従来のソフトウェア開発では、ソフトウェア開発ライフサイクル (SDLC) は、構造化された段階的なアプローチでアプリケーションを構築します。これにより、品質が確立され、リスクが軽減され、アイデアからリリースまでの明確なロードマップが提供されます。エージェント開発ライフサイクル (ADLC) も、自律エージェントの構築特有の複雑さに対応するために明確に調整された同様の手法です。
エージェントは受動的なアプリケーションではなく、動的実行環境内で判断、行動、学習するシステムです。非確定的な動作のため、従来の QA では不十分です。Agentforce などのプラットフォームでサポートされるエージェント開発ライフサイクル (ADLC) は、次の 5 つのフェーズでこれに対応します。アイデア出しと設計、開発 (「内部ループ」)、テストと検証、リリース、継続的な監視と調整 (「外部ループ」)。
このドキュメントは、ソフトウェア開発ライフサイクル (SDLC) の複雑さにすでに精通しており、エージェントベースのシステムに専門知識を拡大したいと考えている開発者とエンタープライズアーキテクト向けの包括的なガイドです。主な目的は、エージェント開発ライフサイクル (ADLC) の従来の SDLC 手法との主要な違いを強調し、インテリジェントなエージェントの作成、リリース、および管理のプロセス全体を概念化するための構造化されたフレームワークを提供することで、ADLC の迅速な理解を促進することです。
このドキュメントは 3 つの個別の章で構成され、各章は Knowledge と実践スキルを段階的に構築するように設計されています。
- **Chapter 1:ADLC フレームワーク。**この章では、エージェント開発ライフサイクル (ADLC) を紹介し、自律エージェントの開発固有の課題による SDLC との違いについて詳しく説明します。これにより、エージェントの設計、開発、テスト、リリースを行うためのフレームワークが確立されます。
- **第 2:Agentforce プラットフォーム。**この章では、エージェント開発ライフサイクル全体を合理化および高速化する統合プラットフォームである Agentforce について説明します。Agentforce は、エージェントの設計、データ処理、モデルのトレーニング、導入、継続的な監視のためのツールを提供し、複雑なタスクを簡素化して効率を向上させます。
- **第 3: Pro-Code Implementation (プロコード実装)。**このガイドでは、Agentforce のプロコードツールを使用して、エージェント開発に関する実践的な手順と実際の例を紹介します。プロトタイプ作成や機能エンジニアリングからモデルリリース、パフォーマンスチューニング、メンテナンスまでエージェント開発ライフサイクル全体をカバーし、本番対応のエージェントを作成するためのスキルを開発者に付与します。
このドキュメントは、Agentforce のプロコードツールの理論的および実用的な Knowledge を習得することを目的としています。エージェントを効率的、安全、確実に構築、導入、監視する方法を学習し、ADLC を包括的に理解して、インテリジェントなエージェント開発における Agentforce の可能性を最大化します。
AI エージェントの非確定的性質には、特殊な開発フレームワークが必要です。この章では、エージェント開発ライフサイクル (ADLC) の概要を説明します。この章では、ADLC の 5 つのコアフェーズ (最初のアイデア出しと設計から継続的な監視とチューニングまで) の概要を説明します。この章では、堅牢で信頼性の高いエージェントを作成するために必要な基礎 Knowledge について説明します。
ここでは、SDLC の概念を ADLC の 5 つのフェーズに対応付けます。
これは、エージェントの戦略目的と業務境界を定義する基本的なフェーズです。適切に構造化された設計フェーズは、ビジネスニーズを技術的なブループリントに変換するため、成功のための最も重要なステップです。設計プロセスでは、エージェントが機能するだけでなく、責任を持ち、ユーザーの期待と一致するようにします。コードを記述する前に「What」と「Why」が確立される場所です。
- エージェントの目標および機能の定義:まず、エージェントの主な目的と、エージェントが実行する具体的で測定可能な ToDo を明確にする必要があります。これには、その役割 (「カスタマーサービスアシスタント」など)、コア機能 (「予定の予約」、「商品の質問への回答」など)、それぞれの成功指標の定義が含まれます。
- 人格と倫理的なガードレールの確立:このステップでは、エージェントの人格を設計し、信頼性と安全性を確保するために倫理的な境界を定義します。エージェントの口調 (「フォーマル」、「フレンドリー」など) を確立し、有害な応答、バイアスのかかった応答、不適切な応答を防止するための厳格なルールを実装します。
- マップのコンテキストと理解:エージェントが理解し、効果的にするために覚えておくべき情報を判断する必要があります。これには、Knowledge ベースの範囲と会話記憶の定義が含まれます。これにより、一貫性のある複数ターンの会話が可能になります。
- ツールとシステムインテグレーションの特定:これには、エージェントが ToDo を実行するために接続する必要がある外部システム、API、データソースのインベントリが含まれます。各ツール (予約 API、顧客データベースなど) が識別され、その機能が特定のエージェント機能に対応付けられます。
- Human-in-the-Loop のエスカレーションの計画:エージェントが人間にエスカレーションする条件を定義することが重要です。これには、潜在的な失敗ポイントと会話の「行き詰まり」を確認し、エージェントが人間のオペレーターにエスカレーションするタイミングを判断することが含まれます。設計では、十分なコンテキストを確実に移行するためにこのハンドオフをどのように実行するかを記述し、すばやく消費してシームレスなカスタマーエクスペリエンスを確保できるようにする必要があります。
これは、設計ブループリントを機能エージェントに変換する実践的な構築フェーズです。開発者はエージェントを作成してツールに接続し、職務に必要なデータでエージェントを強化します。構築と調整のこの反復的な「内部ループ」は、エージェントが真に命を吹き込む場所です。
- エージェントのロジックと意思決定の設定:このステップでは、意思決定フレームワークをコンテキスト、ツール、データソースに接続して、エージェントの推論を形成します。開発者の役割は、API を作成したり既存の API を再利用したり、運用上のガードレールを設定したり、エージェントが複雑な複数ステップの ToDo を完了するために使用可能なツールを選択して使用したりして、エージェントの動作を定義することです。
- エンジニアプロンプトとモデルの微調整:エージェントの人格、指示、制約は、綿密なプロンプトエンジニアリングによって成文化されています。このプロセスでは、大規模言語モデル (LLM) のガイドとなるマスタープロンプトを作成し、より高度な使用事例として、ドメイン固有のデータに基づいてモデルを微調整してパフォーマンスを向上させます。
- AI ツールの統合と保護:設計フェーズで特定された関数と API がエージェントに接続されます。SDK を使用して、開発者は既存の関数をラップするか、新しい関数を作成して、エージェントが安全にコールできるようにし、適切な認証とエラー処理ができるようにします。
