Este documento describe las opciones actuales para implementar aplicaciones en CloudHub 2.0 para cumplir los requisitos de alta disponibilidad y recuperación de desastres. Utiliza la región de EE.UU. como ejemplo y se puede aplicar a otras regiones.
CloudHub 2.0 es una plataforma de integración nativa de la nube completamente gestionada que elimina los gastos generales de infraestructura automatizando la implementación, la ampliación y la gestión de las API de MuleSoft y las integraciones en la nube. Es la plataforma de implementación en la nube moderna de MuleSoft, que se ejecuta en la infraestructura de Amazon AWS.
En la mayoría de los casos, la Alta disponibilidad (HA) y la Recuperación de desastres (DR) predeterminadas proporcionadas por CloudHub 2.0 son suficientes. CloudHub 2.0 proporciona HA y DR a nivel regional (para obtener más detalles, consulte Escenarios de fallos de funcionamiento de CloudHub 2.0). La sección Consideraciones clave de CloudHub 2.0 proporciona más detalles acerca de HA y DR compatibles con CloudHub-2.0.
Las condiciones que exigen un diseño más allá de la disponibilidad predeterminada de CloudHub 2.0 incluyen:
- Una aplicación necesita garantizar que no se produzca ninguna pérdida de datos en un escenario de desastre (por ejemplo, una región de Amazon fallida).
- Una aplicación depende del Almacén de objetos y necesita garantizar la continuidad si la región de implementación se interrumpe.
- Los sistemas backend están configurados para una disponibilidad equivalente. CloudHub 2.0 puede a veces proporcionar fiabilidad a través de colas o mecanismos similares, pero independientemente de que la integración sea en tiempo real o asíncrona, los sistemas backend deben admitir un nivel comparable de HA y DR.
- Cuando un fallo de funcionamiento a nivel de región de AWS afecta a sistemas backend, se asume que su recuperación se ejecuta en paralelo con la recuperación de CloudHub 2.0.
- La configuración del espacio privado está completa en múltiples regiones.
Las opciones de diseño en esta guía se centran en soluciones para la disponibilidad de aplicaciones en CloudHub 2.0 cuando toda una Zona o región de disponibilidad de AWS deja de estar disponible.
En esta guía no se abordan estos escenarios de recuperación, aunque sí se señalan las consecuencias cuando procede:
- Recuperación de sistemas backend, aplicaciones, bases de datos, componentes de red y centros de datos gestionados y aprovisionados fuera de Anypoint CloudHub, ya sea en las instalaciones o en la nube.
- Recuperación de vínculos VPN entre CloudHub 2.0 y el centro de datos privado del cliente (por ejemplo, túneles IPsec y pasarelas VPN). Algunas opciones de DR en esta guía pueden solucionar parcialmente estos escenarios.
- Los cambios en MuleSoft generan direcciones IP durante la recuperación de desastres cuando se utiliza la lista de admisión de direcciones IP para integraciones. Algunas opciones de DR en esta guía pueden solucionar parcialmente estos escenarios.
- Sistemas de mensajería externos utilizados en soluciones de clientes, ya sean proporcionados por MuleSoft (como Anypoint MQ) u otros proveedores (como AWS MSK o Heroku Kafka).
Cuando evalúe CloudHub 2.0 para requisitos de recuperación de desastres, piense en estas consideraciones clave.
Dependencia de CloudHub 2.0 de la disponibilidad regional de AWS
- CloudHub 2.0 se ejecuta en AWS; su disponibilidad está vinculada a regiones de AWS.
- Las implementaciones y la disponibilidad de aplicaciones están organizadas por región. Estas regiones corresponden a regiones de AWS.
Si falla una región de AWS completa, las aplicaciones en esa región no están disponibles y no se replican automáticamente en otro lugar.
Aplicación Alta disponibilidad (HA) y Gestión de réplicas
- CloudHub 2.0 vuelve a implementar automáticamente aplicaciones en la misma región cuando falla el hardware, pero una aplicación con una única réplica puede experimentar tiempo de inactividad.
- Las aplicaciones con múltiples réplicas se implementan entre zonas de disponibilidad separadas de forma predeterminada, proporcionando HA entre zonas.
- Si la zona de disponibilidad para una aplicación de réplica única falla, la aplicación se muestra automáticamente en otra zona de disponibilidad en la misma región.
Repercusión específica de la región este de EE.UU.
- En caso de un fallo de funcionamiento de la región Este de EE.UU.:
- La interfaz de usuario de gestión de CloudHub 2.0 y los servicios de REST de implementación no están disponibles y no se pueden implementar nuevas aplicaciones.
- Las aplicaciones en otras regiones no se ven afectadas en la mayoría de los escenarios de fallo. Estas aplicaciones continúan funcionando normalmente; sin embargo, las funciones de supervisión y gestión a través del plano de control no estarán disponibles durante el fallo.
- Los módulos de Core CloudHub 2.0 (como la configuración de la aplicación) se mantienen en el Este de EE.UU., de modo que la configuración no se puede modificar durante el fallo.
Supervisión y alerta
- Configure alertas para fallos a nivel de región o zona de disponibilidad a través de status.mulesoft.com.
- Utilice un mecanismo de alerta y comprobación de estado separado fuera de CloudHub 2.0 de modo que se notifique a los equipos si las réplicas fallan o las aplicaciones dejan de responder.
Persistencia de datos (Object Store V2)
- Object Store V2 está vinculado a la región donde se implementó la aplicación por primera vez.
