多くの場合、企業は Salesforce と、Snowflake、Google BigQuery、Databricks、Redshift、Amazon S3 などのクラウドストレージなどの他の外部データレイクの両方にデータを保存します。このように異なるソースシステムでデータがサイロ化されているため、データを最大限に活用したいと考えている企業にとって課題となっています。
複数のデータレークのデータを統合しようとするアーキテクトは、そのデータを統合する最適な方法に関する主要なアーキテクチャ上の決定に直面します。Data 360 では、データインテグレーションに複数のオプションがあり、それぞれに長所と短所があります。
このガイドでは、データ統合時の遅延、コスト、拡張性、ガバナンス、複雑さの要件にどのパターンが最適かを評価するフレームワークを提供し、データ取り込み、ゼロコピーデータ統合、またはハイブリッドアプローチを使用するタイミングを選択するのに役立ちます。また、このガイドは、さまざまなニーズに対応するさまざまなデータ取り込み方法とデータ統合方法の選択にも役立ちます。
外部データレイクハウスを Data 360 と統合するには、データの新鮮さ、ガバナンス、パイプラインの効率性のトレードオフを慎重に検討する必要があります。たとえば、Zero Copy データ統合ライブクエリを使用すると、データの新鮮度が最大限に高まりますが、ネットワークを介して移動するデータが多くなるとパイプラインの効率が低下する可能性があります。そのため、ほとんどの実際の実装では、マルチクラウド Lakehouse エコシステム内で取り込みと統合を組み合わせることが最適なパスです。このハイブリッド アプローチにより、リアルタイムのパーソナライズや不正行為の検出などの低レイテンシの運用ワークロードと、規制レポートや履歴トレンド分析などの分析ワークロードの両方をシームレスにサポートする、拡張性の高い管理された相互運用性のあるアーキテクチャが実現します。この意思決定ガイドは、これらのトレードオフをどのように操作し、適切な戦略を選択するかを理解するのに役立ちます。
- **データ取り込み:**データを Salesforce Data 360 にコピーし、管理された正規データモデルを作成します。次のような場合に最適です。
- **包括的なCustomer 360の構築:**異種ソースを統合し、1 つの信頼できるプロファイルに変換します。
- **厳格な規制コンプライアンスへの対応:**データアクセスと系統を厳密に制御できる監査可能な一元化されたコピーを作成します。
- **ゼロコピー統合:**重複のないリアルタイムで外部ソースを照会し、リアルタイムのパーソナライズ、ライブダッシュボード、迅速なソースオンボーディングを可能にします。バランスを取る必要があるトレードオフの 2 つの主なオプション:
- **ライブおよびキャッシュ (クエリの高速化):**Snowflake、Google BigQuery、Redshift、Databricks などの外部データプラットフォームに存在するデータの対話型分析やリアルタイムダッシュボードに最適です。処理をソース・システムに転送して、低速でコストのかかるデータの重複を回避します。
- **ファイルフェデレーション:**クラウドデータレイク (S3、ADLS) のデータに関する大規模なバッチ処理や AI モデルのトレーニングに最適です。開いているテーブル形式でファイルを直接照会し、ETL およびデータサイエンスのワークロードの膨大なデータセットを解放することで、コストと時間のかかる取り込みを回避します。
- **ハイブリッド モデル:**統合プロファイルの取り込みと新鮮さのための統合がブレンドされ、オムニチャネル エンゲージメント、Agentforce駆動型アクション、AI/MLトレーニングがサポートされます。
-
**ハイブリッド アーキテクチャ:**多くの場合、データ取り込みとデータ統合を組み合わせる必要があります。
- 正規データモデルとコアガバナンスの重要なデータでデータ取り込みを使用します。
- Zero Copy を使用して他のすべてのデータを統合することで、取り込みデータパイプラインの作成と管理にかかる運用オーバーヘッドを最小限に抑えます。
-
**データ取り込み頻度が重要:**ビジネス価値、遅延のニーズ、運用の複雑さに基づいて頻度を選択します。
- 時間的制約のあるワークフロー(パーソナライズ、ライブ ダッシュボード、Agentforceアクション)にはリアルタイムを使用します。
- 緊急度が中程度のプロセス (キャンペーン、運用レポート) の場合はほぼリアルタイム。
- 履歴データセットまたは低速データセットのバッチ。
-
