Ondernemingen slaan gegevens vaak op in zowel Salesforce als andere externe gegevens-lakes zoals Snowflake, Google BigQuery, Databricks, Redshift of cloudopslag zoals Amazon S3. Dit onderbrengen van gegevens in verschillende bronsystemen vormt een uitdaging voor bedrijven die de volledige kracht van hun gegevens willen benutten.
Architecten die werken aan het samenbrengen van gegevens binnen meerdere gegevens-lakes, staan voor belangrijke architectonische beslissingen over de beste manier om die gegevens te integreren. Data 360 biedt meerdere opties voor gegevensintegratie, die elk verschillende voor- en nadelen bieden.
Deze handleiding biedt een raamwerk om te evalueren welk patroon het beste past bij uw vereisten voor latentie, kosten, schaalbaarheid, governance en complexiteit bij het integreren van gegevens, en helpt u te kiezen wanneer u gegevensopname, Zero Copy-gegevensbundeling of een hybride benadering gebruikt. De handleiding helpt u ook bij het kiezen tussen verschillende methoden voor gegevensopname en gegevensbundeling, waarbij elke methode een andere behoefte vervult.
Het integreren van externe gegevens-lakehouses met Data 360 vereist een zorgvuldige afweging tussen versheid van gegevens, governance en efficiëntie van de pijplijn. Als u bijvoorbeeld live query's voor gegevensbundeling met nul kopieën gebruikt, wordt de versheid van de gegevens gemaximaliseerd, maar kan de efficiëntie van de pijplijn afnemen naarmate u meer gegevens over het netwerk verplaatst. Daarom is voor de meeste implementaties in de praktijk een combinatie van opname en bundeling binnen een ecosysteem met meerdere clouds het optimale pad. Deze hybride benadering zorgt voor een schaalbare, beheerde, interoperabele architectuur die naadloos ondersteuning biedt voor zowel operationele werkbelastingen met lage latentie zoals real-time personalisatie en fraudedetectie, als analytische werkbelastingen zoals rapportage over regelgeving en historische trendanalyse. Deze beslissingshandleiding helpt u begrijpen hoe u deze nadelen kunt oplossen en de juiste strategie kunt selecteren.
- Gegevensopname: Kopieert gegevens naar Salesforce Data 360, waardoor beheerde, canonieke gegevensmodellen worden gemaakt. Ideaal wanneer u:
- Bouw een uitgebreide Customer 360: Combineer en transformeer verschillende bronnen in één vertrouwd profiel.
- Voldoe aan strikte naleving van regelgeving: Maak een controleerbare, gecentraliseerde kopie waarin gegevenstoegang en herkomst nauwkeurig kunnen worden bepaald.
- Federatie met nul kopiëren: Voert in real-time een query uit op externe bronnen zonder duplicatie, waardoor real-time personalisatie, live dashboards en snelle brononboarding mogelijk zijn. Twee primaire opties met trade-offs die u moet balanceren:
- Live en cachegeheugen (versnelde query): Ideaal voor interactieve analyses en real-time dashboards voor gegevens die zich bevinden op externe gegevensplatforms zoals Snowflake, Google BigQuery, Redshift of Databricks. Voorkomt langzame, kostbare gegevensduplicatie door verwerking naar het bronsysteem te pushen.
- Bestandsbundeling: Ideaal voor grootschalige batchverwerking en training in AI-modellen voor gegevens in uw cloudgegevens-lake (S3, ADLS). Voorkomt dure en langzame opname door rechtstreeks query's uit te voeren op bestanden in open tabelindelingen, waardoor enorme gegevenssets worden ontgrendeld voor ETL- en datawetenschapswerk.
- Hybride model: Combineer opname voor gecombineerde profielen met bundeling voor versheid, ondersteuning van omni-channel betrokkenheid, Agentforce gestuurde acties en AI/ML-training.
-
Hybrid Architecture: Het combineren van gegevensopname en gegevensbundeling is vaak nodig.
- Gebruik Gegevensopname voor kritieke gegevens voor canonieke gegevensmodellen en core governance.
- Bundel alle andere gegevens via Zero Copy om de operationele overhead bij het samenstellen en onderhouden van de opnamegegevenspijplijnen te minimaliseren.
-
Gegevensopnamefrequentie is belangrijk: Kies de frequentie op basis van bedrijfswaarde, latentiebehoeften en operationele complexiteit.
- Realtime gebruiken voor tijdgevoelige werkstromen (personalisatie, live dashboards, Agentforce acties).
- Bijna realtime voor matig urgente processen (campagnes, operationele rapporten).
- Batch voor historische of lagesnelheidsgegevenssets.
-
Het bundelpatroon afstemmen op latentie en prestaties: Kies de optie die het beste past bij uw toegangspatronen en de vereisten voor versheid, prestaties en kosten.
- Gebruik Live Query voor operationele dashboards en real-time personalisatie waar een lage latentie van cruciaal belang is.
- Gebruik Caching (Versnelde query) wanneer query's frequent zijn, maar enigszins verouderde resultaten acceptabel zijn, waardoor prestaties en kosten in evenwicht zijn.
- Gebruik Bestandsbundeling voor grootschalige analyses of batchwerkbelastingen die ideaal zijn voor historische of minder tijdgevoelige gegevenssets.
-
De governance afstemmen op vereisten voor gegevensverblijf:
- Gebruik opname waar gecentraliseerd bestuur cruciaal is.
- Gebruik bundeling waar gedecentraliseerd bestuur acceptabel is, terwijl u strikt bestuur afdwingt bij de externe bron. Zero Copy houdt zich aan beleidsvormen op bronniveau zoals beveiliging op rijniveau (RLS) en gegevensmaskering.
