Современные архитектуры Salesforce все больше зависят от асинхронной обработки, но не как удобства, а как стратегического требования к масштабу. В последние годы мы видим все больше компаний, сталкивающихся с резким увеличением объемов данных, сложными интеграциями, включающими несколько точек касания, и ростом автономных систем, работающих круглосуточно/365. Все это подталкивает архитекторов к созданию систем, которые являются асинхронными первыми.
Асинхронная обработка в Salesforce часто означает проектирование с учетом контролирующих ограничений и сложности. Эти ограничения выступают в качестве ограждений и архитектурных ограничений, которые помогают создать безопасные для массовых перевозок масштабируемые системы. Хотя никакие ограничения платформы напрямую не позволяют управлять сложностью, схемы проектирования могут способствовать уменьшению рисков на этом направлении. Внутренне Salesforce часто расширяет границы платформы для тестирования новых функций и автоматизации сложных бизнес-процессов. Мы создали инфраструктуру поэтапной асинхронной обработки для выполнения асинхронных заданий с произвольным количеством этапов. Каждый этап может выполняться, повторно запускаться и перезапускаться независимо посредством общедоступных элементов управления и полной оперативной доступности посредством централизованной регистрации. В настоящем документе излагаются его ключевые архитектурные компоненты: Apex и Finalizer в очереди, запланированный поток, курсоры Apex, вызываемые действия и интеграции со Slack. Вместе эти компоненты предоставляют модульную, масштабируемую и наблюдаемую архитектуру, соответствующую меняющимся потребностям предприятия.
- Современные архитектуры Salesforce должны использовать асинхронный первый подход для достижения масштаба, устойчивости и операционной прозрачности.
- Разделение сложной работы на независимо выполняемые этапы позволяет прогнозировать производительность, более безопасные попытки, контрольные точки, откат и модульную эволюцию без реорганизации базовых бизнес-правил.
- Инфраструктура предоставляет масштабируемую альтернативу монолитным и устаревшим пакетным заданиям, цепным асинхронным вызовам и глубоко вложенным потокам и создана для массовых загруженностей, которые должны масштабироваться горизонтально в Salesforce без внеплатформенной оркестрации.
- Детерминистское и наблюдаемое выполнение обеспечивает отслеживание прогресса, мониторинг SLA, диагностику сбоев и прозрачность на уровне аудита посредством централизованной регистрации и управления.
- Создается для строгости корпоративного уровня, включительно с единым управлением, соответствием и распределенным государственным контролем в долгосрочных бизнес-процессах.
Прежде чем просмотреть требования, ознакомьтесь с некоторыми рекомендациями по использованию подобной инфраструктуры. Прежде всего, обратите внимание, какая система является единым источником истины. Если ваша организация Salesforce минимально зависит от внешних данных, но нуждается в масштабировании от сотен до миллионов записей, рассмотрите инфраструктуру поэтапной асинхронизации.
Используйте данную инфраструктуру, если:
- Большая часть (или вся) информации для обработки уже существует в CRM.
- Начальные или текущие затраты на обслуживание задания Extract Transform Load (ETL) для гармонизации внешних данных слишком высоки.
- Вам нужно отложить обработку большого количества записей Salesforce по установленному расписанию.
- Вы можете разделить обработку на отдельные этапы. Например, можно создать иерархический или древовидный набор записей, особенно если объем данных перемещается по иерархии или дереву.
Не используйте данную инфраструктуру, если:
- Создание или обновление записей требует немедленного пересчета.
- Интеграция затруднена, поскольку внешние системы размещают первичные данные для обновлений записей. (Рассмотрим перенос обновленных данных в Salesforce посредством Bulk API.)
Учитывая эти практики, давайте пересмотрим наши требования и начнем строить.
Рассмотрите постановку задачи:
Учитывая задание, которое должно выполняться ежедневно, проверьте соответствие определенных записей предварительно установленным критериям для дальнейшей обработки. В противном случае, начните эти задания по обработке. Обработка записей может означать извлечение данных из нескольких внешних систем для выполнения расчетов. Этапы заданий должны уведомлять пользователей посредством Slack о готовности обработанных записей к проверке. Этапы также должны расширить уведомления для менеджеров и вышестоящих руководителей в иерархии ролей на основе настраиваемой задержки после первого раунда уведомлений.
