Yritykset sisältävät tietoja usein Salesforcessa ja muissa ulkoisissa datasäiliöissä, kuten Snowflake, Google BigQuery, Databricks, Redshift tai pilvitallennustilassa, kuten Amazon S3. Tämä datan erottaminen eri lähdejärjestelmistä aiheuttaa haasteita yrityksille, jotka haluavat hyödyntää datansa kaikkia ominaisuuksia.
Arkkitehdit, jotka työskentelevät datan yhdistämiseksi useiden data-järvien välillä, kohtaavat tärkeitä arkkitehtonisia päätöksiä siitä, miten nämä tiedot integroidaan parhaiten. Data 360 tarjoaa useita vaihtoehtoja datan integrointiin, joista jokainen tarjoaa eri etuja ja haittoja.
Tämä opas tarjoaa kehyksen, jolla voit arvioida, mikä kuvio sopii parhaiten viiveen, kustannusten, skaalattavuuden, hallinnan ja monimutkaisuuden vaatimuksiin, kun integroit dataa, ja auttaa sinua valitsemaan, milloin käyttää datan tuontia, nollakopiodatan yhdistämistä tai hybridimenetelmää. Ohje auttaa sinua myös valitsemaan eri menetelmiä datan tuontiin ja yhdistämiseen, jotka kaikki täyttävät eri tarpeet.
Ulkoisten datamerkkien integrointi Data 360:n kanssa vaatii tarkkaa harkintaa datan tuoreuden, hallinnan ja myyntiputken tehokkuuden välisistä kompromisseista. Esimerkiksi Zero Copy -datayhdistämisen live-kyselyiden käyttäminen maksimoi datan tuoreuden, mutta voi heikentää myyntiputken tehokkuutta, kun siirrät enemmän dataa verkkoon. Tästä syystä useimmille todellisille toteutuksille optimaalinen polku on syöttö- ja yhdistämiskertojen yhdistelmä usean pilven järven ekosysteemissä. Tämä hybridimenetelmä varmistaa skaalattavan, hallittavan ja yhteentoimivan arkkitehtuurin, joka tukee saumattomasti sekä vähäisen viiveen operatiivisia työkuormia, kuten reaaliaikaista personalisointia ja petosten havaitsemista, että analyyttisiä työkuormia, kuten sääntelyraportointia ja historiallisten trendien analyysiä. Tämä päätösoppaasi auttaa sinua ymmärtämään, miten voit siirtyä näihin kompromisseihin ja valita oikean strategian.
- Datan syöttö: Kopioi dataa Salesforce Data 360 -palveluun ja luo hallittuja, kanonisia datamalleja. Ihanteellinen, kun sinun täytyy:
- Laadi kattava Customer 360: Yhtenäistä ja muunna eri lähteet yhdeksi luotetuksi profiiliksi.
- Noudata tiukkoja säännöksiä: Luo tarkastettava, keskitetty kopio, jossa tietojen käyttöoikeuksia ja linjaa voidaan hallita tarkasti.
- Zero Copy -liitos: Kyselee ulkoisia lähteitä reaaliajassa ilman identtisiä tietueita, mikä mahdollistaa reaaliaikaisen personalisoinnin, live-mittaristojen ja lähdekäynnistyksen nopeasti. Sinun täytyy tasapainottaa kaksi ensisijaista vaihtoehtoa, joilla on kompromisseja:
- Live ja välimuisti (Ac accelerated query): Soveltuu interaktiivisiin analyyseihin ja reaaliaikaisiin mittaristoihin ulkoisissa datalustoilla, kuten Snowflake, Google BigQuery, Redshift tai Databricks. Vältä hitaalta ja kalliilta datan kopioinnilta siirtämällä käsittelyn lähdejärjestelmään.
- Tiedoston yhdyskäyttö: Soveltuu parhaiten suuria eräkäsittelytapoja ja tekoälymallin koulutusta varten pilvitietojesi datalle (S3, ADLS). Vältä kalliita ja hitaita syötteitä kyselemällä tiedostoja suoraan avoimien taulukoiden muodossa ja avaamalla suuria datajoukkoja ETL:lle ja datatieteelle.
- Hybridimalli: Yhdistä yhtenäistettyjen profiilien syöttö yhdistämällä tuoreus, omni-channel-osallistumistoimintojen tuki, Agentforcen määrittämät toiminnot ja tekoäly-/ML-koulutus.
-
Hybridirakenne: Datan tuonnin ja yhdistämisen yhdistämistä tarvitaan usein.
- Käytä Datan syöttö -ominaisuutta kriittiselle datalle kanonisia datamalleja ja ydinhallintaa varten.
- Yhdistä kaikki muut tiedot Zero Copyn kautta minimoidaksesi syötettävien dataputkien rakentamisen ja ylläpitämisen toiminnalliset kustannukset.
-
Datan syöttötaajuudella on merkitystä: Valitse yleisyys liiketoiminta-arvon, viiveiden tarpeiden ja monimutkaisuuden perusteella.
- Käytä reaaliaikaa ajasta riippuvaisille työnkuluille (personalisointi, live-mittaristot, Agentforce).
- Lähes reaaliaikaisesti kohtalaisen kiireellisille prosesseille (kampanjat, toimintoraportit).
- Historiallisten tai hitaiden datajoukkojen erä.
-
Yhdistämiskuvion täsmääminen viiveeseen ja suorituskykyyn: Valitse käyttökokemuksiasi ja tuoreuden, suorituskyvyn ja kustannusten vaatimuksia parhaiten vastaava vaihtoehto.
- Käytä Live-kyselyä operatiivisille mittaristoille ja reaaliaikaiselle personalisoinnille, kun matala viive on kriittinen.
- Käytä välimuistiin tallentamista (Accelerated Query), kun kyselyt ovat yleisiä, mutta hieman vanhentuneet tulokset ovat hyväksyttäviä, mikä tasapainottaa suorituskykyä ja kustannuksia.
- Käytä tiedostoja yhdyskäyttöä suuren skaalan, raskaan analyysin tai erätyökuormitusten suorittamiseen, mikä sopii hyvin historiallisille tai vähemmän ajasta riippuvaisille datajoukoille.
-
Hallinnan yhdenmukaistaminen datan sijaintivaatimusten kanssa:
- Käytä syötettä, kun keskitetty hallinta on tärkeää.
- Käytä yhdistämistä, jos hajautettu hallinta on hyväksyttävää, ja noudata tiukkaa hallintaa ulkoisessa lähteessä. Zero Copy noudattaa lähdetason käytäntöjä, kuten rivitason suojausta (RLS) ja datan peittämistä.
