Bruke de riktige verktøyene og mønstrene for hendelsesdrevne arkitekturer
Hendelsesdrevne arkitekturer støtter effektiv produksjon og forbruk av hendelser, som kommuniserer endringer i system- eller programtilstand. Disse arkitekturene muliggjør fleksible tilkoblinger mellom systemer og støtteprosesser og nær sanntidsoppdateringer som fungerer på tvers av systemer. Selvom fordelene ved hendelsesdrevne arkitekturer er lette at se, er implementeringsdetaljer ikke altid så tydelige. Hvilke funksjoner trenger du å vurdere i hendelsesdrevne arkitektoniske mønstre? Hvilke spesifikke problemer løser disse mønstrene? Hvilke spesielle vurderinger gjelder for løsningene, og hva er de optimale mønstrene for å håndtere dem?
Denne veiledningen viser mønstre som brukes til å bygge optimale hendelsesdrevne arkitekturer når du arbeider med Salesforce-teknologier. Den diskuterer også utløsende verktøy som er tilgjengelig fra Salesforce, og gir verktøyanbefalinger for et utvalg av brukstilfeller. Hvis du vil ha informasjon om datanivåintegrasjoner som involverer Salesforce, kan du se vår Data Integration Decision Guide.
-
Bruk hendelsesdrevne arkitekturer for prosesser som ikke krever synkrone svar på forespørsler. Mønstrene som er skissert i denne veiledningen, er utformet for datakonsistens, skalerbarhet og gjenbruk, noe som bidrar til å holde teknisk gjeld på et minimum etter hvert som organisasjonens applikasjonslandskap utvikler seg. (Se Well-Architected - Throughput for å få mer informasjon.)
-
Hvis MuleSoft eller en annen Enterprise Service Bus (ESB)-løsning er en del av ditt eksisterende landskap, bruker du den der det er mulig. Disse løsningene er spesialbygd for å støtte hendelsesdrevne arkitekturmønstre og har kraftige funksjoner som gir deg mulighet til å gjenbruke integrasjoner på tvers av virksomheten.
-
Bruk Pub/Sub API til fremtidige publiserings- eller abonnementsmønstre i stedet for å bygge dine egne hendelsesbehandlere ved bruk av andre API-er, inkludert Streaming API. Nå som Pub/Sub API er generelt tilgjengelig, bruker du det til eventuelle nye publiserings- eller abonnementsmønstre. Planlegg å overføre eksisterende hendelseskommunikasjon ved bruk av andre plattform-API-er, som Streaming API eller tilpassede Apex, til Pub/Sub API når det er mulig å gjøre det.
-
Plattformhendelser og endringsdatafangst (CDC) er de foretrukne mekanismene for publisering av post- og feltendringer som må forbrukes av andre systemer. Vi anbefaler at du ikke bruker Push-emne og generelle hendelser til nye implementeringer. Salesforce vil fortsatt støtte Push-emne og generelle hendelser innenfor gjeldende funksjonalitet, men har ikke planer om å gjøre ytterligere investeringer i denne teknologien.
 |
Salesforce Platform er en omfattende AI-drevet plattform som forener ansatte, autonome AI-agenter, firmadata og programmer i ett enkelt, pålitelig system for å forbedre produktiviteten og kundeopplevelsen. Den aktiverer opprettelse av et "agentistisk foretak" ved å koble til Customer 360, Data Cloud og Slack for ende-til-ende-automatisering. |
 |
MuleSoft er Salesforces ledende integrasjonsplattform som gjør det mulig for organisasjoner å koble til programmer, data og enheter på tvers av lokale og skymiljøer. MuleSoft er en plattform som gir IT-plattformene mulighet til å låse opp data på tvers av systemer, utvikle skalerbare integrasjons- og automatiseringsrammeverk og opprette differensierte, tilkoblede opplevelser – raskt. |
Hendelsesdrevne arkitekturer (EDA) anbefales for scenarier som krever varsler i nær sanntid, fordeler behandlingsbelastningen for store eller komplekse meldinger, og integrerer systemer som IoT og mobile enheter som krever tilkoblingsresiliens via køer. EDA-er bør imidlertid ikke implementeres for prosesser som krever umiddelbare, synkrone menneskelige svar, fordi de er utformet for asynkron utførelse. De passer heller ikke hvis kildedata endres så sjeldent at et enklere mønster som gruppebehandling ville være tilstrekkelig.
Her er flere vanlige scenarier som ofte passer godt for en hendelsesdrevet arkitektur:
| Beslutningspunkt | Veiledning |
|---|---|
| Nær sanntids varsler | Hendelsesdrevne arkitekturmønstre som publiser/abonnere, overfør og strømming har en tendens til å fungere godt i scenarier der flere programmer må varsles om statusendringer eller postoppdateringer i nær sanntid. |
| Parallell behandling | Mønstre som publisere/abonnere har en tendens til å fungere godt i scenarier der store datavolumer eller svært komplekse meldinger krever fordeling av behandlingsbelastningen mellom flere systemer. |
| Høyvolumleser | Mønstrene for sendte meldinger og køer brukes vanligvis i scenarier der organisasjoner opplever høyde, og volumet av meldinger som produseres, kan overskride abonnenters mulighet til å behandle dem umiddelbart. |
| Skriver med stor trafikk | Mønstrene for strømming og å legge i kø fungerer godt i mange scenarier der organisasjoner opplever høyere antall produserte meldinger. |
| Sende de samme dataene til forskjellige systemer | Publisere/abonnere har en tendens til å være en ganske vanlig løsning for organisasjoner som trenger å sende de samme dataene til flere systemer, men det kan løses av de fleste mønstrene som dekkes her. Pass på å se gjennom dem i detalj for å finne den som passer best. |
| Ofte innføring av nye systemer eller anordninger | Mønstrene publisere/abonnere, strømme og legge i kø fungerer vanligvis bra for scenarier der det generelle landskapet har en tendens til å være i flyt, med nye systemer og enheter som legges til regelmessig. I dette scenariet trenger et nytt system eller enhet bare å bli abonnent på hendelsesbussen eller knyttet til en kø for å begynne å motta meldinger i stedet for å kreve en tilpasset punkt-til-punkt-integrering. |
| IoT-enheter | I og med at IoT-enheter vanligvis leverer hyppige oppdateringer og også kan generere en strøm av meldinger i enkelte scenarier, fungerer strømmings- og kømønstrene vanligvis godt når de integreres i et IT-landskap. |
| Offline mobile enheter og systemer | Mobilenheter som trenger å arbeide i områder med lav kvalitet eller ingen internettilgang eller systemer som kan være offline på det tidspunktet meldinger leveres, vil dra nytte av kømønsteret, som gir dem mulighet til å koble til køene sine og hente eventuelle relevante meldinger når de er online igjen. |
De fleste store organisasjoner har komplekse IT-landskap som har en kombinasjon av systemer med ulik funksjonalitet. Det er mulig, eller sannsynligvis, at organisasjonen har eldre systemer som ikke støtter hendelsesdrevne integrasjoner. Du kan også ha brukstilfeller der hendelsesdrevne integrasjoner ikke gir mening, selv om systemene støtter dem (for eksempel SFTP-filoverføringer fra tredjeparter). Hvis du tar et skritt tilbake og ser på organisasjonens IT-landskap som helhet, er det sannsynligvis – på samme måte som med andre arkitektoniske løsninger – at du bruker en blanding av mønstre til å støtte forskjellige scenarier. Når du bestemmer deg for å gjøre hendelsesdrevet til den foretrukne tilnærmingen til integrasjoner, kan du tenke på det som et annet verktøy i verktøykassen din. Den kan og bør brukes i de riktige scenariene, men den er ikke en tilnærming som skal håndheves på alle systemer. Utvikling av en omfattende integreringsstrategi vil hjelpe deg med å finne ut når mønstrene som er beskrevet i denne veiledningen, kan være eller ikke være riktige.
