Datalustat ovat kehittyneet yli kolmen vuosikymmenen ajan. Aluksi toimialaa hallitsivat paikalliset, keskitetyt ja rakenteelliset (enimmäkseen suhteelliset) toiminta- ja OLTP-tietokannat. Tämä laajeni sisältämään datan varastoihin OLAP/Big Data -alustat, joita käytettiin ensisijaisesti analyyttiseen käsittelyyn ja jotka pysyivät suhteellisina ja keskitetyinä. Pilvitallennustila on vaikuttanut hajautettuihin arkkitehtuurityyppeihin, kuten datan varastoihin, järvialueisiin ja eriteltyyn tallennustilaan. Toiminta- ja analyysialustat pysyivät kuitenkin erillään toisistaan. Nykyään pilvipalvelut ja tekoälyn vallankumous muuttavat datalustan arkkitehtuuria perusteellisesti.
Yritykset investoivat jo kehittyneisiin Big Data -alustoihin, kuten Snowflake, Databricks, BigQuery ja Redshift. Nämä alustat toimivat kuitenkin datasiloina. Asiakkaat eivät luo liiketoiminta-arvoa datastaan, koska dataa ei voi käsitellä suoraan liiketoimintakulkujen ja sovellusten sisällä. Näillä ratkaisuilla ei ole generoivaa agenttien tekoälyä ja ne eivät voi tarjota datan käyttöoikeuksia reaaliajassa, joten ne eivät voi tarjota tekoälyyn perustuvaa personalisointia asiakkaan osallistumisen aikana tai muita alan johtavia ominaisuuksia.
Datalustojen tulevaisuutta kuvaavat yhtenäistetty, joustava, helppokäyttöinen ja avoin datan infrastruktuuri. Tämä uusi arkkitehtuuri perustuu nykyaikaisiin laskenta- ja tallennustrendeihin — GPU:t, big memory, NVMe SSD:t ja pilvitallennustila — integroituna pilvitallennuksen ja tekoälyn kanssa. He voivat tarjota reaaliaikaisia havaintoja, edistää itsenäistä päätöksentekoa ja edistää reaaliaikaisia sovelluksia. Tämä sisältää agenteellisen tekoälyn, ennakoivan tekoälyn, analyysien, reaaliaikaisten korkean skaalan OLTP-tietokantojen, datan järvien ja järvien kasvun. Nämä modernit datalustat on suunniteltu yksinkertaisuutta, skaalattavuutta, joustavuutta, suorituskykyä, tietoturvaa, saatavuutta ja kustannustehokkuutta varten.
Seuraavat datatrendit edistävät seuraavan sukupolven datalustan arkkitehtuuria.
- Tekoäly, koneoppiminen ja Analytics ytimessä: Agenttien tekoälyn nousu muuttaa datalustan kehittämistä, käyttöönottoa ja käyttöä/käyttöoikeuksia merkittävästi. Agenttien tekoäly ymmärtää keskustelun/kyselyiden tarkoituksen, suunnittelee, luo työnkulkuja ja automatisoi päätöksenteon. Agenttien (lyhyen ja pitkän aikavälin) muisti on rakennettu keskusteluhistoriasta, jota käytetään agenttien suunnittelun ja päätösten personalisointiin, reaaliaikaiseen keskustelumallintaan ja datalustojen kriittiseen personalisoinnin tukeen. Agentit auttavat automatisoimaan operatiivisia ”kykyjä”, kuten datan hallintaa (eli tietoturvaa, vaatimustenmukaisuutta, Trustia), suorituskykyä (eli automaattista skaalaa samanaikaisuutta, läpimenoa ja viiveä varten), häiriönsiirtoa ja saatavuutta sekä havaittavuutta ja ylläpitoa. AI-pohjaiset analyysit, ennusteet, luonnollisen kielen käsittely (NLP) analyyseille Q/A ja jäsentämättömän datan (kuten PDF-tiedostojen, kuvien, äänen ja videon) analyysit ovat vakiomuotoisia, jolloin yritykset voivat saada syvällisempiä tietoja useista eri tietolähteistä.
- Datan hajauttaminen, mutta yhtenäistetty tietojen käyttöoikeus: Agentit tarvitsevat yritystietoja saadakseen havaintoja ja tehdäkseen päätöksiä sekä automatisoidakseen liiketoimintatoimintoja. Data on luonnostaan hajautettu yrityksissä, eri sovelluksissa ja datalustoilla. Silojen yhdistäminen yrityksen eri liiketoimintayksiköille ja yrityksen ulkopuolisille kumppaneille ei kuitenkaan ole helppoa. Datan yhtenäistämiseen liittyy datan jakaminen, joko syöttämällä tietoja lähteistä tai yhdistämällä tietoja tietolähteisiin; datan valmistelusta, harmonisoinnista ja mallinnuksesta saatu raakadata analyyttistä ja tekoälymallien käsittelyä varten; datan tallentaminen ja hallinta mittakaavassa tehokkaan käytön varmistamiseksi alhaisen CTS:n avulla; ja datan käyttö eri kysely- ja analyysimekanismeilla ja -työkaluilla, jotka on integroitu syvällisesti perustana olevaan tallennus- ja datan käyttöympäristöön
- pilvipohjaiset Open Lakehouses: Pilvipohjaiset Big Data (OLAP) -alustat ovat lähestymässä avoimien tiedostomuotojen (Parquet) ja taulukkomuotojen (Iceberg) käyttöönottoa, mikä mahdollistaa datan yhdistämisen (data sisään) ja jakamisen (data ulos).
- Rakenteeton datan käsittely: Generoivan tekoälyn syntymisen, kehityksen ja käyttöönoton myötä yritykset alkavat saada arvokkaita havaintoja ja liiketoiminta-arvoa datasta, joka muodostaa suuria määriä tekstiasiakirjoja, audiolokit, videoiden nauhoitteita ja muita välineitä. Rakenteeton datan käsittely, mukaan lukien pilkkominen, vektorointi, semanttinen haku ja Knowledge, mahdollistaa nämä havainnot. Tekniikoista, kuten RAG (palautuksen augmentoitu generointi) ja CAG (välimuistin augmentoitu generointi), on tulossa pääasiallisia edistäjiä nopealle ja agenteelliselle haulle koko datan corpussiin.
- Knowledge-hallinta: Knowledge ylittää pelkän raakasisällön (asiakirjat, artikkelit, videot). Se edustaa kyseisen sisällön aggregointia muodostamalla merkitystä, keräämällä metadataa ja asettamalla sen asiayhteyteen kehittääkseen yhteisen ymmärryksen sisällöstä organisaatiossa tai yrityksessä. Knowledge on yleensä rakenteellinen. Knowledge käsittää sisällön hallinnan, Knowledge, esityksen mallien, kuten kaavioiden, kautta ja navigoinnin.
- Muotoillun datan käyttöoikeus: Muotoillun datan käyttöoikeus tarkoittaa, että tietoja, analyysejä ja tekoälytyökaluja täytyy voida käyttää useille henkilöille, mukaan lukien loppukäyttäjät, yrityskäyttäjät, pääkäyttäjät ja analyytikot. Helppokäyttöisyys saavutetaan mekanismeilla, kuten yhdistetty kysely (suhteellinen, avainsana ja semanttinen kysely), luonnollisen kielen SQL-kysely (NL2SQL), reaaliaikainen pääsy jne.
- Reaaliaikainen käsittely: Agenttisovellukset tekevät reaaliaikaisia päätöksiä nykyisen tilan ja uusien tapahtumien, personalisoivien vastausten ja toimintojen perusteella, mikä vaatii reaaliaikaisten tietojen käyttämisen, käsittelyn ja toiminnan. Reaaliaikainen käsittely vaatii ajankohtaisia tietoja (tietojen viive) ja interaktiivisia käyttöoikeuksia (käyttöoikeuksien viive). Tällaiset datan ja käyttöoikeuksien viiveet vaativat, että niiden perustana oleva datalusta tukee päivitettyjä datan käyttöoikeuksia operaatio- ja analyysimyymälöistä, matalan viiveen käyttöoikeuksia (pistehakuja ja kyselyitä), suurta datan skaalaa ja korkeaa läpimenoa.
- Datan tietoturva, hallinta ja sijainti: Agenteellinen ja selkokielinen tekoäly yksinkertaistaa sovelluksen käyttöliittymää, jolloin kuka tahansa, kuluttajista työntekijöihin ja muihin tekoälyagentteihin, voi vuorovaikuttaa sovellusten kanssa selkokielisesti käyttämällä puhuttua tai kirjoitettua luonnollista kieltä. Arvokkaat asiakas- ja henkilötiedot, jotka täytyy tallentaa ja mallinntaa Agenttic-sovelluksille, täytyy suojata ja hallita hyvin määritettyjen käyttöoikeuksien ja jakokäytäntöjen avulla. Monien asiakkaiden on yhä enemmän noudatettava säännöksiä, jotka vaativat tietojen oleskelua omassa maassaan tai alueellaan, varsinkin kun he ovat hallituksessa tai työskentelevät hallituksen kanssa.
Salesforce Data 360 on suunniteltu vastaamaan näihin datatrendeihin tulevaisuudessa. Data 360 on pilvipohjainen, metadataan perustuva datalusta, joka yhdistää eristettyä dataa koko organisaatiossa, jolloin organisaatiot voivat tallentaa, mallinntaa ja käsitellä dataansa ottaakseen käyttöön analyysejä, tekoälyä, koneoppimista ja agenttisovelluksia.
Tämä asiakirja on tärkeä opas yritysarkkitehdeille ja johtajille. Se kuvaa Data 360:n arkkitehtuurin, ominaisuudet, suunnitteluperiaatteet ja käyttötarkoitukset. Se esittelee Data 360 -arkkitehtuurin perusteet alustavasti, minkä jälkeen se syventyy sen tärkeimpiin eroavaisuuksiin, kuten yhteentoimivuuteen olemassa olevien datapalustojen kanssa, mukaan lukien usean organisaation strategia, tietoturva, hallinta ja yksityisyys, reaaliaikainen aktivointi ja datan puhdistamat tilat.
Salesforce Data 360 perustuu ydinperiaatteisiin, jotka tekevät yritystiedoista toimivia, luotettavia ja reaaliaikaisia.
- Avoimuus ja yhteensopivuus: Rakennettu usean pilven ekosysteemille. Yhdistetään datalustoihin, kuten Snowflake, Databricks, BigQuery ja Redshift, ilman identtisiä tietueita, mikä laajentaa Customer 360 -sovellusta säilyttämällä nykyiset sijoitukset.
- Tallennustilan ja laskennan erotus: Skaalaa tallennustilaa ja käsittelyä (erä, striimaus ja interaktiivinen) itsenäisesti. Tarjoaa joustavuutta ja tehokkuutta raskaille ja tehokkaille työkuormille.
- Monimallien tallennus ja käsittely: Tukee rakenteellisia ja erilaisia jäsentämättömiä datatyyppejä, kuten tekstiä, kuvan ääniä ja videota. Tarjoaa tehokkaan tallennustilan, reaaliaikaisen ja eräkäsittelyn, laajennettavan indeksoinnin, yhtenäistetyn haun, kyselyiden ja analyysien.
- Metadataan perustuva suunnittelu: Sovellukset määritetään metadatalla eikä koodilla. Metadataa käsitellään ensimmäisen luokan omaisuutena, mikä mahdollistaa yhtenäisen hallinnan, joustavuuden ja syvällisen integraation Salesforce-alustaan.
- Reaaliaikainen hybridikäsittely: Tukee vähäisen viiveen kyselyitä ja pikaista päätöksentekoa sekä eräkäsittelyä ja analyyttisiä työkuormia.
- Älykäs ja aktiivinen data: Tuottaa, analysoi ja siirtää havaintoja jatkuvasti suoraan liiketoimintatyönkulkuihin. Edistää ilman koodia, vähäistä koodia, pro-koodia ja tekoälyyn perustuvaa automatisointia uusimmalla asiayhteydellä.
- Hallinta ja yksityisyys suunnitellusti: Linjaus, käyttöoikeuksien hallinta, residenssi, datan salaus ja vaatimustenmukaisuus ovat sisäänrakennettuja. Trust ja lakisääteinen luottamus vahvistetaan kaikilla tasoilla.
- Ykseltä-monelle-vuokraus: Keskitetty Data 360 -organisaatio toimii yksittäisenä totuuden lähteenä Customer 360:lle, joka tukee saumattomasti Salesforce-asiakkaiden laajalti käyttämää usean organisaation Salesforce-ympäristöä.
Nämä periaatteet varmistavat, että Data 360 tekee datasta avoimen, älykkään ja interaktiivisen reaaliajassa.
Salesforce Data 360 on moderni datalusta, joka perustuu suunnitteluperiaatteisiin, jotka käsittelevät nykyisiä datatrendejä. Sen arkkitehtuurin ominaisuudet varmistavat, että yritystiedot ovat luotettavia, yhtenäistettyjä ja interaktiivisia reaaliajassa sen ohjaavien periaatteiden mukaisesti.
- Cloud-Native Foundation: Suoritetaan Hyperforcessa, joka on otettu käyttöön Hyperscalereissa (kuten AWS) ja jossa on muuttumaton mikropalveluihin perustuva infrastruktuuri. Tarjoaa joustavan skaalautumisen, nollan Trust-suojauksen, jatkuvan toimituksen ja globaalin vaatimustenmukaisuuden.
- Metadataan perustuva Salesforce (Core): Metadata on suunniteltu, mallinnettu ja tallennettu Salesforce-metadatana, joka sallii kaikkien Salesforce-sovellusten välittömän käytön. Tällaista metadataa säilytetään täysin ACID-yhteensopivassa RDBMS-järjestelmässä. Varmistaa hallinnan, elinkaaren yhdenmukaisuuden ja syvällisen integraation Salesforce Lightning Platformin kanssa.
- Lakehouse Storage: Rakennettu Apache Icebergille ja Parquetille, joka yhdistää datan järven skaalan varaston hallintaan, joka tukee skeeman evoluutiota, aikamatkaa ja suuria määriä päivityksiä. Data 360 tallentaa, mallinntaa ja käsittelee rakenteellista ja jäsentämätöntä dataa äärimmäisen laajalla tallennustilalla, jossa on nykyaikaiset avoimet standardit, sekä kattavia transformaatio- ja datan käsittelyominaisuuksia erä- ja tapahtumiin perustuville työkuormille.
- Lähtevän datan myyntiputki joustavalla syötteellä: Kattaa koko elinkaaren — syöttämisen, valmistelun, mallinnuksen, yhtenäistämisen, analysoinnin ja aktivoinnin — vähentämällä riippuvuutta hajanaisista pisteratkaisuista. Tukee eräversiota, lähes reaaliaikaa ja striimausta yli 270 liittimellä ja MuleSoftilla. ELT-yhteensopiva lähestymistapa mahdollistaa nopean datan saatavuuden ja myöhempien transformaatioiden joustavuuden.
- Yritystietojen yhteensopivuus avoimien kehysten ja yhdistämisen kanssa: Yhtenäistää silo'd-datan koko yritykselle kaksisuuntaisella Zero Copy -liitoksella, jossa Snowflake, Databricks, BigQuery ja Redshift välttävät datan siirtoa tai identtisiä tietueita.
- Datan luokittelu, mallinnus ja organisointi: Data 360 organisoi datan raakatuiksi tuoduiksi tiedoiksi, puhdistetuiksi ja tallennetuiksi tiedoiksi ja mallinnetuiksi tiedoiksi, jotka noudattavat yleistä SSOT-todennusta (Single Source of Truth). Nämä SSOT-objektit toimivat perustana semanttisille datamalleille (SDM) ja muille kerätyille ja sovelluskohtaisille malleille.
- Käyttöönotettu semanttinen datamallinnus laajennettaviin analyyseihin avoimien semanttisten kyselyiden API-rajapintojen avulla, joka edistää Tableau Next -ominaisuutta ja ottaa käyttöön sovelluskohtaisia analyysejä.
- High Performance SQL -kyselyjärjestelmä, joka tukee yhtenäistettyä Data 360 SQL -kyselyä rakenteellisesta, jäsentämättömästä ja kaavion datasta.
- Low-Latency Data Stores: Avainarvon tallennustila kuumalle datalle millisekuntien vastausajoilla. Ottaa käyttöön personalisoinnin ja tapahtumiin perustuvat skenaariot reaaliajassa. Kerää ja käsittelee asiakkaan osallistumistiedot reaaliajassa. Yhdistää identiteetit, vuorovaikutukset ja keskustelut yhteen luotettuun Customer 360 -profiili- ja kontekstikaavioon.
- Rakentamattomat datan käsittelyputket tarjoavat joustavan ja laajennettavan tuen jäsentämättömään datan tallennukseen, pilkkomiseen, upottamiseen (vektorisointi), metadatan noutamiseen (augmentointi), yhteenvetoon, indeksointiin, Knowledge-noutoon, älykkään asiakirjan käsittelyyn, lyhyen ja pitkän aikavälin (keskustelun) muistin luomiseen jne.
- Natiivi avainsanojen, vektoreiden ja hybridien indeksointi käyttääksesi tarkasti ja tehokkaasti jäsentämättömiä tietoja, kuten Nopea ja agenttinen haku, RAG, Knowledge-nouto, agenttien muistin muodostaminen jne.
- AI/ML- ja Agenttic-sovellusten käyttöönottamiseen käytetyt Profile-, Personalization-, Context-palvelut.
- Jokaisella kerroksella on sisäänrakennettu hallinta ja tietoturva sukupolven seurantaan, datan peittämiseen, datan säilyttämiseen ja nollatason Trust-suojaukseen, mikä varmistaa vaatimustenmukaisuuden ja Trust.
- Elastic Compute Fabric: Kubernetes-natiivi, usean vuokralaisen laskentatausta. Suorittaa Spark jaetulle käsittelylle ja Hyper for SQL -työkuormat. Skaalaa joustavasti eri töissä ja tukee epäluotetun koodin eristämistä.
Kaikki tämä toimii Salesforcen pilvitason Hyperforcessa. Hyperforce tarjoaa:
- Null Trust -suojaus ja salaus-, eristys- ja vähiten käyttöoikeuksia käyttävät käytännöt.
- Resilience usean alueen käyttöönoton kautta. Salesforce Data 360 hyödyntää Hyperforcen monen alueen kestävyyttä ja sovellusalustan tason vianmääritystä, mutta todellinen yritystason katastrofien palautus (DR) vaatii laajemman arkkitehtuurin kuin mikä tahansa datalusta, jolla on tärkeitä ominaisuuksia: toistettavat syöttöputket, replikointi ja metadataan perustuva rehydraatio kaikissa riippuvaisissa ekosysteemeissä.
- Observability ja sisäänrakennettu valvonta, tilastot ja seuranta.
- Automaattinen skaalautuminen ja FinOps-tietämys tehokkuudesta ilman ylikustannuksia.
Data 360 ei korvaa olemassa olevia yritysinvestointeja. Sen sijaan Data 360 tekee jo luottamastasi, hallitsemastasi ja interaktiivisesta datasta reaaliaikaisen, tekoälyyn perustuvan osallistumisen siellä, missä se on tärkeintä. Lyhyesti sanottuna Salesforce muuntaa kaikki yritystiedot, mukaan lukien ulkoiset tiedot, metadataan perustuviksi objekteiksi (Salesforce) ja ottaa käyttöön agenttisovelluksia löytämiseen, päätöksentekoon ja toimintojen tekemiseen.
Seuraava kuva kuvaa Data 360 -viitearkkitehtuuria:
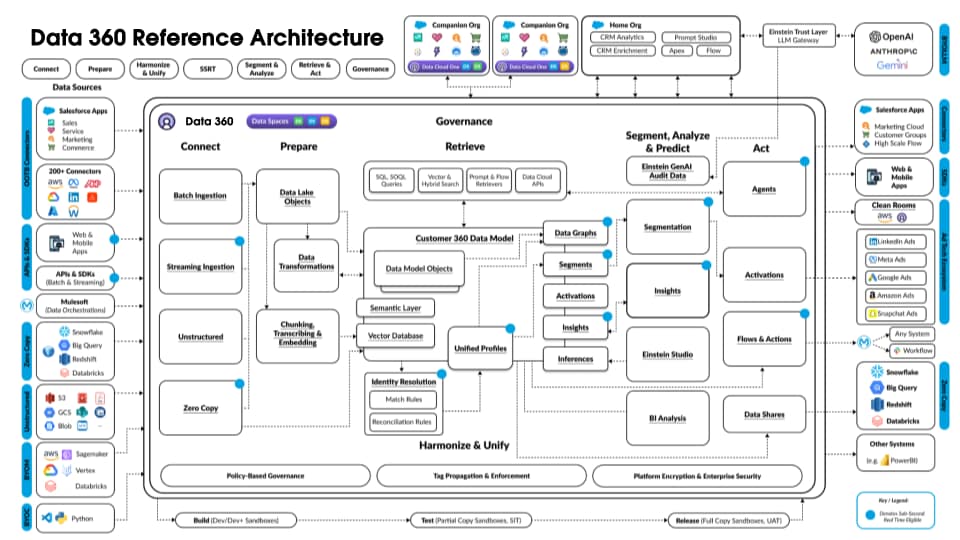
Tutustutaanpa hypoteettiseen Agentforce Loan Agent -luokkaan, joka on kerrostettu Data 360:lle kuvaamaan arkkitehtuurin esimerkkikulkua. Oletetaan esimerkiksi, että lainaagentti on asiakaskohtainen agentti, jossa asiakkaat (kuluttajat) hakevat lainoja ja saavat välittömiä lainahyväksyntöjä.
Data 360 suorittaa nämä vaiheet ajoitetulla tavalla ja valmistelee tiedot lainaagentille.
- Data 360 tuo rakenteelliset asiakastilien tiedot CRM:stä ja tallentaa ne Data Lakeen.
- Data 360 käsittelee jäsentämättömiä yhtiön laina- ja talouskäytäntötietoja.
- Data 360 yhdistää henkilökohtaisia tietoja ulkoisesta tietolähteestä, kuten Snowflakesta.
- Data 360 muuntaa ja mallinntaa tuodun ja yhdistetyn datan.
- Data 360 rakentaa ja ylläpitää profiilitietojen kaaviota.
Nämä toiminnot suoritetaan joka kerta, kun asiakas hakee lainaa.