**[統合パターン] を [レイテンシとパフォーマンス] に一致させます。**アクセスパターンと、最新性、パフォーマンス、コストの要件に最も適したアクセスパターンを選択します。
- ライブクエリは、低遅延が重要な運用ダッシュボードやリアルタイムのパーソナライズに使用します。
- キャッシュ (高速化されたクエリ) は、クエリが頻繁に発生するが、パフォーマンスとコストのバランスを取るために若干古い結果でも問題ない場合は使用します。
- ファイルフェデレーションは、履歴データセットや時間的制約の少ないデータセットに最適な、スループット負荷の高い大規模な分析またはバッチ ワークロードに使用します。
-
ガバナンスとデータ レジデンシー要件の整合性:
- 取り込みは、一元化されたガバナンスが重要な場合に使用します。
- 分散ガバナンスが許容される場合には統合を使用し、外部ソースでは厳格なガバナンスを適用します。Zero Copy では、行レベルセキュリティ (RLS) やデータマスキングなどのソースレベルのポリシーが適用されます。
-
**価値の高いワークフローの取り込みに優先順位を付ける:**ID 解決、規制レポート、業務の有効化などの重要なプロセスに取り込みを選択的に適用します。
-
**コストと複雑さが意思決定を促進:**リアルタイム取り込みは、コストがかかり複雑になる可能性があります。アーキテクトは、データのオンボーディング、保存、変換のコストと、ゼロコピーでデータを直接照会するコストを比較する必要があります。
適切なインテグレーションパターン (データ取り込み、ゼロコピー、ハイブリッドアプローチ) を選択することは、マルチクラウドプラットフォーム全体のレイテンシ、ガバナンス、運用効率、コストに直接影響します。この決定により、リアルタイムのインサイト、AI 主導の有効化、パーソナライズされたエンゲージメントを信頼性高く大規模に提供する方法が決まります。
次の表に、Salesforce Data 360 のデータ取り込みパターンとゼロコピーパターンの技術的な比較を示します。機能、トレードオフ、メリットに焦点を当て、エンタープライズの使用事例と結果を示します。アーキテクトは、パフォーマンス、コスト、コンプライアンスのバランスを取るハイブリッド マルチクラウド データ プラットフォームを設計する際の参考にできます。
| パターン種別 | モード/ツール | 利点 | 考慮事項 | 結果 |
|---|---|---|---|---|
| データ取り込み | リアルタイム:CDC サポートの取り込み API を介した 1 秒未満の遅延の取り込み。継続的なストリーミングパイプライン。 | - 即時インサイト -低レイテンシの運用およびパーソナライズの使用事例に最適 -イベント駆動型ワークフローをサポート |
- 高いコスト - 複雑なアーキテクチャ - 低レイテンシのソースシステムが必要 - 大量のソースにより過剰なストリーミングが発生し、パイプラインが飽和状態になる可能性がある - I/O集中型 オーバーヘッドを削減するための選択項目と絞り込みを考慮する |
Agentforce: リアルタイムの不正行為アラート、小売のパーソナライズ、運用アラート 分析: - 1 秒未満のダッシュボード、KPI 監視 コンプライアンス: - 規制対象のワークフローの顧客レコードの継続的な更新 |
| ストリーミング:ネイティブコネクタを使用して 1 ~ 3 分ごとにマイクロバッチを取り込み | - コストと新鮮さのバランス -リアルタイムよりもシンプルなアーキテクチャ -増分更新をサポート |
- 若干の遅延 - 重要な1秒未満の意思決定には適していない可能性がある -バッチサイズがメモリ/コンピューティングに影響する - I/O が中程度 -予測可能で反復的な更新パターンに最適 -処理負荷を軽減するためにウィンドウ集計を考慮する |
Agentforce: - タイムリーなキャンペーントリガー、ほぼ稼働中のエンゲージメント 分析: - レコメンデーションエンジン、ほぼ稼働中のダッシュボード コンプライアンス: - 監査機能を備えた頻繁な更新 |
|
| バッチ:コネクタまたは API を介してスケジュールされた大量の読み込み。オブジェクトストレージと ETL/ELT パイプラインをサポートします。 | -大規模なデータセットのコスト効率 - 実装が容易 - 履歴分析の信頼性 |
- データ遅延 - 時間的制約のある操作には不向き - 読み込みウィンドウ中にI/Oを集中 -大きなファイルでは、ネットワークのスループットがボトルネックになる可能性がある -履歴集計や規制対象のレポートワークフローに最適 |
Agentforce: - IT サポートチケット (Jira/ServiceNow)、集計されたワークフロー 分析: ・履歴分析、トレンド評価 苦情: - 規制レポート、患者/請求データの集計 |
|
| Zero Copy | Live Query:外部システムでの直接クエリ、読み取り時のスキーマ、データの重複なし | - 最大限の新鮮度 -最小限のストレージオーバーヘッド、リアルタイムの運用インサイトのサポート |
