Las integraciones modernas de Salesforce deben admitir mucho más que un simple intercambio de datos. Se espera que potencien experiencias de clientes en tiempo real, coordinen acciones entre múltiples sistemas y operen de forma fiable a escala de la compañía, todo ello cumpliendo al mismo tiempo estrictos requisitos de seguridad y cumplimiento. Por lo tanto, la selección del enfoque de integración correcto es una decisión arquitectónica crítica, no un detalle de implementación. Considere un escenario de compañía común. Un cliente completa una compra en una aplicación móvil, desencadenando una comprobación de aptitud en tiempo real para una oferta personalizada. Al mismo tiempo, los datos de transacciones deben registrarse en un sistema ERP, los atributos de clientes actualizarse en Salesforce y los análisis transmitirse a un lago de datos, sin introducir latencia, duplicación de datos o riesgo de cumplimiento. Escenarios como este son ahora típicos en entornos modernos de Salesforce, donde Salesforce rara vez opera de forma aislada y debe integrarse a la perfección con un ecosistema más amplio de aplicaciones y plataformas de datos. Esta guía existe para ayudar a los arquitectos y desarrolladores a diseñar esas integraciones con claridad y confianza. En vez de centrarse en implementaciones de punto a punto, presenta un conjunto de patrones de integración que abordan escenarios de compañía recurrentes, como orquestación de procesos, sincronización de datos y acceso a datos en tiempo real. Cada patrón enfatiza la intención arquitectónica, las compensaciones y los modelos de ejecución, permitiendo a los equipos tomar decisiones de diseño fundamentadas que se amplían y perduran. Dentro de este documento, encontrará:
- Patrones de integración que representan “arquetipos” de compañía comunes entre procesos, datos y escenarios de acceso virtual
- Un marco de trabajo de selección de patrones para ayudar a identificar el enfoque correcto basándose en la intención de integración y el tiempo de ejecución
- Directrices prácticas sobre consideraciones de escalabilidad, resiliencia, gobernanza y seguridad
- Mejores prácticas extraídas de implementaciones reales de Salesforce y Data 360 El objetivo de este documento es proporcionar un lenguaje arquitectónico compartido para la integración, ayudando los equipos a diseñar soluciones que equilibren desempeño, flexibilidad y Trust mientras se alinean con datos de compañía y estrategias de gobernanza.
Este documento es para diseñadores y arquitectos que necesitan integrar datos de otras aplicaciones en su compañía con Salesforce Data 360 (anteriormente Data Cloud). Este contenido es una destilación de muchas implementaciones correctas por arquitectos y socios de Salesforce. Para familiarizarse con las funciones y opciones de integración disponibles para la adopción a gran escala de Data 360, lea las secciones Resumen de patrón y Guía de selección de patrón a continuación. Los arquitectos y desarrolladores deben tener en cuenta estos detalles de patrón y mejores prácticas durante la fase de diseño e implementación de proyectos de interacción de datos en Data 360. Si se implementan correctamente, estos patrones le permiten llegar a producción lo más rápido posible y tener el conjunto de aplicaciones más estable, ampliable y sin mantenimiento posible. Los propios arquitectos consultores de Salesforce utilizan estos patrones como puntos de referencia durante revisiones arquitectónicas y los mantienen y mejoran activamente. Como con todos los patrones, este contenido cubre la mayoría de los escenarios de integración, pero no todos. Aunque Salesforce permite la integración de la interfaz de usuario (UI), mashups, por ejemplo, dicha integración está fuera del ámbito de este documento.
Cada patrón de integración sigue una estructura coherente. Esto proporciona coherencia en la información proporcionada en cada patrón y también facilita la comparación de patrones.
- Nombre: El identificador de patrón que también indica el tipo de integración contenida en el patrón.
- Contexto: Escenario de integración general que soluciona el patrón. El contexto proporciona información acerca de lo que los usuarios están intentando lograr y cómo se comporta la aplicación para dar cobertura a los requisitos.
- Problema: Expresado como una pregunta, este es el escenario que el patrón está diseñado para resolver. Lea esta sección para comprender si el patrón es apropiado para su escenario de integración.
- Fuerzas: Las restricciones y circunstancias que hacen que el escenario establecido sea difícil de resolver.
- Solución: La forma recomendada de resolver el escenario de integración.
- Boceto: Un diagrama de secuencia UML que le muestra cómo la solución aborda el escenario.
- Resultados: Explica los detalles de cómo aplicar la solución a su escenario de integración y cómo resuelve las fuerzas asociadas con ese escenario. Esta sección también contiene nuevos retos que pueden surgir como resultado de la aplicación del patrón.
- Barras laterales: Secciones adicionales relacionadas con el patrón que contienen problemas técnicos clave, variaciones del patrón, problemas específicos del patrón, etc.
- Ejemplo: Un escenario del mundo real que describe cómo se utiliza el patrón de diseño en un escenario de Salesforce del mundo real. El ejemplo explica los objetivos de integración y cómo implementar el patrón para alcanzar esos objetivos.
Utilice esta tabla como una tabla de contenidos para los patrones de integración contenidos en este documento.
| Nivel de patrón1 | Nivel de patrón2 | Patrón | Escenario |
|---|---|---|---|
| Patrones de ingreso de datos: Datos entrantes | Patrones de ingreso por lotes | Ingreso masivo de datos desde Cloud Storage | Los datos se ingresan desde un origen de almacenamiento de Enterprise Cloud como Amazon S3, Azure Blob o Google Cloud Storage en Data 360 en forma de grandes lotes de datos sin procesar (por ejemplo, transacciones o registros de productos). |
| Ingreso masivo de datos desde Salesforce Cloud | Data 360 recibe datos de CRM de forma masiva desde múltiples organizaciones de Salesforce (por ejemplo, Sales Cloud, Service Cloud) para crear perfiles de clientes unificados. | ||
| Patrones de transmisión e ingreso en tiempo real | Ingreso dirigido por eventos a través de API de ingreso: Transmisión | Data 360 se suscribe a extremos de ingreso de transmisión que reciben cargas de eventos continuas (por ejemplo, eventos de compra, telemetría de IoT) desde sistemas de compañía para actualizaciones de perfil en tiempo real. | |
| Ingreso de comportamiento web y móvil en tiempo real | Data 360 recopila y procesa datos de comportamiento de sitios web y aplicaciones móviles en tiempo real a través de SDK para enriquecer mediciones de implicación y modelos de personalización. | ||
| Sincronización de CRM casi en tiempo real a través de transmisión | Data 360 recibe actualizaciones de datos de CRM (por ejemplo, cambios de contacto, caso u oportunidad) casi en tiempo real a través de transmisiones de eventos para mantener una vista Customer 360 sincronizada continuamente. | ||
| Ingreso de transmisiones de eventos desde plataformas de mensajería de nube: Kinesis y MSK | Data 360 consume datos de transmisión directamente desde plataformas de eventos en la nube como AWS Kinesis o Kafka (MSK) para procesar eventos operativos o de IoT de alta frecuencia. | ||
| Cero patrones de copia: entrante y saliente | Copia de cero entrante: Plataformas externas en Data 360 | Data 360 consulta conjuntos de datos externos (por ejemplo, Snowflake, BigQuery) on demand a través de Cero ingreso de copia, sin mover físicamente datos en Salesforce. | |
| Copia cero saliente: Data 360 en plataformas externas | Los sistemas externos como Databricks o Tableau acceden a segmentos enriquecidos y perspectivas en Data 360 a través de conexiones salientes de copia cero sin replicación de datos. | ||
| Plataforma de datos de múltiples organizaciones unificada con Data Cloud One | Data Cloud One unifica múltiples organizaciones de Salesforce y orígenes de datos externos bajo un modelo semántico y de metadatos compartidos, proporcionando un Customer 360 coherente sin duplicación de datos. | ||
| Patrones de activación de datos: Datos salientes | Patrones de activación por lotes | Activación de segmentos en plataformas de marketing y publicidad | Data 360 activa segmentos de clientes depurados directamente en Marketing Cloud, Meta, Google Ads u otras plataformas de anuncios para la entrega de campañas personalizadas |
| Exportación de datos a Cloud Storage | Data 360 exporta conjuntos de datos unificados o filtrados (por ejemplo, registros de clientes consentidos) como archivos CSV o Parquet a almacenamiento de Enterprise Cloud para análisis o archivado de cumplimiento. | ||
| Activación basada en API On Demand | Integración de aplicaciones personalizadas a través de la API de Connect | Las aplicaciones externas invocan la API de Data 360 Connect en tiempo real para recuperar o desencadenar acciones personalizadas (por ejemplo, comprobación de balance de fidelidad o generación de ofertas de IA) basándose en datos de clientes actuales.Las aplicaciones web o móviles creadas a medida recuperan perspectivas de Data 360 armonizadas de forma segura a través de la API de REST de Connect para mostrar en las interfaces de usuario de compañías o socios. | |
| Recuperación de perfil de cliente completa a través de API de gráficos de datos | Un sistema recupera el perfil unificado de un cliente utilizando la API de gráfico de datos, devolviendo una representación JSON en tiempo real unida previamente de la vista completa de 360° para la decisión o la personalización. | ||
| Acciones de datos en tiempo real | Acción de datos en tiempo real Conversión de señales de clientes en acciones instantáneas | Data 360 detecta y procesa un evento en vivo (por ejemplo, actualización de consentimiento, desencadenador de compra) e invoca inmediatamente un sistema conectado o Salesforce Flow para una acción descendente.Una señal de actividad de cliente (por ejemplo, riesgo de abandono detectado) en Data 360 desencadena una acción instantánea en tiempo real, como la actualización de CRM, la invocación de puntuaje Einstein o el inicio de una trayectoria de retención. |
Los patrones de integración de este documento se clasifican en tres categorías: datos, procesos e integraciones visuales.
Los patrones de integración de datos en Data 360 abordan el movimiento y la sincronización de datos entre sistemas para garantizar que tanto Data 360 como las plataformas externas albergan información coherente, oportuna y fiable. Estos patrones normalmente gestionan flujos de datos de gran volumen y gran escala y se basan en oportunidades en curso gobernadas que aplican reglas de coherencia, seguimiento de linaje y masterización de esquemas.
- Los patrones de ingreso por lotes representan la capa fundamental de incorporación de datos de compañía. El ingreso masivo de datos desde servicios de almacenamiento en la nube como AWS S3, Azure Blob o Google Cloud Storage permite cargar conjuntos de datos históricos de gran tamaño periódicamente en Data 360 para la resolución de identidad, segmentación y análisis. Del mismo modo, el ingreso masivo desde Salesforce Cloud (como Sales, Service o Marketing Cloud) utiliza conectores nativos y Transmisiones de datos para aportar datos de CRM a la capa de datos unificada, garantizando Armonización y continuidad entre sistemas de implicación.
- Los patrones de transmisión e ingreso en tiempo real amplían esto capturando datos de eventos de alta velocidad. El ingreso dirigido por eventos a través de la API de ingreso permite a los sistemas externos transmitir continuamente la actividad de los clientes en Data 360. El ingreso de comportamiento web y móvil en tiempo real captura datos de interacciones y transmisiones de clics directamente desde puntos de contacto digitales para dirigir la personalización inmediata. La sincronización de CRM casi en tiempo real a través de las API de transmisión garantiza que los atributos del cliente y las actualizaciones de consentimiento se reflejen rápidamente entre sistemas. El ingreso de transmisiones de eventos desde plataformas de mensajería como Amazon Kinesis o Confluent MSK admite oportunidades en curso de alto rendimiento continuas, alineando Data 360 con arquitecturas de eventos de compañía.
- Unified Multi-Org Data Platform with Data Cloud One ejemplifica aún más la integración de datos, proporcionando un entorno consolidado para unificar datos desde múltiples organizaciones de Salesforce y orígenes externos bajo una gobernanza común y una capa semántica. Esto permite a las organizaciones alcanzar la coherencia de datos de toda la compañía, modelos de datos compartidos y análisis ampliables.
- En la fase de activación, los patrones de activación por lotes siguen el mismo principio de integración de datos. Los segmentos depurados en Data 360 se exportan en trabajos programados a plataformas de marketing y publicidad descendentes, como Marketing Cloud, Meta Ads o Google Ads, donde desencadenan la ejecución de campañas. Del mismo modo, los conjuntos de datos se pueden exportar a destinos de almacenamiento en la nube para impulsar oportunidades en curso de análisis externo y ciencia de datos. En todos estos casos de uso, Data 360 actúa como la fuente de la verdad para datos de clientes sincronizados y depurados.
Los patrones de integración de procesos en Data 360 implican desencadenar u orquestar procesos de negocio entre sistemas casi en tiempo real. Estos patrones permiten que Data 360 participe activamente en flujos de trabajo de compañía, permitiendo respuestas contextuales y activación de datos dinámica.
- La activación basada en API On-Demand activa escenarios de implicación en tiempo real. A través de la API de Connect, las aplicaciones personalizadas pueden consultar o activar perfiles de clientes directamente desde Data 360 como parte de procesos operativos, como una consola de agente recuperando perspectivas de perfil unificadas durante una interacción de cliente. La Recuperación completa de perfiles de clientes a través de la API de gráficos de datos admite aplicaciones compuestas y microservicios que se basan en acceso dirigido por API al gráfico de entidad completo de un cliente, permitiendo experiencias dinámicas sin segmentos preestablecidos.
- Las acciones de datos en tiempo real amplían aún más este enfoque de integración al permitir la capacidad de respuesta inmediata. Cuando se detecta una señal de cliente, como una compra, un envío de formulario o un evento de umbral, Data 360 puede desencadenar acciones como la actualización de un registro de CRM, la invocación de un gancho web externo o el inicio de un flujo de trabajo de oferta personalizado. Estos patrones encarnan una verdadera orquestación de procesos, uniendo Inteligencia de clientes en tiempo real con la ejecución operativa automatizada.
Los patrones de integración virtual en Data 360 permiten el acceso en vivo a orígenes de datos externos o federados sin copiar físicamente o duplicar datos. Estas son críticas para las compañías que requieren información actualizada gobernada en el momento de la consulta minimizando al mismo tiempo el movimiento de datos.
- Federación de datos de copia cero entrante (Plataformas externas a Data 360) permite a los sistemas externos, como almacenes de datos o lagos de datos, compartir conjuntos de datos con Data 360 a través de conexiones seguras y gobernadas (por ejemplo, Colaboración de datos segura de Snowflake). Esto garantiza que Data 360 pueda acceder y operar en datos externos virtualmente, preservando la actualización y eliminando replicaciones innecesarias.
- La colaboración de datos de copia cero saliente (Data 360 to External Platforms) permite a Data 360 exponer conjuntos de datos depurados para consumo externo, como modelado de IA, inteligencia de negocio o análisis avanzado, a través de mecanismos de federación de datos y consulta en vivo seguros. La selección de la mejor estrategia de integración para su sistema no es trivial. Existen muchos aspectos a tener en cuenta y muchas herramientas que se pueden utilizar, siendo algunas herramientas más apropiadas que otras para ciertas tareas. Cada patrón aborda áreas críticas específicas incluyendo las funciones de cada uno de los sistemas, el volumen de datos, la gestión de fallos y la transaccionalidad.
Al seleccionar un patrón de integración, comience respondiendo a dos preguntas fundamentales que dan forma al diseño y el comportamiento generales de la integración. ¿Qué está integrando? — Proceso, Datos o Acceso virtual Esta dimensión define el propósito principal de la integración.
- Las integraciones de procesos se centran en orquestar flujos de trabajo de negocio y coordinar acciones entre sistemas.
- Las integraciones de datos se centran en la sincronización, el enriquecimiento o la propagación de datos entre sistemas.
- Las integraciones virtuales se centran en acceder a datos externos en tiempo real sin copiarlos o persistir en Salesforce o Data 360. Comprender esta intención ayuda a determinar el nivel de orquestación, el movimiento de datos y el acoplamiento requeridos entre sistemas.
- ¿Cómo se necesita ejecutar?: El método Síncrono o Asíncrono define el modelo de ejecución de la integración.
- Las integraciones síncronas son en tiempo real y de bloqueo, donde el llamante espera una respuesta inmediata, utilizada habitualmente para escenarios dirigidos por el usuario o de validación.
- Las integraciones asíncronas no son de bloqueo y están desacopladas, diseñadas para gestionar procesos de escala, larga ejecución, reintentos y altos volúmenes de datos. Juntos, estas dos dimensiones (intención de integración y tiempo de ejecución) proporcionan un marco claro y coherente para seleccionar el patrón de integración correcto mientras equilibran la experiencia del usuario, la capacidad de ampliación y la resiliencia operativa. Nota: Una integración puede requerir un middleware externo o una solución de integración (por ejemplo, Enterprise Service Bus) dependiendo de qué aspectos se aplican a su escenario de integración.
Esta tabla enumera los patrones y sus aspectos clave para ayudarle a determinar qué patrón se ajusta mejor a sus requisitos cuando su integración es desde Salesforce a otro sistema
| Tipo | Cronología | Consideraciones de salida |
|---|---|---|
| Integración de datos | Asíncrono | Activación de segmentos en plataformas de marketing y publicidad |
| Integración de procesos/datos | Síncrono | Integración de aplicaciones personalizadas a través de la API de Connect Recuperación de perfil de cliente completa a través de API de gráficos de datos |
| Integración de datos | Síncrono | Acción de datos en tiempo real Conversión de señales de clientes en acciones instantáneas |
| Integración virtual (utilizando copia cero) | Asíncrono | Copia cero saliente: Data 360 en plataformas externas |
| Integración virtual | Asíncrono | Plataforma de datos de múltiples organizaciones unificada con Data Cloud One |
Esta tabla enumera los patrones y sus aspectos clave para ayudarle a determinar el patrón que mejor se ajusta a sus requisitos cuando su integración es desde otro sistema en Salesforce.
| Tipo | Cronología | Consideraciones sobre el ingreso |
|---|---|---|
| Integración de datos | Asíncrono | Ingreso masivo de datos desde Cloud Storage Ingreso masivo de datos desde Salesforce Cloud |
| Integración de datos | Asíncrono | Ingreso de transmisiones de eventos desde plataformas de mensajería de nube: Kinesis y MSK Sincronización de CRM casi en tiempo real a través de transmisión |
| Integración de procesos | Síncrono | Ingreso dirigido por eventos a través de API de ingreso: Transmisión Ingreso de comportamiento web y móvil en tiempo real |
| Integración virtual | Asíncrono | Copia de cero entrante: Plataformas externas en Data 360 |
Esta tabla enumera algunos términos clave relacionados con middleware y sus definiciones con respecto a estos patrones.
| Plazo | Definición |
|---|---|
| Gestión de eventos | La gestión de eventos hace referencia a la recepción, el enrutamiento y la respuesta a incidencias identificables desde un sistema o una aplicación de origen. El middleware gestiona eventos identificando el extremo de destino, reenviando el evento y desencadenando la acción de negocio requerida (por ejemplo, registro, reintentos o activación de servicios descendentes). En arquitecturas de Data 360, la gestión de eventos es clave para el ingreso de datos en tiempo real, desencadenadores de activación y patrones de publicación/suscripción. Los eventos pueden originarse desde sistemas externos (Kafka, AWS Kinesis) o Eventos de Salesforce Platform y se enrutan por middleware o el bus de eventos de Data 360 para su procesamiento inmediato. |
| Conversión de protocolo | La conversión de protocolos permite la comunicación entre sistemas utilizando diferentes estándares de transporte de datos. El middleware traduce protocolos propios o heredados (como AMQP, MQTT, FTP) en protocolos de Data 360 compatibles (REST, gRPC o HTTPS). Esto garantiza la interoperabilidad entre sistemas heterogéneos. Como Data 360 no gestiona de forma nativa la conversión de protocolos, el middleware proporciona la capa de adaptación, encapsulando o transformando mensajes en un formato que las API y conectores de Data 360 pueden interpretar. |
| Traducción y transformación | La traducción y la transformación garantizan la interoperabilidad asignando un formato de datos o esquema a otro. Middleware realiza estas transformaciones para alinear diversas cargas de datos (CSV, XML, JSON) con objetos de modelo de datos (DMO) y objetos de capa de datos unificados (UDLO) de Data 360. Esto incluye la limpieza, el enriquecimiento y la aplicación de asignaciones semánticas u ontológicas antes de la ingesta. Aunque Salesforce ofrece herramientas de transformación como Recetas de Preparación de datos, las transformaciones complejas (especialmente para Armonización semántica) se gestionan mejor en middleware. |
| Cola y almacenamiento en memoria intermedia | Las colas y el almacenamiento en memoria intermedia dependen del paso de mensajes asíncronos para garantizar una comunicación resiliente y desvinculada. Las plataformas de middleware (por ejemplo, MuleSoft, Kafka o Azure Event Hub) proporcionan colas persistentes que almacenan temporalmente datos cuando Data 360 o sistemas descendentes están ocupados o no se puede acceder a ellos. Esto evita la pérdida de datos y admite reintentos de ingreso o activación casi en tiempo real. Data 360 admite el ingreso de transmisiones y la mensajería saliente basada en flujos, pero el middleware suele gestionar las colas duraderas y la entrega garantizada. |
| Protocolos de transporte síncronos | Los protocolos de transporte síncronos implican operaciones de bloqueo de solicitudes/respuestas en tiempo real. El remitente espera una respuesta antes de continuar. En Data 360, estos se utilizan para activaciones basadas en API on-demand, enriquecimiento en tiempo real o búsquedas de perfil, donde se requieren respuestas de inmediato. El middleware garantiza la fiabilidad de la conexión y gestiona reintentos o gestión de reserva para llamadas de API de Data 360 síncronas. |
| Protocolos de transporte asíncronos | Los protocolos de transporte asíncronos admiten la comunicación desvinculada no bloqueada donde el remitente continúa procesando sin esperar una respuesta. El middleware gestiona flujos asíncronos para activaciones por lotes, ingreso de transmisiones y activación dirigida por eventos. Esto permite un alto rendimiento y capacidad de recuperación, clave para la transmisión de eventos y patrones de ingreso de datos casi en tiempo real en Data 360. |
| Enrutamiento de mediación | El enrutamiento de mediación define un flujo de mensajes complejo entre sistemas, garantizando que los datos o eventos correctos llegan al consumidor correcto. El middleware actúa como mediador, gestionando la lógica de enrutamiento basándose en reglas, encabezados, contenido o tipo de evento. En integraciones de Data 360, la mediación garantiza que los eventos y las actualizaciones de perfil desde múltiples sistemas se enruten correctamente a las API de ingreso de datos, los extremos de activación o los consumidores externos. Esto simplifica la orquestación y admite la sincronización de datos de múltiples sistemas. |
| Coreografía de proceso y Orquestación de servicio | La coreografía de procesos y la orquestación coordinan procesos de múltiples sistemas. Coreografía admite flujos autónomos dirigidos por eventos asíncronos, donde los sistemas actúan basándose en reglas compartidas sin un controlador central. Orquestación es un flujo gestionado de forma centralizada que dirige la ejecución del servicio. En arquitecturas de Data 360, el middleware gestiona la orquestación para el ingreso y la activación entre sistemas, mientras que los flujos de trabajo o flujos de Salesforce gestionan coreografías ligeras dentro de la plataforma. La orquestación compleja, que requiere coordinación de transacciones o gestión de estados, se recomienda en la capa de middleware. |
| Transacción (Cifrado, Firma, Entrega fiable, Gestión de transacciones) | La transaccionalidad garantiza operaciones atómicas, coherentes, aisladas y duraderas (ACID) entre sistemas. Salesforce y Data 360 son transaccionales dentro de sus límites pero no admiten transacciones distribuidas entre sistemas externos. El middleware gestiona el control de transacciones globales, incluyendo cifrado, firma de mensajes, reversión, compensación y entrega fiable. Para flujos de datos de misión crítica (por ejemplo, actualizaciones financieras o de consentimiento), el middleware garantiza la integridad y la recuperación de extremo a extremo entre Data 360 y sistemas externos. |
| Enrutamiento | El enrutamiento especifica el flujo controlado de mensajes o datos entre componentes. Puede basarse en encabezados, tipo de contenido, prioridad o reglas. El middleware gestiona la lógica de enrutamiento para eventos y activaciones que implican Data 360, como dirigir segmentos de audiencia enriquecidos a diferentes sistemas descendentes (plataformas de anuncios, almacenes, aplicaciones CRM). Aunque el enrutamiento se puede implementar dentro de Salesforce (Apex, Flows), el enrutamiento middleware se prefiere por su capacidad de ampliación, flexibilidad y gobernanza. |
| Extracción, transformación y carga (ETL) | ETL implica extraer datos de sistemas de origen, transformarlos en un esquema coherente y cargarlos en un destino (como Data 360). Las herramientas de middleware o ETL gestionan estas operaciones antes del ingreso de datos. Data 360 puede recibir salidas de ETL a través de API, conectores o oportunidades en curso de ingreso masivo, y también admite Captura de datos de cambios (CDC) para la sincronización casi en tiempo real. Los procesos ETL de middleware son esenciales para integrar sistemas heredados y garantizar la calidad de los datos antes de la unificación en Data 360. |
| Votación larga | Sondeo largo (Programación de cometas) es un método para mantener la comunicación abierta entre sistemas para actualizaciones en tiempo real. El cliente envía una solicitud y el servidor la mantiene hasta que se produzca un evento, luego responde y reabre una nueva conexión. Salesforce utiliza esto en la API de transmisión y los protocolos CometD/Bayeux para la sincronización de datos dirigida por eventos. El middleware puede suscribirse a estos eventos y reenviarlos a Data 360 para desencadenadores de ingreso o activación en tiempo real, garantizando una latencia mínima entre sistemas de compañía. |
El ingreso de datos es el primer paso y el más crítico en el ciclo de vida de datos de Salesforce Data 360. Es cómo la información sin procesar de múltiples sistemas externos (CRM, ERP, API web, móviles o externas) entra en la plataforma y se convierte en parte de una vista de cliente unificada. El patrón de ingreso correcto depende de lo que necesita el negocio:
- Volumen de datos: cuántos datos se están moviendo a la vez
- Latencia: cuán actualizados deben ser los datos
- Funciones del sistema de origen: cómo el sistema puede conectar y entregar datos Data 360 admite múltiples modos de ingreso para satisfacer estas necesidades: lote para cargas de gran volumen, transmisión para actualizaciones casi en tiempo real, basado en eventos para inmediatez de transacciones e ingreso Cero copia para acceso instantáneo a datos externos sin moverlos físicamente. Juntos, estos patrones garantizan que cada señal de cliente (ya sea un evento de compra, un registro de transmisión de clics o una actualización de fidelidad) fluya en Data 360 de forma eficiente, segura y en el plazo de tiempo correcto para potenciar análisis de confianza y experiencias dirigidas por IA.
Los patrones de ingreso por lotes son la columna vertebral de la incorporación de datos a gran escala en Data 360. Están optimizados para escenarios donde los datos se procesan de forma masiva (normalmente de forma programada o periódica) en vez de de forma continua. Estos patrones son los más adecuados para:
- Cargas de datos históricos para inicializar la plataforma con registros de compañía existentes
- Sincronización regular con sistemas de registro como sistemas ERP, almacenes de datos o bases de datos propias
- Utilice casos donde la actualización en tiempo real no es crítica, pero la coherencia, la integridad y la capacidad de auditoría son El ingreso por lotes ofrece desempeño predecible y sencillez operativa, lo que lo convierte en una opción de confianza para las empresas que gestionan terabytes de datos estructurados o semiestructurados. Data 360 proporciona un conjunto de conectores listos para la producción y disponibles de forma general que admiten el ingreso por lotes de forma nativa. Estos conectores simplifican la configuración de la integración, reducen el desarrollo de ETL personalizado y garantizan la calidad y la seguridad de los datos en cada importación. La tabla siguiente resalta los conectores más comunes utilizados para el ingreso por lotes a escala de compañía.
Contexto
Este patrón está diseñado para escenarios de compañía que implican el ingreso de grandes volúmenes de datos estructurados, como archivos CSV o Parquet, y activos no estructurados desde lagos de datos centralizados o caídas de archivos programadas. Los orígenes de datos incluyen comúnmente plataformas de almacenamiento en la nube como Amazon S3, Google Cloud Storage (GCS) y Microsoft Azure Blob Storage, donde los archivos se entregan periódicamente como parte de oportunidades en curso de datos ascendentes o exportaciones por lotes.
Problema
¿Cómo puede una organización establecer un proceso fiable, seguro y de alto rendimiento para ingresar conjuntos de datos masivos basados en archivos desde su plataforma de almacenamiento de nube principal en Data 360 de forma predecible y recurrente, sin sacrificar la gobernanza, la capacidad de ampliación o el desempeño?
Fuerzas
Ingresar conjuntos de datos masivos basados en archivos en Data 360 no es un ejercicio de transferencia de datos sencillo: es un reto arquitectónico modelado por restricciones de escala, gobernanza y plataforma.
Volumen y escala de datos: Los conectores de ingreso de Data 360 están optimizados para la fiabilidad y la regulación, no el rendimiento masivo arbitrario. Por ejemplo, el conector de Amazon S3 admite hasta 100 millones de filas o 50 GB por objeto, cualquiera que sea el límite que se alcance primero. Para empresas con conjuntos de datos históricos que se ejecutan en miles de millones de registros, este límite se convierte en una restricción de diseño clave. Un enfoque de una sola fila, elevación y cambio se vuelve rápidamente inviable, requiriendo estrategias inteligentes de partición, fragmentación y orquestación de datos para alcanzar la escala sin alcanzar los límites del conector.
Definición y mantenimiento del esquema: Data 360 requiere definiciones de esquema explícitas para cada canalización de ingreso para garantizar la integridad semántica y estructural. En el caso del ingreso de S3, un archivo csv debe definir encabezados de columna y una única fila de datos representativa. Este archivo actúa como el contrato canónico entre el sistema de origen, es decir, almacenamiento en la nube y Data 360. Cualquier desalineación (en nombres de campo, tipos de datos o codificación) puede causar fallos de ingreso o daños de datos silenciosos. Mantener este archivo de esquema en el control de versiones y aplicar la validación a través de flujos de trabajo de CI/CD o gobernanza de datos se convierte en una mejor práctica para entornos de producción.
Convenios de nomenclatura estricta: Data 360 aplica reglas estrictas de nomenclatura de objetos y campos para mantener la coherencia en el gráfico de metadatos.
- Los nombres de objetos deben comenzar por una letra y solo pueden incluir letras, dígitos o guiones bajos.
- Los nombres de campo deben seguir los mismos patrones. Los archivos que infringen estas convenciones (por ejemplo, campos que contienen espacios, caracteres especiales o símbolos no admitidos) fallarán en la validación de esquemas durante el ingreso. Las compañías deben implementar procesos de higiene de datos previos al ingreso para limpiar y normalizar las estructuras de archivos entrantes.
Posición de autenticación y seguridad: Cada conexión al almacenamiento externo debe cumplir con estándares de seguridad y cumplimiento de nivel de compañía.
- La autenticación se gestiona habitualmente a través de claves secretas/acceso de AWS o autenticación de proveedor de identidad federado (IdP).
- Las funciones de IAM deben tener un ámbito para aplicar el menor privilegio, permitiendo solo el acceso de lectura a las rutas de almacenamiento especificadas.
- Para un acceso seguro, las direcciones IP salientes deben agregarse directamente a la lista de admisión del sistema de origen. Estos controles por capas garantizan que cada transferencia de archivos funcione dentro de un perímetro auditable de confianza cero, equilibrando el cumplimiento de la compañía con la flexibilidad requerida para el ingreso a gran escala.
