Företag lagrar ofta data i både Salesforce och andra externa datasjöar som Snowflake, Google BigQuery, Databricks, Redshift eller molnlagring som Amazon S3. Denna siloing av data i olika källsystem innebär en utmaning för företag som vill utnyttja den fulla kraften hos sina data.
Arkitekter som arbetar med att föra samman data över flera datasjöar står inför viktiga arkitektoniska beslut om hur dessa data bäst integreras. Data 360 erbjuder flera alternativ för dataintegrering, var och en med olika för- och nackdelar.
Denna guide tillhandahåller ett ramverk för att utvärdera vilket mönster som bäst passar dina krav på latens, kostnad, skalbarhet, styrning och komplexitet vid integrering av data, vilket hjälper dig välja när du vill använda dataintag, Zero Copy-datafederation eller en hybridmetod. Guiden hjälper dig även att välja mellan olika metoder för dataintag och datafederation, var och en med olika behov.
Att integrera externa datasjöhus med Data 360 kräver noggrant övervägande av avvägningar mellan färskhet, styrning och pipelineeffektivitet. Till exempel maximerar livefrågor för Zero Copy-datafederation färskheten av data men kan minska pipelineeffektiviteten när du flyttar mer data över nätverket. Därför är en kombination av intag och federation inom ett ekosystem med flera moln av sjöar den optimala vägen för de flesta implementeringar i verkligheten. Denna hybridmetod säkerställer en skalbar, styrd, interoperabel arkitektur som sömlöst har stöd för både operativa arbetsbelastningar med låg latens som personanpassning i realtid och upptäckt av bedrägerier, och analytiska arbetsbelastningar som regelrapportering och historisk trendanalys. Denna beslutsguide hjälper dig förstå hur du navigerar i dessa kompromisser och väljer rätt strategi.
- Dataintag: Kopierar data till Salesforce Data 360 och skapar styrda, kanoniska datamodeller. Idealisk när du behöver:
- Bygg en omfattande Customer 360: Sammanslag och transformera olika källor till en enda, betrodd profil.
- Uppfyll strikt regelefterlevnad: Skapa en granskningsbar, centraliserad kopia där dataåtkomst och härkomst kan kontrolleras noggrant.
- Nollkopieringsfederation: Frågar externa källor i realtid utan dubbletter, vilket möjliggör personanpassning i realtid, liveinstrumentpaneler och snabb källintroduktion. Två primära alternativ med kompromisser som du måste balansera:
- Live och cachning (snabbsökning): Bäst för interaktiv analys och instrumentpaneler i realtid för data som finns i externa dataplattformar som Snowflake, Google BigQuery, Redshift eller Databricks. Undvik långsam och kostsam dataduplicering genom att flytta bearbetning ner till källsystemet.
- Filfederation: Bäst för storskalig batchbearbetning och utbildning i AI-modeller för data i din molndatasjö (S3, ADLS). Undvik kostsamt och långsamt intag genom att direkt fråga filer i öppna tabellformat, vilket låser upp massiva datauppsättningar för ETL- och datavetenskapsarbetsbelastningar.
- Hybridmodell: Blanda intag för enhetliga profiler med federation för färskhet, med stöd för engagemang i flera kanaler, Agentforce åtgärder och AI/ML-utbildning.
-
Hybridarkitektur: Att blanda dataintag och datafederation behövs ofta.
- Använd Dataintag för viktiga data för kanoniska datamodeller och kärnstyrning.
- Sammanslag alla andra data via Zero Copy för att minimera operativt arbete med att bygga och underhålla pipelines för intagsdata.
-
Frekvens för dataintag spelar roll: Välj frekvens baserat på verksamhetsvärde, latensbehov och operativ komplexitet.
- Använd realtid för tidskänsliga arbetsflöden (personalisering, liveinstrumentpaneler, Agentforce åtgärder).
- Nästan i realtid för måttligt brådskande processer (kampanjer, operativa rapporter).
- Batch för historiska datauppsättningar eller datauppsättningar med låg hastighet.
-
Matcha samlingsmönstret till latens och prestanda: Välj den som bäst matchar dina åtkomstmönster och kraven på färskhet, prestanda och kostnad.
- Använd Livefråga för operativa instrumentpaneler och personanpassning i realtid där låg latens är viktigt.
- Använd Caching (Accelerated Query) när sökfrågor är vanliga men lite gamla resultat är acceptabla som balanserar prestanda och kostnad.
- Använd Filfederation för storskaliga, dataflödestunga analyser eller batcharbetsbelastningar som är idealiska för historiska eller mindre tidskänsliga datauppsättningar.
-
Anpassa styrningen till kraven för datalagring:
- Använd intag där centraliserad styrning är viktigt.
- Använd federation där decentraliserad styrning accepteras, samtidigt som du tillämpar strikt styrning vid den externa källan. Zero Copy respekterar källnivåpolicyer som säkerhet på radnivå (RLS) och datamaskering.
-
Prioritera intag för arbetsflöden med högt värde: Tillämpa intag selektivt för viktiga processer som identitetslösning, regelrapportering och operativ aktivering.
-
Kostnad och komplexitet driver beslutet: Intag i realtid kan vara dyrt och komplext. Arkitekter bör väga kostnaden för att introducera, lagra och transformera data mot kostnaden för att fråga dem direkt via Zero Copy.
