Dette dokumentet beskriver de gjeldende alternativene for distribusjon av programmer til CloudHub 2.0 for å oppfylle kravene til høy tilgjengelighet og katastrofegjenoppretting. Den bruker USA-området som et eksempel og kan brukes på andre regioner.
CloudHub 2.0 er en fullt administrert, skybasert integrasjonsplattform som eliminerer infrastrukturoverhead ved å automatisere distribusjon, skalering og behandling av MuleSoft API-er og integrasjoner i skyen. Det er MuleSofts moderne skydistribusjonsplattform som kjører på Amazon AWS-infrastruktur.
I de fleste tilfeller er standardteksten Høy tilgjengelighet (HA) og Disaster Recovery (DR) fra CloudHub 2.0 tilstrekkelig. CloudHub 2.0 leverer HA og DR på regionalt nivå (mer informasjon finner du i CloudHub 2.0 Outage Scenarios). Delen CloudHub 2.0 Key Considerations gir flere detaljer om CloudHub 2.0-støttet HA og DR.
Betingelser som krever en utforming utover CloudHub 2.0s standard tilgjengelighet, inkluderer følgende:
- Et program trenger å sikre at ingen data mistes i et katastrofscenario (for eksempel et område av Amazon som går ned).
- Et program er avhengig av objektlager og må sikre kontinuitet hvis distribusjonsområdet går ned.
- Serverdelsystemer er konfigurert for tilsvarende tilgjengelighet. CloudHub 2.0 kan noen ganger gi pålitelighet via køer eller lignende mekanismer, men enten integrasjonen er sanntid eller asynkron, må serverdelsystemer støtte et sammenlignbart nivå av HA og DR.
- Når et avbrudd på AWS-områdenivå påvirker serverdelsystemer, antas gjenoppretting av dem å kjøre parallelt med gjenoppretting av CloudHub 2.0.
- Oppsett av private områder er fullført i flere områder.
Utformingsalternativene i denne veiledningen fokuserer på løsninger for programtilgjengelighet i CloudHub 2.0 når en hel AWS-tilgjengelighetssone eller -region blir utilgjengelig.
Denne veiledningen tar ikke hensyn til disse gjenopprettingsscenariene, men tar hensyn til konsekvensene der det er relevant:
- Gjenoppretting av serverdelsystemer, programmer, databaser, nettverkskomponenter og datasentre som administreres og klargjøres utenfor Anypoint CloudHub, enten på stedet eller i skyen.
- Gjenoppretting av VPN-lenker mellom CloudHub 2.0 og kundens private datasenter (for eksempel IPsec-tunneler og VPN-gatewayer). Nogle DR-indstillinger i denne vejledning kan delvist håndtere disse scenarier.
- Endringer i MuleSoft uttrekker IP-adresser under katastrofegjenoppretting når tillatelsesliste for IP-adresser brukes til integrasjoner. Nogle DR-indstillinger i denne vejledning kan delvist håndtere disse scenarier.
- Eksterne meldingssystemer som brukes i kundeløsninger, enten de leveres av MuleSoft (som Anypoint MQ) eller andre leverandører (som AWS MSK eller Heroku Kafka).
Når du evaluerer CloudHub 2.0 for katastrofe-gjenopprettingskrav, må du tenke over disse viktige punktene.
CloudHub 2.0-avhengighet av AWS regional tilgjengelighet
- CloudHub 2.0 kjører på AWS. Tilgjengeligheten er knyttet til AWS-områder.
- Distribusjoner og programtilgjengelighet er organisert etter region. Disse områdene tilsvarer AWS-områder.
Hvis et helt AWS-område mislykkes, blir ikke programmer i dette området tilgjengelig og replikeres ikke automatisk andre steder.
Application High Availability (HA) og Replica Management
- CloudHub 2.0 distribuerer automatisk programmer på nytt i samme område når maskinvare mislykkes, men et program med en enkelt kopi kan oppleve nedetid.
- Programmer med flere kopier distribueres som standard på tvers av separate tilgjengelighetssoner, og gir HH på tvers av soner.
- Hvis tilgjengelighetssonen for et program med én kopi mislykkes, bringes programmet automatisk opp i en annen tilgjengelighetssone i samme område.
Spesifikk innvirkning fra USA Østregion
- I tilfelle av et avbrudd i USA Øst-regionen:
- CloudHub 2.0-behandlingens brukergrensesnitt og distribusjon REST-tjenester er ikke tilgjengelig, og nye programmer kan ikke distribueres.
- Programmer i andre områder forblir upåvirket i de fleste feilscenarier. Disse programmene fortsetter å fungere som normalt, men overvåkings- og behandlingsfunksjonalitet via kontrollplanet vil ikke være tilgjengelig under avbruddet.
- Core CloudHub 2.0-moduler (som programinnstillinger) beholdes i US East, så innstillinger kan ikke redigeres under pausen.
Overvåking og varsler
- Konfigurer varsel for tilgjengelighetssone- eller regionnivåfeil via status.mulesoft.com.
- Bruk en separat tilstandssjekk- og varselmekanisme utenfor CloudHub 2.0 slik at team varsles hvis kopier mislykkes eller programmer slutter å svare.
Dataoppbevaring (Objektlager V2)
- Objektlager V2 er knyttet til området der programmet distribueres først.
- Hvis du flytter programmet til et annet område, beholdes Objektlager V2 i det opprinnelige området for å unngå tap av data.
