Die Salesforce Platform hat ihre Automatisierungsarchitektur kontinuierlich weiterentwickelt, um die Anforderungen komplexer Geschäftsprozesse zu erfüllen. Frühere Generationen – Workflow-Regeln und Prozessgenerator – boten die ersten Schritte in der ereignisgesteuerten Logik, erweiterten die Automatisierungsfunktionen für ereignisgesteuerte Logik und erweiterten die Reichweite auf eine breitere Palette von Generatoren.
Diese Entwicklung hat zu einer leistungsstarken, konsolidierten Architektur geführt, die sich auf zwei komplementäre Säulen konzentriert: Durch Datensätze ausgelöster Flow und Apex-Auslöser. In diesem Dokument finden Sie den Rahmen und die Richtlinien, um fundierte Entscheidungen beim Entwerfen von Auslöserautomatisierungen zu treffen.
| Flow | Salesforce Flow ist ein leistungsstarkes Zeigen-und-Klicken-Automatisierungstool, mit dem Benutzer komplexe Geschäftsprozesse, Bildschirme und Logik visuell mit Flow Builder erstellen können, ohne Code schreiben zu müssen. Sie automatisiert Aufgaben wie Datenaktualisierungen, das Senden von E-Mails und das Führen von Benutzern und bietet Flexibilität durch Typen wie Bildschirm-Flows (Benutzerinteraktion) und Ausgelöste Flows (Datensatz-/geplante Ereignisse). |
| Apex | Salesforce Apex ist eine proprietäre, objektorientierte Programmiersprache für die Salesforce Platform, die ähnlich wie Java zum Erstellen von benutzerdefinierter Geschäftslogik, Automatisieren von Prozessen und Erweitern der zentralen CRM-Funktionen über deklarative Tools hinaus verwendet wird. |
Die Erstellung einer durch Datensätze ausgelösten skalierbaren, wartungsfreundlichen und leistungsfähigen Automatisierung auf der Salesforce Platform erfordert einen disziplinierten, von der Architektur geführten Ansatz. Die Auswahl zwischen Flow und Apex und die Implementierung der einzelnen Elemente richten sich nach einem klaren Satz von Prinzipien. Diese Punkte fassen diese Prinzipien zusammen und dienen als grundlegende Regeln für das moderne Automatisierungsdesign.
-
Wählen Sie basierend auf der Salesforce-Objektautomatisierungsdichte das richtige Tool für den Auftrag aus.
-
Verwenden Sie "Durch Datensätze ausgelöster Flow" für Salesforce-Objekte für Automatisierungen mit niedriger Dichte.
-
Erweitern Sie die Logik des durch einen Datensatz ausgelösten Flows um Invocable Apex für Automatisierungen mittlerer Dichte.
-
Verwenden Sie Apex-Auslöser für Salesforce-Objekte für Automatisierungen mit hoher Dichte.
-
-
Gehen Sie beim Auslösen asynchroner Prozesse mit Bedacht vor.
Diese Regel gilt unabhängig davon, ob Sie asynchrone Prozesse in einem durch einen Datensatz ausgelösten Flow aufrufen oder einen warteschlangenfähigen Auftrag aus Apex in die Warteschlange stellen. Auch wenn dieses Muster für das Abladen von Arbeit verlockend sein kann, kann es komplexe Fehlerbehandlungsszenarien einführen und das Risiko erhöhen, die Obergrenzen zu erreichen. -
Verwenden Sie einen Einstiegspunkt pro Salesforce-Objekt.
Verwenden Sie für ein bestimmtes Salesforce-Objekt einen Mechanismus als Einstieg in die Automatisierung. Versuchen Sie, zu vermeiden, dass Flow- und Apex-Auslöser als Einstiegspunkte für dasselbe Objekt miteinander kombiniert werden.
Flow und Apex verwenden gemeinsame grundlegende Funktionen. Jedes Tool kann Datensätze abfragen, bedingte Logik ausführen, Variablen zuweisen und DML-Vorgänge wie das Erstellen, Aktualisieren und Löschen von Datensätzen ausführen, die in einer angegebenen Reihenfolge ausgeführt werden.
Diese funktionale Überschneidung bedeutet jedoch nicht, dass die Werkzeuge austauschbar sind. Bei der architektonischen Entscheidung geht es nicht darum, ob eine Aufgabe gelöst werden kann, sondern wie sie durchgeführt wird und welche langfristigen Auswirkungen sie auf die Leistung, Skalierbarkeit und Wartungsfähigkeit hat. Flows zeichnen sich durch klare und schnelle Implementierung für einfache Prozesse aus, während Apex die für komplexe Lösungen erforderliche granulare Kontrolle und Rohleistung bietet.
Bei der Automatisierungsdichte handelt es sich um die Belastung eines bestimmten Salesforce-Objekts. Sie dient als Heuristik, um die optimale Implementierung des Objekts zu bestimmen. Mit zunehmender Automatisierungsdichte steigt die Wahrscheinlichkeit, dass Transaktionsobergrenzen überschritten werden.
Berechnen Sie die Automatisierungsdichte, indem Sie drei spezifische Dimensionen von Volumen und Komplexität untersuchen:
-
Automatisierungsmenge: Die Rohanzahl eindeutiger Metadateneinträge für die Automatisierung (Flows, Auslöseraktionen usw.), die während eines einzelnen DML-Ereignisses (Data Manipulation Language) ausgeführt werden.
-
Datensatzvolumen: Die Datensätze pro Transaktion, die über API-Ladungen oder die Verarbeitung schwerer Batches verarbeitet werden, wobei die Leistung entscheidend wird.
-
Abhängigkeitsverbreitung: Eine Maßeinheit für die durch den anfänglichen CRUD-Vorgang ausgelösten nachgelagerten DML-Vorgänge. Sie quantifiziert die Tiefe des Diagramms, in dem eine Aktualisierung zu Aktualisierungen an verwandten Objekten führt (z. B. Kundenvorgang → Account → Kontakt → benutzerdefiniertes Rollup).
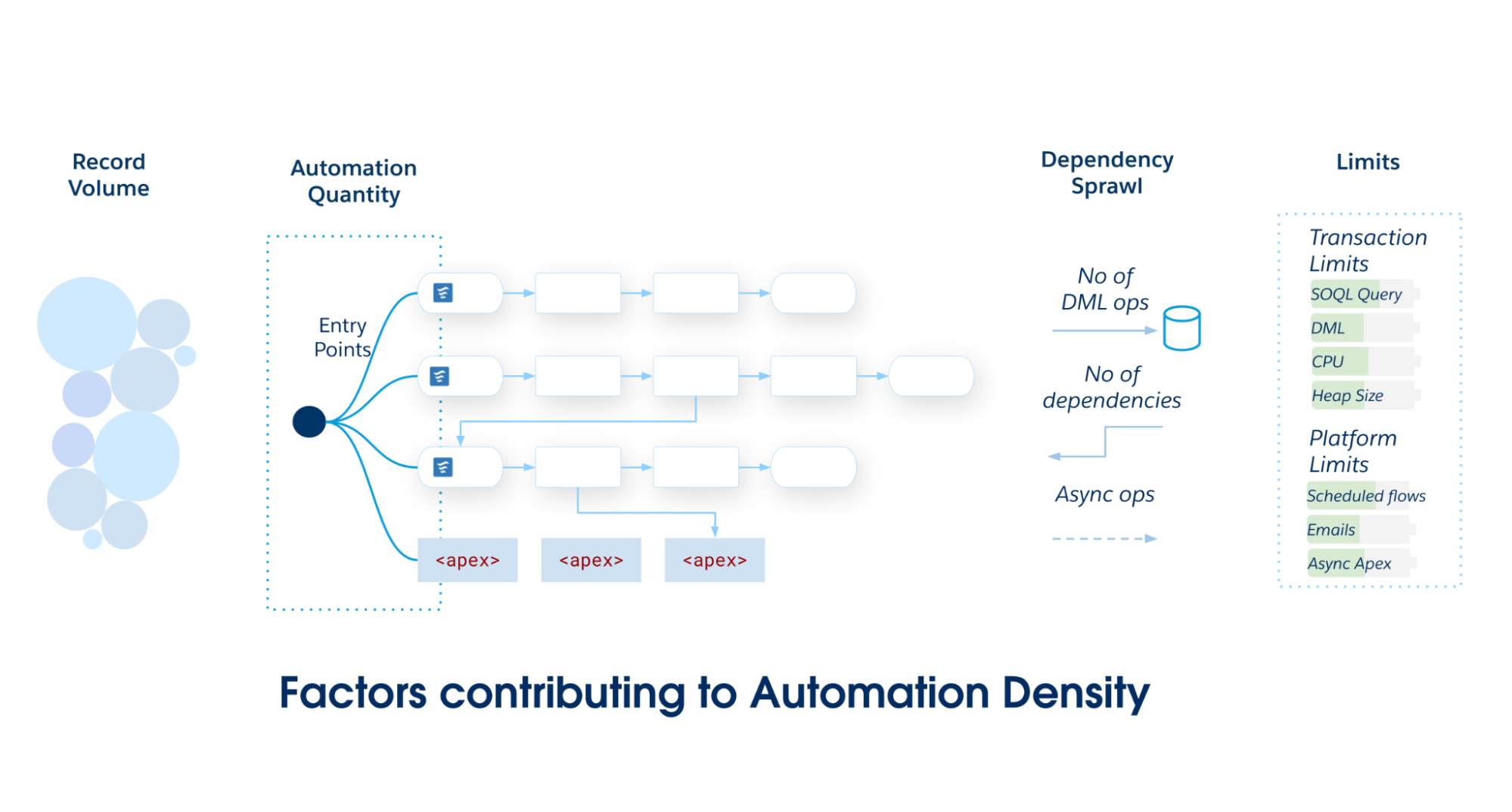
Wenn der Umfang und die Komplexität Ihrer Salesforce-Anwendung zunehmen, können Sie sich für einen einzigen primären Einstiegspunkt entscheiden – entweder durch Datensätze ausgelöster Flow oder Apex Triggers. Vermeiden Sie die Partitionierung von Automatisierungen über mehrere Mechanismen in einem einzelnen Salesforce-Objekt, da dies zu einer schlechten Wartungsfähigkeit und einer fragmentierten Verwaltung führt.
