In dit document worden de huidige opties beschreven voor het implementeren van toepassingen naar CloudHub 2.0 om te voldoen aan de vereisten voor hoge beschikbaarheid en noodherstel. Het gebruikt de Amerikaanse regio als voorbeeld en kan worden toegepast op andere regio's.
CloudHub 2.0 is een volledig beheerd, cloud-native integratieplatform dat infrastructuuroverhead elimineert door de implementatie, schaalbaarheid en het beheer van MuleSoft-API's en -integraties in de cloud te automatiseren. Het is het moderne cloudimplementatieplatform van MuleSoft, dat draait op Amazon AWS-infrastructuur.
In de meeste gevallen is de standaard High Availability (HA) en Disaster Recovery (DR) van CloudHub 2.0 voldoende. CloudHub 2.0 biedt HA en DR op regionaal niveau (zie CloudHub 2.0-uitvalscenario's voor meer informatie). De CloudHub 2.0-hoofdoverwegingen bevatten meer details over door CloudHub-2.0 ondersteunde HA en DR.
Voorwaarden die een ontwerp vereisen dat verder gaat dan de standaardbeschikbaarheid van CloudHub 2.0, omvatten:
- Een toepassing moet ervoor zorgen dat er geen gegevens verloren gaan in een rampscenario (bijvoorbeeld een regio van Amazon die ten onder gaat).
- Een toepassing is afhankelijk van de Objectstore en moet continuïteit garanderen als de implementatieregio uitvalt.
- Back-endsystemen worden geconfigureerd voor gelijkwaardige beschikbaarheid. CloudHub 2.0 kan soms betrouwbaarheid bieden via wachtrijen of soortgelijke mechanismen, maar of de integratie nu real-time of asynchroon is, back-endsystemen moeten een vergelijkbaar niveau van HA en DR ondersteunen.
- Wanneer een uitval op AWS-regioniveau van invloed is op back-endsystemen, wordt aangenomen dat het herstel ervan parallel loopt met het herstel van CloudHub 2.0.
- De set-up van privéruimte is voltooid in meerdere regio's.
De ontwerpopties in deze handleiding richten zich op oplossingen voor de beschikbaarheid van toepassingen in CloudHub 2.0 wanneer een volledige AWS-beschikbaarheidszone of -regio niet beschikbaar is.
Deze handleiding behandelt deze herstelscenario's niet, maar vermeldt wel implicaties waar relevant:
- Herstel van back-endsystemen, toepassingen, databases, netwerkcomponenten en gegevenscentra die worden beheerd en geleverd buiten Anypoint CloudHub, on-premises of in de cloud.
- Herstel van VPN-koppelingen tussen CloudHub 2.0 en het privégegevenscentrum van de klant (bijvoorbeeld IPsec-tunnels en VPN-gateways). Sommige DR-opties in deze handleiding kunnen deze scenario's gedeeltelijk oplossen.
- Wijzigingen in MuleSoft-uitgaande IP's tijdens noodherstel wanneer IP-whitelisting wordt gebruikt voor integraties. Sommige DR-opties in deze handleiding kunnen deze scenario's gedeeltelijk oplossen.
- Externe berichtenverkeerssystemen die worden gebruikt in klantoplossingen, ongeacht of deze worden geleverd door MuleSoft (zoals Anypoint MQ) of andere leveranciers (zoals AWS MSK of Heroku Kafka).
Denk bij het evalueren van CloudHub 2.0 voor noodherstelvereisten aan de volgende belangrijke overwegingen.
CloudHub 2.0-afhankelijkheid van regionale beschikbaarheid van AWS
- CloudHub 2.0 draait op AWS; de beschikbaarheid ervan is afhankelijk van AWS-regio's.
- Implementaties en beschikbaarheid van toepassingen worden geordend op regio. Deze regio's komen overeen met AWS-regio's.
Als een volledige AWS-regio mislukt, zijn toepassingen in die regio niet beschikbaar en worden ze niet automatisch elders gerepliceerd.
Application High Availability (HA) en Replicabeheer
- CloudHub 2.0 implementeert toepassingen binnen dezelfde regio automatisch opnieuw wanneer hardware uitvalt, maar een toepassing met één replica kan downtime ervaren.
- Toepassingen met meerdere replica's worden standaard geïmplementeerd in afzonderlijke beschikbaarheidszones, waarbij HA wordt geboden in zones.
- Als de beschikbaarheidszone voor een toepassing met één replica mislukt, wordt de toepassing automatisch weergegeven in een andere beschikbaarheidszone binnen dezelfde regio.
Specifieke impact regio VS-oost
- In geval van uitval van de regio VS-Oost:
- De UI voor CloudHub 2.0-beheer en de implementatie-REST-services zijn niet beschikbaar en nieuwe toepassingen kunnen niet worden geïmplementeerd.
- Toepassingen in andere regio's worden onder de meeste foutscenario's niet beïnvloed. Deze toepassingen blijven normaal functioneren; tijdens de storing zijn echter geen bewakings- en beheermogelijkheden via het regelvlak beschikbaar.
- Core CloudHub 2.0-modules (zoals toepassingsinstellingen) worden onderhouden in de VS Oost, waardoor instellingen niet kunnen worden bewerkt tijdens uitval.
Bewaking en waarschuwing
- Configureer waarschuwingen voor storingen in beschikbaarheidszones of regioniveaus via status.mulesoft.com.
- Gebruik een afzonderlijk statuscontrole- en waarschuwingsmechanisme buiten CloudHub 2.0 zodat teams worden geïnformeerd als replica's mislukken of toepassingen niet meer reageren.
Gegevenscontinuïteit (Object Store V2)
- Object Store V2 is gekoppeld aan de regio waar de toepassing voor het eerst wordt geïmplementeerd.