Solución
Esta tabla contiene soluciones a este problema de integración.
| Solución | Ajuste | Comentarios |
|---|---|---|
| Utilizar conectores de almacenamiento de nube nativos (Amazon S3, Google Cloud Storage, Azure Blob Storage) | Mejor | Este es el patrón recomendado y más fiable para el ingreso recurrente a gran escala basado en archivos en Data 360\. Los conectores nativos proporcionan autenticación gestionada, asignación de esquemas y movimiento de datos seguro directamente en los objetos de lago de datos (DLO) de Data 360. Ideal para cargas por lotes programadas donde la latencia no es crítica (por ejemplo, programación cada hora o diariamente). |
| Gestión de grandes conjuntos de datos (más allá de los límites del conector) | Mejor con preprocesamiento | Cada conector aplica límites de admisión (por ejemplo, S3: 100M filas o 50 GB por objeto). Para conjuntos de datos más grandes, implemente un paso de preprocesamiento de ETL para particionar datos en archivos/carpetas más pequeños que se encuentren por debajo de estos umbrales. A continuación, configure múltiples transmisiones de datos para ingresar cada partición en paralelo, y utilice el nodo adjunto en transformaciones de datos por lotes) dentro de Data 360 para recombinar las particiones en un conjunto de datos unificado. |
| Seguridad y gobernanza | Mejor | Todos los conectores admiten la autenticación segura a través de métodos nativos de la nube (funciones IAM, cuentas de servicio o claves de acceso). Para mayor control, restrinja el acceso a intervalos de IP de Data 360 a través de la lista de admisión del proveedor de nube. La transferencia de datos se produce en canales cifrados, con archivos almacenados en una capa de organización temporal y segura durante el ingreso. |
| Cuándo no utilizar | Suboptimal | Este patrón no es óptimo para:
|
Boceto
Este diagrama ilustra la secuencia de pasos para ingresar los datos desde el almacenamiento en la nube en Data 360
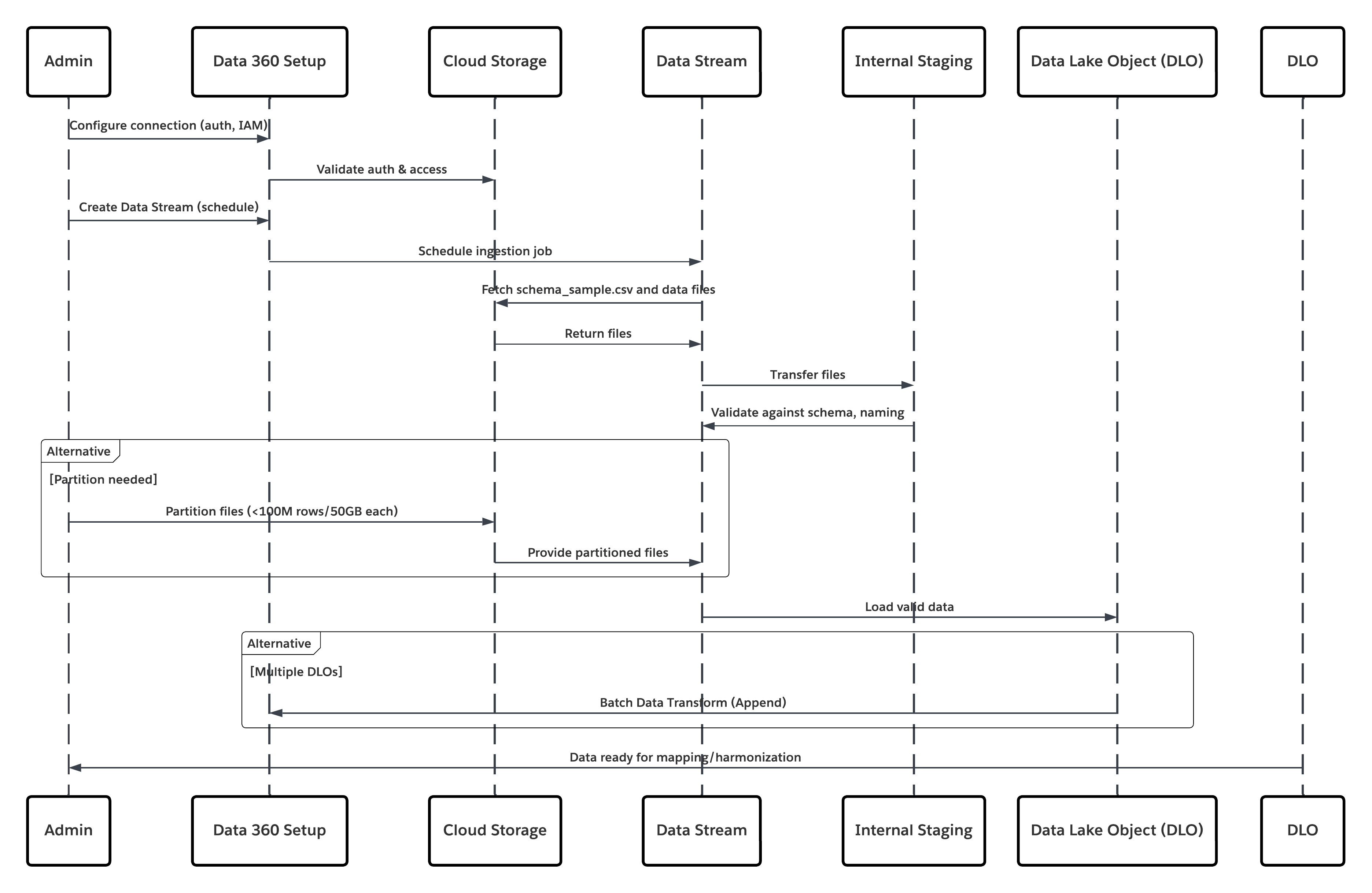
En este escenario:
- El administrador configura una conexión al almacenamiento en la nube a través de la interfaz Configuración de Data 360 (especificando autenticación, detalles de depósito, funciones de IAM y listas blancas).
- La interfaz de configuración de Data Cloud se autentica con Cloud Storage Platform, verificando credenciales y acceso.
- El administrador crea una transmisión de datos en Data 360, vinculando la transmisión de datos al objeto/carpeta en Cloud Storage y definiendo la programación de ingreso.
- En el desencadenador de programación, la transmisión de datos solicita archivos de origen (por ejemplo, CSV, Parquet) desde Cloud Storage Platform.
- Cloud Storage Platform entrega archivos, incluyendo el schema_sample.csv válido requerido y otros archivos de datos que cumplen con convenciones de nomenclatura.
- Transmisión de datos transfiere archivos al entorno de organización interno en Data 360.
- Canalizaciones de Data 360 procesa los archivos: Utiliza la definición de esquema de schema_sample.csv Valida la estructura, los nombres de campo y divide la carga si está por encima de los umbrales de ingreso (100 millones de filas/50 GB por archivo). Si se detectan archivos de gran tamaño, se realiza un paso de partición de preprocesamiento (notificado al administrador para la siguiente ejecución) de forma externa.
- Los registros se importan desde la organización en un objeto de lago de datos (DLO).
- Si es necesario y los datos están particionados, utilice el nodo de anexado en una Trasformación de datos por lotes para combinar múltiples DLO.
- Data 360 registra el éxito/fallo, actualiza el estado para el monitoreo y señala que los datos están listos para la asignación, Armonización y Unificación.
Resultados
La aplicación de este patrón permite el ingreso seguro, programado y a gran escala de archivos estructurados o no estructurados desde plataformas de almacenamiento de Enterprise Cloud en Data 360. El proceso es automatizado, ampliable y resistente, entregando datos sin procesar en objetos de lago de datos (DLO) que sirven como la base para Armonización y asignación al modelo de datos Customer 360.
Mecanismos de admisión
El mecanismo de ingreso depende del conector y la estrategia de programación definidos en Data 360.
| Mecanismo de admisión | Descripción |
|---|---|
| Conector de almacenamiento de nube nativo (Amazon S3, GCS, Azure) | Recomendado para el ingreso directo de archivos en formato CSV o Parquet desde el lago de datos de nube de la compañía. Estos conectores admiten programaciones de actualización incrementales y completas. Por ejemplo, un banco puede configurar una sincronización diaria de archivos de transacciones de clientes desde un depósito de S3 a un DLO. |
| Estrategia de archivo particionado | Para conjuntos de datos muy grandes (más de 100 millones de filas o 50 GB por objeto), los datos se dividen en conjuntos lógicos más pequeños (por ejemplo, por mes o región). Cada partición se gestiona como una Transmisión de datos separada y se recombina más adelante utilizando una Trasformación de datos por lotes con un nodo Anexado. |
| Sincronización programada automatizada | Data 360 proporciona un programador declarativo (cadencia horaria, diaria o personalizada) que desencadena trabajos de ingreso automáticamente, garantizando la actualización de los datos sin intervención manual. |
Gestión y recuperación de errores
La gestión y recuperación de errores son fundamentales para garantizar la fiabilidad en operaciones de ingreso de gran volumen.
- Detección de errores: Cada ejecución de Transmisión de datos registra errores de ingreso (por ejemplo, errores de coincidencia de esquemas, daños en archivos o infracciones de nombres) en Monitoreo de Data 360. Los administradores pueden revisar y reprocesar lotes con fallos.
- Mecanismo de recuperación: Data 360 mantiene puntos de control para garantizar que los lotes con fallos no corrompen las ingestas anteriores. Los reintentos se pueden configurar después de corregir problemas de origen (por ejemplo, CSV defectuosos).
- Validación de esquema: El archivo schema_sample.csv define los tipos de datos y la estructura. Cualquier cambio desencadena la validación para evitar la desviación silenciosa de esquemas entre ejecuciones.
Consideraciones de diseño idempotentes
El ingreso es idempotente por diseño: el reprocesamiento del mismo archivo no da como resultado registros duplicados. Las estrategias clave incluyen:
- Huella de archivo: Data 360 calcula sumas de comprobación para identificar y omitir archivos procesados anteriormente.
- Ingreso transaccional: Los datos se organizan y solo se confirman con el DLO cuando se procesan correctamente todos los registros.
- Anexar vs. Sustituya: Dependiendo de la lógica de negocio, las transmisiones pueden anexar o sustituir completamente el DLO de destino; esto garantiza resultados deterministas y evita la superposición parcial de datos.
Consideraciones de seguridad
La seguridad es integral en todas las oportunidades en curso de ingreso, desde la autenticación hasta el cifrado y el control de acceso.
- Autenticación y autorización: Los conectores utilizan el Marco de trabajo de integración seguro de Salesforce, aprovechando credenciales nombradas y credenciales externas para la autenticación sin exponer secretos.
- Cifrado: Los datos se cifran en tránsito (TLS 1,2+) y en reposo (AES-256).
- Controles de red: Los sistemas de almacenamiento de origen (por ejemplo, depósitos de S3) deben incluir en la lista de admisión direcciones IP de Data 360.
- Alineación de cumplimiento: Admite marcos de trabajo de protección de datos de compañía como RGPD, HIPAA y directrices FFIEC cuando se emparejan con Claves gestionadas por el cliente (CMK).
- Auditabilidad: Cada trabajo de ingreso y acceso a credenciales se registra para la trazabilidad y la creación de reportes de cumplimiento.
Barras laterales
Oportunidad
La puntualidad depende de la programación de ingreso y el volumen de datos.
- Los conjuntos de datos de grandes compañías (más de 100 filas) pueden requerir particiones para el ingreso paralelo.
- La latencia de ingreso habitual oscila entre minutos y algunas horas, dependiendo del tamaño del archivo y la complejidad de la transformación.
- Para el ingreso casi en tiempo real, los conectores basados en API o Transmisión de Data 360 pueden complementar el modelo basado en archivos.
Volúmenes de datos
- Mejor adaptado para el ingreso por lotes periódico de gran volumen.
- Cada objeto procesado a través del conector S3 admite hasta 100 millones de filas o 50 GB por archivo.
- Para sistemas de escala de petabytes, utilice particiones de datos y orquestación de múltiples transmisiones.
Capacidad de extremo y compatibilidad de estándares
La capacidad y la compatibilidad estándar para el extremo depende de la solución que seleccione.
| Tipo de conector | Requisitos de extremo |
|---|---|
| Conector de Amazon S3 | Depósito de S3 con política de IAM apropiada y archivo schema\_sample.csv que define el esquema. |
| Conector de Google Cloud Storage | Credenciales de cuentas de servicio y acceso a depósitos con convenciones de nomenclatura uniforme. |
| Conector de almacenamiento de Azure | Clave de acceso o autenticación basada en tokens de SAS; la estructura de carpetas o blob debe seguir las convenciones de Data 360. |
Gestión de estado
Se realiza un seguimiento del estado a través de Transmisiones de datos y su última marca de tiempo de ejecución correcta.
- Data 360 mantiene automáticamente los estados de sincronización y las compensaciones, garantizando que solo se procesen archivos nuevos o modificados en ejecuciones posteriores.
- Al integrar con herramientas ETL externas, se recomiendan identificadores de archivo exclusivos (por ejemplo, UUID o marcas de tiempo) para evitar la duplicación.
Escenarios de integración complejos
En arquitecturas de negocio avanzadas, este patrón puede integrarse con:
- Oportunidades en curso de ETL de middleware (por ejemplo, Informatica, MuleSoft): para orquestar el procesamiento previo, la validación y la partición de archivos antes de la transferencia a Data 360.
- Flujos de trabajo IA/ML: los datos de DLO procesados se pueden publicar a través de DMO para modelar entornos de entrenamiento o índices RAG a través de Destinos de activación de Data 360.
- Sistemas transaccionales: los DMO armonizados pueden desencadenar actualizaciones descendentes en Salesforce CRM o sistemas externos a través de Acciones de datos o Eventos de plataforma.
Ejemplo
Una institución financiera global almacena datos de clientes y transacciones en un lago de datos de AWS S3, donde los archivos Parquet particionados se generan cada noche por región (como EE.UU., UE y APAC). El equipo de arquitectura de datos configura múltiples Transmisiones de datos en Data 360, cada una conectada a una carpeta regional, con un schema_sample.csv compartido garantizando encabezados y tipos de datos coherentes entre todas las particiones. Las programaciones de ingreso nocturno cargan automáticamente los datos en DLO, tras lo cual Transformaciones de datos por lotes anexan todas las particiones regionales en Customer_Transactions_DLO unificado. Este conjunto de datos armonizado se asigna a continuación al modelo de datos Customer 360, lo que permite la activación de análisis descendente y IA. El enfoque entrega un ingreso automatizado y confiable desde el lago de datos existente, aplica una autenticación y cifrado sólidos alineados con políticas de TI de negocio y proporciona una base modular ampliable que admite la expansión futura y la evolución de esquemas.
Contexto
Un caso de uso principal y crítico para Data 360 es la unificación de datos de clientes en el ecosistema de Salesforce. Este patrón cubre el ingreso nativo de datos desde plataformas principales de Salesforce: Sales Cloud y Service Cloud (colectivamente Salesforce CRM) y Marketing Cloud Engagement. Los orígenes incluyen objetos estándar y personalizados de CRM (por ejemplo, Cuenta, Contacto, Caso, Oportunidad) y extensiones de datos de Marketing Cloud Engagement que albergan eventos de implicación, envíos de email y datos de seguimiento.
Problema
¿Cómo puede una organización ingresar de forma eficiente y fiable objetos CRM estándar y personalizados y extensiones de datos de Marketing Cloud Engagement en Data 360 de modo que los datos puedan utilizarse para crear perfiles de clientes unificados (resolución de identidad, Customer 360), manteniendo al mismo tiempo el desempeño, la gobernanza y la interrupción mínima en los sistemas de origen?
Fuerzas
Los conectores nativos simplifican el trabajo, pero se deben gestionar varias fuerzas operativas y arquitectónicas:
- Permisos de origen integrales: Un usuario de conexión exclusivo (cuenta de integración) debe tener permisos de lectura a nivel de campo y objeto apropiados. El fallo en la asignación de conjuntos de permisos requeridos (por ejemplo, un conjunto de permisos de conector de Data 360 preconstruido) es una causa común de fallo de ingreso.
- Modos y costo de actualización de datos: Los conectores admiten modos de actualización completos y delta/incrementales. Las actualizaciones completas son más pesadas en desempeño y créditos; los extractos delta reducen la carga pero dependen de un seguimiento de cambios fiable en el sistema de origen.
- Esquema personalizado y asignación de campos: Las instancias de CRM a menudo incluyen objetos/campos personalizados. Se requiere una asignación de esquemas precisa y la gestión de campos personalizados (nombres, tipos) para evitar errores de asignación o desviación semántica.
- Iniciar paquetes de datos frente a Asignación personalizada: Los paquetes de datos de inicio aceleran la incorporación seleccionando previamente objetos/campos típicos, pero las organizaciones altamente personalizadas necesitarán definiciones de transmisión a medida.
- Límites de API y rendimiento: Los límites de API de la organización de origen y los índices de extracción de Marketing Cloud limitan la agresividad con la que puede programar actualizaciones.
- Convenciones de higiene y nomenclatura de datos: Los nombres de campo de origen, el comportamiento nulo y los tipos de datos deben normalizarse antes de la introducción para evitar problemas de asignación descendente.
- Seguridad y privilegios mínimos: El conector se basa en autenticación segura y debe respetar los patrones de IAM de menor privilegio, la capacidad de auditoría y los controles de red.
Solución
Esta tabla contiene soluciones a este problema de integración.
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Ajuste de solución | Mejor | Utilice el conector nativo de Salesforce CRM y el conector de Marketing Cloud Engagement en Data 360\. Comience con Paquetes de datos de inicio para casos de uso estándar y acelere la incorporación. Utilice la personalización de transmisiones manual para modelos de datos a medida o específicos de dominio. |
| Gestión de instancias de CRM altamente personalizadas | Mejor con taller de asignación | Trate los paquetes de inicio como una línea base y realice un taller de asignación para identificar: Relaciones y objetos personalizados. Fórmula o campos calculados. Extensiones de paquetes gestionados. Para campos de fórmula pesados, calcule valores en un ETL previo a la etapa o dentro de Transformaciones de Data 360 para minimizar la carga de API en organizaciones de origen. |
| Cuándo no utilizar | Escenarios subóptimos | Evite este patrón si: Necesita ingreso de eventos de alta frecuencia o en tiempo real (en su lugar, utilice Conectores de transmisión, Eventos de plataforma o Federación de copia cero). La organización de origen tiene una capacidad de API limitada y no puede mantener las extracciones programadas sin demoras de estrangulación o cola. |
| Seguridad y gobernanza | Controles obligatorios | Principio de menor privilegio: utilice un usuario de integración exclusivo con acceso de lectura mínimo. Nunca utilice administradores de toda la organización. Autenticación: Utilice OAuth 2.0 y aplicaciones conectadas; rote secretos de cliente regularmente y monitoree el uso de tokens de actualización. Auditoría y trazabilidad: registre todas las ejecuciones de ingreso, cambios de esquema y eventos de conector. Reenvíe registros a SIEM o sistemas de cumplimiento para la preparación de auditorías. Clasificación de datos: Aplique el etiquetado PII/PHI y el Control de acceso basado en atributos (ABAC) utilizando políticas de CEDAR inmediatamente después del ingreso para aplicar el enmascaramiento, el consentimiento y el cumplimiento descendente. |
Boceto
Este diagrama ilustra la secuencia de pasos para ingresar los datos desde el almacenamiento en la nube en Data 360
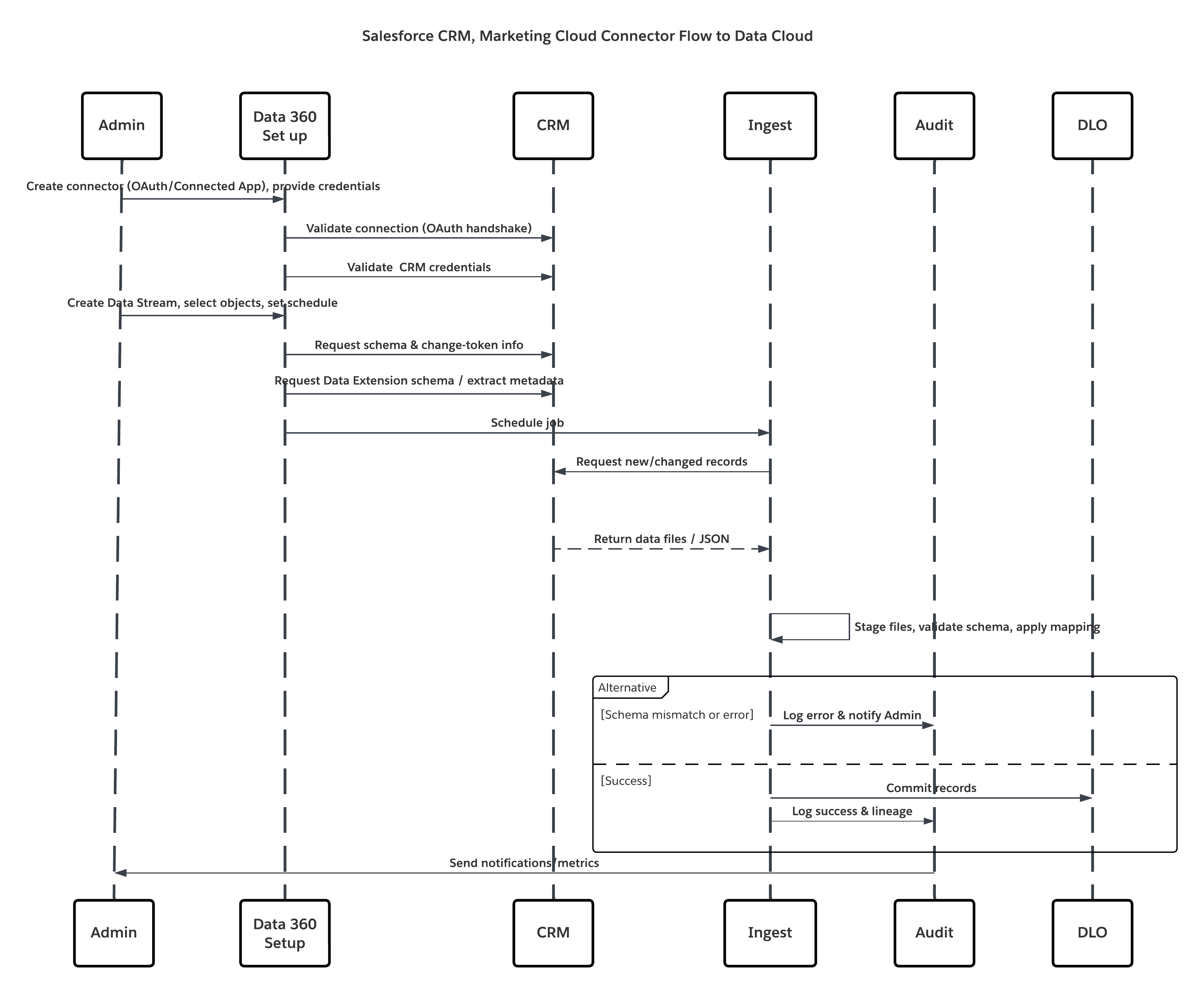
En este escenario:
- El administrador proporciona usuarios de integración y asigna conjuntos de permisos de conector en organizaciones de origen.
- El administrador configura conectores en Configuración de Data 360 (se conecta a Salesforce CRM y Marketing Cloud a través de OAuth/aplicación conectada).
- El administrador crea Transmisiones de datos seleccionando objetos y Extensiones de datos, selecciona la actualización completa o delta y establece programaciones.
- En la ejecución programada, Data 360 solicita tokens de esquema y delta desde la(s) fuente(s).
- Los sistemas de origen devuelven registros (delta o carga completa). Marketing Cloud puede entregar extractos; CRM puede devolver resultados de JSON/Consulta.
- Data 360 organiza archivos en su área de organización segura interna y valida con el esquema asignado.
- Si falla la validación, el error de registro de ingreso, el administrador de alertas y la confirmación se detiene. Si la validación se realiza correctamente, Data 360 confirma registros atómicamente en el DLO de destino.
- Los registros de monitoreo y auditoría se actualizan con el linaje, la duración de la ejecución, los conteos de filas y el uso de credenciales. Alertas emitidas a administradores si se desencadenan umbrales o errores.
Resultados
Los datos principales de relaciones con los clientes e implicación de marketing se ingresan en Data 360 como Objetos de lago de datos (DLO). Esto proporciona:
- Conjunto de datos unificado que contiene perfiles, casos, oportunidades y mediciones de email/implicación.
- Fundamento para resolución de identidad y construcción de perfiles de particulares unificados.
- Preparación operativa para Armonización descendente, enriquecimiento, modelado de IA y activación preservando al mismo tiempo la gobernanza y la capacidad de auditoría.
Mecanismos de admisión
El mecanismo de ingreso depende del conector y la estrategia de programación definidos en Data 360.
| Mecanismo | Cuándo utilizar |
|---|---|
| Conector de Salesforce CRM (nativo) | Lo mejor para objetos CRM estándar/personalizados; admite la actualización completa y delta. |
| Conector de implicación de Marketing Cloud (nativo) | Lo mejor para extensiones de datos, envíos y seguimiento de extractos; admite modos completo/delta. |
| Paquetes de datos de inicio | Acelere la incorporación para objetos comunes de Ventas/Servicio/Marketing. |
| Transmisiones personalizadas + preprocesamiento | Se utiliza cuando se requieren transformaciones complejas o normalización de esquemas intensa. |
Gestión y recuperación de errores
La gestión y recuperación de errores son fundamentales para garantizar la fiabilidad en operaciones de ingreso de gran volumen.
- Registros por ejecución: Cada ejecución de Transmisión de datos proporciona detalles de operación correcta/fallo y errores a nivel de fila.
- Reintentos y puntos de control: Las ejecuciones fallidas se pueden reintentar después de solucionar problemas de origen o esquema; Data 360 utiliza la semántica de preparación y confirmación atómica.
- Alertas: Configure alertas para desviación de esquemas, fallos repetidos o brechas de secuencia delta.
Consideraciones de diseño idempotentes
El ingreso es idempotente por diseño: el reprocesamiento del mismo no da como resultado registros duplicados. Las estrategias clave incluyen:
- Detección de cambios: Los extractos Delta se basan en indicadores de cambio del sistema de origen (LastModifiedDate / Captura de datos de cambio del sistema). Verifique que el origen proporciona marcas de tiempo/marcas fiables.
- Deduplicación: Utilice claves de negocio exclusivas (por ejemplo, Contact.ExternalId) para deduplicar o alterar en DLO.
- Compromiso transaccional: Los registros se organizan y solo se confirman cuando el procesamiento por lotes se completa correctamente.
Consideraciones de seguridad
La seguridad es integral en todas las oportunidades en curso de ingreso, desde la autenticación hasta el cifrado y el control de acceso.
- Autenticación y autorización: Los conectores utilizan el Marco de trabajo de integración seguro de Salesforce, aprovechando credenciales nombradas y credenciales externas para la autenticación sin exponer secretos.
- Cifrado: Los datos se cifran en tránsito (TLS 1,2+) y en reposo (AES-256).
- Controles de red: Los sistemas de almacenamiento de origen (por ejemplo, depósitos de S3) deben incluir en la lista de admisión direcciones IP de Data 360.
- Alineación de cumplimiento: Admite marcos de trabajo de protección de datos de compañía como RGPD, HIPAA y directrices FFIEC cuando se emparejan con Claves gestionadas por el cliente (CMK).
- Auditabilidad: Cada trabajo de ingreso y acceso a credenciales se registra para la trazabilidad y creación de reportes de cumplimiento
Barras laterales
Oportunidad
La puntualidad depende de la programación de ingreso y el volumen de datos.
- La cadencia ideal depende de las necesidades de negocio: cada hora para desencadenadores de marketing casi en tiempo real, cada noche para conciliaciones de gran tamaño.
- Los modos Delta reducen la carga y el costo; las actualizaciones completas son más pesadas y se utilizan para cargas iniciales o cambios de esquema importantes.
Volúmenes de datos
- Los conectores de CRM están optimizados para conjuntos de datos transaccionales y de volumen medio (millones de registros).
- Para volúmenes históricos extremadamente grandes, considere ETL por etapas para particionar y cargar por etapas.
Capacidad de extremo y compatibilidad de estándares
La capacidad y la compatibilidad estándar para el extremo depende de la solución que seleccione.
| Conector | Requisitos de extremo |
|---|---|
| Conector de Salesforce CRM | La organización de origen debe permitir una aplicación conectada, tokens de OAuth y un usuario de integración exclusivo con permisos de lectura. |
| Conector de Marketing Cloud | Credenciales de API de Marketing Cloud o paquete instalado; las extensiones de datos deben exponer datos a través de Extractos/API. |
Gestión de estado
- Estado conector: Las transmisiones de datos mantienen las últimas marcas de tiempo de sincronización correctas y las compensaciones delta.
- Estrategia clave principal: Prefiera identificadores de negocio coherentes (Id. externos) de modo que la reconciliación descendente y las alteraciones sean deterministas.
Escenarios de integración complejos
En arquitecturas de negocio avanzadas, este patrón puede integrarse con:
- Topologías híbridas: Combine el ingreso de CRM con la transmisión (Eventos de plataforma) para actualizaciones casi en tiempo real.
- Orquestación de middleware: Utilice herramientas MuleSoft o ETL cuando se requiera orquestación compleja, enriquecimiento o ingreso previo de transformación.
- Bucles de comentarios de activación: Los DMO armonizados pueden desencadenar actualizaciones descendentes en sistemas de origen a través de Acciones de datos o API de plataforma (cuidado con los controles de SoD).
Ejemplo
Un minorista multinacional consolida mediciones de implicación de Cuentas, Contactos, Casos, Oportunidades y Marketing Cloud en Data 360 para crear una vista de cliente unificada. El Paquete de datos de inicio inicializa objetos principales de Ventas y Servicio, mientras que el equipo amplía el modelo con campos personalizados como Loyalty_Membershipc y Customer_Tierc para capturar contexto de fidelidad. Las transmisiones de datos de CRM se ejecutan cada hora en modo delta, y Marketing Cloud Engagement se sincroniza diariamente utilizando extractos delta para eventos de implicación. Estos conjuntos de datos se procesan a través de DLO y resolución de identidad, dando como resultado un perfil de cliente unificado que combina CRM y señales de implicación para potenciar la personalización y los modelos de IA descendentes.
Estos patrones se crean para escenarios donde los milisegundos importan, cuando las interacciones, transacciones o señales de los clientes deben desencadenar perspectivas o acciones inmediatas. Van más allá del ingreso por lotes programado tradicional para activar el flujo de datos dirigido por eventos, donde la información se procesa en el momento en que se genera. En el ecosistema de Salesforce Data 360, el “tiempo real” no es un modo único, es un continuo de modelos de latencia. En un extremo se encuentra la sincronización casi en tiempo real, donde las actualizaciones desde sistemas de registro (como CRM o ERP) se reflejan en Data 360 en cuestión de segundos o minutos. En el otro extremo se encuentra la captura de eventos en tiempo real verdadera, donde las señales de comportamiento del lado del cliente, como clics, compras o interacciones móviles, se ingresan y activan en milisegundos. Para los arquitectos, la distinción es más que semántica. Define cómo se diseñan las oportunidades en curso, cómo se invocan las API y cómo se toman las decisiones posteriores. La selección del patrón correcto (ya sea sincronización casi en tiempo real o ingreso de transmisiones de eventos) garantiza que el sistema cumpla los objetivos de latencia operativa del negocio mientras mantiene la integridad, la capacidad de ampliación y la gobernanza de los datos.
Contexto
Este patrón permite a cualquier sistema externo, como una aplicación personalizada, una plataforma de Internet de las cosas (IoT), un sistema de punto de venta (POS) o un servicio externo, enviar programáticamente datos de eventos en Data 360 casi en tiempo real a medida que se producen eventos discretos.
Problema
¿Cómo puede un desarrollador enviar de forma fiable registros únicos o pequeños lotes asíncronos de eventos desde una aplicación externa a Data 360 con baja latencia de modo que los datos estén disponibles rápidamente para su procesamiento, segmentación y activación?
Fuerzas
Este patrón entrega baja latencia y un mejor control del desarrollador, pero presenta varias restricciones técnicas y dependencias operativas:
- Dependencia de desarrollador: Requiere esfuerzo del desarrollador para implementar clientes de API de REST autenticados y lógica de error/reintento: no es un conector de apuntar y hacer clic.
- Esquema estricto en escritura: La API de ingreso aplica el esquema sobre escritura. Debe definirse un esquema preciso y cargarse en la configuración del conector; todas las cargas deben ajustarse exactamente o rechazarse.
- Modos de interacción dual: El mismo conector admite tanto la transmisión (JSON) para actualizaciones registro por registro de baja latencia como la masiva (CSV) para sincronizaciones periódicas de mayor tamaño: los arquitectos deben elegir por caso de uso.
