Virksomheter lagrer ofte data i både Salesforce og andre eksterne datasjøer som Snowflake, Google BigQuery, Databricks, Redshift eller skylagring som Amazon S3. Denne isoleringen av data i forskjellige kildesystemer utgjør en utfordring for firmaer som ønsker å utnytte hele kraften i dataene sine.
Arkitekter som arbeider med å samle data på tvers av flere datasjøer, står overfor viktige arkitektoniske beslutninger om hvordan de best kan integrere disse dataene. Data 360 tilbyr flere alternativer for dataintegrering, som hver har forskjellige fordeler og ulemper.
Denne veiledningen gir et rammeverk for å evaluere hvilket mønster som passer best til kravene for latens, kostnad, skalerbarhet, styring og kompleksitet når du integrerer data, og hjelper deg med å velge når du skal bruke datainntak, datakopiforbund eller en hybrid tilnærming. Veiledningen vil også hjelpe deg med å velge mellom forskjellige metoder for datainntak og dataforbund, som alle dekker et annet behov.
Integrering av eksterne datasjøer med Data 360 krever omhyggelig vurdering av avveining mellom dataoppdatering, styring og pipelineffektivitet. Hvis du for eksempel bruker Live-spørringer for datakonfederasjon med Zero Copy, maksimeres nyheten av dataene, men det kan redusere pipelineffektiviteten etter hvert som du flytter flere data over nettverket. For de fleste implementeringer i den virkelige verden er derfor en kombinasjon av inntak og forening i et økosystem med flere skyer i innsjøen den optimale banen. Denne hybridtilnærmingen sikrer en skalerbar, styrt, interoperabel arkitektur som sømløst støtter både driftsarbeidsbelastninger med lav latens, som sanntidstilpassing og svindeloppdagelse, og analytiske arbeidsbelastninger som regulatorisk rapportering og analyse av historiske trender. Denne beslutningsveiledningen hjelper deg å forstå hvordan du navigerer i disse avveiningene og velger den riktige strategien.
- Datainntak: Kopierer data til Salesforce Data 360 for å opprette styrte, kanoniske datamodeller. Ideelt når du trenger å
- Bygge en omfattende Customer 360: Forene og transformere forskjellige kilder til en enkelt, klarert profil.
- Overholder strenge forskrifter: Opprett en reviderbar, sentralisert kopi der datatilgang og linje kan kontrolleres nøye.
- Zero Copy Federation: Spør eksterne kilder i sanntid uten duplikater, aktiverer sanntidstilpassing, direktekontrollpaneler og rask introduksjon av kilder. To primære alternativer med avveininger du må balansere:
- Live og bufring (akselerert spørring): Best for interaktiv analyse og sanntidskontrollpaneler på data som befinner seg i eksterne dataplattformer som Snowflake, Google BigQuery, Redshift eller Databricks. Unngår langsom, kostbar dataduplisering ved å pushe behandling ned til kildesystemet.
- Filforbund: Best for batchbehandling i stor skala og AI-modellopplæring på data i skydatasjøen (S3, ADLS). Unngår kostbart og tregt inntak ved å spørre filer direkte i åpne tabellformater og låse opp massive datasett for ETL- og datavitenskapsarbeidsbelastninger.
- Hybridmodell: Bland inntak for forente profiler med forbund for oppdatering, støtte for omnikanalengasjement, Agentforce handlinger og AI/ML-opplæring.
-
Hybrid arkitektur: Det er ofte nødvendig å blande datainntak og dataforbund.
- Bruk Dataoverføring på viktige data for kanoniske datamodeller og kjernestyring.
- Samle alle andre data via Zero Copy for å minimere driftskostnader ved å bygge og vedlikeholde inntaksdatapipelinjene.
-
Inntaksfrekvens er viktig: Velg frekvensen basert på forretningsverdi, latensbehov og operasjonell kompleksitet.
- Bruk sanntid til tidssensitive arbeidsflyter (tilpassing, direktekontrollpaneler, Agentforce).
- Nær sanntid for prosesser med moderat haster (kampanjer, driftsrapporter).
- Gruppe for historiske eller lavhastighets datasett.
-
Samsvar Federation-mønsteret med latens og ytelse: Velg det som passer best til tilgangsmønstrene og kravene til friskhet, ytelse og kostnad.
- Bruk Direkte spørring til operasjonelle kontrollpaneler og sanntidstilpassing der lav latens er avgjørende.
- Bruk Bufring (Accelerated Query) når spørringer er hyppige, men noe foreldede resultater er akseptable, noe som balanserer ytelse og kostnad.
- Bruk Filforbund til analyse i stor skala og med stor kapasitet eller batcharbeidsbelastninger som er ideelle for historiske eller mindre tidssensitive datasett.
-
Juster styringen med krav til dataoppbevaring:
- Bruk inntak der sentralisert styring er avgjørende.
- Bruk forbund der desentralisert styring er akseptabel, samtidig som du håndhever streng styring på den eksterne kilden. Zero Copy respekterer policyer på kildenivå, som sikkerhet på radnivå (RLS) og datamaskering.
-
Prioriter inntak for arbeidsflyter med høy verdi: Bruk inntak selektivt på viktige prosesser som identitetsløsning, regulatorisk rapportering og operasjonell aktivering.
