Moderna Salesforce-arkitekturer drivs i allt högre grad av asynkron bearbetning, inte som en bekvämlighet utan som ett strategiskt krav för skala. Under de senaste åren har vi sett fler och fler företag brottas med stora datavolymer, komplexa integreringar som involverar flera beröringspunkter och ökningen av autonoma system som körs 24/7/365. Alla dessa saker driver arkitekter mot att designa system som är asynkrona först.
Asynkron bearbetning i Salesforce innebär ofta att utforma kring styrande gränser och komplexitet. Dessa gränser fungerar som skyddsräcken och arkitektoniska begränsningar som hjälper till att skapa säkra, skalbara system i bunt. Även om inga plattformsgränser direkt används för att hantera komplexitet kan designmönster hjälpa till att minska riskerna på den fronten. Internt tänjer Salesforce ofta på plattformens gränser för att testa nya funktioner och automatisera komplexa verksamhetsprocesser. Vi byggde ett stegbaserat asynkront bearbetningsramverk för att köra asynkrona jobb med ett godtyckligt antal steg. Varje steg kan köras, försökas och startas om oberoende med delade styrningskontroller och fullständig operativ synlighet genom centraliserad loggning. Detta dokument beskriver dess viktigaste arkitektoniska komponenter: Köbara Apex och Finalizers, Schemalagt flöde, Apex, Åberopbara åtgärder och integreringar med Slack. Tillsammans ger dessa komponenter en modulär, skalbar och observerbar arkitektur som passar företagets växande behov.
- Moderna Salesforce-arkitekturer bör omfatta en asynkron metod för att uppnå skala, motståndskraft och operativ transparens.
- Att dela upp komplext arbete i oberoende körbara steg möjliggör förutsägbar prestanda, säkrare försök, kontrollpunkter, tillbakadragande och modulär utveckling utan att ändra kärnflöden.
- Ramverket är ett skalbart alternativ till monolitiska och åldrande batchjobb, kedjade asynkrona anrop och djupt kapslade flöden, och är byggt för arbetsbelastningar med hög volym som måste skalas horisontellt inuti Salesforce utan orkestrering utanför plattformen.
- Deterministisk och observerbar körning säkerställer förloppsspårning, övervakning av servicenivåavtal, feldiagnostik och transparens på granskningsnivå genom centraliserad loggning och styrning.
- Utformad för stränghet i företagsklass, inklusive enhetlig styrning, efterlevnad och distribuerad statlig kontroll över långa verksamhetsprocesser.
Innan du går igenom kraven är här några saker att tänka på vad gäller när ett ramverk som detta ska användas. Tänk framför allt på vilket system som är den enskilda källan till sanning. Om din Salesforce-organisation förlitar sig minimalt på externa data men behöver skala från hundratals till miljoner poster, överväg ett stegbaserat asynkront ramverk.
Använd detta ramverk om**:**
- Den mesta (eller all) informationen att agera efter finns redan i ditt CRM.
- Den inledande eller pågående kostnaden för att upprätthålla ett ETL-jobb (Extrah Transform Load) för att harmonisera externa data är för hög.
- Du måste skjuta upp bearbetningen av ett stort antal Salesforce-poster enligt ett fast schema.
- Du kan dela upp bearbetningen i diskreta steg. Du kan till exempel skapa en hierarkisk eller trädbaserad uppsättning poster, särskilt om datavolym fans ut i hierarkin eller trädet.
Använd inte detta ramverk om:
- Att skapa eller uppdatera poster kräver omedelbar omräkning.
- Integration är en utmaning eftersom externa system är värdar för primära data för postuppdateringar. (Överväg att pusha uppdaterade data till Salesforce med Bulk API.)
Med dessa metoder i åtanke, låt oss gå igenom våra krav och börja bygga.
Tänk på problemuttrycket:
Med ett jobb som behöver köras dagligen, kontrollera om vissa poster uppfyller fördefinierade kriterier för ytterligare bearbetning. Om de gör det, starta dessa bearbetningsjobb. Att bearbeta poster kan innebära att hämta data från flera externa system för att utföra beräkningar. Steg i jobb ska meddela personer via Slack att bearbetade poster är redo för granskning. Steg ska även flytta om notiser till chefer och högre upp i rollhierarkin baserat på en konfigurerbar fördröjning efter den första notisrundan.