-
Opname prioriteren voor waardevolle werkstromen: Pas opname selectief toe op kritieke processen zoals identiteitsoplossing, wettelijke rapportage en operationele activering.
-
Kosten en complexiteit bepalen de beslissing: Realtime opname kan duur en complex zijn. Architecten moeten de kosten van onboarding, opslag en transformatie van gegevens afwegen tegen de kosten van het rechtstreeks uitvoeren van een query via Zero Copy.
Het kiezen van het juiste integratiepatroon – Gegevensopname, Zero Copy of een hybride benadering – heeft een directe invloed op latentie, governance, operationele efficiëntie en kosten voor meerdere cloudplatforms. Deze beslissing bepaalt hoe real-time insights, AI-gestuurde activering en gepersonaliseerde betrokkenheid betrouwbaar en op schaal kunnen worden geleverd.
Deze tabel biedt een technische vergelijking van patronen voor Gegevensopname en Zero Copy in Salesforce Data 360, waarbij de nadruk ligt op mogelijkheden, nadelen en voordelen, in combinatie met gebruikscases en uitkomsten voor de onderneming. Architecten kunnen dit gebruiken als referentie voor het ontwerpen van hybride gegevensplatforms met meerdere clouds die prestaties, kosten en naleving in balans brengen.
| Patroontype | Modus / tool | Voordelen | Overwegingen | Uitkomsten |
|---|---|---|---|---|
| Gegevensopname | Real-time: opname van subseconden latentie via opname-API's met CDC-ondersteuning. Doorlopende streamingpijplijnen. | - Onmiddellijke insights - Ideaal voor operationele gebruikscases met lage latentie en personalisatie - Ondersteunt eventgestuurde werkstromen |
- Hoge kosten - Complexe architectuur - Vereist bronsystemen met lage latentie - Bronnen met groot volume kunnen overmatige streaming veroorzaken, wat leidt tot verzadigde pijplijnen - I/O intensief - Overweeg selectieve velden en filtering om overhead te verminderen |
Agentforce: - Realtime fraudewaarschuwingen, personalisatie voor detailhandel, operationele waarschuwingen Analytics: - Sub-seconde dashboards, KPI monitoring Naleving: - Continue updates van klantenrecords voor gereguleerde werkstromen |
| Streaming: Micro-batch opname elke 1–3 minuten via native connectoren | - Evenwichtige kosten versus versheid - Eenvoudigere architectuur dan real-time - Ondersteunt incrementele updates |
- Lichte latentie - Mogelijk niet geschikt voor kritieke beslissingen van subseconden - Batchgrootte beïnvloedt geheugen / computer - I/O is matig - Beste voor voorspelbare, herhaalde update patronen - Overweeg windowed aggregatie om verwerkingsbelasting te verminderen |
Agentforce: - Tijdige campagnetriggers, bijna live betrokkenheid Analytics: - Aanbevelingsengines, bijna-live dashboards Naleving: - Frequente updates met controlemogelijkheden |
|
| Batch: Geplande ladingen met groot volume via connectoren of API's. Ondersteunt objectopslag en ETL/ELT-pijplijnen. | - Kostenefficiënt voor enorme gegevenssets - Eenvoudig te implementeren - Betrouwbaar voor historische analyses |
- Data latency - Niet geschikt voor tijdgevoelige bewerkingen - I/O intensief tijdens laadvensters - Netwerkdoorvoer kan een bottleneck worden voor grote bestanden - Beste voor historische aggregatie of gereguleerde rapportagewerkstromen |
Agentforce: - IT-ondersteuningstickets (Jira / ServiceNow), geaggregeerde werkstromen Analytics: - Historische analyse, trendevaluatie Klacht: - Regelgeving rapportage, patiënt/claims gegevens aggregatie |
|
| Zero Copy | Live query: Directe query's op externe systemen; schema-op-lezen; geen gegevensduplicatie | - Maximale versheid - Minimale opslag overhead; ondersteunt real-time operationele insights |
- Afhankelijk van bronprestaties - Hoog queryvolume kan de latentie beïnvloeden - Ideaal voor query's met predicaat pushdown & aggregatie te minimaliseren I / O - Vermijd ongefilterde query's op enorme gegevenssets |
Agentforce: - Dynamische werkstromen die zich aanpassen aan live activiteit Analytics: - Operationele dashboards, live rapportage Naleving: - Respecteert beveiliging op rijniveau en maskeren bij de bron |
| Versnelde query (caching): Lokale kopieën in cachegeheugen voor gebundelde query's. Configureerbaar van 15 min tot 7 dagen. Geoptimaliseerde query-uitvoering | - Vermindert latentie - Lagere kosten dan herhaalde live query's - Verbetert de prestaties voor frequente toegangspatronen |
- Cachebeheer vereist - Staleness is afhankelijk van cache-interval - Beste voor query's met hoge frequentie - Niet geschikt voor sub-seconde besluitvorming |
Agentforce: - Vooraf geaggregeerde betrokkenheidsmeetgegevens voor snelle beslissingen Analytics: - BI dashboards, segmentering, analytische rapportage Naleving: - Consistente gereguleerde dashboards met auditlogboeken |
|
| Bestandsbundeling: Directe toegang tot grote historische gegevenssets in objectstores of lakes (S3, Iceberg, Google BigQuery, Redshift). | - Verwerkt grootschalige gegevenssets - Minimale opslag in Data 360 - Ondersteunt AI / ML-werkbelastingen |
- Alleen-lezen - Queryprestaties zijn afhankelijk van externe systeemdoorvoer - Geoptimaliseerd voor batch-zware, doorvoer-intensieve taken - Niet geschikt voor real-time dashboard |
Agentforce: - (Niet typisch - batch-zwaar) Analytics: - ML / AI-training, historische analyses, rapportage op petabyteschaal Naleving: - Beheerde toegang tot externe gegevenssets zonder duplicatie |
Met gegevensopname worden gegevens fysiek gekopieerd naar Data 360 en volledig beheerd, in tegenstelling tot Zero Copy, waarbij gegevens bij de bron blijven. Berekenen voor transformaties vindt plaats binnen Data 360, wat gecentraliseerd bestuur en controle mogelijk maakt.