-ソースのパフォーマンスによる - クエリ量が多いと遅延に影響する可能性がある -述語プッシュダウンと集計を使用して I/O を最小限に抑えるクエリに最適 -大量のデータセットに対する絞り込まれていないクエリを回避する |
Agentforce: - ライブ活動に適応する動的ワークフロー 分析: - 運用ダッシュボード、ライブレポート コンプライアンス: - ソースでの行レベルセキュリティとマスキングを遵守 |
| Accelerated Query (Caching):統合クエリ用のキャッシュされたローカルコピー。15 分から 7 日の間で設定できます。最適化されたクエリ実行 | - 遅延を削減 - 繰り返しのライブクエリよりも低コスト - 頻繁なアクセスパターンのパフォーマンスを向上 |
キャッシュ管理が必要 -キャッシュ間隔によって停滞 - 頻度の高いクエリに最適 - 秒未満の判断には適していません。 |
Agentforce: - 迅速な意思決定のための事前集計されたエンゲージメント評価指標 分析: - BI ダッシュボード、セグメンテーション、分析レポート コンプライアンス: -監査ログを含む一貫した規制対象ダッシュボード |
|
| ファイルフェデレーション:オブジェクト ストアまたはレーク(S3、Iceberg、Google BigQuery、Redshift)内の大規模な履歴データセットへの直接アクセス。 | - 大規模なデータセットを処理する Data 360 の最小ストレージ -AI/MLワークロードをサポート |
- 参照のみ -クエリのパフォーマンスは外部システムのスループットによって異なる -バッチ処理が多く、スループット要件の厳しいジョブに最適化 - リアルタイムダッシュボードには適していません。 |
Agentforce: - (一般的ではない — バッチ処理が多い) 分析: -ML/AIトレーニング、履歴分析、ペタバイト規模のレポート コンプライアンス: -重複のない外部データセットへのアクセスを管理 |
データの取り込みでは、ソースにデータが残る Zero Copy とは異なり、データは物理的に Data 360 にコピーされ、完全に管理されます。Compute for Transformations は Data 360 内で実行されるため、ガバナンスと監査を一元化できます。
データの取り込みを使用して、正規の管理データセットを Salesforce Data 360 に保存することで、コンプライアンスと業務管理を実現します。取り込みは、完全な制御、監査、トレーサビリティが必要な場合に使用します。一元的なコンピューティングとガバナンスが重要な規制対象のワークフローや価値の高いワークフローに最適です。
取り込みは、ID 解決、規制レポート、ミッションクリティカルな AI 駆動型ワークフロー、顧客エンゲージメントのための信頼できる基盤を構築するのに最適です。

データの取り込み方法は、データの取り込みに使用するコネクタによって異なります。さまざまな取り込み方法を提供するコネクタもあれば、バッチモードまたはストリーミングモードでのみ動作するコネクタもあります。「Data 360:Data 360 コネクタとその使用可能な方法の完全なリストについては、Integrations and Connectors (インテグレーションとコネクタ) を参照してください。
- リアルタイム
- ストリーミングパイプラインまたは Change データキャプチャ (CDC) を使用した 1 秒未満の取り込み。
- 時間的制約のあるワークフロー (不正検出、パーソナライズ、運用ダッシュボード) に最適です。
- Data 360 内の変換と集計をプッシュして、下流の I/O を削減し、コンピューティングの使用状況を最適化します。増分 CDC を使用して、データの入れ替えを最小限に抑えます。
- ストリーミング
- 1 ~ 3 分おきに少しずつ取り込みます。
- キャンペーンオーケストレーション、ニアライブエンゲージメント、運用レポートに適した、新鮮さとコストのバランスの取れたソリューション。
- マイクロバッチを使用して、I/O スパイクを制御します。可能な場合はソースでデータを集計して、転送量を削減し、ストレージを最適化します。
- バッチ (スケジュール済み負荷)
- 大規模なデータセットの定期的な取り込み (毎時、毎日、毎週)。
- 履歴データセット、規制レポート、コンプライアンスの使用事例のコスト効率と信頼性。
- パフォーマンスとコストを最適化するために、ソースストレージと同じ領域でコンピューティングの局所性を確保します。
- データ取り込みの使用事例
- **Customer 360統合プロファイルの生成:**顧客の ID と属性の一元化された情報源を構築します。
