Note: "Topics" have been renamed to "subagents" throughout this article, per our latest product naming conventions.
You might build an agent that performs well in a test environment, only to have it follow entirely different routes when processing the same workflow twice. This fundamental limitation shows how the previous Agentforce model handled execution: every decision, from intent interpretation to action selection, was made in real time by the LLM, with no guaranteed path through the workflow.
LLMs can produce inconsistent outcomes in response to identical inputs. Subtle variations in context, system prompts, or token generation are enough to send an agent down a different route. For many interactions, this variability is acceptable. However, for multi-stage workflows that require auditability, reproducibility, and traceability, it isn't. A loan approval, an inventory transfer, or a patient triage process can't depend on an agent that reasons its way through the steps differently each time.
The new Agentforce Builder and Agent Script address this issue by separating deterministic execution from LLM reasoning. Agentforce's hybrid model ensures that the agent follows a precisely defined structure for every workflow execution, while still using LLM reasoning where judgment, natural language understanding, or contextual interpretation is genuinely needed.
In the previous version of Agentforce, an agent operated as a simple reactive loop. Every decision, from interpreting intent to selecting the next action, was made in real time by the LLM based solely on the user's most recent input. There was no guaranteed execution path, no persistent state, and no mechanism to enforce a sequence of steps.
Execution paths couldn't be guaranteed
Because every decision depended on the LLM's real-time reasoning, minor variations in input, system prompt, or model version produced different action selections on identical requests. This made the previous model difficult to test rigorously: a workflow that passed in staging could behave differently in production, and no reliable way existed to reproduce a specific execution path for debugging or audit purposes.
Every interaction paid the full LLM cost
Even simple conversational scenarios required a minimum of three LLM cycles: subagent selection, action selection, and final response generation. Multi-step tasks extended to five or more cycles. For architects designing high-volume or latency-sensitive workflows, this wasn't just a performance concern. It meant you couldn't short-circuit the reasoning loop for steps that didn't require judgment, because the architecture had no mechanism to distinguish between the two.
Non-deterministic execution created an audit gap
In regulated industries, auditability means being able to demonstrate that a specific process was followed in a specific way for a specific transaction. A purely non-deterministic model can't provide that guarantee. If the execution path varies between runs, the audit trail varies too, and "the agent decided" is not a defensible answer in a compliance review.
State didn't survive the conversation
Relying on single-turn processing meant the agent had no persistent memory of earlier steps. If the conversation deviated even slightly, the agent could drop previously captured context and force the user to restart. For multi-step transactional workflows, this created a reliability ceiling: the more steps in the process, the higher the probability of context loss before completion.
Completed steps weren't remembered
Without state management, agents had no record of which mandatory steps a user had already completed. This produced unpredictable looping, where an agent would return to a step the user had already finished. Beyond the user experience impact, this created a deeper architectural problem: designing a reliable sequential workflow was impossible because the agent couldn't enforce sequence.
The new Agentforce, GA since February 2026, shifts from purely probabilistic LLM reasoning to a hybrid model. Rather than routing every decision through the LLM, it separates deterministic execution from LLM reasoning and lets each handle only what it's suited for. To support this, Agentforce introduced two authoring tools: Agent Script for code-based development, and Agentforce Studio, a no-code building environment.
Agentforce Builder
Agentforce Builder is the recommended environment for developing new agents. It's hosted within Agentforce Studio and replaces the legacy Setup experience, which remains available but is no longer the primary authoring path. In Builder, you work either in a visual Canvas view or directly in Script view, editing the Agent Script that defines your agent's behavior.
Agent Script
Agent Script is a declarative, domain-specific language (DSL) that defines everything about how an agent behaves: its configuration, business logic, and prompting. It's structured as key-value pairs that can span multiple lines or include nested sub-properties, and it's designed to be human-readable without requiring knowledge of the underlying graph architecture.
