Le aziende spesso archiviano i dati sia in Salesforce che in altri data lake esterni come Snowflake, Google BigQuery, Databricks, Redshift o cloud storage come Amazon S3. Questo insilamento dei dati in sistemi di origine diversi rappresenta una sfida per le aziende che desiderano sfruttare tutta la potenza dei propri dati.
Gli architetti che lavorano per riunire i dati in più data lake devono affrontare le principali decisioni architettoniche su come integrare al meglio i dati. Data 360 offre diverse opzioni per l'integrazione dei dati, ognuna delle quali offre diversi pro e contro.
Questa guida fornisce un framework per valutare quale schema si adatta meglio alle proprie esigenze in termini di latenza, costo, scalabilità, governance e complessità durante l'integrazione dei dati, consentendo di scegliere quando utilizzare l'inserimento dati, la federazione dati Copia zero o un approccio ibrido. La guida consente inoltre di scegliere tra diversi metodi di inserimento dati e federazione dei dati, ognuno dei quali risponde a esigenze diverse.
L'integrazione di data lakehouse esterni con Data 360 richiede un'attenta considerazione dei compromessi tra aggiornamento dei dati, governance ed efficienza delle opportunità in corso di realizzazione. Ad esempio, l'utilizzo delle query live della federazione dei dati Copia zero ottimizza la freschezza dei dati ma può ridurre l'efficienza delle opportunità in corso di realizzazione man mano che si spostano più dati nella rete. Pertanto, per la maggior parte delle implementazioni del mondo reale, una combinazione di inserimento e federazione all'interno di un ecosistema lakehouse multi-cloud è il percorso ottimale. Questo approccio ibrido garantisce un'architettura scalabile, gestita e interoperabile che supporta in modo semplice sia carichi di lavoro operativi a bassa latenza come la personalizzazione in tempo reale e il rilevamento delle frodi, sia carichi di lavoro analitici come la reportistica normativa e l'analisi del trend storico. Questa guida alle decisioni ti aiuterà a capire come gestire questi compromessi e a selezionare la strategia giusta.
- Inserimento dati: Copia i dati in Salesforce Data 360, creando modelli di dati canonici e governati. Ideale quando è necessario:
- Creare un Customer 360 completo: Unificare e trasformare fonti diverse in un unico profilo affidabile.
- Rispettare la rigorosa conformità normativa: Creare una copia controllabile centralizzata in cui l'accesso ai dati e la discendenza possono essere controllati in modo rigoroso.
- Federazione copia zero: Esegue query sulle fonti esterne in tempo reale senza duplicazioni, abilitando la personalizzazione in tempo reale, i cruscotti digitali live e l'orientamento rapido delle fonti. È necessario bilanciare due opzioni principali con compromessi:
- Live & caching (query accelerata): Ideale per l'analisi interattiva e i cruscotti digitali in tempo reale sui dati presenti in piattaforme dati esterne come Snowflake, Google BigQuery, Redshift o Databricks. Evita la duplicazione lenta e costosa dei dati inviando l'elaborazione al sistema di origine.
- Federazione file: Ideale per l'elaborazione batch su larga scala e l'addestramento del modello AI sui dati nel data lake cloud (S3, ADLS). Evita l'inserimento lento e costoso eseguendo query dirette sui file in formati di tabella aperti, sbloccando serie di dati di grandi dimensioni per carichi di lavoro ETL e di data science.
- Modello ibrido: Combinare l'inserimento per Profili unificati con la federazione per la freschezza, supportando il coinvolgimento Omnicanale, le azioni basate su Agentforce e l'addestramento AI/ML.
-
Architettura ibrida: Spesso è necessario combinare l'inserimento dei dati e la federazione dei dati.
- Utilizzare l'inserimento dati sui dati critici per i modelli di dati canonici e la governance di base.
- Federare tutti gli altri dati tramite Copia zero per ridurre al minimo il sovraccarico operativo di creazione e manutenzione delle opportunità in corso di realizzazione dei dati di inserimento.
-
Questioni di frequenza di inserimento dati: Scegliere la frequenza in base al valore aziendale, alle esigenze di latenza e alla complessità operativa.
- Utilizzare in tempo reale i flussi di lavoro sensibili al tempo (personalizzazione, cruscotti digitali live, azioni Agentforce).
- Quasi in tempo reale per i processi moderatamente urgenti (campagne, rapporti operativi).
- Batch per le serie di dati storiche o a bassa velocità.
-
Abbinare lo schema federazione a latenza e prestazioni: Scegliere quello che meglio soddisfa i propri schemi di accesso e i requisiti di freschezza, prestazioni e costo.
- Utilizzare Live Query per i cruscotti digitali operativi e la personalizzazione in tempo reale in cui la latenza bassa è fondamentale.
- Utilizzare il caching (query accelerata) quando le query sono frequenti ma i risultati leggermente obsoleti sono accettabili, bilanciando prestazioni e costi.
- Utilizzare Federazione file per carichi di lavoro analitici o batch su larga scala e molto produttivi, ideali per le serie di dati storiche o meno sensibili al tempo.
-
Allineamento della governance ai requisiti di residenza dei dati:
- Utilizzare l'inserimento dove la governance centralizzata è fondamentale.
- Utilizzare Federation dove la governance decentralizzata è accettabile, imponendo al contempo una governance rigorosa alla fonte esterna. Copia zero rispetta le policy a livello di origine, ad esempio la protezione a livello di riga e il mascheramento dei dati.
-
Dare priorità all'inserimento per i flussi di lavoro di alto valore: Applicare l'inserimento in modo selettivo a processi critici come la risoluzione dell'identità, la generazione di rapporti normativi e l'attivazione operativa.
