Detta dokument beskriver de aktuella alternativen för att distribuera program till CloudHub 2.0 för att uppfylla krav på hög tillgänglighet och katastrofåterställning. Den använder USA-regionen som ett exempel och kan tillämpas på andra regioner.
CloudHub 2.0 är en fullständigt hanterad, molnbaserad integreringsplattform som eliminerar infrastrukturoverhead genom att automatisera distribuering, skalning och hantering av MuleSoft API:er och integreringar i molnet. Det är MuleSofts moderna molndistribueringsplattform som körs på Amazon AWS-infrastruktur.
I de flesta fall är standard för hög tillgänglighet (HA) och katastrofåterställning (DR) som tillhandahålls av CloudHub 2.0 tillräckligt. CloudHub 2.0 tillhandahåller HA och DR på regional nivå (mer information finns i CloudHub 2.0-avbrottsscenarier). Sektionen Viktiga överväganden för CloudHub 2.0 ger mer information om HA och DR som stöds av CloudHub-2.0-.
Villkor som kräver en design utöver CloudHub 2.0:s standardtillgänglighet inkluderar:
- Ett program måste säkerställa att inga data förloras i ett katastrofscenario (till exempel att en region i Amazon går ner).
- Ett program beror på Objektlagring och behöver säkerställa kontinuitet om distributionsregionen går ner.
- Backendsystem är konfigurerade för motsvarande tillgänglighet. CloudHub 2.0 kan ibland ge pålitlighet genom köer eller liknande mekanismer, men oavsett om integreringen är i realtid eller asynkron måste backendsystem ha stöd för en jämförbar nivå av HA och DR.
- När ett avbrott på AWS-regionnivå påverkar backendsystem antas deras återställning köras parallellt med CloudHub 2.0-återställning.
- Konfigurationen av privat utrymme är klar i flera regioner.
Designalternativen i denna guide fokuserar på lösningar för programtillgänglighet i CloudHub 2.0 när en hel AWS-tillgänglighetszon eller region blir otillgänglig.
Denna guide tar inte upp dessa återställningsscenarion, men den noterar konsekvenser där det är relevant:
- Återställning av backendsystem, program, databaser, nätverkskomponenter och datacenter som hanteras och provisioneras utanför Anypoint CloudHub, oavsett om det är på plats eller i molnet.
- Återställning av VPN-länkar mellan CloudHub 2.0 och kundens privata datacenter (till exempel IPsec-tunnlar och VPN-gateways). Vissa DR-alternativ i denna guide kan delvis hantera dessa scenarion.
- Ändringar av MuleSofts utgångs-IP under katastrofåterställning när IP-tillåtelselista används för integreringar. Vissa DR-alternativ i denna guide kan delvis hantera dessa scenarion.
- Externa meddelandesystem som används i kundlösningar, oavsett om de tillhandahålls av MuleSoft (som Anypoint MQ) eller andra leverantörer (som AWS MSK eller Heroku Kafka).
Tänk på dessa viktiga saker när du utvärderar CloudHub 2.0 för katastrofåterställningskrav.
CloudHub 2.0-beroende av AWS-regional tillgänglighet
- CloudHub 2.0 körs på AWS; dess tillgänglighet är knuten till AWS-regioner.
- Distributioner och programtillgänglighet organiseras efter region. Dessa regioner motsvarar AWS-regioner.
Om en hel AWS-region misslyckas är program i den regionen inte tillgängliga och replikeras inte automatiskt någon annanstans.
Programmets höga tillgänglighet (HA) och replikhantering
- CloudHub 2.0 återdistribuerar automatiskt program inom samma region om hårdvaran misslyckas, men ett program med en enda replik kan uppleva nedtid.
- Program med flera repliker distribueras över separata tillgänglighetszoner som standard, vilket ger HA över alla områden.
- Om tillgänglighetszonen för ett enskilt replikaprogram misslyckas öppnas programmet automatiskt i en annan tillgänglighetszon inom samma region.
Särskild påverkan på USA:s östra region
- I händelse av ett avbrott i USA:s östra region:
- CloudHub 2.0-hanteringsgränssnittet och REST-tjänsterna för distribuering är inte tillgängliga och nya program kan inte distribueras.
- Program i andra regioner påverkas inte under de flesta felscenarier. Dessa program fortsätter att fungera normalt, men övervaknings- och hanteringsfunktioner via styrplanet kommer inte att vara tillgängliga under avbrottet.
- Core CloudHub 2.0-moduler (till exempel programinställningar) underhålls i US East, så inställningar kan inte redigeras under avbrottet.
Övervaka och varna
- Konfigurera varningar för fel i tillgänglighetszoner eller regioner via status.mulesoft.com.
- Använd en separat hälsokontroll och varningsmekanism utanför CloudHub 2.0 så att team meddelas om repliker misslyckas eller program slutar svara.
Databeständighet (objektlagring V2)
- Objektlagring V2 är knuten till den region där programmet distribueras första gången.
- Om du flyttar programmet till en annan region stannar Object Store V2 i den ursprungliga regionen för att undvika dataförlust.
- Om regionen där Object Store V2 är distribuerat misslyckas är objektlagringen inte tillgänglig.
Intrångskontroller och privata utrymmen
- CloudHub 2.0:s ingresskontroller är mycket tillgängliga på regionnivå.