Эта проблема включает несколько разных этапов, некоторые из которых могут происходить независимо друг от друга. Существует много способов разделить работу. Ниже указана одна группировка:
- Планировщик.
- Интерфейс этапа и конкретные внедрения, обрабатывающие записи (независимо от типа обработки).
- Процессор, систематизирующий этапы.
- Вызываемый Apex Avocable, вызванный планировщиком.
- Часть уведомления. Мы используем Apex Slack SDK.
- Фраза «настраиваемая задержка» скрывает некоторую сложность. Ниже мы рассмотрим эту сложность.
Ниже указана самоуверенная диаграмма для встроенной инфраструктуры:
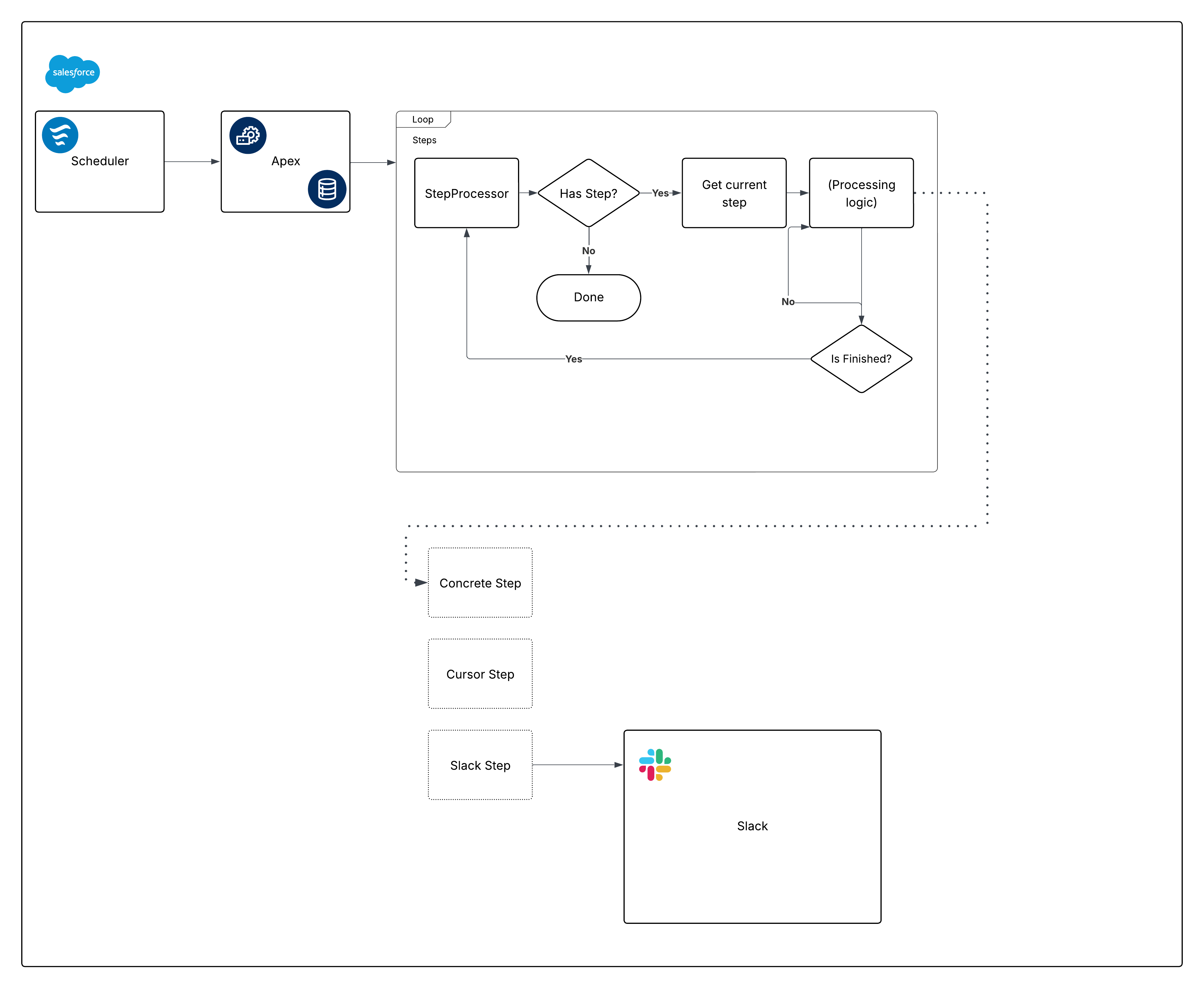 Теперь разобьем диаграмму и начнем создавать части.