-
Costo e complessità determinano la decisione: L'inserimento in tempo reale può essere costoso e complesso. Gli architetti devono valutare il costo dell'orientamento, dell'archiviazione e della trasformazione dei dati rispetto al costo dell'esecuzione di query direttamente tramite Copia zero.
La scelta dello schema di integrazione corretto (inserimento dati, copia zero o approccio ibrido) influisce direttamente su latenza, governance, efficienza operativa e costi nelle piattaforme multi-cloud. Questa decisione determina in che modo gli approfondimenti in tempo reale, l'attivazione basata sull'intelligenza artificiale e il coinvolgimento personalizzato possono essere forniti in modo affidabile e su larga scala.
Questa tabella offre un confronto tecnico tra gli schemi di inserimento dati e Copia zero in Salesforce Data 360, concentrandosi su funzionalità, compromessi e vantaggi, oltre a casi d'uso e risultati aziendali. Gli architetti possono utilizzarlo come riferimento per progettare piattaforme dati ibride multi-cloud che bilanciano prestazioni, costi e conformità.
| Tipo di schema | Modalità / Strumento | Vantaggi | Considerazioni | Esiti |
|---|---|---|---|---|
| Inserimento dati | Real-Time: Inserimento di latenza al di sotto del secondo tramite le API di inserimento con supporto CDC. Pipeline di streaming continue. | - Approfondimenti immediati - Ideale per casi d'uso operativi e di personalizzazione a bassa latenza - Supporta flussi di lavoro basati sugli eventi |
- Costo elevato - Architettura complessa - Richiede sistemi di origine a bassa latenza - Fonti a volume elevato possono causare uno streaming eccessivo che porta a pipeline sature - I/O intensivo Considerare i campi selettivi e i filtri per ridurre l'overhead |
Agenteforce: - Avvisi frodi in tempo reale, personalizzazione della vendita al dettaglio, avvisi operativi Analytics: - Cruscotti digitali sub-secondi, monitoraggio KPI Conformità: Aggiornamenti continui dei record cliente per i flussi di lavoro regolamentati |
| Streaming: Inserimento di micro batch ogni 1–3 minuti tramite connettori nativi | - Costo bilanciato vs freschezza - Architettura più semplice rispetto al tempo reale - Supporta aggiornamenti incrementali |
- Lieve latenza - Può non essere adatto per decisioni critiche sub-secondi - Le dimensioni del batch influiscono sulla memoria/calcolo - I/O è moderato - Ideale per schemi di aggiornamento prevedibili e ripetuti - Considerare l'aggregazione finestrata per ridurre il carico di elaborazione |
Agenteforce: - Trigger campagna tempestivi, coinvolgimento quasi live Analytics: - Motori di consiglio, cruscotti digitali quasi live Conformità: - Aggiornamenti frequenti con verificabilità |
|
| Batch: carichi a volume elevato pianificati tramite connettori o API. Supporta l'archiviazione di oggetti e le opportunità in corso di realizzazione ETL/ELT. | - Economico per serie di dati di grandi dimensioni - Facile da implementare - Affidabile per l'analisi storica |
- Latenza dei dati - Inadatto per operazioni sensibili al tempo - I/O intensivo durante le finestre di carico - La produttività della rete può diventare un collo di bottiglia per i file di grandi dimensioni - Ideale per l'aggregazione storica o i flussi di lavoro di generazione di rapporti regolamentati |
Agenteforce: - ticket di assistenza IT (Jira/ServiceNow), flussi di lavoro aggregati Analytics: - Analisi storica, valutazione del trend Reclamo: - Reportistica normativa, aggregazione dati paziente/richiesta |
|
| Copia zero | Live Query: query dirette su sistemi esterni; schema in lettura; nessuna duplicazione dei dati | - Massima freschezza - Overhead di memoria minimo; supporta approfondimenti operativi in tempo reale |
- A seconda delle prestazioni della fonte - Volume di query elevato può influire sulla latenza Ideale per query con pushdown e aggregazione del predicato per ridurre al minimo gli I/O - Evitare query non filtrate su serie di dati di grandi dimensioni |
Agenteforce: Flussi di lavoro dinamici che si adattano all'attività live Analytics: - Cruscotti digitali operativi, reportistica live Conformità: Rispetta la protezione a livello di riga e il mascheramento alla fonte |
| Query accelerata (Caching): copie locali memorizzate nella cache per le query federate. Configurabile da 15 min a 7 giorni. Esecuzione di query ottimizzata | - Riduce la latenza - Costo inferiore rispetto alle query live ripetute Migliora le prestazioni per gli schemi di accesso frequenti |
- Gestione della cache richiesta - Stabilità dipende dall'intervallo di cache - Ideale per query ad alta frequenza - Non adatto per decisioni sub-secondarie |
Agenteforce: - Metriche di coinvolgimento pre-aggregate per decisioni rapide Analytics: - Cruscotti digitali BI, segmentazione, reportistica analitica Conformità: - Cruscotti digitali regolamentati coerenti con i registri di controllo |
|
| Federazione file: accesso diretto a grandi serie di dati storici in negozi di oggetti o laghi (S3, Iceberg, Google BigQuery, Redshift). | - Gestisce serie di dati su larga scala - Memoria minima in Data 360 - Supporta i carichi di lavoro AI/ML |
- Sola lettura - Le prestazioni delle query dipendono dalla produttività del sistema esterno - Ottimizzato per processi batch-heavy, throughput-intensive - Non adatto per cruscotti digitali in tempo reale |
Agenteforce: - (Non tipico — pesante in batch) Analytics: - Formazione ML/AI, analisi storica, reportistica su scala petabyte Conformità: - Accesso governato alle serie di dati esterne senza duplicazione |
Con l'inserimento dei dati, i dati vengono copiati fisicamente in Data 360 e completamente gestiti, a differenza di Copia zero in cui i dati rimangono all'origine. Il calcolo delle trasformazioni avviene all'interno di Data 360, che consente una governance e un controllo centralizzati.