Gebruik gegevensopname om canonieke, beheerde gegevenssets op te slaan in Salesforce Data 360 voor naleving en operationele controle. Gebruik opname wanneer volledige controle, controle en traceerbaarheid vereist zijn. Ideaal voor gereguleerde of hoogwaardige werkstromen waar gecentraliseerde berekeningen en governance van cruciaal belang zijn.
Opname is het beste om een vertrouwde basis te creëren voor identiteitsoplossing, wettelijke rapportage en missiekritieke AI-gestuurde werkstromen en klantbetrokkenheid.

Methoden voor gegevensopname variëren afhankelijk van de connector die u gebruikt om uw gegevens op te nemen. Sommige connectoren bieden een verscheidenheid aan opnamemethoden, terwijl andere alleen in batch- of streamingmodus werken. Zie Data 360: Integraties en connectoren voor een volledige lijst van Data 360-connectoren en hun beschikbare methoden.
- Realtime
- Subseconde opname met behulp van streamingpijplijnen of Change Gegevensvastlegging (CDC).
- Ideaal voor tijdgevoelige werkstromen (fraudedetectie, personalisatie, operationele dashboards).
- Push transformaties en aggregaties binnen Data 360 om I/O verderop in de stroom te verminderen en het gebruik van berekeningen te optimaliseren. Gebruik incrementele CDC om het verschuiven van gegevens te minimaliseren.
- Streaming
- Inname elke 1–3 minuten in kleine stappen.
- Brengt versheid en kosten in balans, geschikt voor campagne-indeling, bijna-live betrokkenheid en operationele rapportage.
- Gebruik microbatches om I/O-pieken te controleren. Aggregeer gegevens bij de bron indien mogelijk om overdrachtvolumes te verminderen en opslag te optimaliseren.
- Batch (geplande ladingen)
- Periodieke opname van grote gegevenssets (per uur, dagelijks, wekelijks).
- Kostenefficiënt en betrouwbaar voor historische gegevenssets, rapportage over regelgeving en gebruikscases voor naleving.
- Zorg voor een berekeningslocatie in dezelfde regio als bronopslag voor prestatie- en kostenoptimalisering.
- Gebruikscases voor gegevensopname
- Customer 360 gecombineerde profielen genereren: Eén bron van waarheid samenstellen voor klantidentiteit en -kenmerken.
- Gegevenssets voor naleving van regelgeving onderhouden: Het afdwingen van governance, afkomst en controleerbaarheid voor gevoelige gegevens.
- Centrale campagne-indeling: Ervoor zorgen dat marketing, verkoop en service allemaal werken vanuit consistente, vertrouwde gegevenssets.
- Ontwerppraktijken
- Geef de voorkeur aan batchgewijs opnemen voor historische of lage latentietolerante behoeften, zoals archiveringsrapportage of periodieke momentopnamen.
- Gebruik CDC- of streaming-API's om operationele en personalisatiewerkstromen vers te houden, zodat updates vrijwel in realtime plaatsvinden.
- Beheers opslag en groei van berekeningen door incrementele belastingen toe te passen in plaats van volledige gegevenssets opnieuw te laden om de kosten en efficiëntie te optimaliseren.
- Stem opnamepijplijnen af op de locatie van de berekening en incrementele verwerking om netwerk-I/O te verminderen. Pas transformaties toe binnen Data 360 om onnodige verplaatsing van ruwe gegevens te voorkomen.
- Overwegingen bij kosten
- Real-time opname: Hoogste berekenings- en pijplijnkosten; gerechtvaardigd voor waardevolle, tijdgevoelige werkstromen zoals personalisatie, operationele dashboards of Agentforce gestuurde acties.
- Streamingopname: Matige berekenings- en opslagkosten; geschikt voor frequente updates die lichte vertragingen kunnen verdragen, zoals campagne-combinatie of operationele rapportage.
- Batchopname: Lagere berekeningskosten, voorspelbare opslag; het beste voor historische gegevenssets of updates met een lage frequentie. Het opnemen van batchgegevens uit Salesforce-organisaties met behulp van bepaalde connectoren is gratis.
- Vernieuwingsmodus: Als u de modus Incrementeel vernieuwen selecteert, worden de totale opname- en berekeningskosten verlaagd. U wordt aangeraden om waar mogelijk incrementele vernieuwing te gebruiken om de efficiëntie voor alle opnametypen te optimaliseren.
- Kosten worden ook beïnvloed door I/O-volume van bron tot Data 360. Het optimaliseren van batchgrootten, partities en regionale uitlijning verlaagt de overdrachtskosten en verbetert de prestaties.
- Industriescenario's
- Financiën: Gegevenssets opnemen die vereist zijn voor het kennen van uw klant (KYC), antiwitwassen (AML) en fraudedetectie, waarbij controle en naleving niet kunnen worden besproken.
- Gezondheidszorg: Gebruik opname voor patiëntenidentiteitsoplossing en HIPAA-conforme records, waardoor veilige, gecombineerde weergaven mogelijk worden.