- I ett delat utrymme, om en region misslyckas, förblir en ingresskontroller i en annan region tillgänglig men kan endast serva program som distribuerats i den regionen.
- I ett privat utrymme, om en region misslyckas, är ingresskontroller i andra regioner inte tillgängliga om de inte har konfigurerats där i förväg.
- Konfigurationen av privat utrymme är regional; om en region misslyckas är det privata utrymmet inte tillgängligt om inte en annan region har konfigurerats.
| Komponentstatus | Salesforce-ansvar |
|---|---|
| Replicera nedåt | Åtgärd: CloudHub 2.0 startar automatiskt om repliken i en annan tillgänglighetszon om något är fel i den aktuella tillgänglighetszonen. Men programmet kommer att vara offline tills den nya repliken har startats helt. Villkor: Standardkonfiguration. Tidsåtgång: Cirka 2-15 minuter beroende på programmets komplexitet och replikeringsstorlek. |
| Tillgänglighetszon nedåt | Åtgärd: Samma som replikan nere. Villkor: Standardkonfiguration. Tidsåtgång: Samma som replikan nere. Notis: Samma som replikan nere. |
| Region nedåt | Åtgärd: Ingen automatisk återställning. En överlämningsdesign måste finnas. |
| Komponentstatus | Kundansvar |
|---|---|
| Replicera nedåt | Notis: Utför regelbundna hälsokontroller med hjälp av en hjärtslagsmekanism som är inbyggd i API. Mitigation: Distribuera programmet till flera repliker i samma region. Test / Simulering: Höj ett ärende med MuleSofts support och de kommer att stödja ett failover-test för att kontrollera om en ny replika hamnar i en annan AZ inom 1 till 15 minuter. |
| Tillgänglighetszon nedåt | Notis: Samma som replikan nere. Mitigation: Distribuera programmet till flera repliker i samma region eller i olika regioner. Test / Simulering: AZ Down-scenariot är svårt att simulera. Det kräver medverkan av MuleSoft Engineering för att stödja möjliga testscenarion. |
| Region nedåt | Notis: Samma som replikan nere. Kontrollera även statusuppdateringar på https://status.aws.amazon.com. Mitigation: Samma som AZ Down. Beredskapsplan för katastrofåterställning: 2 privata utrymmen med samma konfiguration i olika regioner. Test / Simulering: Samma som AZ Down. |
| Komponentstatus | Salesforce-ansvar |
|---|---|
| VPN Gateway nere | Replikstatus: Kör men kan inte ansluta till några resurser som värdas på plats och kan nås genom VPN-tunneln. Åtgärd: Ingen automatisk återställning. En överlämningsdesign måste finnas. |
| Ingresskontroller (delat utrymme) nedåt | Replikstatus: Kontrollen Ingress är en klusterkonfiguration med flera instanser, liknande programkopior. Om en programreplik misslyckas skapas en ny och startas automatiskt. Om en instans för ingresskontroll misslyckas förblir program tillgängliga genom den andra instansen. Om hela kontrollen Ingress är nere anses regionen vara nere. |
| Ingresskontroller (Privat utrymme) nere | Replikstatus: Samma som Ingress Controller i delat utrymme nedåt. |
| Komponentstatus | Kundansvar |
|---|---|
| VPN Gateway nere | Notis: Utför regelbundna hälsokontroller med hjälp av en hjärtslagsmekanism som är inbyggd i API. Mitigation: CloudHub 2.0 VPN-gateways har stöd för hög tillgänglighet genom en arkitektur med två tunnlar med automatisk växling mellan tunnlar. En kund måste konfigurera detta mönster. Test / Simulering: VPN Gateway Down-scenariot är svårt att simulera. Kräver medverkan av MuleSoft Engineering för att stödja möjliga testscenarion. |
| Ingresskontroller (delat utrymme) nere | Notis: Samma som VPN Gateway Down. Mitigation: Samma som Region nere. Migrera program till ett vänteläge eller aktivt utrymme i en annan region. Test / Simulering: Samma som VPN Gateway Down. |
| Ingresskontroller (Privat utrymme) nere | Notis: Samma som VPN Gateway Down. Mitigation: Samma som Region nere. Migrera program till ett vänteläge eller aktivt privat utrymme i en annan region, i samordning med AWS Route 53 (eller motsvarande) konfiguration. Test / Simulering: Samma som VPN Gateway Down. |
Översikt av plattformstjänster – Objektsbutik
| Lagring av objekt i minne | Persistent Object Store v2 | |
|---|---|---|
| Plats för data | Endast lokalt för programmet. | I samma region där MuleSoft-programmet först distribuerades. |
| Delade mellan repliker? | Nej | Ja |
| Återställning av objektlagring i program | Data förloras; alla data i minnet förloras vid omstart av appen, ny distribuering eller replikeringsfel. | Data förloras inte om inte appen tas bort. |
| Återställning av objektbutik inom region | Data förloras (samma som ovan). | Data förloras inte (samma som ovan). |
| Regional återhämtning | Samma som ovan. | Data är inte tillgängliga. Även med en aktiv aktiv DR-konfiguration är Objektlagring endast tillgängligt i den ursprungliga distributionsregionen. |
| Minskning | Externalisera data för regional återhämtning. | Data förblir tillgängliga medan den ursprungliga distributionsregionen är tillgänglig. För HA eller DR för flera regioner, externalisera data utanför objektlagringen. |
Hög tillgänglighet (HA) är måttet på ett systems förmåga att förbli tillgängligt i händelse av ett systemkomponentfel. I allmänhet implementeras HA genom att bygga in flera nivåer av feltolerans och/eller kapacitet för lastbalansering i ett system. Det är vanligtvis en aktiv konfiguration och resulterar i begränsad eller ingen påverkan på företagstjänster.
