Moderne Salesforce-architecturen worden steeds meer aangedreven door asynchrone verwerking; niet als gemak, maar als strategische vereiste voor schaalbaarheid. In de afgelopen jaren hebben we steeds meer bedrijven zien kampen met toenemende gegevensvolumes, complexe integraties met meerdere aanspreekpunten en de opkomst van autonome systemen die 24/7/365 draaien. Al deze zaken duwen architecten in de richting van het ontwerpen van systemen die asynchroon-eerst zijn.
Asynchrone verwerking in Salesforce betekent vaak dat er moet worden ontworpen rond beheerlimieten en complexiteit. Die limieten fungeren als vangrails en architectonische beperkingen die helpen bulkveilige, schaalbare systemen te produceren. Hoewel er geen platformlimieten zijn die rechtstreeks dienen om complexiteit te beheren, kunnen ontwerppatronen helpen om risico's op dat front te beperken. Intern verlegt Salesforce vaak de grenzen van het platform om nieuwe voorzieningen vooruit te testen en complexe bedrijfsprocessen te automatiseren. We hebben een op stappen gebaseerd framework voor asynchrone verwerking samengesteld voor het uitvoeren van asynchrone taken met een willekeurig aantal stappen. Elke stap kan onafhankelijk worden uitgevoerd, opnieuw worden geprobeerd en opnieuw worden gestart met gedeelde governance-besturingselementen en volledige operationele zichtbaarheid via gecentraliseerd vastleggen. Dit document geeft een overzicht van de belangrijkste architectonische componenten: Apex en Finalizers die in de wachtrij kunnen worden geplaatst, Geplande stroom, Apex Cursors, Aanroepbare acties en integraties met Slack. Samen bieden deze componenten een modulaire, schaalbare en waarneembare architectuur die geschikt is voor veranderende bedrijfsbehoeften.
- Moderne Salesforce-architecturen moeten een asynchrone benadering hanteren om schaalbaarheid, veerkracht en operationele transparantie te bereiken.
- Complex werk verdelen in onafhankelijk uitvoerbare stappen maakt voorspelbare prestaties, veiligere pogingen, controlepunten, terugdraaien en modulaire evolutie mogelijk zonder kernwerkstromen opnieuw te ontwerpen.
- Het framework biedt een schaalbaar alternatief voor monolithische en verouderde batchtaken, geketende asynchrone aanroepen en diep geneste stromen, en is ontwikkeld voor workloads met groot volume die horizontaal moeten worden geschaald binnen Salesforce zonder doeltreffende combinaties buiten het platform.
- Deterministische en waarneembare uitvoering garandeert voortgangsregistratie, SLA-bewaking, foutdiagnostiek en transparantie op auditniveau door middel van gecentraliseerd vastleggen en governance.
- Ontworpen voor ondernemingskwaliteit, inclusief gecombineerd bestuur, naleving en gedistribueerde staatscontrole voor langlopende bedrijfsprocessen.
Voordat u de vereisten doorneemt, zijn hier enkele do's en don'ts voor wanneer u een framework als dit moet gebruiken. Denk vooral na over welk systeem de enige bron van waarheid is. Als uw Salesforce-organisatie minimaal afhankelijk is van externe gegevens, maar moet schalen van honderden naar miljoenen records, kunt u een op stappen gebaseerd asynchroon raamwerk overwegen.
Gebruik dit framework wel als:
- De meeste (of alle) informatie waarop moet worden gehandeld, komt al voor in uw CRM.
- De voorafgaande of doorlopende kosten voor het onderhouden van een taak Extract Transform Load (ETL) voor het harmoniseren van externe gegevens zijn te hoog.
- U moet de verwerking van een groot aantal Salesforce-records volgens een vaste planning uitstellen.
- U kunt de verwerking opsplitsen in afzonderlijke stappen. Zo kunt u een hiërarchische of op een structuur gebaseerde set records maken, met name als het gegevensvolume de hiërarchie of structuur verbreedt.
Gebruik dit framework niet als:
- Records maken of bijwerken vereist onmiddellijke herberekening.
