Modernit Salesforce-arkkitehtuurit hyödyntävät yhä enemmän ei-synkronoitua käsittelyä, ei hyödyllisyydellä, vaan skaalan strategisena vaatimuksena. Viime vuosina yhä useammat yritykset ovat kohtaaneet kasvavia datamääriä, monimutkaisia integraatioita, jotka sisältävät useita yhteydenottopisteitä, ja itsenäisten järjestelmien kasvua, jotka toimivat 24/7/365. Kaikki nämä asiat ohjaavat arkkitehtuurin suunnittelemaan järjestelmiä, jotka eivät ole synkronoituja ensin.
Salesforcessa ei-synkronoitu käsittely tarkoittaa usein hallintarajoitusten ja monimutkaisuuden ympärille suunnittelua. Nämä rajoitukset toimivat suojausriidoina ja arkkitehtuurirajoituksina, jotka auttavat luomaan joukkoturvallisia ja skaalattavia järjestelmiä. Vaikka sovellusalustan rajoitukset eivät toimi suoraan monimutkaisuuden hallinnassa, suunnittelukuvio voi auttaa riskien vähentämisessä. Sisäisesti Salesforce ylittää sovellusalustan rajat testatakseen uusia ominaisuuksia ja automatisoidakseen monimutkaisia liiketoimintaprosesseja. Laadimme vaiheittain perustuvan asynkronisen käsittelykehyksen, joka suorittaa asynkronisia töitä, joilla on satunnainen määrä vaiheita. Jokainen vaihe voidaan suorittaa, yrittää uudelleen ja käynnistää uudelleen itsenäisesti jaetuilla hallinta-ohjaimilla ja täydellä toiminnallisella näkyvyydellä keskitetyn lokin avulla. Tämä asiakirja kuvaa sen tärkeimmät arkkitehtokomponentit: Jonotettavat Apex ja Finalizer-koodit, Ajoitettu kulku, Apex, Kutsuttavat toiminnot ja Slack-integraatiot. Yhdessä nämä komponentit tarjoavat modulaarisen, skaalattavan ja havaittavan arkkitehtuurin, joka soveltuu muuttuviin yritystarpeisiin.
- Modernin Salesforce-arkkitehtuurin tulisi noudattaa ei-synkronoitua lähestymistapaa skaalan, kestävän kehityksen ja toiminnan läpinäkyvyyden saavuttamiseksi.
- Monimutkaisten töiden pilkkominen itsenäisesti suoritettaviin vaiheisiin sallii ennustettavan suorituskyvyn, turvallisemman uudelleenkäynnistyksen, tarkastuspisteytyksen, periytymisen ja modulaarisen kehityksen suunnittelematta ydintyönkulkuja uudelleen.
- Kehysjärjestelmä tarjoaa skaalattavan vaihtoehdon monoliittisille ja ikääntyville erätöille, ketjutetuille asynkronipuheluille ja syvällisesti sisäkkäisille kuluille, ja se on suunniteltu raskaille työkuormille, joiden täytyy skaalaa vaakasuorasti Salesforcessa ilman sovellusalustan ulkopuolista orkestrointia.
- Deterministinen ja havaittavissa oleva suoritus varmistaa edistymisen seurannan, palvelutasosopimuksen valvonnan, virheiden diagnosoinnin ja tilintarkastustason läpinäkyvyyden keskitetyn lokin ja hallinnan avulla.
- Suunniteltu yritystason tarkkuudelle, mukaan lukien yhtenäistetty hallinta, vaatimustenmukaisuus ja jaettu osavaltion hallinta pitkäaikaisissa liiketoimintaprosesseissa.
Ennen kuin tarkastat vaatimukset, alla on joitakin hyödyllisiä tietoja siitä, milloin käyttää tätä kehysjärjestelmää. Mieti ennen kaikkea, mikä järjestelmä on ainoa totuuden lähde. Jos Salesforce-organisaatiosi luottaa vain vähän ulkoiseen dataan, mutta sen täytyy skaalaa sadoista miljooniin tietueisiin, harkitse vaiheittaista asynkronointikehystä.
Käytä tätä kehysjärjestelmää, jos:
- Useimmat (tai kaikki) toimitettavat tiedot ovat jo olemassa CRM:ssäsi.
- Ulkoisten tietojen yhdenmukaistamiseen käytetyn Nouda muunnoslataus (ETL) -työn ylläpito- tai ylläpitokustannukset ovat liian korkeita.
