Moderne Salesforce-integraties moeten veel meer ondersteunen dan alleen gegevensuitwisseling. Van hen wordt verwacht dat ze realtime klantervaringen aansturen, acties binnen meerdere systemen coördineren en betrouwbaar werken op ondernemingsniveau—alles terwijl ze voldoen aan strenge beveiligings- en nalevingsvereisten. Het kiezen van de juiste integratiebenadering is daarom een kritische architectonische beslissing, geen implementatiedetail. Overweeg een veelvoorkomend ondernemingsscenario. Een klant voltooit een aankoop in een mobiele app en activeert via een trigger een realtime aanspraakcontrole voor een gepersonaliseerde aanbieding. Tegelijkertijd moeten transactiegegevens worden vastgelegd in een ERP-systeem, moeten klantkenmerken worden bijgewerkt in Salesforce en moeten analyses worden gestreamd naar een gegevens-lake—zonder latentie, gegevensduplicatie of nalevingsrisico te introduceren. Scenario's zoals deze zijn nu typisch in moderne Salesforce-omgevingen, waar Salesforce zelden geïsoleerd werkt en naadloos moet worden geïntegreerd met een breder ecosysteem van toepassingen en gegevensplatforms. Deze handleiding is bedoeld om architecten en ontwikkelaars te helpen deze integraties met duidelijkheid en vertrouwen te ontwerpen. In plaats van zich te richten op punt-naar-punt implementaties, biedt het een set bewezen integratiepatronen die betrekking hebben op terugkerende ondernemingsscenario's, zoals procescombinatie, gegevenssynchronisatie en realtime gegevenstoegang. Elk patroon legt de nadruk op architectonische intent, trade-offs en uitvoeringsmodellen, waardoor teams weloverwogen ontwerpbeslissingen kunnen nemen die schaalbaar en duurzaam zijn. In dit document vindt u:
- Integratiepatronen die veelvoorkomende ondernemings“archetypen” vertegenwoordigen voor proces-, gegevens- en virtuele-toegangsscenario's
- Een framework voor patroonselectie om de juiste aanpak te identificeren op basis van integratie-intent en uitvoeringstiming
- Praktische richtlijnen voor schaalbaarheid, veerkracht, governance en beveiligingsoverwegingen
- Best practices uit Salesforce- en Data 360-implementaties uit de praktijk Het doel van dit document is om een gedeelde architectuurtaal voor integratie te bieden, die teams helpt oplossingen te ontwerpen die prestaties, flexibiliteit en Trust in balans brengen en tegelijkertijd overeenkomen met ondernemingsgegevens en governance-strategieën.
Dit document is bedoeld voor ontwerpers en architecten die gegevens uit andere toepassingen in hun onderneming moeten integreren met Salesforce Data 360 (voorheen Data Cloud). Deze inhoud is een distillatie van vele succesvolle implementaties door Salesforce-architecten en -partners. Als u vertrouwd wilt raken met integratiemogelijkheden en opties die beschikbaar zijn voor grootschalige toepassing van Data 360, leest u de secties Patroonsamenvatting en Patroonselectiehandleiding hieronder. Architecten en ontwikkelaars moeten rekening houden met deze patroondetails en best practices tijdens de ontwerp- en implementatiefase van gegevensinteractieprojecten in Data 360. Als deze patronen op de juiste manier worden geïmplementeerd, kunt u zo snel mogelijk naar productie gaan en beschikt u over de meest stabiele, schaalbare en onderhoudsvrije set toepassingen. De eigen consultingarchitecten van Salesforce gebruiken deze patronen als referentiepunten tijdens architectuurbeoordelingen en onderhouden en verbeteren ze actief. Zoals bij alle patronen omvat deze inhoud de meeste integratiescenario's, maar niet alle. Hoewel Salesforce integratie van de gebruikersinterface (UI) toestaat, vallen mashups bijvoorbeeld buiten het bereik van dit document.
Elk integratiepatroon volgt een consistente structuur. Dit biedt consistentie in de informatie die in elk patroon wordt gegeven en maakt het ook gemakkelijker om patronen te vergelijken.
- Naam: De patroonidentifier die ook het type integratie aangeeft dat in het patroon is opgenomen.
- Context: Het algemene integratiescenario waarop het patroon betrekking heeft. Context geeft informatie over wat gebruikers proberen te bereiken en hoe de toepassing werkt om aan de vereisten te voldoen.
- Probleem: Uitgedrukt als een vraag is dit het scenario dat het patroon moet oplossen. Lees deze sectie om te begrijpen of het patroon geschikt is voor uw integratiescenario.
- Krachten: De beperkingen en omstandigheden die het opgegeven scenario moeilijk op te lossen maken.
- Oplossing: De aanbevolen manier om het integratiescenario op te lossen.
- Schets: Een UML-volgordediagram dat toont hoe de oplossing het scenario aanpakt.
- Resultaten: Legt de details uit van de manier waarop u de oplossing toepast op uw integratiescenario en hoe deze de krachten oplost die aan dat scenario zijn gekoppeld. Deze sectie bevat ook nieuwe uitdagingen die kunnen ontstaan als gevolg van het toepassen van het patroon.
- Sidebars: Aanvullende secties gerelateerd aan het patroon die belangrijke technische problemen, variaties van het patroon, patroonspecifieke problemen, enzovoort bevatten.
- Voorbeeld: Een scenario uit de echte wereld waarin wordt beschreven hoe het ontwerppatroon wordt gebruikt in een Salesforce-scenario uit de echte wereld. In het voorbeeld worden de integratiedoelen uitgelegd en wordt uitgelegd hoe u het patroon implementeert om die doelen te bereiken.
Gebruik deze tabel als inhoudsopgave voor de integratiepatronen in dit document.
| Patroonniveau1 | Patroonniveau2 | Patroon | Secenario |
|---|---|---|---|
| Gegevensopnamepatronen--Inkomende gegevens | Batchgewijze opnamepatronen | Bulkgegevensopname vanuit Cloud Storage | Gegevens worden opgenomen vanuit een Enterprise Cloud-opslagbron zoals Amazon S3, Azure Blob of Google Cloud Storage in Data 360 in de vorm van grote batches ruwe gegevens (bijv. transacties of productlogboeken). |
| Bulkgegevensopname vanuit Salesforce Clouds | Data 360 ontvangt CRM-gegevens in bulk uit meerdere Salesforce-organisaties (bijvoorbeeld Sales Cloud, Service Cloud) om gecombineerde klantprofielen samen te stellen. | ||
| Streaming en realtime opnamepatronen | Eventgestuurde opname via opname-API--Streaming | Data 360 abonneert zich op streaming opname-eindpunten die continue eventpayloads (bijv. aankoopevents, IoT-telemetrie) van ondernemingssystemen ontvangen voor realtime profielupdates. | |
| Realtime opname van web en mobiel gedrag | Data 360 verzamelt en verwerkt realtime gedragsgegevens van websites en mobiele apps via SDK's om betrokkenheidsmeetgegevens en personalisatiemodellen te verrijken. | ||
| Vrijwel realtime CRM-synchronisatie via streaming | Data 360 ontvangt CRM-gegevensupdates (bijv. contactpersoon, case, opportunitywijzigingen) in nearReal-Time via eventstromen om een continu gesynchroniseerde Customer 360 weergave te behouden. | ||
| Opname van eventstromen vanuit Cloud Berichtenplatforms--Kinesis en MSK | Data 360 verbruikt streaminggegevens rechtstreeks van cloudeventplatforms zoals AWS Kinesis of Kafka (MSK) om hoogfrequente operationele of IoT-events te verwerken. | ||
| Nul kopieerpatronen--Inkomend en uitgaand | Inkomende nulkopie--Externe platforms naar Data 360 | Data 360 voert op verzoek een query uit op externe gegevenssets (bijv. Snowflake, BigQuery) via Zero Copy-opname, zonder gegevens fysiek naar Salesforce te verplaatsen. | |
| Uitgaande nulkopie--Data 360 naar externe platforms | Externe systemen zoals Databricks of Tableau hebben toegang tot verrijkte segmenten en insights in Data 360 via uitgaande nulkopieverbindingen zonder gegevensreplicatie. | ||
| Gecombineerd gegevensplatform voor meerdere organisaties met Data Cloud One | Data Cloud One verenigt meerdere Salesforce-organisaties en externe gegevensbronnen onder een gedeeld metagegevens- en semantisch model, waardoor een consistente Customer 360 zonder gegevensduplicatie ontstaat. | ||
| Gegevensactiveringspatronen--Gegevens uitgaand | Batchactiveringspatronen | Segmentactivering naar marketing- en advertentieplatforms | Data 360 activeert beheerde klantsegmenten rechtstreeks in Marketing Cloud, Meta, Google Ads of andere advertentieplatforms voor gepersonaliseerde campagnelevering |
| Gegevens exporteren naar cloudopslag | Data 360 exporteert gecombineerde of gefilterde gegevenssets (bijv. goedgekeurde klantrecords) als CSV- of parketbestanden naar Enterprise Cloud-opslag voor analyse of archivering van naleving. | ||
| Op aanvraag API-gebaseerde activering | Integratie van aangepaste toepassingen via Connect-API | Externe toepassingen roepen de Data 360 Connect-API in realtime aan om gepersonaliseerde acties op te halen of te activeren (bijvoorbeeld controle van loyaliteitssaldo of genereren van AI-aanbod) op basis van huidige klantgegevens.Op maat gemaakte web- of mobiele toepassingen halen geharmoniseerde Data 360-insights veilig op via de Connect REST-API om weer te geven binnen UI's van ondernemingen of partners. | |
| Ophalen van klantprofiel voltooien via Data Graph API | Een systeem haalt het gecombineerde profiel van een klant op met behulp van de Data Graph API, waarbij een vooraf samengevoegde, real-time JSON-weergave van de volledige 360°-weergave wordt geretourneerd voor besluitvorming of personalisering. | ||
| Realtime gegevensacties | Realtime gegevensactie Klantsignalen omzetten in onmiddellijke actie | Data 360 detecteert en verwerkt een live event (bijv. instemmingsupdate, aankooptrigger) en roept onmiddellijk een verbonden systeem of Salesforce-stroom aan voor actie verderop in de stroom.Een signaal van een klantactiviteit (bijv. verlooprisico gedetecteerd) in Data 360 activeert een onmiddellijke real-time actie, zoals het bijwerken van CRM, Einstein Scores aanroepen of een retentietraject starten. |
De integratiepatronen in dit document zijn ingedeeld in drie categorieën: gegevens, proces en visuele integraties.
Gegevensintegratiepatronen in Data 360 hebben betrekking op de verplaatsing en synchronisatie van gegevens tussen systemen om ervoor te zorgen dat zowel Data 360 als externe platforms consistente, tijdige en betrouwbare informatie bevatten. Deze patronen verwerken doorgaans grootschalige gegevensstromen met groot volume en vertrouwen op beheerde pijplijnen die schemaconsistentie, tracering van afstamming en hoofdregels afdwingen.
- Batchopnamepatronen vertegenwoordigen de basislaag van onboarding van ondernemingsgegevens. Met bulkgegevensopname vanuit cloudopslagservices zoals AWS S3, Azure Blob of Google Cloud Storage kunnen grote historische gegevenssets periodiek in Data 360 worden geladen voor identiteitsoplossing, segmentering en analyses. Op soortgelijke wijze gebruikt bulkopname vanuit Salesforce Clouds, zoals Sales, Service of Marketing Cloud, native connectoren en gegevensstromen om CRM-gegevens in de gecombineerde gegevenslaag te brengen, wat harmonisering en continuïteit tussen systemen van betrokkenheid garandeert.
- Streaming en realtime opnamepatronen breiden dit uit door eventgegevens met hoge snelheid vast te leggen. Eventgestuurde opname via de opname-API maakt het voor externe systemen mogelijk om continu klantactiviteit te streamen naar Data 360. Realtime opname van web- en mobiel gedrag legt klikstroom- en interactiegegevens rechtstreeks vanaf digitale aanspreekpunten vast om directe personalisatie te stimuleren. Bijna-realtime CRM-synchronisatie via Streaming-API's zorgt ervoor dat klantkenmerken en instemmingsupdates snel worden weergegeven in alle systemen. Opname van eventstromen vanuit berichtenverkeersplatforms zoals Amazon Kinesis of Confluent MSK ondersteunt continue pijplijnen met hoge doorvoer, waardoor Data 360 wordt afgestemd op eventarchitecturen voor de onderneming.
- Unified Multi-Org Data Platform with Data Cloud One is een voorbeeld van gegevensintegratie en biedt een geconsolideerde omgeving om gegevens uit meerdere Salesforce-organisaties en externe bronnen te combineren onder een gemeenschappelijke governance- en semantische laag. Hierdoor kunnen organisaties consistentie van gegevens voor de hele onderneming, gedeelde gegevensmodellen en schaalbare analyses realiseren.
- In de activeringsfase volgen batchactiveringspatronen hetzelfde gegevensintegratieprincipe. Segmenten die zijn gemodereerd in Data 360, worden in geplande taken geëxporteerd naar marketing- en advertentieplatforms verderop in de stroom—zoals Marketing Cloud, Meta Ads of Google Ads—waar ze campagne-uitvoering activeren. Op soortgelijke wijze kunnen gegevenssets worden geëxporteerd naar cloudopslagdoelen om externe analyses en pijplijnen voor gegevenswetenschappen aan te wakkeren. In al deze gebruikscases fungeert Data 360 als de bron van waarheid voor gesynchroniseerde en beheerde klantgegevens.
Procesintegratiepatronen in Data 360 omvatten het activeren of orkestreren van bedrijfsprocessen binnen systemen in nearReal-Time. Met deze patronen kan Data 360 actief deelnemen aan ondernemingswerkstromen, waardoor contextuele reacties en dynamische gegevensactivering mogelijk worden.
- Op on-demand API gebaseerde activering maakt real-time betrokkenheidsscenario's mogelijk. Via de Connect-API kunnen aangepaste toepassingen rechtstreeks vanuit Data 360 query's uitvoeren op of klantprofielen activeren als onderdeel van operationele processen, zoals een agentconsole die gecombineerde profielinsights ophaalt tijdens een interactie met de klant. De API Klantprofiel ophalen via gegevensgrafiek ondersteunt samengestelde toepassingen en microservices die afhankelijk zijn van API-gestuurde toegang tot de volledige entiteitsgrafiek van een klant, waardoor dynamische omgevingen mogelijk zijn zonder vooraf gefaseerde segmenten.
- Realtime gegevensacties stimuleren deze integratiebenadering door onmiddellijke responsiviteit in te schakelen. Wanneer een klantsignaal—zoals een aankoop, formulierindiening of drempelwaarde-event—wordt gedetecteerd, kan Data 360 acties activeren zoals het bijwerken van een CRM-record, het aanroepen van een externe webhook of het starten van een werkstroom voor een gepersonaliseerde aanbieding. Deze patronen belichamen echte procescombinatie, waarbij real-time Klantenintelligence wordt verbonden met geautomatiseerde operationele uitvoering.
Virtuele integratiepatronen in Data 360 maken live toegang tot externe of gebundelde gegevensbronnen mogelijk zonder gegevens fysiek te kopiëren of dupliceren. Deze zijn van cruciaal belang voor ondernemingen die gecontroleerde, actuele informatie nodig hebben op het moment van de query en tegelijkertijd de gegevensverplaatsing minimaliseren.
- Met Inbound Zero Copy Data Federation (Externe platforms-naar-Data 360) kunnen externe systemen—zoals gegevensmagazijnen of gegevens-lakes—gegevenssets delen met Data 360 via beveiligde, beheerde verbindingen (bijvoorbeeld Snowflake Secure Data Sharing). Dit zorgt ervoor dat Data 360 virtuele toegang heeft tot en kan werken met externe gegevens, waardoor versheid wordt behouden en onnodige replicatie wordt voorkomen.
- Met Outbound Zero Copy Data Sharing (Data 360-naar-externe platforms) kan Data 360 beheerde gegevenssets beschikbaar stellen voor extern gebruik, zoals AI-modellering, bedrijfsintelligence of geavanceerde analyses, via beveiligde mechanismen voor gegevensbundeling en live query's. Het kiezen van de beste integratiestrategie voor uw systeem is niet triviaal. Er zijn vele aspecten om rekening mee te houden en vele tools die kunnen worden gebruikt, waarbij sommige tools geschikter zijn dan andere voor bepaalde taken. Elk patroon behandelt specifieke kritieke gebieden, waaronder de mogelijkheden van elk van de systemen, het volume van gegevens, de afhandeling van storingen en transactionaliteit.
Wanneer u een integratiepatroon selecteert, begint u met het beantwoorden van twee fundamentele vragen die het algemene ontwerp en de werking van de integratie bepalen. Wat integreert u? — Proces, Gegevens of Virtuele toegang Deze dimensie definieert het primaire doel van de integratie.
- Procesintegraties richten zich op het orkestreren van bedrijfswerkstromen en het coördineren van acties binnen systemen.
- Gegevensintegraties richten zich op het synchroniseren, verrijken of verspreiden van gegevens tussen systemen.
- Virtuele integraties richten zich op toegang tot externe gegevens in Realtime zonder deze te kopiëren of te bewaren in Salesforce of Data 360. Inzicht in deze intent helpt bij het bepalen van het niveau van doeltreffende combinatie, gegevensverplaatsing en koppeling tussen systemen.
- Hoe moet deze worden uitgevoerd? — Synchrone of asynchrone methode definieert het uitvoeringsmodel van de integratie.
- Synchrone integraties zijn real-time en blokkerend, waarbij de beller een onmiddellijke reactie verwacht—veelal gebruikt voor door de gebruiker gestuurde of validatiescenario's.
- Asynchrone integraties zijn niet-blokkerend en ontkoppeld, ontworpen voor het afhandelen van schaal, langlopende processen, opnieuw proberen en grote gegevensvolumes. Samen vormen deze twee dimensies – integratie-intent en uitvoeringstijdstip – een duidelijk, consistent raamwerk voor het selecteren van het juiste integratiepatroon, waarbij een evenwicht wordt gevonden tussen gebruikerservaring, schaalbaarheid en operationele veerkracht. Opmerking: Een integratie kan een externe middleware- of integratieoplossing (bijvoorbeeld Enterprise Service Bus) vereisen, afhankelijk van welke aspecten van toepassing zijn op uw integratiescenario.
Deze tabel vermeldt de patronen en hun belangrijkste aspecten om u te helpen bepalen welk patroon het beste aansluit op uw vereisten wanneer uw integratie plaatsvindt van Salesforce naar een ander systeem
| Type | Timing | Uitgaande overwegingen |
|---|---|---|
| Gegevensintegratie | Asynchronous | Segmentactivering naar marketing- en advertentieplatforms |
| Proces-/gegevensintegratie | Synchroon | Integratie van aangepaste toepassingen via Connect-API Ophalen van klantprofiel voltooien via Data Graph API |
| Gegevensintegratie | Synchroon | Realtime gegevensactie Klantsignalen omzetten in onmiddellijke actie |
| Virtuele integratie (met behulp van Zero Copy) | Asynchronous | Uitgaande nulkopie--Data 360 naar externe platforms |
| Virtuele integratie | Asynchronous | Gecombineerd gegevensplatform voor meerdere organisaties met Data Cloud One |
Deze tabel vermeldt de patronen en hun belangrijkste aspecten om u te helpen het patroon te bepalen dat het beste aansluit op uw vereisten wanneer uw integratie plaatsvindt vanuit een ander systeem naar Salesforce.
| Type | Timing | Inkomende overwegingen |
|---|---|---|
| Gegevensintegratie | Asynchronous | Bulkgegevensopname vanuit Cloud Storage Bulkgegevensopname vanuit Salesforce Clouds |
| Gegevensintegratie | Asynchronous | Opname van eventstromen vanuit Cloud Berichtenplatforms--Kinesis en MSK Vrijwel realtime CRM-synchronisatie via streaming |
| Procesintegratie | Synchroon | Eventgestuurde opname via opname-API--Streaming Realtime opname van web en mobiel gedrag |
| Virtuele integratie | Asynchronous | Inkomende nulkopie--Externe platforms naar Data 360 |
Deze tabel vermeldt enkele belangrijke termen die zijn gerelateerd aan middleware en hun definities met betrekking tot deze patronen.
| Term | Definitie |
|---|---|
| Afhandeling van events | Eventafhandeling verwijst naar het ontvangen, routeren en reageren op identificeerbare voorvallen vanuit een bronsysteem of toepassing. Middleware verwerkt events door het doeleindpunt te identificeren, de event door te sturen en de vereiste bedrijfsactie te activeren (bijvoorbeeld vastleggen, opnieuw proberen of downstream services activeren). In Data 360-architecturen is eventverwerking van cruciaal belang voor het opnemen van realtime gegevens, activeringstriggers en publicatie-/abonneerpatronen. Events kunnen afkomstig zijn van externe systemen (Kafka, AWS Kinesis) of Salesforce Platform-events en worden gerouteerd door middleware of de Data 360-eventbus voor onmiddellijke verwerking. |
| Protocolconversie | Protocolconversie maakt communicatie mogelijk tussen systemen die verschillende standaarden voor gegevenstransport gebruiken. Middleware vertaalt gepatenteerde of verouderde protocollen (zoals AMQP, MQTT, FTP) naar ondersteunde Data 360-protocollen (REST, gRPC of HTTPS). Dit garandeert interoperabiliteit tussen heterogene systemen. Aangezien Data 360 geen eigen protocolconversie afhandelt, biedt middleware de aanpassingslaag, die berichten inkapselt of transformeert in een indeling die Data 360-API's en -connectoren kunnen interpreteren. |
| Vertaling en transformatie | Vertaling en transformatie zorgen voor interoperabiliteit door de ene gegevensindeling of het ene schema toe te wijzen aan de andere. Middleware voert deze transformaties uit om diverse gegevenspayloads (CSV, XML, JSON) uit te lijnen met Data 360-gegevensmodelobjecten (DMO's) en gecombineerde gegevenslaagobjecten (UDLO's). Dit omvat het reinigen, verrijken en toepassen van semantische of op ontologie gebaseerde toewijzing vóór opname. Salesforce biedt transformatietools zoals Gegevensvoorbereiding-recepten, maar complexe transformaties (met name voor semantische harmonisering) kunnen het best worden afgehandeld in middleware. |
| Wachtrij en bufferen | Wachtrijen en bufferen vertrouwen op het doorgeven van asynchrone berichten om veerkrachtige, ontkoppelde communicatie te garanderen. Middlewareplatforms (bijvoorbeeld MuleSoft, Kafka of Azure Event Hub) bieden aanhoudende wachtrijen waarin gegevens tijdelijk worden opgeslagen wanneer Data 360 of downstreamsystemen bezet of onbereikbaar zijn. Dit voorkomt gegevensverlies en ondersteunt opname- of activeringspogingen in vrijwel realtime. Data 360 ondersteunt streamingopname en op stroom gebaseerd uitgaand berichtenverkeer, maar duurzame wachtrijen en gegarandeerde levering worden doorgaans afgehandeld door middleware. |
| Synchrone transportprotocollen | Synchrone transportprotocollen omvatten blokkering en realtime verzoek-/reactiebewerkingen. De afzender wacht op een antwoord voordat deze doorgaat. In Data 360 worden deze gebruikt voor op on-demand API gebaseerde activeringen, real-time verrijking of profielzoekopdrachten, waarbij onmiddellijk moet worden gereageerd. Middleware zorgt voor betrouwbaarheid van de verbinding en beheert nieuwe pogingen of reserveverwerking voor synchrone Data 360 API-aanroepen. |
| Asynchrone transportprotocollen | Asynchrone transportprotocollen ondersteunen niet-blokkerende, ontkoppelde communicatie waarbij de afzender doorgaat met de verwerking zonder te hoeven wachten op een reactie. Middleware verwerkt asynchrone stromen voor batchactiveringen, streamingopname en eventgestuurde activering. Dit maakt een hoge doorvoer en veerkracht mogelijk — essentieel voor eventstreaming en vrijwel realtime gegevensopnamepatronen in Data 360. |
| Routering voor bemiddeling | Bemiddelingsroutering definieert een complexe berichtenstroom tussen systemen en zorgt ervoor dat de juiste gegevens of events de juiste consument bereiken. Middleware treedt op als bemiddelaar en handelt routeringslogica af op basis van regels, kopteksten, inhoud of eventtype. In Data 360-integraties zorgt bemiddeling ervoor dat events en profielupdates van meerdere systemen op de juiste manier worden gerouteerd naar gegevensopname-API's, activeringseindpunten of externe consumenten. Dit vereenvoudigt doeltreffende combinatie en ondersteunt gegevenssynchronisatie voor meerdere systemen. |
| Proceschoreografie en servicecombinatie | Proceschoreografie en doeltreffende combinatie coördineren processen van meerdere systemen. Choreografie ondersteunt autonome, asynchrone eventgestuurde stromen, waarbij systemen werken op basis van gedeelde regels zonder een centrale controller. Orchestration is een centraal beheerde stroom die de uitvoering van de service stuurt. In Data 360-architecturen beheert middleware doeltreffende combinaties voor opname en activering binnen systemen, terwijl Salesforce-werkstromen of stromen lichtgewicht choreografieën afhandelen binnen het platform. Complexe doeltreffende combinatie, die transactiecoördinatie of statusbeheer vereist, wordt aanbevolen in de middlewarelaag. |
| Transactionaliteit (encryptie, ondertekening, betrouwbare levering, transactiebeheer) | Transactionaliteit garandeert atomaire, consistente, geïsoleerde en duurzame (ACID) bewerkingen binnen systemen. Salesforce en Data 360 zijn transactioneel binnen hun grenzen, maar ondersteunen geen gedistribueerde transacties binnen externe systemen. Middleware verwerkt globale transactiecontrole, inclusief encryptie, ondertekening van berichten, terugdraaien, compensatie en betrouwbare levering. Voor bedrijfskritieke gegevensstromen (bijvoorbeeld financiële updates of updates van instemming) zorgt middleware voor end-to-end integriteit en herstel binnen Data 360 en externe systemen. |
| Routering | Routering geeft de gecontroleerde stroom van berichten of gegevens tussen componenten aan. Dit kan zijn gebaseerd op kopteksten, inhoudstype, prioriteit of regels. Middleware verwerkt routeringslogica voor events en activeringen waarbij Data 360 betrokken is, zoals het omleiden van verrijkte doelgroepsegmenten naar verschillende downstream systemen (advertentieplatforms, magazijnen, CRM-apps). Hoewel routering kan worden geïmplementeerd binnen Salesforce (Apex, Stromen), heeft middlewareroutering de voorkeur vanwege schaalbaarheid, flexibiliteit en governance. |
| Extraheren, transformeren en laden (ETL) | ETL omvat het extraheren van gegevens uit bronsystemen, het transformeren ervan in een consistent schema en het laden ervan in een doel (zoals Data 360). Middleware- of ETL-tools verwerken deze bewerkingen vóór gegevensopname. Data 360 kan ETL-uitvoer ontvangen via API's, connectoren of bulkopnamepijplijnen, en ondersteunt ook Change Gegevensvastlegging (CDC) voor vrijwel realtime synchronisatie. Middleware-ETL-processen zijn essentieel voor het integreren van verouderde systemen en het waarborgen van de gegevenskwaliteit vóór het combineren in Data 360. |
| Lange polling | Long polling (Comet-programmering) is een methode voor het onderhouden van open communicatie tussen systemen voor real-time updates. De client verzendt een verzoek en de server houdt dit vast totdat er een event optreedt, reageert vervolgens en opent opnieuw een nieuwe verbinding. Salesforce gebruikt dit in de Streaming API- en CometD/Bayeux-protocollen voor eventgestuurde gegevenssynchronisatie. Middleware kan zich abonneren op deze events en deze doorsturen naar Data 360 voor realtime opname- of activeringstriggers, wat zorgt voor een minimale latentie in alle bedrijfssystemen. |
Gegevensopname is de eerste en meest kritieke stap in de gegevenslevenscyclus van Salesforce Data 360. Ruwe informatie uit meerdere externe systemen (CRM, ERP, web, mobiel of externe API's) komt zo het platform binnen en wordt onderdeel van een uniforme klantenweergave. Het juiste opnamepatroon is afhankelijk van wat het bedrijf nodig heeft:
- Gegevensvolume: hoeveel gegevens er tegelijk worden verplaatst
- Latency: hoe vers de gegevens moeten zijn
- Bronsysteemmogelijkheden: hoe het systeem gegevens kan verbinden en leveren Data 360 ondersteunt meerdere opnamemodi om aan deze behoeften te voldoen: batchgewijs laden van grote volumes, streaming voor vrijwel realtime updates, op event gebaseerd voor onmiddellijke transactie en opname met nul kopiëren voor onmiddellijke toegang tot externe gegevens zonder deze fysiek te verplaatsen. Samen zorgen deze patronen ervoor dat elk klantsignaal—of het nu een aankoopevent, een klikstroomlogboek of een loyaliteitsupdate is—efficiënt, veilig en binnen het juiste tijdsbestek Data 360 binnenstroomt om vertrouwde analyses en AI-gestuurde omgevingen te stimuleren.
Batchgewijze opnamepatronen vormen de ruggengraat van grootschalige gegevensonboarding in Data 360. Ze zijn geoptimaliseerd voor scenario's waarin gegevens in bulk worden verwerkt—doorgaans op geplande of periodieke basis—in plaats van continu. Deze patronen zijn het meest geschikt voor:
- Historische gegevens laden om het platform te initialiseren met bestaande ondernemingsrecords
- Regelmatige synchronisatie met recordsystemen zoals ERP's, gegevensmagazijnen of eigen databases
- Gebruikscases waarin realtime versheid niet kritiek is, maar consistentie, volledigheid en controleerbaarheid wel belangrijk zijn Batchopname biedt voorspelbare prestaties en operationele eenvoud, waardoor het een vertrouwde keuze is voor ondernemingen die terabytes aan gestructureerde of semigestructureerde gegevens beheren. Data 360 biedt een set productieklare, algemeen beschikbare connectoren die batchgewijs opnemen ondersteunen. Deze connectoren stroomlijnen de set-up van integratie, reduceren de ontwikkeling van aangepaste ETL en zorgen voor gegevenskwaliteit en beveiliging bij elke import. De onderstaande tabel markeert de meest gebruikte connectoren voor batchopname op ondernemingsniveau.
Context
Dit patroon is ontworpen voor ondernemingsscenario's die betrekking hebben op het opnemen van grote volumes gestructureerde gegevens—zoals CSV- of parketbestanden—en ongestructureerde activa uit gecentraliseerde gegevens-lakes of geplande bestandsdrops. Gegevensbronnen omvatten doorgaans cloudopslagplatforms zoals Amazon S3, Google Cloud Storage (GCS) en Microsoft Azure Blob Storage, waarbij bestanden periodiek worden geleverd als onderdeel van upstream gegevenspijplijnen of batchexports.
Probleem
Hoe kan een organisatie een betrouwbaar, veilig en high-throughput proces opzetten voor het opnemen van enorme, op bestanden gebaseerde gegevenssets vanuit haar primaire cloudopslagplatform in Data 360 volgens een voorspelbare, terugkerende planning—zonder in te boeten op governance, schaalbaarheid of prestaties?
Krachten
Het opnemen van enorme, op bestanden gebaseerde gegevenssets in Data 360 is geen eenvoudige oefening voor gegevensoverdracht — het is een architectonische uitdaging die wordt bepaald door schaal, governance en platformbeperkingen.
Gegevensvolume en schaal: Data 360-opnameconnectoren zijn geoptimaliseerd voor betrouwbaarheid en governance, niet voor willekeurige bulkdoorvoer. Zo ondersteunt de Amazon S3-connector maximaal 100 miljoen rijen of 50 GB per object, afhankelijk van welke limiet het eerst wordt bereikt. Voor ondernemingen met historische gegevenssets die miljarden records bevatten, wordt deze grens een belangrijke ontwerpbeperking. Een benadering met één bestand, lift-and-shift, wordt al snel onhaalbaar en vereist intelligente gegevenspartitionering, blokken en doeltreffende combinatiestrategieën om schaalbaarheid te bereiken zonder connectorlimieten te bereiken.
Definitie en onderhoud van schema's: Data 360 vereist expliciete schemadefinities voor elke opnamepijplijn om semantische en structurele integriteit te waarborgen. In het geval van S3-opname moet een csv-bestand kolomkoppen en één representatieve gegevensrij definiëren. Dit bestand fungeert als het canonieke contract tussen het bronsysteem, d.w.z. cloudopslag en Data 360. Elke verkeerde uitlijning – in veldnamen, gegevenstypen of codering – kan leiden tot opnamefouten of stille gegevensbeschadiging. Het onderhouden van dit schemabestand in versiebeheer en het afdwingen van validatie via CI/CD- of gegevens-governancewerkstromen wordt een best practice voor productieomgevingen.
Strikte naamgevingsconventies: Data 360 dwingt strikte object- en veldnaamregels af om consistentie in de metagegevensgrafiek te behouden.
- Objectnamen moeten beginnen met een letter en mogen alleen letters, cijfers of onderstrepingstekens bevatten.
- Veldnamen moeten dezelfde patronen volgen. Bestanden die deze conventies schenden — bijvoorbeeld velden met spaties, speciale lettertekens of niet-ondersteunde symbolen — mislukken schemavalidatie tijdens opname. Ondernemingen moeten pre-opnameprocessen voor gegevenshygiëne implementeren om inkomende bestandsstructuren te zuiveren en normaliseren.
Authenticatie- en beveiligingshouding: Elke verbinding met externe opslag moet voldoen aan beveiligings- en nalevingsnormen van ondernemingsniveau.
- Authenticatie wordt doorgaans afgehandeld via AWS Access/Secret Keys of IdP-authenticatie (Federated Identity Provider).
- IAM-rollen moeten zo worden ingesteld dat ze de minste rechten hebben en alleen leestoegang tot de opgegeven opslagpaden toestaan.
- Voor veilige toegang moeten uitgaande IP-adressen rechtstreeks worden toegevoegd aan de goedgekeurde lijst van het bronsysteem. Deze gelaagde besturingselementen zorgen ervoor dat elke bestandsoverdracht binnen een Trustloze, controleerbare perimeter werkt, waarbij naleving van de onderneming in evenwicht is met de flexibiliteit die vereist is voor grootschalige opname.
