Detta dokument presenterar en synvinkel som beskriver den IT-arkitektur som företag kommer att behöva under de kommande 3-5 åren för att helt fånga upp värdet hos en agentstyrka. Det beskriver den IT-transformation som krävs för att stödja storskalig distribuering av AI-agenter. Målet är att tillhandahålla en strategisk guide och referensarkitektur för att hjälpa CIO:er, CDO:er och IT-ledare planera sin resa mot att bli ett agentföretag.
Kraftfulla AI-modeller möjliggör skapandet av en agentisk arbetsstyrka som kan känna av miljön, resonera kring data, fatta autonoma beslut, utföra uppgifter och effektivt samarbeta med mänskliga medarbetare. Denna nya arbetsstyrka lovar en stegvis förändring i innovation, produktivitet och flexibilitet, vilket skapar värde för aktieägare och kunder. För att förverkliga denna vision måste organisationer genomgå en verksamhets- och IT-transformation för att bli Agentföretag.
Idag står det traditionella företaget inför ineffektivitet som uppstår på grund av informationssilos, anställda begravda i manuellt arbete, felaktiga incitament i organisationsstrukturer och osammanhängande feedbackloopar mellan strategier och resultat. Dessa problem leder till suboptimala kundupplevelser, ineffektiva processer och missade möjligheter till tillväxt.
Agentföretaget övervinner dessa begränsningar genom att integrera en digital arbetsstyrka av intelligenta AI-agenter med mänskliga medarbetare. Med denna nya AI-utökade arbetsstyrka kan en organisation främja innovation för tillväxt, driva på verksamhetens excellens och bygga upp företagets motståndskraft med flera typer av nya verksamhetsmöjligheter.
Ny verksamhetskapacitet för att främja innovation:
- Utökad mänsklig produktivitet: Hastigheten, skalan och den kontinuerliga karaktären hos AI-agenter låter företag automatisera repetitivt arbete och frigöra mänskliga medarbetare för att fokusera på mer kreativa uppgifter med högre värde.
- Adaptiv kapacitetsförbättring: Eftersom AI-agenter kan resonera kan de dynamiskt lära sig och distribuera nya kompetenser, vilket gör att företaget kontinuerligt kan förbättra sina resultat för att uppfylla sina verksamhetsmål och snabbt anpassa sig till nya marknadsmöjligheter.
Exempel i aktion – Innovation av kundupplevelsen i finansiella tjänster: Ett förmögenhetsförvaltningsföretag kan använda en AI-agent för att återuppfinna sin klientengagemangsmodell. Agenten övervakar portföljer, identifierar viktiga ögonblick för en klientgranskning och förbereder planen innan samtal för rådgivaren och justerar planen när nyheter dyker upp. Detta låter den mänskliga rådgivaren leverera en proaktiv, personlig kundupplevelse i stor skala, stärka relationer och upptäcka nya säljprojekt.
Ny verksamhetskapacitet för att skydda och säkerställa organisatorisk motståndskraft:
- Elastisk arbetskraftskapacitet: Företag kan snabbt skala upp sin förmåga att möta den ökade arbetsbelastningen från ändrade verksamhetsvillkor, utan att behöva öka kostnaderna och förseningarna för att utöka en helt mänsklig arbetsstyrka.
- Prediktiv operativ motståndskraft: AI-agenters 24/7-karaktär gör att de autonomt kan förutse, modellera och minska operativa risker, efterlevnadsrisker och säkerhetsrisker i realtid, vilket säkerställer att företaget upprätthåller sina kunders och intressenters Trust.
Exempel på åtgärd — Skydda kunddata: Ett stort företag kan distribuera en agent för AI-datastyrning för att söka igenom regelverken efter ändringar i datasekretesslagar, upptäcka och klassificera känslig information i företagets datauppsättningar och sedan tillämpa lämplig styrningspolicy. Agenten kan granska begäranden om dataåtkomst och dirigera undantag till en mänsklig analytiker för granskning, vilket minskar efterlevnadsrisken och samtidigt gör att data kan användas på ett tillförlitligt sätt.
Ny verksamhetskapacitet som optimerar verksamhetens kvalitet:
- Autonom processkörning: En digital arbetsstyrka kan utföra komplexa uppgifter i flera steg dygnet runt med maskinhastighet (med människor i loopen), vilket minskar kostnader och skalar processer effektivt.
- Gränsöverskridande orkestrering: AI-agenter kan arbeta över de informations- och incitamentssilor som normalt begränsar mänskliga medarbetare, vilket främjar smidighet för korsfunktionella processer.
Exempel på åtgärd — Optimera marknadsföringstratten i detaljhandeln: Ett team för butiksmarknadsföring kan distribuera en AI-agent för att snabba på dess kampanjprocess som svar på nya konsumenttrender. Agenten kan skapa marknadsföringsplaner, samarbeta med marknadsförings-, produkt- och säljteam för granskning och sedan automatiskt skapa digitala säkerheter och utföra dem i flera kanaler och dynamiskt justera kampanjen baserat på feedback i realtid.
Företagets IT-arkitektur kan avbildas med en lagerkonstruktion. Skikten grupperar logiskt relaterade tekniska funktioner och underlättar strukturerade resonemang, men innebär inte nödvändigtvis specifika implementeringar eller i vilken grad ett lager ska utformas monolitiskt eller på ett mer heterogent sätt. I denna lagervy (figur 1) består den traditionella IT-arkitekturen av fem huvudlager: Infrastruktur, data, integrering, program och upplevelse. Två korslager, Säkerhet och IT-drift, täcker dessa lager för att säkerställa styrning, övervakning och skydd.
Den traditionella IT-arkitekturen utformades för ett paradigm där företagets intelligens fanns hos medarbetare som utförde åtgärder i program för att komma åt data, tillämpa verksamhetslogik, underlätta samarbete och utföra arbetsflöden. Den är inte utformad för ett paradigm där AI-agenter kan resonera och vidta åtgärder för vissa användningsfall som tidigare gjorts av människor (eller inte gjorts alls) medan människor övervakar AI-agenterna och fokuserar på mer kreativa och tvetydiga uppgifter.
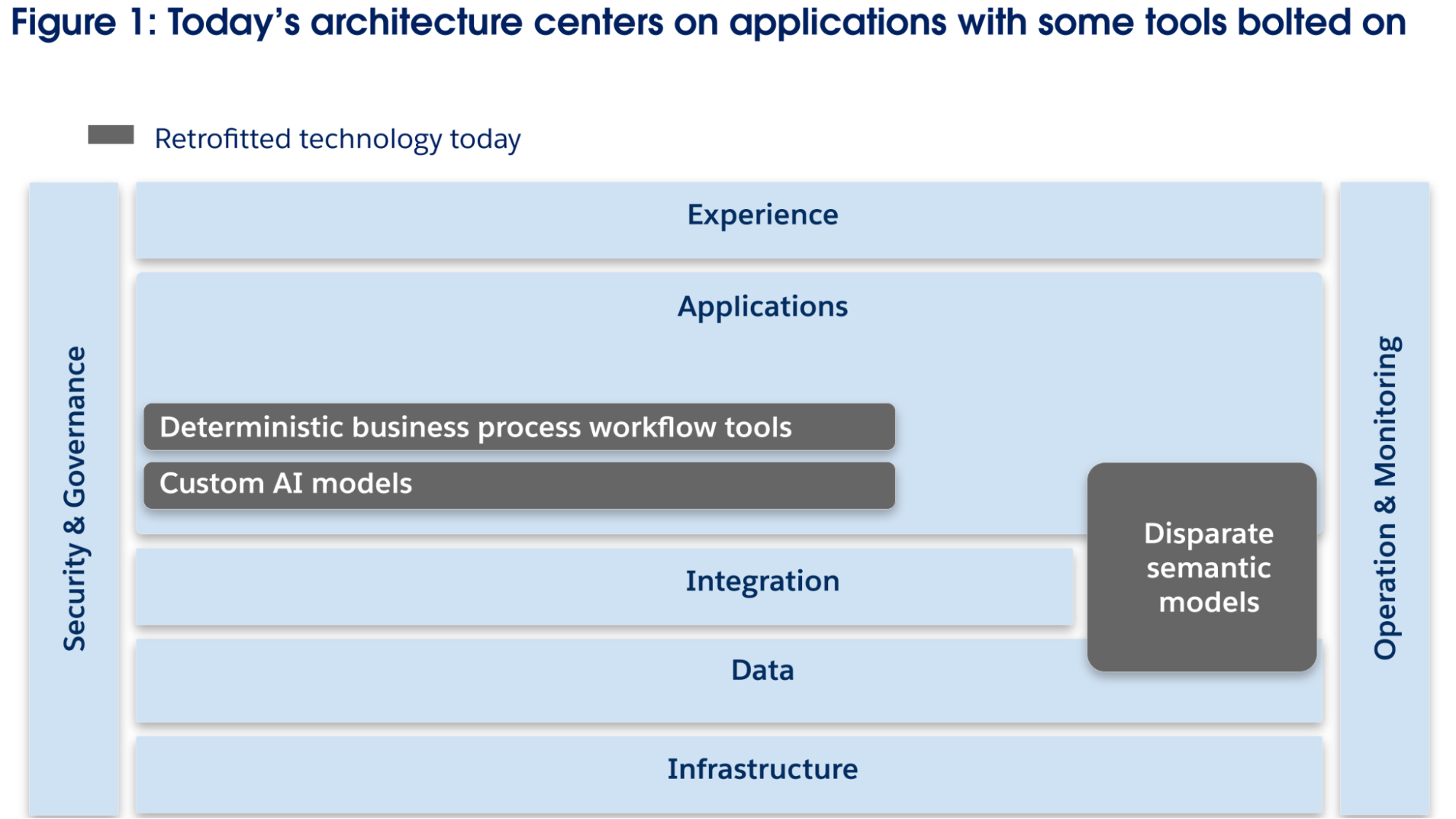
Även om traditionell arkitektur har stöd för distribueringar av AI-agenter i underskala idag kan den inte helt leverera verksamhetskapaciteten hos Agentic Enterprise som beskrivs ovan. Att förverkliga dessa kapaciteter kräver en IT-arkitektur utformad för bred distribuering av kraftfulla AI-agenter som kan hantera breda användningsfall istället för att begränsas till begränsade distribueringar som är inriktade på smala användningsfall.