- Sinun täytyy lykätä suuren määrän Salesforce-tietueiden käsittelyä määritetyn aikataulun mukaisesti.
- Voit jakaa käsittelyn erillisiin vaiheisiin. Voit esimerkiksi luoda hierarkkisen tai puupohjaisen tietuejoukon, varsinkin jos datamäärä tuhoaa hierarkian tai hakemiston alaspäin.
Älä käytä tätä kehysjärjestelmää, jos:
- Tietueiden luominen tai päivittäminen vaatii välittömän uudelleenlaskennan.
- Integraatio on haastavaa, koska ulkoiset järjestelmät isännöivät tietueiden päivitysten ensisijaista dataa. (Harkitse päivitettyjen tietojen lähettämistä Salesforceen Bulk API:lla).
Tutustu näihin käytäntöihin ja tarkasta vaatimuksemme ja aloita rakentaminen.
Mieti ongelman lausuntoa:
Jos työn täytyy suorittaa päivittäin, tarkasta, täyttävätkö tietyt tietueet valmiiksi määritetyt ehdot jatkokäsittelyä varten. Jos ne toimivat, käynnistä niiden käsittelytöitä. Tietueiden käsittely saattaa tarkoittaa datan noutamista useista ulkoisista järjestelmistä laskutoimien suorittamiseen. Työn vaiheiden tulisi ilmoittaa ihmisille Slackin kautta, että käsitellyt tietueet ovat valmiita tarkastettavaksi. Vaiheiden tulisi myös eskaloida ilmoituksia päälliköille ja roolihierarkiassa ylempänä oleville käyttäjille määritettävän viiveen perusteella ilmoitusten ensimmäisen kierroksen jälkeen.
Tämä ongelma sisältää useita eri vaiheita, joista osa voi tapahtua toisistaan erillään. Töitä voidaan jakaa monella eri tavalla. Alla on yksi ryhmittely:
- Ajoittaja.
- Vaiheen käyttöliittymä ja tietueita käsittelevät konkreettiset toteutukset (käsittelytyypistä riippumatta).
- Käsittelijä, joka organisoi vaiheet.
- Ajoittajan kutsuma Apex
- Ilmoitusosa. Käytämme Apex Slack SDK -pakettia.
- Lausekkeesta ”määritettävä viive” on piilotettu monimutkaisuus. Tätä monimutkaisuutta tarkastellaan myöhemmin tässä artikkelissa.
Alla on rakennettujen kehysjärjestelmien arvioitu kaavio:
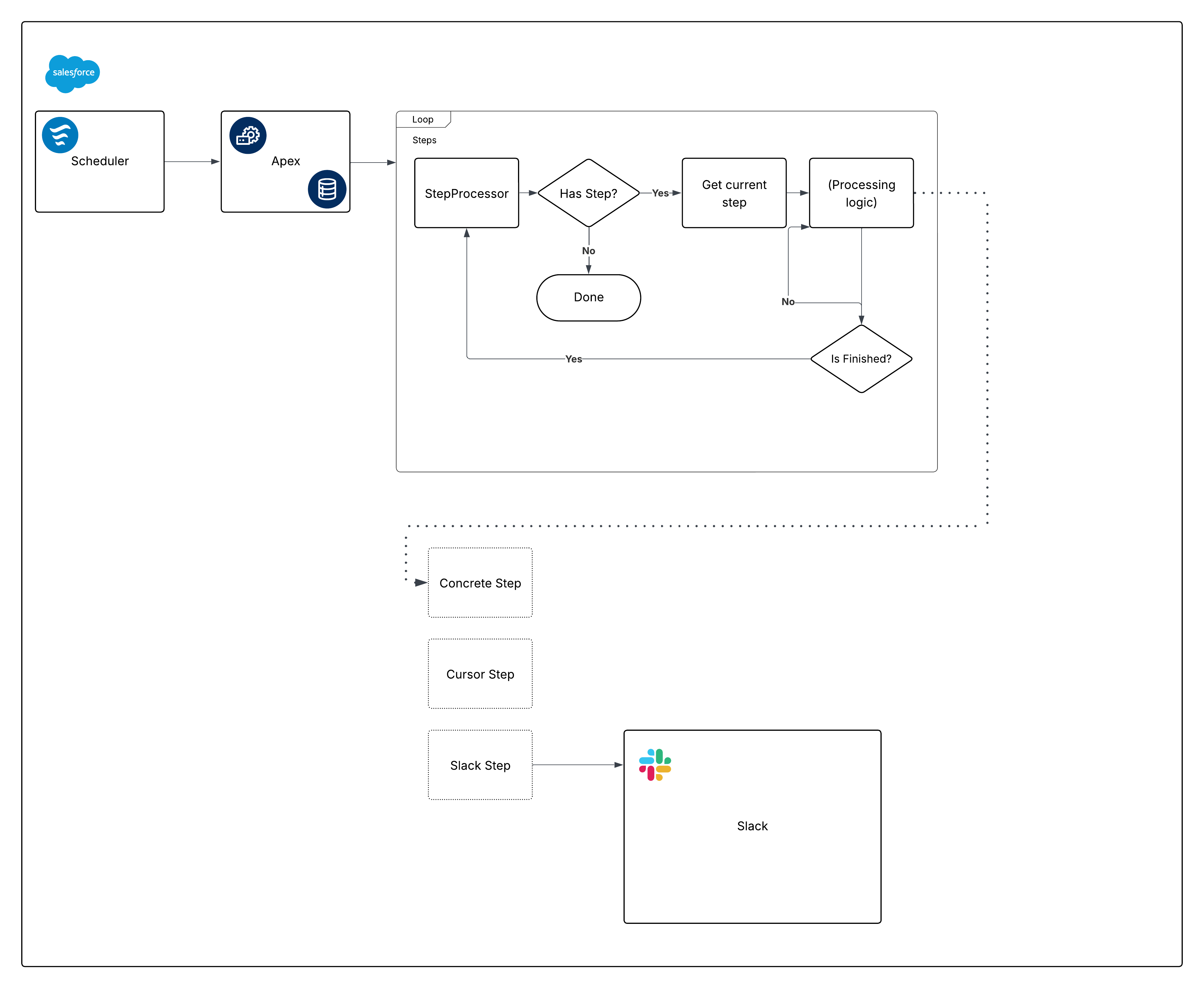 Pura kaavio ja aloita sen osien rakentaminen.
Pura kaavio ja aloita sen osien rakentaminen.
Ajoitettu kulku tarjoaa useita etuja ajoitusmekanisminä:
- Ajoitetut kulut voidaan pakata ja ottaa käyttöön metadatana. Tämä ei koske töitä, jotka on ajoitettu Apexin kautta (tai Ajoitetut työt -sivulta).
- Odotuselementti on tärkeä kehysjärjestelmille, jotka vaativat callout-kutsuja. Kun käytät sitä kulussa, callout-kutsuja ei tarvita kehyksen Kutsuttava-osiossa.
- Ajoituksen tarkkuus täyttää vaatimukset: Ajoitettujen kulkujen vähimmäisvälit ovat päivittäin. Jos tarvitset korkeamman yleisyyden (esimerkiksi tunneittain), harkitse ajoitettua kulkua uudelleen tälle vaatimukselle.
Toinen ajoitetun kulun määrittämisessä huomioitava seikka on ympäristön portitus. Ennen kuin käynnistät Apex-toiminnon, lisää päätös-elementti, joka arvioi {!$Api.Enterprise_Server_URL_100}-muuttujan. Tämä varmistaa, että työ suoritetaan vain suunnitelluissa ympäristöissä, kuten UAT ja Tuotanto. Tämä kuvio on tärkeä, koska sandboxit päivitetään tai luodaan usein SDLC:n aikana, ja ilman erillistä ympäristötarkistusta ajoitettu kulku saattaa suorittaa tahattomasti ympäristöissä, joissa kehysjärjestelmää ei ole tarkoitettu suoritettavaksi. Päätös-elementin contains-operaattorin käyttäminen tekee määrityksistä kestävämpiä sandboxien tuleville luomisille tai URL-osoitteiden muutoksille.
Mieti lopuksi, miten kehysjärjestelmän tulisi tallentaa virheet. Lisää aina vikapolku, kun kulku kutsuu jotakin toimintoa. Voit esimerkiksi lähettää vikojen Nebula Loggerin "Lisää lokimerkintä" -toimintoon. Nebula Logger kirjoittaa lokeja mukautettuihin objekteihin, joten asiakkaiden tulisi olla tietoisia siitä, että lokitiedot kuluttavat organisaation tallennustilaa — lokeja säilytetään oletusarvoisesti 14 päivän ajan organisaatiossa ja ne tyhjennetään. Tämä säilytysaika on määritettävissä. Nebula Logger käyttää myös sovellusalustan tapahtumia lokien julkaisemiseen, joten lokimerkinnät tallennetaan riippumatta datan käsittelyn päätapahtumasta — tämä varmistaa, että virheet tallennetaan, vaikka ensisijainen kulku- tai Apex peruuttaisiin. Asiakkaiden tulisi arvioida lokien odotetut määrät ja säilytysvaatimukset, kun he harkitsevat lokien kehysjärjestelmän lisäämistä.
