Verwenden der richtigen Tools und Muster für ereignisgesteuerte Architekturen
Ereignisgesteuerte Architekturen unterstützen die effiziente Produktion und Nutzung von Ereignissen, die System- oder Anwendungsstatusänderungen kommunizieren. Diese Architekturen ermöglichen flexible Verbindungen zwischen Systemen und Supportprozessen und Aktualisierungen nahezu in Echtzeit, die systemübergreifend funktionieren. Obwohl die Vorteile von ereignisgesteuerten Architekturen leicht zu erkennen sind, sind die Implementierungsdetails nicht immer so klar. Welche Funktionen müssen bei ereignisgesteuerten Architekturmustern berücksichtigt werden? Welche spezifischen Probleme lösen diese Muster? Welche besonderen Überlegungen gelten für Ihre Lösungen und welche Muster sind optimal, um sie anzugehen?
In dieser Anleitung werden Muster vorgestellt, die zum Erstellen optimaler ereignisgesteuerter Architekturen bei der Arbeit mit Salesforce-Technologien verwendet werden. Darüber hinaus werden bei Salesforce verfügbare Eventing-Tools diskutiert und Tool-Empfehlungen für eine Auswahl von Anwendungsfällen bereitgestellt. Informationen zu Integrationen auf Datenebene in Salesforce finden Sie im Data Integration Decision Guide.
-
Verwenden Sie ereignisgesteuerte Architekturen für Prozesse, für die keine synchronen Antworten auf Anforderungen erforderlich sind. Die in diesem Leitfaden beschriebenen Muster sind auf Datenkonsistenz, Skalierbarkeit und Wiederverwendung ausgelegt, wodurch die technische Verschuldung bei der Entwicklung der Anwendungslandschaft Ihrer Organisation auf ein Minimum reduziert wird. (Weitere Informationen finden Sie unter Well-Architected – Throughput.)
-
Wenn MuleSoft oder eine andere Enterprise Service Bus-Lösung (ESB) Teil Ihrer vorhandenen Landschaft ist, verwenden Sie sie nach Möglichkeit. Diese Lösungen wurden speziell für die Unterstützung von ereignisgesteuerten Architekturmustern entwickelt und verfügen über leistungsstarke Funktionen, mit denen Sie Integrationen in Ihrem gesamten Unternehmen wiederverwenden können.
-
Verwenden Sie die Pub/Sub-API für künftige Veröffentlichungs-/Abonnementmuster, statt Ihre eigenen Ereignis-Handler mithilfe anderer APIs, einschließlich der Streaming-API, zu erstellen. Da die Pub/Sub-API nun allgemein verfügbar ist, können Sie sie für neue Veröffentlichungs-/Abonnementmuster verwenden. Planen Sie, vorhandene Ereigniskommunikationen mit anderen Plattform-APIs wie der Streaming-API oder benutzerdefinierten Apex-Services zur Pub/Sub-API zu migrieren, sofern dies möglich ist.
-
Plattformereignisse und die Datenerfassung (CDC) sind die bevorzugten Mechanismen zur Veröffentlichung von Datensatz- und Feldänderungen, die von anderen Systemen verwendet werden müssen. Es wird davon abgeraten, PushTopic und generische Ereignisse für neue Implementierungen zu verwenden. Salesforce wird PushTopic und generische Ereignisse im Rahmen der aktuellen Funktionsfunktionen weiterhin unterstützen, plant jedoch keine weiteren Investitionen in diese Technologie.
 |
Bei der Salesforce Platform handelt es sich um eine umfassende AI-gestützte Plattform, die Mitarbeiter, autonome AI-Agenten, Unternehmensdaten und Anwendungen in einem einzigen, vertrauenswürdigen System zusammenführt, um die Produktivität und die Kundenerfahrung zu steigern. Durch die Verbindung von Customer 360-Anwendungen, Data Cloud und Slack für eine durchgängige Automatisierung kann ein "Agentenunternehmen" erstellt werden. |
 |
MuleSoft ist die führende Integrationsplattform von Salesforce, mit der Organisationen Anwendungen, Daten und Geräte lokal und Cloud-Umgebungen miteinander verbinden können. MuleSoft ist eine Plattform, die der IT die Plattformen bietet, um Daten systemübergreifend freizugeben, skalierbare Integrations- und Automatisierungs-Frameworks zu entwickeln und differenzierte, verbundene Erfahrungen zu schaffen – und zwar schnell. |
Ereignisgesteuerte Architekturen werden für Szenarien empfohlen, die Benachrichtigungen nahezu in Echtzeit erfordern, die Verarbeitungslast für Nachrichten mit hohem Volumen oder komplexe Nachrichten verteilen und Systeme wie IoT und Mobilgeräte integrieren, die Konnektivitätsresilienz durch Warteschlangen erfordern. EDAs sollten jedoch nicht für Prozesse implementiert werden, die sofortige synchrone menschliche Reaktionen erfordern, da sie für die asynchrone Ausführung konzipiert sind. Sie passen auch nicht gut, wenn sich Quelldaten so selten ändern, dass ein einfacheres Muster wie die Batchverarbeitung ausreichen würde.
Im Folgenden finden Sie verschiedene gängige Szenarien, die sich oft gut für eine ereignisgesteuerte Architektur eignen:
| Entscheidungspunkt | Anleitung |
|---|---|
| Benachrichtigungen nahezu in Echtzeit | Ereignisgesteuerte Architekturmuster wie Veröffentlichen/Abonnieren, Fanout und Streaming funktionieren in der Regel gut in Szenarien, in denen mehrere Anwendungen nahezu in Echtzeit über Statusänderungen oder Datensatzaktualisierungen benachrichtigt werden müssen. |
| Parallelverarbeitung | Muster wie Veröffentlichen/Abonnieren funktionieren in der Regel gut in Szenarien, in denen große Datenmengen oder hochkomplexe Nachrichten die Verarbeitungslast auf mehrere Systeme verteilen müssen. |
| Lesevorgänge mit hohem Volumen | Die Muster "Übergebene Nachrichten" und "Warteschlange" werden häufig in Szenarien verwendet, in denen Organisationen Anstiege verzeichnen und das Volumen der produzierten Nachrichten die Fähigkeit der Abonnenten übersteigen kann, sie sofort zu verarbeiten. |
| Schreibvorgänge mit hohem Volumen | Die Streaming- und Warteschlangenmuster funktionieren gut in vielen Szenarien, in denen Organisationen einen Anstieg der Anzahl der produzierten Nachrichten feststellen. |
| Senden derselben Daten an unterschiedliche Systeme | Während das Veröffentlichen/Abonnieren für Organisationen, die dieselben Daten an mehrere Systeme senden müssen, tendenziell eine recht häufige Lösung ist, können die meisten hier behandelten Muster darauf reagieren. Überprüfen Sie sie im Detail, um die beste Passform zu finden. |
| Häufige Einführung neuer Systeme oder Geräte | Die Muster "Veröffentlichen/Abonnieren", "Streamen" und "Warteschlange" funktionieren in der Regel gut in Szenarien, in denen sich die gesamte Landschaft in einem Wandel befindet und regelmäßig neue Systeme und Geräte hinzugefügt werden. In diesem Szenario muss ein neues System oder Gerät lediglich Abonnent des Ereignis-Busses werden oder einer Warteschlange zugeordnet werden, um Nachrichten zu empfangen, statt eine benutzerdefinierte Punkt-zu-Punkt-Integration erforderlich zu machen. |
| IoT-Geräte | Da IoT-Geräte in der Regel häufige Aktualisierungen bereitstellen und in einigen Szenarien auch eine Welle von Nachrichten generieren können, funktionieren die Streaming- und Warteschlangenmuster in der Regel gut, wenn sie in eine IT-Landschaft integriert werden. |
| Mobilgeräte und -systeme im Offline-Modus | Mobilgeräte, die in Bereichen mit minderwertigem oder nicht vorhandenem Internetzugang arbeiten müssen, oder Systeme, die zum Zeitpunkt der Nachrichtenzustellung offline sein können, profitieren vom Warteschlangenmuster, mit dem sie eine Verbindung zu ihren Warteschlangen herstellen und alle relevanten Nachrichten abrufen können, sobald sie wieder online sind. |
Die meisten großen Organisationen verfügen über komplexe IT-Landschaften mit einer Kombination aus Systemen mit unterschiedlichen Funktionen. Es ist möglich oder wahrscheinlich, dass Ihre Organisation über veraltete Systeme verfügt, die keine ereignisgesteuerten Integrationen unterstützen. Möglicherweise gibt es auch Anwendungsfälle, in denen ereignisgesteuerte Integrationen keinen Sinn ergeben, selbst wenn sie von den Systemen unterstützt werden (z. B. SFTP-Dateiübertragungen von Drittanbietern). Wenn Sie einen Schritt zurückgehen und die IT-Landschaft Ihrer Organisation als Ganzes betrachten, werden Sie wahrscheinlich – genau wie bei anderen architektonischen Lösungen – eine Mischung aus Mustern verwenden, um verschiedene Szenarien zu unterstützen. Wenn Sie sich entscheiden, den ereignisgesteuerten Ansatz für Integrationen zu bevorzugen, sollten Sie ihn als ein anderes Tool in Ihrer Toolbox betrachten. Sie kann und sollte in den richtigen Szenarien verwendet werden, aber sie ist nicht ein Ansatz, der jedem System auferlegt werden muss. Durch die Entwicklung einer umfassenden Integrationsstrategie können Sie bestimmen, wann die in diesem Leitfaden beschriebenen Muster geeignet sein können, aber nicht.
