Moderne Salesforce-integrasjoner må støtte langt mer enn bare datautveksling. De forventes å levere sanntids kundeopplevelser, koordinere handlinger på tvers av flere systemer og operere pålitelig i bedriftsskala – alt sammen samtidig som de oppfyller strenge krav til sikkerhet og samsvar. Valg av riktig integreringstilnærming er derfor en viktig arkitektonisk beslutning, ikke en implementeringsdetalj. Vurder et vanlig forretningsscenarium. En kunde fullfører et kjøp i en mobilapp og utløser en sanntidskontroll av berettigelse for et tilpasset tilbud. Samtidig må transaksjonsdata registreres i et ERP-system, kundeattributter oppdateres i Salesforce, og analyser strømmes til et datasjø – uten å innføre latens, datadoplisering eller samsvarsrisiko. Scenarier som dette er nå typisk i moderne Salesforce-miljøer, der Salesforce sjelden opererer isolert og må integreres sømløst med et bredere økosystem av programmer og dataplattformer. Denne veiledningen finnes for å hjelpe arkitekter og utviklere med å utforme disse integrasjonene med klarhet og tillit. I stedet for å fokusere på punkt-til-punkt-implementasjoner presenterer den et sett av beviste integrasjonsmønstre som håndterer gjentagende forretningsscenarier – som prosessorkestrering, datasynkronisering og sanntids datatilgang. Hvert mønster fremhever arkitektoniske hensikter, avveininger og utførelsesmodeller, slik at team kan ta informerte designbeslutninger som skaleres og varer. I dette dokumentet finner du følgende:
- Integrasjonsmønstre som representerer vanlige "arketyper" for virksomheten på tvers av prosess-, data- og virtuelle tilgangsscenarier
- Et rammeverk for mønstervalg for å identifisere den riktige tilnærmingen basert på integrasjonshensikt og utførelsestid
- Praktisk veiledning om viktige punkter om skalerbarhet, fleksibilitet, styring og sikkerhet
- Gode fremgangsmåter trukket fra virkelige Salesforce- og Data 360-implementasjoner Formålet med dette dokumentet er å gi et felles arkitektonisk språk for integrasjon, og hjelpe team med å designe løsninger som balanserer ytelse, fleksibilitet og Trust samtidig som de tilpasses virksomhetens data og styringsstrategier.
Dette dokumentet er for designere og arkitekter som trenger å integrere data fra andre programmer i virksomheten sin med Salesforce Data 360 (tidligere Data Cloud). Dette innholdet er en destillasjon av mange vellykkede implementeringer av Salesforce-arkitekter og -partnere. Hvis du vil gjøre deg kjent med integrasjonsfunksjoner og alternativer som er tilgjengelig for omfattende bruk av Data 360, kan du lese delene Mønstersammendrag og Veiledning for mønstervalg nedenfor. Arkitekter og utviklere bør vurdere disse mønsterdetaljene og gode fremgangsmåter under utformings- og implementeringsfasen av datainteraksjonsprosjekter i Data 360. Hvis de implementeres riktig, gir disse mønstrene deg mulighet til å komme i produksjon så raskt som mulig og ha det mest stabile, skalerbare og vedlikeholdsfrie settet av programmer som er mulig. Salesforces egne rådgivningsarkitekter bruker disse mønstrene som referansepunkter under arkitektoniske gjennomganger, og vedlikeholder og forbedrer dem aktivt. Som med alle mønstre dekker dette innholdet de fleste integrasjonsscenarier, men ikke alle. Salesforce tillater for eksempel brukergrensesnittintegrering, men en slik integrasjon er utenfor omfanget av dette dokumentet.
Hvert integrasjonsmønster følger en konsistent struktur. Dette gir konsistens i informasjonen som gis i hvert mønster, og gjør det også enklere å sammenligne mønstre.
- Navn: Mønsteridentifikatoren som også angir typen integrasjon som finnes i mønsteret.
- Kontekst: Det generelle integreringsscenarie, som mønsteret håndterer. Kontekst gir informasjon om hva brukere prøver å oppnå og hvordan programmet oppfører seg for å oppfylle kravene.
- Problem: Uttrykt som et spørsmål er dette scenariet som mønsteret er utformet for å løse. Les denne delen for å forstå om mønsteret er riktig for integrasjonsscenariet.
- Krefter: Begrensningene og omstendighetene som gjør det angitte scenariet vanskelig å løse.
- Løsning: Den anbefalte måten å løse integrasjonsscenariet på.
- Skisse: Et UML-sekvensdiagram som viser deg hvordan løsningen håndterer scenariet.
- Resultater: Forklarer detaljene om hvordan du bruker løsningen på integrasjonsscenariet og hvordan den løser kreftene knyttet til dette scenariet. Denne delen inneholder også nye utfordringer som kan oppstå som et resultat av å bruke mønsteret.
- Sidefelt: Andre deler relatert til mønsteret som inneholder viktige tekniske problemer, variasjoner av mønsteret, mønsterspesifikke bekymringer og så videre.
- Eksempel: Et scenario i den virkelige verden som beskriver hvordan utformingsmønsteret brukes i et Salesforce-scenarium i den virkelige verden. Eksempelet forklarer integrasjonsmålene og hvordan du implementerer mønsteret for å oppnå disse målene.
Bruk denne tabellen som en innholdsfortegnelse for integrasjonsmønstrene i dette dokumentet.
| Mønsternivå1 | Mønsternivå2 | Mønster | Secenario |
|---|---|---|---|
| Datainntaksmønstre – Datainnkommende | Batch inntaksmønstre | Bulk datainntak fra skylagring | Data hentes inn fra en Enterprise Cloud Storage-kilde som Amazon S3, Azure Blob eller Google Cloud Storage til Data 360 i form av store batcher med rådata (for eksempel transaksjoner eller produktlogger). |
| Masseinntak av data fra Salesforce Clouds | Data 360 mottar CRM-data samlet fra flere Salesforce-organisasjoner (for eksempel Sales Cloud, Service Cloud) for å bygge forente kundeprofiler. | ||
| Streaming og mønstre for inntak i sanntid | Event Driven Inntaks via Inntaks-API--Streaming | Data 360 abonnerer på strømmede inntaksendepunkter som mottar kontinuerlige hendelsesbelastninger (for eksempel kjøpshendelser, IoT-telemetri) fra bedriftssystemer for sanntids profiloppdateringer. | |
| Sanntids nett- og mobilvirkemåteinntak | Data 360 samler inn og behandler atferdsdata for nettsteder og mobilapper i sanntid via SDK-er for å berike engasjementsmålinger og tilpassingsmodeller. | ||
| Nær sanntid CRM Synchronization via Streaming | Data 360 mottar CRM-dataoppdateringer (for eksempel kontakt, sak, salgsmulighetsendringer) i nærSanntid via hendelsesstrømmer for å opprettholde en kontinuerlig synkronisert Customer 360. | ||
| Event Stream-inntak fra Cloud Messaging Platforms – Kinesis og MSK | Data 360 forbruker strømmedata direkte fra skyehendelsesplattformer som AWS Kinesis eller Kafka (MSK) for å behandle operasjonelle eller IoT-hendelser med høy frekvens. | ||
| Null kopieringsmønstre – innkommende og utgående | Inbound Zero Copy – Eksterne plattformer til Data 360 | Data 360 spør eksterne datasett (for eksempel Snowflake, BigQuery) på forespørsel via null kopieinntak, uten å flytte data fysisk til Salesforce. | |
| Outbound Zero Copy – Data 360 til eksterne plattformer | Eksterne systemer som Databricks eller Tableau får tilgang til forbedrede segmenter og innsikt i Data 360 via Zero Copy Outbound-tilkoblinger uten datareplikering. | ||
| Forent dataplattform for flere organisasjoner med Data Cloud One | Data Cloud One forener flere Salesforce-organisasjoner og eksterne datakilder under en delt metadata- og semantisk modell, noe som gir en ensartet Customer 360 uten dataduplisering. | ||
| Dataktiveringsmønstre – Datautgående | Batchaktiveringsmønstre | Segmentaktivering til markedsførings- og reklameplattformer | Data 360 aktiverer kuraterte kundesegmenter direkte til Marketing Cloud, Meta, Google Ads eller andre annonseplattformer for å levere tilpassede kampanjer |
| Dataeksport til skylagring | Data 360 eksporterer forente eller filtrerte datasett (for eksempel samtykkede kundeposter) som CSV- eller Parket-filer til enterprise cloud-lagring for analyse eller overholdelsesarkivering. | ||
| On Demand API-basert aktivering | Tilpasset programintegrering via Connect API | Eksterne programmer kaller opp Data 360 Connect API iSanntid for å hente eller utløse tilpassede handlinger (for eksempel lojalitetsbalansekontroll eller generering av AI-tilbud) basert på gjeldende kundedata.Tilpassede nett- eller mobilprogrammer henter harmoniserte Data 360-innsikter sikkert via Connect REST API for å vises i virksomhetens eller partnerens brukergrensesnitt. | |
| Komplett kundeprofilering via Data Graph API | Et system henter en kundes forente profil ved bruk av Data Graph API, og returnerer en forhåndssamlet, sanntids JSON-representasjon av den fullstendige 360°-visningen for beslutningstaking eller tilpassing. | ||
| Sanntids datahandlinger | Sanntids datahandling som gjør kundesignaler til umiddelbar handling | Data 360 oppdager og behandler en direktehendelse (for eksempel samtykkeoppdatering, kjøpsutløser) og kaller umiddelbart opp et tilkoblet system eller Salesforce-flyt for nedstrømshandling.Et kundeaktivitetssignal (for eksempel oppdaget frafallsrisiko) i Data 360 utløser en umiddelbar sanntidshandling – som å oppdatere CRM, kalle opp Einstein eller starte en oppbevaringsreise. |
Integrasjonsmønstrene i dette dokumentet er klassifisert i tre kategorier: data, prosess og visuelle integrasjoner.
Dataintegreringsmønstre i Data 360 tar for seg bevegelsen og synkroniseringen av data på tvers av systemer for å sikre at både Data 360-plattformer og eksterne plattformer har konsistent, rettidig og pålitelig informasjon. Disse mønstrene håndterer vanligvis dataflyter i stor skala og med stor trafikk, og baserer seg på styrte pipelines som håndhever skjemakonformitet, linjesporing og overordningsregler.
- Batchinntaksmønstre representerer det grunnleggende laget av introduksjon av virksomhetens data. Masseinntak av data fra skylagringstjenester som AWS S3, Azure Blob eller Google Cloud Storage, tillater at store historiske datasett lastes inn regelmessig i Data 360 for identitetsløsning, segmentering og analyse. På samme måte bruker masseinntak fra Salesforce Clouds – som Sales, Service eller Marketing Cloud – innebygde koblinger og datastrømmer til å bringe CRM-data inn i det forente datalaget, og sikre harmonisering og kontinuitet på tvers av systemer med engasjement.
- Streaming- og sanntidsinntaksmønstre utvider dette ved å fange opp hendelsesdata med høy hastighet. Hendelsesdrevet inntak via Inntaks-API gir eksterne systemer mulighet til kontinuerlig å strømme kundeaktivitet til Data 360. Inntak av sanntids nett- og mobilvirkemåte fanger opp klikkstrøm- og interaksjonsdata direkte fra digitale kontaktpunkter for å få umiddelbar tilpassing. Nær sanntids CRM-synkronisering via Streaming API-er sikrer at kundeattributter og samtykkeoppdateringer gjenspeiles raskt på tvers av systemer. Hendelsesstrøminntak fra meldingsplattformer som Amazon Kinesis eller Confluent MSK støtter kontinuerlige pipelines med stor gjennomstrømning, og justerer Data 360 med organisasjonshendelsesarkitekturer.
- Unified Multi-Org Data Platform med Data Cloud One illustrerer ytterligere dataintegrering og gir et konsolidert miljø for å forene data fra flere Salesforce-organisasjoner og eksterne kilder under et felles styrings- og semantisk lag. Dette gir organisasjoner mulighet til å oppnå konsistens i hele virksomheten, delte datamodeller og skalerbar analyse.
- I aktiveringsfasen følger batchaktiveringsmønstre samme dataintegreringsprinsipp. Segmenter som kurateres i Data 360, eksporteres i planlagte jobber til nedstrøms markedsførings- og annonseringsplattformer – som Marketing Cloud, Meta Ads eller Google Ads – der de utløser utførelse av kampanjer. På samme måte kan datasett eksporteres til skylagringsmål for å fremme eksterne analyser og datavitenskap under behandling. I alle disse brukstilfellene fungerer Data 360 som sannhetskilde for synkroniserte og kuraterte kundedata.
Prosessintegreringsmønstre i Data 360 involverer utløsing eller orkestrering av forretningsprosesser på tvers av systemer i nærSanntid. Disse mønstrene tillater at Data 360 deltar aktivt i arbeidsflyter i virksomheten, og aktiverer kontekstuelle svar og aktivering av dynamiske data.
- API-basert aktivering på forespørsel muliggjør engasjementsscenarier i sanntid. Via Connect API kan tilpassede programmer spørre eller aktivere kundeprofiler direkte fra Data 360 som en del av driftsprosesser, som en agentkonsoll som henter forent profilinnsikt under en kundeinteraksjon. Complete Customer Profile Retrieval via Data Graph API støtter sammensatte programmer og mikrotjenester som er avhengige av API-drevet tilgang til en kundes fullstendige enhetsgraf, noe som gir dynamiske opplevelser uten forhåndsfasede segmenter.
- Sanntids datahandlinger fremhever denne integrasjonstilnærmingen ytterligere ved å aktivere umiddelbar responsivitet. Når et kundesignal, som et kjøp, en innsending av skjema eller en terskelhendelse, oppdages, kan Data 360 utløse handlinger som å oppdatere en CRM-post, kalle opp en ekstern webhook eller starte en tilpasset tilbudsarbeidsflyt. Disse mønstrene innebærer sann prosessorkestrering, som bygger bro mellom sanntids Kundeintelligens og automatisert driftsutførelse.
Virtuelle integrasjonsmønstre i Data 360 gir direkte tilgang til eksterne eller forente datakilder uten å kopiere eller duplisere data fysisk. Disse er avgjørende for virksomheter som krever styrt, oppdatert informasjon på spørringstidspunktet samtidig som dataflyten minimeres.
- Med Inbound Zero Copy Data Federation (External Platforms-to-Data 360) kan eksterne systemer, som datalagrer eller datasjøer, dele datasett med Data 360 via sikre, administrerte tilkoblinger (for eksempel sikker datadeling med Snowflake). Dette sikrer at Data 360 kan få tilgang til og operere på eksterne data virtuelt, og dermed beholde friskhet og eliminere unødvendig replikering.
- Outbound Zero Copy Data Sharing (Data 360-til-ekstern plattformer) gjør det mulig for Data 360 å eksponere kuraterte datasett for ekstern forbruk, som AI-modellering, forretningsintelligens eller avansert analyse, gjennom sikre dataforbunds- og direktespørringsmekanismer. Å velge den beste integreringsstrategien for systemet er ikke noe trivielt. Det er mange aspekter å vurdere og mange verktøy som kan brukes, med noen verktøy som er mer passende enn andre for bestemte oppgaver. Hvert mønster tar seg av bestemte kritiske områder, inkludert funksjonaliteten til hvert av systemene, datavolumet, feilhåndtering og transaksjonalitet.
Når du velger et integrasjonsmønster, starter du med å svare på to grunnleggende spørsmål som former den generelle utformingen og virkemåten til integrasjonen. Hva integrerer du? – Prosess-, Data- eller Virtuell tilgang Denne dimensjonen definerer det primære formålet med integrasjonen.
- Prosessintegrasjoner fokuserer på å orkestrere forretningsarbeidsflyter og koordinere handlinger på tvers av systemer.
- Dataintegrasjoner fokuserer på å synkronisere, berike eller overføre data mellom systemer.
- Virtuelle integrasjoner fokuserer på å få tilgang til eksterne data i sanntid uten å kopiere eller beholde dem i Salesforce eller Data 360. Forståelse av denne hensikten bidrar til å bestemme nivået av orkestrering, dataflytting og kobling som kreves mellom systemer.
- Hvordan må den utføres? – Synkron eller asynkron metode definerer utførelsesmodellen for integrasjonen.
- Synkrone integrasjoner er sanntids og blokkerende, der anroperen forventer en umiddelbar respons – vanligvis brukt til brukerdrevne eller valideringsscenarier.
- Asynkrone integrasjoner er ikke-blokkerende og frakoblet, utformet for å håndtere skalering, langvarige prosesser, repetisjoner og store datavolumer. Sammen gir disse to dimensjonene – integreringsformålet og utførelsestidspunktet – et klart og konsistent rammeverk for å velge riktig integrasjonsmønster samtidig som brukeropplevelsen, skalerbarheten og driftsresiliensen balanseres. Note: En integrasjon kan kreve en ekstern mellomprogramvare eller integrasjonsløsning (for eksempel Enterprise Service Bus) avhengig av hvilke aspekter som gjelder for integreringsscenariet.
Denne tabellen viser mønstrene og deres viktige aspekter for å hjelpe deg med å finne ut hvilket mønster som passer best til behovene dine når integrasjonen er fra Salesforce til et annet system.
| Type | Tidsplan | Utgående vurderinger |
|---|---|---|
| Dataintegrering | Asynkron | Segmentaktivering til markedsførings- og reklameplattformer |
| Prosess/dataintegrering | Synkron | Tilpasset programintegrering via Connect API Komplett kundeprofilering via Data Graph API |
| Dataintegrering | Synkron | Sanntids datahandling som gjør kundesignaler til umiddelbar handling |
| Virtuell integrasjon (ved bruk av nullkopi) | Asynkron | Outbound Zero Copy – Data 360 til eksterne plattformer |
| Virtuell integrasjon | Asynkron | Forent dataplattform for flere organisasjoner med Data Cloud One |
Denne tabellen viser mønstrene og deres viktige aspekter for å hjelpe deg med å finne det mønsteret som passer best til behovene dine når integrasjonen er fra et annet system til Salesforce.
| Type | Tidsplan | Innkommende vurderinger |
|---|---|---|
| Dataintegrering | Asynkron | Bulk datainntak fra skylagring Masseinntak av data fra Salesforce Clouds |
| Dataintegrering | Asynkron | Event Stream-inntak fra Cloud Messaging Platforms – Kinesis og MSK Nær sanntid CRM Synchronization via Streaming |
| Prosessintegrering | Synkron | Event Driven Inntaks via Inntaks-API--Streaming Sanntids nett- og mobilvirkemåteinntak |
| Virtuell integrasjon | Asynkron | Inbound Zero Copy – Eksterne plattformer til Data 360 |
Denne tabellen viser noen viktige termer relatert til mellomprodukter og deres definisjoner med hensyn til disse mønstrene.
| Term | Definisjon |
|---|---|
| Håndtering av hendelser | Hendelsesbehandling henviser til å motta, rute og svare på identifiserbare forekomster fra et kildesystem eller program. Mellomprogramvare håndterer hendelser ved å identifisere målendepunktet, videresende hendelsen og utløse den nødvendige forretningshandlingen (for eksempel logging, nye forsøk eller aktivering av nedstrøms tjenester). I Data 360-arkitekturer er hendelsesbehandling avgjørende for sanntids datainntak, aktiveringsutløsere og publiserings- og abonnementsmønstre. Hendelser kan komme fra eksterne systemer (Kafka, AWS Kinesis) eller Salesforce Platform-hendelser og rutes av mellomprogramvare eller datahendelsesbussen 360 for umiddelbar behandling. |
| Protokollkonvertering | Protokolkonvertering tillater kommunikasjon mellom systemer som bruker forskjellige datatransportstandarder. Mellomprogramvare oversetter proprietære eller eldre protokoller (som AMQP, MQTT, FTP) til støttede Data 360-protokoller (REST, gRPC eller HTTPS). Dette sikrer interoperabilitet på tvers av heterogene systemer. I og med at Data 360 ikke håndterer protokollkonvertering som standard, sørger mellomprogramvaren for tilpassingssjiktet ved innkapsling eller transformasjon av meldinger til et format som Data 360-API-er og -koblinger kan tolke. |
| Oversettelse og transformasjon | Oversettelse og transformasjon sikrer interoperabilitet ved å tilordne ett dataformat eller et skjema til et annet. Middleware utfører disse transformasjonene for å justere ulike datarelaterte belastninger (CSV, XML, JSON) med datamodellobjekter (DMO-er) for Data 360 og forente datalagobjekter (UDLO-er). Dette inkluderer å rydde, berike og bruke semantisk eller ontologibasert tilordning før inntak. Salesforce tilbyr transformasjonsverktøy som Dataklargjøringsoppskrifter, men komplekse transformasjoner (spesielt for semantisk harmonisering) håndteres best i mellomprodukter. |
| Kø og bufring | Kø og bufring er avhengig av at asynkron melding overføres for å sikre fleksibel, frakoblet kommunikasjon. Mellomprogramvareplattformer (for eksempel MuleSoft, Kafka eller Azure Event Hub) har faste køer som midlertidig lagrer data når Data 360- eller nedstrømsystemer er opptatt eller utilgjengelige. Dette hindrer tap av data og støtter inntak eller aktiveringsforsøk i nær sanntid. Data 360 støtter strømmede inntak og flytbaserte utgående meldinger, men holdbar kø og garantert levering håndteres vanligvis av mellomprogramvare. |
| Synkrone transportprotokoller | Synkrone transportprotokoller involverer blokkering, forespørsels-/svaroperasjoner i sanntid. Avsenderen venter på et svar før den fortsetter. I Data 360 brukes disse til API-baserte aktiveringer på forespørsel, sanntidsforbedring eller profiloppslag der det kreves svar umiddelbart. Mellomprogramvare sikrer tilkoblingssikkerhet og administrerer nye forsøk eller reservebehandling for synkrone Data 360 API-kall. |
| Asynkrone transportprotokoller | Asynkrone transportprotokoller støtter ikke-blokkerende, frakoblet kommunikasjon der avsenderen fortsetter å behandle uten å vente på et svar. Mellomprogramvare håndterer asynkrone flyter for gruppeaktiveringer, strømmede inntak og hendelsesdrevet aktivering. Dette tillater høy gjennomstrømning og fleksibilitet – avgjørende for hendelsesstrømming og mønstre for inntak av data i nær sanntid i Data 360. |
| Mediation Routing | Medieringsruting definerer kompleks meldingsflyt mellom systemer for å sikre at de riktige dataene eller hendelsen når den riktige forbrukeren. Mellomprogramvare fungerer som mediator og håndterer rutingslogikk basert på regler, topptekster, innhold eller hendelsestype. I Data 360-integrasjoner sikrer formidling at hendelser og profiloppdateringer fra flere systemer rutes riktig til Datainntak-API-er, aktiveringsendepunkter eller eksterne forbrukere. Dette forenkler orkestrering og støtter datasynkronisering med flere systemer. |
| Prosess koreografi og serviceorkestrering | Prosess koreografi og orkestrering koordinerer prosesser med flere systemer. Koreografi støtter autonome, asynkrone hendelsesdrevne flyter der systemer handler basert på delte regler uten en sentral kontroller. Orchestration er en sentralt administrert flyt som dirigerer tjenesteutførelse. I Data 360-arkitekturer administrerer middleware orkestrering for inntak og aktivering på tvers av systemer, mens Salesforce-arbeidsflyter eller flyter håndterer lette koreografier i plattformen. Komplekst orkestrering, som krever transaksjonskoordinering eller statusbehandling, anbefales på mellomliggende lag. |
| Transaksjonalitet (kryptering, signering, pålitelig levering, transaksjonsbehandling) | Transaksjonalitet sikrer atomiske, konsistente, isolerte og varige (ACID)-operasjoner på tvers av systemer. Salesforce og Data 360 er transaksjonelle innenfor sine grenser, men støtter ikke distribuerte transaksjoner på tvers av eksterne systemer. Mellomprogramvaren håndterer global transaksjonskontroll, inkludert kryptering, meldingssignering, tilbakeføring, kompensasjon og pålitelig levering. For oppgavekritiske dataflyter (for eksempel økonomiske eller samtykkeoppdateringer) sikrer mellomliggende programvare integritet og gjenoppretting på tvers av Data 360- og eksterne systemer. |
| Ruting | Ruting angir den kontrollerte flyten av meldinger eller data mellom komponenter. Den kan være basert på hoder, innholdstype, prioritet eller regler. Mellomprogramvare håndterer rutingslogikk for hendelser og aktiveringer som involverer Data 360, som å dirigere beregnede målgruppesegmenter til forskjellige nedstrøms systemer (annonseplattformer, lagre, CRM-apper). Selv om ruting kan implementeres i Salesforce (Apex, Flyter), foretrekkes mellomprogramruting for skalerbarhet, fleksibilitet og styring. |
| Uttrekk, transformasjon og innlasting (ETL) | ETL innebærer å trekke ut data fra kildesystemer, transformere dem til et konsistent skjema og laste dem inn i et mål (som Data 360). Mellomprogram- eller ETL-verktøy håndterer disse operasjonene før datainntak. Data 360 kan motta ETL-utdata via API-er, koblinger eller masseinntak under behandling, og støtter også CDC (Change datafangst) for synkronisering i nær sanntid. ETL-prosesser i mellomprogramvare er viktig for å integrere eldre systemer og sikre datakvalitet før forening i Data 360. |
| Lang avstemming | Lang avspørring (kometprogrammering) er en metode for å opprettholde åpen kommunikasjon mellom systemer for sanntidsoppdateringer. Klienten sender en forespørsel, og serveren beholder den til en hendelse skjer, deretter svarer og åpner en ny tilkobling på nytt. Salesforce bruker dette i Streaming API- og CometD/Bayeux-protokollene til hendelsesdrevet datasynkronisering. Mellomprogramvare kan abonnere på disse hendelsene og videresende dem til Data 360 for sanntids inntak eller aktiveringsutløsere, noe som sikrer minimal latens på tvers av virksomhetssystemer. |
Datainntak er det første og viktigste trinnet i Salesforce Data 360s livssyklus for data. Det er slik råinformasjon fra flere eksterne systemer – CRM, ERP, nett-, mobil- eller tredjeparts API-er – kommer inn i plattformen og blir en del av en forent kundevisning. Det riktige inntaksmønsteret avhenger av hva virksomheten trenger:
- Datavolum – hvor mye data som flyttes samtidig
- Latency – hvor oppdaterte dataene må være
- Kildesystemfunksjoner – hvordan systemet kan koble til og levere data Data 360 støtter flere inntaksmoduser for å dekke disse behovene: batch for innlastinger med stor trafikk, strømming for oppdateringer i nær sanntid, hendelsesbasert for umiddelbar transaksjon og Zero Copy-inntak for umiddelbar tilgang til eksterne data uten å flytte dem fysisk. Sammen sikrer disse mønstrene at hvert kundesignal – enten det er en kjøpshendelse, en klikkstrømlogg eller en lojalitetsoppdatering – flyter inn i Data 360 effektivt, sikkert og i riktig tidsramme for å levere klarert analyse og AI-drevne opplevelser.
Mønstre for gruppeinntak er ryggraden i introduksjon av data i stor skala i Data 360. De er optimalisert for scenarier der data behandles samlet – vanligvis på en planlagt eller periodisk basis – i stedet for kontinuerlig. Disse mønstrene passer best for:
- Historiske datalastinger for å initialisere plattformen med eksisterende forretningsposter
- Regelmessig synkronisering med postsystemer som ERP, datalager eller proprietære databaser
- Brukstilfeller der sanntidsoppdatering ikke er avgjørende, men konsistens, fullstendighet og revisjonskapasitet er avgjørende Gruppeinntak tilbyr forutsigbar ytelse og operasjonell enkelhet, noe som gjør det til et klarert valg for virksomheter som behandler terabyte med strukturerte eller semi-strukturerte data. Data 360 tilbyr et sett produksjonsklare, allment tilgjengelige koblinger som støtter gruppeinntak som standard. Disse koblingene effektiviserer integrasjonsoppsettet, reduserer tilpasset ETL-utvikling og sikrer datakvalitet og sikkerhet på tvers av hver import. Tabellen nedenfor fremhever de vanligste koblingene som brukes til batchinntak i bedriftsskala.
Kontekst
Dette mønsteret er utformet for virksomhetsscenarier som involverer inntak av store mengder strukturerte data, som CSV- eller Parket-filer, og ustrukturerte aktiva fra sentraliserte datasjøer eller planlagte filslipp. Datakilder inkluderer vanligvis skylagringsplattformer som Amazon S3, Google Cloud Storage (GCS) og Microsoft Azure Blob Storage, der filer leveres regelmessig som del av oppstrøms data under behandling eller gruppeksporter.
Problem
Hvordan kan en organisasjon etablere en pålitelig, sikker og omfattende prosess for å hente inn store, filbaserte datasett fra sin primære skylagringsplattform til Data 360 på en forutsigbar, gjentagende tidsplan – uten å ofre styring, skalerbarhet eller ytelse?
Styrker
Å hente inn massive, filbaserte datasett i Data 360 er ikke en enkel dataoverføringsøvelse – det er en arkitektonisk utfordring som er formet av skala, styring og plattformbegrensninger.
Datavolum og skalering : Data 360-inntakskoblinger er optimalisert for pålitelighet og styring, ikke vilkårlig masseinntak. Amazon S3-koblingen støtter for eksempel opptil 100 millioner rader eller 50 GB per objekt avhengig av hvilken grense som nås først. For virksomheter med historiske datasett som kjører i milliarder av poster, blir denne grensen en viktig designbegrensning. En enkeltfil, løft-og-skift-tilnærming blir raskt ikke mulig, og krever intelligente datapartisjonerings-, fordeling- og orkestreringsstrategier for å oppnå skalering uten å nå koblingsgrenser.
Skjemadefinisjon og vedlikehold : Data 360 krever eksplisitte skjemadefinisjoner for hver inntaksflyt for å sikre semantisk og strukturell integritet. I tilfelle av S3-inntak må en CSV-fil definere kolonneoverskrifter og en enkelt representativ datarad. Denne filen fungerer som den kanoniske kontrakten mellom kildesystemet, det vil si skylagring og Data 360. Eventuelle feiljusteringer – i feltnavn, datatyper eller koding – kan føre til inntaksfeil eller ødeleggelse av stille data. Vedlikehold av denne skjemafilen i versjonskontroll og håndheving av validering via CI/CD- eller datastyringsarbeidsflyter blir en god fremgangsmåte for produksjonsmiljøer.
Streng navngivingskonvensjoner: Data 360 håndhever strenge objekt- og feltnavnregler for å opprettholde konsistens på tvers av metadatadiagrammet.
- Objektnavn må starte med en bokstav og kan bare inneholde bokstaver, sifre eller understrekingstegn.
- Feltnavn må følge de samme mønstrene. Filer som bryter disse konvensjonene, for eksempel felt som inneholder mellomrom, spesialtegn eller symboler som ikke støttes, vil mislykkes med skjemavalideringen under inntak. Virksomheter må implementere hygieneprosesser for data før inntak for å sanitere og normalisere innkommende filstrukturer.
Godkjennings- og sikkerhetstilstand: Hver tilkobling til eksternt lagringsplass må samsvare med sikkerhets- og samsvarsstandarder på bedriftsnivå.
- Godkjenning håndteres vanligvis via AWS-tilgang/hemmelige nøkler eller godkjenning med forent identitetsleverandør (IdP).
- IAM-roller må ha omfang for å håndheve minste rettigheter og gi bare lesetilgang til de angitte lagringsbanene.
- For å få sikker tilgang må utgående IP-adresser legges til direkte i kildesystemets tillatelsesliste. Disse lagdelte kontrollene sikrer at alle filoverføringer opererer innenfor en Trust-omfang som kan revideres, og balanserer virksomhetens overholdelse av kravene med fleksibiliteten som kreves for storskala inntak.