AI-agenter kommer att fortsätta att förbättras under de kommande 5 åren, och IT-arkitekturen måste utvecklas för att inse värdet av mer kraftfulla och intelligenta AI-agenter, för att bli framtidssäkrad. För det första kommer agenter att bli mer intelligenta när de underliggande AI-modellerna (som multimodala LLM) och agenternas kognitiva arkitekturer utvecklas (till exempel planering i flera steg, uppgiftsdekomposition och så vidare). För det andra kommer AI-agenter att ha förbättrad inlärnings- och anpassningsförmåga med minnesförbättringar, förmåga till självreflektion och förmågan att lära sig från feedback. För det tredje kommer AI-agenter att ha en större förmåga att interagera med andra agenter, verktyg och data, vilket framgår av det snabbt växande ekosystemet av öppna teknikstandarder (till exempel Model Context Protocol, Agent2Agent och så vidare). Även om dessa tre tekniktrender kommer att göra AI-agenter mer kraftfulla när de utför mer abstrakta och komplexa uppgifter, kommer det också att medföra många utmaningar för dagens IT-arkitektur.
För det första förlitar sig AI-agenter i grunden på AI-modeller, både internt utvecklade och externt hämtade, som utvecklas snabbt och kräver sofistikerad, delad och standardiserad AI/ML-modellhantering. Idag är AI-modeller låsta för specifika användningsfall i ett program, inte som delade kapaciteter för återanvändning med gemensamma verktyg för utbildning, distribution, styrning och riskhantering. Framöver måste företag kunna använda olika AI-modeller för olika agentiska användningsfall som kräver verktyg som låter agenter byta ut underliggande modeller (t.ex. grundmodell vs. domänspecifik mindre modell) baserat på verksamhetssammanhang. Detta kräver hantering av internt utvecklade eller värdbaserade AI-modeller med sammanslagna livscykelverktyg för att säkerställa enhetlighet, återanvändning, skalbarhet och effektivitet. På samma sätt kräver åtkomst till externa AI-modeller ett företagsomfattande kontrollramverk för att säkerställa optimal prestanda, säkerhet, efterlevnad, tillgänglighet och pålitlighet.
För det andra har AI-agenter distinkta skalningsmönster och operativa krav som värdskap, utveckling, resonemang, inlärning, minneshantering och operationer, vilket kräver en separat och dedikerad arkitektonisk gräns för agenter. Att bädda in denna funktionalitet direkt i dagens statiska och deterministiska applikationsarkitektur skulle introducera onödig arkitektonisk komplexitet och risk. Dessutom bör AI-agenter interagera med befintliga program genom standardiserade gränssnitt eller meddelandesystem för interaktion i realtid.
För det tredje måste AI-agenter kunna resonera kring olika datauppsättningar och samarbeta med varandra, ofta över silobaserade programstackar, men i dagens arkitektur finns det ingen gemensam semantisk funktionalitet för att ge dessa agenter en delad förståelse för att resonera kring olika datauppsättningar. På grund av detta är det fortfarande svårt och riskabelt att skala upp agenter till att arbeta i stora mängder med komplexa korssilouppgifter, även om agenter kan distribueras framgångsrikt.
Slutligen saknar den nuvarande IT-arkitekturen ett effektivt sätt att orkestrera, optimera och styra övergripande verksamhetsprocesser som inkluderar dynamiska arbetsflöden som utförs av mer kraftfulla agenter, vilket kommer att utöka och i vissa fall ersätta den roll som utförs av mänskliga medarbetare i processen. Idag används automatiseringsverktyg för att hantera linjära, deterministiska arbetsflöden som vanligtvis följer en fördefinierad sekvens, dokumenterad på processspecifika språk, och förlitar sig på statisk logik som sällan ändras. AI-teknik kan förbättra vissa av dessa linjära processer (till exempel genom att använda ML-modeller istället för hårdkodade affärsregler för att beräkna tröskelvärden för godkännande av lån), men de strategiska aspekterna och utförandeaspekterna av de flesta viktiga verksamhetsprocesser förblir i sig dynamiska och flexibla. Uppgifter som att utveckla marknadsföringsstrategier, lösa komplexa kundproblem eller prospektera kunder har tydliga mål (kundnöjdhet, lösningshastighet för kundcase och så vidare) men följer inte en fast, fördefinierad sekvens för utförandet.
För närvarande förlitar sig traditionella företag främst på människor för att koordinera och utföra dessa komplexa verksamhetsprocesser (som att fastställa strategier och hantera komplexa program). I takt med att AI-agenter fortsätter att utvecklas (större intelligens, inlärning och interaktionskapacitet) under de kommande 3-5 åren kommer deras förmåga att köra sådana dynamiska processer autonomt att öka avsevärt, vilket kommer att introducera komplexitet och integreringsutmaningar som vida överstiger kapaciteten hos befintliga integrerings- och automatiseringsverktyg. Den anpassningsbara och dynamiska karaktären hos AI-agenter skapar ett stort behov av nya orkestreringsfunktioner för att säkerställa kontroll på företagsnivå, omfattande synlighet och enhetlig anpassning till företagsomfattande strategiska mål, särskilt vid hantering av komplexa, långa och flerstegsflöden som omfattar AI-agenter, människor, automatiseringsverktyg och andra deterministiska system.
IT-arkitekturen för Agentic Enterprise etablerar en plattform för intelligenta åtgärder genom att sömlöst integrera mänskliga medarbetare, AI-agenter och deterministiska system. Denna arkitektur ger både personal och AI-agenter möjlighet att dynamiskt få åtkomst till och använda enhetlig Knowledge från olika datakällor, berikad med semantiskt sammanhang för att effektivt utföra komplexa arbetsflöden och processer i linje med strategiska verksamhetsmål. Den befintliga IT-arkitekturen för en uppsättning silobaserade plattformar och punktlösningar kommer att utvecklas mot en uppsättning komponerbara applikationstjänster, semantiska verktyg och dataverktyg, och nätverk av AI-agenter som övervakas och styrs av nya intelligenta verktyg för orkestrering av verksamhetsprocesser.
Denna arkitektur låter agenter känna, resonera och agera inom sina respektive omfattningar, arbeta inom och mellan verksamhetsdomäner och kontinuerligt lära sig, förbättra och anpassa sig. Detta kräver en design som fokuserar på robusta mekanismer för åtkomst till data och Knowledge (semantisk förståelse), flexibla och standardiserade kommunikationsprotokoll och gränssnitt (som agent till agent, agent till deterministiska system och agent till människa) och kritiskt, orkestrera arbetsflöden och processer mellan agenter, människor och automatiseringsverktyg och deterministiska system.
För att förverkliga den arkitektoniska visionen av en plattform för intelligenta åtgärder rekommenderas dessa designprinciper som bästa praxis:
- Sammansättning och modularitet: Utforma arkitektoniska element som modulära komponenter med standardiserade gränssnitt för att möjliggöra snabb och dynamisk montering av agentkapacitet, arbetsflöden och mänskliga ytor. Prioritera tydliga gränssnittkontrakt och abstraktioner för att ge AI-agenter största möjliga flexibilitet att skapa arbetsflöden.
- Data och semantisk först: Säkerställ omfattande, korrekt, snabb, säker och kostnadseffektiv åtkomst till data, med delad semantisk förståelse för agenter för att effektivt resonera i silosystem. Detta kräver att data (och metadata) behandlas som en produkt, med verktyg för att säkerställa kvalitet, härkomst, styrning och åtkomst samt ett sätt att ge semantisk förståelse som delas mellan agenter och människor.
- IT och verksamhetsobserverbarhet inbäddad: Bädda in funktioner för övervakning, spårning, utvärdering och förklaring från början till slut i hela arkitekturen för insikt i agenters resonemang, beteenden, systeminteraktioner och påverkan på nyckeltal för verksamheten för att möjliggöra kontinuerlig optimering av agenters resultat. Detta inkluderar kostnadsoptimering (FinOps), hållbarhetsmått och operativ telemetri med bibehållen Trust, efterlevnad och ansvarsfull resursanvändning. Eftersom AI-agenter i sig är icke-deterministiska är observerbarhet av största vikt för att säkerställa att AI-agenter kan arbeta på ett tillförlitligt, medgörligt och granskningsbart sätt med mänsklig tillsyn.
- Genomgående Trust: Tillämpa dynamiska, detaljerade behörigheter baserat på syftet med agentens uppgifter (dataåtkomst, åtgärder och så vidare) och implementera omfattande säkerhetsrutiner, inklusive röd teaming, automatiserad CVE-skanning, upptäckt av sårbarhet och riskbaserade valideringskontroller. Mer detaljerade och dynamiska kontroller behövs med tanke på risken för att agenter orsakar kaskadrisker på grund av sin förmåga att arbeta med maskinhastigheter. Se till att alla AI-genererade utdata (från agenter eller modeller) valideras noggrant mot definierade policyer för efterlevnad, säkerhet, toxicitet och biasering innan användning eller leverans, vilket kräver loggnings- och förklaringsmekanismer med verifierbara granskningskedjor för AI-beslut, åtgärder, innehåll och förutsägelser.
- Agenten först med mänsklig tillsyn: Låt AI-agenter vara standardverktyget för att lösa verksamhetsanvändning, med undantag för andra överväganden (t.ex. kostnad, teknisk passform) och utforma IT-system så att de är tillgängliga för agentiska arbetsflöden. Detta inkluderar möjligheten för människor att övervaka, ingripa i och åsidosätta alla steg i en agents process. Agenter behöver självreflekterande kapacitet för att proaktivt söka mänsklig vägledning om dess förtroende för beslutsfattande hamnar under förprogrammerade tröskelvärden.
- Reaktiv och multimodal interaktion: Aktivera arkitekturen för att stödja omfattande agentåberopnings- och svarsmekanismer över alla interaktionstyper, inklusive agent-till-agent-protokoll, mänskliga multimodala inmatningar (röst, text, visuell), affärshändelser, systemsignaler och strömmande data. Aktivera kapacitet för både händelsedriven bearbetning och bearbetning i realtid för att säkerställa att agenter kan reagera på alla signaler i rätt tid från alla källor eller format.
- AI-färdig infrastruktur: Säkerställ att infrastruktur kan skalas elastiskt med redundans inbyggd för att hantera varierande AI-arbetsbelastningar, och integrera ML/LLM-pipelines i data- och programarkitektur, samtidigt som efterlevnad av datalagringskrav bibehålls.
