Las empresas a menudo almacenan datos en Salesforce y otros lagos de datos externos como Snowflake, Google BigQuery, Databricks, Redshift o almacenamiento en la nube como Amazon S3. Este aislamiento de datos en diferentes sistemas de origen supone un reto para las empresas que desean aprovechar toda la potencia de sus datos.
Los arquitectos que trabajan para reunir datos entre múltiples lagos de datos se enfrentan a decisiones arquitectónicas clave sobre cómo integrar mejor esos datos. Data 360 ofrece múltiples opciones para la integración de datos, cada una de las cuales ofrece diferentes pros y contras.
Esta guía proporciona un marco de trabajo para evaluar qué patrón se ajusta mejor a sus requisitos de latencia, coste, escalabilidad, regulación y complejidad al integrar datos, ayudándole a elegir cuándo utilizar la introducción de datos, la federación de datos de copia cero o un enfoque híbrido. La guía también le ayudará a seleccionar entre diferentes métodos de introducción de datos y federación de datos, cada uno de los cuales satisface una necesidad diferente.
La integración de lagos de datos externos con Data 360 requiere una cuidadosa consideración de las compensaciones entre la actualización de datos, la gobernanza y la eficiencia de las oportunidades en curso. Por ejemplo, el uso de consultas en vivo de federación de datos de copia cero maximiza la actualización de los datos pero puede reducir la eficiencia de las oportunidades en curso a medida que mueve más datos por la red. Por lo tanto, para la mayoría de las implementaciones del mundo real, una combinación de introducción y federación dentro de un ecosistema de lago de múltiples nubes es la ruta óptima. Este enfoque híbrido garantiza una arquitectura ampliable, gobernada e interoperable que admite a la perfección cargas de trabajo operativas de baja latencia como la personalización en tiempo real y la detección de fraudes, así como cargas de trabajo analíticas como informes normativos y análisis de tendencias históricas. Esta guía de decisiones le ayudará a comprender cómo navegar por estas compensaciones y seleccionar la estrategia correcta.
- Ingestión de datos: Copia datos en Salesforce Data 360, creando modelos de datos gobernados y canónicos. Ideal cuando necesita:
- Cree un Customer 360 completo: Unifique y transforme orígenes dispares en un perfil único y de confianza.
- Cumplir el estricto cumplimiento normativo: Cree una copia auditable y centralizada donde el acceso a los datos y el linaje puedan controlarse estrictamente.
- Federación de copia cero: Consulta fuentes externas en tiempo real sin duplicaciones, lo que permite la personalización en tiempo real, paneles en vivo e incorporación rápida de fuentes. Dos opciones principales con compensaciones que debe equilibrar:
- Live & Caching (Consulta acelerada): Lo mejor para análisis interactivos y paneles en tiempo real en datos que viven en plataformas de datos externas como Snowflake, Google BigQuery, Redshift o Databricks. Evita la duplicación de datos lenta y costosa empujando el procesamiento hacia abajo al sistema de origen.
- Federación de archivos: Lo mejor para el procesamiento por lotes a gran escala y el entrenamiento de modelo de IA en datos en su lago de datos de nube (S3, ADLS). Evita la introducción costosa y lenta consultando directamente archivos en formatos de tabla abiertos, desbloqueando conjuntos de datos masivos para cargas de trabajo de ETL y ciencia de datos.
- Modelo híbrido: Combine la introducción para Perfiles unificados con la federación para la actualización, la asistencia a la implicación de OmniCanal, acciones dirigidas por Agentforce y formación de IA/ML.
-
Arquitectura híbrida: A menudo se necesita mezclar datos introducidos y federación de datos.
- Utilice Introducción de datos en datos críticos para modelos de datos canónicos y regulación principal.
- Organice todos los demás datos a través de Cero copia para minimizar el gasto operativo de creación y mantenimiento de las oportunidades en curso de datos de introducción.
-
La frecuencia de introducción de datos importa: Seleccione la frecuencia basándose en el valor comercial, las necesidades de latencia y la complejidad operativa.
- Utilice el tiempo real para flujos de trabajo sensibles al tiempo (personalización, paneles en vivo, acciones Agentforce).
- Casi en tiempo real para procesos de urgencia moderada (campañas, informes operativos).
- Lote para conjuntos de datos históricos o de baja velocidad.
-
Coincidir el patrón de federación con Latencia y rendimiento: Seleccione la que mejor se ajuste a sus patrones de acceso y los requisitos de actualización, rendimiento y coste.
- Utilice Live Query para paneles operativos y personalización en tiempo real donde la baja latencia es crítica.
- Utilice el almacenamiento en caché (Consulta acelerada) cuando las consultas son frecuentes pero los resultados ligeramente obsoletos son aceptables, lo que equilibra el rendimiento y el coste.
- Utilice Federación de archivos para análisis a gran escala y con gran rendimiento o cargas de trabajo por lotes, ideales para conjuntos de datos históricos o menos sensibles al tiempo.
-
Alinear la gobernanza con requisitos de residencia de datos:
- Utilice la introducción donde la regulación centralizada es crítica.
- Utilice la federación donde la gobernanza descentralizada es aceptable, mientras aplica una gobernanza estricta en el origen externo. Cero copia respeta las políticas a nivel de origen, como la seguridad a nivel de filas (RLS) y el enmascaramiento de datos.
-
Priorizar la introducción para flujos de trabajo de alto valor: Aplique la introducción de forma selectiva a procesos críticos como la resolución de identidad, la creación de informes normativos y la activación operativa.
