Använda rätt verktyg och mönster för händelsedrivna arkitekturer
Händelsedrivna arkitekturer har stöd för effektiv produktion och användning av händelser som kommunicerar ändringar av system- eller programstatus. Dessa arkitekturer möjliggör flexibla anslutningar mellan system och supportprocesser och uppdateringar nästan i realtid som fungerar mellan system. Fördelarna med händelsedrivna arkitekturer är enkla att se, men implementeringsdetaljerna är inte alltid lika tydliga. Vilka kapaciteter behöver du överväga i händelsedrivna arkitektoniska mönster? Vilka specifika problem löser dessa mönster? Vilka speciella överväganden gäller för dina lösningar och vilka är de optimala mönstren för att hantera dem?
Denna guide presenterar mönster som används för att bygga optimala händelsedrivna arkitekturer vid arbete med Salesforce-tekniker. Den diskuterar även händelseverktyg som är tillgängliga från Salesforce och ger verktygsrekommendationer för ett urval av användningsfall. Mer information om datanivåintegreringar som involverar Salesforce finns i vår Beslutsguide för dataintegrering.
-
Använd händelsedrivna arkitekturer för processer som inte kräver synkrona svar på begäranden. De mönster som beskrivs i denna guide är utformade för enhetlighet, skalbarhet och återanvändning av data, vilket hjälper till att hålla den tekniska skulden till ett minimum i takt med att din organisations programlandskap utvecklas. (Se Väl arkitektonisk - Genomströmning för mer information.)
-
Om MuleSoft eller en annan Enterprise Service Bus-lösning (ESB) är en del av ditt befintliga landskap, använd den där det är möjligt. Dessa lösningar är specialbyggda för att stödja händelsedrivna arkitekturmönster och har kraftfulla funktioner som låter dig återanvända integreringar i hela din verksamhet.
-
Använd Pub/Sub API för framtida publicerings-/prenumerationsmönster istället för att bygga dina egna händelsehanterare med andra API:n, inklusive Streaming API. Nu när Pub/Sub API är allmänt tillgängligt, använd det för nya publicerings-/prenumerationsmönster. Planera att migrera befintlig händelsekommunikation med andra plattforms-API:n, som Streaming API eller egna Apex tjänster, till Pub/Sub API när det är möjligt.
-
Plattformshändelser och datainsamling (CDC) är de mekanismer som föredras för att publicera ändringar av poster och fält som behöver konsumeras av andra system. Vi rekommenderar inte att använda PushTopic och generiska händelser för nya implementeringar. Salesforce kommer att fortsätta att stödja PushTopic och generiska händelser inom nuvarande funktionalitet, men planerar inte att göra ytterligare investeringar i denna teknik.
 |
Salesforce Platform är en omfattande, AI-driven plattform som förenar anställda, autonoma AI-agenter, företagsdata och program i ett enda, tillförlitligt system för att förbättra produktiviteten och kundupplevelsen. Det gör det möjligt att skapa ett "agentföretag" genom att ansluta Customer 360 appar, Data Cloud och Slack för automatisering från början till slut. |
 |
MuleSoft är Salesforces ledande integreringsplattform som låter organisationer ansluta program, data och enheter mellan lokala miljöer och molnmiljöer. MuleSoft är en plattform som ger IT plattformarna för att låsa upp data mellan system, utveckla skalbara ramverk för integration och automatisering och skapa differentierade, anslutna upplevelser – snabbt. |
Händelsedrivna arkitekturer (EDA) rekommenderas för scenarion som kräver notiser nästan i realtid, distribuerar bearbetningsbelastning för meddelanden med hög volym eller komplexa meddelanden och integrerar system som IoT och mobila enheter som kräver anslutningstålighet genom köer. EDA bör dock inte implementeras för processer som kräver omedelbara, synkrona mänskliga svar, eftersom de är utformade för asynkron körning. De passar inte heller bra om källdata ändras så sällan att ett enklare mönster som batchbearbetning skulle räcka.
Här är flera vanliga scenarion som ofta passar bra för en händelsedriven arkitektur:
| Beslutspunkt | Vägledning |
|---|---|
| Notiser nästan i realtid | Händelsedrivna arkitekturmönster som publicera/prenumerera, fanout och streaming tenderar att fungera bra i scenarion där flera program behöver meddelas om statusändringar eller postuppdateringar nästan i realtid. |
| Parallell bearbetning | Mönster som publicera/prenumerera tenderar att fungera bra i scenarion där stora datavolymer eller mycket komplexa meddelanden kräver att bearbetningsbelastningen fördelas mellan flera system. |
| Läsning med hög volym | Mönstren Skickade meddelanden och Köer används ofta i scenarion där organisationer upplever ökningar och volymen meddelanden som produceras kan överstiga prenumeranters möjlighet att omedelbart bearbeta dem. |
| Skriver med hög volym | Mönstren Streaming och Kö fungerar bra i många scenarion där organisationer upplever ökningar i antalet meddelanden som produceras. |
| Skicka samma data till olika system | Publicera/prenumerera tenderar att vara en ganska vanlig lösning för organisationer som behöver skicka samma data till flera system, men det kan hanteras av de flesta mönster som tas upp här. Se till att gå igenom dem i detalj för att hitta den bästa passformen. |
| Frekvent införande av nya system eller enheter | Mönstren publicera/prenumerera, strömmande och köer tenderar att fungera bra för scenarion där det övergripande landskapet tenderar att vara i förändring, med nya system och enheter som läggs till regelbundet. I detta scenario behöver ett nytt system eller enhet helt enkelt bli prenumerant på händelsebussen eller associerad med en kö för att börja ta emot meddelanden istället för att kräva en egen punkt-till-punkt-integrering. |
| IoT-enheter | Eftersom IoT-enheter vanligtvis levererar frekventa uppdateringar och även kan generera en ström av meddelanden i vissa scenarion tenderar ström- och kömönster att fungera bra när de integreras i ett IT-landskap. |
| Mobila enheter och system offline | Mobilenheter som behöver arbeta i områden med låg kvalitet eller obefintlig internetåtkomst eller system som kan vara offline när meddelanden levereras kommer att dra nytta av kömönstret, som låter dem ansluta till sina köer och hämta relevanta meddelanden när de är online igen. |
De flesta stora organisationer har komplexa IT-landskap som har en kombination av system med olika kapacitet. Det är möjligt, eller kanske troligt, att din organisation har äldre system som inte har stöd för händelsedrivna integreringar. Du kan även ha användningsfall där händelsedrivna integreringar inte fungerar, även om systemen kommer att stödja dem (till exempel SFTP-filöverföringar från tredje part). Om du tar ett steg tillbaka och ser på din organisations IT-landskap som en helhet är chansen stor att du, precis som med andra arkitektoniska lösningar, använder en blandning av mönster för att stödja olika scenarion. När du bestämmer dig för att göra händelsedriven din föredragna metod för integreringar, tänk på det som ett annat verktyg i din verktygslåda. Det kan och bör användas i rätt scenarion, men det är inte ett tillvägagångssätt som ska tillämpas på alla system. Att utveckla en omfattande integreringsstrategi hjälper dig avgöra när de mönster som beskrivs i denna guide kan vara lämpliga eller inte.