- Retail: Gegevens van verkooppunten, eCommerce en loyaliteitsprogramma's consolideren in gecombineerde profielen voor segmentering en personalisering
- Telecom: Ondersteun verlooppreventie en gebruiksanalyses met canonieke, beheerde abonneegegevens.
| Functie | Real-time opname | Streamingopname | Batchopname |
|---|---|---|---|
| Latency en versheid | Opname van subseconden latentie via opname-API's met ondersteuning voor Change Gegevensvastlegging (CDC). Biedt continue streamingpijplijnen. Beste voor operationele gebruikscases met lage latentie. | Microbatchgewijze opname elke 1–3 minuten via native connectoren. Ondersteunt incrementele updates. Lichte latentie wordt verwacht. | Gegevenslatentie wordt verwacht. Geplande ladingen met groot volume. Periodieke opname (per uur, dagelijks, wekelijks). Niet geschikt voor tijdgevoelige bewerkingen. |
| Primaire gebruikscases | Ideaal voor operationele gebruikscases met lage latentie en personalisatie. Gebruikt voor tijdgevoelige werkstromen. Ondersteunt eventgestuurde werkstromen. Gebruikt voor realtime fraudewaarschuwingen en operationele waarschuwingen. | Geschikt voor matig dringende processen. Gebruikt voor campagne-combinatie, near-live betrokkenheid en operationele rapportage. Gebruikt voor tijdige campagnetriggers. | Kostenefficiënt voor enorme gegevenssets. Betrouwbaar voor historische analyses. Gebruikt voor historische aggregatie of gereguleerde rapportagewerkstromen. Beste voor historische of lagesnelheidsgegevenssets. |
| Architectonische complexiteit en I/O | Hoge kosten en complexe architectuur. Vereist bronsystemen met lage latentie. I/O intensief. Bronnen met groot volume kunnen verzadigde pijplijnen veroorzaken. | Eenvoudigere architectuur dan realtime. I/O is matig. Beste voor voorspelbare, herhaalde updatepatronen. Batchgrootte heeft invloed op geheugen/compute. | Eenvoudig te implementeren. I/O intensief tijdens laadvensters. Netwerkdoorvoer kan een bottleneck worden voor grote batches. |
| Overwegingen bij kosten | Hoogste berekenings- en pijplijnkosten. Alleen gerechtvaardigd voor waardevolle, tijdgevoelige werkstromen. | Reken- en opslagkosten modereren. Biedt een evenwichtige benadering van kosten en versheid. Geschikt voor frequente updates die lichte vertragingen kunnen verdragen. | Lagere rekenkosten en voorspelbare opslag. Aanbevolen voor historische gegevenssets of updates met een lage frequentie. Opname via interne Salesforce-pijplijnen is gratis. |
| Ontwerppraktijken | Gebruik incrementele CDC om het verschuiven van gegevens te minimaliseren. Filter en gebruik selectieve velden om overhead te verminderen. | Gebruik microbatches om I/O-pieken te controleren. Overweeg aggregatie met vensters om de verwerkingsbelasting te verminderen. | Geef hier de voorkeur aan voor archiveringsrapportage of periodieke momentopnamen. Zorg voor een berekeningslocatie in dezelfde regio als bronopslag voor kostenoptimalisering. |
Gebruik Zero Copy voor real-time query's op externe systemen zonder gegevensduplicatie, waardoor flexibiliteit, versheid en schaalbare toegang tot grote of tijdelijke gegevenssets mogelijk wordt. Het is het beste voor live dashboards, verkennende analyses, AI/ML-modeltraining en realtime klantbetrokkenheid rechtstreeks via Salesforce Data 360.
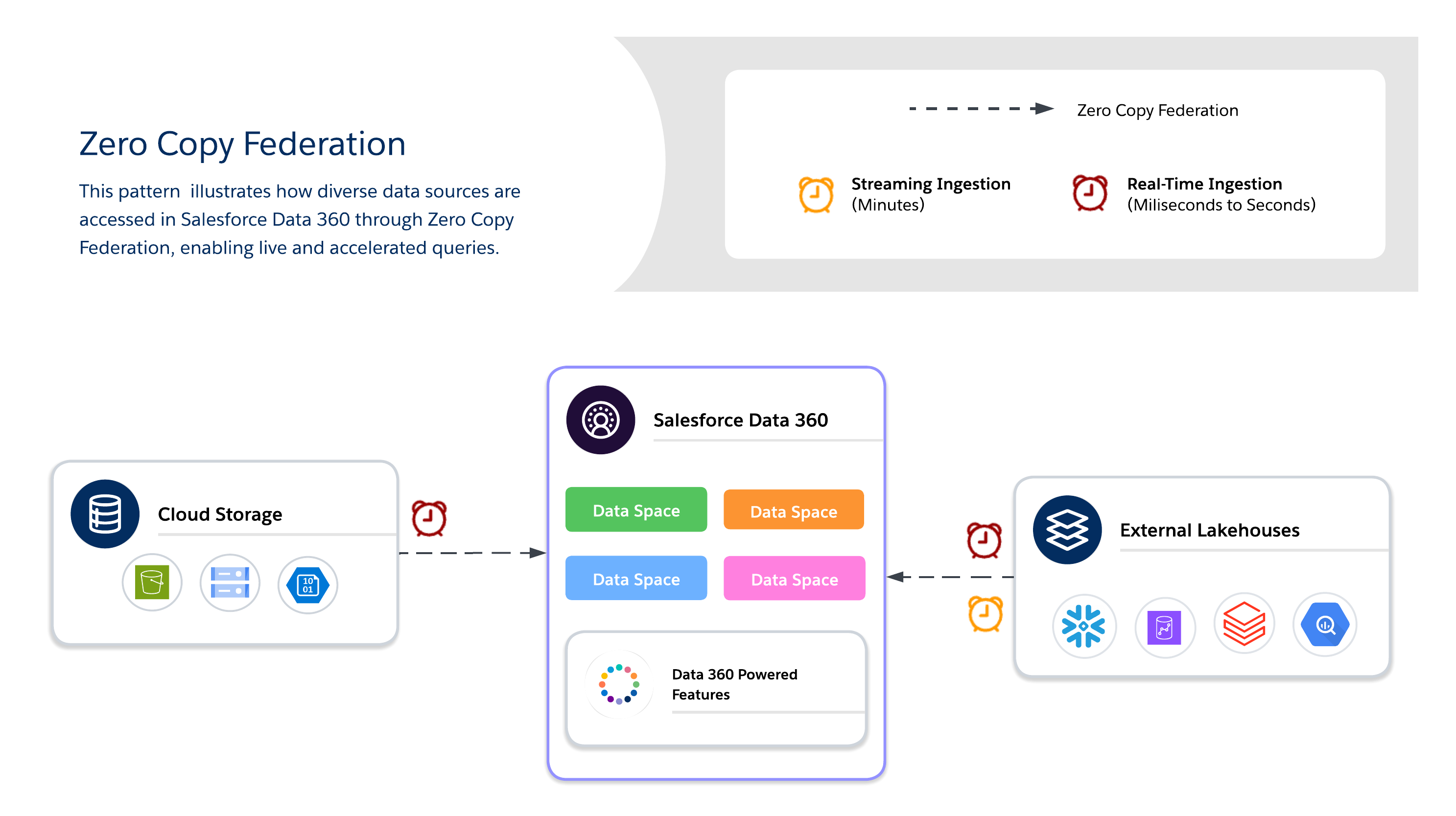
Bij het gebruik van Zero Copy moeten architecten verder kiezen tussen drie beschikbare methoden voor gegevensbundeling, die elk hun eigen nadelen bieden tussen versheid, prestaties en kosten.