- Asiakas kirjautuu sisään lainaagenttiin, joka aloittaa asiakastapaamisen reaaliajassa. Asiakkaan yhtenäistetty profiili noudetaan reaaliaikaiseen kerrokseen.
- Asiakas täyttää lainahakemuksen antamalla vaaditut tiedot.
- Asiakas lataa finanssiasiakirjoja (kuten veroilmoituksia, sijoituksia, pankkitilastoja) Data 360:ään jäsentämättömän datan käsittelyä varten.
- Ladatut tiedot pilkotaan ja vektoroidaan (upottamisen generointi) ja indeksejä (avainsana ja vektori) luodaan.
- Seuraavaksi asiakas täyttää lainahakemuksen asiakirjan ja lataa sen palvelimelle. Data 360 noutaa lainan summan ja keston reaaliajassa.
- Lainaagentti noutaa asiaankuuluvia taloustietoja käyttämällä Data 360 -kyselyä ja hybridihakua profiilien ja muiden esimääritettyjen indeksien perusteella.
- Lainaagentti aktivoi hyväksymistoimiston lainatiedoilla ja muilla finanssiprofiilitiedoilla tehdäkseen lainan hyväksymispäätöksen.
- Lainaagentti vastaa asiakkaalle päätöksellä.
- Tämä koko asiakkaan ja lainaagentin välinen vuorovaikutus tallennetaan myös Data 360:ään.
Yllä oleva esimerkki tarjoaa yleiskatsauksen Data 360 -arkkitehtuurikomponenteista, joita käytetään agenttisovelluksen, kuten lainaagenttien, rakentamiseen. Seuraavassa osiossa kuvataan Data 360 -arkkitehtuurin kerrokset ja komponentit.
Tässä osiossa tutustumme Salesforce Data 360 -sovelluksen perusrakennuspalikoihin, aloittaen sen kestävän tallennusmallin avulla ja tutustumalla sitten datan yhdistämisen, tuonnin ja valmistelun mekanismeihin. Seuraavaksi tutustumme siihen, miten rakenteellisia ja jäsentämättömiä tietoja tallennetaan, mallinnetaan ja käsitellään, jolloin ymmärrämme niiden harmonisointi-, yhtenäistäminen-, haku- ja älykkään aktivoinnin ominaisuudet.
Salesforce Data 360 perustuu tasoitettuun, mutta integroituun tallennusmalliin, joka yhdistää järvialueen vahvuudet reaaliaikaiseen tallennustilaan. Lakehouse-kerros tarjoaa skaalattavan ja kustannustehokkaan tallennustilan suurille historiallisten ja erädatan määriin, mikä mahdollistaa edistyneet analyysit ja koneoppimisen käyttötarkoitukset. Toisaalta reaaliaikainen tallennustila on optimoitu vähäisen viiveen käyttöoikeudelle ja yleisille päivityksille, mikä varmistaa, että asiakasvuorovaikutukset, profiilit ja osallistumissignaalit ovat aina ajan tasalla. Yhdessä nämä tasot toimivat saumattomasti, mikä sallii datan siirtyä saumattomasti historiallisten ja reaaliaikaisten asiayhteyksien välillä — mikä tarjoaa sekä syvällisyyttä että välittömyyttä yhtenäistetyssä datakannassa personalisointia, tekoälyä ja aktivointia varten.
Data 360 on suunniteltu käsittelemään suuria datan hallintaa ja käsittelyä erä-, streaming- ja reaaliaikaisissa skenaarioissa, jotka tukevat sekä rakenteellista että jäsentämättömää dataa, mikä on tärkeää tekoäly- ja analyysisovelluksille.
Pilvipohjaisissa datasuhteissa, kuten Azure, AWS tai GCP, perustallennusyksikkö on tiedosto, joka on tavallisesti järjestetty kansioihin ja hierarkioihin. Lakehouse parantaa tätä rakennetta ottamalla käyttöön korkeampia rakenteellisia ja semanttisia abstraktioita helpottaakseen toimintoja, kuten kyselyitä ja tekoälyn/ML-käsittelyä. Ensisijainen abstraktio on taulukko, jossa on metadataa, joka määrittää sen rakenteen ja semantiikan, ja joka sisältää elementtejä avoimista lähdekoodeista, kuten Iceberg tai Delta Lake, sekä Data 360:n lisäämiä semanttisia kerroksia.
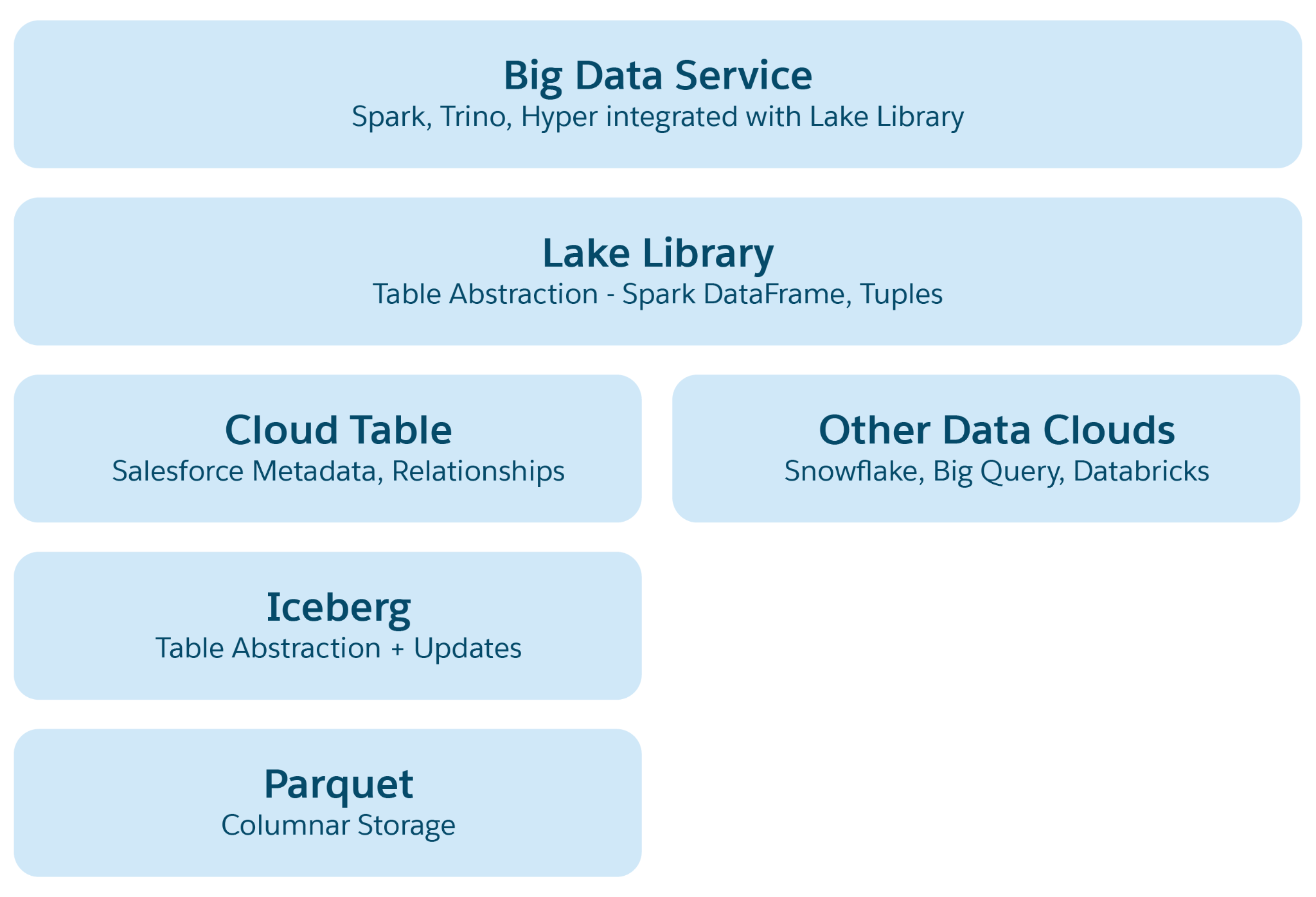
Abstraction-kerrokset Lakehouse:ssä:
- Parquet-tiedoston abstraktio: Alustassa tallennustila koostuu Data Lake -tiedostoista (esimerkiksi S3-tiedosto AWS:ssä tai Blob Azuressa) parkettimuodossa. Lähdetaulukon tiedot tallennetaan useisiin osioihin parkettitiedostoina, ja jokainen taulukko on näiden tiedostojen kokoelma.
- Iceberg-taulukon abstraktio: Taulukot on järjestetty kansioiksi, ja datan osiot tallennetaan niihin parkettitiedostoina. Osioon tehdyt muutokset johtavat uusiin Parquet-tiedostoihin tilannekuvina. Iceberg hallitsee kunkin taulukon metadatatiedostoa, joka sisältää lisätietoja skeemasta, osioiden määrityksistä ja tilannekuvista.
- Salesforce Cloud -taulukon abstraktio: Tämä kerros perustuu jäätikköön ja lisää semanttista metadataa, kuten sarakkeiden nimiä ja suhteita, sekä kokoonpanoja, kuten tiedoston koon ja pakkauksen. Se poimii taulukoita useista eri sovellusalustoista, kuten Snowflake ja Databricks, ja suojaa Data 360 -sovellukset niiden perustana olevista tallennusalustan tiedoista.
- Lake Access -kirjasto: Tämä kirjasto tarjoaa pääsyn Salesforce Cloud -taulukkoon, joka käsittelee sekä dataa että metadataa, ja se kuvaa sovelluskehittäjien perustana olevat tallennusmekanismit.
- Big Data -palvelun abstraktio: Tämä sisältää käsittelykehykset, kuten Hyper kyselyitä varten, ja Spark käsittelyä varten mille tahansa pilvipöytäalustalle.
Data 360 täydentää Lakehouse Big Data -tallennustilaa Low Latency Storella tukeakseen reaaliaikaisia analyysejä ja agenttisia sovelluksia. Data 360 Real-Time -kerros käsittelee reaaliaikaisia signaaleja ja osallistumistietoja muistissa. Koska muistiin perustuva tallennuskapasiteetti on kuitenkin rajoitettu, kaikki data ei välttämättä mahdu ja käsittely ei välttämättä tapahdu reaaliajassa. Data 360 lisää alhaisen viiveen säiliön (LLS) poistaakseen nämä rajoitukset, mikä mahdollistaa skaalattavan reaaliaikaisen käsittelyn.
Alhaisen viiveen säiliö on Lakehousen NVMe (SSD) -tallennuskerros petatavun skaalalla. Kaikkia tietoja ei tarvitse säilyttää vähäisen viiveen säiliössä. Se on kestävä välimuisti. Useimmat tiedot päätyvät lopulta Lakehouseen pitkäaikaista säilyttämistä varten. Istunnon sisäinen data reaaliaikaisessa kerroksessa voidaan tyhjentää matalan viiveen säiliöön myöhempää nopeaa käyttöä varten. Esimerkiksi agenttikeskustelussa viimeisimmät viestit voidaan käsitellä muistissa. Vanhat viestit voidaan tyhjentää matalan viiveen säiliöön. Jos edellistä keskustelua tarvitaan, se voidaan käyttää muutamassa millisekunnissa alhaisen viiveen myymälästä. NVMe-pohjainen tallennustila sallii suuren määrän datan tallentamisen ja käytön millisekuntien viiveellä. Data saattaa siirtyä Lakehouse-pilvitallennustilaan pitkän aikavälin säilyttämiseksi. Lisäksi Lakehouse-tiedot, joita tarvitaan reaaliaikaiseen käsittelyyn tai reaaliaikaisten käyttökokemusten täydentämiseen, noudetaan ja säilytetään matalan viiveen säiliössä. Esimerkiksi asiakasprofiilin konteksti noudetaan valmiiksi tai tuodaan Lakehouse-tilasta ja tallennetaan välimuistiin vähäisen viiveen myymälässä. Lisäksi kaikki lakehouse-objektit ja muut objektit, jotka tarvitaan reaaliaikaiseen käsittelyyn istunnon käsittelyn aikana, voidaan tallentaa myös välimuistiin alhaisen viiveen tallennustilassa.
Data 360:n alhaisen viiveen tallennus ottaa Real Timer -kerroksen käyttöön todellisessa tallennushierarkiassa, jossa on Memory (SSD) Lakehouse -tallennuskerrokset, joiden välillä data siirtyy saumattomasti. Käsittelemme Data 360 Real Time -kerrosta myöhemmin tässä asiakirjassa.
Salesforce Data 360 on suunniteltu standardoimaan, yhdenmukaistamaan ja aktivoimaan kaikkia asiakastietoja — rakenteellisia ja jäsentämättömiä — noudattamalla tiukkaa elinkaarta, joka muuntaa raakadatan yhtenäistettyyn ja ajankohtaiseen datamalliin.
Elinkaari keskittyy erilaisten ulkoisten tietojen syöttämiseen ja niiden rakentamiseen pysyviksi, mallinnetuiksi objekteiksi. Mallinnettu data voidaan harmonisoida yhtenäistettyihin Customer 360 -profiileihin.
Rahkaan tuodut tiedot ja alustavat transformaatiot
Prosessi alkaa raakadatasta, joka tuodaan sellaisenaan lähdejärjestelmistä (CRM, markkinointi, tiedostot jne.). Tämä sisältää datan täyden latauksen ja jatkuvan muutoksen tapahtumat (deltas), joita hallitaan ja yhdistetään pysyvään dataan tämänhetkisen tilan ylläpitämiseksi.
Inline-transformaatioita (esimerkiksi leikkaus, normalisointi, ketjutus) sovelletaan välittömästi syötteen aikana, jotta varmistetaan datan alustava laatu ja puhtaus.
Data Lake -objektit (DLO): Pysyvä kerros
DLO-objektit (Data Lake -objektit) muodostavat Data 360:n ydinsä pysyvän tallennuskerroksen. Ne säilyttävät puhtaan, muunnetun datan ja toimivat järjestettynä ja pitkäaikaisena säiliönä kaikille asiakastiedoille.
Lähde-DLO-objekteihin sovelletaan edistyneitä datatransformaatioita (esimerkiksi liitoksia, aggregaatioita, laskettuja havaintoja) luodakseen uusia, hyvin kerättyjä johdettuja DLO-objekteja.
Zero Copy -datan yhdistämisen kautta käytettävissä olevat tiedot esitetään suoraan DLO-objekteina.
Rakenteeton data ja metadataorganisaatio
Jos kyseessä on jäsentämätön sisältö (kuten teksti, media, asiakirjat), Data 360 integroi datan keräämällä ja säilyttämällä sen rakenteellisen metadatan tietyissä DLO-objekteissa nimeltään jäsentämättömät Data Lake -objektit (UDLO).
Nämä erikoistuneet DLO-objektit toimivat hakemistotaulukoina, jotka tarjoavat kartoituksen jäsentämättömien resurssien fyysiseen sijaintiin ja kontekstiin. Tämä ominaisuus sallii arkkitehtien liittää jäsentämättömän datan metadataa saumattomasti muuhun rakenteelliseen asiakastietoon, mikä mahdollistaa yhtenäistetyn kyselyn ja harmonisoinnin.
Datamalliobjektit (DMO): Harmonisoitu kerros
DMO-organisaatiot (datamalliobjektit) edustavat lopullista, yhdenmukaistettua ja rakenteellista datakerrosta.
Ne luodaan kartoittamalla DLO-kentät (lähdedatasta, johdetuista ja jäsentämättömistä metadatan DLO-objekteista) Customer 360 -vakiomuotoiseen datamalliin.
DMO-kerros toimii yhtenäisen totuuden lähteenä kaikille asiakastiedoille, mikä mahdollistaa yhtenäisen profiilien luomisen, segmentoinnin ja aktivoinnin laajemmassa ekosysteemissä.
Datatila on perustason looginen säiliö, jota käytetään kaiken datan ja metadatan organisointiin Data 360:ssa, mukaan lukien kaikki DLO-organisaatiot (rakenteelliset ja jäsentämättömät) ja DMO-organisaatiot. Datatilat tarjoavat turvallisen ja eristyneen ympäristön datan käsittelyyn ja mallinnukseen.
Datatilat toimivat loogisina ja hallinnallisina rajoina, mikä mahdollistaa sisäisen monivaltuuden erottamalla tiedot erillisille yksiköille, kuten liiketoimintayksiköille, alueille tai brändeille — samalla kun ne säilyttävät yrityksenlaajuisen näkyvyyden, sukupolven ja vaatimustenmukaisuuden, mikä toimii perustana rajattujen käyttöoikeuksien hallintaan.
Datatiloissa eristystä sovelletaan sovellusalustan useille kerroksille:
- Datan tason eristys: Jokainen DLO/DMO kuuluu yhteen datatilaan, mikä varmistaa, että kyselyt, transformaatiot ja objektien kartoitukset eivät voi ylittää datatilan rajoja, ellei niitä ole erikseen valtuutettu.
- Käyttöoikeuksien hallinnan integrointi: Käyttöoikeusjoukot liittyvät oletusarvoisesti datatiloihin, jotta voit hallita luku-, kirjoitus- ja hallintatoimintoja. Näin varmistetaan, että vain valtuutetut käyttäjät ja palvelut voivat käyttää objekteja, havaintoja ja aktivointeja datatilassa.
- Hallinta ja auditointi: Datatilan kaikki toiminnot kirjataan lokiin yritystason kirjausketjuilla, mikä mahdollistaa noudattamisen, hallinnan ja lakisääteisen raportoinnin jäljitettävyyden.
Käyttöoikeuksia ja käyttöoikeuksia hallitaan käyttöoikeusjoukkojen avulla, mikä varmistaa tarkan näkyvyyden, hallittuja päivityksiä ja toimialueiden välisten tietovuotojen estämisen. Kun datatilan rajat integroidaan Data 360:n suojaus- ja hallinta-arkkitehtuuriin, arkkitehtit voivat toteuttaa sekä keskitettyjä että hajautettuja hallintastrategioita luottavaisin mielin ja säilyttää yhdenmukaisuuden useissa pilvipalvelimissa ja liiketoiminta-alueissa.
Data 360 -tietojen tekstiosa tarjoaa yhtenäisen kerroksen kaikkien big data -työkuormien hallintaan ja suorittamiseen, mikä yksinkertaistaa sen perustana olevia infrastruktuurin monimutkaisuuksia. Sen ydinkomponentti on datan käsittelyohjain (DPC).
DPC on kattava, usean työkuorman datan käsittelyn orkestrointipalvelu, joka tarjoaa Työ palveluna -ominaisuuden (JaS) eri pilviympäristöissä. Se kumoaa infrastruktuurin monimutkaisuuden ja yhtenäistää töiden suoritusta kehysjärjestelmille, kuten Spark (EMR EC2:ssa ja EMR EKS:ssä) ja Kubernetes Resource Controller (KRC) -työkuormat. DPC toimii keskitetyn hallintasuunnitelman yhdyskäytävänä, joten se organisoi, ajoittaa ja valvoo töitä useilla datatasoilla varmistaakseen luotettavuuden, skaalattavuuden, kustannustehokkuuden ja yhdenmukaisen kehityskokemuksen.
DPC:n tarve johtuu sen rajoituksista, että voit käyttää suoraan natiivien klusterien hallintajärjestelmiä, kuten EMR:ää.
Infrastruktuuri ja pilvi abstraktio
Vaikka EMR tarjoaa API-rajapintoja klustereille, tehtäville ja vaiheille, se rasittaa asiakastiimejä edelleen kriittisillä infrastruktuurin hallintatehtävillä, kuten provisioinnilla, skaalaamisella, suorituskyvyn hienosäätämisellä ja kustannusten optimoinnilla. DPC korjaa tämän tarjoamalla yksinkertaistetun sovellusalustan API-rajapinnan töiden lähettämiseen. Se tukee automaattista virheiden käsittelyä, uudelleenyrityksiä ja dynaamista kuormituksen tasapainottamista. Tarjoaa kustannustehokkuuden säiliö-, piste- ja graviton-pohjaisten noodien avulla. Tarjoaa vahvan tietoturvan TLS, PKI, IAM-eristys ja automatisoitu korjaus. Hallitsee Spark- ja EMR-versioiden suorituksen aikaisia päivityksiä tarjotakseen parannuksia suorituskykyyn, suojauskorjauksia ja ominaisuuksien parannuksia.
Lisäksi DPC tarjoaa yhtenäistetyn, pilvipohjaisen käyttöliittymän datatöiden lähettämiseen ja hallintaan, ja se käsittelee sen perustana olevan pilvisubstratin (AWS, tulevat tarjoajat) monimutkaisuudet ja omistamat API-rajapinnat. Näin varmistetaan, että asiakastiimit käyttävät vain yhteistä Data 360 API:iin perustuvaa työtoimitusten käyttöliittymää, joka poistaa sen perustana olevien resurssien päälliköiden monimutkaisuudet, kuten Kubernetes ja YARN. Näin asiakastiimit voivat lähettää Spark-töitä yksinkertaisen ja yhtenäistetyn API:n kautta ilman, että heidän täytyisi hallita pods-, noodien pool- tai Spark-klusterikokoonpanoja suoraan.
Spark-parametrien mukauttaminen manuaalisesti vaatii erikoistuneita taitoja, ja väärät kokoonpanot voivat hidastaa töiden suorittamista. DPC-tiimi keskittää tämän ammattitaidon tarjoamalla optimoituja kokoonpanoja yleisten suorituskykyongelmien välttämiseksi. Tämä erikoistunut tiimi integroi jatkuvasti Knowledgea avoimen lähdekoodin yhteisöstä varmistaakseen optimaalisen suorituskyvyn kaikissa ohjaimen hallitsemissa työkuormissa.
DPC ei rajoitu Sparkiin, vaan se tukee useita eri työkuormia. Näihin sisältyy:
- Käsittelyn reaaliaikaiset työkuormat
- Datatoiminnot-ominaisuuden tapahtumien toimitus
- Milvuksen (rakenteettoman datan indeksoinnin vektori-tietokannan) hallinta
- Matalan viiveen tallennusinfrastruktuuri
DPC hyödyntää myös Kubernetes Resource Controller (KRC) -kehystä, joka tukee työkuormia, kuten Trino for Query, Event Delivery for Data Actions, Data Extraction -töitä liittimille ja reaaliaikaista käsittelyä. DPC tarjoaa kaikille KRC-työkuormille keskeisiä Työ palveluna -ominaisuuksia, jotka käsittelevät laskutoimien provisiointia, käyttöönottoa ja hallintaa yleisen tason töiden abstraktiossa.
