Предприятия часто хранят данные в Salesforce и других внешних озерах данных, например, Snowflake, Google BigQuery, Databricks, Redshift или облачном хранилище, например, Amazon S3. Такая изолированность данных в разных исходных системах создает проблемы для компаний, которые хотят использовать всю мощь своих данных.
Архитекторы, работающие над объединением данных в нескольких озерах данных, сталкиваются с ключевыми архитектурными решениями относительно оптимальных способов интеграции этих данных. Data 360 предлагает несколько вариантов интеграции данных, каждый из которых содержит разные плюсы и минусы.
Это руководство предоставляет основу для оценки схемы, наиболее соответствующей вашим требованиям к задержке, стоимости, масштабируемости, управлению и сложности при интеграции данных, помогая выбрать, когда использовать прием данных, федерацию данных Zero Copy или гибридный подход. Руководство также поможет выбрать между разными методами приема данных и интегрирования данных, каждый из которых удовлетворяет разные потребности.
Интеграция внешних озер данных с Data 360 требует тщательного рассмотрения компромиссов между свежестью данных, управлением и эффективностью ожидаемых продаж. Например, использование оперативных запросов федерации данных Zero Copy повышает свежесть данных, но может снизить эффективность ожидаемых продаж при перемещении большего количества данных по сети. Поэтому для большинства реальных реализаций оптимальным путем является сочетание приема и федерирования в многооблачной экосистеме Lakehouse. Этот гибридный подход обеспечивает масштабируемую, управляемую и совместимую архитектуру, которая беспрепятственно поддерживает как оперативные нагрузки с низкой задержкой, например персонализацию в реальном времени и обнаружение мошенничества, так и аналитические нагрузки, например, нормативную отчетность и анализ архивных тенденций. Это руководство по принятию решений поможет вам понять, как ориентироваться в этих компромиссах и выбрать правильную стратегию.
- Прием данных: Копирует данные в Salesforce Data 360, создавая управляемые канонические модели данных. Идеально, когда нужно:
- Создайте универсальный Customer 360: Объедините и трансформируйте разные источники в единый надежный профиль.
- Соответствовать строгому соблюдению нормативных требований: Создайте проверяемую централизованную копию, где доступ к данным и родословную можно жестко контролировать.
- Zero Copy Federation: Запрашивает внешние источники в режиме реального времени без дублирования, включая персонализацию в режиме реального времени, панели мониторинга в реальном времени и адаптацию к быстрому источнику. Необходимо сбалансировать два основных варианта с компромиссами:
- Оперативное и кэширование (ускоренный запрос): Лучше всего подходит для интерактивного анализа и панелей мониторинга в реальном времени для данных, которые живут во внешних платформах данных, например, Snowflake, Google BigQuery, Redshift или Databricks. Избегает медленного и дорогостоящего дублирования данных, перенося обработку в исходную систему.
- Интеграция файлов: Лучше всего подходит для масштабной пакетной обработки и обучения модели на основе искусственного интеллекта по данным в облачном озере данных (S3, ADLS). Избегает дорогостоящего и медленного приема, напрямую запрашивая файлы в открытых форматах таблиц, разблокируя массивы наборов данных для загруженности ETL и Data science.
- Гибридная модель: Смешайте прием для объединенных профилей с федерированием для свежести, поддержки занятости мультиканала, действий под управлением Agentforce и обучения на основе искусственного интеллекта/ML.
-
Гибридная архитектура: Часто требуется смешивание приема данных и объединения данных.
- Используйте принятие данных для критических данных для канонических моделей данных и базового управления.
- Объедините все другие данные посредством Zero Copy, чтобы минимизировать операционные расходы на создание и обслуживание ожидаемых продаж данных приема.
-
Вопросы частоты принятия данных: Выберите частоту на основе бизнес-ценности, потребностей задержки и операционной сложности.
- Используйте в реальном времени для бизнес-правил, чувствительных к времени (персонализация, живые панели мониторинга, действия Agentforce).
- Практически в режиме реального времени для умеренно срочных процессов (кампании, операционные отчеты).
- Пакет для архивных или низкоскоростных наборов данных.
-
Соотнесение схемы интегрирования с задержкой и производительностью: Выберите ту, которая больше всего соответствует схемам доступа и требованиям к свежести, производительности и стоимости.
- Используйте Live Query для операционных панелей мониторинга и персонализации в реальном времени, где низкая задержка является критической.
- Используйте кэширование (ускоренный запрос), если запросы частые, но немного устаревшие результаты приемлемы, что балансирует производительность и стоимость.
- Используйте интеграцию файлов для крупномасштабной аналитики с высокой производительностью или пакетных загруженностей, идеально подходящих для архивных или менее срочных наборов данных.
-
Согласование управления с требованиями резидентства данных:
- Используйте прием там, где централизованное управление является критическим.
- Рекомендуем использовать федеративное управление там, где это приемлемо, применяя при этом строгое управление из внешних источников. Zero Copy учитывает политики исходного уровня, например, безопасность строки (RLS) и маскировку данных.
-
Приоритизация принятия для ценных бизнес-правил: Выборочно применяйте прием к критическим процессам, например, разрешающей способности при опознавании, отчетам по регламентам и активации операций.