Løsning
Denne tabellen inneholder løsninger på dette integrasjonsproblemet.
| Løsning | Tilpass | Kommentarer |
|---|---|---|
| Bruke Native Cloud Storage-koblinger (Amazon S3, Google Cloud Storage, Azure Blob Storage) | Best | Dette er det anbefalte og mest pålitelige mønsteret for storskala, gjentagende filbasert inntak i Data 360\. Innebygde koblinger sørger for administrert godkjenning, skjematilordning og sikker dataflytting direkte til Datasjøobjektene (DLO-er) i Data 360. Ideelt for planlagte batchinnlastinger der latens ikke er kritisk (for eksempel planlegging per time eller daglig). |
| Håndtering av store datasett (ut over koblingsgrenser) | Best med forhåndsbehandling | Hver kobling håndhever inntaksgrenser (for eksempel S3: 100M rader eller 50 GB per objekt). For større datasett implementerer du et ETL-forhåndsbehandlingstrinn for å partisjonere data i mindre filer/mapper som faller under disse tersklene. Konfigurer deretter flere datastrømmer til å hente inn hver partisjon parallelt, og bruk tilføyningsnoden i en gruppedata-transformasjon) i Data 360 til å kombinere partisjonene på nytt til et forent datasett. |
| Sikkerhet og styring | Best | Alle koblinger støtter sikker godkjenning via skybaserte metoder (IAM-roller, tjenestekontoer eller tilgangsnøkler). For å få mer kontroll begrenser du tilgang til Data 360-IP-områder via skyleverandørens tillatelsesliste. Dataoverføring skjer over krypterte kanaler, med filer lagret i et midlertidig, sikkert oppstillingslag under inntak. |
| Når den ikke kan brukes | Underoptimalt | Dette mønsteret er ikke optimalt for
|
Skisse
Dette diagrammet illustrerer en sekvens av trinn for å hente inn data fra skylagring til Data 360
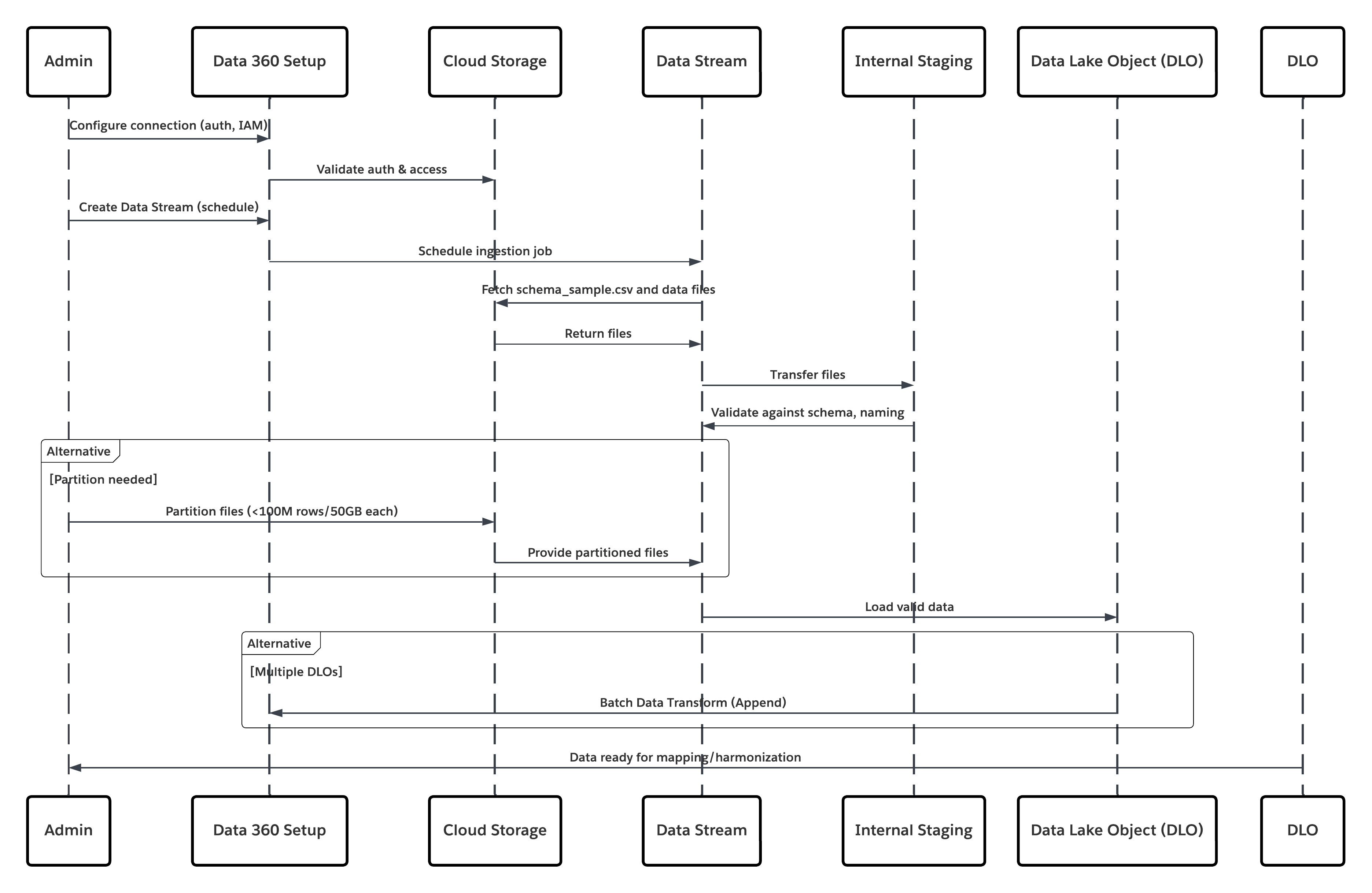
I dette scenariet:
- Administrator konfigurerer en tilkobling til skylagring via Data 360-oppsettgrensesnittet (angir godkjenning, samlekategoridetaljer, IAM-roller og hviteliste).
- Data Cloud-oppsettgrensesnittet godkjennes med Cloud Storage Platform og bekrefter legitimasjon og tilgang.
- Administrator oppretter en datastrøm i Data 360, kobler datastrømmen til objektet/mappen i Cloud Storage og definerer inntaksplanen.
- I tidsplanutløseren ber datastrømmen om kildefiler (for eksempel CSV, Parket) fra skylagringsplattformen.
- Cloud Storage Platform leverer filer, inkludert den nødvendige gyldige schema_sample.csv og andre datafiler som samsvarer med navnekonvensjoner.
- Datastrøm overfører filer til det interne oppstillingsmiljøet i Data 360.
- Data 360 Pipeline behandler filene: Bruker skjemadefinisjonen fra schema_sample.csv Validerer struktur, feltnavn og deler innlastingen hvis det er over inntaks terskler (100 millioner rader/50 GB per fil). Hvis store filer oppdages, utføres et forhåndsbehandlingspartisjoneringstrinn (varsles administrator for neste kjøring) eksternt.
- Poster importeres fra oppstillingen til et datasjøobjekt (DLO).
- Hvis nødvendig og data er partisjonert, bruker du append-noden i en gruppedatatatransformasjon for å kombinere flere DLO-er.
- Data 360 logger suksess/suksess, oppdaterer status for overvåking og signaliserer at data er klare for tilordning, harmonisering og forening.
Resultater
Bruk av dette mønsteret muliggjør sikker, planlagt og storskala inntak av strukturerte eller ustrukturerte filer fra Enterprise Cloud Storage Platforms til Data 360. Prosessen er automatisert, skalerbar og fleksibel – leverer rådata til datasjøobjekter (DLO-er) som tjener som grunnlag for harmonisering og tilordning til Customer 360.
Inntaksmekanismer
Inntaksmekanismen avhenger av koblings- og planleggingsstrategien som er definert i Data 360.
| Inntaksmekanisme | Beskrivelse |
|---|---|
| Native Cloud Storage Connector (Amazon S3, GCS, Azure) | Anbefales for direkte inntak av filer i CSV- eller Parket-format fra virksomhetens skydatasjø. Disse koblingene støtter inkrementelle og full oppdateringsplaner. En bank kan for eksempel konfigurere en daglig synkronisering av kundetransaksjonsfiler fra en S3-samlekategori til en DLO. |
| Partisjonert filstrategi | For meget store datasett (ut over 100 millioner rader eller 50 GB per objekt) partisjoneres dataene i mindre logiske sett (for eksempel etter måned eller område). Hver partisjon behandles som en separat datastrøm og kombineres senere med en gruppedatatatransformasjon med en Føy til-node. |
| Automatisert planlagt synkronisering | Data 360 leverer en deklarativ planlegger (timer, dager eller tilpasset kadens) som utløser inntaksjobber automatisk og sikrer datafriskhet uten manuell intervensjon. |
Feilhåndtering og gjenoppretting
Feilhåndtering og gjenoppretting er avgjørende for å sikre pålitelighet i inntaksoperasjoner med stor trafikk.
- Feildeteksjon: Hver Datastrøm-kjøring logger inntaksfeil (for eksempel skjemafeil, filskader eller navngivingsbrudd) i Data 360-overvåking. Administratorer kan se gjennom og behandle mislykkede grupper på nytt.
- Gjenopprettingsmekanisme: Data 360 vedlikeholder sjekkpunkter for å sikre at mislykkede batcher ikke ødelegger tidligere inntak. Gjenopptagelser kan konfigureres etter å ha rettet opp kildeproblemer (for eksempel feil utformede CSV-filer).
- Skjemavalidering: schema_sample.csv-filen definerer datatyper og struktur. Eventuell endring utløser validering for å unngå stille skjemaavvik på tvers av kjøringer.
Viktige punkter om Idempotent-design
Inntak er idempotent etter utforming – gjenbehandling av den samme filen fører ikke til duplikatposter. Viktige strategier inkluderer følgende:
- Filavtrykk: Data 360 beregner sjekksummer for å identifisere og hoppe over tidligere behandlede filer.
- Transaksjonsinntak: Data er faset og bare bekreftet til DLO ved vellykket behandling av alle poster.
- Føy til kontra. Erstatt: Avhengig av forretningslogikk kan strømmer føyes til eller fullstendig erstatte mål-DLO. Dette sikrer deterministiske utfall og hindrer delvis dataoverlapping.
Sikkerhetsvurderinger
Sikkerhet er integrert i hele inntaksprosessen, fra godkjenning til kryptering og tilgangskontroll.
- Godkjenning og godkjenning: Koblinger bruker Salesforces sikre integrasjonsrammeverk og benytter navngitt legitimasjon og ekstern legitimasjon til godkjenning uten å vise hemmeligheter.
- Kryptering: Data krypteres underveis (TLS 1.2+) og under lagring (AES-256).
- Nettverkskontroller: Kildelagringssystemer (for eksempel S3-samlekategorier) må ha Data 360-IP-adresser i tillatelseslisten.
- Samsvar Justering: Støtter databeskyttelsesrammeverk for virksomheter som GDPR, HIPAA og FFIEC-retningslinjer når de er paret med Kundeadministrerte nøkler (CMK).
- Revisjonsmuligheter: Hver inntaksjobb og legitimasjonstilgang logges for sporbarhet og samsvarsrapportering.
Sidefelt
Tidlighet
Tidspunktet avhenger av inntaksplanen og datavolumet.
- Store bedriftsdatasett (100M+ rader) kan kreve partisjonering for parallelt inntak.
- Typisk inntakslatens varierer fra minutter til noen timer, avhengig av filstørrelse og transformasjonskompleksitet.
- For inntak i nær sanntid kan Data 360 Streaming eller API-baserte koblinger supplere den filbaserte modellen.
Datavolumer
- Best egnet for inntak av periodiske batcher med stor trafikk.
- Hvert objekt som behandles via S3-koblingen, støtter opptil 100 millioner rader eller 50 GB per fil.
- For systemer i petabyte-skala bruker du datapartisjonering og orkestrering med flere strømmer.
Støtte for endepunktsfunksjonalitet og standarder
Funksjonaliteten og standardstøtten for endepunktet avhenger av løsningen du velger.
| Koblingstype | Krav til sluttpunkt |
|---|---|
| Amazon S3-kobling | S3-samlekategori med riktig IAM-policy og skjema\_sample.csv-fil som definerer skjemaet. |
| Google Cloud Storage-kobling | Tjenestekontolegitimasjon og samlekategoritilgang med ensartede navnekonvensjoner. |
| Azure Storage-kobling | Tilgang til nøkkel- eller SAS-tokenbasert godkjenning. Blob- eller mappestrukturen må følge Data 360-konvensjonene. |
Statbehandling
Status spores gjennom datastrømmer og deres tidsstempel for siste vellykkede kjøring.
- Data 360 opprettholder automatisk synkroniseringsstatuser og forskyvninger slik at bare nye eller endrede filer behandles ved etterfølgende kjøringer.
- Når du integrerer med eksterne ETL-verktøy, anbefales det å bruke unike filidentifikatorer (for eksempel UUID-er eller tidsstempler) for å unngå duplisering.
Komplekse integrasjonsscenarier
I avanserte forretningsarkitekturer kan dette mønsteret integreres med
- Middleware ETL Pipelines (f.eks. Informatica, MuleSoft): for å orkestrere forhåndsbehandling, validering og filpartisjonering før overføring til Data 360.
- AI/ML-arbeidsflyter: Behandlede DLO-data kan publiseres via DMO til modellopplæringsmiljøer eller RAG-indekser via Data 360-aktiveringsmål.
- Transaksjonssystemer: harmoniserte DMO-er kan utløse nedstrøms oppdateringer i Salesforce CRM eller eksterne systemer via datahandlinger eller plattformhendelser.
Eksempel
En global finansinstitusjon lagrer kundedata og transaksjonsdata i en AWS S3-datasjø, der partisjonerte Parket-filer genereres nattvis etter region (som USA, EU og APAC). Dataarkitekturteamet konfigurerer flere datastrømmer i Data 360, hver koblet til en regional mappe, med en delt schema_sample.csv som sikrer ensartede topptekster og datatyper på tvers av alle partisjoner. Nattlige inntaksplaner laster automatisk inn dataene i DLO-er, og deretter føyer gruppedatatatransformasjoner til alle regionale partisjoner i et forent Customer_Transactions_DLO. Dette harmoniserte datasettet tilordnes deretter til Customer 360 for å aktivere nedstrøms analyse og AI-aktivering. Tilnærmingen leverer automatisert og pålitelig inntak fra den eksisterende datasjøen, håndhever sterk godkjenning og kryptering i samsvar med IT-policyer for virksomheten, og gir et skalerbart, modulært grunnlag som støtter fremtidig utvidelse og skjemautvikling.
Kontekst
Et primært og viktig bruksområde for Data 360 er å forene kundedata på tvers av Salesforce-økosystemet. Dette mønsteret dekker innebygd inntak av data fra Salesforce-kjerneplattformer – Sales Cloud og Service Cloud (samlet Salesforce CRM) og Marketing Cloud-engasjement. Kilder inkluderer standard og tilpassede CRM-objekter (for eksempel Konto, Kontakt, Sak, Salgsmulighet) og Marketing Cloud-engasjementsdatautvidelser som inneholder engasjementshendelser, e-postsendinger og sporingsdata.
Problem
Hvordan kan en organisasjon effektivt og pålitelig hente inn standard CRM-objekter og tilpassede CRM-objekter og Marketing Cloud Engagement-datautvidelser til Data 360, slik at dataene kan brukes til å bygge forente kundeprofiler (identitetsløsning, Customer 360), samtidig som ytelse, styring og minimale avbrudd i kildesystemer opprettholdes?
Styrker
Innebygde koblinger forenkler jobben, men flere operasjonelle og arkitektoniske krefter må håndteres:
- Omfattende kildetillatelser: En dedikert tilkoblingsbruker (integreringskonto) må ha riktige lesetillatelser på objekt- og feltnivå. Mislykket tildeling av nødvendige tillatelsessett (for eksempel et forhåndsbygd Data 360-koblingstillatelsessett) er en vanlig årsak til inntaksfeil.
- Dataoppdateringsmoduser og kostnad: Koblinger støtter oppdateringsmoduser full og delta/inkrementell. Full oppdatering er tyngre på ytelse og kreditter. deltauttrekk reduserer belastningen, men er avhengig av pålitelig endringssporing i kildesystemet.
- Tilpasset skjema og felttilordning: CRM-forekomster inkluderer ofte tilpassede objekter/felt. Nøyaktig skjematilordning og håndtering av tilpassede felt (navn, typer) kreves for å unngå tilordningsfeil eller semantisk avvik.
- Startdatapakker kontra Tilpasset tilordning: Startdatapakker øker hastigheten på introduksjonen ved å forhåndsvelge typiske objekter/felt, men mye tilpassede organisasjoner trenger tilpassede strømdefinisjoner.
- Gjennomløps- og API-grenser: Kildeorganisasjons API-grenser og Marketing Cloud-uttrekksrater begrenser hvor aggressivt du kan planlegge oppdateringer.
- Data Hygiene og navngivingskonvensjoner: Kildefeltnavn, null-virkemåte og datatyper må normaliseres før inntak for å unngå problemer med nedstrøms tilordning.
- Sikkerhet og minst privilegium: Koblingen er avhengig av sikker godkjenning og må respektere IAM-mønstre med minst rettigheter, revisjonskapasitet og nettverkskontroller.
Løsning
Denne tabellen inneholder løsninger på dette integrasjonsproblemet.
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| Løsningstilpasset | Best | Bruk den innebygde Salesforce CRM-koblingen og Marketing Cloud Engagement-koblingen i Data 360\. Start med Startdatapakker for standardbrukstilfeller og øk hastigheten på introduksjonen. Bruk manuell strømtilpassing for tilpassede eller domenespesifikke datamodeller. |
| Håndtering av svært tilpassede CRM-forekomster | Best med tilordningsverksted | Behandle startpakker som en standard, og utfør en tilordningsarbeidsplass for å identifisere: Tilpassede objekter og relasjoner. Formelfelt eller beregnede felt. Utvidelser for administrert pakke. For store formelfelt beregner du verdier i et forfase-ETL eller i Data 360-transformasjoner for å minimere API-belastningen i kildeorganisasjoner. |
| Når den ikke kan brukes | Underoptimale scenarier | Unngå dette mønsteret hvis Du trenger inntak av hendelser med høy frekvens eller i sanntid (bruk i stedet Streaming-koblinger, plattformhendelser eller Zero-Copy-forbund). Kildeorganisasjonen har begrenset API-kapasitet og kan ikke vedlikeholde planlagte uttrekk uten trussel eller køforsinkelser. |
| Sikkerhet og styring | Obligatoriske kontroller | Principle of Least Privilege - Bruk en dedikert integrasjonsbruker med minimal lesetilgang. Bruk aldri organisasjonsomfattende administratorer. Godkjenning: Bruk OAuth 2.0 og tilkoblede apper, roter klienthemmeligheter regelmessig og overvåk bruk av oppdateringstoken. Revisjon og sporbarhet – Logg alle inntakskjøringer, skjemaendringer og koblingshendelser. Videresend logger til SIEM eller samsvarssystemer for revisjonsklargjøring. Dataklassifisering – Bruk PII/PHI-koding og Attributtbasert tilgangskontroll (ABAC) ved å bruke CEDAR-policyer umiddelbart etter inntak for å håndheve maskering, samtykke og nedstrøms samsvar. |
Skisse
Dette diagrammet illustrerer en sekvens av trinn for å hente inn data fra skylagring til Data 360
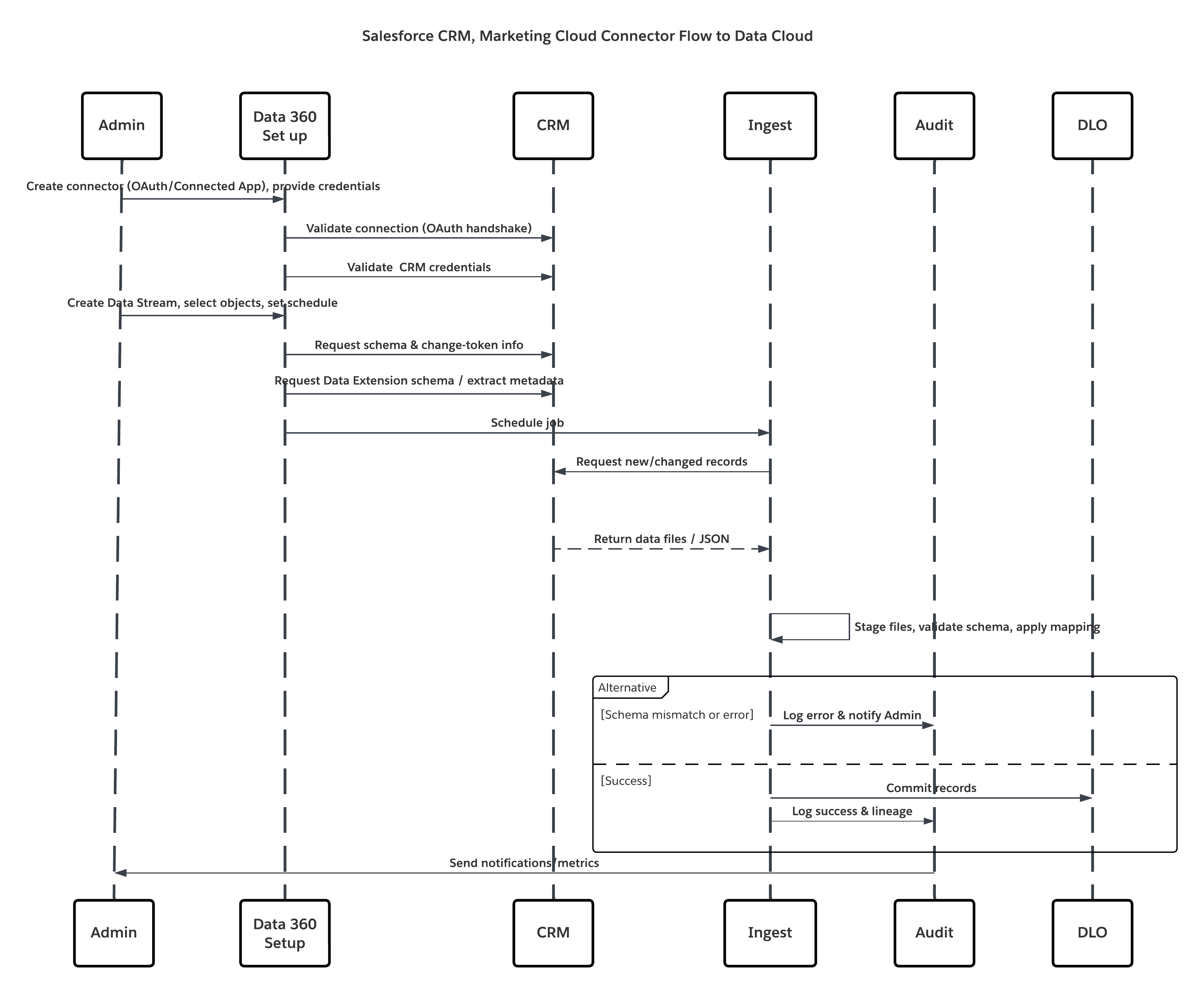
I dette scenariet:
- Administrator klargjør integrasjonsbrukere og tildeler koblingstillatelsessett i kildeorganisasjoner.
- Administrator konfigurerer koblinger i Oppsett for Data 360 (kobler til Salesforce CRM og Marketing Cloud via OAuth/tilkoblet app).
- Administrator oppretter datastrømmer som velger objekter og datautvidelser, velger full eller delta oppdatering og angir tidsplaner.
- På planlagt kjøring ber Data 360 om skjema- og delta-tokener fra kilden(e).
- Kildesystemer returnerer poster (delta eller full last). Marketing Cloud kan levere uttrekk, og CRM kan returnere JSON/Query-resultater.
- Data 360 faser filer i sitt interne sikre oppstillingsområde og validerer mot tilordnet skjema.
- Hvis valideringen mislykkes, logger inntaket feil, varsler administrator og stopper bekreftelse. Hvis valideringen er vellykket, bekrefter Data 360 poster atomvis til mål-DLO.
- Overvåkings- og revisjonslogger oppdateres med linje, kjørelengde, radantall og legitimasjonsbruk. Varsler utstedt til administratorer hvis terskler eller feil utløses.
Resultater
Kjernedata om kunderelasjoner og markedsføringsengasjement hentes inn i Data 360 som Datasjøobjekter (DLO-er). Dette gir følgende:
- Enhetsdatasett som inneholder profiler, saker, salgsmuligheter og e-post/engasjementsmålinger.
- Grunnlaget for identitetsløsning og bygging av Forente persondata-profiler.
- Operativ klargjøring for nedstrøms harmonisering, anriking, AI-modellering og aktivering, samtidig som styring og revisjonsmuligheter bevares.
Inntaksmekanismer
Inntaksmekanismen avhenger av koblings- og planleggingsstrategien som er definert i Data 360.
| Mekanisme | Når skal brukes |
|---|---|
| Salesforce CRM-kobling (innebygd) | Best for standard/tilpassede CRM-objekter. støtter full oppdatering og deltaoppdatering. |
| Marketing Cloud Engagement-kobling (innebygd) | Best for datautvidelser, sender og sporingsuttrekk. Støtter full/delta-moduser. |
| Startdatapakker | Øk hastigheten på introduksjonen for vanlige Salg/Tjeneste/Marketing-objekter. |
| Tilpassede strømmer + forhåndsbehandling | Brukes når komplekse transformasjoner eller omfattende skjemanormalisering kreves. |
Feilhåndtering og gjenoppretting
Feilhåndtering og gjenoppretting er avgjørende for å sikre pålitelighet i inntaksoperasjoner med stor trafikk.
- Logger per kjøring: Hver datastrømkjøring inneholder detaljer om vellykket utførelse/feil og feil på radnivå.
- Retries & Checkpointing: Mislykkede kjøringer kan prøves på nytt etter å ha løst kilde- eller skjemaproblemer. Data 360 bruker oppstillings- og atomisk bekreftelsessemantikk.
- Varsler: Konfigurer varsler for skjemaavvik, gjentatte feil eller gap i delta-sekvens.
Viktige punkter om Idempotent-design
Inntak er idempotent etter utforming – gjenbehandling av samme fører ikke til duplikatposter. Viktige strategier inkluderer følgende:
- Endringsdeteksjon: Delta-uttrekk er avhengig av kildesystemendringsindikatorer (LastModifiedDate / datafangst av systemendringer). Kontroller at kilden har pålitelige tidsstempler/flagg.
- Fjern duplikat: Bruk unike forretningsnøkler (for eksempel Contact.ExternalId) til å fjerne eller sette inn i DLO-er.
- Transaksjonsforpliktelse: Poster fases og bekreftes bare når gruppebehandlingen er fullført.
Sikkerhetsvurderinger
Sikkerhet er integrert i hele inntaksprosessen, fra godkjenning til kryptering og tilgangskontroll.
- Godkjenning og godkjenning: Koblinger bruker Salesforces sikre integrasjonsrammeverk og benytter navngitt legitimasjon og ekstern legitimasjon til godkjenning uten å vise hemmeligheter.
- Kryptering: Data krypteres underveis (TLS 1.2+) og under lagring (AES-256).
- Nettverkskontroller: Kildelagringssystemer (for eksempel S3-samlekategorier) må ha Data 360-IP-adresser i tillatelseslisten.
- Samsvar Justering: Støtter databeskyttelsesrammeverk for virksomheter som GDPR, HIPAA og FFIEC-retningslinjer når de er paret med Kundeadministrerte nøkler (CMK).
- Revisjonsmuligheter: Hver inntaksjobb og legitimasjonstilgang logges for rapportering av sporbarhet og samsvar
Sidefelt
Tidlighet
Tidspunktet avhenger av inntaksplanen og datavolumet.
- Ideell kadens avhenger av forretningsbehov – time for nær sanntidsmarkedsføringsutløsere, natt for store avstemminger.
- Delta-moduser reduserer belastningen og kostnadene. Full oppdatering er tyngre og brukes til første innlasting eller store skjemaendringer.
Datavolumer
- CRM-koblinger er optimalisert for transaksjonsdatasett og datasett med middels trafikk (millioner poster).
- For ekstremt store historiske volumer kan du vurdere faset ETL for å partisjonere og laste inn i faser.
Støtte for endepunktsfunksjonalitet og standarder
Funksjonaliteten og standardstøtten for endepunktet avhenger av løsningen du velger.
| Kobling | Krav til sluttpunkt |
|---|---|
| Salesforce CRM-kobling | Kildeorganisasjonen må tillate en tilkoblet app, OAuth-tokener og en dedikert integrasjonsbruker med lesetillatelser. |
| Marketing Cloud-kobling | Marketing Cloud API-legitimasjon eller installert pakke. Datautvidelser må vise data via Uttrekk/API. |
Statbehandling
- Koblingsstatus: Datastrømmer vedlikeholder tidsstempler for siste vellykkede synkronisering og deltaforskyvninger.
- Master Key Strategy: Foretrukk konsistente forretningsidentifikatorer (eksterne ID-er) slik at nedstrøms avstemming og oppdateringer er deterministiske.
Komplekse integrasjonsscenarier
I avanserte forretningsarkitekturer kan dette mønsteret integreres med
- Hybridtopologier: Kombiner CRM-inntak med strømming (Plattformhendelser) for å få oppdateringer i nær sanntid.
- Mellomproduktorkestrering: Bruk MuleSoft- eller ETL-verktøy når kompleks orkestrering, anriking eller forhåndsinntak av transformasjon kreves.
- Aktiveringstilbakemeldingsluker: Harmoniserte DMO-er kan utløse nedstrøms oppdateringer til kildesystemer via Datahandlinger eller plattform-API-er (pass på SoD-kontroller).
Eksempel
En multinasjonal forhandler konsoliderer engasjementsmålinger for kontoer, kontakter, saker, salgsmuligheter og Marketing Cloud i Data 360 for å opprette en forent kundevisning. Startdatapakken initialiserer kjerneobjektene Salg og Tjeneste, mens teamet utvider modellen med tilpassede felt som Loyalty_Membershipc og Customer_Tierc for å fange opp lojalitetskontekst. CRM-datastrømmer kjøres hver time i deltamodus, og Marketing Cloud-engasjement synkroniseres daglig ved bruk av deltauttrekk for engasjementshendelser. Disse datasettene behandles via DLO-er og identitetsløsning, noe som resulterer i en forent kundeprofil som kombinerer CRM- og engasjementssignaler til krafttilpassing og nedstrøms AI-modeller.
Disse mønstrene er bygget for scenarier der millisekunder betyr noe – når kundeinteraksjoner, transaksjoner eller signaler må utløse umiddelbar innsikt eller handling. De går ut over tradisjonell, planlagt inntak av batcher for å aktivere hendelsesdrevet dataflyt, der informasjon behandles så snart den genereres. I Salesforce Data 360-økosystemet er "sanntid" ikke en enkelt modus – det er et kontinuerlig antall latensmodeller. På den ene enden ligger synkronisering i nær sanntid, der oppdateringer fra postsystemer (som CRM eller ERP) gjenspeiles i Data 360 i løpet av sekunder eller minutter. På den andre enden er sann hendelsesfangst i sanntid, der virkemåteignaler på klientsiden – som klikk, kjøp eller mobilinteraksjoner – tas inn og aktiveres i millisekunder. For arkitekter er forskjellen mer enn semantisk. Den definerer hvordan pipelines utformes, hvordan API-er kalles opp og hvordan nedstrøms beslutninger tas. Valg av riktig mønster – enten det gjelder synkronisering i nær sanntid eller inntak av hendelsesstrømmer – sikrer at systemet oppfyller virksomhetens operasjonelle latensmål samtidig som dataintegritet, skalerbarhet og styring opprettholdes.
Kontekst
Dette mønsteret aktiverer alle eksterne systemer, som et tilpasset program, en Internett-av-saker-plattform (IoT), et salgsstedssystem (POS) eller en tredjepartstjeneste, for å programmatisk pushe hendelsesdata til Data 360 i nær sanntid etter hvert som diskrete hendelser skjer.
Problem
Hvordan kan en utvikler pålitelig sende enkeltposter eller små asynkrone grupper av hendelser fra et eksternt program til Data 360 med lav latens, slik at dataene raskt blir tilgjengelige for behandling, segmentering og aktivering?
Styrker
Dette mønsteret gir lav latens og bedre utviklerkontroll, men introduserer flere tekniske begrensninger og driftsavhengigheter:
- Utvikleravhengighet: Krever utviklerinnsats for å implementere godkjente REST API-klienter og feil/gjen-prøve-logikk – det er ikke en pek-og-klikk-kobling.
- Streng skjema-på-skrive: Inntaks-API-et håndhever skjema-ved-skriving. Et presist skjema må defineres og lastes opp til koblingskonfigurasjonen. Alle belastninger må samsvare nøyaktig eller avvises.