-
Kostnader og kompleksitet driver beslutningen: Inntak i sanntid kan være kostbart og komplekst. Arkitekter bør vekte kostnadene ved introduksjon, lagring og transformasjon av data mot kostnadene ved å spørre dem direkte via Zero Copy.
Valg av det riktige integrasjonsmønsteret – Datainntak, Zero Copy eller en Hybrid-tilnærming – påvirker direkte latens, styring, driftseffektivitet og kostnader på tvers av plattformer med flere skyer. Denne beslutningen bestemmer hvordan sanntidsinnsikt, AI-drevet aktivering og tilpasset engasjement kan leveres pålitelig og i stor skala.
Denne tabellen gir en teknisk sammenligning av mønstre for datainntak og nullkopiering i Salesforce Data 360, med fokus på funksjoner, avveininger og fordeler sammen med brukstilfeller og utfall i virksomheten. Arkitekter kan bruke dette som en referanse for utforming av hybrid, flerskydataplattformer som balanserer ytelse, kostnad og samsvar.
| Mønstertype | Modus/verktøy | Fordeler | Viktige punkter | Utfall |
|---|---|---|---|---|
| Datainntak | Sanntid: Inntak av sub-sekunders latens via Inntaks-API-er med CDC-støtte. Kontinuerlig strømming under behandling. | - Umiddelbar innsikt - Ideelt for brukstilfeller med lav latens i drift og tilpassing - støtter hendelsesdrevne arbeidsflyter |
- Høy kostnad - Komplekst arkitektur - Krever kildesystemer med lav latens - Kilder med stor trafikk kan føre til overdreven strømning som fører til mettet pipelines - I/O intensiv - Vurder valgfrie felt og filtrering for å redusere overhead |
Agentforce: - Sanntids varsler om bedrageri, detaljhandelstilpassing, operasjonelle varsler Analytics: - under-sekund-kontrollpaneler, KPI-overvåking Samsvar: - Kontinuerlige kundepostoppdateringer for regulerte arbeidsflyter |
| Streaming: Mikrobatchinntak hvert 1-3 min via innebygde koblinger | - Balansert kostnad kontra friskhet - Enklere arkitektur enn i sanntid - støtter trinnvise oppdateringer |
- Liten latens - Kan ikke være egnet for viktige under sekundbeslutninger - Batchstørrelse påvirker minne/beregning - I/O er moderert - Best for forutsigbare, gjentatte oppdateringsmønstre - Vurder vindusaggregering for å redusere behandlingsbelastningen |
Agentforce: - Tidsrettede kampanjeutløsere, næraktivt engasjement Analytics: - Anbefalingsmotorer, direktekontrollpaneler Samsvar: - Hyppige oppdateringer med revisjonsmuligheter |
|
| Batch: Planlagte lastinger med stor trafikk via koblinger eller API-er. Støtter objektlagring og ETL/ELT pipelines. | - Kostnadseffektiv for massive datasett - Enkel å implementere - Pålitelig for historiske analyser |
- Datalatens - Ikke egnet for tidssensitive operasjoner - I/O intensivt ved innlastingsvinduer - Nettverksgjennomgang kan bli en flaskehals for store filer - Best for historiske aggregerings- eller regulerte rapporteringsarbeidsflyter |
Agentforce: - IT-støttebilletter (Jira/ServiceNow), aggregerte arbeidsflyter Analytics: - Historikkanalyse, trendvurdering Klage: - Regulatorisk rapportering, aggregering av pasient-/kravdata |
|
| Zero Copy | Direkt spørring:Direkte spørringer på eksterne systemer; skjema-på-lese; ingen dataduplisering | - Maksimal friskhet - Minimum lagringsplass, støtte for sanntids driftsinnsikt |
- Avhengig av kildeytelse - Høyt spørringsvolum kan påvirke latens - Ideelt for spørringer med predikat nedtrekksmeny og aggregering for å minimere I/O - Unngå ufiltrerte spørringer på massive datasett |
Agentforce: - Dynamiske arbeidsflyter som tilpasser seg aktiv aktivitet Analytics: - Driftskontrollpaneler, direkterapportering Samsvar: - Respekterer sikkerhet og maskering på radnivå ved kilde |
| Accelerated Query (Caching): Bufrede lokale kopier for forente spørringer. Konfigurerbar fra 15 minutter til 7 dager. Utføring av optimalisert spørring | - Reduserer latens - Lavere kostnad enn gjentatte direktespørringer - Forbedrer ytelsen for hyppige tilgangsmønstre |
- Bufferbehandling kreves - Foreldet avhenger av bufferintervall - Best for spørringer med høy frekvens - Ikke egnet for under andre beslutninger |
Agentforce: - Forhåndsaggregerte engasjementsmålinger for rask beslutningstaking Analytics: - BI-kontrollpaneler, segmentering, analytisk rapportering Samsvar: - Konsistente, regulerte kontrollpaneler med revisjonslogger |
|
| Filforbund:Direkt tilgang til store historiske datasett i objektbutikker eller innsjøer (S3, Iceberg, Google BigQuery, Redshift). | - Håndterer datasett i stor skala - Minimum lagringsplass i Data 360 - støtter AI/ML-arbeidsbelastninger |
- Skrivebeskyttet - Spørringsytelse avhenger av gjennomløp fra eksternt system - Optimalisert for batchtunge, gjennomløpsintensive jobber - Ikke egnet for kontrollpaneler i sanntid |
Agentforce: - (ikke typisk – massiv) Analytics: - ML/AI-opplæring, historiske analyser, rapportering i petabyteformat Samsvar: - Administrert tilgang til eksterne datasett uten duplisering |
Ved datainntak kopieres data fysisk til Data 360 og styres fullstendig, i motsetning til Zero Copy der data forblir ved kilden. Beregning av transformasjoner skjer i Data 360, som tillater sentralisert styring og revisjon.
