Dataplatforms evolueren al meer dan drie decennia. Aanvankelijk werd de industrie gedomineerd door on-premise, gecentraliseerde en gestructureerde (meestal relationele) operationele/OLTP-databases. Dit werd uitgebreid met datawarehouses OLAP/Big Data-platforms die voornamelijk werden gebruikt voor analytische verwerking en relationeel en gecentraliseerd bleven. Cloudopslag heeft gedistribueerde architecturen aangestuurd, zoals gegevensmagazijnen, meerhuizen en gedesaggregeerde opslag. Operationele platforms en analytische platforms bleven echter gescheiden. Vandaag veranderen cloud computing en de AI-revolutie de architectuur van het gegevensplatform fundamenteel.
Ondernemingen investeren al in volwassen Big Data-platforms zoals Snowflake, Databricks, BigQuery en Redshift. Maar deze platforms fungeren als gegevenssilo's. Klanten halen geen bedrijfswaarde uit hun gegevens, omdat er niet rechtstreeks vanuit de bedrijfsstromen en toepassingen actie kan worden ondernomen op de gegevens. Deze oplossingen hebben geen generatieve Agentic AI-verwerking en kunnen geen gegevenstoegang in real-time leveren, waardoor ze geen AI-gestuurde personalisatie kunnen leveren op het moment van klantbetrokkenheid en andere toonaangevende voorzieningen.
De toekomst van dataplatforms wordt gekenmerkt door een gecombineerde, flexibele, toegankelijke en open data-infrastructuur. Deze nieuwe architectuur is gebaseerd op moderne computer- en opslagtrends (GPU's, groot geheugen, NVMe SSD's en cloudopslag) om te integreren met cloud computing en AI. Ze kunnen realtime insights leveren, autonome besluitvorming stimuleren en realtime toepassingen aansturen. Dit omvat de opkomst van agentische AI, voorspellende AI, analyses, realtime grootschalige OLTP-databases, gegevens-lakes en meerhuizen. Deze moderne gegevensplatforms zijn ontworpen met het oog op eenvoud, schaalbaarheid, flexibiliteit, prestaties, beveiliging, beschikbaarheid en kostenefficiëntie.
De volgende gegevenstrends sturen de architectuur van het gegevensplatform van de volgende generatie aan.
- AI, machine learning en Analytics vormen de kern: De opkomst van Agentic AI zal de ontwikkeling, implementatie en gebruik/toegang van dataplatforms fundamenteel veranderen. Agentische AI begrijpt gespreks-/query-intentie, plant, genereert werkstromen en automatiseert besluitvorming. Agentisch geheugen (korte en lange termijn) is samengesteld op basis van gesprekshistorie voor het personaliseren van planning en beslissingen van agenten, real-time gespreksmodellering en personaliseringsondersteuning die van cruciaal belang zijn voor gegevensplatforms. Agenten helpen bij het automatiseren van operationele "mogelijkheden" zoals gegevensbeheer (beveiliging, naleving, Trust), prestaties (automatische schaalbaarheid voor gelijktijdigheid, doorvoer en latentie), failover en beschikbaarheid, en waarneembaarheid en onderhoud. AI-gestuurde analyses, prognoses, natuurlijke taalverwerking (NLP) voor vragen en antwoorden op analyses en analyses op ongestructureerde gegevens (tekst zoals PDF-bestanden, afbeeldingen, audio, video) worden standaard, waardoor ondernemingen diepergaande insights kunnen ontlenen aan diverse gegevensbronnen.
- Decentralisatie van gegevens, maar toegang tot gecombineerde gegevens: Agenten hebben ondernemingsgegevens nodig om inzichten af te leiden en beslissingen te nemen, en om bedrijfsactiviteiten te automatiseren. Gegevens zijn inherent gedecentraliseerd in ondernemingen, in verschillende toepassingen en gegevensplatforms. Maar het is niet eenvoudig om de silo's naadloos te combineren tussen verschillende bedrijfseenheden binnen de onderneming en met partners buiten de onderneming. Het combineren van gegevens omvat het delen van gegevens, hetzij via opname uit bronnen, hetzij via bundeling met gegevensbronnen; ruwe gegevens uit gegevensvoorbereiding, harmonisering en modellering voor analytische en AI-verwerking; opslag en beheer van gegevens op schaal voor efficiënte toegang met een laag CTS; en gegevenstoegang via verschillende query- en analysemechanismen en -tools, diep geïntegreerd met de onderliggende opslag- en gegevenstoegangsplatforms
- Cloudgebaseerde Open Lakehouses: Cloudgebaseerde Big Data-platforms (OLAP-platforms) convergeren naar het gebruik van open bestandsindelingen (Parquet) en tabelindelingen (Iceberg), waardoor gegevensbundeling (gegevens in) en delen (gegevens uit) mogelijk worden.
- Niet-gestructureerde gegevensverwerking: Met de opkomst, vooruitgang en acceptatie van generatieve AI beginnen ondernemingen waardevolle inzichten en zakelijke waarde te ontlenen aan het ondernemingscorpus van gegevens die grote volumes tekstdocumenten, audiotranscripties, video-opnamen en andere media vormen. Ongestructureerde gegevensverwerking, inclusief blokken, vectorisering, semantisch zoeken en Knowledge grafieken, maken deze insights mogelijk. Technieken zoals RAG (retrieval augmented generation) en CAG (cache augmented generation) worden de belangrijkste drivers van snel en agentisch zoeken binnen het gegevensbestand.
- Knowledge Management: Knowledge gaat verder dan alleen de ruwe inhoud zelf (documenten, artikelen, video's). Het vertegenwoordigt augmentatie van die inhoud door betekenis af te leiden, metagegevens te beheren en deze in context te plaatsen om een gedeeld begrip van inhoud binnen een organisatie of onderneming te ontwikkelen. Knowledge zelf is over het algemeen gestructureerd. Knowledge management omvat content management, Knowledge extractie, representatie door middel van modellen zoals grafieken en navigatie.
- Rich Data-toegang: Toegang tot Rich Data betekent dat gegevens, analyses en AI-tools toegankelijk moeten zijn voor verschillende identiteiten, waaronder eindgebruikers, zakelijke gebruikers, beheerders en analisten. Toegankelijkheid wordt bereikt door middel van mechanismen zoals ensemblequery's (met relationele, trefwoord- en semantische query's), query's met natuurlijke taal naar SQL (NL2SQL), realtime toegang, enzovoort.
- Realtime verwerking: Agentische toepassingen nemen real-time beslissingen op basis van de huidige status en op basis van nieuwe events, waarbij responsen en acties worden gepersonaliseerd, hetgeen toegang tot, verwerking van en handelen op real-time gegevens vereist. Realtime verwerking vereist actuele gegevens (gegevenslatentie) en interactieve toegang (toegangslatentie). Dergelijke gegevens en toegangslatentie vereisen dat het onderliggende gegevensplatform up-to-date gegevenstoegang vanuit operationele en analytische stores, verwerking met lage latentie (puntzoekopdrachten en query's), hoge gegevensschaal en hoge doorvoer ondersteunt.
- Gegevensbeveiliging, governance en woonplaats: Agentische en conversationele AI vereenvoudigt de UI van toepassingen, waardoor iedereen, van consumenten tot werknemers tot andere AI-agenten, met toepassingen kan werken via gesproken of geschreven natuurlijke taal. De waardevolle klant- en persoonsgegevens die moeten worden opgeslagen en gemodelleerd voor Agentic-toepassingen, moeten worden beveiligd en beheerd met goed gedefinieerde beleidsvormen voor toegang en delen. Steeds meer klanten moeten voldoen aan regelgeving die gegevensverblijf in hun eigen land of regio vereist, met name die bij de overheid of bij overheden.
Salesforce Data 360 is ontworpen voor de toekomst en is gericht op deze gegevenstrends. Data 360 is een cloud-native, metagegevensgestuurd gegevensplatform dat gegevens in silo's verenigt binnen de hele onderneming, waardoor organisaties hun gegevens kunnen opslaan, modelleren en verwerken om analyses, AI, machine learning en Agentic-toepassingen mogelijk te maken.
Dit document is een essentiële handleiding voor enterprise architecten en CTO's. Het beschrijft de architectuur, mogelijkheden, ontwerpprincipes en gebruikscases van Data 360. Het introduceert de grondbeginselen van Data 360-architectuur als primer, gevolgd door een reeks diepgaande duiken in de belangrijkste differentiators ervan, zoals interoperabiliteit met bestaande gegevensplatforms, inclusief strategie voor meerdere organisaties, beveiliging, governance en privacy, real-time activering en Clean Rooms voor gegevens.
Salesforce Data 360 is gebaseerd op een kernset principes die ondernemingsgegevens operationeel, vertrouwd en realtime maken.
- Openheid en interoperabiliteit: Gebouwd voor ecosystemen met meerdere clouds. Samengevoegd met gegevensplatforms zoals Snowflake, Databricks, BigQuery en Redshift zonder duplicatie, waarbij Customer 360 wordt uitgebreid met behoud van bestaande investeringen.
- Scheiding van opslag-berekening: Schaalt opslag en verwerking (batch, streaming en interactief) onafhankelijk. Levert elasticiteit en efficiëntie voor werkbelastingen met groot volume en hoge prestaties.
- Opslag en verwerking van meerdere modellen: Ondersteunt gestructureerde en diverse ongestructureerde gegevenstypen zoals tekst, beeldaudio en video. Biedt efficiënte opslag, real-time en batchverwerking, uitbreidbare indexering, gecombineerd zoeken, query's uitvoeren en analyse.
- Metadata-Driven Design: Toepassingen worden gedefinieerd door metagegevens in plaats van code. Metagegevens worden behandeld als een eersteklas activum, wat gecombineerd bestuur, flexibiliteit en diepe integratie in het Salesforce-platform mogelijk maakt.
- Real-time hybride verwerking: Ondersteunt query's met lage latentie en onmiddellijke besluitvorming, in combinatie met batchverwerking en analytische werkbelastingen.
- Intelligente en actieve gegevens: Neemt continu insights op, analyseert ze en pusht ze rechtstreeks naar bedrijfswerkstromen. Voorziet in no-code, low-code, pro-code en AI-gestuurde automatisering met de meest actuele context.
- Governance en Privacy by Design: Afstamming, toegangscontrole, residentie, gegevensencryptie en naleving zijn ingebouwd. Trust en vertrouwen in de regelgeving worden op elke laag versterkt.
- Eén-op-veel huurder: Een gecentraliseerde Data 360-organisatie fungeert als de enige bron van waarheid voor Customer 360 en ondersteunt naadloos salesforce-omgevingen voor meerdere organisaties die veel door Salesforce-klanten worden gebruikt.
Deze principes zorgen ervoor dat Data 360 gegevens in realtime open, intelligent en bruikbaar maakt.
Salesforce Data 360 is een modern gegevensplatform dat is gebaseerd op ontwerpprincipes die rekening houden met actuele gegevenstrends. De architectuurmogelijkheden ervan zorgen ervoor dat ondernemingsgegevens in real-time vertrouwd, gecombineerd en bruikbaar zijn, in overeenstemming met de leidende principes ervan.
- Cloud-Native Foundation: Wordt uitgevoerd op Hyperforce, geïmplementeerd op Hyperscalers (zoals AWS), met een onveranderbare, op microservices gebaseerde infrastructuur. Biedt elastische schaalbaarheid, zero Trust beveiliging, continue levering en wereldwijde naleving.
- Door Salesforce (Core) aangestuurde metagegevens: Metagegevens worden ontworpen, gemodelleerd en opgeslagen als Salesforce-metagegevens, waardoor onmiddellijk gebruik door ALLE Salesforce-toepassingen mogelijk is. Dergelijke metagegevens worden opgeslagen in een volledig ACID-conform RDBMS. Garandeert governance, consistentie van levenscyclus en diepe integratie met Salesforce Lightning Platform.
- Lakehouse-opslag: Gebouwd op Apache Iceberg en Parquet, waarbij schaalbaarheid van gegevens-lakes wordt gecombineerd met warehouse-governance die schema-evolutie, tijdreizen en updates met groot volume ondersteunt. Data 360 slaat gestructureerde en ongestructureerde gegevens op, modelleert en verwerkt deze met extreme opslag met moderne open standaarden, en met rijke transformatie- en gegevensverwerkingsmogelijkheden voor batch- en eventgestuurde werkbelastingen.
- End-to-end gegevenspijplijn met flexibele opname: Dekt de volledige levenscyclus—opnemen, voorbereiden, modelleren, combineren, analyseren en activeren—zodat u minder afhankelijk bent van gefragmenteerde puntoplossingen. Ondersteunt batches, vrijwel realtime en streaming met meer dan 270 connectoren en MuleSoft. De ELT-first-benadering maakt snelle beschikbaarheid van gegevens mogelijk met flexibiliteit bij transformatie verderop in de stroom.
- Interoperabiliteit van ondernemingsgegevens met open frameworks en bundeling: Combineert geïsoleerde gegevens binnen de hele onderneming met bidirectionele Zero Copy-bundeling met Snowflake, Databricks, BigQuery en Redshift, waardoor gegevensmigratie of duplicatie wordt voorkomen.
- Gegevensclassificatie, modellering en organisatie: Data 360 ordent gegevens als ruwe opgenomen gegevens, opgeschoonde en opgeslagen gegevens, en gegevens die zijn gemodelleerd volgens het gangbare informatieschema dat bekend staat als SSOT (Single Source of Truth). Dergelijke SSOT-objecten vormen de basis voor het definiëren van Semantic Data Models (SDM) en andere beheerde en toepassingsspecifieke modellen.
- Ingebouwde semantische gegevensmodellering voor uitbreidbare analyses met open semantische query-API's, die Tableau Next aansturen en toepassingsspecifieke analyses inschakelen.
- Hoogwaardige SQL-query-engine die een gecombineerde Data 360 SQL-query ondersteunt voor gestructureerde, ongestructureerde en grafiekgegevens.
- Gegevensopslag met lage vertraging: Opslag met sleutelwaarde voor hot data met millisecondenresponstijden. Maakt personalisatie en eventgestuurde scenario's in real-time mogelijk. Verzamelt en verwerkt klantbetrokkenheidsgegevens in real-time. Combineert identiteiten, interacties en gesprekken in één vertrouwde Customer 360 profiel- en contextgrafiek.
- Ongestructureerde gegevensverwerkingspijplijnen voor flexibele en uitbreidbare ondersteuning voor ongestructureerde gegevensopslag, Chunking, Genereren van inbedden (vectorisatie), Extractie van metagegevens (augmentatie), Samenvatting, Indexering, Knowledge extractie, Intelligente documentverwerking, Maken van geheugen voor korte en lange termijn (gespreks) enzovoort.
- Native Keyword, Vector en Hybrid Indexing voor nauwkeurige en efficiënte ongestructureerde toegang tot gegevens zoals Snel en Agentisch zoeken, RAG, Knowledge extractie, Agentisch geheugenafleiding, enz.
- Profiel, Personalisatie, Contextservices voor het inschakelen van AI/ML- en Agentic-toepassingen.
- Ingebouwde governance en beveiliging op elke laag voor tracering van afstamming, gegevensmaskering, gegevensverblijf en zero Trust beveiliging die naleving en Trust garandeert.
- Elastische rekenstof: Kubernetes-native, multi-tenant compute fabric. Voert Spark uit voor gedistribueerde verwerking en Hyper voor SQL-werkbelastingen. Kan elastisch worden geschaald voor verschillende taken en ondersteunt isolatie bij het uitvoeren van niet-vertrouwde code.
Dit alles draait op Hyperforce, de cloudbasis van Salesforce. Hyperforce biedt:
- Zero Trust beveiliging met encryptie, isolatie en beleid met de minste rechten.
- Veerkracht door implementaties in meerdere regio's. Hoewel Salesforce Data 360 profiteert van Hyperforce's veerkracht voor meerdere regio's en fouttolerantie op platformniveau, vereist echt disaster recovery (DR) op ondernemingsniveau een bredere architectuur die lijkt op elk gegevensplatform met de belangrijkste mogelijkheden: herspeelbare opnamepijplijnen, replicatie en metagegevensgestuurde rehydratie binnen alle afhankelijke ecosystemen.
- Waarneembaarheid met ingebouwde bewaking, meetgegevens en tracering.
- Geautomatiseerde schaal en FinOps-bewustzijn voor efficiëntie zonder kostenoverloop.
Data 360 vervangt bestaande ondernemingsinvesteringen niet. In plaats daarvan maakt Data 360 de gegevens die u al hebt vertrouwd, bestuurd en navolgbaar—en levert real-time, AI-gestuurde betrokkenheid waar dat het belangrijkste is. Kortom, Salesforce maakt van alle ondernemingsgegevens inclusief externe gegevens (Salesforce) metagegevensgestuurde objecten en schakelt Agentic-toepassingen in voor ontdekking, besluitvorming en het ondernemen van acties.
De volgende figuur illustreert de Data 360-referentiearchitectuur:
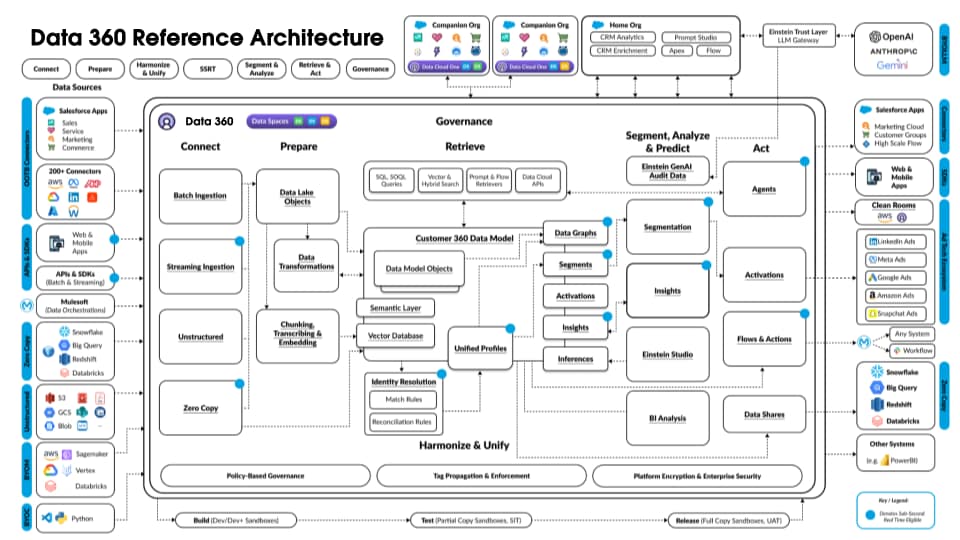
Laten we eens kijken naar een hypothetische Agentforce Loan Agent gelaagd op Data 360 om een voorbeeld van een architectuurstroom te beschrijven. Stel dat de leningagent een klantgerichte agent is waar klanten (consumenten) leningen aanvragen en onmiddellijke goedkeuringen voor leningen krijgen.
Data 360 voert deze stappen uit zoals gepland, waarbij gegevens worden voorbereid voor gebruik door de leningagent.
- Data 360 neemt gestructureerde klantaccountgegevens op uit CRM en slaat deze op in het gegevens-lake.
- Data 360 verwerkt ongestructureerde gegevens over bedrijfsleningen en financiële polissen.
- Data 360 bundelt persoonsgegevens uit een externe gegevensbron zoals Snowflake.
- Data 360 transformeert en modelleert opgenomen en gebundelde gegevens.
- Data 360 stelt de profielgegevensgrafiek samen en onderhoudt deze.
Telkens wanneer een klant een lening aanvraagt, worden deze acties uitgevoerd.
- Een klant meldt zich aan bij de leningagent, die een klantsessie start in de real-time laag. Het gecombineerde profiel van de klant wordt in de realtime laag getrokken.
- De klant voltooit een leningaanvraag door de vereiste informatie te verstrekken.