Detta problem innefattar flera olika steg, varav vissa kan inträffa oberoende av varandra. Det finns många sätt att dela upp arbetet. Här är en gruppering:
- Schemaläggaren.
- Steggränssnittet och konkreta implementeringar som bearbetar poster (oavsett typ av bearbetning).
- Processorn som organiserar steg.
- Apex åberopbar som anropas av schemaläggningen.
- Notisdelen. Vi använder Apex Slack SDK.
- Det finns en viss komplexitet dold i frasen "konfigurerbar fördröjning". Vi går igenom denna komplexitet senare i denna artikel.
Här är ett uttalat diagram för det inbyggda ramverket:
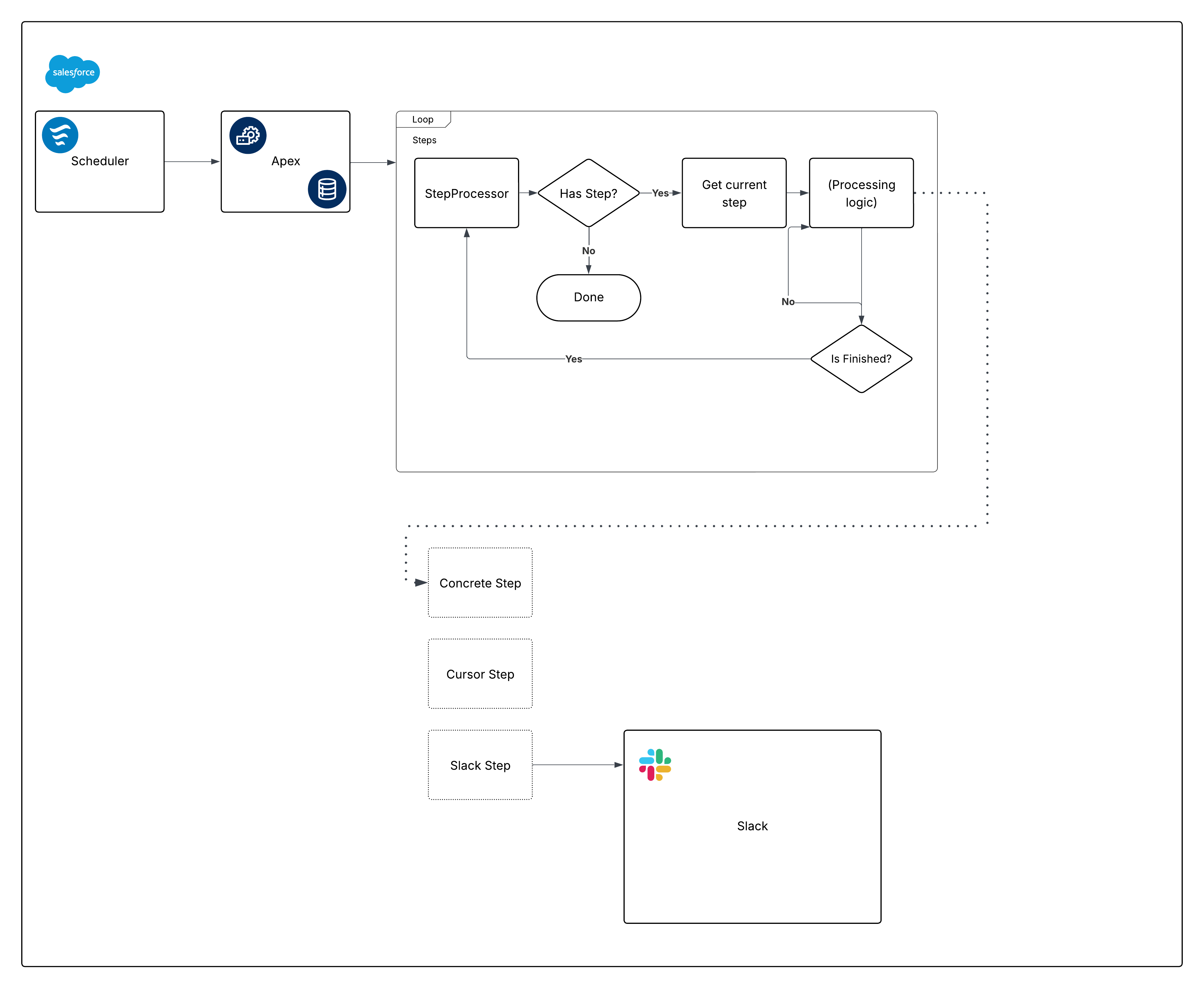 Bryt ner diagrammet och börja bygga bitarna.