In vielen Szenarien sind ereignisgesteuerte Architekturen erforderlich. In einigen Szenarien funktionieren ereignisgesteuerte Architekturen auch dann, wenn sie nicht am besten passen. In einigen Szenarien sollten ereignisgesteuerte Architekturen jedoch einfach nicht verwendet werden. Im Folgenden finden Sie einige Fragen zu Entscheidungspunkten, mit denen Sie diese Szenarien identifizieren können:
| Entscheidungspunkt | Anleitung/Fragen |
|---|---|
| Geschäftsanforderungen | Besteht ein echter Geschäftsbedarf für eine der Funktionen, die im Abschnitt [When-to-use an event-driven-architecture] (#when-to-use-an-event-driven-architecture) beschrieben sind? |
| Technische Anforderungen | Passt die Integration, die Sie entwerfen, offensichtlich zu einem anderen Muster, beispielsweise Datenvirtualisierung, Batch oder Anforderung/Antwort? Mit anderen Worten, versuchen Sie, einen Vierkantzapfen in ein rundes Loch zu passen? |
| Prozesse, bei denen Menschen auf Antworten warten müssen | Jede Integration, bei der ein Mensch auf eine Antwort vom Zielsystem wartet, eignet sich nicht für ereignisgesteuerte Architekturen, da sie für die asynchrone Ausführung konzipiert sind und keine Antwortzeit garantieren können. Überlegen Sie, ob solche Prozesse für Ihre Organisation optimal sind, bevor Sie technische Lösungen implementieren. Weitere Informationen finden Sie unter [Well-Architected – Process Design](/docs/architect/de-de/well-architected/guide/automated#prozessdesign). |
| Häufig geänderte Quelldaten | Wenn sich die Daten in Ihrem Quellsystem so selten ändern, dass regelmäßige Aktualisierungen ausreichend sind, können Sie Ihre Architektur wahrscheinlich vereinfachen, indem Sie [batch patterns] (https://developer.salesforce.com/docs/atlas.en-us.integration_patterns_and_practices.meta/integration_patterns_and_practices/integ_pat_batch_data_sync.htm) anstelle von ereignisgesteuerten Mustern verwenden. |
| Implementierungsanforderungen | Unterstützen die meisten an Ihrer Lösung beteiligten Systeme ereignisgesteuerte Architekturen? Was wäre erforderlich, um ereignisgesteuerte Architekturen mit Systemen zu verwenden, die sie nicht unterstützen (z. B. Upgrades, Anpassungen oder Middleware)? Welcher Aufwand wäre erforderlich, um diese Anforderungen zu erfüllen? |
| Messaging-Strukturstabilität | Wie oft müssen sich Ihre Nachrichtenstrukturen ändern? Welche Systeme sind von einer solchen Änderung betroffen und wie sieht der Sanierungsprozess aus? |
| Organisationsführung | Verfügen Sie über eine Governance-Struktur, um sicherzustellen, dass alle Beteiligten über Änderungen an Nachrichtenstrukturen, Auslösern und anderen architektur- und prozessbezogenen Entscheidungen informiert sind und Einfluss darauf haben? |
| Erforderliche Fertigkeiten | Verfügen Ihre Mitarbeiter über Erfahrung mit ereignisgesteuerten Architekturen und wissen sie, wie sie sie unterstützen können? |
Es gibt eine Vielzahl von ereignisgesteuerten Architekturmustern. Einige davon sind allgemeine Muster, die in Anwendungsfällen angewendet werden können, die keine besonderen Anforderungen außerhalb der Ereignissteuerung aufweisen. Entsprechende Informationen finden Sie unter Wohlüberlegt – Interoperabilität. Andere Muster sind auf die hier diskutierten spezifischen Anwendungsfälle anwendbar, beispielsweise Integrationen mit großen Datenmengen oder Szenarien, die eine längere Nachrichtenaufbewahrung erfordern.
In der folgenden Tabelle werden die Attribute der in diesem Dokument beschriebenen Muster verglichen. Verwenden Sie sie als Schnellreferenz, wenn Sie potenzielle Muster für einen bestimmten Anwendungsfall identifizieren müssen.
| Muster | Nahezu in Echtzeit | Kopie einer eindeutigen Nachricht | Garantiezustellung | Reduzieren der Nachrichtengröße | Umwandeln von Daten |
|---|---|---|---|---|---|
| Veröffentlichen/Abonnieren | ✓ | ✓ | ✓ | ||
| Fanout | ✓ | ✓ | ✓ | ||
| Übergebene Nachrichten | ✓ | ✓ | ✓ | ✓ | |
| Streaming | ✓ | ✓ | ✓ | ||
| Warteschlange | ✓ | ✓ | ✓ |
Salesforce bietet mehrere Tools, mit denen Sie Ihre ereignisgesteuerten Anwendungsfälle bewältigen können. Diese Tabelle enthält eine allgemeine Übersicht über die verfügbaren Tools.
| Tool | Beschreibung | Erforderliche Fertigkeiten | |
|---|---|---|---|
| MuleSoft | Beliebige Punktplattform | Plattform, die die Datenintegration mithilfe von API-Ebenen ermöglicht. | Pro-Code |
| Salesforce Pub/Sub-Konnektor | Konnektor für die Pub/Sub-API, der eine einzige Oberfläche für die Veröffentlichung und Abonnierung von Plattformereignissen, Ereignissen der Echtzeit-Ereignisüberwachung und Ereignissen der Datenerfassung von Änderungen bietet. | Pro-Code | |
| MuleSoft Anypoint JMS Connector | Konnektor, der das Senden und Empfangen von Nachrichten an Warteschlangen und Themen für jeden Nachrichtenservice ermöglicht, der die Java Message Service-Spezifikation (JMS) implementiert. | Pro-Code | |
| MuleSoft Anypoint Apache Kafka Connector | Konnektor zum Verschieben von Daten zwischen Apache Kafka und Unternehmensanwendungen und -services. | Pro-Code | |
| MuleSoft Anypoint Solace-Konnektor | Konnektor für Solace PubSub+-Ereignisbroker mit nativer API-Integration mithilfe des JCSMP Java-SDK | Pro-Code | |
| MuleSoft Anypoint MQ-Konnektor | Ein mandantenübergreifender Cloud-Messaging-Service, mit dem Kunden erweiterte asynchrone Nachrichten zwischen ihren Anwendungen ausführen können. | Pro-Code | |
| MuleSoft Anypoint-MQTT-Konnektor | Eine MuleSoft-Erweiterung, die mit dem Protokoll MQTT (Message Queuing Telemetry Transport) v3.x kompatibel ist. | Pro-Code | |
| MuleSoft Anypoint AMQP-Konnektor | Ein Konnektor, mit dem Ihre Anwendung Nachrichten mithilfe eines AMQP 0.9.1-kompatiblen Brokers veröffentlichen und konsumieren kann. | Pro-Code | |
| MuleSoft Anypoint Event-Driven (ASync)-API | Branchenunabhängige Sprache, die die Veröffentlichung von ereignisgesteuerten APIs unterstützt, indem sie in Ereignis-, Kanal- und Transportebenen unterteilt werden. | Pro-Code | |
| MuleSoft Anypoint MQ | Messaging-Service für mehrere Mandanten, mit dem Kunden erweiterte asynchrone Nachrichten zwischen ihren Anwendungen ausführen können. | Pro-Code | |
| MuleSoft Anypoint-Datenströme | Das in MuleSoft Anypoint verfügbare Framework zum Veröffentlichen und Abonnieren von Streaming-Daten. | Pro-Code | |
| Salesforce Platform | Apache Kafka auf Heroku | Heroku-Add-On, das Apache Kafka als Service mit vollständiger Plattformintegration in die Heroku-Plattform bereitstellt. | Pro-Code |
| Datenerfassung ändern | Änderungsereignisprotokoll, das Änderungen an Salesforce-Datensätzen veröffentlicht. Zu den Änderungen zählen die Erstellung eines neuen Datensatzes, Aktualisierungen an einem vorhandenen Datensatz, das Löschen eines Datensatzes und das Rückgängigmachen der Löschung eines Datensatzes. | Low-Code zu Pro-Code | |
| Ausgehende Nachrichten | Aktionen, die XML-Nachrichten an externe Endpunkte senden, wenn Feldwerte in Salesforce aktualisiert werden. | Low-Code | |
| Plattformereignisse | Sichere und skalierbare Nachrichten, die benutzerdefinierte Ereignisdaten enthalten. | Low-Code zu Pro-Code | |
| Pub/Sub API | API, die Abonnements für Plattformereignisse, Ereignisse der Datenerfassung ändern und/oder Ereignisse der Echtzeit-Ereignisüberwachung aktiviert. | Pro-Code | |
| Ereignisweiterleitungen | Ermöglicht die Übertragung von Plattformereignissen und Ereignissen der Datenerfassung von Salesforce an Amazon EventBridge. Beachten Sie, dass Ereignisweiterleitungen nur eine Verbindung mit AWS Eventbridge herstellen. | Low-Code | |
Wenn ein wichtiger Datensatz den Status in einer Kernanwendung ändert – beispielsweise wird der Status eines Auftrags von "Verarbeitung" zu "Versandt" geändert –, benötigen mehrere andere Systeme wahrscheinlich eine Benachrichtigung nahezu in Echtzeit, um ihre jeweiligen Aufgaben ausführen zu können. Ein spezifischer Geschäftsbedarf ergibt sich, wenn das Volumen dieser Änderungen hoch ist und die Nachrichten komplex sind, was herkömmliche Punkt-zu-Punkt-Integrationen aufwändig und schwierig zu verwalten macht. Das Einrichten empfindlicher, benutzerdefinierter Verbindungen für jede einzelne abhängige Anwendung führt zu technischen Schulden und verhindert die schnelle Skalierbarkeit der Organisation. Zum Verwalten dieser häufigen Datensynchronisierungen ist ein zuverlässiger Integrationsansatz erforderlich, ohne das Quellsystem direkt mit jedem verbrauchenden System zu verknüpfen.