Теперь разобьем диаграмму и начнем создавать части.
Запланированный поток предлагает несколько преимуществ в качестве механизма планирования:
- Запланированные потоки можно пакетировать и развернуть в качестве метаданных. Это не относится к заданиям, запланированным посредством Apex (или на странице запланированных заданий).
- Элемент «Ожидание» важен для инфраструктур, требующих выносок. Используя его в потоке, выноски не нужны в вызываемой части инфраструктуры.
- Детализация планирования соответствует требованиям: минимальный интервал для запланированных потоков является ежедневным. Если вам нужна более высокая частота (например, ежечасно), пересмотрите «Запланированный поток» для этого требования.
Еще одним соображением при настройке запланированного потока является создание среды. Прежде чем вызвать действие Apex, добавьте элемент «Решение», оценивающий переменную {!$Api.Enterprise_Server_URL_100}. Это обеспечивает выполнение задания только в заданных средах, например, UAT и Production. Эта схема важна, поскольку безопасные среды часто обновляются или создаются недавно во время SDLC, и без четкой проверки среды запланированный поток может непреднамеренно выполниться в средах, где инфраструктура не предназначена для выполнения. Использование оператора contains в элементе «Решение» делает настройку устойчивой к будущим созданиям безопасной среды или изменениям URL-адреса.
Наконец, подумайте, как инфраструктура должна собирать сбои. Всегда добавляйте путь ошибки, когда поток вызывает любое действие. Например, можно перенаправить ошибки в действие «Добавить запись журнала» Nebula Logger. Nebula Logger записывает журналы в настраиваемые объекты, поэтому клиенты должны знать, что данные журнала используют хранилище организации — по умолчанию журналы хранятся в организации 14 дней, а потом очищаются; этот период хранения можно настроить. Nebula Logger также использует события