Las plataformas de datos han evolucionado durante más de tres décadas. Inicialmente, la industria estaba dominada por bases de datos operativas/OLTP locales, centralizadas y estructuradas (principalmente relacionales). Esto se amplió para incluir almacenes de datos plataformas OLAP/Big Data que se utilizaron principalmente para el procesamiento analítico y permanecieron relacionales y centralizadas. El almacenamiento en la nube impulsó arquitecturas distribuidas como almacenes de datos, lagos y almacenamiento desglosado. Sin embargo, las plataformas de operaciones y las plataformas analíticas permanecieron separadas. Hoy en día, la computación en nube y la revolución de la IA están cambiando de forma fundamental la arquitectura de la plataforma de datos.
Las empresas ya invierten en plataformas de Big Data maduras como Snowflake, Databricks, BigQuery y Redshift. Pero estas plataformas sirven como silos de datos. Los clientes no están obteniendo valor comercial de sus datos porque no se puede actuar sobre los datos directamente dentro de los flujos comerciales y las aplicaciones. Estas soluciones carecen de procesamiento generativo de IA de agente y no pueden entregar acceso a datos en tiempo real, de modo que no pueden entregar personalización dirigida por IA en el momento de la implicación del cliente y otras funciones líderes del sector.
El futuro de las plataformas de datos se caracteriza por una infraestructura de datos unificada, flexible, accesible y abierta. Esta nueva arquitectura se basa en tendencias de computación y almacenamiento modernas (GPU, gran memoria, SSD de NVMe y almacenamiento en la nube) para integrar con la computación en la nube y la IA. Pueden entregar perspectivas en tiempo real, potenciar la toma de decisiones autónoma e impulsar aplicaciones en tiempo real. Esto incluye el aumento de IA agente, IA predictiva, análisis, bases de datos OLTP de alta escala en tiempo real, lagos de datos y casas de lagos. Estas modernas plataformas de datos están diseñadas para sencillez, escalabilidad, agilidad, rendimiento, seguridad, disponibilidad y rentabilidad.
Las siguientes tendencias de datos dirigen la arquitectura de la plataforma de datos de próxima generación.
- IA, aprendizaje automático y Analytics en el núcleo: El aumento de la IA de Agentes cambiará fundamentalmente el desarrollo, la implementación y el uso/acceso de la plataforma de datos. La IA agente comprenderá la intención de conversación/consulta, planificará, generará flujos de trabajo y automatizará la toma de decisiones. La memoria agente (a corto y largo plazo) se construye a partir del historial de conversaciones para personalizar la planificación y las decisiones de los agentes, el modelado de conversaciones en tiempo real y la asistencia de personalización crítica en plataformas de datos. Los agentes ayudarán a automatizar “capacidades” operativas como la regulación de datos (por ejemplo, seguridad, cumplimiento, Trust), rendimiento (por ejemplo, escalado automático para concurrencia, rendimiento y latencia), conmutación por error y disponibilidad, observabilidad y mantenimiento. Análisis con tecnología de IA, previsiones, procesamiento de lenguaje natural (NLP) para preguntas/respuestas de análisis y análisis en datos no estructurados (texto como PDF, imágenes, audio, vídeo) serán estándar, permitiendo a las empresas derivar perspectivas más profundas desde diversos orígenes de datos.
- Descentralización de datos pero acceso a datos unificado: Los agentes necesitan datos empresariales para derivar perspectivas y tomar decisiones, así como para automatizar actividades comerciales. Los datos están inherentemente descentralizados en empresas, en aplicaciones y plataformas de datos dispares. Pero no es fácil unificar los silos entre diferentes unidades comerciales dentro de la empresa y con socios fuera de la empresa. La unificación de datos implica el uso compartido de datos, ya sea a través de la introducción desde orígenes o la federación con orígenes de datos; Datos sin procesar desde la Preparación, Armonización y Modelado de datos para el procesamiento analítico y de IA; Almacenamiento y gestión de datos a escala para un acceso eficiente con bajo CTS; y Acceso a datos a través de varios mecanismos y herramientas de consulta y análisis, profundamente integrados con las plataformas de almacenamiento y acceso a datos subyacentes
- Casas abiertas basadas en la nube: Las plataformas de Big Data basadas en la nube (OLAP) están convergiendo en la adopción de formatos de archivo abiertos (Parquet) y formatos de tabla (Iceberg) que permiten la federación de datos (entrada de datos) y la colaboración (salida de datos).
- Procesamiento de datos no estructurado: Con la aparición, el avance y la adopción de la IA generativa, las empresas están comenzando a obtener perspectivas valiosas y valor comercial a partir del corpus de datos de la empresa que constituyen grandes volúmenes de documentos de texto, transcripciones de audio, grabaciones de vídeo y otros medios. El procesamiento de datos no estructurado, incluyendo fragmentos, vectorización, búsqueda semántica y gráficos Knowledge, hacen posible estas perspectivas. Técnicas como RAG (generación aumentada de recuperación) y CAG (generación aumentada de caché) se están convirtiendo en controladores principales de búsqueda rápida y agente en el corpus de datos.
- Knowledge Management: Knowledge va más allá del propio contenido sin procesar (documentos, artículos, vídeos). Representa el aumento de ese contenido derivando significado, depurando metadatos y colocándolos en contexto para desarrollar una comprensión compartida del contenido en una organización o empresa. Knowledge está estructurado de forma general. Knowledge management implica gestión de contenido, extracción Knowledge, representación a través de modelos como gráficos y navegación.
- Acceso a datos enriquecido: Acceso a datos enriquecido significa que las herramientas de datos, análisis e IA deben ser accesibles para una variedad de personas, incluyendo usuarios finales, usuarios comerciales, administradores y analistas. La accesibilidad se logra a través de mecanismos como consulta de conjunto (con consulta relacional, de palabra clave y semántica), consulta de lenguaje natural a SQL (NL2SQL), acceso en tiempo real, etc.
- Procesamiento en tiempo real: Las aplicaciones agentes toman decisiones en tiempo real basándose en el estado actual y en nuevos eventos, personalizando respuestas y acciones, lo que requiere acceder, procesar y actuar en datos en tiempo real. El procesamiento en tiempo real requiere datos actualizados (latencia de datos) y acceso interactivo (latencia de acceso). Estos datos y la latencia de acceso requieren que la plataforma de datos subyacente admita el acceso a datos actualizado desde establecimientos operacionales y analíticos, el procesamiento de acceso de baja latencia (búsquedas y consultas de puntos), alta escala de datos y alto rendimiento.
- Seguridad, gobernanza y residencia de datos: La IA agente y conversacional simplifica la interfaz de usuario de la aplicación, permitiendo a cualquier usuario, desde consumidores a empleados y otros agentes de IA, interactuar con aplicaciones conversacionalmente utilizando lenguaje natural hablado o escrito. Los valiosos datos personales y de clientes que deben almacenarse y modelarse para aplicaciones de Agentes deben protegerse y gobernarse con políticas de acceso y colaboración bien definidas. Cada vez más, muchos clientes deben cumplir con las leyes que requieren la residencia de datos en su propio país o región, especialmente aquellos en el gobierno o haciendo trabajo con gobiernos.
Salesforce Data 360 está diseñado para el futuro abordando estas tendencias de datos. Data 360 es una plataforma de datos dirigida por metadatos nativa de la nube que unifica datos aislados en toda la empresa, permitiendo a las organizaciones almacenar, modelar y procesar sus datos para permitir aplicaciones de análisis, IA, aprendizaje automático y Agentes.
Este documento es una guía esencial para arquitectos empresariales y CTO. Detalla la arquitectura, las funciones, los principios de diseño y los casos de uso de Data 360. Presenta los fundamentos de la arquitectura de Data 360 como un cebador, seguido de una serie de profundizaciones en sus diferenciadores clave como la interoperabilidad con plataformas de datos existentes, incluyendo estrategia de múltiples organizaciones, seguridad, gobernanza y privacidad, activación en tiempo real y Salas blancas de datos.
Salesforce Data 360 está diseñado en torno a un conjunto principal de principios que hacen que los datos empresariales sean operativos, de confianza y en tiempo real.
- Apertura e interoperabilidad: Construido para ecosistemas de múltiples nubes. Se federa con plataformas de datos como Snowflake, Databricks, BigQuery y Redshift sin duplicación, ampliando Customer 360 preservando las inversiones existentes.
- Separación de almacenamiento-cálculo: Escala el almacenamiento y el procesamiento (por lotes, transmisión e interactivo) de forma independiente. Ofrece elasticidad y eficiencia para cargas de trabajo de alto volumen y alto rendimiento.
- Almacenamiento y procesamiento de múltiples modelos: Admite varios tipos de datos estructurados y no estructurados como texto, audio de imagen y vídeo. Proporciona almacenamiento eficiente, procesamiento en tiempo real y por lotes, indexación ampliable, búsqueda unificada, consulta y análisis.
- Diseño dirigido por metadatos: Las aplicaciones se definen por metadatos en vez de por código. Los metadatos se tratan como un activo de primera clase, lo que permite una gobernanza unificada, flexibilidad e integración profunda en la plataforma Salesforce.
- Procesamiento híbrido en tiempo real: Admite consultas de baja latencia y toma de decisiones instantánea, junto con procesamiento por lotes y cargas de trabajo analíticas.
- Datos inteligentes y activos: Introduce, analiza y distribuye continuamente perspectivas directamente en flujos de trabajo comerciales. Potencia la automatización sin código, con código bajo, pro-código y dirigida por IA con el contexto más actual.
- Gobierno y privacidad por diseño: Linaje, control de acceso, residencia, cifrado de datos y cumplimiento están integrados. Trust y la confianza regulatoria se refuerzan en cada nivel.
- Arrendamiento de uno a varios: Una organización de Data 360 centralizada sirve como la única fuente de verdad para Customer 360, admitiendo a la perfección entornos de Salesforce de múltiples organizaciones ampliamente utilizados por clientes de Salesforce.
Estos principios garantizan que Data 360 haga que los datos sean abiertos, inteligentes y con capacidad de acción en tiempo real.
Salesforce Data 360 es una plataforma de datos moderna creada sobre principios de diseño que abordan tendencias de datos actuales. Sus funciones de arquitectura garantizan que los datos empresariales sean de confianza, unificados y con capacidad de acción en tiempo real, en sintonía con sus principios rectores.
- Cloud-Native Foundation: Se ejecuta en Hyperforce, implementado en Hyperscalers (como AWS), con infraestructura inmutable basada en microservicios. Proporciona escala elástica, seguridad zero Trust, entrega continua y cumplimiento global.
- Impulsado por metadatos de Salesforce (Núcleo): Los metadatos se diseñan, modelan y almacenan como metadatos de Salesforce que permiten el uso inmediato por TODAS las aplicaciones de Salesforce. Dichos metadatos se almacenan en un RDBMS completamente compatible con ACID. Garantiza la gobernanza, la coherencia del ciclo de vida y la integración profunda con Salesforce Lightning Platform.
- Almacenamiento de lago: Construido sobre Apache Iceberg y Parquet, combinando la escala de lago de datos con la regulación de almacén compatible con la evolución de esquemas, desplazamientos en el tiempo y actualizaciones de gran volumen. Data 360 almacena, modela y procesa datos estructurados y no estructurados con almacenamiento a escala extrema con Estándares abiertos modernos y con funciones de transformación y procesamiento de datos enriquecidas para cargas de trabajo dirigidas por lotes y eventos.
- Oportunidades en curso de datos de extremo a extremo con introducción flexible: Cubre el ciclo de vida completo (introducir, preparar, modelar, unificar, analizar y activar), reduciendo la dependencia de soluciones de puntos fragmentadas. Admite lotes, casi en tiempo real y transmisión con más de 270 conectores y MuleSoft. El enfoque ELT-first permite una disponibilidad de datos rápida con flexibilidad de transformación descendente.
- Interoperabilidad de datos de empresa con marcos de trabajo abiertos y federación: Unifica datos de silos en toda la empresa con federación bidireccional de copia cero con Snowflake, Databricks, BigQuery y Redshift evitando la migración o duplicación de datos.
- Clasificación, modelado y organización de datos: Data 360 organiza datos como datos introducidos sin procesar, datos limpiados y almacenados y datos modelados de acuerdo con un esquema de información común conocido como SSOT (Fuente Única de Verdad). Dichos objetos SSOT forman la base para definir modelos de datos semánticos (SDM) y otros modelos depurados y específicos de la aplicación.
- Modelado de datos semánticos integrado para análisis ampliables con API de consulta semántica abiertas, impulsando Tableau Next y activando análisis específicos de la aplicación.
- Motor de consultas SQL de alto rendimiento compatible con una consulta SQL de Data 360 unificada entre datos estructurados, no estructurados y gráficos.
- Almacenes de datos de baja latencia: Almacenamiento de valores clave para datos activos con tiempos de respuesta de milisegundos. Activa la personalización y los escenarios dirigidos por eventos en tiempo real. Recopila y procesa datos de implicación de clientes en tiempo real. Unifica identidades, interacciones y conversaciones en un único gráfico de perfil y contexto de Customer 360 de confianza.
- Oportunidades en curso de procesamiento de datos no estructuradas para compatibilidad flexible y ampliable para almacenamiento de datos no estructurados, segmentación, generación de integración (vectorización), extracción de metadatos (aumento), resumen, indexación, extracción Knowledge, procesamiento de documentos inteligente, creación de memoria a corto y largo plazo (conversación), etc.
- Palabra clave nativa, Vector e Indexación híbrida para un acceso preciso y eficiente a los datos no estructurados como búsqueda rápida y agente, RAG, extracción Knowledge, derivación de memoria agente, etc.
- Servicios de perfil, personalización y contexto para activar aplicaciones de IA/ML y agentes.
- Gobierno y seguridad integrados en cada nivel para el seguimiento de linajes, el enmascaramiento de datos, la residencia de datos y la seguridad zero Trust garantizando el cumplimiento y Trust.
- Tela de computación elástica: Tela de computación nativa de Kubernetes, multiusuario. Ejecuta Spark para procesamiento distribuido e Hyper para cargas de trabajo SQL. Se amplía elásticamente entre diversos trabajos y admite el aislamiento para la ejecución de código no de confianza.
Todo esto se ejecuta en Hyperforce, la base de Salesforce en la nube. Hyperforce proporciona:
- Seguridad Zero Trust con políticas de cifrado, aislamiento y menos privilegios.
- Resistencia a través de implementaciones de múltiples regiones. Aunque Salesforce Data 360 se beneficia de la resiliencia de múltiples regiones de Hyperforce y la tolerancia a fallos a nivel de plataforma, la verdadera recuperación de desastres (DR) de nivel empresarial exige una arquitectura más amplia similar a cualquier plataforma de datos con funciones clave: oportunidades en curso de introducción reproducibles, replicación y rehidratación dirigida por metadatos en todos los ecosistemas dependientes.
- Observabilidad con supervisión, mediciones y rastreo integrados.
- Escala automatizada y conciencia de FinOps para mayor eficiencia sin desbordamiento de costes.
Data 360 no sustituye las inversiones empresariales existentes. En su lugar, Data 360 hace que los datos que ya tiene sean de confianza, gobernados y con capacidad de acción, proporcionando implicación en tiempo real dirigida por IA donde más importa. En resumen, Salesforce convierte todos los datos de la empresa, incluyendo los datos externos, como objetos dirigidos por metadatos (de Salesforce) y activa aplicaciones Agente para el descubrimiento, la toma de decisiones y la realización de acciones.
La siguiente figura ilustra la Arquitectura de referencia de Data 360:
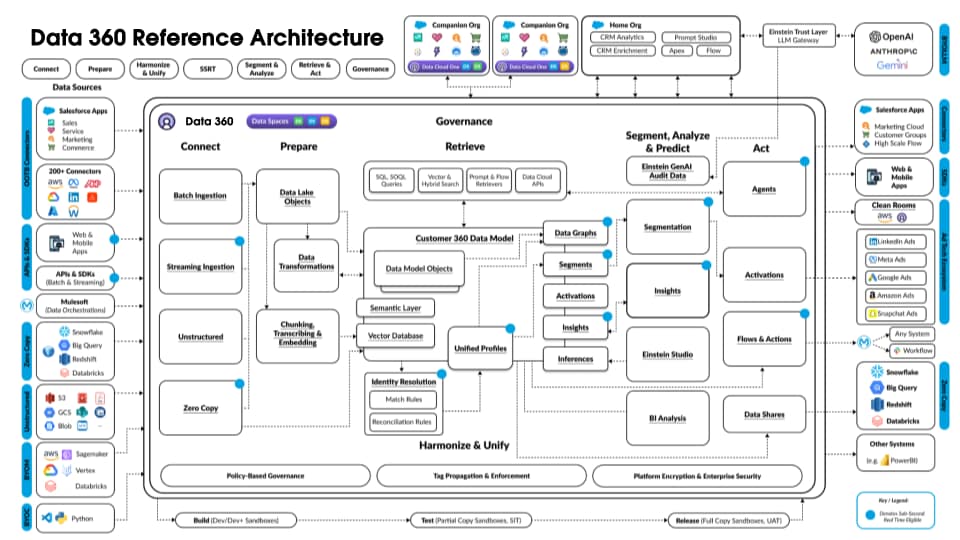
Consideremos un hipotético Agentforce Loan Agent en capas sobre Data 360 para describir un flujo de arquitectura de ejemplo. Supongamos que el Agente de préstamos es un agente de cara al cliente donde los clientes (consumidores) solicitan préstamos y obtienen aprobaciones de préstamos instantáneas.
Data 360 realiza estos pasos según lo programado, preparando datos para su uso por el Agente de préstamos.
- Data 360 introduce datos estructurados de Cuenta de cliente desde CRM y los almacena en el lago de datos.
- Data 360 procesa datos de préstamos de empresa y políticas financieras no estructurados.
- Data 360 federa datos personales desde una fuente de datos externa como Snowflake.
- Data 360 transforma y modela datos introducidos y federados.
- Data 360 crea y mantiene el gráfico de datos de perfil.
Cada vez que un cliente solicita un préstamo, se realizan estas acciones.
- Un cliente inicia sesión en el Agente de préstamos, que inicia una sesión de cliente en la capa en tiempo real. El perfil unificado del cliente se extrae a la capa en tiempo real.
