Dataplattformar har utvecklats i över tre decennier. Från början dominerades branschen av lokala, centraliserade och strukturerade (mestadels relationella), operativa/OLTP-databaser. Detta utökades till att omfatta datalagers OLAP/Big Data-plattformar som främst användes för analytisk bearbetning och förblev relationella och centraliserade. Molnlagring drev distribuerade arkitekturer som datalager, sjöhus och uppdelad lagring. Driftplattformar och analysplattformar förblev dock åtskilda. Idag förändrar molntjänster och AI-revolutionen i grunden dataplattformens arkitektur.
Företag investerar redan i mogna Big Data-plattformar som Snowflake, Databricks, BigQuery och Redshift. Men dessa plattformar fungerar som datasilos. Kunder deriverar inte verksamhetsvärde från sina data eftersom det inte går att agera på data direkt i verksamhetsflöden och program. Dessa lösningar saknar genererande Agentisk AI-bearbetning och kan inte leverera dataåtkomst i realtid, så de kan inte leverera AI-driven personanpassning just nu med kundengagemang och andra branschledande funktioner.
Framtiden för dataplattformar kännetecknas av enhetlig, flexibel, tillgänglig och öppen datainfrastruktur. Denna nya arkitektur bygger på moderna beräknings- och lagringstrender—GPU:er, stort minne, NVMe SSD:er och molnlagring—för att integrera med molntjänster och AI. De kan leverera insikter i realtid, driva autonomt beslutsfattande och driva program i realtid. Detta inkluderar ökningen av agentisk AI, prediktiv AI, analyser, OLTP-databaser i realtid, datasjöar och sjöbodar. Dessa moderna dataplattformar är utformade för enkelhet, skalbarhet, smidighet, prestanda, säkerhet, tillgänglighet och kostnadseffektivitet.
Följande datatrender driver nästa generations dataplattformsarkitektur.
- AI, maskininlärning och Analytics i centrum: Ökningen av Agentisk AI kommer i grunden att förändra dataplattformens utveckling, distribuering och användning/åtkomst. Agentisk AI kommer att förstå syftet med konversationer/frågor, planera, skapa arbetsflöden och automatisera beslutsfattande. Agentminne (kort och långsiktigt) konstrueras från konversationshistorik för att personanpassa agenters planering och beslut, konversationsmodellering i realtid och stöd för personanpassning som är viktigt i dataplattformar. Agenter kommer att hjälpa till med att automatisera operativa "förmågor" som datastyrning (t.ex. säkerhet, efterlevnad, Trust), prestanda (t.ex. automatisk skalning för samtidighet, genomströmning och latens), växling vid fel och tillgänglighet samt observerbarhet och underhåll. AI-drivna analyser, prognoser, naturlig språkbehandling (NLP) för Analytics Q/A och analyser av ostrukturerade data (text som PDF-filer, bilder, ljud, video) kommer att vara standard, vilket låter företag derivera djupare insikter från olika datakällor.
- Decentralisering av data men enhetlig dataåtkomst: Agenter behöver företagsdata för att derivera insikter och fatta beslut, och för att automatisera verksamhetsaktiviteter. Data är i sig decentraliserade i företag, i olika program och dataplattformar. Men det är inte lätt att sömlöst förena silos mellan olika affärsenheter inom företaget och med partners utanför företaget. Sammanslagning av data innefattar datadelning, antingen via intag från källor eller sammanslagning med datakällor; rådata från dataförberedelse, harmonisering och modeller för analytisk och AI-bearbetning; lagring och hantering av data i stor skala för effektiv åtkomst med låg CTS; och dataåtkomst via olika mekanismer och verktyg för frågor och analyser, djupt integrerade med de underliggande lagrings- och dataåtkomstplattformarna
- Molnbaserade öppna sjöhus: Molnbaserade Big Data-plattformar (OLAP) konvergerar för att börja använda öppna filformat (Parquet) och tabellformat (Iceberg) som möjliggör datafederation (data in) och delning (data ut).
- Ostrukturerad databearbetning: Med uppkomsten, utvecklingen och användningen av generativ AI börjar företag derivera värdefulla insikter och affärsvärde från företagets korpus av data som utgör stora volymer av textdokument, ljudavskrifter, videoinspelningar och andra medier. Ostrukturerad databearbetning, inklusive uppdelning, vektorisering, semantisk sökning och Knowledge grafer, gör dessa insikter möjliga. Tekniker som RAG (hämtning utökad skapande) och CAG (cache utökad skapande) håller på att bli vanliga drivkrafter för snabb och agentisk sökning i hela datakorpusen.
- Kunskapshantering: Knowledge sträcker sig längre än bara själva det råa innehållet (dokument, artiklar, videor). Den representerar en utökning av detta innehåll genom att derivera mening, välja ut metadata och placera det i ett sammanhang för att utveckla en delad förståelse av innehåll i en organisation eller ett företag. Knowledge är i allmänhet strukturerat. Knowledge management innefattar innehållshantering, Knowledge extrahering, representation genom modeller som grafer och navigering.
- Rik dataåtkomst: Rik dataåtkomst innebär att data, analyser och AI-verktyg måste vara tillgängliga för olika personas, inklusive slutanvändare, företagsanvändare, administratörer och analytiker. Tillgänglighet uppnås genom mekanismer som ensemblefråga (med relationell, nyckelords- och semantisk fråga), naturligt språk till SQL-fråga (NL2SQL), åtkomst i realtid och så vidare.
- Realtidsbearbetning: Agentprogram fattar beslut i realtid baserat på aktuellt läge och baserat på nya händelser, personliga svar och åtgärder, vilket kräver åtkomst, bearbetning och åtgärder för realtidsdata. Realtidsbearbetning kräver uppdaterade data (datalatens) och interaktiv åtkomst (åtkomstlatens). Sådana data och åtkomstlatens kräver att den underliggande dataplattformen har stöd för uppdaterad dataåtkomst från operativa och analytiska lager, åtkomst med låg latens (punktsökningar och sökfrågebearbetning), hög dataskala och hög genomströmning.
- Datasäkerhet, styrning och hemvist: Agent- och konversations-AI förenklar programmets användargränssnitt och låter vem som helst, från konsumenter till anställda till andra AI-agenter, interagera med program konversationsvis med naturligt språk i tal eller skrift. De värdefulla kund- och personuppgifter som måste lagras och modelleras för agentprogram måste säkras och styras med väldefinierade åtkomst- och delningspolicyer. I allt högre grad måste många kunder följa föreskrifter som kräver att data lagras i deras eget land eller region, särskilt de som sitter i regeringen eller arbetar med myndigheter.
Salesforce Data 360 är utformat för framtiden och hanterar dessa datatrender. Data 360 är en molnbaserad, metadatadriven dataplattform som förenar silonerade data i hela företaget, vilket låter organisationer lagra, modellera och bearbeta sina data för att aktivera Analytics, AI, maskininlärning och Agentprogram.
Detta dokument är en viktig guide för företagsarkitekter och teknikchefer. Den beskriver arkitektur, kapacitet, designprinciper och användningsfall för Data 360. Den introducerar grunderna i Data 360-arkitektur som en primer, följt av en serie djupdykningar i dess nyckelfaktorer som interoperabilitet med befintliga dataplattformar, inklusive strategi för flera organisationer, säkerhet, styrning och sekretess, aktivering i realtid och datarensningsrum.
Salesforce Data 360 är utformat kring en kärnuppsättning principer som gör företagsdata operativa, betrodda och i realtid.
- Öppenhet och interoperabilitet: Byggd för ekosystem med flera moln. Fungerar med dataplattformar som Snowflake, Databricks, BigQuery och Redshift utan dubbletter, vilket utökar Customer 360 samtidigt som befintliga investeringar behålls.
- Separering mellan lagring och beräkning: Skalar lagring och bearbetning (batch, streaming och interaktiv) oberoende. Ger elasticitet och effektivitet för högpresterande arbetsbelastningar med hög volym.
- Lagring och bearbetning med flera modeller: Stöder strukturerade och olika ostrukturerade datatyper som text, bildljud och video. Ger effektiv lagring, realtids- och batchbearbetning, utökningsbar indexering, enhetlig sökning, förfrågan och analys.
- Metadatadriven design: Program definieras av metadata istället för kod. Metadata behandlas som en förstklassig tillgång, vilket möjliggör enhetlig styrning, flexibilitet och djup integrering i Salesforce Platform.
- Hybridbearbetning i realtid: Stöder sökfrågor med låg latens och direkt beslutsfattande, tillsammans med batchbearbetning och analytiska arbetsbelastningar.
- Intelligenta och aktiva data: Tar kontinuerligt in, analyserar och pushar insikter direkt i verksamhetsflöden. Drivs med no-code, low-code, pro-code och AI-driven automatisering med det senaste sammanhanget.
- Styrning och sekretess efter design: Härkomst, åtkomstkontroll, hemvist, datakryptering och efterlevnad är inbyggda. Trust och regelförtroende stärks i alla led.
- En-till-många-arrendator: En centraliserad Data 360-organisation fungerar som en enskild Sanningskälla för Customer 360 och har sömlöst stöd för Salesforce-miljöer med flera organisationer som används av Salesforce-kunder.
Dessa principer säkerställer att Data 360 gör data öppna, intelligenta och användbara i realtid.
Salesforce Data 360 är en modern dataplattform byggd på designprinciper som hanterar aktuella datatrender. Dess arkitekturkapacitet säkerställer att företagsdata är betrodda, enhetliga och användbara i realtid, i enlighet med dess vägledande principer.
- Molnbaserad grund: Körs på Hyperforce, distribuerad på Hyperscalers (som AWS), med oföränderlig, microservices-baserad infrastruktur. Ger elastisk skalning, säkerhet med noll Trust, kontinuerlig leverans och global efterlevnad.
- Metadatadriven Salesforce (kärna): Metadata utformas, modelleras och lagras som Salesforce-metadata vilket möjliggör omedelbar användning av ALLA Salesforce-program. Sådana metadata lagras i en fullständigt ACID-kompatibel RDBMS. Säkerställer styrning, enhetlighet i livscykeln och djup integrering med Salesforce Lightning Platform.
- Lagerbyggnad: Byggd på Apache Iceberg och Parkett, kombinerar datasjöskala med lagerstyrning som stöder schemautveckling, tidsresor och uppdateringar med hög volym. Data 360 lagrar, modellerar och bearbetar strukturerade och ostrukturerade data med lagring i extrem skala med moderna öppna standarder, och med rika transformations- och databearbetningsfunktioner för batch- och händelsedrivna arbetsbelastningar.
- Datapipeline från början till slut med flexibelt intag: Omfattar hela livscykeln—ta in, förbered, modellera, slå samman, analysera och aktivera—minska beroendet av fragmenterade punktlösningar. Stöder batch, nästan i realtid, och streaming med 270+-anslutare och MuleSoft. ELT-first-metoden möjliggör snabb datatillgänglighet med transformationsflexibilitet längre ner.
- Företagsdatainteroperabilitet med öppna ramverk och federation: Sammanför silodata i hela företaget med dubbelriktad Zero Copy-federation med Snowflake, Databricks, BigQuery och Redshift för att undvika datamigrering eller duplicering.
- Dataklassificering, modeller och organisation: Data 360 organiserar data som rådata som intas, rensade och lagrade data och data som modelleras i enlighet med vanligt informationsschema som kallas SSOT (Enskild källa till sanning). Sådana SSOT-objekt utgör grunden för att definiera semantiska datamodeller (SDM) och andra utvalda och programspecifika modeller.
- Inbyggd semantisk datamodellering för utökningsbara analyser med öppna API:n för semantiska frågor, driver Tableau Next och aktiverar programspecifika analyser.
- Högpresterande SQL-sökfrågemotor som har stöd för en enhetlig Data 360 SQL-sökfråga över strukturerade, ostrukturerade och grafdata.
- Datalagringar med låg latens: Nyckelvärdeslagring för heta data med millisekunders svarstider. Aktiverar personanpassning och händelsedrivna scenarion i realtid. Samlar in och bearbetar data om kundengagemang i realtid. Sammanför identiteter, interaktioner och konversationer i en enda betrodd Customer 360 Profil- och Sammanhangsgraf.
- Ostrukturerade databearbetningspipelines för flexibelt och utökningsbart stöd för ostrukturerad datalagring, fragmentering, skapande av inbäddade data (vektorisering), extrahering av metadata (utökning), sammanfattning, indexering, Knowledge extrahering, intelligent dokumentbehandling, skapande av kort- och långtidsminnen (konversationer) och så vidare.
- Inbyggd nyckelords-, vektor- och hybridindexering för korrekt och effektiv ostrukturerad dataåtkomst, t.ex. snabb och agentiell sökning, RAG, Knowledge extrahering, derivering av agentminne etc.
- Profil, Personanpassning, Sammanhangstjänster för att aktivera AI/ML och Agentprogram.
- Inbyggd styrning och säkerhet i varje lager för härkomstspårning, datamaskering, datalagring och säkerhet med noll Trust som säkerställer efterlevnad och Trust.
- Elastiskt beräkningstyg: Kubernetes inbyggda beräkningsväv med flera arrendatorer. Kör Spark för distribuerad bearbetning och Hyper för SQL-arbetsbelastningar. Skalar elastiskt över olika jobb och stöder isolering för att köra opålitlig kod.
Allt detta körs i Hyperforce, Salesforces molnstiftelse. Hyperforce tillhandahåller:
- Zero Trust-säkerhet med kryptering, isolering och policyer med minst behörighet.
- Resiliens genom distribueringar i flera regioner. Salesforce Data 360 drar nytta av Hyperforces motståndskraft i flera regioner och plattformsnivå för feltolerans, men verklig katastrofåterställning (DR) i företagsklass kräver en bredare arkitektur som liknar alla dataplattformar med nyckelfunktioner: pipelines för återspelbara intag, replikering och metadatadriven återhydratisering i alla beroende ekosystem.
- Observerbarhet med övervakning, mått och spårning inbyggt.
- Automatiserad skala och FinOps-medvetenhet för effektivitet utan kostnadsspill.
Data 360 ersätter inte befintliga företagsinvesteringar. Istället gör Data 360 de data du redan har betrodda, styrda och användbara—leverera AI-drivet engagemang i realtid där det är viktigast. Kort sagt, Salesforce förvandlar alla företagsdata inklusive externa data som (Salesforce) metadatadrivna objekt och aktiverar Agentprogram för upptäckt, beslutsfattande och för att vidta åtgärder.
Följande figur illustrerar Data 360-referensarkitekturen:
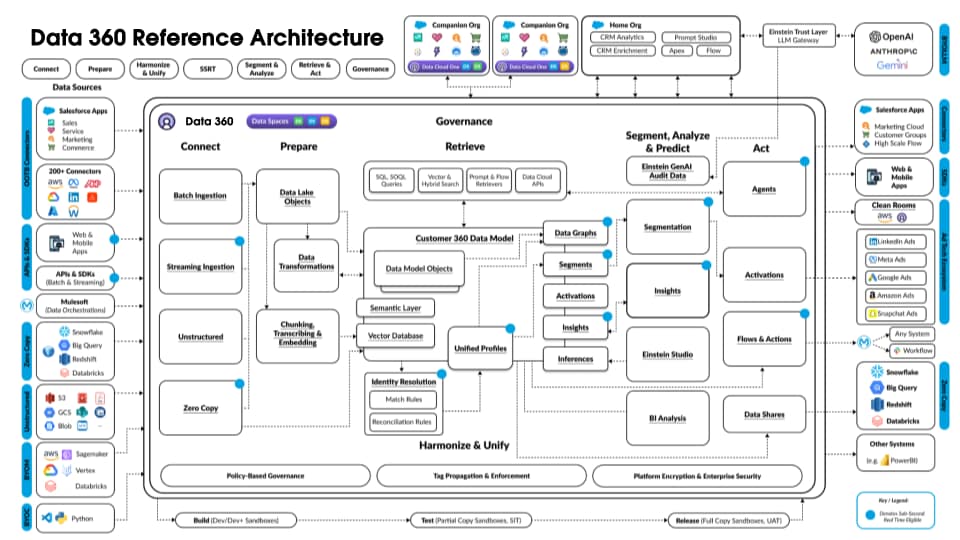
Låt oss överväga en hypotetisk Agentforce Loan Agent som finns i lager på Data 360 för att beskriva ett exempel på arkitekturflöde. Låt säga att låneagenten är en kundriktad agent där kunder (konsumenter) ansöker om lån och får godkännanden av direktlån.
Data 360 utför dessa steg enligt schemat och förbereder data för användning av låneagenten.
- Data 360 tar in strukturerade kundkontodata från CRM och lagrar dem i datasjön.
- Data 360 bearbetar ostrukturerade företagslån och finanspolicydata.
- Data 360 sammanför personuppgifter från en extern datakälla som Snowflake.
- Data 360 transformerar och modellerar intagna och sammanslagna data.
- Data 360 bygger och underhåller profildatagrafen.
Varje gång en kund ansöker om ett lån utförs dessa åtgärder.
- En kund loggar in i låneagenten, som startar en kundsession i realtidslagret. Kundens enhetliga profil hämtas till realtidslagret.
- Kunden fyller i en låneansökan genom att ange den information som behövs.
- Kunden laddar upp ekonomiska dokument (som skattedeklarationer, investeringar, kontoutdrag) till Data 360 för ostrukturerad databearbetning.
- Uppladdade data delas upp och vektoriseras (skapande av inbäddning) och index (nyckelord och vektor) skapas.
- Sedan fyller kunden i låneansökan och laddar upp den. Data 360 extraherar lånebeloppet och varaktigheten i realtid.
- Låneagenten hämtar relevanta ekonomiska data med hjälp av Data 360-sökfrågor och hybridsökning över profilindex och andra förskapade index.
- Låneagenten aktiverar en godkännandeagent med lånedata och andra ekonomiska profildata för att fatta beslutet om godkännande av lånet.
- Låneagenten svarar kunden med ett beslut.
- Hela denna interaktion mellan kunden och låneagenten samlas också in och lagras i Data 360.