Bruk datainntak til å lagre kanoniske, administrerte datasett i Salesforce Data 360 for overholdelse og driftskontroll. Bruk inntak når full kontroll, revisjon og sporing kreves. Ideelt for regulerte eller arbeidsflyter med høy verdi der sentralisert databehandling og styring er avgjørende.
Inntak er best for å bygge et klarert grunnlag for identitetsløsning, forskriftsrapportering og oppgavekritiske AI-drevne arbeidsflyter og kundeengasjement.

Metoder for datainntak varierer avhengig av hvilken kobling du bruker til å hente inn data. Enkelte koblinger tilbyr en rekke inntaksmetoder, mens andre bare fungerer i gruppemodus eller strømmemodus. Se Data 360: Integrasjoner og koblinger for en fullstendig liste over Data 360-koblinger og deres tilgjengelige metoder.
- Sanntid
- Sub-sekund inntak ved hjelp av strømming pipelines eller Change Datafangst (CDC).
- Best for tidssensitive arbeidsflyter (svindeloppdagelse, tilpassing, driftskontrollpaneler).
- Pushe transformasjoner og aggregeringer i Data 360 for å redusere nedstrøms I/O og optimalisere databehandlingsbruk. Bruk inkrementell CDC til å minimere dataoppheving.
- Streaming
- Inntak hvert 1-3 minutt i små trinn.
- Balanserer friskhet og kostnader, egnet for kampanjeorkestrering, næraktivt engasjement og driftsrapportering.
- Bruk mikrobatcher til å kontrollere I/O-spikes. Aggreger data ved kilden hvis det er mulig for å redusere overføringsvolumer og optimalisere lagringsplass.
- Batch (planlagte innlastinger)
- Periodisk inntak av store datasett (timevis, daglig, ukentlig).
- Kostnadseffektiv og pålitelig for brukstilfeller med historiske datasett, regelrapportering og samsvar.
- Sørg for datamaskinplassering i samme område som kildelageret for ytelses- og kostnadsoptimalisering.
- Brukstilfeller for datainntak
- Generer Customer 360 Unified-profiler: Bygg en enkelt sannhetskilde for kundeidentitet og -attributter.
- Vedlikeholde datasett for etterlevelse av forskrifter: Håndheve styring, linje og revisjonskapasitet for sensitive data.
- Sentralisere kampanjeorkestrering: Sikre at markedsføring, salg og service alle opererer fra konsistente, klarerte datasett.
- Design Practices
- Favoriser batchinntak for historiske behov eller behov med lav latens, som arkiveringsrapportering eller periodiske øyeblikksbilder.
- Bruk CDC- eller strømmede API-er til å opprettholde oppdatering for drifts- og tilpassingsarbeidsflyter, og sørge for at oppdateringer skjer i nær sanntid.
- Kontrollere lagrings- og datavekst ved å bruke inkrementelle belastninger i stedet for å laste hele datasett på nytt for å optimalisere kostnader og effektivitet.
- Juster inntaks under arbeid med datamaskinlokalisering og inkrementell behandling for å redusere nettverksinntak. Bruk transformasjoner i Data 360 for å unngå å flytte rådata unødvendig.
- Kostnadsvurderinger
- Sanntids inntak: Høyeste beregnings- og pipelinekostnader, berettiget for arbeidsflyter med høy verdi og som skiller mellom tid og verdi, som tilpassing, driftskontrollpaneler eller Agentforce handlinger.
- Streaming Inntak: Moderer beregnings- og lagerkostnader, egnet for hyppige oppdateringer som tåler små forsinkelser, som kampanjeorkestrering eller driftsrapportering.
- Batchinntak: Lavere datakostnader, forutsigbar lagring, best for historiske datasett eller oppdateringer med lav frekvens. Henting av gruppedata fra Salesforce-organisasjoner med bestemte koblinger er gratis.
- Oppdateringsmodus: Valg av inkrementell oppdateringsmodus reduserer totalt inntak og beregningskostnader. Vi anbefaler å bruke inkrementell oppdatering der det er mulig for å optimalisere effektiviteten på tvers av alle inntakstyper.
- Kostnad påvirkes også av I/O-volum fra kilde til Data 360. Optimalisering av batchstørrelser, partisjoner og områdejustering reduserer overføringskostnader og forbedrer ytelsen.
- Industry Scenarios
- Finans: Hent inn datasett som kreves for å kjenne kunden (KYC), Anti Money Laundering (AML) og svindeloppdagelse, der revisjon og overholdelse ikke kan forhandles.
- Helse: Bruk inntak for pasientidentitetsløsning og HIPAA-kompatible poster for å aktivere sikre, forente visninger.