Verwenden Sie diese Matrix, um den erforderlichen Architekturstandard für Ihr Salesforce-Objekt zu bestimmen.
-
Durch Datensätze ausgelöster Flow ist die bevorzugte Lösung für eine niedrige Automatisierungsdichte. Sie bietet ein ausgewogenes Verhältnis zwischen Leistung und Zugänglichkeit, das sich ideal für einfache und voneinander unabhängige Automatisierungen eignet.
-
Das Hybridmuster (Record-Triggered Flow with Invocable Apex) ist eine leistungsstarke und wartbare Wahl für Automatisierungen mittlerer Dichte mit steigender Komplexität. Durch dieses Muster können Teams die geordnete Choreografie im deklarativen Flow beibehalten und gleichzeitig rechenintensive Vorgänge an Apex delegieren, um den barrierefreien Zugriff mit der Leistung abzugleichen.
-
Apex Auslöser bieten die notwendigen Bausteine für eine solide architektonische Grundlage, um Automatisierungen mit hoher Dichte zu unterstützen. Die Leistung, die granulare Steuerung sowie die objektorientierte Abstraktion und Polymorphie von Apex eignen sich besser, um die Komplexität und den Umfang dieser Szenarien zu bewältigen.
| Dichtestufe | Automatisierungsmenge | Datenvolumen (Batchgröße) | Abhängigkeitszersiedelung | Architektonischer Standard |
|---|---|---|---|---|
| Niedrig | < 15 Automatisierungen |
Standard Benutzergesteuerte Benutzeroberflächeninteraktionen oder kleine API-Lastungen (1–200 Datensätze) |
Diskret In sich geschlossene Logik. 0–1 nachgelagerte DML-Vorgänge für dasselbe Objekt oder ein verwandtes Objekt. |
Durch einen Datensatz ausgelöster Flow |
| Mittel | 15–30 Automatisierungen |
Mittel Standardmäßige Batchverarbeitung (mit Logik, die eine sorgfältige Massenverarbeitung erfordert) |
Gekoppelt "Übergeordnet/Untergeordnet" aktualisiert 2–4 nachgelagerte DML-Vorgänge. Rekursionsrisiko |
Hybridmuster Flow + aufrufbares Apex |
| Hoch | > 30 Automatisierungen |
Hoch Große Datenvolumen mit Massen-API-Last (2.000 – 10.000+ Datensätze) |
Komplex und rekursiv Diagramm mit tiefer Abhängigkeit (5+ nachgelagerte DML-Vorgänge). Risiko von Dreiecksrekursionsschleifen |
Apex-Auslöser-Metadaten-Framework |
Beachten Sie auch die tägliche Gesamtanzahl der DML-Vorgänge, da Salesforce die Verwaltung gemeinsamer Ressourcen in einer Umgebung mit mehreren Mandanten und Obergrenzen erzwingt, um zu verhindern, dass Automatisierungen gemeinsam genutzte Ressourcen monopolisieren. Salesforce-Objekte mit einem hohen täglichen DML-Volumen erfordern eine sorgfältige Automatisierungsauswahl. Beispielsweise sind die asynchronen Obergrenzen für die CPU-Zeit (60.000 ms) und die Heap-Größe (12 MB) höher als die synchronen Obergrenzen. Darüber hinaus muss die organisationsweite 24-Stunden-Obergrenze für asynchrone Ausführungen – berechnet auf das 250.000- oder 200-fache Ihrer Benutzerlizenzen – die gesamte tägliche DML in Ihren Architekturentwurf einbeziehen, um Laufzeitausnahmen zu vermeiden.
Durch Datensätze ausgelöster Flow ist das wichtigste deklarative Tool der Plattform für die durch Datensätze ausgelöste Automatisierung. Die Benutzerfreundlichkeit von Flow und die integrierten Plattformsicherungen ermöglichen es Teams, einfach skalierbare und zuverlässige Lösungen zu erstellen. Dies ist die ideale Wahl für die meisten Teams, die Lösungen auf der Salesforce Platform erstellen.
Apex ist die proprietäre, stark typisierte, objektorientierte Programmiersprache der Plattform. Verwenden Sie Apex für Salesforce-Objekte mit hoher Automatisierungsdichte und für Anwendungsfälle, die eine hohe Leistung, komplexe Logik oder genaue Kontrolle über Transaktionen erfordern.
Diese Matrix bietet einen direkten Vergleich von Flow und Apex zwischen wichtigen Architekturfunktionen, um die Entscheidungsfindung zu unterstützen.
| Kapazität | Durch einen Datensatz ausgelöster Flow | Apex Trigger |
|---|---|---|
| Liefer- und Wartungsgeschwindigkeit | Empfohlen Über die visuelle Benutzeroberfläche von Flow Builder können Administratoren und andere deklarative Generatoren Automatisierungen schneller erstellen und ändern als Apex Code schreiben, testen und bereitstellen. Diese Oberfläche ermöglicht es einem breiteren Spektrum von Teammitgliedern, Geschäftswerte zu liefern, und reduziert die Abhängigkeit von spezialisierten Entwicklerressourcen für einfache Aufgaben. |
Fachwissen erforderlich Für die Implementierung, den Test und die Wartung des Codes benötigt Apex entsprechend qualifizierte Softwareentwickler. |
| Modularität | Verfügbar Durch Datensätze ausgelöste Flows sind standardmäßig modular. Statt monolithischer Logik erstellen Teams diskrete Flows für bestimmte Anforderungen und choreographieren sie zusammen mit dem Flow-Auslöser-Explorer. Diese Modularität ermöglicht eine isolierte Änderung und einfache Erweiterung, wodurch die langfristigen Betriebskosten erheblich reduziert werden. |
Verfügbar Apex ist nach Design in Funktionsmodule unterteilt. Jede Apex-Klasse soll ein einzelnes Funktionsmodul implementieren. |
| Sichtbarkeit und Governance | Empfohlen Der visuelle Charakter von Flow bietet eine intuitive Darstellung der Geschäftslogik. Der Flow-Auslöser-Explorer bietet eine konsolidierte Ansicht aller Flows in einem Objekt, sodass Architekten und Administratoren einfacher verstehen, steuern und Fehler beheben können, ohne Code lesen zu müssen. |
Fachwissen erforderlich Die Verwendung eines Metadaten-Frameworks zum Organisieren von Auslösern ist vorteilhaft. Apex erfordert jedoch ein diszipliniertes Entwicklungsteam, um den Code organisiert und wartbar zu halten. |
| Hochleistungsfähige Massendatenverarbeitung | Nicht empfohlen Bei komplexen Logiken oder großen Datenmengen besteht ein erhöhtes Risiko, dass Obergrenzen erreicht werden. |
Empfohlen Apex Code wird näher an den Kernservices der Plattform ausgeführt und bietet Entwicklern mehr Kontrolle über die Abfrageoptimierung, die Datenverarbeitung und die algorithmische Effizienz. Dies führt zu mehr Leistung und Skalierbarkeit, insbesondere in komplexen Szenarien mit großen Datenmengen. |
| Robuste Logik und Datenstrukturen | Verfügbar Das Element "Flowtransformation" kann bei einigen komplexen Verarbeitungsaufgaben hilfreich sein. Dem Flow fehlen jedoch native Zuordnungs- und Set-Datenstrukturen, was die komplexe Datenverarbeitung umständlich und rechenineffizient macht. |
Empfohlen Apex bietet vollständigen Zugriff auf Karten-, Satz- und Programmschleifen für hocheffiziente und sichere Datenbearbeitungen. Als Programmiersprache mit vollem Funktionsumfang bietet Apex zudem Zugriff auf komplexe logische Konstrukte, Datenstrukturen und Designmuster, mit denen komplexe Geschäftsprobleme wartungsfreundlich und effizient gelöst werden können. Apex enthält eine umfangreiche Standardbibliothek mit erweiterten Funktionen (z. B. BusinessHours, Crypto), die derzeit in deklarativen Tools nicht verfügbar sind. |
| Transaktionssteuerung | Nicht verfügbar Der Flow bietet keinen Zugriff auf "Database.savepoint", "Database.rollback" oder teilweise erfolgreiche DML-Vorgänge für teilweise Transaktions-Commits oder -Rollbacks. |
Verfügbar Apex bietet vollständige und detaillierte Kontrolle über die Transaktionsintegrität und komplexe Fehlerbehebungsszenarien. |
| E-Mail-Verteilung | Empfohlen Das Senden vorkonfigurierter E-Mail-Benachrichtigungen über einen durch einen Datensatz ausgelösten Flow ist einfach und skalierbar. Benutzerdefinierte E-Mail-Benachrichtigungen können zur Laufzeit erstellt und verteilt werden. Für benutzerdefinierte E-Mails gelten die täglichen Obergrenzen für den Versand von E-Mails. |
Verfügbar Apex kann benutzerdefinierte E-Mail-Nachrichten generieren und senden. Für alle über Apex gesendeten E-Mails gelten die täglichen Obergrenzen für den E-Mail-Versand. |
| Anwendung von Plattformsicherungen | Empfohlen Der Flow enthält integrierte Schutzmaßnahmen wie automatische Massenverarbeitung und automatische Wiederholungen. Diese Sicherungen erhöhen die Bewertungsgeschwindigkeit und verhindern Leistungseinbußen, die andernfalls eine komplexe manuelle Codierung erfordern. |