Ovanstående exempel ger en översikt av Data 360-arkitekturkomponenter som används för att bygga ett Agentprogram, till exempel en låneagent. I nästa avsnitt beskriver vi Data 360-arkitekturens lager och komponenter.
I denna sektion kommer vi att fördjupa oss i de grundläggande byggstenarna i Salesforce Data 360, med början i dess robusta lagringsmodell och därefter utforska mekanismerna för att ansluta, ta in och förbereda data. Vi kommer sedan att undersöka hur strukturerade och ostrukturerade data lagras, modelleras och bearbetas, vilket kulminerar i en förståelse av dess harmonisering, sammanslagning, hämtning och intelligenta aktiveringskapacitet.
Salesforce Data 360 bygger på en stegvis men integrerad lagringsmodell som kombinerar styrkan hos ett sjöhus med lagring i realtid. Lakehouse-lagret ger skalbar, kostnadseffektiv lagring för stora volymer historiska data och batchdata, vilket möjliggör avancerade analyser och maskininlärningsfall. Lagring i realtid är däremot optimerat för åtkomst med låg latens och hög frekvens, vilket säkerställer att kundinteraktioner, profiler och engagemangssignaler alltid är aktuella. Tillsammans fungerar dessa nivåer sömlöst och låter data röra sig flytande mellan historiska sammanhang och realtidssammanhang – vilket ger både djup och omedelbarhet i en enhetlig datagrund för personanpassning, AI och aktivering.
Data 360 har en inbyggd Lakehouse-arkitektur baserad på Iceberg/Parquet, utformad för att hantera storskalig datahantering och bearbetning för batch-, streaming- och realtidsscenarion med stöd för både strukturerade och ostrukturerade data, avgörande för AI- och Analytics-program.
I molnbaserade datasjöar som Azure, AWS eller GCP är den grundläggande lagringsenheten en fil, vanligtvis organiserad i mappar och hierarkier. Lakehouse förbättrar denna struktur genom att introducera strukturella och semantiska abstraktioner på högre nivå för att underlätta operationer som sökfrågor och AI/ML-bearbetning. Den primära abstraktionen är en tabell med metadata som definierar dess struktur och semantik, och innehåller element från projekt med öppen källkod som Iceberg eller Delta Lake, med ytterligare semantiska lager tillagda av Data 360.
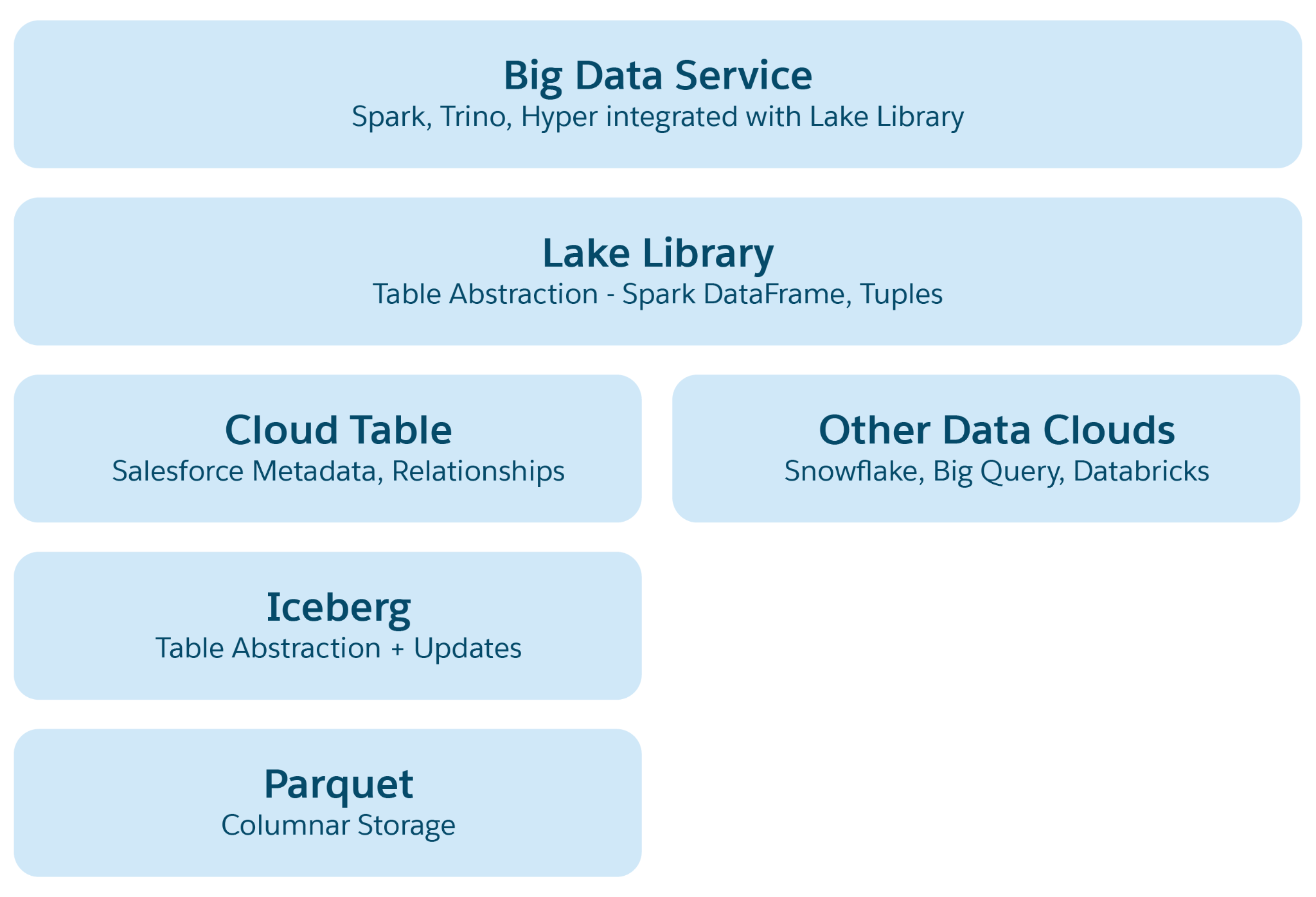
Abstraktionslager i Lakehouse:
- Abstrahering av parkettfil: I grunden består lagring av datasjöfiler (till exempel S3 i AWS eller Blob i Azure) i parkettformat. Data för en källtabell lagras över flera partitioner som parkettfiler, där varje tabell är en samling av dessa filer.
- Isbergstabellens abstraktion: Tabeller är organiserade som mappar, med datapartitioner lagrade som parkettfiler i dessa mappar. Ändringar av en partition resulterar i nya parkettfiler som ögonblicksbilder. Iceberg hanterar en metadatafil för varje tabell med detaljer om scheman, partitionsspecifikationer och ögonblicksbilder.
- Salesforce Cloud-tabellabstraktion: Detta lager bygger på Iceberg och lägger till semantiska metadata som kolumnnamn och relationer, tillsammans med konfigurationer som målfilstorlek och komprimering. Den abstraherar tabeller över olika plattformar som Snowflake och Databricks, vilket skyddar Data 360-program från underliggande plattformsdetaljer.
- Lake Access-bibliotek: Detta bibliotek ger åtkomst till Salesforce Cloud-tabellen, hanterar både data och metadata, och abstraherar de underliggande lagringsmekanismerna för programutvecklare.
- Abstrahering av stordatatjänst: Detta inkluderar bearbetningsramverk som Hyper för sökfrågor och Spark för bearbetning över alla molntabellplattformar.
För att stödja analyser i realtid och agentprogram utökar Data 360 Lakehouses big data-lagring med lagring med låg latens. Data 360-realtidslager bearbetar realtidssignaler och engagemangsdata i minnet. Eftersom den minnesbaserade lagringskapaciteten är begränsad får dock inte alla data plats och bearbetning kanske inte utförs i realtid. Data 360 lägger till ett lagringsutrymme med låg latens (LLS) för att ta bort sådana begränsningar, vilket möjliggör skalbar bearbetning i realtid.
Lagret med låg latens är ett NVMe-lagringslager i petabyteskala (SSD) på Lakehouse. Alla data behöver inte lagras i butiken med låg latens. Det är en hållbar cache. De flesta data når så småningom Lakehouse för långsiktig uthållighet. Sessionsdata i realtidslagret kan spolas till lagringen med låg latens för efterföljande snabb åtkomst. Till exempel, i en agentkonversation kan senaste meddelanden bearbetas i minnet; äldre meddelanden kan spolas till butiken med låg latens. Om en tidigare konversation krävs kan den nås inom några millisekunder från butiken med låg latens. NVMe-baserad lagring gör att stora mängder data kan lagras och kommas åt vid millisekunders latens. Data kan ta sig till Lakehouses molnlagring för långsiktig beständighet. Utöver detta hämtas och behålls data från Lakehouse som behövs för realtidsbearbetning eller för att utöka upplevelser i realtid i butiken med låg latens. Till exempel hämtas kundens profilsammanhang i förväg eller hämtas från Lakehouse och cachas i butiken med låg latens. Även sjöhusobjekt och andra objekt som behövs för realtidsbearbetning under sessionsbearbetning kan cachas i butiken med låg latens.
Data 360-lagring med låg latens aktiverar lagret Real Timer i en sann lagringshierarki med minneslager (SSD) i Lakehouse, med data som sömlöst migreras mellan dessa lager. Vi diskuterar Data 360-realtidslagret senare i detta dokument.
Salesforce Data 360 är utformat för att standardisera, harmonisera och aktivera alla kunddata—strukturerade och ostrukturerade—efter en rigorös livscykel som omvandlar rådata till en enhetlig, aktuell datamodell.
Livscykeln fokuserar på att ta olika externa datainmatningar och strukturera dem i beständiga, modellerade objekt. Modellerade data kan harmoniseras till enhetliga profiler för Customer 360.
Intagna rådata och inledande transformationer
Processen börjar med rådata som intas i befintligt skick från källsystem (CRM, Marknadsföring, filer etc.). Detta inkluderar fullständiga datainläsningar och kontinuerliga ändringshändelser (deltas), som hanteras och slås samman med beständiga data för att upprätthålla ett aktuellt läge.
Inbäddade transformationer (t.ex. trimning, normalisering, sammanslagning) tillämpas omedelbart under intag för att säkerställa preliminär datakvalitet och renhet.
Datasjöobjekt (DLO): Det bestående lagret
DLO (Datasjöobjekt) utgör det huvudsakliga beständiga lagringslagret i Data 360. De lagrar rensade, transformerade data och fungerar som en organiserad, långsiktig databas för all kundinformation.
Avancerade datatransformationer (t.ex. sammanslagningar, aggregeringar, beräknade insikter) tillämpas på käll-DLO för att skapa nya, härledda DLO som är mycket utvalda.
Data som görs tillgängliga genom Zero Copy Data Federation representeras direkt som DLO.
Organisering av ostrukturerade data och metadata
För ostrukturerat innehåll (som text, media, dokument) införlivar Data 360 data genom att extrahera och behålla dess strukturerade metadata inom specifika DLO som kallas ostrukturerade datasjöobjekt (UDLO).
Dessa specialiserade DLO fungerar som katalogtabeller och ger en karta till den fysiska platsen och sammanhanget för de ostrukturerade tillgångarna. Denna kapacitet låter arkitekter sömlöst relatera metadata för ostrukturerade data med resten av de strukturerade kunddata, vilket möjliggör enhetlig förfrågan och harmonisering.
Datamodellobjekt (DMO): Det harmoniserade lagret
DMO (Datamodellobjekt) representerar det slutgiltiga, harmoniserade och strukturerade datalagret.
De skapas genom att mappa DLO-fält (från käll-, deriverade och ostrukturerade metadata-DLO) till standarddatamodellen Customer 360.
DMO-lagret fungerar som den enskilda källan till sanning för alla kunddata och möjliggör enhetligt profilskapande, segmentering och aktivering i hela det bredare ekosystemet.
Ett datautrymme är den grundläggande logiska behållaren för att organisera alla data och metadata inom Data 360, inklusive alla DLO (strukturerade och ostrukturerade) och DMO. Datautrymmen erbjuder en säker, isolerad miljö för databearbetning och modellering.
Datautrymmen fungerar som logiska och styrande gränser och möjliggör intern multitenancy genom att separera data för unika enheter som affärsenheter, regioner eller varumärken – samtidigt som de behåller företagsomfattande synlighet, härkomst och efterlevnad, vilket fungerar som grunden för att definiera grovkornig åtkomstkontroll.
Isolering inom datautrymmen tillämpas på flera lager av plattformen:
- Datanivåisolering: Varje DLO/DMO hör till ett enskilt datautrymme, vilket säkerställer att sökfrågor, transformationer och objektmappningar inte kan korsa datautrymmesgränser om de inte uttryckligen auktoriseras.
- Integrering av åtkomstkontroll: Behörighetsuppsättningar är inbyggt knutna till datautrymmen, vilket ger kontroll över läs-, skriv- och administrativa åtgärder. Detta säkerställer att endast auktoriserade användare och tjänster kan komma åt objekt, insikter och aktiveringar inom ett datautrymme.
- Styrning och revision: Alla operationer inom ett datautrymme loggas med granskningsloggar av företagsklass, vilket möjliggör spårbarhet för efterlevnad, förvaltning och rapportering.
Åtkomst och behörigheter hanteras genom behörighetsuppsättningar, vilket säkerställer detaljerad synlighet, kontrollerade uppdateringar och förhindrar dataläckage mellan domäner. Genom att integrera datautrymmesgränser med Data 360:s säkerhets- och styrningsarkitektur kan arkitekter med tillförsikt implementera både centraliserade och decentraliserade styrningsstrategier samtidigt som de upprätthåller enhetlighet över flera moln och verksamhetsdomäner.
Data 360-beräkningsmaterialet ger ett enhetligt lager för hantering och utförande av alla stordataarbetsbelastningar, vilket förenklar underliggande infrastrukturkomplexitet. Dess kärnkomponent är den personuppgiftsansvariga (DPC).
DPC är en omfattande orkestreringstjänst för databearbetning med flera arbetsbelastningar som tillhandahåller Job-as-a-Service-funktioner (JaaS) över olika molnberäkningsmiljöer. Den abstraherar infrastrukturkomplexitet och förenar jobbkörning för ramverk som Spark (EMR på EC2 och EMR på EKS) och Kubernetes Resource Controller (KRC). Genom att fungera som en central styrplansgateway orkestrerar, schemalägger och övervakar DPC jobb över flera dataplan, vilket säkerställer pålitlighet, skalbarhet, kostnadseffektivitet och en enhetlig utvecklarupplevelse.
Behovet av DPC kommer från begränsningarna i att direkt interagera med inbyggda klusterhanteringssystem som EMR.
Abstrahering av infrastruktur och moln
Även om EMR erbjuder API:n för kluster, uppgifter och steg, belastar det fortfarande klientteam med viktiga infrastrukturhanteringsuppgifter som provisionering, skalning, prestandajustering och kostnadsoptimering. DPC hanterar detta genom att erbjuda en förenklad API på plattformsnivå för jobbinskickning. Den har stöd för automatisk felhantering, försök och dynamisk lastbalansering. Ger kostnadseffektivitet genom binpacking, spot- och gravitonbaserade noder. Ger stark säkerhet med TLS, PKI, IAM-isolering och automatiserad patchning. Hanterar uppgraderingar av Spark- och EMR-versioner för att leverera prestandaförbättringar, säkerhetskorrigeringar och funktionsförbättringar.
Dessutom tillhandahåller DPC ett enhetligt, molnagnostiskt gränssnitt för att skicka in och hantera datajobb, vilket abstraherar komplexiteten och egenutvecklade API:n för det underliggande molnsubstratet (AWS, framtida leverantörer). Detta säkerställer att klientteam endast interagerar med ett vanligt Data 360 API-baserat gränssnitt för jobbinskickning som abstraherar bort komplexiteten hos underliggande resurshanterare som Kubernetes och YARN. Detta låter klientteam skicka Spark-jobb genom en enkel, enhetlig API utan att behöva hantera pods, nodpooler eller Spark-klusterkonfigurationer direkt.
Manuell inställning av Spark-parametrar kräver specialkompetens och felaktiga konfigurationer kan leda till långsamma jobbkörningar. DPC-teamet centraliserar denna expertis och tillhandahåller optimerade konfigurationer för att förhindra vanliga prestandaproblem. Detta specialiserade team integrerar kontinuerligt Knowledge från diskussionsgruppen med öppen källkod för att säkerställa optimal prestanda över alla arbetsbelastningar som hanteras av kontrollenheten.
DPC är inte begränsat till Spark; det har stöd för en bred uppsättning arbetsbelastningar. Dessa inkluderar:
- Bearbetningsarbetsbelastningar i realtid
- Händelseleverans för funktionen Dataåtgärder
- Hantering av Milvus (vektordatabasen för ostrukturerad dataindexering)
- Infrastruktur för lagring med låg latens
DPC använder även ramverket Kubernetes Resource Controller (KRC), som har stöd för arbetsbelastningar som Trino för sökfråga, Händelseleverans för dataåtgärder, Dataextraheringsjobb för anslutare och realtidsbearbetning. För alla KRC-arbetsbelastningar tillhandahåller DPC centrala Jobb-som-en-tjänst-funktioner som hanterar beräkningsprovisionering, distribuering och hantering på en övergripande jobbabstraktion.
JaaS-förmåner och -arkitektur
Modellen Jobb-som-en-tjänst, som tillhandahålls av DPC, säkerställer en kostnadseffektiv och motståndskraftig pipeline för jobbbearbetning.
Användare tillhandahåller enkla klusterspecifikationer, med fokus på nödvändig CPU, minne, lagring, instansantal och Min/Max-antal och taggar för klustermatchning. DPC hanterar sedan automatiskt abstrakta infrastrukturdetaljer, inklusive att välja optimala VM SKU:er, hantera instansflottor, avgöra förhållandet mellan Core vs. Uppgiftsnoder och hantering av På-begäran vs. Upptäck instanser baserat på indata. Den hanterar även hantering av EMR- och komponentversioner och uppgraderingar utan nedtid.
