Dataplattformer har utviklet seg i over tre tiår. Bransjen ble i utgangspunktet dominert av sentraliserte og strukturerte (hovedsakelig relasjonsbaserte) driftsbaserte/OLTP-databaser på stedet. Dette utvidet til å inkludere datalagrer OLAP/Big Data-plattformer som primært ble brukt til analytisk behandling og forble relasjonelle og sentraliserte. Skylagring drev distribuerte arkitekturer som datalagrer, innsjøbygg og desaggregert lagring. Men driftsplattformer og analytiske plattformer beholdt seg atskilt. I dag endrer skydatabehandling og AI-revolusjonen fundamentalt dataplattformarkitekturen.
Virksomheter investerer allerede i modne Big Data-plattformer som Snowflake, Databricks, BigQuery og Redshift. Men disse plattformene fungerer som datasiloser. Kunder utleder ikke forretningsverdi fra dataene sine fordi dataene ikke kan håndteres direkte i forretningsflyter og programmer. Disse løsningene mangler generativ AI-behandling fra Agent og kan ikke levere datatilgang i sanntid, så de kan ikke levere AI-drevet tilpassing i øyeblikket for kundeengasjement og andre bransjeledende funksjoner.
Fremtiden for dataplattformer er preget av en forent, fleksibel, tilgjengelig og åpen datainfrastruktur. Denne nye arkitekturen bygger på moderne databehandlings- og lagringstrender – GPU-er, stort minne, NVMe SSD-er og skylagring – for å integreres med skydatabehandling og AI. De kan levere sanntidsinnsikt, aktivere autonom beslutningstaking og drive sanntids programmer. Dette inkluderer økningen av agentisk AI, prediktiv AI, analyse, sanntids OLTP-databaser i stor skala, datasjøer og innsjøer. Disse moderne dataplattformene er utformet for enkelhet, skalerbarhet, smidighet, ytelse, sikkerhet, tilgjengelighet og kostnadseffektivitet.
Følgende datatrender driver nestegenerasjonsarkitektur for dataplattformen.
- AI, maskinlæring og Analytics i kjernen: Fremveksten av agentisk AI vil fundamentalt endre utviklingen, distribusjonen og bruken/tilgangen til dataplattformen. Agentisk AI vil forstå samtale-/spørringshensikt, planlegge, generere arbeidsflyter og automatisere beslutningstaking. Agentisk (kort- og langsiktig) minne konstrueres fra samtalehistorikk for å tilpasse agentplanlegging og -beslutninger, samtalmodellering i sanntid og støtte for tilpassing som er avgjørende i dataplattformer. Agenter vil bidra til å automatisere operasjonelle "egenskaper" som datastyring (dvs. sikkerhet, samsvar, Trust), ytelse (dvs. automatisk skalering for samtidighet, gjennomstrømning og latens), feiloverføring og tilgjengelighet, og observabilitet og vedlikehold. AI-drevne analyser, prognoser, naturlig språkbehandling (NLP) for analyser Q/A og analyser på ustrukturerte data (tekst som PDF-filer, bilder, lyd og video) vil bli standard, slik at virksomheter kan utlede dypere innsikter fra ulike datakilder.
- Decentralisering av data, men forent datatilgang: Agenter trenger bedriftsdata for å utlede innsikt og ta beslutninger, og for å automatisere forretningsaktiviteter. Data er innebygd desentralisert i virksomheter, i forskjellige programmer og dataplattformer. Men det er ikke enkelt å sømløst forene enhetene på tvers av ulike forretningsenheter i virksomheten og med partnere utenfor virksomheten. Forening av data involverer deling av data, enten via inntak fra kilder eller sammenføyning med datakilder, rådata fra dataklargjøring, harmonisering og modellering for analytisk og AI-behandling, lagring og administrasjon av data i stor skala for effektiv tilgang med lav CTS, og datatilgang via ulike spørrings- og analysemekanismer og verktøy, dypt integrert med de underliggende lagrings- og datatilgangsplattformene
- Skybaserte åpne innsjøer: Skybaserte Big Data-plattformer (OLAP) konvergerer om å ta i bruk åpne filformater (Parquet) og tabellformater (Iceberg) som aktiverer dataforbund (data inn) og deling (data ut).
- Ustrukturert databehandling: Med fremveksten, utviklingen og innføringen av generativ AI begynner virksomheter å utlede verdifull innsikt og forretningsverdi fra bedriftens datakorpus som utgjør store mengder tekstdokumenter, lydavskrifter, videoopptak og andre medier. Ustrukturert databehandling, inkludert fordeling, vektorisering, semantisk søk og Knowledge, gjør disse innsiktene mulige. Teknikker som RAG (henteforbedret generering) og CAG (bufferforbedret generering) blir hoveddrivere for raskt og effektivt søk på tvers av datagrunnlaget.
- Knowledge Management: Knowledge går utover selve råinnholdet (dokumenter, artikler, videoer). Den representerer utvidelse av det innholdet ved å utlede mening, kurere metadata og plassere det i kontekst for å utvikle en delt forståelse av innhold på tvers av en organisasjon eller et foretak. Knowledge selv er generelt strukturert. Knowledge management involverer innholdsbehandling, Knowledge utvinning, representasjon gjennom modeller som grafer og navigering.
- Rik datatilgang: Tilgang til rike data betyr at data, analyse- og AI-verktøy må være tilgjengelig for en rekke personer, inkludert sluttbrukere, forretningsbrukere, administratorer og analytikere. Tilgjengelighet oppnås via mekanismer som ensemble-spørring (med relasjonsspørring, nøkkelordspørring og semantisk spørring), spørring med naturlig språk til SQL (NL2SQL), sanntidstilgang og så videre.
- Sanntidsbehandling: Agentprogrammer tar sanntidsbeslutninger basert på gjeldende tilstand og basert på nye hendelser, tilpassede svar og handlinger, som krever tilgang, behandling og handling på sanntidsdata. Behandling i sanntid krever oppdaterte data (datatalatensiering) og interaktiv tilgang (tilgangslatensiering). Slike data og tilgangslatens krever at den underliggende dataplattformen støtter oppdatert datatilgang fra drifts- og analytiske butikker, behandling med lav latens (punktoppslag og spørringer), høy dataskala og høy gjennomgang.
- Datasikkerhet, styring og opphold: Agentisk og konversasjonsbasert AI forenkler programgrensesnittet og tillater at alle, fra forbrukere til ansatte til andre AI-agenter, samhandler med programmer ved bruk av muntlig eller skrevet naturlig språk. De verdifulle kundedataene og personopplysningene som må lagres og modelleres for Agentic-programmer, må sikres og styres med veldefinerte tilgangs- og delingspolicyer. Flere og flere kunder må overholde forskrifter som krever dataopphold i sitt eget land eller område, spesielt de som er i myndigheter eller arbeider med myndigheter.
Salesforce Data 360 er utformet for å i fremtiden håndtere disse datatrendene. Data 360 er en skybasert, metadatastyrt dataplattform som forener isolerte data på tvers av virksomheten, slik at organisasjoner kan lagre, modellere og behandle dataene sine for å aktivere analyser, AI, maskinlæring og Agentic-programmer.
Dette dokumentet er en viktig veiledning for bedriftsarkitekter og CTO-er. Den beskriver arkitekturen, funksjonene, utformingsprinsippene og brukstilfellene for Data 360. Den introduserer det grunnleggende om Data 360-arkitektur som en primer, etterfulgt av en serie dypere dykkere inn i nøkkelforskjeller som interoperabilitet med eksisterende dataplattformer, inkludert strategi for flere organisasjoner, sikkerhet, styring og personvern, aktivering i sanntid og ryddige rom for data.
Salesforce Data 360 er utviklet rundt et kjernesett av prinsipper som gjør bedriftsdata operative, klarerte og sanntids.
- Åpenhet og interoperabilitet: Bygd for ekosystemer med flere skyer. Samler med dataplattformer som Snowflake, Databricks, BigQuery og Redshift uten duplikater, og utvider Customer 360 samtidig som eksisterende investeringer bevares.
- Storage-Calculate Separation: Skalerer lagring og behandling (batch, strømming og interaktiv) uavhengig. Gir elastisitet og effektivitet for arbeidsbelastninger med stor trafikk og høy ytelse.
- Multi-modell lagring og behandling: Støtter strukturerte og ulike ustrukturerte datatyper som tekst, bilde-lyd og video. Gir effektiv lagring, sanntids- og gruppebehandling, utvidbar indeksering, forent søk, spørring og analyse.
- Metadatastyrt design: Programmer defineres av metadata i stedet for kode. Metadata behandles som et førsteklasses aktivum som muliggjør forent styring, fleksibilitet og dyp integrasjon i Salesforce-plattformen.
- Sanntids hybridbehandling: Støtter spørringer med lav latens og umiddelbar beslutningstaking sammen med gruppebehandling og analytiske arbeidsbelastninger.
- Intelligente og aktive data: Innhenter, analyserer og overfører innsikt kontinuerlig direkte til forretningsarbeidsflyter. Leverer ingen kode, lavkode, pro-kode og AI-drevet automatisering med den nyeste konteksten.
- Forvaltning og personvern etter utforming: Linje, tilgangskontroll, opphold, datakryptering og samsvar er innebygd. Trust og regulatorisk tillit styrkes på alle nivåer.
- En-til-mange Leasing: En sentralisert Data 360-organisasjon fungerer som den eneste sannhetskilden for Customer 360, og støtter sømløst salgsmiljøer for flere organisasjoner som brukes mye av Salesforce-kunder.
Disse prinsippene sikrer at Data 360 gjør data åpne, intelligente og handlingsrettede i sanntid.
Salesforce Data 360 er en moderne dataplattform som bygger på designprinsipper som tar hånd om aktuelle datatrender. Dens arkitekturfunksjoner sikrer at bedriftsdata er klarert, forent og kan handles i sanntid, i samsvar med dens veiledende prinsipper.
- Cloud-Native Foundation: Kjører på Hyperforce, distribuert på Hyperscalers (som AWS), med uforanderlig mikroservicesbasert infrastruktur. Gir elastisk skalering, Zero Trust-sikkerhet, kontinuerlig levering og global overholdelse av krav.
- Salesforce (kjerne) Metadata-drevet: Metadata utformes, modelleres og lagres som Salesforce-metadata som aktiverer umiddelbar bruk av ALLE Salesforce-programmer. Slike metadata lagres i et fullt ACID-kompatibelt RDBMS. Sikrer styring, livssykluskonsistens og dyp integrasjon med Salesforce Lightning Platform.
- Lakehouse Storage: Bygd på Apache Iceberg og Parquet, som kombinerer datasjøskala med lagerstyring som støtter skjemautvikling, tidsreiser og oppdateringer med stor trafikk. Data 360 lagrer, modellerer og behandler strukturerte og ustrukturerte data med storskala lagring med moderne åpne standarder og med omfattende transformasjons- og databehandlingsfunksjoner for gruppe- og hendelsesdrevne arbeidsbelastninger.
- End-to-End Data Pipeline med fleksibel inntak: Dekker hele livssyklusen – inntak, klargjøring, modellering, forening, analyse og aktivering – og reduserer avhengigheten av fragmenterte punktløsninger. Støtter batch, nær sanntid og strømming med 270+ koblinger og MuleSoft. ELT-første tilnærming muliggjør rask datatilgjengelighet med nedstrøms transformasjonsfleksibilitet.
- Enterprise Data Interoperability med Open Frameworks og Federation: Forener isolerte data på tvers av virksomheten med toveis Zero Copy-forbund med Snowflake, Databricks, BigQuery og Redshift som unngår dataoverføring eller duplisering.
- Dataklassifisering, modellering og organisasjon: Data 360 organiserer data som rå inntatte data, ryddede og lagrede data og data som modelleres i samsvar med felles informasjonsskjema som kalles SSOT (Single Source of Truth). Slike SSOT-objekter danner grunnlaget for å definere semantiske datamodeller (SDM) og andre kuraterte og programspesifikke modeller.
- Inbygd semantisk datamodellering for utvidbar analyse med åpne semantiske spørrings-API-er, som driver Tableau Next og aktiverer programspesifikk analyse.
- High Performance SQL-spørringsmotor som støtter en forent Data 360 SQL-spørring på tvers av strukturerte, ustrukturerte og grafdata.
- Datalager med lav latens: Nøkkelverdibeholdning for varme data med svartider på millisekunder. Aktiverer tilpassing og hendelsesdrevne scenarier i sanntid. Samler inn og behandler kundeengasjementsdata i sanntid. Forener identiteter, interaksjoner og samtaler til en enkelt, klarert Customer 360 og kontekstgraf.
- Ustrukturerte databehandlingspipeliner for fleksibel og utvidbar støtte for ustrukturert datalagring, fordeling, generering av innbygging (vektorisering), uttrekking av metadata (augmentering), sammendrag, indeksering, Knowledge-uttrekking, intelligent dokumentbehandling, opprettelse av kortsiktig og langsiktig (samtale) minne og så videre.
- Nativ nøkkelord, vektor og hybrid indeksering for nøyaktig og effektiv ustrukturert datatilgang som Rask og Agentisk søk, RAG, Knowledge uttrekking, Agentisk minneutledning, etc.
- Profil-, Tilpassing-, Kontekst-tjenester for aktivering av AI/ML og Agentic-programmer.
- Inbygd styring og sikkerhet på alle lag for slektsporing, datamaskering, dataopphold og null Trust-sikkerhet for å sikre overholdelse og Trust.
- Elastic Compute stoff: Kubernetes-innebygd datamaskin med flere leietagere. Kjører Spark for distribuert behandling og Hyper for SQL-arbeidsbelastninger. Skalerer elastisk på tvers av ulike jobber og støtter isolasjon for kjøring av kode som ikke er klarert.
Alt dette kjører på Hyperforce, Salesforces skygrunnlag. Hyperforce tilbyr:
- Null Trust-sikkerhet med kryptering, isolasjon og policyer for minst privilegium.
- Resiliens gjennom distribusjoner i flere regioner. Selv om Salesforce Data 360 drar nytte av Hyperforces flerområder og feiltoleranse på plattformnivå, krever sann katastrofebehandling (DR) i bedriftsgrad en mer omfattende arkitektur som ligner på hvilken som helst dataplattform med nøkkelfunksjoner: gjengivelige inntaksledninger, replikering og metadatadrevet rehydrering på tvers av alle avhengige økosystemer.
- Observabilitet med innebygd overvåking, målinger og sporing.
- Automatisk skala og FinOps-bevissthet for effektivitet uten kostnadsoverflyt.
Data 360 erstatter ikke eksisterende investeringer i virksomheten. I stedet gjør Data 360 dataene du allerede har klarert, styrt og gjort tilgjengelige for handling – leverer sanntids, AI-drevet engasjement der det betyr mest. Kort sagt gjør Salesforce alle bedriftsdata, inkludert eksterne data, til metadatadrevne objekter (Salesforce) og aktiverer Agentic-programmer for oppdagelse, beslutningstaking og handling.
Følgende figur illustrerer Data 360 Reference-arkitekturen:
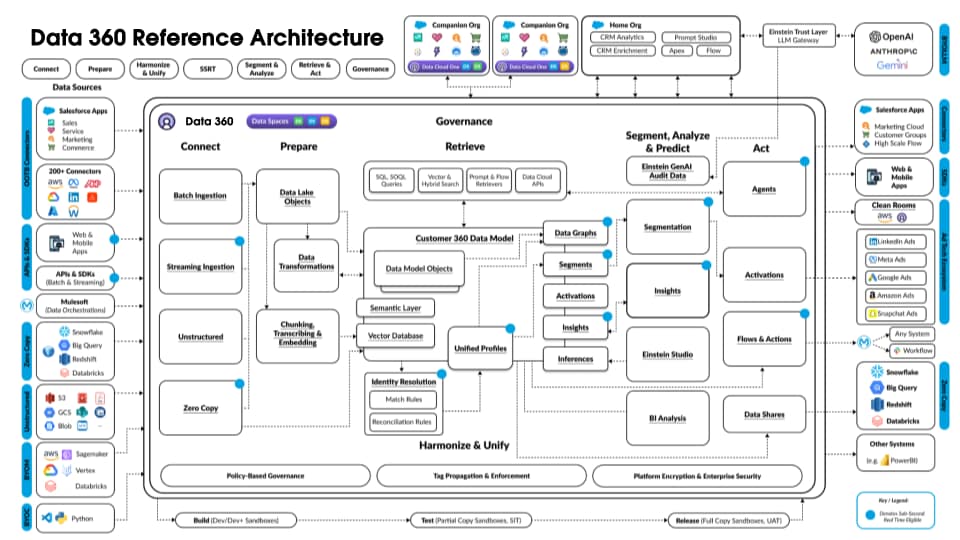
La oss se på en hypotetisk Agentforce Loan Agent laget på Data 360 for å beskrive et eksempel på en arkitekturflyt. La oss si at Låneagent er en kunderettet agent der kunder (forbrukere) søker om lån og får umiddelbare lånegodkjenninger.
Data 360 utfører disse trinnene som planlagt og klargjør data for bruk av låneagenten.
- Data 360 henter inn strukturerte kundekontodata fra CRM og lagrer dem i datasjøen.
- Data 360 behandler ustrukturerte firmalån- og økonomipolisedata.
- Data 360 forener personopplysninger fra en ekstern datakilde som Snowflake.
- Data 360 transformerer og modeller inntatte og forente data.
- Data 360 bygger og vedlikeholder profildatadiagrammet.
Hver gang en kunde søker om et lån, utføres disse handlingene.
- En kunde logger seg på Låneagent, som starter en kundeøkt i det sanntids laget. Kundens forente profil trekkes ut i sanntidslaget.
- Kunden fyller ut et lån ved å oppgi den nødvendige informasjonen.
- Kunden laster opp økonomiske dokumenter (som avdrag, investeringer, bankregnskap) til Data 360 for ustrukturert databehandling.
- Opplastede data deles og vektoriseres (generering av innbygging), og indekser (nøkkelord og vektor) opprettes.
- Deretter fyller kunden ut lånesøknadens dokument og laster det opp. Data 360 trekker ut lånebeløpet og varigheten i sanntid.
- Låneagenten henter relevante økonomiske data ved bruk av Data 360-spørring og hybrid søk over profil og andre forhåndsopprettede indekser.
- Låneagenten aktiverer en godkjenningsagent med lånedata og andre økonomiske profildata for å ta beslutningen om godkjenning av lånet.
- Låneagenten svarer til kunden med en beslutning.
