Salesforce Platform har kontinuerligt utvecklat sin automatiseringsarkitektur för att uppfylla kraven i komplexa verksamhetsprocesser. Tidigare generationer — Arbetsflödesregler och Processbyggaren — tillhandahöll de inledande stegen i händelsedriven logik, utökade automatiseringsmöjligheter för händelsedriven logik och breddade räckvidden till ett bredare spektrum av byggare.
Denna utveckling har kulminerat i en högpresterande, konsoliderad arkitektur med fokus på två kompletterande pelare: Postutlöst flöde och Apex. Detta dokument tillhandahåller ramverket och riktlinjerna för att fatta välgrundade beslut vid utformning av utlösarautomatiseringar.
| Flöde | Salesforce-flöde är ett kraftfullt peka-och-klicka-automatiseringsverktyg som låter användare bygga komplexa verksamhetsprocesser, skärmar och logik visuellt med Flow Builder, utan att skriva kod. Den automatiserar uppgifter som datauppdateringar, skicka e-post och guida användare, och erbjuder flexibilitet genom typer som skärmflöden (användarinteraktion) och utlösta flöden (post/schemalagda händelser). |
| Apex | Salesforce Apex är ett egenutvecklat, objektorienterat programmeringsspråk för Salesforce Platform, liknande Java, som används för att bygga egen verksamhetslogik, automatisera processer och utöka CRM-kärnfunktioner utöver deklarativa verktyg. |
Att bygga skalbar, underhållsbar och prestandabaserad postutlöst automatisering på Salesforce Platform kräver en disciplinerad, arkitekturledd metod. Valet mellan flöde och Apex, och implementeringen av båda, styrs av en tydlig uppsättning principer. Dessa punkter sammanfattar dessa principer och fungerar som grundregler för modern automatiseringsdesign.
-
Välj rätt verktyg för jobbet baserat på Salesforce-objektets automatiseringsdensitet.
-
Använd postutlöst flöde för Salesforce-objekt för automatisering med låg densitet.
-
Utöka postutlöst flödeslogik med åberopbar Apex för automatisering med medelhög densitet.
-
Använd Apex-utlösare för Salesforce-objekt för automatisering med hög densitet.
-
-
Var försiktig när du utlöser asynkrona processer.
Denna regel gäller oavsett om du åberopar asynkrona processer i ett postutlöst flöde eller ställer ett jobb i kö från Apex. Även om detta mönster kan vara frestande för avlastningsarbete kan det introducera komplexa scenarion för felhantering och öka risken för att uppnå styrande gränser. -
Använd en ingångspunkt per Salesforce-objekt.
För ett givet Salesforce-objekt, använd en mekanism som din inkörsport till automatisering. Försök undvika att blanda flödes- och Apex som ingångar för samma objekt.
Flöde och Apex har samma grundläggande kapacitet. Varje verktyg kan fråga poster, köra villkorlig logik, tilldela variabler och utföra DML-operationer som att skapa, uppdatera och ta bort poster — sekvenserade för att köras i en specificerad ordning.
Denna funktionella överlappning innebär dock inte att verktygen är utbytbara. Det arkitektoniska valet handlar inte om om en uppgift kan utföras, utan hur den utförs och vilka de långsiktiga konsekvenserna är för prestanda, skalbarhet och underhåll. Flödet utmärker sig i deklarativ tydlighet och snabb implementering för enkla processer, medan Apex ger den detaljerade kontroll och råstyrka som behövs för komplexa lösningar.
Automatiseringsdensitet är belastningen på ett specifikt Salesforce-objekt. Den fungerar som en heuristik för att avgöra objektets optimala implementering. I takt med att automatiseringsdensiteten ökar ökar sannolikheten att överskrida transaktionsgränser.
Beräkna automatiseringsdensitet genom att inspektera tre specifika dimensioner av volym och komplexitet:
-
Automatiseringskvantitet: Det råa antalet unika metadataposter för automatisering (flöden, utlösaråtgärder och så vidare) som körs under en enskild händelse i Data Manipulation Language (DML).
-
Postvolym: Posterna per transaktion bearbetas via API-inläsningar eller tung batchbearbetning, där prestanda blir avgörande.
-
Beroendespridning: Ett mått på de DML-operationer längre ner som utlöses av den inledande CRUD-operationen. Den kvantifierar djupet i grafen där en uppdatering kaskadar till uppdateringar för relaterade objekt (till exempel kundcase → konto → kontakt → egen summering).
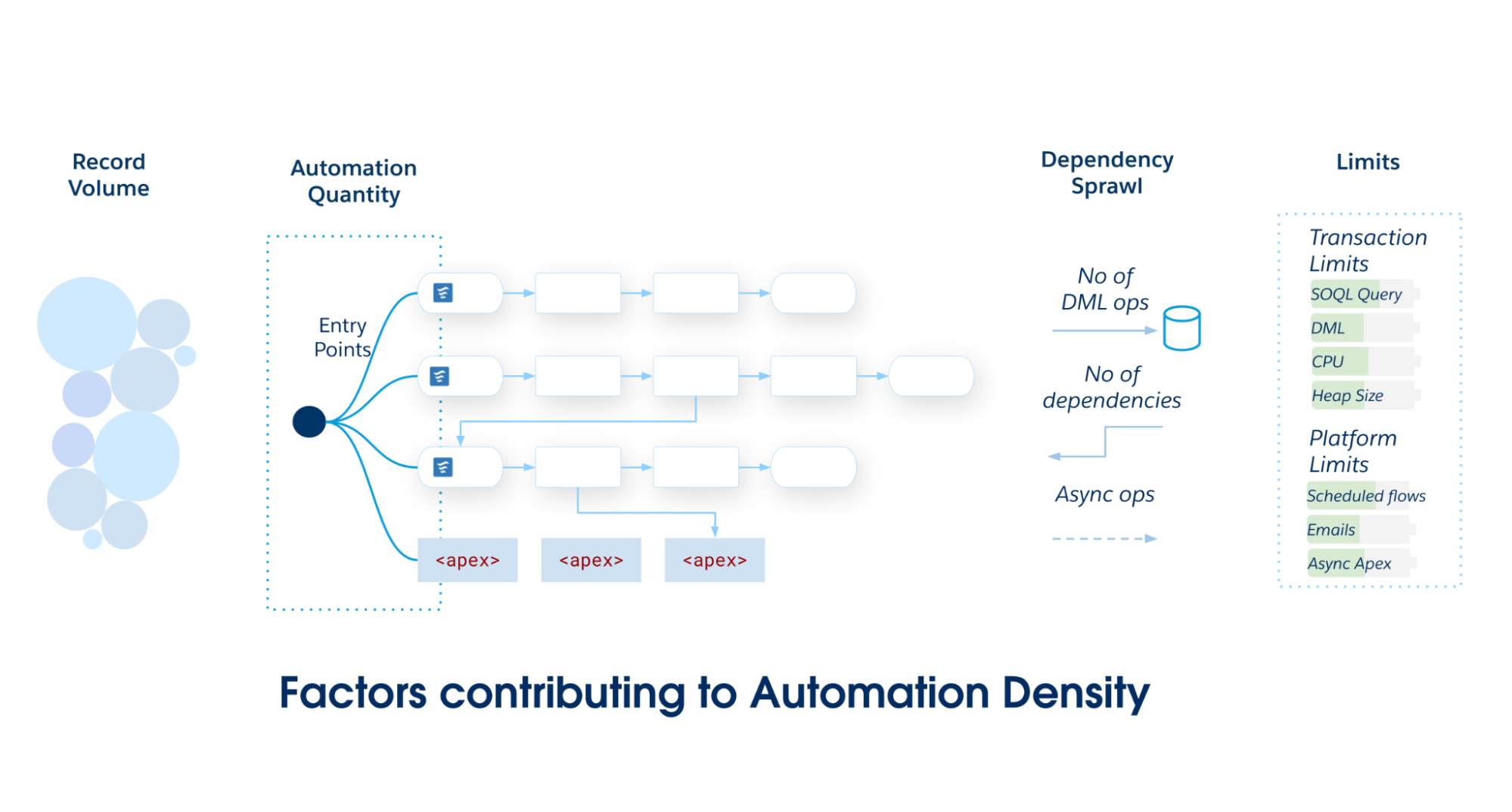
Allt eftersom omfattningen och komplexiteten i din Salesforce-app växer, förplikta dig till en enda primär ingång—antingen postutlöst flöde eller Apex. Undvik partitionering av automatiseringar över flera mekanismer i ett enskilt Salesforce-objekt, eftersom det leder till dålig underhållsbarhet och fragmenterad styrning.