Oplossing
Deze tabel bevat oplossingen voor dit integratieprobleem.
| Oplossing | Passen | Opmerkingen |
|---|---|---|
| Native Cloud Storage-connectoren gebruiken (Amazon S3, Google Cloud Storage, Azure Blob Storage) | Beste | Dit is het aanbevolen en meest betrouwbare patroon voor grootschalige, terugkerende op bestanden gebaseerde opname in Data 360\. Oorspronkelijke connectoren bieden beheerde authenticatie, schematoewijzing en beveiligde gegevensverplaatsing rechtstreeks naar Data Lake Objects (DLO's) van Data 360. Ideaal voor geplande batchladingen waarbij latentie niet kritiek is (bijvoorbeeld per uur of dagelijks plannen). |
| Omgaan met grote gegevenssets (voorbij connectorlimieten) | Beste met Voorverwerking | Elke connector dwingt opnamelimieten af (bijvoorbeeld S3: 100M rijen of 50 GB per object). Implementeer voor grotere gegevenssets een ETL-voorverwerkingsstap om gegevens te partitioneren in kleinere bestanden/mappen die onder deze drempelwaarden vallen. Configureer vervolgens meerdere gegevensstromen om elke partitie parallel op te nemen en gebruik het append-knooppunt in een batchgegevenstransformatie) binnen Data 360 om de partities opnieuw te combineren tot een gecombineerde gegevensset. |
| Beveiliging en governance | Beste | Alle connectoren ondersteunen veilige authenticatie via cloud-native methoden (IAM-rollen, serviceaccounts of toegangssleutels). Voor extra controle beperkt u toegang tot Data 360 IP-bereiken via de goedgekeurde lijst van de cloudprovider. Gegevensoverdracht vindt plaats via versleutelde kanalen, waarbij bestanden tijdens opname worden opgeslagen in een tijdelijke, veilige faseringslaag. |
| Wanneer niet te gebruiken | Suboptimal | Dit patroon is niet optimaal voor:
|
Schets
Dit diagram illustreert de volgorde van stappen voor het opnemen van de gegevens vanuit cloudopslag in Data 360
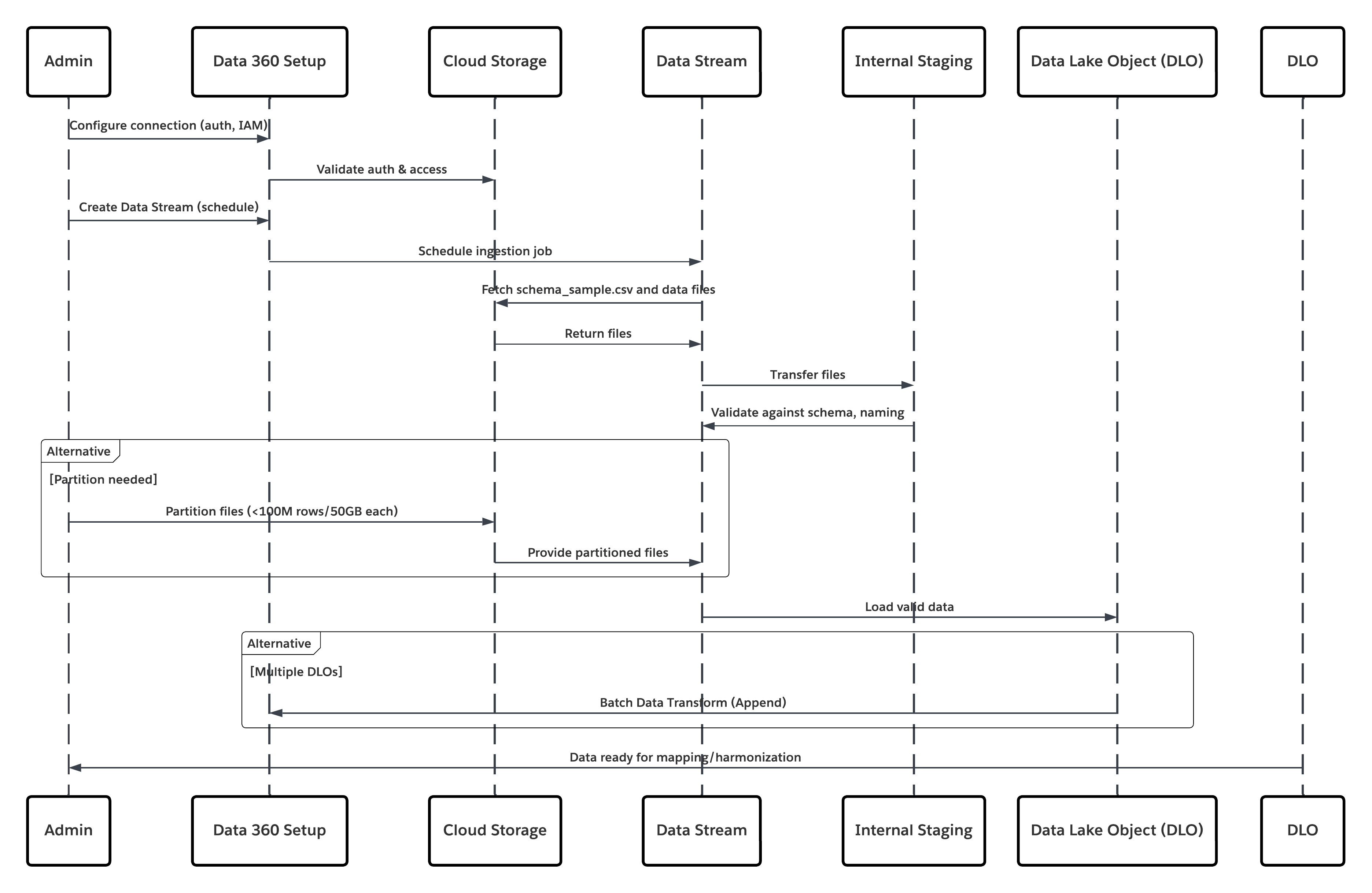
In dit scenario:
- Beheerder configureert een verbinding met cloudopslag via de Set-upinterface van Data 360 (authenticatie, bucketdetails, IAM-rollen en whitelisting opgeven).
- De Set-upinterface van Data Cloud wordt geverifieerd met het Cloud Storage Platform, waarbij inloggegevens en toegang worden geverifieerd.
- De beheerder maakt een gegevensstroom in Data 360, koppelt de gegevensstroom aan het object/de map in Cloud Storage en definieert het opnameschema.
- Bij planningstrigger vraagt de gegevensstroom bronbestanden (bijv. CSV, Parket) aan vanuit het Cloud Storage Platform.
- Cloud Storage Platform levert bestanden, inclusief de vereiste geldige schema_sample.csv en andere gegevensbestanden die voldoen aan naamgevingsconventies.
- Gegevensstroom draagt bestanden over naar de interne faseringsomgeving binnen Data 360.
- Data 360 Pipeline verwerkt de bestanden: Gebruikt de schemadefinitie uit schema_sample.csv Valideert structuur, veldnamen en verdeelt de belasting indien boven de opnamedrempelwaarden (100 miljoen rijen/50 GB per bestand). Als er grote bestanden worden gedetecteerd, wordt er extern een partitioneringsstap voor de verwerking uitgevoerd (kennisgeving aan de beheerder voor de volgende uitvoering).
- Records worden geïmporteerd vanuit fasering in een gegevens-lakeobject (Data Lake Object, DLO).
- Indien vereist en gegevens zijn gepartitioneerd, gebruikt u het append-knooppunt in een batch gegevenstransformatie om meerdere DLO's te combineren.
- Data 360 registreert succes/mislukt, werkt de status bij voor bewaking en signaleert dat gegevens gereed zijn voor toewijzing, harmonisering en samenvoeging.
Resultaten
De toepassing van dit patroon maakt veilige, geplande en grootschalige opname van gestructureerde of ongestructureerde bestanden vanuit Enterprise Cloud Storage Platforms in Data 360 mogelijk. Het proces is geautomatiseerd, schaalbaar en veerkrachtig en levert ruwe gegevens in gegevens-lakeobjecten (Data Lake Objects, DLO's) die de basis vormen voor harmonisering en toewijzing aan het Customer 360 Data Model.
Opnamemechanismen
Het opnamemechanisme is afhankelijk van de connector en planningsstrategie die zijn gedefinieerd binnen Data 360.
| Opnamemechanisme | Beschrijving |
|---|---|
| Native Cloud Storage-connector (Amazon S3, GCS, Azure) | Aanbevolen voor directe opname van bestanden in CSV- of parketindeling vanuit het cloud-gegevens-lake van de onderneming. Deze connectoren ondersteunen incrementele en volledige vernieuwingsschema's. Zo kan een bank een dagelijkse synchronisatie configureren van transactiebestanden van klanten vanuit een S3-bucket naar een DLO. |
| Strategie voor gepartitioneerde bestanden | Voor zeer grote gegevenssets (meer dan 100 miljoen rijen of 50 GB per object) worden de gegevens gepartitioneerd in kleinere logische sets (bijvoorbeeld op maand of regio). Elke partitie wordt beheerd als een afzonderlijke gegevensstroom en later opnieuw gecombineerd met behulp van een batch gegevenstransformatie met een knooppunt Toevoegen. |
| Geautomatiseerde geplande synchronisatie | Data 360 biedt een declaratieve planner (per uur, dagelijks of aangepaste cadans) die opnametaken automatisch activeert, waardoor gegevens vers blijven zonder handmatige tussenkomst. |
Afhandeling en herstel van fouten
Afhandeling en herstel van fouten zijn van cruciaal belang om betrouwbaarheid te garanderen bij opnamebewerkingen met groot volume.
- Foutopsporing: Elke uitvoering van Gegevensstroom registreert opnamefouten (bijv. schemafouten, bestandsbeschadiging of naamsschendingen) in Data 360 Monitoring. Beheerders kunnen mislukte batches beoordelen en opnieuw verwerken.
- Herstelmechanisme: Data 360 handhaaft controlepunten om ervoor te zorgen dat mislukte batches eerdere opnames niet beschadigen. Opnieuw proberen kan worden geconfigureerd na het corrigeren van bronproblemen (bijv. CSV's met onjuiste notatie).
- Schemavalidatie: Het bestand schema_sample.csv definieert gegevenstypen en -structuur. Elke wijziging activeert validatie om stille schemadrift tussen uitvoeringen te voorkomen.
Overwegingen bij impotent ontwerp
Opname is idempotent van opzet — het opnieuw verwerken van hetzelfde bestand resulteert niet in duplicaatrecords. Belangrijke strategieën omvatten:
- Bestandsvingerafdrukken: Data 360 berekent controlesommen om eerder verwerkte bestanden te identificeren en over te slaan.
- Transactionele opname: Gegevens worden gefaseerd en alleen naar het DLO gecommit bij een succesvolle verwerking van alle records.
- Toevoegen vs. Vervangen: Afhankelijk van de bedrijfslogica kunnen stromen worden toegevoegd aan het doel-DLO of dit volledig vervangen; dit garandeert deterministische uitkomsten en voorkomt gedeeltelijke overlapping van gegevens.
Beveiligingsoverwegingen
Beveiliging is een integraal onderdeel van de opnamepijplijn, van authenticatie tot encryptie en toegangscontrole.
- Authenticatie en autorisatie: Connectoren gebruiken het Secure Integration Framework van Salesforce, waarbij Benoemde inloggegevens en Externe inloggegevens worden gebruikt voor authenticatie zonder geheimen openbaar te maken.
- Encryptie: Gegevens worden versleuteld onderweg (TLS 1.2+) en in ruste (AES-256).
- Netwerkbesturingselementen: Bronopslagsystemen (bijvoorbeeld S3-buckets) moeten Data 360-IP's op een goedgekeurde lijst zetten.
- Uitlijning van naleving: Ondersteunt frameworks voor gegevensbescherming voor ondernemingen zoals AVG, HIPAA en FFIEC-richtlijnen indien gekoppeld aan Customer-Managed Keys (CMK).
- Controleerbaarheid: Elke opnametaak en toegang tot inloggegevens wordt vastgelegd voor traceerbaarheid en nalevingsrapportage.
Sidebars
Tijdigheid
Tijdigheid is afhankelijk van het opnameschema en het gegevensvolume.
- Grote ondernemingsgegevenssets (100M+ rijen) vereisen mogelijk partitionering voor parallelle opname.
- Typische opnamelatentie varieert van minuten tot enkele uren, afhankelijk van de bestandsgrootte en de complexiteit van de transformatie.
- Voor opname in vrijwel realtime kunnen op Data 360 Streaming of API gebaseerde connectoren het op bestanden gebaseerde model aanvullen.
Gegevensvolumes
- Het meest geschikt voor periodieke batches met groot volume.
- Elk object dat wordt verwerkt via de S3-connector ondersteunt maximaal 100 miljoen rijen of 50 GB per bestand.
- Gebruik voor systemen op petabyteschaal gegevenspartitionering en doeltreffende combinatie van meerdere stromen.
Ondersteuning voor eindpuntmogelijkheden en standaarden
De mogelijkheden en standaardondersteuning voor het eindpunt zijn afhankelijk van de oplossing die u kiest.
| Type connector | Eindpuntvereisten |
|---|---|
| Amazon S3-connector | S3-bucket met het juiste IAM-beleid en schema\_sample.csv-bestand dat het schema definieert. |
| Google Cloud Storage-connector | Serviceaccountgegevens en toegang tot buckets met uniforme naamgevingsconventies. |
| Azure-opslagconnector | Toegangssleutel of op SAS-tokens gebaseerde authenticatie; blob of mapstructuur moet voldoen aan Data 360-conventies. |
Statusbeheer
Status wordt bijgehouden via Gegevensstromen en het tijdstempel van de laatste geslaagde uitvoering.
- Data 360 handhaaft automatisch synchronisatiestatussen en verschuivingen, waardoor alleen nieuwe of gewijzigde bestanden worden verwerkt bij daaropvolgende uitvoeringen.
- Bij integratie met externe ETL-tools worden unieke bestands-ID's (bijv. UUID's of tijdstempels) aanbevolen om duplicatie te voorkomen.
Complexe integratiescenario's
In geavanceerde ondernemingsarchitecturen kan dit patroon worden geïntegreerd met:
- Middleware-ETL-pijplijnen (bijv. Informatica, MuleSoft): voor het organiseren van pre-verwerking, validatie en bestandspartitionering vóór overdracht aan Data 360.
- AI/ML-werkstromen: verwerkte DLO-gegevens kunnen via DMO worden gepubliceerd om trainingsomgevingen of RAG-indexen te modelleren via Data 360-activeringsdoelen.
- Transactionele systemen: geharmoniseerde DMO's kunnen updates verderop in de stroom activeren in Salesforce CRM of externe systemen via gegevensacties of platformevents.
Voorbeeld
Een wereldwijde financiële instelling slaat klant- en transactiegegevens op in een AWS S3-gegevens-lake, waar 's nachts gepartitioneerde parketbestanden worden gegenereerd per regio (zoals de VS, de EU en APAC). Het team van de gegevensarchitectuur configureert meerdere gegevensstromen in Data 360, elk verbonden met een regionale map, waarbij een gedeeld schema_sample.csv zorgt voor consistente headers en gegevenstypen voor alle partities. Met nachtelijke opnameschema's worden de gegevens automatisch geladen in DLO's, waarna batchgegevenstransformaties alle regionale partities toevoegen aan een gecombineerd Customer_Transactions_DLO. Deze geharmoniseerde gegevensset wordt vervolgens toegewezen aan het Customer 360 gegevensmodel, waardoor analyses verderop in de stroom en AI-activering mogelijk worden. De benadering biedt geautomatiseerde en betrouwbare opname vanuit het bestaande gegevens-lake, dwingt sterke authenticatie en encryptie af die zijn afgestemd op IT-beleid voor de onderneming, en biedt een schaalbare, modulaire basis die toekomstige uitbreiding en schema-evolutie ondersteunt.
Context
Een primaire en kritieke gebruikscase voor Data 360 is het combineren van klantgegevens binnen het Salesforce-ecosysteem. Dit patroon bestrijkt het native opnemen van gegevens van kernplatforms van Salesforce: Sales Cloud en Service Cloud (gezamenlijk Salesforce CRM) en Marketing Cloud Engagement. Bronnen omvatten standaard en aangepaste CRM-objecten (bijv. Account, Contactpersoon, Case, Opportunity) en Marketing Cloud Engagement-gegevensextensies die betrokkenheidsevents, e-mailverzendingen en trackinggegevens bevatten.
Probleem
Hoe kan een organisatie efficiënt en betrouwbaar standaard- en aangepaste CRM-objecten en Marketing Cloud Engagement-gegevensextensies opnemen in Data 360, zodat de gegevens kunnen worden gebruikt voor het samenstellen van gecombineerde klantprofielen (identiteitsoplossing, Customer 360), met behoud van prestaties, governance en minimale onderbreking van bronsystemen?
Krachten
Oorspronkelijke connectoren vereenvoudigen de taak, maar er moeten verschillende operationele en architectonische krachten worden beheerd:
- Uitgebreide bronmachtigingen: Een speciale verbindende gebruiker (integratieaccount) moet de juiste machtigingen voor lezen op object- en veldniveau hebben. Het niet toewijzen van vereiste machtigingensets (bijvoorbeeld een vooraf samengestelde Data 360-connectormachtigingenset) is een veel voorkomende oorzaak van opnamefouten.
- Gegevensvernieuwingsmodi en -kosten: Connectoren ondersteunen volledige en delta/incrementele vernieuwingsmodi. Volledige vernieuwingen zijn zwaarder voor prestaties en kredieten; delta-extracties verminderen de belasting, maar zijn afhankelijk van betrouwbaar bijhouden van wijzigingen in het bronsysteem.
- Aangepast schema en veldtoewijzing: CRM-exemplaren bevatten vaak aangepaste objecten/velden. Nauwkeurige schematoewijzing en afhandeling van aangepaste velden (namen, typen) is vereist om toewijzingsfouten of semantische afwijking te voorkomen.
- Startgegevensbundels vs. Aangepaste toewijzing: Startergegevensbundels versnellen onboarding door het vooraf selecteren van typische objecten/velden, maar sterk aangepaste organisaties hebben specifieke stroomdefinities nodig.
- Doorvoer- en API-limieten: API-limieten voor de bronorganisatie en Marketing Cloud-extractiescores beperken hoe agressief u vernieuwingen kunt plannen.
- Gegevenshygiëne en naamgevingsconventies: Bronveldnamen, null-werking en gegevenstypen moeten vóór opname worden genormaliseerd om problemen met toewijzing verderop in de stroom te voorkomen.
- Beveiliging en minste rechten: De connector vertrouwt op veilige authenticatie en moet rekening houden met IAM-patronen met de minste rechten, controlemogelijkheden en netwerkbesturingselementen.
Oplossing
Deze tabel bevat oplossingen voor dit integratieprobleem.
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Oplossing passend | Beste | Gebruik de eigen Salesforce CRM-connector en Marketing Cloud Engagement-connector in Data 360\. Begin met startgegevensbundels voor standaardgebruikscases en versnel onboarding. Gebruik handmatige stroomaanpassing voor op maat gemaakte of domeinspecifieke gegevensmodellen. |
| Omgaan met sterk aangepaste CRM-exemplaren | Beste met Mapping Workshop | Behandel startbundels als baseline en geef een mappingworkshop om het volgende te identificeren: Aangepaste objecten en relaties. Formule- of berekende velden. Beheerde pakketextensies. Voor zware formulevelden berekent u waarden in een pre-fase-ETL of binnen Data 360-transformaties om API-belasting voor bronorganisaties te minimaliseren. |
| Wanneer niet te gebruiken | Suboptimale scenario's | Vermijd dit patroon als: U hebt opname van hoogfrequente of real-time events nodig (gebruik in plaats daarvan Streaming-connectoren, Platform-events of Zero-Copy Federation). De bronorganisatie heeft beperkte API-capaciteit en kan geplande extracties niet aanhouden zonder throttling of wachtrijvertragingen. |
| Beveiliging en governance | Verplichte controles | Principe van minste rechten - Gebruik een speciale integratiegebruiker met minimale leestoegang. Gebruik nooit beheerders voor de hele organisatie. Authenticatie: gebruik OAuth 2.0 en verbonden apps; roteer clientgeheimen regelmatig en bewaak het gebruik van vernieuwingstokens. Audit en traceerbaarheid — Leg alle opnameuitvoeringen, schemawijzigingen en connectorevents vast. Stuur logboeken door naar SIEM of nalevingssystemen voor auditgereedheid. Gegevensclassificatie — Pas persoonsgegevens/PHI-tagging en op kenmerken gebaseerde toegangscontrole (ABAC) toe met behulp van CEDAR-beleidsvormen onmiddellijk na opname om maskering, instemming en naleving verderop in de stroom af te dwingen. |
Schets
Dit diagram illustreert de volgorde van stappen voor het opnemen van de gegevens vanuit cloudopslag in Data 360
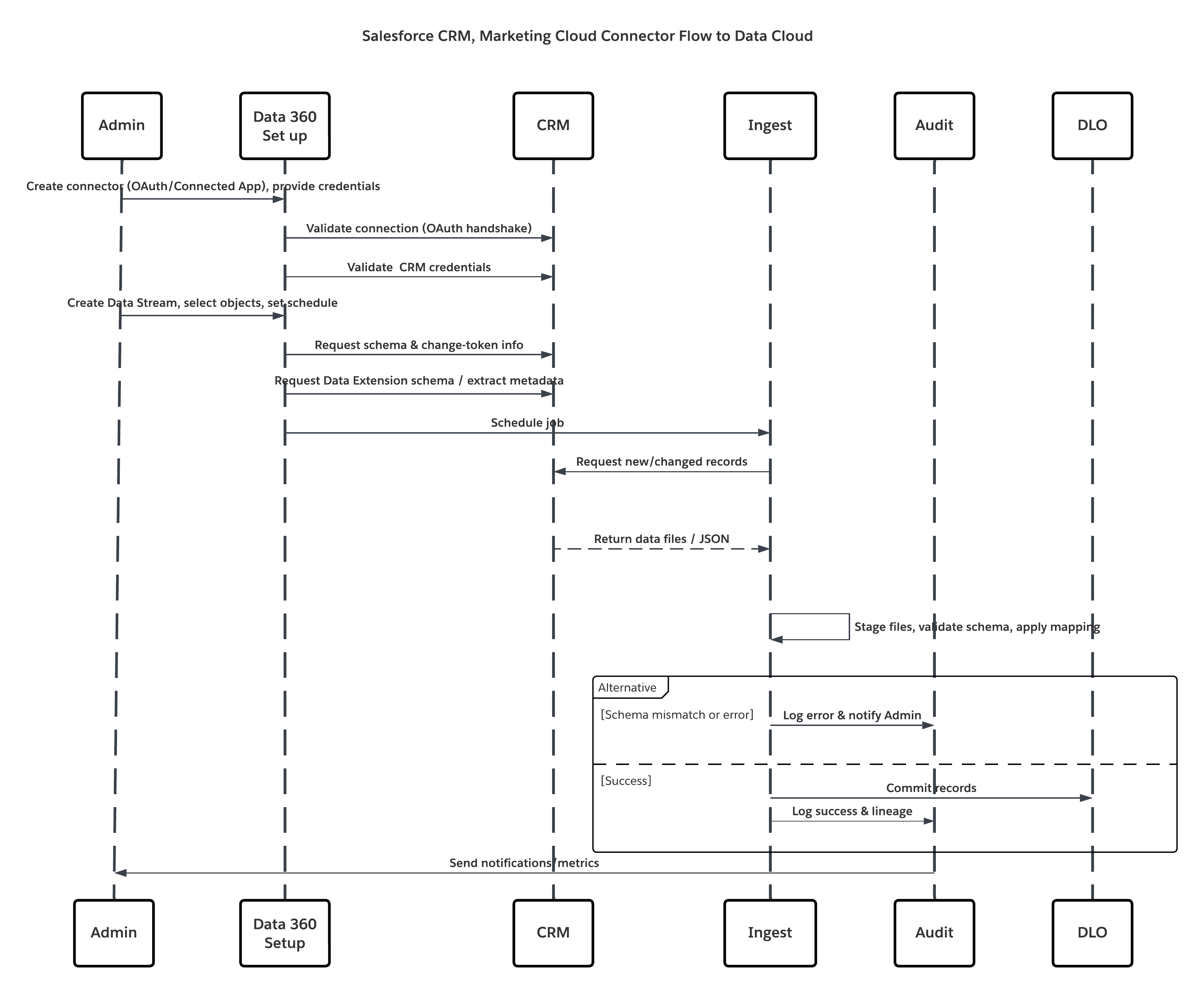
In dit scenario:
- De beheerder levert integratiegebruikers en wijst connectormachtigingensets toe in bronorganisatie(s).
- Beheerder configureert connectoren in Set-up van Data 360 (maakt verbinding met Salesforce CRM en Marketing Cloud via OAuth/verbonden app).
- De beheerder maakt gegevensstromen door objecten en gegevensextensies te selecteren, kiest voor volledige of deltavernieuwing en stelt planningen in.
- Bij geplande uitvoering vraagt Data 360 schema- en deltatokens aan bij de bron(nen).
- Bronsystemen retourneren records (delta of volledige payload). Marketing Cloud levert mogelijk extracties; CRM retourneert mogelijk JSON-/queryresultaten.
- Data 360 faseert bestanden in het interne beveiligde faseringsgebied en valideert op basis van toegewezen schema's.
- Als validatie mislukt, wordt een fout in het opnamelogboek vastgelegd, wordt de beheerder gewaarschuwd en wordt het vastleggen gestopt. Als de validatie slaagt, verbindt Data 360 records atomisch aan het doel-DLO.
- Bewakings- en auditlogboeken worden bijgewerkt met herkomst, uitvoeringsduur, rijtellingen en inloggegevensgebruik. Waarschuwingen die worden uitgegeven aan beheerders als drempelwaarden of fouten worden geactiveerd.
Resultaten
Kerngegevens over klantrelaties en marketingbetrokkenheid worden opgenomen in Data 360 als gegevens-lakeobjecten (Data Lake Objects, DLO's). Dit levert op:
- Gecombineerde gegevensset met profielen, cases, opportunities en meetgegevens over e-mail/betrokkenheid.
- Stichting voor identiteitsoplossing en constructie van gecombineerde individuele profielen.
- Operationele gereedheid voor harmonisering, verrijking, AI-modellering en activering verderop in de stroom, met behoud van governance en controleerbaarheid.
Opnamemechanismen
Het opnamemechanisme is afhankelijk van de connector en planningsstrategie die zijn gedefinieerd binnen Data 360.
| Mechanisme | Wanneer gebruiken |
|---|---|
| Salesforce CRM-connector (native) | Beste voor standaard/aangepaste CRM-objecten; ondersteunt volledige en deltavernieuwing. |
| Marketing Cloud-betrokkenheidsconnector (native) | Beste voor gegevensextensies, verzenden en bijhouden van extracties; ondersteunt volledige / delta-modi. |
| Startgegevensbundels | Versnel onboarding voor veelvoorkomende objecten voor Verkoop/Service/Marketing. |
| Aangepaste stromen + voorverwerking | Gebruik dit wanneer complexe transformaties of zware schemanormalisatie vereist is. |
Afhandeling en herstel van fouten
Afhandeling en herstel van fouten zijn van cruciaal belang om betrouwbaarheid te garanderen bij opnamebewerkingen met groot volume.
- Per uitvoering logboeken: Elke uitvoering van Gegevensstroom biedt details over slagen/mislukken en fouten op rijniveau.
- Opnieuw proberen en controlepunten: Mislukte uitvoeringen kunnen opnieuw worden geprobeerd na het oplossen van bron- of schemaproblemen; Data 360 gebruikt fasering en atomaire semantiek voor vastleggen.
- Waarschuwingen: Configureer waarschuwingen voor schemaafwijking, herhaalde mislukkingen of hiaten in de deltareeks.
Overwegingen bij impotent ontwerp
Opname is idempotent van opzet — opwerking hetzelfde resulteert niet in duplicaatrecords. Belangrijke strategieën omvatten:
- Wijzigingsdetectie: Delta-extracties vertrouwen op bronsysteemwijzigingsindicatoren (LastModifiedDate / gegevensvastlegging systeemwijziging). Controleer of de bron betrouwbare tijdstempels/vlaggen levert.
- Deduplicatie: Gebruik unieke bedrijfssleutels (bijv. Contact.ExternalId) om DLO's te ontdubbelen of in te voegen.
- Transactionele verbintenis: Records worden gefaseerd en alleen vastgelegd wanneer de batchverwerking met succes is voltooid.
Beveiligingsoverwegingen
Beveiliging is een integraal onderdeel van de opnamepijplijn, van authenticatie tot encryptie en toegangscontrole.
- Authenticatie en autorisatie: Connectoren gebruiken het Secure Integration Framework van Salesforce, waarbij Benoemde inloggegevens en Externe inloggegevens worden gebruikt voor authenticatie zonder geheimen openbaar te maken.
- Encryptie: Gegevens worden versleuteld onderweg (TLS 1.2+) en in ruste (AES-256).
- Netwerkbesturingselementen: Bronopslagsystemen (bijvoorbeeld S3-buckets) moeten Data 360-IP's op een goedgekeurde lijst zetten.
- Uitlijning van naleving: Ondersteunt frameworks voor gegevensbescherming voor ondernemingen zoals AVG, HIPAA en FFIEC-richtlijnen indien gekoppeld aan Customer-Managed Keys (CMK).
- Controleerbaarheid: Elke opnametaak en toegang tot inloggegevens wordt vastgelegd voor traceerbaarheids- en nalevingsrapportage
Sidebars
Tijdigheid
Tijdigheid is afhankelijk van het opnameschema en het gegevensvolume.
- De ideale cadans is afhankelijk van de bedrijfsbehoeften: elk uur voor marketingtriggers in bijna realtime en elke nacht voor grote afstemmingen.
- Delta-modi verlagen de belasting en kosten; volledige vernieuwingen zijn zwaarder en worden gebruikt voor initiële ladingen of grote schemawijzigingen.
Gegevensvolumes
- CRM-connectoren zijn geoptimaliseerd voor transactionele gegevenssets en gegevenssets met gemiddeld volume (miljoenen records).
- Overweeg voor extreem grote historische volumes gefaseerde ETL voor partitioneren en laden in fasen.
Ondersteuning voor eindpuntmogelijkheden en standaarden
De mogelijkheden en standaardondersteuning voor het eindpunt zijn afhankelijk van de oplossing die u kiest.
| Connector | Eindpuntvereisten |
|---|---|
| Salesforce CRM-connector | Bronorganisatie moet een verbonden app, OAuth-tokens en een speciale integratiegebruiker met leesmachtigingen toestaan. |
| Marketing Cloud-connector | Marketing Cloud API-inloggegevens of geïnstalleerd pakket; gegevensextensies moeten gegevens zichtbaar maken via extracties/API. |
Statusbeheer
- Connectorstatus: Gegevensstromen onderhouden laatste geslaagde synchronisatietijdstempels en deltaverschuivingen.
- Hoofdsleutelstrategie: Geef de voorkeur aan consistente bedrijfs-ID's (externe ID's), zodat afstemming verderop in de stroom en upserts deterministisch zijn.
Complexe integratiescenario's
In geavanceerde ondernemingsarchitecturen kan dit patroon worden geïntegreerd met:
- Hybride topologieën: Combineer CRM-opname met streaming (Platform-events) voor vrijwel realtime updates.
- Middleware doeltreffende combinatie: Gebruik MuleSoft- of ETL-tools wanneer complexe doeltreffende combinatie, verrijking of transformatie vooraf vereist is.
- Activeringsfeedbacklussen: Geharmoniseerde DMO's kunnen updates van bronsystemen verderop in de stroom activeren via gegevensacties of platform-API's (voorzichtig met SoD-besturingselementen).
Voorbeeld
Een multinationale detailhandelaar consolideert Accounts, Contactpersonen, Cases, Opportunities en Marketing Cloud-betrokkenheidsmeetgegevens in Data 360 om een uniforme klantweergave te maken. De startgegevensbundel initialiseert de kernobjecten Verkoop en Service, terwijl het team het model uitbreidt met aangepaste velden zoals Loyaliteitslidmaatschapc en Klantniveauc om de loyaliteitscontext vast te leggen. CRM-gegevensstromen worden elk uur uitgevoerd in de deltamodus en Marketing Cloud Engagement synchroniseert dagelijks met behulp van delta-extracties voor betrokkenheidsevents. Deze gegevenssets worden verwerkt via DLO's en identiteitsoplossing, wat resulteert in een gecombineerd klantprofiel dat CRM- en betrokkenheidssignalen combineert om personalisatie en AI-modellen verderop in de stroom aan te sturen.
Deze patronen zijn ontwikkeld voor scenario's waarin milliseconden ertoe doen, wanneer interacties, transacties of signalen van klanten onmiddellijk inzicht of actie moeten activeren. Ze gaan verder dan traditionele, geplande batchopname en schakelen eventgestuurde gegevensstromen in, waarbij informatie wordt verwerkt op het moment dat deze wordt gegenereerd. In het Salesforce Data 360-ecosysteem is "realtime" niet één modus, maar een continuüm van latentiemodellen. Aan de ene kant ligt vrijwel realtime synchronisatie, waarbij updates vanuit recordsystemen (zoals CRM of ERP) binnen enkele seconden of minuten worden weerspiegeld in de Data 360. Aan de andere kant is er het vastleggen van echte realtime events, waarbij gedragssignalen aan de clientzijde, zoals klikken, aankopen of mobiele interacties, worden opgenomen en geactiveerd in milliseconden. Voor architecten is het onderscheid meer dan semantisch. Het definieert hoe pijplijnen worden ontworpen, hoe API's worden aangeroepen en hoe beslissingen verderop in de stroom worden genomen. Het selecteren van het juiste patroon – of het nu gaat om opname via vrijwel realtime synchronisatie of eventstreaming – zorgt ervoor dat het systeem voldoet aan de operationele latentiedoelen van het bedrijf, terwijl de gegevensintegriteit, schaalbaarheid en governance behouden blijven.
Context
Met dit patroon kan elk extern systeem — zoals een aangepaste toepassing, een IoT-platform (Internet-of-Things), een point-of-sale-systeem (POS) of een externe service — eventgegevens programmatisch in Data 360 pushen in vrijwel realtime wanneer afzonderlijke events plaatsvinden.
Probleem
Hoe kan een ontwikkelaar op betrouwbare wijze enkelvoudige records of kleine asynchrone batches events van een externe toepassing naar Data 360 verzenden met een lage latentie, zodat de gegevens snel beschikbaar zijn voor verwerking, segmentering en activering?