Bryt ner diagrammet och börja bygga bitarna.
Schemalagt flöde erbjuder flera fördelar som en schemaläggningsmekanism:
- Schemalagda flöden kan paketeras och distribueras som metadata. Detta gäller inte för jobb schemalagda via Apex (eller via sidan Schemalagda jobb).
- Elementet Vänta är viktigt för ramverk som kräver anrop. Genom att använda det i Flöde behövs inte anrop i den åberopbara delen av ramverket.
- Schemaläggningens detaljnivå uppfyller kraven: det lägsta intervallet för schemalagda flöden är dagligen. Om du behöver en högre frekvens (till exempel per timme), överväg Schemalagt flöde igen för detta krav.
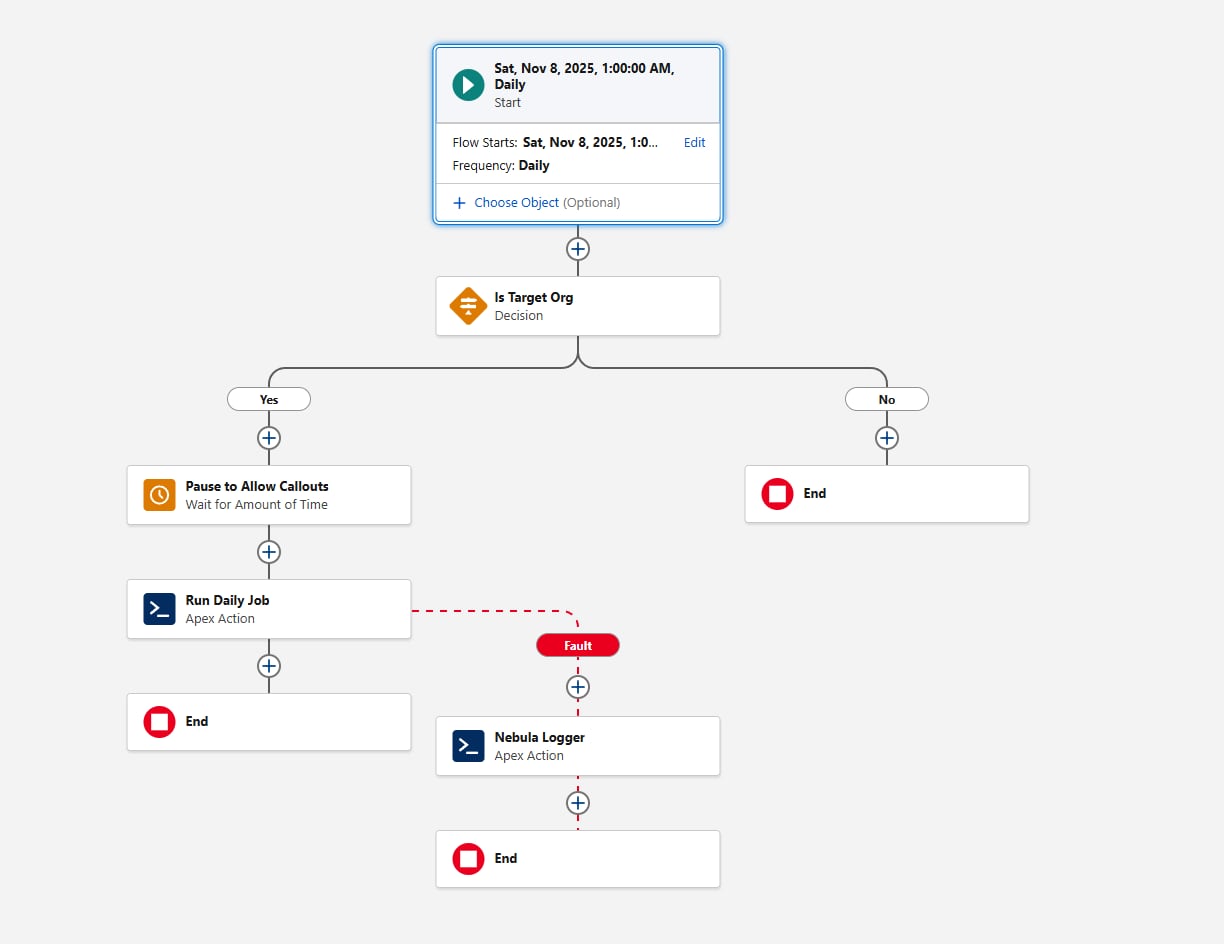
En annan faktor att tänka på vid konfigurering av det schemalagda flödet är miljöanpassning. Innan du åberopar Apex-åtgärden, lägg till ett Beslut-element som utvärderar {!$Api.Enterprise_Server_URL_100}. Detta säkerställer att jobbet endast körs i de avsedda miljöerna, som UAT och Produktion. Detta mönster är viktigt eftersom sandboxar ofta uppdateras eller nyligen skapas under SDLC, och utan en uttrycklig miljökontroll kan ett schemalagt flöde oavsiktligen köras i miljöer där ramverket inte är avsett att köras. Att använda operatoren contains i elementet Beslut gör konfigurationen motståndskraftig mot framtida sandboxskapanden eller URL-ändringar.
Överväg slutligen hur ramverket ska fånga upp fel. Lägg alltid till en felsökväg när flödet anropar en åtgärd. Du kan till exempel överföra fel till Nebula Loggers åtgärd "Lägg till loggpost". Nebula Logger skriver loggar till egna objekt, så kunder bör vara medvetna om att loggdata konsumerar organisationslagring — som standard lagras loggar i 14 dagar inom en organisation och rensas sedan; denna lagringsperiod är konfigurerbar. Nebula Logger använder även plattformshändelser för att publicera