Dataplatforme har udviklet sig i over tre årtier. Indledningsvis var branchen domineret af lokale, centraliserede og strukturerede (hovedsageligt relationsmæssige), driftsmæssige/OLTP-databaser. Dette blev udvidet til at inkludere datalager OLAP/Big Data-platforme, der primært blev brugt til analytisk behandling og forblev relationelle og centraliserede. Cloud-lagring styrer distribuerede arkitekturer som dataoplag, søhus og desegregeret lager. Men driftsplatforme og analyseplatforme forblev adskilte. I dag ændrer cloud computing og AI-revolutionen grundlæggende dataplatformens arkitektur.
Virksomheder investerer allerede i modne Big Data-platforme som Snowflake, Databricks, BigQuery og Redshift. Men disse platforme fungerer som datasiloer. Kunder afleder ikke forretningsværdi ud af deres data, da data ikke kan handles på direkte i forretningsforløb og applikationer. Disse løsninger mangler genererende agent-AI-behandling og kan ikke levere dataadgang i realtid, så de kan ikke levere AI-styret tilpasning på tidspunktet for kundeengagement og andre brancheførende funktioner.
Fremtiden for dataplatforme er kendetegnet ved en forenet, fleksibel, tilgængelig og åben datainfrastruktur. Denne nye arkitektur er bygget på moderne computing- og lagertendenser – GPU'er, stor hukommelse, NVMe SSD'er og cloudlagring – for at integrere med cloud computing og AI. De kan levere indsigter i realtid, fremme autonom beslutningstagning og fremme applikationer i realtid. Dette inkluderer stigningen af agentisk AI, forudsigende AI, analyser, realtids OLTP-databaser i høj skala, datalager og lakehuse. Disse moderne dataplatforme er designet til enkelhed, skalerbarhed, smidighed, ydeevne, sikkerhed, tilgængelighed og omkostningseffektivitet.
Følgende datatendenser styrer den næste generations dataplatformsarkitektur.
- AI, maskinlæring og Analytics i kernen: Fremkomsten af Agentic AI vil fundamentalt ændre dataplatformsudvikling, implementering og anvendelse/adgang. Agentisk AI vil forstå samtale-/forespørgselshensigt, planlægge, generere arbejdsflows og automatisere beslutningstagning. Agentmæssig (kort- og langsigtet) hukommelse er konstrueret fra samtalehistorik til personliggørelse af agentplanlægning og beslutninger, samtalemodellering i realtid og tilpasningssupport, der er afgørende i dataplatforme. Agenterne vil hjælpe med at automatisere driftsmæssige "funktioner" som dataadministration (dvs. sikkerhed, compliance, Trust), ydeevne (dvs. automatisk skalering for samtidighed, gennemsnit og forsinkelse), fejloverførsel og tilgængelighed samt observation og vedligeholdelse. AI-drevne analyser, prognoser, naturlig sprogbehandling (NLP) for analyse af spørgsmål/svar og analyser på ustrukturerede data (tekst som PDF'er, billeder, lyd, video) vil være standard, så virksomheder kan aflede dybere indsigter fra forskellige datakilder.
- Decentralisering af data, men forenet dataadgang: Agenter har brug for virksomhedsdata for at aflede indsigter og træffe beslutninger og for at automatisere forretningsaktiviteter. Data er iboende decentraliseret i virksomheder, i uensartede applikationer og dataplatforme. Men det er ikke nemt problemfrit at forene siloerne på tværs af forskellige forretningsenheder i virksomheden og med partnere uden for virksomheden. Forening af data involverer datadeling, enten via overførsel fra kilder eller forening med datakilder; rå data fra dataforberedelse, harmonisering og modellering til analytisk og AI-behandling; lagring og administration af data på skala for effektiv adgang med lav CTS; og dataadgang via forskellige forespørgsels- og analysemekanismer og værktøjer, der er dybt integreret med de underliggende lagrings- og dataadgangsplatforme
- Cloudbaserede åbne søhuse: Cloudbaserede Big Data-platforme (OLAP) konvergerer om at indføre åbne filformater (Parket) og tabelformater (Iceberg), der aktiverer dataforening (data i) og deling (data ud).
- Ustruktureret databehandling: Med fremkomsten, udviklingen og indførelsen af genererende AI begynder virksomheder at aflede værdifulde indsigter og forretningsværdi fra virksomhedens korpus af data, der udgør store mængder tekstdokumenter, lydafskrifter, videooptagelser og andre medier. Ustruktureret databehandling, herunder segmentering, vektorisering, semantisk søgning og Knowledge, gør disse indsigter mulige. Teknikker som RAG (recovery augmented generation) og CAG (cache augmented generation) bliver mainstream drivere af hurtig og agentisk søgning på tværs af datakredsen.
- Vidensstyring: Knowledge går ud over selve det rå indhold (dokumenter, artikler, videoer). Det repræsenterer forøgelse af dette indhold ved at aflede mening, arrangere metadata og placere dem i kontekst for at udvikle en delt forståelse af indhold på tværs af en organisation eller virksomhed. Knowledge selv er generelt struktureret. Knowledge management involverer indholdsstyring, Knowledge udvinding, repræsentation gennem modeller som grafer og navigation.
- Rich Data Access: Rich dataadgang betyder, at data, analyser og AI-værktøjer skal være tilgængelige for en række personaer, herunder slutbrugere, forretningsbrugere, administratorer og analytikere. Tilgængelighed opnås gennem mekanismer som ensartet forespørgsel (med relationel, nøgleord og semantisk forespørgsel), naturlig sprog til SQL-forespørgsel (NL2SQL), adgang i realtid osv.
- Behandling i realtid: Agentapplikationer træffer beslutninger i realtid baseret på den aktuelle tilstand og baseret på nye begivenheder, personlige svar og handlinger, hvilket kræver adgang, behandling og handling på realtidsdata. Behandling i realtid kræver opdaterede data (dataforsinkelse) og interaktiv adgang (adgangsforfald). Sådan data- og adgangsforsinkelse kræver, at den underliggende dataplatform understøtter opdateret dataadgang fra driftsmæssige og analytiske butikker, lav forsinkelsesadgang (punktopslag og forespørgsel) behandling, høj dataskala og høj effektivitet.
- Datasikkerhed, styring og bopæl: Agentisk og konverserende AI forenkler applikationsbrugergrænsefladen og tillader alle, fra forbrugere til medarbejdere til andre AI-agenter, at interagere med applikationer samtalemæssigt ved brug af tale eller skriftligt naturligt sprog. De værdifulde kunde- og personlige data, der skal lagres og modelleres for Agenttic-applikationer, skal være sikre og administreres med veldefinerede adgangs- og delingspolitikker. I stigende grad skal mange kunder overholde bestemmelser, der kræver dataplacering i deres eget land eller område, især dem i regeringen eller som arbejder med regeringer.
Salesforce Data 360 er oprettet til fremtiden for at håndtere disse datatendenser. Data 360 er en cloud-oprindelig metadatastyret dataplatform, der forener enkeltstående data på tværs af virksomheden, hvilket tillader organisationer at lagre, modellere og behandle deres data for at aktivere analyser, AI, maskinlæring og agentapplikationer.
Dette dokument er en vigtig vejledning for virksomhedsarkitekter og CTO'er. Den beskriver arkitekturen, funktionerne, designprincipperne og anvendelsessituationer for Data 360. Den introducerer det grundlæggende i Data 360-arkitekturen som en klargøring, efterfulgt af en række dybdegående dykker i dens nøgleforskelle, f.eks. interoperabilitet med eksisterende dataplatforme, herunder strategi for flere organisationer, sikkerhed, styring og fortrolighed, aktivering i realtid og Data Clean Rooms.
Salesforce Data 360 er udviklet omkring et kernesæt af principper, der gør virksomhedsdata driftsmæssige, betroede og i realtid.
- Åbenhed og interoperabilitet: Bygget til multi-cloud-økosystemer. Føder med dataplatforme som Snowflake, Databricks, BigQuery og Redshift uden at duplikere, hvilket udvider Customer 360 og bevarer eksisterende investeringer.
- Lager-beregning-separation: Skalerer lager og behandling (batch, streaming og interaktiv) uafhængigt. Leverer elasticitet og effektivitet til højvolumen, højtydende arbejdsbelastninger.
- Lager og behandling med flere modeller: Understøtter strukturerede og forskellige ustrukturerede datatyper som tekst, billedlyd og video. Giver effektiv lagring, realtids- og batchbehandling, udvidelig indeksering, forenet søgning, forespørgsel og analyse.
- Metadata-drevet design: Applikationer er defineret af metadata snarere end kode. Metadata behandles som et førsteklasses aktiv, der aktiverer forenet styring, fleksibilitet og dyb integration i Salesforce Platform.
- Hybridbehandling i realtid: Understøtter forespørgsler med lav forsinkelse og øjeblikkelig beslutningstagning sammen med batchbehandling og analytiske arbejdsbelastninger.
- Intelligente og aktive data: Kontinuerligt overfører, analyserer og overfører indsigter direkte til forretningsarbejdsflows. Styrker ingen kode, lav kode, pro-code og AI-styret automatisering med den mest aktuelle kontekst.
- Forvaltning og privatliv efter design: Afstamning, adgangskontrol, ophold, datakryptering og compliance er indbygget. Trust og tillid til lovgivningen styrkes på alle niveauer.
- En-til-mange lejemål: En centraliseret Data 360-organisation fungerer som den eneste kilde til sandhed for Customer 360 og understøtter problemfrit multi-org salesforce-miljøer, der bruges bredt af Salesforce-kunder.
Disse principper sikrer, at Data 360 gør data åbne, intelligente og kan handles på i realtid.
Salesforce Data 360 er en moderne dataplatform, der bygger på designprincipper, der håndterer aktuelle datatendenser. Dets arkitektoniske funktioner sikrer, at virksomhedsdata er betroede, forenede og kan handles på i realtid, så de stemmer overens med dets vejledende principper.
- Cloud-Native Foundation: Kører på Hyperforce, implementeret på Hyperscalers (som AWS), med uforanderlig mikroservicebaseret infrastruktur. Giver elastisk skalering, sikkerhed uden Trust, kontinuerlig levering og global compliance.
- Salesforce (Kerne) metadatastyrede: Metadata designes, modelleres og lagres som Salesforce-metadata, der aktiverer øjeblikkelig brug af ALLE Salesforce-applikationer. Sådanne metadata lagres i et fuldt ACID-kompatibelt RDBMS. Sikrer styring, ensartethed i livscyklussen og dyb integration med Salesforce Lightning Platform.
- Lakehouse Storage: Bygget på Apache Iceberg og Parquet, der kombinerer datalake-skala med lagerstyring, der understøtter skemaudvikling, tidsrejse og højvolumen opdateringer. Data 360 lagrer, modellerer og behandler strukturerede og ustrukturerede data med lagring i ekstrem skala med moderne åbne standarder og med avancerede transformations- og databehandlingsfunktioner for batch- og begivenhedsstyrede arbejdsbelastninger.
- End-to-end-datapipeline med fleksibel overførsel: Dækker den fulde livscyklus – overfør, forbered, modeller, foren, analyser og aktiver – hvilket reducerer afhængigheden af fragmenterede punktløsninger. Understøtter batch, næsten i realtid og streaming med 270+ forbindelser og MuleSoft. ELT-første tilgang aktiverer hurtig datatilgængelighed med downstream-transformationens fleksibilitet.
- Enterprise Data Interoperability med Open Frameworks og Federation: Ensretter silo'd-data på tværs af virksomheden med bidirektionel Zero Copy-federation med Snowflake, Databricks, BigQuery og Redshift, der undgår datamigrering eller duplikering.
- Dataklassificering, modellering og organisation: Data 360 organiserer data som rå overførte data, rensede og lagrede data og data, der er modelleret i overensstemmelse med almindelige oplysningsskemaer, der kaldes SSOT (Single Source of Truth). Sådanne SSOT-objekter udgør grundlaget for definition af semantiske datamodeller (SDM) og andre organiserede og applikationsspecifikke modeller.
- Indbygget semantisk datamodellering til udvidelige analyser med åbne semantiske forespørgsels-API'er, der kører Tableau Next og aktiverer applikationsspecifik analyse.
- Høj ydeevne SQL-forespørgselssystem, der understøtter en forenet Data 360 SQL-forespørgsel på tværs af strukturerede, ustrukturerede og grafiske data.
- Low-latency-datalager: Lagring af nøgleværdi for varme data med millisekunders svartider. Aktiverer tilpasning og begivenhedsstyrede scenarier i realtid. Indsamler og behandler kundeengagementsdata i realtid. Samler identiteter, interaktioner og samtaler i et enkelt, betroet Customer 360 og kontekstdiagram.
- Ustrukturerede databehandlingspipelines til fleksibel og udvidelig understøttelse af ustruktureret datalagring, segmentering, indlejringsproduktion (vektorisering), metadataudtrækning (forøgelse), opsummering, indeksering, Knowledge-udtrækning, intelligent dokumentbehandling, kortsigtet og langsigtet (samtale) hukommelsesoprettelse osv.
- Indbygget søgeord, vektor og hybrid indeksering for nøjagtig og effektiv ustruktureret dataadgang som hurtig og agentisk søgning, RAG, Knowledge udtrækning, agentisk hukommelsesafledning osv.
- Profil, Tilpasning, Kontekst-tjenester til aktivering af AI/ML og agentiske applikationer.
- Indbygget styring og sikkerhed på alle lag for afstamningssporing, datamaskering, dataplacering og null Trust-sikkerhed, der sikrer compliance og Trust.
- Elastic Compute stof: Kubernetes-oprindelige, multi-lejer-computervæv. Kører Spark for distribueret behandling og Hyper for SQL-arbejdsbelastninger. Skaleres elastisk på tværs af forskellige job og understøtter isolering for kørsel af usikret kode.
Alt dette kører på Hyperforce, Salesforces cloudfoundation. Hyperforce leverer:
- Nul Trust-sikkerhed med kryptering, isolering og politikker for mindste rettigheder.
- Resilience gennem multiregionale implementeringer. Mens Salesforce Data 360 drager fordel af Hyperforces multiregionelle modstandsdygtighed og fejltolerance på platformsniveau, kræver sand katastrofeafhjælp (DR) på virksomhedsniveau en bredere arkitektur svarende til enhver dataplatform med nøglefunktioner: genspilbare overførselspipelines, replikering og metadatastyret rehydrering på tværs af alle afhængige økosystemer.
- Observation med overvågning, metrikker og sporing indbygget.
- Automatiseret skalering og FinOps-bevidsthed for effektivitet uden omkostningsoverløb.
Data 360 erstatter ikke eksisterende virksomhedsinvesteringer. I stedet gør Data 360 de data, du allerede har tillid til, administreres og kan handles på – leverer AI-styret engagement i realtid der, hvor det betyder mest. Kort sagt omdanner Salesforce alle virksomhedsdata, herunder eksterne data, som (Salesforce) metadatastyrede objekter og aktiverer agentapplikationer til opdagelse, beslutningstagning og til at udføre handlinger.
Følgende figur illustrerer Data 360-referencearkitekturen:
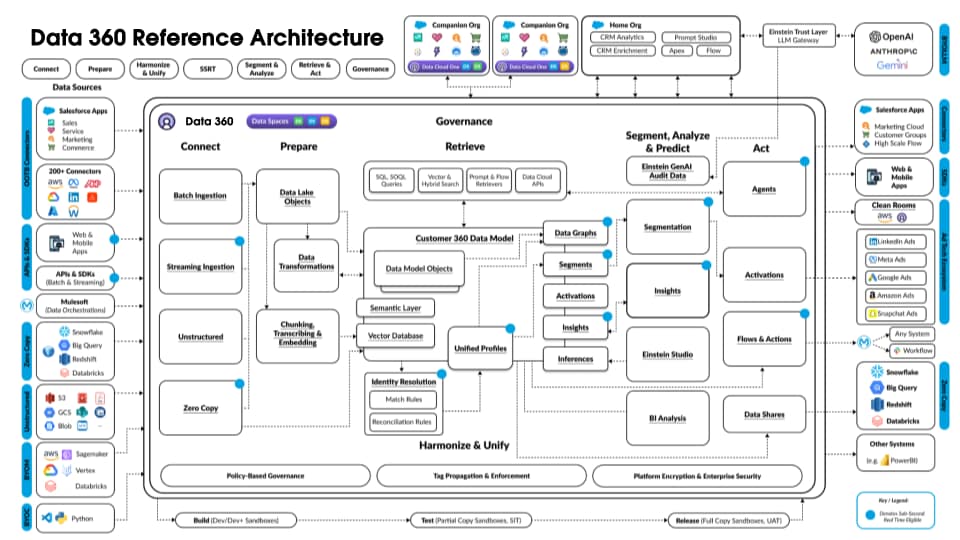
Lad os overveje en hypotetisk Agentforce Lån Agent lagret på Data 360 for at beskrive et eksempel på arkitektonisk forløb. Lad os antage, at Låneagenten er en kundeorienteret agent, hvor kunder (forbrugere) ansøger om lån og får øjeblikkelige lånegodkendelser.
Data 360 udfører disse trin som planlagt og forbereder data til brug af långivningsagenten.
- Data 360 overfører strukturerede kundekontodata fra CRM og lagrer dem i datalaget.
- Data 360 behandler ustrukturerede firmalån og finansielle policedata.
- Data 360 forener personlige data fra en ekstern datakilde, f.eks. Snowflake.
- Data 360 transformerer og modellerer overførte og forenede data.
- Data 360 opbygger og vedligeholder profildatadiagrammet.
Hver gang en kunde ansøger om et lån, udføres disse handlinger.
- En kunde logger på Låneagenten, som starter en kundesession i realtidslaget. Kundens forenede profil hentes ind i laget i realtid.
- Kunden udfylder en låneansøgning ved at angive de krævede oplysninger.
- Kunden uploader økonomiske dokumenter (f.eks. momsrapporter, investeringer, bankopgørelser) til Data 360 til ustruktureret databehandling.
- Uploadede data segmenteres og vektoriseres (integrationsgenerering), og der oprettes indekser (nøgleord og vektor).
- Derefter udfylder kunden dokumentet for låneansøgningen og uploader det. Data 360 udtrækker lånebeløbet og varigheden i realtid.
- Låneagenten henter relevante økonomiske data ved brug af Data 360-forespørgsel og hybrid søgning over profil og andre forhåndsoprettede indekser.
- Låneagenten aktiverer en godkendelsesagent med lånedata og andre finansielle profildata for at træffe beslutningen om lånegodkendelse.