- Si traslada la aplicación a otra región, Object Store V2 permanece en la región original para evitar la pérdida de datos.
- Si la región donde se implementa Object Store V2 falla, el establecimiento de objetos no estará disponible.
Controladores de ingreso y espacios privados
- Los controladores de ingreso de CloudHub 2.0 están altamente disponibles a nivel de región.
- En un espacio compartido, si una región falla, un controlador de ingreso en otra región permanece disponible pero solo puede servir aplicaciones implementadas en esa región.
- En un espacio privado, si una región falla, los controladores de ingreso en otras regiones no están disponibles a menos que se hayan configurado allí con antelación.
- La configuración del espacio privado es regional; si una región falla, el espacio privado no estará disponible a menos que se haya configurado otra región.
| Estado de componente | Responsabilidad de Salesforce |
|---|---|
| Réplica hacia abajo | Acción: CloudHub 2.0 reinicia automáticamente la réplica en una zona de disponibilidad diferente si hay algún problema con la zona de disponibilidad actual. Pero la aplicación estará sin conexión hasta que la nueva réplica se inicie completamente. Condición: Configuración predeterminada. Tiempo empleado: Aproximadamente 2-15 minutos dependiendo de la complejidad de la aplicación y el tamaño de la réplica. |
| Zona de disponibilidad abajo | Acción: Igual que la réplica. Condición: Configuración predeterminada. Tiempo empleado: Igual que la réplica. Notificación: Igual que la réplica. |
| Región hacia abajo | Acción: Sin recuperación automática. Debe existir un diseño de conmutación por error. |
| Estado de componente | Responsabilidad del cliente |
|---|---|
| Réplica hacia abajo | Notificación: Realice comprobaciones de estado periódicas utilizando un mecanismo de latidos integrado en las API. Mitigación: Implemente la aplicación en múltiples réplicas en la misma región. Prueba / Simulación: Eleve un ticket con la asistencia de MuleSoft y admitirán una prueba de conmutación por error para comprobar si una nueva réplica aparece en una AZ diferente en 1 a 15 minutos. |
| Zona de disponibilidad abajo | Notificación: Igual que la réplica. Mitigación: Implemente la aplicación en múltiples réplicas en la misma región o en regiones diferentes. Prueba / Simulación: El escenario AZ Down es difícil de simular. Requiere la participación de MuleSoft Engineering para dar cobertura a posibles escenarios de prueba. |
| Región hacia abajo | Notificación: Igual que la réplica. Compruebe también las actualizaciones de estado en https://status.aws.amazon.com. Mitigación: Igual que AZ Down. Plan de contingencia de recuperación de desastres: 2 espacios privados con la misma configuración en diferentes regiones. Prueba / Simulación: Igual que AZ Down. |
| Estado de componente | Responsabilidad de Salesforce |
|---|---|
| VPN Gateway Down | Estado de réplica: Ejecución pero no se puede conectar a ningún recurso alojado en las instalaciones y accesible a través del túnel VPN. Acción: Sin recuperación automática. Debe existir un diseño de conmutación por error. |
| Controlador de ingreso (Espacio compartido) Abajo | Estado de réplica: El controlador de ingreso es una configuración en clúster con múltiples instancias, similar a réplicas de aplicación. Si una réplica de aplicación falla, se crea una nueva y se inicia automáticamente. Si una instancia del controlador de ingreso falla, las aplicaciones permanecen disponibles a través de la otra instancia. Si todo el controlador de ingreso está desactivado, la región se considera desactivada. |
| Controlador de ingreso (Espacio privado) Abajo | Estado de réplica: Igual que Controlador de ingreso en espacio compartido hacia abajo. |
| Estado de componente | Responsabilidad del cliente |
|---|---|
| Pasarela VPN hacia abajo | Notificación: Realice comprobaciones de estado periódicas utilizando un mecanismo de latidos integrado en las API. Mitigación: Las pasarelas VPN CloudHub 2.0 admiten alta disponibilidad a través de una arquitectura de doble túnel con conmutación por error automática entre túneles; un cliente debe configurar este patrón. Prueba / Simulación: El escenario VPN Gateway Down es difícil de simular. Requiere la participación de MuleSoft Engineering para dar cobertura a posibles escenarios de prueba. |
| Controlador de ingreso (Espacio compartido) Abajo | Notificación: Igual que VPN Gateway Down. Mitigación: Igual que Región hacia abajo. Migre aplicaciones a un espacio activo o en espera en otra región. Prueba / Simulación: Igual que VPN Gateway Down. |
| Controlador de ingreso (Espacio privado) Abajo | Notificación: Igual que VPN Gateway Down. Mitigación: Igual que Región hacia abajo. Migre aplicaciones a un espacio privado activo o en espera en otra región, en coordinación con la configuración de AWS Route 53 (o equivalente). Prueba / Simulación: Igual que VPN Gateway Down. |
Escenario descendente de Servicios de plataforma de descripción general - Object Store
| Almacén de objetos en memoria | Establecimiento de objetos persistente v2 | |
|---|---|---|
| Ubicación de datos | Local solo para la aplicación. | En la misma región donde se implementó por primera vez la aplicación MuleSoft. |
| ¿Compartido entre réplicas? | No | Sí |
| Recuperación de establecimiento de objetos en aplicaciones | Los datos se pierden; todos los datos en memoria se pierden en el reinicio de la aplicación, nueva implementación o fallo de réplica. | Los datos no se pierden a menos que se elimine la aplicación. |
| Recuperación de establecimiento de objetos dentro de región | Los datos se pierden (igual que anteriormente). | Los datos no se pierden (igual que anteriormente). |
| Recuperación regional | Igual que antes. | Los datos no están disponibles. Incluso con una configuración de DR activa-activa, Object Store solo está disponible en la región de implementación original. |
| Mitigación | Externalice datos para la recuperación regional. | Los datos permanecen disponibles mientras la región de implementación original está disponible. Para HA o DR entre regiones, externalice datos fuera del almacenamiento de objetos. |
Alta disponibilidad (HA) es la medición de la capacidad de un sistema para permanecer accesible en caso de fallo de un componente del sistema. En general, HA se implementa incorporando múltiples niveles de tolerancia a fallos y/o funciones de equilibrio de carga en un sistema. Normalmente es una configuración Activo-Activo y da como resultado un impacto limitado o nulo en Servicios comerciales.
