Moderne Salesforce-arkitekturer leveres i økende grad av asynkron behandling, ikke som en bekvemmelighet, men som et strategisk krav til skalering. I løpet av de siste årene har vi sett flere og flere firmaer slite med stigende datavolumer, komplekse integrasjoner som involverer flere kontaktpunkter, og økningen av autonome systemer som kjører 24/7/365. Alle disse tingene driver arkitekter mot å utforme systemer som er asynkrone først.
Asynkron behandling i Salesforce betyr ofte å utforme rundt styringsgrenser og kompleksitet. Disse grensene fungerer som vakthaller og arkitektoniske begrensninger som bidrar til å produsere massesikre, skalerbare systemer. Selv om ingen plattformgrenser direkte tjener til å håndtere kompleksitet, kan designmønstre bidra til å redusere risiko på den fronten. Internt overfører Salesforce ofte plattformens grenser for å teste nye funksjoner og automatisere komplekse forretningsprosesser. Vi bygde et trinnbasert asynkront behandlingsrammeverk for å kjøre asynkrone jobber med et vilkårlig antall trinn. Hvert trinn kan kjøres, prøves på nytt og startes på nytt uavhengig med delte styringskontroller og full operativ synlighet via sentralisert logging. Dette dokumentet beskriver viktige arkitektoniske komponenter: Købar Apex og Finalizers, Planlagt flyt, Apex, Kallbare handlinger og integrasjoner med Slack. Sammen gir disse komponentene en modulær, skalerbar og observerbar arkitektur som er egnet for evoluerende bedriftsbehov.
- Moderne Salesforce-arkitekturer bør ta imot en asynkron første-tilnærming for å oppnå skala, fleksibilitet og operasjonell gjennomsiktighet.
- Brudd av komplekst arbeid i uavhengig kjørbare trinn muliggjør forutsigbar ytelse, sikrere nye forsøk, sjekk, tilbakevolking og modulær utvikling uten å omutvikle kjernearbeidsflyter.
- Rammeverket gir et skalerbart alternativ til monolittiske og aldrende gruppejobber, kjede asynkrone kall og dypt nestede flyter, og er bygget for arbeidsbelastninger med stor trafikk som må skaleres horisontalt i Salesforce uten orkestrering utenfor plattformen.
- Deterministisk og observerbar utførelse sikrer sporing av fremdrift, SLA-overvåking, feildiagnostikk og gjennomsiktighet på revisjonsnivå gjennom sentralisert logging og styring.
- Utformet for streng virksomhet, inkludert forent styring, samsvar og distribuert statskontroll på tvers av langvarige forretningsprosesser.
Før du går gjennom kravene, er her noen viktige punkter om når du skal bruke et rammeverk som dette. Overvej først og fremmest, hvilket system der er den eneste kilde til sandhed. Hvis Salesforce-organisasjonen din er minst avhengig av eksterne data, men må skalere fra hundrevis til millioner av poster, kan du vurdere et trinnbasert asynkront rammeverk.
Bruk dette rammeverket hvis
- Det meste (eller alt) av informasjonen som det skal handles på, finnes allerede i CRM-et.
- Den innledende eller pågående kostnaden ved vedlikehold av en ETL-jobb (Extract Transform Load) for å harmonisere eksterne data er for høy.
- Du må utsette behandling av et stort antall Salesforce-poster etter en angitt tidsplan.
- Du kan dele opp behandlingen i diskrete trinn. Du kan for eksempel opprette et hierarkisk eller trebasert sett med poster, spesielt hvis datavolumet er i ventiler nedover hierarkiet eller treet.
Ikke bruk dette rammeverket hvis
- Oppretting eller oppdatering av poster krever umiddelbar ny beregning.
- Integrering er utfordrende fordi eksterne systemer er vert for primærdata for postoppdateringer. (Vurder å pushe oppdaterte data til Salesforce med Bulk API.)
La oss se gjennom kravene våre og begynne å bygge med disse fremgangsmåtene.
Vurder problemsetningen:
Hvis du har en jobb som må kjøres daglig, kontrollerer du om bestemte poster oppfyller forhåndsdefinerte kriterier for videre behandling. Hvis de gjør det, starter du disse behandlingsjobbene. Behandling av poster kan bety å trekke ut data fra flere eksterne systemer for å utføre beregninger. Trinn i jobber skal varsle personer via Slack om at behandlede poster er klare for gjennomgang. Trinn bør også eskalere varsler til ledere og overordnede i rollehierarkiet basert på en konfigurerbar forsinkelse etter den første runden med varsler.