- El cliente completa una solicitud de préstamo proporcionando la información requerida.
- El cliente carga documentos financieros (como declaraciones de impuestos, inversiones, extractos bancarios) en Data 360 para el procesamiento de datos no estructurado.
- Los datos cargados se segmentan y vectorizan (generación de integración) y se crean índices (palabra clave y vector).
- A continuación, el cliente rellena el documento de solicitud de préstamo y lo carga. Data 360 extrae el importe y la duración del préstamo en tiempo real.
- El Agente de préstamos recupera datos financieros relevantes utilizando la consulta Data 360 y la búsqueda híbrida sobre el perfil y otros índices precreados.
- El Agente de préstamos activa un Agente de aprobaciones con datos de préstamos y otros datos de perfil financiero para tomar la decisión de aprobación de préstamos.
- El agente de préstamos responde al cliente con una decisión.
- Esta interacción completa entre el cliente y el agente de préstamos también se captura y almacena en Data 360.
El ejemplo anterior proporciona una descripción general de componentes de arquitectura de Data 360 utilizados para crear una aplicación de agente como un agente de préstamos. En la siguiente sección describimos las capas y los componentes de arquitectura de Data 360.
En esta sección, profundizaremos en las partes integrantes fundamentales de Salesforce Data 360, comenzando con su sólido modelo de almacenamiento y explorando posteriormente los mecanismos para conectar, introducir y preparar datos. Luego examinaremos cómo se almacenan, modelan y procesan los datos estructurados y no estructurados, culminando en una comprensión de su Armonización, Unificación, Recuperación y Capacidades de Activación Inteligente.
Salesforce Data 360 se basa en un modelo de almacenamiento por niveles pero integrado que combina los puntos fuertes de un lago con almacenamiento en tiempo real. La capa de lago proporciona almacenamiento escalable y rentable para grandes volúmenes de datos históricos y por lotes, permitiendo análisis avanzados y casos de uso de aprendizaje automático. El almacenamiento en tiempo real, por otro lado, está optimizado para el acceso de baja latencia y actualizaciones de alta frecuencia, garantizando que las interacciones, los perfiles y las señales de implicación de los clientes estén siempre actualizados. Juntos, estos niveles funcionan a la perfección, permitiendo que los datos se muevan de forma fluida entre contextos históricos y en tiempo real, proporcionando profundidad e inmediatez en una base de datos unificada para la personalización, la IA y la activación.
Data 360 cuenta con una arquitectura de lago nativa basada en Iceberg/Parquet, diseñada para gestionar la gestión y el procesamiento de datos a gran escala para escenarios por lotes, de transmisión y en tiempo real que admiten datos estructurados y no estructurados, cruciales para aplicaciones de IA y análisis.
En lagos de datos basados en la nube como Azure, AWS o GCP, la unidad de almacenamiento fundamental es un archivo, normalmente organizado en carpetas y jerarquías. Lakehouse mejora esta estructura introduciendo abstracciones estructurales y semánticas de nivel superior para facilitar operaciones como consultas y procesamiento de IA/ML. La abstracción principal es una tabla con metadatos que define su estructura y semántica, incorporando elementos de proyectos de código abierto como Iceberg o Delta Lake, con capas semánticas adicionales agregadas por Data 360.
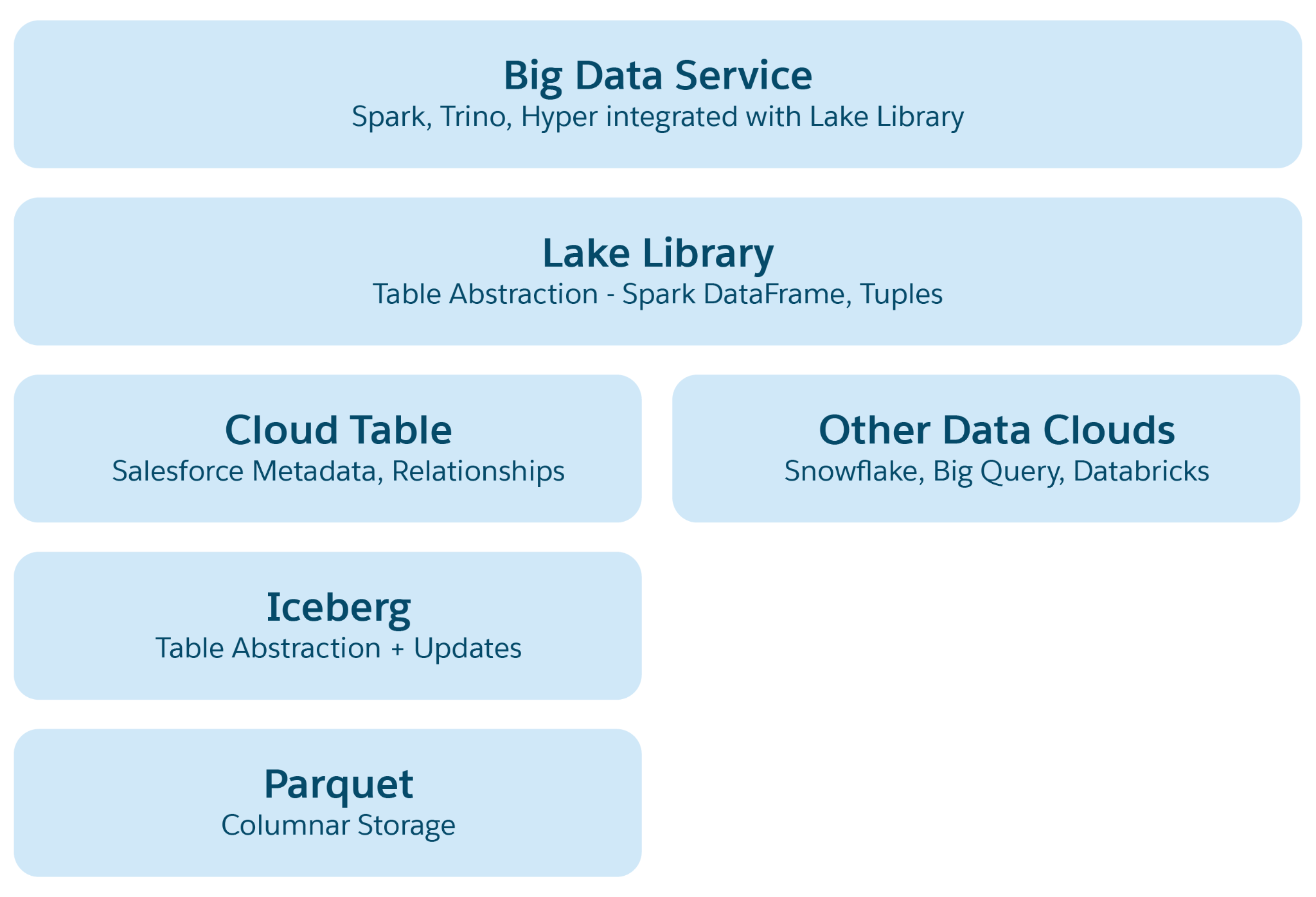
Capas de abstracción en Lakehouse:
- Abstracción de archivos de parquet: En la base, el almacenamiento consiste en archivos de lago de datos (por ejemplo, S3 en AWS o Blob en Azure) en formato Parquet. Los datos de una tabla de origen se almacenan en múltiples particiones como archivos Parquet, siendo cada tabla una recopilación de estos archivos.
- Abstracción de tabla de iceberg: Las tablas se organizan como carpetas, con particiones de datos almacenadas como archivos Parquet dentro de estas carpetas. Las modificaciones en una partición dan como resultado nuevos archivos Parquet como instantáneas. Iceberg gestiona un archivo de metadatos para cada tabla, detallando esquemas, especificaciones de partición e instantáneas.
- Abstracción de tabla de Salesforce Cloud: Basándose en Iceberg, esta capa agrega metadatos semánticos como nombres de columnas y relaciones, junto con configuraciones como tamaño y compresión de archivos de destino. Abstrae tablas entre varias plataformas como Snowflake y Databricks, protegiendo aplicaciones de Data 360 de especificaciones de plataforma de almacenamiento subyacentes.
- Biblioteca de acceso a lago: Esta biblioteca proporciona acceso a la Tabla de Salesforce Cloud, gestionando datos y metadatos, y resume los mecanismos de almacenamiento subyacentes para desarrolladores de aplicaciones.
- Abstracción de Big Data Service: Esto incluye marcos de trabajo de procesamiento como Hyper para consultas y Spark para el procesamiento en cualquier plataforma de tabla en la nube.
Para admitir aplicaciones de análisis y agentes en tiempo real, Data 360 aumenta el almacenamiento de Big Data de Lakehouse con Low Latency Store. Capa en tiempo real de Data 360 procesa señales en tiempo real y datos de implicación en memoria. Sin embargo, dado que la capacidad de almacenamiento basado en memoria es limitada, todos los datos no pueden caber y es posible que el procesamiento no se realice en tiempo real. Data 360 agrega un almacén de baja latencia (LLS) para eliminar dichas limitaciones, permitiendo el procesamiento en tiempo real ampliable.
El establecimiento de baja latencia es una capa de almacenamiento NVMe (SSD) a escala de petabytes en Lakehouse. No todos los datos deben mantenerse en el almacén de baja latencia. Es una caché duradera. La mayoría de los datos finalmente llegan al Lago House para la persistencia a largo plazo. Los datos en sesión en la capa en tiempo real se pueden enjuagar al establecimiento de baja latencia para un acceso rápido posterior. Por ejemplo, en una conversación de agente, los mensajes recientes se pueden procesar en memoria; los mensajes antiguos se pueden enjuagar al establecimiento de baja latencia. Si se requiere una conversación anterior, se puede acceder a ella en unos milisegundos desde el establecimiento de baja latencia. El almacenamiento basado en NVMe permite almacenar grandes cantidades de datos y acceder a ellos en latencias de milisegundos. Los datos pueden llegar al almacenamiento de Lakehouse Cloud para la persistencia a largo plazo. Además, los datos de Lakehouse requeridos para el procesamiento en tiempo real o para aumentar experiencias en tiempo real se obtienen y se mantienen en el almacenamiento de baja latencia. Por ejemplo, Contexto de perfil de cliente se obtiene previamente o se trae desde Lakehouse y se almacena en caché en el establecimiento de baja latencia. Además, cualquier objeto de lago y otros objetos requeridos para el procesamiento en tiempo real durante el procesamiento en sesión también se pueden almacenar en caché en el establecimiento de baja latencia.
El almacenamiento de baja latencia de Data 360 activa la capa Temporizador real en una verdadera jerarquía de almacenamiento con capas de almacenamiento Lakehouse de memoria (SSD), con datos migrando sin problemas entre estas capas. Tratamos la capa Tiempo real de Data 360 más adelante en este documento.
Salesforce Data 360 está diseñado para estandarizar, armonizar y activar todos los datos de clientes, estructurados y no estructurados, siguiendo un ciclo de vida riguroso que transforma la entrada sin procesar en un modelo de datos actual unificado.
El ciclo de vida se centra en tomar varias entradas de datos externas y estructurarlas en objetos modelados persistentes. Los datos modelados se pueden armonizar en perfiles unificados Customer 360.
Datos introducidos sin procesar y transformaciones iniciales
El proceso comienza con datos sin procesar introducidos tal cual desde sistemas de origen (CRM, Marketing, archivos, etc.). Esto incluye cargas de datos completas y eventos de cambio continuo (deltas), que se gestionan y combinan con datos persistentes para mantener un estado actual.
Las transformaciones en línea (por ejemplo, recortar, normalizar, concatenar) se aplican inmediatamente durante la introducción para garantizar la calidad y limpieza preliminar de los datos.
Objetos de lago de datos (DLO): La capa persistente
Los DLO (Objetos de lago de datos) forman la capa de almacenamiento persistente principal en Data 360. Almacenan los datos limpios y transformados y sirven como el repositorio organizado a largo plazo para toda la información del cliente.
Las transformaciones de datos avanzadas (por ejemplo, uniones, agregaciones, perspectivas calculadas) se aplican a los DLO de origen para producir nuevos DLO derivados altamente depurados.
Los datos disponibles a través de la Federación de datos de copia cero se representan directamente como DLO.
Organización de metadatos y datos no estructurados
Para contenido no estructurado (como texto, medios, documentos), Data 360 incorpora los datos extrayendo y manteniendo sus metadatos estructurados dentro de DLO específicos denominados Objetos de lago de datos no estructurados (UDLO).
Estos DLO especializados funcionan como tablas de directorio, proporcionando un mapa a la ubicación física y el contexto de los activos no estructurados. Esta función permite a los arquitectos relacionar sin problemas los metadatos de datos no estructurados con el resto de los datos de clientes estructurados, permitiendo una consulta y Armonización unificada.
Objetos de modelo de datos (DMO): La capa armonizada
Los DMO (Objetos de modelo de datos) representan la capa de datos final, armonizada y estructurada.
Se crean asignando campos de DLO (desde DLO de metadatos de origen, derivados y no estructurados) al modelo de datos estándar Customer 360.
La capa de DMO actúa como la única fuente de verdad para todos los datos de clientes, permitiendo la creación, segmentación y activación de perfiles unificados en todo el ecosistema.
Un espacio de datos es el contenedor lógico fundamental para organizar todos los datos y metadatos dentro de Data 360, incluyendo todos los DLO (estructurados y no estructurados) y DMO. Los espacios de datos ofrecen un entorno seguro y aislado para el procesamiento y modelado de datos.
Los espacios de datos actúan como límites lógicos y de regulación, permitiendo el multiarrendamiento interno separando datos para distintas entidades como unidades comerciales, regiones o marcas, mientras mantienen la visibilidad, el linaje y el cumplimiento de toda la empresa, sirviendo como la base para definir el control de acceso de grano grueso.
El aislamiento en espacios de datos se aplica en múltiples capas de la plataforma:
- Aislamiento a nivel de datos: Cada DLO/DMO pertenece a un único espacio de datos, garantizando que las consultas, transformaciones y asignaciones de objetos no puedan cruzar los límites del espacio de datos a menos que se autoricen explícitamente.
- Integración de control de acceso: Los conjuntos de permisos están vinculados de forma nativa a espacios de datos, permitiendo el control sobre operaciones de lectura, escritura y administrativas. Esto garantiza que solo los usuarios y servicios autorizados puedan acceder a objetos, perspectivas y activaciones en un espacio de datos.
- Gobernanza y auditoría: Todas las operaciones en un espacio de datos se registran con seguimientos de auditoría de nivel empresarial, lo que permite la trazabilidad para el cumplimiento, la administración y la creación de informes normativos.
El acceso y los permisos se gestionan a través de Conjuntos de permisos, garantizando visibilidad granular, actualizaciones controladas y prevención de fugas de datos entre dominios. Al integrar límites de espacio de datos con la arquitectura de seguridad y gobernanza de Data 360, los arquitectos pueden implementar con confianza estrategias de gobernanza centralizadas y descentralizadas mientras mantienen la coherencia entre múltiples nubes y dominios comerciales.
La estructura de computación de Data 360 proporciona una capa unificada para gestionar y ejecutar todas las cargas de trabajo de Big Data, simplificando las complejidades de infraestructura subyacentes. Su componente principal es el controlador de procesamiento de datos (DPC).
DPC es un servicio de orquestación de procesamiento de datos completo y con múltiples cargas de trabajo que proporciona funciones de trabajo como servicio (JaaS) entre diversos entornos de computación en nube. Abstracta la complejidad de la infraestructura y unifica la ejecución de trabajos para marcos como Spark (EMR en EC2 y EMR en EKS) y cargas de trabajo de Controlador de recursos de Kubernetes (KRC). Al servir como una pasarela de plano de control centralizada, DPC orquesta, programa y supervisa trabajos entre múltiples planos de datos, garantizando fiabilidad, escalabilidad, eficiencia de costes y una experiencia de desarrollador coherente.
La necesidad de DPC proviene de las limitaciones de interactuar directamente con sistemas de gestión de clúster nativos como EMR.
Abstracción de infraestructura y nube
Aunque EMR ofrece API para clústeres, tareas y pasos, aún carga a los equipos de clientes con tareas de gestión de infraestructura críticas como aprovisionamiento, ampliación, ajuste de rendimiento y optimización de costes. DPC soluciona esto ofreciendo una API simplificada a nivel de plataforma para el envío de trabajos. Admite la gestión automática de fallos, reintentos y equilibrio de carga dinámico. Proporciona eficiencia de costes a través de nodos basados en binpacking, spot y graviton. Proporciona seguridad sólida con aislamiento TLS, PKI, IAM y parches automatizados. Gestiona actualizaciones de versión de tiempo de ejecución de Spark y EMR para entregar mejoras de rendimiento, parches de seguridad y mejoras de funciones.
Además, DPC proporciona una interfaz unificada y específica de la nube para enviar y gestionar trabajos de datos, abstrayendo las complejidades y las API propias del sustrato de nube subyacente (AWS, futuros proveedores). Esto garantiza que los equipos de clientes interactúen únicamente con una interfaz de envío de trabajos basada en API de Data 360 común que abstrae las complejidades de gestores de recursos subyacentes como Kubernetes e HILO. Esto permite a los equipos de clientes enviar trabajos de Spark a través de una API sencilla y unificada sin necesidad de gestionar módulos, conjuntos de nodos o configuraciones de clúster de Spark directamente.
El ajuste manual de los parámetros de Spark requiere habilidades especializadas y las configuraciones incorrectas pueden ralentizar la ejecución de trabajos. El equipo de DPC centraliza esta experiencia, proporcionando configuraciones optimizadas para evitar problemas de rendimiento comunes. Este equipo especializado integra continuamente Knowledge de la comunidad de código abierto para garantizar un rendimiento óptimo entre todas las cargas de trabajo gestionadas por el controlador.