Att välja rätt integreringsmönster — Dataintag, Zero Copy eller en hybridmetod — påverkar latens, styrning, operativ effektivitet och kostnad över flera molnplattformar direkt. Detta beslut formar hur insikter i realtid, AI-driven aktivering och personligt engagemang kan levereras tillförlitligt och i stor skala.
Denna tabell ger en teknisk jämförelse av mönster för dataintag och nollkopiering i Salesforce Data 360, med fokus på kapacitet, kompromisser och fördelar, tillsammans med användningsfall och resultat för företag. Arkitekter kan använda detta som en referens för att utforma hybriddataplattformar med flera moln som balanserar prestanda, kostnad och efterlevnad.
| Mönstertyp | Läge / verktyg | Fördelar | Att tänka på | Resultat |
|---|---|---|---|---|
| Dataintag | Realtid: Intag av latens under andra sekunden via Ingestion API med CDC-stöd. Kontinuerliga streamingpipelines. | - Omedelbara insikter - Idealisk för låg latens operativa och personliga användningsfall - Stöder händelsedrivna arbetsflöden |
- Hög kostnad - Komplex arkitektur - Kräver källsystem med låg latens - Källor med hög volym kan orsaka överdriven streaming som leder till mättade pipelines - I/O-intensiv - Överväg selektiva fält och filtrering för att minska overhead |
Agentforce: - Bedrägerivarningar i realtid, personanpassning, operativa varningar Analytics: - Sub-sekund instrumentpaneler, nyckeltalsövervakning Efterlevnad: - Kontinuerliga kundpostuppdateringar för reglerade arbetsflöden |
| Streaming: Intag av mikrosats var 1-3 minut via inbyggda anslutare | - Balanserad kostnad vs färskhet - Enklare arkitektur än realtid - Stöder inkrementella uppdateringar |
- Lite latens - Kanske inte är lämplig för viktiga beslut under andra sekunden - Satsstorlek påverkar minne / beräkning - I/O är måttlig - Bäst för förutsägbara, upprepade uppdateringsmönster - Överväg fönster aggregering för att minska bearbetningsbelastning |
Agentforce: - Aktuella kampanjutlösare, nästan liveengagemang Analytics: - Rekommendationsmotorer, nästan live-instrumentpaneler Efterlevnad: - Frekventa uppdateringar med granskningsbarhet |
|
| Batch:Schemalagda inläsningar av stora volymer via anslutare eller API. Stöder objektlagring och ETL/ELT-pipeline. | - Kostnadseffektiv för massiva datauppsättningar - Lätt att implementera - Pålitlig för historiska analyser |
- Datalatens - Olämplig för tidskänsliga operationer - I / O intensiv under belastningsfönster - Nätverksgenomströmning kan bli en flaskhals för stora filer - Bäst för historisk aggregering eller reglerade rapporteringsflöden |
Agentforce: - IT-supportärenden (Jira / ServiceNow), aggregerade arbetsflöden Analytics: - Historisk analys, trendutvärdering Klagomål: - Regulatorisk rapportering, patient / anspråk data aggregering |
|
| Noll kopia | Livesökfråga:Direktsökfrågor på externa system; schema-vid-läsning; ingen dataduplicering | - Maximal färskhet - Minimal lagring overhead; stöder operativa insikter i realtid |
- Beroende på källprestanda - Hög sökfrågevolym kan påverka latens - Idealisk för frågor med predikat pushdown och aggregering för att minimera I / O - Undvik ofiltrerade sökfrågor på massiva datauppsättningar |
Agentforce: - Dynamiska arbetsflöden som anpassar sig till liveaktivitet Analytics: - Operativa instrumentpaneler, liverapportering Efterlevnad: - Respekterar säkerhet på radnivå och maskering vid källan |
| Accelererad sökfråga (cache):Cachade lokala kopior för sammanslagna sökfrågor. Konfigurerbar från 15 min till 7 dagar. Optimerat utförande av sökfrågor | - Minskar latens - Lägre kostnad än upprepade livefrågor - Förbättrar prestandan för frekventa åtkomstmönster |
- Cache-hantering krävs - Stabilitet beror på cacheintervall - Bäst för högfrekventa frågor - Inte lämplig för subsekundbeslut |
Agentforce: - Föraggregerade engagemangsmått för snabba beslut Analytics: - BI-instrumentpaneler, segmentering, analytisk rapportering Efterlevnad: - Konsekvent reglerade instrumentpaneler med granskningsloggar |
|
| Filfederation:Direkt åtkomst till stora historiska datauppsättningar i objektaffärer eller sjöar (S3, Iceberg, Google BigQuery, Redshift). | - Hanterar storskaliga datauppsättningar - Minimal lagring i Data 360 - Stöder AI / ML-arbetsbelastningar |
- Skrivskyddad - Sökfrågeprestanda beror på extern systemgenomströmning - Optimerad för batch-tunga, genomströmningsintensiva jobb - Inte lämplig för instrumentpanel i realtid |
Agentforce: - (Ovanligt — satsvis tung) Analytics: - ML / AI utbildning, historiska analyser, petabyte skala rapportering Efterlevnad: - Styrd åtkomst till externa datauppsättningar utan dubbletter |
Med dataintag kopieras data fysiskt till Data 360 och styrs fullständigt, till skillnad från Zero Copy där data stannar vid källan. Beräkna för transformationer sker inom Data 360, vilket möjliggör centraliserad styrning och granskning.