Använd denna matris för att avgöra vilken arkitektonisk standard som behövs för ditt Salesforce-objekt.
-
Postutlöst flöde är den föredragna lösningen för låg automatiseringsdensitet. Den erbjuder en balans mellan kraft och tillgänglighet som är idealisk för automatiseringar som är enkla och oberoende av varandra.
-
Hybridmönstret (postutlöst flöde med åberopbar Apex) är ett kraftfullt och underhållsvänligt val för automatisering med medelhög densitet och stigande komplexitet. Detta mönster ger team möjlighet att upprätthålla ordnad koreografi i deklarativa flöden samtidigt som beräkningstunga åtgärder delegeras till Apex, vilket balanserar tillgänglighet med prestanda.
-
Apex-utlösare ger de byggstenar som behövs för en solid arkitektonisk grund för att stödja automatisering med hög densitet. Prestanda, detaljerad kontroll och objektorienterad abstraktion och polymorfism i Apex är bättre lämpade för att hantera komplexiteten och skalan i dessa scenarion.
| Densitetsnivå | Automatiseringskvantitet | Datavolym (satsstorlek) | Beroendespridning | Arkitektonisk standard |
|---|---|---|---|---|
| Låg | < 15 Automatiseringar |
Standard Användardrivna användargränssnittinteraktioner eller små API-inläsningar (1-200 poster) |
Diskret Självständig logik. 0–1 DML-operationer längre ner på samma objekt eller ett relaterat objekt. |
Postutlöst flöde |
| Medel | 15–30 Automatiseringar |
Moderera Standard batchbearbetning (med logik som kräver noggrann buntning) |
Kopplat Överordnad/underordnad uppdaterar 2-4 DML-operationer längre ner. Risk för rekursion |
Hybridmönster Flöde + åberopbar Apex |
| Hög | > 30 Automatiseringar |
Hög Stora datavolymer med massinläsningar av API (2 000 - 10 000+ poster) |
Komplex och återkommande Djup beroendegraf (5+ DML-operationer längre ner). Risk för triangelformade rekursionsloopar |
Metadataramverk för Apex-utlösare |
Överväg även det totala dagliga antalet DML-operationer eftersom Salesforce tillämpar hantering av delade resurser i en miljö med flera klienter och styrande gränser för att förhindra automatiseringar från att monopolisera delade resurser. Salesforce-objekt med hög daglig DML-volym kräver noggrant automatiseringsval. Till exempel är asynkrona gränser för CPU-tid (60 000 ms) och heapstorlek (12 MB) högre än synkrona gränser. Dessutom kräver den organisationsomfattande 24-timmarsgränsen för asynkrona körningar—beräknade som 250 000, eller 200 gånger dina användarlicenser—att total daglig DML faktoreras i din arkitektoniska design för att undvika runtimeundantag.
Postutlöst flöde är plattformens främsta deklarativa verktyg för postutlöst automatisering. Flödets användarvänlighet och inbyggda plattformsskydd låter team enkelt bygga skalbara och pålitliga lösningar. Det är det perfekta valet för de flesta team som bygger lösningar på Salesforce Platform.
Apex är plattformens egenutvecklade, starkt typade, objektorienterade programmeringsspråk. Använd Apex för Salesforce-objekt med hög automatiseringsdensitet och för användningsfall som kräver hög prestanda, sofistikerad logik eller detaljerad kontroll över transaktioner.
För att hjälpa till i beslutsprocessen ger denna matris en direkt jämförelse av flöden och Apex mellan viktiga arkitektoniska kapaciteter.
| Kapacitet | Postutlöst flöde | Apex Trigger |
|---|---|---|
| Leverans- och underhållshastighet | Rekommenderas Det visuella användargränssnittet i Flow Builder låter administratörer och andra deklarativa byggare skapa och ändra automatisering snabbare än att skriva, testa och distribuera Apex kod. Detta gränssnitt ger ett bredare spektrum av teammedlemmar möjlighet att leverera verksamhetsvärde och minskar beroendet av specialiserade utvecklarresurser för enkla uppgifter. |
Kräver expertis Apex kräver kompetenta programutvecklare för att implementera, testa och underhålla koden. |
| Modularitet | Tillgänglig Postutlösta flöden är modulära som standard. Istället för monolitisk logik bygger team diskreta flöden för specifika krav och koreograferar dem tillsammans med Flow Trigger Explorer. Denna modularitet möjliggör isolerade ändringar och enkel utökning, vilket avsevärt minskar den långsiktiga ägandekostnaden. |
Tillgänglig Apex är indelat i funktionella moduler efter design. Varje Apex klass är avsedd att implementera en enskild funktionalitetsmodul. |
| Synlighet och styrning | Rekommenderas Flödets visuella karaktär ger en intuitiv representation av verksamhetslogik. Flödesutforskaren ger en samlad vy över alla flöden för ett objekt, vilket gör det enklare för arkitekter och administratörer att förstå, styra och felsöka utan att läsa kod. |
Kräver expertis Att använda ett metadataramverk för att organisera utlösare är fördelaktigt, men Apex kräver ett disciplinerat utvecklingsteam för att hålla koden organiserad och underhållsbar. |
| Högpresterande massdatabearbetning | Rekommenderas inte Det finns en förhöjd risk att uppnå styrande gränser vid hantering av komplex logik eller stora datavolymer. |
Rekommenderas Apex kod körs närmare plattformens kärntjänster och erbjuder utvecklare utökad kontroll över sökfrågeoptimering, datahantering och algoritmisk effektivitet. Detta resulterar i bättre prestanda och skala, särskilt i komplexa scenarion med stora datavolymer. |
| Robust logik och datastrukturer | Tillgänglig Flödestransformationselementet kan hjälpa till med vissa komplexa bearbetningsuppgifter. Flödet saknar dock inbyggda datastrukturer för kartor och uppsättningar, vilket gör komplex databearbetning besvärlig och beräkningsineffektiv. |
Rekommenderas Apex ger fullständig åtkomst till mappnings-, uppsättnings- och programmatiska loopar för mycket effektiv, säker hantering av data i bunt. Som ett fullfjädrat programmeringsspråk ger Apex även åtkomst till komplexa logiska konstruktioner, datastrukturer och designmönster som kan hjälpa till att lösa komplexa verksamhetsproblem på ett underhållbart och effektivt sätt. Apex innehåller ett rikt standardbibliotek med avancerade funktioner (till exempel BusinessHours, krypto) som för närvarande inte är tillgängliga i deklarativa verktyg. |
| Transaktionskontroll | Ej tillgängligt Flödet ger ingen åtkomst till `Database.savepoint`, `Database.rollback` eller delvis framgångsrika DML-operationer för delvisa transaktionsåtaganden eller rollbacks. |
Tillgänglig Apex ger fullständig, detaljerad kontroll över transaktionsintegritet och komplexa scenarion för felåterställning. |
| E-postdistribution | Rekommenderas Att skicka förkonfigurerade e-postmeddelanden från ett postutlöst flöde är enkelt och skalbart. Egna e-postmeddelanden kan skapas och distribueras vid runtime. Egna e-postmeddelanden är föremål för dagliga e-postutskicksgränser. |
Tillgänglig Apex kan skapa och skicka egna e-postmeddelanden. All e-post som skickas från Apex omfattas av de dagliga gränserna för e-postutskick. |