- Öppet ekosystem: Prioritera interoperabilitet och undvik tekniklåsning genom att gynna öppna standarder, protokoll och väldefinierade gränssnitt (API:er, händelser) för att dra nytta av det tekniska ekosystemet.
För att framgångsrikt aktivera och skala den agentiska transformationen måste företag gå längre än att bara förbättra befintliga lager. De måste överväga att uttryckligen införa fyra ytterligare arkitektoniska lager (figur 2) som utformats specifikt för att uppfylla behoven hos AI-agenter.
Det agentiska lagret är dedikerat till utveckling och hantering av AI-agenter och omfattar kognitiv kapacitet som planering, resonemang, minne, verktygsanvändning, tillståndshantering och livscykelkontroll. Detta lager hanterar de unika tekniska och operativa kraven för AI-agenter, säkerställer interoperabilitet mellan program och datalagring genom standardiserade protokoll och underlättar agent-till-agent-samarbete. Det befintliga applikationslagret kommer att utvecklas till applikationstjänster för att dynamiskt komponeras för agentiska arbetsflöden.
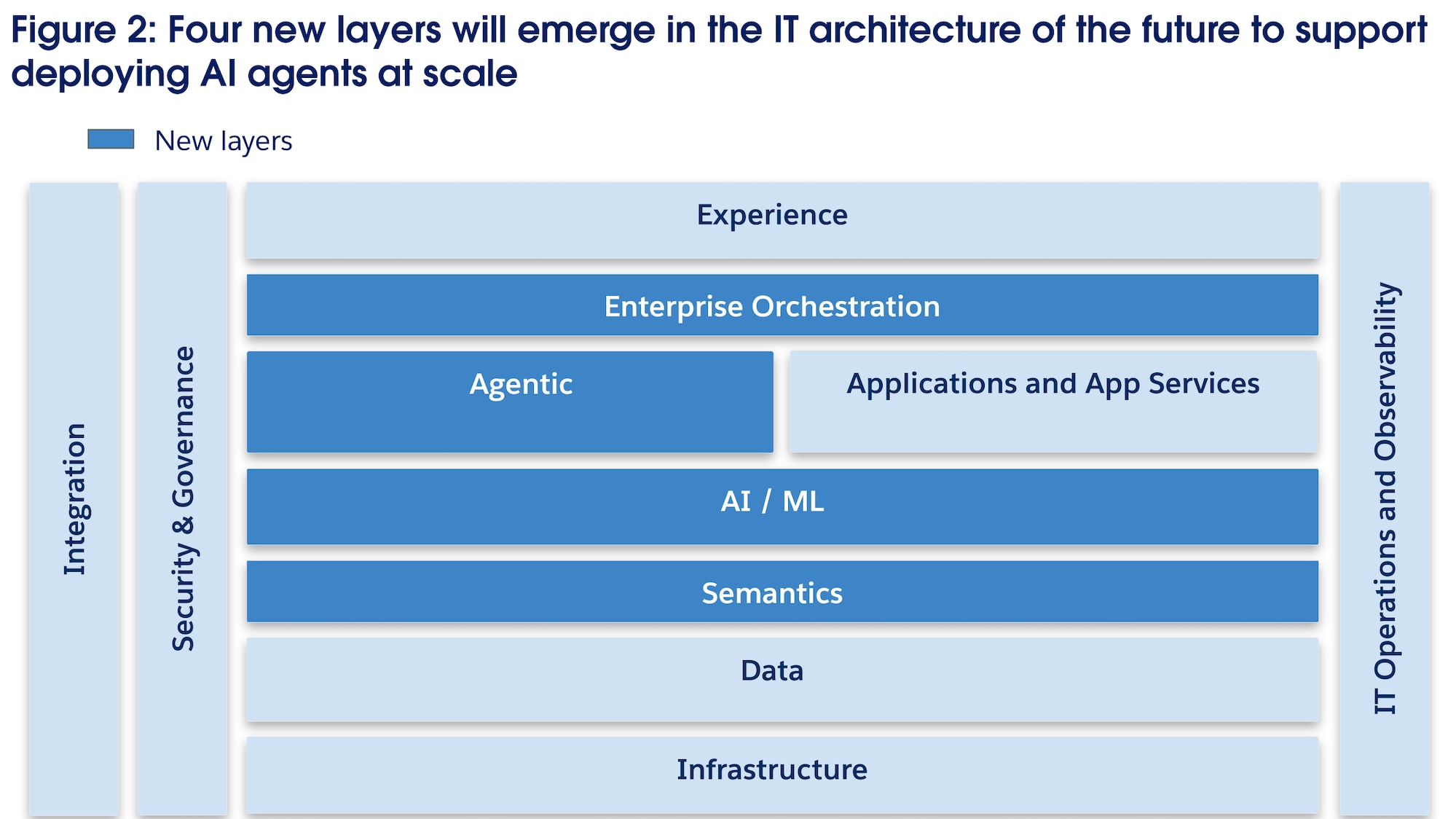
Det semantiska lagret används för att lösa kopplingen mellan rådata och den semantiska förståelse som AI-agenter behöver. Den kodar och hanterar uttryckligen affärsenheter, koncept, definitioner och inbördes relationer, vilket skapar en ontologi och representation av verksamhetskunskap för att möjliggöra delad semantisk förståelse som driver mer komplexa arbetsflöden med flera agenter som utför uppgifter på högre nivå. Utöver en datakatalog översätter det semantiska lagret en sökfråga på naturligt språk till exakta sökfrågor mot specifika datalagringar, harmoniserar resultaten och returnerar ett sammanhangsberoende och rikare svar för agenten. Det befintliga datalagret sammanförs under tiden via användning av centraliserade sjöhus och breddar samtidigt dataåtkomst via en AI-redo datastruktur för att stödja principer för datanätoperativmodeller.
AI/ML-lagret centraliserar hanteringen av företagets AI-kapacitet, inklusive stora språkmodeller, stora åtgärdsmodeller och domänspecifika ML-modeller, och hanterar både internt utvecklade AI-modeller under hela deras livscykel och kontrollerad åtkomst/användning till externa AI-tjänster. Till skillnad från traditionella arkitekturer där AI-modeller är inbäddade i program etablerar detta lager AI-modeller som förstklassiga komponenter och delade tjänster i företaget. Den fokuserar på företagsstyrd AI-kapacitet (inte AI-kapacitet som tillhandahålls av externa leverantörer). Detta lager tillhandahåller information för olika agenter och andra AI-arbetsbelastningar i företaget med standardiserade mekanismer för Trust, säkerhet, efterlevnad och distribuering.
Enterprise Orchestration Layer är en funktionell abstraktion för att koordinera, styra och optimera komplexa arbetsflöden och verksamhetsprocesser i flera steg som omfattar AI-agenter, människor, automatiseringsverktyg och deterministiska system. Detta lager använder en blandad orkestreringsmodell som låter individuella agenter och system hantera lokalt koreograferade uppgifter med hjälp av öppna protokoll som MCP och A2A samtidigt som de ger centraliserad överblick från början till slut och samordning av hela processen. För att implementera den blandade orkestreringsmodellen representerar detta lager viktiga verksamhetsprocesser i maskinläsbara semantiskt rika format som definierar både de deterministiska stegen (modellerade under designtiden) och de dynamiska stegen (beslutade av agenter under körning) i en verksamhetsprocess, vilket skapar processmodellgrunden för styrning och optimering.
Traditionellt sett förblir betydande delar av mänskligt drivna verksamhetsprocesser odokumenterade eller oåtkomliga i maskinläsbara former. Den detaljerade observerbarheten av AI-agenters aktiviteter, inklusive rika data och metadata om deras uppgifter och åtgärder, gör det möjligt att samla in, dokumentera och integrera dynamiskt, tidigare ostrukturerat arbete med deterministiska linjära arbetsflöden för att skapa omfattande processmodeller. Den detaljerade processdokumentationen samlar in tidigare osynliga beroenden och körningsvägar, vilket låter företaget kontinuerligt optimera effektiviteten, effektivt hantera flaskhalsar och systematiskt koda agentidentifierade bästa praxis till återanvändbara företagsomfattande spelböcker. Detta resulterar i en holistisk digital tvilling av individuella processer, och vid skalning hela företaget.
Till exempel innefattar komplexa processer som att utföra omfattande försäljningsstrategier eller introducera nya medarbetare många ömsesidigt beroende steg där orkestreringslagret kan säkerställa lämpliga nivåer av mänskligt engagemang (t.ex. undantagshantering), begränsad autonomi för AI-agenter och tillämpa efterlevnad. Genom dessa processer lägger det översta orkestreringslagret till förutsägbarhet och styrning, följer och utvärderar kontinuerligt nyckeltal (KPI), säkerställer transaktionsintegriteten för arbetsflöden och tillbakadragande logik och bibehåller synligheten i varje fas i arbetsflödet för att säkerställa anpassning till övergripande verksamhetsmål. För att implementera denna funktionalitet använder detta lager policyer, regler och skyddsräcken från säkerhets- och styrningslagret (via policy-som-kod) och verksamhetsmål och nyckeltal som lagras i det semantiska lagret. Med tanke på den autonoma och snabba karaktären hos AI-drivna interaktioner riskerar att enbart förlita sig på en decentraliserad koreografi strategisk felanpassning eller överträdelser av efterlevnad, särskilt i långa arbetsflöden med flera steg. Den blandade orkestreringsmetoden minskar dessa risker genom att bädda in företagsomfattande verksamhetsregler, efterlevnadskontroller och policytillämpning direkt i komplexa arbetsflöden och integrerar mänsklig tillsyn vid kritiska tidpunkter.
Vart och ett av dessa 11 lager bidrar med specifik funktionalitet för att distribuera AI-agenter i stor skala på ett säkert, tillförlitligt och effektivt sätt som frigör den fulla potentialen hos agentisk AI för att förändra hur arbete utförs i ett företag. Nedanstående avsnitt beskriver lagrets funktion, nya förändringar på grund av ökningen av AI-agenter och dess nyckelfunktioner.
