Платформы данных развиваются более трех десятилетий. Первоначально в отрасли преобладали локальные, централизованные и структурированные (в основном связанные), операционные базы данных/базы данных OLTP. Это расширение было распространено на хранилища данных OLAP/платформы больших данных, которые в основном использовались для аналитической обработки и оставались относительными и централизованными. Облачное хранилище стимулировало распределенные архитектуры, например, хранилища данных, озерные домики и дезагрегированные хранилища. Однако операционные платформы и аналитические платформы остались раздельными. Сегодня облачные вычисления и революция на основе искусственного интеллекта коренным образом меняют архитектуру платформы данных.
Предприятия уже инвестируют в зрелые платформы больших данных, например, Snowflake, Databricks, BigQuery и Redshift. Но эти платформы служат хранилищами данных. Клиенты не извлекают бизнес-ценности из своих данных, поскольку над данными невозможно работать напрямую в бизнес-потоках и приложениях. Эти решения не поддерживают генерируемую обработку искусственного интеллекта Agentic и не могут предоставлять доступ к данным в режиме реального времени, поэтому они не могут обеспечить персонализацию на основе искусственного интеллекта в момент вовлечения клиентов и другие ведущие функции отрасли.
Будущее платформ данных характеризуется объединенной, гибкой, доступной и открытой инфраструктурой данных. Эта новая архитектура основана на современных тенденциях вычисления и хранения данных (GPU, большая память, NVMe SSD и облачное хранилище) для интеграции с облачными вычислениями и искусственным интеллектом. Они могут предоставлять важные данные в реальном времени, управлять автономным принятием решений и управлять приложениями в реальном времени. Это включает развитие агентского искусственного интеллекта, прогнозируемого искусственного интеллекта, аналитики, крупномасштабных баз данных OLTP в реальном времени, озер данных и озер. Эти современные платформы данных созданы для простоты, масштабируемости, гибкости, производительности, безопасности, доступности и эффективности затрат.
Следующие тенденции данных определяют архитектуру платформы данных следующего поколения.
- ИИ, компьютерное обучение и Analytics в основе: Развитие искусственного интеллекта коренным образом изменит процесс разработки, развертывания и использования/доступа к платформе данных. Agentic AI будет понимать намерение разговора/запроса, планировать, создавать бизнес-правила и автоматизировать принятие решений. Агентская (краткосрочная и долгосрочная) память создается на основе журнала разговора для персонализации планирования и решений агентов, моделирования разговоров в реальном времени и поддержки персонализации, критически важной в платформах данных. Агенты будут оказывать помощь в автоматизации операционных "способностей", таких как управление данными (т.е. безопасность, соответствие, Trust), производительность (т.е. автоматическое масштабирование на соответствие, пропускную способность и задержку), отказоустойчивость и доступность, а также наблюдаемость и обслуживание. Аналитика на основе искусственного интеллекта, прогнозирование, обработка естественно-языковых данных (NLP) для аналитических вопросов и ответов и аналитика неструктурированных данных (например, PDF-документы, изображения, аудио- и видеоматериалы) будут стандартными, что позволит предприятиям получать более глубокие важные данные из различных источников данных.
- Децентрализация данных, но объединенный доступ к данным: Агентам нужны корпоративные данные для получения важных данных и принятия решений, а также для автоматизации бизнес-действий. Данные изначально децентрализованы на предприятиях, в разных приложениях и платформах данных. Но нелегко без труда объединить элеваторы в разных бизнес-единицах внутри предприятия и с партнерами за его пределами. Объединение данных предполагает обмен данными либо посредством приема из источников, либо посредством интегрирования в источники данных; исходные данные, полученные в результате подготовки данных, гармонизации и моделирования для аналитической обработки и обработки на основе искусственного интеллекта; хранение данных и управление ими в широких масштабах для обеспечения эффективного доступа при низком уровне CTS; и доступ к данным посредством различных механизмов и инструментов запросов и аналитики, глубоко интегрированных в базовые платформы хранения и доступа к данным
- Облачные открытые озерные домики: Облачные платформы больших данных (OLAP) объединяются в принятии открытых форматов файлов (паркет) и форматов таблиц (айсберг), включающих федерацию данных (данные в) и общий доступ (данные вне).
- Неструктурированная обработка данных: С появлением, развитием и внедрением генерирующего искусственного интеллекта предприятия начинают извлекать ценные важные данные и бизнес-ценность из корпоративного корпуса данных, представляющих собой большие объемы текстовых документов, аудиотранскриптов, видеозаписей и других носителей. Неструктурированная обработка данных, включительно с фрагментами, векторизацией, семантическим поиском и графиками Knowledge, делает эти важные данные возможными. Такие методы, как RAG (создание дополненного извлечения) и CAG (создание дополненного кэша), становятся основными факторами быстрого и агентского поиска в корпусе данных.
- Управление: знаниями Knowledge выходит за рамки только самого исходного содержимого (документов, статей, видеоматериалов). Она представляет собой дополнение этого содержимого путем извлечения смысла, обработки метаданных и их размещения в контексте для выработки общего понимания содержимого в организации или предприятии. Сама база Knowledge обычно структурирована. Управление Knowledge включает управление содержимым, извлечение Knowledge, представление посредством таких моделей, как графики и навигация.
- Доступ к обогащенным данным: Доступ к обогащенным данным означает, что данные, аналитика и инструменты искусственного интеллекта должны быть доступны разным персонам, включая конечных пользователей, бизнес-пользователей, администраторов и аналитиков. Доступность достигается посредством таких механизмов, как ансамблевые запросы (с относительными, ключевыми словами и семантическими запросами), естественно-языковые запросы SQL (NL2SQL), доступ в реальном времени и т. д.
- Обработка в реальном времени: Агентские приложения принимают решения в реальном времени на основе текущего состояния и новых событий, персонализируя ответы и действия, что требует доступа, обработки и действий над данными в реальном времени. Обработка в реальном времени требует актуальных данных (задержка данных) и интерактивного доступа (задержка доступа). Такие данные и задержка доступа требуют поддержки базовой платформой данных доступа к актуальным данным из операционных и аналитических хранилищ, низкого доступа к задержке (точечные поиски и запросы), высокого масштаба данных и высокой производительности.
- Безопасность данных, управление и место жительства: Агентский и разговорный искусственный интеллект упрощает пользовательский интерфейс приложения, позволяя любому пользователю, от потребителей до сотрудников и других агентов искусственного интеллекта, взаимодействовать с приложениями разговорно посредством разговорного или письменного естественного языка. Ценные клиентские и личные данные, которые должны храниться и моделироваться для приложений Agentic, должны быть защищены и управляться посредством четко определенных политик доступа и общего доступа. Многие клиенты все чаще должны соответствовать регламентам, требующим наличия данных в своей собственной стране или регионе, особенно те из них, которые находятся в правительстве или работают с правительствами.
Salesforce Data 360 создан для будущего, учитывающего данные тенденции. Data 360 - это облачная платформа данных под управлением метаданных, которая объединяет изолированные данные на предприятии, позволяя организациям хранить, моделировать и обрабатывать свои данные для включения приложений аналитики, искусственного интеллекта, компьютерного обучения и Agentic.
Этот документ является важным руководством для архитекторов предприятия и ЦТО. Он содержит сведения об архитектуре, возможностях, принципах создания и способах использования Data 360. Она представляет основы архитектуры Data 360 в качестве подводки, а затем выполняет ряд глубоких исследований ее ключевых дифференциалов, например, совместимость с существующими платформами данных, включительно со стратегией нескольких организаций, безопасностью, управлением и конфиденциальностью, активацией в реальном времени и «Чистые комнаты данных».
Salesforce Data 360 разработана на основе базового набора принципов, которые делают корпоративные данные оперативными, надежными и в режиме реального времени.
- Открытость и совместимость: Создано для многооблачных экосистем. Объединяется с платформами данных, такими как Snowflake, Databricks, BigQuery и Redshift, без дублирования, расширяя Customer 360, сохраняя существующие инвестиции.
- Разделение между хранилищем и компьютером: Хранение и обработка весов (пакетная, потоковая и интерактивная) независимо друг от друга. Обеспечивает эластичность и эффективность для больших объемов работы с высокой производительностью.
- Хранение и обработка нескольких моделей: Поддерживает структурированные и разные неструктурированные типы данных, например, текст, аудио- и видеоизображение. Предоставляет эффективное хранилище, обработку в реальном времени и пакетно, расширяемую индексацию, объединенный поиск, запросы и анализ.
- Дизайн под управлением метаданных: Приложения определяются метаданными, а не кодом. Метаданные рассматриваются как первоклассный актив, что обеспечивает единое управление, гибкость и глубокую интеграцию в Salesforce Platform.
- Гибридная обработка в реальном времени: Поддерживает запросы с низкой задержкой и мгновенное принятие решений, а также пакетную обработку и аналитические нагрузки.
- Интеллектуальные и активные данные: Постоянно принимает, анализирует и внедряет важные данные непосредственно в бизнес-процессы. Предоставляет возможность автоматизации без кода, без кода, без кода и на основе искусственного интеллекта в самом актуальном контексте.
- Управление и конфиденциальность по дизайну: Встроены строки, контроль доступа, место жительства, шифрование данных и соответствие. Trust и доверие регуляторов укрепляются на каждом слое.
- Одно ко многим аренду: Централизованная организация Data 360 служит единым Источником истины для Customer 360, безупречно поддерживая мультиорганизационные среды salesforce, широко используемые клиентами Salesforce.
Эти принципы обеспечивают открытость, интеллектуальность и действенность данных Data 360 в режиме реального времени.
Salesforce Data 360 — современная платформа обработки данных, созданная на основе принципов проектирования, которые учитывают текущие тенденции данных. Его архитектурные возможности обеспечивают надежность, объединение и действенность корпоративных данных в режиме реального времени в соответствии с руководящими принципами.
- Cloud-Native Foundation: Работает в Hyperforce, развернута в Hyperscalers (например, AWS), с неизменяемой инфраструктурой на основе микросервисов. Предоставляет эластичное масштабирование, безопасность zero- Trust, постоянную доставку и глобальное соответствие.
- Базовые метаданные Salesforce: Метаданные создаются, моделируются и хранятся как метаданные Salesforce, позволяющие немедленно использовать их ВСЕМИ приложениями Salesforce. Такие метаданные хранятся в полностью совместимых с ACID RDBMS. Обеспечивает управление, согласованность жизненного цикла и глубокую интеграцию с Salesforce Lightning Platform.
- Lakehouse Storage: Созданный на основе айсберга и паркета Apache, сочетающий масштаб озера данных с управлением складом, поддерживающим эволюцию схемы, путешествия во времени и массовые обновления. Data 360 сохраняет, моделирует и обрабатывает структурированные и неструктурированные данные с экстремальным хранилищем с современными открытыми стандартами и с богатыми возможностями трансформации и обработки данных для пакетных и управляемых событиями загруженности.
- Конвейеры сквозных данных с гибким приемом: Охватывает полный жизненный цикл (прием, подготовка, моделирование, объединение, анализ и активация), снижая зависимость от фрагментированных точечных решений. Поддерживает пакетное, близкое к реальному, потоковое вещание с коннекторами 270+ и MuleSoft. Метод ELT-first обеспечивает быструю доступность данных с гибкостью трансформации в нисходящем направлении.
- Совместимость корпоративных данных с открытыми инфраструктурами и интегрированием: Объединяет изолированные данные на предприятии с двусторонней федерацией нулевой копии с Snowflake, Databricks, BigQuery и Redshift, избегая миграции данных или дублирования.
- Классификация данных, моделирование и организация: Data 360 систематизирует данные как исходные принятые данные, очищенные и сохраненные данные и данные, смоделированные в соответствии с распространенной информационной схемой, известной как SSOT (единый источник истины). Такие объекты SSOT являются основой для определения семантической модели данных (SDM) и других рекомендованных и прикладных моделей.
- Встроенное семантическое моделирование данных для расширяемой аналитики с открытыми API семантического запроса, привод Tableau Next и включение аналитики приложения.
- Высокопроизводительный механизм запросов SQL, поддерживающий объединенный запрос Data 360 SQL в структурированных, неструктурированных и графических данных.
- Низколатентные хранилища данных: Хранилище ключевых значений для горячих данных с миллисекундным временем ответа. Включает персонализацию и сценарии под управлением событий в режиме реального времени. Собирает и обрабатывает данные о занятости клиентов в режиме реального времени. Объединяет удостоверения, взаимодействия и разговоры в один надежный график профиля Customer 360 и контекста.
- Конвейеры обработки неструктурированных данных для гибкой и расширяемой поддержки неструктурированного хранилища данных, фрагментации, создания вставки (vectorization), извлечения метаданных (augmentation), резюмирования, индексации, извлечения Knowledge, интеллектуальной обработки документов, создания краткосрочной и долгосрочной (диаграммы) памяти и т. д.
- Собственное ключевое слово, вектор и гибридная индексация для точного и эффективного доступа к неструктурированным данным, например, быстрый и агентский поиск, RAG, извлечение Knowledge, извлечение агентской памяти и т. д.
- Службы профиля, персонализации, контекста для включения приложений на основе искусственного интеллекта/ML и Agentic.
- Встроенное управление и безопасность на каждом уровне для отслеживания линии, маскировки данных, резидентства данных и безопасности zero-Trust, обеспечивающей соответствие и Trust.
- Эластичная вычислительная ткань: Кубернеты - туземная многопользовательская компьютерная ткань. Запускает Spark для распределенной обработки и Hyper для загруженности SQL. Эластичные масштабы в разных заданиях и поддержка изоляции для выполнения ненадежного кода.
Все это выполняется на Hyperforce, облачной основе Salesforce. Hyperforce предоставляет:
- Zero- Trust security с политиками шифрования, изоляции и наименьших привилегий.
- Устойчивость посредством многорегиональных развертываний. В то время как Salesforce Data 360 выигрывает от многорегиональной устойчивости Hyperforce и отказоустойчивости на уровне платформы, истинное послеаварийное восстановление (DR) корпоративного уровня требует более широкой архитектуры, аналогичной любой платформе данных с ключевыми возможностями: воспроизводимые ожидаемые приемы, репликация и регидратация на основе метаданных во всех зависимых экосистемах.
- Наблюдаемость со встроенными мониторингом, показателями и трассировкой.
- Автоматическое масштабирование и информирование FinOps для повышения эффективности без перерасхода средств.
Data 360 не заменяет существующие инвестиции предприятия. Вместо этого Data 360 делает данные, которым вы уже доверяете, которыми управляете и которые доступны для действий, обеспечивая занятость в реальном времени на основе искусственного интеллекта там, где это наиболее важно. Короче говоря, Salesforce превращает все корпоративные данные, включая внешние данные, в объекты, управляемые метаданными (Salesforce), и включает приложения Agentic для обнаружения, принятия решений и действий.
Ниже приведен рисунок, иллюстрирующий справочную архитектуру Data 360:
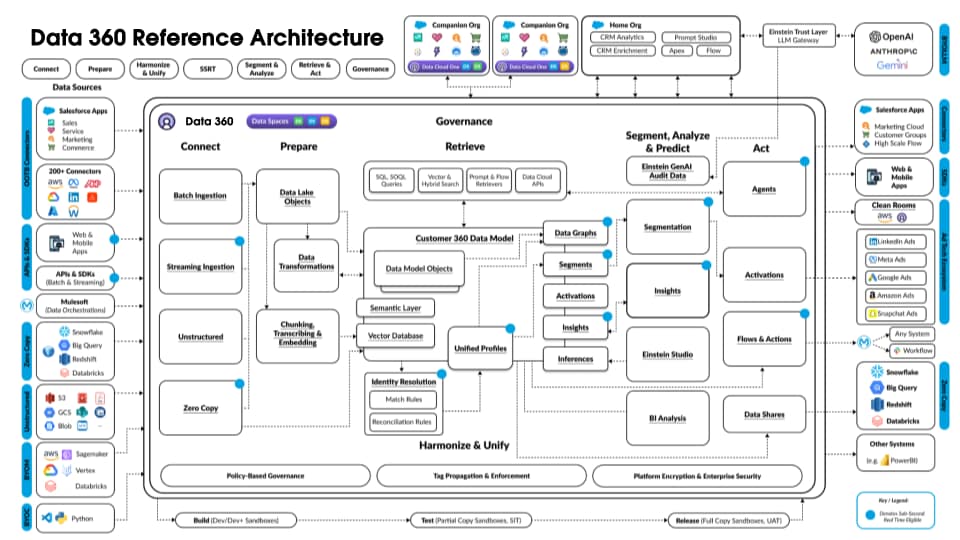
Рассмотрим гипотетический Agentforce Loan Agent, наслоенный на Data 360 для описания примера потока архитектуры. Например, кредитный агент является клиентским агентом, когда клиенты (потребители) обращаются за кредитами и получают мгновенные утверждения кредита.
Data 360 выполняет эти действия согласно расписанию, подготавливая данные для использования кредитным агентом.
- Data 360 принимает структурированные данные организации-клиента из CRM и сохраняет их в озере данных.
- Data 360 обрабатывает неструктурированные данные о кредитах и финансовой политике компании.
- Data 360 федерирует личные данные из внешнего источника данных, например, Snowflake.
- Data 360 трансформируется и моделирует принятые и интегрированные данные.
- Data 360 создает и обслуживает график данных профиля.
При каждом обращении клиента за кредитом выполняются данные действия.
- Клиент регистрируется в качестве кредитного агента, который начинает сеанс клиента в слое реального времени. Объединенный профиль клиента извлекается в слой в реальном времени.
- Клиент заполняет заявку на кредит, предоставив необходимые сведения.
- Клиент загружает финансовые документы (например, налоговые декларации, инвестиции, банковские счета) в Data 360 для неструктурированной обработки данных.