-
Priorisoi syöttö arvokkaille työnkuluille: Sovella syötettä valikoiden mukaan kriittisiin prosesseihin, kuten identiteetin ratkaisemiseen, lakisääteiseen raportointiin ja toiminnalliseen aktivointiin.
-
Kustannukset ja monimutkaisuus vaikuttavat päätökseen: Reaaliaikainen tuonti voi olla kalliita ja monimutkaisia. Arkkitehtien tulisi punnita datan perehdytyksen, tallentamisen ja muuntamisen kustannukset verrattuna sen kyselemiseen suoraan nollakopiolla.
Oikean integraatiokuvion valitseminen — datan syöttö, nollakopiointi tai hybridimenetelmä — vaikuttaa suoraan viiveeseen, hallintaan, toimintatehokkuuteen ja kustannuksiin usean pilvitason alustoilla. Tämä päätös määrittää, miten reaaliaikaisia havaintoja, tekoälyn perustuvaa aktivointia ja henkilökohtaista osallistumista voidaan toimittaa luotettavasti ja laajalti.
Tämä taulukko tarjoaa datan syöttö- ja nollakopiokuvioiden teknisen vertailun Salesforce Data 360:ssa, keskittyen ominaisuuksiin, kompromisseihin ja etuihin sekä yrityksen käyttötarkoituksiin ja lopputuloksiin. Arkkitehdit voivat käyttää tätä viiteoppaana, kun he suunnittelevat hybridisiä, usean pilven datalustoja, jotka tasapainottavat suorituskykyä, kustannuksia ja vaatimustenmukaisuutta.
| Kuvion tyyppi | Tila / Työkalu | Hyödyt | Huomioitavia asioita | Lopputulokset |
|---|---|---|---|---|
| Datan syöttö | Reaaliaikainen: Välisekuntien viiveen syöttö Käsittely-API:n kautta CDC-tuella. Jatkuvat streaming-putket. | - Välittömät havainnot - Ihanteellinen vähäisen viiveen toiminta- ja personalisointitarkoituksiin - Tukee tapahtumiin perustuvia työnkulkuja |
- Korkea hinta Monimutkainen arkkitehtuuri - Vaatii alhaisen viiveen lähdejärjestelmät - Suuri määrä lähteitä voi aiheuttaa liikaa suoratoistoa, joka johtaa tyydyttyneisiin myyntiputkeihin - I/O intensive - Harkitse valikoivia kenttiä ja suodatusta vähentääksesi ylijäämiä |
Agentforce: - Reaaliaikaiset huijaushälytykset, vähittäismyymälöiden personalisointi, toimintahälytykset Analytics: - Sub-second-mittaristot, KPI-mittareiden valvonta Yhteensopivuus: - Säädettyjen työnkulkujen jatkuvat asiakastietueiden päivitykset |
| Streaming: Mikrobatch-syöte 1–3 minuutin välein natiiviliittimien kautta | - Tasapainoiset kustannukset vs. tuoreus - Yksinkertaisempi arkkitehtuuri kuin reaaliaikainen - Tukee asteittaisia päivityksiä |
- Kevyt viive - Ei välttämättä sovellu kriittisille alitason päätöksille - Erän koko vaikuttaa muistiin/laskentaan - I/O on moderoitu - Paras ennustettaville ja toistuville päivityskuvioille - Harkitse ikkunoitua aggregointia vähentääksesi käsittelyn kuormitusta |
Agentforce: - Ajankohtaiset kampanjan käynnistimet, lähes live-osallistuminen Analytics: - Suositusjärjestelmät, lähes live-mittaristot Yhteensopivuus: - Useita päivityksiä ja tarkastettavuutta |
|
| Batch: Ajoitetut suurten volyymien lataukset liittimien tai API-rajapintojen kautta. Tukee objektin tallennustilaa ja ETL/ELT-putkea. | - Kustannustehokas suurille datajoukoille - Helppo toteuttaa - Luotettava historiallisille analyyseille |
- Datan viive - Ei sovellu ajasta riippuvaisiin toimintoihin - I/O-intensiteetti latausikkunoiden aikana - Verkon läpimeno voi olla pullonkaula isoille tiedostoille - Soveltuu parhaiten historialliseen aggregointiin tai säänneltyihin raportointityönkulkuihin |
Agentforce: - IT-tukiliput (Jira/ServiceNow), aggregoidut työnkulut Analytics: - Historiallinen analyysi, trendien arviointi Valitus: - Sääntelyraportointi, potilas-/korvausvaatimusten datan aggregointi |
|
| Nullakoodi | Live-kysely: Suorat kyselyt ulkoisissa järjestelmissä; skeema-on-read; ei datan kopiointia | - Maksimaalinen tuoreus - Minimi tallennustila käytössä; tukee reaaliaikaisia operaatiohavaintoja |
- Riippuvainen lähteen suorituskyvystä - Suuri kyselyiden määrä saattaa vaikuttaa viiveeseen - Soveltuu erinomaisesti predikaattien ponnahdusikkunoille ja aggregoinnille I/O:n minimoimiseksi - Vältä suodattamattomia kyselyitä massiivisille datajoukoille |
Agentforce: - Dynaamiset työnkulut, jotka mukautuvat live-toimintoihin Analytics: - Toiminnalliset mittaristot, live-raportointi Yhteensopivuus: - Noudattaa rivitason suojausta ja peittämistä lähteessä |
| Kiireistetty kysely (välimuisti): Yhdistettyjen kyselyiden paikalliset välimuistiin tallennetut kopiot. Määritettävissä 15 min-7 päivää. Optimoitu kyselyn suoritus | - vähentää viive - Alhaisemmat kustannukset kuin toistuvat live-kyselyt - Parantaa suorituskykyä yleisten käyttöoikeuksien kuvioille |
- Vaatii välimuistin hallinnan - Vanhentuminen riippuu välimuistin aikavälistä - Paras yleisille kyselyille - Ei sovellu alitason päätöksentekoon |
Agentforce: - Esimääritetyt osallistumistilastot nopeuttaakseen päätöksentekoa Analytics: - BI-mittaristot, segmentointi, analyysiraportointi Yhteensopivuus: - Johdonmukaiset, säännellyt mittaristot ja lokit |
|
| Tiedostojen yhdyskäyttö: Suora pääsy suuriin historiallisiin datajoukkoihin objektien myymälöissä tai järvissä (S3, Iceberg, Google BigQuery, Redshift). | - Käsittelee suuria datajoukkoja - Pienin tallennustila Data 360:ssa - Tukee tekoälyn/ML-työkuormia |
- Vain luku - Kyselyn suorituskyky riippuu ulkoisen järjestelmän läpimäärästä - Optimoitu erien raskaille, läpimenointensiteettisille töille - Ei sovellu reaaliaikaiselle mittaristolle |
Agentforce: - (Ei tavallista — eräpainoinen) Analytics: - ML/AI-koulutus, historialliset analyysit, petatavun skaalan raportointi Yhteensopivuus: - Hallittu pääsy ulkoisiin datajoukkoihin ilman identtisiä tietueita |
Kun data tuodaan, data kopioidaan fyysisesti Data 360:een ja hallitaan täysin, toisin kuin nollakopiossa, jossa data pysyy lähteessä. Transformaatioiden laskenta tapahtuu Data 360:ssa, mikä mahdollistaa keskitetyn hallinnan ja auditoinnin.