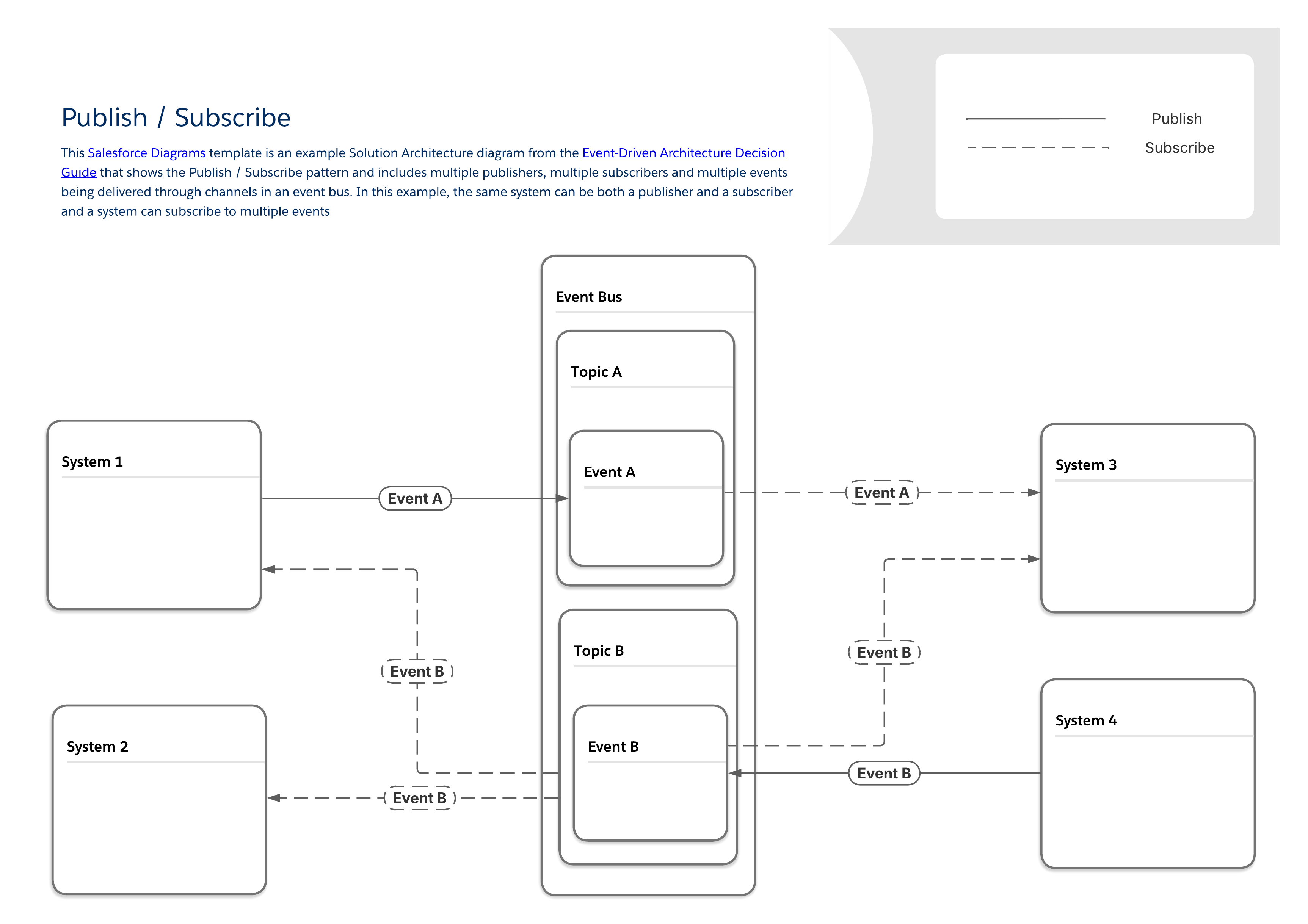
Das folgende Diagramm zeigt ein typisches Veröffentlichungs-/Abonnementmuster, bei dem mehrere Publisher und Abonnenten Daten über einen Ereignis-Bus freigeben. Dieses grundlegende Muster bildet die Grundlage für die spezifischeren Muster, die im Rest dieses Handbuchs zu finden sind. Einige wichtige Merkmale dieses Musters sind:
-
Es besteht keine direkte Verbindung zwischen Publishern und Abonnenten. Publisher senden Nachrichten einfach an einen Ereignis-Bus, der sie an jedes andere System sendet, das sie anhören möchte.
-
Das gleiche System kann sowohl ein Publisher als auch ein Abonnent sein.
-
Systeme können mehrere Ereignistypen veröffentlichen oder abonnieren.
-
Wie bei allen Mustern in dieser Anleitung fällt das Veröffentlichungs-/Abonnementmuster in eine allgemeine Integrationsmusterkategorie, die als Remote Procedure Invocation (RPI) bezeichnet wird oder einfach "fire and forget".
