Moderne Salesforce-integrationer skal understøtte meget mere end simpel dataudveksling. De forventes at styre kundeoplevelser i realtid, koordinere handlinger på tværs af flere systemer og fungere pålideligt på virksomhedsskala – alt sammen samtidig med at de opfylder strenge sikkerheds- og compliancekrav. Valg af den rigtige integrationsmetode er derfor en vigtig arkitektonisk beslutning, ikke en implementeringsdetalje. Overvej et almindeligt virksomhedsscenarie. En kunde fuldfører et køb i en mobilapp og udløser en berettigelseskontrol i realtid for et personliggjort tilbud. På samme tid skal transaktionsdata registreres i et ERP-system, kundeattributter opdateres i Salesforce og analyser streames til en data lake – uden at introducere forsinkelse, dataduplikering eller compliancerisiko. Scenarier som dette er nu typiske i moderne Salesforce-miljøer, hvor Salesforce sjældent fungerer isoleret og skal integreres uden problemer med et bredere økosystem af applikationer og dataplatforme. Denne vejledning findes for at hjælpe arkitekter og udviklere med at designe disse integrationer med tydelighed og tillid. I stedet for at fokusere på punkt-til-punkt-implementeringer, præsenterer den et sæt af beviste integrationsmønstre, der håndterer tilbagevendende virksomhedsscenarier – f.eks. procesorkestrering, datasynkronisering og realtidsdataadgang. Hvert mønster fremhæver arkitektoniske hensigter, afvejninger og kørselsmodeller, så team kan træffe informerede designbeslutninger, der skaleres og udholdes. I dette dokument finder du:
- Integrationsmønstre, der repræsenterer almindelige virksomhedsarkityper på tværs af proces-, data- og virtuelle adgangsscenarier
- En mønstervalgstruktur til at hjælpe med at identificere den rigtige tilgang baseret på integrationshensigt og kørselstidsangivelse
- Praktisk vejledning om skalerbarhed, modstandsdygtighed, styring og sikkerhedsovervejelser
- Bedste fremgangsmåder, der trækkes fra Salesforce- og Data 360-implementeringer i den virkelige verden Formålet med dette dokument er at levere et fælles arkitektonisk sprog til integration, der hjælper teams med at designe løsninger, der balancerer ydeevne, fleksibilitet og Trust, samtidig med at de er i overensstemmelse med virksomhedsdata og styringsstrategier.
Dette dokument er til designere og arkitekter, der har brug for at integrere data fra andre applikationer i deres virksomhed med Salesforce Data 360 (tidligere Data Cloud). Dette indhold er en destillation af mange vellykkede implementeringer af Salesforce-arkitekter og -partnere. Hvis du vil gøre dig bekendt med integrationsfunktioner og indstillinger, der er tilgængelige for ibrugtagning af Data 360 i stor skala, kan du læse afsnittene Mønstersammendrag og vejledning til mønstervalg nedenfor. Architekter og udviklere bør overveje disse mønsterdetaljer og bedste fremgangsmåder under design- og implementeringsfasen af datainteraktionsprojekter i Data 360. Hvis de implementeres korrekt, giver disse mønstre dig mulighed for at komme i produktion så hurtigt som muligt og have det mest stabile, skalerbare og vedligeholdelsesfrie sæt af applikationer. Salesforces egne konsulentarkitekter bruger disse mønstre som referencepunkter under arkitektoniske gennemgange og vedligeholder og forbedrer dem aktivt. Som med alle mønstre dækker dette indhold de fleste integrationsscenarier, men ikke alle. Selvom Salesforce tillader f.eks. brugergrænsefladeintegration, er en sådan integration uden for dette dokuments omfang.
Hvert integrationsmønster følger en ensartet struktur. Dette giver ensartethed i de oplysninger, der leveres i hvert mønster, og gør det også nemmere at sammenligne mønstre.
- Navn: Den mønsteridentifikator, der også angiver den type integration, der er indeholdt i mønsteret.
- Context: Det generelle integrationsscenarie, som mønsteret håndterer. Kontekst giver oplysninger om, hvad brugerne forsøger at opnå, og hvordan applikationen optræder for at understøtte kravene.
- Problem: Udtrykt som et spørgsmål er dette det scenarie, som mønsteret er designet til at løse. Læs dette afsnit for at forstå, om mønsteret er relevant for dit integrationsscenarie.
- Forces: De begrænsninger og omstændigheder, der gør det angivne scenarie vanskeligt at løse.
- Løsning: Den anbefalede måde at løse integrationsscenariet på.
- Sketch: Et UML-sekvensdiagram, der viser dig, hvordan løsningen håndterer scenariet.
- Resultater: Forklarer detaljerne for, hvordan du anvender løsningen på dit integrationsscenarie, og hvordan det løser de kræfter, der er knyttet til dette scenarie. Dette afsnit indeholder også nye udfordringer, der kan opstå som et resultat af anvendelse af mønsteret.
- Sidebars: Yderligere afsnit, der er relateret til mønsteret, der indeholder vigtige tekniske problemer, variationer af mønsteret, mønsterspecifikke problemer osv.
- Eksempel: Et scenarie i den virkelige verden, der beskriver, hvordan designmønsteret bruges i et Salesforce-scenarie i den virkelige verden. Eksemplet forklarer integrationsmålene, og hvordan du implementerer mønsteret for at nå disse mål.
Brug denne tabel som en indholdsfortegnelse for de integrationsmønstre, der er indeholdt i dette dokument.
| Mønsterniveau1 | Mønsterniveau2 | Mønster | Sekenarier |
|---|---|---|---|
| Dataoverførselsmønstre - Data Indgående | Batter overførselsmønstre | Bulk dataoverførsel fra Cloud-lagring | Data overføres fra en Enterprise Cloud-lagringskilde som Amazon S3, Azure Blob eller Google Cloud Storage i Data 360 i form af store batches af rå data (f.eks. transaktioner eller produktlogfiler). |
| Massedataoverførsel fra Salesforce Clouds | Data 360 modtager CRM-data i grupper fra flere Salesforce-organisationer (f.eks. Sales Cloud, Service Cloud) for at opbygge forenede kundeprofiler. | ||
| Streaming og overførselsmønstre i realtid | Begivenhedsstyret overførsel via overførsels-API--Streaming | Data 360 abonnerer på streamingoverførselsslutpunkter, der modtager kontinuerlige begivenhedsdata (f.eks. købsbegivenheder, IoT-telemetri) fra virksomhedssystemer for profilopdateringer i realtid. | |
| Overførsel af web- og mobiladfærd i realtid | Data 360 indsamler og behandler website- og mobilappadfærdsmæssige data i realtid gennem SDK'er for at berige engagementmetrikker og tilpasningsmodeller. | ||
| Tæt på realtid CRM Synchronization via streaming | Data 360 modtager CRM-dataopdateringer (f.eks. kontakt, sag, salgsmulighedsændringer) i nærrealtid via begivenhedsstreams for at vedligeholde en kontinuerligt synkroniseret Customer 360. | ||
| Event Stream overførsel fra Cloud-meddelelsesplatforme - Kinesis og MSK | Data 360 forbruger streamingdata direkte fra cloudbegivenhedsplatforme som AWS Kinesis eller Kafka (MSK) til at behandle driftsmæssige eller IoT-begivenheder med høj frekvens. | ||
| Nulkopier mønstre - indgående og udgående | Inbound Zero Copy – Eksterne platforme til Data 360 | Data 360 forespørger på eksterne datasæt (f.eks. Snowflake, BigQuery) efter behov gennem nulkopieringsoverførsel, uden fysisk at flytte data ind i Salesforce. | |
| Outbound Zero Copy--Data 360 til eksterne platforme | Eksterne systemer som Databricks eller Tableau får adgang til berigede segmenter og indsigter i Data 360 via nulkopier udgående forbindelser uden datareplikering. | ||
| Unified Multi Org Data Platform med Data Cloud One | Data Cloud One forener flere Salesforce-organisationer og eksterne datakilder under en delt metadata- og semantisk model, hvilket giver en ensartet Customer 360 uden dataduplikering. | ||
| Dataktiveringsmønstre--Data udgående | Batchaktiveringsmønstre | Segmentaktivering til marketing- og annonceringsplatforme | Data 360 aktiverer organiserede kundesegmenter direkte i Marketing Cloud, Meta, Google Ads eller andre annonceringsplatforme til personlig kampagnelevering |
| Dataeksport til Cloud-lagring | Data 360 eksporterer forenede eller filtrerede datasæt (f.eks. samtykkede kunderegistreringer) som CSV- eller Parket-filer til enterprise cloud-lagring til analyse eller overholdelsesarkivering. | ||
| On-demand API-baseret aktivering | Tilpasset applikationsintegration via Connect API | Eksterne applikationer kalder Data 360 Connect API inReal-Time for at hente eller udløse personlige handlinger (f.eks. loyalitetsbalancekontrol eller AI-tilbudsgenerering) baseret på aktuelle kundedata.Tilpassede web- eller mobilapplikationer henter harmoniserede Data 360-indsigter sikkert via Connect REST API til visning i virksomheds- eller partnerbrugergrænseflader. | |
| Fuldstændig hentning af kundeprofil via Data Graph API | Et system henter en kundes forenede profil ved brug af Data Graph API og returnerer en forhåndssammenføjet, realtids-JSON-repræsentation af den komplette 360°-visning til beslutningstagning eller tilpasning. | ||
| Datahandlinger i realtid | Datahandling i realtid, der omdanner kundesignaler til øjeblikkelig handling | Data 360 registrerer og behandler en live-begivenhed (f.eks. samtykkeopdatering, købsudløser) og kalder straks et tilsluttet system eller Salesforce-forløb til downstream-handling.Et kundens aktivitetssignal (f.eks. afgangsrisiko registreret) i Data 360 udløser en øjeblikkelig handling i realtid – f.eks. opdatering af CRM, kald af Einstein eller start af en bevarelsesrejse. |
Integrationsmønstrene i dette dokument er klassificeret i tre kategorier: data, proces og visuelle integrationer.
Dataintegrationsmønstre i Data 360 håndterer flytning og synkronisering af data på tværs af systemer for at sikre, at både Data 360 og eksterne platforme indeholder ensartede, rettidige og pålidelige oplysninger. Disse mønstre håndterer typisk store, højvolumen dataforløb og er afhængige af administrerede pipelines, der håndhæver skemakontrol, afledningssporing og overordnede regler.
- Batchoverførselsmønstre repræsenterer det grundlæggende lag af virksomhedsdataintroduktion. Masseoverførsel af data fra cloud-lagringstjenester som f.eks. AWS S3, Azure Blob eller Google Cloud Storage tillader, at store historiske datasæt indlæses regelmæssigt i Data 360 til identitetsløsning, segmentering og analyser. På samme måde bruger masseoverførsel fra Salesforce Clouds – f.eks. Sales, Service eller Marketing Cloud – oprindelige forbindelser og datastreams til at bringe CRM-data ind i det forenede datalag, hvilket sikrer harmonisering og kontinuitet på tværs af systemer af engagement.
- Streaming- og overførselsmønstre i realtid udvider dette ved at registrere begivenhedsdata med høj hastighed. Begivenhedsstyret overførsel via overførsels-API'en gør det muligt for eksterne systemer kontinuerligt at streame kundeaktivitet i Data 360. Overførsel af web- og mobiladfærd i realtid registrerer clickstream- og interaktionsdata direkte fra digitale kontaktpunkter for at fremme øjeblikkelig tilpasning. CRM-synkronisering næsten i realtid gennem streaming-API'er sikrer, at kundeattributter og samtykkeopdateringer afspejles hurtigt på tværs af systemer. Begivenhedsstreamoverførsel fra meddelelsesplatforme som Amazon Kinesis eller Confluent MSK understøtter kontinuerlige pipelines med høj gennemsnit, der justerer Data 360 med virksomhedsbegivenhedsarkitekturer.
- Unified Multi-Org Data Platform med Data Cloud One er et yderligere eksempel på dataintegration, der giver et konsolideret miljø til at forene data fra flere Salesforce-organisationer og eksterne kilder under et fælles styring og semantisk lag. Dette sætter organisationer i stand til at opnå dataoverensstemmelse for hele virksomheden, delte datamodeller og skalerbare analyser.
- I aktiveringsfasen følger batchaktiveringsmønstre det samme dataintegrationsprincip. Segmenter, der er arrangeret i Data 360, eksporteres i planlagte job til downstream-marketing- og annonceringsplatforme – f.eks. Marketing Cloud, Meta Ads eller Google Ads – hvor de udløser kampagnekørsel. På samme måde kan datasæt eksporteres til cloud-lagringsmål for at fremme eksterne analyser og datavidenskabspipelines. På tværs af alle disse anvendelsessituationer fungerer Data 360 som kilden til sandheden for synkroniserede og arrangerede kundedata.
Procesintegrationsmønstre i Data 360 involverer udløsning eller orkestrering af forretningsprocesser på tværs af systemer i næsten realtid. Disse mønstre giver Data 360 mulighed for aktivt at deltage i virksomhedsarbejdsflows og aktiverer kontekstbaserede svar og dynamisk dataaktivering.
- On-demand API-baseret aktivering aktiverer engagementsscenarier i realtid. Gennem Connect API kan tilpassede applikationer forespørge på eller aktivere kundeprofiler direkte fra Data 360 som en del af operationelle processer – f.eks. en agentkonsol, der henter forenede profilindsigter under en kundeinteraktion. Komplet hentning af kundeprofil via Data Graph API understøtter sammensatte applikationer og mikroservices, der er afhængige af API-styret adgang til en kundes fulde enhedsdiagram, hvilket giver mulighed for dynamiske oplevelser uden forudfasede segmenter.
- Datahandlinger i realtid fremmer denne integrationsmetode yderligere ved at aktivere øjeblikkelig responsivitet. Når et kundesignal – f.eks. et køb, en formularindsendelse eller en tærskelbegivenhed – registreres, kan Data 360 udløse handlinger som opdatering af en CRM-registrering, kald af et eksternt webhook eller start af et personliggjort tilbudsarbejdsflow. Disse mønstre udtrykker ægte procesorkestrering, der skaber bro mellem realtidskundeintelligens og automatiseret kørsel.
Virtuelle integrationsmønstre i Data 360 aktiverer liveadgang til eksterne eller forenede datakilder uden at kopiere eller duplikere data fysisk. Disse er vigtige for virksomheder, der kræver administrerede, opdaterede oplysninger på forespørgselstidspunktet, mens dataflytning minimeres.
- Inbound Zero Copy Data Federation (External Platforms-to-Data 360) gør det muligt for eksterne systemer – f.eks. datalagre eller datalager – at dele datasæt med Data 360 gennem sikre, administrerede forbindelser (f.eks. Snowflake Secure Data Sharing). Dette sikrer, at Data 360 kan få adgang til og fungere på eksterne data virtuelt, hvilket bevarer opdateringen og eliminerer unødvendig replikering.
- Outbound Zero Copy Data Sharing (Data 360-til-External Platforms) gør det muligt for Data 360 at vise organiserede datasæt til ekstern forbrug, f.eks. AI-modellering, forretningsintelligens eller avanceret analyse, gennem sikker datafederation og live-forespørgselsmekanismer. Valg af den bedste integrationsstrategi for dit system er ikke trivielt. Der er mange aspekter, der skal overvejes, og mange værktøjer, der kan bruges, med nogle værktøjer, der er mere relevante end andre for bestemte opgaver. Hvert mønster håndterer specifikke kritiske områder, herunder funktionerne i hvert af systemerne, mængden af data, fejlhåndtering og transaktionalitet.
Når du vælger et integrationsmønster, skal du starte med at besvare to grundlæggende spørgsmål, der udgør det overordnede design og adfærd for integrationen. Hvad integrerer du? – Proces, Data eller Virtuel adgang Denne dimension definerer integrationens primære formål.
- Procesintegrationer fokuserer på orkestrering af forretningsarbejdsflows og koordinering af handlinger på tværs af systemer.
- Dataintegrationer fokuserer på synkronisering, berigelse eller udbredelse af data mellem systemer.
- Virtuelle integrationer fokuserer på at få adgang til eksterne data i realtid uden at kopiere eller vedligeholde dem i Salesforce eller Data 360. Forståelse af denne hensigt hjælper med at bestemme niveauet af orkestrering, dataflytning og kobling, der kræves mellem systemer.
- Hvordan skal den udføres? — Synkron eller asynkron metode definerer kørselsmodellen for integrationen.
- Synkrone integrationer er i realtid og blokerer, hvor opkalderen forventer et øjeblikkeligt svar – almindeligt anvendt til brugerdrevne eller valideringsscenarier.
- Asynkrone integrationer er ikke-blokerende og afkoblede, designet til at håndtere skalering, langvarige processer, genprøvninger og store datamængder. Sammen giver disse to dimensioner – integrationsintentionen og udførelsestidspunktet – en klar og ensartet ramme for at vælge det rigtige integrationsmønster, mens du afbalancerer brugeroplevelsen, skalerbarheden og den operationelle modstandsdygtighed. Bemærk: En integration kan kræve en ekstern middleware eller integrationsløsning (f.eks. Enterprise Service Bus), afhængigt af hvilke aspekter der gælder for dit integrationsscenarie.
Denne tabel viser mønstrene og deres nøgleaspekter for at hjælpe dig med at bestemme, hvilket mønster der bedst passer til dine krav, når din integration er fra Salesforce til et andet system
| Type | Tid | Overvejelser i forbindelse med udgående |
|---|---|---|
| Dataintegration | Asynkron | Segmentaktivering til marketing- og annonceringsplatforme |
| Proces-/dataintegration | Synkron | Tilpasset applikationsintegration via Connect API Fuldstændig hentning af kundeprofil via Data Graph API |
| Dataintegration | Synkron | Datahandling i realtid, der omdanner kundesignaler til øjeblikkelig handling |
| Virtuel integration (ved brug af nul-kopiering) | Asynkron | Outbound Zero Copy--Data 360 til eksterne platforme |
| Virtuel integration | Asynkron | Unified Multi Org Data Platform med Data Cloud One |
Denne tabel viser mønstrene og deres nøgleaspekter for at hjælpe dig med at bestemme det mønster, der bedst passer til dine krav, når din integration er fra et andet system til Salesforce.
| Type | Tid | Overvejelser i forbindelse med indgående |
|---|---|---|
| Dataintegration | Asynkron | Bulk dataoverførsel fra Cloud-lagring Massedataoverførsel fra Salesforce Clouds |
| Dataintegration | Asynkron | Event Stream overførsel fra Cloud-meddelelsesplatforme - Kinesis og MSK Tæt på realtid CRM Synchronization via streaming |
| Procesintegration | Synkron | Begivenhedsstyret overførsel via overførsels-API--Streaming Overførsel af web- og mobiladfærd i realtid |
| Virtuel integration | Asynkron | Inbound Zero Copy – Eksterne platforme til Data 360 |
Denne tabel viser nogle nøgleudtryk, der er relateret til middleware og deres definitioner med hensyn til disse mønstre.
| Vilkår | Definition |
|---|---|
| Begivenhedshåndtering | Begivenhedshåndtering refererer til at modtage, distribuere og reagere på identificerbare forekomster fra et kildesystem eller en applikation. Middleware håndterer begivenheder ved at identificere målslutpunktet, videresende begivenheden og udløse den krævede forretningshandling (f.eks. logføring, forsøg eller aktivering af downstream-tjenester). I Data 360-arkitekturer er begivenhedshåndtering vigtig for realtidsdataoverførsel, aktiveringsudløsere og udgiv/abonnementsmønstre. Begivenheder kan stamme fra eksterne systemer (Kafka, AWS Kinesis) eller Salesforce Platform-begivenheder og distribueres af middleware eller Data 360-begivenhedsbussen til øjeblikkelig behandling. |
| Konvertering af protokol | Protokolkonvertering tillader kommunikation mellem systemer ved brug af forskellige dataoverførselsstandarder. Middleware oversætter egne eller ældre protokoller (f.eks. AMQP, MQTT, FTP) til understøttede Data 360-protokoller (REST, gRPC eller HTTPS). Dette sikrer interoperabilitet på tværs af heterogene systemer. Da Data 360 ikke som standard håndterer protokolkonvertering, leverer middleware tilpasningslaget, der indkapsler eller transformerer meddelelser til et format, Data 360-API'er og forbindelser kan fortolkes. |
| Oversættelse og transformation | Oversættelse og transformation sikrer interoperabilitet ved at tilknytte et dataformat eller et skema til et andet. Middleware udfører disse transformationer for at justere forskellige datadata (CSV, XML, JSON) med DMO'er (Data 360-datamodelobjekter) og forenede datalagsobjekter (UDLO'er). Dette inkluderer rensning, berigelse og anvendelse af semantisk eller ontologibaseret tilknytning før overførsel. Selvom Salesforce tilbyder transformationsværktøjer som opskrifter i Dataforberedelse, håndteres komplekse transformationer (især til semantisk harmonisering) bedst i middleware. |
| Kø og buffering | Kø og buffering er afhængige af asynkron meddelelse, der overføres for at sikre fleksibel, afskilt kommunikation. Mellemwareplatforme (f.eks. MuleSoft, Kafka eller Azure Event Hub) leverer vedvarende køer, der midlertidigt lagrer data, når Data 360 eller downstream-systemer er optaget eller utilgængelige. Dette forhindrer datatab og understøtter næsten realtidsoverførsel eller aktiveringsforsøg. Data 360 understøtter streaming overførsel og forløbsbaserede udgående meddelelser, men holdbar kø og garanteret levering håndteres typisk af middleware. |
| Synkrone transportprotokoller | Synkrone transportprotokoller involverer blokering af anmodnings-/svarhandlinger i realtid. Afsenderen venter på et svar, før han eller hun fortsætter. I Data 360 bruges disse til on-demand API-baserede aktiveringer, berigelse i realtid eller profilopslag, hvor der kræves svar med det samme. Middleware sikrer forbindelsessikkerhed og administrerer forsøg eller tilbagerulningshåndtering for synkrone Data 360 API-kald. |
| Asynkrone transportprotokoller | Asynkrone transportprotokoller understøtter ikke-blokerende, afkoblet kommunikation, hvor afsenderen fortsætter med at behandle uden at vente på et svar. Middleware håndterer asynkrone forløb for batchaktiveringer, streaming overførsel og begivenhedsstyret aktivering. Dette tillader høj gennemsnit og fleksibilitet – afgørende for begivenhedsstreaming og dataoverførselsmønstre i næsten realtid i Data 360. |
| Mediation Routing | Mediationsdistribution definerer kompleks meddelelsesforløb mellem systemer, så du sikrer, at de rigtige data eller begivenheder når den rigtige forbruger. Middleware fungerer som en mediator og håndterer distributionslogik baseret på regler, sidehoveder, indhold eller begivenhedstype. I Data 360-integrationer sikrer mediation, at begivenheder og profilopdateringer fra flere systemer distribueres korrekt til dataoverførsels-API'er, aktiveringsslutpunkter eller eksterne forbrugere. Dette forenkler orkestrering og understøtter datasynkronisering med flere systemer. |
| Proces koreografi og serviceorkestrering | Proceskoreografi og orkestrering koordinerer multi-systemprocesser. Koreografi understøtter autonome, asynkrone begivenhedsstyrede forløb, hvor systemer handler baseret på delte regler uden en central controller. Orkestrering er et centralt administreret forløb, der dirigerer servicekørsel. I Data 360-arkitekturer administrerer middleware orkestrering for overførsel og aktivering på tværs af systemer, mens Salesforce-arbejdsflows eller -forløb håndterer letvægts koreografier på platformen. Kompleks orkestrering, der kræver transaktionskoordination eller statsstyring, anbefales på middleware-laget. |
| Transaktionalitet (kryptering, signering, pålidelig levering, transaktionsstyring) | Transaktionalitet sikrer atomiske, ensartede, isolerede og holdbare (ACID)-handlinger på tværs af systemer. Salesforce og Data 360 er transaktionelle inden for deres grænser, men understøtter ikke distribuerede transaktioner på tværs af eksterne systemer. Middleware håndterer global transaktionskontrol, herunder kryptering, meddelelsessignering, tilbagerulning, kompensation og pålidelig levering. For missionskritiske dataforløb (f.eks. finansielle eller samtykkeopdateringer) sikrer middleware end-to-end-integritet og gendannelse på tværs af Data 360- og eksterne systemer. |
| Rute | Distribution angiver det kontrollerede forløb af meddelelser eller data mellem komponenter. Det kan være baseret på sidehoveder, indholdstype, prioritet eller regler. Middleware håndterer distributionslogik for begivenheder og aktiveringer, der involverer Data 360, f.eks. dirigering af berigede målgruppesegmenter til forskellige downstream-systemer (annonceplatforme, lagerbygninger, CRM-apps). Selvom distribution kan implementeres i Salesforce (Apex, Forløb), foretrækkes middleware-distribution af hensyn til skalerbarhed, fleksibilitet og styring. |
| Udtræk, transformer og indlæs (ETL) | ETL involverer udtrækning af data fra kildesystemer, transformation af dem til et ensartet skema og indlæsning af dem i et mål (f.eks. Data 360). Mellemware- eller ETL-værktøjer håndterer disse handlinger før dataoverførsel. Data 360 kan modtage ETL-output via API'er, forbindelser eller masseoverførselspipelines, og understøtter også Change Dataregistrering (CDC) til synkronisering i næsten realtid. Middleware ETL-processer er vigtige for integration af forældede systemer og sikring af datakvalitet før forening i Data 360. |
| Lange afstemninger | Lang polling (Comet-programmering) er en metode til at vedligeholde åben kommunikation mellem systemer for opdateringer i realtid. Klienten sender en anmodning, og serveren bevarer den, indtil der forekommer en begivenhed, og derefter svarer og genåbner en ny forbindelse. Salesforce bruger dette i streaming-API- og CometD/Bayeux-protokollerne til begivenhedsstyret datasynkronisering. Middleware kan abonnere på disse begivenheder og videresende dem til Data 360 for realtidsoverførsel eller aktiveringsudløsere, hvilket sikrer minimal forsinkelse på tværs af virksomhedssystemer. |
Dataoverførsel er det første og mest vigtige trin i Salesforce Data 360's datalivscyklus. Det er, hvordan rå oplysninger fra flere eksterne systemer – CRM, ERP, web, mobil eller tredjeparts-API'er – føres til platformen og bliver en del af en forenet kundevisning. Det rigtige overførselsmønster afhænger af, hvad forretningen har brug for:
- Datamængde – hvor mange data der flytter på én gang
- Latency – hvor opdaterede data skal være
- Kildesystemfunktioner – hvordan systemet kan tilslutte og levere data Data 360 understøtter flere overførselstilstande for at opfylde disse behov: batch for højvolumen indlæsninger, streaming for næsten realtidsopdateringer, begivenhedsbaseret for transaktionsmæssig umiddelbarhed og Zero Copy-overførsel for øjeblikkelig adgang til eksterne data uden fysisk at flytte dem. Sammen sikrer disse mønstre, at hvert kundesignal – uanset om det er en købsbegivenhed, en clickstream-log eller en loyalitetsopdatering – flyder ind i Data 360 effektivt, sikkert og i den rigtige tidsramme for at styrke betroede analyser og AI-styrede oplevelser.
Batchoverførselsmønstre er grundlaget for introduktion af data i stor skala i Data 360. De er optimeret til scenarier, hvor data behandles i grupper – typisk på en planlagt eller regelmæssig basis – snarere end kontinuerligt. Disse mønstre er bedst egnede til:
- Historiske dataindlæsninger til at initialisere platformen med eksisterende virksomhedsregistreringer
- Regelmæssig synkronisering med registreringssystemer som ERP, datalager eller proprietære databaser
- Brug sager, hvor opdatering i realtid ikke er afgørende, men ensartethed, fuldstændighed og revisionsmulighed er afgørende Batchoverførsel tilbyder forudsigelig ydeevne og driftssammenhæng, hvilket gør det til et betroet valg for virksomheder, der administrerer terabyte strukturerede eller semistrukturerede data. Data 360 leverer et sæt produktionsklar, almindeligt tilgængelige forbindelser, der understøtter batchoverførsel som standard. Disse forbindelser strømliner integrationsopsætning, reducerer tilpasset ETL-udvikling og sikrer datakvalitet og sikkerhed på tværs af hver import. Tabellen nedenfor fremhæver de mest almindelige forbindelser, der bruges til batchoverførsel på virksomhedsskala.
Kontekst
Dette mønster er designet til virksomhedsscenarier, der involverer overførsel af store mængder strukturerede data – f.eks. CSV- eller Parket-filer – og ustrukturerede aktiver fra centraliserede datalager eller planlagte fillaps. Datakilder omfatter sædvanligvis cloud-lagringsplatforme som Amazon S3, Google Cloud Storage (GCS) og Microsoft Azure Blob Storage, hvor filer leveres regelmæssigt som en del af upstream-datapipelines eller batcheksporter.
Problem
Hvordan kan en organisation etablere en pålidelig, sikker og højproduktproces til at overføre massive, filbaserede datasæt fra dens primære cloud-lagringsplatform til Data 360 på en forudsigelig, tilbagevendende tidsplan – uden at ofre styring, skalerbarhed eller ydeevne?
Kræfter
Overførsel af massive, filbaserede datasæt i Data 360 er ikke en enkel dataoverførselsøvelse – det er en arkitektonisk udfordring, der er udformet af skala, styring og platformsbegrænsninger.
Datamængde og skala: Data 360-overførselsforbindelser optimeres til pålidelighed og styring, ikke til vilkårlig massegennemsnit. Amazon S3-forbindelsen understøtter f.eks. op til 100 millioner rækker eller 50 GB pr. objekt, afhængig af hvilken grænse der først nås. For virksomheder med historiske datasæt, der kører i milliarder af registreringer, bliver denne grænse til en nøgledesignbegrænsning. En enkelt fil, lift-og-vagt-tilgang bliver hurtigt ikke gennemførlig, hvilket kræver intelligente datapartitionerings-, segmenterings- og orkestreringsstrategier for at opnå skalering uden at nå forbindelsesgrænser.
Skemadefinition og vedligeholdelse : Data 360 kræver eksplicitte skemadefinitioner for hver overførselspipeline for at sikre semantisk og strukturel integritet. I tilfælde af S3-overførsel skal en csv-fil definere kolonnesidehoveder og en enkelt repræsentativ datarække. Denne fil fungerer som den kanoniske kontrakt mellem kildesystemet, dvs. cloud-lagring og Data 360. Enhver fejljustering – i feltnavne, datatyper eller kodning – kan forårsage overførselsfejl eller skjult datakorruption. Vedligeholdelse af denne skemafil i versionskontrol og håndhævelse af validering gennem CI/CD eller dataadministrationsarbejdsflows bliver en bedste fremgangsmåde for produktionsmiljøer.
Streng navngivningskonventioner: Data 360 håndhæver strenge objekt- og feltnavngivningsregler for at opretholde ensartethed på tværs af metadatadiagrammet.
- Objektnavne skal starte med et bogstav og kan kun indeholde bogstaver, cifre eller understregninger.
- Feltnavne skal følge de samme mønstre. Filer, der overtræder disse konventioner – f.eks. felter, der indeholder mellemrum, specialtegn eller ikke-understøttede symboler – vil mislykkes skemavalidering under overførsel. Virksomheder skal implementere data hygiejne før indtagelse for at sanere og normalisere indgående filstrukturer.
Authentication og sikkerhedstilstand : Hver forbindelse til eksternt lager skal overholde sikkerheds- og compliancestandarder på virksomhedsniveau.
- Godkendelse håndteres typisk gennem AWS-adgang/hemmelige nøgler eller idP-godkendelse (forenet identitetsudbyder).
- IAM-roller skal være tilpasset for at håndhæve mindste rettigheder og kun tillade læseadgang til de angivne lagringsstier.
- For at opnå sikker adgang skal udgående IP-adresser føjes direkte til kildesystemets tilladelsesliste. Disse lagdelte kontrolelementer sikrer, at hver filoverførsel fungerer inden for en Trust-perimeter, der kan revideres, og afbalancerer virksomhedens overholdelse med den fleksibilitet, der kræves for storstilet overførsel.