loggar, så loggposter sparas oberoende av den huvudsakliga databearbetningstransaktionen — detta säkerställer att fel samlas in även om den primära flödes- eller Apex dras tillbaka. Kunder bör utvärdera förväntad loggvolym och lagringskrav när de överväger att lägga till ett loggningsramverk.
Så här ser flödet ut:
Låt oss gå vidare till de första delarna av Apex kod med schemaläggningskravet nu uppfyllt.
Definiera ett Step:
För denna artikel visas step som en yttre klass för tydlighet. Själva ramverket är flexibelt – team kan organisera gränssnittet och dess implementeringar med hjälp av vilket Apex paketeringsmönster de vill, så länge som alla stegklasser refererar till samma gränssnitt.
Det finns några saker att notera om metoderna som definieras i vårt gränssnitt:
- Även om
executeför tillfället inte är argumenterat förbättras det när vi skickar enState(eller ett gränssnitt) för att orkestrera data mellan steg när ordern är viktig. getNamekan returnera ettSystem.Typeistället för ettString. Målet är att ge orkestreringslagret ett sätt att logga stegnamn utan att exponera andra egenskaper.
Här är den första konkreta implementeringen som visar hur dessa bitar hänger ihop. Med ett senare undantag rekommenderar vi att använda Queueable Apex för att implementera asynkron bearbetning inom Apex. Batch-Apex är vanligtvis onödigt (och @future rekommenderas inte). Köbara Apex startar snabbt och har många fördelar jämfört med batch-Apex.
Apex-markörer erbjuder ett modernt alternativ till den traditionella Apex modellen i batch. På liknande sätt som med batchbearbetning kan en implementering av Markör hämta poster i delar (upp till 2 000 per sats). Markörer tillåter dock flera hämtningar inom en enskild transaktion, vilket möjliggör betydligt högre genomströmning för operationer med stor volym.