Dette problemet involverer flere forskjellige trinn, og noen av dem kan skje uavhengig av hverandre. Det finnes mange måter å dele opp arbeidet på. Her er én gruppering:
- Planleggeren.
- Trinngrensesnittet og konkrete implementeringer som behandler poster (uavhengig av behandlingstypen).
- Prosessoren som organiserer trinn.
- Apex Kallbar kalt opp av planleggeren.
- Varselstykket. Vi bruker Apex Slack SDK.
- Det er en del kompleksitet skjult i uttrykket "konfigurerbar forsinkelse". Vi går gjennom denne kompleksiteten senere i denne artikkelen.
Her er et uttrykt diagram over det innebygde rammeverket:
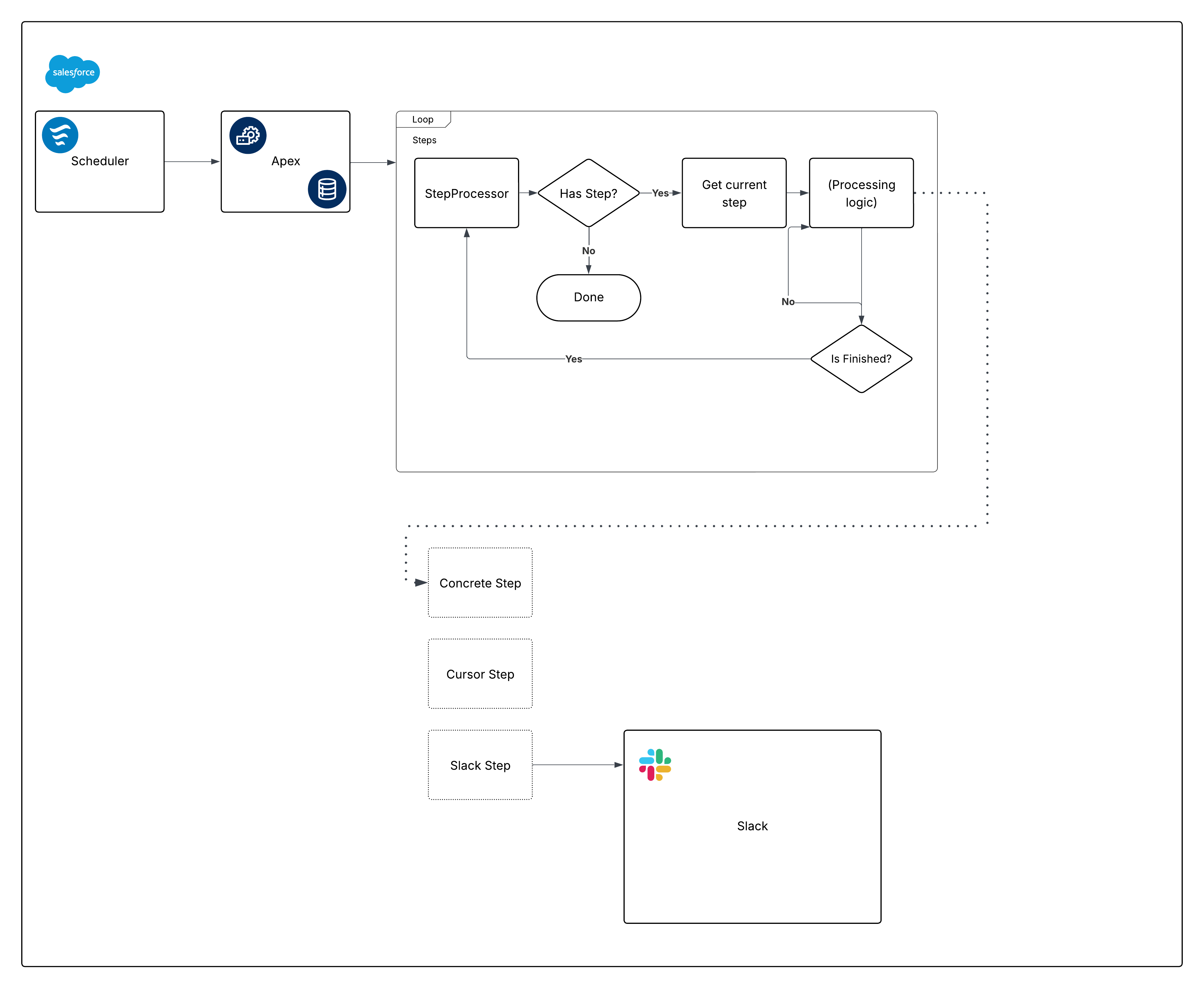 Nå bryter du opp det diagrammet og begynner å bygge bitene.