Mange scenarier krever hendelsesdrevne arkitekturer, og i noen scenarier vil hendelsesdrevne arkitekturer fungere selv om de ikke passer best. Men i noen scenarier bør hendelsesdrevne arkitekturer bare ikke brukes. Her er noen beslutningsspørsmål som kan hjelpe deg å identifisere disse scenariene:
| Beslutningspunkt | Veiledning/spørsmål å stille |
|---|---|
| Forretningskrav | Er det et reelt forretningsbehov for noen av funksjonene som er beskrevet i delen [Når skal en hendelsesdrevet arkitektur brukes](#når-skal-en-hendelsesdrevet-arkitektur-brukes)? |
| Tekniske krav | Er integrasjonen du utformer, tydelig egnet for et annet mønster, som datavirtualisering, batch eller forespørsel/svar? Prøver du med andre ord å plassere en hakepinne i et rundhull? |
| Prosesser som krever at mennesker venter på svar | Eventuelle integrasjoner som involverer en person som venter på et svar fra målsystemet, passer ikke godt for hendelsesdrevne arkitekturer fordi de er utformet for asynkron utførelse og ikke kan garantere responstid. Vurder om prosesser som dette er optimale for organisasjonen før du implementerer tekniske løsninger. Se [Well-Architected - Process Design](/docs/architect/nb-no/well-architected/guide/automated#prosessutforming) for å få mer informasjon. |
| Ofte endrede kildedata | Hvis dataene i kildesystemet endres så sjeldent at periodiske oppdateringer er tilstrekkelige, kan du sannsynligvis forenkle arkitekturen ved å bruke [batchmønstre](https://developer.salesforce.com/docs/atlas.en-us.integration_patterns_and_practices.meta/integration_patterns_and_practices/integ_pat_batch_data_sync.htm) i stedet for hendelsesdrevne mønstre. |
| Krav til gjennomføring | Støtter de fleste systemer som er involvert i løsningen, hendelsesdrevne arkitekturer? Hva kreves for å bruke hendelsesdrevne arkitekturer med systemer som ikke støtter dem (for eksempel oppgraderinger, tilpassinger eller mellomprogramvare)? Hvilket innsatsnivå kreves for å oppfylle disse kravene? |
| Meldingsstruktur stabilitet | Hvor ofte må meldingsstrukturene endres? Hvilke systemer vil bli berørt av en slik endring, og hva vil rettelsesprosessen være? |
| Organisasjonsstyring | Har du en styringsstruktur på plass for å sikre at alle interessenter er informert om og kan veie inn endringer i meldingsstrukturer, utløsere og andre arkitektur- og prosessrelaterte beslutninger? |
| Nødvendige kvalifikasjonssett | Har ansatte erfaring med hendelsesdrevne arkitekturer, og vil de vite hvordan de kan støtte dem? |
Det finnes en rekke hendelsesdrevne arkitekturmønstre. Noen er generelle formålsmønstre som kan brukes i bruksområder som ikke har noen spesielle krav, bortsett fra å være hendelsesdrevet, for eksempel se Well-Architected - Interoperability. Andre mønstre gjelder for de spesifikke brukstilfellene som diskuteres her, som integrasjoner som involverer store datavolumer, eller scenarier som krever lengre meldingsoppbevaring.
Tabellen nedenfor sammenligner attributtene til mønstrene som er skissert i dette dokumentet. Bruk den som en hurtigreferanse når du trenger å identifisere potensielle mønstre for et gitt bruksområde.
| Mønster | I nærheten av sanntid | Unik meldingskopi | Garantilevering | Reduser meldingsstørrelse | Transformere data |
|---|---|---|---|---|---|
| Publisere / abonnere | ✓ | ✓ | ✓ | ||
| Fanout (Fanout) | ✓ | ✓ | ✓ | ||
| Sendte meldinger | ✓ | ✓ | ✓ | ✓ | |
| Streaming | ✓ | ✓ | ✓ | ||
| Legge i kø | ✓ | ✓ | ✓ |
Salesforce tilbyr flere verktøy for å hjelpe deg med hendelsesdrevne brukstilfeller. Denne tabellen inneholder en generell oversikt over tilgjengelige verktøy.
| Verktøy | Beskrivelse | Nødvendige kvalifikasjoner | |
|---|---|---|---|
| MuleSoft | Anypoint Platform | Plattform som aktiverer dataintegrering ved bruk av lag med API-er. | Pro-kode |
| Salesforce Pub/Sub-kobling | Kobling for Pub/Sub API, som gir et enkelt grensesnitt for publisering og abonnement på plattformhendelser, hendelser for hendelsesovervåking i sanntid og hendelser for datafangst av endringer. | Pro-kode | |
| MuleSoft Anypoint JMS-kobling | Kobling som aktiverer sending og mottak av meldinger til køer og emner for alle meldingstjenester som implementerer JMS-spesifikasjonen (Java Message Service). | Pro-kode | |
| MuleSoft Anypoint Apache Kafka-kobling | Kobling for å flytte data mellom Apache Kafka og bedriftsprogrammer og -tjenester. | Pro-kode | |
| MuleSoft Anypoint Solace-kobling | En kobling for Solace PubSub+-hendelsesmeglere med innebygd API-integrering ved bruk av JCSMP Java SDK | Pro-kode | |
| MuleSoft Anypoint MQ-kobling | En skymeldingstjeneste for flere leietagere som gir kunder mulighet til å utføre avanserte asynkrone meldinger blant sine programmer. | Pro-kode | |
| MuleSoft Anypoint MQTT-kobling | En MQTT (Melding Queuing Telemetry Transport) v3.x-protokollkompatibel MuleSoft-utvidelse. | Pro-kode | |
| MuleSoft Anypoint AMQP-kobling | En kobling som gir programmet mulighet til å publisere og bruke meldinger med en AMQP 0.9.1-kompatibel megler. | Pro-kode | |
| MuleSoft Anypoint hendelsesdrevet (ASync) API | Bransjeagnostisk språk som støtter publisering av hendelsesdrevne API-er ved å skille dem i hendelses-, kanal- og transportlag. | Pro-kode | |
| MuleSoft Anypoint MQ | Multitenant skymeldingstjeneste som gir kunder mulighet til å utføre avanserte asynkrone meldinger mellom sine programmer. | Pro-kode | |
| MuleSoft Anypoint-datastrømmer | Rammeverk tilgjengelig i MuleSoft Anypoint for publisering og abonnement på strømmedata. | Pro-kode | |
| Salesforce Platform | Apache Kafka på Heroku | Heroku-tillegget som tilbyr Apache Kafka som en tjeneste med full plattformintegrering i Heroku-plattformen. | Pro-kode |
| Change Datafangst | Endringshendelseslogg, som publiserer endringer i Salesforce-poster. Endringer inkluderer opprettelse av en ny post, oppdatering av en eksisterende post, sletting av en post og oppheving av sletting av en post. | Lavkode til Pro-kode | |
| Utgående meldinger | Handlinger som sender XML-meldinger til eksterne endepunkter når feltverdier oppdateres i Salesforce. | Lavkode | |
| Plattformhendelser | Sikker og skalerbar melding som inneholder tilpassede hendelsesdata. | Lavkode til Pro-kode | |
| Pub/Sub API | API som aktiverer abonnementer på plattformhendelser, Hendelser for datafangst og/eller Hendelsesovervåking i sanntid. | Pro-kode | |
| Event Relays | Gir mulighet til å sende plattformhendelser og hendelser for datafangst av endringer fra Salesforce til Amazon EventBridge. Vær oppmerksom på at Hendelsesoverføringer kobler bare til AWS Eventbridge. | Lavkode | |
Når en viktig post endrer status i et kjerneprogram – en bestillings status flyttes for eksempel fra Behandler til Sendt – krever flere andre systemer sannsynligvis et varsel i nær sanntid for å utføre sine respektive oppgaver. Et bestemt forretningsbehov oppstår når volumet av disse endringene er stort og meldingene er komplekse, noe som gjør tradisjonelle punkt-til-punkt-integrasjoner omfattende og vanskelige å vedlikeholde. Opprettelse av skjøre, tilpassede tilkoblinger for hvert enkelt avhengig program fører til teknisk gjeld og hindrer organisasjonens mulighet til å skalere raskt. Det er nødvendig med en robust integreringstilnærming for å behandle disse hyppige datasynkroniseringene uten å koble kildesystemet direkte til alle forbrukersystemer.