-
Результат решения — стоимость и сложность: Прием в реальном времени может быть дорогим и сложным. Архитекторы должны соотносить стоимость адаптации, хранения и трансформации данных с затратами на их запрос напрямую посредством Zero Copy.
Выбор правильной схемы интеграции — принятие данных, нулевая копия или гибридный подход — напрямую влияет на задержку, управление, эффективность работы и стоимость на многооблачных платформах. Это решение определяет способ надежной и масштабной доставки важных данных в реальном времени, активации на основе искусственного интеллекта и персонализированной занятости.
Данная таблица предоставляет техническое сравнение схем принятия данных и нулевой копии в Salesforce Data 360, фокусируясь на возможностях, преимуществах и преимуществах, а также на сценариях корпоративного использования и результатах. Архитекторы могут использовать это в качестве ссылки для создания гибридных многооблачных платформ данных, которые балансируют производительность, стоимость и соответствие.
| Тип схемы | Режим/инструмент | Преимущества | Рекомендации | Результаты |
|---|---|---|---|---|
| Прием данных | В реальном времени:Прием с субсекундной задержкой посредством API принятия с поддержкой CDC. Непрерывные потоковые ожидаемые продажи. | Немедленные важные данные - Идеально подходит для низколатентных операционных и персонализированных способов использования - Поддержка бизнес-правил под управлением событий |
Высокая стоимость Сложная архитектура - Требуются исходные системы с низкой задержкой - Крупномасштабные источники могут стать причиной чрезмерной потоковой передачи, ведущей к насыщению трубопроводов Интенсивный ввод-вывод - Рекомендуем использовать выборочные поля и фильтрацию для уменьшения накладных расходов |
Agentforce: - Предупреждения о мошенничестве в реальном времени, персонализация розничной торговли, оперативные предупреждения Analytics: Подвторые панели мониторинга, мониторинг КПЭ Соответствие: - Постоянные обновления записей клиентов для регламентированных бизнес-правил |
| Потоковая передача:Микропакетный прием каждые 1-3 минуты посредством собственных коннекторов | Сбалансированная стоимость и свежесть - Более простая архитектура, чем в реальном времени - Поддерживает инкрементные обновления |
Небольшая задержка - Может не подходить для важных подвторых решений Размер пакета влияет на память/вычисления - Ввод-вывод умеренный - Лучше для предсказуемых повторяющихся схем обновления - Рекомендуем использовать агрегацию окон для уменьшения загрузки обработки |
Agentforce: Своевременные триггеры кампании, близкая к оперативной занятость Analytics: - Механизмы рекомендаций, близкие к реальному панели мониторинга Соответствие: - Частые обновления с возможностью аудита |
|
| Пакет:Запланированные массовые загрузки посредством коннекторов или API. Поддерживает хранилище объектов и ожидаемые продажи ETL/ELT. | Экономичность для массивных наборов данных - Простота внедрения - Надежный для архивной аналитики |
- Задержка данных - Непригодно для срочных операций - Интенсивность ввода-вывода во время окон загрузки - Пропускная способность сети может стать препятствием для больших файлов - Лучше для архивного агрегирования или регламентированных бизнес-правил отчетности |
Agentforce: Билеты на ИТ-поддержку (Jira/ServiceNow), агрегированные бизнес-правила Analytics: - Архивный анализ, оценка тенденций Жалоба: - Нормативная отчетность, агрегация данных пациентов/претензий |
|
| Zero Copy | Оперативный запрос:Прямые запросы к внешним системам; схема для чтения; отсутствие дублирования данных | Максимальная свежесть - Минимальное хранилище накладных расходов; поддерживает оперативные важные данные в реальном времени |
- Зависит от производительности источника - Большой объем запроса может повлиять на задержку - Идеально подходит для запросов с выноской и агрегацией предиката для минимизации ввода-вывода - Избежание нефильтрованных запросов к массивным наборам данных |
Agentforce: Динамические бизнес-правила, адаптирующиеся к оперативной деятельности Analytics: Оперативные панели мониторинга, оперативная отчетность Соответствие: - Соблюдение безопасности строки и маскировки в источнике |
| Ускоренный запрос (кэширование):Кэшированные локальные копии для интегрированных запросов. Настраивается от 15 минут до 7 дней. Оптимизированное выполнение запроса | - Уменьшает задержку - Низкая стоимость по сравнению с повторяющимися оперативными запросами - Повышение производительности для схем частого доступа |
Требуется управление кэшем - Интервал кэширования зависит от скрытности - Лучше для высокочастотных запросов - Не подходит для подвторого решения |
Agentforce: - Предварительно агрегированные показатели занятости для быстрого принятия решений Analytics: Панели мониторинга BI, сегментация, аналитическая отчетность Соответствие: - Согласованные регламентированные панели мониторинга с журналами аудита |
|
| Интеграция файлов: Прямой доступ к большим архивным наборам данных в хранилищах объектов или озерах (S3, Айсберг, Google BigQuery, Redshift). | - Обработка массивных наборов данных Минимальное хранилище в Data 360 - Поддерживает загруженность искусственным интеллектом/ML |
-Только для чтения - Производительность запроса зависит от пропускной способности внешней системы - Оптимизировано для пакетных, интенсивных заданий - Не подходит для панели мониторинга в реальном времени |
Agentforce: - (Не типично — пакетное) Analytics: Обучение ML/AI, архивная аналитика, отчетность в петабайтном масштабе Соответствие: Регулируемый доступ к внешним наборам данных без дублирования |
При принятии данных данные физически копируются в Data 360 и полностью управляются, в отличие от Zero Copy, где данные остаются в источнике. Расчет трансформаций выполняется в Data 360, что позволяет централизованно управлять и аудировать.