Funktion: Upplevelselagret fungerar som det primära gränssnittet för mänskliga användare och möjliggör multimodal interaktion genom att samla in indata (text, röst, visuell) och leverera sammanhangsrelevanta svar över flera enheter. Den överför sömlöst användares avsikter till agentlagret för åtgärd samtidigt som den tillhandahåller det dynamiska användargränssnittet och visualiseringar som underlättar mänskliga omflyttningar och godkännanden inom agentflöden.
Vad är skillnaden jämfört med idag: AI kommer att utöka traditionella GUI-baserade gränssnitt med naturlig språkbehandling, kontextuell medvetenhet och proaktivt beslutsstöd. AI-agenter kommer att proaktivt kunna inleda interaktioner och leverera personliga rekommendationer i realtid i alla kanaler och modaliteter.
Viktiga tekniska möjligheter:
- Konversations-AI och digitala assistenter: Aktivera UX som standard för att ha AI-hjälp för att stödja mänskliga användare.
- Användargränssnitt för Attribution och transparens: Gör svar förklarliga i användargränssnittet, till exempel att visa referenser, källor till filer/system och tillvägagångssätt/motivering för besluten.
- Proaktiv och omgivande notistjänst: Låter agenter proaktivt pusha insikter eller varningar till användare om den lämpligaste kanalen och formulärfaktorn, baserat på användarens aktuella sammanhang.
- Omnikanalupplevelser: Ger en sömlös, enhetlig och enhetlig upplevelse i alla kanaler med kontinuerlig resa, där konversationer och uppgifter följer personen istället för appen.
- Kapacitet för flera lägen: Låter människor interagera med agenter och program via text, röst, bild, touch, video och AR/VR så att agenter kan förstå och presentera information på det mest effektiva sättet.
- Kontextmedveten personanpassning och dynamiskt användargränssnitt: Aktiverar kontextuellt medvetna användarupplevelser i realtid (tid, plats, användaråtgärder) för att aktivera personanpassning, inklusive användargränssnittskapande i farten.
Funktion: Agentlagret fungerar som standardkörningsmiljön för att utföra arbete i företaget där AI-agenter delar upp uppgifter från upplevelselagret och utför uppgifter genom att dynamiskt sammanställa arbetsflöden med hjälp av verktyg från program- och apptjänstlagret och datalagret. Konfigurationsläget för AI-agenter lagras och hanteras i detta lager. Agenter instansieras för specifika uppgifter och de specifika agentinstanserna avvecklas efteråt. Denna implementering låter agenter alltid åberopas från det senaste konfigurationsläget baserat på offlineoptimeringar (med funktionalitet från AI/ML, observerbarhet och orkestreringslager). Detta lager ansvarar för AI-agenternas omfattande livscykelhantering, samordning och styrning.
Vad är skillnaden jämfört med idag: Detta lager kommer att växa fram dagens disparata uppsättning piloter och begränsade agentdistribueringar. Även om regelbaserade botar finns finns det få anpassningsbara, icke-deterministiska och målinriktade program som distribueras i stor skala.
Viktiga tekniska möjligheter:
- Agentkörningsmiljö: Hanterar livscykeln, utförandet och resursallokeringen för AI-agenter.
- Svit för hantering av agentlivscykel: Inkluderar utvecklingsramverk, utvecklingsverktyg och testverktyg, och hanteringssystem för agentaktiviteter och versionshantering.
- Motor för agentresonemang: Ett kognitivt ramverk där agenter kan dela upp mål, planera och bestämma vilka verktyg som ska användas för att lösa komplexa problem.
- Agentminne och sammanhangslagring: Låter agentinstanser återkalla och upprätthålla sammanhang om tidigare interaktioner, vilket säkerställer enhetlighet och personanpassning.
- Agentinteroperabilitetsprotokoll: Standardiserade gränssnitt för agent-till-agent-kommunikation (A2A) och för agenter att interagera med externa system (till exempel via Model Context Protocol).
- Verktygsregister: En utvald uppsättning interna och externa verktyg som stöds för agenter att åberopa för att utföra en viss uppgift.
- Agentregister: Ett utvalt ekosystem av färdigbyggda AI-lösningar och agenter som stöder upptäckt och kapacitetsmatchning.
- Tillämpning av distribuerad agentpolicy: Aktiverar företagsomfattande styrning genom att låta agenter själv kontrollera efterlevnad innan de utför åtgärder.
- Ramverk för agenters självreflektion och anpassning: Ger en mekanism för en agent att analysera sin egen prestanda och, med mänskligt godkännande, utlösa förbättringar eller föreslå ändringar av sig själv.
Funktion: Detta lager fungerar som ett centraliserat intelligensnav och erbjuder AI-modeller som en uppsättning delade tjänster som ska konsumeras av agentlagret (och program) för att driva dess kapacitet för resonemang och beslutsfattande med inbyggda säkerhetsramverk och övervakning.
Vad är skillnaden jämfört med idag: Tidigare var AI-modeller inbäddade i specifika applikationer. I IT-arkitekturen för Agentic Enterprise kommer AI/ML-lagret att vara en förstklassig, centraliserad uppsättning tjänster som driver många program och agenter, som stöder hela modellens livscykel från utveckling till realtidsbetjäning i stor skala.
Viktiga tekniska möjligheter:
- Färdigbyggda grundmodeller: Stora ML-modeller utbildade på ett brett spektrum av data, som kan utföra en mängd olika allmänna uppgifter.
- Ökat skapande av hämtning (RAG): En AI-centrerad pipeline som grundar grundmodeller i företagsspecifika data för att förbättra precisionen och minska hallucinationer.
- AI Trust, Safety & Governance Hub: En uppsättning verktyg som integrerats i modellens livscykel för att tillämpa ansvarsfulla AI-principer som biasupptäckt, förklarlighet och säkerhetsövervakning.
- Modellgateway: En dirigeringsmotor som fungerar som en enda ingång för alla begäranden om modellslutsatser och hanterar samtal till olika interna och externa modeller för att optimera för kostnad, prestanda och efterlevnad.
- Modellutveckling Workbench: En integrerad utvecklingsmiljö för dataforskare med verktyg för förbehandling av data, modellutbildning och experiment.
- Pipeline för automatisering av MLOps och livscykel: CI/CD-motorn för maskininlärning, automatiserar livscykeln från början till slut för modeller från utbildning till distribution och tillbakadragande.
- Modellservering och inferenskörning: En skalbar miljö med låg latens för att distribuera utbildade modeller som säkra API-slutpunkter för användning i realtid.
- Modell- och tillgångsregister: Ett centraliserat, versionsstyrt arkiv för alla AI/ML-tillgångar, inklusive modeller, datauppsättningar och källkod, vilket säkerställer reproducerbarhet och granskningsbarhet.
- Skapande och hantering av syntetiska data: Verktyg för att skapa och hantera syntetiska data som bibehåller de statistiska egenskaperna hos verkliga data utan att exponera känslig information.
Funktion: Enterprise Orchestration Layer är styrplanet för arbete från början till slut i ett agentföretag. Det säkerställer att agentflöden och interaktioner följer företagets mål och styrningspolicyer. Den använder observerbarhetstelemetri från andra lager för att bygga omfattande affärsmodeller, vilket möjliggör optimering mot nyckeltal hämtade från det semantiska lagret. Detta lager tillhandahåller det delade sammanhanget och det långvariga minnet för varje ny instans av en AI-agent för viktiga arbetsflöden.
Vad är skillnaden jämfört med idag: Detta lager ger enhetlig insyn i verksamhetsprocesser genom att skapa maskinläsbara modeller som samlar in både strukturerade, deterministiska steg och det ostrukturerade, dynamiska arbete som utförs av människor och agenter. Den går längre än dagens människocentrerade samarbets- och styrningsmodeller genom att programmatiskt koda verksamhetsmål och efterlevnadsregler som begränsningar i agentflöden för att styra den agentiska arbetsstyrkan.
Viktiga tekniska möjligheter:
- Hybridmotor för arbetsflödesutförande: Kärnruntime som kör ”blandad orkestreringsmodell”, vilket ger centraliserad överblick samtidigt som lokal agentkoreografi tillåts.
- Processstyrning och begränsningsmotor: En styrningstjänst i realtid som använder och tillämpar deklarativa verksamhetsregler, policyer och begränsningar för alla processer under flygning.
- Delat minne och sammanhangshantering: Ett delat minneslager som är tillgängligt för alla aktörer i ett arbetsflöde för att upprätthålla kontinuitet och enhetlighet över flera steg.
- Process Modeling Studio: En designtidsmiljö för att skapa och hantera maskinläsbara, semantiskt rika processmodeller som definierar både deterministiska och dynamiska, målorienterade steg.
- Processoptimering och simulering: En kapacitet som konstruerar digitala simuleringar av verksamhetsprocesser för avancerad analys, simuleringar om vad händer och prediktiv optimering.
- Processupptäckt och hälsoövervakning: Intar processmodeller och realtidsdata för att rapportera om verksamhetsmått för processhälsa.
- Digital tvillingprocessmodellering: En realtidsspegel av liveflöden för att testa, simulera ändringar och optimera utan att påverka produktionen.
Funktion: Detta lager exponerar befintlig funktionalitet för affärsprogram som komponerbara och modulära verktyg och tjänster för agenter att använda. Den fungerar även som presentationsruntime för att bädda in agentkapacitet i användarupplevelsen. Program fortsätter att vara postsystemet men omkonstrueras för att vara "huvudlösa" kapaciteter för agenter.
Vad är skillnaden jämfört med idag: Program kommer att utvecklas från monolitiska användargränssnitt till "backendtjänster" som agenter dynamiskt kan anropa via API:n och händelser. Detta lager kommer att integreras inbyggt med AI-agenter och modeller, och spridningen av LLMs för kodskapande kommer att leda till en ökning av antalet egna, agentbyggda mikroprogram.
Viktiga tekniska möjligheter:
- Modulära applikationstjänster: Nedbruten verksamhetslogik från traditionella program, publicerad som maskinläsbara åtgärder för agenter att anropa.
- SDK för agentinbäddning: Verktygssatser och bibliotek som låter utvecklare bädda in agenter säkert direkt i programgränssnitt.
- Genereringstjänster för dynamiska användargränssnitt: Tjänster som låter en AI-agent skapa eller ändra användargränssnittkomponenter i realtid baserat på användarsammanhang.
- AI-inbyggda UI-ramverk: Frontend-ramverk utformade med inbyggt stöd för att hantera AI-drivna användargränssnitt, som att hantera probabilistiska data och strömma textsvar.