Manuelle Implementierung erforderlich Schutzmaßnahmen wie die Massenverarbeitung müssen explizit codiert werden (beispielsweise das Verwalten von Sammlungen und das Vermeiden von SOQL in Schleifen). Automatische Wiederholungen sind nicht nativ für Auslöser und erfordern eine komplexe benutzerdefinierte Logik. |
| Asynchrone Verarbeitung | Verfügbar Flow bietet einfache Mechanismen für Automatisierungen, die eine separate Transaktion in einem asynchronen Pfad erfordern. Für diese Automatisierungen gelten tägliche Obergrenzen. |
Verfügbar Apex ermöglicht die vollständige Kontrolle über die Datenerfassung ändern und warteschlangenfähige Ereignisse, die von einem entkoppelten Auslöserabonnenten verarbeitet werden. |
| Geplante Verarbeitung | Empfohlen Die geplanten Pfade des Flows bieten eine einzigartige und leistungsstarke Planungsfunktion (z. B. "3 Tage vor Schlusstermin auslösen"). Diese Funktion beinhaltet die automatische Stornierung und Neuplanung, wenn sich die Daten des Datensatzes ändern. Für diese Automatisierungen gelten tägliche Obergrenzen. |
Nicht verfügbar Ein Apex Auslöser kann ein zeitliches, datensatzspezifisches Ereignis mit automatischer Stornierung nicht nativ planen. Geplantes Apex ist zwar vorhanden, es handelt sich jedoch um einen grundlegend anderen Mechanismus, der zu einem bestimmten Zeitpunkt ausgeführt wird und nicht während der Verarbeitung eines einzelnen Datensatzes als Teil eines Auslösers geplant wird. |
| Ordnung und Choreografie | Verfügbar Mit dem Flow-Auslöser-Explorer können Administratoren eine relative Ausführungsreihenfolge für mehrere Flows desselben Objekts definieren. |
Verfügbar Ein Auslöser-Framework bietet genaue Kontrolle über die genaue Reihenfolge der Automatisierungen. |
| Aktualisierungen desselben Datensatzfelds | Verfügbar (vor dem Speichern) Durch einen Datensatz ausgelöster Flow ist die leistungsfähigste deklarative Option zum Aktualisieren des auslösenden Datensatzes vor dem anfänglichen DML-Commit. |
Verfügbar (vor dem Speichern) Apex bietet das leistungsstärkste Angebot mit minimalem Overhead. |
| Objektübergreifende CRUD | Verfügbar (nach dem Speichern) Flow eignet sich für einfache objektübergreifende DML-Vorgänge mit geringer Komplexität. |
Verfügbar (nach dem Speichern) Apex bietet eine überlegene Kontrolle über die Deduplizierung, Fehlerbehandlung und Leistung für objektübergreifende DML-Vorgänge. |
| Duplizierung teurer Berechnungen | Verfügbar Flow zeichnet sich durch die Beseitigung redundanter Abfragen und DML-Anweisungen durch automatische Massenverarbeitung aus. Der Status kann jedoch nicht zwischen verschiedenen Flow-Auslösern oder über mehrere Aufrufe desselben Flows innerhalb einer Transaktion zwischengespeichert oder freigegeben werden. Diese Einschränkung kann in extremen Leistungsszenarien wichtig werden. |
Empfohlen Apex bietet Mechanismen zum Deduplizieren teurer Vorgänge. Entwickler können die transaktionale Zwischenspeicherung mithilfe statischer Eigenschaften und Variablen und die Zwischenspeicherung auf Plattformebene mithilfe des Plattform-Cache nutzen, um Daten zu speichern und wiederzuverwenden. Diese Techniken sind wichtig, um den Verbrauch von Obergrenzen für Transaktionen wie SOQL-Abfragen zu reduzieren und eine hohe Leistung und Skalierbarkeit zu gewährleisten. |
| Benutzerdefinierte Fehlerverarbeitung | Verfügbar Das Element CustomError kann einen Speichervorgang blockieren und dem Benutzer eine Meldung anzeigen. |
Empfohlen Die Methode addError() bietet flexible Fehlermeldungen auf Feldebene und bedingte Fehlermeldungen. |
Diese Tabelle enthält allgemeine Empfehlungen für allgemeine Anwendungsfälle, die auf den vorgestellten Funktionen basieren. Letztlich werden Sie zusätzliche Überlegungen berücksichtigen, um eine optimale Anpassung an Ihre speziellen Szenarien zu finden, wie sie beispielsweise im Abschnitt "Verwandte bewährte Vorgehensweisen" dieses Dokuments enthalten sind. Dort erfahren Sie mehr darüber, wann eine bestimmte Kombination aus Flow und Apex den besten Ansatz bietet.
| Anwendungsfall | Beschreibung | Best-Fit | Begründung |
|---|---|---|---|
| Hochleistungsfähige Batchverarbeitung | Jede Automatisierung, die Tausende von Datensätzen effizient verarbeiten muss | Apex | Apex bietet umfangreiche APIs für die Anbindung an die Plattform und für die Rohgeschwindigkeit. |
| Komplexe Datenverarbeitung | Szenarien, in denen erweiterte Datenmanipulationen erforderlich sind | Apex | Apex stellt Datenstrukturen wie "Karte" und "Satz" bereit, die in Flow nicht nativ verfügbar sind und für das Schreiben von performantem Code mit Massensicherheit entscheidend sein können. |
| Transaktionssteuerung | Kontrollmechanismen wie Speicherpunkte, Rollbacks und Teil-Commits | Apex | Apex bietet Zugriff auf Mechanismen wie Database.savepoint und Database.rollback und kann teilweise erfolgreiche DML-Vorgänge verarbeiten. |
| Hochentwickelte benutzerdefinierte Validierung | Datenvalidierung über mehrere Felder in einem Datensatz hinweg | Apex | Flow kann zwar mit dem Element "CustomError" ein Speichern verhindern, ist jedoch nicht in allen Flow-Typen verfügbar, einschließlich Subflows. Die Apex addError()-Methode stellt mehrere feldspezifische Fehlermeldungen bereit, die einem Datensatz jederzeit während der Auslöserverarbeitung hinzugefügt werden können. |
| Mittelkomplexe Logik in einem einfachen Prozess | Logik- und Datenmanipulation mit moderater Komplexität, vereinfacht durch eine Standardbibliothek erweiterter Funktionen, die als Teil eines unkomplizierten Prozesses erfolgt | Flow + Apex | Durch einen Datensatz ausgelöster Flow fungiert als Orchestrierungsebene, während hochkomplexe Vorgänge in aufrufbarem Apex gekapselt sind. |
| Einfache bis mittelkomplexe Logik | Datenmanipulation mit geringer bis mittlerer Komplexität mit Auslöseraktualisierungen an den primären und verwandten Datenobjekten | Flow | Flow ist in der Regel die Option, die aufgerufen werden kann, da er auf einem deklarativen Modell basiert, das sowohl für Administratoren als auch für Entwickler zugänglich ist. |
| Benachrichtigungen und ausgehende Nachrichten | Senden von ausgehenden E-Mails und Nachrichten | Flow | Mit Flow können E-Mail-Benachrichtigungen und ausgehende Nachrichten zu Datensatzänderungen einfach und hochgradig skaliert werden. |
| Geplante Verarbeitung | Automatisierung zu einem zukünftigen dynamischen Datum (z. B. 3 Tage vor einem Schlusstermin) | Flow | Geplante Pfade bieten Flow eine einzigartige Stärke, da die Plattform automatisch die Planung, Stornierung und Neuplanung dieser Pfade übernimmt, wenn sich die Daten des Datensatzes ändern. |
Die Skalierbarkeit ist eine wichtige Überlegung beim Entwerfen Ihrer Implementierung. Wenn die Geschäftslogik einer durch einen Datensatz ausgelösten Automatisierung komplex, langfristig oder mit hohen Datenvolumen verbunden wird, werden die zentralen Obergrenzen der Salesforce Platform zu einer architektonischen Einschränkung. Vorgänge wie Massendatenaktualisierungen, komplexe API-Callouts oder schwere Berechnungen erhöhen das Risiko, dass Obergrenzen überschritten werden, beispielsweise die CPU-Gesamtzeit oder die Anzahl der DML-Anweisungen innerhalb einer einzelnen Datenbanktransaktion. Ein Fehler in einem synchronen Auslöser aufgrund einer Obergrenzenausnahme führt dazu, dass die gesamte Speichertransaktion des Benutzers zurückgesetzt wird, was zu einer schlechten Benutzererfahrung und potenziellem Datenverlust führt. Dieses inhärente Risiko erfordert ein Architekturmuster, um komplexe Arbeiten abzuladen.
Die asynchrone Automatisierung wird in diesem Fall unerlässlich. Mithilfe asynchroner Mechanismen können Architekten die Arbeit mit langem oder hohem Volumen effektiv von der primären synchronen Datensatzspeichertransaktion entkoppeln. Speichert den Vorgang schnell und zuverlässig, während die schwere Verarbeitung an eine separate, von der Plattform verwaltete Transaktion delegiert wird, die später ausgeführt wird. Die Entkopplung verbessert die Stabilität, verhindert Transaktionsfehler und ist entscheidend für die Erstellung skalierbarer Unternehmensanwendungen. Die Plattform bietet hierfür mehrere spezielle Tools, die jeweils unterschiedliche Vorteile und Kompromisse hinsichtlich Zuverlässigkeit, Volumen und Komplexität bieten.