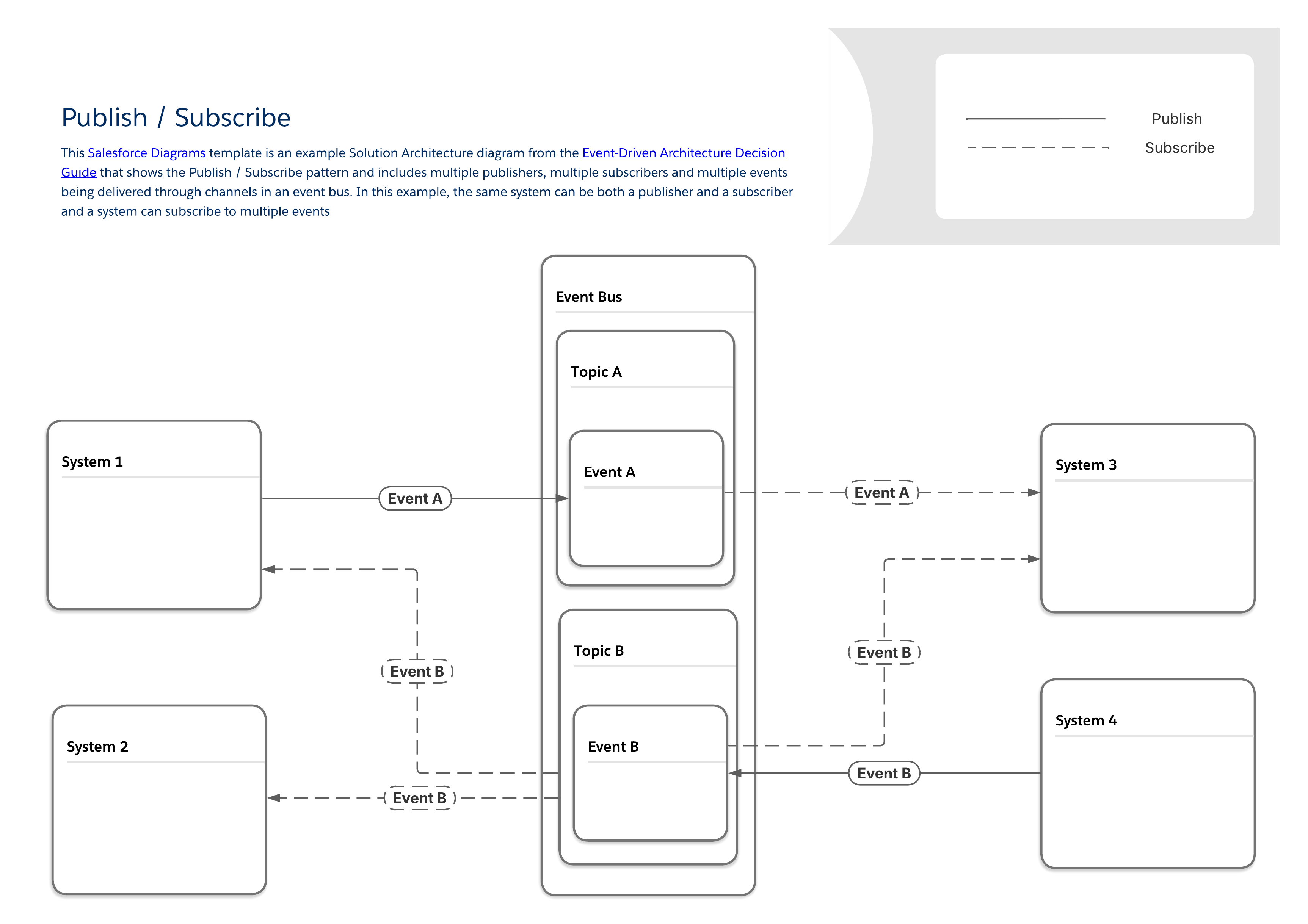
Diagrammet nedenfor viser et typisk publiserings- og abonnementsmønster der flere utgivere og abonnenter deler data via en hendelsesbuss. Dette grunnmønsteret danner grunnlaget for de mer spesifikke mønstrene som finnes i resten av denne veiledningen. Noen viktige egenskaper for dette mønsteret er:
-
Det er ingen direkte tilkobling mellom utgivere og abonnenter. Utgivere sender bare meldinger til en hendelsesbuss, som kringkaster dem til alle andre systemer som ønsker å lytte etter dem.
-
Det samme systemet kan være både en publisering og en abonnent.
-
Systemer kan publisere eller abonnere på flere typer hendelser.
-
Som med alle mønstrene i denne veiledningen, faller publisere / abonnere mønsteret inn i en generell integrasjonsmønster kategori kjent som ekstern prosedyre oppkall (RPI) eller bare "fire and forget."