DPC no se limita a Spark; admite una amplia gama de cargas de trabajo. Estos incluyen:
- Cargas de trabajo de procesamiento en tiempo real
- Función Entrega de eventos para acciones de datos
- Gestión de Milvus (la base de datos vectorial para el indexado de datos no estructurados)
- Infraestructura de almacenamiento de baja latencia
DPC también aprovecha el marco de trabajo Kubernetes Resource Controller (KRC), que admite cargas de trabajo como Trino para consulta, Entrega de eventos para acciones de datos, Trabajos de extracción de datos para conectores y Procesamiento en tiempo real. Para todas las cargas de trabajo de KRC, DPC proporciona funciones centrales de Trabajo como servicio, gestión de aprovisionamiento informático, implementación y gestión en una abstracción de trabajo de alto nivel.
Arquitectura y beneficios de JaaS
El modelo Trabajo como servicio, proporcionado por DPC, garantiza una canalización de procesamiento de trabajos rentable y resistente.
Los usuarios proporcionan especificaciones de clúster sencillas, centrándose en CPU, memoria, almacenamiento, recuentos de instancias y recuentos de clúster mínimos/máximos y etiquetas requeridos para la coincidencia de clústeres. A continuación, DPC gestiona automáticamente detalles de infraestructura abstractos, incluyendo la selección de SKU de máquinas virtuales óptimas, la gestión de flotas de instancias, la determinación del índice de Core frente a. Nodos de tareas y gestión On-Demand frente a. Localice instancias basadas en entradas. También gestiona la gestión de versiones de componentes y EMR y actualizaciones sin tiempo de inactividad.
De forma crucial, DPC admite de forma inherente el multiarrendamiento, diseñado para comprender y aplicar límites de arrendamiento de Data 360 y separación de recursos. También garantiza Seguridad y Cumplimiento aplicando imágenes de máquinas certificadas por Salesforce, gestionando funciones de IAM específicas del servicio y garantizando el cifrado tanto en tránsito como en reposo. Para el enrutamiento y el control de capacidad, la coincidencia de trabajo a clúster se gestiona utilizando Etiquetas de clúster, y el enrutamiento basado en capacidad utiliza una configuración de concurrencia de trabajo máxima para controlar de forma efectiva la utilización de recursos.
Cloud Agnostic Client Experience es un beneficio principal, ya que la complejidad de los entornos de nube subyacentes está oculta a los servicios de cliente, permitiéndoles centrarse puramente en la lógica comercial. Esto logra el objetivo de Abstracción de proveedor de nube. Finalmente, DPC permite un uso sencillo y un seguimiento de costes, permitiendo segmentar la utilización de clústeres y los costes por servicio para una contabilización precisa. En general, DPC sigue una arquitectura conectable que permite que los nuevos motores de ejecución (por ejemplo, Flink, Ray) y sustratos de nube (GKE/Dataproc) se integren sin problemas sin exponer detalles de infraestructura subyacentes a los usuarios. Este diseño desvincula el plano de control de la capa de ejecución, garantizando una API coherente y una experiencia operativa independientemente del backend.
Data 360 afina y enriquece los datos sin procesar, acortando la brecha entre la información sin procesar y el consumo comercial con capacidad de acción. Complementa el ciclo de vida de objetos de datos preparando datos complejos para una activación y análisis sofisticados. Data 360 admite varios tipos de procesamiento, incluyendo Transformaciones de datos por lotes y transmisión, Perspectivas calculadas por lotes y transmisión, Procesamiento de datos no estructurado y Resolución de identidad. Para permitir estas diversas operaciones de forma eficiente, especialmente en tiempo casi real y entre conjuntos de datos masivos, se requiere un mecanismo sofisticado para gestionar los cambios de datos de forma efectiva.
Para lograr un procesamiento de datos eficiente casi en tiempo real, especialmente con tablas de tamaño de terabytes y millones de actualizaciones potenciales, Data 360 necesitaba un avance. Requirió una forma de notificar a los sistemas con precisión cuando cambian los datos y luego identificar de forma eficiente qué datos cambiaron de modo que solo se procesen las actualizaciones relevantes y solo cuando se actualizan. Este reto dio lugar a dos innovaciones complementarias: Eventos de cambio nativos de almacenamiento (SNCE) para notificar cuando algo cambia y Cambiar noticias en tiempo real de datos (CDF) para identificar lo que cambió.
Eventos de cambio nativos de almacenamiento (SNCE)
SNCE ha cambiado fundamentalmente Data 360 en una plataforma de datos reactiva e incremental. Este cambio implica pasar de sondear activamente el lago de datos a supervisar de forma pasiva eventos de confirmación atómica, utilizando un formato de evento estandarizado y un sistema de entrega de mensajes de alto rendimiento.
Cada operación de escritura correcta (INSERT, UPDATE, DELETE) en una tabla de Iceberg culmina en un intercambio atómico del puntero del archivo de metadatos actual de la tabla en el catálogo. La capa de almacenamiento de objetos subyacente (digamos S3) está configurada para emitir un evento de notificación nativo (como un evento S3) siempre que se escribe una nueva instantánea de metadatos en el directorio de la tabla.
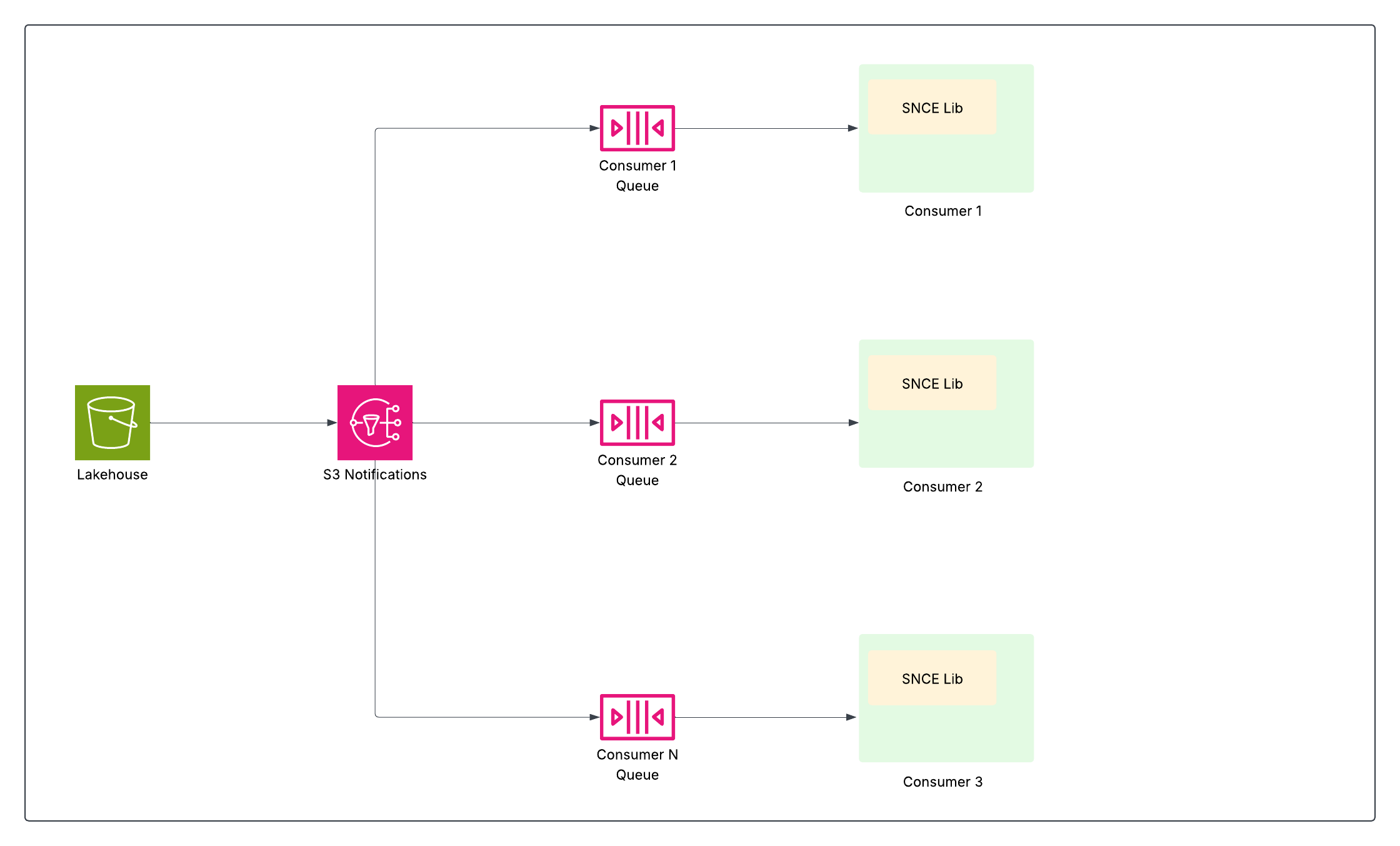
La biblioteca SNCE ofrece un método estandarizado para consumir estos eventos y también puede enriquecerlos con metadatos de instantáneas bajo solicitud.
Esto permite que las oportunidades en curso de datos descendentes (como perspectivas calculadas de transmisión, resolución de identidad y segmentación) se suscriban y actúen solo cuando cambien los datos, aumentando significativamente la eficiencia al evitar costosas exploraciones de tabla completa.
Cambiar noticias en tiempo real de datos (CDF)
Basándose en SNCE, las Noticias en tiempo real de datos de cambios (CDF) proporcionan un mecanismo simplificado para consumir y procesar incrementalmente los cambios.
CDF aprovecha instantáneas de Iceberg para generar de forma eficiente la transmisión de cambios. De forma crítica, el redactor Iceberg optimizado de Data 360 calcula y mantiene los cambios como parte de la operación de escritura en sí, haciendo que la generación de CDF sea altamente eficiente y minimizando el gasto adicional. Esto permite que los trabajos de procesamiento (como transformaciones de transmisión o perspectivas calculadas de transmisión) procesen selectivamente solo los registros alterados evitando el costoso cálculo de diferencias de instantáneas.
Esta estrategia incremental proporciona varios beneficios para grandes conjuntos de datos, incluyendo ahorros de costes, latencia reducida y eficiencia mejorada. Activa funciones como transformaciones de transmisión y resolución de identidad incremental, que a su vez conducen a perspectivas más rápidas, cargas del sistema más predecibles, rendimiento mejorado y menores gastos operativos.
Data 360 ofrece funciones de introducción sólidas con compatibilidad nativa para productos de Salesforce, garantizando un flujo de datos sencillo. Para fuentes externas, proporciona una amplia conectividad a través de más de 270 conectores, API, SDK y MuleSoft. Además, Data 360 cuenta con federación de copia cero, permitiendo BI y análisis sin duplicación de datos.
El marco de trabajo del conector de Data 360 (DCF) es la base para la mayoría de la conectividad de Data 360. Permite la introducción, federación y salida a través de una arquitectura unificada. DCF define los estándares para crear y gestionar conectores, desde la interfaz de usuario para la configuración y administración hasta la persistencia de metadatos, la extracción de datos y la entrega en Lakehouse o a través de consultas en vivo en orígenes externos. También admite opciones de conectividad privada (como vínculos privados, VPN y túneles seguros) para garantizar la seguridad y el cumplimiento de los datos de nivel empresarial al conectar con entornos de clientes o socios. Proporcionando un enfoque coherente entre todos los conectores, DCF potencia Data 360 para conectarse a la perfección en el ecosistema más amplio garantizando la extensibilidad, fiabilidad e integración segura.
Data 360 proporciona una conectividad robusta a un vasto ecosistema de orígenes de datos, admitiendo tanto productos nativos de Salesforce como numerosos sistemas externos. Esta amplia conectividad es crucial para unificar datos empresariales aislados y activar aplicaciones de IA/ML y Agentes.
Data 360 ofrece más de 270 conectores de forma nativa o a través de MuleSoft, API y SDK para dar cobertura a sus funciones de canalización de datos de extremo a extremo con introducción por lotes, transmisión o en tiempo real. Estos conectores se pueden categorizar ampliamente por el tipo de sistema de origen que integran.
Conectores nativos de Salesforce
Estos conectores garantizan un flujo de datos sencillo y nativo desde productos de Salesforce.
Ejemplos incluyen conectores para Salesforce CRM, Data Cloud One , Marketing Cloud Engagement, Marketing Cloud Account Engagement y B2C Commerce.
Aplicaciones externas y SaaS
Los conectores para varias aplicaciones comerciales y servicios en la nube permiten la introducción de datos desde plataformas de software externas.
Algunos ejemplos incluyen Adobe Marketo Engage, Microsoft Dynamics 365, Mailchimp y Airtable.
Bases de datos y almacenes de datos
Data 360 se conecta a una variedad de plataformas de almacenamiento de datos relacionales y basadas en la nube.
Algunos ejemplos incluyen Amazon Redshift, Amazon DynamoDB, Amazon RDS (MySQL, PostgreSQL, Oracle), Google BigQuery y Microsoft SQL Server.
Almacenamiento de objetos de nube y sistemas de archivos
Estos conectores se integran con soluciones de almacenamiento de hiperescala para datos estructurados y no estructurados.
Algunos ejemplos incluyen Amazon S3, Google Cloud Storage (GCS) y Azure Blob Storage.
Servicios de transmisión y mensajería
Los conectores que gestionan transmisiones de datos continuas en tiempo real son críticos para escenarios dirigidos por eventos y procesamiento en tiempo real.
Un ejemplo es el conector de Amazon Kinesis.
Plataformas de integración
El conector MuleSoft Anypoint amplía el alcance de Data 360 integrándolo con una gama más amplia de aplicaciones y bases de datos a través de Anypoint Exchange.
Conectores de almacenamiento de datos y objetos de nube no estructurados
Estos conectores son críticos para introducir y hacer referencia a datos no estructurados (datos que carecen de un modelo predefinido) a funciones de IA generativa de energía.
Todos estos conectores están construidos sobre el marco de trabajo del conector de Data 360 proporcionando una experiencia coherente.
La transformación de datos es un componente arquitectónico fundamental en Data 360, diseñado para limpiar, enriquecer y dar forma a datos introducidos sin procesar en activos de datos normalizados y con capacidad de acción alineados con el modelo de datos Customer 360. Este proceso es esencial para Armonización, mejora de la calidad y garantizar que los datos están listos para casos de uso descendentes como unificación, segmentación y activación de perfiles. Las transformaciones aprovechan tanto los objetos de lago de datos de origen (DLO) como los objetos de modelo de datos (DMO) como entrada, produciendo los resultados en nuevos DLO o DMO, respectivamente.
Data 360 proporciona dos paradigmas de transformación principales para tratar diferentes requisitos de velocidad de datos: transformaciones de datos por lotes y transformaciones de datos de transmisión.
Transformaciones de datos por lotes
Las transformaciones de datos por lotes están diseñadas para el procesamiento de gran volumen basándose en una programación definida o desencadenador on-demand. Este motor está optimizado para gestionar operaciones de reestructuración complejas que requieren muchos recursos.
El proceso Transformación por lotes se configura utilizando un lienzo de oportunidades en curso de código bajo visual que permite a los usuarios definir lógica de transformación de múltiples etapas. Este motor admite de forma exclusiva operaciones de reestructuración complejas vitales para la alineación de modelos de datos canónicos: estructuración y normalización de datos. Esto incluye pivotar (descomponer registros desnormalizados en múltiples registros normalizados) y aplanar (reestructurar datos jerárquicos, como JSON, en tablas estructuradas). El modo de ejecución del sistema admite la sincronización completa (procesando todos los registros) y un modo de procesamiento incremental altamente eficiente. El modo incremental reduce significativamente el tiempo de procesamiento y el consumo de recursos solo procesando registros que cambiaron desde la última ejecución correcta. Las transformaciones por lotes son ideales para tareas donde las actualizaciones en tiempo real no son esenciales, como agregaciones periódicas y reestructuración de datos compleja.
Transformaciones de datos de transmisión
Los datos de transmisión transforman los datos del proceso de forma continua e incremental casi en tiempo real a medida que fluyen al sistema, lo que los hace esenciales para casos de uso de baja latencia.
La interfaz principal es un enfoque SQL-first, donde las transformaciones se definen como una consulta SQL SELECT que se ejecuta continuamente en la transmisión entrante de cambios de registro. Este motor admite funciones de transformación principales, incluyendo limpieza y estandarización de datos (por ejemplo, validación de PII y estandarización de formatos de datos) y enriquecimiento y combinación de datos (utilizando Uniones y Uniones). De forma crítica, admite uniones de búsqueda de transmisión para permitir el enriquecimiento de datos en tiempo real y búsquedas en datos de referencia estáticos o que cambian lentamente, garantizando actualizaciones de perfil instantáneas. Para optimizar el coste de servicio, la arquitectura emplea un diseño de trabajo de alta densidad (HD), que empaqueta múltiples definiciones de transformación de transmisión para un único arrendatario en un único trabajo de computación subyacente, maximizando la utilización de recursos. Las transformaciones de transmisión son esenciales para casos de uso como supervisión de eventos, personalización inmediata y actualizaciones de perfil en tiempo real.
Data 360 revoluciona la gestión de datos al admitir la federación de copia cero y el uso compartido de datos, lo que elimina la necesidad de mover o duplicar datos. Esta función permite a los usuarios acceder de forma sencilla y directa a datos desde diversos orígenes externos y compartir datos con entornos externos, reduciendo significativamente la complejidad, reduciendo los costes de almacenamiento y garantizando que todas las decisiones se basan en la información más actualizada y fiable.