- De klant uploadt financiële documenten (zoals belastingaangiften, investeringen, bankafschriften) naar Data 360 voor ongestructureerde gegevensverwerking.
- Geüploade gegevens worden in blokken verdeeld en gevectoriseerd (genereren inbedden) en er worden indexen (trefwoord en vector) gemaakt.
- Vervolgens vult de klant het document voor de leningaanvraag in en uploadt het. Data 360 extraheert het leningbedrag en de duur in real-time.
- De leningagent haalt relevante financiële gegevens op met behulp van een Data 360-query en hybride zoekopdracht via profiel en andere vooraf gemaakte indices.
- De leningagent activeert een goedkeuringsagent met leninggegevens en andere financiële profielgegevens om de beslissing over de goedkeuring van de lening te nemen.
- De leningagent reageert op de klant met een beslissing.
- Deze gehele interactie tussen de klant en de leningagent wordt ook vastgelegd en opgeslagen in Data 360.
Het bovenstaande voorbeeld biedt een overzicht van Data 360-architectuurcomponenten die worden gebruikt voor het samenstellen van een Agentic-toepassing zoals een leningagent. In de volgende sectie beschrijven we de Data 360-architectuurlagen en -componenten.
In deze sectie gaan we dieper in op de basisbouwstenen van Salesforce Data 360, beginnend met het robuuste opslagmodel en vervolgens de mechanismen verkennen voor het verbinden, opnemen en voorbereiden van gegevens. Vervolgens zullen we onderzoeken hoe gestructureerde en ongestructureerde gegevens worden opgeslagen, gemodelleerd en verwerkt, met als resultaat inzicht in de mogelijkheden voor harmonisering, samenvoeging, opvraging en intelligente activering.
Salesforce Data 360 is gebaseerd op een gelaagd maar geïntegreerd opslagmodel dat de sterke punten van een lakehouse combineert met realtime opslag. De Lakehouse-laag biedt schaalbare, kostenefficiënte opslag voor grote volumes historische en batchgegevens, waardoor geavanceerde analyses en gebruikscases voor machine learning mogelijk worden. Realtime opslag is daarentegen geoptimaliseerd voor toegang met lage latentie en updates met hoge frequentie, waardoor interacties met klanten, profielen en betrokkenheidssignalen altijd actueel zijn. Samen werken deze lagen naadloos, waardoor gegevens vloeiend kunnen schakelen tussen historische en real-time contexten—en zowel diepte als onmiddellijkheid bieden in een gecombineerde gegevensbasis voor personalisering, AI en activering.
Data 360 biedt een native Lakehouse-architectuur op basis van Iceberg/Parquet, ontworpen voor het afhandelen van grootschalige gegevensbeheer en verwerking voor batch-, streaming- en real-time scenario's die zowel gestructureerde als ongestructureerde gegevens ondersteunen, wat cruciaal is voor AI- en analysetoepassingen.
In op de cloud gebaseerde gegevens-lakes zoals Azure, AWS of GCP is de basisopslageenheid een bestand, doorgaans geordend in mappen en hiërarchieën. Lakehouse verbetert deze structuur door structurele en semantische abstracties op een hoger niveau te introduceren om bewerkingen zoals query's en AI/ML-verwerking te vergemakkelijken. De primaire abstractie is een tabel met metagegevens die de structuur en semantiek ervan definieert, waarbij elementen uit open-sourceprojecten zoals Iceberg of Delta Lake worden opgenomen, met extra semantische lagen toegevoegd door Data 360.
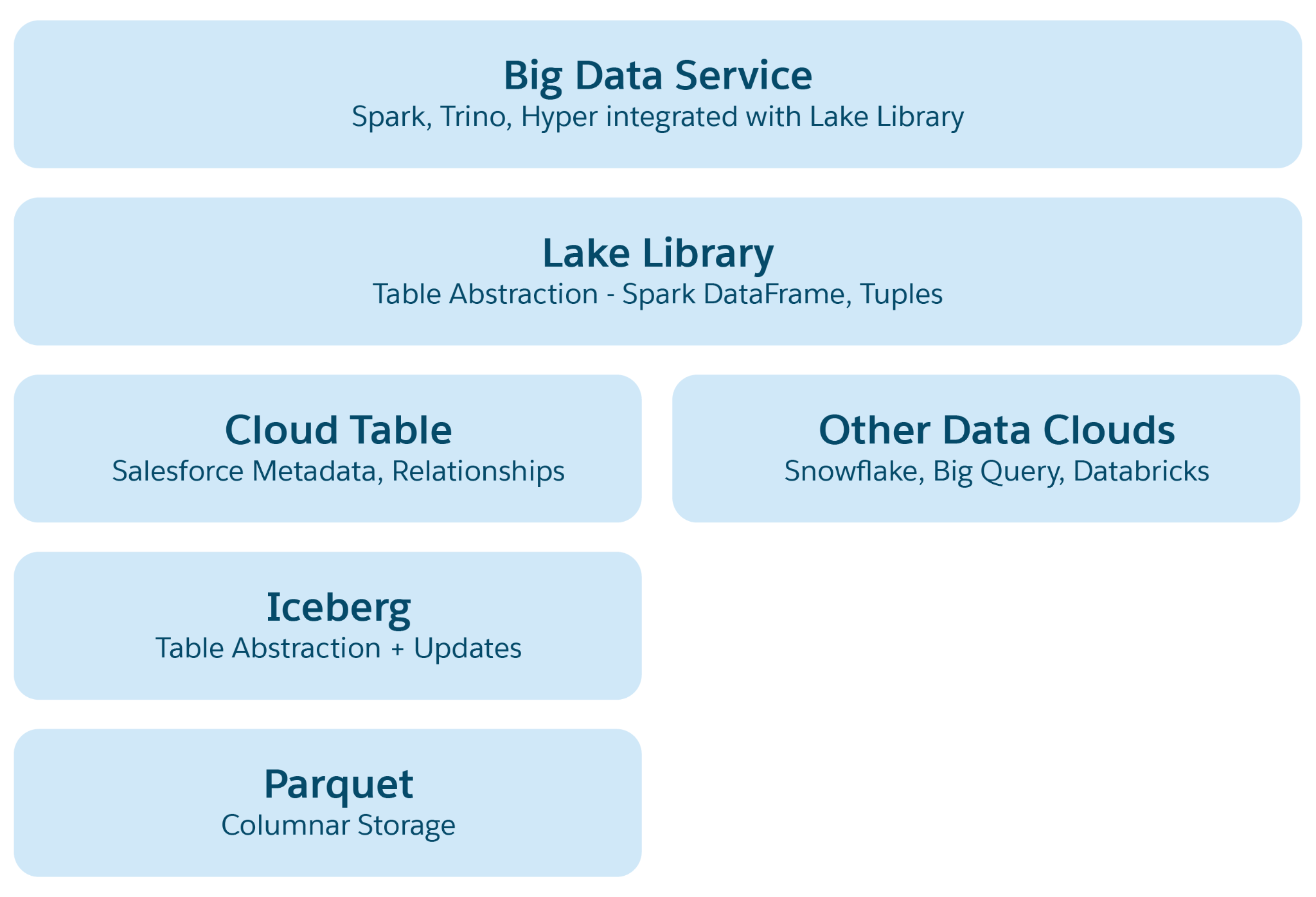
Abstractielagen in Lakehouse:
- Abstraheren van parketbestanden: Aan de basis bestaat opslag uit gegevens-lakebestanden (bijvoorbeeld S3 in AWS of Blob in Azure) in parketindeling. Gegevens voor een brontabel worden over meerdere partities opgeslagen als parketbestanden, waarbij elke tabel een verzameling van deze bestanden is.
- Iceberg tabel abstractie: Tabellen zijn ingedeeld als mappen, met gegevenspartities opgeslagen als parketbestanden binnen deze mappen. Wijzigingen aan een partitie resulteren in nieuwe parketbestanden als momentopnamen. Iceberg beheert een metagegevensbestand voor elke tabel, met gedetailleerde schema's, partitiespecificaties en momentopnamen.
- Salesforce Cloud-tabelabstratie: Voortbouwend op Iceberg voegt deze laag semantische metagegevens toe zoals kolomnamen en relaties, in combinatie met configuraties zoals doelbestandsgrootte en compressie. Het abstraheert tabellen op verschillende platforms zoals Snowflake en Databricks, waarbij Data 360-toepassingen worden afgeschermd van onderliggende details van opslagplatforms.
- Bibliotheek voor toegang tot meer: Deze bibliotheek biedt toegang tot de Salesforce Cloud Table, die zowel gegevens als metagegevens verwerkt, en abstraheert de onderliggende opslagmechanismen voor toepassingsontwikkelaars.
- Big Data Service Abstractie: Dit omvat verwerkingsframeworks zoals Hyper voor query's en Spark voor verwerking binnen elk cloudtabelplatform.
Ter ondersteuning van real-time analyses en agentische toepassingen breidt Data 360 de Big Data-opslag van Lakehouse uit met de Low Latency Store. Data 360 Real-time Layer verwerkt realtime signalen en betrokkenheidsgegevens in het geheugen. Aangezien de op geheugen gebaseerde opslagcapaciteit echter beperkt is, passen niet alle gegevens en wordt de verwerking mogelijk niet in real-time uitgevoerd. Data 360 voegt een store met lage latentie (LLS) toe om dergelijke beperkingen weg te nemen, waardoor schaalbare realtime verwerking mogelijk wordt.
De opslag met lage latentie is een NVMe-opslaglaag op petabyteschaal (SSD) op het Lakehouse. Niet alle gegevens hoeven in de store met lage latentie te worden bewaard. Het is een duurzaam cachegeheugen. De meeste gegevens komen uiteindelijk in het Lakehouse voor langdurige persistentie. In-sessie gegevens in de real-time laag kunnen naar de store met lage latentie worden gespoeld voor daaropvolgende snelle toegang. In een Agentisch gesprek kunnen recente berichten bijvoorbeeld in het geheugen worden verwerkt; oudere berichten kunnen worden doorgespoeld naar de store met een lage latentie. Als een vorig gesprek vereist is, is het binnen enkele milliseconden toegankelijk vanuit de store met lage latentie. Op NVMe gebaseerde opslag maakt het mogelijk om grote hoeveelheden gegevens op te slaan en te openen met milliseconde latenties. Gegevens komen mogelijk terecht in de Lakehouse-cloudopslag voor langdurige persistentie. Daarnaast worden gegevens uit Lakehouse die nodig zijn voor real-time verwerking of om real-time ervaringen te verbeteren, opgehaald en bewaard in de store met lage latentie. Context van klantprofiel wordt bijvoorbeeld vooraf opgehaald of binnengehaald vanuit het Lakehouse en in het cachegeheugen opgeslagen in de store met lage latentie. Ook kunnen alle Lakehouse-objecten en andere objecten die vereist zijn voor real-time verwerking tijdens verwerking tijdens de sessie, ook in het cachegeheugen worden opgeslagen in de store met lage latentie.
Data 360-opslag met lage latentie schakelt de Real Timer-laag in een echte opslaghiërarchie met geheugen (SSD) Lakehouse-opslaglagen in, waarbij gegevens naadloos tussen deze lagen worden gemigreerd. We bespreken de laag Data 360 Real Time verderop in dit document.
Salesforce Data 360 is ontworpen voor het standaardiseren, harmoniseren en activeren van alle klantgegevens—gestructureerde en niet-gestructureerde—volgens een strenge levenscyclus die ruwe invoer omzet in een gecombineerd, actueel gegevensmodel.
De levenscyclus richt zich op het nemen van verschillende externe gegevensinvoer en deze structureren in persistente, gemodelleerde objecten. Gemodelleerde gegevens kunnen worden gecombineerd in Customer 360 gecombineerde profielen.
Ruwe opgenomen gegevens en aanvankelijke transformaties
Het proces begint met ruwe gegevens die ongewijzigd worden opgenomen uit bronsystemen (CRM, Marketing, bestanden, enz.). Dit omvat volledige gegevensladingen en continue wijzigingsevents (delta's), die worden beheerd en samengevoegd met aanhoudende gegevens om een huidige status te behouden.
Inline transformaties (bijv. trimmen, normaliseren, aaneenvoegen) worden onmiddellijk toegepast tijdens opname om de kwaliteit en netheid van de voorlopige gegevens te waarborgen.
Data Lake Objects (DLO's): De aanhoudende laag
DLO's (Data Lake Objects) vormen de kern van de persistente opslaglaag binnen Data 360. Ze slaan de opgeschoonde, getransformeerde gegevens op en dienen als de georganiseerde opslagplaats voor alle klantinformatie op lange termijn.
Geavanceerde gegevenstransformaties (bijv. joins, aggregaties, berekende insights) worden toegepast op bron-DLO's om nieuwe, uiterst zorgvuldig samengestelde afgeleide DLO's te produceren.
Gegevens die beschikbaar worden gesteld via Zero Copy Data Federation, worden rechtstreeks weergegeven als DLO's.
Organisatie van ongestructureerde gegevens en metagegevens
Voor ongestructureerde inhoud (zoals tekst, media, documenten) neemt Data 360 de gegevens op door de gestructureerde metagegevens ervan te extraheren en te bewaren binnen specifieke DLO's die Ongestructureerde gegevens-lakeobjecten (UDLO's) worden genoemd.
Deze gespecialiseerde DLO's fungeren als directorytabellen en bieden een overzicht van de fysieke locatie en context van de ongestructureerde activa. Met deze mogelijkheid kunnen architecten de metagegevens van niet-gestructureerde gegevens naadloos relateren aan de rest van de gestructureerde klantgegevens, wat gecombineerde query's en harmonisering mogelijk maakt.
Gegevensmodelobjecten (DMO's): De geharmoniseerde laag
DMO's (Data Model Objects) vertegenwoordigen de definitieve, geharmoniseerde en gestructureerde gegevenslaag.
Ze worden gemaakt door DLO-velden (van bron-, afgeleide en ongestructureerde metagegevens-DLO's) toe te wijzen aan het standaard Customer 360 gegevensmodel.
De DMO-laag fungeert als de enige waarheidsbron voor alle klantgegevens, waardoor een gecombineerd profiel kan worden gemaakt, gesegmenteerd en geactiveerd binnen het bredere ecosysteem.
Een gegevensruimte is de fundamentele logische container voor het ordenen van alle gegevens en metagegevens binnen Data 360, inclusief alle DLO's (gestructureerde en ongestructureerde) en DMO's. Gegevensruimten bieden een veilige, geïsoleerde omgeving voor gegevensverwerking en modellering.
Gegevensruimten fungeren als logische en governance-grenzen, maken interne multitenancy mogelijk door gegevens te scheiden voor afzonderlijke entiteiten zoals bedrijfseenheden, regio's of merken, terwijl de zichtbaarheid, herkomst en naleving voor de hele onderneming behouden blijven, en dienen als basis voor het definiëren van grofkorrelige toegangscontrole.
Isolatie binnen gegevensruimten wordt afgedwongen op meerdere lagen van het platform:
- Isolatie op gegevensniveau: Elk DLO/DMO behoort tot één gegevensruimte, zodat query's, transformaties en objecttoewijzingen geen grenzen van gegevensruimte kunnen overschrijden, tenzij expliciet geautoriseerd.
- Integratie van toegangscontrole: Machtigingensets zijn standaard gekoppeld aan gegevensruimten, waardoor controle mogelijk is over lees-, schrijf- en beheerbewerkingen. Dit zorgt ervoor dat alleen geautoriseerde gebruikers en services toegang hebben tot objecten, insights en activeringen binnen een gegevensruimte.
- Governance en audit: Alle bewerkingen binnen een gegevensruimte worden vastgelegd met audittrajecten op ondernemingsniveau, waardoor traceerbaarheid voor naleving, rentmeesterschap en wettelijke rapportage mogelijk is.
Toegang en machtigingen worden beheerd via machtigingensets, waardoor fijnmazige zichtbaarheid, gecontroleerde updates en preventie van gegevenslekkage tussen domeinen worden gegarandeerd. Door grenzen van gegevensruimte te integreren met de beveiligings- en governance-architectuur van Data 360 kunnen architecten met vertrouwen zowel gecentraliseerde als gedecentraliseerde governance-strategieën implementeren, terwijl ze consistentie behouden in meerdere clouds en bedrijfsdomeinen.
Data 360-compute fabric biedt een gecombineerde laag voor het beheer en de uitvoering van alle Big Data-werkbelastingen, wat de onderliggende complexiteit van de infrastructuur vereenvoudigt. De kerncomponent ervan is de gegevensverwerkingsverantwoordelijke (Data Processing Controller, DPC).
DPC is een uitgebreide, doeltreffende combinatieservice voor gegevensverwerking met meerdere werkbelastingen die Job-as-a-Service-mogelijkheden (JaaS) biedt voor diverse cloud-computeomgevingen. Het abstraheert de complexiteit van de infrastructuur en verenigt taakuitvoering voor frameworks zoals Spark (EMR voor EC2 en EMR voor EKS) en Kubernetes Resource Controller (KRC)-werkbelastingen. Door te fungeren als een gecentraliseerde gateway voor besturingsvlakken orkestreert, plant en bewaakt DPC taken over meerdere gegevensvlakken, wat zorgt voor betrouwbaarheid, schaalbaarheid, kostenefficiëntie en een consistente ontwikkelaarservaring.
De behoefte aan DPC komt voort uit de beperkingen van directe interactie met native cluster management systemen zoals EMR.
Infrastructuur en Cloud-abstractie
Hoewel EMR API's biedt voor clusters, taken en stappen, belast het klantenteams nog steeds met kritieke infrastructuurbeheertaken zoals levering, schaalbaarheid, prestatieafstemming en kostenoptimalisering. DPC lost dit op door een vereenvoudigde API op platformniveau voor het indienen van taken aan te bieden. Het ondersteunt automatische afhandeling van storingen, opnieuw proberen en dynamische load balancing. Biedt kostenefficiëntie door middel van binpacking, spot en graviton gebaseerde knooppunten. Biedt sterke beveiliging met TLS, PKI, IAM-isolatie en geautomatiseerde patching. Beheert run-time versie-upgrades van Spark en EMR om prestatieverbeteringen, beveiligingspatches en uitbreidingen van voorzieningen te leveren.
Bovendien biedt DPC een gecombineerde, cloudonafhankelijke interface voor het indienen en beheren van gegevenstaken, die de complexiteiten en gepatenteerde API's van het onderliggende cloudsubstraat (AWS, toekomstige aanbieders) abstraheert. Dit zorgt ervoor dat klantenteams uitsluitend werken met een gemeenschappelijke op de Data 360 API gebaseerde interface voor het indienen van taken, die de complexiteiten van onderliggende resourcemanagers zoals Kubernetes en YARN wegneemt. Hierdoor kunnen clientteams Spark-taken indienen via een eenvoudige, gecombineerde API zonder dat ze pods, knooppuntpools of Spark-clusterconfiguraties rechtstreeks hoeven te beheren.
Het handmatig afstemmen van Spark-parameters vereist gespecialiseerde vaardigheden en onjuiste configuraties kunnen leiden tot trage taakuitvoering. Het DPC-team centraliseert deze expertise en biedt geoptimaliseerde configuraties om veelvoorkomende prestatieproblemen te voorkomen. Dit gespecialiseerde team integreert continu Knowledge uit de open-source community om optimale prestaties te garanderen voor alle werkbelastingen die door de controller worden beheerd.
DPC is niet beperkt tot Spark; het ondersteunt een breed scala aan werkbelastingen. Deze omvatten:
- Realtime verwerkingswerkbelastingen
- Eventlevering voor gegevensacties
- Beheer van Milvus (de vectordatabase voor ongestructureerde gegevensindexering)
- Opslaginfrastructuur met lage latentie
DPC maakt ook gebruik van het framework Kubernetes Resource Controller (KRC), dat werkbelastingen ondersteunt zoals Trino voor query, Eventlevering voor gegevensacties, Gegevensextractietaken voor connectoren en Realtime verwerking. Voor alle KRC-werkbelastingen biedt DPC centrale mogelijkheden voor Taak-als-service, waarbij levering van berekeningen, implementatie en beheer op hoog niveau worden afgehandeld.