Krachten
Dit patroon levert een lage latentie en betere ontwikkelaarscontrole, maar introduceert diverse technische beperkingen en operationele afhankelijkheden:
- Ontwikkelaarsafhankelijkheid: Vereist inspanning van ontwikkelaars voor het implementeren van geauthenticeerde REST API-clients en fout-/opnieuw-proberen-logica. Het is geen "point-and-click"-connector.
- Strikt schema-op-schrijven: De opname-API dwingt schema-op-schrijven af. Er moet een nauwkeurig schema worden gedefinieerd en geüpload naar de connectorconfiguratie; alle payloads moeten exact conform zijn of worden afgewezen.
- Dubbele interactiemodi: Dezelfde connector ondersteunt zowel streaming (JSON) voor record-voor-record updates met lage latentie als bulk (CSV) voor grotere periodieke synchronisaties — architecten moeten per gebruikscase kiezen.
- Authenticatie en beveiliging: Aanroepen moeten worden geauthenticeerd via een verbonden app voor Salesforce met behulp van OAuth 2.0 (bijvoorbeeld JWT-bearerstroom voor server-naar-server). Tokenbeheer, rotatie en bereiken met de minste rechten zijn verplicht.
- Operationele zichtbaarheid: Ontwikkelaars en platformteams moeten bewaking implementeren voor responscodes, nieuwe pogingen, wachtrijen met dode letters en waarschuwingen over schemaafwijkingen.
- Vereiste realtime grafiek: Voor echte onmiddellijke activering (onmiddellijke segmentering, realtime DMO-toewijzing) moet het doelgegevensmodelobject (Data Model Object, DMO) deel uitmaken van de realtime gegevensgrafiek; anders doorlopen events een pijplijn met een iets hogere latentie.
Oplossing
Deze tabel bevat oplossingen voor dit integratieprobleem.
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Oplossing passend | Beste voor het vastleggen van events met lage latentie | Gebruik de Data 360-opname-API (streaming JSON) voor het pushen van enkelvoudige events of microbatches. Configureer de Ingestion API-connector met een strikt OAS 3.0-schema (.yaml). Gebruik bulk CSV-opname voor grotere, minder frequente synchronisaties. |
| Omgaan met schemawijzigingen | Strikt / beheerd | Schemawijzigingen worden verbroken: werk OAS .yaml bij, versie de connector en voer contracttests uit. Implementeer doorlopende schemamigratie als producenten niet tegelijkertijd kunnen wijzigen. |
| Wanneer niet gebruiken | Suboptimal | Niet ideaal als voorbewerking nodig is (bijv. deduplicatie, gegarandeerde order etc.) of voor extreem grote bulkladingen (gebruik native bulkconnectoren of batch-ETL). Als de bron geen schema-geldige payloads kan produceren of niet veilig kan worden geauthenticeerd, gebruikt u alternatieve opnamemethoden. |
| Beveiliging en governance | Verplicht | Gebruik OAuth 2.0 met bereiken met de minste rechten, roteer sleutels en leg tokengebruik vast. Dwing TLS 1.2+ af, valideer client-IP's indien nodig en zorg voor payload-PII-tagging. Alle events moeten herkomstmetagegevens hebben (bron, tijdstempel, schemaversie, idempotentiesleutel). |
Schets
Dit diagram illustreert de volgorde van stappen voor het opnemen van de gegevens vanuit de opname-API in Data 360
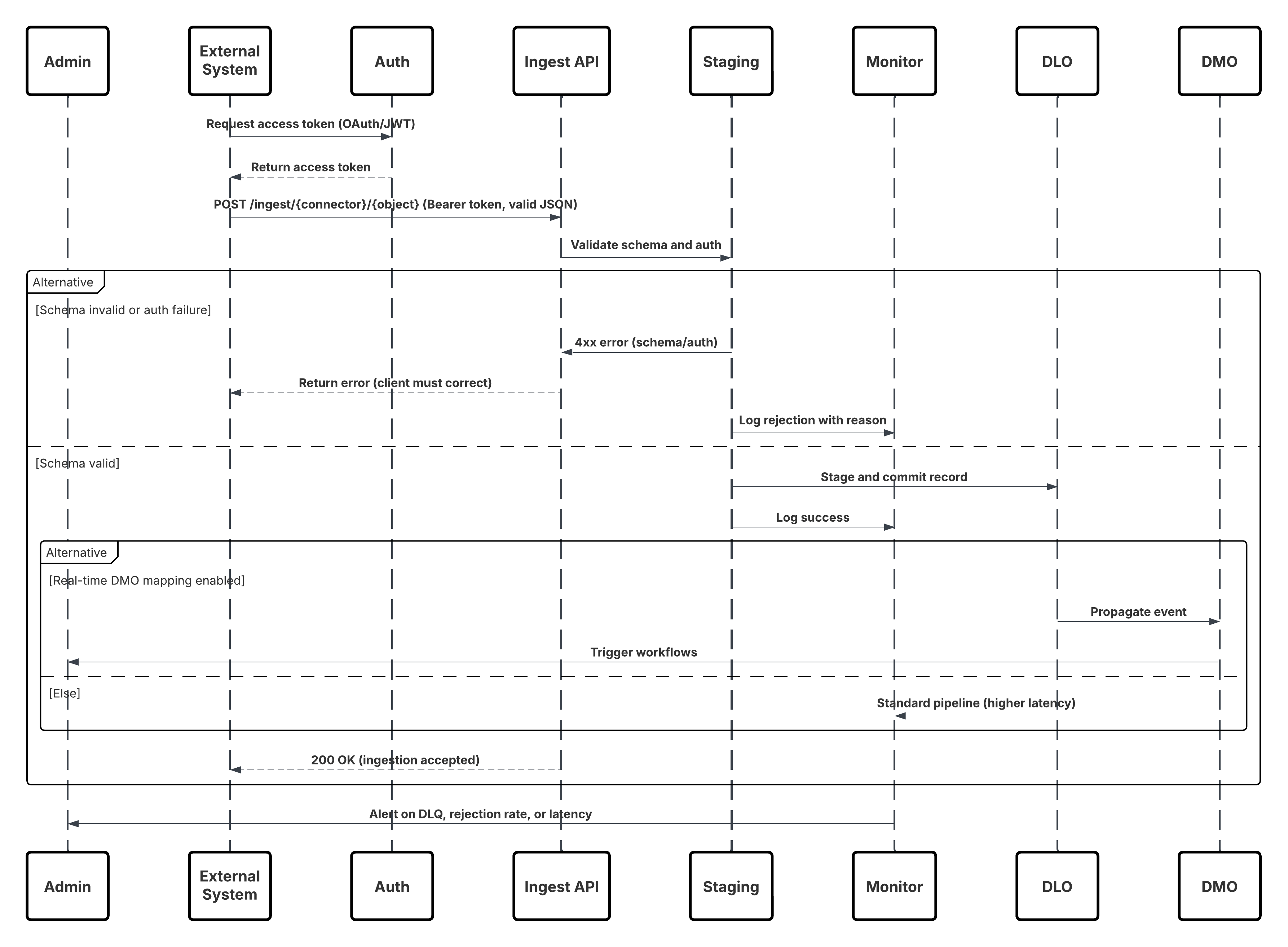
In dit scenario:
- Extern systeem vraagt authenticatie via OAuth/JWT aan bij Auth Server.
- Auth.-server retourneert toegangstoken naar Extern systeem.
- Extern systeem verzendt POST-aanvraag voor gegevensopname naar Data 360-opname-API met autorisatie en JSON-payload.
- De opname-API valideert het aanvraagschema en de authenticatie via de module Staging & Validation.
- Bij schema-/authenticatiefout:
- Fout geretourneerd naar Extern systeem.
- Afwijzing vastgelegd voor bewaking en waarschuwing.
- Bij succesvolle validatie:
- Records die zijn gefaseerd en vastgelegd in het gegevens-lakeobject (Data Lake Object, DLO).
- Succes vastgelegd voor bewaking.
- Indien ingeschakeld, worden gegevens gepropageerd naar Real-time Data Graph (DMO) die downstream werkstromen activeren.
- Anders worden gegevens verwerkt via een standaardbatch of een pijplijn met een hogere latentie.
- Opname-API bevestigt succes voor Extern systeem.
- Bewakingscomponenten waarschuwen de beheerder voor wachtrijen met dode letters, afwijzingsscores of latentieproblemen.
Resultaten
Externe eventgegevens worden met een lage latentie opgenomen in Data 360-DLO's. Wanneer het doel-DMO deel uitmaakt van de realtime grafiek, zijn de gegevens beschikbaar voor onmiddellijke segmentering, agentwerkstromen, AI-modellen en operationele activering. Dit maakt snelle bedrijfsreacties mogelijk op events die afkomstig zijn van elk verbonden systeem.
Opnamemechanismen
Het opnamemechanisme is afhankelijk van de connector en planningsstrategie die zijn gedefinieerd binnen Data 360.
| Mechanisme | Wanneer gebruiken |
|---|---|
| Streaming JSON (Ingestion API) | Enkelvoudige events, microbatches, gedragsevents, klikstromen, IoT-telemetrie — wanneer een lage latentie vereist is. |
| Bulk CSV (bulkmodus opname-API) | Grotere, periodieke uploads waarbij de latentievereisten worden versoepeld. |
| Edge / Middleware | Gebruik dit wanneer u validatie, transformatie, verrijking of scorebeperking nodig hebt voordat u naar de opname-API pusht. |
Afhandeling en herstel van fouten
- Onmiddellijke (synchronisatie)fouten: 4xx-responsen voor schema-/authenticatiefouten: client moet payload of token corrigeren en het opnieuw proberen.
- Voorbijgaande (asynchrone) storingen: 5xx-responsen: opnieuw proberen van cliënten met exponentiële backoff en jitter.
- Dead-Letter Queue (DLQ): Aanhoudende storingen landen in DLQ voor handmatige inspectie en opnieuw afspelen.
- Bewaking: Houd het percentage afgewezen schema's, authenticatiefouten, latentiepercentielen en DLQ-achterstand bij. Waarschuwing over drempelwaarden.
Overwegingen bij impotent ontwerp
- Idempotentiesleutel: Elke event moet een unieke idempotentiesleutel/bericht-ID bevatten.
- Strategie voor upsert: Gebruik bedrijfssleutels (ExternalId) om duplicaten bij opnieuw afspelen te voorkomen.
- Ded-upvenster: Architect moet deduplicatievensters en retentie definiëren voor het bijhouden van idempotentie.
Beveiligingsoverwegingen
Beveiliging is een integraal onderdeel van de opnamepijplijn, van authenticatie tot encryptie en toegangscontrole.
- Authenticatie: OAuth 2.0 (JWT Bearer) aanbevolen voor server-naar-server. Beperk bereiken tot alleen opname.
- Encryptie: TLS 1.2+ voor transport; Data 360 dwingt encryptie at rest af.
- Minste rechten: Inloggegevens voor verbonden apps hebben minimale rechten; roteer geheimen en toegangslogboeken voor instrumenten.
- Bestuur van payload: Neem instemmings-/verbruiksvlaggen op in eventmetagegevens; pas ABAC-/CEDAR-beleid onmiddellijk na opname toe.
- IP-besturingselementen / Privé verbinden: Beperk indien nodig toegang via goedgekeurde lijsten of gebruik Privé verbinden voor privénetwerken.
Sidebars
Tijdigheid
Tijdigheid is afhankelijk van het opnameschema en het gegevensvolume. Streaming JSON levert een latentie van subseconde tot seconde, afhankelijk van de verwerking en de configuratie van de grafiek. Bulk CSV is minuten tot uren. Kies op basis van bedrijfs-SLA's.
Gegevensvolumes
Afzonderlijke eventgrootten moeten klein zijn (< paar kB). Overweeg voor producenten met hoge doorvoer batching bij de producent of gebruik een streamingbuffer (Kafka/Kinesis) voordat u de API aanroept.
Statusbeheer
- Schemaversiebeheer: Onderhoud schemaversie in eventmetagegevens en gebruik connectorversiebeheer bij het bijwerken van het OAS-contract.
- Connectorverschuivingen: Data 360 verwerkt commitsemantiek; producenten moeten idempotentiesleutels en laatste succesvolle volgorde bijhouden voor veilig opnieuw afspelen.
Complexe integratiescenario's
In geavanceerde ondernemingsarchitecturen kan dit patroon worden geïntegreerd met:
- Randvalidatielaag: Gebruik middleware voor het vertalen van heterogene producentennotaties naar het vereiste OAS-contract, het uitvoeren van scorebeperkingen en pre-verrijking.
- Hybride architecturen: Combineer opname-API voor events en connectoren voor bulkafstemming.
- Agentactivering: Events die zijn toegewezen aan realtime DMO's kunnen Agentforce werkstromen en Einstein modellen activeren voor geautomatiseerde besluitvorming.
Voorbeeld
Een detailhandelsketen streamt verkooppuntaankoopevents in real-time naar Data 360 om directe klantbetrokkenheid te stimuleren. Elke store voert een lichtgewicht servercomponent uit die transacties verzamelt, deze verrijkt met locatie- en apparaatmetagegevens en JSON-events veilig post met behulp van JWT Bearer OAuth met idempotentiesleutels om duplicaten te voorkomen. Een beheerder definieert de eventstructuur door een OAS-schema voor het verkooppunt te uploaden en de connector van de opname-API te configureren. Inkomende events worden opgenomen in het DLO pos_sale, toegewezen aan het DMO Verkoop en toegevoegd aan de realtime grafiek. Als gevolg hiervan worden aankopen met een hoge waarde onmiddellijk gedetecteerd, waardoor VIP-werkstromen in Agentforce worden geactiveerd en klantsegmentering wordt bijgewerkt om real-time personalisatie te stimuleren.
Context
Dit patroon maakt het mogelijk om gedetailleerde gebruikersinteractiegegevens met groot volume—zoals paginaweergaven, knopklikken, productimpressies en videoweergaven—vast te leggen vanaf websites en mobiele toepassingen in trueReal-Time. Het is essentieel voor het leveren van personalisatie op het moment, waarbij elke digitale interactie dynamisch de gebruikerservaring kan beïnvloeden en betrokkenheid kan stimuleren.
Probleem
Hoe kan een onderneming een continue stroom van gedragsevents vastleggen en verwerken vanuit digitale eigenschappen, die miljoenen gebruikersinteracties per minuut bestrijken, en die gegevens onmiddellijk beschikbaar maken in Data 360 om realtime segmentering, personalisering en activering aan te sturen?
Krachten
Deze gebruikscase introduceert diverse ontwerpuitdagingen die een doelgerichte opnamearchitectuur met lage latentie vereisen:
- Extreme doorvoer: Websites of mobiele apps met veel verkeer kunnen miljoenen events per minuut uitzenden. De opnamelaag moet horizontaal worden geschaald om dit volume te verwerken zonder eventverlies of tegendruk, wat zorgt voor een consistente latentie bij piekbelastingen.
- Instrument aan cliëntzijde: In tegenstelling tot servergestuurde integraties is dit patroon afhankelijk van SDK's aan clientzijde. Op elke pagina moet een JavaScript-baken (Salesforce Interactions SDK) zijn ingebed of een native SDK die is geïntegreerd in mobiele apps. Dit vereist robuuste clientimplementatie, versiebeheer en governance van eventschema's.
- Verwerking van event met lage vertraging: Gebruikersacties—zoals “toevoegen aan winkelwagentje” of “video afspelen”—moeten Data 360 binnen enkele seconden bereiken, waardoor real-time activering en contextuele reacties (bijv. gerichte aanbiedingen, gepersonaliseerde aanbevelingen) mogelijk worden.
- Gegevens harmonisering en Identiteitsoplossing: Vastgelegde events bevatten vaak anonieme identifiers (cookies, apparaat-ID's, sessietokens). Voor Customer 360 gebruikscases moeten deze worden toegewezen aan bekende profielen via de identiteitsoplossing van Data 360 en worden gecombineerd met het Customer 360 gegevensmodel.
Oplossing
De aanbevolen benadering is het gebruik van de Salesforce Marketing Cloud Personalization-connector, een eigen, volledig beheerde streamingpijplijn die is ontworpen voor opname met hoge doorvoer.
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Op SDK gebaseerde event vastleggen | Best | Implementeer de Salesforce Interactions SDK (web) of native SDK (mobiel). Deze lichtgewicht bibliotheken leggen interacties van gebruikers in realtime vast en serialiseren deze, waarbij metagegevens (sessie-ID, tijdstempel, context) worden bijgevoegd. |
| Eventstreamingpijplijn | Best | Events worden verzonden naar de eventstreamingservice van Marketing Cloud Personalization via beveiligde HTTPS. Deze laag is horizontaal schaalbaar en geoptimaliseerd voor transmissie met lage latentie (<2s). |
| Data 360-integratie | Best | De Personaliseringsconnector van Data 360 abonneert zich op de streamingfeed en neemt elke event in nearReal-Time op in een Data Lake-object (DLO). |
| Gegevensmodeltoewijzing | Best practice | Het opgenomen DLO wordt toegewezen aan Customer 360 Data Model Objects (DMO's). Hierdoor kunnen anonieme en bekende gebruikers worden gekoppeld via Identiteitsoplossing. |
| Inschakelen van realtime grafieken | Optioneel / aanbevolen | Neem toegewezen DMO's op in de realtime grafiek voor onmiddellijke segmentering, waardoor gepersonaliseerde acties worden geactiveerd via Einstein of Agentforce werkstromen. |
| Wanneer niet gebruiken | Suboptimal | Dit patroon is niet ideaal wanneer: De brongegevens zijn webclient en events (gebruik in plaats daarvan de opname-API). De organisatie heeft geen controle over web-/mobiele clients. Realtime gedrag bijhouden is niet vereist (gebruik batchgewijs opnemen). |
| Omgaan met het schema Wijzigingen | Beheerde evolutie | Eventschema's evolueren naarmate nieuwe interacties worden toegevoegd. SDK's moeten eventdefinities versieren. Achterwaarts compatibele wijzigingen (het toevoegen van optionele velden) zijn veilig; het breken van wijzigingen vereist opnieuw configureren van de connector en testen van contracten. |
Schets
Dit diagram illustreert de volgorde van stappen voor het opnemen van de gegevens uit mobiele en webkanalen in Data 360
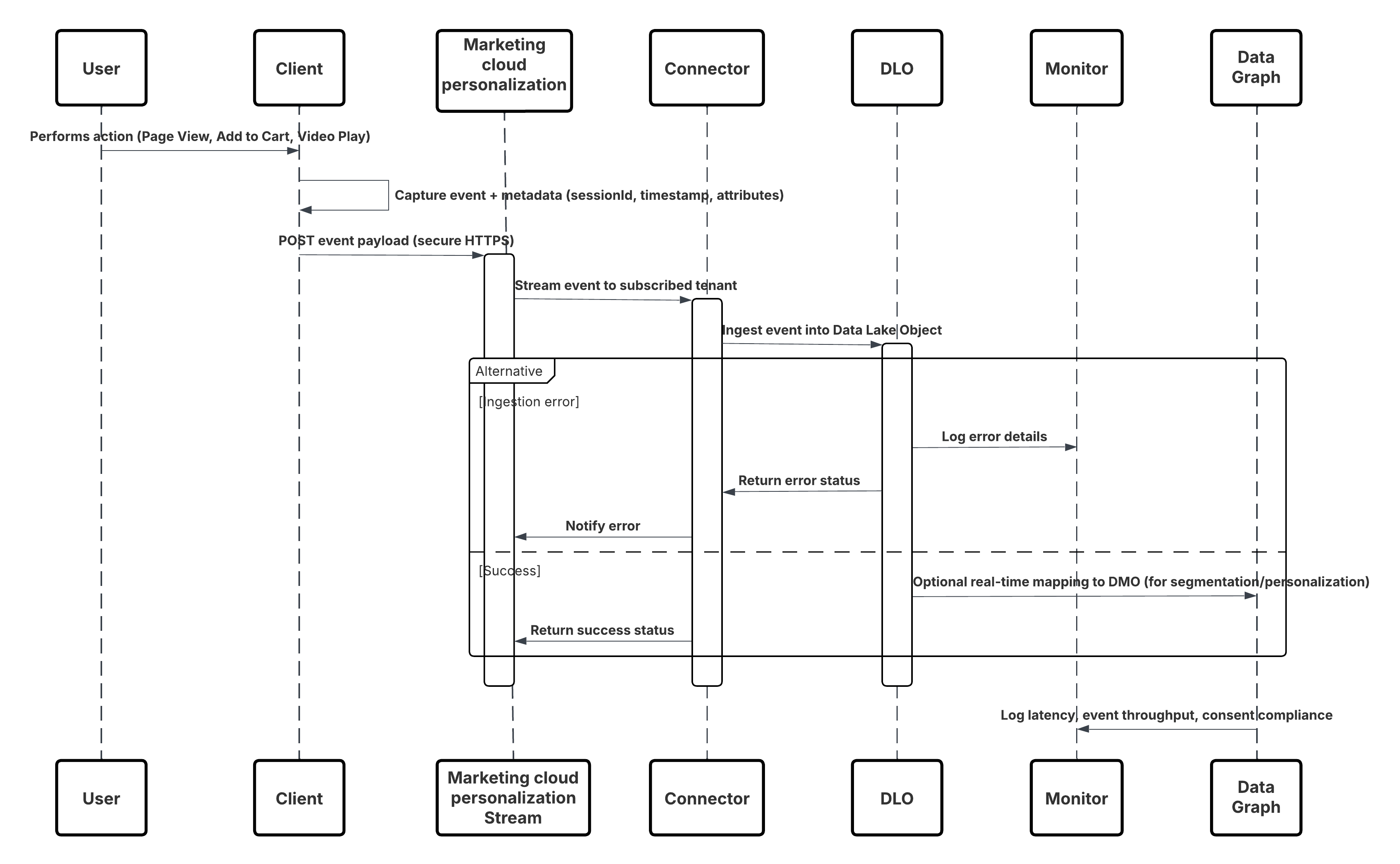
In dit scenario:
- Implementeer de SDK in web- of mobiele kanalen (vastleggen van gebruikersinteractie).
- Configureer SDK met belanghebbenden-ID, omgevings- en instemmingsbesturingselementen.
- Stream vastgelegde JSON-events (metagegevens + kenmerken) naar Marketing Cloud-streamingeindpunt.
- Maak en configureer in Set-up van Data 360 de Personalisatieconnector voor de belanghebbende.
- Neem events op in een DLO en wijs het DLO → DMO toe binnen Data 360.
- Schakel het DMO in de realtime grafiek in voor onmiddellijke activering.
- Bewaak latentie, schemaconformiteit, instemmingsvlaggen, doorvoer en foutpercentages.
- Implementeren naar productie en continu bewaken.
Resultaten
Een continue stroom van gedragsevents met een lage latentie stroomt van digitale kanalen naar Data 360. Binnen enkele seconden is elke gebruikersactie beschikbaar voor real-time segmentering, voorspellend modelleren of geactiveerde personalisering, waardoor echt adaptieve klantervaringen mogelijk worden.
Opnamemechanismen
Het opnamemechanisme is afhankelijk van de connector en planningsstrategie die zijn gedefinieerd binnen Data 360.
| Mechanisme | Wanneer gebruiken |
|---|---|
| Interactions SDK (Web) | Realtime vastleggen vanuit webbrowsers en SPA's. |
| Mobile SDK | Realtime vastleggen vanuit native mobiele toepassingen. |
| Personalisatieconnector | Beheerd abonnement tussen Marketing Cloud en Data 360\. |
| Realtime grafiektoewijzing | Schakelt onmiddellijke activering in Segmentering, Einstein en Journeys in. |
Afhandeling en herstel van fouten
- Gelaagde fouttolerantie: Implementeer validatie- en hernieuwde pogingen op meerdere lagen: client-SDK's verwerken tijdelijke storingen met exponentiële backoff, terwijl de opnamelaag duurzame wachtrijen en afspeelbare pijplijnen gebruikt om gegevensverlies te voorkomen.
- Schema en gegevensbeheer: Versieer en valideer eventschema's continu; ongeldige of zich ontwikkelende events worden naar een wachtrij Schemaafwijzing of Dode letter gerouteerd voor veilig testen en opnieuw afspelen.
- Idempotentie en deduplicatie: Gebruik stabiele event-ID's en upsert-semantiek om exacte eenmalige verwerking te garanderen, zelfs tijdens opnieuw proberen of opnieuw afspelen.
- Bewaking en herstelautomatisering: Continue bewaking van doorvoer, latentie en foutpercentages activeert geautomatiseerde herstelwerkstromen, wat zorgt voor een lage latentie, betrouwbare levering en consistente real-time personalisatie-uitkomsten.
Overwegingen bij impotent ontwerp
- Elke event moet een unieke idempotentiesleutel of bericht-ID hebben, zodat dubbele indieningen verderop in de stroom kunnen worden ontdubbeld.
- Gebruik waar nodig bedrijfssleutels (bijv. sessionID + eventTimestamp + userID) om duplicaten te identificeren.
- Definieer een deduplicatieperiode (bijvoorbeeld 24 uur) waarin duplicaatevents worden genegeerd of gefilterd.
- Gebruik upsert-strategieën waar van toepassing (bijvoorbeeld tellers of vlaggen bijwerken in plaats van duplicaten invoegen).
Beveiligingsoverwegingen
Beveiliging is een integraal onderdeel van de opnamepijplijn, van authenticatie tot encryptie en toegangscontrole.
- Transport-encryptie: TLS 1.2+ voor alle SDK → streaming service verbindingen.
- Gegevensencryptie in ruste in Data 360 en marketingstroom.
- SDK respecteert gebruikersinstemmingsvlaggen (GDPR/CCPA) en onderdrukt tracking als instemming wordt geweigerd.
- Authenticatie van SDK-verkeer: zorg ervoor dat alleen goedgekeurde belanghebbenden/klanten events kunnen streamen.
- Metagegevens: elke event moet bron-ID, tijdstempel, schemaversie, sessie-ID en idempotentiesleutel bevatten.
- Toegang met minste rechten: SDK-eindpunten en -connectoren die zijn beperkt tot het opnamebereik van events; roteer inloggegevens regelmatig.
- Gegevensclassificatie: Persoonsgegevens annoteren in eventpayloads, beleid onmiddellijk na opname afdwingen
Sidebars
Tijdigheid
- Tijdigheid is afhankelijk van de activiteit van eindgebruikers en de configuratie van eventstreaming.
- Events die zijn vastgelegd via de Salesforce Interactions SDK en worden geleverd via de Marketing Cloud Personalization Stream, bereiken doorgaans een latentie van minder dan een seconde tot ongeveer een seconde voordat ze beschikbaar komen in de realtime grafiek van Data 360.
- Dit maakt vrijwel onmiddellijke segmentering, personalisering en activering binnen actieve gebruikerssessies mogelijk.
Gegevensvolumes
Afzonderlijke gedragsevents (bijvoorbeeld klikken, weergeven, toevoegen aan winkelwagentje) zijn licht van gewicht — over het algemeen 1–5 kB per payload. Verwacht voor grootschalige digitale eigenschappen duizenden tot miljoenen events per minuut. Doorvoer en veerkracht garanderen:
- Gebruik de ingebouwde batching- en hernieuwde pogingsmechanismen van de SDK voor pagina's met veel verkeer.
- Offload burstverwerking naar de Marketing Cloud-bufferlaag voor streaming.
- Bewaak opnamedoorvoer en foutverhoudingen met behulp van het dashboard voor connectormeetgegevens.
Statusbeheer
Elke event omvat metagegevens voor status- en versiebeheer:
- Schemaversiebeheer: Schemaversie inbedden in elke event; versie van de personalisatieconnector bij het bijwerken van het schema.
- Afhandeling van opnieuw afspelen: Events die mislukken vanwege tijdelijke netwerkproblemen, worden automatisch opnieuw geprobeerd door de SDK met exponentiële backoff.
- Idempotentiesleutels: Unieke identifiers (sessionId + eventType + tijdstempel) zorgen ervoor dat opnieuw afgespeelde events geen duplicaten maken in Data 360.
- Offsetbeheer: Data 360 houdt succesvolle commits bij; niet-verwerkte events worden opnieuw in de wachtrij geplaatst door de connector totdat ze met succes worden opgenomen.
Complexe integratiescenario's
Dit patroon kan naadloos worden geïntegreerd in geavanceerde ondernemingsarchitecturen:
- Randverrijkingslaag: Voeg middleware (bijvoorbeeld reverse proxy of serverloze functie) toe om extra context te injecteren, zoals geo, apparaattype of campagnemetagegevens, voordat events Marketing Cloud bereiken.
- Hybride (streaming + batch): Gebruik de Marketing Cloud-connector voor realtime stromen en combineer deze met batch-ETL-taken (bijv. ordergegevens) voor afstemming verderop in de stroom.
- Agentactivering: Events die zijn toegewezen aan real-time DMO's, kunnen Einstein Personalisering, Agentforce werkstromen of AI-gestuurde beslissingen activeren om de digitale omgeving op dat moment aan te passen.
- Governance voor meerdere belanghebbenden: Gebruik instemmingsvlaggen en metagegevens voor belanghebbenden om privacy en naleving af te dwingen in omgevingen met meerdere merken of regio's.
Voorbeeld
Een wereldwijd e-commercebedrijf levert gepersonaliseerde productaanbevelingen en dynamische inhoud aan shoppers terwijl ze actief surfen op www.retailx.com, een op React gebaseerde toepassing van één pagina. Met behulp van de Salesforce Interactions SDK aan de clientzijde legt de site paginaweergaven, productklikken, winkelwagentjeacties en video-interacties in realtime vast. Deze events stromen via de Marketing Cloud Personalization-eventstroom en de Personalization-connector naar Data 360-DLO's, waar ze worden gemodelleerd in DMO's en worden opgenomen in de realtime grafiek. Deze architectuur maakt gedragssignalen onmiddellijk beschikbaar voor segmentering, Einstein gestuurde personalisatie en Agentforce activering, waardoor responsieve, in-sessie klantervaringen mogelijk worden
Context
Voor veel bedrijfskritieke processen is het essentieel dat Data 360 perfect is afgestemd op de nieuwste updates in de belangrijkste CRM-systemen. Klantenservice-, verkoop- en marketingteams zijn afhankelijk van actuele informatie om beslissingen te nemen, journeys te activeren en automatisering te activeren. Dit patroon biedt een mechanisme om wijzigingen aan belangrijke Salesforce CRM-objecten—zoals Contactpersoon, Account en Case—met minimale vertraging te synchroniseren naar Data 360, zonder de inefficiëntie of latentie van frequente batchopiniepeilingen.
Probleem
Hoe kan Data 360 een vrijwel perfect gesynchroniseerde status behouden met de belangrijkste Salesforce CRM-objecten, zodat analyses verderop in de stroom, segmentering en AI-gestuurde activering altijd werken met de meest actuele gegevens die beschikbaar zijn?
Krachten
Dit patroon introduceert verschillende technische beperkingen en architectonische overwegingen:
- Event-gestuurde architectuur: Synchronisatie moet reactief zijn—aangestuurd door wijzigingsevents in de CRM-bronorganisatie in plaats van periodieke batchtaken.
- Selectieve objectondersteuning: Niet alle standaard- en aangepaste Salesforce-objecten ondersteunen realtime streaming. Architecten moeten tijdens het ontwerp naar de lijst van ondersteunde objecten verwijzen om hiaten te voorkomen.
- Toegang en machtigingen: Het inschakelen van streaming vereist dat aan de integratiegebruiker in de bronorganisatie de systeemmachtiging "Machtigingen voor CRM Streaming inschakelen" is toegewezen.
- Gegevensversheid vs. Verwerkingskosten: Synchronisatie in bijna realtime verbetert de reactiesnelheid, maar buitensporige eventdoorvoer vereist mogelijk horizontale schaalbaarheid en robuuste mechanismen voor foutherstel.
- Integratie van beveiliging en Trust Layer: Alle eventgegevens moeten voldoen aan de Trust en Security frameworks van Salesforce—versleuteld onderweg, gevalideerd voor schemanaleving en verwerkt binnen de Trust grens van de organisatie.
Oplossing
De aanbevolen benadering is de Salesforce CRM-connector te gebruiken met Streaming (Gegevensvastlegging wijzigen) ingeschakeld. Bij het maken van een gegevensstroom voor een ondersteund CRM-object (bijv. Contactpersoon) kunnen beheerders de optie "Streaming inschakelen" inschakelen. Het CDC-platform (Change Gegevensvastlegging) van Salesforce publiceert een ChangeEvent-bericht telkens wanneer een record wordt gemaakt, bijgewerkt, verwijderd of verwijderd in de bron-CRM-organisatie. De Data 360 CRM-connector abonneert zich op deze CDC-events en past de corresponderende wijzigingen toe op het toegewezen Data Lake Object (DLO) binnen Data 360 in vrijwel realtime. Dit zorgt voor continue synchronisatie tussen CRM en Data 360 met minimale handmatige tussenkomst.