Utilizzare l'inserimento dati per archiviare le serie di dati canoniche governate in Salesforce Data 360 per la conformità e il controllo operativo. Utilizzare l'inserimento quando sono necessari controllo completo, controllo e tracciabilità. Ideale per flussi di lavoro regolamentati o di valore elevato in cui l'elaborazione centralizzata e la governance sono fondamentali.
L'inserimento è ideale per creare una base affidabile per la risoluzione dell'identità, la generazione di rapporti normativi e i flussi di lavoro mission-critical basati sull'intelligenza artificiale e sul coinvolgimento dei clienti.

I metodi di inserimento dati variano a seconda del connettore utilizzato per inserire i dati. Alcuni connettori offrono una varietà di metodi di inserimento, mentre altri funzionano solo in modalità batch o streaming. Vedere Data 360: Integrazioni e connettori per un elenco completo dei connettori Data 360 e dei relativi metodi disponibili.
- In tempo reale
- Inserimento al di sotto del secondo utilizzando le opportunità in corso di realizzazione in streaming o Acquisizione dati di modifica (CDC).
- Ideale per i flussi di lavoro sensibili al tempo (rilevamento di frodi, personalizzazione, cruscotti digitali operativi).
- Trasformazioni push e aggregazioni in Data 360 per ridurre l'I/O a valle e ottimizzare l'utilizzo dell'elaborazione. Utilizzare CDC incrementale per ridurre al minimo il rimescolamento dei dati.
- Streaming
- Inserimento ogni 1–3 minuti a piccoli incrementi.
- Bilancia freschezza e costo, adatto per l'orchestrazione delle campagne, il coinvolgimento quasi live e la generazione di rapporti operativi.
- Utilizzare i micro batch per controllare i picchi di I/O. Se possibile, aggregare i dati alla fonte per ridurre i volumi di trasferimento e ottimizzare l'archiviazione.
- Batch (carichi pianificati)
- Inserimento periodico di serie di dati di grandi dimensioni (orarie, giornaliere, settimanali).
- Economico e affidabile per le serie di dati storiche, i rapporti normativi e i casi d'uso di conformità.
- Assicurarsi che la posizione di calcolo si trovi nella stessa regione dello spazio di archiviazione sorgente per ottimizzare le prestazioni e i costi.
- Casi d'uso per l'inserimento dati
- Generazione di profili unificati Customer 360: Creare un'unica fonte di dati per l'identità e gli attributi dei clienti.
- Gestire le serie di dati di conformità ai regolamenti: Imponendo governance, discendenza e verificabilità per i dati sensibili.
- Centralizzare l'orchestrazione delle campagne: Garantire che marketing, vendite e assistenza operino tutti da serie di dati coerenti e affidabili.
- Processi di progettazione
- Favorire l'inserimento in batch per esigenze storiche o tolleranti la bassa latenza, ad esempio rapporti di archiviazione o istantanee periodiche.
- Utilizzare le API CDC o streaming per mantenere aggiornati i flussi di lavoro operativi e di personalizzazione, garantendo aggiornamenti quasi in tempo reale.
- Controllare la crescita dello storage e del calcolo applicando carichi incrementali anziché ricaricare intere serie di dati per ottimizzare i costi e l'efficienza.
- Allineare le opportunità di inserimento in corso di realizzazione con la località di calcolo e l'elaborazione incrementale per ridurre gli I/O della rete. Applicare trasformazioni all'interno di Data 360 per evitare di spostare dati non elaborati inutilmente.
- Considerazioni sui costi
- Inserimento in tempo reale: Costi di elaborazione e pipeline più elevati; giustificati per flussi di lavoro di valore elevato e sensibili al tempo come personalizzazione, cruscotti digitali operativi o azioni basate su Agentforce.
- Inserimento streaming: Moderare i costi di calcolo e archiviazione; adatto per aggiornamenti frequenti che possono tollerare lievi ritardi, come l'orchestrazione delle campagne o la generazione di rapporti operativi.
- Inserimento batch: Minori costi di calcolo, memoria prevedibile; ideale per le serie di dati storiche o gli aggiornamenti a bassa frequenza. L'inserimento di dati batch da organizzazioni Salesforce utilizzando determinati connettori è gratuito.
- Modalità di aggiornamento: La selezione della modalità Aggiornamento incrementale riduce i costi totali di inserimento e calcolo. Si consiglia di utilizzare l'aggiornamento incrementale ove possibile per ottimizzare l'efficienza in tutti i tipi di inserimento.
- Il costo è influenzato anche dal volume di I/O dalla fonte a Data 360. L'ottimizzazione delle dimensioni dei batch, delle partizioni e dell'allineamento regionale riduce i costi di trasferimento e migliora le prestazioni.
- Scenari di settore
- Finanza: Inserire le serie di dati necessarie per conoscere il cliente (KYC), l'Antiriciclaggio (AML) e il rilevamento delle frodi, in cui la verificabilità e la conformità non sono negoziabili.
- Assistenza sanitaria: Utilizzare l'inserimento per la risoluzione dell'identità del paziente e i record conformi all'HIPAA, abilitando visualizzazioni unificate sicure.