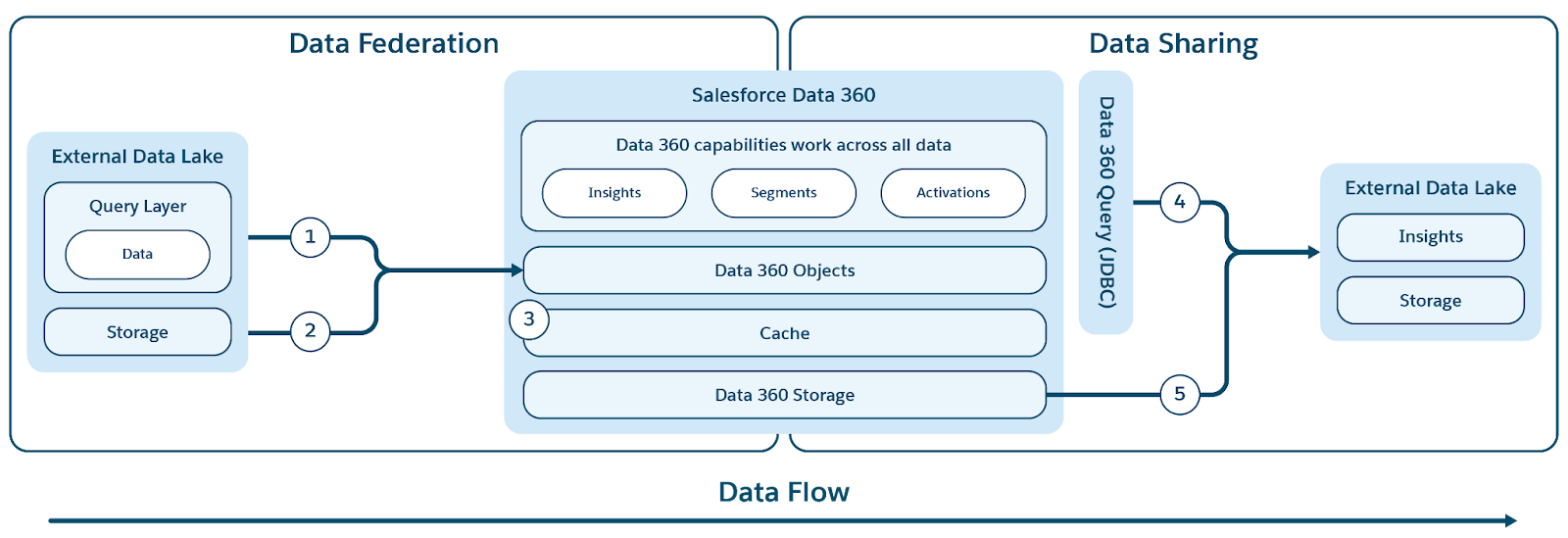
Data 360 admite la federación de copia cero con almacenes de datos externos (Snowflake, Redshift), lagos (Google BigQuery, Databricks, Azure Fabric), bases de datos SQL y muchas otras fuentes. Sus capas de abstracción permiten la consulta directa de datos externos sin duplicación, reduciendo el tiempo de introducción, los costes de almacenamiento y garantizando información actualizada.
Data 360 simplifica el acceso a datos externos y federados proporcionando una capa de metadatos unificados que abstrae objetos externos y de Salesforce. Esto permite que toda la plataforma Salesforce y sus aplicaciones utilicen estos datos sin problemas.
Data 360 admite la federación basada en archivos y consultas, con consulta en vivo y aceleración de acceso como se muestra en la figura.
Las etiquetas (1) y (2) ilustran la consulta de Data 360 (incluyendo envíos de consultas en vivo) y la federación basada en archivos para acceder a datos desde lagos de datos/almacenes/fuentes de datos externos; y la etiqueta (3) resalta la aceleración del acceso federado desde lagos de datos/fuentes de datos externos.
Federación de consultas
El núcleo de la función de federación de Data 360 se encuentra en su capa de federación de consultas, que gestiona el complejo proceso de acceder a datos externos y realizar envíos de consultas inteligentes (ilustrado por la etiqueta 1). Data 360 se conecta y recupera datos desde orígenes utilizando el protocolo JDBC, mejorado con lógica adicional para una eficiencia mejorada. La Capa de federación de consultas es responsable de comprender y traducir diferentes dialectos de SQL, determinando la parte más óptima de la consulta que se enviará a sistemas externos para un procesamiento eficiente, recuperando los resultados y realizando cualquier procesamiento posterior necesario para derivar perspectivas finales.
Almacenamiento en caché (Aceleración de consultas)
Para una utilidad mejorada, Data 360 proporciona una función de aceleración opcional para sus funciones federadas.
Cuando se activa Aceleración, Data 360 almacena en caché los datos federados para lograr un acceso más rápido y menores costes, ya que evita el acceso directo repetido a fuentes externas. Esta memoria caché se trata como una capa de aceleración y se actualiza de forma incremental para reflejar rápidamente cualquier cambio en los datos de origen externo, garantizando que la vista acelerada permanece casi en tiempo real.
Federación de archivos
Data 360 admite la federación basada en archivos (ilustrada por la etiqueta 2) para acceder a datos desde orígenes y lagos de datos externos. La base técnica para esta función de copia cero se basa en la estandarización: los datos subyacentes deben estar en el formato de archivo Apache Parquet y utilizar el formato tabular Apache Iceberg. Data 360 puede federarse en cualquier origen que exponga un Catálogo de REST de Iceberg (IRC) para acceso de metadatos y almacenamiento, garantizando un acceso sencillo y controlado a archivos que residen fuera de la plataforma.
Con la federación basada en archivos, el cálculo de Data 360 gestiona todo el procesamiento de datos porque acceden directamente al almacenamiento subyacente. Esto elimina la necesidad de distribución de consultas y gestión de varios dialectos de SQL, que a menudo se requieren con la federación basada en consultas.
Además de esto, la función Cero copia también se extiende a orígenes de datos no estructurados como soluciones de almacenamiento de hiperescala (almacenamiento S3/GCS/Azure), Slack y Google Drive, a los que se puede acceder por las oportunidades en curso de procesamiento no estructurado de Data 360.
Data 360 facilita el uso compartido de datos basado en consultas y basado en archivos que gestiona con almacenes y lagos de datos externos (ilustrado por las etiquetas 4 y 5 en el contexto de la figura original).
Colaboración basada en consultas
Para el uso compartido de datos basado en consultas, Data 360 expone un controlador de JDBC utilizando el que los motores y aplicaciones externos pueden obtener acceso seguro a los datos. Este mecanismo permite a los sistemas externos conectar, autenticar y ejecutar consultas en vivo directamente con los datos en Data 360.
Colaboración basada en archivos (Compartición de datos y DaaS)
El mecanismo principal para la colaboración basada en archivos implica dos conceptos: colaboración de datos y destino de colaboración de datos, que aprovechan la API de DaaS (Datos como servicio).
- Control granular: El concepto de colaboración de datos permite a los clientes definir con precisión qué objetos (DLO, DMO, CIO, etc.) se comparten de forma externa, evitando la exposición no intencionada a datos.
- Objetivos seguros: También controla el objetivo de colaboración de datos, garantizando que los datos solo estén disponibles para entornos externos autorizados explícitamente, cuentas u organizaciones de socios (por ejemplo, colaboración con una instancia específica de Redshift o Databricks).
La API de DaaS proporciona una interfaz segura y gobernada para que los motores externos consuman datos. Otorga acceso a los metadatos esenciales y al almacenamiento de tabla subyacente preservando al mismo tiempo toda la semántica de Data 360. Esto garantiza que los motores externos accedan a los datos en un contexto coherente y significativo de una forma segura.
Muchos clientes sensibles a la seguridad, especialmente grandes empresas, sectores regulados y organizaciones del sector público, restringen todo el acceso a Internet a sus lagos de datos como parte de su estado de seguridad. Esta política, aunque esencial para el cumplimiento y la reducción de riesgos, también evita que Salesforce Data 360 y Agentforce se conecten a esos entornos a través de Internet pública.
La mayoría de estos lagos de datos se implementan en entornos hiperescalantes como AWS, Azure o Google Cloud. Como Data 360 se ejecuta en AWS, acceder a lagos de datos de clientes alojados en un proveedor de nube diferente requiere una conexión de red entre nubes. Sin una opción de conectividad privada y segura que omita Internet pública, los clientes a menudo no pueden o no desean adoptar Data 360 o Agentforce para casos de uso que se basan en esos lagos de datos.
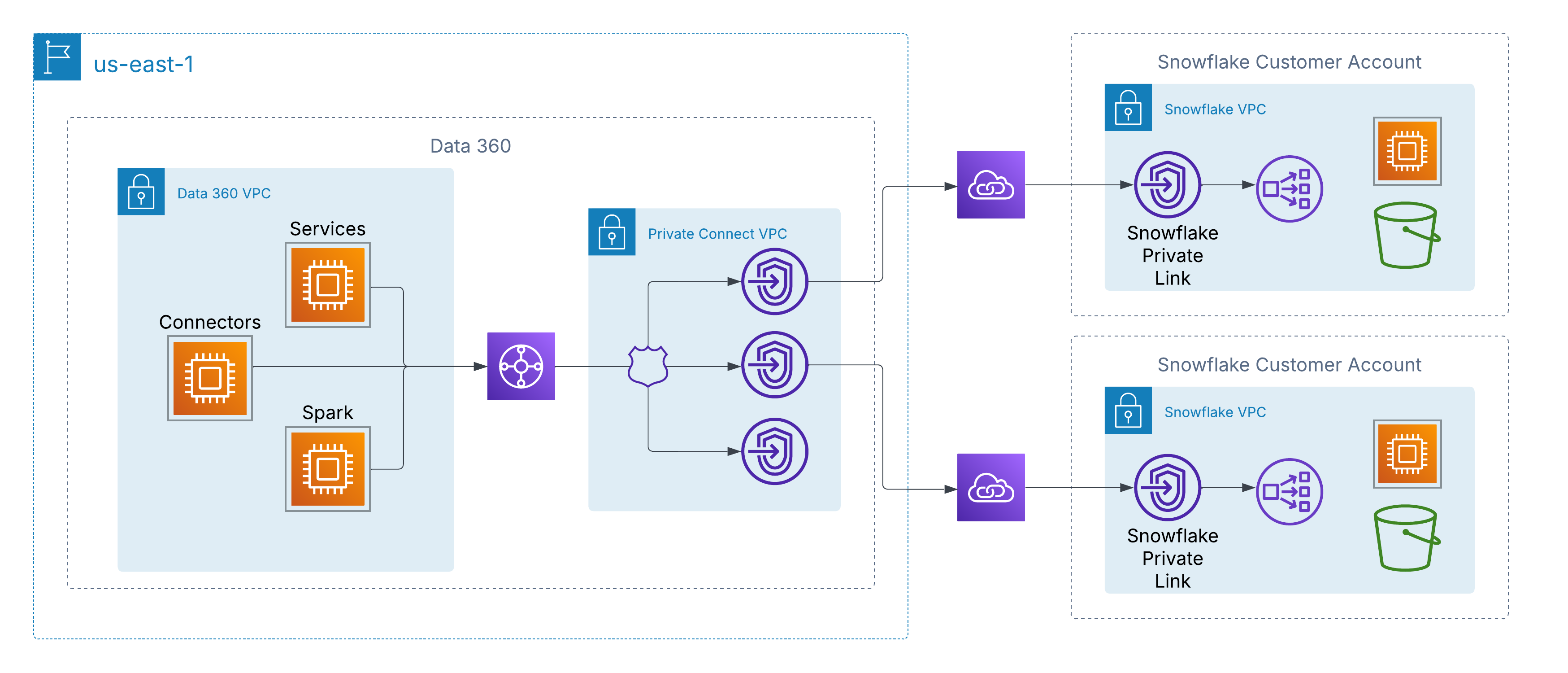
Para solucionar esto, Data 360 admite conectividad privada a nivel de red con orígenes de datos gestionados por clientes entre nubes. En AWS, esto se activa a través de AWS PrivateLink, que permite a Data 360 conectarse directamente a extremos aprovisionados por el cliente, ya sea dentro de sus propias cuentas o dentro de entornos de lago de datos externos (por ejemplo, Snowflake), sin atravesar Internet pública.
Esta arquitectura garantiza que todo el tráfico permanezca completamente en la columna vertebral de AWS, utilizando direcciones IP privadas y rutas de red no enrutables, satisfaciendo así estrictos requisitos de seguridad y cumplimiento al tiempo que permite un acceso sencillo a los datos de los clientes.
Para clientes con arquitecturas de múltiples nubes, Data 360 está ampliando la conectividad privada más allá de AWS a través de la compatibilidad de interconexión entre nubes. Esto permite rutas de red seguras y solo troncales desde Data 360 a lagos de datos y servicios alojados en Azure o Google Cloud, manteniendo los mismos principios que AWS PrivateLink: dirección IP privada, enrutamiento no público y cero exposición a Internet.
Los clientes pueden elegir entre dos modelos de implementación:
-
Interconexión gestionada por clientes: Integre circuitos privados existentes como Azure ExpressRoute, Google Cloud Interconnect o Equinix Fabric directamente con los VPC de Data 360.
-
Interconexión gestionada por Salesforce: Utilice una conexión llave en mano completamente gestionada donde Salesforce aprovisiona y opera el vínculo entre nubes, exponiendo extremos privados en la nube de destino.
En ambos modelos, la experiencia es coherente: Los servicios de Data 360 se conectan a fuentes de datos externas entre hiperescaladores como si fueran locales, permitiendo la introducción, activación y consulta seguras sin atravesar Internet pública.
Para los arquitectos empresariales, una gobernanza de datos sólida no es solo una casilla de verificación de cumplimiento, sino un pilar fundamental para crear Inteligencia de clientes confiable, ampliable y con capacidad de acción. Salesforce Data 360 está diseñado con un marco de gobernanza integral que garantiza la calidad, la seguridad y el cumplimiento de los mandatos normativos en todo su ciclo de vida de los datos.
Data 360 funciona como un núcleo de regulación centralizado, garantizando que todos los datos, desde la introducción sin procesar hasta las perspectivas activadas, se gestionan con integridad y control.
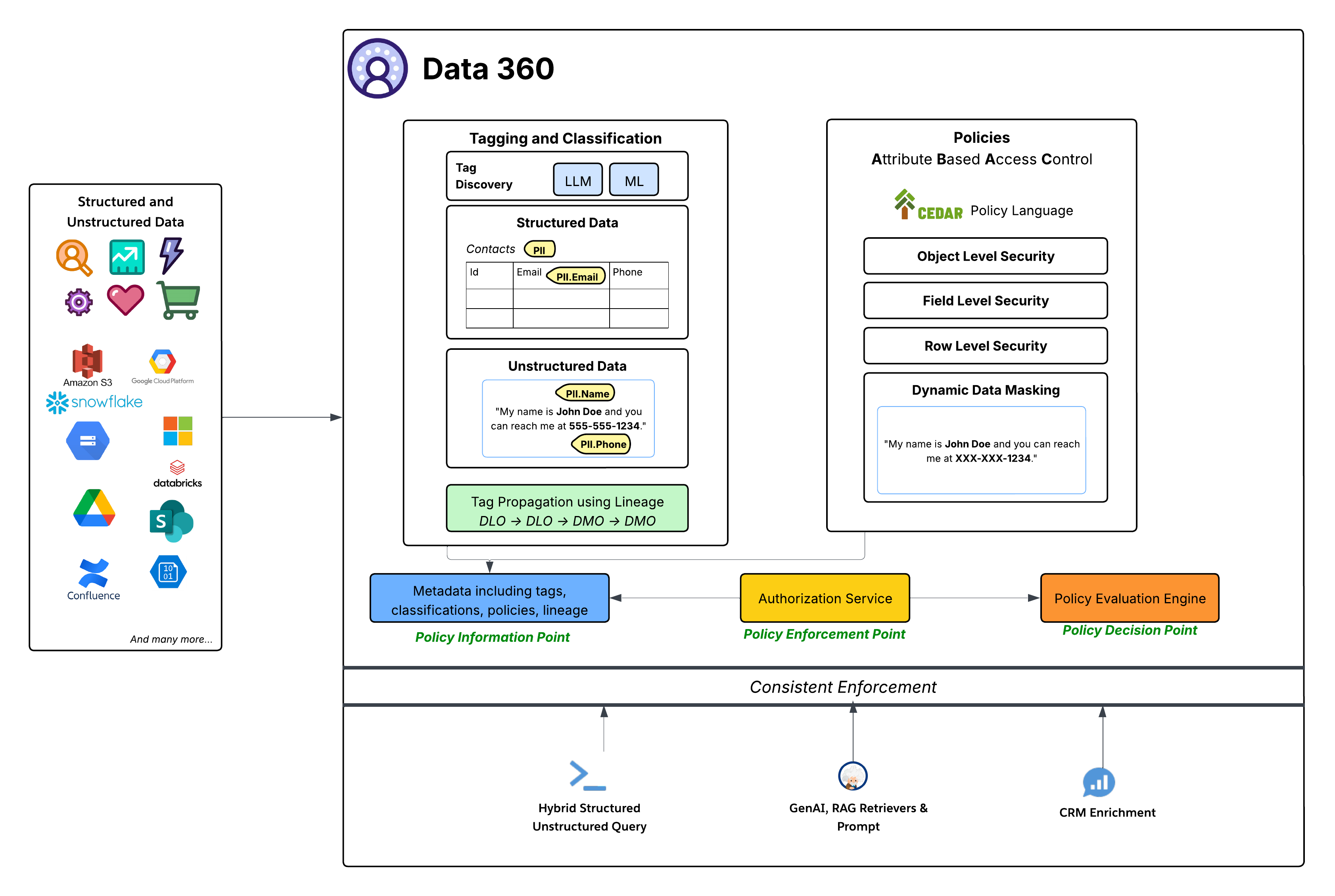
Aunque el espacio de datos proporciona un control de acceso de grano grueso para determinar el acceso a todos los objetos en un espacio de datos, las políticas basadas en ABAC proporcionan un control de acceso de grano fino a objetos individuales, campos y filas en un espacio de datos. Data 360 ha adoptado el Control de acceso basado en atributos (ABAC) como su modelo de autorización principal para el control de acceso de grano fino. Esta opción estratégica proporciona flexibilidad y capacidad de ampliación superiores en comparación con el Control de acceso basado en funciones (RBAC) tradicional, particularmente crucial para entornos empresariales complejos y dinámicos con grandes cantidades de datos y necesidades de acceso variadas. ABAC permite que las decisiones de acceso se basen en atributos del usuario (por ejemplo, departamento, función, ubicación), los datos (por ejemplo, PII, sensibilidad, espacio de datos) y el entorno (por ejemplo, hora del día), en vez de solo funciones predefinidas. Esto permite políticas de acceso altamente granulares y contextuales que se adaptan a medida que cambian los datos y los atributos de usuario.
- Idioma de política de CEDAR: El núcleo de la implementación de ABAC de Data 360 es el uso del lenguaje de políticas CEDAR. Este lenguaje de políticas formal creado específicamente proporciona una forma precisa y verificable de definir reglas de autorización complejas, garantizando que las políticas no sean ambiguas y se puedan evaluar de forma coherente a escala.