Recuperación de desastres (DR) es el proceso por el que un sistema se restaura a un estado aceptable anterior después de un escenario de desastre, ya sea natural (como inundaciones, tornados, terremotos o incendios) o provocado por el hombre (como fallos de energía, fallos de servidor o configuraciones incorrectas). DR es normalmente una configuración Activo-Pasivo y da como resultado alguna repercusión en Servicios comerciales.
Si se desea una Alta disponibilidad regional o una Recuperación de desastres regional para reducir las repercusiones comerciales en caso de un fallo regional de AWS, tenga en cuenta estos puntos al diseñar su solución en MuleSoft CloudHub 2.0:
- Las réplicas de CloudHub 2.0 y las funciones relacionadas (espacios privados, controladores de ingreso y destinos de Anypoint MQ) son específicas de la región.
- Si falla una región de AWS completa, todas las réplicas y los servicios asociados en esa región dejan de estar disponibles.
- Cuando se recupera una región, se restauran las configuraciones; debe reiniciar las aplicaciones.
- Si la región Este de EE.UU. falla, los servicios de Anypoint Platform (por ejemplo, Gestión de acceso y Gestor de tiempo de ejecución) tampoco están disponibles.
- MuleSoft proporciona un SLA del 99,95% de disponibilidad para Servicios de plataforma, incluyendo réplicas de CloudHub 2.0 en una configuración activo-activo dentro de una región; consulte el último SLA de oferta de MuleSoft Cloud para obtener detalles actualizados.
- CloudHub 2.0 no admite HA o DR de múltiples regiones de forma inmediata; la disponibilidad solo se proporciona dentro de una única región.
Estas directrices de diseño se aplican independientemente de la configuración que seleccione.
Configuración de espacios privados multirregionales
Todas las opciones descritas en las siguientes secciones requieren que las aplicaciones se implementen en regiones separadas. Eso solo es posible si la configuración del espacio privado se completa con antelación, antes de un desastre. Como la configuración del espacio privado es regional, una estrategia de DR requiere al menos dos espacios privados, uno por región, y un mecanismo para cambiar el tráfico al extremo VPN apropiado.
Configuración de espacio privado altamente disponible en una región
CloudHub 2.0 no proporciona conmutación por error automática cuando falla un espacio privado en una región. Una solución es una configuración activa-pasiva entre múltiples entornos, que requiere:
- Configuración de múltiples pasarelas VPN en el espacio privado.
- Establecimiento de entornos separados en la región CloudHub 2.0, cada uno con su propio espacio privado.
- Designando uno de estos entornos como pasivo (donde las aplicaciones no se implementan inicialmente pero se muestran si falla el espacio privado principal).
Si una configuración de alta disponibilidad sin que la pasarela VPN sea un único punto de fallo es un requisito difícil, la implementación en dos regiones es la mejor opción. Un fallo de pasarela VPN en este escenario podría resolverse haciendo fallar la región afectada a la región alternativa donde el espacio privado ya está configurado.
Pérdida de mensajes cero
Para alcanzar la pérdida cero de mensajes cuando falla una región completa, una aplicación debe evitar la pérdida de datos y solucionar estos puntos:
- Utilice mensajería externa para lograr la fiabilidad de los mensajes.
- Asegúrese de que Object Store no se utiliza para datos transaccionales en vuelo que son transaccionales por naturaleza. Si la región de implementación donde se implementó por primera vez la aplicación MuleSoft se interrumpe, el Establecimiento de objetos no estará disponible.
- Envuelva todo el acceso a Establecimiento de objetos en un flujo o sección separados que continúe funcionando (tanto para la gestión de excepciones como para el comportamiento) cuando las operaciones de lectura o escritura de Establecimiento de objetos fallen.
Nota. En la mayoría de los casos, los requisitos de DR no necesitan garantizar una pérdida de mensajes cero en caso de un desastre y necesitan garantizar que la pérdida de datos es inferior al valor de datos de un periodo concreto (por ejemplo, 1 hora).
Mantener la integración sin estado
Como principio general de diseño, siempre es importante garantizar que las integraciones sean de naturaleza apátrida. Esto significa que no se comparte información transaccional entre varias invocaciones o ejecuciones de clientes (en el caso de servicios programados). Si el middleware tiene que mantener algunos datos debido a una limitación del sistema, se deben mantener en un establecimiento externo, como una base de datos o una cola de mensajería y no dentro de la infraestructura o la memoria de MuleSoft. Es importante tener en cuenta que a medida que ampliamos, especialmente en la nube, el estado y los recursos utilizados por cada réplica deben ser independientes de otras réplicas. Este modelo garantiza un mejor rendimiento, capacidad de ampliación y fiabilidad.