Använd dataintag för att lagra kanoniska, styrda datauppsättningar i Salesforce Data 360 för efterlevnad och operativ kontroll. Använd intag när fullständig kontroll, granskning och spårbarhet krävs. Idealisk för reglerade eller värdefulla arbetsflöden där centraliserad beräkning och styrning är avgörande.
Intag är bäst för att bygga en betrodd grund för identitetslösning, regelrapportering och verksamhetskritiska AI-drivna arbetsflöden och kundengagemang.

Dataintagsmetoder varierar beroende på vilken anslutare du använder för att ta in dina data. Vissa anslutare erbjuder flera olika intagsmetoder, medan andra endast arbetar i batch- eller streamingläge. Se Data 360: Integreringar och anslutare för en fullständig lista över Data 360-anslutare och deras tillgängliga metoder.
- Realtid
- Subsekundintag med streamingpipeline eller ändring av datainsamling (CDC).
- Bäst för tidskänsliga arbetsflöden (bedrägeriupptäckt, personanpassning, operativa instrumentpaneler).
- Pushtransformationer och aggregeringar inom Data 360 för att minska I/O längre ner och optimera beräkningsanvändningen. Använd inkrementell CDC för att minimera datablandning.
- Streaming
- Intag var 1–3 minut i små steg.
- Balanserar färskhet och kostnad, lämplig för kampanjorkestrering, engagemang nästan live och operativ rapportering.
- Använd mikrosatser för att styra I/O-toppar. Aggregera data vid källan om möjligt för att minska överföringsvolymer och optimera lagring.
- Batch (schemalagda laddningar)
- Periodiskt intag av stora datauppsättningar (timvis, dagligen, veckovis).
- Kostnadseffektivt och pålitligt för historiska datauppsättningar, rapporter och användningsfall för efterlevnad.
- Säkerställ beräkningsplats i samma region som källlagring för prestanda och kostnadsoptimering.
- Använd kundcase för dataintag
- Skapa enhetliga Customer 360-profiler: Bygga en enda källa till sanning för kundidentitet och attribut.
- Upprätthåll datauppsättningar för regelefterlevnad: Tillämpa styrning, härkomst och granskningsbarhet för känsliga data.
- Centralisera kampanjorkestrering: Säkerställ att marknadsföring, försäljning och service fungerar från enhetliga, betrodda datauppsättningar.
- Designpraxis
- Gynna batchintag för historiska eller låglatenstoleranta behov, som arkivrapportering eller periodiska ögonblicksbilder.
- Använd CDC eller strömmande API:er för att upprätthålla färskhet för arbetsflöden för drift och personanpassning, vilket säkerställer uppdateringar nästan i realtid.
- Styr lagring och beräkna tillväxt genom att tillämpa inkrementella inläsningar, istället för att läsa in hela datauppsättningar igen, för att optimera kostnad och effektivitet.
- Anpassa pipelines för intag med beräkningsplats och inkrementell bearbetning för att minska nätverks-I/O. Tillämpa transformationer inuti Data 360 för att undvika att flytta rådata i onödan.
- Kostnadsöverväganden
- Intag i realtid: Högsta beräknings- och pipelinekostnader, motiverat för tidskänsliga arbetsflöden med högt värde som personanpassning, operativa instrumentpaneler eller Agentforce.
- Streamingintag: Moderera beräknings- och lagringskostnader; lämplig för frekventa uppdateringar som kan tolerera mindre förseningar, som kampanjorkestrering eller verksamhetsrapportering.
- Batchintag: Lägre beräkningskostnader, förutsägbar lagring, bäst för historiska datauppsättningar eller uppdateringar med låg frekvens. Att ta in batchdata från Salesforce-organisationer med vissa anslutare är gratis.
- Uppdateringsläge: Att välja läget Inkrementell uppdatering minskar totalt intag och beräkningskostnader. Vi rekommenderar att använda inkrementell uppdatering när så är möjligt för att optimera effektiviteten för alla intagstyper.
- Kostnaden påverkas även av I/O-volym från källa till Data 360. Att optimera batchstorlekar, partitioner och regional anpassning minskar överföringskostnader och förbättrar prestandan.
- Branschscenarier
- Finans: Ta in datauppsättningar som behövs för att känna din kund (KYC), förhindra penningtvätt (AML) och upptäcka bedrägerier, där granskning och efterlevnad inte är förhandlingsbara.
- Hälsovård: Använd intag för patientidentitetslösning och HIPAA-kompatibla poster, vilket möjliggör säkra, enhetliga vyer.