Käytä datan tuontia tallentaaksesi kanonisia, hallittuja datajoukkoja Salesforce Data 360 -palveluun vaatimustenmukaisuuden ja toiminnan hallinnan varmistamiseksi. Käytä syötettä, kun täysi hallinta, auditointi ja jäljitettävyys vaaditaan. Soveltuu hyvin säänneltyihin tai arvokkaisiin työnkulkuihin, joissa keskitetty laskenta ja hallinta ovat tärkeitä.
Käsittely on paras tapa luoda luotettu perusta henkilöllisyyden ratkaisemiselle, lakisääteiselle raportoinnille ja tehtävien kriittisille tekoälyyn perustuville työnkuluille ja asiakkaiden osallistumiselle.

Datan tuontitavat vaihtelevat datan tuontiin käyttämäsi liittimen mukaan. Jotkin liittimet tarjoavat useita syöttömenetelmiä, kun taas toiset toimivat vain erätilassa tai streaming-tilassa. Katso Data 360: Data 360 -liittimien ja niiden käytettävissä olevien metodien täydellinen luettelo integraatioista ja liittimistä.
- Reaaliaikainen
- Subsecond syöttö käyttämällä streaming-putkea tai Change Data Taltiointi (CDC).
- Soveltuu parhaiten ajasta riippuvaisille työnkuluille (petosten havaitseminen, personalisointi, toimintomittaristot).
- Työnnä transformaatioita ja aggregaatioita Data 360:ssa vähentääksesi myöhempiä I/O-kulkuja ja optimoidaksesi laskutoimien käyttöä. Käytä asteittaista CDC:tä vähentääksesi datan häiriintymistä.
- Streaming
- Syötetään 1–3 minuutin välein pieninä osina.
- Tasapainottaa tuoreuden ja kustannukset, sopii kampanjoiden orkestrointiin, lähes live-osallistumistoimintoon ja toimintoraportteihin.
- Käytä mikrobatteja hallitaksesi I/O-hälytyksiä. Kerää lähdedataa tarvittaessa vähentääksesi siirtojen määrää ja optimoidaksesi tallennustilaa.
- Erä (ajoitetut lataukset)
- Suurien datajoukkojen säännöllinen tuonti (tunti, päivä, viikko).
- Kustannustehokas ja luotettava historiallisille datajoukoille, lakisääteiselle raportoinnille ja vaatimustenmukaisuuden käyttötarkoituksille.
- Varmista, että laskutoimi sijaitsee samassa alueessa kuin lähdesäiliö suorituskyvyn ja kustannusten optimointia varten.
- Datan syöttämisen käyttöskenaariot
- Yhtenäistettyjen Customer 360 -profiilien luominen: Rakenna yksi asiakkaan identiteetin ja attribuuttien totuuden lähde.
- Säännösten noudattamisen datajoukkojen ylläpito: Luottamuksellisten tietojen hallinnan, periytymisen ja auditoinnin noudattaminen.
- Kampanjoiden orkestroinnin keskittäminen: Varmista, että markkinointi, myynti ja palvelu toimivat yhdenmukaisista ja luotetuista datajoukoista.
- Suunnittelukäytännöt
- Suosita erätuotantoa historiallisille tai vähäisen viiveen sietäville tarpeille, kuten arkistointiraporteille tai säännöllisille tilannekuville.
- Käytä CDC- tai streaming-rajapintoja pitääksesi toiminta- ja personalisointityönkulut tuoreina ja varmistaaksesi lähes reaaliaikaiset päivitykset.
- Hallitse tallennustilaa ja laskennan kasvua käyttämällä asteittaisia latauksia koko datajoukkojen uudelleen lataamisen sijaan optimoidaksesi kustannukset ja tehokkuuden.
- Tasauta syöttöputkia laskennan paikallisuuden ja asteittaisen käsittelyn kanssa vähentääksesi verkko-I/O-pääsyä. Käytä transformaatioita Data 360:ssa välttyäksesi raakadatan siirtämiseltä tarpeettomasti.
- Kustannuksissa huomioitavia asioita
- Reaaliaikainen syöttö: Korkeimmat laskenta- ja myyntiputken kustannukset, jotka ovat perusteltuja arvokkaille ja ajasta riippuvaisille työnkuluille, kuten personalisoinnille, operatiivisille mittaristoille tai Agentforceen perustuville toiminnoille.
- Streaming-syöttö: Moderoi laskenta- ja tallennuskustannuksia. Soveltuu usein päivityksiin, jotka voivat kestää pieniä viiveitä, kuten kampanjoiden orkestrointi tai toimintoraportit.
- Erin syöttö: Alhaisemmat laskentakustannukset, ennustettava tallennustila; sopii parhaiten historiallisille datajoukoille tai hitaille päivityksille. Erädatan tuominen Salesforce-organisaatioista tiettyjen liittimien avulla on ilmaista.
- Päivitystila: Asteittainen päivitys -tilan valitseminen vähentää syöttö- ja laskentakustannuksia. Suosittelemme käyttämään asteittaista päivitystä aina, kun se on mahdollista optimoidaksesi tehokkuuden kaikissa syötetyypeissä.
- Kustannukset vaikuttavat myös I/O-lähdekoodin määrään Data 360 -palveluun. Erän koon, osioiden ja alueellisten kohdistusten optimointi vähentää siirtojen kustannuksia ja parantaa suorituskykyä.
- Toimialan skenaariot
- Finanssi: Tuo datajoukkoja, joita tarvitaan asiakkaasi tuntemiseen (KYC), rahanpesun estämiseen (AML) ja petosten havaitsemiseen, kun tarkastettavuutta ja vaatimustenmukaisuutta ei voi neuvotella.