Kulku näyttää tältä:
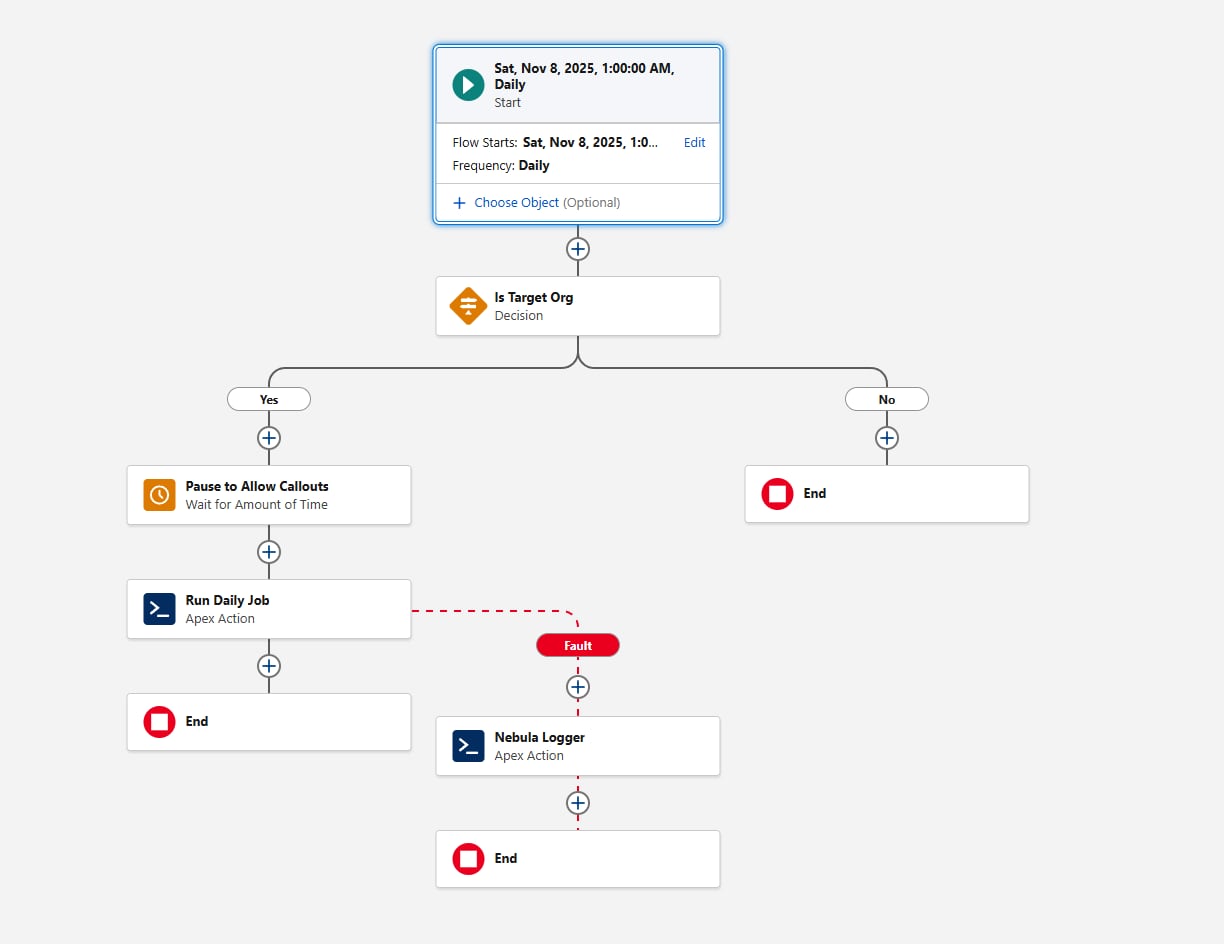
Siirtymme Apex ensimmäisiin osioihin, joiden ajoitusvaatimus on nyt täytetty.
Määritä Step-käyttöliittymä:
Tässä artikkelissa step-käyttöliittymä näytetään ulkoisena luokana selkeyttämistä varten. Itse kehysjärjestelmä on joustava — tiimit voivat organisoida käyttöliittymän ja sen toteutukset haluamansa Apex perusteella, kunhan kaikki Vaihe-luokat viittaavat samaan käyttöliittymään.