El sistema de gobernanza de Data 360 sigue una arquitectura ABAC sólida y estándar:
- Etiquetado, clasificación y redacción de políticas (Punto de información de políticas - PIP):
- Data 360 proporciona mecanismos automatizados de Etiquetado y Clasificación, aprovechando LLM (Gran Modelo de Idioma) y ML (Aprendizaje Automático) para identificar categorías de datos confidenciales (por ejemplo, PII.Email, PII.Phone, PII.Name) y otras taxonomías creadas específicamente (PHI, FinancialData) tanto en Datos estructurados (por ejemplo, tabla Contactos) como Datos no estructurados (por ejemplo, desde Google Drive).
- De forma crucial, la propagación de etiquetas se produce a lo largo del linaje de datos (DLO -> DLO -> DMO), garantizando que las clasificaciones sigan automáticamente las transformaciones y derivaciones de datos, desde los datos introducidos sin procesar a la capa de DMO armonizada y a través de datos derivados creados desde definiciones de procesos.
- Finalmente, el panel de creación de políticas proporciona una experiencia sencilla para aprovechar los datos y atributos de usuario para definir reglas de acceso dinámicas para una organización.
- Estos metadatos enriquecidos (incluyendo etiquetas, clasificaciones, políticas y linaje) se alimentan al Punto de información de políticas (PIP).
- Servicio de autorización (Punto de aplicación de políticas - PEP):
- El Servicio de autorización actúa como el Punto de aplicación de políticas (PEP). Intercepta todas las solicitudes de acceso a datos desde varias capas de consumo (Consulta estructurada/no estructurada híbrida, Recuperadores y solicitud de RAG de GenAI, Enriquecimiento de CRM) y consulta el Punto de decisión de política para determinar si el acceso está permitido.
- Motor de evaluación de políticas (Punto de decisión de política - PDP):
- Este motor sirve como el Punto de decisión de política (PDP). Toma el contexto de solicitud de acceso desde el PEP, junto con definiciones de políticas (en CEDAR) y atributos desde el PIP, para tomar una decisión de acceso autorizada.
- Políticas de seguridad granular: Las políticas definidas en CEDAR aplican varios niveles de seguridad, incluyendo:
- Seguridad a nivel: de objeto Controlar el acceso a DLO o DMO completos basándose en etiquetas asociadas con estos objetos.
- Seguridad a nivel de campo: Restringir el acceso a campos confidenciales específicos en un objeto basándose en etiquetas.
- Seguridad de nivel: Filtrado de datos en objetos específicos para mostrar solo filas relevantes basándose en atributos de usuario.
- Enmascaramiento de datos dinámico: Enmascare dinámicamente ciertos datos (basándose en etiquetas) en el punto de acceso, sin alterar los datos subyacentes. Esto garantiza que la información confidencial esté protegida mientras permite una amplia utilidad. Esto se aplica al enmascaramiento de campos en datos estructurados así como contenido en datos no estructurados.
- Aplicación coherente: Todo el marco de trabajo de ABAC garantiza la aplicación coherente de políticas en todos los patrones de consumo de Data 360, ya sea consulta de datos directa, recuperación para aplicaciones de IA generativa (RAG) o enriquecimiento de experiencias de Salesforce CRM a través de Listas relacionadas, por ejemplo.
- Integración profunda con Salesforce Platform: Las funciones de regulación de Data 360 se definen y administran directamente dentro de la plataforma principal de Salesforce. Esta integración permite a los administradores gestionar políticas de acceso, identidades de usuario y gestión de atributos utilizando herramientas familiares de Salesforce, garantizando una capa de gobernanza unificada y coherente en todo el ecosistema de Salesforce.
Al crear este sofisticado marco de trabajo de ABAC con políticas de CEDAR, Data 360 proporciona a los arquitectos un nivel de control y flexibilidad sin igual, garantizando que los datos de los clientes no solo sean procesables, sino también seguros, que cumplan y sean fiables en toda la empresa.
En todas las industrias, las organizaciones están poniendo un mayor énfasis en la seguridad de datos de extremo a extremo para garantizar la protección contra la fuga de datos, el acceso no autorizado, la manipulación o la destrucción. La mayoría de las plataformas de datos, incluyendo Data 360 hoy en día, proporcionan cifrado en tiempo real utilizando una clave de cifrado gestionada por el proveedor. Sin embargo, las empresas (en particular las de los sectores regulados) exigen cada vez más funciones de cifrado gestionadas por los clientes tanto para datos en tiempo de inactividad como en tránsito.
Este modelo permite a las empresas controlar sus propias claves de cifrado, garantizando que incluso en el caso altamente improbable de una brecha a nivel de plataforma o acceso no autorizado, los datos permanecen protegidos criptográficamente. Sin la clave propia del cliente, ninguna entidad (incluyendo el proveedor de plataforma) puede descifrar o reconstruir los datos, manteniendo así la confidencialidad y el control completos.
Data 360 admite el almacenamiento y la gestión de datos estructurados (tablas), semiestructurados (JSON) y no estructurados de forma sencilla entre mecanismos de introducción, procesamiento, indexación y consulta de datos. Data 360 admite varios tipos de datos no estructurados más allá del texto, incluyendo audio, vídeo e imágenes, ampliando el alcance de la gestión y el análisis de datos. La figura siguiente ilustra los dos lados de la fundamentación (ingesta y recuperación).
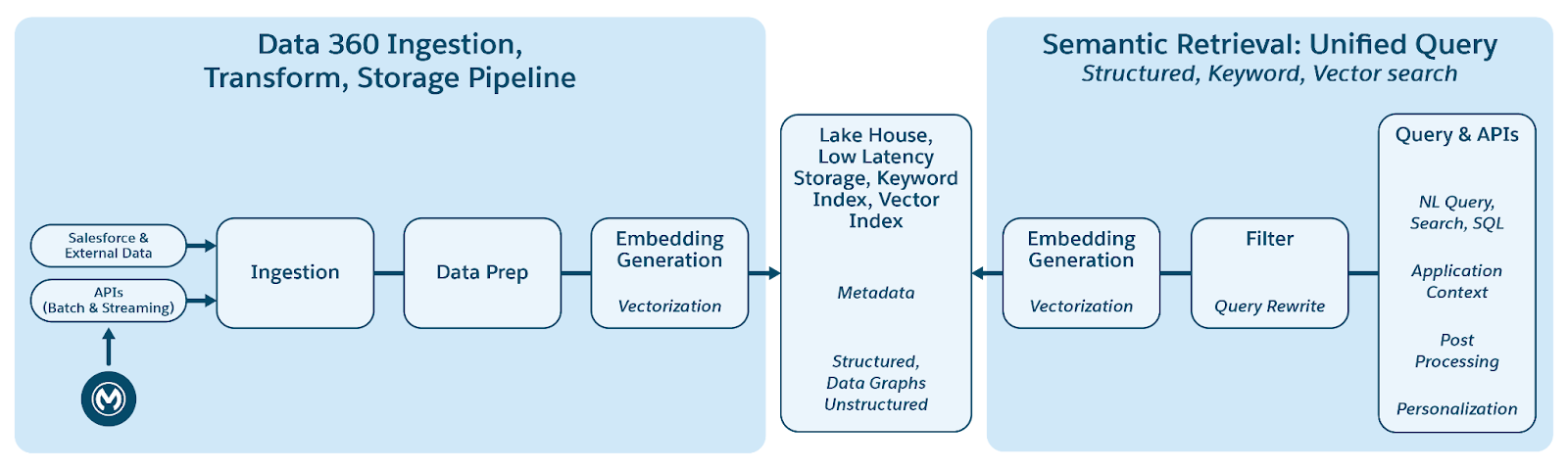
Data 360 gestiona datos no estructurados almacenándolos en columnas como texto o en archivos para conjuntos de datos de mayor tamaño. Admite la federación de datos para contenido no estructurado, lo que permite la integración y gestión de datos desde múltiples orígenes.
Los datos se preparan y segmentan a continuación, se generan incrustaciones y se procesan para indexación de palabras clave e indexación de vectores. Data 360 aloja múltiples modelos listos para su uso y conectables para la generación de fragmentos e incrustación. Data 360 admite la transcripción automatizada y configurable de contenido de audio y vídeo para su posterior procesamiento e indexación. El servicio de búsqueda se utiliza para el indexado de palabras clave. Para el indexado vectorial, Data 360 admite el indexado nativo (con Hyper) y también aprovecha bases de datos vectoriales como Milvus de código abierto. Data 360 también se integra con Salesforce Search Platform para admitir el indexado de palabras clave en datos no estructurados. Este indexado multimodal integrado en Data 360 potencia la búsqueda en cualquier dato no estructurado, como se describe en la sección Búsqueda de empresa agente más adelante en el documento.
Para la recuperación, Data 360 proporciona API para la búsqueda. Nuestra consulta unificada basada en Hyper facilita las consultas de conjunto entre índices estructurados de palabras clave e índices vectoriales, manteniendo una visibilidad y permisos estrictos, mejorando así el RAG y la búsqueda.
La canalización de indexación de datos no estructurada de Data 360 está diseñada como una arquitectura modular y ampliable que comprende cinco etapas principales:
- Analización
- Procesamiento previo
- Chunking
- Postprocesamiento
- Integración
Todas las etapas también admiten el procesamiento basado en LLM que permite a los clientes obtener las solicitudes personalizadas. Tanto la fase de preprocesamiento como la de postprocesamiento pueden incluir múltiples pasos secuenciales, permitiendo que las transformaciones complejas se compongan de forma flexible. Cada etapa está completamente dirigida por metadatos, permitiendo una configuración y extensión sencillas sin cambios de código.
Ejemplos de preprocesamiento incluyen operaciones como la eliminación de ruido, la normalización de idioma y la comprensión de imágenes (reconocimiento óptico de caracteres y subtítulos), mientras que las etapas de postprocesamiento pueden incluir enriquecimiento de metadatos, agrupación semántica o técnicas avanzadas como el desplazamiento de Raptor.
Las oportunidades en curso admiten completamente Extensión de código de Data 360, permitiendo a los clientes y equipos internos conectar lógica personalizada en cualquier etapa. Los componentes de extensión de código son funciones Python ligeras cuyo ciclo de vida (ejecución, escala y gestión de fallos) está completamente gestionado por Data 360. Este enfoque garantiza que la innovación y el procesamiento específico del dominio puedan introducirse rápidamente, manteniendo al mismo tiempo la coherencia operativa y la gobernanza en toda la plataforma.
Indexado de contexto
Para configurar RAG con procesamiento no estructurado, dos factores clave son:
- Iteración rápida: La capacidad de validar rápidamente con consultas de prueba de muestra.
- Contenido específico de persona: La capacidad de configurar contenido adaptado a la persona consumidora.
Indexado de contexto es una herramienta práctica diseñada para tratar ambos aspectos. Esta interfaz de usuario interactiva funciona con una canalización en tiempo real (RT) que ejecuta las cinco etapas descritas anteriormente. Las oportunidades en curso utilizan GPU cuando es necesario para tareas como la generación de integración y el reconocimiento óptico de caracteres (OCR). Además, permite a los clientes probar rápidamente las oportunidades en curso de RAG con un agente antes de implementar la configuración para el procesamiento integral de contenido.
IA de documento
La IA de documentos de Data 360 permite leer e importar datos no estructurados o semiestructurados desde documentos como facturas, currículums, informes de laboratorio y pedidos de compra. Esta función admite procesamiento interactivo ad hoc así como procesamiento por lotes masivo. Esta es una función clave que permite la automatización de procesos comerciales para nuestros clientes. Esta tecnología está impulsada por inteligencia artificial incluyendo modelos LLM y ML.
Las empresas poseen grandes cantidades de Knowledge distribuidas entre sistemas dispares como wikis, colaboraciones de archivos, sistemas de gestión de contenido, bases de datos internas y mucho más. Esta fragmentación dificulta que los empleados (especialmente los agentes de servicio y los representantes de ventas) y los clientes encuentren información relevante de forma rápida y eficiente. Los problemas clave incluyen: Falta de una experiencia de búsqueda única y unificada entre todas las fuentes Knowledge; Presentación y presentación incoherentes de contenido de diferentes fuentes; Falta de regulación de acceso a información confidencial dispersa entre sistemas; y dificultad para aprovechar la fuente Knowledge autorizada en flujos de trabajo comerciales básicos (por ejemplo, adjuntar artículos relevantes a un caso).
Enterprise Knowledge representa contenido que se ha depurado, ya sea manualmente o automáticamente, desde el conjunto más amplio de datos empresariales. La depuración manual implica acciones deliberadas, como crear artículos de Salesforce Knowledge o desarrollar Knowledge dentro de sistemas externos que luego se introducen. Prevemos una depuración automatizada que utiliza procesos, como agentes y transformaciones de Salesforce, que se ejecutan sobre datos introducidos para generar capas depuradas y depuradas, mezclando potencialmente contenido estructurado y no estructurado. Si se depura manualmente o automáticamente, internamente en Salesforce o externamente antes de la introducción, el resultado es contenido de valor añadido distinto de los datos sin procesar.
La solución Enterprise Knowledge Hub aprovecha las funciones de Data 360 para :
- Ingestión y almacenamiento: CRM Connector está introduciendo artículos de Salesforce Knowledge, y los conectores no estructurados del marco de trabajo del conector de datos (DCF) introducen contenido sin procesar y metadatos desde orígenes externos. El contenido se introduce en objetos de lago de datos no estructurados (UDLO) específicos de origen que se asignan al contenido en SFDrive (u origen en caso de copia cero).
- Armonización y estructuración: Las Canalizaciones de Armonización procesan datos de UDLO y archivos, realizando limpieza, normalización, enriquecimiento (NLP, etc.), enmascaramiento de PII y transformación en el formato intermedio armonizado, almacenado en SF Drive y un UDLO armonizado (HUDLO) que se asigna a él.
- Indización: Canalizaciones no estructuradas (UDS) se desencadena sobre el contenido armonizado y los índices de búsqueda están configurados para cada HUDMO.
- Consumo: Las aplicaciones de consumo incluyen búsqueda, recuperación, representación y vinculación a objetos comerciales como Caso. La implicación mediante el consumo de aplicaciones se recopila para proporcionar análisis de uso (como clics, revisiones, etc.)
Las perspectivas calculadas (CI) en Data 360 permiten a los clientes definir y generar mediciones agregadas desde sus datos. Estas mediciones se utilizan a continuación para la implicación, el análisis, la segmentación y la activación puntuales de los clientes. Los datos agregados calculados por los CI se redactan en Lakehouse y se representan como un objeto de perspectiva calculada (CIO).
Existen dos tipos principales de perspectivas calculadas:
- Perspectivas calculadas por lotes: Diseñado para agregación de datos compleja y de gran volumen, donde las mediciones se pueden calcular periódicamente (por ejemplo, diariamente o semanalmente).
- Perspectivas de transmisión: Proporcione la capacidad de generar mediciones y acciones a partir de datos de eventos en tiempo real, permitiendo la implicación inmediata y de baja latencia de los clientes.
Las perspectivas calculadas se definen en objetos de modelo de datos (DMO) y también se pueden definir en otros objetos de perspectivas calculadas. El servicio de perspectivas calculadas gestiona la orquestación de trabajos por lotes y de transmisión.
Tanto los cálculos de perspectivas por lotes como de transmisión utilizan Spark. La diferencia clave es que las perspectivas de transmisión utilizan Transmisión estructurada de Spark, mientras que los CI por lotes se ejecutan utilizando trabajos periódicos por lotes programados de Spark. Para la eficiencia de costes, el servicio de perspectivas calculadas agrupa CI para calcularse juntos en el mismo trabajo de CI por lotes o trabajo de CI de transmisión, basándose en factores como dependencias y solapamiento de objetos de datos de origen.
SNCE y CDF desempeñan un papel significativo en el cálculo de Perspectivas de transmisión.
La resolución de identidad es responsable de transformar datos dispares desde múltiples orígenes en un perfil unificado único y completo.
Es importante comprender que un perfil unificado no es un “registro de oro” y que la resolución de identidad no selecciona valores ganadores o sustituye cualquier dato existente mientras unifica perfiles. Los perfiles unificados sirven como un conjunto de claves que desbloquean sus datos de origen identificando todos los registros coincidentes que se relacionan con la misma entidad, dentro de un origen de datos o entre muchos orígenes. Con esta información, puede seleccionar los datos del sistema de origen correctos para utilizar para un caso de uso comercial concreto.
La resolución de identidad puede consolidar una variedad de tipos de registro, incluyendo Particulares, Cuentas y Domicilios. También se puede utilizar para hacer coincidir candidatos con cuentas existentes. El proceso de unificación es esencial para lograr una vista completa Customer 360 e impulsar la implicación personalizada en tiempo real entre escenarios B2C y B2B.
Las oportunidades en curso de resolución de identidad están construidas en un marco nativo de la nube altamente ampliable diseñado para gestionar volúmenes masivos de datos de forma continua. El proceso implica tres etapas clave, basándose en un potente índice de búsqueda para gestionar el proceso de coincidencia:
- Coincidencia (Selección de candidatos): El objetivo del proceso de coincidencia es buscar registros que puedan pertenecer a la misma entidad. Los registros se analizan con un conjunto de reglas personalizable, cada una de las cuales contiene un conjunto de criterios que definen qué datos coincidir con qué nivel de rigor. Para recuperar de forma eficiente posibles coincidencias desde el almacenamiento de datos, el sistema genera índices para encontrar posibles registros coincidentes utilizando dos técnicas:
- Claves de bloqueo: Una clave de bloqueo es un valor generado a partir de los datos de un registro y reglas de coincidencia (como las primeras letras de un nombre, número de teléfono normalizado, etc.) para agrupar registros potencialmente similares. Cada registro tiene múltiples claves de bloqueo indexadas y almacenadas como un índice invertido, garantizando que el sistema solo realice comparaciones detalladas en pequeños grupos de registros, en vez de en todo el conjunto de datos.
- Hash sensible a la localidad (LSH): Para reglas de coincidencia con coincidencia parcial, los hash se generan basándose en incrustaciones desde modelos entrenados.
