Salesforce Platform ha continuamente avanzato la propria architettura di automazione per soddisfare le esigenze dei processi aziendali complessi. Le generazioni precedenti (Regole di flusso di lavoro e Process Builder) hanno fornito i passaggi iniziali della logica basata sugli eventi, ampliando le funzionalità di automazione per la logica basata sugli eventi e ampliando la portata a una gamma più ampia di generatori.
Questa evoluzione è culminata in un’architettura consolidata e ad alte prestazioni incentrata su due pilastri complementari: Flusso attivato da record e trigger Apex. Questo documento fornisce il framework e le linee guida per prendere decisioni informate durante la progettazione delle automazioni dei trigger.
| Flusso | Salesforce Flow è un potente strumento di automazione point-and-click che consente agli utenti di creare processi aziendali complessi, schermate e logica visivamente utilizzando Flow Builder, senza scrivere codice. Automatizza operazioni come l'aggiornamento dei dati, l'invio di email e la guida degli utenti, offrendo flessibilità attraverso tipi come Flussi schermata (interazione dell'utente) e Flussi attivati (eventi record/pianificati). |
| Apex | Salesforce Apex è un linguaggio di programmazione proprietario orientato agli oggetti per la piattaforma Salesforce, simile a Java, utilizzato per creare logiche aziendali personalizzate, automatizzare i processi ed estendere le funzionalità CRM principali oltre gli strumenti dichiarativi. |
La creazione di un'automazione attivata da record scalabile, manutenibile e performante in Salesforce Platform richiede un approccio disciplinato e basato sull'architettura. La scelta tra Flusso e Apex, e l'implementazione di ciascuno, è guidata da un chiaro insieme di principi. Questi punti riassumono questi principi e fungono da regole di base per la moderna progettazione dell'automazione.
-
Scegliere lo strumento giusto per il lavoro in base alla densità di automazione di Salesforce Object.
-
Utilizzare Flusso attivato da record per gli oggetti Salesforce per le automazioni a bassa densità.
-
Migliorare la logica dei flussi attivati da record con Apex invocabile per le automazioni a media densità.
-
Utilizzare trigger Apex per gli oggetti Salesforce per le automazioni ad alta densità.
-
-
Prestare attenzione quando si attivano processi asincroni.
Questa regola si applica sia quando si invocano processi asincroni in un flusso attivato da record sia quando si inserisce in area di attesa un processo accodabile da Apex. Sebbene questo schema possa essere allettante per scaricare il lavoro, può introdurre scenari complessi di gestione degli errori e aumentare il rischio di superare i limiti del governor. -
Utilizzare un punto di ingresso per ogni oggetto Salesforce.
Per un determinato oggetto Salesforce, utilizzare un meccanismo come punto di ingresso nell'automazione. Cercare di evitare di mescolare trigger Flusso e Apex come punti di ingresso per lo stesso oggetto.
Flusso e Apex condividono una serie di funzionalità fondamentali. Ogni strumento può eseguire query sui record, eseguire logica condizionale, assegnare variabili ed eseguire operazioni DML come la creazione, l'aggiornamento e l'eliminazione di record, in sequenza per l'esecuzione in un ordine specificato.
Tuttavia, questa sovrapposizione funzionale non implica che gli strumenti siano intercambiabili. La scelta architetturale non riguarda se un'operazione può essere eseguita, ma come viene eseguita e quali sono le implicazioni a lungo termine per prestazioni, scalabilità e manutenibilità. Il flusso eccelle in chiarezza dichiarativa e velocità di implementazione per i processi semplici, mentre Apex offre il controllo granulare e la potenza grezza necessari per le soluzioni complesse.
La densità di automazione è il carico posto su un oggetto Salesforce specifico. Serve come euristica per determinare l'implementazione ottimale dell'oggetto. Man mano che la densità dell'automazione aumenta, la probabilità di superare i limiti delle transazioni aumenta.
Calcolare la densità di automazione esaminando tre dimensioni specifiche di volume e complessità:
-
Quantità di automazione: Numero non formattato di voci di metadati di automazione univoche (flussi, azioni di trigger e così via) eseguite durante un singolo evento DML (Data Manipulation Language).
-
Volume record: I record per transazione elaborati tramite caricamenti API o elaborazione batch pesante, in cui le prestazioni diventano critiche.
-
Diffusione delle dipendenze: Misura delle operazioni DML a valle attivate dall'operazione CRUD iniziale. Quantifica la profondità del grafico in cui un aggiornamento si trasforma in aggiornamenti sugli oggetti correlati (ad esempio, caso → account → referente → roll-up personalizzato).
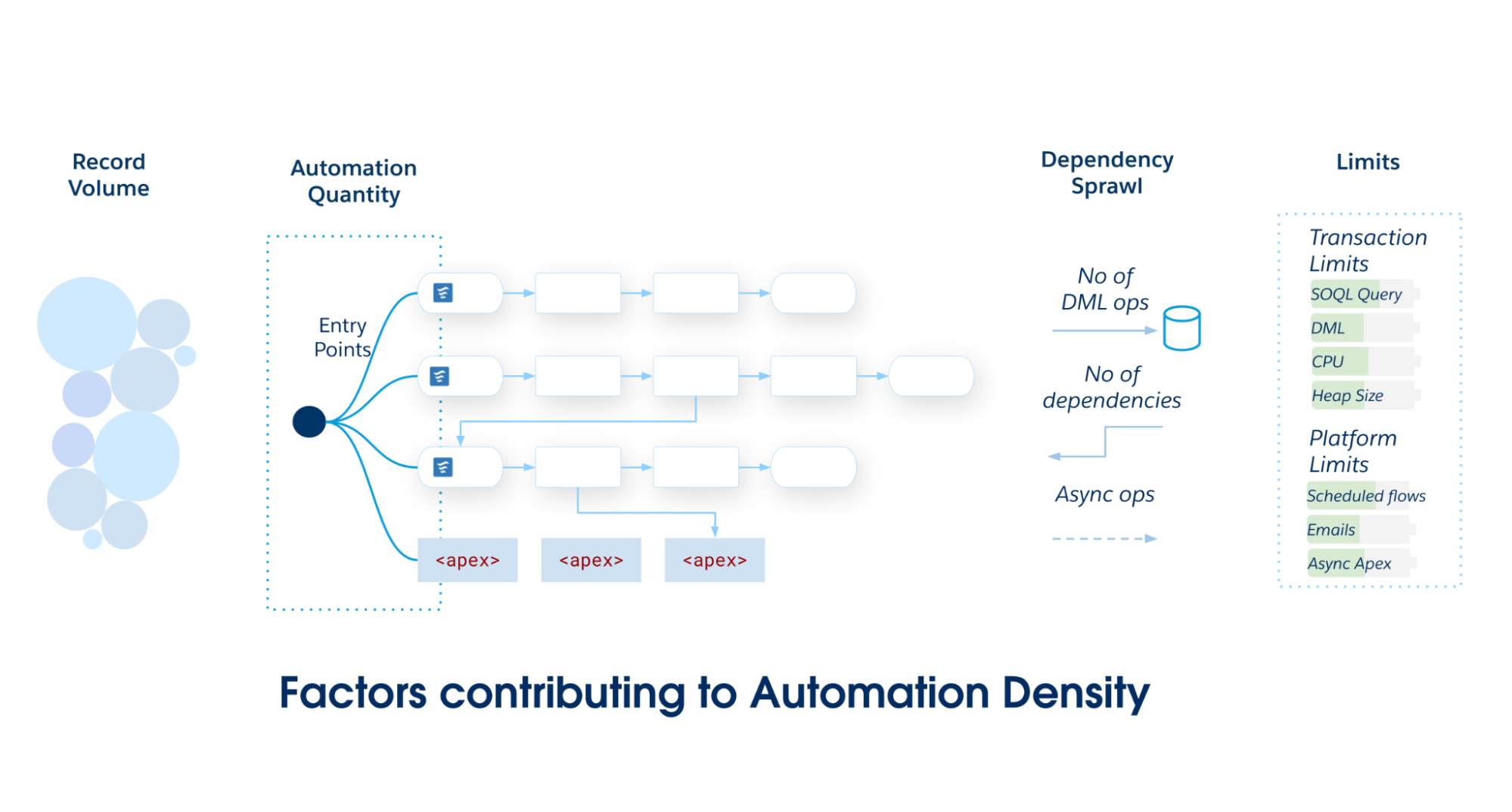
Man mano che l'ambito e la complessità dell'applicazione Salesforce aumentano, impegnarsi in un unico punto di ingresso principale, Flusso attivato da record o Trigger Apex. Evitare di suddividere le automazioni in più meccanismi in un unico oggetto Salesforce, poiché ciò causa una scarsa manutenibilità e una governance frammentata.