Der Pfad "Asynchron ausführen" in einem durch einen Datensatz ausgelösten Flow bietet den einfachsten Mechanismus für die asynchrone Logik "auslösen und vergessen". Dieser Pfad wird in einer separaten Transaktion ausgeführt, nachdem die ursprüngliche Datensatzspeichertransaktion erfolgreich in die Datenbank übernommen wurde.
-
Idealer Anwendungsfall: Dies eignet sich gut für Aufgaben, die keine sofortige Ausführung oder benutzerdefinierte Fehlerbehandlung erfordern. Beispiele sind das Senden einer E-Mail-Benachrichtigung, das Erstellen einer Folgeaufgabe oder das Senden eines einfachen Callouts an ein externes System.
-
Einschränkungen: Dieser Mechanismus hat dieselben Obergrenzen für tägliche Flows wie andere asynchrone Flow-Interviews. Sie ist nicht für die Verarbeitung extrem hoher Volumen ausgelegt.
Bei der Datenerfassung für Änderungen handelt es sich um ein skalierbares und robustes Muster mit hohem Durchsatz für die Verarbeitung asynchroner Logik, die durch eine Datensatzänderung in Szenarien mit hohem Volumen ausgelöst wird. In diesem Modell besteht die einzige Verantwortung des Auslösers darin, den Datensatz synchron zu speichern. Anschließend veröffentlicht die Plattform eine detaillierte Ereignismeldung, die die Änderungen des Datensatzes an einem Ereignis-Bus mit hohem Volumen enthält. Dieses Änderungsereignis wird von einem separaten, dedizierten Apex-Auslöser abonniert. Sie führt komplexe, langfristige oder asynchrone Arbeit aus.
-
Vorteil: Durch dieses Muster wird der asynchrone Prozess von der anfänglichen Benutzertransaktion entkoppelt. Ein Fehler bei der asynchronen Verarbeitung führt nicht dazu, dass der Datensatzspeicher des Benutzers wiederhergestellt wird. Das Muster bietet auch einen dauerhaften Ereignis-Stream, den mehrere interne Abonnenten oder externe Systeme nutzen können, und Ereignisse können bis zu 72 Stunden lang wiedergegeben werden, was eine hohe Widerstandsfähigkeit bietet.
-
Einschränkungen: CDC-Ereignismeldungen enthalten nicht den vorherigen Status des Datensatzes, was einer Apex
Trigger.oldMapentspricht. Die Ereignisnutzlast enthält die neuen Feldwerte, jedoch nicht die Werte, von denen sie geändert wurden. Dies macht es schwierig, Logik basierend auf einer bestimmten Statusumstellung zu implementieren (beispielsweise nur dann auszuführen, wenn dieStatus__cvon "Ausstehend" zu "Genehmigt" geändert wurde). Sie können dies abmildern, indem Sie den Feldverlauf des Objekts im Ereignisabonnenten abfragen. Dies erhöht jedoch die Komplexität des Prozesses und die Feldverlaufsverfolgung ist möglicherweise für das betreffende Feld nicht verfügbar. Dies kann die Arten von Automatisierung einschränken, die Sie auf CDC ausladen können.
CDC kann standardmäßig für maximal fünf Salesforce-Objekte aktiviert werden. Organisationen, die mehr benötigen, können eine Add-On-Lizenz erwerben, die diese Obergrenze entfernt und die Zuteilungen für die Ereigniszustellung erhöht.
Die direkte Warteschlange für einen warteschlangenfähigen Apex-Auftrag über einen Auslöser sollte als riskantes Muster betrachtet werden, das nur verwendet wird, wenn Apex Steuerung erforderlich ist (z. B. für komplexe Logik oder benutzerdefinierte Wiederholungsmechanismen) und CDC keine praktikable Option ist.
Wenn Queueable Apex erforderlich ist, muss die Implementierung die entsprechenden Schutzmaßnahmen enthalten:
-
Einschränkungsprüfungen: Der Code muss die Anzahl der Aufträge überprüfen, die bereits in der Transaktion in die Warteschlange gestellt wurden, bevor versucht wird, einen weiteren hinzuzufügen.
-
Kontextbewusstsein: Der Code muss erkennen, ob er in einem asynchronen Kontext ausgeführt wird, beispielsweise einem Batchauftrag (
System.isBatch()), und sein Verhalten ändern, um die strengere Obergrenze von einem Auftrag pro Transaktion in diesem Kontext einzuhalten.
Das Aufrufen von asynchronem Apex über einen synchronen Auslöser birgt Stabilitätsrisiken. Um Auswirkungen auf Organisationsebene (z. B. Überschreiten von Obergrenzen) zu vermeiden, erfordert dieses Muster ein strenges Design und Tests.
-
Die tägliche Obergrenze für asynchrone Apex-Ausführungen (
Batch,Queueable,@Future) wird organisationsweit freigegeben (in der Regel 250 000 oder eine Berechnung anhand von Benutzerlizenzen). Bei einem Massenvorgang mit 20.000 Datensätzen wird ein Auslöser in 200 Blöcken ausgeführt, was zu 100 separaten Auslöseraufrufen führt – noch mehr, wenn die Massenvorgangsgröße weniger als 200 Datensätze beträgt. Wenn jeder Aufruf einen asynchronen Auftrag in die Warteschlange stellt, kann ein erheblicher Teil der täglichen Obergrenze aus einer einzelnen Datenladung verbraucht werden. Dieser Verbrauch kann andere wichtige Geschäftsprozesse asynchroner Ressourcen potenziell aussterben lassen. -
Die Obergrenzen für die Warteschlange für Aufträge sind je nach Kontext drastisch unterschiedlich. Bei einem Auslöser, der durch eine Benutzeraktion auf der Benutzeroberfläche ausgelöst wird (eine synchrone Transaktion), können bis zu 50 warteschlangenfähige Aufträge in die Warteschlange gestellt werden. Bei einem Auslöser, der innerhalb der
execute-Methode einer Batch-Apex-Klasse ausgelöst wird (eine asynchrone Transaktion), kann jedoch nur ein warteschlangenfähiger Auftrag in die Warteschlange gestellt werden. Wenn dieser Unterschied nicht berücksichtigt wird, ist dies ein häufiger und wichtiger Fehlerpunkt, der bei Vorgängen mit großen Daten zuLimitExceptionführt. -
Ein Anti-Pattern stellt das Aufrufen von Planbarem Apex (
System.schedule) oder Batch Apex (Database.executeBatch) direkt über einen Auslöserkontext dar. Diese Methoden sind nicht für den Aufruf im Auslöserkontext vorgesehen. Dies führt zu einem schnellen Verbrauch Ihrer asynchronen Apex Zuteilung, was zu Einschränkungen führt.
Jeder asynchrone Mechanismus weist spezifische Kompromisse hinsichtlich Leistung, Obergrenzen und Zuverlässigkeit auf. Anhand dieser Entscheidungsstruktur können Sie in diesen Optionen navigieren und den richtigen Mechanismus für Ihren Anwendungsfall auswählen.
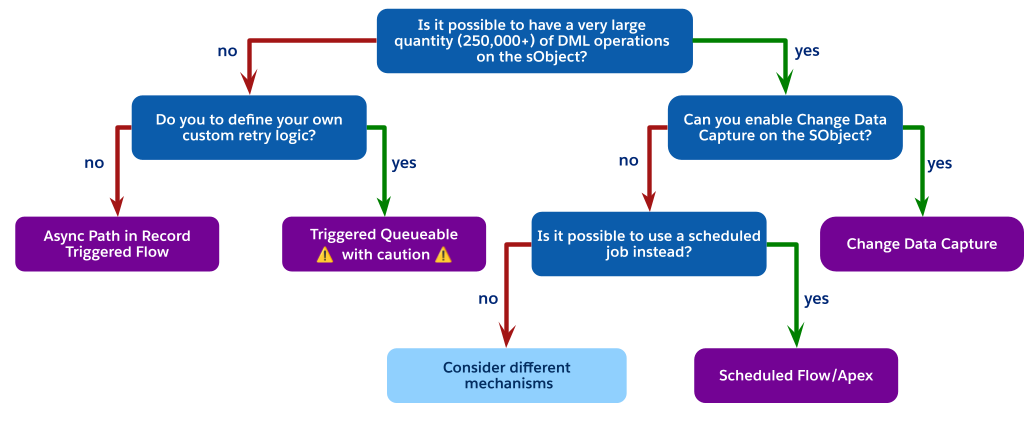
Wie aus dem Diagramm hervorgeht, besteht die beste architektonische Wahl oft darin, einen durch einen Auslöser aufgerufenen Prozess vollständig zu vermeiden, wenn Sie mit DML-Vorgängen mit hohem Volumen konfrontiert sind, die Datenerfassung jedoch nicht verwenden können (möglicherweise aufgrund von Objektobergrenzen).
Verwenden Sie stattdessen einen geplanten Prozess. Dies kann entweder ein geplanter Flow oder geplanter Apex sein. Erforderliche Schritte sind:
-
Führen Sie eine einfache kostengünstige Aktualisierung im synchronen Auslöser aus. Legen Sie beispielsweise ein
Status__c-Feld auf "Verarbeitung ausstehend" fest oder fügen Sie einen verwandten Datensatz mit niedrigen Kosten ein, beispielsweise einen Chatter Post, um anzugeben, dass der Datensatz verarbeitet werden muss. -
Erstellen Sie einen geplanten Auftrag, entweder einen geplanten Flow oder geplanten Apex, der regelmäßig ausgeführt wird, beispielsweise alle 15 Minuten oder stündlich.