- Låneagenten svarer til kunden med en beslutning.
- Hele denne interaktion mellem kunden og låneagenten registreres og lagres også i Data 360.
Eksemplet ovenfor giver en oversigt over Data 360-arkitekturkomponenter, der bruges til at opbygge en agentapplikation som en låneagent. I det næste afsnit beskriver vi Data 360-arkitekturslag og -komponenter.
I dette afsnit vil vi gå i detaljer med de grundlæggende byggeblokke i Salesforce Data 360, startende med dens robuste lagermodel og derefter udforske mekanismerne til tilslutning, overførsel og forberedelse af data. Vi vil derefter undersøge, hvordan strukturerede og ustrukturerede data lagres, modelleres og behandles, hvilket resulterer i en forståelse af deres harmonisering, forening, hentning og intelligente aktiveringsfunktioner.
Salesforce Data 360 bygger på en lagret, men integreret lagermodel, der kombinerer styrkerne ved en lakehus med lagring i realtid. Lakehouse-laget leverer skalerbar, omkostningseffektiv lagring til store mængder historiske og batchdata, hvilket aktiverer avancerede analyser og maskinlæringsanvendelsessituationer. Lagring i realtid er på den anden side optimeret til adgang med lav forsinkelse og opdateringer med høj frekvens, hvilket sikrer, at kundeinteraktioner, profiler og engagementssignaler altid er aktuelle. Sammen fungerer disse niveauer uden problemer og tillader, at data flyttes uden problemer mellem historiske og realtidskontekster – hvilket giver både dybde og umiddelbarhed i et forenet databrundlag til personliggørelse, AI og aktivering.
Data 360 har en oprindelig lakehouse-arkitektur baseret på Iceberg/Parquet, der er designet til at håndtere datastyring og -behandling i stor skala for batch-, streaming- og realtidsscenarier, der understøtter både strukturerede og ustrukturerede data, som er vigtige for AI- og analyseapplikationer.
I cloudbaserede datalager som Azure, AWS eller GCP er den grundlæggende lagerenhed en fil, der typisk er organiseret i mapper og hierarkier. Lakehouse forbedrer denne struktur ved at introducere strukturelle og semantiske abstraktioner på højere niveau for at gøre det nemmere at udføre handlinger som forespørgsler og AI/ML-behandling. Den primære abstraktion er en tabel med metadata, der definerer dens struktur og semantik, der integrerer elementer fra open source-projekter som Iceberg eller Delta Lake med yderligere semantiske lag tilføjet af Data 360.
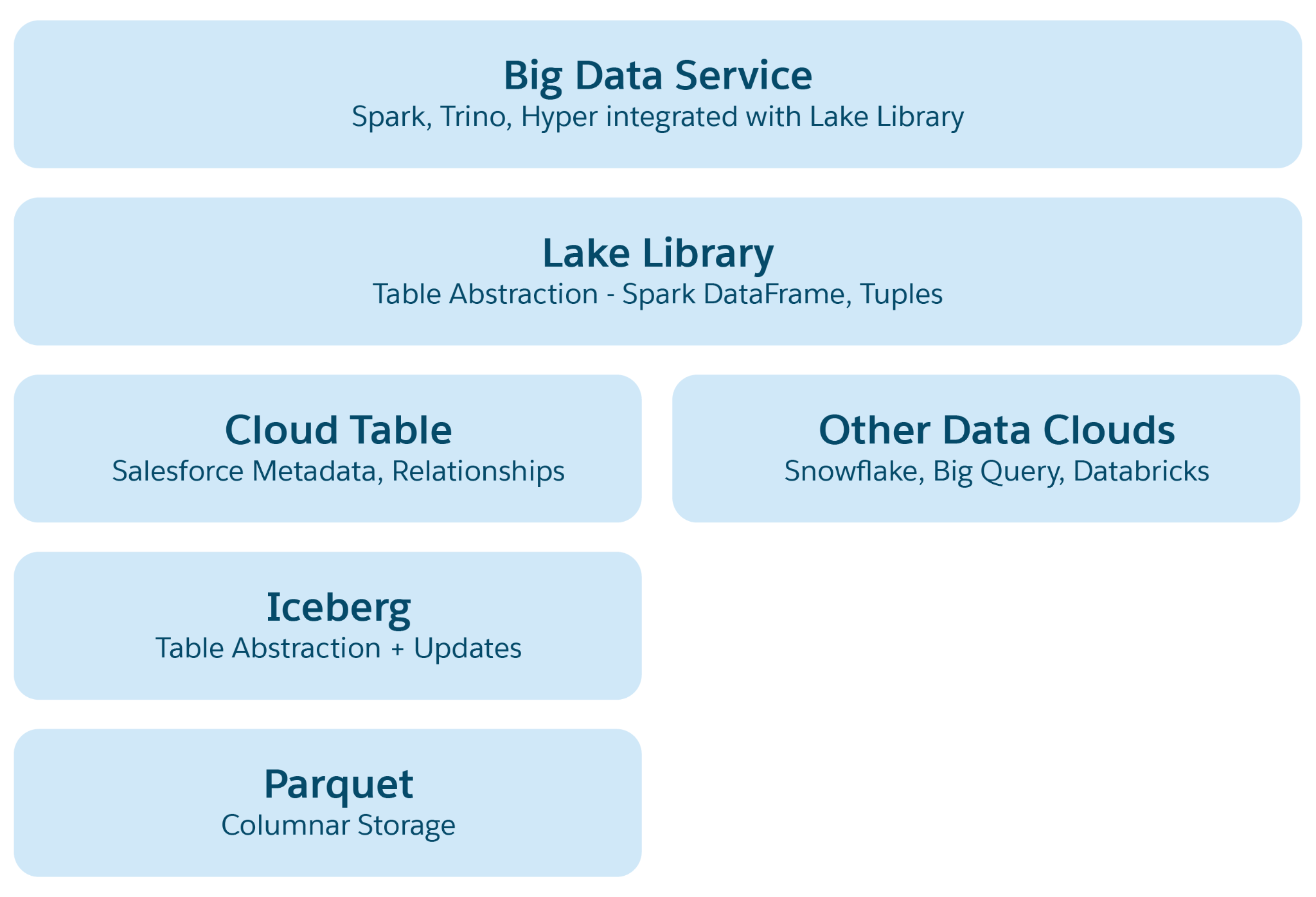
Abstraktionslag i Lakehouse:
- Parket Fil Abstraktion: I basisen består lageret af data lake-filer (f.eks. S3 i AWS eller Blob i Azure) i Parket-format. Data for en kildetabel lagres på tværs af flere partitioner som parketfiler, hvor hver tabel er en samling af disse filer.
- Iceberg tabel abstraktion: Tabeller er organiseret som mapper med datapartitioner, der er lagret som Parket-filer i disse mapper. Ændringer af en partition resulterer i nye Parket-filer som øjebliksbilleder. Iceberg administrerer en metadatafil for hver tabel med detaljerede skemaer, partitionsspecifikationer og øjebliksbilleder.
- Salesforce Cloud-tabeloversigt: Baseret på Iceberg tilføjer dette lag semantiske metadata, f.eks. kolonnenavne og relationer, sammen med konfigurationer som målfilstørrelse og komprimering. Den udtrækker tabeller på tværs af forskellige platforme som Snowflake og Databricks og beskytter Data 360-applikationer mod underliggende lagringsplatformsspecifikationer.
- Lake Access Library: Dette bibliotek giver adgang til Salesforce Cloud-tabellen, håndterer både data og metadata og abstrakterer de underliggende lagringsmekanismer for applikationsudviklere.
- Big Data Service Abstraction: Dette inkluderer behandling af strukturer som Hyper til forespørgsel og Spark til behandling på tværs af enhver cloud-tabelplatform.
For at understøtte realtidsanalyser og agentapplikationer udvider Data 360 lageret Big Data i Lakehouse med lager med lav forsinkelse. Data 360-lags i realtid behandler realtidssignaler og engagementsdata i hukommelsen. Men da den hukommelsesbaserede lagerkapacitet er begrænset, kan alle data ikke passe ind, og behandling sker muligvis ikke i realtid. Data 360 tilføjer et lavt forsinkelseslager (LLS) for at fjerne sådanne begrænsninger og aktivere skalerbar realtidsbehandling.
Lageret med lav forsinkelse er et NVMe-lag på petabyte-skala (SSD) på Lakehouse. Det er ikke alle data, der skal bevares i lageret med lav forsinkelse. Det er en holdbar cache. De fleste data fører til sidst til Lakehouse til langsigtet bevarelse. Sessionsdata i realtidslag kan slettes til lageret med lav forsinkelse for efterfølgende hurtig adgang. I en agent-samtale kan f.eks. seneste meddelelser behandles i hukommelsen. Ældre meddelelser kan slettes til lageret med lav forsinkelse. Hvis der kræves en tidligere samtale, kan du få adgang til den inden for nogle få millisekunder fra lageret med lav forsinkelse. NVMe-baseret lager tillader, at store mængder af data lagres og åbnes med forsinkelser i millisekunder. Data kan komme til Lakehouse Cloud-lageret for at opnå langsigtet bevarelse. Endvidere hentes der data fra Lakehouse, der er påkrævet til realtidsbehandling eller for at udvide oplevelser i realtid, og de bevares i lageret med lav forsinkelse. F.eks. hentes kundeprofilkontekst på forhånd eller hentes fra Lakehouse og cachelagres i lageret med lav forsinkelse. Og alle lakehouse-objekter og andre objekter, der er påkrævede til realtidsbehandling under sessionsbehandling, kan også cachelagres i lageret med lav forsinkelse.
Data 360-lager med lav forsinkelse aktiverer laget Realtimer på et sandt lagerhierarki med lageret memory (SSD) Lakehouse, hvor data migreres uden problemer mellem disse lag. Vi diskuterer Data 360 Real Time-laget senere i dette dokument.
Salesforce Data 360 er designet til at standardisere, harmonisere og aktivere alle kundedata – strukturerede og ustrukturerede – efter en streng livscyklus, der omdanner rå input til en forenet, aktuel datamodel.
Livscyklussen fokuserer på at tage forskellige eksterne datainput og strukturere dem i vedvarende, modellerede objekter. Modellerede data kan harmoniseres i Customer 360 forenede profiler.
Rå overførte data og indledende transformationer
Processen starter med rå data, der overføres som de er fra kildesystemer (CRM, Marketing, filer osv.). Dette inkluderer fulde dataindlæsninger og kontinuerlige ændringsbegivenheder (deltas), som administreres og flettes med vedvarende data for at vedligeholde en aktuel tilstand.
Inline transformationer (f.eks. trim, normalisere, sammenkædning) påføres straks under overførsel for at sikre foreløbig datakvalitet og renhed.
Data Lake-objekter (DLO'er): Det vedvarende lag
DLO'er (Data Lake-objekter) udgør det vedvarende lagerlag i Data 360. De lagrer de rene, transformerede data og fungerer som det organiserede, langsigtede lager for alle kundeoplysninger.
Avancerede datatransformationer (f.eks. sammenføjninger, aggregeringer, beregnede indsigter) anvendes på kilde-DLO'er for at oprette nye, højt organiserede afledte DLO'er.
Data, der gøres tilgængelige gennem Zero Copy Data Federation, vises direkte som DLO'er.
Organisation af ustrukturerede data og metadata
For ustruktureret indhold (f.eks. tekst, medier, dokumenter) indarbejder Data 360 dataene ved at udtrække og bevare deres strukturerede metadata i specifikke DLO'er ved navn Ustrukturerede Data Lake-objekter (UDLO'er).
Disse specialiserede DLO'er fungerer som mappetabeller, der giver et kort over den fysiske placering og kontekst for de ustrukturerede aktiver. Denne funktion giver arkitekter mulighed for problemfrit at relatere metadata fra ustrukturerede data til resten af de strukturerede kundedata, hvilket muliggør forespørgsler og harmonisering.
DMO'er (datamodelobjekter): Det harmoniserede lag
DMO'er (datamodelobjekter) repræsenterer det endelige, harmoniserede og strukturerede datalag.
De oprettes ved at tilknytte DLO-felter (fra kilde-, afledte og ustrukturerede metadata-DLO'er) til Customer 360.
DMO-laget fungerer som den eneste kilde til sandhed for alle kundedata og aktiverer forenet profiloprettelse, segmentering og aktivering på tværs af det bredere økosystem.
Et dataområde er den grundlæggende logiske beholder til organisering af alle data og metadata i Data 360, herunder alle DLO'er (strukturerede og ustrukturerede) og DMO'er. Dataområder tilbyder et sikkert, isoleret miljø til databehandling og modellering.
Dataområder fungerer som logiske og styringsgrænser, der aktiverer intern flertilling ved at adskille data for særskilte enheder, f.eks. forretningsenheder, regioner eller brands – mens de bevarer synlighed, afstamning og overensstemmelse for hele virksomheden og fungerer som grundlag for definition af groft detaljeadgangskontrol.
Isolering i dataområder håndhæves på flere lag af platformen:
- Isolering på dataniveau: Hvert DLO/DMO hører til et enkelt dataområde, hvilket sikrer, at forespørgsler, transformationer og objekttilknytninger ikke kan krydse databrugsgrænser, medmindre de er udtrykkeligt godkendt.
- Adgangskontrolintegration: Tilladelsessæt er som standard bundet til dataområder og tillader kontrol over læse-, skrive- og administrative handlinger. Dette sikrer, at kun godkendte brugere og tjenester kan få adgang til objekter, indsigter og aktiveringer i et dataområde.
- Forvaltning og revision: Alle handlinger i et dataområde logføres med revisionsspor på virksomhedsniveau, hvilket aktiverer sporbarhed for overholdelse, forvaltning og regulerende rapportering.
Adgang og tilladelser administreres gennem tilladelsessæt, hvilket sikrer detaljeret synlighed, kontrollerede opdateringer og forebyggelse af datalækage på tværs af domæner. Ved at integrere dataplaceringsgrænser med Data 360's sikkerheds- og styringsarkitektur kan arkitekter med tillid implementere både centraliserede og decentraliserede styringsstrategier, mens de bevarer ensartethed på tværs af flere clouds og forretningsdomæner.
Data 360-computertekst leverer et forenet lag til administration og kørsel af alle Big Data-arbejdsbelastninger og forenkler de underliggende infrastrukturers kompleksitet. Dens kernekomponent er DPC (databehandling controller).
DPC er en omfattende orkestreringstjeneste til databehandling med flere arbejdsbelastninger, der leverer Job-as-a-Service-funktioner på tværs af forskellige cloud computingmiljøer. Den abstrakterer infrastrukturkompleksitet og ensretter jobkørsel for strukturer som Spark (EMR på EC2 og EMR på EKS) og Kubernetes Resource Controller (KRC)-arbejdsbelastninger. Ved at fungere som en centraliseret control plane-gateway orkestrerer, planlægger og overvåger DPC job på tværs af flere dataplaner, hvilket sikrer pålidelighed, skalerbarhed, omkostningseffektivitet og en ensartet udvikleroplevelse.
Behovet for DPC stammer fra begrænsningerne ved at interagere direkte med oprindelige klyngestyringssystemer som EMR.
Infrastruktur og Cloud-abstraktion
Mens EMR tilbyder API'er for klynger, opgaver og trin, belaster det stadig klientteams med vigtige infrastrukturstyringsopgaver som provisionering, skalering, ydeevnetuning og omkostningsoptimering. DPC håndterer dette ved at tilbyde en forenklet API på platformsniveau for jobindsendelse. Den understøtter automatisk fejlhåndtering, forsøg og dynamisk indlæsningsbalancering. Giver omkostningseffektivitet gennem sammenpaknings-, spot- og gravitonbaserede noder. Giver stærk sikkerhed med TLS, PKI, IAM-isolering og automatiseret fejlretning. Administrerer opgraderinger af Spark- og EMR-kørselsversioner for at levere ydeevneforbedringer, sikkerhedsfejlretninger og funktionsforbedringer.
Desuden leverer DPC en forenet, cloud-agnostisk grænseflade til indsendelse og administration af datajob, abstraktering af kompleksiteten og de proprietære API'er for det underliggende cloud-substrat (AWS, fremtidige udbydere). Dette sikrer, at klientteams kun interagerer med en fælles Data 360 API-baseret jobindsendelsesgrænseflade, der abstrakterer kompleksiteten af underliggende ressourceadministratorer som Kubernetes og YARN. Dette giver klientteams mulighed for at indsende Spark-job gennem en enkel, forenet API uden at skulle administrere pods, nodepools eller Spark-klyngekonfigurationer direkte.
Manuel tilpasning af Spark-parametre kræver specialiserede færdigheder, og ukorrekte konfigurationer kan føre til langsom kørsel af job. DPC-teamet centraliserer denne ekspertise og leverer optimerede konfigurationer til at forhindre almindelige ydeevneproblemer. Dette specialiserede team integrerer kontinuerligt Knowledge fra open-source-fællesskabet for at sikre optimal ydeevne på tværs af alle arbejdsbyrder, der administreres af controlleren.
DPC er ikke begrænset til Spark. Det understøtter en lang række arbejdsbelastninger. Disse omfatter:
- Behandler arbejdsbelastninger i realtid
- Begivenhedslevering for funktionen Datahandlinger
- Administration af Milvus (vektordatabasen for ustruktureret dataindeksering)
- Lagringsinfrastruktur med lav forsinkelse
DPC bruger også Kubernetes Resource Controller-strukturen, som understøtter arbejdsbelastninger som Trino for forespørgsel, Begivenhedslevering for datahandlinger, Dataudtrækningsjob for forbindelser og behandling i realtid. For alle KRC-arbejdsbelastninger leverer DPC centrale Job-as-a-Service-funktioner, der håndterer beregningsprovisionering, implementering og administration ved en jobabstraktion på højt niveau.
JaaS-fordele og -arkitektur
Job-as-a-Service-modellen, der leveres af DPC, sikrer en omkostningseffektiv og fleksibel jobbehandlingspipeline.
Brugere leverer enkle klyngespecifikationer med fokus på krævet CPU, hukommelse, lager, forekomstantal og Min/Max-klyngeantal og tags til klyngematchning. DPC administrerer derefter automatisk abstrakte infrastrukturdetaljer, herunder valg af optimale VM-SKU'er, administration af forekomstflåder, bestemmelse af forholdet mellem Kerne vs. Opgavens noder og administration af On-Demand vs. Spotforekomster baseret på input. Den håndterer også EMR og komponentversionsstyring og opgraderinger uden nedetid.