Utilizzare questa matrice per determinare lo standard architettonico richiesto per l'oggetto Salesforce.
-
Il flusso attivato da record è la soluzione preferita per una bassa densità di automazione. Offre un equilibrio di potenza e accessibilità ideale per automazioni semplici e indipendenti l'una dall'altra.
-
Lo schema ibrido (Record-Triggered Flow with Invocable Apex) è una scelta potente e manutenibile per le automazioni a media densità con complessità crescente. Questo schema consente ai team di mantenere coreografie ordinate in un flusso dichiarativo delegando al contempo le operazioni complesse di calcolo ad Apex, bilanciando l'accessibilità con le prestazioni.
-
I trigger Apex forniscono i componenti base necessari per una solida base architettonica per supportare automazioni ad alta densità. Le prestazioni, il controllo granulare e l'astrazione e il polimorfismo orientati agli oggetti di Apex sono più adatti per gestire la complessità e la scala di questi scenari.
| Livello di densità | Quantità automazione | Volume di dati (dimensioni batch) | Dependance Sprawl (Diffusione delle dipendenze) | Standard architettonico |
|---|---|---|---|---|
| Basso | < 15 Automazioni |
Standard Interazioni dell'interfaccia utente basate sugli utenti o piccoli carichi API (1-200 record) |
Discreto Logica autonoma. 0–1 operazioni DML a valle sullo stesso oggetto o su un oggetto correlato. |
Flusso attivato da record |
| Medio | 15–30 Automazioni |
Modera Elaborazione batch standard (con logica che richiede un'attenta messa in blocco) |
Accoppiato Parent/Child aggiorna da 2 a 4 operazioni DML a valle. Rischio di ricorsione |
Schema ibrido Flusso + Apex invocabile |
| Alto | > 30 Automazioni |
Alto Grandi volumi di dati con caricamenti API in blocco (2.000 - 10.000+ record) |
Complesso e ricorsivo Grafico delle dipendenze profonde (5+ operazioni DML a valle). Rischio di loop di ricorsione triangolari |
Framework di metadati trigger Apex |
Considerare inoltre il numero totale giornaliero di operazioni DML poiché Salesforce impone la gestione delle risorse condivise in un ambiente multi-tenant e i limiti del governor per impedire che le automazioni incontrollate monopolizzino le risorse condivise. Gli oggetti Salesforce con elevati volumi giornalieri di DML richiedono un'accurata selezione dell'automazione. Ad esempio, i limiti asincroni per il tempo CPU (60.000 ms) e le dimensioni dell'heap (12 MB) sono superiori ai limiti sincroni. Inoltre, il limite di 24 ore dell'organizzazione per le esecuzioni asincrone, calcolato come 250.000 o 200 volte le licenze utente, richiede di considerare il DML giornaliero totale nella progettazione architettonica per evitare eccezioni in fase di esecuzione.
Flusso attivato da record è lo strumento dichiarativo principale della piattaforma per l'automazione attivata da record. La facilità d'uso e le protezioni della piattaforma incorporate di Flow consentono ai team di creare facilmente soluzioni scalabili e affidabili. È la scelta ideale per la maggior parte dei team che creano soluzioni su Salesforce Platform.
Apex è il linguaggio di programmazione proprietario, fortemente tipizzato e orientato agli oggetti della piattaforma. Utilizzare Apex per gli oggetti Salesforce con elevata densità di automazione e per i casi d'uso che richiedono prestazioni elevate, logica sofisticata o un controllo granulare sulle transazioni.
Per facilitare il processo decisionale, questa matrice offre un confronto diretto tra Flusso e Apex nelle principali funzionalità architetturali.
| Capacità | Flusso attivato da record | Trigger Apex |
|---|---|---|
| Velocità di consegna e manutenzione | Consigliato L'interfaccia utente visiva di Flow Builder consente agli amministratori e ad altri generatori dichiarativi di creare e modificare l'automazione più rapidamente rispetto alla scrittura, al test e alla distribuzione di Apex Code. Questa interfaccia consente a una gamma più ampia di membri del team di offrire valore aziendale e riduce la dipendenza da risorse per sviluppatori specializzate per operazioni semplici. |
Richiede esperienza Apex richiede sviluppatori di software esperti per implementare, testare e gestire il codice. |
| Modularità | Disponibile I flussi attivati da record sono modulari per impostazione predefinita. Anziché la logica monolitica, i team creano flussi discreti per esigenze specifiche e li coreografano insieme utilizzando Explorer trigger di flusso. Questa modularità consente la modifica isolata e l'estensione semplice, riducendo notevolmente il costo di proprietà a lungo termine. |
Disponibile Apex è suddiviso in moduli funzionali in base alla progettazione. Ogni classe Apex è destinata a implementare un singolo modulo di funzionalità. |
| Visibilità e governance | Consigliato La natura visiva del flusso offre una rappresentazione intuitiva della logica aziendale. Explorer trigger di flusso offre una visualizzazione consolidata di tutti i flussi di un oggetto, semplificando la comprensione, il governo e la risoluzione dei problemi per architetti e amministratori senza leggere il codice. |
Richiede esperienza L'utilizzo di un framework di metadati per organizzare i trigger è vantaggioso, ma Apex richiede un team di sviluppo disciplinato per mantenere il codice organizzato e manutenibile. |
| Elaborazione in blocco dei dati ad alte prestazioni | Sconsigliato Esiste un rischio elevato di superare i limiti del governor quando si ha a che fare con logica complessa o volumi di dati elevati. |
Consigliato Apex Code viene eseguito più vicino ai servizi principali della piattaforma e offre agli sviluppatori un controllo avanzato sull'ottimizzazione delle query, la gestione dei dati e l'efficienza algoritmica. Ciò si traduce in prestazioni e scalabilità migliori, soprattutto in scenari complessi che coinvolgono volumi di dati elevati. |
| Logica e strutture di dati solide | Disponibile L'elemento Trasforma flusso può essere utile per alcune operazioni di elaborazione complesse. Tuttavia, il flusso non dispone di strutture di dati native Map and Set (Mappa e imposta), il che rende l'elaborazione dei dati complessa complessa complessa e inefficiente dal punto di vista computazionale. |
Consigliato Apex offre accesso completo ai loop Map, Set e programmatic per una manipolazione dei dati altamente efficiente e sicura in blocco. Essendo un linguaggio di programmazione completo, Apex offre anche l'accesso a costrutti logici complessi, strutture di dati e schemi di progettazione che possono aiutare a risolvere problemi aziendali complessi in modo manutenibile ed efficiente. Apex include una ricca libreria standard di funzioni avanzate (ad esempio, BusinessHours, Crypto) attualmente non disponibili negli strumenti dichiarativi. |
| Controllo delle transazioni | Non disponibile Il flusso non fornisce alcun accesso a `Database.savepoint`, `Database.rollback` o a operazioni DML parzialmente riuscite per conferme o rollback parziali delle transazioni. |
Disponibile Apex offre un controllo completo e granulare sull'integrità delle transazioni e su scenari di ripristino degli errori complessi. |
| Distribuzione email | Consigliato L'invio di avvisi tramite email preconfigurati da un flusso attivato da record è semplice e scalabile. Gli avvisi tramite email personalizzati possono essere creati e distribuiti in fase di esecuzione. I messaggi email personalizzati sono soggetti a limiti giornalieri. |
Disponibile Apex può generare e inviare messaggi email personalizzati. Tutte le email inviate da Apex sono soggette ai limiti giornalieri. |
| Applicazione di protezioni piattaforma | Consigliato Il flusso include protezioni incorporate, ad esempio la bulkificazione automatica e i tentativi automatici. Queste protezioni aumentano la velocità di calcolo e impediscono insidie nelle prestazioni che altrimenti richiedono una codifica manuale complessa. |