-
Coste y complejidad impulsan la decisión: La ingesta en tiempo real puede ser costosa y compleja. Los arquitectos deben ponderar el coste de incorporación, almacenamiento y transformación de datos con el coste de consultarlos directamente a través de Cero copia.
La selección del patrón de integración correcto (ingesta de datos, copia cero o un enfoque híbrido) afecta directamente a la latencia, la gobernanza, la eficiencia operativa y el coste entre plataformas de múltiples nubes. Esta decisión determina cómo se pueden entregar perspectivas en tiempo real, activación dirigida por IA e implicación personalizada de forma fiable y a escala.
Esta tabla proporciona una comparación técnica de patrones de introducción de datos y copia cero en Salesforce Data 360, centrándose en funciones, compensaciones y beneficios, junto con casos de uso y resultados empresariales. Los arquitectos pueden utilizar esto como una referencia para diseñar plataformas de datos híbridas de múltiples nubes que equilibran el rendimiento, el coste y el cumplimiento.
| Tipo de patrón | Modo / Herramienta | Beneficios | Consideraciones | Resultados |
|---|---|---|---|---|
| Ingestión de datos | Tiempo real: Ingestión de latencia de subsegundos a través de API de introducción con compatibilidad de CDC. Canalizaciones de transmisión continua. | - Perspectivas inmediatas - Ideal para casos de uso operativos y de personalización de baja latencia - Admite flujos de trabajo dirigidos por eventos |
- Coste elevado - Arquitectura compleja - Requiere sistemas de origen de baja latencia - Las fuentes de gran volumen pueden causar una transmisión excesiva que conduce a oportunidades en curso saturadas - E/S intensiva - Considerar campos selectivos y filtrado para reducir los gastos generales |
Agentforce: - Alertas de fraude en tiempo real, personalización minorista, alertas operativas Analytics: - Paneles de subsegundos, supervisión de KPI Cumplimiento: - Actualizaciones continuas de registros de clientes para flujos de trabajo regulados |
| Transmisión:Ingestión de microlotes cada 1-3 minutos a través de conectores nativos | Coste equilibrado frente a frescura - Arquitectura más sencilla que en tiempo real - Admite actualizaciones incrementales |
- Latencia ligera - Puede no ser adecuado para decisiones críticas de subsegundos - El tamaño de lote afecta a la memoria/cómputo - E/S es moderada - Lo mejor para patrones de actualización predecibles y repetidos - Considerar la agregación con ventanas para reducir la carga de procesamiento |
Agentforce: - Desencadenadores de campaña oportunos, implicación casi en vivo Analytics: - Motores de recomendación, paneles casi en vivo Cumplimiento: - Actualizaciones frecuentes con capacidad de auditoría |
|
| Lote: Cargas de gran volumen programadas a través de conectores o API. Admite almacenamiento de objetos y oportunidades en curso de ETL/ELT. | - Coste-eficiente para conjuntos de datos masivos - Fácil de implementar - Fiable para análisis históricos |
- Latencia de datos - Inadecuado para operaciones sensibles al tiempo - E/S intensiva durante ventanas de carga - El rendimiento de red puede convertirse en un cuello de botella para archivos de gran tamaño - Ideal para flujos de trabajo de agregación histórica o creación de informes regulados |
Agentforce: - Tickets de asistencia de TI (Jira/ServiceNow), flujos de trabajo agregados Analytics: - Análisis histórico, evaluación de tendencias Queja: - Creación de informes reguladores, agregación de datos de pacientes/reclamaciones |
|
| Zero Copy | Consulta en vivo: Consultas directas en sistemas externos; esquema en lectura; sin duplicación de datos | - Frescura máxima - Gasto de almacenamiento mínimo; admite perspectivas operativas en tiempo real |
-Dependiendo del rendimiento de origen - Un alto volumen de consultas puede afectar a la latencia - Ideal para consultas con agregación y distribución de predicados para minimizar las E/S - Evitar consultas sin filtrar en conjuntos de datos masivos |
Agentforce: - Flujos de trabajo dinámicos adaptándose a la actividad en vivo Analytics: - Paneles operativos, creación de informes en vivo Cumplimiento: - Respeta la seguridad a nivel de filas y el enmascaramiento en origen |
| Consulta acelerada (almacenamiento en caché): Copias locales en caché para consultas federadas. Configurable de 15 min a 7 días. Ejecución de consultas optimizada | - Reduce la latencia - Menor coste que las consultas en vivo repetidas - Mejora el rendimiento para patrones de acceso frecuentes |
- Gestión de caché requerida - La caducidad depende del intervalo de caché - Ideal para consultas de alta frecuencia - No apto para la decisión de subsegundos |
Agentforce: - Mediciones de implicación preagregadas para una decisión rápida Analytics: - Paneles de BI, segmentación, creación de informes analíticos Cumplimiento: - Paneles regulados coherentes con registros de auditoría |
|
| Federación de archivos: Acceso directo a grandes conjuntos de datos históricos en establecimientos de objetos o lagos (S3, Iceberg, Google BigQuery, Redshift). | - Gestiona conjuntos de datos de escala masiva - Almacenamiento mínimo en Data 360 - Admite cargas de trabajo de IA/ML |
- Solo lectura - El rendimiento de las consultas depende del rendimiento del sistema externo Optimizado para trabajos intensivos en rendimiento y lotes - No apto para paneles en tiempo real |
Agentforce: - (No es típico — pesado por lotes) Analytics: - Formación de ML/IA, análisis histórico, creación de informes a escala de petabytes Cumplimiento: - Acceso gobernado a conjuntos de datos externos sin duplicación |
Con la introducción de datos, los datos se copian físicamente en Data 360 y se rigen completamente, a diferencia de Cero copia donde los datos permanecen en el origen. Computar transformaciones se produce dentro de Data 360, lo que permite la regulación y auditoría centralizadas.
