Dette dokument skitserer de aktuelle indstillinger for implementering af applikationer i CloudHub 2.0 for at opfylde kravene til høj tilgængelighed og katastrofegendannelse. Den bruger det amerikanske område som et eksempel og kan anvendes på andre områder.
CloudHub 2.0 er en fuldt administreret, cloud-indbygget integrationsplatform, der eliminerer infrastrukturoverhead ved at automatisere implementering, skalering og administration af MuleSoft-API'er og -integrationer i clouden. Det er MuleSoft's moderne cloud-implementeringsplatform, der kører på Amazon AWS-infrastruktur.
I de fleste tilfælde er standarden High Availability (HA) og Disaster Recovery (DR), der leveres af CloudHub 2.0, tilstrækkelig. CloudHub 2.0 leverer HA og DR på regionalt niveau (for yderligere oplysninger henvises til CloudHub 2.0 Outage Scenarios). Afsnittet CloudHub 2.0-nøgleovervejelser indeholder flere oplysninger om CloudHub-2.0-understøttet HA og DR.
Betingelser, der kræver et design ud over CloudHub 2.0-standardtilgængelighed, inkluderer:
- En applikation skal sikre, at der ikke er noget tab af data i et katastrofscenarie (f.eks. et område i Amazon, der går ned).
- En applikation afhænger af objektlager og skal sikre kontinuitet, hvis implementeringsområdet går ned.
- Backendsystemer konfigureres til ækvivalent tilgængelighed. CloudHub 2.0 kan nogle gange give pålidelighed gennem køer eller lignende mekanismer, men uanset om integrationen er realtid eller asynkron, skal backendsystemer understøtte et sammenligneligt niveau af HA og DR.
- Når et AWS-områdeniveauafbrydelse påvirker backendsystemer, antages deres gendannelse at køre parallelt med CloudHub 2.0-gendannelse.
- Opsætning af private områder er fuldført i flere områder.
Designindstillingerne i denne vejledning fokuserer på løsninger for applikationstilgængelighed i CloudHub 2.0, når en hel AWS-tilgængelighedszone eller et område bliver utilgængeligt.
Denne vejledning behandler ikke disse opsvingsscenarier, men den noterer sig konsekvenser, hvor det er relevant:
- Gendannelse af backendsystemer, applikationer, databaser, netværkskomponenter og datacentre, der administreres og klargøres uden for Anypoint CloudHub, uanset om de er på stedet eller i clouden.
- Genoprettelse af VPN-links mellem CloudHub 2.0 og kundens private datacenter (f.eks. IPsec-tunneller og VPN-gateways). Nogle DR-indstillinger i denne vejledning kan delvist håndtere disse scenarier.
- Ændringer af MuleSoft-udgangs-IP'er under katastrofegendannelse, når IP-tilladelseslister bruges til integrationer. Nogle DR-indstillinger i denne vejledning kan delvist håndtere disse scenarier.
- Eksterne meddelelsessystemer, der bruges i kundeløsninger, uanset om de leveres af MuleSoft (f.eks. Anypoint MQ) eller andre leverandører (f.eks. AWS MSK eller Heroku Kafka).
Når du evaluerer CloudHub 2.0 for katastroferesultatkrav, skal du overveje disse vigtige overvejelser.
CloudHub 2.0-afhængighed af regional AWS-tilgængelighed
- CloudHub 2.0 kører på AWS. Tilgængeligheden er bundet til AWS-områder.
- Implementeringer og applikationstilgængelighed er organiseret efter område. Disse områder svarer til AWS-områder.
Hvis et helt AWS-område mislykkes, er applikationer i dette område utilgængelige og replikeres ikke automatisk andre steder.
Høj tilgængelighed af applikationer (HA) og replikstyring
- CloudHub 2.0 genimplementerer automatisk applikationer i samme område, når hardware mislykkes, men en applikation med en enkelt replika kan opleve nedetid.
- Applikationer med flere repliker implementeres på tværs af separate tilgængelighedszoner som standard, hvilket giver HA på tværs af zoner.
- Hvis tilgængelighedszonen for en enkelt replikaapplikation mislykkes, hentes applikationen automatisk i en anden tilgængelighedszone i det samme område.