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Op CDC gebaseerde streamingconnector | Beste | Native Salesforce-mechanisme; volledig beheerd en geïntegreerd met platformeventinfrastructuur. |
| Abonnement en levering van event | Beste | Connector abonneert zich op ChangeEvent-kanalen (bijvoorbeeld /data/ContactChangeEvent) via ID's voor duurzaam opnieuw afspelen. |
| Gegevenstoewijzing en schema-evolutie | Best practice | Wijs gestreamde payloads toe aan het overeenkomende DLO; handel schemaversiebeheer in metagegevens af om opnamepauzes te voorkomen. |
| Replay en foutherstel | Aanbevolen | Gebruik ID's voor opnieuw afspelen en idempotentiesleutels om duplicatie te voorkomen en te herstellen van tijdelijke fouten. |
| Hybride modus (streaming + batch) | Optioneel | Gebruik voor niet-ondersteunde objecten of initieel in bulk laden batchgewijs opnemen in combinatie met CDC-streaming. |
| Wanneer niet gebruiken | Suboptimal | Dit patroon kan suboptimaal zijn wanneer: Het bronobject is niet ingeschakeld voor CDC. De gebruikscase vereist geen real-time updates (batch is voldoende). Netwerkuitgangen uit de bronorganisatie worden beperkt of eventlimieten worden overschreden. |
Schets
Dit diagram illustreert de volgorde van stappen voor het opnemen van de gegevens vanuit CRM in Data 360 in nearReal-Time
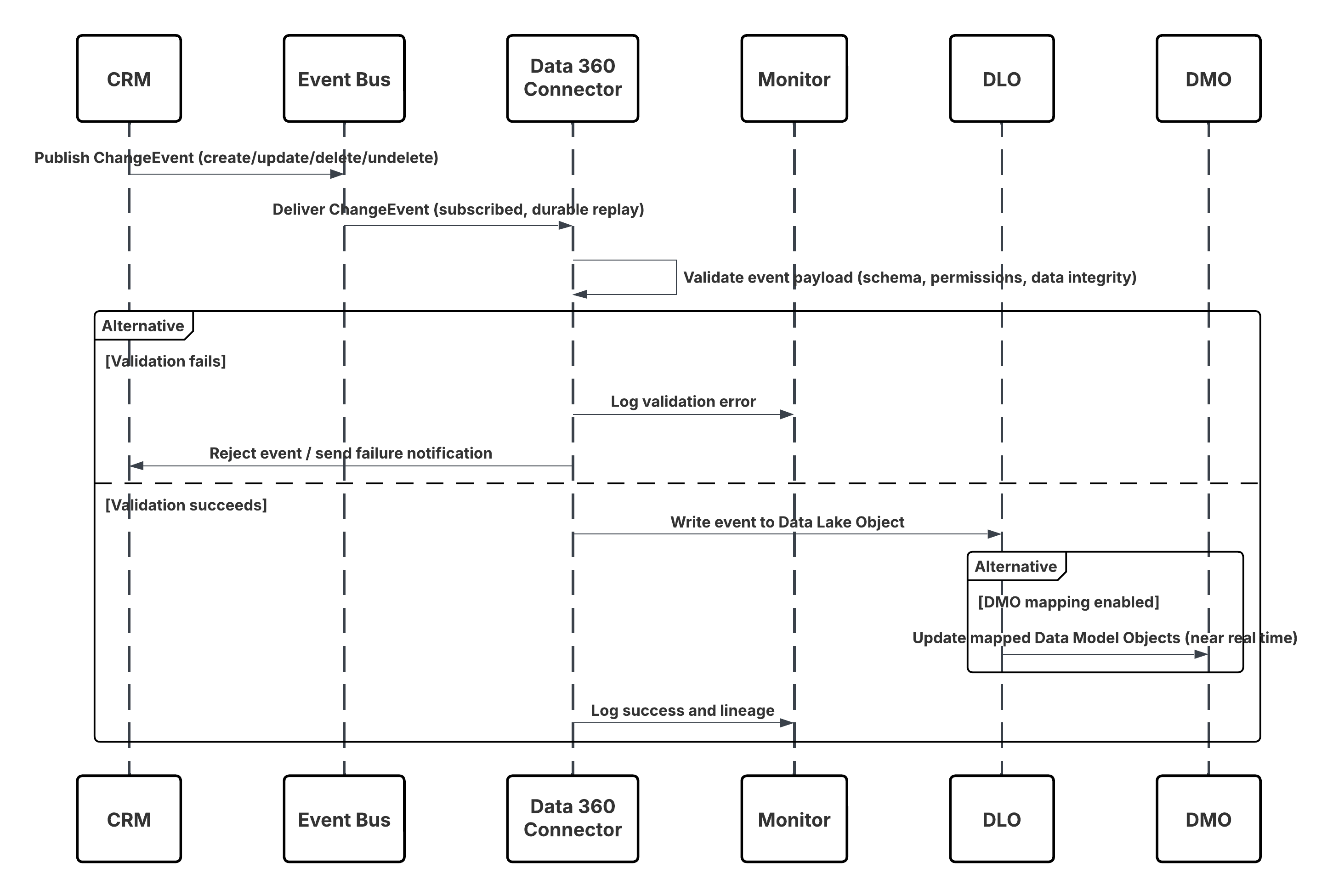
In dit scenario:
- Wijziging vindt plaats in Salesforce CRM (maken/bijwerken/verwijderen/verwijderen).
- CDC publiceert een ChangeEvent naar de interne Salesforce Event Bus.
- Data 360 CRM-connector abonneert zich op de Event Bus met behulp van een duurzame cursor voor opnieuw afspelen.
- Eventpayload wordt gevalideerd voor schema, machtigingen en gegevensintegriteit.
- Data 360 schrijft de gevalideerde event naar het toegewezen Data Lake Object (DLO).
- Indien ingeschakeld, worden toegewezen gegevensmodelobjecten (Data Model Objects, DMO's) bijgewerkt in nearReal-Time, wat segmentering en activering aanstuurt.
Resultaten
Data 360 onderhoudt een continu gesynchroniseerde spiegel van de belangrijkste CRM-gegevens. Dit maakt het volgende mogelijk:
- Realtime triggers (bijv. Journey wordt gestart wanneer een case wordt gemaakt).
- Up-to-date segmentering (bijv. klanten verplaatsen naar het segment "Gold" bij wijziging van accountstatus).
- Nauwkeurigere analyses en personalisatie op basis van live CRM-context.
Opnamemechanismen
Het opnamemechanisme voor dit patroon wordt intern beheerd via de Salesforce CRM-connector met Change Gegevensvastlegging (CDC) ingeschakeld. Data 360 fungeert als abonnee van de CDC-eventstroom, wat zorgt voor betrouwbare synchronisatie met lage latentie tussen de bron-CRM-organisatie en Data 360.
| Mechanisme | Wanneer gebruiken |
|---|---|
| Streamen via CDC (voorkeur) | Voor alle ondersteunde standaard- en aangepaste Salesforce-objecten waarvoor vrijwel realtime synchronisatie is vereist. |
| Hybride modus (CDC + batch) | Voor objecten waarvoor CDC nog niet is ingeschakeld of waarvoor initieel historisch laden vereist is. |
| Abonnementsmodus Opnieuw afspelen | Voor hersynchronisatie na downtime of implementatie. |
| Foutisolatiemodus | Voor test- en validatieomgevingen. |
Afhandeling en herstel van fouten
- Automatisch herstel van fouten: De CRM-connector probeert automatisch tijdelijke netwerk- of platformfouten opnieuw met behulp van exponentiële backoff en routeert hardnekkige fouten naar de Dead-Letter Queue (DLQ) voor opnieuw afspelen.
- Schema- en authenticatiebestendigheid: Schemamismatches worden in quarantaine geplaatst in de wachtrij Schemaafwijzing voor beoordeling door de beheerder, terwijl authenticatie- of machtigingsfouten gecontroleerde pogingen en waarschuwingen via Data 360 Monitoring activeren.
- Gegarandeerde continuïteit van event: Duurzame ReplayID's garanderen geen eventverlies tijdens downtime van de connector; gemiste events worden opnieuw gehydrateerd via afspeelvensters of batchgewijs opnieuw synchroniseren.
- Gegevensintegriteit en ordening: Ingebouwde idempotentie (RecordID + SequenceNumber) voorkomt duplicaten en ChangeEventHeader.sequenceNumber behoudt de juiste volgorde van events voor elke CRM-record.
Overwegingen bij impotent ontwerp
- Uniekheid van event: Elke CDC-event draagt een ReplayID en ChangeEventHeader.entityName voor deterministische deduplicatie.
- Strategie voor upsert: Implementeer UPSERT-logica op basis van record-ID om ervoor te zorgen dat herhaalde events geen duplicaten veroorzaken.
- Afhandeling van opnieuw afspelen: Gebruik de cursor voor opnieuw afspelen van de connector om te hervatten vanaf de laatst vastgelegde verschuiving in geval van tijdelijke storingen.
- **Schema-evolutie: **Onderhoud een schemaversie in eventmetagegevens en werk DLO-toewijzingen bij wanneer het CRM-schema verandert.
Beveiligingsoverwegingen
Beveiliging is een integraal onderdeel van de opnamepijplijn, van authenticatie tot encryptie en toegangscontrole.
- Encryptie en Trust: Alle events worden verzonden met behulp van TLS 1.2+ en versleuteld opgeslagen in Data 360.
- Toegangscontrole: Alleen geauthenticeerde connectoren met de juiste integratiemachtigingen kunnen zich abonneren op CDC-kanalen.
- Schemavalidatie: Elke eventpayload wordt gevalideerd op basis van het DLO-schema vóór opname.
- Verspreiding van instemming: Metagegevens voor instemming en gegevensclassificatie stromen stroomafwaarts met elke event om privacy en naleving te waarborgen (AVG, CCPA).
- Operationele governance: Events worden vastgelegd, gecontroleerd en bewaakt op opnieuw afspelen, schemaafwijzing en doorvoeranomalieën via de Data 360 Trust Layer.
Sidebars
Tijdigheid
- CDC-events worden bijna in realtime verwerkt—doorgaans binnen enkele seconden na de wijziging in CRM.
- Latentie kan variëren op basis van eventvolume en connectordoorvoer, maar Data 360 garandeert beschikbaarheid van subminuten voor ondersteunde objecten.
Gegevensvolumes
- Elke eventpayload is licht (~1–5 kB).
- Zorg er bij objecten met hoge wijzigingsscores zoals Case of Contactpersoon voor dat doorvoerlimieten overeenkomen met Salesforce CDC-eventtoewijzingen.
Statusbeheer
Elke event omvat metagegevens voor status- en versiebeheer:
- Herhalings-ID's: Gebruikt voor sequentieel eventherstel.
- Schemaversiebeheer: Onderhoud versiemetagegevens om contractwijzigingen te beheren.
- Idempotentiesleutels: Duplicaatherhalingen tussen pogingen.
- Verbintenis voor verschuiving: Data 360 behoudt de verbintenisstatus na elke succesvolle batch events.
Complexe integratiescenario's
Dit patroon kan naadloos worden geïntegreerd in geavanceerde ondernemingsarchitecturen:
- Hybride (streaming + batch): Gebruik CDC voor delta-updates en bulktaken voor volledige vernieuwingen.
- Streaming tussen organisaties: Meerdere bronorganisaties kunnen naar dezelfde Data 360-belanghebbende streamen, gecombineerd via DMO-toewijzingen.
- Agentactivering: Realtime objectupdates activeren Einstein of Agentforce automatiseringen.
- Eventroutering: Middleware (bijv. MuleSoft of Event Relay) kan CDC-berichten verrijken of routeren vóór opname.
Voorbeeld
Een wereldwijde bank wil ervoor zorgen dat wijzigingen van klantgegevens in Salesforce Sales Cloud onmiddellijk worden weergegeven in Data 360.Wanneer het adres van een contactpersoon wordt bijgewerkt in Sales Cloud, publiceert het mechanisme Gegevensvastlegging wijzigen een ContactChangeEvent.De Data 360 CRM-connector verbruikt deze event, past de update toe op het Customer DLO en werkt automatisch alle gekoppelde Customer 360 profielen bij. Dit activeert een Einstein Next Best Action om het nieuwe adres te verifiëren—waarbij de feedbacklus binnen enkele seconden na de oorspronkelijke CRM-wijziging wordt voltooid.
Context
Moderne digitale ondernemingen vertrouwen op realtime eventstreamingplatforms zoals Amazon Kinesis-gegevensstromen en Amazon MSK (Managed Streaming for Apache Kafka) voor het vastleggen van continue gegevensstromen vanuit gedistribueerde toepassingen, IoT-apparaten en transactiesystemen. Data 360 maakt directe opname vanaf deze platforms mogelijk via eigen connectoren van derden, waardoor aangepaste ETL- of op middleware gebaseerde oplossingen overbodig worden. Dit patroon is ontworpen voor gegevensopname met een hoge doorvoersnelheid en lage latentie, voor vrijwel realtime insights, personalisering en AI-gestuurde activering.
Probleem
Hoe kan een onderneming Data 360 veilig en efficiënt verbinden met AWS Kinesis- of AWS MSK Kafka-onderwerpen om continu gestructureerde event- en profielgegevens op te nemen, waardoor naleving van schema's, schaalbaarheid en governance worden gegarandeerd?
Krachten
Dit patroon introduceert meerdere architectonische en operationele overwegingen:
- Beschikbaarheid van oorspronkelijke connector: Salesforce biedt algemeen beschikbare native connectoren voor zowel Amazon Kinesis als Amazon MSK. Deze connectoren bieden directe ondersteuning en elimineren de noodzaak van aangepaste op API gebaseerde pijplijnen.
- Authenticatie en beveiliging: Elke connector vereist authenticatie op AWS-niveau.
- Voor Kinesis gebruikt dit de AWS-toegangssleutel en de geheime sleutel, die onder IAM-beleid vallen.
- Voor MSK kan authenticatie worden geconfigureerd via Toegangssleutel/geheim of OpenID Connect (OIDC).
- Schemadefinitie: Data 360 vereist een schema om de streamingpayload te interpreteren. Voor Kinesis wordt het schemabestand geüpload tijdens het instellen van de verbinding, waarbij eventstructuur en veldtoewijzingen worden gedefinieerd.
- Configuratiebron:
- Kinesis-connector abonneert zich op een specifieke Kinesis-stroomnaam.
- MSK-connector abonneert zich op een Kafka-onderwerp binnen het MSK-cluster.
- Netwerktoegang: Voor veilige omgevingen kunnen connectoren worden geconfigureerd met PrivateLink- of VPC-routering, zodat er geen gegevens over het openbare internet gaan.
- Operationele governance: Streamingdoorvoer, schemavalidatie en authenticatie-events worden bewaakt binnen de Data 360 Trust Layer, wat naleving en traceerbaarheid garandeert.
Oplossing
De oplossing maakt gebruik van de eigen Amazon Kinesis- of Amazon MSK-connectoren binnen Data 360.
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Oorspronkelijke Kinese-connector | Beste | Eigen integratie met AWS Kinesis; ondersteunt continue opname met hoge doorvoer. |
| Native MSK-connector | Beste | Beheerde Kafka-opname met OIDC en ondersteuning voor op sleutels gebaseerde authenticatie. |
| Schematoewijzing en validatie | Best practice | Uploadschema (.json/.avro) dat de eventstructuur definieert; dwingt consistentie af tijdens opname. |
| IAM-configuratie | Aanbevolen | Wijs de IAM-rol met de minste rechten met alleen-lezen toegang toe aan de doel-Kinese-stroom of het MSK-onderwerp. |
| Privénetwerkroutering | Optioneel | Configureer PrivateLink-/VPC-eindpunten voor veilige, interne routering. |
| Hybride patroon (streaming + batch) | Optioneel | Gebruik streaming voor delta's en batchopname voor backfills of historische ladingen. |
| Foutisolatiemodus | Aanbevolen | Routeringsschema wijst fouten af en tijdelijke fouten naar DLQ voor opnieuw afspelen |
Schets
Dit diagram illustreert de volgorde van stappen voor het opnemen van de gegevens van eventplatforms zoals Kafka en Kinesis in Data 360 in nearReal-Time
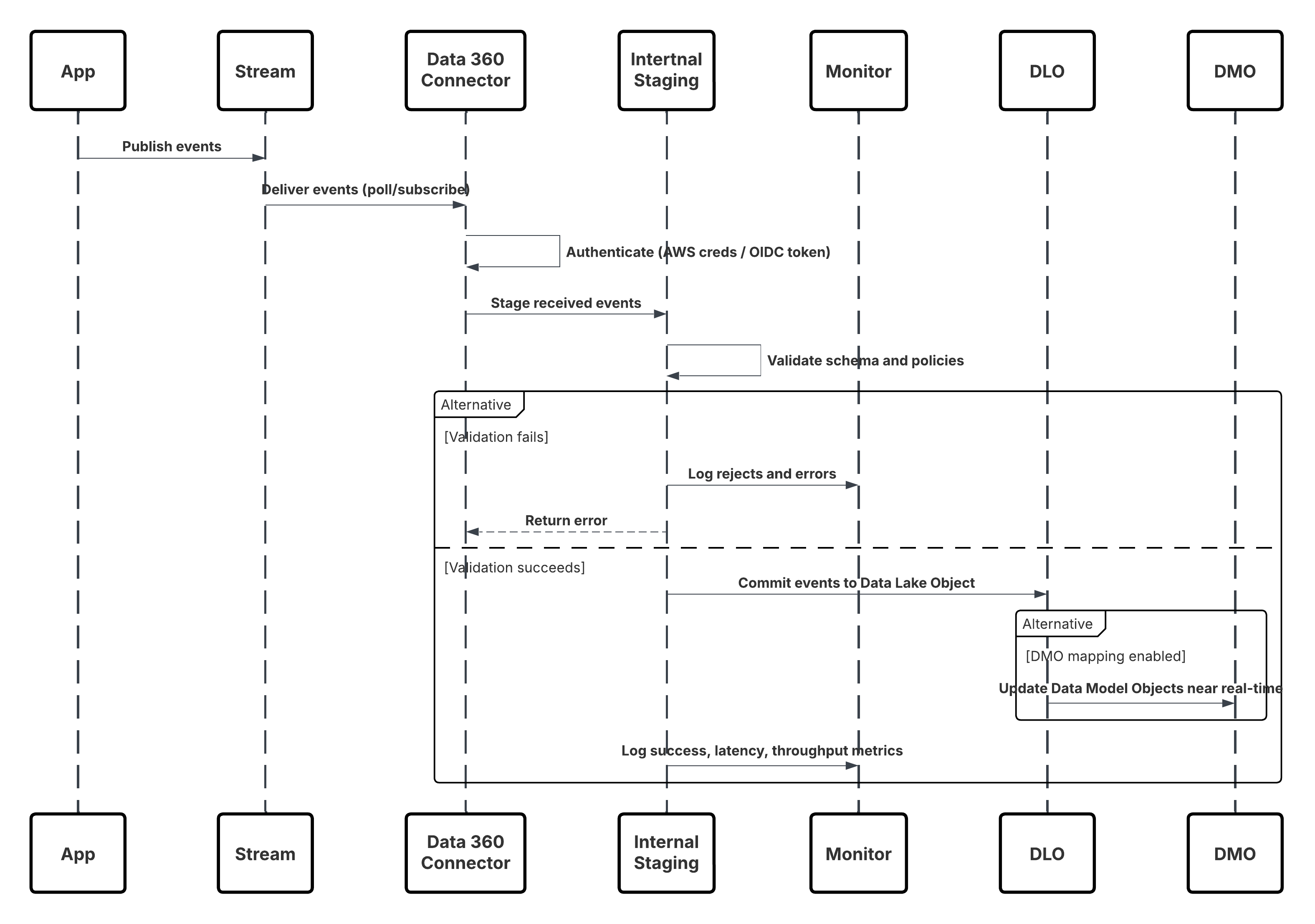
In dit scenario:
- Toepassingen of apparaten publiceren events naar Kinesis-stroom of MSK-onderwerp.
- Data 360-connector wordt geverifieerd met behulp van AWS-inloggegevens of OIDC-token.
- Connector voert continu opiniepeilingen uit of abonneert zich op de stroom.
- Events worden gefaseerd, gevalideerd voor schema en beleid, en vervolgens vastgelegd in Data Lake Object (DLO).
- Indien toegewezen, worden gegevensmodelobjecten (Data Model Objects, DMO's) in vrijwel realtime bijgewerkt voor activering.
- Bewakingslaag houdt meetgegevens, schemaafwijzingen en latentie bij.
Resultaten
Continue opname van gestructureerde gegevens met lage latentie rechtstreeks vanuit AWS Kinesis of MSK in Data 360. Gegevens zijn onmiddellijk beschikbaar voor:
- Identiteitsoplossing
- Realtime segmentering
- Einstein AI-activering
- Agentforce-driven Triggers Elimineert afhankelijkheid van batch-ETL, waardoor op stroom gebaseerde architecturen mogelijk worden die zijn afgestemd op eventgestuurde ontwerpen voor de onderneming.
Opnamemechanismen
| Mechanisme | Wanneer gebruiken |
|---|---|
| Kinesis-connector (voorkeur) | Voor AWS-native streamingbronnen die continue opname van gestructureerde gegevens met groot volume vereisen. |
| MSK-connector | Voor organisaties die eventpijplijnen uitvoeren op Kafka-compatibele platforms. |
| Hybride (Streaming + batch) | Voor incrementele eventopname in combinatie met periodieke bulkladingen. |
Afhandeling en herstel van fouten
- Automatisch opnieuw proberen: Connectoren proberen tijdelijke netwerk- of platformfouten opnieuw met exponentiële backoff.
- Schemaafwijzingen: Ongeldige payloads worden naar de afwijzingswachtrij van het schema gerouteerd voor beoordeling door de beheerder.
- DLQ Replay: Hardnekkige storingen worden vastgelegd in wachtrijen met dode letters voor opwerking.
- Idempotentiecontrole: Eventsleutels of volgnummers zorgen voor deduplicatie en geordende opname.
- Integratie bewaken: Alle mislukkingen, pogingen en doorvoermeetgegevens worden weergegeven in Data 360 Monitoring-dashboards.
Overwegingen bij impotent ontwerp
- Uniekheid en bijhouden van event: Aan elke event wordt een deterministische unieke sleutel toegewezen (bijv. PartitionKey + SequenceNumber voor Kinesis of Topic + Partition + Offset voor MSK) om te zorgen voor exacte eenmalige opname.
- Controlepunten van connector: Data 360-connectoren behouden het laatst verwerkte verschuivings- of volgordenummer om opname veilig te hervatten na mislukkingen of herstarts.
- Deduplicatie en UPSERT-logica: Tijdens DLO-verbintenissen worden duplicaatevents gedetecteerd en overgeslagen; geldige records worden ingevoegd met behulp van de unieke sleutel om consistentie te behouden.
- Controle over opnieuw afspelen en herstel: Mislukte of vertraagde events worden opnieuw afgespeeld vanuit opgeslagen verschuivingen via Dead-Letter- en Replay-wachtrijen, wat zorgt voor betrouwbaar herstel zonder dupliceren.
Beveiligingsoverwegingen
Beveiliging is een integraal onderdeel van de opnamepijplijn, van authenticatie tot encryptie en toegangscontrole.
- Authenticatie: Beveilig de uitwisseling van inloggegevens met behulp van AWS IAM-beleidsvormen of OIDC.
- Encryptie: Gegevens versleuteld onderweg (TLS 1.2+) en at rest (AES-256) binnen Data 360.
- Toegangscontrole: Rollen met de minste rechten afgedwongen; connectoren gericht op specifieke stromen/onderwerpen.
- Bestuur: Metagegevens voor afstamming en classificatie toegepast op elke record voor volledige traceerbaarheid.
- Netwerkbeveiliging: Implementeer optioneel binnen privésubnetten met behulp van AWS PrivateLink.
Sidebars
Tijdigheid
- Bijna realtime verwerking: CDC- en streamingconnectoren verwerken events binnen enkele seconden na bronwijzigingen, wat doorgaans zorgt voor versheid van gegevens in subminuten.
- Deterministische latentie: End-to-end vertraging is afhankelijk van brondoorvoer, eventbatching en netwerkomstandigheden, maar Data 360 garandeert voorspelbare SLA-gestuurde latentie voor ondersteunde objecten.
- Elastische schaal: De opnamepijplijn wordt automatisch geschaald bij groot eventvolume, waardoor de tijdigheid behouden blijft, zelfs tijdens piekgegevensbursts.
- Operationele zichtbaarheid: Bewakingsdashboards tonen eventvertraging, tijdstempels voor vastleggen en status voor opnieuw afspelen voor latentiezekerheid en probleemoplossing.
Gegevensvolumes
- Lichtgewicht payloads: Afzonderlijke CDC- of streamingevents zijn compact (doorgaans 1-5 kB groot), geoptimaliseerd voor updates met hoge frequentie.
- Objecten met grote verandering: Voor vluchtige entiteiten (bijv. Case, Contactpersoon, Order) moeten architecten ervoor zorgen dat CDC-toewijzingen en eventdoorvoer overeenkomen met de verwachte updatescores.
- Parallelle stromen: Data 360 ondersteunt opname van meerdere stromen voor horizontale schaalbaarheid over grote objectvolumes of meerdere bronorganisaties.
- Omgaan met tegendruk: Ingebouwde throttling-mechanismen handhaven de opnamestabiliteit onder belasting zonder events te laten vallen.
Statusbeheer
Elke event omvat metagegevens voor status- en versiebeheer:
- Opnieuw afspelen en verschuiving bijhouden: Elke event draagt Replay-ID en sequentiemetagegevens, waardoor bestelde levering en op controlepunten gebaseerd herstel mogelijk zijn.
- Schemaversiebeheer: Versietags binnen eventheaders zorgen voor terugwaarts compatibele verwerking wanneer bronschema's zich ontwikkelen.
- Idempotentiesleutels: Elke event bevat een unieke transactie- of commitsleutel, waardoor Data 360 herhalingen en pogingen veilig kan ontdubbelen.
- Atomic Commit: De opnamepijplijn markeert verschuivingen pas als voltooid wanneer downstream toezeggingen aan DLO's slagen, wat consistentie garandeert.
Complexe integratiescenario's
Dit patroon kan naadloos worden geïntegreerd in geavanceerde ondernemingsarchitecturen:
- Hybride opname: Combineer CDC voor incrementele delta's met bulkgegevensstromen voor volledige vernieuwingen, waarbij zowel versheid als volledigheid behouden blijft.
- Streaming tussen organisaties: Meerdere CRM- of ERP-organisaties kunnen publiceren naar dezelfde Data 360-belanghebbende, gecombineerd via DMO-toewijzing en ontologie-uitlijning.
- Eventverrijking: Middleware (bijv. MuleSoft, Event Relay) kan streaminggegevens verrijken, filteren of routeren voordat deze Data 360 bereiken.
- AI en Agentactivering: Realtime updates activeren downstream automatisering, zoals Einstein voorspellingen of Agentforce responsen, binnen enkele seconden na de oorspronkelijke event.
Voorbeeld
Een wereldwijde detailhandelsonderneming gebruikt AWS Kinesis voor het streamen van point-of-sale- en webinteractiegegevens.De Kinesis-connector van Data 360 authenticeert via IAM-inloggegevens en neemt continu events op in een transactie-DLO.Elke record wordt schemagevalideerd, verrijkt met metagegevens en onmiddellijk doorgevoerd naar het DMO Klant.Binnen enkele seconden werken Einstein AI-modellen klantsegmenten bij en activeert Agentforce real-time next-best-offer-aanbevelingen, waardoor een volledig eventgestuurde personalisatielus wordt bereikt.
Zero Copy is meer dan een integratiemethode. Het is een fundamentele verschuiving in de manier waarop ondernemingsgegevens worden verplaatst, of beter gezegd, niet worden verplaatst. Van oudsher vereiste gegevensintegratie het kopiëren van grote volumes records door ETL-pijplijnen, het maken van redundante gegevensopslagplaatsen, synchronisatievertragingen en governance-uitdagingen. Nul kopiëren elimineert dat alles. In dit model maakt Data 360 rechtstreeks verbinding met externe gegevensplatforms zoals Snowflake en Databricks, waarbij gegevens veilig worden gelezen en geactiveerd, zonder ze te verplaatsen of dupliceren. Het resultaat is een naadloze brug tussen het gegevens-lakehouse van uw onderneming en het Salesforce-ecosysteem, wat directe toegang, lagere operationele overhead en een sterkere gegevensgovernance biedt.
Met de mogelijkheden voor kopiëren met inkomende nul kan Data 360 een query uitvoeren op en externe gegevens harmoniseren bij de bron, zoals klantprofielen, transacties of productgegevens, die zijn opgeslagen in Snowflake of Databricks. In plaats van bestanden op te nemen, maakt Data 360 een veilige, metagegevensbewuste verbinding die gebruikmaakt van bestaande schemadefinities en beveiligingsbeleidsvormen in het externe magazijn.
- Directe bundeling: Data 360 leest gegevens op zijn plaats via veilige, geoptimaliseerde query's zonder replicatie.
- Gecombineerde governance: Gegevens blijven onder het raamwerk voor beveiliging, toegangscontrole en naleving van het bronsysteem.
- Operationele efficiëntie: Elimineert ETL-overhead en opslagduplicatie, waardoor kosten en complexiteit worden verminderd.
- Realtime gereedheid: Schakelt on-demand harmonisering in: zodra gegevens worden bijgewerkt in Snowflake, zijn ze onmiddellijk beschikbaar voor activering in Data 360.
Context
Moderne gegevensgestuurde ondernemingen beheren petabytes aan klant-, transactie- en telemetriegegevens binnen cloudschaal data lakehouse-platforms zoals Snowflake en Databricks. Deze omgevingen vormen de enige bron van waarheid voor analyses, AI en naleving. Data 360 introduceert Zero CopyData Federation, waarmee Data 360 rechtstreeks query's kan uitvoeren op externe gegevenssets en deze kan gebruiken, zonder redundante gegevens te kopiëren, transformeren of opslaan. Dit patroon stelt organisaties in staat om de Customer 360 fabric uit te breiden naar hun bestaande datawarehouse- of lakehouse-infrastructuur — waardoor real-time samenvoeging en activering wordt bereikt zonder duplicatie, zonder latentie en zonder compromissen op het gebied van governance.
Probleem
Hoe kunnen ondernemingen gebruikmaken van rijke gegevenssets die al zijn samengesteld in Snowflake, Databricks of open-lake-indelingen zoals Apache Iceberg – voor segmentering, identiteitsoplossing en activering in Data 360 – zonder de kosten, latentie en governance-overhead van ETL-pijplijnen of fysieke gegevensverplaatsing?
Krachten
Dit patroon introduceert meerdere overwegingen op het gebied van architectuur, beveiliging en prestaties:
Netwerk en beveiliging
- Data 360 moet een veilige, privéverbinding tot stand brengen met het externe magazijn of meerhuis.
- Doorgaans geconfigureerd met behulp van Salesforce Private Connect of PrivateLink/VPC Peering, zodat verkeer nooit het beheerde netwerk van de klant verlaat.
- Externe systemen moeten Data 360-IP's op een goedgekeurde lijst zetten en TLS 1.2+-encryptie afdwingen.
Authenticatie en toegangscontrole
- Ondersteunt authenticatie via sleutelpaar, OAuth 2.0 of op identiteitsleverancier (IdP) gebaseerde Trust delegatie (Data 360 fungeert als een vertrouwde client)
- Op rollen gebaseerde toegangscontrole (RBAC) in het externe systeem dwingt de toegang met de minste machtigingen af voor de uitvoering van query's.
Prestaties en afhankelijkheid berekenen
- Querybundeling duwt de SQL-uitvoering naar Snowflake of Databricks, waarbij gebruik wordt gemaakt van hun rekenclusters.
- Prestaties en kostenschaal met externe query's laden — segmenteringslatentie en kosten zijn gekoppeld aan externe berekeningsconfiguratie.
Evoluerende standaarden: Bestandsbundeling
- Een model van de volgende generatie, Bestandsbundeling, maakt gebruik van open tabelindelingen zoals Apache Iceberg of Delta Lake, waardoor Data 360 rechtstreeks kan worden gelezen vanuit objectopslag (bijvoorbeeld Amazon S3, Azure ADLS, Google Cloud Storage).
- Door de bronberekeningslaag te omzeilen, reduceert Bestandsbundeling de latentie en kosten voor zware analytische werkbelastingen drastisch, terwijl de schema-integriteit behouden blijft.
Governance en naleving
- Gegevens verlaten nooit het bronplatform — nalevings-, encryptie- en bewaarbeleid blijft gehandhaafd bij de oorsprong.
- Alle kenmerken van metagegevens, afkomst en instemming worden doorgevoerd in de Trust Layer van Data 360 om end-to-end traceerbaarheid te garanderen.
Oplossing
De aanbevolen benadering is native Zero Copy-connectoren te gebruiken voor Snowflake, Databricks of Bestandsbundeling binnen Data 360.
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Snowflake Zero Copy-connector | Best | Eigen integratie; brengt live querybundeling tot stand via Snowflake-API's voor delen van gegevens of externe tabellen. |
| Databricks Zero Copy-connector | Best | Ondersteunt directe live toegang tot tabellen/weergaven in Delta Lake; pushdownquery's worden uitgevoerd in Databricks-runtime. |
| Bestandsbundeling (Apache Iceberg / Delta / Parquet) | Opkomende best practices | Data 360 leest open tabelindelingen rechtstreeks uit objectopslag zonder externe rekenafhankelijkheid. Ideaal voor enorme gegevenssets. |
| Configuratie privénetwerk | Aanbevolen | Gebruik Salesforce Private Connect of VPC-peering voor veilige bundeling op netwerkniveau. |
| Authenticatie en sleutelbeheer | Best practice | Implementeer veilige op sleutels of OAuth gebaseerde authenticatie met periodieke rotatie en kluisbeheer. |
| Schemaregistratie | Verplicht | Data 360 haalt een extern schema op en wijst dit toe aan een extern gegevens-lakeobject (Extern DLO). |
| Geregelde metagegevens | Aanbevolen | Alle externe DLO's nemen classificatie, instemming en afstammingsmetagegevens over voor de zichtbaarheid van naleving. |
Schets
Het volgende diagram illustreert hoe u een nulkopieverbinding instelt en externe DLO's maakt in Data 360.