Vigtigst er det, at DPC understøtter flertillæg, der er designet til at forstå og håndhæve Data 360-lejergrænser og ressourceseparation. Det sikrer også Sikkerhed og overensstemmelse ved at håndhæve Salesforce-certificerede maskinbilleder, administrere servicespecifikke IAM-roller og garantere kryptering både undervejs og inaktive. For distribution og kapacitetskontrol administreres job-til-klynge-matchning ved brug af klyngetags, og kapacitetsbaseret distribution bruger en maksimal jobtidsindstilling til effektivt at kontrollere ressourceanvendelse.
Cloud Agnostic-klientoplevelsen er en kernefordel, da kompleksiteten af de underliggende cloudmiljøer er skjult for klienttjenester, så de kan fokusere udelukkende på forretningslogik. Dette opnår målet i Cloud-udbyderabstraktion. Endelig aktiverer DPC nem anvendelse og omkostningssporing, hvilket tillader, at klyngeanvendelse og omkostninger segmenteres efter service for nøjagtig regnskabsføring. Generelt følger DPC en plug-in-arkitektur, der tillader, at nye kørselssystemer (f.eks. Flink, Ray) og cloud-substrater (GKE/Dataproc) integreres uden problemer uden at vise underliggende infrastrukturdetaljer for brugere. Dette design adskiller kontrolplanen fra kørselslaget, hvilket sikrer en ensartet API og driftsmæssig oplevelse, uanset backend.
Data 360 justerer og beriger rå data og danner bro mellem rå oplysninger og forretningsforbrug, der kan handles på. Den supplerer dataobjektets livscyklus ved at forberede komplekse data til sofistikeret aktivering og analyse. Data 360 understøtter forskellige behandlingstyper, herunder batch- og streamingdatatransformationer, batch- og streamingberegnede indsigter, ustruktureret databehandling og identitetsløsning. Hvis du vil aktivere disse forskellige handlinger effektivt, især i næsten realtid og på tværs af massive datasæt, kræves der en sofistikeret mekanisme til at håndtere dataændringer effektivt.
Hvis du vil opnå effektiv databehandling i næsten realtid – især med tabeller på terabyte og millioner af potentielle opdateringer – skal Data 360 have et gennembrud. Det krævede en måde til at advisere systemer præcist, når data ændres og derefter effektivt identificere, hvilke data der blev ændret, så kun relevante opdateringer behandles og kun når de opdateres. Denne udfordring førte til to supplerende innovationer: Storage Native Change Events (SNCE) til at advisere, når noget ændres, og Change Data Feed (CDF) til at identificere, hvad der er ændret.
SNCE (Storage Native Change Events)
SNCE har grundlæggende ændret Data 360 til en reaktiv og trinvis dataplatform. Denne skift involverer flytning fra aktiv polling af datalaget til passiv overvågning for atomiske bekræftelsesbegivenheder ved brug af et standardiseret begivenhedsformat og et højgennemgangsmeddelelsesleveringssystem.
Hver vellykket skrivehandling (INSERT, UPDATE, DELETE) til en Iceberg-tabel kulminerer i et atomisk udskiftning af tabellens aktuelle metadatafilmarkør i kataloget. Det underliggende objektlagringslag (som S3) er konfigureret til at udsende en indbygget adviseringsbegivenhed (som en S3-begivenhed), når et nyt metadataøjebliksbillede skrives til tabellens mappe.
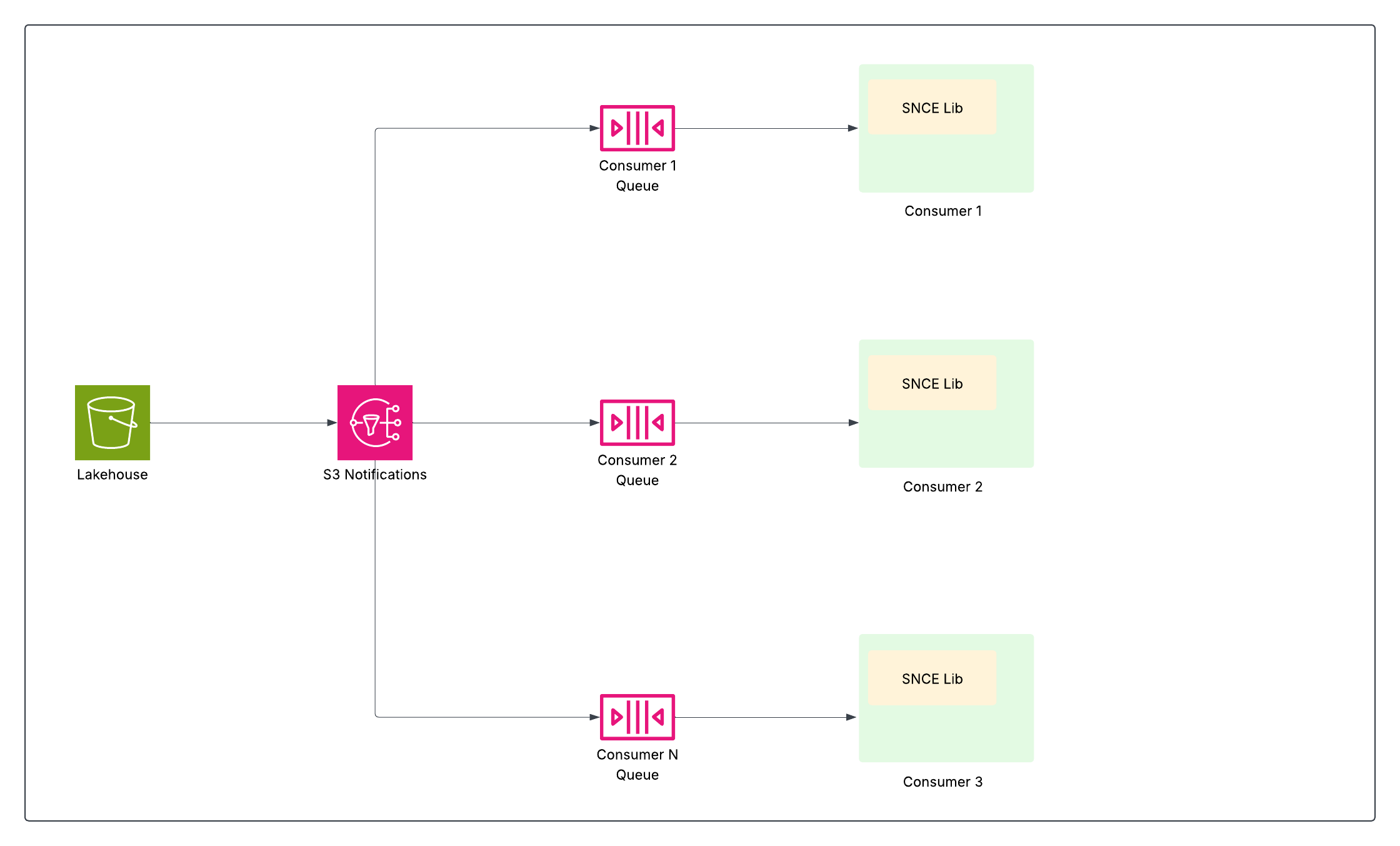
SNCE-biblioteket tilbyder en standardiseret metode til forbrug af disse begivenheder, og det kan også berige dem med øjebliksbilledmetadata efter anmodning.
Dette aktiverer downstream-datapipelines – f.eks. streaming af beregnede indsigter, identitetsløsning og segmentering – til kun at abonnere og reagere, når data er ændret, hvilket øger effektiviteten markant ved at undgå dyre fuldtabelscanninger.
Rediger datafeed (CDF)
Baseret på SNCE leverer Change Data Feed (CDF) en strømlinet mekanisme til at forbruge og trinvist behandle ændringerne.
CDF bruger Iceberg-øjebliksbilleder til effektivt at generere en stream af ændringer. Kritisk set beregner og bevarer Data 360's optimerede Iceberg-forfatter ændringerne som en del af selve skrivehandlingen, hvilket gør CDF-generering meget effektiv og minimerer yderligere overhead. Dette gør det muligt for behandlingsjob (f.eks. streaming-transformationer eller streaming af beregnede indsigter) at kun selektivt behandle de ændrede registreringer og undgå den dyre forskydningsberegning for øjebliksbilleder.
Denne trinvise strategi giver flere fordele for store datasæt, herunder omkostningsbesparelser, reduceret forsinkelse og forbedret effektivitet. Den aktiverer funktioner som streaming-transformationer og trinvis identitetsløsning, hvilket igen fører til hurtigere indsigter, mere forudsigelige systemindlæsninger, forbedret ydeevne og lavere driftsomkostninger.
Data 360 tilbyder robuste overførselsfunktioner med indbygget understøttelse af Salesforce-produkter, hvilket sikrer problemfrit dataforløb. For eksterne kilder giver den omfattende tilslutning gennem over 270 forbindelser, API'er, SDK'er og MuleSoft. Endvidere har Data 360 nul-kopi-federation, der tillader BI og analyser uden dataduplikering.
DCF (Data 360 Connector Framework) er grundlaget for de fleste Data 360-forbindelser. Den aktiverer overførsel, federation og udløb gennem en forenet arkitektur. DCF definerer standarderne for opbygning og administration af forbindelser fra brugergrænsefladen til opsætning og administration til metadataopbevaring, dataudtrækning og levering til Lakehouse eller via live-forespørgsler mod eksterne kilder. Den understøtter også private forbindelsesindstillinger (f.eks. private links, VPN'er og sikre tunneler) for at sikre datasikkerhed og compliance på virksomhedsniveau, når du opretter forbindelse til kunde- eller partnermiljøer. Ved at levere en ensartet tilgang på tværs af alle forbindelser, sætter DCF Data 360 i stand til at oprette en problemfri forbindelse til det bredere økosystem ved at sikre udvidelighed, pålidelighed og sikker integration.
Data 360 leverer robust tilslutning til et stort økosystem af datakilder, der understøtter både oprindelige Salesforce-produkter og utallige eksterne systemer. Denne omfattende forbindelsesmulighed er vigtig for at forene enkeltstående virksomhedsdata og aktivere AI/ML og agentapplikationer.
Data 360 tilbyder over 270 forbindelser som standard eller gennem MuleSoft, API'er og SDK'er for at understøtte dens end-to-end-datapipelinefunktioner med batch, streaming eller realtidsoverførsel. Disse forbindelser kan kategoriseres bredt efter typen af kildesystem, som de integrerer.
Salesforce-oprindelige forbindelser
Disse forbindelser sikrer problemfrit og oprindeligt dataforløb fra Salesforce-produkter.
Eksempler inkluderer forbindelser til Salesforce CRM, Data Cloud One, Marketing Cloud-engagement, Marketing Cloud-kontoengagement og B2C Commerce.
Eksterne applikationer og SaaS
Forbindelser til forskellige forretningsapplikationer og cloudtjenester tillader dataoverførsel fra eksterne softwareplatforme.
Eksempler omfatter Adobe Marketo Engage, Microsoft Dynamics 365, Mailchimp og Airtable.
Databaser og datalagre
Data 360 opretter forbindelse til en række relations- og cloudbaserede datalagringsplatforme.
Eksempler omfatter Amazon Redshift, Amazon DynamoDB, Amazon RDS (MySQL, PostgreSQL, Oracle), Google BigQuery og Microsoft SQL Server.
Cloud-objektlager og filsystemer
Disse forbindelser integreres med hyperscaler-lagringsløsninger for både strukturerede og ustrukturerede data.
Eksempler inkluderer Amazon S3, Google Cloud Storage (GCS) og Azure Blob Storage.
Streaming- og Meddelelsestjenester
Forbindelser, der håndterer kontinuerlige datastreams i realtid, er vigtige for begivenhedsstyrede scenarier og realtidsbehandling.
Et eksempel er Amazon Kinesis-forbindelsen.
Integrationsplatforme
MuleSoft Anypoint-forbindelsen udvider Data 360's rækkevidde ved at integrere den med en bredere række applikationer og databaser via Anypoint Exchange.
Ustrukturerede data- og Cloud-objektlagringsforbindelser
Disse forbindelser er vigtige for at overføre og henvise til ustrukturerede data (data, der mangler en foruddefineret model) for at styrke genererende AI-funktioner.
Alle disse forbindelser bygger på Data 360-forbindelsesstrukturen, der giver ensartet oplevelse.
Datatransformation er en grundlæggende arkitektonisk komponent i Data 360, der er designet til at rense, berige og forme rå overførte data til normaliserede dataaktiver, der kan handles på, i overensstemmelse med Customer 360. Denne proces er vigtig for harmonisering, kvalitetsforbedring og sikring af, at data er klar til downstream-anvendelsessituationer som profilforening, segmentering og aktivering. Transformationer anvender både DLO'er (source data lake objects) og DMO'er (datamodelobjekter) som input og opretter resultaterne til henholdsvis nye DLO'er eller DMO'er.
Data 360 leverer to primære transformationsparadigmer til at håndtere forskellige krav til datahastighed: batchdata-transformationer og streamingdata-transformationer.
Batch-datatransformationer
Batch-datatransformationer er designet til højvolumen behandling baseret på en defineret tidsplan eller on-demand-udløser. Dette system er optimeret til håndtering af komplekse, ressourceintensive omstruktureringshandlinger.
Batch-transformationsprocessen konfigureres ved brug af et visuelt pipeline-lærred med lav kode, der gør det muligt for brugere at definere transformationslogik med flere faser. Dette system understøtter entydigt komplekse omstruktureringshandlinger, der er vigtige for kanonisk datamodeljustering: datastrukturering og normalisering. Dette inkluderer pivotering (opdeling af denormaliserede registreringer i flere normaliserede registreringer) og fladgøring (omstrukturering af hierarkiske data, f.eks. JSON, i strukturerede tabeller). Systemets kørselstilstand understøtter både fuld synkronisering (behandling af alle registreringer) og en meget effektiv trinvis behandlingstilstand. Trinvis tilstand reducerer behandlingstid og ressourceforbrug betydeligt ved kun at behandle registreringer, der er ændret siden den sidste vellykkede kørsel. Batchtransformationer er ideelle til opgaver, hvor opdateringer i realtid ikke er vigtige, f.eks. periodiske aggregeringer og kompleks dataomstrukturering.
Streaming af datatransformationer
Streamingdata transformerer data kontinuerligt og trinvist i næsten realtid, når de flyder ind i systemet, hvilket gør dem vigtige for anvendelsessituationer med lav forsinkelse.
Den primære grænseflade er en SQL-første tilgang, hvor transformationer er defineret som en SQL SELECT-forespørgsel, der kontinuerligt udføres mod den indgående stream af registreringsændringer. Dette system understøtter kerne-transformationsfunktioner, herunder datarensning og standardisering (f.eks. validering af personligt identificerbare oplysninger og standardisering af dataformater) og databerigelse og fletning (ved brug af sammenføjninger og unioner). Kritisk understøtter den streamingopslags-JOIN'er for at aktivere databerigelse i realtid og opslag mod statiske eller langsomt ændrede referencedata, hvilket sikrer øjeblikkelige profilopdateringer. For at optimere serviceomkostninger anvender arkitekturen et HD-jobdesign (High-Density), der pakker flere streaming-transformationsdefinitioner for en enkelt lejer i et enkelt underliggende computingjob og maksimerer ressourceanvendelsen. Streaming-transformationer er vigtige for anvendelsessituationer som begivenhedsovervågning, øjeblikkelig tilpasning og profilopdateringer i realtid.
Data 360 revolutionerer dataadministration ved at understøtte Zero Copy-federation og datadeling, hvilket eliminerer behovet for at flytte eller duplikere data. Denne funktion giver brugere mulighed for problemfrit og direkte at få adgang til data fra forskellige eksterne kilder og dele data med eksterne miljøer, hvilket reducerer kompleksiteten, reducerer lagringsomkostninger og sikrer, at alle beslutninger er baseret på de nyeste, mest pålidelige oplysninger.
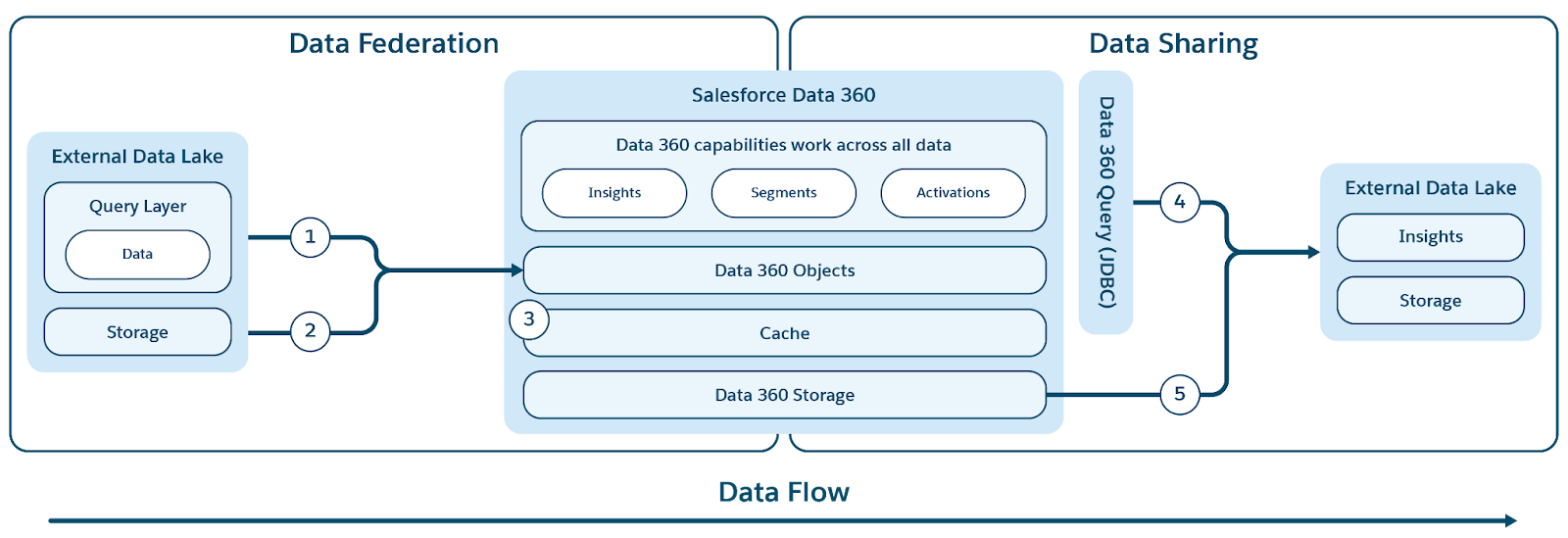
Data 360 understøtter nul-kopi-federation med eksterne datalager (Snowflake, Redshift), lakehuse (Google BigQuery, Databricks, Azure Fabric), SQL-databaser og mange andre kilder. Dens abstrakteringslag aktiverer direkte forespørgsel på eksterne data uden duplikering, reducerer overførselstid, lagringsomkostninger og sikrer opdaterede oplysninger.