- Dobbel interaksjonsmodus: Den samme koblingen støtter både strømming (JSON) for oppdateringer med lav latens, post-for-post-oppdateringer og massesynkronisering (CSV) for større periodiske synkroniseringer – arkitekter må velge per bruksområde.
- Godkjenning og sikkerhet: Samtaler må godkjennes via en tilkoblet Salesforce-app med OAuth 2.0 (for eksempel JWT-bærerflyt for server-til-server). Tokenbehandling, rotasjon og omfang med færrest rettigheter er obligatoriske.
- Operative synlighet: Utviklere og plattformteam må implementere overvåking for svarkoder, nye forsøk, dødskrivetekøer og skjemaavvikvarsler.
- Sanntids grafkrav: For sann umiddelbar aktivering (øyeblikkelig segmentering, sanntids DMO-tilordning) må datamodellobjektet (DMO) være en del av sanntidsdatadiagrammet. Ellers går hendelser gjennom en pipeline med litt høyere latens.
Løsning
Denne tabellen inneholder løsninger på dette integrasjonsproblemet.
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| Løsningstilpassing | Best for hendelsesfangst med lav latens | Bruk Data 360 Inntaks-API (strømming JSON) til å pushe enkelthendelser eller mikro-batcher. Konfigurer Inntaks-API-koblingen med et strengt OAS 3.0-skjema (.yaml). Bruk masse-CSV-inntak til større, mindre hyppige synkroniseringer. |
| Håndtering av skjemaendringer | Streng / Administrert | Skjemaendringer brytes: Oppdater OAS .yaml, versjoner koblingen og utfør kontrakttesting. Implementer overføring av rullerende skjemaer hvis produsenter ikke kan endre samtidig. |
| Når ikke å bruke | Suboptimal | Ikke ideelt hvis forhåndsbehandling er nødvendig ( for eksempel nedduplisering, garantert bestilling osv.) eller for ekstremt store masseinnlastinger (bruk innebygde massekoblinger eller gruppe-ETL). Hvis kilden ikke kan produsere skjema gyldige nyttelast eller ikke kan godkjennes sikkert, bruker du alternative inntaksmetoder. |
| Sikkerhet og styring | Mandatorisk | Bruk OAuth 2.0 med omfang med færrest rettigheter, rotere nøkler, loggtokenbruk. Håndhev TLS 1.2+, valider klient-IP-adresser hvis det er nødvendig, og forsikre deg om lastbar PII-koding. Alle hendelser må ha metadata for opphav (kilde, tidsstempel, skjemaversjon, idempotensnøkkel). |
Skisse
Dette diagrammet illustrerer en sekvens av trinn for å hente inn dataene fra Inntaks-API til Data 360
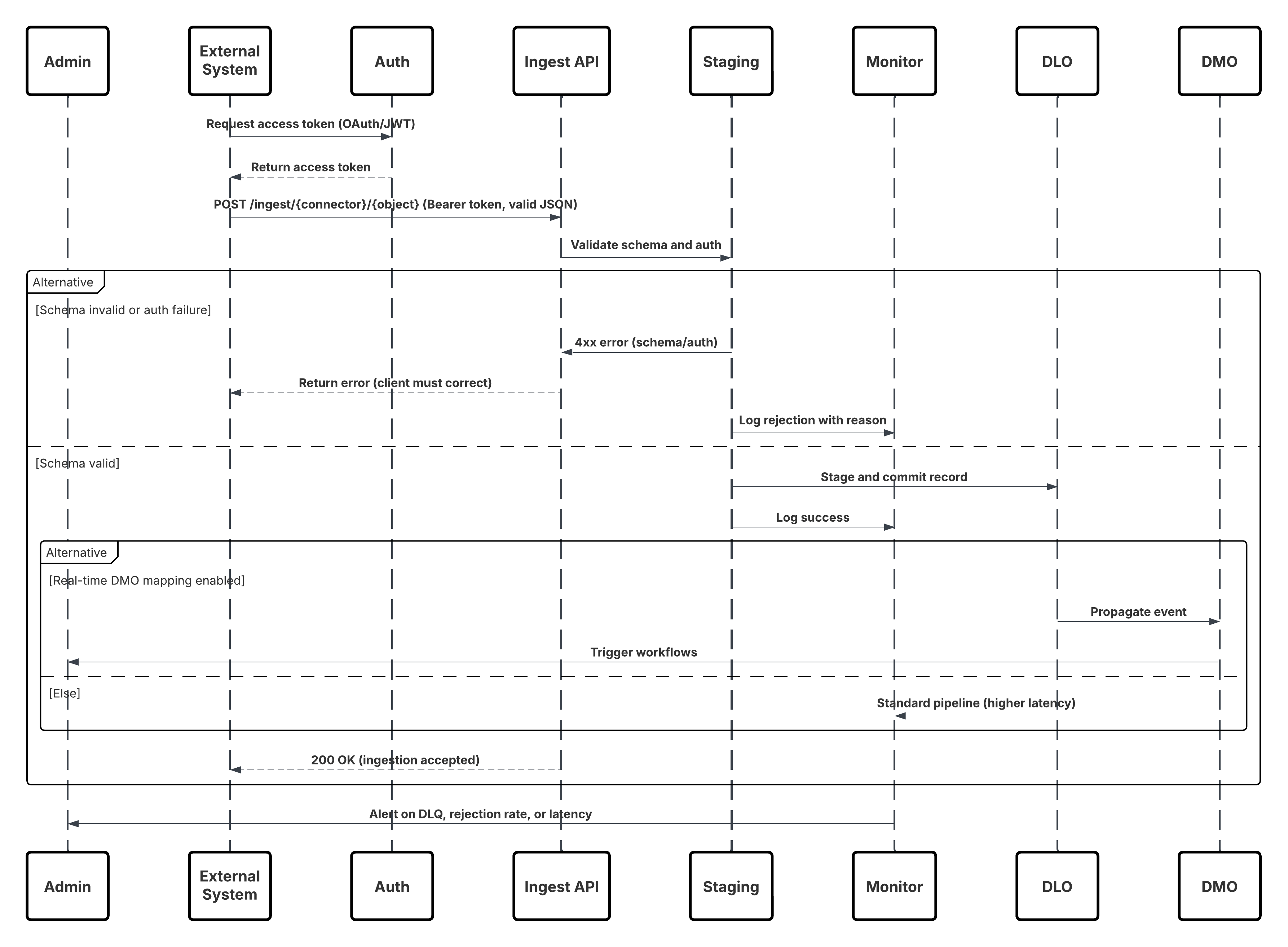
I dette scenariet:
- Eksternt system ber om godkjenning via OAuth/JWT fra godkjenningsserver.
- Godkjenningsserveren returnerer tilgangstokenet til eksternt system.
- Eksternt system sender POST-forespørsel om datainntak til Data 360 Inntaks-API med godkjenning og JSON-belastning.
- Inntaks-API validerer forespørselsskjema og godkjenning via modulen Staging & Validation.
- Ved feil i skjema/godkjenning:
- Feil returnert til eksternt system.
- Avvisning logget for overvåking og varsel.
- Ved vellykket validering:
- Poster faset og bekreftet til Datasjøobjekt (DLO).
- Vellykket logging for overvåking.
- Hvis aktivert, overføres data til Sanntids datagraf (DMO) som utløser nedstrøms arbeidsflyter.
- Ellers behandles data via standard gruppe- eller pipeline med høyere latens.
- Inntaks-API bekrefter vellykket utførelse av eksternt system.
- Overvåkingskomponenter varsler administrator om dødsbrevkøer, avvisningsfrekvenser eller latensproblemer.
Resultater
Eksterne hendelsesdata hentes inn i Data 360-DLO-er med lav latens. Når mål-DMO-et er en del av sanntidsdiagrammet, er dataene tilgjengelig for umiddelbar segmentering, agentarbeidsflyter, AI-modeller og operasjonell aktivering. Dette aktiverer raske forretningsreaktioner på begivenheder, der kommer fra ethvert tilsluttet system.
Inntaksmekanismer
Inntaksmekanismen avhenger av koblings- og planleggingsstrategien som er definert i Data 360.
| Mekanisme | Når skal brukes |
|---|---|
| Streaming JSON (Inntaks-API) | Enkelthendelser, mikro-batcher, virkemåtehendelser, klikkstrømmer, IoT-telemetri – når lav latens kreves. |
| Bulk CSV (Inntaks-API-modus) | Større, periodiske opplastinger der latenskravene er lettet. |
| Edge / Mellomprodukter | Brukes når du trenger validering, transformasjon, berikelse eller frekvensbegrensning før du går til Inntaks-API. |
Feilhåndtering og gjenoppretting
- Umiddelbare (synkroniserings)-feil: 4xx-svar for skjema-/godkjenningsfeil – klienten må fikse belastningen eller tokenet og prøve på nytt.
- Transient (asynkron) feil: 5xx-svar – klientforsøk på nytt med eksponentiell tilbakemelding og jitter.
- Døde brevkø (DLQ): Vedvarende feil lander i DLQ for manuell inspeksjon og avspilling.
- Overvåking: Spor skjemaavvisningsgrad, godkjenningsfeil, latensprosentiler og DLQ-etterslepslogg. Varsel om terskler.
Viktige punkter om Idempotent-design
- Idempotency Key: Hver hendelse må inneholde en unik idempotency-nøkkel/melding-ID.
- Upsert-strategi: Bruk forretningsnøkler (ExternalId) for å unngå duplikater i repetisjoner.
- Dedup-vindu: Arkitekt bør definere opphevingsvinduer og oppbevaring for idempotenssporing.
Sikkerhetsvurderinger
Sikkerhet er integrert i hele inntaksprosessen, fra godkjenning til kryptering og tilgangskontroll.
- Godkjenning: OAuth 2.0 (JWT-bærer) anbefales for server-til-server. Begrens omfang til bare inntak.
- Kryptering: TLS 1.2+ for transport. Data 360 håndhever kryptering under lagring.
- Minste privilegium: Legitimasjon for tilkoblet app har et minimum av rettigheter. Roter hemmeligheter og instrumenttilgangslogger.
- Belastningsstyring: Inkluder samtykke-/forbruksflagg i hendelsesmetadata. Bruk ABAC/CEDAR-policyer umiddelbart etter inntak.
- IP-elementer / privat tilkobling: Begrens om nødvendig tilgang via tillatelseslister eller bruk Privat tilkobling til privat nettverk.
Sidefelt
Tidlighet
Tidspunktet avhenger av inntaksplanen og datavolumet. Strømming av JSON gir latens fra sekund til sekund avhengig av behandling og grafkonfigurasjon. Masse-CSV er minutter til timer. Velg basert på forretnings-SLA-er.
Datavolumer
Individuelle hendelsesstørrelser bør være små (< noen få kB). For produsenter med stor gjennomstrømning kan du vurdere å gruppere hos produsenten eller bruke en strømmebuffer (Kafka/Kinesis) før du kaller opp API-et.
Statbehandling
- Skjemaversjonering: Behold skjemaversjon i hendelsesmetadata, og bruk koblingsversjonsbehandling når du oppdaterer OAS-kontrakt.
- Koblingsforskyvninger: Data 360 håndterer bekreftelsessemantik; produsenter bør spore idempotensnøkler og siste vellykkede sekvens for sikker avspilling.
Komplekse integrasjonsscenarier
I avanserte forretningsarkitekturer kan dette mønsteret integreres med
- Kandvalideringslag: Bruk mellomprogramvare til å oversette heterogene produsentformater til den nødvendige OAS-kontrakten, utføre frekvensbegrensning og forhåndsforbedring.
- Hybridarkitekturer: Kombiner inntaks-API for hendelser og Koblinger for masseavstemming.
- Agentaktivering: Hendelser som er tilordnet til sanntids DMO-er, kan utløse Agentforce og Einstein for automatisert beslutningstaking.
Eksempel
En butikkkjede strømmer kjøpshendelser fra salgssted (POS) til Data 360 i sanntid for å gi umiddelbar kundeengasjement. Hver butikk kjører en enkel serverkomponent som samler inn transaksjoner, beriker dem med steds- og enhetsmetadata og sikkert legger inn JSON-hendelser ved å bruke JWT Bearer OAuth med idempotency-nøkler for å hindre duplikater. En administrator definerer hendelsesstrukturen ved å laste opp et OAS-skjema for salgsstedet og konfigurere Inntaks-API-koblingen. Innkommende hendelser hentes inn i pos_sale DLO, tilordnes til Sale DMO og legges til i sanntidsgrafen. Resultatet er at kjøp med høy verdi oppdages umiddelbart, noe som utløser VIP-arbeidsflyter i Agentforce og oppdaterer kundesegmenteringen for å fremme tilpassing i sanntid.
Kontekst
Dette mønsteret aktiverer fangst av detaljerte brukerinteraksjonsdata med stor trafikk – som sidevisninger, knappeklikk, produktinntrykk og videospill – fra nettsteder og mobilprogrammer i trueReal-Time. Den er grunnleggende for å levere tilpassing i øyeblikket, der hver digital interaksjon dynamisk kan påvirke brukeropplevelsen og fremme engasjement.
Problem
Hvordan kan et foretak fange opp og behandle en kontinuerlig strøm av atferdshendelser fra digitale egenskaper – som spenner over millioner av brukerinteraksjoner per minutt – og gjøre disse dataene umiddelbart tilgjengelig i Data 360 for å fremme sanntidssegmentering, tilpassing og aktivering?
Styrker
Dette brukstilfellet introduserer flere utformingsutfordringer som krever en hensiktsmessig bygd inntaksarkitektur med lav latens:
- Extreme Throughput : Nettsteder eller mobilapper med stor trafikk kan sende ut millioner av hendelser per minutt. Inntakslaget må skaleres horisontalt for å håndtere dette volumet uten hendelsestap eller tilbaketrykk, slik at konsekvent latens sikres ved toppbelastninger.
- Instrumentering på klientsiden: Til forskjell fra serverdrevne integrasjoner er dette mønsteret avhengig av SDK-er på klientsiden. Et JavaScript-beacon (Salesforce Interactions SDK) må være innebygd på hver side, eller et innebygd SDK integrert i mobilapper. Dette krever robust klientdistribusjon, versjonsbehandling og hendelsesskjemastyring.
- Behandling av hendelser med lav latens: Brukerhandlinger, som "tillegg til handlevogn" eller "videospilling", må nå Data 360 innen sekunder og aktivere sanntidsaktivering og kontekstuelle svar (for eksempel målrettede tilbud, tilpassede anbefalinger).
- Dataharmonisering og identitetsløsning : Registrerte hendelser inkluderer ofte anonyme identifikatorer (informasjonskapsler, enhets-IDer, økttokener). For å kunne bruke Customer 360 må disse tilordnes til kjente profiler via Data 360-identitetsløsningen og harmoniseres med Customer 360.
Løsning
Den anbefalte tilnærmingen er å bruke Salesforce Marketing Cloud Personalization-koblingen – en innebygd, fullstendig administrert streaming pipeline utformet for opptak av virkemåte med stor gjennomstrømning.
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| SDK-basert hendelsesfangst | Best | Distribuer Salesforce Interactions SDK (nett) eller innebygd SDK (mobil). Disse lette bibliotekene fanger opp og serialiserer brukerinteraksjoner i sanntid ved å legge ved metadata (økt-ID, tidsstempel, kontekst). |
| Event Streaming Pipeline | Best | Hendelser sendes til Hendelsesstrømmingstjenesten i Marketing Cloud Personalization via sikker HTTPS. Dette laget kan skaleres horisontalt og er optimalisert for overføring med lav latens (<2s). |
| Data 360-integrering | Best | Data 360s Tilpassingskobling abonnerer på strømmen og henter inn hver hendelse i et Datasjøobjekt (DLO) i nærSanntid. |
| Datatilordning | Beste praksis | Den inntatte DLO-en tilordnes til Customer 360 (DMO-er). Dette aktiverer kobling av anonyme brukere og kjente brukere via Identitetsløsning. |
| Sanntids grafaktivering | Valgfritt / anbefalt | Inkluder tilordnede DMO-er i sanntidsgrafen for umiddelbar segmentering som utløser tilpassede handlinger via Einstein eller Agentforce. |
| Når ikke å bruke | Suboptimal | Dette mønsteret er ikke ideelt når Kildedataene er nettklient og hendelser (bruk Inntaks-API i stedet). Organisasjonen mangler kontroll over nett/mobilklienter. Sanntids oppførselssporing kreves ikke (bruk batchinntak). |
| Håndtering av skjemaendringer | Administrert utvikling | Hendelsesskjemaer utvikles etter hvert som nye interaksjoner legges til. SDK-er må versjonere hendelsesdefinisjoner. Bakoverkompatible endringer (ved å legge til valgfrie felt) er sikre. Å bryte endringer krever omkonfigurering av koblingen og kontrakttesting. |
Skisse
Dette diagrammet illustrerer en sekvens av trinn for å hente inn data fra Mobile- og nettkanaler til Data 360
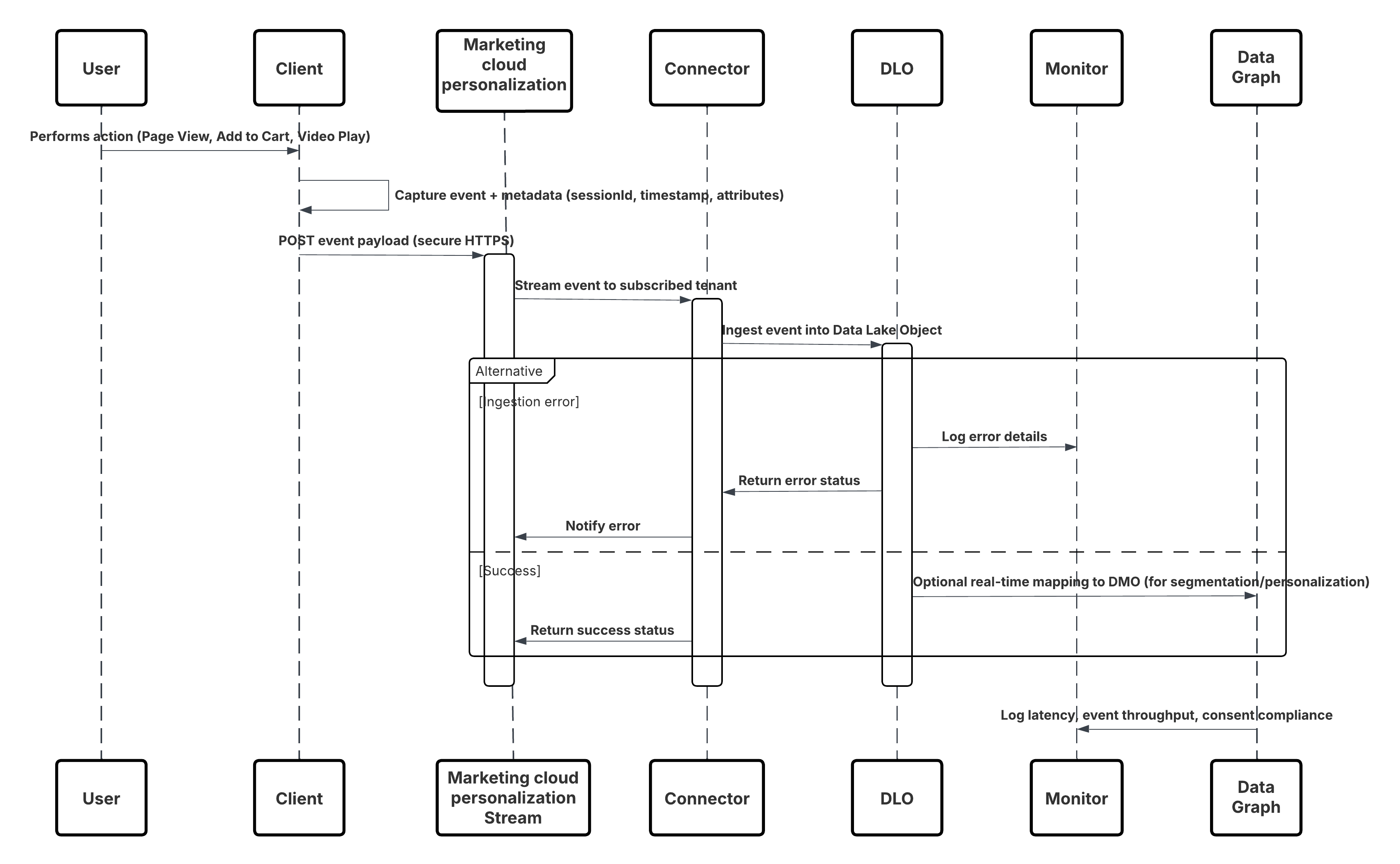
I dette scenariet:
- Distribuer SDK-et i nett- eller mobilkanaler (fangst av brukerinteraksjon).
- Konfigurer SDK med leietager-ID, miljø- og samtykketillatelser.
- Strøm oppfangede JSON-hendelser (metadata + attributter) til Marketing Cloud-sluttpunkt for strømming.
- Opprett og konfigurer Tilpassingskobling for leietageren i Data 360-oppsett.
- Hent inn hendelser i en DLO, og tilordne DLO → DMO i Data 360.
- Aktiver DMO-et i sanntidsdiagrammet for umiddelbar aktivering.
- Overvåk latens, skjemaoverholdelse, samtykkesflagg, gjennomstrømning, feilfrekvenser.
- Distribuer til produksjon og overvåk kontinuerlig.
Resultater
En kontinuerlig strøm med lite latens av atferdshendelser flyter fra digitale kanaler til Data 360. I løpet av sekunder blir hver brukerhandling tilgjengelig for sanntidssegmentering, prediktiv modellering eller utløst tilpassing, noe som aktiverer virkelig tilpassede kundeopplevelser.
Inntaksmekanismer
Inntaksmekanismen avhenger av koblings- og planleggingsstrategien som er definert i Data 360.
| Mekanisme | Når brukes |
|---|---|
| Interaksjoner SDK (Web) | Sanntidsfangst fra nettlesere og tjenesteleverandører. |
| Mobile SDK | Sanntidsfangst fra innebygde mobilprogrammer. |
| Personlig tilpassingskobling | Administrert abonnement mellom Marketing Cloud og Data 360\. |
| Sanntids graftilordning | Aktiverer umiddelbar aktivering i Segmentering, Einstein og Reiser. |
Feilhåndtering og gjenoppretting
- Lagert feiltoleranse: Implementer validerings- og prøvingsmekanismer med flere nivåer – klient-SDK-er håndterer midlertidige feil med eksponentielt tilbakeslag, mens inntakslaget bruker holdbare køer og gjenspillbare pipelines for å hindre tap av data.
- Skjema og datastyring: Versjoner og valider hendelsesskjemaer kontinuerlig. Ugyldige eller utviklende hendelser rutes til en Skjemaavvisning- eller Dødstekst-kø for sikker sortering og avspilling.
- Idempotency & Deduplication (Idempotensi og oppheving av duplikater): Bruk stabile hendelsesidentifikatorer og upsert-semantikk for å garantere nøyaktig behandling én gang selv under nye forsøk eller repetisjoner.
- Overvåking og gjenopprettingsautomatisering: Kontinuerlig overvåking av gjennomløps-, latens- og feilsatser utløser automatiske gjenopprettingsarbeidsflyter – som sikrer lav latens, pålitelig levering og konsistente sanntidstilpassingsresultater.
Viktige punkter om Idempotent-design
- Hver hendelse må ha en unik idempotency-nøkkel eller meldings-ID slik at duplikatsendinger kan fjernes nedstrøms.
- Bruk forretningsnøkler (for eksempel sessionID + eventTimestamp + userID) der det er aktuelt for å identifisere duplikater.
- Definer et fjerningsvindu (for eksempel 24 timer) der duplikathendelser ignoreres eller filtreres.
- Bruk oppdateringsstrategier der det er aktuelt (for eksempel oppdater tellere eller flagg i stedet for å sette inn duplikater).
Sikkerhetsvurderinger
Sikkerhet er integrert i hele inntaksprosessen, fra godkjenning til kryptering og tilgangskontroll.
- Transportkryptering: TLS 1.2+ for alle SDK → strømmingstjenestetilkoblinger.
- Datakryptering under lagring i Data 360 og markedsføringsstrøm.
- SDK respekterer brukersamtykkeflagg (GDPR/CCPA) og undertrykker sporing hvis samtykke avslås.
- Godkjenning av SDK-trafikk: Sørg for at bare godkjente leietagere/kunder kan streame hendelser.
- Metadata: Hver hendelse må inkludere kilde-ID, tidsstempel, skjemaversjon, økt-ID, idempotency-nøkkel.
- Minste tilgang: SDK-endepunkter og -koblinger er begrenset til hendelsesinntaksomfanget. Roter legitimasjonen regelmessig.
- Dataklassifisering: Merk PII i hendelsesbelastninger, håndheve policyer umiddelbart etter inntak
Sidefelt
Tidlighet
- Tidsrommet avhenger av sluttbrukeraktivitet og hendelsesstrømmingskonfigurasjonen.
- Hendelser som fanges opp via Salesforce Interactions SDK og leveres via Marketing Cloud-tilpassingsstrømmen, oppnår vanligvis sub-sekund til ~2-sekunders latens før de blir tilgjengelig i Data 360 Real-Time-grafen.
- Dette aktiverer nær umiddelbar segmentering, tilpassing og aktivering i aktive brukerøkter.
Datavolumer
Individuelle virkemåtehendelser (for eksempel klikk, visning, legge til i handlevogn) er lette – vanligvis 1–5 kB per last. For digitale egenskaper i stor skala forventer du tusenvis til millioner av hendelser per minutt. For å sikre gjennomløp og fleksibilitet:
- Bruk SDKs innebygde batcherings- og prøvemekanismer for sider med stor trafikk.
- Utlast håndtering av utbrudd til bufferlaget for Marketing Cloud-strømming.
- Overvåk inntaksgjennomløp og feilforhold ved bruk av kontrollpanelet for koblingsmålinger.
Statbehandling
Hver hendelse inneholder metadata for stat- og versjonskontroll:
- Skjemaversjonering: Bygg inn skjemaversjon i hver hendelse, og versjoner Tilpassingskobling når du oppdaterer skjemaet.
- Håndtering av gjentakelse: Hendelser som mislykkes på grunn av midlertidige nettverksproblemer, prøves automatisk på nytt av SDK med eksponentiell tilbakeslag.
- Idempotency Keys: Unike identifikatorer (sessionId + eventType + tidsstempel) sikrer at gjentatte hendelser ikke oppretter duplikater i Data 360.
- Offsetstyring: Data 360 sporer vellykkede bekreftelser. Eventuelle ubehandlede hendelser legges inn på nytt av koblingen til de tas inn riktig.
Komplekse integrasjonsscenarier
Dette mønsteret integreres sømløst i avanserte forretningsarkitekturer:
- Edge Enrichment Layer: Legg til mellomprogramvare (for eksempel omvendt proxyfunksjon eller serverløs funksjon) for å injisere ekstra kontekst – som geo-, enhetstype- eller kampanjemetadata – før hendelser når Marketing Cloud.
- Hybrid(strømming + batch): Bruk Marketing Cloud-koblingen til sanntidsstrømmer, og kombiner den med gruppe-ETL-jobber (for eksempel bestillingsdata) for nedstrøms avstemming.
- Agentaktivering: Hendelser som er tilordnet til sanntids DMO-er, kan utløse Einstein-tilpassing, Agentforce eller AI-drevet beslutningsprosess for å tilpasse den digitale opplevelsen i øyeblikket.
- Forvaltning med flere leietagere: Bruk samtykkeflagg og leietakersensitive metadata til å håndheve personvern og samsvar i miljøer med flere merker eller flere områder.
Eksempel
Et globalt e-handelsselskap leverer personlige produktanbefalinger og dynamisk innhold til kjøpere mens de aktivt surfer på www.retailx.com, et React-basert enkeltsideprogram. Ved å bruke Salesforce Interactions SDK på klientsiden fanger nettstedet opp sidevisninger, produktklikk, handlinger og videointeraksjoner i Sanntid. Disse hendelsene flyter gjennom hendelsesstrømmen Marketing Cloud-tilpassing og Tilpassing-koblingen til Data 360-DLO-er, der de modelleres til DMO-er og innlemmes i sanntidsdiagrammet. Denne arkitekturen gjør atferdsignaler umiddelbart tilgjengelig for segmentering, Einstein tilpassing og Agentforce, og aktiverer responsive, øktkundeopplevelser
Kontekst
For mange forretningskritiske prosesser er det viktig å holde Data 360 perfekt tilpasset de nyeste oppdateringene i kjernes CRM-systemer. Kundeservice-, salgs- og markedsføringsteam er avhengige av oppdatert informasjon for å drive beslutninger, utløse reiser og aktivere automatisering. Dette mønsteret gir en mekanisme for å synkronisere endringer i viktige Salesforce CRM-objekter, som Kontakt, Konto og Sak, til Data 360 med minimal forsinkelse, uten ineffektiviteten eller forsinkelsen av hyppig gruppespørring.
Problem
Hvordan kan Data 360 opprettholde en nesten perfekt synkronisert tilstand med viktige Salesforce CRM-objekter, og sikre at nedstrøms analyse, segmentering og AI-drevet aktivering alltid fungerer på de nyeste tilgjengelige dataene?
Styrker
Dette mønsteret introduserer flere tekniske begrensninger og arkitektoniske vurderinger:
- Event-Driven Architecture : Synkroniseringen må være aktiv – drevet av endringshendelser i CRM-kildeorganisasjonen i stedet for periodiske gruppejobber.
- Selektivt objektstøtte: Ikke alle Salesforce-standardobjekter og tilpassede objekter støtter strømming i sanntid. Arkitekter må referere til listen over støttede objekter under utformingen for å unngå hull.
- Tilgang og tillatelser: Aktivering av strømming krever at integrasjonsbrukeren i kildeorganisasjonen er tildelt systemtillatelsen Aktivere tillatelser for CRM-strømming.
- Data Freshness vs. Behandlingskostnader: Synkronisering i nær sanntid forbedrer responsiviteten, men overdreven hendelsesgjennomgang kan kreve horisontal skalering og robuste feilgjenopprettingsmekanismer.
- Integrering av sikkerhets- og klareringslag: Alle hendelsesdata må samsvare med Salesforces Trust og Security-rammeverk – krypteres under overføring, valideres for skjemasamsvar og behandles innenfor organisasjonens Trust.
Løsning
Den anbefalte løsningen er å bruke Salesforce CRM-koblingen med strømming (endring av datafangst) aktivert. Når administratorer oppretter en datastrøm for et støttet CRM-objekt (for eksempel Kontakt), kan de velge alternativet Aktiver strømming. Under toppteksten publiserer Salesforces CDC-plattform (Change Datafangst) en ChangeEvent-melding hver gang en post opprettes, oppdateres, slettes eller oppheves sletting i kildeorganisasjonen CRM. Data 360 CRM-koblingen abonnerer på disse CDC-hendelsene og bruker de tilsvarende endringene på det tilordnede Data Lake-objektet (DLO) i Data 360 i nær sanntid. Dette sikrer kontinuerlig synkronisering mellom CRM og Data 360 med minimal manuell intervensjon.