- **規制コンプライアンスデータセットの管理:**機密データのガバナンス、系統、監査可能性を適用します。
- **キャンペーンのオーケストレーションを一元化:**マーケティング、営業、サービスのすべてが一貫性のある信頼できるデータセットから実行されるようにします。
- 設計プラクティス
- アーカイブレポートや定期的なスナップショットなど、履歴や低レイテンシーを必要とする場合にバッチ取り込みを推奨します。
- CDC またはストリーミング API を使用して、業務およびパーソナライズワークフローの新鮮さを維持し、ほぼリアルタイムの更新を保証します。
- データセット全体を再読み込みするのではなく、増分負荷を適用してコストと効率を最適化し、ストレージとコンピューティングの増加を制御します。
- 取り込みパイプラインをコンピューティングの局所性および増分処理に合わせて、ネットワーク I/O を削減します。Data 360 内で変換を適用して、未加工データを不必要に移動しないようにします。
- コストに関する考慮事項
- **リアルタイム取り込み:**コンピューティングとパイプラインのコストが最も高い。パーソナライズ、運用ダッシュボード、Agentforce駆動型アクションなど、価値が高く時間的制約のあるワークフローが妥当。
- **ストリーミング取り込み:**コンピューティングコストとストレージコストを中程度に抑えます。キャンペーンオーケストレーションや運用レポートなど、わずかな遅延を許容できる頻繁な更新に適しています。
- **バッチ取り込み:**コンピューティング コストの削減と予測可能なストレージ。履歴データセットや頻度の低い更新に最適です。特定のコネクタを使用して Salesforce 組織から一括処理データを取り込むことは無料です。
- **更新モード:**増分更新モードを選択すると、取り込みと計算の合計コストを削減できます。すべての取り込み種別で効率を最適化するために、可能な限り増分更新を使用することをお勧めします。
- コストは、ソースから Data 360 への I/O 量にも影響されます。バッチサイズ、パーティション、地域調整を最適化すると、転送コストが削減され、パフォーマンスが向上します。
- 業種シナリオ
- **財務:**顧客 (KYC)、アンチマネーロンダリング (AML)、不正検出 (監査可能性とコンプライアンスが譲れない場合) を知るために必要なデータセットを取得します。
- **医療:**患者の ID 解決と HIPAA 準拠レコードの取り込みを使用して、安全で統合されたビューを実現します。
- **小売:**セグメンテーションとパーソナライズのために、POS、eコマース、ロイヤルティプログラムデータを統合プロファイルに統合
- **通信:**正規管理された登録者データを使用して、離脱防止と利用状況の分析をサポートします。
| 機能 | リアルタイム取り込み | ストリーミング取り込み | 一括取り込み |
|---|---|---|---|
| レイテンシと新鮮さ | 変更データキャプチャ (CDC) をサポートする取り込み API を介した 1 秒未満の遅延の取り込み。継続的なストリーミングパイプラインを提供します。低レイテンシの運用使用事例に最適です。 | ネイティブコネクタを使用して 1 ~ 3 分ごとにマイクロバッチを取り込みます。増分更新をサポートします。若干の遅延が予想されます。 | データ遅延が予想されます。スケジュールされた大量の読み込み。定期的な取り込み (毎時、毎日、毎週)。時間的制約のある操作には適していません。 |
| 主な使用事例 | 低レイテンシの運用およびパーソナライズの使用事例に最適です。時間的制約のあるワークフローに使用されます。イベント駆動型ワークフローをサポートします。リアルタイムの不正行為アラートと業務アラートに使用されます。 | 緊急度が中程度のプロセスに適しています。キャンペーンオーケストレーション、ニアライブエンゲージメント、運用レポートに使用されます。タイムリーなキャンペーントリガーに使用されます。 | 大規模なデータセットのコスト効率が高い。履歴分析の信頼性。履歴集計または規制対象のレポートワークフローに使用されます。履歴データセットや低速データセットに最適です。 |
| アーキテクチャの複雑さと I/O | 高コストで複雑なアーキテクチャ。低レイテンシのソースシステムが必要。I/O 集約型。大量のソースがあると、パイプラインが飽和する可能性があります。 | リアルタイムよりもシンプルなアーキテクチャ。I/O は中程度です。予測可能で反復的な更新パターンに最適です。バッチサイズはメモリ/コンピューティングに影響します。 | 実装が容易。読み込みウィンドウ中は I/O 集中型。大規模なバッチでは、ネットワークのスループットがボトルネックになる可能性があります。 |