JaaS-hyödyt ja arkkitehtuuri
DPC:n tarjoama Työ palveluna -malli varmistaa kustannustehokkaan ja kestävän työn käsittelyputken.
Käyttäjät tarjoavat yksinkertaisia klusterin määrityksiä ja keskittyvät vaadittuihin CPU-, muisti-, tallennustila-, instanssien määriin sekä klusterin vähimmäis- ja enimmäismääriin ja tunnisteisiin klusterin täsmäämiseksi. DPC hallitsee sitten automaattisesti abstrakteja infrastruktuurin lisätietoja, mukaan lukien optimaalisten VM-SKU-tuotteiden valitseminen, instanssikokoonpanojen hallinta ja Core vs. Tehtävänoodien hallinta ja On-Demand vs. Löydä esiintymiä syötteiden perusteella. Se käsittelee myös EMR- ja komponenttien versioiden hallinnan ja päivitykset ilman käyttökatkoksia.
Tärkeintä on, että DPC tukee luonnostaan usean vuokrauksen käyttöä, joka on suunniteltu ymmärtämään ja noudattamaan Data 360 -vuokrauksen rajoituksia ja resurssien erottamista. Se varmistaa myös tietoturvan ja vaatimustenmukaisuuden noudattamalla Salesforcen sertifioimia koneiden kuvia, hallitsemalla palvelukohtaisia IAM-rooleja ja takaamalla salauksen sekä liikenteessä että paikallisesti. Kun käytät reititystä ja kapasiteetin hallintaa, töiden ja klusterien täsmäystä hallitaan käyttämällä Klusteri-tunnisteita, ja kapasiteettiin perustuva reititys käyttää töiden samanaikaisen enimmäismäärän asetusta hallitakseen resurssien käyttöastetta tehokkaasti.
Cloud Agnostic -asiakaskokemus on keskeinen etu, koska sen perustana olevien pilviympäristöjen monimutkaisuus on piilotettu asiakaspalveluista, jolloin he voivat keskittyä pelkästään liiketoimintalogiikkaan. Tämä saavuttaa Cloud Provider Abstraction -tavoitteen. Lopuksi DPC sallii helpon käytön ja kustannusten seurannan, jolloin klusterin käyttöaste ja kustannukset voidaan segmentoida palvelun mukaan tarkan kirjanpidon aikaansaamiseksi. Kokonaisuutena DPC noudattaa kiinnitettävää arkkitehtuuria, joka sallii uusien suoritusjärjestelmien (esimerkiksi Flink, Ray) ja pilvitasojen (GKE/Dataproc) integroinnin saumattomasti paljastamatta käyttäjille infrastruktuurin tietoja. Tämä rakenne irrottaa ohjaussuunnitelman suorituskerroksesta varmistaakseen yhdenmukaisen API- ja toimintokokemuksen taustajärjestelmästä riippumatta.
Data 360 hienosäätää ja rikastaa raakadataa solmimalla sillan raakadatan ja toimivan liiketoimintakulutuksen välille. Se täydentää datan objektin elinkaarta valmistelemalla monimutkaista dataa monimutkaista aktivointia ja analyysiä varten. Data 360 tukee useita käsittelytyyppejä, mukaan lukien erä- ja Streaming-datamuunnokset, erä- ja Streaming-lasketut havainnot, jäsentämätön datan käsittely ja Identiteetin vahvistus. Näiden monipuolisten toimintojen ottaminen käyttöön tehokkaasti, varsinkin lähes reaaliajassa ja suurissa datajoukoissa, vaatii hienostuneen mekanismin datan muutosten käsittelemiseksi tehokkaasti.
Data 360 tarvitsee läpimurron saavuttaakseen tehokkaan, lähes reaaliaikaisen datan käsittelyn — varsinkin teratavukokoisten taulukoiden ja miljoonien mahdollisten päivitysten avulla. Se vaati tapaa ilmoittaa järjestelmille tarkasti, kun tietoja muutetaan, ja tunnistaa tehokkaasti muutetut tiedot, jotta vain asiaankuuluvat päivitykset käsitellään ja vain, kun ne päivitetään. Tämä haaste johti kahteen täydentävään innovaatioon: Tallenna natiiviset muutostapahtumat (SNCE) ilmoittaaksesi, kun jotakin muuttuu, ja Muuta datasyötettä (CDF) tunnistaaksesi muutokset.
Tallennustilan natiivi muutostapahtumat (SNCE)
SNCE on muuttanut Data 360:n perusteellisesti reagoivaksi ja asteittaiseksi datalustaksi. Tämä työvuoro käsittää siirtymisen datameren aktiivisesta kyselystä passiiviseen valvontaan atomien sitoumustapahtumien varalta käyttämällä standardoitua tapahtumamuotoa ja tehokäyttöistä viestien toimitusjärjestelmää.
Jokainen onnistunut kirjoitustoiminto (INSERT, UPDATE, DELETE) Iceberg-taulukkoon johtaa luettelossa olevan taulukon tämänhetkisen metadatatiedoston osoittimen atomivaihtoon. Sen perustana oleva objektin tallennustaso (esimerkiksi S3) on määritetty lähettämään natiivilmoitustapahtuma (kuten S3-tapahtuma), kun taulukon hakemistoon kirjoitetaan uusi metadatan vedos.
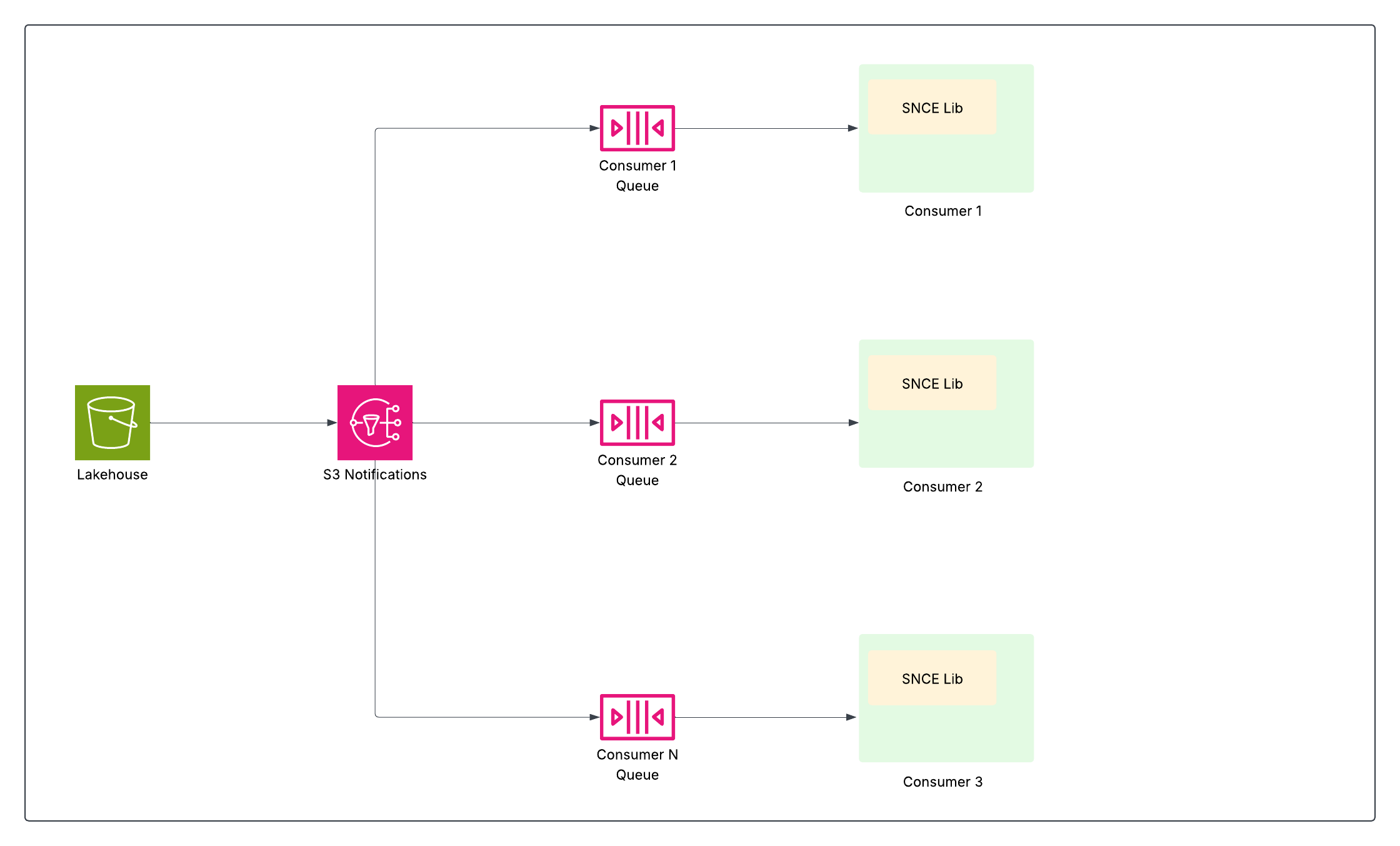
SNCE-kirjasto tarjoaa standardoidun tavan näiden tapahtumien kuluttamiseen, ja se voi myös rikastaa niitä tilannekuvan metadatalla pyynnöstä.
Näin myöhemmät dataputket — kuten laskettujen havaintojen suoratoisto, identiteetin vahvistus ja segmentointi — voivat tilata ja toimia vain, kun data on muuttunut, mikä parantaa tehokkuutta merkittävästi välttämällä kalliita koko taulukon skannauksia.
Muutosdatan syöte (CDF)
SNCE:n pohjalta Change Data Feed (CDF) tarjoaa virtaviivaisen mekanismin muutosten kuluttamiseen ja käsittelemiseen vaiheittain.
CDF hyödyntää Icebergin tilannekuvia luodakseen muutosvirran tehokkaasti. Kriittisesti ottaen Data 360:n optimoitu Iceberg-kirjoitin laskee ja säilyttää muutokset osana itse kirjoitustoimintoa, mikä tekee CDF:n luomisesta erittäin tehokasta ja minimoi lisäkustannukset. Tämä sallii käsittelytöiden (kuten streaming-transformaatioiden tai streaming-laskettujen havaintojen) käsitellä vain muutetut tietueet valikoidusti välttyäkseen kalliilta tilannekuvan diff-laskutoimilta.
Tämä asteittainen strategia tarjoaa useita etuja suurille datajoukoille, kuten säästää kustannuksia, vähentää viiveitä ja parantaa tehokkuutta. Se ottaa käyttöön ominaisuuksia, kuten streaming-transformaatioita ja asteittaista identiteetin vahvistusta, mikä puolestaan johtaa nopeampiin havaintoihin, ennustettavissa oleviin järjestelmälatauksiin, parannettuun suorituskykyyn ja pienempiin toimintakustannuksiin.
Data 360 tarjoaa vahvoja tuontitoimintoja Salesforce-tuotteille tarkoitetulla tuella, mikä varmistaa saumattoman datan kulun. Ulkoisille lähteille se tarjoaa laajan yhteyden yli 270 liittimen, API:n, SDK:n ja MuleSoftin kautta. Lisäksi Data 360 sisältää nollakopioliitännän, joka sallii BI:n ja analyysien käyttämisen ilman datan kopiointia.
Data 360 -liittimen kehysjärjestelmä (DCF) on useimpien Data 360 -yhteyksien perusta. Se sallii syöttämisen, yhdistämisen ja poistamisen yhtenäistetyn arkkitehtuurin kautta. DCF määrittää standardit liittimiesi rakentamiseen ja hallintaan, aina määritysten ja hallinnan käyttöliittymästä metadatan säilyttämiseen, datan noutamiseen ja toimitukseen Lakehouseen tai ulkoisten lähteiden live-kyselyiden kautta. Se tukee myös yksityisiä yhteysvaihtoehtoja (kuten yksityisiä linkkejä, VPN-yhteyksiä ja suojattuja tunneleita) varmistaakseen yritystason tietoturvan ja vaatimustenmukaisuuden, kun muodostat yhteyden asiakas- tai kumppaniympäristöihin. DCF tarjoaa yhdenmukaisen lähestymistavan kaikille liittimille, jotta Data 360 voi muodostaa saumattoman yhteyden laajempaan ekosysteemiin varmistamalla laajennettavuuden, luotettavuuden ja turvallisen integraation.
Data 360 tarjoaa vahvan yhteyden datalähteiden laajaan ekosysteemiin, joka tukee sekä Salesforcen natiivituotteita että useita ulkoisia järjestelmiä. Tämä laaja yhteys on tärkeää erillisen yritystietojen yhdistämiseksi ja tekoälyn/ML- ja agenttisovellusten käyttöönotolle.
Data 360 tarjoaa yli 270 liitintä natiivisesti tai MuleSoftin, API-rajapintojen ja SDK-rajapintojen kautta tukeakseen sen datan myyntiputken ominaisuuksia erä-, suoratoisto- tai reaaliaikaisella tuonnilla. Nämä liittimet voidaan luokitella laajasti niiden integroiman lähdejärjestelmän tyypin mukaan.
Salesforcen natiiviliittimet
Nämä liittimet varmistavat Salesforce-tuotteiden saumattoman ja luontaisen datan kulun.
Esimerkkejä ovat Salesforce CRM-, Data Cloud One-, Marketing Cloud Engagement-, Marketing Cloud Account Engagement- ja B2C Commerce -liittimet.
Ulkoiset sovellukset ja SaaS
Useiden liiketoimintasovellusten ja pilvipalveluiden liittimet sallivat datan tuonnin ulkoisista ohjelmistoalustoista.
Esimerkkejä ovat Adobe Marketo Engage, Microsoft Dynamics 365, Mailchimp ja Airtable.
Datakannat ja tietovarastot
Data 360 muodostaa yhteyden useisiin suhteellisiin ja pilvipohjaisiin datan tallennusjärjestelmiin.
Esimerkkejä ovat Amazon Redshift, Amazon DynamoDB, Amazon RDS (MySQL, PostgreSQL, Oracle), Google BigQuery ja Microsoft SQL Server.
Cloud-objektien tallennustila ja tiedostojärjestelmät
Nämä liittimet integroituvat hyperscaler-tallennusratkaisuihin sekä rakenteelliselle että jäsentämättömälle datalle.
Esimerkkejä ovat Amazon S3, Google Cloud Storage (GCS) ja Azure Blob Storage.
Streaming- ja Messaging-palvelut
Liittimet, jotka käsittelevät jatkuvia reaaliaikaisia datavirtoja, ovat tärkeitä tapahtumiin perustuville skenaarioille ja reaaliaikaiselle käsittelylle.
Esimerkki Amazon Kinesis -liittimestä.
Integrointialustat
MuleSoft Anypoint -liitin laajentaa Data 360:n vaikutusaluetta integroimalla sen laajempiin sovelluksiin ja tietokantoihin Anypoint Exchangessa.
Rakenteettoman datan ja Cloud-objektien tallennusliittimet
Nämä liittimet ovat tärkeitä, kun tuodaan ja viitataan jäsentämättömiä tietoja (tietoja, joilla ei ole esimääritettyä mallia) tekoälyn luomiseen.
Kaikki nämä liittimet perustuvat Data 360 -liittimen kehykseen, joka tarjoaa yhdenmukaisen käyttökokemuksen.
Data-transformaatio on Data 360:n perustava arkkitehtuurikomponentti, joka on suunniteltu puhdistamaan, rikastuttamaan ja muokkaamaan tuotua raakadataa Customer 360 -datamallin mukaisiksi normalisoiduiksi ja interaktiivisiksi dataresursseiksi. Tämä prosessi on välttämätön datan harmonisointiin, laadun parantamiseen ja sen varmistamiseen, että data on valmiina myöhempiin käyttötarkoituksiin, kuten profiilien yhtenäistämiseen, segmentointiin ja aktivointiin. Transformaatiot hyödyntävät sekä lähdedatan Lake-objekteja (DLO) että datamalliobjekteja (DMO) input-arvona, tuottaen tulokset uusiin DLO-objekteihin tai DMO-objekteihin.
Data 360 tarjoaa kaksi ensisijaista transformaatiopredikaattia eri datan nopeusvaatimusten ratkaisemiseksi: erädatan transformaatiot ja streaming-datan transformaatiot.
Erädatan transformaatiot
Erädatan transformaatiot on suunniteltu raskaan käsittelyyn määritetyn aikataulun tai tarvittaessa käynnistimen perusteella. Tämä järjestelmä on optimoitu monimutkaisten ja resurssiintensivisten rakenneuudistustoimintojen käsittelemiseksi.
Erämuunnoksen prosessi määritetään käyttämällä visuaalista, vähäisen koodin myyntiputken esitysaluetta, jonka avulla käyttäjät voivat määrittää monivaiheisen transformaatiologiikan. Tämä järjestelmä tukee ainutlaatuisesti monimutkaisia rakenneuudistustoimintoja, jotka ovat välttämättömiä kanonisen datamallin tasaamiseksi: datan rakenne ja normalisointi. Tämä sisältää pivotoinnin (denormalisoitujen tietueiden pilkkominen useiksi normalisoiduiksi tietueiksi) ja litistäminen (hierarkian datan, kuten JSON:n, uudelleenrakentaminen rakenteellisiksi taulukoiksi). Järjestelmän suoritustila tukee täyttä synkronointia (käsittelee kaikki tietueet) ja erittäin tehokasta asteittaista käsittelytilaa. Asteittainen tila vähentää käsittelyaikaa ja resurssien kulutusta merkittävästi käsittelemällä vain tietueet, jotka ovat muuttuneet edellisen onnistuneen suorituksen jälkeen. Erätransformaatiot sopivat hyvin tehtäviin, joissa reaaliaikaiset päivitykset eivät ole välttämättömiä, kuten säännöllisiin aggregointeihin ja monimutkaisten tietojen uudelleenjärjestelyihin.
Streaming-datan transformaatiot
Streaming-data muuntaa prosessien datan jatkuvasti ja asteittain lähes reaaliajassa, kun se kulkee järjestelmään, mikä tekee siitä välttämättömän vähäisen viiveen käyttötapauksissa.
Ensisijainen käyttöliittymä on SQL-ensisijainen lähestymistapa, jossa transformaatiot määritetään SQL SELECT -kyselyksi, joka suoritetaan jatkuvasti tietueiden saapuville muutosvirroille. Tämä järjestelmä tukee ydintransformaatiofunktioita, mukaan lukien datan puhdistamista ja standardointia (esimerkiksi henkilötietojen vahvistamista ja datamuotojen standardointia) sekä datan rikastamista ja yhdistämistä (yhdistämisen ja yhdistämisen avulla). Kriittisesti ottaen se tukee Streaming Lookup JOIN -profiileja salliakseen reaaliaikaisen datan rikastamisen ja hakujen tekemisen staattista tai hitaasti muuttuvaa viitetietoja vastaan, mikä varmistaa, että profiilit päivitetään välittömästi. Palvelukustannusten optimoimiseksi arkkitehtuuri käyttää High-Density (HD) -työn suunnittelua, joka pakkaa useita streaming-transformaatioiden määritelmiä yhdelle vuokralaiselle yhteen perustana olevaan laskentatyöhön, mikä maksimoi resurssien käyttöasteen. Streaming-transformaatiot ovat välttämättömiä käyttötapauksiin, kuten tapahtumien valvonta, välitön personalisointi ja profiilien reaaliaikaiset päivitykset.
Data 360 mullistaa datan hallinnan tukemalla Zero Copy -liitosta ja datan jakamista, jolloin sinun ei tarvitse siirtää tai kopioida dataa. Tämä ominaisuus sallii käyttäjien käyttää dataa saumattomasti ja suoraan useista ulkoisista lähteistä ja jakaa dataa ulkoisten ympäristöjen kanssa, mikä vähentää monimutkaisuutta merkittävästi, vähentää tallennuskustannuksia ja varmistaa, että kaikki päätökset perustuvat tuoreimpiin ja luotettavimpiin tietoihin.
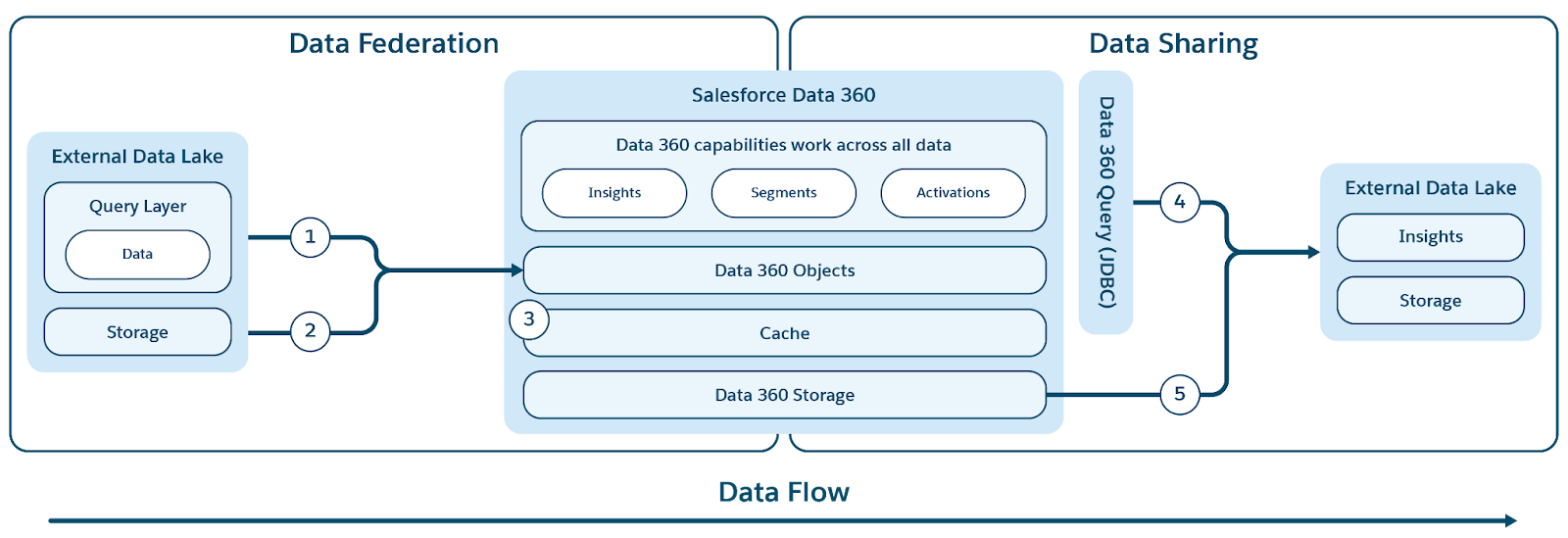
Data 360 tukee nollakopioliitosta ulkoisten tietovarastojen (Snowflake, Redshift), järvikeskusten (Google BigQuery, Databricks, Azure Fabric), SQL-tietokantojen ja monien muiden lähteiden kanssa. Sen abstraktiotasot sallivat ulkoisten tietojen suoran kyselyn ilman identtisiä tietueita, mikä vähentää tuontiaikoja, tallennuskustannuksia ja varmistaa, että tiedot ovat ajan tasalla.