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| CDC-basert strømmingskobling | Best | Innebygd Salesforce-mekanisme, fullstendig administrert og integrert med plattformhendelsesinfrastruktur. |
| Event Abonnement & Levering | Best | Koblingen abonnerer på ChangeEvent-kanaler (for eksempel /data/ContactChangeEvent) via varige ID-er for avspilling. |
| Datatilordning og skjemautvikling | Gode fremgangsmåter | Tilordne strømmede last til den tilsvarende DLO-en. Håndter skjemaversjonering i metadata for å hindre inntakspauser. |
| Oppdatering og feilgjenoppretting | Anbefalt | Bruk ID-er for gjentagelse og idempotensnøkler for å unngå duplisering og gjenopprette fra midlertidige feil. |
| Hybridmodus (strømming + batch) | Valgfritt | Når det gjelder objekter som ikke støttes, eller første masselasting, bruker du batchinntak i kombinasjon med CDC-strømming. |
| Når ikke å bruke | Underoptimalt | Dette mønsteret kan være underoptimalt når: Kildeobjektet er ikke CDC-aktivert. Bruksområdet krever ikke sanntidsoppdateringer (batch er tilstrekkelig). Nettverksutgang fra kildeorganisasjonen er begrenset, eller hendelsesgrenser overskrides. |
Skisse
Dette diagrammet illustrerer en sekvens av trinn for å hente inn dataene fra CRM til Data 360 i nærSanntid
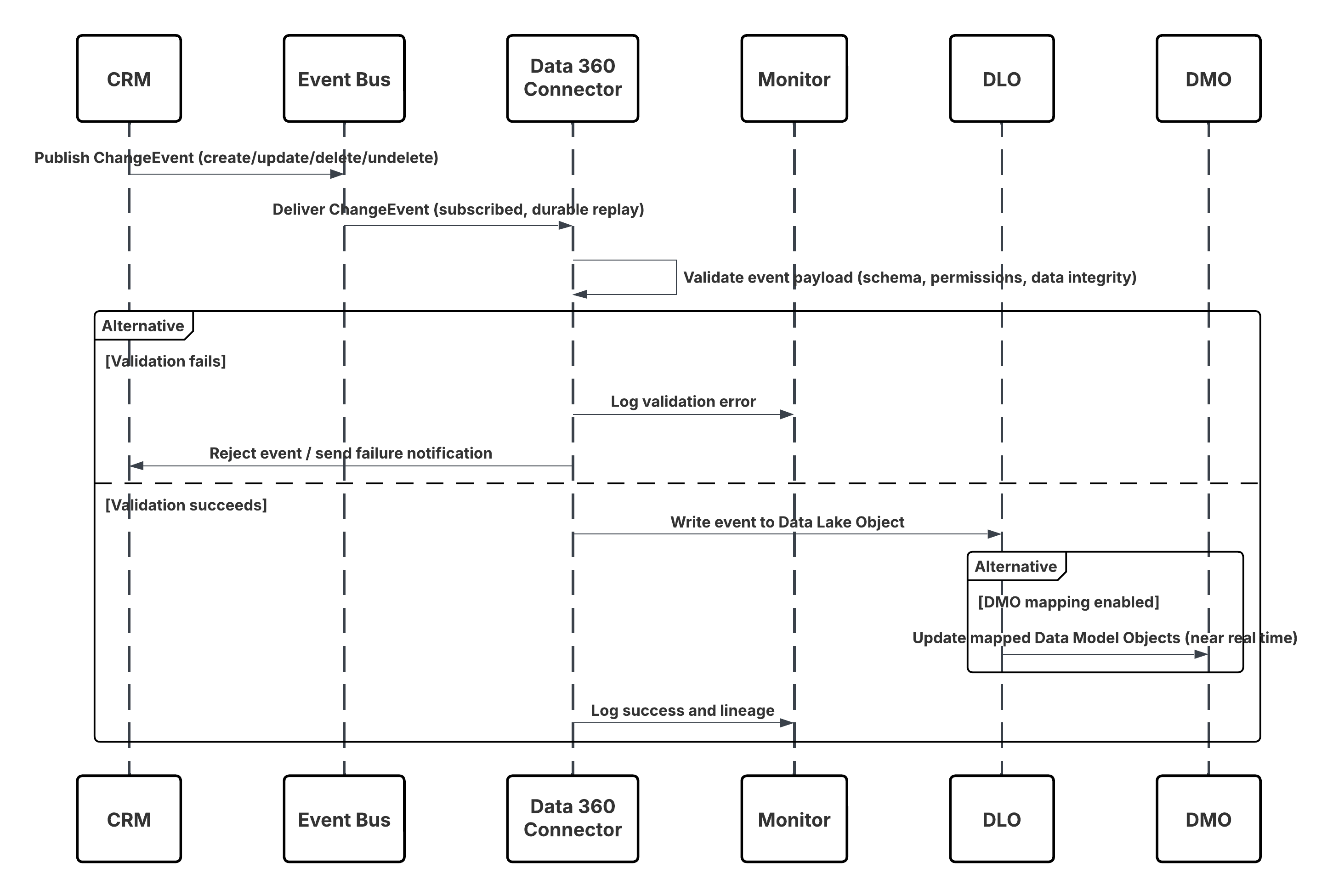
I dette scenariet:
- Endring skjer i Salesforce CRM (opprett/oppdater/slett/opphev sletting).
- CDC publiserer en ChangeEvent til den interne Salesforce-hendelsesbussen.
- Data 360 CRM-kobling abonnerer på hendelsesbussen ved å bruke en holdbar gjentagelsesmarkør.
- Hendelsesbelastning valideres for skjema, tillatelser og dataintegritet.
- Data 360 skriver den validerte hendelsen til det tilordnede Data Lake-objektet (DLO).
- Hvis dette alternativet er aktivert, oppdateres tilordnede Data Model Objects (DMO-er) i nearReal-Time, som gir segmentering og aktivering.
Resultater
Data 360 vedlikeholder et kontinuerlig synkronisert speil av viktige CRM-data. Dette aktiverer følgende:
- Sanntidsutløsere (for eksempel at reise starter når en sak opprettes).
- Oppdatert segmentering (for eksempel flytte kunder til Gull-segmentet ved endring av kontostatus).
- Mer nøyaktig analyse og tilpassing basert på direkte CRM-kontekst.
Inntaksmekanismer
Inntaksmekanismen for dette mønsteret administreres som standard via Salesforce CRM-koblingen med CDC (Change Datafangst) aktivert. Data 360 fungerer som en abonnent på CDC-hendelsesstrømmen og sikrer pålitelig synkronisering med lav latens mellom kilde CRM-organisasjonen og Data 360.
| Mekanisme | Når brukes |
|---|---|
| Streaming via CDC (Foretrukket) | For alle støttede Salesforce-standardobjekter og tilpassede objekter der nær sanntidssynkronisering kreves. |
| Hybridmodus (CDC + batch) | For objekter som ennå ikke er CDC-aktivert, eller der første historiske innlasting kreves. |
| Gjenspill abonnementsmodus | For ny synkronisering etter nedetid eller distribusjon. |
| Feil isolasjonsmodus | For testing og valideringsmiljøer. |
Feilhåndtering og gjenoppretting
- Automatisk feilgjenoppretting: CRM-koblingen prøver automatisk på nytt forbigående nettverks- eller plattformfeil ved bruk av eksponentiell tilbakekobling og ruter vedvarende feil til Dead-Letter-køen (DLQ) for avspilling.
- Schema & Authentication Resilience: Skjemavvik er i karantene i køen for avvisning av skjemaer for administratorgjennomgang, mens godkjennings- eller tillatelsesfeil utløser kontrollerte forsøk og varsler via Data 360-overvåking.
- Garantert hendelseskontinuitet: Holdbare ReplayID-er sikrer ingen hendelsestap under koblingsnedetid. Manglende hendelser rehydreres via gjenspillingsvinduer eller gruppers omsynkroniseringsjobber.
- Dataintegritet og bestilling: Innebygd idempotency (RecordID + SequenceNumber) hindrer duplikater, og ChangeEventHeader.sequenceNumber beholder riktig hendelsesrekkefølge for hver CRM-post.
Viktige punkter om Idempotent-design
- Event Uniqueness: Hver CDC-hendelse bærer en ReplayID og ChangeEventHeader.entityName for deterministisk duplikatfjerning.
- Upsert-strategi: Implementer UPSERT-logikk basert på post-ID for å sikre at gjentatte hendelser ikke oppretter duplikater.
- Håndtering av gjentakelse: Bruk koblingens gjentagelsesmarkør til å gjenoppta fra den siste bekreftede forskyvningen i tilfelle midlertidige feil.
- Skjemautvikling: Mvedlikeholde en skjemaversjon i hendelsesmetadata og oppdatere DLO-tilordninger når CRM-skjema endres.
Sikkerhetsvurderinger
Sikkerhet er integrert i hele inntaksprosessen, fra godkjenning til kryptering og tilgangskontroll.
- Kryptering og klarering : Alle hendelser overføres med TLS 1.2+ og lagres kryptert under lagring i Data 360.
- Tilgangskontroll: Bare godkjente koblinger med riktige integreringstillatelser kan abonnere på CDC-kanaler.
- Skjemavalidering: Hver hendelsesbelastning valideres mot DLO-skjemaet før inntak.
- Samtykkefordeling: Metadata for samtykke og dataklassifisering flyter nedstrøms med hver hendelse for å bevare personvern og samsvar (GDPR, CCPA).
- Driftsstyring: Hendelser logges, revideres og overvåkes for avspilling, skjemaavvisning og gjennomløpsavvik via Data 360 Trust.
Sidefelt
Tidlighet
- CDC-hendelser behandles i nær sanntid – vanligvis innen sekunder etter endringen i CRM.
- Latens kan variere basert på hendelsesvolum og koblingsgjennomløp, men Data 360 garanterer tilgjengelighet i underminutter for støttede objekter.
Datavolumer
- Hver hendelses belastning er enkel (~1–5 kB).
- For objekter med stor endringsgrad, som Sak eller Kontakt, må du sørge for at gjennomstrømsgrensene er i samsvar med tildelingene av Salesforce CDC-hendelser.
Statbehandling
Hver hendelse inneholder metadata for stat- og versjonskontroll:
- Gjentagelses-IDer: Brukes til sekvensiell hendelsesgjenoppretting.
- Skjemaversjonering: Behold versjonsmetadata for å behandle kontraktsendringer.
- Idempotency Keys: Opphev duplikater på tvers av nye forsøk.
- Offset Commit: Data 360 beholder bekreftelsestilstanden etter hver vellykket batch av hendelser.
Komplekse integrasjonsscenarier
Dette mønsteret integreres sømløst i avanserte forretningsarkitekturer:
- Hybrid(strømming + batch): Bruk CDC til deltaoppdateringer og massejobber til fullstendige oppdateringer.
- Cross-Org Streaming: Flere kildeorganisasjoner kan strømme til samme Data 360-leietager, forent via DMO-tilordninger.
- Agentaktivering: Sanntids objektoppdateringer utløser Einstein eller Agentforce.
- Hendelsesruting: Mellomprogramvare (for eksempel MuleSoft eller Hendelsesoverføring) kan berike eller rute CDC-meldinger før inntak.
Eksempel
En global bank ønsker å sikre at endringer i kundedata i Salesforce Sales Cloud umiddelbart gjenspeiles i Data 360.Når adressen til en kontakt oppdateres i Sales Cloud, publiserer mekanismen for datafangst en ContactChangeEvent.Data 360 CRM-koblingen bruker denne hendelsen, bruker oppdateringen på kunde-DLO og oppdaterer automatisk alle tilknyttede Customer 360. Dette utløser en Einstein Next Best Action for å bekrefte den nye adressen – fullføre tilbakemeldingssløyfen innen sekunder etter den opprinnelige CRM-endringen.
Kontekst
Moderne digitale virksomheter baserer seg på sanntids hendelsesstrømmingsplattformer som Amazon Kinesis-datastrømmer og Amazon MSK (administrert strømming for Apache Kafka) for å fange opp kontinuerlige dataflyter fra distribuerte programmer, IoT-enheter og transaksjonssystemer. Data 360 aktiverer direkte inntak fra disse plattformene via innebygde, førstepartskoblinger – og eliminerer behovet for tilpassede ETL- eller mellomprogramvarebaserte løsninger. Dette mønsteret er utformet for datainntak med høy gjennomstrømning og lav latens, nær sanntidsinnsikt, tilpassing og AI-drevet aktivering.
Problem
Hvordan kan et foretak koble Data 360 sikkert og effektivt til AWS Kinesis- eller AWS MSK Kafka-emner for å kontinuerlig hente inn strukturerte hendelses- og profildata, og sikre skjemasamsvar, skalerbarhet og styring?
Styrker
Dette mønsteret introduserer flere viktige punkter om arkitektur og drift:
- Tilgjengelighet av innebygd kobling: Salesforce tilbyr generelt tilgjengelige innebygde koblinger for både Amazon Kinesis og Amazon MSK. Disse koblingene tilbyr førstepartsstøtte og eliminerer behovet for tilpassede API-baserte pipelines.
- Godkjenning og sikkerhet: Hver kobling krever godkjenning på AWS-nivå.
- For Kinesis bruker dette AWS-tilgangsnøkkel og hemmelig nøkkel, som styres av IAM-policyer.
- For MSK kan godkjenning konfigureres via Access Key/Secret eller OpenID Connect (OIDC).
- Skjemadefinisjon: Data 360 krever et skjema for å tolke strømmingsbelastningen. For Kinesis lastes skjemafilen opp under tilkoblingsoppsett for å definere hendelsesstruktur og felttilordninger.
- Konfigurasjonskilde:
- Kinesis-koblingen abonnerer på et bestemt Kinesis-strømnavn.
- MSK-kobling abonnerer på et Kafka-emne i MSK-klyngen.
- Nettilgang: For sikre miljøer kan koblinger konfigureres med PrivateLink- eller VPC-ruting slik at ingen data går gjennom det offentlige Internett.
- Driftsstyring: Strømmedeffekt, skjemavalidering og godkjenningshendelser overvåkes i Data 360 Trust Layer for å sikre samsvar og sporbarhet.
Løsning
Løsningen benytter de innebygde Amazon Kinesis- eller Amazon MSK-koblingene i Data 360.
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| Kinesis innebygd kobling | Best | Førsteparts integrasjon med AWS Kinesis. støtter kontinuerlig inntak av høy gjennomstrømning. |
| MSK innebygd kobling | Best | Administrert Kafka-inntak med støtte for OIDC og nøkkelbasert godkjenning. |
| Skjematilordning og validering | Gode fremgangsmåter | Last opp skjema (.json/.avro) som definerer hendelsesstrukturen. Håndhever konsistens under inntak. |
| IAM-konfigurasjon | Anbefalt | Tildel minst privilegerte IAM-roller med skrivebeskyttet tilgang til målstyrte Kinesis-strømmer eller MSK-emner. |
| Privat nettverksruting | Valgfritt | Konfigurer PrivateLink/VPC-endepunkter for sikker, intern ruting. |
| Hybrid mønster(strømming + batch) | Valgfritt | Bruk strømming for deltaer og batchinntak for tilbakefyllinger eller historiske innlastinger. |
| Feil isolasjonsmodus | Anbefalt | Rut skjemaavvisninger og midlertidige feil til DLQ for avspilling |
Skisse
Dette diagrammet illustrerer en sekvens av trinn for å hente inn dataene fra Hendelse-plattformer som Kafka og Kinesis til Data 360 i nærSanntid
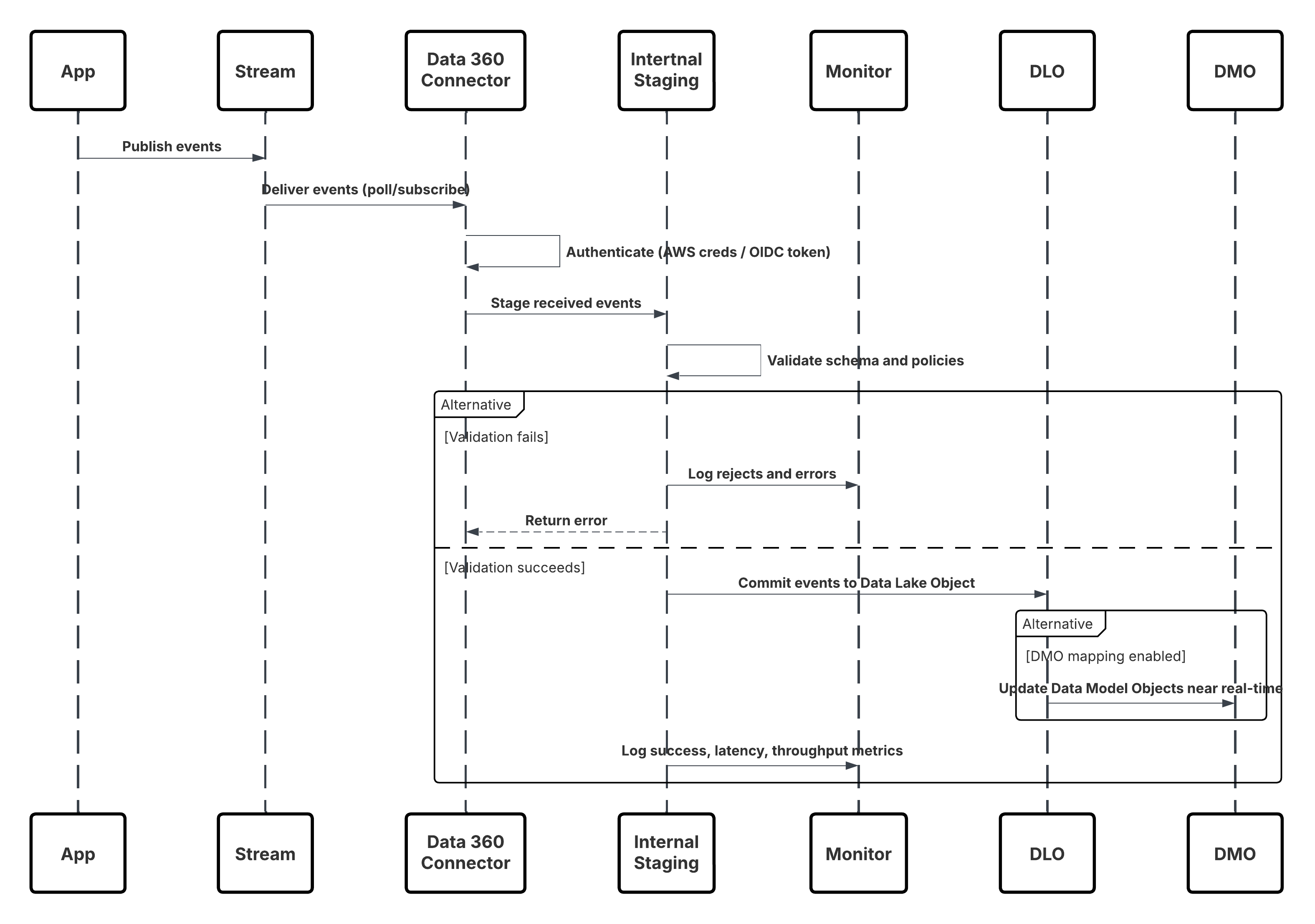
I dette scenariet:
- Programmer eller enheter publiserer hendelser til Kinesis-strøm eller MSK-emne.
- Data 360-kobling godkjennes med AWS-legitimasjon eller OIDC-token.
- Koblingen spør eller abonnerer kontinuerlig på strømmen.
- Hendelser faseres, valideres for skjema og policy og deretter bekreftes til Datasjøobjekt (DLO).
- Hvis datamodellobjekter (DMO-er) tilordnes, oppdateres de i nær sanntid for aktivering.
- Overvåkingslag sporer målinger, skjemaavvisninger og latens.
Resultater
Kontinuerlig inntak med lav latens av strukturerte data direkte fra AWS Kinesis eller MSK til Data 360. Data er umiddelbart tilgjengelig for
- Identitetsløsning
- Sanntidssegmentering
- Einstein AI-aktivering
- Agentforce utløsere Eliminerer avhengighet av gruppe-ETL ved å aktivere strømbaserte arkitekturer i samsvar med organisasjonshendelsesdrevne utforminger.
Inntaksmekanismer
| Mekanisme | Når brukes |
|---|---|
| Kinesis-kobling (foretrukket) | For AWS-innebygde strømmekilder som krever kontinuerlig inntak av strukturerte data med stor trafikk. |
| MSK-kobling | For organisasjoner som kjører hendelses under behandling på Kafka-kompatible plattformer. |
| Hybrid(Streaming + Batch) | For trinnvis hendelsesinntak kombinert med periodiske masseinnlastinger. |
Feilhåndtering og gjenoppretting
- Automatisk gjentagelse: Koblinger prøver på nytt forbigående nettverks- eller plattformfeil med eksponentiell tilbakeslag.
- Skjemaavvisninger: Ugyldige belastninger rutes til køen for skjemaavvisning for administratorgjennomgang.
- DLQ Replay: Vedvarende feil fanges opp i køer med død bokstav for gjenbehandling.
- Idempotency Control: Hendelsesnøkler eller sekvensnumre sikrer fjerning av duplikater og ordnet inntak.
- Overvåkingsintegrering: Alle feil, nye forsøk og gjennomløpsmålinger vises i Data 360 Monitoring-kontrollpaneler.
Viktige punkter om Idempotent-design
- Event Unikhet & Sporing: Hver hendelse tildeles en deterministisk unik nøkkel (for eksempel PartitionKey + SequenceNumber for Kinesis eller Topic + Partition + Offset for MSK) for å sikre nøyaktig inntak av én gang.
- Koblingskontroll: Data 360-koblinger beholder den siste behandlede forskyvningen eller sekvensnummeret for å gjenoppta inntaket sikkert etter feil eller omstart.
- Dedupliserings- og UPSERT-logikk: Under DLO-bekreftelser oppdages duplikathendelser og hoppes over. Gyldige poster settes inn med den unike nøkkelen for å opprettholde konsistens.
- Oppdatering og gjenopprettingskontroll: Mislykkede eller forsinkede hendelser spilles på nytt fra lagrede forskyvninger via Dead-Letter- og Replay-køer for å sikre pålitelig gjenoppretting uten duplikater.
Sikkerhetsvurderinger
Sikkerhet er integrert i hele inntaksprosessen, fra godkjenning til kryptering og tilgangskontroll.
- Godkjenning: Sikre legitimasjonsutveksling med AWS IAM-policyer eller OIDC.
- Kryptering: Data kryptert i transitt (TLS 1.2+) og i ro (AES-256) i Data 360.
- Tilgangskontroll: Roller med færrest rettigheter håndhevet, koblinger med omfang til bestemte strømmer/emner.
- Styring: Metadata for linje og klassifisering brukt på hver post for å oppnå full sporing.
- Nettverkssikkerhet: Du kan eventuelt distribuere i private undernett ved bruk av AWS PrivateLink.
Sidefelt
Tidlighet
- Nær sanntidsbehandling: CDC- og strømmekoblinger behandler hendelser innen sekunder etter at kildeendringer har skjedd, som vanligvis sikrer dataregistrering under minuttet.
- Deterministisk latens: Slutt-til-slutt-forsinkelse avhenger av kildedata, hendelsesbatching og nettverksbetingelser, men Data 360 garanterer forutsigbar SLA-drevet latens for støttede objekter.
- Elastic skalering: Inntaksbehandlingen skaleres automatisk under høyt hendelsesvolum, og beholder tidsriktigheten selv under toppdatabrudd.
- Operative synlighet: Overvåkingskontrollpaneler viser hendelsesforsinkelse, bekreftelsestidsstempler og gjentaksstatus for latenssikkerhet og feilsøking.
Datavolumer
- Lette nyttelast: Individuelle CDC- eller strømmehendelser er kompakt (1–5 kB typisk størrelse), optimalisert for oppdateringer med høy frekvens.
- Høyendring-objekter: For flyktige enheter (for eksempel Sak, Kontakt, Bestilling) må arkitekter sikre at CDC-tildelinger og hendelsesgjennomgang er i samsvar med forventede oppdateringsfrekvenser.
- Parallelle strømmer: Data 360 støtter inntak med flere strømmer for horisontal skalering på tvers av store objektvolumer eller flere kildeorganisasjoner.
- Tilbaketrykkbehandling: Innebygde trusselmekanismer opprettholder inntaksstabilitet under belastning uten å slippe hendelser.
Statbehandling
Hver hendelse inneholder metadata for stat- og versjonskontroll:
- Oppspel og forskyvning sporing: Hver hendelse bærer avspillings-ID og sekvensmetadata som aktiverer bestilt levering og sjekkpunktbasert gjenoppretting.
- Skjemaversjonering: Versjonskoder i hendelseshoder sikrer bakoverkompatibel behandling når kildeskjemaer utvikles.
- Idempotency Keys: Hver hendelse inkluderer en unik transaksjons- eller bekreftelsesnøkkel slik at Data 360 trygt kan fjerne duplikater og nye forsøk.
- Atomic Commit: Inntaksforløbet markerer forskyvninger som fullført bare når nedstrøms bekreftelser til DLO-er lykkes, slik at konsistens sikres.
Komplekse integrasjonsscenarier
Dette mønsteret integreres sømløst i avanserte forretningsarkitekturer:
- Hybrid inntak: Kombiner CDC for inkrementelle deltaer med gruppedatatastrømmer for full oppdatering, samtidig som du beholder både friskhet og fullstendighet.
- Cross-Org Streaming: Flere CRM- eller ERP-organisasjoner kan publisere til samme Data 360-leietager, forent via DMO-tilordning og ontologijustering.
- Event Enrichment: Mellomprogramvare (for eksempel MuleSoft, Hendelsesoverføring) kan berike, filtrere eller rute strømmedata før de når Data 360.
- AI og Agent-aktivering: Sanntidsoppdateringer utløser nedstrøms automatisering, som Einstein eller Agentforce, innen sekunder etter den opprinnelige hendelsen.
Eksempel
Et globalt detaljhandelsforetak bruker AWS Kinesis til å strømme salgssted- og nettinteraksjonsdata.Data 360s Kinesis-kobling godkjenner via IAM-legitimasjon og henter kontinuerlig inn hendelser i en Transaksjons-DLO. Hver post er skjemavalidert, beriket med metadata og umiddelbart overført til kundedemoen.I løpet av sekunder oppdaterer Einstein AI-modeller kundesegmenter og Agentforce utløser neste beste tilbudsanbefalinger i sanntid – noe som gir en fullstendig hendelsesdrevet tilpassingsløyfe.
Zero Copy er mer enn en integrasjonsmetode – det er et grunnleggende skift i hvordan bedriftsdata flyttes, eller snarere ikke flyttes. Tradisjonelt krevde dataintegrering kopiering av store mengder poster via ETL pipelines, opprettelse av overflødige datalager, synkroniseringsforsinkelser og styringsutfordringer. Zero copy eliminerer alt dette. I denne modellen kobler Data 360 direkte til eksterne dataplattformer som Snowflake og Databricks, og leser og aktiverer data sikkert på plass – uten å flytte eller duplisere dem. Resultatet er en sømløs bro mellom datasjøen for virksomheten og Salesforce-økosystemet, som gir umiddelbar tilgang, lavere driftsavgifter og sterkere datastyring.
Med innkommende null-kopieringsfunksjonalitet kan Data 360 spørre og harmonisere eksterne data ved kilden, som kundeprofiler, transaksjoner eller produktdata, som er lagret i Snowflake eller Databricks. I stedet for å hente inn filer etablerer Data 360 en sikker, metadatavennlig tilkobling som benytter eksisterende skjemadefinisjoner og sikkerhetspolicyer i den eksterne lageret.
- Direct Federation: Data 360 leser data på plass via sikre, optimaliserte spørringer uten replikering.
- Forent styring: Data forblir under kildesystemets sikkerhets-, tilgangskontroll- og samsvarsrammeverk.
- Driftseffektivitet: Eliminerer ETL-overhead og lagrings duplisering, noe som reduserer kostnad og kompleksitet.
- Sanntids klargjøring: Aktiverer harmonisering på forespørsel – når data oppdateres i Snowflake, blir de umiddelbart tilgjengelig for aktivering i Data 360.
Kontekst
Moderne datadrevne virksomheter behandler petabyte av kundedata, transaksjonsdata og telemetridata i skyskalerte datasjøplattformer som Snowflake og Databricks. Disse miljøene tjener som den eneste sannhetskilden for analyse, AI og samsvar. Data 360 introduserer Zero CopyData Federation, som tillater at Data 360 direkte spør og bruker eksterne datasett på plass – uten å kopiere, transformere eller lagre overflødige data. Dette mønsteret gir organisasjoner mulighet til å utvide Customer 360 til sin eksisterende datalagring eller innsjøinfrastruktur – oppnå sanntids forening og aktivering med null duplikater, null latens og null kompromiss om styring.
Problem
Hvordan kan virksomheter utnytte rike datasett som allerede er kuratert i Snowflake, Databricks eller åpne innsjøformater som Apache Iceberg – for segmentering, identitetsløsning og aktivering i Data 360 – uten kostnadene, latensen og styringskostnadene for ETL pipelines eller fysisk dataflyt?
Styrker
Dette mønsteret introduserer flere viktige punkter om arkitektur, sikkerhet og ytelse:
Nettverk og sikkerhet
- Data 360 må etablere en sikker, privat tilkobling til den eksterne lagerbygningen eller innsjøbygningen.
- Konfigureres vanligvis med Salesforce Private Connect eller PrivateLink/VPC Peering, slik at trafikk aldri forlater kundens kontrollerte nettverk.
- Eksterne systemer må inkludere Data 360-IP-adresser i tillatelseslisten og håndheve TLS 1.2+-kryptering.
Godkjenning og tilgangskontroll
- Støtter nøkkelpargodkjenning, OAuth 2.0 eller Identity Provider-basert Trust-delegering (Data 360 fungerer som en klarert klient)
- Rollebasert tilgangskontroll (RBAC) i det eksterne systemet håndhever minst tillatelsestilgang for utføring av spørringer.
Ytelse og beregningsavhengighet
- Spørringsforbund pusher ned SQL-utførelse til Snowflake eller Databricks ved å benytte sine dataklynger.
- Ytelses- og kostnadsskala med ekstern spørringsbelastning – segmenteringslatens og -kostnad er knyttet til ekstern databehandlingskonfigurasjon.
Utviklende standarder: Filforbund
- En nestegenerasjonsmodell, Filforbund, benytter åpne tabellformater som Apache Iceberg eller Delta Lake, slik at Data 360 kan leses direkte fra objektlagring (for eksempel Amazon S3, Azure ADLS, Google Cloud Storage).
- Ved å omgå kildedatasjiktet reduserer Filforbund drastisk latens og kostnader for lesetunge analytiske arbeidsbelastninger, samtidig som skjemaintegriteten opprettholdes.
Forvaltning og overholdelse
- Data forlater aldri kildeplattformen – samsvars-, krypterings- og oppbevaringspolicyer håndheves ved opphavet.
- Alle metadata, linje- og samtykkeattributter overføres til Data 360s Trust for å sikre slutt-til-slutt-sporing.
Løsning
Den anbefalte løsningen er å bruke innebygde Zero Copy-koblinger for Snowflake, Databricks eller Filforbund i Data 360.
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| Snowflake Zero kopikobling | Best | Førsteparts innebygd integrasjon; etablerer direkteforbundsspørring via Snowflakes API-er for datadeling eller ekstern tabell. |
| Databricks Zero kopikobling | Best | Støtter direkte direkte tilgang til tabeller/visninger i Delta Lake. Nedtrekksspørringer utføres ved kjøretid i Databricks. |
| Filforbundet (Apache Iceberg / Delta / Parquet) | Beste fremgangsmåte | Data 360 leser direkte åpne tabellformater fra objektlagring uten ekstern beregningsavhengighet. Ideelt for massive datasett. |
| Privat nettverkskonfigurasjon | Anbefalt | Bruk Salesforce Private Connect eller VPC-paring for å få sikker forening på nettverksnivå. |
| Godkjenning og nøkkeladministrasjon | Beste praksis | Implementer sikker nøkkelbasert eller OAuth-basert godkjenning med periodisk rotasjon og varebeholdningsadministrasjon. |
| Skjemaregistrering | Nødvendig | Data 360 henter et eksternt skjema og tilordner det til et eksternt datasjøobjekt (Extern DLO). |
| Governed Metadata | Anbefalt | Alle eksterne DLO-er arver klassifisering, samtykke og linjemetadata for synlighet av samsvar. |
Skisse
Følgende diagram illustrerer hvordan du konfigurerer en 0-kopieringstilkobling og oppretter eksterne DLO-er i Data 360.