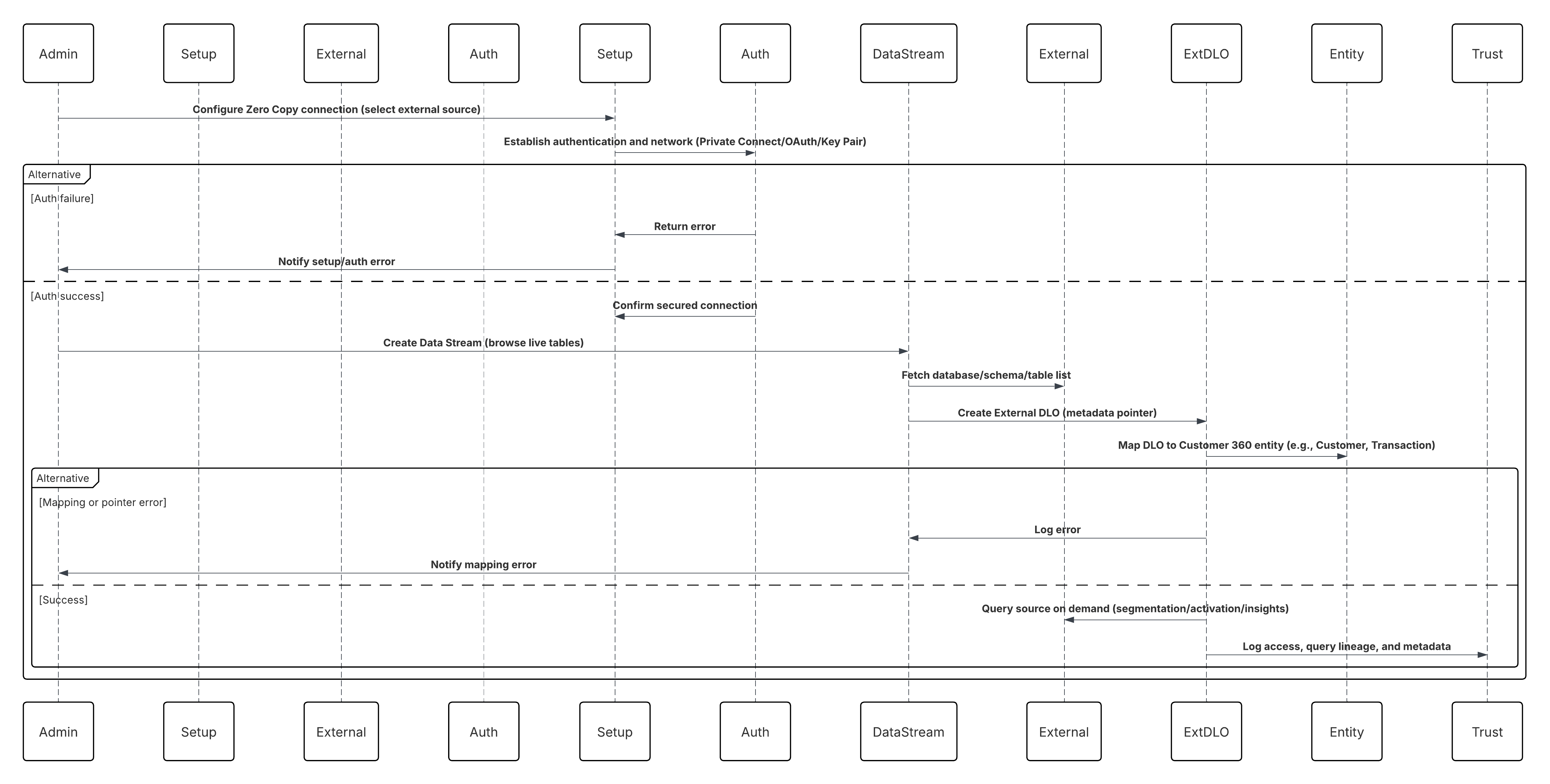
In dit scenario:
- Beheerder configureert een Zero Copy-verbinding in Set-up van Data 360 (Snowflake, Databricks of Bestandsbundeling).
- Veilige authenticatie en netwerkroutering worden tot stand gebracht (Private Connect / OAuth / Key Pair).
- Beheerder maakt een gegevensstroom door de externe bron te selecteren: bladeren in live databases, schema's en tabellen.
- In plaats van gegevens te kopiëren, maakt Data 360 een Extern DLO (Data Lake Object) — een metagegevenswijzer die verwijst naar de live tabel of het Iceberg-bestand.
- Externe DLO's worden toegewezen aan Customer 360 entiteiten (bijv. Customer, Transaction, Product).
- Data 360 voert een query uit op de bron die aanwezig is tijdens segmentering, activering of insightberekening.
- Alle toegang, queryafstamming en metagegevens worden gecontroleerd binnen de Data 360 Trust Layer.
Resultaten
- Externe gegevens blijven in Snowflake, Databricks of S3 — geen ETL, geen duplicatie, geen extra opslag.
- Data 360 krijgt realtime, leesbare toegang tot gegevens op ondernemingsniveau voor identiteitsoplossing, berekende insights en activering.
- Organisaties behouden volledige controle onder hun bestaande governance-, encryptie- en nalevingsframeworks.
- Dit patroon maakt een echte Zero Copy-architectuur mogelijk, waarbij de prestaties van lokale toegang worden gecombineerd met de governance van gebundelde opslag.
Aanroepmechanismen
Het aanroepmechanisme is afhankelijk van de oplossing die is gekozen om dit patroon te implementeren.
| Mechanisme | Wanneer gebruiken |
|---|---|
| Snowflake Federation (voorkeur) | Voor live, hoogwaardige querybundeling met gegevensmagazijnen voor ondernemingen. |
| Databricks Federation | Voor gecombineerde analyses en Lakehouse-omgevingen met door Delta of Parket ondersteunde gegevenssets. |
| Bestandsbundeling (Apache Iceberg / Delta Lake) | Voor grootschalige gegevenssets in objectopslag waarbij ontkoppeling van berekeningen en kostenoptimalisering essentieel zijn. |
| Hybride modus (nul kopiëren + opname) | Wanneer historische gegevens eenmalig moeten worden opgenomen, maar live gegevens toegankelijk zijn via Zero Copy. |
Afhandeling en herstel van fouten
- Automatische back-off voor opnieuw proberen en query's: Voorbijgaande connectiviteit of querytime-outs worden automatisch opnieuw geprobeerd met behulp van exponentiële back-off.
- Schema komt niet overeen met isolatie: Wijzigingen in het bronschema (bijv. nieuwe kolommen) worden vastgelegd in de wachtrij Schemaafwijzing; beheerders kunnen schemametagegevens opnieuw toewijzen of vernieuwen.
- Failover van authenticatie: Als inloggegevens verlopen, probeert Data 360 opnieuw verbinding te maken met behulp van opgeslagen vernieuwingstokens of sleutelrotatiebeleidsvormen.
- Beschikbaarheidsdetectie berekenen: Als Snowflake- of Databricks-clusters worden onderbroken, schort Data 360 bundeltaken en pogingen op wanneer de berekening wordt hervat.
- Integratie bewaken: Alle metagegevens over verbindingstoestand, querylatentie en afstamming zichtbaar in Data 360 Monitoring-dashboards.
Overwegingen bij impotent ontwerp
- Querydeterminisme: Gebundelde query's gebruiken consistente momentopnamesemantiek om stabiele, herhaalbare lezingen te garanderen tijdens segmentering of activering.
- Externe DLO-versiebeheer: Elke gebundelde query omvat schema- en tijdstempelmetagegevens voor het bijhouden van de afstamming.
- Offset-less toegang: Aangezien Zero Copy alleen-lezen is, is het niet afhankelijk van eventverschuivingen — consistentie wordt afgedwongen via de ACID-garanties van het externe systeem (Snowflake/Delta Lake).
- Schemadriftbeheer: Onderhoud schematoewijzingen met versiebeheer in Data 360; vernieuw externe DLO-metagegevens over bronevolutie.
Beveiligingsoverwegingen
Beveiliging is integraal in het hele bundelingsmodel en garandeert geen compromissen in Trust of naleving.
- Encryptie: Alle gegevensuitwisselingen gebruiken TLS 1.2+; externe magazijnen versleutelen at rest met behulp van AES-256.
- Toegangscontrole: Externe tabellen zijn toegankelijk via rollen met de minste machtigingen met alleen-lezen machtigingen.
- Netwerkisolatie: Private Connect- of VPC-routes voorkomen blootstelling aan openbare eindpunten.
- Geregeerde gegevensstroom: Metagegevens voor afstamming, instemming en classificatie stromen naar de Data 360 Trust Layer voor het afdwingen van beleid.
- Controleerbaarheid: Elke gebundelde query en schematoegangsevent wordt vastgelegd voor traceerbaarheid van naleving (GDPR, CCPA, HIPAA).
Sidebars
Tijdigheid
- Query's worden live uitgevoerd vanuit het externe magazijn of de externe opslag, wat zorgt voor realtime zichtbaarheid van de meest actuele gegevensstatus.
- Segmenterings- of activeringsuitvoeringen weerspiegelen tot op de seconde nauwkeurig wijzigingen in Snowflake-, Databricks- of door S3 ondersteunde Iceberg-tabellen.
- Querylatentie is afhankelijk van de prestatielaag van het bronsysteem, doorgaans seconden tot tientallen seconden per query.
- Ideaal voor analytische en AI-werkbelastingen die toegang vereisen tot "verse, niet gekopieerde" gegevens.
Gegevensvolumes
- Ondersteunt gegevenssets op petabyteschaal die intern zijn opgeslagen in Snowflake of Databricks zonder replicatie.
- Data 360 haalt alleen resultaten op — geen ruwe gegevenssets — waardoor netwerk- en berekeningskosten worden geminimaliseerd.
- Bestandsbundeling optimaliseert grote analytische scans door middel van partition pruning en columnar pushdown.
- Schaalt lineair met de rekencapaciteit van het magazijn en de gebundelde querycombinatielaag van Data 360.
Statusbeheer
- Externe DLO's behouden verbindings-, schema- en versiemetagegevens in Data 360.
- Schema-evolutie wordt automatisch beheerd via vernieuwingscycli voor metagegevens.
- Queryafstamming omvat tijdstempels, gebruikersidentiteit en uitvoeringsmeetgegevens voor traceerbaarheid.
- Er worden geen statelijke opname of verschuivingen gehandhaafd — consistentie wordt overgenomen van de ACID-garanties van de externe bron.
Complexe integratiescenario's
- Hybride modus: Combineer Zero Copy (voor live bundeling) met opname (voor historische gegevenssets).
- Toegang tot cross-warehouse: Data 360 kan worden gebundeld vanuit meerdere Snowflake- of Databricks-belanghebbenden binnen één organisatie.
- AI/BI-interoperabiliteit: Externe systemen (bijvoorbeeld SageMaker, Tableau, Power BI) kunnen verrijkte profielen van Data 360 terugvragen via reverse Zero Copy.
- Bestandsbundeling extensie: Ondernemingen die open-lake-indelingen (Iceberg/Delta) gebruiken, kunnen gestructureerde en ongestructureerde gegevens combineren in één gebundeld model.
Voorbeeld
Een wereldwijde financiële onderneming slaat alle transactie- en interactiegegevens op in Snowflake, terwijl klantkenmerken en marketingevents worden onderhouden in Data 360. Met behulp van Zero Copy Data Federation maakt Data 360 veilig verbinding met Snowflake via Privé verbinden.Wanneer een segmenteringstaak wordt uitgevoerd, bijvoorbeeld "Klanten met een uitgaven van >$10K in de afgelopen 30 dagen, pusht Data 360 de query naar Snowflake, haalt deze geaggregeerde resultaten op en activeert deze profielen onmiddellijk in Journey Builder. Geen replicatie of ETL nodig. In dit voorbeeld wordt gebruikgemaakt van realtime, gebundelde intelligentie die is gecombineerd binnen het gegevensecosysteem van de onderneming.
Uitgaande nulkopie breidt hetzelfde principe omgekeerd uit. In plaats van gegevenssets te exporteren of kopiëren vanuit Data 360, kunnen externe systemen zoals Snowflake rechtstreeks een query uitvoeren op Data 360 en deze beschouwen als een gebundelde bron van verrijkte Klantenintelligence.
- Omgekeerde bundeling: Externe analyses of AI-platforms hebben toegang tot gecombineerde profielgegevens van Data 360 zonder deze te extraheren.
- Gegevensactivering bij bron: Bedrijfsteams kunnen insights benutten waar de gegevens al aanwezig zijn, of het nu gaat om AI-modellering, rapportage of personalisering van klanten.
- Laattijdsvrije interoperabiliteit: Geen batchexports of synchronisatietaken; insights stromen onmiddellijk tussen platforms.
- Consistente semantiek: Omdat beide systemen dezelfde ontologie en schematoewijzingen hebben, blijven context en betekenis binnen ecosystemen behouden. Zero copy definieert de rol van Data 360 opnieuw van een gegevensopslagplaats naar een semantische activeringslaag. Het stelt organisaties in staat om gegevens precies daar te houden waar ze thuishoren – in beheerde, hoogwaardige magazijnen – en toch de volledige waarde binnen de Trust grens van Salesforce te ontsluiten. Dit patroon komt overeen met moderne data mesh en AI-native architecturen: gegevens blijven gedecentraliseerd, maar intelligentie wordt gecombineerd. Architecten kunnen nu activeringspijplijnen samenstellen die sneller, slanker en meer conform zijn — kopiëren is niet nodig.
Context
Moderne ondernemingen werken steeds vaker in gegevensecosystemen met meerdere platforms, waar Salesforce Data 360 gecombineerde klantprofielen en activering aanstuurt, terwijl gegevenswarehouses voor ondernemingen zoals Snowflake of Databricks dienen als analytische ruggengraat voor gegevenswetenschappen, machine learning en BI-werkbelasting. Salesforce Data 360's mogelijkheid voor uitgaand delen zonder kopiëren overbrugt deze omgevingen naadloos, waardoor rechtstreeks binnen Snowflake of Databricks beheerde, veilige en real-time toegang tot geharmoniseerde Data 360-gegevens mogelijk is, zonder replicatie of ETL. Hierdoor kunnen analisten en datawetenschappers query's uitvoeren op, visualiseren van en modelleren op dezelfde live, vertrouwde gegevens die marketing, verkoop en serviceactivering aansturen.
Probleem
Hoe kan een onderneming de gecombineerde klantprofielen en berekende meetgegevens van Data 360 (bijvoorbeeld Levenswaarde, Verlooprisico) veilig en efficiënt zichtbaar maken voor externe analytische systemen, zonder gegevens te kopiëren, governance te doorbreken of latentie te introduceren via traditionele reverse ETL-pijplijnen?
Krachten
Dit patroon introduceert meerdere architectonische, governance- en operationele overwegingen:
- Geregelde beveiliging: Toegang tot Data 360-gegevens moet gecontroleerd, fijnmazig en controleerbaar zijn. Delen met nul kopieën gebruikt expliciete toegang op objectniveau, waardoor alleen goedgekeurde gegevensmodelobjecten (Data Model Objects, DMO's) en berekende insightobjecten (CIO's) beschikbaar zijn voor aangewezen consumenten.
- Expliciete objectselectie: Beheerders beheren deelbare gegevens via Gegevens delen, waarbij ze expliciet selecteren welke objecten zichtbaar moeten worden gemaakt. Dit handhaaft governance en minimaliseert risicoblootstelling.
- Bi-laterale configuratie: Zowel Data 360 als het externe magazijn vereisen set-up. Data 360 definieert het doel voor het delen van gegevens (Snowflake/Databricks), terwijl het ontvangende systeem het delen moet accepteren en instantiëren.
- Querybundelmodel: Eenmaal geaccepteerd, voert het externe platform een query uit op live, beheerde Data 360-gegevens via gebundelde weergaven, waardoor extractietaken of handmatige vernieuwingscycli worden geëlimineerd.
- Evolutie van open standaarden: Opkomende benaderingen zoals Bestandsbundeling maken gebruik van open tabelindelingen (bijvoorbeeld Apache Iceberg) om alleen-lezen toegang op de opslaglaag in te schakelen, wat de schaalbaarheid, prestaties en interoperabiliteit binnen multi-cloudarchitecturen verbetert.
Oplossing
De oplossing maakt gebruik van Salesforce Data 360’s native Zero Copy Sharing met gegevensplatforms zoals Snowflake of Databricks.
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Aanmaken van gegevens delen | Best | Beheerder maakt een Gegevens delen binnen Data 360 en voegt geselecteerde DMO's en CIO's toe (bijv. Gecombineerd individu, Klantgezondheidsscore). |
| Doelconfiguratie | Best | Maak een doel voor het delen van gegevens door Snowflake- of Databricks-account-ID's en authenticatieparameters op te geven. |
| Publiceren delen | Best practice | Koppel Gegevens delen aan Doel voor gegevens delen om veilig te publiceren. |
| Magazijnacceptatie | Verplicht | De externe beheerder accepteert het delen en realiseert gedeelde objecten als alleen-lezen weergaven/tabellen in het magazijn. |
| Granulaire toegangscontrole | Aanbevolen | Pas object- en rolgebaseerde machtigingen toe binnen Data 360; stem deze af op op rollen gebaseerde toegangscontrole op magazijnniveau. |
| Toegang tot gebundelde query | Best | Analisten voeren query's uit op live gedeelde gegevens via standaard-SQL; joins met native magazijngegevens voor analyses verderop in de stroom en ML. |
| Optie Bestandsbundeling | Optioneel | Gebruik voor grote gegevenssets op Apache Iceberg gebaseerde bundeling voor direct S3- of Delta Lake-lezen zonder rekenafhankelijkheid. |
Schets
Het volgende diagram toont een aanroep vanuit Salesforce Data 360 naar een extern gegevensplatform.
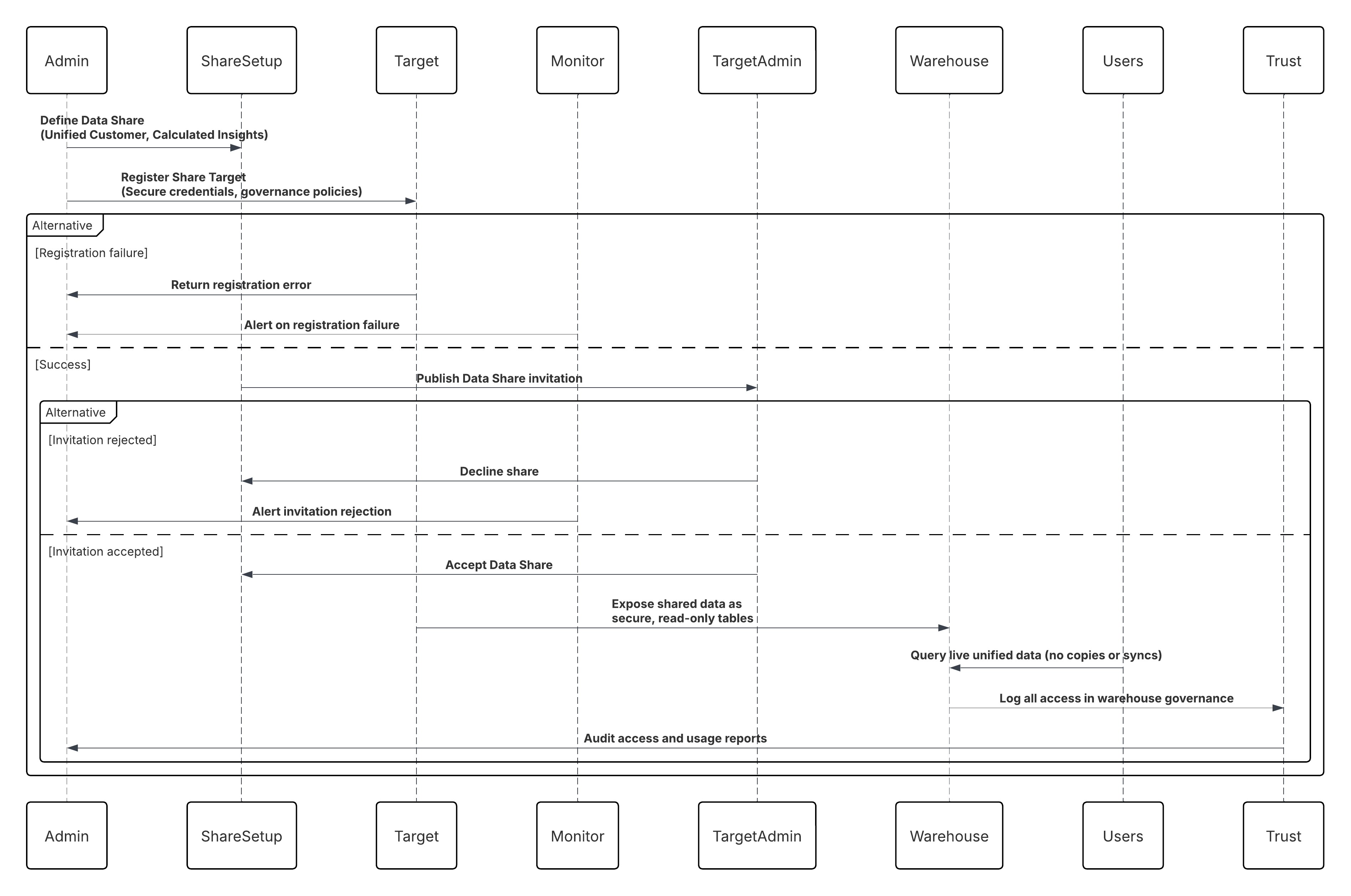
In dit scenario:
- De Data 360-beheerder definieert een Gegevens delen inclusief objecten Gecombineerde klant en Berekende insight.
- Een doel voor het delen van gegevens (Snowflake- of Databricks-account) wordt geregistreerd met veilige inloggegevens en governancebeleid.
- Data 360 publiceert de share; Snowflake-/Databricks-beheerders accepteren deze.
- Gedeelde gegevens worden weergegeven als veilige, alleen-lezen tabellen binnen het magazijn.
- Analisten, BI-tools of ML-pijplijnen voeren een query uit op de live, gecombineerde klantgegevens zonder te kopiëren of synchroniseren.
- Alle toegang wordt gecontroleerd binnen de logboeken van Data 360 Trust Layer en warehouse governance.
Resultaten
- Externe magazijnen krijgen real-time, opvraagbare toegang tot geharmoniseerde Data 360-gegevens.
- Elimineert Reverse ETL-pijplijnen, waardoor operationele lasten en latentie worden verminderd.
- Schakelt AI/ML-training, voorspellend modelleren en geavanceerde BI rechtstreeks in voor gecombineerde gegevens.
- Handhaaft nul duplicatie, sterke governance en toegangscontrole die veilig is door het ontwerp.
- Voltooit de bidirectionele Zero Copy-lus, waarbij inkomende bundeling en uitgaand delen naast elkaar bestaan onder één governance-model.
Aanroepmechanismen
Het aanroepmechanisme is afhankelijk van de oplossing die is gekozen om dit patroon te implementeren.
| Mechanisme | Wanneer gebruiken |
|---|---|
| Veilig delen van Snowflake-gegevens (voorkeur) | Gebruik dit wanneer uw bedrijfswarehouse Snowflake is en u live, gecontroleerde toegang nodig hebt tot geharmoniseerde Data 360-gegevenssets zonder gegevensverplaatsing of duplicatie. Ideaal voor analyses, AI en nalevingsgestuurde werkbelastingen die delen zonder latentie en native afdwinging van afstamming vereisen. |
| Databricks Delta delen | Gebruik dit wanneer downstreamconsumenten actief zijn in Databricks- of Delta Lake-omgevingen en realtime, alleen-lezen toegang nodig hebben tot gecombineerde of geactiveerde gegevenssets via het open Delta Sharing-protocol. |
| Extern tabelaandeel (Apache Iceberg / Parket) | Gebruik dit wanneer u open-format architecturen onderhoudt in objectopslag (S3, ADLS of GCS) en interoperabel, goedkoop delen nodig hebt tussen analytische engines zoals Athena, BigQuery of Snowflake-on-Iceberg. |
| API voor delen van gegevens (programmatische toegang) | Gebruik dit wanneer aangepaste apps of middleware (bijvoorbeeld MuleSoft) gedeelde gegevenssets veilig moeten ontdekken, abonneren of verbruiken via API's, met op events gebaseerde vernieuwingskennisgevingen en verfijnde toegangscontrole. |
| Hybride aandeel (nulkopie + uitgaand aandeel) | Gebruik dit bij het implementeren van bidirectionele uitwisselingspatronen: gebruik Zero Copy voor inkomende gegevens en Uitgaande gegevens delen voor het publiceren van insights, wat zorgt voor semantische en governanceconsistentie in alle ondernemingsgegevensvlakken. |
Afhandeling en herstel van fouten
- Verbindingspogingen: Geautomatiseerde pogingen voor tijdelijke verbindings- of authenticatiefouten tussen Data 360 en magazijn.
- validatie van delen: Ongeldige of ongeoorloofde shareconfiguraties worden in quarantaine geplaatst in een wachtrij Beoordeling door beheerder.
- Bewaking van synchronisatietoestand: Data 360 biedt live status voor delen, querylatentie en toegangslogboeken via Bewakingsdashboards.
- Intrekking van toegang: Beheerders kunnen shares onmiddellijk intrekken, waarbij toegang aan beide zijden wordt uitgeschakeld zonder kopieën van resterende gegevens.
- Beheerd controletraject: Alle configuratie- en toegangswijzigingen worden vastgelegd voor nalevingsverificatie.
Overwegingen bij impotent ontwerp
- Consistente identificatie van delen: Elk Gegevens delen- en Gegevens delen-doelpaar heeft een unieke identifier, wat zorgt voor exacte governance en traceerbaarheid van toegang.
- Onveranderlijke weergaven: Gedeelde gegevensobjecten zijn alleen-lezen; consumenten kunnen status niet muteren, wat deterministische resultaten en naleving garandeert.
- Levenscyclus van Atomic Share: Publiceren, intrekken en bijwerken van aandelen zijn atomaire bewerkingen — volledig voltooid of teruggedraaid.
- Consistentie voor opnieuw afspelen: Wanneer Data 360-gegevens worden vernieuwd, retourneren query's aan magazijnzijde altijd de meest recente consistente momentopname, waardoor verouderde leesbewerkingen worden geëlimineerd.
Beveiligingsoverwegingen
Beveiliging ondersteunt elk aspect van Zero Copy Sharing:
- Authenticatie: Mutual Trust opgericht met behulp van OAuth 2.0, uitwisseling van persoonlijke sleutels of identiteitsbundeling (OIDC).
- Encryptie: Gegevens versleuteld onderweg (TLS 1.2+) en in ruste (AES-256).
- Toegangscontrole: Machtigingen op objectniveau dwingen toegang met de minste machtigingen af; beheerd door de Data 360 Trust Layer.
- Netwerkbeveiliging: Gegevensuitwisseling vindt plaats via privénetwerkkoppelingen zoals Salesforce Private Connect of Secure Data Exchange-API's.
- Governance-metagegevens: Elk gedeeld object draagt kenmerken van afstamming, classificatie en instemming voor volledige traceerbaarheid en naleving van regelgeving.
Sidebars
Tijdigheid
- Beschikbaarheid in realtime: Gedeelde gegevens geven de meest actuele status van Data 360 weer zonder replicatievertragingen.
- Queryversheid: Wijzigingen in DMO's of CIO's worden onmiddellijk doorgevoerd naar gedeelde magazijnweergaven.
- Prestatie-elasticiteit: Querypushdown past zich dynamisch aan resources van magazijnberekeningen aan.
- Bewaking: Live dashboards tonen gedeelde latentie en queryprestatiemeetgegevens voor operationele zekerheid.
Gegevensvolumes
- Schaalbaar delen: Ondersteunt fijnmazig delen van gegevens op objectniveau of volledig domein, afhankelijk van analytische behoeften.
- Geoptimaliseerde queryprestaties: Snowflake/Databricks slaan gedeelde gegevens intelligent in het cachegeheugen op om de latentie te minimaliseren.
- Opslagefficiëntie: Geen duplicatie elimineert redundante opslagkosten.
- Optie bestandsbundeling: Voor gegevenssets op petabyteschaal omzeilt direct delen op basis van Iceberg berekeningen en versnelt het de toegang.
Statusbeheer
- Schema-evolutie: Versiegestuurde schema's zorgen voor compatibiliteit wanneer het Data 360-model wordt ontwikkeld.
- Toegangsstatus bijhouden: Statussen voor actief/inactief delen die worden onderhouden binnen Data 360 voor levenscyclusbeheer.
- Synchronisatie van metagegevens: Updates van gedeelde objectdefinities worden automatisch doorgevoerd in magazijncatalogi verderop in de stroom.
- Garantie van onroerende staat: Magazijnweergaven vertegenwoordigen altijd een consistente, punt-in-tijd status van Data 360-gegevens.
Complexe integratiescenario's
- Hybride modus: Combineer Zero Copy (voor live bundeling) met opname (voor historische gegevenssets).
- Toegang tot cross-warehouse: Data 360 kan worden gebundeld vanuit meerdere Snowflake- of Databricks-belanghebbenden binnen één organisatie.
- AI/BI-interoperabiliteit: Externe systemen (bijvoorbeeld SageMaker, Tableau, Power BI) kunnen verrijkte profielen van Data 360 terugvragen via reverse Zero Copy.
- Bestandsbundeling extensie: Ondernemingen die open-lake-indelingen (Iceberg/Delta) gebruiken, kunnen gestructureerde en ongestructureerde gegevens combineren in één gebundeld model.
Voorbeeld
Met cross-cloud analyses kunnen organisaties beheerde Salesforce Data 360-gegevens combineren met native gegevenssets in platforms zoals Snowflake en Databricks om een volledige, 360-graden analytische weergave te bieden. Via toegang voor meerdere belanghebbenden kunnen verschillende bedrijfseenheden op een veilige manier beheerde en beleidsgestuurde gegevensslices gebruiken via afzonderlijke shares zonder gegevens te dupliceren. Datawetenschappers kunnen vervolgens gebundelde AI en machine learning uitvoeren door modellen rechtstreeks op gecombineerde klantprofielen binnen Snowflake ML- of Databricks ML-stroomomgevingen te trainen. Gedurende dit hele proces zorgen ingebouwde afstammings-, governance- en controlemogelijkheden ervoor dat alle gegevenstoegang en -gebruik conform ondernemingsbeleid en wettelijke vereisten zoals AVG en HIPAA blijven.
Met Data Cloud One kunnen organisaties met meerdere Salesforce-organisaties (bijvoorbeeld vanwege bedrijfseenheden, regio's, productlijnen of overnames) één centraal Data 360-exemplaar delen. Deze organisatie fungeert als de "thuisorganisatie", terwijl andere organisaties, die "gezelschapsorganisaties" worden genoemd, toegang hebben tot die gecombineerde gegevens en daarop actie kunnen ondernemen — met minimale inspanning, geen aangepaste code en volledige governance-controles.
Context
Ondernemingen beheren vaak meer dan één Salesforce-organisatie (bijvoorbeeld een voor verkoop, een voor service, een voor marketing of afzonderlijke regio's). Elke organisatie kan zijn eigen gegevens, configuratie en processen hebben. Vóór Data Cloud One vereiste elke organisatie een eigen Data 360-set-up of complexe aangepaste code om gegevens te delen tussen organisaties. Data Cloud One vereenvoudigt dit door één "thuis"-organisatie toe te staan met Data 360 en meerdere "metgezel"-organisaties die verbinding maken via configuratie met weinig code en het delen van metagegevens.
Probleem
Hoe kan een bedrijf consistent gebruik mogelijk maken van de gecombineerde Customer 360 gegevens—opgenomen, geharmoniseerd en beheerd door Data 360 van de thuisorganisatie—binnen al zijn Salesforce-organisaties (zodat verkoop, marketing, service, enz. allemaal dezelfde onderliggende gegevens gebruiken), zonder daarbij dubbele inspanningen, aangepaste codering, afzonderlijke Data 360-exemplaren per organisatie en hiaten in governance te hoeven doen?
Krachten
Dit patroon introduceert meerdere overwegingen op het gebied van architectuur, beveiliging en prestaties:
- Complexiteit voor meerdere organisaties: De organisatie van elke bedrijfseenheid kan verschillende gegevens, aangepaste objecten, beveiliging en processen hebben—het onderhouden van consistente gecombineerde weergaven is moeilijk.
- Duplicatie & kosten: Het uitvoeren van een afzonderlijk Data 360-exemplaar per organisatie betekent extra set-up, extra governance, extra licenties en risico op gegevenssilo's.
- Besturing en besturingselementen voor het delen van gegevens: U moet bepalen welke gegevens elke begeleidende organisatie kan zien en gebruiken. U kunt niet zomaar "alles" delen zonder governancerisico.
- Snelheid van instellen: Marketing-, verkoop- of serviceteams kunnen geen weken wachten op aangepaste code om gegevens tussen organisaties beschikbaar te maken. Ze hebben oplossingen voor klikconfiguratie nodig.
- Gegevensverblijf, regionale overwegingen: Als thuis- en gezelschapsorganisaties zich in verschillende regio's bevinden, kunnen er wettelijke of reglementaire beperkingen zijn over waar gegevens worden opgeslagen of hoe ze worden gedeeld.
Oplossing
De volgende tabel bevat diverse oplossingen voor dit integratieprobleem.
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Thuisorganisatievoorzieningen | Best | Wijs één Salesforce-organisatie aan als de thuisorganisatie waar Data 360 wordt geleverd; dit wordt de centrale gegevensopslagplaats en governancehub. |
| Verbinding met bedrijfsorganisatie | Best | Configureer Companion-verbindingen vanuit de thuisorganisatie met een of meer Companion-organisaties via de Data Cloud One-app — geen aangepaste code vereist. |
| Definitie van gegevensruimte | Best practice | Definieer gegevensruimten binnen de thuisorganisatie om gegevens logisch te segmenteren (bijv. Detailhandel, Service, Marketing) en toegangsgrenzen te isoleren. |
| Delen van gegevensruimte | Best | Deel geselecteerde gegevensruimten expliciet vanuit de thuisorganisatie met gezelschapsorganisaties, zodat op rollen gebaseerde zichtbaarheid van gecombineerde gegevens wordt gegarandeerd. |
| Toegangsconfiguratie | Verplicht | Schakel in Companion-organisaties de Data Cloud One-app in en wijs gebruikersmachtigingen toe voor profiel-, insight- en segmenttoegang. |
| Governance en beleidscontrole | Aanbevolen | Centraliseer alle opname-, identiteitsoplossings- en Trust configuraties in de thuisorganisatie, met behoud van end-to-end governance. |
| Synchronisatie voor meerdere organisaties | Best | Gegevenswijzigingen en berekende insights in de thuisorganisatie worden weergegeven in Real-time binnen Companion-organisaties via beheerde synchronisatiepijplijnen. |
| Optie voor hybride implementatie | Optioneel | Voor grote ondernemingen kunnen meerdere Companion-organisaties verbinding maken met één thuisorganisatie, terwijl de lokale context en nalevingsgrenzen behouden blijven. |
Schets
Het volgende diagram illustreert de volgorde van events in dit patroon, waarbij Salesforce het gegevenshoofdmodel is.