Många scenarion kräver händelsedrivna arkitekturer, och i vissa scenarion fungerar händelsedrivna arkitekturer även om de inte passar bäst. Men i vissa scenarion ska händelsedrivna arkitekturer helt enkelt inte användas. Här är några frågor om beslutspunkter för att hjälpa dig identifiera dessa scenarion:
| Beslutspunkt | Vägledning/frågor att ställa |
|---|---|
| Verksamhetskrav | Finns det ett genuint verksamhetsbehov för någon av funktionaliteten som beskrivs i sektionen [När man ska använda en händelsedriven arkitektur](#när-man-ska-använda-en-händelsedriven-arkitektur)? |
| Tekniska krav | Är integreringen som du utformar en uppenbar passform för ett annat mönster, till exempel datavirtualisering, batch eller begäran/svar? Med andra ord, försöker du passa in en fyrkantig pinne i ett runt hål? |
| Processer som kräver att människor väntar på svar | Ingen integrering som involverar att en person väntar på ett svar från målsystemet passar bra för händelsedrivna arkitekturer, eftersom de är utformade för asynkron körning och inte kan garantera en svarstid. Tänk igenom om processer som denna är optimala för din organisation innan du implementerar tekniska lösningar. Se [Väl arkitektat - Processdesign](/docs/architect/sv-se/well-architected/guide/automated#processdesign) för mer information. |
| Källdata ändras sällan | Om data i ditt källsystem ändras så sällan att periodiska uppdateringar är tillräckliga kan du troligen förenkla din arkitektur genom att använda [batch patterns](https://developer.salesforce.com/docs/atlas.en-us.integration_patterns_and_practices.meta/integration_patterns_and_practices/integ_pat_batch_data_sync.htm) istället för händelsedrivna mönster. |
| Genomförandekrav | Har majoriteten av systemen som är involverade i din lösning stöd för händelsedrivna arkitekturer? Vad skulle krävas för att använda händelsedrivna arkitekturer med de system som inte har stöd för dem (till exempel uppgraderingar, anpassningar eller middleware)? Hur stora ansträngningar skulle behövas för att uppfylla dessa krav? |
| Meddelandestrukturstabilitet | Hur ofta behöver dina meddelandestrukturer ändras? Vilka system kommer att påverkas av en sådan förändring och hur kommer saneringsprocessen att se ut? |
| Organisatorisk styrning | Har du en styrstruktur som säkerställer att alla intressenter är informerade om och kan väga in ändringar av meddelandestrukturer, utlösare och andra arkitektur- och processrelaterade beslut? |
| Kompetensuppsättningar som behövs | Har din personal erfarenhet av händelsedrivna arkitekturer och vet de hur de ska stödja dem? |
Det finns flera olika händelsedrivna arkitekturmönster. Vissa är allmänna mönster som kan tillämpas i användningsfall som inte har några särskilda krav utöver att vara händelsedrivna. Se till exempel Väl arkitektoniska - Interoperabilitet. Andra mönster är tillämpliga för de specifika användningsfall som diskuteras här, till exempel integreringar som involverar stora datavolymer, eller scenarion som kräver längre meddelandelagring.
Tabellen nedan jämför attribut för de mönster som beskrivs i detta dokument. Använd den som en snabbreferens när du behöver identifiera potentiella mönster för ett givet användningsfall.
| Pattern | Nästan i realtid | Unik meddelandekopia | Garantileverans | Minska meddelandestorlek | Transformera data |
|---|---|---|---|---|---|
| Publicera / Prenumerera | ✓ | ✓ | ✓ | ||
| Fanout | ✓ | ✓ | ✓ | ||
| Skickade meddelanden | ✓ | ✓ | ✓ | ✓ | |
| Streaming | ✓ | ✓ | ✓ | ||
| Kö | ✓ | ✓ | ✓ |
Salesforce erbjuder flera verktyg för att hjälpa dig hantera dina händelsedrivna användningsfall. Denna tabell innehåller en översikt på hög nivå över tillgängliga verktyg.
| Verktyg | Beskrivning | Kompetens som behövs | |
|---|---|---|---|
| MuleSoft | Anypoint Platform | Plattform som möjliggör dataintegrering med hjälp av lager av API:n. | Pro-kod |
| Salesforce Pub/Sub-anslutare | Anslutare för Pub/Sub API, som ger ett enda gränssnitt för att publicera och prenumerera på plattformshändelser, händelser för händelseövervakning i realtid och händelser för datainsamling av ändringar. | Pro-kod | |
| MuleSoft Anypoint JMS-anslutare | Anslutare som gör det möjligt att skicka och ta emot meddelanden till köer och ämnen för alla meddelandetjänster som implementerar Java Message Service-specifikationen (JMS). | Pro-kod | |
| MuleSoft Anypoint Apache Kafka-anslutare | Anslutare för att flytta data mellan Apache Kafka och företagsprogram och tjänster. | Pro-kod | |
| MuleSoft Anypoint Solace-anslutare | En anslutare för Solace PubSub+-händelseförmedlare med inbyggd API-integrering med JCSMP Java SDK | Pro-kod | |
| MuleSoft Anypoint MQ-anslutare | En molnmeddelandetjänst med flera klienter som låter kunder utföra avancerade asynkrona meddelanden mellan sina program. | Pro-kod | |
| MuleSoft Anypoint MQTT-anslutare | Ett MQTT-tillägg (Message Queuing Telemetry Transport) v3.x-protokollkompatibelt MuleSoft. | Pro-kod | |
| MuleSoft Anypoint AMQP-anslutare | En anslutare som låter ditt program publicera och konsumera meddelanden med en AMQP 0.9.1-kompatibel förmedlare. | Pro-kod | |
| MuleSoft Anypoint Händelsedriven (ASync) API | Branschagnostiskt språk som stöder publicering av händelsedrivna API:n genom att dela upp dem i händelse-, kanal- och transportlager. | Pro-kod | |
| MuleSoft Anypoint MQ | Multitenant molnmeddelandetjänst som låter kunder utföra avancerade asynkrona meddelanden mellan sina program. | Pro-kod | |
| MuleSoft Anypoint-dataströmmar | Ramverk tillgängligt inom MuleSoft Anypoint för publicering och prenumeration på strömmande data. | Pro-kod | |
| Salesforce Platform | Apache Kafka på Heroku | Heroku-tillägg som tillhandahåller Apache Kafka som en tjänst med fullständig plattformsintegrering i Heroku-plattformen. | Pro-kod |
| Ändra datainsamling | Ändringshändelselogg, som publicerar ändringar av Salesforce-poster. Ändringar inkluderar skapande av en ny post, uppdateringar av en befintlig post, borttagning av en post och återborttagning av en post. | Lågkod till Pro-kod | |
| Utgående meddelanden | Åtgärder som skickar XML-meddelanden till externa slutpunkter när fältvärden uppdateras i Salesforce. | Lågkod | |
| Plattformshändelser | Säkra och skalbara meddelanden som innehåller egna händelsedata. | Lågkod till Pro-kod | |
| Pub/Sub API | API som aktiverar prenumerationer på plattformshändelser, händelser för datainsamling och/eller händelser för händelseövervakning i realtid. | Pro-kod | |
| Händelsereläer | Aktiverar plattformshändelser och händelser för datainsamling som ska skickas från Salesforce till Amazon EventBridge. Observera att händelsereläer endast ansluter till AWS Eventbridge. | Lågkod | |
När en viktig post ändrar status i ett huvudprogram—till exempel en orders status flyttas från "Bearbetar" till "Levererad"—kräver flera andra system troligen en notis nästan i realtid för att utföra sina respektive uppgifter. Ett specifikt verksamhetsbehov uppstår när volymen på dessa ändringar är hög och meddelandena är komplexa, vilket gör traditionella punkt-till-punkt-integreringar betungande och svåra att underhålla. Att etablera ömtåliga, egna anslutningar för varje enskilt beroende program leder till tekniska skulder och hämmar organisationens förmåga att snabbt skala upp. En robust integreringsmetod behövs för att hantera dessa frekventa datasynkroniseringar utan att koppla källsystemet direkt till varje konsumerande system.