| Ereignis-Flow und -Verhalten | Überlegungen zur Nutzlast | ||||||
|---|---|---|---|---|---|---|---|
| Verfügbare Tools | Erforderliche Fertigkeiten | Veröffentlichen über | Abonnieren über | Wiederholungszeitraum | Nutzlaststruktur | Nutzlastobergrenzen | |
| MuleSoft | Beliebige Punktplattform | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine |
| Salesforce Pub/Sub-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint JMS Connector | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint Apache Kafka Connector | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint Solace-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint MQ-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint-MQTT-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint AMQP-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint Event-Driven (ASync)-API | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint MQ | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| Salesforce Platform | Apache Kafka auf Heroku | Pro-Code | APIs, Datensatzänderungen in Heroku Postgres | N/A | 1-6 Wochen | Vom Benutzer definiert | Vom Benutzer definiert |
| Datenerfassung ändern | Low-Code zu Pro-Code | Datensatzänderungen | Apex, APIs, Lightning Web Components (LWC) | 3 Tage | Vordefiniert | 1 MB | |
| Ausgehende Nachrichten* | Low-Code | Flow- und Workflow-Regeln | N/A | 24 Stunden | Vom Benutzer definiert | 100 Benachrichtigungen pro Nachricht | |
| Plattformereignisse | Low-Code zu Pro-Code | APIs, Apex, Flow | Apex, APIs, Flow, LWC | 3 Tage | Vom Benutzer definiert | 1 MB | |
| Pub/Sub API | Pro-Code | Pub/Sub API oder APIs, Apex, Flow | Pub/Sub-API | 3 Tage | Vom Benutzer definiert | 1 MB | |
| Ereignisweiterleitungen** | Low-Code | Plattformereignisse, Datenerfassung ändern | API | 3 Tage | Vom Benutzer definiert | 1 MB | |
| * Salesforce unterstützt ausgehende Nachrichten weiterhin im Rahmen der aktuellen Funktionsfunktionen, plant jedoch keine weiteren Investitionen in diese Technologie. **Ereignisweiterleitungen stellen nur eine Verbindung mit AWS Eventbridge her | |||||||
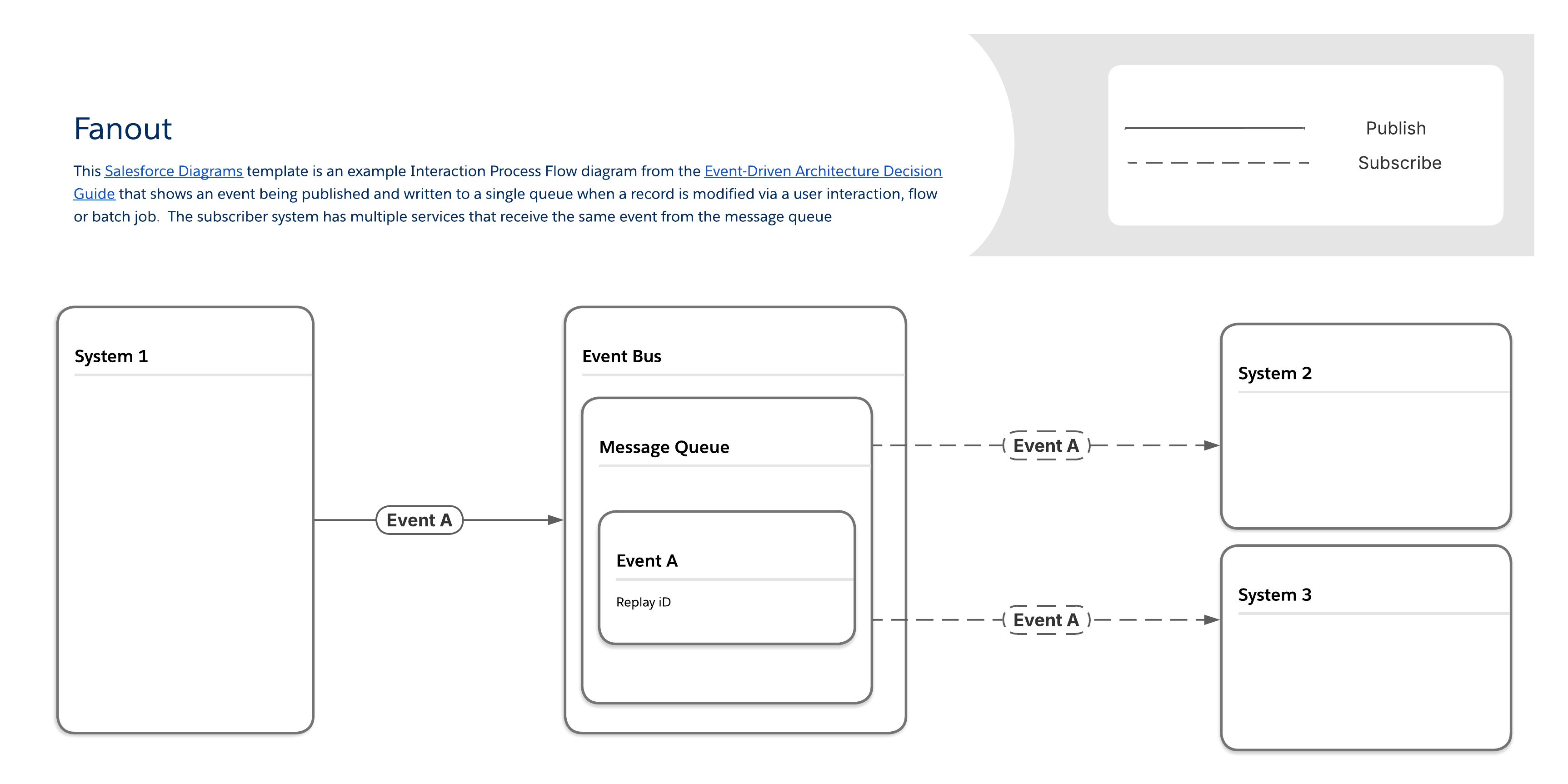
Wenn eine Organisation sofortige Aktualisierungen an einer großen Anzahl von Client-Anwendungen senden muss, beispielsweise Push-Benachrichtigungen oder SMS-Nachrichten an Mobilgeräte, wird der herkömmliche Prozess der Erstellung eindeutiger Übertragungen für jeden einzelnen Empfänger schnell zu einem Engpass bei der Skalierbarkeit. Der Kerngeschäftsbedarf besteht in diesem Fall in der schnellen und leistungsstarken Verteilung einer einzelnen Information wie einer Accountbenachrichtigung oder einer wichtigen Serviceänderungsanzeige an zahlreiche Endpunktanwendungen gleichzeitig. Ein optimierter Ansatz, um diese Anforderung zu erfüllen, besteht darin, alle Nachrichten durch eine einzelne Warteschlange weiterzuleiten, die als zentraler Punkt der Ereignisinformationen für alle verbrauchenden Systeme fungiert. Dieser Ansatz verbessert die Leistung, da viele separate Nachrichtenkopien nicht mehr verwaltet werden müssen.
Mit dem Fanout-Muster werden Nachrichten über eine einzige Nachrichtenwarteschlange an ein oder mehrere Ziele (d. h. an hörende Clients oder Abonnenten) zugestellt. Abonnenten rufen dieselbe Nachricht aus der Warteschlange ab und nicht ihre eigene eindeutige Kopie. (Beachten Sie, dass dies zwar die Leistung verbessert, es jedoch auch erschweren kann, zu überprüfen, ob ein bestimmter Abonnent die Nachricht erhalten hat.)
| Ereignis-Flow und -Verhalten | Überlegungen zur Nutzlast | ||||||
|---|---|---|---|---|---|---|---|
| Verfügbare Tools | Erforderliche Fertigkeiten | Veröffentlichen über | Abonnieren über | Wiederholungszeitraum | Nutzlaststruktur | Nutzlastobergrenzen | |
| MuleSoft | MuleSoft Anypoint JMS Connector | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine |
| Salesforce Pub/Sub-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint Apache Kafka Connector | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint Solace-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint MQ-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint-MQTT-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint AMQP-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint MQ | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| Salesforce Platform | Apache Kafka auf Heroku | Pro-Code | APIs, Datensatzänderungen in Heroku Postgres | N/A | 1-6 Wochen | Vom Benutzer definiert | Vom Benutzer definiert |
| Datenerfassung ändern | Low-Code zu Pro-Code | Datensatzänderungen | Apex, APIs, Lightning Web Components (LWC) | 3 Tage | Vordefiniert | 1 MB | |
| Plattformereignisse | Low-Code zu Pro-Code | APIs, Apex, Flow | Apex, APIs, Flow, LWC | 3 Tage | Vom Benutzer definiert | 1 MB | |
| Pub/Sub API | Pro-Code | Pub/Sub API oder Apex, APIs, Flow | Pub/Sub-API | 3 Tage | Vom Benutzer definiert | 1 MB | |
| Ereignisweiterleitungen* | Low-Code | Plattformereignisse, Datenerfassung ändern | API | 3 Tage | Vom Benutzer definiert | 1 MB | |
| * Ereignisweiterleitungen senden nur Daten an AWS Eventbridge | |||||||
Einige Ereignisszenarien zeichnen sich durch einen erheblichen Nachrichtenvolumenzustrom aus, der die Kapazität von Synchronisierungs- und Transformationsprozessen zu überfordern droht, oder durch eine komplexe Logik aus mehreren Schritten, die zum Verarbeiten und Umwandeln von Ereignisdaten erforderlich ist.
Einige Beispiele:
-
Saisonale Volumenspitzen: Es kann zu Volumenspitzen kommen, die Online-Händler erleben, wenn eine Auswahl ihrer Produkte "in der Saison" ist. Wenn viele Kunden gleichzeitig Käufe tätigen, kann die Anzahl der generierten Ereignisse vorübergehend die Kapazität der Synchronisierungs- und Transformationsprozesse überschreiten. Weitere Informationen finden Sie unter Well-Architected – Data Handling.