- Build Data and RAG Pipelines (データパイプラインと RAG パイプラインの作成):エージェントに外部 Knowledge を提供するために、開発者は RAG(Retrieval-Augmented Generation)のデータ パイプラインを構築します。これには、ベクトルストア、リレーショナルデータベース、グラフデータベース、内部ドキュメントなどのソースからのデータへの接続とインデックス付けが含まれます。これにより、エージェントはその情報にアクセスして、コンテキストを認識する正確な応答を提供できます。
AI エージェントのテストでは、従来のソフトウェアを確定的に検証するパラダイムシフトが導入されます。従来のアプリケーションは正しさがテストされますが (特定の入力によって期待される 1 つの出力が生成される必要があります)、エージェントの非確定的性質にはより高度なアプローチが必要です。目標は、1 つの正しい回答を検証することではなく、エージェントの行動がその目的と一致し、予期しない入力に対して堅牢で、許容される結果の範囲全体で信頼性を維持することです。
- 単体テスト:このレイヤーは、エージェントの確定的で AI 以外のコンポーネントに焦点を絞ります。従来の単体テストでは、個々のツールと機能が個別に正しく機能することを検証し、エージェントの複雑な推論が適用される前に信頼性の高い基盤を確保します。
- エンドツーエンド (E2E) テスト:このフェーズでは、エージェントが現実的なシナリオで目標を達成する能力を評価します。これは、その非確定性を考慮すると重要です。これらのエンドツーエンドテストでは、正確な出力を確認するのではなく、エージェントが ToDo を正常に完了し、変更を加えてもパフォーマンスが低下しないことを確認します。
- 敵対および堅牢性テスト:これは、エージェントの弱点を積極的に発見するために、エージェントを意図的に破壊しようとする手法です。テスト担当者は、あいまいな要求、悪意のあるプロンプト、その他のエッジケースを使用して脆弱性を明らかにし、エージェントがプレッシャーにさらされても復元力と安全性を維持できるようにします。
- HITL(Human-in-the-Loop)評価:自動テストでは口調や会話の流れなどの微妙な部分を測定できないため、このフェーズは人間のフィードバックに依存します。テスト担当者はエージェントとやりとりして、その応答の有用性と全体的なユーザーエクスペリエンスをスコアリングし、エージェントの動作を微調整するための重要なデータを提供します。
- パフォーマンスと拡張性のテスト:これは、パフォーマンスのボトルネックがユーザーに影響する前に防止する重要なステップです。このプロセスでは、エージェントとアプリケーションが大量のデータをスムーズかつ予測的に処理できるように、現実的なピーク時の使用シナリオをシミュレーションします。ソリューションが正しいだけでなく、拡張性があることも検証します。
AI エージェントのリリースは、検証済みエージェントが信頼性が高く反復可能な方法でユーザーが操作できるようにすることに重点を置いた管理プロセスです。これには、エージェントをバージョン管理対象のアセットからライブの監視対象サービスに移行する構造化されたアプローチが必要です。
- パッケージ化とバージョン管理:プロンプトやツールを含むエージェントの定義全体がメタデータとしてファイルに取得され、Git などのソース制御システムに保存されます。これにより、一元化された情報源とすべての変更の監査可能な履歴が作成されます。
- CI/CD パイプライン:本番へのパスは自動化され、人為的ミスを排除して一貫性を確保します。これらのパイプラインは、開発環境、テスト環境、本番環境でエージェントを自動的に昇格させ、各フェーズでエンドツーエンドのテストを実行して品質ゲートとして機能します。
- 段階的ロールアウト戦略:リスクを最小限に抑えるために、新しいエージェントバージョンは最初に Canary Releases などの戦略を使用して一部のユーザーにリリースされます。これにより、完全なロールアウトの前に実際のパフォーマンスを監視し、問題が見つかった場合はすぐに元に戻すことができます。
- 有効化とガバナンス:エージェントをロールアウトする重要なステップは、適切な権限でエージェントを安全に有効化し、監視ツールに接続できるようにすることです。これにより、新しくリリースされたエージェントが稼働を開始した瞬間から、その状態とパフォーマンスをすぐに確認できます。
リリースはエージェント開発ライフサイクルの終わりではなく、継続的な「外部ループ」の始まりです。エージェントは、予測できない実際の環境で動作する動的システムです。このフェーズは、エージェントのライブパフォーマンスを監視し、インタラクションからインサイトを収集し、そのデータを使用して、その有効性、安全性、効率性を経時的に体系的に調整および改善することに専念します。
- リアルタイムパフォーマンス監視:これは、エージェントがユーザーとやりとりするときにエージェントの主要な業務評価指標を追跡する方法です。ダッシュボードを使用して、遅延、トークン消費 (コスト)、API エラー率を監視し、エージェントの健全性と効率の概要をすぐに確認できます。
- 行動分析と成功分析:これには、会話ログを分析して、エージェントが実際にその職務をどのように遂行しているかを把握する作業が含まれます。ToDo の完了率を追跡し、一般的な失敗ポイントや会話の「行き詰まり」を特定し、エージェントが目標を正しく達成しているかどうかを判断するためにユーザー満足度を測定することに重点を置いています。サービスエージェントの例として、エージェントが人間にエスカレーションする頻度と理由に関する評価指標を提供できます。
- インテリジェントなチューニングと調整:これは、監視からのインサイトを使用してエージェントを改善する有効なプロセスです。これは、プロンプトエンジニアリングからツールの最適化まで多岐にわたります。
- データ駆動型 RAG の機能強化:エージェントの Knowledge ベースの品質は、実際のクエリに基づいて継続的に改善されます。監視により、エージェントが特定のトピックに苦労していることが判明し、データソースや取得プロセス (RAG 絞り込み) を調整して応答の精度を向上させることができます。
- 継続的な学習と適応:これには、本番データを使用してエージェントをよりスマートにするフィードバックループの作成が含まれます。インタラクションログに (人の監視または LLM ベースのラベリングを使用して) ラベリングすることで、選定されたデータセットが作成され、基盤となるモデルを微調整してさらなる改善を推奨できます。
Agentforce は、設計、開発、テスト、導入、監視、分析の統合ツールを使用してすべての ADLC フェーズをサポートします。これらすべてを 1 つの統合プラットフォーム内で実行し、堅牢なエージェントをすばやく構築してテストします。
Agentforce ADLC は、次の指針に基づいています。
- ローコードとプロコードの両方に対応:設定ベースのリリース (ローコード) とプログラムによる拡張性 (プロコード) のサポート。
- 継続的な AI 主導の支援とフィードバック ループ:会話データを取得して分析し、AI 主導の継続的な改善のためにエージェントに調整を通知します。
- すべてのレベルのテスト駆動開発:すべてのフェーズで厳格なテストを行い、従来の単体テストで確定的コンポーネントを検証し、エージェントの推論と非確定的動作をテストするための新しいアプローチを提供します。