- Загруженные данные разделяются на фрагменты и векторизируются (создание внедрения), а также создаются индексы (ключевое слово и вектор).
- Далее клиент заполняет документ заявки на кредит и загружает его. Data 360 извлекает сумму кредита и продолжительность в режиме реального времени.
- Кредитный агент извлекает актуальные финансовые данные посредством запроса Data 360 и гибридного поиска по профилю и другим предварительно созданным индексам.
- Агент кредита активирует агента утверждения с данными кредита и другими данными финансового профиля для принятия решения об утверждении кредита.
- Кредитный агент отвечает клиенту решением.
- Все это взаимодействие между клиентом и кредитным агентом также собирается и сохраняется в Data 360.
Выше приведенный пример предоставляет обзор компонентов архитектуры Data 360, используемых для создания приложения Agentic, например, Loan Agent. В следующем разделе описаны уровни и компоненты архитектуры Data 360.
В этом разделе мы рассмотрим основные элементы Salesforce Data 360, начиная с его надежной модели хранилища, а затем изучим механизмы подключения, приема и подготовки данных. Затем мы рассмотрим, как структурированные и неструктурированные данные хранятся, моделируются и обрабатываются, что приведет к пониманию их гармонизации, объединения, извлечения и интеллектуальных возможностей активации.
Salesforce Data 360 построена на многоуровневой, но интегрированной модели хранилища, сочетающей сильные стороны озерного домика с хранилищем в реальном времени. Слой Lakehouse предоставляет масштабируемое, экономичное хранилище для больших объемов архивных и пакетных данных, что позволяет использовать расширенную аналитику и сценарии использования компьютерного обучения. Хранилище в реальном времени, с другой стороны, оптимизировано для доступа с низкой задержкой и высокочастотных обновлений, обеспечивая постоянную актуальность взаимодействий с клиентами, профилей и сигналов занятости. Вместе эти уровни работают без проблем, позволяя данным быстро перемещаться между архивным и оперативным контекстами, предоставляя глубину и непосредственность в объединенной основе данных для персонализации, искусственного интеллекта и активации.
Data 360 содержит нативную архитектуру Lakehouse на основе айсберга/паркетника, предназначенную для обработки крупномасштабных процессов управления данными и их обработки для пакетных, потоковых и сценариев в реальном времени, поддерживающих структурированные и неструктурированные данные, что важно для приложений на основе искусственного интеллекта и аналитики.
В облачных озерах данных, например, Azure, AWS или GCP, базовой единицей хранения является файл, обычно систематизированный по папкам и иерархиям. Lakehouse расширяет эту структуру, внедряя структурные и семантические абстракции более высокого уровня для облегчения таких операций, как запрос и обработка искусственного интеллекта/ML. Основная абстракция - это таблица с метаданными, определяющая ее структуру и семантику, содержащая элементы из открытых проектов, например, Айсберг или Дельта-Лейк, с дополнительными семантическими слоями, добавленными Data 360.
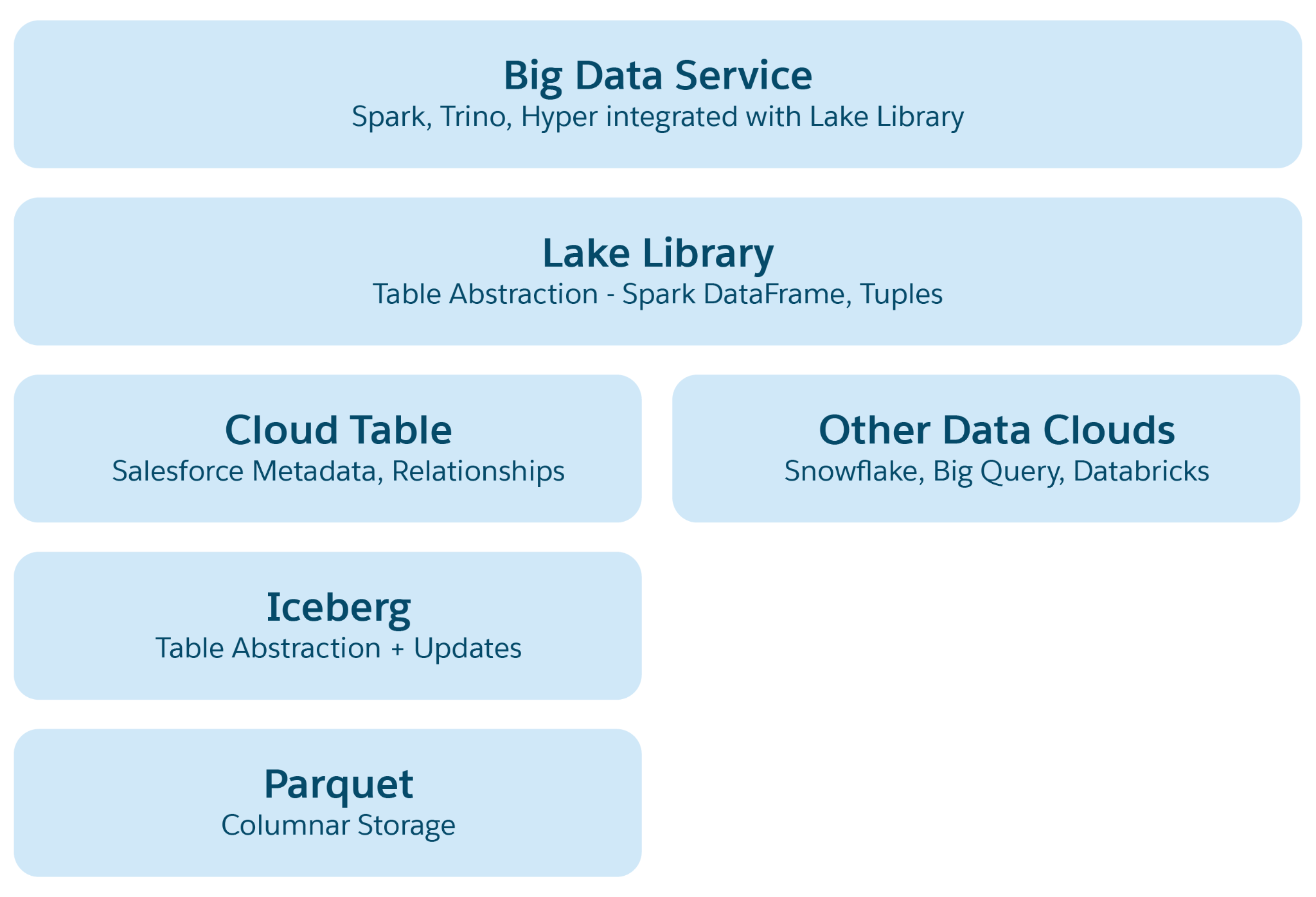
Слои абстракции в Lakehouse:
- Абстракция файла паркета: В базе хранилище состоит из файлов озера данных (например, S3 в AWS или Blob в Azure) в формате паркета. Данные для исходной таблицы хранятся в нескольких разделах в виде файлов паркета, каждая таблица является коллекцией этих файлов.
- Абстракция таблицы Айсберга: Таблицы систематизированы как папки, а разделы данных хранятся как файлы паркета в этих папках. Изменения раздела приводят к созданию новых файлов паркета в качестве снимков. Айсберг управляет файлом метаданных для каждой таблицы, содержащим схемы, характеристики разделов и снимки.
- Абстракция таблицы Salesforce Cloud: Созданный на основе айсберга, этот слой добавляет семантические метаданные, например, имена столбцов и взаимосвязи, а также конфигурации, например, размер целевого файла и сжатие. Он абстрагирует таблицы на разных платформах, например, Snowflake и Databricks, защищая приложения Data 360 от основных особенностей платформы хранения.
- Библиотека доступа к озеру: Эта библиотека предоставляет доступ к Salesforce Cloud Table, обрабатывая данные и метаданные, и абстрагирует основные механизмы хранения для разработчиков приложений.
- Абстракция: службы больших данных Сюда входят инфраструктуры обработки, например, Hyper для запросов и Spark для обработки на любой облачной платформе таблицы.
Для поддержки аналитики и агентских приложений в реальном времени Data 360 дополняет хранилище больших данных Lakehouse магазином с низкой задержкой. Слой Data 360 в реальном времени обрабатывает сигналы в реальном времени и данные занятости в памяти. Однако, поскольку объем хранилища на основе памяти ограничен, все данные не помещаются и обработка может не выполняться в режиме реального времени. Data 360 добавляет магазин с низкой задержкой (LLS) для устранения таких ограничений, включая масштабируемую обработку в реальном времени.
Магазин с низкой задержкой является петабайтным слоем NVMe (SSD) в Lakehouse. Не все данные нужно хранить в магазине с низкой задержкой. Это прочный кэш. Большинство данных в конечном итоге попадают в Озерный дом для длительного хранения. Сеансовые данные в реальном временном слое можно смыть в магазин с низкой задержкой для последующего быстрого доступа. Например, в разговоре Agentic недавние сообщения можно обработать в памяти; старые сообщения можно смыть в магазин с низкой задержкой. Если требуется предыдущий разговор, его можно открыть в течение нескольких миллисекунд из магазина с низкой задержкой. Хранилище на основе NVMe позволяет хранить и открывать большие объемы данных с опозданиями в миллисекунду. Данные могут попасть в облачное хранилище Lakehouse для длительного хранения. Кроме того, данные из Lakehouse, необходимые для обработки в реальном времени или для дополнения взаимодействий в реальном времени, извлекаются и хранятся в магазине с низкой задержкой. Например, контекст профиля клиента предварительно извлекается или доставляется из Lakehouse и кэшируется в магазине с низкой задержкой. Кроме того, любые объекты озера и другие объекты, необходимые для обработки в режиме реального времени во время обработки в сеансе, также могут кэшироваться в магазине с низкой задержкой.
Хранилище данных с низкой задержкой Data 360 включает уровень «Реальный таймер» в истинной иерархии хранилищ с уровнями хранилища памяти Lakehouse (SSD), с данными, легко мигрирующими между этими уровнями. Ниже в этом документе рассматривается слой «Данные 360 в реальном времени».
Salesforce Data 360 разработана для стандартизации, гармонизации и активации всех данных клиентов (структурированных и неструктурированных) в соответствии с строгим жизненным циклом, трансформирующим исходный ввод в объединенную текущую модель данных.
Жизненный цикл фокусируется на получении разных внешних вводных данных и структурировании их в постоянные смоделированные объекты. Смоделированные данные можно гармонизировать в объединенные профили Customer 360.
Исходные принятые данные и первичные трансформации
Процесс начинается с принятия исходных данных как есть из исходных систем (CRM, Marketing, файлы и т. д.). Это включает полную загрузку данных и непрерывные события изменений (дельты), которые управляются и объединяются с постоянными данными для поддержания текущего состояния.
Встроенные трансформации (например, обрезка, нормализация, конкатенация) немедленно применяются во время приема для обеспечения предварительного качества и чистоты данных.
Объекты озера данных (DLO): Постоянный слой
ООД (объекты озера данных) формируют базовый постоянный слой хранилища в Data 360. Они хранят чистые трансформированные данные и служат организованным долгосрочным хранилищем для всех сведений о клиентах.
Расширенные трансформации данных (например, объединения, агрегации, вычисленные важные данные) применяются к исходным ООД для создания новых высокоэффективных производных ООД.
Данные, доступные посредством федерации данных нулевой копии, представлены напрямую как DLO.
Неструктурированная организация данных и метаданных
Для неструктурированного содержимого (например, текста, медиа, документов) Data 360 внедряет данные, извлекая и сохраняя свои структурированные метаданные в определенных ООД под названием «Неструктурированные объекты озера данных (UDLO)».
Эти специализированные ООД функционируют как таблицы каталога, предоставляя соотнесение с физическим расположением и контекстом неструктурированных активов. Эта возможность позволяет архитекторам без труда связывать метаданные неструктурированных данных с остальными структурированными данными клиентов, что обеспечивает возможность объединенного запроса и гармонизации.
Объекты модели данных (DMO): Гармонизированный слой
ОМД (объекты модели данных) представляют собой конечный, гармонизированный и структурированный слой данных.
Они создаются путём соотнесения полей ООД (из исходных, производных и неструктурированных ООД метаданных) со стандартной моделью данных Customer 360.
Уровень DMO действует как единый источник истины для всех данных клиентов, обеспечивая создание объединенного профиля, сегментацию и активацию в более широкой экосистеме.
Пространство данных - это основной логический контейнер для систематизации всех данных и метаданных в Data 360, включительно со всеми ООД (структурированными и неструктурированными) и DMO. Пространства данных предлагают безопасную изолированную среду для обработки данных и моделирования.
Пространства данных действуют как логические границы и границы управления, обеспечивая внутреннюю многопользовательность, разделяя данные для разных объектов, например бизнес-единиц, регионов или фирменных стилей, сохраняя общекорпоративную видимость, родословную и соответствие, служа основой для определения грубого гранулированного контроля доступа.
Изоляция в пространствах данных применяется на нескольких уровнях платформы:
- Изоляция на уровне данных: Каждая DLO/DMO принадлежит одному пространству данных, гарантируя, что запросы, трансформации и соотнесения объектов не могут пересекать границы пространства данных, если они явно не авторизованы.
- Интеграция управления доступом: Наборы полномочий изначально связаны с пространствами данных, позволяя контролировать операции чтения, записи и администрирования. Это обеспечивает доступ только авторизованных пользователей и служб к объектам, важным данным и активациям в пространстве данных.
- Управление и ревизия: Все операции в пространстве данных регистрируются с помощью контрольных журналов корпоративного уровня, что позволяет отслеживать соответствие, управление и нормативную отчетность.
Доступ и полномочия управляются посредством наборов полномочий, обеспечивая детализацию, управляемые обновления и предотвращение утечки данных между доменами. Интегрируя границы пространства данных с архитектурой безопасности и управления Data 360, архитекторы могут уверенно внедрять как централизованные, так и децентрализованные стратегии управления, сохраняя согласованность в нескольких облаках и бизнес-доменах.
Компьютерная ткань Data 360 предоставляет объединенный слой для управления и выполнения всех загруженности больших данных, упрощая основные сложности инфраструктуры. Его базовым компонентом является контроллер обработки данных (DPC).
DPC — это универсальная многозагрузочная служба оркестрации обработки данных, предоставляющая возможности Jaa-a-Service (JaaS) в разных средах облачной обработки данных. Он абстрагирует сложность инфраструктуры и унифицирует выполнение заданий для таких инфраструктур, как Spark (EMR в EC2 и EMR в EKS) и Kubernetes Resource Controller (KRC). Используя централизованный шлюз панели управления, ЦОД организует, планирует и отслеживает задания на нескольких плоскостях данных, обеспечивая надежность, масштабируемость, эффективность затрат и согласованное взаимодействие разработчика.
Потребность в DPC обусловлена ограничениями прямого взаимодействия с нативными системами управления кластерами, например, EMR.
Инфраструктура и облачная абстракция
Хотя EMR предлагает API для кластеров, задач и этапов, он по-прежнему нагружает группы клиентов критическими задачами управления инфраструктурой, например, инициализацией, масштабированием, настройкой производительности и оптимизацией затрат. ЦОДД решает эту проблему, предлагая упрощенный API-интерфейс на уровне платформы для отправки задания. Он поддерживает автоматическую обработку сбоев, повторные попытки и динамическую балансировку нагрузки. Обеспечивает эффективность затрат посредством бинпакетирования, узлов на основе пятен и гравитона. Предоставляет надежную безопасность с изоляцией TLS, PKI, IAM и автоматическим исправлением. Управление обновлениями версий выполнения Spark и EMR для предоставления улучшений производительности, исправлений безопасности и расширений функций.
Кроме того, DPC предоставляет объединенный облачный интерфейс для отправки заданий данных и управления ими, абстрагируя сложности и собственные API базовой облачной подложки (AWS, будущие поставщики). Это обеспечивает взаимодействие рабочих групп клиентов только с общим интерфейсом отправки заданий на основе Data 360 API, который устраняет сложности основных менеджеров ресурсов, например, Kubernetes и YARN. Это позволяет группам клиентов отправлять задания Spark посредством простого объединенного API без необходимости управления капсулами, пулами узлов или конфигурациями кластера Spark напрямую.
Настройка параметров Spark вручную требует специальных навыков, а неправильные конфигурации могут привести к медленному выполнению задания. Группа ЦОДД централизует эти знания, предоставляя оптимизированные конфигурации для предотвращения распространенных проблем производительности. Эта специализированная группа постоянно интегрирует Knowledge из открытого сообщества для обеспечения оптимальной производительности во всех загруженности, управляемых контроллером.
DPC не ограничивается Spark; он поддерживает широкий диапазон загруженности. К ним относятся:
- Обработка загруженности в реальном времени
- Доставка событий для функции действий над данными
- Управление Milvus (векторная база данных для неструктурированной индексации данных)
- Инфраструктура хранения данных с низкой задержкой
DPC также использует инфраструктуру контроллера ресурсов Куберенеса (KRC), поддерживающую такие нагрузки, как Trino для запроса, доставка событий для действий над данными, задания извлечения данных для коннекторов и обработка в реальном времени. Для всех загруженности KRC DPC предоставляет централизованные возможности «Работа как услуга», обрабатывая инициализацию вычислений, развертывание и управление на высоком уровне абстракции заданий.
Преимущества и архитектура JaaS
Модель Job-as-a-Service, предоставленная ЦОДД, обеспечивает экономичность и устойчивость ожидаемых продаж обработки заданий.
Пользователи предоставляют простые характеристики кластера, фокусируясь на обязательном процессоре, памяти, хранилище, количестве экземпляров и минимальном/максимальном количестве кластеров и тегах для сопоставления кластеров. ЦОДД потом автоматически управляет абстрактными сведениями об инфраструктуре, включительно с выбором оптимальных SKU ВМ, управлением парками экземпляров, определением соотношения «Базовый» и «Базовый». Узлы задач и управление по запросу в сравнении с Определите экземпляры на основе вводных данных. Он также обрабатывает управление версиями EMR и компонентов и обновления без простоя.