- Terveydenhuolto: Käytä syötettä potilaan henkilöllisyyden ratkaisemiseksi ja HIPAA-yhteensopiville tietueille, mikä mahdollistaa turvalliset ja yhtenäistettyjä näkymiä.
- Vähittäiskauppa: Yhdistä myyntipisteen (POS), verkkokaupan ja kanta-asiakasohjelman data yhtenäistettyihin profiileihin segmentointia ja personalisointia varten
- Telecom: Tukee häiriöiden ennaltaehkäisyn ja käytön analyysejä kanonisella, hallitulla tilaaja-datalla.
| Ominaisuus | Reaaliaikainen syöttö | Streaming-syöttö | Erän syöttö |
|---|---|---|---|
| Viive ja tuoreus | Välisekuntien viiveen tuonti Käsittely-API:n kautta muutostietojen datan taltiointi (CDC) tuella. Tarjoaa jatkuvat streaming-putket. Soveltuu parhaiten vähäisen viiveen käyttötapauksiin. | Mikrobatch-syöte 1–3 minuutin välein natiiviliittimien kautta. Tukee asteittaisia päivityksiä. Pieni viive on odotettavissa. | Tietojen viive on odotettavissa. Ajoitetut raskaan lataukset. Säännöllinen syöte (tunti, päivä, viikko). Ei sovellu ajasta riippuvaisiin toimintoihin. |
| Ensisijaiset käyttötarkoitukset | Soveltuu hyvin toiminnallisiin ja personalisointitarkoituksiin, joilla on vähän viiveitä. Käytetään ajasta riippuvaisille työnkuluille. Tukee tapahtumiin perustuvia työnkulkuja. Käytetään reaaliaikaisille huijaushälytyksille ja toimintahälytyksille. | Soveltuu kohtalaisen kiireellisille prosesseille. Käytetään kampanjoiden orkestrointiin, lähes live-osallistumistoimintoon ja operatiiviseen raportointiin. Käytetään kampanjoiden ajoitetuille käynnistimille. | Kustannustehokas suurille datajoukoille. Luotettava historiallisille analyyseille. Käytetään historialliseen aggregointiin tai säänneltyihin raportointityönkulkuihin. Soveltuu parhaiten historiallisille tai hitaille datajoukoille. |
| Arkkitehtuurin monimutkaisuus ja I/O | Korkea hinta ja monimutkainen arkkitehtuuri. Vaatii lähdesysteemit, joiden viive on alhainen. I/O intensive. Raskaat lähteet voivat aiheuttaa kyllästyneitä myyntiputkia. | Yksinkertaisempi arkkitehtuuri kuin reaaliaikainen. I/O on moderoitu. Soveltuu parhaiten ennustettaville ja toistuville päivityskuvioille. Erän koko vaikuttaa muistiin/laskentaan. | Helppo toteuttaa. I/O-intensiteetti latausikkunoiden aikana. Verkon läpimeno voi olla pullonkaula suurille erille. |
| Kustannuksissa huomioitavia asioita | Korkeimmat laskenta- ja myyntiputken kustannukset. Perusteltu vain arvokkaille ja ajasta riippuvaisille työnkuluille. | Moderoi laskenta- ja tallennuskulut. Tarjoaa tasapainoisen hinnan vs. tuoreuden lähestymistavan. Soveltuu usein päivityksiin, jotka kestävät pieniä viiveitä. | Alhaisemmat laskentakustannukset ja ennustettava tallennustila. Suositus historiallisille datajoukoille tai hitaille päivityksille. Syöttö Salesforcen sisäisten myyntiputkien kautta on ilmaista. |
| Suunnittelukäytännöt | Käytä asteittaista CDC:tä vähentääksesi datan häiriintymistä. Suodata ja käytä valikoivia kenttiä vähentääksesi ylijäämiä. | Käytä mikrobatteja hallitaksesi I/O-hälytyksiä. Harkitse ikkunoitua aggregointia vähentääksesi käsittelyn kuormitusta. | Suosittelemme tätä arkistointiraporteille tai säännöllisille tilannekuville. Varmista, että laskutoimi sijaitsee samassa alueessa kuin lähdesäiliö kustannusten optimointia varten. |
Käytä Zero Copy -funktiota kyselläksesi ulkoisia järjestelmiä reaaliajassa ilman datan kaksoiskappaleita, mikä mahdollistaa joustavuuden, tuoreuden ja skaalattavan pääsyn suuriin tai väliaikaisiin datajoukkoihin. Se soveltuu parhaiten live-mittaristoihin, tutkinta-analyyseihin, tekoälyn/ML-mallin koulutukseen ja reaaliaikaiseen asiakasosallistumiseen suoraan Salesforce Data 360:n kautta.
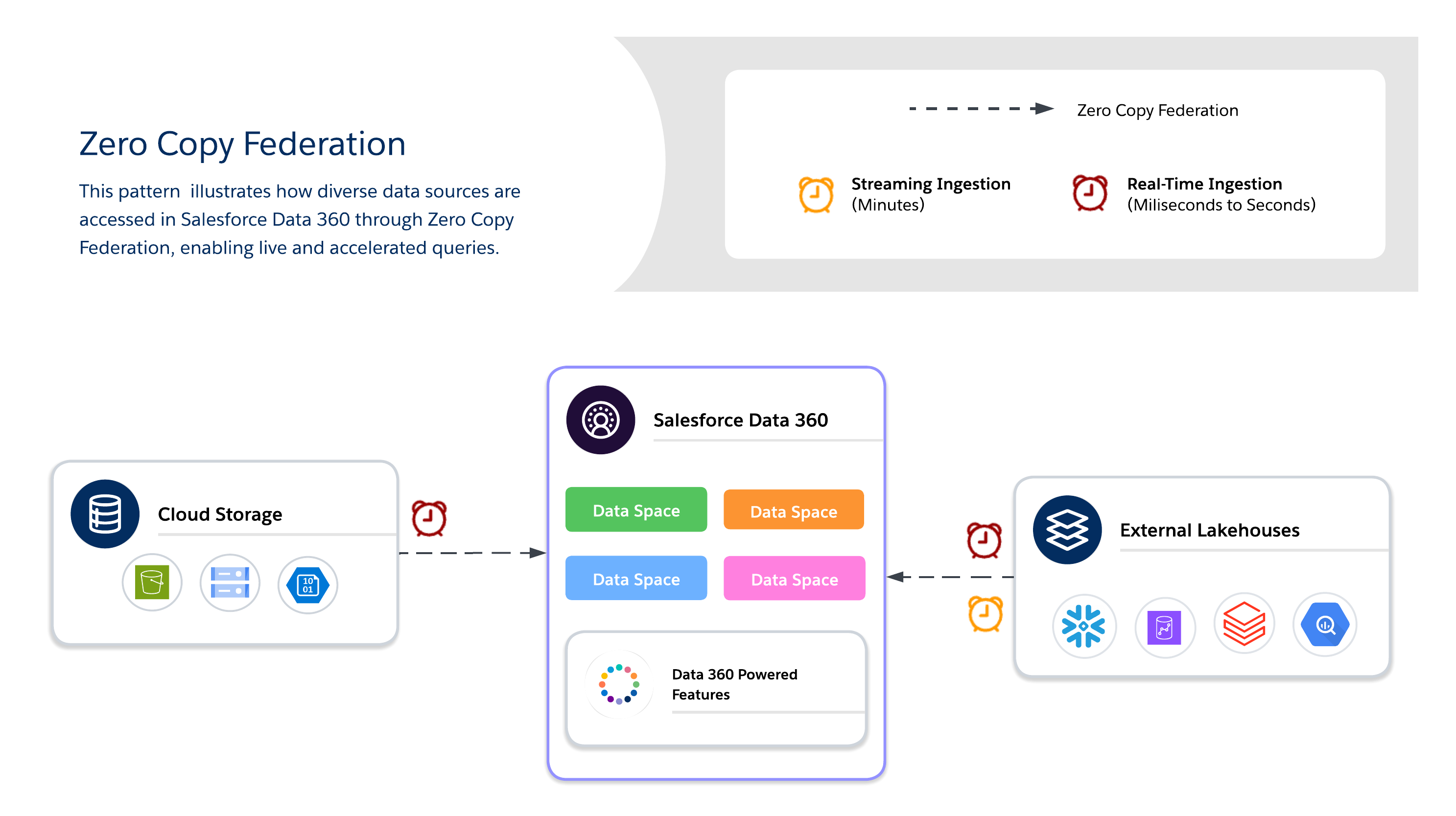