- エグゼクティブおよび LOB の可観測性:業務関係者とエグゼクティブ関係者にコスト、使用状況、パフォーマンス評価指標を提供します。
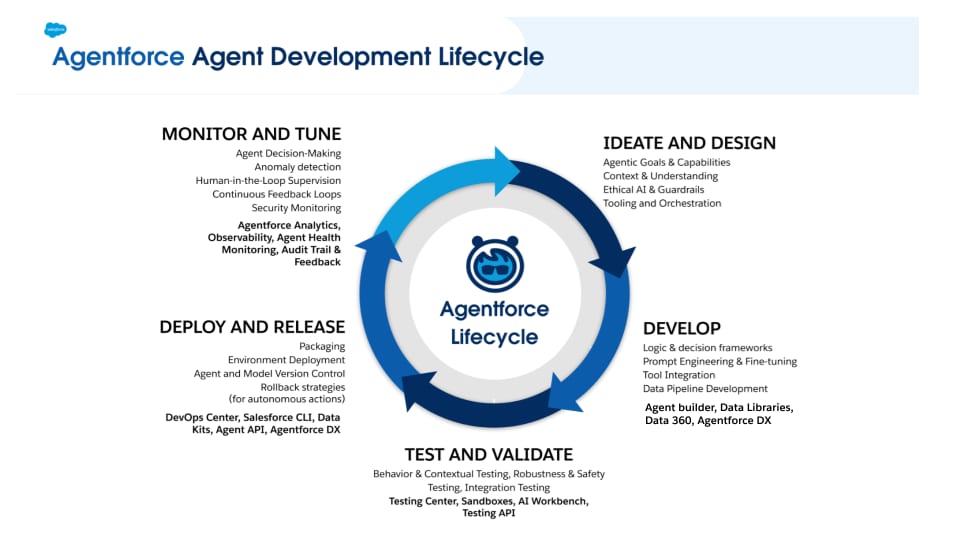
この章では、Agentforce が 1 つの統合プラットフォーム内で ADLC のすべてのフェーズをサポートする方法について説明します
アイデア
アイデア出しフェーズは、エージェントの初期ビジョンと要件が策定される ADLC の基礎フェーズです。これには、問題の理解、潜在的なソリューションの特定、エージェントのコア機能の概要説明について深く掘り下げます。
エージェントのアイデア出しプロセスを開始するには、その主要な属性を定義します。
- 目的/目標:エージェントの主な目的を明確に定義します。どのような問題を解決するために設計されているか、またはどのようなタスクを達成しようとしているか?エージェントは誰にサービスを提供すべきか?これは、開発プロセス全体の指針となる簡潔で測定可能なステートメントである必要があります。
- 人格:エージェントの詳細な人格を作成します。これには、ID、コミュニケーションスタイル、ユーザーや他のシステムとのやり取りで果たす役割の定義が含まれます。口調、格式、および意図したコンテキストで効果を発揮する特定の特性を考慮します。
- パターン:関連するエージェントパターンと実装戦略を特定してリンクします。これには、エージェントの構造と動作を知らせることができるアーキテクチャ設計またはベストプラクティスが含まれます。"Salesforce Agentforce でのエージェントのパターンと実装:"テクニカルホワイトペーパー』は、このステップの貴重なリソースとして役立ち、Salesforce Platform と Agentforce での効果的なエージェント設計に関するインサイトを提供します。
設計
設計フェーズでは、アイデアから概念をエージェントの構築の詳細なブループリントに変換します。これには、エージェントのアーキテクチャ、ユーザーフロー、インタラクションモデル、技術仕様 (トピック、ツール、ガードレールなど) の定義が含まれます。
設計フェーズでは、エージェントの工事の詳細なブループリントを作成します。このブループリントには次のものが含まれます。
- エージェント設計:コンポーネント、モジュール、およびそれらがどのようにやりとりするかなど、エージェントの内部構造の概要を説明します。これには、Knowledge ベース、エージェントの動作を制御するための設定とロジック、自然言語処理 (NLP) コンポーネント、他のシステムとのインテグレーションポイントの定義が含まれる場合があります。
- ユーザーフロー/インタラクション設計:完全なユーザージャーニーとエージェントのインタラクションを対応付けます。会話フロー、ディシジョンツリー、エラー処理、フィードバックメカニズムを定義して、直感的で効果的な環境を作成します。
- 技術仕様:パフォーマンス評価指標、拡張性に関する考慮事項、セキュリティプロトコル、インテグレーション仕様など、エージェントの機能以外の技術的な要件を文書化します。
- プロトタイピング & モックアップ:エージェントのインターフェースとインタラクションの視覚表現または対話型のプロトタイプを作成します。これにより、早期のテストとフィードバックが可能になり、本格的な開発を開始する前に設計を調整できます。
- データ:エージェントが必要とするデータの種別とソースを決定するときに、エージェントがアクセスする必要があるデータセット、API、データベース、リポジトリを特定します。Agentforce では、コンテキストとして提供されるデータ、構造化されたデータと構造化されていないデータ、リアルタイムデータとバッチデータのどちらであるかに焦点を絞ります。Agentforce プラットフォームは、Data 360 との緊密な統合に基づいて構築されており、Salesforce CRM やその他のソースからの構造化データと非構造化データの両方を使用できます。非構造化コンテンツはネイティブにチャンク化してインデックス付けし、RAG で使用できます。MuleSoft では、外部システムに接続できます。
- ツール:エージェントが実行する必要があるアクションを特定します。Agentforce アクションを使用して、ビジネス目標を達成するツールを公開します。これらのアクションは、プロンプトビルダーを介したプロンプト、MuleSoft、Apex、フロー、OpenAPI 仕様の API などの既存の Salesforce アセットを活用します。呼び出し可能なアクションはすべて Agentforce に統合してエージェントが使用でき、使い慣れたすべての Salesforce 開発ツールを Agentforce アクションとしてすぐに使用できます。
- エージェントの入力データ:従来の SDLC では、入力は正確に指定されます。ADLC では、入力は多くの場合、自然で非確定的な自由形式の発言です。適切な回答が得られると期待される発言の代表的なコーパスを収集する。
開発フェーズでは、アイデアと設計フェーズで決定された定義済みのエージェントの目的、機能、および業務範囲を新しい Agentforce Agent に変換することに重点を置いています。
開発者がエージェントを作成できるように、Agentforce には Agent Builder と **Agentforce Developer Experience(AFDX)の両方が用意されています。**これらの基盤ツールは、エージェントを構築および設定するための主要な環境として機能します。
- エージェントビルダーでは、エージェントのコア機能を定義するための UI 環境が提供されます。
- AFDX は、カスタマイズや他のシステムと統合するためのプログラム・インタフェースを提供します。
エージェントの開発と構築には、エージェントビルダーまたは AFDX を使用して実行できる次の手順が含まれます。
- 人格の定義:エージェント設計の重要な側面は、個別の人格を確立することです。これには、次の設定が含まれます。
- エージェントの説明:エージェントの役割、目的、および処理するように設計された特定のカスタマーサービス ToDo の詳細な説明。
- トーン:エージェントのコミュニケーションスタイル、共感のレベル、遵守する必要がある特定のブランドガイドライン。
- エージェントのトピックとアクションの定義:エージェントを高度化し、多様なタスクを処理できるようにするには、その機能を個別のトピックとそれに対応するアクションに分割することが不可欠です。
- トピック:各トピックは、独自の指示とツールのセットを持つ独自の専門エージェントとして概念化できます。
- **モジュラー型アーキテクチャ。**トピックへのモジュラーアプローチにより、組織と拡張性が向上します。複数のトピックを定義することで、エージェントはより広範な複雑なシナリオを処理できます。たとえば、エージェントには「注文管理」、「よくある質問 (FAQ)」、「テクニカルサポート」、「請求に関する問い合わせ」という個別のトピックがあります。
- トピックの手順 (ガードレール):各トピックには、ガードレールとして機能する特定の手順が付属し、エージェントがそのトピック内で議論したり実行したりできる範囲を定義します。これらの手順により、エージェントがトピックから外れたり、無関係な情報を提供したりすることがなくなります。また、回答の一貫性と正確性も維持できます。