Løsning
Denne tabel indeholder løsninger på dette integrationsproblem.
| Løsning | Tilpas | Kommentarer |
|---|---|---|
| Brug Native Cloud-lagringsforbindelser (Amazon S3, Google Cloud-lagring, Azure Blob-lagring) | Best | Dette er det anbefalede og mest pålidelige mønster for storskala, tilbagevendende filbaseret overførsel i Data 360\. Indbyggede forbindelser giver administreret godkendelse, skematilknytning og sikker dataflytning direkte i Data 360's Data Lake-objekter (DLO'er). Ideel til planlagte batchindlæsninger, hvor forsinkelse ikke er vigtig (f.eks. planlægning pr. time eller dag). |
| Håndtering af store datasæt (ud over forbindelsesgrænser) | Bedst med forbehandling | Hver forbindelse håndhæver overførselsgrænser (f.eks. S3: 100M rækker eller 50 GB pr. objekt). For større datasæt skal du implementere et ETL-forhåndsbehandlingstrin for at partitionere data i mindre filer/mapper, der falder under disse tærskler. Konfigurer derefter flere datastreams til at overføre hver partition parallelt, og brug tilføjelsesnoden i en batchdatatransformation) i Data 360 til at kombinere partitionerne i et forenet datasæt. |
| Sikkerhed og styring | Best | Alle forbindelser understøtter sikker godkendelse via cloud-oprindelige metoder (IAM-roller, servicekonti eller adgangsnøgler). Hvis du ønsker yderligere kontrol, skal du begrænse adgang til Data 360 IP-områder via cloududbyderens tilladelsesliste. Dataoverførsel sker over krypterede kanaler med filer, der er lagret i et midlertidigt, sikkert midlertidigt lag under overførsel. |
| Hvornår ikke at bruge | Suboptimal | Dette mønster er ikke optimalt for:
|
Skitser
Dette diagram illustrerer sekvensen af trin til at overføre data fra cloudlageret i Data 360
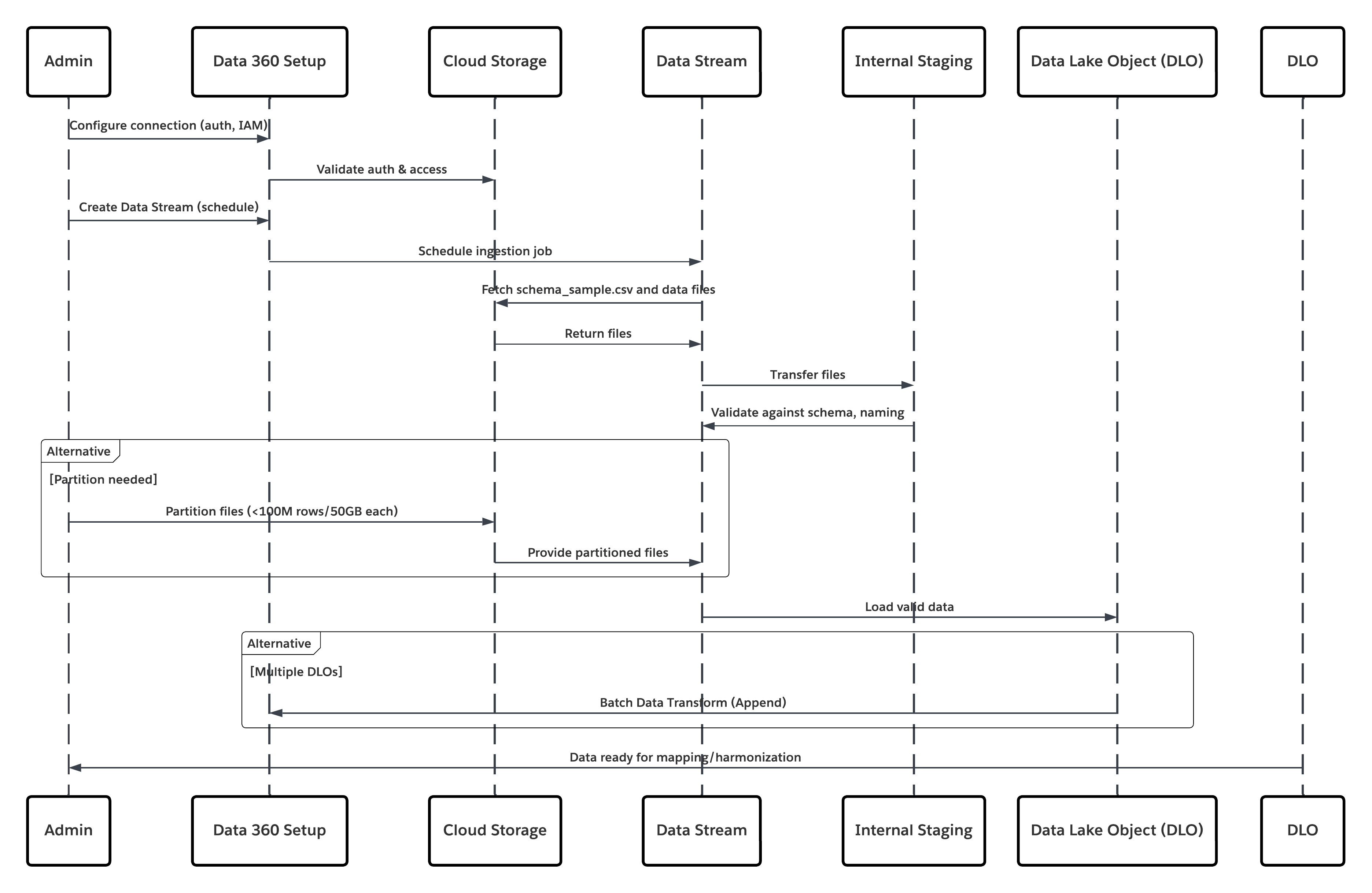
I dette scenarie:
- Administrator konfigurerer en forbindelse til cloud-lagring via Data 360-opsætningsgrænsefladen (angiver godkendelse, inddelingsdetaljer, IAM-roller og whitelisting).
- Data Cloud-opsætningsgrænseflade godkendes med Cloud-lagringsplatformen og bekræfter legitimationsoplysninger og adgang.
- Administrator opretter en datastream i Data 360, linker datastreamen til objektet/mappen i Cloud Storage og definerer overførselstidsplanen.
- På planlægningsudløser anmoder datastreamen om kildefiler (f.eks. CSV, Parket) fra Cloud Storage Platform.
- Cloud Storage Platform leverer filer, herunder den krævede gyldige schema_sample.csv og andre datafiler, der er kompatible med navnekonventioner.
- Datastream overfører filer til det interne faseinddelingsmiljø i Data 360.
- Data 360 Pipeline behandler filerne: Bruger skemadefinitionen fra schema_sample.csv Validerer struktur, feltnavne og dividerer indlæsningen, hvis den overskrider overførselstærsklerne (100 millioner rækker/50 GB pr. fil). Hvis der registreres store filer, udføres et forbehandlingspartitioneringstrin (adviseres til administrator for næste kørsel) eksternt.
- Registreringer importeres fra faseinddeling i et DLO (data lake object).
- Hvis der kræves, og data er partitioneret, skal du bruge tilføjelsesnoden i en batchdatatransformering til at kombinere flere DLO'er.
- Data 360 logfører succes/fejl, opdaterer status for overvågning og signalerer, at data er klar til kortlægning, harmonisering og forening.
Resultater
Anvendelsen af dette mønster aktiverer sikker, planlagt og storskalaoverførsel af strukturerede eller ustrukturerede filer fra Enterprise Cloud-lagringsplatforme i Data 360. Processen er automatiseret, skalerbar og fleksibel – leverer rå data i DLO'er (data lake objects), der tjener som grundlag for harmonisering og tilknytning til Customer 360
Overførselsmekanismer
Overførselsmekanismen afhænger af forbindelsen og planlægningsstrategien, der er defineret i Data 360.
| Overførselsmekanisme | Beskrivelse |
|---|---|
| Indbygget Cloud-lagringsforbindelse (Amazon S3, GCS, Azure) | Anbefales til direkte overførsel af filer i CSV- eller parketformat fra virksomhedens clouddatalake. Disse forbindelser understøtter trinvise og fulde opdateringsplaner. En bank kan f.eks. konfigurere en daglig synkronisering af kundetransaktionsfiler fra en S3-inddeling til en DLO. |
| Partitioneret filstrategi | For meget store datasæt (ud over 100 millioner rækker eller 50 GB pr. objekt) partitioneres dataene i mindre logiske sæt (f.eks. efter måned eller område). Hver partition administreres som en separat datastream og kombineres senere ved brug af en datatransformering med en tilføjelsesnode. |
| Automatiseret planlagt synkronisering | Data 360 leverer en deklarativ planlægning (time, daglig eller tilpasset kadence), der udløser overførselsjob automatisk og sikrer datafriskhed uden manuel intervention. |
Fejlhåndtering og gendannelse
Fejlhåndtering og gendannelse er afgørende for at sikre pålideligheden i højvolumen overførselshandlinger.
- Fejlregistrering: Hver datastream kører overførselsfejl (f.eks. skemauoverensstemmelse, filkorruption eller navneovertrædelser) i Data 360-overvågning. Administratorer kan gennemse og behandle mislykkede batches igen.
- Recovery Mechanism: Data 360 vedligeholder kontrolpunkter for at sikre, at mislykkede batches ikke ødelægger tidligere overførsler. Gentagelser kan konfigureres efter rettelse af kildeproblemer (f.eks. forkert udformede CSV'er).
- Skemavalidering: Filen schema_sample.csv definerer datatyper og struktur. Enhver ændring udløser validering for at undgå tavse skemaforskydninger på tværs af kørsler.
Overvejelser i forbindelse med idempotent design
Overførsel er idempotent af design – genbehandling af den samme fil resulterer ikke i dubletregistreringer. Nøglestrategier omfatter:
- Filer Fingeraftryk: Data 360 beregner kontrolsummer for at identificere og ignorere tidligere behandlede filer.
- Transaktionsoverførsel: Data er faseinddelt og kun bekræftet til DLO efter vellykket behandling af alle registreringer.
- Append vs. Erstat: Afhængig af forretningslogik kan streams føjes til eller erstatte mål-DLO fuldstændigt. Dette sikrer deterministiske resultater og forhindrer delvise dataoverlapninger.
Sikkerhedsovervejelser
Sikkerhed er integreret i hele overførselspipelinen fra godkendelse til kryptering og adgangskontrol.
- Godkendelse og autorisation: Forbindelser bruger Salesforces sikre integrationsstruktur og anvender navngivne legitimationsoplysninger og eksterne legitimationsoplysninger til godkendelse uden at vise hemmeligheder.
- Kryptering: Data krypteres under transit (TLS 1.2+) og inaktive (AES-256).
- Netværkskontroller: Kildelagersystemer (f.eks. S3-inddelinger) skal sætte Data 360-IP'er på tilladelseslisten.
- Overensstemmelsesjustering: Understøtter databeskyttelsesstrukturer for virksomheder som f.eks. GDPR, HIPAA og FFIEC-retningslinjer, når de er parret med Customer-Managed Keys (CMK).
- Auditerbarhed: Hvert overførselsjob og adgang til legitimationsoplysninger logføres til sporbarhed og overensstemmelsesrapportering.
Sidebars
Tidlighed
Tidlighed afhænger af overførselstidsplanen og datamængden.
- Store virksomhedsdatasæt (100M+ rækker) kan kræve partitionering for parallel overførsel.
- Den typiske overførselsforsinkelse varierer fra minutter til nogle få timer, afhængigt af filstørrelse og transformationskompleksitet.
- For overførsel næsten i realtid kan Data 360-streaming eller API-baserede forbindelser supplere den filbaserede model.
Datamængder
- Best egnet til højvolumen, periodisk batchoverførsel.
- Hvert objekt, der behandles gennem S3-forbindelsen, understøtter op til 100 millioner rækker eller 50 GB pr. fil.
- For petabyte-skala-systemer skal du bruge datapartitionering og orkestrering med flere streams.
Slutpunktsfunktionalitet og standardsupport
Funktionaliteten og standardunderstøttelsen af slutpunktet afhænger af den løsning, du vælger.
| Forbindelsestype | Slutpunkts krav |
|---|---|
| Amazon S3-forbindelse | S3-inddeling med relevant IAM-politik og skema\_sample.csv-fil, der definerer skemaet. |
| Google Cloud Storage-forbindelse | Servicekontolegitimationsoplysninger og inddelingsadgang med ensartede navnekonventioner. |
| Azure Storage-forbindelse | Adgangsnøgle eller SAS-tokenbaseret godkendelse. Blob- eller mappestruktur skal følge Data 360-konventionerne. |
Statsadministration
Stat spores gennem datastreams og deres seneste vellykkede kørselstidsstempel.
- Data 360 vedligeholder automatisk synkroniseringstilstande og forskydninger, så det er kun nye eller redigerede filer, der behandles på efterfølgende kørsler.
- Når du integrerer med eksterne ETL-værktøjer, anbefales der entydige filidentifikatorer (f.eks. UUID'er eller tidsstempler) for at undgå duplikering.
Komplekse integrationsscenarier
I avancerede virksomhedsarkitekturer kan dette mønster integreres med:
- Middleware ETL Pipelines (f.eks. Informatica, MuleSoft): til at orkestrere forbehandling, validering og filpartitionering før overførsel til Data 360.
- AI/ML Workflows: behandlede DLO-data kan udgives via DMO til modelleringsmiljøer eller RAG-indekser gennem Data 360-aktiveringsmål.
- Transaktionssystemer: harmoniserede DMO'er kan udløse downstream-opdateringer i Salesforce CRM eller eksterne systemer via datahandlinger eller platformsbegivenheder.
Eksempel
En global finansiel institution lagrer kunde- og transaktionsdata i et AWS S3-datalager, hvor partitionerede Parket-filer genereres hver nat efter område (f.eks. USA, EU og APAC). Dataarkitekturteamet konfigurerer flere datastreams i Data 360, der hver er tilsluttet en regional mappe, med en delt schema_sample.csv, der sikrer ensartede sidehoveder og datatyper på tværs af alle partitioner. Nattlige overførselsplaner indlæser automatisk dataene i DLO'er, hvorefter batchdata-transformationer tilføjer alle regionale partitioner i en forenet Customer_Transactions_DLO. Dette harmoniserede datasæt tilknyttes derefter til Customer 360 og aktiverer downstream-analyser og AI-aktivering. Tilgangen leverer automatiseret og pålidelig overførsel fra den eksisterende datalager, håndhæver stærk godkendelse og kryptering i overensstemmelse med virksomhedens it-politikker og leverer et skalerbart, modulært fundament, der understøtter fremtidig udvidelse og skemaudvikling.
Kontekst
En primær og vigtig anvendelsessituation for Data 360 er at forene kundedata på tværs af Salesforce-økosystemet. Dette mønster dækker data, der overføres som standard fra Salesforce-kerneplatforme – Sales Cloud og Service Cloud (samlet Salesforce CRM) og Marketing Cloud-engagement. Kilder inkluderer standard og tilpassede CRM-objekter (f.eks. Konto, Kontakt, Sag, Salgsmulighed) og Marketing Cloud-engagements dataudvidelser, der indeholder engagementbegivenheder, mails og sporingsdata.
Problem
Hvordan kan en organisation effektivt og pålideligt overføre standard og tilpassede CRM-objekter og Marketing Cloud Engagement-dataudvidelser til Data 360, så dataene kan bruges til at opbygge forenede kundeprofiler (identitetsløsning, Customer 360), samtidig med at ydeevnen, styringen og minimale afbrydelser af kildesystemer bevares?
Kræfter
Indbyggede forbindelser forenkler jobbet, men flere driftsmæssige og arkitektoniske kræfter skal administreres:
- Omfattende kildetilladelser: En dedikeret forbindelsesbruger (integrationskonto) skal have de rette læsetilladelser på objekt- og feltniveau. Mislykkede tildelinger af krævede tilladelsessæt (f.eks. et tilladelsessæt for en Data 360-forbindelse, der er bygget på forhånd) er en almindelig årsag til overførselsfejl.
- Dataopdateringstilstande og omkostninger: Forbindelser understøtter fuld og delta-opdateringstilstande. Fuld opdateringer er tungere på ydeevne og kreditter. Deltaudtrækninger reducerer indlæsningen, men afhænger af pålidelig ændringssporing i kildesystemet.
- Tilpasset skema og felttilknytning: CRM-forekomster inkluderer ofte tilpassede objekter/felter. Nøjagtig skematilknytning og håndtering af tilpassede felter (navne, typer) kræves for at undgå tilknytningsfejl eller semantisk afvigelse.
- Starter-datapakker vs. Tilpasset tilknytning: Starterdatapakker sætter fart på introduktion ved at vælge typiske objekter/felter på forhånd, men kraftigt tilpassede organisationer skal have tilpassede streamdefinitioner.
- Gennemsnit og API-grænser: Kildeorganisationens API-grænser og Marketing Cloud-udtrækningsfrekvenser begrænser, hvor aggressivt du kan planlægge opdateringer.
- Konventioner om datahygiejne og navngivning: Kildefeltnavne, null-adfærd og datatyper skal normaliseres før overførsel for at forhindre downstream-tilknytningsproblemer.
- Sikkerhed og mindste rettighed: Forbindelsen er baseret på sikker godkendelse og skal respektere IAM-mønstre med mindst rettigheder, revisionsmuligheder og netværkskontroller.
Løsning
Denne tabel indeholder løsninger på dette integrationsproblem.
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| Løsning passer | Best | Brug den oprindelige Salesforce CRM-forbindelse og Marketing Cloud-engagementforbindelse i Data 360\. Start med Starter-datapakker for standardanvendelsessituationer, og skub i introduktion. Brug manuel streamtilpasning til tilpassede eller domænespecifikke datamodeller. |
| Håndtering af højt tilpassede CRM-forekomster | Bedst med tilknytningsværksted | Behandl starterpakker som en basislinje, og gennemfør en tilknytningsworkshop for at identificere: Tilpassede objekter og relationer. Formelfelter eller beregnede felter. Administrerede pakkeudvidelser. For tunge formelfelter skal du beregne værdier i en før fase-ETL eller i Data 360-transformationer for at minimere API-indlæsning på kildeorganisationer. |
| Hvornår ikke at bruge | Underoptimerede scenarier | Undgå dette mønster, hvis: Du skal bruge højfrekvent eller realtidsbegivenhedsoverførsel (brug i stedet streamingforbindelser, platformsbegivenheder eller nul-kopi-federation). Kildeorganisationen har begrænset API-kapacitet og kan ikke vedligeholde planlagte udtrækninger uden begrænsning eller køforsinkelser. |
| Sikkerhed og styring | Obligatoriske kontroller | Princippet om mindste rettighed - Brug en dedikeret integrationsbruger med minimal læseadgang. Brug aldrig administratorer for hele organisationen. Godkendelse – Brug OAuth 2.0 og tilsluttede apps. Roter klienthemmeligheder regelmæssigt og overvåg brugen af opdateringstoken. Audit og sporbarhed – Registrer alle overførselskørsler, skemaændringer og forbindelsesbegivenheder. Videresend logfiler til SIEM eller compliancesystemer for revisionsparathed. Dataklassificering – Anvend PII/PHI-tagging og attributbaseret adgangskontrol (ABAC) ved hjælp af CEDAR-politikker umiddelbart efter overførslen for at håndhæve maskering, samtykke og downstream compliance. |
Skitser
Dette diagram illustrerer sekvensen af trin til at overføre data fra cloudlageret i Data 360
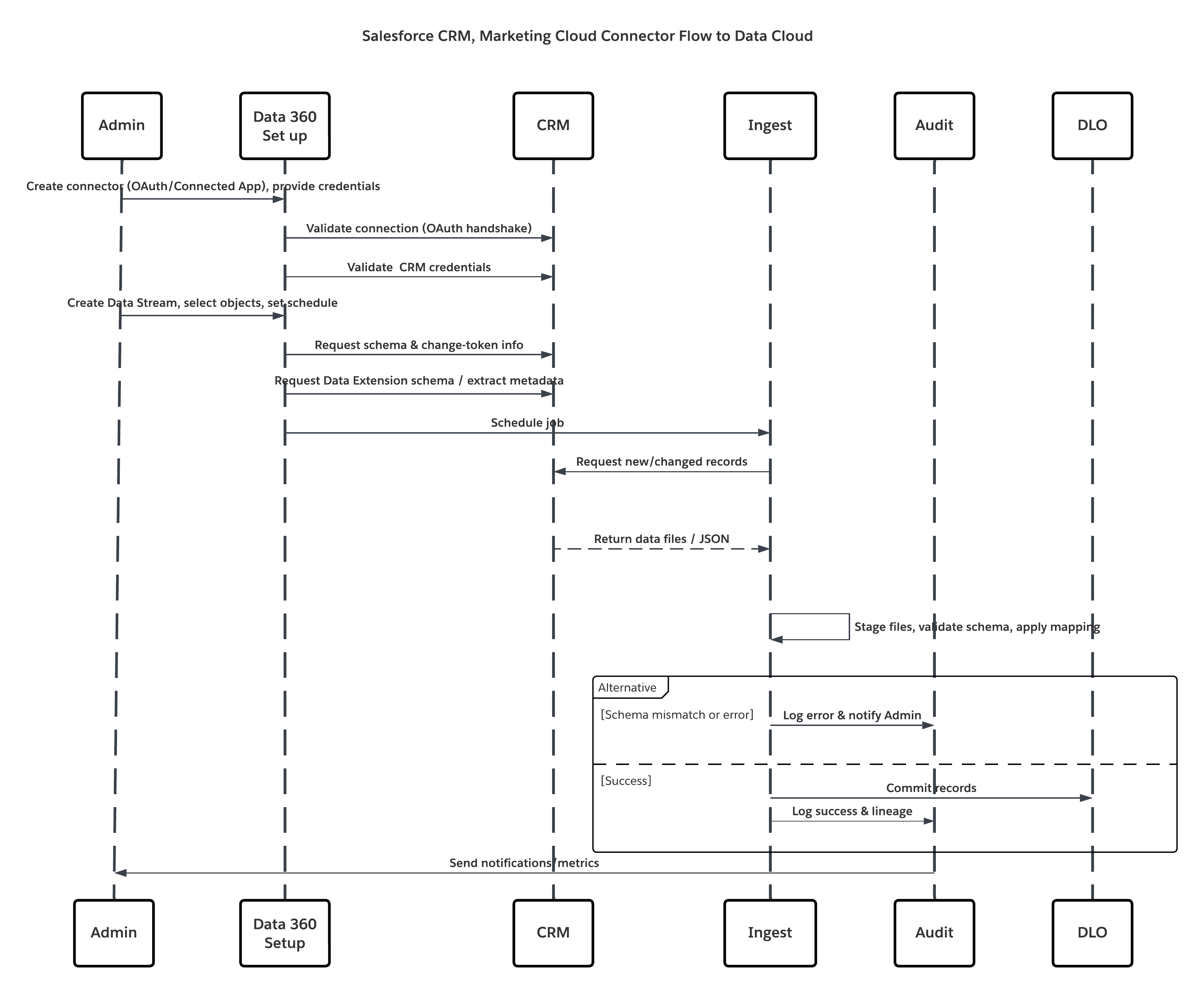
I dette scenarie:
- Administrator klargør integrationsbrugere og tildeler forbindelsestilladelsessæt i kildeorganisationer.
- Administratoren konfigurerer forbindelser i Data 360-opsætning (tilslutter til Salesforce CRM og Marketing Cloud via OAuth/tilsluttet app).
- Administrator opretter datastreams, der vælger objekter og dataudvidelser, vælger fuld eller delta-opdatering og angiver tidsplaner.
- På planlagt kørsel anmoder Data 360 om skema- og delta-tokener fra kilden eller kilderne.
- Kildesystemer returnerer registreringer (delta eller fuld data). Marketing Cloud kan levere udtrækninger. CRM kan returnere JSON/Forespørgselsresultater.
- Data 360 faseinddeler filer i sit interne sikre faseinddelingsområde og validerer mod tilknyttet skema.
- Hvis valideringen mislykkes, logfører overførslen fejl, advarer administratoren og stopper bekræftelsen. Hvis valideringen lykkes, bekræfter Data 360 registreringer atomisk til mål-DLO.
- Overvågnings- og revisionslogfiler opdateres med afstamning, kørselsvarighed, rækkeantal og anvendelse af legitimationsoplysninger. Advarsler udstedes til administratorer, hvis tærskler eller fejl udløses.
Resultater
Kerne-kunderelations- og marketingengagementsdata overføres til Data 360 som DLO'er (Data Lake Objects). Dette resulterer i:
- Forenet datasæt, der indeholder profiler, sager, salgsmuligheder og mail-/engagementmetrikker.
- Grundlag for identitetsløsning og opbygning af forenede personprofiler.
- Operativ parathed til downstream harmonisering, berigelse, AI-modellering og aktivering, mens styring og revisionsmulighed bevares.
Overførselsmekanismer
Overførselsmekanismen afhænger af forbindelsen og planlægningsstrategien, der er defineret i Data 360.
| Mekanisme | Hvornår bruges |
|---|---|
| Salesforce CRM-forbindelse (oprindelig) | Bedst til standard/tilpassede CRM-objekter, understøtter fuld og delta-opdatering. |
| Marketing Cloud-engagementforbindelse (oprindelig) | Bedst til dataudvidelser, afsendelser og sporingsudtrækninger understøtter fuld/delta-tilstande. |
| Starterdatapakker | Sæt skub i introduktion for almindelige objekter Salg/Service/Marketing. |
| Tilpassede streams + Forhåndsbehandling | Bruges, når der kræves komplekse transformationer eller kraftig skemastandardisering. |
Fejlhåndtering og gendannelse
Fejlhåndtering og gendannelse er afgørende for at sikre pålideligheden i højvolumen overførselshandlinger.
- Pro-run Logs: Hver datastreamkørsel indeholder oplysninger om gennemførelse/fejl og fejl på rækkeniveau.
- Retries & Checkpointing: Mislykkede kørsler kan forsøges igen efter rettelse af kilde- eller skemaproblemer. Data 360 bruger faseinddeling og atomisk bekræftelsessemantik.
- Alarmer: Konfigurer advarsler for skemaforskydning, gentagne fejl eller delta-sekvensmangler.
Overvejelser i forbindelse med idempotent design
Overførsel er idempotent efter design – genbehandling af den samme resulterer ikke i dubletregistreringer. Nøglestrategier omfatter:
- Ændringsregistrering: Delta-udtrækninger er afhængige af kildesystemændringsindikatorer (LastModifiedDate / systemændringsdataregistrering). Bekræft, at kilden leverer pålidelige tidsstempler/flag.
- Deduplikering: Brug entydige forretningsnøgler (f.eks. Contact.ExternalId) til at slette eller upsert til DLO'er.
- Transaktionsbekræftelse: Registreringer er faseinddelt og kun bekræftet, når batchbehandling er fuldført.
Sikkerhedsovervejelser
Sikkerhed er integreret i hele overførselspipelinen fra godkendelse til kryptering og adgangskontrol.
- Godkendelse og autorisation: Forbindelser bruger Salesforces sikre integrationsstruktur og anvender navngivne legitimationsoplysninger og eksterne legitimationsoplysninger til godkendelse uden at vise hemmeligheder.
- Kryptering: Data krypteres under transit (TLS 1.2+) og inaktive (AES-256).
- Netværkskontroller: Kildelagersystemer (f.eks. S3-inddelinger) skal sætte Data 360-IP'er på tilladelseslisten.
- Overensstemmelsesjustering: Understøtter databeskyttelsesstrukturer for virksomheder som f.eks. GDPR, HIPAA og FFIEC-retningslinjer, når de er parret med Customer-Managed Keys (CMK).
- Auditerbarhed: Hvert overførselsjob og adgang til legitimationsoplysninger logføres til sporbarhed og compliancerapportering
Sidebars
Tidlighed
Tidlighed afhænger af overførselstidsplanen og datamængden.
- Den ideelle kadence afhænger af forretningsbehovet – hver time for marketingudløsere i næsten realtid, hver nat for store afstemninger.
- Delta-tilstande reducerer belastning og omkostninger. Fuld opdateringer er tungere og bruges til indledende indlæsninger eller større skemaændringer.
Datamængder
- CRM-forbindelser optimeres til transaktionsmæssige og mellemvolumen datasæt (milioner registreringer).
- For ekstremt store historiske mængder kan du overveje faseinddelt ETL til at partitionere og indlæse i faser.
Slutpunktsfunktionalitet og standardsupport
Funktionaliteten og standardunderstøttelsen af slutpunktet afhænger af den løsning, du vælger.
| Forbindelse | Slutpunkts krav |
|---|---|
| Salesforce CRM-forbindelse | Kildeorganisationen skal tillade en tilsluttet app, OAuth-tokener og en dedikeret integrationsbruger med læsetilladelser. |
| Marketing Cloud-forbindelse | Marketing Cloud API-legitimationsoplysninger eller installerede pakker. Dataudvidelser skal vise data via udtrækninger/API. |
Statsadministration
- Forbindelsesstat: Datastreams bevarer de sidste vellykkede synkroniseringstidsstempler og delta-forskydninger.
- Master nøgle strategi: Foretræk ensartede forretningsidentifikatorer (eksterne id'er), så downstream afstemning og upserts er deterministiske.
Komplekse integrationsscenarier
I avancerede virksomhedsarkitekturer kan dette mønster integreres med:
- Hybridtopologier: Kombiner CRM-overførsel med streaming (platformsbegivenheder) for næsten realtidsopdateringer.
- Middleware orkestrering: Brug MuleSoft- eller ETL-værktøjer, når der kræves kompleks orkestrering, berigelse eller transformation før overførsel.
- Aktiveringsfeedback-løkker: Harmoniserede DMO'er kan udløse downstream-opdateringer til kildesystemer via datahandlinger eller platforms-API'er (pas på SoD-kontroller).
Eksempel
En multinational detailhandler konsoliderer engagementmetrikkerne Konti, Kontakter, Sager, Salgsmuligheder og Marketing Cloud i Data 360 for at oprette en forenet kundevisning. Starterdatapakken initialiserer kerneobjekterne Salg og Service, mens teamet udvider modellen med tilpassede felter som Loyalty_Membershipc og Customer_Tierc for at registrere loyalitetskontekst. CRM-datastreams kører hver time i delta-tilstand, og Marketing Cloud-engagement synkroniseres dagligt ved brug af deltaudtrækninger for engagementbegivenheder. Disse datasæt behandles gennem DLO'er og identitetsløsning, hvilket resulterer i en forenet kundeprofil, der kombinerer CRM og engagementssignaler til at styrke tilpasning og downstream AI-modeller.
Disse mønstre er opbygget til scenarier, hvor millisekunder betyder noget – når kundeinteraktioner, transaktioner eller signaler skal udløse øjeblikkelig indsigt eller handling. De går ud over traditionel planlagt batchoverførsel for at aktivere begivenhedsstyret dataforløb, hvor oplysninger behandles i det øjeblik, de genereres. I Salesforce Data 360-økosystemet er "real-time" ikke en enkelt tilstand – det er en kontinuum af forsinkelsesmodeller. På den ene ende findes synkronisering næsten i realtid, hvor opdateringer fra registreringssystemer (f.eks. CRM eller ERP) afspejles i Data 360 inden for sekunder eller minutter. På den anden ende er begivenhedsregistrering i realtid, hvor adfærdsmæssige signaler fra klienten – f.eks. klik, køb eller mobilinteraktioner – overføres og aktiveres i millisekunder. For arkitekter er forskellen mere end semantisk. Den definerer, hvordan pipelines designes, hvordan API'er kaldes, og hvordan downstream-beslutninger træffes. Valg af det rigtige mønster – uanset om det er synkronisering i næsten realtid eller begivenhedsstreamingoverførsel – sikrer, at systemet opfylder virksomhedens driftsmæssige forsinkelsesmål, mens det bevarer dataintegritet, skalerbarhed og styring.
Kontekst
Dette mønster aktiverer ethvert eksternt system – f.eks. en tilpasset applikation, en Internet of Things-platform (IoT), et point-of-sale-system (POS) eller en tredjepartstjeneste – til programmeringsmæssigt at overføre begivenhedsdata til Data 360 næsten i realtid, når der forekommer særskilte begivenheder.
Problem
Hvordan kan en udvikler pålideligt sende enkelte registreringer eller små asynkrone batches af begivenheder fra en ekstern applikation til Data 360 med lav forsinkelse, så dataene er tilgængelige hurtigt til behandling, segmentering og aktivering?
Kræfter
Dette mønster leverer lav forsinkelse og bedre udviklerkontrol, men introducerer flere tekniske begrænsninger og driftsmæssige afhængigheder:
- Udviklerafhængighed: Kræver udviklerindsats for at implementere godkendte REST API-klienter og fejl-/forsøgslogik – det er ikke en peg-og-klik-forbindelse.