- Agentinfunderade engagemangssystem: Företagets produktivitets- och samarbetsprogram som införlivar AI-agentkapacitet genom visuella komponenter.
- Utveckling av AI-utökade program med låg kod/inget kod: Verktyg som låter användare och agenter skapa egna appar och tjänster med naturligt språk och uppmaningar.
- Appskyddsräcken för agentanvändning: Kontroller på programsidan för agentanvändning, som begränsning av hastighet, behörigheter och telemetri.
Funktion: Det semantiska lagret ger en enhetlig förståelse av data och Knowledge i hela företaget, vilket gör att både människor och AI-agenter kan tolka och agera på information enhetligt. Den använder Knowledge representationsverktyg som ontologier och Knowledge grafer för att översätta sökfrågor på naturligt språk till exakta, sammanhangsbaserade datafrågor.
Vad är skillnaden jämfört med idag: Dagens företag har olika metadatalagringar, men IT-arkitekturen för Agentic Enterprise kräver en centraliserad Enterprise Knowledge Graph (EKG) som länkar data mellan domäner med uttryckligen definierade semantiska relationer. Detta ger det rika sammanhang som AI-agenter kan gå igenom för att utföra komplexa resonemang, vilket skapar krav på en uppsättning tekniska kapaciteter för att driva Knowledge grafer som sträcker sig över flera funktionella domäner.
Viktiga tekniska möjligheter:
- Metadatatjänst: Ger beskrivande metadata, inklusive datahärkomst, ägarskap och klassificeringar.
- Hantering av affärsordlista och taxonomi: Ett verktyg för företagsanvändare för att definiera och enas om standardvillkor för verksamheten.
- Hantering av semantisk modell: En arbetsbänk för Knowledge tekniker för att skapa, hantera och styra semantiska modeller och ontologier.
- Enterprise Knowledge Graph (EKG): En runtimeinstansiering av företagets ontologi som lagrar och mappar relationerna mellan affärsenheter.
- Motor för metadataintag och harmonisering: En automatiserad pipeline som fyller i och underhåller Enterprise Knowledge Graph från olika källsystem.
- Semantisk sökfrågemotor: Tolkar sökfrågor på naturligt språk och konstruerar strukturerade sökfrågor baserade på EKG för att hämta data från olika källor.
- Semantisk resonemangsmotor: Analyserar och deriverar implicit Knowledge och dolda relationer från EKG.
Funktion: Datalagret är den grundläggande källan till sanning, som hanterar och ger säker, styrd åtkomst till alla företagsdata för det semantiska lagret att tolka, AI/ML-lagret att använda för utbildning, program att använda för transaktioner och agenter för resonemang.
Vad är skillnaden jämfört med idag: Datalagret utvecklas till att vara mer enhetligt, fokuserat på realtid och styrning, ofta centrerat på ett datasjöhus i molnskala. Den måste hantera en större mängd och variation av data och växla från batchorienterad bearbetning till streaming i realtid för att stödja reaktiva agenter. Datastyrning och kvalitet får ännu större betydelse för att förhindra att dåliga data skapar felaktiga AI-utdata.
Viktiga tekniska möjligheter:
- VectorDB: En specialiserad databas optimerad för att lagra och fråga högdimensionella vektorinbäddningar, viktiga för RAG.
- Intelligenta analytiska datapipelines: En automatiserad, metadatadriven tjänst för dataintag, transformation och inläsning (ETL/ELT) i datalagret.
- Enterprise Data Lakehouse: En central databas för strukturerade, semistrukturerade och ostrukturerade data, optimerad för både Analytics- och AI-arbetsbelastningar.
- Sammanslagning och sökning av data utan kopia: Tekniker för att komma åt, fråga och söka data i flera butiker utan fysisk dataförflyttning.
- Naturligt språk till SQL: En teknik för att konvertera sökfrågor på naturligt språk till SQL.
- Enterprise Data Catalog & Discovery Service: Ett centraliserat, sökbart lager av alla datatillgångar i hela företaget.
- Huvud- och referensdatahantering (MDM): Hanterar den "gyllene posten" för viktiga affärsenheter som Kund och Produkt.
- Adaptiv datakvalitetstjänst: En tjänst för kontinuerlig övervakning som använder AI för att automatiskt upptäcka och åtgärda Problem med datakvalitet i realtid.
- Datakontrakt: Maskinläsbara avtal mellan dataproducenter och konsumenter som specificerar schema, semantik och servicenivåavtal för datautbyte.
- AI-specialiserade datalagringar: Databaser utformade för specifika AI-användningsfall, som tidsserier eller grafdatabaser.
- AI-färdigt datatyg: Ett logiskt dataabstraktionslager som ger en enhetlig, virtualiserad vy av data i olika fysiska system.
- Bearbetar data i realtid: Kapacitet för att bearbeta och analysera multimodala dataströmmar kontinuerligt med maskinhastigheter.
Funktion: Infrastrukturlagret stöder alla andra lager och tillhandahåller de beräknings-, lagrings-, nätverks- och molnfunktioner som behövs för att köra AI och agentiska arbetsbelastningar i stor skala på ett motståndskraftigt och kostnadseffektivt sätt.
Vad är skillnaden jämfört med idag: AI-arbetsbelastningar kräver större skalbarhet och elasticitet för att hantera den probabilistiska karaktären hos agentsystem. Infrastruktur måste stödja snabb provisionering, specialiserad hårdvara som GPU:er och nätverkstrafik med låg latens och hög genomströmning för kommunikation mellan agenter.
Viktiga tekniska möjligheter:
- Infrastruktur som kod: Automatiserad provisionering och hantering av infrastruktur med pipelines för CI/CD-distribuering.
- Infrastruktur för hybrid- och multimoln-AI: Använder offentlig molnelasticitet och specialiserad infrastruktur för generativa AI-arbetsbelastningar.
- AI-optimerad beräkning, lagring och nätverk: Allokerar och skalar infrastrukturresurser dynamiskt baserat på variabel efterfrågan från AI-arbetsbelastningar.
- Edge AI-infrastruktur: Gör att AI-modeller och agenter kan distribueras i utkanten av nätverket för användningsfall med unika latens- eller sekretesskrav.
- Självläkande infrastruktur: Använder AI för att hantera systemåterställning utan manuell inmatning, vilket säkerställer hög tillgänglighet.
- Hållbar AI-beräkning: Energieffektiva metoder för att minska miljöpåverkan av AI-arbetsbelastningar.
- Kostnads- och koldioxidmedveten automatisk skalning: Använder FinOps och hållbarhetssignaler för att driva skalning och placering av kapacitet.
Funktion: Integreringslagret fungerar som den universella kommunikationsstrukturen för alla system (äldre och nya) genom API:n, händelser, protokoll och mellanprogramvara för att säkerställa att agenter kan upptäcka och interagera sömlöst med tjänster, data och verktyg.
Vad är skillnaden jämfört med idag: Integreringen måste utvecklas för att stödja dynamiska, många-till-många-kommunikationsmönster för AI-agenter, istället för att bara hantera förutbestämda, statiska interaktioner mellan några få kända system. Det kräver databearbetning i realtid och måste rymma ad hoc-upptäckt och samarbete mellan agenter.
Viktiga tekniska möjligheter:
- Pipeline för anslutning av driftsdata: AI-stödda verktyg för automatisk schemamappning, datatransformation och skapande av arbetsflöden, inklusive API-ledda, händelsedrivna och omvända ETL-funktioner.
- Adaptiv API-hantering och servicenät: API-gateways och servicenätteknik som dynamiskt kan registrera, upptäcka och styra tjänster med adaptiv policytillämpning för agenter.
- Semantiska Knowledge adapters: En integreringskomponent som ger en delad vokabulär och datamodell mellan agenter och program för enhetlig datatolkning.
- Händelsedriven integreringsväv: En backbone för meddelanden och streaming med hög genomströmning och låg latens som möjliggör frikopplad, asynkron kommunikation.
- Agentprotokollgateway: En gateway för MCP-tjänster som låter agenter säkert upptäcka verktyg och utlösa åtgärder och överbrygga MCP till interna API:n och händelser.
- Katalog och marknadsplats för kompositkapacitet: En centraliserad, styrd katalog för all företagskapacitet—API:er, tjänster, agentkompetens, modeller och datauppsättningar—annoterad med semantiska metadata för sammansättning på begäran.
Funktion: Detta lager övervakar och hanterar agenters hälsa och operativa prestanda och hela systemet (inbäddad princip för observerbarhet), vilket ger transparens och kontroll genom att skapa insikter för att möjliggöra granskning, felsökning, förklaring, kostnad och resursoptimering för företagets agentstyrka.
Vad är skillnaden jämfört med idag: Detta lager blir ännu viktigare med tanke på risken för att AI-agenter skapar fel vid maskinhastighet. Den måste expandera utöver infrastrukturövervakning till att inkludera oförutsägbart beteende hos autonoma agenter, vilket kräver nya typer av telemetri och förmågan att förstå semantisk korrekthet, inte bara teknisk prestanda.
Viktiga tekniska möjligheter:
- Plattform för övervakning och observation i realtid: Samlar kontinuerligt in loggar, mått och spår över hela IT-miljön, med tillägg för ML-mått och agentbeteende.
- Kostnadshantering för FinOps & Cloud: Ansvarig för övervakning, analys och optimering av infrastrukturkostnader associerade med AI och agentiska arbetsbelastningar.
- Agent- och ML-specifik övervakning: Loggar varje steg i en agents körning i en oföränderlig granskningskedja och profilerar kontinuerligt agentbeteenden för att upptäcka avvikelser från etablerade normer.
- AIOps, incident- och ändringshantering: Använder AI/ML för att förutsäga potentiella IT-problem, identifiera grundorsaker och skapa arbetsflöden för avhjälpande.
- Stängd feedbackloop för utbildning: Integrerar observerbarhetstelemetri från agenter tillbaka till MLOps-pipelines, vilket möjliggör automatiserad modellomskolning eller snabb justering.
- Semantisk observerbarhetsmotor: Integrerar observerbarhet med det semantiska lagret för sammanhangsanpassning för att möjliggöra upptäckt av semantiska avvikelser i agentbeteende.