- Hele denne interaksjonen mellom kunden og låneagenten fanges også opp og lagres i Data 360.
Eksempelet ovenfor gir en oversikt over Data 360-arkitekturkomponenter som brukes til å bygge et Agentisk-program som en låneagent. I den neste delen beskriver vi Data 360-arkitekturlagene og -komponentene.
I denne delen vil vi gå dypere inn i de grunnleggende byggeblokkene i Salesforce Data 360, starte med dens robuste lagringsmodell og deretter utforske mekanismene for tilkobling, inntak og klargjøring av data. Vi vil deretter undersøke hvordan strukturerte og ustrukturerte data lagres, modelleres og behandles, og kulminere i en forståelse av harmonisering, forening, henting og intelligent aktivering.
Salesforce Data 360 bygger på en gradert, men integrert lagringsmodell som kombinerer styrkene i et innsjøhus med sanntidslagring. Lakehouse-laget gir skalerbar, kostnadseffektiv lagring for store mengder historiske og gruppedata, og aktiverer avanserte analyser og brukstilfeller med maskinlæring. Sanntidslagring er derimot optimalisert for tilgang med lav latens og oppdateringer med høy frekvens, slik at kundeinteraksjoner, profiler og engasjementssignaler alltid er oppdaterte. Sammen fungerer disse nivåene sømløst, slik at data flyttes flytende mellom historiske og sanntidskontekster – og gir både dybde og umiddelbarhet i et forent datakilde for tilpassing, AI og aktivering.
Data 360 har en innebygd innsjøarkitektur basert på Iceberg/Parquet, utformet for å håndtere databehandling og behandling i stor skala for gruppescenarier, strømming og sanntidsscenarier som støtter både strukturerte og ustrukturerte data, som er avgjørende for AI- og analyseprogrammer.
I skybaserte datasjøer som Azure, AWS eller GCP er den grunnleggende lagerenheten en fil, vanligvis organisert i mapper og hierarkier. Lakehouse forbedrer denne strukturen ved å introdusere strukturelle og semantiske abstraksjoner på høyere nivå for å lette operasjoner som spørring og AI/ML-behandling. Den primære abstraksjonen er en tabell med metadata som definerer strukturen og semantikken, og som inkluderer elementer fra åpne kildekodeprosjekter som Iceberg eller Delta Lake, med flere semantiske lag lagt til av Data 360.
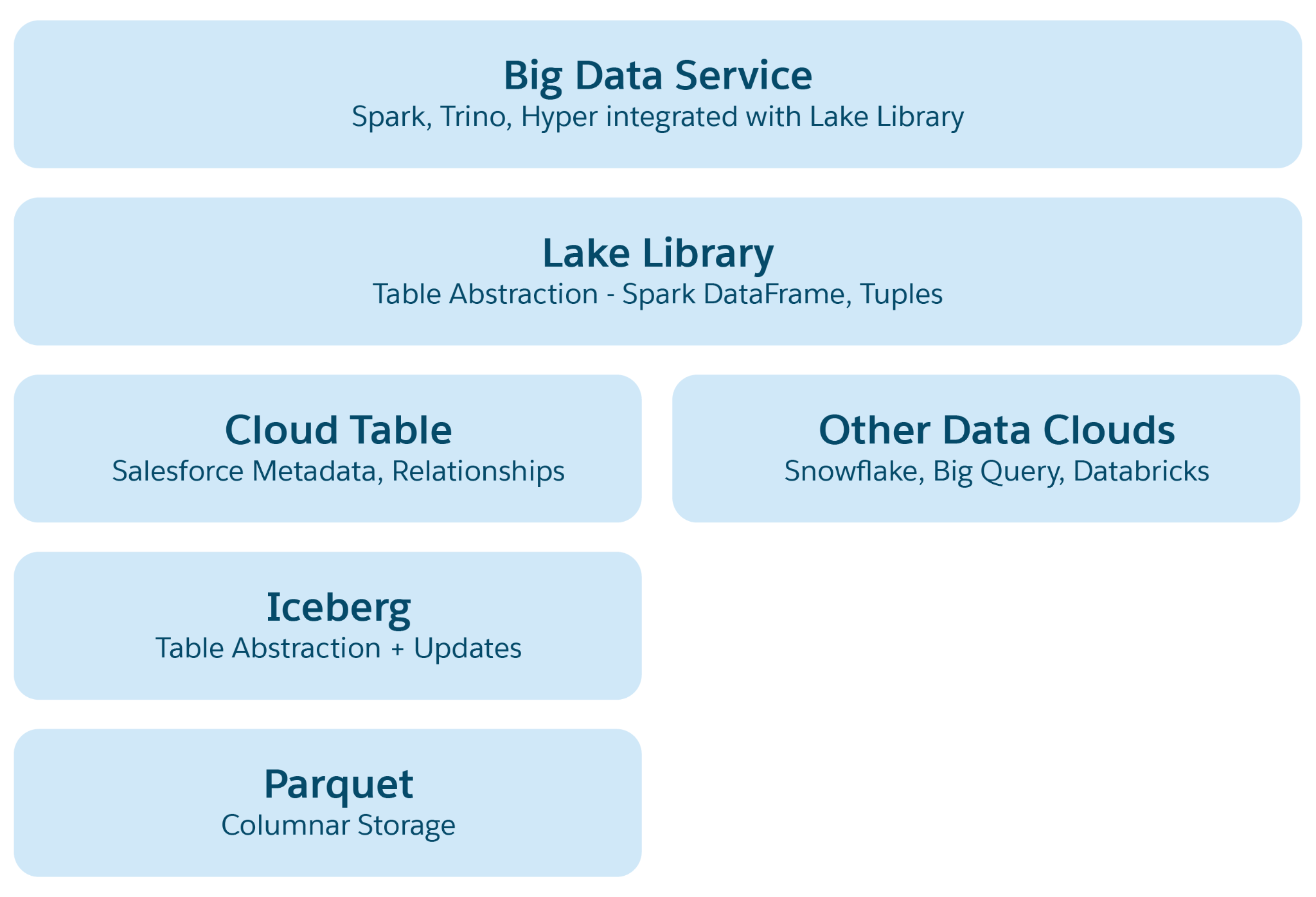
Abstraksjonslag i Lakehouse:
- Parkettefil abstraksjon: I bunnen består lagringsplass av datasjøfiler (for eksempel S3 i AWS eller Blob i Azure) i Parket-format. Data for en kildetabell lagres på tvers av flere partisjoner som Parket-filer, der hver tabell er en samling av disse filene.
- Iceberg Table Abstraction: Tabeller er ordnet som mapper, med datapartisjoner lagret som Parket-filer i disse mappene. Endringer i en partisjon fører til nye Parquet-filer som øyeblikksbilder. Iceberg behandler en metadatafil for hver tabell med detaljerte skjemaer, partisjonsspesifikasjoner og øyeblikksbilder.
- Salesforce Cloud-tabellabstraksjon: Dette laget bygger på Iceberg og legger til semantiske metadata som kolonnenavn og relasjoner, sammen med konfigurasjoner som målfilstørrelse og komprimering. Den abstrakterer tabeller på tvers av ulike plattformer som Snowflake og Databricks, og beskytter Data 360-programmer mot underliggende plattformspesifikasjoner for lagringsplass.
- Lake Access Library: Dette biblioteket gir tilgang til Salesforce Cloud-tabellen, håndterer både data og metadata, og abstrakterer de underliggende lagringsmekanismene for programutviklere.
- Big Data Service Abstraction: Dette inkluderer behandling av rammeverk som Hyper for spørring og Spark for behandling på tvers av hvilken som helst skytabellplattform.
For å støtte sanntidsanalyse og agentiske programmer utvider Data 360 lagringsplassen for store data i Lakehouse med lav latensbutikk. Data 360 Sanntid-lag behandler sanntidssignaler og engasjementsdata i minnet. I og med at den minnebaserte lagringskapasiteten er begrenset, kan imidlertid ikke alle data passe inn og behandling kan ikke utføres i sanntid. Data 360 legger til et lavlatenslager (LLS) for å fjerne slike begrensninger, slik at skalerbar sanntidsbehandling er aktivert.
Lageret for lav latens er et lagringslag NVMe (SSD) i petabyteformat på Lakehouse. Ikke alle data beholdes i lageret med lav latens. Det er en varig buffer. De fleste dataene kommer til slutt til Lakehouse for langsiktig oppbevaring. Øktdata i sanntidslag kan overføres til lageret med lav latens for etterfølgende rask tilgang. I en agentdiskusjon kan for eksempel nylige meldinger behandles i minnet. Eldre meldinger kan overføres til lageret med lav latens. Hvis en tidligere samtale kreves, kan den åpnes innen noen få millisekunder fra lageret med lav latens. NVMe-basert lagring gjør det mulig å lagre og få tilgang til store mengder data med millisekundlatenser. Data kan komme til Lakehouse Cloud Storage for langsiktig varighet. I tillegg hentes data fra Lakehouse som kreves for sanntidsbehandling eller for å utvide sanntidsopplevelser, og beholdes i lageret med lav latens. Kundeprofilkontekst blir for eksempel forhånds hentet eller hentet fra Lakehouse og bufret i lageret med lav latens. Eventuelle lakehouse-objekter og andre objekter som kreves for sanntidsbehandling under øktbehandling, kan også bufres i lageret med lav latens.
Lagring med lav latens for Data 360 aktiverer Real Timer-laget i et sant lagringshierarki med lagringsoverlegg i Lakehouse (SSD) for minne, der data overføres sømløst mellom disse lagene. Vi diskuterer Data 360 Real Time-laget senere i dette dokumentet.
Salesforce Data 360 er utformet for å standardisere, harmonisere og aktivere alle kundedata – strukturerte og ustrukturerte – etter en streng livssyklus som transformerer rådata til en forent, gjeldende datamodell.
Livssyklusen fokuserer på å ta forskjellige eksterne datainndata og strukturere dem til faste, modellerte objekter. Modellerte data kan harmoniseres til Customer 360 forente profiler.
Råinntak av data og første transformasjoner
Prosessen starter med rådata som hentes inn som de er fra kildesystemer (CRM, markedsføring, filer og så videre). Dette inkluderer fullstendige datalastinger og kontinuerlige endringshendelser (deltas), som behandles og slås sammen med faste data for å opprettholde en gjeldende status.
Innbygde transformasjoner (f.eks. trim, normalisere, sammenkjeding) påføres umiddelbart under inntak for å sikre foreløpig datakvalitet og renhet.
Datasjøobjekter (DLO-er): Det faste laget
DLO-er (Data Lake-objekter) danner kjernelaget for fast lagring i Data 360. De lagrer de ryddige, transformerte dataene og fungerer som det organiserte, langsiktige oppbevaringsstedet for all kundeinformasjon.
Avanserte datatransformasjoner (f.eks. sammenføyninger, aggregeringer, beregnede innsikter) brukes på kilde-DLO-er for å produsere nye, høyt kuraterte utledede DLO-er.
Data som gjøres tilgjengelig via Zero Copy Data Federation, representeres direkte som DLO-er.
Ustrukturerte data og metadataorganisasjon
For ustrukturert innhold (som tekst, medier, dokumenter) innlemmer Data 360 dataene ved å trekke ut og beholde sine strukturerte metadata i spesifikke DLO-er kalt ustrukturerte datasjøobjekter (UDLO-er).
Disse spesialiserte DLO-ene fungerer som katalogtabeller som gir et kart over den fysiske plasseringen og konteksten til de ustrukturerte aktivaene. Denne funksjonen gjør det mulig for arkitekter å sømløst relatere metadata fra ustrukturerte data til resten av de strukturerte kundedataene, noe som muliggjør forent spørring og harmonisering.
Datamodellobjekter (DMO-er): Det harmoniserte laget
DMO-er (datamodellobjekter) representerer det endelige, harmoniserte og strukturerte datalaget.
De opprettes ved å tilordne DLO-felt (fra kilde-, utledede og ustrukturerte metadata-DLO-er) til standard Customer 360.
DMO-laget fungerer som den ene sannhetskilden for alle kundedata, og aktiverer forent profiloppretting, segmentering og aktivering på tvers av det bredere økosystemet.
Et dataområde er den grunnleggende logiske beholderen for å organisere alle data og metadata i Data 360, inkludert alle DLO-er (strukturerte og ustrukturerte) og DMO-er. Dataområder tilbyr et sikkert, isolert miljø for databehandling og modellering.
Dataområder fungerer som logiske grenser og styringsgrenser, og aktiverer intern flertilgang ved å skille data for distinkte enheter som forretningsenheter, regioner eller merker – samtidig som de opprettholder virksomhetens synlighet, linje og samsvar, og tjener som grunnlag for å definere grunnet tilgangskontroll.
Isolasjon i dataområder håndheves på flere lag i plattformen:
- Datanivåisolering: Hvert DLO/DMO tilhører ett enkelt dataområde, slik at spørringer, transformasjoner og objekttilordninger ikke kan krysse dataromsgrenser med mindre de er eksplisitt godkjent.
- Tilgangskontrollintegrasjon: Tillatelsessett er innebygd knyttet til dataområder slik at du kan kontrollere lese-, skrive- og administrative operasjoner. Dette sikrer at bare godkjente brukere og tjenester får tilgang til objekter, innsikt og aktiveringer i et datarom.
- Forvaltning og revisjon: Alle operasjoner i et dataområde logges med revisjonsspor på bedriftsnivå, som aktiverer sporbarhet for samsvar, forvaltning og regulatorisk rapportering.
Tilgang og tillatelser behandles via tillatelsessett for å sikre detaljert synlighet, kontrollerte oppdateringer og hindring av datalekkasje på tvers av domener. Ved å integrere dataromsgrenser med Data 360s sikkerhets- og styringsarkitektur kan arkitekter trygt implementere både sentraliserte og desentraliserte styringsstrategier samtidig som de opprettholder konsistens på tvers av flere skyer og forretningsdomener.
Datagrunnlaget i Data 360 gir et forent lag for behandling og utføring av alle arbeidsbelastninger med store data, noe som forenkler den underliggende infrastrukturens kompleksitet. Dens kjernekomponent er databehandlingskontrolleren (DPC).
DPC er en omfattende orkestreringstjeneste for databehandling med flere arbeidsbelastninger som tilbyr Jobb som en tjeneste-funksjonalitet (JaaS) på tvers av ulike skydatabehandlingsmiljøer. Den abstrakterer infrastrukturkompleksitet og forener jobbutførelse for rammeverk som Spark (EMR på EC2 og EMR på EKS) og Kubernetes Resource Controller (KRC)-arbeidsbelastninger. Ved å fungere som en sentralisert kontrollplangateway orkestrerer, tidsplanlegger og overvåker DPC jobber på tvers av flere dataplaner, slik at det sikres pålitelighet, skalerbarhet, kostnadseffektivitet og en ensartet utvikleropplevelse.
Nødvendigheten av DPC stammer fra begrensningene ved direkte samhandling med innebygde klyngebehandlingssystemer som EMR.
Infrastruktur og skyabstraksjon
Selv om EMR tilbyr API-er for klynger, oppgaver og trinn, belastes det fremdeles klientteam med viktige infrastrukturbehandlingsoppgaver som klargjøring, skalering, ytelsesjustering og kostnadsoptimalisering. DPC håndterer dette ved å tilby en forenklet API på plattformnivå for jobbinnsending. Den støtter automatisk feilhåndtering, nye forsøk og dynamisk belastningsbalanse. Gir kostnadseffektivitet via binpacking-, spot- og gravitonbaserte noder. Gir sterk sikkerhet med TLS, PKI, IAM-isolering og automatisert patching. Behandler oppgraderinger av Spark- og EMR-kjøretidsversjoner for å levere ytelsesforbedringer, sikkerhetsoppdateringer og funksjonsforbedringer.
I tillegg gir DPC et forent, skyagnostisk grensesnitt for sending og behandling av databehandlingsjobber, og abstrakterer kompleksiteten og de proprietære API-ene til det underliggende skysubstratet (AWS, fremtidige leverandører). Dette sikrer at klientteam bare samhandler med et vanlig Data 360 API-basert jobbsendingsgrensesnitt som abstrakterer kompleksiteten til underliggende ressursledere som Kubernetes og YARN. Dette gir klienteam mulighet til å sende Spark-jobber via en enkel, forent API uten å måtte behandle pods, nodepuljer eller Spark-klyngekonfigurasjoner direkte.
Manuell justering av Spark-parametere krever spesialiserte kvalifikasjoner, og feil konfigurasjon kan føre til langsom utføring av jobb. DPC-teamet sentraliserer denne ekspertisen og sørger for optimaliserte konfigurasjoner for å hindre vanlige ytelsesproblemer. Dette spesialiserte teamet integrerer kontinuerlig Knowledge fra fellesskapet med åpen kildekode for å sikre optimal ytelse på tvers av alle arbeidsbelastninger som behandles av kontrolleren.
DPC er ikke begrenset til Spark, den støtter et bredt spekter av arbeidsbelastninger. Disse inkluderer følgende:
- Arbeidsbelastninger for behandling i sanntid
- Hendelseslevering for funksjonen Datahandlinger
- Behandling av Milvus (vektordatabasen for ustrukturert dataindeksering)
- Infrastruktur for lagring med lav latens
DPC benytter også rammeverket Kubernetes Resource Controller (KRC), som støtter arbeidsbelastninger som Trino for spørring, Hendelseslevering for datahandlinger, Datauttrekksjobber for koblinger og sanntidsbehandling. For alle KRC-arbeidsbelastninger sørger DPC for sentral Jobb som en tjeneste-funksjonalitet, håndtering av databehandling, distribusjon og administrasjon på en jobbabstraksjon på høyt nivå.
JaaS-fordeler og -arkitektur
Job-as-a-Service-modellen, levert av DPC, sikrer en kostnadseffektiv og fleksibel jobbbehandling under behandling.
Brukere oppgir enkle klyngespesifikasjoner med fokus på nødvendig CPU, minne, lagringsplass, forekomstantall og antall min/maks klynger og koder for klyngesamsvar. DPC behandler deretter automatisk abstrakte infrastrukturdetaljer, inkludert valg av optimale VM-SKU-er, behandling av forekomstflotteder, bestemmelse av forholdet mellom kjerne og forekomst. Oppgavenoder og behandling på forespørsel kontra. Spotforekomster basert på inndata. Den håndterer også EMR- og komponentversjonsbehandling og oppgraderinger uten nedetid.