Avgörande är att DPC har inbyggt stöd för multitenancy, utformat för att förstå och tillämpa Data 360-arrendatorgränser och resursseparation. Det säkerställer även säkerhet och efterlevnad genom att tillämpa Salesforce-certifierade maskinavbildningar, hantera servicespecifika IAM-roller och garantera kryptering både under överföring och i vila. För dirigering och kapacitetskontroll hanteras jobb-till-kluster-matchning med klustertaggar och kapacitetsbaserad dirigering använder en maximal inställning för jobbsamtidighet för att effektivt styra resursanvändning.
Cloud Agnostic Client Experience är en huvudfördel, eftersom komplexiteten i underliggande molnmiljöer är dold från klienttjänster, vilket låter dem fokusera enbart på verksamhetslogik. Detta uppnår målet för abstraktion av molnleverantörer. Slutligen möjliggör DPC enkel användning och kostnadsspårning, vilket låter klusteranvändning och kostnader segmenteras efter tjänst för korrekt redovisning. Generellt följer DPC en pluggbar arkitektur som låter nya utförandemotorer (t.ex. Flink, Ray) och molnsubstrat (GKE/Dataproc) integreras sömlöst utan att exponera underliggande infrastrukturdetaljer för användare. Denna design kopplar bort kontrollplanet från utförandelagret, vilket säkerställer en enhetlig API- och verksamhetsupplevelse oavsett backend.
Data 360 förfinar och berikar rådata och överbryggar klyftan mellan rådata och användbar företagskonsumtion. Den kompletterar dataobjektets livscykel genom att förbereda komplexa data för sofistikerad aktivering och analys. Data 360 har stöd för olika bearbetningstyper, inklusive batch- och strömmande datatransformationer, batch- och strömmande beräknade insikter, ostrukturerad databearbetning och identitetslösning. För att möjliggöra dessa olika åtgärder effektivt, särskilt i nästan realtid och över massiva datauppsättningar, krävs en sofistikerad mekanism för att hantera dataändringar effektivt.
För att uppnå effektiv databearbetning nästan i realtid—särskilt med tabeller i terabytestorlek och miljontals potentiella uppdateringar—behövde Data 360 ett genombrott. Det krävdes ett sätt att meddela system exakt när data ändras och sedan effektivt identifiera vilka data som ändrades så att endast relevanta uppdateringar bearbetas och endast när de uppdateras. Denna utmaning ledde till två kompletterande innovationer: Ursprungliga ändringshändelser för lagring (SNCE) för att meddela när något ändras och Ändra datakanal (CDF) för att identifiera vad som ändrats.
Ursprungliga ändringshändelser för lagring (SNCE)
SNCE har i grunden ändrat Data 360 till en reaktiv och inkrementell dataplattform. Detta skift innefattar att gå från att aktivt polla datasjön till att passivt övervaka atomära händelser, med ett standardiserat händelseformat och ett meddelandeleveranssystem med hög genomströmning.
Varje framgångsrik skrivoperation (INSERT, UPDATE, DELETE) till en Iceberg-tabell kulminerar i ett atombyte av tabellens aktuella metadatafilpekare i katalogen. Det underliggande objektlagringslagret (säg S3) är konfigurerat att avge en inbyggd notishändelse (som en S3-händelse) när en ny metadataögonblicksbild skrivs till tabellens katalog.
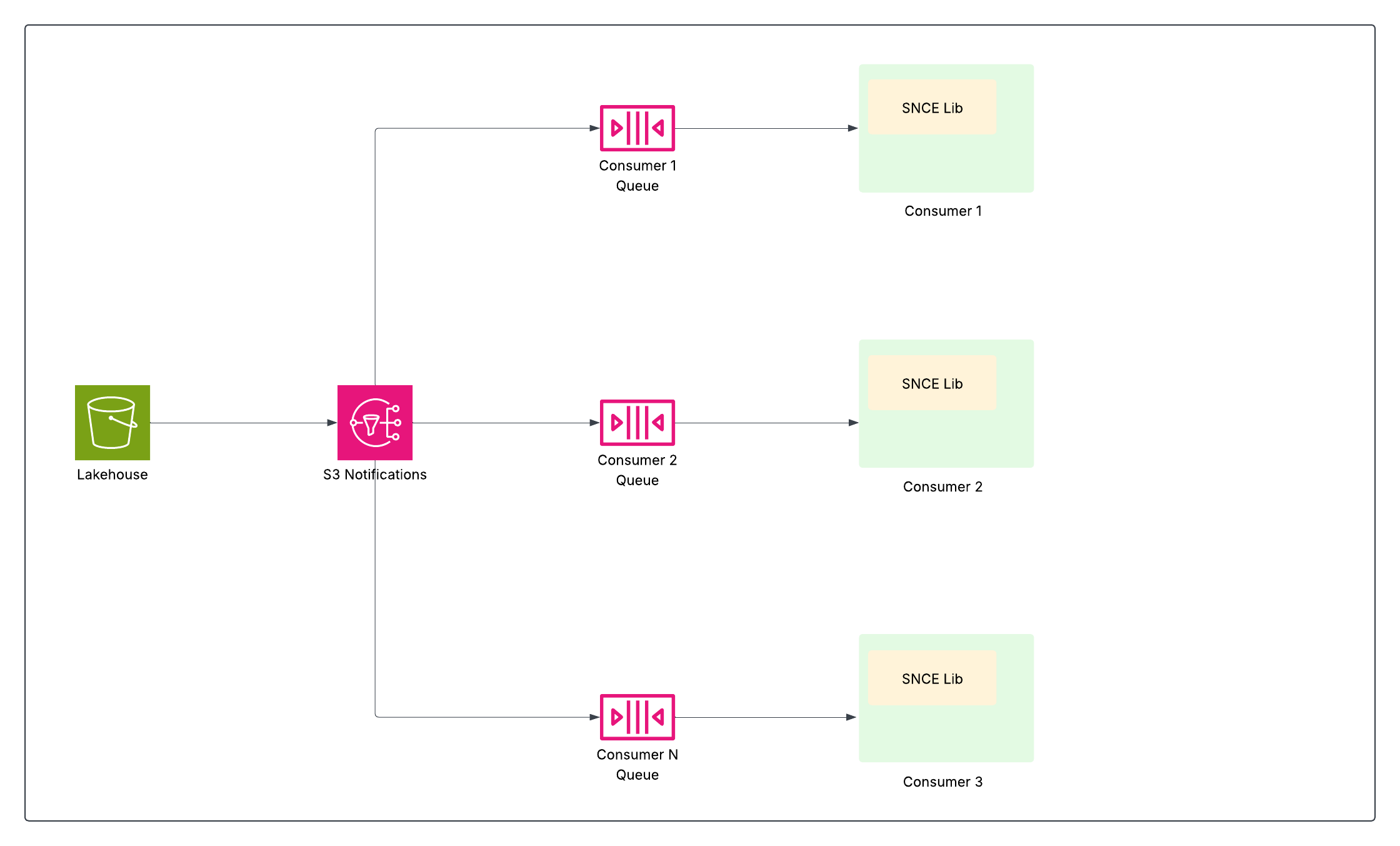
SNCE-biblioteket erbjuder en standardiserad metod för att konsumera dessa händelser, och det kan även berika dem med ögonblicksbildmetadata på begäran.
Detta gör att pipelines längre ner—som streaming av beräknade insikter, identitetslösning och segmentering—endast kan prenumerera och agera när data har ändrats, vilket avsevärt ökar effektiviteten genom att undvika kostsamma fullständiga tabellskanningar.
Ändra datakanal (CDF)
Ändringsdatakanalen (CDF) bygger på SNCE och är en effektiv mekanism för att konsumera och stegvis bearbeta ändringarna.
CDF använder ögonblicksbilder av Iceberg för att effektivt skapa strömmen av ändringar. Kritiskt är att Data 360:s optimerade Iceberg-brännare beräknar och behåller ändringarna som en del av själva skrivoperationen, vilket gör CDF-skapandet mycket effektivt och minimerar ytterligare overhead. Detta låter bearbetningsjobb (som streamingtransformationer eller strömmande beräknade insikter) endast bearbeta de ändrade posterna selektivt och undviker den dyra beräkningen av ögonblicksbilddiff.
Denna inkrementella strategi ger flera fördelar för stora datauppsättningar, inklusive kostnadsbesparingar, minskad latens och förbättrad effektivitet. Den aktiverar funktioner som streamingtransformationer och inkrementell identitetslösning, vilket i sin tur leder till snabbare insikter, mer förutsägbara systembelastningar, förbättrad prestanda och lägre driftskostnader.
Data 360 erbjuder robusta intagsfunktioner med inbyggt stöd för Salesforce-produkter, vilket säkerställer sömlöst dataflöde. För externa källor ger den omfattande anslutning genom över 270 anslutare, API, SDK och MuleSoft. Utöver detta har Data 360 funktioner för federation med nollkopior, vilket tillåter BI och analyser utan dataduplicering.
Data 360-anslutarramverket (DCF) är grunden för de flesta Data 360-anslutningar. Den möjliggör intag, federation och utträde genom en enhetlig arkitektur. DCF definierar standarderna för att bygga och hantera anslutare, från användargränssnittet för konfiguration och administration till metadatabeständighet, dataextrahering och leverans till Lakehouse eller via livefrågor mot externa källor. Den har även stöd för privata anslutningsalternativ (som privata länkar, VPN och säkra tunnlar) för att säkerställa datasäkerhet och efterlevnad i företagsklass vid anslutning till kund- eller partnermiljöer. Genom att tillhandahålla ett enhetligt tillvägagångssätt över alla anslutare ger DCF Data 360 möjlighet att ansluta sömlöst till det bredare ekosystemet genom att säkerställa utökningsbarhet, pålitlighet och säker integrering.
Data 360 ger robust anslutning till ett brett ekosystem av datakällor, med stöd för både inbyggda Salesforce-produkter och många externa system. Denna omfattande anslutning är avgörande för att slå samman silonerade företagsdata och aktivera AI/ML och Agentic-program.
Data 360 erbjuder över 270 anslutare inbyggt eller genom MuleSoft, API:er och SDK:er för att stödja dess kapacitet för end-to-end-datapipeline med batch, streaming eller intag i realtid. Dessa anslutare kan kategoriseras brett efter vilken typ av källsystem de integrerar.
Inbyggda Salesforce-anslutare
Dessa anslutare säkerställer sömlöst och inbyggt dataflöde från Salesforce-produkter.
Exempel på detta är anslutare för Salesforce CRM, Data Cloud One , Marketing Cloud-engagemang, Marketing Cloud-kontoengagemang och B2C Commerce.
Externa program och SaaS
Anslutare för olika affärsprogram och molntjänster tillåter dataintag från externa programvaruplattformar.
Exempel inkluderar Adobe Marketo Engage, Microsoft Dynamics 365, Mailchimp och Airtable.
Databaser och datalager
Data 360 ansluter till flera olika relations- och molnbaserade datalagringsplattformar.
Exempel inkluderar Amazon Redshift, Amazon DynamoDB, Amazon RDS (MySQL, PostgreSQL, Oracle), Google BigQuery och Microsoft SQL Server.
Lagring och filsystem för molnobjekt
Dessa anslutare integreras med hyperscalerlagringslösningar för både strukturerade och ostrukturerade data.
Exempel inkluderar Amazon S3, Google Cloud Storage (GCS) och Azure Blob Storage.
Streaming- och meddelandetjänster
Anslutare som hanterar kontinuerliga dataströmmar i realtid är viktiga för händelsedrivna scenarion och bearbetning i realtid.
Ett exempel är Amazon Kinesis-anslutaren.
Integreringsplattformar
MuleSoft Anypoint-anslutaren utökar Data 360:s räckvidd genom att integrera den med ett bredare utbud av program och databaser via Anypoint Exchange.
Anslutare för ostrukturerade data och molnobjektlagring
Dessa anslutare är viktiga för att ta in och referera till ostrukturerade data (data som inte har en fördefinierad modell) till kraftgenererande AI-kapacitet.
Alla dessa anslutare är byggda på Data 360-anslutarramverk som ger en enhetlig upplevelse.
Datatransformation är en grundläggande arkitektonisk komponent i Data 360, utformad för att rensa, berika och forma rådata till normaliserade, användbara datatillgångar i enlighet med datamodellen Customer 360. Denna process är viktig för harmonisering, kvalitetsförbättring och för att säkerställa att data är redo för användning i efterföljande led, som till exempel sammanslagning, segmentering och aktivering av profiler. Transformationer använder både källdatasjöobjekt (DLO) och datamodellobjekt (DMO) som indata och producerar resultaten till nya DLO respektive DMO.
Data 360 tillhandahåller två primära transformationsparadigmer för att hantera olika datahastighetskrav: batchdatatransformationer och strömmande datatransformationer.
Batchdatatransformationer
Batchdatatransformationer är utformade för bearbetning med hög volym baserat på ett definierat schema eller en utlösare på begäran. Denna motor är optimerad för att hantera komplexa, resursintensiva omstruktureringar.
Batchtransformationsprocessen konfigureras med en visuell pipelinearbetsyta med låg kod som låter användare definiera transformationslogik i flera steg. Denna motor har unikt stöd för komplexa omstruktureringsåtgärder som är viktiga för anpassning av kanoniska datamodeller: datastrukturering och normalisering. Detta inkluderar att pivotera (dela upp denormaliserade poster i flera normaliserade poster) och platta ut (omstrukturera hierarkiska data, som JSON, till strukturerade tabeller). Systemets utförandeläge har stöd för både fullständig synkronisering (bearbetning av alla poster) och ett mycket effektivt inkrementellt bearbetningsläge. Det inkrementella läget minskar bearbetningstiden och resursförbrukningen avsevärt genom att endast bearbeta poster som har ändrats sedan den senaste framgångsrika körningen. Batchtransformationer är idealiska för uppgifter där uppdateringar i realtid inte är nödvändiga, till exempel periodiska aggregeringar och komplex dataomstrukturering.
Strömmande datatransformationer
Att strömma data transformerar processdata kontinuerligt och stegvis i nästan realtid när de flödar in i systemet, vilket gör dem viktiga för användningsfall med låg latens.
Det primära gränssnittet är en SQL-first-metod, där transformationer definieras som en SQL SELECT-fråga som kontinuerligt körs mot den inkommande strömmen av poständringar. Denna motor har stöd för kärntransformationsfunktioner, inklusive datarensning och standardisering (t.ex. validering av PII och standardisering av dataformat) och dataförbättring och -koppling (med sammanslagningar och unioner). Den har stöd för Streaming Searchup JOINs för att aktivera dataförbättring i realtid och sökningar mot statiska eller långsamt föränderliga referensdata, vilket säkerställer direkta profiluppdateringar. För att optimera kostnad-till-service använder arkitekturen en HD-jobbdesign, som paketerar flera definitioner av streamingtransformation för en enskild arrendator till ett enskilt underliggande beräkningsjobb, vilket maximerar resursanvändningen. Streamingtransformationer är viktiga för användningsfall som händelseövervakning, omedelbar personanpassning och profiluppdateringar i realtid.
Data 360 revolutionerar datahantering genom att stödja federation av Zero Copy och datadelning, vilket eliminerar behovet av att flytta eller duplicera data. Denna kapacitet låter användare få sömlös och direkt åtkomst till data från olika externa källor och dela data med externa miljöer, vilket avsevärt minskar komplexiteten, sänker lagringskostnaderna och säkerställer att alla beslut baseras på den senaste, mest pålitliga informationen.
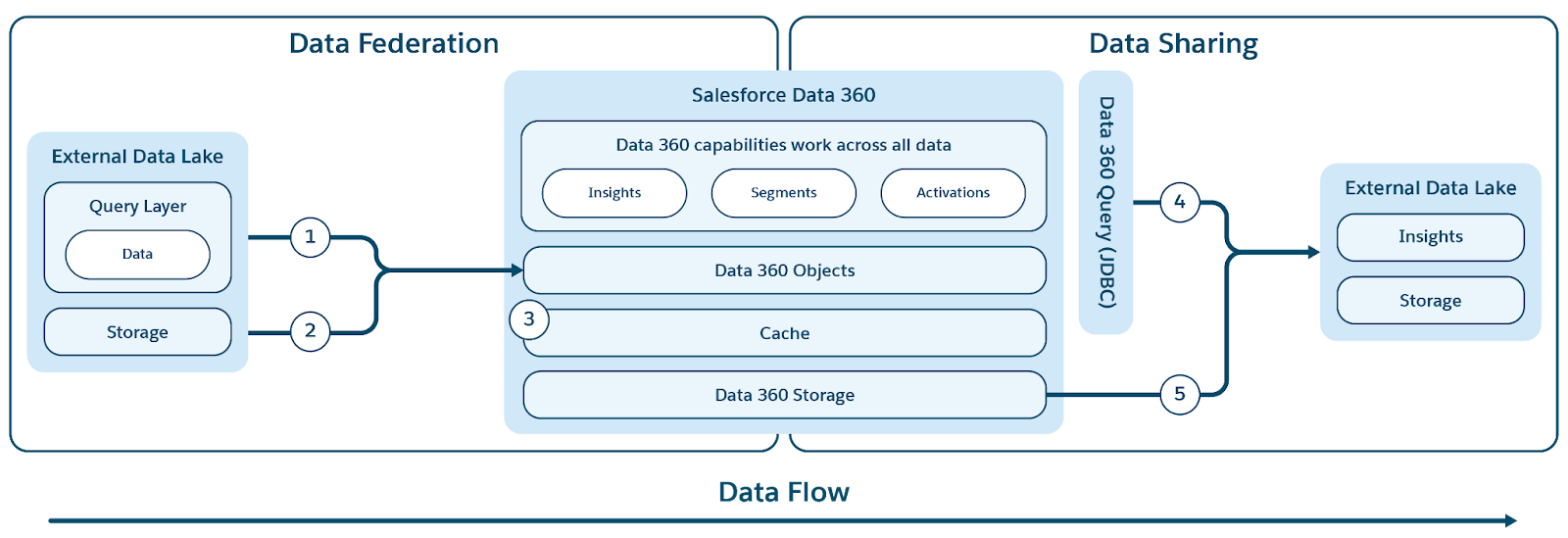
Data 360 har stöd för nollkopiering med externa datalager (Snowflake, Redshift), sjöhus (Google BigQuery, Databricks, Azure Fabric), SQL-databaser och många andra källor. Dess abstraktionslager möjliggör direkt förfrågan av externa data utan dubbletter, vilket minskar intagstid, lagringskostnader och säkerställer uppdaterad information.