| Tillämpa plattformsskydd | Rekommenderas Flödet innehåller inbyggda skydd, som automatisk buntning och automatiska försök. Dessa skyddsåtgärder ökar hastigheten för att värdera och förhindrar prestandafel som annars kräver komplex, manuell kodning. |
Manuell implementering krävs Skyddsåtgärder som massutskick måste uttryckligen kodas (till exempel att hantera samlingar och undvika SOQL inuti loopar). Automatiska försök är inte inbyggda i utlösare och kräver komplex egen logik för att implementeras. |
| Asynkron bearbetning | Tillgänglig Flödet erbjuder enkla mekanismer för automatisering som kräver en separat transaktion i en asynkron väg. Dessa automatiseringar är föremål för dagliga gränser. |
Tillgänglig Apex aktiverar fullständig kontroll via datainsamling och köhändelser som hanteras av en frånkopplad utlösarprenumerant. |
| Schemalagd bearbetning | Rekommenderas Flödets schemalagda vägar ger en unik och kraftfull schemaläggningskapacitet (till exempel "skjut 3 dagar innan avslutsdatum"). Denna kapacitet inkluderar automatisk annullering och omschemaläggning om postens data ändras. Dessa automatiseringar är föremål för dagliga gränser. |
Ej tillgängligt En Apex kan inte schemalägga en tidsspecifik, postspecifik händelse med automatisk annullering. Schemalagd Apex finns men är en helt annan mekanism som körs vid en specifik tidpunkt och inte schemaläggs under en enskild posts bearbetning som en del av en utlösare. |
| Ordning och koreografi | Tillgänglig Flödesutforskaren låter administratörer definiera en relativ utförandeordning för flera flöden på samma objekt. |
Tillgänglig Ett utlösarramverk ger detaljerad kontroll över den exakta ordningen på automatiseringar. |
| Uppdateringar av samma postfält | Tillgänglig (innan sparande) Postutlöst flöde är det mest effektiva deklarativa alternativet för att uppdatera den utlösande posten innan den inledande DML-överlämningen. |
Tillgänglig (innan sparande) Apex ger det högsta prestandaerbjudandet med minimal overhead. |
| Korsobjekt-CRUD | Tillgänglig (efter sparande) Flödet är lämpligt för enkla korsobjekts-DML-operationer med låg komplexitet. |
Tillgänglig (efter sparande) Apex ger överlägsen kontroll över deduplicering, felhantering och prestanda för korsobjekts DML-operationer. |
| Deduplicering av dyr beräkning | Tillgänglig Flödet är utmärkt på att eliminera överflödiga sökfrågor och DML-uttryck via automatisk buntning. Status kan dock inte cachas eller delas mellan olika flödesutlösare eller över flera åberopningar av samma flöde inom en transaktion. Denna begränsning kan bli viktig i extrema prestandascenarier. |
Rekommenderas Apex tillhandahåller mekanismer för att avduplicera dyra åtgärder. Utvecklare kan använda transaktionscachning med statiska egenskaper och variabler, och plattformsnivåcachning med plattformscache, för att lagra och återanvända data. Dessa tekniker är viktiga för att minska användningen av styrande transaktionsgränser, som SOQL-frågor, och säkerställa hög prestanda och skalbarhet. |
| Egen felhantering | Tillgänglig Elementet CustomError kan blockera en spara-operation och visa ett meddelande för användaren. |
Rekommenderas Metoden addError() ger flexibla fältnivå- och villkorliga felmeddelanden. |
Denna tabell ger allmänna rekommendationer för bästa passform för allmänna användningsfall, baserat på de kapaciteter som presenteras. I slutändan kommer du att ta hänsyn till ytterligare överväganden för att komma fram till en bästa passform för dina specifika scenarion, till exempel de som inkluderas i sektionen Relaterade rekommenderade metoder i detta dokument. Där får du reda på mer om när en viss kombination av flöde och Apex är den bästa metoden.
| Användningsfall | Beskrivning | Passar bäst | Motivering |
|---|---|---|---|
| Högpresterande batchbearbetning | All automatisering som måste bearbeta tusentals poster effektivt | Apex | Apex tillhandahåller rika API:n för att interagera med plattformen och för rå hastighet. |
| Komplex databearbetning | Scenarion som kräver avancerad datamanipulation | Apex | Apex tillhandahåller datastrukturer, som Karta och Ställ in, som inte är tillgängliga i Flöde, och kan vara viktiga för att skriva högpresterande, masssäker kod. |
| Transaktionskontroll | Styrmekanismer som till exempel savepoints, rollbacks och delvis commits | Apex | Apex ger åtkomst till mekanismer som Database.savepoint och Database.rollback och har förmågan att bearbeta delvis framgångsrika DML-operationer. |
| Sofistikerad egen validering | Datavalidering över flera fält i en post | Apex | Flöde kan förhindra en sparning med elementet `CustomError`, men det är inte tillgängligt i alla flödestyper—inklusive underflöden. Apex-metoden addError() tillhandahåller flera fältspecifika felmeddelanden som kan läggas till i en post när som helst under utlösarbearbetningen. |
| Lågt komplex logik i en enkel process | Logik- och datamanipulation med måttlig komplexitet, förenklad av ett standardbibliotek med avancerade funktioner, som sker som en del av en okomplicerad process | Flöde + Apex | Postutlöst flöde fungerar som orkestreringslagret, medan operationer med hög komplexitet är inkapslade i åberopbara Apex. |
| Enkel till måttligt komplex logik | Datamanipulation med låg till måttlig komplexitet, med utlösaruppdateringar av både primära och relaterade dataobjekt | Flöde | Flöde är vanligtvis alternativet eftersom det baseras på en deklarativ modell som gör det tillgängligt för både administratörer och utvecklare. |
| Notiser och utgående meddelanden | Skicka utgående e-postmeddelanden och meddelanden | Flöde | Flödet gör det enkelt och mycket skalbart att skicka e-postmeddelanden och utgående meddelanden om poständringar. |
| Schemalagd bearbetning | Automatisering vid ett framtida, dynamiskt datum (till exempel 3 dagar innan ett avslutsdatum) | Flöde | Schemalagda vägar ger en unik styrka till Flöde, eftersom plattformen automatiskt hanterar schemaläggning, annullering och omschemaläggning av dessa vägar om postens data ändras. |
Skalbarhet är viktigt när du utformar din implementering. När en postutlöst automatiserings verksamhetslogik blir komplex, tidskrävande eller involverar stora datavolymer blir Salesforce-plattformens centrala styrande begränsningar en arkitektonisk begränsning. Operationer som massdatauppdateringar, komplexa API-anrop eller tunga beräkningar ökar risken för att överskrida gränser, till exempel total CPU-tid eller antalet DML-uttryck i en enskild databastransaktion. Ett fel i en synkron utlösare på grund av ett gränsundantag kommer att göra att användarens hela spartransaktion dras tillbaka, vilket resulterar i dålig användarupplevelse och potentiell dataförlust. Denna inneboende risk kräver ett arkitektoniskt mönster för att avlasta komplext arbete.