- アクション:トピックには、エージェントが実行できるアクションを表す「ツール」も用意されています。次のツールを使用できます。
- 情報アクション:Knowledge Base または外部システムからデータを取得してクエリに回答する。
- トランザクションアクション:ユーザーに代わってアクションを実行する (注文の実行、顧客レコードの更新、返金プロセスの開始など)。これらのアクションは、多くの場合、他のシステム (CRM、ERP など) と統合されます。
- トピック:各トピックは、独自の指示とツールのセットを持つ独自の専門エージェントとして概念化できます。
AI エージェントのパフォーマンスと信頼性を評価する場合、テスト担当者は多くの場合、ユーザーエクスペリエンスを低下させる可能性のあるさまざまな課題に直面します。これらの問題は、ユーザーインテントの誤った解釈から ToDo の適切な実行の失敗まで多岐にわたります。
一般的なエージェントの失敗のシナリオ
堅牢なエージェントを構築するには、その失敗方法と原因を理解する必要があります。次の表は、欠陥のある推論から不十分な Knowledge 取得に至るまで、エージェントのライフサイクル中に発生する一般的な問題を分類したものです。これは、エージェントが機能するだけでなく、エンドユーザーにとって信頼性が高く直感的であることを確認するために、開発時の戦略ガイドやテスト時のチェックリストとして使用します。次の失敗シナリオは、テストケースを定義するのに役立ちます。
| カテゴリ | 説明 | 失敗の例 |
|---|---|---|
| トピック分類 | エージェントがユーザーのインテントまたは目標を正しく識別できなかった。 |
|
| 応答品質 | エージェントの返信の内容、正確性、および形式の失敗。 |
|
| アクションの実行 | エージェントが特定の機能またはタスクを実行しようとすると失敗します。 |
|
| ガードレールと手順 | エージェントが定義済みのルール、制約、または会話の境界に違反した。 |
|
| Knowledgeの取得 | エージェントがKnowledgeベースからの情報の調達と表示で問題が発生している。 |
|
| 構造化されたガイダンス | エージェントが複数ステップのプロセスでユーザーをガイドするのに苦労している。 |
|
AI エージェントをテストするためのベストプラクティス
Agentforce でエージェントをテストするときのベストプラクティスの概要を次に示します。
-
テストデータの拡張
効果的なテストの基盤は、包括的で現実的なテストデータです。次の原則に従って、エージェントをテストするための効果的なテストデータを用意します。- 十分な補償:すべての重要なトピックとユーザー人格をカバーする十分なテストデータを目指します。
- 現実的なシナリオ:テストデータが実際のユーザー操作を正確に表していることを確認します。
- 負のケースとエッジケース:否定的なテストケース (エージェントが実行しないこと) と、エージェントの境界に挑戦するエッジシナリオを含めます。
- Guardrails テスト:エージェントのガードレールが正しく機能していることを確認するために設計された特定のテストケースを追加します。
-
テスト実行の最適化
テストリソースを最大限に活用するには、テストの実行方法を最適化します。Agentforce エージェントをテストするときの考慮事項は次のとおりです。- テストケース量:最大 1,000 個のテストケースを使用できます。
- 同時テストの実行:10 時間以内に一度に最大 10 個のテストケースを実行できます。
- リソースの管理:テストを実行するとクレジットが消費されることに注意してください。不要なコストを回避するために、実行を開始する前にテストデータに満足していることを確認してください。
-
結果の確認
テスト結果を慎重に分析し、改善すべき領域を特定します。- 障害の分析:失敗した各テストケースを個別に検査します。予想される結果と実際の結果の違いを慎重に読んで理解し、問題を特定します。
- Sandbox 環境の使用:テストエージェントは CRM データを変更できます。ライブデータが意図せずに変更されないように、Sandbox やスクラッチ組織などの本番以外の環境でテストを必ず実施してください。
-
調整と再テスト
テストは、エージェントが進化しながら続行される反復プロセスです。- 継続的なテスト:エージェントのトピックまたはアクションを変更するたびにテストを実行します。これにより、変更が検証され、品質が維持されます。
- テスト対象範囲の拡大:新しいテストケースを使用してデータセットを継続的に選定および拡張し、エージェントの全体的なカバー率と堅牢性を向上させます。
テスト方法
エージェントの複雑さを考えると、1 つのテスト方法では不十分です。包括的な検証戦略は、予測可能な確定的アクションから、その非確定的な会話動作の微妙なニュアンスまで、さまざまなアプローチを組み合わせて階層化する必要があります。これらのアプローチでは、エージェントのすべてのコンポーネントを体系的に評価し、堅牢性、信頼性、安全性を確保します。
-
エージェントシミュレーターとプラントレーサーを使用した手動テスト
- 目的:これは、エージェントをテストする最初の方法であり、多くの場合最も簡単な方法です。これは、少数のサンプルの使用事例や、エージェントの動作に関する基本的な理解を得るのに最適です。
- メカニズム:エージェントシミュレーターは、開発者と管理者がエージェントと直接やりとりできる制御された環境を提供します。このシミュレーターでは、管理者/開発者によって提供される情報を詳細に追跡できるため、エージェントが入力をどのように処理して出力を生成するかに関するインサイトが得られます。
- 利点:
- クイックフィードバック
- 差し迫った問題の特定が容易
- エージェントのロジックフローを理解するのに役立つ
-
テストセンターまたは AFDX テストスイートを使用したテストの自動化
- 目的:手動テストで機能のベースラインが確立されると、自動化テストは拡張性、徹底性、回帰テストにとって非常に重要になります。
- メカニズム:テストセンターや AFDX テストスイートなどのツールを使用すると、定義済みのサンプル使用事例に基づいて自動テストを生成できます。これらのテストは、エージェントの指示とサブエージェント分類がより広範なシナリオで正しく機能しているかどうかを検証するように設計されています。
- 利点:
- 一貫したパフォーマンスを確保
- 微妙なバグを識別する
- 継続的インテグレーション/継続的リリース (CI/CD) パイプラインをサポート
- 包括的なカバーを提供
-
Apex とフローを使用したアクション固有の単体テスト
- 目的:エージェントアクション内にカプセル化された確定的ビジネスロジックを検証する。エージェントの全体的な動作は確定的ではありませんが、多くの場合、エージェントのアクションには、標準の開発方法が適用されるフローや Apex などのテクノロジーが使用されます。
- メカニズム:開発者は、エージェントアクションが呼び出す特定のフローまたは Apex クラスの単体テストを作成します。これらのテストでは、エージェントのロジックの個々のコンポーネントを検証し、特定の入力セットに対して期待される出力が生成されることを確認します。
- 利点:
- これらの単体テストを DevOps パイプラインに統合することで、自動化されたセーフティネットが提供されます。