- Hvis området der Objektlager V2 er distribuert, mislykkes, er ikke objektlageret tilgjengelig.
Inngangskontrollere og private områder
- CloudHub 2.0s inngangskontrollere er svært tilgjengelig på regionnivå.
- Hvis ett område mislykkes i et delt område, forblir en inngangskontroller i et annet område tilgjengelig, men kan betjene bare programmer som er distribuert i det området.
- Hvis et område mislykkes i et privat område, er ikke inngangskontrollere i andre områder tilgjengelig med mindre de er konfigurert der på forhånd.
- Oppsett for privat område er regionalt. Hvis et område mislykkes, blir ikke det private området tilgjengelig med mindre et annet område har blitt konfigurert.
| Komponentstatus | Salesforce-forpliktelse |
|---|---|
| Replica ned | Handling: CloudHub 2.0 starter automatisk kopien på nytt i en annen tilgjengelighetssone hvis det er noe galt med den gjeldende tilgjengelighetssonen. Men programmet vil være offline til den nye kopien er fullstendig startet. Betingelse: Standardkonfigurasjon. Tid brukt: Omtrent 2-15 minutter avhengig av programkompleksitet og kopistørrelse. |
| Sone ned for tilgjengelighet | Handling: Samme som kopien nedover. Betingelse: Standardkonfigurasjon. Tid brukt: Samme som kopien nedover. Varsel: Samme som kopien nedover. |
| Region Ned | Handling: Ingen automatisk gjenoppretting. En failover-utforming må være på plass. |
| Komponentstatus | Kundeansvar |
|---|---|
| Replica ned | Varsel: Utfør periodiske tilstandssjekker med en hjertebeat-mekanisme innebygd i API-ene. Avbøying: Distribuer programmet til flere kopier i samme område. Test / Simulering: Hent en billett med MuleSoft Support, og de vil støtte en failover-test for å sjekke om en ny kopi spinner opp i en annen AZ etter 1 til 15 minutter. |
| Sone ned for tilgjengelighet | Varsel: Samme som kopien nedover. Avbøying: Distribuer programmet til flere kopier i samme område eller i forskjellige områder. Test / Simulering: AZ Down-scenariet er vanskelig å simulere. Det krever involvering fra MuleSoft Engineering for å støtte mulige testscenarier. |
| Region Ned | Varsel: Samme som kopien nedover. Sjekk også statusoppdateringer på https://status.aws.amazon.com. Avbøying: Samme som AZ Down. Disaster Recovery-avviksplan: 2 private områder med samme konfigurasjon i forskjellige områder. Test / Simulering: Samme som AZ Down. |
| Komponentstatus | Salesforce-forpliktelse |
|---|---|
| VPN Gateway ned | Replisestatus: Kjører, men kan ikke koble til noen ressurser som befinner seg på stedet, og som er tilgjengelig via VPN-tunnelen. Handling: Ingen automatisk gjenoppretting. En failover-utforming må være på plass. |
| Inngangskontroll (delt område) Ned | Replisestatus: Inntakskontrolleren er et klynget oppsett med flere forekomster, på samme måte som programkopier. Hvis en programkopi mislykkes, opprettes og startes en ny automatisk. Hvis én inntakskontrollerforekomst mislykkes, forblir programmer tilgjengelig via den andre forekomsten. Hvis hele inntakskontrolleren er nede, vurderes området som nede. |
| Inngangskontroll (Privat plass) Ned | Replica Status: Samme som Inntakskontroller i delt plass nedover. |
| Komponentstatus | Kundeansvar |
|---|---|
| VPN-gateway ned | Varsel: Utfør periodiske tilstandssjekker med en hjertebeat-mekanisme innebygd i API-ene. Avbøying: CloudHub 2.0 VPN-gatewayer støtter høy tilgjengelighet via en dualtunnelarkitektur med automatisk overføring av feil mellom tunneler. En kunde må konfigurere dette mønsteret. Test / Simulering: VPN Gateway Down-scenariet er vanskelig å simulere. Krever involvering fra MuleSoft Engineering for å støtte mulige testscenarier. |
| Inngangskontroller (delt område) Pil ned | Varsel: Samme som VPN Gateway Down. Avbøying: Samme som Region Down (Område ned). Overfør søknader til et standby- eller aktivt område i et annet område. Test / Simulering: Samme som VPN Gateway Down. |
| Inngangskontroller (privat område) Pil ned | Varsel: Samme som VPN Gateway Down. Avbøying: Samme som Region Down (Område ned). Overfør programmer til et standby- eller aktivt privat område i et annet område, i samordning med AWS Route 53 (eller tilsvarende) konfigurasjon. Test / Simulering: Samme som VPN Gateway Down. |
Oversikt Platform Services Down-scenario – Objektbutikk
| Lagre i minnet-objekt | Store for fast objekt v2 | |
|---|---|---|
| Plassering av data | Bare lokalt for programmet. | I samme område der MuleSoft-programmet ble distribuert første gang. |
| Delt på tvers av kopier? | Nei | Ja |
| Objektlaggggjenoppretting i programmer | Data mistes. Alle data i minnet mistes ved gjenstart av appen, ny distribusjon eller feil i kopien. | Data mistes ikke. med mindre appen slettes. |
| Objektlaggggjenoppretting innen område | Data mistes (samme som ovenfor). | Data mistes ikke (samme som ovenfor). |
| Regional Recovery | Samme som ovenfor. | Data er ikke tilgjengelig. Selv med en aktiv DR-konfigurasjon er Objektbutikk tilgjengelig bare i det opprinnelige distribusjonsområdet. |
| Avbøying | Eksterne data for regional gjenoppretting. | Data beholdes tilgjengelig mens det opprinnelige distribusjonsområdet er tilgjengelig. Når det gjelder HA eller DR på tvers av områder, eksternaliserer du data utenfor objektlageret. |
Høy tilgjengelighet (HA) er målingen av et systems evne til å forbli tilgjengelig i tilfelle en systemkomponent mislykkes. Generelt sett implementeres HA ved å bygge i flere nivåer av feiltoleranse og/eller funksjoner for belastningsbalanse i et system. Det er vanligvis en Aktiv-aktiv-konfigurasjon og fører til begrenset eller ingen innvirkning på Business Services.