Gestión de redes y tráfico
- Los dominios vanity son obligatorios para la disponibilidad regional; actúan como un DNS global para todos los controladores de ingreso entre regiones.
- Un equilibrador de carga global enruta el tráfico entre los espacios privados de la región principal y de DR. Los clientes proporcionan este componente; utilice AWS Route 53 o una CDN global con políticas de enrutamiento para enrutar el tráfico entre regiones.
- Configure controladores de ingreso en regiones principales y DR con un dominio de tocador personalizado.
- Planifique y mantenga reglas de cortafuegos y túneles VPN de modo que las aplicaciones locales sean accesibles desde los espacios privados de la región principal y de DR.
- El mantenimiento de certificados TLS debe cubrir espacios privados en regiones principales y DR para una recuperación sencilla.
Implementación y configuración de aplicaciones
- Los nombres de solicitud deben ser exclusivos en todas las regiones. Por ejemplo, una canalización de CI/CD puede anexar el nombre de región (o un código de región) a los nombres de aplicación antes de la implementación para mantener la exclusividad entre regiones principales y de DR.
- Configure las oportunidades en curso de CI/CD para implementar aplicaciones en las regiones principales y DR de modo que todas las aplicaciones estén disponibles en ambas regiones.
Infraestructura y capacidad
El rendimiento es mejor cuando todos los aspectos de la infraestructura tienen idéntica capacidad de región principal y DR. El rendimiento se degrada cuando estos aspectos de infraestructura no son idénticos.
Almacenamiento y persistencia de datos
- El almacenamiento persistente debe sincronizarse periódicamente entre las dos regiones. Los clientes son responsables de la replicación del almacenamiento; MuleSoft no lo proporciona. Es posible un único almacenamiento compartido entre VPC en las regiones principal y DR, pero el almacenamiento compartido debe estar altamente disponible o se convierte en un único punto de fallo para ambas regiones.
- Object Store V2 es regional y solo está disponible en la región donde se implementó por primera vez la aplicación Mule. Si la aplicación se traslada a otra región, Object Store V2 permanece en la región original para evitar la pérdida de datos. Utilice otro almacenamiento persistente para estrategias de DR de múltiples regiones.
Pruebas y procedimientos operativos
Adopte una estrategia de prueba de DR formal y ejecute simulacros de DR periódicos. Para DR activo-activo, utilice una estrategia de implementación canaria para validar ambas regiones.
Acuerdos de rendimiento y nivel de servicio (SLA)
Puede producirse cierta degradación del rendimiento porque la región DR puede estar más lejos de los usuarios finales o sistemas backend que la región principal. Defina y comunique un SLA de DR a las partes interesadas.
Comportamiento del modo de recuperación (Nota contextual)
En modo activo-activo, la conmutación por error desde la región principal al espacio privado de la región DR es rápida: el equilibrador de carga global detecta que la principal no es saludable y enruta el tráfico a la región saludable (DR). En modo activo-pasivo, debe implementar la aplicación en el espacio privado de la región DR cuando se produce un desastre.
Existen 3 opciones para lograr una mayor disponibilidad de nivel de DR:
Una configuración activo-activo se basa en trabajadores activos distribuidos entre regiones, utilizando un equilibrador de carga externo para enrutar el tráfico entre las dos instancias.
Configuración de Warm Standby
Una configuración activo-pasivo se basaría en un trabajador activo en una región y un trabajador pasivo en otra región. La Región pasiva se iniciaría cuando fuera necesario.
Algunos elementos de la región pasiva deben permanecer activos para la conmutación por error o configurarse de antemano, incluyendo espacios privados, VPN y archivos adjuntos de pasarelas de tránsito.
Como anteriormente, las réplicas y los controladores de ingreso se aprovisionan en una segunda región a través de un proceso de DevOps completamente automatizado tras la conmutación por error. Algunos elementos de la región pasiva necesitan permanecer activos para la conmutación por error, incluyendo espacios privados, VPN y Archivos adjuntos de pasarela de tránsito.