-
Lassen Sie den geplanten Auftrag für alle Datensätze im Status "Ausstehend" abfragen, führen Sie die komplexe Logik in einem kontrollierten Kontext mit hohem Volumen aus und aktualisieren Sie dann die verarbeiteten Datensätze.
Dieses Muster entkoppelt die schwere Verarbeitung vollständig vom synchronen Speichern des Benutzers, unterliegt nicht der Obergrenze von einem Auftrag pro Transaktion eines ausgelösten Batches und bietet eine hochgradig skalierbare und regelbare Lösung für Nicht-Echtzeitanforderungen.
Wenn die Latenz eines geplanten Auftrags für die Geschäftsanforderungen nicht akzeptabel ist und Sie weiterhin CDC oder eine ausgelöste Warteschlange nicht verwenden können, deutet dies auf eine erhebliche architektonische Inkongruenz hin. An dieser Stelle müssen verschiedene Mechanismen in Betracht gezogen werden. Die erneute Bewertung des Designs der Kernanwendung kann zu bestimmten Schlussfolgerungen führen, beispielsweise:
-
Erwerb des Add-Ons zum Entfernen der CDC-Objektobergrenzen.
-
Die geschäftliche Anforderung, festzustellen, ob die Verarbeitung nahezu in Echtzeit wirklich ein "Must-have" ist oder ob die Latenz eines geplanten Auftrags ein akzeptabler Kompromiss für die Plattformstabilität ist, wird grundlegend herausgefordert.
Der Komplexitätsgrad einer Implementierung ist Teil der Gesamtbetriebskosten einer Lösung und ihrer Fähigkeit, sich an sich ändernde Geschäftsanforderungen anzupassen. Komplexität kann sich auf jede Implementierung auswirken, wenn bewährte Vorgehensweisen nicht befolgt werden. Im Abschnitt "Verwandte bewährte Vorgehensweisen" dieses Dokuments finden Sie Empfehlungen zur Reduzierung der Komplexität Ihrer Lösung, einschließlich der folgenden Muster:
-
Hybridmuster: Aufrufbares Apex für komplexe Logik im Flow
-
Verwenden eines Metadaten-Frameworks für Apex-Auslöser
-
Mega-Flows vs. Mehrere Flows
Die Dokumentation ist so wichtig wie die Automatisierung selbst. Sie gewährleistet nicht nur die Wartbarkeit, sondern ist auch für AI und agentenbasierte Tools entscheidend. Mithilfe der Dokumentation können Sie Ihre Geschäftsprozesse verstehen und verwalten.
Im Flow
-
Richten Sie eine konsistente Benennungskonvention für alle Elemente und Variablen ein.
-
Verwenden Sie das Feld "Beschreibung" für den Flow, um seinen allgemeinen Zweck, seine Auslösekriterien und sein beabsichtigtes Ergebnis zu erläutern.
-
Verwenden Sie das Feld Beschreibung für jedes einzelne Element (z. B.
Get Records,Action,Transform). Diese Vorgehensweise ist die beste Möglichkeit, Intent zu vermitteln. Dies ist besonders wichtig für aufrufbare Aktionen und Subflows, bei denen die Beschreibung der primäre Ort ist, um die komplexe Logik zu erklären, die von der Aktion ausgeführt wird.
In Apex
-
Kommentieren Sie Ihren Code deutlich, um zu erklären, warum Ihre Logik dahintersteckt, und nicht nur, was.
-
Stellen Sie bei Verwendung eines metadatengesteuerten Frameworks sicher, dass Ihre Metadatensätze ein für Menschen lesbares Beschreibungsfeld enthalten und ausfüllen, um zu erläutern, was jede Handler-Klasse vornimmt und wann sie ausgeführt werden soll.
DevOps- und Quellcodeverwaltung ist Teil eines ausgereiften Entwicklungslebenszyklus. Verwenden Sie immer ein Quellcodeverwaltungstool wie Git für Salesforce-Projekte. Sowohl Apex-Klassen als auch Salesforce-Flows sind Metadaten, die Ihre Geschäftslogik definieren. Sie müssen versioniert und verwaltet werden.
Im Kontext der Verwaltung von durch Datensätze ausgelösten Automatisierungen bietet eine moderne DevOps-Pipeline wesentliche Vorteile.
-
Automatische Qualitätsprüfungen: Tools wie Salesforce Code Analyzer können so konfiguriert werden, dass sie automatisch in Ihrer Pipeline ausgeführt werden. Statische Analysen können problematische Muster in beiden Automatisierungstools erkennen, bevor sie höhergestuft werden, und Probleme wie ineffiziente
Get Recordsin einer Flow-Schleife oderSOQLin einer Apex-Schleife kennzeichnen, die häufige Ursachen für Leistungseinbußen sind. -
Regressionsprävention: Wenn Ihre Automatisierungsdichte steigt, kann eine Änderung an einer Flow- oder Apex-Klasse unbeabsichtigte Konsequenzen für andere Automatisierungen im selben Objekt haben. Eine zuverlässige DevOps-Teststrategie, bei der automatisierte Apex-Tests anhand vorgeschlagener Änderungen ausgeführt werden, ist die zuverlässigste Methode, um sicherzustellen, dass eine neue Flow-Version die vorhandene Apex-Logik nicht beschädigt (und umgekehrt).
-
Zusammenarbeit und Sichtbarkeit: Die Quellcodeverwaltung ist die "einzige Quelle der Wahrheit". Dadurch können Administratoren und Entwickler parallel an der Automatisierung für dasselbe Objekt arbeiten. Sie bietet zudem einen unschätzbaren Überprüfungspfad: Wenn ein Produktionsprozess fehlschlägt, können Sie sofort sehen, wer die Automatisierung geändert hat, wann sie geändert wurde und – über Commit-Meldungen –, warum sie geändert wurde.
Teams mit einer Mischung aus Administratoren und Entwicklern bietet das DevOps Center eine vereinheitlichte Oberfläche, mit der alle diese Schritte choreographiert werden können, sodass jeder im Team auf einen skalierbaren, auf Quellcodeverwaltung basierenden Entwicklungsprozess zugreifen kann.
Diese kombinierte Disziplin der Dokumentation und DevOps gewährleistet die langfristige Integrität und Wartungsfähigkeit Ihrer Organisation, was jedem Architekten und Administrator zugute kommt, der Ihnen folgt.
Die oben stehende Entscheidungsanleitung wird am besten vor der Planung Ihrer Implementierung verwendet. Es soll Ihnen bei der Auswahl des besten Produkts für Ihre Anwendungsfälle helfen. Nach der Produktauswahl ist es wichtig, die vorhandenen bewährten Vorgehensweisen für Ihre Implementierung zu verstehen.
Das Prinzip "Ein Tool pro Objekt" ist für die Verwaltung der Automatisierung mit hoher Dichte wichtig. Sie sollten es jedoch nicht als binäre Auswahl zwischen einem rein deklarativen oder einem rein programmgesteuerten Stapel interpretieren. Ein effektiveres und pflegeleichteres Architekturmuster nutzt ein Hybridmodell: Positionieren Sie "Durch einen Datensatz ausgelöster Flow" als Orchestrierungsebene und kapseln Sie gleichzeitig hochkomplexe Vorgänge in "Aufrufbarer Apex".
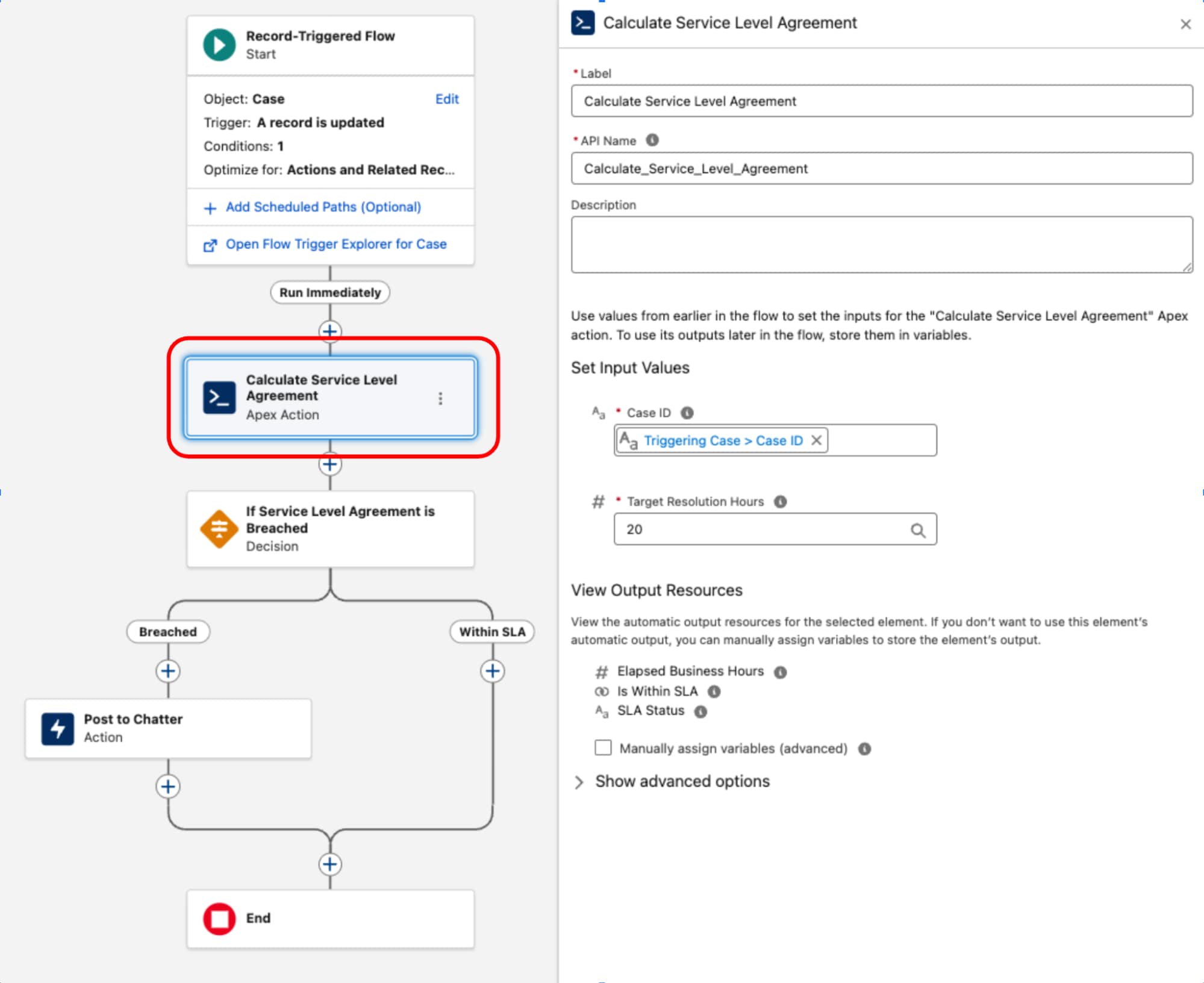
Durch einen Datensatz ausgelöster Flow dient als Orchestrierungsebene für den Geschäftsprozess. Er ist Inhaber der Eingabekriterien und des Ausführungskontexts (das Was und Wann). Durch Beibehaltung der Entscheidungslogik und der Weiterleitung innerhalb dieser Ebene bleibt die Prozesstopologie der Architektur transparent und kann über den Flow-Auslöser-Explorer verwaltet werden, wodurch verhindert wird, dass wichtige Geschäftslogik im Code verdeckt wird.