Data 360 förenklar åtkomst till externa och sammanslagna data genom att tillhandahålla ett enhetligt metadatalager som abstraherar både Salesforce och externa objekt. Detta låter hela Salesforce Platform och dess program använda dessa data sömlöst.
Data 360 har stöd för både fil- och sökfrågebaserad federation, med livesökfrågor och åtkomstacceleration enligt figuren.
Etiketter (1) och (2) illustrerar Data 360:s sökfråga (inklusive pushdowns för livefrågor) och filbaserade federation för åtkomst till data från externa datasjöar/lager/datakällor, och etikett (3) belyser acceleration av sammanslagen åtkomst från externa datasjöar/datakällor.
Sökfrågefederation
Kärnan i Data 360:s federationskapacitet ligger i dess frågefederationslager, som hanterar den komplexa processen att komma åt externa data och utföra intelligenta pushdowns för frågor (illustreras av etikett 1). Data 360 ansluter till och hämtar data från källor med JDBC-protokollet, utökat med ytterligare logik för förbättrad effektivitet. Frågefederationslagret ansvarar för att förstå och översätta olika SQL-dialekter, räkna ut den mest optimala delen av sökfrågan som ska pushas ner till externa system för effektiv bearbetning, hämta resultaten och utföra all ytterligare bearbetning som behövs för att få slutgiltiga insikter.
Caching (sökfrågeacceleration)
För utökade verktyg tillhandahåller Data 360 en valfri accelerationsfunktion för sina sammanslagna kapaciteter.
När Acceleration har aktiverats cachar Data 360 sammanslagna data för att uppnå snabbare åtkomst och lägre kostnader—eftersom det undviker upprepad, direkt åtkomst till externa källor. Detta cacheminne behandlas som ett accelerationslager och uppdateras stegvis för att snabbt återspegla ändringar i externa källdata, vilket säkerställer att den accelererade vyn förblir nästan i realtid.
Filfederation
Data 360 har stöd för filbaserad federation (illustrerat med etikett 2) för åtkomst till data från externa datasjöar och källor. Den tekniska grunden för denna nollkopieringskapacitet bygger på standardisering: underliggande data måste vara i filformatet Apache Parquet och använda tabellformatet Apache Iceberg. Data 360 kan federeras till alla källor som exponerar en Iceberg REST-katalog (IRC) för metadata- och lagringsåtkomst, vilket säkerställer sömlös, styrd åtkomst till filer som finns utanför plattformen.
Med filbaserad federation hanterar Data 360-beräkningar all databearbetning eftersom de har direkt åtkomst till det underliggande lagringsutrymmet. Detta eliminerar behovet av pushdown och hantering av olika SQL-dialekter, vilket ofta krävs med sökfrågebaserad federation.
Utöver detta utökas kapaciteten för Zero Copy även till ostrukturerade datakällor som hyperscalerlagringslösningar (S3/GCS/Azure-lagring), Slack och Google Drive, som kan nås av Data 360:s ostrukturerade bearbetningspipelines.
Data 360 underlättar både sökfrågebaserad och filbaserad delning av data som hanteras med externa datasjöar och lagerbyggnader (illustreras av etiketterna 4 och 5 i det ursprungliga figursammanhanget).
Sökfrågebaserad delning
För sökfrågebaserad datadelning exponerar Data 360 en JDBC-drivrutin som externa motorer och program kan använda för att få säker åtkomst till data. Denna mekanism låter externa system ansluta, autentisera och utföra livefrågor direkt mot data i Data 360.
Filbaserad delning (Datadelning och DaaS)
Den primära mekanismen för filbaserad delning innefattar två koncept: datadelning och datadelningsmål, som använder DaaS (Data as a Service) API.
- Granulär kontroll: Datadelningskonceptet låter kunder exakt definiera vilka objekt (DLO, DMO, CIOs etc.) som delas externt, vilket förhindrar oavsiktlig dataexponering.
- Säker inriktning: Den styr även datadelningsmålet, vilket säkerställer att data endast görs tillgängliga för uttryckligen auktoriserade externa miljöer, konton eller partnerorganisationer (t.ex. delning med en specifik Redshift- eller Databricks-instans).
DaaS API tillhandahåller ett säkert och styrt gränssnitt för externa motorer för att konsumera data. Den beviljar åtkomst till både de viktigaste metadata och den underliggande tabelllagringen samtidigt som all Data 360-semantik bevaras. Detta säkerställer att externa motorer får åtkomst till data i ett enhetligt och meningsfullt sammanhang på ett säkert sätt.
Många säkerhetskänsliga kunder, särskilt stora företag, reglerade branscher och organisationer inom den offentliga sektorn, begränsar all internetåtkomst till sina datasjöar som en del av sitt säkerhetsarbete. Denna policy är viktig för efterlevnad och riskminskning, men förhindrar även Salesforce Data 360 och Agentforce från att ansluta till dessa miljöer över det offentliga internet.
De flesta av dessa datasjöar distribueras i hyperscalermiljöer som AWS, Azure eller Google Cloud. Eftersom Data 360 själv körs på AWS kräver åtkomst till kunddatasjöar som värdas på en annan molnleverantör en nätverksanslutning mellan moln. Utan ett säkert, privat anslutningsalternativ som kringgår det offentliga internetet kan kunder ofta inte eller inte vilja använda Data 360 eller Agentforce för användningsfall som förlitar sig på dessa datasjöar.
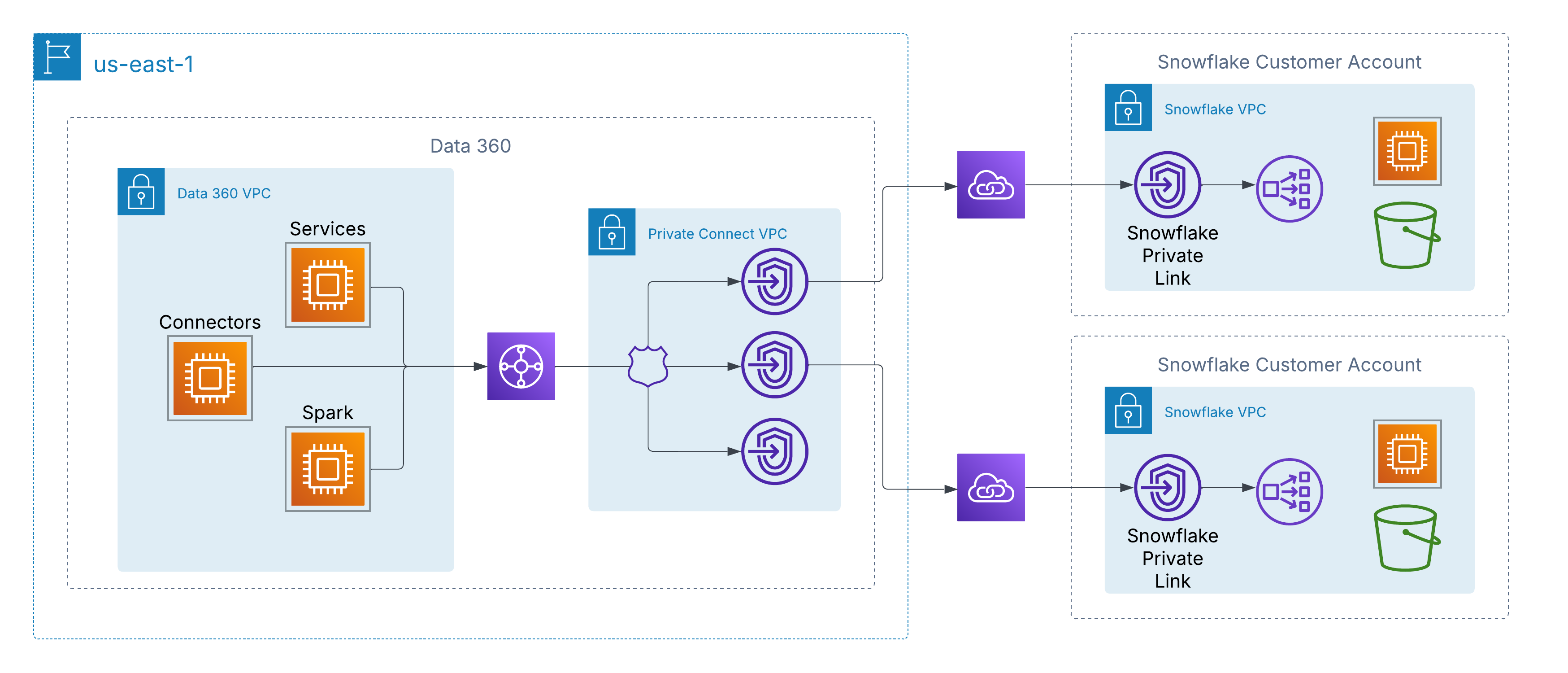
För att hantera detta har Data 360 stöd för privata nätverksanslutningar till kundhanterade datakällor över moln. På AWS aktiveras detta genom AWS PrivateLink, vilket låter Data 360 ansluta direkt till kundprovisionerade slutpunkter, antingen inom sina egna konton eller inom datasjömiljöer från tredje part (t.ex. Snowflake), utan att gå igenom det offentliga internet.
Denna arkitektur säkerställer att all trafik förblir helt på AWS-stamnätet, med hjälp av privat IP-adressering och icke-dirigerbara nätverksvägar, vilket därmed uppfyller strikta säkerhets- och efterlevnadskrav samtidigt som sömlös åtkomst till kunddata möjliggörs.
För kunder med flera molnarkitekturer utökar Data 360 privata anslutningar utöver AWS genom stöd för korsmolnanslutning. Detta aktiverar säkra nätverksvägar endast i stamnätet från Data 360 till datasjöar och tjänster som värdas i Azure eller Google Cloud, vilket bevarar samma principer som AWS PrivateLink — privat IP-adress, icke-offentlig dirigering och noll internetexponering.
Kunder kan välja mellan två distributionsmodeller:
-
Kundhanterad sammankoppling: Integrera befintliga privata kretsar som Azure ExpressRoute, Google Cloud Interconnect eller Equinix Fabric direkt med Data 360:s VPC:er.
-
Salesforce-hanterad sammanlänkning: Använd en fullständigt hanterad, nyckelfärdig anslutning där Salesforce provisionerar och hanterar korsmolnlänken och exponerar privata slutpunkter i målmolnet.
I båda modellerna är upplevelsen enhetlig: Data 360-tjänster ansluter till externa datakällor över hyperskalare som om de vore lokala, vilket möjliggör säkert intag, aktivering och sökfrågor utan att gå igenom det offentliga internet.
För företagsarkitekter är robust datastyrning inte bara en kryssruta för efterlevnad utan en grundpelare för att bygga betrodd, skalbar och användbar Kundintelligens. Salesforce Data 360 är utformat med ett omfattande ramverk för styrning som säkerställer datakvalitet, säkerhet och efterlevnad av lagstadgade mandat över hela dess datalivscykel.
Data 360 fungerar som ett centraliserat styrningsnav och säkerställer att alla data—från rått intag till aktiverade insikter—hanteras med integritet och kontroll.
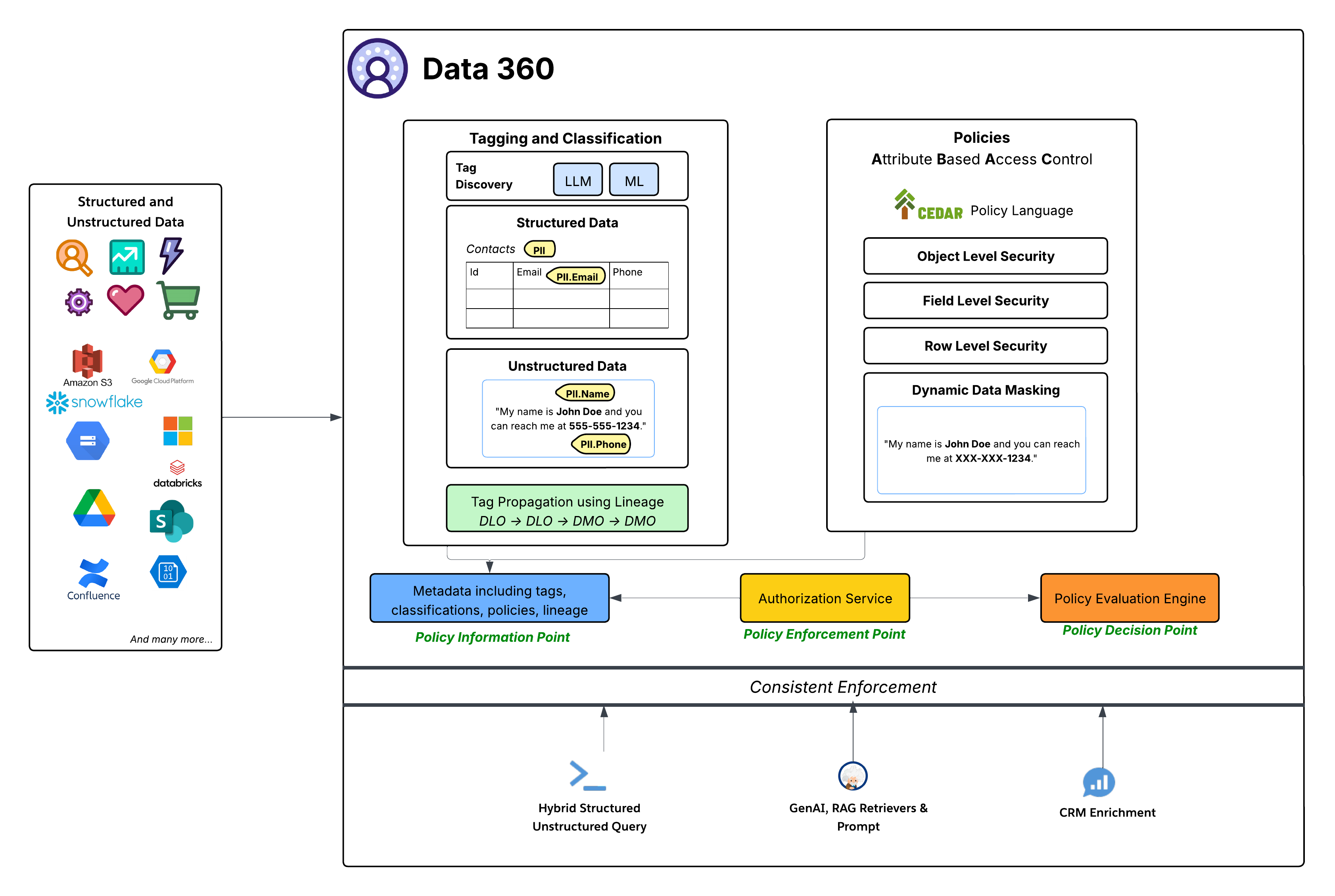
Datautrymme ger grovkornig åtkomstkontroll för att avgöra åtkomst till alla objekt inom ett datautrymme, men ABAC-baserade policyer ger finkornig åtkomstkontroll till enskilda objekt, fält och rader inom ett datautrymme. Data 360 har börjat använda attributbaserad åtkomstkontroll (ABAC) som sin kärnauktoriseringsmodell för finkornig åtkomstkontroll. Detta strategiska val ger överlägsen flexibilitet och skalbarhet jämfört med traditionell rollbaserad åtkomstkontroll (RBAC), särskilt viktigt för dynamiska, komplexa företagsmiljöer med stora mängder data och varierande åtkomstbehov. ABAC låter åtkomstbeslut baseras på attribut för användaren (t.ex. avdelning, roll, plats), data (t.ex. PII, känslighet, datautrymme) och miljön (t.ex. tid på dagen), snarare än bara fördefinierade roller. Detta möjliggör mycket detaljerade och sammanhangsberoende åtkomstpolicyer som anpassas allt eftersom data och användarattribut ändras.
- CEDAR Policyspråk: Hjärtat i Data 360s ABAC-implementering är användningen av CEDAR-policyspråket. Detta syftesbyggda, formella policyspråk ger ett exakt och verifierbart sätt att definiera komplexa auktoriseringsregler, vilket säkerställer att policyer är entydiga och kan utvärderas enhetligt i stor skala.
Styrningssystemet inom Data 360 följer en standard, robust ABAC-arkitektur:
- Taggning, klassificering och policyförfattande (Policyinformationspunkt - PIP):
- Data 360 tillhandahåller automatiserade taggnings- och klassificeringsmekanismer som använder LLM (stor språkmodell) och ML (maskininlärning) för att identifiera känsliga datakategorier (t.ex. PII.Email, PII.Phone, PII.Name) och andra syftesbyggda taxonomier (PHI, FinancialData) i både strukturerade data (t.ex. kontakttabell) och ostrukturerade data (t.ex. från Google Drive).
- Avgörande är att taggpropagering sker längs Datahärkomst (DLO -> DLO -> DMO), vilket säkerställer att klassificeringar automatiskt följer datatransformationer och deriveringar, från rådata som intas till det harmoniserade DMO-lagret och genom deriverade data som skapas från processdefinitioner.
- Slutligen ger policyförfattarpanelen en enkel upplevelse för att använda data och användarattribut för att definiera dynamiska åtkomstregler för en organisation.
- Denna utökade metadata (inklusive taggar, klassificeringar, policyer och härkomst) matas in i Policyinformationspunkten (PIP).
- Auktoriseringstjänst (Policy Enforcement Point - PEP):
- Auktoriseringstjänsten fungerar som policyns tillämpningspunkt (PEP). Den fångar upp alla begäranden om dataåtkomst från olika konsumtionslager (Hybridstrukturerad/ostrukturerad fråga, GenAI RAG Retrievers & Prompt, CRM-förbättring) och konsulterar Policybeslutspunkten för att avgöra om åtkomst tillåts.