- Autenticación y seguridad: Las llamadas deben autenticarse a través de una aplicación conectada de Salesforce utilizando OAuth 2.0 (por ejemplo, Flujo de soporte JWT para servidor a servidor). Los ámbitos de gestión de tokens, rotación y menor privilegio son obligatorios.
- Visibilidad operativa: Los desarrolladores y equipos de plataforma deben implementar el monitoreo para códigos de respuesta, reintentos, colas de letra muerta y alertas de desviación de esquemas.
- Requisito de gráfico en tiempo real: Para una activación instantánea verdadera (segmentación instantánea, asignación de DMO en tiempo real), el Objeto de modelo de datos (DMO) de destino debe formar parte del gráfico de datos en tiempo real; de lo contrario, los eventos atraviesan una canalización de latencia ligeramente superior.
Solución
Esta tabla contiene soluciones a este problema de integración.
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Ajuste de solución | Mejor para captura de eventos de baja latencia | Utilice la API de ingreso de Data 360 (JSON de transmisión) para enviar eventos únicos o microlotes. Configure el conector de API de ingreso con un esquema estricto de OAS 3.0 (.yaml). Utilice el ingreso masivo de CSV para sincronizaciones más grandes y menos frecuentes. |
| Gestión de cambios de esquema | Estricto / Gestionado | Los cambios de esquemas se están interrumpiendo: actualice .yaml de OAS, versione el conector y realice pruebas de contratos. Implemente la migración de esquemas progresiva si los productores no pueden cambiar simultáneamente. |
| Cuándo no utilizar | Suboptimal | No es ideal si se necesita preprocesamiento (ej: deduplicación, pedido garantizado, etc.) o para cargas masivas extremadamente grandes (utilice conectores masivos nativos o ETL por lotes). Si el origen no puede producir cargas válidas para esquemas o no puede autenticarse de forma segura, utilice métodos de ingreso alternativos. |
| Seguridad y gobernanza | Obligatorio | Utilice OAuth 2.0 con ámbitos de menor privilegio, rotar claves, registrar uso de tokens. Aplique TLS 1.2+, valide direcciones IP de clientes si es necesario y garantice el etiquetado de PII de carga. Todos los eventos deben incluir metadatos de procedencia (origen, marca de tiempo, versión de esquema, clave de idempotencia). |
Boceto
Este diagrama ilustra la secuencia de pasos para ingresar los datos desde la API de ingreso en Data 360
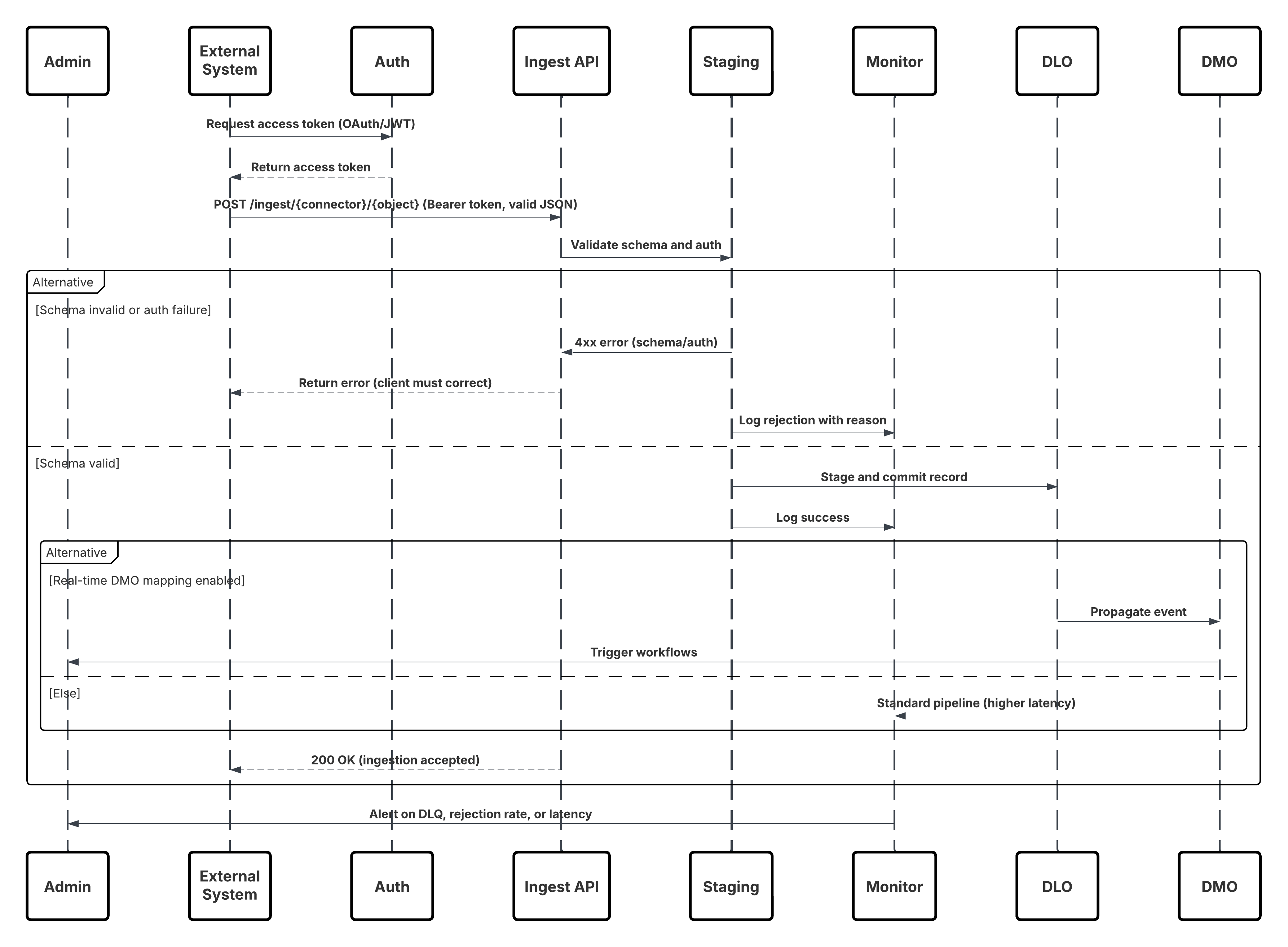
En este escenario:
- El sistema externo solicita autenticación a través de OAuth/JWT desde el servidor de autenticación.
- Servidor de autenticación devuelve el token de acceso a Sistema externo.
- El sistema externo envía la solicitud POST de ingreso de datos a la API de ingreso de Data 360 con autorización y carga JSON.
- La API de ingreso valida el esquema de solicitud y la autenticación a través del módulo Etapa y validación.
- En caso de fallo de esquema/autenticación:
- Error devuelto a Sistema externo.
- Rechazo registrado para monitoreo y alerta.
- En validación correcta:
- Registros organizados y confirmados en Objeto de lago de datos (DLO).
- Éxito registrado para el monitoreo.
- Si se activa, los datos se propagan a Gráfico de datos en tiempo real (DMO) desencadenando flujos de trabajo descendentes.
- De lo contrario, los datos procesados a través de lotes estándar o oportunidades en curso de latencia superior.
- API de ingreso confirma el éxito en Sistema externo.
- Los componentes de monitoreo alertan al administrador sobre colas de letra muerta, índices de rechazo o problemas de latencia.
Resultados
Los datos de eventos externos se ingresan en los DLO de Data 360 con baja latencia. Cuando el DMO de destino forma parte del gráfico en tiempo real, los datos están disponibles para segmentación instantánea, flujos de trabajo de agentes, modelos de IA y activación operativa. Esto permite respuestas de negocio rápidas a eventos originados desde cualquier sistema conectado.
Mecanismos de admisión
El mecanismo de ingreso depende del conector y la estrategia de programación definidos en Data 360.
| Mecanismo | Cuándo utilizar |
|---|---|
| JSON de transmisión (API de ingreso) | Eventos únicos, microlotes, eventos de comportamiento, transmisiones de clics, telemetría de IoT: cuando se requiere baja latencia. |
| CSV masivo (modo masivo de API de ingreso) | Cargas periódicas más grandes donde los requisitos de latencia se relajan. |
| Perfil / Middleware | Utilice cuando necesite validación, transformación, enriquecimiento o limitación de velocidad antes de enviar a la API de ingreso. |
Gestión y recuperación de errores
- Errores inmediatos (sincronización): Respuestas 4xx para errores de esquema/autenticación: el cliente debe solucionar la carga o el token y reintentarlo.
- Fallos transitorios (asíncronos): Respuestas 5xx: el cliente reintenta con retroceso exponencial y fluctuación.
- Cola de letras muertas (DLQ): Los fallos persistentes llegan a DLQ para la inspección manual y la reproducción.
- Monitoreo: Realice un seguimiento del índice de rechazo de esquemas, los fallos de autenticación, los percentiles de latencia y el retraso de DLQ. Alerta sobre umbrales.
Consideraciones de diseño idempotentes
- Clave de impotencia: Cada evento debe incluir una clave de idempotencia/Id. de mensaje exclusivos.
- Estrategia de inserción: Utilice claves de negocio (ExternalId) para evitar duplicados en reproducciones.
- Ventana de duplicado: El arquitecto debe definir plazos de deduplicación y retención para el seguimiento de la idempotencia.
Consideraciones de seguridad
La seguridad es integral en todas las oportunidades en curso de ingreso, desde la autenticación hasta el cifrado y el control de acceso.
- Autenticación: OAuth 2.0 (portador JWT) recomendado para servidor a servidor. Limite los ámbitos a solo la admisión.
- Cifrado: TLS 1.2+ para el transporte; Data 360 aplica el cifrado en periodos de inactividad.
- Privilegio mínimo: Las credenciales de Aplicación conectada tienen derechos mínimos; gire secretos y registros de acceso a instrumentos.
- Gobernanza de carga: Incluya indicadores de consentimiento/consumo en metadatos de eventos; aplique políticas ABAC/CEDAR inmediatamente después del ingreso.
- Controles de IP / Conexión privada: Donde sea necesario, restrinja el acceso a través de listas de admisión o utilice Conexión privada para redes privadas.
Barras laterales
Oportunidad
La puntualidad depende de la programación de ingreso y el volumen de datos. El JSON de transmisión ofrece una latencia de subsegunda a segunda dependiendo del procesamiento y la configuración del gráfico. El CSV masivo es de minutos a horas. Seleccione basándose en SLA de negocio.
Volúmenes de datos
Los tamaños de eventos individuales deben ser pequeños (< pocos KB). Para productores de alto rendimiento, considere realizar lotes en el productor o utilizar un buffer de transmisión (Kafka/Kinesis) antes de llamar a la API.
Gestión de estado
- Versión de esquema: Mantenga la versión de esquema en metadatos de eventos y utilice la versión de conector al actualizar el contrato de OEA.
- Compensaciones de conector: Data 360 controla la semántica de confirmación; los productores deben realizar un seguimiento de las claves de idempotencia y la última secuencia correcta para una reproducción segura.
Escenarios de integración complejos
En arquitecturas de negocio avanzadas, este patrón puede integrarse con:
- Capa de validación de borde: Utilice middleware para traducir formatos de productor heterogéneos al contrato de OEA requerido, realizar limitaciones de velocidad y enriquecimiento previo.
- Arquitecturas híbridas: Combine la API de ingreso para eventos y conectores para una reconciliación masiva.
- Activación de agente: Los eventos asignados en DMO en tiempo real pueden desencadenar flujos de trabajo Agentforce y modelos Einstein para la toma de decisiones automatizada.
Ejemplo
Una cadena minorista transmite eventos de compra de punto de venta (POS) en Data 360 en tiempo real para potenciar la implicación inmediata del cliente. Cada establecimiento ejecuta un componente de servidor ligero que recopila transacciones, las enriquece con metadatos de ubicación y dispositivo y publica de forma segura eventos JSON utilizando JWT Bearer OAuth con claves de idempotencia para evitar duplicados. Un administrador define la estructura del evento cargando un esquema de OAS para el punto de venta y configurando el conector de API de ingreso. Los eventos entrantes se ingresan en el DLO pos_sale, se asignan al DMO de ventas y se agregan al gráfico en tiempo real. Como resultado, las compras de alto valor se detectan al instante, desencadenando flujos de trabajo VIP en Agentforce y actualizando la segmentación de clientes para dirigir la personalización en tiempo real.
Contexto
Este patrón permite la captura de datos de interacción de usuario granulares de gran volumen (como vistas de página, clics de botón, impresiones de productos y reproducciones de video) desde sitios web y aplicaciones móviles en tiempo real. Es fundamental para entregar personalización en el momento, donde cada interacción digital puede influir dinámicamente en la experiencia del usuario e impulsar la implicación.
Problema
¿Cómo puede una compañía capturar y procesar una transmisión continua de eventos de comportamiento desde propiedades digitales (que abarcan millones de interacciones de usuario por minuto) y hacer que esos datos estén disponibles de inmediato en Data 360 para potenciar la segmentación, personalización y activación en tiempo real?
Fuerzas
Este caso de uso presenta varios retos de diseño que requieren una arquitectura de ingreso de baja latencia creada específicamente:
- Rendimiento extremo: Los sitios web de alto tráfico o las aplicaciones móviles pueden emitir millones de eventos por minuto. La capa de admisión debe ampliarse horizontalmente para gestionar este volumen sin pérdida de eventos o contrapresión, garantizando una latencia coherente bajo cargas máximas.
- Instrumentación del lado del cliente: A diferencia de las integraciones dirigidas por servidor, este patrón depende de los SDK del lado del cliente. Una baliza de JavaScript (SDK de interacciones de Salesforce) debe estar integrada en cada página, o un SDK nativo integrado en aplicaciones móviles. Esto requiere una implementación de cliente sólida, versiones y regulación de esquemas de eventos.
- Procesamiento de eventos de baja latencia: Las acciones de usuario, como “agregar al carrito” o “reproducción de video”, deben alcanzar Data 360 en cuestión de segundos, lo que permite la activación en tiempo real y las respuestas contextuales (por ejemplo, ofertas dirigidas, recomendaciones personalizadas).
- Armonización y resolución de identidad: Los eventos capturados a menudo incluyen identificadores anónimos (cookies, Id. de dispositivo, tokens de sesión). Para potenciar casos de uso Customer 360, estos deben asignarse a perfiles conocidos a través de la resolución de identidad de Data 360 y armonizarse con el modelo de datos Customer 360.
Solución
El enfoque recomendado es utilizar el Conector de personalización de Salesforce Marketing Cloud: una canalización de transmisión completamente gestionada nativa diseñada para el ingreso de comportamiento de alto rendimiento.
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Captura de eventos basada en SDK | Mejor | Implemente el SDK de interacciones de Salesforce (web) o el SDK nativo (móvil). Estas bibliotecas ligeras capturan y serializan interacciones de usuarios en tiempo real, adjuntando metadatos (Id. de sesión, marca de tiempo, contexto). |
| Oportunidades en curso de transmisión de eventos | Mejor | Los eventos se envían al servicio de transmisión de eventos de Marketing Cloud Personalization a través de HTTPS seguro. Esta capa es ampliable horizontalmente y está optimizada para la transmisión de baja latencia (<2s). |
| Integración de Data 360 | Mejor | El Conector de personalización de Data 360 se suscribe a las noticias en tiempo real de transmisión, ingresando cada evento en un Objeto de lago de datos (DLO) casi en tiempo real. |
| Asignación de modelo de datos | Mejor práctica | El DLO ingresado se asigna a Objetos de modelo de datos (DMO) Customer 360. Esto permite vincular usuarios anónimos y conocidos a través de Resolución de identidad. |
| Activación de gráficos en tiempo real | Opcional / Recomendado | Incluya DMO asignados en el gráfico en tiempo real para segmentación instantánea, desencadenando acciones personalizadas a través de flujos de trabajo Einstein o Agentforce. |
| Cuándo no utilizar | Suboptimal | Este patrón no es ideal cuando: Los datos de origen son cliente web y eventos (utilice la API de ingreso en su lugar). La organización carece de control sobre clientes web/móviles. No se requiere el seguimiento del comportamiento en tiempo real (utilice el ingreso por lotes). |
| Gestionar los cambios de esquema | Evolución gestionada | Los esquemas de eventos evolucionan a medida que se agregan nuevas interacciones. Los SDK deben versionar definiciones de eventos. Los cambios compatibles con versiones anteriores (agregar campos opcionales) son seguros; la interrupción de los cambios requiere la reconfiguración del conector y pruebas de contratos. |
Boceto
Este diagrama ilustra la secuencia de pasos para ingresar los datos desde canales móviles y web en Data 360
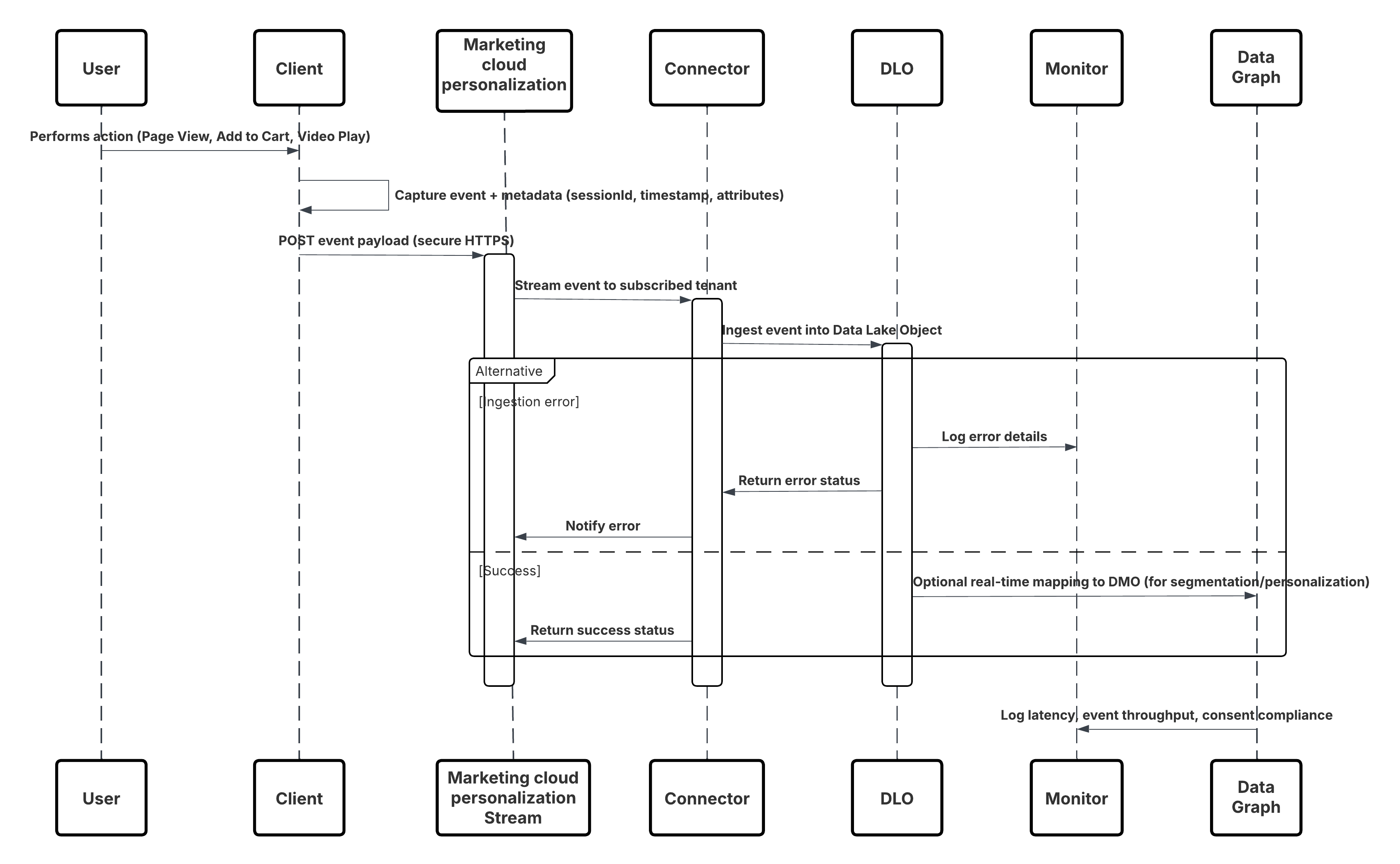
En este escenario:
- Implemente el SDK en canales web o móviles (captura de interacción de usuario).
- Configure SDK con controles de Id. de arrendatario, entorno y consentimiento.
- Transmita eventos JSON capturados (metadatos + atributos) al extremo de transmisión de Marketing Cloud.
- En Configuración de Data 360, cree y configure el Conector de personalización para el arrendatario.
- Ingrese eventos en un DLO y asigne el DLO → DMO dentro de Data 360.
- Active el DMO en el gráfico en tiempo real para una activación inmediata.
- Monitoree la latencia, la conformidad de esquemas, los indicadores de consentimiento, el rendimiento y los índices de error.
- Implemente en producción y monitoree continuamente.
Resultados
Una transmisión continua y de baja latencia de eventos de comportamiento fluye desde canales digitales a Data 360. En cuestión de segundos, cada acción de usuario queda disponible para segmentación en tiempo real, modelado predictivo o personalización desencadenada, permitiendo experiencias de cliente verdaderamente adaptativas.
Mecanismos de admisión
El mecanismo de ingreso depende del conector y la estrategia de programación definidos en Data 360.
| Mecanismo | Cuándo utilizar |
|---|---|
| SDK de interacciones (Web) | Captura en tiempo real desde navegadores web y SPA. |
| SDK móvil | Captura en tiempo real desde aplicaciones móviles nativas. |
| Conector de personalización | Suscripción gestionada entre Marketing Cloud y Data 360\. |
| Asignación de gráficos en tiempo real | Activa la activación inmediata en Segmentación, Einstein y Trayectorias. |
Gestión y recuperación de errores
- Tolerancia a fallos por capas: Implemente mecanismos de validación y reintento de múltiples niveles: los SDK de cliente gestionan fallos transitorios con retroceso exponencial, mientras que la capa de ingreso utiliza colas duraderas y oportunidades en curso reproducibles para evitar la pérdida de datos.
- Esquema y gobernanza de datos: Verifique y valide esquemas de eventos de forma continua; los eventos no válidos o en evolución se enrutan a una cola de rechazo de esquema o letra muerta para un triaje y reproducción seguros.
- Impotencia y deduplicación: Utilice identificadores de eventos estables y altere la semántica para garantizar el procesamiento una vez exacto incluso durante reintentos o repeticiones.
- Automatización de monitoreo y recuperación: El monitoreo continuo del rendimiento, la latencia y los índices de error desencadena flujos de trabajo de recuperación automatizados, garantizando una baja latencia, una entrega fiable y resultados de personalización en tiempo real coherentes.
Consideraciones de diseño idempotentes
- Cada evento debe llevar una clave de idempotencia o un Id. de mensaje exclusivos de modo que los envíos duplicados puedan deduplicarse aguas abajo.
- Utilice claves de negocio (por ejemplo, sessionID + eventTimestamp + userID) donde corresponda para identificar duplicados.
- Defina un plazo de deduplicación (por ejemplo, 24 horas) durante el cual se ignoran o se filtran los eventos duplicados.
- Utilice estrategias de alteración cuando sea apropiado (por ejemplo, actualizar contadores o indicadores en vez de insertar duplicados).
Consideraciones de seguridad
La seguridad es integral en todas las oportunidades en curso de ingreso, desde la autenticación hasta el cifrado y el control de acceso.
- Cifrado de transporte: TLS 1.2+ para todas las conexiones de servicio de SDK → transmisión.
- Cifrado de datos en periodos de inactividad en Data 360 y transmisión de marketing.
- El SDK respeta los indicadores de consentimiento y suprime el seguimiento si se deniega el consentimiento.
- Autenticación del tráfico del SDK: asegúrese de que solo los arrendatarios/clientes aprobados puedan transmitir eventos.
- Metadatos: cada evento debe incluir Id. de origen, marca de tiempo, versión de esquema, Id. de sesión, clave de idempotencia.
- Acceso de menor privilegio: Extremos y conectores de SDK limitados al ámbito de ingreso de eventos; rotar credenciales regularmente.
- Clasificación de datos: Anotar PII en cargas de eventos, aplicar políticas inmediatamente después del ingreso
Barras laterales
Oportunidad
- La puntualidad depende de la actividad del usuario final y la configuración de transmisión de eventos.
- Los eventos capturados a través del SDK de interacciones de Salesforce y entregados a través de la Transmisión de personalización de Marketing Cloud normalmente alcanzan una latencia de subsegundo a ~2 segundos antes de estar disponibles en el Gráfico en tiempo real de Data 360.
- Esto permite la segmentación, la personalización y la activación casi instantáneas en sesiones de usuario activas.
Volúmenes de datos
Los eventos de comportamiento individuales (por ejemplo, hacer clic, ver, agregar al carrito) son ligeros, generalmente de 1 a 5 KB por carga. Para propiedades digitales a gran escala, espere de miles a millones de eventos por minuto. Para garantizar el rendimiento y la resiliencia:
- Utilice los mecanismos de reintento y lotes integrados del SDK para páginas de alto tráfico.
- Cargue la gestión de ráfagas en la capa intermedia de transmisión de Marketing Cloud.
- Monitoree los índices de errores y el rendimiento de ingreso utilizando el tablero de mediciones del conector.
Gestión de estado
Cada evento incluye metadatos para el control de estado y versión:
- Versión de esquema: Incruste la versión del esquema en cada evento; versione el Conector de personalización cuando actualice el esquema.
- Tratamiento de reproducción: Los eventos que fallan debido a problemas de red transitorios se reintentan automáticamente por el SDK con retroceso exponencial.
- Claves de impotencia: Los identificadores exclusivos (sessionId + eventType + timestamp) garantizan que los eventos reproducidos no creen duplicados en Data 360.
- Gestión de compensación: Data 360 realiza un seguimiento de las confirmaciones correctas; cualquier evento no procesado se vuelve a poner en cola por el conector hasta que se ingrese correctamente.
Escenarios de integración complejos
Este patrón se integra perfectamente en arquitecturas de negocio avanzadas:
- Capa de enriquecimiento de borde: Agregue middleware (por ejemplo, proxy inverso o función sin servidor) para inyectar contexto adicional (como geodatos, tipo de dispositivo o campaña) antes de que los eventos lleguen a Marketing Cloud.
- Híbrido (Transmisión + Lote): Utilice el conector de Marketing Cloud para transmisiones en tiempo real y combínelo con trabajos de ETL por lotes (por ejemplo, datos de pedidos) para la reconciliación descendente.
- Activación de agente: Los eventos asignados a DMO en tiempo real pueden desencadenar Personalización de Einstein, flujos de trabajo Agentforce o decisiones dirigidas por IA para adaptar la experiencia digital en el momento.
- Gobernanza de múltiples arrendatarios: Utilice indicadores de consentimiento y metadatos conscientes del arrendatario para aplicar la privacidad y el cumplimiento en entornos de múltiples marcas o regiones.
Ejemplo
Una compañía de comercio electrónico global entrega recomendaciones de productos personalizadas y contenido dinámico a compradores mientras navegan activamente por www.retailx.com, una aplicación de una sola página basada en React. Utilizando el SDK de interacciones de Salesforce en el lado del cliente, el sitio captura vistas de página, clics de productos, acciones de carrito e interacciones de video en tiempo real. Estos eventos fluyen por la transmisión de eventos Personalización de Marketing Cloud y el conector Personalización en DLO de Data 360, donde se modelan en DMO y se incorporan en el gráfico en tiempo real. Esta arquitectura hace que las señales de comportamiento estén disponibles al instante para segmentación, personalización dirigida por Einstein y activación Agentforce, permitiendo experiencias de clientes con capacidad de respuesta en sesión
Contexto
Para muchos procesos críticos de negocio, mantener Data 360 perfectamente alineado con las actualizaciones más recientes en sistemas CRM principales es esencial. Los equipos de servicio al cliente, ventas y marketing dependen de información actualizada para dirigir decisiones, desencadenar trayectorias y activar la automatización. Este patrón proporciona un mecanismo para sincronizar cambios en objetos clave de Salesforce CRM (como Contacto, Cuenta y Caso) en Data 360 con un retraso mínimo, sin la ineficiencia o latencia de los sondeos por lotes frecuentes.
Problema
¿Cómo puede Data 360 mantener un estado casi perfectamente sincronizado con objetos clave de Salesforce CRM, garantizando que los análisis descendentes, la segmentación y la activación dirigida por IA siempre funcionan en los datos más actuales disponibles?
Fuerzas
Este patrón introduce varias restricciones técnicas y consideraciones arquitectónicas:
- Arquitectura dirigida por eventos: La sincronización debe ser reactiva, dirigida por eventos de cambio en la organización de origen de CRM en vez de trabajos por lotes periódicos.
- Soporte de objetos selectivos: No todos los objetos estándar y personalizados de Salesforce admiten la transmisión en tiempo real. Los arquitectos deben hacer referencia a la lista de objetos admitidos durante el diseño para evitar brechas.
- Acceso y permisos: La activación de la transmisión requiere que el usuario de integración en la organización de origen tenga asignado el permiso del sistema “Activar permisos para transmisión de CRM”.
- Actualización de datos frente a Costo de procesamiento: Aunque la sincronización casi en tiempo real mejora la capacidad de respuesta, un rendimiento de eventos excesivo puede requerir escala horizontal y mecanismos de recuperación de errores sólidos.
- Integración de capa de seguridad y confianza : Todos los datos de eventos deben cumplir los marcos de trabajo Trust and Security de Salesforce, cifrados en tránsito, validados para el cumplimiento de esquemas y procesados dentro del límite Trust de la organización.
Solución
El enfoque recomendado es utilizar el Conector de Salesforce CRM con Transmisión (Captura de datos de cambio) activada. Al crear una transmisión de datos para un objeto de CRM compatible (por ejemplo, Contacto), los administradores pueden alternar la opción “Activar transmisión”. Bajo el capó, la plataforma Captura de datos Change (CDC) de Salesforce publica un mensaje ChangeEvent cada vez que se crea, se actualiza, se elimina o no se elimina un registro en la organización de CRM de origen. El Conector de CRM de Data 360 se suscribe a estos eventos de CDC y aplica los cambios correspondientes al Objeto de lago de datos (DLO) asignado dentro de Data 360 casi en tiempo real. Esto garantiza una sincronización continua entre CRM y Data 360 con una intervención manual mínima.