Используйте прием данных для хранения канонических управляемых наборов данных в Salesforce Data 360 для соответствия и оперативного контроля. Используйте прием, когда требуется полный контроль, аудит и отслеживаемость. Идеально подходит для регламентированных или ценных бизнес-правил, где централизованные вычисления и управление являются критически важными.
Прием лучше всего подходит для создания надежной основы для разрешающей способности при опознавании, составления отчетов по регулированию и бизнес-процессов на основе искусственного интеллекта и вовлечения клиентов.

Методы приема данных определяются используемым коннектором для приема данных. Некоторые коннекторы предлагают разные методы приема, в то время как другие работают только в пакетном или потоковом режиме. См. Data 360: Интеграции и коннекторы для полного списка коннекторов Data 360 и их доступных методов.
- Real-Time
- Подвторный прием с использованием потоковых конвейеров или сбора данных об изменении (CDC).
- Лучше всего подходит для бизнес-правил, чувствительных к времени (обнаружение мошенничества, персонализация, операционные панели мониторинга).
- Внедрите трансформации и агрегации в Data 360 для уменьшения ввода-вывода и оптимизации использования вычислений. Используйте инкрементный CDC для минимизации перетасовки данных.
- Streaming
- Принимать каждые 1–3 минуты с небольшим шагом.
- Балансирует свежесть и стоимость, подходит для оркестрации кампании, оперативной занятости и оперативной отчетности.
- Используйте микропакеты для управления скачками ввода-вывода. Агрегируйте данные в источнике, если возможно, чтобы сократить объемы передачи и оптимизировать хранилище.
- Пакет (запланированные загрузки)
- Периодический прием больших наборов данных (ежечасно, ежедневно, еженедельно).
- Экономичные и надежные для архивных наборов данных, отчетов по регламентам и сценариев использования соответствия.
- Обеспечьте вычисление местности в одном регионе с исходным хранилищем для повышения производительности и оптимизации затрат.
- Использование сценариев для приема данных
- Создание объединенных профилей Customer 360: Создание единого источника истины для идентификации клиента и атрибутов.
- Обслуживание наборов данных о соответствии нормативным требованиям: Внедрение управления, родословной и аудита конфиденциальных данных.
- Централизованная оркестрация кампаний: Обеспечение функционирования маркетинга, продаж и обслуживания на основе последовательных надежных наборов данных.
- Практика проектирования
- Рекомендуем принимать пакетно для архивных или низколатентных нужд, например, для составления архивных отчетов или периодических снимков.
- Используйте CDC или потоковые API для поддержки обновления операционных и персональных бизнес-правил, обеспечивая обновления в близком к реальному режиме времени.
- Управление хранилищем и вычисление роста посредством применения дополнительных нагрузок, а не перегрузки целых наборов данных, для оптимизации затрат и эффективности.
- Выравнивание ожидаемых приемов с вычислением местности и инкрементной обработки для уменьшения ввода-вывода сети. Примените трансформации внутри Data 360, чтобы избежать ненужного перемещения исходных данных.
- Рекомендации по затратам
- Прием в реальном времени: Самые высокие затраты на компьютеры и ожидаемые продажи; оправдано для ценных, срочных бизнес-процессов, например, персонализация, операционные панели мониторинга или действия под управлением Agentforce.
- Потоковое принятие: Умерьте затраты на компьютер и хранение; подходит для частых обновлений, которые могут перенести небольшие задержки, например, оркестрация кампании или оперативная отчетность.
- Пакетное принятие: Низкая стоимость вычисления, предсказуемое хранилище; лучше для архивных наборов данных или низкочастотных обновлений. Прием пакетных данных из организаций Salesforce посредством определенных коннекторов бесплатен.
- Режим обновления: Выбор режима «Инкрементное обновление» уменьшает общий прием и вычисление расходов. Рекомендуем использовать инкрементное обновление при любой возможности для оптимизации эффективности во всех типах приема.
- На стоимость также влияет объем ввода-вывода от источника к Data 360. Оптимизация размеров пакетов, разделов и регионального выравнивания уменьшает расходы на перемещение и повышает производительность.
- Сценарии отрасли
- Финансы: Примите наборы данных, обязательные для получения сведений о клиенте (KYC), борьбе с отмыванием денег (AML) и обнаружении мошенничества, где проверяемость и соответствие не подлежат обсуждению.
- Здравоохранение: Используйте прием для разрешающей способности при опознавании пациента и записей, соответствующих HIPAA, включив безопасные объединенные представления.