- アクションのロジックの変更または機能強化によって回帰が発生しないことを確認する
- 本番にリリースする前にエージェントの機能の信頼性を確保
-
敵対テスト - セキュリティとガードレールの適用:
- 目的:さまざまな種類のエージェントを構築するには、セキュリティを重視し、定義されたパラメーターとガードレールの範囲内で操作できるようにする必要があります。これは、意図しないアクション、データ漏洩、誤用を防止するために重要です。したがって、攻撃者テストの目的は、安全メカニズムを回避するように設計された入力でエージェントに意図的に挑戦し、その堅牢性と操作に対する耐性をテストすることで、潜在的な脆弱性を事前に特定して修正することです。
- メカニズム:敵対的テストは、エージェントの意図する動作の境界を押し広げる、困難、あいまい、または悪意のある入力を作成することで実装されます。エージェントビルダーの「ガードレール」機能のようなプラットフォームツールは、指示の遵守に関するインサイトを提供しますが、開発者は、制御された環境でエージェントを積極的に失敗させるカスタム敵対的テストケースを作成する必要もあります。
- 利点:このアプローチにより、リリース前にセキュリティとコンプライアンスのリスクを計画的に軽減できます。潜在的な障害点を特定することで、攻撃者テストはエージェントの信頼性を高め、ユーザーとやりとりするときにエージェントが安全かつ意図したとおりに動作することを確認します。
スクラッチ組織と Sandbox での反復テスト
「内部ループ」は、エージェントが概念から検証済みコンポーネントに移行してリリースの準備が整う重要な反復サイクルです。この継続的な調整プロセスには、開発とテストの両方の環境が必要です。Agentforce は、共有環境に影響を与えない迅速なプロトタイピングのための一時的な隔離環境であるスクラッチ組織と、本番環境へのパスを促進する現実的なデータを使用して徹底的なテストを可能にする Sandbox を通じて、このフレームワークを提供します。
- スクラッチ組織での開発:初期開発はスクラッチ組織で行う必要があります。ここでは、エージェントビルダーや AFDX など、開発環境内で提供されるツールを十分に活用しています。スクラッチ組織は、単体テストの実行、コード分析の実行、上位環境への変更の促進を行うための CI/CD パイプラインの有力な候補です。
- 実データテスト用の Sandbox へのリリース:エージェントのコア機能がスクラッチ組織で開発されたら、Sandbox にリリースします。Sandbox は、より現実的なテスト環境を提供する本番環境のコピーです。
- Real Data vs.モックデータ:一部の開発者は初期テストでスクラッチ組織のデータをモックすることがありますが、Sandbox にリリースすると「実際のデータ」を使用してテストできます。これは、実際の顧客とのやりとりを密接に反映するシナリオでエージェントのパフォーマンスを評価するために重要です。Sandbox でより多くの代表的なデータを使用すると、開発と調整のプロセスが大幅に加速されます。
- CRM コアデータの完全または部分的な Sandbox:データ量と特定のテスト要件に応じて、Full Sandbox または Partial Sandbox を使用できます。
- Full Sandbox:すべてのメタデータとデータを含む本番環境の完全なレプリカを提供します。大規模なデータセットを使用する広範なテストとパフォーマンスチューニングに最適です。
- Partial Sandbox:本番データのサブセットが含まれます。多くの場合、完全なデータセットが厳密に必要ではない特定の機能をテストするのに十分です。
- Knowledge および RAG 管理:エージェントが Knowledge ベースまたは RAG (Retrieval-Augmented Generation) モデルに依存している場合は、すべての関連コンテンツを Sandbox に取り込んでインデックスを再作成します。これにより、エージェントはテスト中に現在の情報を使用し、コンテンツを正確に取得して統合できます。
Agentforce はメタデータを使用してエージェントを定義するため、変更セットや AFDX などの標準の Salesforce 手順を使用してエージェントを導入できます。このフェーズでは、エージェントのバージョン管理や個別の有効化ステップなどの重要な機能による安全で制御されたロールアウトが強調されます。これにより、システムの安定性が確保され、問題からの迅速な復旧が可能になります。
次の手順に従って、新しいエージェントをリリースします。
- 変更セット/メタデータ API または AFDX を使用した導入:エージェントのリリースプロセスでは、エージェントをメタデータとして扱い、標準の Salesforce 手順を使用します。これは、Salesforce の開発とリリースに慣れているすべてのユーザーにとって馴染みのあるプロセスです。変更セットまたは AFDX を使用すると、Sandbox から本番環境など、環境間でエージェント設定を移行するための体系的で一貫したアプローチが実現します。この方法により、システムの安定性と信頼性を維持するために重要なバージョン管理と適切な変更管理が容易になります。
- リリース後のエージェントの有効化:リリースの成功後、システム管理者はエージェントを積極的に「有効化」する必要があります。リリースでは、エージェントのコードとメタデータが対象環境に配置されます。有効化は、エージェントを動作可能にして使用可能にするステップです。この分離により、エージェントが稼働し、エンドユーザーや他のシステムコンポーネントを操作する前にロールアウトとテストを制御できます。
- 安全なエージェント管理のためのバージョン管理の使用:エージェントのバージョン管理は、エージェントの開発とメンテナンスの安全性と柔軟性を大幅に向上させる重要な機能です。
- 新しいバージョンの作成、テスト、および発行:変更や機能強化が必要な場合、エージェントの新しいバージョンを作成することをお勧めします。その後、この新しいバージョンは、有効化されたライブエージェントに影響を与えることなく Sandbox 環境で徹底的にテストできます。新しいバージョンが検証され、準備が整っているとみなされると、公開して有効化し、以前の運用バージョンを置き換えることができます。この反復プロセスにより、中断を最小限に抑えながら、継続的な改善と革新が可能になります。
- 以前のバージョンへのロールバック:バージョン管理の主な利点は、新しくリリースされたエージェントや有効化されたエージェントで問題が発生した場合に、以前の安定したバージョンにすばやく簡単に戻すことができることです。エージェントの不適切な動作や予期しないエラーの発生など、何らかの問題が発生した場合、管理者は既知の正常な最後のバージョンにロールバックして有効化できます。この機能により、迅速なリカバリとダウンタイムの最小化が可能になり、ビジネス継続性とユーザー満足度が確保されます。
エージェントの監視
Agentforce セッション トレーシングは、Data 360 上に構築されたオープンで拡張可能なモデルで、エンドツーエンドのエージェントのやり取りを取得します。Agentforce セッション追跡では、さまざまなソースからデータが取り込まれ(まず推論エンジンログから開始)、セッション ID の下にすべてが結合されます。