Asynkron automatisering blir viktigt i detta fall. Med hjälp av asynkrona mekanismer kan arkitekter effektivt koppla bort det långvariga arbetet eller arbetet med hög volym från den primära, synkrona transaktionen för att spara poster. Sparar snabbt och tillförlitligt, medan den tunga bearbetningen delegeras till en separat, plattformshanterad transaktion som utförs senare. Frånkoppling förbättrar stabiliteten, förhindrar transaktionsmisslyckanden och är viktigt för att bygga skalbara företagsprogram. Plattformen erbjuder flera specialiserade verktyg för detta, var och en med tydliga fördelar och kompromisser vad gäller pålitlighet, volym och komplexitet.
Vägen Kör asynkront i ett postutlöst flöde ger den enklaste mekanismen för "brand och glöm" asynkron logik. Denna väg körs i en separat transaktion efter att den ursprungliga postsparande transaktionen har överlämnats till databasen.
-
Idealiskt användningsfall: Detta passar bra för uppgifter som inte kräver omedelbar körning eller egen felhantering. Exempel på detta är att skicka ett e-postmeddelande, skapa en uppföljningsuppgift eller göra ett enkelt anrop till ett externt system.
-
Begränsningar: Denna mekanism delar samma dagliga styrande gränser som andra asynkrona flödesintervjuer. Den är inte utformad för bearbetning med extremt hög volym.
Datainsamling (CDC) är ett skalbart och motståndskraftigt mönster med hög genomströmning för hantering av asynkron logik som utlöses av en poständring i scenarion med hög volym. I denna modell är utlösarens enda ansvar att spara posten synkront. Plattformen publicerar sedan ett detaljerat händelsemeddelande som innehåller postens ändringar av en händelsebuss med hög volym. En separat, dedikerad Apex prenumererar på denna ändringshändelse. Den utför komplext, tidskrävande eller asynkront arbete.
-
Förmån: Detta mönster kopplar bort den asynkrona processen från den inledande användartransaktionen. Ett fel i den asynkrona bearbetningen gör inte att användarens postsparande dras tillbaka. Mönstret ger även en hållbar händelseström som flera interna prenumeranter eller externa system kan konsumera, och händelser kan spelas upp igen i upp till 72 timmar, vilket ger stark motståndskraft.
-
Begränsningar: CDC-händelsemeddelanden innehåller inte postens tidigare status – motsvarande en Apex
Trigger.oldMap. Händelsebelastningen inkluderar de nya fältvärdena, men inte de värden de ändrades från. Detta gör det svårt att implementera logik baserat på en specifik lägesövergång (till exempel, kör endast omStatus__cändrades från "Väntar" till "Godkänd"). Du kan minska detta genom att fråga objektets fälthistorik i händelseprenumeranten, men detta gör processen mer komplicerad och fälthistorikspårning kanske inte är tillgänglig för det specifika fältet av intresse. Detta kan begränsa vilka typer av automatisering du kan avladda till CDC.
Som standard kan CDC aktiveras för högst fem Salesforce-objekt. Organisationer som behöver mer kan köpa en tilläggslicens som tar bort denna gräns och ökar allokeringar för händelseleveranser.
Att placera ett Apex jobb i kö direkt från en utlösare bör betraktas som ett riskabelt mönster, och det används endast när Apex tillhandahåller kontroll (till exempel för komplex logik eller egna försöksmekanismer), och CDC är inte ett hållbart alternativ.
Om Queueable Apex krävs måste implementeringen innehålla lämpliga skyddsåtgärder:
-
Begränsa kontroller: Koden måste kontrollera antalet jobb som redan står i kö i transaktionen innan du försöker lägga till ett till.
-
Sammanhangsmedvetenhet: Koden måste upptäcka om den körs i ett asynkront sammanhang, till exempel ett batchjobb (
System.isBatch()), och ändra dess beteende så att den följer den striktare gränsen för ett jobb per transaktion i det sammanhanget.
Att åberopa asynkrona Apex från en synkron utlösare introducerar stabilitetsrisker. För att förhindra påverkan på organisationsnivå (till exempel att överskrida gränser) kräver detta mönster noggrann design och tester.
-
Den dagliga gränsen för asynkrona Apex-körningar (
Batch,Queueable,@Future) delas i hela organisationen (vanligtvis 250 000 eller en beräkning baserad på användarlicenser). En massinläsning av data på 20 000 poster gör att en utlösare körs i delar om 200, vilket resulterar i 100 separata utlösarop — ännu fler om massbuntstorleken är färre än 200 poster. Om varje åberopning köar ett asynkront jobb kan en betydande del av den dagliga gränsen från en enskild datainläsning konsumeras. Denna konsumtion kan potentiellt svälta andra viktiga verksamhetsprocesser av asynkrona resurser. -
Styrande begränsningar för köjobb skiljer sig drastiskt åt beroende på sammanhanget. Från en utlösare som utlöses av en användaråtgärd i användargränssnittet – en synkron transaktion – kan upp till 50 köjobb placeras i kö. Från en utlösare som utlöses inom
executeför en Apex satsklass – en asynkron transaktion – kan dock endast ett köjobb placeras i kö. Att inte ta hänsyn till denna skillnad är en vanlig och kritisk felpunkt som leder tillLimitExceptionunder stora dataoperationer. -
Att anropa Schemaläggningsbar Apex (
System.schedule) eller Batch Apex (Database.executeBatch) direkt från ett utlösarsammanhang är ett antimönster. Dessa metoder är inte utformade för att åberopas från utlösarsammanhang. Detta kommer att leda till snabb användning av din asynkrona Apex allokering, vilket resulterar i gränsundantag.
Varje asynkron mekanism har specifika kompromisser vad gäller prestanda, styrande begränsningar och pålitlighet. Använd detta beslutsträd som en guide för att hjälpa dig navigera bland dessa alternativ och välja rätt mekanism för ditt användningsfall.
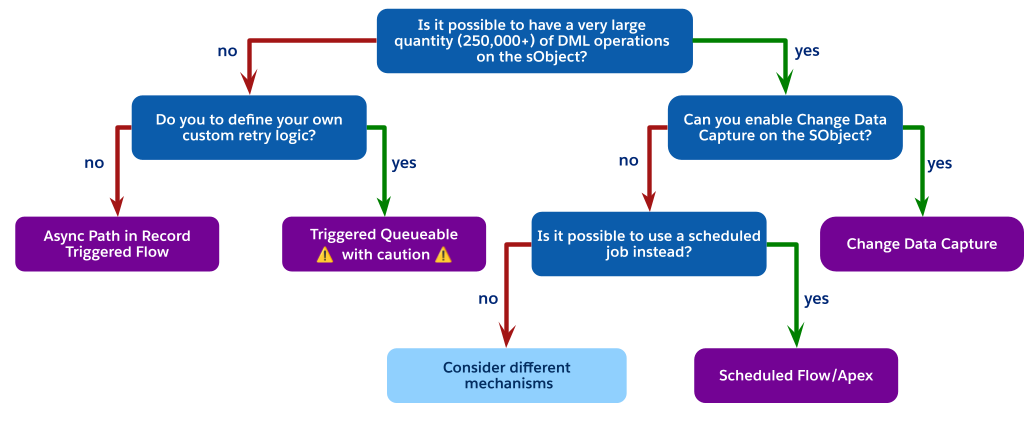
Som flödesdiagrammet indikerar är det bästa arkitektoniska valet ofta att undvika en process som utlöses helt och hållet när du står inför DML-operationer med hög volym men inte kan använda Ändra datainsamling (kanske på grund av objektgränser).
Överväg istället att använda en schemalagd process. Detta kan antingen vara ett Schemalagt flöde eller Schemalagt Apex. Obligatoriska steg är:
-
Utför en enkel, billig uppdatering i den synkrona utlösaren. Sätt till exempel ett
Status__ctill "väntar på bearbetning" eller infoga en relaterad post till låg kostnad, till exempel ett Chatter-inlägg, för att indikera att posten behöver bearbetas. -
Skapa ett schemalagt jobb, antingen ett schemalagt flöde eller schemalagd Apex, som körs periodiskt, till exempel var 15:e minut eller varje timme.