- Live query
- Voert query's rechtstreeks uit op externe systemen (Snowflake, Google BigQuery, Redshift, Databricks, enz.) zonder gegevensduplicatie.
- Optimaal wanneer predicaten en aggregaties omlaag kunnen worden geduwd, waardoor gegevensverplaatsingen over het netwerk worden geminimaliseerd en de I/O voor de Salesforce Data 360-berekening wordt verminderd.
- Ideaal voor realtime insights en operationele dashboards met een lage latentie. Afhankelijk van de prestaties van het externe systeem.
- Caching (versnelde query)
- Slaat tijdelijk cachekopieën van gebundelde gegevens op in Salesforce Data 360.
- Vermindert de kosten van herhaalde query's en de latentie voor vaak geopende gegevenssets, met configureerbare duur (minuten tot dagen).
- Gegevens worden niet permanent gekopieerd of volledig beheerd; versheid wordt beheerd via geplande vernieuwingen vanuit de bron.
- Bestandsbundeling
- Biedt directe, alleen-lezen toegang tot grootschalige gegevenssets in objectstores (bijv. S3, GCS met Iceberg).
- Ideaal voor AI/ML-werkbelastingen, historische analyses en rapportage op petabyteschaal zonder gegevens te verplaatsen.
- Queryprestaties zijn sterk afhankelijk van objectindeling, partitionering en netwerk-I/O. Grote scans kunnen aanzienlijke I/O genereren als ze niet worden geoptimaliseerd.
- Gebruikscases
- Realtime personalisatie en adaptieve werkstromen: Bied dynamische aanbiedingen, aanbevelingen en next-best acties terwijl het gedrag van klanten verandert.
- Live dashboards en operationele analyses: Voorzie bedrijfskritieke dashboards en KPI's rechtstreeks vanuit externe magazijnen.
- AI/ML-modeltraining met grote externe gegevenssets: Maak gebruik van gegevens op petabyteschaal uit gegevens-lakes en magazijnen met behulp van bestandsbundeling zonder deze te verplaatsen.
- Industriescenario's
- Retail/Media: Schakel gepersonaliseerde aanbevelingen en real-time klantbetrokkenheid in door klikstroom- of inhoudsinteractiegegevens te bundelen.
- Financiën: Voer fraudedetectie en risicoscores in vrijwel realtime uit door een query uit te voeren op externe magazijnen zonder vertrouwelijke gegevens te dupliceren.
- Tech/Enterprise: Ondersteuning van cross-cloud rapportage, IT-servicedashboards en operationele analyses waarbij gegevenssets zich in meerdere systemen bevinden.
- Ontwerppraktijken
- Live query
- Gebruik dit voor query's met een hoge QPS en lage latentie wanneer versheid kritiek is.
- Push predicaten en aggregaties naar het externe systeem om het schuiven van gegevens over het netwerk te verminderen.
- Vermijd query's die onnodig grote gegevensvolumes scannen; overweeg partities afkappen en filters.
- Bestandsbundeling
- Toegang tot gegevenssets op petabyteschaal in objectstores zonder opname.
- Houd objectopslag in dezelfde cloudregio als Salesforce compute om de latentie en de kosten van uitgaan te minimaliseren.
- Gebruik gepartitioneerde, kolomindelingen (Parquet/ORC) en pushdownfilters om I/O- en netwerkoverdracht te verminderen.
- Maak gebruik van pushdown van query's en predicaten om gegevens bij de bron te filteren en aggregeren, waardoor gegevens minder worden verplaatst.
- Vermijd toegang tot gegevens over meerdere regio's, tenzij noodzakelijk, omdat dit de I/O, latentie en kosten verhoogt.
- Caching (versnelde query)
- Vaak geopende gegevenssets in het cachegeheugen opslaan om kosten en prestaties in evenwicht te brengen.