När du använder Markörer som en del av detta ramverk bör team vara medvetna om aktuella begränsningar för tester och hånlighet. Markörbeteendet i tester kan skilja sig från produktionsbeteendet, så det är viktigt att utforma teststrategier som undviker att förlita sig på interna Markörer och istället validera orkestreringslogik vid gränserna. Allt eftersom plattformen utvecklas kommer dessa områden att fortsätta förbättras, men den centrala vägledningen är fortfarande: Markörer ger högre prestanda och minskad orkestreringsoverhead jämfört med Batch Apex för många användningsfall.
För att definiera en tydlig gräns mellan den systemlevererade markören och din egen kod rekommenderar vi att skapa en markörliknande representation vid implementering av Step. Tänk på denna kod:
Notera Cursor. Apex pekare är exempel på Database.Cursor, men vår Cursor ger oss flexibilitet kring bristerna hos pekare. Här är implementeringen:
För resten av denna artikel utelämnar vi sharing när vi refererar till Apex klasser. I praktiken, se till att toppnivåklasser uttryckligen använder med eller utan delning för att följa din objektmodell och behörigheter.
Notera även att vår Cursor delegerar till plattformen Database.Cursor, med ytterligare fördelar som diskuteras härnäst.
Först, här är motsvarande tester:
Genom att göra Cursor virtuellt kan konkreta CursorStep fungera utan en Database.Cursor när de inte behöver upprepa en stor postuppsättning – liknande att returnera en System.Iterable<T> istället för en Database.QueryLocator i Apex-sats. Här är ett exempel:
Observera att eftersom denna klass också är abstrakt överlåter den den konkreta implementeringen av innerExecute till underklasser.
Det finns även ett alternativ till den inre underklassen CursorLike. Om du vet att konkreta versioner av ett steg som detta inte kommer att gå igenom andra styrande begränsningar kan du returnera this.records från CursorLike.fetch och åsidosätta den överordnade CursorStep.shouldRestart() för att returnera falskt. Detta låter dig upprepa över en lista som endast begränsas av Apex heapgräns på 12 MB per asynkron transaktion.
Vår markörbaserade implementering ger oss mycket flexibilitet vid paginering över stora mängder data. Gränssnittet Step ger oss flexibiliteten att beskriva och sammanfatta steg av alla slag.
Överväg ett flödesbaserat steg:
Eftersom flöden inte kan returnera utdataparametrar som följer en Apex definierad typ kontrollerar vi om det finns en shouldRestart innan vi använder den.
Vissa steg kan vara funktionsflaggade. Du kan implementera logik för att bestämma vilka steg som ska inkluderas, eller använda ett no‐op-steg för en inaktiverad funktion. Nullobjektmönstret är ett vanligt sätt att minska komplexiteten i orkestreringslagret:
Vi har nu ganska många byggstenar att arbeta med. Låt oss titta på orkestreringslagret som är ansvarigt för att upprepa över steg.
Processorn är en inflektionspunkt i arkitekturen. Vi måste bestämma vem som definierar vilka steg som inleds och var. Alternativen inkluderar:
- Låt processorn definiera vilka steg som mappar till verksamhetslogik. Detta alternativ är enkelt, men skalar dåligt för läsbarhet.
- Definiera mappningen med egna metadata (CMDT). Metadatarelationsfält har inte stöd för
ApexClass, vilket löst kopplar ihop klassnamnstavning med din verksamhetsprocessinställning. Du kan minska administratörsrisken genom att göra fältet till en kombinationsruta och validera typen (Type.forName()eller genom att frågaApexClass), men eftersom CMDT-poster inte har stöd för utlösare sker validering vid körning. Denna rutt går att testa, men administratörer kan fortfarande skapa CMDT-poster endast i produktion — fortsätt försiktigt. - Definiera mappningen med poster. Icke-administratörer kan konfigurera steg, men distribueringar blir svårare och miljöer kan driva. Var försiktig.
Det finns ett berömt citat från Clean Code om hur man hanterar denna specifika komplexitet:
Lösningen på detta problem är att begrava
switch[för att göra objekt] i källaren i en abstrakt fabrik och aldrig låta någon se det.