Utilice la introducción de datos para almacenar conjuntos de datos gobernados canónicos en Salesforce Data 360 para el cumplimiento y el control operativo. Utilice la introducción cuando se requiera control completo, auditoría y trazabilidad. Ideal para flujos de trabajo regulados o de alto valor donde la computación centralizada y la gobernanza son fundamentales.
La introducción es la mejor para crear una base de confianza para la resolución de identidad, la creación de informes reguladores y flujos de trabajo dirigidos por IA de misión crítica y la implicación de los clientes.

Los métodos de introducción de datos varían dependiendo del conector que utilice para introducir sus datos. Algunos conectores ofrecen una variedad de métodos de introducción, mientras que otros solo funcionan en modo de lotes o transmisión. Consulte Datos 360: Integraciones y conectores para obtener una lista completa de conectores de Data 360 y sus métodos disponibles.
- En tiempo real
- Ingestión de subsegundos utilizando oportunidades en curso de transmisión o Captura de datos de cambios (CDC).
- Lo mejor para flujos de trabajo que detectan el tiempo (detección de fraude, personalización, paneles operativos).
- Proporcione transformaciones y agregaciones dentro de Data 360 para reducir las E/S descendentes y optimizar el uso informático. Utilice CDC incremental para minimizar la combinación de datos.
- Streaming
- Ingestión cada 1-3 minutos en pequeños incrementos.
- Equilibra la frescura y el coste, adecuados para la orquestación de campañas, la implicación casi en vivo y los informes operativos.
- Utilice microlotes para controlar picos de E/S. Agregue datos en origen si es posible para reducir los volúmenes de transferencia y optimizar el almacenamiento.
- Lote (Cargas programadas)
- Ingestión periódica de grandes conjuntos de datos (por hora, diariamente, semanalmente).
- Rentable y fiable para conjuntos de datos históricos, informes normativos y casos de uso de cumplimiento.
- Asegúrese de calcular la localidad en la misma región que el almacenamiento de origen para la optimización de rendimiento y costes.
- Casos de uso para introducción de datos
- Generar perfiles unificados Customer 360: Construcción de una única fuente de verdad para la identidad y los atributos del cliente.
- Mantener conjuntos de datos de cumplimiento normativo: Aplicación de la regulación, el linaje y la capacidad de auditoría para datos confidenciales.
- Centralice la orquestación de campañas: Garantizar que marketing, ventas y servicio funcionan desde conjuntos de datos coherentes y de confianza.
- Prácticas de diseño
- Favorezca la ingesta por lotes para necesidades históricas o tolerantes a baja latencia, como informes de archivo o instantáneas periódicas.
- Utilice las API de transmisión o CDC para mantener la actualización para flujos de trabajo operativos y de personalización, garantizando actualizaciones casi en tiempo real.
- Controle el almacenamiento y calcule el crecimiento aplicando cargas incrementales, en vez de volver a cargar conjuntos de datos completos, para optimizar el coste y la eficiencia.
- Alinee las oportunidades en curso de introducción con la localización de cálculo y el procesamiento incremental para reducir la E/S de red. Aplique transformaciones dentro de Data 360 para evitar mover datos sin procesar innecesariamente.
- Consideraciones de costes
- Ingestión en tiempo real: Costes de cómputo y oportunidades en curso más altos; justificados para flujos de trabajo de alto valor y urgentes como la personalización, paneles operativos o acciones dirigidas por Agentforce.
- Ingestión de transmisión: Costes de computación y almacenamiento moderados; adecuados para actualizaciones frecuentes que pueden tolerar ligeros retrasos, como orquestación de campañas o creación de informes operativos.
- Ingestión por lotes: Menores costes de computación, almacenamiento predecible; lo mejor para conjuntos de datos históricos o actualizaciones de baja frecuencia. Introducir datos por lotes desde organizaciones de Salesforce utilizando ciertos conectores es gratuito.
- Modo de actualización: La selección del modo Actualización incremental reduce el ingreso total y calcula los costes. Recomendamos utilizar la actualización incremental siempre que sea posible para optimizar la eficiencia en todos los tipos de ingesta.
- El coste también se ve afectado por el volumen de E/S desde el origen a Data 360. La optimización de tamaños de lote, particiones y alineación regional reduce los costes de transferencia y mejora el rendimiento.
- Escenarios industriales
- Finanzas: Introduzca los conjuntos de datos requeridos para conocer a su cliente (KYC), Lucha contra el blanqueo de dinero (AML) y detección de fraude, donde la capacidad de auditoría y el cumplimiento no son negociables.
- Asistencia sanitaria: Utilice la introducción para la resolución de identidad de pacientes y registros compatibles con HIPAA, permitiendo vistas seguras y unificadas.