- Integratie is een uitdaging omdat externe systemen primaire gegevens hosten voor recordupdates. (Overweeg bijgewerkte gegevens naar Salesforce te pushen met de Bulk-API.)
Laten we met deze praktijken in gedachten onze vereisten bekijken en beginnen met samenstellen.
Denk aan de probleemstelling:
Voor een taak die dagelijks moet worden uitgevoerd, controleert u of bepaalde records voldoen aan vooraf vastgestelde criteria voor verdere verwerking. Als ze dat doen, start u die verwerkingstaken. Het verwerken van records kan inhouden dat u gegevens ophaalt uit meerdere externe systemen om berekeningen uit te voeren. Stappen in taken moeten mensen via Slack informeren dat verwerkte records gereed zijn voor beoordeling. Stappen moeten ook kennisgevingen aan managers en hogere posities in de rollenhiërarchie escaleren op basis van een configureerbare vertraging na de eerste ronde kennisgevingen.
Dit probleem omvat verschillende stappen, waarvan sommige onafhankelijk van elkaar kunnen plaatsvinden. Er zijn vele manieren om het werk te verdelen. Hier is één groepering:
- De planner.
- De stappeninterface en concrete implementaties die records verwerken (ongeacht het type verwerking).
- De processor die stappen organiseert.
- De Apex Invocable die wordt aangeroepen door de planner.
- Het stuk kennisgeving. We gebruiken de Apex Slack SDK.
- Er zit wat complexiteit verborgen in de zinsnede "configureerbare vertraging". We zullen deze complexiteit later in dit artikel bekijken.
Hier is een eigen diagram voor het samengestelde framework:
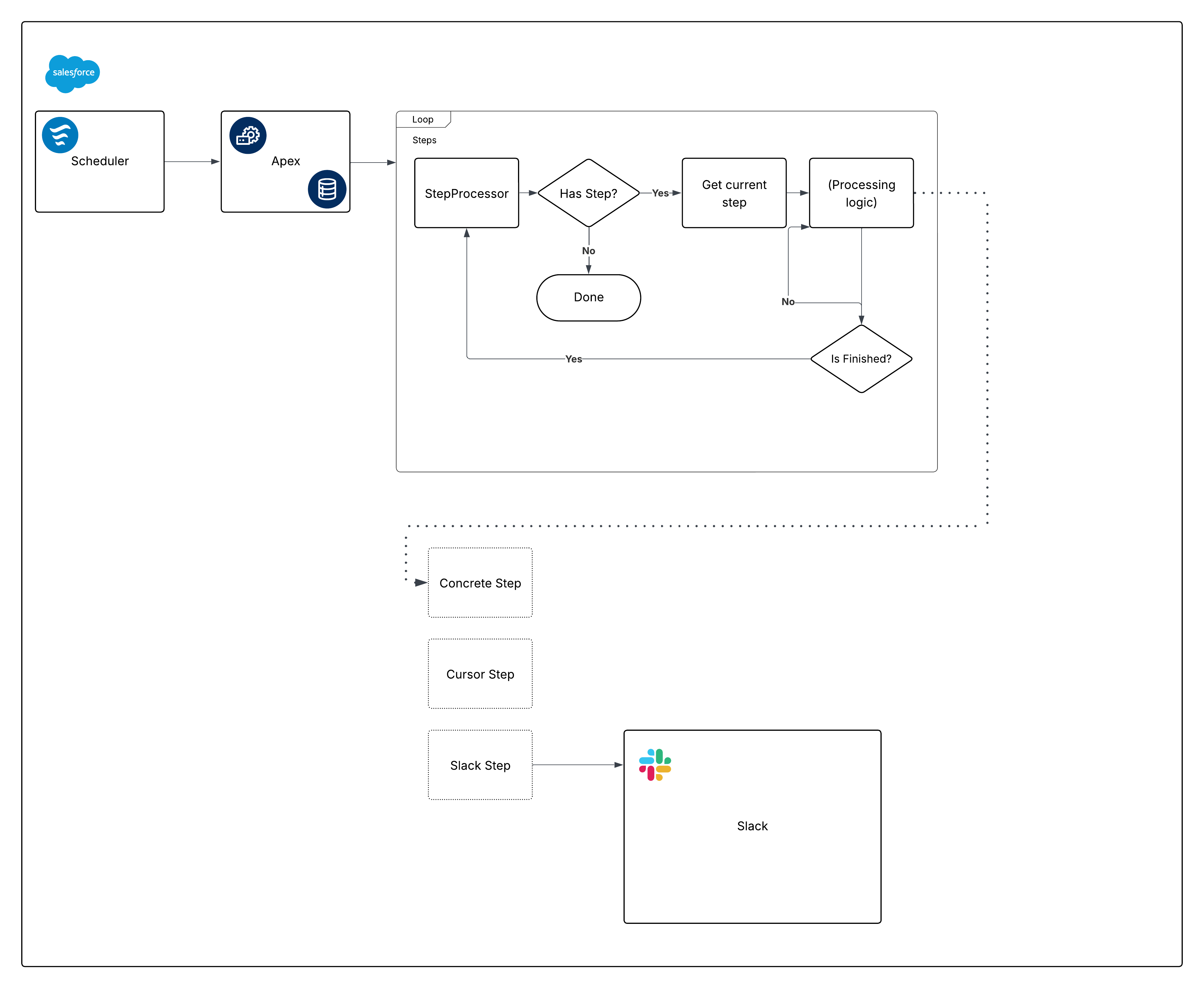 Breek dat diagram af en begin met het samenstellen van de stukken.
Breek dat diagram af en begin met het samenstellen van de stukken.
Geplande stroom biedt diverse voordelen als planningsmechanisme:
- Geplande stromen kunnen in een pakket worden opgenomen en geïmplementeerd als metagegevens. Dit geldt niet voor taken die zijn gepland via Apex (of via de pagina Geplande taken).