- Policyutvärderingsmotor (Policybeslutspunkt - PDP):
- Denna motor fungerar som Policy Decision Point (PDP). Det tar sammanhanget för åtkomstbegäran från PEP, tillsammans med policydefinitioner (i CEDAR) och attribut från PIP, för att fatta ett auktoritativt åtkomstbeslut.
- Granna säkerhetspolicyer: Policyer som definieras i CEDAR tillämpar olika säkerhetsnivåer, inklusive:
- Objektnivåsäkerhet: Styr åtkomst till hela DLO eller DMO baserat på taggar associerade med dessa objekt.
- Fältnivåsäkerhet: Begränsa åtkomst till specifika känsliga fält inom ett objekt baserat på taggar.
- Radnivåsäkerhet: Filtrering av data på specifika objekt för att endast visa relevanta rader baserat på användarattribut.
- Dynamisk datamaskering: Maskera dynamiskt vissa data (baserade på taggar) vid åtkomstpunkten, utan att ändra underliggande data. Detta säkerställer att känslig information skyddas samtidigt som det tillåter bred användning. Detta gäller för maskeringsfält i strukturerade data samt innehåll i ostrukturerade data.
- Konsekvent tillämpning: Hela ABAC-ramverket säkerställer enhetlig tillämpning av policyer i alla Data 360-användningsmönster, till exempel direktdatasökning, hämtning för Generativa AI-program (RAG) eller berikning av Salesforce CRM-upplevelser via relaterade listor.
- Djup integrering med Salesforce Platform: Data 360:s styrfunktioner definieras och administreras direkt i Salesforces kärnplattform. Denna integrering låter administratörer hantera åtkomstpolicyer, användaridentiteter och attributhantering med hjälp av välbekanta Salesforce-verktyg, vilket säkerställer ett enhetligt och enhetligt styrningslager över hela Salesforces ekosystem.
Genom att bygga detta sofistikerade ABAC-ramverk med CEDAR-policyer ger Data 360 arkitekter en oöverträffad nivå av kontroll och flexibilitet, vilket säkerställer att kunddata inte bara är användbara utan även säkra, efterlevnadsvänliga och pålitliga i hela företaget.
I olika branscher lägger organisationer större vikt vid datasäkerhet från början till slut för att säkerställa skydd mot dataläckage, obehörig åtkomst, manipulering eller förstörelse. De flesta dataplattformar, inklusive Data 360 idag, tillhandahåller kryptering vid vila med en leverantörshanterad krypteringsnyckel. Företag (särskilt de inom reglerade sektorer) kräver dock i allt högre grad kundhanterad krypteringskapacitet för både data vid vila och överföring.
Denna modell låter företag styra sina egna krypteringsnycklar, vilket säkerställer att även i den högst osannolika händelsen av ett intrång på plattformsnivå eller obehörig åtkomst förblir data kryptografiskt skyddade. Utan kundens egenutvecklade nyckel kan ingen enhet (inklusive plattformsleverantören) avkryptera eller rekonstruera datan och därmed upprätthålla full sekretess och kontroll.
Data 360 har stöd för lagring och hantering av strukturerade (tabeller), semistrukturerade (JSON) och ostrukturerade data sömlöst över mekanismer för dataintag, bearbetning, indexering och sökfrågor. Data 360 har stöd för olika ostrukturerade datatyper utöver text, inklusive ljud, video och bilder, vilket breddar omfattningen av datahantering och analys. Figuren nedan illustrerar de två sidorna av jordning (intag och hämtning).
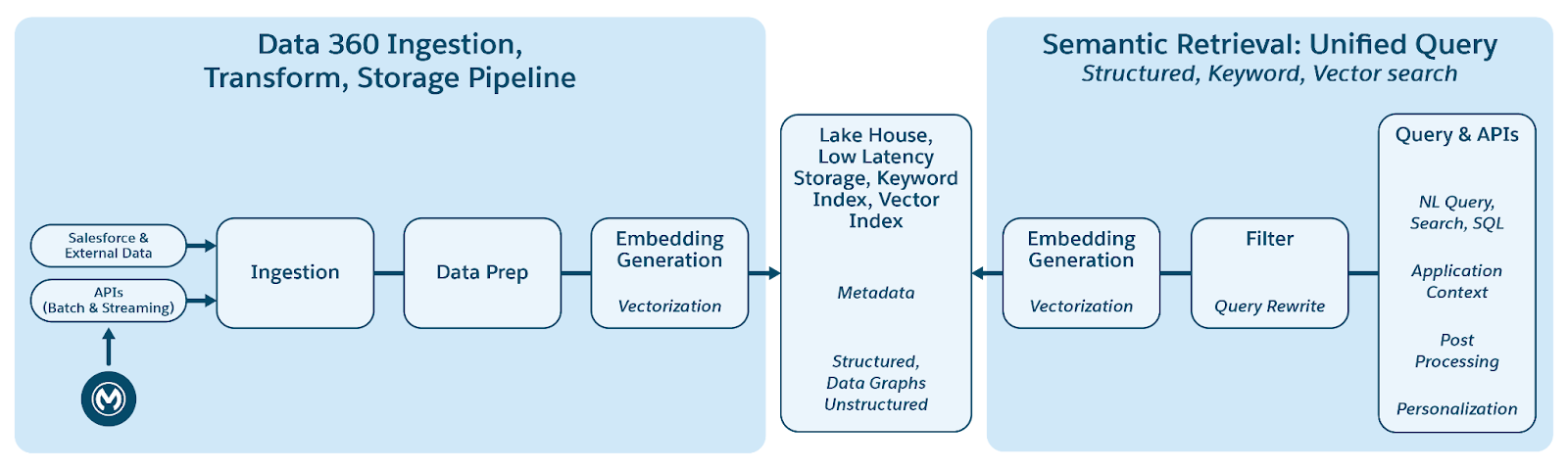
Data 360 hanterar ostrukturerade data genom att lagra dem i kolumner som text eller i filer för större datauppsättningar. Den har stöd för datafederation för ostrukturerat innehåll, vilket tillåter integrering och hantering av data från flera källor.
Data förbereds och delas sedan upp, inbäddningar skapas och bearbetas för nyckelordsindexering och vektorindexering. Data 360 är värd för flera färdiga och pluggbara modeller för att dela upp och bädda in skapande. Data 360 har stöd för automatiserad och konfigurerbar avskrift av ljud- och videoinnehåll för efterföljande bearbetning och indexering. Söktjänsten används för nyckelordsindexering. För vektorindexering har Data 360 stöd för både inbyggd indexering (med Hyper) och använder även vektordatabaser som Milvus med öppen källkod. Data 360 integreras även med Salesforce Search Platform för att stödja nyckelordsindexering för ostrukturerade data. Sådan integrerad multimodal indexering i Data 360 driver sökning efter alla ostrukturerade data, enligt vad som diskuteras i avsnittet Agentföretagssökning senare i dokumentet.
För hämtning tillhandahåller Data 360 API:n för sökning. Vår hyperbaserade sammanslagna sökfråga underlättar ensemblesökfrågor över strukturerade index, nyckelordsindex och vektorindex och upprätthåller strikt synlighet och behörigheter, vilket förbättrar RAG och sökning.
Data 360:s ostrukturerade dataindexeringspipeline är utformad som en modulär, utökningsbar arkitektur som består av fem kärnsteg:
- Tolkning
- Förbearbetning
- Uppdelning
- Efterbearbetning
- Bädda in
Alla faser har även stöd för LLM-baserad bearbetning som låter kunder komma med egna uppmaningar. Både förbearbetnings- och efterbearbetningsfaserna kan innehålla flera sekventiella steg, vilket gör att komplexa transformationer kan komponeras flexibelt. Varje fas är helt metadatadriven, vilket möjliggör sömlös konfiguration och tillägg utan kodändringar.
Exempel på förbearbetning inkluderar operationer som bruseliminering, språknormalisering och bildförståelse (optisk teckenigenkänning och bildtextning), medan efterbearbetningssteg kan inkludera metadataförbättring, semantisk gruppering eller avancerade tekniker som Raptordelning.
Pipeline har fullständigt stöd för Data 360 Code Extension, vilket låter kunder och interna team ansluta egen logik när som helst. Kodtilläggskomponenterna är lätta Python-funktioner vars livscykel—utförande, skalning och felhantering—hanteras fullständigt av Data 360. Detta tillvägagångssätt säkerställer att innovation och domänspecifik bearbetning kan införas snabbt samtidigt som operativ enhetlighet och styrning upprätthålls över hela plattformen.
Sammanhangsindexering
För att konfigurera RAG med ostrukturerad bearbetning är två viktiga faktorer:
- Snabb upprepning: Möjligheten att snabbt validera med exempel på testfrågor.
- Personspecifikt innehåll: Kapaciteten att konfigurera innehåll anpassat till den konsumerande personen.
Sammanhangsindexering är ett användarvänligt verktyg som utformats för att hantera båda dessa aspekter. Detta interaktiva användargränssnitt drivs av en pipeline i realtid (RT) som utför alla fem tidigare skisserade faser. Pipeline använder grafikprocessorer vid behov för uppgifter som att skapa inbäddning och optisk teckenigenkänning (OCR). Dessutom låter det kunder snabbt testa RAG-pipeline med en agent innan de distribuerar konfigurationen för omfattande innehållsbearbetning.
Dokument-AI
Data 360 Document AI möjliggör läsning och import av ostrukturerade eller semistrukturerade data från dokument som fakturor, CV:n, labbrapporter och inköpsordrar. Denna funktion har stöd för interaktiv ad hoc-bearbetning samt massbearbetning av satser. Detta är en nyckelkapacitet som möjliggör automatisering av verksamhetsprocesser för våra kunder. Detta drivs av artificiell intelligens inklusive LLMs och ML-modeller.
Företag har stora mängder Knowledge spridda över olika system som wikis, fildelningar, innehållshanteringssystem, interna databaser, med mera. Denna fragmentering gör det svårt för anställda (särskilt serviceagenter och säljare) och kunder att hitta relevant information snabbt och effektivt. Viktiga problem inkluderar: Avsaknad av en enda enhetlig sökupplevelse i alla Knowledge källor, inkonsekvent presentation och återgivning av innehåll från olika källor, brist på åtkomststyrning för känslig information som är utspridd över olika system och svårigheter att använda auktoritativ Knowledge källa i kärnverksamhetsflöden (t.ex. att bifoga relevanta artiklar till ett kundcase).
Enterprise Knowledge representerar innehåll som har valts ut, antingen manuellt eller automatiskt, från den bredare poolen av företagsdata. Manuell kurering innefattar avsiktliga åtgärder, som att skapa Salesforce Knowledge eller utveckla Knowledge inom externa system som sedan intas. Vi föreställer oss automatiserad utvaltning som använder processer, som Salesforce-agenter och -transformationer, som kör över intagna data för att skapa förfinade, utvalda lager, vilket potentiellt kan blanda strukturerat och ostrukturerat innehåll. Oavsett om den väljs ut manuellt eller automatiskt, internt i Salesforce eller externt innan intag, är resultatet mervärdesinnehåll som skiljer sig från rådata.
Lösningen Enterprise Knowledge Hub använder Data 360-kapacitet för att:
- Intag och lagring: CRM-anslutaren tar in Salesforce Knowledge och ostrukturerade DCF-anslutare (Data Connector Framework) tar in rått innehåll och metadata från externa källor. Innehållet tas in i källspecifik mappning av ostrukturerade datasjöobjekt (UDLO) till innehållet på SFDrive (eller källa vid nollkopiering).
- Harmonisering och strukturering: harmonisering bearbetar UDLO och fildata, utför rensning, normalisering, anrikning (NLP, etc.), PII-maskering och transformation till det harmoniserade mellanformatet, lagrat i SF Drive och ett harmoniserat UDLO (HUDLO) som mappar till det.
- Indexering: Ostrukturerad pipeline (UDS) utlöses över det harmoniserade innehållet och sökindex konfigureras för varje HUDMO.
- Förbrukning: Använda program inkluderar sökning, hämtning, återgivning och länkning till affärsobjekt som Kundcase. Engagemang genom att konsumera program samlas in för att tillhandahålla användningsanalyser (som klick, granskningar etc.)
Beräknade insikter (CI) i Data 360 låter kunder definiera och generera aggregerade mått från sina data. Dessa mått används sedan för kundengagemang, analys, segmentering och aktivering i rätt tid. Aggregerade data som beräknas av CI skrivs till Lakehouse och representeras som ett beräknat insiktsobjekt (CIO).
Det finns två huvudtyper av beräknade insikter:
- Batchberäknade insikter: Utformad för komplex dataaggregering med hög volym, där mått kan beräknas periodiskt (t.ex. dagligen eller veckovis).
- Streaminginsikter: Ge möjlighet att generera mått och åtgärder från händelsedata i realtid, vilket möjliggör omedelbart kundengagemang med låg latens.
Beräknade insikter definieras i datamodellobjekt (DMO) och kan även definieras i andra beräknade insiktsobjekt. Tjänsten för beräknade insikter hanterar orkestreringen av både batch- och streamingjobb.
Både batch- och streaminginsiktsberäkningar använder Spark. Den viktigaste skillnaden är att streaminginsikter använder Spark Structured Streaming, medan batch-CI utförs med periodiska, schemalagda batch Spark-jobb. För kostnadseffektivitet grupperar de beräknade insikternas servicekontor CI som ska beräknas tillsammans i samma sats av CI-jobb eller streaming CI-jobb, baserat på faktorer som beroenden och överlappning av källdataobjekt.
SNCE och CDF spelar en viktig roll i beräkningen av Streaminginsikter.
Identitetslösning är ansvarig för att transformera olika data från flera källor till en enda, omfattande enhetlig profil.
Det är viktigt att förstå att en enhetlig profil inte är en "gyllene post" och att identitetslösning inte väljer vinnande värden eller åsidosätter befintliga data när profiler slås samman. Sammanslagna profiler fungerar som en uppsättning nycklar som låser upp dina källdata genom att identifiera alla matchande poster som relaterar till samma enhet, inom en datakälla eller över många källor. Med denna information kan du välja rätt källsystemdata att använda för ett givet verksamhetsanvändningsfall.
Identitetslösning kan slå samman flera olika posttyper, inklusive individer, konton och hushåll. Den kan även användas för att matcha leads till befintliga konton. Sammanslagningsprocessen är viktig för att uppnå en fullständig Customer 360 och driva personligt engagemang i realtid i både B2C- och B2B-scenarion.
Pipeline för identitetslösning är byggd på ett mycket skalbart, molnbaserat ramverk som är utformat för att hantera enorma mängder data kontinuerligt. Processen består av tre nyckelsteg som förlitar sig på ett kraftfullt sökindex för att hantera matchningsprocessen:
- Matchning (kandidatval): Målet med matchningsprocessen är att söka efter poster som kan tillhöra samma enhet. Poster analyseras mot en anpassningsbar uppsättning regler, var och en innehåller en uppsättning kriterier som definierar vilka data som ska matchas vid vilken nivå av strikthet. För att effektivt hämta potentiella matchningar från datalagringen skapar systemet index för att hitta troliga matchande poster med två tekniker:
- Blockera nycklar: En blockeringsnyckel är ett värde som skapas från en posts data- och matchningsregler (som de första bokstäverna i ett namn, normaliserat telefonnummer, etc.) för att gruppera potentiellt liknande poster. Varje post har flera blockerande nycklar som indexeras och lagras som ett inverterat index, vilket säkerställer att systemet endast utför detaljerade jämförelser på små grupper av poster, snarare än över hela datauppsättningen.
- Lokalitetskänslig hashning (LSH): För matchningsregler med fuzzy matchning skapas hashvärden baserat på inbäddningar från utbildade modeller.
- Djup matchning: Efter att steget för kandidaturval har skapat mindre grupper av potentiella matchningar påbörjar systemet en mer detaljerad jämförelse. I denna fas analyserar AI-modeller och avancerade algoritmer varje par av poster för att beräkna ett troligt matchningsbetyg. Detta betyg kvantifierar sannolikheten för att två poster refererar till samma enhet genom att på ett intelligent sätt jämföra fält som ofta innehåller felstavningar, variationer eller formateringsskillnader.
- Kluster och sammanslagning: När matchande poster har identifierats från kandidaterna grupperas de i ett kluster. Denna process inkluderar kritiskt att lösa transitiva matchningar. Till exempel, om post A matchar post B och post B matchar post C länkas alla tre till samma kluster även om A och C aldrig jämfördes direkt. Dessa fullständiga kluster utgör den grundläggande strukturen för den enhetliga profilen. Denna klusterprocess säkerställer att alla relaterade källposter är korrekt länkade under en enda, beständig identifierare.
- Avstämning: Datavärden från alla klustrade källposter utvärderas med definierade avstämningsregler (t.ex. Frekventaste, Senaste eller Källprioritet) för att fylla i den resulterande Sammanslagna profilen med ett utdrag av profildata. Avstämning skriver inte över några befintliga data, eftersom alla källdata är tillgängliga med nycklarna som är länkade till den enhetliga profilen.
Arkitekturen har stöd för lösning av flera enhetstyper för att uppfylla en mängd olika användningsfall.
- Individuell matchning: Fokuserar på att skapa profilerna Sammanslagna individer, som länkar alla kända personliga identifierare (e-postmeddelanden, telefonnummer, lojalitets-ID:n, cookies) till en enda person.
- Kontomatchning: Fokuserar på att skapa profilerna Sammanslagna konton, som länkar data om konton. Vid matchning av företagsnamn använder motorn en finjusterad modell vid fuzzy matchning.
- Hushållsmatchning: Utökar matchningslogiken för att aggregera poster för Sammanslagna individer till grupper av relaterade individer.
- Matchning mellan enheter: Utöver sammanslagning skapar identitetslösning även länkar mellan profilobjekt genom att använda samma matchningsregler. Till exempel kan ett lead länkas till ett konto med hjälp av fuzzy matchning för Kontonamn.
För att säkerställa att den enhetliga profilen alltid är aktuell arbetar identitetslösningsmotorn med en arkitektur som nästan är i realtid. Denna molnoptimerade arkitektur är utformad för kontinuerlig bearbetning och uppnår snabba bearbetningstider. Bearbetningshastigheten varierar beroende på hur källdata tas emot, men små satser av ändringar kan bearbetas med identitetslösning så ofta som var 15:e minut.
