekund till låg sekund för synkrona åtgärder.
- Kantcache (kort TTL) och förberäknade insikter minskar rundturer.
- Asynkrona vägar ger nästan omedelbart erkännande med bakgrundsbehandling för tunga uppgifter.
Datavolymer
- Optimerad för interaktioner med enskilda poster eller små satser (1-100 poster).
- Inte avsedd för massexport—använd batchaktivering för stora volymer.
- Hög genomströmning använder återanvändning av poolning/anslutning och parallella orkestreringsköer.
Delstatshantering
- Modell för statuslös begäran för synkrona samtal; minimal åtgärdsstatus kvarstod för beviljanden/transaktioner.
- Cachevalidering driven av ändringshändelser—säkerställ att TTL:er och ogiltighetssignaler håller cacharna fräscha.
- Orkestreringsjobb upprätthåller varaktigt läge (jobId, status, försök) som lagras i Trust Layer.
Komplexa integreringsscenarion
- Agenthjälp: Profilsökning i realtid + beräknad benägenhet returnerad till servicekonsolen på undersekund för agenter.
- POS/Edge-enheter: Lokal SDK + tillfällig dataåtgärd för att validera erbjudanden eller lojalitetsstatus.
- Hybridflöden: Synkronisera dataåtgärd för beslut + asynkron orkestrering för att uppdatera system längre ner och utlösa kampanjer.
- Mellanprogramvara från tredje part: MuleSoft- eller API-gateways kan förmedla autentisering, förbättra sammanhanget och tillämpa extra policykontroller.
Exempel
En mobilapp för detaljhandeln avgör om en personlig direktkupong ska visas när en kund trycker på Checkout genom att åberopa dataåtgärden om erbjudanderätt med kundens e-post och varukorgssammanhang. Begäran valideras av API Gateway och vidarebefordras till Dataåtgärdstjänsten, som löser e-postmeddelandet till ett enhetligt individuellt ID med hjälp av en cacheträff, verifierar marknadsföringssamtycke genom PDP och utvärderar rätten baserat på kundens livstidsvärde och senaste inköpsfrekvens. Om kunden kvalificerar returnerar tjänsten en signerad kupongtoken och loggar beslutet. När kupongutgivning kräver lagerreservation utlöses en asynkron orkestrering för att reservera lager och meddela CRM-system. Appen visar kupongen direkt, medan uppdateringar längre ner slutförs i bakgrunden och Trust Layer samlar in en fullständig verifieringskedja för styrning och efterlevnad.
- Anslutare och integrering
- Webb- och mobil-SDK
- Undersekundintag i realtid
- Ta med egen sjö (nollkopieringsfråga)
- Ta med egen sjö (nollkopieringsfil)
- Datagrafer
- Aktivering: MC-engagemang
- Aktivering: MC-personalisering
- Aktivering: B2C Commerce
- Datadelning (noll kopia)
- Aktivering: Fillagring
- Dataåtgärder
- Subsekunddataåtgärder i realtid
- Extern aktiveringsplattform