| コストに関する考慮事項 | 最も高いコンピューティングコストとパイプラインコスト。価値が高く、時間的制約のあるワークフローでのみ有効です。 | コンピューティングコストとストレージコストを節減します。コストと新鮮さのバランスの取れたアプローチを提供します。わずかな遅延を許容できる頻繁な更新に適しています。 | コンピューティングコストの削減と予測可能なストレージ。履歴データセットや頻度の低い更新にお勧めします。Salesforce 内部パイプラインを介した取り込みは無料です。 |
| 設計プラクティス | 増分 CDC を使用して、データの入れ替えを最小限に抑えます。選択項目を絞り込んで使用し、オーバーヘッドを削減します。 | マイクロバッチを使用して、I/O スパイクを制御します。処理の負荷を軽減するために、ウィンドウ集計を検討します。 | これは、アーカイブレポートや定期的なスナップショットに使用します。コストを最適化するために、ソースストレージと同じ領域でコンピューティングの局所性を確保します。 |
Zero Copy を使用して、データの重複のない外部システムのリアルタイムクエリを実行し、大規模または一時的なデータセットへの機敏性、新鮮さ、拡張性のあるアクセスを実現します。ライブダッシュボード、探索分析、AI/ML モデルのトレーニング、Salesforce Data 360 を介したリアルタイムの顧客エンゲージメントに最適です。
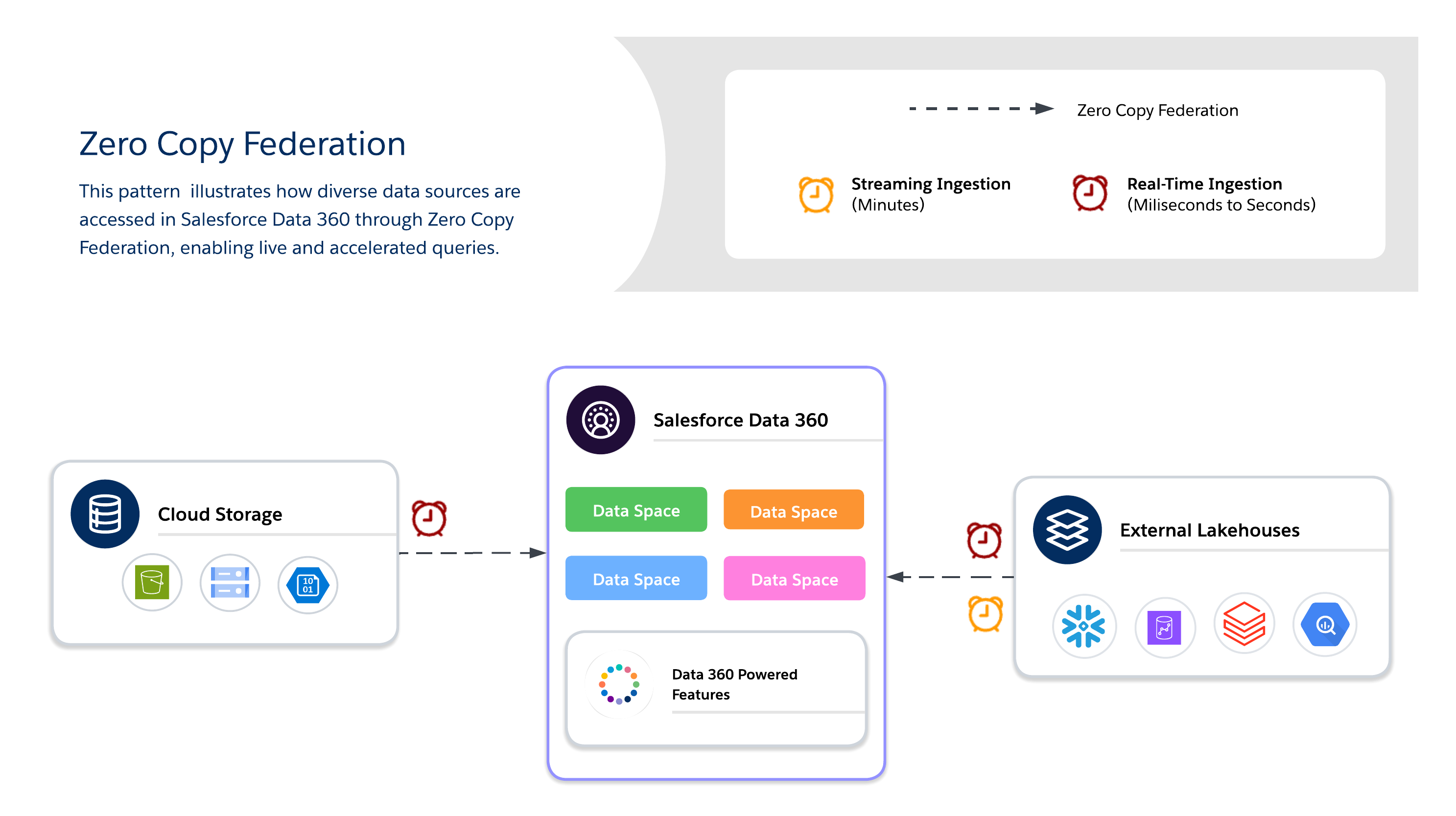
Zero Copy を使用する場合、アーキテクトは使用可能な 3 つのデータ統合方法のいずれかをさらに決定する必要があります。各方法には、新鮮さ、パフォーマンス、コストのトレードオフがあります。
- Live Query
- 外部システム (Snowflake、Google BigQuery、Redshift、Databricks など) に対してデータの重複なしで直接クエリを実行します。
- 述語と集計を押し下げられる場合に最適で、ネットワーク上のデータ移動を最小限に抑え、Salesforce Data 360 コンピューティングの I/O を削減します。
- リアルタイムのインサイトと低レイテンシの運用ダッシュボードに最適です。外部システムのパフォーマンスによって異なります。
- キャッシュ (高速化されたクエリ)
- Salesforce Data 360 に統合データのキャッシュコピーを一時的に保存します。
- 頻繁にアクセスされるデータセットの反復クエリコストと遅延を削減し、期間 (分~日) を設定可能。
- データが完全にコピーされたり、完全に管理されたりすることはありません。更新はソースからのスケジュールされた更新で管理されます。
- ファイルフェデレーション
- オブジェクトストアの大規模なデータセット (S3、Iceberg を使用する GCS など) への参照のみの直接アクセスを提供します。
- データを移動することなく、AI/ML ワークロード、履歴分析、ペタバイト規模のレポートに最適です。
- クエリのパフォーマンスは、オブジェクト形式、パーティショニング、ネットワーク I/O に大きく依存します。大規模なスキャンでは、最適化されていない場合、大量の I/O が生成される可能性があります。
- 使用事例
- **リアルタイムのパーソナライズと適応型ワークフロー:**顧客の行動の変化に応じて、動的な提案、おすすめ、Next Best Action を提供します。
- **ライブ ダッシュボードと運用分析:**ビジネスクリティカルなダッシュボードと KPI を外部倉庫から直接強化します。
- **大規模な外部データセットを使用したAI/MLモデルのトレーニング:**ファイルフェデレーションを使用して、データレークやデータウェアハウスからペタバイト規模のデータを移動せずに活用します。
- 業種シナリオ
- **小売/メディア:**クリックストリームまたはコンテンツインタラクションデータを統合することで、パーソナライズされたおすすめとリアルタイムの顧客エンゲージメントを実現します。
- **財務:**機密データを重複させることなく外部倉庫を照会することで、ほぼリアルタイムで不正行為の検出とリスクスコアリングを実行します。
- **テクノロジー/エンタープライズ:**データセットが複数のシステムに存在するクロスクラウドレポート、IT サービスダッシュボード、運用分析をサポートします。
- 設計プラクティス
- Live Query
- 新鮮さが重要な場合に、高 QPS で低遅延のクエリに使用します。
- 述語と集計を外部システムに転送して、ネットワーク上のデータの入れ替えを減らします。
- 大量のデータを不必要にスキャンするクエリは避け、パーティションプルーニングとフィルターを検討します。
- ファイルフェデレーション