- Detaljhandel: Konsolidere salgsstedsdata (POS), eCommerce og lojalitetsprogramdata til forente profiler for segmentering og tilpassing
- Telekom: Støtt forhindring av frafall og bruksanalyse med kanoniske, administrerte abonnentdata.
| Funksjon | Sanntids inntak | Strømmede inntak | Batchinntak |
|---|---|---|---|
| Latency and Freshness | Opptak av subsekunders latens via Inntaks-API-er med støtte for CDC (Change Datafangst). Gir kontinuerlige streaming under arbeid. Best for driftstilfeller med lav latens. | Micro-batch-inntak hvert 1-3 minutt via innebygde koblinger. Støtter trinnvise oppdateringer. Liten latens forventes. | Datalatens er forventet. Planlagte lastinger med stor trafikk. Periodisk inntak (timevis, daglig, ukentlig). Ikke egnet for tidssensitive operasjoner. |
| Hovedbrukstilfeller | Ideelt for brukstilfeller med lav latens for drift og tilpassing. Brukes til tidssensitive arbeidsflyter. Støtter hendelsesdrevne arbeidsflyter. Brukes til sanntidsvarsler om bedrageri og driftsvarsler. | Egnet for prosesser med middels stor haster. Brukes til kampanjeorkestrering, nærliggende engasjement og operasjonell rapportering. Brukes til tidsriktige kampanjeutløsere. | Kostnadseffektiv for massive datasett. Pålitelig for historiske analyser. Brukes til historiske aggregeringer eller regulerte rapporteringsarbeidsflyter. Best for historiske eller lavhastighets datasett. |
| Arkitektonisk kompleksitet og I/O | Høy kostnad og kompleks arkitektur. Krever kildesystemer med lav latens. I/O intensiv. Kilder med stor trafikk kan føre til mettet under arbeid. | Enklere arkitektur enn i sanntid. I/O er moderat. Best for forutsigbare, gjentatte oppdateringsmønstre. Batchstørrelse påvirker minne/beregning. | Enkel å implementere. I/O intensivt under innlastingsvinduer. Nettverksgjennomgang kan bli en flaskehals for store batcher. |
| Kostnadsvurderinger | Høyeste beregnings- og pipelinekostnader. Berettiget bare for arbeidsflyter med høy verdi og som skiller mellom tid og verdi. | Moderer beregnings- og lagringskostnader. Gir en balansert kostnads- kontra oppdateringstilnærming. Egnet for hyppige oppdateringer som tåler små forsinkelser. | Lavere datakostnader og forutsigbar lagring. Anbefales for historiske datasett eller oppdateringer med lav frekvens. Inntak via interne Salesforce pipelines er gratis. |
| Design Practices | Bruk inkrementell CDC til å minimere dataoppheving. Filtrer og bruk selektive felt til å redusere overhead. | Bruk mikrobatcher til å kontrollere I/O-spikes. Vurder vindusaggregering for å redusere behandlingsbelastningen. | Foretrukk dette for arkiveringsrapportering eller periodiske øyeblikksbilder. Forsikre deg om datagrunnlaget i samme område som kildelageret for kostnadsoptimalisering. |
Bruk Zero Copy til sanntidsspørring av eksterne systemer uten dataduplisering, og aktiver fleksibilitet, friskhet og skalerbar tilgang til store eller midlertidige datasett. Den er best egnet for direktekontrollpaneler, utforskende analyser, AI/ML-modellopplæring og kundeengasjement i sanntid direkte via Salesforce Data 360.
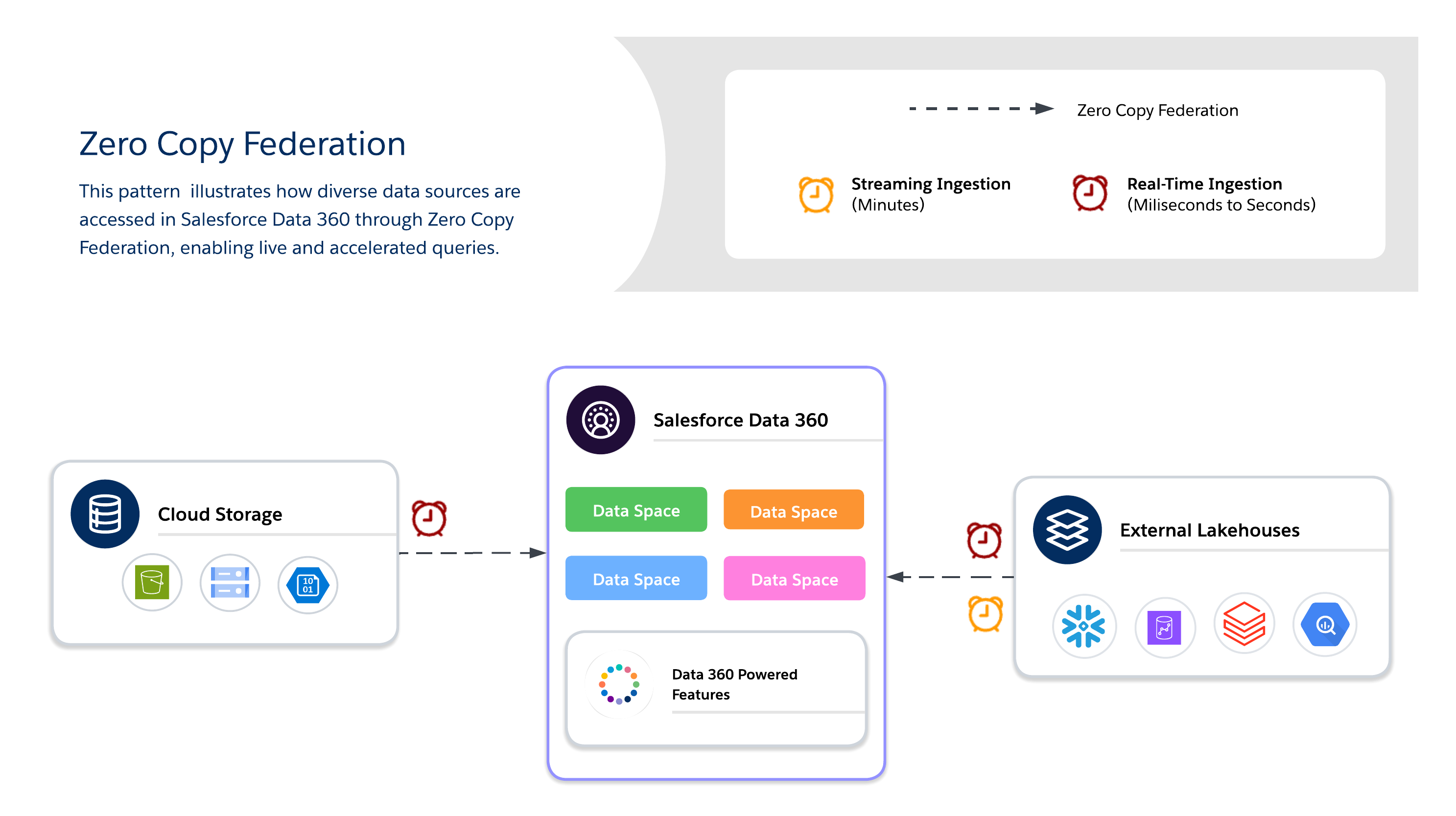