- Configureer vernieuwingsintervallen om de versheid en querykosten in evenwicht te brengen.
- Naleving: Dwing governance bij de bron af door beveiliging op rijniveau (RLS) te gebruiken en beleidsvormen rechtstreeks binnen gebundelde systemen te maskeren. Hieronder vindt u best practices voor uniforme RLS en maskeren over platforms.
- Gebruik een gecentraliseerde ondernemings-ID: Wijs gebruikers en entiteiten in Salesforce Data 360 toe aan een unieke, gecentraliseerde ondernemings-ID die overeenkomt met identiteiten in externe systemen.
- Beveiligingsbeleid afstemmen: Zorg ervoor dat beleidsvormen voor beveiliging op rijniveau en maskeren in gebundelde systemen worden toegepast op basis van de toegewezen identiteit. Dit behoudt naleving bij het uitvoeren van query's op externe gegevens.
- Identiteitsschema's standaardiseren: Handhaaf consistente identiteitskenmerken (e-mail, gebruikers-ID, klant-ID, enz.) voor alle gegevensbronnen om mismatches en toegangsschendingen te voorkomen.
- Live query
- Overwegingen bij kosten
- Live query: Pay-per-query-model: kosten worden opgebouwd door externe Lakehouse-berekening en kunnen pieken bij hoge QPS. Het beste voor versheidskritische gebruikscases waarin waarde groter is dan kostenvariabiliteit.
- Versnelde query (caching): Verlaagt de querykosten in vergelijking met Live Query door het aantal hits naar het bronsysteem te verminderen, maar verhoogt de kosten voor het opnemen van batchgegevens voor het vullen en vernieuwen van het cachegeheugen. Beste voor gegevenssets die vaak worden geopend.
- Bestandsbundeling: Goedkoopste opslagoptie als gegevens in Objectstore, maar querykosten zijn afhankelijk van bestandsgrootte, partitionering en afkappen. Beste voor historische of bulkgegevens op petabyteschaal.
| Beslissingspunt | Live query | Caching (versnelde query) | Bestandsbundeling |
|---|---|---|---|
| Gegevensbronlocatie | Lakehouses voor externe gegevens (Snowflake, Google BigQuery, Redshift, Databricks). | Lakehouses voor externe gegevens (Snowflake, Google BigQuery, Redshift, Databricks) | Objectopslag of cloudgegevens-lakes (S3, ADLS, GCS), vaak met behulp van open tabelindelingen zoals Iceberg. |
| Doel/gebruikscase | Ideaal voor interactieve analyses en realtime dashboards. Ideaal voor real-time personalisatie en dynamische werkstromen. | Ideaal voor wanneer query's frequent zijn, maar enigszins verouderde resultaten acceptabel zijn. Geschikt voor BI dashboards en segmentering. | Ideaal voor grootschalige batchverwerking en AI/ML-modeltraining. Ideaal voor historische analyses en rapportage op petabyteschaal. |
| Versheid/latentie | Maximale versheid; query's worden rechtstreeks in real-time uitgevoerd. Ondersteunt beslissingen van subseconden. | Licht muffe resultaten zijn acceptabel. De versheid is afhankelijk van het cache-interval, dat kan worden geconfigureerd van 15 minuten tot 7 dagen. | Geoptimaliseerd voor batchzware, doorvoerintensieve taken. Niet geschikt voor realtime dashboarding. |
| Toegangspatroon | Beste voor zeldzame of ad-hocquery's. Gebruik dit voor query's met hoge QPS (query per seconde), query's met lage latentie waarbij versheid van cruciaal belang is. | Beste voor scenario's met lezen met hoge frequentie. Verbetert prestaties voor frequente toegangspatronen. | Alleen-lezen toegang. Geschikt voor gegevenssets op petabyteschaal zonder opname. |
| Prestatiedrivers | Sterk afhankelijk van de prestaties van het externe bronsysteem. Geoptimaliseerd wanneer predicaten en aggregaties naar de bron kunnen worden gepusht. | Vermindert de latentie in vergelijking met herhaalde live query's. Prestaties zijn afhankelijk van cachebeheer en interval. | Prestaties zijn sterk afhankelijk van objectindeling, partitionering en externe systeemdoorvoer. Gebruik gepartitioneerde, kolomindelingen (Parket/ORC). |
| Gevolgen voor kosten | Pay-per-query-model. Kosten worden opgebouwd voor externe Lakehouse-berekening. Kostenefficiënt voor zeldzame query's, maar onkosten kunnen pieken met een hoog volume query's per seconde (QPS). | Lagere kosten dan herhaalde live query's. Vermindert de noodzaak om herhaaldelijk een query uit te voeren op de externe bron. Voegt cacheopslag en vernieuwingsoverhead toe. | Goedkoopste opslagoptie. Querykosten zijn afhankelijk van de bestandsgrootte en partitionering. |
| Belangrijkste overweging | Vermijd ongefilterde query's die onnodig grote hoeveelheden gegevens scannen. | Vereist cachebeheer. Niet geschikt voor subsecondenbeslissing. | Queryprestaties zijn sterk afhankelijk van optimalisering via partitionering en predicaatpushdown. |
Hybride architecturen stellen architecten in staat om kritieke gegevenssets te verankeren in Data 360 voor gecentraliseerd bestuur en tegelijkertijd gebundelde query's te gebruiken voor versheid, minder duplicatie en schaalbare toegang tot grote externe gegevenssets. Deze benadering houdt rekening met I/O, berekeningslocatie, kosten en nalevingsvereisten.