- Als u de toepassing naar een andere regio verplaatst, blijft Object Store V2 in de oorspronkelijke regio om gegevensverlies te voorkomen.
- Als de regio waarin Objectstore V2 is geïmplementeerd, mislukt, is de objectstore niet beschikbaar.
Ingangscontrollers en privéruimten
- CloudHub 2.0-invoercontrollers zijn zeer beschikbaar op regioniveau.
- Als in een gedeelde ruimte een regio mislukt, blijft een inkomende controller in een andere regio beschikbaar, maar kan deze alleen toepassingen bedienen die in die regio zijn geïmplementeerd.
- Als een regio mislukt in een privéruimte, zijn inkomende controllers in andere regio's niet beschikbaar, tenzij ze daar vooraf zijn ingesteld.
- De set-up van privéruimte is regionaal. Als een regio mislukt, is de privéruimte niet beschikbaar, tenzij er een andere regio is ingesteld.
| Componentstatus | Salesforce-verantwoordelijkheid |
|---|---|
| Replica omlaag | Actie: CloudHub 2.0 start de replica automatisch opnieuw in een andere beschikbaarheidszone als er iets mis is met de huidige beschikbaarheidszone. Maar de toepassing blijft offline totdat de nieuwe replica volledig is gestart. Voorwaarde: Standaardconfiguratie. Genomen tijd: Ongeveer 2-15 minuten, afhankelijk van de complexiteit van de toepassing en de replicagrootte. |
| Beschikbaarheidszone omlaag | Actie: Zelfde als de replica. Voorwaarde: Standaardconfiguratie. Genomen tijd: Zelfde als de replica. Kennisgeving: Zelfde als de replica. |
| Regio omlaag | Actie: Geen automatisch herstel. Er moet een failoverontwerp zijn. |
| Componentstatus | Klantverantwoordelijkheid |
|---|---|
| Replica omlaag | Kennisgeving: Voer periodieke gezondheidscontroles uit met behulp van een hartslagmechanisme dat is ingebouwd in de API's. Verzachting: Implementeer de toepassing naar meerdere replica's in dezelfde regio. Test/simulatie: Maak een ticket aan met MuleSoft-ondersteuning en ze ondersteunen een failovertest om te controleren of er binnen 1 tot 15 minuten een nieuwe replica wordt weergegeven in een andere AZ. |
| Beschikbaarheidszone omlaag | Kennisgeving: Zelfde als de replica. Verzachting: Implementeer de toepassing op meerdere replica's in dezelfde regio of in verschillende regio's. Test/simulatie: Het scenario AZ Down is moeilijk te simuleren. Het vereist betrokkenheid van MuleSoft Engineering om mogelijke testscenario's te ondersteunen. |
| Regio omlaag | Kennisgeving: Zelfde als de replica. Controleer ook statusupdates op https://status.aws.amazon.com. Verzachting: Zelfde als AZ Down. Rampenplan voor herstel bij rampen: 2 privéruimten met dezelfde configuratie in verschillende regio's. Test/simulatie: Zelfde als AZ Down. |
| Componentstatus | Salesforce-verantwoordelijkheid |
|---|---|
| VPN-gateway omlaag | Replicastatus: Wordt uitgevoerd, maar kan geen verbinding maken met resources die op locatie worden gehost en bereikbaar zijn via de VPN-tunnel. Actie: Geen automatisch herstel. Er moet een failoverontwerp zijn. |
| Ingangscontroller (gedeelde ruimte) omlaag | Replicastatus: De Ingress-controller is een geclusterde set-up met meerdere exemplaren, vergelijkbaar met toepassingsreplica's. Als een toepassingsreplica mislukt, wordt er automatisch een nieuwe gemaakt en gestart. Als één exemplaar van de invoercontroller mislukt, blijven toepassingen beschikbaar via het andere exemplaar. Als de gehele Ingress-controller is uitgeschakeld, wordt de regio als uitgeschakeld beschouwd. |
| Ingangscontroller (privéruimte) omlaag | Status replica: Zelfde als Ingress Controller in gedeelde ruimte naar beneden. |
| Componentstatus | Klantverantwoordelijkheid |
|---|---|
| VPN-gateway omlaag | Kennisgeving: Voer periodieke gezondheidscontroles uit met behulp van een hartslagmechanisme dat is ingebouwd in de API's. Verzachting: CloudHub 2.0 VPN-gateways ondersteunen hoge beschikbaarheid via een dual-tunnelarchitectuur met automatische failover tussen tunnels; een klant moet dit patroon configureren. Test/simulatie: Het scenario VPN Gateway Down is moeilijk te simuleren. Vereist betrokkenheid van MuleSoft Engineering om mogelijke testscenario's te ondersteunen. |
| Ingress Controller (gedeelde ruimte) omlaag | Kennisgeving: Zelfde als VPN Gateway Down. Verzachting: Zelfde als Regio omlaag. Migreer toepassingen naar een standby- of actieve ruimte in een andere regio. Test/simulatie: Zelfde als VPN Gateway Down. |
| Ingangscontroller (privéruimte) omlaag | Kennisgeving: Zelfde als VPN Gateway Down. Verzachting: Zelfde als Regio omlaag. Migreer toepassingen naar een standby- of actieve privéruimte in een andere regio, in coördinatie met de configuratie van AWS Route 53 (of gelijkwaardig). Test/simulatie: Zelfde als VPN Gateway Down. |
Overzicht Platform Services omlaag-scenario – Object Store
| Objectstore in geheugen | Persistent Object Store v2 | |
|---|---|---|
| Locatie van gegevens | Alleen lokaal voor de toepassing. | In dezelfde regio waar de MuleSoft-toepassing voor het eerst werd geïmplementeerd. |
| Gedeeld over replica's? | Nee | Ja |
| Herstel van objectstore in toepassingen | Gegevens gaan verloren; alle in-memory gegevens gaan verloren bij opnieuw opstarten van de app, nieuwe implementatie of replicafout. | Gegevens gaan niet verloren, tenzij de app wordt verwijderd. |
| Herstel van objectstore binnen regio | Gegevens gaan verloren (zelfde als hierboven). | Gegevens gaan niet verloren (zelfde als hierboven). |
| Regionaal herstel | Zelfde als hierboven. | Gegevens zijn onbeschikbaar. Zelfs met een actief-actieve DR-configuratie is Object Store alleen beschikbaar in de oorspronkelijke implementatieregio. |
| Verzachting | Externaliseer gegevens voor regionaal herstel. | Gegevens blijven beschikbaar terwijl de oorspronkelijke implementatieregio beschikbaar is. Voor HA of DR voor meerdere regio's externaliseert u gegevens buiten de objectopslag. |
High Availability (HA) is de meeteenheid voor het vermogen van een systeem om toegankelijk te blijven in geval van een systeemcomponentstoring. Over het algemeen wordt HA geïmplementeerd door meerdere niveaus van fouttolerantie en/of load balancing-mogelijkheden in een systeem in te bouwen. Het is doorgaans een Actief-actieve configuratie en heeft beperkte of geen gevolgen voor Business Services.