Når du bruker Zero Copy, må arkitekter bestemme ytterligere mellom tre tilgjengelige dataforbundsmetoder, som hver tilbyr sin egen avveining mellom friskhet, ytelse og kostnad.
- Direkte spørring
- Kjører spørringer direkte mot eksterne systemer (Snowflake, Google BigQuery, Redshift, Databricks og så videre) uten dataduplisering.
- Optimalt når predikater og aggregeringer kan skyves nedover, noe som minimerer dataflyten over nettverket og reduserer I/O på Salesforce Data 360-datamaskinen.
- Best for sanntidsinnsikt og driftskontrollpaneler med lav latens. Avhengig av det eksterne systemets ytelse.
- Buffering (Accelerated Query)
- Lagrer midlertidig bufrede kopier av forente data i Salesforce Data 360.
- Reduserer gjentagende spørringskostnader og latens for datasett med hyppig tilgang, med konfigurerbar varighet (minutter til dager).
- Data kopieres ikke permanent eller styres fullstendig. Ferskheten behandles via planlagte oppdateringer fra kilden.
- Filforbund
- Gir direkte, skrivebeskyttet tilgang til datasett i stor skala i objektbutikker (for eksempel S3, GCS med Iceberg).
- Best for AI/ML-arbeidsbelastninger, historiske analyser og rapportering i petabyteformat uten å flytte data.
- Spørringsytelsen er sterkt avhengig av objektformat, partisjonering og nettverksinnstillinger. Store skanninger kan generere betydelige I/O hvis de ikke er optimalisert.
- Brukstilfeller
- Sanntids tilpassing og tilpassede arbeidsflyter: Lever dynamiske tilbud, anbefalinger og Next Best-handlinger etter hvert som kundevirkemåten endres.
- Direktekontrollpaneler og driftsanalyse: Lever forretningskritiske kontrollpaneler og KPI-er direkte fra eksterne lagre.
- AI/ML modellopplæring med store eksterne datasett: Dra nytte av data i petabyte-skala fra datasjøer og lagre med filforbund uten å flytte dem.
- Industry Scenarios
- Detaljhandel/Media: Aktiver tilpassede anbefalinger og sanntids kundeengasjement ved å forene klikkstrøm- eller innholdsinteraksjonsdata.
- Finans: Kjør oppdagelse av svindel og risikoscore i nær sanntid ved å spørre eksterne lagre uten å duplisere sensitive data.
- Tech/Enterprise: Støtt rapportering på tvers av skyer, kontrollpaneler for IT-tjenester og operasjonell analyse der datasett befinner seg i flere systemer.
- Design Practices
- Direkte spørring
- Brukes til spørringer med høy QPS og lav latens når friskhet er avgjørende.
- Pushe predikater og aggregeringer til det eksterne systemet for å redusere datahulling over nettverket.
- Unngå spørringer som skanner store datavolumer unødvendig. Vurder å beskjære partisjoner og filtrere.
- Filforbund
- Få tilgang til datasett i petabyte-skala i objektbutikker uten inntak.
- Behold objektlagring i samme skyområde som Salesforce-databehandling for å minimere latens og utgangskostnader.
- Bruk partisjonerte, kolonneformater (Parquet/ORC) og nedtrekksfiltre for å redusere I/O- og nettverksoverføring.
- Bruk spørring og predikat nedtrekksmeny til å filtrere og aggregere data ved kilden, noe som reduserer dataflyten.
- Unngå datatilgang på tvers av områder med mindre det er nødvendig, fordi det øker I/O, latens og kostnader.
- Buffering (Accelerated Query)
- Bufr ofte brukte datasett for å balansere kostnad og ytelse.