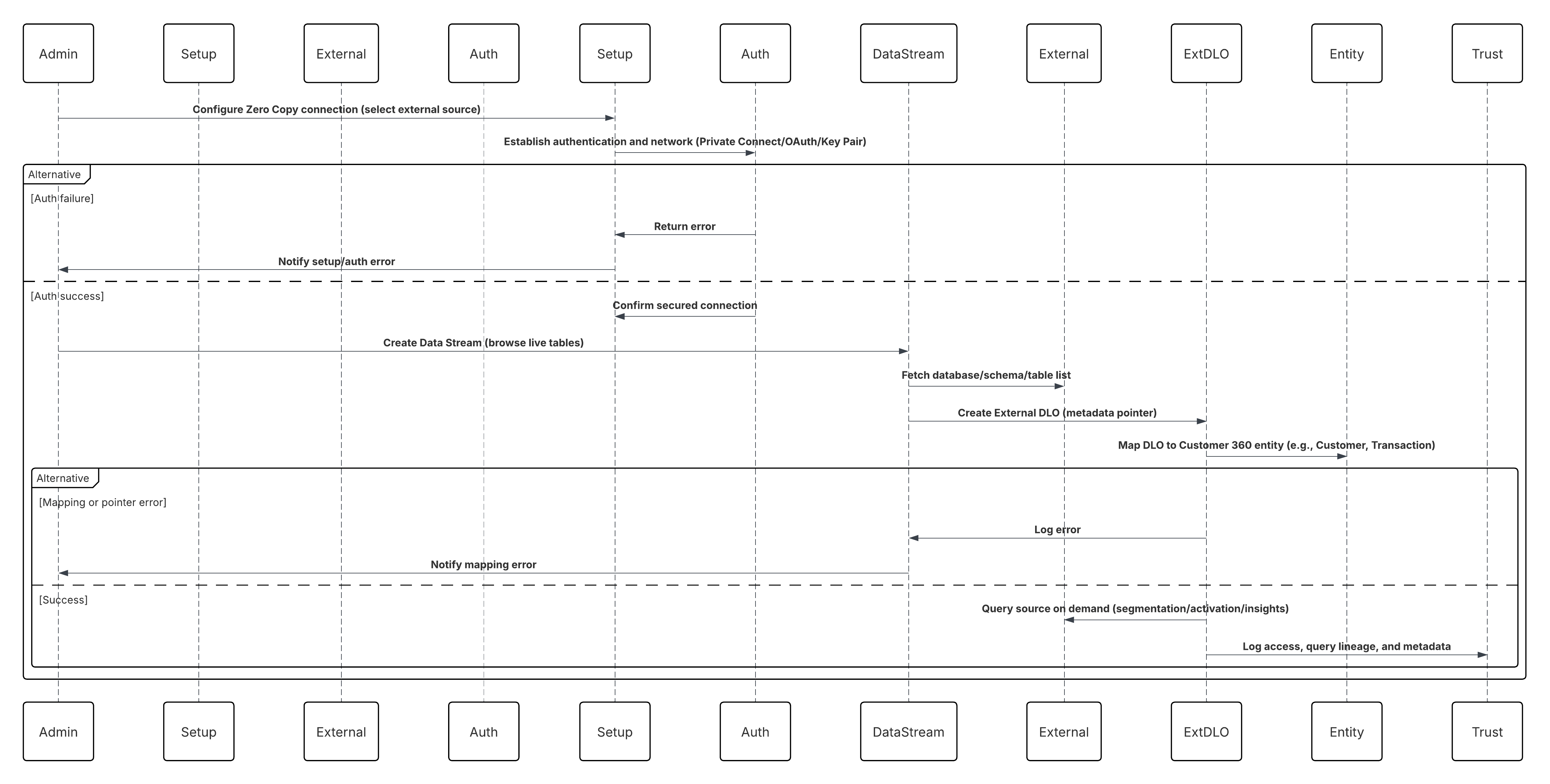
I dette scenariet:
- Administrator konfigurerer en Zero Copy-tilkobling i Oppsett for Data 360 (Snowflake, Databricks eller Filforbund).
- Sikker godkjenning og nettverksruting er etablert (Private Connect / OAuth / Key Pair).
- Administrator oppretter en datastrøm som velger den eksterne kilden – bla direkte i databaser, skjemaer og tabeller.
- I stedet for å kopiere data oppretter Data 360 et eksternt DLO (Data Lake Object) – en metadatapeker som refererer til direktetabellen eller Iceberg-filen.
- Eksterne DLO-er tilordnes til Customer 360 (for eksempel Kunde, Transaksjon, Produkt).
- Data 360 spør kilden på plass under segmentering, aktivering eller innsiktsberegning.
- All tilgang, spørringslinje og metadata revideres i Data 360 Trust.
Resultater
- Eksterne data beholdes i Snowflake, Databricks eller S3 – ingen ETL, ingen duplikater, ingen ekstra lagringsplass.
- Data 360 får sanntidstilgang, lesetilgang til data i bedriftsskala for identitetsløsning, beregnet innsikt og aktivering.
- Organisasjoner beholder full kontroll under sine eksisterende rammeverk for styring, kryptering og samsvar.
- Dette mønsteret aktiverer en sann Zero Copy-arkitektur – som kombinerer ytelsen til lokal tilgang med styringen av samlet lagring.
Kalle opp mekanismer
Oppkallmekanismen avhenger av løsningen som er valgt for å implementere dette mønsteret.
| Mekanisme | Når brukes |
|---|---|
| Snowflake-forbund (foretrukket) | For direkteforening av spørringer med høy ytelse med styrte datalagrer for virksomheten. |
| Databricks-forbund | For forent analyse og innsjømiljøer med Delta- eller Parket-støttede datasett. |
| Filforbund (Apache Iceberg / Delta Lake) | For datasett i stor skala i objektlager der beregningsfjerning og kostnadsoptimalisering er nøkkelen. |
| Hybridmodus (null kopi + inntak) | Når historiske data trenger engangsinntak, men direktedata får tilgang via Zero Copy. |
Feilhåndtering og gjenoppretting
- Automatisk tilbakestilling av forsøk og spørring: Midlertidig tilkobling eller spørringstidsavbrudd prøves automatisk på nytt med eksponentiell tilbakekobling.
- Skjemaversjonsisolering: Endringer i kildeskjema (for eksempel nye kolonner) logges i køen for skjemaavvisning. Administratorer kan tilordne eller oppdatere skjemametadata på nytt.
- Godkjenningsfeilover: Hvis legitimasjonen utløper, prøver Data 360 tilkoblingen på nytt med lagrede oppdateringstokener eller nøkkelrotasjonspolicyer.
- Beregne tilgjengelighetsdeteksjon: Hvis Snowflake- eller Databricks-klyngen er midlertidig stanset, suspenderer Data 360 forbundsjobber og prøver på nytt når beregningen gjenopptas.
- Overvåkingsintegrering: Alle tilkoblingstilstands-, spørringslatens- og linjemetadata er synlige i Data 360 Monitoring-kontrollpaneler.
Viktige punkter om Idempotent-design
- Query Deterministism: Samlet spørring bruker konsistent øyeblikksbildesemantik for å sikre stabile, gjentagende avlesninger under segmentering eller aktivering.
- Ekstern DLO-versjonering: Hver samlet spørring inkluderer skjema- og tidsstempelmetadata for linjesporing.
- Offset-less-tilgang: I og med at Zero Copy er skrivebeskyttet, er den ikke avhengig av hendelsesforskyvninger – konsistens håndheves via det eksterne systemets ACID-garantier (Snowflake/Delta Lake).
- Skjema Glidebehandling: Vedlikehold skjematilordninger med versjoner i Data 360. Oppdater eksterne DLO-metadata i kildeutvikling.
Sikkerhetsvurderinger
Sikkerhet er integrert i hele føderasjonsmodellen – og sikrer ingen kompromiss i Trust eller overholdelse.
- Kryptering: Alle datautvekslinger bruker TLS 1.2+, eksterne lagre krypterer under lagring med AES-256.
- Tilgangskontroll: Tilgang til eksterne tabeller skjer via roller med færrest rettigheter med skrivebeskyttelse.
- Nettverksisolasjon: Private Connect- eller VPC-rutene hindrer eventuell eksponering for felles endepunkter.
- Styrt dataflyt: Metadataflyt for linje, samtykke og klassifisering til Data 360 Trust for policyhåndhevelse.
- Revisjonsmuligheter: Hver forent spørring og skjematilgangshendelse logges for sporbarhet av samsvar (GDPR, CCPA, HIPAA).
Sidefelt
Tidlighet
- Spørringer utføres direkte mot den eksterne lageret eller lageret for å sikre sanntids synlighet av den siste datatilstanden.
- Segmenterings- eller aktiveringskjøringer gjenspeiler endringer på opptil et sekund i Snowflake-, Databricks- eller S3-støttede Iceberg-tabeller.
- Spørringslatens avhenger av ytelsessjiktet i kildesystemet – vanligvis sekunder til titalls sekunder per spørring.
- Ideelt for analyse- og AI-arbeidsbelastninger som krever "frisk, ikke kopiert" datatilgang.
Datavolumer
- Støtter datasett i petabyte-skala som er lagret som standard i Snowflake eller Databricks, uten replikering.
- Data 360 henter bare resultater, ikke rådata, noe som minimerer nettverks- og datakostnader.
- Filforbund optimaliserer store analytiske skanninger gjennom partisjonssnitt og rullegardinliste for kolonner.
- Skaleres lineært med lagerbeholdningskapasitet og Data 360s forente spørringsorkestreringslag.
Statbehandling
- Eksterne DLO-er beholder tilkoblings-, skjema- og versjonsmetadata i Data 360.
- Skjemautvikling behandles automatisk via oppdateringssykluser for metadata.
- Spørringslinjen inkluderer tidsstempler, brukeridentitet og utførelsesmålinger for sporbarhet.
- Ingen statlige inntak eller forskyvninger beholdes – konsistens arves fra den eksterne kildens ACID-garantier.
Komplekse integrasjonsscenarier
- Hybridmodus: Kombiner Zero Copy (for direkteforbund) med inntak (for historiske datasett).
- Tilgang på tvers av lagerbygning: Data 360 kan forenes fra flere Snowflake- eller Databricks-leietagere i én organisasjon.
- AI/BI-interoperabilitet: Eksterne systemer (for eksempel SageMaker, Tableau, Power BI) kan spørre Data 360s forbedrede profiler tilbake via omvendt nullkopiering.
- File Federation Extension (Filforbundsutvidelse): Virksomheter som bruker åpne innsjøformater (Iceberg/Delta), kan forene strukturerte og ustrukturerte data under én forent modell.
Eksempel
Et globalt finansforetak lagrer alle transaksjons- og interaksjonsdata i Snowflake samtidig som det vedlikeholder kundeattributter og markedsføringshendelser i Data 360. Ved å bruke Zero Copy Data Federation kobler Data 360 seg sikkert til Snowflake via privat tilkobling.Når en segmenteringsjobb kjører, for eksempel: "Kunder med >$10K brukt de siste 30 dagene, skyver Data 360 ned spørringen til Snowflake, henter aggregerte resultater og aktiverer disse profilene umiddelbart i Journey Builder. Ingen replikering eller ETL kreves. Dette eksemplet bruker sanntids, samlet intelligens som er forent på tvers av virksomhetens dataøkosystem.
Utgående null-kopi utvider det samme prinsippet omvendt. I stedet for å eksportere eller kopiere datasett fra Data 360, kan eksterne systemer som Snowflake spørre Data 360 direkte, og behandle den som en forent kilde til beriket Kundeintelligens.
- Reverse Federation: Eksterne analyser eller AI-plattformer kan få tilgang til Data 360s forente profildata uten å trekke dem ut.
- Dataktivering ved kilde: Forretningsteam kan benytte innsikt der dataene allerede finnes – enten for AI-modellering, rapportering eller kundetilpassing.
- Latency-free interoperability: Ingen gruppeeksporterer eller synkroniserer jobber. Innsikt flyter umiddelbart mellom plattformer.
- Konsistent semantikk: I og med at begge systemene deler samme ontologi og skjematilordninger, beholdes kontekst og betydning på tvers av økosystemer. Zero copy omdefinerer rollen til Data 360 fra et dataregister til et semantisk aktiveringslag. Det gjør det mulig for organisasjoner å beholde data nøyaktig der de tilhører – i styrte, høyytelseslagre – samtidig som de låser opp hele verdien innenfor Salesforces Trust grenser. Dette mønsteret er i samsvar med moderne datanettverk og innebygde AI-arkitekturer: Data beholdes desentralisert, men intelligens blir forent. Architects kan nå bygge aktivering pipelines som er raskere, slankere og mer kompatible – ingen kopiering kreves.
Kontekst
Moderne virksomheter opererer i økende grad i dataplattformøkosystemer der Salesforce Data 360 leverer forente kundeprofiler og aktivering, mens bedriftens datalagrer som Snowflake eller Databricks fungerer som analytiske ryggrader for datavitenskap, maskinlæring og BI-arbeidsbelastninger. Salesforce Data 360s Zero Copy Outbound Sharing-funksjon overbryter disse miljøene sømløst – og gir styrt, sikker og sanntidstilgang til harmoniserte Data 360-data direkte i Snowflake eller Databricks, uten replikering eller ETL. Dette gir analysatorer og datateknikere mulighet til å spørre, visualisere og modellere på samme direkte, klarerte data som leverer markedsføring, salg og serviceaktivering.
Problem
Hvordan kan et foretak eksponere Data 360s forente kundeprofiler og beregnede målinger (for eksempel Lifetime Value, Churn Risk) sikkert og effektivt for eksterne analysesystemer – uten å kopiere data, bryte styring eller introdusere latens gjennom tradisjonelle omvendte ETL-ledninger?
Styrker
Dette mønsteret introduserer flere viktige punkter om arkitektur, styring og drift:
- Styret sikkerhet: Tilgang til Data 360-data må være kontrollert, detaljert og reviderbart. Zero Copy-deling bruker eksplisitt tilgang på objektnivå, slik at bare godkjente datamodellobjekter (DMO-er) og beregnede innsiktsobjekter (CIO-er) er tilgjengelig for utpekte forbrukere.
- Explicit Object Selection: Administratorer organiserer delbare data via en datadeling og velger eksplisitt hvilke objekter som skal eksponeres. Dette opprettholder styring og minimerer risikoeksponering.
- Bilateral konfigurasjon: Både Data 360 og den eksterne lageret krever oppsett. Data 360 definerer målet for datadeling (Snowflake/Databricks), mens mottakersystemet må godta og instansiere delingen.
- Spørringsforbundsmodell: Når den er godtatt, spør den eksterne plattformen direkte, administrerte Data 360-data via forente visninger, og eliminerer uttrekksjobber eller manuelle oppdateringssykluser.
- Open Standards Evolution: Nye tilnærminger som Filforbund benytter åpne tabellformater (for eksempel Apache Iceberg) for å muliggjøre skrivebeskyttet tilgang på lagringsnivået – noe som forbedrer skalerbarhet, ytelse og interoperabilitet på tvers av flerskyarkitekturer.
Løsning
Løsningen benytter Salesforce Data 360s innebygde Zero Copy-deling med dataplattformer som Snowflake eller Databricks.
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| Datadelingsoppretting | Best | Administrator oppretter en datadeling i Data 360 og legger til valgte DMO-er og CIO-er (for eksempel Forente persondata, Kundetilstandsscore). |
| Målkonfigurasjon | Best | Opprett et datadelingsmål som angir Snowflake- eller Databricks-kontoidentifikatorer og godkjenningsparametere. |
| Dele publisering | Beste praksis | Koble datadelingen til datadelingsmålet for å publisere sikkert. |
| Lagergodkjenning | Nødvendig | Den eksterne administratoren godtar delingen og materialiserer delte objekter som skrivebeskyttede visninger/tabeller i lagerbygningen. |
| Granular Access Control | Anbefalt | Bruk objekts- og rollebaserte tillatelser i Data 360, og juster med rollebasert tilgangskontroll på lagernivå. |
| Forent spørringstilgang | Best | Analytikere spør direkte delte data via standard SQL. Sammenføyer med innebygde lagerbeholdningsdata for nedstrøms analyse og ML. |
| Filforbund-alternativ | Valgfritt | For store datasett kan du benytte deg av Apache Iceberg-basert forening for direkte S3- eller Delta Lake-leser uten datavennlighet. |
Skisse
Følgende diagram illustrerer et kall fra Salesforce Data 360 til en ekstern dataplattform.
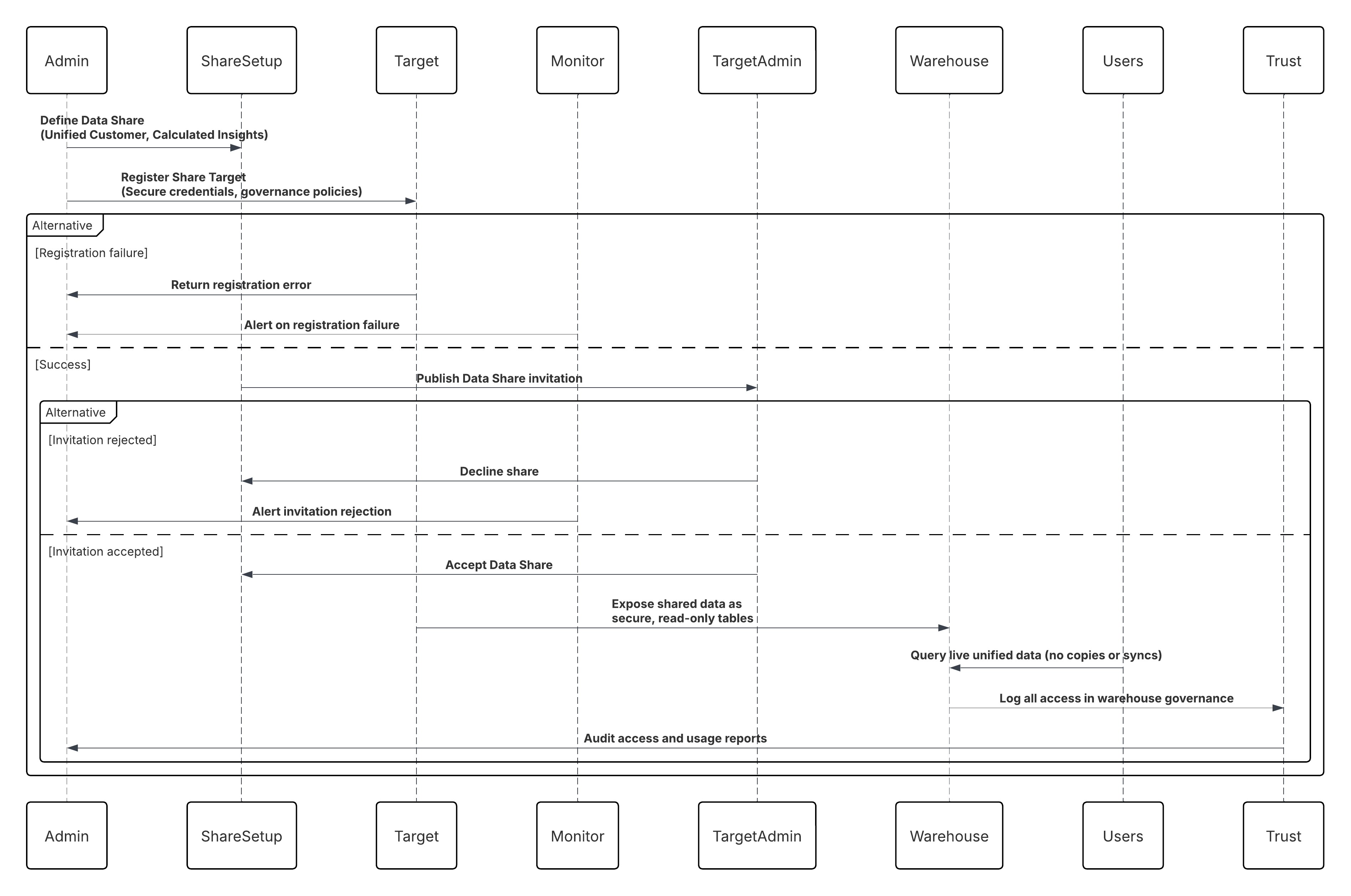
I dette scenariet:
- Data 360-administrator definerer en datadeling som inkluderer objektene Forente kunder og Beregnet innsikt.
- Et datadelingsmål (Snowflake- eller Databricks-konto) registreres med sikker legitimasjon og styringspolicyer.
- Data 360 publiserer delingen. Snowflake/Databricks-administratorer godtar den.
- Delte data vises som sikre, skrivebeskyttede tabeller i lagerbygningen.
- Analysatorer, BI-verktøy eller ML pipelines spør direkte, forente kundedata uten å kopiere eller synkronisere.
- All tilgang blir kontrollert i Data 360 Trust Layer og lagerstyringslogger.
Resultater
- Eksterne lagre får sanntidstilgang og kan spørres mot harmoniserte Data 360-data.
- Eliminerer omvendt ETL under arbeid, noe som reduserer driftsbelastning og latens.
- Aktiverer AI/ML-opplæring, prediktiv modellering og avansert BI direkte på forente data.
- Opprettholder null duplisering, sterk styring og sikker tilgangskontroll etter utforming.
- Fullfører den toveisige Zero Copy-sløyfen, der innkommende forbunds- og utgående deling finnes sammen under en enkelt styringsmodell.
Kalle opp mekanismer
Oppkallmekanismen avhenger av løsningen som er valgt for å implementere dette mønsteret.
| Mekanisme | Når brukes |
|---|---|
| Snowflake-sikker datadeling (foretrukket) | Brukes når virksomhetens lagerbygning er Snowflake og du trenger direkte, administrert tilgang til harmoniserte Data 360-datasett uten databevegelse eller duplisering. Ideelt for analyser, AI og samsvarsdrevne arbeidsbelastninger som krever deling med null latens og håndheving av innebygd linje. |
| Databricks Delta Share | Brukes når nedstrøms forbrukere opererer i Databricks- eller Delta Lake-miljøer og krever sanntidstilgang, skrivebeskyttet tilgang til forente eller aktiverte datasett via den åpne Delta-delingsprotokollen. |
| External Table Share (Apache Iceberg / Parquet) | Brukes når du vedlikeholder arkitekturer i åpent format i objektlagring (S3, ADLS eller GCS) og trenger interoperabel, billig deling på tvers av analysemotorer som Athena, BigQuery eller Snowflake-on-Iceberg. |
| Data Share API (programmatisk tilgang) | Brukes når tilpassede apper eller mellomprogramvare (for eksempel MuleSoft) må oppdage, abonnere på eller forbruke delte datasett sikkert via API-er, med hendelsesbaserte oppdateringsvarsler og detaljert tilgangskontroll. |
| Hybriddeling (Zero Copy + Outbound Share) | Brukes ved implementering av toveis utvekslingsmønstre – utnytte nullkopiering for innkommende data og utgående datadeling for publisering av innsikt, og sikre semantisk og styringskonsistens på tvers av virksomhetens dataplaner. |
Feilhåndtering og gjenoppretting
- Tilkoblingsforløb: Automatiske forsøk på nytt for midlertidig tilkobling eller godkjenningsfeil mellom Data 360 og lagerbygning.
- Dele validering: Ugyldige eller uautoriserte delingskonfigurasjoner settes i karantene i en Administratorgjennomgangskø.
- Synkron tilstandsovervåking: Data 360 viser direkte delingsstatus, spørringslatens og tilgangslogger via Overvåking-kontrollpaneler.
- Tilgangsavbrudd: Administratorer kan oppheve delinger umiddelbart og deaktivere tilgang på begge ender uten gjenværende datakopier.
- Governed Audit Trail: Alle konfigurasjons- og tilgangsendringer logges for bekreftelse av samsvar.
Viktige punkter om Idempotent-design
- Konsistent delingsidentifikasjon: Hvert datadelings- og datadelingsmålpar har en unik identifikator som sikrer nøyaktig styring og tilgangssporing.
- Uendelig visninger: Delte dataobjekter er skrivebeskyttet. Forbrukere kan ikke endre status, noe som sikrer deterministiske resultater og samsvar.
- Atomisk delings livssyklus: Deling av publisering, oppheving og oppdatering er atomoperasjoner – enten fullført eller rullet tilbake.
- Gjentagelseskonsistens: Når Data 360-data oppdateres, returnerer spørringer på lagersiden alltid det siste konsistente øyeblikksbildet, noe som eliminerer foreldede avlesninger.
Sikkerhetsvurderinger
Sikkerhet ligger til grunn for alle aspekter ved deling med null kopier:
- Godkjenning: Mutual Trust etablert med OAuth 2.0, private key exchange eller identity federation (OIDC).
- Kryptering: Data kryptert underveis (TLS 1.2+) og under lagring (AES-256).
- Tilgangskontroll: Tillatelser på objektnivå håndhever tilgang med færrest rettigheter, styrt av Data 360 Trust.
- Nettverkssikkerhet: Datautvekslinger skjer via private nettverkslenker som Salesforce Private Connect eller API-er for sikker datautveksling.
- Governance Metadata: Hvert delt objekt bærer arv, klassifisering og samtykkeattributter for full sporbarhet og etterlevelse av forskrifter.
Sidefelt
Tidlighet
- Sanntidstilgjengelighet: Delte data gjenspeiler den nyeste statusen til Data 360 uten replikeringsforsinkelser.
- Query Freshness: Endringer i DMO-er eller CIO-er overføres umiddelbart til delte lagervisninger.
- Ydeevne Elasticity: Spørringsnedtrekksmeny tilpasser seg dynamisk til lagerbeholdningsdataressurser.
- Overvåking: Direktekontrollpaneler viser delt latens og spørringsytelsesmålinger for driftssikkerhet.
Datavolumer
- Skalerbar deling: Støtter deling av detaljerte data på objektnivå eller på fullt domene avhengig av analytiske behov.
- Optimalisert spørringsytelse: Snowflake/Databricks bufrer delte data intelligent for å minimere latens.
- Lagringseffektivitet: Duplisering null eliminerer overflødige lagringskostnader.
- Filforbund-alternativ: For datasett i petabyte-skala omgår direkte Iceberg-basert deling beregninger og akselererer tilgang.
Statbehandling
- Schema Evolution: Versjonskontrollerte skjemaer sikrer kompatibilitet når Data 360-modellen utvikles.
- Sporing av tilgangstilstand: Aktive/ inaktive delingstilstander som vedlikeholdes i Data 360 for livssyklusstyring.
- Metadatasynkronisering: Oppdateringer av felles objektdefinisjoner gjenspeiles automatisk i nedstrøms lagerkataloger.
- Uendelig statlig garanti: Lagervisninger representerer alltid en konsistent, tidsavhengig tilstand for Data 360-data.
Komplekse integrasjonsscenarier
- Hybridmodus: Kombiner Zero Copy (for direkteforbund) med inntak (for historiske datasett).
- Tilgang på tvers av lagerbygning: Data 360 kan forenes fra flere Snowflake- eller Databricks-leietagere i én organisasjon.
- AI/BI-interoperabilitet: Eksterne systemer (for eksempel SageMaker, Tableau, Power BI) kan spørre Data 360s forbedrede profiler tilbake via omvendt nullkopiering.
- File Federation Extension (Filforbundsutvidelse): Virksomheter som bruker åpne innsjøformater (Iceberg/Delta), kan forene strukturerte og ustrukturerte data under én forent modell.
Eksempel
Analyse på tvers av skyer gir organisasjoner mulighet til å kombinere styrte Salesforce Data 360-data med innebygde datasett i plattformer som Snowflake og Databricks for å levere en fullstendig 360-graders analytisk visning. Gjennom tilgang for flere leietagere kan forskjellige forretningsenheter sikkert bruke kuraterte og policykontrollerte datastykker via separate delinger uten duplikatdata. Datateknikere kan deretter utføre forent AI og maskinlæring ved å lære opp modeller direkte i forente kundeprofiler i Snowflake ML- eller Databricks MLflytmiljøer. Gjennom hele denne prosessen sikrer innebygd linje, styring og revisjonsfunksjonalitet at all datatilgang og bruk forblir i samsvar med firmaets policyer og lovpålagte krav som GDPR og HIPAA.
Data Cloud One gir organisasjoner med flere Salesforce-organisasjoner (for eksempel på grunn av forretningsenheter, regioner, produktlinjer eller anskaffelser) mulighet til å dele én enkelt, sentral Data 360-forekomst. Denne organisasjonen fungerer som "hjemmeorganisasjonen", mens andre organisasjoner, kalt "fellesorganisasjoner", kan få tilgang til og handle på disse forente dataene – med minimal innsats, ingen tilpasset kode og fullstendige styringskontroller.
Kontekst
Virksomheter kjører ofte flere enn én Salesforce-organisasjon (for eksempel én for salg, én for service, én for markedsføring eller distinkte områder). Hver organisasjon kan ha sine egne data, konfigurasjon og prosesser. Før Data Cloud One krevde hver organisasjon enten sitt eget Data 360-oppsett eller kompleks tilpasset kode for å dele data på tvers av organisasjoner. Data Cloud One forenkler dette ved å tillate en enkelt "hjemmeorganisasjon" med Data 360 og flere "fellesorganisasjoner" som kobler til via konfigurasjon med lite kode og metadatadeling.
Problem
Hvordan kan en virksomhet muliggjøre konsekvent bruk av de forente Customer 360 – inntatt, harmonisert og administrert av hjemmeorganisasjonens Data 360 – i alle Salesforce-organisasjoner (slik at salg, markedsføring, service osv. alle bruker de samme underliggende dataene), samtidig som du unngår duplisering av innsats, tilpasset koding, separate Data 360-forekomster per organisasjon og hull i styringen?
Styrker
Dette mønsteret introduserer flere viktige punkter om arkitektur, sikkerhet og ytelse:
- Kompleksitet for flere organisasjoner: Hver forretningsenhets organisasjon kan ha forskjellige data, tilpassede objekter, sikkerhet og prosesser – det er vanskelig å opprettholde konsistente forente visninger.
- Duplisering & kostnad: Å kjøre en separat Data 360-forekomst per organisasjon betyr ekstra oppsett, ekstra styring, ekstra lisensiering og risiko for datasiloser.
- Styring og datadelingskontroller: Du må bestemme hvilke data hver organisasjon kan se og handle på – du kan ikke bare dele «alt» uten styringsrisiko.
- Oppsetthastighet: Markedsførings-, salgs- eller serviceteam kan ikke vente uker med tilpasset kode for å gjøre data for flere organisasjoner tilgjengelig – de trenger klikkkonfigurasjonsløsninger.
- Datatopphold, regionale vurderinger: Hvis hjem- og partnerorganisasjoner er i forskjellige regioner, kan det være juridiske eller lovpålagte begrensninger for hvor data lagres eller hvordan de deles.
Løsning
Følgende tabell inneholder ulike løsninger på dette integrasjonsproblemet.
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| Hjemmeorganisasjonsklargjøring | Best | Utpek én Salesforce-organisasjon som Hjem-organisasjonen der Data 360 er klargjort. Dette blir det sentrale datarepositoriet og styringsknutepunktet. |
| Kobling til partnerorganisasjon | Best | Konfigurer Fellesskapstilkoblinger fra Hjem-organisasjonen til én eller flere Fellesskapsorganisasjoner via Data Cloud One-appen – ingen tilpasset kode kreves. |
| Data Space Definition | Beste praksis | Definer dataområder i startorganisasjonen for å logisk segmentere data (for eksempel Detaljhandel, Service, Markedsføring) og isolere tilgangsgrenser. |
| Data Space Sharing | Best | Del eksplisitt valgte dataområder fra startorganisasjonen til partnerorganisasjoner for å sikre styrt, rollebasert synlighet av forente data. |
| Tilgangskonfigurasjon | Nødvendig | I partnerorganisasjoner aktiverer du Data Cloud One-appen og tildeler brukertillatelser for profil-, innsikts- og segmenttilgang. |
| Styring og policykontroll | Anbefalt | Sentraliser alle inntaks-, identitetsløsnings- og Trust i Hjem-organisasjonen ved å opprettholde enhetlig styring. |
| Synkronisering for flere organisasjoner | Best | Dataendringer og beregnede innsikter i Hjem-organisasjonen gjenspeiles i Sanntid på tvers av partnerorganisasjoner via administrerte synkroniseringsledninger. |
| Hybrid Deployment Option | Valgfritt | For store virksomheter kan flere følgesorganisasjoner koble til én enkelt hjemmesideorganisasjon samtidig som grensene for lokal kontekst og samsvar opprettholdes. |
Skisse
Følgende diagram illustrerer sekvensen av hendelser i dette mønsteret der Salesforce er dataoverordnet.