Важно отметить, что ЦОДД изначально поддерживает многопользовательский подход, предназначенный для понимания и внедрения границ аренды Data 360 и разделения ресурсов. Он также обеспечивает безопасность и соответствие, внедряя сертифицированные Salesforce изображения компьютера, управляя ролями IAM и гарантируя шифрование как в пути, так и в дежурном режиме. Для маршрутизации и управления пропускной способностью сопоставление заданий между кластерами управляется посредством тегов кластера, а маршрутизация на основе пропускной способности использует максимальный параметр параллельности заданий для эффективного управления использованием ресурсов.
Cloud Agnostic Client Experience является базовым преимуществом, поскольку сложность базовых облачных сред скрыта от служб поддержки, что позволяет им сосредоточиться исключительно на бизнес-логике. Таким образом достигается цель абстракции облачного поставщика. Наконец, ЦОДД поддерживает простое использование и отслеживание расходов, позволяя сегментировать использование кластера и затраты по обслуживанию для точного учета. В целом, DPC использует подключаемую архитектуру, которая позволяет без труда интегрировать новые механизмы выполнения (например, Flink, Ray) и облачные подложки (GKE/Dataproc), не открывая пользователям основные сведения об инфраструктуре. Эта конструкция отделяет плоскость управления от уровня выполнения, обеспечивая последовательное API и взаимодействие работы, вне зависимости от фона.
Data 360 настраивает и пополняет исходные данные, сокращая разрыв между исходной информацией и потреблением бизнеса. Он дополняет жизненный цикл объекта данных, подготавливая сложные данные для сложной активации и анализа. Data 360 поддерживает разные типы обработки, включая пакетные и потоковые трансформации данных, пакетные и потоковые вычисленные важные данные, обработку неструктурированных данных и разрешающую способность при опознавании. Для эффективного выполнения этих разнообразных операций, особенно в близком к реальному режиме времени и в массивных наборах данных, требуется сложный механизм для эффективной обработки изменений данных.
Для обеспечения эффективной обработки данных в близком к реальному режиме времени, особенно с помощью таблиц терабайтного размера и миллионов потенциальных обновлений, Data 360 нужен прорыв. Это требует способа точного уведомления систем об изменении данных, а потом эффективного определения измененных данных, чтобы обрабатывались только актуальные обновления и только при их обновлении. Эта проблема привела к двум взаимодополняющим инновациям: Хранение нативных событий изменения (SNCE) для уведомления о внесении изменений и ленты изменения данных (CDF) для идентификации изменений.
Нативные события изменения хранилища (SNCE)
SNCE коренным образом изменила Data 360 в реактивную и инкрементную платформу данных. Эта смена включает переход от активного опроса озера данных к пассивному мониторингу событий атомного подтверждения посредством стандартизированного формата события и высокопроизводительной системы доставки сообщений.
Каждая успешная операция записи (ВСТАВКА, ОБНОВЛЕНИЕ, УДАЛЕНИЕ) в таблицу айсберга завершается атомной заменой указателя файла метаданных таблицы в каталоге. Основной слой хранилища объекта (например, S3) настроен на излучение собственного события уведомления (например, события S3) при каждой записи нового снимка метаданных в каталог таблицы.
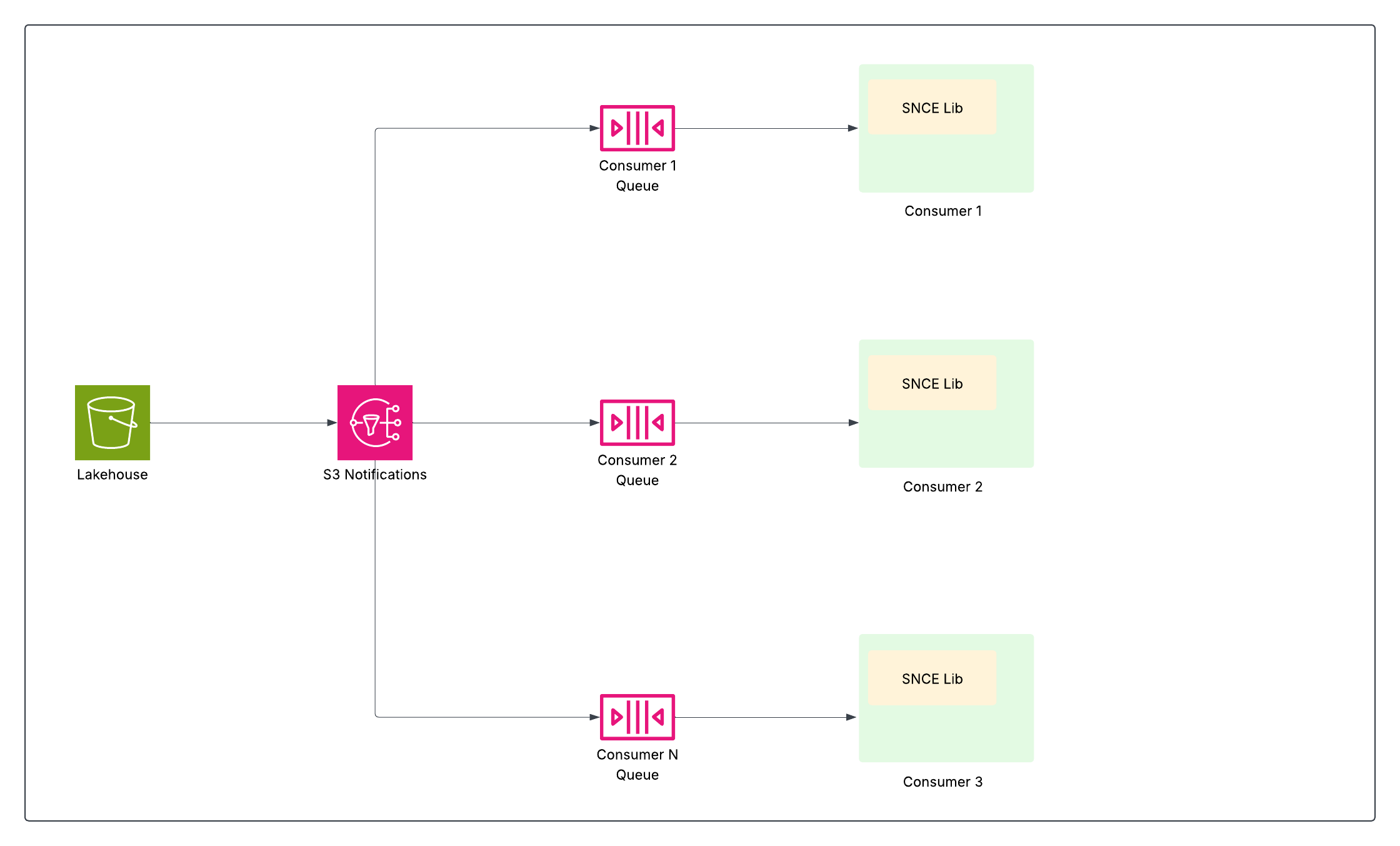
Библиотека SNCE предлагает стандартизированный метод потребления этих событий, а также может пополнить их метаданными снимка по запросу.
Это позволяет ожидаемым продажам данных в нисходящем направлении (например, потоковые вычисленные важные данные, разрешающая способность при опознавании и сегментация) подписываться и действовать только при изменении данных, значительно повышая эффективность, избегая дорогостоящего сканирования полной таблицы.
Изменение ленты данных (CDF)
На основе SNCE лента данных об изменении (CDF) предоставляет упрощенный механизм для потребления и инкрементной обработки изменений.
ВПР использует снимки айсберга для эффективного создания потока изменений. Важно отметить, что оптимизированный автор айсберга Data 360 вычисляет и сохраняет изменения как часть самой операции записи, что делает создание CDF высокоэффективным и минимизирует дополнительные расходы. Это позволяет заданиям обработки (например, потоковые трансформации или потоковые вычисленные важные данные) выборочно обрабатывать только измененные записи, избегая дорогостоящего вычисления отличия снимка.
Эта инкрементная стратегия предоставляет несколько преимуществ для больших наборов данных, включая экономию средств, уменьшение задержки и повышение эффективности. Он включает такие функции, как потоковые трансформации и инкрементное разрешение идентификации, что, в свою очередь, приводит к более быстрым важным данным, более предсказуемой загрузке системы, повышению производительности и снижению операционных расходов.
Data 360 предлагает надежные возможности принятия с собственной поддержкой продуктов Salesforce, обеспечивая безупречный поток данных. Для внешних источников он предоставляет широкое подключение посредством более 270 коннекторов, API, SDK и MuleSoft. Кроме того, Data 360 поддерживает функцию нулевой копии, что позволяет использовать функцию BI и аналитики без дублирования данных.
Инфраструктура коннектора Data 360 (DCF) является основой для большинства подключений Data 360. Он включает прием, федерацию и выход посредством объединенной архитектуры. DCF определяет стандарты для создания коннекторов и управления ими, от пользовательского интерфейса для настройки и администрирования до сохранения метаданных, извлечения данных и доставки в Lakehouse или посредством оперативных запросов к внешним источникам. Она также поддерживает личные параметры подключения (например, личные ссылки, VPN и защищенные туннели) для обеспечения безопасности данных корпоративного уровня и соответствия при подключении к клиентской или партнерской среде. Предоставляя последовательный подход во всех коннекторах, DCF предоставляет Data 360 возможность беспрепятственного подключения к более широкой экосистеме, обеспечивая расширяемость, надежность и безопасную интеграцию.
Data 360 обеспечивает надежное подключение к обширной экосистеме источников данных, поддерживая как собственные продукты Salesforce, так и многочисленные внешние системы. Это широкое подключение важно для объединения изолированных корпоративных данных и включения приложений на основе искусственного интеллекта/ML и Agentic.
Data 360 предлагает более 270 коннекторов нативно или посредством MuleSoft, API и SDK для поддержки возможностей конвейера данных посредством пакетного, потокового или реального приема. Эти коннекторы можно разделить на общие категории по типу интегрированной исходной системы.
Собственные коннекторы Salesforce
Эти коннекторы обеспечивают безупречный и собственный поток данных из продуктов Salesforce.
Примеры включают коннекторы для Salesforce CRM, Data Cloud One , Marketing Cloud Engagement, Marketing Cloud Account Engagement и B2C Commerce.
Внешние приложения и SaaS
Коннекторы для разных бизнес-приложений и облачных служб позволяют принимать данные из внешних программных платформ.
Например, Adobe Marketo Engage, Microsoft Dynamics 365, Mailchimp и Airtable.
Базы данных и хранилища данных
Data 360 подключается к разным относительным и облачным платформам хранения данных.
Например, Amazon Redshift, Amazon DynamoDB, Amazon RDS (MySQL, PostgreSQL, Oracle), Google BigQuery и Microsoft SQL Server.
Облачное хранилище объектов и файловые системы
Эти коннекторы интегрируются с решениями гипермасштабного хранилища для структурированных и неструктурированных данных.
Например, Amazon S3, Google Cloud Storage (GCS) и Azure Blob Storage.
Службы потоковой передачи и службы сообщений
Коннекторы, обрабатывающие непрерывные потоки данных в реальном времени, важны для сценариев под управлением событий и обработки в реальном времени.
Пример - коннектор Amazon Kinesis.
Интеграционные платформы
Коннектор MuleSoft Anypoint расширяет охват Data 360, интегрируя его в более широкий диапазон приложений и баз данных посредством Anypoint Exchange.
Неструктурированные коннекторы хранилища данных и облачного объекта
Эти коннекторы важны для приема и обращения к неструктурированным данным (данным, не имеющим предопределенной модели) для питания генерирующих возможностей искусственного интеллекта.
Все эти коннекторы созданы на основе инфраструктуры коннекторов Data 360, предоставляющей последовательное взаимодействие.
Трансформация данных — это фундаментальный архитектурный компонент в Data 360, предназначенный для очистки, обогащения и формирования исходных принимаемых данных в нормализованные, действенные активы данных, согласованные с моделью данных Customer 360. Этот процесс необходим для гармонизации данных, повышения качества и обеспечения готовности данных к сценариям последующего использования, например, объединения, сегментации и активации профиля. Трансформации используют объекты озера исходных данных (DLO) и объекты модели данных (DMO) в качестве вводных данных, получая результаты в новые DLO или DMO соответственно.
Data 360 предоставляет две основные парадигмы трансформации для обработки разных требований к скорости данных: пакетные трансформации данных и трансформации потоковых данных.
Пакетные трансформации данных
Пакетные трансформации данных созданы для массовой обработки на основе определенного расписания или триггера по запросу. Этот механизм оптимизирован для обработки сложных, ресурсоемких операций реструктуризации.
Процесс пакетной трансформации настроен посредством визуального низкокодового холста ожидаемых продаж, позволяющего пользователям определить логику многоэтапной трансформации. Этот механизм уникально поддерживает сложные операции реструктуризации, важные для канонического выравнивания модели данных: структурирование и нормализацию данных. Это включает сводку (разложение ненормализованных записей на несколько нормализированных записей) и выравнивание (перестройка иерархических данных, например, JSON, в структурированные таблицы). Режим выполнения системы поддерживает полную синхронизацию (обработку всех записей) и высокоэффективный режим инкрементной обработки. Инкрементный режим значительно сокращает время обработки и расход ресурсов, обрабатывая только записи, измененные после последнего успешного выполнения. Пакетные трансформации идеально подходят для задач, где обновления в реальном времени не являются важными, например, периодические агрегации и сложная перестройка данных.
Трансформации потоковых данных
Потоковые данные трансформируют данные обработки непрерывно и инкрементно в близком к реальному режиме времени при их поступлении в систему, что делает их важными для сценариев использования с низкой задержкой.
Основной интерфейс - это метод SQL-first, где трансформации определяются как запрос SQL SELECT, который постоянно выполняется относительно входящего потока изменений записи. Этот механизм поддерживает базовые функции трансформации, включая очистку и стандартизацию данных (например, проверка персональных данных и стандартизация форматов данных), а также пополнение и объединение данных (посредством объединений и союзов). Важно отметить, что он поддерживает ПОТОКОВЫЙ ПОИСК JOINS для включения пополнения данных в реальном времени и поиска по статическим или медленно меняющимся справочным данным, обеспечивая мгновенное обновление профиля. Чтобы оптимизировать затраты на обслуживание, архитектура использует высокоплотный (HD) дизайн заданий, который упаковывает несколько определений потоковой трансформации для одного клиента в одно базовое задание компьютера, увеличивая использование ресурсов. Потоковые трансформации необходимы для сценариев использования, например, мониторинга событий, немедленной персонализации и обновления профиля в реальном времени.
Data 360 революционизирует управление данными, поддерживая федерацию Zero Copy и общий доступ к данным, что исключает необходимость перемещения или дублирования данных. Эта возможность позволяет пользователям беспрепятственно и напрямую получать доступ к данным из разных внешних источников и предоставлять общий доступ к данным внешним средам, значительно уменьшая сложность, снижая затраты на хранение и обеспечивая принятие всех решений на основе самой свежей и надежной информации.
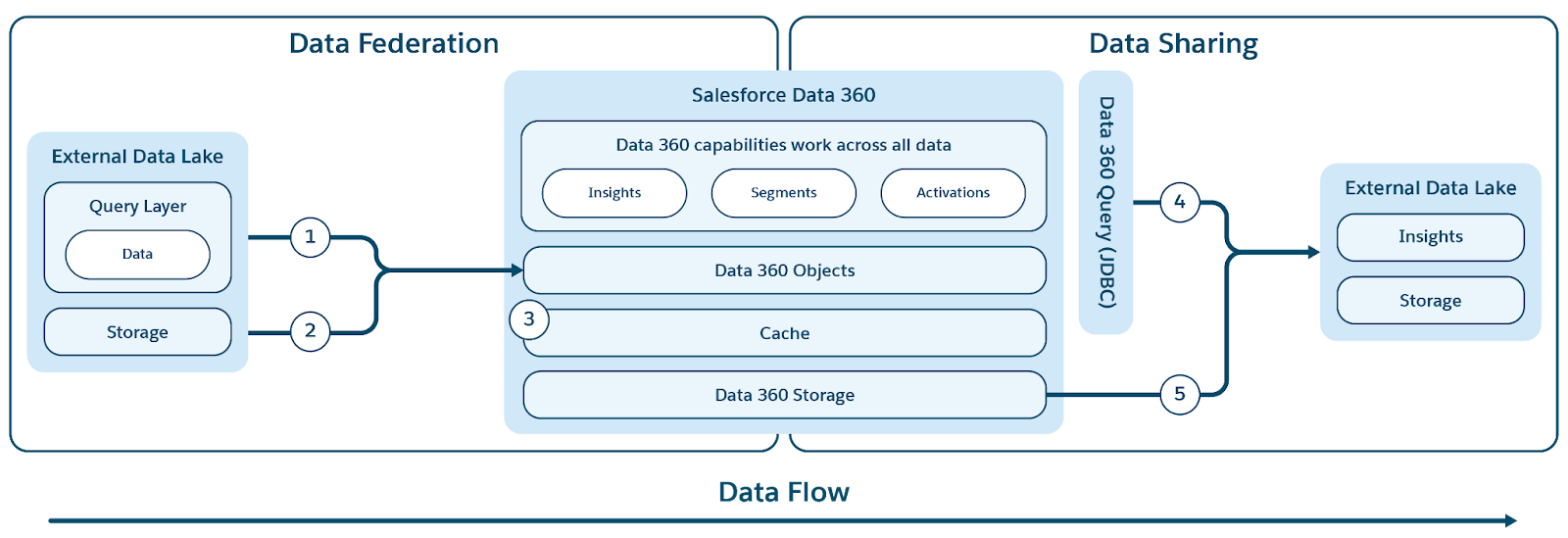
Data 360 поддерживает функцию нулевой копии с внешними хранилищами данных (Snowflake, Redshift), озерными хранилищами (Google BigQuery, Databricks, Azure Fabric), базами данных SQL и многими другими источниками. Его слои абстракции позволяют напрямую запрашивать внешние данные без дублирования, сокращая время приема, затраты на хранение и обеспечивая актуальность информации.