Viktigst er at DPC i utgangspunktet støtter flertilgang, utformet for å forstå og håndheve Data 360-leietagergrenser og ressursseparasjon. Den sikrer også sikkerhet og samsvar ved å håndheve Salesforce-sertifiserte maskinbilder, behandle tjenestespesifikke IAM-roller og garantere kryptering både underveis og under lagring. For ruting og kapasitetskontroll administreres jobb-til-klynge-samsvar med klyngekoder, og kapasitetsbasert ruting bruker en innstilling for maksimalt antall samtidige jobber for å effektivt kontrollere ressursutnyttelse.
Cloud Agnostic Client Experience er en kjernefordel fordi kompleksiteten til underliggende skymiljøer er skjult for kundetjenester, slik at de kan fokusere bare på forretningslogikk. Dette oppnår målet med Cloud-leverandørabstraksjon. Til slutt aktiverer DPC enkel sporing av bruk og kostnader, slik at klyngebruk og kostnader kan segmenteres etter tjeneste for nøyaktig regnskap. Generelt sett følger DPC en pluggbar arkitektur som tillater at nye utførelsesmotorer (for eksempel Flink, Ray) og skybaserte substrater (GKE/Dataproc) integreres sømløst uten å vise underliggende infrastrukturdetaljer til brukere. Denne utformingen kobler kontrollplanet fra utførelseslaget og sikrer en konsistent API- og driftsopplevelse uavhengig av serverdelen.
Data 360 forbedrer og beriker rådata ved å bygge bro mellom rådata og forretningsforbruk som kan handles. Den supplerer livssyklusen til dataobjektet ved å klargjøre komplekse data for avansert aktivering og analyse. Data 360 støtter ulike behandlingstyper, inkludert batch- og strømmedatatatransformasjoner, batch- og strømmede beregnede innsikter, ustrukturert databehandling og Identitetsløsning. For å aktivere disse ulike operasjonene effektivt, spesielt i nær sanntid og på tvers av massive datasett, kreves det en avansert mekanisme for å håndtere dataendringer effektivt.
For å oppnå effektiv, nær sanntids databehandling – spesielt med tabeller på terabyte og millioner av potensielle oppdateringer – trengte Data 360 et gjennombrudd. Det krevde en måte å varsle systemer nøyaktig når data endres, og deretter effektivt identifisere hvilke data som ble endret, slik at bare relevante oppdateringer behandles og bare når de oppdateres. Denne utfordringen førte til to komplementære innovasjoner: Lagre innebygde endringshendelser (SNCE) for å varsle når noe endres, og Endre datafeed (CDF) for å identifisere hva som er endret.
Innebygde endringshendelser for lagring (SNCE)
SNCE har fundamentalt endret Data 360 til en reaktiv og inkrementell dataplattform. Dette skiftet involverer overgang fra aktiv spørring av datasjøen til passiv overvåking av atomære bekreftelseshendelser ved bruk av et standardisert hendelsesformat og et leveringssystem for meldinger med stor trafikk.
Hver vellykkede skriveoperasjon (INSERT, UPDATE, DELETE) i en Iceberg-tabell fører til et atomisk bytte av tabellens gjeldende metadatafilpeker i katalogen. Det underliggende objektlagringslaget (for eksempel S3) er konfigurert til å sende ut en innebygd varselhendelse (som en S3-hendelse) når et nytt metadataøyeblikksbilde skrives til tabellens mappe.
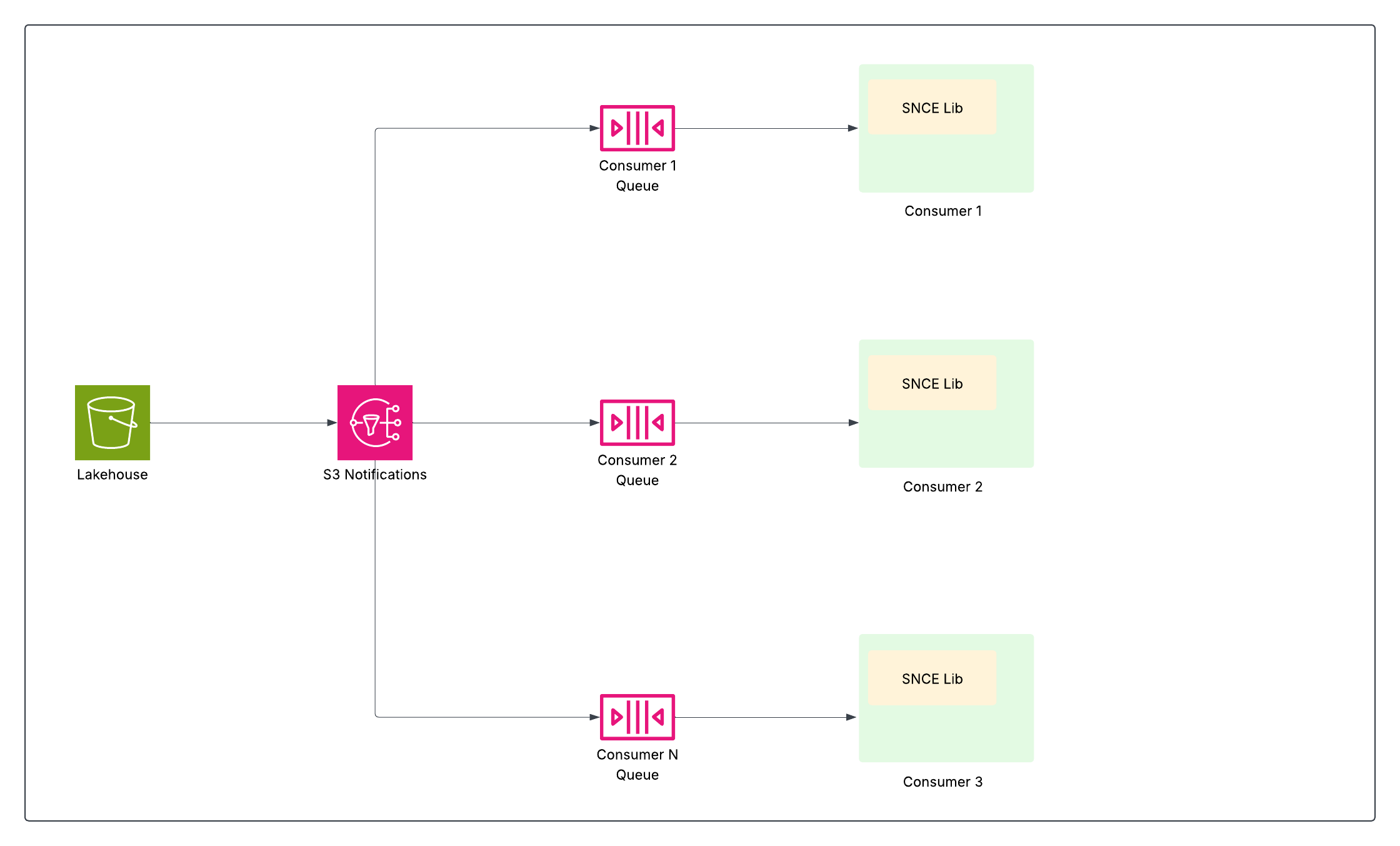
SNCE-biblioteket tilbyr en standardisert metode for forbruk av disse hendelsene, og det kan også berike dem med øyeblikksbildemetadata på forespørsel.
Dette aktiverer nedstrøms data under arbeid, som strømmede beregnede innsikter, identitetsløsning og segmentering, til å abonnere og handle bare når data har blitt endret, noe som betydelig øker effektiviteten ved å unngå kostbare fulltabellskanninger.
Endre datafeed (CDF)
Basert på SNCE gir endringsfeeden (CDF) en strømlinjeformet mekanisme for å forbruke og trinnvis behandle endringene.
CDF bruker Iceberg-øyeblikksbilder til å effektivt generere strømmen av endringer. Viktigere er at Data 360s optimaliserte Iceberg-skriver beregner og beholder endringene som en del av selve skrivingsoperasjonen, noe som gjør CDF-generering svært effektiv og minimerer ekstra overhead. Dette tillater behandlingjobber (som strømmede transformasjoner eller strømmede beregnede innsikter) å selektivt behandle bare de endrede postene, og unngå den dyre øyeblikksbildets forskjellsberegning.
Denne inkrementelle strategien gir flere fordeler for store datasett, inkludert kostnadsbesparelser, redusert latens og forbedret effektivitet. Den aktiverer funksjoner som strømmingstransformasjoner og inkrementell identitetsløsning, som igjen fører til raskere innsikt, mer forutsigbare systembelastninger, forbedret ytelse og lavere driftsutgifter.
Data 360 tilbyr robust inntaksfunksjonalitet med innebygd støtte for Salesforce-produkter for å sikre en sømløs dataflyt. For eksterne kilder gir den omfattende tilkobling via over 270 koblinger, API-er, SDK-er og MuleSoft. I tillegg har Data 360 null-kopifedering som tillater BI og analyse uten dataduplisering.
DCF (Data 360 Connector Framework) er grunnlaget for de fleste Data 360-tilkoblinger. Den aktiverer inntak, forening og utgang gjennom en forent arkitektur. DCF definerer standardene for å bygge og behandle koblinger, fra grensesnittet for oppsett og administrasjon til metadataoppbevaring, datauttrekking og levering til Lakehouse eller via direktespørringer mot eksterne kilder. Den støtter også private tilkoblingsalternativer (som private lenker, VPN-er og sikre tunneler) for å sikre datasikkerhet og samsvar på bedriftsnivå når du kobler til kunde- eller partnermiljøer. Ved å tilby en konsistent tilnærming på tvers av alle koblinger gir DCF Data 360 muligheten til å koble seg sømløst til det bredere økosystemet ved å sikre utvidbarhet, pålitelighet og sikker integrering.
Data 360 gir robust tilkobling til et stort økosystem av datakilder som støtter både innebygde Salesforce-produkter og mange eksterne systemer. Denne omfattende tilkoblingen er avgjørende for å forene isolerte bedriftsdata og aktivere AI/ML og Agentic-programmer.
Data 360 tilbyr over 270 koblinger som standard eller via MuleSoft, API-er og SDK-er for å støtte dens ende-til-ende-data under arbeid med batch-, strømming- eller sanntidsinntak. Disse koblingene kan generelt kategoriseres etter kildesystemtypen de integrerer.
Salesforce innebygde koblinger
Disse koblingene sikrer en sømløs og innebygd dataflyt fra Salesforce-produkter.
Eksempler inkluderer koblinger for Salesforce CRM, Data Cloud One , Marketing Cloud Engagement, Marketing Cloud Account Engagement og B2C Commerce.
Eksterne programmer og SaaS
Koblinger for ulike forretningsprogrammer og skytjenester tillater datainntak fra eksterne programvareplattformer.
Eksempler er Adobe Marketo Engage, Microsoft Dynamics 365, Mailchimp og Airtable.
Databaser og datalagrer
Data 360 kobler til en rekke relasjonsbaserte og skybaserte datalagringsplattformer.
Eksempler inkluderer Amazon Redshift, Amazon DynamoDB, Amazon RDS (MySQL, PostgreSQL, Oracle), Google BigQuery og Microsoft SQL Server.
Skyobjektlagring og filsystemer
Disse koblingene integreres med lagringsløsninger i hyperskala for både strukturerte og ustrukturerte data.
Eksempler er Amazon S3, Google Cloud Storage (GCS) og Azure Blob Storage.
Streaming og meldingstjenester
Koblinger som håndterer kontinuerlige sanntids datastrømmer, er avgjørende for hendelsesdrevne scenarier og sanntidsbehandling.
Et eksempel er Amazon Kinesis-koblingen.
Integrasjonsplattformer
MuleSoft Anypoint-koblingen utvider Data 360s rekkevidde ved å integrere den med et bredere spekter av programmer og databaser via Anypoint Exchange.
Ustrukturerte datalagringskoblinger og skyobjektlagringskoblinger
Disse koblingene er avgjørende for å hente inn og referere til ustrukturerte data (data som mangler en forhåndsdefinert modell) til kraftgenererende AI-egenskaper.
Alle disse koblingene bygger på et Data 360-koblingsrammeverk som gir en ensartet opplevelse.
Datatransformasjon er en grunnleggende arkitektonisk komponent i Data 360, utformet for å rense, berike og forme inntatte rådata til normaliserte, handlingsrettede dataaktiva i samsvar med Customer 360. Denne prosessen er viktig for harmonisering, kvalitetsforbedring og sikring av at data er klare for nedstrøms brukstilfeller som profilforening, segmentering og aktivering. Transformasjoner bruker både kildeobjekter (DLO-er) og datamodellobjekter (DMO-er) som inndata, og produserer resultatet til henholdsvis nye DLO-er eller DMO-er.
Data 360 tilbyr to primære transformasjonsparadigmer for å håndtere forskjellige krav til datahastighet: gruppedatatatransformasjoner og strømmedatatatransformasjoner.
Gruppedata-transformasjoner
Gruppedata-transformasjoner er utformet for behandling med stor trafikk basert på en definert tidsplan eller utløser på forespørsel. Denne motoren er optimalisert for å håndtere komplekse, ressursintensive omstruktureringsoperasjoner.
Batchtransformasjonsprosessen konfigureres med et visuelt pipelinelerret med lite kode som gir brukere mulighet til å definere transformasjonslogikk med flere faser. Denne motoren støtter unikt komplekse omstruktureringsoperasjoner som er avgjørende for kanonisk datamodelljustering: datastrukturering og normalisering. Dette inkluderer å pivotere (sammensette avnormaliserte poster til flere normaliserte poster) og flate ut (strukturere hierarkiske data, som JSON, til strukturerte tabeller). Systemets utføringsmodus støtter både full synkronisering (behandling av alle poster) og en svært effektiv trinnvis behandlingsmodus. Den inkrementelle modusen reduserer behandlingstid og ressursforbruk betydelig ved å behandle bare poster som har blitt endret siden forrige vellykkede kjøring. Gruppetransformasjoner er ideelle for oppgaver der sanntidsoppdateringer ikke er viktige, som periodiske aggregeringer og kompleks dataomstrukturering.
Strømmede data-transformasjoner
Strømmede data transformerer prosessdata kontinuerlig og inkrementelt i nær sanntid etter hvert som de flyter inn i systemet, noe som gjør dem viktig for brukstilfeller med lav latens.
Det primære grensesnittet er en SQL-første tilnærming der transformasjoner er definert som en SQL SELECT-spørring som utføres kontinuerlig mot den innkommende strømmen med postendringer. Denne motoren støtter kjernetransformasjonsfunksjoner, inkludert datarensing og standardisering (for eksempel validering av PII og standardisering av dataformater) og dataforbedring og fletting (ved bruk av sammenføyninger og sammenføyninger). Det er viktig at den støtter Strømmede oppslagsJOIN-er for å aktivere sanntids dataforbedring og oppslag mot statiske eller langsomt endrede referansedata, slik at umiddelbare profiloppdateringer sikres. For å optimalisere kostnad-til-tjening bruker arkitekturen en jobbutforming med høy tetthet (HD), som pakker flere strømmingstransformasjonsdefinisjoner for en enkelt leietaker til en enkelt underliggende databehandlingsjobb for å maksimere ressursutnyttelsen. Strømming av transformasjoner er viktig for brukstilfeller som hendelsesovervåking, umiddelbar tilpassing og sanntids profiloppdateringer.
Data 360 revolusjonerer databehandlingen ved å støtte forbund med null kopier og datadeling, noe som eliminerer behovet for å flytte eller duplisere data. Denne funksjonen gir brukere sømløs og direkte tilgang til data fra ulike eksterne kilder og deler data med eksterne miljøer, noe som reduserer kompleksiteten betydelig, reduserer lagringskostnader og sikrer at alle beslutninger baseres på den nyeste og mest pålitelige informasjonen.
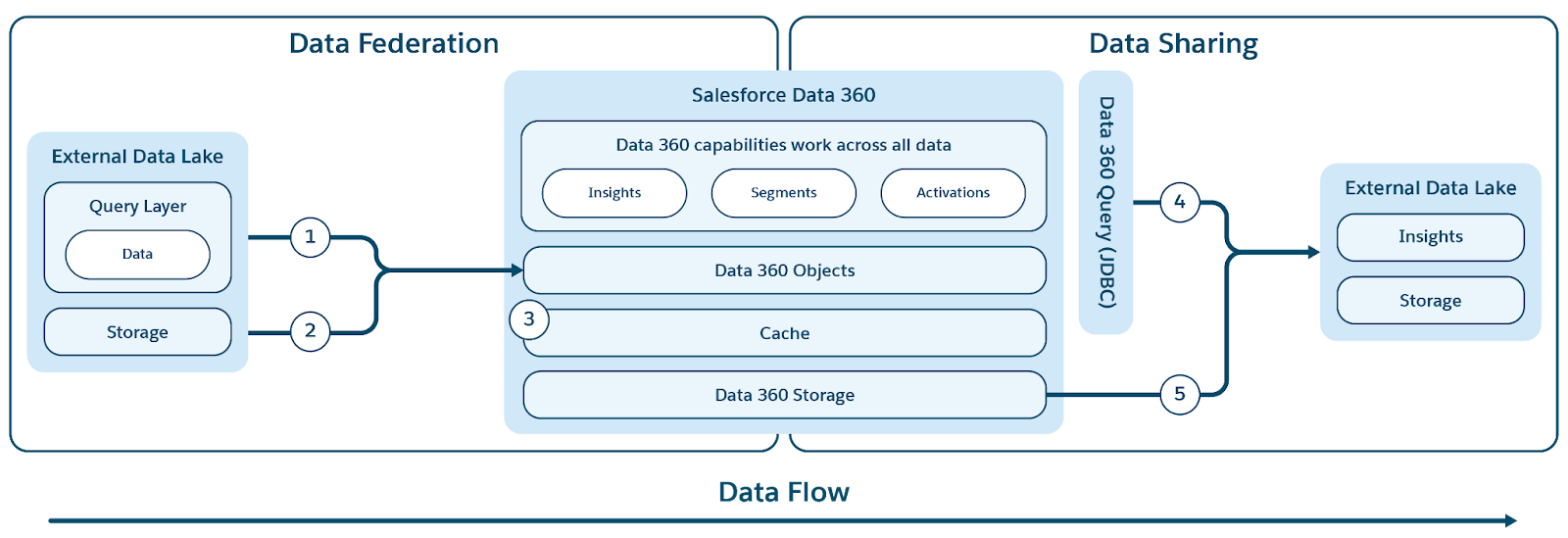
Data 360 støtter null-kopifedering med eksterne datalagrer (Snowflake, Redshift), innsjøbygg (Google BigQuery, Databricks, Azure Fabric), SQL-databaser og mange andre kilder. Dens abstraksjonslag muliggjør direkte spørring av eksterne data uten duplikater, reduserer inntakstiden, lagringskostnader og sikrer oppdatert informasjon.