Ein häufiges Beispiel für eine komplexe Komponente ist die Implementierung von Service Level Agreement-Berechnungen (SLA) für Kundenvorgangsdatensätze. Da das Objekt "BusinessHours" und die zugehörige Logik, die für genaue Berechnungen ohne Arbeitszeiten und Feiertage wichtig sind, in Flow nicht nativ zugänglich sind, wird eine spezielle Apex-Klasse verwendet. Diese Klasse, die oft als ServiceLevelAgreementCalculator bezeichnet wird, wurde mit einer einzigen statischen Methode entwickelt, die mit @InvocableMethod gekennzeichnet ist, um die verstrichenen Geschäftszeiten zu berechnen, zu bestimmen, ob das SLA "Innerhalb des Ziels" oder "Verletzt" lautet, und eine strukturierte Ausgabe zurückzugeben. Dieser Ansatz fasst die komplexe Hochleistungslogik in Apex zusammen und ermöglicht ihre nahtlose Ausführung und Integration in die deklarative Orchestrierungsebene eines durch einen Datensatz ausgelösten Flows.
Sobald die Apex ServiceLevelAgreementCalculator definiert ist, kann sie in einem durch einen Datensatz ausgelösten Flow verwendet werden:
Dieses Muster zeigt eine strikte Trennung der Bedenken. Die deklarative Ebene wird zum Verwalten des Transaktionslebenszyklus und der Orchestrierung verwendet, während Code für die Ausführung mit hoher Komplexität verwendet wird. Indem Code als funktionales Dienstprogramm und nicht als Grundlage behandelt wird, halten wir Leistung und Wartungsfreundlichkeit in Einklang.
Modularität: Die Entscheidung weicht von der Besonderheit der Verwendung von Apex oder Flow für den gesamten Prozess ab. Stattdessen kapselt die Architektur komplexe Logik in diskrete, massensichere und unabhängig testbare Einheiten. Diese Einheiten fungieren als wiederverwendbare Komponenten, die von der deklarativen Ebene verbraucht werden, und stellen sicher, dass die Automatisierung skaliert wird, ohne dass die architektonische Planung kompliziert wird.
Wiederverwendbarkeit: Die Logik ist vom Auslöserereignis getrennt. Eine gut gestaltete Code-Einheit (z. B. ein InvocableMethod) wird einmal geschrieben, jedoch über mehrere Eingangspunkte hinweg verwendet: Durch Datensätze ausgelöste Flows, Bildschirm-Flows oder externe Integrationen. Durch diese Code-Wiederverwendung entfällt die redundante Entwicklung.
Wartbarkeit: Die Prozess-Flow-Logik bleibt im deklarativen Flow sichtbar und verwaltbar. Durch diese Zentralisierung wird der Debugging-Overhead drastisch reduziert und sichergestellt, dass die Ausführungsreihenfolge des Systems deterministisch und transparent ist.
Das hybride Modell der Verwendung von aufrufbarem Apex aus Flow ist zwar leistungsfähig, aber kein Ansatz für alle. Architekten müssen sich der spezifischen Einschränkungen und Kompromisse bewusst sein, bevor sie sich auf eine Hybridlösung festlegen.
-
Keine Unterstützung vor dem Speichern: Dies ist die wichtigste Einschränkung. Aufrufbare Aktionen sind nur im Kontext nach dem Speichern verfügbar (Flows für Aktionen und verwandte Datensätze). Sie können nicht im leistungsstarken Kontext vor dem Speichern verwendet werden (Flows für schnelle Feldaktualisierungen). Daher kann dieses Muster nicht zum Delegieren von Feldaktualisierungen desselben Datensatzes verwendet werden. Erledigen Sie diese leistungsstarke Arbeit mit nativen Flow-Elementen in einem Flow vor dem Speichern oder in einem Apex-Auslöser vor dem Kontext.
-
Keine Unterstützung nach dem Rückgängigmachen der Löschung: Der durch einen Datensatz ausgelöste Flow unterstützt derzeit den Kontext nach dem Rückgängigmachen des Löschens nicht. Wenn für ein Salesforce-Objekt eine geschäftliche Anforderung besteht, die Automatisierung auszuführen, wenn ein Datensatz aus dem Papierkorb wiederhergestellt wird, ist ein Apex-Auslöser die einzige Lösung.
-
Leistungs-Overhead in Szenarien mit hohem Volumen: Der Übergang von der Flow-Laufzeit zur Apex-Laufzeit ist kein Nullkostenvorgang. Obwohl sie im Allgemeinen schnell ist, ist der Vorgang, bei dem Sie von der Laufzeit des Flows aus in eine aufrufbare Aktion wechseln, nicht so rechenschnell wie die native Ausführung, die vollständig in einem Apex Auslöser verbleibt. Für die meisten Automatisierungen mittlerer Dichte ist dieser Micro-Overhead ein vernachlässigbarer und lohnender Kompromiss für die verbesserte Barrierefreiheit. Bei extrem leistungsstarken Szenarien mit hohem Volumen bietet ein reines Apex-Framework jedoch einen Vorteil bei der Berechnungsgeschwindigkeit.
Während die Heuristik der Automatisierungsdichte eine definitive Orientierungshilfe für neuere Greenfield-Architekturen bietet, ist die Realität in Salesforce-Unternehmensumgebungen oft differenzierter. In ausgereiften Organisationen finden sich häufig durch Datensätze ausgelöste Flows und Apex-Auslöser, die mit demselben Salesforce-Objekt arbeiten. Dieses Szenario unterscheidet sich von dem zuvor erläuterten hybriden Muster: Hier sind die Flows und Apex-Auslöser weder gekoppelt noch für die Zusammenarbeit ausgelegt.
Diese Koexistenz ist oft das Ergebnis sich entwickelnder Plattformfunktionen oder veralteter technischer Schulden. Obwohl dies ein tolerierter Betriebszustand ist, müssen Architekten ihn als berechneten Kompromiss und nicht als Endzustand behandeln.
Die fragmentierte Orchestrierung verursacht einen erheblichen Verwaltungs- und Wartungsaufwand, wodurch Entwicklungs-, Test- und Vorfallsbearbeitungsaktivitäten uneinheitlich und umständlich werden. Dies führt zu einer erhöhten Time to Resolution (TTR) und betrieblichen Komplexität.
-
Halten Sie sich bei neuen Salesforce-Objekten an das Prinzip der Automatisierungsdichte als primäre Anleitung.
-
Bewerten Sie bei vorhandenen Salesforce-Objekten mit hybrider Bilanz und doppeltem Apex-Auslöser und durch einen Datensatz ausgelösten Flow-Eingangspunkten die Dichte und konzipieren Sie dann den Refaktor in einen aufrechterhaltenswerten Hybridzustand.
-
Bei geringer Dichte werden durch Refaktor-Apex ausgelöste Flows durch einen Datensatz ausgelöst und die Ausführungsreihenfolge angegeben, wodurch sie an einen einzigen Automatisierungs-Eingangspunkt gelangen.
-
Bei mittlerer Dichte fließen komplexe Mega-Flows in eine Teilmenge von Flows mit der richtigen Ausführungsreihenfolge ein. Führen Sie Apex-Auslöser nur dann ein, wenn dies unbedingt erforderlich ist, z. B. zur Unterstützung nach dem Rückgängigmachen des Kontexts.
-
Bei hoher Dichte bevorzugen Sie die Implementierung von Apex Auslösern.