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Conector de transmisión basado en CDC | Mejor | Mecanismo nativo de Salesforce; completamente gestionado e integrado con la infraestructura de eventos de plataforma. |
| Suscripción y entrega de eventos | Mejor | El conector se suscribe a canales ChangeEvent (por ejemplo, /data/ContactChangeEvent) a través de identificadores de reproducción duraderos. |
| Asignación de datos y evolución de esquemas | Mejores prácticas | Asigne cargas transmitidas al DLO correspondiente; gestione la versión de esquemas en metadatos para evitar interrupciones de ingreso. |
| Reproducción y recuperación de fallos | Recomendado | Utilice los Id. de reproducción y las claves de idempotencia para evitar duplicaciones y recuperarse de errores transitorios. |
| Modo híbrido (Transmisión + Lote) | Opcional | Para objetos no admitidos o carga masiva inicial, utilice el ingreso por lotes en combinación con la transmisión de CDC. |
| Cuándo no utilizar | Suboptimal | Este patrón puede ser subóptimo cuando: El objeto de origen no está activado por CDC. El caso de uso no requiere actualizaciones en tiempo real (lote es suficiente). La salida de red de la organización de origen está restringida o se superan los límites de eventos. |
Boceto
Este diagrama ilustra la secuencia de pasos para ingresar los datos desde CRM en Data 360 casi en tiempo real
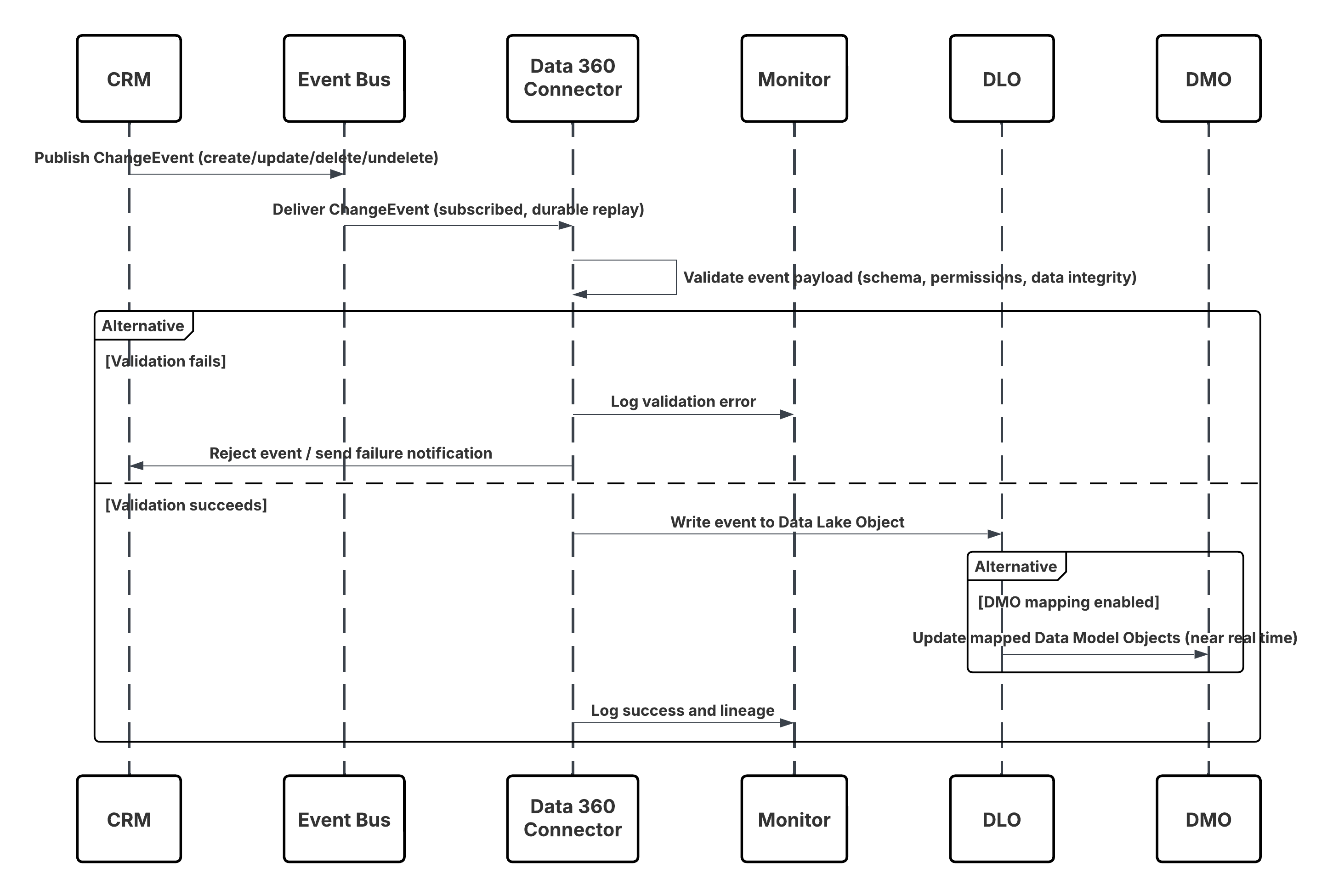
En este escenario:
- El cambio se produce en Salesforce CRM (create/update/delete/undelete).
- Los CDC publican un ChangeEvent en el Bus de eventos de Salesforce interno.
- Conector de CRM de Data 360 se suscribe al Bus de eventos utilizando un cursor de reproducción duradero.
- La carga de evento se valida para esquema, permisos e integridad de datos.
- Data 360 escribe el evento validado en el Objeto de lago de datos (DLO) asignado.
- Si está activado, los Objetos de modelo de datos (DMO) asignados se actualizan casi en tiempo real, potenciando la segmentación y la activación.
Resultados
Data 360 mantiene un espejo sincronizado continuamente de datos de CRM clave. Esto activa:
- Desencadenadores en tiempo real (por ejemplo, la trayectoria se inicia cuando se crea un caso).
- Segmentación actualizada (por ejemplo, mover clientes al segmento “Oro” tras el cambio de estado de Cuenta).
- Análisis y personalización más precisos basados en contexto de CRM en vivo.
Mecanismos de admisión
El mecanismo de ingreso para este patrón se gestiona de forma nativa a través del Conector de Salesforce CRM con Captura de datos de cambios (CDC) activada. Data 360 actúa como un suscriptor de la transmisión de eventos de CDC, garantizando una sincronización fiable y de baja latencia entre la organización de CRM de origen y Data 360.
| Mecanismo | Cuándo utilizar |
|---|---|
| Transmisión a través de CDC (Preferido) | Para todos los objetos estándar y personalizados de Salesforce admitidos donde se requiere sincronización casi en tiempo real. |
| Modo híbrido (CDC + Lote) | Para objetos aún no activados por CDC o donde se requiere carga histórica inicial. |
| Modo de suscripción de reproducción | Para la resincronización después del tiempo de inactividad o la implementación. |
| Modo de aislamiento de error | Para entornos de prueba y validación. |
Gestión y recuperación de errores
- Recuperación de fallos automática: El Conector de CRM reintenta automáticamente errores transitorios de red o plataforma utilizando retroceso exponencial y enruta fallos persistentes a la Cola de letras muertas (DLQ) para su reproducción.
- Resistencia a esquemas y autenticación: Los desajustes de esquemas se ponen en cuarentena en la Cola de rechazo de esquemas para su revisión por el administrador, mientras que los errores de autenticación o permisos desencadenan reintentos controlados y alertas a través de Monitoreo de Data 360.
- Continuidad de eventos garantizada: Los ReplayID duraderos garantizan que no haya pérdida de eventos durante el tiempo de inactividad del conector; los eventos perdidos se rehidratan a través de plazos de reproducción o trabajos de resincronización por lotes.
- Integridad y ordenación de datos: La idempotencia integrada (RecordID + SequenceNumber) evita duplicados, y ChangeEventHeader.sequenceNumber mantiene la ordenación correcta de eventos para cada registro de CRM.
Consideraciones de diseño idempotentes
- Exclusividad de evento: Cada evento de CDC lleva un ReplayID y ChangeEventHeader.entityName para la deduplicación determinista.
- Estrategia de inserción: Implemente la lógica UPSERT basada en el Id. de registro para garantizar que los eventos repetidos no crean duplicados.
- Tratamiento de reproducción: Utilice el cursor de reproducción del conector para reanudar desde la última compensación confirmada en caso de fallos transitorios.
- **Evolución de esquema: **Mantenga una versión de esquema en metadatos de eventos y actualice asignaciones de DLO cuando cambie el esquema de CRM.
Consideraciones de seguridad
La seguridad es integral en todas las oportunidades en curso de ingreso, desde la autenticación hasta el cifrado y el control de acceso.
- Encryption and Trust: Todos los eventos se transmiten utilizando TLS 1.2+ y se almacenan cifrados en periodos de inactividad en Data 360.
- Control de acceso: Solo los conectores autenticados con permisos de integración apropiados pueden suscribirse a canales de CDC.
- Validación de esquema: Cada carga de evento se valida con el esquema de DLO antes del ingreso.
- Propagación de consentimiento: Los metadatos de consentimiento y clasificación de datos fluyen aguas abajo con cada evento para preservar la privacidad y el cumplimiento (RGPD, CCPA).
- Gobernanza operativa: Los eventos se registran, auditan y monitorean en busca de reproducción, rechazo de esquemas y anomalías de rendimiento a través de Data 360 Trust Layer.
Barras laterales
Oportunidad
- Los eventos de CDC se procesan casi en tiempo real, normalmente en cuestión de segundos desde el cambio en CRM.
- La latencia puede variar basándose en el volumen de eventos y el rendimiento del conector, pero Data 360 garantiza la disponibilidad de subminutos para objetos compatibles.
Volúmenes de datos
- Cada carga de evento es ligera (~1-5 KB).
- Para objetos de alto índice de cambio como Caso o Contacto, asegúrese de que los límites de rendimiento se alinean con las asignaciones de eventos de Salesforce CDC.
Gestión de estado
Cada evento incluye metadatos para el control de estado y versión:
- Id. de reproducción: Se utiliza para la recuperación de eventos secuencial.
- Versión de esquema: Mantenga los metadatos de versión para gestionar los cambios de contrato.
- Claves de impotencia: Deduplique repeticiones entre reintentos.
- Comprobar compensación: Data 360 mantiene el estado de confirmación después de cada lote de eventos correcto.
Escenarios de integración complejos
Este patrón se integra perfectamente en arquitecturas de negocio avanzadas:
- Híbrido (Transmisión + Lote): Utilice CDC para actualizaciones delta y trabajos masivos para actualizaciones completas.
- Transmisión entre organizaciones: Múltiples organizaciones de origen pueden transmitir en el mismo arrendatario de Data 360, unificado a través de asignaciones de DMO.
- Activación de agente: Las actualizaciones de objetos en tiempo real desencadenan automatizaciones Einstein o Agentforce.
- Enrutamiento de eventos: El middleware (por ejemplo, MuleSoft o Retransmisión de eventos) puede enriquecer o enrutar mensajes de CDC antes de su ingreso.
Ejemplo
Un banco global desea asegurarse de que los cambios de datos de clientes en Salesforce Sales Cloud se reflejan instantáneamente en Data 360.Cuando se actualiza la dirección de un contacto en Sales Cloud, el mecanismo Captura de datos Cambiar publica un ContactChangeEvent.El Conector CRM de Data 360 consume este evento, aplica la actualización al DLO de cliente y actualiza automáticamente todos los perfiles Customer 360 asociados. Esto desencadena una Einstein Next Best Action para verificar la nueva dirección, completando el bucle de comentarios en cuestión de segundos desde el cambio de CRM original.
Contexto
Las empresas digitales modernas se basan en plataformas de transmisión de eventos en tiempo real como Amazon Kinesis Data Streams y Amazon MSK (Transmisión gestionada para Apache Kafka) para capturar flujos de datos continuos desde aplicaciones distribuidas, dispositivos IoT y sistemas de transacciones. Data 360 permite el ingreso directo desde estas plataformas a través de conectores nativos de primera parte, eliminando la necesidad de soluciones ETL personalizadas o basadas en middleware. Este patrón está diseñado para el ingreso de datos de alto rendimiento y baja latencia, potenciando perspectivas casi en tiempo real, personalización y activación dirigida por IA.
Problema
¿Cómo puede una compañía conectar Data 360 de forma segura y eficiente con temas de AWS Kinesis o AWS MSK Kafka para ingresar continuamente datos de eventos y perfiles estructurados, garantizando el cumplimiento de esquemas, la capacidad de ampliación y la gobernanza?
Fuerzas
Este patrón presenta múltiples consideraciones arquitectónicas y operativas:
- Disponibilidad de conector nativo: Salesforce proporciona conectores nativos disponibles de forma general para Amazon Kinesis y Amazon MSK. Estos conectores ofrecen asistencia de primera parte y eliminan la necesidad de oportunidades en curso basadas en API personalizadas.
- Autenticación y seguridad: Cada conector requiere autenticación a nivel de AWS.
- Para Kinesis, utiliza Clave de acceso de AWS y Clave secreta, regidas por políticas de IAM.
- Para MSK, la autenticación se puede configurar a través de Clave de acceso/Secreto u OpenID Connect (OIDC).
- Definición de esquema: Data 360 requiere un esquema para interpretar la carga de transmisión. Para Kinesis, el archivo de esquema se carga durante la configuración de la conexión, definiendo la estructura del evento y las asignaciones de campos.
- Origen de configuración:
- El conector de Kinesis se suscribe a un nombre de Transmisión de Kinesis específico.
- El conector MSK se suscribe a un tema Kafka en el clúster MSK.
- Acceso de red: Para entornos seguros, los conectores se pueden configurar con el enrutamiento PrivateLink o VPC, garantizando que ningún dato atraviese la Internet pública.
- Gobernanza operativa: El rendimiento de transmisión, la validación de esquemas y los eventos de autenticación se monitorean en Data 360 Trust Layer, garantizando el cumplimiento y la trazabilidad.
Solución
La solución aprovecha los conectores nativos de Amazon Kinesis o Amazon MSK en Data 360.
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Conector nativo de Kinesis | Mejor | Integración de primera parte con AWS Kinesis; admite el ingreso continuo de alto rendimiento. |
| Conector nativo MSK | Mejor | Ingreso de Kafka gestionado con OIDC y compatibilidad de autenticación basada en claves. |
| Validación y asignación de esquemas | Mejores prácticas | Cargue el esquema (.json/.avro) que define la estructura del evento; aplica la coherencia durante el ingreso. |
| Configuración de IAM | Recomendado | Asigne la función IAM de menor privilegio con acceso de solo lectura a la transmisión de Kinesis de destino o el tema MSK. |
| Enrutamiento de red privado | Opcional | Configure extremos PrivateLink/VPC para un enrutamiento interno seguro. |
| Patrón híbrido (Transmisión + Lote) | Opcional | Utilice la transmisión para deltas y el ingreso por lotes para rellenos o cargas históricas. |
| Modo de aislamiento de error | Recomendado | Enrutar rechazos de esquemas y errores transitorios a DLQ para su reproducción |
Boceto
Este diagrama ilustra la secuencia de pasos para ingresar los datos desde plataformas de eventos como Kafka y Kinesis en Data 360 casi en tiempo real
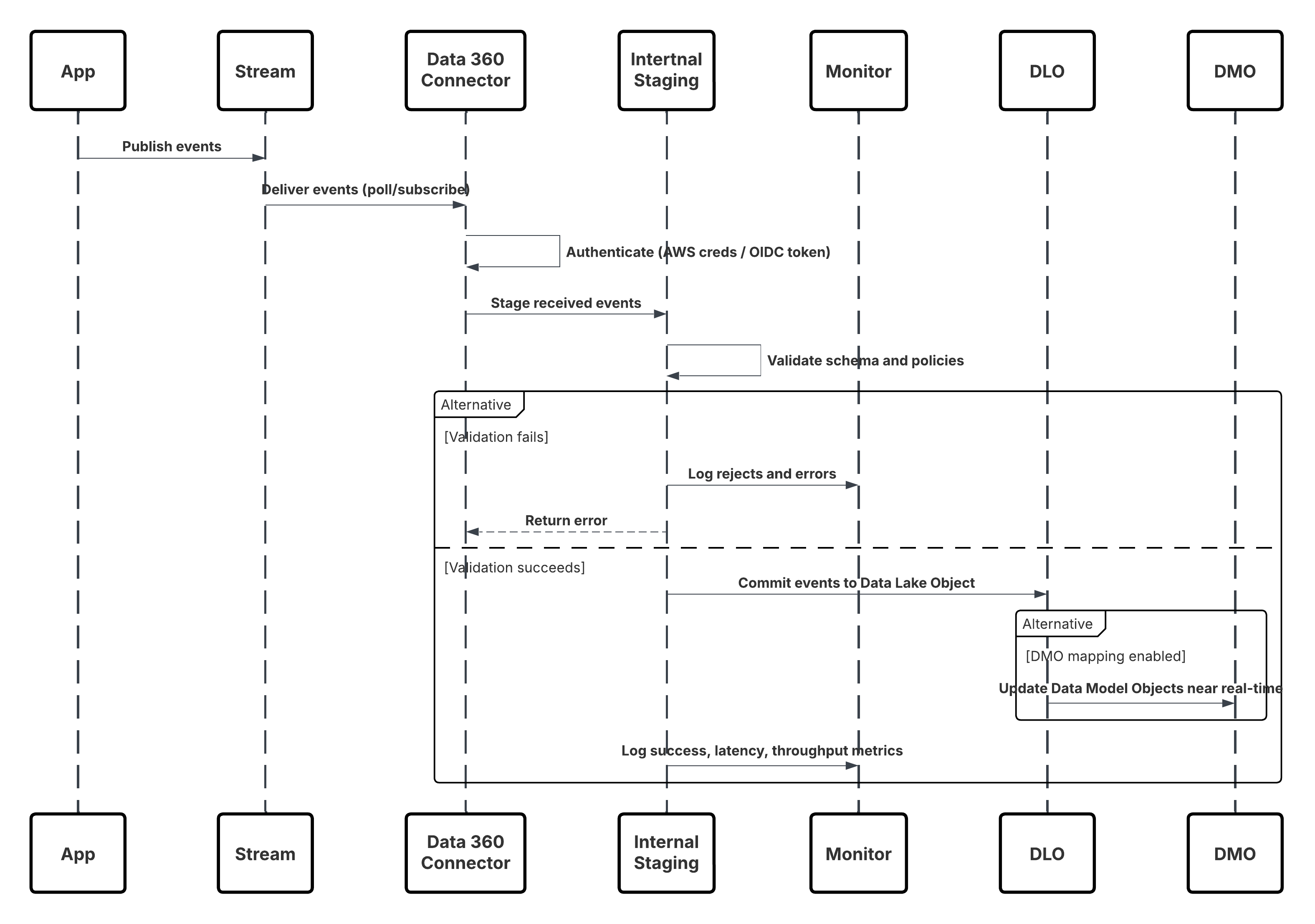
En este escenario:
- Las aplicaciones o dispositivos publican eventos en Transmisión de Kinesis o Tema MSK.
- Conector de Data 360 se autentica utilizando credenciales de AWS o token de OIDC.
- El conector sondea o se suscribe continuamente a la transmisión.
- Los eventos se organizan, se validan para esquemas y políticas, luego se confirman en Objeto de lago de datos (DLO).
- Si se asignan, los objetos de modelo de datos (DMO) se actualizan casi en tiempo real para su activación.
- Capa de monitoreo realiza un seguimiento de mediciones, rechazos de esquemas y latencia.
Resultados
Ingreso continuo y de baja latencia de datos estructurados directamente desde AWS Kinesis o MSK en Data 360. Los datos están disponibles de inmediato para:
- Resolución de identidad
- Segmentación en tiempo real
- Activación de IA Einstein
- Desencadenadores dirigidos por Agentforce Elimina la dependencia de ETL por lotes, permitiendo arquitecturas basadas en transmisiones alineadas con diseños dirigidos por eventos de negocio.
Mecanismos de admisión
| Mecanismo | Cuándo utilizar |
|---|---|
| Conector Kinesis (Preferido) | Para orígenes de transmisión nativos de AWS que requieren el ingreso continuo de datos estructurados de gran volumen. |
| Conector MSK | Para organizaciones que ejecutan oportunidades en curso de eventos en plataformas compatibles con Kafka. |
| Híbrido (Transmisión + Lote) | Para el ingreso de eventos incremental combinado con cargas masivas periódicas. |
Gestión y recuperación de errores
- Reintentos automáticos: Los conectores reintentan errores transitorios de red o plataforma con retroceso exponencial.
- Rechazos de esquemas: Las cargas no válidas se dirigen a la cola de rechazo de esquemas para su revisión por el administrador.
- Reproducción DLQ: Los fallos persistentes se capturan en colas de letra muerta para su reprocesamiento.
- Control de impotencia: Las claves de eventos o los números de secuencia garantizan la deduplicación y el ingreso ordenado.
- Integración de monitoreo: Todos los fallos, reintentos y mediciones de rendimiento afloran en tableros de Monitoreo de Data 360.
Consideraciones de diseño idempotentes
- Exclusividad y seguimiento de eventos: Cada evento tiene asignada una clave exclusiva determinista (por ejemplo, PartitionKey + SequenceNumber para Kinesis o Topic + Partition + Offset para MSK) para garantizar el ingreso una vez exacto.
- Punto de control de conector: Los conectores de Data 360 mantienen la última compensación procesada o número de secuencia para reanudar el ingreso de forma segura tras fallos o reinicios.
- Deduplicación y lógica UPSERT: Durante las confirmaciones de DLO, los eventos duplicados se detectan y se omiten; los registros válidos se alteran utilizando la clave exclusiva para mantener la coherencia.
- Control de reproducción y recuperación: Los eventos fallidos o retrasados se reproducen desde compensaciones almacenadas a través de colas de letras muertas y reproducción, garantizando una recuperación fiable sin duplicaciones.
Consideraciones de seguridad
La seguridad es integral en todas las oportunidades en curso de ingreso, desde la autenticación hasta el cifrado y el control de acceso.
- Autenticación: Proteja el intercambio de credenciales utilizando políticas de AWS IAM u OIDC.
- Cifrado: Datos cifrados en tránsito (TLS 1,2+) y en reposo (AES-256) dentro de Data 360.
- Control de acceso: Funciones de menor privilegio aplicadas; conectores con ámbito a transmisiones/temas específicos.
- Gobernanza: Metadatos de linaje y clasificación aplicados a cada registro para una trazabilidad completa.
- Seguridad de red: Implemente opcionalmente dentro de subredes privadas utilizando AWS PrivateLink.
Barras laterales
Oportunidad
- Procesamiento casi en tiempo real: Los conectores de CDC y transmisión procesan eventos en cuestión de segundos desde los cambios de origen, normalmente garantizando la actualización de datos subminutos.
- Latencia determinista: El desfase de extremo a extremo depende del rendimiento de origen, los lotes de eventos y las condiciones de red, pero Data 360 garantiza una latencia dirigida por SLA predecible para objetos compatibles.
- Escala elástica: Las oportunidades en curso de ingreso se escalan automáticamente bajo un alto volumen de eventos, preservando la puntualidad incluso durante ráfagas de datos de pico.
- Visibilidad operativa: Los tableros de monitoreo exponen el desfase de eventos, confirman marcas de tiempo y reproducen el estado para garantizar la latencia y solucionar problemas.
Volúmenes de datos
- Cargas ligeras: Los eventos de transmisión o CDC individuales son compactos (tamaño habitual de 1 a 5 KB), optimizados para actualizaciones de alta frecuencia.
- Objetos de alto cambio: Para entidades volátiles (por ejemplo, Caso, Contacto, Pedido), los arquitectos deben garantizar que las asignaciones de CDC y el rendimiento de eventos se alinean con los índices de actualización esperados.
- Transmisiones paralelas: Data 360 admite el ingreso de múltiples transmisiones para la ampliación horizontal entre grandes volúmenes de objetos u múltiples organizaciones de origen.
- Tratamiento de contrapresión: Los mecanismos de estrangulación integrados mantienen la estabilidad de admisión bajo carga sin eventos de caída.
Gestión de estado
Cada evento incluye metadatos para el control de estado y versión:
- Seguimiento de reproducción y compensación: Cada evento lleva metadatos de secuencia e Id. de reproducción, lo que permite la entrega ordenada y la recuperación basada en puntos de control.
- Versión de esquema: Las etiquetas de versión en encabezados de eventos garantizan un procesamiento compatible con versiones anteriores cuando evolucionan los esquemas de origen.
- Claves de impotencia: Cada evento incluye una transacción exclusiva o una clave de confirmación, lo que permite a Data 360 deduplicar repeticiones y reintentos de forma segura.
- Compromiso atómico: Las oportunidades en curso de ingreso solo marcan las compensaciones como completas una vez que se confirman los DLO con éxito, garantizando la coherencia.
Escenarios de integración complejos
Este patrón se integra perfectamente en arquitecturas de negocio avanzadas:
- Ingestión híbrida: Combine CDC para deltas incrementales con Transmisiones de datos masivas para actualizaciones completas, manteniendo la frescura y la integridad.
- Transmisión entre organizaciones: Múltiples organizaciones de CRM o ERP pueden publicar en el mismo arrendatario de Data 360, unificado a través de la asignación de DMO y la alineación de ontología.
- Enriquecimiento de eventos: El middleware (por ejemplo, MuleSoft, Retransmisión de eventos) puede enriquecer, filtrar o enrutar datos de transmisión antes de que lleguen a Data 360.
- Activación de IA y agente: Las actualizaciones en tiempo real desencadenan una automatización descendente, como predicciones Einstein o respuestas Agentforce, en cuestión de segundos desde el evento de origen.
Ejemplo
Una compañía minorista global utiliza AWS Kinesis para transmitir datos de interacción de punto de venta y web.El conector Kinesis de Data 360 se autentica a través de credenciales IAM e ingresa eventos continuamente en un DLO de transacción.Cada registro se valida con esquemas, se enriquece con metadatos y se propaga inmediatamente al DMO de cliente.En cuestión de segundos, los modelos de IA de Einstein actualizan segmentos de clientes y Agentforce desencadena recomendaciones de la siguiente mejor oferta en tiempo real, logrando un bucle de personalización completamente dirigido por eventos.
Cero copia es más que un método de integración: es un cambio fundamental en el modo en que se mueven los datos de compañía, o mejor dicho, no se mueven. Tradicionalmente, la integración de datos requería copiar grandes volúmenes de registros a través de oportunidades en curso de ETL, creando almacenes de datos redundantes, retrasos de sincronización y retos de gobernanza. La copia cero elimina todo eso. En este modelo, Data 360 se conecta directamente a plataformas de datos externas como Snowflake y Databricks, leyendo y activando datos de forma segura, sin moverlos o duplicarlos nunca. El resultado es un puente sin problemas entre su centro de datos de compañía y el ecosistema de Salesforce, proporcionando acceso instantáneo, menor sobrecarga operativa y una gobernanza de datos más sólida.
Las funciones de copia cero entrantes permiten a Data 360 consultar y armonizar datos externos en el origen, como perfiles de clientes, transacciones o datos de productos, almacenados en Snowflake o Databricks. En vez de ingresar archivos, Data 360 establece una conexión segura y consciente de los metadatos que aprovecha las definiciones de esquemas y las políticas de seguridad existentes en el almacén externo.
- Federación directa: Data 360 lee datos existentes a través de consultas seguras y optimizadas sin replicación.
- Gobernanza unificada: Los datos permanecen bajo el marco de trabajo de seguridad, control de acceso y cumplimiento del sistema de origen.
- Eficiencia operativa: Elimina la duplicación de los gastos generales y el almacenamiento de ETL, reduciendo el costo y la complejidad.
- Preparación en tiempo real: Activa Armonización on-demand: en el momento en que se actualizan los datos en Snowflake, están disponibles inmediatamente para su activación en Data 360.
Contexto
Las empresas modernas dirigidas por datos gestionan petabytes de datos de clientes, transacciones y telemetría en plataformas de lago de datos a escala de nube como Snowflake y Databricks. Estos entornos sirven como la única fuente de verdad para análisis, IA y cumplimiento. Data 360 presenta la federación Zero CopyData, que permite a Data 360 consultar y utilizar directamente conjuntos de datos externos en su lugar, sin copiar, transformar o almacenar datos redundantes. Este patrón permite a las organizaciones ampliar el tejido Customer 360 a su infraestructura de almacén de datos o lago existente, logrando la unificación y activación en tiempo real con cero duplicaciones, cero latencias y cero compromisos en la gobernanza.
Problema
¿Cómo pueden las compañías aprovechar los conjuntos de datos enriquecidos ya depurados en Snowflake, Databricks o formatos de lago abierto como Apache Iceberg, para segmentación, resolución de identidad y activación en Data 360, sin el costo, la latencia y la sobrecarga de gobernanza de las oportunidades en curso de ETL o el movimiento de datos físicos?
Fuerzas
Este patrón presenta múltiples consideraciones arquitectónicas, de seguridad y de desempeño:
Red y seguridad
- Data 360 debe establecer una conexión privada segura con el almacén externo o el lago.
- Normalmente se configura utilizando Salesforce Private Connect o PrivateLink/VPC Peering, garantizando que el tráfico nunca sale de la red controlada del cliente.
- Los sistemas externos deben incluir en la lista de admisión direcciones IP de Data 360 y aplicar el cifrado TLS 1.2+.
Autenticación y control de acceso
- Admite autenticación de pares de claves, OAuth 2.0 o delegación de Trust basada en proveedor de identidad (IdP) (Data 360 actuando como un cliente de confianza)
- El control de acceso basado en funciones (RBAC) en el sistema externo aplica el acceso de menor privilegio para la ejecución de consultas.
Desempeño y Calcular dependencia
- La federación de consultas empuja hacia abajo la ejecución de SQL en Snowflake o Databricks, aprovechando sus clústeres de computación.
- Escala de desempeño y costo con carga de consulta externa: La latencia y el costo de segmentación están vinculados a la configuración de computación externa.
Estándares en evolución: Federación de archivos
- Un modelo de próxima generación, Federación de archivos, aprovecha formatos de tabla abiertos como Apache Iceberg o Delta Lake, permitiendo a Data 360 leer directamente desde el almacenamiento de objetos (por ejemplo, Amazon S3, Azure ADLS, Google Cloud Storage).
- Al omitir la capa de cálculo de origen, Federación de archivos reduce drásticamente la latencia y el costo de cargas de trabajo analíticas pesadas de lectura manteniendo al mismo tiempo la integridad del esquema.
Gobernanza y cumplimiento
- Los datos nunca salen de la plataforma de origen: las políticas de cumplimiento, cifrado y retención se mantienen aplicadas en el origen.
- Todos los atributos de metadatos, linaje y consentimiento se propagan a Trust Layer de Data 360 para garantizar la trazabilidad de extremo a extremo.
Solución
El enfoque recomendado es utilizar conectores de copia cero nativos para Snowflake, Databricks o Federación de archivos en Data 360.
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Conector de copia de Snowflake Zero | Mejor | Integración nativa de primera parte; establece la federación de consultas en vivo a través de las API de colaboración de datos o tabla externa de Snowflake. |
| Conector de copia cero de Databricks | Mejor | Admite acceso directo en vivo a tablas/vistas en Delta Lake; las consultas distribuidas se ejecutan en tiempo de ejecución de Databricks. |
| Federación de archivos (Apache Iceberg / Delta / Parquet) | Mejor práctica emergente | Data 360 lee directamente formatos de tabla abiertos desde el almacenamiento de objetos sin dependencia de computación externa. Ideal para conjuntos de datos masivos. |
| Configuración de red privada | Recomendado | Utilice Salesforce Private Connect o VPC peering para una federación segura a nivel de red. |
| Autenticación y gestión de claves | Mejor práctica | Implemente la autenticación segura basada en claves o basada en OAuth con rotación periódica y gestión de bóveda. |
| Registro de esquema | Obligatorio | Data 360 recupera el esquema externo y lo asigna a un objeto de lago de datos externo (DLO externo). |
| Metadatos gubernamentales | Recomendado | Todos los DLO externos heredan metadatos de clasificación, consentimiento y linaje para la visibilidad del cumplimiento. |
Boceto
El siguiente diagrama ilustra cómo configurar una conexión de copia cero y crear DLO externos en Data 360.