Data 360 forenkler adgang til eksterne og forenede data ved at levere et forenet metadatalag, der abstrakterer både Salesforce- og eksterne objekter. Dette sætter hele Salesforce-platformen og dens applikationer i stand til problemfrit at bruge disse data.
Data 360 understøtter både fil- og forespørgselsbaseret federation med liveforespørgsel og adgangshastighed som vist i figuren.
Betegnelser (1) og (2) illustrerer Data 360's forespørgsel (herunder live-forespørgsels-push-downs) og filbaseret federation for at få adgang til data fra eksterne datalager/lager/datakilder, og betegnelse (3) fremhæver acceleration af forenet adgang fra eksterne datalager/datakilder.
Forespørgselsfederation
Kernen i Data 360's federationsfunktionalitet ligger i dets forespørgselsfederationslag, som administrerer den komplekse proces med at få adgang til eksterne data og udføre intelligente forespørgsels-pushdowns (illustreret med betegnelse 1). Data 360 opretter forbindelse til og henter data fra kilder ved brug af JDBC-protokollen, forbedret med yderligere logik for forbedret effektivitet. Forespørgselsfederationslag er ansvarlig for at forstå og oversætte forskellige SQL-dialogbokse, finde ud af den mest optimale del af forespørgslen, der skal overføres til eksterne systemer for effektiv behandling, hente resultaterne og udføre enhver nødvendig yderligere behandling for at aflede endelige indsigter.
Cachelagring (forespørgselsforøgelse)
For forbedret hjælpeprogram giver Data 360 en valgfri accelerationsfunktion for dens forenede funktioner.
Når Acceleration er aktiveret, cachelagrer Data 360 de forenede data for at opnå hurtigere adgang og lavere omkostninger – da det undgår gentaget direkte adgang til eksterne kilder. Denne cache behandles som et accelerationslag og opdateres trinvist til hurtigt at afspejle ændringer i de eksterne kildedata, hvilket sikrer, at den accelererede visning forbliver tæt på realtid.
Filforening
Data 360 understøtter filbaseret federation (illustreret med betegnelse 2) til at få adgang til data fra eksterne datalager og kilder. Det tekniske grundlag for denne nul-kopieringsfunktionalitet er baseret på standardisering: De underliggende data skal være i filformatet Apache Parquet og bruge tabelformatet Apache Iceberg. Data 360 kan forenes til enhver kilde, der viser et Iceberg REST Catalog (IRC) for metadata og lageradgang, hvilket sikrer problemfri, administreret adgang til filer, der findes uden for platformen.
Med filbaseret federation håndterer Data 360-computer al databehandling, da de direkte får adgang til det underliggende lager. Dette eliminerer behovet for forespørgsels-push-down og administration af forskellige SQL-dialogbokse, som ofte er påkrævet med forespørgselsbaseret federation.
Udover dette udvides Zero Copy-funktionalitet også til ustrukturerede datakilder som hyperscaler-lagringsløsninger (S3/GCS/Azure-lagring), Slack og Google Drive, som kan fås adgang til af Data 360's ustrukturerede behandlings-pipelines.
Data 360 gør det nemmere både forespørgselsbaseret og filbaseret deling af data, det administrerer med eksterne datalager og lagerbygninger (illustreret af betegnelser 4 og 5 i den oprindelige figurkontekst).
Forespørgselsbaseret deling
For forespørgselsbaseret datadeling viser Data 360 en JDBC-driver ved brug af hvilke eksterne systemer og applikationer der kan få sikker adgang til dataene. Denne mekanisme tillader eksterne systemer at tilslutte, godkende og eksekvere live-forespørgsler direkte mod dataene i Data 360.
Filbaseret deling (datadeling og DaaS)
Den primære mekanisme for filbaseret deling involverer to koncepter: datadeling og datadelingsmål, som anvender DaaS (Data as a Service) API.
- Granulær kontrol: Datadelingskonceptet gør det muligt for kunder nøjagtigt at definere, hvilke objekter (DLO'er, DMO'er, CIO'er osv.) der deles eksternt, hvilket forhindrer utilsigtet visning af data.
- Sikker målretning: Det kontrollerer også datadelingsmålet, så det sikrer, at data kun stilles til rådighed for eksplicit autoriserede eksterne miljøer, konti eller partnerorganisationer (f.eks. deling med en specifik Redshift- eller Databricks-forekomst).
DaaS API leverer en sikker og administreret grænseflade til eksterne systemer til at forbruge data. Den giver adgang til både de vigtige metadata og den underliggende tabellagring, mens alle Data 360-semantik bevares. Dette sikrer eksterne systemer adgang til dataene i en ensartet og meningsfuld kontekst på en sikker måde.
Mange sikkerhedsfølsomme kunder, især store virksomheder, regulerede brancher og organisationer i den offentlige sektor, begrænser al internetadgang til deres datalager som en del af deres sikkerhedstilstand. Denne politik er vigtig for overensstemmelse og risikoreduktion, men forhindrer også Salesforce Data 360 og Agentforce i at oprette forbindelse til disse miljøer via det offentlige internet.
De fleste af disse datalager implementeres i hyperscaler-miljøer som f.eks. AWS, Azure eller Google Cloud. Da Data 360 selv kører på AWS, kræver adgang til kundedata lakes, der hostes på en anden cloududbyder, en kryds-cloud-netværksforbindelse. Uden en sikker, privat forbindelsesmulighed, der omgår det offentlige internet, er kunderne ofte ude af stand til eller ikke villige til at indføre Data 360 eller Agentforce til anvendelsessituationer, der er afhængige af disse datalager.
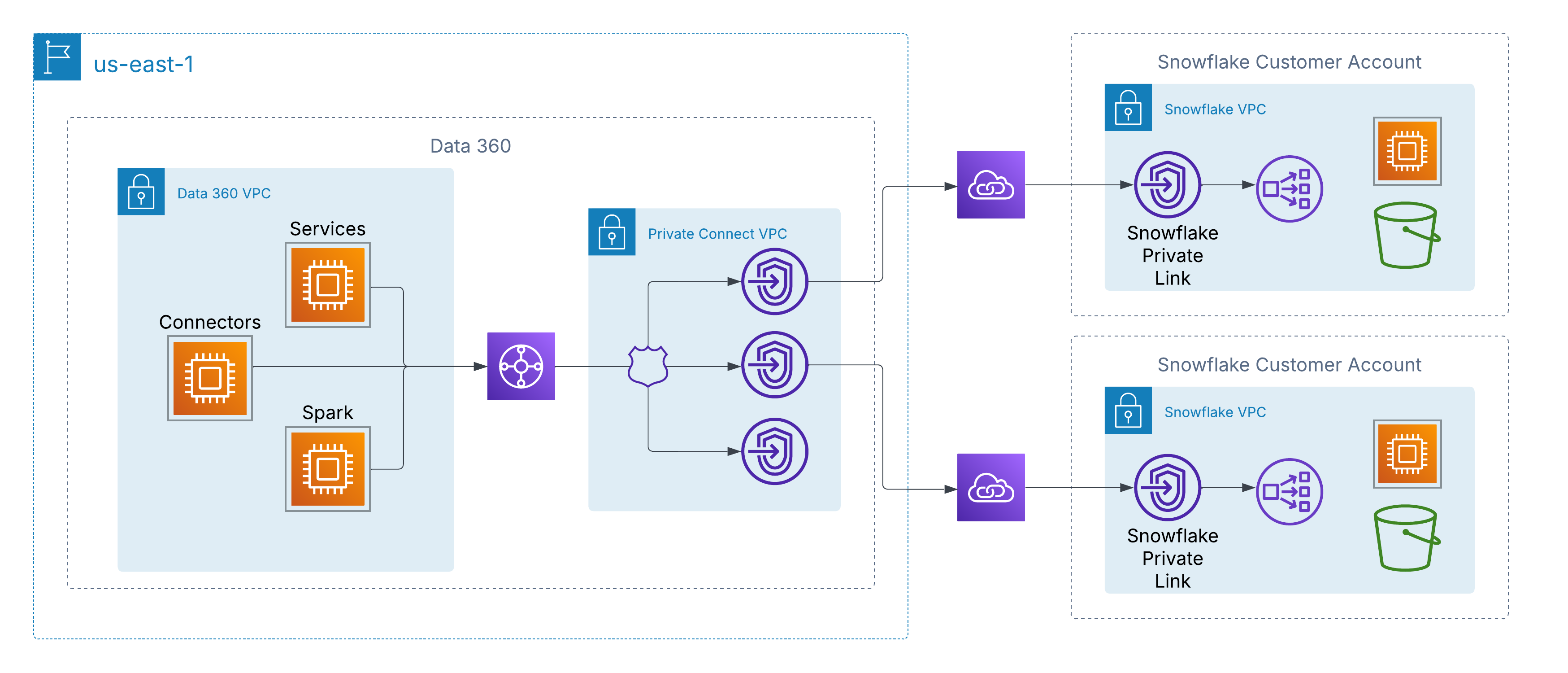
For at håndtere dette understøtter Data 360 forbindelse på privat netværksniveau til kundestyrede datakilder på tværs af clouds. På AWS er dette aktiveret gennem AWS PrivateLink, som tillader Data 360 at oprette forbindelse direkte til kundeprovisionerede slutpunkter, enten i deres egne konti eller i tredjeparts data lake-miljøer (f.eks. Snowflake), uden at krydse det offentlige internet.
Denne arkitektur sikrer, at al trafik forbliver fuldstændig på AWS-backbone ved brug af privat IP-adresse og ikke-distribuerbare netværksstier, hvilket opfylder strenge sikkerheds- og compliancekrav, mens du aktiverer problemfri adgang til kundedata.
For kunder med multi-cloud-arkitekturer udvider Data 360 privat tilslutning ud over AWS gennem understøttelse af kryds-cloud-forbindelser. Dette aktiverer sikre, kun-backbone-netværksstier fra Data 360 til datalager og tjenester, der hostes i Azure eller Google Cloud, og bevarer de samme principper som AWS PrivateLink – privat IP-adresse, ikke-offentlig distribution og nul interneteksponering.
Kunder kan vælge mellem to implementeringsmodeller:
-
Kundestyret forbindelse: Integrer eksisterende private kredsløb som Azure ExpressRoute, Google Cloud-interconnect eller Equinix Fabric direkte med Data 360's VPC'er.
-
Salesforce-administreret forbindelse: Brug en fuldt administreret, turnkey-forbindelse, hvor Salesforce klargør og administrerer kryds-cloud-linket og viser private slutpunkter i målclouden.
I begge modeller er oplevelsen ensartet: Data 360-tjenester opretter forbindelse til eksterne datakilder på tværs af hyperskaler, som om de var lokale, og aktiverer sikker overførsel, aktivering og forespørgsel uden at krydse det offentlige internet.
For virksomhedsarkitekter er robust dataforvaltning ikke blot en overensstemmelsesafkrydsningsfelt, men en grundlæggende søjle for opbygning af pålidelig, skalerbar og håndterbar Kundeintelligens. Salesforce Data 360 er bygget med en omfattende styringsstruktur, der sikrer datakvalitet, sikkerhed og overholdelse af bestemmelsesbestemmelser på tværs af hele dens datalivscyklus.
Data 360 fungerer som en centraliseret styringshub og sikrer, at alle data – fra rå overførsel til aktiverede indsigter – administreres med integritet og kontrol.
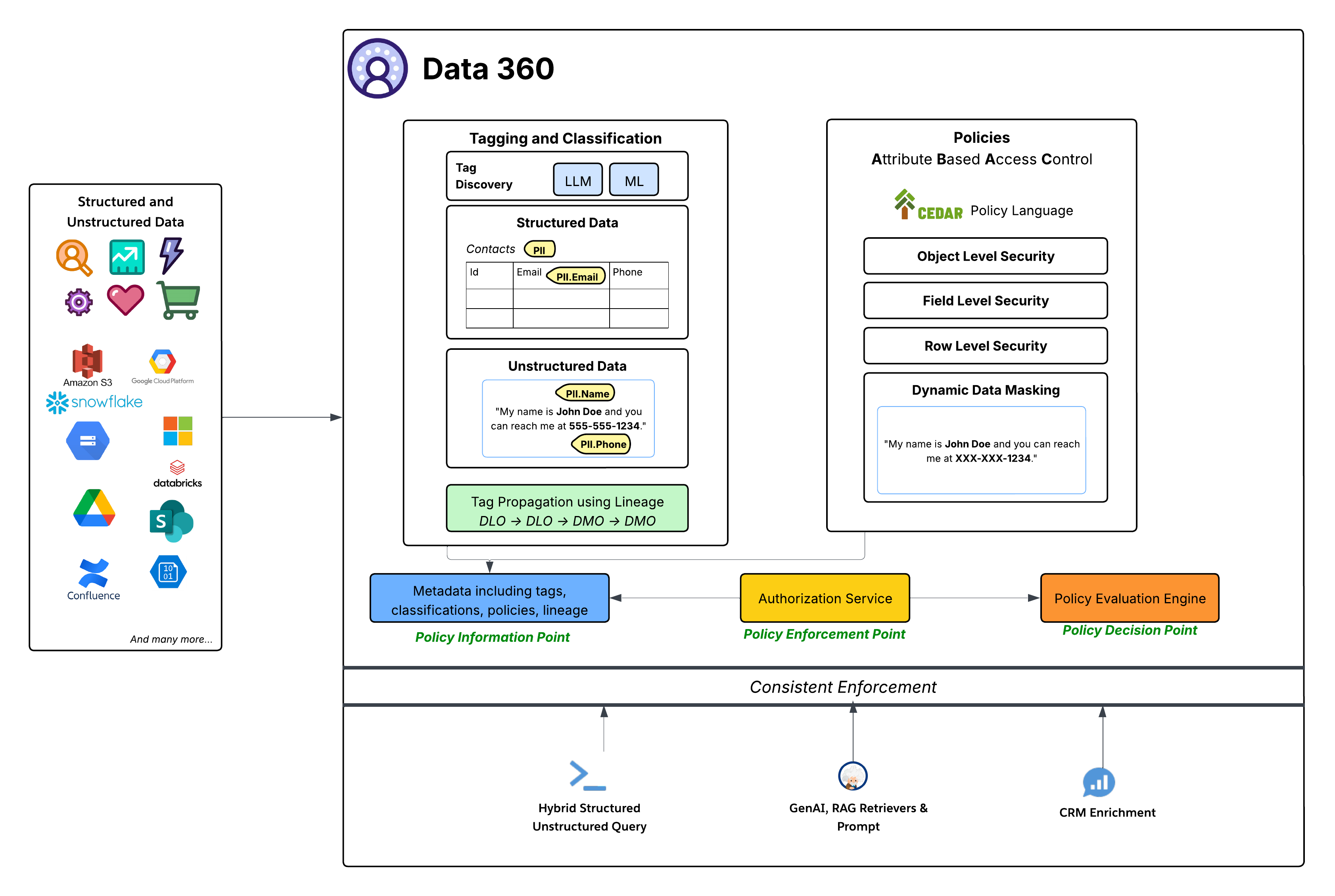
Mens dataområde leverer grove detaljeadgangskontrol til at bestemme adgang til alle objekter i et dataområde, leverer ABAC-baserede politikker detaljeret adgangskontrol til individuelle objekter, felter og rækker i et dataområde. Data 360 har ibrugtaget Attributbaseret adgangskontrol (ABAC) som sin kerneautorisationsmodel for fininddelt adgangskontrol. Dette strategiske valg giver overlegen fleksibilitet og skalerbarhed sammenlignet med traditionel rollebaseret adgangskontrol (RBAC), især afgørende for dynamiske, komplekse virksomhedsmiljøer med store mængder data og varierede adgangsbehov. ABAC tillader, at adgangsbeslutninger baseres på brugerens attributter (f.eks. afdeling, rolle, placering), data (f.eks. personligt identificerbare oplysninger, følsomhed, dataplacering) og miljøet (f.eks. tidspunktet på dagen) snarere end blot foruddefinerede roller. Dette aktiverer meget detaljerede og kontekstbaserede adgangspolitikker, der tilpasser sig, efterhånden som data og brugerattributter ændres.
- CEDAR-politiksprog: I hjertet af Data 360's ABAC-implementering er brugen af CEDAR-politiksproget. Dette formålsbyggede, formelle politiksprog giver en præcis og bekræftelig måde til at definere komplekse autorisationsregler på, hvilket sikrer, at politikker er entydige og kan evalueres ensartet på skala.
Styringssystemet i Data 360 overholder en robust ABAC-standardarkitektur:
- Tagging, klassificering og politikoprettelse (PIP - Policy Information Point):
- Data 360 leverer automatiserede tagging- og klassificeringsmekanismer, der anvender LLM (Large Language Model) og ML (Machine Learning) til at identificere følsomme datakategorier (f.eks. PII.Email, PII.Phone, PII.Name) og andre formålsbyggede taxonomier (PHI, FinancialData) i både strukturerede data (f.eks. kontakttabel) og ustrukturerede data (f.eks. fra Google Drive).
- Vigtigt er, at tagudbredelse forekommer langs Datalinage (DLO -> DLO -> DMO), hvilket sikrer, at klassificeringer automatisk følger datatransformationer og afledninger, fra rå overførte data til det harmoniserede DMO-lag og gennem afledte data, der er oprettet fra procesdefinitioner.
- Endelig giver politikoprettelsesruden en enkel oplevelse til at udnytte data og brugerattributter til at definere dynamiske adgangsregler for en organisation.
- Disse berigede metadata (herunder tags, klassificeringer, politikker og afstamning) føres til Politikoplysningspunktet (PIP).
- Tilladelsestjeneste (Police Enforcement Point - PEP):
- Godkendelsestjenesten fungerer som PEP (Police Enforcement Point). Den opfanger alle dataadgangsanmodninger fra forskellige forbrugslag (Hybrid struktureret/ustruktureret forespørgsel, GenAI RAG Retrievers & Prompt, CRM-berigelse) og konsulterer Politikbeslutningspunktet for at bestemme, om adgang er tilladt.
- Police Evaluation Engine (Polic Decision Point - PDP):
- Dette system fungerer som PDP (Police Decision Point). Den tager adgangsanmodningskonteksten fra PEP sammen med politikdefinitioner (i CEDAR) og attributter fra PIP for at træffe en autoriseret adgangsbeslutning.