JaaS-voordelen en architectuur
Het Job-as-a-Service-model, dat wordt geleverd door DPC, zorgt voor een kosteneffectieve en veerkrachtige taakverwerkingspijplijn.
Gebruikers bieden eenvoudige clusterspecificaties, waarbij de focus ligt op de vereiste CPU, geheugen, opslag, instantietellingen en Min/Max-clustertellingen en tags voor clusterovereenkomsten. DPC beheert vervolgens automatisch abstracte infrastructuurdetails, inclusief het selecteren van optimale VM-SKU's, het beheren van instancevloten, het bepalen van de verhouding tussen Core en Core. Taakknooppunten en On-demand t.o.v. Spotexemplaren op basis van invoer. Het verwerkt ook EMR en componentversiebeheer en upgrades zonder downtime.
Cruciaal is dat DPC inherent multitenancy ondersteunt, ontworpen om Data 360-tenancygrenzen en resourcescheiding te begrijpen en af te dwingen. Het garandeert ook beveiliging en naleving door door door Salesforce gecertificeerde machineafbeeldingen af te dwingen, servicespecifieke IAM-rollen te beheren en encryptie te garanderen, zowel onderweg als in ruste. Voor routering en capaciteitscontrole wordt taak-naar-clusterafstemming beheerd met behulp van Clustertags, terwijl op capaciteit gebaseerde routering een maximale instelling voor taakgelijktijd gebruikt om resource-inzet effectief te controleren.
De Cloud Agnostic Client Experience is een kernvoordeel, omdat de complexiteit van onderliggende cloudomgevingen verborgen is voor clientservices, waardoor ze zich puur kunnen richten op bedrijfslogica. Hiermee wordt het doel van Cloud Provider Abstraction bereikt. Ten slotte maakt DPC eenvoudig gebruik en kosten bijhouden mogelijk, waardoor clusterinzet en kosten kunnen worden gesegmenteerd op service voor een nauwkeurige boekhouding. Over het algemeen volgt DPC een invoegbare architectuur waarmee nieuwe uitvoeringsengines (bijvoorbeeld Flink, Ray) en cloudsubstraten (GKE/Dataproc) naadloos kunnen worden geïntegreerd zonder onderliggende infrastructuurdetails zichtbaar te maken voor gebruikers. Dit ontwerp ontkoppelt het besturingsvlak van de uitvoeringslaag, wat zorgt voor een consistente API en operationele ervaring, ongeacht de back-end.
Data 360 verfijnt en verrijkt ruwe gegevens en overbrugt de kloof tussen ruwe informatie en bruikbaar bedrijfsverbruik. Het vormt een aanvulling op de levenscyclus van gegevensobjecten door complexe gegevens voor te bereiden voor geavanceerde activering en analyse. Data 360 ondersteunt verschillende verwerkingstypen, waaronder transformaties van batch- en streaminggegevens, berekende insights van batches en streamings, ongestructureerde gegevensverwerking en Identiteitsoplossing. Om deze diverse bewerkingen efficiënt mogelijk te maken, met name in vrijwel realtime en binnen enorme gegevenssets, is een geavanceerd mechanisme vereist om gegevenswijzigingen effectief af te handelen.
Om efficiënte, vrijwel realtime gegevensverwerking te realiseren, met name met tabellen ter grootte van terabytes en miljoenen potentiële updates, had Data 360 een doorbraak nodig. Het vereiste een manier om systemen precies te informeren wanneer gegevens worden gewijzigd en vervolgens efficiënt te identificeren welke gegevens zijn gewijzigd, zodat alleen relevante updates worden verwerkt en alleen wanneer ze worden bijgewerkt. Deze uitdaging leidde tot twee complementaire innovaties: Storage Native Change Events (SNCE) om te informeren wanneer er iets is gewijzigd en Change Data Feed (CDF) om te bepalen wat er is gewijzigd.
Storage Native Change Events (SNCE)
SNCE heeft Data 360 fundamenteel veranderd in een reactief en incrementeel gegevensplatform. Deze verschuiving omvat de overstap van actieve polling van het gegevens-lake naar passieve bewaking op atomaire commit-events, met behulp van een gestandaardiseerde eventindeling en een berichtenleveringssysteem met hoge doorvoer.
Elke geslaagde schrijfbewerking (INSERT, UPDATE, DELETE) naar een Iceberg-tabel leidt tot een atomaire wissel van de huidige metagegevensbestandsaanwijzer van de tabel in de catalogus. De onderliggende objectopslaglaag (bijvoorbeeld S3) is geconfigureerd om een native kennisgevingsevent (zoals een S3-event) uit te zenden telkens wanneer een nieuwe momentopname van metagegevens naar de directory van de tabel wordt geschreven.
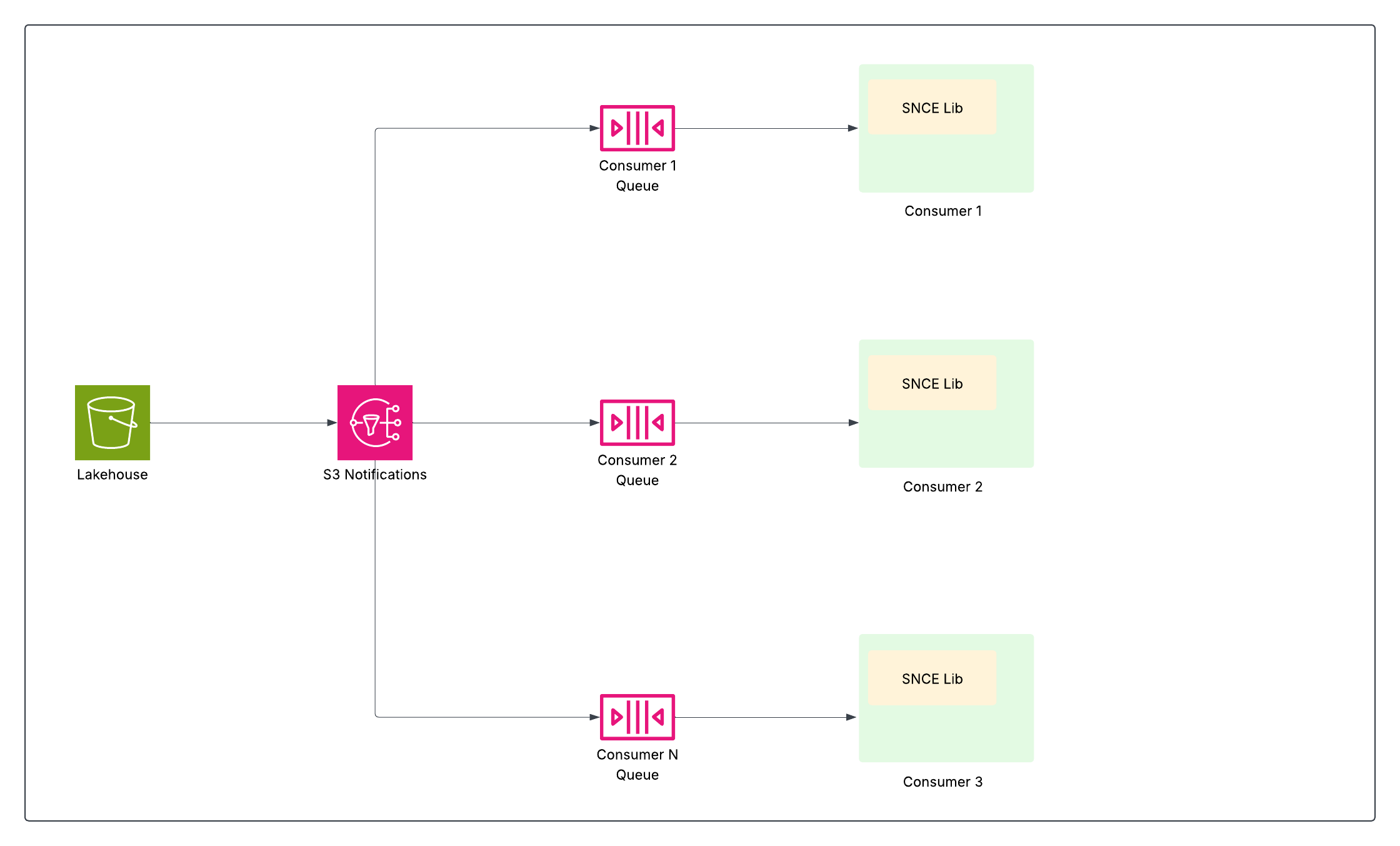
De SNCE-bibliotheek biedt een gestandaardiseerde methode voor het verbruik van deze events en kan deze op verzoek ook verrijken met metagegevens van momentopnamen.
Hierdoor kunnen gegevenspijplijnen verderop in de stroom, zoals streaming berekende insights, identiteitsoplossing en segmentering, zich alleen abonneren en actie ondernemen wanneer gegevens zijn gewijzigd, wat de efficiëntie aanzienlijk verhoogt door kostbare scans van volledige tabellen te vermijden.
Gegevensfeed wijzigen (CDF)
Voortbouwend op SNCE biedt de Change Data Feed (CDF) een gestroomlijnd mechanisme om de wijzigingen te consumeren en stapsgewijs te verwerken.
CDF gebruikt Iceberg-momentopnamen om de stroom van wijzigingen efficiënt te genereren. De geoptimaliseerde Iceberg-schrijver van Data 360 berekent en bewaart de wijzigingen als onderdeel van de schrijfbewerking zelf, waardoor het genereren van CDF zeer efficiënt wordt en extra overhead wordt geminimaliseerd. Hierdoor kunnen verwerkingstaken (zoals streaming-transformaties of streaming berekende insights) alleen de gewijzigde records selectief verwerken, waardoor de dure berekening van momentopnameverschillen wordt vermeden.
Deze incrementele strategie biedt diverse voordelen voor grote gegevenssets, waaronder kostenbesparingen, verminderde latentie en verbeterde efficiëntie. Het maakt voorzieningen mogelijk zoals streaming-transformaties en incrementele identiteitsoplossing, die op hun beurt leiden tot snellere insights, meer voorspelbare systeembelastingen, verbeterde prestaties en lagere operationele kosten.
Data 360 biedt robuuste opnamemogelijkheden met native ondersteuning voor Salesforce-producten, waardoor een naadloze gegevensstroom wordt gegarandeerd. Voor externe bronnen biedt het uitgebreide connectiviteit via meer dan 270 connectoren, API's, SDK's en MuleSoft. Daarnaast biedt Data 360 zero-copy bundeling, waardoor BI en analyses mogelijk zijn zonder gegevensduplicatie.
Het Data 360-connectorframework (DCF) vormt de basis voor het grootste deel van de Data 360-connectiviteit. Het maakt opname, bundeling en uitgang mogelijk via een gecombineerde architectuur. DCF definieert de standaarden voor het samenstellen en beheren van connectoren, van de UI voor set-up en beheer tot persistentie van metagegevens, gegevensextractie en levering in het Lakehouse of via live query's op externe bronnen. Het ondersteunt ook privéconnectiviteitsopties (zoals privékoppelingen, VPN's en veilige tunnels) om gegevensbeveiliging en naleving op ondernemingsniveau te garanderen bij het verbinden met klant- of partneromgevingen. Door een consistente aanpak te bieden voor alle connectoren, stelt DCF Data 360 in staat om naadloos aan te sluiten op het bredere ecosysteem door uitbreidbaarheid, betrouwbaarheid en veilige integratie te garanderen.
Data 360 biedt robuuste connectiviteit met een uitgebreid ecosysteem van gegevensbronnen en ondersteunt zowel native Salesforce-producten als tal van externe systemen. Deze uitgebreide connectiviteit is cruciaal voor het combineren van bedrijfsgegevens in een silo en het inschakelen van AI/ML- en Agentic-toepassingen.
Data 360 biedt meer dan 270 connectoren native of via MuleSoft, API's en SDK's om de end-to-end gegevenspijplijnmogelijkheden te ondersteunen met batch-, streaming- of realtime opname. Deze connectoren kunnen grofweg worden gecategoriseerd op het type bronsysteem dat ze integreren.
Native Salesforce-connectoren
Deze connectoren zorgen voor een naadloze en native gegevensstroom vanuit Salesforce-producten.
Voorbeelden omvatten connectoren voor Salesforce CRM, Data Cloud One, Marketing Cloud Engagement, Marketing Cloud Account Engagement en B2C Commerce.
Externe toepassingen en SaaS
Connectoren voor verschillende bedrijfstoepassingen en cloudservices maken gegevensopname vanuit externe softwareplatforms mogelijk.
Voorbeelden zijn Adobe Marketo Engage, Microsoft Dynamics 365, Mailchimp en Airtable.
Databases en gegevensmagazijnen
Data 360 maakt verbinding met een verscheidenheid aan relationele en cloudgebaseerde gegevensopslagplatforms.
Voorbeelden zijn Amazon Redshift, Amazon DynamoDB, Amazon RDS (MySQL, PostgreSQL, Oracle), Google BigQuery en Microsoft SQL Server.
Cloud-objectopslag en bestandssystemen
Deze connectoren worden geïntegreerd met hyperscaler-opslagoplossingen voor zowel gestructureerde als ongestructureerde gegevens.
Voorbeelden zijn Amazon S3, Google Cloud Storage (GCS) en Azure Blob Storage.
Streaming- en berichtenverkeersdiensten
Connectoren die continue, real-time gegevensstromen afhandelen, zijn essentieel voor eventgestuurde scenario's en real-time verwerking.
Een voorbeeld is de Amazon Kinesis-connector.
Integratieplatforms
De MuleSoft Anypoint-connector breidt het bereik van Data 360 uit door het te integreren met een breder scala aan toepassingen en databases via de Anypoint Exchange.
Ongestructureerde connectoren voor gegevensopslag en cloudobjectopslag
Deze connectoren zijn van cruciaal belang voor het opnemen van en verwijzen naar ongestructureerde gegevens (gegevens waarvoor geen vooraf gedefinieerd model is gedefinieerd) om genererende AI-mogelijkheden aan te drijven.
Al deze connectoren zijn gebaseerd op het Data 360-connectorframework en bieden een consistente ervaring.
Gegevenstransformatie is een fundamentele architectonische component in Data 360, ontworpen voor het opschonen, verrijken en vormgeven van ruwe opgenomen gegevens tot genormaliseerde, navolgbare gegevensactiva die zijn afgestemd op het Customer 360 gegevensmodel. Dit proces is essentieel voor gegevens harmonisering, kwaliteitsverbetering en ervoor zorgen dat gegevens gereed zijn voor gebruik verderop in de stroom, zoals profielsamenvoeging, segmentering en activering. Transformaties gebruiken zowel bronobjecten voor gegevens-lakes (Data Lake Objects, DLO's) als gegevensmodelobjecten (Data Model Objects, DMO's) als invoer, waardoor de resultaten worden geproduceerd voor respectievelijk nieuwe DLO's of DMO's.
Data 360 biedt twee primaire transformatieparadigma's voor verschillende vereisten voor gegevenssnelheid: batchgegevenstransformaties en transformaties van streaminggegevens.
Batchgegevenstransformaties
Batchgegevenstransformaties zijn ontworpen voor verwerking met groot volume op basis van een gedefinieerde planning of on-demand trigger. Deze engine is geoptimaliseerd voor het afhandelen van complexe, resource-intensieve herstructureringen.
Het proces Batchtransformatie wordt geconfigureerd met behulp van een visueel pijplijndoek met weinig code waarmee gebruikers transformatielogica in meerdere fasen kunnen definiëren. Deze engine ondersteunt op unieke wijze complexe herstructureringsbewerkingen die van vitaal belang zijn voor het uitlijnen van canonieke gegevensmodellen: gegevensstructurering en normalisatie. Dit omvat draaien (het ontbinden van gedenormaliseerde records in meerdere genormaliseerde records) en afvlakken (het herstructureren van hiërarchische gegevens, zoals JSON, in gestructureerde tabellen). De uitvoeringsmodus van het systeem ondersteunt zowel volledige synchronisatie (verwerking van alle records) als een zeer efficiënte incrementele verwerkingsmodus. De incrementele modus reduceert de verwerkingstijd en het resourceverbruik aanzienlijk door alleen records te verwerken die zijn gewijzigd sinds de laatste geslaagde uitvoering. Batchtransformaties zijn ideaal voor taken waarbij real-time updates niet essentieel zijn, zoals periodieke aggregaties en complexe gegevensherstructureringen.
Transformaties van streaminggegevens
Streaminggegevens transformeren procesgegevens continu en incrementeel in vrijwel real-time terwijl ze in het systeem stromen, waardoor ze essentieel zijn voor gebruikscases met een lage latentie.
De primaire interface is een SQL-first-benadering, waarbij transformaties worden gedefinieerd als een SQL SELECT-query die continu wordt uitgevoerd op de inkomende stroom van recordwijzigingen. Deze engine ondersteunt kerntransformatiefuncties, waaronder opschoning en standaardisering van gegevens (bijv. validatie van persoonsgegevens en standaardisering van gegevensnotaties) en gegevensverrijking en -samenvoeging (met behulp van joins en vakbonden). Kritiek is dat het Streaming Lookup JOINs ondersteunt om realtime gegevensverrijking en opzoekopdrachten tegen statische of langzaam veranderende referentiegegevens in te schakelen, waardoor onmiddellijke profielupdates worden gegarandeerd. Voor het optimaliseren van de cost-to-service maakt de architectuur gebruik van een High-Density-taakontwerp (HD-taakontwerp), dat meerdere streaming-transformatiedefinities voor één belanghebbende in één onderliggende rekentaak onderbrengt, waardoor de inzet van resources wordt gemaximaliseerd. Streaming-transformaties zijn essentieel voor gebruikscases zoals eventbewaking, onmiddellijke personalisatie en real-time profielupdates.
Data 360 zorgt voor een revolutie in gegevensbeheer door ondersteuning van Zero Copy-bundeling en het delen van gegevens, waardoor gegevens niet meer hoeven te worden verplaatst of gedupliceerd. Met deze mogelijkheid hebben gebruikers naadloos en rechtstreeks toegang tot gegevens uit diverse externe bronnen en kunnen ze gegevens delen met externe omgevingen, wat de complexiteit aanzienlijk vermindert, de opslagkosten verlaagt en ervoor zorgt dat alle beslissingen zijn gebaseerd op de nieuwste, meest betrouwbare informatie.