- Streng skema-på-skriv: Overførsels-API'en håndhæver skema-på-skriv. Der skal defineres et præcist skema og uploades til forbindelseskonfigurationen. Alle data skal overholde nøjagtigt eller afvises.
- Dobbeltinteraktionstilstande: Den samme forbindelse understøtter både streaming (JSON) for lav forsinkelse, registrerings-for-registreringsopdateringer og massesynkronisering (CSV) for større periodiske synkroniseringer – arkitekter skal vælge pr. anvendelsessituation.
- Godkendelse og sikkerhed: Opkald skal godkendes via en Salesforce-tilsluttet app ved brug af OAuth 2.0 (f.eks. JWT Bearer-forløb for server-til-server). Tokenadministration, rotation og omfang med mindst rettigheder er obligatoriske.
- Driftsmæssig synlighed: Udviklere og platformsteams skal implementere overvågning for svarkoder, forsøg, dødstavskøer og skemaafledningsadvarsler.
- Diagramkrav i realtid: For ægte øjeblikkelig aktivering (øjeblikkelig segmentering, DMO-tilknytning i realtid) skal måldatamodelobjektet (DMO) være en del af datadiagrammet i realtid. Ellers gennemgår begivenheder en pipeline med en lidt højere forsinkelse.
Løsning
Denne tabel indeholder løsninger på dette integrationsproblem.
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| Løsningstilpasning | Bedst til begivenhedsregistrering med lav forsinkelse | Brug Data 360 Overførsels-API (streaming JSON) til at overføre enkelte begivenheder eller mikrobatches. Konfigurer overførsels-API-forbindelsen med et strengt OAS 3.0-skema (.yaml). Brug masse-CSV-overførsel til større, mindre hyppige synkroniseringer. |
| Håndtering af skemaændringer | Streng / administreret | Skemaændringerne bryder: opdater OAS .yaml, versioner forbindelsen, og udfør kontrakttest. Implementer rullende skemamigrering, hvis producenter ikke kan ændres samtidigt. |
| Når ikke at bruge | Suboptimal | Ikke ideel, hvis der er brug for forbehandling (f.eks. fjernelse af dubletter, garanteret bestilling osv.) eller for ekstremt store masseindlæsninger (brug oprindelige masseforbindelser eller batch-ETL). Hvis kilden ikke kan oprette skemavalgsmæssige data eller ikke kan godkende sikkert, skal du bruge alternative overførselsmetoder. |
| Sikkerhed og styring | Påkrævet | Brug OAuth 2.0 med omfang med færrest rettigheder, rotere taster, logfør tokenanvendelse. Håndhæv TLS 1.2+, valider klient-IP'er, hvis det er nødvendigt, og sørg for data-PII-tagging. Alle begivenheder skal indeholde afledningsmetadata (kilde, tidsstempel, skemaversion, idempotensnøgle). |
Skitser
Dette diagram illustrerer sekvensen af trin til at overføre data fra overførsels-API i Data 360
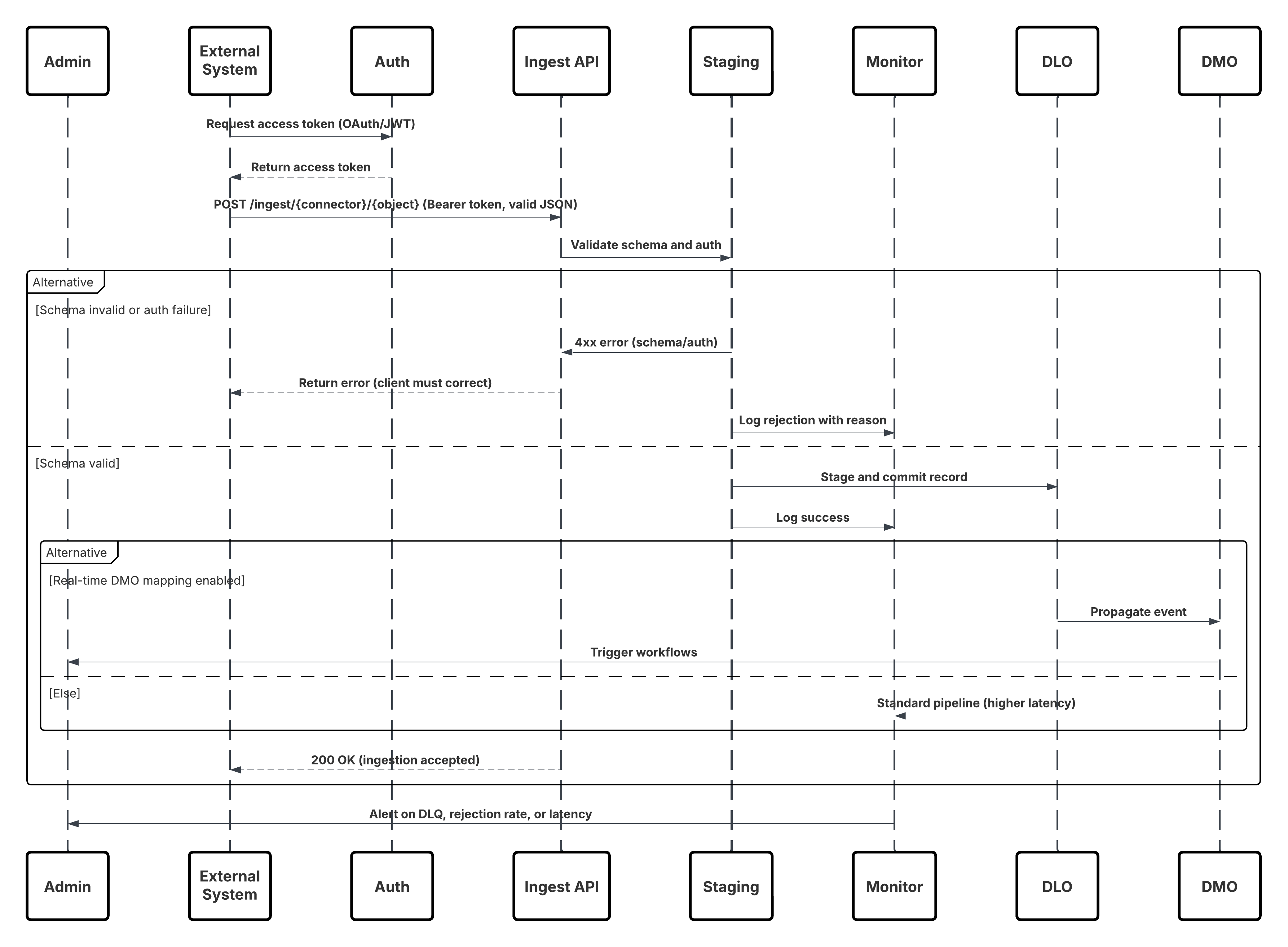
I dette scenarie:
- Eksternt system anmoder om godkendelse via OAuth/JWT fra godkendelsesserver.
- Godkendelsesserver returnerer adgangstoken til det eksterne system.
- Eksternt system sender POST-anmodning om dataoverførsel til Data 360-overførsels-API med autorisation og JSON-data.
- Overførsels-API validerer anmodningsskema og godkendelse via modulet Fase og validering.
- Ved skema-/godkendelsesfejl:
- Fejl returneret til Eksternt system.
- Afvisning er registreret til overvågning og advarsel.
- Ved vellykket validering:
- Registreringer, der er faseinddelt og bekræftet i DLO (Data Lake Object).
- Gennemført registrering til overvågning.
- Hvis det er aktiveret, udbredes data til DMO (Real-Time Data Graph), der udløser downstream-arbejdsflows.
- Ellers behandles data via standardbatch eller pipeline med højere forsinkelse.
- Overførsels-API bekræfter, at det er lykkedes for det eksterne system.
- Overvågningskomponenter advarer administratorer om dødstavskøer, afvisningsfrekvenser eller forsinkelsesproblemer.
Resultater
Eksterne begivenhedsdata overføres til Data 360-DLO'er med lav forsinkelse. Når mål-DMO er en del af realtidsdiagrammet, er dataene tilgængelige for øjeblikkelig segmentering, agentarbejdsflows, AI-modeller og driftsmæssig aktivering. Dette aktiverer hurtige forretningssvar på begivenheder, der stammer fra ethvert tilsluttet system.
Overførselsmekanismer
Overførselsmekanismen afhænger af forbindelsen og planlægningsstrategien, der er defineret i Data 360.
| Mekanisme | Hvornår bruges |
|---|---|
| Streaming JSON (overførsels-API) | Enkeltbegivenheder, mikrobatches, adfærdsmæssige begivenheder, clickstreams, IoT-telemetrie – når der kræves en lav forsinkelse. |
| Bulk CSV (overførsels-API-masseindstilling) | Større periodiske uploads, hvor forsinkelseskravene er lette. |
| Edge / Middleware | Bruges, når du har brug for validering, transformation, berigelse eller frekvensbegrænsning, før du overfører til overførsels-API'en. |
Fejlhåndtering og gendannelse
- Omgående (synkronisering) fejl: 4xx svar for skema-/godkendelsesfejl – klienten skal rette data eller token og prøve igen.
- Forbigående (asynkroniseret) fejl: 5xx-svar – klientforsøg med eksponentiel tilbagerulning og jitter.
- Dead-Letter Kø (DLQ): Vedvarende fejl lander i DLQ til manuel inspektion og afspilning.
- Overvågning: Spor skemaafvisningsfrekvens, godkendelsesfejl, forsinkelsespercentiler og DLQ-forsinkelse. Advarsel om tærskler.
Overvejelser i forbindelse med idempotent design
- Idempotensnøgle: Hver begivenhed skal indeholde et entydigt idempotency-nøgle-/meddelelses-id.
- Upsert-strategi: Brug forretningsnøgler (ExternalId) til at undgå dubletter på replays.
- Dedup-vindue: Architekt skal definere fjernelsesvinduer og bevarelse for idempotenssporing.
Sikkerhedsovervejelser
Sikkerhed er integreret i hele overførselspipelinen fra godkendelse til kryptering og adgangskontrol.
- Godkendelse: OAuth 2.0 (JWT Bearer) anbefales for server-til-server. Begræns omfang til kun overførsel.
- Kryptering: TLS 1.2+ til transport. Data 360 håndhæver kryptering, mens de er inaktive.
- Mindste rettighed: Tilsluttede applegitimationsoplysninger har minimale rettigheder. Roter hemmeligheder og instrumentadgangslogfiler.
- Payload Governance: Inkluder samtykke-/forbrugsflag i begivenhedsmetadata. Anvend ABAC/CEDAR-politikker straks efter overførsel.
- IP-kontroller / Private Connect: Om nødvendigt kan du begrænse adgang via tilladelseslister eller bruge Private Connect til privat netværk.
Sidebars
Tidlighed
Tidlighed afhænger af overførselstidsplanen og datamængden. Streaming af JSON giver sekunders til sekunders forsinkelse afhængigt af behandling og diagramkonfiguration. Massescv er minutter til timer. Vælg baseret på forretnings-SLA'er.
Datamængder
Individuelle begivenhedsstørrelser skal være små (< få KB). For producenter med høj gennemsnit kan du overveje at batche hos produceren eller bruge en streamingbuffer (Kafka/Kinesis), før du kalder API.
Statsadministration
- Schema Versioning: Vedligehold skemaversion i begivenhedsmetadata, og brug forbindelsesversionering, når du opdaterer OAS-kontrakt.
- Forbindelsesforskydninger: Data 360 håndterer bekræftelsessemantik. Producenter bør spore idempotency-nøgler og sidste vellykkede sekvens for sikker afspilning.
Komplekse integrationsscenarier
I avancerede virksomhedsarkitekturer kan dette mønster integreres med:
- Kant valideringslag: Brug middleware til at oversætte heterogene producentformater til den krævede OAS-kontrakt, udføre frekvensbegrænsning og forhåndsberigelse.
- Hybridarkitekturer: Kombiner overførsels-API for begivenheder og forbindelser til masseafstemning.
- Agentaktivering: Begivenheder, der er tilknyttet i realtids-DMO'er, kan udløse Agentforce og Einstein til automatiseret beslutningstagning.
Eksempel
En detailkæde streamer POS-købsbegivenheder (point-of-sale) i Data 360 inReal-Time for at fremme øjeblikkeligt kundeengagement. Hver butik kører en letvægtsserverkomponent, der indsamler transaktioner, beriger dem med placerings- og enhedsmetadata og opretter JSON-begivenheder sikkert ved brug af JWT Bearer OAuth med idempotency-nøgler for at forhindre dubletter. En administrator definerer begivenhedsstrukturen ved at uploade et OAS-skema for salgsstedet og konfigurere overførsels-API-forbindelsen. Indgående begivenheder overføres til pos_sale DLO, tilknyttes til salgs-DMO og føjes til realtidsdiagrammet. Resultatet er, at køb af høj værdi registreres med det samme, hvilket udløser VIP-arbejdsflows i Agentforce og opdaterer kundesegmenteringen for at fremme personliggørelse i realtid.
Kontekst
Dette mønster aktiverer registreringen af højvolumen, detaljerede brugerinteraktionsdata – f.eks. sidevisninger, knapklik, produktindtryk og videoafspilninger – fra websites og mobilapplikationer i trueReal-Time. Det er grundlæggende for at levere tilpasning i øjeblikket, hvor hver digital interaktion dynamisk kan påvirke brugeroplevelsen og fremme engagementet.
Problem
Hvordan kan en virksomhed registrere og behandle en kontinuerlig stream af adfærdsmæssige begivenheder fra digitale egenskaber – der strækker sig over millioner af brugerinteraktioner pr. minut – og gøre disse data øjeblikkeligt tilgængelige i Data 360 for at fremme segmentering, tilpasning og aktivering i realtid?
Kræfter
Denne anvendelsessituation introducerer adskillige designudfordringer, der kræver en formålsopbygget overførselsarkitektur med lav forsinkelse:
- Ekstrem gennemsnit : Websites eller mobilapps med høj trafik kan udsende millioner af begivenheder pr. minut. Overførselslaget skal skaleres vandret for at håndtere denne mængde uden begivenhedstab eller bagtryk, hvilket sikrer ensartet forsinkelse under spidsbelastninger.
- Klientsideinstrumentering: I modsætning til serverstyrede integrationer afhænger dette mønster af SDK'er på klientsiden. Et JavaScript-beacon (Salesforce Interactions SDK) skal være integreret på hver side, eller et oprindeligt SDK skal være integreret i mobilapps. Dette kræver robust klientimplementering, versionering og begivenhedsskemastyring.
- Behandling af begivenhed med lav forsinkelse: Brugerhandlinger – f.eks. "tilføj til indkøbsvogn" eller "videoafspilning" – skal nå Data 360 inden for sekunder og aktivere aktivering i realtid og kontekstbaserede svar (f.eks. målrettede tilbud, personlige anbefalinger).
- Dataharmonisering og identitetsløsning: Registrerede begivenheder inkluderer ofte anonyme identifikatorer (cookies, enheds-id'er, sessionstokener). For at fremme Customer 360 skal disse tilknyttes til kendte profiler via Data 360's identitetsløsning og harmoniseres med Customer 360.
Løsning
Den anbefalede tilgang er at bruge Salesforce Marketing Cloud-tilpasningsforbindelsen – en indbygget, fuldt administreret streaming-pipeline, der er designet til adfærdsmæssig overførsel med høj gennemsnit.
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| SDK-baseret begivenhedsregistrering | Best | Implementer Salesforce Interactions SDK (web) eller indbygget SDK (mobil). Disse letvægtsbiblioteker registrerer og serialiserer brugerinteraktioner i realtid ved at vedhæfte metadata (sessions-id, tidsstempel, kontekst). |
| Event Streaming Pipeline | Best | Begivenheder sendes til Marketing Cloud-tilpasningens begivenhedsstreamingtjeneste over sikker HTTPS. Dette lag kan skaleres vandret og optimeres til transmission med lav forsinkelse (<2s). |
| Data 360-integration | Best | Data 360's Tilpasningsforbindelse abonnerer på streamingfeedet og overfører hver begivenhed til et Data Lake-objekt (DLO) i næstenReal-Time. |
| Datamodeltilknytning | Bedste fremgangsmåder | Den overførte DLO tilknyttes til Customer 360 (DMO'er). Dette aktiverer linkning af anonyme og kendte brugere gennem Id-løsning. |
| Aktivering af diagram i realtid | Valgfrit/anbefales | Inkluder tilknyttede DMO'er i realtidsdiagrammet for øjeblikkelig segmentering, der udløser personlige handlinger via Einstein eller Agentforce |
| Når ikke at bruge | Suboptimal | Dette mønster er ikke ideelt, når: Kildedataene er webklient og begivenheder (brug i stedet overførsels-API). Organisationen mangler kontrol over web-/mobilklienter. Adfærdssporing i realtid er ikke påkrævet (brug batchoverførsel). |
| Håndtering af skemaændringer | Administreret udvikling | Begivenhedsskemaer udvikles, efterhånden som der tilføjes nye interaktioner. SDK'er skal versionsbegivenhedsdefinitioner. Tilbagekompatible ændringer (tilføjelse af valgfri felter) er sikre. Afbrydelse af ændringer kræver forbindelsesomkonfiguration og kontrakttest. |
Skitser
Dette diagram illustrerer sekvensen af trin til at overføre data fra mobil- og webkanaler i Data 360
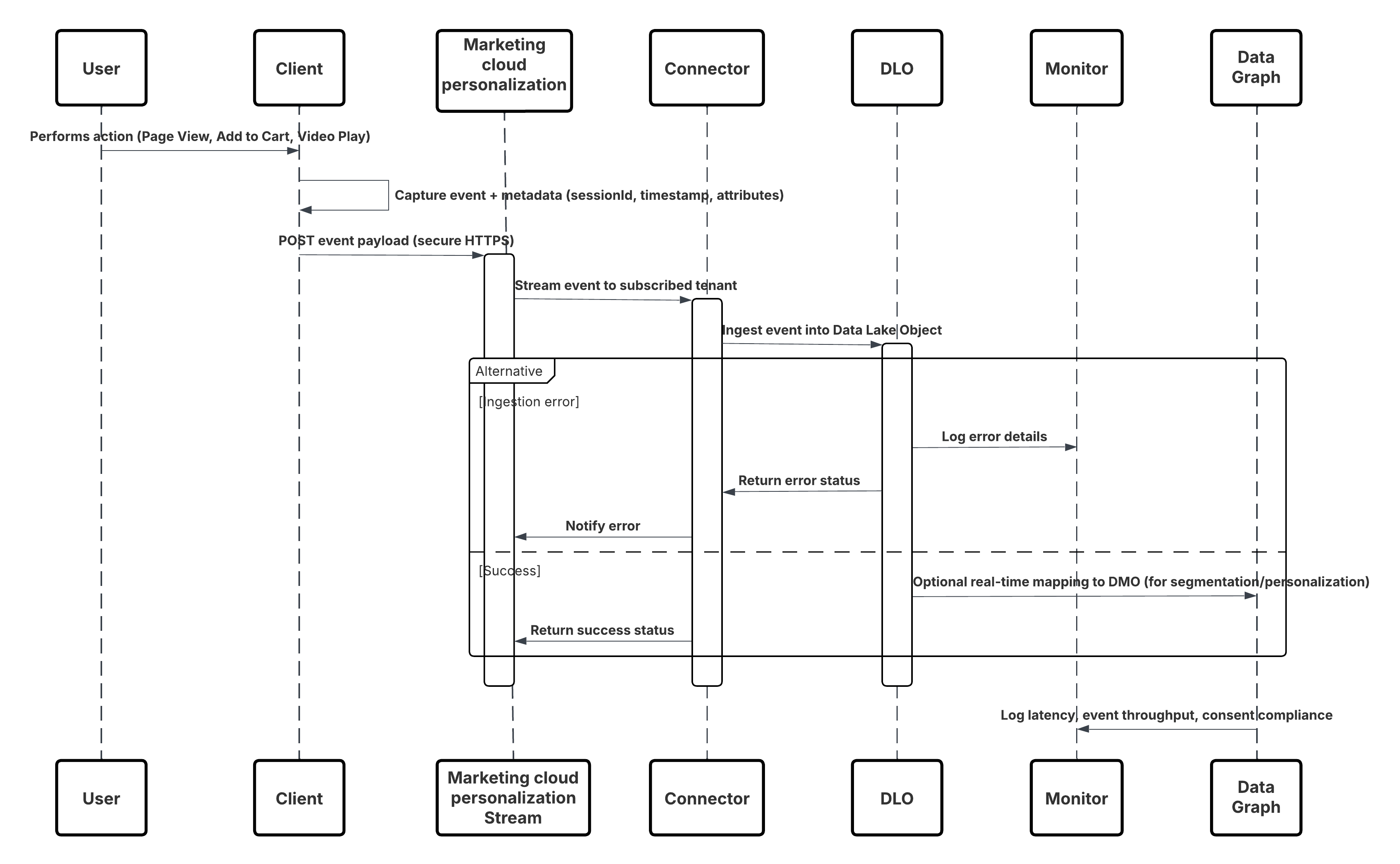
I dette scenarie:
- Implementer SDK i web- eller mobilkanaler (brugerinteraktionsregistrering).
- Konfigurer SDK med lejer-id, miljø og samtykkekontroller.
- Stream registrerede JSON-begivenheder (metadata + attributter) til Marketing Cloud-streamingslutpunkt.
- I Data 360-opsætning skal du oprette og konfigurere Tilpasningsforbindelsen for lejeren.
- Overfør begivenheder til en DLO, og tilknyt DLO → DMO i Data 360.
- Aktiver DMO i realtidsdiagrammet for øjeblikkelig aktivering.
- Overvåg forsinkelse, skemaoverensstemmelse, samtykkeflag, gennemsnit, fejlfrekvenser.
- Implementer til produktion, og overvåg kontinuerligt.
Resultater
En kontinuerlig stream med lav forsinkelse af adfærdsmæssige begivenheder flyder fra digitale kanaler til Data 360. Inden for sekunder bliver hver brugerhandling tilgængelig for segmentering i realtid, forudsigende modellering eller udløst tilpasning, hvilket aktiverer virkelig adaptive kundeoplevelser.
Overførselsmekanismer
Overførselsmekanismen afhænger af forbindelsen og planlægningsstrategien, der er defineret i Data 360.
| Mekanisme | Hvornår bruges |
|---|---|
| Interaktioner SDK (web) | Registrering i realtid fra webbrowsere og SPA'er. |
| Mobil SDK | Registrering i realtid fra oprindelige mobilapplikationer. |
| Personalisering Connector | Administreret abonnement mellem Marketing Cloud og Data 360\. |
| Diagramtilknytning i realtid | Aktiverer øjeblikkelig aktivering i Segmentering, Einstein og Rejser. |
Fejlhåndtering og gendannelse
- Lagsfejltolerance: Implementer validerings- og prøvemekanismer på flere niveauer – klient-SDK'er håndterer midlertidige fejl med eksponentiel tilbagerulning, mens overførselslaget bruger holdbare køer og pipelines, der kan afspilles igen, for at forhindre datatab.
- Skema og dataadministration: Versions- og valider begivenhedsskemaer kontinuerligt. Ugyldige eller udviklende begivenheder distribueres til en skemaafvisning eller en Dead-Letter-kø for sikker sortering og afspilning.
- Idempotency & Deduplication: Brug stabile begivenhedsidentifikatorer og upsert-semantik til at garantere præcis en gangs behandling, selv under forsøg eller gentagelser.
- Overvågning og gendannelsesautomatisering: Kontinuerlig overvågning af gennemsnit, forsinkelse og fejlfrekvens udløser automatiserede gendannelsesarbejdsflows – hvilket sikrer lav forsinkelse, pålidelig levering og ensartede tilpasningsresultater i realtid.
Overvejelser i forbindelse med idempotent design
- Hver begivenhed skal indeholde en entydig idempotensnøgle eller et meddelelses-id, så dubletindsendelser kan fjernes downstream.
- Brug forretningsnøgler (f.eks. sessionID + eventTimestamp + userID), hvor det er relevant, til at identificere dubletter.
- Definer et fjernelsesvindue (f.eks. 24 timer), hvor dubletbegivenheder ignoreres eller filtreres.
- Brug upsert-strategier, hvor det er relevant (f.eks. opdater optællere eller flag i stedet for at indsætte dubletter).
Sikkerhedsovervejelser
Sikkerhed er integreret i hele overførselspipelinen fra godkendelse til kryptering og adgangskontrol.
- Transportkryptering: TLS 1.2+ for alle SDK → streamingtjenesteforbindelser.
- Datakryptering, der er inaktive i Data 360 og marketingstream.
- SDK respekterer brugerens samtykkeflag (GDPR/CCPA) og undertrykker sporing, hvis samtykke nægtes.
- Godkendelse af SDK-trafik: Sørg for, at kun godkendte lejere/kunder kan streame begivenheder.
- Metadata: Hver begivenhed skal indeholde kilde-id, tidsstempel, skemaversion, sessions-id, idempotensnøgle.
- Mindste adgang: SDK-slutpunkter og forbindelser er begrænset til omfanget af begivenhedsoverførsel. Roter legitimationsoplysninger regelmæssigt.
- Dataklassificering: Anmærk personligt identificerbare oplysninger i begivenhedsdata, håndhæv politikker straks efter overførsel
Sidebars
Tidlighed
- Tidspunktet afhænger af slutbrugeraktivitet og begivenhedsstreamingkonfigurationen.
- Begivenheder, der registreres via Salesforce Interactions SDK og leveres gennem Marketing Cloud-tilpasningsstream, har typisk en forsinkelse på mellem et sekund og ~2 sekunder, før de bliver tilgængelige i Data 360-diagrammet i realtid.
- Dette aktiverer næsten øjeblikkelig segmentering, tilpasning og aktivering i aktive brugersessioner.
Datamængder
Individuelle adfærdsmæssige begivenheder (f.eks. klik, visning, tilføjelse til indkøbsvogn) er letvægts – generelt 1-5 KB pr. data. For digitale egenskaber i stor skala kan du forvente tusindvis til millioner af begivenheder pr. minut. Hvis du vil sikre gennemsnit og fleksibilitet:
- Brug SDK's indbyggede batch- og prøvemekanismer til sider med stor trafik.
- Offload-udbrudshåndtering til Marketing Cloud-streamingbufferlaget.
- Overvåg overførsel af gennemsnit og fejlforhold ved brug af dashboardet for forbindelsesmetrikker.
Statsadministration
Hver begivenhed inkluderer metadata for stats- og versionskontrol:
- Schema Versioning: Integrer skemaversion i hver begivenhed, og versioner Tilpasningsforbindelsen, når du opdaterer skemaet.
- Genafspilningshåndtering: Begivenheder, der mislykkes på grund af midlertidige netværksproblemer, forsøges automatisk af SDK med eksponentiel tilbagerulning.
- Idempotensnøgler: Entydige identifikatorer (sessionId + eventType + timestamp) sikrer, at genafspilede begivenheder ikke opretter dubletter i Data 360.
- Forskelingsstyring: Data 360 sporer vellykkede bekræftelser. Alle ubearbejdede begivenheder gendannes af forbindelsen, indtil de overføres korrekt.
Komplekse integrationsscenarier
Dette mønster integreres problemfrit i avancerede virksomhedsarkitekturer:
- Edge Enrichment Layer: Tilføj middleware (f.eks. omvendt proxy eller serverløs funktion) for at indsætte yderligere kontekst – f.eks. geografisk, enhedstype eller kampagnemetadata – før begivenheder når Marketing Cloud.
- Hybrid (Streaming + Batch): Brug Marketing Cloud-forbindelsen til streams i realtid, og kombiner den med ETL-batchjob (f.eks. bestillingsdata) til downstream afstemning.
- Agentaktivering: Begivenheder, der er tilknyttet realtids-DMO'er, kan udløse Einstein-personalisering, Agentforce eller AI-styret beslutningstagning for at tilpasse den digitale oplevelse i øjeblikket.
- Multi-lejer governance: Brug samtykkeflag og lejerbevidste metadata til at håndhæve fortrolighed og overensstemmelse i miljøer med flere brands eller flere områder.
Eksempel
En global e-handelsvirksomhed leverer personlige produktanbefalinger og dynamisk indhold til købere, mens de aktivt gennemser www.retailx.com, et React-baseret enkeltsideprogram. Ved at bruge Salesforce Interactions SDK på klientsiden registrerer lokaliteten sidevisninger, produktklik, indkøbsvognshandlinger og videointeraktioner i realtid. Disse begivenheder flyder gennem begivenhedsstreamen Marketing Cloud-tilpasning og tilpasningsforbindelsen i Data 360-DLO'er, hvor de oprettes i DMO'er og indarbejdes i realtidsdiagrammet. Denne arkitektur gør adfærdssignaler øjeblikkeligt tilgængelige for segmentering, Einstein tilpasning og Agentforce, hvilket aktiverer responsive kundeoplevelser i sessionen
Kontekst
For mange forretningskritiske processer er det vigtigt at holde Data 360 perfekt i overensstemmelse med de seneste opdateringer i CRM-kernesystemer. Kundeservice, salg og marketingteams er afhængige af opdaterede oplysninger for at styre beslutninger, udløse rejser og aktivere automatisering. Dette mønster leverer en mekanisme til at synkronisere ændringer af Salesforce CRM-nøgleobjekter – f.eks. Kontakt, Konto og Sag – i Data 360 med minimal forsinkelse, uden ineffektivitet eller forsinkelse i hyppig batchpolling.
Problem
Hvordan kan Data 360 vedligeholde en næsten perfekt synkroniseret tilstand med Salesforce CRM-nøgleobjekter og sikre, at downstream-analyser, segmentering og AI-styret aktivering altid fungerer på de mest aktuelle tilgængelige data?
Kræfter
Dette mønster introducerer adskillige tekniske begrænsninger og arkitektoniske overvejelser:
- Begivenhedsstyret arkitektur : Synkronisering skal være genaktiv – drevet af ændringsbegivenheder i CRM-kildeorganisationen snarere end periodiske batchjob.
- Selektiv objektsupport : Det er ikke alle Salesforce-standardobjekter og tilpassede objekter, der understøtter streaming i realtid. Architekter skal referere til den understøttede objektliste under design for at undgå huller.
- Adgang og tilladelser: Aktivering af streaming kræver, at integrationsbrugeren i kildeorganisationen tildeles systemtilladelsen "Aktiver tilladelser for CRM-streaming".
- Dataopdatering vs. Behandlingsomkostninger : Mens synkronisering næsten i realtid forbedrer responsivitet, kan overdreven begivenhedsgennemstrømning kræve vandret skalering og robuste fejlgendannelsesmekanismer.
- Security og Trust Layer Integration : Alle begivenhedsdata skal overholde Salesforces Trust og sikkerhedsstrukturer – krypteret under overførsel, valideret til skemaoverensstemmelse og behandlet inden for organisationens Trust.
Løsning
Den anbefalede tilgang er at bruge Salesforce CRM-forbindelsen med streaming (Skift dataregistrering) aktiveret. Når du opretter en datastream for et understøttet CRM-objekt (f.eks. Kontakt), kan administratorer skifte til indstillingen "Aktiver streaming". Under overfladen udgiver Salesforces CDC-platform (Change dataregistrering) en ChangeEvent-meddelelse, hver gang en registrering oprettes, opdateres, slettes eller fortrydes sletning i kilde-CRM-organisationen. Data 360 CRM-forbindelsen abonnerer på disse CDC-begivenheder og anvender de tilsvarende ændringer på det tilknyttede Data Lake-objekt (DLO) i Data 360 i næsten realtid. Dette sikrer kontinuerlig synkronisering mellem CRM og Data 360 med minimal manuel intervention.