-
Ha den schemalagda jobbfrågan för alla poster i väntande läge, kör den komplexa logiken i ett kontrollerat sammanhang med hög volym och uppdatera sedan posterna som bearbetade.
Detta mönster kopplar helt bort den tunga bearbetningen från användarens synkrona sparande, är inte föremål för gränsen på ett jobb per transaktion för en utlösarutlöst sats och ger en mycket skalbar och styrbar lösning för krav som inte är i realtid.
Om latensen för ett schemalagt jobb inte är acceptabel för verksamhetskraven och du fortfarande är begränsad från att använda CDC eller en utlösarutlöst kö indikerar detta en betydande arkitektonisk felmatchning. Här måste olika mekanismer övervägas. Att omvärdera utformningen av kärnprogrammet kan leda till vissa slutsatser, till exempel:
-
Köp av tillägget för att ta bort CDC-objektgränser.
-
Grundläggande utmaningar för verksamhetskravet att avgöra om bearbetning nästan i realtid verkligen är ett "måste" eller om latensen för ett schemalagt jobb är en acceptabel kompromiss för plattformsstabilitet.
Komplexiteten i en implementering är en del av en lösnings totala ägandekostnad, samt dess förmåga att anpassa sig till ändrade verksamhetskrav. Komplexitet kan påverka alla implementeringar om rekommenderade metoder inte följs. I sektionen Relaterade rekommenderade metoder i detta dokument finns rekommendationer för att minska komplexiteten i din lösning, inklusive dessa mönster:
-
Hybridmönster: Åberopbar Apex för komplex logik i flöde
-
Använda ett metadataramverk för Apex
-
Mega-Flows vs. Flera flöden
Dokumentation är lika viktigt som själva automatiseringen. Det säkerställer inte bara underhållbarhet, det är även viktigt för AI och agentbaserade verktyg. Dokumentation hjälper dig förstå och hantera dina verksamhetsprocesser.
I flöde
-
Upprätta en enhetlig namnkonvention för alla element och variabler.
-
Använd fältet Beskrivning för flödet för att förklara dess övergripande syfte, utlösarkriterier och avsedda resultat.
-
Använd fältet Beskrivning för varje enskilt element (till exempel
Get Records,Action,Transform). Detta är det bästa sättet att förmedla syfte. Det är särskilt viktigt för åberopbara åtgärder och underflöden, där beskrivningen är den primära platsen för att förklara den komplexa logik som utförs av åtgärden.
I Apex
-
Kommentera din kod tydligt för att förklara varför bakom din logik, inte bara vad.
-
Om du använder ett metadatadrivet ramverk, se till att dina metadataposter inkluderar och fyller i ett mänskligt läsbart beskrivningsfält för att förklara vad varje hanterarklass gör och när den ska köras.
DevOps och källkontroll är en del av en mogen utvecklingslivscykel. Använd alltid ett källkontrollverktyg som Git för Salesforce-projekt. Både Apex klasser och Salesforce-flöden är metadata som definierar din verksamhetslogik och de måste vara versionerade och hanterade.
Inom ramen för hantering av postutlösta automatiseringar ger en modern DevOps-pipeline viktiga fördelar.
-
Automatiserade kvalitetskontroller: Verktyg som Salesforce Code Analyzer kan konfigureras att köras automatiskt i din pipeline. Statisk analys kan upptäcka problematiska mönster i båda automatiseringsverktygen innan de flyttas upp och flagga problem som ineffektiva
Get Recordsinuti en flödesloop ellerSOQLinuti en Apex för loop, som är vanliga orsaker till prestandaförsämring. -
Regressionsförebyggande: När din automatiseringsdensitet ökar kan en ändring av ett flöde eller Apex få oavsiktliga konsekvenser för andra automatiseringar på samma objekt. En robust DevOps-teststrategi, där automatiserade Apex körs mot alla föreslagna ändringar, är det mest pålitliga sättet att säkerställa att en ny flödesversion inte bryter befintlig Apex (och vice versa).
-
Samarbete och synlighet: Källkontroll är den "enda källan till sanning". Det låter administratörer och utvecklare arbeta med automatisering för samma objekt parallellt. Den ger också en ovärderlig granskningslogg: när en produktionsprocess bryts kan du direkt se vem som ändrade automatiseringen, när de ändrade den och – via meddelanden – varför de ändrade den.
För team med en blandning av administratörer och utvecklare tillhandahåller DevOps Center ett enhetligt gränssnitt för att hjälpa till att koreografera alla dessa steg, vilket gör en skalbar, källkontrollbaserad utvecklingsprocess tillgänglig för alla i teamet.
Denna kombinerade disciplin av dokumentation och DevOps säkerställer långsiktig hälsa och underhållbarhet för din organisation, vilket kommer att gynna varje arkitekt och administratör som följer dig.
Beslutsguiden ovan används bäst innan du planerar din implementering. Den är inriktad på att hjälpa dig välja den bästa produkten för dina användningsfall. Efter produktvalet är det viktigt att förstå befintliga rekommenderade metoder för din implementering.
Principen Ett verktyg per objekt är viktig för att hantera automatisering med hög densitet, men tolka den inte som ett binärt val mellan en rent deklarativ eller en rent programmatisk stack. Ett mer effektivt och underhållbart arkitektoniskt mönster använder en hybridmodell: placera postutlöst flöde som orkestreringslagret, samtidigt som högkomplexa operationer sammanfattas i åberopbara Apex.
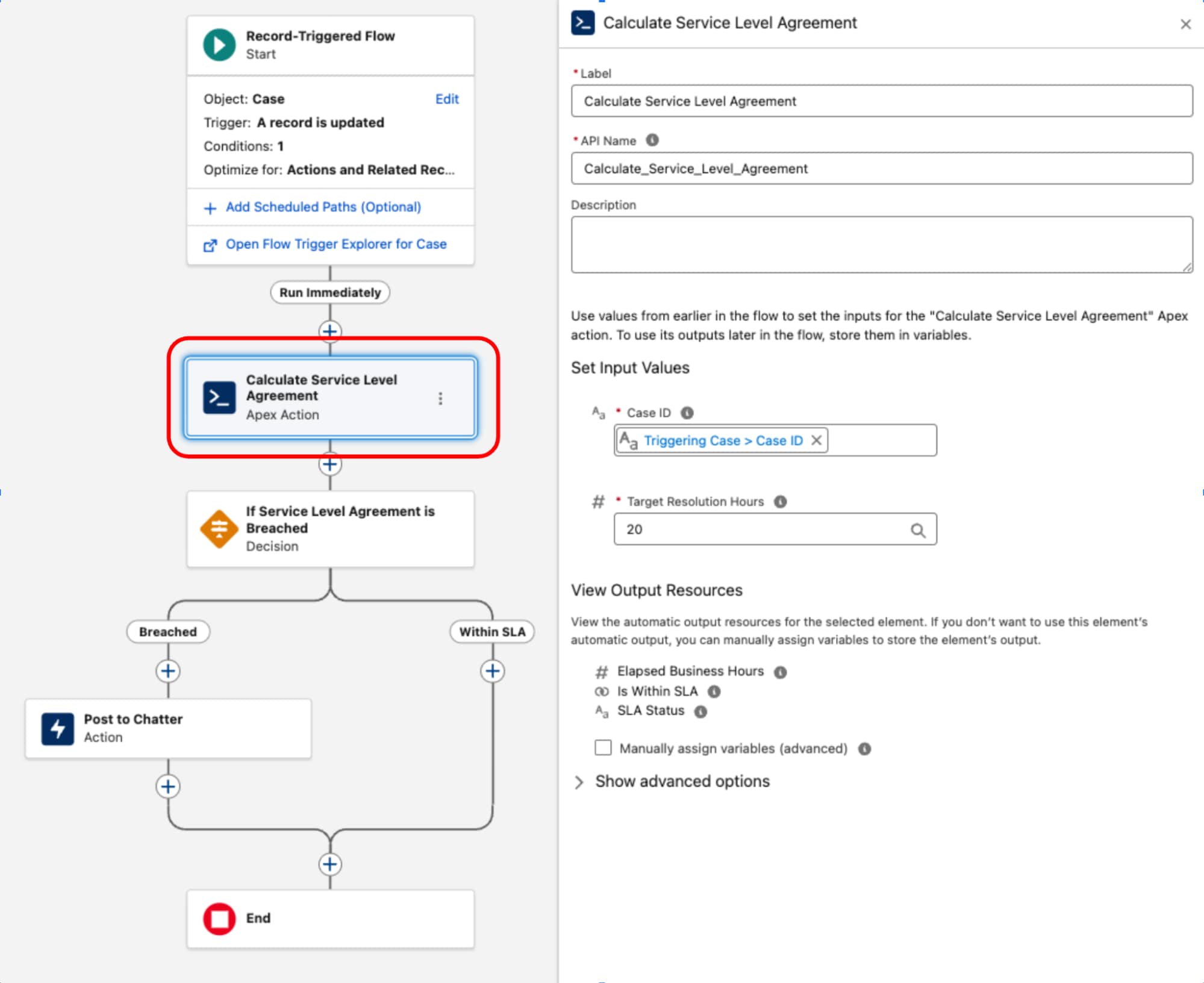
Postutlöst flöde fungerar som det orkestrerade lagret för verksamhetsprocessen. Den äger inmatningskriterier och utförandesammanhang (vad och när). Genom att behålla beslutslogik och dirigering inom detta lager förblir arkitekturens processtopologi transparent och hanterbar via Flow Trigger Explorer, vilket förhindrar att viktig verksamhetslogik döljs i kod.