Gebruik een hybride benadering voor evenwichtig bestuur, versheid en operationele efficiëntie door gegevensopname en zero copy te combineren om real-time, navolgbare insights te leveren. Gebruik opname voor hoogwaardige, gereguleerde gegevenssets waarbij traceerbaarheid, RLS en maskering vereist zijn, en bundeling voor gegevenssets met een kort of groot volume waarbij versheid en prestaties essentieel zijn.
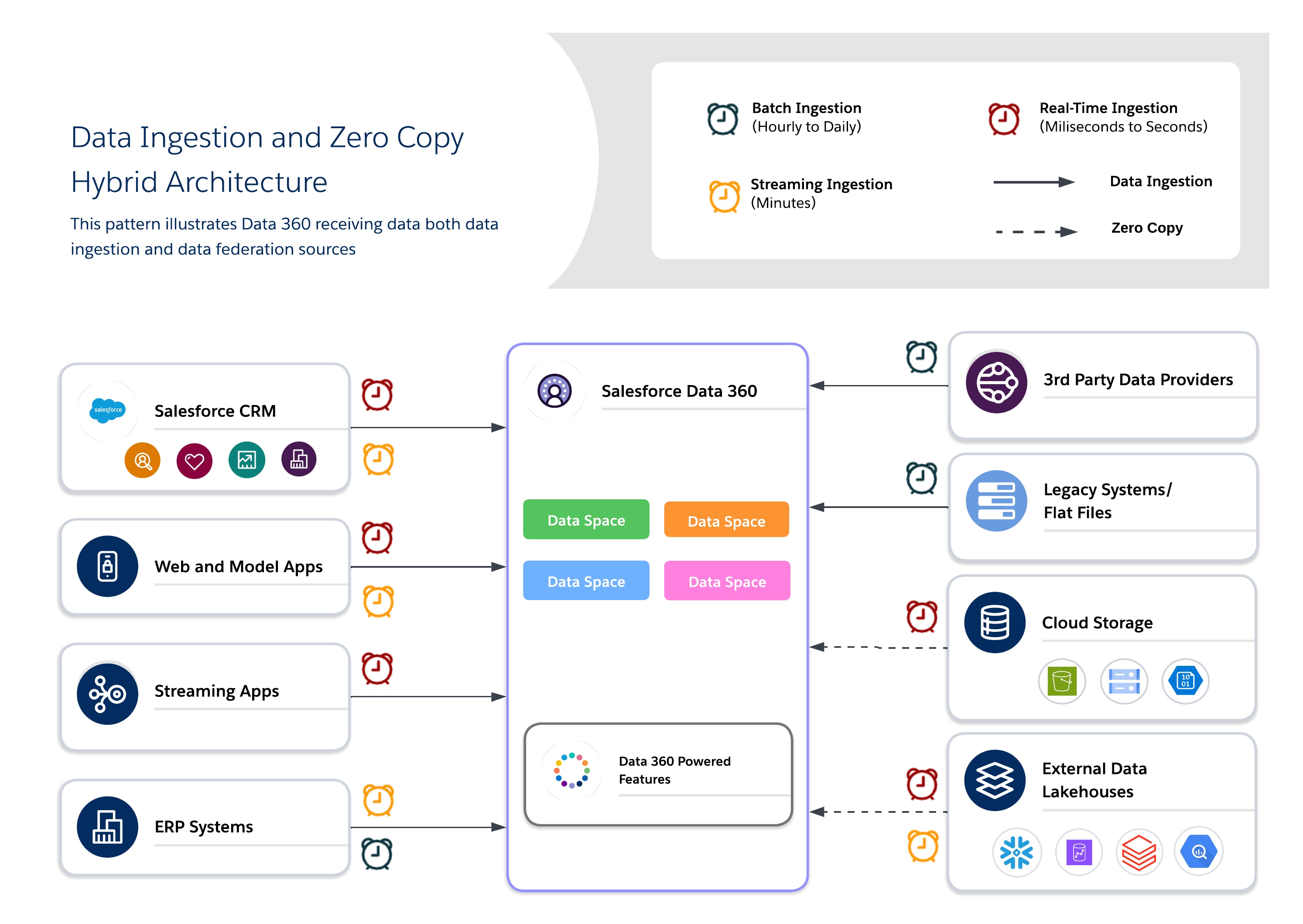
- Gebruikscases
- Omni-channel betrokkenheid: Combineer historische klantgegevens met real-time gedrag om consistente, contextbewuste ervaringen te bieden.
- AI/ML-pijplijnen: Train modellen op gemodereerde, canonieke gegevenssets en verrijk ze met ruwe of realtime signalen van externe bronnen.
- Gemengde behoeften op het gebied van naleving en flexibiliteit: Pas strikte governance toe voor gevoelige gegevens, maar bundel voor operationele flexibiliteit.
- Industriescenario's
- Retail: Gebruik opname voor identiteitsoplossing en profielsamenvoeging; bundel voor realtime aanbiedingen en personalisering.
- Gezondheidszorg: Houd gouden patiëntenrecords bij via opname terwijl u IoT-apparaatstromen en sensorgegevens bundelt voor directe context.
- Financiële diensten: Neem gereguleerde gegevens op in een door naleving bestuurd meer terwijl u externe query's bundelt voor fraudedetectie en risicobewaking.
- Ontwerppraktijken
- Governance van anker met opname: Neem waardevolle of gereguleerde gegevens op in canonieke modellen om Trust en naleving te garanderen.
- Federatie voor versheid gebruiken: Laat externe lakehouses realtime of grootschalige gegevenstoegang bieden zonder dupliceren.
- Saldokosten vs. Prestaties: Profielwerkbelastingen om te bepalen wat er moet worden opgenomen versus gebundeld, waardoor onnodige opslag- of querykosten worden geminimaliseerd.