Kun käytät Zero Copy -versiota, arkkitehtien täytyy valita kolme saatavilla olevaa datan yhdistämismenetelmää, joista jokaisella on omat vaihtoehtonsa tuoreuden, suorituskyvyn ja kustannusten välillä.
- Live-kysely
- Suorittaa kyselyitä suoraan ulkoisille järjestelmille (Snowflake, Google BigQuery, Redshift, Databricks jne.) ilman datan kopiointia.
- Optimaalinen, kun predikaatteja ja aggregaatteja voidaan työntää alas, mikä minimoi datan liikkuvuuden verkossa ja vähentää Salesforce Data 360 -tietokoneen I/O-kertakirjautumista.
- Soveltuu parhaiten reaaliaikaisille havainnoille ja matalan viiveen toiminta-mittaristoille. Riippuvat ulkoisen järjestelmän suorituskyvystä.
- Välimuistiin tallentaminen (Ac accelerated query)
- Tallentaa yhdistettyjen tietojen välimuistiin tallennetut kopiot väliaikaisesti Salesforce Data 360 -palveluun.
- Vähentää usein käytettyjen datajoukkojen toistuvien kyselyiden kustannuksia ja viiveitä määritettynä kestolla (minuutteista päivään).
- Dataa ei kopioida pysyvästi tai hallita kokonaan. Tuoreutta hallitaan lähteestä ajoitettujen päivitysten kautta.
- Tiedostojen yhdyskäyttö
- Tarjoaa suoran Vain luku -oikeuden suuria datajoukkoja varten objektien myymälöissä (esimerkiksi S3, GCS ja Iceberg).
- Soveltuu parhaiten tekoälyn/ML-työkuormiin, historiallisiin analyyseihin ja petatavun mittaiseen raportointiin siirtämättä dataa.
- Kyselyn suorituskyky riippuu suuresti objektin muodosta, osioinnista ja verkko-I/O-toiminnosta. Suuri skannaus voi luoda paljon I/O-päästöjä, jos sitä ei optimoida.
- Käyttöskenaariot
- Reaaliaikainen personalisointi ja mukautetut työnkulut: Tarjoa dynaamisia tarjouksia, suosituksia ja parhaita toimintoja, kun asiakastyytyväisyys muuttuu.
- Live-mittaristot ja operatiiviset analyysit: Tehosta liiketoimintaan liittyviä mittaristoja ja KPI-mittareita suoraan ulkoisista varastoista.
- AI/ML-mallin koulutus suurilla ulkoisilla datajoukoilla: Hyödynnä petatavuisia tietoja datamajoista ja varastoista käyttämällä tiedostojen yhdyskäyttöä siirtämättä niitä.
- Toimialan skenaariot
- Vähittäiskauppa/Media: Ota käyttöön henkilökohtaisia suosituksia ja reaaliaikaista asiakasosallistumista yhdistämällä napsautusketjun tai sisällön vuorovaikutustiedot.
- Finanssi: Suorita petosten havaitseminen ja riskien pisteytys lähes reaaliajassa kyselemällä ulkoisia varastoja kopioimatta luottamuksellisia tietoja.
- Tech/Enterprise: Tukee cross-cloud-raportointia, IT-palvelumittaristoja ja operatiivisia analyysejä, joissa datajoukot sijaitsevat useissa järjestelmissä.
- Suunnittelukäytännöt
- Live-kysely
- Käytä korkean QPS:n, matalan viiveen kyselyille, kun tuoreus on tärkeää.
- Työnnä predikaatteja ja aggregaatteja ulkoiseen järjestelmään välttyäksesi datan häiritsemiseltä verkossa.
- Vältä kyselyitä, jotka skannaavat tarpeettomia datamääriä. Harkitse osioiden rajoittamista ja suodattimia.
- Tiedostojen yhdyskäyttö
- Käytä petatavuisia datajoukkoja objektien myymälöissä ilman syöttämistä.
- Pidä objektin tallennustila samassa pilvipalvelualueessa kuin Salesforce Computessa vähentääksesi viiveitä ja siirtymiskustannuksia.
- Käytä osioituja, sarakkeellisia formaatteja (Parquet/ORC) ja ponnahdussuodattimia vähentääksesi I/O- ja verkon siirtoja.
- Hyödynnä kyselyitä ja predikaattien alasvetovalikoita suodattaaksesi ja aggregoidaksesi lähdedataa, mikä vähentää datan liikkuvuutta.
- Vältä alueiden välistä datan käyttöä, ellei se ole tarpeen, koska se kasvattaa I/O-kertakirjautumista, viiveitä ja kustannuksia.
- Välimuistiin tallentaminen (Ac accelerated query)
- Tallenna usein käytetyt datajoukot välimuistiin tasapainottaaksesi kustannukset ja suorituskyvyn.