Katastrofåterställning (DR) är processen där ett system återställs till ett tidigare acceptabelt läge efter ett katastrofscenario, antingen naturligt (som översvämningar, tornados, jordbävningar eller bränder) eller orsakat av människan (som strömavbrott, serverfel eller felkonfigurationer). DR är vanligtvis en aktiv-passiv konfiguration och resulterar i viss påverkan på företagstjänster.
Om regional hög tillgänglighet eller regional katastrofåterställning önskas för att minska verksamhetspåverkan i händelse av ett regionalt AWS-fel, tänk på dessa punkter när du utformar din lösning i MuleSoft CloudHub 2.0:
- CloudHub 2.0-kopior och relaterade funktioner—privata utrymmen, ingresskontroller och Anypoint MQ-destinationer—är regionspecifika.
- Om en hel AWS-region misslyckas blir alla repliker och associerade tjänster i den regionen otillgängliga.
- När en region återhämtar sig återställs konfigurationer. Du måste starta om program.
- Om regionen Östra USA misslyckas är Anypoint Platform-tjänster (till exempel Åtkomsthantering och Runtime Manager) inte heller tillgängliga.
- MuleSoft tillhandahåller ett servicenivåavtal på 99,95 % tillgänglighet för Platform Services, inklusive CloudHub 2.0-kopior i en aktiv aktiv konfiguration inom en region. Se det senaste serviceavtalet för MuleSoft Cloud-erbjudandet för aktuella detaljer.
- CloudHub 2.0 har inte stöd för färdigbyggda HA eller DR med flera regioner. Tillgänglighet tillhandahålls endast inom en region.
Dessa designriktlinjer gäller oavsett vilken konfiguration du väljer.
Konfiguration av privata utrymmen med flera regioner
Alla alternativ som beskrivs i följande avsnitt kräver att program distribueras i separata regioner. Detta är endast möjligt om konfigurationen av privat utrymme har slutförts i förväg, innan en katastrof. Eftersom konfigurationen av privat utrymme är regional kräver en DR-strategi minst två privata utrymmen—ett per region—och en mekanism för att växla trafik till lämplig VPN-slutpunkt.
Högtillgänglig konfiguration av privat utrymme inom en region
CloudHub 2.0 ger inte automatisk växling vid fel om ett privat utrymme inom en region misslyckas. En lösning är en aktiv-passiv konfiguration i flera miljöer, vilket kräver:
- Konfigurera flera VPN-gateways på det privata utrymmet.
- Etablera separata miljöer i CloudHub 2.0-regionen, var och en med sitt eget privata utrymme.
- Utse en av dessa miljöer som passiv (där program inte distribueras från början men öppnas om det primära privata utrymmet misslyckas).
Om en konfiguration med hög tillgänglighet utan att VPN Gateway är en enskild felpunkt är ett svårt krav är att distribuera till två regioner det bästa alternativet. Ett VPN Gateway-fel i detta scenario kan lösas genom att misslyckas med den region som påverkas över till den alternativa region där det privata utrymmet redan har konfigurerats.
Ingen meddelandeförlust
För att uppnå noll meddelandeförlust om en hel region misslyckas måste ett program förhindra dataförlust och hantera dessa punkter:
- Använd externa meddelanden för att uppnå meddelandetillförlitlighet.
- Se till att Objektslagring inte används för transaktionsdata som är av transaktionskaraktär. Om distributionsregionen där MuleSoft-programmet först distribuerades går ner kommer Objektslagring inte att vara tillgänglig.
- Omge all åtkomst till Objektbutik i ett separat flöde eller sektion som fortsätter att fungera—för både undantagshantering och beteende—om läs- eller skrivoperationer för Objektbutik misslyckas.
Notera. I de flesta fall behöver DR-krav inte säkerställa att meddelanden går förlorade i noll vid en katastrof och måste säkerställa att dataförlusten är mindre än en given periods data (till exempel 1 timme).
Håll integreringen statslös
Som en allmän designprincip är det alltid viktigt att säkerställa att integreringarna är statslösa till sin natur. Detta innebär att ingen transaktionsinformation delas mellan olika klientåberopningar eller utföranden (vid schemalagda tjänster). Om vissa data måste underhållas av mellanprogramvaran på grund av en systembegränsning bör de finnas kvar i en extern butik, som en databas eller en meddelandekö och inte i MuleSoft-infrastrukturen eller minnet. Det är viktigt att notera att när vi skalar, särskilt i molnet, ska läget och resurserna som används av varje replika vara oberoende av andra repliker. Denna modell säkerställer bättre prestanda, skalbarhet och pålitlighet.
Nätverk och trafikhantering
- Fåfänga domäner krävs för regional tillgänglighet; de fungerar som en global DNS för alla ingresskontroller över regioner.