セッショントレーシングデータモデル (STDM) では、エージェントセッション中に何が発生したかに関する詳細情報が次のように提供されます。
- ターンバイターンインタラクション
- 推論エンジンの実行
- アクション、プロンプト、ゲートウェイの入力/出力
- エラーメッセージ
- 最終回答
STDM は、開発者を支援する重要なツールです。
- 構築時にエージェントの設定の問題をデバッグします。
- バッチテスト中に特定のテストケースが失敗した理由を確認します。
- エージェントが一連のユーザー質問を処理できない理由や、トピック外になる理由を説明します。
開発者は、このセッション追跡データを使用して、エージェントの行動、インシデント、および行動パターンの監視、監視、調査、トラブルシューティングを行う必要があります。
STDM は、エージェントの行動の詳細なログを保存するデータレークオブジェクト (DLO) とデータモデルオブジェクト (DMO) で構成されます。推論エンジンによって行われた各 LLM コールに関するメタデータは、フィードバックまたはガードレール評価指標と結合できます。データは Data 360 の DLO にストリームされ、該当する DMO にマッピングされます。
開発者は、STDM に対してクエリとレポートを実行することで、このデータにアクセスし、インサイトを取得できます。STDM のコンポーネントを次に示します。
Agentforce セッション トレーシング データ モデル ERD
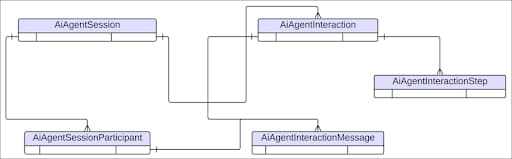
| データレークオブジェクト/データモデルオブジェクト | 説明 |
|---|---|
| AIAgentSession | 1 人以上の AI エージェントとの連続するインタラクションを取得する包括的なコンテナ。 |
| AIAgentSessionParticipant | AIAgentSession に参加するエンティティ (人間または AI)。 |
| AIAgentInteraction | セッション内のセグメント。通常、ユーザーの要求で始まり、AI エージェントがその要求に応答したときに終了します。 |
| AIAgentInteractionStep | ユーザーの要求を履行するためにインタラクション中に実行される個別のアクションまたは操作。 |
| AIAgentInteractionMessage | セッション中にユーザーが提供した、または AI エージェントが生成した 1 つのコミュニケーション。 |
Agentforce 最適化
Agentforce 最適化は、ユーザー操作に関する詳細なインサイトを提供して AI エージェントのパフォーマンスを向上させるように設計された強力な機能です。セッショントレーシングデータモデル (STDM) の分析機能に基づいて構築されているため、システム管理者と開発者はユーザーのトピック、エンゲージメントパターン、エージェントの解決の有効性を把握できます。
Agentforce 最適化の主な側面は次のとおりです。
- Moment-Specific Data:Agentforce 最適化では、セッション中に特定のユーザーインテントまたは要求に焦点を絞ったインタラクションを表す「モーメント」を導入することで STDM を拡張します。この詳細なデータにより、最初のユーザー要求からエージェントの解決まで、インタラクションのあらゆる側面を詳細に検査できます。
- 自動化された瞬間処理:モーメントは毎日生成され、高度な大規模言語モデル (LLM) を使用してすべての有効なエージェントで毎週クラスター化され、タグ付けされます。このセグメンテーションにより、クエリが簡素化され、エージェントセッションのさまざまな側面に関するインサイトが提供されます。
- クエリと分析:ユーザーはタグ、品質スコア、その他の条件に基づいてモーメントを照会できます。これにより、瞬間所要時間や関連性品質スコアなどの評価指標でユーザーエンゲージメントを評価できるため、改善すべき領域を特定できます。
- 統合データモデル:Agentforce の最適化では、統合セッション追跡データモデル(STDM)を活用して、個々の会話のターン数を含む、セッション内のすべての記録イベントを取得します。すべての関連エンティティは、設定で STDM を有効にするとプロビジョニングされます。
AI エージェントのインタラクションを分析することで、Agentforce 最適化により、ユーザーは改善すべき領域を特定し、ユーザーのニーズにより適した構成に調整できます。
詳細については、「Data Model for Agentforce Optimization」を参照してください。
この章は、プロコード開発者向けの実用的なガイドです。Agentforce DX(AFDX)と Python SDK を使用してエージェントを迅速かつ安全に構築、テスト、導入する方法について説明します。AFDX と Python SDK の強力な組み合わせを使用して、初期設計からバージョン管理されたエージェントまでのライフサイクル全体について説明します。
次の例では、Agentforce プラットフォームでエージェントを構築および管理するために設計された 2 つの主要なツールセットを活用します。このガイドを最大限に活用するには、これらのツールについての基礎を理解することをお勧めします。
1.Agentforce DX(AFDX):ライフサイクルの管理
Agentforce DX は、使い慣れた Salesforce Developer Experience(SFDX)ツールセット(Salesforce CLI や VS Code 拡張機能など)を拡張して、エージェント開発ライフサイクル全体をサポートします。これは、バージョン管理されたメタデータとしてエージェントを管理し、コマンドラインからテストを自動化し、開発 Sandbox と本番間のリリースを調整するために使用されます。
詳細は、以下を参照してください。Agentforce DX Developmentの使用開始。
2.Agentforce Python SDK:エージェントの構築
Python SDK は、開発の「内部ループ」用のプログラムインターフェースを提供します。これにより、使い慣れた Python 環境内でエージェントの推論ロジックを定義し、ツールを接続し、プロンプトテンプレートを直接管理できるため、ADLC のコア構築フェーズを合理化できます。
SDK は、PyPI(https://pypi.org/project/Agentforce-sdk/)で入手できます。
完全なプロジェクトは、以下から入手できます。
https://github.com/akshatasawant9699/ADLC_Whitepaper.
この基礎フェーズでは、エージェントの目的、人格、コア機能を定義します。コードを記述する前に、エージェントの「頭脳」を構築するための重要な質問に回答します。この例では、Coral Cloud Resorts のエージェントを設計しています。
- ミッション:エージェントはリゾートマネージャーとして、顧客の苦情の処理、従業員のスケジュールの管理、円滑なリゾート運営を行います。
- 人格:エージェントは、親切で専門的、会話調です。
- ツールと機能:エージェントには、予約システム、従業員スケジュールソフトウェア、リゾートポリシーへのアクセス権が必要です。
- 決定ロジック:エージェントは AI が生成したトピックを使用してユーザーのインテントを判断し、適切なアクションを生成します。