Specifik påvirkning for Øst-USA
- I tilfælde af et nedbrud i det østlige USA:
- CloudHub 2.0-administrationsbrugergrænsefladen og implementerings-REST-tjenester er ikke tilgængelige, og nye applikationer kan ikke implementeres.
- Applikationer i andre områder forbliver upåvirkede under de fleste fejlscenarier. Disse applikationer fortsætter med at fungere normalt. Men overvågnings- og administrationsfunktioner via kontrolplanen vil være utilgængelige under afbrydelsen.
- Core CloudHub 2.0-moduler (f.eks. applikationsindstillinger) vedligeholdes i det østlige USA, så indstillinger kan ikke redigeres under afbrydelsen.
Overvågning og advarsel
- Konfigurer advarsler for fejl på tilgængelighedszone eller på områdeniveau via status.mulesoft.com.
- Brug en separat tilstandscheck- og advarselsmekanisme uden for CloudHub 2.0, så teams adviseres, hvis replikker mislykkes, eller applikationer stopper med at svare.
Datakvarighed (objektlager V2)
- Objektlager V2 er knyttet til det område, hvor applikationen implementeres først.
- Hvis du flytter applikationen til et andet område, forbliver Objektlager V2 i det oprindelige område for at undgå tab af data.
- Hvis det område, hvor Objektlager V2 er implementeret, mislykkes, er objektlageret utilgængeligt.
Indgangskontroller og private rum
- CloudHub 2.0's inputcontrollere er meget tilgængelige på områdeniveau.
- Hvis et område mislykkes i et fælles område, forbliver en overførselscontroller i et andet område tilgængelig, men kan kun vise applikationer, der er implementeret i dette område.
- Hvis et område mislykkes i et privat område, er overførselscontrollere i andre områder utilgængelige, medmindre de er opsat der på forhånd.
- Privat områdeopsætning er regional. Hvis et område mislykkes, er det private område utilgængeligt, medmindre der er opsat et andet område.
| Komponentstatus | Salesforce-ansvar |
|---|---|
| Replica Down | Action: CloudHub 2.0 genstarter automatisk repliken i en anden tilgængelighedszone, hvis der er noget galt med den aktuelle tilgængelighedszone. Men applikationen vil være offline, indtil den nye replika er fuldt startet. Betingelse: Standardkonfiguration. Tid taget: Ca. 2-15 minutter afhængigt af applikationens kompleksitet og replikeringsstørrelse. |
| Tilgængelighedszone ned | Action: Det samme som replikaen ned. Betingelse: Standardkonfiguration. Tid taget: Det samme som replikaen ned. Meddelelse: Det samme som replikaen ned. |
| Region Down | Action: Ingen automatisk gendannelse. Der skal være et overførselsdesign. |
| Komponentstatus | Kundernes ansvar |
|---|---|
| Replica Down | Meddelelse: Udfør periodiske tilstandschecks ved brug af en hjertefrekvensmekanisme, der er indbygget i API'er. Reduktion: Implementer applikationen til flere repliker i samme område. Test / Simulation: Hent en billet med MuleSoft Support, og de understøtter en fejlover-test for at kontrollere, om en ny replika ruller op i en anden AZ efter 1 til 15 minutter. |
| Tilgængelighedszone ned | Meddelelse: Det samme som replikaen ned. Reduktion: Implementer applikationen til flere repliker i samme område eller i forskellige områder. Test / Simulation: AZ Down-scenariet er vanskeligt at simulere. Det kræver involvering fra MuleSoft Engineering for at understøtte mulige testscenarier. |
| Region Down | Meddelelse: Det samme som replikaen ned. Kontroller også statusopdateringer på https://status.aws.amazon.com. Reduktion: Det samme som AZ Down. Katastrofegenoprettelsesplan: 2 private områder med den samme konfiguration i forskellige områder. Test / Simulation: Det samme som AZ Down. |
| Komponentstatus | Salesforce-ansvar |
|---|---|
| VPN Gateway Down | Replikstatus: Kører, men kan ikke oprette forbindelse til nogen ressourcer, der hostes på stedet, og som kan nås via VPN-tunnellen. Action: Ingen automatisk gendannelse. Der skal være et overførselsdesign. |