- 取り込みなしでオブジェクトストアのペタバイト規模のデータセットにアクセスできます。
- オブジェクトストレージを Salesforce コンピューティングと同じクラウド領域に保持して、遅延と出力コストを最小限に抑えます。
- パーティション分割された列形式 (Parquet/ORC) とプッシュダウン検索条件を使用して、I/O とネットワーク転送を削減します。
- クエリと述語のプッシュダウンを活用して、ソースでデータを絞り込んで集計し、データの移動を減らします。
- I/O、遅延、コストが増加するため、必要時以外は地域間のデータアクセスは避けてください。
- キャッシュ (高速化されたクエリ)
- コストとパフォーマンスのバランスを取るために、頻繁にアクセスするデータセットをキャッシュします。
- 更新間隔を設定して、新鮮度とクエリコストのバランスを取ります。
- **コンプライアンス:**行レベルセキュリティ (RLS) を活用し、統合システム内でポリシーを直接マスキングすることで、ソースでガバナンスを適用します。以下は、プラットフォーム全体で統一的な RLS とマスキングを行うためのベストプラクティスです。
- **一元化されたエンタープライズ ID を使用します。**Salesforce Data 360 のユーザーとエンティティを、外部システムの ID に対応する一意の一元化されたエンタープライズ識別子に対応付けます。
- **セキュリティポリシーの調整:**対応付けられた ID に基づいて、統合システムの行レベルセキュリティとマスキングポリシーが適用されるようにします。これにより、外部データを照会するときのコンプライアンスが保持されます。
- **ID スキーマの標準化:**すべてのデータソースで ID 属性 (メール、ユーザー ID、顧客 ID など) の一貫性を維持し、不一致やアクセス違反を回避します。
- Live Query
- コストに関する考慮事項
- **ライブクエリ:**クエリごとの支払モデル — 外部 Lakehouse コンピューティングでコストが発生し、高い QPS で急増する可能性があります。コストの変動よりも価値の方が大きい、新鮮さを重視する使用事例に最適です。
- **高速化されたクエリ (キャッシュ):**ソースシステムへのヒットを減らすことで Live Query よりもクエリコストを削減しますが、キャッシュへの入力と更新のための一括処理データ取り込みのコストが増加します。頻繁にアクセスされるデータセットに最適です。
- **ファイルフェデレーション:**オブジェクトストアのデータとして最も安価なストレージオプション。ただし、クエリコストはファイルサイズ、パーティション分割、およびプルーニングによって異なります。ペタバイト規模の履歴データや一括データに最適です。
| 決定ポイント | ライブクエリ | キャッシュ (高速化されたクエリ) | ファイルフェデレーション |
|---|---|---|---|
| データソースの場所 | 外部データレイクハウス (Snowflake、Google BigQuery、Redshift、Databricks)。 | 外部データレイクハウス (Snowflake、Google BigQuery、Redshift、Databricks) | オブジェクトストアまたはクラウドデータレイク (S3、ADLS、GCS)。多くの場合、Iceberg などのオープンテーブル形式が使用されます。 |
| 目的/使用事例 | 対話型の分析やリアルタイムダッシュボードに最適です。リアルタイムのパーソナライズと動的なワークフローに最適です。 | クエリが頻繁に発生するが、若干古い結果が許容される場合に最適です。BI ダッシュボードおよびセグメンテーションに適しています。 | 大規模なバッチ処理や AI/ML モデルのトレーニングに最適です。履歴分析やペタバイト規模のレポートに最適です。 |
| 新鮮さ/レイテンシ | 最大限の新鮮さ。クエリはリアルタイムで直接実行されます。1 秒未満の決定をサポートします。 | 若干古い結果でも問題ありません。新鮮度はキャッシュ間隔によって異なり、15 分から 7 日間の範囲で設定できます。 | バッチ負荷が高く、スループット要件の厳しいジョブに最適化されています。リアルタイムダッシュボードには適していません。 |
| アクセスパターン | 頻度の低いクエリやアドホッククエリに最適です。新鮮さが重要な高 QPS (1 秒あたりのクエリ数) で低遅延のクエリに使用します。 | 高頻度の読み取りシナリオに最適です。頻繁なアクセスパターンのパフォーマンスが向上します。 | 参照のみアクセス権。取り込みなしのペタバイト規模のデータセットに適しています。 |