Implementazione manuale richiesta Le protezioni come la creazione in blocco devono essere codificate in modo esplicito (ad esempio, la gestione delle raccolte ed evitare SOQL all'interno dei loop). I tentativi automatici non sono nativi dei trigger e richiedono una complessa logica personalizzata per essere implementati. |
| Elaborazione asincrona | Disponibile Il flusso offre meccanismi semplici per le automazioni che richiedono una transazione separata in un percorso asincrono. Queste automazioni sono soggette a limiti giornalieri. |
Disponibile Apex consente il controllo completo tramite Acquisizione dati di modifica ed eventi in area di attesa gestiti da un abbonato trigger disaccoppiato. |
| Elaborazione pianificata | Consigliato I percorsi pianificati del flusso offrono una funzionalità di pianificazione unica e potente (ad esempio, "attiva 3 giorni prima della data di chiusura"). Questa funzionalità include l'annullamento automatico e la riprogrammazione se i dati del record cambiano. Queste automazioni sono soggette a limiti giornalieri. |
Non disponibile Un trigger Apex non può pianificare in modo nativo un evento temporale specifico del record con annullamento automatico. Sebbene esista Apex pianificato, si tratta di un meccanismo fondamentalmente diverso che viene eseguito in un momento specifico e non viene pianificato durante l'elaborazione di un singolo record come parte di un trigger. |
| Ordinamento e coreografia | Disponibile Explorer trigger di flusso consente agli amministratori di definire un ordine di esecuzione relativo per più flussi sullo stesso oggetto. |
Disponibile Un framework trigger offre un controllo granulare sull'ordine esatto delle automazioni. |
| Aggiornamenti di campo dello stesso record | Disponibile (prima del salvataggio) Il flusso attivato da record è l'opzione dichiarativa più efficace per aggiornare il record di attivazione prima della conferma DML iniziale. |
Disponibile (prima del salvataggio) Apex offre le prestazioni più elevate con un sovraccarico minimo. |
| CRUD oggetti incrociati | Disponibile (dopo il salvataggio) Il flusso è adatto per operazioni DML tra oggetti semplici, di bassa complessità. |
Disponibile (dopo il salvataggio) Apex offre un controllo superiore su deduplica, gestione degli errori e prestazioni per le operazioni DML oggetti incrociate. |
| Deduplicazione di calcoli costosi | Disponibile Il flusso eccelle nell'eliminazione delle query ridondanti e delle istruzioni DML tramite il blocco automatico. Tuttavia, lo stato non può essere memorizzato nella cache o condiviso tra trigger di flusso diversi o tra più chiamate dello stesso flusso all'interno di una sola transazione. Questa limitazione può diventare importante in scenari di prestazioni estreme. |
Consigliato Apex fornisce meccanismi per deduplicare operazioni costose. Gli sviluppatori possono sfruttare il caching transazionale utilizzando proprietà e variabili statiche e il caching a livello di piattaforma utilizzando la cache piattaforma per archiviare e riutilizzare i dati. Queste tecniche sono importanti per ridurre il consumo dei limiti del governor transazionale, ad esempio le query SOQL, e garantire prestazioni e scalabilità elevate. |
| Gestione errori personalizzati | Disponibile L'elemento CustomError può bloccare un'operazione di salvataggio e visualizzare un messaggio all'utente. |
Consigliato Il metodo addError() offre una messaggistica di errore flessibile a livello di campo e condizionale. |
Questa tabella fornisce consigli generali "migliori" per i casi d'uso generali, in base alle funzionalità presentate. Infine, si terranno presenti ulteriori considerazioni per individuare la soluzione più adatta ai propri scenari specifici, ad esempio quelli inclusi nella sezione Procedure consigliate correlate di questo documento. Qui, imparerai di più su quando una particolare combinazione di Flusso e Apex offre l'approccio migliore.
| Caso d'uso | Descrizione | Best-Fit | Motivo |
|---|---|---|---|
| Elaborazione batch ad alte prestazioni | Qualsiasi automazione che deve elaborare migliaia di record in modo efficiente | Apex | Apex fornisce API complete per l'interfacciamento con la piattaforma e per la velocità di stampa. |
| Elaborazione dati complessa | Scenari che richiedono una manipolazione avanzata dei dati | Apex | Apex fornisce strutture di dati, ad esempio Mappa e Imposta, che non sono disponibili in modo nativo in Flusso e possono essere fondamentali per scrivere codice efficiente e sicuro in blocco. |
| Controllo transazionale | Meccanismi di controllo come savepoint, rollback e conferme parziali | Apex | Apex fornisce l'accesso a meccanismi come Database.savepoint e Database.rollback e ha la capacità di elaborare operazioni DML parzialmente riuscite. |
| Convalida personalizzata sofisticata | Convalida dei dati in più campi di un record | Apex | Sebbene il flusso possa impedire il salvataggio con l'elemento 'CustomError', non è disponibile in tutti i tipi di flusso, inclusi i sottoflussi. Il metodo Apex addError() fornisce più messaggi di errore specifici del campo che possono essere aggiunti a un record in qualsiasi momento durante l'elaborazione del trigger. |
| Logica moderatamente complessa in un processo semplice | Logica e manipolazione dei dati di moderata complessità, semplificate da una libreria standard di funzioni avanzate, che si verificano nell'ambito di un processo semplice | Flusso + Apex | Il flusso attivato da record funge da livello di orchestrazione, mentre le operazioni di elevata complessità sono incapsulate in Apex invocabile. |
| Logica da semplice a moderatamente complessa | Manipolazione dei dati di complessità da bassa a moderata, con aggiornamenti dei trigger sia agli oggetti dati principali che a quelli correlati | Flusso | Il flusso è in genere l'opzione da seguire, poiché è basato su un modello dichiarativo che lo rende accessibile sia agli amministratori che agli sviluppatori. |
| Notifiche e messaggi in uscita | Invio di email e messaggi in uscita | Flusso | Il flusso consente di inviare avvisi tramite email e messaggi in uscita sulle modifiche dei record in modo semplice e altamente scalabile. |
| Elaborazione pianificata | Automazione in una data futura e dinamica (ad esempio, 3 giorni prima di una data di chiusura) | Flusso | I percorsi pianificati rappresentano un punto di forza unico per il flusso, poiché la piattaforma gestisce automaticamente la pianificazione, l'annullamento e la riprogrammazione di questi percorsi se i dati del record cambiano. |
La scalabilità è una considerazione fondamentale quando si progetta l'implementazione. Quando la logica aziendale di un'automazione attivata da record diventa complessa, di lunga durata o comporta volumi di dati elevati, i limiti del governor centrale della piattaforma Salesforce diventano un vincolo architettonico. Operazioni come aggiornamenti globali dei dati, chiamate API complesse o calcoli complessi aumentano il rischio di superare i limiti, ad esempio il tempo totale della CPU o il numero di istruzioni DML all'interno di una singola transazione del database. Un errore in un trigger sincrono dovuto a un'eccezione del limite causerà il ritiro dell'intera transazione di salvataggio dell'utente, causando una scarsa esperienza utente e una potenziale perdita di dati. Questo rischio intrinseco impone a uno schema architettonico di scaricare il lavoro complesso.
L'automazione asincrona diventa essenziale in questo caso. Utilizzando meccanismi asincroni, gli architetti possono disaccoppiare efficacemente il lavoro di lunga durata o a volume elevato dalla transazione di salvataggio dei record principale sincrona. I salvataggi vengono completati in modo rapido e affidabile, mentre l'elaborazione pesante viene delegata a una transazione separata gestita dalla piattaforma che viene eseguita in seguito. Il disaccoppiamento migliora la stabilità, previene gli errori delle transazioni ed è fondamentale per la creazione di applicazioni aziendali scalabili. La piattaforma offre diversi strumenti specializzati per questo, ciascuno con vantaggi e compromessi distinti in termini di affidabilità, volume e complessità.