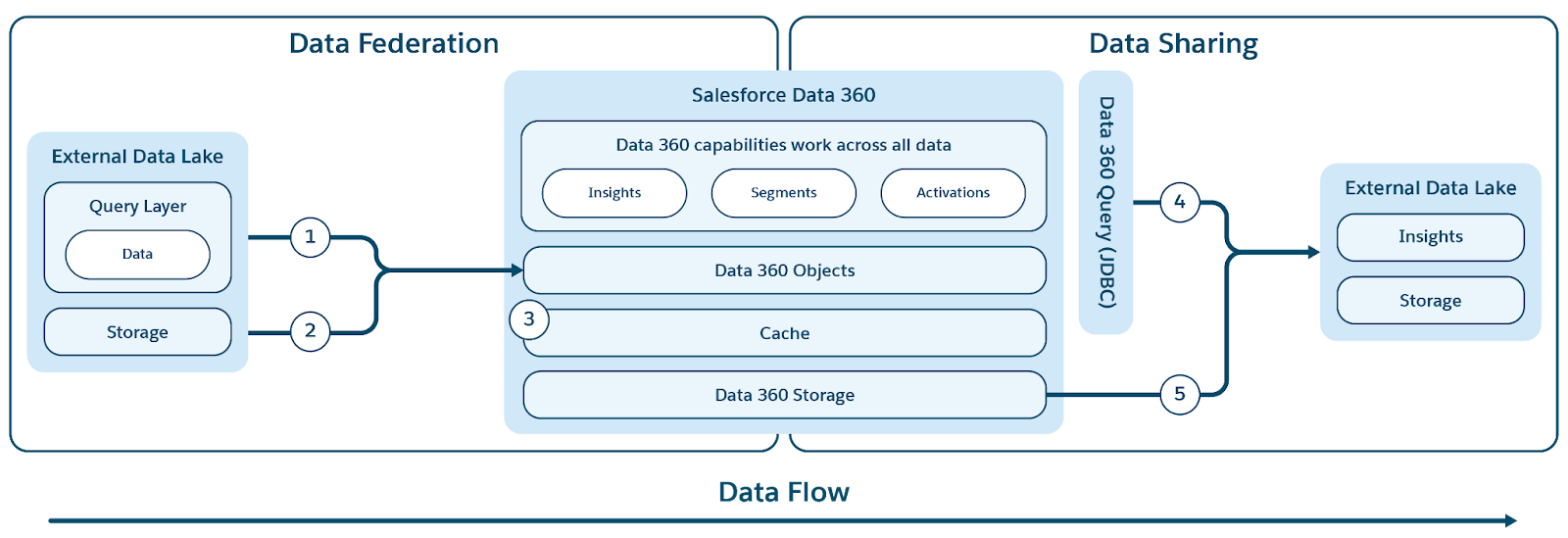
Data 360 ondersteunt zero-copy bundeling met externe gegevenswarehouses (Snowflake, Redshift), lakehouses (Google BigQuery, Databricks, Azure Fabric), SQL-databases en vele andere bronnen. De abstractielagen ervan maken directe query's op externe gegevens mogelijk zonder dupliceren, waardoor opnametijd en opslagkosten worden verkort en actuele informatie wordt gegarandeerd.
Data 360 vereenvoudigt toegang tot externe en gebundelde gegevens door een gecombineerde metagegevenslaag te bieden die zowel Salesforce als externe objecten abstraheert. Hierdoor kunnen het gehele Salesforce-platform en de bijbehorende toepassingen naadloos gebruikmaken van deze gegevens.
Data 360 ondersteunt zowel bestands- als querygebaseerde bundeling, met live query's en toegangsversnelling zoals getoond in de figuur.
Labels (1) en (2) illustreren de query (inclusief live querypushdowns) en op bestanden gebaseerde bundeling van Data 360 voor toegang tot gegevens vanuit externe gegevens-lakes/magazijnen/gegevensbronnen; en label (3) markeert de versnelling van gebundelde toegang vanuit externe gegevens-lakes/gegevensbronnen.
Querybundeling
De kern van de bundelingsmogelijkheden van Data 360 ligt in de bundelingslaag van de query, die het complexe proces beheert van toegang tot externe gegevens en het uitvoeren van intelligente querypushdowns (geïllustreerd door label 1). Data 360 maakt verbinding met en haalt gegevens op uit bronnen met behulp van het JDBC-protocol, uitgebreid met extra logica voor verbeterde efficiëntie. De Query Federation Layer is verantwoordelijk voor het begrijpen en vertalen van verschillende SQL-dialecten, het bepalen van het meest optimale deel van de query dat naar externe systemen moet worden gepusht voor efficiënte verwerking, het ophalen van de resultaten en het uitvoeren van eventuele noodzakelijke verdere verwerking om definitieve insights af te leiden.
Caching (Queryversnelling)
Voor een uitgebreid hulpprogramma biedt Data 360 een optionele versnellingsvoorziening voor de gebundelde mogelijkheden.
Wanneer Versnelling is geactiveerd, slaat Data 360 de gebundelde gegevens in het cachegeheugen op om snellere toegang en lagere kosten te verkrijgen, omdat herhaalde, directe toegang tot externe bronnen wordt vermeden. Dit cachegeheugen wordt behandeld als een versnellingslaag en wordt incrementeel bijgewerkt om snel wijzigingen in de externe brongegevens weer te geven, zodat de versnelde weergave vrijwel in realtime blijft.
Bestandsbundeling
Data 360 ondersteunt op bestanden gebaseerde bundeling (geïllustreerd met label 2) voor toegang tot gegevens vanuit externe gegevens-lakes en bronnen. De technische basis voor deze zero-copy-mogelijkheid is gebaseerd op standaardisatie: de onderliggende gegevens moeten de Apache Parquet-bestandsindeling hebben en de Apache Iceberg-tabelindeling gebruiken. Data 360 kan worden gebundeld in elke bron die een Iceberg REST Catalog (IRC) beschikbaar stelt voor toegang tot metagegevens en opslag, wat zorgt voor naadloze, gereguleerde toegang tot bestanden die zich buiten het platform bevinden.
Met op bestanden gebaseerde bundeling verwerkt Data 360-compute alle gegevensverwerking omdat ze rechtstreeks toegang hebben tot de onderliggende opslag. Dit elimineert de noodzaak van querypushdown en het beheer van verschillende SQL-dialecten, die vaak vereist zijn bij op query's gebaseerde bundeling.
Daarnaast wordt de mogelijkheid van Zero Copy ook uitgebreid naar ongestructureerde gegevensbronnen zoals hyperscaler-opslagoplossingen (S3/GCS/Azure-opslag), Slack en Google Drive, die toegankelijk zijn via de ongestructureerde verwerkingspijplijnen van Data 360.
Data 360 vergemakkelijkt zowel op query's gebaseerd als op bestanden gebaseerd delen van gegevens die het beheert met externe gegevens-lakes en magazijnen (geïllustreerd door labels 4 en 5 in de oorspronkelijke figuurcontext).
Op query's gebaseerd delen
Voor het delen van op query's gebaseerde gegevens maakt Data 360 een JDBC-stuurprogramma beschikbaar waarmee externe motoren en toepassingen beveiligde toegang tot de gegevens kunnen krijgen. Met dit mechanisme kunnen externe systemen rechtstreeks met de gegevens binnen Data 360 verbinding maken, authenticeren en live query's uitvoeren.
Op bestanden gebaseerd delen (Data Share & DaaS)
Het primaire mechanisme voor op bestanden gebaseerd delen omvat twee concepten: gegevens delen en gegevens delen als doel, die gebruikmaken van de DaaS-API (Data as a Service).
- Granulaire controle: Met het concept voor het delen van gegevens kunnen klanten nauwkeurig definiëren welke objecten (DLO's, DMO's, CIO's, enz.) extern worden gedeeld, waardoor onbedoelde blootstelling aan gegevens wordt voorkomen.
- Veilig richten: Het bepaalt ook het doel voor het delen van gegevens, waardoor gegevens alleen beschikbaar worden gesteld aan expliciet geautoriseerde externe omgevingen, accounts of partnerorganisaties (bijvoorbeeld delen met een specifiek Redshift- of Databricks-exemplaar).
De DaaS-API biedt een veilige en beheerde interface voor externe engines om gegevens te verbruiken. Het verleent toegang tot zowel de essentiële metagegevens als de onderliggende tabelopslag, terwijl alle Data 360-semantiek behouden blijft. Dit zorgt ervoor dat externe engines op een veilige manier toegang hebben tot de gegevens in een consistente en betekenisvolle context.
Veel beveiligingsgevoelige klanten, met name grote ondernemingen, gereguleerde sectoren en organisaties uit de publieke sector, beperken alle internettoegang tot hun gegevens-lakes als onderdeel van hun beveiligingsstatus. Hoewel dit beleid essentieel is voor naleving en risicovermindering, voorkomt het ook dat Salesforce Data 360 en Agentforce verbinding maken met die omgevingen via het openbare internet.
De meeste van deze gegevens-lakes worden geïmplementeerd in hyperscaler-omgevingen zoals AWS, Azure of Google Cloud. Omdat Data 360 zelf op AWS wordt uitgevoerd, is voor toegang tot klantgegevens-lakes die worden gehost op een andere cloudprovider, een cross-cloud netwerkverbinding vereist. Zonder een veilige, privéconnectiviteitsoptie die het openbare internet omzeilt, kunnen of willen klanten vaak Data 360 of Agentforce niet gebruiken voor gebruikscases die op die gegevens-lakes vertrouwen.
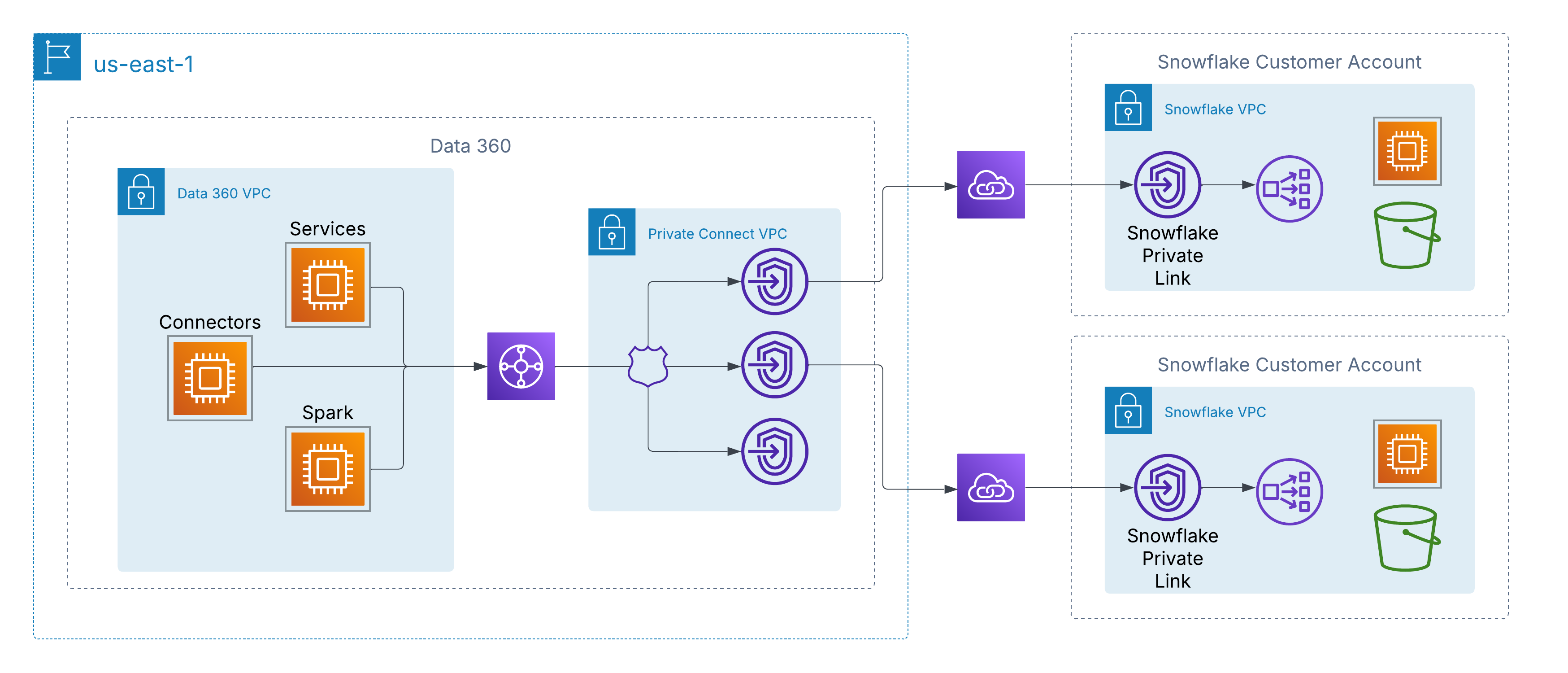
Data 360 ondersteunt privéconnectiviteit op netwerkniveau met door de klant beheerde gegevensbronnen in clouds. Op AWS wordt dit ingeschakeld via AWS PrivateLink, waarmee Data 360 rechtstreeks verbinding kan maken met door de klant geleverde eindpunten, hetzij binnen hun eigen accounts, hetzij binnen externe gegevens-lakeomgevingen (bijvoorbeeld Snowflake), zonder het openbare internet te hoeven gebruiken.
Deze architectuur zorgt ervoor dat al het verkeer volledig op de AWS-backbone blijft, met behulp van privé-IP-adressering en niet-routeerbare netwerkpaden, waardoor wordt voldaan aan strenge beveiligings- en nalevingsvereisten en naadloze toegang tot klantgegevens mogelijk is.
Voor klanten met multi-cloudarchitecturen breidt Data 360 de privéconnectiviteit buiten AWS uit door middel van interconnectie tussen clouds. Dit maakt veilige netwerkpaden met alleen backbones mogelijk van Data 360 naar gegevens-lakes en services die worden gehost in Azure of Google Cloud, waarbij dezelfde principes worden behouden als AWS PrivateLink: privé-IP-adressering, niet-openbare routering en nul blootstelling aan internet.
Klanten kunnen kiezen tussen twee implementatiemodellen:
-
Door klant beheerde interconnectie: Integreer bestaande privécircuits zoals Azure ExpressRoute, Google Cloud Interconnect of Equinix Fabric rechtstreeks met de VPC's van Data 360.
-
Door Salesforce beheerde interconnectie: Gebruik een volledig beheerde, kant-en-klare verbinding waarbij Salesforce de cross-cloud koppeling levert en beheert, waarbij privé-eindpunten in de doelcloud zichtbaar worden.
In beide modellen is de ervaring consistent: Data 360-services maken verbinding met externe gegevensbronnen via hyperscalers alsof ze lokaal zijn, waardoor veilige opname, activering en query's mogelijk zijn zonder het openbare internet te hoeven doorlopen.
Voor enterprise-architecten is robuuste gegevensgovernance niet alleen een selectievakje voor naleving, maar ook een basispijler voor het opbouwen van vertrouwde, schaalbare en navolgbare Klantenintelligence. Salesforce Data 360 is ontworpen met een uitgebreid governance-framework dat de gegevenskwaliteit, beveiliging en naleving van wettelijke verplichtingen garandeert gedurende de gehele gegevenslevenscyclus.
Data 360 fungeert als een gecentraliseerde governancehub, die ervoor zorgt dat alle gegevens, van ruwe opname tot geactiveerde insights, met integriteit en controle worden beheerd.
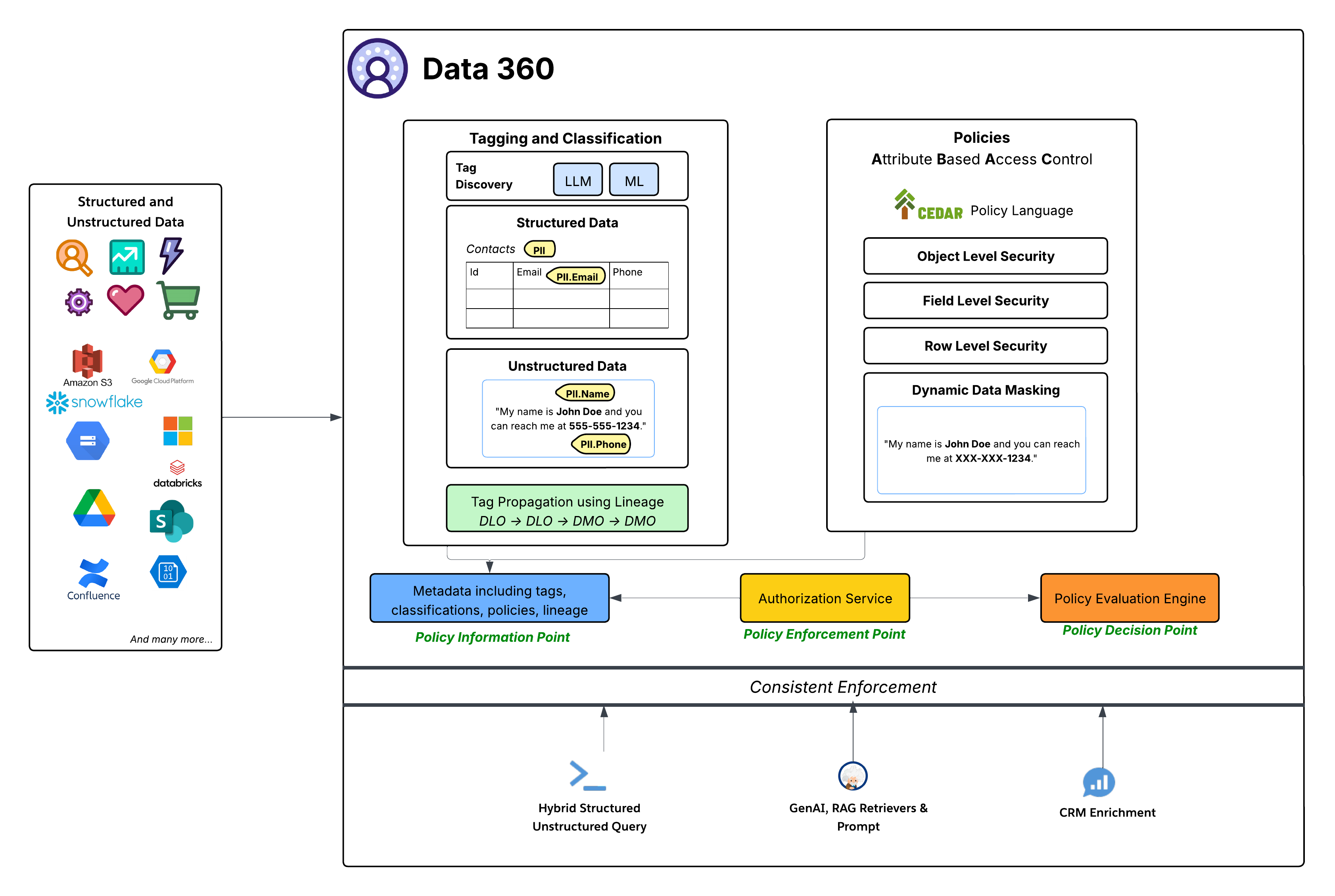
Hoewel gegevensruimte grofkorrelige toegangscontrole biedt om toegang tot alle objecten binnen een gegevensruimte te bepalen, bieden op ABAC gebaseerde beleidsvormen fijnkorrelige toegangscontrole tot afzonderlijke objecten, velden en rijen binnen een gegevensruimte. Data 360 heeft Op kenmerken gebaseerde toegangscontrole (ABAC) geïmplementeerd als het kernautorisatiemodel voor fijnmazige toegangscontrole. Deze strategische keuze biedt superieure flexibiliteit en schaalbaarheid in vergelijking met traditionele op rollen gebaseerde toegangscontrole (RBAC), met name cruciaal voor dynamische, complexe ondernemingsomgevingen met grote hoeveelheden gegevens en uiteenlopende toegangsbehoeften. Met ABAC kunnen toegangsbeslissingen worden gebaseerd op kenmerken van de gebruiker (bijv. afdeling, rol, locatie), de gegevens (bijv. PII, gevoeligheid, gegevensruimte) en de omgeving (bijv. tijdstip), in plaats van alleen vooraf gedefinieerde rollen. Dit maakt uiterst fijnmazig en contextueel toegangsbeleid mogelijk dat wordt aangepast naarmate gegevens en gebruikerskenmerken veranderen.
- Taal van Cedar-beleid: De kern van de ABAC-implementatie van Data 360 is het gebruik van de CEDAR-beleidstaal. Deze doelgerichte, formele beleidstaal biedt een nauwkeurige en controleerbare manier om complexe autorisatieregels te definiëren, zodat beleidsvormen ondubbelzinnig zijn en consistent op schaal kunnen worden geëvalueerd.