- Sikkerhedspolitikker: Politikker, der er defineret i CEDAR, håndhæver forskellige sikkerhedsniveauer, herunder:
- Sikkerhed på objektniveau: Kontrol af adgang til hele DLO'er eller DMO'er baseret på tags, der er tilknyttet disse objekter.
- Sikkerhed på feltniveau: Begrænsning af adgang til specifikke følsomme felter i et objekt baseret på tags.
- Sikkerhed på rækkeniveau: Filtrering af data på specifikke objekter for kun at vise relevante rækker baseret på brugerattributter.
- Dynamisk datamaskering: Masker dynamisk bestemte data (baseret på tags) på adgangspunktet uden at ændre de underliggende data. Dette sikrer, at følsomme oplysninger er beskyttet, mens du stadig tillader bred hjælp. Dette gælder for maskeringsfelter i strukturerede data såvel som indhold i ustrukturerede data.
- Sammenhængende håndhævelse: Hele ABAC-strukturen sikrer ensartet håndhævelse af politikker på tværs af alle Data 360-forbrugsmønstre, uanset om det f.eks. er direkte dataforespørgsel, hentning for genererende AI-applikationer (RAG) eller berigelse af Salesforce CRM-oplevelser via relaterede lister.
- Dyb integration med Salesforce Platform: Data 360's styringsfunktioner er defineret og administreret direkte i Salesforce-kerneplatformen. Denne integration giver administratorer mulighed for at administrere adgangspolitikker, brugeridentiteter og attributstyring ved brug af velkendte Salesforce-værktøjer, hvilket sikrer et forenet og ensartet styringslag på tværs af hele Salesforce-økosystemet.
Ved at opbygge denne sofistikerede ABAC-struktur med CEDAR-politikker giver Data 360 arkitekter et uovertruffen niveau af kontrol og fleksibilitet, der sikrer, at kundedata ikke kun kan handles på, men også er sikre, kompatible og pålidelige på tværs af virksomheden.
På tværs af brancher lægger organisationer øget vægt på end-to-end-datasikkerhed for at sikre beskyttelse mod datalækage, uautoriseret adgang, manipulation eller ødelæggelse. De fleste dataplatforme, herunder Data 360 i dag, leverer kryptering, der er inaktive, ved brug af en leverandøradministreret krypteringsnøgle. Men virksomheder (især dem i regulerede sektorer) kræver i stigende grad kundestyrede krypteringsfunktioner for både inaktive og undergående data.
Denne model giver firmaer mulighed for at kontrollere deres egne krypteringsnøgler, hvilket sikrer, at dataene forbliver kryptografisk beskyttede, selv i den meget usandsynlige situation af et brud på platformsniveau eller uautoriseret adgang. Uden kundens egne nøgle kan ingen enhed (herunder platformudbyderen) dekryptere eller genopbygge dataene og derved bevare fuld fortrolighed og kontrol.
Data 360 understøtter lagring og administration af strukturerede (tabeller), semi-strukturerede (JSON) og ustrukturerede data uden problemer på tværs af dataoverførsel, behandling, indeksering og forespørgselsmekanismer. Data 360 understøtter forskellige ustrukturerede datatyper udover tekst, herunder lyd, video og billeder, hvilket udvider omfanget af datahåndtering og -analyse. Figuren nedenfor illustrerer de to sider af jordning (overførsel og hentning).
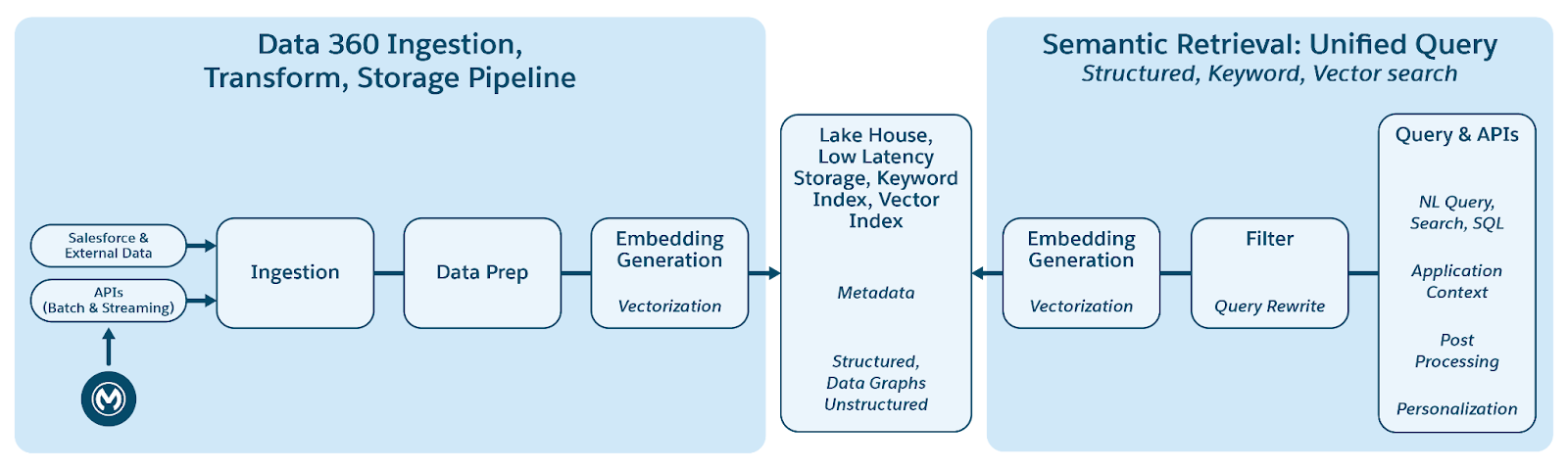
Data 360 administrerer ustrukturerede data ved at lagre dem i kolonner som tekst eller i filer til større datasæt. Den understøtter datafederation for ustruktureret indhold, hvilket tillader integration og administration af data fra flere kilder.
Dataene forberedes og segmenteres derefter, integreringer genereres og behandles til nøgleordindeksering og vektorindeksering. Data 360 er vært for flere køreklare og tilsluttelige modeller til segmentering og integrering af generering. Data 360 understøtter automatiseret og konfigurerbar afskrift af lyd- og videoindhold til efterfølgende behandling og indeksering. Søgetjeneste bruges til søgeordsindeksering. For vektorindeksering understøtter Data 360 både indbygget indeksering (med Hyper) og benytter også vektordatabaser som open-source Milvus. Data 360 integreres også med Salesforce Search-platformen for at understøtte nøgleordindeksering på ustrukturerede data. Sådan integreret multi-modal-indeksering i Data 360 styrker søgning på alle ustrukturerede data, som diskuteret i afsnittet Agentisk virksomhedssøgning senere i dokumentet.
Til hentning leverer Data 360 API'er til søgning. Vores hyperbaserede forenede forespørgsel gør det nemmere at samle forespørgsler på tværs af strukturerede, søgeordsindeks og vektorindekser, vedligeholde streng synlighed og tilladelser og dermed forbedre RAG og søgning.
Data 360's ustrukturerede datapipeline er designet som en modulær, udvidelig arkitektur, der består af fem kernefaser:
- Parsing
- Forbehandling
- Fragmentering
- Efterbehandling
- Integrering
Alle faserne understøtter også LLM-baseret behandling, hvilket gør det muligt for kunder at komme med de tilpassede meddelelser. Både før- og efter-behandlingsfaserne kan inkludere flere sekventielle trin, så komplekse transformationer kan oprettes fleksibelt. Hver fase er fuldstændig metadatastyret og aktiverer problemfri konfiguration og udvidelse uden kodeændringer.
Eksempler på forbehandling omfatter handlinger som f.eks. støjfjernelse, sprognormalisering og billedforståelse (optisk tegngenkendelse og teksttegn), mens efterbehandlingstrin kan omfatte metadataberigelse, semantisk gruppering eller avancerede teknikker som Raptor- segmentering.
Pipelinen understøtter Data 360 Code Extension fuldt ud, hvilket gør det muligt for kunder og interne teams at tilslutte tilpasset logik i enhver fase. Kodeudvidelseskomponenterne er letvægts Python-funktioner, hvis livscyklus – kørsel, skalering og fejlhåndtering – er fuldt administreret af Data 360. Denne tilgang sikrer, at innovation og domænespecifik behandling kan introduceres hurtigt, mens der bevares driftsmæssig ensartethed og styring på tværs af platformen.
Kontekstindeksering
For opsætning af RAG med ustruktureret behandling er to vigtige faktorer vigtige:
- Rapid Iteration: Muligheden for hurtigt at validere med eksempeltestforespørgsler.
- Personspecifikt indhold: Muligheden for at konfigurere indhold, der er skræddersyet til den forbrugende persona.
Kontekstindeksering er et brugervenligt værktøj, der er designet til at håndtere begge disse aspekter. Denne interaktive brugergrænseflade er drevet af en RT-pipeline (real-time), der eksekverer alle fem tidligere skitserede faser. Pipelinen bruger GPU'er, når det er nødvendigt for opgaver som integreringsgenerering og OCR (Optical Character Recognition). Desuden giver det kunder mulighed for hurtigt at teste RAG-pipelinen med en agent, før de implementerer konfigurationen til omfattende indholdsbehandling.
Dokument-AI
Data 360-dokument-AI gør det muligt at læse og importere ustrukturerede eller semistrukturerede data fra dokumenter som fakturaer, sammendrag, laboratorierapporter og købsbestillinger. Denne funktion understøtter ad hoc interaktiv behandling såvel som massebatchbehandling. Dette er en nøglefunktion, der aktiverer forretningsprocesautomatisering for vores kunder. Dette er drevet af kunstig intelligens, herunder LLM'er og ML-modeller.
Virksomheder har enorme mængder af Knowledge fordelt på tværs af forskellige systemer som wikis, fildelinger, indholdsstyringssystemer, interne databaser med mere. Denne fragmentering gør det vanskeligt for medarbejdere (især serviceagenter og sælgere) og kunder at finde relevante oplysninger hurtigt og effektivt. Nøgleproblemer omfatter: Manglende en enkelt, ensartet søgeoplevelse på tværs af alle Knowledge kilder; inkonsekvent præsentation og gengivelse af indhold fra forskellige kilder; manglende adgangsstyring til følsomme oplysninger, der er spredt på tværs af systemer; og vanskeligheder med at udnytte autoriserede Knowledge kilder i kerneforretningsarbejdsflows (f.eks. vedhæftning af relevante artikler til en sag).
Enterprise Knowledge repræsenterer indhold, der er organiseret, enten manuelt eller automatisk, fra den bredere pulje af virksomhedsdata. Manuel organisering involverer bevidste handlinger, f.eks. oprettelse af Salesforce Knowledge eller udvikling af Knowledge i eksterne systemer, som derefter overføres. Vi forestiller os automatiseret parathed, der bruger processer, som f.eks. Salesforce-agenter og transformationer, der kører over overførte data for at generere raffinerede, arrangerede lag og potentielt blande struktureret og ustruktureret indhold. Uanset om det organiseres manuelt eller automatisk, internt i Salesforce eller eksternt før overførsel, er resultatet indhold med tilføjet værdi, der er forskelligt fra rå data.
Enterprise Knowledge Hub-løsningen udnytter Data 360-funktioner til:
- Forbrug og opbevaring: CRM-forbindelse overfører Knowledge, og ustrukturerede DCF-forbindelser overfører rå indhold og metadata fra eksterne kilder. Indholdet overføres til kildespecifikke ustrukturerede data lake-objekter (UDLO'er) tilknytning til indholdet på SFDrive (eller kilde i tilfælde af nulkopiering).
- Harmonisering & strukturering: Harmonisering Pipelinen behandler UDLO- og fildata, udfører rengøring, normalisering, berigelse (NLP osv.), PII-maskering og transformation til det harmoniserede mellemliggende format, der er lagret i SF-drev og en harmoniseret UDLO (HUDLO), der knyttes til det.
- Indeksering: Ustruktureret pipeline (UDS) udløses over det harmoniserede indhold, og søgeindekser konfigureres for hvert HUDMO.
- Forbrug: Forbrug af applikationer inkluderer søgning, hentning, gengivelse og linkning til forretningsobjekter som Sag. Engagement ved forbrug af applikationer indsamles for at levere anvendelsesanalyser (f.eks. klik, gennemgange osv.).
Beregnede indsigter (CI'er) i Data 360 gør det muligt for kunder at definere og generere aggregerede metrikker fra deres data. Disse metrikker bruges derefter til rettidigt kundeengagement, analyse, segmentering og aktivering. De aggregerede data, der beregnes af CIs, skrives til Lakehouse og repræsenteres som et beregnet indsigtsobjekt (CIO).
Der er to hovedtyper af beregnede indsigter:
- Batchberegnede indsigter: Designet til kompleks, højvolumen dataggregering, hvor metrikker kan beregnes regelmæssigt (f.eks. dagligt eller ugentligt).
- Streamingindsigter: Giv mulighed for at generere metrikker og handlinger fra begivenhedsdata i realtid, så der aktiveres øjeblikkeligt kundeengagement med lav forsinkelse.
Beregnede indsigter defineres på datamodelobjekter (DMO'er) og kan også defineres på andre beregnede indsigtsobjekter. Tjenesten Beregnede indsigter administrerer orkestreringen af både batch- og streamingjob.
Både batch- og streamingindsigter beregnes ved brug af Spark. Nøgleforskellen er, at streamingindsigter bruger Structured Streaming, mens batch-CIs afvikles ved brug af periodiske, planlagte batch-Spark-job. Af hensyn til omkostningseffektiviteten skal de beregnede indsigtsservicegrupper CIs beregnes sammen i det samme batch CI-job eller streaming CI-job, baseret på faktorer som afhængigheder og overlapninger af kildedataobjekter.
SNCE og CDF spiller en væsentlig rolle i beregning af streamingindsigter.
Id-løsning er ansvarlig for at transformere uensartede data fra flere kilder til en enkelt, omfattende forenet profil.
Det er vigtigt at forstå, at en forenet profil ikke er en "gylden registrering", og at identitetsløsning ikke vælger vindende værdier eller tilsidesætter eksisterende data, mens du forener profiler. Forenede profiler fungerer som et sæt nøgler, der låser op for dine kildedata ved at identificere alle matchende registreringer, der er relateret til den samme enhed, i en datakilde eller på tværs af mange kilder. Med disse oplysninger kan du vælge de rigtige kildesystemdata, der skal bruges til en given forretningsanvendelsessituation.
Id-løsning kan konsolidere en række registreringstyper, herunder Enkeltperson, Konti og Husstande. Det kan også bruges til at matche emner med eksisterende konti. Foreningsprocessen er vigtig for at opnå en komplet Customer 360 og fremme personligt engagement i realtid på tværs af både B2C- og B2B-scenarier.
Pipelinen til identitetsløsning er bygget på en skalerbar, cloud-oprindelig struktur, der er designet til at håndtere store mængder af data kontinuerligt. Processen omfatter tre nøglefaser, der er afhængige af et stærkt søgeindeks til at administrere matchningsprocessen:
- Matchning (Kandidatvalg): Målet med matchprocessen er at søge efter registreringer, der kan høre til den samme enhed. Registreringer analyseres op mod et sæt regler, der kan tilpasses, og som hver indeholder et sæt kriterier, der definerer, hvilke data der skal matches på hvilket niveau af nøjagtighed. For effektivt at hente potentielle matches fra datalageret genererer systemet indekser for at finde sandsynligvis matchende registreringer ved brug af to teknikker:
- Låsning af nøgler: En blokeringsnøgle er en værdi, der genereres fra en registrerings data og matchregler (f.eks. de første få bogstaver af et navn, normaliseret telefonnummer osv.) for at gruppere potentielt lignende registreringer sammen. Hver registrering har flere blokeringsnøgler, der indekseres og lagres som et inverteret indeks, hvilket sikrer, at systemet kun foretager detaljerede sammenligninger på små grupper af registreringer, snarere end på tværs af hele datasættet.
- Locality Sensitive Hashing (LSH): For matchregler med fuzzy-matchning genereres hashtags baseret på integrationer fra trænede modeller.
- Deep Matching: Når trinnet til valg af kandidat opretter mindre grupper af potentielle matches, starter systemet en mere detaljeret sammenligning. I denne fase analyserer AI-modeller og avancerede algoritmer hvert par registreringer for at beregne en sandsynlighedsscore. Denne score kvantificerer sandsynligheden for, at to registreringer refererer til den samme enhed ved intelligent at sammenligne felter, der ofte indeholder stavefejl, variationer eller formateringsforskelle.
- Clustering og forening: Når matchende registreringer identificeres fra kandidaterne, grupperes de i en klynge. Denne proces inkluderer afgørende at løse overførselsmatches. Hvis f.eks. registrering A matcher registrering B, og registrering B matcher registrering C, linkes alle tre til den samme klynge, selvom A og C aldrig blev sammenlignet direkte. Disse komplette klynger udgør grundlæggende struktur for den forenede profil. Denne klyngeproces sikrer, at alle relaterede kilderegistreringer er korrekt linket under en enkelt, vedvarende identifikator.
- Forlig: Dataværdier fra alle klyngede kilderegistreringer evalueres ved brug af definerede afstemningsregler (f.eks. Mest hyppige, Nyeste eller Kildeprioritet) for at udfylde den resulterende forenede profil med et uddrag af profildata. Afstemning overskriver ikke nogen eksisterende data, da alle kildedata er tilgængelige ved brug af de nøgler, der er linket til den forenede profil.
Arkitekturen understøtter løsningen af flere enhedstyper for at opfylde en række anvendelsessituationer.
- Individuel matchning: Fokuserer på oprettelse af forenede personprofiler, som linker alle kendte personlige identifikatorer (mails, telefonnumre, loyalitets-id'er, cookies) til en enkelt person.
- Kontomatchning: Fokuserer på oprettelse af forenede kontoprofiler, som linker data om konti. Når der matches på firmanavne, bruger systemet en finjusteret model, når der matches fuzzy.
- Husstandsmatchning: Udvider matchningslogikken til at aggregere forenede enkeltperson-registreringer i grupper af relaterede enkeltpersoner.
- Krydsenhedsmatchning: Udover forening opretter identitetsløsning også links mellem profilobjekter ved brug af de samme matchregler. Et emne kan f.eks. linkes til en konto ved brug af fuzzy-matchning på Kontonavn.