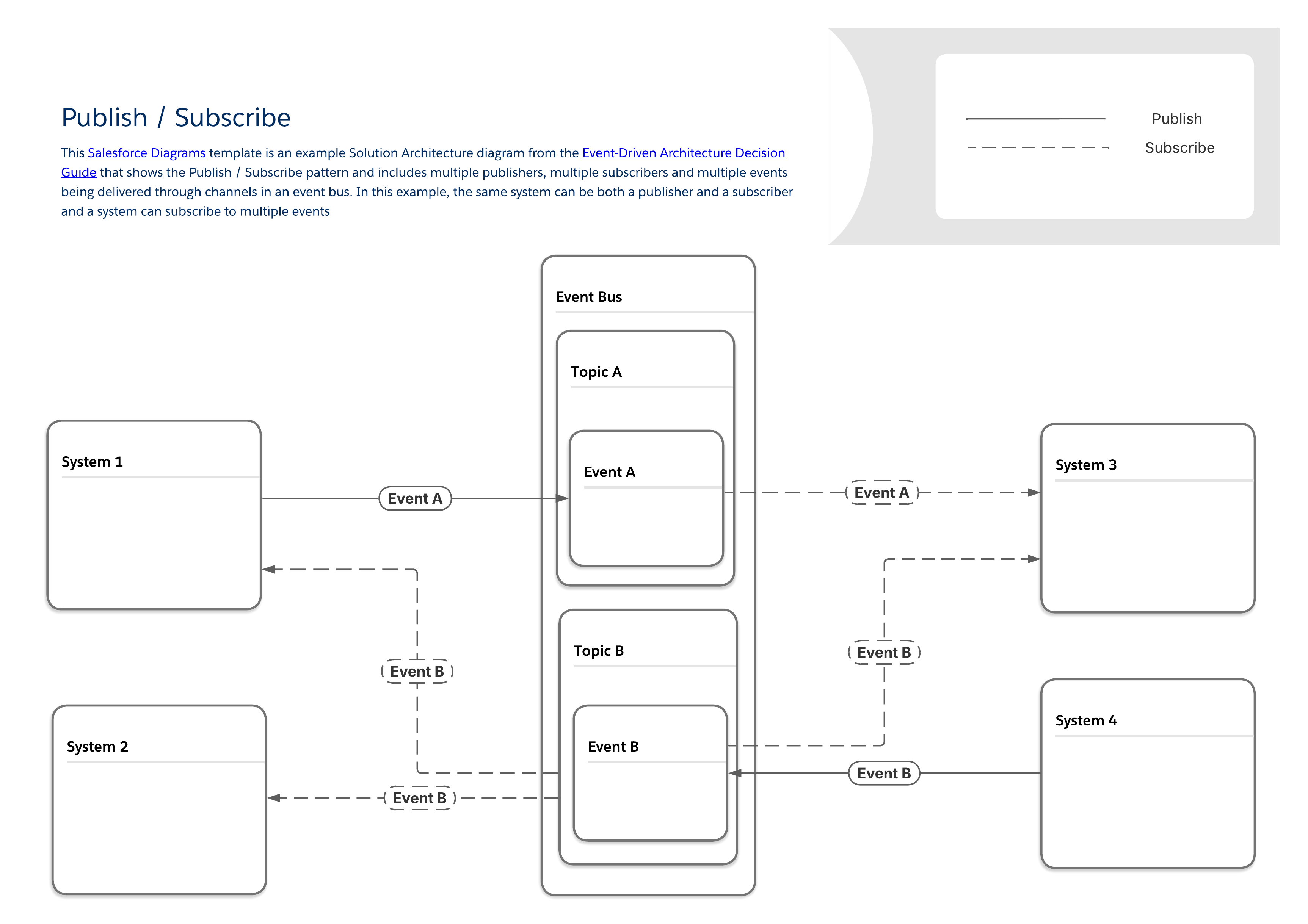
Diagrammet nedan visar ett typiskt mönster för publicering/prenumeration med flera utgivare och prenumeranter som delar data genom en händelsebuss. Detta grundläggande mönster utgör grunden för de mer specifika mönster som finns i resten av denna guide. Några viktiga egenskaper hos detta mönster är:
-
Det finns ingen direkt anslutning mellan utgivare och prenumeranter. Utgivare skickar bara meddelanden till en händelsebuss, som skickar dem till andra system som vill lyssna efter dem.
-
Samma system kan vara både en utgivare och en prenumerant.
-
System kan publicera eller prenumerera på flera typer av händelser.
-
Som med alla mönster i denna guide hamnar publicerings-/prenumerationsmönstret i en allmän kategori för integreringsmönster som kallas RPI (fjärrproceduranrop) eller helt enkelt "skjut och glöm".