Nå bryter du opp det diagrammet og begynner å bygge bitene.
Planlagt flyt har flere fordeler som planleggingsmekanisme:
- Planlagte flyter kan pakkes og distribueres som metadata. Dette gjelder ikke for jobber som er planlagt via Apex (eller via siden Planlagte jobber).
- Vent-elementet er avgjørende for rammeverk som krever oppkall. Ved å bruke den i Flyt er oppkall ikke nødvendige i Kallbar-delen av rammeverket.
- Planleggingens detaljnivå oppfyller kravene: Minste intervall for planlagte flyter er daglig. Hvis du trenger en høyere frekvens (for eksempel per time), bør du vurdere Planlagt flyt på nytt for dette kravet.
En annen vurdering når du konfigurerer den planlagte flyten, er miljøport. Før du kaller opp Apex-handlingen legger du til et Beslutning-element som evaluerer {!$Api.Enterprise_Server_URL_100}. Dette sikrer at jobben kjører bare i de tiltenkte miljøene, som UAT og Produksjon. Dette mønsteret er viktig fordi Sandbox-organisasjoner ofte oppdateres eller nylig opprettes under SDLC, og uten en eksplisitt miljøkontroll kan en planlagt flyt utføres utilsiktet i miljøer der rammeverket ikke er ment å kjøre. Bruk av contains-operatoren i Beslutning-elementet gjør oppsettet fleksibelt for fremtidige Sandbox-oppretting eller URL-endringer.
Vurder til slutt hvordan rammeverket skal fange opp feil. Legg alltid til en feilbane når flyten kaller opp en handling. Du kan for eksempel sende feil til handlingen Legg til loggoppføring i Nebula Logger. Nebula Logger skriver logger til tilpassede objekter, så kunder bør være oppmerksomme på at loggdata forbruker organisasjonslagring – som standard lagres logger i 14 dager i en organisasjon, og deretter rydder de opp. Denne oppbevaringsperioden kan konfigureres. Nebula Logger bruker også plattformhendelser til å publisere logger, så loggoppføringer lagres uavhengig av hoveddatabehandlingstransaksjonen – dette sikrer at feil fanges opp selv om den primære flyten eller Apex rulles tilbake. Kunder bør evaluere forventet loggvolum og krav til oppbevaring når de vurderer å legge til et loggingsrammeverk.
Slik ser flyten ut:
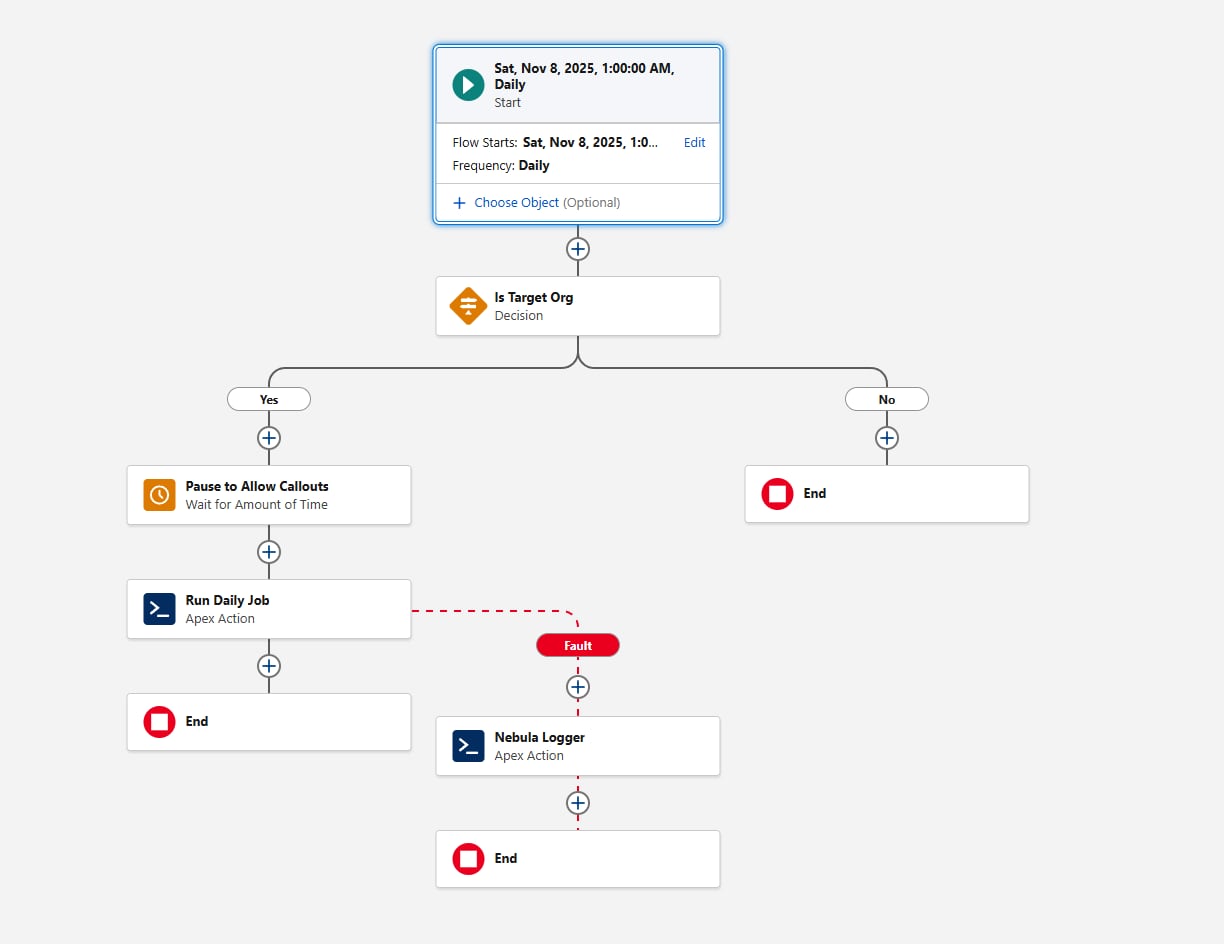
La oss gå videre til de første bitene av Apex der planleggingskravet nå er oppfylt.
Definer et Step-grensesnitt:
I denne artikkelen vises step-grensesnittet som en ytre klasse for å gjøre det tydeligere. Selve rammeverket er fleksibelt – team kan organisere grensesnittet og dets implementeringer med hvilket som helst Apex de foretrekker, så lenge alle trinnklasser refererer til det samme grensesnittet.
Det er noen ting du bør merke deg om metodene som er definert i grensesnittet vårt:
execute, selv om det er lite argument for øyeblikket, forbedres når vi overfører enState(eller grensesnitt) for å orkestrere data mellom trinn når rekkefølgen er viktig.getNamekan returnere enSystem.Type-verdi i stedet for enString. Målet er å gi orkestreringslaget en måte å logge trinnnavn på uten å vise andre egenskaper.
Her er den første konkrete implementeringen som viser hvordan disse bitene passer sammen. Med ett unntak senere anbefaler vi å bruke Apex i kø for å implementere asynkron behandling i Apex. Gruppebehandling av Apex er vanligvis unødvendig (og @future anbefales ikke). Apex i kø starter raskt, og med Apex har den mange fordeler i forhold til Apex.
Apex-markører tilbyr et moderne alternativ til den tradisjonelle batch Apex-modellen. På samme måte som med gruppebehandling kan en markørimplementering hente poster i biter (opptil 2000 per batch). Markører tillater imidlertid flere henting i én enkelt transaksjon, noe som gir betydelig høyere gjennomløp for operasjoner med stor trafikk.
Når du bruker markører som en del av dette rammeverket, bør team være oppmerksomme på gjeldende begrensninger for testing og mockability. Markørvirkemåten i tester kan være forskjellig fra produksjonsvirkemåten, så det er viktig å utforme teststrategier som unngår å bruke markørinterne elementer, og i stedet validere orkestreringslogikk ved grensene. Etter hvert som plattformen utvikler seg, vil disse områdene fortsette å bli bedre, men kjerneveiledningen beholdes: Markører gir høyere ytelse og redusert orkestreringsoverhead sammenlignet med batch Apex for mange brukstilfeller.