- Retail: Consolidare i dati dei punti vendita (POS), dell'eCommerce e dei programmi fedeltà in profili unificati per segmentazione e personalizzazione
- Telecom: Supportare la prevenzione dell'abbandono e l'analisi dell'utilizzo con dati canonici degli abbonati regolati.
| Funzione | Inserimento in tempo reale | Inserimento streaming | Inserimento batch |
|---|---|---|---|
| Latenza e freschezza | Inserimento di latenza inferiore al secondo tramite le API di inserimento con supporto CDC (Cambia acquisizione dati). Fornisce opportunità in streaming continue. Ideale per i casi d'uso operativi a bassa latenza. | Inserimento in micro batch ogni 1–3 minuti tramite connettori nativi. Supporta gli aggiornamenti incrementali. È prevista una leggera latenza. | La latenza dei dati è prevista. Carichi a volume elevato pianificati. Inserimento periodico (orario, giornaliero, settimanale). Non adatto per operazioni sensibili al tempo. |
| Casi d'uso principali | Ideale per casi d'uso operativi e di personalizzazione a bassa latenza. Utilizzato per i flussi di lavoro sensibili al tempo. Supporta i flussi di lavoro basati sugli eventi. Utilizzato per gli avvisi di frode in tempo reale e gli avvisi operativi. | Adatto per processi moderatamente urgenti. Utilizzato per l'orchestrazione delle campagne, il coinvolgimento quasi live e la generazione di rapporti operativi. Utilizzato per trigger campagna puntuali. | Economico per serie di dati di grandi dimensioni. Affidabile per l'analisi storica. Utilizzato per l'aggregazione storica o i flussi di lavoro di generazione di rapporti regolamentati. Ideale per le serie di dati storiche o a bassa velocità. |
| Complessità architettonica e I/O | Costo elevato e architettura complessa. Richiede sistemi di origine a bassa latenza. I/O intensivo. Fonti a volume elevato possono causare pipeline sature. | Architettura più semplice che in tempo reale. I/O è moderato. Ideale per schemi di aggiornamento prevedibili e ripetuti. Le dimensioni del batch influiscono sulla memoria/calcolo. | Facile da implementare. I/O intensivo durante le finestre di carico. La produttività della rete può diventare un collo di bottiglia per batch di grandi dimensioni. |
| Considerazioni sui costi | Massimi costi di calcolo e pipeline. Giustificato solo per i flussi di lavoro di valore elevato e sensibili al tempo. | Moderare i costi di elaborazione e memoria. Offre un approccio bilanciato tra costo e freschezza. Adatto per aggiornamenti frequenti che possono tollerare lievi ritardi. | Minori costi di calcolo e memoria prevedibile. Consigliato per le serie di dati storiche o gli aggiornamenti a bassa frequenza. L'inserimento tramite pipeline interne Salesforce è gratuito. |
| Processi di progettazione | Utilizzare CDC incrementale per ridurre al minimo il rimescolamento dei dati. Filtrare e utilizzare i campi selettivi per ridurre il sovraccarico. | Utilizzare i micro batch per controllare i picchi di I/O. Considerare l'aggregazione con finestre per ridurre il carico di elaborazione. | Privilegiare questa opzione per i rapporti di archivio o le istantanee periodiche. Assicurarsi che la posizione di calcolo sia nella stessa regione dello spazio di archiviazione sorgente per ottimizzare i costi. |
Utilizzare Copia zero per eseguire query in tempo reale su sistemi esterni senza duplicazione dei dati, abilitando agilità, freschezza e accesso scalabile a serie di dati di grandi dimensioni o temporanee. È ideale per cruscotti digitali live, analisi esplorative, formazione sui modelli AI/ML e coinvolgimento dei clienti in tempo reale direttamente tramite Salesforce Data 360.