Data 360 forenkler tilgang til eksterne og forente data ved å tilby et forent metadatalag som abstrakterer både Salesforce-objekter og eksterne objekter. Dette gir hele Salesforce-plattformen og tilhørende programmer mulighet til å bruke disse dataene sømløst.
Data 360 støtter både fil- og spørringsbasert forening, med direkte spørring og tilgangshastighet som vist i figuren.
Etiketter (1) og (2) illustrerer Data 360-spørringen (inkludert push-downs for direktespørringer) og filbasert forening for tilgang til data fra eksterne datasjøer/lagre/datakilder, og etiketten (3) fremhever akselerering av samlet tilgang fra eksterne datasjøer/datakilder.
Spørringsforbund
Kjernen i Data 360s forbundsfunksjon ligger i spørringsforbundslaget, som administrerer den komplekse prosessen med tilgang til eksterne data og utføring av intelligente spørringsnedtrekksverdier (illustrert med etikett 1). Data 360 kobler til og henter data fra kilder ved bruk av JDBC-protokollen, forbedret med ekstra logikk for forbedret effektivitet. Spørringsforbundslaget er ansvarlig for å forstå og oversette forskjellige SQL-dialekter, finne ut den mest optimale delen av spørringen som skal sendes ned til eksterne systemer for effektiv behandling, hente resultatene og utføre eventuell nødvendig ytterligere behandling for å utlede endelig innsikt.
Bufring (forespørselsakselerasjon)
For forbedret verktøy har Data 360 en valgfri akselereringsfunksjon for sine forente funksjoner.
Når Akselerasjon er aktivert, bufrer Data 360 de forente dataene for å oppnå raskere tilgang og lavere kostnader, fordi det unngår gjentatt direkte tilgang til eksterne kilder. Denne bufferen behandles som et akselereringslag og oppdateres trinnvis for å raskt gjenspeile eventuelle endringer i de eksterne kildedataene, slik at den akselererte visningen forblir nær sanntid.
Filforbund
Data 360 støtter filbasert forbundsbehandling (illustrert med etikett 2) for tilgang til data fra eksterne datasjøer og kilder. Det tekniske grunnlaget for denne null-kopieringsfunksjonen er avhengig av standardisering: De underliggende dataene må være i filformatet Apache Parquet og bruke tabellformatet Apache Iceberg. Data 360 kan forenes til hvilken som helst kilde som viser en Iceberg REST Catalog (IRC) for metadata- og lagringstilgang, slik at den sikrer sømløs, administrert tilgang til filer som befinner seg utenfor plattformen.
Med filbasert forening håndterer Data 360-datamaskiner all databehandling fordi de får direkte tilgang til det underliggende lageret. Dette eliminerer behovet for push-down-spørringer og behandling av ulike SQL-dialekter, som ofte kreves med spørringsbasert forbundsbehandling.
I tillegg til dette utvides Zero Copy-funksjonalitet også til ustrukturerte datakilder som lagringsløsninger med høy skala (S3/GCS/Azure-lagring), Slack og Google Drive, som kan åpnes av Data 360s ustrukturerte behandlingslinjer.
Data 360 letter både spørringsbasert og filbasert deling av data som den behandler med eksterne datasjøer og lagre (vist med etiketter 4 og 5 i den opprinnelige figurkonteksten).
Spørringsbasert deling
Når det gjelder spørringsbasert datadeling, viser Data 360 en JDBC-driver som eksterne motorer og programmer kan bruke til å få sikker tilgang til dataene. Denne mekanismen tillater eksterne systemer å koble til, godkjenne og utføre direktespørringer direkte mot dataene i Data 360.
Filbasert deling (Data Share & DaaS)
Den primære mekanismen for filbasert deling involverer to konsepter: datadeling og datadelingsmål, som benytter DaaS (Data as a Service) API.
- Detaljkontroll: Med datadelingskonseptet kan kunder presist definere hvilke objekter (DLO-er, DMO-er, CIO-er og så videre) som deles eksternt, for å hindre utilsiktet dataeksponering.
- Sikker målretting: Den bestemmer også målet for datadeling og sikrer at data bare blir gjort tilgjengelig for eksplisitt godkjente eksterne miljøer, kontoer eller partnerorganisasjoner (for eksempel deling med en bestemt Redshift- eller Databricks-forekomst).
DaaS API gir et sikkert og administrert grensesnitt for eksterne motorer for å forbruke data. Den gir tilgang til både de grunnleggende metadataene og den underliggende tabelllagringen samtidig som alle Data 360-semantikk beholdes. Dette sikrer at eksterne motorer får tilgang til dataene i en konsistent og meningsfylt kontekst på en sikker måte.
Mange sikkerhetsfølsomme kunder, spesielt store bedrifter, regulerte bransjer og organisasjoner i offentlig sektor, begrenser all internettilgang til sine datasjøer som en del av sin sikkerhetstilstand. Selv om denne policyen er avgjørende for overholdelse og risikoreduksjon, hindrer den også at Salesforce Data 360 og Agentforce kobler til disse miljøene via offentlig internett.
De fleste av disse datasjøene distribueres i hyperskaleringsmiljøer som AWS, Azure eller Google Cloud. Fordi Data 360 selv kjører på AWS, krever tilgang til kundedatasjøer som driftes av en annen skyleverandør, en nettverkstilkobling på tvers av skyer. Uten et sikkert, privat tilkoblingsalternativ som omgår det offentlige internett, er kunder ofte ikke i stand til eller ikke villige til å ta i bruk Data 360 eller Agentforce for brukstilfeller som er avhengige av disse datasjøene.
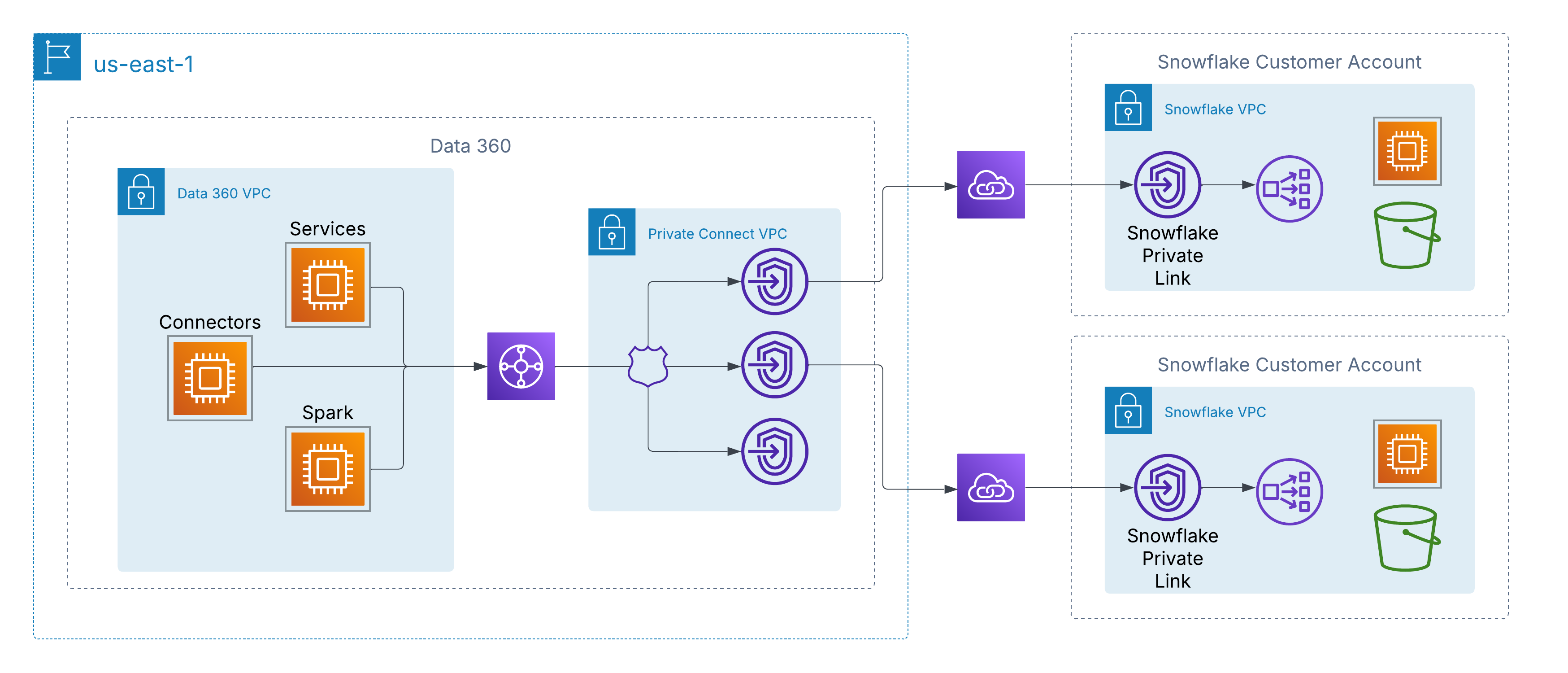
For å løse dette støtter Data 360 privat tilkobling på nettverksnivå til kundestyrte datakilder på tvers av skyer. I AWS aktiveres dette via AWS PrivateLink, som lar Data 360 koble direkte til kundeleverte sluttpunkter, enten i sine egne kontoer eller i tredjeparts datasjømiljøer (for eksempel Snowflake), uten å gå gjennom det offentlige Internett.
Denne arkitekturen sikrer at all trafikk forblir fullstendig på AWS-ryggkjernen ved å bruke privat IP-adresse og ikke-rutbare nettverksbaner, og dermed oppfylle strenge sikkerhets- og samsvarskrav samtidig som du gir sømløs tilgang til kundedata.
For kunder med arkitekturer med flere skyer utvider Data 360 privat tilkobling utover AWS gjennom støtte for sammenkobling på tvers av skyer. Dette aktiverer sikre nettverksbaner som bare er basert på ryggraden, fra Data 360 til datasjøer og tjenester som befinner seg i Azure eller Google Cloud, og beholder de samme prinsippene som AWS PrivateLink – privat IP-adresse, ikke-felles ruting og null Internett-eksponering.
Kunder kan velge mellom to distribusjonsmodeller:
-
Kundeadministrert tilkobling: Integrer eksisterende private kretser som Azure ExpressRoute, Google Cloud Interconnect eller Equinix Fabric direkte med Data 360s VPC-er.
-
Salesforce-administrert tilkobling: Bruk en fullt administrert, nøkkeltilkobling der Salesforce klargjør og driver lenken på tvers av skyer, som viser private endepunkter i målskyen.
I begge modellene er opplevelsen konsistent: Data 360-tjenester kobler til eksterne datakilder på tvers av hyperskaler som om de var lokale, og aktiverer sikker inntak, aktivering og spørring uten å gå gjennom det offentlige Internett.
For bedriftsarkitekter er robust datastyring ikke bare en avmerkingsboks for samsvar, men en grunnleggende søyle for å bygge pålitelig, skalerbar og handlingsorienterbar Kundeintelligens. Salesforce Data 360 er bygd opp med et omfattende styringsrammeverk som sikrer datakvalitet, sikkerhet og overholdelse av lovpålagte bestemmelser i hele livssyklusen for data.
Data 360 fungerer som et sentralisert styringsknutepunkt og sikrer at alle data – fra rå inntak til aktivert innsikt – behandles med integritet og kontroll.
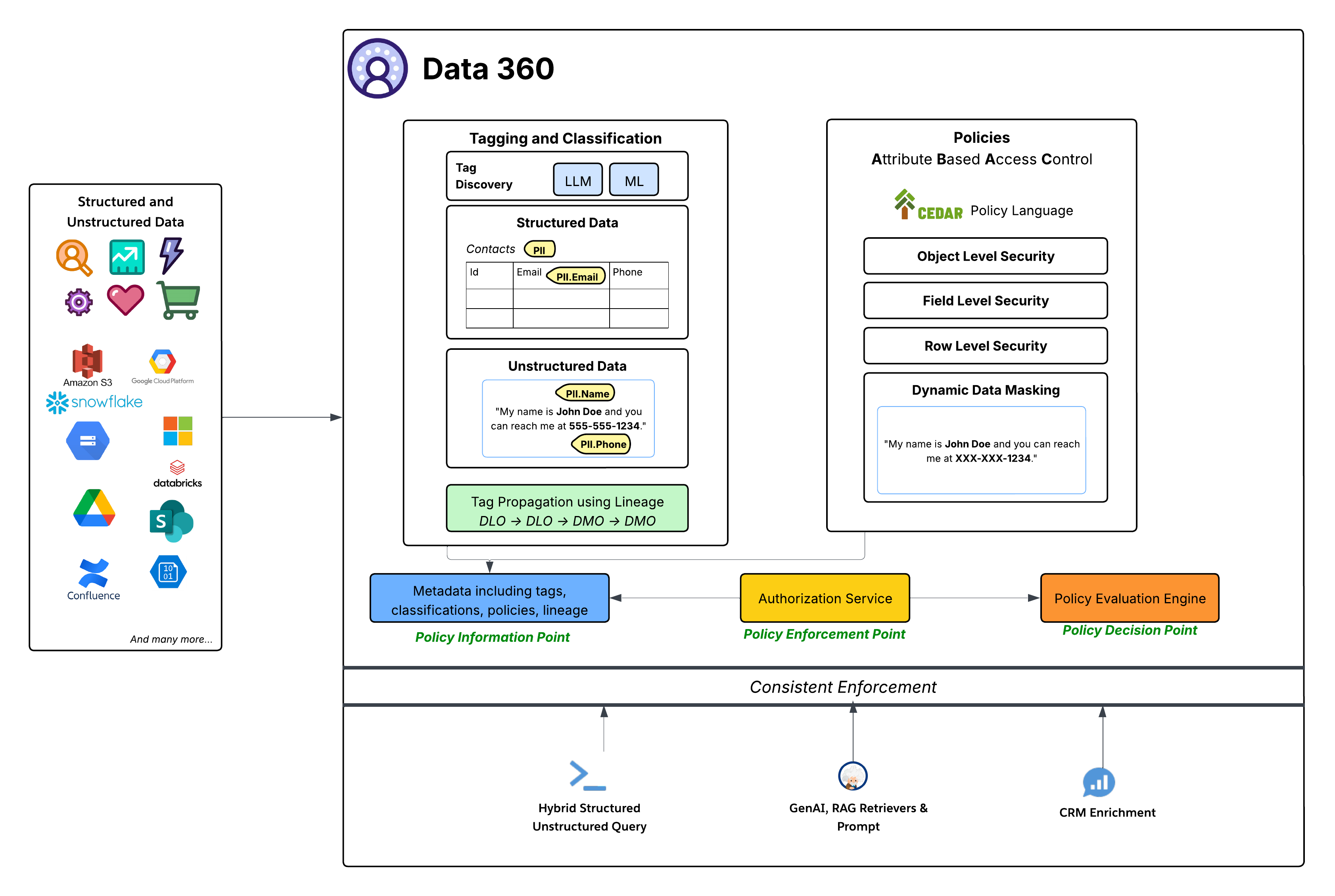
Dataspace gir grovt detaljert tilgangskontroll for å bestemme tilgang til alle objekter i et datområde, mens ABAC-baserte policyer gir detaljert detaljert tilgangskontroll til individuelle objekter, felt og rader i et datområde. Data 360 har tatt i bruk Attributtbasert tilgangskontroll (ABAC) som sin kjerneautorisasjonsmodell for detaljert tilgangskontroll. Dette strategiske valget gir overlegen fleksibilitet og skalerbarhet sammenliknet med tradisjonell rollebasert tilgangskontroll (RBAC), spesielt viktig for dynamiske, komplekse bedriftsmiljøer med store mengder data og varierte tilgangsbehov. Med ABAC kan tilgangsbeslutninger baseres på attributter for brukeren (for eksempel avdeling, rolle, plassering), dataene (for eksempel PII, sensitivitet, datarom) og miljøet (for eksempel klokkeslett), i stedet for bare forhåndsdefinerte roller. Dette aktiverer meget detaljerte og kontekstuelle tilgangspolicyer som tilpasses etter hvert som data og brukerattributter endres.
- CEDAR Policy Language: Kjernen i Data 360s ABAC-implementering er bruken av CEDAR-policyspråket. Dette formålsbygde, formelle policyspråket gir en presis og verifiserbar måte å definere komplekse godkjenningsregler på, slik at policyene er entydige og kan evalueres konsistent i stor skala.
Styringssystemet i Data 360 følger en standard, robust ABAC-arkitektur:
- Koding, klassifisering og policyredigering (Policy Information Point - PIP):
- Data 360 tilbyr automatiserte kodings- og klassifiseringsmekanismer som benytter LLM (Large Language Model) og ML (Machine Learning) til å identifisere sensitive datakategorier (for eksempel PII.Email, PII.Phone, PII.Name) og andre formålsbygde taksonomier (PHI, FinancialData) i både strukturerte data (for eksempel Kontakter-tabell) og ustrukturerte data (for eksempel fra Google Drive).
- Viktigst skjer kodefordeling langs datalinjefølgen (DLO -> DLO -> DMO), og sikrer at klassifiseringer automatisk følger datatransformasjoner og utledninger, fra rå inntatte data til det harmoniserte DMO-laget og gjennom utledede data som opprettes fra prosessdefinisjoner.
- Til slutt gir policyredigeringspanelet en enkel opplevelse for å benytte dataene og brukerattributtene til å definere dynamiske tilgangsregler for en organisasjon.
- Disse beregnede metadataene (inkludert koder, klassifiseringer, policyer og linje) leveres til Policy Information Point (PIP).
- Tillatelsestjenesten (Policy Enforcement Point – PEP):
- Godkjenningstjenesten fungerer som Policy Enforcement Point (PEP). Den fanger opp alle forespørsler om datatilgang fra ulike forbrukslag (Hybrid strukturert/ustrukturert spørring, GenAI RAG Retrievers & Prompt, CRM Enrichment) og konsulterer Policy Decision Point for å finne ut om tilgang er tillatt.
- Policy Evaluation Engine (Policy Decision Point - PDP):
- Denne motoren fungerer som Policy Decision Point (PDP). Det tar tilgangsforespørselskonteksten fra PEP sammen med policydefinisjoner (i CEDAR) og attributter fra PIP for å ta en autorisert tilgangsbeslutning.