- Butik: Slå samman data om försäljningsställen (POS), e-handel och lojalitetsprogram till enhetliga profiler för segmentering och personanpassning
- Telekom: Stöd för förebyggande av bortfall och användningsanalyser med kanoniska, styrda prenumerantdata.
| Funktion | Intag i realtid | Strömmande intag | Satsintag |
|---|---|---|---|
| Latens och fräschör | Intag av latens under andra sekunden via Ingestion API med stöd för ändring av datainsamling (CDC). Ger kontinuerliga streamingpipelines. Bäst för operativa användningsfall med låg latens. | Intag av mikrosatser var 1-3:e minut via inbyggda anslutare. Stöder inkrementella uppdateringar. Lite latens förväntas. | Datalatens förväntas. Schemalagda laddningar med stor volym. Periodiskt intag (timvis, dagligen, veckovis). Olämplig för tidskänsliga operationer. |
| Primära användningsfall | Idealisk för användningsfall med låg latens och personanpassning. Används för tidskänsliga arbetsflöden. Stöder händelsedrivna arbetsflöden. Används för bedrägerivarningar och operativa varningar i realtid. | Lämplig för måttligt brådskande processer. Används för kampanjorkestrering, engagemang nästan live och verksamhetsrapportering. Används för kampanjutlösare i rätt tid. | Kostnadseffektiv för massiva datauppsättningar. Tillförlitlig för historisk analys. Används för historiska aggregeringar eller reglerade rapporteringsflöden. Bäst för historiska datauppsättningar eller datauppsättningar med låg hastighet. |
| Arkitektonisk komplexitet och I/O | Hög kostnad och komplex arkitektur. Kräver källsystem med låg latens. Intensiv I/O. Källor med hög volym kan orsaka mättade pipelines. | Enklare arkitektur än realtid. I/O är måttligt. Bäst för förutsägbara, upprepade uppdateringsmönster. Satsstorlek påverkar minne/beräkning. | Lätt att implementera. I/O-intensiv under laddningsfönster. Nätverksgenomströmning kan bli en flaskhals för stora satser. |
| Kostnadsöverväganden | Högsta beräknings- och pipelinekostnader. Endast motiverat för tidskänsliga arbetsflöden med högt värde. | Moderera beräknings- och lagringskostnader. Ger en balanserad metod för kostnad vs färskhet. Lämplig för frekventa uppdateringar som kan tolerera små fördröjningar. | Lägre beräkningskostnader och förutsägbar lagring. Rekommenderas för historiska datauppsättningar eller uppdateringar med låg frekvens. Intag via Salesforces interna pipelines är gratis. |
| Designpraxis | Använd inkrementell CDC för att minimera datablandning. Filtrera och använd selektiva fält för att minska overhead. | Använd mikrosatser för att styra I/O-toppar. Överväg aggregering i fönster för att minska bearbetningsbelastningen. | Gynna detta för arkivrapportering eller periodiska ögonblicksbilder. Säkerställ beräkningsplats i samma region som källlagring för kostnadsoptimering. |
Använd Zero Copy för sökfrågor i realtid av externa system utan dataduplicering, vilket möjliggör smidighet, färskhet och skalbar åtkomst till stora eller tillfälliga datauppsättningar. Det är bäst för liveinstrumentpaneler, utforskande analyser, utbildning i AI/ML-modeller och kundengagemang i realtid direkt via Salesforce Data 360.
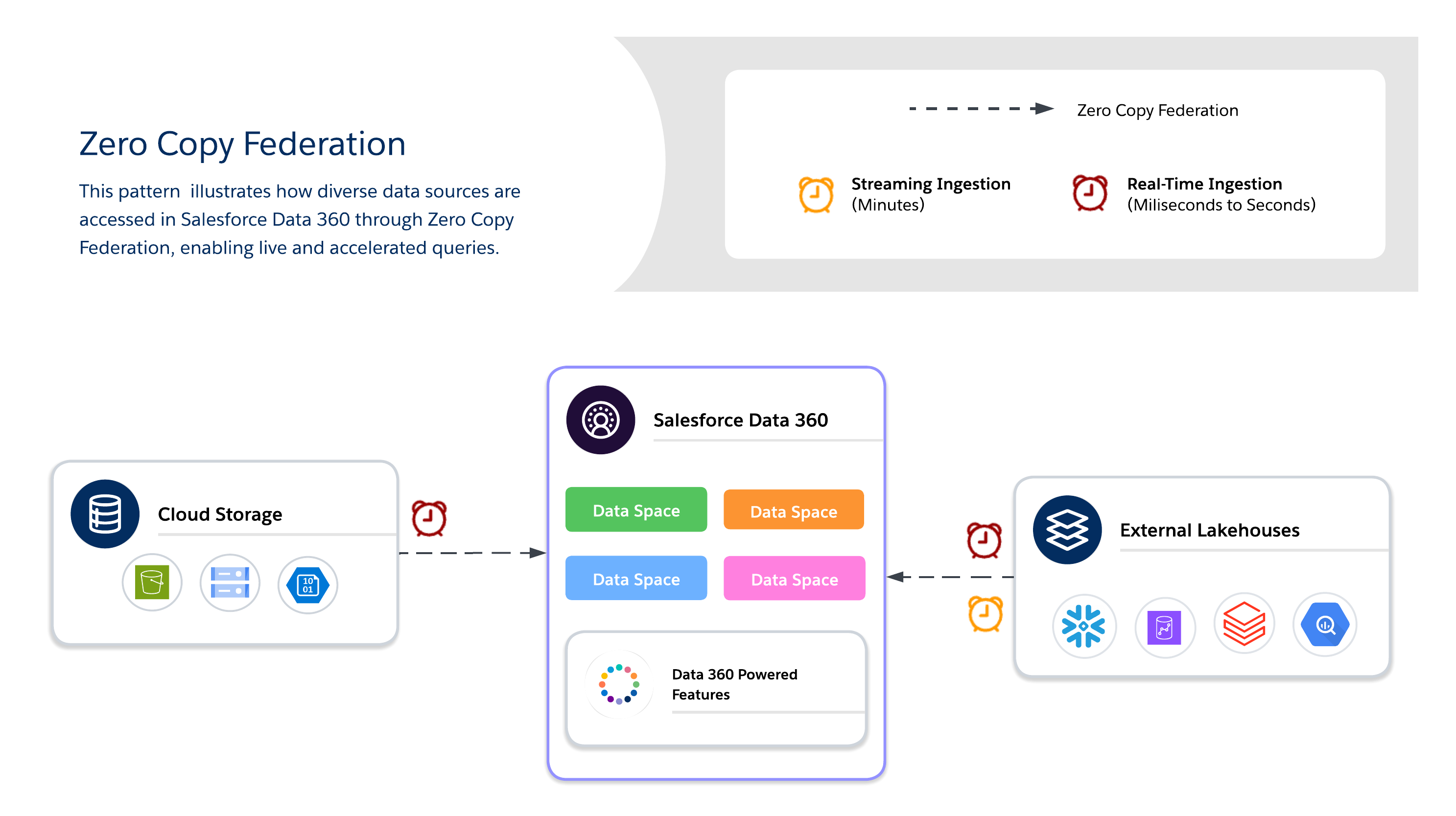