| パフォーマンスの促進要因 | 外部ソースシステムのパフォーマンスに大きく依存します。述語と集計をソースにプッシュできる場合に最適化されます。 | 繰り返されるライブクエリよりも遅延が短縮されます。パフォーマンスは、キャッシュ管理と間隔によって異なります。 | パフォーマンスは、オブジェクト形式、パーティショニング、外部システムのスループットに大きく依存します。パーティション分割された列形式 (Parquet/ORC) を使用します。 |
| コストへの影響 | クエリ単位の支払モデル。外部 Lakehouse コンピューティングで発生するコスト。クエリ頻度が低い場合はコスト効率が高くなりますが、1 秒あたりのクエリ (QPS) 量が多いと経費が急増する可能性があります。 | 繰り返しのライブクエリよりも低コスト。外部ソースを繰り返し照会する必要がなくなります。キャッシュストレージと更新オーバーヘッドが追加されます。 | 最も安価なストレージオプション。クエリコストは、ファイルサイズとパーティション化によって異なります。 |
| 主な考慮事項 | 大量のデータを不必要にスキャンする絞り込まれていないクエリは避けてください。 | キャッシュ管理が必要です。秒未満の判断には適していません。 | クエリのパフォーマンスは、パーティショニングと述語プッシュダウンによる最適化に大きく依存します。 |
ハイブリッドアーキテクチャにより、アーキテクトは、統合クエリを活用して新しさ、重複の削減、大規模な外部データセットへのスケーラブルなアクセスを実現しながら、重要なデータセットを Data 360 に固定して一元管理できます。このアプローチでは、I/O、計算の局所性、コスト、コンプライアンスの要件のバランスを取ります。
ハイブリッドアプローチを使用して、データの取り込みとゼロコピーを組み合わせることで、バランスの取れたガバナンス、新鮮さ、運用効率を実現し、リアルタイムでアクション可能なインサイトを提供します。トレーサビリティ、RLS、マスキングが必要な価値の高い規制対象のデータセットには取り込みを使用し、新鮮さとパフォーマンスが重要な一時的または大量のデータセットには統合を使用します。
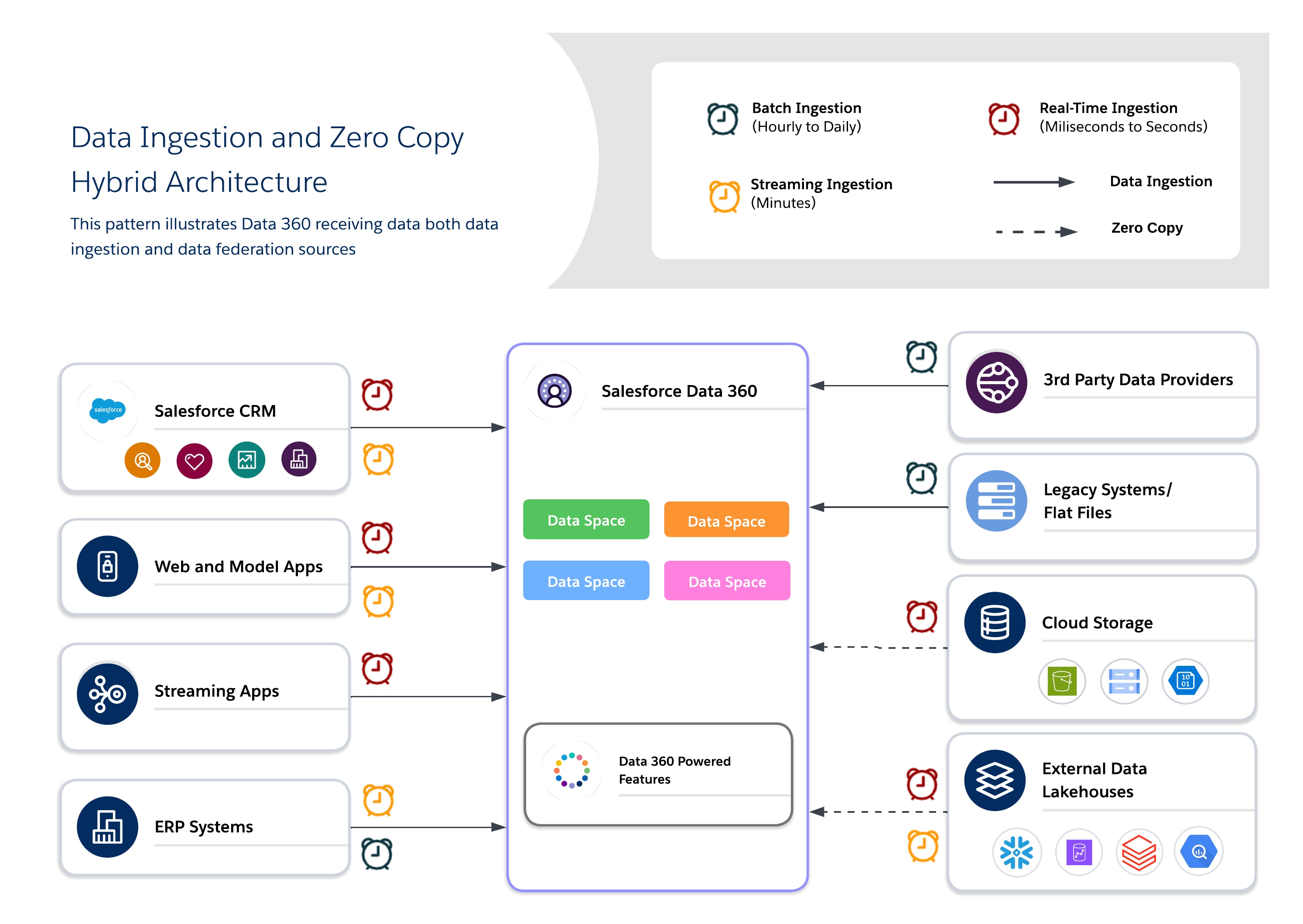
- 使用事例
- **オムニチャネルエンゲージメント:**過去の顧客データとリアルタイムの行動を組み合わせて、一貫性のあるコンテキスト対応環境を提供します。
- **AI/MLパイプライン:**選定された正規データセットでモデルをトレーニングしながら、外部ソースからの未加工またはリアルタイムのシグナルで強化します。
- **混在するコンプライアンスと俊敏性のニーズ:**機密データには厳格なガバナンスを適用し、運用の俊敏性については統合します。
- 業種シナリオ
- **小売:**ID 解決とプロファイル統合には取り込みを使用し、リアルタイムの提案とパーソナライズには統合を使用します。
- **医療:**IoT デバイスストリームとセンサーデータを統合することでコンテキストをすぐに把握しながら、取り込みによってゴールデンの患者レコードを維持します。
- **金融サービス:**不正行為の検出とリスク監視のための外部クエリを統合しながら、規制対象データをコンプライアンスが管理されるレイクに取り込みます。
- 設計プラクティス
- **取り込みを使用したアンカー ガバナンス:**価値の高いデータや規制対象のデータを正規モデルに取り込み、Trustとコンプライアンスを確保します。
- **新鮮さのための統合の使用:**外部レイクハウスで、重複のないリアルタイムまたは大規模なデータアクセスができるようにします。
- **バランスコストとパフォーマンス:**ワークロードをプロファイルして、取り込むものと統合するものを決定し、不要なストレージやクエリのコストを最小限に抑えます。
- **階層化されたガバナンスの適用:**統合システム独自のセキュリティ制御 (RLS、マスキングなど) を活用しながら、取り込まれたデータの一元的なガバナンスを適用します。
- ハイブリッドパイプラインを設計する場合、履歴データセットの増分取り込みを確認し、統合ソースに集計または絞り込みを転送して、I/O と計算の使用量を最適化します。
- コストに関する考慮事項
- コンプライアンスや重要なデータの取り込みと、新鮮さが必要な場合の統合を組み合わせて、総コストとパフォーマンスを最適化します。
- 取り込みと統合を混在させるときに、I/O とコンピューティングの配分を考慮します。クエリが繰り返されるソースシステムでの計算コストを削減するには、読み取り頻度が高く、頻繁にアクセスされる統合データセットのキャッシュ (Accelerated Query) を使用します。
このロジックを適用する方法を示す一般的なアーキタイプを次に示します。
- 「単一の情報源」のアーキタイプ:一元化と管理