-
Kundenvorgangs- oder Anspruchsverwaltung: Bei servicebasierten Unternehmen kann es bei Ausfällen zu einem Anstieg der Anzahl der Kundenvorgänge oder Ansprüche kommen.
-
Komplexe Datentransformationen: Organisationen, die komplexe Logik zum Umwandeln von Nachrichten benötigen, sind oft besorgt darüber, dass Ereignisse schneller generiert werden, als sie umgewandelt werden können.
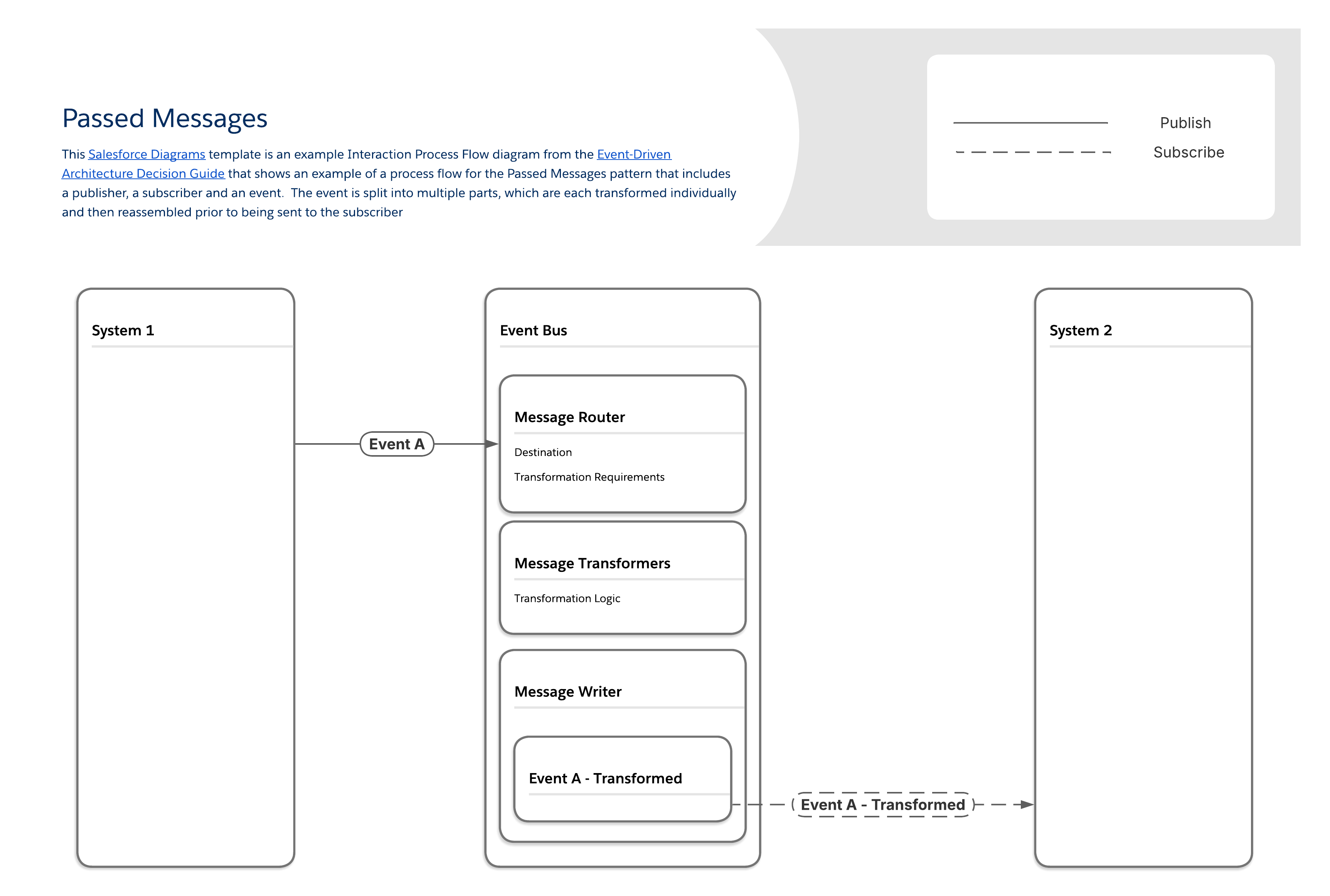
Dieses Muster löst die Herausforderung, dass Nachrichten schneller generiert werden, als sie umgewandelt werden können. Durch die Integration einer Streaming-Nachrichtenplattform und die Segmentierung der Nachrichtenverarbeitungslogik in dedizierte Komponenten wird sichergestellt, dass große Mengen an Nachrichten und erforderliche Datenmanipulationen zuverlässig verarbeitet werden können.
Das Muster "Übergebene Nachrichten" funktioniert, indem die Verarbeitungslogik für Nachrichten in mehrere Komponenten unterteilt wird:
-
Eine Komponente übernimmt die Nachrichtenweiterleitung, bestimmt erforderliche Transformationen und das endgültige Ziel.
-
Ein separater Satz von Komponenten verarbeitet verschiedene Ebenen der Nachrichtentransformation (z. B. Feldzuordnungen, Objektbeziehungen usw.).
-
Die letzte Komponente schreibt die letzte geänderte Nachricht aus.
| Ereignis-Flow und -Verhalten | Überlegungen zur Nutzlast | ||||||
|---|---|---|---|---|---|---|---|
| Verfügbare Tools | Erforderliche Fertigkeiten | Veröffentlichen über | Abonnieren über | Wiederholungszeitraum | Nutzlaststruktur | Nutzlastobergrenzen | |
| MuleSoft | MuleSoft Anypoint Apache Kafka Connector | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine |
| Salesforce Pub/Sub-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| Salesforce Platform | Apache Kafka auf Heroku | Pro-Code | APIs, Datensatzänderungen in Heroku Postgres | N/A | 1-6 Wochen | Vom Benutzer definiert | Vom Benutzer definiert |
| Datenerfassung ändern | Low-Code zu Pro-Code | Datensatzänderungen | Apex, APIs, Lightning Web Components (LWC) | 3 Tage | Vordefiniert | 1 MB | |
| Plattformereignisse | Low-Code zu Pro-Code | APIs, Apex, Flow | Apex, APIs, Flow, LWC | 3 Tage | Vom Benutzer definiert | 1 MB | |
| Pub/Sub API | Pro-Code | Pub/Sub API oder APIs, Apex Flow | Pub/Sub-API | 3 Tage | Vom Benutzer definiert | 1 MB | |
| Ereignisweiterleitungen* | Low-Code | Plattformereignisse, Datenerfassung ändern | API | 3 Tage | Vom Benutzer definiert | 1 MB | |
| * Ereignisweiterleitungen senden nur Daten an AWS Eventbridge | |||||||
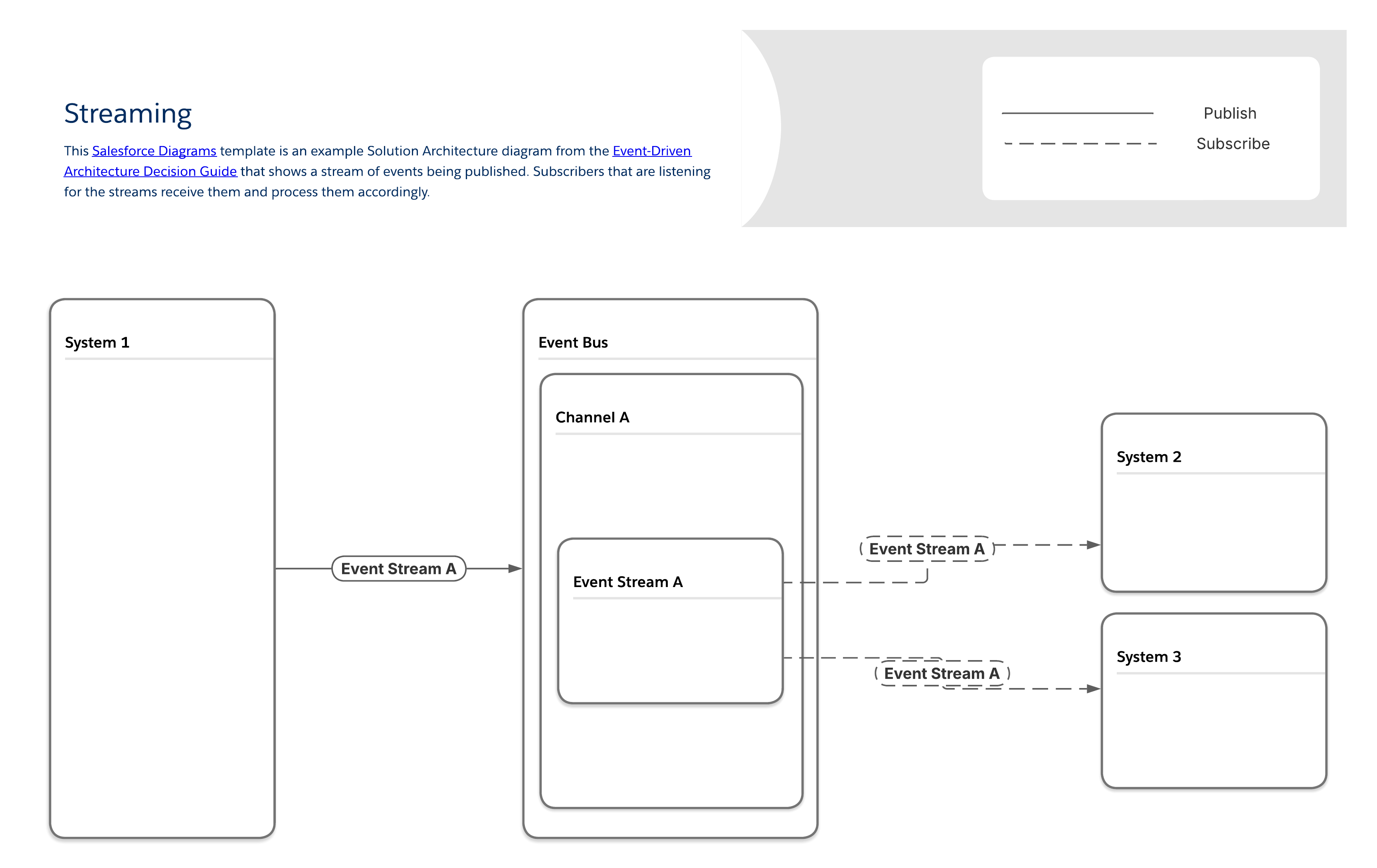
Einige Produzenten generieren einen kontinuierlichen Stream von Ereignissen. Ein häufiges Beispiel ist das Medien-Streaming, bei dem Benutzerinteraktionen berücksichtigt werden, die natürlicherweise als diskrete Ereignisse auftreten. Mehrere Systeme müssen gleichzeitig auf dasselbe Benutzerverhalten reagieren, ohne die zentrale Streaming-Erfahrung zu blockieren.