Ett vanligt exempel på en komplex komponent är implementeringen av beräkningar av servicenivåavtal (SLA) för kundcaseposter. Eftersom objektet BusinessHours och dess relaterade logik – avgörande för korrekta beräkningar som utesluter icke-arbetstider och helgdagar – inte kan kommas åt inbyggt i flödet används en dedikerad Apex klass. Denna klass, som ofta kallas något som ServiceLevelAgreementCalculator, är utformad med en enskild statisk metod, annoterad med @InvocableMethod, för att beräkna arbetstider, avgöra om servicenivåavtalet är "Inom mål" eller "Överskriden" och returnera en strukturerad utdata. Detta tillvägagångssätt sammanfattar den komplexa, högpresterande logiken i Apex samtidigt som det låter den köras sömlöst och integreras i det deklarativa orkestreringslagret i ett postutlöst flöde.
När Apex ServiceLevelAgreementCalculator har definierats är den tillgänglig för användning i ett postutlöst flöde:
Detta mönster visar på en strikt uppdelning av farhågor. Det deklarativa lagret används för att hantera transaktionens livscykel och orkestrering medan kod används för utförande med hög komplexitet. Genom att behandla kod som ett funktionellt verktyg snarare än grunden balanserar vi prestanda och underhållbarhet.
Modularitet: Beslutet rör sig bort från det unika i att använda Apex eller Flöde för hela processen. Istället samlar arkitekturen in komplex logik i diskreta, masssäkra och oberoende testbara enheter. Dessa enheter fungerar som återanvändbara komponenter konsumerade av det deklarativa lagret, vilket säkerställer automatiseringsskalorna utan att komplicera den arkitektoniska designen.
Återanvändbarhet: Logik är frånkopplad från utlösarhändelsen. En väl utformad kodenhet (till exempel en InvocableMethod) skrivs en gång men används över flera inmatningspunkter: Postutlösta flöden, skärmflöden eller externa integreringar. Denna återanvändning av kod eliminerar överflödig utveckling.
Underhållbarhet: Processflödeslogiken förblir synlig och hanterbar inom det deklarativa flödet. Denna centralisering minskar felsökningsoverhead drastiskt och säkerställer att systemets utförandeordning är deterministisk och transparent.
Hybridmodellen för att använda åberopbara Apex från Flow är kraftfull, men den passar inte alla. Arkitekter måste vara medvetna om de specifika begränsningarna och kompromisserna innan de bestämmer sig för en hybridlösning.
-
Inget stöd innan sparande: Detta är den mest kritiska begränsningen. Åberopbara åtgärder är endast tillgängliga i sammanhanget efter sparande (flöden för åtgärder och relaterade poster). De kan inte användas i det högpresterande sammanhanget innan sparande (flöden för snabbfältsuppdateringar). Detta mönster kan därför inte användas för att delegera uppdateringar av samma postfält. Utför detta högpresterande arbete med inbyggda flödeselement i ett flöde innan sparande eller inom en Apex innan sammanhang.
-
Inget stöd efter återställning: Postutlöst flöde har för närvarande inte stöd för sammanhanget efter återställning. Om ett Salesforce-objekt har ett verksamhetskrav för att köra automatisering när en post återställs från papperskorgen är en Apex den enda lösningen.
-
Prestandaoverhead i scenarion med hög volym: Övergången från flödesruntime till Apex runtime är inte en nollkostnadsoperation. Även om det i allmänhet är snabbt går det inte lika snabbt att släppa en åberopbar åtgärd från flödets körning som inbyggt utförande som helt stannar inom en Apex. För de flesta automatiseringar med medelhög densitet är denna micro-overhead en försumbar och värdefull kompromiss för den ökade tillgängligheten. För scenarion med extremt hög prestanda och hög volym har dock ett rent Apex ramverk en fördel vad gäller rå beräkningshastighet.
Även om automatiseringsdensiteten är heuristisk ger den definitiv vägledning för nyare greenfield-arkitektur, är verkligheten i företagets Salesforce-miljöer ofta mer nyanserad. I mogna organisationer är det vanligt att hitta postutlösta flöden och Apex som arbetar med samma Salesforce-objekt. Detta scenario skiljer sig från hybridmönstret som förklaras tidigare: här är flöden och Apex utlösare inte kopplade eller utformade för att fungera tillsammans.
Denna samexistens är ofta ett resultat av utveckling av plattformskapacitet eller äldre teknisk skuld. Även om detta är ett tolererat driftläge måste arkitekter behandla det som en beräknad kompromiss snarare än ett slutläge.
Den fragmenterade orkestreringen orsakar betydande styrning och underhåll, vilket gör aktiviteter för utveckling, test och incidenthantering osammanhängande och besvärliga. Detta leder till ökad tid till lösning (TTR) och operativ komplexitet.
-
För nya Salesforce-objekt, följ principen för automatiseringsdensitet som den primära guiden.
-
För befintliga Salesforce-objekt med ett hybridavtryck och dubbla Apex och postutlösta flödesingångar, bedöm densiteten och arkitekten för att refaktorisera till ett bibehållet hybridläge.
-
Vid låg densitet refaktoriserar Apex postutlösta flöden och anger ordningen på utförandet, vilket tar dem till en enskild automatiseringsingång.
-
För medelhög densitet, refaktorisera komplexa megaflöden till en underuppsättning flöden, med rätt ordning för utförandet. Introducera Apex endast när det är absolut nödvändigt, till exempel för att stödja efter ångrat sammanhang.
-
För hög densitet, gynna implementering av Apex utlösare.