For at sikre, at den forenede profil altid er opdateret, fungerer identitetsløsningssystemet med en næsten realtidsarkitektur. Denne cloudoptimerede arkitektur er designet til kontinuerlig behandling og opnår hurtige behandlingstider. Selvom behandlingshastigheden varierer afhængigt af, hvordan kildedata modtages, kan små batches af ændringer behandles af identitetsløsning så ofte som for hver 15 minutter.
Systemet vedligeholder identitetslinkobjekter, der knytter hvert kilderegistrerings-id til dets tilsvarende forenet profil-id. Denne grundlæggende datastruktur gør det muligt for systemet effektivt at spore relationer og hurtigt udbrede ændringer og opdateringer til den forenede profil, hvilket sikrer, at kundeoplevelser – f.eks. websitetilpasning, næste-bedste-handlingsanbefalinger og segmentering – altid udnytter de nyeste tilgængelige kundedata.
Segmentering er kerneprocessen for at transformere forenede kundeprofiler til målgrupper, der kan handles på. Denne funktionalitet er vigtig for at styrke personlige oplevelser på tværs af marketing, handel og servicekanaler. Salesforce Data 360-segmenteringsplatformen er designet til drift i stor skala. Den administrerer komplicerede metadata og arbejder med en datamodel, der består af tusindvis af objekter og relationer. Platformen understøtter komplekse regler, aggregeringsbaserede filtre og vinduesbaseret rangering, alt sammen samtidig med at der sikres hurtig og pålidelig beregning på petabyte-skala.
Data 360 understøtter forskellige segmenttyper for at opfylde særskilte forretningskrav til hastighed, kompleksitet og hierarki:
- Standard Segment: Den primære batchbehandlede segmenttype. Det udgives efter en tidsplan, der kan tilpasses, med en standardudgivelseskadence på mindst 12 timer op til 24 timer eller en hurtig udgivelseskadence på 1 til 4 timer, som er optimeret til seneste engagementsdata.
- Segment i realtid: Dette segment fuldfører on-demand i millisekunder for øjeblikkelig handling baseret på seneste begivenheder og profildata. Det er højt optimeret til øjeblikkelig tilpasning, men kan ikke bruge udeladelseskriterier eller indlejrede segmenter.
- Waterfall Segment: En hierarkisk struktur af undersegmenter, der bruges til at prioritere en kunde i et enkelt, mest værdifuldt segment, hvis de kvalificerer sig til flere kriterier.
- Nested Segment: Dette tillader genbrug af et eksisterende segment som et filter for et nyt, mere specifikt segment (en justering af et basissegment), der overtager tidsplanen for det overordnede segment.
Segmenteringssystemet kører på en robust, cloud-oprindelig arkitektur, der sikrer hastighed, skalering og fleksibilitet.
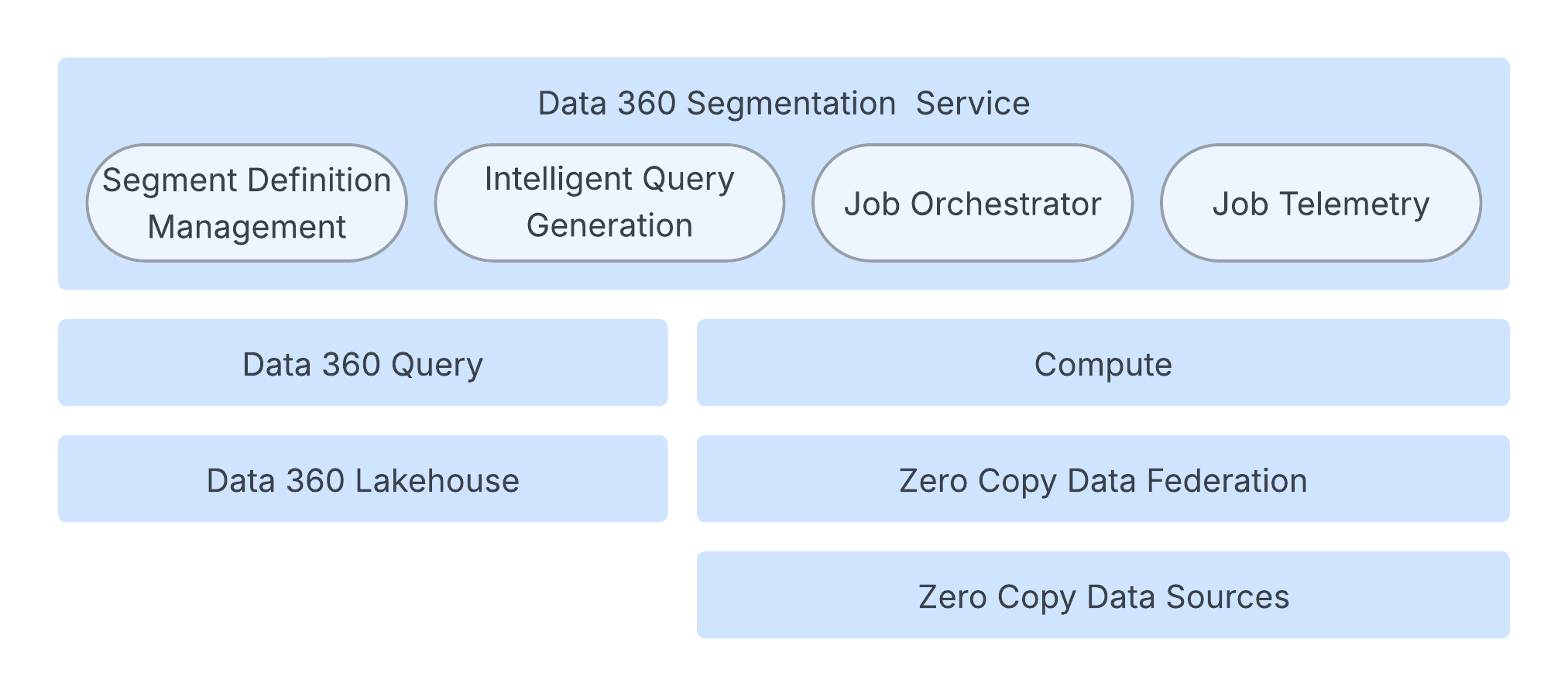
Kerneprocessen administreres af en joborkestreringstjeneste, der styrer segmentets livscyklus, genererer den nødvendige jobkonfiguration og udløser kørslen. Dette orkestreringslag bevarer tilstand og metadata i en opdelt database af hensyn til skalerbarhed.
Selvom Data 360-forespørgsel håndterer segmenteringsantalberegninger, er Spark-beregningslaget ansvarlig for beregning af faktisk segmentmedlemskab. Spark-applikationen eksekverer Spark SQL-forespørgsler på omfattende kundedata. Disse data kan findes i Data 360 Lakehouse, eksterne systemer via Zero Copy-dataforening eller en kombination af begge.
Systemet optimeres højt gennem intelligent forespørgselsgenerering, som justerer den underliggende Spark SQL-forespørgsel. Dette inkluderer teknikker som intelligent partitionsopdeling for at minimere datascanning og eliminering af overflødige underudtryk. For at sikre en pålidelig service har arkitekturen tilpasset ressourceadministration, der dynamisk justerer beregningsressourcer baseret på arbejdsbelastningsstørrelse og kompleksitet. Desuden administreres SLO-overholdelse proaktivt med tilpassede varigheder og forsøgslogik. For at få en hurtig brugeroplevelse bruger accelererede segmentoptællinger en prøvebaseret tilgang til at levere hurtige skøn over størrelse under segmentoprettelse og undgå en fuld forespørgselskørsel.
Endelig bevares der et dybt fokus på observabilitet og grundlæggende årsagstilskrivning gennem omfattende Spark-kørselsmetrikker og automatiseret klassificering af fejl (f.eks. kunde-sides vs. systemproblemer), hvilket reducerer diagnosetid væsentligt og sikrer en meget fleksibel dataplatform.
Aktivering er det kritiske sidste trin i Data 360-livscyklussen. Dens kernefunktion er at transformere statiske, segmenterede, forenede kundeprofiler til handlingsrettede og berigede data og levere disse data til interne og eksterne slutpunkter (f.eks. Marketing Cloud, Commerce Cloud og Adtech-platforme). Denne proces er designet til at udløse personlige kunderejser og interaktioner i næsten realtid. Den understøtter avancerede funktioner som relaterede attributter, aktiveringsmedlemskabsfiltrering, samtykkefiltrering, begrænsning og rangering.
Aktivering tilbyder tre forskellige metoder til ekstern levering og kanaloverensstemmelse:
- Batchaktivering: Designet til højvolumen, planlagte handlinger, f.eks. mailkampagner i stor skala og opdateringer af annonceringsmålgrupper. Data leveres ved at sætte dem midlertidigt i Sikker interne inddelinger (Cloud Object Storage) eller via Sikker filoverførsel efterfulgt af en API-overførselsproces, der initieres af målsystemet. Batchaktiveringer kan bruge speciel opdateringstilstand - trinvis - til at reducere mængder, der sendes til og behandles af Salesforce-partnere.
- Streamingaktivering: Optimeret til anvendelsessituationer i næsten realtid, der kræver begivenhedsstyret automatisering. Levering opnås gennem direkte API-kald, der sendes til destinationsslutpunktet.
- Aktiveringsudløste forløb: Denne meget platformede kanal leverer en tilgang uden kode/lav kode til integration af målgruppedata med hundredvis af kunde-API-aktiverede engagementsplatforme. Når aktiveringen er fuldført, udfylder Data 360 et målgruppedMO, som derefter udløser et forløb i høj skala. Forløbssystemet forbruger derefter målgruppedataene og bruger platformsfunktioner som Eksterne tjenester og Mule Outbound-destinationer til at foretage kald til den endelige API-baserede destination. Denne metode reducerer den tid, der kræves for at introducere nye aktiveringsmål.
Aktivering bruger de samme mønstre som segmentering til jobstyring, distribueret kørsel og overvågning. Dette inkluderer principperne for joborkestreringstjenesten for livscyklusstyring og beregningslaget (Spark) til behandling og er baseret på jobtelemetri for ydeevneobservation og overholdelse af serviceniveaumålsætning (SLO).
Udover disse har aktivering -
Aktiveringsmålstyring overvåger de sikre forbindelser, legitimationsoplysninger og konfigurationer for alle destinationsslutpunkter. Den garanterer, at dataformater og sikkerhedsprotokoller er standardiseret, hvilket sikrer pålidelig udgående levering til forskellige platforme, herunder Marketing Cloud, Adtech-partnere og andre eksterne applikationer.
Aktivering tilpasser dataene til specifikke mål. For Salesforce Marketing Cloud inkluderer dette BU (Business Unit Aware Filtering), understøttelse af flere EID'er og krydsbestøvningskontroller.
Kommunikationsstyring fungerer som en gatekeeper, der sikrer, at dataanvendelse og kommunikation er i overensstemmelse med kundepræferencer og juridiske krav. Centraliseret samtykkemodel forener alle kundepræferencer, fra globale frameldinger til kanalspecifikt samtykke og formålsspecifikt samtykke, og gemmes på den forenede personprofil. Under kørsel håndhæver platformen strengt disse politikker ved at bruge udeladelsesfiltrering til automatisk at fjerne ikke-samtykke-personer fra den endelige data. Endvidere anvender systemet regler for valg af kontaktpunkt for at sikre, at det bruger det enkelte, mest kompatible og foretrukne kontaktpunkt for den tilsigtede kanal, før der sendes data. Denne håndhævelsesmekanisme er sikret af den underliggende styringsstruktur, som anvender beskyttelsesforanstaltninger som dynamisk datamaskering og adgangskontroller til at sikre følsomme datafelter gennem aktiveringsprocessen.
Den sande værdi af en forenet dataplatform ligger i dens mulighed for at give problemfri, ensartet adgang til alle dens dataaktiver, uanset deres oprindelse eller struktur. Salesforce Data 360's forenede forespørgselsfunktionalitet er præcist designet til at levere dette og abstrakterer de underliggende kompleksiteter i forskellige datalager for at levere en enkelt, effektiv forespørgselsgrænseflade.
Laget Forenet forespørgsel tilbyder avanceret adgang til forskellige forbrugsmønstre:
- Hybrid struktureret og ustruktureret forespørgsel: Den giver omfattende SQL-understøttelse til problemfrit at forespørge på både strukturerede data og strukturerede metadata for ustrukturerede data. Dette forbedres af operatorudvidelighed via tabelfunktioner, der aktiverer specialsøgning på tværs af tekst-, billed- og geografiske typer.
- Accelereret ydeevne med Hyper: Ved at udnytte Hyper, et højtydende hukommelsessystem, sætter Data 360 fart på komplekse analytiske forespørgsler og interaktive dashboards og giver næsten øjeblikkelige svar over massive datasæt.
- Forenet tilgang til AI & Tilpasning: Denne forenede adgang er afgørende for generering af målrettede og personlige resultater, der direkte letter mere præcise LLM-svar ved brug af Retrieval Augmented Generation (RAG) ved at basere AI-modeller i avancerede virksomhedsdata.
- Integration med downstreamforbrug: Det fungerer som det grundlæggende dataadgangslag for brugergrænsefladestyrede oplevelser, robuste API'er, genererende AI-arbejdsflows og CRM-berigelse, der problemfrit tilslutter data til aktivering.
Ved at levere en enkelt, intelligent og højtydende forespørgselsgrænseflade giver Data 360's forenede forespørgsel arkitekter mulighed for at opbygge smidige, datastyrede applikationer, der fuldt ud udnytter deres komplette spektrum af kundeoplysninger.
Data 360 er en aktiv platform, der understøtter aktivering af pipelines som reaktion på databegivenheder. En væsentlig begivenhed, f.eks. et fald i en kundes kontosaldo, kan udløse et Salesforce-forløb til at orkestrere en tilsvarende handling. På samme måde kan opdateringer til nøglemetrikker, f.eks. livstidsforbrug, udbredes automatisk til relevante applikationer.
Datahandlinger overvåger kontinuerligt trinvise data for ændringer ved brug af SNCE (storage native change events) og CDF (change data feed). Disse data evalueres op mod kundekonfigurerede handlingsregler, f.eks. tærskelovervågning eller tilstandsændringer. Når disse regler er opfyldt, genereres der en datahandlingsbegivenhed. Denne begivenhed beriges med yderligere oplysninger (f.eks. kundeloyalitetsstatus) og sendes straks til dens konfigurerede destination, f.eks. Salesforce-forløb eller en ekstern applikation for at udløse forretningsorkestreringer.
Data 360 understøtter oprindelige CDP-funktioner (Customer Data Platform)-funktioner, herunder funktioner til avanceret identitetsløsning og oprettelse af forenede individuelle id'er og profiler sammen med omfattende engagementhistorier. Denne platform er dygtig til at håndtere både B2B- og B2C-strukturer (business-to-business) ved at understøtte identitetsløsning og identitetsdiagrammer, der bruger både nøjagtige og fuzzy-matchningsregler som beskrevet ovenfor. Disse identitetsdiagrammer er beriget med engagementsdata fra forskellige kanaler, hvilket hjælper med at opbygge detaljerede profildiagrammer med værdifulde analytiske indsigter og segmenter.
Et nøglekoncept, der understøtter kundeprofilen, er datadiagrammet. Data 360 tilbyder et virksomhedsdatadiagram i JSON-format, som er et denormaliseret objekt, der er afledt fra forskellige Lakehouse-tabeller og deres interrelationer. Dette inkluderer et "Profil"-datadiagram, der er oprettet af CDP, der omfatter en persons købs- og browsinghistorik, sagshistorik, produktanvendelse og andre beregnede indsigter og kan udvides af kunder og partnere. Disse Datadiagrammer er skræddersyet til specifikke applikationer og forbedrer nøjagtigheden af genererende AI-meddelelser ved at give relevant kunde- eller brugerkontekst. Laget i realtid i Data 360 bruger profildiagrammet til tilpasning og segmentering i realtid. Vi forestiller os modellering Agentforce Context, der omfatter samtaler, sessioner og agent hukommelse som Datadiagrammer.
Endvidere aktiverer CDP effektiv segmentering og aktivering på tværs af forskellige platforme, f.eks. Salesforces Marketing Cloud, Facebook og Google. Den behandler kundeprofiler i batch, næsten i realtid og i realtid, hvilket giver mulighed for øjeblikkelig beslutningstagning og tilpasning. Denne funktionalitet forbedrer interaktioner i både B2C- og B2B-scenarier og sikrer, at forretninger kan reagere hurtigt og nøjagtigt på kundebehov og -adfærd.
Data 360's realtidslag understøttes af Data 360 CDP og udvider dets koncepter til anvendelsessituationer i realtid. Data 360's realtidslag er designet til at behandle begivenheder som web- og mobilklikstreams, besøg, indkøbsvognsdata og checkouts ved forsinkelser i millisekunder, hvilket forbedrer kundeoplevelsestilpasning. Den overvåger kontinuerligt kundeengagement og opdaterer kundeprofilen fra Customer 360 med engagementdata, segmenter og beregninger i realtid for øjeblikkelig personliggørelse.
Når f.eks. en forbruger køber et element på et shoppingwebsite, registrerer og overfører realtidslaget hurtigt denne begivenhed, identificerer forbrugeren og beriger vedkommendes profil med opdaterede oplysninger om levetidsforbrug. Dette tillader tilpasning af deres oplevelse på lokaliteten i sekunder. Endvidere indeholder dette lag funktioner til udløsning og svar i realtid, der aktiverer øjeblikkelige handlinger baseret på kundeinteraktioner.