Data 360 упрощает доступ к внешним и интегрированным данным, предоставляя объединенный слой метаданных, который абстрагирует как Salesforce, так и внешние объекты. Это позволяет всей Salesforce Platform и ее приложениям без труда использовать эти данные.
Data 360 поддерживает федерацию на основе файлов и запросов с оперативным запросом и ускорением доступа, как показано на рисунке.
Метки (1) и (2) иллюстрируют запрос Data 360 (включая оперативные всплывающие запросы) и файловую федерацию для доступа к данным из внешних озер данных/складов/источников данных; а метка (3) подчеркивает ускорение интегрированного доступа из внешних озер данных/источников данных.
Федерация запросов
Основа федеративной способности Data 360 лежит в уровне интегрирования запросов, который управляет сложным процессом доступа к внешним данным и выполнения интеллектуальных всплывающих запросов (иллюстрация приведена на примере метки 1). Data 360 подключается и извлекает данные из источников посредством протокола JDBC, дополненного дополнительной логикой для повышения эффективности. Уровень интегрирования запросов отвечает за понимание и перевод разных диалектов SQL, определение наиболее оптимальной части запроса для внедрения во внешние системы для эффективной обработки, извлечение результатов и выполнение любой необходимой дальнейшей обработки для получения итоговых важных данных.
Кэширование (ускорение запроса)
Для расширенной служебной программы Data 360 предоставляет дополнительную функцию ускорения для своих федеративных возможностей.
При активации ускорения Data 360 кэширует интегрированные данные для обеспечения более быстрого доступа и снижения затрат, поскольку это позволяет избежать повторного прямого доступа к внешним источникам. Этот кэш обрабатывается как слой ускорения и инкрементно обновляется для быстрого отображения изменений во внешних исходных данных, обеспечивая ускоренное представление в близком к реальному режиме времени.
Интеграция файлов
Data 360 поддерживает файловую федерацию (на рисунке 2) для доступа к данным из внешних озер данных и источников. Техническая основа этой возможности нулевой копии зависит от стандартизации: основные данные должны быть в формате файла «Паркет Apache» и использовать табличный формат «Апач Айсберг». Data 360 может интегрироваться в любой источник, открывающий каталог Aceberg REST Catalog (IRC) для доступа к метаданным и хранилищу, обеспечивая беспрепятственный управляемый доступ к файлам, находящимся за пределами платформы.
С помощью объединения на основе файлов вычисления Data 360 обрабатывают все данные, поскольку они напрямую открывают основное хранилище. Это устраняет необходимость вытеснения запросов и управления разными диалектами SQL, которые часто требуются в интегрировании на основе запросов.
В дополнение, возможность Zero Copy также распространяется на неструктурированные источники данных, например, гипермасштабные решения для хранения данных (хранилище S3/GCS/Azure), Slack и Google Drive, которые могут быть доступны неструктурированными ожидаемыми продажами обработки Data 360.
Data 360 упрощает общий доступ к управляемым данным на основе запросов и файлов с внешними озерами данных и складами (иллюстрируется метками 4 и 5 в исходном контексте рисунка).
Общий доступ на основе запроса
Для общего доступа к данным на основе запросов Data 360 открывает драйвер JDBC, с помощью которого внешние двигатели и приложения могут получить безопасный доступ к данным. Этот механизм позволяет внешним системам подключать, проверять подлинность и выполнять оперативные запросы напрямую к данным в Data 360.
Общий доступ на основе файлов (общий доступ к данным и DaaS)
Основной механизм общего доступа на основе файлов использует две концепции: общий доступ к данным и цель общего доступа к данным, которые используют DaaS (Data as a Service) API.
- Функция детального управления: Концепция общего доступа к данным позволяет клиентам точно определить, какие объекты (DLO, DMO, CIO и т. д.) доступны внешне, предотвращая непреднамеренное раскрытие данных.
- Безопасное нацеливание: Он также управляет целью общего доступа к данным, обеспечивая доступность данных только явно авторизованным внешним средам, организациям или партнерским организациям (например, общий доступ к определенному экземпляру Redshift или Databricks).
DaaS API предоставляет безопасный и управляемый интерфейс для использования данных внешними механизмами. Он предоставляет доступ как к основным метаданным, так и к базовому хранилищу таблиц, сохраняя всю семантику Data 360. Это обеспечивает безопасный доступ внешних механизмов к данным в последовательном и содержательном контексте.
Многие клиенты, особенно крупные предприятия, регулируемые отрасли и организации государственного сектора, ограничивают любой доступ к Интернету в озерах данных в рамках своей безопасности. Эта политика, хотя и имеет важное значение для соответствия и снижения риска, также предотвращает подключение Salesforce Data 360 и Agentforce к этим средам через общедоступный интернет.
Большинство этих озер данных развернуты в гипермасштабных средах, например, AWS, Azure или Google Cloud. Поскольку Data 360 сама работает в AWS, доступ к озерам данных клиентов, размещенным в другом облачном поставщике, требует межоблачного подключения к сети. Без безопасного, личного подключения в обход общедоступного интернета клиенты часто не могут или не хотят внедрять Data 360 или Agentforce для сценариев использования, основанных на этих озерах данных.
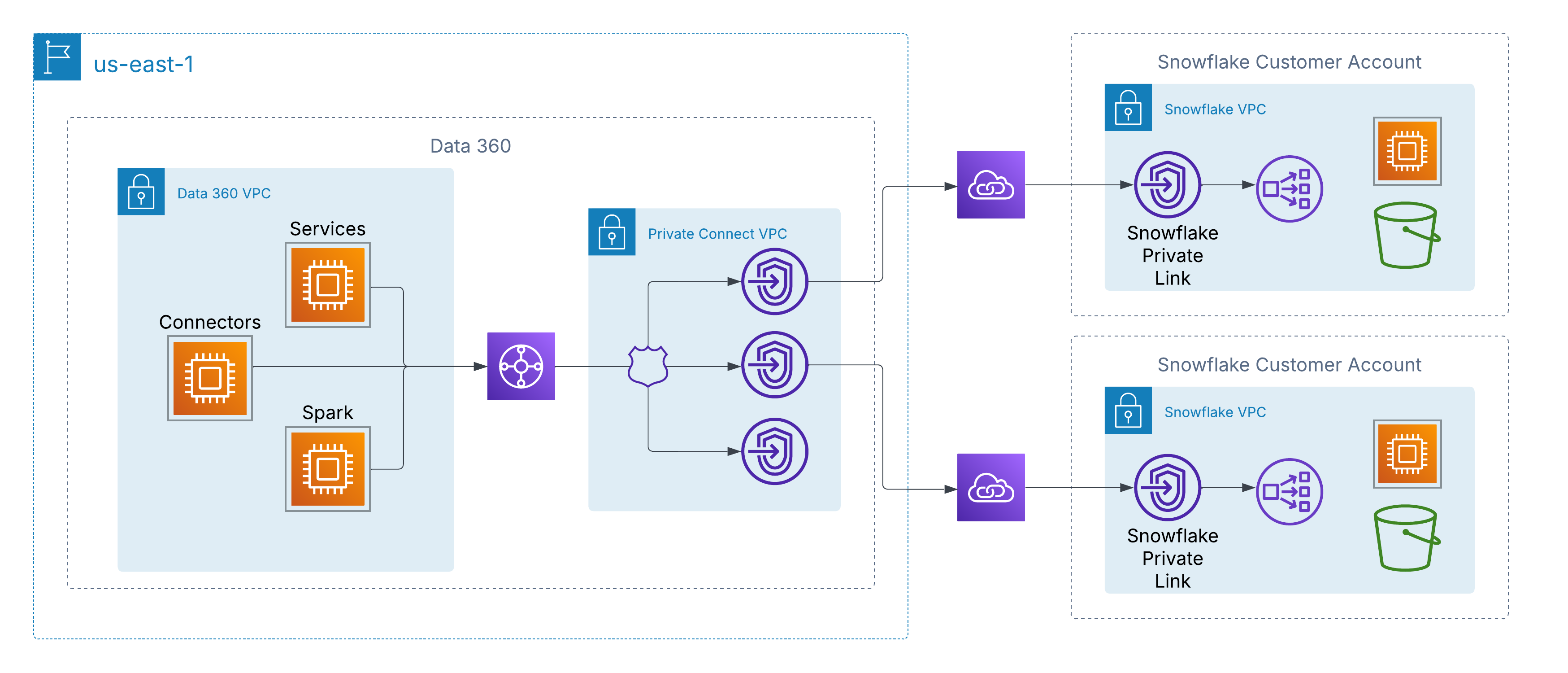
Для решения этой проблемы Data 360 поддерживает частное подключение на уровне сети к управляемым клиентами источникам данных в облаках. В AWS это включено посредством AWS PrivateLink, который позволяет Data 360 напрямую подключаться к предоставленным клиентом конечным точкам либо в собственных организациях, либо в сторонних средах озера данных (например, Snowflake), не пересекая общедоступный интернет.
Эта архитектура обеспечивает, что весь трафик остается полностью в магистрали AWS, используя личную IP-адресацию и немаршрутизируемые пути сети, тем самым удовлетворяя строгие требования безопасности и соответствия, обеспечивая беспрепятственный доступ к данным клиентов.
Для клиентов с многооблачной архитектурой Data 360 расширяет личное подключение за пределы AWS посредством поддержки межоблачных взаимосвязей. Это включает безопасные магистральные сетевые пути из Data 360 к озерам данных и службам, размещенным в Azure или Google Cloud, сохраняя те же принципы, что и AWS PrivateLink — личная IP-адресация, необщая маршрутизация и нулевое интернет-воздействие.
Клиенты могут выбрать одну из двух моделей развертывания:
-
Клиентский интерфейс: Интегрируйте существующие личные схемы, например Azure ExpressRoute, Google Cloud Interconnect или Equinix Fabric напрямую с VPC Data 360.
-
Интерконнектор под управлением Salesforce: Используйте полностью управляемое подключение «под ключ», где Salesforce инициализирует и эксплуатирует ссылку кросс-облака, открывая личные конечные точки в целевом облаке.
В обеих моделях взаимодействие последовательное: Службы Data 360 подключаются к внешним источникам данных в гипермасштабах, как к локальным, обеспечивая безопасный прием, активацию и запросы, не пересекая общедоступный интернет.
Для корпоративных архитекторов надежное управление данными является не просто флажком соответствия, а основой для создания надежного, масштабируемого и действенного Аналитика клиентов. Salesforce Data 360 создана с универсальной основой управления, обеспечивающей качество данных, безопасность и соответствие нормативным требованиям на протяжении всего жизненного цикла данных.
Data 360 функционирует как центр централизованного управления, обеспечивая добросовестное и контрольное управление всеми данными — от принятия исходных до активированных важных данных.
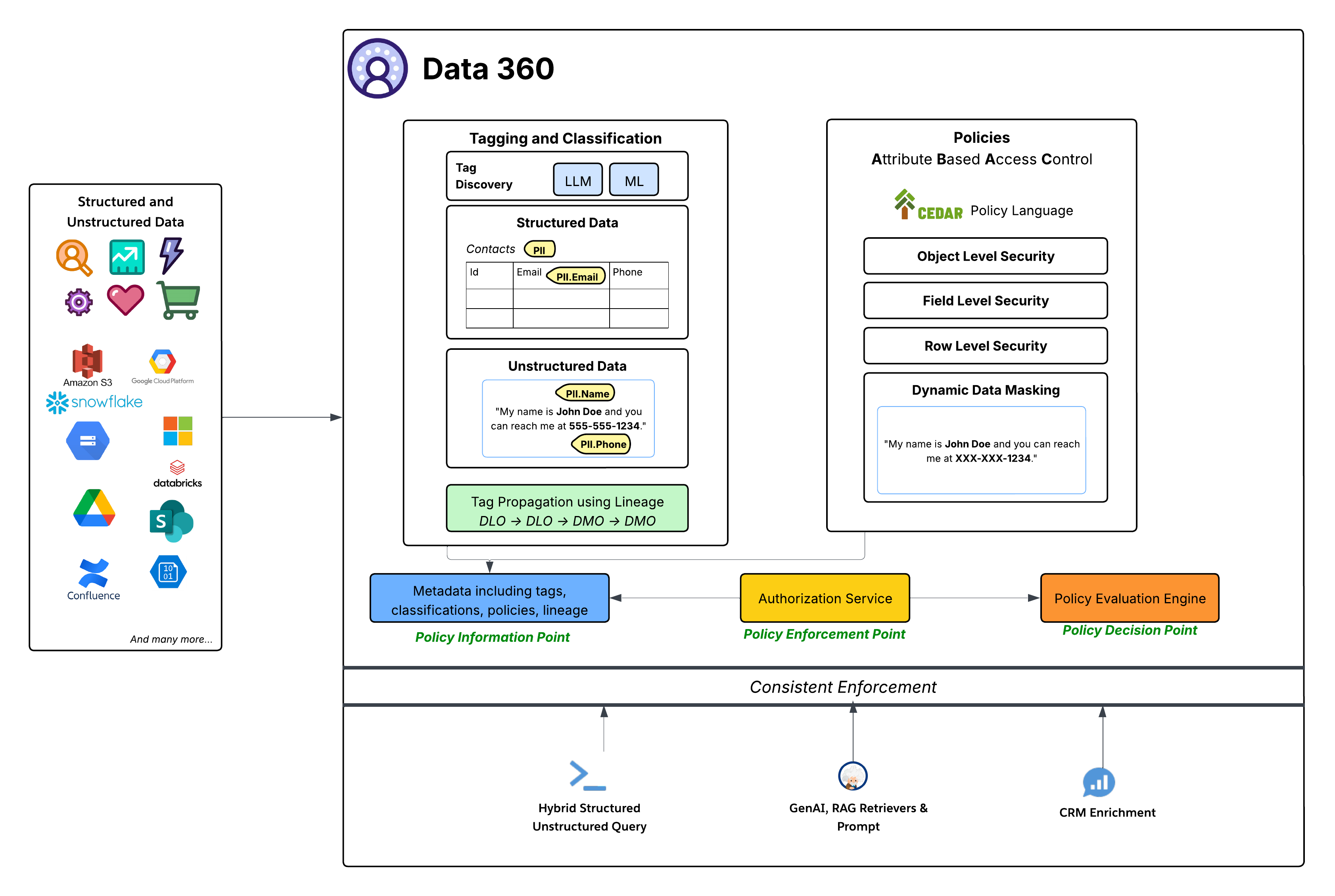
Хотя пространство данных предоставляет грубый гранулированный контроль доступа для определения доступа ко всем объектам в пространстве данных, политики на основе ABAC предоставляют точный гранулированный контроль доступа к отдельным объектам, полям и строкам в пространстве данных. Data 360 использует управление доступом на основе атрибутов (ABAC) в качестве базовой модели авторизации для управления тонким гранулированным доступом. Этот стратегический выбор обеспечивает большую гибкость и масштабируемость по сравнению с традиционным ролевым управлением доступом (RBAC), что особенно важно для динамичных сложных корпоративных сред с огромными объемами данных и различными потребностями в доступе. ABAC разрешает принимать решения доступа на основе атрибутов пользователя (например, отдел, роль, расположение), данных (например, персональные данные, конфиденциальность, пространство данных) и среды (например, время дня), а не только предопределенных ролей. Это включает высокодетализированные и контекстуальные политики доступа, которые адаптируются по мере изменения данных и атрибутов пользователя.
- Язык политики КЕДР: В основе внедрения ABAC Data 360 лежит использование языка политики CEDAR. Эта специально разработанная официальная формулировка политики предоставляет точный и поддающийся проверке способ определения сложных правил авторизации, обеспечивающий однозначность политик и возможность их последовательной оценки в масштабах.
Система управления в Data 360 соответствует стандартной надежной архитектуре ABAC:
- Присвоение тегов, классификация и авторство политик (информационная точка политики - PIP):
- Data 360 предоставляет автоматические механизмы присвоения тегов и классификации, используя LLM (широкоязыковая модель) и ML (машинное обучение) для идентификации категорий конфиденциальных данных (например, PII.Email, PII.Phone, PII.Name) и других специально созданных таксономий (PHI, FinancialData) в структурированных данных (например, таблица контактов) и неструктурированных данных (например, из Google Drive).
- Важно отметить, что распространение тегов происходит вдоль линии данных (DLO -> DLO -> DMO), обеспечивая автоматическое отслеживание трансформаций и извлечений данных, от исходных принятых данных до гармонизированного слоя DMO и посредством извлеченных данных, созданных на основе определений процессов.
- Наконец, панель автора политики предоставляет простое взаимодействие для использования данных и атрибутов пользователя для определения динамических правил доступа для организации.
- Эти обогащенные метаданные (включая теги, классификации, политики и родословную) поступают в точку информации о политике (PIP).
- Служба авторизации (пункт внедрения политики - ОПТОСОЗ):
- Служба авторизации выступает в качестве точки внедрения политики (PEP). Он перехватывает все запросы доступа к данным из разных уровней потребления (Гибридный структурированный/неструктурированный запрос, GenAI RAG Retrievers & Prompt, CRM Enrichment) и обращается к точке принятия политического решения для определения, разрешен ли доступ.
- Механизм оценки политики (Момент принятия политического решения - PDP):
- Этот механизм служит точкой принятия политического решения (PDP). Для принятия авторитетного решения о доступе требуется контекст запроса доступа из ОПТОСОЗ, а также определения политики (в КЕДР) и атрибуты из PIP.