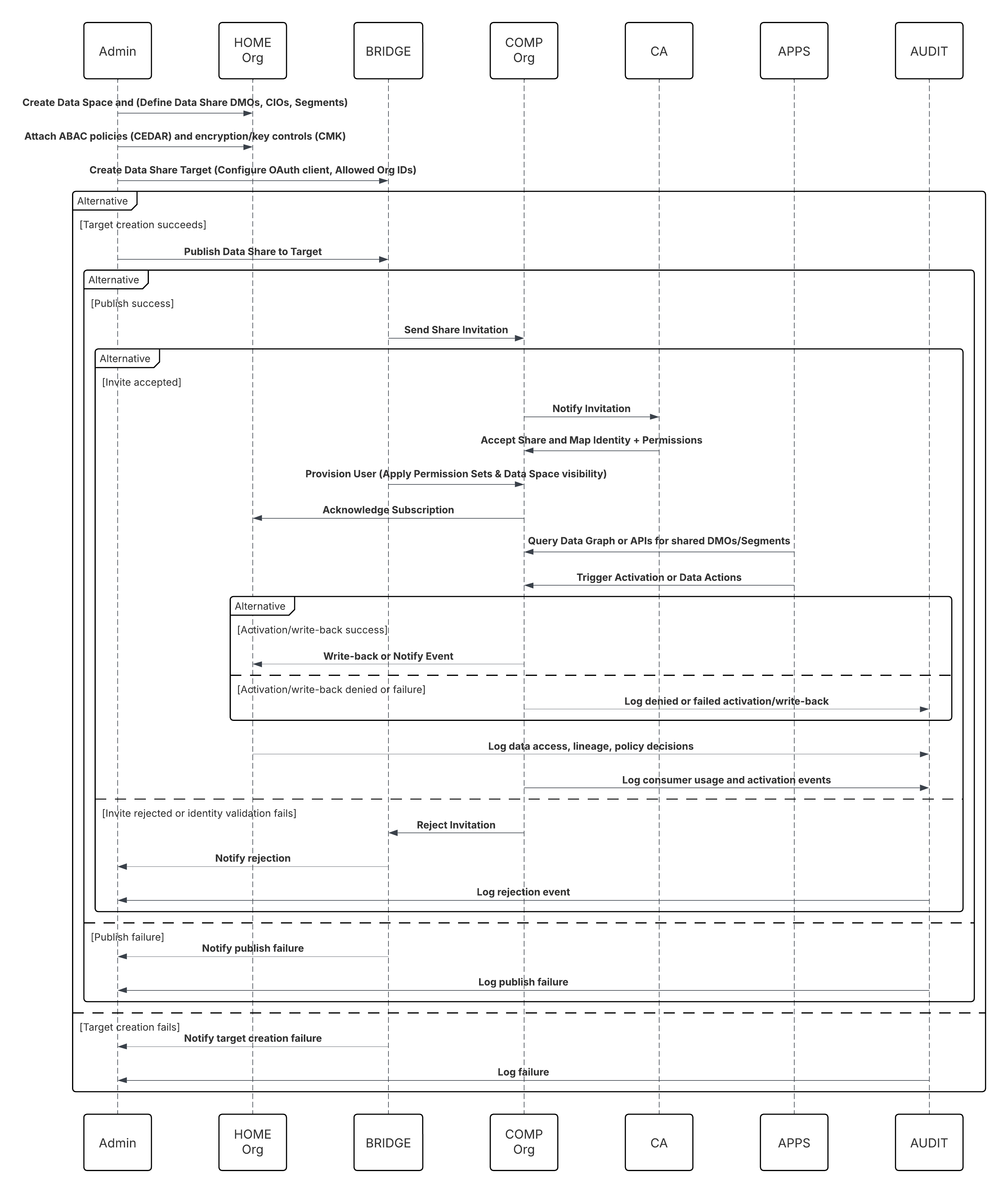
In dit scenario:
- Hoofdpaginabeheerder: maak gegevensruimte en definieer Gegevens delen (selecteer DMO's/CIO's, segmenten).
- Hoofdpaginabeheerder: maak Doel voor delen van gegevens voor Companion-organisatie(s) en configureer Trust (OAuth-client, toegestane organisatie-ID's).
- Hoofdpaginabeheerder: gegevens delen publiceren naar doel; ABAC-beleid (CEDAR) en encryptie-/sleutelbesturingselementen (CMK indien nodig) bijvoegen.
- Beheerder van bedrijfsorganisatie: ontvangt uitnodiging, valideert identiteitstoewijzing en accepteert delen.
- Bedrijfsorganisatie: Data Cloud One Bridge biedt een Data Cloud One-gebruiker en past de zichtbaarheid van machtigingensets en gegevensruimte toe.
- Apps voor bedrijfsorganisaties (stromen / Einstein / Apex): Voer een query uit op een gegevensgrafiek of roep Data Cloud One-API's aan om gedeelde DMO's of segmenten te lezen.
- Activering: De Companion-organisatie activeert activering of schrijft terug via gegevensacties (indien toegestaan).
Resultaten
- Eén enkele waarheidsbron voor klantgegevens (Customer 360) binnen alle verbonden organisaties — geen redundante Data 360-exemplaren.
- Een snellere time-to-value. Companion-organisaties hebben binnen enkele minuten toegang tot gecombineerde gegevens en door Data 360 aangestuurde voorzieningen, niet weken aan aangepaste codering.
- Gecontroleerd delen van gegevens. Alleen geautoriseerde gegevensruimten worden gedeeld, waardoor beveiliging en governance behouden blijven en bedrijfsflexibiliteit mogelijk is.
- Bedrijfsfuncties (verkoop, service, marketing) werken op dezelfde gecombineerde gegevensbasis, waardoor consistente meetgegevens, activering en insights binnen de hele onderneming mogelijk zijn.
Aanroepmechanismen
Het aanroepmechanisme is afhankelijk van de oplossing die is gekozen om dit patroon te implementeren.
| Mechanisme | Wanneer gebruiken |
|---|---|
| Data Cloud One Native Share (voorkeur) | Gebruik dit wanneer meerdere Salesforce-organisaties (Sales, Service of Industry Clouds) realtime toegang nodig hebben tot gecombineerde klantgegevens rechtstreeks vanuit Data 360\. Dit elimineert replicatie en biedt zero-latency toegang tot Golden Records, segmenten en berekende insights. |
| Delen tussen organisaties via Data Cloud One Bridge | Gebruik dit wanneer meerdere bedrijfseenheden of dochterondernemingen in afzonderlijke Salesforce-organisaties werken, maar gedeelde toegang tot gemeenschappelijke klantgegevens en segmenten nodig hebben vanuit een centraal Data 360-exemplaar. Ideaal voor ondernemingen met meerdere organisaties die onafhankelijke operationele systemen onderhouden. |
| Einstein 1 Platform Query-API's | Gebruik dit wanneer Salesforce-apps, Flow of Einstein Copilot programmatisch een query moeten uitvoeren op of Data 360-gegevens moeten activeren. Hiermee kunt u in realtime gecombineerde profielen, meetgegevens of activeringsresultaten ophalen naar andere Salesforce-toepassingen zonder batchexports. |
| Activering naar Salesforce-kanalen | Gebruik dit wanneer Data 360-gegevens (segmenten, insights of kenmerken) moeten worden geactiveerd naar Marketing Cloud, Service Cloud of Commerce Cloud voor personalisering, campagne-uitvoering of ervaringen van agenten. |
| Toegang tot gegevensgrafiek (semantische querylaag) | Gebruik dit wanneer u toegang op semantisch niveau tot het gecombineerde gegevensmodel nodig hebt via de Salesforce-gegevensgrafiek, die Copilot, AI-werkstromen en cross-cloud analyses in realtime ondersteunt, zonder handmatige joins of transformaties. |
Afhandeling en herstel van fouten
- Veerkracht voor synchronisatie tussen organisaties: Data Cloud One probeert mislukte synchronisatietaken tussen Thuis- en Companion-organisaties automatisch opnieuw met behulp van exponentiële backoff voor tijdelijke netwerk- of platformfouten.
- Gedeeltelijke batchisolatie: Mislukte recordbatches worden in quarantaine geplaatst in een wachtrij voor opnieuw proberen binnen de hoofdorganisatie totdat de afstemming is geslaagd, waardoor gegevensverschillen worden voorkomen.
- Governance voor schemaafwijzing: Schema- of toewijzingsfouten worden naar de afwijzingswachtrij voor schema's gerouteerd voor beoordeling en correctie door de beheerder.
- Continuïteit opnieuw afspelen en hervatten: Elke synchronisatietaak handhaaft offsetcontrolepunten, zodat replicatie kan worden hervat vanaf de laatste geslaagde verbintenis zonder duplicatie.
- Geïntegreerde bewaking: Alle mislukkingen, pogingen en herstelmeetgegevens worden vastgelegd in het Trust Layer Monitoring-dashboard voor zichtbaarheid en SLA-zekerheid.
Overwegingen bij impotent ontwerp
- Deterministische idempotentiesleutels: Elke synchronisatie-event heeft een unieke sleutel (Organisatie-ID + Record-ID + Versienummer) om een exacte eenmalige verwerking te garanderen.
- Veiligheid voor opnieuw afspelen: Duplicaat- of opnieuw afgespeelde events worden gefilterd op het moment van vastleggen, waardoor consistente updates van DMO's en CIO's verderop in de stroom worden gegarandeerd.
- Atomic Commit Semantics: Companion-organisaties markeren gegevens alleen als vastgelegd na succesvol schrijven verderop in de stroom, waardoor de transactionele integriteit van organisaties behouden blijft.
- Conflictoplossing: Updates met meerdere bronnen volgen last-write-wins of beleidsgestuurde samenvoeglogica, waardoor de herkomst en consistentie behouden blijven.
- Persistentie van controlepunt: Synchronisatietaken behouden laatst verwerkte verschuivingen en staan binnen de Trust Layer voor veilig herstel en opnieuw afspelen.
Beveiligingsoverwegingen
- Sterke authenticatie: Verbindingen tussen thuis- en gezelschapsorganisaties gebruiken wederzijdse OAuth 2.0 met automatisch geroteerde tokens die worden beheerd via verbonden apps.
- Granulaire autorisatie: Companion-organisaties hebben alleen toegang tot specifieke gegevensruimten, DMO's of CIO's die expliciet worden gedeeld via gereguleerd beleid voor het delen van gegevens.
- Overal encryptie: Gegevens worden versleuteld onderweg (TLS 1.2+) en in ruste (AES-256) binnen zowel thuis- als metgezelorganisaties.
- Minimaal-privilegebeginsel: Integratiegebruikers hebben alleen toegang tot de vereiste objecten; er worden geen machtigingen op beheer- of systeemniveau doorgegeven.
- Zichtbaarheid van audit en naleving: Alle synchronisatie-events, schemawijzigingen, updates van inloggegevens en toegangsverleningen worden vastgelegd in de Data 360 Trust Layer voor volledige traceerbaarheid.
- Isolatie van privénetwerk: Optioneel Salesforce Private Connect of Private Link zorgt ervoor dat gegevensreplicatie alleen plaatsvindt via veilige, interne kanalen.
Sidebars
Tijdigheid
- Synchronisatie tussen hoofd- en metgezelorganisaties vindt plaats in vrijwel realtime, doorgaans binnen enkele seconden na een gegevenswijziging in de bronorganisatie.
- Zero Copy-architectuur zorgt ervoor dat gedeelde gegevens onmiddellijk kunnen worden opgevraagd in alle deelnemende organisaties — zonder replicatie of batchvertragingen.
- Activerings- en segmenteringstaken weerspiegelen automatisch de nieuwste updates van elke verbonden organisatie, waardoor de operationele versheid behouden blijft.
- End-to-end latentie is deterministisch en wordt bepaald door de doeltreffende combinatiepijplijn van Data Cloud One, waardoor consistente tijdigheid tussen organisaties wordt gegarandeerd, zelfs onder belasting.
Gegevensvolumes
- Ontworpen voor gegevenssynchronisatie met meerdere belanghebbenden, hyperschaalbaar tussen regio's en bedrijfseenheden, waarmee miljarden records per organisatie kunnen worden beheerd.
- Naar gegevens wordt verwezen, niet gedupliceerd, waardoor de opslagvoetafdruk wordt verkleind en de globale querybaarheid behouden blijft.
- Streamingdelta's en verdichting van metagegevens optimaliseren bandbreedte en leggen overhead vast voor objecten met een hoge wijzigingssnelheid (bijv. Contactpersoon, Order).
- Schaalt horizontaal over meerdere Companion-organisaties met adaptieve taakverdeling en doeltreffende combinatie door de Trust Layer.
Statusbeheer
- Elke gesynchroniseerde gegevensset handhaaft de context van metagegevensafstamming, versie en eigendom van de organisatie om end-to-end traceerbaarheid te garanderen.
- Controlepuntpersistentie legt laatst gesynchroniseerde verschuivingen tussen organisaties vast, waardoor herstel zonder dupliceren mogelijk is.
- Schemaversiebeheer en semantische uitlijning binnen organisaties worden automatisch bepaald door de Trust Layers.
- Er zijn geen handmatige resets van de status vereist. De synchronisatiestatus wordt onderhouden via de Data Cloud One Orchestration Service.
Complexe integratiescenario's
- Federatie tussen organisaties: Maakt naadloze query's en activering mogelijk voor meerdere Data 360-belanghebbenden of -regio's onder een gecombineerd governance-model.
- Hybride synchronisatie: Combineert vrijwel realtime replicatie voor transactionele updates met geplande synchronisatie voor bulk- of archiveringsgegevens.
- Governance voor meerdere regio's: Ondersteunt geografisch gedistribueerd delen van gegevens met inachtneming van grenzen voor verblijf, instemming en naleving.
- AI- en automatiseringsactivering: Gesynchroniseerde gegevens sturen Einstein AI-, Agentforce of aangepaste ML-modellen onmiddellijk aan binnen organisaties — waardoor realtime intelligentie tussen organisaties mogelijk wordt.
Voorbeeld
Een wereldwijde detailhandelsorganisatie heeft drie Salesforce-organisaties: een voor Consumer Retail, een voor Premium Brands en een voor International Markets. Ze leveren Data 360 in de Consumer Retail-organisatie (waardoor het de thuisorganisatie is). Met Data Cloud One stellen ze begeleidende verbindingen in met de organisaties Premium Brands en International Markets. Ze delen alleen de juiste gegevensruimten (bijv. "Customer 360 – Retail Profiles" en "Customer 360 – Premium Profiles") met elke begeleidende organisatie. In de Premium Brands-organisatie kunnen marketingteams gecombineerde klantprofielen weergeven, segmenten samenstellen op basis van berekende insights (bijv. levenswaarde van premiumklanten) en marketingautomatiseringen activeren — allemaal aangestuurd door het Data 360-exemplaar van de thuisorganisatie, zonder aangepaste codering of gegevensduplicatie.
Gegevensactivering is waar de waarde van Salesforce Data 360 echt tot leven komt. Het is het proces waarbij de gecombineerde, verrijkte en beheerde gegevens die zich binnen het platform bevinden, worden gebruikt om ze binnen het hele bedrijf te laten werken. In de praktijk betekent dit het veilig leveren van beheerde segmenten, berekende insights en contextuele kenmerken vanuit Data 360 aan de systemen die klanten betrekken — of dat nu marketingautomatisering, serviceconsoles, verkoopondersteuning, analyses of AI-modellen zijn. Vanuit technisch perspectief definiëren activeringspatronen de manier waarop deze gegevens worden verplaatst: welke kanalen worden geactiveerd, welke transformaties of toewijzingen plaatsvinden en hoe beleid onderweg wordt afgedwongen. Deze patronen gaan niet alleen over het exporteren van gegevens, maar ook over het orkestreren van real-time, beleidsbewuste gegevensstromen die meetbare bedrijfsresultaten opleveren. Elke activeringsroute maakt van de Customer 360 een live operationeel activum — voor personalisatie, voorspellende beslissingen en continu leren binnen elk contactpunt.
Batchactivering blijft de meest gebruikte en operationeel bewezen methode voor het exporteren van gegevens vanuit Data 360. Het werkt volgens een geplande cadans en publiceert vooraf gedefinieerde doelgroepsegmenten of kenmerkensets met regelmatige tussenpozen naar downstream platforms. Dit patroon is bij uitstek geschikt voor marketing- en betrokkenheidswerkstromen die vertrouwen op consistente levering van doelgroepen met groot volume in plaats van onmiddellijke updates. Typische gebruikscases omvatten het aansturen van e-mailjourneys, direct mail-campagnes of uploads van doelgroepen naar digitale advertentienetwerken. Elke activeringsuitvoering extraheert het gekwalificeerde segment uit de gecombineerde profielgrafiek van Data 360, past governance- en instemmingsbeleid toe en verzendt de uitvoer veilig naar het doelsysteem. Architectonisch gezien biedt batchactivering een voorspelbare, controleerbare en kostenefficiënte benadering van gegevensdistributie, waarbij operationele eenvoud wordt gecombineerd met betrouwbaarheid op ondernemingsniveau. Het is de ruggengraat van grootschalige campagne-uitvoering, waarbij de juiste gegevens, op tijd geleverd en onder controle, meetbare bedrijfsimpact stimuleren.
Context
Moderne marketeers werken via meerdere betrokkenheidskanalen – e-mail, reclame, mobiel en web – waarbij elke kanaal een nauwkeurige, tijdige en gepersonaliseerde doelgroep vereist. Data 360 vormt de gecombineerde basis voor deze doelgroepen en combineert klantgegevens uit elk systeem in rijke, navolgbare segmenten. Batchactivering is het meest voorkomende activeringspatroon dat wordt gebruikt om die segmenten te exporteren van Data 360 naar marketing- of advertentieplatforms verderop in de stroom. Typische bestemmingen zijn Marketing Cloud Engagement, Google Ads, aangepaste doelgroepen voor metagegevens of LinkedIn Ads, waar campagnes rechtstreeks tegen deze beheerde doelgroepen kunnen worden uitgevoerd.
Probleem
Hoe kan een marketingteam een nauwkeurig gedefinieerde doelgroep—samengesteld met behulp van gecombineerde en verrijkte gegevens in Data 360—beschikbaar maken in externe marketing- of advertentiesystemen voor activering? Denk bijvoorbeeld aan het segment: "Klanten met een hoge waarde die in de afgelopen 90 dagen niet hebben gekocht, maar wel recent betrokken zijn geweest bij de website." Marketeers moeten ervoor zorgen dat deze doelgroep nauwkeurig wordt overgedragen, verrijkt met relevante kenmerken (bijvoorbeeld loyaliteitslaag, regio of voorspelde CLV) en regelmatig wordt vernieuwd om de relevantie en effectiviteit van de campagne te behouden.
Krachten
Verschillende technische en operationele factoren bepalen het patroon van batchactivering:
- Identiteitstoewijzing: Nauwkeurige doelgroeplevering vereist het toewijzen van de gecombineerde individu-ID van Data 360 aan de overeenkomende identifier in het bestemmingssysteem, zoals een abonneesleutel in Marketing Cloud of een versleuteld e-mailbericht voor digitale advertentieplatforms. Dit garandeert nauwkeurige overeenkomsten en elimineert fouten bij richten.
- Kenmerkselectie en -verrijking: Marketeers moeten verder gaan dan ID's en aanvullende profielgegevens opnemen—zoals voornaam, loyaliteitsstatus, CLV of andere gepersonaliseerde kenmerken—om personalisering en analyses verderop in de stroom in te schakelen.
- Doelplatformconfiguratie: Elke bestemming moet zijn geregistreerd in Data 360 als een activeringsdoel, inclusief verbindingsdetails, authenticatie en gegevensveldtoewijzingen. Deze eenmalige set-up definieert veilige connectiviteit en bepaalt welke systemen geactiveerde gegevens kunnen ontvangen.
- Governance en naleving: Gegevensactivering moet voldoen aan metagegevens voor instemming, privacybeleid (bijv. AVG of CCPA) en marketingmachtigingen die zijn opgeslagen in het gecombineerde profiel. Instemmingsbewuste activering zorgt ervoor dat gegevens alleen voor geautoriseerde doeleinden worden gebruikt.
- Planning en prestaties: Activeringen worden vaak dagelijks of elk uur gepland om downstream doelgroepen actueel te houden. Het systeem moet efficiënt grote volumes en incrementele vernieuwingen verwerken zonder duplicatie of gegevensverlies.
Oplossing
Het proces van batchactivering in Data 360 volgt een begeleide werkstroom die technische frictie voor marketeers minimaliseert en toch governance en schaalbaarheid behoudt:
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Segment maken | Best | Een marketeer of analist stelt een segment samen op het visuele segmenteringsdoek door filters toe te passen op elk gegevensmodelobject (DMO) of berekend insightobject (CIO). Dit definieert de doelgroep voor activering. |
| Set-up van activering | Best | De gebruiker maakt een activering en selecteert het segment dat deze zojuist heeft samengesteld als bron. Hiermee wordt bepaald welke doelgroep Data 360 gaat exporteren naar systemen verderop in de stroom. |
| Selectie van activeringsdoel | Best practice | De marketeer selecteert een vooraf geconfigureerd activeringsdoel (bijvoorbeeld Marketing Cloud, Google Ads, LinkedIn Ads). Elk doel wordt geregistreerd in Data 360 met authenticatiegegevens en veldtoewijzingen. |
| Definitie payload | Verplicht | De marketeer definieert de payload door contactpersoons-ID's (bijv. e-mail, mobiel, hashed ID) te kiezen en aanvullende profielkenmerken (bijv. voornaam, loyaliteitslaag of CLV) te selecteren voor verrijking in het bestemmingssysteem. |
| Planning en frequentie | Aanbevolen | Activeringen kunnen worden gepland voor eenmalige uitvoering of op terugkerende basis (bijvoorbeeld dagelijks of wekelijks). Planning zorgt ervoor dat doelgroepen verderop in de stroom gesynchroniseerd en actueel blijven. |
| Uitvoering en export | Best | Wanneer de activeringstaak wordt uitgevoerd, voert Data 360 een query uit op het segment, verzamelt het de geselecteerde kenmerken, past het instemmingsfilters toe en exporteert het de gegevens naar het doelplatform. Voor Marketing Cloud leidt dit doorgaans tot het maken of bijwerken van een Gedeelde gegevensextensie. |
| Governance & naleving | Verplicht | De Trust Layer dwingt schemavalidatie, instemmingsmetagegevens en beleidscontroles af om naleving van regelingen en verordeningen voor gegevensbescherming en marketing (bijv. AVG, CCPA) te waarborgen. |
| Bewaking en controle | Best practice | Elke activeringsuitvoering wordt bijgehouden met meetgegevens over succes/mislukking, uitvoeringslogboeken en zichtbaarheid van de herkomst in het Trust Layer Monitoring-dashboard, wat operationele transparantie en SLA-zekerheid mogelijk maakt. |
Schets
Hier is de samenvatting van de stappen:
- Segment samenstellen: Een marketeer of analist maakt een segment met behulp van een visuele segmenteringstool, waarbij filters voor alle gecombineerde gegevensobjecten worden gecombineerd.
- Activering maken: Ze selecteren het segment als bron en kiezen een vooraf geconfigureerde bestemming (zoals Marketing Cloud of Google Ads).
- Payload definiëren: De contactpersoons-ID en andere profielkenmerken worden gekozen voor de export en rapportage van doelgroepen.
- Levering plannen: De activering is gepland voor eenmalige of terugkerende uitvoering, zodat de doelgroep op de hoogte blijft van de bestemming.
- Uitvoering: Bij de trigger voert Data 360 een query uit op het segment, stelt de payload samen, past filters voor instemming toe en pusht het resultaat naar het bestemmingssysteem.
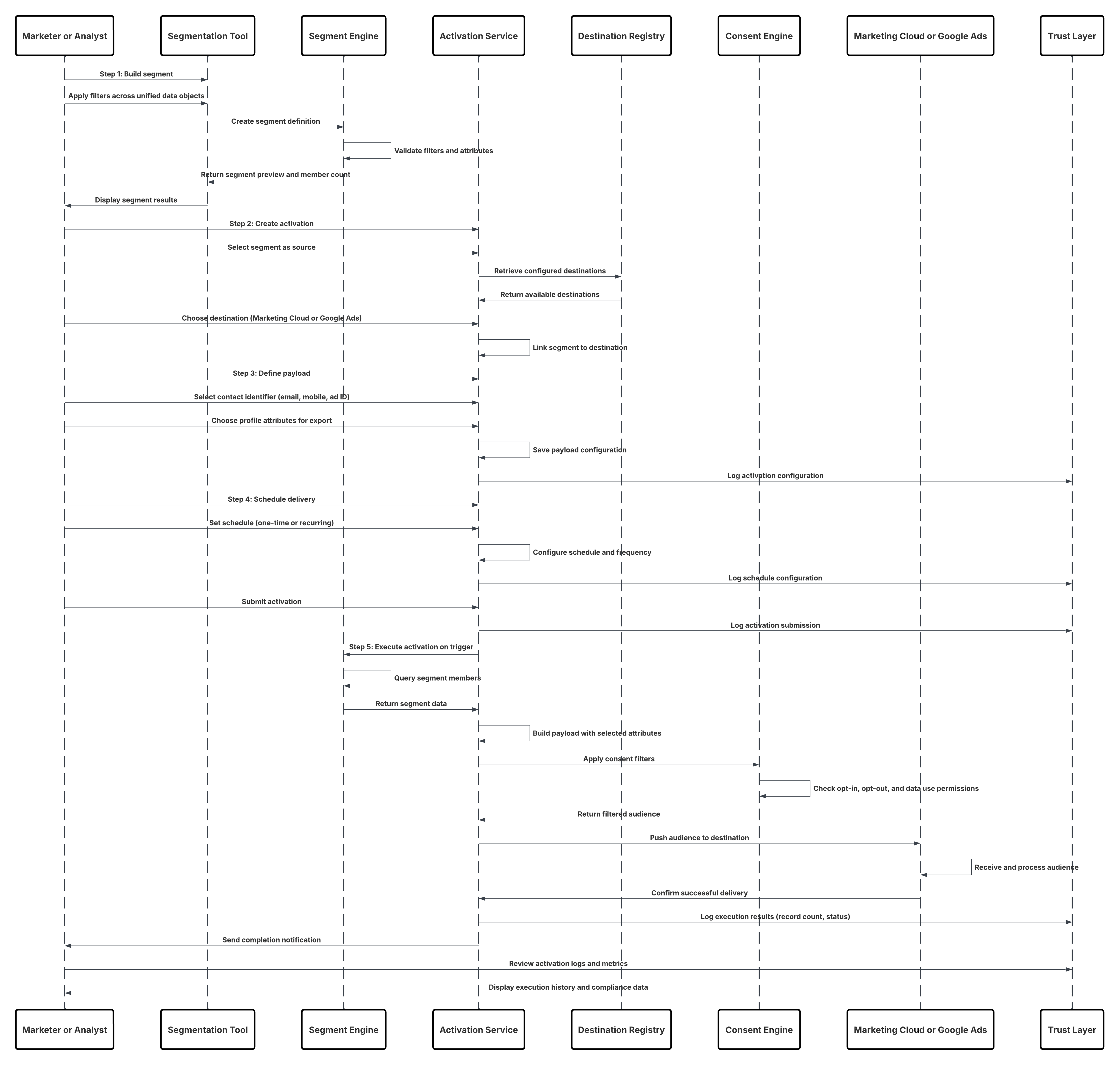
Resultaten
- Doelgerichte, verrijkte doelgroepsegmenten uit Data 360 worden rechtstreeks beschikbaar gesteld in marketing- en advertentieplatforms verderop in de stroom.
- Doelgroepen worden automatisch vernieuwd en gesynchroniseerd met de nieuwste gecombineerde klantgegevens, waardoor real-time campagnerelevantie behouden blijft.
- Marketeers kunnen deze geactiveerde doelgroepen gebruiken als invoerbronnen voor Marketing Cloud-journeys, e-mailcampagnes of aangepaste doelgroepen in digitale advertentieplatforms zoals Google Ads, Meta of LinkedIn Ads.
- Elke activeringsuitvoering handhaaft een end-to-end afstamming, wat naleving, traceerbaarheid en consistentie tussen Data 360 en externe systemen garandeert.
- Zakelijke gebruikers kunnen zeer gepersonaliseerde, gegevensgestuurde omgevingen leveren, aangestuurd door een complete en vertrouwde Customer 360 weergave.
Aanroepmechanismen
Het aanroepmechanisme is afhankelijk van het bestemmingsplatform en de configuratie van het activeringsdoel.
| Mechanisme | Wanneer gebruiken |
|---|---|
| Marketing Cloud-betrokkenheidsactivering (voorkeur) | Gebruik dit bij het uitvoeren van e-mail- of cross-channel journeys die dynamische segmenten, gepersonaliseerde kenmerken en real-time updates in Marketing Cloud vereisen. Data 360 wordt rechtstreeks geëxporteerd naar Gedeelde gegevensextensies voor campagneactivering. |
| Activering van advertentieplatform (Google Ads, LinkedIn Ads, Meta Ads) | Gebruik dit bij het activeren van Data 360-segmenten als aangepaste doelgroepen in advertentieplatforms voor retargeting of lookalike modeling. Ondersteunt hashed identifiers en consent-aware levering. |
| CRM-activering (Verkoop of Service Cloud) | Gebruik dit wanneer u verrijkte klantgegevens, insights of neigingsscores deelt met CRM-gebruikers voor gepersonaliseerde verkoopbetrokkenheid of service-interacties. Gegevens worden beschikbaar gemaakt als verrijkte records of insights via Gegevensacties of Gecombineerde profielcomponenten. |
| Externe activering via MuleSoft of API | Gebruik dit wanneer activering niet-Salesforce-systemen moet bereiken, zoals loyaliteits-, eCommerce- of externe gegevensmagazijnen. MuleSoft of de Data 360-activerings-API zorgt voor veilige, beleidsgestuurde levering met op events gebaseerde vernieuwingsopties. |
| Hybride activering (batch + door event geactiveerd) | Gebruik dit bij het combineren van geplande batchactiveringen met op events gebaseerde triggers, waardoor personalisering altijd ingeschakeld is voor tijdgevoelige campagnes zoals waarschuwingen over verlaten winkelwagentjes of verlooprisico's. |
Afhandeling en herstel van fouten
- Isolatie van fouten op taakniveau: Elke activeringsuitvoering wordt uitgevoerd als een afzonderlijke, traceerbare taak in de Data 360 Orchestration Layer. Mislukte uitvoeringen worden automatisch in quarantaine geplaatst zonder gevolgen voor andere activeringen of segmentdefinities.
- Gedeeltelijk batchherstel: Als bepaalde records niet kunnen worden geëxporteerd (bijvoorbeeld vanwege identifierfouten of API-ratelimieten), probeert het systeem ze opnieuw met behulp van incrementele deltawachtrijen met exponentiële backoff en parallel herstel.
- Schemavalidatiefouten: Wanneer uitgaande payloadkenmerken niet langer overeenkomen met het doelschema (bijv. een verwijderd kenmerk of een veld met een gewijzigde naam), routeert de taak betroffen records naar de wachtrij Schemaafwijzing voor beoordeling door de beheerder.
- Ondersteuning voor opnieuw afspelen en hervatten: Elke activeringstaak onderhoudt een controlepunttoken—waarbij de laatste succesvolle batch wordt vastgelegd. Na herstel wordt de verwerking hervat vanaf het controlepunt, zodat er geen duplicatie of gegevensverlies optreedt.
- Uitgebreide bewaking: Alle activeringsevents, pogingen en leveringsmeetgegevens worden vastgelegd in Trust Layer Monitoring, waardoor SLA-tracering, analyse van de hoofdoorzaak en geautomatiseerde waarschuwing via Event Monitoring-API's mogelijk zijn.
Overwegingen bij impotent ontwerp
- Deterministische activeringssleutels: Elke activeringsuitvoering gebruikt een samengestelde idempotentiesleutel—die Segment-ID, Activerings-ID en Doelsysteem-ID combineert—om een exacte eenmalige levering te garanderen.
- Detectie van opnieuw afspelen: De Data 360-activeringsservice inspecteert inkomende payloads op basis van eerdere taakhashes om herhalingen te detecteren en te onderdrukken.
- Atoomexportverbintenissen: Payloads worden pas naar het doelsysteem gecommit na succesvolle bevestiging van schrijven, waardoor gedeeltelijke updates of dubbeltellingen worden voorkomen.
- Consistente identiteitsoplossing: Aangezien activeringen afhankelijk zijn van gecombineerde ID's (bijv. Gecombineerd individu), zijn herhalingen of pogingen altijd gericht op dezelfde gouden plaat, waarbij de semantische consistentie behouden blijft.
- Persistentie van activeringsstatus: De doeltreffende laag behoudt de metagegevens van de activeringsstatus—tijdstempels, statuscodes en volgordetokens—voor deterministische herverwerking indien nodig.
Beveiligingsoverwegingen
- Sterke authenticatie: Elk activeringsdoel (bijv. Marketing Cloud, Ads of CRM) gebruikt OAuth 2.0 met tokenrotatie en belanghebbendenspecifiek bereik om ongeoorloofde gegevensexport te voorkomen.
- Governance op kenmerkniveau: Alleen goedgekeurde kenmerken uit het gecombineerde profiel komen in aanmerking voor activering, afgedwongen door beleidsvormen voor delen van gegevens en activeringssjablonen.
- Encryptie in transit en at rest: Alle payloads worden versleuteld met behulp van TLS 1.2+ tijdens overdracht en AES-256 at rest binnen zowel Data 360 als het doelplatform.
- Instemming en beleidshandhaving: Activeringstaken respecteren instemmingsobjecten en gegevensbeleidsvormen die zijn opgeslagen in de Trust Layer van Data 360. Records zonder geldige metagegevens voor instemming worden automatisch uitgesloten van export.
- Audit- en nalevingsregistratie: Elke activeringsuitvoering legt vast wie de activering heeft geïnitieerd, welke gegevens zijn verzonden en naar welke bestemming, waardoor volledige wettelijke controletrajecten (GDPR, CCPA) binnen het Trust Layer Dashboard mogelijk zijn.
- Minimale toegang: Integratiegebruikers voor elk doel zijn beperkt tot activeringsspecifieke bereiken—geen beheermachtigingen of schrijftoegang tot niet-gerelateerde systemen.
Sidebars
Tijdigheid
- Ontworpen voor geplande of vrijwel realtime batchexports (minuten-naar-uren latentie).
- Ondersteunt tijdsbestekvernieuwingen die zijn afgestemd op campagneagenda's.
- Activeringstaken kunnen worden gesequenced met markeringen voor gegevensgereedheid om de versheid van gegevens te waarborgen.
- Het meest geschikt voor niet-interactieve activeringsscenario's waarin gegevensnauwkeurigheid zwaarder weegt dan onmiddellijkheid.
Gegevensvolumes
- Verwerkt grootschalige gegevenssets (miljoenen records per uitvoering).
- Schaalt horizontaal door segmentpartitionering en parallelle exportkanalen.
- Maakt gebruik van op blokken gebaseerde batching om time-outs te voorkomen en de doorvoer te optimaliseren.
- Ideaal voor gegevenspijplijnen van ondernemingsniveau waar volledigheid van gegevens van cruciaal belang is.
Statusbeheer
- Onderhoudt activeringsstatusobjecten die taak-ID's, tijdstempels en volgordetokens vastleggen.