- En global lastbalanserare dirigerar trafik mellan det primära och DR-regionens privata utrymmen. Kunder tillhandahåller denna komponent; använd AWS Route 53 eller ett globalt CDN med dirigeringspolicyer för att dirigera trafik över regioner.
- Konfigurera Ingress-kontroller i både primära regioner och DR-regioner med en egen domän.
- Planera och upprätthåll brandväggsregler och VPN-tunnel så att program på plats kan nås från både den primära regionen och DR-regionens privata utrymmen.
- Underhåll av TLS-certifikat måste täcka privata utrymmen i både primära och DR-regioner för sömlös återställning.
Distribuering och konfigurering av program
- Programnamnen måste vara unika i olika regioner. Till exempel kan en CI/CD-pipeline lägga till regionnamnet (eller en regionkod) till programnamn innan distribuering för att behålla sin unikhet över primära regioner och DR-regioner.
- Konfigurera CI/CD-pipeline för att distribuera program till både den primära regionen och DR-regionen så att alla program är tillgängliga i båda regionerna.
Infrastruktur och kapacitet
Prestanda är bäst när alla infrastrukturaspekter har identisk primär kapacitet och DR-regionkapacitet. Prestanda försämras om dessa infrastrukturaspekter inte är identiska.
Databeständighet och lagring
- Persistenslagring måste synkroniseras regelbundet mellan de två regionerna. Kunder är ansvariga för lagringsreplikering; MuleSoft tillhandahåller den inte. En enskild delad lagring mellan VPC i de primära och DR-regionerna är möjlig, men den delade lagringen måste vara mycket tillgänglig, annars blir det en enskild felpunkt för båda regionerna.
- Object Store V2 är regionalt och endast tillgängligt i den region där Mule-programmet först distribuerades. Om programmet flyttas till en annan region stannar Object Store V2 i den ursprungliga regionen för att undvika dataförlust. Använd annan beständig lagring för DR-strategier med flera regioner.
Provnings- och driftsförfaranden
Anta en formell DR-teststrategi och kör periodiska DR-övningar. För aktiv aktiv DR, använd en kanariefågeldistribueringsstrategi för att validera båda regionerna.
Prestanda- och servicenivåavtal (SLA)
Viss prestandaförsämring kan inträffa eftersom DR-regionen kan vara längre från slutanvändare eller backendsystem än den primära regionen. Definiera och kommunicera ett DR SLA till intressenter.
Beteende för återställningsläge (sammanhangsanteckning)
I aktivt aktivt läge går det snabbt att överföra fel från den primära regionen till DR-regionens privata utrymme: den globala belastningsbalanseraren upptäcker att den primära är ohälsosam och dirigerar trafik till den friska (DR) regionen. I aktivt-passivt läge måste du distribuera programmet till DR-regionens privata utrymme när en katastrof inträffar.
Det finns 3 alternativ för att uppnå en högre tillgänglighet på DR-nivå:
En aktiv aktiv konfiguration baseras på aktiva medarbetare fördelade över regioner och använder en extern belastningsbalanserare för att dirigera trafik mellan de två instanserna.
Konfiguration för varm standby
En aktiv-passiv konfiguration skulle baseras på en aktiv medarbetare i en region och en passiv medarbetare i en annan region. Den passiva regionen skulle startas vid behov.
Vissa element i den passiva regionen måste fortsätta vara aktiva för failover eller konfigureras i förväg, inklusive privata utrymmen, VPN-tjänster och bilagor till transitgateway.
Konfiguration för kall standby
Som ovan provisioneras repliker och Ingress-kontroller i en andra region via en helt automatiserad DevOps-process vid failover. Vissa element i den passiva regionen måste fortsätta vara aktiva för växling vid fel, inklusive privata utrymmen, VPN och bilagor till transitgateway.