Käyttöliittymässäsi määritettyihin menetelmiin liittyy muutama huomautettava seikka:
executeparanee, vaikka sillä ei tällä hetkellä ole argumentteja, kun välitetäänState-luokkaa (tai käyttöliittymää) orkestroidaksemme dataa vaiheiden välillä, kun järjestys on tärkeää.getNamevoisi palauttaaSystem.TypearvonString. Tavoitteena on tarjota orkestrointikerrokselle tapa kirjata vaiheiden nimet lokiin paljastamatta muita ominaisuuksia.
Alla on ensimmäinen konkreettinen toteutus, joka osoittaa, miten nämä osat sopivat yhteen. Yhdestä poikkeuksesta huolimatta suosittelemme käyttämään Queueable Apexia asynkronisen käsittelyn toteuttamiseksi Apexissa. Erä-Apex on tavallisesti tarpeeton (ja @future-metodeja ei suositella). Jonotettava Apex käynnistyy nopeasti ja sillä on useita etuja Apex
Apex-kurssit ovat moderni vaihtoehto perinteiselle Apex-erämallille. Eräkäsittelyn tapaan kursorin toteutus voi noutaa tietueita erissä (enintään 2 000 per erä). Kursorit sallivat kuitenkin useita noutotoimintoja yhdessä transaktiossa, mikä mahdollistaa merkittävästi suuremman läpimäärän suurille operaatioille.
Kun tiimit ottavat kursorit käyttöön osana tätä kehysjärjestelmää, niiden tulisi olla tietoisia nykyisistä testaus- ja kumoamisrajoituksista. Kursorin toimintatapa testeissä saattaa olla erilainen kuin tuotantoympäristössä, joten on tärkeää suunnitella testistrategioita, jotka välttyvät riippuen kursorin sisäisistä tiedoista ja vahvistavat orkestrointilogiikan rajoissa. Kun sovellusalusta kehittyy, nämä osa-alueet parantuvat edelleen, mutta ydinohjeet säilyvät: Kursorit tarjoavat parempaa suorituskykyä ja vähemmän orkestrointia kuin Apex useissa käyttötarkoituksissa.
Jos haluat määrittää selkeän rajan järjestelmän tarjoaman kursorin ja oman koodisi välillä, suosittelemme luomaan kursorin kaltaisen esityksen, kun otat käyttöön Step-rajapintaa. Ota seuraava koodi huomioon:
Huomaa Cursor-luokka. Apex-kuvakkeet ovat esimerkkejä Database.Cursor, mutta Cursor-toteutuksemme tarjoaa joustavuutta kursorien puutteiden suhteen. Tässä on toteutus:
Tämän artikkelin lopussa jätämme pois sharing-lausunnot, kun viitataan Apex-luokkiin. Käytännössä varmista, että ylimmän tason luokkia käytetään erikseen jakamisen kanssa tai ilman, jotta ne noudattavat objektin mallia ja käyttöoikeuksia.
Huomaa myös, että Cursor-toteutuksemme delegoi sovellusalustan Database.Cursor-ominaisuuden, ja seuraavaksi keskustelemme lisähyödyistä.
Ensin seuraavat testit:
Kun teet Cursor virtuaaliseksi, konkreettiset CursorStep-toteutukset voivat toimia ilman Database.Cursor, kun niiden ei tarvitse iteroida suurta tietuejoukkoa — aivan kuin ne palauttaisivat System.Iterable<T> erä Apexissa Database.QueryLocator sijaan. Alla on esimerkki:
Huomaa, että koska tämä luokka on myös abstrakti, se jättää innerExecute-ominaisuuden konkreettisen toteutuksen alaluokille.
CursorLike-sisäinen alaluokka on myös vaihtoehtoinen. Jos tiedät, että tämänkaltaisen vaiheen konkreettiset versiot eivät läpäise muita hallintarajoituksia, voit palauttaa this.records-arvon CursorLike.fetch-arvosta ja korvata ylätason CursorStep.shouldRestart()-arvon palauttamalla arvon false. Tämä sallii sinun iteroida luettelon yli, joka on rajoitettu vain Apex rajoitukseen 12 Mt per asynkronoitu tapahtuma.
Kursoripohjainen toteutuksemme tarjoaa meille paljon joustavuutta, kun sivutetaan suuria määriä dataa. Samaan aikaan Step-käyttöliittymä sallii meidän kuvailla ja kapselata kaikenlaisia vaiheita joustavasti.