Data 360 yksinkertaistaa ulkoisen datan ja yhdistetyn datan käyttöä tarjoamalla yhtenäisen metadatakerroksen, joka abstraktoi sekä Salesforcen että ulkoiset objektit. Näin koko Salesforce-alusta ja sen sovellukset voivat käyttää näitä tietoja saumattomasti.
Data 360 tukee tiedostoihin ja kyselyihin perustuvaa yhdistämistä live-kyselyiden ja käyttöoikeuksien nopeuttamiseksi kuvassa kuvatulla tavalla.
Otsikot (1) ja (2) kuvaavat Data 360 -kyselyä (mukaan lukien live-kyselyiden ponnahdusikkunoita) ja tiedostoihin perustuvaa yhdistämistä ulkoisista datamajoista/varastoista/tietolähteistä saadun datan käyttämiseksi. Ja otsikko (3) korostaa yhdistetyn pääsyn nopeuttamista ulkoisista datamajoista/tietolähteistä.
Kyselyn yhdistäminen
Data 360:n yhdistämistoiminnon ydin on sen kyselyiden yhdistämiskerros, joka hallitsee monimutkaista prosessia ulkoisen datan käyttämiseksi ja älykkäiden kyselyiden käynnistämiseksi (kuvassa otsikko 1). Data 360 muodostaa yhteyden ja noutaa tietoja lähteistä käyttämällä JDBC-protokollaa, jota parannetaan lisälogiikalla tehokkuuden parantamiseksi. Kyselyn yhdistämiskerros on vastuussa eri SQL-dialogien ymmärtämisestä ja kääntämisestä, selvittääkseen kyselyn optimaalisimman osan, joka siirretään ulkoisiin järjestelmiin tehokasta käsittelyä varten, hakemaan tulokset ja suorittamaan tarvittavat lisäkäsittelyt lopullisten havaintojen muodostamiseksi.
Välimuistiin tallentaminen (kyselyiden nopeutus)
Jos käytät parannettua apukohdetta, Data 360 tarjoaa valinnaisen nopeutusominaisuuden yhdistetyille ominaisuuksille.
Kun Ac acceleration on aktivoitu, Data 360 tallentaa yhdistetyn datan välimuistiin nopeuttaakseen sen käyttöä ja vähentääkseen kustannuksia — koska se välttää toistuvia suoria ulkoisten lähteiden käyttöoikeuksia. Tätä välimuistia käsitellään kiihtyvyyskerroksena ja sitä päivitetään asteittain vastaamaan nopeasti ulkoisen lähdedatan muutoksia, jotta nopeutettu näkymä pysyy lähellä reaaliaikaa.
Tiedosto yhdyskäyttö
Data 360 tukee tiedostoihin perustuvaa yhdistämistä (kuvassa otsikko 2) käyttääkseen dataa ulkoisista datasakeista ja lähteistä. Tämän nollakopiotoiminnon tekniset perusteet perustuvat standardointiin: sen perustana olevan datan täytyy olla Apache Parquet -tiedostomuoto ja käyttää Apache Iceberg -taulukkomuotoa. Data 360 voidaan yhdistää mihin tahansa lähteeseen, joka paljastaa Iceberg REST Catalog (IRC) -katalogin metadatan ja tallennustilan käyttöä varten, mikä varmistaa saumattoman ja hallitun pääsyn sovellusalustan ulkopuolisiin tiedostoihin.
Tiedostoihin perustuvan yhdistämisen avulla Data 360 -tietokoneet käsittelevät kaiken datan käsittelyn, koska ne käyttävät suoraan sen perustana olevaa tallennustilaa. Tämä välttää kyselyiden ponnahdusikkunan ja useiden SQL-dialogien hallinnan, joita tarvitaan usein kyselyihin perustuvan yhdistämisen yhteydessä.
Tämän lisäksi Zero Copy -ominaisuus laajenee myös jäsentämättömiin tietolähteisiin, kuten hyperscaler-tallennusratkaisuihin (S3/GCS/Azure-tallennus), Slackiin ja Google Driveen, joita voidaan käyttää Data 360:n jäsentämättömien käsittelyputkien kautta.
Data 360 helpottaa sen hallitsemien tietojen kyselyihin ja tiedostoihin perustuvaa jakamista ulkoisten datasäiliöiden ja varastojen kanssa (kuten alkuperäisen kuvan asiayhteyden otsikot 4 ja 5 osoittavat).
Kyselyyn perustuva jakaminen
Data 360 paljastaa kyselyyn perustuvaa datan jakamista varten JDBC-ajurin käyttämällä ulkoisia järjestelmiä ja sovelluksia, joilla voi saada suojatun pääsyn tietoihin. Tämä mekanismi sallii ulkoisten järjestelmien yhdistää, todentaa ja suorittaa live-kyselyitä suoraan Data 360 -datalle.
Tiedostoihin perustuva jakaminen (Datan jakaminen ja DaaS)
Tiedostoihin perustuvan jaon ensisijainen mekanismi sisältää kaksi käsitystä: datan jako ja datan jakotavoite, jotka hyödyntävät DaaS (Data as a Service) API -rajapintaa.
- Tarkennettu hallinta: Datan jakokäsitys sallii asiakkaiden määrittää tarkasti ulkoisesti jaettavat objektit (DLO, DMO, CIO jne.), mikä estää tahattoman datan näyttämisen.
- Suojattu kohdistus: Se hallitsee myös datan jakotavoitetta varmistaakseen, että tiedot ovat käytettävissä vain suoraan valtuutetuille ulkoisille ympäristöille, tileille tai kumppaniorganisaatioille (esimerkiksi tietyn Redshift- tai Databricks-esiintymän kanssa).
DaaS API tarjoaa turvallisen ja hallitun käyttöliittymän ulkoisille järjestelmille, jotka voivat käyttää dataa. Se myöntää käyttöoikeuden sekä olennaiseen metadataan että sen perustana olevaan taulukon tallennustilaan säilyttämällä kaikki Data 360 -semantiikat. Tämä varmistaa, että ulkoiset järjestelmät käyttävät tietoja yhdenmukaisessa ja hyödyllisessä asiayhteydessä turvallisella tavalla.
Monet tietoturvaan liittyvät asiakkaat, erityisesti suuret yritykset, säänneltyjen toimialojen yritykset ja julkisen sektorin organisaatiot, rajoittavat kaikkia internet-käyttöoikeuksia datasäiliöihinsä osana tietoturvaa. Tämä käytäntö on välttämätöntä vaatimustenmukaisuuden ja riskien vähentämisen kannalta, mutta estää myös Salesforce Data 360:n ja Agentforcen muodostamasta yhteyden kyseisiin ympäristöihin julkisen internetin kautta.
Useimmat näistä datasakeista on otettu käyttöön hyperscaler-ympäristöissä, kuten AWS, Azure tai Google Cloud. Koska Data 360 itse toimii AWS:llä, eri pilvipalvelimella isännöityjen asiakastietojen järvien käyttäminen vaatii pilvipohjaisen verkkoyhteyden. Jos asiakkailla ei ole julkisen internetin ohittamaa suojattua ja yksityistä yhteysvaihtoehtoa, he eivät usein pysty tai halua käyttää Data 360- tai Agentforce näihin datasokeihin perustuvissa käyttötarkoituksissa.
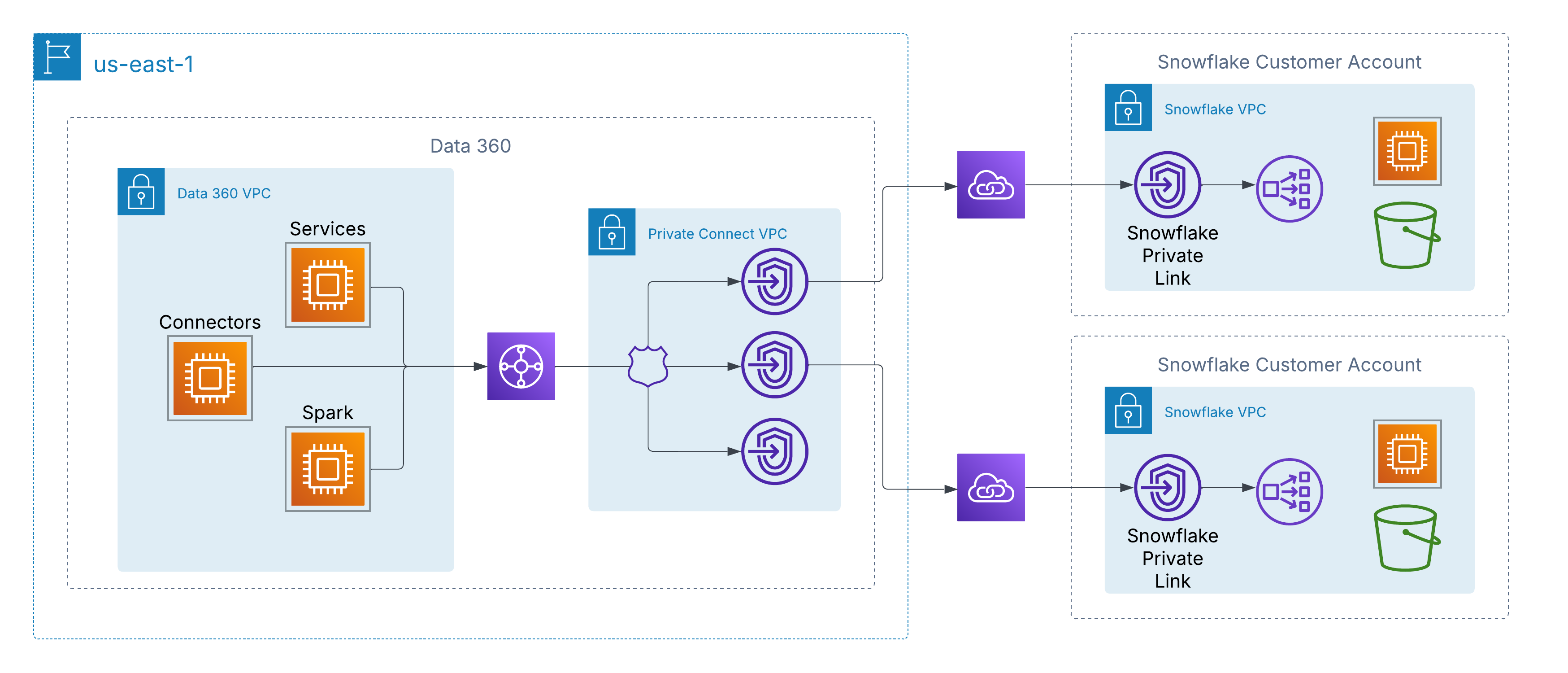
Data 360 tukee yksityistä verkostotason yhteyttä asiakkaan hallitsemiin datalähteisiin pilvipalvelimella. AWS:ssä tämä on käytössä AWS PrivateLinkin kautta, joka sallii Data 360:n muodostaa yhteyden suoraan asiakkaiden tarjoamiin päätepisteisiin joko omissa tileissään tai kolmansien osapuolten data Lake -ympäristöissä (esimerkiksi Snowflake) ylittämättä julkista Internet-yhteyttä.
Tämä arkkitehtuuri varmistaa, että kaikki liikenne pysyy kokonaan AWS:n selkärannassa käyttämällä yksityistä IP-osoitetta ja ei-reititettäviä verkkopolkuja, mikä täyttää tiukat tietoturva- ja vaatimustenmukaisuusvaatimukset ja mahdollistaa saumattoman pääsyn asiakastietoihin.
Data 360 laajentaa yksityisen yhteyden AWS:n ulkopuolelle pilvipohjaisten yhteyksien tuen avulla usean pilven arkkitehtuurien asiakkaille. Tämä mahdollistaa turvalliset ja vain taustalla toimivat verkostopolut Data 360:sta Azuressa tai Google Cloudissa isännöityihin datasäiliöihin ja palveluihin, ja säilyttää samat periaatteet kuin AWS PrivateLink — yksityinen IP-osoite, muu kuin julkinen reititys ja nolla Internet-rajoitus.
Asiakkaat voivat valita kahdesta käyttöönottomallista:
-
Asiakkaan hallitsema yhteys: Integroi olemassa olevia yksityisiä piirejä, kuten Azure ExpressRoute, Google Cloud Interconnect tai Equinix Fabric suoraan Data 360:n VPC-tietokoneisiin.
-
Salesforcen hallitsema yhteys: Käytä täysin hallittua, käyttövalmista yhteyttä, jossa Salesforce provisioi ja ylläpitää pilvipolun linkkiä, paljastaen yksityiset päätepisteet kohdepilvipalvelimelle.
Kokemus on yhdenmukainen molemmissa malleissa: Data 360 -palvelut muodostavat yhteyden ulkoisiin tietolähteisiin hyperskalaattorien kautta kuin ne olisivat paikallisia, mikä mahdollistaa suojatun syöttämisen, aktivoinnin ja kyselyiden tekemisen ilman julkisen internetin käyttämistä.
Yritysarkkitehtien kannalta vahva datan hallinta ei ole pelkästään vaatimustenmukaisuuden valintaruutu, vaan perusarvoinen pilari luotettavien, skaalattavien ja interaktiivisten Älykkäät asiakastietojen rakentamisessa. Salesforce Data 360 on rakennettu kattavalla hallintajärjestelmällä, joka varmistaa datan laadun, tietoturvan ja lakisääteisten velvollisuuksien noudattamisen sen koko datan elinkaaressa.
Data 360 toimii keskitettynä hallintakeskuksena, joka varmistaa, että kaikkea dataa — raaka-aineistosta aktivoituihin havaintoihin — hallitaan eheästi ja hallittavasti.
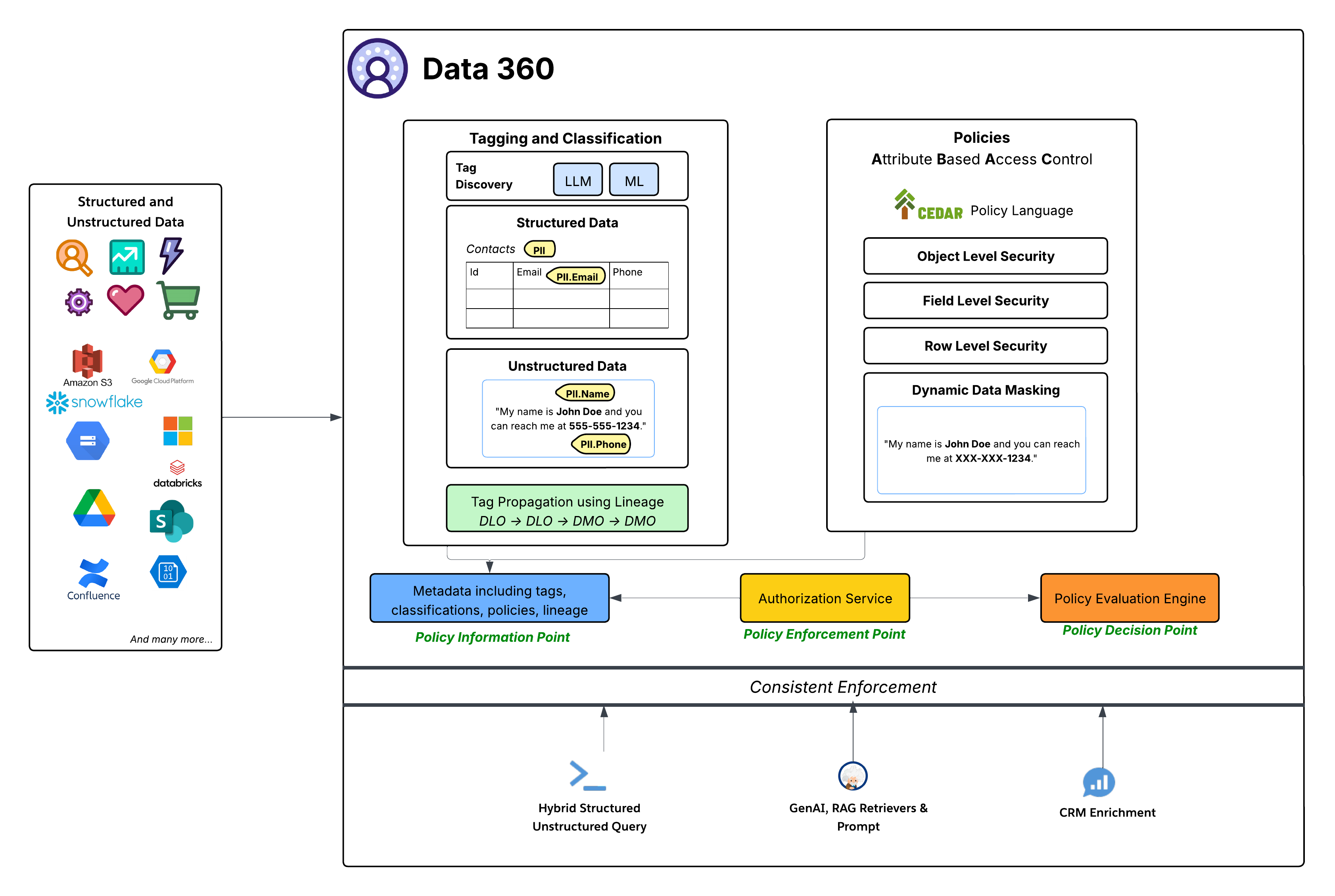
Datatila tarjoaa rajatun käyttöoikeuden määrittääkseen datatilan kaikkien objektien käyttöoikeudet, mutta ABAC-käytännöt tarjoavat rajatun käyttöoikeuden datatilan yksittäisille objekteille, kentille ja riveille. Data 360 on ottanut Attribute-Based Access Control (ABAC) -ominaisuuden käyttöön ydivaltuutuksen mallina hienosäädettyjen käyttöoikeuksien hallintaan. Tämä strateginen valinta tarjoaa parempaa joustavuutta ja skaalattavuutta verrattuna perinteiseen rooleihin perustuvaan käyttöoikeuksien hallintaan (RBAC), joka on erityisen tärkeä dynaamisissa, monimutkaisissa yritysympäristöissä, joissa on paljon dataa ja erilaiset käyttötarpeet. ABAC sallii pääsyn päätöksiin, jotka perustuvat käyttäjän attribuutteihin (esimerkiksi osasto, rooli, sijainti), dataan (esimerkiksi henkilötieto, luottamuksellisuus, datatila) ja ympäristöön (esimerkiksi kellonaika), eikä vain esimääritettyihin rooleihin. Tämä mahdollistaa erittäin tarkkoja ja asiayhteydestä riippuvaisia käyttöoikeuskäytäntöjä, jotka mukautuvat datan ja käyttäjäattribuuttien muuttuessa.
- CEDAR-käytännön kieli: CEDAR-käytäntökielen käyttö on Data 360:n ABAC-toteutuksen ydin. Tämä käyttötarkoituksen mukainen ja virallinen käytäntökieli tarjoaa tarkan ja vahvistettavan tavan määrittää monimutkaisia valtuutussääntöjä, jotta käytännöt ovat yksiselitteisiä ja niitä voidaan arvioida yhdenmukaisesti laajuudeltaan.
Data 360:n hallintajärjestelmä noudattaa vakiomuotoista ja kestävää ABAC-arkkitehtuuria:
- Tunnistaminen, luokittelu ja käytännön luominen (käytäntötietopiste - PIP):
- Data 360 tarjoaa automatisoituja merkintä- ja luokittelumekanismeja, jotka hyödyntävät LLM:ää (Suurin kieli -malli) ja ML:ää (koneoppiminen) tunnistaakseen luottamuksellisia tietoluokkia (esimerkiksi PII.Email, PII.Phone, PII.Name) ja muita käyttötarkoituksiin perustuvia taksonomioita (PHI, FinancialData) sekä rakenteellisessa datassa (esimerkiksi Yhteyshenkilöt-taulukko) että jäsentämättömässä datassa (esimerkiksi Google Drivesta).
- Tärkeintä on, että tunnisteiden propagointi tapahtuu datan linjauksen (DLO -> DLO -> DMO) rinnalla, mikä varmistaa, että luokitukset seuraavat automaattisesti datan transformaatioita ja johdantoja, raakadatasta yhdenmukaistettuun DMO-kerrokseen ja prosessien määritelmistä luodun johdetun datan kautta.
- Lopuksi käytäntöjen luontiikkuna tarjoaa yksinkertaisen käyttökokemuksen, jolla voit hyödyntää dataa ja käyttäjäattribuutteja dynaamisten käyttöoikeussääntöjen määrittämiseksi organisaatiolle.
- Tämä rikastettu metadata (mukaan lukien tunnisteet, luokitukset, käytännöt ja sukupolvi) syötetään käytäntötietopisteeseen (PIP).
- Valtuutuspalvelu (PEC):
- Valtuutuspalvelu toimii käytäntöjen täytäntöönpanopisteenä (PEP). Se sieppaa kaikki tietojen käyttöoikeuspyynnöt useista kulutuskerroksista (Hybrid Structured/Unstructured Query, GenAI RAG Retrievers & Prompt, CRM Enrichment) ja pyytää käytäntöjen päätöspistettä määrittääkseen, onko käyttö sallittu.
- Käytäntöjen arviointijärjestelmä (Käytäntöjen päätöspiste - PDP):
- Tämä järjestelmä toimii käytännön päätöspisteenä (PDP). Se käyttää käyttöoikeuspyynnön kontekstia PEP:stä sekä käytäntöjen määritelmiä (CEDAR:ssa) ja attribuutteja PIP:stä tehdäkseen valtuutetun käyttöoikeuspäätöksen.