| Händelseflöde och beteende | Att tänka på vad gäller belastning | ||||||
|---|---|---|---|---|---|---|---|
| Tillgängliga verktyg | Kompetens som behövs | Publicera via | Prenumerera via | Reprisperiod | Payload-struktur | Gränser för belastning | |
| MuleSoft | Anypoint Platform | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen |
| Salesforce Pub/Sub-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint JMS-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint Apache Kafka-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint Solace-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint MQ-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint MQTT-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint AMQP-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint Händelsedriven (ASync) API | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint MQ | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| Salesforce Platform | Apache Kafka på Heroku | Pro-kod | API, poständringar i Heroku Postgres | EJ TILLÄMPLIGT | 1-6 veckor | Användardefinierad | Användardefinierad |
| Ändra datainsamling | Lågkod till Pro-kod | Poständringar | Apex, API, Lightning webbkomponenter (LWC) | 3 dagar | Fördefinierad | 1 MB | |
| Utgående meddelanden* | Lågkod | Flödes- och arbetsflödesregler | EJ TILLÄMPLIGT | 24 timmar | Användardefinierad | 100 notiser per meddelande | |
| Plattformshändelser | Lågkod till Pro-kod | API, Apex, Flöde | Apex, API, Flöde, LWC | 3 dagar | Användardefinierad | 1 MB | |
| Pub/Sub API | Pro-kod | Pub/Sub API eller API, Apex, Flöde | Pub/Sub API | 3 dagar | Användardefinierad | 1 MB | |
| Händelsereläer** | Lågkod | Plattformshändelser, Ändra datainsamling | API | 3 dagar | Användardefinierad | 1 MB | |
| *Salesforce kommer att fortsätta att stödja utgående meddelanden inom nuvarande funktionalitet, men planerar inte att göra ytterligare investeringar i denna teknik. **Händelsereläer ansluter endast till AWS Eventbridge | |||||||
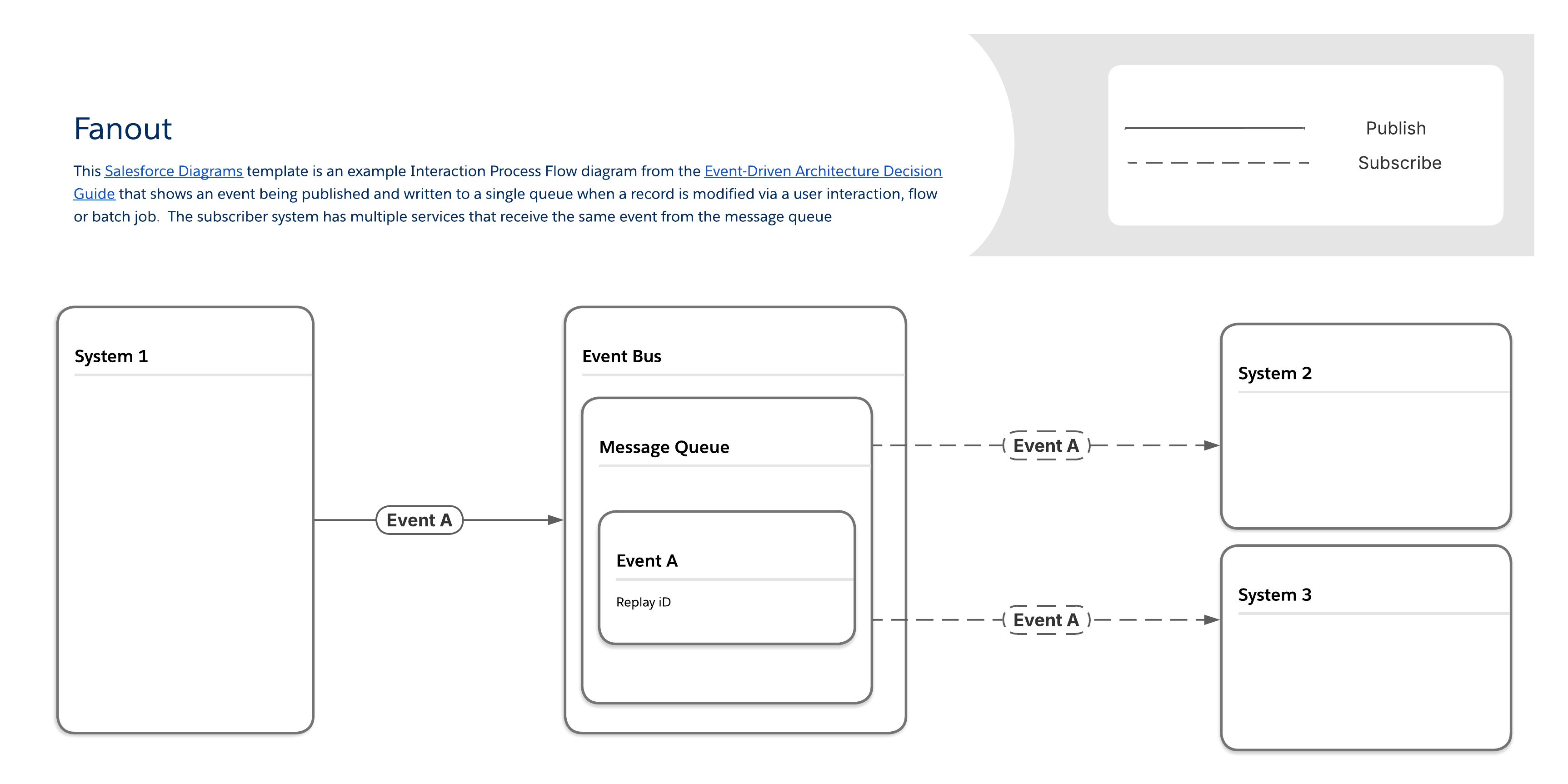
När en organisation behöver skicka omedelbara uppdateringar av ett stort antal klientprogram, som pushnotiser eller SMS till mobila enheter, blir den traditionella processen att skapa unika överföringar för varje enskild mottagare snabbt en flaskhals för skalbarhet. Kärnverksamhetsbehovet i detta fall är snabb, högpresterande distribution av en enskild information—som en kontovarning eller ett viktigt meddelande om serviceändring—till flera slutpunktsprogram samtidigt. Ett effektivt tillvägagångssätt för att uppfylla detta krav innefattar att dirigera alla meddelanden genom en enda kö, vilket fungerar som den centrala punkten för händelseinformation för alla konsumerande system. Detta tillvägagångssätt förbättrar prestandan genom att eliminera behovet av att hantera många separata meddelandekopior.
Med fanoutmönstret levereras meddelanden till en eller flera destinationer (det vill säga lyssnande klienter eller prenumeranter) genom en enda meddelandekö. Prenumeranter hämtar samma meddelande från kön istället för sin egen unika kopia. (Observera att även om detta förbättrar prestandan kan det även göra det svårare att verifiera om en viss prenumerant har fått meddelandet eller inte.)
| Händelseflöde och beteende | Att tänka på vad gäller belastning | ||||||
|---|---|---|---|---|---|---|---|
| Tillgängliga verktyg | Kompetens som behövs | Publicera via | Prenumerera via | Reprisperiod | Payload-struktur | Gränser för belastning | |
| MuleSoft | MuleSoft Anypoint JMS-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen |
| Salesforce Pub/Sub-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint Apache Kafka-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint Solace-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint MQ-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint MQTT-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint AMQP-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint MQ | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| Salesforce Platform | Apache Kafka på Heroku | Pro-kod | API, poständringar i Heroku Postgres | EJ TILLÄMPLIGT | 1-6 veckor | Användardefinierad | Användardefinierad |
| Ändra datainsamling | Lågkod till Pro-kod | Poständringar | Apex, API, Lightning webbkomponenter (LWC) | 3 dagar | Fördefinierad | 1 MB | |
| Plattformshändelser | Lågkod till Pro-kod | API, Apex, Flöde | Apex, API, Flöde, LWC | 3 dagar | Användardefinierad | 1 MB | |
| Pub/Sub API | Pro-kod | Pub/Sub API eller Apex, API, Flöde | Pub/Sub API | 3 dagar | Användardefinierad | 1 MB | |
| Händelsereläer* | Lågkod | Plattformshändelser, Ändra datainsamling | API | 3 dagar | Användardefinierad | 1 MB | |
| *Händelsereläer skickar endast data till AWS Eventbridge | |||||||
Vissa händelsescenarion kännetecknas av ett betydande inflöde av meddelandevolym som hotar att överväldiga kapaciteten hos synkroniserings- och transformationsprocesser, eller av komplex flerstegslogik som krävs för att bearbeta och transformera händelsedata.