Vid användning av Zero Copy måste arkitekter ytterligare bestämma mellan tre tillgängliga datafederationsmetoder, var och en med sin egen kompromiss mellan färskhet, prestanda och kostnad.
- Livefråga
- Kör sökfrågor direkt mot externa system (Snowflake, Google BigQuery, Redshift, Databricks, etc.) utan duplicering av data.
- Optimalt när predikat och aggregeringar kan pushas ner, vilket minimerar datarörelser över nätverket och minskar I/O i Salesforce Data 360-beräkningen.
- Bäst för insikter i realtid och operativa instrumentpaneler med låg latens. Beroende på det externa systemets prestanda.
- Cachning (påskyndad sökfråga)
- Lagrar tillfälligt cachade kopior av sammanslagna data i Salesforce Data 360.
- Minskar upprepade sökfrågekostnader och latens för ofta besökta datauppsättningar, med konfigurerbar varaktighet (minuter till dagar).
- Data kopieras inte permanent eller styrs fullständigt; färskhet hanteras via schemalagda uppdateringar från källan.
- Filfederation
- Ger direkt, skrivskyddad åtkomst till storskaliga datauppsättningar i objektaffärer (t.ex. S3, GCS med Iceberg).
- Bäst för AI/ML-arbetsbelastningar, historiska analyser och rapportering i petabyteskala utan att flytta data.
- Sökfrågeprestanda beror mycket på objektformat, partitionering och nätverks-I/O. Stora skanningar kan generera betydande I/O om de inte är optimerade.
- Användningsfall
- Personanpassning i realtid och anpassningsbara arbetsflöden: Leverera dynamiska erbjudanden, rekommendationer och Next Best-åtgärder allt eftersom kundbeteendet ändras.
- Liveinstrumentpaneler och operativa analyser: Driv affärskritiska instrumentpaneler och nyckeltal direkt från externa lager.
- Utbildning i AI/ML-modell med stora externa datauppsättningar: Använd data i petabyteskala från datasjöar och lagerbyggnader med filfederation utan att flytta dem.
- Branschscenarier
- Butik/Media: Aktivera personliga rekommendationer och kundengagemang i realtid genom att sammanföra data om klickströmmar eller innehållsinteraktioner.
- Finans: Kör bedrägeriupptäckt och riskera betyg i nästan realtid genom att fråga externa lagerbyggnader utan att duplicera känsliga data.
- Teknik/Företag: Stöd för korsmolnrapportering, instrumentpaneler för IT-tjänster och operativa analyser där datauppsättningar finns i flera system.
- Designpraxis
- Livefråga
- Använd för sökfrågor med hög QPS och låg latens när färskhet är viktigt.
- Pusha predikat och aggregeringar till det externa systemet för att minska datablandning över nätverket.
- Undvik sökfrågor som skannar massiva datavolymer i onödan. Överväg partitionsrensning och filter.
- Filfederation
- Åtkomst till datauppsättningar i petabyteskala i objektaffärer utan intag.
- Håll objektlagring i samma molnregion som Salesforce-beräkningar för att minimera latens- och utgångskostnader.
- Använd partitionerade, kolumnära format (Parkett/ORC) och pushdown-filter för att minska I/O och nätverksöverföring.
- Använd sökfrågor och predikatpushdown för att filtrera och aggregera data vid källan, vilket minskar datarörelser.
- Undvik dataåtkomst mellan regioner om det inte behövs, eftersom det ökar I/O, latens och kostnader.
- Cachning (påskyndad sökfråga)
- Cache ofta besökta datauppsättningar för att balansera kostnad och prestanda.
- Konfigurera uppdateringsintervall för att balansera färskhet jämfört med sökfrågekostnad.