Disaster Recovery (DR) er prosessen der et system gjenopprettes til en tidligere akseptabel tilstand etter et katastrofscenario, enten naturlig (som flom, tornadoer, jordskjelv eller branner) eller menneskeskapt (som strømbrudd, serverfeil eller feilkonfigurasjoner). DR er vanligvis en aktiv-passiv-konfigurasjon og fører til en viss innvirkning på Business Services.
Hvis Regional High Availability (Regional høy tilgjengelighet) eller Regional Disaster Recovery (Regional katastrofegjenoppretting) er ønsket for å redusere forretningseffektene i tilfelle en regional AWS-feil, bør du vurdere disse punktene når du utformer løsningen i MuleSoft CloudHub 2.0:
- CloudHub 2.0-kopier og relaterte funksjoner – private områder, inngangskontroller og Anypoint MQ-mål – er områdespesifikke.
- Hvis et helt AWS-område mislykkes, blir ikke alle kopier og tilknyttede tjenester i dette området tilgjengelig.
- Når et område gjenopprettes, gjenopprettes konfigurasjoner. Du må starte programmer på nytt.
- Hvis USA Øst-området mislykkes, blir heller ikke Anypoint Platform-tjenester (for eksempel Tilgangsbehandling og Kjøretidsbehandling) tilgjengelig.
- MuleSoft tilbyr en tjenestenivåavtale med 99,95 % tilgjengelighet for plattformtjenester, inkludert CloudHub 2.0-kopier i en aktiv-aktiv konfigurasjon i et område. Se den nyeste MuleSoft-skyen som tilbyr tjenestenivåavtale for å få aktuelle detaljer.
- CloudHub 2.0 støtter ikke flerområde HA eller DR forhåndsdefinert. Tilgjengelighet gis bare innenfor ett område.
Disse retningslinjene gjelder uavhengig av hvilket oppsett du velger.
Multi-Region Private Spaces Oppsett
Alle alternativene som beskrives i delene nedenfor, krever at programmer distribueres i separate områder. Det er bare mulig hvis oppsett av private områder er fullført på forhånd, før en katastrofe. Fordi oppsett av private områder er regionalt, krever en DR-strategi minst to private områder – én per region – og en mekanisme for å bytte trafikk til det riktige VPN-sluttpunktet.
Høyt tilgjengelig privat plass i et område
CloudHub 2.0 sørger ikke for automatisk overføring av feil når et privat område i et område mislykkes. En midlertidig løsning er et aktivt-passivt oppsett på tvers av flere miljøer, som krever følgende:
- Konfigurere flere VPN-gatewayer i det private området.
- Opprette separate miljøer i CloudHub 2.0-området, hver med sitt eget private område.
- Utpeke ett av disse miljøene som passivt (der programmer ikke distribueres fra start av, men tas opp hvis det primære private området mislykkes).
Hvis et oppsett med høy tilgjengelighet uten at VPN Gateway er et enkelt feilpunkt, er et vanskelig krav, er distribusjon til to områder det beste alternativet. En VPN-gatewayfeil i dette scenariet kan løses ved å feilsøke det berørte området over til det alternative området der det private området allerede er konfigurert.
Null meldingstap
For å oppnå null tap av meldinger når et helt område mislykkes, må et program hindre tap av data og løse disse punktene:
- Bruk eksterne meldinger til å oppnå meldingspålitelighet.
- Forsikre deg om at objektlager ikke brukes til transaksjonsdata under utførelse som er transaksjonelle av natur. Hvis distribusjonsområdet der MuleSoft-programmet først ble distribuert, reduseres, blir Objektbutikk ikke tilgjengelig.
- Pakk inn all Objektbutikk-tilgang i en separat flyt eller del som fortsetter å fungere – både for håndtering av unntak og virkemåte – når Lese- eller Skrive-operasjoner i Objektbutikk mislykkes.
Notat. I de fleste tilfeller trenger ikke DR-kravene å sikre et tap av meldinger i tilfelle en katastrofe, og de trenger å sikre at tap av data er mindre enn en gitt periodes dataverdi (for eksempel 1 time).
Behold integrasjon statsløs
Som et generelt utformingsprinsipp er det alltid viktig å sikre at integrasjonene er uten status. Det betyr at ingen transaksjonsinformasjon deles mellom ulike klientkall eller utførelser (i tilfelle planlagte tjenester). Hvis noen data må vedlikeholdes av mellomprogramvaren på grunn av en systembegrensning, bør de beholdes i et eksternt lager, som en database eller en meldingskø, og ikke i MuleSoft-infrastrukturen eller minnet. Det er viktig å merke seg at når vi skalerer, spesielt i nettskyen, bør statusen og ressursene som brukes av hver kopi, være uavhengig av andre kopier. Denne modellen sikrer bedre ytelse, skalerbarhet og pålitelighet.