Några exempel inkluderar:
-
Säsongsmässiga volymtoppar: Det kan finnas ökningar i volym som onlinebutiker upplever när ett urval av deras produkter är "i säsong". Om ett stort antal kunder gör inköp samtidigt kan antalet händelser som skapas tillfälligt överskrida kapaciteten för synkroniserings- och transformationsprocesser. Mer information finns i Väl arkitekterade - Datahantering.
-
Kundcase- eller anspråkshantering: Servicebaserade företag kan uppleva ökningar i antalet kundcase eller anspråk under avbrott.
-
Komplexa datatransformationer: Organisationer som behöver komplex logik för att transformera meddelanden är ofta oroliga för att händelser skapas snabbare än de kan transformeras.
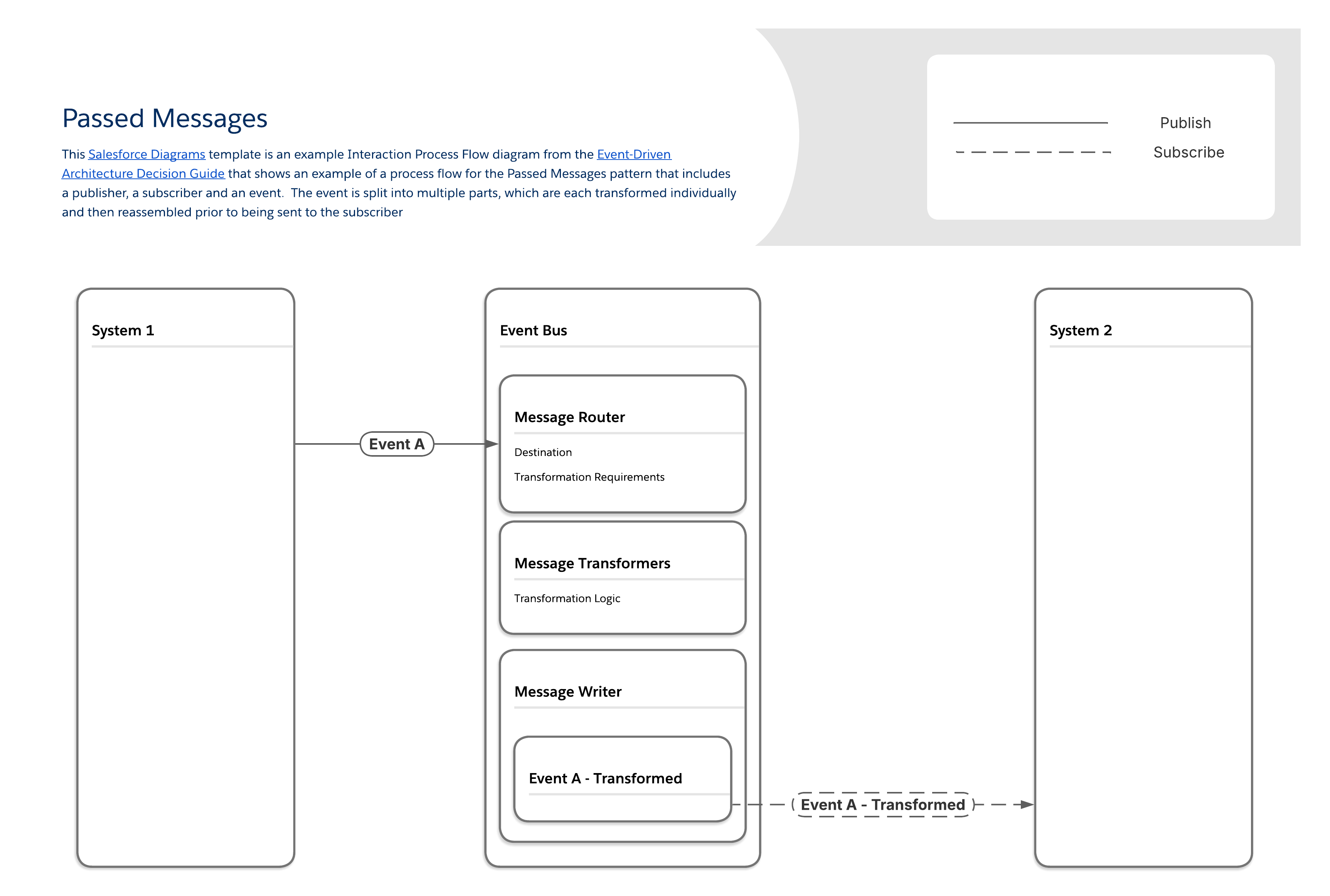
Detta mönster hanterar utmaningen med att meddelanden skapas snabbare än de kan transformeras. Det säkerställer att stora mängder meddelanden och nödvändiga datamanipulationer kan hanteras tillförlitligt, med en plattform för strömmande meddelanden och segmentering av meddelandehanteringslogik i dedikerade komponenter.
Mönstret Skickade meddelanden fungerar genom att segmentera meddelandehanteringslogik i flera komponenter:
-
En komponent hanterar meddelandedirigering, avgör vilka transformationer som behövs och slutdestinationen.
-
En separat uppsättning komponenter hanterar olika lager av meddelandetransformation (till exempel fältmappningar, objektrelationer och så vidare).
-
Den sista komponenten skriver ut det slutgiltiga, ändrade meddelandet.