- Efterlevnad: Tillämpa styrning vid källan genom att använda säkerhet på radnivå (RLS) och maskera policyer direkt i sammanslagna system. Nedan följer rekommenderade metoder för enhetlig RLS och maskering över plattformar.
- Använd ett centraliserat företags-ID: Mappa användare och enheter i Salesforce Data 360 till en unik, centraliserad företagsidentifierare som motsvarar identiteter i externa system.
- Anpassa säkerhetspolicyer: Se till att radnivåsäkerhet och maskeringspolicyer i sammanslagna system tillämpas baserat på den mappade identiteten. Detta bevarar efterlevnaden vid förfrågan av externa data.
- Standardisera identitetsscheman: Upprätthåll enhetliga identitetsattribut (e-post, användar-ID, kund-ID, etc.) i alla datakällor för att undvika felaktiga matchningar och åtkomstöverträdelser.
- Livefråga
- Kostnadsöverväganden
- Livesökfråga: Pay-per-query-modell — kostnader uppstår för extern beräkning av sjöbodar och kan öka med hög QPS. Bäst för färskhetskritiska användningsfall där värdet är större än kostnadsvariationen.
- Accelererad sökfråga (cache): Lägre sökfrågekostnad jämfört med Live Query genom att minska träffar till källsystemet, men lägger till kostnader för batchdataintag för att fylla i och uppdatera cacheminnet. Bäst för ofta besökta datauppsättningar.
- Filfederation: Billigaste lagringsalternativet som data i Objektslagring, men sökfrågekostnaderna beror på filstorlek, partitionering och beskärning. Bäst för historiska data eller massdata i petabyteskala.
| Beslutspunkt | Livefråga | Caching (påskyndad sökfråga) | Filfederation |
|---|---|---|---|
| Datakällas plats | Externa datasjöhus (Snowflake, Google BigQuery, Redshift, Databricks). | Externa datasjöhus (Snowflake, Google BigQuery, Redshift, Databricks) | Objektlagringar eller molndatasjöar (S3, ADLS, GCS), använder ofta öppna tabellformat som Iceberg. |
| Syfte/användningsfall | Idealisk för interaktiv analys och instrumentpaneler i realtid. Bäst för personanpassning i realtid och dynamiska arbetsflöden. | Bäst för när sökfrågor är frekventa men något gamla resultat är acceptabla. Lämplig för BI-instrumentpaneler och segmentering. | Bäst för storskalig batchbearbetning och AI/ML-modellutbildning. Idealisk för historiska analyser och rapportering i petabyteskala. |
| Färskhet/Latens | Maximal färskhet; sökfrågor körs direkt i realtid. Stöder beslut under andra sekunden. | Något gamla resultat är acceptabla. Färskhet beror på cacheintervallet, konfigurerbart från 15 minuter till 7 dagar. | Optimerad för batchtunga, genomströmningsintensiva jobb. Inte lämplig för instrumentpaneler i realtid. |
| Åtkomstmönster | Bäst för sällan förekommande eller ad hoc-frågor. Använd för sökfrågor med hög QPS (sökfråga per sekund) och låg latens där färskhet är viktigt. | Bäst för högfrekventa lässcenarion. Förbättrar prestandan för frekventa åtkomstmönster. | Skrivskyddad åtkomst. Passar för datauppsättningar i petabyteskala utan intag. |
| Prestandadrivkrafter | Mycket beroende av det externa källsystemets prestanda. Optimerat när predikat och aggregeringar kan pushas ner till källan. | Minskar latens jämfört med upprepade livefrågor. Prestanda beror på cachehantering och intervall. | Prestandan beror mycket på objektformat, partitionering och extern systemgenomströmning. Använd partitionerade kolumnformat (Parkett/ORC). |
| Kostnadskonsekvenser | Pay-per-query-modell. Kostnader uppstår för extern beräkning av sjöbodar. Kostnadseffektivt för sällan förekommande sökfrågor men utgifter kan öka med hög volym för sökfrågor per sekund (QPS). | Lägre kostnad än upprepade livefrågor. Minskar behovet av att upprepat fråga den externa källan. Lägger till cachelagring och uppdatering ovanför. | Billigaste lagringsalternativet. Sökfrågekostnaderna beror på filstorlek och partitionering. |
| Viktigt att tänka på | Undvik ofiltrerade sökfrågor som skannar massiva datavolymer i onödan. | Kräver cachehantering. Inte lämplig för beslut under andra sekunden. | Sökfrågeprestanda är starkt beroende av optimering via partitionering och predikatpushdown. |
Hybridarkitekturer låter arkitekter förankra viktiga datauppsättningar i Data 360 för centraliserad styrning och samtidigt använda sammanslagna sökfrågor för färskhet, minskad dubblett och skalbar åtkomst till stora externa datauppsättningar. Detta tillvägagångssätt balanserar krav på I/O, beräkningsplats, kostnad och efterlevnad.
Använd en hybridmetod för balanserad styrning, färskhet och operativ effektivitet genom att kombinera dataintag och nollkopiering för att leverera användbara insikter i realtid. Använd intag för reglerade datauppsättningar med högt värde där spårbarhet, RLS och maskering krävs, och sammanslagning för kortlivade datauppsättningar eller datauppsättningar med hög volym där färskhet och prestanda är nyckeln.