- Het element Wachten is essentieel voor frameworks die aanroepen vereisen. Door het te gebruiken in Flow zijn aanroepen niet nodig in het Aanroepbare gedeelte van het framework.
- De fijnkorreligheid van de planning voldoet aan de vereisten: het minimale interval voor geplande stromen is dagelijks. Als u een hogere frequentie nodig hebt (bijvoorbeeld elk uur), overweeg dan Geplande stroom voor deze vereiste.
Een andere overweging bij het configureren van de geplande stroom is Omgevingsgating. Voeg voordat u de Apex actie aanroept, een element Decision toe dat de {!$Api.Enterprise_Server_URL_100} evalueert. Hierdoor wordt de taak alleen uitgevoerd in de beoogde omgevingen, zoals UAT en Production. Dit patroon is belangrijk omdat sandboxen vaak worden vernieuwd of nieuw worden gemaakt tijdens de SDLC, en zonder een expliciete omgevingscontrole kan een geplande stroom onbedoeld worden uitgevoerd in omgevingen waarin het framework niet bedoeld is om te worden uitgevoerd. Het gebruik van de operator contains in het element Beslissing maakt de set-up bestand tegen toekomstige sandboxcreaties of URL-wijzigingen.
Denk ten slotte na over de manier waarop het framework mislukkingen moet opvangen. Voeg altijd een defectenpad toe wanneer Stroom een actie aanroept. Zo kunt u fouten overzetten naar de actie "Logboekinvoer toevoegen". Nebula Logger schrijft logboeken naar aangepaste objecten, dus klanten moeten zich ervan bewust zijn dat logboekgegevens organisatieopslag verbruiken. Standaard worden logboeken 14 dagen binnen een organisatie opgeslagen en vervolgens opgeschoond; deze bewaarperiode kan worden geconfigureerd. Nebula Logger gebruikt ook Platform Events voor het publiceren van logboeken, waardoor logboekvermeldingen onafhankelijk van de hoofdgegevensverwerkingstransactie worden opgeslagen — dit zorgt ervoor dat fouten worden vastgelegd, zelfs als de primaire stroom of Apex actie wordt teruggedraaid. Klanten moeten het verwachte logboekvolume en de bewaarvereisten evalueren wanneer ze overwegen een framework voor vastleggen toe te voegen.