Il percorso Esegui in modo asincrono in un flusso attivato da record offre il meccanismo più semplice per la logica asincrona "attiva e dimentica". Questo percorso viene eseguito in una transazione separata dopo che la transazione di salvataggio dei record originale è stata confermata correttamente nel database.
-
Caso d'uso ideale: Questo è adatto per le operazioni che non richiedono un'esecuzione immediata o la gestione personalizzata degli errori. Gli esempi includono l'invio di una notifica tramite email, la creazione di un'operazione di follow-up o una semplice chiamata a un sistema esterno.
-
Limitazioni: Questo meccanismo condivide gli stessi limiti giornalieri del governor delle altre interviste del flusso asincrono. Non è progettato per l'elaborazione a volume estremamente elevato.
Acquisizione dati di modifica (CDC) è uno schema ad alta produttività, scalabile e resiliente per la gestione della logica asincrona attivata da una modifica record in scenari a volume elevato. In questo modello, l'unica responsabilità del trigger è salvare il record in modo sincronizzato. La piattaforma pubblica quindi un messaggio di evento dettagliato che contiene le modifiche apportate dal record a un bus degli eventi a volume elevato. Un trigger Apex dedicato separato si abbona a questo evento di modifica. Esegue lavori complessi, di lunga durata o asincroni.
-
Vantaggio: Questo schema separa il processo asincrono dalla transazione utente iniziale. Un errore nell'elaborazione asincrona non causerà il ritiro del salvataggio del record dell'utente. Lo schema fornisce anche uno stream di eventi durevole che può essere utilizzato da più abbonati interni o sistemi esterni e gli eventi possono essere riprodotti per un massimo di 72 ore, offrendo una forte resilienza.
-
Limitazioni: I messaggi degli eventi CDC non contengono lo stato precedente del record, l'equivalente di un
Trigger.oldMapApex. Il payload dell'evento include i nuovi valori dei campi, ma non i valori da cui sono stati modificati. Ciò rende difficile implementare una logica basata su una transizione di stato specifica (ad esempio, eseguire solo se ilStatus__cè cambiato da "In sospeso" a "Approvato"). È possibile mitigare questo problema eseguendo query nella cronologia dei campi dell'oggetto nell'abbonato evento, ma questo aumenta la complessità del processo e il tracciamento della cronologia dei campi potrebbe non essere disponibile per il campo specifico di interesse. Ciò può limitare i tipi di automazione che è possibile scaricare in CDC.
Per impostazione predefinita, CDC può essere abilitato su un massimo di cinque oggetti Salesforce. Le organizzazioni che necessitano di più possono acquistare una licenza aggiuntiva che rimuove questo limite e aumenta le allocazioni di consegne degli eventi.
L'inserimento di un processo Apex in area di attesa direttamente da un trigger deve essere considerato uno schema rischioso, utilizzato solo quando è necessario un controllo fornito da Apex (ad esempio, per logica complessa o meccanismi di tentativo personalizzati) e CDC non è un'opzione praticabile.
Se è necessario Queueable Apex, l'implementazione deve includere adeguate misure di protezione:
-
Limita controlli: Il codice deve controllare il numero di processi già presenti nell'area di attesa della transazione prima di tentare di aggiungerne un altro.
-
Consapevolezza contesto: Il codice deve rilevare se viene eseguito in un contesto asincrono, ad esempio un processo batch (
System.isBatch()), e modificarne il comportamento per rispettare il limite più rigoroso di un processo per transazione in quel contesto.
L'invocazione di Apex asincrono da un trigger sincrono introduce rischi per la stabilità. Per evitare l'impatto a livello di organizzazione (ad esempio, il superamento dei limiti), questo schema richiede progettazione e test rigorosi.
-
Il limite giornaliero per le esecuzioni Apex asincrone (
Batch,Queueable,@Future) è condiviso in tutta l'organizzazione (in genere 250.000 o un calcolo basato sulle licenze utente). Un caricamento di dati in blocco di 20.000 record causerà l'esecuzione di un trigger in blocchi di 200, dando luogo a 100 chiamate di trigger separate, anche di più se la dimensione del batch in blocco è inferiore a 200 record. Se ogni chiamata inserisce in area di attesa un processo asincrono, è possibile che venga utilizzata una parte significativa del limite giornaliero di un singolo caricamento di dati. Questo consumo può potenzialmente ridurre alla fame altri processi aziendali critici di risorse asincrone. -
I limiti del governor per l'inserimento in area di attesa dei processi sono drasticamente diversi a seconda del contesto. Da un trigger attivato da un'azione utente nell'interfaccia utente (una transazione sincrona) è possibile inserire in area di attesa fino a 50 processi. Tuttavia, da un trigger attivato all'interno del metodo
executedi una classe Batch Apex — una transazione asincrona — può essere inserito in area di attesa un solo processo. Non tenere conto di questa differenza è un punto di errore comune e critico, che causa errori diLimitExceptiondurante le grandi operazioni sui dati. -
Chiamare Apex pianificabile (
System.schedule) o Apex batch (Database.executeBatch) direttamente da un contesto trigger costituisce un anti-schema. Questi metodi non sono progettati per essere richiamati dal contesto del trigger. In questo modo si determinerà un rapido consumo dell'allocazione Apex asincrona, con conseguenti eccezioni limite.
Ogni meccanismo asincrono ha compromessi specifici in termini di prestazioni, limiti del governor e affidabilità. Utilizzare questo albero decisionale come guida per spostarsi tra queste opzioni e scegliere il meccanismo giusto per il proprio caso d'uso.
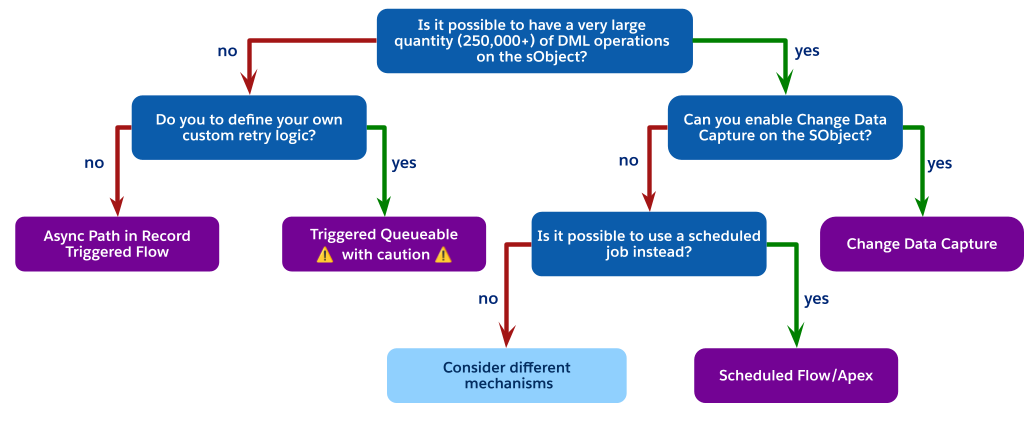
Come indica il diagramma di flusso, quando ci si trova di fronte a operazioni DML a volume elevato ma non è possibile utilizzare Acquisizione dati di modifica (forse a causa dei limiti degli oggetti), la scelta architettonica migliore è spesso evitare completamente un processo invocato da trigger.
Valutare invece la possibilità di utilizzare un processo pianificato. Può essere un flusso pianificato o Apex pianificato. I passaggi obbligatori sono:
-
Eseguire un aggiornamento semplice e a basso costo nel trigger sincrono. Ad esempio, impostare un campo
Status__csu "elaborazione in sospeso" o inserire un record correlato a basso costo, ad esempio un post Chatter, per indicare che il record deve essere elaborato. -
Creare un processo pianificato, un flusso pianificato o Apex pianificato, che viene eseguito periodicamente, ad esempio ogni 15 minuti o ogni ora.