Syfte: Detta lager bäddar in Trust och säkerhet i hela arkitekturen genom att skydda företagets tillgångar från hot, hantera risker och säkerställa efterlevnad av lagstadgade krav. Den omfattar identitetshantering, hotdetektering, GRC och AI-specifika säkerhetsåtgärder.
Vad är skillnaden jämfört med idag: Säkerhetslagret måste utvecklas för att hantera nya attackytor som presenteras av AI-modeller och agenter, till exempel snabb injektion och modellförgiftning. Identitets- och åtkomsthantering måste övergå från statiska, rollbaserade kontroller till dynamiska, syftesbaserade behörigheter som beviljas precis-i-tid och återkallas direkt efter användning.
Viktiga tekniska möjligheter:
- Säkerhet och skyddsräcken för LLM-indata/utdata: Företagets skyddsräcken tillämpade vid uppmaning och svarstid för att blockera osäkert innehåll, PII-läckor och jailbreaks.
- Zero Trust Architecture med AI-verifiering: Kontinuerlig autentisering utökad med AI-baserad beteendeanalys, med detaljerad, precis-i-tid-åtkomst för agenter baserat på deras specifika uppgift.
- Ramverk för agentsäkerhet: Finkorniga behörighetsmodeller, övervakning för skadliga beteenden och begränsningsmekanismer för att säkert avbryta agentaktiviteter.
- Säkerhet för AI-modeller: En djupgående försvarsstrategi med kontroller i varje fas i modellens livscykel för att skydda mot förgiftning, extrahering och kontradiktoriska attacker.
- Sekretessbevarande AI: Tekniker som sammanslagen inlärning och differentierad sekretess för att skydda känsliga data.
- AI-utökad GRC: Användning av AI-agenter för att kontinuerligt övervaka efterlevnad av IT-arkitektur med kontroller.
- Policy-som-kod-motor: En enskild källa till sanning för att definiera verksamhetsregler och efterlevnadsbegränsningar i ett deklarativt, maskinläsbart format för att ange skyddsräcken för agentbeteende.
- Kontinuerlig röd-teaming: Automatiserade, pågående kontradiktoriska tester av AI-modeller och agenter för att identifiera sårbarheter innan attacker utnyttjar dem.
Att transformera till Agentföretag kräver att man följer en resa i flera steg genom att lägga den tekniska grunden och samtidigt skapa konkret verksamhetsvärde (se figur 3 nedan). Även om den exakta vägkartan beror på företagets strategi, kultur, AI-styrningsmodell och IT-arkitektoniska utgångspunkt, bör de flesta organisationer använda ett stegvis tillvägagångssätt när fortsatta IT-investeringar driver agenter med växande omfattning, komplexitet och värdeskapande. Salesforces Agentic Maturity Model erbjuder ett användbart ramverk av mognadsnivåer för företag för att planera sin transformation, som beskriver hur agenters kapacitet kan växa från grundläggande informationshämtning (nivå 1) till orkestrering av mer komplexa arbetsflöden med flera domäner (nivå 2 och 3) och flera agenter (nivå 4). För att framgångsrikt ta sig igenom dessa faser måste IT-arkitekturen utvecklas på ett samordnat sätt, med riktade investeringar i olika lager av arkitekturen i varje fas för att uppfylla behoven hos de mer komplexa och mer värdefulla distribueringarna av AI-agenter. För varje mognadsnivå identifieras den specifika teknikkapacitet som behövs i de elva arkitektoniska skikten med en motivering för investeringen.
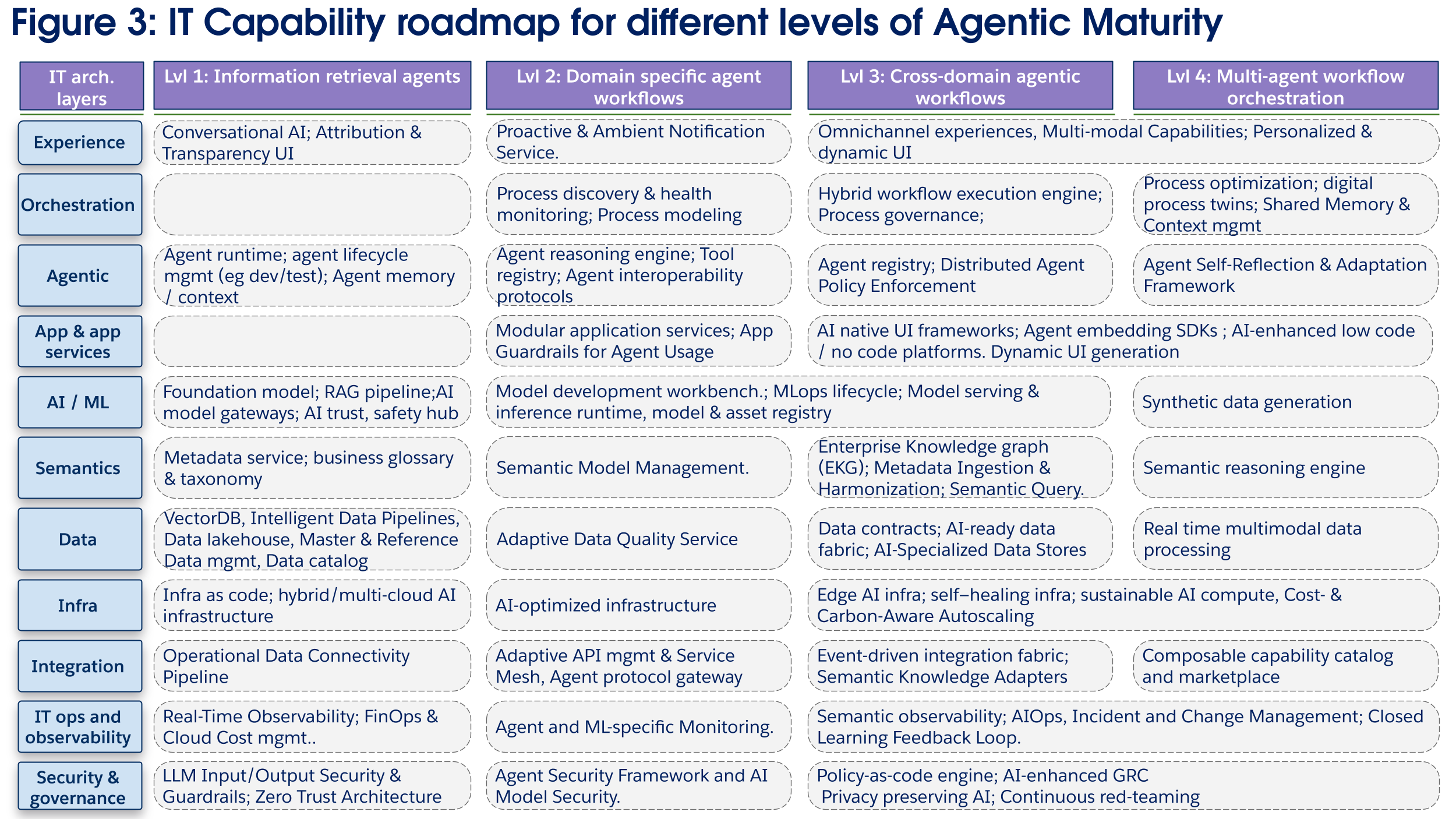
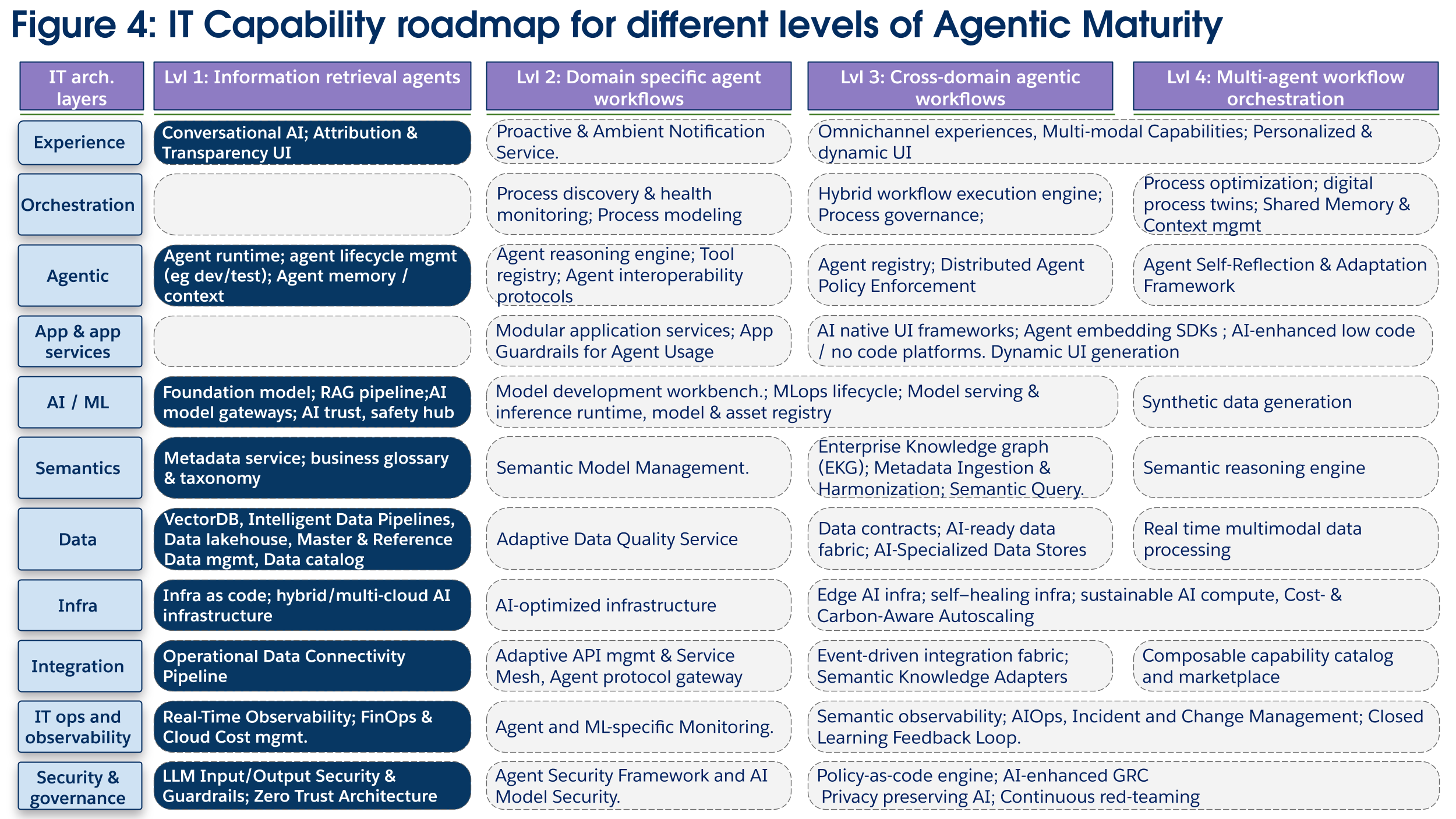
Löptidsnivå 1: Agenter för informationssökning
Verksamhetsmål och värde: Förbättra produktiviteten för mänskliga medarbetare genom att tillhandahålla ett tillförlitligt konversationsgränssnitt för att fråga Enterprise Knowledge. Det primära värdet ligger i att öka den mänskliga kapaciteten, inte att ersätta den. Dessa agenter hjälper människor genom att hämta information och rekommendera åtgärder.