Agent Script lets you express two fundamentally different types of instructions in the same agent: deterministic logic instructions and prompt instructions. Deterministic logic instructions define conditions and action sequences that execute as code with no LLM involvement. Prompt instructions define natural language guidance that the LLM interprets at runtime. The boundary between the two is explicit and deliberate, and understanding where to place that boundary is one of the core design decisions you'll make when building with the new Agentforce.
Deterministic logic in practice
When instructions are deterministic, the agent follows a defined execution path regardless of how the user phrases their input. The example below shows a subagent that loads a customer intelligence dashboard. It checks for a customer ID, fetches profile data, order history, and support tickets, then calculates customer lifetime value and churn risk. None of these steps require LLM reasoning.
This logic calls actions in a fixed sequence every time certain conditions are met.
Prompt instructions and deliberate LLM handoff
Where deterministic logic handles conditions and sequences that can be expressed as code, prompt instructions handle everything that requires judgment, interpretation, or natural language generation. When the Atlas Reasoning Engine encounters a node with prompt instructions, it triggers an LLM call. When it doesn't, it executes deterministically.
The example below shows a subagent for product and services. The instructions are a multi-line prompt that tells the LLM how to respond, when to look up information, and how to handle ambiguity. This is the right pattern when the range of possible user inputs is too broad to anticipate with conditional logic, or when the quality of the response depends on the LLM's ability to interpret context and generate a natural reply.
The prompt instructions on a node trigger the LLM call. That's not incidental—it's the mechanism by which Agent Script makes the LLM boundary explicit and enforceable, rather than leaving it to runtime inference.
This subagent shows deterministic logic and LLM handoff in action.
The three-stage execution pipeline
Agentforce Builder and Agent Script are the authoring layer, but Agent Graph and the Atlas Reasoning Engine actually run your agent. By design, neither of these components is directly accessible to you. Separating authoring and execution allows the platform to enforce deterministic behavior independently of how the script was written.
The pipeline moves through three stages.
- Authoring is where you work. Agent Script is human-readable and editable in either Canvas view or Script view in Agentforce Builder. This is the only layer you interact with directly.
- Compilation is where the Salesforce compiler transforms your Agent Script into an Agent Graph, a serialized execution plan optimized for machine execution rather than human readability. You don't debug at this layer. Compilation produces a representation the runtime can traverse efficiently.
- Runtime execution is where the Atlas Reasoning Engine takes over. It reads the Agent Graph, traverses it based on current session state, and decides at each node whether to execute deterministically or invoke the LLM. The engine explicitly enforces guard clauses and conditional routing here, rather than inferring.
Agent Graph
Agent Graph is the intermediate representation that sits between your human-readable script and actual runtime execution. Its structure is optimized for the state machine that consumes it, not for the architect who authored the script. Understanding that it exists, and what it represents, matters because it's the artifact the Reasoning Engine uses to enforce the execution plan your script defines.
Atlas Reasoning Engine
The Atlas Reasoning Engine is a state machine executor. On each turn, it traverses the Agent Graph based on session state, executes deterministic nodes as code, and triggers LLM calls only where prompt instructions are present. It also enforces guard clauses and handles conditional routing. The Reasoning Engine is where the hybrid reasoning model is actually implemented; the script defines the boundary, and the engine respects it.