Beachten Sie die Ereignisse für eine Musik-Streaming-Plattform. Dazu zählen beispielsweise:
-
Verfolgen von gestarteten/angehaltenen/übersprungenen Ereignissen
-
Abhören von Sitzungsereignissen mit Zeitstempeln
-
Wiedergabelistenerstellung/-änderungsereignisse
-
Social-Sharing-Ereignisse
-
Herunterladen zum Offline-Hören
Im Streaming-Muster greifen Abonnenten auf jeden Ereignisstrom zu und verarbeiten die Ereignisse in der genauen Reihenfolge, in der sie empfangen werden. An jeden Abonnenten werden eindeutige Kopien jedes Nachrichtenstroms gesendet, wodurch teilnehmerspezifische Inhalte bereitgestellt und identifiziert werden können, welche Abonnenten welche Streams erhalten.
| Ereignis-Flow und -Verhalten | Überlegungen zur Nutzlast | ||||||
|---|---|---|---|---|---|---|---|
| Verfügbare Tools | Erforderliche Fertigkeiten | Veröffentlichen über | Abonnieren über | Wiederholungszeitraum | Nutzlaststruktur | Nutzlastobergrenzen | |
| MuleSoft | MuleSoft Anypoint-Datenströme | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine |
| Salesforce Pub/Sub-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint Apache Kafka Connector | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| Salesforce Platform | Apache Kafka auf Heroku | Pro-Code | APIs, Datensatzänderungen in Heroku Postgres | N/A | 1-6 Wochen | Vom Benutzer definiert | Vom Benutzer definiert |
| Pub/Sub API | Pro-Code | Pub/Sub API oder APIs, Apex Flow | Pub/Sub-API | 3 Tage | Vom Benutzer definiert | 1 MB | |
Damit ein Stream sinnvoll ist, müssen alle seine Ereignisse und die zugehörigen Nachrichten in der richtigen Reihenfolge vorliegen. Wenn Sie die Daten in einem Stream aus unterschiedlichen Systemen beziehen, müssen Sie zusätzliche Anordnungslogik als Teil des Designprozesses integrieren.
Warteschlangenanwendungsfälle sind allgegenwärtig. Beispiele:
-
Internetverbindung geringer Qualität: Außendienstorganisationen oder andere Organisationen, in denen Teams mit Mobilgeräten in Bereichen mit minderwertigem oder zeitweiligem Internetzugang arbeiten müssen, profitieren von der Warteschlange, da die Anwendungen auf diesen Geräten eine Verbindung zu ihren Warteschlangen herstellen und alle relevanten Nachrichten abrufen können, wenn die Verbindung wiederhergestellt ist.
-
Nachrichtenpufferung: Wenn das Nachrichtenvolumen gelegentlich die Verarbeitungskapazität eines Abonnenten überschreitet und eine erhöhte Latenz keine zusätzlichen Probleme verursacht, können Warteschlangen ein Puffer sein, um überschüssige Nachrichten zu speichern und Datenverluste zu verhindern.
-
Transportmanagement: Logistikorganisationen, die ihre Flotten überwachen müssen, können dieses Muster verwenden, um die Routen anzuzeigen, die jedes Fahrzeug nahezu in Echtzeit fährt, und sicherzustellen, dass die Fahrer so effizient wie möglich sind.
-
IoT-Geräte: Hersteller verwenden häufig Systeme, die schnelle Datenströme generieren, und diese können sich nachgelagert auf zusätzliche Systeme auswirken. Dieses Muster kann verwendet werden, um Sequenzen von Ereignissen zu identifizieren, die ein Eingreifen des Menschen erfordern, bevor katastrophale Fehler auftreten, die sich über mehrere Systeme erstrecken.
Im Warteschlangenmuster senden Produzenten Nachrichten an Warteschlangen, die die Nachrichten so lange speichern, bis sie von Abonnenten abgerufen werden. Die meisten Nachrichtenwarteschlangen folgen der FIFO-Anordnung (First-in, First-out) und löschen jede Nachricht, nachdem sie abgerufen wurde. Jeder Abonnent verfügt über eine eindeutige Warteschlange, die zusätzliche Setup-Schritte erfordert, jedoch die Zustellung garantiert und identifiziert, welche Abonnenten welche Nachrichten erhalten haben.