Zo ziet de stroom eruit:
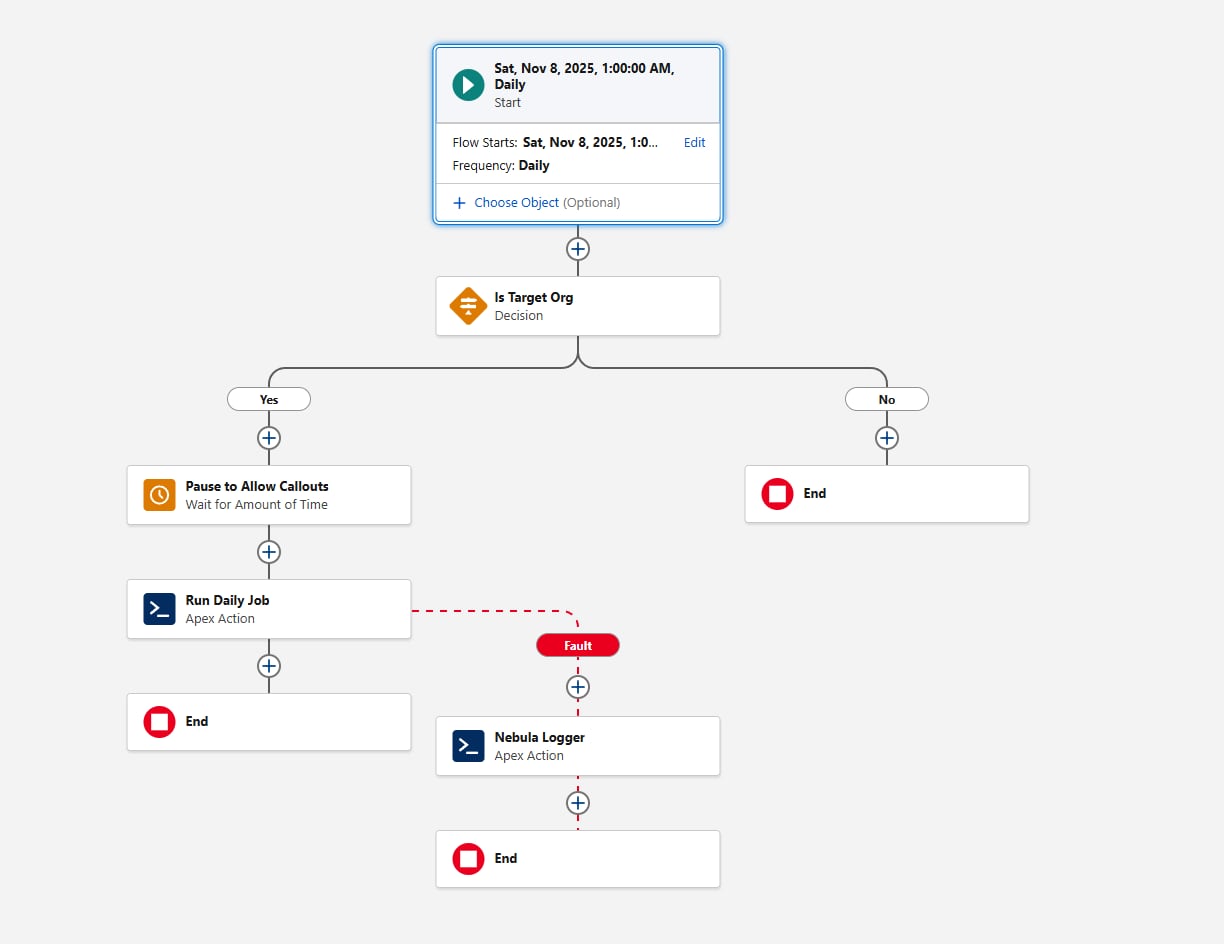
Laten we verder gaan met de eerste stukjes Apex code, nu aan de planningsvereiste is voldaan.
Een Step definiëren:
Voor dit artikel wordt de step weergegeven als een buitenste klasse voor de duidelijkheid. Het framework zelf is flexibel: teams kunnen de interface en de implementaties ervan organiseren met behulp van elk Apex pakketpatroon van hun voorkeur, zolang alle Stap-klassen naar dezelfde interface verwijzen.