- Гранулированные политики безопасности: Политики, определенные в КЕДАР, обеспечивают разные уровни безопасности, включая:
- Безопасность объекта: Управление доступом к целым ООД или DMO на основе тегов, связанных с этими объектами.
- Безопасность поля: Ограничение доступа к определенным конфиденциальным полям в объекте на основе тегов.
- Безопасность строки: Фильтрация данных по определенным объектам для отображения только соответствующих строк на основе атрибутов пользователя.
- Динамическая маскировка данных: Динамически маскируйте определенные данные (на основе тегов) в точке доступа, не изменяя основные данные. Это обеспечивает защиту конфиденциальной информации, но при этом позволяет широкую служебную программу. Это относится к маскировке полей в структурированных данных, а также к содержимому в неструктурированных данных.
- Последовательное применение: Вся инфраструктура ABAC обеспечивает последовательное внедрение политик во всех схемах потребления Data 360, будь то прямой запрос данных, извлечение для приложений на основе искусственного интеллекта (RAG) или пополнение взаимодействий Salesforce CRM посредством связанных списков, например.
- Глубокая интеграция с Salesforce Platform: Возможности управления Data 360 определяются и администрируются напрямую на базовой платформе Salesforce. Эта интеграция позволяет администраторам управлять политиками доступа, удостоверениями пользователей и управлением атрибутами посредством известных инструментов Salesforce, обеспечивая объединенный и последовательный уровень управления во всей экосистеме Salesforce.
Создавая эту сложную инфраструктуру ABAC с политиками CEDAR, Data 360 предоставляет архитекторам беспрецедентный уровень контроля и гибкости, обеспечивая не только действенность, но и безопасность, соответствие и надежность данных клиентов на предприятии.
В разных отраслях организации уделяют повышенное внимание комплексной безопасности данных, чтобы обеспечить защиту от утечки данных, несанкционированного доступа, подделки или уничтожения. Большинство платформ данных, включая Data 360 сегодня, предоставляют шифрование в дежурном режиме посредством управляемого поставщиком ключа шифрования. Однако предприятия (особенно в регулируемых секторах) все чаще требуют наличия управляемых клиентами возможностей шифрования как для данных в дежурном режиме, так и для транзитных данных.
Эта модель позволяет компаниям контролировать собственные ключи шифрования, обеспечивая, что даже в крайне маловероятном случае взлома платформы или несанкционированного доступа данные остаются криптографически защищенными. Без секретного ключа клиента ни один объект (включая поставщика платформы) не может расшифровать или восстановить данные, сохраняя тем самым полную конфиденциальность и контроль.
Data 360 поддерживает хранение и управление структурированными (таблицы), полуструктурированными и неструктурированными данными без проблем в механизмах приема, обработки, индексации и запросов данных. Data 360 поддерживает разные неструктурированные типы данных помимо текста, включая аудио, видео и изображения, расширяя диапазон обработки и анализа данных. На рисунке ниже показаны две стороны заземления (прием и извлечение).
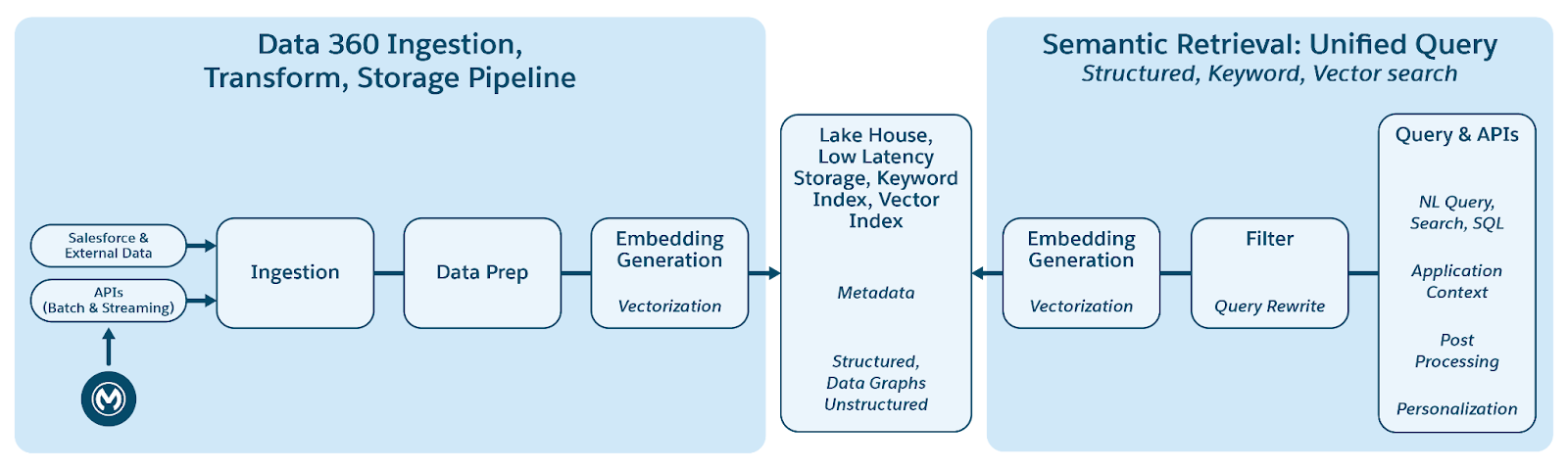
Data 360 управляет неструктурированными данными, сохраняя их в столбцах в виде текста или в файлах для больших наборов данных. Она поддерживает функцию интегрирования данных для неструктурированного содержимого, что позволяет интегрировать данные из нескольких источников и управлять ими.
Затем данные подготавливаются и разделяются на фрагменты, создаются вложения и обрабатываются для индексации ключевых слов и векторной индексации. Data 360 размещает несколько готовых и подключаемых моделей для создания фрагментов и встраивания. Data 360 поддерживает автоматизированную и настраиваемую транскрибирование аудио и видео содержимого для последующей обработки и индексации. Поисковая служба используется для индексации ключевых слов. Для векторной индексации Data 360 поддерживает как нативную индексацию (с Hyper), так и использует векторные базы данных, например, Milvus с открытым исходным кодом. Data 360 также интегрируется с платформой поиска Salesforce для поддержки индексации ключевых слов по неструктурированным данным. Такая интегрированная мультимодальная индексация в Data 360 предоставляет возможность поиска по любым неструктурированным данным, как указано в разделе «Агентский поиск предприятия» ниже в документе.
Для извлечения Data 360 предоставляет API для поиска. Наш объединенный запрос на основе Hyper облегчает ансамблевые запросы в структурированных, индексах ключевых слов и векторных индексах, сохраняя строгую видимость и полномочия, расширяя тем самым RAG и поиск.
Конвейеры индексации неструктурированных данных Data 360 спроектированы как модульная расширяемая архитектура, состоящая из пяти базовых этапов:
- Анализ
- Предварительная обработка
- Разделение на фрагменты
- Постобработка
- Встраивание
Все этапы также поддерживают обработку на основе LLM, которая позволяет клиентам создавать настраиваемые напоминания. Этапы предварительной и последующей обработки могут содержать несколько последовательных этапов, что позволяет гибко составлять сложные трансформации. Каждый этап полностью определяется метаданными, что обеспечивает беспрепятственную настройку и расширение без изменений кода.
Примеры предварительной обработки включают такие операции, как устранение шума, нормализацию языка и понимание изображения (оптическое распознавание символов и заголовков), в то время как этапы последующей обработки могут включать пополнение метаданных, семантические группировки или расширенные методы, например, фрагментирование Raptor.
Ожидаемые продажи полностью поддерживают расширение кода Data 360, позволяя клиентам и внутренним группам подключать настраиваемую логику на любом этапе. Компоненты расширения кода - это легкие функции Python, жизненный цикл которых - выполнение, масштабирование и обработка сбоев - полностью управляется Data 360. Этот подход обеспечивает возможность быстрого внедрения инноваций и обработки данных по конкретным доменам при сохранении операционной последовательности и управления в рамках платформы.
Индексация контекста
Для настройки RAG с неструктурированной обработкой ключевыми являются два фактора:
- Быстрая итерация: Возможность быстрой проверки с помощью образцов тестовых запросов.
- Личностное содержимое: Возможность настройки содержимого, настроенного под пользователя.
Индексация контекста — это удобный инструмент, предназначенный для решения обоих аспектов. Этот интерактивный пользовательский интерфейс поддерживается ожидаемыми продажами в реальном времени (RT), которые выполняют все пять ранее описанных этапов. Ожидаемые продажи используют графические интерфейсы при необходимости для таких задач, как создание встраивания и оптическое распознавание символов (OCR). Кроме того, он позволяет клиентам быстро протестировать ожидаемые продажи RAG с агентом перед развертыванием конфигурации для комплексной обработки содержимого.
Искусственный интеллект документа
ИИ документа Data 360 позволяет просматривать и импортировать неструктурированные или полуструктурированные данные из таких документов, как счета, резюме, лабораторные отчеты и заказы на покупку. Эта функция поддерживает специальную интерактивную обработку, а также пакетную обработку. Это ключевая возможность, которая обеспечивает автоматизацию бизнес-процессов для наших клиентов. Это обеспечивается искусственным интеллектом, включительно с LLM и моделями ML.
Предприятия владеют огромными объемами Knowledge, распределенными по разрозненным системам, например, вики, файлообменники, системы управления содержимым, внутренние базы данных и прочее. Эта фрагментация затрудняет сотрудникам (особенно сервисным агентам и торговым представителям) и клиентам быстрый и эффективный поиск актуальной информации. Ключевые проблемы включают: отсутствие единого единого интерфейса унифицированного поиска во всех источниках Knowledge; непоследовательность представления и отображения содержимого из разных источников; отсутствие управления доступом к конфиденциальной информации, разбросанной по разным системам; и трудности с использованием авторитетного источника Knowledge в основных бизнес-процессах (например, прикрепление соответствующих статей к обращению).
Enterprise Knowledge представляет содержимое, курируемое вручную или автоматически из более широкого пула данных предприятия. Ручное курирование предполагает преднамеренные действия, например, создание статей Salesforce Knowledge или развитие Knowledge во внешних системах, которые потом принимаются. Мы планируем автоматическое курирование, использующее процессы, например, агенты Salesforce и трансформации, которые выполняются над принятыми данными для создания уточненных, проверенных слоев, потенциально смешивая структурированное и неструктурированное содержимое. Вне зависимости от того, лечатся ли они вручную или автоматически, внутри системы Salesforce или внешне перед приемом, результатом будет добавленное содержимое, отличное от исходных данных.
Решение Enterprise Knowledge Hub использует возможности Data 360 для :
- Прием и хранение: Коннектор CRM принимает статьи Salesforce Knowledge, а неструктурированные коннекторы инфраструктуры коннекторов данных (DCF) принимают исходное содержимое и метаданные из внешних источников. Содержимое принимается в исходные неструктурированные объекты озера данных (UDLO), соотносящиеся с содержимым в SFDrive (или источником в случае нулевой копии).
- Гармонизация и структурирование: Конвейеры гармонизации обрабатывают данные UDLO и файла, выполняя очистку, нормализацию, обогащение (NLP и т. д.), маскировку PII и трансформацию в гармонизированный промежуточный формат, сохраненный в SF Drive и гармонизированный UDLO (HUDLO), который соотносится с ним.
- Индексация: Неструктурированные ожидаемые продажи (UDS) запускаются над гармонизированным содержимым, и поисковые индексы настроены для каждого HUDMO.
- Расход: Потребительские приложения включают поиск, извлечение, отображение и ссылку на бизнес-объекты, например, обращение. Занятость посредством потребления приложений собирается для предоставления аналитики использования (например, переходы, проверки и т. д.)
Вычисленные важные данные (CI) в Data 360 позволяют клиентам определять и создавать агрегированные показатели на основе своих данных. Эти показатели потом используются для своевременной занятости клиентов, анализа, сегментации и активации. Агрегированные данные, вычисленные CI, записываются в Lakehouse и представляются как объект вычисленных важных данных (CIO).
Существует два основных типа вычисленных важных данных:
- Пакетные вычисленные важные данные: Предназначены для сложной агрегации больших объемов данных, где показатели можно вычислять периодически (например, ежедневно или еженедельно).
- Потоковые важные данные: Предоставьте возможность создавать показатели и действия на основе данных событий в реальном времени, включив немедленное вовлечение клиентов с низкой задержкой.
Вычисленные важные данные определяются в объектах модели данных (DMO), а также могут быть определены в других объектах вычисленных важных данных. Служба вычисленных важных данных управляет оркестрацией пакетных и потоковых заданий.
Вычисления пакетных и потоковых важных данных используют Spark. Ключевое отличие заключается в том, что потоковые важные данные используют Spark Structured Streaming, в то время как пакетные CI выполняются посредством периодических запланированных пакетных заданий Spark. Для повышения эффективности затрат вычисленные важные данные группируют CI для вычисления вместе в одном пакетном задании CI или потоковом задании CI на основе таких факторов, как зависимости и накладка объектов исходных данных.
SNCE и CDF играют важную роль в вычислении потоковых важных данных.
Разрешающая способность при опознавании отвечает за трансформацию разрозненных данных из нескольких источников в единый комплексный объединенный профиль.
Важно понимать, что объединенный профиль не является «золотой записью» и что разрешающая способность при опознавании не выбирает выигранные значения и не переопределяет существующие данные во время объединения профилей. Объединенные профили служат набором ключей, которые разблокируют исходные данные, определяя все совпадающие записи, связанные с одним объектом, в одном источнике данных или во многих источниках. С помощью этой информации можно выбрать соответствующие исходные системные данные для использования в данном бизнес-сценарии использования.
Разрешающая способность при опознавании может консолидировать разные типы записей, включая отдельных лиц, организации и хозяйства. Его также можно использовать для сопоставления интересов с существующими организациями. Процесс объединения необходим для достижения полного представления Customer 360 и стимулирования персонализированной занятости в реальном времени в сценариях как B2C, так и B2B.
Конвейеры разрешающей способности при опознавании созданы на основе высокомасштабируемой облачной инфраструктуры, предназначенной для непрерывной обработки массивов данных. Процесс включает три ключевых этапа, опирающихся на мощный поисковый индекс для управления процессом соответствия:
- Соответствие (выбор кандидата): Целью процесса сопоставления является поиск записей, которые могут принадлежать одному объекту. Записи анализируются по настраиваемому набору правил, каждое из которых содержит набор критериев, определяющих, какие данные должны соответствовать на каком уровне строгости. Для эффективного извлечения потенциальных совпадений из хранилища данных система создает индексы для поиска вероятных совпадающих записей с помощью двух методов:
- Блокировка ключей: Ключ блокировки - это значение, созданное на основе данных записи и правил соответствия (например, первые буквы имени, нормализированный номер телефона и т. д.) для группировки потенциально похожих записей. Каждая запись содержит несколько ключей блокировки, индексируемых и хранящихся в виде перевернутого индекса, что обеспечивает выполнение системой подробных сравнений только для небольших групп записей, а не для всего набора данных.
- Хэширование с учетом населенного пункта (LSH): Для правил соответствия с нечетким совпадением хэши создаются на основе встраивания из обученных моделей.
- Глубокое совпадение: После создания этапом выбора кандидата меньших групп потенциальных совпадений система начинает более подробное сравнение. На этом этапе модели на основе искусственного интеллекта и расширенные алгоритмы анализируют каждую пару записей для вычисления вероятностного рейтинга соответствия. Эта оценка количественно оценивает вероятность того, что две записи ссылаются на один объект, интеллектуально сравнивая поля, которые часто содержат ошибки, варианты или различия форматирования.
- Кластеризация и объединение: После определения совпадающих записей из кандидатов они группируются в кластер. Этот процесс включает в себя решение транзитивных совпадений. Например, если запись А соответствует записи Б, а запись Б соответствует записи В, все три связаны в один кластер, даже если А и В не сравнивались напрямую. Эти полные кластеры образуют базовую структуру объединенного профиля. Этот процесс кластеризации обеспечивает корректное связывание всех связанных исходных записей под одним постоянным идентификатором.
- Сверка: Значения данных из всех кластеризованных исходных записей оцениваются посредством заданных правил сверки (например, «Последние», «Последние» или «Приоритет источника»), чтобы заполнить итоговый объединенный профиль фрагментом данных профиля. Сверка не перезаписывает текущие данные, поскольку все исходные данные доступны посредством ключей, связанных с объединенным профилем.
Архитектура поддерживает разрешающую способность нескольких типов объектов для выполнения разных способов использования.
- Индивидуальное совпадение: Фокусируется на создании профилей объединенного отдельного лица, которые связывают все известные персональные идентификаторы (электронная почта, номера телефонов, коды лояльности, cookie-файлы) с одним лицом.
- Сопоставление организаций: Основное внимание уделяется созданию профилей объединенной организации, которые связывают данные об организациях. При сопоставлении названий компаний механизм использует точно настроенную модель при нечетком сопоставлении.
- Сопоставление хозяйств: Расширяет логику соответствия для агрегации записей объединенного отдельного лица в группы связанных отдельных лиц.
- Кросс-совпадение объектов: Помимо объединения, разрешающая способность при опознавании также создает ссылки между объектами профиля посредством одинаковых правил соответствия. Например, интерес может быть связан с организацией посредством нечеткого совпадения в поле «Имя организации».
Чтобы обеспечить актуальность объединенного профиля, механизм разрешающей способности при опознавании работает с архитектурой, близкой к реальному времени. Эта облачная архитектура предназначена для непрерывной обработки, что обеспечивает быстрое время обработки. Хотя скорость обработки зависит от способа получения исходных данных, небольшие пакеты изменений могут обрабатываться разрешающей способностью при опознавании каждые 15 минут.