Het governancesysteem binnen Data 360 houdt zich aan een standaard, robuuste ABAC-architectuur:
- Tags, classificatie en schrijven van beleid (beleidsinformatiepunt - PIP):
- Data 360 biedt geautomatiseerde mechanismen voor tags en classificatie, waarbij gebruik wordt gemaakt van LLM (Large Language Model) en ML (Machine Learning) voor het identificeren van gevoelige gegevenscategorieën (bijv. PII.Email, PII.Phone, PII.Name) en andere speciaal samengestelde taxonomieën (PHI, FinancialData) in zowel gestructureerde gegevens (bijv. tabel Contactpersonen) als ongestructureerde gegevens (bijv. uit Google Drive).
- Cruciaal is dat Tag Propagation plaatsvindt langs Data Lineage (DLO -> DLO -> DMO), waardoor classificaties automatisch gegevenstransformaties en -afleidingen volgen, van ruwe opgenomen gegevens tot de geharmoniseerde DMO-laag en via afgeleide gegevens die zijn gemaakt op basis van procesdefinities.
- Ten slotte biedt het deelvenster voor het schrijven van beleid een eenvoudige ervaring voor het gebruik van de gegevens en gebruikerskenmerken voor het definiëren van dynamische toegangsregels voor een organisatie.
- Deze verrijkte metagegevens (inclusief tags, classificaties, polissen en afstamming) worden ingevoerd in het Polisinformatiepunt (PIP).
- Autorisatieservice (Policy Enforcement Point - PEP):
- De Autorisatieservice fungeert als het Polishandhavingspunt (PEP). Het onderschept alle verzoeken om toegang tot gegevens uit verschillende verbruikslagen (Hybride gestructureerde/ongestructureerde query, GenAI RAG Retrievers & Prompt, CRM-verrijking) en raadpleegt het beleidsbeslissingspunt om te bepalen of toegang is toegestaan.
- Engine voor beleidsevaluatie (Policy Decision Point - PDP):
- Deze engine fungeert als het beleidsbeslissingspunt (PDP). Het vereist de context van de toegangsaanvraag uit de PEP, samen met beleidsdefinities (in CEDAR) en kenmerken uit de PIP, om een gezaghebbende toegangsbeslissing te nemen.
- Granulaire beveiligingsbeleidsvormen: In CEDAR gedefinieerde beleidsvormen dwingen verschillende beveiligingsniveaus af, waaronder:
- Beveiliging op objectniveau: Toegang tot volledige DLO's of DMO's bepalen op basis van tags die aan deze objecten zijn gekoppeld.
- Beveiliging op veldniveau: Toegang beperken tot specifieke gevoelige velden binnen een object op basis van tags.
- Beveiliging op laag niveau: Filteren van gegevens voor specifieke objecten om alleen relevante rijen weer te geven op basis van gebruikerskenmerken.
- Dynamisch gegevensmaskeren: Maskeer dynamisch bepaalde gegevens (op basis van tags) op het toegangspunt, zonder de onderliggende gegevens te wijzigen. Dit zorgt ervoor dat gevoelige informatie wordt beschermd en toch een breed nut heeft. Dit geldt voor het maskeren van velden in gestructureerde gegevens en inhoud in niet-gestructureerde gegevens.
- Consistente handhaving: Het gehele ABAC-framework zorgt voor consistente handhaving van beleidsvormen voor alle Data 360-verbruikspatronen, of het nu gaat om het uitvoeren van directe gegevensquery's, het ophalen voor Generative AI-toepassingen (RAG) of het verrijken van Salesforce CRM-omgevingen via bijvoorbeeld Gerelateerde lijsten.
- Diepe integratie met Salesforce Platform: De governancemogelijkheden van Data 360 worden rechtstreeks binnen het kernplatform van Salesforce gedefinieerd en beheerd. Met deze integratie kunnen beheerders toegangsbeleid, gebruikersidentiteiten en kenmerkbeheer beheren met behulp van vertrouwde Salesforce-tools, waardoor een uniforme en consistente governancelaag binnen het gehele Salesforce-ecosysteem wordt gegarandeerd.
Door dit geavanceerde ABAC-framework met CEDAR-beleidsvormen samen te stellen, biedt Data 360 architecten een ongeëvenaard niveau van controle en flexibiliteit, wat ervoor zorgt dat klantgegevens niet alleen bruikbaar zijn, maar ook veilig, conform en betrouwbaar in de hele onderneming.
In alle sectoren leggen organisaties meer nadruk op end-to-end gegevensbeveiliging om bescherming te bieden tegen gegevenslekkage, ongeoorloofde toegang, manipulatie of vernietiging. De meeste gegevensplatforms, waaronder Data 360, bieden encryptie at rest met behulp van een door de leverancier beheerde encryptiesleutel. Ondernemingen (met name in gereguleerde sectoren) eisen echter steeds meer door de klant beheerde encryptiemogelijkheden voor zowel gegevens in ruste als gegevens onderweg.
Met dit model kunnen bedrijven hun eigen encryptiesleutels beheren, waardoor zelfs in het hoogst onwaarschijnlijke geval van een inbreuk op platformniveau of ongeoorloofde toegang de gegevens cryptografisch beschermd blijven. Zonder de eigen sleutel van de klant kan geen enkele entiteit (inclusief de platformleverancier) de gegevens ontsleutelen of reconstrueren, waardoor volledige vertrouwelijkheid en controle behouden blijven.
Data 360 ondersteunt naadloos opslag en beheer van gestructureerde (tabellen), semigestructureerde (JSON) en ongestructureerde gegevens binnen gegevensopname-, verwerkings-, indexerings- en querymechanismen. Data 360 ondersteunt diverse ongestructureerde gegevenstypen buiten tekst, waaronder audio, video en afbeeldingen, waardoor het bereik van gegevensverwerking en analyse wordt uitgebreid. De onderstaande figuur illustreert de twee kanten van aarding (opname en ophalen).
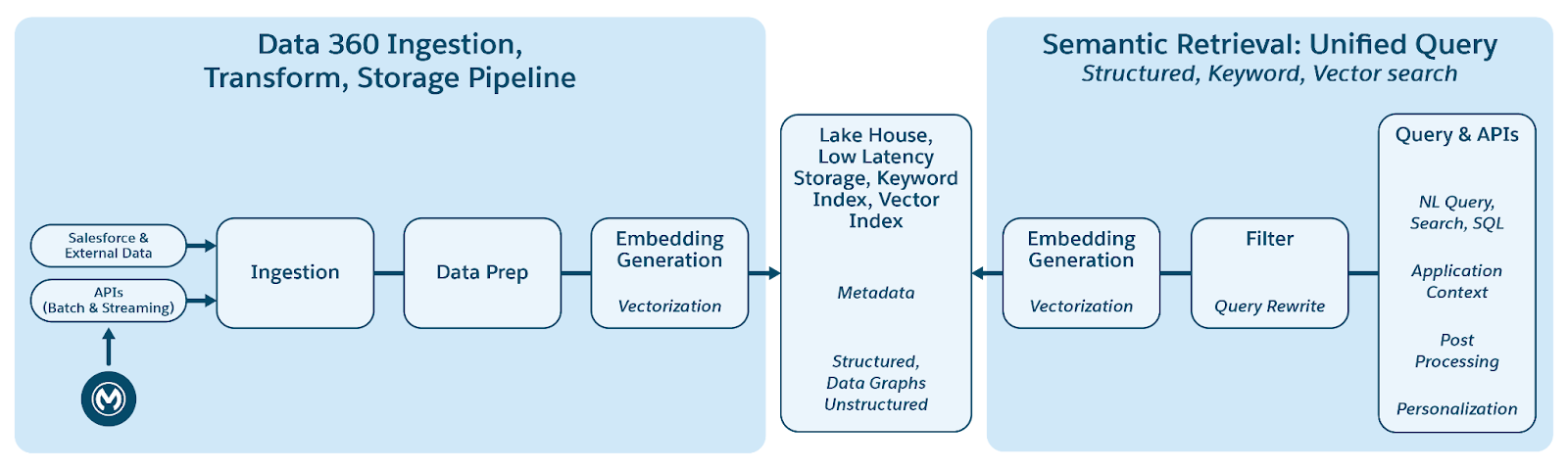
Data 360 beheert ongestructureerde gegevens door deze op te slaan in kolommen als tekst of in bestanden voor grotere gegevenssets. Het ondersteunt gegevensbundeling voor ongestructureerde inhoud, waardoor gegevens uit meerdere bronnen kunnen worden geïntegreerd en beheerd.
De gegevens worden vervolgens voorbereid en in blokken verdeeld, inbedding wordt gegenereerd en verwerkt voor trefwoordenindexering en vectorindexering. Data 360 host meerdere kant-en-klare en insteekbare modellen voor het genereren in blokken en inbedden. Data 360 ondersteunt geautomatiseerde en configureerbare transcriptie van audio- en video-inhoud voor daaropvolgende verwerking en indexering. De zoekservice wordt gebruikt voor het indexeren van trefwoorden. Voor vectorindexering ondersteunt Data 360 zowel native indexering (met Hyper) als maakt het ook gebruik van vectordatabases zoals open-source Milvus. Data 360 kan ook worden geïntegreerd met het Salesforce Search-platform om indexering van trefwoorden voor ongestructureerde gegevens te ondersteunen. Dergelijke geïntegreerde multimodale indexering in Data 360 maakt zoeken mogelijk voor alle ongestructureerde gegevens, zoals besproken in de sectie Agentic Enterprise Search verderop in het document.
Voor het ophalen biedt Data 360 API's voor zoeken. Onze op Hyper gebaseerde gecombineerde query vergemakkelijkt ensemblequery's voor gestructureerde indexen, trefwoordenindexen en vectorindices, waarbij strikte zichtbaarheid en machtigingen worden gehandhaafd, waardoor RAG en Zoeken worden verbeterd.
De ongestructureerde pijplijn voor gegevensindexering van Data 360 is ontworpen als een modulaire, uitbreidbare architectuur die bestaat uit vijf kernfasen:
- Parseren
- Pre-verwerking
- Chunking
- Post-Processing
- Inbedden
Alle fasen ondersteunen ook op LLM gebaseerde verwerking, waardoor klanten de aangepaste aanwijzingen kunnen bedenken. Zowel de fase vóór als na de verwerking kan meerdere sequentiële stappen bevatten, waardoor complexe transformaties flexibel kunnen worden samengesteld. Elke fase is volledig metagegevensgestuurd, waardoor naadloze configuratie en uitbreiding zonder codewijzigingen mogelijk is.
Voorbeelden van pre-verwerking omvatten bewerkingen zoals ruiseliminatie, taalnormalisatie en beeldbegrip (optische tekenherkenning en bijschriften), terwijl nabewerkingsfasen metagegevensverrijking, semantische groepering of geavanceerde technieken zoals Raptor-blokken kunnen omvatten.
De pijplijn ondersteunt Data 360 Code Extension volledig, waardoor klanten en interne teams in elke fase aangepaste logica kunnen inpluggen. De code-extensiecomponenten zijn lichtgewicht Python-functies waarvan de levenscyclus (uitvoering, schalen en foutafhandeling) volledig wordt beheerd door Data 360. Deze benadering zorgt ervoor dat innovatie en domeinspecifieke verwerking snel kunnen worden geïntroduceerd, terwijl de operationele consistentie en governance binnen het platform behouden blijven.
Contextindexering
Voor het instellen van RAG met ongestructureerde verwerking zijn twee kritieke factoren belangrijk:
- Snelle herhaling: De mogelijkheid om snel te valideren met voorbeeldtestquery's.
- Persoonsspecifieke inhoud: De capaciteit om inhoud te configureren die is afgestemd op de consumerende identiteit.
Contextindexering is een gebruiksvriendelijke tool die is ontworpen om beide aspecten aan te pakken. Deze interactieve UI wordt aangestuurd door een RT-pijplijn (Real-Time) die alle vijf eerder beschreven fasen uitvoert. De pijplijn gebruikt GPU's wanneer dat nodig is voor taken zoals het inbedden van genereren en optische tekenherkenning (OCR). Bovendien kunnen klanten de RAG-pijplijn snel testen met een agent voordat ze de configuratie implementeren voor uitgebreide inhoudsverwerking.
Document-AI
Data 360 Document AI maakt het lezen en importeren mogelijk van ongestructureerde of semigestructureerde gegevens uit documenten zoals facturen, cv's, laboratoriumrapporten en inkooporders. Deze voorziening ondersteunt zowel ad-hoc interactieve verwerking als bulkbatchverwerking. Dit is een belangrijke mogelijkheid die automatisering van bedrijfsprocessen voor onze klanten mogelijk maakt. Dit wordt mogelijk gemaakt door kunstmatige intelligentie, waaronder LLM's en ML-modellen.
Ondernemingen beschikken over grote hoeveelheden Knowledge verspreid over verschillende systemen zoals wiki's, bestandsdelingen, content management systemen, interne databases en meer. Deze versnippering maakt het voor medewerkers (met name serviceagenten en verkoopvertegenwoordigers) en klanten moeilijk om snel en efficiënt relevante informatie te vinden. Belangrijke problemen omvatten: Gebrek aan één uniforme zoekervaring voor alle Knowledge bronnen; Inconsistente presentatie en weergave van inhoud uit verschillende bronnen; Gebrek aan governance voor toegang tot gevoelige informatie verspreid over systemen; en moeilijkheden bij het benutten van gezaghebbende Knowledge bron binnen core business werkstromen (bijv. het bijvoegen van relevante artikelen bij een case).
Enterprise Knowledge vertegenwoordigt inhoud die handmatig of automatisch is samengesteld uit de bredere pool van ondernemingsgegevens. Handmatig beheren omvat doelbewuste acties, zoals het maken van Salesforce Knowledge Artikelen of het ontwikkelen van Knowledge binnen externe systemen die vervolgens wordt opgenomen. We hebben geautomatiseerde curatie voor ogen die processen, zoals Salesforce-agenten en -transformaties, gebruikt die worden uitgevoerd over opgenomen gegevens om verfijnde, gemodereerde lagen te genereren, die potentieel gestructureerde en ongestructureerde inhoud mengen. Handmatig of automatisch gemodereerd, intern binnen Salesforce of extern vóór opname, het resultaat is inhoud met toegevoegde waarde die verschilt van ruwe gegevens.
De Enterprise Knowledge Hub-oplossing maakt gebruik van Data 360-mogelijkheden voor:
- Opname en opslag: CRM Connector neemt Salesforce Knowledge artikelen op en ongestructureerde connectoren van het Data Connector Framework (DCF) nemen ruwe inhoud en metagegevens op uit externe bronnen. De inhoud wordt opgenomen in bronspecifieke ongestructureerde gegevens-lakeobjecten (UDLO's) die worden toegewezen aan de inhoud op SFDrive (of bron in het geval van nul kopieën).
- Harmonisatie & structurering: De harmonisering verwerkt UDLO- en bestandsgegevens, voert opschoning, normalisering, verrijking (NLP, enz.) uit, maskeert persoonsgegevens en transformeert deze naar de geharmoniseerde tussenindeling, opgeslagen in SF Drive en een geharmoniseerde UDLO (HUDLO) die eraan is toegewezen.
- Indexeren: Ongestructureerde pijplijn (Unstructured Pipeline, UDS) wordt geactiveerd via de geharmoniseerde inhoud en zoekindexen worden geconfigureerd voor elk HUDMO.
- Verbruik: Verbruikende toepassingen omvatten zoeken, ophalen, weergeven en koppelen naar bedrijfsobjecten zoals Case. Betrokkenheid door het verbruiken van toepassingen wordt verzameld om gebruiksanalyses (zoals klikken, beoordelingen, enz.)
Met berekende insights (CI's) in Data 360 kunnen klanten geaggregeerde meetgegevens definiëren en genereren op basis van hun gegevens. Deze meetgegevens worden vervolgens gebruikt voor tijdige klantbetrokkenheid, analyse, segmentering en activering. De geaggregeerde gegevens die door CI's worden berekend, worden naar Lakehouse geschreven en weergegeven als een berekend insightobject (CIO).
Er zijn twee hoofdtypen berekende insights:
- Batchberekende insights: Ontworpen voor complexe gegevensaggregatie met groot volume, waarbij meetgegevens periodiek kunnen worden berekend (bijv. dagelijks of wekelijks).
- Streaming insights: Bied de mogelijkheid om meetgegevens en acties te genereren op basis van real-time eventgegevens, waardoor onmiddellijke betrokkenheid van klanten met een lage latentie mogelijk wordt.
Berekende insights worden gedefinieerd voor gegevensmodelobjecten (Data Model Objects, DMO's) en kunnen ook worden gedefinieerd voor andere berekende insightobjecten. De service voor berekende insights beheert de doeltreffende combinatie van zowel batch- als streamingtaken.
Zowel batch- als streaming insights-berekeningen gebruiken Spark. Het belangrijkste verschil is dat streaming insights gebruikmaken van Spark Structured Streaming, terwijl batch-CI's worden uitgevoerd met behulp van periodieke, geplande batch-Spark-taken. Voor kostenefficiëntie groepeert de service Berekende insights CI's die moeten worden berekend in dezelfde batchtaak voor CI of streaming CI-taak, op basis van factoren zoals afhankelijkheden en overlapping van brongegevensobjecten.
SNCE en CDF spelen een belangrijke rol bij het berekenen van streaming insights.
Identiteitsoplossing is verantwoordelijk voor het transformeren van ongelijksoortige gegevens uit meerdere bronnen in één uitgebreid gecombineerd profiel.
Het is belangrijk om te begrijpen dat een gecombineerd profiel geen "gouden record" is en dat identiteitsoplossing geen winnende waarden kiest of bestaande gegevens overschrijft tijdens het combineren van profielen. Gecombineerde profielen fungeren als een set sleutels die uw brongegevens ontgrendelen door alle overeenkomende records te identificeren die betrekking hebben op dezelfde entiteit, binnen één gegevensbron of binnen vele bronnen. Aan de hand van deze informatie kunt u de juiste bronsysteemgegevens selecteren die u wilt gebruiken voor een bepaalde zakelijke gebruikscase.
Identiteitsoplossing kan een verscheidenheid aan recordtypen consolideren, waaronder individuen, accounts en huishoudens. Het kan ook worden gebruikt om leads te koppelen aan bestaande accounts. Het samenvoegingsproces is essentieel voor het realiseren van een volledig Customer 360 overzicht en het stimuleren van gepersonaliseerde, real-time betrokkenheid in zowel B2C- als B2B-scenario's.
De pijplijn voor identiteitsoplossing is gebaseerd op een zeer schaalbaar, cloud-native framework dat is ontworpen om continu enorme hoeveelheden gegevens te verwerken. Het proces bestaat uit drie belangrijke fasen, die vertrouwen op een krachtige zoekindex om het matchingproces te beheren:
- Overeenkomsten (kandidaatselectie): Het doel van het overeenkomstproces is zoeken naar records die mogelijk tot dezelfde entiteit behoren. Records worden geanalyseerd aan de hand van een aanpasbare set regels, die elk een set criteria bevatten die definiëren welke gegevens op welk niveau van striktheid moeten worden vergeleken. Voor het efficiënt ophalen van potentiële overeenkomsten uit de gegevensopslag genereert het systeem indexen om waarschijnlijk overeenkomende records te vinden met behulp van twee technieken:
- Sleutels blokkeren: Een blokkeringssleutel is een waarde die wordt gegenereerd op basis van de gegevens en overeenkomstenregels van een record (zoals de eerste paar letters van een naam, een genormaliseerd telefoonnummer, enz.) om potentieel soortgelijke records te groeperen. Elke record heeft meerdere blokkeringssleutels die worden geïndexeerd en opgeslagen als een omgekeerde index, waardoor het systeem alleen gedetailleerde vergelijkingen uitvoert op kleine groepen records, in plaats van over de gehele gegevensset.
- Locality Sensitive Hashing (LSH): Voor overeenkomstenregels met fuzzy overeenkomsten worden hashes gegenereerd op basis van inbedding vanuit getrainde modellen.