| Inputcontroller (Delt plads) Ned | Replikstatus: Overførselscontrolleren er en klynget opsætning med flere forekomster, svarende til applikationsreplikker. Hvis en applikationsreplik mislykkes, oprettes der en ny og startes automatisk. Hvis en overførselscontrollerforekomst mislykkes, forbliver applikationer tilgængelige gennem den anden forekomst. Hvis hele overførselscontrolleren er nede, betragtes området som nede. |
| Ingress Controller (Privat område) Ned | Replica Status: Det samme som Overførselscontroller i det delte område ned. |
| Komponentstatus | Kundernes ansvar |
|---|---|
| VPN-gateway ned | Meddelelse: Udfør periodiske tilstandschecks ved brug af en hjertefrekvensmekanisme, der er indbygget i API'er. Reduktion: CloudHub 2.0 VPN-gateways understøtter høj tilgængelighed gennem en dual-tunnel-arkitektur med automatisk overførsel mellem tunneller. En kunde skal konfigurere dette mønster. Test / Simulation: VPN Gateway Down-scenariet er vanskeligt at simulere. Kræver involvering fra MuleSoft Engineering for at understøtte mulige testscenarier. |
| Ingress-controller (delt område) ned | Meddelelse: Det samme som VPN Gateway Down. Reduktion: Det samme som Region Down. Migrer applikationer til et standby- eller aktivt område i et andet område. Test / Simulation: Det samme som VPN Gateway Down. |
| Ingress-controller (privat område) ned | Meddelelse: Det samme som VPN Gateway Down. Reduktion: Det samme som Region Down. Migrer applikationer til et standby- eller aktivt privat område i et andet område i koordination med AWS Route 53-konfiguration (eller ækvivalent). Test / Simulation: Det samme som VPN Gateway Down. |
Oversigt Platform Services Down Scenario – Objektbutik
| Objektlager i hukommelse | Vedvarende objektlager v2 | |
|---|---|---|
| Placering af data | Kun lokal til applikationen. | I det samme område, hvor MuleSoft-applikationen først blev implementeret. |
| Delt på tværs af replikaer? | Nej | Ja |
| Objektlager gendannelse i applikationer | Data går tabt. Alle data i hukommelsen går tabt ved genstart af app, ny implementering eller replikfejl. | Data går ikke tabt, medmindre appen slettes. |
| Objektlagergendannelse i område | Data går tabt (samme som ovenfor). | Data går ikke tabt (samme som ovenfor). |
| Regional opsving | Samme som ovenfor. | Data er ikke tilgængelige. Selv med en aktiv DR-konfiguration er Objektlager kun tilgængelig i det oprindelige implementeringsområde. |
| Mitigation | Eksternaliser data til regional gendannelse. | Data forbliver tilgængelige, mens det oprindelige implementeringsområde er tilgængeligt. For tværgående HA eller DR skal du eksternere data uden for objektlageret. |
Høj tilgængelighed (HA) er målet på et systems evne til at forblive tilgængelig i tilfælde af en systemkomponents fejl. Generelt implementeres HA ved at bygge i flere niveauer af fejltolerance og/eller indlæsningsbalanceringsfunktioner i et system. Det er typisk en Aktiv-aktiv-konfiguration og resulterer i begrænset eller ingen påvirkning af Forretningstjenester.
Disaster Recovery (DR) er den proces, hvorved et system gendannes til en tidligere acceptabel tilstand efter et katastrofscenarie, enten naturligt (som oversvømmelser, tornadoer, jordskælv eller brande) eller menneskeskabt (som strømafbrydelser, serverfejl eller fejlkonfigurationer). DR er typisk en aktiv-passiv konfiguration og resulterer i en vis påvirkning af Business Services.
Hvis du ønsker Regional High Availability eller Regional Disaster Recovery for at reducere forretningseffekter i tilfælde af en regional AWS-fejl, skal du overveje disse punkter, når du designer din løsning i MuleSoft CloudHub 2.0:
- CloudHub 2.0-replikker og relaterede funktioner – private områder, overførselscontrollere og Anypoint MQ-destinationer – er områdespecifikke.
- Hvis et helt AWS-område mislykkes, bliver alle replikker og tilknyttede tjenester i dette område utilgængelige.
- Når et område gendannes, gendannes konfigurationer. Du skal genstarte applikationer.
- Hvis det østlige amerikanske område mislykkes, er Anypoint Platform-tjenester (f.eks. Adgangsstyring og Kørselsmanager) heller ikke tilgængelige.