Systemet upprätthåller identitetslänkobjekt som mappar varje källpost-ID till motsvarande enhetligt profil-ID. Denna grundläggande datastruktur gör att motorn effektivt kan följa relationer och snabbt propagera ändringar och uppdateringar av den enhetliga profilen, vilket säkerställer att kundupplevelser—som personanpassning av webbplatser, rekommendationer om nästa åtgärd och segmentering—alltid använder de senaste tillgängliga kunddata.
Segmentering är kärnprocessen för att omvandla sammanslagna kundprofiler till användbara målgrupper. Denna kapacitet är viktig för att driva personliga upplevelser i marknadsförings-, handels- och tjänstekanaler. Salesforce Data 360 Segmentation-plattformen är utformad för storskalig verksamhet. Den hanterar intrikata metadata och arbetar med en datamodell som består av tusentals objekt och relationer. Plattformen har stöd för komplexa regler, aggregeringsbaserade filter och fönsterbaserad rangordning, samtidigt som den säkerställer snabb och pålitlig beräkning i petabyteskala.
Data 360 har stöd för olika segmenttyper för att uppfylla olika verksamhetskrav på hastighet, komplexitet och hierarki:
- Standardsegment: Den primära, batchbehandlade segmenttypen. Den publiceras enligt ett anpassningsbart schema, med en standardpubliceringkadens på minst 12 timmar upp till 24 timmar, eller en snabbare snabbpubliceringkadens på 1 till 4 timmar, som är optimerad för senaste engagemangsdata.
- Realtidssegment: Detta segment slutförs på begäran på millisekunder för omedelbara åtgärder baserat på senaste händelser och profildata. Den är mycket optimerad för omedelbar personanpassning men kan inte använda uteslutningskriterier eller kapslade segment.
- Vattenfallssegment: En hierarkisk struktur av undersegment som används för att prioritera en kund till ett enskilt, mest värdefullt segment om de uppfyller flera kriterier.
- Kapslat segment: Detta gör det möjligt att återanvända ett befintligt segment som ett filter för ett nytt, mer specifikt segment (en förfining av ett bassegment), vilket ärver schemat för det överordnade segmentet.
Segmenteringsmotorn arbetar på en robust, molnbaserad arkitektur som säkerställer hastighet, skala och motståndskraft.
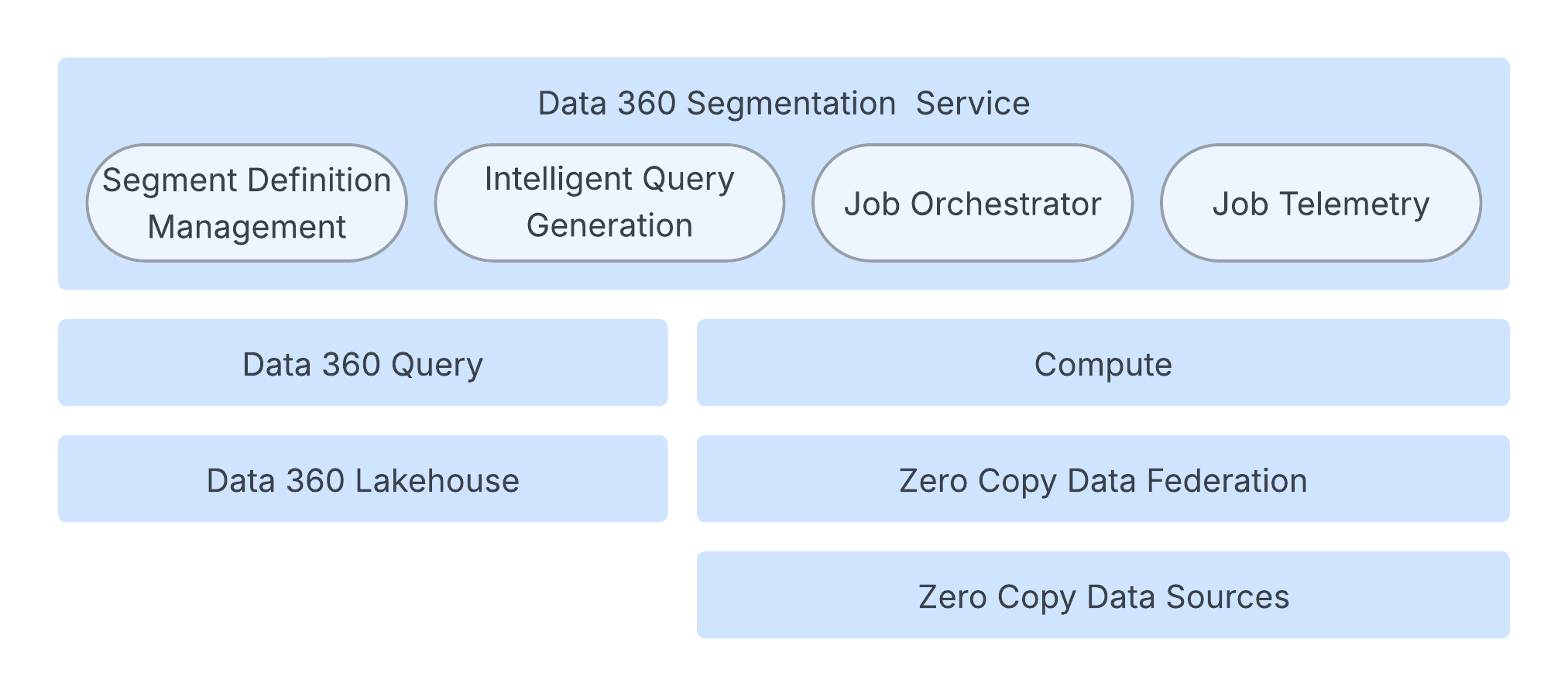
Kärnprocessen hanteras av en jobborkestreringstjänst som styr segmentets livscykel, skapar den nödvändiga jobbkonfigurationen och utlöser utförandet. Detta orkestreringslager behåller status och metadata i en fragmenterad databas för skalbarhet.
Även om Data 360 Query hanterar segmenteringsberäkningar är beräkningslagret Spark ansvarigt för att beräkna faktiskt segmentmedlemskap. Spark-programmet utför Spark SQL-frågor på omfattande kunddata. Dessa data kan finnas i Data 360 Lakehouse, externa system via datafederationen Zero Copy eller en kombination av båda.
Systemet är mycket optimerat genom intelligent skapande av sökfrågor, vilket förfinar den underliggande Spark SQL-frågan. Detta inkluderar tekniker som intelligent partitionsbeskärning för att minimera dataskanning och eliminering av överflödiga underuttryck. För att säkerställa servicetillförlitlighet har arkitekturen anpassningsbar resurshantering som dynamiskt justerar beräkningsresurser baserat på arbetsbelastningens storlek och komplexitet. Dessutom hanteras SLO-efterlevnad proaktivt med anpassningsbara varaktigheter och återförsökslogik. För en snabb användarupplevelse använder accelererade segmenträkningar en samplingsbaserad metod för att ge snabba storleksuppskattningar när segment skapas, vilket undviker en fullständig sökfrågekörning.
Slutligen bibehålls ett djupt fokus på observerbarhet och grundorsaksattribuering genom omfattande Spark-körningsmått och automatiserad klassificering av fel (t.ex. problem på kundsidan vs. system), vilket avsevärt minskar diagnostiden och säkerställer en mycket motståndskraftig dataplattform.
Aktivering är det avgörande slutgiltiga steget i Data 360-livscykeln. Dess kärnfunktion är att transformera statiska, segmenterade, enhetliga kundprofiler till användbara och förbättrade data och leverera dessa data till interna och externa slutpunkter (som Marketing Cloud, Commerce Cloud och Adtech-plattformar). Denna process är utformad för att utlösa personliga kundresor och interaktioner nästan i realtid. Den har stöd för avancerade funktioner som relaterade attribut, aktiveringsmedlemskapsfiltrering, samtyckesfiltrering, begränsning och rangordning.
Aktivering erbjuder tre unika metoder för extern leverans och kanalefterlevnad:
- Batchaktivering: Utformad för schemalagda åtgärder med hög volym, som till exempel storskaliga e-postkampanjer och uppdateringar av reklammålgrupper. Data levereras genom att fasa dem till säkra interna hinkar (molnobjektlagring) eller via säker filöverföring, följt av en API-intagningsprocess som inleds av målsystemet. Batchaktiveringar kan använda speciellt uppdateringsläge - inkrementellt - för att minska volymer som skickas till och bearbetas av Salesforce-partners.
- Streamingaktivering: Optimerad för användningsfall nästan i realtid som kräver händelsedriven automatisering. Leverans uppnås genom direkta API-anrop som skickas till destinationsslutpunkten.
- Aktiveringsutlösta flöden: Denna mycket plattformsbaserade kanal tillhandahåller en metod utan kod/låg kod för att integrera målgruppsdata med hundratals kunders API-aktiverade engagemangsplattformar. När aktiveringen är klar fyller Data 360 i en målgrupps-DMO, som sedan utlöser ett flöde i hög skala. Flödesmotorn använder därefter målgruppsdata och använder plattformskapacitet som Externa tjänster och Mule-utgående destinationer för att göra anrop till den slutgiltiga API-baserade destinationen. Denna metod minskar avsevärt tiden det tar att introducera nya aktiveringsmål.
Aktivering använder samma mönster som segmentering för jobbhantering, distribuerat utförande och övervakning. Detta inkluderar principerna för jobborkestreringstjänsten för livscykelhantering och beräkningslagret (Gnistan) för bearbetning, och förlitar sig på jobbtelemetri för prestandaobserverbarhet och efterlevnad av servicenivåmål (SLO).
Utöver dessa har aktivering -
Hantering av aktiveringsmål övervakar säkra anslutningar, inloggningsuppgifter och konfigurationer för alla destinationsslutpunkter. Det garanterar att dataformat och säkerhetsprotokoll är standardiserade, vilket säkerställer pålitlig utgående leverans till olika plattformar, inklusive Marketing Cloud, Adtech-partners och andra externa program.
Aktivering skräddarsyr belastningen för specifika mål. För Salesforce Marketing Cloud inkluderar detta medveten filtrering av affärsenheter (BU), stöd för flera EID och korspollinering.
Kommunikationsstyrning fungerar som en grindvakt och säkerställer att dataanvändning och kommunikation följer kunders preferenser och juridiska krav. Centraliserad samtyckesmodell förenar alla kunders preferenser, från globala avböjanden till kanal- och syftesspecifikt samtycke, och lagras i den enhetliga individuella profilen. Under körningen tillämpar plattformen strikt dessa policyer genom att använda uteslutningsfiltrering för att automatiskt ta bort individer som inte samtycker från den slutgiltiga belastningen. Dessutom tillämpar systemet regler för att välja kontaktpunkter för att säkerställa att det använder den enskilda, mest efterföljande och föredragna kontaktpunkten för den avsedda kanalen innan några data överförs. Denna tillämpningsmekanism säkras av det underliggande styrramverket, som använder skyddsåtgärder som dynamisk datamaskering och åtkomstkontroller för att säkra känsliga datafält genom hela aktiveringsprocessen.
Det verkliga värdet av en enhetlig dataplattform ligger i dess förmåga att ge enkel och enhetlig åtkomst till alla dess datatillgångar, oavsett deras ursprung eller struktur. Salesforce Data 360:s kapacitet för sammanslagna frågor är exakt utformad för att leverera detta, och abstraherar den underliggande komplexiteten i olika datalagringar för att tillhandahålla ett enda, kraftfullt sökfrågegränssnitt.
Lagret Sammanslagen fråga erbjuder sofistikerad åtkomst för olika användningsmönster:
- Hybridstrukturerade och ostrukturerade sökfrågor: Den ger omfattande SQL-stöd för att sömlöst fråga både strukturerade data och strukturerade metadata för ostrukturerade data. Detta utökas av operatorutökning via tabellfunktioner, vilket möjliggör specialiserad sökning över text, bild och rumstyper.
- Accelererad prestanda med Hyper: Med Hyper, en högpresterande in-memory-motor, snabbar Data 360 på komplexa analytiska sökfrågor och interaktiva instrumentpaneler och ger nästan omedelbara svar över massiva datauppsättningar.
- Enhetlig metod för AI och personanpassning: Denna sammanslagna åtkomst är avgörande för att skapa målinriktade och personanpassade resultat, vilket direkt underlättar mer precisa LLM-svar med hjälp av RAG (Retrieval Augmented Generation) genom att grunda AI-modeller i rika företagsdata.
- Integrering med förbrukning nedströms: Den fungerar som det grundläggande dataåtkomstlagret för användargränssnittdrivna upplevelser, robusta API:n, Generativa AI-flöden och CRM-berikning, och ansluter sömlöst data till aktivering.
Genom att tillhandahålla ett enda, intelligent och högpresterande sökfrågegränssnitt låter Data 360:s sammanslagna sökfråga arkitekter bygga smidiga, datadrivna program som fullständigt utnyttjar deras fullständiga spektrum av kundinformation.
Data 360 är en aktiv plattform som stöder aktivering av pipelines som svar på datahändelser. Till exempel kan en viktig händelse, som en minskning i en kunds kontosaldo, utlösa ett Salesforce-flöde för att orkestrera en motsvarande åtgärd. På samma sätt kan uppdateringar av nyckelmått, som livstidsanvändning, automatiskt propageras till relevanta program.
Dataåtgärder övervakar kontinuerligt inkrementella data för ändringar med hjälp av inbyggda ändringshändelser för lagring (SNCE) och ändringsdatakanal (CDF). Dessa data utvärderas mot kundkonfigurerade åtgärdsregler, till exempel tröskelövervakning eller statusändringar. När dessa regler uppfylls skapas en dataåtgärdshändelse. Denna händelse berikas med ytterligare information (t.ex. kundlojalitetsstatus) och skickas omedelbart till dess konfigurerade destination, som Salesforce-flöde eller ett externt program, för att utlösa verksamhetsorkestreringar.
Data 360 har stöd för inbyggda CDP-funktioner (Customer Data Platform), inklusive avancerade funktioner för identitetslösning och att skapa sammanslagna individuella identifierare och profiler tillsammans med omfattande engagemangshistorik. Denna plattform är bra på att hantera både ramverk för business-to-business (B2B) och business-to-consumer (B2C) genom att stödja identitetslösning och identitetsgrafer som använder både exakta och fuzzy matchningsregler, enligt beskrivningen ovan. Dessa identitetsgrafer är berikade med engagemangsdata från olika kanaler, vilket hjälper till att bygga detaljerade profilgrafer med värdefulla analytiska insikter och segment.
Ett nyckelkoncept som stöder kundprofilen är datagrafen. Data 360 erbjuder en företagsdatagraf i JSON-format, vilket är ett denormaliserat objekt som deriveras från olika Lakehouse-tabeller och deras inbördes relationer. Detta inkluderar en "Profil"-datagraf skapad av CDP som omfattar en persons inköps- och webbläsarhistorik, kundcasehistorik, produktanvändning och andra beräknade insikter, och kan utökas av kunder och partners. Dessa Datagrafer är skräddarsydda för specifika tillämpningar och förbättrar precisionen för genererande AI-uppmaningar genom att tillhandahålla relevant kund- eller användarsammanhang. Realtidslagret i Data 360 använder profilgrafen för personanpassning och segmentering i realtid. Vi föreställer oss Agentforce Context som modellerar konversationer, sessioner och agentminne som Datagrafer.
Utöver detta möjliggör CDP effektiv segmentering och aktivering över olika plattformar som Salesforces Marketing Cloud, Facebook och Google. Den bearbetar kundprofiler i sats, nästan i realtid och i realtid, vilket möjliggör omedelbart beslutsfattande och personanpassning. Denna funktionalitet förbättrar interaktioner i både B2C- och B2B-scenarion och säkerställer att företag kan svara snabbt och korrekt på kunders behov och beteenden.
Data 360:s realtidslager backas upp av Data 360 CDP och utökar dess koncept för användningsfall i realtid. Data 360:s realtidslager är utformat för att bearbeta händelser som klickströmmar för webb och mobil, besök, varukorgsdata och checkouts vid millisekunders latenser, vilket förbättrar kundupplevelsens personanpassning. Den övervakar kontinuerligt kundengagemang och uppdaterar kundprofilen från Customer 360 med engagemangsdata, segment och beräkningar i realtid för omedelbar personanpassning.
Till exempel, när en konsument köper ett objekt på en shoppingwebbplats upptäcker och tar realtidslagret snabbt in denna händelse, identifierar konsumenten och berikar deras profil med uppdaterad information om livstids spenderande. Detta gör det möjligt att anpassa deras upplevelse på webbplatsen på några sekunder. Dessutom innehåller detta lager kapacitet för utlösare och svar i realtid, vilket möjliggör omedelbara åtgärder baserade på kundinteraktioner.
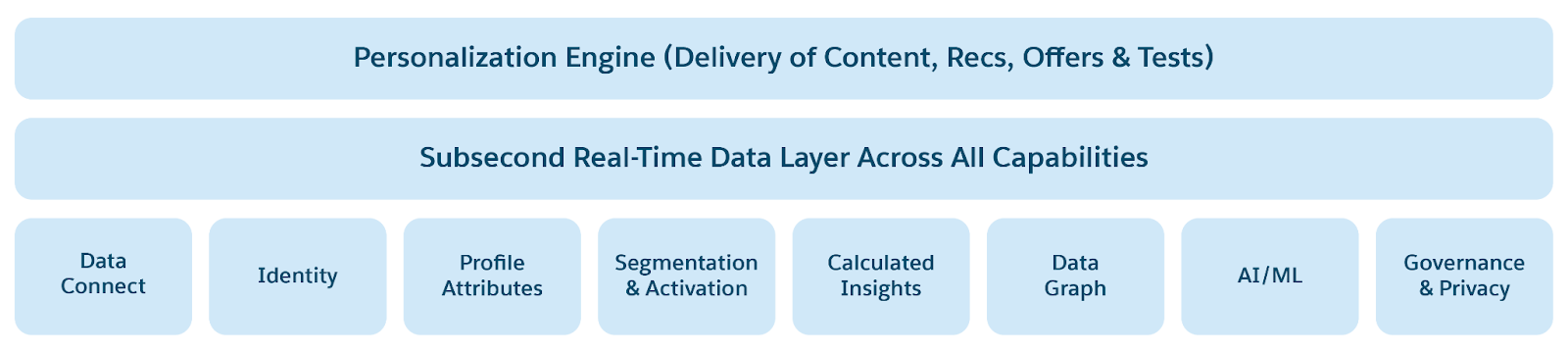
Den subandra realtidsplattformen driver denna transformation genom flera nyckelfunktioner:
- Datagrafer i realtid: En Customer 360 profil byggs med hjälp av en denormaliserad graf som inkluderar nyckelobjekt och fält som är mest relevanta för varumärken. Dessa Datagrafer möjliggör databearbetning i realtid och levererar användbart innehåll och insikter inom några millisekunder
- Inta och transformera i realtid: Ta in användarhändelser och profil i millisekunder från webb- och mobilkällor.