| Händelseflöde och beteende | Att tänka på vad gäller belastning | ||||||
|---|---|---|---|---|---|---|---|
| Tillgängliga verktyg | Kompetens som behövs | Publicera via | Prenumerera via | Reprisperiod | Payload-struktur | Gränser för belastning | |
| MuleSoft | MuleSoft Anypoint Apache Kafka-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen |
| Salesforce Pub/Sub-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| Salesforce Platform | Apache Kafka på Heroku | Pro-kod | API, poständringar i Heroku Postgres | EJ TILLÄMPLIGT | 1-6 veckor | Användardefinierad | Användardefinierad |
| Ändra datainsamling | Lågkod till Pro-kod | Poständringar | Apex, API, Lightning webbkomponenter (LWC) | 3 dagar | Fördefinierad | 1 MB | |
| Plattformshändelser | Lågkod till Pro-kod | API, Apex, Flöde | Apex, API, Flöde, LWC | 3 dagar | Användardefinierad | 1 MB | |
| Pub/Sub API | Pro-kod | Pub/Sub API eller API, Apex flöde | Pub/Sub API | 3 dagar | Användardefinierad | 1 MB | |
| Händelsereläer* | Lågkod | Plattformshändelser, Ändra datainsamling | API | 3 dagar | Användardefinierad | 1 MB | |
| *Händelsereläer skickar endast data till AWS Eventbridge | |||||||
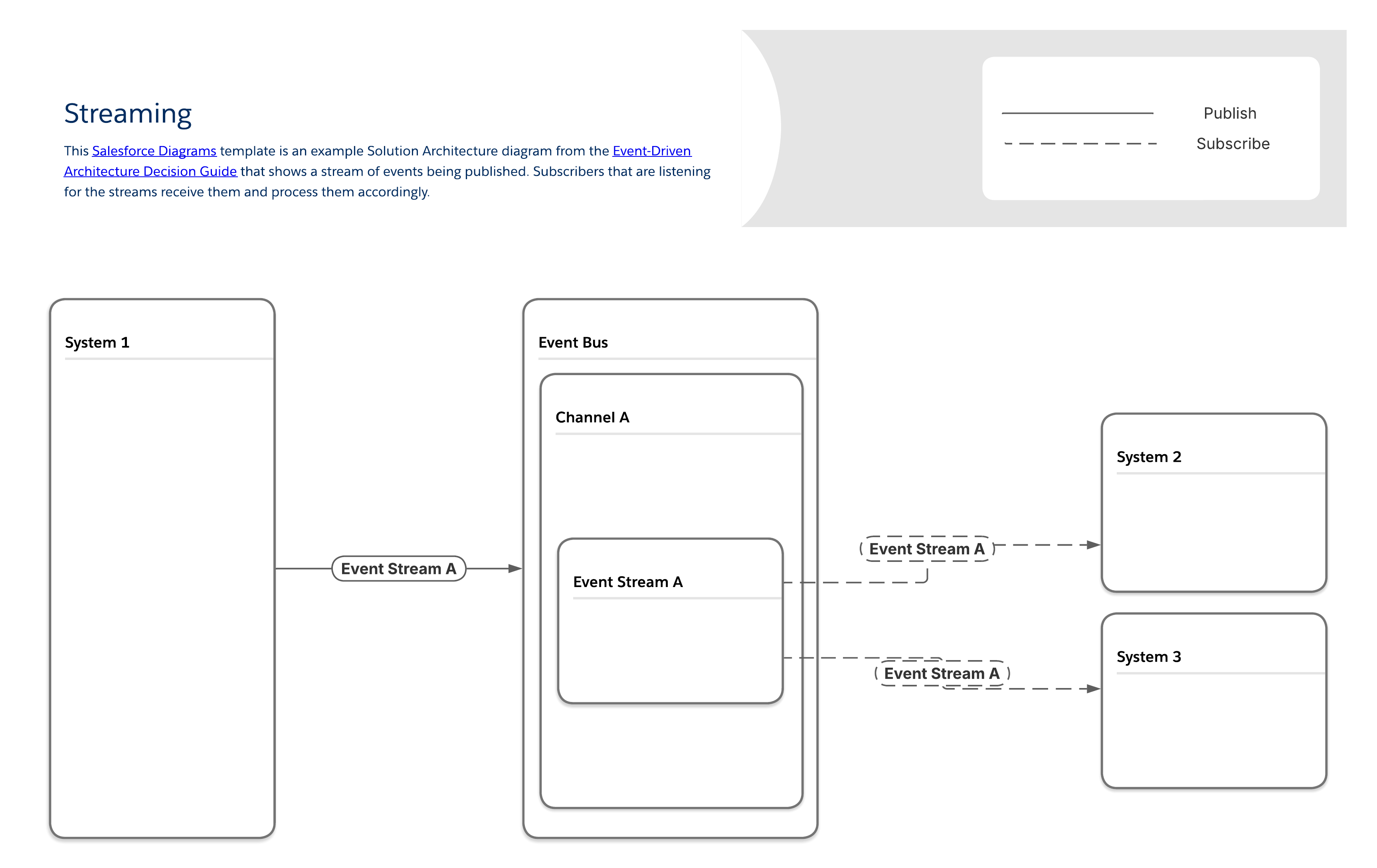
Vissa producenter skapar en kontinuerlig ström av händelser. Ett vanligt exempel är mediestreaming, som involverar användarinteraktioner som naturligt inträffar som diskreta händelser. Flera system måste reagera på samma användarbeteende samtidigt utan att blockera huvudupplevelsen av streaming.
Tänk på händelserna för en plattform för musikstreaming. Dessa kan inkludera:
-
Följ startade/pausade/överhoppade händelser
-
Lyssna sessionshändelser med tidsstämplar
-
Spellisteskapande/ändringshändelser
-
Sociala delningshändelser
-
Ladda ner för offlinelyssning
I mönstret Streaming kommer prenumeranter åt varje händelseström och bearbetar händelserna i exakt den ordning de tas emot. Unika kopior av varje meddelandeström skickas till varje prenumerant, vilket gör det möjligt att leverera prenumerantspecifikt innehåll och identifiera vilka prenumeranter som får vilka strömmar.
| Händelseflöde och beteende | Att tänka på vad gäller belastning | ||||||
|---|---|---|---|---|---|---|---|
| Tillgängliga verktyg | Kompetens som behövs | Publicera via | Prenumerera via | Reprisperiod | Payload-struktur | Gränser för belastning | |
| MuleSoft | MuleSoft Anypoint-dataströmmar | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen |
| Salesforce Pub/Sub-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint Apache Kafka-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| Salesforce Platform | Apache Kafka på Heroku | Pro-kod | API, poständringar i Heroku Postgres | EJ TILLÄMPLIGT | 1-6 veckor | Användardefinierad | Användardefinierad |
| Pub/Sub API | Pro-kod | Pub/Sub API eller API, Apex flöde | Pub/Sub API | 3 dagar | Användardefinierad | 1 MB | |
För att en ström ska fungera måste alla dess händelser och deras associerade meddelanden vara i rätt ordning. Om du hämtar data i en ström från olika system måste du införliva ytterligare orderlogik som en del av designprocessen.
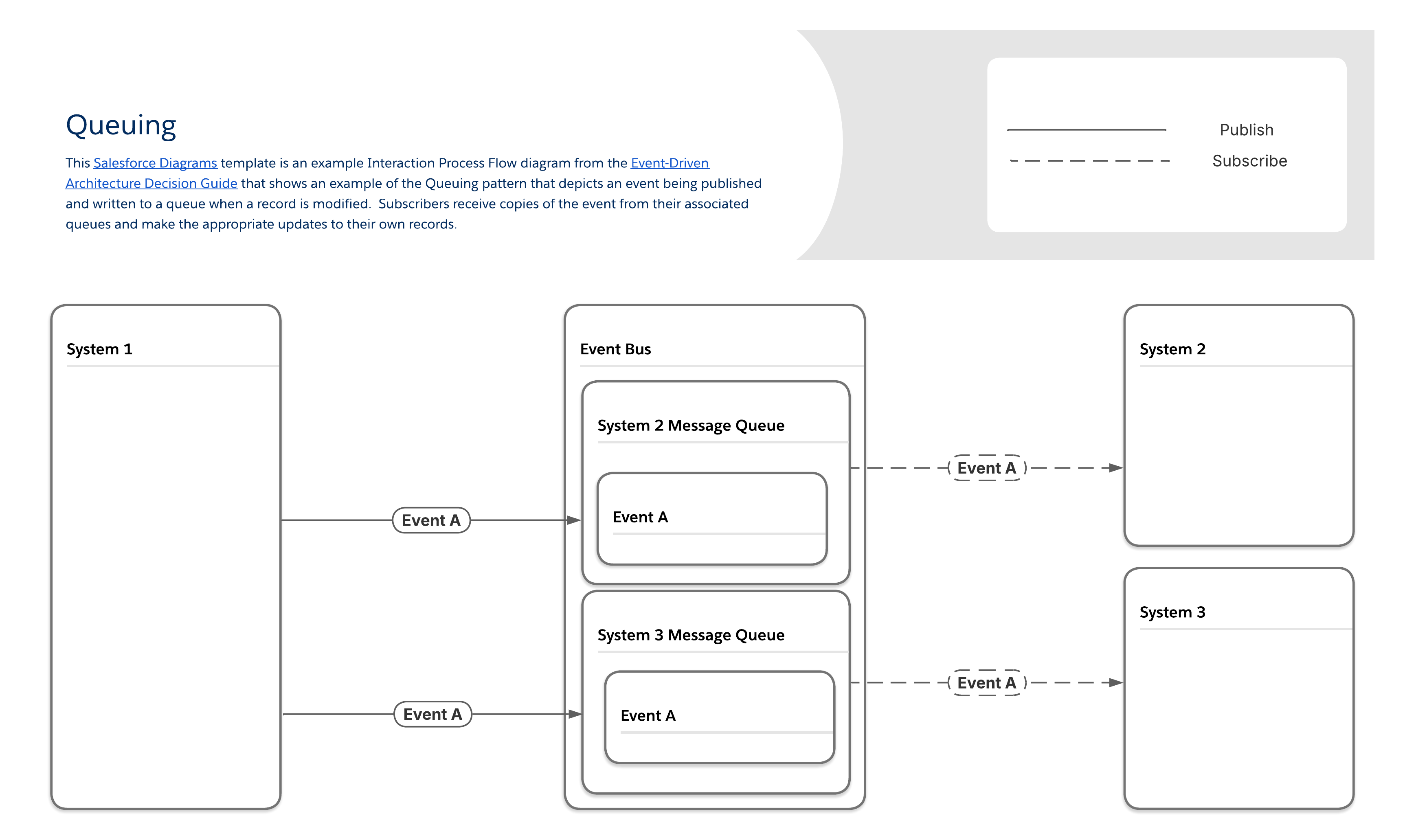
Köanvändningsfall är allmänt förekommande. Exempel inkluderar:
-
Internetanslutningar av låg kvalitet: Field Service-organisationer eller andra organisationer där team med mobila enheter behöver arbeta i områden med låg kvalitet eller intermittent internetåtkomst gynnas av köer eftersom programmen på dessa enheter kan ansluta till sina köer och hämta relevanta meddelanden när anslutningen återställs.