Nettverk og trafikkstyring
- Tomme domener kreves for regional tilgjengelighet. De fungerer som en global DNS for alle inngangskontrollere på tvers av områder.
- En global belastningsbalanserer ruter trafikk mellom det primære og DR-regionens private områder. Kunder leverer denne komponenten. Bruk AWS Route 53 eller et globalt CDN med rutingspolicyer til å rute trafikk på tvers av områder.
- Konfigurer inntakskontrollere i både primær- og DR-områder med et tilpasset tomt domene.
- Planlegg og vedlikehold brannmurregler og VPN-tunneler slik at programmer på stedet kan nås fra både det primære og DR-områdets private områder.
- TLS-sertifikatvedlikehold må dekke private områder i både primær- og DR-områder for sømløs gjenvinning.
Programdistribusjon og konfigurasjon
- Søknadens navn må være unike på tvers av områder. En CI/CD pipeline kan for eksempel føye til områdenavnet (eller en områdekode) i programnavn før distribusjon for å opprettholde unikhet på tvers av primær- og DR-områder.
- Konfigurer CI/CD pipelinen til å distribuere programmer til både primær- og DR-områdene slik at alle programmer er tilgjengelig i begge områdene.
Infrastruktur og kapasitet
Ytelsen er best når alle infrastrukturaspekter har identisk kapasitet for primær- og DR-område. Ytelsen reduseres når disse infrastrukturaspektene ikke er identiske.
Dataklargjøring og lagring
- Permanent lagring må synkroniseres regelmessig mellom de to områdene. Kunder er ansvarlige for lagringsreplikering, men MuleSoft leverer ikke dette. Et enkelt delt lagringssted mellom VPC-er i primær- og DR-områdene er mulig, men det delte lageret må være svært tilgjengelig, ellers blir det et enkelt feilpunkt for begge områdene.
- Objektbutikk V2 er regional og er tilgjengelig bare i området der Mule-programmet først ble distribuert. Hvis programmet flyttes til et annet område, beholdes Objektlager V2 i det opprinnelige området for å unngå tap av data. Bruk annen fast lagring til DR-strategier med flere områder.
Testing og driftsprosedyrer
Ta i bruk en formell DR-teststrategi og utfør periodiske DR-veiledninger. For aktivt aktivt DR bruker du en kanarisk distribusjonsstrategi til å validere begge regionene.
Ytelses- og tjenestenivåavtaler (SLA-er)
En del ytelsesreduksjon kan skje fordi DR-området kan være lengre unna sluttbrukere eller serverdelsystemer enn det primære området. Definer og kommuniser en DR SLA til interessenter.
Virkemåte for gjenopprettingsmodus (kontekstnotat)
I aktiv-aktiv modus er overføring av feil fra det primære området til DR-områdets private plass rask: Den globale belastningsbalanceringen oppdager at det primære er usunn og ruter trafikk til det gode (DR)-området. I aktiv-passiv modus må du distribuere programmet til det private området DR når det oppstår en katastrofe.
Det finnes tre alternativer for å oppnå et høyere tilgjengelighetsnivå:
Et aktivt aktivt oppsett er basert på aktive arbeidere fordelt på områder ved å bruke en ekstern belastningsbalanse til å rute trafikk mellom de to forekomstene.
Varm standby-konfigurasjon
Et aktivt-passivt oppsett vil være basert på en aktiv arbeider i ett område og en passiv arbeider i et annet område. Det passive området startes når det er nødvendig.
Enkelte elementer i det passive området må forbli aktive for overføring av feil eller konfigureres på forhånd, inkludert private områder, VPN-er og vedlegg til transittgatewayer.
Som ovenfor klargjøres repliker og inntakskontrollere i et andre område via en fullt automatisert DevOps-prosess ved overføring til feil. Enkelte elementer i det passive området må forbli aktive for overføring av feil, inkludert private områder, VPN-er og vedlegg for overføringsport.