Med detta i åtanke, och eftersom vårt nuvarande antal steg är väldefinierat och inte kommer att växa sig för stort, är det okej att stegprocessorn också är fabriken för steg. Detta kan använda ett enum för att driva växeluttrycket:
Och sen för vår StepProcessor:
De fabriksmetoder som visas, som addTypeOneSteps(), kan delegera problem som funktionsflaggning. cleanSteps() utför en engångskontroll av de insamlade stegen för att säkerställa att det inte finns några "tomma" steg innan de verkligen blir asynkrona. Det kan se ut så här:
Vi har inte diskuterat felhantering sedan Nebula Logger nämndes i sektionen Schemalagt flöde. Detta på grund av att System.Finalizer låter oss täcka loggning för alla felvillkor utan att lägga till specifik felhantering i varje steg. Varje Step fokuserar på att köra, medan vi loggar och kastar om alla olyckliga vägar så att de visas i enhetstester. Detta har stöd för säker iteration och varning på produktionsnivå (med Slack Logger-plugin för Nebula för alla WARN- och ERROR-loggar).
En anmärkning om felloggning: att skicka steginstansen till loggmeddelanden förutsätter en nivå av Trust för vad som blir synligt i loggar. Standard toString() för Apex klasser inkluderar alla statiska egenskaper och instansnivåegenskaper i meddelandet. Det kan vara önskvärt — eller så kan det läcka känslig information. Loggning och säkerhet är inte fokus här, men observera att för vissa system kan efterlevnad av ett gränssnitt som Step även innebära att tvinga fram en åsidosättning för toString().
En sådan metod lägger ansvaret på varje objektskapare att bestämma vad som är tillåtet att skriva ut, vilket kan vara önskvärt.
På loggningsnivåer: på StepProcessor använder vi INFO, den högsta nivån utan fel. Allt eftersom du får mer detaljer i programmet bör loggningsnivåerna minskas enligt detta. Enskilda steg kan använda DEBUG för information på hög nivå, med FINE, FINER och FINEST reserverade för mer detaljerad utdata. Loggning är lika mycket en konst som en vetenskap, men att följa dessa principer hjälper till att hålla loggar enhetliga och användbara.
Innan vi går vidare, låt oss kort reflektera över beslutet att låta vår stegbehandlare vara värd för logiken för vilka steg som används. I en stor kodbas, överväg att göra StepProcessor virtuellt eller abstrakt, och låt underklasser identifiera specifika steg för att etablera en korrekt separation av problem.
Schemaläggaren åberopar så småningom Apex. När resten av installationen är klar kan sektionen Åberopbar Apex bestämma vilka steg som ska köras och skicka List<StepType> till processorn:
Detta är en enkel del av ekvationen — med hjälp av poster, data eller logik för att avgöra vilka stegtyper som ska köras. Den åberopbara åtgärden är enkel eftersom vi har inkapslat komplexitet någon annanstans. Vi har även skyddat mot oväntade undantag och gjort varje del enkel att testa separat.
Apex Slack SDK ligger utanför denna artikels räckvidd, men en potentiell hake från kraven kräver återbesök: att meddela personer uppåt i rollhierarkin baserat på en konfigurerbar fördröjning. På papper är detta enkelt och du kan (med rätta) överväga System.enqueueJob(this) i StepProcessor. Med System.AsyncOptions var vår ursprungliga benägenhet att använda enqueueJob för att uppfylla detta krav.
För tillfället är dock den maximala fördröjningen via System.AsyncOptions.MinimumQueueableDelayInMinutes 10 minuter. Eftersom kravet är 120 minuter återstår några alternativ. Ett naivt tillvägagångssätt kan se ut så här:
I praktiken skulle fördröjningen skickas till denna klass eftersom fördröjningen är konfigurationsdriven.
Vi rekommenderar inte detta tillvägagångssätt om du inte är säker på att det bara kommer att finnas en typ av försenad notis. Den bränner igenom 11 extra asynkrona jobb innan start (eller fler om fördröjningen ökar). Den kostnaden kanske är bra för ett jobb — inte för många. Du måste även lägga till en metod i Step så att varje steg kan berätta för processorn hur länge den ska vänta innan den startar om, vilket skapar brus.