Er zijn enkele dingen om op te letten over de methoden die zijn gedefinieerd binnen onze interface:
execute, hoewel op dit moment zonder argumenten, verbetert wanneer we eenState(of interface) doorlopen om gegevens tussen stappen te ordenen wanneer de volgorde belangrijk is.getNamekan eenSystem.Typeretourneren in plaats van eenString. Het doel is om de doeltreffende laag een manier te bieden om stapnamen vast te leggen zonder andere eigenschappen zichtbaar te maken.
Hier is de eerste concrete implementatie die laat zien hoe deze onderdelen in elkaar passen. Op één uitzondering na, raden we aan om Apex Wachtrij te gebruiken om asynchrone verwerking binnen Apex te implementeren; Batch Apex is meestal onnodig (en @future wordt afgeraden). Apex start snel en heeft met Apex Cursors veel voordelen ten opzichte van Batch Apex.
Apex Cursors bieden een modern alternatief voor het traditionele Batch Apex model. Net als bij batchverwerking kan een Cursor-implementatie records in blokken ophalen (maximaal 2000 per batch). Cursors staan echter meerdere ophaalbewerkingen binnen één transactie toe, waardoor een aanzienlijk hogere doorvoercapaciteit mogelijk is voor bewerkingen met groot volume.
Wanneer teams Cursors gebruiken als onderdeel van dit framework, moeten ze zich bewust zijn van de huidige beperkingen voor testen en schijnbaarheid. De werking van de cursor in tests kan verschillen van de werking van de productie. Het is daarom belangrijk om teststrategieën te ontwerpen die voorkomen dat u vertrouwt op interne cursors en in plaats daarvan doeltreffende combinatielogica valideren aan de grenzen. Naarmate het platform zich ontwikkelt, zullen deze gebieden blijven verbeteren, maar de kernrichtlijnen blijven: Cursors bieden betere prestaties en verminderde doeltreffende combinatie-overhead in vergelijking met Batch Apex voor veel gebruikscases.
Als u een duidelijke grens wilt definiëren tussen de door het systeem geleverde cursor en uw eigen code, wordt aangeraden om een cursorachtige weergave te maken bij het implementeren van de Step. Denk aan deze code:
Let op de Cursor. Apex cursors zijn gevallen van Database.Cursor, maar onze Cursor implementatie geeft ons flexibiliteit rond de tekortkomingen van Cursors. Dit is de implementatie:
Voor de rest van dit artikel laten we de sharing weg wanneer we verwijzen naar Apex klassen. Zorg er in de praktijk voor dat klassen op het hoogste niveau expliciet met of zonder delen worden gebruikt om te voldoen aan uw objectmodel en machtigingen.
Merk ook op dat onze Cursor implementatie wordt gedelegeerd naar de Platform Database.Cursor, met extra voordelen die hierna worden besproken.
Eerst zijn hier de corresponderende tests:
Door Cursor virtueel te maken kunnen concrete CursorStep zonder Database.Cursor werken wanneer ze geen grote recordset hoeven te herhalen — vergelijkbaar met het retourneren van een System.Iterable<T> in plaats van een Database.QueryLocator in Batch Apex. Hier is een voorbeeld:
Omdat deze klasse ook abstract is, wordt de concrete implementatie van innerExecute overgelaten aan subklassen.
Er is ook een alternatief voor de binnenste subklasse van CursorLike. Als u weet dat concrete versies van een stap als deze niet door andere beheerlimieten heen zullen branden, kunt u this.records uit CursorLike.fetch retourneren en de bovenliggende CursorStep.shouldRestart() overschrijven om false (onwaar) te retourneren. Hierdoor kunt u herhalen over een lijst die alleen wordt begrensd door de Apex heaplimiet van 12 MB per asynchrone transactie.
Onze op cursors gebaseerde implementatie biedt ons veel flexibiliteit bij het pagineren van grote hoeveelheden gegevens. De Step interface biedt ons ondertussen de flexibiliteit om allerlei stappen te beschrijven en in te kapselen.