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| CDC-baseret streamingforbindelse | Best | Indbygget Salesforce-mekanisme, fuldt administreret og integreret med platformsbegivenhedsinfrastruktur. |
| Event Abonnement & Levering | Best | Forbindelsen abonnerer på ChangeEvent-kanaler (f.eks. /data/ContactChangeEvent) via holdbare afspilnings-id'er. |
| Datatilknytning og skemaudvikling | Bedste fremgangsmåder | Tilknyt streamede data til den tilsvarende DLO. Håndter skemaversionering i metadata for at forhindre overførselspauser. |
| Genafspilning og fejlgendannelse | Anbefales | Brug af afspilnings-id'er og idempotencenøgler til at undgå duplikering og gendanne fra midlertidige fejl. |
| Hybrid tilstand (streaming + batch) | Valgfrit | For ikke-understøttede objekter eller indledende masseindlæsning skal du bruge batchoverførsel i kombination med CDC-streaming. |
| Når ikke at bruge | Suboptimal | Dette mønster kan være underoptimalt, når: Kildeobjektet er ikke CDC-aktiveret. Anvendelsessituationen kræver ikke opdateringer i realtid (batch er tilstrækkelig). Netværksudløb fra kildeorganisationen er begrænset, eller begivenhedsgrænserne overskrides. |
Skitser
Dette diagram illustrerer sekvensen af trin til at overføre data fra CRM til Data 360 i næsten realtid
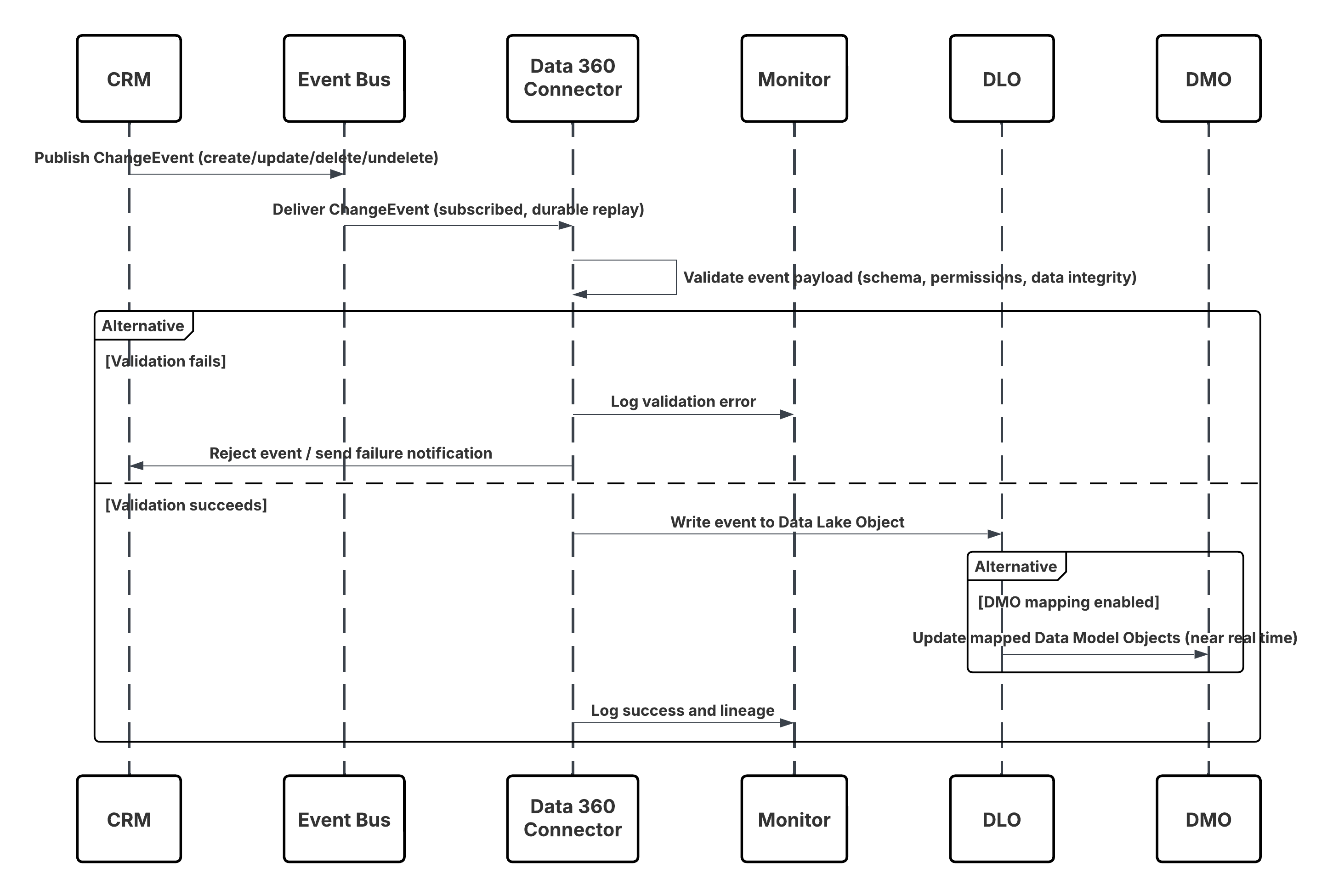
I dette scenarie:
- Ændring forekommer i Salesforce CRM (opret/opdater/slet/fortryd sletning).
- CDC udgiver en ChangeEvent til den interne Salesforce-begivenhedsbus.
- Data 360 CRM-forbindelse abonnerer på begivenhedsbussen ved brug af en holdbar afspilningskursor.
- Begivenhedsdata er valideret for skema, tilladelser og dataintegritet.
- Data 360 skriver den validerede begivenhed til det tilknyttede Data Lake Object (DLO).
- Hvis det er aktiveret, opdateres tilknyttede DMO'er (Data Model Objects) i nearReal-Time, hvilket fremmer segmentering og aktivering.
Resultater
Data 360 vedligeholder et kontinuerligt synkroniseret spejl af vigtige CRM-data. Dette aktiverer:
- Udløsere i realtid (f.eks. Rejse starter, når der oprettes en sag).
- Opdater segmentering (f.eks. flytte kunder til segmentet "Gold" ved ændring af kontostatus).
- Mere nøjagtige analyser og tilpasning baseret på live CRM-kontekst.
Overførselsmekanismer
Overførselsmekanismen for dette mønster administreres som standard gennem Salesforce CRM-forbindelsen med CDC (Change Dataregistrering) aktiveret. Data 360 fungerer som en abonnent på CDC-begivenhedsstream, hvilket sikrer pålidelig synkronisering med lav forsinkelse mellem kilde-CRM-organisationen og Data 360.
| Mekanisme | Hvornår bruges |
|---|---|
| Streaming via CDC (Foretrukket) | For alle understøttede Salesforce-standardobjekter og tilpassede objekter, hvor synkronisering i næsten realtid er påkrævet. |
| Hybrid tilstand (CDC + batch) | For objekter, der endnu ikke er CDC-aktiveret, eller hvor indledende historisk indlæsning er påkrævet. |
| Genafspil abonnementstilstand | Til gensynkronisering efter nedetid eller implementering. |
| Fejlsisoleringstilstand | Til test- og valideringsmiljøer. |
Fejlhåndtering og gendannelse
- Automatisk fejlgendannelse: CRM-forbindelsen forsøger automatisk forbigående netværks- eller platformsfejl ved brug af eksponentiel tilbagerulning og distribuerer vedvarende fejl til DLQ (Dead-Letter-køen) til afspilning.
- Skema- og godkendelsesstabilitet: Skemauoverensstemmelser er sat i karantæne i skemaafvisningskøen til administratorgennemgang, mens godkendelses- eller tilladelsesfejl udløser kontrollerede forsøg og advarsel gennem Data 360-overvågning.
- Garanteret begivenhedskontinuitet: Holdbare ReplayID'er sikrer ingen begivenhedstab under forbindelsesnedetid. Manglende begivenheder rehydreres gennem genafspilningsvinduer eller batchgensynkroniseringsjob.
- Dataintegritet & bestilling: Indbygget idempotency (RecordID + SequenceNumber) forhindrer dubletter, og ChangeEventHeader.sequenceNumber bevarer den korrekte begivenhedsrækkefølge for hver CRM-registrering.
Overvejelser i forbindelse med idempotent design
- Event Unicity: Hver CDC-begivenhed indeholder et ReplayID og et ChangeEventHeader.entityName til deterministisk fjernelse af dubletter.
- Upsert-strategi: Implementer UPSERT-logik baseret på registrerings-id for at sikre, at gentagne begivenheder ikke opretter dubletter.
- Genafspilningshåndtering: Brug forbindelsens afspilningskursor til at genoptage fra den sidste bekræftede forskydning i tilfælde af midlertidige fejl.
- Skemaudvikling: Mvedligeholde en skemaversion i begivenhedsmetadata og opdatere DLO-tilknytninger, når CRM-skemaet ændres.
Sikkerhedsovervejelser
Sikkerhed er integreret i hele overførselspipelinen fra godkendelse til kryptering og adgangskontrol.
- Kryptering og Trust : Alle begivenheder overføres ved hjælp af TLS 1.2+ og lagres krypteret, mens de er inaktive i Data 360.
- Adgangskontrol: Kun godkendte forbindelser med relevante integrationstilladelser kan abonnere på CDC-kanaler.
- Skemavalidering: Hver begivenhedsdata valideres op mod DLO-skemaet før overførsel.
- Samtykkeudbredelse: Samtykke- og dataklassificeringsmetadata flyder downstream med hver begivenhed for at bevare fortrolighed og compliance (GDPR, CCPA).
- Operationel styring: Begivenheder logføres, revideres og overvåges for genafspilning, skemaafvisning og afvigelser i gennemsnit via Data 360 Trust Layer.
Sidebars
Tidlighed
- CDC-begivenheder behandles næsten i realtid – typisk inden for sekunder af ændringen i CRM.
- Forsinkelse kan variere baseret på begivenhedsmængde og forbindelsesgennemstrømning, men Data 360 garanterer tilgængelighed for underminutter for understøttede objekter.
Datamængder
- Hver begivenhedsdata er let (~1-5 KB).
- For objekter med høj ændringsfrekvens som Sag eller Kontakt skal du sørge for, at gennemsnitsbegrænsningerne er i overensstemmelse med Salesforce CDC-begivenhedstildelinger.
Statsadministration
Hver begivenhed inkluderer metadata for stats- og versionskontrol:
- Genafspilnings-id'er: Bruges til sekventiel begivenhedsgendannelse.
- Schema Versioning: Vedligehold versionsmetadata for at administrere kontraktændringer.
- Idempotensnøgler: Fjern dubletter på tværs af forsøg.
- Forskudsbekræftelse: Data 360 bevarer bekræftelsestilstanden efter hvert vellykket batch af begivenheder.
Komplekse integrationsscenarier
Dette mønster integreres problemfrit i avancerede virksomhedsarkitekturer:
- Hybrid (Streaming + Batch): Brug CDC til deltaopdateringer og massejob til fuld opdatering.
- Cross-Org Streaming: Flere kildeorganisationer kan streame til den samme Data 360-lejer, forenet via DMO-tilknytninger.
- Agentaktivering: Objektopdateringer i realtid udløser Einstein eller Agentforce.
- Begivenhedsdistribution: Mellemprogrammer (f.eks. MuleSoft eller Begivenhedsvideresendelse) kan berige eller distribuere CDC-meddelelser før overførsel.
Eksempel
En global bank ønsker at sikre, at kundedataændringer i Salesforce Sales Cloud straks afspejles i Data 360.Når en kontakts adresse opdateres i Sales Cloud, udgiver Change dataregistrering en ContactChangeEvent.Data 360 CRM-forbindelsen forbruger denne begivenhed, anvender opdateringen på Customer DLO og opdaterer automatisk alle tilknyttede Customer 360 Dette udløser en Einstein Next Best Action for at bekræfte den nye adresse – fuldføre feedbackløbet inden for sekunder af den oprindelige CRM-ændring.
Kontekst
Moderne digitale virksomheder er afhængige af begivenhedsstreamingplatforme i realtid som Amazon Kinesis-datastreams og Amazon MSK (Managed Streaming for Apache Kafka) til at registrere kontinuerlige dataforløb fra distribuerede applikationer, IoT-enheder og transaktionssystemer. Data 360 aktiverer direkte overførsel fra disse platforme gennem oprindelige førstepartsforbindelser – eliminerer behovet for tilpassede ETL- eller middleware-baserede løsninger. Dette mønster er designet til dataoverførsel med høj gennemsnit, lav forsinkelse, styring af indsigter i næsten realtid, tilpasning og AI-styret aktivering.
Problem
Hvordan kan en virksomhed sikkert og effektivt tilslutte Data 360 til AWS Kinesis- eller AWS MSK Kafka-emner for kontinuerligt at overføre strukturerede begivenheds- og profildata og sikre skemaoverensstemmelse, skalerbarhed og styring?
Kræfter
Dette mønster introducerer flere arkitektoniske og driftsmæssige overvejelser:
- Native Connector Tilgængelighed: Salesforce leverer generelt tilgængelige oprindelige forbindelser til både Amazon Kinesis og Amazon MSK. Disse forbindelser tilbyder support fra førstepart og eliminerer behovet for tilpassede API-baserede pipelines.
- Godkendelse og sikkerhed: Hver forbindelse kræver godkendelse på AWS-niveau.
- For Kinesis bruger dette AWS-adgangsnøgle og hemmelig nøgle, der er styret af IAM-politikker.
- For MSK kan godkendelse konfigureres via adgangsnøgle/hemmelighed eller OpenID Connect (OIDC).
- Skemadefinition: Data 360 kræver et skema for at fortolke streaming-dataene. For Kinesis uploades skemafilen under opsætning af forbindelsen og definerer begivenhedsstrukturen og felttilknytninger.
- Konfigurationskilde:
- Kinesis-forbindelsen abonnerer på et specifikt Kinesis-stream-navn.
- MSK-forbindelsen abonnerer på et Kafka-emne i MSK-klyngen.
- Netværksadgang: For sikre miljøer kan forbindelser konfigureres med PrivateLink- eller VPC-distribution, så du sikrer, at der ikke overføres nogen data til det offentlige internet.
- Operationel styring: Streaming-gennemstrømning, skemavalidering og godkendelsesbegivenheder overvåges i Data Trust, så du sikrer overensstemmelse og sporbarhed.
Løsning
Løsningen udnytter de indbyggede Amazon Kinesis eller Amazon MSK-forbindelser i Data 360.
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| Kinesis indbygget forbindelse | Best | Førstepartsintegration med AWS Kinesis understøtter kontinuerlig overførsel med høj gennemsnit. |
| MSK indbygget forbindelse | Best | Administreret Kafka-overførsel med OIDC og nøglebaseret godkendelsessupport. |
| Skematilknytning og validering | Bedste fremgangsmåder | Uploadskema (.json/.avro), der definerer begivenhedsstrukturen. Håndhæver ensartethed under overførsel. |
| IAM-konfiguration | Anbefales | Tildel IAM-rolle med mindst rettighed med skrivebeskyttet adgang til mål-Kinesis-stream eller MSK-emne. |
| Privat netværksdistribution | Valgfrit | Konfigurer PrivateLink/VPC-slutpunkter for sikker intern distribution. |
| Hybrid mønster (Streaming + batch) | Valgfrit | Brug streaming til deltaer og batchoverførsel til tilbagerulninger eller historiske indlæsninger. |
| Fejlsisoleringstilstand | Anbefales | Distribuer skemaafvisninger og midlertidige fejl til DLQ til afspilning |
Skitser
Dette diagram illustrerer sekvensen af trin til at overføre data fra begivenhedsplatforme som Kafka og Kinesis til Data 360 i næsten realtid
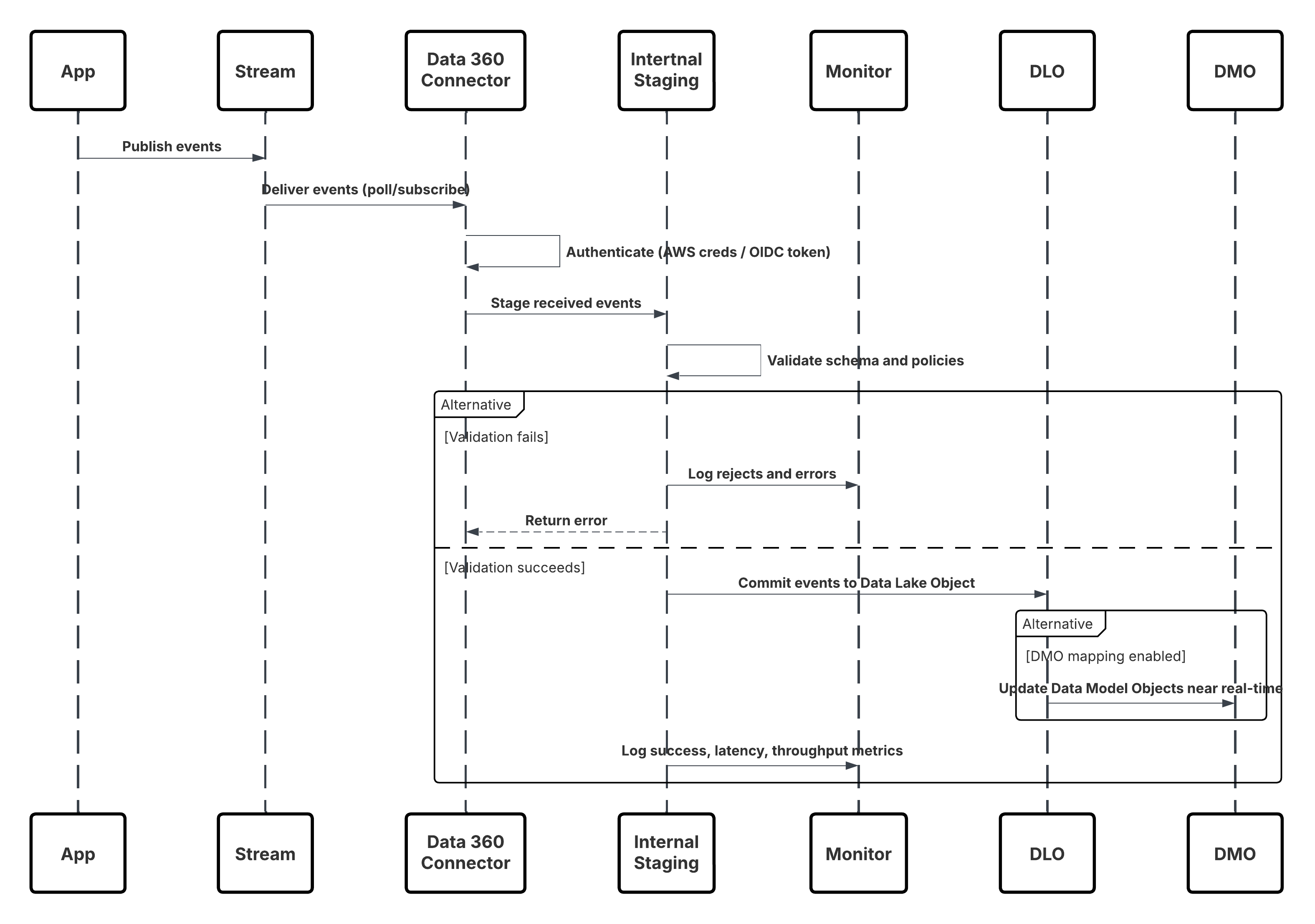
I dette scenarie:
- Applikationer eller enheder udgiver begivenheder til Kinesis Stream eller MSK-emne.
- Data 360-forbindelse godkendes ved brug af AWS-legitimationsoplysninger eller OIDC-token.
- Forbindelsen afstemmer eller abonnerer kontinuerligt på streamen.
- Begivenheder faseinddeles, valideres for skema og politik og bekræftes derefter til DLO (Data Lake Object).
- Hvis de tilknyttes, opdateres datamodelobjekter (DMO'er) næsten i realtid til aktivering.
- Overvågning af lag sporer metrikker, skemaafvisninger og forsinkelse.
Resultater
Kontinuerlig overførsel med lav forsinkelse af strukturerede data direkte fra AWS Kinesis eller MSK i Data 360. Data er straks tilgængelige for:
- Id-løsning
- Segmentering i realtid
- Einstein AI-aktivering
- Agentforce udløsere Eliminerer afhængighed af batch-ETL og aktiverer streambaserede arkitekturer, der er i overensstemmelse med organisationsbegivenhedsstyrede designs.
Overførselsmekanismer
| Mekanisme | Hvornår bruges |
|---|---|
| Kinesis-forbindelse (foretrukket) | For AWS-oprindelige streamingkilder, der kræver kontinuerlig overførsel af højvolumen strukturerede data. |
| MSK-forbindelse | For organisationer, der kører begivenhedspipelines på Kafka-kompatible platforme. |
| Hybrid (Streaming + batch) | For trinvis begivenhedsoverførsel kombineret med periodiske masseindlæsninger. |
Fejlhåndtering og gendannelse
- Automatisk gentagelse: Forbindelser forsøger forbigående netværks- eller platformsfejl med eksponentiel tilbagerulning.
- Skemaafvisninger: Ugyldige data distribueres til skemaafvisningskøen til administratorgennemgang.
- DLQ Replay: Vedvarende fejl registreres i køer med døde bogstaver til genbehandling.
- Idempotenskontrol: Begivenhedsnøgler eller sekvensnumre sikrer fjernelse af dubletter og sorteret overførsel.
- Overvågningsintegration: Alle fejl, forsøg og gennemsnitsmetrikker vises i Data 360 Monitoring-dashboards.
Overvejelser i forbindelse med idempotent design
- Event Unicity & sporing: Hver begivenhed tildeles en deterministisk entydig nøgle (f.eks. PartitionKey + SequenceNumber for Kinesis eller Emne + Partition + Forskydning for MSK) for at sikre præcis en gang-overførsel.
- Forbindelseskontrol: Data 360-forbindelser bevarer det sidst behandlede forskydnings- eller sekvensnummer for at genoptage overførslen sikkert efter fejl eller genstarter.
- Fjernelse af dubletter og UPSERT-logik: Under DLO-bekræftelser registreres dubletbegivenheder og ignoreres. Gyldige registreringer upserts ved brug af den entydige nøgle for at bevare ensartethed.
- Genafspilning og gendannelseskontrol: Mislykkede eller forsinkede begivenheder afspilles fra lagrede forskydninger gennem Dead-Letter- og Replay-køer, hvilket sikrer pålidelig gendannelse uden duplikering.
Sikkerhedsovervejelser
Sikkerhed er integreret i hele overførselspipelinen fra godkendelse til kryptering og adgangskontrol.
- Godkendelse: Udveksl sikre legitimationsoplysninger ved brug af AWS IAM-politikker eller OIDC.
- Kryptering: Data krypteret i transit (TLS 1.2+) og i ro (AES-256) i Data 360.
- Adgangskontrol: Mindste-rettighedsroller håndhævet, forbindelser tilpasset til specifikke streams/emner.
- Styring: Afstamnings- og klassificeringsmetadata anvendes på hver registrering for at opnå fuld sporbarhed.
- Netværkssikkerhed: Du kan eventuelt implementere i private undernet ved brug af AWS PrivateLink.
Sidebars
Tidlighed
- Næsten realtidsbehandling: CDC og streamingforbindelser behandler begivenheder inden for sekunder efter kildeændringer, hvilket typisk sikrer opdatering af underminutters data.
- Deterministisk forsinkelse: End-to-end-forsinkelse afhænger af kildeproduktion, begivenhedsbatching og netværksbetingelser, men Data 360 garanterer forudsigelig SLA-styret forsinkelse for understøttede objekter.
- Elastic skalering: Overførselspipelinen skaleres automatisk under høj begivenhedsmængde, hvilket bevarer rettidigheden, selv under spidsdatabrud.
- Driftsmæssig synlighed: Overvågning af dashboards viser begivenhedsforsinkelse, forpligtelsestidsstempler og genafspilningsstatus for forsinkelsessikkerhed og fejlfinding.
Datamængder
- Lette data: Individuelle CDC- eller streamingbegivenheder er kompakte (1-5 KB typisk størrelse), optimeret til opdateringer med høj frekvens.
- Høj ændring-objekter: For flydende enheder (f.eks. Sag, Kontakt, Bestilling) skal arkitekter sikre, at CDC-tildelinger og begivenhedstransport stemmer overens med forventede opdateringsfrekvenser.
- Parallelle streams: Data 360 understøtter overførsel med flere streams for vandret skalering på tværs af store objektvolumener eller flere kildeorganisationer.
- Bagtrykshåndtering: Indbyggede begrænsningsmekanismer bevarer overførselsstabilitet under indlæsning uden at droppe begivenheder.
Statsadministration
Hver begivenhed inkluderer metadata for stats- og versionskontrol:
- Genafspilning og forskydningssporing: Hver begivenhed indeholder Genafspilnings-id og sekvensmetadata, der aktiverer bestilt levering og kontrolpunktbaseret gendannelse.
- Schema Versioning: Versionstags i begivenhedssidehoveder sikrer bagudkompatibel behandling, når kildeskemaer udvikles.
- Idempotensnøgler: Hver begivenhed inkluderer en entydig transaktion eller bekræftelsesnøgle, så Data 360 kan fjerne dubletter og forsøg sikkert.
- Atomic Commit: Overførselspipelinen markerer kun forskydninger som fuldførte, når downstream-forpligtelser til DLO'er lykkes, hvilket sikrer ensartethed.
Komplekse integrationsscenarier
Dette mønster integreres problemfrit i avancerede virksomhedsarkitekturer:
- Hybrid overførsel: Kombiner CDC for trinvise deltaer med massedatastreams for at få fulde opdateringer, mens du bevarer både friskhed og fuldstændighed.
- Cross-Org Streaming: Flere CRM- eller ERP-organisationer kan udgive til den samme Data 360-lejer, forenet gennem DMO-tilknytning og ontologijustering.
- Begivenhedsberigelse: Mellemprogrammer (f.eks. MuleSoft, Begivenhedsrelæ) kan berige, filtrere eller distribuere streamingdata, før de når Data 360.
- AI og agentaktivering: Opdateringer i realtid udløser downstream-automatisering, f.eks. Einstein eller Agentforce, inden for sekunder efter den oprindelige begivenhed.
Eksempel
En global detailvirksomhed bruger AWS Kinesis til at streame salgs- og webinteraktionsdata.Data 360's Kinesis-forbindelse godkender via IAM-legitimationsoplysninger og overfører kontinuerligt begivenheder til en transaktions-DLO.Hver registrering er skemavalideret, beriget med metadata og straks udbredt til kunde-DMO.Inden for sekunder opdaterer Einstein AI-modeller kundesegmenter og Agentforce udløser næste bedste tilbudsanbefalinger i realtid – hvilket opnår en fuldt begivenhedsstyret tilpasningscyklus.
Zero Copy er mere end en integrationsmetode – det er en grundlæggende ændring i, hvordan virksomhedsdata flyttes eller snarere ikke flyttes. Traditionelt krævede dataintegration kopiering af store mængder registreringer gennem ETL-pipelines, oprettelse af overflødige datalager, synkroniseringsforsinkelser og styringsudfordringer. Nulkopier eliminerer alt dette. I denne model opretter Data 360 forbindelse direkte til eksterne dataplatforme som Snowflake og Databricks og læser og aktiverer data sikkert på plads – uden nogensinde at flytte eller duplikere dem. Resultatet er en problemfri bro mellem din virksomheds datalager og Salesforce-økosystemet, der giver øjeblikkelig adgang, lavere driftsmæssige overhead og stærkere dataadministration.
Indgående nul-kopifunktioner gør det muligt for Data 360 at forespørge på og harmonisere eksterne data ved kilden – f.eks. kundeprofiler, transaktioner eller produktdata – lagret i Snowflake eller Databricks. I stedet for at overføre filer etablerer Data 360 en sikker, metadata-bevidst forbindelse, der anvender eksisterende skemadefinitioner og sikkerhedspolitikker i den eksterne lagerbygning.
- Direct Federation: Data 360 læser data på plads gennem sikre, optimerede forespørgsler uden replikering.
- Forenet forvaltning: Data forbliver under kildesystemets sikkerhed, adgangskontrol og overensstemmelsesstruktur.
- Driftseffektivitet: Eliminerer ETL overhead og lagerdubletter, hvilket reducerer omkostninger og kompleksitet.
- Parathed i realtid: Aktiverer on-demand harmonisering – så snart data opdateres i Snowflake, er de straks tilgængelige for aktivering i Data 360.
Kontekst
Moderne datastyrede virksomheder administrerer petabyte af kunde-, transaktions- og telemetridata i cloud-skala-data lakehouse-platforme som Snowflake og Databricks. Disse miljøer fungerer som den eneste kilde til sandhed for analyser, AI og compliance. Data 360 introducerer Zero CopyData Federation, der giver Data 360 mulighed for direkte at forespørge på og bruge eksterne datasæt på plads – uden at kopiere, transformere eller lagre overflødige data. Dette mønster sætter organisationer i stand til at udvide Customer 360 til deres eksisterende datalager eller lakehouse-infrastruktur – opnå realtidsforening og aktivering med nul dubletter, nul forsinkelse og nul kompromis på styring.
Problem
Hvordan kan virksomheder udnytte avancerede datasæt, der allerede er arrangeret i Snowflake, Databricks eller åbne søformater som Apache Iceberg – til segmentering, identitetsløsning og aktivering i Data 360 – uden omkostninger, forsinkelser og styring af ETL-pipelines eller fysisk dataflytning?
Kræfter
Dette mønster introducerer flere overvejelser i forbindelse med arkitektur, sikkerhed og ydeevne:
Netværk og sikkerhed
- Data 360 skal etablere en sikker, privat forbindelse til den eksterne lagerbygning eller lakehus.
- Konfigureres typisk ved brug af Salesforce Private Connect eller PrivateLink/VPC Peering, hvilket sikrer, at trafik aldrig forlader kundens kontrollerede netværk.
- Eksterne systemer skal sætte Data 360 IP'er på tilladelseslisten og håndhæve TLS 1.2+-kryptering.
Godkendelse og adgangskontrol
- Understøtter nøglepargodkendelse, OAuth 2.0 eller IdP-baseret Trust uddelegering (Data 360 fungerer som en betroet klient)
- Rollebaseret adgangskontrol (RBAC) i det eksterne system håndhæver mindst rettighedsadgang for forespørgselsudførelse.
Ydeevne og beregningsafhængighed
- Forespørgselsføderation overfører SQL-kørsel ned i Snowflake eller Databricks og udnytter deres dataklynger.
- Ydeevne- og omkostningsskala med ekstern forespørgselsindlæsning – segmenteringsforsinkelse og omkostninger er bundet til ekstern beregningskonfiguration.
Udviklende standarder: Filforening
- En næste generations model, Filforening, bruger åbne tabelformater som Apache Iceberg eller Delta Lake, så Data 360 kan læses direkte fra objektlagret (f.eks. Amazon S3, Azure ADLS, Google Cloud Storage).
- Ved at tilsidesætte kildedatalaget reducerer Filforening drastisk forsinkelsen og omkostningerne ved læsbare analytiske arbejdsbelastninger, mens skemaintegriteten bevares.
Forvaltning og overholdelse
- Data forlader aldrig kildeplatformen – overensstemmelse, kryptering og bevarelsespolitikker forbliver håndhævet ved oprindelse.
- Alle metadata, afstamning og samtykkeattributter udbredes i Data 360's Trust Layer for at sikre end-to-end sporbarhed.
Løsning
Den anbefalede tilgang er at bruge oprindelige Zero Copy-forbindelser til Snowflake, Databricks eller Filforening i Data 360.
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| Snowflake Zero Copy-forbindelse | Best | Førsteparts indbygget integration. Etablerer live-forespørgselsfederation via Snowflakes datadeling eller eksterne tabel-API'er. |
| Databricks Zero Copy-forbindelse | Best | Understøtter direkte liveadgang til tabeller/visninger i Delta Lake. Push-down-forespørgsler køres i Databricks-kørsel. |
| Filforening (Apache Iceberg / Delta / Parket) | Ny bedste fremgangsmåde | Data 360 læser direkte åbne tabelformater fra objektlager uden ekstern beregningsafhængighed. Ideel til massive datasæt. |
| Konfiguration af privat netværk | Anbefales | Brug Salesforce Private Connect eller VPC-peering til sikker federation på netværksniveau. |
| Godkendelse og nøglestyring | Bedste fremgangsmåder | Implementer sikker nøglebaseret eller OAuth-baseret godkendelse med regelmæssig rotation og vagtstyring. |
| Skemaregistrering | Påkrævet | Data 360 henter et eksternt skema og tilknytter det til et eksternt DLO (External Data Lake Object). |
| Administrerede metadata | Anbefales | Alle eksterne DLO'er overtager klassificering, samtykke og afledningsmetadata for compliancesynlighed. |
Skitser
Følgende diagram illustrerer, hvordan du opsætter en nul-kopieringsforbindelse og opretter eksterne DLO'er i Data 360.