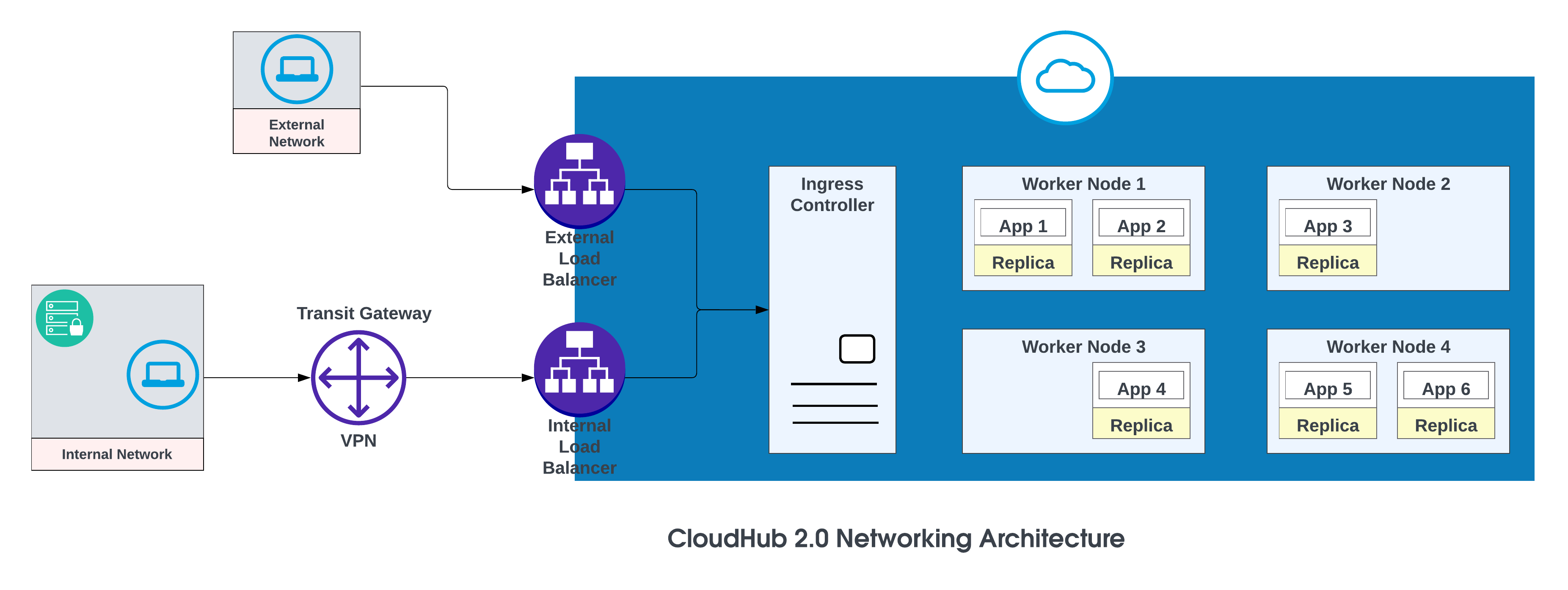
De grunnleggende komponentene i nettverksarkitekturen CloudHub 2.0 er:
- En HTTP-belastningsbalancer
- Mule-kopi av DNS-poster
- Private områder
- Regionale tjenester
Se CloudHub 2.0-nettverksarkitektur for å få mer informasjon.
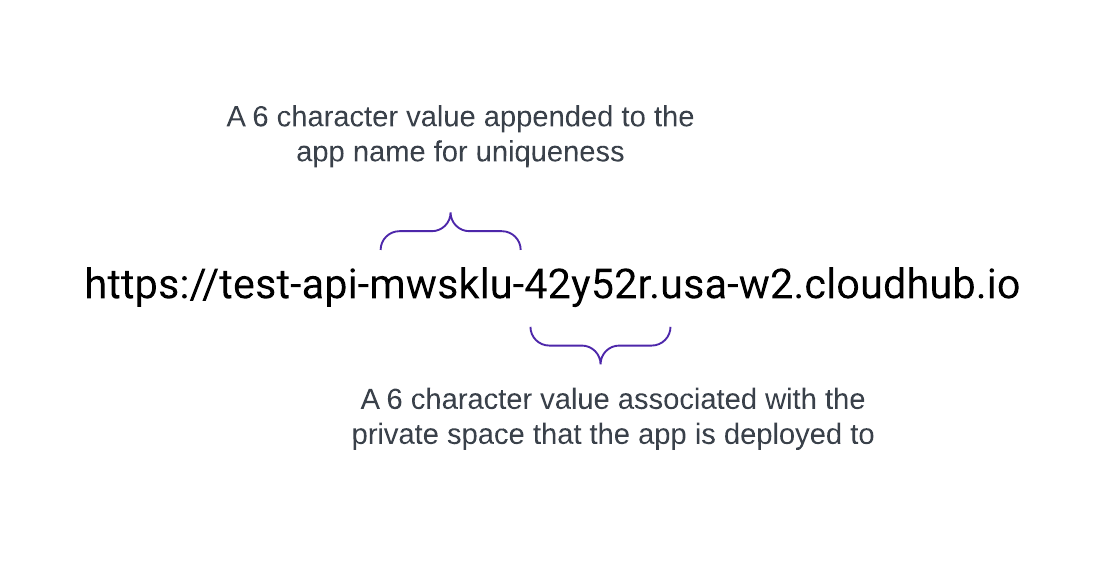
Vanity-domener
Når et privat område opprettes, mottar det et DNS-målnavn i formatet: <space-id>.<region>.cloudhub.io . Ved distribusjon av en app med navnet test-api i dette private området vil endepunktet følge dette formatet:
CloudHub 2.0 støtter også tilpassede domener, eller tomme domener, ved å konfigurere dem i et privat område ved bruk av TLS-kontekster og DNS-poster. Hvis du vil opprette en TLS-kontekst i Kjøretidsbehandling for et privat område, laster du opp det felles sertifikatet og den private nøkkelen, og deretter legger du til et tilpasset endepunkt i programets innstillinger for å bruke det domenet. Opprett en DNS-post (som en CNAME) som peker til det private rommets standard vertsnavn.
Et program med navnet test-api som er distribuert i us-west-2 med standard DNS 42y52r.usa-w2.cloudhub.io, har for eksempel et API-endepunkt som
https://test-api-mwsklu-42y52r.usa-w2.cloudhub.io
Denne URL-adressen bruker ikke et tomt eller tilpasset domene. Følg denne fremgangsmåten for å bruke acme.com slik at API-URL-adresser vises som https://test-api.acme.com.