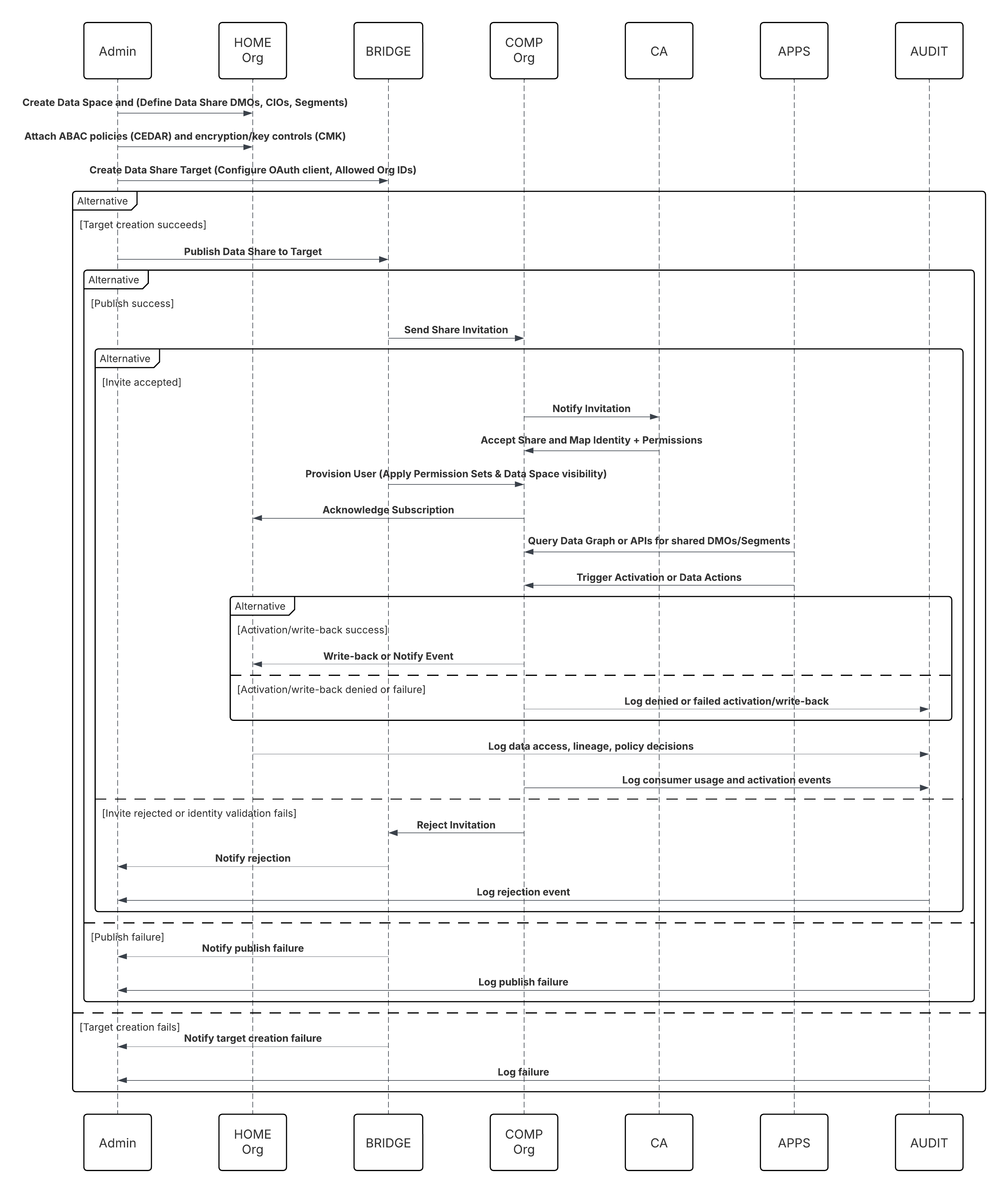
I dette scenariet:
- Home Admin: opprette Data Space og definere Data Share (velg DMO-er/CIO-er, segmenter).
- Hjemadministrator: Opprett Datadelingsmål for ledsagerorganisasjoner og konfigurer Trust (OAuth-klient, tillatte organisasjons-IDer).
- Hjemadministrator: publiser Datadeling til mål, legg ved ABAC-policyer (CEDAR) og kryptering/nøkkelkontroller (CMK hvis det er nødvendig).
- Companion Org Admin: mottar invitasjon, validerer identitetstilordning og godtar deling.
- Companion-organisasjon: Data Cloud One Bridge klargjør en Data Cloud One-bruker og bruker synlighet av tillatelsessett og dataområder.
- Samsvarende organisasjonsapper (flyter / Einstein / Apex): Spør en datadiagram eller kall Data Cloud One API-er for å lese delte DMO-er eller segmenter.
- Aktivering: Fellesorganisasjon utløser aktivering eller skriver tilbake via datahandlinger (hvis tillatt).
Resultater
- En enkelt sannhetskilde for kundedata (Customer 360) på tvers av alle tilkoblede organisasjoner – ingen overflødige Data 360-forekomster.
- En raskere tid til verdier. Medfølgende organisasjoner kan få tilgang til forente data og Data 360-drevne funksjoner på minutter, ikke uker med tilpasset koding.
- Kontrollert datadeling. Bare autoriserte dataområder deles for å bevare sikkerhet og styring samtidig som forretningshastighet aktiveres.
- Forretningsfunksjoner (salg, service, markedsføring) opererer på samme forente datakilde som aktiverer ensartede målinger, aktivering og innsikt på tvers av virksomheten.
Kalle opp mekanismer
Oppkallmekanismen avhenger av løsningen som er valgt for å implementere dette mønsteret.
| Mekanisme | Når brukes |
|---|---|
| Data Cloud One innebygd deling (foretrukket) | Brukes når flere Salesforce-organisasjoner (Sales, Service eller Industry Cloud) trenger sanntidstilgang til forente kundedata direkte fra Data 360\. Dette eliminerer replikering og aktiverer nulllatenstilgang til Golden Records, segmenter og beregnede innsikter. |
| Del organisasjon-til-organisasjon via Data Cloud One Bridge | Brukes når flere forretningsenheter eller datterselskaper opererer i separate Salesforce-organisasjoner, men trenger delt tilgang til vanlige kundedata og segmenter fra en sentral Data 360-forekomst. Ideelt for virksomheter med flere organisasjoner som vedlikeholder uavhengige driftssystemer. |
| API-er for Einstein 1-plattformspørringer | Brukes når Salesforce-apper, Flyt eller Einstein Copilot må spørre eller aktivere Data 360-data programmatisk. Aktiverer sanntids henting av forente profiler, målinger eller aktiveringsresultater i andre Salesforce-programmer uten gruppeeksport. |
| Aktivering til Salesforce-kanaler | Brukes når Data 360-data (segmenter, innsikt eller attributter) må aktiveres i Marketing Cloud, Service Cloud eller Commerce Cloud for tilpassing, utførelse av kampanjer eller agenthjelpsopplevelser. |
| Tilgang til datagraf (semantisk spørringslag) | Brukes når du trenger tilgang på semantisk nivå til den forente datamodellen via Salesforce Data Graph – som støtter Copilot, AI-arbeidsflyter og analyse på tvers av skyer i sanntid, uten manuelle koblinger eller transformasjoner. |
Feilhåndtering og gjenoppretting
- Synkronisering på tvers av organisasjoner: Data Cloud One prøver automatisk mislykkede synkroniseringsjobber på nytt mellom Hjem- og Samleorganisasjoner ved bruk av eksponentiell tilbakekobling for midlertidige nettverks- eller plattformfeil.
- Delvis gruppeisolasjon: Mislykkede registreringsbatcher er i karantæne i en genprøvekø i startorganisationen, indtil afstemmelse lykkes, hvilket forhindrer datadivergencer.
- Schema Rejection Governance: Skjema- eller tilordningsfeil rutes til køen for avvisning av skjemaer for administratorgjennomgang og korrigering.
- Fortsett- og fortsett-kontinuitet: Hver synkroniseringsjobb opprettholder forskyvningssjekkpunkter slik at replikering kan gjenopptas fra den siste vellykkede bekreftelsen uten duplisering.
- Integrert overvåking: Alle feil, nye forsøk og gjenopprettingsmålinger fanges opp i Trust Layer Monitoring-kontrollpanelet for synlighet og SLA-sikkerhet.
Viktige punkter om Idempotent-design
- Deterministiske idempotensnøkler: Hver synkroniseringshendelse bærer en unik nøkkel (Organisasjons-ID + Post-ID + Versjonsnummer) for å garantere nøyaktig behandling én gang.
- Gjentagelsessikkerhet: Duplikat- eller gjentakelseshendelser filtreres på bekreftelsestidspunkt for å sikre konsistente nedstrøms DMO- og CIO-oppdateringer.
- Atomic Commit Semantics: Samleorganisasjoner merker data som bekreftet først etter vellykkede nedstrøms skrivinger, slik at transaksjonell integritet på tvers av organisasjoner bevares.
- Konfliktløsning: Oppdateringer med flere kilder følger last-write-win- eller policy-drevet flettelogikk for å opprettholde linje og konsistens.
- Checkpoint Persistence: Synkroniseringsjobber beholder sist behandlede forskyvninger og status i Trust for sikker gjenoppretting og avspilling.
Sikkerhetsvurderinger
- Stor godkjenning: Tilkoblinger mellom Hjem- og Samleorganisasjoner bruker gjensidig OAuth 2.0 med automatisk roterte tokener som behandles via tilkoblede apper.
- Granular Authorization: Samleorganisasjoner kan bare få tilgang til bestemte dataområder, DMO-er eller CIO-er som eksplisitt deles via styrte datadelingspolicyer.
- Kryptering overalt: Data krypteres underveis (TLS 1.2+) og under lagring (AES-256) på tvers av både start- og partnerorganisasjoner.
- Prioritetsprinsippet: Integrasjonsbrukere får omfang bare for de nødvendige objektene. Ingen administrative tillatelser eller tillatelser på systemnivå overføres.
- Synlighet av revisjon og samsvar: Alle synkroniseringshendelser, skjemaendringer, legitimasjonsoppdateringer og tilgangstildelinger logges i Data 360 Trust for full sporing.
- Privat nettverksisolasjon: Valgfri Salesforce Privat tilkobling eller Privat lenke sikrer at datareplikering skjer bare over sikre interne kanaler.
Sidefelt
Tidlighet
- Synkronisering mellom Hjem- og Fellesorganisasjoner skjer i nær sanntid, vanligvis innen sekunder etter en dataendring i kildeorganisasjonen.
- Zero Copy-arkitektur sikrer at delte data umiddelbart kan spørres på tvers av alle deltakende organisasjoner – ingen replikerings- eller gruppeforsinkelser.
- Aktiverings- og segmenteringsjobber gjenspeiler automatisk de nyeste oppdateringene fra hvilken som helst tilkoblet organisasjon, og beholder operasjonell oppdatering.
- Slutt-til-slutt-latens er deterministisk og styres av Data Cloud Ones orkestreringsfunksjon under behandling, som sikrer konsistent tidsriktighet på tvers av organisasjoner selv under belastning.
Datavolumer
- Utformet for synkronisering av data på tvers av områder og forretningsenheter med flere leietagere – som kan behandle milliarder av poster per organisasjon.
- Det refereres til data, ikke duplikater, som reduserer lagringsfotavtrykk samtidig som det opprettholdes global spørringsmulighet.
- Strømmede deltaer og komprimering av metadata optimaliserer båndbredde og bekrefter overhead for objekter med høy endringsgrad (for eksempel Kontakt, Bestilling).
- Skaleres horisontalt på tvers av flere partnerorganisasjoner med adaptiv belastningsbalansering og orkestrering gjennom Trust.
Statbehandling
- Hvert synkronisert datasett opprettholder metadatagrunnlaget, versjonen og organisasjonseierskapskonteksten for å sikre slutt-til-slutt-sporing.
- Sjekkpunktoppbevaring fanger opp sist synkroniserte forskyvninger mellom organisasjoner slik at gjenoppretting er mulig uten duplikater.
- Skjemaversjonsbehandling og semantisk justering på tvers av organisasjoner styres automatisk av Trust.
- Ingen manuelle tilbakestillinger av status kreves – synkroniseringsstatusen beholdes via Data Cloud One Orchestration Service.
Komplekse integrasjonsscenarier
- Forbundsorganisasjoner: Aktiverer sømløs spørring og aktivering på tvers av flere Data 360-leietagere eller -områder under en forent styringsmodell.
- Hybrid synkronisering: Kombinerer replikering i nær sanntid for transaksjonsoppdateringer med planlagt synkronisering for masse- eller arkiveringsdata.
- Multi-Region Governance: Støtter geografisk distribuert datadeling samtidig som grensene for opphold, samtykke og overholdelse respekteres.
- AI og Automatisering Aktivering: Synkroniserte data leverer umiddelbart Einstein AI, Agentforce eller tilpassede ML-modeller på tvers av organisasjoner – og aktiverer sanntids intelligens på tvers av organisasjoner.
Eksempel
En global detaljistorganisasjon har tre Salesforce-organisasjoner: én for Consumer Retail, én for Premium-merker og én for internasjonale markeder. De klargjør Data 360 i Consumer Retail-organisasjonen (som gjør den til hjemmebehandlingen). Med Data Cloud One konfigurerer de tilhørende tilkoblinger til Premium Brands- og International Markets-organisasjonene. De deler bare de riktige dataområdene (for eksempel Customer 360 – Retail Profiles og Customer 360 – Premium Profiles) med hver tilhørende organisasjon. I Premium Brands-organisasjonen kan markedsføringsteam vise forente kundeprofiler, bygge segmenter basert på beregnede innsikter (for eksempel premium kundelivsverdi) og utløse markedsføringsautomatiseringer – alt drevet av startorganisasjonens Data 360-forekomst, uten tilpasset koding eller dataduplisering.
Dataktivering er stedet der verdien i Salesforce Data 360 virkelig kommer til liv. Det er prosessen med å ta de forente, beregnede og styrte dataene som befinner seg innenfor plattformen, og få dem til å fungere på tvers av virksomheten. I praksis betyr dette sikker levering av kuraterte segmenter, beregnede innsikter og kontekstuelle attributter fra Data 360 til systemene som engasjerer kunder – enten det er markedsføringsautomatisering, servicekonsoller, salgsaktivering, analyse eller AI-modeller. Fra et teknisk perspektiv definerer aktiveringsmønstre hvordan disse dataene flyttes: hvilke kanaler som utløses, hvilke transformasjoner eller tilordninger som skjer, og hvordan policyer håndheves underveis. Disse mønstrene handler ikke bare om å eksportere data – de handler om å orkestrer sanntids, policysensitive dataflyter som fører til målbare forretningsutfall. Hver aktiveringsrute gjør Customer 360 til et aktivt driftsaktivum – som leverer tilpassing, prediktive beslutninger og kontinuerlig læring på tvers av hvert kontaktpunkt.
Batchaktivering forblir den mest brukte og operasjonelt bekreftede metoden for eksport av data fra Data 360. Den opererer på en planlagt kadens – publiserer forhåndsdefinerte målgruppesegmenter eller attributtsett til nedstrøms plattformer med jevne mellomrom. Dette mønsteret er ideelt egnet for markedsførings- og engasjementsarbeidsflyter som er avhengig av konsekvent levering av målgrupper med stor trafikk i stedet for umiddelbare oppdateringer. Typiske brukstilfeller inkluderer e-postreiser, direktepostkampanjer eller målgruppelastinger til digitale annonsenettverk. Hver aktiveringskjøring trekker ut det kvalifiserte segmentet fra Data 360s forente profilgraf, bruker styrings- og samtykkepolicyer og overfører utdataene sikkert til målsystemet. Arkitektonisk gir gruppeaktivering en forutsigbar, reviderbar og kostnadseffektiv tilnærming til datadistribusjon – som balanserer operasjonell enkelhet med pålitelighet i bedriftsnivå. Det er ryggraden i utførelse av kampanjer i stor skala, der de riktige dataene, levert til rett tid og under kontroll, gir målbar forretningseffekt.
Kontekst
Moderne markedsførere opererer på tvers av flere engasjementskanaler – e-post, annonsering, mobil og nett – hver av dem krever nøyaktige, tidsriktige og tilpassede kundemålgrupper. Data 360 fungerer som det forente grunnlaget for disse målgruppene, og kombinerer kundedata fra alle systemer i rike segmenter som kan handles. Batchaktivering er det vanligste aktiveringsmønsteret som brukes til å eksportere disse segmentene fra Data 360 til nedstrøms markedsførings- eller annonseringsplattformer. Typiske destinasjoner inkluderer Marketing Cloud-engasjement, Google Ads, Meta-tilpassede målgrupper eller LinkedIn-annonser, der kampanjer kan utføres direkte mot disse kuraterte målgruppene.
Problem
Hvordan kan et markedsføringsteam ta en nøyaktig definert målgruppe – bygd med forente og beregnede data i Data 360 – og gjøre den tilgjengelig i eksterne markedsførings- eller annonseringssystemer for aktivering? Vurder for eksempel segmentet: "Kunder med høy verdi som ikke har kjøpt de siste 90 dagene, men nylig har engasjert seg på nettstedet." Markedsførere må sikre at denne målgruppen overføres nøyaktig, blir beriket med relevante attributter (for eksempel lojalitetssjikt, område eller forutsagt CLV) og oppdateres med jevne mellomrom for å opprettholde kampanjens relevans og effektivitet.
Styrker
Flere tekniske og operasjonelle faktorer former mønsteret for batchaktivering:
- Identitetstilordning: Nøyaktig målgruppelevering krever tilordning av Data 360s Forente persondata-ID til den tilsvarende identifikatoren i målsystemet, som en abonnentnøkkel i Marketing Cloud eller en hash-kodet e-postmelding for digitale annonseplattformer. Dette sikrer nøyaktig samsvar og eliminerer målringsfeil.
- Attributtvalg og berikelse: Markedsførere må gå utover ID-er og inkludere flere profildata – som fornavn, lojalitetsstatus, CLV eller andre tilpassede attributter – for å aktivere nedstrøms tilpassing og analyse.
- Målplattformkonfigurasjon: Hvert mål må registreres i Data 360 som et aktiveringsmål, inkludert tilkoblingsdetaljer, godkjenning og datatilordninger. Dette engangsoppsettet definerer sikker tilkobling og bestemmer hvilke systemer som kan motta aktiverte data.
- Forvaltning og overholdelse: Dataaktivering må overholde samtykkemetadata, personvernpolicyer (for eksempel GDPR eller CCPA) og markedsføringstillatelser som er lagret i den forente profilen. Samtykkesensitiv aktivering sikrer at data bare brukes til autoriserte formål.
- Planlegging og ytelse: Aktiveringer planlegges ofte daglig eller hver time for å holde nedstrøms målgrupper oppdatert. Systemet må effektivt håndtere store volumer og inkrementelle oppdateringer uten duplikater eller tap av data.
Løsning
Prosessen med batchaktivering i Data 360 følger en veiledet arbeidsflyt som minimerer teknisk friksjon for markedsførere samtidig som styring og skalerbarhet bevares:
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| Segmentoppretting | Best | En markedsfører eller analytiker bygger et segment på det visuelle segmenteringslerretet ved å bruke filtre på tvers av hvilket som helst datamodellobjekt (DMO) eller Beregnet innsikt-objekt (CIO). Dette definerer målgruppen for aktivering. |
| Aktiveringsoppsett | Best | Brukeren oppretter en aktivering og velger segmentet de nettopp har bygd som kilde. Dette definerer hvilken målgruppe Data 360 skal eksportere til nedstrøms systemer. |
| Aktiveringsmålvalg | Beste praksis | Markedsføreren velger et forhåndskonfigurert aktiveringsmål (for eksempel Marketing Cloud, Google Ads, LinkedIn Ads). Hvert mål registreres i Data 360 med godkjenningslegitimasjon og felttilordninger. |
| Belastningsdefinisjon | Nødvendig | Markedsføreren definerer belastningen ved å velge kontaktidentifikatorer (for eksempel e-post, mobil, hash-kodet ID) og velge flere profilattributter (fornavn, lojalitetssjikt eller CLV) for anriking i målsystemet. |
| Planlegging og frekvens | Anbefalt | Aktiveringer kan planlegges til å kjøres én gang eller regelmessig (for eksempel daglig eller ukentlig). Planlegging sikrer at nedstrøms målgrupper forblir synkroniserte og oppdaterte. |
| Utførelse og eksport | Best | Når aktiveringsjobben kjører, spør Data 360 segmentet, samler inn de valgte attributtene, bruker samtykkefiltre og eksporterer dataene til målplattformen. For Marketing Cloud fører dette vanligvis til opprettelse eller oppdatering av en delt datautvidelse. |
| Governance & Compliance | Nødvendig | Trust Layer håndhever skjemavalidering, samtykkemetadata og policykontroller for å sikre overholdelse av datasikrings- og markedsføringsforskrifter (f.eks. GDPR, CCPA). |
| Overvåking og revisjon | Beste praksis | Hver aktiveringskjøring spores med målinger for suksess/suksess, utførelseslogger og synlighet av linje i Trust Layer Monitoring-kontrollpanelet, noe som aktiverer operasjonell gjennomsiktighet og SLA-sikkerhet. |
Skisse
Her er sammendraget av trinnene:
- Byggingssegment: En markedsfører eller analytiker oppretter et segment ved bruk av et visuelt segmenteringsverktøy som kombinerer filtre på tvers av eventuelle forente dataobjekter.
- Opprett aktivering: De velger segmentet som kilde og velger et forhåndskonfigurert mål (som Marketing Cloud eller Google Ads).
- Definer belastning: Kontaktidentifikatoren og andre profilattributter velges for målgruppeeksport og rapportering.
- Tidsplan Levering: Aktiveringen er planlagt til å kjøre én gang eller regelmessig for å holde målgruppen i målgruppen oppdatert.
- Utførelse: Ved utløser spør Data 360 segmentet, bygger belastningen, bruker filtre for samtykke og overfører resultatet til målsystemet.
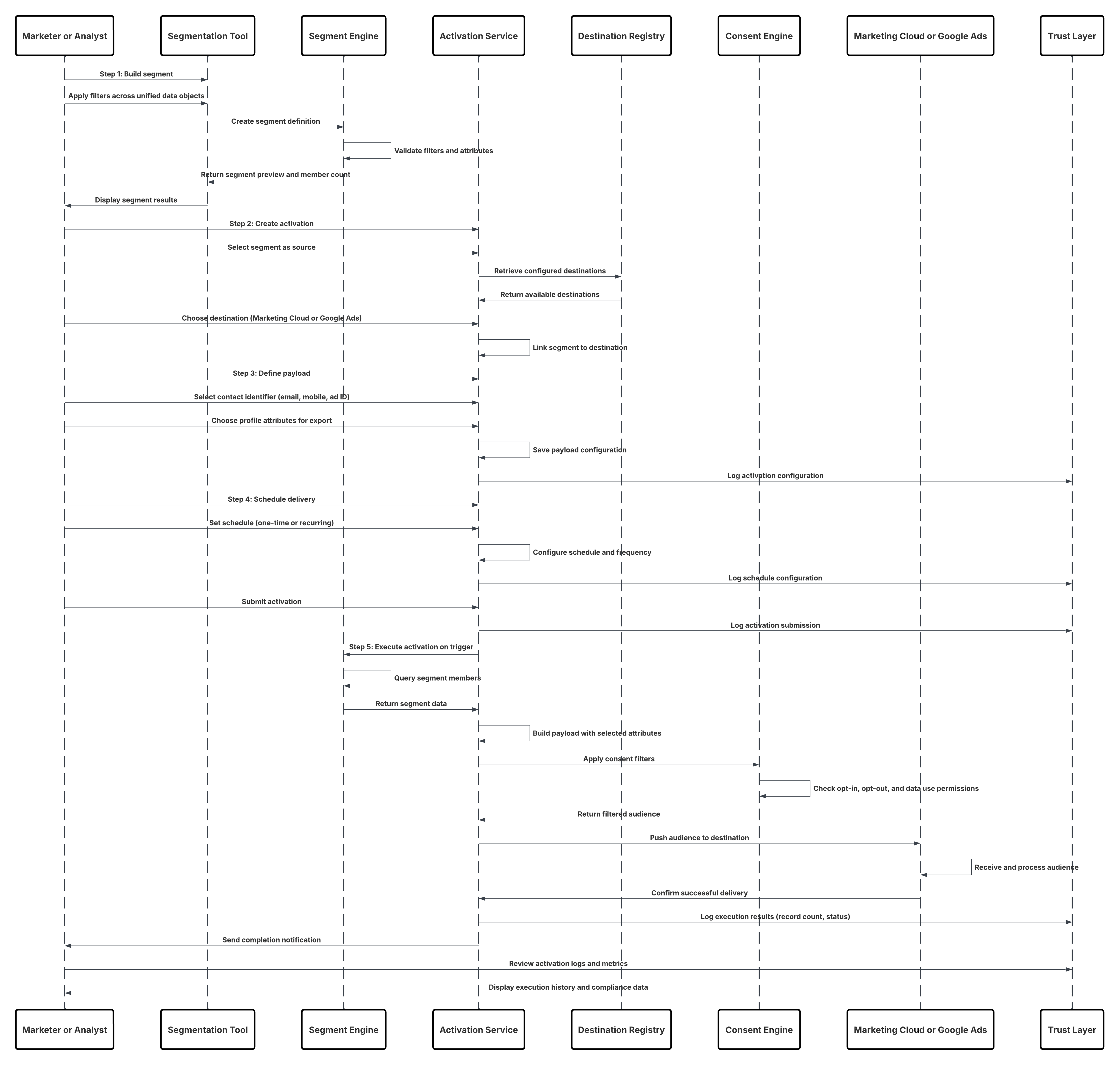
Resultater
- Målrettede, beregnede målgruppesegmenter fra Data 360 gjøres tilgjengelig direkte i nedstrøms markedsførings- og annonseringsplattformer.
- Målgrupper oppdateres automatisk og synkroniseres med de nyeste forente kundedataene for å opprettholde sanntidskampanjerelevans.
- Markedsførere kan bruke disse aktiverte målgruppene som inngangskilder for Marketing Cloud-reiser, e-postkampanjer eller tilpassede målgrupper i digitale annonseplattformer som Google Ads, Meta eller LinkedIn Ads.
- Hver aktiveringskjøring opprettholder en ende-til-ende-linje og sikrer samsvar, sporbarhet og konsistens mellom Data 360 og eksterne systemer.
- Firmabrukere kan levere svært tilpassede, datadrevne opplevelser som leveres av en komplett og klarert Customer 360.
Kalle opp mekanismer
Oppkallmekanismen avhenger av målplattformen og konfigurasjonen av aktiveringsmål.
| Mekanisme | Når brukes |
|---|---|
| Marketing Cloud-engasjementsaktivering (foretrukket) | Brukes ved utføring av e-postreiser eller reiser på tvers av kanaler som krever dynamiske segmenter, tilpassede attributter og sanntidsoppdateringer i Marketing Cloud. Data 360 eksporteres direkte til delte datautvidelser for aktivering av kampanjer. |
| Aktivering av annonseplattformen (Google Ads, LinkedIn Ads, Meta Ads) | Brukes når du aktiverer Data 360-segmenter som tilpassede målgrupper i reklameplattformer for ommålretting eller tilsvarende modellering. Støtter hash-kodede identifikatorer og samtykkesensitiv levering. |
| CRM-aktivering (Sales eller Service Cloud) | Brukes når du deler beregnede kundedata, innsikt eller tilbøyelighetsscore til CRM-brukere for tilpasset salgsengasjement eller tjenesteinteraksjoner. Data gjøres tilgjengelig som beregnede poster eller innsikt via Datahandlinger eller Forente profilkomponenter. |
| Ekstern aktivering via MuleSoft eller API | Brukes når aktivering må nå ikke-Salesforce-systemer som lojalitet, eCommerce eller tredjeparts datalager. MuleSoft eller Data 360 Activation API sikrer sikker, policyadministrert levering med hendelsesbaserte oppdateringsalternativer. |
| Hybridaktivering (batch + hendelsesutløst) | Brukes når du kombinerer planlagte gruppeaktiveringer med hendelsesbaserte utløsere – aktiverer alltid på-tilpassing for tidssensitive kampanjer som forladte handlevogn- eller frafallsrisikovarsler. |
Feilhåndtering og gjenoppretting
- Feilisolering på jobbnivå: Hver aktiveringskjøring utføres som en distinkt, sporbar jobb i Data 360 Orchestration Layer. Mislykkede kjøringer karanteneres automatisk uten å påvirke andre aktiveringer eller segmentdefinisjoner.
- Delvis batchgjenoppretting: Hvis visse poster ikke eksporteres (for eksempel på grunn av identifikasjonssamsvar eller API-grenser), prøver systemet dem på nytt ved å bruke inkrementelle deltakøer med eksponentiell tilbakekobling og parallell gjenoppretting.
- Skjemavalideringsfeil: Når utgående belastningsattributter ikke lenger samsvarer med målskjemaet (for eksempel et slettet attributt eller et felt med nytt navn), ruter jobben berørte poster til Skjemaavvisningskøen for administratorgjennomgang.
- Støtte for avspilling og gjenopptagelse: Hver aktiveringsjobb vedlikeholder et sjekkpunkttoken – som fanger opp den siste vellykkede batchen. Ved gjenoppretting gjenopptas behandlingen fra sjekkpunktet for å sikre at det ikke skjer duplikater eller tap av data.
- Omfattende overvåking: Alle aktiveringshendelser, nye forsøk og leveringsmålinger logges i Trust Layer Monitoring, som aktiverer SLA-sporing, rotårsaksanalyse og automatisert varsling via Event Monitoring API-er.
Viktige punkter om Idempotent-design
- Deterministiske aktiveringsnøkler: Hver aktiveringskjøring bruker en sammensatt idempotency-nøkkel – som kombinerer Segment-ID, Aktiverings-ID og Målsystem-ID – for å garantere levering nøyaktig én gang.
- Gjentagelsesregistrering: Data 360-aktiveringstjeneste inspiserer innkommende nyttelast mot tidligere jobb-hash-koder for å oppdage og undertrykke repetisjoner.
- Atomeeksportforpliktelser: Belastninger bekreftes til målsystemet først etter vellykket skrivebekreftelse, noe som hindrer delvise oppdateringer eller dobbeltantall.
- Konsistent identitetsløsning: I og med at aktiveringer avhenger av forente ID-er (for eksempel Forente persondata), målrettes gjentakelser eller nye forsøk alltid mot den samme gyldne posten og opprettholder semantisk konsistens.
- Aktiveringstilstandspermanens: Orchestration-laget beholder aktiveringsstatusmetadata – tidsstempler, statuskoder og sekvenstokener – for deterministisk gjenbehandling hvis det er nødvendig.
Sikkerhetsvurderinger
- Stor godkjenning: Hvert aktiveringsmål (for eksempel Marketing Cloud, Ads eller CRM) bruker OAuth 2.0 med tokenrotasjon og leietakerspesifikt omfang for å hindre uautorisert dataeksport.
- Attributtnivåstyring: Bare godkjente attributter fra den forente profilen er berettiget til aktivering, håndhevet av Datadelingspolicyer og Aktiveringsmaler.
- Kryptering i transitt og under lagring: Alle belastninger krypteres med TLS 1.2+ under overføring og AES-256 under lagring i både Data 360 og målplattformen.
- Samtykke og policykontroll: Aktiveringsjobber tar hensyn til samtykkeobjekter og datapolicyer som er lagret i Data 360s Trust. Poster uten gyldige samtykkemetadata ekskluderes automatisk fra eksport.
- Revisjons- og samsvarslogging: Hver aktiveringskjøring fanger opp hvem som startet den, hvilke data som ble sendt og hvilken destinasjon – og aktiverer fullstendige revisjonsspor (GDPR, CCPA) i Trust Layer-kontrollpanelet.
- Minst tillatelsestilgang: Integrasjonsbrukere for hvert mål er begrenset til aktiveringsspesifikke omfang – ingen administrative rettigheter eller skrivetilgang til ikke-relaterte systemer.
Sidefelt
Tidlighet
- Utformet for planlagte eller nær sanntids gruppeeksporter (minutters-til-timers latens).
- Støtter tidsvinduoppdateringer som er justert med kampanjekalendere.
- Aktiveringsjobber kan sekvenseres med dataklargjøringsmarkører for å sikre dataklargjøring.
- Best egnet for ikke-interaktive aktiveringsscenarier der datanøyaktighet er større enn umiddelbarhet.
Datavolumer
- Håndterer datasett i stor skala (millioner poster per kjøring).
- Skaleres horisontalt via segmentpartisjonering og parallelle eksportkanaler.
- Bruker batchbasert batching for å unngå tidsavbrudd og optimalisere gjennomløp.
- Ideelt for data under arbeid i bedriftsgrad der datafullstendighet er avgjørende.
Statbehandling
- Vedlikeholder aktiveringsstatusobjekter som registrerer jobb-ID-er, tidsstempler og sekvenstokener.