-
Fare in modo che la query del processo pianificata per tutti i record nello stato In sospeso, eseguire la logica complessa in un contesto controllato a volume elevato e quindi aggiornare i record come elaborati.
Questo schema separa completamente l'elaborazione pesante dal salvataggio sincrono dell'utente, non è soggetto al limite di un processo per transazione di un batch attivato da trigger e offre una soluzione altamente scalabile e governabile per i requisiti non in tempo reale.
Se la latenza di un processo pianificato non è accettabile per i requisiti aziendali e si è ancora costretti a non utilizzare CDC o un trigger in attesa, ciò indica una significativa non corrispondenza architettonica. A questo punto occorre considerare diversi meccanismi. Rivalutando la progettazione dell'applicazione di base si possono trarre alcune conclusioni, ad esempio:
-
Acquisto del componente aggiuntivo per rimuovere i limiti degli oggetti CDC.
-
È fondamentale mettere in discussione il requisito aziendale di determinare se l'elaborazione quasi in tempo reale è davvero un "must-have" o se la latenza di un processo pianificato è un compromesso accettabile per la stabilità della piattaforma.
Il livello di complessità di un'implementazione fa parte del costo totale di proprietà di una soluzione, nonché della sua capacità di adattarsi alle mutevoli esigenze aziendali. La complessità può influire su qualsiasi implementazione se non vengono seguite le procedure consigliate. Nella sezione Procedure consigliate correlate di questo documento sono riportati i consigli per ridurre la complessità della soluzione, inclusi questi schemi:
-
Schema ibrido: Apex invocabile per logica complessa nel flusso
-
Utilizzo di un framework di metadati per trigger Apex
-
Mega-flussi vs. Più flussi
La documentazione è importante tanto quanto l'automazione stessa. Non solo garantisce la manutenibilità, ma è anche fondamentale per l'intelligenza artificiale e gli strumenti basati sugli agenti. La documentazione consente di comprendere e gestire i processi aziendali.
Nel flusso
-
Stabilire una convenzione di denominazione coerente per tutti gli elementi e le variabili.
-
Utilizzare il campo Descrizione del flusso per spiegarne lo scopo generale, i criteri di attivazione e l'esito previsto.
-
Utilizzare il campo Descrizione per ogni singolo elemento (ad esempio,
Get Records,Action,Transform). Questa procedura è il modo migliore per trasmettere l'intento. È particolarmente importante per le azioni invocabili e i sottoflussi, dove la descrizione è il punto principale per spiegare la complessa logica eseguita dall'azione.
In Apex
-
Commentare chiaramente il codice per spiegare il perché della logica, non solo il cosa.
-
Se si utilizza un framework basato sui metadati, assicurarsi che i record dei metadati includano e compilino un campo Descrizione in formato leggibile per spiegare le operazioni di ogni classe di handler e quando deve essere eseguita.
DevOps e il controllo sorgente fanno parte di un ciclo di vita di sviluppo maturo. Utilizzare sempre uno strumento di controllo sorgente come Git per i progetti Salesforce. Sia le classi Apex che i flussi Salesforce sono metadati che definiscono la logica aziendale e devono essere modificati e gestiti.
Nel contesto della gestione delle automazioni attivate da record, una pipeline DevOps moderna offre vantaggi essenziali.
-
Controlli di qualità automatici: Strumenti come Salesforce Code Analyzer possono essere configurati per l'esecuzione automatica nelle opportunità in corso di realizzazione. L'analisi statica può rilevare schemi problematici in entrambi gli strumenti di automazione prima che vengano promossi, segnalando problemi come elementi di
Get Recordsinefficienti all'interno di un loop di flusso o query diSOQLall'interno di un loop Apex per il loop, che sono cause comuni di deterioramento delle prestazioni. -
Prevenzione della regressione: Man mano che la densità di automazione aumenta, la modifica a una classe Flusso o Apex può avere conseguenze indesiderate per altre automazioni sullo stesso oggetto. Una strategia di test DevOps efficace, in cui i test Apex automatici vengono eseguiti in base a qualsiasi modifica proposta, è il modo più affidabile per assicurarsi che una nuova versione del flusso non interrompa la logica Apex esistente (e viceversa).
-
Collaborazione e visibilità: Il controllo sorgente è la "singola fonte della verità". Consente ad amministratori e sviluppatori di lavorare sull'automazione per lo stesso oggetto in parallelo. Offre anche un itinerario di controllo prezioso: quando un processo di produzione si interrompe, è possibile vedere immediatamente chi ha modificato l'automazione, quando l'ha modificata e, tramite messaggi di conferma, perché l'ha modificata.
Per i team con un mix di amministratori e sviluppatori, DevOps Center fornisce un'interfaccia unificata che aiuta a coreografare tutte queste fasi, rendendo un processo di sviluppo scalabile e basato sul controllo sorgente accessibile a tutti i membri del team.
Questa disciplina combinata di documentazione e DevOps garantisce la salute e la manutenibilità a lungo termine dell'organizzazione, a vantaggio di ogni architetto e amministratore che vi segue.
La guida alle decisioni riportata sopra è consigliabile prima di pianificare l'implementazione. Ha lo scopo di aiutare l'utente a scegliere il prodotto migliore per i propri casi d'uso. Dopo la selezione del prodotto, è importante conoscere le procedure consigliate esistenti per l'implementazione.
Il principio One Tool Per Object è fondamentale per la gestione dell'automazione ad alta densità, ma non lo si interpreta come una scelta binaria tra uno stack puramente dichiarativo o puramente programmatico. Un modello architetturale più efficace e manutenibile sfrutta un modello ibrido: posizionare il flusso attivato da record come livello di orchestrazione, incapsulando al contempo le operazioni di elevata complessità in Apex invocabile.
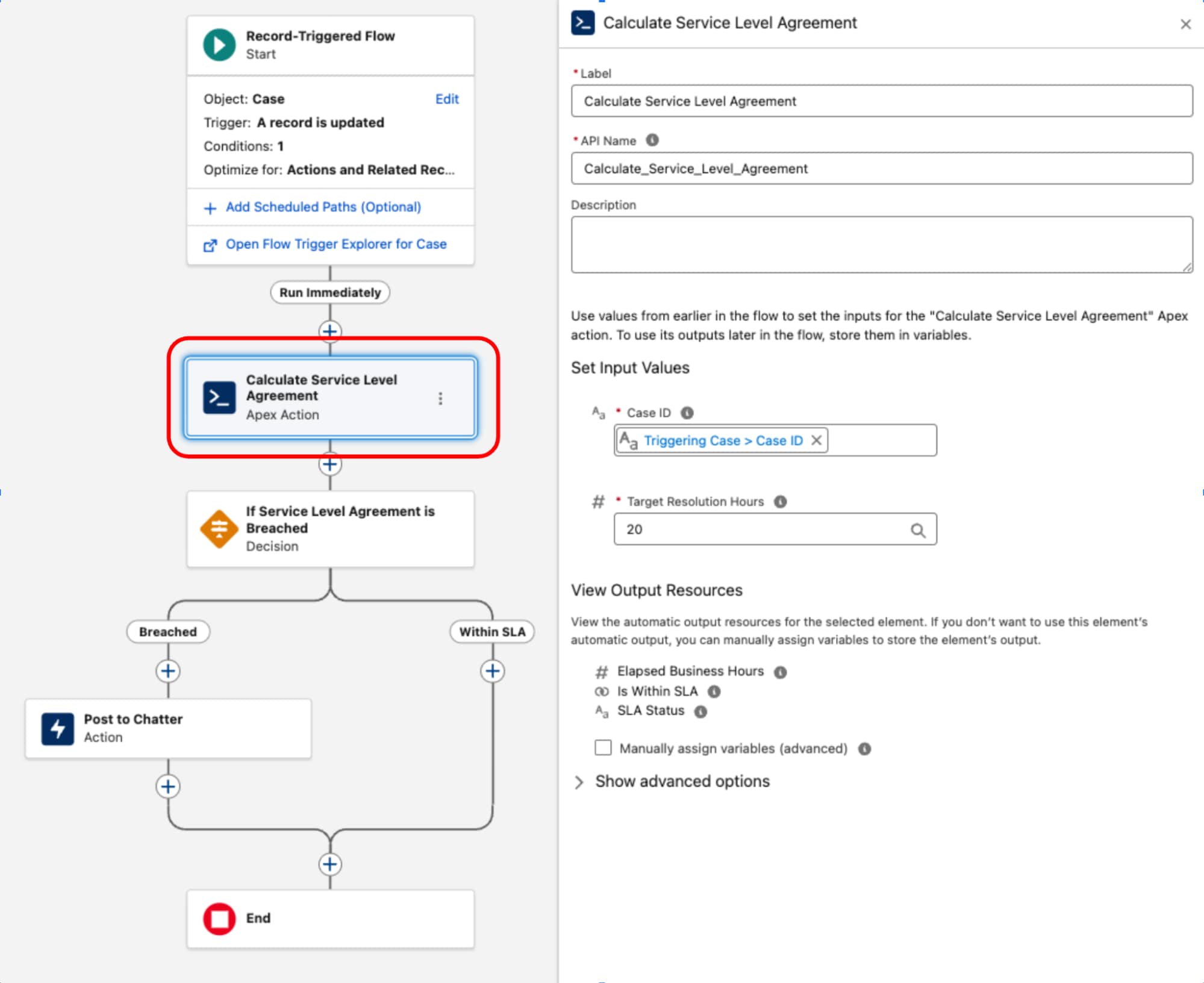
Il flusso attivato da record funge da livello di orchestrazione per il processo aziendale. È titolare dei criteri di immissione e del contesto di esecuzione (cosa e quando). Mantenendo la logica decisionale e l'instradamento all'interno di questo livello, la topologia dei processi dell'architettura rimane trasparente e gestibile tramite Explorer trigger di flusso, evitando che la logica aziendale critica venga oscurata nel codice.