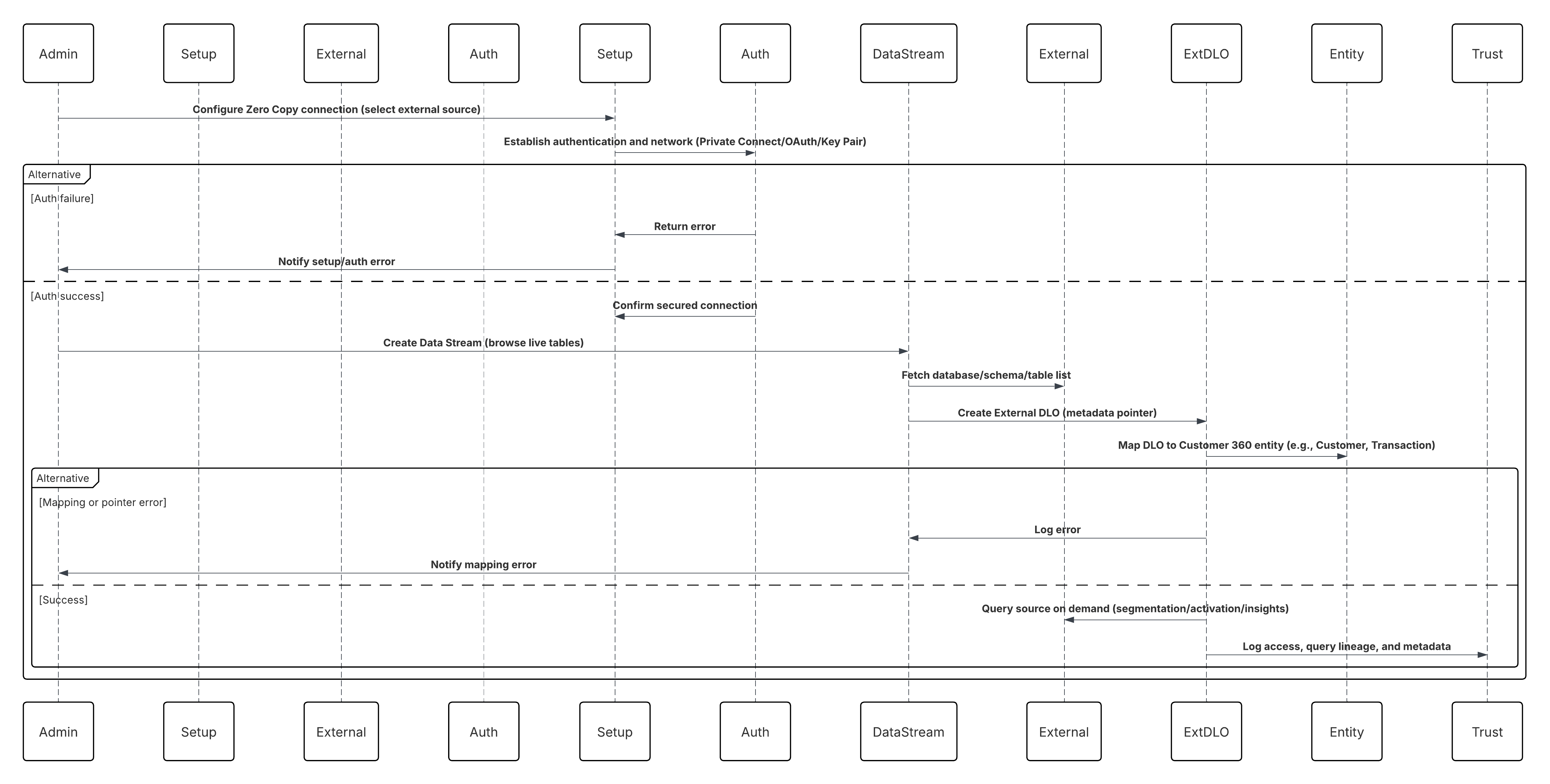
En este escenario:
- El administrador configura una conexión Cero copia en Configuración de Data 360 (Snowflake, Databricks o Federación de archivos).
- La autenticación segura y el enrutamiento de red están establecidos (Conexión privada / OAuth / Par de claves).
- El administrador crea una Transmisión de datos seleccionando el origen externo: exploración de bases de datos en vivo, esquemas y tablas.
- En vez de copiar datos, Data 360 crea un DLO externo (Objeto de lago de datos): un puntero de metadatos que hace referencia a la tabla en vivo o el archivo Iceberg.
- Los DLO externos se asignan a entidades Customer 360 (por ejemplo, Cliente, Transacción, Producto).
- Data 360 consulta el origen durante la segmentación, la activación o el cálculo de perspectivas.
- Todo el acceso, el linaje de la consulta y los metadatos se auditan en Data 360 Trust Layer.
Resultados
- Los datos externos permanecen en Snowflake, Databricks o S3: sin ETL, sin duplicación ni almacenamiento adicional.
- Data 360 obtiene acceso en tiempo real y en tiempo de lectura a datos a escala de compañía para la resolución de identidad, perspectivas calculadas y activación.
- Las organizaciones mantienen el control completo bajo sus marcos de trabajo de gobernanza, cifrado y cumplimiento existentes.
- Este patrón activa una verdadera arquitectura Cero copia: combinando el desempeño del acceso local con la regulación del almacenamiento federado.
Mecanismos de llamada
El mecanismo de llamada depende de la solución elegida para implementar este patrón.
| Mecanismo | Cuándo utilizar |
|---|---|
| Federación de Snowflake (Preferido) | Para una federación de consultas en vivo y de alto desempeño con almacenes de datos de compañía gobernados. |
| Federación de Databricks | Para análisis unificados y entornos de lago con conjuntos de datos respaldados por Delta o Parquet. |
| Federación de archivos (Apache Iceberg / Delta Lake) | Para conjuntos de datos a gran escala en almacenamiento de objetos donde la separación de cálculos y la optimización de costos son clave. |
| Modo híbrido (Copia cero + ingreso) | Cuando los datos históricos necesitan un ingreso puntual pero se accede a los datos en vivo a través de Cero copia. |
Gestión y recuperación de errores
- Reintento automático y retroceso de consulta: La conectividad transitoria o los tiempos de espera de consultas se reintentan automáticamente utilizando retroceso exponencial.
- Aislamiento de errores de coincidencia de esquema: Los cambios en el esquema de origen (por ejemplo, nuevas columnas) se registran en la Cola de rechazo de esquemas; los administradores pueden volver a asignar o actualizar metadatos de esquemas.
- Fallo de autenticación: Si las credenciales caducan, Data 360 reintenta la conexión utilizando tokens de actualización almacenados o políticas de rotación de claves.
- Calcular detección de disponibilidad: Si Snowflake o el clúster Databricks están en pausa, Data 360 suspende los trabajos y reintentos de federación cuando se reanuda el cálculo.
- Integración de monitoreo: Todos los metadatos de estado de conexión, latencia de consulta y linaje visibles en tableros de Monitoreo de Data 360.
Consideraciones de diseño idempotentes
- Determinismo de consulta: Las consultas federadas utilizan semántica de instantánea coherente para garantizar lecturas estables y repetibles durante la segmentación o activación.
- Versión de DLO externa: Cada consulta federada incluye metadatos de esquema y marca de tiempo para el seguimiento del linaje.
- Acceso sin compensación: Dado que Cero copia es de solo lectura, no se basa en compensaciones de eventos: la coherencia se aplica a través de las garantías ACID del sistema externo (Snowflake/Delta Lake).
- Gestión de deriva de esquemas: Mantenga asignaciones de esquemas versionadas en Data 360; actualice metadatos de DLO externo en la evolución de origen.
Consideraciones de seguridad
La seguridad es integral en todo el modelo de federación, lo que garantiza que no haya compromisos en Trust o cumplimiento.
- Cifrado: Todos los intercambios de datos utilizan TLS 1.2+; los almacenes externos cifran en periodos de inactividad utilizando AES-256.
- Control de acceso: Se accede a las tablas externas a través de funciones de menor privilegio con permisos de solo lectura.
- Aislamiento de red: Las rutas privadas Connect o VPC evitan cualquier exposición a extremos públicos.
- Flujo de datos gestionado: Los metadatos de linaje, consentimiento y clasificación fluyen a Data 360 Trust Layer para la aplicación de políticas.
- Auditabilidad: Cada consulta federada y evento de acceso a esquemas se registra para la trazabilidad del cumplimiento (GDPR, CCPA, HIPAA).
Barras laterales
Oportunidad
- Las consultas se ejecutan en vivo en el almacén o almacenamiento externo, garantizando la visibilidad en tiempo real del estado de datos más reciente.
- Las ejecuciones de segmentación o activación reflejan cambios de última hora en tablas de Snowflake, Databricks o Iceberg respaldadas por S3.
- La latencia de la consulta depende del nivel de desempeño del sistema de origen, normalmente de segundos a decenas de segundos por consulta.
- Ideal para cargas de trabajo analíticas y de IA que requieren acceso a datos “actualizados, no copiados”.
Volúmenes de datos
- Admite conjuntos de datos a escala de petabytes almacenados de forma nativa en Snowflake o Databricks sin replicación.
- Data 360 solo recupera resultados (no conjuntos de datos sin procesar) minimizando los costos de computación y red.
- Federación de archivos optimiza las exploraciones analíticas de gran tamaño a través de la poda de particiones y la distribución de columnas.
- Se amplía linealmente con la capacidad de cálculo del almacén y la capa de orquestación de consultas federadas de Data 360.
Gestión de estado
- Los DLO externos mantienen la conexión, el esquema y los metadatos de versión en Data 360.
- La evolución de esquemas se gestiona automáticamente a través de ciclos de actualización de metadatos.
- El linaje de la consulta incluye marcas de tiempo, identidad de usuario y mediciones de ejecución para la trazabilidad.
- No se mantiene ningún ingreso de estado o compensación: la coherencia se hereda de las garantías ACID de la fuente externa.
Escenarios de integración complejos
- Modo híbrido: Combine Cero copia (para federación en vivo) con ingreso (para conjuntos de datos históricos).
- Acceso de almacén cruzado: Data 360 puede federarse desde múltiples arrendatarios de Snowflake o Databricks en una organización.
- Interoperabilidad IA/BI: Los sistemas externos (por ejemplo, SageMaker, Tableau, Power BI) pueden consultar los perfiles enriquecidos de Data 360 de vuelta a través de Cero copia inversa.
- Extensión Federación de archivos: Las compañías que adoptan formatos de lago abierto (Iceberg/Delta) pueden unificar datos estructurados y no estructurados bajo un modelo federado.
Ejemplo
Una compañía financiera global almacena todos los datos de transacciones e interacciones en Snowflake, mientras mantiene los atributos de clientes y eventos de marketing en Data 360. Utilizando Federación de datos de copia cero, Data 360 se conecta de forma segura a Snowflake a través de Conexión privada.Cuando se ejecuta un trabajo de segmentación, por ejemplo, “Clientes con un gasto de >10.000 USD en los últimos 30 días, Data 360 envía la consulta a Snowflake, recupera resultados agregados y activa esos perfiles al instante en Journey Builder. No se necesita replicación o ETL. Este ejemplo utiliza inteligencia federada en tiempo real que está unificada en el ecosistema de datos de la compañía.
La copia cero saliente amplía el mismo principio a la inversa. En vez de exportar o copiar conjuntos de datos desde Data 360, los sistemas externos como Snowflake pueden consultar Data 360 directamente, tratándolo como una fuente federada de Inteligencia de clientes enriquecida.
- Federación inversa: Las plataformas de análisis externo o IA pueden acceder a los datos de perfil unificado de Data 360 sin extraerlos.
- Activación de datos en origen: Los equipos de negocio pueden aprovechar perspectivas donde ya residen los datos, ya sea para el modelado de IA, la creación de reportes o la personalización de clientes.
- Interoperabilidad sin latencia: Sin exportaciones por lotes ni trabajos de sincronización; las perspectivas fluyen al instante entre plataformas.
- Semántica coherente: Como ambos sistemas comparten la misma ontología y asignaciones de esquemas, el contexto y el significado se mantienen entre ecosistemas. La copia cero redefine la función de Data 360 desde un depósito de datos a una capa de activación semántica. Permite a las organizaciones mantener los datos exactamente donde pertenecen (en almacenes gobernados de alto desempeño) mientras desbloquean su valor completo dentro del límite de Trust de Salesforce. Este patrón se alinea con la malla de datos moderna y las arquitecturas nativas de IA: los datos permanecen descentralizados, pero la inteligencia se unifica. Los arquitectos ahora pueden crear oportunidades en curso de activación que son más rápidas, ágiles y compatibles, sin necesidad de copiar.
Contexto
Las empresas modernas operan cada vez más en ecosistemas de datos multiplataforma, donde Salesforce Data 360 potencia la activación y los perfiles de clientes unificados, mientras que los almacenes de datos empresariales como Snowflake o Databricks sirven como ejes analíticos para la ciencia de datos, el aprendizaje automático y las cargas de trabajo de BI. La función Colaboración saliente de copia cero de Salesforce Data 360 acorta estos entornos de forma transparente, permitiendo el acceso gobernado, seguro y en tiempo real a datos armonizados de Data 360 directamente en Snowflake o Databricks, sin replicación o ETL. Esto permite a los analistas y científicos de datos consultar, visualizar y modelar en los mismos datos en vivo y de confianza potenciando la activación de marketing, ventas y servicio.
Problema
¿Cómo puede una compañía exponer de forma segura y eficiente los perfiles de clientes unificados y las mediciones calculadas de Data 360 (por ejemplo, Valor de vida útil, Riesgo de abandono) a sistemas analíticos externos, sin copiar datos, interrumpir la gobernanza o introducir latencia a través de oportunidades en curso de ETL inversas tradicionales?
Fuerzas
Este patrón presenta múltiples consideraciones arquitectónicas, de gobernanza y operativas:
- Seguridad gubernamental: El acceso a datos de Data 360 debe ser controlado, granular y auditable. La colaboración Cero copia utiliza acceso explícito a nivel de objeto, garantizando que solo los objetos de modelo de datos (DMO) y los objetos de perspectivas calculadas (CIO) aprobados estén disponibles para consumidores designados.
- Selección de objetos explícita: Los administradores depuran los datos que se pueden compartir a través de una Colaboración de datos, seleccionando explícitamente qué objetos exponer. Esto mantiene la gobernanza y minimiza la exposición al riesgo.
- Configuración bilateral: Tanto Data 360 como el almacén externo requieren configuración. Data 360 define el Objetivo de colaboración de datos (Snowflake/Databricks), mientras que el sistema receptor debe aceptar e instanciar la colaboración.
- Modelo de federación de consultas: Una vez aceptadas, la plataforma externa consulta datos de Data 360 gobernados en vivo a través de vistas federadas, eliminando trabajos de extracción o ciclos de actualización manuales.
- Evolución de estándares abiertos: Los enfoques emergentes como Federación de archivos aprovechan formatos de tabla abiertos (por ejemplo, Apache Iceberg) para activar el acceso de solo lectura en la capa de almacenamiento, mejorando la escalabilidad, el desempeño y la interoperabilidad entre arquitecturas de múltiples nubes.
Solución
La solución aprovecha la colaboración de copia cero nativa de Salesforce Data 360 con plataformas de datos como Snowflake o Databricks.
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Creación de colaboración de datos | Mejor | El administrador crea una colaboración de datos en Data 360, agregando DMO y CIO seleccionados (por ejemplo, Particular unificado, Puntuaje de salud del cliente). |
| Configuración de destino | Mejor | Cree un Objetivo de colaboración de datos especificando parámetros de autenticación e identificadores de cuentas de Snowflake o Databricks. |
| Compartir publicación | Mejor práctica | Vincule la colaboración de datos al objetivo de colaboración de datos para publicar de forma segura. |
| Aceptación de almacén | Obligatorio | El administrador externo acepta la colaboración, materializando objetos compartidos como vistas/tablas de solo lectura en el almacén. |
| Control de acceso granular | Recomendado | Aplique permisos basados en objetos y funciones en Data 360; alinee con el control de acceso basado en funciones a nivel de almacén. |
| Acceso a consultas federadas | Mejor | Los analistas consultan datos compartidos en vivo a través de SQL estándar; se une con datos de almacén nativos para análisis descendentes y ML. |
| Opción Federación de archivos | Optional | Para conjuntos de datos de gran tamaño, aproveche la federación basada en Apache Iceberg para lecturas directas de S3 o Delta Lake sin calcular la dependencia. |
Boceto
El siguiente diagrama ilustra una llamada desde Salesforce Data 360 a una plataforma de datos externa.
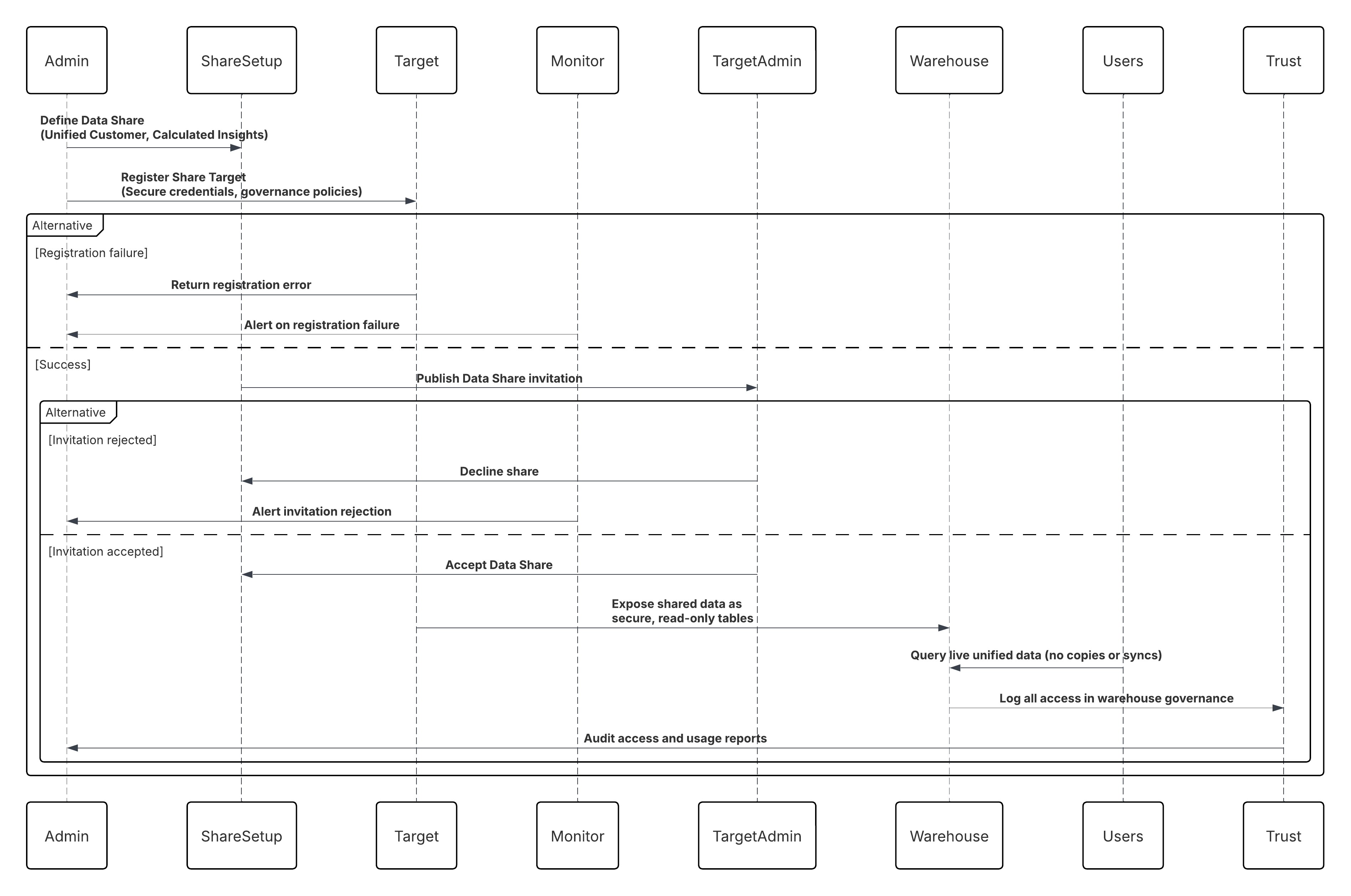
En este escenario:
- Administrador de Data 360 define una colaboración de datos incluyendo objetos Cliente unificado y Perspectiva calculada.
- Un Objetivo de colaboración de datos (cuenta de Snowflake o Databricks) está registrado con credenciales seguras y políticas de gobernanza.
- Data 360 publica la colaboración; los administradores de Snowflake/Databricks la aceptan.
- Los datos compartidos aparecen como tablas de solo lectura seguras en el almacén.
- Analistas, herramientas de BI o oportunidades en curso de ML consultan los datos de clientes unificados en vivo sin copiar o sincronizar.
- Todo el acceso se audita en los registros de Data 360 Trust Layer y de gobernanza de almacén.
Resultados
- Los almacenes externos obtienen acceso consultable en tiempo real a datos armonizados de Data 360.
- Elimina las oportunidades en curso de ETL inversas, reduciendo la carga operativa y la latencia.
- Activa el entrenamiento de IA/ML, el modelado predictivo y la BI avanzada directamente en datos unificados.
- Mantiene cero duplicaciones, una gobernanza sólida y un control de acceso seguro por diseño.
- Completa el bucle Cero copia bidireccional, donde la federación entrante y la colaboración saliente coexisten bajo un único modelo de gobernanza.
Mecanismos de llamada
El mecanismo de llamada depende de la solución elegida para implementar este patrón.
| Mecanismo | Cuándo utilizar |
|---|---|
| Compartir datos seguros de Snowflake (Preferido) | Utilice cuando su almacén de negocio es Snowflake y necesita acceso en vivo y controlado a conjuntos de datos de Data 360 armonizados sin movimiento de datos o duplicación. Ideal para análisis, IA y cargas de trabajo dirigidas por cumplimiento que requieren colaboración de latencia cero y aplicación forzosa de linajes nativos. |
| Databricks Delta Compartir | Se utiliza cuando los consumidores descendentes operan en entornos Databricks o Delta Lake y requieren acceso de solo lectura en tiempo real a conjuntos de datos unificados o activados a través del protocolo Delta Sharing abierto. |
| Cuota de tabla externa (Apache Iceberg / Parquet) | Utilice esta función cuando mantenga arquitecturas de formato abierto en almacenamiento de objetos (S3, ADLS o GCS) y necesite colaboración interoperable y de bajo costo entre motores analíticos como Athena, BigQuery o Snowflake-on-Iceberg. |
| API de colaboración de datos (acceso programático) | Utilice cuando aplicaciones personalizadas o middleware (por ejemplo, MuleSoft) deben descubrir, suscribirse o consumir conjuntos de datos compartidos de forma segura a través de API, con notificaciones de actualización basadas en eventos y un control de acceso preciso. |
| Cuota híbrida (Copia cero + Cuota saliente) | Utilice cuando implemente patrones de intercambio bidireccionales: aprovechando Cero copia para datos entrantes y Compartir datos salientes para publicar perspectivas, garantizando la coherencia semántica y de gobernanza entre planos de datos de compañía. |
Gestión y recuperación de errores
- Reintentos de conexión: Reintentos automatizados para fallos de autenticación o conexión transitorios entre Data 360 y el almacén.
- Validación de colaboración: Las configuraciones de colaboración no válidas o no autorizadas se ponen en cuarentena en una Cola de revisión de administrador.
- Monitoreo de estado de sincronización: Data 360 aflora el estado de colaboración en vivo, la latencia de consultas y los registros de acceso a través de tableros de Monitoreo.
- Revocación de acceso: Los administradores pueden revocar colaboraciones al instante, desactivando el acceso en ambos extremos sin copias de datos residuales.
- Seguimiento de auditoría gobernado: Todos los cambios de configuración y acceso se registran para la verificación del cumplimiento.
Consideraciones de diseño idempotentes
- Identificación de colaboración coherente: Cada par Uso compartido de datos y Objetivo de uso compartido de datos tiene un identificador exclusivo, garantizando una gobernanza exacta y trazabilidad de acceso.
- Vistas inmutables: Los objetos de datos compartidos son de solo lectura; los consumidores no pueden mutar el estado, garantizando resultados y cumplimiento deterministas.
- Ciclo de vida de colaboración atómica: La publicación, la revocación y las actualizaciones de colaboración son operaciones atómicas: completamente completadas o revertidas.
- Coherencia de reproducción: Cuando se actualizan datos de Data 360, las consultas del lado del almacén siempre devuelven la instantánea coherente más reciente, eliminando lecturas obsoletas.
Consideraciones de seguridad
La seguridad sustenta cada aspecto de Colaboración de copia cero:
- Autenticación: Mutual Trust establecido utilizando OAuth 2.0, intercambio de claves privadas o federación de identidad (OIDC).
- Cifrado: Datos cifrados en tránsito (TLS 1,2+) y en reposo (AES-256).
- Control de acceso: Los permisos a nivel de objeto aplican el acceso con menos privilegios; gobernados por Data 360 Trust Layer.
- Seguridad de red: Los intercambios de datos se producen a través de vínculos de red privados como Salesforce Private Connect o las API de intercambio de datos seguro.
- Metadatos de gobernanza: Cada objeto compartido lleva atributos de linaje, clasificación y consentimiento para una trazabilidad completa y cumplimiento normativo.
Barras laterales
Oportunidad
- Disponibilidad en tiempo real: Los datos compartidos reflejan el estado más actual de Data 360 sin demoras de replicación.
- Actualización de consulta: Los cambios en DMO o CIO se propagan instantáneamente a vistas de almacén compartidas.
- Elasticidad de desempeño: La distribución de consultas se adapta de forma dinámica a recursos de computación de almacén.
- Monitoreo: Los tableros en vivo exponen la latencia compartida y consultan mediciones de desempeño para la seguridad operativa.
Volúmenes de datos
- Compartición ampliable: Admite el uso compartido de datos granulares a nivel de objeto o de dominio completo dependiendo de las necesidades analíticas.
- Desempeño de consulta optimizado: Snowflake/Databricks almacenan en caché datos compartidos de forma inteligente para minimizar la latencia.
- Eficiencia de almacenamiento: La duplicación cero elimina costos de almacenamiento redundantes.
- Opción Federación de archivos: Para conjuntos de datos a escala de petabytes, la colaboración basada en Iceberg directa omite el cálculo y acelera el acceso.
Gestión de estado
- Evolución de esquema: Los esquemas controlados por versión garantizan la compatibilidad cuando evoluciona el modelo de Data 360.
- Seguimiento de estado de acceso: Estados de colaboración activos/inactivos mantenidos en Data 360 para la regulación del ciclo de vida.
- Sincronización de metadatos: Las actualizaciones en definiciones de objetos compartidos se reflejan automáticamente en catálogos de almacén descendentes.
- Garantía estatal inmutable: Las vistas de almacén siempre representan un estado coherente y puntual de los datos de Data 360.
Escenarios de integración complejos
- Modo híbrido: Combine Cero copia (para federación en vivo) con ingreso (para conjuntos de datos históricos).
- Acceso de almacén cruzado: Data 360 puede federarse desde múltiples arrendatarios de Snowflake o Databricks en una organización.
- Interoperabilidad IA/BI: Los sistemas externos (por ejemplo, SageMaker, Tableau, Power BI) pueden consultar los perfiles enriquecidos de Data 360 de vuelta a través de Cero copia inversa.
- Extensión Federación de archivos: Las compañías que adoptan formatos de lago abierto (Iceberg/Delta) pueden unificar datos estructurados y no estructurados bajo un modelo federado.
Ejemplo
Análisis entre nubes permite a las organizaciones combinar datos de Salesforce Data 360 gobernados con conjuntos de datos nativos en plataformas como Snowflake y Databricks para ofrecer una vista analítica completa de 360 grados. A través del acceso de múltiples arrendatarios, diferentes unidades de negocio pueden consumir de forma segura sectores de datos depurados y controlados por pólizas a través de colaboraciones separadas sin duplicar datos. Los científicos de datos pueden luego realizar aprendizaje automático e IA federada entrenando modelos directamente en perfiles de clientes unificados en entornos Snowflake ML o Databricks MLflow. A lo largo de este proceso, el linaje integrado, la gobernanza y las funciones de auditoría garantizan que todo el acceso y el uso de los datos siguen cumpliendo las políticas de la compañía y los requisitos normativos como el RGPD y la HIPAA.
Data Cloud One permite a las organizaciones con múltiples organizaciones de Salesforce (por ejemplo, debido a unidades de negocio, regiones, líneas de productos o adquisiciones) compartir una única instancia central de Data 360. Esta organización actúa como la “organización de inicio”, mientras que otras organizaciones, denominadas “organizaciones complementarias”, pueden acceder y actuar sobre esos datos unificados, con un esfuerzo mínimo, sin código personalizado y controles de gobernanza completos.
Contexto
Las compañías a menudo ejecutan más de una organización de Salesforce (por ejemplo, una para ventas, una para servicio, una para marketing o regiones distintas). Cada organización puede tener sus propios datos, configuración y procesos. Antes de Data Cloud One, cada organización requería su propia configuración de Data 360 o código personalizado complejo para compartir datos entre organizaciones. Data Cloud One simplifica esto permitiendo una única organización de “inicio” con Data 360 y múltiples organizaciones “compañeras” que se conectan a través de configuración de código bajo y colaboración de metadatos.
Problema
¿Cómo puede un negocio permitir el uso coherente de los datos unificados de Customer 360 (ingresados, armonizados y gestionados por Data 360 de la organización de inicio) entre todas sus organizaciones de Salesforce (de modo que ventas, marketing, servicio, etc., utilicen los mismos datos subyacentes), evitando al mismo tiempo la duplicación de esfuerzos, la codificación personalizada, instancias de Data 360 separadas por organización y brechas de gobernanza?
Fuerzas
Este patrón presenta múltiples consideraciones arquitectónicas, de seguridad y de desempeño:
- Complejidad de múltiples organizaciones: La organización de cada unidad de negocio puede tener diferentes datos, objetos personalizados, seguridad y procesos; mantener vistas unificadas coherentes es difícil.
- Duplicación y costo: La ejecución de una instancia de Data 360 separada por organización significa configuración adicional, regulación adicional, licencias adicionales y riesgo de silos de datos.
- Controles de gobernanza y colaboración de datos: Debe decidir qué datos puede ver y sobre los que puede actuar cada organización complementaria: no puede simplemente compartir “todo” sin riesgo de gobernanza.
- Velocidad de configuración: Los equipos de marketing, ventas o servicio no pueden esperar semanas para que el código personalizado haga que los datos entre organizaciones estén disponibles; necesitan soluciones de configuración de clics.
- Residencia de datos, Consideraciones regionales: Si las organizaciones de inicio y acompañantes están en diferentes regiones, puede haber restricciones legales o regulatorias acerca de dónde se almacenan los datos o cómo se comparten.
Solución
La siguiente tabla contiene varias soluciones a este problema de integración.
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Aprovisionamiento de organización principal | Mejor | Designe una organización de Salesforce como la organización de inicio donde se aprovisiona Data 360; esta se convierte en el repositorio de datos central y el núcleo de gobernanza. |
| Conexión de organización de compañía | Mejor | Configure conexiones de compañía desde la organización de inicio a una o más organizaciones de compañía a través de la aplicación Data Cloud One: no se requiere código personalizado. |
| Definición de espacio de datos | Mejor práctica | Defina Espacios de datos en la organización de inicio para segmentar lógicamente datos (por ejemplo, Retail, Servicio, Marketing) y aislar límites de acceso. |
| Compartir espacio de datos | Mejor | Comparta explícitamente espacios de datos seleccionados desde la organización de inicio a organizaciones complementarias, garantizando la visibilidad gobernada basada en funciones de datos unificados. |
| Configuración de acceso | Obligatorio | En Organizaciones de compañía, active la aplicación Data Cloud One y asigne permisos de usuario para el acceso a perfiles, perspectivas y segmentos. |
| Control de políticas y gobernanza | Recomendado | Centralice todas las configuraciones de ingreso, resolución de identidad y Trust en la organización doméstica, manteniendo la gobernanza de extremo a extremo. |
| Sincronización de múltiples organizaciones | Mejor | Los cambios de datos y las perspectivas calculadas en la organización de inicio se reflejan en tiempo real entre organizaciones de compañía a través de oportunidades en curso de sincronización gestionadas. |
| Opción de implementación híbrida | Optional | Para grandes empresas, múltiples organizaciones de compañía pueden conectarse a una única organización de inicio manteniendo al mismo tiempo el contexto local y los límites de cumplimiento. |
Boceto
El siguiente diagrama ilustra la secuencia de eventos en este patrón, donde Salesforce es el principal de datos.