- Diepe overeenkomsten: Nadat de kandidaatselectiestap kleinere groepen potentiële overeenkomsten heeft gemaakt, begint het systeem met een meer gedetailleerde vergelijking. In deze fase analyseren AI-modellen en geavanceerde algoritmen elk paar records om een probabilistische overeenkomstscore te berekenen. Deze score kwantificeert de waarschijnlijkheid dat twee records naar dezelfde entiteit verwijzen door velden te vergelijken die vaak spelfouten, variaties of opmaakverschillen bevatten.
- Clusteren en combineren: Zodra overeenkomende records zijn geïdentificeerd vanuit de kandidaten, worden ze gegroepeerd in een cluster. Dit proces omvat cruciaal het oplossen van transitieve overeenkomsten. Als record A bijvoorbeeld overeenkomt met record B en record B overeenkomt met record C, worden ze alle drie in hetzelfde cluster gekoppeld, zelfs als A en C nooit rechtstreeks zijn vergeleken. Deze volledige clusters vormen de basisstructuur van het gecombineerde profiel. Dit clusterproces zorgt ervoor dat alle gerelateerde bronrecords correct worden gekoppeld onder één aanhoudende identifier.
- Afstemming: Gegevenswaarden uit alle geclusterde bronrecords worden geëvalueerd met behulp van gedefinieerde afstemmingsregels (bijv. Meest frequent, Meest recent of Bronprioriteit) om het resulterende gecombineerde profiel te vullen met een uittreksel van profielgegevens. Afstemming overschrijft geen bestaande gegevens, aangezien alle brongegevens beschikbaar zijn met behulp van de sleutels die zijn gekoppeld aan het gecombineerde profiel.
De architectuur ondersteunt de oplossing van meerdere entiteitstypen om te voldoen aan een verscheidenheid aan gebruikscases.
- Individuele overeenkomsten: Richt zich op het maken van de profielen Gecombineerd individu, die alle bekende persoonlijke identifiers (e-mails, telefoonnummers, loyaliteits-ID's, cookies) koppelen aan één persoon.
- Accountovereenkomst: Richt zich op het maken van de gecombineerde accountprofielen, die gegevens over accounts koppelen. Bij overeenkomsten op bedrijfsnamen gebruikt de engine een nauwkeurig afgestemd model bij fuzzy overeenkomsten.
- Afstemming huishouden: Breidt de overeenkomstenlogica uit om records Gecombineerd individu te aggregeren in groepen van gerelateerde individuen.
- Vergelijking tussen entiteiten: Naast het combineren maakt identiteitsoplossing ook koppelingen tussen profielobjecten door middel van dezelfde overeenkomstenregels. Een lead kan bijvoorbeeld aan een account worden gekoppeld met behulp van fuzzy overeenkomsten voor Accountnaam.
Om ervoor te zorgen dat het gecombineerde profiel altijd actueel is, werkt de identiteitsoplossingsengine met een vrijwel realtime architectuur. Deze voor de cloud geoptimaliseerde architectuur is ontworpen voor continue verwerking, waardoor snelle verwerkingstijden worden bereikt. Hoewel de verwerkingssnelheid varieert afhankelijk van de manier waarop brongegevens worden ontvangen, kunnen kleine batches wijzigingen net zo vaak als elke 15 minuten worden verwerkt via identiteitsoplossing.
Het systeem onderhoudt identiteitskoppelingsobjecten die elke bronrecord-ID toewijzen aan de overeenkomende gecombineerde profiel-ID. Met deze basisgegevensstructuur kan de engine relaties efficiënt bijhouden en snel wijzigingen en updates doorgeven aan het gecombineerde profiel, zodat klantervaringen—zoals websitepersonalisatie, next-best-action aanbevelingen en segmentering—altijd gebruikmaken van de nieuwste beschikbare klantgegevens.
Segmentering is het kernproces van het transformeren van gecombineerde klantprofielen in navolgbare doelgroepen. Deze mogelijkheid is van cruciaal belang voor het aansturen van gepersonaliseerde omgevingen binnen marketing-, commerce- en servicekanalen. Het Salesforce Data 360-segmenteringsplatform is ontworpen voor grootschalige bewerkingen. Het beheert ingewikkelde metagegevens en werkt met een gegevensmodel dat duizenden objecten en relaties omvat. Het platform ondersteunt complexe regels, op aggregatie gebaseerde filters en op vensters gebaseerde plaatsing, terwijl snelle en betrouwbare berekeningen op petabyteschaal worden gegarandeerd.
Data 360 ondersteunt verschillende segmenttypen om te voldoen aan verschillende bedrijfsvereisten voor snelheid, complexiteit en hiërarchie:
- Standaardsegment: Het primaire, batchverwerkte segmenttype. Het publiceert volgens een aanpasbare planning, met een Standaardpublicatie-cadans van minimaal 12 uur tot 24 uur, of een snellere Rapid Publish-cadans van 1 tot 4 uur, die is geoptimaliseerd voor recente betrokkenheidsgegevens.
- Realtime segment: Dit segment voltooit on-demand in milliseconden voor onmiddellijke actie op basis van recente events en profielgegevens. Het is sterk geoptimaliseerd voor onmiddellijke personalisatie, maar kan geen uitsluitingscriteria of geneste segmenten gebruiken.
- Watervalsegment: Een hiërarchische structuur van subsegmenten die wordt gebruikt om een klant te prioriteren in één waardevol segment als deze voldoet aan meerdere criteria.
- Genest segment: Hierdoor kan een bestaand segment worden hergebruikt als filter voor een nieuw, specifieker segment (een verfijning van een basissegment), waarbij de planning van het bovenliggende segment wordt overgenomen.
De segmenteringsengine werkt op een robuuste, cloud-native architectuur die snelheid, schaal en veerkracht garandeert.
Het kernproces wordt beheerd door een taakcombinatieservice die de levenscyclus van het segment bepaalt, de benodigde taakconfiguratie genereert en de uitvoering activeert. Deze doeltreffende laag handhaaft staat/provincie en metagegevens in een versnipperde database voor schaalbaarheid.
Hoewel de Data 360-query berekeningen van segmenttellingen afhandelt, is de Spark-berekeningslaag verantwoordelijk voor het berekenen van het feitelijke segmentlidmaatschap. De Spark-toepassing voert Spark SQL-query's uit op uitgebreide klantgegevens. Deze gegevens kunnen zich bevinden in het Data 360 Lakehouse, externe systemen via Zero Copy-gegevensbundeling of een combinatie van beide.
Het systeem is sterk geoptimaliseerd door intelligente querygeneratie, die de onderliggende Spark SQL-query verfijnt. Dit omvat technieken zoals intelligent partitiebeheer om het scannen van gegevens tot een minimum te beperken en het elimineren van redundante subexpressies. Om de betrouwbaarheid van de service te waarborgen, biedt de architectuur adaptief resourcebeheer dat rekenresources dynamisch aanpast op basis van werkbelastinggrootte en complexiteit. Bovendien wordt SLO Adherence proactief beheerd met adaptieve duur en logica voor opnieuw proberen. Voor een snelle gebruikerservaring gebruiken versnelde segmenttellingen een op steekproeven gebaseerde benadering om snelle grootteschattingen te bieden tijdens het maken van segmenten, waardoor een volledige queryuitvoering wordt vermeden.
Ten slotte wordt een diepe focus op observatie en hoofdoorzaaktoekenning gehandhaafd door middel van uitgebreide Spark-uitvoeringsmeetgegevens en geautomatiseerde classificatie van fouten (bijv. problemen aan de kant van de klant t.o.v. het systeem), wat de diagnosetijd aanzienlijk verkort en een zeer veerkrachtig gegevensplatform garandeert.
Activering is de kritieke laatste stap in de Data 360-levenscyclus. De kernfunctie is het transformeren van statische, gesegmenteerde, gecombineerde klantprofielen in navolgbare en verrijkte gegevens en deze gegevens leveren aan interne en externe eindpunten (zoals Marketing Cloud, Commerce Cloud en Adtech-platforms). Dit proces is ontworpen om gepersonaliseerde klantjourneys en vrijwel realtime interacties te activeren. Het ondersteunt geavanceerde mogelijkheden zoals gerelateerde kenmerken, filteren van lidmaatschap voor activering, filteren van instemming, beperken en rangschikken.
Activering biedt drie verschillende methoden voor externe levering en kanaalnaleving:
- Batchactivering: Ontworpen voor grootschalige, geplande bewerkingen zoals grootschalige e-mailcampagnes en vernieuwingen van advertentiedoelgroepen. Gegevens worden geleverd door ze te faseren naar Secure Internal Buckets (Cloud Object Storage) of via Secure File Transfer, gevolgd door een API-opnameproces dat wordt geïnitieerd door het doelsysteem. Batchactiveringen kunnen gebruikmaken van een speciale vernieuwingsmodus - incrementeel - om volumes te reduceren die worden verzonden naar en verwerkt door Salesforce-partners.
- Streamingactivering: Geoptimaliseerd voor vrijwel realtime gebruikscases die eventgestuurde automatisering vereisen. Levering wordt bereikt door directe API-aanroepen die naar het bestemmingseindpunt worden verzonden.
- Door activering geactiveerde stromen: Dit zeer geplatformiseerde kanaal biedt een benadering zonder code/lage code voor het integreren van Doelgroepgegevens met honderden betrokkenheidsplatforms met API's van klanten. Na voltooiing van de activering vult Data 360 een DMO Doelgroep in, dat vervolgens een stroom op grote schaal activeert. De Flow-engine verbruikt vervolgens de doelgroepgegevens en gebruikt platformmogelijkheden zoals Externe services en Uitgaande Mule-bestemmingen om aanroepen te doen naar de uiteindelijke op API gebaseerde bestemming. Deze methode verkort de tijd die nodig is voor het onboarden van nieuwe activeringsdoelen aanzienlijk.
Activering gebruikt dezelfde patronen als segmentering voor taakbeheer, gedistribueerde uitvoering en bewaking. Dit omvat de principes van de taakcombinatieservice voor levenscyclusbeheer en de berekeningslaag (Spark) voor verwerking, en vertrouwt op taaktelemetrie voor prestatieobservatie en naleving van serviceniveaudoelstellingen (SLO).
Daarnaast heeft activering -
Activeringsdoelbeheer houdt toezicht op de beveiligde verbindingen, inloggegevens en configuraties voor alle bestemmingseindpunten. Het garandeert dat gegevensindelingen en beveiligingsprotocollen zijn gestandaardiseerd, wat zorgt voor betrouwbare uitgaande levering aan verschillende platforms, waaronder Marketing Cloud, Adtech-partners en andere externe toepassingen.
Activering past de payload voor specifieke doelen aan. Voor Salesforce Marketing Cloud omvat dit Aware Filtering (BU) van bedrijfseenheden, ondersteuning voor meerdere EID's en controles voor kruisbestuiving.
Communication Governance fungeert als een poortwachter en zorgt ervoor dat gegevensgebruik en communicatie voldoen aan de voorkeuren en wettelijke vereisten van de klant. Het gecentraliseerde instemmingsmodel verenigt alle klantvoorkeuren, van globale afmeldingen tot kanaal- en doelspecifieke instemming, en wordt opgeslagen in het profiel Gecombineerd individu. Tijdens de uitvoering handhaaft het platform deze beleidsvormen strikt door uitsluitingsfiltering te gebruiken om niet-instemmende individuen automatisch uit de definitieve payload te verwijderen. Bovendien past het systeem selectieregels voor aanspreekpunten toe om ervoor te zorgen dat het één, meest conforme en voorkeurscontactpunt voor het beoogde kanaal gebruikt voordat gegevens worden verzonden. Dit afdwingingsmechanisme wordt beveiligd door het onderliggende governance-framework, dat beschermende maatregelen zoals dynamisch maskeren van gegevens en toegangscontroles gebruikt om gevoelige gegevensvelden tijdens het activeringsproces te beveiligen.
De echte waarde van een gecombineerd gegevensplatform ligt in het vermogen om moeiteloze, consistente toegang te bieden tot alle gegevensactiva, ongeacht hun herkomst of structuur. De functie Gecombineerde query van Salesforce Data 360 is precies ontworpen om dit te leveren en abstraheert de onderliggende complexiteiten van diverse gegevensopslagplaatsen om één krachtige query-interface te bieden.
De laag Gecombineerde query biedt geavanceerde toegang voor diverse verbruikspatronen:
- Hybride gestructureerde en ongestructureerde query's: Het biedt uitgebreide SQL-ondersteuning voor een naadloze query op zowel gestructureerde gegevens als de gestructureerde metagegevens van ongestructureerde gegevens. Dit wordt verbeterd door de uitbreidbaarheid van de operator via tabelfuncties, waardoor gespecialiseerd zoeken binnen tekst-, afbeeldings- en ruimtelijke typen mogelijk is.
- Versnelde prestaties met Hyper: Met behulp van Hyper, een krachtige engine in het geheugen, versnelt Data 360 complexe analytische query's en interactieve dashboards, die vrijwel onmiddellijke reacties bieden via enorme gegevenssets.
- Gecombineerde aanpak voor AI en personalisatie: Deze gecombineerde toegang is van cruciaal belang voor het genereren van doelgerichte en gepersonaliseerde resultaten, waarbij preciezere LLM-responsen direct worden vergemakkelijkt met behulp van Retrieval Augmented Generation (RAG) door AI-modellen te baseren op rijke, zakelijke gegevens.
- Integratie met stroomafwaarts verbruik: Het dient als de basislaag voor gegevenstoegang voor UI-gestuurde omgevingen, robuuste API's, Generatieve AI-werkstromen en CRM-verrijking, waarbij gegevens naadloos worden verbonden met activering.
Door één intelligente en uiterst performante query-interface te bieden, stelt de gecombineerde query van Data 360 architecten in staat om flexibele, gegevensgestuurde toepassingen te bouwen die hun volledige spectrum aan klantinformatie volledig benutten.
Data 360 is een actief platform dat de activering van pijplijnen ondersteunt als reactie op gegevensevents. Zo kan een belangrijke event, zoals een daling van het saldo van een klant, een Salesforce-stroom activeren om een overeenkomende actie te organiseren. Op soortgelijke wijze kunnen updates van belangrijke meetgegevens, zoals levenslange uitgaven, automatisch worden doorgevoerd naar relevante toepassingen.
Gegevensacties bewaken continu incrementele gegevens op wijzigingen met behulp van native wijzigingsevents (SNCE) en wijzigingsgegevensfeeds (CDF). Deze gegevens worden geëvalueerd op basis van door de klant geconfigureerde actieregels, zoals drempelwaardenbewaking of statuswijzigingen. Wanneer aan deze regels wordt voldaan, wordt er een gegevensactie-event gegenereerd. Deze event wordt verrijkt met aanvullende informatie (bijv. loyaliteitsstatus van klanten) en onmiddellijk verzonden naar de geconfigureerde bestemming, zoals Salesforce Flow of een externe toepassing, om bedrijfscombinaties te activeren.
Data 360 ondersteunt native CDP-voorzieningen (Customer Data Platform), waaronder geavanceerde identiteitsoplossingsmogelijkheden en het maken van gecombineerde individuele identifiers en profielen, samen met uitgebreide betrokkenheidshistories. Dit platform is bedreven in het afhandelen van zowel B2B-frameworks (business-to-business) als B2C-frameworks (business-to-consumer) door identiteitsoplossing en identiteitsgrafieken te ondersteunen die zowel exacte als fuzzy overeenkomstenregels gebruiken, zoals hierboven beschreven. Deze identiteitsgrafieken worden verrijkt met betrokkenheidsgegevens uit verschillende kanalen, wat helpt bij het samenstellen van gedetailleerde profielgrafieken met waardevolle analytische insights en segmenten.
Een belangrijk concept dat het klantprofiel ondersteunt, is de gegevensgrafiek. Data 360 biedt een ondernemingsgegevensgrafiek in JSON-indeling, een gedenormaliseerd object dat is afgeleid van diverse Lakehouse-tabellen en hun onderlinge relaties. Dit omvat een gegevensgrafiek "Profiel" die is gemaakt door CDP en die de aankoop- en bladerhistorie, casehistorie, productgebruik en andere berekende insights van een persoon omvat, en die kan worden uitgebreid door klanten en partners. Deze Gegevensgrafieken zijn afgestemd op specifieke toepassingen en verbeteren de nauwkeurigheid van genererende AI-aanwijzingen door relevante klant- of gebruikerscontext te bieden. De real-time laag van Data 360 gebruikt de Profielgrafiek voor real-time personalisatie en segmentering. We zien Agentforce Context als Gegevensgrafieken die Gesprekken, Sessies en Agentisch geheugen omvatten.
Daarnaast maakt het CDP effectieve segmentering en activering mogelijk op verschillende platforms, zoals Marketing Cloud, Facebook en Google van Salesforce. Het verwerkt klantprofielen in batches, vrijwel realtime en real-time, wat onmiddellijke besluitvorming en personalisering mogelijk maakt. Deze functionaliteit verbetert interacties in zowel B2C- als B2B-scenario's, waardoor bedrijven snel en nauwkeurig kunnen reageren op de behoeften en het gedrag van klanten.
De real-time laag van Data 360 wordt ondersteund door het Data 360 CDP en breidt de concepten ervan uit voor real-time gebruikscases. De real-time laag van Data 360 is ontworpen voor het verwerken van events zoals web- en mobiele klikstreams, bezoeken, winkelwagentjesgegevens en checkouts met milliseconde latenties, waardoor de klantervaring persoonlijker wordt. Het bewaakt continu klantbetrokkenheid en werkt het klantprofiel vanuit Customer 360 bij met realtime betrokkenheidsgegevens, segmenten en berekeningen voor onmiddellijke personalisatie.
Wanneer een consument bijvoorbeeld een item koopt op een winkelwebsite, detecteert de real-time laag deze event snel en neemt deze op, identificeert deze de consument en verrijkt diens profiel met bijgewerkte informatie over levenslange uitgaven. Dit maakt het mogelijk om hun ervaring op de site in subseconden te personaliseren. Daarnaast omvat deze laag mogelijkheden voor real-time triggering en responsen, waardoor directe acties mogelijk zijn op basis van interacties met klanten.
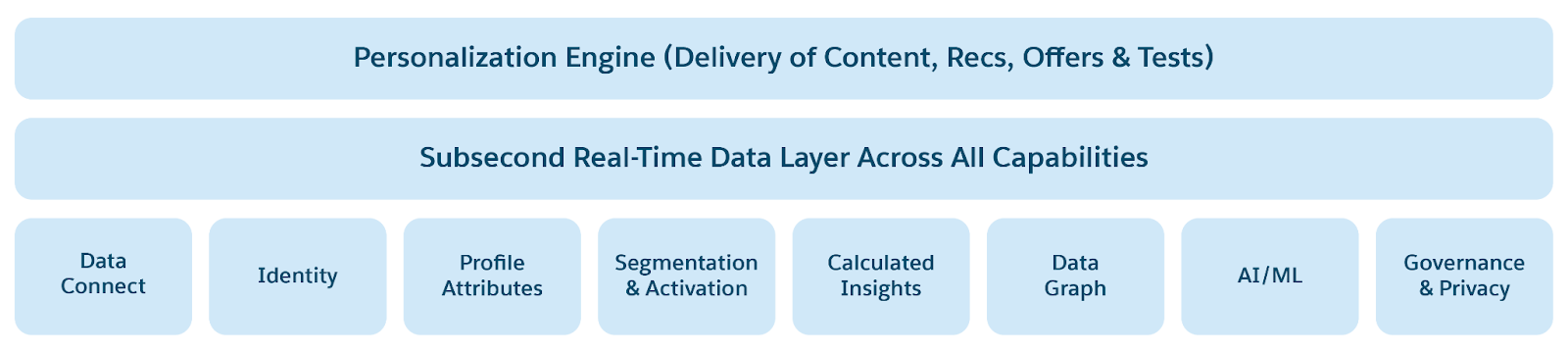
Het Sub-Second Real-Time-platform ondersteunt deze transformatie via verschillende belangrijke voorzieningen:
- Realtime Gegevensgrafieken: Een Customer 360 profiel wordt samengesteld met behulp van een gedenormaliseerde grafiek die de belangrijkste objecten en velden bevat die het meest relevant zijn voor merken. Deze Gegevensgrafieken maken realtime gegevensverwerking mogelijk en leveren binnen milliseconden navolgbare inhoud en insights
- Real-time opname en transformatie: Neem gebruikersevents en -profielen in milliseconden op vanuit web- en mobiele bronnen.