Disaster Recovery (DR) is het proces waarbij een systeem wordt hersteld naar een eerdere acceptabele toestand na een rampscenario, hetzij natuurlijk (zoals overstromingen, tornado's, aardbevingen of branden), hetzij door de mens veroorzaakt (zoals stroomuitval, serverstoringen of verkeerde configuraties). DR is doorgaans een Actief-passieve configuratie en heeft enige invloed op de zakelijke dienstverlening.
Als Regional High Availability of Regional Disaster Recovery gewenst is om de gevolgen van uw bedrijf te verminderen in het geval van een regionaal AWS-falen, houdt u rekening met de volgende punten bij het ontwerpen van uw oplossing in MuleSoft CloudHub 2.0:
- CloudHub 2.0-replica's en gerelateerde mogelijkheden—privéruimten, invoercontrollers en Anypoint MQ-bestemmingen—zijn regiospecifiek.
- Als een volledige AWS-regio mislukt, worden alle replica's en gekoppelde services in die regio niet beschikbaar.
- Wanneer een regio herstelt, worden configuraties hersteld; u moet toepassingen opnieuw starten.
- Als de regio US East mislukt, zijn Anypoint Platform-services (bijvoorbeeld Toegangsbeheer en Runtime Manager) ook niet beschikbaar.
- MuleSoft biedt een SLA van 99,95% beschikbaarheid voor Platform Services, inclusief CloudHub 2.0-replica's in een actief-actieve configuratie binnen een regio. Raadpleeg de nieuwste MuleSoft Cloud-aanbod-SLA voor actuele details.
- CloudHub 2.0 biedt geen kant-en-klare ondersteuning voor HA of DR voor meerdere regio's; beschikbaarheid wordt alleen geboden binnen één regio.
Deze ontwerprichtlijnen zijn van toepassing ongeacht de set-up die u kiest.
Set-up van privéruimten voor meerdere regio's
Alle opties die in de volgende secties worden beschreven, vereisen dat toepassingen in afzonderlijke regio's worden geïmplementeerd. Dat is alleen mogelijk als de set-up van privéruimte vooraf is voltooid, vóór een ramp. Omdat de set-up van privéruimte regionaal is, vereist een DR-strategie minstens twee privéruimten—één per regio—en een mechanisme om verkeer over te schakelen naar het juiste VPN-eindpunt.
Instelling van zeer beschikbare privéruimte binnen een regio
CloudHub 2.0 biedt geen automatische failover wanneer een privéruimte binnen een regio mislukt. Een tijdelijke oplossing is een actief-passieve set-up voor meerdere omgevingen, die het volgende vereist:
- Meerdere VPN-gateways configureren op de privéruimte.
- Afzonderlijke omgevingen instellen in de CloudHub 2.0-regio, elk met een eigen privéruimte.
- Een van deze omgevingen aanduiden als passief (waarbij toepassingen aanvankelijk niet worden geïmplementeerd, maar worden geactiveerd als de primaire privéruimte mislukt).
Als een set-up met hoge beschikbaarheid zonder VPN-gateway één enkel foutpunt is, is implementeren naar twee regio's de beste optie. Een VPN-gatewayfout in dit scenario kan worden opgelost door de betroffen regio niet over te zetten naar de alternatieve regio waar de privéruimte al is geconfigureerd.
Berichtverlies nul
Als u nul berichtenverlies wilt bereiken wanneer een hele regio mislukt, moet een toepassing gegevensverlies voorkomen en deze punten oplossen:
- Gebruik extern berichtenverkeer om betrouwbaarheid van berichten te bereiken.
- Zorg ervoor dat Objectstore niet wordt gebruikt voor transactionele gegevens tijdens de vlucht die transactioneel van aard zijn. Als de implementatieregio waarin de MuleSoft-toepassing voor het eerst is geïmplementeerd, uitvalt, is de Objectstore niet beschikbaar.
- U kunt alle toegang tot Objectstore onderbrengen in een afzonderlijke stroom of sectie die blijft functioneren—voor zowel de afhandeling van uitzonderingen als de werking—wanneer lees- of schrijfbewerkingen van Objectstore mislukken.