-
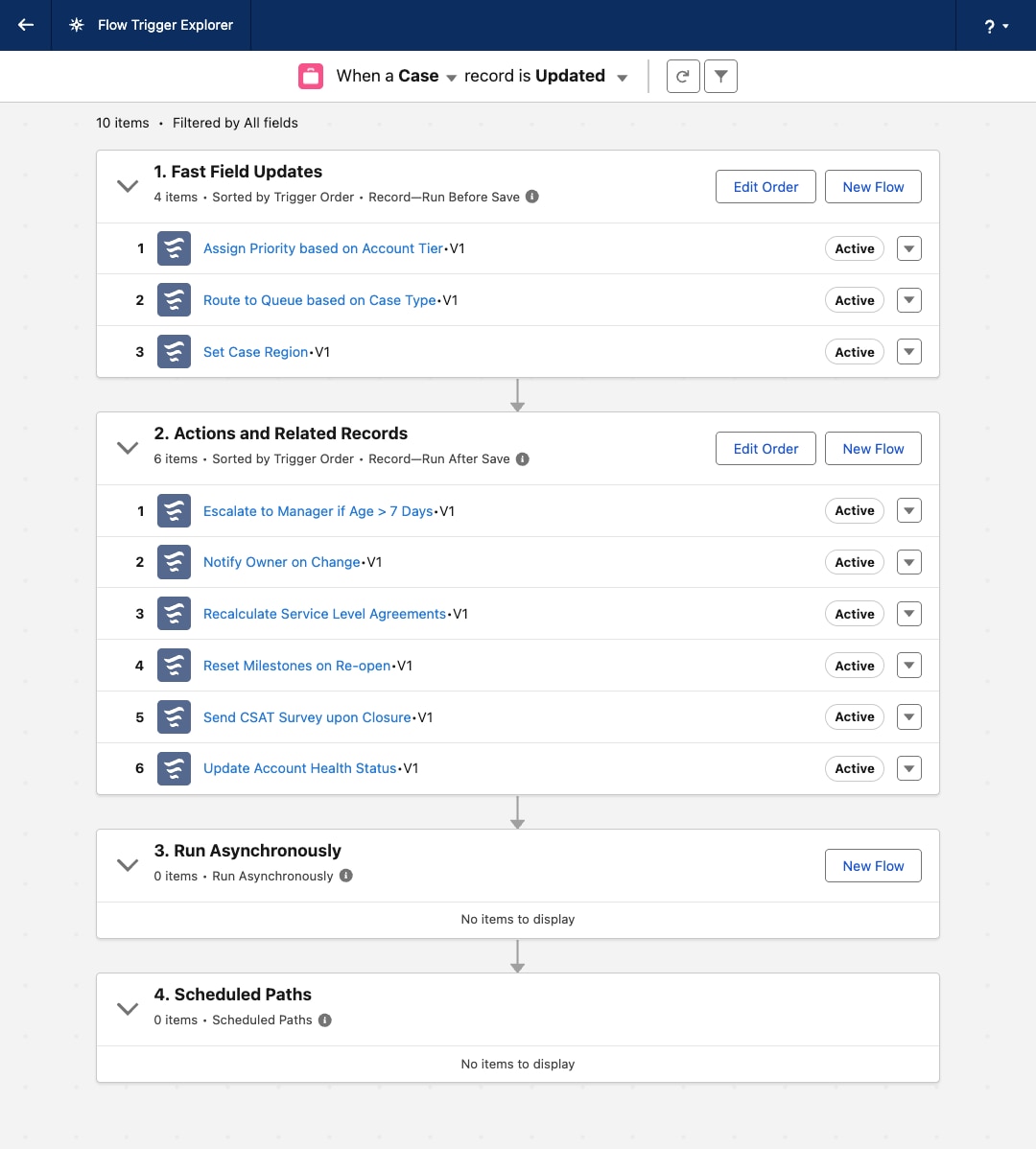
När en organisations verksamhetsprocesser på Salesforce Platform mognar ökar oundvikligen volymen och komplexiteten hos postutlöst automatisering. En grundläggande rekommenderad metod är att upprätthålla en Apex-utlösare per Salesforce-objekt. Denna regel är viktig eftersom plattformen inte garanterar utförandeordningen för flera utlösare på samma objekt för samma händelse. Denna begränsning kan leda till icke-deterministiskt beteende, rasförhållanden och problem som är svåra att felsöka.
Att följa principen om en utlösare innebär dock en arkitektonisk utmaning: att hantera och orkestrera all verksamhetslogik som åberopas från den enskilda ingången på ett underhållsbart, skalbart sätt.
Den första utvecklingen av denna arkitektur var Classic Trigger Handler-mönstret. På detta sätt delegerar den enskilda Apex-utlösaren all sin logik till en motsvarande hanterarklass (till exempel OpportunityTriggerHandler). Denna metod separerar logiken från utlösarfilen och ger utvecklare deterministisk kontroll över ordningen på utförandet inom hanterarklassens metoder (till exempel afterInsert()).
Även om det är en förbättring leder detta mönster ofta till monolitiska hanterarklasser. Med tiden, när fler verksamhetskrav läggs till, blir klassen stor, svår att hantera och svår att testa separat. Utförandeordningen för alla individuella processer hårdkodas inom en enda metod, vilket gör klassen benägen att slå samman konflikter, vilket dramatiskt ökar styrningen och underhållet i en stor företagsmiljö.
För att lösa kärnproblemen med modularitet och orkestrering övergår arkitekter till ett metadatadrivet utlösarramverk. Detta är ett betydande arkitektoniskt språng som kopplar bort själva automatiseringslogiken från konfigurationen av hur och när den körs.
Detta ramverk bygger på tre viktiga fördelar:
-
Partitionering: Istället för en enskild hanterarklass delas kärnverksamhetslogiken upp i små atomära Apex klasser (till exempel en
RecalculateAccountValueseller enNotifySalesLeads) där varje klass följer principen om enskilt ansvar. Denna modularitet gör logiken enklare att testa, felsöka och förstå separat. -
Order och koreografi: Utförandeordningen är inte längre hårdkodad i Apex. Istället definieras det deklarativt av konfigurationsposter, vanligtvis lagrade i en egen metadatatyp (till exempel
TriggerAction__mdt). Detta låter administratörer ändra ordning på, lägga till eller ta bort automatiseringsåtgärder helt enkelt genom att ändra en metadatapost, vilket inte kräver en distribuering eller kodändring. -
Kringgå funktionalitet: Ramverket tillhandahåller standardiserad, detaljerad förbikopplingsfunktionalitet. Varje automatiseringsåtgärd kan konfigureras via sin metadatapost för att stängas av globalt, eller förbigås för specifika administrativa användare genom hänvisning till en egen behörighet.
Den enskilda Apex för objektet fungerar sedan endast som en dynamisk utskickare. Den innehåller ingen verksamhetslogik utan instansierar istället en central MetadataTriggerHandler. Denna hanterare frågar de egna metadataposterna för att dynamiskt bestämma utförandesekvensen och åberopa rätt atomiska Apex klasser i den föreskrivna ordningen. Automatisering är sammanslagen i ett enda, transparent och styrbart lager.
En viktig fördel med att använda Apex i ett robust ramverk är möjligheten att hantera transaktionsstatus och optimera prestandan genom att eliminera överflödigt arbete. Allt eftersom logiken ackumuleras är det vanligt att olika automatiseringar inom sparordern oberoende utför samma dyra operationer, vilket konsumerar värdefulla styrande begränsningar och ökar DML-operationstiden.