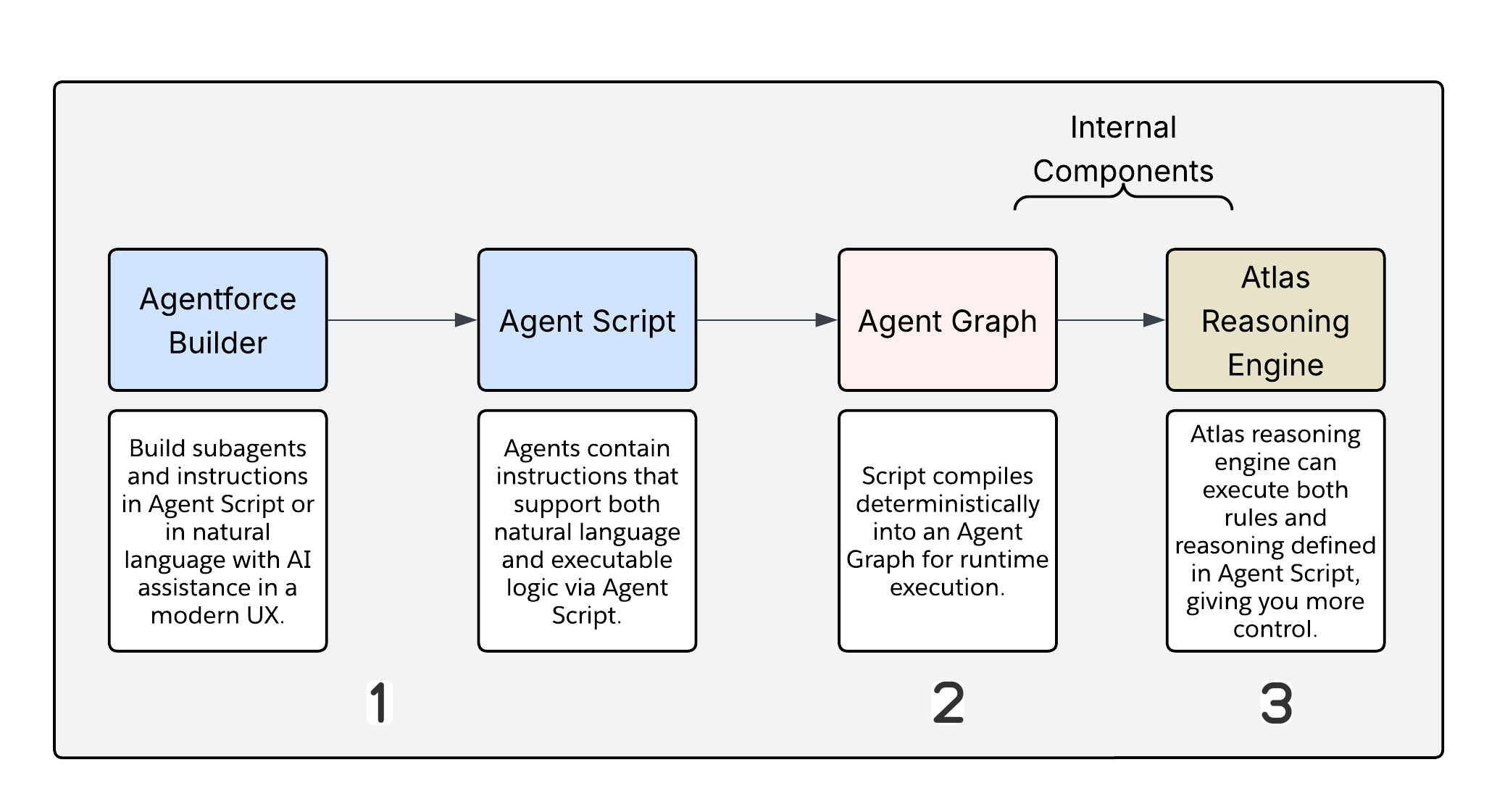
Agent Graph isn't an LLM wrapper. It's a hybrid reasoning engine that separates deterministic execution from probabilistic reasoning. The governing rule is straightforward: if you can express a decision as code, it should be written as logic. If the decision requires judgment, interpretation, or natural language generation, the LLM should handle it. This design decision is the most important architectural choice in the new Agentforce model. Where the LLM boundary falls directly affects your solution's cost, latency, auditability, and reliability.
The Atlas Reasoning Engine evaluates every incoming user turn and routes it down one of two paths.