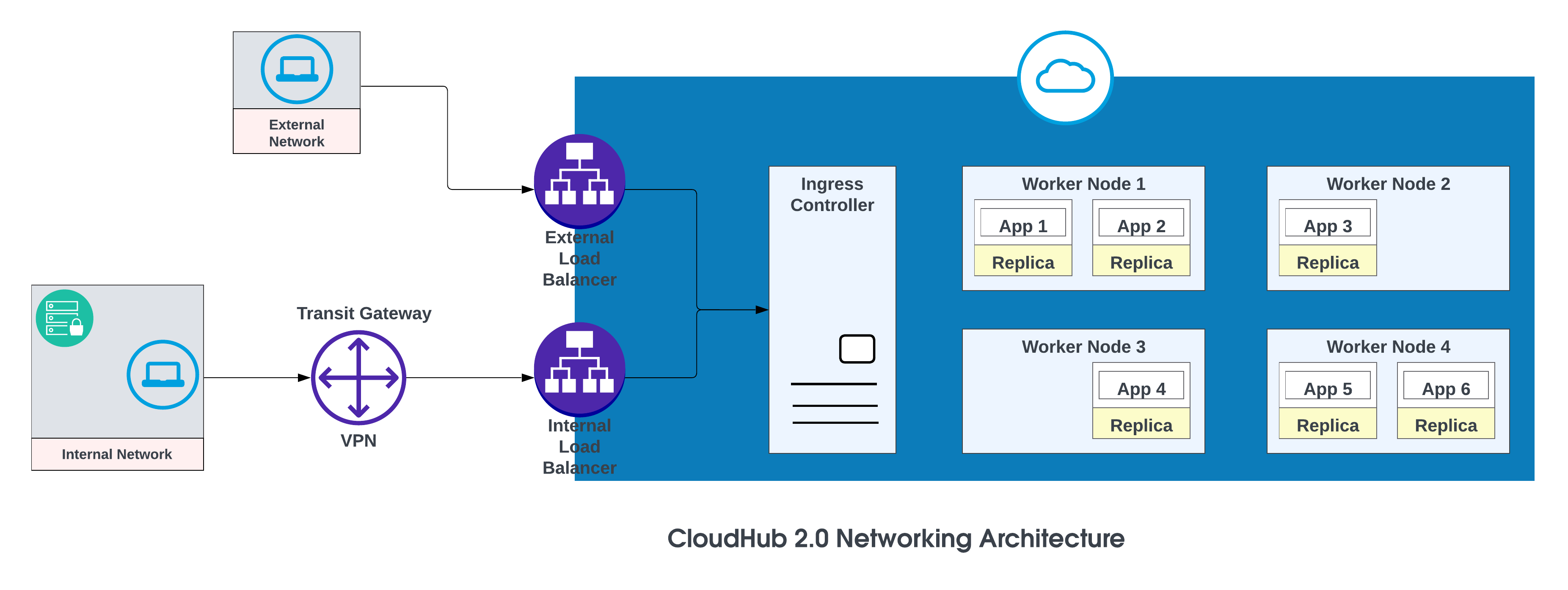
Los componentes básicos de la arquitectura de red CloudHub 2.0 son:
- Un equilibrador de carga HTTP
- Registros DNS de réplica de mula
- Espacios privados
- Servicios regionales
Para obtener más detalles, consulte Arquitectura de redes CloudHub 2.0.
Dominios de Vanity
Cuando se crea un Espacio privado, recibe un nombre de destino DNS en el formato: <space-id>.<region>.cloudhub.io . Al implementar una aplicación denominada test-api en ese espacio privado, su extremo seguirá este formato:
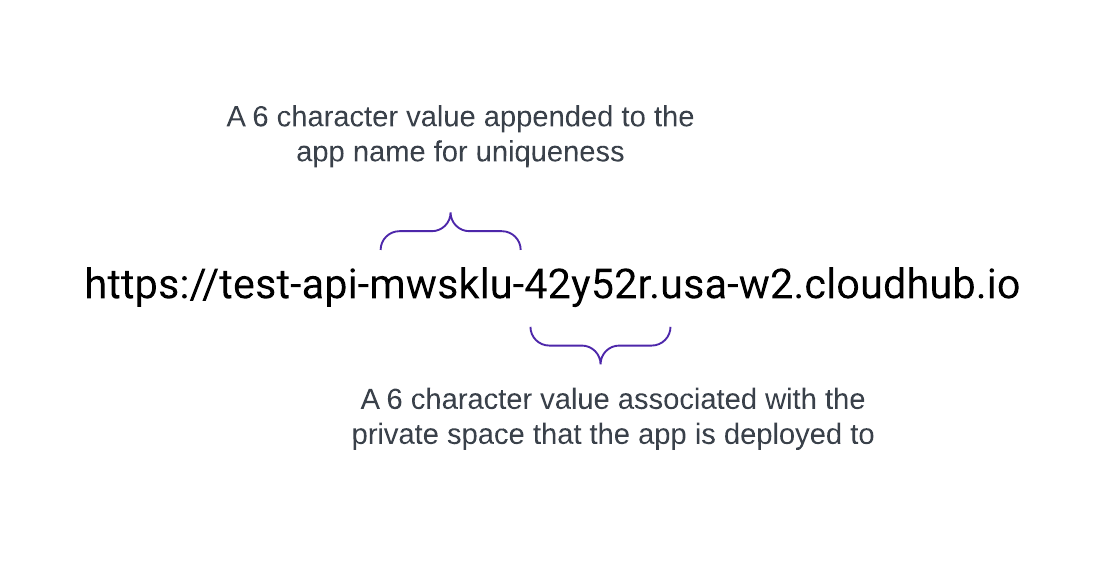
CloudHub 2.0 también admite dominios personalizados, o vanidad, configurándolos dentro de un espacio privado utilizando contextos TLS y registros DNS. Para crear un contexto TLS en Gestor de tiempo de ejecución para un espacio privado, cargue el certificado público y la clave privada, luego agregue un extremo personalizado en la configuración de su aplicación para utilizar ese dominio. Cree un registro DNS (como un CNAME) que apunte su dominio de tocador al nombre de host predeterminado de su espacio privado.
Por ejemplo, una aplicación denominada test-api implementada en us-west-2 con DNS predeterminado 42y52r.usa-w2.cloudhub.io tiene un extremo de API de:
https://test-api-mwsklu-42y52r.usa-w2.cloudhub.io
Esta URL no utiliza un vanidad o dominio personalizado. Para utilizar acme.com de modo que las direcciones URL de API aparezcan como https://test-api.acme.com, siga estos pasos.