платформы для публикации журналов, поэтому записи журнала сохраняются независимо от основной транзакции обработки данных — это обеспечивает сбор сбоев даже при откате основного действия Flow или Apex. Клиенты должны оценить ожидаемый объем журнала и требования к сохранности при рассмотрении добавления инфраструктуры журнала.
Вот как выглядит поток:
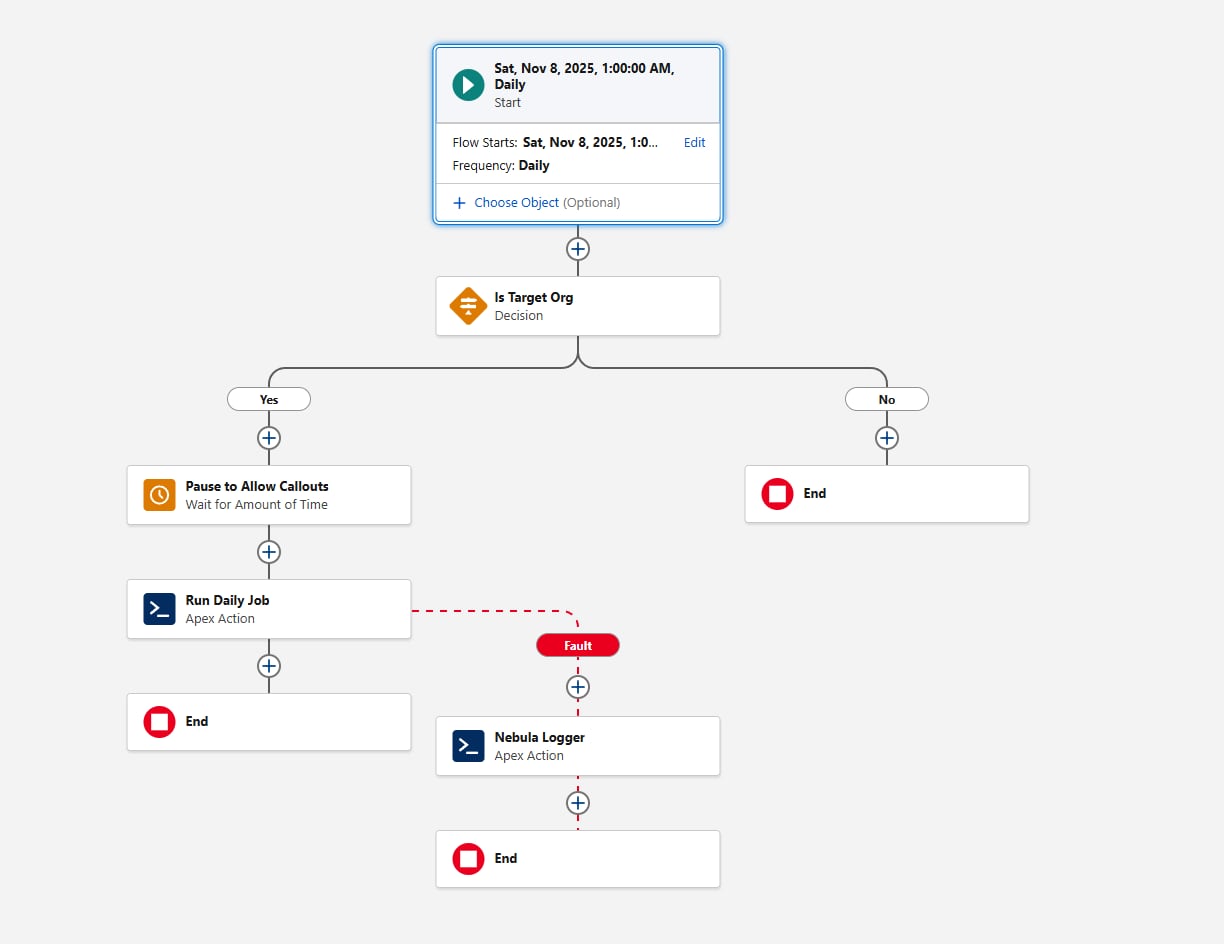
Перейдем к первым частям кода Apex с требованием планирования, которое теперь удовлетворено.
Определение Step интерфейса:
В этой статье интерфейс step отображается как внешний класс. Сама инфраструктура гибкая — рабочие группы могут систематизировать интерфейс и его реализации посредством любой предпочтительной схемы пакетирования Apex, если все классы Step ссылаются на один интерфейс.
Ниже перечислены некоторые рекомендации по методам, определенным в нашем интерфейсе.
execute, хотя в данный момент и меньше аргументов, улучшается при передаче классаState(или интерфейса) для систематизации данных между этапами, когда порядок важен.getNameможет вернуть значениеSystem.TypeвместоString. Цель - предоставить слою оркестрации способ регистрации имен этапов без открытия других свойств.
Ниже приведено первое конкретное внедрение, отображающее, как эти элементы сочетаются. За одним исключением, рекомендуем использовать Queueable Apex для внедрения асинхронной обработки в Apex; пакетный Apex обычно не нужен (и методы @future не рекомендуются). Поставленный в очередь Apex запускается быстро и с помощью Apex Cursors имеет много преимуществ перед пакетным Apex.
Apex Cursors предлагает современную альтернативу традиционной модели Batch Apex. Подобно пакетной обработке, внедрение курсора может извлекать записи фрагментами (до 2 000 записей на пакет). Однако, курсоры позволяют извлекать несколько элементов в одной транзакции, что позволяет значительно увеличить производительность для массовых операций.