Nota. In de meeste gevallen hoeven DR-vereisten niet te zorgen voor nul berichtenverlies in geval van een calamiteit en moeten ze ervoor zorgen dat gegevensverlies kleiner is dan de waarde van gegevens voor een bepaalde periode (bijvoorbeeld 1 uur).
Integratie staatloos houden
Als algemeen ontwerpprincipe is het altijd belangrijk om ervoor te zorgen dat de integraties staatloos van aard zijn. Dit betekent dat er geen transactionele informatie wordt gedeeld tussen verschillende clientaanroepen of uitvoeringen (in het geval van geplande services). Als bepaalde gegevens moeten worden onderhouden door de middleware vanwege een systeembeperking, moeten ze worden bewaard in een externe opslagplaats, zoals een database of een berichtenwachtrij, en niet binnen de MuleSoft-infrastructuur of het geheugen. Het is van cruciaal belang op te merken dat naarmate we opschalen, met name in de cloud, de status en resources die door elke replica worden gebruikt, onafhankelijk moeten zijn van andere replica's. Dit model zorgt voor betere prestaties, schaalbaarheid en betrouwbaarheid.
Netwerken en verkeersbeheer
- Vanity-domeinen zijn vereist voor regionale beschikbaarheid; ze fungeren als een globaal DNS voor alle inkomende controllers in verschillende regio's.
- Een globale load balancer routeert verkeer tussen de privéruimten in de primaire regio en de regio DR. Klanten bieden deze component; gebruik AWS Route 53 of een globaal CDN met routeringsbeleid om verkeer door regio's te routeren.
- Configureer Ingress-controllers in zowel primaire als DR-regio's met een aangepast vanity-domein.
- Plan en onderhoud firewallregels en VPN-tunneling zodat on-premises toepassingen toegankelijk zijn vanuit zowel de primaire als de DR-regio.
- TLS-certificaatonderhoud moet privéruimten in zowel primaire als DR-regio's dekken voor naadloos herstel.
Implementatie en configuratie van toepassingen
- Toepassingsnamen moeten uniek zijn voor alle regio's. Zo kan een CI/CD-pijplijn de regionaam (of een regiocode) vóór implementatie toevoegen aan toepassingsnamen om de uniciteit tussen primaire en DR-regio's te behouden.
- Configureer de CI/CD-pijplijn om toepassingen te implementeren naar zowel de primaire regio als de DR-regio, zodat alle toepassingen beschikbaar zijn in beide regio's.
Infrastructuur en capaciteit
Prestaties zijn het best wanneer alle infrastructuuraspecten identieke capaciteit hebben voor de primaire regio en de regio DR. Prestaties verslechteren wanneer deze infrastructuuraspecten niet identiek zijn.
Gegevenscontinuïteit en -opslag
- Persistentieopslag moet periodiek worden gesynchroniseerd tussen de twee regio's. Klanten zijn verantwoordelijk voor opslagreplicatie; MuleSoft biedt deze niet. Eén gedeelde opslag tussen VPC's in de primaire regio en de DR-regio is mogelijk, maar de gedeelde opslag moet hoog beschikbaar zijn, anders wordt het één punt van mislukking voor beide regio's.
- Object Store V2 is regionaal en is alleen beschikbaar in de regio waar de Mule-toepassing voor het eerst is geïmplementeerd. Als de toepassing naar een andere regio wordt verplaatst, blijft Object Store V2 in de oorspronkelijke regio om gegevensverlies te voorkomen. Gebruik andere persistente opslag voor DR-strategieën voor meerdere regio's.
Test- en operationele procedures
Keur een formele DR-teststrategie goed en voer periodieke DR-boringen uit. Gebruik voor actief-actief DR een strategie voor de implementatie van Kanarie om beide regio's te valideren.
Prestatie- en serviceniveau-overeenkomsten (SLA's)
Er kan sprake zijn van een zekere achteruitgang van de prestaties omdat de DR-regio zich mogelijk verder van eindgebruikers of back-endsystemen bevindt dan de primaire regio. Definieer en communiceer een DR SLA aan belanghebbenden.
Werking van herstelmodus (contextuele opmerking)
In de actief-actieve modus verloopt de failover van de primaire regio naar de privéruimte van de DR-regio snel: de globale loadbalancer detecteert dat de primaire regio ongezond is en routeert verkeer naar de gezonde regio (DR). In de actief-passieve modus moet u de toepassing implementeren naar de privéruimte van de DR-regio wanneer zich een ramp voordoet.
Er zijn 3 opties om een hogere beschikbaarheid van DR-niveaus te bereiken:
Een actief-actieve set-up is gebaseerd op actieve medewerkers die zijn verdeeld over regio's, waarbij een External Load Balancer wordt gebruikt om verkeer tussen de twee exemplaren te routeren.
Warme standby-configuratie
Een actief-passieve opstelling zou gebaseerd zijn op een actieve medewerker in de ene regio en een passieve medewerker in een andere regio. De passieve regio zou worden gestart wanneer dat nodig is.
Bepaalde elementen van de passieve regio moeten actief blijven voor failover of vooraf worden ingesteld, inclusief privéruimten, VPN's en bijlagen bij de transitgateway.
Zoals hierboven worden replica's en Ingress-controllers bij failover geleverd in een tweede regio via een volledig geautomatiseerd DevOps-proces. Sommige elementen van de passieve regio moeten actief blijven voor failover, inclusief privéruimten, VPN's en Transit Gateway-bijlagen.