- Retail: Consolidar datos de punto de venta (POS), comercio electrónico y programa de fidelidad en perfiles unificados para segmentación y personalización
- Telecom: Compatibilidad con análisis de prevención de abandonos y uso con datos de suscriptor gobernados canónicos.
| Función | Ingestión en tiempo real | Ingestión de transmisión | Ingestión por lotes |
|---|---|---|---|
| Latencia y frescura | Ingestión de latencia por debajo del segundo a través de API de introducción con compatibilidad con Captura de datos de cambios (CDC). Proporciona oportunidades en curso de transmisión continua. Ideal para casos de uso operativos de baja latencia. | Ingestión de microlotes cada 1 a 3 minutos a través de conectores nativos. Admite actualizaciones incrementales. Se espera una ligera latencia. | Se espera latencia de datos. Cargas de gran volumen programadas. Ingestión periódica (por hora, diariamente, semanalmente). Inadecuado para operaciones sensibles al tiempo. |
| Casos de uso principales | Ideal para casos de uso operativos y de personalización de baja latencia. Se utiliza para flujos de trabajo sensibles al tiempo. Admite flujos de trabajo dirigidos por eventos. Se utiliza para alertas de fraude en tiempo real y alertas operativas. | Adecuado para procesos moderadamente urgentes. Se utiliza para orquestación de campañas, implicación casi en vivo y creación de informes operativos. Se utiliza para desencadenadores de campaña oportunos. | Rentable para conjuntos de datos masivos. Fiable para análisis históricos. Se utiliza para flujos de trabajo de agregación histórica o creación de informes regulados. Ideal para conjuntos de datos históricos o de baja velocidad. |
| Complejidad arquitectónica y E/S | Alto coste y arquitectura compleja. Requiere sistemas de origen de baja latencia. E/S intensiva. Los orígenes de gran volumen pueden causar oportunidades en curso saturadas. | Arquitectura más sencilla que en tiempo real. La E/S es moderada. Lo mejor para patrones de actualización predecibles y repetidos. El tamaño de lote afecta a la memoria/el cálculo. | Fácil de implementar. Intensivo de E/S durante los plazos de carga. El rendimiento de red puede convertirse en un cuello de botella para lotes grandes. |
| Consideraciones de costes | Costes de computación y oportunidades en curso más altos. Solo se justifica para flujos de trabajo de alto valor y sensibles al tiempo. | Modere los costes de computación y almacenamiento. Proporciona un enfoque de coste equilibrado frente a frescura. Adecuado para actualizaciones frecuentes que pueden tolerar ligeros retrasos. | Menores costes de computación y almacenamiento predecible. Recomendado para conjuntos de datos históricos o actualizaciones de baja frecuencia. La introducción a través de oportunidades en curso internas de Salesforce es gratuita. |
| Prácticas de diseño | Utilice CDC incremental para minimizar la combinación de datos. Filtre y utilice campos selectivos para reducir los gastos generales. | Utilice microlotes para controlar picos de E/S. Considere la agregación con ventanas para reducir la carga de procesamiento. | Favorezca esto para la creación de informes de archivo o instantáneas periódicas. Asegúrese de calcular la localidad en la misma región que el almacenamiento de origen para la optimización de costes. |
Utilice Cero copia para la consulta en tiempo real de sistemas externos sin duplicación de datos, lo que permite la agilidad, la actualización y el acceso ampliable a conjuntos de datos grandes o transitorios. Es mejor para paneles en vivo, análisis exploratorios, entrenamiento de modelo de IA/ML e implicación de clientes en tiempo real directamente a través de Salesforce Data 360.