-
Meddelandebuffring: Om meddelandevolymen ibland överskrider en prenumerants bearbetningskapacitet och ökad latens inte skapar ytterligare problem kan köer vara en buffert för att lagra överflödiga meddelanden och förhindra dataförlust.
-
Transporthantering: Logistikorganisationer som behöver övervaka sina fordonsflottor kan använda detta mönster för att se rutterna som varje fordon kör nästan i realtid och säkerställa att förarna är så effektiva som möjligt.
-
IoT-enheter: Tillverkare använder ofta system som skapar snabba dataströmmar, och dessa strömmar kan ha effekter längre ner på ytterligare system. Detta mönster kan användas för att identifiera sekvenser av händelser som kräver mänskligt ingripande innan katastrofala fel som sträcker sig över flera system inträffar.
I kömönstret skickar producenter meddelanden till köer, som håller meddelandena tills prenumeranter hämtar dem. De flesta meddelandeköer följer ordningen first-in, first-out (FIFO) och tar bort varje meddelande efter att det har hämtats. Varje prenumerant har en unik kö som kräver ytterligare inställningssteg men gör det möjligt att garantera leverans och identifiera vilka prenumeranter som fått vilka meddelanden.
| Händelseflöde och beteende | Att tänka på vad gäller belastning | ||||||
|---|---|---|---|---|---|---|---|
| Tillgängliga verktyg | Kompetens som behövs | Publicera via | Prenumerera via | Reprisperiod | Payload-struktur | Gränser för belastning | |
| MuleSoft | MuleSoft Anypoint MQ | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen |
| Salesforce Pub/Sub-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint Apache Kafka-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint MQ-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint MQTT-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| MuleSoft Anypoint AMQP-anslutare | Pro-kod | APIs | APIs | Som konfigurerat | Användardefinierad | Ingen | |
| Salesforce Platform | Apache Kafka på Heroku | Pro-kod | API, poständringar i Heroku Postgres | EJ TILLÄMPLIGT | 1-6 veckor | Användardefinierad | Användardefinierad |
| Ändra datainsamling | Lågkod till Pro-kod | Poständringar | Apex, API, Lightning webbkomponenter (LWC) | 3 dagar | Fördefinierad | 1 MB | |
| Plattformshändelser | Lågkod till Pro-kod | API, Apex, Flöde | Apex, API, Flöde, LWC | 3 dagar | Användardefinierad | 1 MB | |
| Pub/Sub API | Pro-kod | Pub/Sub API eller API, Apex, Flöde | Pub/Sub API | 3 dagar | Användardefinierad | 1 MB | |
| Händelsereläer* | Lågkod | Plattformshändelser, Ändra datainsamling | API | 3 dagar | Användardefinierad | 1 MB | |
| *Händelsereläer skickar endast data till AWS Eventbridge | |||||||
På grund av att kömönstret är asynkront kan det ta lång tid mellan att ett meddelande läggs till i en kö och att meddelandet hämtas. Köer kräver minne eller lagringsutrymme för att hålla sina meddelanden, så de kan inte växa i oändlighet, vilket innebär att en prenumerant som är offline i oändlighet kan orsaka ett fel om tillräckligt med meddelanden byggs upp i kön. Meddelandebuffring kan ha samma effekt om prenumerantens bearbetningstider blir för långa, vilket gör att stora mängder meddelanden byggs upp i deras köer. För att minska dessa risker, utför en grundlig analys av lagringskraven för alla meddelandeköer och utforma vid behov processer som rensar och inaktiverar köer om meddelanden inte hämtas inom en viss tid eller när de når en förbestämd volym.
Även om du är helt övertygad om att en händelsedriven arkitektur är rätt för din organisation kanske du börjar med ett landskap som redan har ett stort antal punkt-till-punkt-integreringar. Att få finansiering för ett projekt för att ersätta alla dina integreringar samtidigt kan vara svårt, och det kanske inte ens är möjligt att använda en händelsedriven arkitektur direkt med vissa äldre system. I dessa scenarion kan du använda en inkrementell metod för att migrera till en mer löst kopplad arkitektur genom att först konvertera de mest affärskritiska programmen och sedan konvertera andra system när de uppdateras eller ersätts i framtida projekt. Detta tillvägagångssätt gör det enkelt att lägga till nya program i händelsebussen och gör att ditt övergripande IT-landskap förblir skalbart och motståndskraftigt allt eftersom system fortsätter att läggas till över tid.
Som arkitekter vet vi att varje arkitektur har kompromisser. En händelsedriven arkitektur är inget undantag. Även om ett landskap fullt av löst kopplade system är mycket skalbart och motståndskraftigt finns det några kompromisser att tänka på:
-
Övergripande integreringsstrategi: Oavsett vilka verktyg och mönster du väljer att använda är det viktigt att börja med att skapa en strategi för hur data ska delas mellan de olika systemen i din organisations landskap. Denna strategi bör inkludera din organisations mål för sina data, hur data kan delas och mönster användas, samt datakällor, mål, strukturer och krav på ägarskap och åtkomst.