- MuleSoft leverer en SLA på 99,95 % tilgængelighed for platformstjenester, herunder CloudHub 2.0-replikker i en aktiv-aktiv konfiguration i et område. Se den seneste MuleSoft-cloud, der tilbyder SLA for at få aktuelle oplysninger.
- CloudHub 2.0 understøtter ikke flerområde-HA eller DR, der er klar til brug. Tilgængelighed angives kun i et enkelt område.
Disse designretningslinjer gælder, uanset hvilken opsætning du vælger.
Opsætning af private områder med flere områder
Alle indstillinger, der er beskrevet i følgende afsnit, kræver, at applikationer implementeres i særskilte områder. Dette er kun muligt, hvis opsætning af private områder er fuldført på forhånd, før en katastrofe. Da opsætning af private områder er regional, kræver en DR-strategi mindst to private områder – et pr. område – og en mekanisme til at skifte trafik til det relevante VPN-slutpunkt.
Høj tilgængelighed af privat plads i et område
CloudHub 2.0 leverer ikke automatisk overførsel, når et privat område i et område mislykkes. En løsning er en aktiv-passiv opsætning på tværs af flere miljøer, hvilket kræver:
- Konfiguration af flere VPN-gateways på det private område.
- Etablering af særskilte miljøer i CloudHub 2.0-området, hver med sit eget private område.
- Udpegning af et af disse miljøer som passivt (hvor applikationer til en start ikke implementeres, men hentes, hvis det primære private område mislykkes).
Hvis en opsætning med høj tilgængelighed uden VPN-gateway, der er et enkelt fejlpunkt, er et hårdt krav, er implementering til to områder den bedste løsning. En VPN-gatewayfejl i dette scenarie kan løses ved at lade det påvirkede område flytte til det alternative område, hvor det private område allerede er konfigureret.
Nul meddelelsestab
Hvis du vil opnå nul-meddelelsestab, når et helt område mislykkes, skal en applikation forhindre datatab og håndtere disse punkter:
- Brug eksterne meddelelser til at opnå meddelelsessikkerhed.
- Sørg for, at Objektlager ikke bruges til flytransaktionsdata, der er af transaktionel karakter. Hvis implementeringsområdet, hvor MuleSoft-applikationen først blev implementeret, går ned, vil Objektbutikken være utilgængelig.
- Ombryd al objektbutiksadgang i et separat forløb eller et separat afsnit, der fortsætter med at fungere – både for undtagelseshåndtering og adfærd – når objektbutikslæse- eller skrivehandlinger mislykkes.
Notat. I de fleste tilfælde behøver DR-krav ikke at sikre et nul-meddelelsestab i tilfælde af en katastrofe, og behovet for at sikre, at datatab er mindre end en angivet periodes værdi af data (f.eks. 1 time).
Gør integrationen statløs
Som et generelt designprincip er det altid vigtigt at sikre, at integrationerne er statløse af natur. Dette betyder, at der ikke deles nogen transaktionsoplysninger mellem forskellige klientkald eller kørsler (i tilfælde af planlagte tjenester). Hvis nogle data skal vedligeholdes af middleware på grund af en systembegrænsning, skal de bevares i en ekstern butik, f.eks. en database eller en meddelelseskø og ikke i MuleSoft-infrastrukturen eller i hukommelsen. Det er vigtigt at bemærke, at når vi skalerer, især i clouden, skal tilstanden og ressourcerne, der bruges af hver replika, være uafhængige af andre replikaer. Denne model sikrer bedre ydeevne, skalerbarhed og pålidelighed.
Netværk og trafikstyring
- Der kræves ikke-domæner for regional tilgængelighed. De fungerer som en global DNS for alle overførselscontrollere på tværs af områder.
- En global load balancer distribuerer trafik mellem den primære og DR region private rum. Kunder leverer denne komponent. Brug AWS Route 53 eller et globalt CDN med distributionspolitikker til at distribuere trafik på tværs af områder.
- Konfigurer inputcontrollere i både primære og DR-områder med et tilpasset vanity-domæne.
- Planlæg og vedligehold firewallregler og VPN-tunneling, så lokale applikationer kan nås fra både de primære og DR-områdets private områder.
- Vedligeholdelse af TLS-certifikatet skal dække private lokaler i både primære og DR-områder for problemfri udvinding.