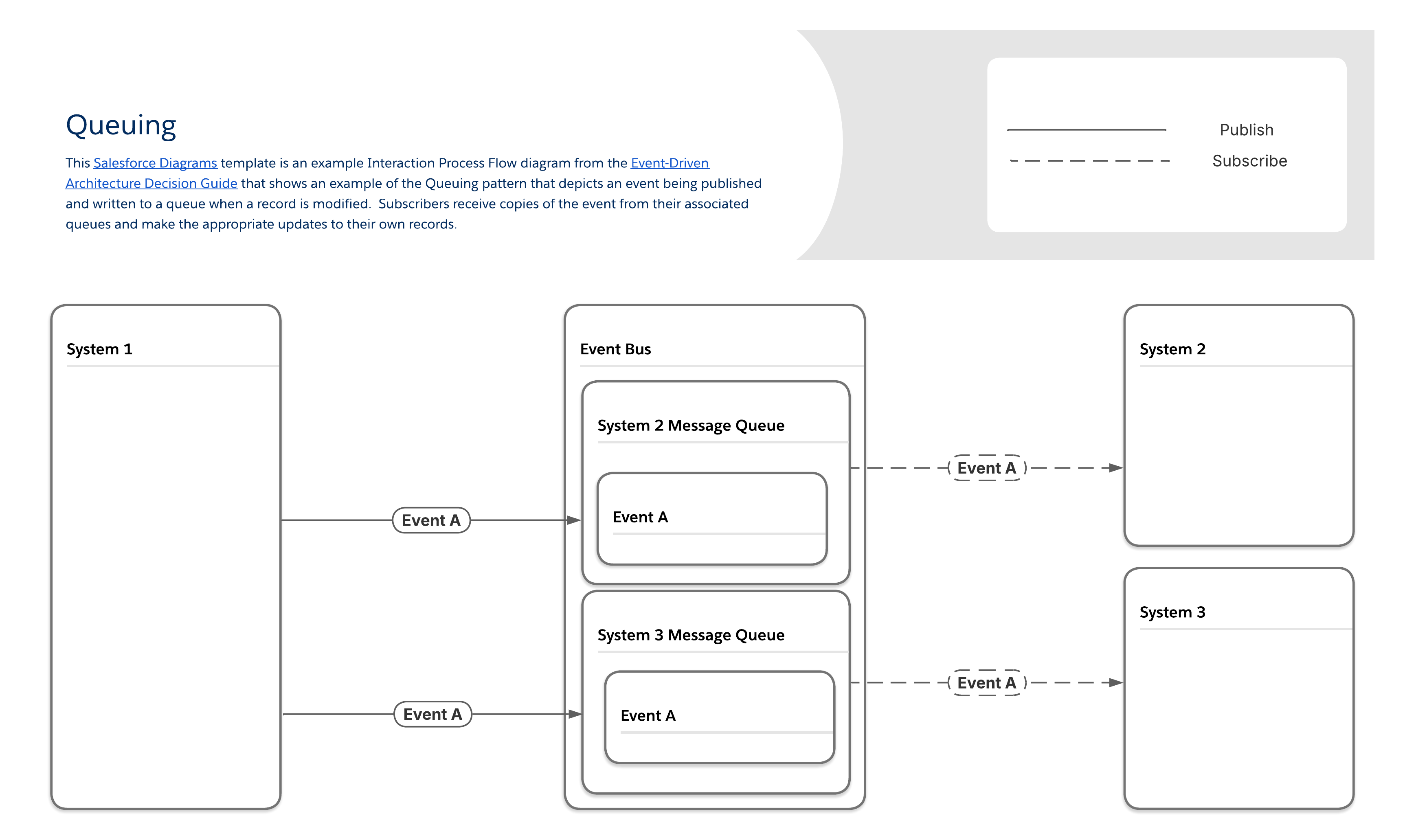
| Ereignis-Flow und -Verhalten | Überlegungen zur Nutzlast | ||||||
|---|---|---|---|---|---|---|---|
| Verfügbare Tools | Erforderliche Fertigkeiten | Veröffentlichen über | Abonnieren über | Wiederholungszeitraum | Nutzlaststruktur | Nutzlastobergrenzen | |
| MuleSoft | MuleSoft Anypoint MQ | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine |
| Salesforce Pub/Sub-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint Apache Kafka Connector | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint MQ-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint-MQTT-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| MuleSoft Anypoint AMQP-Konnektor | Pro-Code | APIs | APIs | Wie konfiguriert | Vom Benutzer definiert | Keine | |
| Salesforce Platform | Apache Kafka auf Heroku | Pro-Code | APIs, Datensatzänderungen in Heroku Postgres | N/A | 1-6 Wochen | Vom Benutzer definiert | Vom Benutzer definiert |
| Datenerfassung ändern | Low-Code zu Pro-Code | Datensatzänderungen | Apex, APIs, Lightning Web Components (LWC) | 3 Tage | Vordefiniert | 1 MB | |
| Plattformereignisse | Low-Code zu Pro-Code | APIs, Apex, Flow | Apex, APIs, Flow, LWC | 3 Tage | Vom Benutzer definiert | 1 MB | |
| Pub/Sub API | Pro-Code | Pub/Sub API oder APIs, Apex, Flow | Pub/Sub-API | 3 Tage | Vom Benutzer definiert | 1 MB | |
| Ereignisweiterleitungen* | Low-Code | Plattformereignisse, Datenerfassung ändern | API | 3 Tage | Vom Benutzer definiert | 1 MB | |
| * Ereignisweiterleitungen senden nur Daten an AWS Eventbridge | |||||||
Aufgrund der Asynchronität des Warteschlangenmusters kann es zu einer längeren Verzögerung zwischen dem Hinzufügen einer Nachricht zu einer Warteschlange und dem Abruf dieser Nachricht kommen. Warteschlangen benötigen Speicherplatz oder Speicherplatz, um ihre Nachrichten speichern zu können. Daher können sie nicht unbegrenzt wachsen. Das bedeutet, dass ein Abonnent, der auf unbestimmte Zeit offline ist, einen Fehler verursachen kann, wenn sich genügend Nachrichten in der Warteschlange ansammeln. Die Nachrichtenpufferung kann den gleichen Effekt haben, wenn die Verarbeitungszeiten der Abonnenten zu lang werden, was dazu führt, dass sich große Mengen an Nachrichten in ihren Warteschlangen ansammeln. Führen Sie eine gründliche Analyse des Speicherbedarfs für alle Nachrichtenwarteschlangen durch und entwerfen Sie bei Bedarf Prozesse, die Warteschlangen bereinigen und deaktivieren, wenn Nachrichten nicht innerhalb einer festgelegten Zeit abgerufen werden oder wenn sie ein vorbestimmtes Volumen erreichen.
Selbst wenn Sie vollkommen davon überzeugt sind, dass eine ereignisgesteuerte Architektur für Ihre Organisation geeignet ist, beginnen Sie möglicherweise mit einer Landschaft, die bereits eine große Anzahl von Punkt-zu-Punkt-Integrationen aufweist. Es kann schwierig sein, Fördermittel für ein Projekt zu erhalten, um alle Ihre Integrationen auf einmal zu ersetzen, und es kann nicht einmal möglich sein, eine ereignisgesteuerte Architektur direkt mit einigen alten Systemen zu verwenden. In diesen Szenarien können Sie die Migration zu einer locker gekoppelten Architektur schrittweise vornehmen, indem Sie zunächst die geschäftskritischsten Anwendungen konvertieren und dann andere Systeme konvertieren, wenn sie in künftigen Projekten aktualisiert oder ersetzt werden. Dieser Ansatz erleichtert das Hinzufügen neuer Anwendungen zum Ereignis-Bus und ermöglicht es Ihrer gesamten IT-Landschaft, skalierbar und widerstandsfähig zu bleiben, da Systeme im Laufe der Zeit immer mehr hinzugefügt werden.
Als Architekten wissen wir, dass jede Architektur Kompromisse mit sich bringt. Eine ereignisgesteuerte Architektur ist keine Ausnahme. Obwohl eine Landschaft voller lose gekoppelter Systeme hochgradig skalierbar und widerstandsfähig ist, gibt es auch einige Kompromisse zu beachten:
-
Gesamtintegrationsstrategie: Unabhängig von den Tools und Mustern, für die Sie sich entscheiden, ist es wichtig, zunächst eine Strategie für die gemeinsame Nutzung von Daten in den verschiedenen Systemen Ihrer Organisation zu erstellen. Diese Strategie sollte die Ziele Ihrer Organisation für ihre Daten, die Art und Weise, wie Daten freigegeben und Muster verwendet werden können, sowie Datenquellen, Ziele, Strukturen und Inhaberschafts- und Zugriffsanforderungen enthalten.
-
Unterstützung für ältere Systeme: Ihre Organisation verfügt möglicherweise über veraltete Systeme, die einfach keine ereignisgesteuerten Architekturmuster unterstützen. Auch wenn es möglich ist, Übergangslösungen zu erstellen (beispielsweise mit einem Prozess, der als Durchleitung fungiert, indem Ereignisse abonniert und die Ausgabe dann über eine andere Datenübertragung an das Zielsystem gesendet wird), sollten Sie in diesem Fall möglicherweise andere Integrationsmethoden in Betracht ziehen.
-
Strukturänderungen an Nachrichten: Sobald die ursprüngliche Nachrichtenstruktur definiert und zwischen Herausgebern und Abonnenten vereinbart wurde, kann es schwierig sein, sie zu ändern, insbesondere wenn die Abonnenten extern sind. Es gibt mehrere Möglichkeiten, dieses Problem zu beheben. Sie können versionierte Endpunkte verwenden. Stellen Sie jedoch sicher, dass Sie für jede Version einen klaren Lebenszyklus definieren und kommunizieren, damit Ihre Entwickler nicht zu viele Versionen gleichzeitig pflegen müssen. Wenn Apache Kafka in Heroku Teil Ihrer Landschaft ist, können Sie auch eine Schemaregistrierung oder ein ähnliches Tool in Betracht ziehen. Stellen Sie jedoch sicher, dass es auch von den anderen Systemen in Ihrer Landschaft unterstützt wird (und verwendet wird).