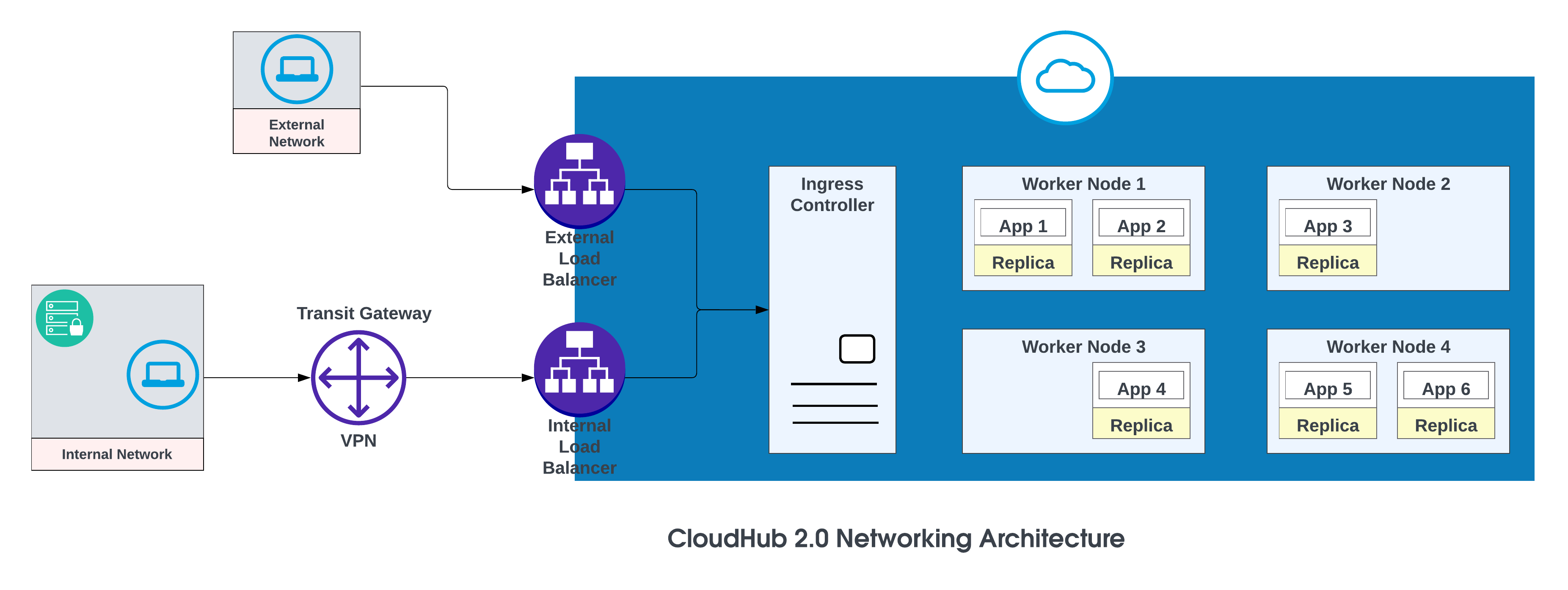
De basiscomponenten van de CloudHub 2.0-netwerkarchitectuur zijn:
- Een HTTP-loadbalancer
- Mule replica DNS-records
- Privéruimten
- Regionale diensten
Zie CloudHub 2.0-netwerkarchitectuur voor meer informatie.
Vanity-domeinen
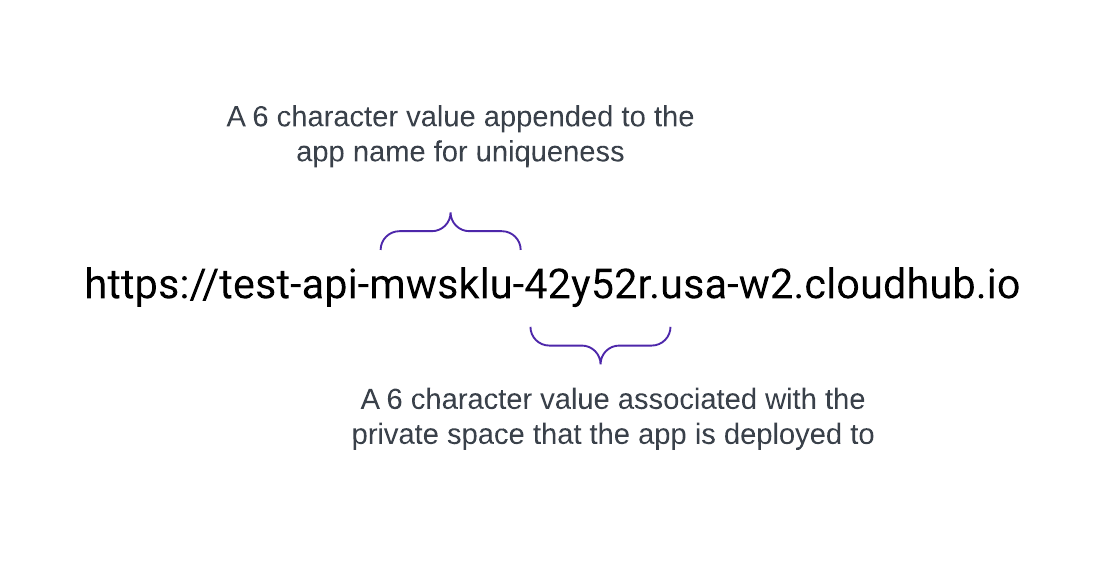
Wanneer een Privéruimte wordt gemaakt, ontvangt deze een DNS-doelnaam in de indeling: <space-id>.<region>.cloudhub.io . Bij implementatie van een app met de naam test-api in die privéruimte volgt het eindpunt ervan deze indeling:
CloudHub 2.0 ondersteunt ook aangepaste domeinen, of ijdelheidsdomeinen, door ze binnen een privéruimte te configureren met behulp van TLS-contexten en DNS-records. Als u een TLS-context wilt maken in Runtime Manager voor een privéruimte, uploadt u het openbare certificaat en de privésleutel en voegt u vervolgens een aangepast eindpunt toe in de instellingen van uw toepassing om dat domein te gebruiken. Maak een DNS-record (zoals een CNAME) die uw vanitydomein laat verwijzen naar de standaardhostnaam van uw privéruimte.