- Granular Security Policies: Policyer som er definert i CEDAR, håndhever ulike sikkerhetsnivåer, inkludert:
- Objektnivåsikkerhet: Kontrollere tilgang til hele DLO-er eller DMO-er basert på koder som er knyttet til disse objektene.
- Sikkerhet på feltnivå: Begrense tilgang til bestemte sensitive felt i et objekt basert på koder.
- Sikkerhet på radnivå: Filtrere data på bestemte objekter for å vise bare relevante rader basert på brukerattributter.
- Dynamisk datamaskering: Masker dynamisk bestemte data (basert på koder) på tilgangspunktet uten å endre de underliggende dataene. Dette sikrer at sensitiv informasjon beskyttes samtidig som det fortsatt er brukervennlig. Dette gjelder for maskeringsfelt i strukturerte data i tillegg til innhold i ustrukturerte data.
- Sammenhengende håndheving: Hele ABAC-rammeverket sikrer konsekvent håndheving av policyer på tvers av alle Data 360-forbruksmønstre, enten det er direkte dataspørring, henting for generative AI-programmer (RAG) eller berikende Salesforce CRM-opplevelser via relaterte lister, for eksempel.
- Dyb integrasjon med Salesforce Platform: Data 360s styringsfunksjoner defineres og administreres direkte i Salesforce-kjerneplattformen. Denne integrasjonen gir administratorer mulighet til å behandle tilgangspolicyer, brukeridentiteter og attributtbehandling ved å bruke kjente Salesforce-verktøy, slik at det sikres et forent og konsistent styringslag på tvers av hele Salesforce-økosystemet.
Ved å bygge dette sofistikerte ABAC-rammeverket med CEDAR-policyer gir Data 360 arkitekter et uovertruffen nivå av kontroll og fleksibilitet, og sikrer at kundedata ikke bare kan handles, men også er sikre, samsvarende og pålitelige på tvers av virksomheten.
På tvers av bransjer legger organisasjoner økt vekt på ende-til-ende-datasikkerhet for å sikre beskyttelse mot datalekkasje, uautorisert tilgang, manipulering eller ødeleggelse. De fleste dataplattformer, inkludert Data 360 i dag, tilbyr kryptering under lagring ved bruk av en leverandøradministrert krypteringsnøkkel. Men virksomheter (spesielt i regulerte sektorer) krever i økende grad kundestyrt krypteringsfunksjonalitet for både data under lagring og data under overføring.
Denne modellen gir firmaer mulighet til å kontrollere sine egne krypteringsnøkler, og sikrer at selv i svært usannsynlig tilfelle av brudd på plattformnivå eller uautorisert tilgang, forblir dataene kryptografisk beskyttet. Uten kundens proprietære nøkkel kan ingen enhet (inkludert plattformleverandøren) dekryptere eller rekonstruere dataene, og dermed opprettholde full konfidensialitet og kontroll.
Data 360 støtter lagring og behandling av strukturerte (tabeller), semi-strukturerte (JSON) og ustrukturerte data sømløst på tvers av datainntak, behandling, indeksering og spørringsmekanismer. Data 360 støtter ulike ustrukturerte datatyper utover tekst, inkludert lyd, video og bilder, og utvider omfanget av databehandling og -analyse. Figuren nedenfor illustrerer de to sidene av jording (inntak og henting).
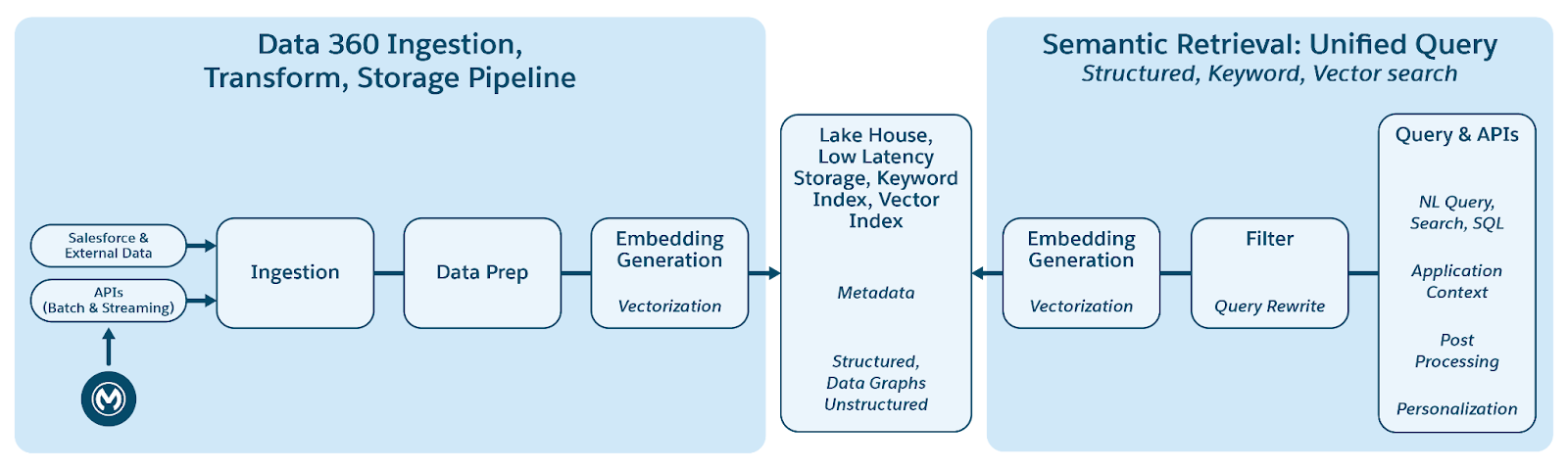
Data 360 behandler ustrukturerte data ved å lagre dem i kolonner som tekst eller i filer for større datasett. Den støtter dataforbund for ustrukturert innhold, som tillater integrering og behandling av data fra flere kilder.
Dataene blir deretter klargjort og fordelt, innebyggingene genereres og behandles for nøkkelordindeksering og vektorindeksering. Data 360 er vert for flere forhåndsdefinerte og pluggbare modeller for fordeling og innbygging av generering. Data 360 støtter automatisk og konfigurerbar avskrift av lyd- og videoinnhold for etterfølgende behandling og indeksering. Søketjeneste brukes til nøkkelordindeksering. For vektorindeksering støtter Data 360 både innebygd indeksering (med Hyper) og benytter også vektordatabaser som åpen kildekode Milvus. Data 360 integreres også med Salesforce Search-plattformen for å støtte nøkkelordindeksering på ustrukturerte data. Slike integrerte indekser for flere modaler i Data 360 gir muligheten til å søke på eventuelle ustrukturerte data, som diskutert i delen Agentisk virksomhetssøk senere i dokumentet.
Data 360 har API-er for søk for henting. Vår hyperbaserte forente spørring letter sammendragsspørringer på tvers av strukturerte, nøkkelordindeks og vektorindekser, og opprettholder streng synlighet og tillatelser, og forbedrer dermed RAG og Søk.
Data 360s ikke-strukturerte dataindeksering under behandling er utformet som en modulær, utvidbar arkitektur som består av fem kjernefaser:
- Analysere
- Forhåndsbehandling
- Bruke
- Etterbehandling
- Innbygging
Alle fasene støtter også LLM-basert behandling som lar kunder komme opp med de tilpassede ledetekstene. Både fasene for forhåndsbehandling og etterbehandling kan inkludere flere sekvensielle trinn, slik at komplekse transformasjoner kan utformes fleksibelt. Hver fase er fullstendig metadatastyrt og muliggjør sømløs konfigurasjon og utvidelse uten kodeendringer.
Eksempler på forhåndsbehandling inkluderer operasjoner som støyfjerning, språknormalisering og bildeforståelse (optisk tegngjenkjenning og teksting), mens etterbehandlingstrinn kan inkludere metadataforbedring, semantisk gruppering eller avanserte teknikker som Raptor-bryting.
Pipelinen støtter fullstendig Data 360 Code Extension, slik at kunder og interne team kan plugge inn tilpasset logikk i hvilken som helst fase. Kodeutvidelseskomponentene er enkle Python-funksjoner der livssyklusen – utførelse, skalering og feilhåndtering – administreres fullstendig av Data 360. Denne tilnærmingen sikrer at innovasjon og domenespesifikk behandling kan introduseres raskt samtidig som driftskonsistens og styring på tvers av plattformen opprettholdes.
Kontekstindeksering
For å konfigurere RAG med ustrukturert behandling er to viktige faktorer viktige:
- Rapid Iteration: Mulighet til å raskt validere med eksempeltestspørringer.
- Personspesifikt innhold: Kapasiteten til å konfigurere innhold skreddersydd til den forbrukende personligheten.
Kontekstindeksering er et brukervennlig verktøy utformet for å løse begge disse aspektene. Dette interaktive brukergrensesnittet leveres av en sanntids under arbeid (RT) som utfører alle fem fasene som er skissert tidligere. Pipelinen bruker GPU-er når det er nødvendig for oppgaver som generering av innebygde og optisk tegngjenkjenning (OCR). I tillegg kan kunder raskt teste RAG pipelinen med en agent før de distribuerer konfigurasjonen for omfattende innholdsbehandling.
Dokument-AI
Data 360 Dokument-AI aktiverer lesing og import av ustrukturerte eller semi-strukturerte data fra dokumenter som fakturaer, resymer, laboratorierapporter og innkjøpsbestillinger. Denne funksjonen støtter interaktiv behandling ad hoc i tillegg til gruppebehandling. Dette er en nøkkelfunksjon som muliggjør automatisering av forretningsprosesser for kundene våre. Dette drives av kunstig intelligens, inkludert LLM-er og ML-modeller.
Virksomheter har store mengder Knowledge spredt over ulike systemer som wikier, fildelinger, innholdsbehandlingssystemer, interne databaser og mer. Denne fragmenteringen gjør det vanskelig for ansatte (spesielt serviceagenter og selgere) og kunder å finne relevant informasjon raskt og effektivt. Viktige problemer er: Mangel på en enkelt, forent søkeopplevelse på tvers av alle Knowledge; inkonsekvent presentasjon og gjengivelse av innhold fra forskjellige kilder; manglende tilgangsstyring av sensitiv informasjon spredt på tvers av systemer; og vanskeligheter med å benytte en autorisert Knowledge i kjernearbeidsflyter (for eksempel vedlegg av relevante artikler i en sak).
Enterprise Knowledge representerer innhold som er kuratert, enten manuelt eller automatisk, fra den bredere gruppen av virksomhetens data. Manuell kurering involverer hensiktsmessige handlinger, som å opprette Salesforce Knowledge eller utvikle Knowledge i eksterne systemer som deretter hentes inn. Vi forestiller oss automatisert kurering som benytter prosesser, som Salesforce-agenter og transformasjoner, som kjører over inntatte data for å generere forbedrede, kuraterte lag, som potensielt kan blande strukturert og ustrukturert innhold. Enten det kurateres manuelt eller automatisk, internt i Salesforce eller eksternt før inntak, blir utfallet verdiforbedret innhold forskjellig fra rådata.
Enterprise Knowledge Hub-løsningen benytter Data 360-funksjonalitet for:
- Inntak og lagring: CRM-kobling henter inn Salesforce Knowledge, og ustrukturerte DCF-koblinger (Data Connector Framework) henter inn rått innhold og metadata fra eksterne kilder. Innholdet hentes inn i kildespesifikke ustrukturerte datasjøobjekter (UDLO-er) som tilordnes innholdet på SFDrive (eller kilde i tilfelle null kopiering).
- Harmonisering og strukturering: Harmonisering Pipeline behandler UDLO og fildata, utfører rensing, normalisering, anrikning (NLP, etc.), PII maskering og transformasjon til det harmoniserte mellomliggende formatet, lagret i SF Drive og en harmonisert UDLO (HUDLO) som tilordnes til den.
- Indeksering: Ustrukturert pipeline (UDS) utløses over det harmoniserte innholdet, og søkeindekser konfigureres for hvert HUDMO.
- Forbruk: Bruk av programmer inkluderer søk, henting, gjengivelse og lenking til forretningsobjekter som Sak. Engasjement ved forbruk av programmer samles inn for å gi bruksanalyse (som klikk, gjennomganger og så videre).
Beregnede innsikter (CI-er) i Data 360 lar kunder definere og generere aggregerte målinger fra dataene sine. Disse målingene brukes deretter til rettidig kundeengasjement, analyse, segmentering og aktivering. De aggregerte dataene som beregnes av CIs, skrives til Lakehouse og representeres som et beregnet innsiktsobjekt (CIO).
Det finnes to hovedtyper beregnet innsikt:
- Batch Beregnede innsikter: Utformet for kompleks dataaggregering med stor trafikk, der målinger kan beregnes regelmessig (for eksempel daglig eller ukentlig).
- Streaming Insights: Gi muligheten til å generere målinger og handlinger fra hendelsesdata i sanntid for å aktivere umiddelbart kundeengasjement med lav latens.
Beregnede innsikter defineres i datamodellobjekter (DMO-er) og kan også defineres i andre beregnede innsiktsobjekter. Tjenesten for beregnet innsikt administrerer orkestreringen av både gruppe- og strømmingsjobber.
Beregninger av både batch- og strømmede innsikter bruker Spark. Nøkkelforskjellen er at strømmede innsikter bruker Spark-strukturert strømming, mens gruppe-CI-er utføres med periodiske, planlagte gruppe-Spark-jobber. For å oppnå kostnadseffektivitet grupperer de beregnede innsiktstjenestene CIs som skal beregnes sammen i den samme gruppe CI-jobben eller strømmede CI-jobben, basert på faktorer som avhengigheter og overlappinger av kildedataobjekter.
SNCE og CDF spiller en betydelig rolle i beregning av strømmede innsikter.
Identitetsløsning er ansvarlig for å transformere forskjellige data fra flere kilder til en enkelt, omfattende forent profil.
Det er viktig å forstå at en forent profil ikke er en "gylden post", og at identitetsløsning ikke velger vunnede verdier eller overstyrer eksisterende data når profiler forenes. Forente profiler fungerer som et sett nøkler som låser opp kildedataene ved å identifisere alle samsvarende poster som er relatert til samme enhet, i én datakilde eller på tvers av mange kilder. Med denne informasjonen kan du velge de riktige kildesystemdataene som skal brukes i et gitt forretningsbruksområde.
Identitetsløsning kan konsolidere en rekke posttyper, inkludert Individuelle, Kontoer og Husholdninger. Den kan også brukes til å samsvare salgsemner med eksisterende kontoer. Foreningsprosessen er viktig for å oppnå en fullstendig Customer 360 og få tilpasset engasjement i sanntid på tvers av både B2C- og B2B-scenarier.
Identitetsløsning under behandling bygger på et meget skalerbart, skybasert rammeverk utformet for å håndtere store mengder data kontinuerlig. Prosessen består av tre viktige trinn, basert på en kraftig søkeindeks for å administrere matchingsprosessen:
- Samsvar (Kandidatutvalg): Målet med samsvarsprosessen er å søke etter poster som kan tilhøre samme enhet. Poster analyseres mot et tilpassbart sett regler, som hver inneholder et sett kriterier som definerer hvilke data som skal samsvare med hvilket nivå av strenghet. For å hente potensielle samsvar effektivt fra datalageret genererer systemet indekser for å finne sannsynlig samsvarende poster ved bruk av to teknikker:
- Blokkere nøkler: En blokkeringsnøkkel er en verdi som genereres fra en posts data og samsvarsregler (som de første bokstavene i et navn, normalisert telefonnummer og så videre) for å gruppere potensielt lignende poster sammen. Hver post har flere blokkeringsnøkler som indekseres og lagres som en omvendt indeks, slik at systemet bare utfører detaljerte sammenligninger på små grupper av poster, i stedet for på tvers av hele datasettet.
- Locality Sensitive Hashing (LSH): For samsvarsregler med tilnærmet samsvar genereres hash-koder basert på innbygginger fra opplærte modeller.
- Dyp samsvar: Når kandidatvalgstrinnet har opprettet mindre grupper av potensielle samsvar, starter systemet en mer detaljert sammenligning. I denne fasen analyserer AI-modeller og avanserte algoritmer hvert par av poster for å beregne en sannsynlighetssamsvarscore. Denne scoren kvantifiserer sannsynligheten for at to poster refererer til samme enhet, ved å intelligent sammenligne felt som ofte inneholder feil stavemåte, variasjoner eller formateringsforskjeller.
- Klynger og forening: Når samsvarende poster identifiseres fra kandidatene, grupperes de i en klynge. Denne prosessen inkluderer kritisk å løse midlertidige samsvar. Hvis for eksempel Post A samsvarer med Post B og Post B samsvarer med Post C, kobles alle tre til samme klynge selv om A og C aldri ble sammenlignet direkte. Disse fullstendige klyngene danner den grunnleggende strukturen til den forente profilen. Denne klyngeprocessen sikrer, at alle relaterede kilderegistreringer er korrekt linket under en enkelt, fast identifikator.
- Forlik: Dataverdier fra alle klyngede kildeposter evalueres ved å bruke definerte avstemmingsregler (for eksempel Mest frekvente, Nyeste eller Kildeprioritet) for å fylle ut den resulterende forente profilen med et utdrag av profildata. Avstemming overskriver ikke noen eksisterende data fordi alle kildedata er tilgjengelig med nøklene som er knyttet til den forente profilen.
Arkitekturen støtter løsningen av flere enhetstyper for å innfri en rekke bruksområder.
- Individual Matching: Fokuserer på å opprette Forente persondata-profiler, som kobler alle kjente personlige identifikatorer (e-postadresser, telefonnumre, lojalitets-IDer, informasjonskapsler) til én enkelt person.
- Kontosamsvar: Fokuserer på å opprette Forente konto-profiler, som kobler sammen data om kontoer. Når det brukes samsvar på firmanavn, bruker motoren en finjustert modell ved tilnærmet samsvar.
- Husholdningssamsvar: Utvider samsvarslogikken til å aggregere Forente persondata-poster i grupper av relaterte persondata.
- Samsvar på tvers av enheter: I tillegg til forening oppretter identitetsløsning også lenker mellom profilobjekter ved å bruke de samme samsvarsreglene. Et salgsemne kan for eksempel være knyttet til en konto ved bruk av tilnærmet samsvar i Kontonavn.
For å sikre at den forente profilen alltid er oppdatert, fungerer identitetsløsningsmotoren med en nesten sanntidsarkitektur. Denne skyoptimaliserte arkitekturen er utformet for kontinuerlig behandling for å oppnå raske behandlingstider. Behandlingshastigheten varierer avhengig av hvordan kildedata mottas, men små batcher med endringer kan behandles med identitetsløsning så ofte som hvert 15. minutt.