Система поддерживает объекты ссылки на удостоверение, которые соотносят каждый код исходной записи с соответствующим кодом объединенного профиля. Эта базовая структура данных позволяет механизму эффективно отслеживать взаимосвязи и быстро распространять изменения и обновления в объединенном профиле, обеспечивая, что взаимодействия клиентов (например, персонализация веб-сайта, рекомендации Next-Best- Action и сегментация) всегда используют самые свежие доступные данные клиентов.
Сегментация - это базовый процесс трансформации объединенных профилей клиентов в действенные аудитории. Эта возможность важна для поддержки персонализированных взаимодействий в маркетинговых, торговых и сервисных каналах. Платформа Salesforce Data 360 Segmentation предназначена для крупномасштабных операций. Он управляет сложными метаданными, работая с моделью данных, содержащей тысячи объектов и взаимосвязей. Платформа поддерживает сложные правила, фильтры на основе агрегации и ранжирование на основе окон, обеспечивая быстрые и надежные вычисления в петабайтном масштабе.
Data 360 поддерживает разные типы сегментов для соответствия разным бизнес-требованиям к скорости, сложности и иерархии:
- Стандартный сегмент: Основной, обработанный пакетом тип сегмента. Он публикуется по настраиваемому расписанию со стандартной каденцией публикации минимум 12 часов до 24 часов или более быстрой каденцией быстрой публикации от 1 до 4 часов, которая оптимизирована для недавних данных занятости.
- Сегмент в реальном времени: Этот сегмент выполняется по запросу в миллисекундах для немедленного действия на основе недавних событий и данных профиля. Он высоко оптимизирован для мгновенной персонализации, но не может использовать критерии исключения или вложенные сегменты.
- Каскадный сегмент: Иерархическая структура подсегментов, используемых для приоритизации клиента в одном наиболее ценном сегменте, если они соответствуют нескольким критериям.
- Вложенный сегмент: Это позволяет повторно использовать существующий сегмент в качестве фильтра для нового, более конкретного сегмента (уточнение базового сегмента), наследуя расписание родительского сегмента.
Механизм сегментации работает в надежной облачной архитектуре, обеспечивающей скорость, масштаб и устойчивость.
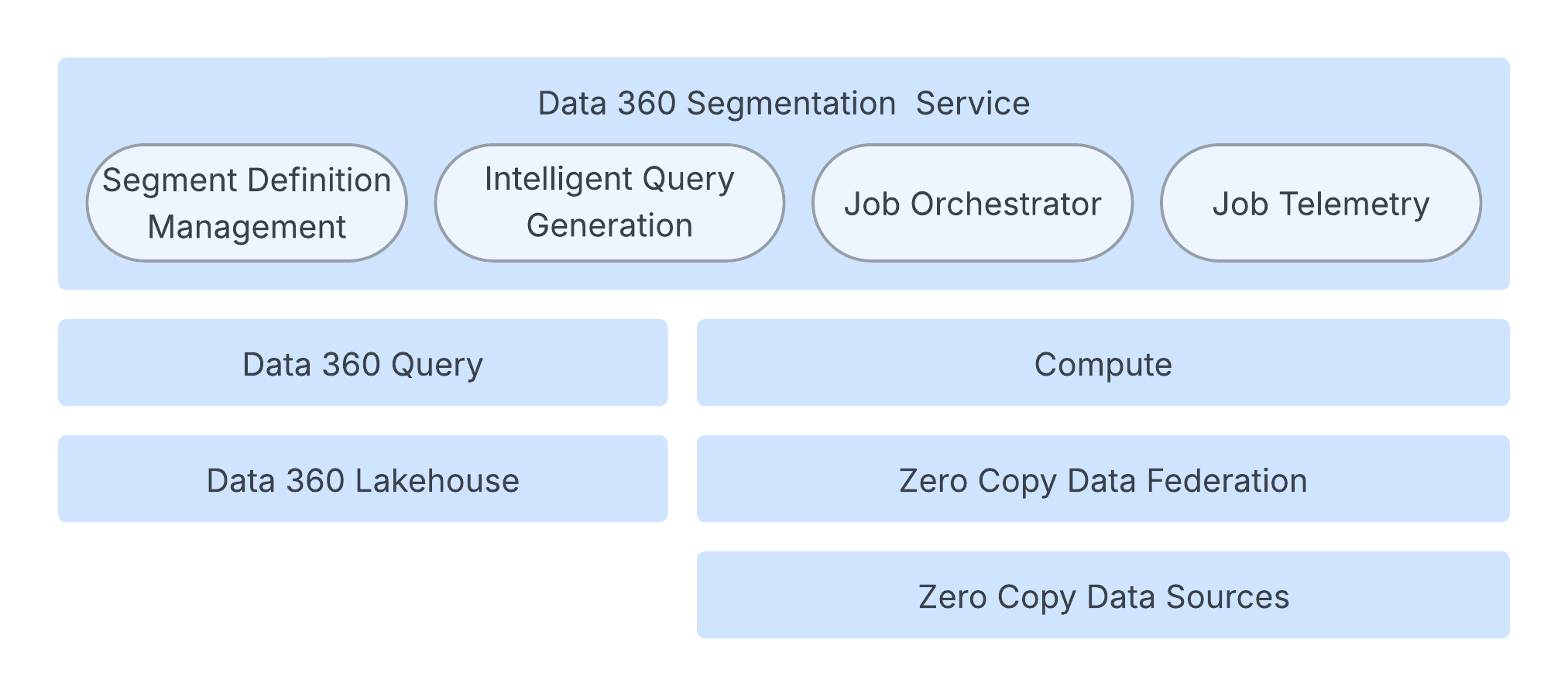
Базовый процесс управляется службой оркестрации заданий, которая управляет жизненным циклом сегмента, создавая необходимую конфигурацию задания и запуская выполнение. Этот слой оркестрации сохраняет состояние и метаданные в изолированной базе данных для масштабируемости.
Хотя запрос Data 360 обрабатывает вычисления количества сегментов, уровень вычисления Spark отвечает за вычисление фактического участия в сегменте. Приложение Spark выполняет запросы Spark SQL над обширными данными клиентов. Эти данные могут храниться в озере Data 360, внешних системах посредством федерации данных Zero Copy или в сочетании двух компонентов.
Система высоко оптимизирована посредством интеллектуального создания запросов, что настраивает основной запрос Spark SQL. Это включает такие методы, как интеллектуальная обрезка разделов для минимизации сканирования данных и устранения избыточных вложенных выражений. Для обеспечения надежности обслуживания архитектура поддерживает адаптивное управление ресурсами, которое динамически настраивает вычисляемые ресурсы в зависимости от объема и сложности загруженности. Кроме того, выполнение SLO активно управляется посредством адаптивных продолжительностей и логики повтора попытки. Для быстрого взаимодействия пользователей ускоренное количество сегментов использует метод на основе выборки для предоставления быстрых оценок размера во время создания сегмента, избегая полного выполнения запроса.
Наконец, глубокая ориентация на обозримость и атрибуцию первопричин поддерживается посредством комплексных показателей выполнения Spark и автоматической классификации ошибок (например, проблемы клиента по сравнению с системными проблемами), что значительно сокращает время диагностики и обеспечивает высокую устойчивость платформы данных.
Активация - это важнейший последний этап жизненного цикла Data 360. Его основная функция - трансформация статических, сегментированных, объединенных профилей клиентов в действенные и обогащенные данные и доставка этих данных во внутренние и внешние конечные точки (например, Marketing Cloud, Commerce Cloud и платформы Adtech). Этот процесс предназначен для запуска персонализированных путешествий клиентов и взаимодействий в близком к реальному режиме времени. Он поддерживает расширенные возможности, например, связанные атрибуты, фильтрацию участия активации, фильтрацию согласия, ограничение и ранжирование.
Активация предлагает три разных метода для внешней доставки и соответствия канала:
- Пакетная активация: Предназначены для массовых запланированных операций, например, крупномасштабных электронных кампаний и обновлений рекламной аудитории. Данные доставляются поэтапно в безопасные внутренние области (облачное хранилище объектов) или посредством безопасного переноса файлов, после чего выполняется процесс принятия API, инициированный целевой системой. Пакетные активации могут использовать специальный режим обновления - инкрементный - для уменьшения объемов, отправляемых и обрабатываемых партнерами Salesforce.
- Потоковая активация: Оптимизировано для сценариев использования в близком к реальному режиме времени, требующих автоматизации под управлением событий. Доставка осуществляется посредством прямых вызовов API, отправленных в конечную точку назначения.
- Потоки, запущенные активацией: Этот высокоплатформенный канал предоставляет безкодовый/низкокодовый подход для интеграции данных аудитории с сотнями платформ занятости с поддержкой API клиента. После завершения активации Data 360 заполняет DMO аудитории, который потом запускает крупномасштабный поток. Механизм потока впоследствии потребляет данные аудитории и использует возможности платформы, например, внешние службы и исходящие назначения Mule, для осуществления вызовов конечного назначения на основе API. Этот метод значительно сокращает время, необходимое для адаптации новых целей активации.
Активация использует те же схемы, что и сегментация для управления заданиями, распределенного выполнения и мониторинга. Это включает принципы службы оркестрации заданий для управления жизненным циклом и вычислительного слоя (Spark) для обработки и зависит от телеметрии задания для наблюдения за производительностью и соблюдения цели уровня обслуживания (SLO).
В дополнение к ним активация имеет:
Управление целями активации контролирует безопасные подключения, регистрационные данные и конфигурации для всех конечных точек назначения. Он гарантирует стандартизацию форматов данных и протоколов безопасности, обеспечивая надежную исходящую доставку на разные платформы, включая Marketing Cloud, партнеров Adtech и другие внешние приложения.
Активация настраивает полезные данные для определенных целей. В Salesforce Marketing Cloud это включает фильтрацию с учетом бизнес-единицы (BU), поддержку Multi-EID и управление перекрестным опылением.
Управление коммуникациями действует в качестве привратника, обеспечивая соответствие использования данных и коммуникации предпочтениям клиентов и юридическим требованиям. Модель централизованного согласия объединяет все предпочтения клиента, от глобальных отказов до согласия по каналу и цели, и сохраняется в объединенном профиле отдельного лица. Во время выполнения платформа строго применяет эти политики, используя фильтрацию исключения для автоматического удаления несогласных отдельных лиц из конечной полезной нагрузки. Кроме того, система применяет правила выбора точки контакта, чтобы обеспечить использование единой, наиболее соответствующей и предпочтительной точки контакта для предполагаемого канала до передачи данных. Этот механизм правоприменения обеспечивается базовой системой управления, которая использует такие защитные меры, как динамическая маскировка данных и контроль доступа для обеспечения безопасности полей конфиденциальных данных на протяжении всего процесса активации.
Подлинная ценность объединенной платформы данных заключается в ее способности предоставлять без особых усилий последовательный доступ ко всем ее активам данных, независимо от их происхождения или структуры. Возможности объединенного запроса Salesforce Data 360 созданы именно для этого, абстрагируя основные сложности разных хранилищ данных для предоставления единого мощного интерфейса запроса.
Слой объединенного запроса предлагает сложный доступ для разных схем потребления:
- Гибридный структурированный и неструктурированный запрос: Он предоставляет широкую поддержку SQL для беспрепятственного запроса как структурированных данных, так и структурированных метаданных неструктурированных данных. Этому способствует расширяемость оператора посредством функций таблицы, включающая специализированный поиск по тексту, изображению и пространственным типам.
- Ускоренная производительность посредством Hyper: Используя Hyper, высокопроизводительный механизм в памяти, Data 360 ускоряет сложные аналитические запросы и интерактивные панели мониторинга, предоставляя практически мгновенные ответы в массивных наборах данных.
- Единый подход к искусственному интеллекту и персонализации: Этот объединенный доступ имеет решающее значение для создания целевых и персонализированных результатов, напрямую облегчая более точные ответы LLM посредством Retrieval Augmented Generation (RAG) посредством привязки моделей искусственного интеллекта к обогащенным корпоративным данным.
- Интеграция с дальнейшим потреблением: Он служит базовым слоем доступа к данным для взаимодействий под управлением пользовательского интерфейса, надежных API, бизнес-процессов на основе искусственного интеллекта и обогащения CRM, без труда подключая данные к активации.
Предоставляя единый, интеллектуальный и высокопроизводительный интерфейс запроса, объединенный запрос Data 360 позволяет архитекторам создавать гибкие приложения под управлением данных, которые полностью используют весь спектр клиентской информации.
Data 360 - это активная платформа, поддерживающая активацию ожидаемых продаж в ответ на события данных. Например, важное событие, например, падение баланса организации клиента, может запустить поток Salesforce для оркестрации соответствующего действия. Таким же образом, обновления ключевых показателей, например, срока действия, могут автоматически распространяться на соответствующие приложения.
Действия над данными постоянно отслеживают инкрементные данные на наличие изменений посредством событий нативных изменений хранилища (SNCE) и ленты данных об изменении (CDF). Эти данные оцениваются по настроенным клиентом правилам действий, например, мониторинг порога или изменения состояния. При соблюдении этих правил создается событие действия над данными. Это событие пополняется дополнительными сведениями (например, статус лояльности клиента) и немедленно отправляется в настроенное место назначения, например, в Salesforce Flow или во внешнее приложение, для запуска бизнес-оркестраций.
Data 360 поддерживает собственные функции CDP (Customer Data Platform), включительно с расширенными возможностями разрешающей способности при опознавании и созданием объединенных отдельных идентификаторов и профилей вместе с комплексными журналами занятости. Эта платформа умеет работать с инфраструктурами типа «Бизнес для бизнеса» (B2B) и «Бизнес для потребителя» (B2C), поддерживая разрешающую способность при опознавании и графики опознавания, использующие точные и нечеткие правила соответствия, как описано выше. Эти графики удостоверений пополняются данными занятости из разных каналов, что помогает создавать подробные графики профиля с ценными аналитическими важными данными и сегментами.
Ключевым понятием, поддерживающим профиль клиента, является график данных. Data 360 предлагает корпоративный график данных в формате JSON, являющийся ненормализованным объектом, производным из разных таблиц Lakehouse и их взаимосвязей. Это включает график данных «Профиль», созданный CDP, который охватывает журнал покупок и просмотров лица, журнал обращений, использование продуктов и другие вычисленные важные данные, а также расширяемый клиентами и партнерами. Эти Графики данных адаптированы к конкретным приложениям и повышают генеративную точность запросов на основе искусственного интеллекта, предоставляя соответствующий контекст клиента или пользователя. Слой Data 360 в реальном времени использует график профиля для персонализации и сегментации в реальном времени. Мы планируем моделирование контекста Agentforce, охватывающего диалоги, сеансы и память Agentic в виде Графики данных.
Кроме того, CDP поддерживает эффективную сегментацию и активацию на разных платформах, например, Salesforce’s Marketing Cloud, Facebook и Google. Он обрабатывает профили клиентов в пакетном, близком к реальному и реальном времени, что позволяет немедленно принимать решения и персонализировать их. Эта функция расширяет взаимодействия в сценариях B2C и B2B, обеспечивая возможность быстрого и точного реагирования предприятий на потребности и поведение клиентов.
Реальный временной слой Data 360 поддерживается Data 360 CDP и расширяет его концепции для сценариев использования в реальном времени. Слой Data 360 в реальном времени создан для обработки событий, например, веб- и мобильных кликстримов, посещений, данных корзины и касс с миллисекундными задержками, улучшая персонализацию работы клиентов. Он постоянно отслеживает занятость клиентов и обновляет профиль клиента из Customer 360 данными занятости в реальном времени, сегментами и вычислениями для немедленной персонализации.
Например, когда клиент покупает товар на веб-сайте, слой в реальном времени быстро обнаруживает и принимает это событие, идентифицирует клиента и пополняет его профиль обновленными сведениями о расходе на протяжении срока действия. Это позволяет персонализировать работу на сайте за несколько секунд. Кроме того, этот уровень содержит возможности для запуска в реальном времени и ответов, что позволяет выполнять немедленные действия на основе взаимодействий с клиентами.
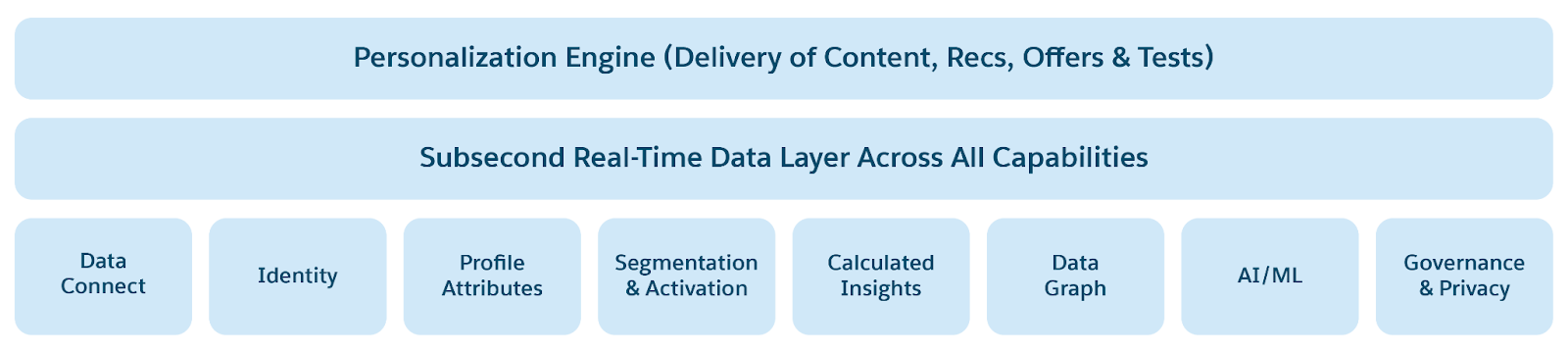
Подвторая платформа в реальном времени поддерживает эту трансформацию посредством нескольких ключевых функций:
- Графики данных в реальном времени: Профиль Customer 360 создается с помощью ненормализованного графика, содержащего ключевые объекты и поля, наиболее актуальные для торговых марок. Эти Графики данных позволяют обрабатывать данные в режиме реального времени и предоставлять действенное содержимое и важные данные в течение миллисекунд
- Прием и трансформация в реальном времени: Прием событий и профиля пользователя в миллисекундах из веб- и мобильных источников.