| Hendelsesflyt og virkemåte | Belastningsvurderinger | ||||||
|---|---|---|---|---|---|---|---|
| Tilgjengelige verktøy | Nødvendige kvalifikasjoner | Publiser via | Abonnere via | Avspillingsperiode | Belastningsstruktur | Belastningsgrenser | |
| MuleSoft | Anypoint Platform | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen |
| Salesforce Pub/Sub-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint JMS-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint Apache Kafka-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint Solace-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint MQ-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint MQTT-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint AMQP-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint hendelsesdrevet (ASync) API | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint MQ | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| Salesforce Platform | Apache Kafka på Heroku | Pro-kode | API-er, postendringer i Heroku Postgres | N/A | 1-6 uker | Bruker definert | Bruker definert |
| Change Datafangst | Lavkode til Pro-kode | Postendringer | Apex, API-er, Lightning (LWC) | 3 dager | Forhåndsdefinert | 1 MB | |
| Utgående meldinger* | Lavkode | Flyt- og arbeidsflytregler | N/A | 24 timer | Bruker definert | 100 varsler per melding | |
| Plattformhendelser | Lavkode til Pro-kode | API-er, Apex, Flyt | Apex, APIs, Flow, LWC | 3 dager | Bruker definert | 1 MB | |
| Pub/Sub API | Pro-kode | Pub/Sub API eller API-er, Apex, Flyt | Pub/Sub API | 3 dager | Bruker definert | 1 MB | |
| Event Relays** | Lavkode | Plattformhendelser, datafangst | API | 3 dager | Bruker definert | 1 MB | |
| *Salesforce vil fortsatt støtte utgående meldinger innenfor gjeldende funksjonell funksjonalitet, men har ikke planer om å gjøre ytterligere investeringer i denne teknologien. **Event Relays kobler bare til AWS Eventbridge | |||||||
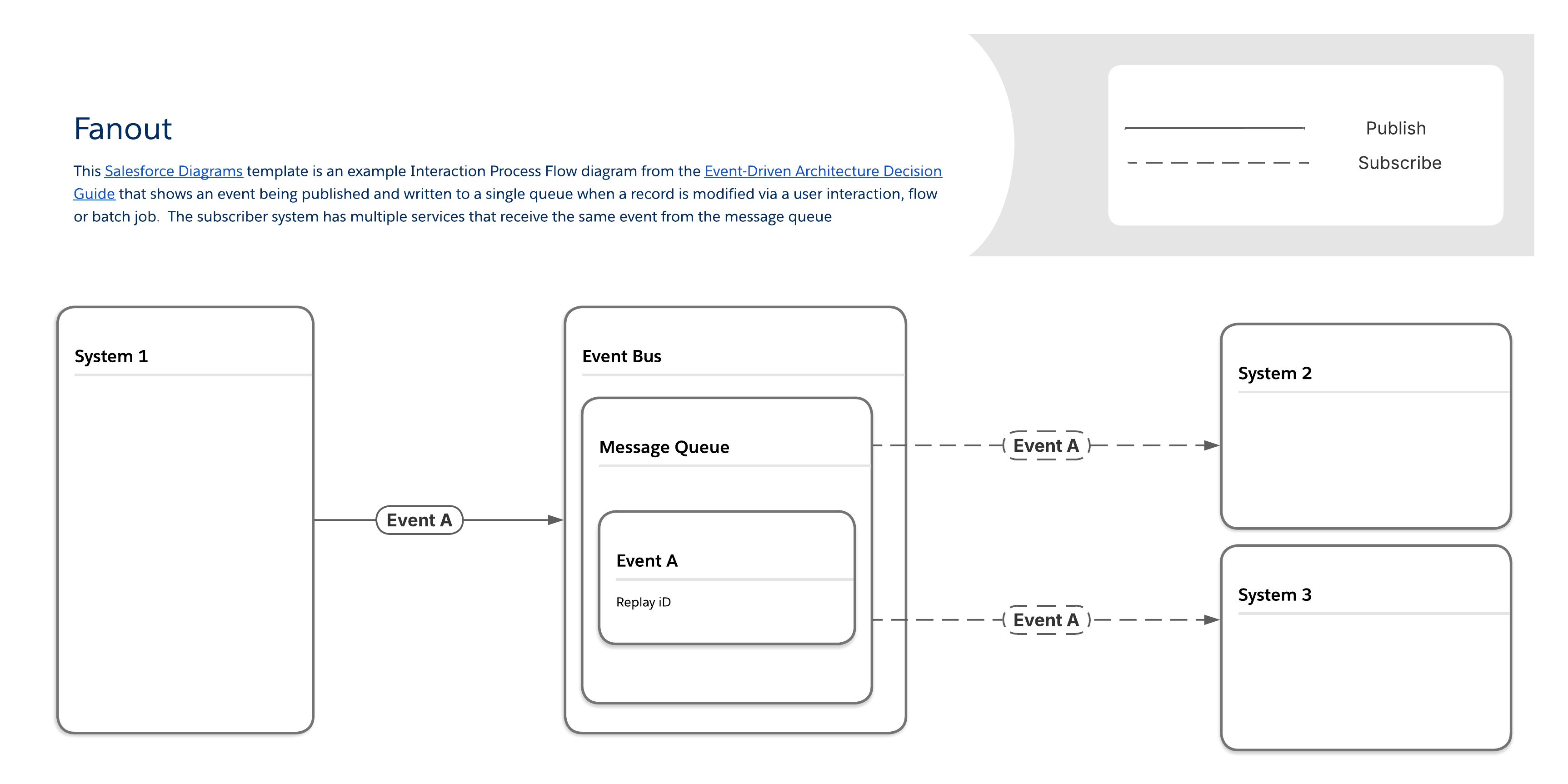
Når en organisasjon trenger å sende umiddelbare oppdateringer til et stort antall klientprogrammer, som push-varsler eller SMS-meldinger til mobilenheter, blir den tradisjonelle prosessen med å opprette unike overføringer for hver enkelt mottaker raskt en flaskehals for skalerbarhet. Kjerneforretningsbehovet i dette tilfellet er rask, høyytelsesdistribusjon av en enkelt bit informasjon – som et kontovarsel eller et varsel om viktig tjenesteendring – til mange endepunktsprogrammer samtidig. En strømlinjeformet løsning for å oppfylle dette kravet involverer ruting av alle meldinger gjennom en enkelt kø, som fungerer som det sentrale punktet for hendelsesinformasjon for alle forbrukersystemer. Denne tilnærmingen forbedrer ytelsen ved å eliminere behovet for å behandle mange separate meldingskopier.
Med fanout-mønsteret leveres meldinger til én eller flere mål (det vil si lytterklienter eller abonnenter) via en enkelt meldingskø. Abonnenter henter den samme meldingen fra køen i stedet for sin egen unike kopi. (Vær oppmerksom på at selv om dette forbedrer ytelsen, kan det også gjøre det vanskeligere å bekrefte om en bestemt abonnent har mottatt meldingen eller ikke.)
| Hendelsesflyt og virkemåte | Belastningsvurderinger | ||||||
|---|---|---|---|---|---|---|---|
| Tilgjengelige verktøy | Nødvendige kvalifikasjoner | Publiser via | Abonnere via | Avspillingsperiode | Belastningsstruktur | Belastningsgrenser | |
| MuleSoft | MuleSoft Anypoint JMS-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen |
| Salesforce Pub/Sub-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint Apache Kafka-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint Solace-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint MQ-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint MQTT-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint AMQP-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint MQ | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| Salesforce Platform | Apache Kafka på Heroku | Pro-kode | API-er, postendringer i Heroku Postgres | N/A | 1-6 uker | Bruker definert | Bruker definert |
| Change Datafangst | Lavkode til Pro-kode | Postendringer | Apex, API-er, Lightning (LWC) | 3 dager | Forhåndsdefinert | 1 MB | |
| Plattformhendelser | Lavkode til Pro-kode | API-er, Apex, Flyt | Apex, APIs, Flow, LWC | 3 dager | Bruker definert | 1 MB | |
| Pub/Sub API | Pro-kode | Pub/Sub API eller Apex, APIer, Flyt | Pub/Sub API | 3 dager | Bruker definert | 1 MB | |
| Event Relays* | Lavkode | Plattformhendelser, datafangst | API | 3 dager | Bruker definert | 1 MB | |
| *Event Relays sender data bare til AWS Eventbridge | |||||||
Enkelte hendelsesscenarier er preget av en betydelig innstrømning av meldingsvolum som truer med å overvelde kapasiteten til synkroniserings- og transformasjonsprosesser, eller av kompleks logikk med flere trinn som kreves for å behandle og transformere hendelsesdata.