- Coincidencia profunda: Después de que el paso de selección de candidatos cree grupos más pequeños de posibles coincidencias, el sistema comienza una comparación más detallada. En esta etapa, los modelos de IA y algoritmos avanzados analizan cada par de registros para calcular una puntuación de coincidencia probabilista. Esta puntuación cuantifica la posibilidad de que dos registros hagan referencia a la misma entidad comparando de forma inteligente campos que a menudo contienen errores ortográficos, variaciones o diferencias de formato.
- Agrupación y unificación: Una vez identificados los registros coincidentes desde los candidatos, se agrupan en un clúster. Este proceso incluye de forma crítica la resolución de coincidencias transitivas. Por ejemplo, si Registro A coincide con Registro B y Registro B coincide con Registro C, los tres están vinculados en el mismo clúster incluso si A y C nunca se compararon directamente. Estos clústeres completos forman la estructura fundamental del Perfil unificado. Este proceso de agrupación en clúster garantiza que todos los registros de origen relacionados estén correctamente vinculados bajo un identificador único y persistente.
- Reconciliación: Los valores de datos de todos los registros de origen agrupados se evalúan utilizando reglas de reconciliación definidas (por ejemplo, Más frecuente, Más reciente o Prioridad de origen) para rellenar el perfil unificado resultante con un fragmento de datos de perfil. La reconciliación no sobrescribe ningún dato existente, ya que todos los datos de origen están disponibles utilizando las claves vinculadas al perfil unificado.
La arquitectura admite la resolución de múltiples tipos de entidades para realizar una variedad de casos de uso.
- Coincidencia individual: Se centra en la creación de perfiles Particular unificado, que vinculan todos los identificadores personales conocidos (correos electrónicos, números de teléfono, Id. de fidelidad, cookies) a una única persona.
- Coincidencia de cuenta: Se centra en la creación de los perfiles Cuenta unificada, que vinculan datos acerca de cuentas. Cuando se compara en nombres de empresa, el motor utiliza un modelo ajustado al comparar de forma parcial.
- Coincidencia de domicilio: Amplía la lógica de coincidencia para agregar registros Particular unificado en grupos de individuos relacionados.
- Coincidencia entre entidades: Además de la unificación, la resolución de identidad también crea vínculos entre objetos de perfil utilizando las mismas reglas de coincidencia. Por ejemplo, un Candidato puede vincularse a una Cuenta utilizando una coincidencia parcial en Nombre de cuenta.
Para garantizar que el Perfil unificado está siempre actualizado, el motor de resolución de identidad funciona con una arquitectura casi en tiempo real. Esta arquitectura optimizada para la nube está diseñada para el procesamiento continuo, logrando tiempos de procesamiento rápidos. Aunque la velocidad de procesamiento varía dependiendo de cómo se reciban los datos de origen, se pueden procesar pequeños lotes de cambios por resolución de identidad con una frecuencia de hasta cada 15 minutos.
El sistema mantiene objetos de vínculo de identidad que asignan cada Id. de registro de origen a su Id. de perfil unificado correspondiente. Esta estructura de datos fundamental permite al motor realizar un seguimiento eficiente de las relaciones y propagar rápidamente cambios y actualizaciones en el Perfil unificado, garantizando que las experiencias de los clientes, como la personalización del sitio web, las recomendaciones de la siguiente mejor acción y la segmentación, siempre aprovechen los datos de clientes disponibles más actualizados.
La segmentación es el proceso principal de transformación de perfiles de clientes unificados en audiencias con capacidad de acción. Esta función es fundamental para potenciar experiencias personalizadas entre canales de marketing, comercio y servicio. La plataforma Salesforce Data 360 Segmentation está diseñada para operaciones a gran escala. Gestiona metadatos complejos, trabajando con un modelo de datos que comprende miles de objetos y relaciones. La plataforma admite reglas complejas, filtros basados en agregación y clasificación basada en ventanas, al tiempo que garantiza un cálculo rápido y fiable a escala de petabytes.
Data 360 admite varios tipos de segmentos para cumplir distintos requisitos comerciales de velocidad, complejidad y jerarquía:
- Segmento estándar: El tipo de segmento principal procesado por lotes. Se publica en una programación personalizable, con una cadencia de publicación estándar de un mínimo de 12 horas hasta 24 horas, o una cadencia de publicación rápida más rápida de 1 a 4 horas, que está optimizada para datos de implicación recientes.
- Segmento en tiempo real: Este segmento se completa on-demand en milisegundos para una acción inmediata basándose en eventos recientes y datos de perfil. Está altamente optimizado para la personalización instantánea pero no puede utilizar criterios de exclusión o segmentos anidados.
- Segmento de cascada: Una estructura jerárquica de subsegmentos utilizados para dar prioridad a un cliente en un segmento único y más valioso si califican para múltiples criterios.
- Segmento anidado: Esto permite reutilizar un segmento existente como un filtro para un nuevo segmento más específico (un perfeccionamiento de un segmento base), heredando la programación del segmento principal.
El motor de segmentación funciona en una arquitectura robusta nativa de la nube que garantiza velocidad, escala y resiliencia.
El proceso principal está gestionado por un servicio de orquestación de trabajos que controla el ciclo de vida del segmento, generando la configuración de trabajo necesaria y desencadenando la ejecución. Esta capa de orquestación mantiene el estado y los metadatos en una base de datos dividida para su capacidad de ampliación.
Aunque la consulta Data 360 gestiona cálculos de recuento de segmentación, la capa de cálculo de Spark es responsable de calcular la pertenencia a segmentos real. La aplicación Spark ejecuta consultas SQL de Spark en datos de clientes extensos. Estos datos pueden residir en el Lago de Data 360, sistemas externos a través de la federación de datos de copia cero o una combinación de ambos.
El sistema está altamente optimizado a través de la generación de consultas inteligentes, que afina la consulta Spark SQL subyacente. Esto incluye técnicas como la poda de particiones inteligente para minimizar el escaneo de datos y la eliminación de subexpresiones redundantes. Para garantizar la fiabilidad del servicio, la arquitectura cuenta con una gestión de recursos adaptativa que ajusta dinámicamente los recursos de computación basándose en el tamaño y la complejidad de la carga de trabajo. Además, la adhesión de SLO se gestiona de forma proactiva con duraciones adaptativas y lógica de reintento. Para una experiencia de usuario rápida, los recuentos de segmentos acelerados utilizan un enfoque basado en muestreo para proporcionar estimaciones de tamaño rápidas durante la creación de segmentos, evitando una ejecución de consulta completa.
Finalmente, se mantiene un enfoque profundo en la observabilidad y la atribución de causas raíz a través de mediciones de ejecución de Spark integrales y clasificación automatizada de errores (por ejemplo, problemas del lado del cliente frente al sistema), reduciendo significativamente el tiempo de diagnóstico y garantizando una plataforma de datos altamente resistente.
La activación es el paso final crítico en el ciclo de vida de Data 360. Su función principal es transformar perfiles de clientes estáticos, segmentados y unificados en datos procesables y enriquecidos y entregar estos datos a extremos internos y externos (como Marketing Cloud, Commerce Cloud y plataformas Adtech). Este proceso está diseñado para desencadenar trayectorias de clientes personalizadas e interacciones casi en tiempo real. Admite funciones avanzadas como atributos relacionados, filtrado de suscripción de activación, filtrado de consentimiento, limitación y clasificación.
La activación ofrece tres métodos diferentes para la entrega externa y el cumplimiento de canal:
- Activación por lotes: Diseñado para operaciones programadas de gran volumen, como campañas de correo electrónico a gran escala y actualizaciones de audiencia publicitaria. Los datos se entregan por etapas en Depósitos internos seguros (Almacenamiento de objetos de nube) o a través de Transferencia de archivos segura, seguido de un proceso de introducción de API iniciado por el sistema de destino. Las activaciones por lotes pueden utilizar el modo de actualización especial (incremental) para reducir los volúmenes enviados y procesados por socios de Salesforce.
- Activación de transmisión: Optimizado para casos de uso casi en tiempo real que requieren automatización dirigida por eventos. La entrega se logra a través de llamadas de API directas enviadas al extremo de destino.
- Flujos desencadenados por activación: Este canal altamente plataformado proporciona un enfoque sin código/bajo código para integrar Datos de audiencia con cientos de plataformas de implicación activadas por API de clientes. Tras completar la activación, Data 360 rellena un DMO de audiencia, que luego desencadena un flujo de alta escala. El motor de flujos consume posteriormente los datos de audiencia y utiliza funciones de plataforma como Servicios externos y Destinos salientes de silenciamiento para realizar llamadas al destino basado en API final. Este método reduce significativamente el tiempo necesario para incorporar nuevos destinos de activación.
La activación utiliza los mismos patrones que la segmentación para la gestión de trabajos, la ejecución distribuida y la supervisión. Esto incluye los principios del servicio de orquestación de trabajos para la gestión del ciclo de vida y la capa de cálculo (Spark) para el procesamiento, y se basa en la telemetría de trabajos para la observabilidad del rendimiento y el cumplimiento del objetivo a nivel de servicio (SLO).
Además de eso, la activación tiene:
Activation Target Management supervisa las conexiones, credenciales y configuraciones seguras para todos los extremos de destino. Garantiza que los formatos de datos y protocolos de seguridad están estandarizados, garantizando una entrega saliente fiable a varias plataformas, incluyendo Marketing Cloud, socios de Adtech y otras aplicaciones externas.
La activación adapta la carga para objetivos específicos. Para Salesforce Marketing Cloud, esto incluye Filtrado consciente de unidad comercial (BU), compatibilidad con múltiples EID y controles de polinización cruzada.
Communication Governance actúa como un guardián, garantizando que el uso y la comunicación de datos cumplen con las preferencias y los requisitos legales del cliente. El modelo de consentimiento centralizado unifica todas las preferencias de los clientes, desde las anulaciones de suscripción globales hasta el consentimiento específico del canal y el propósito, y se almacena en el Perfil de particular unificado. Durante la ejecución, la plataforma aplica estrictamente estas políticas utilizando filtrado de exclusión para eliminar automáticamente individuos no consentidos de la carga final. Además, el sistema aplica reglas de selección de punto de contacto para garantizar que utiliza el punto de contacto único, más compatible y preferido para el canal previsto antes de transmitir cualquier dato. Este mecanismo de aplicación está protegido por el marco de gobernanza subyacente, que emplea medidas de protección como el enmascaramiento dinámico de datos y controles de acceso para proteger campos de datos confidenciales durante el proceso de activación.
El verdadero valor de una plataforma de datos unificada radica en su capacidad de proporcionar acceso coherente y sin esfuerzo a todos sus activos de datos, independientemente de su origen o estructura. La función Consulta unificada de Salesforce Data 360 está diseñada con precisión para entregar esto, abstrayendo las complejidades subyacentes de diversos establecimientos de datos para proporcionar una interfaz de consulta única y potente.
La capa Consulta unificada ofrece acceso sofisticado para diversos patrones de consumo:
- Consulta estructurada y no estructurada híbrida: Proporciona una amplia compatibilidad con SQL para consultar sin problemas tanto datos estructurados como los metadatos estructurados de datos no estructurados. Esto se mejora por la extensibilidad del operador a través de funciones de tabla, permitiendo la búsqueda especializada entre tipos de texto, imagen y espacio.
- Rendimiento acelerado con Hyper: Aprovechando Hyper, un motor de alto rendimiento en memoria, Data 360 acelera las consultas analíticas complejas y los paneles interactivos, proporcionando respuestas casi instantáneas sobre conjuntos de datos masivos.
- Enfoque unificado para IA y personalización: Este acceso unificado es crucial para generar resultados dirigidos y personalizados, facilitando directamente respuestas LLM más precisas utilizando Generación aumentada de recuperación (RAG) basando modelos de IA en datos empresariales enriquecidos.
- Integración con consumo descendente: Sirve como la capa de acceso a datos fundamental para experiencias dirigidas por la interfaz de usuario, API sólidas, flujos de trabajo de IA generativa y enriquecimiento de CRM, conectando datos a la activación de forma sencilla.
Al proporcionar una interfaz de consulta única, inteligente y de alto rendimiento, la consulta unificada de Data 360 permite a los arquitectos crear aplicaciones ágiles dirigidas por datos que aprovechan al máximo su espectro completo de información de clientes.
Data 360 es una plataforma activa que admite la activación de oportunidades en curso en respuesta a eventos de datos. Por ejemplo, un evento significativo, como una caída en el saldo de cuenta de un cliente, puede desencadenar un flujo de Salesforce para orquestar una acción correspondiente. Del mismo modo, las actualizaciones en mediciones clave, como el gasto de toda la vida, se pueden propagar automáticamente a aplicaciones relevantes.
Acciones de datos supervisa continuamente datos incrementales para cambios utilizando eventos de cambio nativos de almacenamiento (SNCE) y noticias en tiempo real de cambios (CDF). Estos datos se evalúan con respecto a reglas de acción configuradas por el cliente, como supervisión de umbral o cambios de estado. Cuando se cumplen estas reglas, se genera un evento de acción de datos. Este evento se enriquece con información adicional (por ejemplo, el estado de fidelidad del cliente) y se envía inmediatamente a su destino configurado, como Salesforce Flow o una aplicación externa, para desencadenar orquestaciones comerciales.
Data 360 admite funciones de CDP (Plataforma de datos de clientes) nativas, incluyendo funciones avanzadas de resolución de identidad y la creación de identificadores y perfiles individuales unificados junto con historias de implicación integrales. Esta plataforma es experta en la gestión de marcos de trabajo tanto de empresa a empresa (B2B) como de empresa a consumidor (B2C) admitiendo la resolución de identidad y gráficos de identidad que utilizan reglas de coincidencia exactas y parciales, como se describe anteriormente. Estos gráficos de identidad están enriquecidos con datos de implicación de varios canales, lo que ayuda a crear gráficos de perfil detallados con perspectivas analíticas y segmentos valiosos.
Un concepto clave que admite el perfil de cliente es el gráfico de datos. Data 360 ofrece un gráfico de datos de empresa en formato JSON, que es un objeto desnormalizado derivado de varias tablas Lakehouse y sus interrelaciones. Esto incluye un gráfico de datos "Perfil" creado por CDP que abarca el historial de compras y navegación de una persona, el historial de casos, el uso de productos y otras perspectivas calculadas, y es ampliable por clientes y socios. Estos Gráficos de datos están adaptados a aplicaciones específicas y mejoran la precisión de solicitudes de IA generativa proporcionando contexto de cliente o usuario relevante. La capa en tiempo real de Data 360 utiliza el gráfico Perfil para la personalización y segmentación en tiempo real. Prevemos modelar Contexto Agentforce que abarca Conversaciones, Sesiones y memoria Agente como Gráficos de datos.
Además, el CDP permite la segmentación y activación efectivas entre diferentes plataformas como Marketing Cloud de Salesforce, Facebook y Google. Procesa perfiles de clientes por lotes, casi en tiempo real y en tiempo real, lo que permite la personalización y la toma de decisiones inmediatas. Esta función mejora las interacciones en escenarios B2C y B2B, garantizando que los negocios puedan responder de forma rápida y precisa a las necesidades y comportamientos de los clientes.
La capa en tiempo real de Data 360 está respaldada por el CDP de Data 360 y amplía sus conceptos para casos de uso en tiempo real. La capa en tiempo real de Data 360 está diseñada para procesar eventos como transmisiones de clics web y móviles, visitas, datos de carritos y pasos por caja en latencias de milisegundos, mejorando la personalización de la experiencia del cliente. Supervisa continuamente la implicación de los clientes y actualiza el perfil de cliente de Customer 360 con datos de implicación en tiempo real, segmentos y cálculos para una personalización inmediata.
Por ejemplo, cuando un consumidor adquiere un artículo en un sitio web de compras, la capa en tiempo real detecta e introduce rápidamente este evento, identifica al consumidor y enriquece su perfil con información de gasto de toda la vida actualizada. Esto permite la personalización de su experiencia en el sitio en subsegundos. Además, esta capa incluye funciones para desencadenar y respuestas en tiempo real, permitiendo acciones inmediatas basadas en interacciones de clientes.
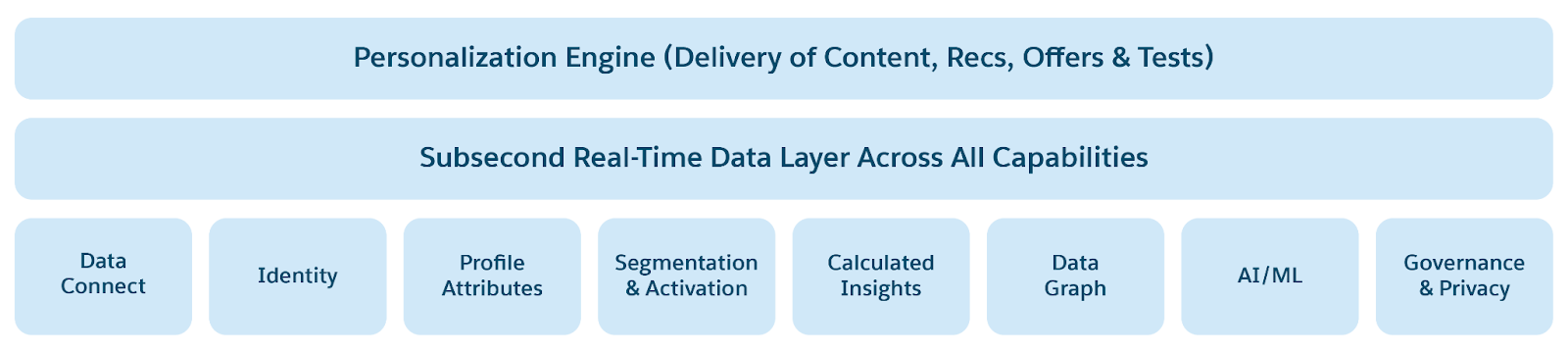
La plataforma Sub-Second Real-Time potencia esta transformación a través de varias funciones clave:
- Gráficos de datos en tiempo real: Un perfil Customer 360 se crea utilizando un gráfico desnormalizado que incluye objetos clave y campos más relevantes para las marcas. Estos Gráficos de datos permiten el procesamiento de datos en tiempo real y entregan contenido con capacidad de acción y perspectivas en milisegundos
- Ingreso y transformación en tiempo real: Introduzca eventos de usuario y perfil en milisegundos desde orígenes web y móviles.