Un esempio comune di componente complesso è l'implementazione dei calcoli del contratto sul livello di servizio (SLA) per i record Caso. Poiché l'oggetto BusinessHours e la relativa logica, essenziali per calcoli accurati che escludono le ore non lavorative e i giorni festivi, non sono accessibili in modo nativo in Flusso, viene utilizzata una classe Apex dedicata. Questa classe, spesso denominata ServiceLevelAgreementCalculator, è progettata con un unico metodo statico, annotato con @InvocableMethod, per calcolare l'orario di ufficio trascorso, determinare se il contratto sul livello di servizio è "Entro il target" o "Violato" e restituire un output strutturato. Questo approccio incapsula la complessa logica ad alte prestazioni di Apex consentendo al contempo di eseguirla e integrarla senza problemi nel livello di orchestrazione dichiarativa di un flusso attivato da record.
Una volta definita, la classe di ServiceLevelAgreementCalculator Apex è disponibile per l'uso all'interno di un flusso attivato da record:
Questo schema dimostra una rigorosa separazione delle preoccupazioni. Il livello dichiarativo viene utilizzato per gestire il ciclo di vita delle transazioni e l'orchestrazione, mentre il codice viene utilizzato per l'esecuzione di elevata complessità. Considerando il codice come un'utilità funzionale anziché come la base, bilanciamo prestazioni e manutenibilità.
Modularità: La decisione si allontana dalla singolarità dell'utilizzo di Apex o Flusso per l'intero processo. L'architettura incapsula invece la logica complessa in unità discrete, sicure in blocco e testabili in modo indipendente. Queste unità funzionano come componenti riutilizzabili consumati dallo strato dichiarativo, garantendo le scale di automazione senza complicare la progettazione architettonica.
Riutilizzabilità: La logica viene disaccoppiata dall'evento trigger. Un'unità di codice ben progettata (ad esempio un InvocableMethod) viene scritta una sola volta ma utilizzata in più punti di ingresso: Flussi attivati da record, flussi schermata o integrazioni esterne. Questo riutilizzo del codice elimina lo sviluppo ridondante.
Gestibilità: La logica del flusso del processo rimane visibile e gestibile all'interno del flusso dichiarativo. Questa centralizzazione riduce drasticamente il sovraccarico di debug e garantisce che l'ordine di esecuzione del sistema sia deterministico e trasparente.
Sebbene il modello ibrido di utilizzo di Apex invocabile da Flusso sia potente, non è un approccio adatto a tutti. Gli architetti devono essere consapevoli delle limitazioni e dei compromessi specifici prima di impegnarsi in una soluzione ibrida.
-
Nessun supporto prima del salvataggio: Questa è la limitazione più importante. Le azioni invocabili sono disponibili solo nel contesto dopo il salvataggio (flussi per azioni e record correlati). Non possono essere utilizzati nel contesto prima del salvataggio ad alte prestazioni (flussi per aggiornamenti rapidi dei campi). Pertanto, questo schema non può essere utilizzato per delegare gli aggiornamenti di campo dello stesso record. Eseguire questo lavoro ad alte prestazioni utilizzando elementi Flusso nativi in un flusso before-save o all'interno di un trigger Apex before-context.
-
Nessun supporto dopo l'annullamento dell'eliminazione: Attualmente, il flusso attivato da record non supporta il contesto di annullamento dell'eliminazione. Se un oggetto Salesforce ha un requisito aziendale per eseguire l'automazione quando un record viene ripristinato dal Cestino, l'unica soluzione è un trigger Apex.
-
Overhead delle prestazioni in scenari a volume elevato: La transizione dal runtime del flusso al runtime Apex non è un'operazione a costo zero. Benché in genere sia veloce, l'esecuzione di un'azione invocabile dal runtime del flusso non è altrettanto veloce dal punto di vista computazionale dell'esecuzione nativa che rimane interamente all'interno di un trigger Apex. Per la maggior parte delle automazioni a media densità, questo micro-overhead è un compromesso trascurabile e utile per una maggiore accessibilità. Tuttavia, per gli scenari estremamente performanti e a volume elevato, un framework solo Apex puro avrà un vantaggio in termini di velocità di calcolo.
Mentre l'euristica della densità di automazione fornisce indicazioni definitive per la nuova architettura greenfield, la realtà degli ambienti Salesforce aziendali è spesso più sfumata. Nelle organizzazioni mature, è comune trovare flussi attivati da record e trigger Apex che operano sullo stesso oggetto Salesforce. Questo scenario è distinto dallo schema ibrido spiegato in precedenza: qui, i flussi e i trigger Apex non sono accoppiati né progettati per funzionare insieme.
Questa coesistenza è spesso il risultato dell'evoluzione delle capacità della piattaforma o del debito tecnico legacy. Sebbene questo sia uno stato operativo tollerato, gli architetti devono trattarlo come un compromesso calcolato anziché come uno stato finale.
L'orchestrazione frammentata causa un notevole sovraccarico di governance e manutenzione, rendendo le attività di sviluppo, test e gestione degli incidenti disgiunte e farraginose. Ciò determina un aumento del Time to Resolution (TTR) e della complessità operativa.
-
Per i nuovi oggetti Salesforce, attenersi al principio della densità di automazione come guida principale.
-
Per gli oggetti Salesforce esistenti con impronta ibrida e doppio trigger Apex e punti di ingresso del flusso attivati da record, valutare la densità e quindi eseguire l'architettura per il refactoring a uno stato ibrido manutenibile.
-
Per una bassa densità, rifattorizzare i trigger Apex in flussi attivati da record e specificare l'ordine di esecuzione, riportandoli a un unico punto di ingresso dell'automazione.
-
Per una densità media, rifattorizzare i flussi mega complessi in un sottoinsieme di flussi, con il giusto ordine di esecuzione. Introdurre trigger Apex solo quando è assolutamente necessario, ad esempio per supportare dopo l'annullamento dell'eliminazione del contesto.
-
Per una densità elevata, preferire l'implementazione dei trigger Apex.
-
Man mano che i processi aziendali di un'organizzazione sulla piattaforma Salesforce maturano, il volume e la complessità dell'automazione attivata da record aumentano inevitabilmente. Una procedura ottimale fondamentale è mantenere un trigger Apex per oggetto Salesforce. Questa regola è fondamentale perché la piattaforma non garantisce l'ordine di esecuzione di più trigger sullo stesso oggetto per lo stesso evento. Questa limitazione può causare comportamenti non deterministici, condizioni di gara e problemi di difficile risoluzione dei problemi.