Harkitse kulkuun perustuvaa vaihetta:
Kulut eivät voi palauttaa Apexin määrittämää tyyppiä vastaavia tulosparametrejä, joten tarkastamme ennen sen käyttämistä shouldRestart-tulosparametrin.
Jotkin vaiheet saattavat olla ominaisuusmerkittyjä. Voit käyttää logiikkaa päättääksesi, mitkä vaiheet sisällytetään mukaan, tai käyttää käytöstä poistetun ominaisuuden no-op-vaihetta. Null-objektikuvio on yleinen tapa vähentää monimutkaisuutta orkestrointikerroksessa:
Nyt meillä on useita rakennuspalikoita työstettäväksi. Katsotaanpa orkestrointikerrosta, joka on vastuussa vaiheiden välillä tapahtuvasta iteroinnista.
Prosestori on arkkitehtuurin käännekohta. Meidän täytyy päättää, kuka määrittää mitkä vaiheet käynnistetään ja missä. Vaihtoehtoihin sisältyy:
- Pyydä käsittelijää määrittämään liiketoimintalogiikkaan kartoitetut vaiheet. Tämä vaihtoehto on yksinkertainen, mutta se skaalaa huonosti luettavuuden vuoksi.
- Määritä kartoitus mukautetulla metadatalla (CMDT). Metadata-suhde-kentät eivät tue
ApexClass-funktiota, mikä yhdistää luokan nimien kirjoittamisen liiketoimintaprosessiesi määrityksiin. Voit vähentää pääkäyttäjien riskejä tekemällä kentästä valintaluettelon ja vahvistamalla, onko tyyppi olemassa (Type.forName()tai kyselemälläApexClass), mutta koska CMDT-tietueet eivät tue käynnistimiä, vahvistus tapahtuu suorituksen aikana. Tätä reittiä voi testata, mutta pääkäyttäjät voivat silti luoda CMDT-tietueita vain tuotantoympäristössä — jatka huolellisesti. - Määritä kartoitus tietueilla. Muut kuin pääkäyttäjät voivat määrittää vaiheita, mutta käyttöönotot vaikeutuvat ja ympäristöt saattavat heikentyä. Jatka varoen.
Clean Codesta löytyy kuuluisa lainausmerkki, joka kertoo, miten tämä erityinen monimutkaisuus käsitellään:
Ratkaisu tähän ongelmaan on haudata
switch-lauseke [objektien tekemiseen] abstraktin tehtaan kellarissa, eikä anna kenenkään nähdä sitä.
Tämä huomioon ottaen, ja koska vaiheiden tämänhetkinen määrä on hyvin määritetty eikä se todennäköisesti kasva liikaa, on hyvä, että vaiheiden käsittelijä on myös vaiheiden tehdas. Tämä voi käyttää enum-arvoa siirtymisen lausekkeen edistämiseen:
Ja sitten meidän StepProcessor:
Näytetyt tehdasmetodit, kuten addTypeOneSteps(), voivat delegoida huolenaiheita, kuten ominaisuuksien merkitsemistä. cleanSteps() suorittaa kerätyille vaiheille kertakäyttöisen tarkastuksen varmistaakseen, ettei ”tyhjiä” vaiheita ole, ennen kuin se siirtyy todelliseen asynkronointiin. Se voisi näyttää tältä:
Emme ole keskustelleet virheiden käsittelystä sen jälkeen, kun olemme maininneet Nebula Loggerin Ajoitettu kulku -osiossa. Tämä johtuu siitä, että System.Finalizer sallii meidän kirjata kaikki virheiden ehdot tyhjäksi ilman, että meidän täytyisi käsitellä virheitä jokaisessa vaiheessa. Jokainen Step keskittyy juoksemiseen, kun taas kirjaamme ja palautamme epäonnistuneet polut, jotta ne näytetään yksikkötesteissä. Tämä tukee turvallista iterointia ja tuotantotason hälytyksiä (käyttämällä kaikkien WARN- ja ERROR-lokien Slack Logger -lisäosaa Nebulalle).
Yksi virhelokiin liittyvä huomautus: vaiheen esiintymän välittäminen lokiviesteihin olettaa, että lokien Trust on luotettavaa. Oletusarvoinen Apex-luokkien toString() sisältää viestissä kaikki staattiset ja instanssitason ominaisuudet. Se voi olla toivottavaa — tai se voi vuotaa luottamuksellisia tietoja. Vaikka lokiin tallentaminen ja tietoturva eivät ole tärkeitä asioita, huomaa, että joissakin järjestelmissä käyttöliittymän, kuten Step, noudattaminen voi myös pakottaa toString()-käyttöliittymän korvaamisen.