Systemet vedlikeholder identitetslenkeobjekter som tilordner hver kildepost-ID til sin tilhørende Forente profil-ID. Med denne grunnleggende datastrukturen kan motoren effektivt spore relasjoner og raskt overføre endringer og oppdateringer til den forente profilen, slik at kundeopplevelser, som nettstedstilpassing, neste beste handlingsanbefalinger og segmentering, alltid bruker de nyeste tilgjengelige kundedataene.
Segmentering er kjerneprosessen for å transformere forente kundeprofiler til målgrupper som kan handles. Denne funksjonaliteten er avgjørende for å kunne levere tilpassede opplevelser på tvers av markedsførings-, handels- og servicekanaler. Salesforce Data 360-segmenteringsplattformen er utformet for operasjoner i stor skala. Den behandler komplekse metadata og arbeider med en datamodell som består av tusenvis av objekter og relasjoner. Plattformen støtter komplekse regler, aggregeringsbaserte filtre og vindusbasert rangering, alt samtidig som den sikrer rask og pålitelig beregning i petabyte-skala.
Data 360 støtter ulike segmenttyper for å oppfylle distinkte forretningskrav for hastighet, kompleksitet og hierarki:
- Standardsegment: Den primære, gruppebehandlede segmenttypen. Den publiseres etter en tilpassbar tidsplan, med en standard publiseringskadens på minst 12 timer opptil 24 timer, eller en raskere hurtig publiseringskadens på 1 til 4 timer, som er optimalisert for nylige engasjementsdata.
- Sanntidssegment: Dette segmentet fullfører på forespørsel i millisekunder for umiddelbar handling basert på nylige hendelser og profildata. Den er sterkt optimalisert for umiddelbar tilpassing, men kan ikke bruke ekskluderingskriterier eller nestede segmenter.
- Fosssegment: En hierarkisk struktur av delsegmenter som brukes til å prioritere en kunde til et enkelt, mest verdifullt segment hvis de kvalifiserer for flere kriterier.
- Nestet segment: Dette tillater gjenbruk av et eksisterende segment som filter for et nytt, mer spesifikt segment (en forbedring av et basissegment) som arver tidsplanen for det overordnede segmentet.
Segmenteringsmotoren opererer på en robust, skybasert arkitektur som sikrer hastighet, skalering og fleksibilitet.
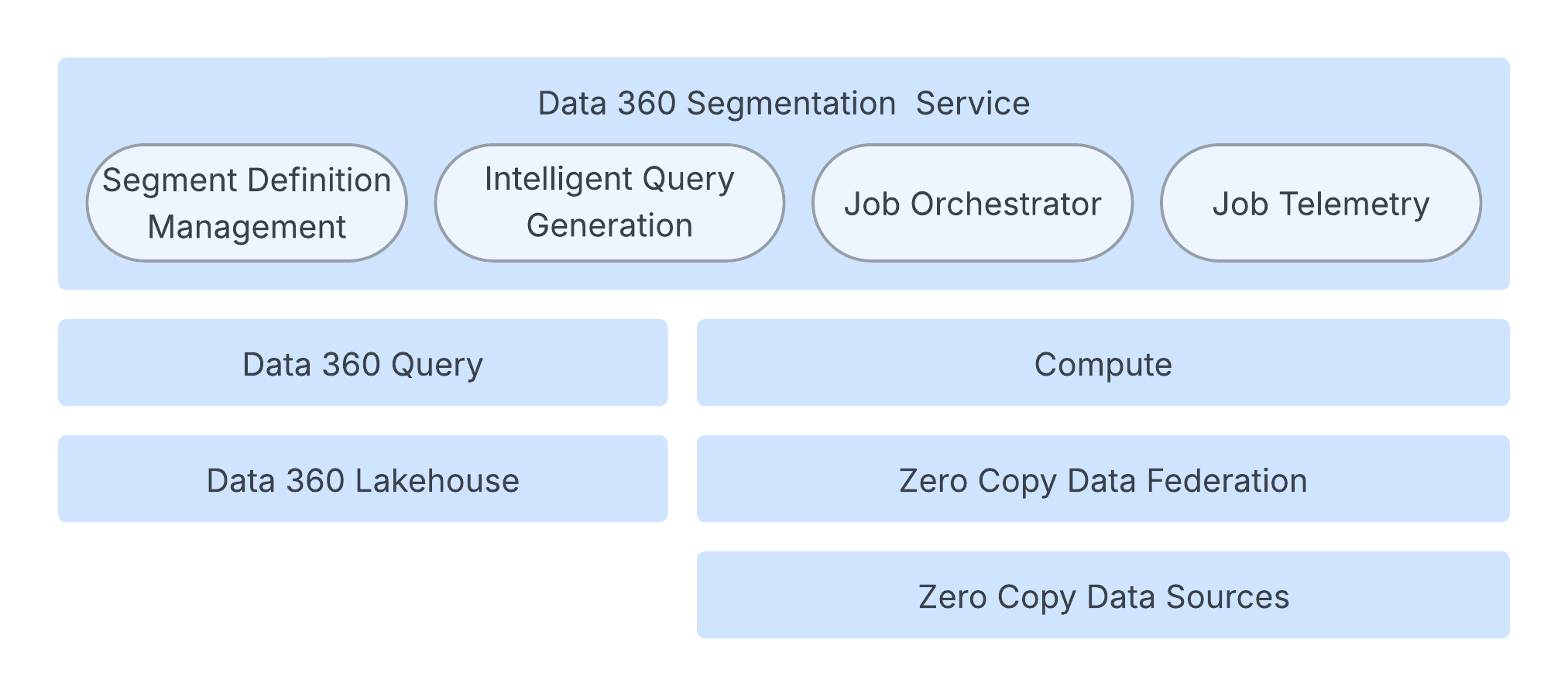
Kjerneprosessen administreres av en jobborkestreringstjeneste som styrer segmentets livssyklus, genererer den nødvendige jobbkonfigurasjonen og utløser utførelsen. Dette orkestreringslaget beholder status og metadata i en fragmentert database for å gi skalerbarhet.
Selv om Data 360-spørring håndterer beregninger av segmenteringsantall, er Spark-datalaget ansvarlig for å beregne faktiske segmentmedlemskap. Spark-programmet utfører Spark SQL-spørringer på omfattende kundedata. Disse dataene kan befinner seg i Data 360 Lakehouse, eksterne systemer via datakonfederasjonen Zero Copy eller en kombinasjon av begge.
Systemet er sterkt optimalisert gjennom generering av intelligente spørringer, som forbedrer den underliggende Spark SQL-spørringen. Dette inkluderer teknikker som intelligent partisjonssnitt for å minimere dataskanning og eliminering av overflødige underuttrykk. For å sikre tjenestenes pålitelighet har arkitekturen tilpasset ressursbehandling som dynamisk justerer databehandlingsressurser basert på belastningsstørrelse og kompleksitet. I tillegg behandles SLO-overholdelse proaktivt med adaptive varigheter og logikk for å prøve på nytt. For å få en rask brukeropplevelse bruker akselererte segmentantall en samplingsbasert tilnærming til å gi raske beregninger av størrelsen under segmentoppretting, og unngå en full spørringskjøring.
Til slutt opprettholdes et dypt fokus på observabilitet og rotårsakstilskriving gjennom omfattende Spark-utførelsesmålinger og automatisk klassifisering av feil (for eksempel problemer på kundesiden kontra systemproblemer), noe som reduserer diagnosetiden betydelig og sikrer en svært fleksibel dataplattform.
Aktivering er det kritiske siste trinnet i Data 360-livssyklusen. Dens kjernefunksjon er å transformere statiske, segmenterte, forente kundeprofiler til handlingsbaserte og berikede data og levere disse dataene til interne og eksterne endepunkter (som Marketing Cloud-, Commerce Cloud- og Adtech-plattformer). Denne prosessen er utformet for å utløse tilpassede kundereiser og interaksjoner i nær sanntid. Den støtter avanserte funksjoner som relaterte attributter, filtrering av aktiveringsmedlemskap, samtykkefiltrering, begrensning og rangering.
Aktivering tilbyr tre distinkte metoder for ekstern levering og kanalsamsvar:
- Batchaktivering: Utformet for planlagte operasjoner med stor trafikk, som e-postkampanjer i stor skala og oppdateringer av annonsemålgrupper. Data leveres ved å sette dem opp i sikre interne samlekategorier (skyobjektlager) eller via sikker filoverføring, etterfulgt av en API-inntaksprosess som startes av målsystemet. Gruppeaktiveringer kan bruke spesiell oppdateringsmodus - inkrementell - til å redusere volumet som sendes til og behandles av Salesforce-partnere.
- Streaming-aktivering: Optimalisert for brukstilfeller i nær sanntid som krever hendelsesdrevet automatisering. Levering oppnås via direkte API-kall sendt til målendepunktet.
- Aktiveringsutløste flyter: Denne meget plattformbaserte kanalen tilbyr en tilgang uten kode/lavkode for å integrere målgruppedata med hundrevis av kunde-API-aktiverte engasjementsplattformer. Når aktiveringen er fullført, fyller Data 360 ut et Målgruppe-DMO, som deretter utløser en flyt i høy skala. Flytmotoren forbruker deretter målgruppedataene og benytter plattformfunksjonalitet som Eksterne tjenester og Mule Outbound-mål for å ringe til det endelige API-baserte målet. Denne metoden reduserer betydelig tiden det tar å sette i gang nye aktiveringsmål.
Aktivering bruker de samme mønstrene som segmentering for jobbbehandling, distribuert utførelse og overvåking. Dette inkluderer prinsippene for jobborkestreringstjenesten for livssyklusbehandling og datalaget (Spark) for behandling, og baserer seg på jobbtelemetri for observasjon av ytelse og overholdelse av tjenestenivåmål (SLO).
I tillegg til disse har aktiveringen -
Aktiveringsmålbehandling overvåker sikre tilkoblinger, legitimasjon og konfigurasjoner for alle målendepunkter. Den sikrer at dataformater og sikkerhetsprotokoller er standardisert og sikrer pålitelig utgående levering til ulike plattformer, inkludert Marketing Cloud, Adtech-partnere og andre eksterne programmer.
Aktivering skreddersyr belastningen for bestemte mål. For Salesforce Marketing Cloud inkluderer dette oppmerksom filtrering for forretningsenheter (BU), støtte for flere EID-er og kontroll av krysspolning.
Kommunikasjonsstyring fungerer som en portvakt, og sikrer at databruk og kommunikasjon er i samsvar med kundepreferanser og juridiske krav. Sentralisert samtykkemodell forener alle kundepreferanser, fra globale reservasjoner til kanalspesifikt samtykke og formålsspesifikt samtykke, og lagres i Forente persondata-profilen. Under utførelse håndhever plattformen nøye disse policyene ved å bruke ekskluderingsfiltrering til automatisk å fjerne ikke-samtykkepersoner fra den endelige lastingen. I tillegg bruker systemet regler for valg av kontaktpunkt for å sikre at det bruker det ene, mest samsvarende og foretrukne kontaktpunktet for den tiltenkte kanalen før data overføres. Denne håndhevingsmekanismen sikres av det underliggende styringsrammeverket, som bruker beskyttelsesforanstaltninger som dynamisk datamaskering og tilgangskontroller for å sikre sensitive datafelt i løpet av aktiveringsprosessen.
Den sanne verdien av en forent dataplattform ligger i dens evne til å gi problemfri, konsistent tilgang til alle dens dataaktiva, uavhengig av opphav eller struktur. Salesforce Data 360s forente spørringsfunksjonalitet er nøyaktig utformet for å levere dette, og abstrakterer den underliggende kompleksiteten til ulike datalager for å gi et enkelt, kraftig spørringsgrensesnitt.
Unified Query-laget tilbyr avansert tilgang for ulike forbruksmønstre:
- Hybrid strukturert og ustrukturert spørring: Den gir omfattende SQL-støtte for å spørre sømløst både strukturerte data og de strukturerte metadataene for ustrukturerte data. Dette forbedres av operatorutvidbarhet via tabellfunksjoner som aktiverer spesialisert søk på tvers av tekst-, bilde- og romtyper.
- Akselerert ytelse med Hyper: Ved å benytte Hyper, en motor med høy ytelse i minnet, akselererer Data 360 komplekse analytiske spørringer og interaktive kontrollpaneler og gir nesten umiddelbare svar over massive datasett.
- Unified Approach for AI & Personalisering: Denne forente tilgangen er avgjørende for å generere målrettede og tilpassede resultater og direkte forenkle mer presise LLM-svar ved å bruke Retrieval Augmented Generation (RAG) ved å grunnlegge AI-modeller i rike, bedriftsdata.
- Integrasjon med nedstrøms forbruk: Den fungerer som det grunnleggende datatilgangslaget for brukergrensesnittdrevne opplevelser, robuste API-er, generative AI-arbeidsflyter og CRM-forbedring, og kobler data sømløst til aktivering.
Ved å tilby et enkelt, intelligent og meget effektivt spørringsgrensesnitt gir Data 360s forente spørring arkitekter mulighet til å bygge smidige, datadrevne programmer som fullt ut utnytter hele spekteret av kundeinformasjon.
Data 360 er en aktiv plattform som støtter aktivering av pipelines som svar på datahendelser. En betydelig hendelse, for eksempel en fall i en kundes kontosaldo, kan for eksempel utløse en Salesforce-flyt for å orkestrere en tilhørende handling. På samme måte kan oppdateringer av viktige målinger, som levetidsforbruk, overføres automatisk til relevante programmer.
Datahandlinger overvåker kontinuerlig trinnvise data for endringer ved bruk av lagringens innebygde endringshendelser (SNCE) og endringsdatatilførsel (CDF). Disse dataene evalueres mot kundekonfigurerte handlingsregler, som terskelovervåking eller statusendringer. Når disse reglene oppfylles, genereres det en datahandlingshendelse. Denne hendelsen blir beriket med tilleggsinformasjon (for eksempel kundelojalitetsstatus) og umiddelbart sendt til sin konfigurerte destinasjon, som Salesforce-flyt eller et eksternt program, for å utløse forretningsorkestreringer.
Data 360 støtter innebygde CDP-funksjoner (kundedataplattform) inkludert avanserte identitetsløsningsfunksjoner og oppretting av forente enkeltpersonidentifikatorer og profiler sammen med omfattende engasjementshistorikk. Denne plattformen er dyktig til å håndtere både forretning-til-forretning- (B2B) og forretning-til-kunde-rammeverk (B2C) ved å støtte identitetsløsning og identitetsgrafer som bruker både eksakte og usikre samsvarsregler, som beskrevet ovenfor. Disse identitetsgrafene er beriket med engasjementsdata fra ulike kanaler, noe som bidrar til å bygge detaljerte profilgrafer med verdifull analytisk innsikt og segmenter.
Et nøkkelbegrep som støtter kundeprofilen, er datadiagrammet. Data 360 tilbyr et enterprise-datagraf i JSON-format, som er et unormalisert objekt utledet fra ulike Lakehouse-tabeller og deres sammenhenger. Dette inkluderer en Profil-datadiagram opprettet av CDP som omfatter en persons kjøps- og nettleserhistorikk, sakshistorikk, produktbruk og annen beregnet innsikt, og som kan utvides av kunder og partnere. Disse Datagrafer er skreddersydde for bestemte programmer og forbedrer nøyaktigheten av generativ AI-melding ved å gi relevant kunde- eller brukerkontekst. Sanntidslaget i Data 360 bruker Profil-grafen til sanntids tilpassing og segmentering. Vi forestiller oss å modellere Agentforce Context som omfatter samtaler, økter og agentisk minne som Datagrafer.
I tillegg muliggjør CDP effektiv segmentering og aktivering på tvers av ulike plattformer som Salesforces Marketing Cloud, Facebook og Google. Den behandler kundeprofiler i batcher, i nær sanntid og i sanntid, noe som gir umiddelbar beslutningstaking og tilpassing. Denne funksjonaliteten forbedrer interaksjoner i både B2C- og B2B-scenarier, slik at virksomheter kan svare raskt og nøyaktig på kundebehov og -virkemåte.
Datagrunnlaget i sanntid støttes av Data 360 CDP og utvider konseptene for sanntidsbrukstilfeller. Data 360s sanntidslag er utformet for å behandle hendelser som nett- og mobilklikkstrømmer, besøk, handlevogndata og utsendelser med millisekundlatenser, noe som gir bedre tilpassing av kundeopplevelsen. Den overvåker kontinuerlig kundeengasjement og oppdaterer kundeprofilen fra Customer 360 med engasjementsdata, segmenter og beregninger i sanntid for umiddelbar tilpassing.
Når en forbruker for eksempel kjøper en artikkel på et kjøpsnettsted, oppdager og henter sanntidslag raskt denne hendelsen, identifiserer forbrukeren og beriker profilen med oppdatert informasjon om levetidsforbruk. Det gjør det mulig å tilpasse brukeropplevelsen på nettstedet i undersekunder. I tillegg inkluderer dette laget funksjoner for sanntidsutløsning og svar, som aktiverer umiddelbare handlinger basert på kundeinteraksjoner.
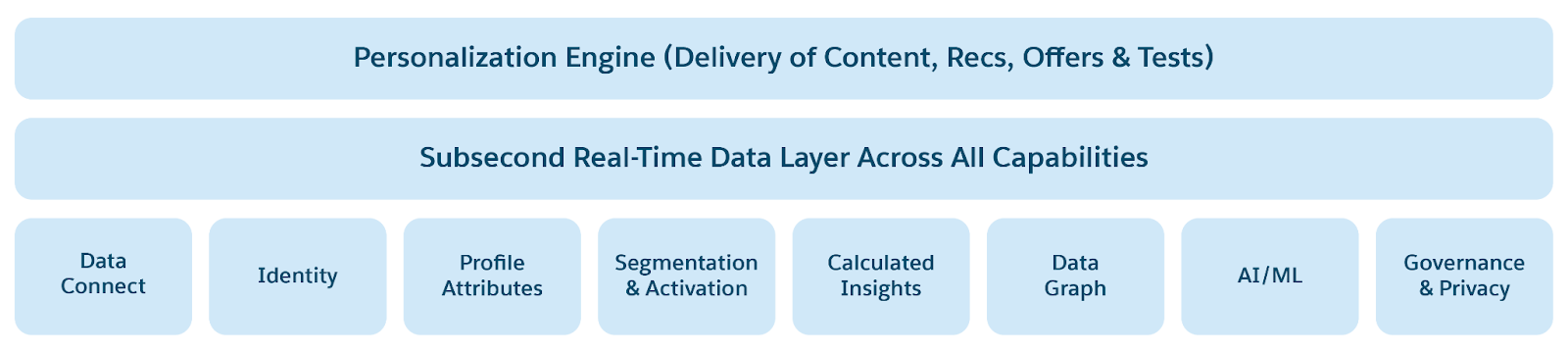
Sub-Second Real-Time-plattformen leverer denne transformasjonen via flere viktige funksjoner:
- Sanntids Datagrafer: En Customer 360 bygges med en avnormalisert graf som inkluderer viktige objekter og felt som er mest relevante for merker. Disse Datagrafer aktiverer sanntids databehandling og leverer innhold og innsikt som kan handles i løpet av millisekunder
- Sanntids inntak og transformasjon: Hent inn brukerhendelser og profiler på millisekunder fra nett- og mobilkilder.