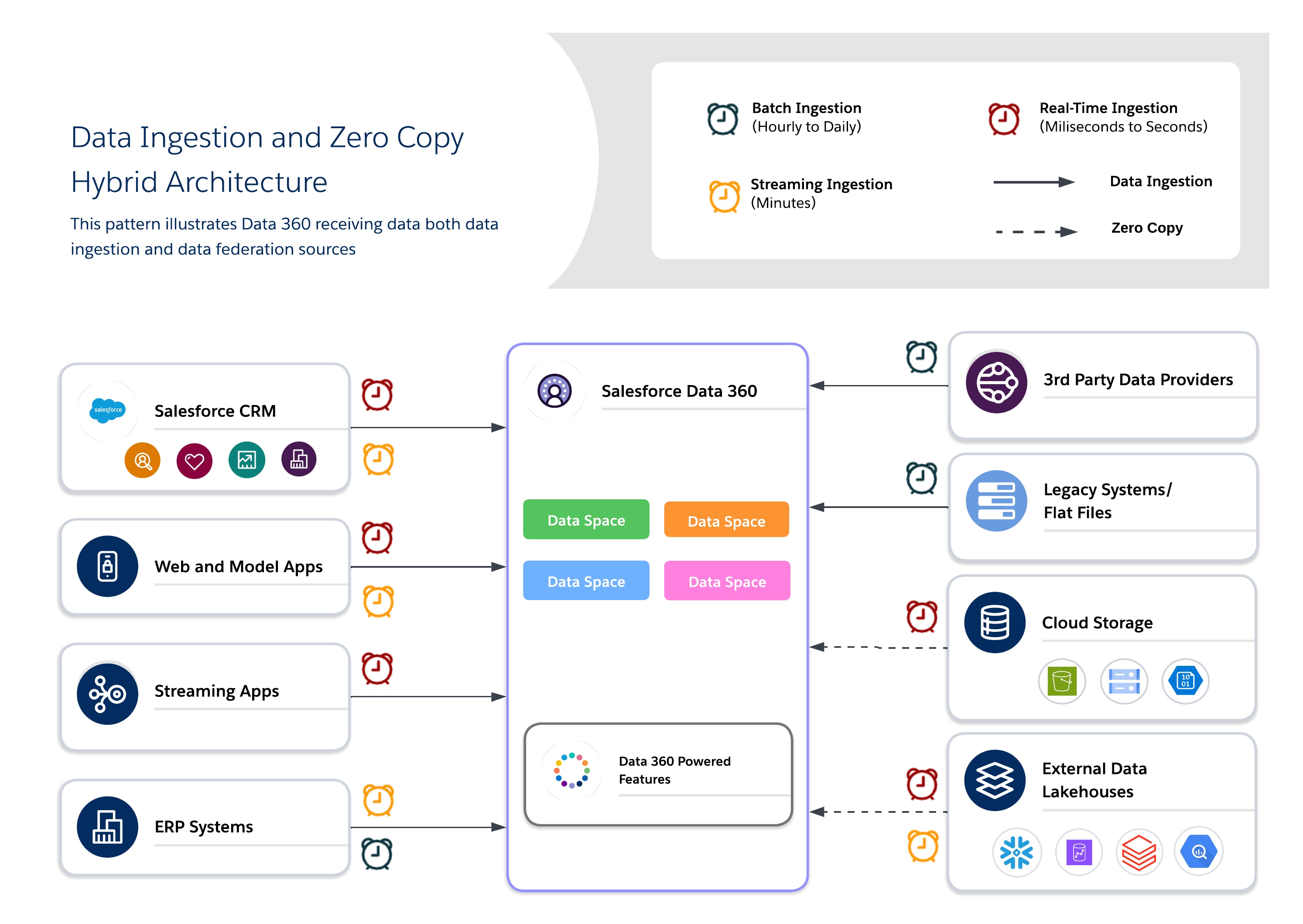
- Användningsfall
- Engagemang i flera kanaler: Blanda historiska kunddata med beteenden i realtid för att leverera enhetliga, sammanhangsbaserade upplevelser.
- AI/ML-pipeline: Utbilda modeller på utvalda, kanoniska datauppsättningar och berika dem med rådata eller realtidssignaler från externa källor.
- Blandade behov av efterlevnad och flexibilitet: Tillämpa strikt styrning för känsliga data men samarbeta för att uppnå smidighet i verksamheten.
- Branschscenarier
- Butik: Använd intag för identitetslösning och profilsammanslagning; samla för erbjudanden och personanpassning i realtid.
- Hälsovård: Upprätthåll gyllene patientposter via intag samtidigt som du sammanför IoT-enhetsströmmar och sensordata för ett omedelbart sammanhang.
- Finansiella tjänster: Ta in reglerade data i en efterlevnadsstyrd sjö medan du sammanför externa sökfrågor för att upptäcka bedrägerier och övervaka risker.
- Designpraxis
- Förankra styrning med intag: Ta in data med högt värde eller reglerade data i kanoniska modeller för att säkerställa Trust och efterlevnad.
- Använd Federation för färskhet: Låt externa sjöbodar tillhandahålla dataåtkomst i realtid eller i stor skala utan dubbletter.