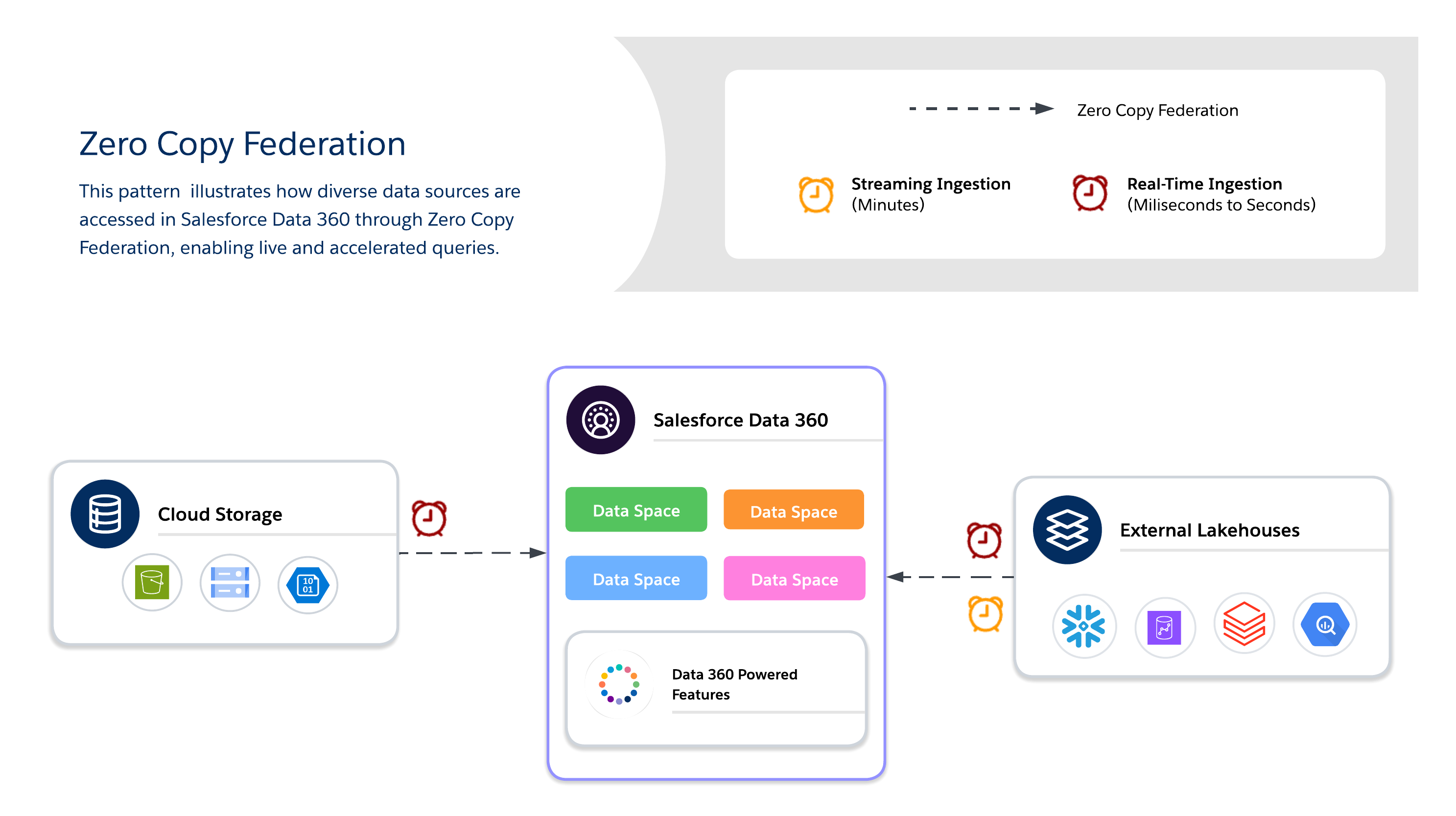
Quando si utilizza Copia zero, gli architetti devono scegliere ulteriormente tra tre metodi di federazione dei dati disponibili, ciascuno dei quali offre i propri compromessi tra freschezza, prestazioni e costo.
- Query live
- Esegue query direttamente su sistemi esterni (Snowflake, Google BigQuery, Redshift, Databricks, ecc.) senza duplicazione dei dati.
- Ottimale quando predicati e aggregazioni possono essere spostati verso il basso, riducendo al minimo lo spostamento dei dati sulla rete e l'I/O nell'elaborazione di Salesforce Data 360.
- Ideale per approfondimenti in tempo reale e cruscotti digitali operativi a bassa latenza. Dipende dalle prestazioni del sistema esterno.
- Caching (query accelerata)
- Memorizza temporaneamente le copie memorizzate nella cache dei dati federati in Salesforce Data 360.
- Riduce i costi di query ripetute e la latenza per le serie di dati a cui si accede di frequente, con durata configurabile (da minuti a giorni).
- I dati non vengono copiati in modo permanente o completamente governati; la freschezza viene gestita tramite aggiornamenti pianificati dall'origine.
- Federazione file
- Fornisce accesso diretto in sola lettura alle serie di dati su larga scala negli archivi di oggetti (ad esempio, S3, GCS con Iceberg).
- Ideale per carichi di lavoro AI/ML, analisi storica e rapporti su scala petabyte senza spostare i dati.
- Le prestazioni delle query dipendono fortemente dal formato dell'oggetto, dal partizionamento e dall'ingresso/uscita di rete. Scansioni di grandi dimensioni possono generare I/O sostanziali se non ottimizzate.
- Casi d'uso
- Personalizzazione in tempo reale e flussi di lavoro adattivi: Offrire offerte dinamiche, consigli e azioni Next Best man mano che il comportamento dei clienti cambia.
- Cruscotto digitale live e analytics operativo: Consente di alimentare i cruscotti digitali e i KPI business critical direttamente dai magazzini esterni.
- Addestramento del modello AI/ML con serie di dati esterne di grandi dimensioni: Sfruttare i dati su scala petabyte di data lake e warehouse utilizzando federazione file senza spostarli.
- Scenari di settore
- Retail/Media: Abilitare i consigli personalizzati e il coinvolgimento dei clienti in tempo reale federando i dati di clickstream o di interazione con i contenuti.
- Finanza: Eseguire il rilevamento delle frodi e il calcolo del punteggio del rischio quasi in tempo reale eseguendo query sui magazzini esterni senza duplicare dati sensibili.
- Tecnologia/impresa: Supportare i rapporti tra cloud, i cruscotti digitali dei servizi IT e le analisi operative in cui le serie di dati risiedono in più sistemi.
- Processi di progettazione
- Query live
- Utilizzare per query con QPS elevato e bassa latenza quando la freschezza è critica.
- Inviare tramite push predicati e aggregazioni al sistema esterno per ridurre il rimescolamento dei dati sulla rete.
- Evitare le query che eseguono la scansione di volumi di dati elevati inutilmente; considerare la potatura delle partizioni e i filtri.
- Federazione file
- Accedere alle serie di dati su scala petabyte negli archivi di oggetti senza inserimento.
- Mantenere la memoria degli oggetti nella stessa area cloud utilizzata da Salesforce per ridurre al minimo i costi di latenza e uscita.
- Utilizzare formati partizionati e colonnari (Parquet/ORC) e filtri pushdown per ridurre il trasferimento di I/O e di rete.