-
Stöd för äldre system: Din organisation kan ha äldre system som helt enkelt inte har stöd för händelsedrivna arkitekturmönster. Även om det kan vara möjligt att bygga lösningar (till exempel med en process som fungerar som en genomgång genom att prenumerera på händelser och sedan skicka utdata till målsystemet via ett annat sätt att överföra data), kanske du vill överväga andra integreringsmetoder i detta fall.
-
Strukturella ändringar av meddelanden: När den inledande meddelandestrukturen har definierats och överenskommits mellan utgivare och prenumeranter kan den vara svår att ändra, särskilt om prenumeranterna är externa. Det finns flera sätt att åtgärda detta problem. Du kan använda versionerade slutpunkter, men se till att definiera och kommunicera en tydlig livscykel för varje version så att dina utvecklare inte behöver upprätthålla för många versioner samtidigt. Om Apache Kafka på Heroku är en del av ditt landskap kan du även överväga ett schemaregister eller liknande verktyg, men se till att de andra systemen i ditt landskap också har stöd för det (och använder det).
-
Osynlighet mellan utgivare och prenumeranter: I de flesta händelsedrivna arkitekturmönster är utgivarna inte medvetna om statusen för sina prenumeranter. Så om en utgivare skickar ett viktigt meddelande medan alla prenumeranter är offline kanske meddelandet aldrig levereras. Du kan åtgärda detta problem genom att använda reprisfunktionalitet eller lägga till överflödiga prenumeranter som körs på separata servrar för alla viktiga meddelanden.
-
Flaskhalsar i prestanda: Som en händelsedriven arkitektur kan händelsebussen bli en flaskhals för meddelandeleverans om den blir överväldigad av för många utgivare som försöker skicka meddelanden till för många prenumeranter samtidigt. Du kan åtgärda detta genom att öka minnet och bearbetningsresurserna som allokeras till händelsebussen eller genom att använda flera händelsebussar för att bearbeta olika typer av meddelanden parallellt.
Innan du implementerar en händelsedriven arkitektur, överväg om du verkligen behöver använda en från början. Föregående avsnitt beskriver vanliga verksamhetsscenarion som passar bra för varje händelsedrivet arkitekturmönster. Du kan även läsa mer i Väl arkitektonisk - Interoperabilitet. Gå igenom utmaningar att tänka på vid implementering av händelsedrivna arkitekturer för att avgöra om de mönster du har i åtanke passar bäst för dina specifika användningsfall.
Notera att även om de flesta scenarion som tas upp i denna guide involverar integreringar kan händelsedrivna arkitekturer även användas för att skicka meddelanden inom en enskild Salesforce-organisation, till exempel med hjälp av plattformshändelser. Tänk på eventuella tillämpliga händelsetilldelningsgränser när du utformar processer som använder plattformshändelser som ett internt meddelandesystem.
Ofta kommer antimönster kring händelsedrivna arkitekturer från att använda händelser som en lösning för intern kommunikation inom en Salesforce-organisation. Vanliga antimönster inkluderar:
-
Publicera händelser från Apex utlösare associerade med samma händelseobjekt: Detta kommer att resultera i en oändlig utlösarloop.
-
Publicera händelser från Apex innan en DML-transaktion slutförs: Om en transaktion misslyckas och dras tillbaka inkluderas inte publicerade händelser som har publiceringsbeteendet Publicera omedelbart i tillbakadragandet.
-
Publicera händelser i Flöde för att orkestrera efterföljande automatisering: Det bästa sättet att koordinera logik över flera automatiseringar är att använda underflöden eller Flow Orchestrator.
-
Skapa runtimeberoenden: Publicera inte händelser för att underlätta kommunikation mellan paket utan att vidta rätt steg för att eliminera körningsberoenden.
-
Onödigt stora belastningar: När du gör begäranden är det bäst att skicka och ta emot så lite data som möjligt i belastningen. Varje åtgärd av en användare kan potentiellt skapa flera begäranden, och det är viktigt att dessa behandlas effektivt. Att skicka mer data än nödvändigt kan bidra till långsamma transporter och ökad bearbetningstid.
-
Oselektiv hantering av programhändelser: Om det finns flera komponenter som lyssnar efter en programhändelse bör utvecklare säkerställa att händelsehanteraren endast körs när den faktiskt är önskad och användbar. I Lightning Console kan till exempel komponenter i flikar som inte är fokuserade fortfarande lyssna även om de inte är synliga. En utvecklare kan använda olika tekniker som att använda ett bakgrundsverktygsobjekt som den enda lyssnaren, eller anropa getEnclosingTabId() för att avgöra om denna instans av komponenten är innesluten i den fokuserade fliken för att säkerställa att varje händelse endast hanteras när den är avsedd.
-
Att använda plattformshändelser publicerar beteenden felaktigt: Plattformshändelser har två publiceringsbeteenden — Publicera direkt och Publicera efter åtagande. Det kan vara användbart att använda plattformshändelser i realtid för användningsfall som Loggning, där du vill publicera loggningshändelsen oavsett om transaktionen lyckas eller inte. Använd dock Publicera direkt mycket noggrant med plattformshändelser i realtid. Händelser kan konsumeras av prenumeranter inom samma transaktion och orsaka radlåsningar eller andra racevillkor.
Vid implementering av en händelsedriven arkitektur är en av nycklarna till framgång att sätta standarder för hur själva händelserna är utformade. Specifika egenskaper varierar beroende på din organisations användningsfall, men här är några allmänna riktlinjer:
-
Bestäm den optimala strukturen för dina händelsebelastningar. Mindre meddelandestorlekar minskar bearbetningstider, men att bombardera prenumeranter med stora mängder meddelanden kan orsaka flaskhalsar i prestandan. Du kan behöva upprepa dina belastningsstorlekar och strukturer för att hitta rätt balans. MuleSoft och liknande ESB-verktyg ger möjligheten att utforma egna belastningar i meddelanden som är associerade med dina händelser, vilket kan hjälpa dig visualisera datastrukturer för att förbättra prestandan på prenumerantsidan. (Se Väl arkitektade - API-hantering för mer information.)
-
Tänk igenom dina processer från början till slut. Se till att du inte skapar några scenarion med "endless loop", vilket kan vara svårt att spåra när integreringarna har lanserats. Ett exempel på detta är två system som publicerar händelser när poster uppdateras, samtidigt som de lyssnar efter varandras händelser, vilket utlöser ytterligare publicerade händelser när de bearbetas.
Du kan åtgärda denna typ av antimönster genom att lägga till logik i båda systemen som säkerställer att ändringar som görs som ett resultat av att en händelse används inte resulterar i att en ny händelse publiceras. Du bör även se till att dokumentera alla dina händelser, deras associerade utlösare och de system längre ner som kan påverkas. Använd denna dokumentation som en referens under designsessioner för att hjälpa till att fånga oändliga loopar och liknande scenarion så tidigt som möjligt. (Se Väl arkitektonisk - Processdesign för mer information.)
-
Använd vanliga namnkonventioner i alla system. Konsekventa namnkonventioner är en rekommenderad metod för all programvaruutveckling, inklusive händelsedrivna arkitekturer. Lägg tid på att dokumentera en uppsättning standarder för händelsenamn, strukturer, associerade objekt och felhanteringsprocesser för att säkerställa enhetlighet i alla system. (Se Välarkitekterade - Designstandarder för mer information.)