Overweeg een op stroom gebaseerde stap:
Omdat stromen geen uitvoerparameters kunnen retourneren die voldoen aan een door Apex gedefinieerd type, controleren we op een shouldRestart uitvoerparameter voordat we deze gebruiken.
Sommige stappen zijn mogelijk gemarkeerd met voorzieningen. U kunt logica implementeren om te bepalen welke stappen moeten worden opgenomen, of een no-op-stap gebruiken voor een uitgeschakelde voorziening. Het null-objectpatroon is een veelgebruikte manier om complexiteit binnen de doeltreffende combinatielaag te verminderen:
We hebben nu een flink aantal bouwstenen om mee te werken. Laten we eens kijken naar de doeltreffende laag die verantwoordelijk is voor het herhalen van stappen.
De processor is een omleidingspunt in de architectuur. We moeten beslissen wie bepaalt welke stappen worden geïnitialiseerd en waar. Opties omvatten:
- Laat de processor definiëren welke stappen worden toegewezen aan bedrijfslogica. Deze optie is eenvoudig, maar wordt slecht geschaald voor de leesbaarheid.
- Definieer de toewijzing met aangepaste metagegevens (CMDT). Velden voor Metagegevensrelatie ondersteunen geen
ApexClass, waardoor de spelling van klassennamen losjes wordt gekoppeld aan de set-up van uw bedrijfsproces. U kunt het risico voor beheerders verkleinen door van het veld een keuzelijst te maken en het type te valideren (Type.forName()of door een query uit te voeren opApexClass), maar omdat CMDT-records geen triggers ondersteunen, vindt de validatie plaats tijdens run-time. Deze route is testbaar, maar beheerders kunnen nog steeds CMDT-records alleen in productie maken — ga voorzichtig te werk. - Definieer de toewijzing met records. Niet-beheerders kunnen stappen configureren, maar implementaties worden moeilijker en omgevingen kunnen afwijken. Wees voorzichtig.
Er is een beroemde quote van Clean Code over hoe om te gaan met dit specifieke stukje complexiteit:
De oplossing voor dit probleem is het begraven van de
switch[voor het maken van objecten] in de kelder van een abstracte fabriek, en het nooit aan iemand laten zien.
Met dat in gedachten, en omdat ons huidige aantal stappen duidelijk is gedefinieerd en waarschijnlijk niet te groot wordt, is het oké dat de stappenprocessor ook de fabriek voor stappen is. Dit kan een enum gebruiken om de overschakelinstructie aan te sturen:
En dan voor onze StepProcessor:
De getoonde fabrieksmethoden, zoals addTypeOneSteps(), kunnen problemen delegeren zoals signaleren van voorzieningen; cleanSteps() voert een eenmalige controle uit op de verzamelde stappen om ervoor te zorgen dat er geen "lege" stappen zijn voordat ze echt asynchroon gaan. Dat ziet er dan als volgt uit:
We hebben de foutafhandeling niet besproken sinds de vermelding van Nebula Logger in de sectie Geplande stroom. Dat komt omdat System.Finalizer ons in staat stelt om het vastleggen van alle foutcondities volledig te dekken zonder specifieke foutafhandeling in elke stap toe te voegen. Elke Step richt zich op hardlopen, terwijl we eventuele ongelukkige paden vastleggen en opnieuw gooien, zodat ze zichtbaar worden in eenheidstests. Dit ondersteunt veilige herhaling en waarschuwing op productieniveau (met behulp van de Slack Logger-invoegtoepassing voor Nebula voor alle WARN- en ERROR-logboeken).
Eén opmerking over het vastleggen van fouten: het doorgeven van het stappenexemplaar aan logboekberichten veronderstelt een niveau van Trust in wat zichtbaar wordt in logboeken. De standaard toString() voor Apex klassen omvat alle statische eigenschappen en eigenschappen op instantieniveau in het bericht. Dat kan wenselijk zijn of gevoelige informatie lekken. Hoewel vastleggen en beveiliging hier niet de focus zijn, moet u er rekening mee houden dat voor sommige systemen het volgen van een interface zoals Step ook kan inhouden dat een overschrijving voor toString() wordt afgedwongen.