For å definere en klar grense mellom den systemleverte markøren og din egen kode anbefaler vi å opprette en markørlignende representasjon når du implementerer Step-grensesnittet. Vurder denne koden:
Legg merke til Cursor-klassen. Apex markører er tilfeller av Database.Cursor, men vår implementering av Cursor gir oss fleksibilitet rundt manglene i markører. Her er implementeringen:
For resten av denne artikkelen utelater vi sharing når det refereres til Apex-klasser. I praksis må du forsikre deg om at klasser på øverste nivå eksplisitt brukes med eller uten deling for å samsvare med objektmodellen og tillatelsene dine.
Merk også at vår Cursor implementering delegerer til plattformens Database.Cursor, med ekstra fordeler diskutert nedenfor.
Her er først de tilsvarende testene:
Ved å gjøre Cursor virtuell kan konkrete CursorStep-implementasjoner fungere uten Database.Cursor når de ikke trenger å gjenta et stort postsett – på samme måte som å returnere en System.Iterable<T> i stedet for en Database.QueryLocator i batch Apex. Her er et eksempel:
Vær oppmerksom på at fordi denne klassen også er abstrakt, overlater den den konkrete implementeringen av innerExecute til underklasser.
Det finnes også et alternativ til den indre underklassen CursorLike. Hvis du vet at konkrete versjoner av et trinn som dette ikke brenner gjennom andre styringsgrenser, kan du returnere this.records fra CursorLike.fetch og overstyre den overordnede CursorStep.shouldRestart() for å returnere false. Da kan du gjenta en liste som bare er avgrenset av Apex heap-grensen på 12 MB per asynkron transaksjon.
Vår markørbaserte implementering gir oss rikelig med fleksibilitet ved sideinndeling over store mengder data. I mellomtiden gir Step grensesnittet oss fleksibilitet til å beskrive og innkapsling trinn av alle slag.
Vurder et flytbasert trinn:
Fordi flyter ikke kan returnere utdataparametere som samsvarer med en Apex-definert type, kontrollerer vi en shouldRestart-utdataparameter før du bruker den.
Enkelte trinn kan være funksjonsflaggede. Du kan implementere logikk for å bestemme hvilke trinn som skal inkluderes, eller du kan bruke et ikke-valgstrinn for en deaktivert funksjon. Null Object-mønsteret er en vanlig måte å redusere kompleksiteten i orkestreringslaget på:
Vi har nå ganske mange byggeblokker å arbeide med. La oss se på orkestreringslaget som er ansvarlig for gjentagelse over trinn.
Prosessoren er et infleksjonspunkt i arkitekturen. Vi må bestemme hvem som skal definere hvilke trinn som skal initialiseres, og hvor. Alternativene inkluderer følgende:
- La prosessoren definere hvilke trinn som skal tilordnes til forretningslogikk. Dette alternativet er enkelt, men skalerer dårlig for lesbarhet.
- Definer tilordningen med tilpassede metadata (CMDT). Metadatarelasjon-felt støtter ikke
ApexClass, som løst kobler stavemåte for klassenavn til forretningsprosessoppsettet. Du kan redusere administratorrisiko ved å gjøre feltet til en valgliste og validere typen finnes (Type.forName()eller ved å spørreApexClass), men fordi CMDT-poster ikke støtter utløsere, skjer validering ved kjøretid. Denne ruten kan testes, men administratorer kan fremdeles opprette CMDT-poster bare i produksjonsorganisasjonen – fortsett med omtanke. - Definer tilordningen med poster. Ikke-administratorer kan konfigurere trinn, men distribusjoner blir vanskeligere og miljøer kan avvikle. Fortsett med forsiktighet.
Det er et kjent sitat fra Clean Code om hvordan man håndterer denne spesielle kompleksiteten:
Løsningen på dette problemet er å begrave
switch[for å lage objekter] i kjelleren til en abstrakt fabrikk, og aldri la noen se den.