- Cree contexto TLS en Gestor de tiempo de ejecución con claves públicas y privadas.
- Agregue un dominio de tocador en la configuración de la aplicación para utilizar ese dominio.
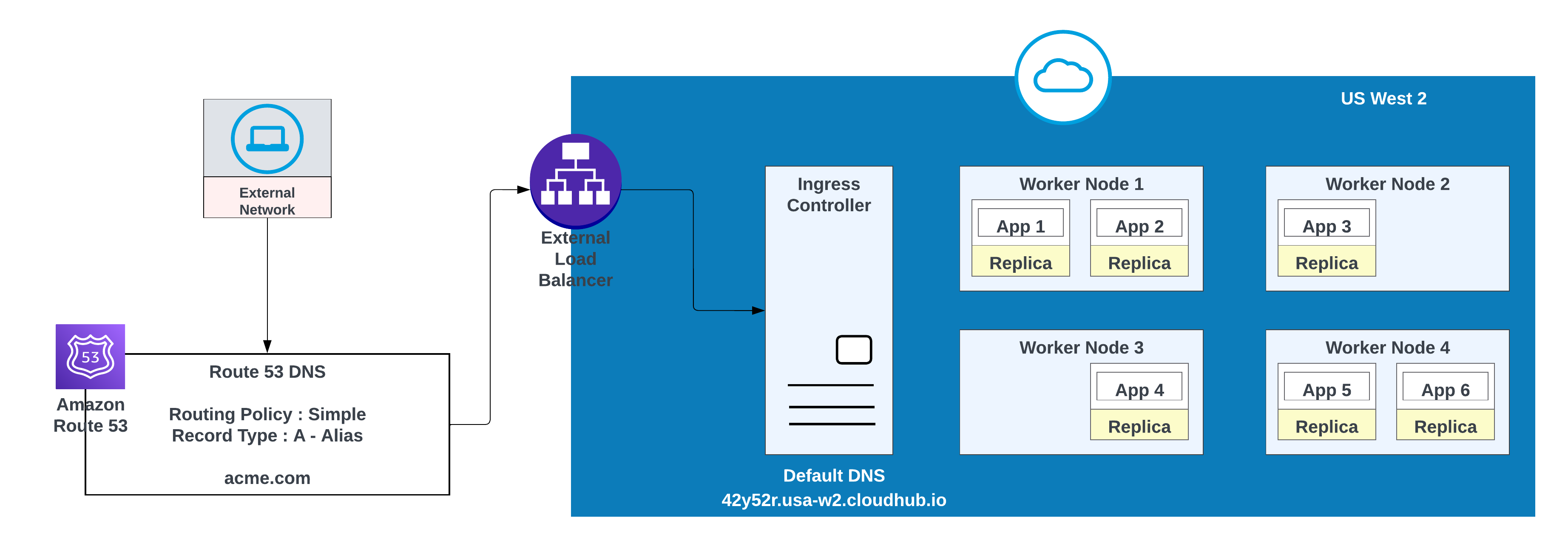
- Cree un registro DNS en AWS Route 53 y configure una política de enrutamiento sencilla (por ejemplo, CNAME) de modo que el dominio de vanidad se resuelva en el nombre de host predeterminado del espacio privado.
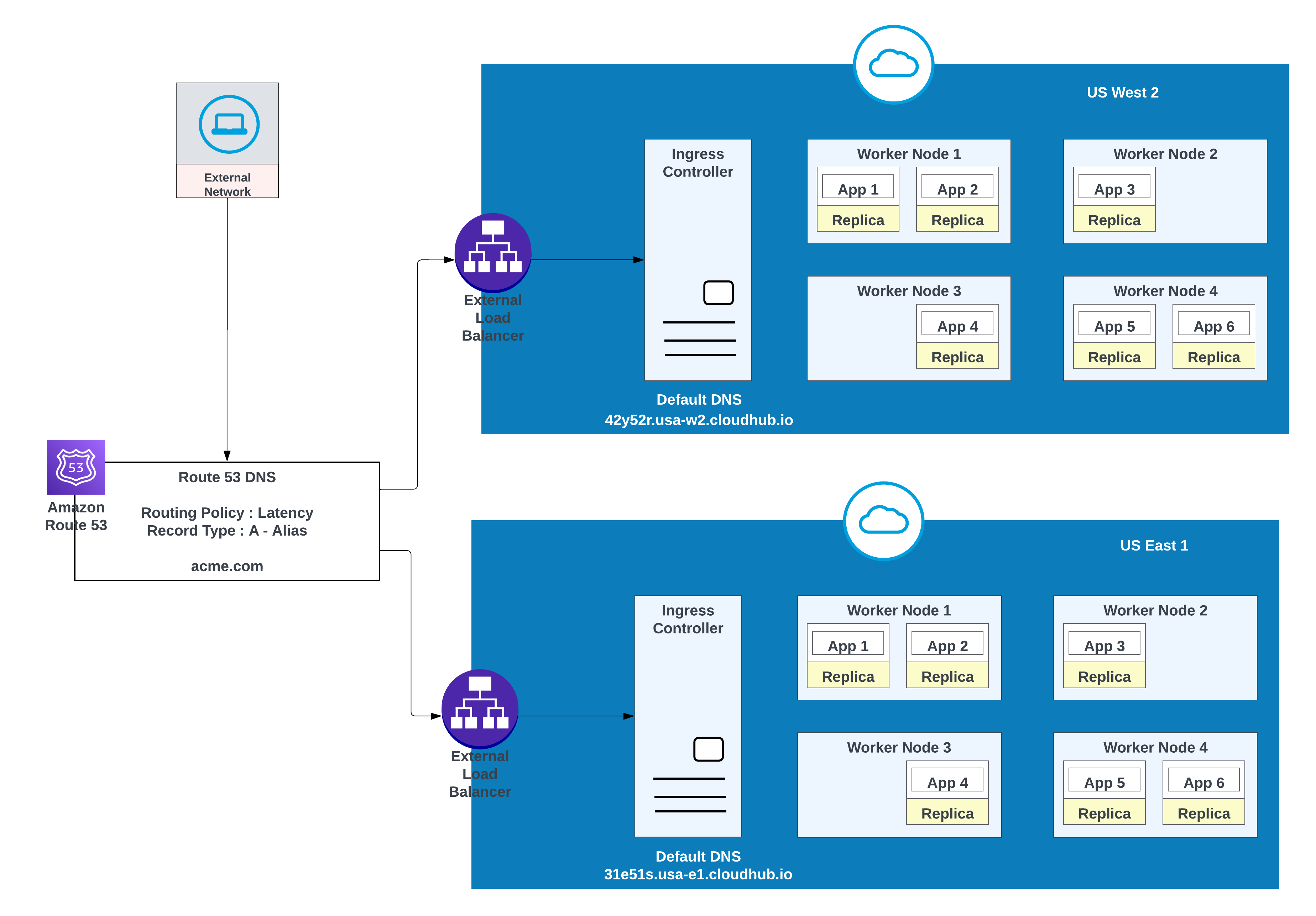