- Saldokostnad vs. Prestanda: Profilarbetsbelastningar för att avgöra vad som ska tas in jämfört med federering, vilket minimerar onödiga lagrings- eller sökfrågekostnader.
- Tillämpa skiktad styrning: Tillämpa centraliserad styrning för intagna data, samtidigt som du använder sammanslagna systems egna säkerhetskontroller (t.ex. RLS, maskering).
- När du utformar hybridpipelines, säkerställ inkrementellt intag för historiska datauppsättningar och pushaggregeringar eller filter till sammanslagna källor för att optimera I/O och beräkna användning.
- Kostnadsöverväganden
- Optimera totalkostnad jämfört med prestanda genom att kombinera intag för efterlevnad eller viktiga data med federation när färskhet behövs.
- Ta hänsyn till I/O och beräkna distribution vid blandning av intag och federation. För att minska beräkningskostnaden i källsystem för upprepade sökfrågor, använd cachning (Accelerated Query) för sammanslagna datauppsättningar med hög läsbarhet.
Nedan följer vanliga arketyper som illustrerar hur man tillämpar denna logik.
- Arketypen "Enskild källa till sanning": Centralisera och styr
- Scenario: Du behöver bygga enhetliga Customer 360 profiler för hela ditt globala företag. Data kommer från ett dussin olika system, måste följa strikta GDPR- och CCPA-föreskrifter och kommer att fungera som den betrodda källan för all marknadsföring och serviceinteraktioner.
- Rekommenderade mönster: Dataintag. Prioritet är governance, Trust och control. Att ta in data i Data 360 är det enda sättet att skapa en fullständigt granskningsbar, kanonisk profil som är isolerad från källsystemen.
- Arketypen "Realtidsinsikter": Analysera utan att flytta
- Scenario: Ditt datavetenskapsteam behöver köra utforskande sökfrågor på en massiv, ständigt uppdaterad transaktionstabell i Snowflake. Samtidigt vill ditt chefsteam ha en live BI-instrumentpanel som drivs av samma data. Att flytta petabyte data dagligen är för långsamt och dyrt.
- Rekommenderade mönster: Zero Copy Federation. Prioritet är snabbhet, smidighet och kostnadseffektivitet i stor skala. Zero Copy låter dig använda den enorma kraften hos ditt befintliga datalager för sökfrågor i realtid utan att duplicera data över tid och latens.
- Arketypen "Hybrid Intelligence": Styr kärnan, Sammanslagna kanten
- Scenario: Du vill berika dina styrda, intagna kundprofiler med beteendesignaler i realtid (som webbplatsklick) från en datasjö. Du behöver stabiliteten hos kärnprofilen men omedelbarheten hos livedata för att driva personanpassning direkt.
- Rekommenderade mönster: En hybridmetod. Använd Dataintag för att skapa den stabila, styrda kärnan i dina kunddata. Använd sedan Zero Copy för att slå samman flyktiga "edge"-data i realtid och slå samman dem vid sökfrågetid för en fullständig, uppdaterad vy.
Enterprise-datastrategi handlar inte längre om att välja ett enskilt integreringsmönster — det handlar om att skapa kontrollerad flexibilitet inom ett interoperabelt dataekosystem. Att välja rätt dataintegreringsmetod för varje källdatasystem baserat på verksamhetsbehov leder ofta till en hybridmetod som blandar styrkorna hos både dataintag och datafederation.:
- Ta in verksamhetskritiska, styrda datauppsättningar i Salesforce Data 360 för efterlevnad, identitetslösning och operativa arbetsflöden.
- Sammanslagna data via Zero Copy för live, utforskande och AI-drivna analyser utan att duplicera lagring.
Salesforce Data 360 på Hyperforce ger motståndskraft och skalbarhet i flera regioner. Det öppna sjöhuset med Iceberg-tabeller möjliggör beräkningsseparering och interoperabilitet med plattformar som Snowflake, Databricks och S3 Iceberg – vilket utgör ryggraden i ett verkligt interoperabelt dataekosystem med flera moln.
När dataekosystem utvecklas, balansera kontinuerligt färskhet, kostnad, prestanda och efterlevnad för att upprätthålla arkitektonisk smidighet. Framtidssäkra din plattform genom att slå samman intagna, styrda data med sammanslagen åtkomst. Detta möjliggör intelligens i realtid, AI-aktivering och personanpassning i företagsskala över moln, regioner och verksamhetsdomäner.
En-storlek-passar-alla-lösningar passar inte de flesta verksamheter. Den optimala strategin mappar rätt mönster till rätt verksamhetsdrivkraft.
Yugandhar Bora är arkitekt inom programvaruteknik på Salesforce, specialiserad på dataarkitektur inom plattformen Data & Intelligence Applications. Han leder initiativ för granskningsnämnder för företagsarkitektur (EARB) med fokus på datastyrning och enhetliga datamodeller, samtidigt som han bidrar till automatiserade plattformsprovisioneringslösningar.
Jan Fernando är förstearkitekt på chefsarkitektens kontor på Salesforce. Han började på Salesforce 2012, med en mängd erfarenheter från sin tid i ekosystemet för uppstartsföretag. Innan han började på chefsarkitektens kontor tillbringade han över ett decennium i plattformsorganisationen, där han ledde flera viktiga teknikomvandlingar.