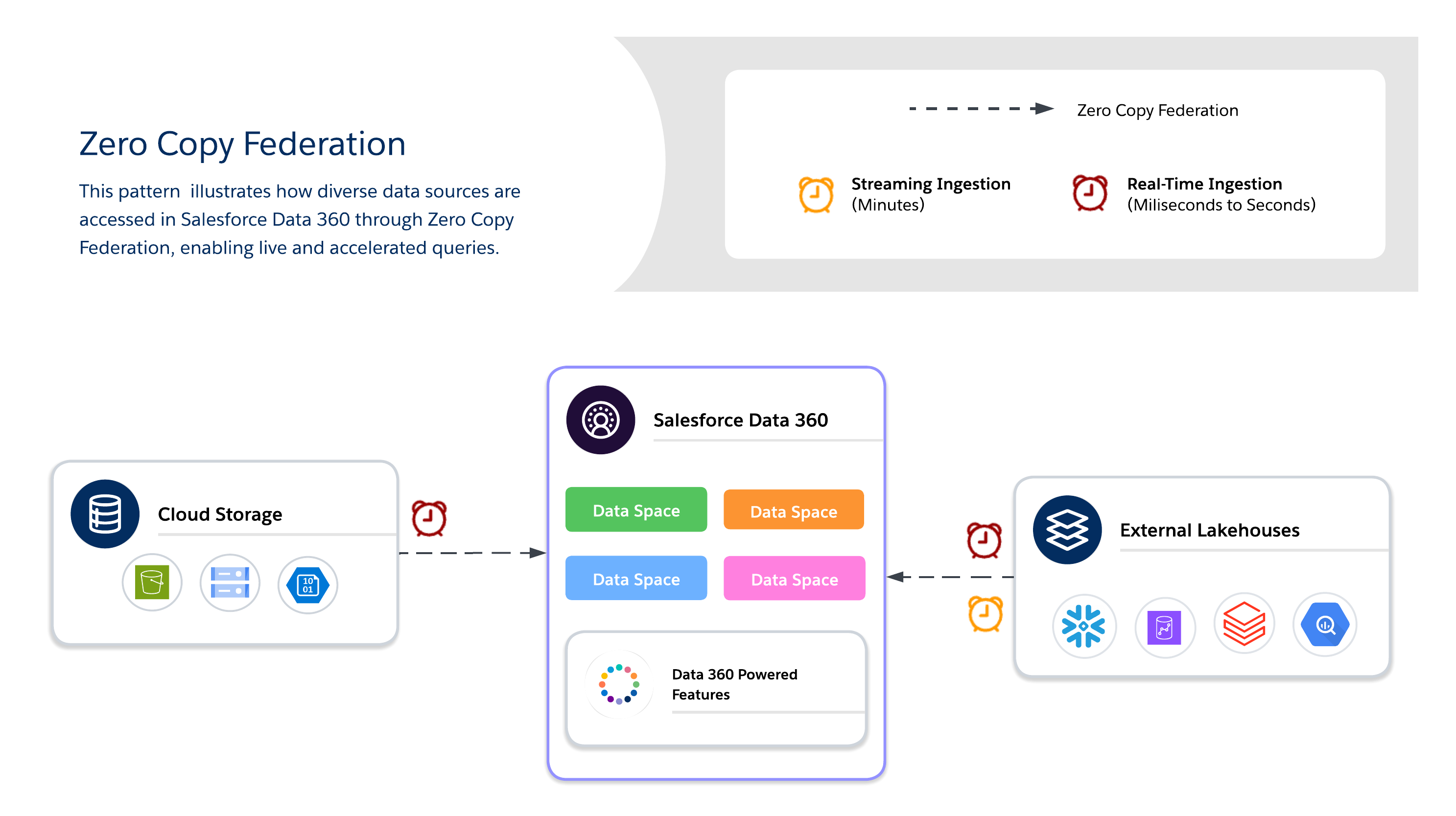
Al utilizar Cero copia, los arquitectos deben decidir además entre tres métodos de federación de datos disponibles, cada uno de los cuales ofrece sus propias ventajas entre frescura, rendimiento y coste.
- Consulta en vivo
- Ejecuta consultas directamente en sistemas externos (Snowflake, Google BigQuery, Redshift, Databricks, etc.) sin duplicación de datos.
- Óptimo cuando los predicados y las agregaciones se pueden empujar hacia abajo, minimizando el movimiento de datos a través de la red y reduciendo la E/S en el cálculo de Salesforce Data 360.
- Lo mejor para perspectivas en tiempo real y paneles operativos de baja latencia. Dependiendo del rendimiento del sistema externo.
- Almacenamiento en caché (Consulta acelerada)
- Almacena temporalmente copias en caché de datos federados en Salesforce Data 360.
- Reduce los costes y la latencia de consultas repetidas para conjuntos de datos a los que se accede con frecuencia, con una duración configurable (minutos a días).
- Los datos no se copian de forma permanente ni se rigen completamente; la actualización se gestiona a través de actualizaciones programadas desde el origen.
- Federación de archivos
- Proporciona acceso directo de solo lectura a conjuntos de datos a gran escala en establecimientos de objetos (por ejemplo, S3, GCS con Iceberg).
- Ideal para cargas de trabajo de IA/ML, análisis históricos y creación de informes a escala de petabytes sin mover datos.
- El rendimiento de las consultas depende en gran medida del formato del objeto, la partición y la E/S de red. Las exploraciones de gran tamaño pueden generar E/S sustanciales si no se optimizan.
- Casos de uso
- Personalización en tiempo real y flujos de trabajo adaptativos: Ofrezca ofertas dinámicas, recomendaciones y las siguientes mejores acciones a medida que cambia el comportamiento de los clientes.
- Paneles en vivo y análisis operativos: Proporcione energía a paneles críticos para el negocio y KPI directamente desde almacenes externos.
- Entrenamiento de modelo de IA/ML con grandes conjuntos de datos externos: Aproveche los datos a escala de petabytes de lagos de datos y almacenes utilizando Federación de archivos sin moverlos.
- Escenarios industriales
- Retail/Media: Active recomendaciones personalizadas e implicación de clientes en tiempo real federando datos de interacciones de contenido o transmisiones de clics.
- Finanzas: Ejecute la detección de fraude y la puntuación de riesgo casi en tiempo real consultando almacenes externos sin duplicar datos confidenciales.
- Tech/Enterprise: Admite informes entre nubes, paneles de servicio de TI y análisis operativos donde los conjuntos de datos residen en múltiples sistemas.
- Prácticas de diseño
- Consulta en vivo
- Utilizar para consultas de alto QPS y baja latencia cuando la actualización es crítica.
- Distribuya predicados y agregaciones al sistema externo para reducir la mezcla de datos en la red.
- Evite consultas que exploran volúmenes de datos masivos innecesariamente; considere filtros y poda de particiones.
- Federación de archivos
- Acceda a conjuntos de datos a escala de petabytes en establecimientos de objetos sin introducción.
- Mantenga el almacenamiento de objetos en la misma región de nube que Salesforce Compute para minimizar la latencia y los costes de salida.
- Utilice formatos particionados y columnares (Parquet/ORC) y filtros desplegables para reducir la transferencia de E/S y de red.
- Aproveche la distribución de consultas y predicados para filtrar y agregar datos en el origen, reduciendo el movimiento de datos.
- Evite el acceso a datos entre regiones a menos que sea necesario, ya que aumenta la E/S, la latencia y los costes.