При принятии курсоров в рамках этой инфраструктуры рабочие группы должны знать о текущих ограничениях тестирования и издевательств. Алгоритм курсора в тестах может отличаться от производственного, поэтому важно создать стратегии тестирования, которые не будут зависеть от внутренних параметров курсора и будут проверять логику оркестрации на границах. По мере развития платформы эти области будут совершенствоваться, но основные руководящие принципы сохраняются: Курсоры обеспечивают более высокую производительность и снижение оркестрации над головой по сравнению с пакетным Apex для многих способов использования.
Чтобы определить четкую границу между предоставленным системой курсором и собственным кодом, рекомендуем создать представление, похожее на курсор, при внедрении Step интерфейса. Учитывайте этот код:
Обратите внимание на класс Cursor. Курсоры Apex являются экземплярами Database.Cursor, но наша Cursor реализация предоставляет нам гибкость в устранении недостатков курсоров. Ниже указано внедрение:
В остальной части статьи описания sharing пропускаются при обращении к классам Apex. На практике обеспечьте четкое использование классов верхнего уровня с общим доступом или без него в соответствии с моделью объекта и полномочиями.
Также обратите внимание, что наши Cursor делегаторы внедрения на платформу Database.Cursor, с дополнительными преимуществами обсуждаются далее.
Сначала выполните соответствующие тесты:
Благодаря виртуальному Cursor, конкретные внедрения CursorStep могут работать без Database.Cursor, если им не нужно повторять большой набор записей, подобно возврату System.Iterable<T> вместо Database.QueryLocator в пакетном Apex. Ниже указан пример:
Обратите внимание, что, поскольку этот класс также является абстрактным, он оставляет конкретное осуществление innerExecute подклассам.
Существует также альтернатива внутреннему подклассу CursorLike. Если вы знаете, что конкретные версии такого этапа не будут просматривать другие контролирующие ограничения, вы можете вернуть this.records из CursorLike.fetch и переопределить родительский CursorStep.shouldRestart() для возврата false. Это позволяет повторять список, ограниченный только ограничением кучности Apex 12 Мб на асинхронную транзакцию.
Внедрение на основе курсора предоставляет большую гибкость при обработке больших объемов данных. Step интерфейс, тем временем, предоставляет нам возможность гибкого описания и инкапсулирования всевозможных шагов.
Рассмотрим этап на основе потока:
Поскольку потоки не могут возвращать параметры вывода, соответствующие заданному Apex типу, мы проверяем параметр вывода shouldRestart перед использованием.
Некоторые этапы могут быть помечены функцией. Вы можете внедрить логику, чтобы решить, какие этапы добавлять, или использовать этап без вариантов для отключенной функции. Схема нулевого объекта - это распространенный способ уменьшения сложности в слое оркестрации:
Сейчас у нас достаточно много структурных элементов для работы. Рассмотрим слой оркестрации, ответственный за итерацию этапов.
Процессор является точкой перегиба в архитектуре. Мы должны решить, кто и где определяет этапы инициализации. Варианты включают:
- Пусть процессор определит, какие этапы соотносятся с бизнес-логикой. Этот параметр прост, но он плохо масштабируется для чтения.
- Определите соотнесение посредством настраиваемых метаданных (CMDT). Поля взаимосвязи метаданных не поддерживают
ApexClass, что не позволяет связать написание имени класса с настройками бизнес-процессов. Вы можете уменьшить риск администратора, сделав поле раскрывающимся списком и проверив наличие типа (Type.forName()или запросивApexClass), но поскольку записи CMDT не поддерживают триггеры, проверка происходит при запуске. Этот маршрут можно тестировать, но администраторы могут создавать записи CMDT только в производстве — действуйте осторожно. - Определите соотнесение с записями. Не-администраторы могут настраивать этапы, но развертывания становятся более сложными и среды могут отдаляться. Действуйте осторожно.
Есть известная цитата из "Чистого кода" о том, как обрабатывать именно эту часть сложности:
Решение этой проблемы - закопать
switchведомость [о создании предметов] в подвале абстрактной фабрики и никому не показывать ее.