Path A: deterministic execution
This path has no LLM exposure. It behaves like compiled code at runtime. The Reasoning Engine classifies the user's intent and determines that a logic instruction matches, bypassing the LLM entirely. The compiled Agent Script runs top to bottom, with if-else rules executing unconditionally on every turn. Flow, Apex, or API actions are called with deterministic parameters, with no prompt assembly or model call involved. The result passes back through the trust layer with full audit logging.
Path B: LLM reasoning
The Reasoning Engine takes this path when it can't resolve intent using logic instructions alone. It traverses the Agent Graph and evaluates each node. Nodes with prompt instructions trigger an LLM call. Nodes without them execute deterministically. The presence of a prompt instruction is the trigger, and it's explicit in the script rather than inferred at runtime.
What triggers an LLM call
There are eight points in the execution lifecycle where the LLM is invoked. Subagent classification, or deciding which subagent matches the user's request, is one, though a short-circuit path can bypass the full LLM call when classification is unambiguous. Agent reasoning, where the agent decides what action to take next, always goes through the LLM. So does response generation, where the final reply is assembled from a hydrated prompt.
The remaining triggers are more operational: groundedness validation confirms the output is grounded in retrieved data; action simulation emulates responses in the Preview and Simulate environment instead of executing live; structured output generation handles cases where the response needs to conform to a defined schema; and localization and progress indicator generation handle formatting and transient messaging where no pre-authored default exists.
What stays deterministic
Graph traversal and state transitions never involve the LLM. The before_reasoning and after_reasoning lifecycle blocks execute deterministically as long as they contain only action nodes with no prompt instructions. Math, data fetching, validation, and conditional logic all belong in code. Any action executing Flow, Apex, or a REST API directly stays on the deterministic path. Any node without prompt instructions executes without an LLM call.
Being explicit about this boundary with your team matters. Every unnecessary LLM call adds latency, cost, and variability. Architects should push deterministic logic by default, reserving the LLM for cases where the task actually requires its reasoning capability.
Design guidance: push logic to code by default
Use Agent Script logic instructions when writing prompt instructions that could be expressed as a condition, a variable assignment, or an action filter. Every unnecessary LLM call adds latency, cost, and variability.
The default position should be deterministic. Isolate every agent behavior that can be codified as a rule and move it into Agent Script. The remaining tasks that require natural language synthesis, contextual judgment, or complex interpretation belong in prompt-bearing nodes. That's not a limitation; it's the boundary working as intended. The LLM handles what it's best suited for, and everything else runs as code.
The primary unit of execution in Agent Script isn't the user turn. It's the parse: a single complete cycle through a subagent's three lifecycle blocks. The Atlas Reasoning Engine initiates a parse each time a subagent needs to process something, which happens in three situations: on first entry into the subagent, after every tool call when an action completes and returns a result, and on every new user turn within the same subagent.
Understanding the parse boundary matters because it determines how many times each block runs, and therefore where you can and can't rely on a given piece of logic executing exactly once.
Every subagent defines three execution zones:
| Block | When it runs | LLM involvement |
|---|---|---|
before_reasoning | At the start of every parse, before the LLM sees anything | None |
reasoning | During deterministic resolution, prior to any LLM calls | Mixed |
after_reasoning | After reasoning completes and the LLM has responded | None (with a critical caveat) |
Both before_reasoning and after_reasoning are fully deterministic. They execute actions, set variables, and apply conditional logic without involving the LLM. This makes them the reliable, low-cost blocks in the script.
When to use before_reasoning
before_reasoning runs at the start of every parse without exception. It executes on first entry into the subagent and again after every tool call or new user turn within that subagent. A run @actions.X in before_reasoning is code. Unlike an instruction inside a prompt block, which the LLM may or may not follow, before_reasoning executes unconditionally.