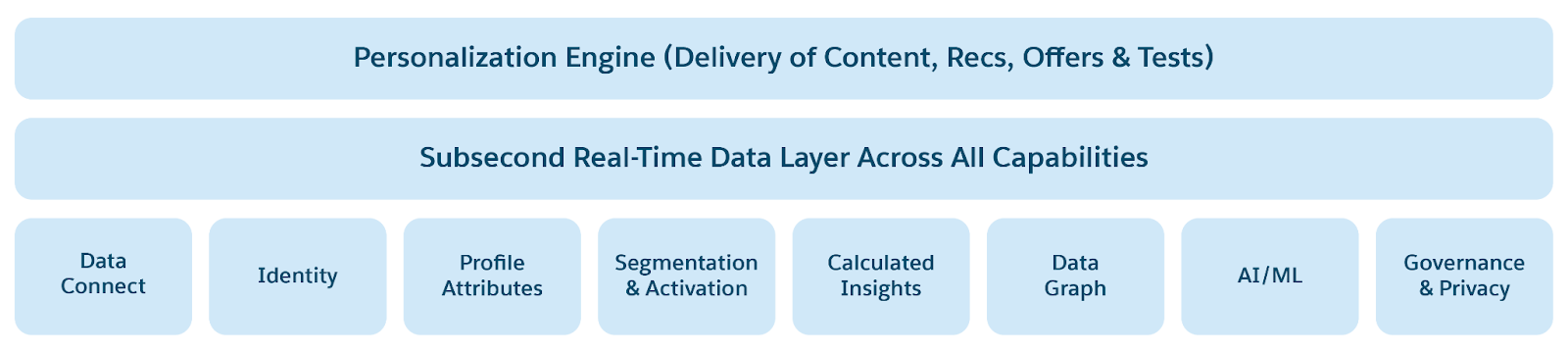
Sub-second real-time-platformen styrker denne transformation gennem flere nøglefunktioner:
- Real-time Datadiagrammer: En Customer 360 profil opbygges ved hjælp af en denormaliseret graf, der indeholder nøgleobjekter og felter, der er mest relevante for brands. Disse Datadiagrammer gør det muligt at behandle data i realtid og levere indhold og indsigter, der kan handles på, inden for millisekunder
- Overfør og transformer i realtid: Overfør brugerbegivenheder og profiler på millisekunder fra web- og mobilkilder.
- Identitetsløsning i realtid: Flet kundeprofiler på tværs af enheder, og saml ukendte og kendte brugere med det samme.
- Beregnede indsigter i realtid: Beregn metrikker som levetidsværdi (LTV) eller brugerbesøgshistorik i millisekunder for at aktivere Tilpasning eller Tilbud for web, ChatBot eller Serviceagent.
- Segmentering i realtid: Segmenter målgrupper på farten, og personliggør meddelelser og interaktioner i realtid.
- Handlinger i realtid: Sæt brands i stand til at evaluere hvert brugerengagement og reagere via Salesforce-forløb eller andre relevante kommunikationskanaler.
I Data 360 har vi opbygget en ny realtidsplatform med realtidspipeline, lagring med lav forsinkelse og et databehandlingslag på under sekunder. Når hurtigt interaktive data overføres fra web- og mobilkanaler, gennemgår de en række hurtige processer.
Vores Web- og Mobile SDK'er og API'er i realtid indsamler data fra web-/mobilapplikationer (i fremtidige Agenttic-interaktioner) og sender dem til vores beaconserver. Disse data distribueres derefter til lag i realtid til millisekundsbehandling og lag i Lakehouse til integration med batch-/streamingdata. Laget Realtid behandler de indgående realtidsdata i konteksten af en brugerprofil (anonym eller logget ind), f.eks. opdatering af brugerens samlede forbrug eller livstidsværdi osv. til session, realtidstilpasning. Laget i realtid understøttes af hovedhukommelse og SSD-lagring (NVme) til lagring af realtidsdata og kundeprofiler. Når dataene er i lag i realtid, gennemgår de følgende processer, før de opdateres til datadiagrammet i realtid:
- Enkel overførsel og transformationer: Dataene overføres og transformeres til yderligere behandling.
- Id-løsning: Eksakt matchregler anvendes til at forene profiler med alle eksisterende matchregelsæt, så databevidste specialister ikke behøver at oprette nye Id-løsningsregelsæt specifikt til realtid.
- Computed Insights: Hvert engagement evalueres, enkle beregninger som sum og antal i millisekunder køres, og data opdateres i datadiagrammet i realtid.
- Segmenter i realtid: Hvert engagement evalueres for at bestemme, om det opfylder kriterierne for definerede realtidssegmenter, og brugere føjes til kvalificerende segmenter i millisekunder.
- Handlinger og udløsere i realtid: Hvert engagement evalueres op mod definerede regler for at udløse handlinger til en række mål i realtid, når reglerne opfyldes i millisekunder.
- Datadiagram og API i realtid: Datadiagram i realtid, som også inkluderer en realtids-API, giver brands mulighed for at hente opdaterede JSON-formatdata for hver bruger, hvilket sikrer, at alle kundeinteraktioner informeres af de nyeste data.
Tilpasning handler om at vide, hvem der skal målrettes mod, hvornår og hvor der skal leveres relevant indhold og anbefalinger, hvad der skal siges, og hvilken frekvens. Tilpasningstjenesteplatformen er orkestrator for, hvilke beslutninger der træffes for at optimere målopnåelse gennem personlige oplevelser.
Tilpasningstjenester leverer følgende funktioner:
- Ensartet sæt af modeller og måder til at fortolke profil-, aktivitets- og aktivdata i Data 360
- Platformsintegreret eksperimentering (A/B/n, Multi-Arm Bandit)
- Integration af mål på designtidspunktet (konfiguration), ML-træningstid og -kørsel (ML-afledning)
- Understøttelse af B2C-skalaer i realtid og batchinteraktion (anonyme brugere, højvolumen realtid/interaktiv ekstern, højvolumen internt batch)
- Analytics drevet gennem Data 360
- Mønstre til at integrere AI-model og service fra andre parter (intern og ekstern)
- Integration i kernet metadataøkosystemet (PLATE-karakteristika)
- OOTB-implementeringer af AI-styrede anvendelsessituationer af høj værdi (anbefalinger/beslutninger med forskellige ML-algoritmer, herunder kontekstbaserede banditter til promovering/indholdsvalg, produktanbefalinger, prisbeslutninger osv.)
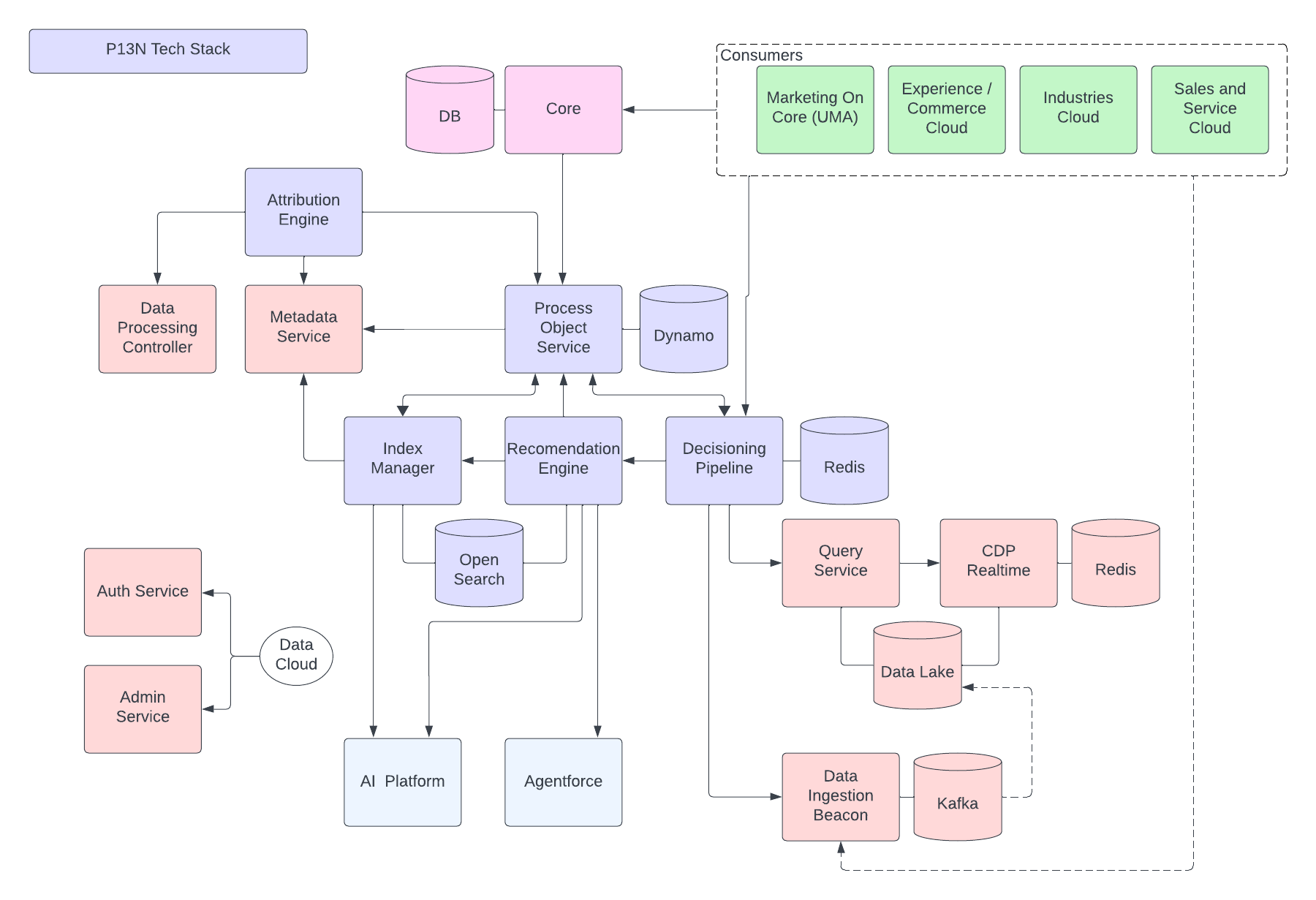
- Beslutningspipeline
- Servicering af eksterne anmodninger om personliggørelsesbeslutninger, herunder profilforøgelse, eksperimentering og anbefalinger.
- Anbefalingssystem
- Kørselsservicering af regel- eller ML-baserede anbefalinger.
- Index Manager
- Administrerer/Orkestrerer arbejdsflow for asynkrone processer, herunder ML-træning for anbefalingsmodeller
- Procesobjekttjeneste
- Ansvarlig for synkronisering af tilpasningsmetadata mellem kerne og off-core
- Tildelingssystem og eksperimentering
- Analytics-tilskrivning og -eksperimentering af tilpasningsanbefalinger
Data 360 er designet som en robust og avanceret platform specifikt til at understøtte de nye agentoplevelser. Vi opnår disse muligheder ved at bygge videre på forskellige eksisterende Data 360-tjenester og gennem dyb integration med Agentforce.
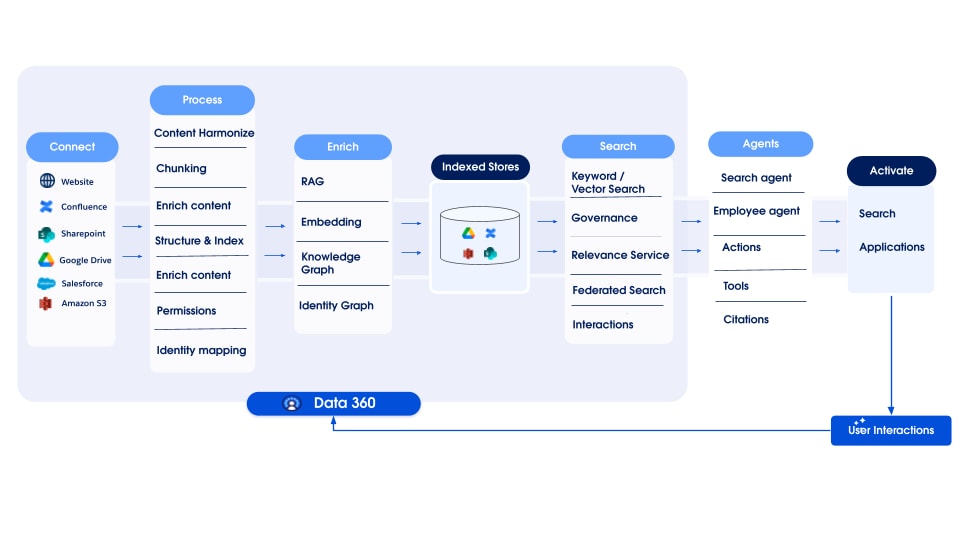
Vores tilgang til Agentic Enterprise Search er baseret på følgende principper:
- Virksomhedsdata bevares i isolerede tjenester eller butikker med sikre tilladelser, der er nødvendige for adgang. Muligheden for at få adgang til disse data og behandle dem, mens du bevarer kildetilladelserne, er afgørende for at sikre Trust.
- Tværgående rangering og relevans på tværs af det komplette datakorpus muliggør bedre resultater, hvilket igen kan give bedre kontekst for agentoplevelser.
For at levere disse oplevelser er Agentic Enterprise Search bygget oven på disse nøglearkitektoniske komponenter:
- Forbindelser: Det brede sæt af forbindelser, der er tilgængelige i Data 360, gør det muligt for en at få adgang til og overføre data fra en lang række forskellige kilder.
- Ustruktureret databehandling: Dette er grundlæggende for håndtering af ikke-tabelindhold, så systemet kan aflede mening og kontekst fra forskellige data.
- Styring: Sikring af sikkerhed, compliance og adgangskontroller på virksomhedsniveau for alle data, der forbruges af søgning. Understøttelse af kildesynlighedstilladelser sikrer, at data kun er tilgængelige for godkendte brugere for både enkel søgning og agentoplevelser. For at sikre hurtig hentning evalueres og håndhæves sikkerhedstilladelser som standard af søgebackendene i den tidligste fase af dataadgang.
- Forenet hentningslag: For at håndtere udfordringen med enkeltstående data, føjer forbindelserne til et omfattende forenet hentning-lag. Dette lag giver et enkelt adgangspunkt til alle data, uanset om det forbliver i eksterne systemer, der åbnes via forenet søgning eller administreres som standard gennem avancerede indekser for nul-kopierede og overførte data.
- Intelligent forespørgselsforståelse: Før hentning bruger systemet AI-drevne mekanismer til at fortolke brugerhensigt. Udover at integrere repræsentationer af forespørgslen for semantisk vektormatchning, kan den omskrive og udvide nøgleordbaserede søgninger for at forbedre nøjagtigheden.
- Hybrid søgning og avanceret forespørgsel: For at finde de mest relevante oplysninger bruger platformen flere strategier parallelt. Hybrid søgning leverer præcis nøgleordmatchning med semantisk vektorsøgning på optimerede segmenter af data, mens fuld registreringssøgning henter hele dokumenter samtidigt. Begge er kombineret for at sikre både semantisk relevans og fuld indholdsdækning.
- Hierarkisk rangering: Når data er hentet, scorer, fletter og omarrangerer en hierarkisk rangeringarkitektur med flere faser resultaterne fra hver kilde og metode. Denne proces opretter en enkelt forenet liste, der viser de mest relevante oplysninger for brugeren eller agenten.
Generativ AI flytter den primære forbruger af virksomhedssøgning fra brugere til store sprogmodeller (LLM'er). Data 360 Search er udviklet fra bunden til at betjene begge. Den er optimeret til at håndtere de længere, mere komplekse forespørgsler fra agenter og returnere de avancerede kontekstbaserede resultater, der er nødvendige for programmeringsmæssig forbrug og ræsonnementsløkker. På samme tid kan systemet håndtere de kortere, ofte tvetydige forespørgsler, der er typiske for brugere, og leverer funktioner som kodestykker og fremhævelse til hurtig vurdering i en brugergrænseflade.
Den ultimative levering af agentmæssige søgeoplevelser kombinerer begge tilgange:
- Direkte søgeresultater: applikationen kan vise en traditionel liste over rangerede resultater ved at bruge en metadata-styret API, der er bygget på det forenede Data 360-søgningsgrundlag.
- Agentiske samtalesvar: Agentiske svar implementeres gennem indbygget integration med Agentforce. Denne samtaleoplevelse er styret af en primær agent, der orkestrerer handlinger og forespørgsler og uddelegerer alle oplysninger hentningsopgaver til en specialiseret, intern søgeagent.
Denne specialiserede søgeagent er optimeret til hentning af virksomhedsoplysninger. Den bruger en grundlæggende løkke til at formulere og udføre parallelle søgninger for at udforske forskellige facetter af en brugers anmodning. Den bruger et effektivt sæt værktøjer, herunder den forenede Data 360-søgning efter alle datatyper og strukturerede forespørgselssprog til at hente præcise data fra tabeller og enheder.
Gennem denne arkitektoniske syntese styrker Data 360 oprettelsen af meget intelligente, kontekstbevidste og handlingsrettede agentmæssige virksomhedssøgeoplevelser.
Udvidelighed er en nøglefunktion på Salesforce Platform. Kodeudvidelse giver mulighed for udvidelse i Data 360, hvilket tillader pro-code-brugere at køre tilpasset Python-logik direkte i Data 360-miljøet og supplerer dets avancerede deklarative og low-code-funktioner. Ved at bruge kodeudvidelse kan brugere sikkert udvide Data 360-kernefunktioner som transformationer og ustrukturerede datapipelines (tilpasset segmentering).
Vores design for kodeudvidelse prioriterer fleksibilitet, sikkerhed, effektivitet og en strømlinet udvikleroplevelse. Den understøtter to primære kørselsmodeller, der hver er skræddersyet til specifikke arkitektoniske behov:
- Scriptmodel:
- Formål: For omfattende tilpasset logik, der kræver direkte interaktion med Data 360 Lakehouse.
- Funktionalitet: Kunder skriver fulde Python-scripts ved brug af Code Extension SDK, hvilket aktiverer læse- og skriveadgang til Lakehouse via SDK-API'er. Ideel til tilpasset/komplekse dataforberedelse eller tilpasset datamanipulering.
- Isolation og sikkerhed: Mens scripts får adgang til Lakehouse, er deres kørsel begrænset til et sikkert, isoleret miljø inden for Data 360-kørsel, hvilket forhindrer interferens med andre processer eller uautoriseret systemadgang.
- Funktionsmodel:
- Formål: Analog til en serverløs funktion for modulære, statsløse beregninger, der kaldes fra eksisterende Data 360-pipelines (f.eks. tilpasset segmentering i en ustruktureret pipeline).
- Funktionalitet: Kundeangivne funktioner tager input, beregner og returnerer output.
- Isolation og sikkerhed: Disse funktioner er designet til streng isolering. De har ikke direkte adgang til Lakehouse. Deres kørsel er sandboxed, statless og ressource-begrænset, hvilket gør dem egnede til fokuserede, statless-behandlingstrin, der sikrer sikkerhed, forudsigelig kørsel og minimerer eksplosionsradius.