Учитывая это, а также то, что наше текущее количество этапов четко определено и вряд ли увеличится слишком сильно, процессор этапов может быть фабрикой этапов. При этом может использоваться число для управления оператором переключения:
А потом для нашей StepProcessor:
Отображаемые заводские методы, например, addTypeOneSteps(), могут делегировать такие проблемы, как пометка функций. cleanSteps() выполняет одноразовую проверку собранных этапов, чтобы убедиться в отсутствии « пустых » этапов перед подлинной асинхронизацией. Это может выглядеть следующим образом:
Обработка ошибок не обсуждалась после упоминания регистратора туманностей в разделе запланированного потока. Это потому, что System.Finalizer позволяет регистрировать все условия ошибок без добавления конкретной обработки ошибок на каждом этапе. Каждая Step фокусируется на выполнении, в то время как мы регистрируем и бросаем все несчастные пути, чтобы они появлялись в тестах единицы измерения. Это поддерживает безопасную итерацию и оповещение на уровне производства (используя модуль Slack Logger для туманности для всех журналов ПРЕДУПРЕЖДЕНИЙ и ОШИБОК).
Одно примечание к записи ошибок: передача экземпляра этапа в сообщения журнала предполагает уровень Trust к тому, что становится видимым в журналах. toString() по умолчанию для классов Apex содержит все статические свойства и свойства на уровне экземпляра в сообщении. Это может быть желательным — или может привести к утечке конфиденциальной информации. Хотя журналирование и безопасность здесь не в центре внимания, обратите внимание, что в некоторых системах соблюдение интерфейса, например, Step, может также привести к принудительному переопределению для toString().
Такой метод возлагает на каждого автора объекта бремя выбора допустимого для печати, что может быть желательным.
На уровнях регистрации: на уровне StepProcessor используется INFO, самый высокий уровень без ошибок. По мере детализации приложения уровни регистрации должны уменьшаться. Отдельные этапы могут использовать DEBUG для получения высокоуровневой информации, а FINE, FINER и FINEST могут быть зарезервированы для получения более подробных результатов. Регистрация - это такое же искусство, как и наука, но следование этим принципам помогает поддерживать последовательность и полезность журналов.
Прежде чем перейти к следующему, давайте кратко обдумаем решение о том, чтобы наш процессор этапов размещал логику, для которой используются этапы. В большой базе кодов рекомендуем сделать StepProcessor виртуальными или абстрактными, а подклассы определить конкретные шаги для надлежащего разделения проблем.
В итоге планировщик вызывает Apex. После завершения остальной настройки раздел «Вызываемый Apex» может решить, какие этапы следует выполнить и передать List<StepType> процессору:
Это простая часть уравнения — использование записей, данных или логики для определения типов этапов для выполнения. Вызываемое действие просто, поскольку мы интегрировали сложность в другие области. Мы также защитили от непредвиденных исключений и упростили тестирование каждого элемента в изоляции.
Apex Slack SDK выходит за рамки этой статьи, но нужно вернуться к одной потенциальной ошибке в требованиях: уведомлению людей вверх в иерархии ролей на основе настраиваемой задержки. На бумаге это просто, и вы можете (правильно) рассмотреть System.enqueueJob(this) в StepProcessor. С помощью System.AsyncOptions мы изначально склонялись к использованию перегрузки enqueueJob для соответствия этому требованию.
Однако пока максимальная задержка через System.AsyncOptions.MinimumQueueableDelayInMinutes составляет 10 минут. Поскольку требование составляет 120 минут, остается несколько вариантов. Наивный подход может выглядеть следующим образом:
На практике задержка будет передаваться в этот класс, поскольку задержка определяется конфигурацией.
Рекомендуем использовать данный метод только при наличии только одного типа задержанного уведомления. Перед запуском (или более, если задержка увеличивается) выполняется 11 дополнительных асинхронных заданий. Эти расходы могут быть подходящими для одной работы, а не для многих. Вам также нужно добавить метод к Step интерфейсу, чтобы каждый шаг мог сообщить процессору, сколько времени нужно ждать перед повторным запуском, что добавляет шума.