- Sfruttare il pushdown di query e predicati per filtrare e aggregare i dati alla fonte, riducendo lo spostamento dei dati.
- Evitare l'accesso ai dati tra regioni, a meno che non sia necessario, poiché aumenta I/O, latenza e costi.
- Caching (query accelerata)
- Inserire nella cache le serie di dati a cui si accede di frequente per bilanciare costi e prestazioni.
- Configurare gli intervalli di aggiornamento per bilanciare freschezza e costo delle query.
- Conformità: Applicare la governance all'origine sfruttando la protezione a livello di riga (RLS) e mascherando le policy direttamente all'interno dei sistemi federati. Di seguito sono riportate le procedure consigliate per uniformare il mascheramento e l'utilizzo di RLS tra le piattaforme.
- Utilizzare un ID Enterprise centralizzato: Mappare utenti ed entità in Salesforce Data 360 a un identificatore aziendale centralizzato univoco che corrisponde alle identità nei sistemi esterni.
- Allinea policy di sicurezza: Assicurarsi che le policy di protezione e mascheramento a livello di riga nei sistemi federati vengano applicate in base all'identità mappata. Ciò mantiene la conformità durante le query sui dati esterni.
- Standardizzazione degli schemi di identità: Mantenere attributi di identità coerenti (email, ID utente, ID cliente, ecc.) in tutte le fonti di dati per evitare mancate corrispondenze e violazioni dell'accesso.
- Query live
- Considerazioni sui costi
- Query live: Modello pay-per-query: i costi si accumulano sul calcolo lakehouse esterno e possono aumentare con un QPS elevato. Ideale per i casi d'uso critici per la freschezza in cui il valore è maggiore della variabilità dei costi.
- Query accelerata (Caching): Riduce il costo delle query rispetto a Live Query riducendo gli attacchi al sistema di origine, ma aumenta i costi di inserimento dati batch per il riempimento e l'aggiornamento della cache. Ideale per le serie di dati con accesso frequente.
- Federazione file: Opzione di archiviazione più economica come dati in Object Store, ma i costi delle query dipendono dalle dimensioni del file, dal partizionamento e dalla potatura. Ideale per dati storici o in blocco su scala petabyte.
| Punto Decisione | Live query | Caching (query accelerata) | Federazione file |
|---|---|---|---|
| Posizione fonte di dati | Data lakehouse esterni (Snowflake, Google BigQuery, Redshift, Databricks). | Data lakehouse esterni (Snowflake, Google BigQuery, Redshift, Databricks) | Archivi di oggetti o data lake cloud (S3, ADLS, GCS), spesso utilizzando formati di tabelle aperte come Iceberg. |
| Scopo/Caso d'uso | Ideale per analisi interattive e cruscotti digitali in tempo reale. Ideale per la personalizzazione in tempo reale e i flussi di lavoro dinamici. | Ideale per quando le query sono frequenti ma i risultati leggermente obsoleti sono accettabili. Adatto per cruscotti digitali BI e segmentazione. | Ideale per l'elaborazione batch su larga scala e l'addestramento del modello AI/ML. Ideale per l'analisi storica e i rapporti su scala petabyte. |
| Freschezza/latenza | Massima freschezza; le query vengono eseguite direttamente in tempo reale. Supporta le decisioni subsecondarie. | Risultati leggermente obsoleti sono accettabili. La freschezza dipende dall'intervallo di cache, configurabile da 15 minuti a 7 giorni. | Ottimizzato per i processi intensivi e di produzione. Non adatto per il cruscotto digitale in tempo reale. |
| Schema di accesso | Ideale per query poco frequenti o personalizzate. Utilizzare per query con QPS elevato (query al secondo) e bassa latenza in cui la freschezza è fondamentale. | Ideale per gli scenari di lettura ad alta frequenza. Migliora le prestazioni per gli schemi di accesso frequenti. | Accesso in sola lettura. Adatto per serie di dati su scala petabyte senza inserimento. |
| Driver delle prestazioni | Molto dipendente dalle prestazioni del sistema di origine esterno. Ottimizzato quando predicati e aggregazioni possono essere inviati all'origine. | Riduce la latenza rispetto alle query live ripetute. Le prestazioni dipendono dalla gestione della cache e dall'intervallo. | Le prestazioni dipendono fortemente dal formato dell'oggetto, dal partizionamento e dalla produttività del sistema esterno. Utilizzare formati partizionati e colonnari (Parquet/ORC). |
| Implicazioni sui costi | Modello pay-per-query. I costi vengono accumulati per il calcolo esterno della lakehouse. Economico per le query poco frequenti, ma le spese possono aumentare con un volume elevato di query al secondo (QPS). | Costo inferiore rispetto alle query live ripetute. Riduce la necessità di eseguire ripetutamente query sulla fonte esterna. Aggiunge memoria cache e overhead di aggiornamento. | Opzione di memoria più economica. I costi delle query dipendono dalle dimensioni del file e dal partizionamento. |
| Considerazione chiave | Evitare le query non filtrate che eseguono la scansione di volumi di dati elevati inutilmente. | Richiede la gestione della cache. Non adatto per decisioni subsecondarie. | Le prestazioni delle query dipendono fortemente dall'ottimizzazione tramite partizionamento e pushdown del predicato. |
Le architetture ibride consentono agli architetti di ancorare le serie di dati critiche in Data 360 per una governance centralizzata, sfruttando al contempo le query federate per garantire freschezza, riduzione delle duplicazioni e accesso scalabile a serie di dati esterne di grandi dimensioni. Questo approccio bilancia I/O, località di calcolo, costi e requisiti di conformità.