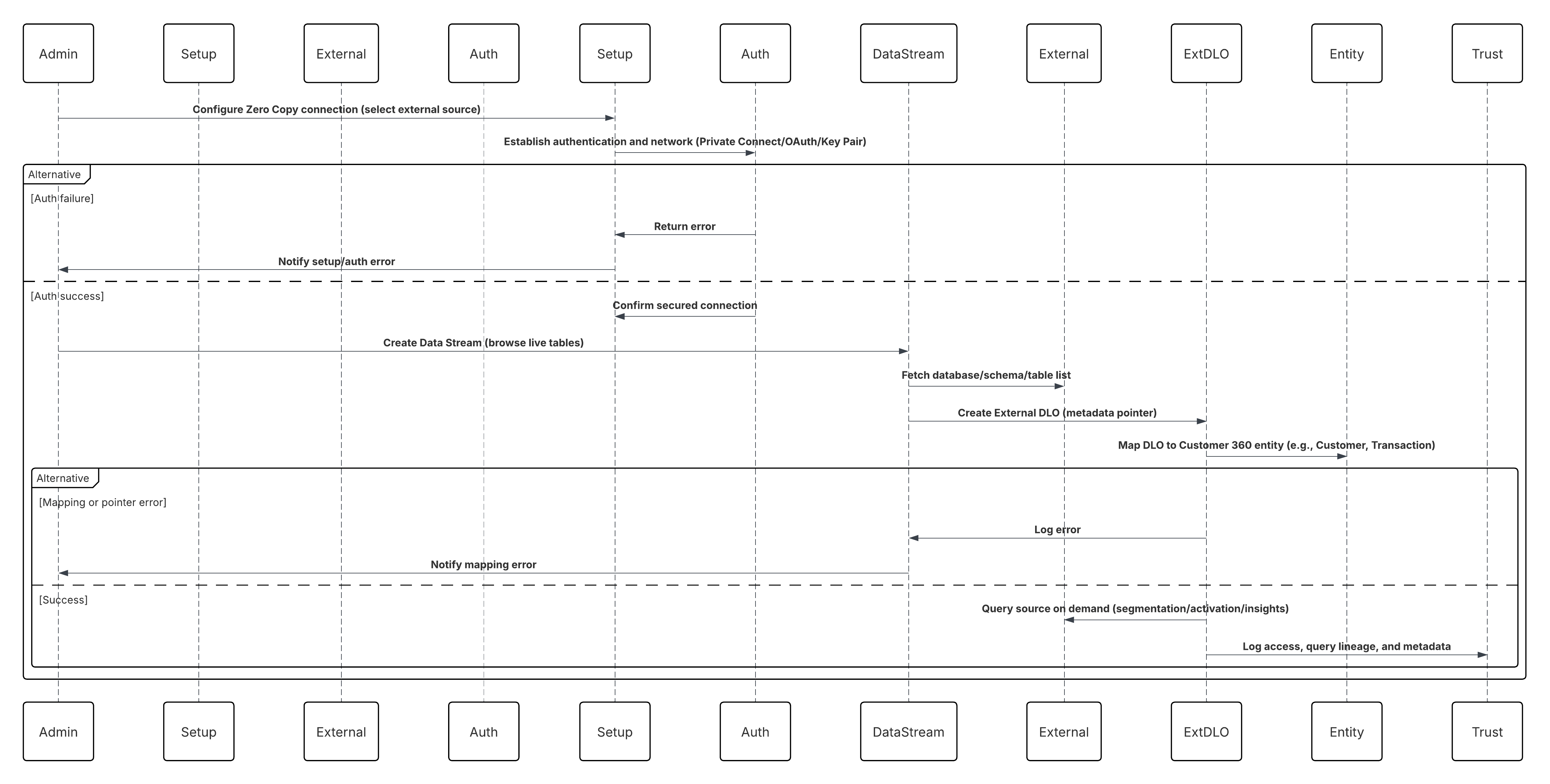
I dette scenarie:
- Administratoren konfigurerer en Zero Copy-forbindelse i Data 360-opsætning (Snowflake, Databricks eller Filforening).
- Sikker godkendelse og netværksdistribution er etableret (Private Connect / OAuth / Key Pair).
- Administrator opretter en datastream, der vælger den eksterne kilde – gennemser live-databaser, skemaer og tabeller.
- I stedet for at kopiere data opretter Data 360 en ekstern DLO (Data Lake Object) – en metadatapakke, der refererer til livetabellen eller Iceberg-filen.
- Eksterne DLO'er tilknyttes til Customer 360 (f.eks. Kunde, Transaktion, Produkt).
- Data 360 forespørger på kilden på plads under segmentering, aktivering eller indsigtsberegning.
- Alle adgang, forespørgselsafstamning og metadata revideres i Data Trust.
Resultater
- Eksterne data forbliver i Snowflake, Databricks eller S3 – ingen ETL, ingen duplikering, ingen yderligere lager.
- Data 360 får læseadgang i realtid til data på virksomhedsskalaen til identitetsløsning, beregnede indsigter og aktivering.
- Organisationer bevarer fuldstændig kontrol under deres eksisterende styrings-, krypterings- og compliancestrukturer.
- Dette mønster aktiverer en sand Zero Copy-arkitektur – kombinerer ydeevnen af lokal adgang med styring af forenet lager.
Opkaldsmekanismer
Kaldsmekanismen afhænger af den løsning, der er valgt for at implementere dette mønster.
| Mekanisme | Hvornår bruges |
|---|---|
| Snowflake Federation (foretrukket) | For live-forespørgselsfederation med høj ydeevne med administrerede virksomhedsdatalager. |
| Databricks Federation | For forenede analyser og lakehouse-miljøer med Delta- eller Parket-backed-datasæt. |
| Filforening (Apache Iceberg / Delta Lake) | For datasæt i stor skala i objektlager, hvor beregningsafbrydelse og omkostningsoptimering er nøglen. |
| Hybrid tilstand (nulkopiering + overførsel) | Når historiske data har brug for engangsoverførsel, men der opnås adgang til live data via Zero Copy. |
Fejlhåndtering og gendannelse
- Automatisk tilbagestilling af forsøg og forespørgsel: Midlertidig forbindelse eller forespørgselstimeouts forsøges automatisk ved brug af eksponentiel tilbagerulning.
- Skema - uoverensstemmende isolering: Ændringer i kildeskemaet (f.eks. nye kolonner) logføres til skemaafvisningskøen. Administratorer kan omformulere eller opdatere skemametadata.
- Godkendelsesfejloverførsel: Hvis legitimationsoplysningerne udløber, forsøger Data 360 forbindelsen ved brug af lagrede opdateringstokener eller nøglerotationspolitikker.
- Beregn tilgængelighedsregistrering: Hvis Snowflake- eller Databricks-klynge sættes på pause, suspenderer Data 360 federationsjob og forsøg, når beregningen genoptages.
- Overvågningsintegration: Alle forbindelsestilstand, forespørgselsforsinkelse og afledningsmetadata er synlige i Data 360 Monitoring-dashboards.
Overvejelser i forbindelse med idempotent design
- Forespørgselsdeterminisme: Forenet forespørgsel bruger ensartet øjebliksbilledsemantik til at sikre stabile, gentagne læsninger under segmentering eller aktivering.
- Ekstern DLO-versionering: Hver forenet forespørgsel inkluderer skema- og tidsstempelmetadata til oprindelsessporing.
- Adgang uden forskydning: Da Zero Copy er skrivebeskyttet, er det ikke afhængigt af begivenhedsforskydninger – ensartethed håndhæves via det eksterne systems ACID-garantier (Snowflake/Delta Lake).
- Skema-driftstyring: Vedligehold versionerede skematilknytninger i Data 360. Opdater eksterne DLO-metadata på kildeudvikling.
Sikkerhedsovervejelser
Sikkerhed er integreret i hele federationsmodellen – uden at gå på kompromis med Trust eller compliance.
- Kryptering: Alle dataudvekslinger bruger TLS 1.2+; eksterne lagerbygninger krypteres som inaktive ved brug af AES-256.
- Adgangskontrol: Der opnås adgang til eksterne tabeller gennem roller med mindst rettigheder med skrivebeskyttede tilladelser.
- Netværksisolering: Private Connect- eller VPC-distributioner forhindrer enhver eksponering for offentlige slutpunkter.
- Administreret dataforløb: Afstamning, samtykke og klassificeringsmetadata flyder ind i Data 360 Trust Layer til håndhævelse af politikker.
- Auditerbarhed: Hver forenet forespørgsel og skemaadgangsbegivenhed logføres til overensstemmelsessporbarhed (GDPR, CCPA, HIPAA).
Sidebars
Tidlighed
- Forespørgsler eksekveres direkte mod den eksterne lagerbygning eller lagerbygning og sikrer synlighed i realtid af den seneste datatilstand.
- Segmenterings- eller aktiveringskørsler afspejler ændringer op til det sekund i Snowflake-, Databricks- eller S3-understøttede Iceberg-tabeller.
- Forespørgselsforsinkelse afhænger af kildesystemets ydeevniveau – typisk sekunder til snesevis af sekunder pr. forespørgsel.
- Ideel til analytiske og AI-arbejdsbelastninger, der kræver "frisk, ikke-kopieret" dataadgang.
Datamængder
- Understøtter datasæt på petabyte-skala, der er lagret som standard i Snowflake eller Databricks uden replikering.
- Data 360 henter kun resultater – ikke rå datasæt – hvilket minimerer netværks- og beregningsomkostninger.
- Filforening optimerer store analytiske scanninger gennem partitionsopdelinger og kolonnedash.
- Skaleres lineært med lagerdatakapacitet og Data 360's forenede forespørgselsorkestreringslag.
Statsadministration
- Eksterne DLO'er bevarer forbindelses-, skema- og versionsmetadata i Data 360.
- Skemaudvikling administreres automatisk gennem metadataopdateringscyklusser.
- Forespørgselsafstamning inkluderer tidsstempler, brugeridentitet og kørselsmetrikker for sporbarhed.
- Ingen statsmæssig overførsel eller forskydninger bevares – ensartethed overtages fra den eksterne kildes ACID-garantier.
Komplekse integrationsscenarier
- Hybridtilstand: Kombiner Zero Copy (for live-federation) med overførsel (for historiske datasæt).
- Cross-Warehouse Access: Data 360 kan forenes fra flere Snowflake- eller Databricks-lejer i en organisation.
- AI/BI-interoperabilitet: Eksterne systemer (f.eks. SageMaker, Tableau, Power BI) kan forespørge på Data 360's berigede profiler tilbage via omvendt nul-kopiering.
- Filforening: Virksomheder, der anvender åbne søformater (Iceberg/Delta), kan forene strukturerede og ustrukturerede data under en forenet model.
Eksempel
En global finansiel virksomhed lagrer alle transaktions- og interaktionsdata i Snowflake, mens du vedligeholder kundeattributter og marketingbegivenheder i Data 360. Ved at bruge Zero Copy Data Federation opretter Data 360 en sikker forbindelse til Snowflake via Private Connect.Når et segmenteringsjob kører, f.eks. "Kunder med >$10.000 forbrug i de sidste 30 dage, overfører Data 360 forespørgslen ned i Snowflake, henter aggregerede resultater og aktiverer disse profiler med det samme i Journey Builder. Der kræves ingen replikering eller ETL. Dette eksempel bruger realtids, forenet intelligens, der er forenet på tværs af virksomhedsdataøkosystemet.
Udgående nul-kopiering udvider det samme princip omvendt. I stedet for at eksportere eller kopiere datasæt fra Data 360, kan eksterne systemer som Snowflake forespørge på Data 360 direkte og behandle det som en forenet kilde til beriget Kundeintelligens.
- Reverse Federation: Eksterne analyser eller AI-platforme kan få adgang til Data 360's forenede profildata uden at udtrække dem.
- Dataktivering ved kilde: Forretningsteams kan udnytte indsigter, hvor data allerede findes – uanset om det gælder AI-modellering, rapportering eller kundetilpasning.
- Latency-free interoperability: Ingen batcheksporter eller synkroniseringsjob. Indsigter flyder med det samme mellem platforme.
- Konsekvent semantik: Da begge systemer deler den samme ontologi og skematilknytninger, bevares kontekst og betydning på tværs af økosystemer. Zero copy omdefinerer rollen for Data 360 fra et datalager til et semantisk aktiveringslag. Det gør det muligt for organisationer at bevare data præcis der, hvor de hører til – i styrede, højtydende lagerbygninger – mens de stadig låser deres fulde værdi op inden for Salesforces Trust grænser. Dette mønster stemmer overens med moderne datasæt og AI-oprindelige arkitekturer: data forbliver decentraliserede, men intelligens bliver forenet. Arkitekter kan nu opbygge aktiveringspipelines, der er hurtigere, smalere og mere kompatible – der kræves ingen kopiering.
Kontekst
Moderne virksomheder opererer i stigende grad i datasystemer med flere platforme, hvor Salesforce Data 360 styrker forenede kundeprofiler og -aktivering, mens virksomhedsdatalager som Snowflake eller Databricks fungerer som analytiske grundlag for datavidenskab, maskinlæring og BI-arbejdsbelastninger. Salesforce Data 360's Zero Copy Outbound Sharing-funktionalitet udbygger problemfrit disse miljøer – og tillader administreret, sikker og realtidsadgang til harmoniserede Data 360-data direkte i Snowflake eller Databricks, uden replikering eller ETL. Dette gør det muligt for analytikere og dataforskere at forespørge, visualisere og modellere på samme live, betroede data, der styrer marketing, salg og serviceaktivering.
Problem
Hvordan kan en virksomhed sikkert og effektivt vise Data 360's forenede kundeprofiler og beregnede metrikker (f.eks. Livstidsværdi, Churn Risk) til eksterne analysesystemer – uden at kopiere data, bryde styring eller introducere forsinkelse gennem traditionelle omvendte ETL-pipelines?
Kræfter
Dette mønster introducerer flere overvejelser i forbindelse med arkitektur, styring og drift:
- Administreret sikkerhed: Adgang til Data 360-data skal være kontrolleret, detaljeret og kan revideres. Nulkopieringsdeling bruger eksplicit adgang på objektniveau, hvilket sikrer, at kun godkendte datamodelobjekter (DMO'er) og beregnede indsigtsobjekter (CIO'er) er tilgængelige for udpegede forbrugere.
- Udtrykkelig objektvalg: Administratorer arrangerer delbare data gennem en datadeling og vælger eksplicit, hvilke objekter der skal vises. Dette bevarer styring og minimerer risikoeksponering.
- Bilateral konfiguration: Både Data 360 og den eksterne lagerbygning kræver opsætning. Data 360 definerer datadelingsmålet (Snowflake/Databricks), mens det modtagende system skal acceptere og oprette en opstilling af delingen.
- Forespørgselsfederationsmodel: Når den eksterne platform er accepteret, forespørger den på live, administrerede Data 360-data via forenede visninger, hvilket eliminerer udtrækningsjob eller manuelle opdateringscyklusser.
- Open Standards Evolution: Nye tilgange som Filforening bruger åbne tabelformater (f.eks. Apache Iceberg) til at aktivere skrivebeskyttet adgang på lageret – hvilket forbedrer skalerbarhed, ydeevne og interoperabilitet på tværs af multi-cloud-arkitekturer.
Løsning
Løsningen anvender Salesforce Data 360's oprindelige nulkopiedeling med dataplatforme som Snowflake eller Databricks.
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| Oprettelse af datadeling | Best | Administrator opretter en datadeling i Data 360 og tilføjer valgte DMO'er og CIO'er (f.eks. Forenet person, Kundetilstandsscore). |
| Målkonfiguration | Best | Opret et datadelingsmål, der angiver Snowflake- eller Databricks-kontoidentifikatorer og godkendelsesparametre. |
| Del udgivelse | Bedste fremgangsmåder | Link datadelen til datadelingsmålet for at udgive sikkert. |
| Lager Accept | Påkrævet | Den eksterne administrator accepterer delingen og materialiserer delte objekter som skrivebeskyttede visninger/tabeller i lagerbygningen. |
| Granulær adgangskontrol | Anbefales | Anvend objekt- og rollebaserede tilladelser i Data 360. Juster med rollebaseret adgangskontrol på lagerbygningsniveau. |
| Federeret forespørgselsadgang | Best | Analysere forespørger på live-delte data via standard-SQL. Sammenføjes med oprindelige lagerdata til downstream-analyser og ML. |
| Filforening | Valgfrit | For store datasæt skal du bruge Apache Iceberg-baseret federation til direkte S3- eller Delta Lake-læsninger uden beregningsafhængighed. |
Skitser
Følgende diagram illustrerer et kald fra Salesforce Data 360 til en ekstern Data Platform.
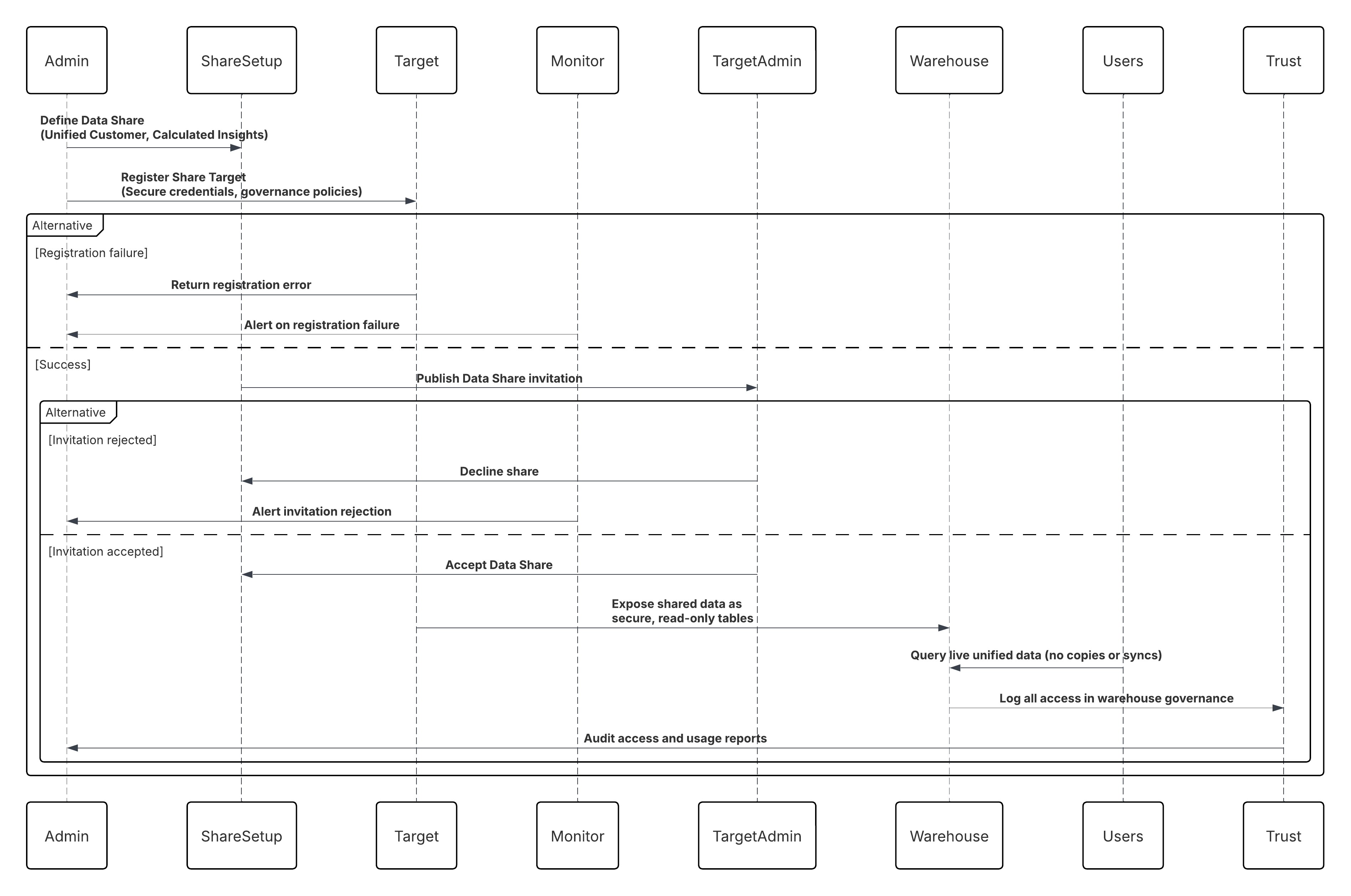
I dette scenarie:
- Data 360-administrator definerer en datadeling, herunder objekterne Forenet kunde og Beregnet indsigt.
- Et datadelingsmål (Snowflake- eller Databricks-konto) registreres med sikre legitimationsoplysninger og styringspolitikker.
- Data 360 udgiver delingen. Snowflake/Databricks-administratorer accepterer den.
- Delte data vises som sikre skrivebeskyttede tabeller i lagerbygningen.
- Analysere, BI-værktøjer eller ML-pipelines forespørger på de live, forenede kundedata uden at kopiere eller synkronisere.
- Al adgang overvåges i Data 360 Trust Layer og lagerstyringslogfiler.
Resultater
- Eksterne lagerbygninger får adgang i realtid, der kan forespørges på, til harmoniserede Data 360-data.
- Eliminerer omvendte ETL-pipelines, hvilket reducerer driftsbelastning og forsinkelse.
- Aktiverer AI/ML-træning, forudsigende modellering og avanceret BI direkte på forenede data.
- Vedligeholder nul-dubletter, stærk styring og sikker adgangskontrol efter design.
- Fuldfører den bidirektionelle Zero Copy-løkke, hvor indgående federation og udgående deling eksisterer sammen under en enkelt styringsmodel.
Opkaldsmekanismer
Kaldsmekanismen afhænger af den løsning, der er valgt for at implementere dette mønster.
| Mekanisme | Hvornår bruges |
|---|---|
| Sikker deling af Snowflake-data (foretrukket) | Bruges, når din virksomhedslager er Snowflake, og du har brug for live, administreret adgang til harmoniserede Data 360-datasæt uden dataflytning eller duplikering. Ideel til analyser, AI og overensstemmelsesstyrede arbejdsbelastninger, der kræver deling med nul forsinkelse og indbygget håndhævelse af overordnede. |
| Databricks Delta Share | Bruges, når downstream-forbrugere opererer i Databricks- eller Delta Lake-miljøer og kræver adgangen Skrivebeskyttet i realtid til forenede eller aktiverede datasæt via den åbne Delta-delingsprotokol. |
| Ekstern borddeling (Apache Iceberg / Parket) | Bruges, når du vedligeholder open-format-arkitekturer i objektlager (S3, ADLS eller GCS) og har brug for interoperabel, lavprisdeling på tværs af analysesystemer som Athena, BigQuery eller Snowflake-on-Iceberg. |
| Data Deling API (Programmatisk adgang) | Bruges, når tilpassede apps eller middleware (f.eks. MuleSoft) skal finde, abonnere på eller forbruge delte datasæt sikkert via API'er med begivenhedsbaserede opdateringsadviseringer og detaljeret adgangskontrol. |
| Hybrid deling (nulkopiering + udgående deling) | Bruges, når du implementerer tovejsudvekslingsmønstre – udnytter Zero Copy for indgående data og Udgående datadeling til udgivelse af indsigter, hvilket sikrer semantisk og styringssammenhæng på tværs af virksomhedsdataplaner. |
Fejlhåndtering og gendannelse
- Forbindelsesforsøg: Automatiserede forsøg for midlertidige forbindelses- eller godkendelsesfejl mellem Data 360 og lagerbygningen.
- Del validering: Ugyldige eller uautoriserede delingskonfigurationer er sat i karantæne i en administratorgennemgangskø.
- Synkronisering af tilstand: Data 360 viser live-delingsstatus, forespørgselsforsinkelse og adgangslogfiler via overvågningsdashboards.
- Adgang tilbagekaldt: Administratorer kan tilbagekalde delinger med det samme og inaktivere adgang i begge ender uden resterende datakopier.
- Administreret revisionsspor: Alle konfigurations- og adgangsændringer logføres til overensstemmelsesbekræftelse.
Overvejelser i forbindelse med idempotent design
- Konsekvent delingsidentifikation: Hvert datadelings- og datadelingsmålpar har en entydig identifikator, der sikrer nøjagtig styring og adgangssporbarhed.
- Uændrede visninger: Delte dataobjekter er skrivebeskyttede. Forbrugere kan ikke ændre tilstanden, hvilket sikrer deterministiske resultater og compliance.
- Atomisk delings livscyklus: Del udgivelse, tilbagekaldelse og opdateringer er atomhandlinger – enten fuldført eller rullet tilbage.
- Genafspilning ensartethed: Når Data 360-data opdateres, returnerer forespørgsler på lagersiden altid det seneste ensartede øjebliksbillede og eliminerer forældede læsninger.
Sikkerhedsovervejelser
Sikkerhed understøtter alle aspekter af nul-kopiedeling:
- Godkendelse: Gensidig Trust etableret ved brug af OAuth 2.0, privat nøgleudveksling eller identitetsføderation (OIDC).
- Kryptering: Data krypteret under transit (TLS 1.2+) og inaktive (AES-256).
- Adgangskontrol: Tilladelser på objektniveau håndhæver adgangen med mindste rettigheder, der styres af Data Trust.
- Netværkssikkerhed: Dataudvekslinger forekommer gennem private netværkslinks, f.eks. Salesforce Private Connect eller Secure Data Exchange-API'er.
- Governance-metadata: Hvert delt objekt har afstamnings-, klassificerings- og samtykkeattributter for fuld sporbarhed og overholdelse af bestemmelser.
Sidebars
Tidlighed
- Tilgængelighed i realtid: Delte data afspejler den mest aktuelle tilstand af Data 360 uden replikeringsforsinkelser.
- Forespørgselsfriskhed: Ændringer i DMO'er eller CIO'er udbredes med det samme til delte lagervisninger.
- Ydeevne Elasticitet: Forespørgsels-push-down tilpasser sig dynamisk til lagerdataressourcer.
- Overvågning: Live-dashboards viser delt forsinkelse og forespørgselsydeevnemetrikker for driftssikkerhed.
Datamængder
- Skalerbar deling: Understøtter deling af detaljerede data på objektniveau eller fuldt domæne afhængigt af analytiske behov.
- Optimeret forespørgselsydeevne: Snowflake/Databricks cachelagrer delte data intelligent for at minimere forsinkelse.
- Lager Effektivitet: Nul-dublet eliminerer overflødige lagringsomkostninger.
- Filforening: For datasæt på petabyte-skala tilsidesætter direkte Iceberg-baseret deling beregning og fremskynder adgang.
Statsadministration
- Skemaudvikling: Versionsstyrede skemaer sikrer kompatibilitet, når Data 360-modellen udvikles.
- Adgangstilstandssporing: Aktive/ inaktive delingstilstande, der bevares i Data 360 til livscyklusstyring.
- Metadatasynkronisering: Opdateringer til delte objektdefinitioner afspejles automatisk i downstream-lagerkataloger.
- Uændret statsgaranti: Lagervisninger repræsenterer altid en ensartet, tidsmæssig tilstand af Data 360-data.
Komplekse integrationsscenarier
- Hybridtilstand: Kombiner Zero Copy (for live-federation) med overførsel (for historiske datasæt).
- Cross-Warehouse Access: Data 360 kan forenes fra flere Snowflake- eller Databricks-lejer i en organisation.
- AI/BI-interoperabilitet: Eksterne systemer (f.eks. SageMaker, Tableau, Power BI) kan forespørge på Data 360's berigede profiler tilbage via omvendt nul-kopiering.
- Filforening: Virksomheder, der anvender åbne søformater (Iceberg/Delta), kan forene strukturerede og ustrukturerede data under en forenet model.
Eksempel
Kryds-cloud-analyser gør det muligt for organisationer at kombinere administrerede Salesforce Data 360-data med oprindelige datasæt på platforme som Snowflake og Databricks for at levere en komplet 360-graders analytisk visning. Gennem flerlejeradgang kan forskellige forretningsenheder sikkert forbruge organiserede og policekontrollerede dataudsnit via separate shares uden at duplikere data. Dataanalytikere kan derefter udføre forenet AI og maskinlæring ved at træne modeller direkte på forenede kundeprofiler i Snowflake ML- eller Databricks MLflow-miljøer. Gennem denne proces sikrer indbyggede afstamnings-, styrings- og revisionsfunktioner, at al dataadgang og -anvendelse forbliver i overensstemmelse med virksomhedspolitikker og bestemmelseskrav som f.eks. GDPR og HIPAA.
Data Cloud One gør det muligt for organisationer med flere Salesforce-organisationer (f.eks. på grund af forretningsenheder, områder, produktlinjer eller overtagelser) at dele en enkelt, central Data 360-forekomst. Denne organisation fungerer som "startsorganisationen", mens andre organisationer, kaldet "kompanionsorganisationer", kan få adgang til og reagere på disse forenede data – med minimal indsats, ingen tilpasset kode og fulde styringskontroller.
Kontekst
Virksomheder kører ofte mere end en Salesforce-organisation (f.eks. en til salg, en til service, en til marketing eller særskilte områder). Hver organisation kan have sine egne data, konfiguration og processer. Før Data Cloud One krævede hver organisation enten sin egen Data 360-opsætning eller kompleks tilpasset kode for at dele data på tværs af organisationer. Data Cloud One forenkler dette ved at tillade en enkelt "hjemme"-organisation med Data 360 og flere "kompanionsorganisationer", der opretter forbindelse via konfiguration med lav kode og metadatadeling.
Problem
Hvordan kan en forretning aktivere ensartet brug af de forenede Customer 360 – der overføres, harmoniseres og administreres af startorganisationens Data 360 – på tværs af alle Salesforce-organisationer (så salgs-, marketing-, service- osv. alle bruger de samme underliggende data), mens du undgår duplikering af indsats, tilpasset kodning, separate Data 360-forekomster pr. organisation og styringsmangler?
Kræfter
Dette mønster introducerer flere overvejelser i forbindelse med arkitektur, sikkerhed og ydeevne:
- Multi-Org Complexity: Hver forretningsenheds organisation kan have forskellige data, tilpassede objekter, sikkerhed og processer – det er svært at vedligeholde ensartede forenede visninger.
- Dubletter og omkostninger: Kørsel af en separat Data 360-forekomst pr. organisation betyder ekstra opsætning, ekstra styring, ekstra licens og risiko for datasiloer.
- Forvaltning og datadelingskontrol: Du skal beslutte, hvilke data hver ledsagerorganisation kan se og reagere på – du kan ikke bare dele “alt” uden styringsrisiko.
- Opsætningshastighed: Marketing-, salgs- eller serviceteams kan ikke vente uger på, at tilpasset kode gør krydsorganisationsdata tilgængelige – de har brug for click-config-løsninger.
- Dataopbevaring, regionale overvejelser: Hvis start- og ledsagerorganisationer er i forskellige områder, kan der være juridiske eller regulerende begrænsninger for, hvor data lagres, eller hvordan de deles.
Løsning
Følgende tabel indeholder forskellige løsninger på dette integrationsproblem.
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| Home Org-provisionering | Best | Udpeg en Salesforce-organisation som den startorganisation, hvor Data 360 er klargjort. Dette bliver det centrale datalager og styringshub. |
| Companion-organisationsforbindelse | Best | Konfigurer ledsagende forbindelser fra startorganisationen til en eller flere ledsagende organisationer via Data Cloud One-appen – der kræves ingen tilpasset kode. |
| Dataområdedefinition | Bedste fremgangsmåder | Definer dataområder i startorganisationen for logisk at segmentere data (f.eks. Detail, Service, Marketing) og isolere adgangsbegrænsninger. |
| Dataområdedeling | Best | Del eksplicit valgte dataområder fra startorganisationen til ledsagende organisationer, så du sikrer styret, rollebaseret synlighed af forenede data. |
| Adgangskonfiguration | Påkrævet | I ledsagende organisationer skal du aktivere Data Cloud One-appen og tildele brugertilladelser for profil-, indsigts- og segmentadgang. |
| Forvaltning og politikkontrol | Anbefales | Centraliser alle konfigurationer af overførsel, identitetsløsning og Trust i startorganisationen og oprethold end-to-end-styring. |
| Synkronisering med flere organisationer | Best | Dataændringer og beregnede indsigter i startorganisationen afspejles i realtid på tværs af ledsagende organisationer gennem administrerede synkroniseringspipelines. |
| Hybridimplementeringsindstilling | Valgfrit | For store virksomheder kan flere ledsagerorganisationer oprette forbindelse til en enkelt startorganisation, mens de bevarer lokale kontekst- og compliancegrænser. |
Skitser
Følgende diagram illustrerer rækkefølgen af begivenheder i dette mønster, hvor Salesforce er den overordnede.