Een dergelijke methode legt de verantwoordelijkheid op elke maker van het object om te beslissen wat toegestaan is om af te drukken, wat wenselijk kan zijn.
Op vastleggingsniveaus: op StepProcessor gebruiken we INFO, het hoogste niet-foutniveau. Naarmate u fijnmaziger wordt binnen de toepassing, moet het vastleggen van niveaus dienovereenkomstig afnemen. Afzonderlijke stappen kunnen DEBUG gebruiken voor informatie op hoog niveau, met FINE, FINER en FINEST die zijn gereserveerd voor steeds gedetailleerdere uitvoer. Vastleggen is evenzeer een kunst als een wetenschap, maar het volgen van deze principes helpt logboeken consistent en nuttig te houden.
Laten we voordat we verder gaan kort nadenken over de beslissing om onze stappenprocessor de logica te laten hosten waarvoor stappen worden gebruikt. Overweeg in een grote codebasis om StepProcessor virtueel of abstract te maken en subklassen specifieke stappen te laten identificeren om een juiste scheiding van zorgen tot stand te brengen.
De planner roept uiteindelijk Apex aan. Met de rest van de set-up voltooid, kan de Aanroepbare Apex sectie beslissen welke stappen moeten worden uitgevoerd en de List<StepType> doorgeven aan de processor:
Dit is een eenvoudig deel van de vergelijking: records, gegevens of logica gebruiken om te bepalen welke staptypen moeten worden uitgevoerd. De aanroepbare actie is eenvoudig omdat we complexiteit elders hebben ingekapseld. We hebben ook beschermd tegen onverwachte uitzonderingen en hebben het testen van elk onderdeel eenvoudig gemaakt.
De Apex Slack SDK valt buiten het bereik van dit artikel, maar één potentieel knelpunt van de vereisten moet opnieuw worden bekeken: mensen hoger in de rollenhiërarchie informeren op basis van een configureerbare vertraging. Op papier is dit eenvoudig en kunt u (correct) System.enqueueJob(this) in de StepProcessor overwegen. Met System.AsyncOptions waren we aanvankelijk geneigd om de enqueueJob te gebruiken om aan deze vereiste te voldoen.
Voorlopig is de maximale vertraging via System.AsyncOptions.MinimumQueueableDelayInMinutes echter 10 minuten. Omdat de vereiste 120 minuten is, blijven er enkele opties over. Een naïeve benadering zou er als volgt kunnen uitzien:
In de praktijk zou de vertraging worden doorgegeven aan deze klasse, omdat de vertraging configuratiegestuurd is.
We raden deze benadering niet aan, tenzij u er zeker van bent dat er ooit slechts één type vertraagde kennisgeving zal zijn. Het brandt door 11 extra asynchrone taken voordat het start (of meer, als de vertraging toeneemt). Die kosten zijn misschien prima voor één taak, niet voor velen. U moet ook een methode toevoegen aan de Step zodat elke stap de processor kan vertellen hoe lang deze moet wachten voordat de processor opnieuw wordt gestart, wat ruis toevoegt.
Dan blijven er twee interessante mogelijkheden over:
- U kunt de vertraagde stap opnemen in uw bestaande taakframework als u al een pollingtaak hebt gepland met een geschikt interval. U moet ook akkoord gaan met de opgegeven vertraging tot 15 minuten later (15 minuten is het minimale vernieuwingsinterval voor een door Apex geplande CRON-expressie). Dit komt grofweg overeen met het Aanroepbare Apex voorbeeld; de planning wordt in plaats daarvan uitgevoerd via Apex. Met andere woorden, u kunt dezelfde op
Stepgebaseerde architectuur hergebruiken om records te verwerken op basis van een "Start After"-tijdstempel en beslissen welke stappen moeten worden gebruikt op basis van een toewijzing van een keuzelijst of keuzelijst met meervoudige selectie terug naar de eerder getoondeStepType. - Als u zich comfortabel voelt met het definiëren van een extra buitenste Apex klasse, kunt u ook terugvallen op Batch Apex (in tegenstelling tot Queue Apex, dat binnenste klassen ondersteunt, moeten Batch Apex klassen buitenste klassen zijn) met behulp van
System.scheduleBatch().