- Gelaagde governance toepassen: Dwing gecentraliseerd bestuur af voor opgenomen gegevens en gebruik daarbij de eigen beveiligingsmaatregelen van gebundelde systemen (bijv. RLS, maskeren).
- Zorg bij het ontwerpen van hybride pijplijnen voor incrementele opname voor historische gegevenssets en push aggregaties of filters naar gebundelde bronnen om I/O- en rekengebruik te optimaliseren.
- Overwegingen bij kosten
- Optimaliseer totale kosten versus prestaties door opname voor naleving of kritieke gegevens te combineren met bundeling wanneer versheid noodzakelijk is.
- Houd rekening met I/O- en berekeningsdistributie bij het mengen van opname en bundeling. Als u de berekeningskosten in bronsystemen van herhaalde query's wilt verlagen, gebruikt u caching (Versnelde query) voor veelgelezen, vaak geopende gebundelde gegevenssets.
Hieronder volgen veelvoorkomende archetypen die illustreren hoe u deze logica toepast.
- Het archetype "Enige bron van waarheid": Centraliseren en beheren
- Scenario: U moet conforme, gecombineerde Customer 360 profielen samenstellen voor uw gehele wereldwijde onderneming. De gegevens zijn afkomstig uit een tiental verschillende systemen, moeten voldoen aan strenge GDPR- en CCPA-regelgeving en dienen als de vertrouwde bron voor alle marketing- en service-interacties.
- Aanbevolen patroon: Gegevensopname. De prioriteit is governance, Trust en controle. Het opnemen van de gegevens in Data 360 is de enige manier om een volledig controleerbaar, canoniek profiel te maken dat is geïsoleerd van de bronsystemen.
- Archetype "Real-time Insights": Analyseren zonder te verplaatsen
- Scenario: Uw Data Science-team moet verkennende query's uitvoeren op een enorme transactietabel die voortdurend wordt bijgewerkt in Snowflake. Tegelijkertijd wil uw managementteam een live BI-dashboard dat op basis van diezelfde gegevens wordt aangestuurd. Het dagelijks verplaatsen van petabytes aan gegevens is te traag en duur.
- Aanbevolen patroon: Zero Copy Federation. De prioriteit ligt bij snelheid, flexibiliteit en kostenefficiëntie op schaal. Met Zero Copy kunt u de enorme kracht van uw bestaande gegevensmagazijn benutten voor real-time query's zonder de overhead en latentie van gegevensduplicatie.
- Het archetype "Hybride intelligentie": De kern besturen, de rand bundelen
- Scenario: U wilt uw beheerde, opgenomen klantprofielen verrijken met real-time gedragssignalen (zoals klikken op websites) uit een gegevens-lake. U hebt de stabiliteit van het kernprofiel nodig, maar de directheid van de live gegevens om personalisatie op het moment mogelijk te maken.
- Aanbevolen patroon: Een hybride aanpak. Gebruik Gegevensopname om de stabiele, gecontroleerde kern van uw klantgegevens te maken. Gebruik vervolgens Zero Copy om de vluchtige, real-time "edge"-gegevens te bundelen en deze op querytijd samen te voegen voor een volledige, tot op de seconde nauwkeurige weergave.
Enterprise Data Strategy gaat niet langer over het kiezen van één integratiepatroon, maar over het ontwerpen van gecontroleerde flexibiliteit binnen een interoperabel gegevensecosysteem. Het selecteren van de juiste gegevensintegratiemethode voor elk brongegevenssysteem op basis van bedrijfsbehoeften leidt vaak tot een hybride benadering die de sterke punten van zowel gegevensopname als gegevensbundeling combineert.:
- Neem bedrijfskritieke, beheerde gegevenssets op in Salesforce Data 360 voor naleving, identiteitsoplossing en operationele werkstromen.
- Bundel gegevens via Zero Copy voor live, verkennende en AI-gestuurde analyses zonder opslag te dupliceren.
Salesforce Data 360 voor Hyperforce biedt veerkracht en schaalbaarheid voor meerdere regio's. 's Open Lakehouse met Iceberg-tabellen maakt scheiding van berekeningen en interoperabiliteit mogelijk met platforms zoals Snowflake, Databricks en S3 Iceberg - de ruggengraat van een echt interoperabel gegevensecosysteem met meerdere clouds.
Naarmate gegevensecosystemen zich ontwikkelen, moet u continu een balans vinden tussen versheid, kosten, prestaties en naleving om architectonische flexibiliteit te behouden. Maak uw platform toekomstbestendig door opgenomen, gereguleerde gegevens te combineren met gebundelde toegang. Dit maakt real-time intelligentie, AI-activering en personalisering op ondernemingsniveau binnen clouds, regio's en bedrijfsdomeinen mogelijk.
One-size-fits-all oplossingen zijn niet geschikt voor de meeste bedrijven. De optimale strategie wijst het juiste patroon toe aan de juiste business driver.
Yugandhar Bora is een Software Engineering Architect bij Salesforce, gespecialiseerd in gegevensarchitectuur binnen het Data & Intelligence Applications-platform. Hij leidt initiatieven van de Enterprise Architecture Review Board (EARB) gericht op data governance en gecombineerde gegevensmodellen, terwijl hij bijdraagt aan oplossingen voor geautomatiseerde platformleveringen.
Jan Fernando is hoofdarchitect bij het kantoor van de hoofdarchitect van Salesforce. Hij kwam in 2012 bij Salesforce en bracht een schat aan ervaring mee uit zijn tijd in het startup-ecosysteem. Voordat hij bij het Office of the Chief Architect kwam, werkte hij meer dan tien jaar in de Platform-organisatie, waar hij verschillende belangrijke technologische transformaties leidde.