Noen eksempler er:
-
Seasonal volume spikes: Det kan være økte volumer som nettbutikker opplever når et utvalg av produktene deres er "i sesongen". Når et stort antall kunder foretar kjøp samtidig, kan antall genererte hendelser midlertidig overskride kapasiteten til synkroniserings- og transformasjonsprosesser. Se Well-Architected - Data Handling for å få mer informasjon.
-
Sak eller kravbehandling: Tjenestebaserte firmaer kan oppleve en økning i antall saker eller krav under avbrudd.
-
Komplekse datatransformasjoner: Organisasjoner som krever kompleks logikk for å transformere meldinger, er ofte bekymret for at hendelser genereres raskere enn de kan transformeres.
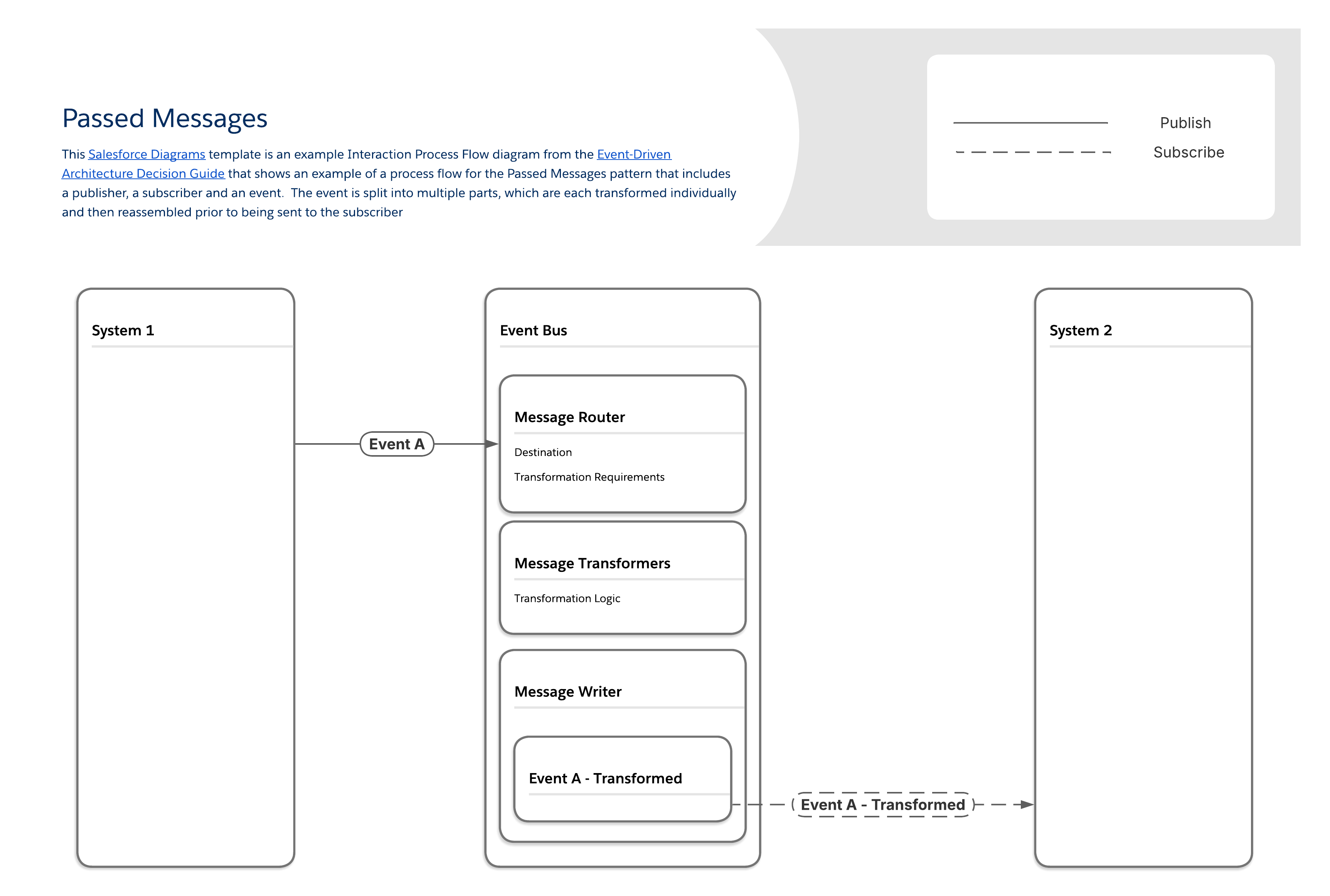
Dette mønsteret løser utfordringen med at meldinger genereres raskere enn de kan transformeres. Den sikrer at store mengder meldinger og nødvendige datamanipulasjoner kan håndteres pålitelig ved å innlemme en strømmeldingsplattform og segmentere meldingsbehandlingslogikk i dedikerte komponenter.
Mønsteret Overførte meldinger fungerer ved å segmentere håndteringslogikk for meldinger i flere komponenter:
-
Én komponent håndterer meldingsruting og bestemmer nødvendige transformasjoner og det endelige målet.
-
Et separat sett komponenter håndterer forskjellige lag av meldingstransformasjon (for eksempel felttilordninger, objektrelasjoner og så videre).
-
Den siste komponenten skriver ut den endelige, endrede meldingen.