- Yleiset suojauskäytännöt: CEDAR:ssä määritetyt käytännöt käyttävät useita suojaustasoja, mukaan lukien:
- Objektitason suojaus: Hallitse koko DLO-objektien tai DMO-organisaatioiden käyttöoikeuksia näihin objekteihin liittyvien tunnisteiden perusteella.
- Kenttätason suojaus: Tiettyjen objektien luottamuksellisten kenttien käyttöoikeuksien rajoittaminen tunnisteiden perusteella.
- Rivitason suojaus: Tiettyjen objektien tietojen suodattaminen näyttääksesi vain asiaankuuluvia rivejä käyttäjäattribuuttien perusteella.
- Dynaminen datan peittäminen: Peitä tietyt tiedot (tunnisteisiin perustuen) dynaamisesti käyttöpisteessä muuttamatta niiden perustana olevaa dataa. Näin varmistetaan, että luottamukselliset tiedot on suojattu ja että niillä on edelleen laaja käyttöliittymä. Tämä koskee rakenteellisten tietojen peittokenttiä sekä jäsentämättömien tietojen sisältöä.
- Yhtenäinen noudattaminen: Koko ABAC-kehys varmistaa, että käytäntöjä noudatetaan yhdenmukaisesti kaikissa Data 360 -kulutuskuvioissa, olipa kyseessä esimerkiksi suora datan kysely, Generoivan tekoälyn sovellusten (RAG) hakeminen tai Salesforce CRM -kokemusten rikastaminen viiteluetteloiden kautta.
- Sisäinen integraatio Salesforce Platformin kanssa: Data 360:n hallintaominaisuudet määritetään ja hallitaan suoraan Salesforcen ydinsovellusalustalla. Tämä integraatio sallii pääkäyttäjien hallita käyttöoikeuskäytäntöjä, käyttäjäidentiteettejä ja attribuuttien hallintaa käyttämällä tuttuja Salesforce-työkaluja, mikä varmistaa yhtenäisen ja yhdenmukaisen hallintakerroksen koko Salesforce-ekosysteemissä.
Data 360 tarjoaa arkkitehdeille vertaansa vailla olevan hallinnan ja joustavuuden rakentamalla tämän hienostuneen ABAC-kehyksen CEDAR-käytännöillä, mikä varmistaa, että asiakastiedot ovat toiminnallisia, turvallisia, yhteensopivia ja luotettavia koko organisaatiossa.
Toimialoilla organisaatiot kiinnittävät entistä enemmän huomiota tietoturvaan kokonaisvaltaisesti tietojen vuotojen, luvattoman käytön, manipuloinnin tai tuhoamisen estämiseksi. Useimmat datalustat, mukaan lukien tämänhetkinen Data 360, tarjoavat salausta paikallisesti käyttämällä toimittajan hallitsemaa salausavainta. Yritykset (erityisesti säänneltyjen sektoreiden yritykset) vaativat kuitenkin yhä enemmän asiakkaan hallitsemien salausominaisuuksien käyttöä sekä paikallisessa että siirretyssä datassa.
Tämä malli sallii yritysten hallita omia salausavaimiaan varmistaakseen, että tiedot pysyvät salasanassa suojattuina, vaikka ne olisivat erittäin epätodennäköisiä sovellusalustan tason rikkomuksesta tai valtuuttamattomasta käytöstä. Ilman asiakkaan omistamaa avainta yksikään yksikkö (mukaan lukien sovellusalustan tarjoaja) ei voi purkaa tai rakentaa dataa uudelleen, mikä ylläpitää täydellistä luottamuksellisuutta ja hallintaa.
Data 360 tukee rakenteellisten (taulukoiden), puolirakenteellisten (JSON) ja jäsentämättömien tietojen tallentamista ja hallintaa saumattomasti datan tuonti-, käsittely-, indeksointi- ja kyselymekanismeissa. Data 360 tukee useita jäsentämättömiä tietotyyppejä tekstin lisäksi, mukaan lukien ääntä, videota ja kuvia, mikä laajentaa tietojen käsittelyä ja analyysiä. Alla oleva kuva kuvaa maadoituksen kaksi puolta (syöttö ja nouto).
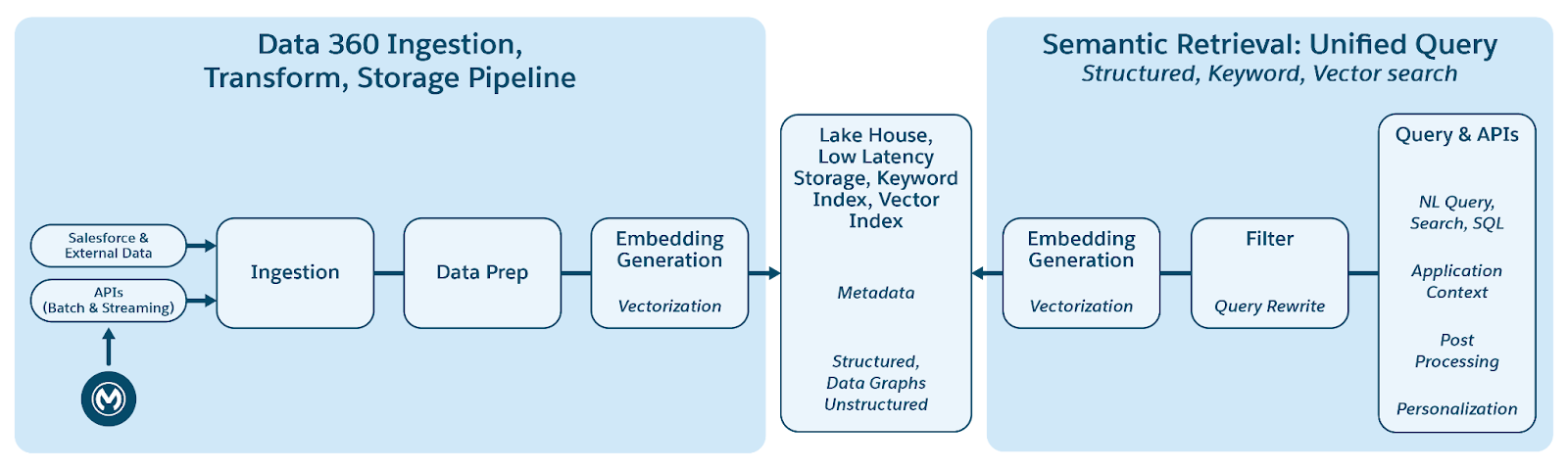
Data 360 hallitsee jäsentämättömiä tietoja tallentamalla ne sarakkeisiin tekstinä tai suurten datajoukkojen tiedostoihin. Se tukee datan yhdistämistä jäsentämättömälle sisällölle, mikä mahdollistaa datan integroinnin ja hallinnan useista lähteistä.
Sen jälkeen data valmistellaan ja pilkotään, upotukset luodaan ja käsitellään avainsanojen indeksointia ja vektoreiden indeksointia varten. Data 360 isännöi useita käyttövalmiita ja kiinnitettäviä malleja pilkkomista ja upottamista varten. Data 360 tukee audio- ja videosisällön automatisoitua ja määritettävää litterointia myöhempää käsittelyä ja indeksointia varten. Hakupalvelua käytetään avainsanojen indeksointiin. Data 360 tukee vektorien indeksointia sekä natiivin indeksoinnin (Hyper) että myös vektoritietokantoja, kuten avoimen lähdekoodin Milvus. Data 360 integroituu myös Salesforce Search -sovellusalustaan tukemaan avainsanojen indeksointia jäsentämättömässä datassa. Tämä Data 360:n integroitu monimenetelmäinen indeksointi sallii haun kaikista jäsentämättömistä tiedoista, niin kuin asiakirjan Agentic Enterprise Search -osiossa on kuvattu myöhemmin.
Data 360 tarjoaa API-rajapintoja hakuun. Hyper-pohjainen yhtenäistetty kyselyemme helpottaa yhdistettyjen kyselyiden tekemistä rakenteellisten, avainsanojen indeksien ja vektorien indeksien välillä, mikä ylläpitää tarkkoja näkyvyysasetuksia ja käyttöoikeuksia, mikä parantaa RAG- ja hakutuloksia.
Data 360:n jäsentämätön datan indeksointiputki on suunniteltu modulaariseksi, laajennettavalta arkkitehtuurilta, joka koostuu viidestä ydivaiheesta:
- Jäsentäminen
- Esikäsittely
- Pura
- Käsittelyn jälkeen
- Upottaminen
Kaikki vaiheet tukevat myös LLM-pohjaista käsittelyä, joka sallii asiakkaiden luoda mukautettuja kehotteita. Esikäsittelyn ja käsittelyn jälkeiset vaiheet voivat sisältää useita peräkkäisiä vaiheita, jolloin monimutkaiset transformaatiot voidaan luoda joustavasti. Jokainen vaihe perustuu täysin metadataan, mikä mahdollistaa saumattoman kokoonpanon ja laajennuksen ilman koodin muutoksia.
Esikäsittelyyn sisältyy esimerkkejä toiminnoista, kuten melun poistaminen, kielen normalisointi ja kuvan ymmärtäminen (optiset merkkien tunnistaminen ja otsikot), kun taas käsittelyn jälkeisiin vaiheisiin voi sisältyä metadatan rikastaminen, semanttinen ryhmittely tai edistyneet tekniikat, kuten Raptorin pilkkominen.
Myyntiputki tukee täysin Data 360 -koodilaajennusta, jolloin asiakkaat ja sisäiset tiimit voivat lisätä mukautettua logiikkaa missä tahansa vaiheessa. Koodilaajennuskomponentit ovat kevyitä Python-funktioita, joiden elinkaaren — suorituksen, skaalan ja virheiden käsittelyn — Data 360 hallitsee kokonaan. Tämä lähestymistapa varmistaa, että innovaatioita ja toimialuekohtaisia käsittelytoimintoja voidaan ottaa käyttöön nopeasti ja että toiminta ja hallinta ovat yhdenmukaisia kaikkialla alustassa.
Kontekstin indeksointi
RAG:n määrittämisessä jäsentämättömällä käsittelyllä on kaksi tärkeää tekijää:
- Nopeampi iterointi: Kyky vahvistaa tiedot nopeasti testien esimerkkikyselyillä.
- Henkilökohtainen sisältö: Kyky määrittää kuluttajan henkilökuvaan räätälöity sisältö.
Kontekstiindeksointi on käyttäjäystävällinen työkalu, joka on suunniteltu käsittelemään molempia näitä seikkoja. Tämä interaktiivinen käyttöliittymä perustuu reaaliaikaiseen (RT) myyntiputkeen, joka suorittaa kaikki viisi aiemmin kuvattua vaihetta. Myyntiputki käyttää GPU-tiedostoja tarvittaessa tehtäviin, kuten upottamiseen ja optiselle merkkien tunnistamiselle (OCR). Lisäksi se sallii asiakkaiden testata RAG-putkea nopeasti agentilla ennen kokoonpanon käyttöönottoa kattavaa sisällön käsittelyä varten.
Asiakirjan tekoäly
Data 360 Document AI sallii jäsentämättömien tai puolirakenteellisten tietojen lukemisen ja tuomisen asiakirjoista, kuten laskuista, ansioluetteloista, laboratorioraporteista ja ostotilauksista. Tämä ominaisuus tukee ad hoc -interaktiivista käsittelyä sekä joukkokäsittelyä erissä. Tämä on tärkeä ominaisuus, joka mahdollistaa liiketoimintaprosessien automatisoinnin asiakkaillemme. Tämä perustuu tekoälyyn, mukaan lukien LLM:t ja ML-mallit.
Yrityksillä on valtavia määriä Knowledgea, joka on jaettu eri järjestelmiin, kuten wikiihin, tiedostojen jakoihin, sisällön hallintajärjestelmiin, sisäisiin tietokantoihin ja muihin. Tämä hajanaisuus vaikeuttaa työntekijöiden (erityisesti palveluagenttien ja myyntiedustajien) ja asiakkaiden löytämistä asiaankuuluvista tiedoista nopeasti ja tehokkaasti. Tärkeimpiin ongelmiin sisältyy: Yksittäisen ja yhtenäisen hakukokemuksen puute kaikista Knowledge; Sisällön esittäminen ja renderöinti eri lähteistä ei ole yhdenmukaista; Järjestelmien välillä hajautettujen luottamuksellisten tietojen käyttöoikeuksien hallinta puuttuu; ja tärkeiden Knowledge on vaikeaa (esimerkiksi asiaankuuluvien artikkelien liittäminen tapaukseen).
Enterprise Knowledge edustaa sisältöä, joka on kerätty manuaalisesti tai automaattisesti laajemmasta yritystietojen joukosta. Manuaalinen keräys sisältää tarkoituksellisia toimintoja, kuten Salesforce Knowledge -artikkelien luominen tai Knowledgen kehittäminen ulkoisissa järjestelmissä, jotka tuodaan. Suunnittelemme automatisoidun keräyksen, joka hyödyntää prosesseja, kuten Salesforce-agentteja ja -transformaatioita, jotka suoritetaan tuodun datan päälle luodakseen hienosäätettyjä kerroksia, jotka voivat sekoittaa rakenteellista ja jäsentämätöntä sisältöä. Riippumatta siitä, kerätäänkö se manuaalisesti vai automaattisesti, sisäisesti Salesforcessa vai ulkoisesti ennen syöttämistä, lopputulos on arvokohtaista sisältöä, joka on erillään raakadatasta.
Enterprise Knowledge Hub -ratkaisu hyödyntää Data 360 -ominaisuuksia seuraavissa kohteissa:
- Syöte ja tallennus: CRM Connector tuo Salesforce Knowledge -artikkeleita, ja dataliittimen kehysjärjestelmän (DCF) jäsentämättömät liittimet tuovat raakisisältöä ja metadataa ulkoisista lähteistä. Sisältö tuodaan lähdekohtaisiin jäsentämättömiin data Lake -objekteihin (UDLO-objekteihin), jotka kartoitetaan SFDrivessa olevaan sisältöön (tai lähde nollan kopion tapauksessa).
- Harmonisointi ja rakenteellisuus: harmonisointi käsittelee UDLO- ja tiedostodataa, suorittaa puhdistusta, normalisointia, rikastusta (NLP, jne.), PII- peittämistä ja transformaatiota harmonisoituun välimuistiin, joka on tallennettu SF Driveen ja siihen kartoitettavaan harmonisoituun UDLO-muotoon (HUDLO).
- Indeksointi: Jäsentämätön myyntiputki (UDS) käynnistyy yhdenmukaistetun sisällön päälle ja hakuindeksit määritetään jokaiselle HUDMO-organisaatiolle.
- Kulutus: Kuluttavien sovellusten haku, noutaminen, renderöinti ja linkittäminen liiketoimintaobjekteihin, kuten Tapaus. Kuluttamien sovellusten osallistuminen kerätään tarjotakseen käyttöanalyysejä (kuten napsautuksia, tarkastuksia jne.)
Data 360:n lasketut havainnot (CI) sallivat asiakkaiden määrittää ja luoda aggregoituja tilastoja datastaan. Näitä tilastoja käytetään asiakkaan osallistumiseen, analyysiin, segmentointiin ja aktivointiin oikeaan aikaan. CIA:n laskemat aggregoidut tiedot kirjoitetaan Lakehousiin ja ne esitetään lasketuksi havainto-objektina (CIO).
Laskettuja havaintoja on kahta päätyyppiä:
- Erän lasketut havainnot: Suunniteltu monimutkaiseen, raskaan datan aggregointiin, jossa tilastot voidaan laskea säännöllisesti (esimerkiksi päivittäin tai viikoittain).
- Streaming-havainnot: Tarjoa kyky luoda tilastoja ja toimintoja reaaliaikaisesta tapahtumadatasta, mikä mahdollistaa välittömän ja vähäisen viiveen asiakkaan osallistumisen.
Lasketut havainnot määritetään datamalliobjekteille (DMO) ja ne voidaan määrittää myös muille lasketuille havainto-objekteille. Lasketut havainnot -palvelu hallitsee erätöiden ja streaming-töiden orkestrointia.
Sekä erä- että streaming-havaintojen laskennat käyttävät Sparkia. Keskeinen eroavaisuus on, että streaming-havainnot hyödyntävät Spark Structured Streaming -ominaisuutta, kun taas eräarvioinnit suoritetaan käyttämällä säännöllisiä ja ajoitettuja Spark-erätöitä. Kustannustehokkuuden vuoksi lasketut havainnot -palvelut ryhmittävät CI-mittareita, jotka lasketaan yhdessä samassa CI-erätyössä tai suoratoistotyössä, perustuen tekijöihin, kuten lähdatan objektien riippuvuuksiin ja päällekkäisyyteen.
SNCE:llä ja CDF:llä on merkittävä rooli Streaming Insights -laskutoimissa.
Identiteetin vahvistus on vastuussa erilaisten tietojen muuntamisesta useista lähteistä yhdeksi kattavaksi yhtenäistetyksi profiiliksi.
On tärkeää ymmärtää, että yhtenäistetty profiili ei ole ”kultainen tietue” eikä identiteetin vahvistus valitse voitettuja arvoja tai korvaa olemassa olevaa dataa, kun profiileja yhdistetään. Yhtenäistettyjä profiileja käytetään avainten joukkoina, jotka avaavat lähdedatasi tunnistamalla kaikki vastaavat tietueet, jotka liittyvät samaan entiteettiin, yhteen tietolähteeseen tai useisiin eri lähteisiin. Näiden tietojen avulla voit valita oikean lähdejärjestelmän datan, jota käytetään tiettyyn liiketoimintatarkoitukseen.
Identiteetin vahvistus voi yhdistää useita tietuetyyppejä, mukaan lukien Yksityishenkilöt, Tilit ja Kotitaloudet. Sitä voidaan käyttää myös liidien täsmäämiseen olemassa oleviin tileihin. Yhtenäistämisprosessi on välttämätöntä, jotta voit saavuttaa täydellisen Customer 360 -näkymän ja edistää henkilökohtaista ja reaaliaikaista osallistumista sekä B2C- että B2B-skenaarioissa.
Identiteetin ratkaisuputki perustuu erittäin skaalattavaan, pilvipohjaiseen kehykseen, joka on suunniteltu käsittelemään suuria määriä dataa jatkuvasti. Prosessi sisältää kolme tärkeintä vaihetta, jotka käyttävät tehokasta hakuindeksi täsmäysprosessin hallitsemiseksi:
- Yhteensopivuus (Candidate Selection): Täsmäysprosessin tavoite on hakea tietueita, jotka saattavat kuulua samaan entiteettiin. Tietueet analysoidaan mukautettavien sääntöjen perusteella, jotka sisältävät jokaisen joukon ehtoja, jotka määrittävät, mitä tietoja täsmätään tietylle tarkkuustasolle. Järjestelmä luo indeksejä löytääkseen todennäköisesti vastaavat tietueet käyttämällä kahta tekniikkaa, jotta mahdolliset vastaavuudet voidaan noutaa tehokkaasti datajoukosta:
- Sulkevat avaimet: Estosavain on arvo, joka luodaan tietueen datasta ja täsmäyssäännöistä (kuten nimen ensimmäisistä kirjaimista, normalisoidusta puhelinnumerosta jne.) ryhmittääkseen mahdollisesti samankaltaisia tietueita toisiinsa. Jokaisella tietueella on useita estoavaimia, jotka indeksoidaan ja tallennetaan käänteisenä indeksinä, jotta järjestelmä suorittaa yksityiskohtaisia vertailuja vain pienille tietueiden ryhmille eikä koko datajoukolle.
- Locality Sensitive Hashing (LSH): Jos täsmäyssääntö on epätarkka, tiivisteet luodaan koulutettujen mallien upottamisen perusteella.
- Syvä täsmäys: Kun ehdokkaiden valintavaihe luo pienempiä mahdollisten vastaavuuksien ryhmiä, järjestelmä aloittaa yksityiskohtaisemman vertailun. Tässä vaiheessa tekoälymallit ja edistyneet algoritmit analysoivat jokaisen tietueen parin laskeakseen todennäköisyyksiin perustuvan pistemäärän. Tämä pistemäärä mittaa, kuinka todennäköisesti kaksi tietuetta viittaavat samaan entiteettiin vertaamalla älykkäästi kenttiä, jotka sisältävät usein kirjoitusvirheitä, variaatioita tai muotoilun eroavaisuuksia.
- Kluserointi ja yhtenäistäminen: Kun vastaavat tietueet on tunnistettu ehdokkaista, ne ryhmitetään klusteriksi. Tämä prosessi sisältää kriittisesti siirrettävien vastaavuuksien ratkaisemisen. Jos esimerkiksi tietue A vastaa tietuetta B ja tietue B vastaa tietuetta C, kaikki kolme on linkitetty samaan klusteriin, vaikka A- ja C-tietueita ei olisi koskaan verrattu suoraan. Nämä kokonaiset klusterit muodostavat yhtenäistetyn profiilin perusrakenteen. Tämä klusterointiprosessi varmistaa, että kaikki siihen liittyvät lähdetietueet on linkitetty oikein yhdellä pysyvällä tunnisteella.
- Sovitus: Kaikkien klusteroitujen lähdetietueiden data-arvot arvioidaan käyttämällä määritettyjä yhteensovitussääntöjä (esimerkiksi Yleisin, Viimeisin tai Lähdeprioriteetti), jotka täyttävät tuloksena olevan yhtenäistetyn profiilin profiilitiedoilla. Yhteensovitus ei korvaa mitään olemassa olevaa dataa, koska kaikki lähdedata on käytettävissä käyttämällä yhtenäistettyyn profiiliin linkitettyjä avaimia.
Arkkitehtuuri tukee useiden entiteettityyppien ratkaisemista useiden käyttötarkoitusten täyttämiseksi.
- Yksittäinen täsmäys: Keskittyy yhtenäistettyjen yksityishenkilöiden profiilien luomiseen, jotka linkittävät kaikki tunnetut henkilötiedot (sähköpostit, puhelinnumerot, kanta-asiakastunnukset, evästeet) yhteen henkilöön.
- Tilin täsmäys: Keskittyy yhtenäistettyjen tilien profiilien luomiseen, jotka linkittävät tilien dataa. Kun järjestelmä täsmää yritysten nimiä, se käyttää hienosäätettyä mallia, kun se täsmää epätarkasti.