- Gebruikt controlepunten voor herstartbaarheid en foutherstel.
- Segmentdefinities met versiebeheer zorgen voor reproduceerbaarheid binnen activeringscycli.
- Schakelt traceerbaarheid van de herkomst in tussen bronsegment, DMO-kenmerken en doelpayloads.
Complexe integratiescenario's
- Integreert naadloos met Salesforce CRM, Marketing Cloud en externe systemen via vooraf samengestelde connectoren.
- Ondersteunt activeringen voor meerdere doelen en distribueert gegevens tegelijkertijd naar verschillende bestemmingen (bijvoorbeeld CRM + Ads).
- Kan samengestelde werkstromen activeren, bijvoorbeeld batchexport gevolgd door API-aanroep verderop in de stroom of AI-scores.
- Handelt schema-evolutie elegant af via de gegevensmodel-governancelaag.
Voorbeeld
Een wereldwijd detailhandelsmerk wil inactieve klanten van de afgelopen 90 dagen opnieuw betrekken. Met behulp van Data 360 definieert de gegevensarchitect een segment "Sluimerende shoppers" verrijkt met aankoophistorie, loyaliteitslaag en metagegevens over instemming. De batchactiveringstaak wordt 's nachts uitgevoerd en pusht dit segment naar Marketing Cloud Engagement om een gepersonaliseerde e-mailcampagne "We missen u" te activeren en naar Ad Studio voor retargeting. De taak maakt gebruik van idempotente levering, waardoor er geen duplicering plaatsvindt tussen pogingen en alle events worden vastgelegd in de Trust Layer voor naleving van audits.
Context
Ondernemingen hebben vaak een beheerd mechanisme nodig om gecombineerde of gesegmenteerde gegevens uit Salesforce Data 360 te exporteren naar een standaardbestandsindeling (bijvoorbeeld CSV of Parquet) voor archivering, naleving of integratie verderop in de stroom. Dit patroon schakelt de export van Data 360-naar-cloud-opslag in—waardoor vertrouwde klantgegevens veilig kunnen stromen naar bedrijfsgegevens-lakes of analysepijplijnen die worden gehost op Amazon S3, Azure Blob of Google Cloud Storage (GCS). Typische gebruikscases zijn:
- Periodieke archivering van goedgekeurde klantgegevenssets voor wettelijke bewaring.
- Gemodereerde segmenten exporteren voor niet-Salesforce analytische werkbelastingen (bijv. Tableau, Databricks of Power BI).
- Externe machine learning-modellen inschakelen die gestructureerde CSV- of parketbestanden als invoer vereisen.
Probleem
Hoe kan een organisatie een beheerd segment of gegevensset exporteren vanuit Data 360 naar een cloudopslagbucket (bijvoorbeeld Amazon S3)—op een beheerde, veilige en geautomatiseerde manier—met behoud van schema-integriteit en nalevingscontroles? Zo moet een nalevingsteam mogelijk: "Haal alle actieve klanten in de EU-regio met geldige instemming op en exporteer de gegevens wekelijks naar een S3-locatie voor externe controle en rapportage." Dit vereist een herhaalbare en beleidsbewuste exportpijplijn die zorgt voor de juiste bestandsindeling, toegangsmachtigingen en leveringsplanning—zonder handmatige tussenkomst of onbeheerde gegevensverplaatsing.
Krachten
Dit exportpatroon wordt bepaald door meerdere operationele en architectonische factoren:
- Authenticatie en autorisatie: Exports moeten voldoen aan het IAM-model van de cloudprovider (bijvoorbeeld AWS IAM-rollen of Azure Service Principals) om ervoor te zorgen dat alleen geautoriseerde systemen naar de doelbucket kunnen schrijven.
- Schema-uitlijning: Het uitgaande schema moet overeenkomen met de verwachte structuur en indeling van het doelsysteem (CSV, Parquet of JSON).
- Gegevensprivacy en toestemming: Geëxporteerde gegevenssets moeten alle records uitfilteren die geen geldige metagegevens voor instemming hebben.
- Scheduling & versheid: Veel exports zijn periodiek (dagelijks, wekelijks of maandelijks) en moeten overeenkomen met vernieuwingscycli van ondernemingsgegevens.
- Governance & monitoring: Elke export moet controleerbaar zijn met volledige zichtbaarheid van de herkomst, waarbij naleving van gegevensbewaring en wettelijke verplichtingen (bijv. AVG, CCPA) wordt gegarandeerd.
Oplossing
Het patroon Activering van export van bestanden hergebruikt dezelfde veilige cloudopslagconnectoren die worden gebruikt voor opname, maar die zijn geconfigureerd voor gegevensuitgang. Beheerders registreren eerst het cloudopslagplatform (bijvoorbeeld Amazon S3, Azure Blob Storage of GCS) als een activeringsdoel in Data 360. Vervolgens configureren en voeren gebruikers een activeringswerkstroom uit om het gewenste segment te exporteren naar het aangewezen bestandsopslagpad.
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Segmentselectie | Best | Analisten selecteren een bestaande Segment- of Querydefinitie binnen Data 360\. Het segment bepaalt welke records en kenmerken worden geëxporteerd. |
| Set-up van activering | Best | Gebruikers maken een nieuwe activering door het segment als bron en het cloudopslagdoel (bijv. S3) als bestemming te kiezen. |
| Configuratie van activeringsdoel | Verplicht | Beheerders configureren het doel vooraf met inloggegevens, IAM-rollen en uitvoerpad. Ondersteunde indelingen zijn CSV, Parquet en JSON. |
| Definitie payload | Best practice | Definieer het exportschema door de vereiste kenmerken te selecteren (bijv. ID, Naam, E-mail, Regio, Instemmingsvlag). Het systeem dwingt governance op kenmerkniveau af. |
| Planning en frequentie | Aanbevolen | Exports kunnen worden gepland voor uitvoering met een gedefinieerde cadans (dagelijks, wekelijks, maandelijks) of handmatig worden geactiveerd. |
| Uitvoering & levering | Best | Bij uitvoering voert Data 360 een query uit op het segment, compileert het exportbestand, versleutelt het en schrijft het naar de geconfigureerde bucket/map met behulp van de API van de cloudprovider. |
| Governance & naleving | Verplicht | De Trust Layer van Data 360 zorgt ervoor dat alle exports voldoen aan instemmingsbeleid, schemavalidatie en nalevingsfilters. |
| Bewaking en controle | Best practice | Elke export wordt bijgehouden in het Trust Layer Monitoring Dashboard met status, uitvoeringslogboeken en metagegevens over de herkomst. |
Schets
Hier is de samenvatting van de stappen.
- Selecteer Segment: Een analist of gegevensbeheerder kiest het gecombineerde segment dat moet worden geëxporteerd.
- Activering maken: Ze maken een nieuwe activeringstaak en selecteren het geregistreerde Cloud Storage-doel.
- Payload definiëren: Geef het exportschema, de lijst met kenmerken en de bestandsindeling (bijv. CSV) op.
- Export plannen: Kies een eenmalige of terugkerende planning.
- Taak uitvoeren: Data 360 genereert het bestand en levert het veilig af op het aangewezen bucketpad.
- Bewaken en verifiëren: Resultaten en logboeken worden beoordeeld in de Trust Layer voor validatie en naleving.
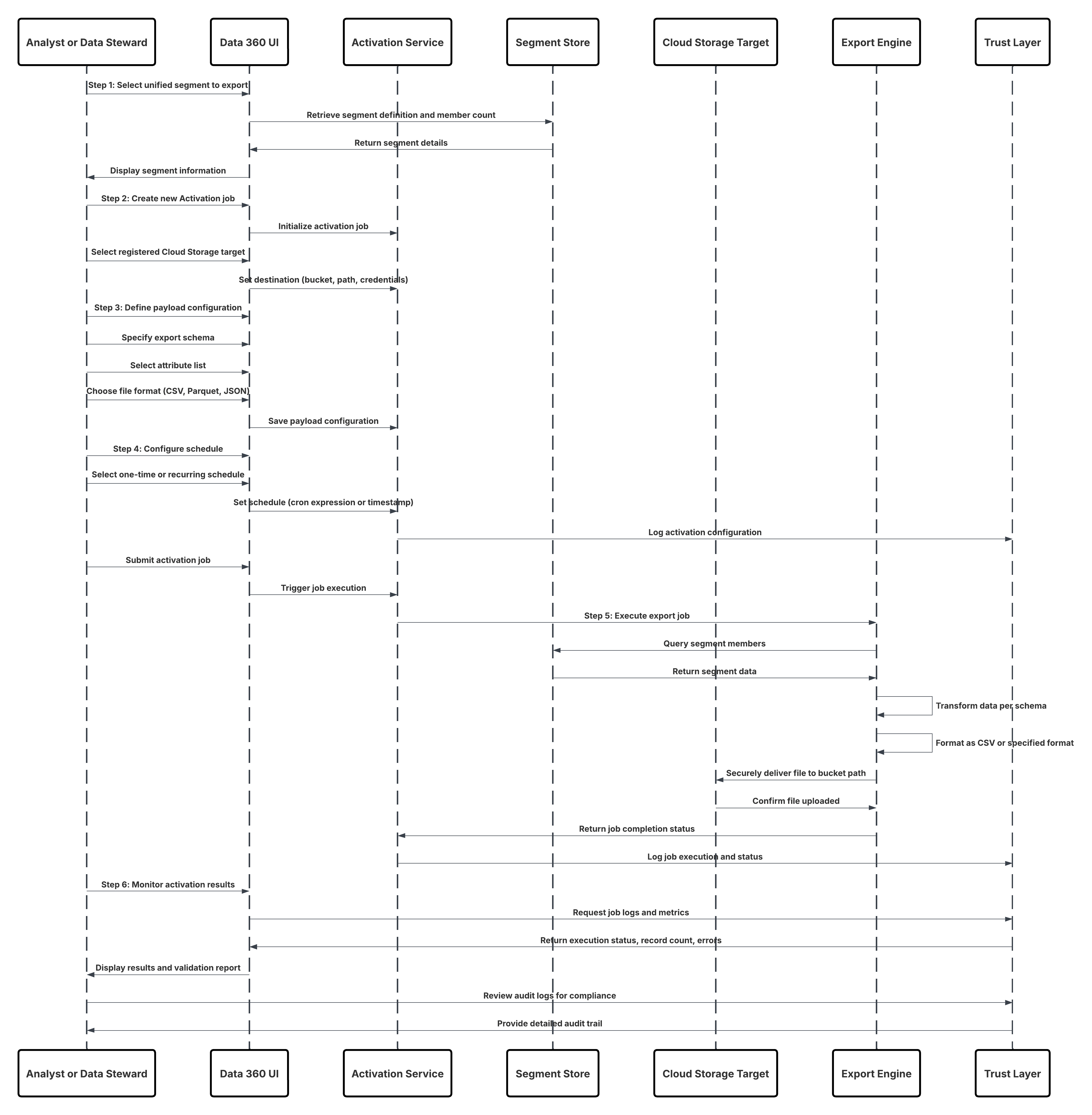
Resultaten
- Doelgerichte, verrijkte doelgroepsegmenten uit Data 360 worden rechtstreeks beschikbaar gesteld in marketing- en advertentieplatforms verderop in de stroom.
- Doelgroepen worden automatisch vernieuwd en gesynchroniseerd met de nieuwste gecombineerde klantgegevens, waardoor real-time campagnerelevantie behouden blijft.
- Marketeers kunnen deze geactiveerde doelgroepen gebruiken als invoerbronnen voor Marketing Cloud-journeys, e-mailcampagnes of aangepaste doelgroepen in digitale advertentieplatforms zoals Google Ads, Meta of LinkedIn Ads.
- Elke activeringsuitvoering handhaaft een end-to-end afstamming, wat naleving, traceerbaarheid en consistentie tussen Data 360 en externe systemen garandeert.
- Zakelijke gebruikers kunnen zeer gepersonaliseerde, gegevensgestuurde omgevingen leveren, aangestuurd door een complete en vertrouwde Customer 360 weergave.
Aanroepmechanismen
Het aanroepmechanisme is afhankelijk van het doelcloudopslagplatform en de activeringsconfiguratie.
| Mechanisme | Wanneer gebruiken |
|---|---|
| Amazon S3-activering | Gebruik dit wanneer uw Enterprise Data Lake wordt gehost op AWS. Data 360 schrijft rechtstreeks naar een S3-bucket met behulp van IAM-rollen of tijdelijke inloggegevens, wat zorgt voor een veilige en schaalbare export. |
| Azure Blob Storage-activering | Gebruik dit wanneer uw organisatie werkt op Microsoft Azure. Data 360 gebruikt SAS-tokens of serviceprincipals om versleutelde bestanden naar Blob-containers te schrijven. |
| Google Cloud Storage (GCS) activeren | Gebruik dit wanneer uw werkbelasting voor gegevenswetenschappen of analyses wordt uitgevoerd op GCP. Data 360 gebruikt OAuth-inloggegevens om bestanden te exporteren naar GCS-buckets in CSV- of parketindeling. |
| SFTP of externe bestandsgateway | Gebruik dit wanneer wettelijke of verouderde systemen veilige bestandslevering via SFTP-eindpunten of door de onderneming beheerde platforms voor bestandsoverdracht vereisen. |
| Hybride export (bestand + API) | Gebruik dit wanneer een toepassing verderop in de stroom zowel op bestanden gebaseerde export voor analyses als een API-trigger voor werkstroomcombinatie (bijv. MuleSoft-stroom) nodig heeft. |
Afhandeling en herstel van fouten
- Isolatie op taakniveau: Elke export wordt uitgevoerd als een afzonderlijke taak. Mislukte taken worden in quarantaine geplaatst en onafhankelijk opnieuw geprobeerd.
- Gedeeltelijk opnieuw proberen van bestand: Als bepaalde batches niet kunnen worden geüpload (bijvoorbeeld vanwege netwerkonderbrekingen), probeert het systeem die blokken opnieuw met behulp van exponentiële backoff.
- Afhandeling van schemafouten: Elke schemaafwijking of veldfout routeert records naar de wachtrij Schemaafwijzing voor beoordeling.
- Controlepunt en hervatten: Exporttaken houden metagegevens van controlepunten bij, waardoor hervatting van het laatste geslaagde schrijven zonder dupliceren mogelijk wordt.
- Geïntegreerde bewaking: Mislukte acties en nieuwe pogingen worden vastgelegd in het Trust Layer Dashboard voor zichtbaarheid en SLA-naleving.
Overwegingen bij impotent ontwerp
- Deterministische exportsleutels: Elke exporttaak bevat een unieke ID die bestaat uit Segment-ID + Doel-ID + Tijdstempel.
- Veiligheid voor opnieuw afspelen: Dubbele taakuitvoeringen worden gedetecteerd met behulp van taakhashes en overgeslagen om redundante exports te voorkomen.
- Atomic-schrijfgarantie: Data 360 zet bestanden pas naar de doelbucket na volledige voltooiing en controlesomvalidatie.
- Consistente schemaversies: Exportdefinities worden door de versie bepaald om schemaconsistentie tussen uitvoeringen te garanderen.
- Persistentie van controlepunt: Exporttaken behouden status voor deterministisch herstel en opwerking indien nodig
Beveiligingsoverwegingen
- Sterke authenticatie: Cloudconnectoren gebruiken OAuth 2.0, IAM-rollen of serviceprincipals voor geauthenticeerd schrijven.
- Overal encryptie: Gegevens worden zowel onderweg (TLS 1.2+) als in ruste (AES-256) versleuteld.
- Instemmingsbewust exporteren: Alleen records met geldige instemming worden geëxporteerd, afgedwongen door Trust Layer-beleidsvormen.
- Principe van minste rechten: Exportgebruikers en serviceaccounts zijn beperkt tot hun toegewezen opslagpaden.
- Uitgebreide controleregistratie: Bij elke export worden metagegevens vastgelegd, waaronder initiator, schema, bestemming en tijdstempels voor nalevingsrapportage.
Sidebars
Tijdigheid
- Ontworpen voor onmiddellijke, eventgestuurde activering met subseconden latentie.
- Ideaal voor scenario's die onmiddellijke personalisatie, aanbeveling of besluitvorming vereisen.
- Werkt in de streamingmodus: triggers worden geactiveerd zodra zich in aanmerking komende gegevenswijzigingen voordoen in Data 360.
- Zorgt voor continue responsiviteit zonder te hoeven wachten op batchplanningen of segmentherberekening.
Gegevensvolumes
- Verwerkt grootschalige gegevenssets (miljoenen records per uitvoering).
- Schaalt horizontaal door segmentpartitionering en parallelle exportkanalen.
- Maakt gebruik van op blokken gebaseerde batching om time-outs te voorkomen en de doorvoer te optimaliseren.
- Ideaal voor gegevenspijplijnen van ondernemingsniveau waar volledigheid van gegevens van cruciaal belang is.
Statusbeheer
- Elke eventactie behoudt zijn eigen eventtoken en replay-ID voor idempotente verwerking.
- Ondersteunt persistentie van controlepunten om te hervatten vanaf de laatste vastgelegde event in geval van tijdelijke storing.
- Omvat ingebouwde deduplicatielogica en vensters voor opnieuw afspelen om exacte semantiek bij eenmalige activering te garanderen.
- Actieresultaten (succes/mislukt) worden realtime vastgelegd en zichtbaar gemaakt via het Trust Layer-waarnemingsdashboard.
Complexe integratiescenario's
- Integreert rechtstreeks met Salesforce-stromen, Einstein 1 Platform-events of externe webhooks voor onmiddellijke reactieketens.
- Kan automatiseringen verderop in de stroom activeren, bijvoorbeeld onmiddellijke CRM-recordupdates, AI-scores of Marketing Cloud-berichtverzendingen.
- Ondersteunt samenstelbare doeltreffende combinatie: eventtriggers kunnen Data 360-acties, Apex aanroepen of externe API's aanroepen.
- Ontworpen voor agentische en adaptieve ondernemingspatronen waarbij contextbewuste reacties onmiddellijk moeten plaatsvinden.
Voorbeeld
Een wereldwijde detailhandelsonderneming moet een wekelijkse export leveren van het segment "Actieve loyaliteitsleden" voor analyse in Databricks. De Data 360-beheerder configureert Amazon S3 als activeringsdoel en plant een wekelijkse CSV-export naar het s3://enterprise-analytics/loyalty/weekly_exports/. De exporttaak wordt elke zondag uitgevoerd en er wordt een bestand met instemmingsfilter gegenereerd met 2M+ records. Alle events, schemadefinities en herkomst worden vastgelegd in het Trust Layer Dashboard, wat transparantie, controleerbaarheid en naleving garandeert.
On-demand op API gebaseerde activering is een real-time, eventgestuurde benadering om Data 360-insights bruikbaar te maken op het moment dat ze nodig zijn, zonder te hoeven wachten op batchtaken of geplande exports. In plaats van vooraf samengestelde segmenten met een vaste cadans te publiceren, laat dit patroon externe systemen, Salesforce-apps of AI-agenten Data 360-API's rechtstreeks aanroepen om specifieke doelgroepsegmenten, klantkenmerken of insights op verzoek op te halen of te activeren. Dit patroon is ontworpen voor interactieve, op triggers gebaseerde omgevingen, zoals wanneer een gebruiker inlogt bij een portal, een agent een klantrecord opent of een AI Copilot een next-best-action-query initieert. In plaats van te vertrouwen op vooraf berekende exports voert het systeem dynamisch een query uit op of activeert het de meest actuele, gereguleerde gegevens uit Data 360 in Real-time. Het belangrijkste voordeel is onmiddellijkheid en precisie:
- Elke API-aanroep krijgt toegang tot de meest actuele Klantenintelligence binnen de gecombineerde, instemmingsbewuste profielgrafiek van Data 360.
- Activeringen zijn idempotent en controleerbaar, in overeenstemming met de Enterprise Trust en nalevingsvereisten.
- Integraties kunnen rechtstreeks vanuit Salesforce-stromen, Apex of externe systemen worden geactiveerd via Einstein 1-platform-API's, Connect-API's of activerings-API's. Deze benadering ondersteunt gebruikscases waar latentie en personalisatie het belangrijkste zijn, bijvoorbeeld:
- Een gepersonaliseerd productaanbod activeren tijdens een servicegesprek.
- Dynamische campagnedoelgroepen genereren op basis van live gedragsevents.
- Realtime beslissingen invoeren in AI- of ML-modellen die werken op het moment van betrokkenheid.
Context
Ondernemingen moeten vaak geharmoniseerde, real-time Data 360-insights naar boven halen binnen op maat gemaakte toepassingen, zoals interne webportals, mobiele apps of partnergerichte webomgevingen. Met dit patroon kunnen ontwikkelaars veilige, op de UI gerichte oplossingen samenstellen die gecombineerde klantgegevens verbruiken en weergeven naast Salesforce CRM en andere contextuele systemen, allemaal via beheerde en op API gebaseerde toegang. Typische gebruikscases zijn:
- Data 360-insights inbedden in interne werknemersdashboards of mobiele apps.
- Partner- of dealerportals maken met zichtbaarheid van klanten en transacties.
- Data 360-gegevens integreren in externe webtoepassingen of ervaringslagen.
- Real-time, gepersonaliseerde aanbevelingen weergeven op basis van Data 360 en Einstein 1.
Probleem
Hoe kan een ontwikkelaar een aangepaste, op de UI gerichte toepassing samenstellen die op een veilige manier toegang heeft tot geharmoniseerde Data 360-gegevens en deze weergeeft, vaak naast andere Salesforce-gegevensbronnen, zonder vertrouwelijke informatie te dupliceren of exporteren? Zo moet een onderneming mogelijk een klantportal samenstellen die gecombineerde klantprofielen, interacties en berekende insights uit Data 360 toont. Dit vereist één veilige en performante API-laag die de front-end ervaring kan aansturen, authenticatie kan afhandelen en governance kan garanderen, terwijl de complexiteit van het interne gegevensmodel van Data 360 wordt weggeabstraheerd.
Krachten
Meerdere architectonische en operationele overwegingen beïnvloeden dit patroon:
- UI-centrische toegang: Het primaire doel is om gegevens zichtbaar te maken binnen aangepaste front-endomgevingen (web of mobiel), niet om batchextractie of back-endsynchronisaties uit te voeren.
- Veilige gateway: De gekozen API moet dienen als een veilig en schaalbaar toegangspunt voor geauthenticeerde toepassingen en gebruikers, waarbij toegangscontroles op ondernemingsniveau worden afgedwongen.
- Context van gecombineerde gegevens: Toepassingen moeten Data 360-gegevens (bijv. gecombineerde profielen, berekende insights) naadloos kunnen combineren met CRM-, ERP- of aangepast-objectgegevens.
- Eenvoud van ontwikkelaar: API's moeten voor presentatie geschikte payloads retourneren die back-endverwerking of schematoewijzing in de clientlaag minimaliseren.
- Governance en waarneembaarheid: Alle toegang moet verlopen via vertrouwde, controleerbare kanalen met een duidelijke herkomst, authenticatie en beleidsafdwinging.
Oplossing
De oplossing is de Salesforce Connect REST-API te gebruiken als primaire integratiegateway voor het bouwen van aangepaste, gegevensgestuurde toepassingen bovenop Data 360. De Connect-API biedt RESTful toegang tot Salesforce-gegevens, inclusief geharmoniseerde profielen, segmenten en berekende insights van Data 360, in responsindelingen die zijn geoptimaliseerd voor UI-verbruik (op JSON gebaseerd, lichtgewicht en mobielvriendelijk). Ontwikkelaars verifiëren via een verbonden app, verkrijgen OAuth 2.0-tokens en roepen Connect API-resources zoals /query, /chatter of /data aan om gecombineerde gegevens rechtstreeks in hun toepassingsinterfaces zichtbaar te maken. Achter de schermen fungeert de Connect-API als de transportbasis voor andere API's, zoals de Query-API, de Data Graph-API en Einstein 1 Platform-API's, waardoor ontwikkelaars meerdere gegevensbronnen kunnen combineren onder één gecombineerd toegangspatroon.
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Authenticatie en appregistratie | Verplicht | Maak een verbonden app in Salesforce voor op OAuth 2.0 gebaseerde authenticatie. Configureer bereiken voor Data 360 API-toegang. |
| Gegevenstoegang (profielen, segmenten, insights) | Beste | Gebruik Connect API-eindpunten (/services/data/vXX.X/connect) voor het uitvoeren van query's op geharmoniseerde Data 360-gegevens, gecombineerde profielen en berekende insights. |
| UI-integratie | Beste | Front-end apps (React, Angular, iOS, Android) roepen de Connect-API aan om Data 360-gegevens weer te geven in dashboards, portals of mobiele interfaces. |
| Gegevensgrafiekquery's uitvoeren | Aanbevolen | Combineer de Connect-API met de Data Graph-API voor query's op semantisch niveau die complexe joins en relaties vereenvoudigen. |
| Realtime vernieuwen | Optioneel | Gebruik de Connect-API met WebSocket of streamingextensies voor live gegevensupdates. |
| Beveiliging en governance | Verplicht | Dwing zichtbaarheid van gegevens af met behulp van OAuth-bereiken, Data 360-beleidsvormen en het auditframework Trust Layer. |
Schets
Hier is de samenvatting van de stappen.
- Verbonden app registreren — Definieer OAuth-bereiken en API-machtigingen voor authenticatie van externe apps.
- Token verkrijgen: de externe app voert OAuth 2.0-authenticatie uit om een token te ontvangen voor Data 360-toegang.
- Connect-API aanroepen: de app voert REST-API-aanroepen uit om gecombineerde profiel-, segment- of insightgegevens op te halen.
- Gegevens weergeven in UI: responsen worden geparseerd en aan gebruikers gepresenteerd in een branded portal of mobiele interface.
- Fouten en vernieuwingstokens afhandelen: apps implementeren logica voor opnieuw proberen en automatisch token vernieuwen voor sessiecontinuïteit.
- Monitor & Audit Access — Alle API-aanroepen worden vastgelegd in de Trust Layer voor zichtbaarheid en naleving.
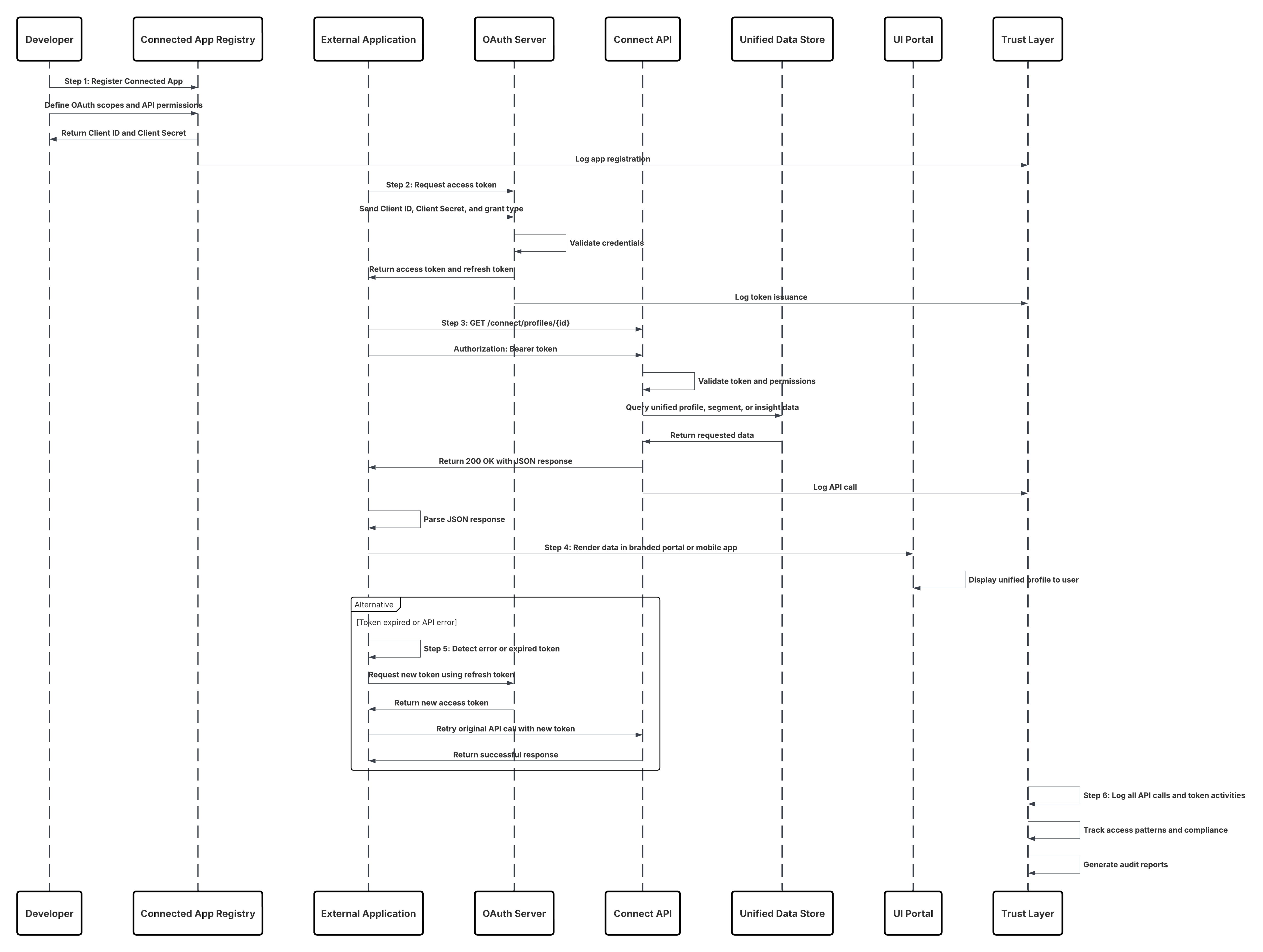
Resultaten
Ontwikkelaars kunnen veilige toepassingen met aangepaste "branding" maken die nauw zijn geïntegreerd met Data 360. Deze apps kunnen:
- Toon geharmoniseerde klantprofielen en insights in Realtime.
- Geef Data 360-gegevens weer naast CRM of aangepaste objecten via gecombineerde API's.
- Maak gebruik van consistente authenticatie-, autorisatie- en auditcontroles via de Trust Layer.
- Bied zakelijke gebruikers of partners naadloze, gecontroleerde toegang tot vertrouwde Klantenintelligence in alle omgevingen.
Aanroepmechanismen
Het aanroepmechanisme is afhankelijk van het doelcloudopslagplatform en de activeringsconfiguratie.
| Mechanisme | Wanneer gebruiken |
|---|---|
| Connect REST API (voorkeur) | Gebruik dit bij het samenstellen van web-, mobiele of externe apps die realtime toegang tot Data 360-gegevens vereisen in een UI-vriendelijke JSON-indeling. |
| Data Graph API | Gebruik dit wanneer de app query's op semantisch niveau moet uitvoeren voor meerdere objecten (bijvoorbeeld Klant → Transacties → Campagnes). |
| Query API | Gebruik dit bij het uitvoeren van SOQL-achtige query's om geharmoniseerde gegevenssets met grote precisie op te halen. |
| Einstein 1 Platform-API's | Gebruik dit bij het integreren van AI-gestuurde insights of door Copilot gegenereerde aanbevelingen binnen aangepaste UI's. |
| MuleSoft of Apex Gateway wrappers | Gebruik dit wanneer extra doeltreffende combinatie, caching of beleidsafdwinging vereist is tussen de app en de Connect-API. |
Afhandeling en herstel van fouten
- Verzoekthrottling: Maakt automatisch een back-up en probeert opnieuw API-aanroepen onder tarieflimieten.
- Schema Drift Protection: Gebruikt GraphQL schema versioning of REST metadata Discovery om zich aan te passen aan schemawijzigingen.
- Tokenvervalbeheer – Toepassingen vernieuwen OAuth-tokens automatisch om sessieonderbrekingen te voorkomen.
- API-foutisolatie – Mislukte API-aanroepen worden vastgelegd en opnieuw geprobeerd zonder gevolgen voor gelijktijdige sessies.
- Trust Layer Observability – API success/failure rates en access logs zijn zichtbaar in het Trust Layer dashboard.
Overwegingen bij impotent ontwerp
- Deterministische verzoek-ID's: Elk API-verzoek bevat een correlatie-ID voor veilige verwerking bij opnieuw afspelen.
- Cachevalidatieheaders: ETag- en Laatst gewijzigd-headers voorkomen het ophalen van redundante gegevens.
- Atomaire leesbewerkingen: Connect-API zorgt ervoor dat elke respons een consistente momentopname van gecombineerde gegevens weergeeft.
- Bescherming tegen opnieuw afspelen – Dubbele API-aanroepen worden gefilterd met behulp van verzoekhandtekeningen en tijdstempels.
Beveiligingsoverwegingen
- OAuth 2.0-authenticatie: Alle API-aanroepen gebruiken veilige, kortdurende OAuth-toegangstokens via verbonden apps.
- Minimale toegang: API-bereiken zijn beperkt tot alleen noodzakelijke objecten en velden.
- Overal encryptie: TLS 1.2+ onderweg; AES-256-encryptie in ruste voor in het cachegeheugen opgeslagen of opgeslagen responsen.
- Instemmingsbewuste gegevenstoegang: Data 360 zorgt ervoor dat alle opgehaalde records voldoen aan het instemmings- en governancebeleid.
- Uitgebreide controleregistratie: Elke API-interactie wordt vastgelegd met metagegevens van gebruikers, apps en tijdstempels in de Trust Layer.
Sidebars
Tijdigheid
- Ontworpen voor realtime API-toegang met lage latentie.
- Ideaal voor interactieve toepassingen die onmiddellijke gegevensweergave vereisen.
- Ondersteunt vrijwel directe responstijden van query's via gecachete en geïndexeerde Data 360-bronnen.
- Geen afhankelijkheid van batchplanningen of asynchrone activeringscycli.
Gegevensvolumes
- Geoptimaliseerd voor interactieve gebruikscases voor het ophalen van kleine tot middelgrote gegevenssets (bijv. profielen, insights of recente transacties).
- Handelt gepagineerde resultaten elegant af door middel van op cursor gebaseerde paginering.
- Niet bedoeld voor bulkexports met groot volume: gebruik batch- of bestandsexportpatronen voor grote gegevenssets.
Statusbeheer
- Toepassingen behouden een lichtgewicht sessiestatus met OAuth-tokens en lokaal cachegeheugen.
- Connect-API ondersteunt voorwaardelijke verzoeken en gedeeltelijke vernieuwing voor efficiëntie.
- API-responsen omvatten versiemarkeringen voor schemaconsistentie tussen releases.