Det ger oss två intressanta möjligheter:
- Du kan lucka in det försenade steget i ditt befintliga jobbramverk om du redan har ett omröstningsjobb schemalagt med ett lämpligt intervall. Du bör även vara OK med den specificerade fördröjningen som inträffar upp till 15 minuter senare (15 minuter är det minsta uppdateringsintervallet för ett Apex schemalagt CRON-uttryck). Detta matchar ungefär exemplet Åberopbar Apex; schemaläggningen utförs istället via Apex. Med andra ord kan du återanvända samma
Steparkitektur för att bearbeta poster baserat på en tidsstämpel för "Starta efter" och bestämma vilka steg som ska användas baserat på en kombinationsruta eller flervalsmappning tillbaka till deStepTypesom tidigare visades. - Alternativt, om du känner dig bekväm med att definiera en extra yttre Apex klass, gå tillbaka till Batch Apex (till skillnad från Queueable Apex, som har stöd för inre klasser, måste Batch Apex klasser vara yttre klasser) med
System.scheduleBatch().
Överväg Apex med sats. Vi rekommenderar i allmänhet Queueable Apex för flexibilitet och kontroll, men detta är ett fall där Batch Apex fortfarande regerar:
Föreställ dig sedan i StepProcessor att den tidigare visade addTypeOneSteps() uppdateras med detta försenade steg:
Även om vi vanligtvis inte rekommenderar så mycket hoppande blir denna stegfördröjning en annan återanvändbar byggsten. Tills längre fördröjningar tillåts i Queueable Apex är det också det enklaste sättet att skapa denna effekt (utan en pollningsmekanism, som diskuterats).
Vi har använt objektorienterad design för att uppfylla kraven och skapat ett system som kommer att skalas upp samtidigt som den långsiktiga kostnaden för byggande och underhåll balanseras. Även om stegdeklaration och instansiering i slutändan kan växa ifrån sin plats i StepProcessor, finns det lite ytterligare teknisk skuld här. Med FlowStep kan administratörer och utvecklare tillsammans bestämma när lösningar utan kod eller prokod passar bäst.
Genom att använda System.Finalizer inom Apex ramverk Queable, tillsammans med Nebula Logger, har vi byggt ett robust, testbart system som varnar oss för oförutsedda fel även om framtida steg inte har uttrycklig loggning. För oss är detta system glatt att knäcka siffror och minska kostnader och komplexitet. Det har också gett oss värdefulla insikter i Apex beteende under verkliga arbetsbelastningar, vilket hjälper oss förfina vår metod och samtidigt förbättra själva funktionen.
Genom att dela upp komplexa arbetsbelastningar med hög volym i modulära utförandesteg omvandlar ramverket för stegbaserad asynkron bearbetning plattformsbegränsningar till konstruerade fördelar, vilket möjliggör förutsägbar prestanda, observerbarhet och styrning på företagsnivå. Steg kan konfigureras av både administratörer och utvecklare, och i båda fallen kan stegförfattare säkert fokusera på att följa de grundläggande styrande gränserna för plattformen (som DML-rader och sökfrågerader som hämtas) utan att behöva oroa sig för hur varje steg ska skalas.
För att operationalisera och använda detta mönster i alla företagsimplementeringar bör arkitekter:
- Utvärdera befintliga automatiseringar för att identifiera områden där asynkron orkestrering kan hjälpa till att förbättra prestandan och förbättra observerbarheten.
- Dela upp stora processer i diskreta, oberoende körbara steg med tydliga bearbetningsmål och diskreta författarpunkter (som Flöde eller Apex).
- Definiera och gruppera stegtyper för att snabba på återanvändning och standardisering av steg i alla affärsenheter.
- Pilotisera tillvägagångssättet med nya processer eller befintliga automatiseringar. Du kanske blir förvånad över hur många edgekundcase du hittar gratis i steg, vård av din inbyggda loggning och observerbarhet!
James Simone är förste programvarutekniker på Salesforce och har mer än tio års erfarenhet av att arbeta på plattformen. Han var en Salesforce-kund – och produktägare – innan han började utveckla, och har skrivit tekniska djupdykningar om Salesforce sedan 2019 inom The Joys Of Apex. Han har tidigare publicerat artiklar på Salesforce Developer-bloggen och även i Salesforce Engineering-bloggen.