-
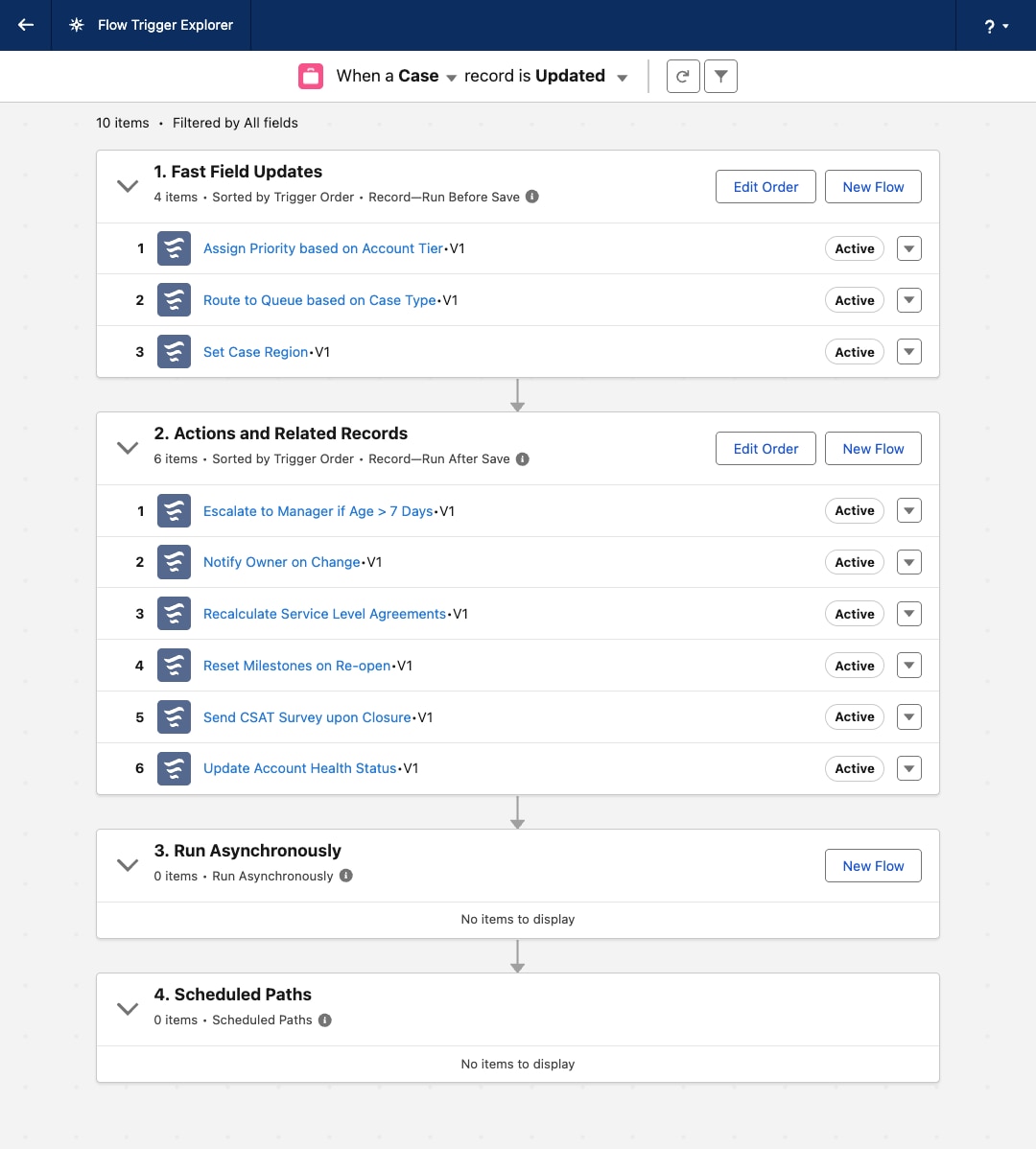
Wenn die Geschäftsprozesse einer Organisation auf der Salesforce Platform reifen, steigen zwangsläufig das Volumen und die Komplexität der durch Datensätze ausgelösten Automatisierung. Eine grundlegende bewährte Vorgehensweise besteht darin, einen Apex-Auslöser pro Salesforce-Objekt beizubehalten. Diese Regel ist wichtig, da die Plattform die Ausführungsreihenfolge mehrerer Auslöser für dasselbe Objekt für dasselbe Ereignis nicht garantiert. Diese Einschränkung kann zu nicht deterministischem Verhalten, Rassenbedingungen und schwierig zu debuggenden Problemen führen.
Die Einhaltung des Prinzips eines Auslösers stellt jedoch eine architektonische Herausforderung dar: die Verwaltung und Orchestrierung sämtlicher Geschäftslogiken, die über diesen zentralen Einstiegspunkt aufgerufen werden, auf wartbare und skalierbare Weise.
Die erste Entwicklung dieser Architektur war das Classic-Auslöser-Handler-Muster. Bei diesem Ansatz delegiert der einzelne Apex-Auslöser seine gesamte Logik an eine entsprechende Handler-Klasse (beispielsweise OpportunityTriggerHandler). Diese Methode trennt die Logik von der Auslöserdatei und bietet Entwicklern deterministische Kontrolle über die Ausführungsreihenfolge innerhalb der Methoden der Handler-Klasse (z. B. afterInsert()).
Obwohl dieses Muster eine Verbesserung darstellt, führt es häufig zu monolithischen Handler-Klassen. Im Laufe der Zeit wird die Klasse groß, schwer zu verwalten und schwer isoliert zu testen, da mehr Geschäftsanforderungen hinzugefügt werden. Die Ausführungsreihenfolge aller einzelnen Prozesse ist innerhalb einer einzelnen Methode hartcodiert, wodurch die Klasse anfällig für Zusammenführungskonflikte ist, was den Verwaltungs- und Wartungsaufwand in einer großen Unternehmensumgebung drastisch erhöht.
Architekten wechseln zum Metadaten-gesteuerten Auslöser-Framework, um die Kernprobleme der Modularität und Orchestrierung zu lösen. Dies ist ein bedeutender architektonischer Sprung, der die Automatisierungslogik selbst von der Konfiguration der Art und Weise der Ausführung entkoppelt.
Dieses Framework basiert auf drei wichtigen Vorteilen:
-
Partitionierung: Anstelle einer einzigen Handler-Klasse wird die Kerngeschäftslogik in kleine, atomare Apex-Klassen (beispielsweise eine
RecalculateAccountValues-Klasse oder eineNotifySalesLeads-Klasse) unterteilt, wobei jede Klasse dem Prinzip der einzelnen Verantwortung folgt. Durch diese Modularität können Logik einfacher isoliert getestet, debuggt und verstanden werden. -
Auftrag und Choreografie: Der Ausführungsauftrag ist in Apex nicht mehr hartcodiert. Stattdessen wird er deklarativ durch Konfigurationsdatensätze definiert, die in der Regel in einem benutzerdefinierten Metadatentyp (z. B.
TriggerAction__mdt) gespeichert sind. Dadurch können Administratoren Automatisierungsaktionen einfach neu anordnen, hinzufügen oder entfernen, indem sie einen Metadatensatz ändern, was keine Bereitstellung oder Codeänderung erfordert. -
Bypass-Funktion: Das Framework bietet standardisierte, granulare Bypass-Funktionen. Jede Automatisierungsaktion kann über ihren Metadatensatz so konfiguriert werden, dass sie global deaktiviert oder für bestimmte Verwaltungsbenutzer durch Verweisen auf eine benutzerdefinierte Berechtigung umgangen wird.
Der einzelne Apex-Auslöser für das Objekt fungiert dann nur noch als dynamischer Disponent. Sie enthält keine Geschäftslogik, sondern instanziiert stattdessen eine zentrale MetadataTriggerHandler. Dieser Handler fragt die benutzerdefinierten Metadatensätze ab, um die Ausführungsreihenfolge dynamisch zu bestimmen und die richtigen atomaren Apex-Klassen in der vorgegebenen Reihenfolge aufzurufen. Die Automatisierung wird unter einer einzigen, transparenten und regelbaren Ebene vereinheitlicht.
Ein wichtiger Vorteil der Verwendung von Apex in einem robusten Framework ist die Möglichkeit, den Transaktionsstatus zu verwalten und die Leistung zu optimieren, da redundante Arbeit entfällt. Wenn sich Logik ansammelt, ist es üblich, dass unterschiedliche Automatisierungen innerhalb des Speicherauftrags dieselben teuren Vorgänge unabhängig ausführen, wodurch wertvolle Obergrenzen verbraucht und die DML-Vorgangszeit erhöht wird.
Das Framework ist so konzipiert, dass es diesem Problem mit zwei primären Strategien begegnet:
-
Gemeinsame Bundesstaatsverwaltung: Im Rahmen einer einzelnen Apex-Transaktion werden statische Eigenschaften und Variablen zum Zwischenspeichern von Daten verwendet. Dadurch wird sichergestellt, dass ein teurer Vorgang wie eine
SOQLfür eine Konfigurationseinstellung nur einmal ausgeführt wird, selbst wenn die Automatisierungslogik mehrfach über verschiedene Datensätze oder Phasen des Auslösers hinweg aufgerufen wird. Der Verbrauch von Transaktionsobergrenzen wird erheblich reduziert. -
Plattform-Cache-Auslastung: Verwenden Sie den Plattform-Cache, um zu vermeiden, dass die gesamte Datenbank nach bestimmten Daten abgefragt wird, um über die einfache Zwischenspeicherung innerhalb der Transaktion hinauszugehen. Dieser verwaltete Speicher-Cache eignet sich ideal zum Abrufen von Daten, die nicht primitiv sind, häufig in der Codebasis gelesen werden und im Laufe einer Transaktion unveränderlich sind (z. B. Profile, Rollen, Geschäftszeiten). Über die
Cache.CacheBuilderüberprüft das System zunächst den Cache und führt die Datenbankabfrage nur aus, wenn die Daten nicht vorhanden sind, was die Leistung und Skalierbarkeit maximiert.