- Bruker sjekkpunktering til gjenoppretting og feilgjenoppretting.
- Versjonsdefinerte segmentdefinisjoner sikrer reproduserbarhet på tvers av aktiveringssykluser.
- Aktiverer linjesporing mellom kildesegment, DMO-attributter og målbelastninger.
Komplekse integrasjonsscenarier
- Integrerer sømløst med Salesforce CRM, Marketing Cloud og eksterne systemer via forhåndsbygde koblinger.
- Støtter aktivering av flere mål ved å distribuere data samtidig til forskjellige destinasjoner (for eksempel CRM + Ads).
- Kan utløse sammensatte arbeidsflyter, for eksempel gruppeeksport fulgt av nedstrøms API-kall eller AI-score.
- Håndterer skjemautvikling på en god måte via datamodellstyringslaget.
Eksempel
Et globalt detaljvareprofileringsmerke ønsker å engasjere inaktive kunder fra de siste 90 dagene på nytt. Ved å bruke Data 360 definerer dataarkitekten et "Dormant Shoppers"-segment som er beriket med kjøpshistorikk, lojalitetssjikt og samtykkemetadata. Gruppeaktiveringsjobben kjører hver natt, og sender dette segmentet til Marketing Cloud-engasjement for å utløse en tilpasset "vi savner deg"-e-postkampanje og til Ad Studio for ommåling. Jobben benytter idempotent-levering for å sikre at det ikke blir duplisert på tvers av nye forsøk, og alle hendelser logges i Trust for revisjonssamsvar.
Kontekst
Virksomheter krever ofte en styrt mekanisme for å eksportere forente eller segmenterte data fra Salesforce Data 360 til et standardfilformat (for eksempel CSV eller Parquet) for arkivering, samsvar eller nedstrøms integrering. Dette mønsteret aktiverer eksport av Data 360-til-sky-lagring – slik at klarerte kundedata kan flyte sikkert til bedriftens datasjøer eller analyse under behandling som driftes på Amazon S3, Azure Blob eller Google Cloud Storage (GCS). Typiske brukstilfeller er:
- Periodisk arkivering av samtykkede kundedatasett for lovpålagt oppbevaring.
- Eksportere kuraterte segmenter for ikke-Salesforce-analytiske arbeidsbelastninger (for eksempel Tableau, Databricks eller Power BI).
- Aktivering av eksterne maskinlæringsmodeller som krever strukturerte CSV- eller Parket-filer som inndata.
Problem
Hvordan kan en organisasjon eksportere et kuratert segment eller datasett fra Data 360 til en samlekategori for skylagring (for eksempel Amazon S3) – på en styrt, sikker og automatisert måte – samtidig som skjemaintegritet og samsvarskontroller opprettholdes? Et samsvarsteam kan for eksempel ha behov for å "Trekk ut alle aktive kunder i EU-området med gyldig samtykke, og eksporter dataene ukentlig til et S3-sted for ekstern revisjon og rapportering." Dette krever en gjentagende og policyoppmerksom eksport under behandling som sikrer riktig filformat, tilgangstillatelser og leveringsplan – uten manuell intervensjon eller ikke-administrert dataflytting.
Styrker
Flere drifts- og arkitektoniske faktorer styrer dette eksportmønsteret:
- Authentication & Authorization: Eksporter må respektere skyleverandørens IAM-modell (for eksempel AWS IAM-roller eller Azure Service Principals) for å sikre at bare godkjente systemer kan skrive til målsamlekategorien.
- Skjemajustering: Det utgående skjemaet må samsvare med målsystemets forventede struktur og format (CSV, Parquet eller JSON).
- Datapersonvern og samtykke: Eksporterte datasett må filtrere ut eventuelle poster som mangler gyldige samtykkemetadata.
- Planlegging og friskhet: Mange eksporter er periodiske (daglige, ukentlige eller månedlige) og må være i samsvar med oppdateringssykluser for bedriftsdata.
- Forvaltning og overvåking: Hver eksport må være reviderbar med full synlighet av linje og sikre overholdelse av oppbevaring av data og lovpålagte mandat (for eksempel GDPR, CCPA).
Løsning
Fileksportaktiveringsmønsteret bruker på nytt de samme sikre skylagringskoblingene som brukes til inntak, men som er konfigurert for datautgang. Administratorer registrerer først skylagringsplattformen (for eksempel Amazon S3, Azure Blob Storage eller GCS) som et aktiveringsmål i Data 360. Deretter konfigurerer og utfører brukerne en aktiveringsarbeidsflyt for å eksportere det ønskede segmentet til den utpekte fillagringsbanen.
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| Segmentvalg | Best | Analysatorer velger en eksisterende Segment- eller Spørringsdefinisjon i Data 360\. Segmentet bestemmer hvilke poster og attributter som skal eksporteres. |
| Aktiveringsoppsett | Best | Brukere oppretter en ny Aktivering ved å velge Segment som kilde og Skylagringsmål (for eksempel S3) som mål. |
| Aktiveringsmålkonfigurasjon | Nødvendig | Administratorer forhåndskonfigurerer målet med legitimasjon, IAM-roller og utdatabane. Støttede formater inkluderer CSV, Parquet og JSON. |
| Belastningsdefinisjon | Beste praksis | Definer eksportskjemaet ved å velge de nødvendige attributtene (for eksempel ID, Name, Email, Region, Consent Flag). Systemet håndhever styring på attributtnivå. |
| Planlegging & Frekvens | Anbefalt | Eksporter kan planlegges til å kjøre etter en definert kadens (daglig, ukentlig, månedlig) eller utløses manuelt etter behov. |
| Utførelse & Levering | Best | Ved utføring spør Data 360 segmentet, kompilerer eksportfilen, krypterer den og skriver den til den konfigurerte samlekategorien/mappen med skyleverandørens API. |
| Governance & Compliance | Nødvendig | Data 360s Trust sikrer at alle eksporter overholder samtykkepolicyer, skjemavalidering og samsvarsfiltre. |
| Overvåking og revisjon | Beste praksis | Hver eksport spores i Trust Layer Monitoring-kontrollpanelet med status, utførelseslogger og linje-metadata. |
Skisse
Her er sammendraget av trinnene.
- Velg segment: En analytiker eller datastyrer velger det forente segmentet som skal eksporteres.
- Opprett aktivering: De oppretter en ny Aktivering-jobb og velger det registrerte Skylagring-målet.
- Definer belastning: Angi eksportskjema, attributtliste og filformat (for eksempel CSV).
- Tidsplaneksport: Velg en engangs eller gjentagende tidsplan.
- Utfør jobb: Data 360 genererer og leverer filen sikkert til den utpekte samlekategoribanen.
- Monitor & Verify: Resultater og logger blir gjennomgått i Trust for validering og samsvar.
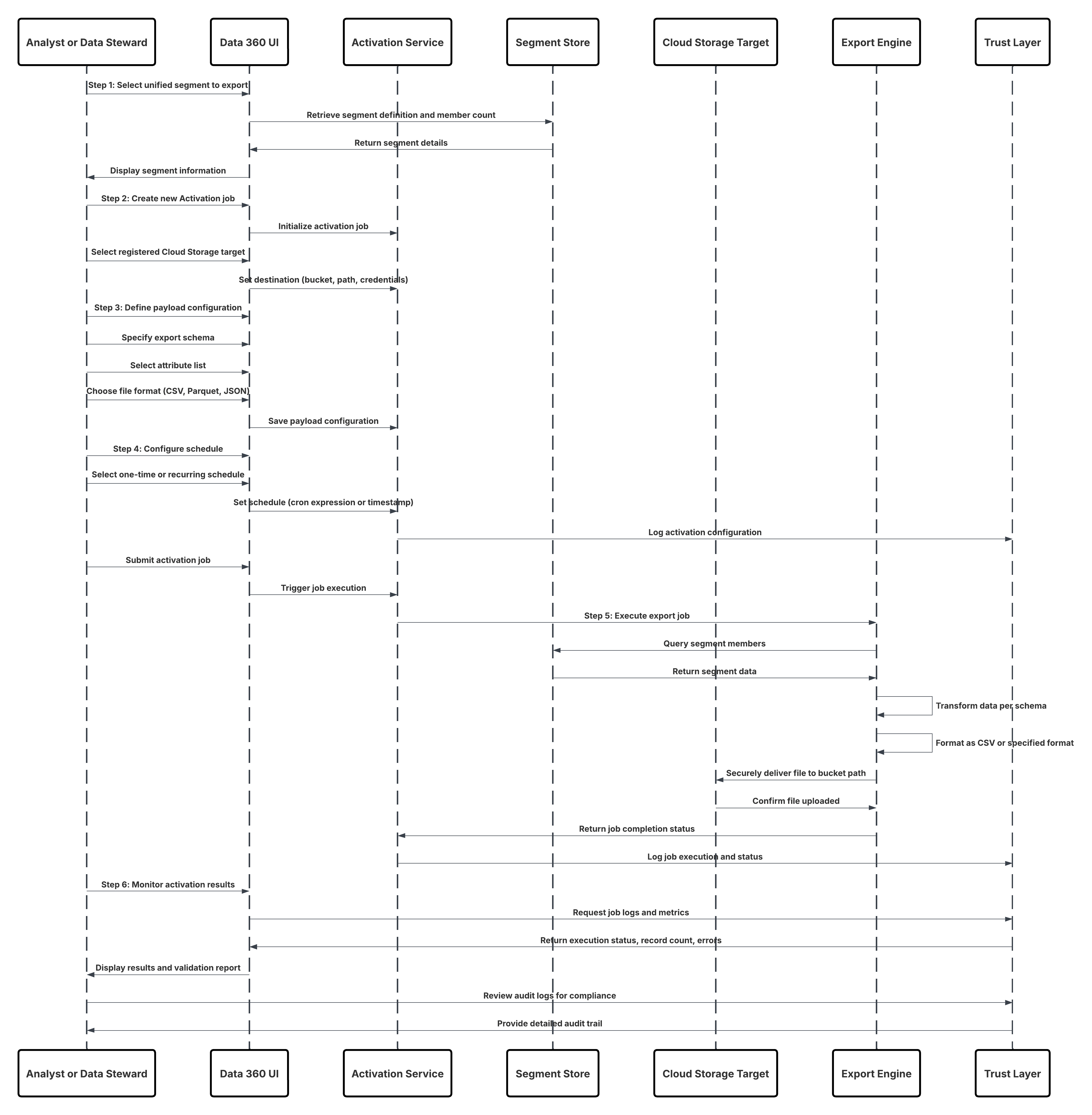
Resultater
- Målrettede, beregnede målgruppesegmenter fra Data 360 gjøres tilgjengelig direkte i nedstrøms markedsførings- og annonseringsplattformer.
- Målgrupper oppdateres automatisk og synkroniseres med de nyeste forente kundedataene for å opprettholde sanntidskampanjerelevans.
- Markedsførere kan bruke disse aktiverte målgruppene som inngangskilder for Marketing Cloud-reiser, e-postkampanjer eller tilpassede målgrupper i digitale annonseplattformer som Google Ads, Meta eller LinkedIn Ads.
- Hver aktiveringskjøring opprettholder en ende-til-ende-linje og sikrer samsvar, sporbarhet og konsistens mellom Data 360 og eksterne systemer.
- Firmabrukere kan levere svært tilpassede, datadrevne opplevelser som leveres av en komplett og klarert Customer 360.
Kalle opp mekanismer
Oppkallmekanismen avhenger av målskylagringsplattformen og aktiveringskonfigurasjonen.
| Mekanisme | Når brukes |
|---|---|
| Amazon S3-aktivering | Brukes når bedriftens datasjø befinner seg på AWS. Data 360 skriver direkte til en S3-samlekategori ved bruk av IAM-roller eller midlertidig legitimasjon for å sikre sikker og skalerbar eksport. |
| Azure Blob Storage-aktivering | Brukes når organisasjonen opererer på Microsoft Azure. Data 360 bruker SAS-tokener eller tjenesteledere til å skrive krypterte filer til Blob-beholdere. |
| Google Cloud Storage (GCS)-aktivering | Brukes når datavitenskaps- eller analysarbeidsbelastningene kjører på GCP. Data 360 bruker OAuth-legitimasjon til å eksportere filer til GCS-samlekategorier i CSV- eller Parket-format. |
| SFTP eller ekstern filgateway | Brukes når lovpålagte eller eldre systemer krever sikker fillevering via SFTP-endepunkter eller bedriftsadministrerte filoverføringsplattformer. |
| Hybrideksport (fil + API) | Brukes når et nedstrøms program trenger både filbasert eksport for analyse og en API-utløser for arbeidsflytorkestrering (for eksempel MuleSoft-flyt). |
Feilhåndtering og gjenoppretting
- Isolasjon på jobbnivå: Hver eksport utføres som en diskret jobb. Mislykkede jobber kontrolleres og prøves på nytt uavhengig.
- Partiell filprøve: Hvis enkelte batcher ikke lastes opp (for eksempel på grunn av nettverksavbrudd), prøver systemet disse bitene på nytt med eksponentiell tilbakemelding.
- Håndtering av feil samsvar med skjemaer: Eventuell skjemaavvik eller feltsamsvar ruter poster til køen for skjemaavvisning for gjennomgang.
- Checkpoint & Resume: Eksportjobber vedlikeholder sjekkpunktmetadata og aktiverer gjenopptagelse fra den siste vellykkede skrivingen uten duplisering.
- Integrert overvåking: Mislykkede og nye forsøk logges i Trust Layer-kontrollpanelet for synlighet og SLA-samsvar.
Viktige punkter om Idempotent-design
- Deterministiske eksportnøkler: Hver eksportjobb inkluderer en unik ID som består av Segment-ID + Mål-ID + Tidsstempel.
- Gjentagelsessikkerhet: Duplikatjobbutførelser oppdages ved bruk av jobbhash-koder og hoppes over for å hindre overflødige eksporter.
- Atomic skrive garanti: Data 360 bekrefter filer til målsamlekategorien først etter full fullføring og sjekksumvalidering.
- Konsistent skjemaversjonering: Eksportdefinisjoner er versjonskontrollert for å sikre skjemakonformitet på tvers av kjøringer.
- Checkpoint Persistence: Eksportjobber beholdes i tilstand for deterministisk gjenoppretting og ombehandling hvis det er nødvendig
Sikkerhetsvurderinger
- Stor godkjenning: Skykoblinger bruker OAuth 2.0-, IAM-roller eller serviceledere til godkjente skrivinger.
- Kryptering overalt: Data krypteres både underveis (TLS 1.2+) og under lagring (AES-256).
- Samtykket eksport: Bare poster med gyldig samtykke eksporteres, håndhevet av Trust Layer-policyer.
- Minste privilegiumprinsipp: Eksportbrukere og tjenestekontoer er begrenset til deres utpekte lagringsbaner.
- Omfattende revisjonslogging: Hver eksport registrerer metadata, inkludert initiator-, skjema-, mål- og tidsstempler for samsvarsrapportering.
Sidefelt
Tidlighet
- Utformet for umiddelbar, hendelsesdrevet aktivering med sub-second latency.
- Ideelt for scenarier som krever umiddelbar tilpassing, anbefaling eller beslutningstaking.
- Opererer i strømmodus – Utløsere utløses så snart kvalifiserende dataendringer skjer i Data 360.
- Sikrer kontinuerlig responsivitet uten å vente på batchplaner eller ny beregning av segmenter.
Datavolumer
- Håndterer datasett i stor skala (millioner poster per kjøring).
- Skaleres horisontalt via segmentpartisjonering og parallelle eksportkanaler.
- Bruker batchbasert batching for å unngå tidsavbrudd og optimalisere gjennomløp.
- Ideelt for data under arbeid i bedriftsgrad der datafullstendighet er avgjørende.
Statbehandling
- Hver hendelseshandling beholder sitt eget hendelsestoken og gjentagelses-ID for idempotent-behandling.
- Støtter sjekkpunktfasthet for å gjenoppta fra den siste bekreftede hendelsen i tilfelle en midlertidig feil.
- Inkluderer innebygd opphevingslogikk og gjentagelsesvinduer for å sikre en nøyaktig aktiveringssemantikk.
- Handlingsresultater (suksess/feil) logges iSanntid og vises gjennom kontrollpanelet for observabilitet av Trust Layer.
Komplekse integrasjonsscenarier
- Integrerer direkte med Salesforce-flyter, Einstein 1-plattformhendelser eller eksterne webhooks for umiddelbare responskjeder.
- Kan utløse nedstrøms automatiseringer, for eksempel umiddelbare CRM-postoppdateringer, AI-score eller Marketing Cloud-meldingssendinger.
- Støtter komponerbar orkestrering: Hendelsesutløsere kan kalle opp Data 360-handlinger, Apex eller eksterne API-er.
- Utformet for agenter og adaptive forretningsmønstre der kontekstbevisste svar må skje umiddelbart.
Eksempel
Et globalt detaljistforetak må levere en ukentlig eksport av segmentet Active Loyalty Members (aktive lojalitetsmedlemmer) for analyse i Databricks. Data 360-administratoren konfigurerer Amazon S3 som et aktiveringsmål og planlegger en ukentlig CSV-eksport til s3://enterprise-analytics/loyalty/weekly_exports/. Eksportjobben kjører hver søndag og genererer en samtykkefiltrert fil med 2M+-poster. Alle hendelser, skjemadefinisjoner og linje registreres i Trust Layer-kontrollpanelet for å sikre gjennomsiktighet, revisjon og samsvar.
API-basert aktivering på forespørsel er en sanntids, hendelsesdrevet tilnærming til å gjøre Data 360-innsikt handlingsbar når de trengs – uten å vente på gruppejobber eller planlagte eksporter. I stedet for å publisere forhåndsbygde segmenter på en fast kadens aktiverer dette mønsteret eksterne systemer, Salesforce-apper eller AI-agenter til å kalle opp Data 360 API-er direkte for å hente eller aktivere bestemte målgruppesnutter, kundeattributter eller innsikt på forespørsel. Dette mønsteret er utformet for interaktive, utløserbaserte opplevelser, som når en bruker logger seg på en portal, en agent åpner en kundepost eller en AI-kopilot starter en Next-Best Action-spørring. I stedet for å basere seg på forhåndsberegnede eksporter, spør eller aktiverer systemet dynamisk de nyeste, administrerte dataene fra Data 360 i sanntid. Den viktigste fordelen er umiddelbarhet og presisjon:
- Hvert API-kall får tilgang til den mest oppdaterte Kundeintelligens i Data 360s forente, samtykkesensitive profildiagram.
- Aktiveringer er idempotente og kan revideres, i samsvar med kravene til Enterprise Trust og samsvar.
- Integrasjoner kan utløses direkte fra Salesforce-flyter, Apex eller eksterne systemer via Einstein 1-plattform-API-er, Connect-API-er eller aktiverings-API-er. Denne løsningen støtter brukstilfeller der latens og tilpassing er viktigst, for eksempel:
- Utløsing av et tilpasset produkttilbud under en servicekall.
- Generere dynamiske kampanjemålgrupper basert på hendelser med direkte virkemåte.
- Feeder sanntidsbeslutninger til AI- eller ML-modeller som opererer på det tidspunktet engasjementet skjer.
Kontekst
Virksomheter må ofte vise harmonisert, sanntids Data 360-innsikt i tilpassede programmer – som interne nettportaler, mobilapper eller partnerrettede nettopplevelser. Dette mønsteret gir utviklere mulighet til å bygge sikre, grensesnittfokuserte løsninger som forbruker og viser forente kundedata sammen med Salesforce CRM og andre kontekstsystemer, alt via styrt og API-basert tilgang. Typiske brukstilfeller er:
- Bygge inn Data 360-innsikt i interne kontrollpaneler eller mobilapper for ansatte.
- Opprette partner- eller forhandlerportaler med synlighet av kunder og transaksjoner.
- Integrere Data 360-data i tredjeparts nettprogrammer eller opplevelseslag.
- Viser sanntids, tilpassede anbefalinger som leveres av Data 360 og Einstein 1.
Problem
Hvordan kan en utvikler bygge et tilpasset, brukergrensesnittfokusert program som trygt får tilgang til og viser harmoniserte Data 360-data, ofte sammen med andre Salesforce-datakilder – uten å duplisere eller eksportere sensitiv informasjon? Et foretak kan for eksempel måtte bygge en kundeportal som viser forente kundeprofiler, interaksjoner og beregnede innsikter fra Data 360. Dette krever et enkelt, sikkert og effektivt API-lag som kan drive frontendopplevelsen, håndtere godkjenning og sikre styring – samtidig som kompleksiteten i Data 360s interne datamodell abstraktes.
Styrker
Flere viktige punkter om arkitektur og drift påvirker dette mønsteret:
- UI-sentrisk tilgang : Det primære målet er å vise data i tilpassede frontend-opplevelser (nett eller mobil), ikke for å utføre gruppeuttrekk eller serverdelsynkroniseringer.
- Sikker gateway : Det valgte API-et må fungere som et sikkert og skalerbart inngangspunkt for godkjente programmer og brukere, og håndheve tilgangskontroller på bedriftsnivå.
- Unified Data Context : Programmer skal kunne kombinere Data 360-data (for eksempel forente profiler, beregnede innsikter) med CRM-, ERP- eller tilpassede objektdata sømløst.
- Utviklerenhet : API-er må returnere presentasjonsklar last som minimerer serverdelbehandling eller skjematilordning i klientlaget.
- Forvaltning og observasjon: All tilgang skal flyte gjennom klarerte, reviderbare kanaler med tydelig linje, godkjenning og policyhåndhevelse.
Løsning
Løsningen er å bruke Salesforce Connect REST API som den primære integrasjonsgatewayen for å bygge tilpassede, datadrevne programmer på toppen av Data 360. Connect API gir RESTful-tilgang til Salesforce-data – inkludert Data 360s harmoniserte profiler, segmenter og beregnede innsikter – i responsformater som er optimalisert for brukergrensesnittforbruk (JSON-basert, lett og mobilvennlig). Utviklere godkjenner via en tilkoblet app, henter OAuth 2.0-tokener og kaller opp Connect API-ressurser som /query, /chatter eller /data for å vise forente data direkte i sine programgrensesnitt. I bakgrunnen fungerer Connect API som transportgrunnlaget for andre API-er – som Query API, Data Graph API og Einstein 1-plattform-API-er – slik at utviklere kan kombinere flere datakilder under ett forent tilgangsmønster.
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| Godkjenning og appregistrering | Nødvendig | Opprett en tilkoblet app i Salesforce for OAuth 2.0-basert godkjenning. Konfigurer omfang for Data 360 API-tilgang. |
| Datatilgang (profiler, segmenter, innsikter) | Best | Bruk Connect API-endepunkter (/services/data/vXX.X/connect) til å spørre mot harmoniserte Data 360-data, forente profiler og beregnede innsikter. |
| Grensesnittintegrering | Best | Frontend-apper (React, Angular, iOS, Android) kaller opp Connect API for å gjengi Data 360-data i kontrollpaneler, portaler eller mobilgrensesnitt. |
| Datakartspørring | Anbefalt | Kombiner Connect API med Data Graph API for spørringer på semantisk nivå som forenkler komplekse koblinger og relasjoner. |
| Sanntids oppdatering | Valgfritt | Bruk Connect API med WebSocket eller strømmede utvidelser til direktedataoppdateringer. |
| Sikkerhet og styring | Nødvendig | Håndhev datasynlighet med OAuth-omfang, Data 360-policyer og Trust Layer-revisjonsrammeverket. |
Skisse
Her er sammendraget av trinnene.
- Registrer tilkoblet app: Definer OAuth-omfang og API-tillatelser for godkjenning av eksterne apper.
- Hent tilgangstoken – Den eksterne appen utfører OAuth 2.0-godkjenning for å motta et token for Data 360-tilgang.
- Invoke Connect API – Appen utfører REST API-kall for å hente forente profil-, segment- eller innsiktsdata.
- Render data i grensesnitt – Svar analyseres og presenteres for brukere i en merkeprofilert portal eller mobilgrensesnitt.
- Håndtering av feil og oppdateringstokener – Apper implementerer prøvelogikk og automatisk tokenoppdatering for øktekontinuitet.
- Overvåkings- og revisjonstilgang – Alle API-kall logges i Trust-laget for synlighet og samsvar.
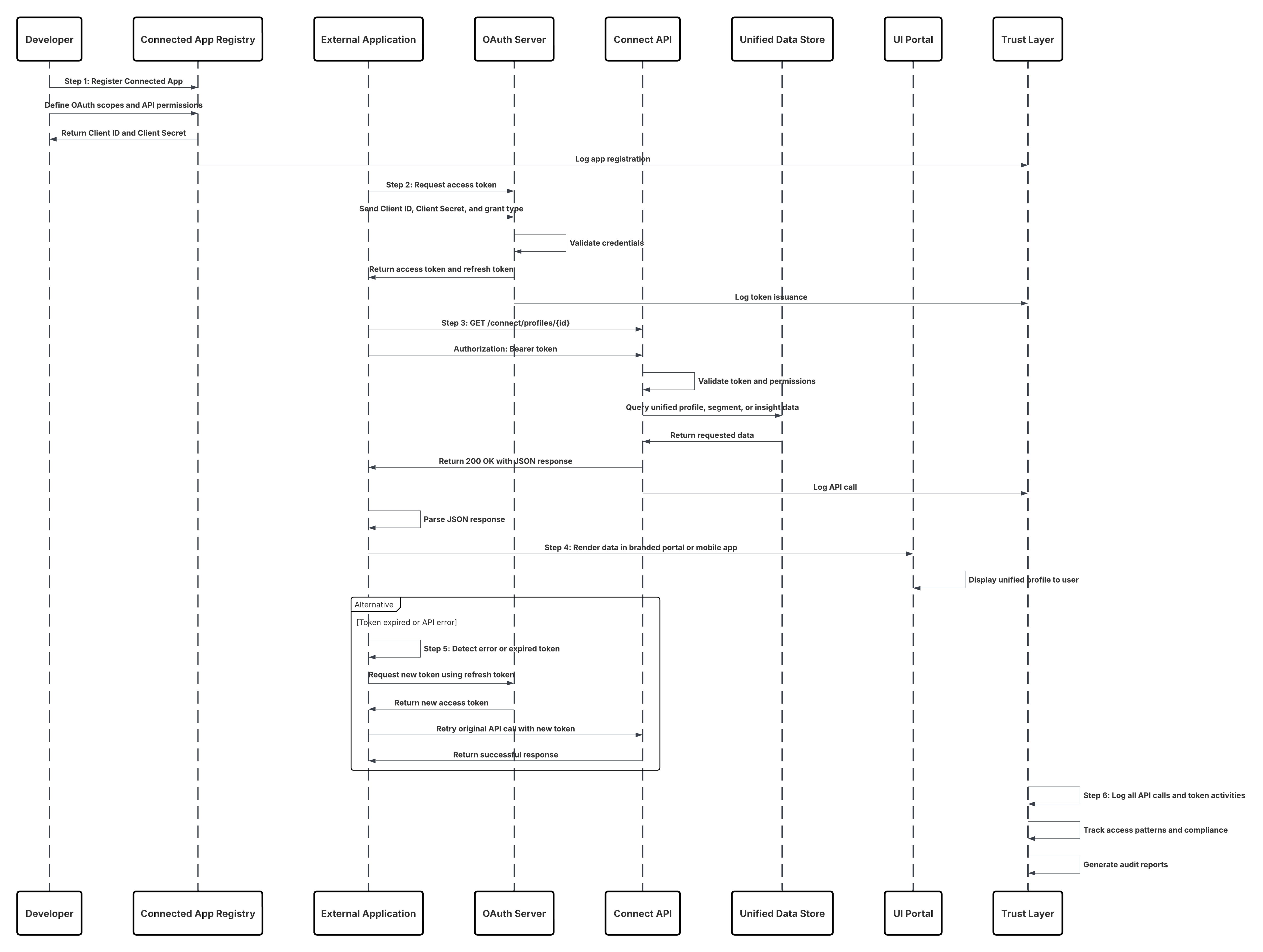
Resultater
Utviklere kan opprette sikre, tilpassede merkeprofilerte programmer som er tett integrert med Data 360. Disse appene kan
- Vis harmoniserte kundeprofiler og innsikt iSanntid.
- Vise Data 360-data sammen med CRM eller tilpassede objekter via forente API-er.
- Dra nytte av konsistente godkjennings-, autorisasjons- og revisjonskontroller via Trust.
- Gi forretningsbrukere eller partnere sømløs, styrt tilgang til klarert Kundeintelligens på tvers av opplevelser.
Kalle opp mekanismer
Oppkallmekanismen avhenger av målskylagringsplattformen og aktiveringskonfigurasjonen.
| Mekanisme | Når brukes |
|---|---|
| Connect REST API (Foretrukket) | Brukes ved bygging av nett-, mobil- eller tredjepartsapper som krever sanntidstilgang til Data 360-data i et grensesnittvennlig JSON-format. |
| Data Graph API | Brukes når appen trenger å utføre spørringer på semantisk nivå på tvers av flere objekter (for eksempel Kunde → Transaksjoner → Kampanjer). |
| Query API | Brukes ved utføring av SOQL-lignende spørringer for å hente harmoniserte datasett med høy presisjon. |
| API-er for Einstein 1-plattform | Brukes når du integrerer AI-drevet innsikt eller Copilot-genererte anbefalinger i tilpassede brukergrensesnitt. |
| MuleSoft eller Apex Gateway Wrappers | Brukes når ekstra orkestrering, bufring eller policykontroll kreves mellom appen og Connect API. |
Feilhåndtering og gjenoppretting
- Forespørsel om tråder: Avverger automatisk og prøver på nytt API-kall under frekvensgrenser.
- Skjemavvikbeskyttelse: Bruker GraphQL-skjemaversjonering eller REST-metadataoppdagelse til å tilpasse seg skjemaendringer.
- Token Expiration Management – Programmer oppdaterer OAuth-tokener automatisk for å unngå øktavbrudd.
- API-feilsolering – Mislykkede API-kall logges og prøves på nytt uten å påvirke samtidige økter.
- Observabilitet av Trust Layer – API-suksess-/feilsatser og tilgangslogger er synlige i Trust Layer-kontrollpanelet.
Viktige punkter om Idempotent-design
- Deterministiske forespørsels-IDer: Hver API-forespørsel inkluderer en korrelasjons-ID for gjentagelsessikker behandling.
- Buffervalideringshoder: ETag- og Sist endret-hoder hindrer overflødige datafangst.
- Atomisk leseoperasjoner: Connect API sikrer at hvert svar gjenspeiler et konsistent øyeblikksbilde av forente data.
- Gjentagelsesbeskyttelse – Duplikat-API-kall filtreres med forespørselssignaturer og tidsstempler.
Sikkerhetshensyn
- OAuth 2.0-godkjenning: Alle API-kall bruker sikre, kortlivede OAuth-tilgangstokener via tilkoblede apper.
- Minst tillatelsestilgang: API-omfang er begrenset til bare nødvendige objekter og felt.
- Kryptering overalt: TLS 1.2+ underveis, AES-256-kryptering under lagring for bufrede eller lagrede svar.
- Samtykket datatilgang: Data 360 sikrer at alle hentede poster overholder samtykke- og styringspolicyer.
- Omfattende revisjonslogging: Hver API-interaksjon registreres med metadata for bruker, app og tidsstempel i Trust.
Sidefelt
Tidlighet
- Utformet for sanntids API-tilgang med lav latens.
- Ideelt for interaktive programmer som krever umiddelbar dataversjon.
- Støtter svartider for spørringer i nær umiddelbar tid via bufrede og indekserte Data 360-kilder.
- Ingen avhengighet av gruppeplaner eller asynkrone aktiveringssykluser.
Datavolumer
- Optimalisert for interaktive brukstilfeller som henter små til middels store datasett (for eksempel profiler, innsikt eller nylige transaksjoner).
- Håndterer sideinndelte resultater elegant gjennom markørbasert sideinndeling.
- Ikke beregnet for masseeksporter med stor trafikk – bruk mønstre for gruppe- eller fileksport for store datasett.
Statbehandling
- Programmer opprettholder en enkel økttilstand med OAuth-tokener og lokal buffer.
- Connect API støtter betingede forespørsler og delvis oppdatering for å øke effektiviteten.
- API-svar inkluderer versjonsmarkører for skjemakonsistens på tvers av utgivelser.