Arkitektoniskt fokus: Fokus ligger på att etablera en säker, pålitlig datagrund och de grundläggande AI-komponenter som behövs för informationssökning. Styrning och observerbarhet är viktigt från dag ett för att bygga user Trust och för att kontrollera kostnader.
Viktiga teknikinvesteringar (figur 4):
I detta skede bör IT fokusera på att skapa en pålitlig data-till-agent-pipeline och andra fundamentkapaciteter. Tekniker i datalagret, som en VectorDB, är viktiga för att aktivera tekniker för hämtning utökad generering (RAG) som driver informationssökningsagenter. Detta är kopplat till ett centraliserat AI/ML-lager som innehåller en modellgateway för säker, kostnadskontrollerad åtkomst till grundmodeller och ett AI Trust, Safety & Governance Hub för att övervaka osäkra utdata och säkerställa efterlevnad. Huvuddatahantering och företagsordlistor i det semantiska lagret är grundläggande för att agenter ska kunna hämta korrekt information. Agenters körtid och livscykelkapacitet krävs för att säkerställa att agenter som byggts i detta steg kan ändras och utökas för framtida användningsfall. För att leverera värde och bygga användarförtroende måste upplevelselagret innehålla ett gränssnitt för Attribution & Transparency, vilket gör att agentsvar kan förklaras genom att visa referenser och informationskällor. Investeringar i grundläggande observerbarhet och säkerhet (till exempel noll trust) måste inledas för att förbereda framtida agentdistribueringar.
Löptidsnivå 2: Enkel orkestrering, Agenter med enskild domän
Verksamhetsmål och värde: Automatisera rutinuppgifter och orkestrera arbetsflöden med låg komplexitet inom en enskild verksamhetsdomän. Detta förbättrar den operativa effektiviteten och minskar manuellt arbete, vilket låter medarbetare fokusera på aktiviteter med högre värde.
Arkitektoniskt fokus: Det viktigaste arkitektoniska skiftet är från skrivskyddad datahämtning till att utföra åtgärder. Detta kräver att man påbörjar en längre resa för att modularisera programfunktionalitet (som ofta visas som API) för agenter att komma åt, implementerar robust säkerhet för agentåtgärder och bygger semantisk och AI-utvecklingsfunktionalitet för att främja intelligensen hos AI-agenter.
Viktiga teknikinvesteringar (figur 5):
Investeringar fokuserar tematiskt på att låta AI-agenter vidta åtgärder med rätt styrning. Program- och apptjänstlagret genomgår en kritisk förändring eftersom monolitisk verksamhetslogik delas upp i modulära programtjänster (API) för agenter att anropa. Dessa skyddas av Appskyddsräcken för att förhindra agenter från att överväldiga system, med integreringar i observerbarhetsverktyg. För att driva dessa agenter måste investeringar göras i agentresonemang, verktygsprotokoll (som MCP) och register. Detta introducerar nya risker, vilket gör ett dedikerat ramverk för agentsäkerhet och AI-modell och agentövervakning avgörande för styrning och säkerhet. Slutligen kan företag börja skala upp sin AI/ML-kapacitet för egna modeller för att driva dessa agenter som hanterar domänspecifika uppgifter.
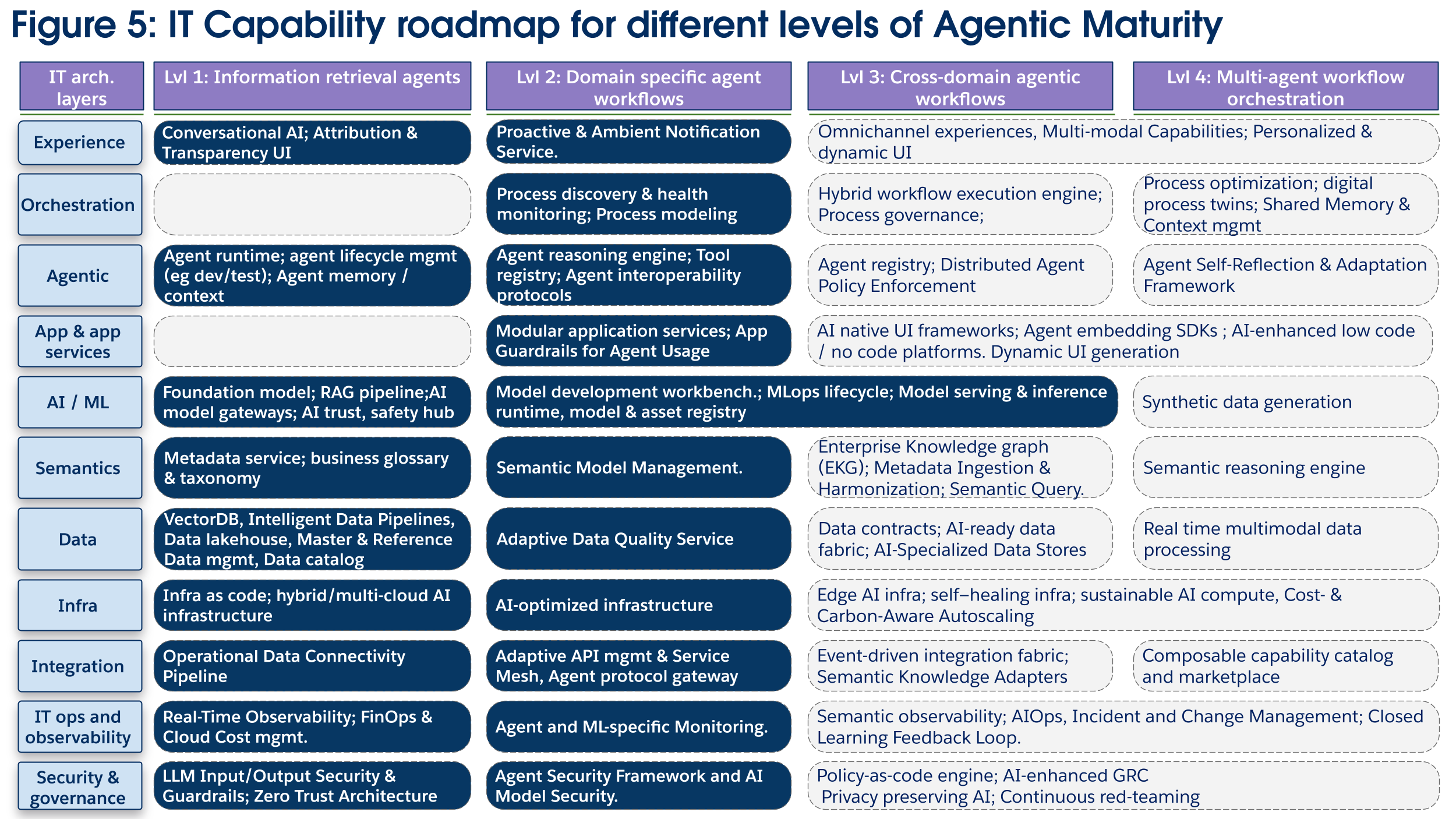
Löptidsnivå 3: Orkestreringsagenter med flera domäner
Verksamhetsmål och värde: Automatisera komplexa, heltäckande verksamhetsprocesser som sträcker sig över organisatoriska och funktionella gränser (som "offert-till-kont", "lead-till-order"). Värdet ligger i att bryta ner silos, snabba på processcykeltider och optimera hela värdekedjor inom verksamheten. Ändringar i mänskliga medarbetares produktivitet är möjliga i högre steg när organisatoriska hinder börjar brytas ner och människor börjar fokusera mer på att övervaka AI-agenter.
Arkitektoniskt fokus: Arkitekturen måste nu stödja övergripande tekniska problem. En delad semantisk förståelse i hela företaget, en centraliserad orkestreringsmotor för styrning och en frånkopplad, händelsedriven integreringsstruktur blir de viktiga möjliggörarna.