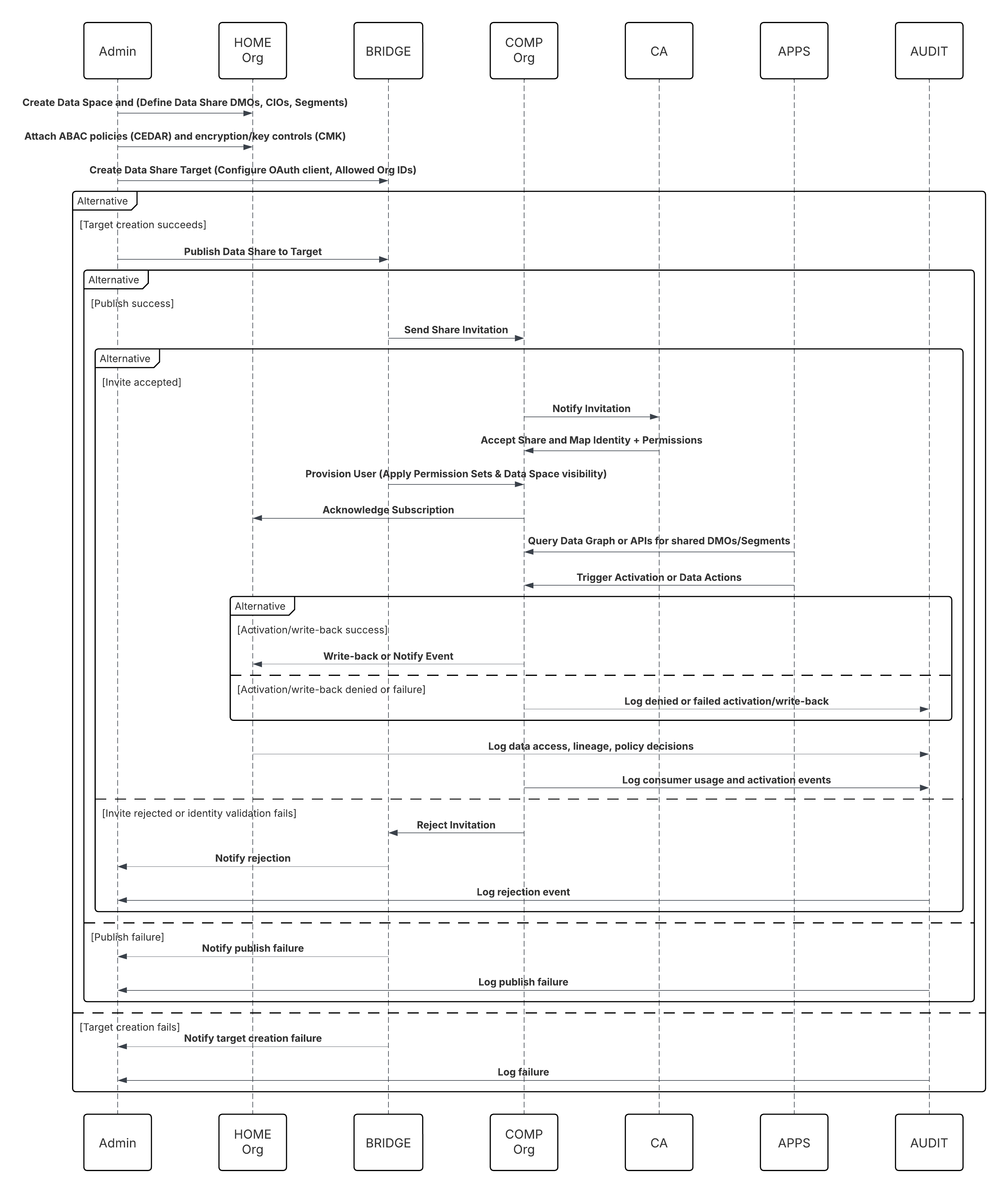
I dette scenarie:
- Startsideadministrator: opret datarum og definer datadeling (vælg DMO'er/CIO'er, segmenter).
- Startsideadministrator: opret datadelingsmål for ledsagende organisationer og konfigurer Trust (OAuth-klient, tilladte organisations-id'er).
- Startadministrator: Udgiv Datadeling til mål; vedhæft ABAC-politikker (CEDAR) og kryptering/nøglekontroller (CMK hvis det er nødvendigt).
- Companion Org Admin: modtager invitation, validerer identitetstilknytning og accepterer deling.
- Companion Org: Data Cloud One Bridge klargør en Data Cloud One-bruger og anvender tilladelsessæt og dataplacesynlighed.
- Medarbejderorganisationsapps (forløb / Einstein / Apex): Forespørg på et datadiagram, eller kald Data Cloud One-API'er for at læse delte DMO'er eller segmenter.
- Aktivering: Begejstret organisation udløser aktivering eller skriver tilbage via datahandlinger (hvis det er tilladt).
Resultater
- En enkelt kilde til sandheden for kundedata (Customer 360) på tværs af alle tilsluttede organisationer – ingen overflødige Data 360-forekomster.
- En hurtigere tid til at evaluere. ledsagende organisationer kan få adgang til forenede data og Data 360-drevne funktioner på minutter, ikke uger med tilpasset kodning.
- Kontrolleret datadeling. Kun autoriserede dataområder deles, hvilket bevarer sikkerhed og styring, mens du aktiverer forretningsagility.
- Forretningsfunktioner (salg, service, marketing) fungerer på samme forenede databaser og aktiverer ensartede metrikker, aktivering og indsigter på tværs af virksomheden.
Opkaldsmekanismer
Kaldsmekanismen afhænger af den løsning, der er valgt for at implementere dette mønster.
| Mekanisme | Hvornår bruges |
|---|---|
| Data Cloud One - indbygget deling (foretrukket) | Bruges, når flere Salesforce-organisationer (salg, service eller Industry Clouds) har brug for adgang i realtid til forenede kundedata direkte fra Data 360\. Dette eliminerer replikering og aktiverer nul-forsinkelsesadgang til Golden Records, segmenter og beregnede indsigter. |
| Organisations-til-organisation-deling via Data Cloud One Bridge | Bruges, når flere forretningsenheder eller datterselskaber opererer i separate Salesforce-organisationer, men har brug for delt adgang til almindelige kundedata og segmenter fra en central Data 360-forekomst. Ideel til virksomheder med flere organisationer, der vedligeholder uafhængige driftssystemer. |
| Einstein 1-platformsforespørgsels-API'er | Bruges, når Salesforce-apps, forløb eller Einstein Copilot skal forespørge på eller aktivere Data 360-data programmeringsmæssigt. Aktiverer hentning i realtid af forenede profiler, metrikker eller aktiveringsresultater i andre Salesforce-applikationer uden batcheksporter. |
| Aktivering til Salesforce-kanaler | Bruges, når Data 360-data (segmenter, indsigter eller attributter) skal aktiveres i Marketing Cloud, Service Cloud eller Commerce Cloud for tilpasning, kampagnekørsel eller agenthjælpoplevelser. |
| Datatadiagramadgang (semantisk forespørgselslag) | Bruges, når du har brug for adgang på semantisk niveau til den forenede datamodel via Salesforce-datadiagrammet – understøtter Copilot, AI-arbejdsflows og cross-cloud-analyser inReal-Time uden manuelle sammenføjninger eller transformationer. |
Fejlhåndtering og gendannelse
- Cross-Org Sync Resilience: Data Cloud One forsøger automatisk mislykkede synkroniseringsjob mellem start- og ledsagende organisationer ved brug af eksponentiel tilbagerulning for midlertidige netværks- eller platformsfejl.
- Delvis batchisolering: Mislykkede registreringsbatches er sat i karantæne i en forsøgskø i startorganisationen, indtil afstemningen lykkes, hvilket forhindrer dataafvigelser.
- Skemaafvisningsstyring: Skema- eller tilknytningsuoverensstemmelser distribueres til skemaafvisningskøen til administratorgennemgang og rettelse.
- Gentag og genoptag kontinuitet: Hvert synkroniseringsjob bevarer forskydningskontrolpunkter, så replikering kan genoptages fra det sidste vellykkede bekræftelse uden duplikering.
- Integreret overvågning: Alle fejl, forsøg og gendannelsesmetrikker registreres i Trust Layer Monitoring Dashboard for at sikre synlighed og SLA.
Overvejelser i forbindelse med idempotent design
- Deterministiske idempotensnøgler: Hver synkroniseringsbegivenhed indeholder en entydig nøgle (organisations-id + registrerings-id + versionsnummer) for at garantere præcis en gang-behandling.
- Genafspilningssikkerhed: Dublet- eller genafspilede begivenheder filtreres på bekræftelsestidspunktet, hvilket sikrer ensartede downstream-DMO- og CIO-opdateringer.
- Atomic Commit Semantics: Begrænsningsorganisationer markerer kun data som bekræftede efter vellykkede downstream-skrivninger, hvilket bevarer krydsorganisationstransaktionsintegritet.
- Konfliktløsning: Flerkildeopdateringer følger sidste-skrive-vundne eller politikstyret flettelogik, mens de bevarer overtagelse og ensartethed.
- Checkpoint Persistence: Synkroniseringsjob bevarer sidst behandlede forskydninger og tilstand i Trust for sikker gendannelse og afspilning.
Sikkerhedsovervejelser
- Stærk godkendelse: Forbindelser mellem start- og ledsagelsesorganisationer bruger gensidig OAuth 2.0 med automatisk roterende tokener, der administreres via tilsluttede apps.
- Granular Authorization: Begrænsningsorganisationer kan kun få adgang til specifikke dataområder, DMO'er eller CIO'er, der eksplicit deles gennem administrerede datadelingspolitikker.
- Kryptering overalt: Data krypteres i overførsel (TLS 1.2+) og inaktive (AES-256) på tværs af både start- og ledsagerorganisationer.
- Princippet om mindste rettighed: Integrationsbrugere omfatter kun de påkrævede objekter. Der udbredes ingen administrative tilladelser eller tilladelser på systemniveau.
- Audit og compliance synlighed: Alle synkroniseringsbegivenheder, skemaændringer, opdateringer af legitimationsoplysninger og adgangstildelinger logføres i Data 360 Trust Layer for fuld sporbarhed.
- Privat netværksisolering: Valgfri Salesforce Private Connect eller Privat link sikrer, at datareplikering kun forekommer over sikre interne kanaler.
Sidebars
Tidlighed
- Synkronisering mellem start- og ledsagelsesorganisationer forekommer næsten i realtid, typisk inden for sekunder af en dataændring i kildeorganisationen.
- Zero Copy-arkitekturen sikrer, at delte data straks kan forespørges på på tværs af alle deltagende organisationer – ingen replikerings- eller batchforsinkelser.
- Aktiverings- og segmenteringsjob afspejler automatisk de seneste opdateringer fra enhver tilsluttet organisation og bevarer den driftsmæssige opdatering.
- End-to-end-forsinkelse er deterministisk og styres af Data Cloud One's orkestrerings-pipeline, hvilket sikrer ensartet krydsorganisationstidsangivelse, selv under indlæsning.
Datamængder
- Designet til datasynkronisering med flere lejere på tværs af områder og forretningsenheder – der kan administrere milliarder af registreringer pr. organisation.
- Der refereres til data, ikke duplikeres, hvilket reducerer lageraftrykket, mens der bevares global forespørgsel.
- Streamingdeltaer og metadatakomprimering optimerer båndbredde og bekræfter overhead for objekter med høj ændringsfrekvens (f.eks. Kontakt, Bestilling).
- Skaleres vandret på tværs af flere ledsagelsesorganisationer med adaptiv indlæsningsbalancering og orkestrering gennem Trust.
Statsadministration
- Hvert synkroniseret datasæt bevarer metadataafstamning, version og organisationsejerskabskontekst for at sikre end-to-end-sporbarhed.
- Kontrolpunktopbevarelse registrerer sidst synkroniserede forskydninger mellem organisationer og tillader gendannelse uden duplikering.
- Skemaversionering og semantisk justering på tværs af organisationer styres automatisk af Trust Layers.
- Der kræves ingen manuelle tilstandsnulstillinger – synkroniseringstilstanden vedligeholdes gennem Data Cloud One-orkestreringstjenesten.
Komplekse integrationsscenarier
- Cross-Org Federation: Aktiverer problemfri forespørgsel og aktivering på tværs af flere Data 360-lejer eller områder under en forenet styringsmodel.
- Hybrid synkronisering: Kombinerer replikering næsten i realtid for transaktionsopdateringer med planlagt synkronisering for massedata eller arkivdata.
- Flerregionsstyring: Understøtter geografisk distribueret datadeling, mens du respekterer grænser for bopæl, samtykke og compliance.
- AI og automatiseringsaktivering: Synkroniserede data styrker øjeblikkeligt Einstein AI, Agentforce eller tilpassede ML-modeller på tværs af organisationer – hvilket aktiverer krydsorganisationsdata i realtid.
Eksempel
En global detailorganisation har tre Salesforce-organisationer: en for Forbrugerdetail, en for Premium-brands og en for internationale markeder. De klargør Data 360 i Consumer Retail-organisationen (gør den til startorganisationen). Med Data Cloud One opsætter de ledsagende forbindelser til organisationer med Premium Brands og International Markets. De deler kun relevante dataområder (f.eks. "Customer 360 – Retail Profiles" og "Customer 360 – Premium Profiles") med hver ledsagende organisation. I organisationen Premium Brands kan marketingteams se forenede kundeprofiler, opbygge segmenter baseret på beregnede indsigter (f.eks. premium kundelivsværdi) og udløse marketingautomatiseringer – alt sammen drevet af startorganisationens Data 360-forekomst uden tilpasset kodning eller dataduplikering.
Dataaktivering er det sted, hvor værdien af Salesforce Data 360 virkelig kommer til live. Det er processen med at tage de forenede, berigede og administrerede data, der findes i platformen, og få dem til at fungere på tværs af forretningen. I praksis betyder dette, at du sikkert leverer organiserede segmenter, beregnede indsigter og kontekstuelle attributter fra Data 360 i de systemer, der engagerer kunder – uanset om det er marketingautomatisering, servicekonsoller, salgsaktivering, analyser eller AI-modeller. Fra et teknisk perspektiv definerer aktiveringsmønstre, hvordan disse data flyttes: hvilke kanaler der udløses, hvilke transformationer eller tilknytninger der forekommer, og hvordan politikker håndhæves undervejs. Disse mønstre handler ikke kun om at eksportere data – de handler om at orkestrere realtids, politikbevidste dataforløb, der fremmer målbare forretningsresultater. Hver aktivering rute omdanner Customer 360 til et levende driftsmæssigt aktiv – der fremmer personliggørelse, forudsigende beslutningstagning og kontinuerlig læring på tværs af hvert kontaktpunkt.
Batchaktivering forbliver den mest anvendte og operationelt bevist metode til eksport af data fra Data 360. Den fungerer på en planlagt kadence – udgivelse af foruddefinerede målgruppesegmenter eller attributsæt til downstream-platforme med regelmæssige intervaller. Dette mønster er ideelt egnet til marketing- og engagementsarbejdsflows, der er afhængige af ensartet levering af højvolumen målgruppe snarere end øjeblikkelige opdateringer. Typiske anvendelsessituationer omfatter power-mailrejser, direkte mailkampagner eller målgruppens uploads til digitale annonceringsnetværk. Hver aktiveringskørsel udtrækker det kvalificerede segment fra Data 360's forenede profildiagram, anvender styrings- og samtykkepolitikker og overfører outputtet sikkert til målsystemet. Architektonisk giver batchaktivering en forudsigelig, revisibel og omkostningseffektiv tilgang til datafordeling – der afbalancerer driftssammenhæng med pålidelighed på virksomhedsniveau. Det er grundlaget for kampagnekørsel i stor skala, hvor de rigtige data, leveret rettidigt og under kontrol, skaber målbar forretningseffekt.
Kontekst
Moderne marketingmedarbejdere opererer på tværs af flere engagementkanaler – mail, annoncering, mobil og web – hver af dem kræver præcise, rettidige og personlige kundemålgrupper. Data 360 fungerer som det forenede grundlag for disse målgrupper og kombinerer kundedata fra hvert system i avancerede segmenter, der kan handles på. Batchaktivering er det mest almindelige aktiveringsmønster, der bruges til at eksportere disse segmenter fra Data 360 til downstreammarketing- eller annonceringsplatforme. Typiske destinationer omfatter Marketing Cloud-engagement, Google Ads, metatilpassede målgrupper eller LinkedIn-annoncer, hvor kampagner kan afvikles direkte mod disse arrangerede målgrupper.
Problem
Hvordan kan et marketingteam tage en præcist defineret målgruppe – opbygget ved brug af forenede og berigede data i Data 360 – og gøre den tilgængelig i eksterne marketing- eller annonceringssystemer til aktivering? Overvej f.eks. segmentet: "Kunder med høj værdi, der ikke har købt inden for de sidste 90 dage, men som for nylig har engageret sig på websitet". Marketingmedarbejdere skal sikre, at denne målgruppe overføres nøjagtigt, beriges med relevante attributter (f.eks. loyalitetsniveau, område eller forudsagt CLV) og opdateres med regelmæssige intervaller for at bevare kampagnens relevans og effektivitet.
Kræfter
Adskillige tekniske og driftsmæssige faktorer udgør batchaktiveringsmønsteret:
- Identitetstilknytning: Nøjagtig målgruppelevering kræver tilknytning af Data 360's forenede person-id til den tilsvarende identifikator i destinationssystemet – f.eks. en abonnentnøgle i Marketing Cloud eller en hashmærket mail for digitale annonceringsplatforme. Dette sikrer præcis matchning og eliminerer målfejl.
- Attributvalg og berigelse: Marketingmedarbejdere skal gå ud over id'er og inkludere yderligere profildata – f.eks. fornavn, loyalitetsstatus, CLV eller andre personlige attributter – for at aktivere downstream-tilpasning og -analyser.
- Målplatformskonfiguration: Hver destination skal registreres i Data 360 som et aktiveringsmål, herunder forbindelsesdetaljer, godkendelse og datatilknytninger for felter. Denne engangsopsætning definerer sikker tilslutning og styrer, hvilke systemer der kan modtage aktiverede data.
- Forvaltning og overholdelse: Dataaktivering skal overholde samtykkemetadata, politikker for beskyttelse af personlige oplysninger (f.eks. GDPR eller CCPA) og marketingtilladelser, der er lagret i den forenede profil. Samtykkebeskyttet aktivering sikrer, at data kun bruges til autoriserede formål.
- Planlægning og ydeevne: Aktiveringer planlægges ofte dagligt eller pr. time for at holde downstream-målgrupper opdaterede. Systemet skal håndtere store mængder og trinvise opdateringer effektivt uden duplikering eller tab af data.
Løsning
Batteraktiveringsprocessen i Data 360 følger et guidet arbejdsflow, der minimerer teknisk friktion for marketingmedarbejdere, mens styring og skalerbarhed bevares:
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| Segmentoprettelse | Best | En marketingmedarbejder eller analytiker opbygger et segment på det visuelle segmenteringslærred ved at anvende filtre på tværs af ethvert DMO (datamodelobjekt) eller CIO (beregnet indsigtsobjekt). Dette definerer målgruppen for aktivering. |
| Aktiveringsopsætning | Best | Brugeren opretter en aktivering og vælger det segment, som vedkommende netop har bygget som kilden. Dette definerer, hvilken målgruppe Data 360 skal eksportere til downstream-systemer. |
| Valg af aktiveringsmål | Bedste fremgangsmåder | Marketingmedarbejderen vælger et prækonfigureret aktiveringsmål (f.eks. Marketing Cloud, Google Ads, LinkedIn Ads). Hvert mål registreres i Data 360 med godkendelseslegitimationsoplysninger og felttilknytninger. |
| Payload-definition | Påkrævet | Marketingmedarbejderen definerer dataene ved at vælge kontaktidentifikatorer (f.eks. mail, mobil, hash-id) og vælge yderligere profilattributter (f.eks. fornavn, loyalitetsniveau eller CLV) til berigelse i destinationssystemet. |
| Planlægning og frekvens | Anbefales | Aktiveringer kan planlægges til at køre en gang eller på en tilbagevendende basis (f.eks. dagligt eller ugentligt). Planlægning sikrer, at downstream-målgrupper forbliver synkroniserede og aktuelle. |
| Udførelse og eksport | Best | Når aktiveringsjobbet kører, forespørger Data 360 på segmentet, indsamler de valgte attributter, anvender samtykkefiltre og eksporterer dataene til målplatformen. For Marketing Cloud resulterer dette typisk i oprettelse eller opdatering af en delt dataudvidelse. |
| Forvaltning og overholdelse | Påkrævet | Trust Layer håndhæver skemavalidering, samtykkemetadata og politikkontrol for at sikre overholdelse af databeskyttelses- og marketingbestemmelser (f.eks. GDPR, CCPA). |
| Overvågning og revisionsmulighed | Bedste fremgangsmåder | Hver aktiveringskørsel spores med succes-/fejlmetrikker, kørselslogfiler og slægtssynlighed i Trust Layer Monitoring-dashboardet, hvilket aktiverer driftsmæssig gennemsigtighed og SLA-sikkerhed. |
Skitser
Her er sammendraget af trinene:
- Build Segment: En marketingmedarbejder eller analytiker opretter et segment ved brug af et visuelt segmenteringsværktøj, der kombinerer filtre på tværs af alle forenede dataobjekter.
- Opret aktivering: De vælger segmentet som en kilde og vælger en prækonfigureret destination (f.eks. Marketing Cloud eller Google Ads).
- Definer data: Kontakt-id'et og andre profilattributter vælges til målgruppens eksport og rapportering.
- Tidsplan Levering: Aktiveringen er planlagt til at køre en gang eller på en tilbagevendende basis, så målgruppen i destinationen holdes opdateret.
- Kørsel: Ved udløser forespørger Data 360 på segmentet, opbygger dataene, anvender filtre til samtykke og overfører resultatet til destinationssystemet.
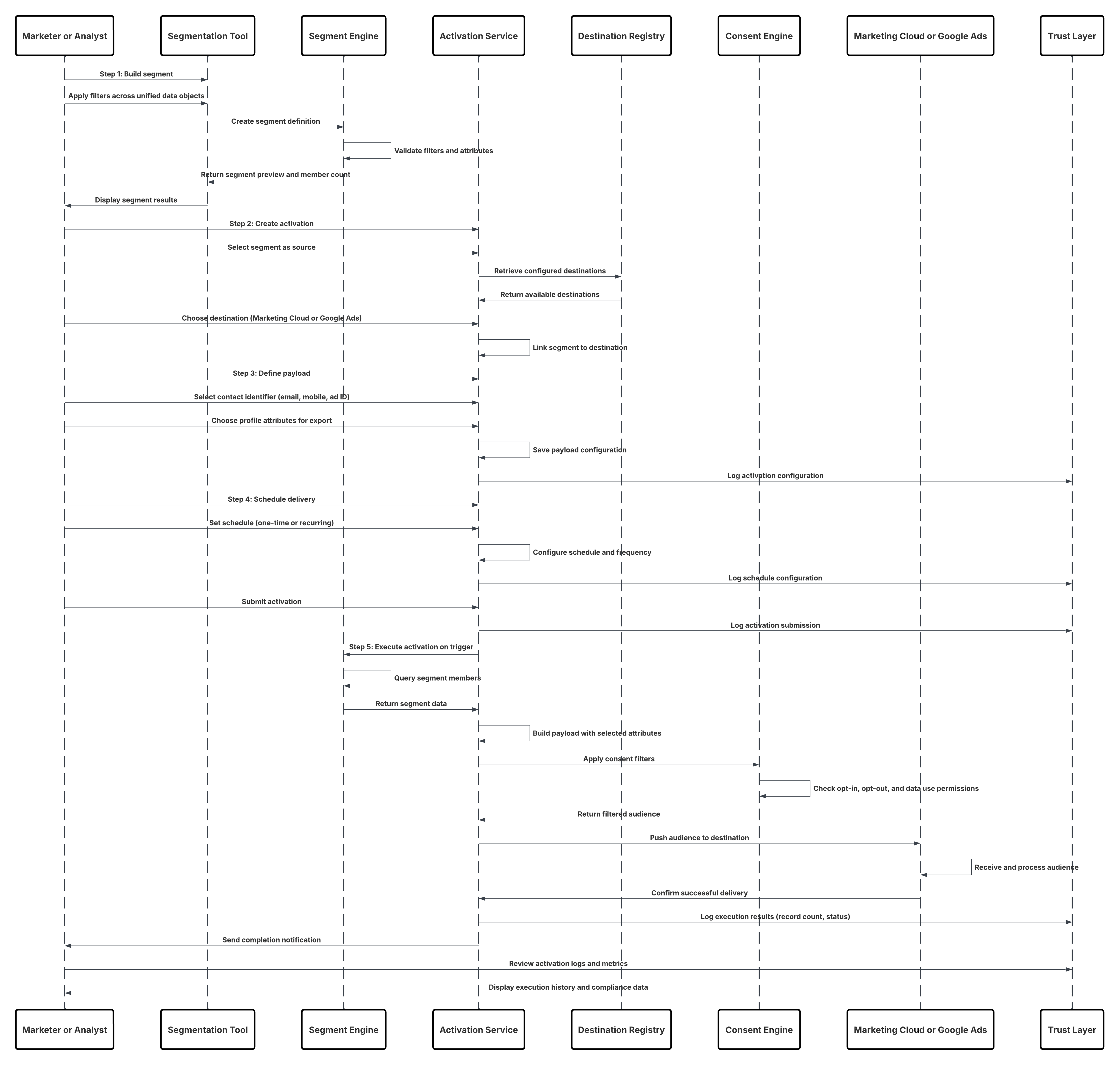
Resultater
- Målrettede, berigede målgruppesegmenter fra Data 360 gøres tilgængelige direkte i downstreammarketing- og annonceringsplatforme.
- Målgrupper opdateres og synkroniseres automatisk med de seneste forenede kundedata og bevarer kampagnerelevans i realtid.
- Marketingmedarbejdere kan bruge disse aktiverede målgrupper som inputkilder for Marketing Cloud-rejser, mailkampagner eller tilpassede målgrupper i digitale annonceringsplatforme som Google Ads, Meta eller LinkedIn-annoncer.
- Hver aktiveringskørsel bevarer end-to-end-afstamning, der sikrer overensstemmelse, sporbarhed og ensartethed mellem Data 360 og eksterne systemer.
- Forretningsbrugere kan levere meget personlige, datastyrede oplevelser drevet af en komplet og betroet Customer 360.
Opkaldsmekanismer
Opkaldsmekanismen afhænger af destinationsplatformen og konfigurationen af aktiveringsmålet.
| Mekanisme | Hvornår bruges |
|---|---|
| Marketing Cloud-engagementaktivering (foretrukket) | Bruges, når der køres mail eller krydskanalrejser, der kræver dynamiske segmenter, personlige attributter og opdateringer i realtid i Marketing Cloud. Data 360 eksporteres direkte til delte dataudvidelser til kampagneaktivering. |
| Ad Platform-aktivering (Google Ads, LinkedIn Ads, Meta Ads) | Bruges, når du aktiverer Data 360-segmenter som tilpassede målgrupper i annonceringsplatforme til retargeting eller opslagslignende modellering. Understøtter hashmærkede identifikatorer og samtykkebeskyttet levering. |
| CRM-aktivering (Sales eller Service Cloud) | Bruges, når du deler berigede kundedata, indsigter eller tendensscores med CRM-brugere til personlig salgsengagement eller serviceinteraktioner. Data gøres tilgængelige som berigede registreringer eller indsigter via datahandlinger eller forenede profilkomponenter. |
| Ekstern aktivering via MuleSoft eller API | Bruges, når aktivering skal nå ud til ikke-Salesforce-systemer, f.eks. loyalitet, eCommerce eller tredjepartsdatalager. MuleSoft eller Data 360-aktiverings-API'en sikrer sikker, politikstyret levering med begivenhedsbaserede opdateringsindstillinger. |
| Hybridaktivering (batch + begivenhedsudløst) | Bruges, når du kombinerer planlagte batchaktiveringer med begivenhedsbaserede udløsere – aktiverer "altid tilpasset" tilpasning for tidssensitive kampagner, f.eks. forladte indkøbsvogn eller advarsler om afgangsrisiko. |
Fejlhåndtering og gendannelse
- Fejlsisolering på jobniveau: Hver aktiveringskørsel udføres som et særskilt, sporbart job i Data 360-orkestreringslaget. Mislykkede kørsler quarantineres automatisk uden at påvirke andre aktiveringer eller segmentdefinitioner.
- Delvis batchgendannelse: Hvis visse registreringer ikke kan eksporteres (f.eks. på grund af id-uoverensstemmelser eller API-frekvensgrænser), forsøger systemet dem igen ved brug af trinvise delta-køer med eksponentiel tilbagerulning og parallel gendannelse.
- Skemavalideringsfejl: Når udgående dataattributter ikke længere matcher målskemaet (f.eks. en slettet attribut eller et omdøbt felt), distribuerer jobbet påvirkede registreringer til skemaafvisningskøen til administratorgennemgang.
- Genafspil og genoptag support: Hvert aktiveringsjob bevarer et kontrolpunkttoken – det registrerer det sidste vellykkede batch. Efter gendannelse genoptages behandling fra kontrolpunktet, så du sikrer, at der ikke duplikeres eller datatab.
- Omfattende overvågning: Alle aktiveringsbegivenheder, forsøg og leveringsmetrikker logføres i Trust Layer Monitoring, hvilket aktiverer SLA-sporing, grundlæggende årsagsanalyse og automatisk advarsel via Event Monitoring-API'er.
Overvejelser i forbindelse med idempotent design
- Deterministiske aktiveringsnøgler: Hver aktiveringskørsel bruger en sammensat idempotensnøgle – der kombinerer Segment-id, Aktiverings-id og Målsystem-id – for at garantere nøjagtig en gangs levering.
- Genafspilningsregistrering: Data 360-aktiveringstjeneste undersøger indgående data mod tidligere job-hashes for at registrere og undertrykke replays.
- Atomic Export Commits: Data er kun bekræftet til målsystemet efter vellykket skrivebekræftelse, hvilket forhindrer delvise opdateringer eller dobbeltoptælling.
- Konsekvent identitetsløsning: Da aktiveringer afhænger af forenede id'er (f.eks. Forenet person), målrettes gentagelser eller forsøg altid mod den samme gyldne registrering og bevarer den semantiske ensartethed.
- Aktiveringstilstand - vedvarende: Orkestreringslaget bevarer aktiveringstilstandsmetadata – tidsstempler, statuskoder og sekvenstokener – til deterministisk genbehandling, hvis det er nødvendigt.
Sikkerhedsovervejelser
- Stærk godkendelse: Hvert aktiveringsmål (f.eks. Marketing Cloud, Ads eller CRM) bruger OAuth 2.0 med tokenrotation og lejerspecifik omfang til at forhindre uautoriseret dataeksport.
- Styring på attributniveau: Kun godkendte attributter fra den forenede profil er kvalificerede til aktivering, håndhævet af datadelingspolitikker og aktiveringsskabeloner.
- Kryptering i transit og på rest: Alle data er krypteret ved brug af TLS 1.2+ under overførsel og AES-256 som inaktive i både Data 360 og målplatformen.
- Samtykke og håndhævelse af politikker: Aktiveringsjob respekterer samtykkeobjekter og datapolitikker, der er lagret i Data 360's Trust Layer. Registreringer uden gyldige samtykkemetadata udelades automatisk fra eksport.
- Audit og overensstemmelsesregistrering: Hver aktiveringskørsel registrerer, hvem der initierede den, hvilke data der blev sendt, og hvilken destination – hvilket aktiverer fuldt regulerende revisionsspor (GDPR, CCPA) i Trust Layer-dashboardet.
- Mindste rettighedsadgang: Integrationsbrugere for hvert mål er begrænset til aktiveringsspecifikke omfang – ingen administrative rettigheder eller skriveadgang til ikke-relaterede systemer.
Sidebars
Tidlighed
- Designet til planlagte eller næsten realtidsbatcheksporter (minutter-til-timer-forsinkelse).
- Understøtter tidsvinduesopdateringer, der er i overensstemmelse med kampagnekalendere.
- Aktiveringsjob kan sættes i rækkefølge med dataklarhedsmærker for at sikre dataopdatering.
- Den er bedst egnet til ikke-interaktive aktiveringsscenarier, hvor datanøjagtighed overvejer øjeblikkelighed.
Datamængder
- Håndterer datasæt i stor skala (milioner registreringer pr. kørsel).
- Skaleres vandret gennem segmentpartitionering og parallelle eksportkanaler.
- Bruger segmentbaseret batchning til at undgå timeouts og optimere gennemsnit.
- Ideel til datapipelines på virksomhedsniveau, hvor datafuldstændighed er vigtig.
Statsadministration
- Vedligeholder aktiveringstilstandsobjekter, der registrerer job-id'er, tidsstempler og sekvenstokener.