Zo heeft een toepassing met de naam test-api die is geïmplementeerd in us-west-2 met het standaard DNS 42y52r.usa-w2.cloudhub.io een API-eindpunt van:
https://test-api-mwsklu-42y52r.usa-w2.cloudhub.io
Deze URL gebruikt geen vanity of aangepast domein. Volg deze stappen om acme.com te gebruiken zodat API-URL's worden weergegeven als https://test-api.acme.com.
- Maak TLS-context in Runtime Manager met openbare en persoonlijke sleutels.
- Voeg een vanitydomein toe in de instellingen van de toepassing om dat domein te gebruiken.
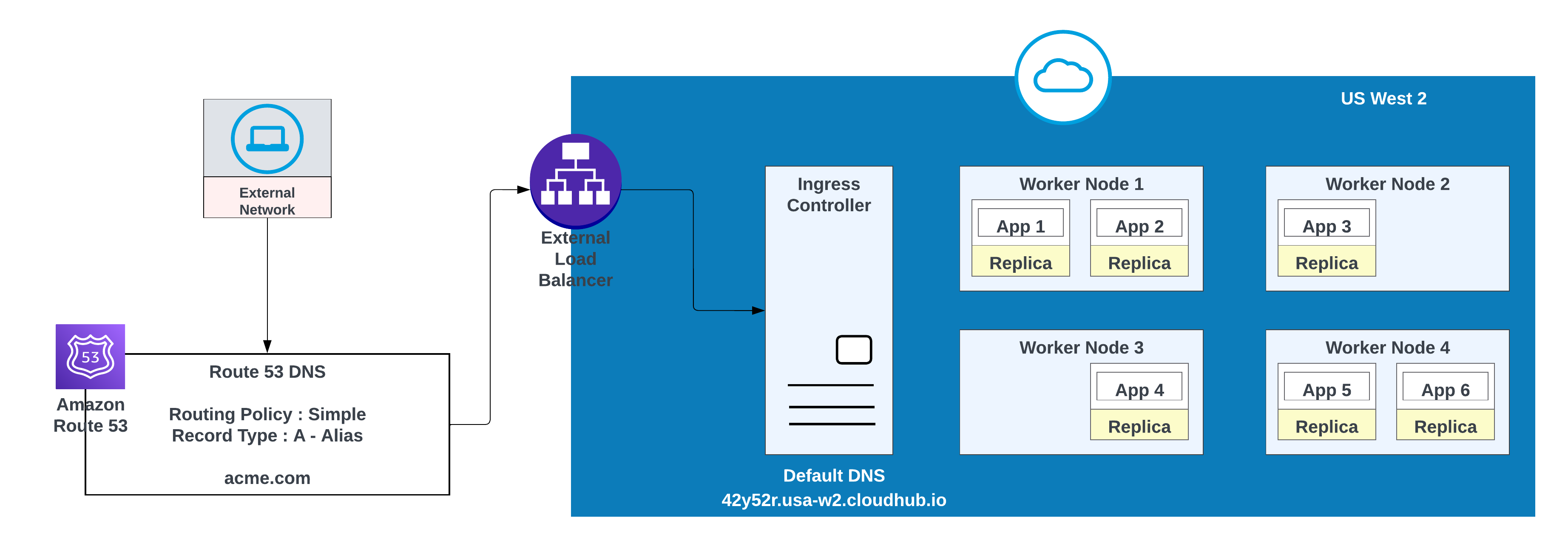
- Maak een DNS-record in AWS Route 53 en configureer een eenvoudig routeringsbeleid (bijvoorbeeld CNAME) zodat het vanitydomein wordt omgezet naar de standaardhostnaam van de privéruimte.
Voor aangepaste domeinen kunt u AWS Route 53 of andere globale CDN-services met routeringsbeleid gebruiken. In het onderstaande diagram wordt AWS Route 53 gebruikt met een "eenvoudig" routeringsbeleid. Wanneer een consument uit een openbaar (extern) netwerk acme.com aanvraagt, routeert AWS Route 53 de aanvraag naar de MuleSoft-controller voor het binnendringen van privéruimte.