Use this block for session initialization: fetching context records, setting session variables from Apex or Flow. It's also where authentication and entitlement checks belong, because you want those verified before the LLM sees any tools. Context hydration fits here too: calling a data retrieval action so the LLM receives pre-populated variables rather than needing to request them. Any counter or audit variable that must be incremented on every parse should be set here, because the set directive in before_reasoning is guaranteed in a way that a pipe instruction is not.
What doesn't belong here is logic that should only run once per session, since before_reasoning runs on every parse, not just on the first entry. Anything that depends on user input from the current turn also doesn't belong here, because that input hasn't been processed yet. And transitions should never be in before_reasoning: a transition to instruction here will fire unconditionally on every parse and create loops.
If you need once-per-session initialization, guard it explicitly:
One user turn can trigger multiple parses: once on entry, then again after each tool call. That functionality has three practical consequences: initialization actions in before_reasoning will run more than once per user turn in multi-action flows, counter variables incremented here will reflect parse count, not turn count, and actions with side effects, external API calls or record writes, should not live in before_reasoning unless re-execution on every parse is explicitly acceptable.
before_reasoning is not a constructor. It's a pre-flight check that runs with every parse. Design it accordingly.
When to use after_reasoning
after_reasoning runs once the reasoning loop is finished, after the LLM has responded and action outputs have been captured. This is where post-action deterministic checks belong: evaluating action outputs and branching based on results. Deterministic transitions, or moving to the next subagent based on variable state rather than LLM judgment, sit here. So does variable cleanup before the next turn, and orchestration sequencing when you need to chain subagents in a predictable order without an LLM routing decision.
Treat after_reasoning as the guardrail layer. It's where you enforce business rules and state management after the LLM has done its work, ensuring that critical process flows remain predictable regardless of what the LLM generated.
Use is_displayable: True wisely
Every architect designing orchestration flows needs to understand this platform behavior. When is_displayable: True is set on an action, the platform exits the reasoning loop as soon as the LLM decides to surface that output. That exit happens immediately, which means after_reasoning never executes.
This is a known platform behavior, but it has a direct consequence for orchestration: any logic you've placed in after_reasoning will be skipped when a displayable action is part of the flow.
The answer is straightforward. Move logic that must execute reliably into the before_reasoning block of the subsequent subagent rather than the after_reasoning block of the current one.
Design guidance: where to place initialization logic
Deciding where to place logic is consequential when designing a subagent. This framework covers the most common scenarios:
| Scenario | Where to put it |
|---|---|
| Must run before the LLM sees any context | before_reasoning |
| Runs every parse, including re-entry on new user turns | before_reasoning |
| Depends on action output from this turn | Conditional if block in reasoning |
| Requires deterministic subagent transition based on outcome | after_reasoning (but see is_displayable caveat below) |
Requires orchestration logic when downstream action uses is_displayable: True | before_reasoning of the next subagent |
| Uses logic that requires judgment or user context | reasoning with prompt instructions |
The underlying principle is straightforward. When you write a prompt instruction telling the LLM to "always run" an action, that's a suggestion. The LLM may or may not follow it depending on context. When you place a run directive in before_reasoning, that's code. It executes on every parse without exception.
Conditional action availability is the mechanism by which Agent Script exposes or hides actions from the LLM based on runtime variable state. When the available when condition evaluates to false, the action is removed from the tool list presented to the LLM entirely. Any false value, including None, False, 0, or an empty string, suppresses the action.
This is not a prompt instruction telling the LLM "don't call this yet," it's a hard platform-level gate. The LLM can't call an action it can't access.
In this example, execute_transfer is invisible to the LLM until validation_passed evaluates to true. The gate is enforced by the platform, not by instruction.
Design guidance: never let the LLM set the gate variable
Give every variable in an available when clause a deterministic code path that sets the variable before the associated action is executed. Use before_reasoning or a deterministic run and set block in reasoning to keep the variable in a known state. If you rely on the LLM to set the gate variable, you've reintroduced the variability the gate was designed to prevent. Depending on the conversation, the LLM may or may not set it, which means the gate may or may not open.