Agentforce DXでは、設計フェーズで具体的な仕様ファイルに翻訳します。Agentforce DX:エージェント・スペシフィケーションの生成。プロコードジャーニーの最初のステップは、agentSpec.yaml ファイルを生成することです。YAML ファイルには、エージェントの役割、関連する会社の詳細、処理できるジョブを定義する AI 生成のトピックのリストなど、エージェントのコア設計が取り込まれます。
Salesforce CLI を使用して、対話型のプロンプトでこの仕様を生成します。Agentforce DX を使用してエージェントの作成を開始するには、次のコマンドを実行します。
アイデア出しフェーズで定義された具体的な詳細を指定する必要があります。
- エージェントのタイプ:顧客
- 会社名:コーラルクラウド・リゾーツ
- 会社の説明:Coral Cloud Resorts は、お客様に卓越したデスティネーションアクティビティ、思い出に残る体験、予約サービスを提供し、そのすべてが一流のカスタマーサービスを提供することに裏付けられています。
- エージェントロール:リゾートマネージャーは、顧客の苦情に対応し、従業員のスケジュールを管理し、すべてのプロセスが円滑に実行されるようにします。
このコマンドを実行すると、DX プロジェクトの specs ディレクトリに agentSpec.yaml ファイルが作成されます。このファイルには、提供された情報と、各トピックの名前と説明を含む AI で生成されたトピックのリストが含まれます。必要に応じてファイルを確認して編集し、エージェントの機能を絞り込みます。
同様に、Python SDK 実装では、対話型の仕様コレクションを使用して、SDK の互換性に必要な適切な範囲項目を含むエージェントトピックを自動生成します。
さらに、フェーズ 2 でエージェントを作成するために使用される完全なエージェント仕様の JSON ファイルが作成されます。
開発フェーズでは、エージェントのコア コンポーネント(推論エンジン、使用可能なツール、Knowledge Base)の構築に焦点が当てられます。Agentforceは複雑さの大部分を抽象化するため、開発者はビジネス・ロジックに集中できます。
このセクションでは、Agentforce 開発フェーズの 2 つのプロコードアプローチについて説明します。まず、Agentforce DX を使用し、次に Python を使用します。
Agentforce DX:スペシフィケーションからのエージェントの作成
agentSpec.yamlファイルの準備ができたら、Salesforce 組織でエージェントを作成します。次のコマンドを実行してエージェントを作成し、関連付けられたメタデータをローカル DX プロジェクトに同期します。
促されたら、デフォルトの API 参照名 Resort_Manager を受け入れます。このコマンドは、仕様を解析し、エージェントを作成して、メタデータを取得します。メタデータには、AI インテリジェンスとエージェントのトピックおよびアクションへの参照を追加する Bot、BotVersion、および GenAiPlannerBundle が含まれます。
作成前にエージェントの構造をプレビューするには、--preview フラグを追加して、LLM が作成するエージェントの種別 (推奨アクションを含む) を詳述するローカル JSON ファイルを生成します。次に例を示します。
詳細については、「Trailhead からの DX プロジェクトからのエージェントの作成」を参照してください。
Agentforce Python SDK:特定のツールの定義
Agent SDK は、疑似アクションを作成してエージェントのテストを促進します。これらの疑似アクションは、最終的に Salesforce 内の実際のアクションに置き換える必要があります。Salesforce では、フロー、Apex、プロンプトテンプレート、API など、さまざまなプラットフォーム機能を提供しています。これらはすべて Agentforce アクションとしてカプセル化できます。
Agentforce アクションの外観を示す模擬アクションコードスニペットを次に示します。
実装により、Salesforce への接続が確立され、エージェントインスタンスが作成され、エージェントが外部システムとのやり取りや特定のビジネス機能の実行に使用できるカスタムツールとアクションが定義されます。
上で説明したように、エージェントのテストは従来のソフトウェアテストよりも複雑です。さまざまなシナリオで動作、推論、堅牢性を検証する必要があります。これには、個々のツールの単体テスト、会話のエンドツーエンドテスト、脆弱性を見つけるための敵対的テストが含まれます。
Agentforce DXでは、テストセンターと直接テスト API に加えて、テストを作成、導入、実行するワークフローの概要が提供されます。このセクションでは、Agentforce DX を使用したテストの実行について説明します。
Agentforce DX:エージェントテストの実行
Agentforce DXを使用して、定義済みのエージェント・テストをコマンド・ラインから直接実行します。これは、エージェントテストを最新の DevOps プロセスに統合する場合に最適です。
Agentforce Python SDK:E2E および敵対テストのシミュレーション
概念的には、Python SDK では、スクリプト化された会話を使用してエンドツーエンド(E2E)テストをシミュレーションし、エージェントの推論を検証できます。
Agentforce Python SDK と Salesforce テスト API
Python SDK の実装では、Salesforce Testing API と AiEvaluationDefinition メタデータを使用した包括的なテストを使用して、トピックシーケンス、アクションシーケンス、文字列の一致、品質評価指標に関する期待を含む構造化されたテストケースを作成します。エージェントのテストと検証を自動化するために Salesforce にリリースできる XML メタデータ定義が生成されます。
検証が完了すると、エージェントは本番環境にリリースされます。このフェーズでは、Agentforce DXは、エージェントメタデータの管理とさまざまな組織間(Sandbox と本番環境など)での移行を支援する上で非常に重要です。エージェントリリースによって新しいバージョンのエージェントが作成され、エージェントは明示的に有効化するまで稼働しません。これにより、新しいバージョンのエージェントをリリースするタイミングを完全に制御できます。
Agentforce DX:エージェントメタデータのリリース
標準Salesforce DXプロジェクト構造では、エージェントメタデータはforce-appディレクトリの下に整理されます。標準 sf project deploy コマンドを使用して、エージェントおよび関連付けられたテストを対象組織にリリースします。
エージェントが作成またはリリースされたら、Agentforce Builder UI で直接開き、次のコマンドを実行してその設定を確認できます。
エージェントがリリースされたことを確認したら、有効化できます。予期しない問題が発生した場合は、エージェントの以前の作業バージョンにロールバックします。
Agentforce Python SDK:エージェントのリリース