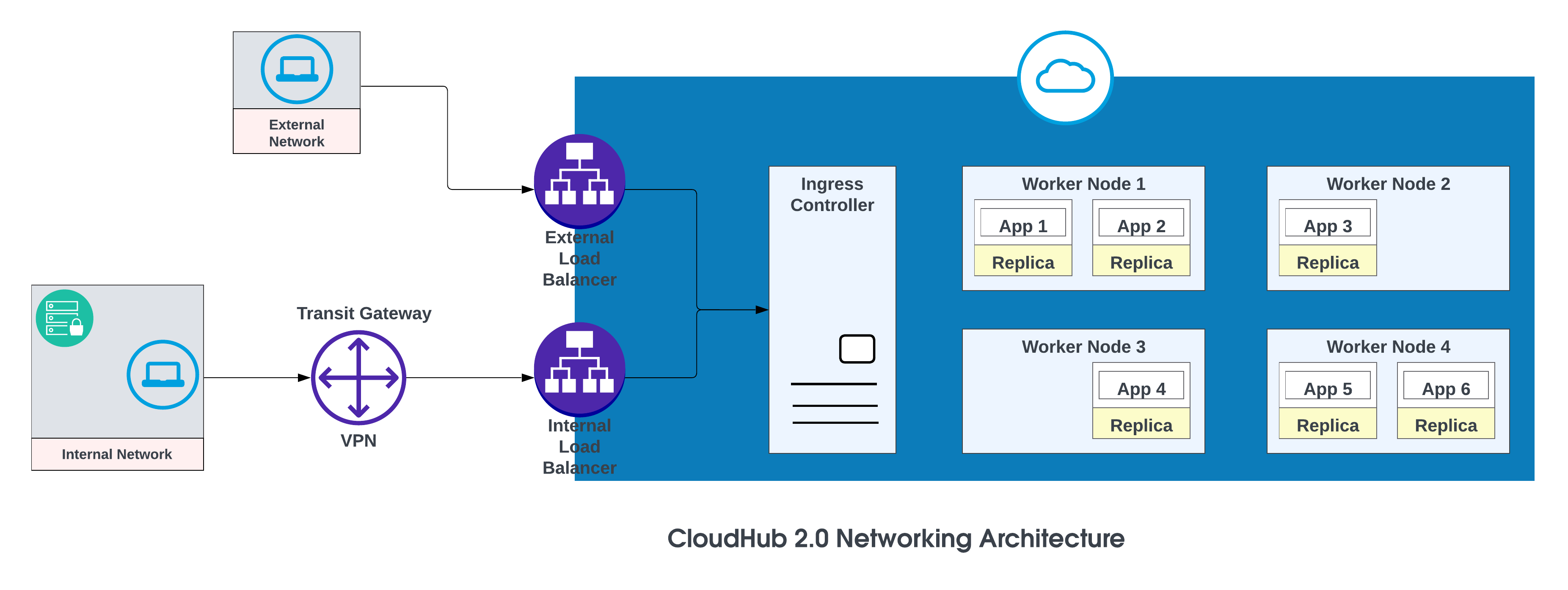
De grundläggande komponenterna i CloudHub 2.0-nätverksarkitekturen är:
- En HTTP-belastningsbalanserare
- Mule replika DNS-poster
- Privata utrymmen
- Regionala tjänster
Mer information finns i CloudHub 2.0-nätverksarkitektur.
Fåfänga domäner
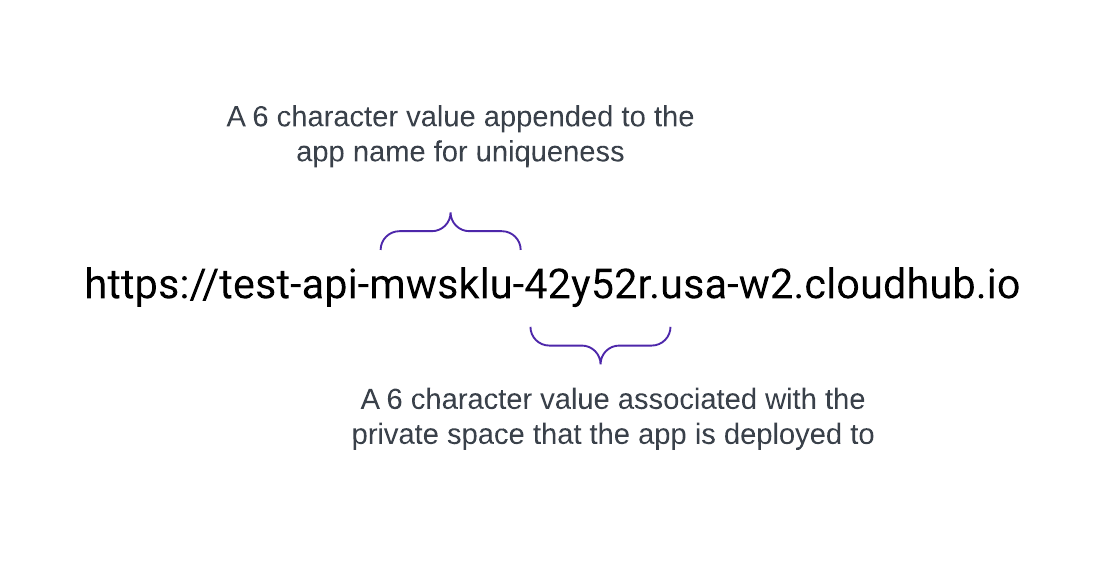
När ett privat utrymme skapas får det ett DNS-målnamn i formatet: <space-id>.<region>.cloudhub.io . Vid distribuering av en app som heter test-api i detta privata utrymme kommer dess slutpunkt att följa detta format:
CloudHub 2.0 har även stöd för egna, eller fåfänga, domäner genom att konfigurera dem inom ett privat utrymme med hjälp av TLS-sammanhang och DNS-poster. För att skapa ett TLS-sammanhang i Runtime Manager för ett privat utrymme, ladda upp det offentliga certifikatet och den privata nyckeln och lägg sedan till en egen slutpunkt i ditt programs inställningar för att använda den domänen. Skapa en DNS-post (till exempel ett CNAME) som pekar din fåfänga domän till ditt privata utrymmes standardvärdnamn.
Till exempel har ett program som heter test-api distribuerat i us-west-2 med standard DNS 42y52r.usa-w2.cloudhub.io en API-slutpunkt på:
https://test-api-mwsklu-42y52r.usa-w2.cloudhub.io
Denna URL använder inte en fåfäng eller egen domän. Följ dessa steg för att använda acme.com så att API-URL:er visas som https://test-api.acme.com.