The action loop problem
An action loop occurs when the LLM calls the same action repeatedly without ever reaching a terminal state. It happens when two conditions are true simultaneously: the available when condition remains satisfied after the action runs, and the reasoning instructions don't explicitly tell the LLM to stop calling it.
The platform doesn't automatically suppress an action after it's been called. If the gate stays open and the reasoning instructions are ambiguous, the LLM calls the same action on every parse indefinitely.
Consider available when @variables.interest != "" as an example. If the action executes but the interest variable is not empty, the gate remains open on the next parse. The LLM sees the action as available, has no instruction telling it to stop, and calls it again.
There are two reliable ways to break the loop. The first is to set the gate variable to a closed state as part of the action's post-execution logic, so that available when evaluates to false on the next parse. The second is to use a separate has_run boolean that closes the gate after first execution. Both approaches give the gate a deterministic closed state, which is the condition the platform needs to suppress the action.
A bank transfer is a useful lens for understanding how these patterns work together in practice. The workflow looks simple from the outside: move money from one account to another. The implementation requires multiple complex steps. Before the transfer executes, the agent must collect account details, validate the amount, check transfer limits, confirm the available balance, and only then expose the transfer action. Each step depends on the previous steps. None of them should be left to LLM judgment.
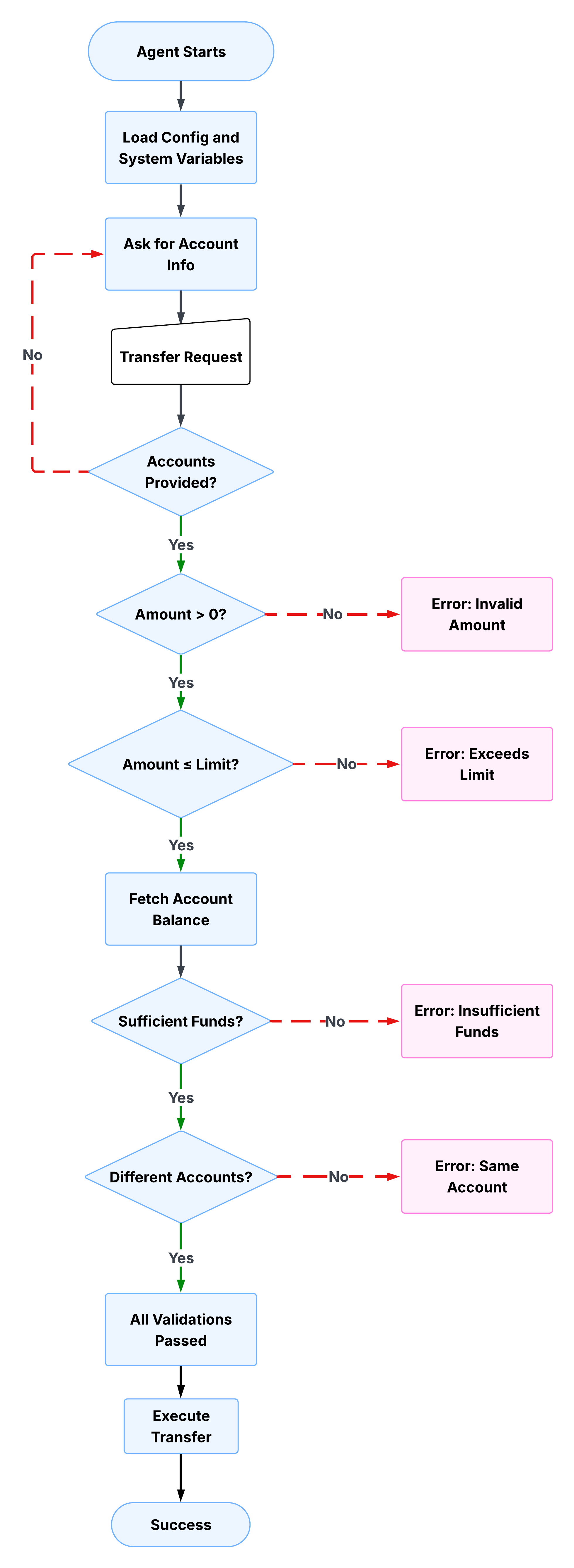
Collect and validate inputs
The first subagent collects the source account, destination account, and transfer amount from the user. It won't proceed until all three are present and valid. The Agent Script checks each field in sequence: if the source account is missing, it asks. If the destination is missing, it asks. If the amount is zero or negative, it asks. The validation_passed variable is only set to true after all checks are clear.