- Opprett TLS-kontekst i Kjøretidsbehandling med felles og private nøkler.
- Legg til et tomt domene i programets innstillinger for å bruke det domenet.
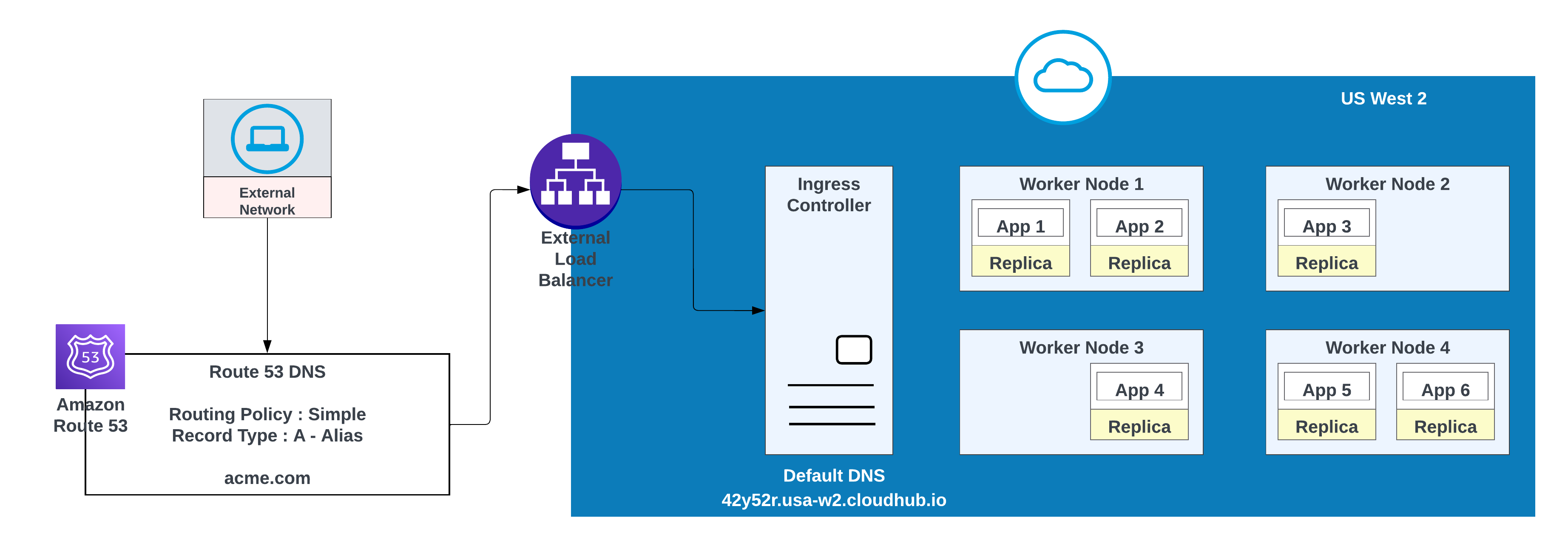
- Opprett en DNS-post i AWS Route 53 og konfigurer en enkel rutingspolicy (for eksempel CNAME) slik at det tomme domenet løses til det private områdets standard vertsnavn.
For tilpassede domener kan du bruke AWS Route 53 eller andre globale CDN-tjenester med rutingspolicyer. I diagrammet nedenfor brukes AWS-rute 53 sammen med en "enkelt" rutingspolicy. Når en forbruker fra et offentlig (eksternt) nettverk ber om acme.com, ruter AWS-rute 53 forespørselen til MuleSoft-kontrolleren for inngang til privat plass.
Bruk dette alternativet når programmer krever overføring av feil: Distribuer én forekomst i det primære området (for eksempel us-west-2) og en annen i et sekundært område (for eksempel us-east-1).
Bruk et eksisterende miljø i det sekundære området når det er mulig. Opprettelse av et nytt miljø krever ekstra innsats.