- **シナリオ:**グローバル企業全体に対して、コンプライアンスに準拠した統合 Customer 360 プロファイルを作成する必要があります。データはさまざまなシステムから取得され、GDPR と CCPA の厳格な規制に準拠する必要があり、すべてのマーケティングおよびサービスインタラクションの信頼できるソースとして機能します。
- **推奨パターン:****データ取り込み。**優先度は、Governance、Trust、Control です。Data 360 にデータを取り込むことが、ソースシステムから隔離された、完全に監査可能な正規プロファイルを作成する唯一の方法です。
- 「リアルタイム インサイト」のアーキタイプ:移動せずに分析
- **シナリオ:**データサイエンスチームは、Snowflake で絶えず更新される大量のトランザクションテーブルに対して探索クエリを実行する必要があります。同時に、エグゼクティブチームは、同じデータに基づいたライブ BI ダッシュボードを必要としています。毎日数ペタバイトのデータを移動すると、時間がかかりすぎる上にコストがかかります。
- **推奨パターン:****ゼロコピー統合。**優先事項は、スピード、俊敏性、大規模なコスト効率です。Zero Copy では、既存のデータウェアハウスの膨大な機能を活用して、データの重複によるオーバーヘッドや遅延を発生させることなくリアルタイムクエリを実行できます。
- 「ハイブリッド インテリジェンス」のアーキタイプ:コアの管理、エッジの統合
- **シナリオ:**データレイクからのリアルタイムの行動シグナル (Web サイトのクリックなど) を使用して、管理され、取り込まれた顧客プロファイルを強化したいと考えています。コアプロファイルの安定性は必要ですが、ライブデータの即時性は、その場のパーソナライズを強化するために必要です。
- **推奨パターン:****ハイブリッド アプローチ。**データ取り込みを使用して、顧客データの安定した管理されたコアを作成します。次に、ゼロコピーを使用して、揮発性のリアルタイムの「エッジ」データを統合し、クエリ時に結合して、最新の完全なビューを表示します。
エンタープライズデータ戦略は、もはや 1 つのインテグレーションパターンを選択することではなく、相互運用可能なデータエコシステム内で制御された柔軟性を構築することです。多くの場合、ビジネスニーズに基づいて各ソースデータシステムに適切なデータインテグレーション方法を選択することで、データ取り込みとデータ統合の両方の長所をブレンドしたハイブリッドアプローチが可能になります。
- コンプライアンス、ID 解決、運用ワークフローのために、ミッションクリティカルな管理データセットを Salesforce Data 360 に取り込みます。
- Zero Copy を使用してデータを統合することで、ストレージを重複させることなくライブ、探索、AI 駆動の分析を行うことができます。
Hyperforce上のSalesforce Data 360は、複数リージョンの復元性と拡張性を実現します。Icebergテーブルを備えたオープンな Lakehouse により、Snowflake、Databricks、S3 Icebergなどのプラットフォームとのコンピューティングの分離と相互運用性が実現し、真に相互運用性のあるマルチクラウドデータエコシステムのバックボーンが形成されます。
データエコシステムの進化に合わせて、新鮮さ、コスト、パフォーマンス、コンプライアンスを継続的にバランスさせ、アーキテクチャの俊敏性を維持します。取り込まれた管理データを統合アクセスで統合することで、プラットフォームを将来にわたって使用できます。これにより、クラウド、地域、ビジネスドメイン全体でリアルタイムインテリジェンス、AI の有効化、エンタープライズ規模のパーソナライズが可能になります。
汎用的なソリューションは、ほとんどのビジネスには適していません。最適な戦略では、適切なパターンを適切なビジネスドライバーに対応付けます。
Yugandhar Bora は、Salesforce のソフトウェアエンジニアリングアーキテクトで、Data & Intelligence アプリケーションプラットフォーム内のデータアーキテクチャを専門としています。データガバナンスと統合データモデルに焦点を絞ったエンタープライズアーキテクチャレビューボード (EARB) イニシアチブを主導しながら、自動化プラットフォームプロビジョニングソリューションに貢献しています。
Jan Fernando は、Salesforce のチーフアーキテクトオフィスのプリンシパルアーキテクトです。2012 年に Salesforce に入社し、スタートアップエコシステム時代から豊富な経験を積んできました。Office of the Chief Architect に入社する前は、プラットフォーム組織で 10 年以上にわたり、いくつかの主要なテクノロジー変革を率いていました。