Tuttavia, l’adesione al principio one trigger introduce una sfida architettonica: come gestire e orchestrare tutta la logica aziendale richiamata da quel singolo punto di ingresso in modo manutenibile e scalabile.
La prima evoluzione di questa architettura è stato lo schema Classic Trigger Handler. In questo approccio, il singolo trigger Apex delega tutta la sua logica a una classe di handler corrispondente (ad esempio, OpportunityTriggerHandler). Questo metodo separa la logica dal file trigger e offre agli sviluppatori un controllo deterministico sull'ordine di esecuzione all'interno dei metodi della classe handler (ad esempio, afterInsert()).
Sebbene sia un miglioramento, questo schema spesso porta a classi di handler monolitici. Con il passare del tempo, man mano che si aggiungono ulteriori requisiti aziendali, la classe diventa grande, difficile da gestire e difficile da testare isolatamente. L'ordine di esecuzione di tutti i singoli processi è codificato all'interno di un unico metodo, rendendo la classe soggetta a conflitti di unione, aumentando notevolmente il sovraccarico di governance e manutenzione in un ambiente aziendale di grandi dimensioni.
Per risolvere i problemi principali della modularità e dell'orchestrazione, gli architetti passano a un trigger framework basato sui metadati. Si tratta di un salto architettonico significativo che separa la logica di automazione stessa dalla configurazione di come e quando viene eseguita.
Questo framework si basa su tre vantaggi chiave:
-
Partizionamento: Anziché una singola classe di handler, la logica aziendale centrale è suddivisa in piccole classi Apex atomiche (ad esempio, una classe
RecalculateAccountValueso una classeNotifySalesLeads), con ciascuna classe che aderisce al principio responsabilità unica. Questa modularità semplifica il test, il debug e la comprensione della logica separatamente. -
Ordine e coreografia: L'ordine di esecuzione non è più codificato in Apex. È invece definito in modo dichiarativo dai record di configurazione, in genere memorizzati in un tipo di metadati personalizzato (ad esempio,
TriggerAction__mdt). Ciò consente agli amministratori di riordinare, aggiungere o rimuovere le azioni di automazione semplicemente modificando un record di metadati, che non richiede una distribuzione o una modifica del codice. -
Funzionalità di bypass: Il framework offre funzionalità di bypass granulari standardizzate. Ogni azione di automazione può essere configurata tramite il relativo record di metadati per essere disattivata globalmente o ignorata per utenti amministrativi specifici facendo riferimento a un'autorizzazione personalizzata.
Il trigger Apex singolo per l'oggetto funge quindi solo da dispatcher dinamico. Non contiene alcuna logica aziendale, ma istanzia una classe di MetadataTriggerHandler centrale. Questo handler esegue query sui record di metadati personalizzati per determinare dinamicamente la sequenza di esecuzione e invocare le classi Apex atomiche corrette nell'ordine prescritto. L'automazione è unificata sotto un unico livello trasparente e controllabile.
Un vantaggio importante dell'utilizzo di Apex in un framework solido è la possibilità di gestire lo stato delle transazioni e ottimizzare le prestazioni eliminando il lavoro ridondante. Man mano che la logica si accumula, è comune che automazioni diverse all'interno dell'ordine di salvataggio eseguano in modo indipendente le stesse operazioni costose, consumando limiti del governor preziosi e aumentando il tempo di operazione DML.
Il framework è progettato per affrontare questo problema con due strategie principali:
-
Gestione condivisa dello stato: Nell'ambito di una singola transazione Apex, le proprietà statiche e le variabili vengono utilizzate per memorizzare nella cache i dati. Ciò garantisce che un'operazione costosa, ad esempio una query
SOQLper un'impostazione di configurazione, venga eseguita una sola volta, anche se la logica di automazione viene richiamata più volte in diversi record o fasi del trigger. Il consumo dei limiti delle transazioni è significativamente ridotto. -
Utilizzo della cache piattaforma: Per andare oltre il semplice caching intra-transazioni, utilizzare la cache della piattaforma per evitare di eseguire query sull'intero database per determinati dati. Questa cache in memoria gestita è ideale per recuperare dati non primitivi, letti spesso nella codebase e immutabili nel corso di una transazione (ad esempio profili, ruoli, orari di ufficio). Utilizzando l'interfaccia
Cache.CacheBuilder, il sistema controlla prima la cache ed esegue la query sul database solo se i dati non sono presenti, ottimizzando le prestazioni e la scalabilità.
Utilizzare sempre un aggiornamento prima del salvataggio quando l'automazione deve solo modificare i valori dei campi del record che avvia la transazione. Questo vale sia per gli aggiornamenti di campo veloce nel flusso (che vengono eseguiti prima del salvataggio) che per la logica before-context nei trigger Apex (prima dell'inserimento, prima dell'aggiornamento).
Questo schema è performante, indipendentemente dallo strumento utilizzato, perché evita una seconda operazione DML e un ciclo di salvataggio ricorsivo. Le modifiche vengono apportate al record in memoria prima che venga confermato nel database e vengono salvate come parte della transazione originale. Viene eliminato il sovraccarico di un secondo salvataggio, che altrimenti eseguirebbe nuovamente l'intero ordine di salvataggio e attiverebbe nuovamente tutta l'automazione.
La ricorsione incontrollata è un'insidia comune nei trigger dopo l'aggiornamento, in cui la logica di un trigger esegue un aggiornamento DML che a sua volta provoca la riattivazione dello stesso trigger. Questo crea un loop infinito che alla fine termina con un'eccezione del limite governor. Mentre i flag booleani statici o le raccolte di ID record elaborati sono stati storicamente utilizzati per impedire tale ricorsione, uno schema più preciso e robusto è quello di bloccare la logica confrontando i valori dei campi tra la nuova e la vecchia versione del record stesso.
Eseguire la logica solo se un campo specifico di interesse è stato effettivamente modificato. Ciò impedisce al trigger di eseguire la sua logica nelle operazioni DML successive all'interno della stessa transazione in cui i dati critici rimangono invariati.
In un flusso attivato da record, impedire la ricorsione incontrollata impostando l'esecuzione del flusso solo quando il record viene aggiornato per soddisfare i requisiti della condizione:

Se si sceglie di utilizzare una formula di criteri di immissione nel flusso, è possibile evitare la ricorsione in fuga confrontando la variabile globale $Record (che rappresenta i nuovi valori) con la variabile globale $RecordPrior (che rappresenta i valori originali prima del salvataggio). Ad esempio, per assicurarsi che un flusso venga eseguito solo se il campo Ammontare di un'opportunità è stato modificato, utilizzare questo criterio nei criteri di immissione:
Confrontare i valori dei campi della nuova versione del record, Trigger.new, con i valori dei campi della vecchia versione del record, Trigger.oldMap, per vedere se si è verificata la modifica specifica desiderata. Questo approccio garantisce che l'automazione sia idempotente e venga eseguita solo quando necessario, rendendo il sistema più efficiente e prevenendo loop ricorsivi catastrofici.
Un'organizzazione Salesforce ben progettata richiede un meccanismo coerente e affidabile per ignorare l'automazione. Non si tratta di una funzione facoltativa, ma di un requisito operativo fondamentale per mantenere l'integrità dei dati e abilitare le operazioni amministrative.
Un framework di bypass è essenziale per alcuni scenari:
-
Quando si caricano grandi volumi di dati, l'attivazione di trigger per ogni record può rallentare drasticamente il processo, causare eccezioni ai limiti e creare record e notifiche correlati errati. Un bypass consente di inserire i dati in modo pulito ed efficiente.
-
Un utente integrazione può avere la necessità di sincronizzare i dati di un sistema di record esterno. L'automazione che normalmente viene attivata per una modifica avviata dall'utente (ad esempio, l'invio di un messaggio email, la creazione di un'operazione) può essere indesiderata o ridondante quando la modifica ha origine da un altro sistema.