- Розница: Консолидация данных точек продаж (POS), eCommerce и программы лояльности в объединенные профили для сегментации и персонализации
- Телекоммуникации: Поддержка аналитики по предотвращению оттока и использованию с помощью канонических управляемых данных подписчика.
| Функция | Прием в реальном времени | Потоковое принятие | Пакетное принятие |
|---|---|---|---|
| Задержка и свежесть | Подсекундная задержка приема посредством API принятия с поддержкой сбора данных об изменении (CDC). Предоставляет непрерывные потоковые ожидаемые продажи. Лучше для сценариев оперативного использования с низкой задержкой. | Микропакетный прием каждые 1–3 минуты посредством собственных коннекторов. Поддерживает инкрементные обновления. Ожидается небольшая задержка. | Ожидается задержка данных. Запланированные массовые загрузки. Периодический прием (ежечасно, ежедневно, еженедельно). Не подходит для срочных операций. |
| Сценарии основного использования | Идеально подходит для сценариев использования операций с низкой задержкой и персонализации. Используется для бизнес-правил, чувствительных к времени. Поддерживает бизнес-процессы под управлением событий. Используются для предупреждений о мошенничестве и оперативных предупреждений в реальном времени. | Подходит для умеренно срочных процессов. Используются для оркестрации кампаний, взаимодействия в близком к реальному режиме и составления оперативных отчетов. Используется для своевременных триггеров кампании. | Экономичность для массивных наборов данных. Надежно для архивной аналитики. Используются для архивного агрегирования или регламентированных бизнес-правил отчетности. Лучше для архивных или низкоскоростных наборов данных. |
| Архитектурная сложность и ввод-вывод | Высокая стоимость и сложная архитектура. Требуются исходные системы с низкой задержкой. Интенсивный ввод-вывод. Массовые источники могут стать причиной насыщения трубопроводов. | Более простая архитектура, чем в реальном времени. Ввод-вывод умеренный. Лучше для предсказуемых повторяющихся схем обновления. Размер пакета влияет на память/вычисления. | Простота внедрения. Интенсивный ввод-вывод во время окон загрузки. Пропускная способность сети может стать препятствием для больших пакетов. |
| Рекомендации по затратам | Самые высокие затраты на вычисления и ожидаемые продажи. Оправдано только для ценных, срочных бизнес-правил. | Модерирование затрат на вычисления и хранение. Предоставляет сбалансированный подход стоимости и свежести. Подходит для частых обновлений, которые могут переносить небольшие задержки. | Низкая стоимость вычисления и предсказуемое хранилище. Рекомендуется для архивных наборов данных или низкочастотных обновлений. Прием через внутренние конвейеры Salesforce бесплатный. |
| Практика проектирования | Используйте инкрементный CDC для минимизации перетасовки данных. Фильтруйте и используйте выборочные поля для уменьшения накладных расходов. | Используйте микропакеты для управления скачками ввода-вывода. Рекомендуем использовать агрегацию окон для уменьшения загрузки обработки. | Рекомендуем использовать данный параметр для составления архивных отчетов или периодических снимков. Обеспечьте вычисление местности в одном регионе с исходным хранилищем для оптимизации затрат. |
Используйте Zero Copy для запросов внешних систем в реальном времени без дублирования данных, обеспечивая гибкость, свежесть и масштабируемый доступ к большим или временным наборам данных. Он лучше подходит для оперативных панелей мониторинга, аналитики, обучения модели на основе искусственного интеллекта/ML и взаимодействия с клиентами в реальном времени напрямую посредством Salesforce Data 360.