-
Mangelnde Sichtbarkeit zwischen Publishern und Abonnenten: In den meisten ereignisgesteuerten Architekturmustern ist den Herausgebern der Status ihrer Abonnenten nicht bekannt. Wenn ein Publisher also eine wichtige Nachricht sendet, während alle Abonnenten offline sind, wird die Nachricht möglicherweise nie zugestellt. Sie können dieses Problem beheben, indem Sie die Funktionen für die erneute Wiedergabe nutzen oder redundante Abonnenten hinzufügen, die auf separaten Servern für alle wichtigen Nachrichten ausgeführt werden.
-
Leistungsengpässe: Wenn eine ereignisgesteuerte Architektur skaliert wird, kann der Ereignis-Bus zu einem Engpass für die Nachrichtenzustellung werden, wenn er überfordert ist, da zu viele Publisher versuchen, zu vielen Abonnenten gleichzeitig Nachrichten zu senden. Sie können dies beheben, indem Sie den dem Ereignis-Bus zugewiesenen Speicher und die Verarbeitungsressourcen erhöhen oder mehrere Ereignis-Busse verwenden, um verschiedene Nachrichtentypen parallel zu verarbeiten.
Bevor Sie eine ereignisgesteuerte Architektur implementieren, sollten Sie überlegen, ob Sie überhaupt eine Architektur verwenden müssen. Im vorherigen Abschnitt werden allgemeine Geschäftsszenarien beschrieben, die für jedes ereignisgesteuerte Architekturmuster gut geeignet sind. Weitere Informationen finden Sie unter Well-Architected – Interoperability (Wohlüberlegt – Interoperabilität). Lesen Sie die Herausforderungen, die beim Implementieren von ereignisgesteuerten Architekturen zu berücksichtigen sind, um zu ermitteln, ob die Muster, die Sie im Kopf haben, für Ihre spezifischen Anwendungsfälle am besten geeignet sind.
Beachten Sie, dass die meisten der in diesem Handbuch behandelten Szenarien Integrationen beinhalten. Ereignisgesteuerte Architekturen können jedoch auch verwendet werden, um Nachrichten innerhalb einer einzelnen Salesforce-Organisation zu senden, beispielsweise mithilfe von Plattformereignissen. Beachten Sie beim Entwerfen von Prozessen, die Plattformereignisse als internes Messaging-System verwenden, alle anwendbaren Ereigniszuteilungsobergrenzen.
Anti-Patterns in ereignisgesteuerten Architekturen stammen häufig aus der Verwendung von Ereignissen als Übergangslösung für die interne Kommunikation in einer Salesforce-Organisation. Allgemeine Anti-Patterns sind:
-
Veröffentlichen von Ereignissen aus Apex-Auslösern, die demselben Ereignisobjekt zugeordnet sind: Dies führt zu einer unendlichen Auslöseschleife.
-
Veröffentlichung von Ereignissen aus Apex vor Abschluss einer DML-Transaktion: Wenn eine Transaktion fehlschlägt und zurückgesetzt wird, werden alle veröffentlichten Ereignisse, die das Verhalten "Sofort veröffentlichen" aufweisen, nicht in das Wiederherstellungsverhalten einbezogen.
-
Veröffentlichen von Ereignissen in Flow zur Orchestrierung der nachfolgenden Automatisierung: Die beste Möglichkeit, Logik über mehrere Automatisierungen hinweg zu koordinieren, besteht darin, Subflows oder Flow Orchestrator zu verwenden.
-
Erstellen von Laufzeitabhängigkeiten: Veröffentlichen Sie keine Ereignisse, um die Kommunikation zwischen Paketen zu erleichtern, ohne die richtigen Schritte zum Beseitigen von Laufzeitabhängigkeiten zu ergreifen.
-
Unnötig große Nutzlasten: Beim Senden von Anforderungen ist es am besten, möglichst wenige Daten in der Nutzlast zu senden und zu empfangen. Jede Aktion eines Benutzers kann potenziell zu mehreren Anforderungen führen. Es ist wichtig, dass diese effizient verarbeitet werden. Das Senden von mehr Daten als erforderlich kann zu einem langsamen Transport und einer längeren Verarbeitungszeit beitragen.
-
Unselektive Verarbeitung von Anwendungsereignissen: Wenn mehrere Komponenten auf ein Anwendungsereignis hören, sollten Entwickler sicherstellen, dass der Ereignis-Handler nur dann ausgeführt wird, wenn dies tatsächlich gewünscht und nützlich ist. In der Lightning Konsole können beispielsweise Komponenten, die auf nicht fokussierten Registerkarten enthalten sind, weiterhin zugehört werden, auch wenn sie nicht sichtbar sind. Ein Entwickler kann verschiedene Techniken verwenden, beispielsweise ein Dienstprogrammelement im Hintergrund als einzigen Listener verwenden oder getEnclosingTabId() aufrufen, um zu bestimmen, ob diese Instanz der Komponente auf der Registerkarte "Fokussiert" enthalten ist, um sicherzustellen, dass jedes Ereignis nur zum vorgesehenen Zeitpunkt verarbeitet wird.
-
Bei falscher Verwendung von Plattformereignissen wird das Veröffentlichungsverhalten wie folgt geändert: Plattformereignisse weisen zwei Veröffentlichungsverhaltensweisen auf: Sofort veröffentlichen und Nach Commit veröffentlichen. Es kann nützlich sein, Plattformereignisse in Echtzeit für Anwendungsfälle wie die Protokollierung zu verwenden, bei denen Sie das Protokollierungsereignis veröffentlichen möchten, unabhängig davon, ob die Transaktion erfolgreich ist und übernommen wird. Verwenden Sie jedoch "Sofort veröffentlichen" sehr vorsichtig bei Plattformereignissen in Echtzeit. Ereignisse können von Abonnenten innerhalb derselben Transaktion verwendet werden und zu Zeilensperren oder anderen Rassebedingungen führen.
Bei der Implementierung einer ereignisgesteuerten Architektur besteht einer der Schlüssel zum Erfolg darin, Standards für die Gestaltung der Ereignisse selbst festzulegen. Die Spezifika variieren je nach Anwendungsfällen Ihrer Organisation. Im Folgenden finden Sie jedoch einige allgemeine Richtlinien:
-
Bestimmen Sie die optimale Struktur für Ihre Ereignisnutzlasten. Während kleinere Nachrichtengrößen die Verarbeitungszeiten reduzieren, kann es zu Leistungseinbußen kommen, wenn Abonnenten mit massiven Nachrichtenmengen bombardiert werden. Möglicherweise müssen Sie Ihre Nutzlastgrößen und -strukturen wiederholen, um die richtige Balance zu finden. MuleSoft und ähnliche ESB-Tools bieten die Möglichkeit, benutzerdefinierte Nutzlasten in den Ihren Ereignissen zugeordneten Nachrichten zu entwerfen, wodurch Sie Datenstrukturen visualisieren und die Leistung auf Abonnentenseite verbessern können. (Weitere Informationen finden Sie unter Wohlüberlegt – API-Verwaltung.)
-
Überlegen Sie sich Ihre Prozesse durchgängig. Stellen Sie sicher, dass Sie keine "Endlosschleife"-Szenarien erstellen, die nach der Einführung der Integrationen schwierig aufzuspüren sein können. Ein Beispiel hierfür wären zwei Systeme, die Ereignisse veröffentlichen, wenn Datensätze aktualisiert werden, und gleichzeitig die Ereignisse des jeweils anderen überwachen, wodurch zusätzliche veröffentlichte Ereignisse ausgelöst werden, wenn sie verarbeitet werden.
Sie können diese Art von Anti-Pattern beheben, indem Sie beiden Systemen Logik hinzufügen, die sicherstellt, dass Änderungen, die infolge eines verbrauchten Ereignisses vorgenommen werden, nicht zur Veröffentlichung eines neuen Ereignisses führen. Sie sollten auch sicherstellen, dass alle Ihre Ereignisse, ihre zugehörigen Auslöser und die untergeordneten Systeme dokumentiert sind, die möglicherweise betroffen sind. Verwenden Sie diese Dokumentation als Referenz während Designsitzungen, um Endlosschleifen und ähnliche Szenarien so früh wie möglich zu erkennen. (Weitere Informationen finden Sie unter Wohlüberlegt – Prozessdesign.)
-
Verwenden Sie systemübergreifend allgemeine Benennungskonventionen. Konsistente Benennungskonventionen sind eine bewährte Vorgehensweise für die gesamte Softwareentwicklung, einschließlich ereignisgesteuerter Architekturen. Nehmen Sie sich Zeit, um eine Reihe von Standards für Ereignisnamen, Strukturen, zugeordnete Objekte und Fehlerbehandlungsprozesse zu dokumentieren, um die Konsistenz zwischen Systemen sicherzustellen. (Weitere Informationen finden Sie unter Well-Architected – Design Standards.)