- Skapa TLS-sammanhang i Runtime Manager med offentliga och privata nycklar.
- Lägg till en fåfäng domän i programmets inställningar för att använda den domänen.
- Skapa en DNS-post i AWS Route 53 och konfigurera en enkel dirigeringspolicy (till exempel CNAME) så att Vanity-domänen löses till det privata utrymmets standardvärdnamn.
För egna domäner kan du använda AWS Route 53 eller andra globala CDN-tjänster med dirigeringspolicyer. I diagrammet nedan används AWS Route 53 med "enkel" dirigeringspolicy. När en konsument från ett offentligt (externt) nätverk begär acme.com dirigerar AWS Route 53 begäran till MuleSofts kontroll för inträngande privat utrymme.
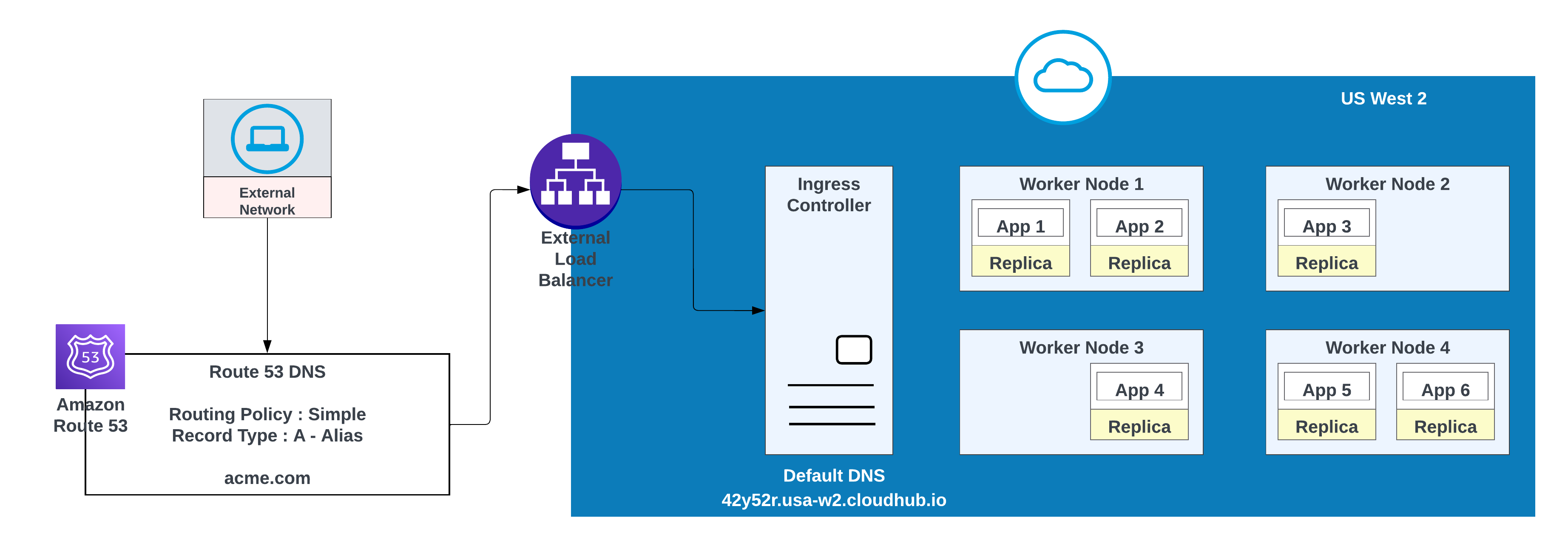
Använd detta alternativ när program kräver failover: distribuera en instans i den primära regionen (till exempel us-west-2) och en annan i en sekundär region (till exempel us-east-1).
Använd en befintlig miljö i den sekundära regionen när så är möjligt. Att skapa en ny miljö kräver ytterligare ansträngning.