| Hendelsesflyt og virkemåte | Belastningsvurderinger | ||||||
|---|---|---|---|---|---|---|---|
| Tilgjengelige verktøy | Nødvendige kvalifikasjoner | Publiser via | Abonnere via | Avspillingsperiode | Belastningsstruktur | Belastningsgrenser | |
| MuleSoft | MuleSoft Anypoint Apache Kafka-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen |
| Salesforce Pub/Sub-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| Salesforce Platform | Apache Kafka på Heroku | Pro-kode | API-er, postendringer i Heroku Postgres | N/A | 1-6 uker | Bruker definert | Bruker definert |
| Change Datafangst | Lavkode til Pro-kode | Postendringer | Apex, API-er, Lightning (LWC) | 3 dager | Forhåndsdefinert | 1 MB | |
| Plattformhendelser | Lavkode til Pro-kode | API-er, Apex, Flyt | Apex, APIs, Flow, LWC | 3 dager | Bruker definert | 1 MB | |
| Pub/Sub API | Pro-kode | Pub/Sub API eller API-er, Apex | Pub/Sub API | 3 dager | Bruker definert | 1 MB | |
| Event Relays* | Lavkode | Plattformhendelser, datafangst | API | 3 dager | Bruker definert | 1 MB | |
| *Event Relays sender data bare til AWS Eventbridge | |||||||
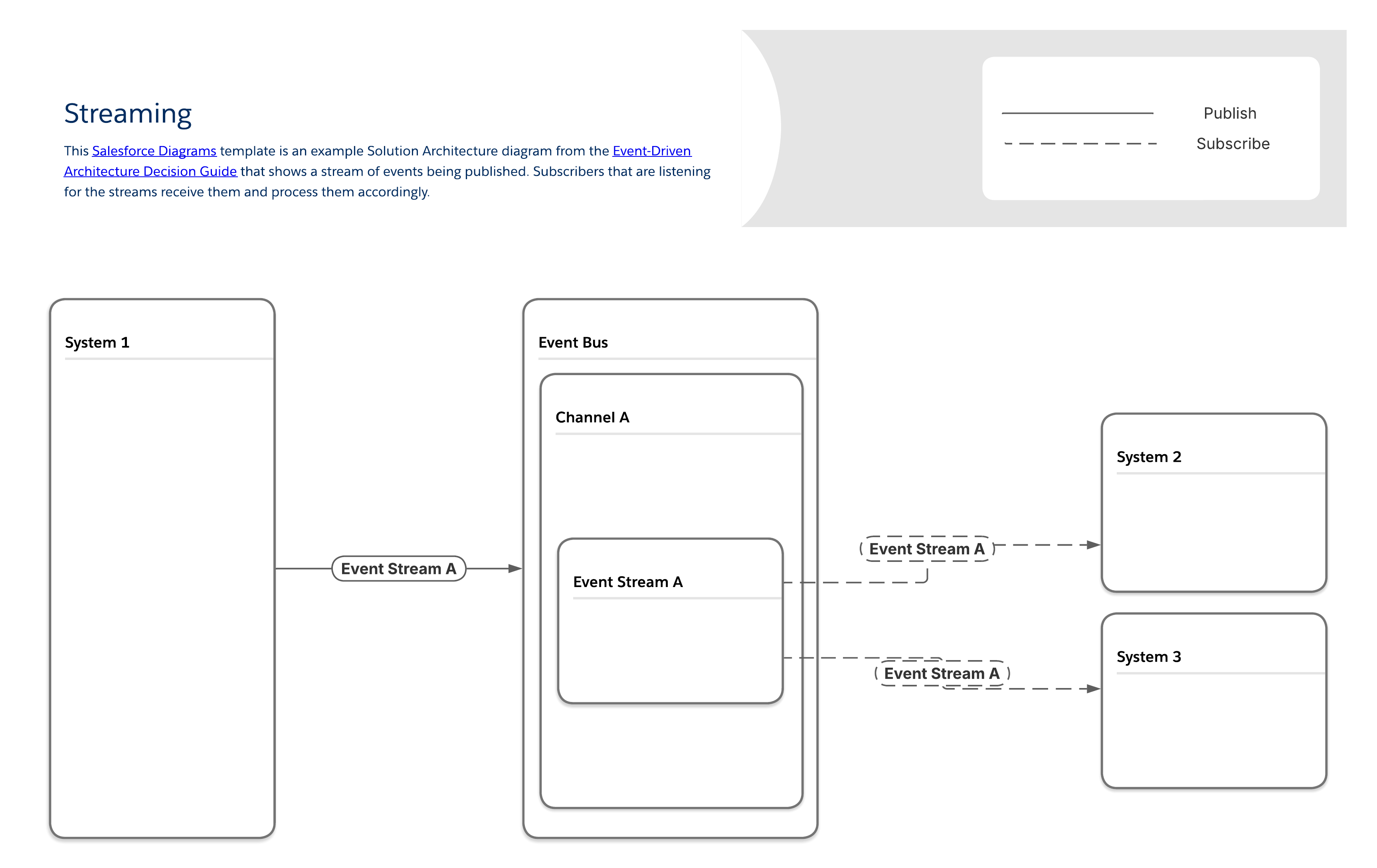
Enkelte produsenter genererer en kontinuerlig strøm av hendelser. Et vanlig eksempel er mediestrømming, som involverer brukerinteraksjoner som naturlig skjer som diskrete hendelser. Flere systemer må reagere på samme brukervirkemåte samtidig uten å blokkere kjernesporingsopplevelsen.
Vurder hendelsene for en musikkstrømmingsplattform. Disse kan inkludere følgende:
-
Spore begynnede / midlertidig stansede / hoppet hendelser
-
Overhøre økthendelser med tidsstempler
-
Hendelser for opprettelse/endring av spillelister
-
Sosiale delingshendelser
-
Last ned for offline lytting
I strømmemønsteret får abonnenter tilgang til hver hendelsesstrøm og behandler hendelsene i den nøyaktige rekkefølgen de mottas i. Unike kopier av hver meldingsstrøm sendes til hver abonnent slik at det blir mulig å levere abonnentspesifikt innhold og å identifisere hvilke abonnenter som mottar hvilke strømmer.
| Hendelsesflyt og virkemåte | Belastningsvurderinger | ||||||
|---|---|---|---|---|---|---|---|
| Tilgjengelige verktøy | Nødvendige kvalifikasjoner | Publiser via | Abonnere via | Avspillingsperiode | Belastningsstruktur | Belastningsgrenser | |
| MuleSoft | MuleSoft Anypoint-datastrømmer | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen |
| Salesforce Pub/Sub-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint Apache Kafka-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| Salesforce Platform | Apache Kafka på Heroku | Pro-kode | API-er, postendringer i Heroku Postgres | N/A | 1-6 uker | Bruker definert | Bruker definert |
| Pub/Sub API | Pro-kode | Pub/Sub API eller API-er, Apex | Pub/Sub API | 3 dager | Bruker definert | 1 MB | |
For at en strøm skal få mening må alle dens hendelser og tilknyttede meldinger være i riktig rekkefølge. Hvis du kildedataene i en strøm fra forskjellige systemer, må du ta med ytterligere bestillingslogikk som en del av utformingsprosessen.
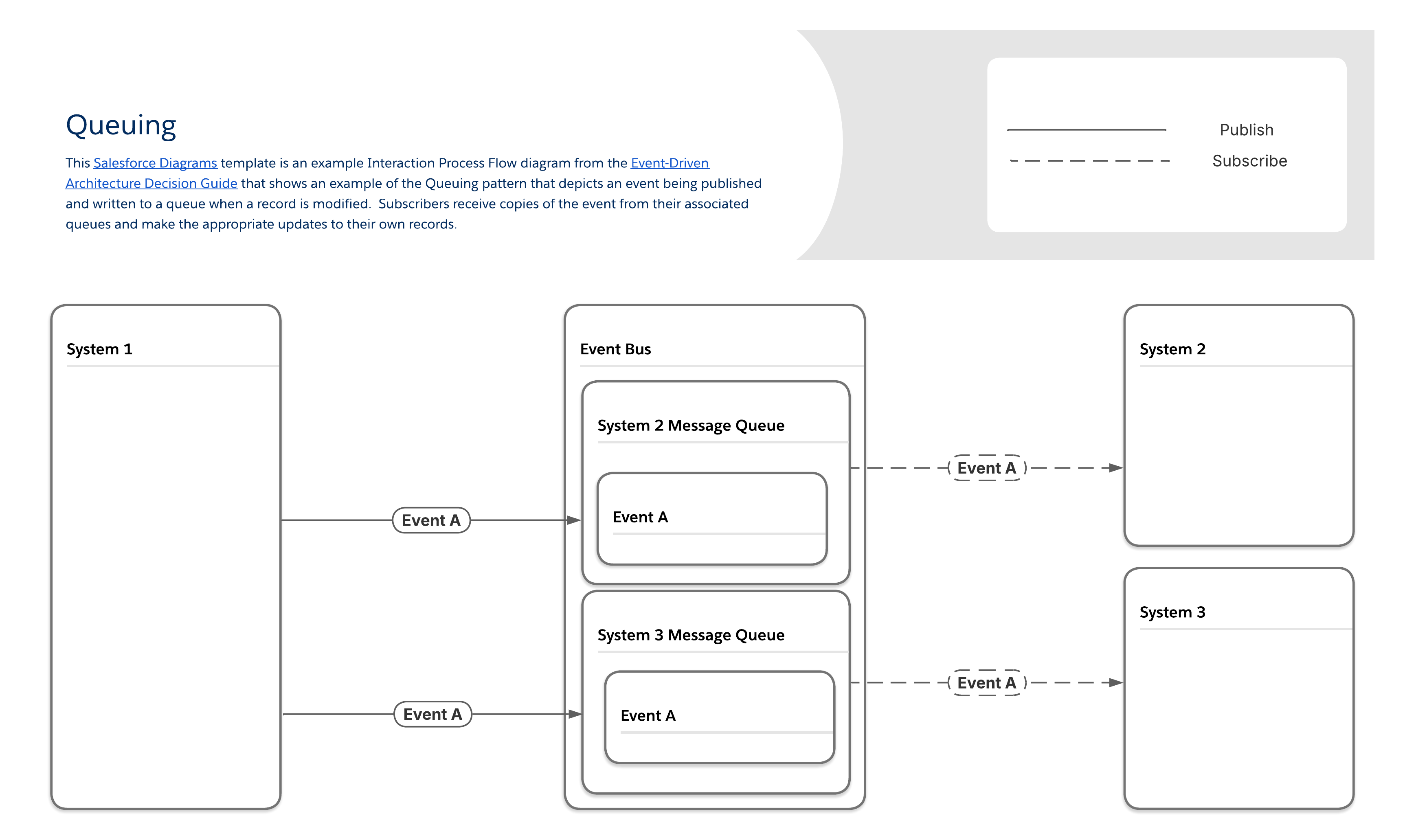
Brukstilfeller med køer finnes overalt. Eksempler er:
-
Lave kvalitet Internett-tilkoblinger: Felttjenesteorganisasjoner eller andre organisasjoner der team med mobilenheter må arbeide i områder med lav kvalitet eller intermitterende internettilgang, drar nytte av køer fordi programmene på disse enhetene kan koble til køene sine og hente eventuelle relevante meldinger når tilkoblingen gjenopprettes.