- Almacenamiento en caché (Consulta acelerada)
- Almacena en caché conjuntos de datos a los que se accede con frecuencia para equilibrar coste y rendimiento.
- Configure intervalos de actualización para equilibrar la actualización frente al coste de consulta.
- Cumplimiento: Aplique la regulación en el origen aprovechando la seguridad a nivel de filas (RLS) y enmascarando políticas directamente dentro de sistemas federados. A continuación se muestran prácticas recomendadas para el enmascaramiento y el RLS uniforme entre plataformas.
- Utilizar un Id. de empresa centralizado: Asigne usuarios y entidades en Salesforce Data 360 a un identificador de empresa único y centralizado que se corresponda con identidades en sistemas externos.
- Alinear políticas de seguridad: Garantice que las políticas de enmascaramiento y seguridad a nivel de filas en sistemas federados se aplican basándose en la identidad asignada. Esto mantiene el cumplimiento al consultar datos externos.
- Estandarizar esquemas de identidad: Mantenga atributos de identidad coherentes (correo electrónico, Id. de usuario, Id. de cliente, etc.) en todos los orígenes de datos para evitar desajustes e infracciones de acceso.
- Consulta en vivo
- Consideraciones de costes
- Consulta en vivo: Modelo de pago por consulta: los costes se acumulan en la computación externa de Lakehouse y pueden aumentar con un alto QPS. Ideal para casos de uso críticos para la frescura donde el valor es superior a la variabilidad de costes.
- Consulta acelerada (almacenamiento en caché): Reduce el coste de las consultas en comparación con Live Query reduciendo las visitas al sistema de origen, pero aumenta los costes de introducción de datos por lotes para rellenar y actualizar la memoria caché. Ideal para conjuntos de datos a los que se accede con frecuencia.
- Federación de archivos: Opción de almacenamiento más barata como datos en Object Store, pero los costes de consulta dependen del tamaño del archivo, la partición y la poda. Mejor para datos históricos o masivos a escala de petabytes.
| Punto de decisión | Consulta en vivo | Almacenamiento en caché (Consulta acelerada) | Federación de archivos |
|---|---|---|---|
| Ubicación de origen de datos | Lagos de datos externos (Snowflake, Google BigQuery, Redshift, Databricks). | Lagos de datos externos (Snowflake, Google BigQuery, Redshift, Databricks) | Almacenamientos de objetos o lagos de datos en la nube (S3, ADLS, GCS), a menudo utilizando formatos de tabla abiertos como Iceberg. |
| Propósito/Caso de uso | Ideal para análisis interactivos y paneles en tiempo real. Lo mejor para la personalización en tiempo real y flujos de trabajo dinámicos. | Lo mejor para cuando las consultas son frecuentes pero los resultados ligeramente obsoletos son aceptables. Adecuado para paneles y segmentación de BI. | Ideal para el procesamiento por lotes a gran escala y el entrenamiento de modelos de IA/ML. Ideal para análisis históricos y creación de informes a escala de petabytes. |
| Frescura/Latencia | Máxima actualización; las consultas se ejecutan directamente en tiempo real. Admite la decisión de subsegundos. | Los resultados ligeramente obsoletos son aceptables. La actualización depende del intervalo de caché, configurable de 15 minutos a 7 días. | Optimizado para trabajos intensivos en rendimiento y por lotes. No es adecuado para paneles en tiempo real. |
| Patrón de acceso | Ideal para consultas poco frecuentes o ad hoc. Utilizar para consultas de alto QPS (consulta por segundo) y baja latencia donde la actualización es crítica. | Ideal para escenarios de lectura de alta frecuencia. Mejora el rendimiento para patrones de acceso frecuentes. | Acceso de solo lectura. Adecuado para conjuntos de datos a escala de petabytes sin introducción. |
| Controladores de rendimiento | Altamente dependiente del rendimiento del sistema de origen externo. Optimizado cuando los predicados y las agregaciones se pueden enviar al origen. | Reduce la latencia en comparación con consultas en vivo repetidas. El rendimiento depende de la gestión y el intervalo de caché. | El rendimiento depende en gran medida del formato del objeto, la partición y el rendimiento del sistema externo. Utilice formatos particionados y de columnas (Parquet/ORC). |
| Consecuencias de costes | Modelo de pago por consulta. Los costes se acumulan en cálculos externos de Lakehouse. Rentable para consultas poco frecuentes, pero los gastos pueden aumentar con un alto volumen de consultas por segundo (QPS). | Menor coste que las consultas en vivo repetidas. Reduce la necesidad de consultar repetidamente el origen externo. Agrega almacenamiento en caché y gastos generales de actualización. | Opción de almacenamiento más barata. Los costes de consulta dependen del tamaño y la partición del archivo. |
| Consideración clave | Evite consultas sin filtrar que exploran volúmenes de datos masivos innecesariamente. | Requiere gestión de caché. No es adecuado para la decisión de subsegundos. | El rendimiento de las consultas se basa en gran medida en la optimización a través de particiones y distribución de predicados. |
Las arquitecturas híbridas permiten a los arquitectos anclar conjuntos de datos críticos en Data 360 para una gobernanza centralizada mientras aprovechan las consultas federadas para la actualización, la duplicación reducida y el acceso ampliable a grandes conjuntos de datos externos. Este enfoque equilibra las E/S, calcula la localidad, el coste y los requisitos de cumplimiento.