Anvendelsesimplementering og konfiguration
- Anvendelsesnavn skal være entydige på tværs af områder. En CI/CD-pipeline kan f.eks. føje områdenavnet (eller en områdekode) til applikationsnavne før implementering for at bevare entydigheden på tværs af primære og DR-områder.
- Konfigurer CI/CD-pipelinen til at implementere applikationer i både primære og DR-områder, så alle applikationer er tilgængelige i begge områder.
Infrastruktur og kapacitet
Ydeevnen er bedst, når alle infrastrukturaspekter har identisk primær kapacitet og DR-områdekapacitet. Ydeevnen nedsættes, når disse infrastrukturaspekter ikke er identiske.
Datakvarighed og lagring
- Permanent lagring skal synkroniseres regelmæssigt mellem de to områder. Kunder er ansvarlige for lagerreplikering. MuleSoft leverer den ikke. Et enkelt delt lager mellem VPC'er i de primære og DR-områder er muligt, men det delte lager skal være meget tilgængeligt, ellers bliver det et enkelt fejlpunkt for begge områder.
- Object Store V2 er regionalt og er kun tilgængelig i det område, hvor Mule-applikationen først blev implementeret. Hvis applikationen flyttes til et andet område, forbliver Objektlager V2 i det oprindelige område for at undgå tab af data. Brug andet vedvarende lager til DR-strategier med flere områder.
Prøvning og driftsprocedurer
Indfør en formel DR-teststrategi, og kør periodiske DR-træninger. For aktiv aktiv DR skal du bruge en canarisk implementeringsstrategi til at validere begge områder.
Ydeevne- og serviceniveauaftaler (SLA'er)
Nogle ydeevnedegraderinger kan forekomme, fordi DR-området kan være længere væk fra slutbrugere eller backendsystemer end det primære område. Definer og kommuniker en DR SLA til interessenter.
Adfærd i gendannelsestilstand (kontekstnotat)
I aktiv-aktiv tilstand er fejloverførsel fra det primære område til DR-regionens private område hurtig: den globale indlæsningsbalancering registrerer, at det primære er usundt og distribuerer trafik til det sunde område (DR). I aktiv-passiv tilstand skal du implementere applikationen i det private område i DR-området, når der forekommer en katastrofe.
Der er 3 muligheder for at opnå en højere tilgængelighed af DR-niveau:
En aktiv-aktiv opsætning er baseret på aktive medarbejdere fordelt på tværs af områder ved brug af en ekstern indlæsningsbalancering til at distribuere trafik mellem de to forekomster.
Varm standby-konfiguration
En aktiv-passiv opsætning vil være baseret på en aktiv medarbejder i et område og en passiv medarbejder i et andet område. Det passive område startes, når der er behov for det.
Nogle elementer i det passive område skal forblive aktive for overførsel af fejl eller være opsat på forhånd, herunder private områder, VPN'er og vedhæftede transitgatewayfiler.
Som nævnt ovenfor klargøres replikker og overførselscontrollere i et andet område via en fuldt automatiseret DevOps-proces ved overførsel med fejl. Nogle elementer i det passive område skal forblive aktive for overførsel af fejl, herunder private områder, VPN'er og vedhæftede transitgatewayfiler.