- Määritä päivitysvälit tasapainottaaksesi tuoreuden vs. kyselyn kustannukset.
- Yhteensopivuus: Noudata lähdehallintaa hyödyntämällä rivitason suojausta (RLS) ja peittokäytäntöjä suoraan yhdistetyissä järjestelmissä. Alla on suositeltuja käytäntöjä RLS:n yhtenäistämiseksi ja peittämiseksi eri sovellusalustoilla.
- Keskitetyn yritystunnuksen käyttäminen: Kartoita Salesforce Data 360 -käyttäjät ja -entiteetit yksilölliseen, keskitettyyn yritystunnukseen, joka vastaa ulkoisten järjestelmien identiteettejä.
- Suojauskäytäntöjen täsmääminen: Varmista, että yhdistettyjen järjestelmien rivitason suojaus- ja peittokäytäntöjä sovelletaan kartoitetun identiteetin perusteella. Tämä säilyttää vaatimustenmukaisuuden, kun ulkoista dataa kysellään.
- Identity-skeemojen standardointi: Ylläpidä yhdenmukaisia identiteettiattribuutteja (sähköposti, käyttäjätunnus, asiakastunnus jne.) kaikissa tietolähteissä välttyäksesi vastaavuuksilta ja käyttöoikeuksien rikkomuksilta.
- Live-kysely
- Kustannuksissa huomioitavia asioita
- Live-kysely: Maksutapahtumakohtainen malli — Ulkoisen järven laskutoimien kustannukset kasvavat ja voivat kasvaa korkealla QPS-arvolla. Soveltuu parhaiten tuoreuteen kriittisiin käyttötarkoituksiin, joissa arvo on suurempi kuin kustannusten vaihtelu.
- Kiireistetty kysely (välimuisti): Alentaa kyselyiden kustannuksia verrattuna Live-kyselyyn vähentämällä lähdejärjestelmään kohdistettuja tapaamisia, mutta lisää erädatan tuontikustannuksia välimuistin täyttämiseksi ja päivittämiseksi. Soveltuu usein käytetyille datajoukoille.
- Tiedoston yhdyskäyttö: Halvin tallennusvaihtoehto objektien tallennustilassa olevaksi dataksi, mutta kyselyiden kustannukset riippuvat tiedoston koosta, osioinnista ja leikkaamisesta. Soveltuu parhaiten historialliseen dataan tai joukkodataan petatavuina.
| Päätöspiste | Live-kysely | Välimuistiin tallentaminen (Ac accelerated query) | Tiedosto yhdyskäyttö |
|---|---|---|---|
| Datan lähteen sijainti | Ulkoiset datahakemistot (Snowflake, Google BigQuery, Redshift, Databricks). | Ulkoiset datahakemistot (Snowflake, Google BigQuery, Redshift, Databricks) | Objektien myymälät tai pilvitietojen järvet (S3, ADLS, GCS), jotka käyttävät usein avoimia taulukkomuotoja, kuten Iceberg. |
| Käyttötarkoitus/käyttötarkoitus | Soveltuu interaktiivisille analyyseille ja reaaliaikaisille mittaristoille. Soveltuu parhaiten reaaliaikaiseen personalisointiin ja dynaamisiin työnkulkuihin. | Soveltuu parhaiten, kun kyselyt ovat yleisiä, mutta hieman vanhentuneet tulokset ovat hyväksyttäviä. Soveltuu BI-mittaristoille ja segmentoinnille. | Soveltuu suuria erien käsittelyyn ja AI/ML-mallin koulutukseen. Soveltuu erinomaisesti historiallisiin analyyseihin ja petatavun mittaiseen raportointiin. |
| Jäähdytys/väliaikaisuus | Maksimaalinen tuoreus: kyselyt suoritetaan suoraan reaaliajassa. Tukee alitason päätöksentekoa. | Hieman vanhentuneet tulokset ovat hyväksyttäviä. Tuoreus riippuu välimuistin aikavälistä, joka voidaan määrittää 15 minuutista 7 päivään. | Optimoitu erien raskaille ja läpimenointensiteettisille töille. Ei sovellu reaaliaikaiseen mittaristoon. |
| Käyttöoikeuskuvio | Soveltuu harvoille tai ad hoc -kyselyille. Käytä korkean QPS-arvon (kysely per sekunti) kyselyille, joissa tuoreus on tärkeää. | Soveltuu parhaiten raskaan lukeman skenaarioille. Parantaa suorituskykyä yleisten käytön kuvioissa. | Vain luku -käyttöoikeus. Soveltuu petatavua suurille datajoukoille ilman syötettä. |
| Suorituskyvyn edistäjät | Riippuvat voimakkaasti ulkoisen lähdejärjestelmän suorituskyvystä. Optimoidaan, kun predikaatteja ja aggregaatteja voidaan siirtää lähteeseen. | Vähentää viiveä verrattuna toistuviin live-kyselyihin. Suorituskyky riippuu välimuistin hallinnasta ja aikavälistä. | Suorituskyky riippuu suuresti objektin muodosta, osioinnista ja ulkoisen järjestelmän läpimäärästä. Käytä osioituja sarakemuotoja (Parquet/ORC). |
| Kustannusten vaikutukset | Maksu per kysely -malli. Ulkoisten järvien laskennasta aiheutuu kustannuksia. Kustannustehokas harvoille kyselyille, mutta kustannukset saattavat kasvaa, kun kyselyiden määrä on korkea per sekunti (QPS). | Alhaisempi hinta kuin toistuvilla live-kyselyillä. Vähentää ulkoisen lähteen kyselemisen tarvetta useita kertoja. Lisää välimuistin tallennustilaa ja päivitystoimia. | Halvin tallennusvaihtoehto. Kyselyiden kustannukset riippuvat tiedoston koosta ja osioista. |
| Tärkeimmät huomioitavat asiat | Vältä suodattamattomia kyselyitä, jotka skannaavat tarpeettomia datamääriä. | Vaatii välimuistin hallinnan. Ei sovellu alitason päätöksentekoon. | Kyselyiden suorituskyky riippuu suuresti optimoinnista osioinnin ja predikaattien pudottamisen kautta. |
Hybridimarkkitehtuurit sallivat arkkitehtien ankkuroida kriittisiä datajoukkoja Data 360 -palveluun keskitetyn hallinnan varmistamiseksi ja hyödyntää yhdistettyjä kyselyitä tuoreuden parantamiseksi, identtisten tietueiden vähentämiseksi ja suurten ulkoisten datajoukkojen skaalattavaksi käyttämiseksi. Tämä lähestymistapa tasapainottaa I/O-, laskenta-paikkamääritys-, kustannus- ja vaatimustenmukaisuusvaatimukset.