The script below shows this in practice. Notice that validation_passed is explicitly set to false at each failure point, and the LLM is instructed not to proceed. The deterministic checks run unconditionally, while the prompt instructions handle the user-facing response.
Enforce business rules
After the agent validates inputs, it checks whether the transfer amount exceeds the configured transfer limit. This is where business rules become code rather than instructions. The limit isn't something the LLM reasons about; it's a hard threshold defined in the script and checked deterministically on every parse.
If the amount exceeds the limit, validation_passed is set back to false and the LLM presents the user with three options: transfer the maximum allowed amount, split into multiple transfers, or contact support for higher limits. The agent can't proceed until the user resolves the exception. Notice how the prompt instruction here is doing exactly what LLM reasoning is suited for: presenting options conversationally and handling the user's response. The business rule itself is deterministic, but the conversation around it is not.
The script below shows how the limit check works. The deterministic condition evaluates the transfer amount against the limit variable, sets validation_passed to false if the threshold is breached, and delegates to a prompt instruction to handle the user-facing response.
Apply guard clauses
With amount and limit checks complete, the agent fetches the source account balance and confirms that sufficient funds are available. Guard clauses prevent the agent from attempting operations when preconditions aren't met. Unlike a prompt instruction that tells the LLM to check the balance, a guard clause in Agent Script makes the check unconditional. The LLM doesn't decide whether to run it.
If the balance is insufficient, the agent calculates the shortfall and presents the user with a concrete alternative. validation_passed is set to false until this check passes, which means the transfer action remains gated.
The script below shows a deterministic action call that fetches the balance, followed by a conditional check that evaluates it. The fetch only runs if the balance hasn't already been retrieved, avoiding redundant API calls on subsequent parses.
Surface errors clearly
Guard clauses set the state. Error messages communicate it. When validation_passed is false, the agent needs to give the user enough information to resolve the problem without restarting. Vague error messages create friction; structured ones close the loop faster.
The script below shows the insufficient funds error message in practice. It doesn't just tell the user the transfer failed. It shows the available balance, the requested amount, the calculated shortfall, and offers a concrete next step, all assembled from session variables rather than generated by the LLM.
The shortfall calculation happens in the script, not in the LLM. The suggested alternative, transferring the available balance, is deterministically derived from session state. The LLM's role here is purely presentational: it delivers a message that the script has already structured.
Gate the transfer action
Every validation check in the preceding steps sets or clears the same variable: validation_passed. That variable is now doing its most important job. The execute_transfer action is conditionally available, meaning it only appears in the LLM's tool list when validation_passed is true. Until every preceding check has passed and set that variable, the action doesn't exist from the LLM's perspective.
This is the pattern from the earlier gate section applied to a production workflow. The transfer action isn't hidden by a prompt instruction. It's hidden by the platform. No amount of conversational pressure or ambiguous phrasing can cause the LLM to invoke it before the preconditions are met.
The script below shows how the gate is configured. The available when clause references validation_passed directly, and the action parameters are bound to the session variables collected and validated in the preceding steps.