Para dominios personalizados, puede utilizar AWS Route 53 o cualquier otro servicio de CDN global con políticas de enrutamiento. En el siguiente diagrama, AWS Route 53 se utiliza con una política de enrutamiento “simple”. Cuando un consumidor de una red pública (externa) solicita acme.com, la Ruta 53 de AWS enruta la solicitud al controlador de ingreso de espacio privado MuleSoft.
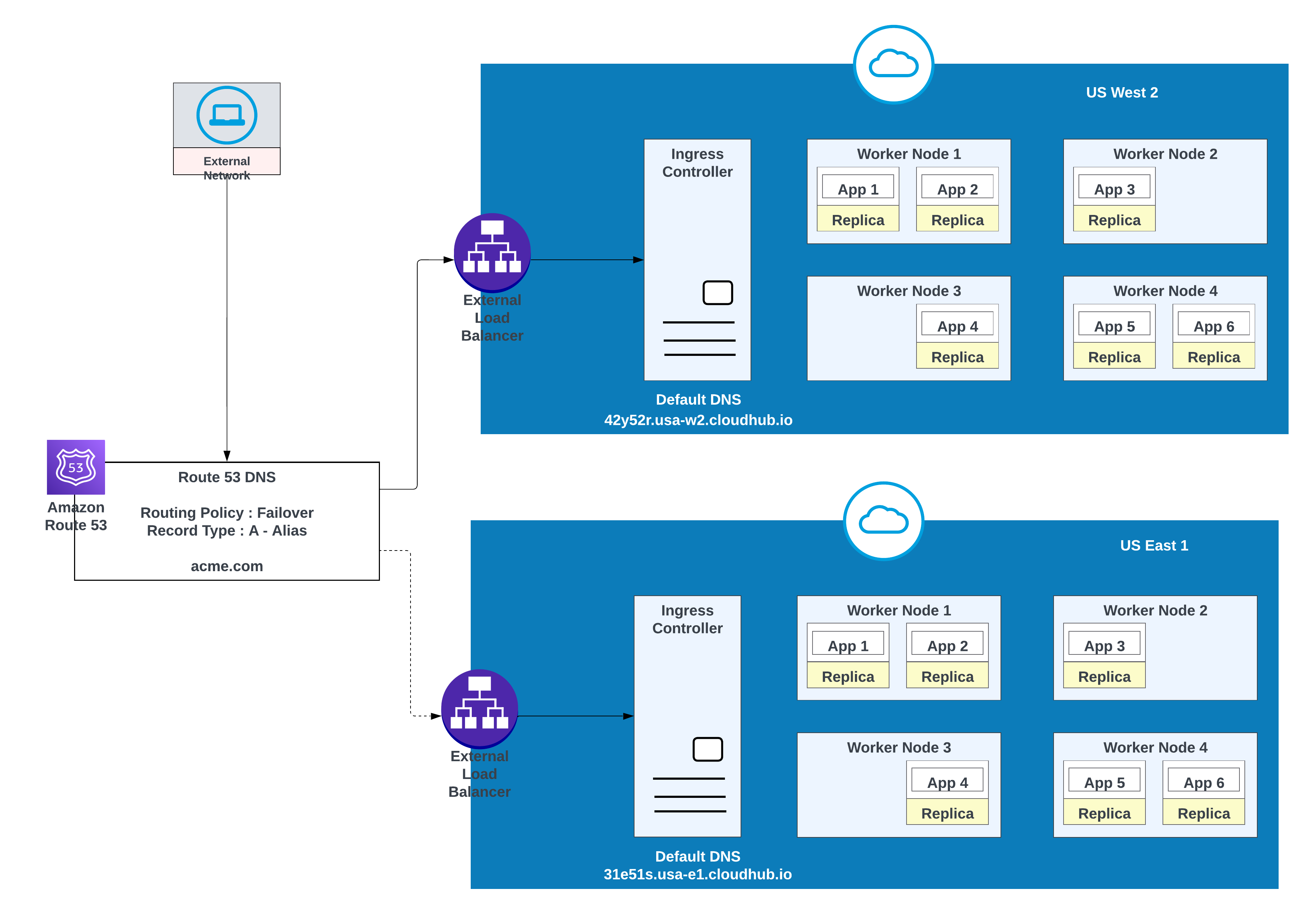
Utilice esta opción cuando las aplicaciones requieren conmutación por error: implemente una instancia en la región principal (por ejemplo, us-west-2) y otra en una región secundaria (por ejemplo, us-east-1).