- Sanntids identitetsløsning: Flett kundeprofiler på tvers av enheter og forene ukjente og kjente brukere umiddelbart.
- Sanntids beregnede innsikter: Beregn målinger som levetidsverdi (LTV) eller brukerbesøkshistorikk i millisekunder for å aktivere Tilpassing eller Tilbud for Web, Chatbot eller tjenesteagent.
- Sanntidssegmentering: Segmenter målgrupper direkte, og tilpass meldinger og interaksjoner i sanntid.
- Sanntidshandlinger: Gi merkeprofileringer mulighet til å evaluere hvert brukerengasjement og iverksette tiltak via Salesforce-flyt eller andre relevante kommunikasjonskanaler.
I Data 360 har vi bygd en ny sanntidsplattform med pågående arbeid i sanntid, lagring med lav latens og et undersekunders databehandlingslag. Fordi interaktive data hentes inn raskt fra nett- og mobilkanaler, går de gjennom en rekke raske prosesser.
Våre Web & Mobile SDK-er og sanntids-API-er samler inn data fra nett/mobilprogrammer (i fremtidige Agentic-interaksjoner) og sender dem til vår beacon-server. Disse dataene rutes deretter til Sanntids-laget for millisekundbehandling og Lakehouse-laget for integrasjon med gruppedata/strømming. Sanntids-laget behandler innkommende sanntidsdata i sammenheng med en brukerprofil (anonym eller pålogget), som å oppdatere total brukerforbruk eller levetidsverdi, etc. for økt, sanntidstilpassing. Sanntidslaget støttes av hovedminne og SSD-lagring (NVme) for lagring av sanntidsdata og kundeprofiler. Når dataene er i Sanntids-laget, går de gjennom følgende prosesser før de oppdateres til Sanntids datagraf:
- Enkle inntak og transformasjoner: Dataene hentes inn og transformeres for ytterligere behandling.
- Identitetsløsning: Eksakte samsvarsregler brukes til å forene profiler med alle eksisterende samsvarsregelsett, så dataoppmerksomme spesialister trenger ikke å opprette nye identitetsløsningsregelsett spesielt for sanntid.
- Beregnede innsikter: Hvert engasjement evalueres, enkle beregninger som sum og antall i millisekunder kjøres, og data oppdateres i sanntids datagrafen.
- Sanntidssegmenter: Alle engasjementsdata evalueres for å finne ut om de oppfyller kriteriene for definerte sanntidssegmenter, og brukere legges til i kvalifiserende segmenter i millisekunder.
- Sanntidshandlinger og utløsere: Hvert engasjement evalueres mot definerte regler for å utløse handlinger til en rekke mål i sanntid når regler oppfylles i millisekunder.
- Sanntids datagraf og API: Sanntids datadiagram, som også inkluderer et sanntids-API, lar merker hente oppdaterte JSON-formatdata for hver bruker, slik at alle kundeinteraksjoner blir informert av de nyeste dataene.
Tilpassing handler om å vite hvem som skal målrettes mot, når og hvor relevant innhold og anbefalinger skal leveres, hva som skal sies og hvor ofte. Personaliseringstjenesteplattformen er orkestrator for hvilke beslutninger som tas for å optimalisere måloppnåelse gjennom tilpassede opplevelser.
Personlig tilpassingstjenester tilbyr følgende funksjoner:
- Konsistent sett med modeller og måter å tolke profil-, aktivitets- og aktivumdata på i Data 360
- Plattformintegrert eksperimentering (A/B/n, Multi-Arm Bandit)
- Integrering av mål på utformingstidspunktet (konfigurasjon), opplæringstid for ML og kjøretid (ML-utledning)
- Støtte for B2C-skala i sanntid og gruppeinteraksjon (anonyme brukere, høy trafikk i sanntid/interaktiv ekstern, høy intern batch)
- Analytics drevet gjennom Data 360
- Mønstre for å integrere AI-modell og -tjeneste fra andre parter (interne og eksterne)
- Integrering i kjernesystemet med metadata (PLATE-egenskaper)
- OOTB-implementasjoner av AI-drevne brukstilfeller med høy verdi (anbefalinger/beslutninger med ulike ML-algoritmer, inkludert kontekstuelle banditter for promotering/innholdsvalg, produktanbefalinger, prisbeslutninger osv.)
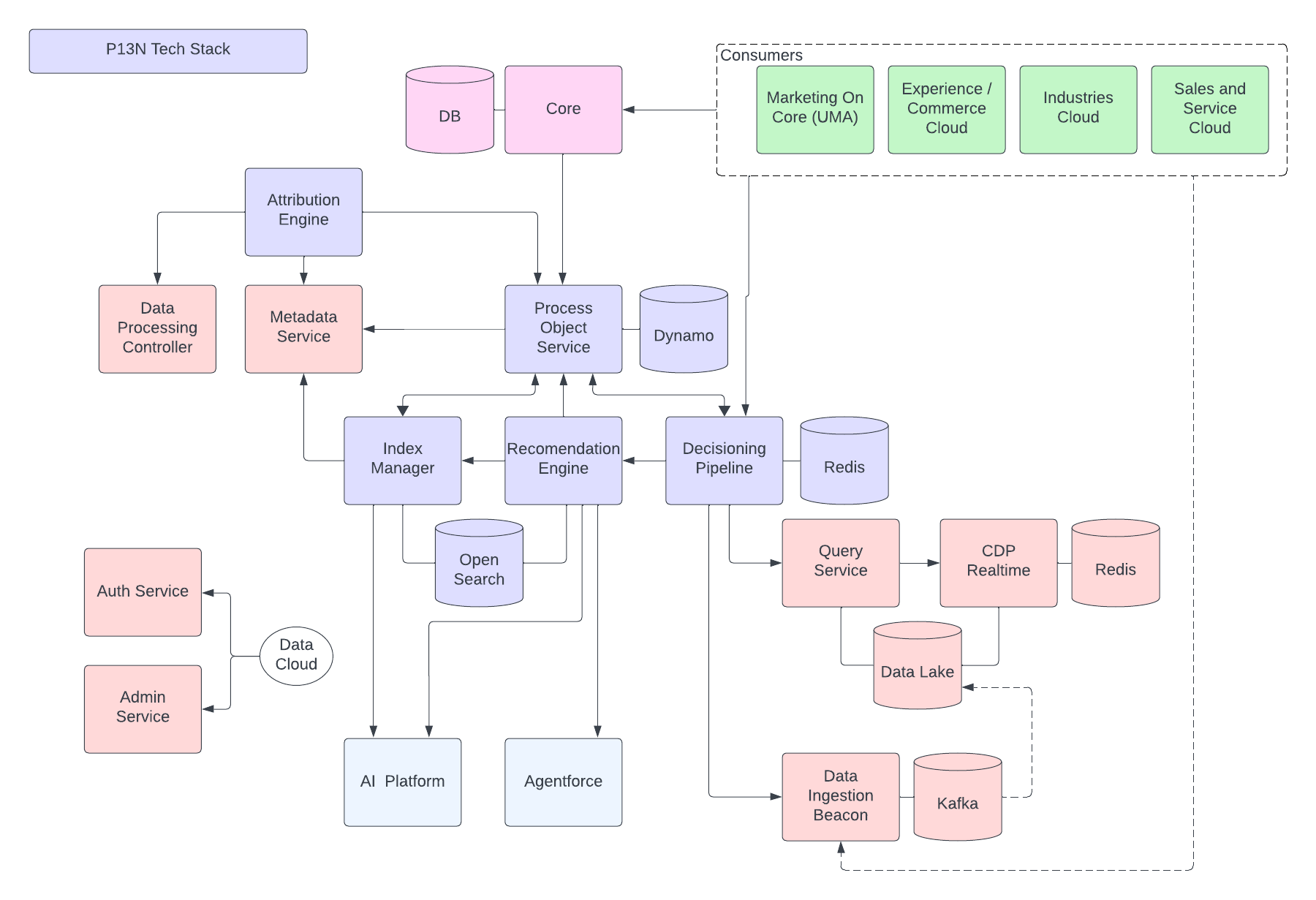
- Decisioning Pipeline
- Betjening av eksterne forespørsler om tilpassingsbeslutninger, inkludert profilforbedring, eksperimentering og anbefalinger.
- Anbefalingsmotor
- Kjøretidsbetjening av regel- eller ML-baserte anbefalinger.
- Index Manager
- Behandler/orkestrer arbeidsflyt for asynkrone prosesser, inkludert ML-opplæring for anbefalingsmodeller
- Process Object Service
- Ansvarlig for å synkronisere tilpassingsmetadata mellom kjernen og utenfor kjernen
- Attribusjonsmotor og eksperimentering
- Analytics-attribusjon og -eksperimentering av tilpassingsanbefalinger
Data 360 er utformet som en robust og rik plattform spesielt for å støtte de nye agentopplevelsene. Vi oppnår disse mulighetene ved å bygge på ulike eksisterende Data 360-tjenester og gjennom dyp integrasjon med Agentforce.
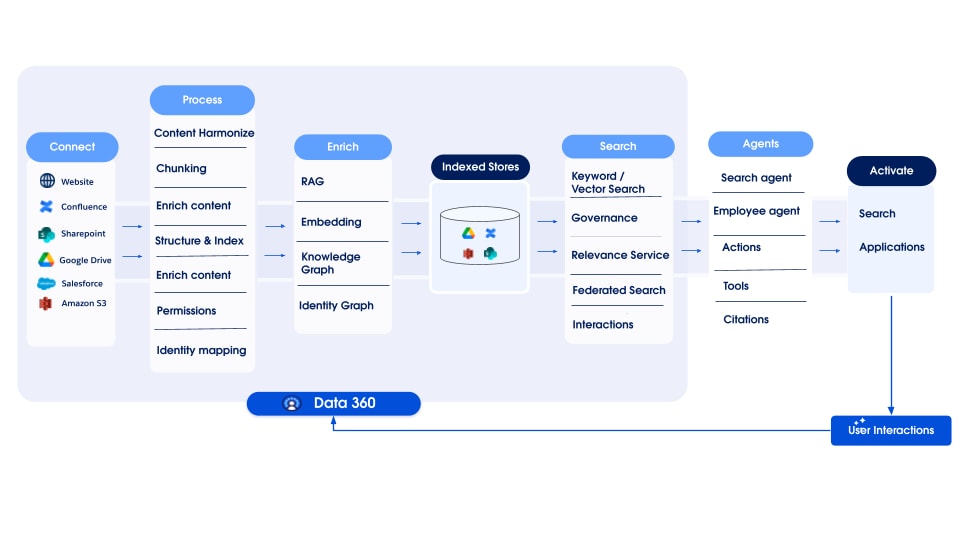
Vår tilnærming til Agentic Enterprise Search er basert på følgende prinsipper:
- Virksomhetens data oppbevares i isolerte tjenester eller butikker, med sikre tillatelser som kreves for tilgang. Muligheten til å få tilgang til disse dataene og behandle dem samtidig som kildetillatelsene opprettholdes, er avgjørende for å sikre Trust.
- Kryssrangering og relevans på tvers av hele datagrunnlaget gir bedre resultater, noe som igjen kan gi bedre kontekst for agentiske opplevelser.
For å levere disse opplevelsene bygger Agentic Enterprise Search på disse viktige arkitektoniske komponentene:
- Koblinger: Det brede settet med koblinger som er tilgjengelig i Data 360, gir tilgang til og henter inn data fra en rekke kilder.
- Ustrukturert databehandling: Dette er grunnleggende for håndtering av ikke-tabellinnhold, slik at systemet kan utlede mening og kontekst fra forskjellige data.
- Styring: Sikre sikkerhet, samsvar og tilgangskontroller på bedriftsnivå for alle data som forbrukes av søk. Støtte for tillatelser for kildesynlighet sikrer at dataene bare er tilgjengelig for autoriserte brukere, for både enkle søk og agentiske opplevelser. For å sikre rask henting evalueres sikkerhetstillatelser og håndheves som standard av søkebackendene i den tidligste fasen av datatilgang.
- Forent hentelag: For å løse utfordringen med isolerte data føyer koblingene til et omfattende Unified Retrieval-lag. Dette laget gir ett enkelt tilgangspunkt til alle data, enten det forblir i eksterne systemer som åpnes via samlet søk, eller det behandles innebygd via avanserte indekser for nullkopiering og innhentede data.
- Forstå intelligente spørringer: Før henting bruker systemet AI-drevne mekanismer til å tolke brukerhensikt. I tillegg til å bygge inn representasjoner av spørringen for semantisk vektorsamsvar, kan den skrive om og utvide nøkkelordsbaserte søk for å forbedre nøyaktigheten.
- Hybrid søk og avansert spørring: For å finne den mest relevante informasjonen bruker plattformen flere strategier parallelt. Hybridsøk gir nøyaktig nøkkelordsamsvar med semantisk vektorsøk på optimaliserte biter med data, mens Full post-søk henter hele dokumenter samtidig. Begge kombineres for å sikre både semantisk relevans og full innholdsdekning.
- hierarkisk rangering: Når data hentes, gir en hierarkisk rangeringsarkitektur med flere faser score, flettes og rangerer resultatene fra hver kilde og metode på nytt. Denne prosessen oppretter en enkelt, forent liste som viser den mest relevante informasjonen for brukeren eller agenten.
Generativ AI flytter den primære forbrukeren av virksomhetssøk fra brukere til store språkmodeller (LLM-er). Data 360-søk er utviklet fra grunnen av for å betjene begge deler. Den er optimalisert for å håndtere lengre og mer komplekse spørringer fra agenter og returnere de rike, kontekstuelle resultatene som er nødvendige for programmatisk forbruk og årsakssykluser. Samtidig kan systemet håndtere de kortere, ofte tvetydige spørringene som er typiske for brukere, og gi funksjoner som snutter og fremheving for rask vurdering i et grensesnitt.
Den ultimate leveringen av agenteresøkeopplevelser kombinerer begge løsningene:
- Direkte søkeresultater: Programmet kan vise en tradisjonell liste med rangerte resultater ved å bruke en metadatadrevet API bygd på grunnlaget for Data 360 forent søk.
- Agentiske samtalesvar: Agentiske svar implementeres gjennom innebygd integrasjon med Agentforce. Denne samtaleopplevelsen drives av en primæragent som orkestrer handlinger og spørringer og delegerer alle oppgaver for henting av informasjon til en spesialisert, intern søkeagent.
Denne spesialiserte søkeagenten er optimalisert for henting av virksomhetsinformasjon. Den bruker en resonanssløyfe til å formulere og utføre parallelle søk for å utforske ulike fasetter av en brukers forespørsel. Den bruker et kraftig sett verktøy, inkludert Data 360-forent søk for alle datatyper og strukturerte spørringsspråk, til å hente presise data fra tabeller og enheter.
Gjennom denne arkitektoniske syntesen gir Data 360 muligheten til å opprette svært intelligente, kontekstbevisste og handlingsorienterte organisasjonssøkeopplevelser.
Utvidbarhet er en nøkkelfunksjon i Salesforce Platform. Code Extension gir utvidbarhet i Data 360, slik at pro-kodebrukere kan kjøre tilpasset Python-logikk direkte i Data 360-miljøet, som et supplement til dets rike deklarative og lavkodede funksjonalitet. Ved å bruke kodeutvidelse kan brukere trygt utvide Data 360-kjernefunksjonalitet som Transformasjoner og ustrukturerte data under arbeid (tilpasset fordeling).
Utformingen vår for kodeutvidelser prioriterer fleksibilitet, sikkerhet, effektivitet og en strømlinjeformet utvikleropplevelse. Den støtter to primære utførelsesmodeller, hver skreddersydd for spesifikke arkitektoniske behov:
- Skripttype:
- Formål: For omfattende tilpasset logikk som krever direkte interaksjon med Data 360 Lakehouse.
- Funksjonalitet: Kunder skriver fullstendige Python-skript med Code Extension SDK, som gir lese- og skrivetilgang til Lakehouse via SDK API-er. Ideelt for tilpasset/komplekse dataklargjøring eller tilpasset datamanipulering.
- Isolasjon og sikkerhet: Mens skript har tilgang til Lakehouse, er utførelsen deres begrenset til et sikkert, isolert miljø innenfor Data 360-kjøretiden for å hindre interferens med andre prosesser eller uautorisert systemtilgang.
- Funksjonsmodell:
- Formål: Analogt med en serverløs funksjon for modulære, statusløse beregninger kalt opp fra eksisterende Data 360 pipelines (for eksempel tilpasset fordeling i en ustrukturert pipeline).
- Funksjonalitet: Kundeleverte funksjoner tar inndata, beregner og returnerer utdata.
- Isolasjon og sikkerhet: Disse funksjonene er utformet for streng isolasjon. De har ikke direkte tilgang til Lakehouse. Utførelsen er Sandbox, statløs og ressursbegrenset, noe som gjør dem egnet for fokuserte, statusløse behandlingstrinn, som sikrer sikkerhet, forutsigbar utførelse og minimerer blastradiusen.