Utilizzare un approccio ibrido per una governance equilibrata, freschezza ed efficienza operativa combinando l'inserimento dei dati e la copia zero per offrire approfondimenti fruibili in tempo reale. Utilizzare l'inserimento per le serie di dati regolamentate di valore elevato in cui sono richiesti tracciabilità, RLS e mascheramento e la federazione per le serie di dati effimere o a volume elevato in cui freschezza e prestazioni sono fondamentali.
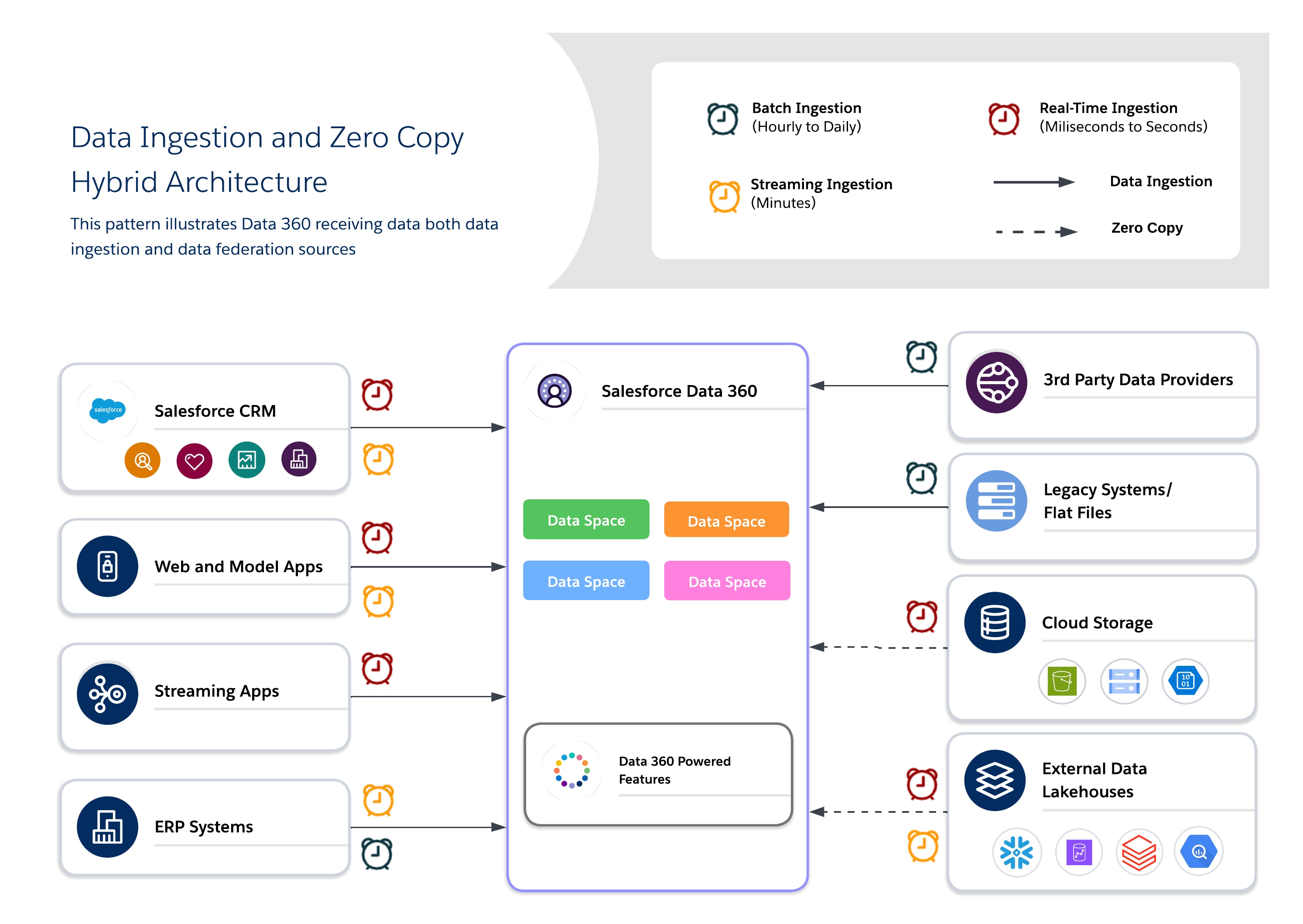
- Casi d'uso
- Coinvolgimento Omnicanale: Combinare i dati storici dei clienti con il comportamento in tempo reale per offrire esperienze coerenti e sensibili al contesto.
- Condotte AI/ML: Addestrare i modelli su serie di dati canoniche curate arricchendole con segnali grezzi o in tempo reale provenienti da fonti esterne.
- Esigenze miste di conformità e agilità: Applicare una governance rigorosa per i dati sensibili ma federarsi per l'agilità operativa.
- Scenari di settore
- Retail: Utilizzare l'inserimento per la risoluzione dell'identità e l'unificazione dei profili; la federazione per le offerte e la personalizzazione in tempo reale.
- Assistenza sanitaria: Gestire le cartelle cliniche dei pazienti tramite inserimento federando gli stream di dispositivi IoT e i dati dei sensori per il contesto immediato.
- Servizi finanziari: Inserire i dati regolamentati in un lago regolamentato dalla conformità durante la federazione delle query esterne per il rilevamento delle frodi e il monitoraggio dei rischi.
- Processi di progettazione
- Ancora governance con inserimento: Inserire dati di valore elevato o regolamentati nei modelli canonici per garantire Trust e conformità.