Verwenden Sie immer eine Aktualisierung vor dem Speichern, wenn Ihre Automatisierung nur Feldwerte für den Datensatz ändern muss, der die Transaktion startet. Dies gilt für Schnellfeldaktualisierungen in Flow (die vor dem Speichern ausgeführt werden) und für Vor-Kontext-Logik in Apex Triggers (vor dem Einfügen, vor der Aktualisierung).
Dieses Muster ist unabhängig vom verwendeten Tool leistungsfähig, da ein zweiter DML-Vorgang und ein rekursiver Speicherzyklus vermieden werden. Die Änderungen werden am Datensatz im Arbeitsspeicher vorgenommen, bevor er in die Datenbank übernommen wird, und als Teil der ursprünglichen Transaktion gespeichert. Der Overhead eines zweiten Speichervorgangs, der andernfalls den gesamten Speicherauftrag erneut ausführen und die gesamte Automatisierung erneut auslösen würde, entfällt.
Unkontrollierte Rekursion ist ein häufiger Fallstrick bei Auslösern nach der Aktualisierung, bei denen die Logik eines Auslösers eine DML-Aktualisierung ausführt, die wiederum dazu führt, dass derselbe Auslöser erneut ausgelöst wird. Dadurch wird eine Endlosschleife erstellt, die schließlich mit einer Ausnahme der Obergrenze endet. Obwohl statische boolesche Kennzeichnungen oder Sammlungen verarbeiteter Datensatz-IDs in der Vergangenheit verwendet wurden, um eine solche Rekursion zu verhindern, besteht ein genaueres und zuverlässigeres Muster darin, die Logik durch Vergleich von Feldwerten zwischen der neuen und der alten Version des Datensatzes selbst zu verbinden.
Führen Sie die Logik nur dann aus, wenn sich ein bestimmtes interessierendes Feld tatsächlich geändert hat. Dadurch wird verhindert, dass der Auslöser seine Logik bei nachfolgenden DML-Vorgängen innerhalb derselben Transaktion ausführt, bei denen die wichtigen Daten unverändert bleiben.
Verhindern Sie in einem durch einen Datensatz ausgelösten Flow eine unkontrollierte Rekursion, indem Sie den Flow so festlegen, dass er nur ausgeführt wird, wenn der Datensatz aktualisiert wird, um die Bedingungsanforderungen zu erfüllen:

Wenn Sie eine Eingabekriterienformel in Ihrem Flow verwenden, können Sie eine Rekursion verhindern, indem Sie die globale Variable $Record (die die neuen Werte darstellt) mit der globalen Variable $RecordPrior (die die ursprünglichen Werte vor dem Speichern darstellt) vergleichen. Wenn Sie beispielsweise sicherstellen möchten, dass ein Flow nur ausgeführt wird, wenn sich das Feld "Betrag" für eine Opportunity geändert hat, verwenden Sie dies in den Eingabekriterien:
Vergleichen Sie Feldwerte aus der neuen Version des Datensatzes Trigger.new mit den Feldwerten aus der alten Version des Datensatzes Trigger.oldMap, um festzustellen, ob die gewünschte Änderung stattgefunden hat. Durch diesen Ansatz wird sichergestellt, dass die Automatisierung idempotent ist und nur bei Bedarf ausgeführt wird, wodurch das System effizienter wird und katastrophale rekursive Schleifen verhindert werden.
Eine gut strukturierte Salesforce-Organisation erfordert einen konsistenten und zuverlässigen Mechanismus zur Umgehung der Automatisierung. Dies ist keine optionale Funktion, sondern eine zentrale betriebliche Voraussetzung für die Aufrechterhaltung der Datenintegrität und die Aktivierung von Verwaltungsaufgaben.
Ein Bypass-Framework ist für einige Szenarien unerlässlich:
-
Beim Laden großer Datenmengen kann das Auslösen von Auslösern für jeden Datensatz den Prozess drastisch verlangsamen, zu Obergrenzenausnahmen führen und fehlerhafte zugehörige Datensätze und Benachrichtigungen erstellen. Über eine Umgehung können die Daten sauber und effizient eingefügt werden.
-
Ein Integrationsbenutzer muss möglicherweise Daten aus einem externen Datensatzsystem synchronisieren. Die Automatisierung, die normalerweise für eine vom Benutzer initiierte Änderung ausgelöst wird (z. B. Senden einer E-Mail oder Erstellen einer Aufgabe), kann unerwünscht oder redundant sein, wenn die Änderung von einem anderen System stammt.
-
Administratoren oder Supportmitarbeiter müssen möglicherweise Korrekturaktualisierungen an Datensätzen vornehmen. Mithilfe eines Bypass-Mechanismus können sie diese Änderungen vornehmen, ohne die standardmäßige Geschäftsautomatisierung auszulösen, was unbeabsichtigte Folgen haben könnte.
Benutzerdefinierte Berechtigungen: Der moderne, skalierbare Standard zum Implementieren der Umgehungslogik sind benutzerdefinierte Berechtigungen. Diese sind älteren Methoden aus mehreren Gründen überlegen:
-
Flexibilität: Benutzerdefinierte Berechtigungen können Benutzern über Berechtigungssätze zugewiesen werden. Diese Vorgehensweise entspricht dem modernen Salesforce-Sicherheits- und -Zugriffsmodell und ermöglicht eine detaillierte und flexible Zuweisung. Eine Umgehung kann einem bestimmten Benutzer oder sogar vorübergehend mit einem bestimmten Ablaufdatum/einer bestimmten Ablaufzeit gewährt werden.
-
Wartbarkeit: Durch die Verwendung benutzerdefinierter Berechtigungen wird vermieden, dass Profile oder Benutzer hartcodiert werden. Wenn sich die Rolle eines Benutzers ändert oder ein neues Profil Umgehungszugriff benötigt, handelt es sich bei der Änderung um eine einfache Berechtigungssatzzuweisung und nicht um eine Code- oder Flow-Änderung, die eine Bereitstellung erfordert.
-
Skalierbarkeit: Benutzerdefinierte Berechtigungen bieten ein skalierbares Framework zum Verwalten von Ausnahmen in einer komplexen Benutzerbasis. Sie können Benutzern über Berechtigungssätze, Berechtigungssatzgruppen oder Profile zugewiesen werden. Ihre Zuordnung zu einem Berechtigungssatz oder Profil kann auch in Quellmetadaten dargestellt werden.
Implementierungsmuster: Wenden Sie ein konsistentes Umgehungsmuster auf alle durch einen Datensatz ausgelösten Automatisierungen in der Organisation an.
Umgehen eines durch einen Datensatz ausgelösten Flows: Die effizienteste Möglichkeit, einen Flow zu umgehen, besteht darin, zu verhindern, dass er überhaupt ausgeführt wird. Dies wird erreicht, indem den Eingabekriterien des Flows eine Bedingung hinzugefügt wird.
-
Legen Sie im Startelement des durch einen Datensatz ausgelösten Flows "Bedingungsanforderungen" auf "Formel wird ausgewertet" auf "Wahr" fest.
-
Integrieren Sie eine Überprüfung auf die benutzerdefinierte Berechtigung mithilfe der globalen Variablen
$Permissionin den Formelgenerator. Kombinieren Sie die Prüfung mit Ihren vorhandenen Eingabekriterien.- Formelmuster:
-
Durch dieses Muster wird sichergestellt, dass der Flow nur ausgeführt wird, wenn dem Benutzer die angegebene benutzerdefinierte Berechtigung nicht zugewiesen ist. Diese Überprüfung wird durchgeführt, bevor das Flow-Interview überhaupt erstellt wird, was es zum leistungsfähigsten Ansatz macht.
-
Umgehen eines Apex Trigger Framework: Integrieren Sie die Bypass-Logik in Apex direkt in das metadatengesteuerte Auslöser-Framework, um eine genaue Steuerung zu ermöglichen.
-
Der benutzerdefinierte Metadatentyp "
TriggerAction__mdt" sollte ein Textfeld enthalten, beispielsweise "BypassPermission__c".-
In der
MetadataTriggerHandler-Klasse sollte der Code vor dem dynamischen Ausführen einer Aktion den Wert aus diesem Feld lesen. -
Wenn das Feld ausgefüllt ist, verwendet der Handler die
FeatureManagement.checkPermission()-Methode, um festzustellen, ob der aktuelle aktuelle Benutzer über die angegebene benutzerdefinierte Berechtigung verfügt. -
Wenn
checkPermission()true zurückgibt, überspringt der Handler diese spezifische Aktion und fährt mit der nächsten in der Sequenz fort. -
Dieses Muster ist leistungsstark, da es sowohl eine globale Umgehung (wenn alle
TriggerAction__mdtauf dieselbe Berechtigung verweisen) als auch eine detaillierte Umgehung pro Aktion (wenn unterschiedliche Datensätze auf unterschiedliche Berechtigungen verweisen oder einige gar keine Umgehungsberechtigung haben) ermöglicht.
-
Es ist ein Anti-Pattern, um die gesamte Automatisierung eines Objekts in einem einzigen, massiven Mega-Flow zu konsolidieren. Die Konsolidierung in einem Flow im Vergleich zur Aufteilung der Logik in mehrere gut konditionierte Flows hat keine großen Auswirkungen auf die Leistung. Die wichtigsten Leistungssteigerungen stammen aus:
-
Verwenden von Flows vor dem Speichern für Feldaktualisierungen desselben Datensatzes.
-
Schreiben genauer Eintrittsbedingungen, um sicherzustellen, dass Flows nicht für Änderungen ausgeführt werden, die sich nicht auf ihren jeweiligen Anwendungsfall auswirken.
Mit dem Flow-Auslöser-Explorer können Sie jedem Flow für ein Objekt einen Auftragswert zuweisen, um eine sequenzielle Ausführungsreihenfolge zu gewährleisten.
| Apex | Flow | Vorgänge |
|---|---|---|