Exempel på appar distribuerade i en region (US West 2) med en övergång vid fel till en annan region (US East 1)
| Postnamn | Värde/Dirigera trafik till | Dirigeringspolicy | ID för hälsokontroll |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Failover | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Failover | 43e131s131sq |
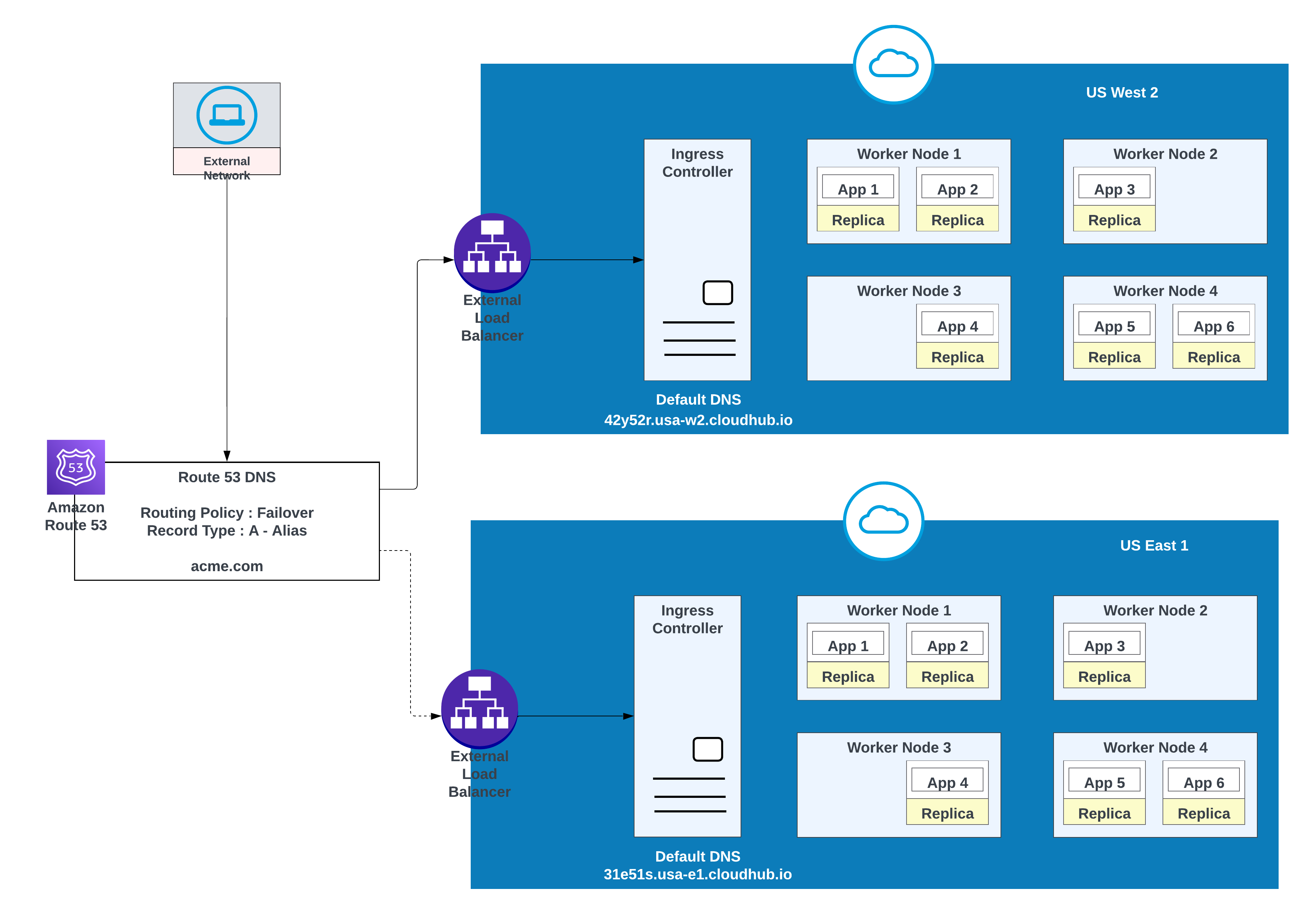
I denna konfiguration dirigerar AWS Route 53 trafik till ingresskontrollerna för de privata utrymmena i US West 2 och US East 1. En dirigeringspolicy för växling vid fel konfigureras med en hälsokontroll.
För lägre latens tillsammans med hög tillgänglighet, använd distributionsstrategin som beskrivs i diagrammet. Med denna strategi kan appar distribueras i två regioner (us-west-2 och us-east-1 i detta exempel).
Använd latensdirigeringspolicyn i AWS Route 53 för att dirigera begäranden till den region som erbjuder den lägsta latensen med bibehållen hög tillgänglighet. Dirigeringspolicyn "latens" i AWS Route 53 för att dirigera begäran om lägre latens som fortfarande har hög tillgänglighet.
Appar distribuerade i båda regionerna (US West 2 och US East 1) för lägre latens och hög tillgänglighet
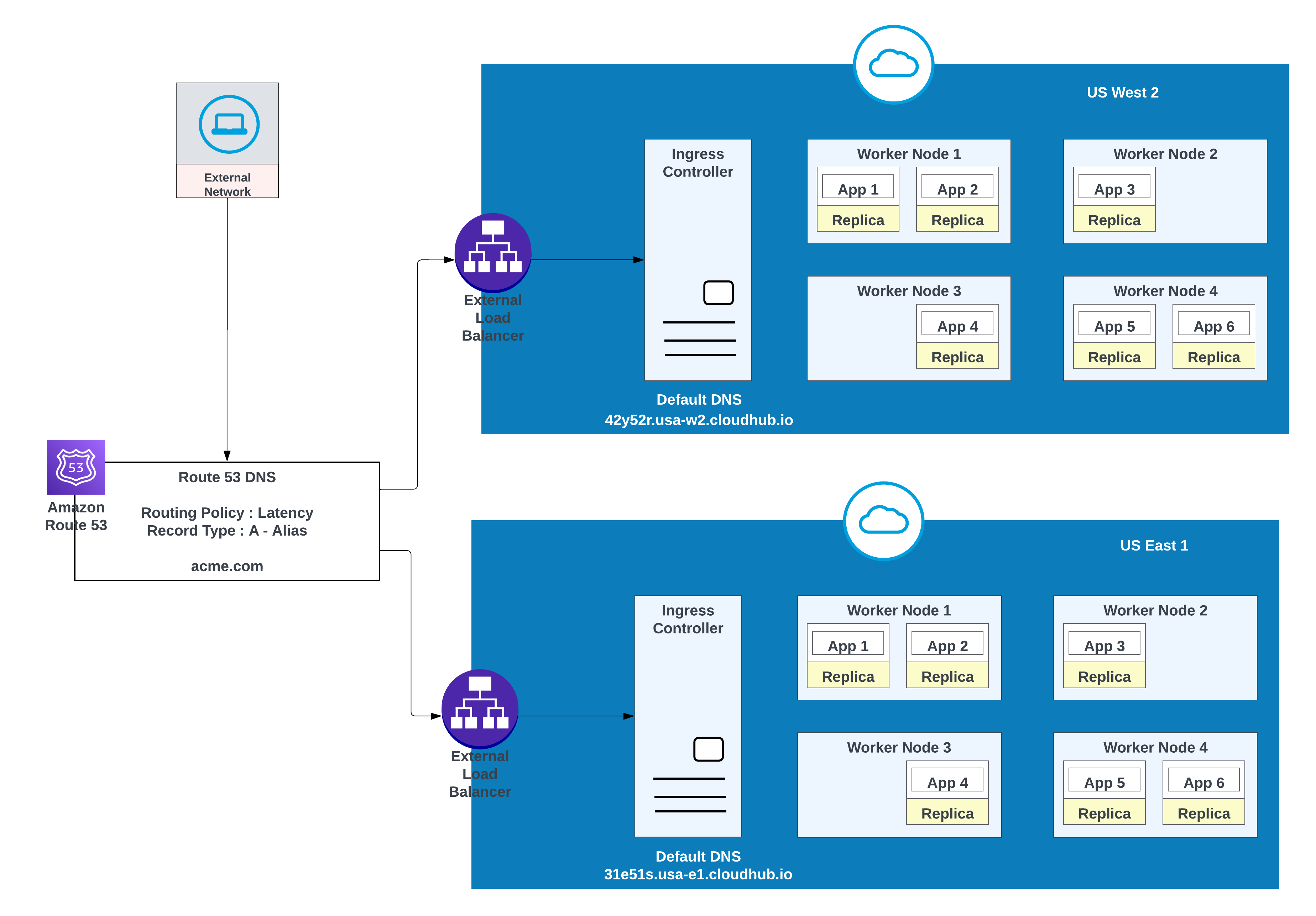
| Postnamn | Värde/Dirigera trafik till | Dirigeringspolicy | ID för hälsokontroll |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Latens | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Latens | 43e131s131sq |
MuleSoft CloudHub 2.0 ger en robust grund för resiliens inom regioner, främst med hjälp av automatiserad replikredundans och intelligent lastbalansering. Inom en enskild molnregion säkerställer att distribuering av program med flera repliker säkerställer att om en instans misslyckas kan andra omedelbart ta över arbetsbelastningen. Den integrerade lastbalanseraren distribuerar effektivt inkommande trafik över dessa friska repliker, vilket minimerar nedtid och säkerställer kontinuerlig servicetillgänglighet under normala driftsförhållanden.