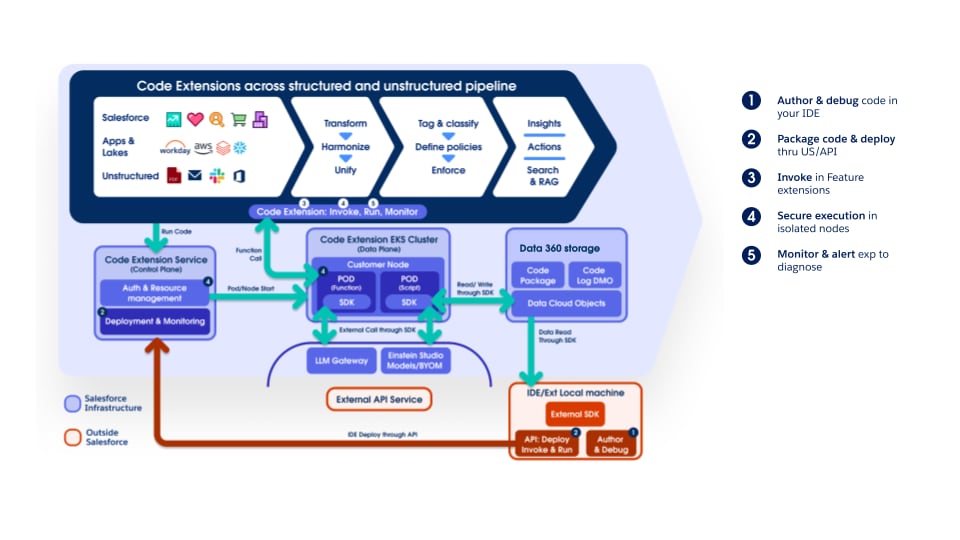
Både script- og funktionsmodellerne sigter mod at køre kundekode sikkert og forhindre, at en lejers kode påvirker andre eller får uautoriseret adgang til andre lejers data, Salesforce-ressourcer eller eksterne ressourcer. Denne sikkerhed opnås gennem en lagdelt (defense-in-depth)-arkitektur. Denne arkitektur leverer et isoleret kørselsmiljø for hver lejers tilpassede kode, der indeholder forskellige guardrails. Disse inkluderer logisk isolering på Kubernetes-niveau (K8'er), netværksisolering, kørsels-sandboxing og mindste rettighedstilladelser, alt sammen suppleret med operativ overvågning og hændelsessvarparathed for registrering og svar.
For at understøtte en robust udviklingslivscyklus tilbyder Code Extension:
- Ekstern oprettelse og fejlfinding: Udviklere kan udarbejde og fejlfinde Python-kode i velkendte miljøer som VSCode og udnytte SDK.
- Fleksibel implementering: Tilpasset kode kan pakkes og implementeres ved brug af SDK-hjælpeprogrammer, Data 360-brugergrænsefladen eller API, der aktiverer integration i CI/CD.
Driftslogfiler: Adgang til detaljerede kørselslogfiler giver gennemsigtighed og hjælper med at fejlfinde i produktion.
Ved at tilbyde disse sikre og fleksible kodeudvidelsesfunktioner sætter Data 360 arkitekter i stand til at skræddersy platformen til deres mest unikke og komplekse databehandlingskrav, hvilket virkelig styrker dens rolle som en udvidelig virksomhedsdatatabehandling.
Efterhånden som virksomheder sætter fart på AI-indføring, bevarer de fleste heterogene ML-økosystemer – herunder Amazon SageMaker, Google Vertex AI og tilpassede Python-baserede miljøer – hostingmodeller, der styrer missionskritiske forudsigelser, f.eks. kreditrisikoscoring, afgangstendens, produktanbefalinger og beslutninger om den næste bedste handling.
Traditionelt krævede integration af disse eksterne modeller i Salesforce tilpassede API-lag, ETL-pipelines eller middleware-orkestrering, introducering af dataduplikering, styringsoverhead, forsinkelse og driftskompleksitet – udfordringer, der er i konflikt med en forenet, kompatibel og realtidsvision for Customer Data Platform (CDP).
Bring Your Own Model (BYOM): Leveret via Einstein Studio i Data 360, håndterer disse udfordringer ved at aktivere direkte kald af eksternt uddannede modeller i Salesforce-arbejdsflows, Apex og automatiseringsværktøjer – uden at flytte eller replikere data. Gennem nul-kopi-federation fungerer Data 360 som den administrerede enkelt kilde til sandheden og viser harmoniserede Customer 360 til konklusion på eksterne slutpunkter. Forudsigelsesresultater flyder tilbage i realtid og styrker forretningsprocesser med skalerbare data.
BYOM lukker effektivt hullet mellem datavidenskab og operativ kørsel ved at afkoble modeludvikling, administrerede data og forbrugslag. Den bevarer platformsafhængighed, reducerer integrationskompleksitet, fremskynder AI-implementering og vedligeholder styring over følsomme data.
Arkitekturen fungerer på følgende måde: Data 360 leverer et forenet Customer 360, mens Einstein Studio orkestrerer forbindelser til eksterne ML-platforme (SageMaker, Vertex AI eller tilpassede slutpunkter). Eksterne modeller udfører inference i realtid, batch eller streamingtilstande. Salesforce-lag – forløbs-, Apex og forespørgsels-API'er – forbruger output til at levere personlige, automatiserede og analytiske indsigter på tværs af Salg, Service, Marketing og Industry Clouds.
Fra et virksomhedsperspektiv leverer BYOM:
- Dataintegritet og styring: Eliminerer ikke-kontrollerede datakopier og håndhæver policeoverensstemmelse.
- AI-demokratisering: Gør komplekse modeller tilgængelige for ikke-tekniske brugere via Salesforce-værktøjer.
- Time-to-value-forøgelse: Eksterne modeller aktiveres straks i Salesforce-processer.
- Skalerbarhed og hybridarkitektursupport: Aktiverer multi-cloud-implementering af AI-arbejdsbelastninger.
- Future-ready AI-arkitektur: Understøtter komponerbare AI-strategier, adskiller data, model og forbrugslag for at opnå driftsmæssig smidighed.
Bring Your Own LLM (BYO-LLM): Tilbyder den samme udvidelsesmekanisme, men for generative modeller. Ved at aktivere direkte kald af eksterne LLM'er giver vi kunderne mulighed for at bruge dem i Agentforce Platform i stedet for Salesforce-leverede modeller. For virksomheder tillader BYO-LLM:
- Adgang til finjusterede modeller
- Integration af modeller, der aktuelt ikke leveres af Salesforce
- Anvendelse af modeller i kundeleverede konti
Moderne virksomheder opererer inden for et komplekst datalager, der er kendetegnet ved to større arkitektoniske udfordringer:
- Intra-Enterprise Fragmentation: Store organisationer bruger ofte flere Salesforce-organisationer (ofte segmenteret efter område, forretningsenhed eller historisk overtagelse) og utallige andre datasystemer. Denne fragmentering opretter interne datasiloer, hvilket gør det umuligt at etablere en enkelt, betroet og forenet visning af kunden for engagement i realtid på tværs af forretningen. Udfordringen er at forene disse data uden fysisk at konsolidere eller duplikere dem på tværs af alle systemer, så du sikrer, at ledelsen forbliver intakt.
- Samarbejde på tværs af virksomheder: Firmaer har ofte brug for at dele data med partnere og leverandører til fælles marketing, måling og forretningsdata. Udfordringen er at aktivere dette samarbejde, mens du beskytter følsomme, beskyttede data og overholder fortrolighedsbestemmelser som GDPR og CCPA samt konkurrencehindringer.
Salesforce Data 360 håndterer disse udfordringer med en nul-kopieret, Trust, der bygger på princippet om delingsadgang og indsigter i stedet for at flytte eller duplikere data.
Salesforce Data 360 håndterer datapragmenterings- og samarbejdsudfordringer med Data Cloud One, Datadeling mellem Data 360'er og Data Clean Rooms, der anvender fortrolighed først. Disse løsninger forener kundedata, aktiverer sikker dataudveksling og giver fortrolighedsbevarende indsigter. Med en Trust by Design-tilgang kan organisationer frigøre datapotentiale til engagement i realtid, forbedrede partnerskaber og intelligent beslutningstagning. Hver af disse indstillinger for datasamarbejde tjener forskellige formål.
Intern virksomhedsaktivering med Data Cloud One
Data Cloud One er den grundlæggende arkitektoniske løsning for virksomheder, der kører flere Salesforce-organisationer. Dens formål strækker sig ud over simpel datadeling. Den er designet til at etablere en enkelt, betroet kundevisning og aktivere fulde Data 360-platformsfunktioner på tværs af hele organisationen.
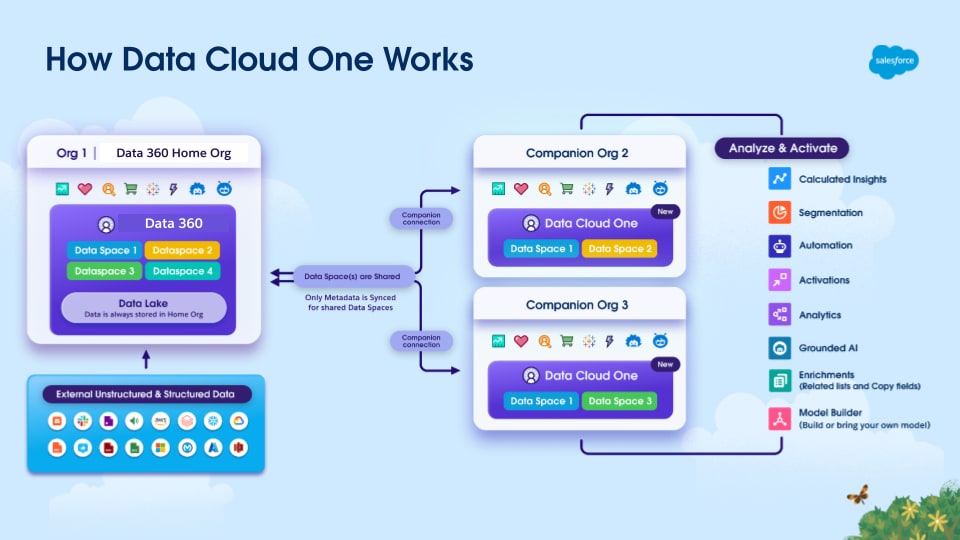
Denne mekanisme fokuserer på en udpeget startorganisations Data 360-forekomst, der fungerer som den centrale autoritet for dataadministration og opbygning af den forenede kundeprofil. Startorganisationen er den organisation, som Data 360 er klargjort på. En Data Cloud One-forbindelse etableres mellem Data 360 og andre Salesforce-organisationer, kaldet ledsagende organisationer. Som en del af Data Cloud One-forbindelsen deler Data 360 et eller flere af dets dataområder med hver ledsaget organisation og giver adgang til både data og metadata i hvert delt dataområde. Dette opnås gennem en nul-kopi-federationsmodel og krydsorganisationsmetasynkronisering.
Data Cloud One tillader også ledsagende organisationer at udnytte startorganisationens Data 360-forekomst til deres egne aktiverings-, tilpasnings- og intelligensbehov. Denne strategi er vigtig for at eliminere intern datapragmentering og sikre, at alle forretningsenheder aktiveres op mod den samme, administrerede og forenede kundeprofil, hvilket maksimerer ROI'en for Kerne-Data 360-implementeringen.
Datadeling mellem Data 360-organisationer
For distribuerede interne miljøer (hvor fuld centralisering ikke er mulig) og for samarbejde med betroede eksterne partnere, forbinder Data 360-til-Data 360-datadeling uafhængige Data 360-forekomster.
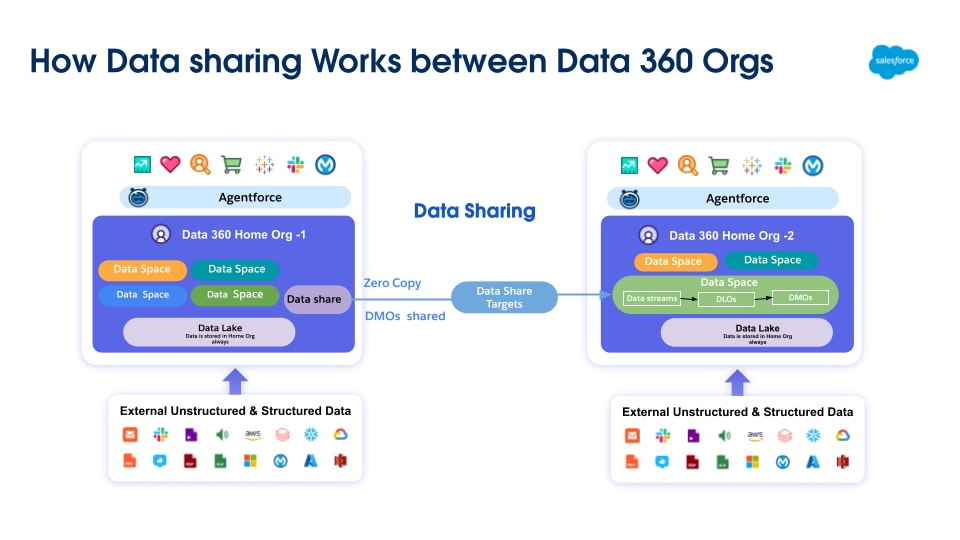
Denne nul-kopieringsdelingsmodel etablerer en forbindelse mellem separate Data 360-lejer, der er klargjort på forskellige Salesforce-organisationer med henblik på sikker udveksling af dataobjekter (DLO'er, DMO'er og CIO'er). Når det er tilsluttet, bliver hele dataobjektet tilgængeligt i modtageren Data 360. Modtagerens Data 360-administrator kan derefter angive styringsregler til at administrere brugeradgang til disse data.
Samarbejde om fortrolighed først med Data 360 Clean Room-samarbejde
Når samarbejde kræver de højeste niveauer af fortrolighed og compliance, eller når konkurrenceproblemer forbyder deling af rå data, er Data 360 Clean Rooms arkitektonisk obligatoriske.
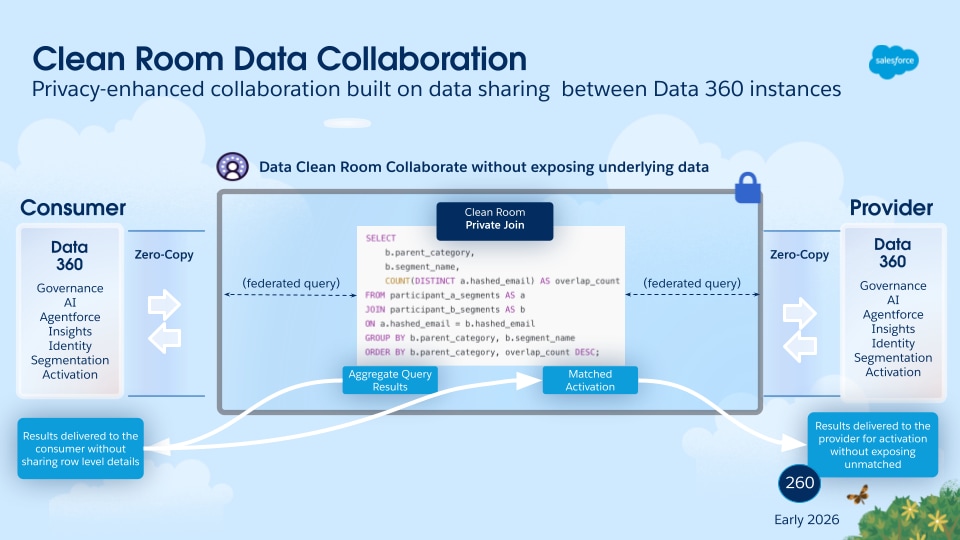
Arkitektonisk er Data 360 Clean Room-samarbejde bygget oven på den nul-kopieringsdelingsstruktur, der bruges af Data 360-til-Data 360-datadeling, men med yderligere lag af styring og beregningsbegrænsninger anvendt. Data 360 Clean Room leverer et sikkert, kontrolleret computingmiljø, hvor parter kan tilslutte sig deres datasæt baseret på anonymiserede nøgler. Dens kerneformål er at tillade fælles analyse og indsigtsgenerering uden at vise de underliggende, private data. Miljøet håndhæver strenge programmerbare regler, f.eks. minimumsaggregeringstærskler og id'er, der ikke kan eksporteres. Disse regler sikrer, at kun godkendte, fortrolighedsforbedrende og aggregerede indsigter afledes og deles. Dette gør Clean Rooms vigtigt for anvendelsessituationer som krydsplatformskampagnemål og følsomme målgruppens overlapningsanalyser.
Data 360 er designet som en intelligent, udvidelig og betroet datatæppe, der er nødvendig for at fremme næste generations AI. Dets arkitektoniske design håndterer problemet med fragmenterede data, hvilket gør det muligt for organisationer at forene, behandle og aktivere alle kundedata på en skala ved brug af Zero Copy Data Federation for at sikre effektivitet.
Dens robuste dataorganisation etablerer en harmoniseret visning fra DLO'er (herunder ustrukturerede data) til DMO'er, som alle er sikret i partitionerede dataområder. Data 360's alsidige databehandlingsfunktioner – herunder batch- og streamingtransformationer, beregnede indsigter, ustruktureret databehandling og identitetsløsning – er drevet af den trinvise SNCE- og CDF-arkitektur, hvilket sikrer effektiv, næsten realtidsbehandling og betydelige omkostningsbesparelser.
Klargørbarhed leveres af kodeudvidelsesarkitekturen og aktiverer sikkert tilpasset Python-logik via scripts eller isolerede funktioner for unikke krav. Desuden garanterer en omfattende datastyringsstruktur, der bygger på attributbaseret adgangskontrol (ABAC) med CEDAR-politikker, detaljeret sikkerhed, dynamisk datamaskering og ensartet håndhævelse på tværs af alt dataforbrug. Dette kulminerer med sofistikerede segmenterings- og aktiveringsfunktioner, der oversætter forenede kundeprofiler til dynamiske flerkanalengagementstrategier med realtidssvar.
Vigtigt er, at Data 360's mulighed for at forene store, forskellige data, levere kontekst i realtid via dens forenede forespørgsel (herunder hybrid struktureret/ustruktureret søgning og Hyper-acceleration) og håndhæve streng styring er afgørende for at styrke intelligente AI-agenter. Den leverer de nødvendige betroede, friske og relevante data til at basere RAG-arbejdsflows (generative AI-arbejdsflows) og til at fremme de multi-turn, handlingsorienterede funktioner i Agentforce agenter, så de fungerer med præcision og nøjagtighed.
Ved at levere en fremtidssikret platform, hvor kildedata transformeres til indsigter, der kan handles på, fungerer Data 360 som et uundværligt arkitektonisk fundament for organisationer, der opbygger Agenttic-kundeoplevelser. Det er det vigtige grundlag, der omdanner kundedata til de sofistikerede, personlige kundeoplevelser, der skaber succes for dagens moderne organisationer.