-
Gli amministratori o il personale di assistenza potrebbero dover eseguire aggiornamenti correttivi sui record. Un meccanismo di bypass consente di apportare queste modifiche senza attivare l'automazione aziendale standard, che potrebbe avere conseguenze indesiderate.
Autorizzazioni personalizzate: Lo standard moderno e scalabile per l'implementazione della logica di bypass sono le autorizzazioni personalizzate. Questi sono superiori ai metodi precedenti per diversi motivi:
-
Flessibilità: Le autorizzazioni personalizzate possono essere assegnate agli utenti tramite gli insiemi di autorizzazioni. Questa procedura è in linea con il moderno modello di sicurezza e accesso di Salesforce, consentendo un'assegnazione granulare e flessibile. Un bypass può essere concesso a un utente specifico o anche temporaneamente con una data/ora di scadenza specifica.
-
Gestibilità: L'uso delle autorizzazioni personalizzate evita il codificaggio dei profili o degli utenti in una logica di automazione. Se il ruolo di un utente cambia o un nuovo profilo deve ignorare l'accesso, la modifica è una semplice assegnazione di insiemi di autorizzazioni, non una modifica del codice o del flusso che richiede una distribuzione.
-
Scalabilità: Le autorizzazioni personalizzate offrono un framework scalabile per la gestione delle eccezioni in una base di utenti complessa. Possono essere assegnati agli utenti tramite insiemi di autorizzazioni, gruppi di insiemi di autorizzazioni o profili. La loro associazione a un insieme di autorizzazioni o a un profilo è rappresentabile anche nei metadati di origine.
Modelli di implementazione: Applicare uno schema di bypass coerente a tutte le automazioni attivate da record dell'organizzazione.
Ignorare un flusso attivato da record: Il modo più efficiente per ignorare un flusso è impedirne l'esecuzione. A questo scopo, aggiungere una condizione ai criteri di immissione del flusso.
-
Nell'elemento iniziale del flusso attivato da record, impostare Requisiti della condizione su La formula valuta True.
-
Nel Generatore di formule, incorporare una verifica dell'autorizzazione personalizzata utilizzando la variabile globale
$Permission. Combinare il controllo con i criteri di immissione esistenti.- Schema di formula:
-
Questo schema garantisce che il flusso venga eseguito solo se all'utente non è assegnata l'autorizzazione personalizzata specificata. Questo controllo viene eseguito prima ancora di creare l'intervista del flusso, rendendolo l'approccio più efficace.
-
Ignorare un trigger framework Apex: In Apex, integrare la logica di bypass direttamente nel framework di trigger basato sui metadati, consentendo un controllo granulare.
-
Il tipo di metadati personalizzato
TriggerAction__mdtdeve includere un campo di testo, ad esempioBypassPermission__c.-
Nella classe
MetadataTriggerHandler, prima di eseguire dinamicamente un'azione, il codice deve leggere il valore di questo campo. -
Se il campo è compilato, l'handler utilizza il metodo
FeatureManagement.checkPermission()per determinare se l'utente corrente in esecuzione dispone dell'autorizzazione personalizzata specificata. -
Se
checkPermission()restituisce true, l'handler salta quell'azione specifica e passa a quella successiva nella sequenza. -
Questo schema è efficace perché consente sia un bypass globale (se tutti i record
TriggerAction__mdtfanno riferimento alla stessa autorizzazione) che un bypass granulare per azione (se record diversi fanno riferimento a autorizzazioni diverse o se alcuni non dispongono di alcuna autorizzazione di bypass).
-
È un anti-schema per consolidare tutta l'automazione di un oggetto in un unico enorme flusso. Il consolidamento in un flusso anziché la suddivisione della logica in più flussi ben condizionati non ha un impatto significativo sulle prestazioni. I guadagni di prestazioni più significativi provengono da:
-
Utilizzo dei flussi before-save per gli aggiornamenti di campo dello stesso record.
-
Scrivere condizioni di immissione precise per garantire che i flussi siano esclusi dall'esecuzione per le modifiche che non influiscono sul loro caso d'uso specifico.
Flow Trigger Explorer consente di assegnare un valore ordine a ogni flusso di un oggetto, garantendo un ordine di esecuzione sequenziale.
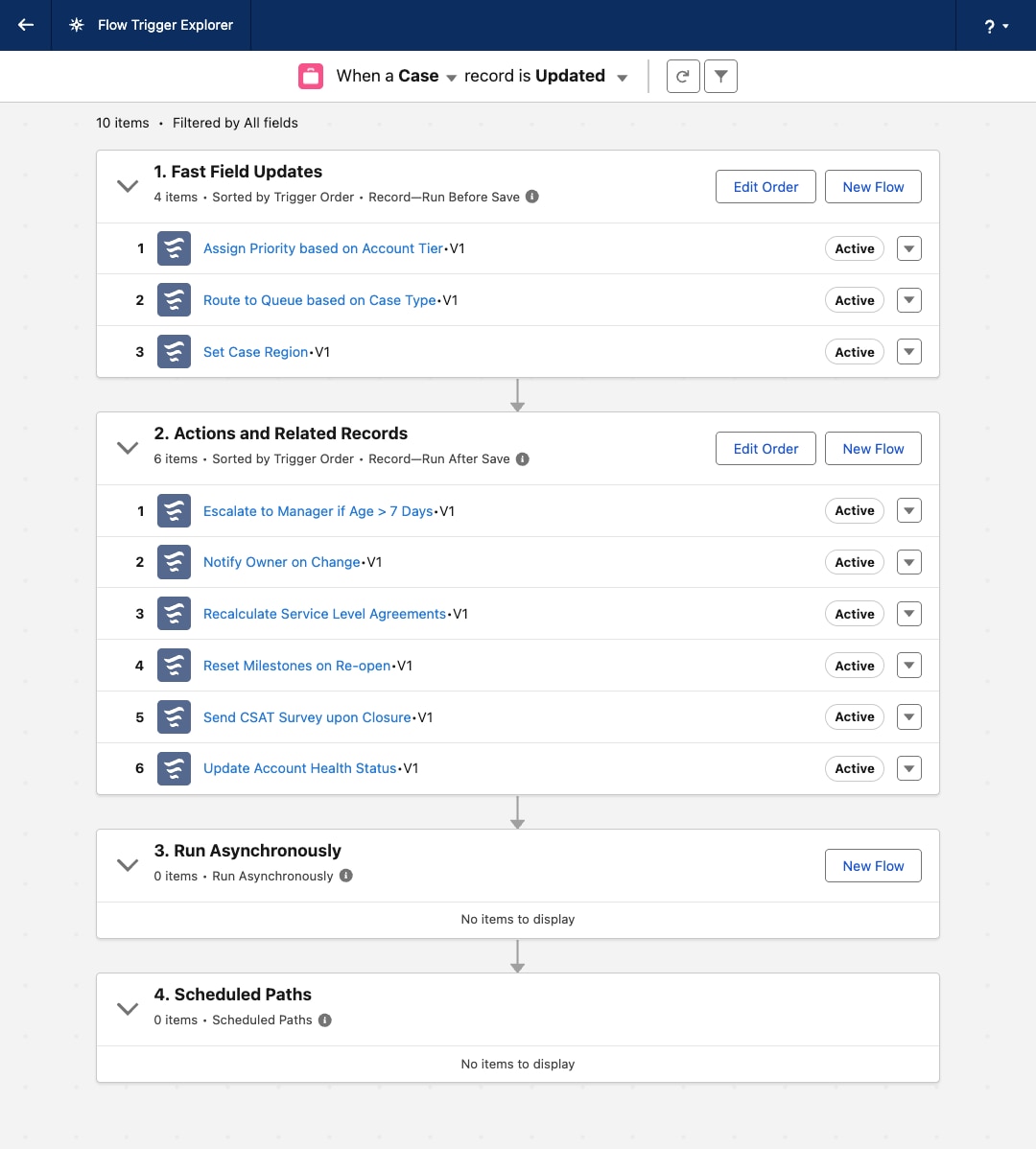
| Apex | Flusso | Operazioni |
|---|---|---|