Neem het voorbeeld van Batch Apex. Hoewel we over het algemeen Apex met wachtrij aanbevelen voor flexibiliteit en controle, is dit één geval waarin Batch Apex nog steeds de overhand heeft:
En stel u vervolgens in de StepProcessor voor dat de eerder getoonde addTypeOneSteps() wordt bijgewerkt met deze vertraagde stap:
Hoewel we doorgaans niet zo veel sprongetje voor stapje zouden aanraden, wordt deze stapvertraging een andere herbruikbare bouwsteen. Totdat langere vertragingen zijn toegestaan in Apex met wachtrij, is dit ook de gemakkelijkste manier om dit effect te bereiken (zonder een pollingmechanisme, zoals besproken).
We hebben objectgeoriënteerd ontwerp gebruikt om aan de vereisten te voldoen en een systeem gemaakt dat schaalbaar is en tegelijkertijd de kosten van bouwen en onderhoud op de lange termijn in evenwicht houdt. Hoewel stapverklaringen en instantiëring uiteindelijk hun plaats in StepProcessor kunnen ontgroeien, is er hier weinig extra technische schuld. Met FlowStep kunnen beheerders en ontwikkelaars samen bepalen welke oplossingen zonder code of pro-code het meest zinnig zijn.
Door gebruik te maken van de System.Finalizer interface binnen het Queueable framework van Apex hebben we samen met Nebula Logger een robuust, testbaar systeem gebouwd dat ons waarschuwt voor onvoorziene fouten, zelfs als in toekomstige stappen expliciete vastlegging ontbreekt. Voor ons rekent dit systeem graag cijfers en reduceert het kosten en complexiteit. Het heeft ons ook waardevolle inzichten gegeven in het gedrag van Apex Cursors onder echte werkbelasting, waardoor we onze aanpak kunnen verfijnen en tegelijkertijd de voorziening zelf kunnen verbeteren.
Door complexe werkbelastingen met groot volume te ontleden in modulaire uitvoeringsstappen, transformeert het framework Op stappen gebaseerde asynchrone verwerking platformbeperkingen in technische voordelen, waardoor voorspelbare prestaties, observatie en governance op ondernemingsniveau mogelijk worden. Stappen kunnen worden ingesteld door zowel beheerders als ontwikkelaars, en in beide gevallen kunnen stapauteurs zich veilig richten op het naleven van de basale platformbeheerlimieten (zoals DML-rijen en opgehaalde queryrijen) zonder zich zorgen te hoeven maken over de manier waarop elke stap moet worden geschaald.
Voor het operationaliseren en toepassen van dit patroon binnen implementaties in ondernemingen moeten architecten:
- Evalueer bestaande automatiseringen om gebieden te identificeren waar asynchrone doeltreffende combinatie kan helpen de prestaties te verbeteren en de waarneembaarheid te verbeteren.
- Verdeel grote processen in afzonderlijke, onafhankelijk uitvoerbare stappen met duidelijke verwerkingsdoelen en afzonderlijke auteurspunten (zoals Flow of Apex).
- Definieer en groepeer staptypen om staphergebruik en standaardisering binnen bedrijfseenheden te versnellen.
- Proef de aanpak met nieuwe processen of bestaande automatiseringen. U zult misschien verbaasd zijn om te vinden hoeveel edge cases u gratis vindt binnen enkele stappen, zorg voor uw ingebouwde vastlegging en observatie!
James Simone is een Principal Software Engineer bij Salesforce en heeft meer dan tien jaar ervaring met het werken op het platform. Hij was een Salesforce-klant – en producteigenaar – voordat hij de overstap maakte naar ontwikkeling, en schrijft sinds 2019 technische dieptepunten over Salesforce binnen The Joys Of Apex. Hij heeft eerder artikelen gepubliceerd op de Salesforce Developer-blog en ook op de Salesforce Engineering-blog.