-
Meldingsbufring: Når meldingsvolumet av og til overskrider en abonnents behandlingskapasitet og økt latens ikke fører til flere problemer, kan køer være en buffer for å lagre overskuddsmeldinger og hindre tap av data.
-
Transportstyring: Logistiske organisasjoner som trenger å overvåke sine flåter, kan bruke dette mønsteret til å vise rutene hvert kjøretøy tar i nær sanntid og sikre at førerne er så effektive som mulig.
-
IoT-enheter: Produsenter bruker ofte systemer som genererer raske datastrømmer, og disse strømmene kan ha nedstrømsvirkninger på flere systemer. Dette mønsteret kan brukes til å identifisere sekvenser av hendelser som krever menneskelig intervensjon før katastrofale feil som spenner over flere systemer, oppstår.
I kømønsteret sender produsenter meldinger til køer, som beholder meldingene til abonnenter henter dem. De fleste meldingskøer følger bestilling av første inn og første ut (FIFO) og sletter alle meldinger etter at de har blitt hentet. Hver abonnent har en unik kø, som krever flere konfigureringstrinn, men gjør det mulig å garantere levering og identifisere hvilke abonnenter som mottar hvilke meldinger.
| Hendelsesflyt og virkemåte | Belastningsvurderinger | ||||||
|---|---|---|---|---|---|---|---|
| Tilgjengelige verktøy | Nødvendige kvalifikasjoner | Publiser via | Abonnere via | Avspillingsperiode | Belastningsstruktur | Belastningsgrenser | |
| MuleSoft | MuleSoft Anypoint MQ | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen |
| Salesforce Pub/Sub-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint Apache Kafka-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint MQ-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint MQTT-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| MuleSoft Anypoint AMQP-kobling | Pro-kode | APIs | APIs | Slik konfigurert | Bruker definert | Ingen | |
| Salesforce Platform | Apache Kafka på Heroku | Pro-kode | API-er, postendringer i Heroku Postgres | N/A | 1-6 uker | Bruker definert | Bruker definert |
| Change Datafangst | Lavkode til Pro-kode | Postendringer | Apex, API-er, Lightning (LWC) | 3 dager | Forhåndsdefinert | 1 MB | |
| Plattformhendelser | Lavkode til Pro-kode | API-er, Apex, Flyt | Apex, APIs, Flow, LWC | 3 dager | Bruker definert | 1 MB | |
| Pub/Sub API | Pro-kode | Pub/Sub API eller API-er, Apex, Flyt | Pub/Sub API | 3 dager | Bruker definert | 1 MB | |
| Event Relays* | Lavkode | Plattformhendelser, datafangst | API | 3 dager | Bruker definert | 1 MB | |
| *Event Relays sender data bare til AWS Eventbridge | |||||||
På grunn av den asynkrone naturen til kømønsteret kan det være en lang forsinkelse mellom en melding som legges til i en kø, og denne meldingen som hentes. Køer krever minne eller lagringsplass for å inneholde meldingene sine, så de kan ikke vokse på ubestemt tid, noe som betyr at en abonnent som er offline på ubestemt tid, kan føre til feil hvis nok meldinger bygges opp i køen. Meldingsbufring kan ha samme effekt hvis abonnentbehandlingstider blir for lange, noe som fører til at store mengder meldinger bygges opp i køene deres. For å redusere disse risikoene utfører du en grundig analyse av lagringskravene for alle meldingskøer og om nødvendig utformer prosesser som vil fjerne og deaktivere køer hvis meldinger ikke hentes innen en angitt tidsperiode eller når de når et forhåndsbestemt volum.
Selv om du er helt overbevist om at en hendelsesdrevet arkitektur er riktig for organisasjonen, kan det hende du starter med et landskap som allerede har et stort antall punkt-til-punkt-integrasjoner. Det kan være vanskelig å få finansiering for et prosjekt for å erstatte alle integrasjonene samtidig, og det kan ikke være mulig å bruke en hendelsesdrevet arkitektur direkte med noen eldre systemer. I disse scenariene kan du ta en trinnvis tilnærming til overføring til en mer løst koblet arkitektur ved å konvertere de mest forretningskritiske programmene først, og deretter konvertere andre systemer etter hvert som de blir oppdatert eller erstattet i fremtidige prosjekter. Denne tilnærmingen gjør det enkelt å legge til nye programmer i hendelsesbussen, og gir det generelle IT-landskapet muligheten til å forbli skalerbart og fleksibelt etter hvert som systemer fortsetter å bli lagt til over tid.
Som arkitekter vet vi at alle arkitekturer har avveininger. En hendelsesdrevet arkitektur er ikke noe unntak. Selv om et landskap fullt av løst koblede systemer er svært skalerbart og elastisk, er det også noen avveininger å vurdere:
-
Samlet integrasjonsstrategi: Uavhengig av verktøyene og mønstrene du bestemmer deg for å bruke, er det viktig å starte med å opprette en strategi for hvordan data skal deles på tvers av de ulike systemene i organisasjonens landskap. Denne strategien bør inkludere organisasjonens mål for dataene, hvordan data kan deles og mønstre som brukes, i tillegg til datakilder, mål, strukturer og eierskaps- og tilgangskrav.
-
Støtte for eldre systemer: Organisasjonen kan ha eldre systemer som bare ikke støtter hendelsesdrevne arkitekturmønstre. Selv om det kan være mulig å bygge omgåelser (for eksempel med en prosess som fungerer som en gjennomgang ved å abonnere på hendelser og deretter sende utdataene til målsystemet via en annen metode for dataoverføring), kan det hende du vil vurdere andre integrasjonsmetoder i dette tilfellet.