Таким образом, у нас есть две интересные возможности:
- Вы можете добавить отложенный этап в текущую структуру заданий, если у вас уже запланировано задание опроса через соответствующий промежуток времени. Вы также должны быть согласны с тем, что указанная задержка попадет до 15 минут спустя (15 минут - минимальный интервал обновления для запланированного Apex выражения CRON). Это примерно соответствует примеру вызываемого Apex; планирование выполняется посредством Apex. Другими словами, можно повторно использовать одну и ту же архитектуру на основе
Stepдля обработки записей на основе отметки времени «Начало после» и решить, какие шаги использовать на основе раскрывающегося списка или раскрывающегося списка со множественным выбором, соотносящегося с предыдущими значениямиStepType. - Или, если вам удобно определить дополнительный внешний класс Apex, вернитесь к пакетному Apex (в отличие от очередного Apex, поддерживающего внутренние классы, пакетные классы Apex должны быть внешними классами) посредством
System.scheduleBatch().
Рассмотрите пример Batch Apex. Хотя мы обычно рекомендуем Queueable Apex для гибкости и контроля, это один из случаев, когда пакет Apex по-прежнему верховодит:
А потом, в StepProcessor, представьте, что ранее показанный метод addTypeOneSteps() обновляется данным отложенным этапом:
Хотя обычно мы не рекомендуем такой прыжок с обручем, задержка этапа становится еще одним многоразовым строительным элементом. До тех пор, пока в Queable Apex не будут разрешены более длительные задержки, он также представляет собой самый простой способ получения этого эффекта (без механизма опроса, как обсуждалось).
Мы использовали объектно-ориентированный дизайн для выполнения требований и создали систему, которая будет масштабироваться и балансировать долгосрочные затраты на строительство и обслуживание. Хотя описание этапов и мгновенность могут в конечном счете занять больше места в StepProcessor, здесь существует небольшая дополнительная техническая задолженность. С помощью FlowStep администраторы и разработчики могут совместно решать, когда решения без кода или прокода наиболее эффективны.
Используя интерфейс System.Finalizer в инфраструктуре очереди Apex, совместно с Nebula Logger мы создали надежную тестируемую систему, которая предупреждает нас о непредвиденных сбоях, даже если на будущих этапах отсутствует четкая регистрация. Для нас эта система радостно хрустит цифрами и снижает стоимость и сложность. Она также дала нам ценные важные данные о поведении Apex Cursors при реальных загруженности, помогая настроить наш подход, одновременно улучшая саму функцию.
Разлагая сложные массовые нагрузки на этапы модульного выполнения, инфраструктура инфраструктуры поэтапной асинхронной обработки трансформирует ограничения платформы в инженерные преимущества, обеспечивая предсказуемую производительность, наблюдаемость и управление в масштабе предприятия. Этапы могут быть настроены администраторами и разработчиками, и в любом случае, авторы этапов могут спокойно сосредоточиться на соблюдении базовых контролирующих ограничений платформы (например, строки DML и извлеченные строки запросов), не беспокоясь о том, как масштабировать каждый этап.
Для внедрения и внедрения этой схемы во всех внедрениях предприятия архитекторам следует:
- Оценить существующие автоматизации для определения областей, в которых асинхронная оркестрация может помочь повысить производительность и улучшить видимость.
- Разделите большие процессы на отдельные, независимо выполняемые этапы с четкими целями обработки и отдельными точками автора (например, Flow или Apex).
- Определите и сгруппируйте типы этапов для ускорения повторного использования и стандартизации этапов в бизнес-единицах.
- Пробная версия с новыми процессами или существующими автоматизациями. Вы можете удивиться, узнав, сколько краевых обращений вы найдете бесплатно в нескольких шагах, заботьтесь о встроенной регистрации и наблюдаемости!
Джеймс Симон является главным инженером по программному обеспечению в Salesforce и имеет более чем десятилетний опыт работы на платформе. До перехода в разработку он был клиентом Salesforce — и владельцем продукта, а с 2019 года пишет технические глубокие погружения о Salesforce в рамках The Joys Of Apex. Ранее он публиковал статьи в блоге Salesforce Developer, а также в Salesforce Engineering.