- Kotitalouden täsmäys: Laajentaa täsmäyslogiikkaa aggregoidaksesi yhtenäistettyjä yksityishenkilötietueita liittyvien yksityishenkilöiden ryhmiin.
- Entiteettien välinen täsmäys: Yhtenäistämisen lisäksi identiteetin vahvistus luo profiilien objektien välille linkkejä käyttämällä samoja täsmäyssääntöjä. Liidi voidaan esimerkiksi linkittää tiliin käyttämällä epätarkkaa täsmäystä tilin nimessä.
Identiteettien ratkaisujärjestelmä toimii lähes reaaliaikaisella arkkitehtuurilla varmistaakseen, että yhtenäistetty profiili on aina ajan tasalla. Tämä pilvioptimoitu arkkitehtuuri on suunniteltu jatkuvaan käsittelyyn ja nopeuttaa käsittelyaikoja. Vaikka käsittelyn nopeus vaihtelee lähdedatan vastaanottomenetelmän mukaan, identiteetin vahvistus voi käsitellä pieniä muutoseräjä 15 minuutin välein.
Järjestelmä ylläpitää identiteettilinkkiobjekteja, jotka kartoittavat jokaisen lähdetietueen tunnuksen sitä vastaavaan yhtenäistettyyn profiilin tunnukseen. Tämä perustietojen rakenne sallii järjestelmän seurata suhteita tehokkaasti ja levittää muutoksia ja päivityksiä nopeasti yhtenäistettyyn profiiliin, mikä varmistaa, että asiakaskokemukset — kuten verkkosivuston personalisointi, Next-Best-Action-suositukset ja segmentointi — hyödyntävät aina uusimpia saatavilla olevia asiakastietoja.
Segmentointi on ydinprosessi, jolla yhtenäistettyjä asiakasprofiileja muunnetaan interaktiivisiksi kohdeyleisöiksi. Tämä ominaisuus on tärkeä henkilökohtaisten käyttökokemusten tarjoamiseksi markkinointi-, kaupankäynti- ja palvelukanavissa. Salesforce Data 360 -segmentointialusta on suunniteltu suurille operaatioille. Se hallitsee monimutkaista metadataa käyttämällä datamallia, joka sisältää tuhansia objekteja ja suhteita. Sovellusalusta tukee monimutkaisia sääntöjä, aggregointiin perustuvia suodattimia ja ikkunoihin perustuvaa sijoitusta, mikä varmistaa nopean ja luotettavan laskennan petatavuina.
Data 360 tukee useita segmenttityyppejä täyttääkseen nopeutta, monimutkaisuutta ja hierarkiaa koskevat erityiset liiketoimintavaatimukset:
- Vakiosegmentti: Ensisijainen eräkäsitelty segmenttityyppi. Se julkaistaan mukautetulla aikataululla, jossa vakiomuotoinen julkaisujakso on vähintään 12 tuntia 24 tuntiin tai nopeampi nopeampi julkaisujakso 1–4 tuntia, joka on optimoitu viimeaikaisille osallistumistiedoille.
- Reaaliaikainen segmentti: Tämä segmentti suoritetaan tarvittaessa millisekunteina välittömästi viimeaikaisten tapahtumien ja profiilitietojen perusteella. Se on erittäin optimoitu välittömään personalisointiin, mutta se ei voi hyödyntää poikkeusehtoja tai sisäkkäisiä segmenttejä.
- Vesiputoussegmentti: Alisegmenttien hierarkkinen rakenne, jota käytetään asiakkaan priorisoimiseen yhdeksi arvokkaimmaksi segmentiksi, jos ne täyttävät useita ehtoja.
- Sisäkkäinen segmentti: Tämä mahdollistaa olemassa olevan segmentin uudelleenkäytön suodattimena uudelle, tarkemmalle segmentille (perussegmentin hienosäätö), joka perii pääsegmentin aikataulun.
Segmentointijärjestelmä toimii vakaalla, pilvipohjaisella arkkitehtuurilla, joka varmistaa nopeuden, skaalan ja keston.
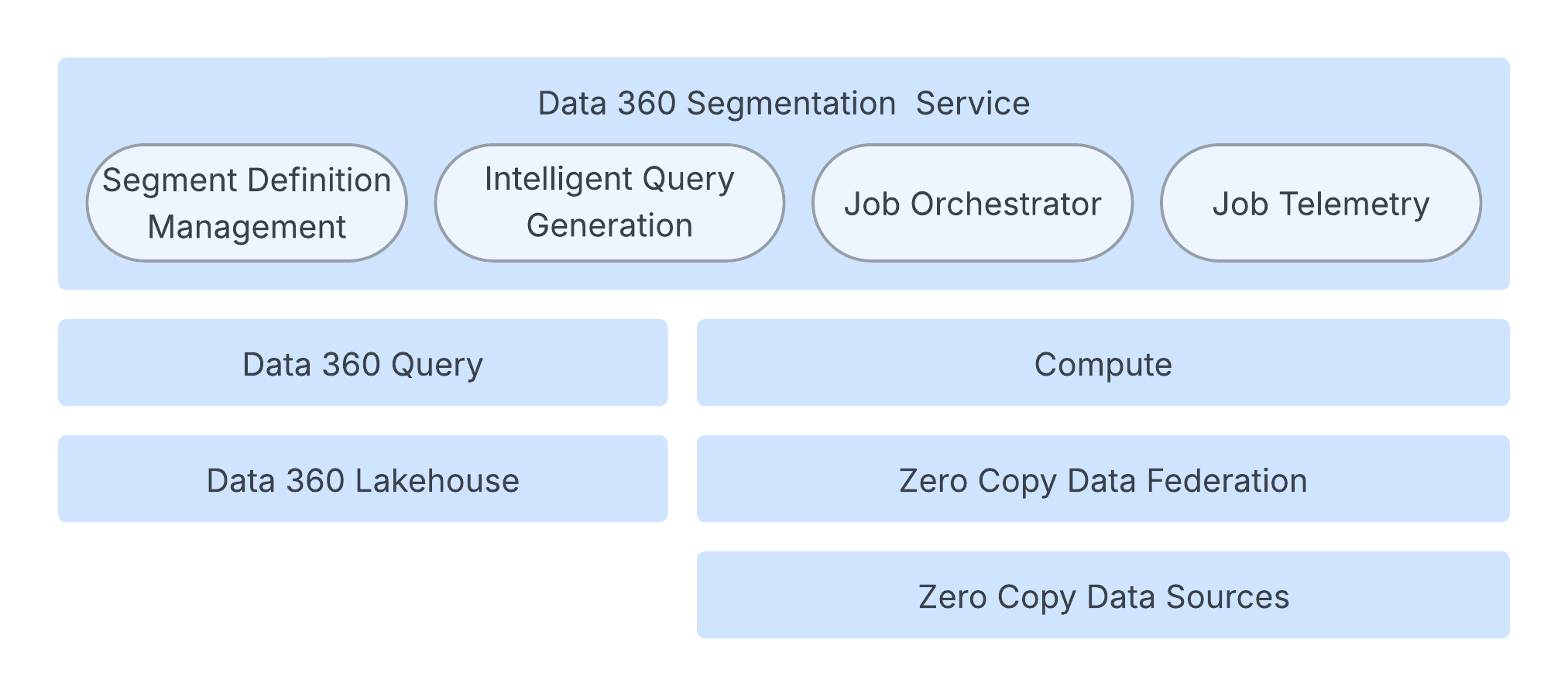
Ydintaprosessia hallitaan työn orkestrointipalvelulla, joka hallitsee segmentin elinkaarta, luo tarvittavan työkokoonpanon ja käynnistää suorituksen. Tämä orkestrointikerros ylläpitää osavaltio- ja metadataa rajatussa tietokannassa skaalattavuutta varten.
Vaikka Data 360 -kysely käsittelee segmentointien määrän laskutoimet, Spark-laskentakerros on vastuussa segmentin todellisen jäsenyyden laskemisesta. Spark-sovellus suorittaa Spark SQL -kyselyitä suurelle asiakkaiden datalle. Nämä tiedot voivat sijaita Data 360 Lakehouse -tietokannassa, ulkoisissa järjestelmissä Zero Copy -datayhdistämisen kautta tai niiden yhdistelmässä.
Järjestelmä on optimoitu tehokkaasti älykkään kyselyn luomisella, joka tarkentaa sen perustana olevaa Spark SQL -kyselyä. Tämä sisältää tekniikoita, kuten osioiden älykkään pienentämisen datan skannauksen vähentämiseksi ja tarpeettomien alilausekkeiden poistamiseksi. Palvelun luotettavuuden varmistamiseksi arkkitehtuuri sisältää mukautetun resurssien hallinnan, joka säätää laskentaresursseja dynaamisesti työkuormien koon ja monimutkaisuuden perusteella. Lisäksi SLO-yhteensopivuutta hallitaan ennakoivasti mukautetuilla kestolla ja uudelleenyrityksellä. Käyttäjäkokemuksen nopeuttamiseksi nopeutetut segmenttien määrät käyttävät näytteenpohjaista lähestymistapaa tarjotakseen nopeita kokoluokituksia segmentin luonnin aikana, jolloin kyselyn täysi suorituskyky välttyy.
Lopuksi havaittavuutta ja juurisyyn kohdistusta koskeva keskitys säilytetään kattavan Spark-suorituksen tilastojen ja virheiden automatisoidun luokittelun avulla (esimerkiksi asiakaspuolen vs. järjestelmäongelmat), mikä vähentää merkittävästi diagnoosiaikaa ja varmistaa erittäin joustavan datalustan.
Aktivointi on kriittinen viimeinen vaihe Data 360 -elinkaaressa. Sen ydintoiminto on muuntaa staattisia, segmentoituja ja yhtenäistettyjä asiakasprofiileja interaktiiviseksi ja rikastetuksi dataksi ja toimittaa nämä tiedot sisäisiin ja ulkoisiin päätepisteisiin (kuten Marketing Cloud, Commerce Cloud ja Adtech-alustat). Tämä prosessi on suunniteltu käynnistämään henkilökohtaisia asiakasmatkoja ja lähes reaaliaikaisia vuorovaikutuksia. Se tukee edistyneitä ominaisuuksia, kuten liittyviä attribuutteja, aktivoinnin jäsenyyksien suodatusta, suostumusten suodatusta, rajoittamista ja sijoitusta.
Aktivointi tarjoaa kolme erillistä menetelmää ulkoisen toimituksen ja kanavan vaatimustenmukaisuuden varmistamiseksi:
- Erän aktivointi: Suunniteltu raskaille ajoitetuille toiminnoille, kuten suurille sähköpostikampanjoille ja mainosyleisöjen päivityksille. Data toimitetaan vaiheistamalla se Secure Internal Buckets (Cloud Object Storage) -tilaan tai Secure File Transfer -toiminnon kautta, jonka jälkeen kohdejärjestelmä käynnistää API-tuontiprosessin. Eräaktivoinnit voivat käyttää erityistä päivitystilaa - asteittaista - vähentääkseen Salesforce-kumppaneille lähetettyjä ja käsiteltyjä määriä.
- Streaming-aktivointi: Optimoitu lähes reaaliaikaisille käyttötapauksille, jotka vaativat tapahtumiin perustuvaa automatisointia. Toimitus tapahtuu suorilla API-kutsuilla, jotka lähetetään kohdepäätepisteeseen.
- Aktivoinnin käynnistämät kulut: Tämä erittäin alustettu kanava tarjoaa ilman koodia ja vähäisen koodin lähestymistavan kohdeyleisöjen datan integroimiseen satojen asiakasrajapintaa tukevien osallistumisalustojen kanssa. Kun aktivointi on suoritettu, Data 360 täyttää kohdeyleisöjen DMO-organisaation, joka käynnistää High Scale -kulun. Kulkujärjestelmä myöhemmin kuluttaa kohdeyleisöjen dataa ja hyödyntää sovellusalustan ominaisuuksia, kuten Ulkoiset palvelut ja Mule-lähtevät kohteet, soittaakseen puheluita lopulliseen API-pohjaiseen kohteeseen. Tämä menetelmä vähentää merkittävästi uusien aktivointikohteiden päivittämiseen tarvittavaa aikaa.
Aktivointi käyttää samoja kuvioita kuin segmentointi töiden hallintaan, jaettuun suoritukseen ja valvontaan. Tämä sisältää työn orkestrointipalvelun periaatteet elinkaaren hallinnalle ja käsittelyn laskentakerroksen (Spark), ja se perustuu töiden telemetriaan suorituskyvyn havaittavuuden ja palvelutasotavoitteiden (SLO) noudattamisen varmistamiseksi.
Näiden lisäksi aktivoinnilla on -
Aktivointikohteiden hallinta valvoo kaikkien kohdepäätepisteiden suojattuja yhteyksiä, tunnuksia ja kokoonpanoja. Se takaa, että datamuodot ja suojausprotokollat on standardoitu, mikä varmistaa luotettavan lähtevän toimituksen eri alustoille, mukaan lukien Marketing Cloud, Adtech-kumppanit ja muut ulkoiset sovellukset.
Aktivointi räätälöi tietyn kohteen hyötykuormaa. Jos käytät Salesforce Marketing Cloudia, tämä sisältää Business Unit (BU) Awareness -suodattamisen, Multi-EID-tuen ja ristiinvalmistuksen hallinnan.
Viestintähallinta-sovellus toimii portinvalvojana ja varmistaa, että datan käyttö ja viestintä noudattavat asiakkaiden valintoja ja lakisääteisiä vaatimuksia. Keskitetty suostumusmalli yhdistää kaikki asiakkaan valinnat, aina globaaleista tilausten peruutuksista kanavien ja käyttötarkoituskohtaisiin suostumuksiin, ja ne tallennetaan yhtenäistettyyn yksityishenkilön profiiliin. Sovellusalusta noudattaa näitä käytäntöjä tarkasti suorituksen aikana käyttämällä poissulkujen suodatusta poistaakseen suostumusta kieltäneet yksityishenkilöt automaattisesti lopullisesta tietosisällöstä. Lisäksi järjestelmä käyttää yhteydenottopisteen valintasääntöjä varmistaakseen, että se käyttää yksittäistä, yhteensopivinta ja suosimaansa yhteydenottopistettä suunnitellulle kanavalle ennen kuin tietoja lähetetään. Tämä täytäntöönpanomekanismi on suojattu sen perustana olevalla hallintajärjestelmällä, joka käyttää suojaustoimia, kuten dynaamista datan peittämistä ja käyttöoikeuksien hallintaa, suojatakseen luottamukselliset datakentät aktivointiprosessin aikana.
Yhtenäistetyn datalustan todellinen arvo on sen kyky tarjota vaivattomasti yhdenmukainen pääsy kaikkiin sen dataresursseihin riippumatta niiden alkuperästä tai rakenteesta. Salesforce Data 360:n yhtenäistetty kysely -ominaisuus on suunniteltu tarkasti tämän saavuttamiseksi, ja se hyödyntää monimutkaisten datasäiliöiden perustana olevia monimutkaisuuksia tarjotakseen yhden tehokkaan kyselyliittymän.
Yhtenäistetty kyselykerros tarjoaa monimutkaisia käyttöoikeuksia erilaisille kulutuskuvioille:
- Hybridirakenteinen ja jäsentämätön kysely: Se tarjoaa laajan SQL-tuen, jolla voit kysellä rakenteellista dataa ja jäsentämättömän datan rakenteellista metadataa saumattomasti. Tämä parantaa operaattorin laajennettavuutta taulukkofunktioiden kautta, mikä mahdollistaa erikoistuneen haun teksti-, kuva- ja tilatyypeissä.
- Kiihtynyt suorituskyky Hypern avulla: Data 360 nopeuttaa monimutkaisia analyyttisiä kyselyitä ja interaktiivisia mittaristoja hyödyntämällä Hyperia, joka on tehokas muistin sisäinen järjestelmä, ja tarjoaa lähes välittömiä vastauksia suurille datajoukoille.
- Yhtenäistetty lähestymistapa tekoälyyn ja personalisointiin: Tämä yhtenäistetty käyttöoikeus on tärkeä kohdennettujen ja henkilökohtaisten tulosten luomiseksi, mikä helpottaa suoraan tarkempia LLM-vastauksia käyttämällä haun parannettua generointia (Retrieval Augmented Generation, RAG) perustamalla tekoälymallit muotoiltuun, yritystietoon.
- Integraatio downstream-kulutukseen: Se toimii perustason datan käyttöoikeuskerroksena käyttöliittymään perustuville käyttökokemuksille, kestäville API-rajapinnoille, generoitaville tekoälyn työnkuluille ja CRM-rikastukselle, mikä yhdistää datan saumattomasti aktivointiin.
Tarjoamalla yhden, älykkään ja tehokkaan kyselyliittymän, Data 360:n yhtenäistetty kysely sallii arkkitehtien laatia joustavia, dataan perustuvia sovelluksia, jotka hyödyntävät asiakkaidensa kaikkia tietoja.
Data 360 on aktiivinen alusta, joka tukee myyntiputkien aktivointia vastauksena datatapahtumiin. Esimerkiksi merkittävä tapahtuma, kuten asiakkaan tilin saldon lasku, voi käynnistää Salesforce-kulun orkestroimaan sitä vastaavan toiminnon. Vastaavasti tärkeimpien tilastojen päivitykset, kuten elinkaaren käyttö, voidaan automaattisesti levittää asiaankuuluville sovelluksille.
Datatoiminnot valvovat muutosten asteittaista dataa jatkuvasti käyttämällä tallennustilan natiivija muutostapahtumia (SNCE) ja muutostietojen syötettä (CDF). Tämä data arvioidaan asiakkaan määrittämien toimintosääntöjen perusteella, kuten kynnysarvon valvonta tai tilojen muutokset. Kun nämä säännöt täyttyvät, datatoiminnon tapahtuma luodaan. Tämä tapahtuma on rikastettu lisätiedoilla (esimerkiksi asiakasuskollisuuden tila) ja se lähetetään välittömästi määritettyyn kohteeseen, kuten Salesforce-kulkuun tai ulkoiseen sovellukseen liiketoiminnan orkestroinnin käynnistämiseksi.
Data 360 tukee CDP (Customer Data Platform) -ominaisuuksia, mukaan lukien edistyneitä identiteettien ratkaisemiseen liittyviä ominaisuuksia sekä yhtenäistettyjen yksittäisten tunnisteiden ja profiilien luomista sekä kattavia osallistumishistorioita. Tämä alusta on hyvä käsittelemään sekä B2B- että B2C-kehyksiä tukemalla identiteettien ratkaisua ja identiteettikaavioita, jotka käyttävät sekä tarkkoja että epätarkkoja täsmäyssääntöjä yllä kuvatulla tavalla. Nämä identiteettikaaviot on rikastettu osallistumistiedoilla useista eri kanavista, mikä auttaa laatimaan yksityiskohtaisia profiilikaavioita arvokkailla analyysihavainnoilla ja segmenteillä.
Datakaavio on tärkeä asiakkaan profiilia tukeva käsite. Data 360 tarjoaa Enterprise-datakaavion JSON-muodossa, joka on denormalisoitu objekti, joka saadaan useista Lakehouse-taulukoista ja niiden välisistä suhteista. Tämä sisältää CDP:n luoman ”Profile”-datakaavion, joka sisältää henkilön ostos- ja selaushistorian, tapaushistorian, tuotteiden käytön ja muita laskettuja havaintoja, ja jonka asiakkaat ja kumppanit voivat laajentaa. Nämä Datakaaviot on räätälöity tietyille sovelluksille ja parantavat luotujen tekoälyn kehotteiden tarkkuutta tarjoamalla asiaankuuluva asiakkaan tai käyttäjän konteksti. Data 360:n reaaliaikainen kerros käyttää profiilikaaviota reaaliaikaiseen personalisointiin ja segmentointiin. Oletetaan, että mallinnamme Agentforce Contextia, joka sisältää keskustelut, istunnot ja agenttien muistin Datakaavioina.
Lisäksi CDP sallii tehokkaan segmentoinnin ja aktivoinnin eri alustoilla, kuten Salesforcen Marketing Cloudissa, Facebookissa ja Googlessa. Se käsittelee asiakasprofiilit erässä, lähes reaaliajassa ja reaaliajassa, mikä mahdollistaa välittömän päätöksenteon ja personalisoinnin. Tämä toiminto parantaa vuorovaikutuksia sekä B2C- että B2B-skenaarioissa, jotta yritykset voivat vastata asiakkaiden tarpeisiin ja toimintatapoihin nopeasti ja tarkasti.
Data 360:n reaaliaikainen kerros tukee Data 360 CDP:tä ja laajentaa sen käsitteitä reaaliaikaisiin käyttötarkoituksiin. Data 360:n reaaliaikainen kerros on suunniteltu käsittelemään tapahtumia, kuten verkko- ja mobiililaitteiden napsautusketjuja, vierailuja, ostoskorin dataa ja checkout-tapahtumia millisekunteina, mikä parantaa asiakaskokemuksen personalisointia. Se valvoo asiakkaiden osallistumista jatkuvasti ja päivittää asiakasprofiilin Customer 360:sta reaaliaikaisilla osallistumistiedoilla, segmenteillä ja laskutoimilla, jotta se voidaan mukauttaa välittömästi.
Kun esimerkiksi kuluttaja ostaa kohteen verkkokaupasta, reaaliaikainen kerros havaitsee ja tuo tapahtuman nopeasti, tunnistaa kuluttajan ja rikastaa hänen profiilinsa päivitetyillä käyttöiän kuluilla. Tämä sallii heidän mukauttaa käyttökokemustaan sivustolla muutamassa sekunnissa. Lisäksi tämä kerros sisältää reaaliaikaisia käynnistimiä ja vastauksia, mikä mahdollistaa välittömät toiminnot asiakkaan vuorovaikutusten perusteella.