実装では、検証済みのエージェント仕様を取得して Salesforce 組織にリリースし、エージェントを使用できるようにします。リリースプロセスには、エージェントの作成、メタデータの同期、成功したリリースの検証が含まれます。
ADLC は継続的なサイクルであり、リリースで終わりではありません。エージェントは、遅延、コスト、成功率などの総計値を追跡するために常時監視する必要がある稼働中のシステムです。監視から取得したインサイトは、迅速なエンジニアリング、ツールの最適化、Knowledge ベースの絞り込みを通じてエージェントのパフォーマンスを調整および改善するために使用されます。
Agentforceプラットフォームは、この重要なフェーズをサポートする包括的なダッシュボードと分析を提供し、エージェントが経時的に進化および改善し続けるようにします。
Agentforce 分析
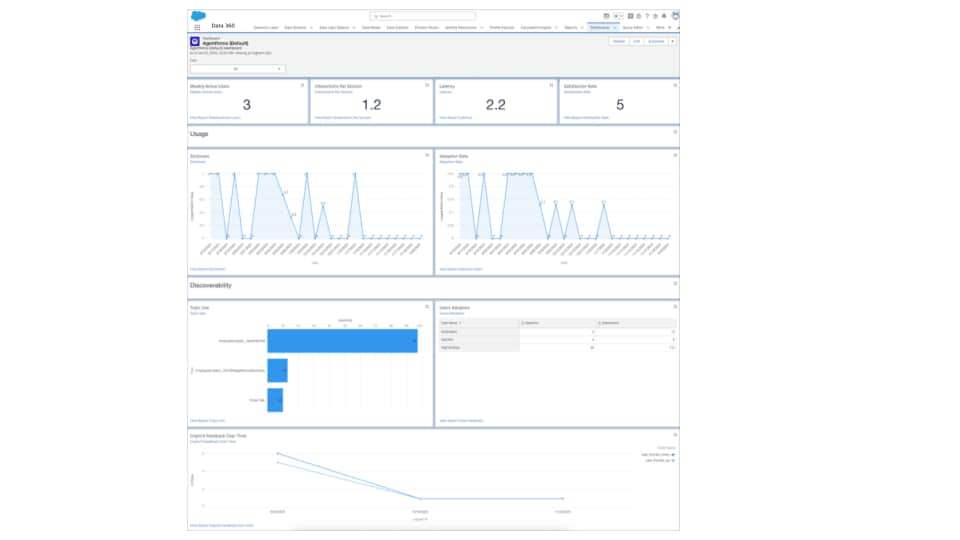
Agentforce Analytics (デフォルト) フォルダにある Agentforce Analytics は、Data 360 を使用してエージェントのパフォーマンスに関するインサイトを提供します。カスタマイズ可能なダッシュボードとレポートでは、採用、フィードバック、利用状況に関するデータが提供され、トピックとアクションを絞り込んでユーザーの満足度を高めることができます。グラフまたはリンクされたレポートをクリックして、結果をドリルダウンできます。カスタマイズするには、既存のレポートをコピーして、分析プロセスが中断されないようにコピーを変更します。
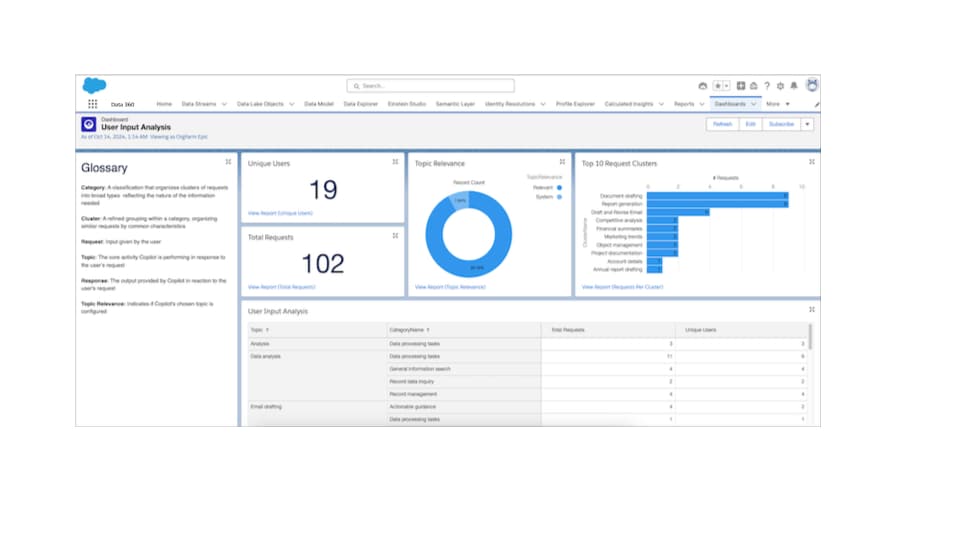
発言分析
発言分析では、Agentforce(デフォルト)ユーザーがエージェントをどのように使用しているか、何を要求しているか、およびエージェントがこれらの要求を処理できたかどうかが示されます。これらのカスタマイズ可能なレポートは、エージェントがより効果的かつ正確に応答できるようにトピックとアクションを調整するのに役立ちます。
Agentforce Python SDK:Data 360 インテグレーションを使用した監視
Agent SDK 実装では、Data 360 Python コネクタを使用した高度な監視と分析を使用して、Salesforce Data 360 への接続を確立し、エージェントのパフォーマンス評価指標を照会して、包括的な監視ダッシュボードを作成します。
応答時間、成功率、ユーザー満足度、コスト総計値を追跡し、エージェントを最適化するためのアクション可能なインサイトを提供します。
Agentforce DX:エージェントの監視
この実装では、CLI ベースのエージェント管理で標準の AFDX コマンドを使用し、プラットフォームの変更に関する最新情報をエージェントに提供し、継続的な改善のためにユーザーのフィードバックを取り入れます。
Agent SDK と AFDX を使用した ADLC の実装については、ここの GitHub リポジトリを参照してください。
エージェント開発ライフサイクルをマスターするには、効率性、信頼性、戦略的な連携を保証する一連の基本原則に準拠する必要があります。次のガイドラインは、ADLC の各フェーズから得られた主要な教訓をアーキテクトと開発者向けの戦略的フレームワークに統合したものです。
1.計画とアイデア
この初期フェーズでは、エージェントの目的をビジネス目標に合わせ、強固な基盤の上に構築することに重点を置いています。
- ビジネスへの影響に対する優先度付け:まず、潜在的な使用事例を戦略的なビジネス目標に直接対応付けます。優先度マトリックスを使用して潜在的な影響を評価し、明確な KPI を含む 1 つの焦点を絞った使用事例から開始します。
- 早い段階で関係者を関与させる:問題点に関するインサイトを収集し、整合性を確保します。
- データインサイトの活用:エージェントは、そのデータによってのみ機能します。Data 360 を使用して、使用可能な構造化データと非構造化データを探索し、エージェントのコンテキストと機能を確認します。既存のレポートとダッシュボードを確認して、使用事例の選択に役立つ可能性がある現在のトレンドを特定します。
- アイデア出し用のフレームワークの使用:構造化されたアイデア出し方法を適用して、デザイン思考や SWOT 分析などの潜在的なアプリケーションをブレインストーミングし、調整します。
2.エージェントの作成
このフェーズでは、パフォーマンスが高く効率的なエージェントを構築するためのベストプラクティスについて説明します。
- トピックが多すぎます:トピック数を制限して、エージェントを困惑させる可能性のある類似トピックや重複トピックを作成するリスクを軽減します。
- 手順とプロンプトの簡潔な維持:直接的でシンプルな言葉を使用し、サンプル発言を提供してエージェントを効果的に誘導します。
- 変数と確定的アクションの活用:これらのツールを使用して、エージェントの行動をガイドし、より予測可能な結果になるようにパフォーマンスを最適化します。
- アクションの出力を小さく簡潔に:エージェントの回答が簡潔で的確であることを確認します。出力が長いほど、使用するコンテキストが多くなり、生成が遅くなります。
- アクションを高速:化必要最小限のデータを返すようにフローと Apex クラスを設計します。可能な場合は前処理することで、応答を生成するために必要なアクションを減らすことを目指します。
- Clear Scope の定義:範囲外の質問に対してエージェントが RAG (Retrieval-Augmented Generation) をコールしないように、アクションの適切な説明、手順、範囲を記述します。
- ハイブリッド検索の慎重な使用:ハイブリッド検索は、遅延に悪影響を及ぼす可能性があるため、どうしても必要な場合のみ使用してください。
3.テスト、監視、チューニング
この反復フェーズは、エージェントの精度とパフォーマンスを向上させるために重要です。
- テストフローの確立:一貫したテストサイクルに従います。
- バッチテストの実行:包括的なテストセットを実行します。
- スコア/エラーの表示:パフォーマンス総計値を分析し、障害を特定します。
- 失敗:を検査各失敗行を調べて、不一致を理解します。
- エージェントの更新:エージェントまたはその評価データに必要な調整を加えます。
- セッション追跡情報の確認:セッション追跡データ モデルと Agentforce Interaction Explorer を使用して、問題または予期しない動作が特定されたときに根本原因分析を実行します。情報に基づいてエージェントを調整し、エージェントの反復を続行します。
エージェント開発ライフサイクルは、インテリジェントな自律システムの時代に合わせて設計された従来のソフトウェア開発原則の重要な進化を表します。
- 置き換えではなく進化:エージェント開発ライフサイクルでは、従来のアプリケーションライフサイクル管理を置き換えることなく拡張および強化できます。
- 第一級市民としてのデータ:データは、エージェント開発においてはるかに動的で中心的な役割を果たします。
- 特殊なツールとスキル:新しいツールと、データサイエンス、ML エンジニアリング、エージェント開発にわたるより広範な専門スキルセットが必要です。
- 継続的な学習:エージェント開発では、システム自体の継続的な学習と適応が追加されます。
- 将来の影響:Agentic AI は、複雑な IT 運用とソフトウェア開発ワークフローの自動化と最適化をさらに推進します。