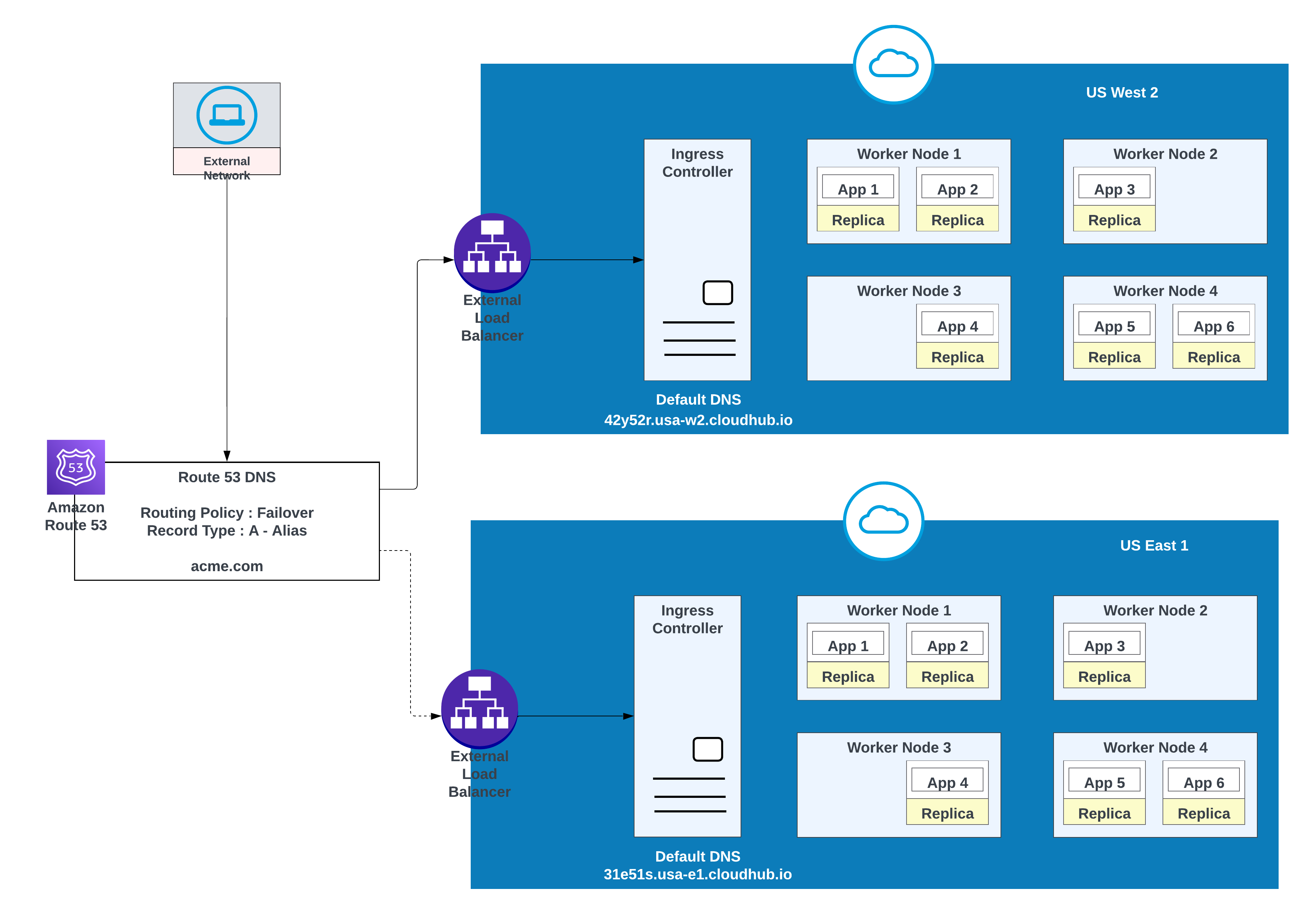
Gebruik deze optie wanneer toepassingen failover vereisen: implementeer een exemplaar in de primaire regio (bijvoorbeeld us-west-2) en een ander in een secundaire regio (bijvoorbeeld us-east-1).
Gebruik indien mogelijk een bestaande omgeving in de secundaire regio; het maken van een nieuwe omgeving vereist extra inspanning.
Voorbeeld van apps die zijn geïmplementeerd in de ene regio (US West 2) met een failover naar een andere regio (US East 1)
| Recordnaam | Waarde/verkeer routeren naar | Routeringsbeleid | ID van toestandscontrole |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Failover | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Failover | 43e131s131sq |
In deze configuratie routeert AWS Route 53 verkeer naar de inkomende controllers voor de privéruimten in US West 2 en US East 1. Een beleid voor failoverroutering wordt geconfigureerd met een toestandcontrole.
Gebruik voor een lagere latentie en een hoge beschikbaarheid de implementatiestrategie die in het diagram wordt beschreven. Met deze strategie kunnen apps worden geïmplementeerd in twee regio's (us-west-2 en us-east-1 in dit voorbeeld).
Gebruik het routeringsbeleid voor latentie in AWS Route 53 om aanvragen te routeren naar de regio met de laagste latentie en toch een hoge beschikbaarheid te behouden.
Apps geïmplementeerd in beide regio's (US West 2 en US East 1) voor een lagere latentie en hoge beschikbaarheid
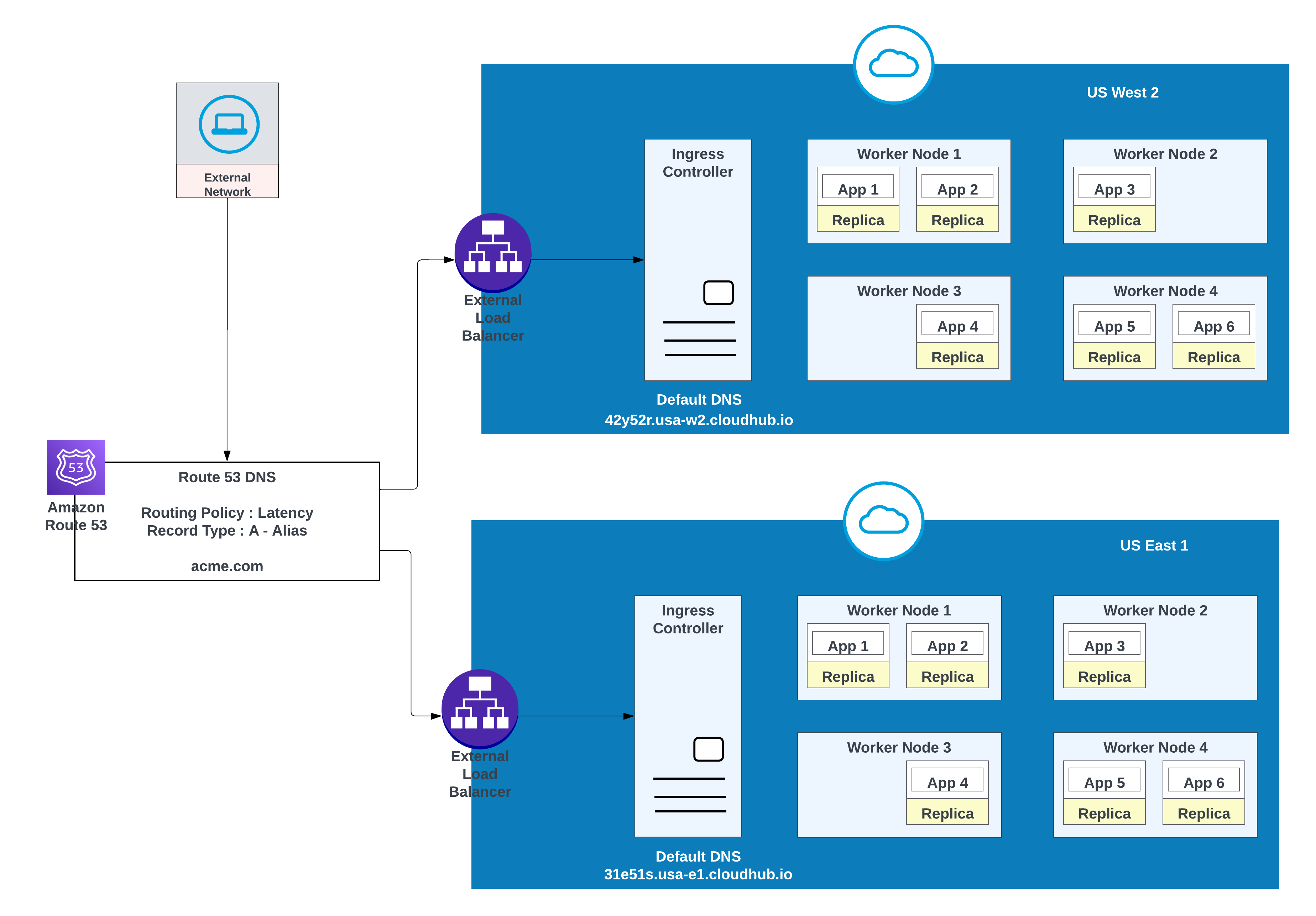
| Recordnaam | Waarde/verkeer routeren naar | Routeringsbeleid | ID van toestandscontrole |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Latentie | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Latentie | 43e131s131sq |
MuleSoft CloudHub 2.0 biedt een robuuste basis voor veerkracht binnen de regio, waarbij voornamelijk gebruik wordt gemaakt van geautomatiseerde replicaredundantie en intelligente taakverdeling. Binnen één cloudregio zorgt het implementeren van toepassingen met meerdere replica's ervoor dat als één exemplaar mislukt, anderen onmiddellijk de werklast kunnen overnemen. De geïntegreerde loadbalancer verdeelt inkomend verkeer efficiënt over deze gezonde replica's, minimaliseert downtime en garandeert continue servicebeschikbaarheid onder normale bedrijfsomstandigheden.