- Разрешение при опознавании в реальном времени: Объединяйте профили клиентов на устройствах, мгновенно объединяя неизвестных и известных пользователей.
- Вычисленные важные данные в реальном времени: Вычислите такие показатели, как значение срока действия (LTV) или журнал посещений пользователей в миллисекундах, чтобы включить персонализацию или предложения для веб, чатбота или агента обслуживания.
- Сегментация в реальном времени: Сегментируйте аудитории в режиме реального времени, персонализируя сообщения и взаимодействия в реальном времени.
- Действия в реальном времени: Предоставьте торговым маркам возможность оценивать каждое взаимодействие пользователя и предпринимать действия посредством Salesforce Flow или других соответствующих каналов связи.
В Data 360 мы создали новую платформу в реальном времени с ожидаемыми продажами в реальном времени, низким хранилищем с задержкой и подвторым слоем обработки данных. Поскольку быстрые интерактивные данные принимаются из веб- и мобильных каналов, они проходят ряд быстрых процессов.
Наши Web & Mobile SDK и API в реальном времени собирают данные из веб-/мобильных приложений (в будущих взаимодействиях Agentic) и отправляют их на сервер маяка. Эти данные потом перенаправляются в слой в реальном времени для обработки в миллисекунду и слой Lakehouse для интеграции с пакетными/потоковыми данными. Слой «В реальном времени» обрабатывает входящие данные в реальном времени в контексте профиля пользователя (анонимного или вошедшего в систему), например, обновление общего расхода пользователя или значения срока действия и т. д. для персонализации в режиме сеанса в реальном времени. Слой в реальном времени поддерживается основной памятью и хранилищем NVme (SSD) для хранения данных в реальном времени и профилей клиентов. Как только данные находятся в слое в реальном времени, они проходят следующие процессы, прежде чем обновляться в графике данных в реальном времени:
- Простой прием и трансформации: Данные принимаются и трансформируются для дальнейшей обработки.
- Разрешение при опознавании: Правила точного соответствия применяются для объединения профилей со всеми существующими наборами правил соответствия, поэтому специалистам по работе с данными не нужно создавать новые наборы правил разрешающей способности при опознавании специально для реального времени.
- Вычисленные важные данные: Каждая занятость оценивается, выполняются простые вычисления, например, сумма и количество в миллисекундах, а данные обновляются в графике данных в реальном времени.
- Сегменты в реальном времени: Каждые данные занятости оцениваются на соответствие критериям для определенных сегментов в реальном времени, и пользователи добавляются к соответствующим сегментам в миллисекундах.
- Действия и триггеры в реальном времени: Каждая занятость оценивается по заданным правилам для запуска действий к ряду целей в реальном времени, когда правила выполняются в миллисекундах.
- График данных и API в реальном времени: График данных в реальном времени, который также содержит API в реальном времени, позволяет торговым маркам извлекать обновленные данные в формате JSON для каждого пользователя, обеспечивая информированность всех взаимодействий с клиентами о последних данных.
Персонализация — это знание того, на кого ориентироваться, когда и где предоставлять актуальное содержимое и рекомендации, что говорить и с какой частотой. Платформа услуг персонализации является оркестратором решений, принимаемых для оптимизации достижения цели посредством персонализированных взаимодействий.
Службы персонализации предоставляют следующие возможности:
- Согласованный набор моделей и способов интерпретации данных профиля, действия и актива в Data 360
- Интегрированный эксперимент платформы (А/Б/н, многорукий бандит)
- Интеграция целей во время проектирования (конфигурация), время обучения ML и время выполнения (вывод ML)
- Поддержка взаимодействия в реальном времени и пакете в масштабе B2C (анонимные пользователи, большие объемы в реальном времени/интерактивные внешние, большие объемы внутреннего пакета)
- Analytics, движущаяся по Data 360
- Схемы интеграции модели искусственного интеллекта и обслуживания от других сторон (внутренних и внешних)
- Интеграция в экосистему базовых метаданных (характеристики ПЛАСТИН)
- Внедрения OOTB ценных сценариев использования на основе искусственного интеллекта (рекомендации/решения с различными алгоритмами ML, включая контекстуальных бандитов для рекламной акции/выбора содержимого, рекомендации продуктов, решения о ценообразовании и т.д.)
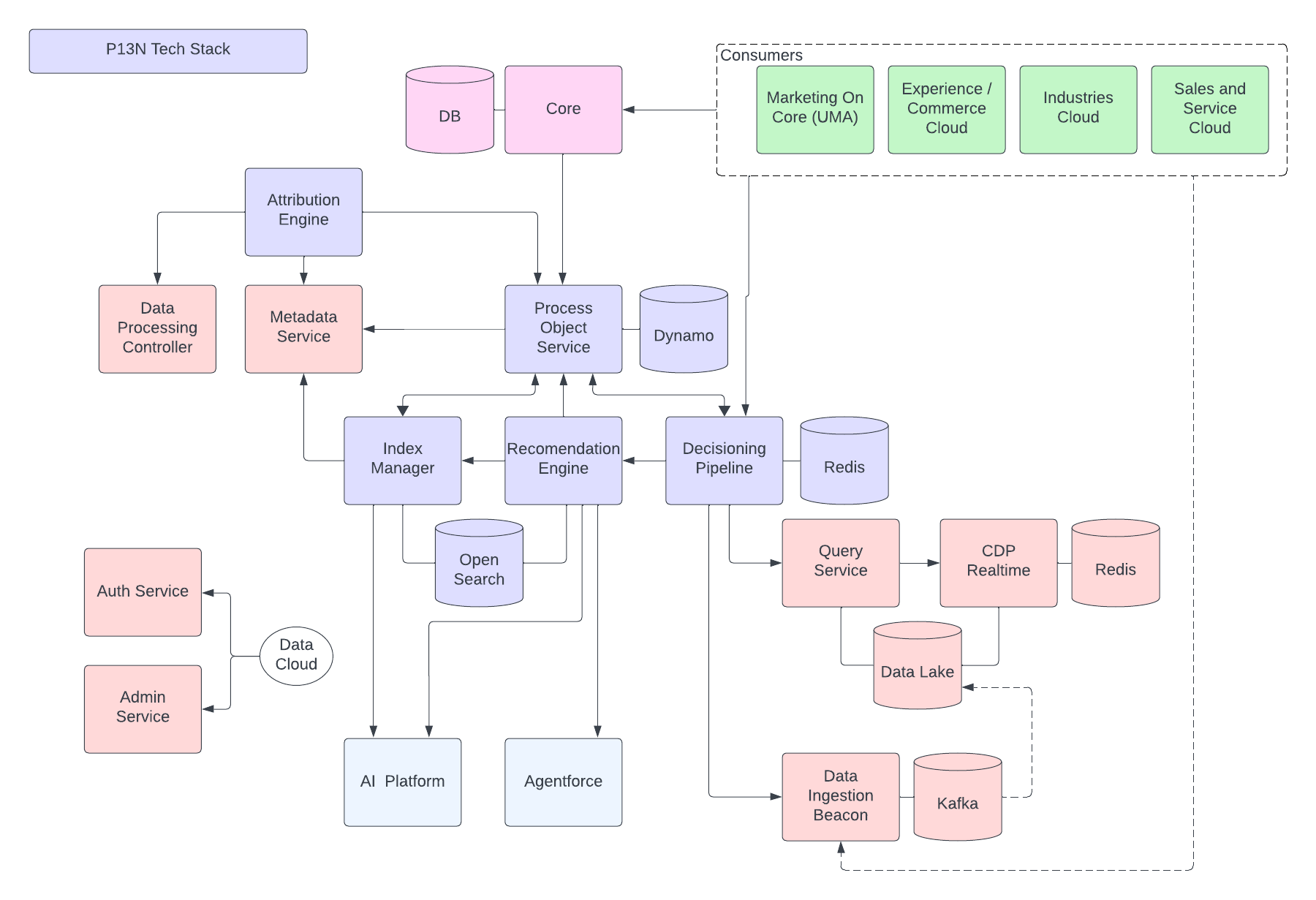
- Ожидаемые продажи решений
- Обслуживание внешних запросов на решения по персонализации, включая расширение профиля, эксперименты и рекомендации.
- Механизм рекомендации
- Обслуживание среды выполнения рекомендаций на основе правила или ML.
- Менеджер индексов
- Управление/Оркестрация бизнес-правил для асинхронных процессов, включая обучение ML для моделей рекомендаций
- Служба объектов процесса
- Отвечает за синхронизацию метаданных персонализации между базовыми и автономными
- Механизм атрибуции и эксперимент
- Атрибуция Analytics и эксперименты с рекомендациями по персонализации
Data 360 разработана как надежная и насыщенная платформа специально для поддержки новых агентских взаимодействий. Мы достигаем этих возможностей, опираясь на различные существующие службы Data 360 и посредством глубокой интеграции с Agentforce.
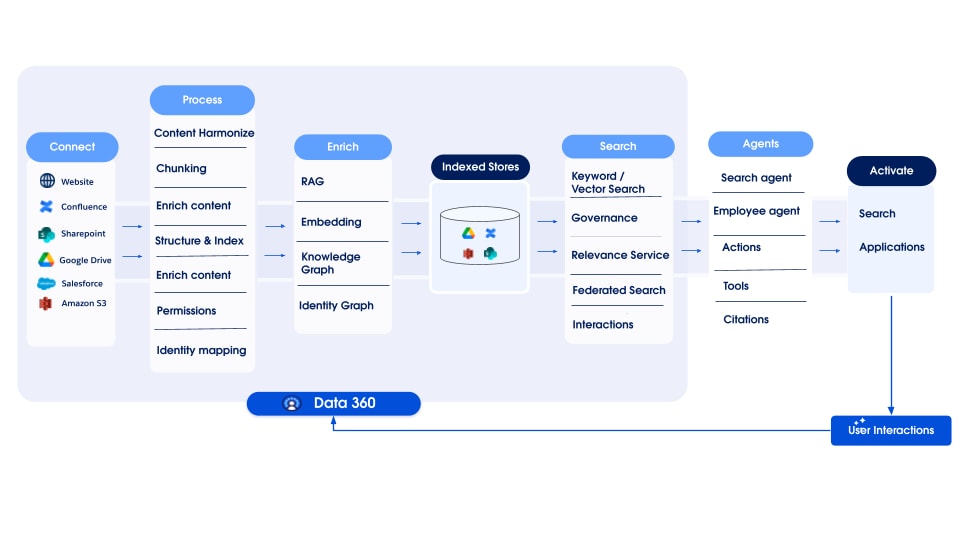
Наш подход к агентскому поиску предприятий основан на следующих принципах:
- Данные предприятия хранятся в изолированных службах или магазинах с безопасными полномочиями, необходимыми для доступа. Возможность доступа к этим данным и их обработки при сохранении полномочий источника жизненно важна для обеспечения Trust.
- Перекрестное ранжирование и релевантность в полном корпусе данных позволяют получить лучшие результаты, что, в свою очередь, может обеспечить лучший контекст для агентского взаимодействия.
Для предоставления этих взаимодействий Agentic Enterprise Search создан на основе следующих ключевых архитектурных компонентов:
- Коннекторы: Широкий набор коннекторов, доступных в Data 360, позволяет открывать и принимать данные из самых разных источников.
- Неструктурированная обработка данных: Это основа обработки нетабличного содержимого, позволяющая системе извлекать смысл и контекст из разных данных.
- Управление: Обеспечение безопасности корпоративного уровня, соответствия и контроля доступа для всех данных, потребляемых поиском. Поддержка полномочий доступности источников обеспечивает доступность данных только авторизованным пользователям, как для простого поиска, так и для агентских взаимодействий. Чтобы обеспечить быстрый поиск, полномочия безопасности оцениваются и внедряются нативно интерфейсами поиска на самом раннем этапе доступа к данным.
- Объединенный слой извлечения: Чтобы решить проблему изолированных данных, коннекторы поступают в универсальный уровень объединенного извлечения. Этот уровень предоставляет единую точку доступа ко всем данным, независимо от того, остаются ли они во внешних системах, доступных посредством интегрированного поиска, или управляются нативно посредством расширенных индексов для нулевых копий и принимаемых данных.
- Интеллектуальное понимание запроса: Перед извлечением система использует механизмы с искусственным интеллектом для толкования намерений пользователя. В дополнение к встраиванию представлений запроса на сопоставление семантического вектора, он может перезаписать и развернуть поиск на основе ключевых слов для повышения точности.
- Гибридный поиск и расширенный запрос: Чтобы найти наиболее актуальные сведения, платформа использует несколько стратегий параллельно. Гибридный поиск предоставляет точное сопоставление ключевых слов с семантическим векторным поиском по оптимизированным фрагментам данных, в то время как поиск по полной записи одновременно извлекает целые документы. Оба варианта сочетаются для обеспечения семантической релевантности и полного охвата содержимого.
- Иерархический рейтинг: После извлечения данных многоэтапная архитектура иерархического ранжирования оценивает, объединяет и повторно оценивает результаты из каждого источника и метода. Этот процесс создает единый объединенный список, в котором отображаются самые важные сведения для пользователя или агента.
Генерационный искусственный интеллект переносит основного потребителя корпоративного поиска с пользователей-людей на широкоязыковые модели (LLM). Data 360 Search создается с нуля для обслуживания обоих компонентов. Он оптимизирован для обработки более длинных и сложных запросов от агентов и возврата обогащенных контекстуальных результатов, необходимых для программного потребления и циклов рассуждений. В то же время система может обрабатывать более короткие, часто неоднозначные запросы, типичные для пользователей-людей, предоставляя такие функции, как фрагменты и выделение для быстрой оценки в пользовательском интерфейсе.
Конечная доставка взаимодействий агентского поиска сочетает оба подхода:
- Результаты прямого поиска: приложение может отображать традиционный список ранжированных результатов посредством API на основе метаданных, созданного на основе объединенного поискового интерфейса Data 360.
- Agentic, multi-turnal talkal answers: агентские ответы внедряются посредством собственной интеграции с Agentforce. Это диалоговое взаимодействие определяется основным агентом, который оркеструет действия и запросы, делегируя все задачи извлечения информации специализированному внутреннему поисковому агенту.
Этот специализированный поисковый агент оптимизирован для извлечения корпоративных сведений. Он использует цикл рассуждения для формулирования и выполнения параллельных поисков для изучения разных фасетов запроса пользователя. Он использует мощный набор инструментов, включительно с объединенным поиском данных Data 360 для всех типов данных и структурированных языков запросов для извлечения точных данных из таблиц и объектов.
С помощью этого архитектурного синтеза Data 360 расширяет возможности создания высокоинтеллектуальных, контекстуальных и действенных взаимодействий агентского корпоративного поиска.
Расширяемость является ключевой функцией Salesforce Platform. Расширение кода предоставляет расширяемость в Data 360, позволяя пользователям прокода выполнять настраиваемую логику Python напрямую в среде Data 360, дополняя ее богатые декларативные и низкокодовые функции. С помощью расширения кода пользователи могут безопасно расширить базовые возможности Data 360, например, трансформации и неструктурированные ожидаемые продажи данных (настраиваемые фрагменты).
В нашем дизайне расширения кода приоритет отдается гибкости, безопасности, эффективности и упрощенному взаимодействию разработчика. Она поддерживает две основные модели выполнения, каждая из которых настроена под определенные архитектурные потребности:
- Модель сценария:
- Цель: Для комплексной настраиваемой логики, требующей прямого взаимодействия с озерным центром Data 360.
- Функциональность: Клиенты пишут полные сценарии Python посредством расширения кода SDK, включая доступ чтения и записи к Lakehouse посредством SDK API. Идеально подходит для подготовки настраиваемых/сложных данных или манипуляции данными на заказ.
- Изоляция и безопасность: Пока сценарии получают доступ к Lakehouse, их выполнение ограничено безопасной изолированной средой в среде выполнения Data 360, предотвращая вмешательство в другие процессы или несанкционированный доступ к системе.
- Модель функции:
- Цель: Аналогично функции без сервера, для модульных вычислений без гражданства, вызываемых из существующих ожидаемых продаж Data 360 (например, настраиваемые фрагменты в неструктурированных ожидаемых продажах).
- Функциональность: Предоставленные клиентом функции принимают вводные, вычисляют и возвращают выводные данные.
- Изоляция и безопасность: Эти функции созданы для строгой изоляции; у них нет прямого доступа к Lakehouse. Их выполнение безопасно в безопасной среде, без состояния и ресурсов, что делает их подходящими для целенаправленных этапов обработки без состояния, обеспечивая безопасность, предсказуемое выполнение и минимизируя радиус взрыва.