- Konfigurer oppdateringsintervaller for å balansere friskhet kontra spørringskostnader.
- Samsvar: Håndhev styring ved kilden ved å benytte radnivåsikkerhet (RLS) og maskere policyer direkte i forente systemer. Her er gode fremgangsmåter for ensartet RLS og maskering på tvers av plattformer.
- Bruk en sentralisert Enterprise-ID: Tilordne brukere og enheter i Salesforce Data 360 til en unik, sentralisert forretningsidentifikator som tilsvarer identiteter i eksterne systemer.
- Juster sikkerhetspolicyer: Forsikre deg om at policyer for sikkerhet og maskering på radnivå i forente systemer brukes basert på den tilordnede identiteten. Dette beholder samsvar når du spør mot eksterne data.
- Standardisere identitetsskjemaer: Oppretthold ensartede identitetsattributter (e-postadresse, bruker-ID, kunde-ID osv.) på tvers av alle datakilder for å unngå mismatch og tilgangsbrudd.
- Direkte spørring
- Kostnadsvurderinger
- Direkte spørring: Betalingsmodell per spørring – kostnader akkumuleres på eksternt laghusdatabehandling og kan øke med høy QPS. Best for nyttekritiske brukstilfeller der verdi er større enn kostnadsvariabilitet.
- Akselerert spørring (bufring): Reduserer spørringskostnader sammenliknet med Direkte spørring ved å redusere treff til kildesystemet, men øker kostnadene for inntak av gruppedata for utfylling og oppdatering av bufferen. Best for ofte brukte datasett.
- Filforbund: Billigste lagringsalternativ som data i objektbutikk, men spørringskostnader avhenger av filstørrelse, partisjonering og beskjæring. Best for historiske data eller gruppedata i stor skala.
| Beslutningspunkt | Direkte spørring | Bufring (accelerated query) | Filforbund |
|---|---|---|---|
| Datakildeplassering | Eksterne datasjøer (Snowflake, Google BigQuery, Redshift, Databricks). | Eksterne datasjøer (Snowflake, Google BigQuery, Redshift, Databricks) | Objektbutikker eller skydatasjøer (S3, ADLS, GCS), ofte ved bruk av åpne tabellformater som Iceberg. |
| Formål/brukstilfelle | Ideelt for interaktiv analyse og kontrollpaneler i sanntid. Best for tilpassing i sanntid og dynamiske arbeidsflyter. | Best for når spørringer er hyppige, men noe foreldede resultater er akseptable. Egnet for BI-kontrollpaneler og segmentering. | Best for batchbehandling i stor skala og AI/ML-modellopplæring. Ideelt for historiske analyser og rapportering i stor skala. |
| Friskhet/latens | Maksimal friskhet. Spørringer kjøres direkte i sanntid. Støtter under andre beslutninger. | Lett foreldede resultater kan godtas. Ferskheten avhenger av bufferintervallet, som kan konfigureres fra 15 minutter til 7 dager. | Optimalisert for batchtunge, gjennomløpsintensive jobber. Ikke egnet for kontrollpaneler i sanntid. |
| Tilgangsmønster | Best for sjeldne eller ad hoc-spørringer. Brukes til spørringer med høy QPS (spørring per sekund) med lav latens der friskhet er avgjørende. | Best for lesescenarier med høy frekvens. Forbedrer ytelsen for hyppige tilgangsmønstre. | Skrivebeskyttet tilgang. Egnet for datasett i petabyte skalering uten inntak. |
| Ytelsesdrivere | Sterkt avhengig av det eksterne kildesystemets ytelse. Optimaliseres når predikater og aggregeringer kan pushes ned til kilden. | Reduserer latens sammenliknet med gjentatte direktespørringer. Ytelsen avhenger av bufferbehandling og intervall. | Ytelsen avhenger sterkt av objektformat, partisjonering og ekstern systemgjennomgang. Bruk partisjonerte, kolonneformater (Parquet/ORC). |
| Kostnadskonsekvenser | Betalingsmodell per spørring. Kostnader akkumuleres på eksternt laghusdatabehandling. Kostnadseffektiv for sjeldne spørringer, men utgifter kan øke med høyt spørringsvolum per sekund (QPS). | Lavere kostnad enn gjentatte direktespørringer. Reduserer behovet for å spørre den eksterne kilden gjentatte ganger. Legger til bufferlagring og oppdateringsoverhead. | Billigste lagringsalternativ. Spørringskostnader er avhengig av filstørrelse og partisjonering. |
| Nøkkelvurderinger | Unngå ufiltrerte spørringer som skanner store datavolumer unødvendig. | Krever bufferbehandling. Ikke egnet for under andre beslutninger. | Spørringsytelsen er sterkt avhengig av optimalisering via partisjonering og rullegardinliste for predikater. |
Hybridarkitekturer gir arkitekter mulighet til å forankre viktige datasett i Data 360 for sentralisert styring samtidig som de benytter forente spørringer for å oppnå friskhet, redusert duplisering og skalerbar tilgang til store eksterne datasett. Denne tilnærmingen balanserer kravene til I/O, datalokalitet, kostnad og samsvar.
Bruk en hybridtilnærming for balansert styring, friskhet og driftseffektivitet ved å kombinere datainntak og null kopiering for å levere sanntids og handlingsorienterte innsikter. Bruk inntak for datasett med høy verdi, regulerte datasett der sporbarhet, RLS og maskering kreves, og forbund for datasett med kortvarig eller stor trafikk der friskhet og ytelse er nøkkelen.