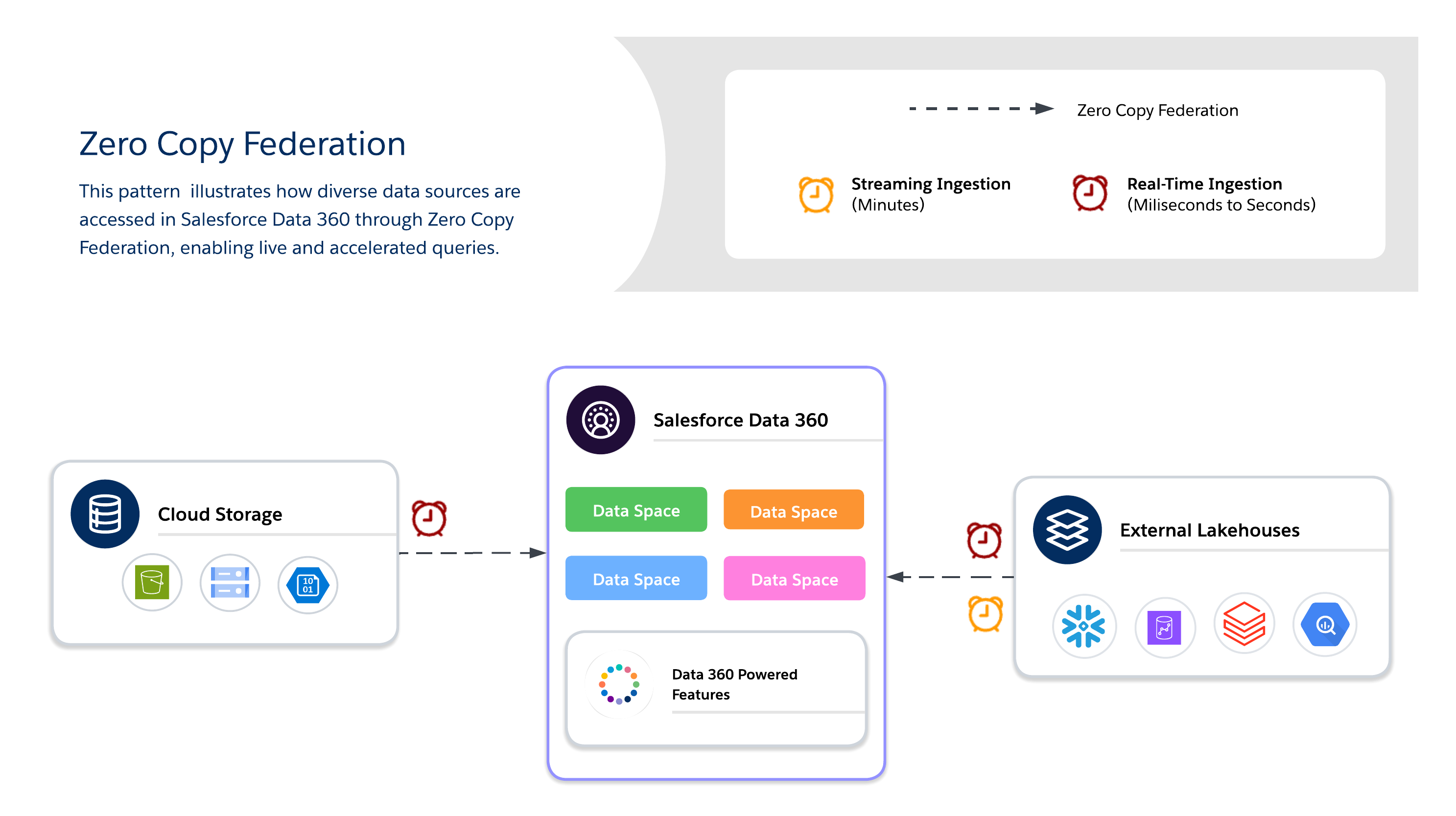
При использовании Zero Copy архитекторы должны также решить между тремя доступными методами интегрирования данных, каждый из которых предлагает собственные преимущества между свежестью, производительностью и стоимостью.
- Живой запрос
- Выполняет запросы напрямую к внешним системам (Snowflake, Google BigQuery, Redshift, Databricks и т. д.) без дублирования данных.
- Оптимально, когда предикаты и агрегации могут быть перенесены вниз, минимизируя перемещение данных по сети и уменьшая ввод-вывод в вычислении Salesforce Data 360.
- Лучше подходит для важных данных в реальном времени и операционных панелей мониторинга с низкой задержкой. Зависит от производительности внешней системы.
- Кэширование (ускоренный запрос)
- Временно сохраняет кэшированные копии федеративных данных в Salesforce Data 360.
- Уменьшает повторные затраты на запрос и задержку для часто используемых наборов данных с настраиваемой продолжительностью (от минут до дней).
- Данные не подлежат постоянному копированию или полному управлению; обновление управляется посредством запланированных обновлений из источника.
- Интеграция файлов
- Предоставляет прямой доступ только для чтения к крупномасштабным наборам данных в магазинах объектов (например, S3, GCS с айсбергом).
- Лучше подходит для загруженности искусственным интеллектом/ML, архивной аналитики и составления отчетов в петабайтном масштабе без перемещения данных.
- Производительность запроса сильно зависит от формата объекта, разделения и ввода-вывода сети. Крупное сканирование может создать существенный ввод-вывод, если не оптимизировать.
- Использование сценариев
- Персонализация в реальном времени и адаптивные бизнес-правила: Предоставьте динамические предложения, рекомендации и действия следующего качества при изменении поведения клиента.
- Оперативные панели мониторинга и оперативная аналитика: Электропитание важных для бизнеса панелей мониторинга и КПЭ напрямую из внешних складов.
- Обучение модели на основе искусственного интеллекта/ML с большими внешними наборами данных: Использование данных в петабайтном масштабе из озер данных и складов посредством интеграции файлов без их перемещения.
- Сценарии отрасли
- Retail/Media: Включите персонализированные рекомендации и вовлечение клиентов в реальном времени, настроив кликстрим или данные взаимодействия содержимого.
- Финансы: Выполните обнаружение мошенничества и рискуйте оценить в близком к реальному режиме времени, запросив внешние склады, не дублируя конфиденциальные данные.
- Техника/предприятие: Поддержка межоблачных отчетов, панелей мониторинга ИТ-служб и операционной аналитики, где наборы данных находятся в нескольких системах.
- Практика проектирования
- Живой запрос
- Рекомендуем использовать для запросов с высоким QPS и низкой задержкой при критической свежести.
- Внедрение предикатов и агрегаций во внешнюю систему для уменьшения перетасовки данных по сети.
- Избегайте запросов, которые без необходимости сканируют массивы данных; рекомендуем обрезать разделы и фильтровать.
- Интеграция файлов
- Доступ к наборам данных в петабайтном масштабе в магазинах объектов без приема.
- Хранилище объектов в той же облачной области, что и компьютер Salesforce, чтобы минимизировать затраты на задержку и выход.
- Используйте разделенные, столбчатые форматы (Parquet/ORC) и раскрывающиеся фильтры для уменьшения ввода-вывода и передачи сети.
- Используйте всплывающее окно запроса и предиката для фильтрации и агрегации данных в источнике, уменьшая перемещение данных.