Tällainen menetelmä asettaa kunkin objektin luojan vastuuseen päättääkseen, mitä voi tulostaa, mikä voi olla toivottavaa.
Lokitasoissa: käytämme StepProcessor-tasolla INFO-arvoa, joka on korkein virheettömyyden taso. Kun sovelluksesi tarkennetaan, lokitasot laskevat vastaavasti. Yksittäiset vaiheet saattavat käyttää yleisen tason tietoja käyttämällä DEBUG-objektia, jossa FINE, FINER ja FINEST on varattu yhä yksityiskohtaisempia tuloksia varten. Lokien kirjaaminen on taidetta, mutta näiden periaatteiden noudattaminen auttaa pitämään lokit yhdenmukaisina ja hyödyllisinä.
Ennen kuin jatkamme, mietimme lyhyesti päätöstä, jonka mukaan vaiheen käsittelijäsi isännöi vaiheiden logiikkaa. Harkitse suuressa koodikannassa, että teet StepProcessor-arvoista virtuaalisia tai abstrakteja, ja anna alaluokkien tunnistaa tietyt vaiheet, joilla voit erottaa huolenaiheet toisistaan.
Ajoittaja kutsuu lopulta Apexia. Kun loput määrityksistä on suoritettu, Kutsuttava Apex -osio voi päättää, mitkä vaiheet tulisi suorittaa ja välittää List<StepType> käsittelijälle:
Tämä on yksinkertainen osa yhtälöä — käytä tietueita, dataa tai logiikkaa määrittääksesi suoritettavat vaihetyypit. Kutsuttava toiminto on yksinkertainen, koska sisällytimme monimutkaisuuden muualle. Olemme myös suojanneet odottamattomilta poikkeuksilta ja tehneet jokaisesta tuotteesta helppoa testata erillään.
Apex Slack SDK on tämän artikkelin vaikutusalueen ulkopuolella, mutta yksi vaatimusten mahdollisista piirteistä kannattaa tutkia uudelleen: ilmoitus roolihierarkiassa ylöspäin määritettävän viiveen perusteella. Tämä on yksinkertaista paperilla, ja saatat (oikein) harkita System.enqueueJob(this)-arvoa StepProcessor. Kun käytät System.AsyncOptionsia, alustava taipumuksemme oli käyttää enqueueJob-ylikäyttöä tämän vaatimuksen täyttämiseksi.
Tällä hetkellä System.AsyncOptions.MinimumQueueableDelayInMinutes-viive on kuitenkin enintään 10 minuuttia. Koska vaatimus on 120 minuuttia, muutama vaihtoehto on jäljellä. Naivinen lähestymistapa saattaa näyttää tältä:
Käytännössä viive välitetään tähän luokkaan, koska viive perustuu kokoonpanoon.
Emme suosittele tätä lähestymistapaa, ellet ole varma, että viivästyneillä ilmoituksilla on aina vain yksi tyyppi. Se polttaa läpi 11 ylimääräistä asynkronoitua työtä ennen aloittamista (tai enemmän, jos viive kasvaa). Tämä hinta voi olla hyvä yhdelle työlle — ei monelle. Sinun täytyy myös lisätä Step-käyttöliittymään metodi, jotta jokainen vaihe voi kertoa käsittelijälle, kuinka kauan sen täytyy odottaa ennen uudelleenkäynnistystä, mikä lisää melua.
Tästä seuraa kaksi mielenkiintoista mahdollisuutta:
- Voit ajoittaa viivästyneen vaiheen olemassa olevaan työkehykseen, jos sinulla on jo kyselytyö ajoitettu asiaankuuluvalla aikavälillä. Sinun tulisi myös olla OK, jos määritetty viive saavuttaa 15 minuuttia myöhemmin (15 minuuttia on Apexin ajoittaman CRON-lausekkeen päivitysväli). Tämä vastaa lähestulkoon kutsuttavan Apexin esimerkkiä. Ajoitus suoritetaan Apexin kautta. Toisin sanoen voit käyttää samaa
Step-pohjaista arkkitehtuuria käsitelläksesi tietueita ”Aloitus jälkeen” -aikaleiman perusteella ja päättääksesi, mitä vaiheita käytetään valintaluetteloiden tai monivalintaluetteloiden kartoituksen perusteella takaisin aiemmin näytettyihinStepTypeenum -arvoihin. - Jos et halua määrittää ylimääräistä Apex-luokkaa, voit myös käyttää Apex-eräluokkaa (toisin kuin Apex, joka tukee sisäisiä luokkia, Apex-eräluokkien täytyy olla ulkoisia luokkia) käyttämällä
System.scheduleBatch()-ominaisuutta.