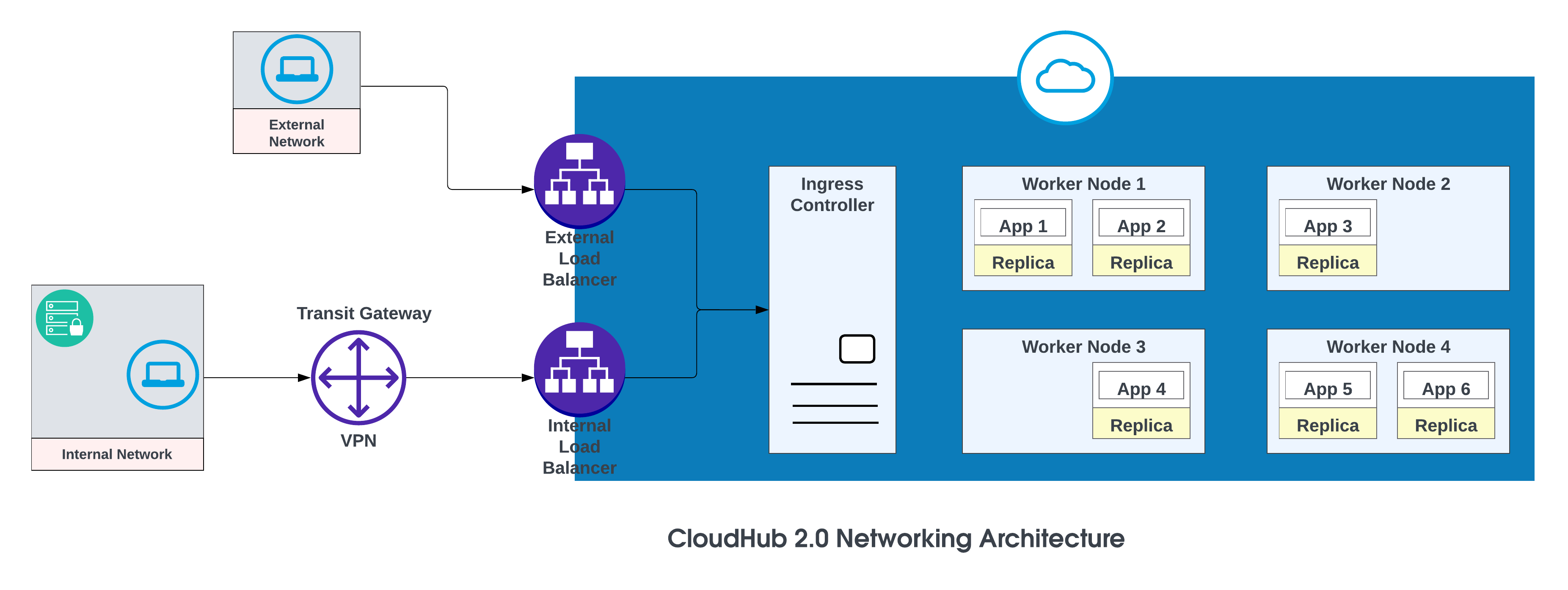
Grundkomponenterne i CloudHub 2.0-netværksarkitekturen er:
- En HTTP-indlæsningsbalancering
- Mule replica DNS-registreringer
- Private områder
- Regionale tjenester
Se CloudHub 2.0 Networking Architecture for at få flere oplysninger.
Vanity-domæner
Når der oprettes et privat område, modtager det et DNS-målnavn i formatet: <space-id>.<region>.cloudhub.io . Ved implementering af en app ved navn test-api i dette private område vil dens slutpunkt følge dette format:
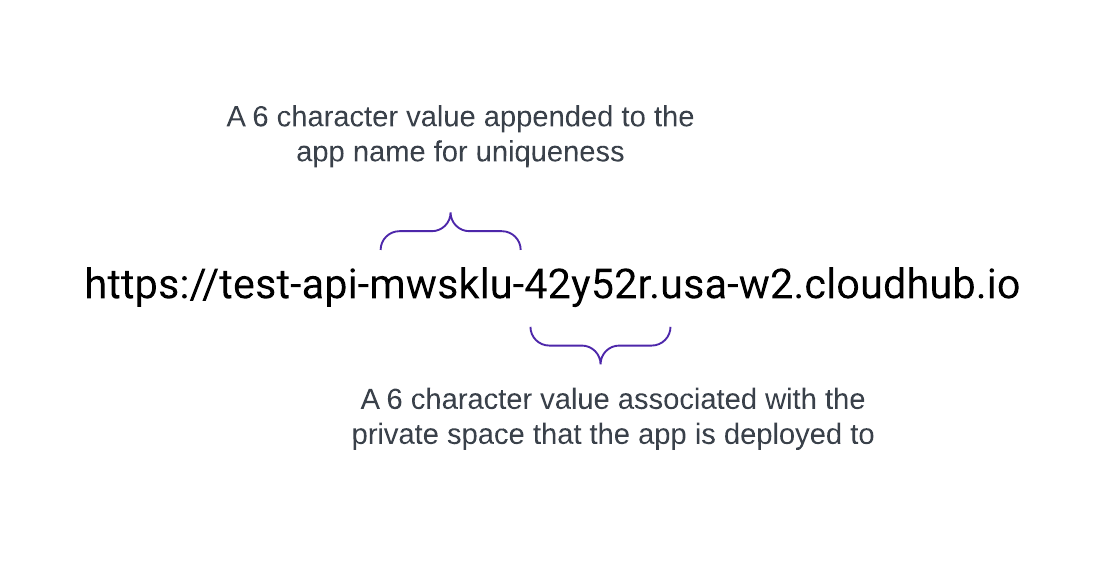
CloudHub 2.0 understøtter også tilpassede domæner eller vanity-domæner ved at konfigurere dem i et privat område ved brug af TLS-kontekster og DNS-registreringer. Hvis du vil oprette en TLS-kontekst i Runtime Manager for et privat område, skal du uploade det offentlige certifikat og den private nøgle og derefter tilføje et tilpasset slutpunkt i din applikations indstillinger for at bruge det pågældende domæne. Opret en DNS-registrering (f.eks. et CNAME), der peger på dit vanity-domæne til dit private områdes standardværtsnavn.