Utilice un enfoque híbrido para una regulación equilibrada, la actualización y la eficiencia operativa combinando la introducción de datos y la copia cero para entregar perspectivas sobre las que se pueden realizar acciones en tiempo real. Utilice la introducción para conjuntos de datos regulados de alto valor donde se requiere trazabilidad, RLS y enmascaramiento, y la federación para conjuntos de datos efímeros o de gran volumen donde la actualización y el rendimiento son clave.
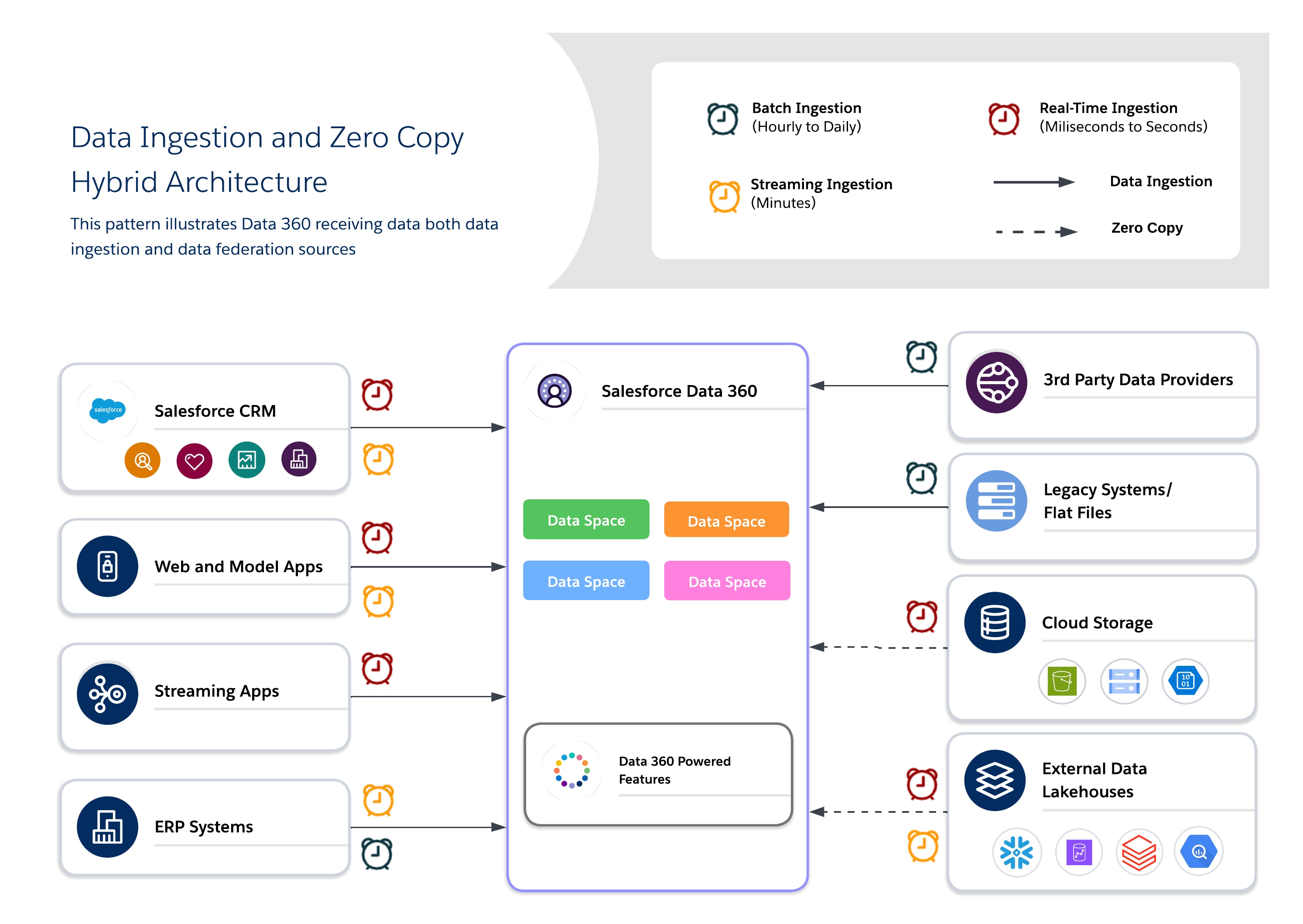
- Casos de uso
- Implicación OmniCanal: Combine datos históricos de clientes con comportamiento en tiempo real para entregar experiencias coherentes y conscientes del contexto.
- Oportunidades en curso de IA/ML: Entrene modelos en conjuntos de datos canónicos depurados mientras los enriquece con señales sin procesar o en tiempo real procedentes de fuentes externas.
- Cumplimiento mixto y necesidades de agilidad: Aplique una regulación estricta para datos confidenciales pero federe para agilidad operativa.
- Escenarios industriales
- Retail: Utilice la introducción para la resolución de identidad y la unificación de perfiles; federe para ofertas en tiempo real y personalización.
- Asistencia sanitaria: Mantenga registros de pacientes dorados a través de la introducción mientras federa transmisiones de dispositivos de IoT y datos de sensores para contexto inmediato.
- Servicios financieros: Introduzca datos regulados en un lago regulado por el cumplimiento mientras federa consultas externas para la detección de fraude y la supervisión de riesgos.
- Prácticas de diseño
- Gobernanza de delimitador con introducción: Introduzca datos de alto valor o regulados en modelos canónicos para garantizar Trust y cumplimiento.
- Utilizar Federation for Freshness: Permita a los lagos externos proporcionar acceso a datos en tiempo real o a gran escala sin duplicación.