- Resolución de identidad en tiempo real: Combine perfiles de clientes entre dispositivos, unificando usuarios desconocidos y conocidos al instante.
- Perspectivas calculadas en tiempo real: Calcule mediciones como el valor de vida útil (LTV) o el historial de visitas de usuarios en milisegundos para activar Personalización u Ofertas para web, ChatBot o Agente de servicio.
- Segmentación en tiempo real: Segmente audiencias sobre la marcha, personalizando mensajes e interacciones en tiempo real.
- Acciones en tiempo real: Permita a las marcas evaluar cada implicación de los usuarios y realizar acciones a través de Salesforce Flow u otros canales de comunicación relevantes.
En Data 360, creamos una nueva plataforma en tiempo real con oportunidades en curso en tiempo real, almacenamiento de baja latencia y una capa de procesamiento de datos de subsegundos. A medida que se introducen datos interactivos rápidos desde canales Web y móviles, pasan por una serie de procesos rápidos.
Nuestros SDK móviles y web y las API en tiempo real recopilan datos de aplicaciones móviles y web (en futuras interacciones de Agentes) y los envían a nuestro servidor de baliza. Estos datos se enrutan a continuación a la Capa en tiempo real para su procesamiento en milisegundos y a la Capa Lakehouse para su integración con datos por lotes/transmisión. La capa Tiempo real procesa los datos en tiempo real entrantes en el contexto de un perfil de usuario (anónimo o que inició sesión), como la actualización del gasto total del usuario o el valor de toda la vida, etc. para la personalización en tiempo real en sesión. La Capa en tiempo real está respaldada por memoria principal y almacenamiento NVme (SSD) para almacenar datos en tiempo real y perfiles de clientes. Una vez que los datos están en la Capa en tiempo real, pasan por los siguientes procesos antes de actualizarse en Gráfico de datos en tiempo real:
- Ingesta sencilla y transformaciones: Los datos se introducen y transforman para su posterior procesamiento.
- Resolución de identidad: Las reglas de coincidencia exactas se aplican para unificar perfiles con todos los conjuntos de reglas de coincidencia existentes, de modo que los especialistas en datos no tienen que crear nuevos conjuntos de reglas de resolución de identidad específicamente para tiempo real.
- Perspectivas calculadas: Cada implicación se evalúa, se ejecutan cálculos sencillos como suma y recuento en milisegundos y los datos se actualizan en el Gráfico de datos en tiempo real.
- Segmentos en tiempo real: Cada dato de implicación se evalúa para determinar si cumple los criterios para segmentos en tiempo real definidos, y los usuarios se agregan a segmentos cualificados en milisegundos.
- Acciones en tiempo real y desencadenadores: Cada implicación se evalúa con reglas definidas para desencadenar acciones en una gama de objetivos en tiempo real cuando se cumplen las reglas en milisegundos.
- API y gráfico de datos en tiempo real: El gráfico de datos en tiempo real, que también incluye una API en tiempo real, permite a las marcas recuperar datos en formato JSON actualizados para cada usuario, garantizando que todas las interacciones de clientes estén informadas por los datos más actualizados.
La personalización se basa en saber a quién dirigirse, cuándo y dónde entregar contenido y recomendaciones relevantes, qué decir y con qué frecuencia. La Plataforma de servicios de personalización es el orquestador de las decisiones que se toman para optimizar el logro de objetivos a través de experiencias personalizadas.
Los Servicios de personalización ofrecen las siguientes funciones:
- Conjunto coherente de modelos y formas de interpretar datos de perfil, actividad y activo en Data 360
- Experimentación integrada de plataforma (A/B/n, Bandido de múltiples brazos)
- Integración de objetivos en tiempo de diseño (configuración), tiempo de entrenamiento de ML y tiempo de ejecución (inferencia de ML)
- Compatibilidad de interacción por lotes y en tiempo real a escala B2C (usuarios anónimos, alto volumen externo interactivo/en tiempo real, alto volumen de lotes internos)
- Analytics dirigido por Data 360
- Patrones para integrar el modelo de IA y el servicio de otras partes (internas y externas)
- Integración en el ecosistema de metadatos principales (características PLACA)
- Implementaciones de OOTB de casos de uso dirigidos por IA de alto valor (Recomendaciones/decisiones con varios algoritmos de ML incluyendo bandas contextuales para promoción/selección de contenido, recomendaciones de productos, decisiones de precios, etc.)
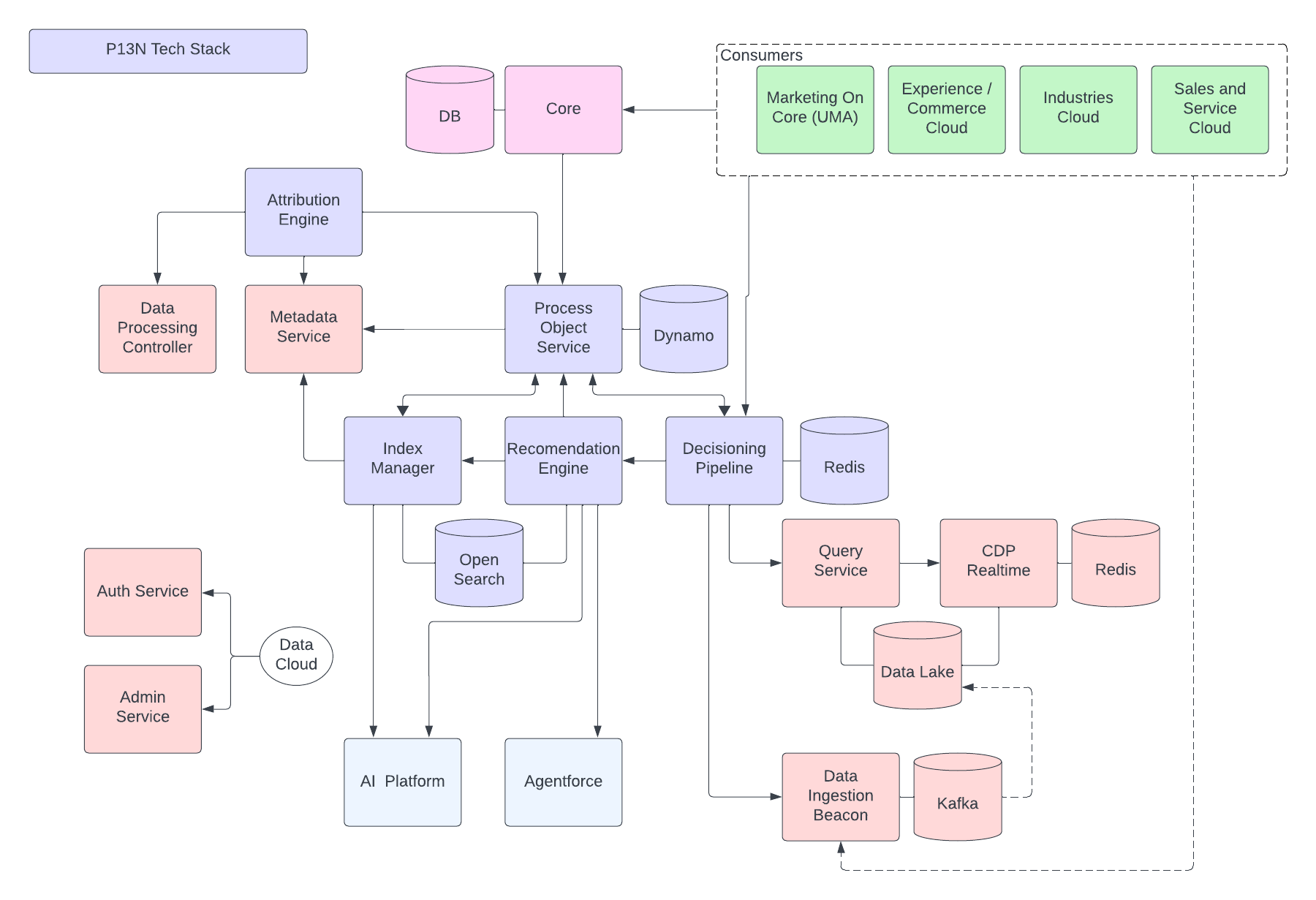
- Decisión de oportunidades en curso
- Servir solicitudes externas para decisiones de personalización incluyendo aumento de perfil, experimentación y recomendaciones.
- Motor de recomendaciones
- Mantenimiento en tiempo de ejecución de recomendaciones basadas en reglas o ML.
- Gestor de índices
- Gestiona/Orquesta flujos de trabajo para procesos asíncronos incluyendo entrenamientos de ML para modelos de recomendación
- Servicio de objetos de proceso
- Responsable de la sincronización de metadatos de personalización entre principales y externos
- Motor de atribución y experimentación
- Atribución de Analytics y experimentación de recomendaciones de personalización
Data 360 está diseñado como una plataforma sólida y enriquecida específicamente para dar cobertura a las experiencias de agentes emergentes. Alcanzamos estas funciones mediante la creación de varios servicios de Data 360 existentes y a través de una integración profunda con Agentforce.
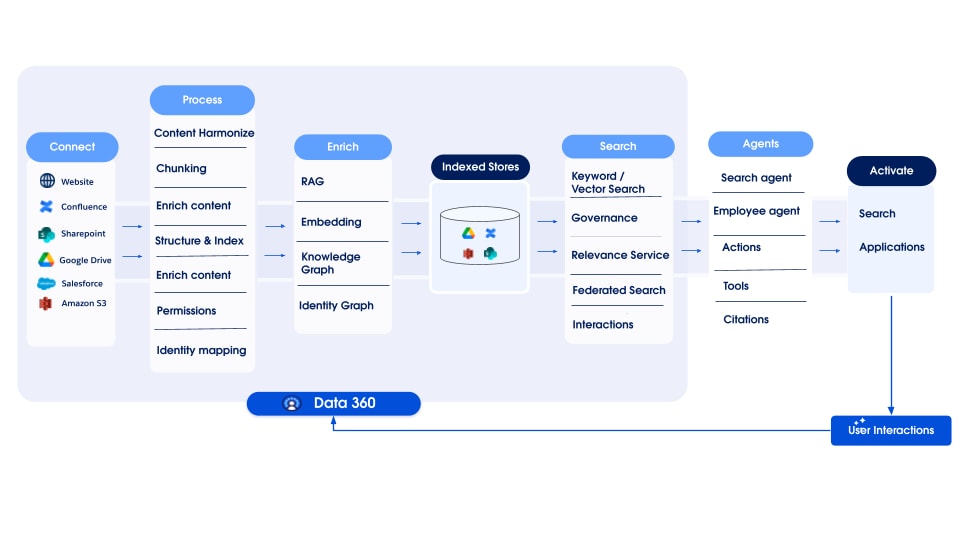
Nuestro enfoque de Búsqueda de empresa agente se basa en los siguientes principios:
- Los datos de empresa se mantienen en establecimientos o servicios aislados, con los permisos seguros necesarios para el acceso. La capacidad de acceder a estos datos y procesarlos mientras mantiene los permisos de origen es vital para garantizar Trust.
- La clasificación cruzada y la relevancia entre el conjunto completo de datos permiten mejores resultados, lo que a su vez puede proporcionar un mejor contexto para experiencias de agentes.
Para entregar estas experiencias, Búsqueda de empresa de agente se crea sobre estos componentes arquitectónicos clave:
- Conectores: El amplio conjunto de conectores disponibles en Data 360 permite acceder e introducir datos desde una amplia variedad de orígenes.
- Procesamiento de datos no estructurado: Esto es fundamental para gestionar contenido no tabular, permitiendo al sistema derivar significado y contexto desde diversos datos.
- Gobernanza: Garantizar la seguridad, el cumplimiento y los controles de acceso de nivel empresarial para todos los datos consumidos por la búsqueda. La compatibilidad con permisos de visibilidad de origen garantiza que los datos sean accesibles solo para usuarios autorizados, tanto para experiencias de búsqueda sencilla como de agentes. Para garantizar una recuperación rápida, los permisos de seguridad se evalúan y aplican de forma nativa por los backends de búsqueda en la etapa más temprana del acceso a los datos.
- Capa de recuperación unificada: Para abordar el reto de los datos aislados, los conectores se alimentan a una capa de Recuperación unificada completa. Esta capa proporciona un único punto de acceso a todos los datos, ya sea que permanezca en sistemas externos a los que se accede a través de Búsqueda federada o que se gestione de forma nativa a través de índices avanzados para datos introducidos y de copia cero.
- Comprensión de consulta inteligente: Antes de la recuperación, el sistema utiliza mecanismos con tecnología de IA para interpretar la intención del usuario. Además de integrar representaciones de la consulta para la coincidencia de vectores semánticos, puede reescribir y ampliar búsquedas basadas en palabras clave para mejorar la precisión.
- Búsqueda híbrida y consulta avanzada: Para encontrar la información más relevante, la plataforma utiliza múltiples estrategias en paralelo. La búsqueda híbrida proporciona una coincidencia de palabras clave precisa con la búsqueda de vectores semánticos en fragmentos de datos optimizados, mientras que la búsqueda de registros completos recupera simultáneamente documentos completos. Ambas se combinan para garantizar la relevancia semántica y la cobertura de contenido completa.
- Clasificación jerárquica: Después de recuperar los datos, una arquitectura de clasificación jerárquica de múltiples etapas puntúa, combina y vuelve a clasificar los resultados de cada origen y método. Este proceso crea una lista única y unificada que aflora la información más pertinente para el usuario o agente.
La IA generativa está cambiando el consumidor principal de la búsqueda empresarial de usuarios humanos a Modelos de idiomas grandes (LLM). Búsqueda de Data 360 está diseñada desde cero para servir a ambos. Está optimizado para gestionar las consultas más largas y complejas de los agentes y devolver los resultados enriquecidos y contextuales necesarios para el consumo programático y los bucles de razonamiento. Al mismo tiempo, el sistema puede gestionar las consultas más cortas y a menudo ambiguas típicas de usuarios humanos, proporcionando funciones como miniprogramas y resaltando para una evaluación rápida en una interfaz de usuario.
La entrega definitiva de experiencias de búsqueda de agentes combina ambos enfoques:
- Resultados de búsqueda directa: la aplicación puede mostrar una lista tradicional de resultados clasificados utilizando una API dirigida por metadatos creada sobre la base de búsqueda unificada Data 360.
- Respuestas conversacionales auténticas de varios turnos: las respuestas de agentes se aplican mediante la integración nativa con Agentforce. Esta experiencia de conversación está dirigida por un agente principal que orquesta acciones y consultas, delegando todas las tareas de recuperación de información a un agente de búsqueda interno especializado.
Este agente de búsqueda especializado está optimizado para la recuperación de información comercial. Utiliza un bucle de razonamiento para formular y ejecutar búsquedas paralelas para explorar diferentes facetas de la solicitud de un usuario. Utiliza un potente conjunto de herramientas, incluyendo la búsqueda unificada de Data 360 para todos los tipos de datos y lenguajes de consulta estructurados para recuperar datos precisos desde tablas y entidades.
A través de esta síntesis arquitectónica, Data 360 potencia la creación de experiencias de búsqueda empresarial altamente inteligentes, conscientes del contexto y con capacidad de acción.
La extensibilidad es una función clave en Salesforce Platform. La extensión de código proporciona extensibilidad en Data 360, permitiendo a los usuarios pro-código ejecutar lógica Python personalizada directamente dentro del entorno de Data 360, complementando sus funciones declarativas enriquecidas y de código bajo. Utilizando Extensión de código, los usuarios pueden ampliar de forma segura funciones principales de Data 360 como Transformaciones y Canalizaciones de datos no estructuradas (desglose personalizado).
Nuestro diseño para Extensión de código prioriza la flexibilidad, la seguridad, la eficiencia y una experiencia de desarrollador simplificada. Admite dos modelos de ejecución principales, cada uno adaptado para necesidades arquitectónicas específicas:
- Modelo de secuencia: de comandos
- Objetivo: Para una lógica personalizada integral que requiere interacción directa con el Lago de Data 360.
- Funcionalidad: Los clientes redactan secuencias de comandos Python completas utilizando el SDK de extensión de código, activando el acceso de lectura y escritura a Lakehouse a través de las API de SDK. Ideal para la preparación de datos personalizados/complejos o la manipulación de datos a medida.
- Aislamiento y seguridad: Aunque las secuencias de comandos acceden al Lakehouse, su ejecución está confinada a un entorno seguro y aislado dentro del tiempo de ejecución de Data 360, evitando interferencias con otros procesos o acceso al sistema no autorizado.
- Modelo de funciones:
- Objetivo: Análogo a una función sin servidor, para cálculos modulares sin estado invocados desde oportunidades en curso de Data 360 existentes (por ejemplo, segmentación personalizada en una oportunidad en curso no estructurada).
- Funcionalidad: Las funciones proporcionadas por el cliente toman entrada, computan y devuelven salida.
- Aislamiento y seguridad: Estas funciones están diseñadas para un aislamiento estricto; no tienen acceso directo a Lakehouse. Su ejecución es sandbox, sin estado y con recursos limitados, lo que las hace adecuadas para pasos de procesamiento centrados y sin estado, garantizando la seguridad, la ejecución predecible y minimizando el radio de explosión.