Het uitsluitend vertrouwen op deze architectuur van één regio, zelfs met een hoge redundantie, vormt echter een aanzienlijk risico op een wijdverspreide, catastrofale regionale uitval. De geschiedenis heeft aangetoond dat zelfs de meest betrouwbare en technologisch geavanceerde cloudproviders gevoelig zijn voor verstorende incidenten die een hele geografische regio kunnen treffen. Deze enkelvoudige foutpunten, hoewel zeldzaam, kunnen ontstaan door verschillende gebeurtenissen, waaronder:
- Grootschalige infrastructuurincidenten
- Grote stroomstoringen
- Wijdverspreide netwerkonderbrekingen
Om echt hoge beschikbaarheid (HA) en disaster recovery (DR) te bereiken, moet een architectuur daarom worden ontworpen om de beperkingen van een model met één regio te overstijgen. De aanbevolen strategie is implementatie in meerdere, geografisch onderscheiden regio's. Deze veerkracht tussen regio's zorgt ervoor dat als een hele cloudregio onbeschikbaar wordt vanwege een onverwachte ramp, verkeer naadloos kan worden overgezet naar een toepassingsexemplaar dat in een afzonderlijke, niet-beïnvloede regio wordt uitgevoerd, wat een minimale serviceonderbreking garandeert en maximale uptimedoelen bereikt.
CloudHub 2.0-netwerkarchitectuur
Failover tussen regio's configureren voor standaardwachtrijen
Object Store V2-implementatieregio's
Uw Object Store-implementatieregio
Gulal Kumar is Software Engineering Architect bij Salesforce, met een focus op data- en integratiearchitectuur. Met meer dan 20 jaar ervaring in integratie en API's, moderniseringsprogramma's, beveiliging en AIML-initiatieven brengt hij een schat aan expertise met zich mee. Gulal zet zich in voor het bevorderen van bedrijfstransformatie-initiatieven, het verbeteren van beveiliging en veerkracht, het bevorderen van architectuurexcellentie en het leiden van AIML-initiatieven binnen verschillende domeinen.
Ajay Nagaraju is Enterprise Architect en Senior Director bij MuleSoft met meer dan 28 jaar ervaring in enterprise architectuur, systeemintegratie en grootschalige digitale transformatie. Hij heeft architectuur en levering geleid voor complexe programma's van meerdere miljoenen dollars in Fortune 100- en Fortune 500-organisaties, met diepgaande expertise in API-geleide connectiviteit, SOA, cloudtechnologieën en integratiepatronen voor de onderneming. Ajay heeft nauw samengewerkt met leidinggevenden om bedrijfsprocessen, gegevensplatforms en integratie-ecosystemen te moderniseren en heeft een passie voor het bouwen van schaalbare architecturen, het begeleiden van teams en het stimuleren van meetbare bedrijfsresultaten door middel van technologie.