Att enbart förlita sig på denna arkitektur med en enda region, även en med hög redundans, innebär dock en betydande risk för ett omfattande, katastrofalt regionalt avbrott. Historien har visat att även de mest pålitliga och tekniskt avancerade molnleverantörerna är mottagliga för störande incidenter som kan påverka en hel geografisk region. Dessa enskilda felpunkter kan uppstå från olika händelser, inklusive:
- Incidenter i storskalig infrastruktur
- Större strömavbrott
- Omfattande nätverksavbrott
För att uppnå verklig hög tillgänglighet (HA) och katastrofåterställning (DR) måste därför en arkitektur utformas för att överskrida begränsningarna för en modell med en region. Den rekommenderade strategin är distribution över flera, geografiskt skilda regioner. Denna motståndskraft mellan regioner säkerställer att om en hel molnregion blir otillgänglig på grund av en oväntad katastrof kan trafiken sömlöst misslyckas över till en programinstans som körs i en separat, opåverkad region, vilket garanterar minimala serviceavbrott och uppnår maximala upptidsmål.
CloudHub 2.0-nätverksarkitektur
Konfigurera regionöverskridande växling vid fel för standardköer
Regioner för distribuering av Object Store V2
Distribueringsregion för din objektbutik
Gulal Kumar är arkitekt inom programvaruteknik på Salesforce, med fokus på data- och integrationsarkitektur. Med över 20 års erfarenhet av integrering och API, moderniseringsprogram, säkerhet och AIML-initiativ bidrar han med en mängd expertis. Gulal har engagerat sig i att främja initiativ för verksamhetstransformation, förbättra säkerhet och motståndskraft, främja arkitekturexcellens och leda AIML-initiativ över olika domäner.
Ajay Nagaraju är Enterprise Architect och Senior Director på MuleSoft med över 28 års erfarenhet av verksamhetsarkitektur, systemintegrering och storskalig digital transformation. Han har lett arkitektur och leverans för komplexa program för flera miljoner dollar i Fortune 100- och Fortune 500-organisationer, med djup expertis inom API-ledd anslutning, SOA, molnteknik och företagsintegreringsmönster. Ajay har ett nära samarbete med chefsledningen för att modernisera verksamhetsprocesser, dataplattformar och integreringsekosystem och brinner för att bygga skalbara arkitekturer, mentorteam och driva mätbara verksamhetsresultat genom teknik.