- Bruger kontrolpunkter til genstartbarhed og fejlgendannelse.
- Versionerede segmentdefinitioner sikrer reproducerbarhed på tværs af aktiveringscyklusser.
- Aktiverer afledningssporbarhed mellem kildesegment, DMO-attributter og måldata.
Komplekse integrationsscenarier
- Integrerer problemfrit med Salesforce CRM, Marketing Cloud og eksterne systemer gennem forhåndsbyggede forbindelser.
- Understøtter aktiveringer med flere mål og distribuerer data samtidigt til forskellige destinationer (f.eks. CRM + Ads).
- Kan udløse sammensatte arbejdsflows – f.eks. batcheksport efterfulgt af downstream API-kald eller AI-scoring.
- Håndterer skemaudvikling gennem styringslag for datamodel.
Eksempel
Et globalt detailbrand ønsker at engagere inaktive kunder igen fra de sidste 90 dage. Ved at bruge Data 360 definerer dataarkitekten et "Dormant Shoppers"-segment, der er beriget med købshistorik, loyalitetsniveau og samtykkemetadata. Batchaktiveringsjobbet kører hver nat og overfører dette segment til Marketing Cloud-engagement for at udløse en personlig "Vi savner dig"-mailkampagne og til Ad Studio til retargeting. Jobbet anvender idempotent levering, hvilket sikrer, at der ikke duplikeres på tværs af forsøg, og alle begivenheder logføres i Trust Layer for overholdelse af revision.
Kontekst
Virksomheder kræver ofte en administreret mekanisme til at eksportere forenede eller segmenterede data fra Salesforce Data 360 til et standardfilformat (f.eks. CSV eller Parquet) til arkivering, overholdelse eller downstream-integration. Dette mønster aktiverer Data 360-til-cloud-lagringseksport – tillader, at betroede kundedata flyder sikkert ind i virksomhedsdatalager eller analyse-pipelines, der hostes på Amazon S3, Azure Blob eller Google Cloud Storage (GCS). Typiske anvendelsessituationer omfatter:
- Periodisk arkivering af samtykkede kundedatasæt til regulerende bevarelse.
- Eksport af organiserede segmenter for ikke-Salesforce-analytiske arbejdsbelastninger (f.eks. Tableau, Databricks eller Power BI).
- Aktivering af eksterne maskinlæringsmodeller, der kræver strukturerede CSV- eller parketfiler som input.
Problem
Hvordan kan en organisation eksportere et arrangeret segment eller datasæt fra Data 360 til en cloudlagringsinddeling (f.eks. Amazon S3) – på en administreret, sikker og automatiseret måde – mens skemaintegritet og compliancekontroller bevares? Et complianceteam kan f.eks. have brug for at: "Udtræk alle aktive kunder i EU-området med gyldigt samtykke, og eksporter dataene ugentligt til en S3-placering til ekstern revision og rapportering". Dette kræver en gentagelig og politikbevidst eksportpipeline, der sikrer det korrekte filformat, adgangstilladelser og leveringstidsplan – uden manuel intervention eller ikke-administreret dataflytning.
Kræfter
Flere driftsmæssige og arkitektoniske faktorer styrer dette eksportmønster:
- Authentication & Authorization: Eksporter skal respektere cloududbyderens IAM-model (f.eks. AWS IAM-roller eller Azure-servicekonstanter) for at sikre, at kun autoriserede systemer kan skrive til målinddelingen.
- Skemajustering: Det udgående skema skal matche målsystemets forventede struktur og format (CSV, Parket eller JSON).
- Fortrolighed og samtykke: Eksporterede datasæt skal udfiltrere eventuelle registreringer, der mangler gyldige samtykkemetadata.
- Planlægning & opdatering: Mange eksporter er periodiske (dagligt, ugentligt eller månedligt) og skal justeres med virksomhedsdataopdateringscyklusser.
- Forvaltning og overvågning: Hver eksport skal kunne revideres med fuld afledningssynlighed, hvilket sikrer overholdelse af datatilbageholdelse og bestemmelser (f.eks. GDPR, CCPA).
Løsning
Mønsteret Fileksportaktivering genbruger de samme sikre cloud-lagringsforbindelser, der er anvendt til overførsel, men som er konfigureret til dataudløb. Administratorer registrerer først cloud-lagringsplatformen (f.eks. Amazon S3, Azure Blob Storage eller GCS) som et aktiveringsmål i Data 360. Derefter konfigurerer og eksekverer brugerne et aktiveringsarbejdsflow for at eksportere det ønskede segment til den udpegede fillagringssti.
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| Segmentvalg | Best | Analysere vælger en eksisterende segment- eller forespørgselsdefinition i Data 360\. Segmentet bestemmer, hvilke registreringer og attributter der eksporteres. |
| Aktiveringsopsætning | Best | Brugere opretter en ny aktivering ved at vælge Segment som kilden og Cloud-lagringsmål (f.eks. S3) som destinationen. |
| Konfiguration af aktiveringsmål | Påkrævet | Administratorer prækonfigurerer målet med legitimationsoplysninger, IAM-roller og outputsti. Understøttede formater omfatter CSV, Parket og JSON. |
| Payload-definition | Bedste fremgangsmåder | Definer eksportskemaet ved at vælge de krævede attributter (f.eks. id, Navn, Mail, Område, Samtykkeflag). Systemet håndhæver styring på attributniveau. |
| Planlægning & Frekvens | Anbefales | Eksporter kan planlægges til at køre på en defineret kadence (dagligt, ugentligt, månedligt) eller udløses manuelt efter behov. |
| Udførelse & Levering | Best | Ved kørsel forespørger Data 360 på segmentet, kompilerer eksportfilen, krypterer den og skriver den til den konfigurerede inddeling/mappe ved brug af cloududbyderens API. |
| Forvaltning og overholdelse | Påkrævet | Data 360's Trust Layer sikrer, at alle eksporter overholder samtykkepolitikker, skemavalidering og compliancefiltre. |
| Overvågning og revisionsmulighed | Bedste fremgangsmåder | Hver eksport spores i dashboardet Trust Layer Monitoring med status, kørselslogfiler og afledningsmetadata. |
Skitser
Her er sammendraget af trinene.
- Vælg segment: En analytiker eller dataforvalter vælger det forenede segment, der skal eksporteres.
- Opret aktivering: De opretter et nyt aktiveringsjob og vælger det registrerede Cloud-lagringsmål.
- Definer data: Angiv eksportskema, attributliste og filformat (f.eks. CSV).
- Tidsplan Eksport: Vælg en engangs- eller tilbagevendende tidsplan.
- Udfør job: Data 360 genererer og leverer filen sikkert til den udpegede inddelingssti.
- Overvåg og bekræft: Resultater og logfiler gennemgås i Trust for validering og compliance.
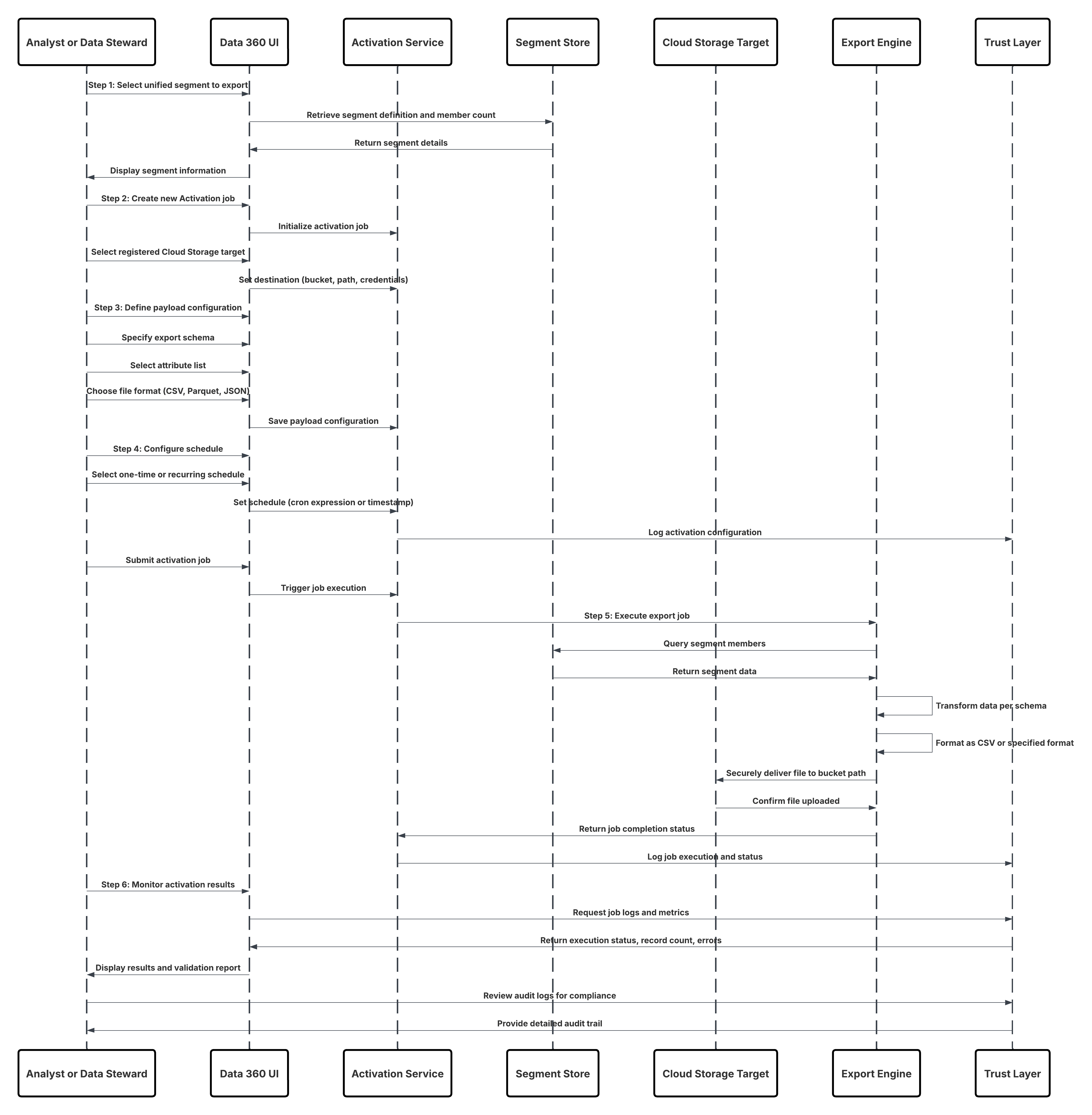
Resultater
- Målrettede, berigede målgruppesegmenter fra Data 360 gøres tilgængelige direkte i downstreammarketing- og annonceringsplatforme.
- Målgrupper opdateres og synkroniseres automatisk med de seneste forenede kundedata og bevarer kampagnerelevans i realtid.
- Marketingmedarbejdere kan bruge disse aktiverede målgrupper som inputkilder for Marketing Cloud-rejser, mailkampagner eller tilpassede målgrupper i digitale annonceringsplatforme som Google Ads, Meta eller LinkedIn-annoncer.
- Hver aktiveringskørsel bevarer end-to-end-afstamning, der sikrer overensstemmelse, sporbarhed og ensartethed mellem Data 360 og eksterne systemer.
- Forretningsbrugere kan levere meget personlige, datastyrede oplevelser drevet af en komplet og betroet Customer 360.
Opkaldsmekanismer
Kaldmekanismen afhænger af målcloud-lagringsplatformen og aktiveringskonfigurationen.
| Mekanisme | Hvornår bruges |
|---|---|
| Amazon S3-aktivering | Bruges, når din virksomhedsdatalake hostes på AWS. Data 360 skriver direkte til en S3-inddeling ved brug af IAM-roller eller midlertidige legitimationsoplysninger, hvilket sikrer sikker og skalerbar eksport. |
| Aktivering af Azure Blob-lagring | Bruges, når din organisation kører på Microsoft Azure. Data 360 bruger SAS-tokener eller servicekonstanter til at skrive krypterede filer til Blob-beholdere. |
| Aktivering af Google Cloud Storage (GCS) | Bruges, når dine datavidenskabs- eller analysearbejdsbelastninger kører på GCP. Data 360 bruger OAuth-legitimationsoplysninger til at eksportere filer til GCS-inddelinger i CSV- eller Parket-format. |
| SFTP eller ekstern filgateway | Bruges, når regulerende eller forældede systemer kræver sikker fillevering via SFTP-slutpunkter eller virksomhedsadministrerede filoverførselsplatforme. |
| Hybrid eksport (fil + API) | Bruges, når en downstreamapplikation har brug for både filbaseret eksport til analyser og en API-udløser til arbejdsfloworkestrering (f.eks. MuleSoft-forløb). |
Fejlhåndtering og gendannelse
- Isolering på jobniveau: Hver eksport udføres som et særskilt job. Mislykkede job quarantineres og prøves igen uafhængigt.
- Delvis filforsøg: Hvis visse batches ikke uploades (f.eks. på grund af netværksafbrydelser), forsøger systemet disse segmenter igen ved brug af eksponentiel tilbagerulning.
- Håndtering af skema uoverensstemmelse: Enhver skemaafvigelse eller feltoverensstemmelse distribuerer registreringer til skemaafvisningskøen til gennemgang.
- Checkpoint & Resume: Eksportjob bevarer kontrolpunktmetadata og aktiverer genoptagelse fra det sidste vellykkede skrivning uden duplikering.
- Integreret overvågning: Fejl og forsøg registreres i Trust Layer-dashboardet for at sikre synlighed og SLA-overensstemmelse.
Overvejelser i forbindelse med idempotent design
- Deterministiske eksportnøgler: Hvert eksportjob indeholder et entydigt id, der består af Segment-id + Mål-id + Tidsstempel.
- Genafspilningssikkerhed: Dubletjobkørsler registreres ved brug af job-hashes og ignoreres for at forhindre overflødige eksporter.
- Atomic Write-garanti: Data 360 bekræfter kun filer til målinddelingen efter fuld fuldførelse og validering af kontrolsum.
- Konsekvent skemaversionering: Eksportdefinitioner er versionskontrollerede for at sikre skemaoverensstemmelse på tværs af kørsler.
- Checkpoint Persistence: Eksporter job bevares tilstand for deterministisk gendannelse og genbehandling, hvis der er behov for det
Sikkerhedsovervejelser
- Stærk godkendelse: Cloudforbindelser bruger OAuth 2.0-, IAM-roller eller servicekonstanter til godkendte skrivninger.
- Kryptering overalt: Data krypteres både under overførsel (TLS 1.2+) og inaktive (AES-256).
- Samtykkebevidst eksport: Kun registreringer med gyldigt samtykke eksporteres, håndhæves af Trust Layer-politikker.
- Princippet Mindste rettighed: Eksporter brugere og servicekonti er begrænset til deres udpegede lagringsstier.
- Omfattende revisionsregistrering: Hver eksport registrerer metadata, herunder initiator, skema, destination og tidsstempler til overensstemmelsesrapportering.
Sidebars
Tidlighed
- Designet til øjeblikkelig begivenhedsstyret aktivering med forsinkelse på under et sekund.
- Ideel til scenarier, der kræver øjeblikkelig tilpasning, anbefaling eller beslutningstagning.
- Fungerer i streamingtilstand – udløsere udløses, så snart der forekommer kvalificerende dataændringer i Data 360.
- Sikrer kontinuerlig responsivitet uden at vente på batchtidsplaner eller segmentgenberegning.
Datamængder
- Håndterer datasæt i stor skala (milioner registreringer pr. kørsel).
- Skaleres vandret gennem segmentpartitionering og parallelle eksportkanaler.
- Bruger segmentbaseret batchning til at undgå timeouts og optimere gennemsnit.
- Ideel til datapipelines på virksomhedsniveau, hvor datafuldstændighed er vigtig.
Statsadministration
- Hver begivenhedshandling bevarer sit eget begivenhedstoken og afspilnings-id for idempotent-behandling.
- Understøtter kontrolpunktbevarelse for at genoptage fra den seneste bekræftede begivenhed i tilfælde af midlertidig fejl.
- Indeholder indbygget deduplikeringslogik og genafspilningsvinduer for at sikre eksakt aktiveringssemantik en gang.
- Handlingsresultater (succes/fejl) logføres i realtid og vises via Trust Layer-observationsdashboardet.
Komplekse integrationsscenarier
- Integrerer direkte med Salesforce-forløb, Einstein 1-platformsbegivenheder eller eksterne webhooks for øjeblikkelige svarkæder.
- Kan udløse downstream-automatiseringer – f.eks. øjeblikkelige CRM-registreringsopdateringer, AI-scoring eller Marketing Cloud-meddelelsessendelser.
- Understøtter sammensat orkestrering: begivenhedsudløsere kan kalde Data 360-handlinger, Apex eller eksterne API'er.
- Designet til agentmæssige og adaptive virksomhedsmønstre, hvor kontekstbevidste svar skal forekomme med det samme.
Eksempel
En global detailvirksomhed skal levere en ugentlig eksport af segmentet "Aktive loyalitetsmedlemmer" til analyse i Databricks. Data 360-administratoren konfigurerer Amazon S3 som et aktiveringsmål og planlægger en ugentlig CSV-eksport til s3://enterprise-analytics/loyalty/weekly_exports/. Eksportjobbet kører hver søndag og genererer en samtykkefiltreret fil med 2M+ registreringer. Alle begivenheder, skemadefinitioner og afstamning registreres i Trust Layer-dashboardet, hvilket sikrer gennemsigtighed, revisionsevne og compliance.
On-demand API-baseret aktivering er en begivenhedsstyret tilgang i realtid til at gøre Data 360-indsigter tilgængelige i det øjeblik, de er nødvendige – uden at vente på batchjob eller planlagte eksporter. I stedet for at udgive segmenter, der er bygget på forhånd, på en fast kadence, gør dette mønster det muligt for eksterne systemer, Salesforce-apps eller AI-agenter at kalde Data 360-API'er direkte for at hente eller aktivere specifikke målgruppestykker, kundeattributter eller indsigter efter behov. Dette mønster er designet til interaktive, udløserbaserede oplevelser – f.eks. når en bruger logger på en portal, en agent åbner en kunderegistrering, eller en AI-copilot starter en forespørgsel om den næstbedste handling. I stedet for at være afhængig af forberegnede eksporter, forespørger eller aktiverer systemet dynamisk de mest aktuelle, administrerede data fra Data 360 i realtid. Nøglefordelene er øjeblikkelighed og præcision:
- Hvert API-kald giver adgang til den mest opdaterede Kundeintelligens i Data 360's forenede samtykkebevidste profildiagram.
- Aktiveringer er idempotente og kan revideres og er i overensstemmelse med kravene til Enterprise Trust og compliance.
- Integrationer kan udløses direkte fra Salesforce-forløb, Apex eller eksterne systemer via Einstein 1-platforms-API'er, Connect-API'er eller aktiverings-API'er. Denne tilgang understøtter anvendelsessituationer, hvor forsinkelse og tilpasning betyder mest – f.eks.:
- Udløsning af et personliggjort produkttilbud under et serviceopkald.
- Generering af dynamiske kampagnemålgrupper baseret på live-adfærdsmæssige begivenheder.
- Feedsning af beslutninger i realtid i AI- eller ML-modeller, der fungerer på engagementets tidspunkt.
Kontekst
Virksomheder har ofte brug for at vise harmoniserede Data 360-indsigter i realtid i tilpassede applikationer – f.eks. interne webportaler, mobilapps eller partnerorienterede weboplevelser. Dette mønster gør det muligt for udviklere at opbygge sikre, brugergrænsefladecentriske løsninger, der forbruger og viser forenede kundedata sammen med Salesforce CRM og andre kontekstsystemer, alt sammen gennem administreret og API-baseret adgang. Typiske anvendelsessituationer omfatter:
- Integrering af Data 360-indsigter i interne medarbejderdashboards eller mobilapps.
- Oprettelse af partner- eller forhandlerportaler med kundesynlighed og transaktionssynlighed.
- Integrering af Data 360-data i tredjepartswebapplikationer eller oplevelseslag.
- Visning af personlige anbefalinger i realtid drevet af Data 360 og Einstein 1.
Problem
Hvordan kan en udvikler opbygge en tilpasset, brugergrænsefokuseret applikation, der sikkert får adgang til og viser harmoniserede Data 360-data, ofte sammen med andre Salesforce-datakilder – uden at duplikere eller eksportere følsomme oplysninger? En virksomhed kan f.eks. have brug for at opbygge en kundeportal, der viser forenede kundeprofiler, interaktioner og beregnede indsigter fra Data 360. Dette kræver et enkelt, sikkert og effektivt API-lag, der kan styre front-end-oplevelsen, håndtere godkendelse og sikre styring – mens kompleksiteten af Data 360's interne datamodel abstraktes.
Kræfter
Flere arkitektoniske og driftsmæssige overvejelser påvirker dette mønster:
- UI-Centric Access : Det primære mål er at vise data i tilpassede front-end-oplevelser (web eller mobil), ikke at udføre batchudtrækning eller backendsynkroniseringer.
- Sikker gateway : Den valgte API skal fungere som et sikkert og skalerbart indgangspunkt for godkendte applikationer og brugere og håndhæve adgangskontroller på virksomhedsniveau.
- Forenet datakontekst : Applikationer skal kunne kombinere Data 360-data (f.eks. forenede profiler, beregnede indsigter) med CRM-, ERP- eller tilpassede objektdata uden problemer.
- Udviklerenhed : API'er skal returnere præsentationsklar data, der minimerer backend-behandling eller skematilknytning i klientlaget.
- Forvaltning og observation: Al adgang skal flyde gennem betroede kanaler, der kan revideres, med tydelig afstamning, godkendelse og håndhævelse af policer.
Løsning
Løsningen er at bruge Salesforce Connect REST API som den primære integrationsgateway til opbygning af tilpassede, datastyrede applikationer oven på Data 360. Connect API giver RESTful-adgang til Salesforce-data – herunder Data 360's harmoniserede profiler, segmenter og beregnede indsigter – i svarformater, der er optimeret til brugergrænsefladebrug (JSON-baseret, letvægt og mobilvenlig). Udviklere godkender via en tilsluttet app, henter OAuth 2.0-tokener og kalder Connect API-ressourcer som /query, /chatter eller /data for at vise forenede data direkte i deres applikationsgrænseflader. I baggrunden fungerer Connect API som transportgrundlag for andre API'er – f.eks. Query API, Data Graph API og Einstein 1 Platform-API'er – hvilket gør det muligt for udviklere at kombinere flere datakilder under ét forenet adgangsmønster.
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| Godkendelse og appregistrering | Påkrævet | Opret en tilsluttet app i Salesforce for OAuth 2.0-baseret godkendelse. Konfigurer omfang for Data 360 API-adgang. |
| Dataadgang (profiler, segmenter, indsigter) | Best | Brug Connect API-slutpunkter (/services/data/vXX.X/connect) til at forespørge på harmoniserede Data 360-data, forenede profiler og beregnede indsigter. |
| UI-integration | Best | Front-end-apps (React, Angular, iOS, Android) kalder Connect API til at gengive Data 360-data i dashboards, portaler eller mobilgrænseflader. |
| Dataforespørgsel | Anbefales | Kombiner Connect API med Data Graph API for forespørgsler på semantisk niveau, der forenkler komplekse forbindelser og relationer. |
| Opdater i realtid | Valgfrit | Brug Connect API med WebSocket eller streamingudvidelser til live-dataopdateringer. |
| Sikkerhed og styring | Påkrævet | Håndhæv datasynlighed ved brug af OAuth-omfang, Data 360-politikker og Trust Layer-revisionsstrukturen. |
Skitser
Her er sammendraget af trinene.
- Registrer tilsluttet app – Definer OAuth-omfang og API-tilladelser for godkendelse af ekstern app.
- Få adgangstoken – Den eksterne app udfører OAuth 2.0-godkendelse for at modtage et token for Data 360-adgang.
- Invoke Connect API – Appen foretager REST API-kald for at hente forenede profil-, segment- eller indsigtsdata.
- Render data i brugergrænsefladen – Svar analyseres og præsenteres for brugere i en brandet portal eller mobilgrænseflade.
- Håndter fejl og opdater tokener – Apps implementerer genprøvelogik og automatisk tokenopdatering for sessionskontinuitet.
- Overvåg og overvåg adgang – Alle API-kald logføres i Trust-laget for at sikre synlighed og compliance.
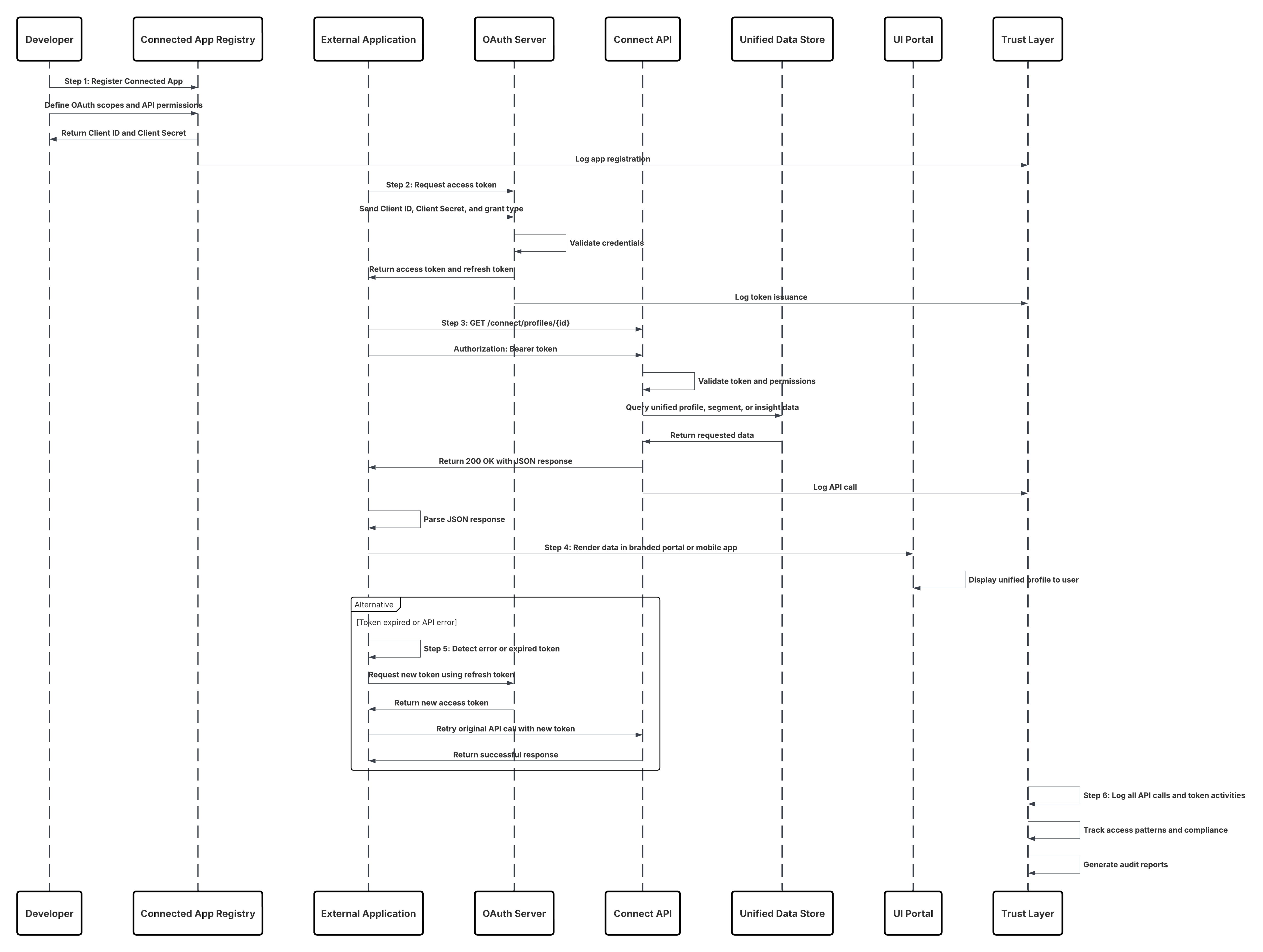
Resultater
Udviklere kan oprette sikre, tilpassede brandede applikationer, der er tæt integreret med Data 360. Disse apps kan:
- Vis harmoniserede kundeprofiler og indsigter i realtid.
- Vis Data 360-data sammen med CRM eller tilpassede objekter gennem forenede API'er.
- Anvend ensartede godkendelses-, autorisations- og revisionskontroller via Trust.
- Giv forretningsbrugere eller partnere problemfri og styret adgang til betroet Kundeintelligens på tværs af oplevelser.
Opkaldsmekanismer
Kaldmekanismen afhænger af målcloud-lagringsplatformen og aktiveringskonfigurationen.
| Mekanisme | Hvornår bruges |
|---|---|
| Forbind REST API (foretrukket) | Bruges, når der opbygges web-, mobil- eller tredjepartsapps, der kræver adgang i realtid til Data 360-data i et brugergrænsefladevenligt JSON-format. |
| Data Graph API | Bruges, når appen har brug for at udføre forespørgsler på semantisk niveau på tværs af flere objekter (f.eks. Kunde → Transaktioner → Kampagner). |
| Forespørgsels-API | Bruges, når der køres SOQL-lignende forespørgsler til at hente harmoniserede datasæt med høj præcision. |
| Einstein 1-platforms-API'er | Bruges, når du integrerer AI-styrede indsigter eller Copilot-genererede anbefalinger i tilpassede brugergrænseflader. |
| MuleSoft eller Apex Gateway Wrappers | Bruges, når der kræves yderligere orkestrering, cachelagring eller politikkørsel mellem appen og Connect API. |
Fejlhåndtering og gendannelse
- Request Throttling: Automatisk tilbagekalder og forsøger API-kald under frekvensgrænser.
- Skema Drift Protection: Bruger GraphQL skema versionering eller REST metadata discovery til at tilpasse til skemaændringer.
- Tokenudløbsstyring – Applikationer opdaterer OAuth-tokener automatisk for at undgå sessionsafbrydelser.
- API-fejleisolering – Mislykkede API-kald registreres og forsøges igen uden at påvirke samtidige sessioner.
- Observation af Trust Layer – API-succes-/fejlfrekvenser og adgangslogfiler er synlige på Trust Layer-dashboardet.
Overvejelser i forbindelse med idempotent design
- Deterministiske anmodnings-id'er: Hver API-anmodning inkluderer et korrelations-id til afspilningssikker behandling.
- Cache Validation-sidehoveder: ETag- og Sidst ændret-sidehoveder forhindrer overflødige hentning af data.
- Atomisk læsehandlinger: Connect API sikrer, at hvert svar afspejler et ensartet øjebliksbillede af forenede data.
- Genafspilningsbeskyttelse – Dublet-API-kald filtreres ved brug af anmodningssignaturer og tidsstempler.
Sikkerhedsovervejelser
- OAuth 2.0-godkendelse: Alle API-kald bruger sikre OAuth-adgangstokener med kort levetid via tilsluttede apps.
- Mindste rettighedsadgang: API-omfang er begrænset til kun nødvendige objekter og felter.
- Kryptering overalt: TLS 1.2+ er undervejs, AES-256-kryptering er ledig for cachelagrede eller lagrede svar.
- Samtykkebevidst dataadgang: Data 360 sikrer, at alle hentede registreringer overholder samtykke- og styringspolitikker.
- Omfattende revisionsregistrering: Hver API-interaktion registreres med bruger-, app- og tidsstempelmetadata i Trust Layer.
Sidebars
Tidlighed
- Designet til lav forsinkelse, API-adgang i realtid.
- Ideel til interaktive applikationer, der kræver øjeblikkelig gengivelse af data.
- Understøtter næsten øjeblikkelige forespørgselssvartider via cachelagrede og indekserede Data 360-kilder.
- Ingen afhængighed af batchplaner eller asynkrone aktiveringscyklusser.
Datamængder
- Optimeret til interaktive anvendelsessituationer, der henter datasæt fra små til mellemstore (f.eks. profiler, indsigter eller seneste transaktioner).
- Håndterer sideinddelte resultater gennem markørbaseret sideinddeling.
- Ikke beregnet til masseeksport af høj mængde – brug batch- eller fileksportmønstre til store datasæt.
Statsadministration
- Applikationer bevarer en sessionstilstand med letvægt med OAuth-tokener og lokal cache.
- Connect API understøtter betingede anmodninger og delvis opdatering af hensyn til effektiviteten.
- API-svar inkluderer versionsmarkører for skemaoverensstemmelse på tværs af versioner.