Eksempel på apper som er distribuert i én region (USA Vest 2) med en feiloverføring til en annen region (USA Øst 1)
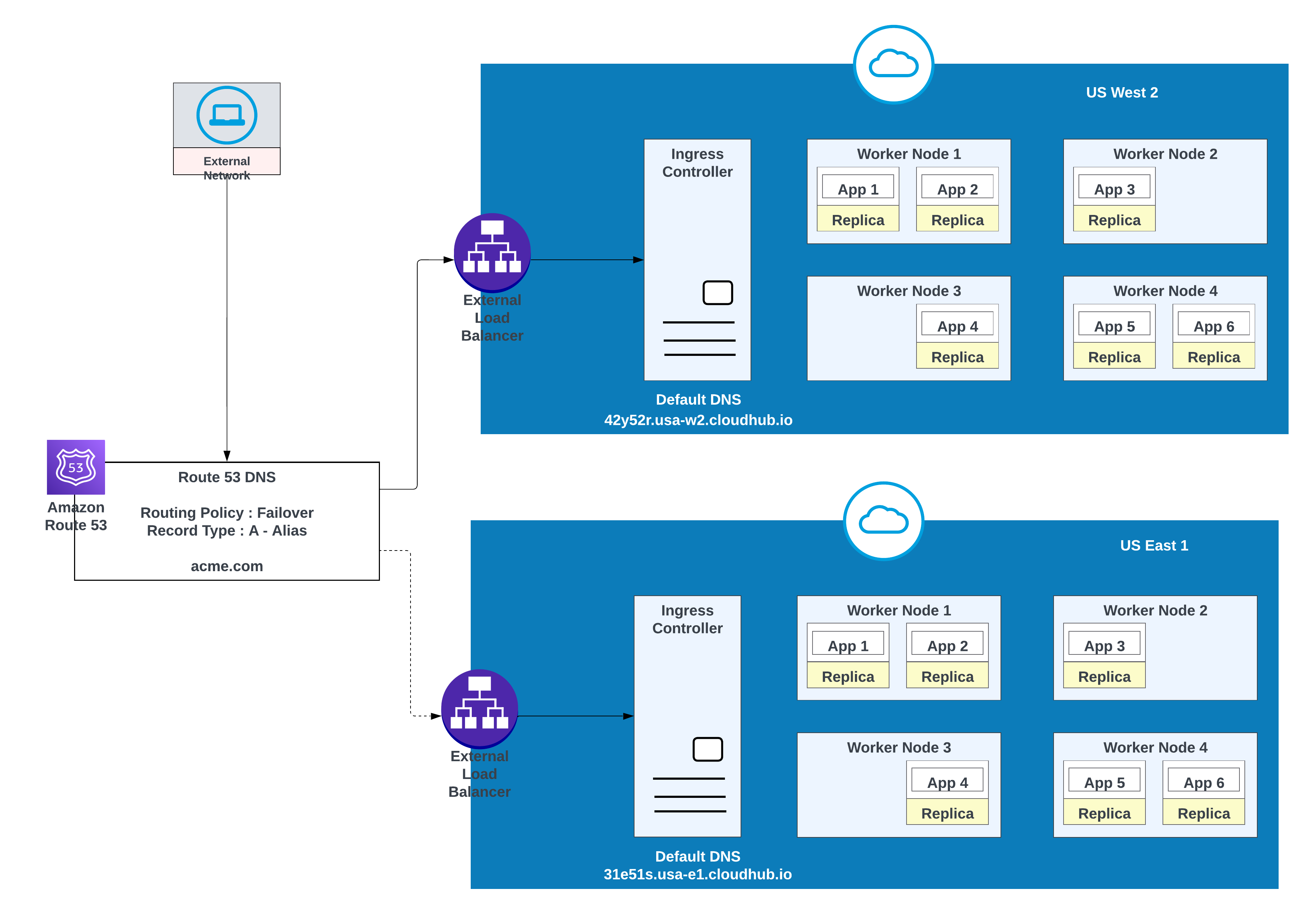
| Postnavn | Verdi/Rute trafikk til | Rutingspolicy | ID for tilstandssjekk |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Feilover | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Feilover | 43e131s131sq |
I denne konfigurasjonen ruter AWS Route 53 trafikk til inngangskontrollerne for de private områdene i US West 2 og US East 1. En policy for overføring av feil konfigureres med en tilstandssjekk.
For lavere latens sammen med høy tilgjengelighet bruker du distribusjonsstrategien som er beskrevet i diagrammet. Med denne strategien kan apper distribueres i to regioner (us-west-2 og us-east-1 i dette eksemplet).
Bruk policyen for latensruting i AWS-rute 53 til å rute forespørsler til området som tilbyr den laveste latensen, samtidig som den beholder høy tilgjengelighet. Rutingspolicy for "latens" i AWS-rute 53 for å rute forespørselen for lavere latens som fremdeles har høy tilgjengelighet.
Apps Distribuert i begge regionene (US West 2 og US East 1) for lavere latens og høy tilgjengelighet
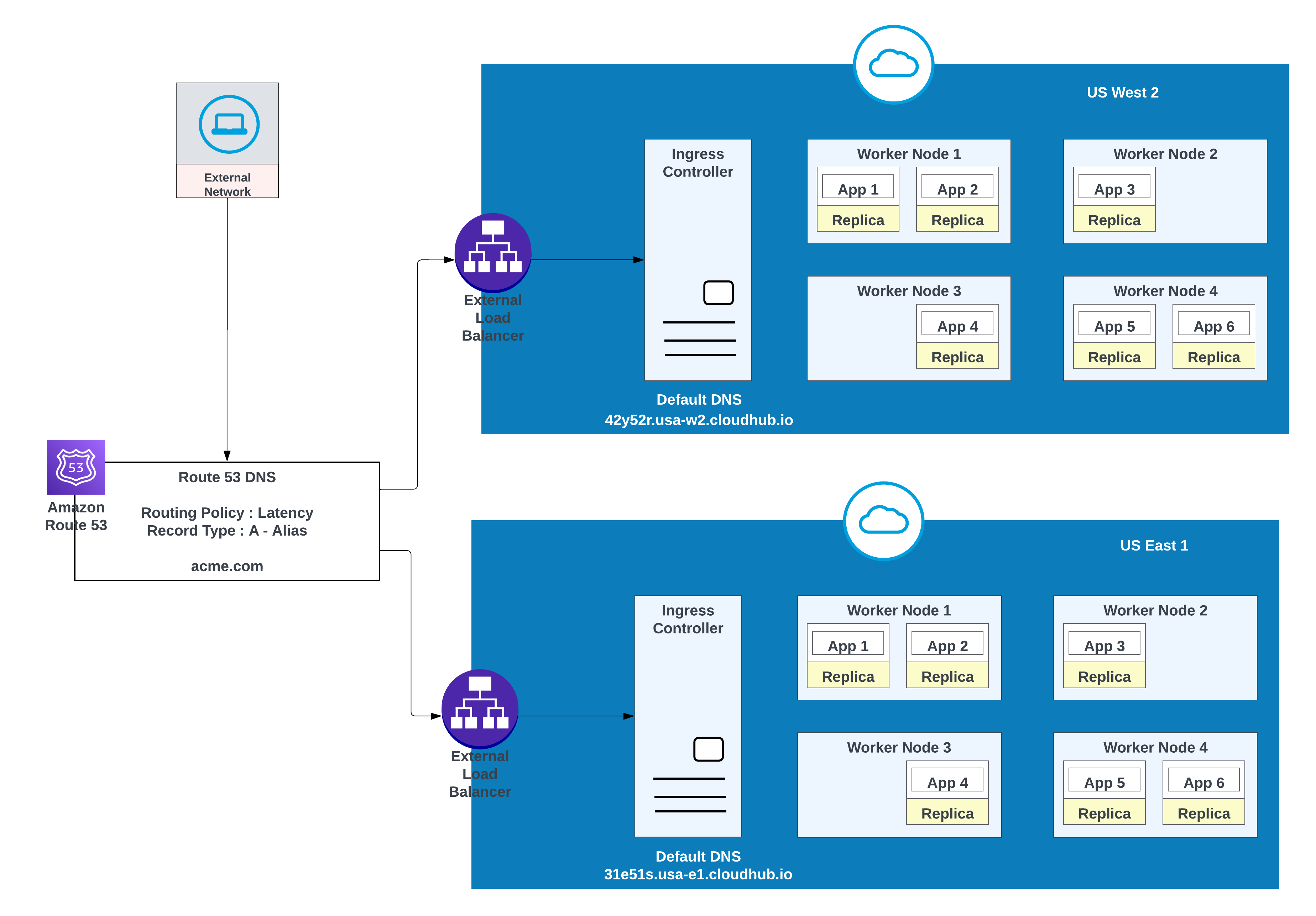
| Postnavn | Verdi/ Rut trafikk til | Rutingspolicy | ID for tilstandssjekk |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Latens | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Latens | 43e131s131sq |
MuleSoft CloudHub 2.0 gir et solid grunnlag for fleksibilitet innen områder, primært ved å benytte automatisert duplikatoverflødighet og intelligent belastningsbalansering. Når du distribuerer programmer med flere kopier i ett skyområde, sikrer du at hvis én forekomst mislykkes, kan andre umiddelbart ta over arbeidsbelastningen. Den integrerte belastningsbalansen fordeler effektivt innkommende trafikk på tvers av disse tilpassede kopiene, og minimerer nedetid og sikrer kontinuerlig tjenestetilgjengelighet under normale driftsbetingelser.