Katso Apex. Yleisesti ottaen suosittelemme jonota Apex joustavuuden ja hallinnan vuoksi, mutta tässä tapauksessa Apex on yhä tärkein:
Kuvittele sitten StepProcessor, että aiemmin kuvattu addTypeOneSteps()-metodi päivitetään tällä viiveellä:
Vaikka emme tavallisesti suosittele näin paljon hyppäämistä, tästä vaiheen viiveestä tulee toinen uudelleenkäytettävä rakennuspalikka. Kunnes pidemmät viiveet sallitaan Queueable Apexissa, se on myös helpoin tapa tuottaa tämä vaikutus (ilman kyselymekanismia, kuten kuvattu).
Olemme käyttäneet objektikohtaista suunnittelua vaatimusten täyttämiseksi ja luoneet järjestelmän, joka skaalaa ja tasapainottaa rakennuksen ja huollon pitkän aikavälin kustannuksia. Vaikka vaiheen esittely ja esittely saattavat loppujen lopuksi heikentää paikkaaan StepProcessor, tässä asiassa on vähän teknistä lisävelkaa. FlowStep avulla pääkäyttäjät ja kehittäjät voivat päättää yhdessä, milloin ei-koodi- tai prosokoodiratkaisut sopivat parhaiten.
Käyttämällä Apexin Queueable-kehyksen System.Finalizer-käyttöliittymää yhdessä Nebula Loggerin kanssa, olemme luoneet kestävän ja testattavan järjestelmän, joka varoittaa meitä odottamattomista virheistä, vaikka tulevissa vaiheissa ei olisikaan tarkkoja lokeja. Meidän mielestämme tämä järjestelmä vähentää numeroita ja kustannuksia ja monimutkaisuutta. Se on myös antanut meille arvokkaita havaintoja Apex toimintatavoista todellisissa työkuormissa, mikä auttaa meitä tarkentamaan lähestymistapaamme ja parantamaan itse ominaisuutta.
Vaihepohjainen ei-synkronoitu käsittelykehys -kehys muuttaa sovellusalustan rajoitukset suunnitelluiksi eduiksi, mikä mahdollistaa ennustettavan suorituskyvyn, havaittavuuden ja hallinnan yritystasolla. Vaiheita voivat määrittää sekä pääkäyttäjät että kehittäjät, ja molemmissa tapauksissa vaiheen kirjoittajat voivat keskittyä turvallisesti sovellusalustan hallintarajoitusten (kuten DML-rivien ja haettujen kyselyrivien) noudattamiseen ilman, että heidän täytyisi huolehtia jokaisen vaiheen skaalaamisesta.
Jotta tämä kuvio toimisi ja otettaisiin käyttöön yritystoteutuksissa, arkkitehtien tulisi:
- Arvioi olemassa olevia automatisointeja tunnistaaksesi alueet, joissa asynkronoitu orkestrointi voi auttaa parantamaan suorituskykyä ja parantaa havaittavuutta.
- Jaa suuret prosessit erillisiin, itsenäisesti suoritettaviin vaiheisiin, joissa on selkeät käsittelyavoitteet ja erilliset tekijäpisteet (kuten Kulku tai Apex).
- Määritä ja ryhmitä vaiheiden tyyppejä nopeuttaaksesi vaiheiden uudelleenkäyttöä ja standardointia liiketoimintayksiköissä.
- Pilotoi lähestymistapa uusilla prosesseilla tai olemassa olevilla automaatioilla. Saatat yllättyä, kuinka monta rintatapausta löydät ilmaiseksi vaiheittain, huolehtimalla sisäänrakennetusta lokista ja havaittavuudesta!
James Simone on Salesforcen pääohjelmistojen insinööri ja hänellä on yli vuosikymmenen kokemus alustalla työskentelystä. Hän oli Salesforce-asiakas — ja tuotteen omistaja — ennen kuin hän siirtyi kehitystyöhön, ja hän on kirjoittanut teknisiä syventymiä Salesforcesta vuodesta 2019 lähtien Apexin iloissa. Hän on julkaissut aiemmin artikkeleita sekä Salesforce Developer -blogissa että Salesforce Engineering -blogissa.