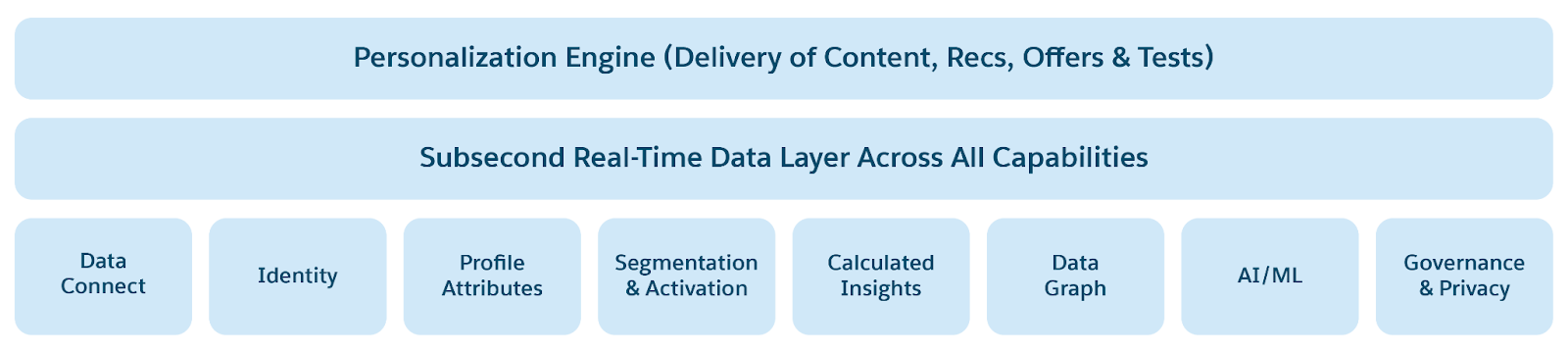
Sub-Second Real-Time -alusta tarjoaa tämän transformaation useilla tärkeimmillä ominaisuuksilla:
- Reaaliaikaiset Datakaaviot: Customer 360 -profiili laaditaan käyttämällä denormalisoitua kaaviota, joka sisältää tärkeimmät objekit ja kentät, jotka ovat tärkeimpiä brändeille. Nämä Datakaaviot sallivat reaaliaikaisen datan käsittelyn ja tarjoavat interaktiivista sisältöä ja havaintoja millisekunteina
- Reaaliaikainen syöttö ja muuntaminen: Tuo käyttäjätapahtumia ja profiileja millisekunteina verkko- ja mobiililaitteilta.
- Reaaliaikainen identiteetin vahvistus: Yhdistä asiakasprofiileja eri laitteilla ja yhdistä tuntemattomat ja tunnetut käyttäjät välittömästi.
- Reaaliaikaiset lasketut havainnot: Laske tilastot, kuten elinkaaren arvo (LTV) tai käyttäjien vierailuhistoria millisekunteina, ottaaksesi Personalisointi- tai Tarjoukset-ominaisuuden käyttöön verkossa, Chatbotissa tai palveluagenteissa.
- Reaaliaikainen segmentointi: Segmentoi kohdeyleisöjä lennolla, mukauttaaksesi viestejä ja vuorovaikutuksia reaaliajassa.
- Reaaliaikaiset toiminnot: Salli brändien arvioida käyttäjien osallistumista ja suorittaa toimintoja Salesforce-kulun tai muiden asiaankuuluvien viestintäkanavien kautta.
Rakensimme Data 360:ssa uuden reaaliaikaisen sovellusalustan, joka sisältää reaaliaikaisen myyntiputken, vähäisen viiveen tallennustilan ja datan käsittelykerroksen alle sekunnissa. Kun interaktiivista dataa tuodaan nopeasti verkkokanavista ja mobiilikanavista, se läpäisee useita nopeita prosesseja.
Web & Mobile SDK-pakettimme ja reaaliaikaiset API-rajapintamme keräävät dataa verkkosovelluksista/mobiilisovelluksista (myöhemmissä Agenttic-vuorovaikutuksissa) ja lähettävät sen virtalähteemme. Tämä data reititetään sitten reaaliaikaiseen kerrokseen millisekuntien käsittelyä varten ja Lakehouse-kerrokseen erä-/virtausdatan integrointia varten. Real-Time-kerros käsittelee saapuvat reaaliaikaiset tiedot käyttäjäprofiilin (anonyymin tai sisäänkirjautuneen) asiayhteydessä, esimerkiksi päivittääkseen käyttäjien kokonaiskulutuksen tai elinkaaren arvon, jne. istunnon sisäiselle reaaliaikaiselle personalisoinnille. Real-Time-kerros tukee päämuistia ja NVme (SSD) -tallennustilaa reaaliaikaisten tietojen ja asiakasprofiilien säilyttämiseen. Kun data on reaaliaikaisessa kerroksessa, se suorittaa seuraavat prosessit ennen kuin se päivitetään reaaliaikaiseen datakaavioon:
- Yksinkertainen syöttö ja transformaatiot: Data tuodaan ja muunnetään jatkokäsittelyä varten.
- Identiteetin vahvistus: Tarkkoja täsmäyssääntöjä sovelletaan profiilien yhtenäistämiseen kaikkien olemassa olevien täsmäyssääntöjen joukkojen kanssa, joten datan tuntevien asiantuntijoiden ei tarvitse luoda uusia identiteettien ratkaisusääntöjä vain reaaliaikaisesti.
- Lasketut havainnot: Jokainen osallistumistoiminto arvioidaan, yksinkertaiset laskutoimet, kuten summa ja määrä millisekunteina, suoritetaan ja data päivitetään reaaliaikaisessa datakaaviossa.
- Reaaliaikaiset segmentit: Jokainen osallistumistiedot arvioidaan määrittääkseen, täyttääkö se määritettyjen reaaliaikaisten segmenttien ehdot, ja käyttäjät lisätään hyväksyttyihin segmentteihin millisekunteina.
- Reaaliaikaiset toiminnot ja käynnistimet: Jokainen osallistumistoiminto arvioidaan määritettyjen sääntöjen perusteella käynnistääkseen toimintoja eri tavoitteisiin reaaliajassa, kun säännöt täyttyvät millisekunteina.
- Reaaliaikainen datakaavio ja API: Reaaliaikainen datakaavio, joka sisältää myös reaaliaikaisen API:n, sallii brändien noutaa päivitettyjä JSON-muotoisia tietoja kullekin käyttäjälle varmistaakseen, että kaikki asiakasvuorovaikutukset ovat ajan tasalla tuoreimmista tiedoista.
Personalisointi tarkoittaa, että tiedät, kenelle kohdistaa, milloin ja missä tarjota asiaankuuluvaa sisältöä ja suosituksia, mitä sanoa ja kuinka usein. Personalization Services Platform on orkestroija päätöksille, joita tehdään tavoitteiden saavuttamisen optimoimiseksi henkilökohtaisilla käyttökokemuksilla.
Mukautuspalvelut tarjoavat seuraavat ominaisuudet:
- Johdonmukainen joukko malleja ja tapoja tulkita profiilien, toimintojen ja omaisuuksien dataa Data 360:ssa
- Sovellusalustan integroitu kokeilu (A/B/n, Multi-Arm Bandit)
- Tavoitteiden integrointi suunnittelun aikana (kokoonpano), ML-koulutusajan ja suorituksen aikana (ML-lauseke)
- B2C-asteikon reaaliaikainen ja erävuorovaikutusten tuki (anonyymit käyttäjät, paljon reaaliaikaa / interaktiivinen ulkoinen, paljon sisäistä erää)
- Analytics, jota käytetään Data 360:n kautta
- Kuvioita tekoälymallin ja palvelun integroimiseen muista osapuolista (sisäisistä ja ulkoisista)
- Integraatio ydinmetadatan ekosysteemiin (PLATE-ominaisuudet)
- OOTB-toteutukset arvokkaille tekoälyn perustuville käyttötarkoituksille (suositukset/päätökset useilla ML-algoritmeilla, mukaan lukien kontekstissa olevat rosvot tarjousta/sisällön valintaa varten, tuotesuositukset, hinnoittelupäätökset jne.)
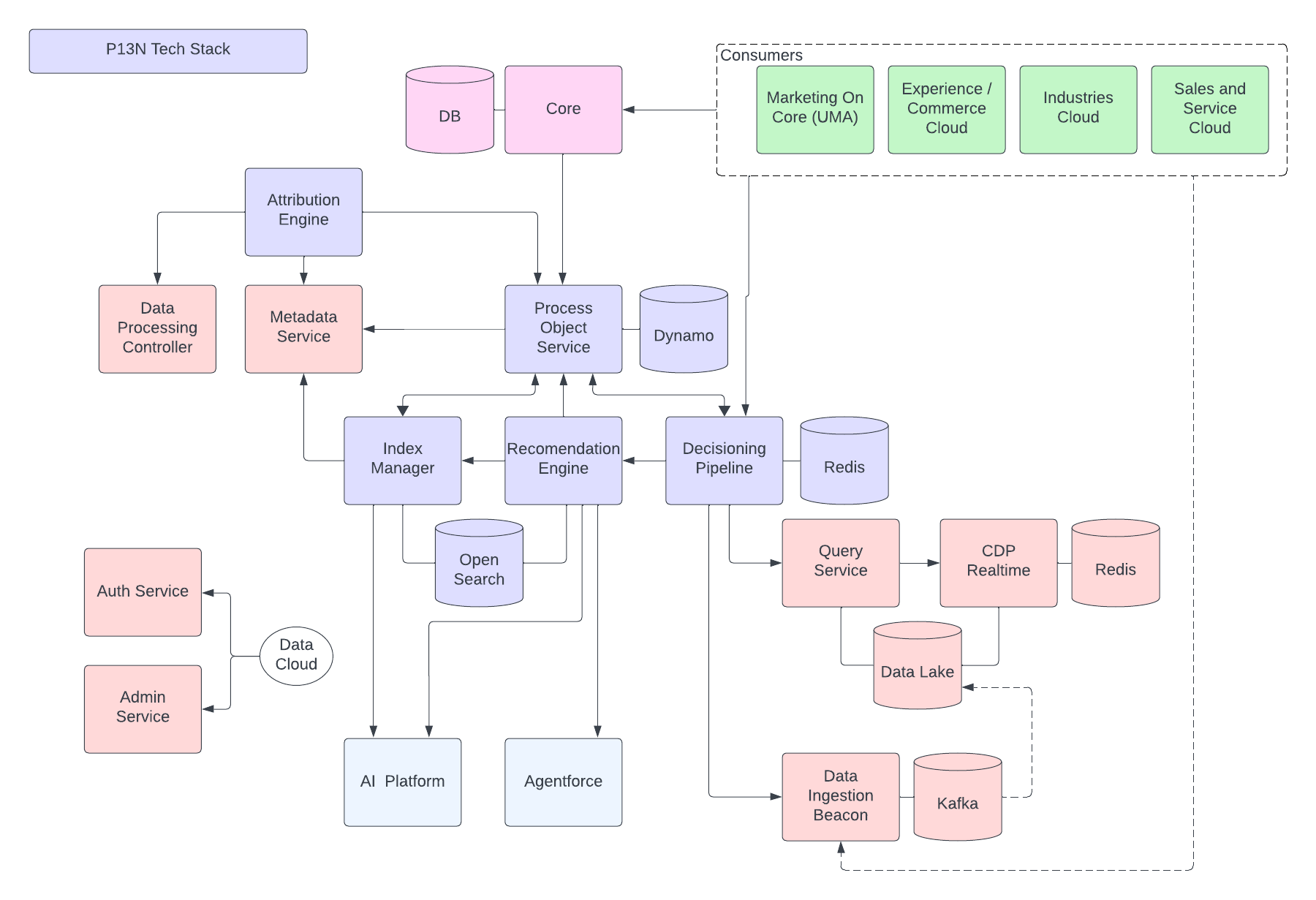
- Päätösputki
- Ulkoisten pyyntöjen tarjoaminen personalisointipäätöksille, mukaan lukien profiilien augmentointi, kokeilu ja suositukset.
- Suositusjärjestelmä
- Sääntö- tai ML-pohjaisten suositusten suorituksen aikainen huolto.
- Index Manager
- Hallitsee/orkestoi ei-synkronoitujen prosessien työnkulkua, mukaan lukien suositusmallien ML-koulutukset
- Process-objektin palvelu
- Vastuuhenkilö, joka synkronoi personalisoinnin metadatan ydin- ja off-core-muuttujien välillä
- Määritysjärjestelmä ja kokeilu
- Analytics-määrittäminen ja personalisointisuositusten kokeileminen
Data 360 on suunniteltu vahvaksi ja kattavaksi alustaksi, joka on suunniteltu tukemaan uusia agenttien käyttökokemuksia. Voimme saavuttaa nämä ominaisuudet käyttämällä useita olemassa olevia Data 360 -palveluita ja syvällistä integraatiota Agentforcen kanssa.
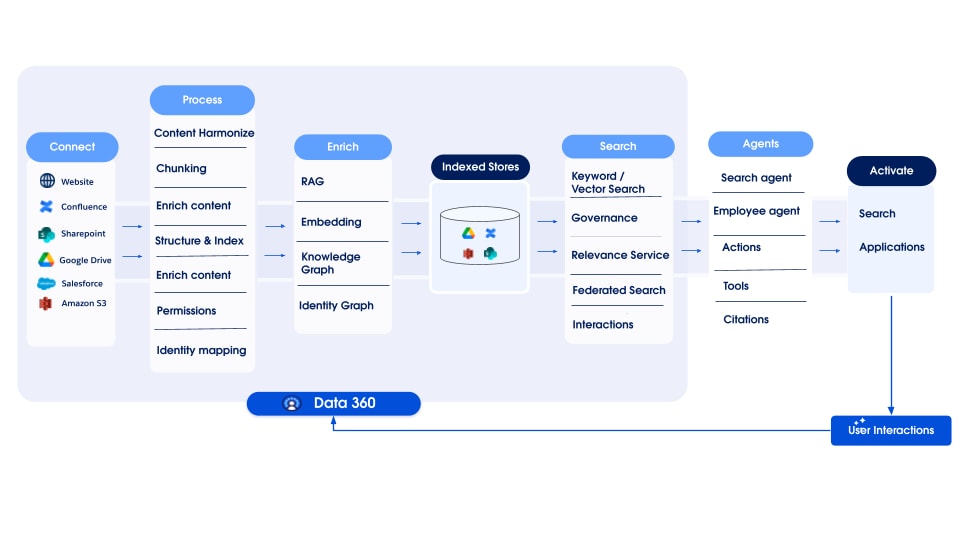
Agentic Enterprise Searchin lähestymistavamme perustuu seuraaviin periaatteisiin:
- Yritystietoja säilytetään erillisissä palveluissa tai myymälöissä, joilla on suojatut käyttöoikeudet. Kyky käyttää näitä tietoja ja käsitellä niitä samalla, kun lähdeoikeudet säilytetään, on tärkeää Trustin varmistamiseksi.
- Ristiinlaskenta ja relevanttius datan koko joukossa mahdollistavat parempia tuloksia, mikä puolestaan voi tarjota parempaa kontekstia agenttien käyttökokemuksille.
Agent Enterprise Search perustuu näihin tärkeimpiin arkkitehtokomponentteihin tarjotakseen näitä käyttökokemuksia:
- Liittimet: Data 360:ssä käytettävissä olevien liittimien laaja joukko sallii sinun käyttää ja tuoda tietoja useista eri lähteistä.
- Rakenteeton datan käsittely: Tämä on olennainen osa ei-taulukkomuotoisen sisällön käsittelyä, jolloin järjestelmä voi luoda merkitystä ja tietoja eri tiedoista.
- Hallinta: Varmistaa yritystason tietoturvan, vaatimustenmukaisuuden ja käyttöoikeuksien hallinnan kaikille haun kuluttamille tiedoille. Lähteiden näkyvyysoikeuksien tuki varmistaa, että tiedot ovat vain valtuutettujen käyttäjien käytettävissä sekä yksinkertaisen haun että agenttien käyttökokemuksissa. Hakukentät arvioivat ja noudattavat tietoturvaa koskevia käyttöoikeuksia oletusarvoisesti tietojen käytön varhaisimmassa vaiheessa, jotta ne voidaan noutaa nopeasti.
- Yhtenäistetty noutokerros: Liittimet syöttävät kattavaan yhtenäistettyyn noutokerrokseen ratkaistakseen eristettyjen tietojen ongelman. Tämä kerros tarjoaa yhden käyttöoikeuspisteen kaikkiin tietoihin riippumatta siitä, säilytetäänkö se ulkoisissa järjestelmissä, joita käytetään yhdistetyn haun kautta, vai hallitaanko sitä oletusarvoisesti nollakopioinnin ja tuodun datan edistyneiden indeksien avulla.
- Älykäs kyselyiden ymmärtäminen: Ennen kuin järjestelmä noudetaan, se käyttää tekoälymekanismeja käyttäjän tarkoituksen tulkinnassa. Sen lisäksi, että se upottaa kyselyn esitelmiä semanttiselle vektori-vastaavuudelle, se voi kirjoittaa ja laajentaa avainsanoihin perustuvia hakuja tarkkuuden parantamiseksi.
- Hybridihaku ja edistynyt kysely: Sovellusalusta käyttää useita strategioita rinnakkain löytääkseen asiaankuuluvimmat tiedot. Hybridihaku tarjoaa tarkat avainsanat, jotka vastaavat semanttista vektorihakua optimoiduille datan osille, kun taas koko tietueen haku noutaa samanaikaisesti kokonaisia asiakirjoja. Molemmat varmistavat semanttisen relevanttiuden ja kattavan sisällön kattavuuden.
- Hierarkkinen järjestys: Kun data on noudettu, monivaiheinen hierarkkinen järjestysarkkitehtuuri pisteyttää, yhdistää ja järjestää tulokset kaikista lähteistä ja metodeista. Tämä prosessi luo yhden yhtenäisen luettelon, joka näyttää käyttäjälle tai agentille tärkeimmät tiedot.
Generoiva tekoäly siirtää yrityshaun ensisijaisen kuluttajan ihmiskäyttäjistä suurten kielten malleihin (LLM). Data 360 Search on suunniteltu tarjoamaan molempia. Se on optimoitu käsittelemään agenttien pitkiä ja monimutkaisempia kyselyitä ja palauttamaan muotoiltuja ja asiayhteydestä riippuvaisia tuloksia, joita tarvitaan ohjelmalliseen kulutukseen ja päättelyyn. Samalla järjestelmä voi käsitellä lyhyempiä ja usein epätarkkoja kyselyitä, jotka ovat tyypillisiä ihmiskäyttäjille, tarjoamalla ominaisuuksia, kuten koodikatkelmia ja korostuksia nopeaa arviointia varten käyttöliittymässä.
Agenteellisten hakukokemusten täydellinen tarjoaminen yhdistää molemmat lähestymistavat:
- Suorat hakutulokset: sovellus voi näyttää perinteisen luettelon lajiteltujen tulosten perusteella käyttämällä metadataan perustuvaa API-rajapintaa, joka perustuu Data 360:n yhtenäistettyyn hakusääntöön.
- Agenttiset, monivaiheiset selkokieliset vastaukset: agenttiset vastaukset toteutetaan natiivin integraation kautta Agentforcen kanssa. Tämä selkokielinen käyttökokemus perustuu ensisijaiseen agenttiin, joka orkestroi toimintoja ja kyselyitä ja delegoi kaikki tietojen hakutehtävät erikoistuneelle, sisäiselle hakuvirkailijalle.
Tämä erikoistunut hakuagentti on optimoitu yrityksen tietojen noutamista varten. Se käyttää perusteluikkunaa laatiakseen ja suorittaakseen rinnakkaisia hakuja tutkiakseen käyttäjän pyynnön eri osa-alueita. Se käyttää tehokkaita työkaluja, kuten Data 360:n yhtenäistettyä hakua kaikille datatyypeille ja rakenteellisille kyselykieleille noutaakseen tarkkoja tietoja taulukoista ja entiteeteistä.
Tämän arkkitehtuurin synteesin avulla Data 360 sallii älykkäiden, asiayhteydestä riippuvaisten ja interaktiivisten agenttien hakukokemusten luomisen yrityksille.
Laajennettavuus on tärkeä Salesforce Platform -ominaisuus. Koodilaajennus tarjoaa laajennettavuuden Data 360:ssa, jolloin koodinkäyttäjät voivat suorittaa mukautettua Python-logiikkaa suoraan Data 360 -ympäristössä, täydentämällä sen kattavia deklaratiivisia ja alhaisen koodin ominaisuuksia. Koodilaajennuksen avulla käyttäjät voivat laajentaa Data 360 -ydintoimintoja turvallisesti, kuten Muunnokset ja Jäsentämättömät dataputket (mukautettu pilkkominen).
Koodilaajennuksen suunnittelumme priorisoi joustavuutta, tietoturvaa, tehokkuutta ja virtaviivaista kehityskokemusta. Se tukee kahta ensisijaista suoritusmallia, jotka on räätälöity tiettyihin arkkitehtuuritarpeisiin:
- Skriptimalli:
- Tavoite: Kattava mukautettu logiikka, joka vaatii suoraa vuorovaikutusta Data 360 Lakehousen kanssa.
- Ominaisuus: Asiakkaat kirjoittavat täysiä Python-komentosarjoja käyttämällä Code Extension SDK -pakettia, joka sallii luku- ja kirjoitusoikeuden Lakehouseen SDK API -rajapintojen kautta. Soveltuu hyvin mukautetun/monimutkaisen datan valmisteluun tai mukautetun datan manipulointiin.
- Eristys ja turvallisuus: Kun komentosarjat käyttävät Lakehousea, niiden suoritus on rajoitettu turvalliseen, eristettyyn ympäristöön Data 360 -suorituksen aikana, mikä estää häiriöitä muihin prosesseihin tai valtuuttamattoman järjestelmän käyttöä.
- Funktiomalli:
- Tavoite: Vastaavasti palvelinottomaan funktioon, jos modulaarisia, tilattomia laskutoimia kutsutaan olemassa olevista Data 360 -putkeista (esimerkiksi mukautettu pilkkominen jäsentämättömässä putkessa).
- Ominaisuus: Asiakkaan tarjoamat funktiot käyttävät input-, compute- ja return-toimintoja.
- Eristys ja turvallisuus: Nämä funktiot on suunniteltu tiukkaa eristystä varten. Niillä ei ole suoraa Lakehouse-käyttöoikeutta. Niiden suorituskyky on sandbox-muotoinen, tilaton ja resurssien rajoittama, joten ne soveltuvat keskitetyille ja tilattomille käsittelyvaiheille, jotka varmistavat tietoturvan, ennustettavan suorituskyvyn ja minimoivat räjähdyksen säteen.