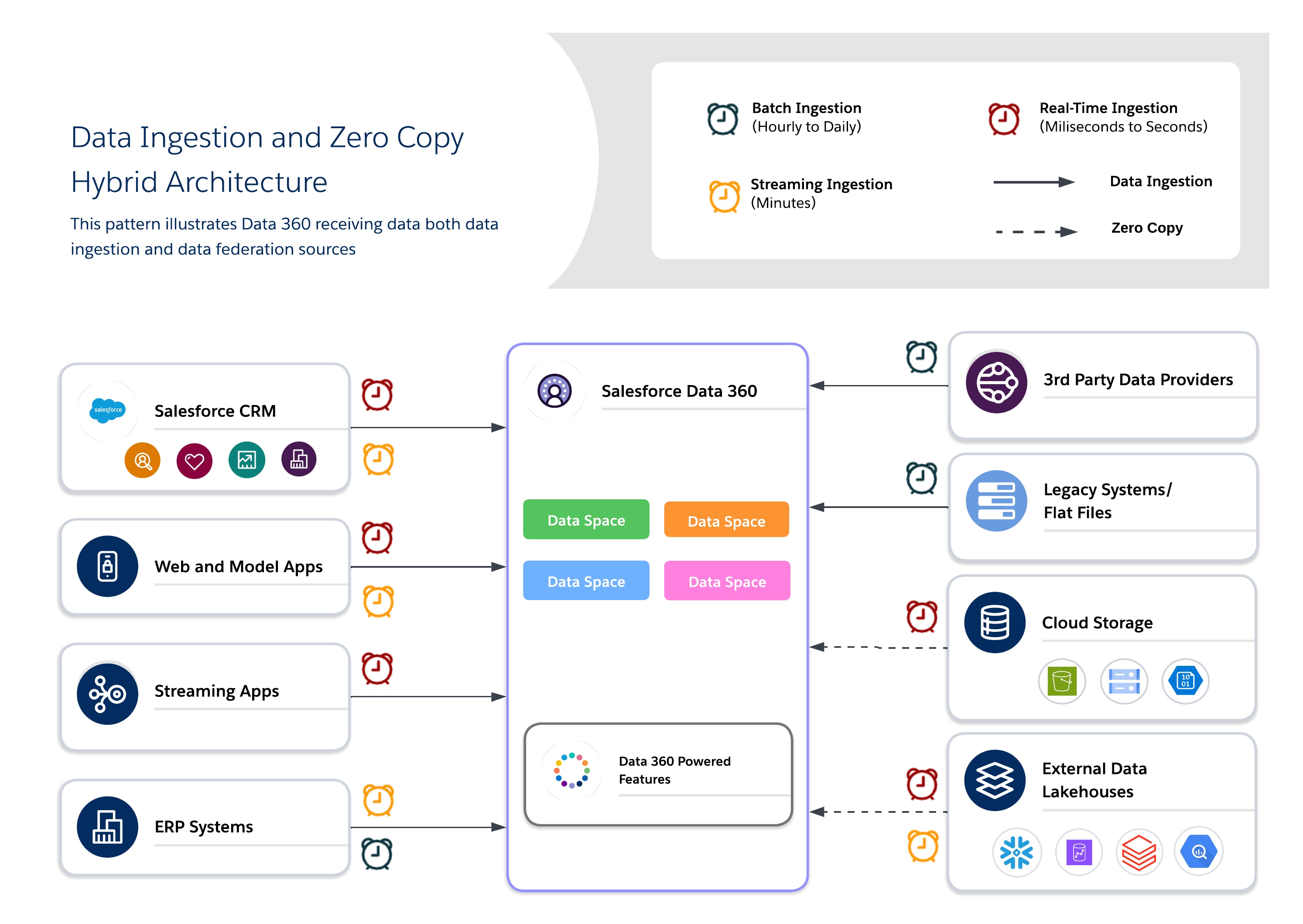
- Brukstilfeller
- Omnikanal-engasjement: Bland historiske kundedata med virkemåte i sanntid for å levere konsistente, kontekstbevisste opplevelser.
- AI/ML pipelines: Lær opp modeller på kuraterte, kanoniske datasett samtidig som du beriker dem med rå eller sanntids signaler fra eksterne kilder.
- Blandt samsvar og fleksibilitetsbehov: Bruk streng styring for sensitive data, men forent for operasjonell fleksibilitet.
- Industry Scenarios
- Detaljhandel: Bruk inntak til identitetsløsning og profilforening. Samle for sanntidstilbud og tilpassing.
- Helse: Oppretthold gyldne pasientposter via inntak samtidig som du forener IoT-enhetsstrømmer og sensordata for umiddelbar kontekst.
- Finansetjenester: Hent inn regulerte data i en overholdelsesstyrt innsjø mens du forener eksterne spørringer for oppdagelse av svindel og risikovurdering.
- Design Practices
- Ankerstyring med inntak: Hent inn verdifulle eller regulerte data i kanoniske modeller for å sikre Trust og overholdelse.
- Bruk Federasjon for friskhet: La eksterne innsjøer gi sanntidstilgang eller datatilgang i stor skala uten duplisering.