Men hvis du utelukkende bruker denne arkitekturen med ett område, selv en med høy overflødighet, utgjør du en betydelig risiko for et omfattende, katastrofal regionalt avbrudd. Historikk har vist at selv de mest pålitelige og teknologisk avanserte skyleverandørene er utsatt for forstyrrende hendelser som kan påvirke et helt geografisk område. Disse enkeltfeilpunktene, selv om de er sjeldne, kan oppstå fra ulike hendelser, inkludert:
- Infrastrukturhendelser i stor skala
- Viktige strømfeil
- Omfattende nettverksavbrudd
For å oppnå sann høy tilgjengelighet (HA) og katastrofegjenoppretting (DR) må en arkitektur derfor utformes slik at den overskrider begrensningene til en enkeltområdemodell. Den anbefalte strategien er distribusjon på tvers av flere geografisk forskjellige områder. Denne fleksibiliteten mellom områder sikrer at hvis et helt skyområde blir utilgjengelig på grunn av en uventet katastrofe, kan trafikk sømløst overføres til en programforekomst som kjører i et separat, uberørt område, noe som garanterer minimal tjenesteavbrudd og oppnår maksimale oppetidsmål.
CloudHub 2.0 nettverksarkitektur
Konfigurere feiloverføring på tvers av områder for standardkøer
Distribusjonsområder for objektlager V2
Distribusjonsområde for objektbutikk
Gulal Kumar er Software Engineering Architect på Salesforce med fokus på data og integrasjonsarkitektur. Med over 20 års erfaring innen integrasjon og API-er, moderniseringsprogrammer, sikkerhet og AIML-initiativer, har han en rik ekspertise. Gulal har vært forpliktet til å fremme forretningstransformasjonsinitiativer, forbedre sikkerhet og motstandskraft, fremme arkitektonisk dyktighet og lede AIML-initiativer på tvers av ulike domener.
Ajay Nagaraju er Enterprise Architect og Senior Director hos MuleSoft med over 28 års erfaring innen enterprise architecture, systemintegrasjon og digital transformasjon i stor skala. Han har ledet arkitektur og levering for komplekse, flere millioner dollar-programmer på tvers av Fortune 100- og Fortune 500-organisasjoner, med dyp ekspertise innen API-ledet tilkobling, SOA, skyteknologier og enterprise-integrasjonsmønstre. Ajay har samarbeidet tett med ledere for å modernisere forretningsprosesser, dataplattformer og integrasjonsøkosystemer, og er opptatt av å bygge skalerbare arkitekturer, veilede team og fremme målbare forretningsresultater gjennom teknologi.