Med det i tankene, og fordi vårt gjeldende antall trinn er godt definert og sannsynligvis ikke vil vokse for stort, er det greit at trinnbehandleren også er fabrikken for trinn. Dette kan bruke en oppføring til å utløse byttesetningen:
Og så for vår StepProcessor:
Fabrikkmetodene som vises, som addTypeOneSteps(), kan delegere bekymringer som funksjonsflagging. cleanSteps() utfører en engangskontroll av de samlede trinnene for å sikre at det ikke er noen "tomme" trinn før du går virkelig asynkront. Det kan se slik ut:
Vi har ikke diskutert feilhåndtering siden omtalen av Nebula Logger i delen Planlagt flyt. Det er fordi System.Finalizer lar oss dekke loggføring for alle feilbetingelser uten å legge til spesifikk feilhåndtering i hvert trinn. Hver Step fokuserer på å løpe, mens vi logger og revurderer eventuelle ulykkelige baner slik at de dukker opp i enhetstester. Dette støtter sikker gjentagelse og varsler på produksjonsnivå (ved bruk av Slack Logger-tillegget for Nebula for alle WARN- og ERROR-logger).
En merknad om feillogging: Overføring av trinnforekomsten til loggmeldinger forutsetter et nivå av Trust i det som blir synlig i logger. Standard toString() for Apex-klasser inkluderer alle statiske egenskaper og egenskaper på forekomstnivå i meldingen. Det kan være ønskelig – eller det kan lekke sensitiv informasjon. Selv om logging og sikkerhet ikke er fokus her, må du merke deg at for noen systemer kan overholdelse av et grensesnitt som Step også innebære å tvinge en overstyring for toString().
En slik metode legger byrden på hver objekttaker for å bestemme hva som er tillatt å skrive ut, noe som kan være ønskelig.
På loggenivåer: På StepProcessor bruker vi INFO, det høyeste ikke-feilnivået. Etter hvert som du blir mer detaljert i programmet, bør loggenivåene reduseres i henhold til dette. Individuelle trinn kan bruke DEBUG for informasjon på høyt nivå, med FINE, FINER og FINEST reservert for stadig mer detaljerte utdata. Logging er like mye en kunst som en vitenskap, men å følge disse prinsippene bidrar til å holde logger konsistente og nyttige.
Før vi går videre, skal vi se litt på beslutningen om at trinnbehandleren skal være vert for logikken som trinnene brukes til. I en stor kodebase kan du vurdere å gjøre StepProcessor virtuell eller abstrakt, og få underklasser til å identifisere spesifikke trinn for å etablere en riktig adskillelse av bekymringer.
Planleggeren kaller til slutt opp Apex. Når resten av oppsettet er fullført, kan delen Kallbar Apex bestemme hvilke trinn som skal kjøres og overføre List<StepType> til prosessoren:
Dette er en enkel del av ligningen – bruk poster, data eller logikk til å bestemme hvilke trinntyper som skal kjøres. Den kallbare handlingen er enkel fordi vi innkapslet kompleksitet andre steder. Vi har også beskyttet mot uventede unntak og gjort det enkelt å teste hver bit isolert.
Apex Slack SDK er utenfor omfanget av denne artikkelen, men en potensiell trussel fra kravene bør ses på nytt: varsler personer oppover i rollehierarkiet basert på en konfigurerbar forsinkelse. På papiret er dette enkelt, og du kan (korrekt) vurdere System.enqueueJob(this) i StepProcessor. Med System.AsyncOptions, vår opprinnelige tilbøyelighet var å bruke enqueueJob overbelastning for å tilfredsstille dette kravet.
Foreløpig er imidlertid maksimal forsinkelse via System.AsyncOptions.MinimumQueueableDelayInMinutes 10 minutter. Fordi kravet er 120 minutter, gjenstår det noen alternativer. En naiv løsning kan se slik ut:
I praksis overføres forsinkelsen til denne klassen fordi forsinkelsen er konfigurasjonsdrevet.
Vi anbefaler ikke denne tilnærmingen med mindre du er sikker på at det noen gang vil være bare én type forsinket varsel. Det brenner gjennom 11 ekstra asynkrone jobber før du starter (eller mer hvis forsinkelsen øker). Denne kostnaden kan være god for én jobb – ikke for mange. Du må også legge til en metode i Step-grensesnittet slik at hvert trinn kan fortelle prosessoren hvor lenge det skal vente før du starter på nytt, noe som gir støy.