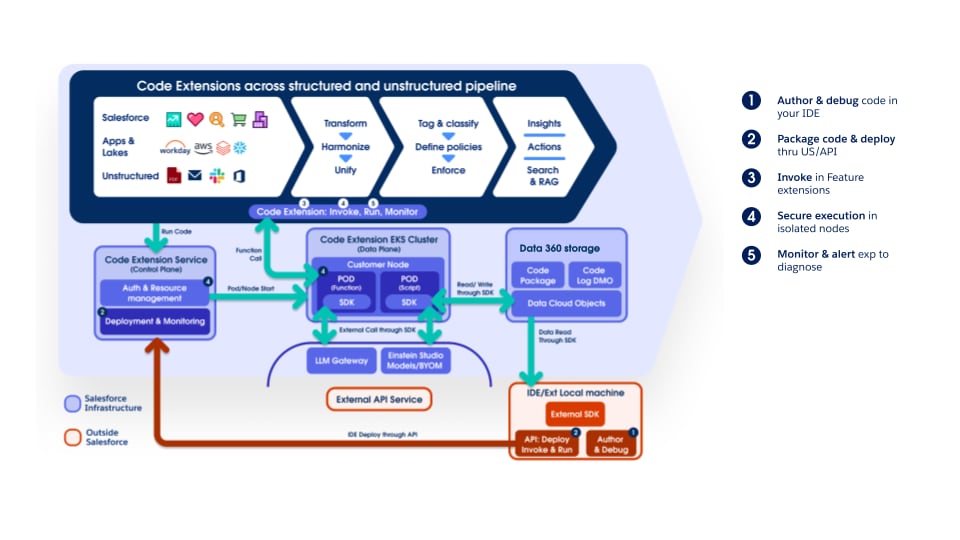
Tanto el modelo de secuencia de comandos como el de función tienen como objetivo ejecutar código de cliente de forma segura, evitando que el código de un arrendatario afecte a otros u obtenga acceso no autorizado a datos de otros arrendatarios, recursos de Salesforce o recursos externos. Esta seguridad se logra a través de una arquitectura por capas (defensa en profundidad). Esta arquitectura proporciona un entorno de ejecución aislado para el código personalizado de cada arrendatario, incorporando varias barandillas. Estos incluyen el aislamiento lógico a nivel de Kubernetes (K8s), el aislamiento de red, el entorno sandbox en tiempo de ejecución y los permisos de privilegios mínimos, todo ello complementado por la supervisión operativa y la preparación de la respuesta ante incidentes para la detección y la respuesta.
Para dar cobertura a un ciclo de vida de desarrollo sólido, Extensión de código ofrece:
- Creación y depuración externa: Los desarrolladores pueden crear y depurar código Python en entornos familiares como VSCode, aprovechando el SDK.
- Implementación flexible: El código personalizado se puede empaquetar e implementar utilizando utilidades de SDK, la interfaz de usuario de Data 360 o la API, lo que permite la integración en CI/CD.
Registros operativos: El acceso a registros de ejecución detallados proporciona transparencia y ayuda a solucionar problemas en producción.
Al ofrecer estas funciones de extensión de código seguras y flexibles, Data 360 permite a los arquitectos adaptar la plataforma a sus requisitos de procesamiento de datos más exclusivos y complejos, consolidando realmente su función como una estructura de datos empresarial ampliable.
A medida que las empresas aceleran la adopción de la IA, la mayoría mantiene ecosistemas de ML heterogéneos, incluyendo Amazon SageMaker, la IA de Google Vertex y entornos basados en Python personalizados, alojando modelos que dirigen predicciones críticas para la misión, como puntuación de riesgo de crédito, propensión a abandonos, recomendaciones de productos y decisiones sobre las siguientes mejores acciones.
Tradicionalmente, la integración de estos modelos externos en Salesforce requería capas de API a medida, oportunidades en curso de ETL u orquestación de middleware, introduciendo duplicación de datos, gastos generales de gobernanza, latencia y complejidad operativa, retos que entran en conflicto con una visión de Customer Data Platform (CDP) unificada, compatible y en tiempo real.
Aportar su propio modelo (BYOM): Proporcionado a través de Einstein Studio en Data 360, soluciona estos retos activando la invocación directa de modelos entrenados de forma externa dentro de flujos de trabajo de Salesforce, lógica Apex y herramientas de automatización, sin mover o replicar datos. A través de la federación de copia cero, Data 360 actúa como la única fuente de verdad gobernada, exponiendo datos Customer 360 armonizados para inferencia en extremos externos. Las salidas de predicción vuelven a fluir en tiempo real, potenciando los procesos comerciales con inteligencia ampliable.
BYOM cierra eficazmente la brecha entre la ciencia de datos y la ejecución operativa desvinculando el desarrollo de modelos, los datos gobernados y las capas de consumo. Preserva la independencia de la plataforma, reduce la complejidad de la integración, acelera la implementación de la IA y mantiene la gobernanza sobre datos confidenciales.
La arquitectura funciona del siguiente modo: Data 360 proporciona una base de datos Customer 360 unificada, mientras Einstein Studio orquesta conexiones a plataformas ML externas (SageMaker, IA de Vertex o extremos personalizados). Los modelos externos ejecutan inferencias en tiempo real, por lotes o en modo transmisión. Las capas de Salesforce (las API de Flujo, Apex y Consulta) consumen resultados para entregar perspectivas personalizadas, automatizadas y analíticas entre Sales Cloud, Servicio, Marketing e Industry Cloud.
Desde el punto de vista empresarial, BYOM ofrece:
- Integridad y gobernanza de datos: Elimina copias de datos no controladas y aplica el cumplimiento de políticas.
- Democratización de IA: Hace que los modelos complejos sean accesibles para usuarios no técnicos a través de herramientas de Salesforce.
- Aceleración de tiempo a valor: Los modelos externos se activan inmediatamente en procesos de Salesforce.
- Escalabilidad y compatibilidad de arquitectura híbrida: Activa la implementación de múltiples nubes de cargas de trabajo de IA.
- Arquitectura de IA lista para el futuro: Admite estrategias de IA componibles, desvinculando datos, modelo y capas de consumo para agilidad operativa.
Aportar su propio LLM (BYO-LLM): Ofrece el mismo mecanismo de extensibilidad pero para modelos generativos. Al activar la invocación directa de LLM externos, permitimos a los clientes utilizarlos en Agentforce Platform en lugar de modelos proporcionados por Salesforce. Para empresas BYO-LLM permite:
- Acceso a modelos ajustados
- Integración de modelos no proporcionados actualmente por Salesforce
- Uso de modelos en cuentas proporcionadas por el cliente
Las empresas modernas operan en un complejo panorama de datos caracterizado por dos grandes retos arquitectónicos:
- Fragmentación intraempresarial: Las grandes organizaciones utilizan con frecuencia múltiples organizaciones de Salesforce (a menudo segmentadas por región, unidad comercial o adquisición histórica) y numerosos otros sistemas de datos. Esta fragmentación crea silos de datos internos, lo que hace imposible establecer una vista única, de confianza y unificada del cliente para la implicación en tiempo real en todo el negocio. El reto es unificar estos datos sin consolidarlos físicamente o duplicarlos en todos los sistemas, garantizando que la gobernanza permanezca intacta.
- Colaboración entre empresas: Las empresas a menudo necesitan compartir datos con socios y proveedores para marketing conjunto, medición e inteligencia comercial. El reto es permitir esta colaboración mientras protege datos confidenciales y patentados y cumple con leyes de privacidad como el RGPD y CCPA, así como barreras competitivas.
Salesforce Data 360 aborda estos retos con un marco Trust by Design de copia cero basado en el principio de compartir el acceso y las perspectivas en vez de mover o duplicar datos.
Salesforce Data 360 soluciona los retos de colaboración y fragmentación de datos con Data Cloud One, Colaboración de datos entre Data 360 y Salas limpias de datos de privacidad. Estas soluciones unifican datos de clientes, permiten el intercambio seguro de datos y proporcionan perspectivas de preservación de la privacidad. Con un enfoque Trust by Design de copia cero, las organizaciones pueden liberar el potencial de datos para la implicación en tiempo real, las asociaciones mejoradas y la toma de decisiones inteligente. Cada una de estas opciones de colaboración de datos tiene diferentes fines.
Activación de empresa interna con Data Cloud One
Data Cloud One es la solución arquitectónica fundamental para empresas que operan con múltiples organizaciones de Salesforce. Su propósito va más allá del simple uso compartido de datos; está diseñado para establecer una vista de cliente única y de confianza y activar funciones de plataforma Data 360 completas en toda la organización.
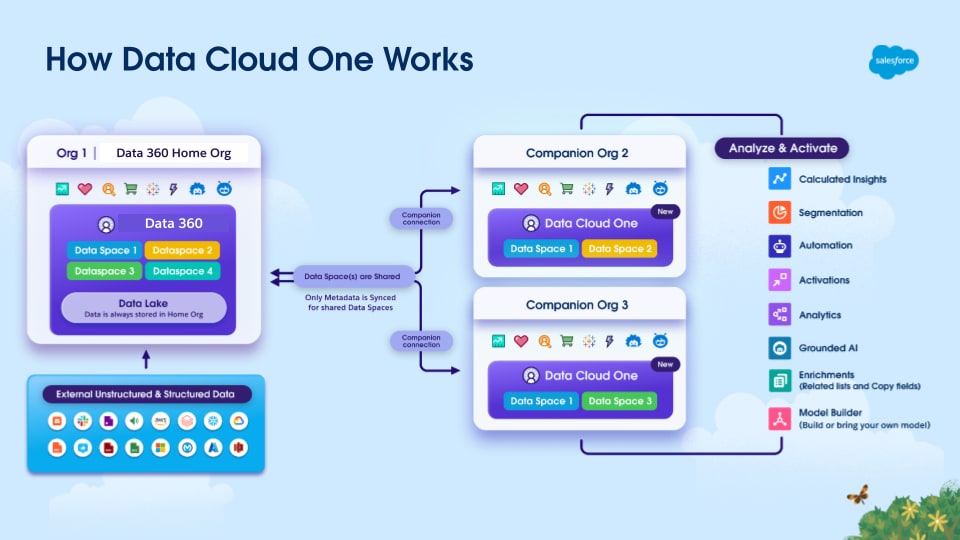
Este mecanismo se centra en una instancia designada de Home Org Data 360, que sirve como la autoridad central para la gestión de datos y la creación del perfil de cliente unificado. La organización de inicio es la organización en la que se aprovisiona Data 360. Se establece una conexión de Data Cloud One entre Data 360 y otras organizaciones de Salesforce, denominadas organizaciones de compañía. Como parte de la conexión de Data Cloud One, Data 360 comparte uno o más de sus espacios de datos con cada organización complementaria, proporcionando acceso a datos y metadatos en cada espacio de datos compartido. Esto se logra a través de un modelo de federación de copia cero y sincronización de metadatos entre organizaciones.
Data Cloud One también permite a las organizaciones complementarias aprovechar la instancia Data 360 de la organización de inicio para sus propias necesidades de activación, personalización e inteligencia. Esta estrategia es esencial para eliminar la fragmentación de datos interna y garantizar que todas las unidades comerciales se activen en el mismo perfil de cliente, gobernado y unificado, maximizando el ROI de la implementación principal de Data 360.
Colaboración de datos entre organizaciones de Data 360
Para entornos internos distribuidos (donde la centralización completa no es factible) y para la colaboración con socios externos de confianza, el uso compartido de datos de Data 360 a Data 360 conecta instancias de Data 360 independientes.
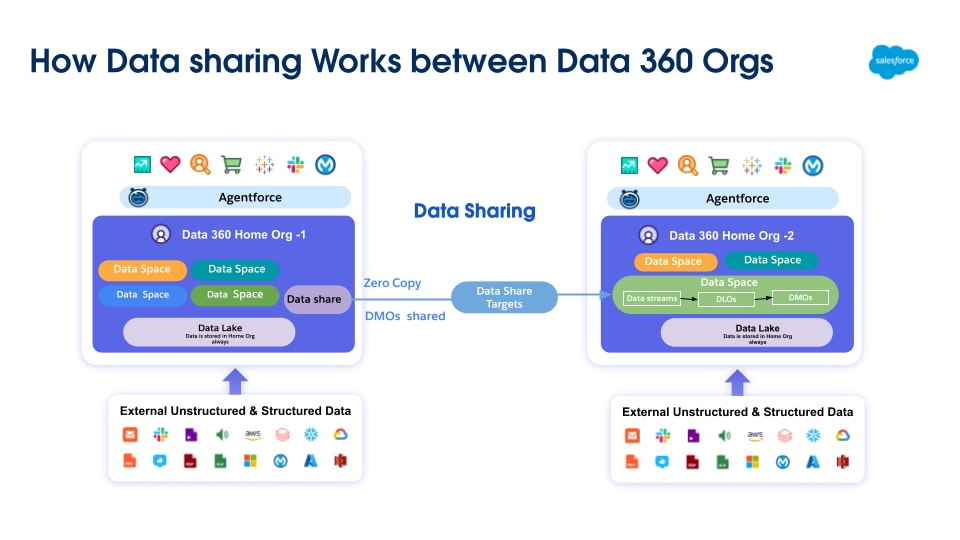
Este modelo de colaboración de copia cero establece una conexión entre arrendatarios de Data 360 separados aprovisionados en diferentes organizaciones de Salesforce con el fin de intercambiar de forma segura objetos de datos (DLO, DMO y CIO). Una vez conectado, todo el objeto de datos se vuelve accesible en Data 360 del destinatario. El administrador de Data 360 del destinatario puede establecer reglas de regulación para gestionar el acceso de los usuarios a estos datos.
Privacidad-Primera colaboración con Colaboración de sala limpia de Data 360
Cuando la colaboración requiere los niveles más altos de privacidad y cumplimiento, o cuando las preocupaciones de la competencia prohíben el uso compartido de datos sin procesar, Data 360 Clean Rooms tiene un mandato arquitectónico.
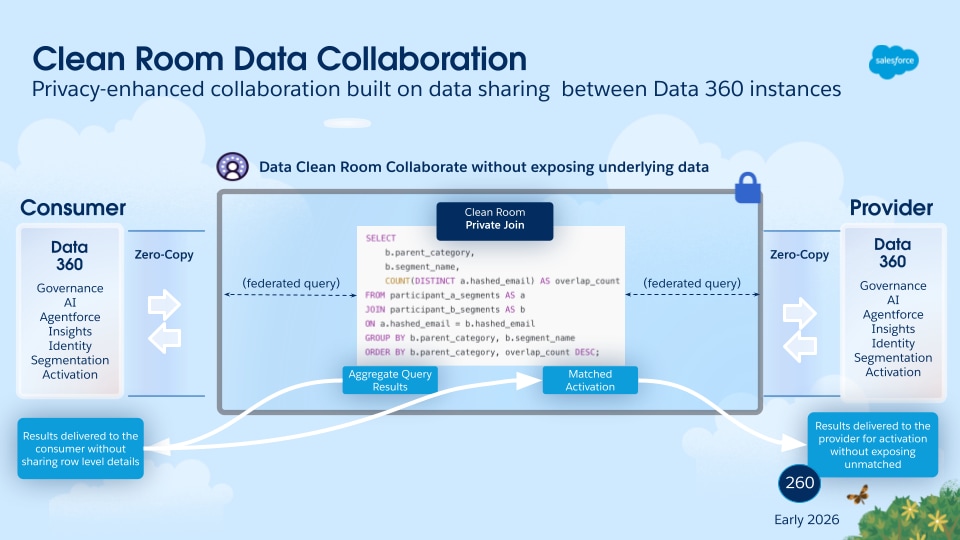
Arquitectónicamente, la colaboración de salas blancas de Data 360 se crea sobre el marco de trabajo Colaboración de copia cero utilizado por la colaboración de datos de Data 360 a Data 360, pero con capas adicionales de regulación y restricciones computacionales aplicadas. Data 360 Clean Room proporciona un entorno informático seguro y controlado donde las partes pueden unir sus conjuntos de datos basándose en claves anónimas. Su objetivo principal es permitir el análisis conjunto y la generación de perspectivas sin exponer los datos propios subyacentes. El entorno aplica reglas estrictas y programables como umbrales de agregación mínimos e identificadores no exportables. Estas reglas garantizan que solo se deriven y compartan perspectivas aprobadas, mejoradas por la privacidad y agregadas. Esto hace que Salas limpias sea esencial para casos de uso como la medición de campañas entre plataformas y el análisis de solapamiento de audiencia confidencial.
Data 360 está diseñado como una estructura de datos inteligente, ampliable y de confianza necesaria para potenciar la IA de próxima generación. Su diseño arquitectónico soluciona el problema de los datos fragmentados, permitiendo a las organizaciones unificar, procesar y activar todos los datos de clientes a escala, utilizando la federación de datos de copia cero para garantizar la eficiencia.
Su sólida organización de datos establece una vista armonizada desde los DLO (incluyendo datos no estructurados) a los DMO, todo ello protegido dentro de espacios de datos particionados. Las versátiles funciones de procesamiento de datos de Data 360, incluyendo transformaciones por lotes y transmisión, perspectivas calculadas, procesamiento de datos no estructurado y resolución de identidad, están impulsadas por la arquitectura incremental de SNCE y CDF, garantizando un procesamiento eficiente casi en tiempo real y ahorros de costes significativos.
La capacidad de ampliación se proporciona por la arquitectura Extensión de código, activando de forma segura la lógica Python personalizada a través de secuencias de comandos o funciones aisladas para requisitos exclusivos. Además, un marco de trabajo de gobernanza de datos integral, construido sobre el control de acceso basado en atributos (ABAC) con políticas de CEDAR, garantiza seguridad granular, enmascaramiento de datos dinámico y aplicación coherente en todo el consumo de datos. Esto culmina en funciones de segmentación y activación sofisticadas, traduciendo perfiles de clientes unificados en estrategias de implicación dinámicas y de múltiples canales con capacidad de respuesta en tiempo real.
De forma crucial, la capacidad de Data 360 para unificar datos vastos y diversos, proporcionar contexto en tiempo real a través de su consulta unificada (incluyendo búsqueda estructurada/no estructurada híbrida e hiperaceleración) y aplicar una regulación estricta es primordial para potenciar agentes de IA inteligentes. Proporciona los datos de confianza, actualizados y relevantes necesarios para fundamentar flujos de trabajo de IA generativa (RAG) y alimentar las funciones de múltiples turnos orientadas a la acción de agentes con tecnología Agentforce, garantizando que operan con precisión y precisión.
Al proporcionar una plataforma preparada para el futuro donde los datos de origen se transforman en perspectivas sobre las que se pueden realizar acciones, Data 360 sirve como una base arquitectónica indispensable para organizaciones que crean experiencias de clientes de Agentes. Es la columna vertebral vital que convierte los datos de los clientes en experiencias de clientes sofisticadas y personalizadas que impulsan el éxito para las organizaciones modernas de hoy.