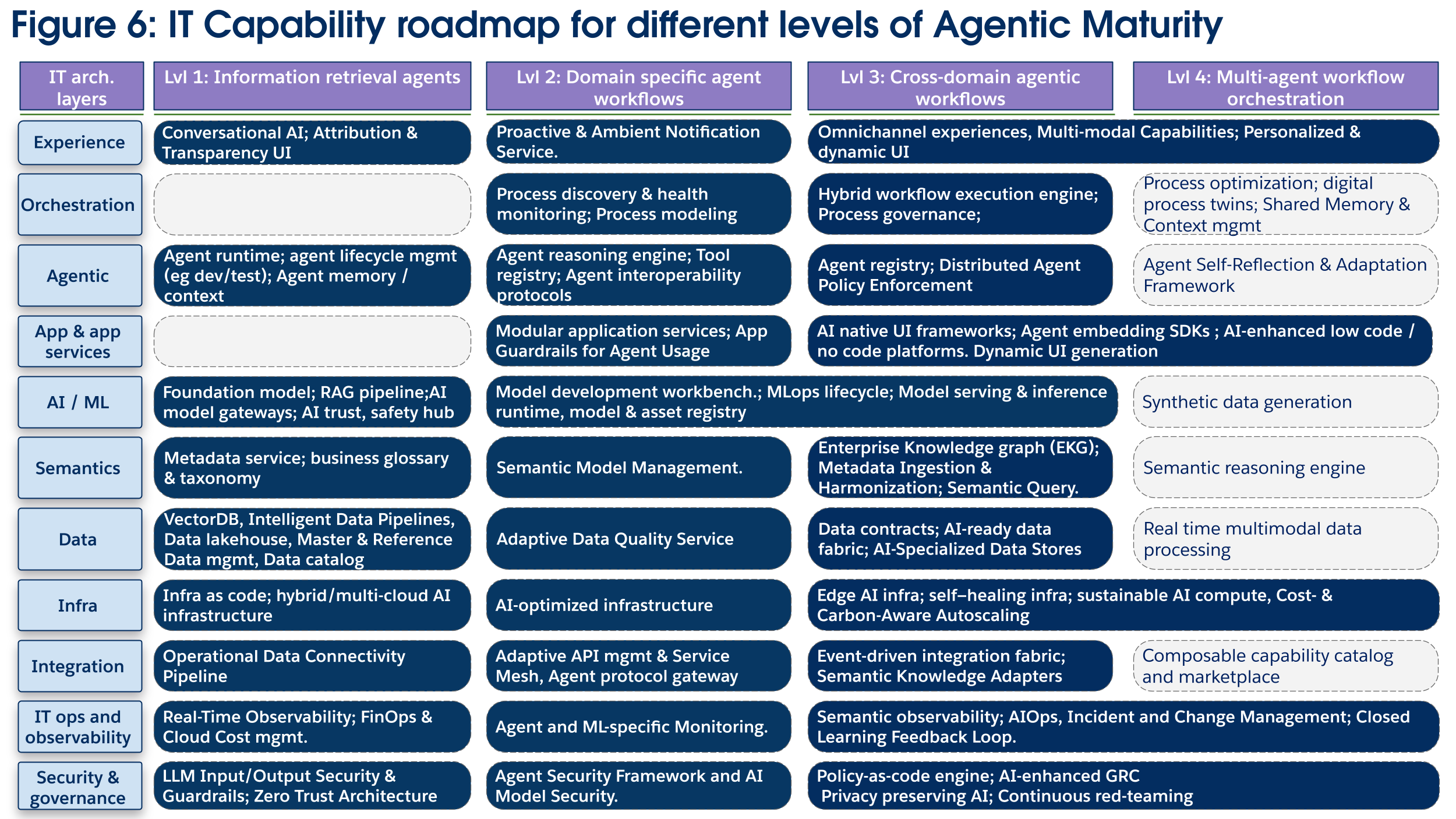
Viktiga teknikinvesteringar (figur 6):
Teknikinvesteringar är tematiskt inriktade på att orkestrera processer på en företagsskala över människor, agenter och deterministiska system. Företagsorkestreringslagret blir ett fokus för investeringar, vilket kräver en hybridmotor för arbetsflödesutförande för att koordinera aktiviteter, och en processtyrning och begränsningsmotor för att tillämpa verksamhetsregler och efterlevnadspolicyer för processer under flygning eftersom agenter arbetar över domäner, ofta med olika policyer och semantiska definitioner. Denna korsdomänsamordning är endast möjlig med ett moget semantiskt lager med en Enterprise Knowledge Graph (EKG), som skapar en delad förståelse för hur affärsenheter relaterar mellan domäner. Integreringslagret måste utvecklas till att inkludera en händelsedriven integreringsväv, som använder en strömmande grund för att koppla bort system och aktivera den motståndskraftiga, asynkrona kommunikation som är typisk för långvariga företagsprocesser. Med tanke på det högre värdet på dessa arbetsflöden och de associerade riskerna blir ytterligare investeringar i säkerhet och övervakning av största vikt (till exempel AIOps, policy-as-code). Slutligen måste ytterligare investeringar göras i applikations- och tjänstelagret (som AI-aktiverad LCNC, mer dynamiska och multimodala användarupplevelser) när mänskliga användare börjar övervaka och samarbeta med mer kapabla AI-agenter.
Löptidsnivå 4: Orkestrering av flera agenter och flera domäner
Verksamhetsmål och värde: Omforma och optimera affärsverksamheten över domäner för att driva på stegvisa förändringar i produktivitet och effektivitet. Denna fas rör sig mot att skapa en holistisk digital simulering (digital twin) av företaget för kontinuerlig förbättring och strategisk planering över stora verksamhetsprocesser och arbetsflöden.
Arkitektoniskt fokus: Det sista steget fokuserar på att möjliggöra dynamiskt, framväxande samarbete mellan agenter. Detta kräver avancerade agent-till-agent-kommunikationsprotokoll (A2A), kapacitet för självinlärning för agenter, ytterligare investeringar i att mogna lagren Orkestrering, Data och Semantiska, och fullständigt dynamisk och självläkande infrastruktur för att stödja de växande behoven av dynamiska AI-arbetsbelastningar när agenter har skalats ut i hela företaget.
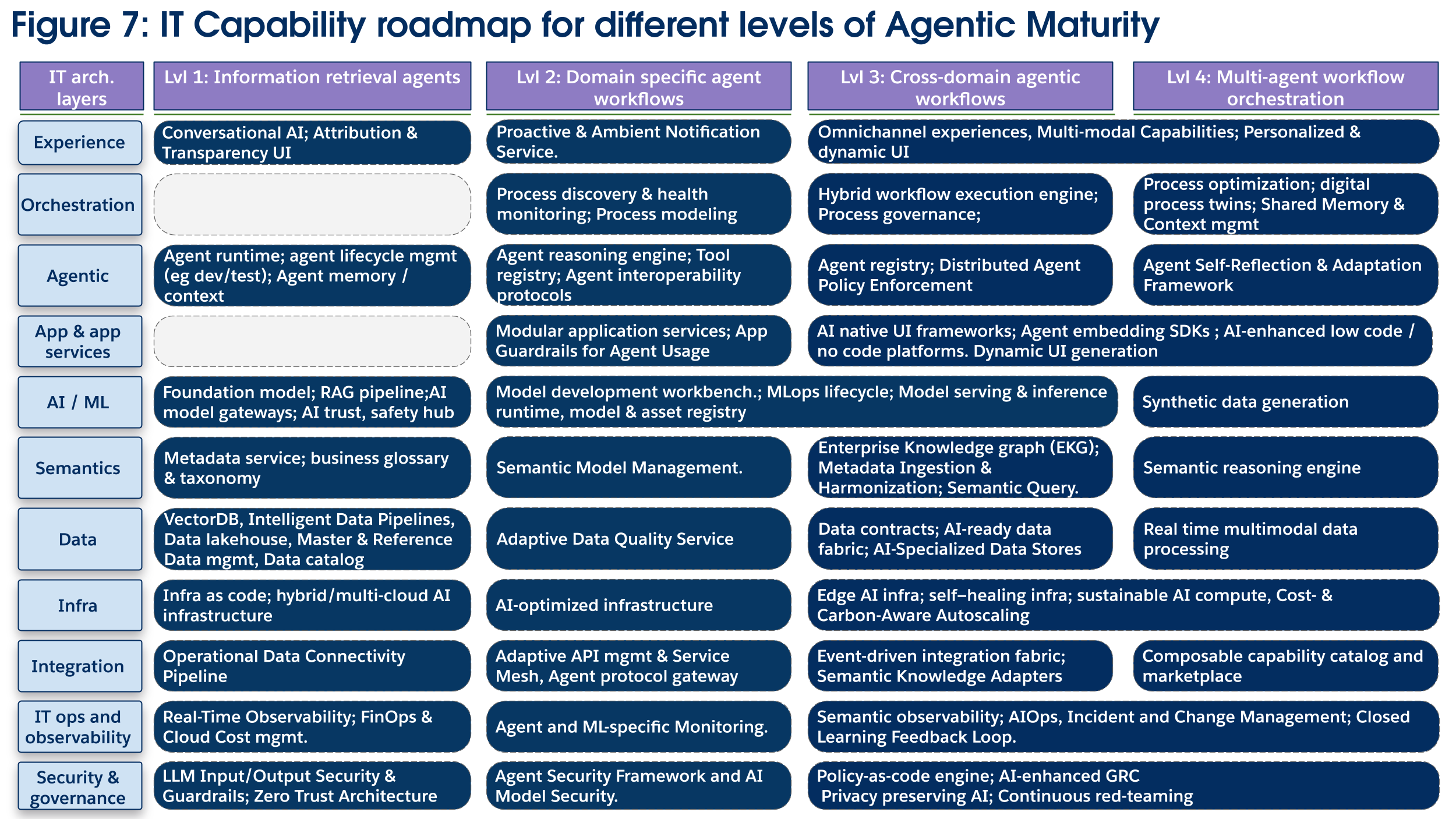
Viktiga teknikinvesteringar (figur 7):
Tematiska investeringar fokuserar på att skapa ett självförbättrande, autonomt system. I det agentiska lagret tillhandahåller ett ramverk för agenters självreflektion och anpassning mekanismen för att låta en agent analysera sina egna prestandaloggar och utlösa förbättringar. Denna utbildning stöds av IT-drifts- och observerbarhetslagret, som implementerar en sluten feedbackloop för lärande för att automatiskt återföra observerbarhetsdata till MLOps-pipelines för modellomskolning, vilket även kan använda skapande av syntetiska data för att ytterligare optimera modellprestanda. Med nätverk av agenter distribuerade över avdelningar tillsammans med pågående programmodulariseringsinsatser blir ytterligare investeringar i säkerhet och en komponerbar kapacitetskatalog avgörande för agenter att dynamiskt skapa kapaciteter för att lösa mer abstrakta och mer värdefulla uppgifter. Dessa processer är alla orkestrerade och optimerade via en ny Digital Twin Process Modeling-kapacitet, som använder realtidsdata för att skapa simuleringar för analys och prediktiv optimering, vilket låter företaget testa och distribuera nya agentdistribueringar på ett säkert sätt.
Slutsats
Vägkartan till ett agentföretag går igenom en IT-arkitektonisk utveckling. Enterprise-arkitekter kommer att vara de avgörande drivkrafterna för denna transformation och driva de viktiga investeringsbesluten, tillsammans med andra partners i verksamheten och IT, som är nödvändiga för att organisationen ska inse värdet av den nya verksamhetskapaciteten hos Agentic Enterprise.