- Identiteitsoplossing in realtime: Voeg klantprofielen samen op verschillende apparaten, waarbij onbekende en bekende gebruikers onmiddellijk worden gecombineerd.
- Realtime berekende insights: Bereken meetgegevens zoals levensduurwaarde (LTV) of gebruikersbezoekhistorie in milliseconden om Personalisatie of Aanbiedingen voor web, ChatBot of serviceagent in te schakelen.
- Realtime segmentering: Segmenteer doelgroepen in één keer en personaliseer berichten en interacties in real-time.
- Realtime acties: Geef merken de mogelijkheid om elke gebruikersbetrokkenheid te evalueren en actie te ondernemen via Salesforce Flow of andere relevante communicatiekanalen.
In Data 360 hebben we een nieuw real-time platform gebouwd met een real-time pijplijn, opslag met lage latentie en een gegevensverwerkingslaag van een seconde. Aangezien snelle interactieve gegevens worden opgenomen vanuit web- en mobiele kanalen, doorlopen ze een reeks snelle processen.
Onze Web & Mobile SDK's en real-time API's verzamelen gegevens van web-/mobiele toepassingen (in toekomstige Agentic-interacties) en verzenden deze naar onze beaconserver. Deze gegevens worden vervolgens naar de Realtime laag gerouteerd voor millisecondenverwerking en de Lakehouse-laag voor integratie met batch-/streaminggegevens. De laag Real-time verwerkt de inkomende real-time gegevens in de context van een gebruikersprofiel (anoniem of ingelogd), zoals het bijwerken van de totale uitgaven of levenswaarde van de gebruiker, enz. voor real-time personalisering tijdens de sessie. De Realtime laag wordt ondersteund door het hoofdgeheugen en NVme-opslagopslag (SSD) voor de opslag van realtime gegevens en klantprofielen. Zodra de gegevens zich in de Realtime laag bevinden, doorlopen ze de volgende processen voordat ze worden bijgewerkt in Realtime gegevensgrafiek:
- Eenvoudige opname en transformaties: De gegevens worden opgenomen en getransformeerd voor verdere verwerking.
- Identiteitsoplossing: Exacte overeenkomstenregels worden toegepast om profielen te combineren met alle bestaande overeenkomstenregelsets, waardoor gegevensbewuste specialisten geen nieuwe identiteitsoplossingsregelsets specifiek voor realtime hoeven te maken.
- Berekende insights: Elke betrokkenheid wordt geëvalueerd, eenvoudige berekeningen zoals som en telling in milliseconden worden uitgevoerd en gegevens worden bijgewerkt in de realtime gegevensgrafiek.
- Realtime segmenten: Elke betrokkenheidsgegevens wordt geëvalueerd om te bepalen of deze voldoen aan de criteria voor gedefinieerde real-time segmenten en gebruikers worden in milliseconden toegevoegd aan kwalificerende segmenten.
- Realtime acties en triggers: Elke betrokkenheid wordt geëvalueerd op basis van gedefinieerde regels om acties te activeren naar een reeks doelen in real-time wanneer aan regels wordt voldaan in milliseconden.
- Real-time gegevensgrafiek en API: Realtime gegevensgrafiek, die ook een real-time API bevat, laat merken bijgewerkte gegevens in JSON-indeling ophalen voor elke gebruiker, zodat alle interacties met klanten worden geïnformeerd door de nieuwste gegevens.
Personalisatie gaat over weten op wie u zich moet richten, wanneer en waar u relevante inhoud en aanbevelingen moet leveren, wat u moet zeggen en met welke frequentie. Het Personalization Services Platform bepaalt welke beslissingen worden genomen om doelen te bereiken door middel van gepersonaliseerde ervaringen.
De personalisatieservices bieden de volgende mogelijkheden:
- Consistente set modellen en manieren om profiel-, activiteits- en activumgegevens te interpreteren in Data 360
- Platform geïntegreerde experimenten (A/B/n, Bandiet met meerdere armen)
- Integratie van doelen op ontwerptijd (configuratie), ML-trainingstijd en run-time (ML-conferentie)
- Ondersteuning van realtime B2C-schaal en batchinteractie (anonieme gebruikers, realtime/interactieve externe batch met groot volume, interne batch met groot volume)
- Analytics aangestuurd door Data 360
- Patronen om AI-model en service van andere partijen (intern en extern) te integreren
- Integratie in het ecosysteem van kernmetagegevens (PLATE-kenmerken)
- OOTB-implementaties van hoogwaardige AI-gestuurde gebruikscases (aanbevelingen/beslissingen met verschillende ML-algoritmen, waaronder contextuele bandieten voor speciale actie/inhoudsselectie, productaanbevelingen, prijsbeslissingen, enz.)
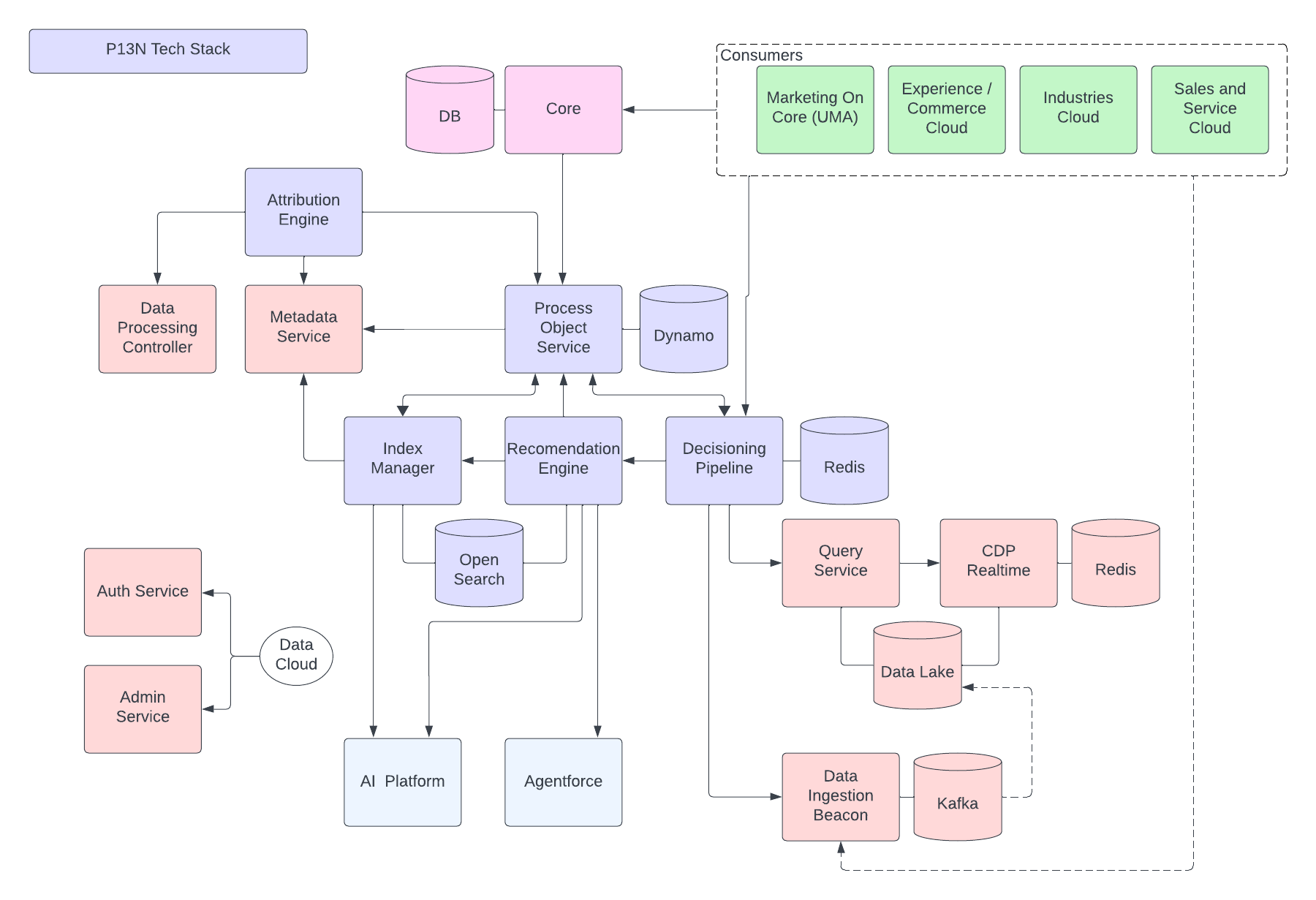
- Beslissingspijplijn
- Externe verzoeken om beslissingen over personalisering te ondersteunen, inclusief profielvergroting, experimenteren en aanbevelingen.
- Aanbevelingsengine
- Run-time service van op regels of ML gebaseerde aanbevelingen.
- Indexbeheer
- Beheert/organiseert werkstromen voor asynchrone processen, inclusief ML-trainingen voor aanbevelingsmodellen
- Process Object Service
- Verantwoordelijk voor het synchroniseren van personalisatiemetagegevens tussen core en off-core
- Toeschrijvingsengine en experimenteren
- Analytics-toekenning en experimenteren van aanbevelingen voor personalisering
Data 360 is ontworpen als een robuust en rijk platform specifiek voor het ondersteunen van de opkomende agentische omgevingen. We bereiken deze mogelijkheden door voort te bouwen op diverse bestaande Data 360-services en door diepgaande integratie met Agentforce.
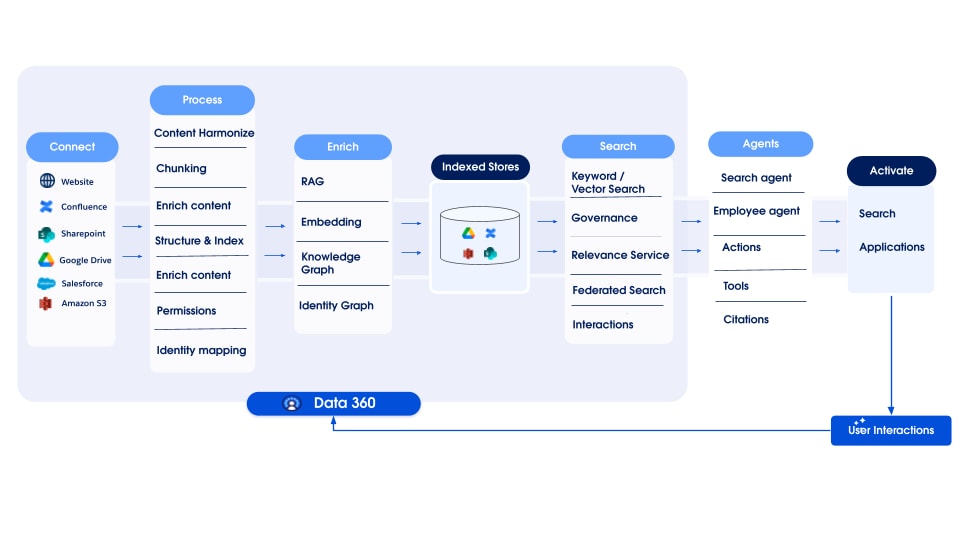
Onze benadering van Agentic Enterprise Search is gebaseerd op de volgende principes:
- Enterprise-gegevens worden bewaard in afzonderlijke services of stores, met beveiligde machtigingen die nodig zijn voor toegang. De mogelijkheid om toegang te krijgen tot deze gegevens en deze te verwerken met behoud van de bronmachtigingen is van vitaal belang om Trust te garanderen.
- Cross-ranking en relevantie voor het volledige gegevensbestand maken betere resultaten mogelijk, wat op zijn beurt weer een betere context voor agentische ervaringen kan bieden.
Om deze omgevingen te bieden is Agentic Enterprise Search gebaseerd op deze belangrijke architectonische componenten:
- Connectoren: De brede set connectoren die beschikbaar is in Data 360, biedt toegang tot en opname van gegevens uit een breed scala aan bronnen.
- Niet-gestructureerde gegevensverwerking: Dit is essentieel voor het afhandelen van niet-tabelinhoud, waardoor het systeem betekenis en context kan ontlenen aan diverse gegevens.
- Bestuur: Beveiliging op ondernemingsniveau, naleving en toegangscontroles voor alle gegevens die worden verbruikt door zoekopdrachten. Ondersteuning voor machtigingen voor bronzichtbaarheid zorgt ervoor dat de gegevens alleen toegankelijk zijn voor geautoriseerde gebruikers, voor zowel eenvoudige zoek- als agentervaringen. Om snel ophalen te garanderen, worden beveiligingsmachtigingen in het vroegste stadium van gegevenstoegang geëvalueerd en afgedwongen door de zoekback-ends.
- Gecombineerde ophaallaag: Om de uitdaging van gegevens in silo's aan te pakken, leveren de connectoren feeds in een uitgebreide laag Gecombineerd ophalen. Deze laag biedt één toegangspunt tot alle gegevens, ongeacht of deze zich bevinden in externe systemen die toegankelijk zijn via Gebundeld zoeken, of intern worden beheerd via geavanceerde indexen voor nulkopieën en opgenomen gegevens.
- Intelligent Query Understanding: Vóór ophalen gebruikt het systeem door AI ondersteunde mechanismen om de intent van de gebruiker te interpreteren. Naast het inbedden van weergaven van de query voor overeenkomsten met semantische vectoren kan deze op trefwoorden gebaseerde zoekopdrachten herschrijven en uitbreiden om de nauwkeurigheid te verbeteren.
- Hybride zoekopdrachten en geavanceerde query's: Om de meest relevante informatie te vinden, gebruikt het platform meerdere strategieën parallel. Hybride zoekopdrachten bieden nauwkeurige overeenkomsten met trefwoorden met semantische vectorzoekopdrachten voor geoptimaliseerde blokken gegevens, terwijl zoekopdrachten met volledige records tegelijkertijd volledige documenten ophalen. Beide worden gecombineerd om zowel semantische relevantie als volledige inhoudsdekking te garanderen.
- Hiërarchische plaatsing: Nadat gegevens zijn opgehaald, scoort een architectuur met hiërarchische plaatsing in meerdere fasen de resultaten uit elke bron en methode, voegt deze samen en plaatst deze opnieuw. Dit proces maakt één gecombineerde lijst die de meest relevante informatie voor de gebruiker of agent zichtbaar maakt.
Generatieve AI verschuift de primaire consument van enterprise search van menselijke gebruikers naar Large Language Models (LLM's). Data 360 Search is van de grond af aan ontwikkeld om beide te bedienen. Deze is geoptimaliseerd voor het afhandelen van de langere, complexere query's van agenten en het retourneren van de rijke, contextuele resultaten die nodig zijn voor programmatisch verbruik en redeneerlussen. Tegelijkertijd kan het systeem de kortere, vaak ambigue query's afhandelen die typisch zijn voor menselijke gebruikers, en biedt het voorzieningen zoals snippets en markering voor snelle beoordeling in een UI.
De ultieme levering van agentische zoekervaringen combineert beide benaderingen:
- Directe zoekresultaten: toepassing kan een traditionele lijst van gerangschikte resultaten weergeven door middel van een metagegevensgestuurde API die is gebaseerd op de Data 360-basis voor gecombineerd zoeken.
- Agentische antwoorden met meerdere beurten: agentische antwoorden worden geïmplementeerd door native integratie met Agentforce. Deze gesprekservaring wordt aangestuurd door een primaire agent die acties en query's organiseert, waarbij alle taken voor het ophalen van informatie worden gedelegeerd aan een gespecialiseerde, interne zoekagent.
Deze gespecialiseerde zoekagent is geoptimaliseerd voor het ophalen van bedrijfsgegevens. Het gebruikt een redeneringslus om parallelle zoekopdrachten te formuleren en uit te voeren om verschillende facetten van het verzoek van een gebruiker te verkennen. Het maakt gebruik van een krachtige set tools, waaronder de gecombineerde Data 360-zoekopdracht voor alle gegevenstypen en gestructureerde querytalen om nauwkeurige gegevens op te halen uit tabellen en entiteiten.
Via deze architectonische synthese maakt Data 360 het mogelijk om zeer intelligente, contextbewuste en navolgbare agentische zoekomgevingen voor ondernemingen te maken.
Uitbreidbaarheid is een belangrijke voorziening in het Salesforce-platform. Code-extensie biedt uitbreidbaarheid in Data 360, waardoor pro-codegebruikers aangepaste Python-logica rechtstreeks binnen de Data 360-omgeving kunnen uitvoeren, als aanvulling op de rijke declaratieve en low-code functionaliteiten. Met Code-extensie kunnen gebruikers Data 360-kernmogelijkheden zoals transformaties en ongestructureerde gegevenspijplijnen (aangepaste blokken) veilig uitbreiden.
Ons ontwerp voor Code-extensie geeft prioriteit aan flexibiliteit, beveiliging, efficiëntie en een gestroomlijnde ontwikkelaarservaring. Het ondersteunt twee primaire uitvoeringsmodellen, elk afgestemd op specifieke architectonische behoeften:
- Scriptmodel:
- Doel: Voor uitgebreide aangepaste logica die directe interactie met het Data 360 Lakehouse vereist.
- Functionaliteit: Klanten schrijven volledige Python-scripts met behulp van de Code-extensie SDK, waardoor lees- en schrijftoegang tot Lakehouse mogelijk is via SDK-API's. Ideaal voor aangepaste/complexe gegevensvoorbereiding of op maat gemaakte gegevensmanipulatie.
- Isolatie en beveiliging: Hoewel scripts toegang hebben tot het Lakehouse, is de uitvoering ervan beperkt tot een veilige, geïsoleerde omgeving binnen de Data 360-run-time, waardoor interferentie met andere processen of ongeoorloofde systeemtoegang wordt voorkomen.
- Functiemodel:
- Doel: Analoog aan een serverloze functie, voor modulaire, staatloze berekeningen die worden aangeroepen vanuit bestaande Data 360-pijplijnen (bijv. aangepaste blokken in een niet-gestructureerde pijplijn).
- Functionaliteit: Door de klant geleverde functies vereisen invoer, berekening en retouruitvoer.
- Isolatie en beveiliging: Deze functies zijn ontworpen voor strikte isolatie; ze hebben geen directe toegang tot Lakehouse. De uitvoering is sandboxed, staatloos en resource-beperkt, waardoor ze geschikt zijn voor gerichte, staatloze verwerkingsstappen, beveiliging, voorspelbare uitvoering en het minimaliseren van de straal van de explosie.