Komplekse integrasjonsscenarier
- Kombiner Connect API med Data Graph API for semantiske spørringer på tvers av flere domener.
- Integrer med Einstein 1 Copilot- eller AI-API-er for å få forutsigelsesrike samtaleopplevelser.
- Brukes sammen med Experience Cloud- eller Lightning Web-komponenter til utvikling av hybridgrensesnitt.
- Utvid via MuleSoft for å orkestrere dataforbedring eller eksterne systemoppslag i sanntid.
Eksempel
Et multinasjonalt forsikringsselskap bygger en selvbetjeningsportal for kunder som lar poliseeiere vise sine forente profiler, nylige krav og tilpassede tilbud. Den frontvendte, eact-baserte appen godkjenner via OAuth 2.0 og henter data ved bruk av Connect REST API og Data Graph API. Alle data vises i Sanntid, samtykkebeskyttet og styres via Data Trust. Utviklere overvåker API-kall og revisjonsspor direkte i Salesforce for å sikre full overholdelse og observasjon.
Kontekst
Virksomheter krever i øyeblikket umiddelbar tilgang til en fullstendig kundeprofil for sanntidsbeslutningssystemer – som servicekonsoller, anbefalingsmotorer eller tilpassingsplattformer. Dette mønsteret gir programmer mulighet til å hente forhåndsberegnede, forente visninger av en kundes data i nærSanntid ved å bruke Data 360s Data Graph API, som gir undersekunders responstider for interaktive opplevelser. Typiske brukstilfeller er:
- Vise en 360-graders kundevisning i en Kundeservice eller Sales Console.
- Levering av AI-baserte Next Best Action- eller Next Best Offer-anbefalinger.
- Levere hypertilpassede nett- eller mobilopplevelser ved sideinnlastingstid.
- Støtte for øktbeslutninger i agent- eller selvbetjeningsmiljøer.
Problem
Hvordan kan et program hente en fullstendig, forhåndsberegnet, forent kundevisning umiddelbart i stedet for å utføre langsomme spørringer med flere objekter ved kjøretid? En netttilpassingsmotor må for eksempel laste inn hele kundekonteksten (demografi, preferanser, transaksjoner og beregnet innsikt) innen millisekunder for å velge et tilpasset tilbud. Tradisjonelle relasjonsspørringer kan kreve flere koblinger og føre til uakseptabel latens. Dette krever et API som leverer unormaliserte, brukerklargjorte profildata som kan hentes via ett enkelt nøkkeloppslag – som kombinerer hastighet, fullstendighet og styring.
Styrker
Flere drifts- og ytelsesfaktorer påvirker dette mønsteret:
- Hastighet: Svartiden må være nærSanntid. API-et må returnere en fullstendig profil innen millisekunder for å støtte synkrone interaksjoner.
- Kompletthet: Svaret må inkludere alle relevante attributter, relasjoner og beregnede innsikter – ideelt sett i en enkelt last.
- Oppslagseffektivitet: Profiler skal kunne hentes via identifikatorer som customerId, contactKey eller e-post, slik at flertrinnspørringer elimineres.
- Data Freshness vs. Latens: Enkelte brukstilfeller foretrekker forhåndsberegnede (bufrede) data for hastighet, mens andre trenger direktedata som godtar høyere latens.
- Styre og sikkerhet: Tilgang må forbli styrt av Salesforce Trust Layer-policyer for å sikre overholdelse av regler for datasynlighet og samtykke.
Løsning
Løsningen er å bruke Salesforce Data Graph API til å hente forhåndsberegnede, avnormaliserte kundevisninger lagret som Datagraf-poster. En datagraf er en materialisert semantisk visning som kombinerer flere datamodellobjekter (DMO-er) – som Enkeltperson, Transaksjon og Produktinteresse – i en enkelt skrivebeskyttet post, ofte representert som en JSON-blob. Utviklere kan bruke REST-endepunkter som: GET /api/v1/dataGraph/{dataGraphEntityName}/{id} for å hente en fullstendig post etter dens unike identifikator. For dynamiske scenarier støtter API-et en live=true-parameter som omgår den materialiserte bufferen, utfører en sanntidsspørring på tvers av Data 360, og bruker minimumslatens for de nyeste dataene. Det gir utviklere mulighet til å velge mellom umiddelbare (bufrede) og gjeldende (direkte) profilhente avhengig av forretningsbehov.
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| Data Graph-definisjon | Nødvendig | Arkitekter definerer en datagraf som kombinerer flere DMO-er til en enkelt semantisk enhet (for eksempel UnifiedCustomerProfile). |
| Profiloppslagssøk | Best | Programmer kaller GET /api/v1/dataGraph/{entity}/{id} for å hente fullstendige, avnormaliserte profiler med unik ID eller nøkkel. |
| Bruk av direkteparameter | Valgfritt | Føy til ?live=true for å tvinge ny beregning i stedet for bufret henting, egnet for beslutninger med høy verdi. |
| Godkjenning | Nødvendig | Bruk OAuth 2.0 via Tilkoblede apper til å godkjenne API-kall sikkert. |
| Svarspørring | Gode fremgangsmåter | Programmer analyserer JSON-svaret direkte i brukergrensesnittet eller beslutningsmotoren sin. Ingen flere koblinger kreves. |
| Bufferstrategi | Anbefalt | Implementer kortsiktig lokal bufring (for eksempel i minnet eller CDN) for gjentatte profiloppslag. |
| Overvåking og observasjon | Nødvendig | Bruk Trust Layer-kontrollpaneler til å overvåke spørringsytelse, responstider og policyoverholdelse. |
Skisse
Her er sammendraget av implementeringsflyten:
- Definere datagraf – Dataarkitekter oppretter en datagraf som modellerer en forent kundevisning på tvers av flere DMO-er.
- Registrer tilkoblet app – Utviklere konfigurerer OAuth-legitimasjon for sikker API-tilgang.
- Invoke Data Graph API – Programmet sender en GET-forespørsel med Data Graph-navnet og post-ID-en.
- Prosessrespons – APIen returnerer en fullstendig JSON-representasjon av kundeprofilen.
- Render eller Handle – Den forbrukerappen (grensesnittet eller motoren) bruker de forente dataene til tilpassing, anbefalinger eller tjenestehandlinger.
- Overvåk og avstem – Ytelsesmålinger og tilgangslogger blir gjennomgått via observasjonskonsollen Trust Layer.
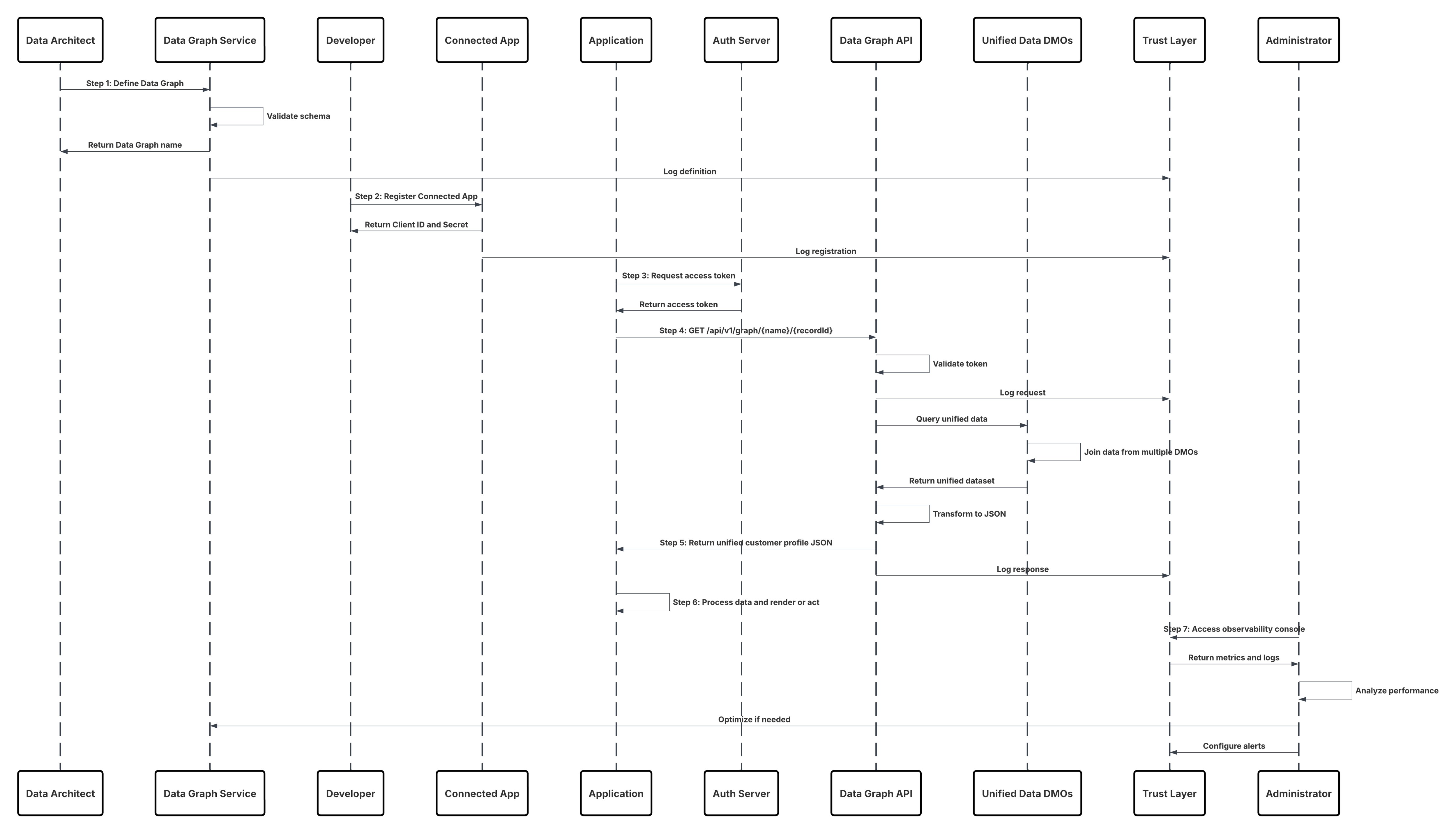
Resultater
Programmer kan nå hente en fullstendig, forhåndsinnkoblet kundeprofil umiddelbart og aktivere sanntidsinteraksjoner som tilpassing, service og beslutningsautomatisering. Dette mønsteret sikrer følgende:
- Responstider under sekund for beslutninger i øyeblikket.
- Konsistent, styrt datahenting i samsvar med den semantiske Data 360-modellen.
- Forenklet programlogikk – ingen sammenføyninger, ingen skjemaavstemming.
- Sporbar og kompatibel tilgang via Trust for revisjon og observasjon.
Kalle opp mekanismer
Oppkallmekanismen avhenger av målskylagringsplattformen og aktiveringskonfigurasjonen.
| Mekanisme | Når brukes |
|---|---|
| Data Graph API (Foretrukket) | Brukes til å hente fullstendige, forhåndsmaterialiserte profiler umiddelbart etter ID eller nøkkel. |
| Data Graph API med live=true | Brukes til brukstilfeller med høy verdi (for eksempel oppdagelse av svindel, direkte tilbud) der de nyeste dataene er nødvendig, og godtar litt høyere latens. |
| Connect API (Fallback) | Brukes til scenarier for sammensatte apper som kombinerer Data Graph-henting med andre Salesforce-data. |
| Query API | Brukes ved konstruksjon av ad hoc-spørringer eller analytiske avlesninger i stedet for umiddelbar profilhenting. |
| MuleSoft API Proxy | Brukes ved ruting av Datagraf-kall via Enterprise-gatewayer eller når det kreves ekstra orkestrering/policyhåndhevelse. |
Feilhåndtering og gjenoppretting
- Graceful Fallbacks – Hvis direktespørringer mislykkes eller overskrider tidsavbrudds terskler, går du automatisk tilbake til bufrede Data Graph-søk.
- Tidsavbruddbehandling – Implementer prøv på nytt og brytelogikk for API-kall under høy belastning.
- Ugyldig ID-håndtering – Returstandard 404 Svar ble ikke funnet for ikke-eksisterende profilnøkler, håndtere pålitelig i grensesnittet.
- Skjemaversjonsvalidering – Valider Data Graph-versjonsmetadata for å hindre feil samsvar når skjemaet utvikler seg.
- Observability Integration – Logg alle feil, nye forsøk og latenser i Trust Layer-kontrollpaneler for SLA-overvåking.
Viktige punkter om Idempotent-design
- Deterministiske nøkler – Hver profil henting bruker en stabil ID (f.eks. IndividualId) som sikrer forutsigbare, gjentakelsessikker spørringer.
- Bufferskonsistens – Bruk ETag- eller Sist endret-hoder til betinget henting og buffervalidering.
- Atomisk henting – Hvert API-svar representerer et konsistent øyeblikksbilde av den materialiserte Datagraf-posten.
- Gjentagelsesbeskyttelse – Sørg for at klientprogrammer oppdager duplikat henting via korrelasjons-ID-er og tidsstempler.
Sikkerhetsvurderinger
- Stærk godkendelse – OAuth 2.0 via tilsluttede apps håndhæver sikker, tokenbaseret adgang.
- Samtykket henting – Bare samtykkede attributter returneres, samtykkesfiltre brukes automatisk av Trust-laget.
- Feltnivåstyring – Tilgang til attributter styres via Data 360s metadata og policydefinisjoner.
- Kryptering underveis og under lagring – Alle svar er kryptert med TLS 1.2+ og AES-256.
- Revisjon og sporbarhet – Hver profilhentehendelse logges med identifikatorer, tidsstempler og policykontekst.
Sidefelt
Tidlighet
- Utformet for umiddelbar henting.
- Støtter direktespørringer for oppdaterte data med litt høyere latens (under sekund).
- Optimalisert for synkron beslutningstaking og interaktive programmer.
- Eliminerer behovet for aktivering før batcher eller ny beregning av segmenter.
Datavolumer
- Ideelt for oppslag på én post eller små sett (ti til hundre) per forespørsel.
- Ikke optimalisert for massetjeneste i stor skala. Bruk gruppe- eller spørrings-API-er til lesinger med stor trafikk.
- Bruker horisontalt skalerbar bufring og forhåndsmaterialisering for å oppnå hastighet.
Statbehandling
- Opprettholder enkel tilgang uten status. Hver forespørsel er uavhengig.
- Støtter bufring av hoder for gjentagelsessikker henting.
- Programmer kan vedlikeholde lokal buffer eller kortsiktig øktlagring for å redusere antall gjentatte oppslag.
Komplekse integrasjonsscenarier
- Integrerer sømløst med Einstein 1, Connect API og MuleSoft for komposittdataopplevelser.
- Kan drive agente systemer (for eksempel Copilot- eller AI-motorer) som krever umiddelbar, kontekstuell bevissthet.
- Kombineres med datahandlinger for sanntidsutløsere ved henting eller endring av status.
- Gir mulighet for tilpassing i stor skala uten å kompromittere ytelse eller styring.
Eksempel
En global e-handelsplattform bruker Data 360s Data Graph API til å hente forente kundeprofiler i sanntid for sin anbefalingsmotor. Når en bruker logger seg på, kaller programmet opp Data Graph-endepunktet for å hente UnifiedCustomerProfile for denne kunden, og returnerer demografiske attributter, atferdsignaler og beregnede innsikter som en enkelt JSON-belastning. Tilpassingsmotoren bruker dette svaret innen millisekunder for å bestemme og vise Next Best Offer under den aktive økten. Alle forespørsler styres og logges gjennom Trust-laget, slik at full synlighet, policyhåndhevelse og overholdelse sikres gjennom hele interaksjonen.
Sanntids datahandlinger aktiverer umiddelbar aktivering av kundedata så snart de endres i Data 360. I stedet for å vente på planlagte gruppeeksporter sender disse handlingene oppdateringer, innsikt eller utløsere direkte til Salesforce eller eksterne systemer i millisekunder. Når en kundes status, samtykke eller engasjementsmåling oppdateres i Data 360, kan dette signalet umiddelbart aktivere tilpassede tilbud, utløse Service Cloud-automatiseringer eller oppdatere lojalitetsnivåer – og sikre at hver kundeopplevelse gjenspeiler den mest oppdaterte, forente sannheten. Dette mønsteret er ideelt for brukstilfeller med høy innvirkning og som skiller mellom latens, som tilpassede nettopplevelser, varsler om svindeloppdagelse, anbefalinger om neste beste handling eller CRM-oppdateringer i sanntid. Den lukker gapet mellom datainnsikt og forretningshandlinger, og gjør forente data om til informasjon i øyeblikket.
Kontekst
Moderne digitale opplevelser og driftsarbeidsflyter krever umiddelbare, kontekstuelle handlinger i øyeblikket en hendelse skjer – for eksempel å oppdatere en kundepost under en Checkout, justere lagerbeholdningen når en retur skannes eller levere en personlig promotering i øyeblikket en bruker forlater en handlevogn. Med sanntids datahandlinger kan systemer kalle opp, berike og handle på forente Data 360-profiler og beregnede innsikter med sub-sekund til sekund latens, noe som muliggjør interaktiv tilpassing, driftsautomatisering og umiddelbar beslutningstaking.
Problem
Hvordan kan programmer, brukergrensesnittinteraksjonsflyter eller mellomprogramvare ringe til Data 360 ved kjøretid for å lese, beregne eller oppdatere en enkelt forent profil eller utløse en handling (for eksempel sende et tilbud, oppdatere CRM, starte en arbeidsflyt) med lav latens, sterk konsistens og styringskontroller – uten å vente på planlagte batchjobber eller tunge pipelines?
Styrker
Flere tekniske, operasjonelle og styringsstyrker former dette mønsteret:
- Krav til lav latens: Samtaler må utføres på under ett til noen få sekunder for å opprettholde en god brukergrensesnitt eller oppfylle operasjonelle tjenestenivåavtaler.
- Deterministisk identitetsløsning: Forespørsler må løses til den riktige Forente persondata-profilen (gylden post) pålitelig og raskt.
- Finkornet godkjenning: Sanntidssamtaler må håndheve policyer på attributtnivå og samtykkekontroller på forespørselstidspunktet.
- Belastningsminimalisme: Sanntids belastninger skal være små og fokuserte (enkeltprofil eller lite attributtsett) for å redusere latens og kostnader.
- Utvikleropplevelse: API-er må være utviklervennlige (REST/gRPC/GraphQL), med tydelige skjemaer og stabile kontrakter for produksjonsbruk.
- Revisibilitet og sporbarhet: Hver sanntidshandling må logges med linje, brukeridentitet og policybeslutninger for å oppnå samsvar.
Løsning
Den anbefalte løsningen er å bruke Data 360s grensesnitt for sanntids datahandlinger (API-er + SDK-er) kombinert med kantbufring og minimale datatransformasjoner der det er nødvendig. Integrasjoner kaller opp et datahandlingssluttpunkt for å lese eller skrive profilattributter, beregne innsikter eller starte orkestreringer. Sanntidspolicykontroller (CEDAR) og dynamisk maskering brukes på Policy Enforcement Point før en last returneres eller handlingen utføres.
| Løsningsområde | Tilpass | Kommentarer / implementeringsdetaljer |
|---|---|---|
| Sanntids datahandling | Best | Eksponer endepunkt for lese/skrive- og handlingsutløsere for enkeltposter. Godkjenn via OAuth/JWT. |
| Identitetsløsning | Nødvendig | Løs innkommende identifikatorer (email, externalId, cookie) til Innebygd enkeltperson-ID. Bruk en deterministisk løser med buffer. |
| Policy Enforcement (CEDAR) | Beste praksis | Evaluer samtykke-, ABAC- og maskeringspolicyer på forespørselstidspunktet, avslå eller masker felt per policybeslutning. |
| Kant/bufferlag | Anbefalt | Bruk kort-TTL-bufringer for profilfragmenter og beregnet innsikt for å redusere latens og gjøre endringshendelser ugyldige. |
| Lette transformasjoner | Anbefalt | Bruk enkle forbedringer eller beregnede felt i handlingsbanen. Viktige transformasjoner må forhåndsberegnes. |
| Action Orchestration | Best | Støtte for synkrone etttrinnshandlinger (for eksempel retur tilbudstoken) og asynkrone orkestreringer (kø \+ webhook) for komplekse flyter. |
| Observability & Tracking | Nødvendig | Logg forespørsel/svar, policybeslutninger og linje til Trust Layer/SIEM for revisjon og feilsøking. |
| Rate Begrensning & Throttling | Nødvendig | Håndhev kundekvoter og gode strategier for nedgang for øyeblikk med stor trafikk. |
Skisse
Her er sammendraget av trinnene.
- Client (UI / middleware / POS) sender godkjente forespørsler om datahandling med identifikatorer og handlingstype.
- API-gateway validerer token, frekvensgrenser og videresender til Data 360 Action Service.
- Handlingstjeneste løser identifikator → Forente persondata-ID (hurtigbanebuffer, tilbakestilling til Graf-oppslag).
- Policy Enforcement (PDP) evaluerer CEDAR-policyer ved bruk av attributter fra PIP og forespørselskontekst.
- Hvis det er tillatt, leser Action Service eventuelle nødvendige profilattributter/innsikt og utfører lette transformasjoner.
- Handlingstjeneste returnerer svar synkront (for eksempel tilbudstoken, oppdatert attributt) eller legger i kø asynkron orkestrering og returnerer bekreftelse.
- Alle hendelser, beslutninger og nyttelast logges til Trust Layer og videresendes eventuelt til SIEM.
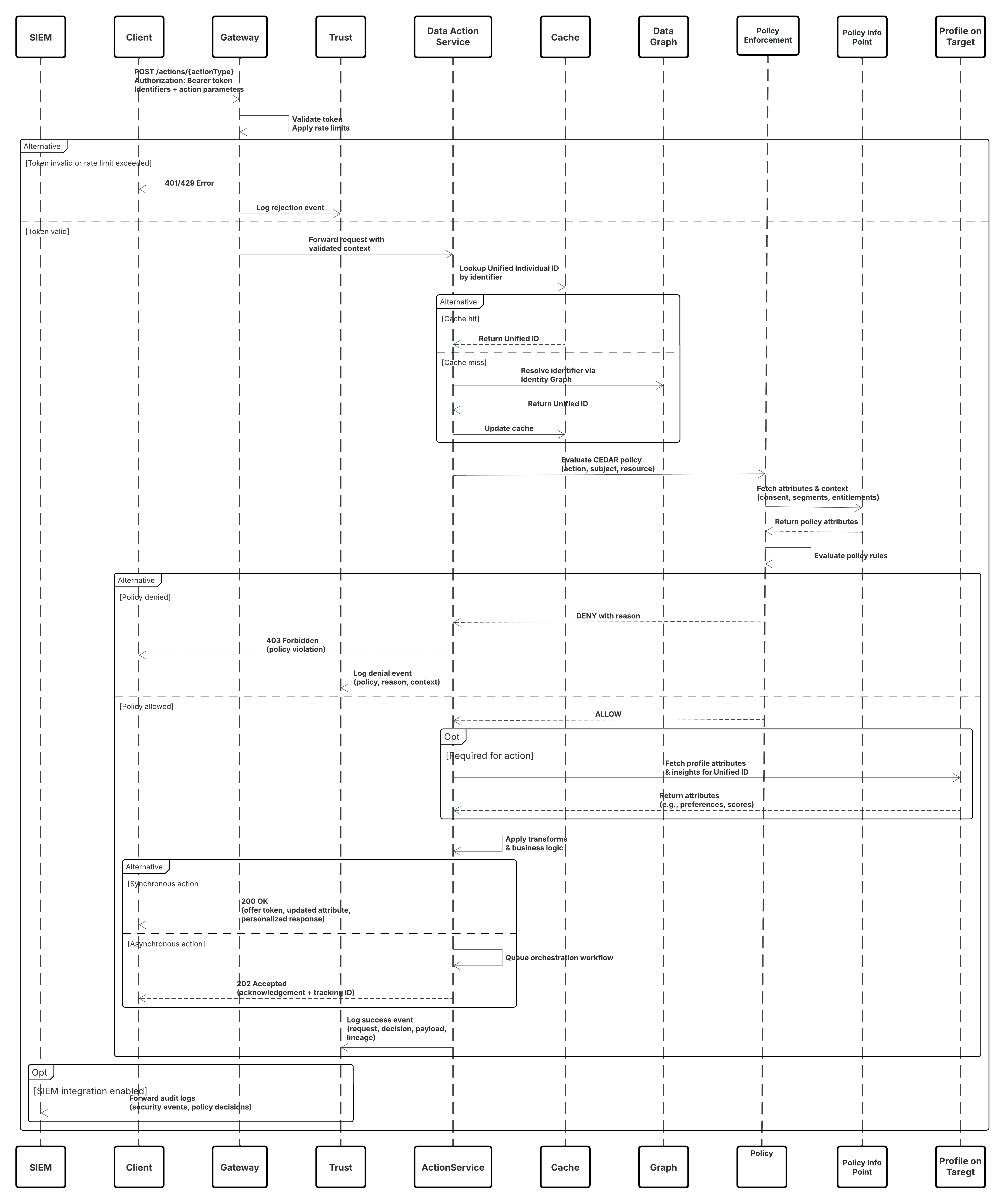
Resultater
- Programmer får umiddelbar, policyadministrert tilgang til forente profillese/skrive- og handlingsutløsere med sekund til sekund latens.
- Sanntidstilpassing, beslutningsprosesser og driftsarbeidsflyter (for eksempel tilbud, agentassistanse, lageroppdateringer) er aktivert uten gruppeforsinkelser.
- Alle handlinger er reviderbare, samtykkesensitive og håndhever maskering på attributtnivå for å opprettholde personvern og samsvar.
Kalle opp mekanismer
Oppkallmekanismen avhenger av målplattformen og konfigurasjonen av aktiveringsmål.
| Mekanisme | Når brukes |
|---|---|
| RESTful Data Actions API | Foretrukket for nettapper/mobilapper og mellomprogramvare som trenger synkrone profillesinger eller handlingssvar. |
| gRPC / Binary RPC | Brukes til virksomhetstjenester med svært lav latens eller interne mikrotjenester med faste tilkoblinger. |
| GraphQL-spørringer med enkeltposter | Brukes når klienter trenger fleksibelt feltvalg og ønsker å minimere belastning. |
| Event-utløste Webhooks | Brukes for asynkrone arbeidsflyter der handlinger utløser nedstrøms prosesser (for eksempel starte en reise). |
| Plattform hendelser / PubSub | Brukes til fan-out-scenarier der flere systemer må reagere på én enkelt handlingshendelse. |
| Edge SDK (klient libs) | Brukes for klienter med lav latens som bufrer profilfragmenter og kaller opp Data Actions API bare når det er nødvendig. |
Feilhåndtering og gjenoppretting
- Synkrone feil: Returner strukturerte feilkoder med menneskelig lesbare meldinger og idempotenstokener.
- Transient Retry (Traserende forsøk): Klienter bør prøve på nytt idempotent-forespørsler med eksponentiell tilbakemelding på 429/5xx-svar.
- Håndtering av poliseavslag: Nektet returnerer tydelige årsakskoder. Sensitive data returneres aldri ved policyfeil.
- Asynkrone orkestreringsfeil: Orchestrationjobber flyttes til DLQ og kan spilles på nytt. Med en jobbstatus-API kan klienter spørre eller motta tilbakekall.
- Fallback-strategier: Hvis identitetsløsningen mislykkes, returneres en deterministisk feil og eventuelt en foreslått rettelse (for eksempel kreve externalId).
Viktige punkter om Idempotent-design
- Idempotency Key: Klienter leverer en idempotency-nøkkel (UUID + klientnavneområde) for mutering av handlinger.
- Deterministiske nøkler: Bruk sammensatte nøkler (UnifiedIndividualId + ActionType + TimestampWindow) til å oppdage duplikater.
- Safe Retries: Utform handlinger som tåler bivirkninger, eller utfør oppdateringer i stedet for blindinnsetting.
- Gjentagelsesbeskyttelse: Behold behandlede idempotensnøkler og TTL dem etter forretningsvinduet for å unngå repetisjoner.
- Statsløshet: Hold synkrone handlinger uten status der det er mulig. Behold minimumsstatus for asynkrone arbeidsflyter.
Sikkerhetsvurderinger
- Godkjenning: OAuth 2.0 (JWT Bearer eller mTLS for tjenestekontoer); kortlivede tokener og oppdateringsrotasjon.
- Tillatelse: Policy Decision Point håndhever attributtbasert tilgangskontroll (CEDAR) og samtykkekontroller per forespørsel.
- Transport og lagringskryptering: TLS 1.2+ underveis, AES-256 under lagring for eventuelle bufrede fragmenter eller revisjonslogger.
- Minste privilegium: API-klienter med minimalt antall tillatelser, roller atskilt for lese kontra skrive kontra orkestrering.
- Dataminimering: Returner bare forespurte og samtykkede attributter. Bruk dynamisk maskering for PII/PHI.
- Nettverkskontroller: Krev eventuelt samtaler fra private nettverk (Privat tilkobling, IP-tillatelseslister) for handlinger med høy risiko.
- Revisjon og overvåking: Logg forespørselsmetadata, policybeslutninger, forespørselsidentitet og svar-hash-koder til Trust Layer og SIEM.
Sidefelt
Tidlighet
- Utformet for middellatenser i området under sekund til lavt antall sekunder for synkrone handlinger.
- Edge-bufringer (kort TTL) og forhåndsberegnet innsikt reduserer avrunding.
- Asynkrone baner gir nær umiddelbar bekreftelse med bakgrunnsbehandling for tunge oppgaver.
Datavolumer
- Optimalisert for interaksjoner med enkeltposter eller små grupper (1–100 poster).
- Ikke beregnet for masseeksport – bruk gruppeaktivering for store volumer.
- Høy gjennomstrømning bruker gjenbruk av pooling/tilkobling og parallelle orkestreringskøer.
Statbehandling
- Statløs forespørselsmodell for synkrone samtaler. Minimum handlingstilstand beholdt for tilskudd/transaksjoner.
- Bufferaktivering drevet av endringshendelser – forsikre deg om at TTL-er og ugyldiggjørelsessignaler holder bufferen oppdatert.
- Orchestration-jobber vedlikeholder en varig tilstand (jobId, status, gjentagelser) lagret i Trust.
Komplekse integrasjonsscenarier
- Agentassistent: Sanntidsprofiloppslag + beregnet tilbøyelighet returnert til servicekonsoll i sekundet for agenter.
- POS / Edge-enheter: Lokalt SDK + tilfeldig datahandling for validering av promoteringer eller lojalitetsstatus.
- Hybridflyter: Synkroniser datahandling for beslutning + asynkron orkestrering for å oppdatere nedstrøms systemer og utløse kampanjer.
- Tredjeparts mellomprodukter: MuleSoft- eller API-gatewayer kan formidle godkjenning, berike kontekst og håndheve ekstra policykontroller.
Eksempel
En detaljhandel-mobilapp bestemmer om en personlig tilpasset umiddelbar kupong skal vises når en kjøper trykker på Checkout ved å kalle opp handlingen tilbudsberettigelsesdata med kjøperens e-postadresse og handlevognkontekst. Forespørselen valideres av API-gatewayen og videresendes til Datahandlingstjenesten, som løser e-postmeldingen til en forent enkeltperson-ID ved bruk av en buffer, bekrefter markedsføringssamtykke via PDP og evaluerer berettigelse basert på kundens levetidsverdi og nylige kjøp. Hvis kjøperen kvalifiserer, returnerer tjenesten et signert kupongtoken og logger beslutningen. Når kupongutstedelse krever reservasjon av lagerbeholdning, utløses en asynkron orkestrering for å reservere lagerbeholdning og varsle CRM-systemer. Appen viser kupongen umiddelbart, mens nedstrømsoppdateringer utføres i bakgrunnen, og Trust fanger opp et fullstendig revisjonsspor for styring og samsvar.
- Koblinger og integrasjon
- Web & Mobile SDK
- Sub-second sanntids inntak
- Bruk din egen innsjø (null kopieringspørring)
- Bruk din egen innsjø (Zero Copy File)
- Datagrafer
- Aktivering: MC-engasjement
- Aktivering: MC Tilpassing
- Aktivering: B2C Commerce
- Datatildeling (zero copy)
- Aktivering: Fillagring
- Datahandlinger
- Sanntids sub-second-datahandlinger
- Ekstern aktiveringsplattform