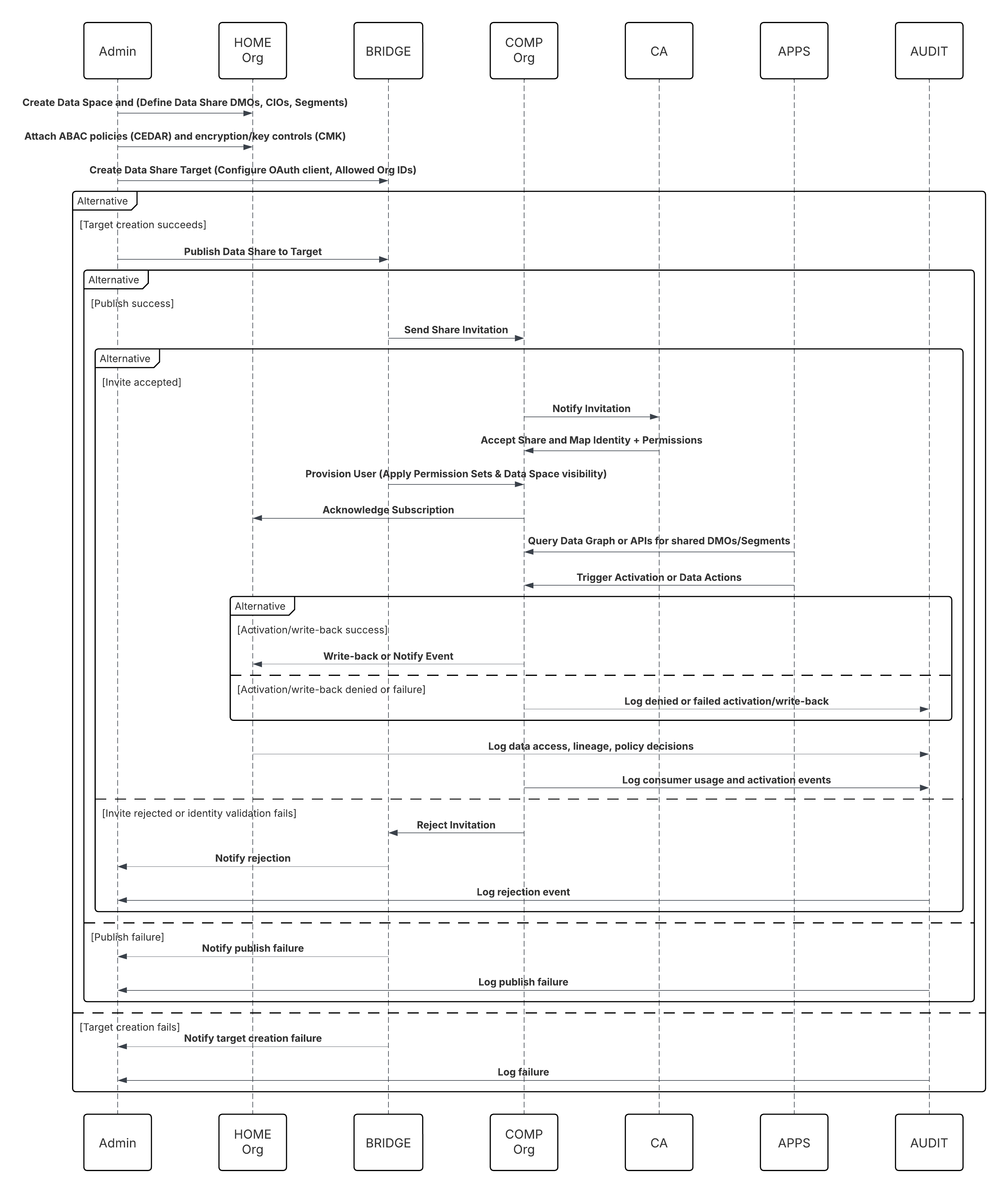
En este escenario:
- Administrador principal: cree Espacio de datos y defina Colaboración de datos (seleccione DMO/CIO, segmentos).
- Administrador de inicio: cree Objetivo de colaboración de datos para organizaciones de compañía y configure Trust (cliente de OAuth, Id. de organización permitidos).
- Administrador principal: publique Compartir datos en destino; adjunte políticas de ABAC (CEDAR) y controles de cifrado/clave (CMK si es necesario).
- Administrador de organización de compañía: recibe invitación, valida asignación de identidad y acepta colaboración.
- Organización de compañía: Puente de Data Cloud One aprovisiona un usuario de Data Cloud One y aplica Conjuntos de permisos y visibilidad de Espacio de datos.
- Aplicaciones de organización de compañía (Flujos / Einstein / Apex): Consulte un gráfico de datos o llame a las API de Data Cloud One para leer segmentos o DMO compartidos.
- Activación: La organización de compañía desencadena la activación o escribe a través de acciones de datos (si se permite).
Resultados
- Una única fuente de verdad para datos de clientes (Customer 360) en todas las organizaciones conectadas: sin instancias de Data 360 redundantes.
- Un tiempo más rápido para valorar. Las organizaciones complementarias pueden acceder a datos unificados y funciones con tecnología Data 360 en minutos, no semanas de codificación personalizada.
- Compartición de datos controlada. Solo se comparten los espacios de datos autorizados, lo que mantiene la seguridad y la gobernanza al tiempo que permite la agilidad de negocio.
- Las funciones de negocio (ventas, servicio, marketing) funcionan sobre la misma base de datos unificada, lo que permite mediciones, activaciones y perspectivas coherentes en toda la compañía.
Mecanismos de llamada
El mecanismo de llamada depende de la solución elegida para implementar este patrón.
| Mecanismo | Cuándo utilizar |
|---|---|
| Compartición nativa de Data Cloud One (Preferido) | Utilice cuando múltiples organizaciones de Salesforce (Ventas, Servicio o Industry Cloud) necesitan acceso en tiempo real a datos de clientes unificados directamente desde Data 360\. Esto elimina la replicación y permite el acceso de latencia cero a registros dorados, segmentos y perspectivas calculadas. |
| Compartición de organización a organización a través de Data Cloud One Bridge | Se utiliza cuando múltiples unidades de negocio o filiales operan en organizaciones de Salesforce separadas pero necesitan acceso compartido a datos y segmentos de clientes comunes desde una instancia central de Data 360. Ideal para empresas de múltiples organizaciones que mantienen sistemas operativos independientes. |
| API de consulta de plataforma Einstein 1 | Se utiliza cuando las aplicaciones Salesforce, Flow o Einstein Copilot deben consultar o activar datos de Data 360 de forma programática. Activa la recuperación en tiempo real de perfiles unificados, mediciones o resultados de activación en otras aplicaciones de Salesforce sin exportaciones por lotes. |
| Activación en canales de Salesforce | Utilice cuando los datos de Data 360 (segmentos, perspectivas o atributos) deben activarse en Marketing Cloud, Service Cloud o Commerce Cloud para la personalización, la ejecución de campañas o experiencias de asistencia de agentes. |
| Acceso a gráficos de datos (Capa de consulta semántica) | Utilice esta función cuando necesite acceso a nivel semántico al modelo de datos unificado a través del gráfico de datos de Salesforce, que admite flujos de trabajo de Copilot, IA y análisis entre nubes en tiempo real, sin uniones o transformaciones manuales. |
Gestión y recuperación de errores
- Resistencia de sincronización entre organizaciones: Data Cloud One reintenta automáticamente trabajos de sincronización fallidos entre organizaciones de inicio y de compañía utilizando retroceso exponencial para errores transitorios de red o plataforma.
- Aislamiento por lotes parcial: Los lotes de registros con fallos se ponen en cuarentena en una Cola de reintento en la organización de inicio hasta que la reconciliación se realice correctamente, evitando la divergencia de datos.
- Gobernanza de rechazo de esquema: Las faltas de coincidencia de esquemas o asignaciones se enrutan a la Cola de rechazo de esquemas para su revisión y corrección por parte del administrador.
- Continuidad de reproducción y reanudación: Cada trabajo de sincronización mantiene puntos de control de compensación de modo que la replicación puede reanudarse desde la última confirmación correcta sin duplicación.
- Monitoreo integrado: Todos los fallos, reintentos y mediciones de recuperación se capturan en el tablero Trust Layer Monitoring para visibilidad y garantía de SLA.
Consideraciones de diseño idempotentes
- Claves de Idempotencia determinista: Cada evento de sincronización lleva una clave exclusiva (Id. de organización + Id. de registro + Número de versión) para garantizar el procesamiento exacto una vez.
- Seguridad de reproducción: Los eventos duplicados o reproducidos se filtran en tiempo de confirmación, garantizando actualizaciones coherentes de DMO y CIO descendentes.
- Semántica de confirmación atómica: Las organizaciones de compañía marcan los datos como confirmados solo después de escrituras descendentes satisfactorias, preservando la integridad de las transacciones entre organizaciones.
- Resolución de conflictos: Las actualizaciones de múltiples orígenes siguen la lógica de combinación basada en las últimas escrituras ganadas o en políticas, manteniendo el linaje y la coherencia.
- Persistencia de punto de control: Los trabajos de sincronización mantienen las compensaciones procesadas por última vez y el estado en Trust Layer para una recuperación y reproducción seguras.
Consideraciones de seguridad
- Autenticación sólida: Las conexiones entre organizaciones domésticas y de compañía utilizan OAuth 2.0 mutuo con tokens con rotación automática gestionados a través de aplicaciones conectadas.
- Autorización granular: Las organizaciones de compañía solo pueden acceder a Espacios de datos, DMO o CIO específicos compartidos explícitamente a través de Políticas de colaboración de datos gobernadas.
- Cifrado en todas partes: Los datos se cifran en tránsito (TLS 1,2+) y en reposo (AES-256) entre organizaciones domésticas y de compañía.
- Principio de menor privilegio: Los usuarios de integración solo tienen ámbito a los objetos requeridos; no se propagan permisos administrativos o a nivel del sistema.
- Visibilidad de auditoría y cumplimiento: Todos los eventos de sincronización, los cambios de esquema, las actualizaciones de credenciales y los otorgamientos de acceso se registran en Data 360 Trust Layer para una trazabilidad completa.
- Aislamiento de red privado: Salesforce Private Connect opcional o Vínculo privado garantiza que la replicación de datos se produzca únicamente en canales internos seguros.
Barras laterales
Oportunidad
- La sincronización entre organizaciones de inicio y de compañía se produce casi en tiempo real, normalmente en cuestión de segundos desde un cambio de datos en la organización de origen.
- La arquitectura Cero copia garantiza que los datos compartidos sean consultables al instante en todas las organizaciones participantes: sin replicación ni retrasos por lotes.
- Los trabajos de activación y segmentación reflejan automáticamente las actualizaciones más recientes desde cualquier organización conectada, manteniendo la actualización operativa.
- La latencia de extremo a extremo es determinista y se rige por las oportunidades en curso de orquestación de Data Cloud One, garantizando una puntualidad coherente entre organizaciones incluso bajo carga.
Volúmenes de datos
- Diseñado para la sincronización de datos a hiperescala de múltiples arrendatarios entre regiones y unidades de negocio, capaz de gestionar miles de millones de registros por organización.
- Se hace referencia a los datos, no se duplican, reduciendo la huella de almacenamiento mientras se mantiene la capacidad de consulta global.
- Los deltas de transmisión y la compactación de metadatos optimizan el ancho de banda y confirman la sobrecarga para objetos de alto índice de cambio (por ejemplo, Contacto, Pedido).
- Se amplía horizontalmente entre múltiples organizaciones de compañía con equilibrio de carga adaptativo y orquestación a través de Trust Layer.
Gestión de estado
- Cada conjunto de datos sincronizado mantiene el linaje de metadatos, la versión y el contexto de propiedad de la organización para garantizar la trazabilidad de extremo a extremo.
- La persistencia de puntos de control captura compensaciones sincronizadas por última vez entre organizaciones, permitiendo la recuperación sin duplicaciones.
- La versión de esquemas y la alineación semántica entre organizaciones se rigen automáticamente por Trust Layers.
- No se requieren restablecimientos de estado manuales: el estado de sincronización se mantiene a través del Servicio de orquestación Data Cloud One.
Escenarios de integración complejos
- Federación entre organizaciones: Activación y consulta sencillas entre múltiples arrendatarios o regiones de Data 360 bajo un modelo de gobernanza unificado.
- Sincronización híbrida: Combina la replicación casi en tiempo real para actualizaciones de transacciones con la sincronización programada para datos masivos o de archivo.
- Gobernanza de múltiples regiones: Admite el uso compartido de datos distribuidos geográficamente respetando los límites de residencia, consentimiento y cumplimiento.
- Activación de IA y automatización: Los datos sincronizados potencian al instante modelos de IA, Agentforce o ML personalizados de Einstein entre organizaciones, lo que permite la inteligencia entre organizaciones en tiempo real.
Ejemplo
Una organización minorista global tiene tres organizaciones de Salesforce: una para Consumer Retail, otra para Premium Brands y otra para International Markets. Aprovisionan Data 360 en la organización Consumer Retail (convirtiéndola en la organización de inicio). Con Data Cloud One, configuran conexiones complementarias con las organizaciones de Marcas Premium y Mercados internacionales. Solo comparten espacios de datos apropiados (por ejemplo, “Customer 360 – Retail Profiles” y “Customer 360 – Premium Profiles”) con cada organización complementaria. En la organización Marcas Premium, los equipos de marketing pueden ver perfiles de clientes unificados, crear segmentos basándose en perspectivas calculadas (por ejemplo, valor vitalicio de cliente premium) y desencadenar automatizaciones de marketing, todo ello con tecnología de la instancia Data 360 de la organización de inicio, sin codificación personalizada ni duplicación de datos.
La activación de datos es donde el valor de Salesforce Data 360 cobra vida realmente. Es el proceso de tomar los datos unificados, enriquecidos y gobernados que viven dentro de la plataforma y hacerlos funcionar en todo el negocio. En la práctica, esto significa entregar de forma segura segmentos depurados, perspectivas calculadas y atributos contextuales desde Data 360 en los sistemas que implican clientes, ya sea automatización de marketing, consolas de servicio, activación de ventas, análisis o modelos de IA. Desde una perspectiva técnica, los patrones de activación definen cómo se mueven estos datos: qué canales se desencadenan, qué transformaciones o asignaciones se producen y cómo se aplican las políticas en el camino. Estos patrones no solo se refieren a la exportación de datos, sino que se refieren a la orquestación de flujos de datos en tiempo real que tienen en cuenta las políticas y que impulsan resultados de negocio mensurables. Cada ruta de activación convierte Customer 360 en un activo operativo en vivo, potenciando la personalización, las decisiones predictivas y el aprendizaje continuo en cada punto de contacto.
La activación por lotes sigue siendo el método más utilizado y probado operativamente para exportar datos desde Data 360. Opera en una cadencia programada: publicando segmentos de audiencia predefinidos o conjuntos de atributos en plataformas descendentes a intervalos regulares. Este patrón es ideal para flujos de trabajo de marketing e implicación que se basan en entrega de audiencia coherente y de gran volumen en vez de actualizaciones instantáneas. Los casos de uso habituales incluyen la potenciación de trayectorias de email, campañas de correo directo o cargas de audiencia en redes de publicidad digital. Cada ejecución de activación extrae el segmento cualificado del gráfico de perfil unificado de Data 360, aplica políticas de gobernanza y consentimiento y transmite de forma segura el resultado al sistema de destino. Arquitectónicamente, la activación por lotes proporciona un enfoque predecible, auditable y rentable para la distribución de datos, equilibrando la simplicidad operativa con la fiabilidad de nivel de compañía. Es la columna vertebral de la ejecución de campañas a gran escala, donde los datos correctos, entregados a tiempo y bajo control, dirigen la repercusión de negocio mensurable.
Contexto
Los especialistas de marketing modernos operan en múltiples canales de implicación (email, publicidad, móvil y web), cada uno de los cuales demanda audiencias de clientes precisas, oportunas y personalizadas. Data 360 sirve como la base unificada para estas audiencias, combinando datos de clientes desde cada sistema en segmentos enriquecidos con capacidad de acción. La activación por lotes es el patrón de activación más común utilizado para exportar esos segmentos desde Data 360 a plataformas de marketing o publicidad descendentes. Los destinos habituales incluyen Marketing Cloud Engagement, Google Ads, Meta Custom Audiences o LinkedIn Ads, donde las campañas se pueden ejecutar directamente contra estas audiencias depuradas.
Problema
¿Cómo puede un equipo de marketing tomar una audiencia definida con precisión (creada utilizando datos unificados y enriquecidos en Data 360) y hacerla disponible en sistemas de marketing o publicidad externos para su activación? Por ejemplo, considere el segmento: “Clientes de alto valor que no compraron en los últimos 90 días pero que se implicaron recientemente en el sitio web”. Los especialistas en marketing deben asegurarse de que esta audiencia se transfiere con precisión, se enriquece con atributos relevantes (por ejemplo, nivel de fidelidad, región o CLV predicho) y se actualiza a intervalos regulares para mantener la relevancia y la eficacia de la campaña.
Fuerzas
Varios factores técnicos y operativos dan forma al patrón Activación por lotes:
- Asignación de identidad: La entrega de audiencia precisa requiere asignar el Id. de Particular unificado de Data 360 al identificador correspondiente en el sistema de destino, como una Clave de suscriptor en Marketing Cloud o un email hash para plataformas de anuncios digitales. Esto garantiza una coincidencia precisa y elimina errores de destino.
- Selección y enriquecimiento de atributos: Los especialistas de marketing deben ir más allá de los Id. e incluir datos de perfil adicionales (como nombre, estado de fidelidad, CLV u otros atributos personalizados) para activar la personalización y los análisis descendentes.
- Configuración de plataforma de destino: Cada destino debe registrarse en Data 360 como un Destino de activación, incluyendo detalles de conexión, autenticación y asignaciones de campos de datos. Esta configuración puntual define la conectividad segura y rige qué sistemas pueden recibir datos activados.
- Gobernanza y cumplimiento: La activación de datos debe cumplir los metadatos de consentimiento, las políticas de privacidad (por ejemplo, RGPD o CCPA) y los permisos de marketing almacenados en el perfil unificado. La activación consciente del consentimiento garantiza que los datos se utilicen solo para fines autorizados.
- Programación y desempeño: Las activaciones a menudo se programan diariamente o cada hora para mantener actualizadas las audiencias descendentes. El sistema debe gestionar de forma eficiente grandes volúmenes y actualizaciones incrementales sin duplicación o pérdida de datos.
Solución
El proceso de activación por lotes en Data 360 sigue un flujo de trabajo guiado que minimiza las fricciones técnicas para los especialistas de marketing mientras mantiene la gobernanza y la capacidad de ampliación:
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Creación de segmentos | Mejor | Un especialista en marketing o analista crea un segmento en el lienzo de segmentación visual aplicando filtros entre cualquier objeto de modelo de datos (DMO) u Objeto de perspectiva calculada (CIO). Esto define la audiencia de destino para la activación. |
| Configuración de activación | Mejor | El usuario crea una activación y selecciona el segmento que acaba de crear como el origen. Esto define qué audiencia exportará Data 360 a sistemas descendentes. |
| Selección de destino de activación | Mejor práctica | El especialista en marketing selecciona un destino de activación preconfigurado (por ejemplo, Marketing Cloud, Google Ads, LinkedIn Ads). Cada destino se registra en Data 360 con credenciales de autenticación y asignaciones de campos. |
| Definición de carga | Obligatorio | El especialista en marketing define la carga seleccionando identificadores de contacto (por ejemplo, email, móvil, Id. de hash) y seleccionando atributos de perfil adicionales (por ejemplo, nombre, nivel de fidelidad o CLV) para enriquecer en el sistema de destino. |
| Programación y frecuencia | Recomendado | Las activaciones pueden programarse para ejecutarse una vez o de forma recurrente (por ejemplo, diariamente o semanalmente). La programación garantiza que las audiencias descendentes permanecen sincronizadas y actualizadas. |
| Ejecución y exportación | Mejor | Cuando se ejecuta el trabajo de activación, Data 360 consulta el segmento, recopila los atributos seleccionados, aplica filtros de consentimiento y exporta los datos a la plataforma de destino. Para Marketing Cloud, esto suele dar como resultado la creación o actualización de una extensión de datos compartida. |
| Gobernanza y cumplimiento | Obligatorio | Trust Layer aplica la validación de esquemas, los metadatos de consentimiento y los controles de políticas para garantizar el cumplimiento de las leyes de marketing y protección de datos (por ejemplo, RGPD, CCPA). |
| Monitoreo y capacidad de auditoría | Mejor práctica | Se realiza un seguimiento de cada ejecución de activación con mediciones de éxito/fallo, registros de ejecución y visibilidad de linaje en el tablero Trust Layer Monitoring, lo que permite la transparencia operativa y la garantía de SLA. |
Boceto
Este es el resumen de los pasos:
- Segmento de construcción: Un especialista en marketing o analista crea un segmento utilizando una herramienta de segmentación visual, combinando filtros entre cualquier objeto de datos unificado.
- Crear activación: Seleccionan el segmento como un origen y eligen un destino preconfigurado (como Marketing Cloud o Google Ads).
- Definir carga: El identificador de contacto y otros atributos de perfil se seleccionan para la exportación y creación de reportes de audiencia.
- Programar entrega: La activación está programada para ejecutarse una vez o de forma recurrente, manteniendo la audiencia en el destino actualizada.
- Ejecución: En el desencadenador, Data 360 consulta el segmento, construye la carga, aplica filtros para el consentimiento y envía el resultado al sistema de destino.
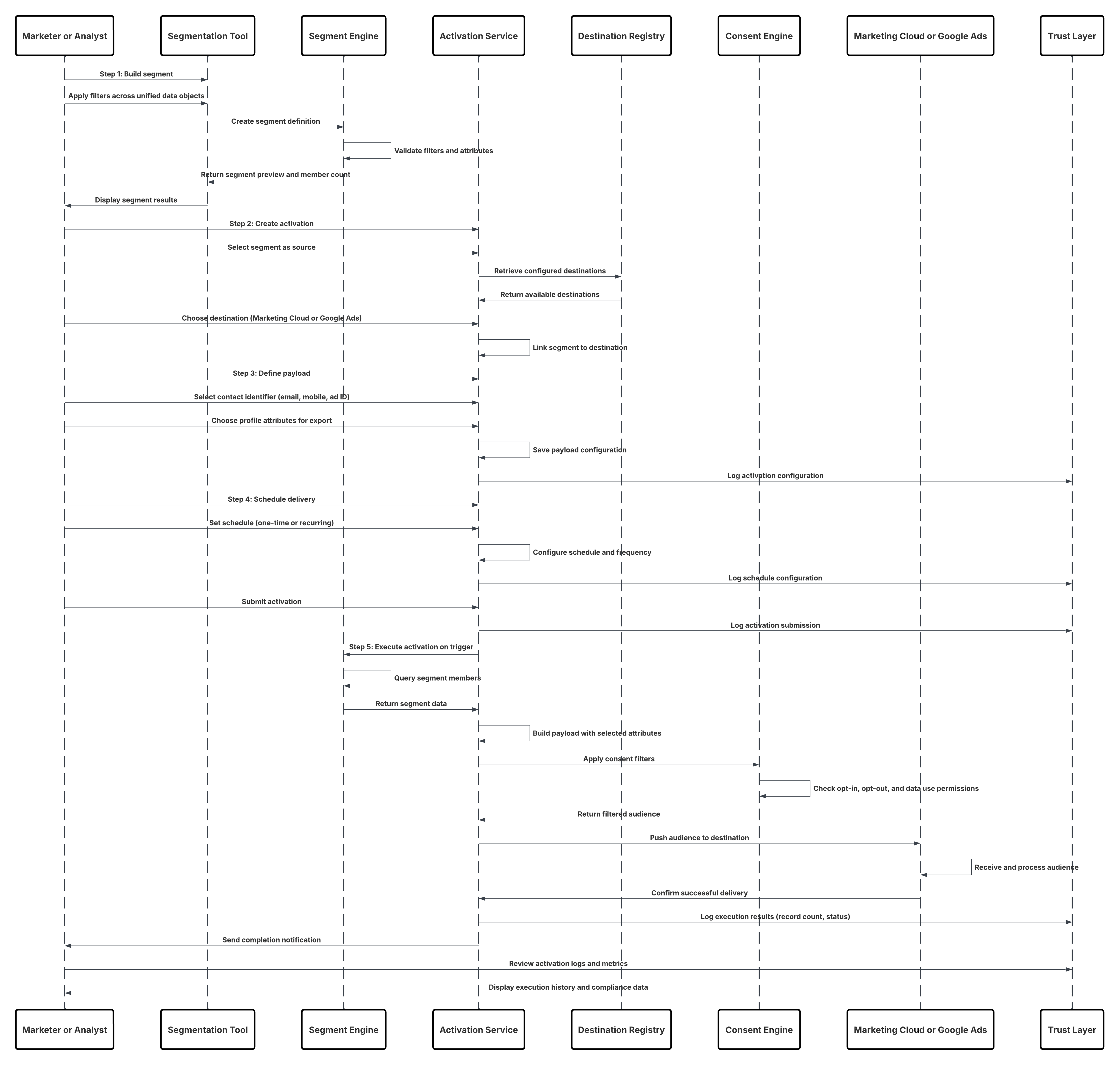
Resultados
- Los segmentos de audiencia enriquecidos dirigidos desde Data 360 están disponibles directamente en plataformas de marketing y publicidad descendentes.
- Las audiencias se actualizan y sincronizan automáticamente con los datos de clientes unificados más recientes, manteniendo la relevancia de la campaña en tiempo real.
- Los especialistas en marketing pueden utilizar estas audiencias activadas como orígenes de entrada para trayectorias de Marketing Cloud, campañas de email o audiencias personalizadas en plataformas de anuncios digitales como Google Ads, Meta o LinkedIn Ads.
- Cada ejecución de activación mantiene un linaje de extremo a extremo, garantizando el cumplimiento, la trazabilidad y la coherencia entre Data 360 y sistemas externos.
- Los usuarios de negocio pueden entregar experiencias altamente personalizadas dirigidas por datos con tecnología de una vista Customer 360 completa y de confianza.
Mecanismos de llamada
El mecanismo de llamada depende de la plataforma de destino y la configuración de destino de activación.
| Mecanismo | Cuándo utilizar |
|---|---|
| Activación de Marketing Cloud Engagement (Preferido) | Utilice esta función cuando ejecute trayectorias de email o canales cruzados que requieran segmentos dinámicos, atributos personalizados y actualizaciones en tiempo real en Marketing Cloud. Data 360 exporta directamente a Extensiones de datos compartidas para la activación de campañas. |
| Activación de plataforma de anuncios (Google Ads, LinkedIn Ads, Meta Ads) | Utilice al activar segmentos de Data 360 como audiencias personalizadas en plataformas de publicidad para modelado de redirección o parecido. Admite identificadores de hash y entrega consciente del consentimiento. |
| Activación de CRM (Ventas o Service Cloud) | Utilice cuando comparta datos de clientes enriquecidos, perspectivas o puntuajes de propensión a usuarios de CRM para interacciones de servicio o implicación de ventas personalizadas. Los datos están disponibles como registros o perspectivas enriquecidos a través de Acciones de datos o Componentes de perfil unificado. |
| Activación externa a través de MuleSoft o API | Utilizar cuando la activación necesita llegar a sistemas que no son de Salesforce como la fidelidad, el comercio electrónico o almacenes de datos externos. MuleSoft o la API de activación de Data 360 garantiza una entrega segura y gobernada por políticas con opciones de actualización basadas en eventos. |
| Activación híbrida (por lotes + desencadenada por evento) | Utilice esta opción cuando combine activaciones por lotes programadas con desencadenadores basados en eventos, lo que permite la personalización “siempre activada” para campañas urgentes como alertas de riesgo de abandono o abandono de carritos. |
Gestión y recuperación de errores
- Aislamiento de fallos a nivel de trabajo: Cada ejecución de activación se ejecuta como un trabajo rastreable distinto en la Capa de orquestación de Data 360. Las ejecuciones con fallos se ponen en cuarentena automáticamente sin afectar a otras activaciones o definiciones de segmentos.
- Recuperación parcial por lotes: Si ciertos registros no se exportan (por ejemplo, debido a errores de coincidencia de identificadores o límites de frecuencia de API), el sistema los reintenta utilizando colas delta incrementales con retroceso exponencial y recuperación paralela.
- Errores de validación de esquemas: Cuando los atributos de carga salientes ya no coinciden con el esquema de destino (por ejemplo, un atributo eliminado o un campo cambiado de nombre), el trabajo enruta los registros afectados a la Cola de rechazo de esquema para su revisión por el administrador.
- Reproducir y reanudar asistencia: Cada trabajo de activación mantiene un token de punto de control, capturando el último lote realizado con éxito. Tras la recuperación, el procesamiento se reanuda desde el punto de control, garantizando que no haya duplicaciones o pérdida de datos.
- Monitoreo integral: Todos los eventos de activación, reintentos y mediciones de entrega se registran en Trust Layer Monitoring, lo que permite el seguimiento de SLA, el análisis de causa raíz y las alertas automatizadas a través de las API de Event Monitoring.
Consideraciones de diseño idempotentes
- Claves de activación determinista: Cada ejecución de activación utiliza una clave de idempotencia compuesta (combinando Id. de segmento, Id. de activación e Id. del sistema de destino) para garantizar la entrega una vez exacta.
- Detección de reproducción: El Servicio de activación de Data 360 inspecciona las cargas entrantes en hash de trabajos anteriores para detectar y suprimir repeticiones.
- Exportación atómica confirma: Las cargas se confirman en el sistema de destino solo después de una confirmación de escritura correcta, evitando actualizaciones parciales o conteo doble.
- Resolución de identidad coherente: Puesto que las activaciones dependen de identificadores unificados (por ejemplo, Particular unificado), las repeticiones o reintentos siempre se dirigen al mismo registro de oro, manteniendo la coherencia semántica.
- Persistencia de estado de activación: La capa de orquestación mantiene los metadatos de estado de activación (marcas de tiempo, códigos de estado y tokens de secuencia) para un reprocesamiento determinista si es necesario.
Consideraciones de seguridad
- Autenticación sólida: Cada destino de activación (por ejemplo, Marketing Cloud, Ads o CRM) utiliza OAuth 2.0 con rotación de token y ámbito específico del arrendatario para evitar la exportación de datos no autorizada.
- Gobernanza a nivel de atributo: Solo los atributos aprobados desde el Perfil unificado son aptos para la activación, aplicada por Políticas de colaboración de datos y Plantillas de activación.
- Cifrado en tránsito y en reposo: Todas las cargas se cifran utilizando TLS 1.2+ durante la transferencia y AES-256 en reposo dentro de Data 360 y la plataforma de destino.
- Consentimiento y aplicación de políticas: Los trabajos de activación respetan los objetos de consentimiento y las políticas de datos almacenados en Trust Layer de Data 360. Los registros sin metadatos de consentimiento válidos se excluyen automáticamente de la exportación.
- Registro de auditoría y cumplimiento: Cada ejecución de activación captura quién la inició, qué datos se enviaron y a qué destino, activando seguimientos de auditoría regulatorios completos (RGPD, CCPA) en el tablero Trust Layer.
- Acceso con menos privilegios: Los usuarios de integración para cada destino están restringidos a ámbitos específicos de activación, sin privilegios administrativos o acceso de escritura a sistemas no relacionados.
Barras laterales
Oportunidad
- Diseñado para exportaciones por lotes programadas o casi en tiempo real (latencia de minutos a horas).
- Admite actualizaciones con plazos de tiempo alineadas con calendarios de campaña.
- Los trabajos de activación se pueden secuenciar con marcadores de preparación de datos para garantizar la actualización de los datos.
- Es el más adecuado para escenarios de activación no interactivos donde la precisión de los datos supera la inmediatez.
Volúmenes de datos
- Gestiona conjuntos de datos a gran escala (millones de registros por ejecución).
- Se amplía horizontalmente a través de particiones de segmentos y canales de exportación paralelos.
- Emplea lotes basados en fragmentos para evitar tiempos de espera y optimizar el rendimiento.
- Ideal para oportunidades en curso de datos de nivel empresarial donde la integridad de los datos es crítica.
Gestión de estado
- Mantiene objetos de estado de activación que registran identificadores de trabajo, marcas de tiempo y tokens de secuencia.
- Utiliza puntos de control para la reiniciabilidad y la recuperación de fallos.
- Las definiciones de segmentos versionados garantizan la reproducibilidad entre ciclos de activación.
- Activa la trazabilidad de linajes entre segmentos de origen, atributos de DMO y cargas de destino.
Escenarios de integración complejos
- Se integra perfectamente con Salesforce CRM, Marketing Cloud y sistemas externos a través de conectores preintegrados.
- Admite activaciones de múltiples objetivos, distribuyendo datos simultáneamente a diferentes destinos (por ejemplo, CRM + Ads).
- Puede desencadenar flujos de trabajo compuestos: por ejemplo, exportación por lotes seguida de llamada de API descendente o puntuaje de IA.
- Gestiona la evolución de esquemas de forma elegante a través de la Capa de gobernanza de modelo de datos.