Det gir oss to interessante muligheter:
- Du kan lukke det forsinkede trinnet til det eksisterende jobbrammeverket hvis du allerede har en avspørringsjobb planlagt med et riktig intervall. Du bør også være OK med den angitte forsinkelsen når opptil 15 minutter senere (15 minutter er det minste oppdateringsintervallet for et Apex CRON-uttrykk). Dette samsvarer omtrent med eksempelet Kallbar Apex. Planleggingen utføres i stedet via Apex. Med andre ord kan du gjenbruke den samme
Step-baserte arkitekturen til å behandle poster basert på et Start etter-tidsstempel og bestemme hvilke trinn som skal brukes basert på en valgliste eller flervalgliste-tilordning tilbake tilStepType-oppføringsverdiene som ble vist tidligere. - Hvis du er komfortabel med å definere en ekstra ytre Apex-klasse, kan du eventuelt gå tilbake til gruppe-Apex (i motsetning til Apex i kø som støtter indre klasser, må gruppe-Apex-klasser være ytre klasser) ved bruk av
System.scheduleBatch().
Vurder Apex for grupper. Selv om vi generelt anbefaler Apex i kø for fleksibilitet og kontroll, er dette et tilfelle der batch Apex fremdeles hersker:
I StepProcessor kan du forestille deg at den tidligere viste addTypeOneSteps()-metoden oppdateres med dette forsinkede trinnet:
Vi anbefaler vanligvis ikke å hoppe så mye, men denne trinnforsinkelsen blir en annen gjenbrukbar byggeblokk. Til lengre forsinkelser er tillatt i Apex, representerer det også den enkleste måten å produsere denne effekten (uten en avspørringsmekanisme, som diskutert).
Vi har brukt objektorientert design til å oppfylle kravene og opprettet et system som skalerer samtidig som den langsiktige kostnaden for bygging og vedlikehold balanseres. Trinndeklarasjon og instansiering kan til slutt vokse ut av sin plass i StepProcessor, men det er lite ekstra teknisk gjeld her. Med FlowStep kan administratorer og utviklere sammen bestemme når ingen-kode- eller pro-kode-løsninger er mest fornuftige.
Ved å bruke System.Finalizer-grensesnittet i Apex 'købar-rammeverk, sammen med Nebula Logger, har vi bygget et robust, testbart system som varsler oss om uforutsette feil selv om fremtidige trinn mangler eksplisitt logging. For oss er dette systemet fornøyd med å knuse tall og redusere kostnad og kompleksitet. Den har også gitt oss verdifull innsikt i Apex virkemåte under reelle arbeidsbelastninger, som hjelper oss med å avgrense tilnærmingen vår samtidig som vi forbedrer selve funksjonen.
Ved å dekomponere komplekse arbeidsbelastninger med stor trafikk til modulære utførelsestrinn, transformerer rammeverket for trinnbasert asynkron behandling plattformbegrensninger til tekniske fordeler, noe som gir forutsigbar ytelse, observabilitet og styring i bedriftsskala. Trinn kan konfigureres av både administratorer og utviklere, og i begge tilfeller kan trinnforfattere trygt fokusere på å observere de grunnleggende plattformstyringsgrensene (som DML-rader og spørringsrader hentet) uten å måtte bekymre seg om hvordan hvert trinn skaleres.
For å operere og ta i bruk dette mønsteret på tvers av organisasjonsimplementasjoner, bør arkitekter
- Evaluer eksisterende automatiseringer for å identifisere områder der asynkron orkestrering kan bidra til å forbedre ytelsen og forbedre observerbarheten.
- Del opp store prosesser i diskrete, uavhengig utførbare trinn med klare behandlingsmål og diskrete forfatterpunkter (som Flyt eller Apex).
- Definer og grupper trinntyper for å øke hastigheten på gjenbruk av trinn og standardisering på tvers av forretningsenheter.
- Pilot tilnærmingen med nye prosesser eller eksisterende automatiseringer. Du vil kanskje bli overrasket over hvor mange kantsaker du finner gratis i trinnene, ta vare på den innebygde loggen og observasjonen!
James Simone er hovedprogramvareingeniør i Salesforce og har mer enn ti års erfaring med å arbeide på plattformen. Han var Salesforce-kunde – og produkteier – før han gikk over til utvikling, og har skrevet tekniske dypdykninger om Salesforce siden 2019 i The Joys Of Apex. Han har tidligere publisert artikler på Salesforce Developer-bloggen, og Salesforce Engineering-bloggen også.