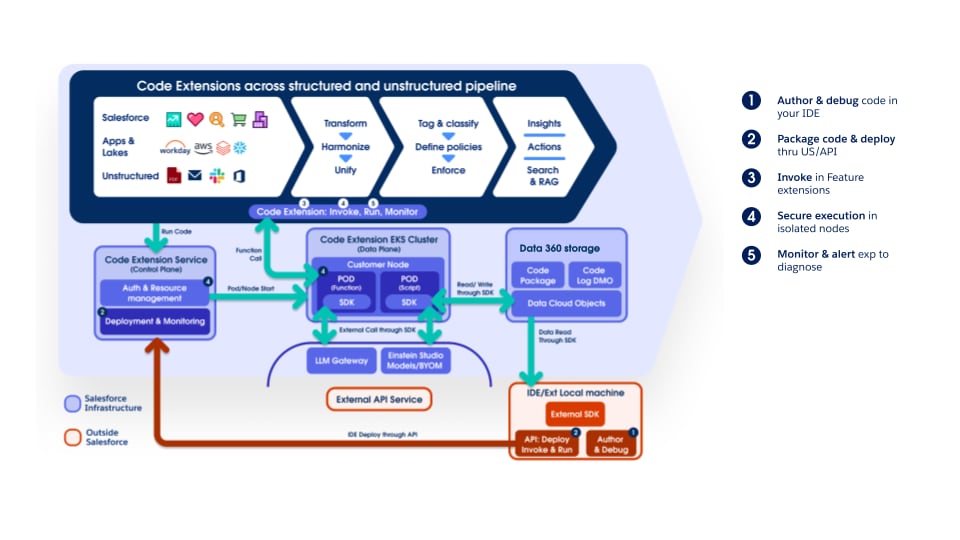
Zowel het Script- als het Functie-model zijn gericht op het veilig uitvoeren van klantcode, waarbij wordt voorkomen dat de code van één belanghebbende anderen beïnvloedt of ongeoorloofde toegang krijgt tot gegevens, Salesforce-resources of externe resources van andere belanghebbenden. Deze beveiliging wordt bereikt door een gelaagde (defensie-in-diepte) architectuur. Deze architectuur biedt een geïsoleerde uitvoeringsomgeving voor de aangepaste code van elke belanghebbende, met verschillende vangrails. Deze omvatten logische isolatie op Kubernetes-niveau (K8's), netwerkisolatie, run-time sandboxing en machtigingen voor de minste machtigingen, allemaal aangevuld met operationele bewaking en gereedheid voor incidentrespons voor detectie en reactie.
Code-extensie ondersteunt een robuuste ontwikkelingslevenscyclus door:
- Extern schrijven en foutopsporing: Ontwikkelaars kunnen Python-code maken en fouten opsporen in vertrouwde omgevingen zoals VSCode, waarbij ze de SDK gebruiken.
- Flexibele implementatie: Aangepaste code kan in een pakket worden opgenomen en geïmplementeerd met behulp van SDK-hulpprogramma's, de Data 360-UI of API, waardoor integratie in CI/CD mogelijk wordt.
Operationele logboeken: Toegang tot gedetailleerde uitvoeringslogboeken biedt transparantie en helpt bij het oplossen van problemen in de productie.
Door deze veilige en flexibele code-extensiemogelijkheden aan te bieden, stelt Data 360 architecten in staat om het platform aan te passen aan hun meest unieke en complexe gegevensverwerkingsvereisten, waardoor de rol van Data 360 als uitbreidbare gegevensstructuur voor de onderneming echt wordt versterkt.
Naarmate bedrijven de acceptatie van AI versnellen, onderhouden de meeste heterogene ML-ecosystemen – waaronder Amazon SageMaker, Google Vertex AI en aangepaste op Python gebaseerde omgevingen – die modellen hosten die kritieke voorspellingen sturen, zoals kredietrisicoscores, verloopneiging, productaanbevelingen en next-best-action beslissingen.
Het integreren van deze externe modellen in Salesforce vereiste van oudsher op maat gemaakte API-lagen, ETL-pijplijnen of middleware doeltreffende combinaties, waarbij gegevensduplicatie, governance-overhead, latentie en operationele complexiteit werden geïntroduceerd. Dit zijn uitdagingen die conflicteren met een gecombineerde, conforme en real-time Customer Data Platform-visie (CDP).
Bring Your Own Model (BYOM): Wordt geleverd via Einstein Studio in Data 360 en lost deze uitdagingen op door het rechtstreeks aanroepen van extern getrainde modellen binnen Salesforce-werkstromen, Apex logica en automatiseringstools mogelijk te maken—zonder gegevens te verplaatsen of te repliceren. Door middel van zero-copy bundeling fungeert Data 360 als de geregeerde enkelvoudige bron van waarheid, waarbij geharmoniseerde Customer 360 gegevens zichtbaar worden voor gevolgtrekking op externe eindpunten. Uitvoer van voorspellingen stroomt in real-time terug, waardoor bedrijfsprocessen worden aangestuurd met schaalbare intelligentie.
BYOM dicht effectief de kloof tussen datawetenschap en operationele uitvoering door modelontwikkeling, beheerde gegevens en verbruikslagen los te koppelen. Het behoudt platformonafhankelijkheid, vermindert de complexiteit van integratie, versnelt de implementatie van AI en handhaaft governance over gevoelige gegevens.
De architectuur werkt als volgt: Data 360 biedt een gecombineerde Customer 360 gegevensbasis, terwijl Einstein Studio verbindingen regelt met externe ML-platforms (SageMaker, Vertex AI of aangepaste eindpunten). Externe modellen voeren gevolgtrekkingen uit in real-time, batch- of streamingmodi. Salesforce-lagen (stroom-, Apex en query-API's) verbruiken uitvoer om gepersonaliseerde, geautomatiseerde en analytische insights te bieden in Sales, Service, Marketing en Industry Clouds.
Vanuit het oogpunt van de onderneming levert BYOM:
- Gegevensintegriteit en governance: Elimineert ongecontroleerde gegevenskopieën en dwingt naleving van beleid af.
- AI-democratisering: Maakt complexe modellen toegankelijk voor niet-technische gebruikers via Salesforce-tools.
- Versnelling van tijd naar waarde: Externe modellen worden onmiddellijk geactiveerd binnen Salesforce-processen.
- Ondersteuning voor schaalbaarheid en hybride architectuur: Schakelt implementatie van AI-werkbelastingen in meerdere clouds in.
- Toekomstgerichte AI-architectuur: Ondersteunt samenstelbare AI-strategieën, het ontkoppelen van gegevens, model- en verbruikslagen voor operationele flexibiliteit.
Bring Your Own LLM (BYO-LLM): Biedt hetzelfde uitbreidbaarheidsmechanisme, maar dan voor generatieve modellen. Door directe aanroep van externe LLM's in te schakelen, kunnen klanten deze gebruiken in het Agentforce Platform in plaats van door Salesforce geleverde modellen. Voor ondernemingen maakt BYO-LLM het volgende mogelijk:
- Toegang tot verfijnde modellen
- Integratie van modellen die momenteel niet door Salesforce worden geleverd
- Gebruik van modellen in door de klant geleverde accounts
Moderne ondernemingen opereren binnen een complex gegevenslandschap dat wordt gekenmerkt door twee belangrijke architectonische uitdagingen:
- Versnippering binnen de onderneming: Grote organisaties maken vaak gebruik van meerdere Salesforce-organisaties (vaak gesegmenteerd op regio, bedrijfseenheid of historische overname) en tal van andere gegevenssystemen. Deze fragmentatie leidt tot interne gegevenssilo's, waardoor het onmogelijk is om één vertrouwd en uniform beeld van de klant te krijgen voor real-time betrokkenheid binnen het hele bedrijf. De uitdaging is om deze gegevens te combineren zonder ze fysiek te consolideren of dupliceren binnen alle systemen, zodat governance intact blijft.
- Samenwerking tussen ondernemingen: Bedrijven moeten vaak gegevens delen met partners en leveranciers voor gezamenlijke marketing, metingen en business intelligence. De uitdaging is om deze samenwerking mogelijk te maken en tegelijkertijd gevoelige, gepatenteerde gegevens te beschermen en te voldoen aan privacywetgeving zoals AVG en CCPA, evenals concurrentiebelemmeringen.
Salesforce Data 360 lost deze uitdagingen op met een Trust by Design-framework zonder kopieën, dat is gebaseerd op het principe van het delen van toegang en insights in plaats van het verplaatsen of dupliceren van gegevens.
Salesforce Data 360 lost problemen op het gebied van gegevensfragmentatie en samenwerking op met Data Cloud One, het delen van gegevens tussen Data 360's en Data Clean Rooms die privacy voorop stellen. Deze oplossingen combineren klantgegevens, maken veilige gegevensuitwisseling mogelijk en bieden privacybeschermende insights. Met een zero-copy, Trust by Design-benadering kunnen organisaties gegevenspotentieel ontsluiten voor realtime betrokkenheid, uitgebreide partnerschappen en intelligente besluitvorming. Elk van deze opties voor gegevenssamenwerking dient verschillende doelen.
Interne Enterprise Enablement met Data Cloud One
Data Cloud One is de basisarchitectuuroplossing voor ondernemingen die meerdere Salesforce-organisaties beheren. Het doel ervan gaat verder dan alleen het delen van gegevens; het is ontworpen om één vertrouwde klantweergave te creëren en volledige Data 360-platformmogelijkheden voor de hele organisatie mogelijk te maken.
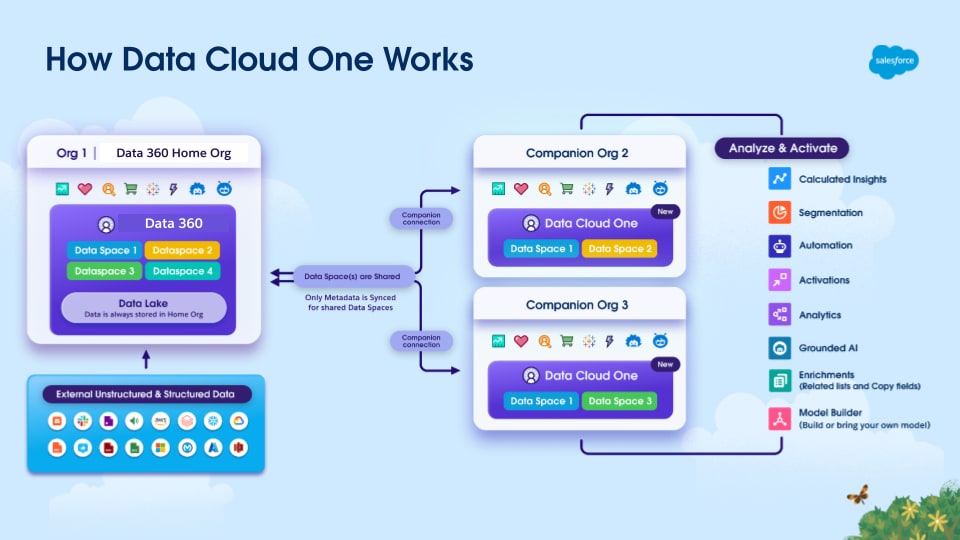
Dit mechanisme richt zich op een aangewezen instantie van Home Org Data 360, die fungeert als de centrale autoriteit voor gegevensbeheer en het samenstellen van het gecombineerde klantprofiel. De hoofdorganisatie is de organisatie waarvoor Data 360 wordt geleverd. Er wordt een Data Cloud One-verbinding tot stand gebracht tussen Data 360 en andere Salesforce-organisaties, Companion-organisaties genaamd. Als onderdeel van de Data Cloud One-verbinding deelt Data 360 een of meer van zijn gegevensruimten met elke begeleidende organisatie, die toegang biedt tot zowel gegevens als metagegevens in elke gedeelde gegevensruimte. Dit wordt bereikt door middel van een zero-copy bundelingsmodel en inter-organisatorische synchronisatie van metagegevens.
Met Data Cloud One kunnen Companion-organisaties ook het Data 360-exemplaar van de hoofdorganisatie gebruiken voor hun eigen activerings-, personalisatie- en intelligentiebehoeften. Deze strategie is essentieel om interne gegevensfragmentatie te elimineren en ervoor te zorgen dat alle bedrijfseenheden worden geactiveerd op basis van hetzelfde, beheerde en gecombineerde klantprofiel, waardoor het investeringsrendement van de Data 360-kernimplementatie wordt gemaximaliseerd.
Gegevens delen tussen Data 360-organisaties
Voor gedistribueerde interne omgevingen (waar volledige centralisatie niet mogelijk is) en voor samenwerking met vertrouwde externe partners verbindt het delen van Data 360-naar-Data 360-gegevens onafhankelijke Data 360-instanties.
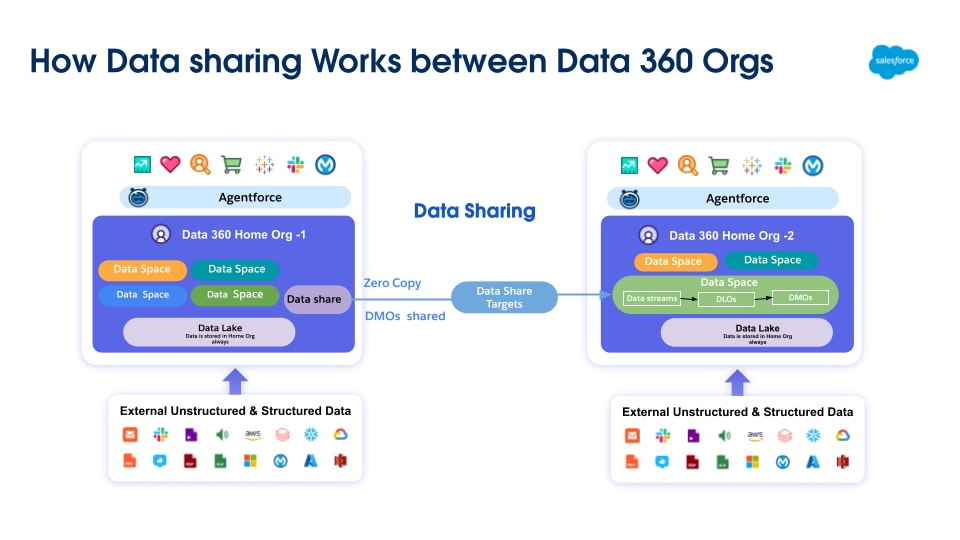
Dit model voor delen met nul kopieën brengt een verbinding tot stand tussen afzonderlijke Data 360-belanghebbenden die zijn aangeleverd voor verschillende Salesforce-organisaties, met het oog op een veilige uitwisseling van gegevensobjecten (DLO's, DMO's en CIO's). Eenmaal verbonden, wordt het gehele gegevensobject toegankelijk in de ontvanger Data 360. De Data 360-beheerder van de ontvanger kan vervolgens governance-regels instellen om gebruikerstoegang tot deze gegevens te beheren.
Privacy-first samenwerking met Data 360 Clean Room-samenwerking
Wanneer samenwerking de hoogste niveaus van privacy en naleving vereist of wanneer concurrentie het delen van ruwe gegevens verbiedt, zijn Data 360 Clean Rooms architectonisch verplicht.
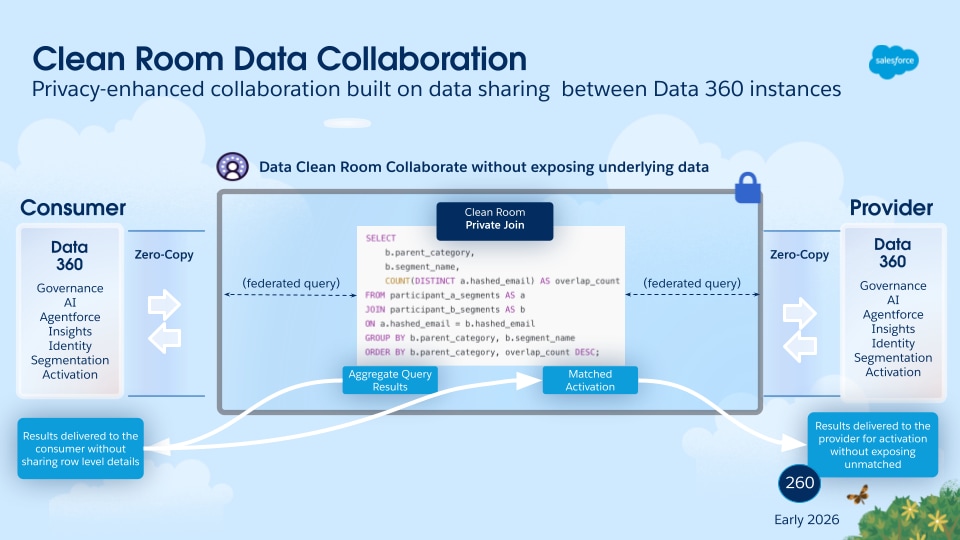
Architectonisch gezien is Data 360 Clean Room Collaboration gebaseerd op het framework Zero-Copy Sharing (Delen zonder kopiëren), dat wordt gebruikt door het delen van gegevens tussen Data 360 en Data 360, maar met extra governancelagen en rekenkundige beperkingen. De Data 360 Clean Room biedt een veilige, gecontroleerde computeromgeving waarin partijen hun gegevenssets kunnen samenvoegen op basis van geanonimiseerde sleutels. Het kerndoel is om gezamenlijke analyse en het genereren van insights mogelijk te maken zonder de onderliggende bedrijfseigen gegevens bloot te leggen. De omgeving dwingt strikte, programmeerbare regels af, zoals minimale aggregatiedrempelwaarden en niet-exporteerbare identifiers. Deze regels zorgen ervoor dat alleen goedgekeurde, privacyverhogende en geaggregeerde insights worden afgeleid en gedeeld. Dit maakt Clean Rooms essentieel voor gebruikscases zoals cross-platform campagnemetingen en gevoelige analyse van overlappingen van doelgroepen.
Data 360 is ontworpen als een intelligente, uitbreidbare en vertrouwde gegevensstructuur die nodig is voor de aansturing van AI van de volgende generatie. Het architectonische ontwerp lost het probleem van gefragmenteerde gegevens op, waardoor organisaties alle klantgegevens op schaal kunnen combineren, verwerken en activeren, met behulp van Zero Copy Data Federation om efficiëntie te garanderen.
De robuuste gegevensorganisatie ervan biedt een geharmoniseerde weergave van DLO's (inclusief ongestructureerde gegevens) tot DMO's, allemaal beveiligd binnen gepartitioneerde gegevensruimten. De veelzijdige gegevensverwerkingsmogelijkheden van Data 360, waaronder batch- en streamingtransformaties, berekende insights, ongestructureerde gegevensverwerking en identiteitsoplossing, worden aangestuurd door de incrementele SNCE- en CDF-architectuur, wat zorgt voor efficiënte, vrijwel realtime verwerking en aanzienlijke kostenbesparingen.
Uitbreidbaarheid wordt geboden door de architectuur van Code-extensie, waarbij aangepaste Python-logica veilig wordt ingeschakeld via scripts of geïsoleerde functies voor unieke vereisten. Bovendien garandeert een uitgebreid raamwerk voor gegevensbeheer, dat is gebaseerd op op kenmerken gebaseerde toegangscontrole (ABAC) met CEDAR-beleidsvormen, fijnmazige beveiliging, dynamisch maskeren van gegevens en consistente afdwinging voor al het gegevensverbruik. Dit resulteert in geavanceerde segmenterings- en activeringsmogelijkheden, waarbij gecombineerde klantprofielen worden vertaald in dynamische betrokkenheidsstrategieën voor meerdere kanalen met realtime responsiviteit.
Het vermogen van Data 360 om grote, diverse gegevens te combineren, real-time context te bieden via de gecombineerde query (inclusief hybride gestructureerd/ongestructureerde zoekopdrachten en Hyper-versnelling) en strikte governance af te dwingen, is cruciaal voor het aansturen van intelligente AI-agenten. Het biedt de nodige vertrouwde, verse en relevante gegevens om Generative AI-werkstromen (RAG) te aarden en de actiegerichte mogelijkheden van Agentforce agenten met meerdere beurten aan te wakkeren, zodat ze met precisie en nauwkeurigheid werken.
Door een toekomstbestendig platform te bieden waarin brongegevens worden getransformeerd naar navolgbare insights, vormt Data 360 een onmisbare architectonische basis voor organisaties die Agentic-klantervaringen samenstellen. Het is de essentiële ruggengraat die klantgegevens omzet in de geavanceerde, gepersonaliseerde klantervaringen die het succes bepalen voor de moderne organisaties van vandaag.