Komplekse integrationsscenarier
- Kombiner Connect API med Data Graph API for semantiske forespørgsler på tværs af flere domæner.
- Integrer med Einstein 1 Copilot- eller AI-API'er for forudsigende samtaleoplevelser.
- Bruges sammen med Experience Cloud eller Lightning Web-komponenter til udvikling af hybridbrugergrænseflade.
- Udvid via MuleSoft for at orkestrere databerigelse eller eksterne systemopslag i realtid.
Eksempel
Et multinationalt forsikringsselskab opbygger en kundeselvbetjeningsportal, der giver policeejere mulighed for at se deres forenede profiler, seneste skader og personlige tilbud. Den front-end eact-baserede app godkendes via OAuth 2.0 og henter data ved brug af Connect REST API og Data Graph API. Alle data vises i realtid, samtykke-bevidst og styres gennem Data 360 Trust lag. Udviklere overvåger API-kald og revisionsspor direkte i Salesforce, så de sikrer fuld overensstemmelse og observation.
Kontekst
Virksomheder kræver i stigende grad øjeblikkelig adgang til en komplet kundeprofil for beslutningssystemer i realtid – f.eks. servicekonsoller, anbefalingssystemer eller tilpasningsplatforme.Dette mønster aktiverer applikationer til at hente forberegnede, forenede visninger af en kundes data i næsten realtid ved brug af Data 360's Data Graph API, hvilket giver sekunders svartider for interaktive oplevelser. Typiske anvendelsessituationer omfatter:
- Visning af en 360-graders kundevisning i en Kundeservice eller Sales Console.
- Styring af AI-baserede "Next Best Action"- eller "Next Best Offer"-anbefalinger.
- Levering af hyper-personlige web- eller mobiloplevelser på sideindlæsningstidspunkter.
- Understøttelse af sessionsbeslutning i agent- eller selvbetjeningsmiljøer.
Problem
Hvordan kan en applikation hente en komplet, forberedt, forenet kundevisning med det samme i stedet for at udføre langsomme forespørgsler med flere objekter på kørselstidspunktet? F.eks. skal et webtilpasningssystem indlæse den fulde kundekontekst (demografi, præferencer, transaktioner og beregnede indsigter) inden for millisekunder for at vælge et personliggjort tilbud. Traditionelle relationsforespørgsler kan kræve flere sammenføjninger og resultere i uacceptabel forsinkelse. Dette kræver en API, der leverer denormaliserede, profildata, der er klar til brug, og som kan hentes via et enkelt nøgleopslag – der kombinerer hastighed, fuldstændighed og styring.
Kræfter
Flere driftsmæssige og ydeevnefaktorer påvirker dette mønster:
- Speed: Svartiden skal være i nærheden afReal-Time. API'en skal returnere en komplet profil inden for millisekunder for at understøtte synkrone interaktioner.
- Fuldstændighed: Svaret skal indeholde alle relevante attributter, relationer og beregnede indsigter – ideelt i en enkelt data.
- Opslagseffektivitet: Profiler skal kunne hentes via identifikatorer som customerId, contactKey eller mail, hvilket eliminerer forespørgsler med flere trin.
- Dataopdatering vs. Forsinkelse: Nogle anvendelsessituationer foretrækker forberegnede (cachelagrede) data for hastighed. Andre har brug for live data, der accepterer højere forsinkelse.
- Forvaltning og sikkerhed: Adgangen skal forblive styret af Salesforce Trust Layer-politikker, der sikrer overholdelse af datasynlighed og samtykkeregler.
Løsning
Løsningen er at bruge Salesforce Data Graph API til at hente forberegnede, denormaliserede kundevisninger, der er lagret som datadiagramregistreringer. Et datadiagram er en materialiseret semantisk visning, der kombinerer flere datamodelobjekter (DMO'er) – f.eks. Enkeltperson, Transaktion og ProductInterest – i en enkelt skrivebeskyttet registrering, ofte repræsenteret som en JSON-blok. Udviklere kan bruge REST-slutpunkter som: GET /api/v1/dataGraph/{dataGraphEntityName}/{id} for at hente en komplet registrering med dens entydige id. For dynamiske scenarier understøtter API'en en live=true-parameter, der tilsidesætter den materialiserede cache, udfører en forespørgsel i realtid på tværs af Data 360 og handler med minimal forsinkelse for de nyeste data. Dette giver udviklere mulighed for at vælge mellem øjeblikkelige (cachelagrede) og opdaterede (live) profil hentninger afhængigt af forretningsbehovet.
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| Definition på datadiagram | Påkrævet | Architekter definerer et datadiagram, der kombinerer flere DMO'er i en enkelt semantisk enhed (f.eks. UnifiedCustomerProfile). |
| Profilopslags hentning | Best | Applikationer kalder GET /api/v1/dataGraph/{entity}/{id} for at hente fulde, denormaliserede profiler med entydigt id eller nøgle. |
| Live-parameteranvendelse | Valgfrit | Tilføj ?live=true for at gennemtvinge opdateret beregning i stedet for cachelagret hentning. egnet til beslutninger af høj værdi. |
| Godkendelse | Påkrævet | Brug OAuth 2.0 via tilsluttede apps til at godkende API-kald sikkert. |
| Svarparsing | Bedste fremgangsmåder | Applikationer parser JSON-svaret direkte i deres brugergrænseflade eller beslutningssystem. Der kræves ingen yderligere sammenføjninger. |
| Cachestrategi | Anbefales | Implementer kortsigtet lokal cachelagring (f.eks. i hukommelse eller CDN) for gentagne profilopslag. |
| Overvågning & observation | Påkrævet | Brug Trust Layer-dashboards til at overvåge forespørgselsydeevne, svartider og politikoverholdelse. |
Skitser
Her er sammendraget af implementeringsforløbet:
- Definer datadiagram – Dataarkitekter opretter et datadiagram, der modellerer en forenet kundevisning på tværs af flere DMO'er.
- Registrer tilsluttet app – Udviklere konfigurerer OAuth-legitimationsoplysninger til sikker API-adgang.
- Kald Data Graph API – applikationen udsteder en GET-anmodning med Data Graph-navnet og registrerings-id'et.
- Processvar – API'en returnerer en komplet JSON-repræsentation af kundeprofilen.
- Visning eller handling – Den forbrugende app (brugergrænseflade eller motor) bruger de forenede data til personliggørelse, anbefalinger eller servicehandlinger.
- Overvåg og tilpas – Ydelsesmetrikker og adgangslogfiler gennemgås via Trust Layer-observationskonsollen.
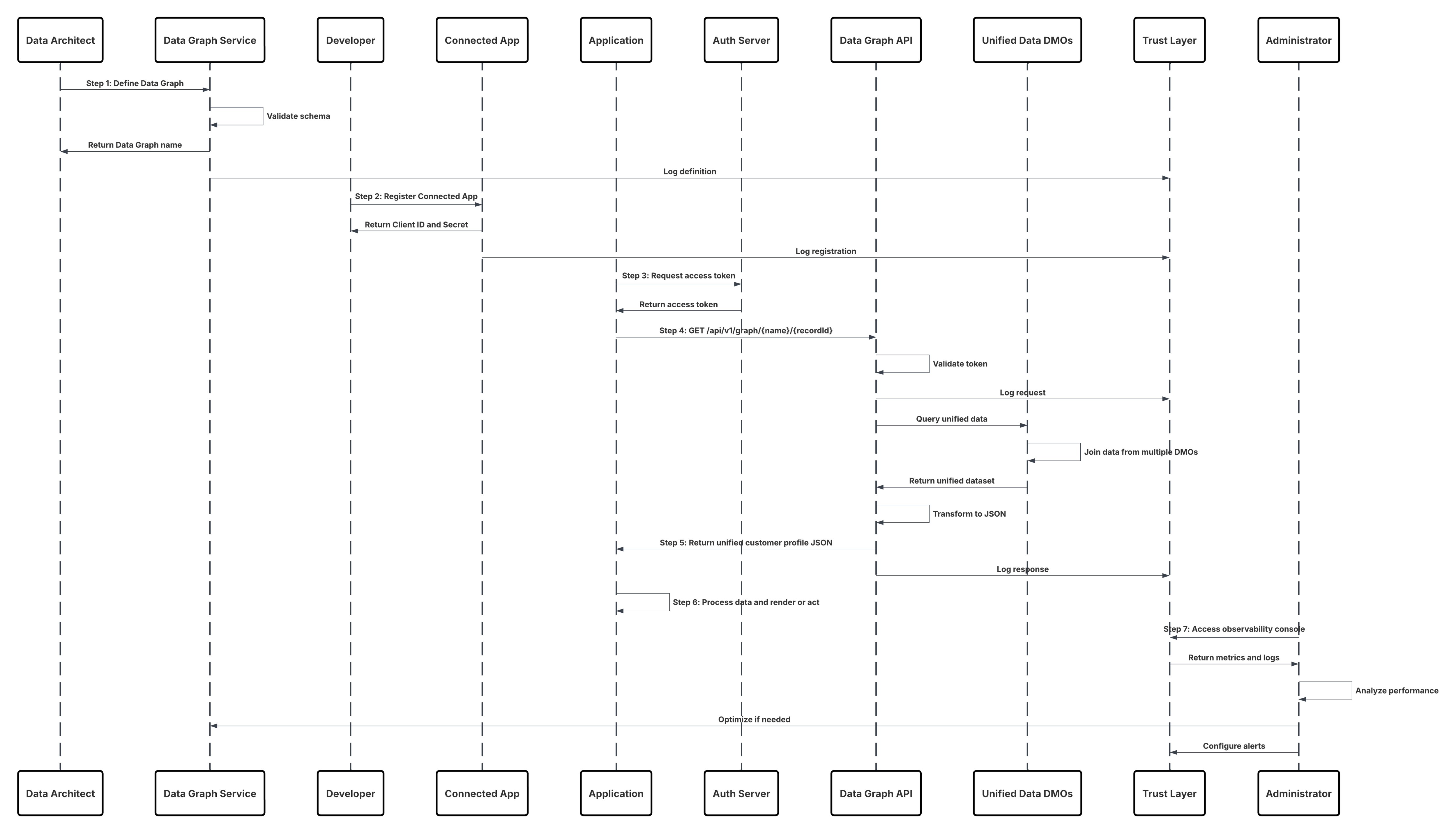
Resultater
Applikationer kan nu hente en komplet, forhåndssammenføjet kundeprofil med det samme, hvilket styrker realtidsinteraktioner som tilpasning, service og beslutningsautomatisering. Dette mønster sikrer:
- Sub-sekundere svartider for beslutningstagning i øjeblikket.
- Ensartet, administreret hentning af data, der er i overensstemmelse med den semantiske Data 360-model.
- Forenklet applikationslogik – ingen sammenføjninger, ingen skemaafstemning.
- Sporbar og kompatibel adgang via Trust Layer for revision og observation.
Opkaldsmekanismer
Kaldmekanismen afhænger af målcloud-lagringsplatformen og aktiveringskonfigurationen.
| Mekanisme | Hvornår bruges |
|---|---|
| Data Graph API (foretrukket) | Bruges til at hente komplette forhåndsmaterialiserede profiler med det samme efter id eller nøgle. |
| Data Graph API med live=true | Bruges til anvendelsessituationer af høj værdi (f.eks. bedrageriregistrering, live-tilbud), hvor der er brug for de mest aktuelle data og accepterer en lidt højere forsinkelse. |
| Connect API (fallback) | Bruges til sammensatte appscenarier, der kombinerer datadiagram hentninger med andre Salesforce-data. |
| Forespørgsels-API | Bruges, når der konstrueres ad hoc-forespørgsler eller analytiske læsninger i stedet for øjeblikkelig profil hentning. |
| MuleSoft API-proxy | Bruges, når der distribueres datadiagramkald gennem virksomhedsgateways, eller når der kræves yderligere orkestrering/politikhåndhævelse. |
Fejlhåndtering og gendannelse
- Graceful Fallbacks – Hvis live-forespørgsler mislykkes eller overskrider timeout-tærskler, vender du automatisk tilbage til cachelagrede Data Graph- hentninger.
- Timeout Management – Implementer genprøvning og afbrydelseslogik for API-kald under høj belastning.
- Ugyldig ID Håndtering – Returstandard 404 Ikke fundet svar for ikke-eksisterende profilnøgler; håndtere venligt i brugergrænsefladen.
- Skemaversionsvalidering – Valider datadiagramversionsmetadata for at forhindre uoverensstemmelser, når skemaet udvikles.
- Observationsintegration – Registrer alle fejl, forsøg og forsinkelser i Trust Layer-dashboards for SLA-overvågning.
Overvejelser i forbindelse med idempotent design
- Deterministiske nøgler – Hver profil hentning bruger et stabilt id (fx, IndividualId) sikrer forudsigelige, afspilningssikker forespørgsler.
- Cache ensartethed – Brug ETag- eller Sidst ændret-sidehoveder til betinget hentning og cachevalidering.
- Atomisk hentning – Hvert API-svar repræsenterer et ensartet øjebliksbillede af den materialiserede Data Graph-registrering.
- Genafspilningsbeskyttelse – Sørg for, at klientapplikationer registrerer dublet hentninger via korrelations-id'er og tidsstempler.
Sikkerhedsovervejelser
- Stærk godkendelse – OAuth 2.0 via tilsluttede apps gennemtvinger sikker, tokenbaseret adgang.
- Samtykkebevidst hentning – Kun samtykkede attributter returneres. Samtykkefiltre anvendes automatisk af Trust-laget.
- Forvaltning på feltniveau – Adgang til attributter styres via Data 360’s metadata og politikdefinitioner.
- Kryptering i transit og på rest – Alle svar er krypteret med TLS 1.2+ og AES-256.
- Revision og sporbarhed – Hver profil hentningsbegivenhed logføres med id'er, tidsstempler og politikkontekst.
Sidebars
Tidlighed
- Designet til øjeblikkelig hentning.
- Understøtter live-forespørgsler for opdaterede data med en lidt højere forsinkelse (under-sekund).
- Optimeret til synkron beslutningstagning og interaktive applikationer.
- Eliminerer behovet for førbatchaktivering eller segmentgenberegning.
Datamængder
- Ideel til enkeltopslag eller små sæt (tider til hundredvis) pr. anmodning.
- Ikke optimeret til massegendannelse i stor skala. Brug batch- eller forespørgsels-API'er til højvolumen læsninger.
- Bruger vandret skalerbar cachelagring og forhåndsmaterialisering for at opnå hastighed.
Statsadministration
- Vedligeholder letvægt, statløs adgang. Hver anmodning er uafhængig.
- Understøtter cachelagring af sidehoveder for genafspilningssikker hentning.
- Applikationer kan vedligeholde en lokal cache eller kortsigtet sessionslager for at reducere gentagne opslag.
Komplekse integrationsscenarier
- Integrerer problemfrit med Einstein 1, Connect API og MuleSoft for sammensatte dataoplevelser.
- Kan drive agente systemer (f.eks. Copilot- eller AI-tænkningssystemer), der kræver øjeblikkelig kontekstbevidsthed.
- Kombineret med datahandlinger for realtidsudløsere ved hentning eller tilstandsændring.
- Giver mulighed for tilpasning på skala uden at gå på kompromis med ydeevne eller styring.
Eksempel
En global e-handelsplatform bruger Data 360’s Data Graph API til at hente forenede kundeprofiler i realtid for sin anbefalingssystem. Når en bruger logger ind, kalder applikationen Data Graph-slutpunktet for at hente UnifiedCustomerProfile for den pågældende kunde, og returnerer demografiske attributter, adfærdssignaler og beregnede indsigter som en enkelt JSON-data. Tilpasningssystemet forbruger dette svar inden for millisekunder for at bestemme og vise "Næste bedste tilbud" under den aktive session. Alle anmodninger styres og logføres gennem Trust Layer, hvilket sikrer fuld synlighed, håndhævelse af politikker og compliance på tværs af interaktionen.
Datahandlinger i realtid aktiverer øjeblikkelig aktivering af kundedata, så snart de ændres i Data 360. I stedet for at vente på planlagte batcheksporter, overfører disse handlinger opdateringer, indsigter eller udløsere direkte til Salesforce eller eksterne systemer i millisekunder. Når en kundes status, samtykke eller engagementsmetrik opdateres i Data 360, kan dette signal straks styrke personlige tilbud, udløse Service Cloud-automatiseringer eller opdatere loyalitetsniveauer – hvilket sikrer, at hver kundeoplevelse afspejler den mest aktuelle, forenede sandhed. Dette mønster er ideelt til højvirknings- og forsinkelsessensitive anvendelsessituationer, f.eks. personlige weboplevelser, svigregistreringsalarmer, næste-bedste-handlingsanbefalinger eller CRM-opdateringer i realtid. Den lukker hullet mellem dataindsigter og forretningshandlinger og omdanner forenede data til øjeblikkelige data.
Kontekst
Moderne digitale oplevelser og driftsmæssige arbejdsflows kræver øjeblikkelige, kontekstbaserede handlinger i det øjeblik en begivenhed indtræffer – f.eks. opdatering af en kunderegistrering under en Checkout, justering af lageret, når en returnering scannes, eller levering af en personlig reklamekampagne i det øjeblik en bruger forlader en indkøbsvogn. Datahandlinger i realtid gør det muligt for systemer at kalde, berige og reagere på forenede Data 360-profiler og beregnede indsigter med forsinkelse fra sekund til sekund, hvilket muliggør interaktiv tilpasning, driftsautomatisering og øjeblikkelig beslutningstagning.
Problem
Hvordan kan applikationer, brugergrænsefladeinteraktionsforløb eller middleware kalde Data 360 på kørselstidspunktet for at læse, beregne eller opdatere en enkelt forenet profil eller for at udløse en handling (f.eks. sende et tilbud, opdatere CRM, starte et arbejdsflow) med lav forsinkelse, stærk ensartethed og styringskontroller – uden at vente på planlagte batchjob eller tungvægtspipelines?
Kræfter
Flere tekniske, driftsmæssige og styringskræfter udgør dette mønster:
- Krav til lav forsinkelse: Opkald skal udføres inden for sekunder til nogle få sekunder for at bevare en god UX eller for at opfylde driftsmæssige servicelaftaler.
- Deterministisk identitetsløsning: Anmodninger skal løses på den korrekte forenede person-profil (gylden registrering) pålideligt og hurtigt.
- Fine granuleret godkendelse: Opkald i realtid skal håndhæve politikker på attributniveau og samtykketjek på anmodningstidspunktet.
- Payload Minimalism: Data i realtid skal være små og fokuserede (enkeltprofil eller lille attributsæt) for at reducere forsinkelse og omkostninger.
- Udvikleroplevelse: API'er skal være udviklervenlige (REST/gRPC/GraphQL) med tydelige skemaer og stabile kontrakter til produktionsbrug.
- Auditability & Traceability: Hver handling i realtid skal logføres med afstamning, brugeridentitet og politikbeslutninger for at overholde.
Løsning
Den anbefalede løsning er at bruge Data 360's Real-time Data Actions-grænseflade (API'er + SDK'er) kombineret med kantcache og minimale transformationer, hvor det er nødvendigt. Integrationer kalder et datahandlingsslutpunkt for at læse eller skrive profilattributter, beregne indsigter eller starte orkestreringer. CEDAR (real-time policy checks) og dynamisk maskering anvendes på policehåndhævelsespunktet, før nogen data returneres eller handlingen udføres.
| Løsningsområde | Tilpas | Kommentarer/implementeringsdetaljer |
|---|---|---|
| Datahandling i realtid | Best | Vis slutpunkt for enkelt registreringslæse-/skrive- og handlingsudløsere. Godkend via OAuth/JWT. |
| Id-løsning | Påkrævet | Løs indgående identifikatorer (email, externalId, cookie) til Id for forenet enkeltperson online. Brug en deterministisk resolver med cache. |
| Police Enforcement (CEDAR) | Bedste fremgangsmåder | Evaluer samtykke-, ABAC- og maskeringspolitikker på anmodningstidspunktet. Afvis eller masker felter pr. politikbeslutning. |
| Kant-/cachelag | Anbefales | Brug korte TTL-caches til profilsegmenter og beregnede indsigter for at reducere forsinkelse. ugyldiggør på ændringsbegivenheder. |
| Lette transformationer | Anbefales | Anvend enkle berigelser eller beregnede felter i handlingsstien. Flotte transformationer skal beregnes på forhånd. |
| Action Orchestration | Best | Understøt synkrone ettrinshandlinger (f.eks. retur tilbudstoken) og asynkrone orkestreringer (kø \+ webhook) for komplekse forløb. |
| Observation & sporing | Påkrævet | Logfør anmodninger/svar, politikbeslutninger og afstamning til Trust Layer/SIEM til revision og fejlfinding. |
| Vurderingsbegrænsning og trussel | Påkrævet | Håndhæv klientkvoter og praktiske nedbrydningsstrategier for øjeblikke med stor trafik. |
Skitser
Her er sammendraget af trinene.
- Client (UI / middleware / POS) sender godkendte anmodninger om datahandling med identifikatorer og handlingstype.
- API-gateway validerer token, vurderingsgrænser og videresender til Data 360 Action Service.
- Handlingstjeneste løser id → Forenet person-id (hurtig stitcache, tilbagerulning til diagramopslag).
- Politikhåndhævelse evaluerer CEDAR-politikker ved brug af attributter fra PIP og anmodningskontekst.
- Hvis det er tilladt, læser handlingstjenesten eventuelle krævede profilattributter/indsigter og udfører lette transformationer.
- Handlingstjeneste returnerer svar synkront (f.eks. tilbudstoken, opdateret attribut) eller køer asynkron orkestrering og returnerer bekræftelse.
- Alle begivenheder, beslutninger og data logføres på Trust Layer og videresendes eventuelt til SIEM.
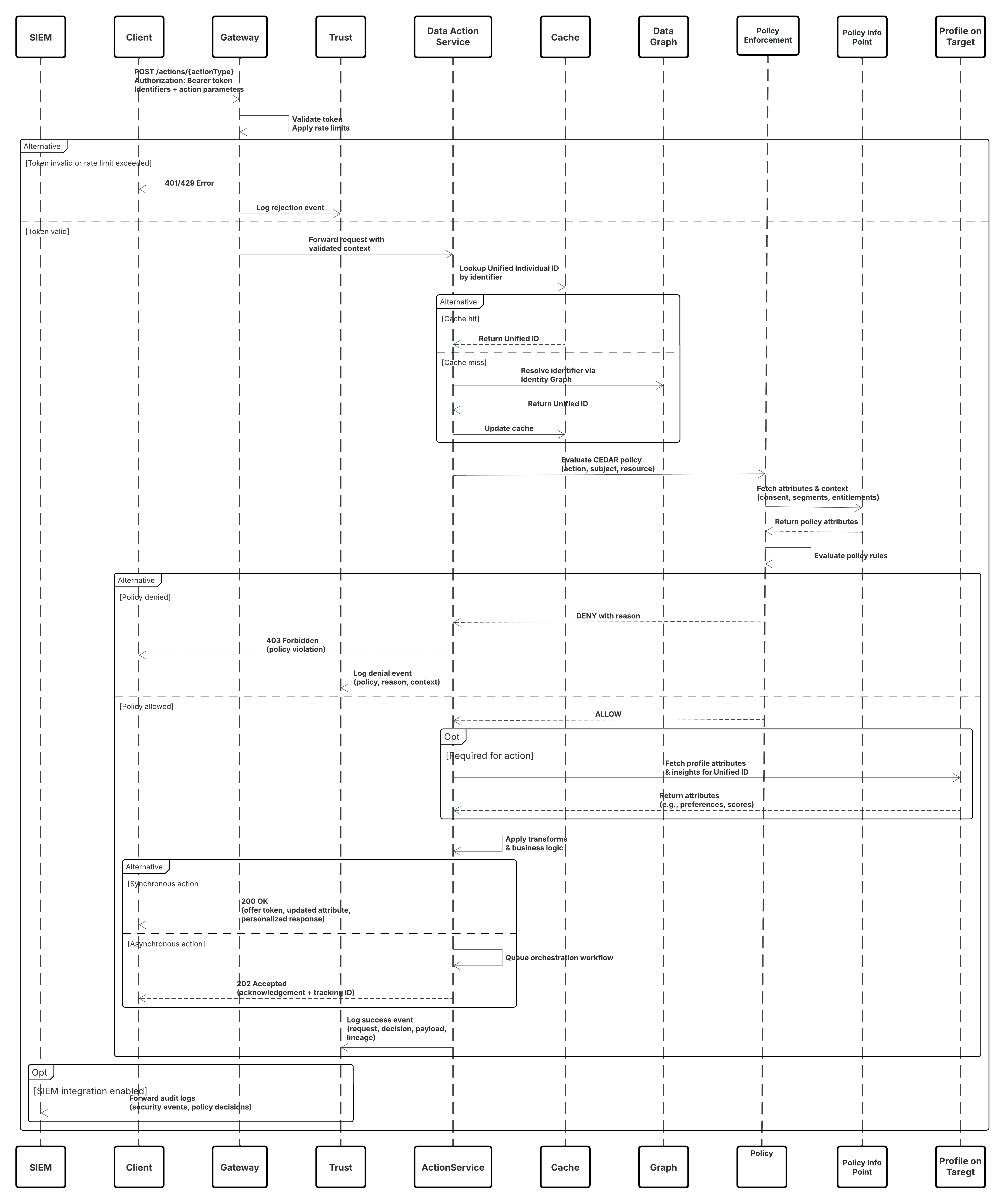
Resultater
- Applikationer modtager øjeblikkelig, politikstyret adgang til forenede profillæsninger/skrivninger og handlingsudløsere med forsinkelse fra sekund til sekund.
- Tilpasning i realtid, beslutningstagning og driftsmæssige arbejdsflows (f.eks. tilbud, agenthjælp, lageropdateringer) er aktiveret uden batchforsinkelser.
- Alle handlinger kan revideres, samtykkebevidst og håndhæve maskering på attributniveau for at bevare fortrolighed og compliance.
Opkaldsmekanismer
Opkaldsmekanismen afhænger af destinationsplatformen og konfigurationen af aktiveringsmålet.
| Mekanisme | Hvornår bruges |
|---|---|
| RESTful Data Actions API | Foretrækkes for web-/mobilapps og middleware, der har brug for synkrone profillæsninger eller handlingssvar. |
| gRPC / binær RPC | Bruges til virksomhedstjenester med ultra-lav forsinkelse eller interne mikrotjenester med vedvarende forbindelser. |
| GraphQL-enkeltregistreringsforespørgsler | Bruges, når klienter har brug for fleksible feltvalg og ønsker at minimere data. |
| Begivenhedsudløste webhooks | Bruges til asynkrone arbejdsflows, hvor handling udløser downstream-processer (f.eks. start en rejse). |
| Platformsbegivenheder / PubSub | Bruges til fan-out-scenarier, hvor flere systemer skal reagere på en enkelt handlingsbegivenhed. |
| Edge SDK (klient-libs) | Bruges til klienter med lav forsinkelse, der cachelagrer profilfragmenter og kun kalder API for datahandlinger, når der er behov for det. |
Fejlhåndtering og gendannelse
- Synkrone fejl: Returner strukturerede fejlkoder med læselige meddelelser og idempotencytokener.
- Tilbagevendende forsøg: Klienter skal prøve idempotente anmodninger igen med eksponentiel tilbagerulning på 429/5xx-svar.
- Håndtering af policeafvisning: Afvisninger returnerer tydelige årsagskoder. Følsomme data returneres aldrig ved policefejl.
- Asynkron orkestreringsfejl: Orkestreringsjob flyttes til DLQ og kan afspilles igen. En jobstatus-API giver klienter mulighed for at afstemme eller modtage tilbagekald.
- Fallback-strategier: Hvis identitetsløsning mislykkes, skal du returnere en deterministisk fejl og eventuelt en foreslået løsning (f.eks. kræve externalId).
Overvejelser i forbindelse med idempotent design
- Idempotensnøgle: Klienter leverer en idempotency-nøgle (UUID + klient-navneområde) til mutationshandlinger.
- Deterministiske nøgler: Brug sammensatte nøgler (UnifiedIndividualId + ActionType + TimestampWindow) til at registrere dubletter.
- Safe Retries: Designhandlinger til at være sideeffekt-tolerante eller til at udføre upserts i stedet for blinde indsættelser.
- Genafspilningsbeskyttelse: Bevar behandlede idempotensnøgler og TTL dem efter forretningsvindue for at undgå gentagne filer.
- Statelessness: Bevar synkrone handlinger statløse, hvor det er muligt. Bevar minimal tilstand for asynkrone arbejdsflows.
Sikkerhedsovervejelser
- Godkendelse: OAuth 2.0 (JWT Bearer eller mTLS for servicekonti); tokener med kort levetid og opdateringsrotation.
- Tilladelse: Politikbeslutningspunkt håndhæver attributbaseret adgangskontrol (CEDAR) og samtykketjek pr. anmodning.
- Transport og lagringskryptering: TLS 1.2+ er undervejs, AES-256 er ledig for eventuelle cachelagrede fragmenter eller revisionslogfiler.
- Mindste rettighed: API-klienter tilpasset til minimale tilladelser. Roller adskilt for læs kontra skriv kontra orkestrering.
- Dataminimering: Returner kun anmodede og samtykkede attributter. Anvend dynamisk maskering for PII/PHI.
- Netværkskontroller: Kræv eventuelt opkald fra private netværk (Private Connect, IP-tilladelseslister) for handlinger med høj risiko.
- Audit & Overvågning: Logfør anmodningsmetadata, politikbeslutninger, anmoderidentitet og svar-hashes til Trust Layer og SIEM.
Sidebars
Tidlighed
- Designet til gennemsnitlige forsinkelser i intervallet mellem sekundet og lavt enkelt sekund for synkrone handlinger.
- Edge-caches (kort TTL) og forberegnede indsigter reducerer rundrejser.
- Asynkrone stier giver næsten øjeblikkelig bekræftelse med baggrundshåndtering for tunge opgaver.
Datamængder
- Optimeret til enkeltregistrerings- eller småbatchinteraktioner (1-100 registreringer).
- Ikke beregnet til masseeksport – brug batchaktivering til store mængder.
- Høj gennemsnit bruger pulje-/forbindelsesgenbrug og parallelle orkestreringskøer.
Statsadministration
- Anmodningsmodel uden stat for synkrone opkald. Minimal handlingstilstand bevaret for bevillinger/transaktioner.
- Cachegyldighed drevet af ændringsbegivenheder – sørg for, at TTL'er og ugyldighedssignaler holder cachen opdateret.
- Orkestreringsjob bevarer en holdbar tilstand (jobId, status, forsøg), der er lagret i Trust.
Komplekse integrationsscenarier
- Agentassistent: Profilopslag i realtid + beregnet tendens returneret til servicekonsollen i sekundet for agenter.
- POS / Edge-enheder: Lokalt SDK + lejlighedsvis datahandling til validering af kampagner eller loyalitetsstatus.
- Hybridforløb: Synkroniser datahandling for beslutning + asynkron orkestrering for at opdatere downstream-systemer og udløse kampagner.
- Tredjepartsmedarbejder: MuleSoft- eller API-gateways kan formidle godkendelse, berige kontekst og håndhæve ekstra policekontroller.
Eksempel
En detailmobilapp bestemmer, om der skal vises en personlig øjeblikkelig kupon, når en køber trykker på Checkout ved at kalde handlingen tilbudsberettigelsesdata med køberens mail og indkøbsvognskontekst. Anmodningen valideres af API-gatewayen og videresendes til datahandlingstjenesten, som løser mailen til et forenet personligt id ved brug af et cache-hit, bekræfter marketingsamtykke gennem PDP og evaluerer berettigelse baseret på kundelivsværdi og seneste køb. Hvis indkøberen kvalificerer sig, returnerer tjenesten et signeret kupontoken og logfører beslutningen. Når kuponudstedelse kræver lagerreservation, udløses der en asynkron orkestrering for at reservere lager og advisere CRM-systemer. Appen viser kuponen med det samme, mens downstream-opdateringer udføres i baggrunden, og Trust Layer opfanger et komplet revisionsspor for styring og compliance.
- Forbindelser og integration
- Web og Mobile SDK
- Sub-sekunders overførsel i realtid
- Bring Your Own Lake (Nul kopier forespørgsel)
- Bring Your Own Lake (Zero kopier fil)
- Datadiagrammer
- Aktivering: MC Engagement
- Aktivering: MC Tilpasning
- Aktivering: B2C Commerce
- Datadeling (nulkopi)
- Aktivering: Fillager
- Datahandlinger
- Subsekundedatahandlinger i realtid
- Ekstern aktiveringsplatform