Käytä hybriditoimintatapaa tasapainoisen hallinnan, tuoreuden ja toiminnan tehokkuuden saavuttamiseksi yhdistämällä datan tuonti ja nolla kopiointia tarjotaksesi reaaliaikaisia, interaktiivisia havaintoja. Käytä syötettä arvokkaille, säänneltyille datajoukoille, joissa seuranta, RLS ja peittäminen vaaditaan, sekä yhdistämistä epävakaille tai raskaille datajoukoille, joissa tuoreus ja suorituskyky ovat tärkeitä.
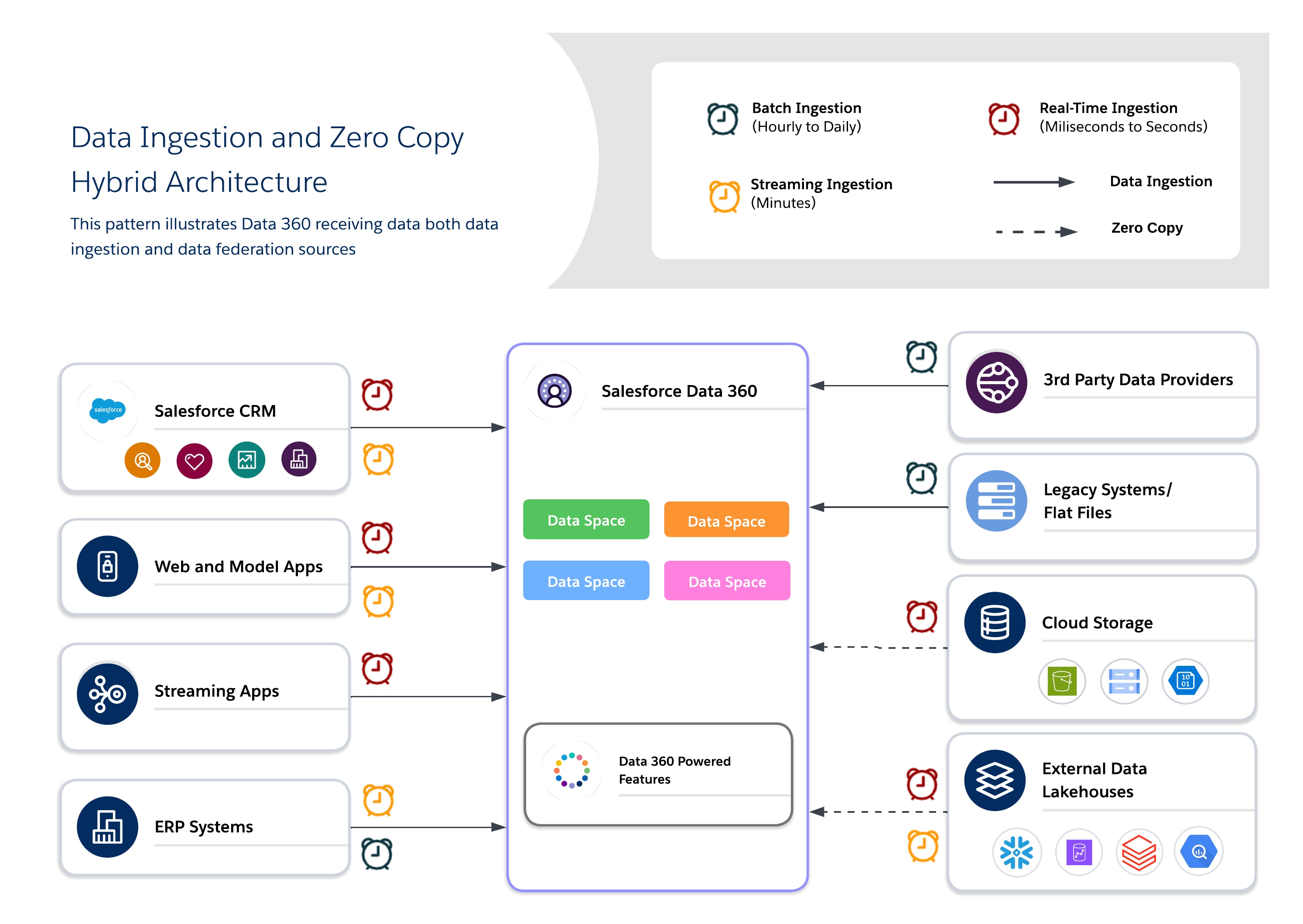
- Käyttöskenaariot
- Omni-channel-osallistumistoiminto: Yhdistä historiallisia asiakastietoja reaaliaikaisiin toimintatapoihin tarjotaksesi yhdenmukaisia ja asiayhteydestä riippuvaisia käyttökokemuksia.
- AI/ML-putket: Kouluta malleja koodattuihin, kanonisiin datajoukkoihin rikastamalla niitä raaka- tai reaaliaikaisilla signaaleilla ulkoisista lähteistä.
- Yhdistetyn vaatimustenmukaisuuden ja joustavuuden vaatimukset: Käytä luottamuksellisille tiedoille tiukkaa hallintaa, mutta yhdistämistä toiminnan joustavuuden vuoksi.
- Toimialan skenaariot
- Vähittäiskauppa: Käytä syötettä henkilöllisyyden ratkaisemiseen ja profiilien yhtenäistämiseen. Yhdistä reaaliaikaisia tarjouksia ja personalisointia varten.
- Terveydenhuolto: Ylläpidä kultaisia potilastietueita syöttämisen kautta yhdistämällä IoT-laitteiden viestiketjuja ja antatietoja välittömään kontekstiin.
- Finanssipalvelu: Tuo säänneltyjä tietoja vaatimustenmukaisuuden hallittuun lakeen yhdistämällä ulkoisia kyselyitä petosten havaitsemista ja riskien valvontaa varten.
- Suunnittelukäytännöt
- Ankkurin hallinta syöttötoiminnolla: Tuo arvokkaita tai säänneltyjä tietoja kanonisiin malleihin varmistaaksesi Trustin ja vaatimustenmukaisuuden.
- Käytä yhdistämistä tuoreudelle: Salli ulkoisten järvien tarjota reaaliaikaista tai laajamittaista datan käyttöä ilman identtisiä tietueita.
- Tasapainokustannukset vs. Suorituskyky: Profiloi työkuormia päättääksesi, mitä tuoda vs. yhdistää, vähentääksesi tarpeettomia tallennustilaa tai kyselyiden kustannuksia.