- Identitetslösning i realtid: Koppla kundprofiler mellan enheter och slå samman okända och kända användare direkt.
- Beräknade insikter i realtid: Beräkna mått som livstidsvärde (LTV) eller besökshistorik för användare i millisekunder för att aktivera Personanpassning eller Erbjudanden för webb, ChatBot eller Serviceagent.
- Realtidssegmentering: Segmentera målgrupper i farten och personanpassa meddelanden och interaktioner i realtid.
- Realtidsåtgärder: Ge varumärken möjlighet att utvärdera varje användarengagemang och vidta åtgärder via Salesforce-flöden eller andra relevanta kommunikationskanaler.
I Data 360 har vi byggt en ny realtidsplattform med pipeline i realtid, lagring med låg latens och ett databearbetningslager under en sekund. Eftersom snabba interaktiva data tas in från webb- och mobilkanaler går de igenom en serie snabba processer.
Våra webb- och mobil-SDK:er och realtids-API:er samlar in data från webb-/mobilappar (i framtida agentinteraktioner) och skickar dem till vår beacon-server. Dessa data dirigeras sedan till realtidslagret för millisekundbearbetning och Lakehouse-lagret för integrering med batch/streaming-data. Realtidslagret bearbetar inkommande realtidsdata i sammanhanget för en användarprofil (anonym eller inloggad) som att uppdatera användarens totala spenderande eller livstidsvärde, etc. för att anpassa i realtid under sessionen. Realtidslagret backas upp av huvudminne och NVme-lagring (SSD) för lagring av realtidsdata och kundprofiler. När data är i realtidslagret går de igenom följande processer innan de uppdateras till realtidsdatagraf:
- Enkelt intag och transformationer: Data tas in och transformeras för ytterligare bearbetning.
- Identitetslösning: Exakta matchningsregler tillämpas för att slå samman profiler med alla befintliga uppsättningar av matchningsregler, så datakunniga specialister behöver inte skapa nya uppsättningar av identitetslösningsregler specifikt för realtid.
- Beräknade insikter: Varje engagemang utvärderas, enkla beräkningar som summa och antal i millisekunder körs och data uppdateras i realtidsdatagrafen.
- Realtidssegment: Varje engagemangsdata utvärderas för att avgöra om de uppfyller kriterierna för definierade realtidssegment, och användare läggs till i kvalificerande segment på millisekunder.
- Åtgärder och utlösare i realtid: Varje engagemang utvärderas mot definierade regler för att utlösa åtgärder till ett intervall av mål i realtid när reglerna uppfylls i millisekunder.
- Graf och API för realtidsdata: Datagraf i realtid, som även inkluderar en realtids-API, låter varumärken hämta uppdaterade JSON-formatdata för varje användare, vilket säkerställer att alla kundinteraktioner informeras av de senaste data.
Personanpassning handlar om att veta vem man ska rikta in sig på, när och var man ska leverera relevant innehåll och rekommendationer, vad man ska säga och hur ofta. Plattformen Personanpassningstjänster är den som styr vilka beslut som fattas för att optimera måluppfyllelse genom personliga upplevelser.
Personanpassningstjänster levererar följande kapacitet:
- Enhetlig uppsättning modeller och sätt att tolka profil-, aktivitets- och tillgångsdata i Data 360
- Plattformsintegrerat experiment (A/B/n, Multi-Arm Bandit)
- Integrering av mål vid design (konfiguration), ML-utbildningstid och körning (ML-slutledning)
- Stöd för B2C-skala i realtid och batchinteraktion (anonyma användare, extern realtid/interaktiv batch med hög volym, intern batch med hög volym)
- Analytics driven genom Data 360
- Mönster för att integrera AI-modeller och tjänster från andra parter (interna och externa)
- Integrering i huvudmetadatasystemet (PLATE-egenskaper)
- OOTB-implementeringar av AI-drivna användningsfall med högt värde (rekommendationer/beslut med olika ML-algoritmer, inklusive kontextuella banditer för erbjudande/innehållsval, produktrekommendationer, prissättningsbeslut etc.)
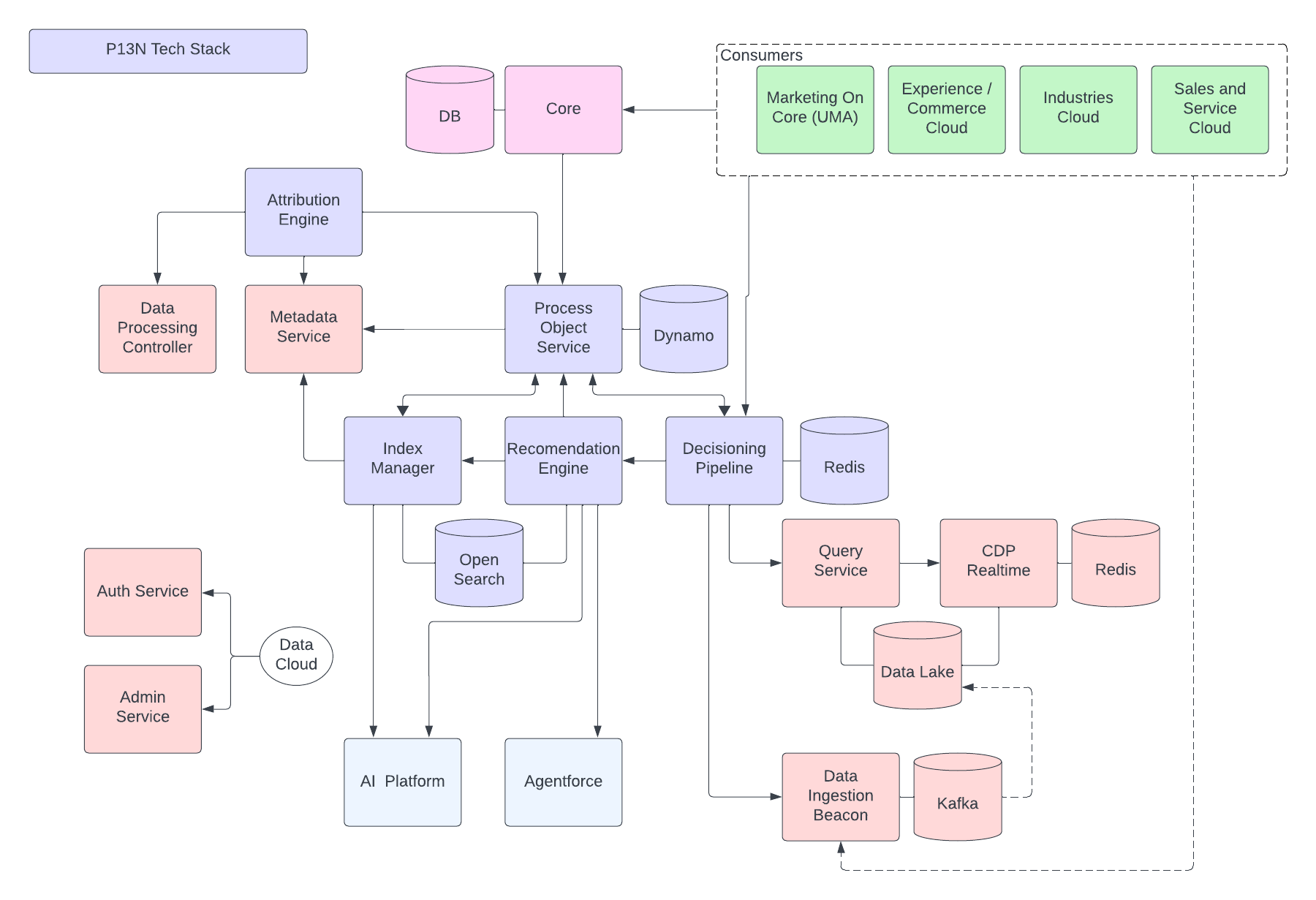
- Beslutspipeline
- Betjäna externa begäranden för personanpassningsbeslut, inklusive profilutökning, experiment och rekommendationer.
- Rekommendationsmotor
- Runtimeservice för regel- eller ML-baserade rekommendationer.
- Indexhanterare
- Hanterar/orkestrerar arbetsflöden för asynkrona processer, inklusive ML-utbildningar för rekommendationsmodeller
- Processobjekttjänst
- Ansvarig för synkronisering av personanpassningsmetadata mellan kärna och off-core
- Attribueringsmotor och experiment
- Analytics-attribution och experimentering av personanpassningsrekommendationer
Data 360 är utformad som en robust och rik plattform specifikt för att stödja nya agentupplevelser. Vi uppnår dessa kapaciteter genom att bygga på olika befintliga Data 360-tjänster och genom djup integrering med Agentforce.
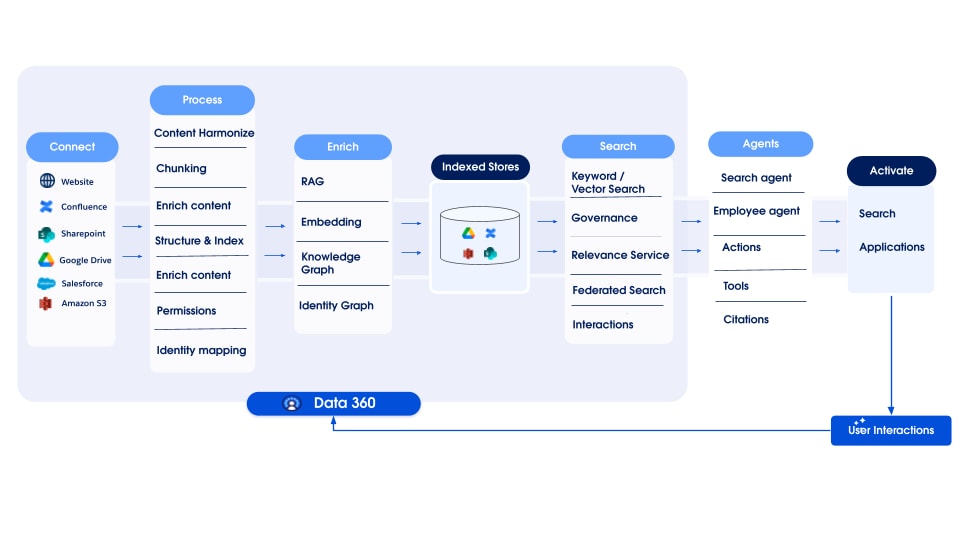
Vår metod för Agentisk företagssökning bygger på följande principer:
- Företagsdata lagras i simulerade tjänster eller butiker, med säkra behörigheter som behövs för åtkomst. Möjligheten att komma åt dessa data och bearbeta dem samtidigt som källbehörigheterna bibehålls är avgörande för att säkerställa Trust.
- Korsrangordning och relevans i hela datasamlingen möjliggör bättre resultat, vilket i sin tur kan ge bättre sammanhang för agentupplevelser.
För att leverera dessa upplevelser bygger Agentisk företagssökning på dessa viktiga arkitektoniska komponenter:
- Anslutare: Den breda uppsättningen anslutare som finns i Data 360 gör att man kan komma åt och ta in data från en mängd olika källor.
- Ostrukturerad databearbetning: Detta är grundläggande för hantering av innehåll som inte är i tabellform, vilket gör att systemet kan derivera mening och sammanhang från olika data.
- Styrning: Säkerställa säkerhet, efterlevnad och åtkomstkontroller i företagsklass för alla data som används av sökning. Stöd för källsynlighetsbehörigheter säkerställer att data endast är tillgängliga för auktoriserade användare, för både enkel sökning och agentupplevelser. För att säkerställa snabb hämtning utvärderas och tillämpas säkerhetsbehörigheter inbyggt av sökbackends i det tidigaste steget av dataåtkomst.
- Samlat hämtningslager: För att hantera utmaningen med siloade data matas anslutarna in i ett omfattande lager för enhetlig hämtning. Detta lager ger en enda åtkomstpunkt till alla data, oavsett om de finns kvar i externa system som nås via Sammanslagen sökning eller hanteras inbyggt genom avancerade index för nollkopior och intagna data.
- Intelligent sökfrågeförståelse: Innan hämtning använder systemet AI-drivna mekanismer för att tolka användarsyfte. Utöver att bädda in representationer av sökfrågan för semantisk vektormatchning kan den skriva om och utöka nyckelordsbaserade sökningar för att förbättra precisionen.
- Hybridsökning och avancerade sökfrågor: För att hitta den mest relevanta informationen använder plattformen flera strategier parallellt. Hybridsökning ger exakt nyckelordsmatchning med semantisk vektorsökning på optimerade delar av data, medan sökning i fullständiga poster samtidigt hämtar hela dokument. Båda kombineras för att säkerställa både semantisk relevans och fullständig innehållstäckning.
- Hierarkisk rangordning: Efter att data har hämtats betygsätter, kopplar och rangordnar en hierarkisk arkitektur i flera steg resultaten från varje källa och metod. Denna process skapar en enskild, enhetlig lista som lyfter fram den mest relevanta informationen för användaren eller agenten.
Generativ AI flyttar den primära konsumenten av företagssökning från mänskliga användare till stora språkmodeller (LLM). Data 360 Search är konstruerad från grunden för att serva båda. Den är optimerad för att hantera de längre, mer komplexa sökfrågorna från agenter och returnera de rika, sammanhangsberoende resultat som behövs för programmatisk användning och resonemang. Samtidigt kan systemet hantera de kortare, ofta tvetydiga sökfrågor som är typiska för mänskliga användare, med funktioner som kodstycken och markering för snabb bedömning i ett användargränssnitt.
Den ultimata leveransen av agentiska sökupplevelser kombinerar båda metoderna:
- Direktsökningsresultat: programmet kan visa en traditionell lista över rangordnade resultat genom att använda en metadatadriven API byggd på Data 360 enhetlig sökgrund.
- Agentiska konversationssvar med flera svar: Agentiska svar implementeras genom inbyggd integrering med Agentforce. Denna konversationsupplevelse drivs av en primär agent som orkestrerar åtgärder och sökfrågor och delegerar alla informationsökningsuppgifter till en specialiserad, intern sökagent.
Denna specialiserade sökagent är optimerad för att hämta företagsinformation. Den använder en resonemangsloop för att formulera och utföra parallella sökningar för att utforska olika aspekter av en användares begäran. Den använder en kraftfull uppsättning verktyg, inklusive Data 360 enhetlig sökning för alla datatyper och strukturerade sökfrågespråk för att hämta exakta data från tabeller och enheter.
Genom denna arkitektoniska syntes gör Data 360 det möjligt att skapa mycket intelligenta, sammanhangsmedvetna och användbara sökupplevelser för agentföretag.
Utökning är en viktig funktion i Salesforce Platform. Kodtillägg ger utökningsbarhet i Data 360, vilket låter pro-kodanvändare köra egen Python-logik direkt i Data 360-miljön, vilket kompletterar dess rika deklarativa och lågkodsfunktioner. Med hjälp av kodtillägg kan användare säkert utöka Data 360-kärnfunktioner som Transformationer och Ostrukturerade datapipelines (anpassad uppdelning).
Vår design för kodtillägg prioriterar flexibilitet, säkerhet, effektivitet och en effektiv utvecklarupplevelse. Den har stöd för två primära utförandemodeller, var och en skräddarsydd för specifika arkitektoniska behov:
- Skriptmodell:
- Syfte: För omfattande egen logik som kräver direkt interaktion med Data 360 Lakehouse.
- Funktionalitet: Kunder skriver fullständiga Python-skript med hjälp av Code Extension SDK, vilket aktiverar läs- och skrivåtkomst till Lakehouse via SDK APIs. Idealisk för egen/komplex dataförberedelse eller skräddarsydd datamanipulation.
- Isolering och säkerhet: Skript får åtkomst till Lakehouse, men deras utförande begränsas till en säker, isolerad miljö inom Data 360-runtime, vilket förhindrar störningar av andra processer eller obehörig systemåtkomst.
- Funktionsmodell:
- Syfte: Analogt med en serverlös funktion, för modulära, tillståndslösa beräkningar som åberopas från befintliga Data 360-pipeline (t.ex. egen uppdelning i en ostrukturerad pipeline).
- Funktionalitet: Kundlevererade funktioner tar indata, beräknar och returnerar utdata.
- Isolering och säkerhet: Dessa funktioner är utformade för strikt isolering; de har inte direkt åtkomst till Lakehouse. Deras utförande är sandboxat, tillståndslöst och resursbegränsat, vilket gör dem lämpliga för fokuserade, tillståndslösa bearbetningssteg, vilket säkerställer säkerhet, förutsägbart utförande och minimerar explosionsradie.