- Избегайте межрегионального доступа к данным без необходимости, поскольку это увеличивает ввод-вывод, задержку и затраты.
- Кэширование (ускоренный запрос)
- Кэшируйте часто используемые наборы данных для баланса стоимости и производительности.
- Настройте интервалы обновления для баланса свежести и стоимости запроса.
- Соответствие: Внедрение управления в источнике посредством использования безопасности строки (RLS) и маскировки политик напрямую в федеративных системах. Ниже указаны рекомендации по единообразному RLS и маскировке на платформах.
- Использование централизованного кода предприятия: Соотнесите пользователей и объекты в Salesforce Data 360 с уникальным централизованным идентификатором предприятия, соответствующим удостоверениям во внешних системах.
- Согласование политик безопасности: Обеспечьте применение политик безопасности строки и маскировки в федеративных системах на основе соотнесенного удостоверения. Это сохраняет соответствие при запросе внешних данных.
- Стандартизация схем удостоверений: Поддерживайте последовательные атрибуты удостоверений (электронная почта, код пользователя, код клиента и т. д.) во всех источниках данных во избежание несоответствий и нарушений доступа.
- Живой запрос
- Рекомендации по затратам
- Живой запрос: Модель оплаты за запрос — стоимость накапливается на вычислениях внешнего озера и может резко возрасти при высоком QPS. Лучше всего подходит для сценариев использования, важных для свежести, где значение больше переменной стоимости.
- Ускоренный запрос (кеширование): Снижает стоимость запроса по сравнению с оперативным запросом, уменьшая обращения к исходной системе, но увеличивает расходы на пакетный прием данных для заполнения и обновления кэша. Лучше для часто используемых наборов данных.
- Интеграция файлов: Самый дешевый вариант хранилища данных в Object Store, но стоимость запроса зависит от размера файла, разделения и обрезки. Лучше для архивных или пакетных данных в петабайтном масштабе.
| Момент принятия решения | Live Query | Кэширование (ускоренный запрос) | Интеграция файлов |
|---|---|---|---|
| Расположение источника данных | Внешние базы данных Lakehouses (Snowflake, Google BigQuery, Redshift, Databricks). | Внешние базы данных Lakehouses (Snowflake, Google BigQuery, Redshift, Databricks) | Объектные хранилища или облачные озера данных (S3, ADLS, GCS), часто использующие открытые форматы таблиц, например, «Айсберг». |
| Цель/Использование | идеально подходит для интерактивного анализа и панелей мониторинга в реальном времени. Лучше подходит для персонализации в реальном времени и динамических бизнес-правил. | Лучше для тех случаев, когда запросы частые, но слегка устаревшие результаты приемлемы. Подходит для панелей мониторинга BI и сегментации. | Лучше подходит для масштабной пакетной обработки и обучения модели на основе искусственного интеллекта/ML. идеально подходит для архивной аналитики и составления отчетов в петабайтном масштабе. |
| Свежесть/задержка | Максимальная свежесть; запросы выполняются напрямую в режиме реального времени. Поддерживает подвторое решение. | Немного черствые результаты приемлемы. Свежесть зависит от интервала кэширования, настраиваемого от 15 минут до 7 дней. | Оптимизировано для пакетных, интенсивных заданий. Не подходит для панели мониторинга в реальном времени. |
| Схема доступа | Лучше для нечастых или разовых запросов. Используйте для запросов с высоким QPS (запрос в секунду) и низким уровнем задержки, где свежесть является критической. | Лучше подходит для сценариев высокочастотного чтения. Повышает производительность для схем частого доступа. | Доступ только для чтения. Подходит для наборов данных в петабайтном масштабе без приема. |
| Движущие факторы производительности | Сильно зависит от производительности внешней исходной системы. Оптимизировано, когда предикаты и агрегации могут быть перенесены в источник. | Уменьшает задержку по сравнению с повторяющимися оперативными запросами. Производительность зависит от управления кэшем и интервала. | Производительность сильно зависит от формата объекта, разделения и производительности внешней системы. Используйте разделенные, столбчатые форматы (Паркет/ORC). |
| Затратные последствия | Модель оплаты за запрос. Расходы накапливаются при вычислении внешнего озера. Экономично для нечастых запросов, но расходы могут увеличиться при высоком объеме запроса в секунду (QPS). | Низкая стоимость по сравнению с повторяющимися оперативными запросами. Уменьшает необходимость многократного запроса внешнего источника. Добавляет хранилище кэша и обновление над головой. | Самый дешевый вариант хранения. Стоимость запроса зависит от размера файла и разделения. |
| Ключевое соображение | Избегайте нефильтрованных запросов, которые без необходимости сканируют массивы данных. | Требует управления кэшем. Не подходит для подсекундного решения. | Производительность запроса во многом зависит от оптимизации посредством разделения и вытеснения предиката. |
Гибридная архитектура позволяет архитекторам закреплять критические наборы данных в Data 360 для централизованного управления, используя интегрированные запросы для свежести, уменьшения дублирования и масштабируемого доступа к большим внешним наборам данных. Этот метод балансирует требования ввода-вывода, вычисления местности, стоимости и соответствия.