Ejemplo
Una marca minorista global desea volver a implicar clientes inactivos de los últimos 90 días. Utilizando Data 360, el arquitecto de datos define un segmento “Compradores latentes” enriquecido con historial de compras, nivel de fidelidad y metadatos de consentimiento. El Trabajo de activación por lotes se ejecuta cada noche, enviando este segmento a Marketing Cloud Engagement para desencadenar una campaña de email personalizada “Te echamos de menos” y a Ad Studio para la redirección. El trabajo aprovecha la entrega idempotente, garantizando que no haya duplicaciones entre reintentos, y todos los eventos se registran en Trust Layer para el cumplimiento de la auditoría.
Contexto
Las compañías a menudo requieren un mecanismo gobernado para exportar datos unificados o segmentados desde Salesforce Data 360 a un formato de archivo estándar (por ejemplo, CSV o Parquet) para la integración de archivo, cumplimiento o descendente. Este patrón activa la exportación de almacenamiento de Data 360 a la nube, permitiendo que los datos de clientes de confianza fluyan de forma segura a lagos de datos de compañía o oportunidades en curso de análisis alojadas en Amazon S3, Azure Blob o Google Cloud Storage (GCS). Los casos de uso típicos incluyen:
- Archivado periódico de conjuntos de datos de clientes consentidos para la retención regulatoria.
- Exportación de segmentos depurados para cargas de trabajo analíticas no de Salesforce (por ejemplo, Tableau, Databricks o Power BI).
- Activación de modelos de aprendizaje automático externos que requieren archivos CSV estructurados o Parquet como entrada.
Problema
¿Cómo puede una organización exportar un segmento o conjunto de datos depurado desde Data 360 a un depósito de almacenamiento en la nube (por ejemplo, Amazon S3), de forma gobernada, segura y automatizada, manteniendo al mismo tiempo la integridad de los esquemas y los controles de cumplimiento? Por ejemplo, un equipo de cumplimiento puede necesitar: “Extraiga todos los clientes activos en la región de la UE con consentimiento válido y exporte los datos semanalmente a una ubicación S3 para la auditoría externa y la creación de reportes.” Esto requiere una canalización de exportación repetible y consciente de las políticas que garantice el formato de archivo, los permisos de acceso y la programación de entrega correctos, sin intervención manual o movimiento de datos no controlado.
Fuerzas
Múltiples factores operativos y arquitectónicos rigen este patrón de exportación:
- Autenticación y autorización: Las exportaciones deben respetar el modelo IAM del proveedor de nube (por ejemplo, Funciones IAM de AWS o Principales de servicio de Azure) para garantizar que solo los sistemas autorizados pueden escribir en el depósito de destino.
- Alineación de esquema: El esquema saliente debe coincidir con la estructura y el formato esperados del sistema de destino (CSV, Parquet o JSON).
- Privacidad de datos y consentimiento: Los conjuntos de datos exportados deben filtrar cualquier registro que carezca de metadatos de consentimiento válidos.
- Programación y actualización: Muchas exportaciones son periódicas (diariamente, semanalmente o mensualmente) y deben alinearse con los ciclos de actualización de datos de la compañía.
- Gobernanza y monitoreo: Cada exportación debe ser auditable con visibilidad de linaje completa, garantizando el cumplimiento de los mandatos reguladores y de retención de datos (por ejemplo, RGPD, CCPA).
Solución
El patrón Activación de exportación de archivos reutiliza los mismos conectores de almacenamiento en la nube seguros empleados para el ingreso pero configurados para la salida de datos. Los administradores primero registran la plataforma de almacenamiento en la nube (por ejemplo, Amazon S3, Azure Blob Storage o GCS) como un Destino de activación en Data 360. A continuación, los usuarios configuran y ejecutan un Flujo de trabajo de activación para exportar el segmento que deseen a la ruta de almacenamiento de archivos designada.
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Selección de segmentos | Mejor | Los analistas seleccionan una definición de Segmento o Consulta existente en Data 360\. El segmento determina qué registros y atributos se exportan. |
| Configuración de activación | Mejor | Los usuarios crean una nueva Activación, seleccionando el Segmento como el origen y el Destino de almacenamiento en nube (por ejemplo, S3) como el destino. |
| Configuración de destino de activación | Obligatorio | Los administradores preconfiguran el destino con credenciales, funciones de IAM y ruta de salida. Los formatos compatibles incluyen CSV, Parquet y JSON. |
| Definición de carga | Mejor práctica | Defina el esquema de exportación seleccionando los atributos requeridos (por ejemplo, Id., Nombre, Email, Región, Indicador de consentimiento). El sistema aplica la regulación a nivel de atributos. |
| Programación y frecuencia | Recomendado | Las exportaciones pueden programarse para ejecutarse en una cadencia definida (diaria, semanal, mensual) o desencadenarse manualmente según sea necesario. |
| Ejecución y entrega | Mejor | En la ejecución, Data 360 consulta el segmento, compila el archivo de exportación, lo cifra y lo escribe en el depósito/carpeta configurado utilizando la API del proveedor de nube. |
| Gobernanza y cumplimiento | Obligatorio | Trust Layer de Data 360 garantiza que todas las exportaciones se adhieren a políticas de consentimiento, validación de esquemas y filtros de cumplimiento. |
| Monitoreo y capacidad de auditoría | Mejor práctica | Cada exportación se sigue en el tablero Trust Layer Monitoring con el estado, los registros de ejecución y los metadatos de linaje. |
Boceto
Este es el resumen de los pasos.
- Seleccionar segmento: Un analista o administrador de datos elige el segmento unificado para exportar.
- Crear activación: Crean un nuevo trabajo Activación y seleccionan el destino de Almacenamiento en nube registrado.
- Definir carga: Especifique el esquema de exportación, la lista de atributos y el formato de archivo (por ejemplo, CSV).
- Programar exportación: Seleccione una programación puntual o recurrente.
- Ejecutar trabajo: Data 360 genera y entrega de forma segura el archivo a la ruta de depósito designada.
- Monitorizar y verificar: Los resultados y los registros se revisan en Trust Layer para su validación y cumplimiento.
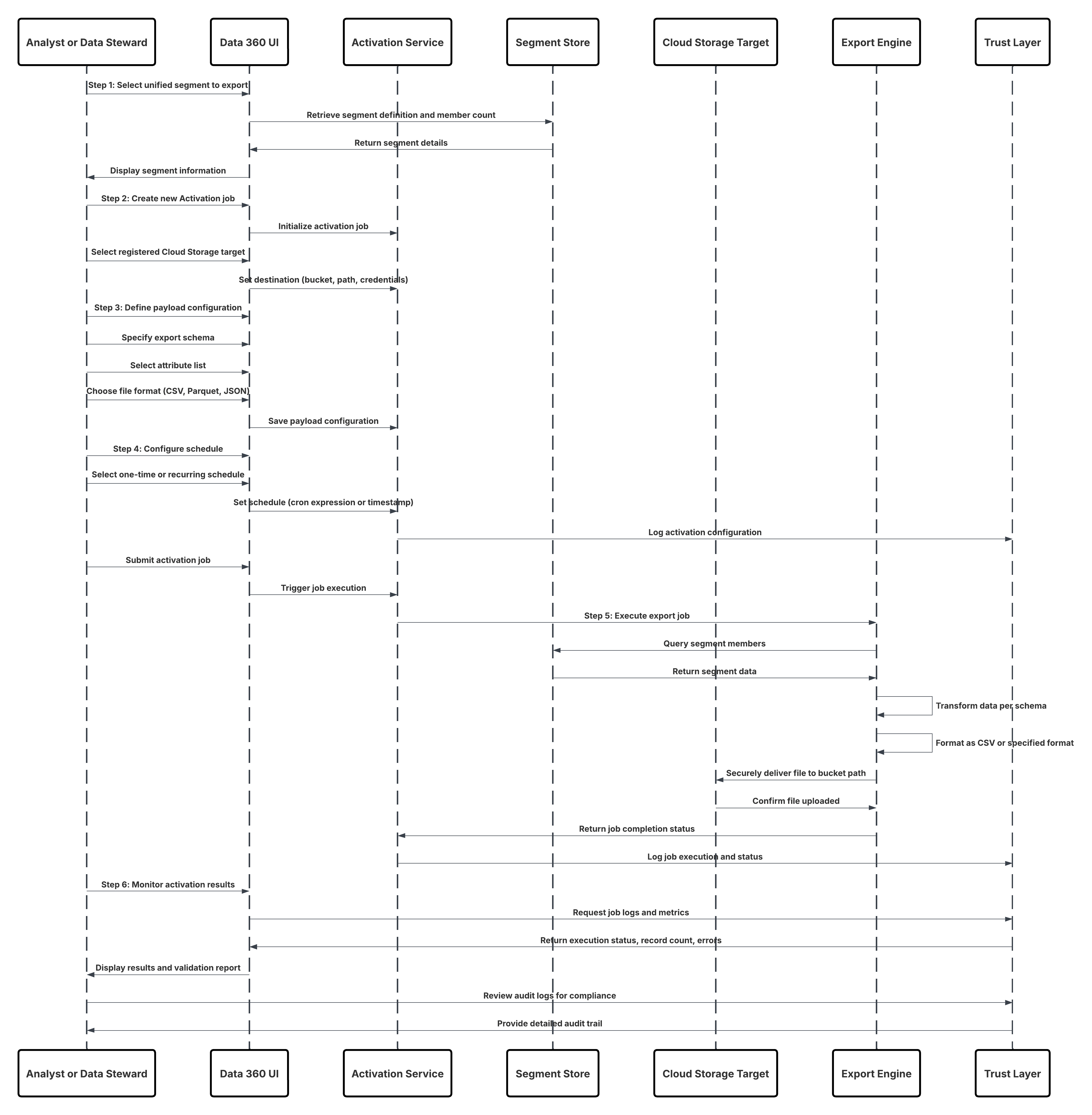
Resultados
- Los segmentos de audiencia enriquecidos dirigidos desde Data 360 están disponibles directamente en plataformas de marketing y publicidad descendentes.
- Las audiencias se actualizan y sincronizan automáticamente con los datos de clientes unificados más recientes, manteniendo la relevancia de la campaña en tiempo real.
- Los especialistas en marketing pueden utilizar estas audiencias activadas como orígenes de entrada para trayectorias de Marketing Cloud, campañas de email o audiencias personalizadas en plataformas de anuncios digitales como Google Ads, Meta o LinkedIn Ads.
- Cada ejecución de activación mantiene un linaje de extremo a extremo, garantizando el cumplimiento, la trazabilidad y la coherencia entre Data 360 y sistemas externos.
- Los usuarios de negocio pueden entregar experiencias altamente personalizadas dirigidas por datos con tecnología de una vista Customer 360 completa y de confianza.
Mecanismos de llamada
El mecanismo de llamada depende de la plataforma de almacenamiento en la nube de destino y la configuración de activación.
| Mecanismo | Cuándo utilizar |
|---|---|
| Activación de Amazon S3 | Utilice cuando su lago de datos de compañía esté alojado en AWS. Data 360 escribe directamente en un depósito de S3 utilizando funciones de IAM o credenciales temporales, garantizando una exportación segura y ampliable. |
| Activación de almacenamiento de Azure Blob | Se utiliza cuando su organización opera en Microsoft Azure. Data 360 utiliza tokens de SAS o principales de servicio para redactar archivos cifrados en contenedores Blob. |
| Activación de Google Cloud Storage (GCS) | Utilice cuando sus cargas de trabajo de análisis o ciencia de datos se ejecutan en GCP. Data 360 utiliza credenciales de OAuth para exportar archivos a depósitos de GCS en formato CSV o Parquet. |
| SFTP o pasarela de archivos externos | Se utiliza cuando los sistemas reguladores o heredados requieren una entrega de archivos segura a través de extremos SFTP o plataformas de transferencia de archivos gestionadas por la compañía. |
| Exportación híbrida (Archivo + API) | Se utiliza cuando una aplicación descendente necesita exportación basada en archivos para análisis y un desencadenador de API para orquestación de flujos de trabajo (por ejemplo, flujo de MuleSoft). |
Gestión y recuperación de errores
- Aislamiento a nivel de trabajo: Cada exportación se ejecuta como un trabajo discreto. Los trabajos con fallos se ponen en cuarentena y se reintentan de forma independiente.
- Reintento de archivo parcial: Si ciertos lotes no se cargan (por ejemplo, debido a interrupciones de red), el sistema reintenta esos fragmentos utilizando retroceso exponencial.
- Tratamiento de errores de coincidencia de esquemas: Cualquier desviación de esquema o desajuste de campo enruta registros a la Cola de rechazo de esquema para su revisión.
- Punto de control y reanudación: Los trabajos de exportación mantienen metadatos de puntos de control, permitiendo la reanudación desde la última escritura correcta sin duplicación.
- Monitoreo integrado: Los fallos y reintentos se registran en el tablero Trust Layer para visibilidad y cumplimiento de SLA.
Consideraciones de diseño idempotentes
- Claves de exportación deterministas: Cada trabajo de exportación incluye un Id. exclusivo compuesto de Id. de segmento + Id. de destino + Marca de tiempo.
- Seguridad de reproducción: Las ejecuciones de trabajos duplicados se detectan utilizando hash de trabajos y se omiten para evitar exportaciones redundantes.
- Garantía de escritura atómica: Data 360 confirma archivos en el depósito de destino solo después de la finalización completa y la validación de la suma de comprobación.
- Versión de esquema coherente: Las definiciones de exportación están controladas por versión para garantizar la coherencia de esquemas entre ejecuciones.
- Persistencia de punto de control: Estado de persistencia de trabajos de exportación para recuperación determinista y reprocesamiento si es necesario
Consideraciones de seguridad
- Autenticación sólida: Los conectores de nube utilizan OAuth 2.0, funciones IAM o principales de servicio para escrituras autenticadas.
- Cifrado en todas partes: Los datos se cifran tanto en tránsito (TLS 1,2+) como en reposo (AES-256).
- Exportación consciente del consentimiento: Solo se exportan registros con consentimiento válido, aplicados por políticas de Trust Layer.
- Principio de menor privilegio: Los usuarios de exportación y las cuentas de servicio están restringidos a sus rutas de almacenamiento designadas.
- Registro de auditoría integral: Cada exportación registra metadatos incluyendo iniciador, esquema, destino y marcas de tiempo para la creación de reportes de cumplimiento.
Barras laterales
Oportunidad
- Diseñado para activación inmediata dirigida por eventos con latencia de subsegundos.
- Ideal para escenarios que requieren personalización instantánea, recomendación o decisión.
- Funciona en modo de transmisión: los desencadenadores se activan en cuanto se producen cambios de datos aptos en Data 360.
- Garantiza una capacidad de respuesta continua sin esperar programaciones por lotes o recalculación de segmentos.
Volúmenes de datos
- Gestiona conjuntos de datos a gran escala (millones de registros por ejecución).
- Se amplía horizontalmente a través de particiones de segmentos y canales de exportación paralelos.
- Emplea lotes basados en fragmentos para evitar tiempos de espera y optimizar el rendimiento.
- Ideal para oportunidades en curso de datos de nivel empresarial donde la integridad de los datos es crítica.
Gestión de estado
- Cada acción de evento mantiene su propio token de eventos e Id. de reproducción para un procesamiento idempotente.
- Admite la persistencia de puntos de control para reanudar desde el último evento confirmado en caso de fallo transitorio.
- Incluye lógica de deduplicación integrada y plazos de reproducción para garantizar una semántica de activación única exacta.
- Los resultados de acciones (éxito/fallo) se registran en tiempo real y afloran a través del tablero de observabilidad Trust Layer.
Escenarios de integración complejos
- Se integra directamente con Salesforce Flows, Eventos de plataforma Einstein 1 o ganchos web externos para cadenas de respuesta instantánea.
- Puede desencadenar automatizaciones descendentes: por ejemplo, actualizaciones de registros de CRM instantáneas, puntuaje de IA o envíos de mensajes de Marketing Cloud.
- Admite orquestación componible: los desencadenadores de eventos pueden llamar a Acciones de Data 360, invocaciones Apex o API externas.
- Diseñado para patrones de negocio agentes y adaptativos donde las respuestas conscientes del contexto deben producirse al instante.
Ejemplo
Una compañía minorista global necesita entregar una exportación semanal de su segmento “Miembros de fidelidad activos” para su análisis en Databricks. El administrador de Data 360 configura Amazon S3 como un destino de activación y programa una exportación CSV semanal a la ruta de s3://enterprise-analytics/loyalty/weekly_exports/. El trabajo de exportación se ejecuta cada domingo, generando un archivo filtrado por consentimiento con más de 2 registros. Todos los eventos, definiciones de esquemas y linajes se registran en el tablero Trust Layer, garantizando la transparencia, la capacidad de auditoría y el cumplimiento.
Activación basada en API On-Demand es un enfoque dirigido por eventos en tiempo real para hacer que las perspectivas de Data 360 sean procesables en el momento en que se necesitan, sin esperar trabajos por lotes o exportaciones programadas. En vez de publicar segmentos preintegrados en una cadencia fija, este patrón permite a sistemas externos, aplicaciones de Salesforce o agentes de IA llamar a las API de Data 360 directamente para obtener o activar sectores de audiencia específicos, atributos de clientes o perspectivas on demand. Este patrón está diseñado para experiencias interactivas basadas en desencadenadores, como cuando un usuario inicia sesión en un portal, un agente abre un registro de cliente o un copiloto de IA inicia una consulta de la siguiente mejor acción. En vez de basarse en exportaciones precalculadas, el sistema consulta o activa dinámicamente los datos gobernados más actuales desde Data 360 en tiempo real. La ventaja clave es la inmediatez y la precisión:
- Cada llamada de API accede a la Inteligencia de clientes más actualizada en el gráfico de perfil unificado de Data 360 que reconoce el consentimiento.
- Las activaciones son idempotentes y auditables, en sintonía con los requisitos de cumplimiento y Enterprise Trust.
- Las integraciones pueden desencadenarse directamente desde Salesforce Flows, Apex o sistemas externos a través de las API de plataforma Einstein 1, las API de Connect o las API de activación. Este enfoque admite casos de uso donde la latencia y la personalización son más importantes, por ejemplo:
- Desencadenar una oferta de producto personalizada durante una llamada de servicio.
- Generación de audiencias de campañas dinámicas basadas en eventos de comportamiento en vivo.
- Alimentación de decisiones en tiempo real en modelos de IA o ML que funcionan en el momento de la implicación.
Contexto
Las compañías a menudo necesitan aflorar perspectivas armonizadas en tiempo real de Data 360 en aplicaciones creadas a medida, como portales web internos, aplicaciones móviles o experiencias web de cara al socio. Este patrón permite a los desarrolladores crear soluciones seguras centradas en la interfaz de usuario que consumen y muestran datos de clientes unificados junto con Salesforce CRM y otros sistemas contextuales, todo ello a través del acceso gobernado y basado en API. Los casos de uso típicos incluyen:
- Incruste perspectivas de Data 360 en tableros de empleados internos o aplicaciones móviles.
- Creación de portales de socios o concesionarios con visibilidad de clientes y transacciones.
- Integración de datos de Data 360 en aplicaciones web externas o capas de experiencia.
- Visualización de recomendaciones personalizadas en tiempo real con tecnología de Data 360 y Einstein 1.
Problema
¿Cómo puede un desarrollador crear una aplicación personalizada centrada en la interfaz de usuario que accede y muestra de forma segura datos armonizados de Data 360, a menudo junto con otras fuentes de datos de Salesforce, sin duplicar o exportar información confidencial? Por ejemplo, una compañía puede necesitar crear un portal de clientes que muestre perfiles de clientes unificados, interacciones y perspectivas calculadas desde Data 360. Esto requiere una capa de API única, segura y con desempeño que pueda potenciar la experiencia de front-end, gestionar la autenticación y garantizar la gobernanza, mientras que se abstrae la complejidad del modelo de datos interno de Data 360.
Fuerzas
Múltiples consideraciones arquitectónicas y operativas influyen en este patrón:
- Acceso centrado en la interfaz de usuario: El objetivo principal es aflorar datos en experiencias de front-end personalizadas (web o móviles), no realizar la extracción por lotes o sincronizaciones de backend.
- Puerta segura: La API elegida debe servir como un punto de entrada seguro y ampliable para aplicaciones y usuarios autenticados, aplicando controles de acceso de nivel de compañía.
- Contexto de datos unificado: Las aplicaciones deben poder combinar datos de Data 360 (por ejemplo, perfiles unificados, perspectivas calculadas) con CRM, ERP u datos de objetos personalizados sin problemas.
- Developer Simplicity: Las API deben devolver cargas listas para la presentación que minimizan el procesamiento backend o la asignación de esquemas en la capa de cliente.
- Gobernanza y observabilidad: Todo el acceso debe fluir a través de canales de confianza auditables con un linaje claro, autenticación y aplicación de políticas.
Solución
La solución es utilizar la API de REST Salesforce Connect como la pasarela de integración principal para la creación de aplicaciones personalizadas dirigidas por datos sobre Data 360. La API de Connect proporciona acceso RESTful a datos de Salesforce, incluyendo perfiles armonizados, segmentos y perspectivas calculadas de Data 360, en formatos de respuesta optimizados para el consumo de la interfaz de usuario (basados en JSON, ligeros y pensados para dispositivos móviles). Los desarrolladores se autentican a través de una aplicación conectada, obtienen tokens de OAuth 2.0 y llaman a recursos de API de Connect como /query, /Chatter o /data para aflorar datos unificados directamente en sus interfaces de aplicación. En segundo plano, la API de Connect sirve como la base de transporte para otras API, como la API de consulta, la API de gráficos de datos y las API de plataforma Einstein 1, permitiendo a los desarrolladores combinar múltiples orígenes de datos bajo un patrón de acceso unificado.
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Registro de autenticación y aplicación | Requerido | Cree una aplicación conectada en Salesforce para la autenticación basada en OAuth 2.0. Configure ámbitos para el acceso de API de Data 360. |
| Acceso a datos (perfiles, segmentos, perspectivas) | Mejor | Utilice extremos de API de Connect (/services/data/vXX.X/connect) para consultar datos de Data 360 armonizados, perfiles unificados y perspectivas calculadas. |
| Integración de interfaz de usuario | Mejor | Las aplicaciones front-end (React, Angular, iOS, Android) llaman a la API de Connect para representar datos de Data 360 en tableros, portales o interfaces móviles. |
| Consulta de gráfico de datos | Recomendado | Combine la API de Connect con la API de gráficos de datos para consultas de nivel semántico que simplifican uniones y relaciones complejas. |
| Actualización en tiempo real | Opcional | Utilice la API de Connect con extensiones WebSocket o de transmisión para actualizaciones de datos en vivo. |
| Seguridad y gobernanza | Requerido | Aplique la visibilidad de datos utilizando ámbitos de OAuth, políticas de Data 360 y el marco de trabajo de auditoría Trust Layer. |
Boceto
Este es el resumen de los pasos.
- Registrar aplicación conectada: Defina ámbitos de OAuth y permisos de API para la autenticación de aplicaciones externas.
- Obtener token de acceso: La aplicación externa realiza la autenticación de OAuth 2.0 para recibir un token para el acceso a Data 360.
- Invocar API de Connect: La aplicación realiza llamadas de API de REST para recuperar datos de perfil, segmento o perspectiva unificados.
- Renderizar datos en interfaz de usuario: Las respuestas se analizan y se presentan a los usuarios en un portal con marca o una interfaz móvil.
- Gestionar errores y tokens de actualización: Las aplicaciones implementan lógica de reintento y actualización de token automática para la continuidad de la sesión.
- Acceso de monitoreo y auditoría: Todas las llamadas de API se registran en Trust Layer para visibilidad y cumplimiento.
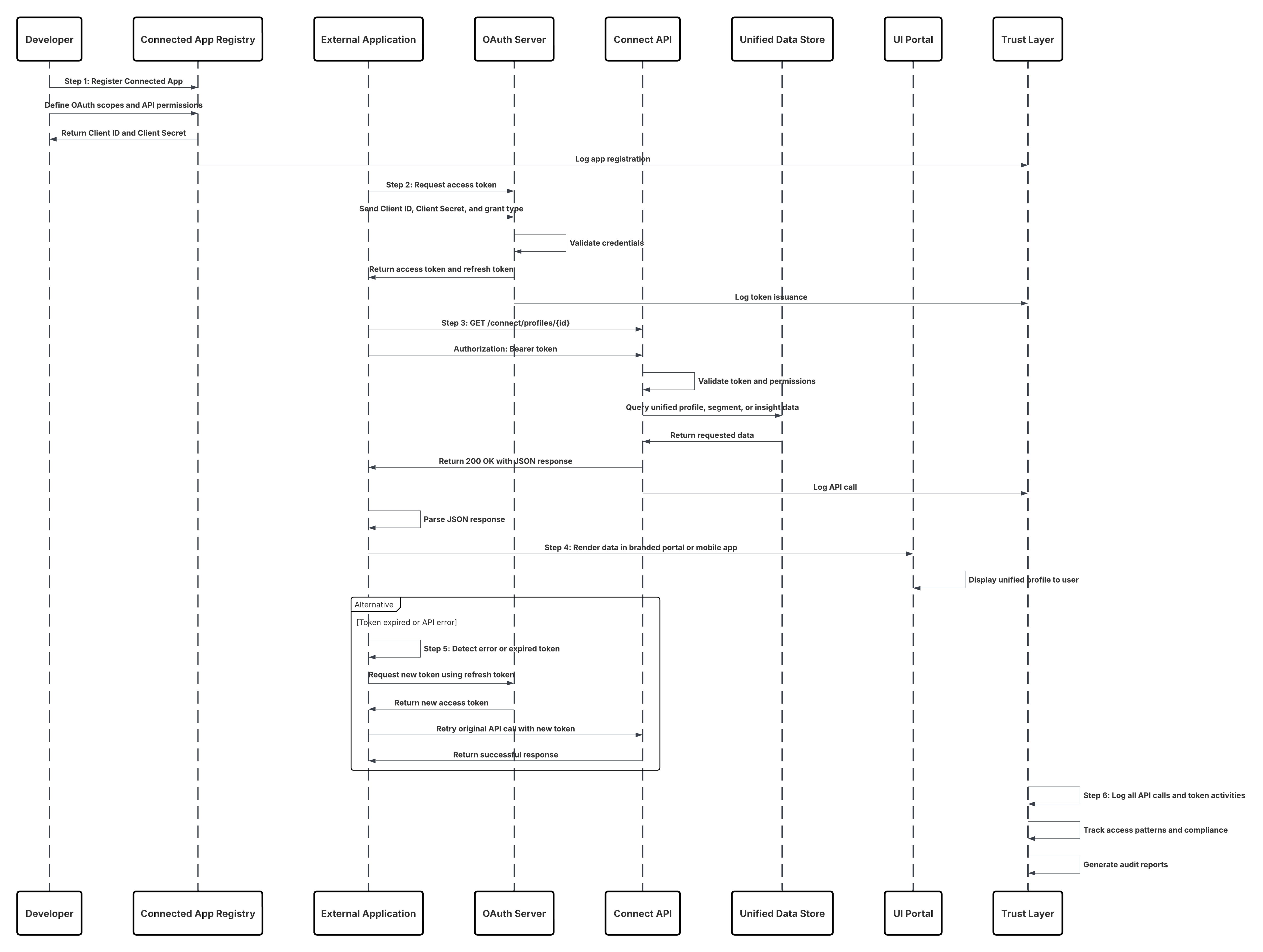
Resultados
Los desarrolladores pueden crear aplicaciones seguras con marca personalizada estrechamente integradas con Data 360. Estas aplicaciones pueden:
- Aflore perspectivas y perfiles de clientes armonizados en tiempo real.
- Muestre datos de Data 360 junto con CRM u objetos personalizados a través de API unificadas.
- Aproveche los controles de autenticación, autorización y auditoría coherentes a través de Trust Layer.
- Proporcione a los usuarios de negocio o socios un acceso sencillo y controlado a Inteligencia de clientes de confianza entre experiencias.
Mecanismos de llamada
El mecanismo de llamada depende de la plataforma de almacenamiento en la nube de destino y la configuración de activación.
| Mecanismo | Cuándo utilizar |
|---|---|
| API de REST de Connect (Preferido) | Se utiliza al crear aplicaciones web, móviles o de terceros que requieren acceso en tiempo real a datos de Data 360 en un formato JSON dirigido a la interfaz de usuario. |
| API de gráfico de datos | Se utiliza cuando la aplicación necesita realizar consultas a nivel semántico entre múltiples objetos (por ejemplo, Cliente → Transacciones → Campañas). |
| API de consulta | Utilice cuando ejecute consultas similares a SOQL para recuperar conjuntos de datos armonizados con alta precisión. |
| API de plataforma Einstein 1 | Utilizar al integrar perspectivas dirigidas por IA o recomendaciones generadas por copiloto en interfaces de usuario personalizadas. |
| MuleSoft o Apex Gateway Wrappers | Se utiliza cuando se requiere orquestación adicional, almacenamiento en caché o aplicación de políticas entre la aplicación y la API de Connect. |
Gestión y recuperación de errores
- Solicitud de aceleración: Retrocede automáticamente y reintenta llamadas de API bajo límites de frecuencia.
- Protección contra deriva de esquemas: Utiliza la versión de esquemas de GraphQL o el descubrimiento de metadatos de REST para adaptarse a cambios de esquemas.
- Gestión de caducidad de tokens: Las aplicaciones actualizan tokens de OAuth automáticamente para evitar interrupciones de sesión.
- Aislamiento de fallos de API: las llamadas de API fallidas se registran y reintentan sin afectar a sesiones simultáneas.
- Fideicomiso Observabilidad: los índices de éxito/fallo de API y los registros de acceso son visibles en el tablero Trust Layer.
Consideraciones de diseño idempotentes
- Id. de solicitud determinista: Cada solicitud de API incluye un Id. de correlación para un procesamiento seguro para la reproducción.
- Encabezados de validación de caché: Los encabezados ETag y Última modificación evitan las recuperaciones de datos redundantes.
- Operaciones de lectura atómica: API de Connect garantiza que cada respuesta refleje una instantánea coherente de datos unificados.
- Protección de reproducción: las llamadas de API duplicadas se filtran utilizando firmas de solicitud y marcas de tiempo.
Consideraciones de seguridad
- Autenticación de OAuth 2.0: Todas las llamadas de API utilizan tokens de acceso de OAuth seguros y de corta duración a través de aplicaciones conectadas.
- Acceso con menos privilegios: Los ámbitos de API están restringidos únicamente a los objetos y campos necesarios.
- Cifrado en todas partes: TLS 1.2+ en tránsito; cifrado AES-256 en reposo para respuestas almacenadas o en caché.
- Acceso a datos consciente del consentimiento: Data 360 garantiza que todos los registros recuperados se adhieren a políticas de consentimiento y gobernanza.
- Registro de auditoría integral: Cada interacción de API se registra con metadatos de usuario, aplicación y marca de tiempo en Trust Layer.
Barras laterales
Oportunidad
- Diseñado para acceso de API en tiempo real de baja latencia.
- Ideal para aplicaciones interactivas que requieren representación de datos inmediata.
- Admite tiempos de respuesta de consultas casi instantáneos a través de orígenes de Data 360 en caché e indexados.
- Sin dependencia de programaciones por lotes o ciclos de activación asíncronos.
Volúmenes de datos
- Optimizado para casos de uso interactivos que obtienen conjuntos de datos pequeños a medianos (por ejemplo, perfiles, perspectivas o transacciones recientes).
- Gestiona resultados paginados con gracia a través de paginación basada en cursor.
- No pensado para exportaciones masivas de gran volumen: utilice patrones de exportación por lotes o archivos para conjuntos de datos de gran tamaño.
Gestión de estado
- Las aplicaciones mantienen un estado de sesión ligero con tokens de OAuth y caché local.
- API de Connect admite solicitudes condicionales y actualización parcial para mayor eficiencia.
- Las respuestas de API incluyen marcadores de versión para la coherencia de esquemas entre versiones.
Escenarios de integración complejos
- Combine la API de Connect con la API de gráficos de datos para consultas semánticas entre múltiples dominios.
- Integre con las API de Einstein 1 Copilot o IA para experiencias predictivas y conversacionales.
- Utilice junto con Experience Cloud o Componentes web Lightning para el desarrollo de la interfaz de usuario híbrida.