-
Strukturelle endringer i meldinger: Når den første meldingsstrukturen er definert og avtalt mellom utgivere og abonnenter, kan det være vanskelig å endre den, spesielt hvis abonnentene er eksterne. Det finnes flere måter å løse dette problemet på. Du kan bruke versjonsdelpunkter, men pass på å definere og kommunisere en tydelig livssyklus for hver versjon, slik at utviklerne ikke trenger å vedlikeholde for mange versjoner samtidig. Hvis Apache Kafka på Heroku er en del av landskapet, kan du også vurdere et skjemaregister eller lignende verktøy, men forsikre deg om at de andre systemene i landskapet støtter det (og bruker det) også.
-
Mangel på synlighet mellom utgivere og abonnenter: I de fleste hendelsesdrevne arkitekturmønstre er ikke utgiverne klar over statusen til abonnentene sine. Så hvis en publisering sender en viktig melding mens alle abonnenter er offline, kan det hende meldingen aldri blir levert. Du kan løse dette problemet ved å bruke repetisjonsfunksjonalitet eller legge til overflødige abonnenter som kjører på separate servere for alle viktige meldinger.
-
Ytelsesflaskehalser: Etter hvert som en hendelsesdrevet arkitektur skaleres, kan hendelsesbussen bli en flaskehals for meldingslevering hvis den blir overveldet med for mange utgivere som prøver å sende meldinger til for mange abonnenter samtidig. Du kan løse dette ved å øke minnet og behandlingsressursene som er tildelt hendelsesbussen, eller ved å bruke flere hendelsesbusser til å behandle forskjellige typer meldinger parallelt.
Før du implementerer en hendelsesdrevet arkitektur bør du vurdere om du virkelig trenger å bruke en i utgangspunktet. Den forrige delen beskriver vanlige forretningsscenarier som passer bra for hvert hendelsesdrevet arkitekturmønster. Du kan også lese mer i Well-Architected - Interoperability. Se gjennom utfordringer som bør vurderes når du implementerer hendelsesdrevne arkitekturer, for å finne ut om mønstrene du har i tankene, er best egnet for de spesifikke brukstilfellene.
Vær oppmerksom på at selv om de fleste av scenariene som dekkes i denne veiledningen, involverer integrasjoner, kan hendelsesdrevne arkitekturer også brukes til å sende meldinger i en enkelt Salesforce-organisasjon, for eksempel ved bruk av plattformhendelser. Pass på å ta hensyn til eventuelle gjeldende arrangementstildelingsgrenser når du utformer prosesser som bruker plattformhendelser som et internt meldingssystem.
Ofte kommer motmønstre rundt hendelsesdrevne arkitekturer fra bruk av hendelser som en løsning for intern kommunikasjon i en Salesforce-organisasjon. Vanlige motmønstre inkluderer følgende:
-
Publiseringshendelser fra Apex-utløsere som er knyttet til samme hendelsesobjekt: Dette fører til en uendelig utløsersløyfe.
-
Publiseringshendelser fra Apex før en DML-transaksjon fullføres: Hvis en transaksjon mislykkes og rulles tilbake, inkluderes ikke eventuelle publiserte hendelser som har virkemåten Publiser umiddelbart, i virkemåten for tilbakeføring.
-
Publisering av hendelser i Flyt for å orkestrere etterfølgende automatisering: Den beste måten å koordinere logikk på tvers av flere automatiseringer på er å bruke underflyter eller Flytorkestrator.
-
Opprette kjøretidsavhengigheter: Ikke publiser hendelser for å lette kommunikasjonen mellom pakker uten å ta de riktige trinnene for å eliminere kjøretidsavhengigheter.
-
Unødvendig store nyttelast: Når du gjør forespørsler, er det best å sende og motta den minste mengden data som er mulig i belastningen. Hver handling av en bruker kan potensielt føre til flere forespørsler, og det er viktig at disse behandles effektivt. Sending av flere data enn nødvendig kan bidra til langsom transport og økt behandlingstid.
-
Uselektiv håndtering av søknadshendelser: Når det er flere komponenter som lytter etter en programhendelse, må utviklere forsikre seg om at hendelsesbehandleren bare utføres når den faktisk er ønsket og nyttig. I Lightning kan for eksempel komponenter i faner som ikke er fokusert, fremdeles lytte selv om de ikke er synlige. En utvikler kan bruke ulike teknikker som å bruke et bakgrunnsverktøyelement som den eneste lytter eller kalle opp getEnclosingTabId() for å finne ut om denne forekomsten av komponenten er omsluttet av den fokuserte fanen for å sikre at hver hendelse håndteres bare når den er tiltenkt.
-
Bruk av plattformhendelser for å publisere virkemåte feil: Plattformhendelser har to publiseringsvirkemåter – Publiser umiddelbart og Publiser etter bekreftelse. Det kan være nyttig å bruke sanntids plattformhendelser til brukstilfeller som Logging, der du vil publisere loggingshendelsen uavhengig av om transaksjonen er vellykket eller bekreftet. Bruk imidlertid Publiser umiddelbart svært forsiktig med sanntids plattformhendelser. Hendelser kan forbrukes av abonnenter i samme transaksjon og føre til radlåser eller andre løpebetingelser.
Når du implementerer en hendelsesdrevet arkitektur, er en av nøklene til suksess å angi standarder for hvordan selve hendelsene utformes. Spesifikasjonene vil variere avhengig av organisasjonens bruksområder, men her er noen generelle retningslinjer:
-
Finn ut den optimale strukturen for hendelsesbelastningene. Mens mindre meldingsstørrelser reduserer behandlingstidene, kan bombardement av abonnenter med store mengder meldinger føre til flaskehalser i ytelsen. Det kan hende du må gjenta belastningsstørrelsene og -strukturene for å finne riktig balanse. MuleSoft og lignende ESB-verktøy gir mulighet til å utforme tilpassede belastninger i meldingene som er knyttet til hendelsene, noe som kan hjelpe deg å visualisere datastrukturer for å forbedre ytelsen på abonnentsiden. (Se Well-Architected - API Management for å få mer informasjon.)
-
Tenk på prosessene dine fra ende til ende. Pass på at du ikke oppretter noen "endløse sløyfer"-scenarier, som kan være vanskelig å spore ned når integrasjonene er rullet ut. Et eksempel på dette er to systemer som publiserer hendelser når poster oppdateres, samtidig som de lytter etter hverandres hendelser, som utløser flere publiserte hendelser når de behandles.
Du kan rette opp denne typen motmønster ved å legge til logikk i begge systemene som sikrer at endringer som gjøres som et resultat av en hendelse som forbrukes, ikke fører til publisering av en ny hendelse. Du bør også passe på å dokumentere alle hendelsene, deres tilknyttede utløsere og nedstrømsystemene som kan bli berørt. Bruk denne dokumentasjonen som en referanse under utformingsøkter for å få tak i endeløse sløyfer og lignende scenarier så tidlig som mulig. (Se Velbygd - Prosessdesign for å få mer informasjon.)
-
Bruk vanlige navnekonvensjoner på tvers av systemer. Konsistente navnekonvensjoner er en god fremgangsmåte for all programvareutvikling, inkludert hendelsesdrevne arkitekturer. Bruk tid på å dokumentere et sett med standarder for hendelsesnavn, strukturer, tilknyttede objekter og feilhåndteringsprosesser for å sikre konsistens på tvers av systemer. (Se Well-Architected - Design Standards for å få mer informasjon.)