Complexe integratiescenario's
- Combineer de Connect-API met de Data Graph-API voor semantische query's over meerdere domeinen.
- Integreer met Einstein 1 Copilot- of AI-API's voor voorspellende, gesprekservaringen.
- Gebruik naast Experience Cloud- of Lightning webcomponenten voor de ontwikkeling van hybride UI's.
- Breid uit via MuleSoft om gegevensverrijking of externe systeemzoekopdrachten in realtime te organiseren.
Voorbeeld
Een multinationale verzekeringsmaatschappij stelt een selfserviceportal voor klanten samen waarmee verzekeringnemers hun gecombineerde profielen, recente claims en gepersonaliseerde aanbiedingen kunnen bekijken. De front-end, op eact gebaseerde app, authenticeert via OAuth 2.0 en haalt gegevens op met behulp van de Connect REST-API en de Data Graph-API. Alle gegevens worden weergegeven in Realtime, op instemming gebaseerd en beheerd via de Data 360 Trust laag. Ontwikkelaars bewaken API-aanroepen en controletrajecten rechtstreeks binnen Salesforce, waardoor volledige naleving en observatie worden gegarandeerd.
Context
Ondernemingen hebben steeds vaker onmiddellijke toegang nodig tot een volledig klantprofiel voor real-time beslissingssystemen, zoals serviceconsoles, aanbevelingsengines of personalisatieplatforms. Met dit patroon kunnen toepassingen vooraf berekende, gecombineerde weergaven van de gegevens van een klant ophalen in nearReal-Time met behulp van de Data Graph-API van Data 360, die reactietijden van minder dan een seconde biedt voor interactieve omgevingen. Typische gebruikscases zijn:
- Een 360-graden klantenweergave weergeven binnen een Klantenservice of Sales Console.
- Op AI gebaseerde aanbevelingen voor Next Best Action of Next Best Offer ondersteunen.
- Hypergepersonaliseerde web- of mobiele omgevingen leveren tijdens het laden van de pagina.
- Ondersteuning van beslissingen tijdens de sessie in agent- of selfserviceomgevingen.
Probleem
Hoe kan een toepassing onmiddellijk een volledige, vooraf berekende, gecombineerde klantenweergave ophalen in plaats van trage query's voor meerdere objecten uit te voeren tijdens run-time? Zo moet een webpersonalisatie-engine de volledige context van de klant (demografie, voorkeuren, transacties en berekende insights) binnen milliseconden laden om een gepersonaliseerde aanbieding te selecteren. Traditionele relationele query's kunnen meerdere joins vereisen en leiden tot onaanvaardbare latentie. Dit vereist een API die gedenormaliseerde, kant-en-klare profielgegevens levert, die kunnen worden opgehaald via één sleutelzoekopdracht, waarbij snelheid, volledigheid en governance worden gecombineerd.
Krachten
Meerdere operationele en prestatiefactoren beïnvloeden dit patroon:
- Snelheid: Reactietijd moet nearReal-Time zijn. De API moet binnen milliseconden een volledig profiel retourneren om synchrone interacties te ondersteunen.
- Volledigheid: De respons moet alle relevante kenmerken, relaties en berekende insights bevatten, idealiter in één payload.
- Opzoekefficiëntie: Profielen moeten kunnen worden opgehaald via identifiers zoals customerId, contactKey of e-mail, waardoor query's in meerdere stappen worden geëlimineerd.
- Gegevensversheid vs. Latentie: Sommige gebruikscases geven de voorkeur aan vooraf berekende (cache) gegevens voor snelheid; andere hebben live gegevens nodig, die een hogere latentie accepteren.
- Bestuur en veiligheid: Toegang moet geregeld blijven via Salesforce Trust Layer-beleidsvormen, waarbij naleving van regels voor zichtbaarheid en instemming van gegevens wordt gegarandeerd.
Oplossing
De oplossing is het gebruik van de Salesforce Data Graph API voor het ophalen van vooraf berekende, gedenormaliseerde klantweergaven die zijn opgeslagen als gegevensgrafiekrecords. Een gegevensgrafiek is een gematerialiseerde semantische weergave die meerdere gegevensmodelobjecten (Data Model Objects, DMO's) combineert, zoals Individu, Transactie en ProductInterest, in één alleen-lezen record, vaak weergegeven als een JSON-blob. Ontwikkelaars kunnen REST-eindpunten gebruiken zoals: GET /api/v1/dataGraph/{dataGraphEntityName}/{id} om een volledige record op te halen op basis van de unieke identifier ervan. Voor dynamische scenario's ondersteunt de API een parameter live=true die het gematerialiseerde cachegeheugen omzeilt en een real-time query uitvoert op Data 360, waarbij een minimale latentie wordt uitgewisseld voor de nieuwste gegevens. Hierdoor kunnen ontwikkelaars kiezen tussen onmiddellijke (cache) en actuele (live) profielophalingen, afhankelijk van de bedrijfsbehoeften.
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Definitie van gegevensgrafiek | Verplicht | Architecten definiëren een gegevensgrafiek die meerdere DMO's combineert in één semantische entiteit (bijvoorbeeld UnifiedCustomerProfile). |
| Opzoeken van profielen | Beste | Toepassingen roepen GET /api/v1/dataGraph/{entity}/{id} aan om volledige, gedenormaliseerde profielen op te halen op basis van een unieke ID of sleutel. |
| Live parametergebruik | Optioneel | Voeg ?live=true toe om nieuwe berekeningen af te dwingen in plaats van ophalen in het cachegeheugen; geschikt voor beslissingen met een hoge waarde. |
| Authenticatie | Verplicht | Gebruik OAuth 2.0 via verbonden apps om API-aanroepen veilig te authenticeren. |
| Responsparseren | Best practice | Toepassingen parseren de JSON-respons rechtstreeks in hun UI of beslissingsengine; er zijn geen verdere joins vereist. |
| Cachingstrategie | Aanbevolen | Implementeer lokale caching voor de korte termijn (bijv. in-memory of CDN) voor herhaalde profielzoekopdrachten. |
| Monitoring en observatie | Verplicht | Gebruik Trust Layer-dashboards om queryprestaties, reactietijden en naleving van beleid te bewaken. |
Schets
Hier is de samenvatting van de implementatiestroom:
- Gegevensgrafiek definiëren — Gegevensarchitecten maken een gegevensgrafiek die een uniforme klantweergave modelleert voor meerdere DMO's.
- Verbonden app registreren: ontwikkelaars configureren OAuth-inloggegevens voor veilige API-toegang.
- API Gegevensgrafiek aanroepen: de toepassing geeft een GET-verzoek uit met de naam van de gegevensgrafiek en de record-ID.
- Procesrespons: de API retourneert een volledige JSON-representatie van het klantprofiel.
- Render of Act: de verbruikende app (UI of engine) gebruikt de gecombineerde gegevens voor personalisatie, aanbevelingen of serviceacties.
- Bewaken en afstemmen — Prestatiemeetgegevens en toegangslogboeken worden beoordeeld via de Trust Layer-observatieconsole.
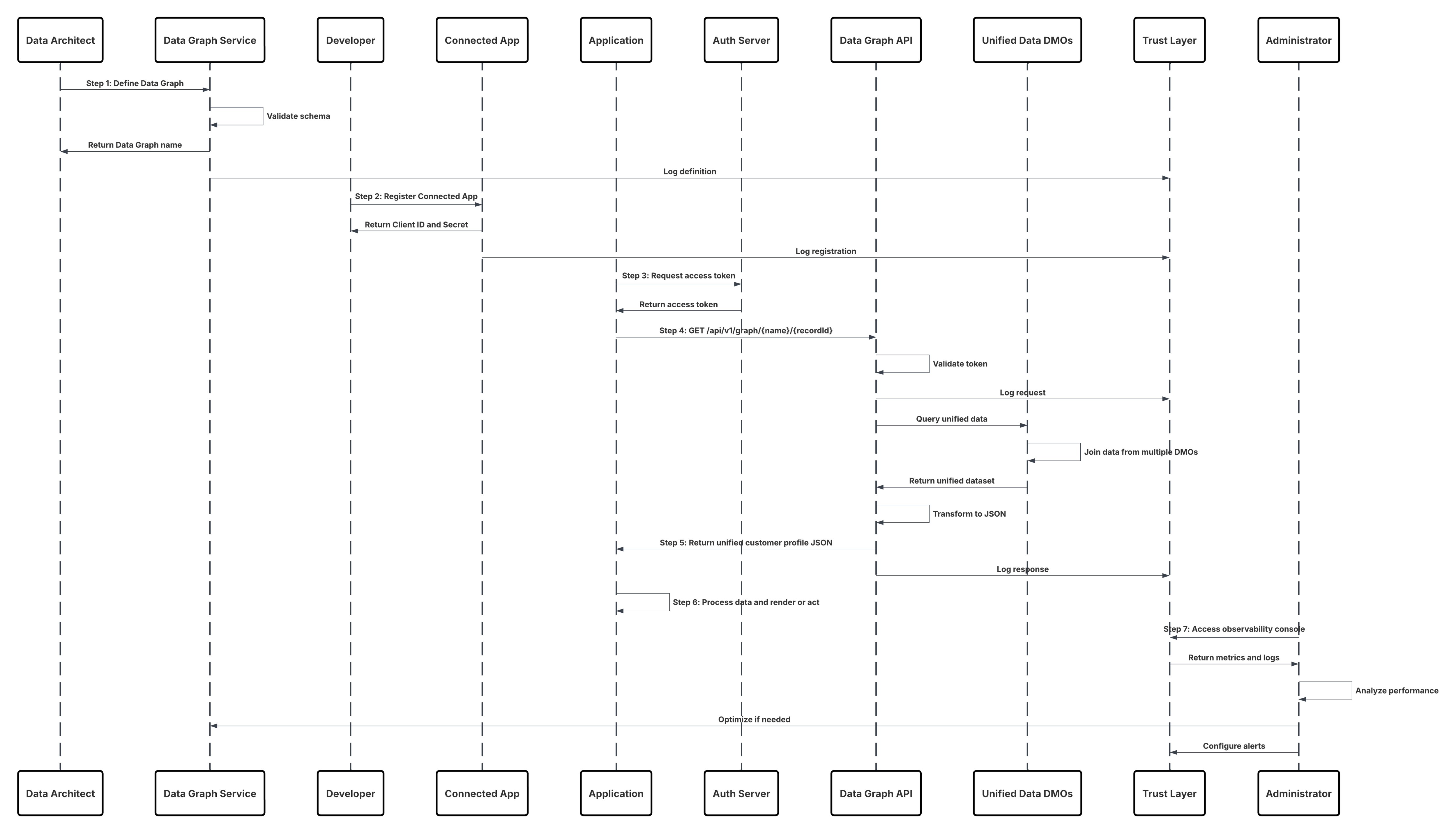
Resultaten
Toepassingen kunnen nu onmiddellijk een volledig, vooraf samengevoegd klantprofiel ophalen, wat real-time interacties mogelijk maakt, zoals personalisatie, service en beslissingsautomatisering. Dit patroon zorgt voor:
- Reactietijden van subseconden voor beslissingen op het moment.
- Consistent, beheerd ophalen van gegevens in overeenstemming met het semantische model van Data 360.
- Vereenvoudigde toepassingslogica: geen joins, geen schemaafstemming.
- Traceerbare en conforme toegang via de Trust Layer voor controle en observatie.
Aanroepmechanismen
Het aanroepmechanisme is afhankelijk van het doelcloudopslagplatform en de activeringsconfiguratie.
| Mechanisme | Wanneer gebruiken |
|---|---|
| Data Graph API (Voorkeur) | Gebruik dit om complete, vooraf gematerialiseerde profielen onmiddellijk op te halen op ID of sleutel. |
| API voor gegevensgrafieken met live=true | Gebruik dit voor gebruikscases met een hoge waarde (bijv. fraudedetectie, live aanbiedingen) waarbij de meest actuele gegevens nodig zijn en een iets hogere latentie wordt geaccepteerd. |
| Connect-API (reserve) | Gebruik dit voor samengestelde appscenario's die Gegevensgrafiek-ophaalacties combineren met andere Salesforce-gegevens. |
| Query API | Gebruik dit bij het samenstellen van ad-hocquery's of analytische leesbewerkingen in plaats van het onmiddellijk ophalen van profielen. |
| MuleSoft API-proxy | Gebruik dit bij het routeren van Gegevensgrafiek-aanroepen door ondernemingsgateways of wanneer extra doeltreffende combinatie/beleidsafdwinging vereist is. |
Afhandeling en herstel van fouten
- Graceful Fallbacks – Als live query's mislukken of time-outdrempels overschrijden, gaat u automatisch terug naar het ophalen van gegevensgrafieken in het cachegeheugen.
- Time-outbeheer – Implementeer logica voor opnieuw proberen en stroomonderbrekers voor API-aanroepen onder hoge belasting.
- Ongeldige ID-afhandeling – Retourneer standaard 404 Niet gevonden responsen voor niet-bestaande profielsleutels; handel dit netjes af in UI.
- Schemaversievalidatie – Valideer de metagegevens van de gegevensgrafiekversie om mismatches te voorkomen wanneer het schema verandert.
- Waarneembaarheidsintegratie – Leg alle fouten, pogingen en latenties vast binnen Trust Layer dashboards voor SLA-bewaking.
Overwegingen bij impotent ontwerp
- Deterministische sleutels – Elke profielophaalactie gebruikt een stabiele ID (bijv. IndividualId) die voorspelbare, veilige query's voor opnieuw afspelen garandeert.
- Cacheconsistentie – Gebruik ETag- of Laatst gewijzigd-headers voor voorwaardelijke ophalingen en cachevalidatie.
- Atomic Retrieval – Elke API-respons vertegenwoordigt een consistente momentopname van de gematerialiseerde gegevensgrafiekrecord.
- Bescherming tegen opnieuw afspelen – Zorg ervoor dat clienttoepassingen dubbele ophaalpogingen detecteren via correlatie-ID's en tijdstempels.
Beveiligingsoverwegingen
- Sterke authenticatie – OAuth 2.0 via verbonden apps dwingt veilige, op tokens gebaseerde toegang af.
- Consent-Aware Retrieval – Alleen goedgekeurde kenmerken worden geretourneerd; instemmingsfilters worden automatisch toegepast door de Trust Layer.
- Governance op veldniveau – Toegang tot kenmerken wordt bepaald via de metagegevens en beleidsdefinities van Data 360.
- Encryptie in transit en at rest – Alle responsen worden versleuteld met TLS 1.2+ en AES-256.
- Audit en traceerbaarheid – Elke event voor het ophalen van een profiel wordt vastgelegd met identifiers, tijdstempels en beleidscontext.
Sidebars
Tijdigheid
- Ontworpen voor onmiddellijk ophalen.
- Ondersteunt live query's voor actuele gegevens met een iets hogere latentie (subseconde).
- Geoptimaliseerd voor synchrone besluitvorming en interactieve toepassingen.
- Elimineert de noodzaak voor pre-batchactivering of segmentherberekening.
Gegevensvolumes
- Ideaal voor opzoekopdrachten met één record of kleine sets (tientallen tot honderden) per verzoek.
- Niet geoptimaliseerd voor bulkverwerking; gebruik batch- of query-API's voor lezen met groot volume.
- Gebruikt horizontaal schaalbare caching en pre-materialisatie voor snelheid.
Statusbeheer
- Handhaaft lichtgewicht, staatloze toegang; elk verzoek is onafhankelijk.
- Ondersteunt cacheheaders voor opnieuw afspelen veilig ophalen.
- Toepassingen kunnen lokale cachegeheugen- of sessieopslag voor de korte termijn onderhouden om herhaalde zoekopdrachten te verminderen.
Complexe integratiescenario's
- Integreert naadloos met Einstein 1, Connect API en MuleSoft voor omgevingen met samengestelde gegevens.
- Kan agentische systemen aansturen (bijv. Copilot- of AI-redeneerengines) die onmiddellijk contextueel bewustzijn vereisen.
- Gecombineerd met gegevensacties voor realtime triggers bij ophalen of statuswijziging.
- Maakt personalisatie op schaal mogelijk zonder afbreuk te doen aan prestaties of governance.
Voorbeeld
Een wereldwijd e-commerceplatform gebruikt de Data Graph API van Data 360 om in real-time gecombineerde klantprofielen op te halen voor de aanbevelingsengine. Wanneer een gebruiker inlogt, roept de toepassing het eindpunt Gegevensgrafiek aan om het UnifiedCustomerProfile voor die klant op te halen, waarbij demografische kenmerken, gedragssignalen en berekende insights worden geretourneerd als één JSON-payload. De personaliseringsengine verbruikt deze respons binnen milliseconden om de "Next Best Offer" (Volgende beste aanbieding) te bepalen en weer te geven tijdens de actieve sessie. Alle verzoeken worden beheerd en vastgelegd via de Trust Layer, wat volledige zichtbaarheid, beleidsafdwinging en naleving binnen de interactie garandeert.
Realtime gegevensacties maken onmiddellijke activering van klantgegevens mogelijk op het moment dat deze veranderen in Data 360. In plaats van te wachten op geplande batchexports pushen deze acties updates, insights of triggers rechtstreeks naar Salesforce of externe systemen in milliseconden. Wanneer de status-, instemmings- of betrokkenheidsmeetgegevens van een klant worden bijgewerkt in Data 360, kan dat signaal onmiddellijk gepersonaliseerde aanbiedingen aansturen, Service Cloud-automatiseringen activeren of loyaliteitslagen bijwerken, zodat elke klantervaring de meest actuele, gecombineerde waarheid weerspiegelt. Dit patroon is ideaal voor sterke, latentiegevoelige gebruikscases zoals gepersonaliseerde webomgevingen, fraudedetectiewaarschuwingen, next-best-action aanbevelingen of realtime CRM-updates. Hiermee wordt de kloof gedicht tussen inzicht in gegevens en bedrijfsacties, waarbij gecombineerde gegevens worden omgezet in intelligentie op het moment.
Context
Moderne digitale omgevingen en operationele werkstromen vereisen onmiddellijke, contextuele acties op het moment dat een event plaatsvindt, bijvoorbeeld het bijwerken van een klantrecord tijdens een Checkout, het aanpassen van de voorraad wanneer een retour wordt gescand, of het leveren van een gepersonaliseerde speciale actie op het moment dat een gebruiker een winkelwagentje verlaat. Met realtime gegevensacties kunnen systemen gecombineerde Data 360-profielen en berekende insights aanroepen, verrijken en gebruiken met een latentie van subseconde tot seconde, waardoor interactieve personalisatie, operationele automatisering en onmiddellijke beslissingen mogelijk worden.
Probleem
Hoe kunnen toepassingen, UI-interactiestromen of middleware Data 360 tijdens run-time aanroepen om één gecombineerd profiel te lezen, te berekenen of bij te werken of om een actie te activeren (bijvoorbeeld een aanbieding verzenden, CRM bijwerken, een werkstroom starten) met een lage latentie, sterke consistentie en governance-besturingselementen — zonder te hoeven wachten op geplande batchtaken of zware pijplijnen?
Krachten
Verschillende technische, operationele en governance-krachten geven dit patroon vorm:
- Vereiste lage latentie: Aanroepen moeten in subseconden tot enkele seconden worden voltooid om een goede UX te behouden of om te voldoen aan operationele SLA's.
- Deterministische identiteitsoplossing: Verzoeken moeten betrouwbaar en snel worden opgelost naar het juiste profiel Gecombineerd individu (gouden record).
- Fijnkorrelige autorisatie: Realtime gesprekken moeten beleid op kenmerkniveau en instemmingscontroles afdwingen op het moment van het verzoek.
- Minimalisme van payload: Realtime payloads moeten klein en gericht zijn (enkelvoudig profiel of kleine kenmerkenset) om latentie en kosten te verminderen.
- Ontwikkelaarservaring: API's moeten ontwikkelaarsvriendelijk zijn (REST/gRPC/GraphQL), met duidelijke schema's en stabiele contracten voor productiegebruik.
- Controleerbaarheid en traceerbaarheid: Elke real-time actie moet worden vastgelegd met afstamming, gebruikersidentiteit en beleidsbeslissingen voor naleving.
Oplossing
De aanbevolen oplossing is het gebruik van de interface van Data 360's Realtime Data Actions (API's + SDK's) in combinatie met edgecaching en minimale rekentransformaties waar nodig. Integraties roepen een eindpunt van gegevensacties aan om profielkenmerken te lezen of schrijven, insights te berekenen of doeltreffende combinaties te starten. Realtime beleidscontroles (CEDAR) en dynamisch maskeren worden toegepast op het beleidshandhavingspunt voordat er payload wordt geretourneerd of actie wordt uitgevoerd.
| Oplossingsgebied | Passen | Opmerkingen / Implementatiedetails |
|---|---|---|
| Actie Realtime gegevens | Best | Eindpunt zichtbaar maken voor lezen/schrijven en actietriggers voor één record. Authenticeren via OAuth/JWT. |
| Identiteitsoplossing | Verplicht | Los inkomende identifiers (e-mail, externalId, cookie) op naar ID van gecombineerd individu in-line. Gebruik een deterministische resolver met cachegeheugen. |
| Beleidshandhaving (CEDAR) | Best practice | Evalueer instemmings-, ABAC- en maskerbeleid op het moment van de aanvraag; weiger of masker velden per beleidsbeslissing. |
| Rand-/cachelaag | Aanbevolen | Gebruik korte-TTL-cachegeheugens voor profielfragmenten en berekende insights om de latentie te verminderen. |
| Lichtgewicht transformaties | Aanbevolen | Pas eenvoudige verrijkingen of berekende velden toe in het actiepad; zware transformaties moeten vooraf worden berekend. |
| Actiecombinatie | Best | Ondersteuning van synchrone acties in één stap (bijv. retouraanbiedingstoken) en asynchrone doeltreffende combinaties (wachtrij \+ webhook) voor complexe stromen. |
| Waarneembaarheid en tracering | Verplicht | Leg verzoek/reactie, beleidsbeslissingen en afstamming vast bij de Trust Layer/SIEM voor controle en foutopsporing. |
| Tariefbeperking en throttling | Verplicht | Dwing cliëntenquota's en elegante degradatiestrategieën af voor momenten met veel verkeer. |
Schets
Hier is de samenvatting van de stappen.
- Client (UI / middleware / POS) verzendt geauthenticeerde gegevensactieverzoeken met identifiers en actietype.
- API Gateway valideert token, scorelimieten en stuurt door naar Data 360 Action Service.
- Actieservice lost identifier → ID van gecombineerd individu op (cachegeheugen voor snel pad; reservekopie naar opzoeken van grafiek).
- Beleidsafdwinging (PDP) evalueert CEDAR-beleid met behulp van kenmerken van PIP en verzoekcontext.
- Indien toegestaan, leest Actieservice alle vereiste profielkenmerken/insights en voert lichttransformaties uit.
- Actieservice retourneert respons synchroon (bijv. aanbiedingstoken, bijgewerkt kenmerk) of plaatst asynchrone doeltreffende combinatie in de wachtrij en retourneert bevestiging.
- Alle events, beslissingen en payloads worden vastgelegd in Trust Layer en optioneel doorgestuurd naar SIEM.
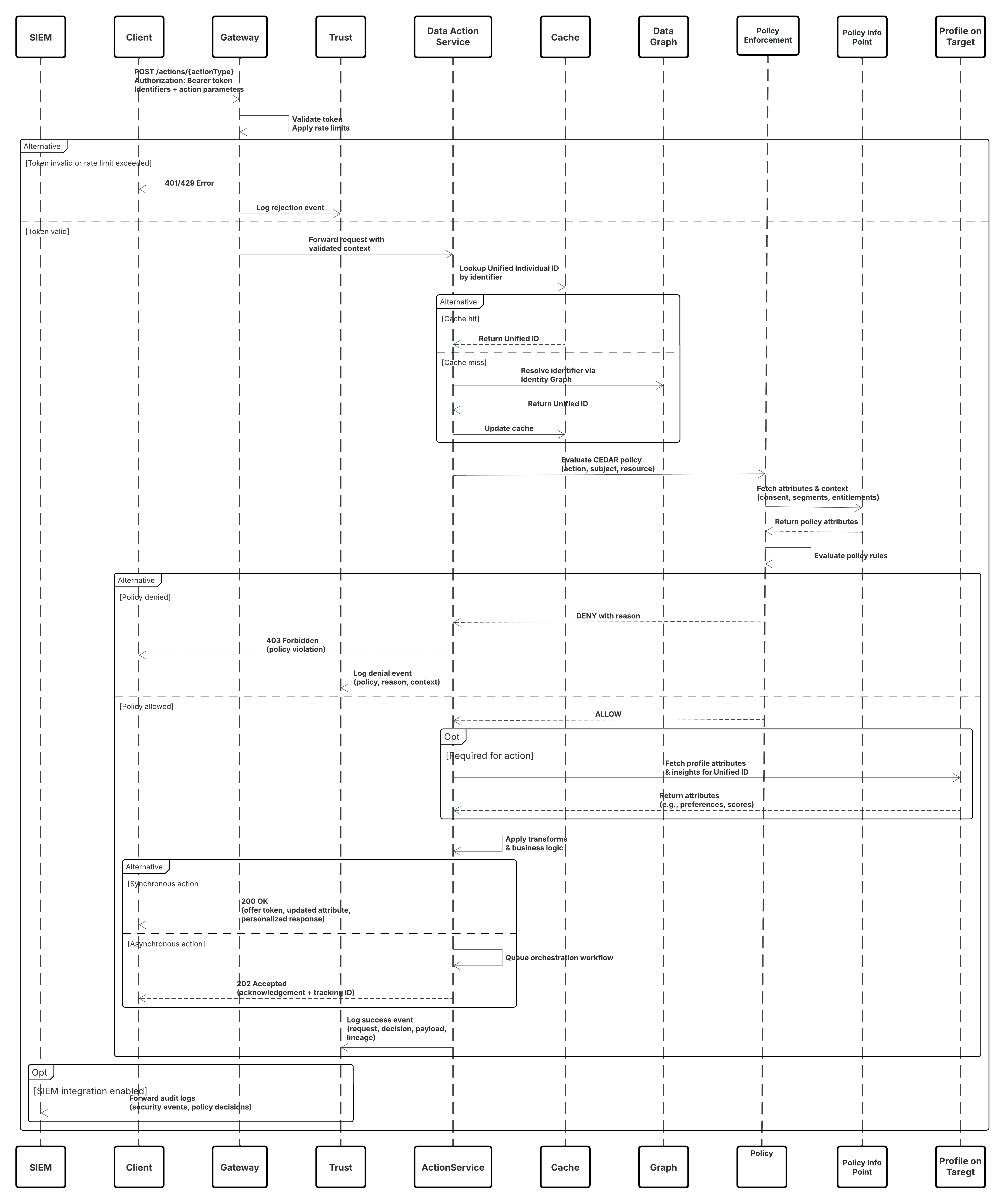
Resultaten
- Toepassingen krijgen onmiddellijke, door beleid bepaalde toegang tot gecombineerd profiel lezen/schrijven en actietriggers met subseconde tot tweede latentie.
- Realtime personalisering, besluitvorming en operationele werkstromen (bijv. aanbiedingen, agentassistentie, voorraadupdates) worden ingeschakeld zonder batchvertragingen.
- Alle acties zijn controleerbaar, instemmingsbewust en dwingen maskeren op kenmerkniveau af om privacy en naleving te waarborgen.
Aanroepmechanismen
Het aanroepmechanisme is afhankelijk van het bestemmingsplatform en de configuratie van het activeringsdoel.
| Mechanisme | Wanneer gebruiken |
|---|---|
| API voor RESTful-gegevensacties | Voorkeur voor web-/mobiele apps en middleware die synchrone profiellezingen of actiereacties vereisen. |
| gRPC / Binary RPC | Gebruik dit voor Enterprise-services met ultralage latentie of interne microservices met persistente verbindingen. |
| GraphQL Single-Record Query's | Gebruik dit wanneer cliënten flexibele veldselectie nodig hebben en payloads willen minimaliseren. |
| Door events geactiveerde webhaken | Gebruik dit voor asynchrone werkstromen waarbij actie downstream processen activeert (bijvoorbeeld een journey starten). |
| Platform-events / PubSub | Gebruik dit voor scenario's waarin meerdere systemen moeten reageren op één actie-event. |
| Edge SDK (client libs) | Gebruik dit alleen voor clients met een lage latentie die profielfragmenten in het cachegeheugen opslaan en de API voor gegevensacties aanroepen wanneer dat nodig is. |
Afhandeling en herstel van fouten
- Synchrone fouten: Retourneer gestructureerde foutcodes met voor mensen leesbare berichten en idempotentietokens.
- Tijdelijk opnieuw proberen: Clients moeten idempotente verzoeken met exponentiële backoff opnieuw proberen voor 429/5xx-responsen.
- Afhandeling van beleidsweigering: Afwijzingen retourneren duidelijke redencodes; gevoelige gegevens worden nooit geretourneerd bij mislukte polissen.
- Fouten bij asynchrone combinaties: Orchestration-taken worden verplaatst naar DLQ en kunnen opnieuw worden afgespeeld. Met een taakstatus-API kunnen cliënten polls uitvoeren of callbacks ontvangen.
- Reservestrategieën: Als identiteitsoplossing mislukt, retourneert u een deterministische fout en optioneel een voorgestelde oplossing (bijvoorbeeld externalId vereisen).
Overwegingen bij impotent ontwerp
- Idempotentiesleutel: Clients leveren een idempotentiesleutel (UUID + clientnaamruimte) voor het muteren van acties.
- Deterministische sleutels: Gebruik samengestelde sleutels (UnifiedIndividualId + ActionType + TimestampWindow) om duplicaten te detecteren.
- Veilige pogingen: Ontwerp acties om neveneffectentolerant te zijn of om upserts uit te voeren in plaats van blinde invoegingen.
- Bescherming tegen opnieuw afspelen: Behoud verwerkte idempotentiesleutels en TTL ze na het bedrijfsvenster om herhalingen te voorkomen.
- Statelessness: Houd synchrone acties waar mogelijk statusloos; behoud minimale status voor asynchrone werkstromen.
Beveiligingsoverwegingen
- Authenticatie: OAuth 2.0 (JWT-bearer of mTLS voor serviceaccounts); kortstondige tokens en vernieuwingsrotatie.
- Autorisatie: Beleidsbeslissingspunt dwingt op kenmerken gebaseerde toegangscontrole (CEDAR) en instemmingscontroles per verzoek af.
- Transport- en opslagencryptie: TLS 1.2+ onderweg; AES-256 in ruste voor alle cachefragmenten of controlelogboeken.
- Minste rechten: API-clients beperkt tot minimale machtigingen; rollen gescheiden voor lezen versus schrijven versus doeltreffende combinatie.
- Gegevensminimalisering: Retourneer alleen aangevraagde en goedgekeurde kenmerken; pas dynamisch maskeren toe voor PII/PHI.
- Netwerkbesturingselementen: Vereist optioneel gesprekken vanuit privénetwerken (Privé verbinden, IP-goedgekeurde lijsten) voor acties met hoog risico.
- Audit en bewaking: Leg metagegevens van verzoeken, beleidsbeslissingen, identiteit van verzoekers en responshashes vast in Trust Layer en SIEM.
Sidebars
Tijdigheid
- Ontworpen voor gemiddelde latenties in het bereik van subseconde tot laag in enkele seconden voor synchrone acties.
- Edge-caches (korte TTL) en vooraf berekende insights reduceren round-trips.
- Asynchrone trajecten bieden vrijwel onmiddellijke bevestiging met achtergrondverwerking voor zware taken.
Gegevensvolumes
- Geoptimaliseerd voor interacties met één record of kleine batches (1–100 records).
- Niet bedoeld voor bulkexport—gebruik batchactivering voor grote volumes.
- Hoge doorvoer gebruikt pooling/verbindingshergebruik en parallelle doeltreffende combinatiewachtrijen.
Statusbeheer
- Statusloos aanvraagmodel voor synchrone gesprekken; minimale actiestatus bleef bestaan voor subsidies/transacties.
- Cache-invalidering aangestuurd door wijzigingsevents—zorg ervoor dat TTL's en ongeldigverklaringssignalen cachegeheugens vers houden.
- Orchestration-taken behouden een duurzame status (jobId, status, opnieuw proberen) die is opgeslagen in de Trust Layer.
Complexe integratiescenario's
- Agentassistentie: Realtime profielopzoekopdracht + berekende neiging die in subseconden wordt geretourneerd naar de serviceconsole voor agenten.
- POS / Edge-apparaten: Lokale SDK + incidentele gegevensactie voor het valideren van speciale acties of loyaliteitsstatus.
- Hybride stromen: Gegevensactie synchroniseren voor beslissing + asynchrone doeltreffende combinatie om downstream systemen bij te werken en campagnes te activeren.
- Externe middleware: MuleSoft- of API-gateways kunnen authenticatie bemiddelen, context verrijken en extra beleidscontroles afdwingen.
Voorbeeld
Een mobiele app voor detailhandel bepaalt of een gepersonaliseerde onmiddellijke coupon moet worden weergegeven wanneer een shopper op Checkout tikt door de gegevensactie voor aanbiedingsdeelname aan te roepen met de context van e-mail en winkelwagentje van de shopper. Het verzoek wordt gevalideerd door de API-gateway en doorgestuurd naar de Data Action Service, die het e-mailbericht naar een gecombineerde ID van een individu leidt met behulp van een cachetreffer, de marketinginstemming verifieert via het PDP en de aanspraak evalueert op basis van de levensduur van de klant en recente aankoop. Als de shopper in aanmerking komt, retourneert de service een ondertekend coupontoken en legt de beslissing vast. Wanneer uitgifte van coupons voorraadreservering vereist, wordt een asynchrone doeltreffende combinatie geactiveerd om voorraad te reserveren en CRM-systemen te informeren. De app geeft de coupon onmiddellijk weer, terwijl updates verderop in de stroom op de achtergrond worden voltooid en de Trust Layer een volledig controletraject voor governance en naleving vastlegt.
- Connectoren & integratie
- Web & Mobile SDK
- Subseconde realtime opname
- Bring Your Own Lake (Zero Copy-query)
- Bring Your Own Lake (Zero Copy-bestand)
- Gegevensgrafieken
- Activering: MC-betrokkenheid
- Activering: MC-personalisatie
- Activering: B2C Commerce
- Gegevens delen (nulkopie)
- Activering: Bestandsopslag
- Gegevensacties
- Realtime subsecondengegevensacties
- Extern activeringsplatform