- Saldokostnad kontra Ytelse: Profiler arbeidsbelastninger for å bestemme hva som skal hentes inn kontra forent, slik at unødvendige lagrings- eller spørringskostnader minimeres.
- Bruk lagdelt styring: Håndhev sentralisert styring for inntatte data samtidig som du benytter de forente systemers egne sikkerhetskontroller (for eksempel RLS, maskering).
- Når du utformer hybrid under arbeid, må du sørge for inkrementelt inntak for historiske datasett og pushe aggregeringer eller filtre til forente kilder for å optimalisere I/O- og databehandlingsbruk.
- Kostnadsvurderinger
- Optimaliser total kostnad kontra ytelse ved å kombinere inntak for samsvar eller viktige data med forbund når det er nødvendig med oppdatering.
- Konto for I/O- og datadistribusjon ved blanding av inntak og forening. For å redusere beregningskostnader i kildesystemer for gjentatte spørringer bruker du bufring (Accelerated Query) for høyt lesede, ofte åpnede, forente datasett.
Nedenfor er vanlige arketyper som illustrerer hvordan denne logikken brukes.
- Arketypen "Enkel sannhetskilde": Sentralisere og styre
- Scenario: Du må bygge samsvarende, forente Customer 360 for hele den globale virksomheten. Dataene kommer fra et dusin forskjellige systemer, må overholde strenge GDPR- og CCPA-forskrifter, og vil fungere som den klarerte kilden for alle markedsførings- og tjenesteinteraksjoner.
- Anbefalt mønster: Datainntak. Prioriteten er styring, Trust og kontroll. Å hente inn dataene i Data 360 er den eneste måten å opprette en fullstendig reviderbar, kanonisk profil som er isolert fra kildesystemene.
- Arkitypen "Sanntidsinnsikt": Analysere uten å flytte
- Scenario: Datavitenskapsteamet må kjøre undersøkelsesspørringer på en massiv, konstant oppdaterende transaksjonstabell i Snowflake. Samtidig ønsker lederteamet et direkte BI-kontrollpanel som leveres av de samme dataene. Å flytte petabyte data daglig er for treg og kostbar.
- Anbefalt mønster: Zero Copy Federation. Prioriteten er hastighet, fleksibilitet og kostnadseffektivitet i stor skala. Zero Copy lar deg benytte den enorme kraften i ditt eksisterende datalager til sanntidsspørringer uten overhead og latens for dataduplisering.
- Arketypen "Hybrid intelligens": Styre kjernen, forene kanten
- Scenario: Du vil berike dine styrte, inntatte kundeprofiler med sanntids atferdsignaler (som nettstedsklikk) fra en datasjø. Du trenger stabiliteten til kjerneprofilen, men umiddelbarheten til direktedataene for å kunne tilpasse i øyeblikket.
- Anbefalt mønster: En hybrid tilnærming. Bruk Datainntak til å opprette den stabile, styrte kjernen av kundedataene. Bruk deretter Zero Copy til å forene de flyktige, sanntids "kantdataene" og slå dem sammen på spørringstidspunktet for å få en fullstendig, oppdatert visning.
Virksomhetens datastrategi handler ikke lenger om å velge ett enkelt integrasjonsmønster – det handler om å arkitektere kontrollert fleksibilitet i et interoperabelt dataøkosystem. Valg av den riktige dataintegreringsmetoden for hvert kildedatasystem basert på forretningsbehov fører ofte til en hybrid tilnærming som kombinerer styrkene i både datainntak og dataforbund:
- Hent inn oppgavekritiske, styrte datasett i Salesforce Data 360 for samsvar, identitetsløsning og driftsarbeidsflyter.
- Samle data via Zero Copy for direkte, utforskende og AI-drevet analyse uten duplikatlagring.
Salesforce Data 360 på Hyperforce leverer fleksibilitet og skalerbarhet for flere områder. ts åpne innsjøhus med Iceberg-tabeller muliggjør dataseparasjon og interoperabilitet med plattformer som Snowflake, Databricks og S3 Iceberg – som danner ryggraden i et virkelig interoperabelt datasystem med flere skyer.
Etter hvert som datasystemer utvikler seg, balanserer du kontinuerlig oppdatering, kostnader, ytelse og samsvar for å opprettholde arkitektonisk fleksibilitet. Fremtidssikre plattformen ved å forene inntatte, administrerte data med samlet tilgang. Dette aktiverer sanntids intelligens, AI-aktivering og tilpassing i bedriftsskala på tvers av skyer, regioner og forretningsdomener.
En løsning som passer alle, passer ikke de fleste virksomheter. Den optimale strategien tilordner det riktige mønsteret til den riktige forretningsdriveren.
Yugandhar Bora er Software Engineering Architect på Salesforce, spesialisert seg på dataarkitektur i Data & Intelligence-plattformen. Han leder EARB-initiativer (Enterprise Architecture Review Board) fokusert på datastyring og forente datamodeller, samtidig som han bidrar til automatiserte plattformklargjøringsløsninger.
Jan Fernando er hovedarkitekt i kontoret til hovedarkitekten i Salesforce. Han sluttet seg til Salesforce i 2012, og tok med seg en mengde erfaring fra sin tid i oppstartsøkosystemet. Før han sluttet seg til Chief Architect-kontoret, brukte han over et tiår i plattformorganisasjonen, der han ledet flere viktige teknologitransformasjoner.