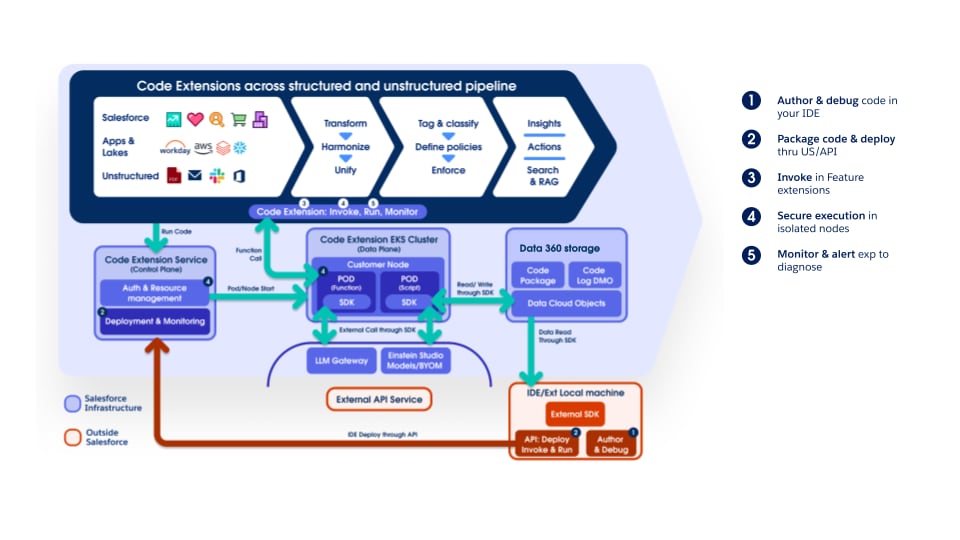
Både Skript- og Funksjon-modellene har som mål å utføre kundekode sikkert og hindre at en leietagerkode påvirker andre eller får uautorisert tilgang til andre leietageres data, Salesforce-ressurser eller eksterne ressurser. Denne sikkerheten oppnås via en lagdelt (defense-in-depth)-arkitektur. Denne arkitekturen sørger for et isolert utførelsesmiljø for hver leietageres tilpassede kode, som inkluderer ulike vakthaller. Disse inkluderer logisk isolasjon på Kubernetes-nivå (K8s), nettverksisolasjon, kjøretids-Sandbox-organisasjoner og tillatelser med færrest rettigheter, som alle suppleres av operativ overvåking og hendelsessvarberedskap for deteksjon og svar.
For å støtte en robust livssyklus for utvikling tilbyr Code Extension følgende:
- Ekstern redigering og feilsøking: Utviklere kan lage og feilsøke Python-kode i kjente miljøer som VSCode, og benytte SDK.
- Fleksibel distribusjon: Tilpasset kode kan pakkes og distribueres med SDK-verktøy, Data 360-grensesnittet eller API, som aktiverer integrasjon i CI/CD.
Driftslogger: Tilgang til detaljerte utførelseslogger gir gjennomsiktighet og bidrar til feilsøking i produksjonsorganisasjonen.
Ved å tilby disse sikre og fleksible kodeutvidelsesfunksjonene gir Data 360 arkitekter muligheten til å skreddersy plattformen til sine mest unike og komplekse databehandlingsbehov, noe som virkelig styrker plattformen sin rolle som en utvidbar datastruktur for virksomheten.
Etter hvert som virksomheter øker hastigheten på å ta i bruk AI, opprettholder de fleste heterogene ML-økosystemer – inkludert Amazon SageMaker, Google Vertex AI og tilpassede Python-baserte miljøer – som er vert for modeller som driver oppgavekritiske forutsigelser, som kredittrisikoscore, tilbøyelighet til avvik, produktanbefalinger og neste beste handlingsbeslutninger.
Tradisjonelt krevde integrering av disse eksterne modellene i Salesforce tilpassede API-lag, ETL pipelines eller mellomproduktororkestrering, innføring av dataduplisering, overhead for styring, latens og operasjonell kompleksitet – utfordringer som står i konflikt med en forent, samsvarende og sanntids CDP-visjon.
Ta med din egen modell (BYOM): Levert via Einstein Studio i Data 360, løser du disse utfordringene ved å aktivere direkte kall til eksternt opplærte modeller i Salesforce-arbeidsflyter, Apex og automatiseringsverktøy – uten å flytte eller replikere data. Data 360 fungerer som den styrte ene sannhetskilden ved å vise harmoniserte Customer 360 for utledninger ved eksterne endepunkter. Forutsigelsesutdata flyter tilbake i sanntid og leverer forretningsprosesser med skalerbar intelligens.
BYOM lukker effektivt gapet mellom datavitenskap og operasjonell utførelse ved å koble fra modellutvikling, styrte data og forbruksoverlegg. Den beholder plattformuavhengigheten, reduserer integrasjonskompleksiteten, akselererer AI-distribusjon og opprettholder styring av sensitive data.
Arkitekturen fungerer som følger: Data 360 gir en forent Customer 360, mens Einstein Studio orkestrerer tilkoblinger til eksterne ML-plattformer (SageMaker, Vertex AI eller tilpassede endepunkter). Eksterne modeller utfører utledning i sanntids-, gruppe- eller strømmemodus. Salesforce-lag – Flyt-, Apex og Spørrings-API-er – bruker utdata til å levere tilpasset, automatisert og analytisk innsikt på tvers av Sales, Service, Marketing og Industry Cloud.
Fra et forretningsperspektiv leverer BYOM:
- Dataintegritet og styring: Eliminerer ukontrollerte datakopier og håndhever policyoverholdelse.
- AI demokratisering: Gjør komplekse modeller tilgjengelig for ikke-tekniske brukere via Salesforce-verktøy.
- Tids-til-verdi-akselerasjon: Eksterne modeller aktiveres umiddelbart i Salesforce-prosesser.
- Skalerbarhet og støtte for hybridarkitektur: Aktiverer distribusjon med flere skyer av AI-arbeidsbelastninger.
- Fremtidsklar AI-arkitektur: Støtter strategier for komponerbar AI, kobling av data, modell og forbrukslag for å gi operasjonell fleksibilitet.
Ta din egen LLM (BYO-LLM): Gir den samme utvidelsesmekanismen, men for generative modeller. Ved å aktivere direkte oppkall av eksterne LLM-er lar vi kunder bruke dem i Agentforce Platform i stedet for Salesforce-leverte modeller. For bedrifter BYO-LLM gjør følgende:
- Tilgang til finjusterte modeller
- Integrering av modeller som for øyeblikket ikke leveres av Salesforce
- Bruk av modeller i kundeleverte kontoer
Moderne virksomheter opererer innenfor et komplekst datalandskap som kjennetegnes av to hovedarkitektoniske utfordringer:
- Intra-Enterprise Fragmentation: Store organisasjoner benytter ofte flere Salesforce-organisasjoner (ofte segmentert etter område, forretningsenhet eller historisk anskaffelse) og mange andre datasystemer. Denne fragmenteringen oppretter interne datasilomer, noe som gjør det umulig å etablere en enkelt, klarert og forent visning av kunden for engasjement i sanntid på tvers av virksomheten. Utfordringen er å forene disse dataene uten å fysisk konsolidere eller duplisere dem på tvers av alle systemer, slik at styringen forblir intakt.
- Samarbeid på tvers av virksomheter: Firmaer må ofte dele data med partnere og leverandører for å få felles markedsføring, måling og forretningsinformasjon. Utfordringen er å aktivere dette samarbeidet samtidig som du beskytter sensitive, proprietære data og overholder personvernforskrifter som GDPR og CCPA, i tillegg til konkurransehindringer.
Salesforce Data 360 løser disse utfordringene med et rammeverk basert på Trust by Design som bygger på prinsippet om å dele tilgang og innsikt i stedet for å flytte eller duplisere data.
Salesforce Data 360 tar hånd om datadistribusjon og samarbeidsutfordringer med Data Cloud One, Datadeling mellom Data 360-er og Personvernførende dataklargjøring. Disse løsningene forener kundedata, aktiverer sikker datautveksling og gir personvernbevarende innsikt. Med en null-kopi, Trust kan organisasjoner låse opp datapotensial for engasjement i sanntid, forbedrede partnerskap og intelligent beslutningstaking. Hvert av disse datasamarbeidsalternativene har forskjellige formål.
Interne Enterprise-aktivering med Data Cloud One
Data Cloud One er den grunnleggende arkitektoniske løsningen for virksomheter som driver flere Salesforce-organisasjoner. Dens formål går ut over enkel datadeling. Den er utformet for å etablere en enkelt, klarert kundevisning og aktivere full Data 360-plattformfunksjonalitet på tvers av hele organisasjonen.
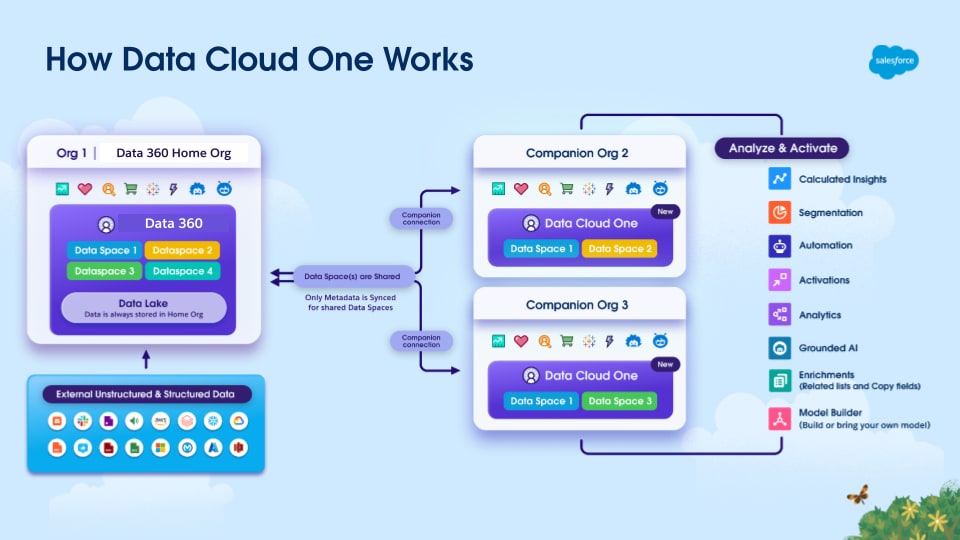
Denne mekanismen sentrerer seg på en utpekt Home Org Data 360-forekomst, som fungerer som sentral myndighet for databehandling og bygging av den forente kundeprofilen. Hjem-organisasjonen er organisasjonen som Data 360 klargjøres i. En Data Cloud One-tilkobling etableres mellom Data 360 og andre Salesforce-organisasjoner, kalt Fellesorganisasjoner. Som en del av Data Cloud One-tilkoblingen deler Data 360 ett eller flere av sine dataområder med hver tilhørende organisasjon og gir tilgang til både data og metadata i hvert delt dataområde. Dette oppnås via en forbundsmodell med null kopier og metadatasynkronisering på tvers av organisasjoner.
Data Cloud One gir også medfølende organisasjoner mulighet til å benytte Hjem-organisasjonens Data 360-forekomst til sine egne aktiverings-, tilpassings- og intelligensbehov. Denne strategien er viktig for å eliminere fragmentering av interne data og sikre at alle forretningsenheter aktiveres mot den samme, styrte og forente kundeprofilen, og dermed maksimere avkastningen på investeringer (ROI) for kjernedata 360-implementeringen.
Datadeling mellom Data 360-organisasjoner
For distribuerte interne miljøer (der full sentralisering ikke er mulig) og for samarbeid med klarerte eksterne partnere kobler Data 360-til-Data 360-datadeling til uavhengige Data 360-forekomster.
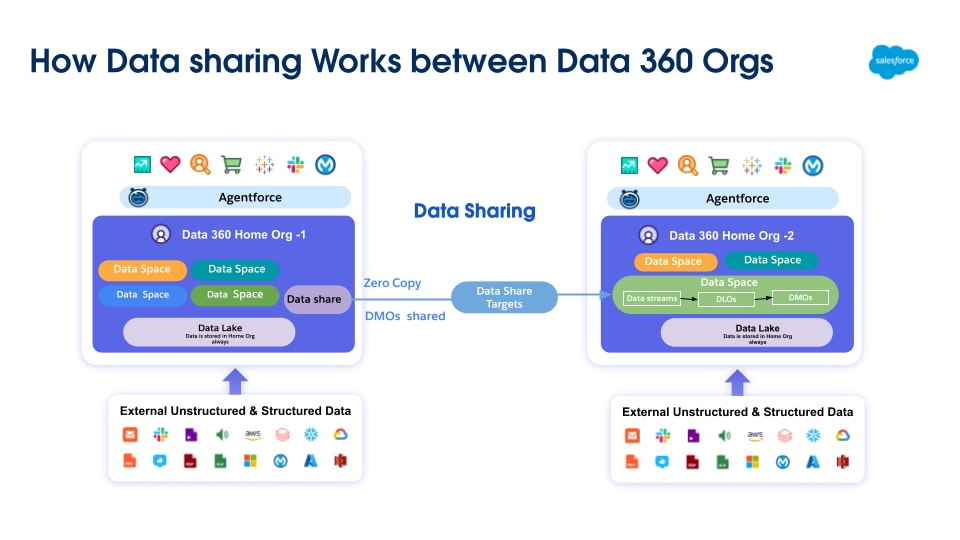
Denne null-kopieringsdelingsmodellen etablerer en tilkobling mellom separate Data 360-leietagere klargjort i forskjellige Salesforce-organisasjoner med det formål å sikre utveksling av dataobjekter (DLO-er, DMO-er og CIO-er). Når den er koblet til, blir hele dataobjektet tilgjengelig i den mottatte Data 360-en. Den mottatte Data 360-administratoren kan deretter angi styringsregler for å behandle brukertilgang til disse dataene.
Personvern først-samarbeid med Data 360 Clean Room-samarbeid
Når samarbeid krever de høyeste nivåene av personvern og samsvar, eller når konkurranseproblemer hindrer deling av rådata, er Data 360 Clean Rooms arkitektonisk pålagt.
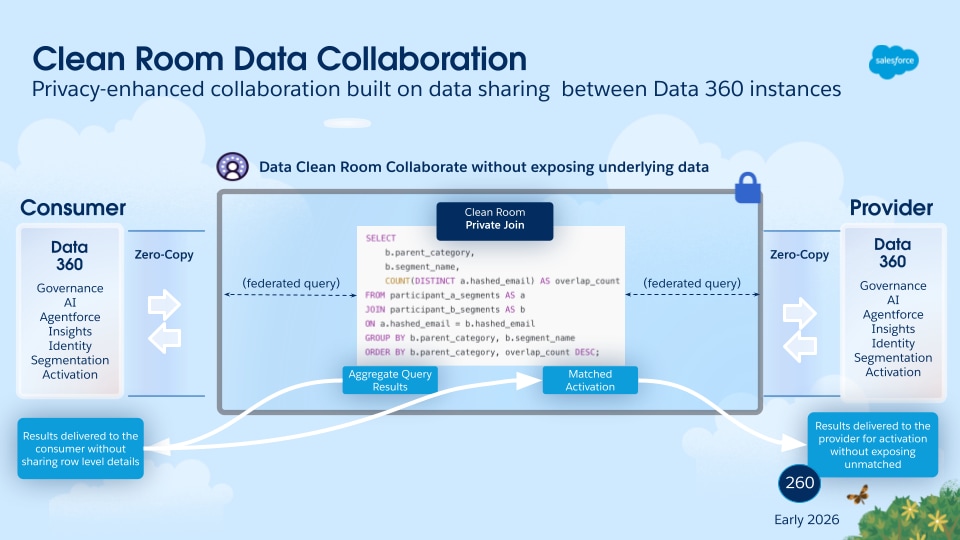
Arkitektonisk er Data 360 Clean Room-samarbeid bygd på toppen av rammeverket for deling med null kopiering som brukes av datadeling med Data 360-til-Data 360, men med flere lag av styring og beregningsrestriksjoner brukt. Data 360 Clean Room tilbyr et sikkert, kontrollert databehandlingsmiljø der parter kan delta i datasettene sine basert på anonymiserte nøkler. Dens kjerneformål er å tillate felles analyse og innsiktsgenerering uten å vise de underliggende, proprietære dataene. Miljøet håndhever strenge, programmerbare regler som minimums aggregeringsterskel og ikke-eksporterbare identifikatorer. Disse reglene sikrer at bare godkjente, personvernforbedrende og aggregerte innsikter utledes og deles. Dette gjør Ryddige rom viktig for brukstilfeller som måling av kampanjer på tvers av plattformer og analyse av overlappinger mellom sensitive målgrupper.
Data 360 er utviklet som en intelligent, utvidbar og klarert datastruktur som er nødvendig for å drive nestegenerasjons AI. Den arkitektoniske utformingen løser problemet med fragmenterte data, slik at organisasjoner kan forene, behandle og aktivere alle kundedata i stor skala ved å bruke Zero Copy Data Federation for å sikre effektivitet.
Dens robuste dataorganisasjon etablerer en harmonisert visning fra DLO-er (inkludert ustrukturerte data) til DMO-er, som alle er sikret i partisjonerte dataområder. Data 360s allsidige databehandlingsfunksjoner – inkludert batch- og strømmetransformasjoner, beregnet innsikt, ustrukturert databehandling og identitetsløsning – leveres med den inkrementelle SNCE- og CDF-arkitekturen, som sikrer effektiv, nær sanntidsbehandling og betydelige kostnadsbesparelser.
Utvidbarhet gis av kodeutvidelsesarkitekturen, som sikkert aktiverer tilpasset Python-logikk via skript eller isolerte funksjoner for unike krav. I tillegg garanterer et omfattende datastyringsrammeverk, bygd på attributtbasert tilgangskontroll (ABAC) med CEDAR-policyer, detaljert sikkerhet, dynamisk datamaskering og konsistent håndhevelse på tvers av all databruk. Dette fører til avanserte segmenterings- og aktiveringsfunksjoner, som oversetter forente kundeprofiler til dynamiske, flerkanalengasjementsstrategier med responsivitet i sanntid.
Avgjørende er at Data 360s evne til å forene store, mangfoldige data, gi sanntidskontekst via sin forente spørring (inkludert hybrid strukturert/ustrukturert søk og Hyper-akselerasjon) og håndheve streng styring er avgjørende for å gi intelligente AI-agenter kraft. Den sørger for de nødvendige klarerte, friske og relevante dataene for å legge til rette for Generative AI-arbeidsflyter (RAG) og for å fremme de flergangs, handlingsorienterte funksjonene til Agentforce agenter, slik at de fungerer med presisjon og nøyaktighet.
Ved å tilby en fremtidssikker plattform der kildedata transformeres til innsikt som kan omsettes i handling, tjener Data 360 som et uunnværlig arkitektonisk grunnlag for organisasjoner som bygger Agentic-kundeopplevelser. Det er den vitale ryggraden som gjør kundedata om til de sofistikerte, tilpassede kundeopplevelsene som driver suksess for dagens moderne organisasjoner.