Используйте гибридный подход для сбалансированного управления, свежести и операционной эффективности, сочетая прием данных и нулевое копирование для предоставления в реальном времени действенных важных данных. Используйте прием для ценных, регулируемых наборов данных, где требуется отслеживаемость, RLS и маскировка, и интегрирование для эфемерных или массовых наборов данных, где ключевое значение имеют свежесть и производительность.
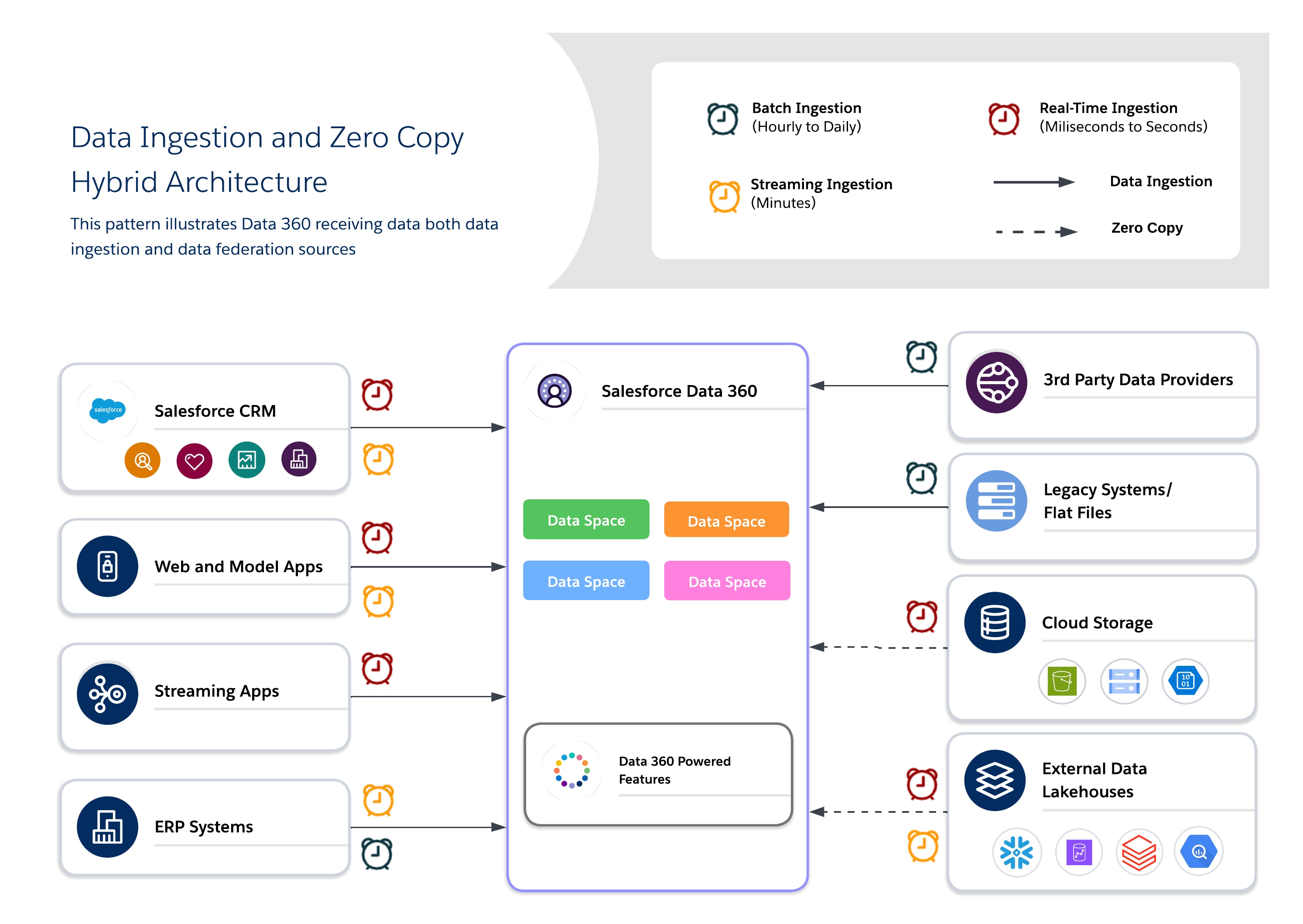
- Использование сценариев
- Занятость мультиканала: Смешайте архивные данные клиентов с поведением в реальном времени, чтобы предоставить последовательные контекстные взаимодействия.
- Конвейеры искусственного интеллекта/ML: Обучите модели на курируемых канонических наборах данных, пополняя их исходными сигналами из внешних источников или в режиме реального времени.
- Смешанные требования соответствия и гибкости: Примените строгое управление к конфиденциальным данным, но федеративное для оперативной гибкости.
- Сценарии отрасли
- Розница: Используйте прием для разрешающей способности при опознавании и объединения профиля; объединяйте для предложений в реальном времени и персонализации.
- Здравоохранение: Сохраняйте золотые записи пациентов посредством приема, создавая потоки устройств IoT и данные сенсоров для немедленного контекста.
- Финансовые услуги: Примите регулируемые данные в озеро, управляемое соответствием, создавая внешние запросы для обнаружения мошенничества и мониторинга рисков.
- Практика проектирования
- Управление привязкой посредством принятия: Принимать ценные или регулируемые данные в канонические модели для обеспечения Trust и соответствия.