- Coste de saldo frente a Rendimiento: Perfilar cargas de trabajo para decidir qué introducir frente a federar, minimizando costes de almacenamiento o consulta innecesarios.
- Aplicar gobernanza por capas: Aplique la regulación centralizada para los datos introducidos, mientras aprovecha los propios controles de seguridad de los sistemas federados (por ejemplo, RLS, enmascaramiento).
- Cuando diseñe oportunidades en curso híbridas, garantice la introducción incremental para conjuntos de datos históricos y distribuya agregaciones o filtros a orígenes federados para optimizar la E/S y calcular el uso.
- Consideraciones de costes
- Optimice el coste total frente al rendimiento combinando la introducción de datos críticos o de cumplimiento con la federación cuando sea necesario actualizar.
- Tenga en cuenta la E/S y calcule la distribución al mezclar la introducción y la federación. Para reducir el coste informático en sistemas de origen de consultas repetidas, utilice el almacenamiento en caché (Consulta acelerada) para conjuntos de datos federados de alta lectura a los que se accede con frecuencia.
A continuación se muestran arquetipos comunes que ilustran cómo aplicar esta lógica.
- El arquetipo "Fuente Única de la Verdad": Centralizar y gobernar
- Escenario: Necesita crear perfiles Customer 360 unificados y compatibles para toda su empresa global. Los datos proceden de una docena de sistemas diferentes, deben cumplir con las estrictas leyes de RGPD y CCPA y servirán como la fuente de confianza para todas las interacciones de marketing y servicio.
- Patrón recomendado: Ingestión de datos. La prioridad es la gobernanza, Trust y control. Introducir los datos en Data 360 es la única forma de crear un perfil canónico completamente auditable que esté aislado de los sistemas de origen.
- El arquetipo "Perspectivas en tiempo real": Analizar sin mover
- Escenario: Su equipo de ciencia de datos necesita ejecutar consultas exploratorias en una tabla de transacciones masiva y en constante actualización en Snowflake. Al mismo tiempo, su equipo ejecutivo desea un panel de BI en vivo con esos mismos datos. Mover petabytes de datos diariamente es demasiado lento y costoso.
- Patrón recomendado: Zero Copy Federation. La prioridad es la velocidad, la agilidad y la rentabilidad a escala. Zero Copy le permite aprovechar el inmenso poder de su almacén de datos existente para consultas en tiempo real sin los gastos generales y la latencia de la duplicación de datos.
- El arquetipo "Inteligencia híbrida": Gobernar el núcleo, federar la ventaja
- Escenario: Desea enriquecer sus perfiles de clientes gobernados e introducidos con señales de comportamiento en tiempo real (como clics de sitio web) desde un lago de datos. Necesita la estabilidad del perfil principal pero la inmediatez de los datos en vivo para potenciar la personalización en el momento.
- Patrón recomendado: Un enfoque híbrido. Utilice la introducción de datos para crear el núcleo estable y gobernado de sus datos de clientes. A continuación, utilice Cero copia para federar los datos volátiles de "borde" en tiempo real, uniéndolos en el momento de la consulta para una vista completa y actualizada.
La estrategia de datos de empresa ya no se trata de elegir un patrón de integración único, sino de diseñar flexibilidad controlada dentro de un ecosistema de datos interoperable. La selección del método de integración de datos correcto para cada sistema de datos de origen basándose en necesidades comerciales a menudo lleva a un enfoque híbrido que combina los puntos fuertes de la introducción de datos y la federación de datos.:
- Introduzca conjuntos de datos gobernados críticos para la misión en Salesforce Data 360 para el cumplimiento, la resolución de identidad y los flujos de trabajo operativos.
- Genere datos a través de Cero copia para análisis en vivo, exploratorios y dirigidos por IA sin duplicar el almacenamiento.
Salesforce Data 360 en Hyperforce ofrece resiliencia y capacidad de ampliación de múltiples regiones. ts open lakehouse with Iceberg tables permite calcular la separación y la interoperabilidad con plataformas como Snowflake, Databricks y S3 Iceberg, formando la columna vertebral de un ecosistema de datos multinube realmente interoperable.
A medida que evolucionan los ecosistemas de datos, equilibre continuamente la frescura, el coste, el rendimiento y el cumplimiento para mantener la agilidad arquitectónica. Prepare su plataforma para el futuro unificando datos introducidos y gobernados con acceso federado. Esto permite inteligencia en tiempo real, activación de IA y personalización a escala empresarial entre nubes, regiones y dominios comerciales.
Las soluciones únicas no se adaptan a la mayoría de los negocios. La estrategia óptima asigna el patrón correcto al impulsor comercial correcto.
Yugandhar Bora es Arquitecto de Ingeniería de Software de Salesforce, especializado en arquitectura de datos dentro de la plataforma Aplicaciones de datos e inteligencia. Lidera iniciativas de la junta de revisión de arquitectura empresarial (EARB) centradas en la gobernanza de datos y modelos de datos unificados, mientras contribuye a soluciones de aprovisionamiento de plataformas automatizadas.
Jan Fernando es Arquitecto Principal de la Oficina del Arquitecto Jefe de Salesforce. Se unió a Salesforce en 2012, aportando una gran experiencia de su época en el ecosistema de startups. Antes de unirse a la Oficina del Arquitecto Jefe, pasó más de una década en la organización de la plataforma, donde dirigió varias transformaciones tecnológicas clave.