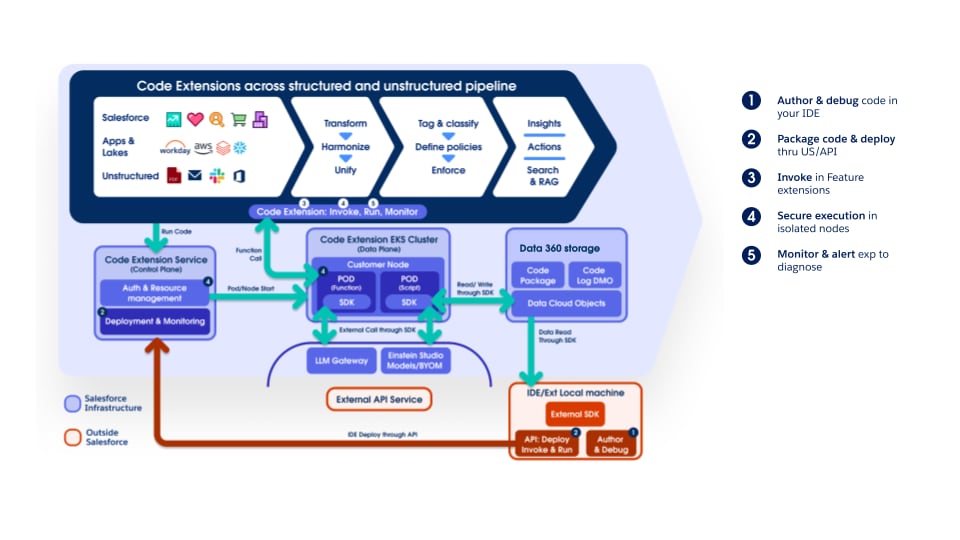
Både skript- och funktionsmodellerna syftar till att köra kundkod på ett säkert sätt och förhindra att en arrendators kod påverkar andra eller får obehörig åtkomst till andra arrendatorers data, Salesforce-resurser eller externa resurser. Denna säkerhet uppnås genom en skiktad (försvarsdjupgående) arkitektur. Denna arkitektur tillhandahåller en isolerad körningsmiljö för varje arrendators egna kod, med olika skyddsräcken. Dessa inkluderar logisk isolering på Kubernetes-nivå (K8s), nätverksisolering, runtime sandboxing och behörigheter med minst behörighet, allt kompletterat med operativ övervakning och incidenthanteringsberedskap för upptäckt och svar.
För att stödja en robust utvecklingslivscykel erbjuder kodtillägg:
- Extern författarskap och felsökning: Utvecklare kan skapa och felsöka Python-kod i bekanta miljöer som VSCode och använda SDK.
- Flexibel distribuering: Egen kod kan paketeras och distribueras med SDK-verktyg, Data 360-användargränssnittet eller API, vilket möjliggör integrering i CI/CD.
Operationsloggar: Tillgång till detaljerade utförandeloggar ger transparens och underlättar felsökning i produktion.
Genom att erbjuda dessa säkra och flexibla möjligheter till kodtillägg låter Data 360 arkitekter skräddarsy plattformen till sina mest unika och komplexa databearbetningskrav, vilket verkligen befäster dess roll som en utökningsbar företagsdatastruktur.
När företag accelererar AI-användning upprätthåller de flesta heterogena ML-ekosystem — inklusive Amazon SageMaker, Google Vertex AI och egna Python-baserade miljöer — värdmodeller som driver verksamhetskritiska förutsägelser, som kreditriskbetyg, bortfallbenägenhet, produktrekommendationer och beslut om nästa bästa åtgärd.
Att integrera dessa externa modeller i Salesforce krävde traditionellt skräddarsydda API-lager, ETL-pipeline eller orkestrering av mellanprogramvara, vilket introducerar dataduplicering, styrningsöverskott, latens och operativ komplexitet – utmaningar som står i konflikt med en enhetlig, kompatibel och realtidsvision för Customer Data Platform (CDP).
Ta med din egen modell (BYOM): Levereras via Einstein Studio i Data 360 och hanterar dessa utmaningar genom att aktivera direkt åberopning av externt utbildade modeller i Salesforce-flöden, Apex och automatiseringsverktyg – utan att flytta eller replikera data. Genom nollkopieringsfederation fungerar Data 360 som den styrda enskilda källan till sanning och exponerar harmoniserade Customer 360 för härledning vid externa slutpunkter. Förutsägelseresultat flödar tillbaka i realtid och driver verksamhetsprocesser med skalbar intelligens.
BYOM åtgärdar effektivt avståndet mellan datavetenskap och operativt utförande genom att koppla bort modellutveckling, styrd data och konsumtionslager. Det bevarar plattformsoberoende, minskar integreringskomplexitet, snabbar på AI-distribuering och upprätthåller styrning över känsliga data.
Arkitekturen fungerar enligt följande: Data 360 ger en enhetlig Customer 360, medan Einstein Studio orkestrerar anslutningar till externa ML-plattformar (SageMaker, Vertex AI eller egna slutpunkter). Externa modeller kör slutledningar i realtid, batch eller streaminglägen. Salesforce-lager—Flow, Apex och Query APIs—använder utdata för att leverera personliga, automatiserade och analytiska insikter i Sales, Service, Marketing och Industry Clouds.
Från ett företags synvinkel levererar BYOM:
- Dataintegritet och styrning: Utesluter okontrollerade datakopior och tillämpar policyefterlevnad.
- AI-demokratisering: Gör komplexa modeller tillgängliga för icke-tekniska användare via Salesforce-verktyg.
- Tid-till-värde-acceleration: Externa modeller aktiveras omedelbart inom Salesforce-processer.
- Stöd för skalbarhet och hybridarkitektur: Aktiverar distribuering av AI-arbetsbelastningar i flera moln.
- Framtidsfärdig AI-arkitektur: Har stöd för sammansatta AI-strategier, frånkoppling av data, modell och användningslager för smidighet i verksamheten.
Bring Your Own LLM (BYO-LLM): Erbjuder samma utökningsmekanism men för generativa modeller. Genom att aktivera direkt åberopning av externa LLM låter vi kunder använda dem i Agentforce Platform istället för Salesforce-modeller. För företag tillåter BYO-LLM:
- Åtkomst till finjusterade modeller
- Integrering av modeller som för närvarande inte tillhandahålls av Salesforce
- Användning av modeller i konton som tillhandahålls av kunder
Moderna företag arbetar inom ett komplext datalandskap som kännetecknas av två stora arkitektoniska utmaningar:
- Företagsintern fragmentering: Stora organisationer använder ofta flera Salesforce-organisationer (ofta segmenterade efter region, affärsenhet eller historiskt förvärv) och många andra datasystem. Denna fragmentering skapar interna datasilos, vilket gör det omöjligt att etablera en enskild, betrodd och enhetlig vy av kunden för engagemang i realtid i hela verksamheten. Utmaningen är att slå samman dessa data utan att fysiskt slå samman eller duplicera dem i alla system, vilket säkerställer att styrningen förblir intakt.
- Företagsövergripande samarbete: Företag behöver ofta dela data med partners och leverantörer för gemensam marknadsföring, mätning och verksamhetsinformation. Utmaningen är att möjliggöra detta samarbete samtidigt som känsliga, egenutvecklade data skyddas och sekretessföreskrifter som GDPR och CCPA följs, samt konkurrenshinder.
Salesforce Data 360 hanterar dessa utmaningar med ett Trust by design-ramverk som bygger på principen att dela åtkomst och insikter istället för att flytta eller duplicera data.
Salesforce Data 360 hanterar datafragmentering och samarbetsutmaningar med Data Cloud One, Datadelning mellan Data 360s och Datarensningsrum med sekretess i fokus. Dessa lösningar slår samman kunddata, möjliggör säkert datautbyte och ger sekretessbevarande insikter. Med en Trust by design-metod som inte kräver någon kopia kan organisationer frigöra datapotential för engagemang i realtid, utökade partnerskap och intelligent beslutsfattande. Vart och ett av dessa datasamarbetsalternativ har olika syften.
Intern företagsaktivering med Data Cloud One
Data Cloud One är den grundläggande arkitektoniska lösningen för företag som driver flera Salesforce-organisationer. Dess syfte sträcker sig utöver enkel datadelning; den är utformad för att etablera en enskild, betrodd kundvy och aktivera fullständig kapacitet för Data 360-plattformen i hela organisationen.
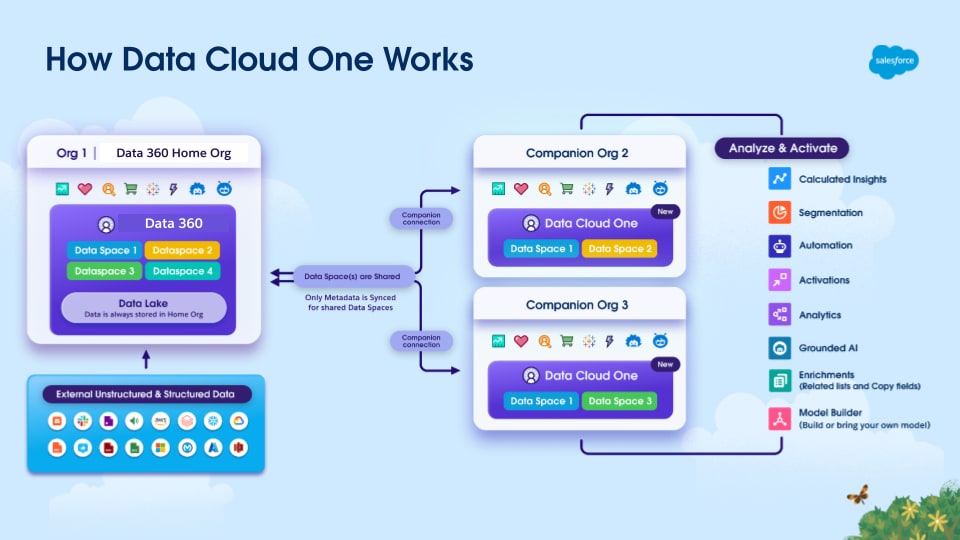
Denna mekanism centrerar sig på en utsedd Home Org Data 360-instans, som fungerar som den centrala myndigheten för datahantering och byggande av den enhetliga kundprofilen. Hemorganisationen är den organisation som Data 360 provisioneras i. En Data Cloud One-anslutning upprättas mellan Data 360 och andra Salesforce-organisationer, som kallas Companion-organisationer. Som en del av Data Cloud One-anslutningen delar Data 360 ett eller flera av sina datautrymmen med varje tillhörande organisation, vilket ger åtkomst till både data och metadata i varje delat datautrymme. Detta uppnås genom en federationsmodell med noll kopia och korsorganisationsmetadatasynkronisering.
Data Cloud One låter även Companion-organisationer använda hemorganisationens Data 360-instans för sina egna behov av aktivering, personanpassning och intelligens. Denna strategi är viktig för att eliminera intern datafragmentering och säkerställa att alla affärsenheter aktiveras mot samma, styrda och enhetliga kundprofil, vilket maximerar ROI för kärnimplementeringen av Data 360.
Datadelning mellan Data 360-organisationer
För distribuerade interna miljöer (där fullständig centralisering inte är möjlig) och för samarbete med betrodda externa partners ansluter Data 360-till-Data 360-datadelning oberoende Data 360-instanser.
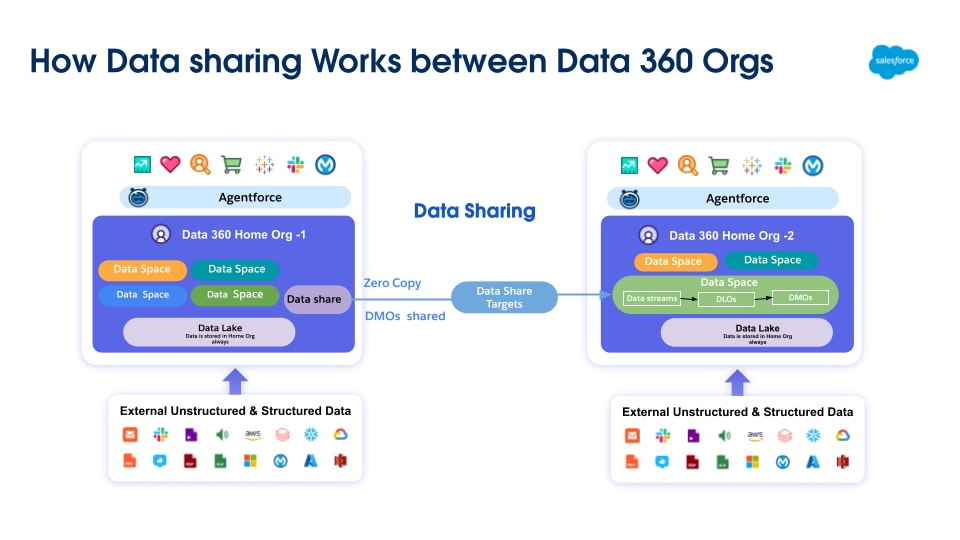
Denna nollkopieringsdelningsmodell etablerar en anslutning mellan separata Data 360-arrendatorer provisionerade i olika Salesforce-organisationer i syfte att säkra utbytet av dataobjekt (DLO, DMO och CIO). När det är anslutet blir hela dataobjektet tillgängligt i mottagarens Data 360. Mottagarens Data 360-administratör kan sedan ställa in styrningsregler för att hantera användaråtkomst till dessa data.
Samarbete i första hand med sekretess i Data 360-renrum
När samarbete kräver högsta nivå av sekretess och efterlevnad, eller när konkurrensproblem förbjuder delning av rådata, är Data 360 Clean Rooms arkitektoniskt godkända.
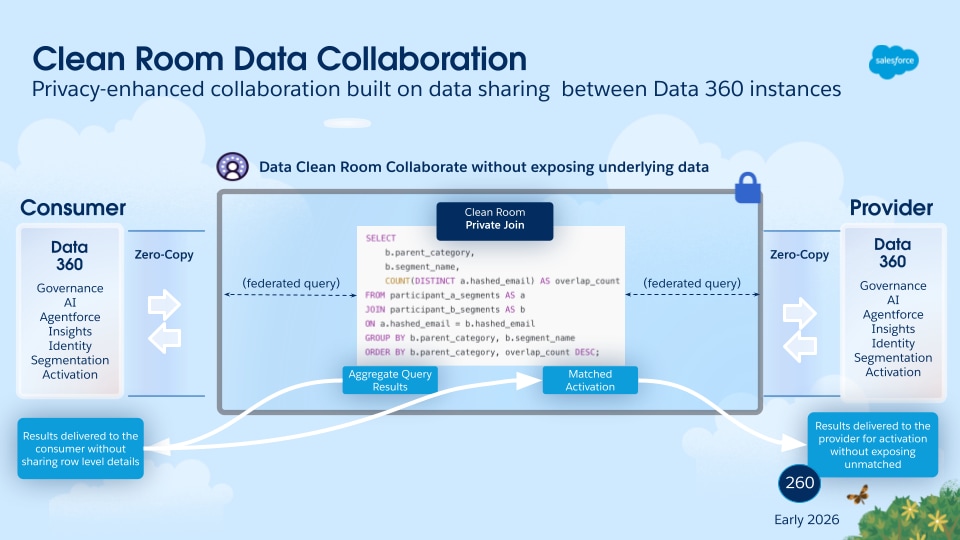
Arkitektoniskt sett är Data 360 Clean Room Collaboration byggt på det ramverk för nollkopiering som används av Data 360-till-Data 360-datadelning, men med ytterligare lager av styrning och beräkningsbegränsningar. Data 360 Clean Room tillhandahåller en säker, kontrollerad beräkningsmiljö där parter kan slå samman sina datauppsättningar baserat på anonymiserade nycklar. Dess huvudsyfte är att tillåta gemensam analys och insiktsskapande utan att exponera underliggande egenutvecklade data. Miljön tillämpar strikta, programmerbara regler som till exempel lägsta aggregeringströsklar och identifierare som inte går att exportera. Dessa regler säkerställer att endast godkända, sekretesshöjande och aggregerade insikter deriveras och delas. Detta gör renrum viktiga för användningsfall som kampanjmätning mellan olika plattformar och analys av överlappning av känsliga målgrupper.
Data 360 är utformat som en intelligent, utökningsbar och betrodd dataväv som behövs för att driva nästa generations AI. Dess arkitektoniska design hanterar problemet med fragmenterade data och låter organisationer slå samman, bearbeta och aktivera alla kunddata i stor skala, med hjälp av Zero Copy Data Federation för att säkerställa effektivitet.
Dess robusta dataorganisation etablerar en harmoniserad vy från DLO (inklusive ostrukturerade data) till DMO, allt säkrat inom partitionerade datautrymmen. Data 360s mångsidiga databearbetningsfunktioner—inklusive batch- och streamingtransformationer, beräknade insikter, ostrukturerad databearbetning och identitetslösning—drivs av den inkrementella SNCE- och CDF-arkitekturen, vilket säkerställer effektiv bearbetning nästan i realtid och betydande kostnadsbesparingar.
Utökning tillhandahålls av kodtilläggsarkitekturen, vilket säkert aktiverar egen Python-logik via skript eller isolerade funktioner för unika krav. Dessutom garanterar ett omfattande ramverk för datastyrning, byggt på attributbaserad åtkomstkontroll (ABAC) med CEDAR-policyer, detaljerad säkerhet, dynamisk datamaskering och konsekvent tillämpning över all dataanvändning. Detta kulminerar i sofistikerade segmenterings- och aktiveringsfunktioner, som omvandlar sammanslagna kundprofiler till dynamiska engagemangsstrategier med flera kanaler och respons i realtid.
Av avgörande betydelse är Data 360s förmåga att slå samman stora, olika data, tillhandahålla sammanhang i realtid via sin sammanslagna sökfråga (inklusive hybridstrukturerad/ostrukturerad sökning och hyperacceleration) och tillämpa stränga styrregler för att driva intelligenta AI-agenter. Den tillhandahåller de nödvändiga tillförlitliga, färska och relevanta data som behövs för att grunda Generativa AI-flöden (RAG) och för att driva Agentforce agenters åtgärdsorienterade kapacitet i flera omgångar, vilket säkerställer att de fungerar med precision och precision.
Genom att tillhandahålla en framtidssäker plattform där källdata transformeras till användbara insikter fungerar Data 360 som en oumbärlig arkitektonisk grund för organisationer som bygger Agentic-kundupplevelser. Det är den viktiga ryggraden som förvandlar kunddata till sofistikerade, personliga kundupplevelser som driver framgång för dagens moderna organisationer.