Ramverket är utformat för att hantera detta med två primära strategier:
-
Delad lägeshantering: Inom ramen för en enskild Apex transaktion används statiska egenskaper och variabler för att cacha data. Detta säkerställer att en dyr operation, som en
SOQLför en konfigurationsinställning, endast utförs en gång, även om automatiseringslogiken åberopas flera gånger över olika poster eller faser i utlösaren. Användningen av transaktionsgränser minskas avsevärt. -
Användning av plattformscache: För att gå utöver enkel intratransaktionscache, använd plattformscache för att undvika att fråga hela databasen efter vissa data. Detta hanterade, in-memory-cache är idealiskt för att hämta data som är icke-primitiva, läses ofta över kodbasen och oföränderliga under hela transaktionen (till exempel profiler, roller, öppettider). Med
Cache.CacheBuilderkontrollerar systemet cacheminnet först och utför endast databasfrågan om data inte finns, vilket maximerar prestandan och skalbarheten.
Använd alltid en uppdatering innan sparande när din automatisering endast behöver ändra fältvärden i posten som startar transaktionen. Detta gäller för både snabbfältsuppdateringar i Flöde (som körs innan sparande) och logik innan sammanhang i Apex (innan infogning, innan uppdatering).
Detta mönster är effektivt, oavsett vilket verktyg som används, eftersom det undviker en andra DML-operation och en återkommande sparcykel. Ändringarna görs i posten i minnet innan den skickas till databasen och sparas som en del av den ursprungliga transaktionen. Overhead för en andra sparning, som annars skulle köra hela sparordern igen och starta all automatisering igen, elimineras.
Okontrollerad rekursion är en vanlig fallgrop i utlösare för efteruppdatering, där utlösarens logik utför en DML-uppdatering som i sin tur gör att samma utlösare aktiveras igen. Detta skapar en oändlig loop som till slut avslutas med ett undantag för styrande begränsningar. Statiska booleska flaggor eller samlingar av bearbetade post-ID:n har historiskt sett använts för att förhindra sådan rekursion, men ett mer exakt och robust mönster är att grinda logiken genom att jämföra fältvärden mellan den nya och gamla versionen av själva posten.
Utför logiken endast om ett specifikt intresseområde faktiskt har ändrats. Detta förhindrar utlösaren från att köra sin logik på efterföljande DML-operationer inom samma transaktion där viktiga data inte ändras.
I ett postutlöst flöde, förhindra okontrollerad rekursion genom att ställa in flödet att endast köras när posten uppdateras för att uppfylla villkorskraven:

Om du väljer att använda en formel för inmatningskriterier i ditt flöde kan du förhindra rekursion genom att jämföra den globala variabeln $Record (som representerar de nya värdena) med den globala variabeln $RecordPrior (som representerar de ursprungliga värdena innan sparandet). Till exempel, för att säkerställa att ett flöde endast körs om fältet Belopp i ett säljprojekt har ändrats, använd detta i inmatningskriterierna:
Jämför fältvärden från den nya versionen av posten, Trigger.new, med fältvärdena från den gamla versionen av posten, Trigger.oldMap, för att se om den specifika ändringen du letar efter har inträffat. Detta tillvägagångssätt säkerställer att automatiseringen är idempotent och endast körs vid behov, vilket gör systemet mer effektivt och förhindrar katastrofala återkommande loopar.
En välstrukturerad Salesforce-organisation kräver en konsekvent och pålitlig mekanism för att kringgå automatisering. Detta är inte en valfri funktion, utan ett grundläggande operativt krav för att upprätthålla dataintegritet och aktivera administrativa uppgifter.
Ett förbigångsramverk är viktigt för vissa scenarion:
-
Vid inläsning av stora mängder data kan utlösare för varje post drastiskt sakta ner processen, orsaka gränsundantag och skapa felaktiga relaterade poster och notiser. En förbikoppling låter data infogas rent och effektivt.
-
En integreringsanvändare kan behöva synkronisera data från ett externt postsystem. Automatiseringen som normalt aktiveras för en användarinitierad ändring (till exempel att skicka ett e-postmeddelande, skapa en uppgift) kan vara oönskad eller överflödig när ändringen kommer från ett annat system.
-
Administratörer eller supportpersonal kan behöva utföra korrigerande uppdateringar av poster. En förbikopplingsmekanism låter dem göra dessa ändringar utan att utlösa standardautomatiseringen, vilket kan få oavsiktliga konsekvenser.
Egna behörigheter: Den moderna, skalbara standarden för att implementera förbigångslogik är egna behörigheter. Dessa är överlägsna äldre metoder av flera anledningar:
-
Flexibilitet: Egna behörigheter kan tilldelas till användare via behörighetsuppsättningar. Denna praxis överensstämmer med den moderna Salesforce-säkerhets- och åtkomstmodellen, vilket möjliggör detaljerad och flexibel tilldelning. En förbigång kan beviljas till en specifik användare, eller till och med tillfälligt med ett specifikt utgångsdatum/-tid.
-
Underhållbarhet: Att använda egna behörigheter undviker att hårdkoda profiler eller användare till automatiseringslogik. Om en användares roll ändras eller en ny profil behöver förbigå åtkomst är ändringen en enkel tilldelning av behörighetsuppsättning, inte en kod eller flödesändring som kräver en distribuering.
-
Skalbarhet: Egna behörigheter ger ett skalbart ramverk för att hantera undantag i en komplex användarbas. De kan tilldelas till användare via behörighetsuppsättningar, behörighetsuppsättningsgrupper eller profiler. Deras associering till en behörighetsuppsättning eller profil är också representativ i källmetadata.
Genomförandemönster: Tillämpa ett enhetligt förbigångsmönster för all postutlöst automatisering i organisationen.
Kringgå ett postutlöst flöde: Det mest effektiva sättet att förbigå ett flöde är att förhindra att det körs alls. Detta uppnås genom att lägga till ett villkor i flödets inmatningskriterier.
-
I startelementet i det postutlösta flödet, sätt Villkorskrav till Formel utvärderar till sant.
-
I formelbyggaren, införliva en kontroll av den egna behörigheten med den globala variabeln
$Permission. Kombinera kontrollen med dina befintliga inmatningskriterier.- Formelmönster:
-
Detta mönster säkerställer att flödet endast körs om användaren inte har den specificerade egna behörigheten tilldelad. Denna kontroll utförs innan flödesintervjun ens har skapats, vilket gör den till den metod som presterar bäst.
-
Kringgå ett Apex-utlösarramverk: I Apex, integrera förbigångslogiken direkt i det metadatadrivna utlösarramverket, vilket möjliggör detaljerad kontroll.
-
Den egna metadatatypen
TriggerAction__mdtska innehålla ett textfält, till exempelBypassPermission__c.-
Innan en åtgärd utförs dynamiskt i klassen
MetadataTriggerHandlerska koden läsa värdet från detta fält. -
Om fältet är ifyllt använder hanteraren metoden
FeatureManagement.checkPermission()för att avgöra om den aktuella aktuella aktuella användaren har den specificerade egna behörigheten. -
Om
checkPermission()returnerar sant hoppar hanteraren över den specifika åtgärden och fortsätter till nästa i sekvensen. -
Detta mönster är kraftfullt eftersom det tillåter både en global förbikoppling (om alla
TriggerAction__mdtrefererar samma behörighet) och en detaljerad förbikoppling per åtgärd (om olika poster refererar olika behörigheter eller vissa inte har någon förbikopplingsbehörighet alls).
-
Det är ett anti-mönster för att slå samman ett objekts automatisering till ett enda, massivt megaflöde. Att slå samman till ett flöde jämfört med att dela upp logik i flera, välbetingade flöden har ingen större påverkan på prestandan. De mest betydande prestandaförbättringarna kommer från:
-
Använda flöden innan sparande för uppdateringar av samma postfält.
-
Skriva exakta inmatningsvillkor för att säkerställa att flöden utesluts från att köras för ändringar som inte påverkar deras specifika användningsfall.
Flödesutforskaren låter dig tilldela ett ordervärde till varje flöde för ett objekt, vilket garanterar en sekventiell utförandeorder.
| Apex | Flöde | Operationer |
|---|---|---|