- Использование Federation for Freshness: Предоставьте внешним озерным станциям доступ к данным в режиме реального времени или в больших масштабах без дублирования.
- Баланс стоимости и Производительность: Профилируйте загруженность, чтобы решить, что принимать по сравнению с федеративными, минимизируя ненужные затраты на хранение или запрос.
- Применить многоуровневое управление: Внедрите централизованное управление для принимаемых данных, используя собственные средства контроля безопасности федеративных систем (например, RLS, маскировка).
- При создании гибридных ожидаемых продаж обеспечьте инкрементный прием для архивных наборов данных и форсирование агрегаций или фильтров в интегрированных источниках для оптимизации ввода-вывода и вычисления использования.
- Рекомендации по затратам
- Оптимизируйте общую стоимость по сравнению с производительностью, объединяя прием для соответствия или критических данных с интегрированием, когда необходимо свежесть.
- Учитывайте ввод-вывод и вычисляйте распределение при смешивании приема и интегрирования. Чтобы сократить стоимость вычисления в исходных системах повторяющихся запросов, используйте кэширование (Ускоренный запрос) для высококачественных, часто доступных интегрированных наборов данных.
Ниже указаны распространенные архетипы, иллюстрирующие способ применения этой логики.
- Архетип "Единый источник истины": Централизация и управление
- Сценарий: Вам нужно создать совместимые, объединенные профили Customer 360 для всего вашего глобального предприятия. Данные поступают из десятка разных систем, должны соответствовать строгим регламентам GDPR и CCPA и служить надежным источником для всех маркетинговых и сервисных взаимодействий.
- Рекомендуемая схема: Прием данных. Приоритет - управление, Trust и контроль. Прием данных в Data 360 - это единственный способ создания полностью проверяемого канонического профиля, изолированного от исходных систем.
- Архетип "Важные данные в реальном времени": Анализ без перемещения
- Сценарий: Вашей группе, работающей с данными, нужно выполнить поисковые запросы в массивной, постоянно обновляемой таблице транзакций в Snowflake. В то же время, ваша рабочая группа хочет, чтобы оперативная панель мониторинга BI работала на тех же данных. Ежедневное перемещение петабайт данных слишком медленное и дорогое.
- Рекомендуемая схема: Zero Copy Federation. Приоритет - скорость, гибкость и эффективность затрат в масштабах. Zero Copy позволяет использовать огромные возможности существующего хранилища данных для запросов в реальном времени без накладок и задержек дублирования данных.
- Архетип "Гибридный интеллект": Управление ядром, объединение края
- Сценарий: Вы хотите пополнить управляемые, принимаемые профили клиентов поведенческими сигналами в реальном времени (например, нажатием на веб-сайт) из озера данных. Вам нужна стабильность базового профиля, но немедленность оперативных данных для мгновенной персонализации.
- Рекомендуемая схема: Гибридный подход. Используйте принятие данных для создания стабильного управляемого ядра данных клиентов. Потом используйте Zero Copy для создания изменчивых «краевых» данных в реальном времени, присоединяясь к ним во время запроса для полного и актуального представления.
Стратегия корпоративных данных больше не предполагает выбор единой схемы интеграции — это создание управляемой гибкости в рамках совместимой экосистемы данных. Выбор правильного метода интеграции данных для каждой исходной системы данных на основе бизнес-потребностей часто приводит к гибридному подходу, сочетающему сильные стороны как приема данных, так и интегрирования данных.:
- Примите важные управляемые наборы данных в Salesforce Data 360 для соответствия, разрешающей способности при опознавании и операционных бизнес-правил.
- Объединяйте данные посредством Zero Copy для оперативной, поисковой аналитики и аналитики на основе искусственного интеллекта, не дублируя хранилище.
Salesforce Data 360 в Hyperforce предоставляет многорегиональную устойчивость и масштабируемость. Открытый Lakehouse с таблицами айсбергов позволяет вычислять разделение и совместимость с такими платформами, как Snowflake, Databricks и S3 Iceberg, создавая основу подлинно совместимой экосистемы данных с несколькими облачными приложениями.
По мере развития экосистем данных постоянно балансируйте между свежестью, стоимостью, производительностью и соответствием, чтобы поддерживать гибкость архитектуры. Защитите платформу от будущего, объединив принятые управляемые данные с интегрированным доступом. Это включает интеллект в реальном времени, активацию искусственного интеллекта и персонализацию предприятия в облаках, регионах и бизнес-доменах.
Универсальные решения не подходят большинству предприятий. Оптимальная стратегия соотносит правильную схему с соответствующим бизнес-драйвером.
Югандхар Бора является архитектором программного обеспечения в Salesforce, специализируется на архитектуре данных в платформе приложений Data & Intelligence. Он руководит инициативами совета по проверке архитектуры предприятия (EARB), сосредоточенными на управлении данными и объединенных моделях данных, одновременно внося вклад в автоматизированные решения инициализации платформы.
Ян Фернандо является главным архитектором в офисе главного архитектора Salesforce. Он пришел в Salesforce в 2012 году, привнеся богатый опыт работы в экосистеме стартапов. До прихода в офис главного архитектора он провел более десяти лет в организации Platform, где руководил несколькими ключевыми технологическими преобразованиями.