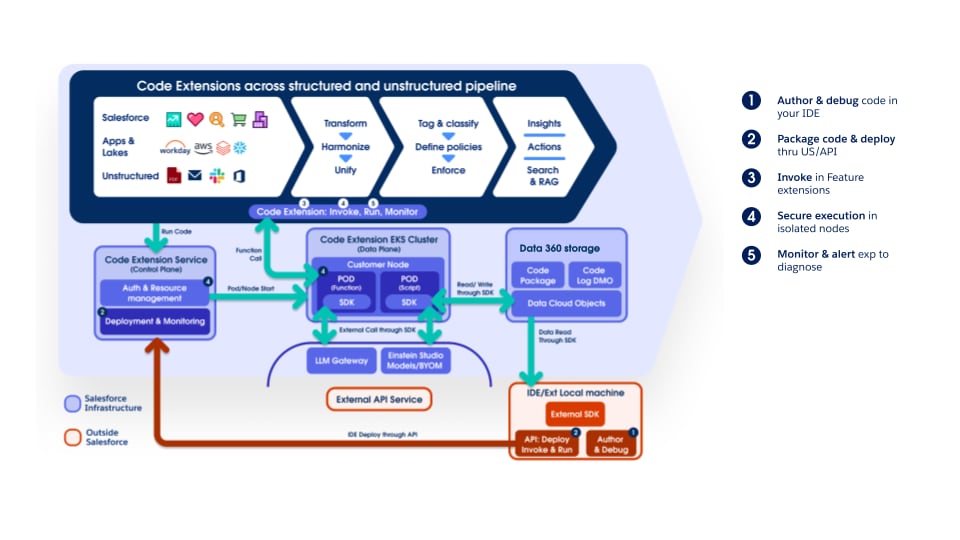
Модели «Сценарий» и «Функция» направлены на безопасное выполнение кода клиента, предотвращая влияние кода одного клиента на других или получение несанкционированного доступа к данным других клиентов, ресурсам Salesforce или внешним ресурсам. Эта безопасность достигается за счет многоуровневой архитектуры (глубокая оборона). Эта архитектура предоставляет изолированную среду выполнения для настраиваемого кода каждого клиента, содержащего разные ограждения. Они включают логическую изоляцию на уровне Kubernetes (K8s), изоляцию сети, безопасную среду выполнения и полномочия наименьших привилегий, дополненные оперативным мониторингом и готовностью к реагированию на инциденты для обнаружения и реагирования.
Чтобы поддержать надежный жизненный цикл разработки, расширение кода предлагает следующее:
- Внешнее авторство и отладка: Разработчики могут создавать и отлаживать код Python в привычных средах, например, VSCode, используя SDK.
- Гибкое развертывание: Настраиваемый код может быть пакетирован и развернут посредством служебных программ SDK, пользовательского интерфейса Data 360 или API, что позволяет интегрировать его в CI/CD.
Операционные журналы: Доступ к подробным журналам выполнения обеспечивает прозрачность и помогает устранить неполадки в производстве.
Предоставляя эти безопасные и гибкие возможности расширения кода, Data 360 позволяет архитекторам настраивать платформу в соответствии с их уникальными и сложными требованиями к обработке данных, действительно укрепляя ее роль как расширяемой корпоративной ткани данных.
По мере ускорения внедрения искусственного интеллекта предприятия поддерживают разнородные экосистемы ML, включительно с Amazon SageMaker, Google Vertex AI и настраиваемыми средами на основе Python, размещая модели, которые определяют важные прогнозы, например, оценку кредитного риска, склонность к оттоку, рекомендации по продуктам и решения следующего лучшего действия.
Традиционно интеграция этих внешних моделей в Salesforce требует уровней API на заказ, ожидаемых продаж ETL или промежуточной оркестрации программного обеспечения, внедряя дублирование данных, управление над головой, задержку и операционную сложность - проблемы, которые противоречат объединенному, соответствующему и реальному видению Customer Data Platform (CDP).
Bring Your Own Model (BYOM): Поставляемая посредством Einstein Studio в Data 360, решает эти проблемы, включив прямой вызов обученных внешними пользователями моделей в бизнес-процессах Salesforce, логике Apex и инструментах автоматизации — без перемещения или репликации данных. Посредством федерации нулевых копий Data 360 действует как управляемый единый источник истины, открывая гармонизированные данные Customer 360 для вывода во внешних конечных точках. Выводы прогноза возвращаются в режиме реального времени, снабжая бизнес-процессы масштабируемыми интеллектуальными данными.
BYOM эффективно устраняет разрыв между наукой о данных и операционным исполнением, отделяя разработку модели, управляемые данные и уровни потребления. Она сохраняет независимость платформы, уменьшает сложность интеграции, ускоряет развертывание искусственного интеллекта и поддерживает управление конфиденциальными данными.
Архитектура работает следующим образом: Data 360 предоставляет объединенную основу данных Customer 360, в то время как Einstein Studio оркеструет подключения к внешним платформам ML (SageMaker, искусственный интеллект Vertex или настраиваемые конечные точки). Внешние модели выполняют вывод в режиме реального времени, пакетном или потоковом режиме. Уровни Salesforce — Flow, Apex и Query API — потребляют результаты для предоставления персонализированных, автоматических и аналитических важных данных в Sales, Service, Marketing и Industry Cloud.
С точки зрения предприятия BYOM предоставляет:
- Целостность данных и управление ими: Устраняет неконтролируемые копии данных и применяет соответствие политики.
- Демократизация на основе искусственного интеллекта: Предоставление доступа к сложным моделям нетехническим пользователям посредством инструментов Salesforce.
- Ускорение до значения: Внешние модели активируются немедленно в процессах Salesforce.
- Поддержка масштабируемости и гибридной архитектуры: Включает мультиоблачное развертывание загруженности искусственным интеллектом.
- Готовая к будущему архитектура на основе искусственного интеллекта: Поддерживает составные стратегии на основе искусственного интеллекта, разделение данных, модели и слоев потребления для оперативной гибкости.
Bring Your Own LLM (BYO-LLM): Предлагает тот же механизм расширяемости, но для генеративных моделей. Включая прямой вызов внешних LLM, мы разрешаем клиентам использовать их на платформе Agentforce вместо предоставленных Salesforce моделей. Для предприятий BYO-LLM разрешает:
- Доступ к точно настроенным моделям
- Интеграция моделей, в настоящее время не предоставленных Salesforce
- Использование моделей в организациях, предоставленных клиентами
Современные предприятия функционируют в сложных условиях данных, характеризующихся двумя основными архитектурными проблемами:
- Фрагментация внутри предприятия: Крупные организации часто используют несколько организаций Salesforce (часто сегментированных по региону, бизнес-единице или архивному приобретению) и множество других систем данных. Эта фрагментация создает внутренние хранилища данных, что делает невозможным создание единого, надежного и единого представления клиента для взаимодействия в реальном времени в рамках предприятия. Задача состоит в том, чтобы объединить эти данные без их фактической консолидации или дублирования во всех системах, обеспечивая неизменность управления.
- Сотрудничество между предприятиями: Компаниям часто нужно предоставлять общий доступ к данным партнерам и поставщикам для совместного маркетинга, измерения и бизнес-аналитики. Проблема заключается в создании условий для такого сотрудничества при одновременной защите конфиденциальных данных и соблюдении таких правил конфиденциальности, как GDPR и CCPA, а также конкурентных барьеров.
Salesforce Data 360 решает эти проблемы с помощью инфраструктуры с нулевой копией Trust-by-design, построенной на принципе общего доступа и важных данных, а не перемещения или дублирования данных.
Salesforce Data 360 решает проблемы фрагментации данных и сотрудничества с Data Cloud One, общим доступом к данным между Data 360 и чистыми комнатами конфиденциальности. Эти решения объединяют данные клиентов, включают безопасный обмен данными и предоставляют важные данные о конфиденциальности. С помощью подхода zerocopy, Trust-by-design организации могут раскрыть потенциал данных для взаимодействия в реальном времени, расширенных партнерств и интеллектуального принятия решений. Каждый из этих вариантов сотрудничества данных служит разным целям.
Включение внутреннего корпоративного режима посредством Data Cloud One
Data Cloud One - это базовое архитектурное решение для предприятий, использующих несколько организаций Salesforce. Его цель выходит за рамки простого общего доступа к данным; он предназначен для создания единого надежного представления клиента и включения всех возможностей платформы Data 360 во всей организации.
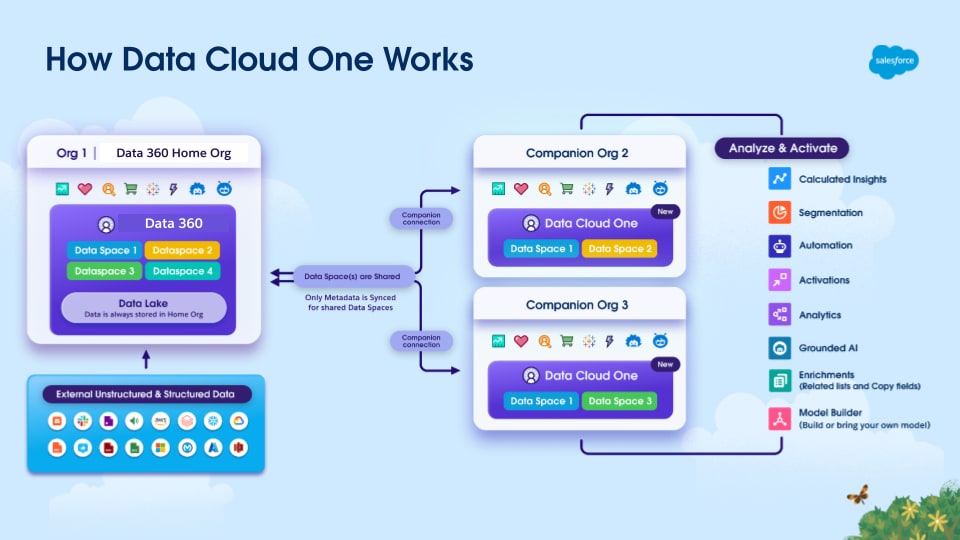
Этот механизм основан на назначенном экземпляре начальной организации Data 360, который служит центральным органом для управления данными и создания объединенного профиля клиента. Начальная организация - это организация, в которой инициализирована Data 360. Подключение Data Cloud One установлено между Data 360 и другими организациями Salesforce, называемыми организациями-компаньонами. Как часть подключения Data Cloud One, Data 360 предоставляет общий доступ к одному или нескольким пространствам данных каждой сопутствующей организации, предоставляя доступ к данным и метаданным в каждом общедоступном пространстве данных. Это достигается посредством модели интегрирования нулевой копии и межорганизационной синхронизации метаданных.
Data Cloud One также позволяет организациям-компаньонам использовать экземпляр Data 360 начальной организации для собственной активации, персонализации и интеллектуальных нужд. Эта стратегия необходима для устранения внутренней фрагментации данных и обеспечения активации всех бизнес-единиц относительно одного, управляемого и объединенного профиля клиента, максимизируя рентабельность базового внедрения Data 360.
Общий доступ к данным между организациями Data 360
В распределенных внутренних средах (где полная централизация невозможна) и для сотрудничества с надежными внешними партнерами общий доступ к данным Data 360-to-Data 360 соединяет независимые экземпляры Data 360.
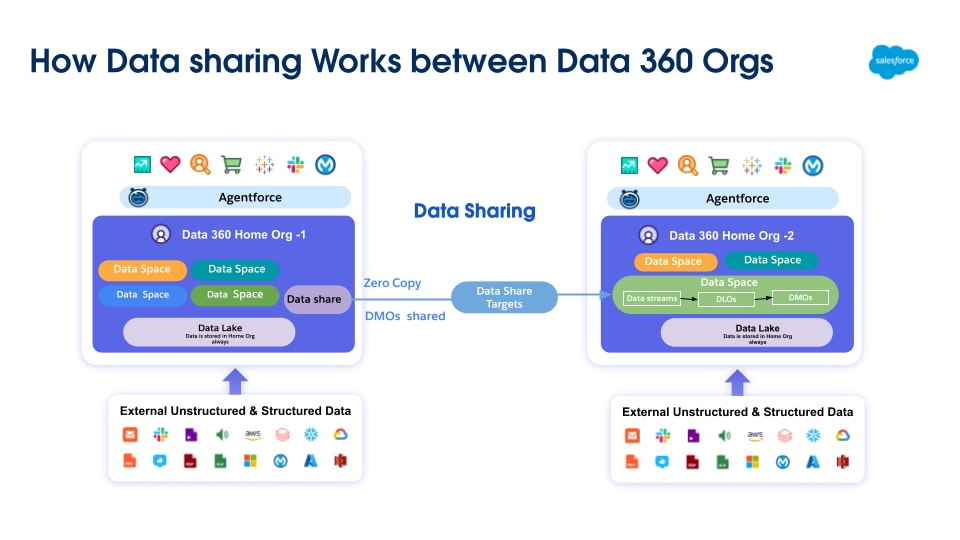
Эта модель общего доступа с нулевой копией устанавливает подключение между отдельными клиентами Data 360, инициализированное в разных организациях Salesforce, с целью безопасного обмена объектами данных (DLO, DMO и CIO). После подключения весь объект данных становится доступным в получателе Data 360. Администратор получателя Data 360 потом может установить правила управления для управления доступом пользователей к этим данным.
Конфиденциальность-Первое сотрудничество с сотрудничеством «Чистая комната» Data 360
Если сотрудничество требует наивысшего уровня конфиденциальности и соответствия или когда конкурентные интересы запрещают общий доступ к исходным данным, «Чистые комнаты Data 360» являются архитектурными требованиями.
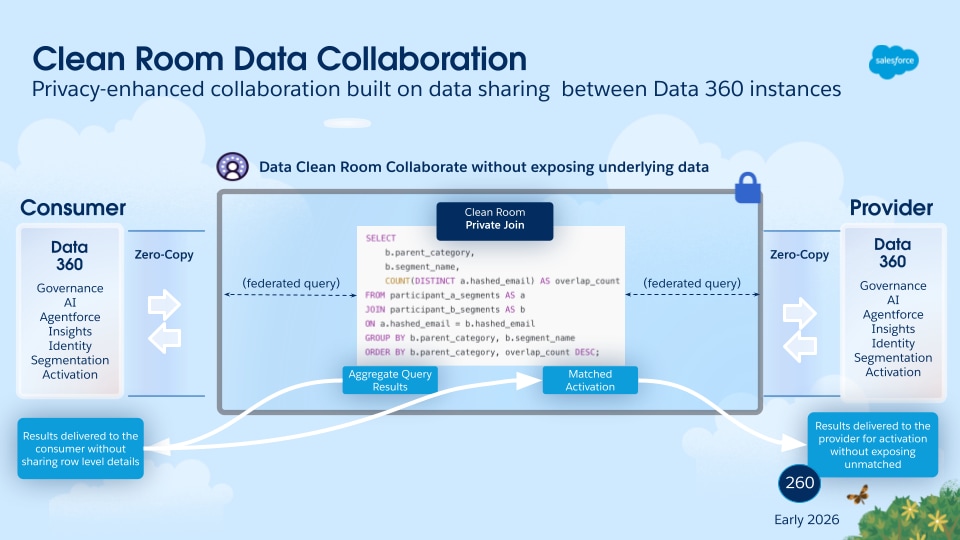
Архитектурно совместная работа в чистых помещениях Data 360 создана на основе инфраструктуры общего доступа Zero-Copy, используемой для общего доступа к данным Data 360-to-Data 360, но с дополнительными уровнями управления и вычислительными ограничениями. Чистая комната Data 360 предоставляет безопасную управляемую компьютерную среду, где стороны могут присоединяться к наборам данных на основе анонимных ключей. Его основная цель состоит в том, чтобы разрешить совместный анализ и создание важных данных без предоставления доступа к основным данным. Среда применяет строгие программируемые правила, например, минимальные пороги агрегации и неэкспортируемые идентификаторы. Эти правила обеспечивают получение и общий доступ только к утвержденным, улучшающим конфиденциальность и агрегированным важным данным. Это делает «Чистые комнаты» важными для сценариев использования, например, кросс-платформенного измерения кампаний и конфиденциального анализа накладки аудитории.
Data 360 разработана как интеллектуальная, расширяемая и надежная ткань данных, необходимая для питания искусственного интеллекта следующего поколения. Архитектурный дизайн позволяет решать проблему фрагментации данных, позволяя организациям объединять, обрабатывать и активировать все данные клиентов в масштабах, используя Zero Copy Data Federation для обеспечения эффективности.
Его надежная организация данных устанавливает гармонизированное представление из ООД (включая неструктурированные данные) в DMO, все защищенные в разделенных пространствах данных. Универсальные возможности обработки данных Data 360, включительно с пакетными и потоковыми трансформациями, вычисленными важными данными, неструктурированной обработкой данных и разрешающей способностью при опознавании, поддерживаются инкрементной архитектурой SNCE и CDF, обеспечивая эффективную обработку данных в близком к реальному режиме времени и значительную экономию средств.
Расширяемость предоставляется архитектурой Code Extension, безопасно включающей настраиваемую логику Python посредством сценариев или изолированных функций для уникальных требований. Кроме того, всеобъемлющая инфраструктура управления данными, основанная на контроле доступа на основе атрибутов (АБАК) с политиками КЕДАР, гарантирует детализацию безопасности, динамическую маскировку данных и последовательное применение во всем потреблении данных. Это приводит к сложным возможностям сегментации и активации, преобразовывая объединенные профили клиентов в динамичные многоканальные стратегии взаимодействия с оперативным реагированием в реальном времени.
Важно отметить, что способность Data 360 объединять обширные разнообразные данные, предоставлять контекст в реальном времени посредством объединенного запроса (включая гибридный структурированный/неструктурированный поиск и ускорение Hyper) и внедрять строгое управление имеет первостепенное значение для поддержки интеллектуальных агентов искусственного интеллекта. Он предоставляет необходимые надежные, свежие и актуальные данные для наземных бизнес-процессов на основе генеративного искусственного интеллекта (RAG) и для подпитки многооборотных, ориентированных на действия возможностей агентов, работающих на Agentforce, обеспечивая их функционирование с точностью и точностью.
Предоставляя защищенную от будущего платформу, где исходные данные трансформируются в действенные важные данные, Data 360 служит незаменимой архитектурной основой для организаций, создающих взаимодействия с клиентами Agentic. Это жизненно важная основа, которая превращает данные клиентов в сложные, персонализированные взаимодействия клиентов, способствующие успеху современных организаций.