Utilice un entorno existente en la región secundaria cuando sea posible; la creación de un nuevo entorno requiere esfuerzo adicional.
Ejemplo de aplicaciones implementadas en una región (oeste de EE.UU. 2) con fallos en otra región (este de EE.UU. 1)
| Nombre de registro | Valor/Enrutar tráfico a | Política de enrutamiento | Id. de Comprobación de estado |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Conmutación por error | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Conmutación por error | 43e131s131sq |
En esta configuración, AWS Route 53 enruta el tráfico a los controladores de entrada para los espacios privados en US West 2 y US East 1. Una política de enrutamiento por error está configurada con una comprobación de estado.
Para una latencia inferior junto con una alta disponibilidad, utilice la estrategia de implementación descrita en el diagrama. Con esta estrategia, las aplicaciones se pueden implementar en dos regiones (us-west-2 y us-east-1 en este ejemplo).
Utilice la política de enrutamiento de latencia en AWS Route 53 para enrutar solicitudes a la región que ofrece la latencia más baja mientras mantiene la alta disponibilidad. Política de enrutamiento de “latencia” en AWS Route 53 para enrutar la solicitud de latencia más baja que aún tiene alta disponibilidad.
Aplicaciones implementadas en ambas regiones (EE.UU. Oeste 2 y EE.UU. Este 1) para una latencia más baja y alta disponibilidad
| Nombre de registro | Valor/ Enrutar tráfico a | Política de enrutamiento | Id. de Comprobación de estado |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Latencia | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Latencia | 43e131s131sq |
MuleSoft CloudHub 2.0 proporciona una base sólida para la resiliencia intrarregional, aprovechando principalmente la redundancia de réplicas automatizada y el equilibrio de carga inteligente. Dentro de una única región de nube, la implementación de aplicaciones con múltiples réplicas garantiza que si una instancia falla, otras puedan asumir inmediatamente la carga de trabajo. El equilibrador de carga integrado distribuye de forma eficiente el tráfico entrante entre estas réplicas saludables, minimizando el tiempo de inactividad y garantizando la disponibilidad de servicio continua en condiciones de funcionamiento normales.
Sin embargo, depender exclusivamente de esta arquitectura de una sola región, incluso una con alta redundancia, presenta un riesgo significativo de un apagón regional generalizado y catastrófico. La historia ha demostrado que incluso los proveedores de nube más altamente fiables y tecnológicamente avanzados son susceptibles a incidentes disruptivos que pueden afectar a toda una región geográfica. Estos únicos puntos de fallo, aunque raros, pueden surgir de varios eventos, incluyendo:
- Incidentes de infraestructura a gran escala
- Fallos importantes de energía
- Interrupciones generalizadas de la red
Por lo tanto, para lograr una verdadera alta disponibilidad (HA) y recuperación de desastres (DR), una arquitectura debe diseñarse para trascender las limitaciones de un modelo de una sola región. La estrategia recomendada es la implementación entre múltiples regiones geográficamente distintas. Esta resiliencia interregional garantiza que si una región de nube completa deja de estar disponible debido a un desastre inesperado, el tráfico puede fallar sin problemas en una instancia de aplicación que se ejecuta en una región separada y no afectada, garantizando una interrupción mínima del servicio y alcanzando objetivos de tiempo de disponibilidad máximo.
Arquitectura de redes CloudHub 2.0
Configuración de fallos entre regiones para colas estándar
Regiones de implementación de Object Store V2
Su región de implementación de Establecimiento de objetos
Gulal Kumar es Arquitecto de Ingeniería de Software en Salesforce, con un enfoque en datos y arquitectura de integración. Con más de 20 años de experiencia en integración y API, programas de modernización, seguridad e iniciativas AIML, aporta una gran experiencia. Gulal se ha comprometido a impulsar iniciativas de transformación comercial, mejorar la seguridad y la resiliencia, promover la excelencia de la arquitectura y liderar iniciativas de AIML en varios dominios.
Ajay Nagaraju es Arquitecto de Empresa y Director Senior de MuleSoft con más de 28 años de experiencia en arquitectura empresarial, integración de sistemas y transformación digital a gran escala. Ha liderado la arquitectura y la entrega de programas complejos y multimillonarios en organizaciones Fortune 100 y Fortune 500, con profunda experiencia en conectividad dirigida por API, SOA, tecnologías en la nube y patrones de integración empresarial. Ajay se ha asociado estrechamente con el liderazgo ejecutivo para modernizar los procesos comerciales, las plataformas de datos y los ecosistemas de integración, y le apasiona crear arquitecturas escalables, equipos de mentores e impulsar resultados comerciales mensurables a través de la tecnología.