- Käytä kerrostettua hallintaa: Ota käyttöön keskittynyt hallinta tuodulle datalle ja hyödynnä yhdistettyjen järjestelmien omia suojausasetuksia (esimerkiksi RLS, peittäminen).
- Kun suunnittelet hybridiputkia, varmista historiallisten datajoukkojen asteittainen tuonti ja työnnä aggregaatteja tai suodattimia yhdistettyihin lähteisiin optimoidaksesi I/O- ja laskentakäytön.
- Kustannuksissa huomioitavia asioita
- Optimoi kokonaiskustannukset vs. suorituskyky yhdistämällä vaatimustenmukaisuuden tai kriittisen datan syöttö yhdistämiseen, kun tuoreus on tarpeen.
- Ota I/O- ja laskentatoimintojen jakauma huomioon, kun syötettä ja yhdistämistä yhdistetään. Jos haluat vähentää toistuvien kyselyiden lähdejärjestelmien laskentakustannuksia, käytä välimuistiin tallentamista (Accelerated Query) luetuille ja usein käytetyille yhdistetyille datajoukoille.
Alla on yleisiä arkkityyppejä, jotka kuvaavat tämän logiikan soveltamista.
- "Yksittäinen totuuden lähde" -arkkityyppi: Keskitä ja hallitse
- Skenaario: Sinun täytyy laatia yhteensopivia ja yhtenäistettyjä Customer 360 -profiileja koko globaalille yrityksellesi. Tiedot saadaan kymmenestä eri järjestelmästä, niiden täytyy noudattaa tiukkoja GDPR- ja CCPA-asetuksia, ja ne toimivat luotettavana lähteenä kaikille markkinointi- ja palvelutoiminnoille.
- Suositeltu kuvio: Datan syöttö. Prioriteetti on hallinta, Trust ja hallinta. Datan tuominen Data 360:ään on ainoa tapa luoda täysin auditoitava, kanoninen profiili, joka on eristetty lähdejärjestelmistä.
- "Real-Time Insights" -arkkityyppi: Analysointi ilman siirtämistä
- Skenaario: Datatieteellisten tiimisi täytyy suorittaa tutkimuskyselyitä massiiviselle ja jatkuvasti päivittyvälle transaktiotaulukolle Snowflakessa. Samalla päätiimisi haluaa live-BI-mittariston, joka perustuu samaan dataan. Päivittäisten petatavujen datan siirtäminen on liian hidasta ja kalliita.
- Suositeltu kuvio: Zero Copy -liitos. Prioriteetti on nopeus, joustavuus ja kustannustehokkuus skaalassa. Zero Copy sallii sinun hyödyntää olemassa olevan datasäiliösi valtavaa tehoa reaaliaikaisiin kyselyihin ilman datan kopioinnin ylijäämiä ja viiveitä.
- "Hybrid Intelligence" -arkkityyppi: Ydimen hallintaoikeus, reunojen yhdistäminen
- Skenaario: Haluat rikastaa hallittuja ja tuotuja asiakasprofiileja reaaliaikaisilla käyttäytymissignaaleilla (kuten verkkosivuston napsautuksilla) datasalissa. Tarvitset ydinprofiilin vakauden, mutta live-datan välittömyyttä tehdäksesi personalisoinnista ajankohtaista.
- Suositeltu kuvio: Hybridimenetelmä. Käytä datan syöttämistä luodaksesi asiakastietojesi vakaan ja hallitun ydintä. Käytä sitten Zero Copy -vaihtoehtoa yhdistääksesi haihtuvan reaaliaikaisen "edge"-datan ja liittääksesi sen kyselyn aikana kokonaiskuvaan, joka on ajan tasalla.
Yrityksen datastrategia ei enää tarkoita yksittäisen integraatiokuvion valitsemista — se tarkoittaa hallitun joustavuuden rakentamista yhteentoimivassa datan ekosysteemissä. Oikean datan integrointimenetelmän valitseminen kullekin lähdedatan järjestelmälle liiketoimintatarpeiden perusteella johtaa usein hybridimenetelmään, joka yhdistää datan tuonnin ja datan yhdistämisen vahvuudet.
- Tuo kriittisiä ja hallittuja datajoukkoja Salesforce Data 360 -palveluun vaatimustenmukaisuutta, identiteettien ratkaisua ja toimivia työnkulkuja varten.
- Yhdistä dataa Zero Copyn kautta live-, tutkinta- ja tekoälyanalyysia varten ilman identtistä tallennustilaa.
Hyperforcen Salesforce Data 360 tarjoaa joustavuutta ja skaalattavuutta useille alueille. Avoin järvikeskus, jossa on jäätikkötaulukoita, mahdollistaa laskutoimien erottamisen ja yhteentoimivuuden sovellusalustojen, kuten Snowflaken, Databricksin ja S3 Icebergin kanssa — mikä muodostaa todellisen yhteentoimivan, usean pilven datan ekosysteemin selkärangan.
Kun datan ekosysteemit kehittyvät, tasapainota tuoreus, kustannukset, suorituskyky ja vaatimustenmukaisuus jatkuvasti säilyttääksesi arkkitehtuurin joustavuuden. Valmistele sovellusalustasi tulevaisuudessa yhdistämällä tuotu, hallittu data yhdistetyllä käyttöoikeudella. Tämä mahdollistaa reaaliaikaisen älykkyyden, tekoälyn aktivoinnin ja yritystason personalisoinnin pilvipalvelimella, alueilla ja liiketoiminta-alueilla.
Kokoon sopivat ratkaisut eivät sovellu useimmille yrityksille. Optimaalinen strategia kartoittaa oikean kuvion oikealle liiketoiminnan edistäjälle.
Yugandhar Bora on Salesforcen ohjelmistojen suunnittelu-arkkitehti, joka on erikoistunut Data & Intelligence -sovellusalustan datan arkkitehtuuriin. Hän johtaa Enterprise Architecture Review Board (EARB) -aloitteita, jotka keskittyvät datan hallintaan ja yhtenäistettyihin datamalleihin, ja edistää samalla automatisoitujen sovellusalustan provisiointiratkaisujen kehittämistä.
Jan Fernando on pääarkkitehti Salesforcen pääarkkitehditoimistossa. Hän liittyi Salesforceen vuonna 2012, jolloin hänellä on paljon kokemusta startup-ekosysteemistä. Ennen kuin hän liittyi pääarkkitehtitoimistoon, hän vietti yli vuosikymmenen alustan organisaatiossa, jossa hän johti useita tärkeimpiä teknologisia transformaatioita.