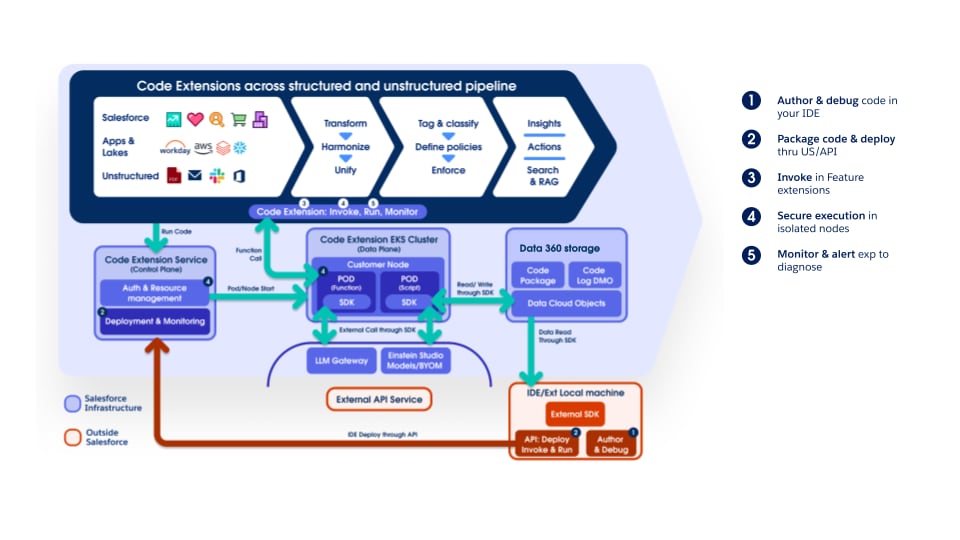
Sekä komentosarja- että funktiomallit pyrkivät suorittamaan asiakaskoodin turvallisesti estämällä yhden vuokralaisen koodia vaikuttamasta muihin tai saamasta luvatonta pääsyä muiden vuokralaisten tietoihin, Salesforce-resursseihin tai ulkoisiin resursseihin. Tämä tietoturva saavutetaan kerrostetulla (defense-in-depth) arkkitehtuurilla. Tämä arkkitehtuuri tarjoaa erillisen suoritusympäristön jokaiselle vuokralaisen mukautetulle koodille, joka sisältää useita suojausruutuja. Näihin sisältyvät looginen eristys Kubernetes-tasolla (K8s), verkon eristys, runtime-sandbox ja vähiten käyttöoikeuksia koskevat käyttöoikeudet, jotka kaikki on täydennetty operatiivisella valvonnalla ja vahinkotapahtumien vastauksen valmiudella havaita ja vastata.
Koodilaajennus tarjoaa seuraavat ominaisuudet kestävän kehitysjakson tukemiseksi:
- Ulkoinen kirjoitus ja virheenkorjaus: Kehittäjät voivat luoda ja korjata Python-koodia tutuissa ympäristöissä, kuten VSCode, hyödyntämällä SDK:tä.
- Joustava käyttöönotto: Mukautettu koodi voidaan pakata ja ottaa käyttöön SDK-apukohteilla, Data 360 -käyttöliittymällä tai API:lla, mikä mahdollistaa integraation CI/CD-tiedostoon.
Toimintolokit: Käyttöoikeus yksityiskohtaisiin suorituslokeihin tarjoaa läpinäkyvyyttä ja auttaa tuotantoympäristössä.
Data 360 tarjoaa nämä turvalliset ja joustavat koodilaajennusominaisuudet salliakseen arkkitehtien räätälöidä sovellusalustaa omien ainutlaatuisten ja monimutkaisten datan käsittelyvaatimustensa mukaisesti, mikä vahvistaa sen roolia laajennettavan yritystietojen kudoksena.
Kun yritykset nopeuttavat tekoälyn sopeutumista, useimmat ylläpitävät heterogeenisiä ML-ekosysteemejä — kuten Amazon SageMaker, Google Vertex AI ja mukautettuja Python-pohjaisia ympäristöjä — isännöimällä malleja, jotka edistävät tehtävään liittyviä ennusteita, kuten luottoriskien pisteytystä, häiriöennusteita, tuotesuosituksia ja Next Best Action -päätöksiä.
Tavallisesti näiden ulkoisten mallien integrointi Salesforceen vaati räätälöityjä API-kerroksia, ETL-putkia tai välisovelluksen orkestrointia, datan identtisyyden, hallinnon ylimääräisten kustannusten, viiveen ja toiminnan monimutkaisuuden käyttöönottoa — haasteita, jotka ovat ristiriidassa yhtenäistetyn, yhteensopivan ja reaaliaikaisen Customer Data Platform (CDP) -vision kanssa.
Bring Your Own Model (BYOM): Toimitetaan Einstein Studion kautta Data 360:ssa ja se ratkaisee nämä haasteet sallimalla ulkoisesti koulutettujen mallien suoran kutsun Salesforcen työnkuluissa, Apex ja automatisointityökaluissa siirtämättä tai replikoimatta dataa. Data 360 toimii hallitun yksittäisen totuuden lähteenä nollakopioyhdistämisen avulla ja paljastaa yhdenmukaistettua Customer 360 -dataa ulkoisten päätepisteiden johtamista varten. Ennusteiden tulokset kulkevat takaisin reaaliajassa, mikä tarjoaa liiketoimintaprosesseille skaalattavaa älykkyyttä.
BYOM sulkee datatieteen ja toimintatavan välisen aukon tehokkaasti irrottamalla mallien kehittämisen, hallitun datan ja kulutuksen kerrokset. Se säilyttää sovellusalustan riippumattomuuden, vähentää integraation monimutkaisuutta, nopeuttaa tekoälyn käyttöönottoa ja ylläpitää luottamuksellisten tietojen hallintaa.
Arkkitehtuuri toimii seuraavalla tavalla: Data 360 tarjoaa yhtenäisen Customer 360 -tietopohjan, kun taas Einstein Studio orkestroi yhteyksiä ulkoisiin ML-alustoihin (SageMaker, Vertex AI tai mukautetut päätepisteet). Ulkoiset mallit suorittavat johtopäätöksiä reaaliajassa, erätilassa tai streaming-tilassa. Salesforce-kerrokset — Kulku-, Apex ja Query API — kuluttavat tuloksia tarjotakseen henkilökohtaisia, automatisoituja ja analyyttisiä havaintoja myynti-, palvelu-, markkinointi- ja Industry Cloudissa.
Yhtiön näkökulmasta BYOM tarjoaa:
- Datan eheys ja hallinta: Estää hallitsemattomat kopioidut tiedot ja noudattaa käytäntöjä.
- AI:n demokratisointi: Sallii monimutkaisten mallien käytön muille kuin teknisille käyttäjille Salesforce-työkalujen avulla.
- Aika-arvojen nopeutus: Ulkoiset mallit aktivoidaan välittömästi Salesforce-prosesseissa.
- Skaalattavuuden ja hybridirakenteiden tuki: Sallii tekoälyn työkuormien käyttöönoton useissa pilvipalvelimissa.
- Tulevaisuuden valmiina oleva tekoälyarkkitehtuuri: Tukee yhdistettäviä tekoälystrategioita, jotka irrottavat datan, mallin ja kulutuksen kerrokset toiminnan joustavuutta varten.
Make Your Own LLM (BYO-LLM): Tarjoaa saman laajennettavuusmekanismin, mutta generoiville malleille. Otamme ulkoisten LLM:ien suoran kutsun käyttöön salliaksemme asiakkaiden käyttää niitä Agentforce Platformissa Salesforcen tarjoamien mallien sijaan. Yrityksille BYO-LLM sallii:
- Käyttöoikeus hienosäätettyihin malleihin
- Mallien integrointi, joita Salesforce ei tarjoa tällä hetkellä
- Mallien käyttö asiakkaan tarjoamissa tileissä
Nykyiset yritykset toimivat monimutkaisessa data-ympäristössä, jolle on ominaista kaksi merkittävää arkkitehtuurin haasteita:
- Yrityksen sisäinen fragmentointi: Suuret organisaatiot käyttävät usein useita Salesforce-organisaatioita (joita segmentoidaan usein alueen, liiketoimintayksikön tai historiallisen hankinnan mukaan) ja useita muita datajärjestelmiä. Tämä hajonta luo sisäisiä datasiloja, jolloin on mahdotonta luoda yksittäistä, luotettua ja yhtenäistettyä näkymää asiakkaasta reaaliaikaista osallistumista varten koko yrityksessä. Haasteena on yhtenäistää nämä tiedot yhdistämättä niitä fyysisesti tai kopioimatta niitä kaikissa järjestelmissä, jotta hallinta pysyy ennallaan.
- Yritysten välinen yhteistyö: Yritysten täytyy usein jakaa dataa kumppaneiden ja toimittajien kanssa yhteistä markkinointia, mittausta ja liiketoimintaälyä varten. Haasteena on ottaa tämä yhteistyö käyttöön samalla, kun suojaat luottamuksellisia, omistettuja tietoja ja noudatat tietoturvaa koskevia säännöksiä, kuten GDPR ja CCPA, sekä kilpailuvälineitä.
Salesforce Data 360 ratkaisee nämä haasteet käyttämällä nollakopioitua ja Trust by Design -kehystä, joka perustuu periaatteeseen, että käyttöoikeudet ja havainnot jaetaan sen sijaan, että dataa siirretään tai kopioidaan.
Salesforce Data 360 käsittelee datan hajanaisuutta ja yhteistyöhaasteita Data Cloud One-, Data 360:n välisen datan jakamisen ja yksityisyyttä koskevien datan puhdistustilan avulla. Nämä ratkaisut yhtenäistävät asiakastietoja, sallivat tietojen turvallisen vaihdon ja tarjoavat yksityisyyttä koskevia havaintoja. Organisaatiot voivat avata datan potentiaalin reaaliaikaista osallistumista, parannettuja kumppanuuksia ja älykästä päätöksentekoa varten käyttämällä Trust by Design -menetelmää. Nämä datan yhteistyövaihtoehdot tarjoavat eri käyttötarkoituksia.
Sisäinen Enterprise-käyttöönotto Data Cloud One:lla
Data Cloud One on perusrakenteellinen ratkaisu useita Salesforce-organisaatioita käyttäville yrityksille. Sen käyttötarkoitus ylittää tietojen yksinkertaisen jakamisen. Se on suunniteltu luomaan yksi luotettu asiakasnäkymä ja ottamaan käyttöön kaikki Data 360 -sovellusalustan ominaisuudet koko organisaatiossa.
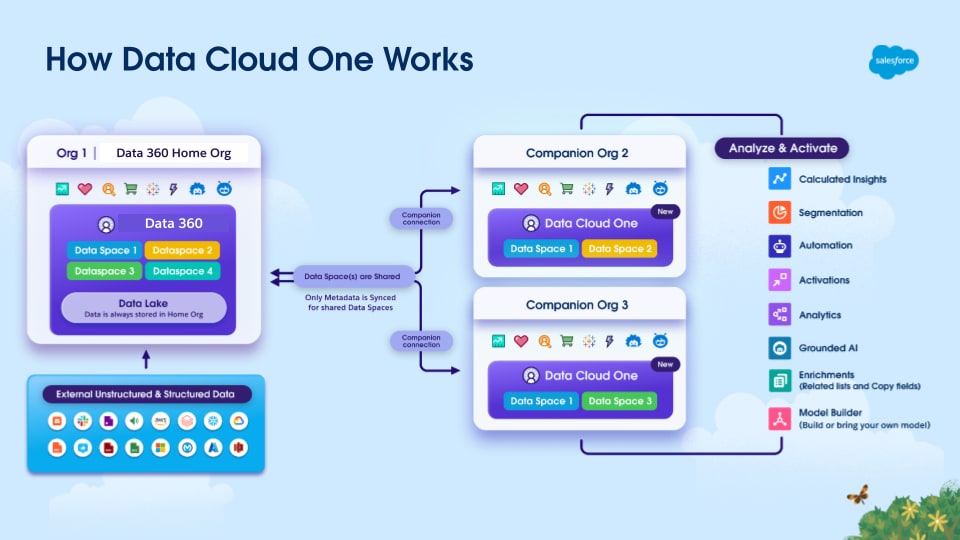
Tämä mekanismi keskittyy valittuun Home Org Data 360 -esiintymään, joka toimii keskeisenä viranomaisena datan hallinnassa ja yhtenäistetyn asiakasprofiilin rakentamisessa. Aloitusorganisaatio on organisaatio, jossa Data 360 provisioidaan. Data 360:n ja muiden Salesforce-organisaatioiden välillä muodostetaan Data Cloud One -yhteys, jota kutsutaan Companion-organisaatioiksi. Data 360 jakaa Data Cloud One -yhteyden osana yhden tai useamman sen datatilan kumppaniorganisaatioiden kanssa, mikä tarjoaa pääsyn jokaisen jaetun datatilan dataan ja metadataan. Tämä saavutetaan nollakopioitujen yhdistämismallien ja organisaatioiden välisen metadatan synkronoinnin avulla.
Data Cloud One sallii myös Companion-organisaatioiden hyödyntää aloitusorganisaation Data 360 -esiintymää omiin aktivointi-, personalisointi- ja älykkyystarpeisiinsa. Tämä strategia on välttämätöntä, jotta voit välttyä sisäisen datan pirstoutumiselta ja varmistaa, että kaikki liiketoimintayksiköt aktivoituvat samaa, hallittua ja yhtenäistettyä asiakasprofiilia vasten, mikä maksimoi Data 360 -ydintoteutuksen ROI:n.
Datan jakaminen Data 360 -organisaatioiden välillä
Data 360 to Data 360 -datan jakaminen yhdistää itsenäiset Data 360 -esiintymät hajautetuille sisäisille ympäristöille (joissa täysi keskittäminen ei ole mahdollista) ja luotettujen ulkoisten kumppanien kanssa tehtävään yhteistyöhön.
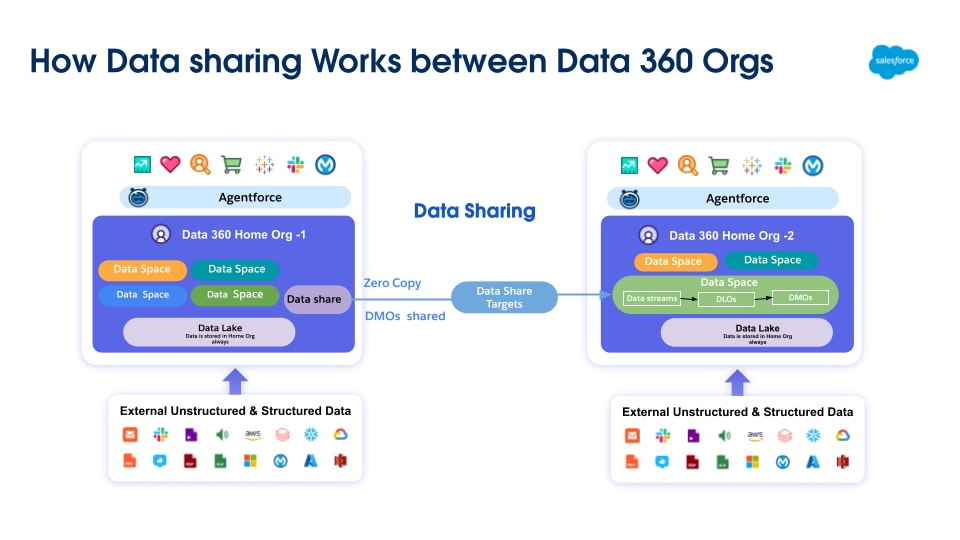
Tämä nollakopioitu jakomalli muodostaa yhteyden eri Data 360 -vuokralaisten välille, jotka on provisioitu eri Salesforce-organisaatioissa datan objektien (DLO-, DMO- ja CIO-objektien) turvallista vaihtoa varten. Kun dataobjekti on yhdistetty, sen koko dataobjekti on käytettävissä vastaanottajan Data 360:ssa. Sen jälkeen vastaanottajan Data 360 -pääkäyttäjä voi määrittää hallintasääntöjä hallitakseen käyttäjien käyttöoikeuksia tähän dataan.
Privacy-first-yhteistyö Data 360 Clean Room -yhteistyötoiminnolla
Kun yhteistyö vaatii korkeimman tason yksityisyyttä ja vaatimustenmukaisuutta tai kun kilpailun aiheuttamat huolenaiheet estävät raakadatan jakamisen, Data 360 Clean Rooms -ominaisuus on arkkitehtuurisesti pakollinen.
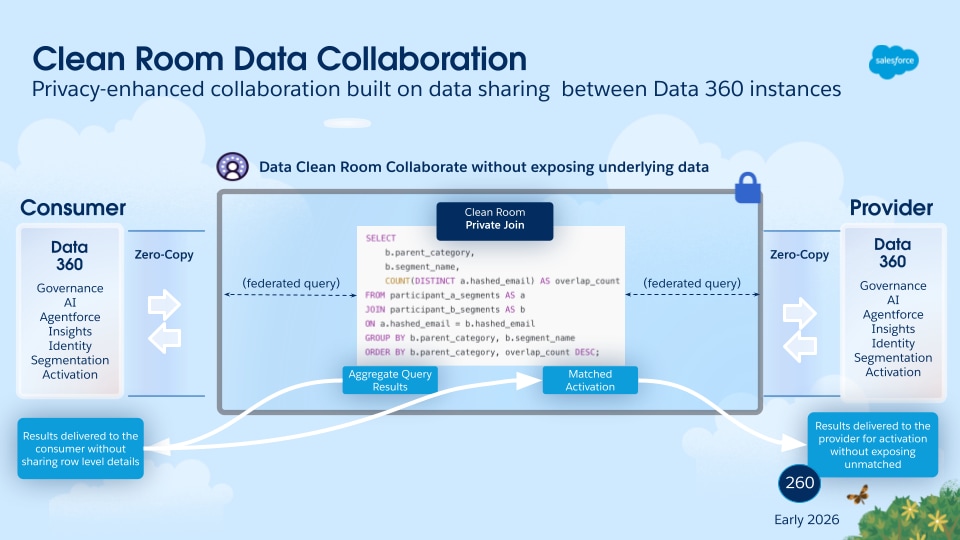
Data 360 Clean Room -yhteistyö -ominaisuus perustuu arkkitehtuurisesti Data 360 to Data 360 -datan jakamisen käyttämään nollakopio-jakamisen kehykseen, mutta siihen on lisätty hallintakerroksia ja laskentarajoituksia. Data 360 Clean Room tarjoaa turvallisen ja hallitun tietojenkäsittelyympäristön, jossa osapuolet voivat liittyä datajoukkoihinsa anonyymien avainten perusteella. Sen ydintehtävänä on mahdollistaa yhteinen analyysi ja havaintojen luominen paljastamatta sen perustana olevaa omaisuutta. Ympäristö noudattaa tiukkoja, ohjelmoitavia sääntöjä, kuten vähimmäisaggregoinnin kynnysarvoja ja ei-vietyjä tunnisteita. Nämä säännöt varmistavat, että vain hyväksytyt, yksityisyyttä parantavat ja aggregoidut havainnot saadaan ja jaetaan. Tämä tekee Clean Roomsista välttämättömän käyttötapauksille, kuten sovellusalustan välisille kampanjoiden mittauksille ja luottamuksellisten kohdeyleisöjen päällekkäisille analyyseille.
Data 360 on suunniteltu älykkääksi, laajennettavaksi ja luotettavaksi datakudokseksi, joka tarvitaan seuraavan sukupolven tekoälyn edistämiseen. Sen arkkitehtuurinen rakenne ratkaisee hajanaisen datan ongelman, jolloin organisaatiot voivat yhtenäistää, käsitellä ja aktivoida kaikkia asiakastietoja laajalti käyttämällä nollakopiodatan yhdistämistä varmistaakseen tehokkuuden.
Sen kestävän datan organisaatio tarjoaa yhdenmukaisen näkymän DLO-organisaatioista (mukaan lukien jäsentämättömistä tiedoista) DMO-organisaatioihin, jotka on suojattu osioitujen datatilojen sisällä. Data 360:n monipuoliset datan käsittelyominaisuudet — mukaan lukien erä- ja streaming-transformaatiot, lasketut havainnot, jäsentämätön datan käsittely ja identiteettien ratkaisu — perustuvat asteittaiseen SNCE- ja CDF-arkkitehtuuriin, mikä varmistaa tehokkaan, lähes reaaliaikaisen käsittelyn ja merkittävät kustannussäästöt.
Laajennettavuutta tarjoaa Code Extension -arkkitehtuuri, joka ottaa mukautetun Python-logiikan käyttöön turvallisesti komentosarjojen tai erillisten funktioiden kautta yksilöllisille vaatimuksille. Lisäksi kattava datan hallintajärjestelmä, joka perustuu attribuutteihin perustuvaan käyttöoikeuksien hallintaan (ABAC) ja CEDAR-käytäntöihin, takaa tarkan tietoturvan, dynaamisen datan peittämisen ja yhdenmukaisen täytäntöönpanon kaikissa datan kulutuksissa. Tämä johtaa hienostuneisiin segmentointi- ja aktivointiominaisuuksiin, jotka muuntavat yhtenäistettyjä asiakasprofiileja dynaamisiksi, monikanavaisiksi osallistumisstrategioiksi reaaliaikaisella reagoinnilla.
Tärkeintä on, että Data 360 voi yhtenäistää laajoja ja monipuolisia tietoja, tarjota reaaliaikaisia tietoja yhtenäistetyn kyselyn kautta (mukaan lukien hybridihybridi/rakenteeton haku ja Hyper-acceleration) ja noudattaa tiukkaa hallintaa, mikä on tärkeää älykkäiden tekoälyagenttien tehostamiseksi. Se tarjoaa tarvitsemansa luotetun, tuoreen ja relevantin datan luodun tekoälyn työnkulkujen (Generative AI) käyttöön ja Agentforcen tarjoamien agenttien monivaiheisten ja toimintaan perustuvien ominaisuuksien tukemiseen, jotta agentit toimivat tarkasti ja tarkasti.
Data 360 tarjoaa tulevaisuuteen perustuvan sovellusalustan, jossa lähdedata muunnetaan interaktiivisiksi havainnoiksi, ja se toimii välttämättömänä arkkitehtuurina organisaatioille, jotka rakentavat agenttien asiakaskokemuksia. Se on tärkeä selkäranka, joka muuntaa asiakastiedot hienostuneiksi ja henkilökohtaisiksi asiakaskokemuksiksi, jotka edistävät nykypäivän nykyaikaisten organisaatioiden menestymistä.