All three parameters, from_account, to_account, and amount, are passed deterministically from session variables. By the time this action becomes available, every value has been validated. The LLM isn't assembling the parameters from conversation context; it's reading them from the state.
Track state throughout the workflow
The patterns in the preceding sections only work because session state persists across the entire workflow. Account numbers captured in the first step are available in the fourth. Validation results set in one check gate actions in another. The conversation can deviate, the user can ask follow-up questions, and the agent will still know exactly where it is in the process.
The variables block below shows the full session state for this workflow. Each variable has a defined type, a default value, and a description. Two variables handle most of the orchestration work: validation_passed controls action availability at every gate, and validation_information carries human-readable context about why a check failed, which the LLM can surface to the user without needing to reason about the underlying state.
Every variable starts in a known default state. Strings default to empty, numbers to zero, and the validation_passed boolean to false. This means the gate is closed by default. The workflow has to actively earn the right to proceed at each step, rather than starting with the gate open and relying on checks to close it.
The bank transfer example illustrates where deterministic logic is the right tool, but it isn't always the best choice. Understanding the boundary is as important as understanding the patterns.
Deterministic logic is the right choice when the workflow requires a guaranteed execution sequence, when errors have significant consequences, when the process needs to produce a reproducible audit trail, or when business rules are well-defined enough to be expressed as conditions and thresholds. Finance, healthcare, and insurance workflows generally fall into this category.
Pure LLM reasoning without strict deterministic constraints makes more sense when the value of the interaction lies in flexibility rather than precision. Open-ended customer support, early-stage products where business processes are still evolving, and low-stakes informational queries are all cases where the variability of LLM reasoning is a feature, not a problem.
In practice, most production agents need both. The decision of where the boundary falls isn't a binary choice between deterministic and probabilistic; it's a design decision you make at the node level for every part of your agent's workflow.
| Use deterministic logic for | Use LLM reasoning for |
|---|---|
| Input validation and sanitization | Natural language understanding and intent detection |
| Business rule enforcement | Generating conversational, empathetic responses |
| Sequential process orchestration | Handling ambiguous or unexpected inputs |
| State management and context preservation | Providing explanations and clarifications |
| Guard clauses preventing invalid operations | Adapting tone and messaging to user context |
The boundary is the design decision
The bank transfer example is an illustration of a design philosophy: that the boundary between deterministic execution and LLM reasoning is the most consequential architectural decision you make when building a production agent.
Place a boundary that's too rigid and you'll end up with an agent that's rigid, expensive to maintain, and incapable of handling the natural variation of real conversations. Getting the boundary wrong in the other direction creates an agent that is flexible but unpredictable, performs well in testing but behaves differently in production, and can't produce a reliable audit trail or be trusted with a high-stakes transaction.
The new Agentforce model gives you the tools to place that boundary deliberately. Agent Script lets you express deterministic logic and prompt instructions in the same file, with an explicit syntax to make the boundary visible. The Atlas Reasoning Engine enforces logic and prompts at runtime. The before_reasoning and after_reasoning blocks give you guaranteed execution zones on either side of the LLM call. Conditional action availability ensures the LLM can only act when preconditions are met.
None of these features are in isolation. They work together to create a coherent architecture for building agents that enterprises can trust with mission-critical workflows. The hybrid reasoning model recognizes that determinism and flexibility both have roles in your architecture; it is the architect's job to decide precisely where each one applies.
Agentforce's Agent Graph: Toward Guided Determinism with Hybrid Reasoning
Gulal Kumar is a Software Engineering Architect at Salesforce with over 20 years of experience. His expertise spans AI, integration, APIs, and enterprise architecture, with a focus on driving business transformation through secure, resilient, and innovative AI solutions. Connect with him on LinkedIn.
Miriam McCabe is Senior Director and leader of the Architect Evangelism team. Her work focuses on enabling the global Salesforce architect community to lead in the agentic era through deeply technical content, live programming, and community engagement. Follow her on LinkedIn.