- Amplíe a través de MuleSoft para orquestar búsquedas de enriquecimiento de datos o sistemas externos en tiempo real.
Ejemplo
Una compañía aseguradora multinacional crea un portal de autoservicio de clientes que permite a los asegurados ver sus perfiles unificados, reclamaciones recientes y ofertas personalizadas. La aplicación front-end basada en hechos, se autentica a través de OAuth 2.0 y recupera datos utilizando la API de REST de Connect y la API de gráficos de datos. Todos los datos se muestran en tiempo real, conscientes del consentimiento y gobernados a través de la capa de confianza Data 360 Trust. Los desarrolladores monitorean llamadas de API y seguimientos de auditoría directamente dentro de Salesforce, garantizando el cumplimiento y la observabilidad completos.
Contexto
Las compañías requieren cada vez más acceso instantáneo a un perfil de cliente completo para sistemas de decisión en tiempo real, como consolas de servicio, motores de recomendaciones o plataformas de personalización.Este patrón permite a las aplicaciones recuperar vistas unificadas precalculadas de los datos de un cliente casi en tiempo real utilizando la API de gráficos de datos de Data 360, proporcionando tiempos de respuesta de subsegundos para experiencias interactivas. Los casos de uso típicos incluyen:
- Visualización de una vista de cliente de 360 grados en Servicio al cliente o Sales Console.
- Potenciación de recomendaciones basadas en IA “Next Best Action” o “Next Best Offer”.
- Entrega de experiencias web o móviles hiperpersonalizadas en tiempo de carga de página.
- Admisión de decisiones en sesión en entornos de autoservicio o agentes.
Problema
¿Cómo puede una aplicación recuperar una vista de cliente completa, precalculada y unificada al instante, en vez de ejecutar consultas lentas de múltiples objetos en tiempo de ejecución? Por ejemplo, un motor de personalización web debe cargar el contexto completo del cliente (datos demográficos, preferencias, transacciones y perspectivas calculadas) en milisegundos para seleccionar una oferta personalizada. Las consultas relacionales tradicionales pueden requerir múltiples uniones y dar como resultado una latencia inaceptable. Esto requiere una API que entregue datos de perfil desnormalizados y listos para su uso, recuperables a través de una única búsqueda clave: combinando velocidad, integridad y regulación.
Fuerzas
Múltiples factores operativos y de desempeño influyen en este patrón:
- Velocidad: El tiempo de respuesta debe ser casi en tiempo real. La API debe devolver un perfil completo en milisegundos para admitir interacciones síncronas.
- Completitud: La respuesta debe incluir todos los atributos relevantes, relaciones y perspectivas calculadas, idealmente en una única carga.
- Eficiencia de búsqueda: Los perfiles deben ser recuperables a través de identificadores como customerId, contactKey o email, eliminando consultas de múltiples pasos.
- Actualización de datos frente a Latencia: Algunos casos de uso prefieren datos precalculados (en caché) para la velocidad; otros necesitan datos en vivo, aceptando mayor latencia.
- Gobernanza y seguridad: El acceso debe permanecer gobernado a través de políticas de Salesforce Trust Layer, garantizando el cumplimiento de las reglas de consentimiento y visibilidad de datos.
Solución
La solución es utilizar la API de gráficos de datos de Salesforce para recuperar vistas de clientes desnormalizadas precalculadas almacenadas como registros de gráficos de datos. Un Gráfico de datos es una vista semántica materializada que combina múltiples Objetos de modelo de datos (DMO) (como Particular, Transacción e ProductInterest) en un único registro de solo lectura, a menudo representado como un blob JSON. Los desarrolladores pueden utilizar extremos de REST como: GET /api/v1/dataGraph/{dataGraphEntityName}/{id} para recuperar un registro completo por su identificador exclusivo. Para escenarios dinámicos, la API admite un parámetro live=true que omite la caché materializada, ejecutando una consulta en tiempo real en Data 360, intercambiando latencia mínima por los datos más actualizados. Esto permite a los desarrolladores seleccionar entre recuperaciones de perfiles instantáneas (en caché) y actualizadas (en vivo) dependiendo de las necesidades de negocio.
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Definición de gráfico de datos | Requerido | Los arquitectos definen un Gráfico de datos que combina múltiples DMO en una única entidad semántica (por ejemplo, UnifiedCustomerProfile). |
| Recuperación de búsqueda de perfil | Mejor | Las aplicaciones llaman GET /api/v1/dataGraph/{entity}/{id} para recuperar perfiles completos y desnormalizados por Id. o clave exclusivos. |
| Uso de parámetros en vivo | Opcional | Anexe ?live=true para forzar el cálculo actualizado en vez de la recuperación en caché; adecuado para decisiones de alto valor. |
| Autenticación | Requerido | Utilice OAuth 2.0 a través de aplicaciones conectadas para autenticar llamadas de API de forma segura. |
| Análisis de respuestas | Mejores prácticas | Las aplicaciones analizan la respuesta JSON directamente en su interfaz de usuario o motor de decisiones; no se requieren más uniones. |
| Estrategia de caché | Recomendado | Implemente caché local a corto plazo (por ejemplo, en memoria o CDN) para búsquedas de perfil repetidas. |
| Monitoreo y observabilidad | Requerido | Utilice tableros Trust Layer para monitorear el desempeño de consultas, los tiempos de respuesta y la adhesión a políticas. |
Boceto
Este es el resumen del flujo de implementación:
- Definir gráfico de datos: Los arquitectos de datos crean un gráfico de datos que modela una vista de cliente unificada entre múltiples DMO.
- Registrar aplicación conectada: Los desarrolladores configuran credenciales de OAuth para un acceso seguro a la API.
- Invocar API de gráficos de datos: La aplicación emite una solicitud GET con el nombre del gráfico de datos y el Id. de registro.
- Respuesta de proceso: La API devuelve una representación JSON completa del perfil de cliente.
- Render o Act: La aplicación que consume (interfaz de usuario o motor) utiliza los datos unificados para la personalización, recomendaciones o acciones de servicio.
- Monitor and Tune: Las mediciones de desempeño y los registros de acceso se revisan a través de la consola de observabilidad Trust Layer.
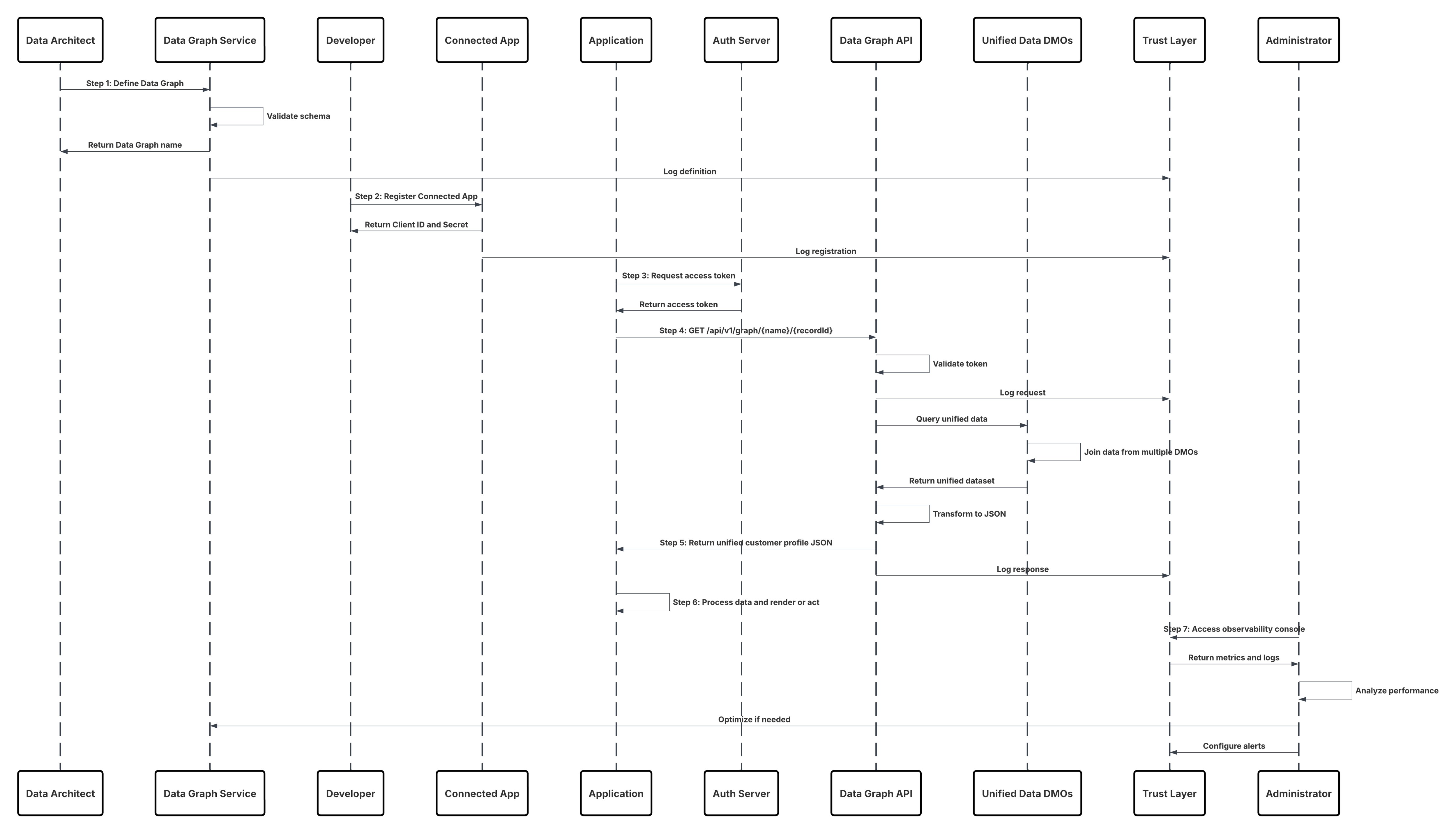
Resultados
Las aplicaciones ahora pueden recuperar un perfil de cliente completo unido previamente al instante, potenciando interacciones en tiempo real como la personalización, el servicio y la automatización de decisiones. Este patrón garantiza:
- Tiempos de respuesta por debajo del segundo para la decisión en el momento.
- Recuperación de datos gobernada coherente alineada con el modelo semántico de Data 360.
- Lógica de aplicación simplificada: sin uniones, sin reconciliación de esquemas.
- Acceso rastreable y compatible a través de Trust Layer para auditoría y observabilidad.
Mecanismos de llamada
El mecanismo de llamada depende de la plataforma de almacenamiento en la nube de destino y la configuración de activación.
| Mecanismo | Cuándo utilizar |
|---|---|
| API de gráficos de datos (Preferido) | Utilizar para recuperar perfiles completos prematerializados al instante por Id. o clave. |
| API de gráfico de datos con live=true | Utilice para casos de uso de alto valor (por ejemplo, detección de fraude, ofertas en vivo) donde se necesitan los datos más actuales, aceptando una latencia ligeramente superior. |
| API de conexión (Respaldo) | Utilizar para escenarios de aplicaciones compuestas que combinan recuperaciones de gráficos de datos con otros datos de Salesforce. |
| API de consulta | Se utiliza al construir consultas ad hoc o lecturas analíticas en vez de la recuperación instantánea de perfiles. |
| Proxy de API de MuleSoft | Se utiliza al enrutar llamadas de Gráfico de datos a través de pasarelas de compañía o cuando se requiere orquestación/aplicación de políticas adicional. |
Gestión y recuperación de errores
- Respaldos elegantes: Si las consultas en vivo fallan o superan los umbrales de tiempo de espera, vuelva automáticamente a las recuperaciones de gráficos de datos en caché.
- Gestión de tiempo de espera: Implemente lógica de reintento e interruptor para llamadas de API bajo alta carga.
- Tratamiento de Id. no válido: Devuelva respuestas estándar 404 No encontradas para claves de perfil no existentes; gestione correctamente en la interfaz de usuario.
- Validación de versión de esquema: Valide metadatos de versión de gráfico de datos para evitar desajustes cuando evoluciona el esquema.
- Integración de observabilidad: registre todos los errores, reintentos y latencias en tableros Trust Layer para el monitoreo de SLA.
Consideraciones de diseño idempotentes
- Claves deterministas: Cada recuperación de perfil utiliza un Id. estable (por ejemplo, IndividualId) garantizando consultas predecibles y seguras de reproducción.
- Coherencia de caché: Utilice encabezados ETag o Última modificación para recuperaciones condicionales y validación de caché.
- Recuperación atómica: Cada respuesta de API representa una instantánea coherente del registro Gráfico de datos materializado.
- Protección de reproducción: Asegúrese de que las aplicaciones cliente detectan recuperaciones duplicadas a través de identificadores de correlación y marcas de tiempo.
Consideraciones de seguridad
- Autenticación sólida: OAuth 2.0 a través de aplicaciones conectadas aplica acceso seguro basado en tokens.
- Recuperación consciente del consentimiento: Solo se devuelven atributos con consentimiento; los filtros de consentimiento se aplican por Trust Layer automáticamente.
- Gobernanza a nivel de campo: El acceso a atributos se controla a través de metadatos y definiciones de políticas de Data 360.
- Cifrado en tránsito y en reposo: Todas las respuestas están cifradas con TLS 1.2+ y AES-256.
- Auditoría y trazabilidad: Cada evento de recuperación de perfil se registra con identificadores, marcas de tiempo y contexto de política.
Barras laterales
Oportunidad
- Diseñado para la recuperación instantánea.
- Admite consultas en vivo para datos actualizados con latencia ligeramente superior (subsegundo).
- Optimizado para decisiones síncronas y aplicaciones interactivas.
- Elimina la necesidad de la activación previa a los lotes o el recálculo de segmentos.
Volúmenes de datos
- Ideal para búsquedas de un solo registro o conjuntos pequeños (de decenas a cientos) por solicitud.
- No está optimizado para la recuperación masiva a gran escala; utilice las API por lotes o de consulta para lecturas de gran volumen.
- Emplea caché y materialización previa ampliables horizontalmente para mayor velocidad.
Gestión de estado
- Mantiene un acceso ligero y sin estado; cada solicitud es independiente.
- Admite el almacenamiento en caché de encabezados para una recuperación segura.
- Las aplicaciones pueden mantener caché local o almacenamiento de sesiones a corto plazo para reducir las búsquedas repetidas.
Escenarios de integración complejos
- Se integra perfectamente con Einstein 1, la API Connect y MuleSoft para experiencias de datos compuestos.
- Puede impulsar sistemas magnéticos (por ejemplo, motores de razonamiento Copilot o IA) que requieren una conciencia instantánea y contextual.
- Combinado con Acciones de datos para desencadenadores en tiempo real tras la recuperación o el cambio de estado.
- Activa la personalización a escala sin comprometer el desempeño o la gobernanza.
Ejemplo
Una plataforma de comercio electrónico global utiliza la API Data Graph de Data 360 para recuperar perfiles de clientes unificados en tiempo real para su motor de recomendaciones. Cuando un usuario inicia sesión, la aplicación invoca el extremo Gráfico de datos para obtener el UnifiedCustomerProfile para ese cliente, devolviendo atributos demográficos, señales de comportamiento y perspectivas calculadas como una única carga JSON. El motor de personalización consume esta respuesta en milisegundos para determinar y mostrar la “Siguiente mejor oferta” durante la sesión activa. Todas las solicitudes se rigen y registran a través de la Confianza Capa, garantizando visibilidad completa, aplicación de políticas y cumplimiento en toda la interacción.
Las acciones de datos en tiempo real permiten la activación instantánea de datos de clientes en el momento en que cambian en Data 360. En vez de esperar exportaciones por lotes programadas, estas acciones envían actualizaciones, perspectivas o desencadenadores directamente a Salesforce o sistemas externos en milisegundos. Cuando se actualiza el estado, el consentimiento o la medición de implicación de un cliente en Data 360, esa señal puede impulsar inmediatamente ofertas personalizadas, desencadenar automatizaciones de Service Cloud o actualizar niveles de fidelidad, garantizando que cada experiencia del cliente refleja la verdad más actual y unificada. Este patrón es ideal para casos de uso de alta repercusión y sensibles a la latencia como experiencias web personalizadas, alertas de detección de fraude, recomendaciones de la mejor acción o actualizaciones de CRM en tiempo real. Cierra la brecha entre la perspectiva de datos y la acción de negocio, convirtiendo datos unificados en inteligencia en el momento.
Contexto
Las experiencias digitales modernas y los flujos de trabajo operativos requieren acciones contextuales inmediatas en el momento en que se produce un evento: por ejemplo, actualizar un registro de cliente durante un Checkout, ajustar el inventario cuando se escanea una devolución o entregar una promoción personalizada en el momento en que un usuario abandona un carrito. Las acciones de datos en tiempo real permiten a los sistemas invocar, enriquecer y actuar sobre perfiles de Data 360 unificados y perspectivas calculadas con latencia de subsegundo a segundo, permitiendo la personalización interactiva, la automatización operativa y la decisión instantánea.
Problema
¿Cómo pueden las aplicaciones, los flujos de interacción de la interfaz de usuario o el middleware llamar a Data 360 en tiempo de ejecución para leer, calcular o actualizar un único perfil unificado o desencadenar una acción (por ejemplo, enviar una oferta, actualizar CRM, iniciar un flujo de trabajo) con baja latencia, coherencia sólida y controles de gobernanza, sin esperar trabajos por lotes programados o oportunidades en curso pesadas?
Fuerzas
Varias fuerzas técnicas, operativas y de gobernanza dan forma a este patrón:
- Requisito de baja latencia: Las llamadas deben completarse en un intervalo de subsegundos a unos segundos para preservar un buen UX o cumplir los SLA operativos.
- Resolución de identidad determinista: Las solicitudes deben resolverse con el perfil Particular unificado correcto (registro de oro) de forma fiable y rápida.
- Autorización precisa: Las llamadas en tiempo real deben aplicar políticas a nivel de atributos y comprobaciones de consentimiento en el momento de la solicitud.
- Minimización de carga: Las cargas en tiempo real deben ser pequeñas y centradas (perfil único o conjunto de atributos pequeño) para reducir la latencia y el costo.
- Experiencia de desarrollador: Las API deben ser aptas para desarrolladores (REST/gRPC/GraphQL), con esquemas claros y contratos estables para el uso de producción.
- Auditabilidad y trazabilidad: Cada acción en tiempo real debe registrarse con linaje, identidad de usuario y decisiones de política para el cumplimiento.
Solución
La solución recomendada es utilizar la interfaz de Acciones de datos en tiempo real (API + SDK) de Data 360 combinada con caché de borde y transformaciones de computación mínimas donde sea necesario. Las integraciones invocan un extremo de acciones de datos para leer o escribir atributos de perfil, calcular perspectivas o iniciar orquestaciones. Las comprobaciones de pólizas en tiempo real (CEDAR) y el enmascaramiento dinámico se aplican en el Punto de aplicación de pólizas antes de que se devuelva cualquier carga o se ejecute una acción.
| Área de solución | Ajuste | Comentarios / Detalles de implementación |
|---|---|---|
| Acción de datos en tiempo real | Mejor | Exponga el extremo para desencadenadores de lectura/escritura y acción de un solo registro. Autentique a través de OAuth/JWT. |
| Resolución de identidad | Obligatorio | Resuelva identificadores entrantes (email, externalId, cookie) en Id. de Particular unificado en línea. Utilice una resolución determinista con caché. |
| Aplicación de políticas (CEDAR) | Mejor práctica | Evalúe las políticas de consentimiento, ABAC y enmascaramiento en el momento de la solicitud; deniegue o enmascare campos por decisiones de política. |
| Capa de borde/caché | Recomendado | Utilice caché de TTL corto para fragmentos de perfil y perspectivas calculadas para reducir la latencia; invalide en eventos de cambio. |
| Transformaciones ligeras | Recomendado | Aplique enriquecimientos sencillos o campos calculados en la ruta de acción; las transformaciones pesadas deben calcularse previamente. |
| Orquestación de acciones | Mejor | Admita acciones de un solo paso síncronas (por ejemplo, token de oferta de devolución) y orquestaciones asíncronas (cola \+ webhook) para flujos complejos. |
| Observabilidad y rastreo | Obligatorio | Registre la solicitud/respuesta, las decisiones de política y el linaje en Trust Layer/SIEM para auditoría y depuración. |
| Limitación y aceleración de índices | Obligatorio | Aplique cuotas de clientes y estrategias de degradación elegantes para momentos de alto tráfico. |
Boceto
Este es el resumen de los pasos.
- Cliente (UI / middleware / POS) envía solicitudes de acciones de datos autenticadas con identificadores y tipo de acción.
- La pasarela de API valida el token, los límites de frecuencia y los reenvíos al Servicio de acciones de Data 360.
- Servicio de acciones resuelve identificador → Id. de Particular unificado (caché de ruta rápida; reserva a búsqueda de gráfico).
- Aplicación de políticas (PDP) evalúa políticas de CEDAR utilizando atributos de PIP y contexto de solicitud.
- Si se permite, Servicio de acciones lee cualquier atributo/perspectiva de perfil requerido y realiza transformaciones de luz.
- Action Service devuelve respuesta de forma síncrona (por ejemplo, token de oferta, atributo actualizado) o pone en cola la orquestación asíncrona y devuelve confirmación.
- Todos los eventos, decisiones y cargas se registran en Trust Layer y se reenvían opcionalmente a SIEM.
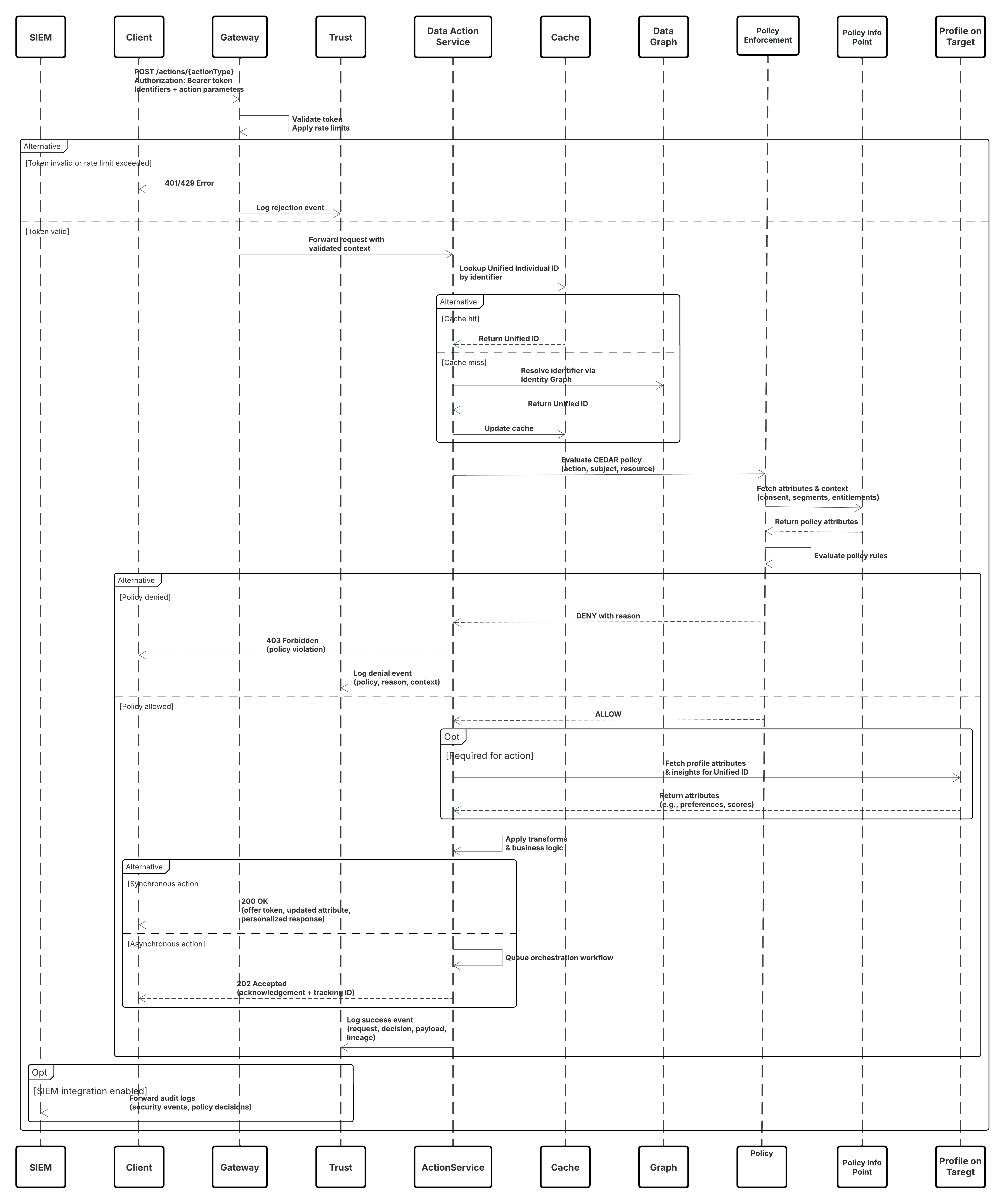
Resultados
- Las aplicaciones reciben acceso inmediato y regulado por políticas a lecturas/escrituras de perfiles unificados y desencadenadores de acciones con latencia de subsegundo a segundo.
- La personalización en tiempo real, la toma de decisiones y los flujos de trabajo operativos (por ejemplo, ofertas, asistencia de agentes, actualizaciones de inventario) se activan sin demoras por lotes.
- Todas las acciones son auditables, conscientes del consentimiento y aplican el enmascaramiento a nivel de atributos para mantener la privacidad y el cumplimiento.
Mecanismos de llamada
El mecanismo de llamada depende de la plataforma de destino y la configuración de destino de activación.
| Mecanismo | Cuándo utilizar |
|---|---|
| API de acciones de datos RESTANTES | Preferido para aplicaciones web/móviles y middleware que necesitan lecturas de perfil síncronas o respuestas de acción. |
| gRPC / RPC binario | Utilizar para servicios de negocio de latencia ultra baja o microservicios internos con conexiones persistentes. |
| Consultas de registro único de GraphQL | Se utiliza cuando los clientes necesitan una selección de campos flexible y desean minimizar las cargas. |
| Webhooks desencadenados por eventos | Utilice para flujos de trabajo asíncronos donde la acción desencadena procesos descendentes (por ejemplo, iniciar una trayectoria). |
| Eventos de plataforma / PubSub | Utilice para escenarios de abanico donde múltiples sistemas deben reaccionar a un único evento de acción. |
| Edge SDK (libertades de clientes) | Utilizar para clientes de baja latencia que almacenan en caché fragmentos de perfil y llaman a la API de acciones de datos solo cuando es necesario. |
Gestión y recuperación de errores
- Errores síncronos: Devuelva códigos de error estructurados con mensajes legibles y tokens de idempotencia.
- Reintento transitorio: Los clientes deben reintentar solicitudes idempotentes con retroceso exponencial en respuestas 429/5xx.
- Política Denegar gestión: Las denegaciones devuelven códigos de motivo claros; los datos confidenciales nunca se devuelven en caso de fallo de la política.
- Fallos de orquestación asíncronos: Los trabajos de orquestación pasan a DLQ y son reproducibles; una API de estado de trabajo permite a los clientes sondear o recibir devoluciones de llamadas.
- Estrategias de reserva: Si la resolución de identidad falla, devuelva un error determinista y opcionalmente una corrección sugerida (por ejemplo, requerir externalId).
Consideraciones de diseño idempotentes
- Clave de impotencia: Los clientes proporcionan una clave de idempotencia (UUID + espacio de nombres de cliente) para acciones de mutación.
- Claves deterministas: Utilice claves compuestas (UnifiedIndividualId + ActionType + TimetampWindow) para detectar duplicados.
- Reintentos seguros: Diseñe acciones para ser tolerante a los efectos secundarios o para realizar alteraciones en vez de inserciones ciegas.
- Protección de reproducción: Persista en claves de idempotencia procesadas y TTL después del plazo de negocio para evitar repeticiones.
- Apatridia: Mantenga las acciones síncronas sin estado donde sea posible; mantenga el estado mínimo para flujos de trabajo asíncronos.
Consideraciones de seguridad
- Autenticación: OAuth 2.0 (portador JWT o mTLS para cuentas de servicio); tokens de corta duración y rotación de actualización.
- Autorización: Punto de decisión de política aplica el Control de acceso basado en atributos (CEDAR) y las comprobaciones de consentimiento por solicitud.
- Cifrado de transporte y almacenamiento: TLS 1.2+ en tránsito; AES-256 en reposo para cualquier fragmento en caché o registro de auditoría.
- Privilegio mínimo: Clientes de API con ámbito a permisos mínimos; funciones separadas para lectura frente a escritura frente a orquestación.
- Minimización de datos: Devuelva solo atributos solicitados y consentidos; aplique enmascaramiento dinámico para PII/PHI.
- Controles de red: Opcionalmente, requiera llamadas desde redes privadas (Private Connect, listas de admisión de IP) para acciones de alto riesgo.
- Auditoría y monitoreo: Registre metadatos de solicitudes, decisiones de políticas, identidad de solicitantes y hash de respuestas en Trust Layer y SIEM.
Barras laterales
Oportunidad
- Diseñado para latencias medias en el intervalo de subsegundo a bajo de un solo segundo para acciones síncronas.
- Las caché Edge (TTL corto) y las perspectivas precalculadas reducen los recorridos de ida y vuelta.
- Las rutas asíncronas proporcionan reconocimiento casi instantáneo con procesamiento en segundo plano para tareas pesadas.
Volúmenes de datos
- Optimizado para interacciones de un solo registro o pequeños lotes (1 a 100 registros).
- No está pensado para exportaciones masivas: utilice la activación por lotes para grandes volúmenes.
- El alto rendimiento utiliza la reutilización de conjuntos/conexiones y colas de orquestación paralelas.
Gestión de estado
- Modelo de solicitud sin estado para llamadas síncronas; el estado de acción mínimo persistió para subvenciones/transacciones.
- Invalidación de caché dirigida por eventos de cambio: asegúrese de que los TTL y las señales de invalidación mantienen las caché actualizadas.
- Los trabajos de orquestación mantienen un estado duradero (Id. de trabajo, estado, reintentos) almacenado en Trust Layer.
Escenarios de integración complejos
- Asistente de agente: Búsqueda de perfil en tiempo real + propensión calculada devuelta a la consola de servicio en subsegundos para agentes.
- POS / Edge Devices: SDK local + Acción de datos ocasional para validar promociones o estado de fidelidad.
- Flujos híbridos: Sincronice la acción de datos para la decisión + orquestación asíncrona para actualizar sistemas descendentes y desencadenar campañas.
- Middleware externo: Las pasarelas de MuleSoft o API pueden mediar en la autenticación, enriquecer el contexto y aplicar comprobaciones de políticas adicionales.
Ejemplo
Una aplicación móvil minorista determina si mostrar un cupón instantáneo personalizado cuando un comprador toca Checkout invocando la acción de datos de aptitud de oferta con el contexto de email y carrito del comprador. La solicitud es validada por la pasarela de API y reenviada al Servicio de acciones de datos, que resuelve el email a un Id. de particular unificado utilizando una coincidencia de caché, verifica el consentimiento de marketing a través del PDP y evalúa la aptitud basándose en el valor de vida útil del cliente y la recencia de compra reciente. Si el comprador cumple los requisitos, el servicio devuelve un token de cupón firmado y registra la decisión. Cuando la emisión de cupones requiere reserva de inventario, se desencadena una orquestación asíncrona para reservar inventario y notificar a los sistemas CRM. La aplicación muestra el cupón inmediatamente, mientras que las actualizaciones descendentes se completan en segundo plano y Trust Layer captura un seguimiento de auditoría completo para la gobernanza y el cumplimiento.
- Conectores e integración
- SDK web y móvil
- Ingreso en tiempo real subsegundo
- Bring Your Own Lake (Consulta de copia cero)
- Bring Your Own Lake (archivo de copia cero)
- Gráficos de datos
- Activación: Implicación de MC
- Activación: Personalización de MC
- Activación: B2C Commerce
- Compartir datos (Copia cero)
- Activación: Almacenamiento de archivos
- Acciones de datos
- Acciones de datos de subsegundos en tiempo real
- Plataforma de activación externa