- Utilizza Federation for Freshness: Consentire ai lakehouse esterni di fornire l'accesso ai dati in tempo reale o su larga scala senza duplicazioni.
- Costo del saldo vs. Prestazioni: Profilare i carichi di lavoro per decidere cosa inserire e cosa federare, riducendo al minimo i costi di archiviazione o query non necessari.
- Applica governance a livelli: Applicare una governance centralizzata per i dati inseriti, sfruttando i controlli di sicurezza dei sistemi federati (ad esempio, RLS, mascheramento).
- Quando si progettano opportunità ibride in corso di realizzazione, assicurarsi dell'inserimento incrementale per le serie di dati storiche e inviare aggregazioni push o filtri alle fonti federate per ottimizzare l'utilizzo di I/O e calcolo.
- Considerazioni sui costi
- Ottimizzare il costo totale rispetto alle prestazioni combinando l'inserimento per la conformità o i dati critici con la federazione quando è necessario un aggiornamento.
- Tenere conto degli I/O e della distribuzione dei calcoli quando si combinano inserimento e federazione. Per ridurre i costi di calcolo nei sistemi di origine di query ripetute, utilizzare il caching (Query accelerata) per le serie di dati federate di lettura elevata e accesso frequente.
Di seguito sono riportati alcuni archetipi comuni che illustrano come applicare questa logica.
- L'archetipo "Un'unica fonte di verità": Centralizzare e gestire
- Scenario: È necessario creare profili Customer 360 unificati conformi per l'intera azienda globale. I dati provengono da una dozzina di sistemi diversi, devono rispettare rigidi regolamenti GDPR e CCPA e fungeranno da fonte affidabile per tutte le interazioni di marketing e assistenza.
- Schema consigliato: Inserimento dati. La priorità è governance, Trust e controllo. L'inserimento dei dati in Data 360 è l'unico modo per creare un profilo canonico completamente controllabile e isolato dai sistemi di origine.
- Archetipo di "Approfondimenti in tempo reale": Analisi senza spostamento
- Scenario: Il team di data science deve eseguire query esplorative su una tabella di transazioni massiccia e in continuo aggiornamento in Snowflake. Allo stesso tempo, il team direttivo desidera un cruscotto digitale di BI live basato sugli stessi dati. Lo spostamento giornaliero di petabyte di dati è troppo lento e costoso.
- Schema consigliato: Federazione copia zero. La priorità sono velocità, agilità ed efficienza economica su larga scala. Copia zero consente di sfruttare l'immensa potenza del data warehouse esistente per eseguire query in tempo reale senza sovraccarico e latenza di duplicazione dei dati.
- Archetipo di "Intelligenza ibrida": Governare il core, federare l'edge
- Scenario: Si desidera arricchire i profili cliente gestiti e inseriti con segnali comportamentali in tempo reale (ad esempio i clic sul sito Web) provenienti da un data lake. È necessaria la stabilità del profilo centrale ma l'immediatezza dei dati live per favorire la personalizzazione immediata.
- Schema consigliato: Un approccio ibrido. Utilizzare l'inserimento dati per creare il nucleo stabile e controllato dei dati dei clienti. Quindi, utilizzare Copia zero per federare i dati volatili in tempo reale, unendoli al momento della query per una visualizzazione completa e aggiornata.
La strategia per i dati aziendali non consiste più nella scelta di un unico modello di integrazione, ma nell'architettura di una flessibilità controllata all'interno di un ecosistema di dati interoperabile. La selezione del metodo di integrazione dei dati giusto per ogni sistema di dati di origine in base alle esigenze aziendali spesso porta a un approccio ibrido che combina i punti di forza sia dell'inserimento dei dati che della federazione dei dati.:
- Inserimento di serie di dati governate mission-critical in Salesforce Data 360 per la conformità, la risoluzione dell'identità e i flussi di lavoro operativi.
- Federare i dati tramite Copia zero per analisi live, esplorative e basate sull'intelligenza artificiale senza duplicare l'archiviazione.
Salesforce Data 360 su Hyperforce offre resilienza e scalabilità multi-regione. L'open lakehouse con tabelle Iceberg consente la separazione dei calcoli e l'interoperabilità con piattaforme come Snowflake, Databricks e S3 Iceberg, costituendo la spina dorsale di un ecosistema di dati multi-cloud davvero interoperabile.
Man mano che gli ecosistemi di dati si evolvono, bilanciare costantemente freschezza, costo, prestazioni e conformità per mantenere l'agilità dell'architettura. È possibile rendere la piattaforma a prova di futuro unificando i dati gestiti inseriti con accesso federato. Ciò consente l'intelligenza in tempo reale, l'attivazione dell'intelligenza artificiale e la personalizzazione su scala aziendale in cloud, regioni e domini aziendali.
Le soluzioni valide per tutti non sono adatte alla maggior parte delle aziende. La strategia ottimale mappa lo schema giusto al giusto driver aziendale.
Yugandhar Bora è un architetto di ingegneria del software di Salesforce, specializzato in architettura dei dati all'interno della piattaforma Data & Intelligence Applications. Dirige iniziative del Comitato di revisione dell'architettura aziendale (EARB) incentrate sulla governance dei dati e sui modelli di dati unificati, contribuendo al contempo alle soluzioni di provisioning automatico della piattaforma.
Jan Fernando è Principal Architect presso lo Studio del Chief Architect di Salesforce. È entrato in Salesforce nel 2012, apportando una vasta esperienza nel settore delle startup. Prima di entrare nello Studio del Chief Architect, ha trascorso oltre un decennio nell'organizzazione Platform, dove ha guidato diverse trasformazioni tecnologiche chiave.