F.eks. har en applikation ved navn test-api implementeret i us-west-2 med standard-DNS 42y52r.usa-w2.cloudhub.io et API-slutpunkt på:
https://test-api-mwsklu-42y52r.usa-w2.cloudhub.io
Denne URL bruger ikke et uformateret domæne eller et tilpasset domæne. Hvis du vil bruge acme.com, så API-URL'er vises som https://test-api.acme.com, skal du følge disse trin.
- Opret TLS-kontekst i Runtime Manager med offentlige og private nøgler.
- Tilføj et vanity-domæne i applikationens indstillinger for at bruge dette domæne.
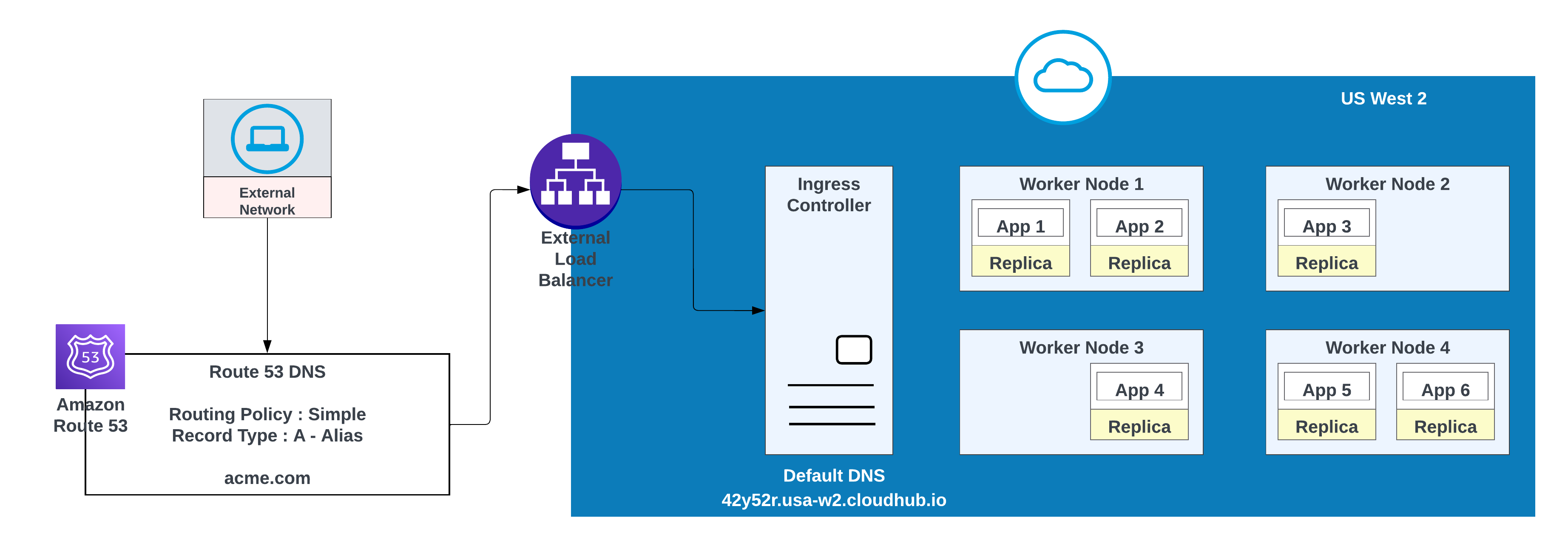
- Opret en DNS-registrering i AWS Route 53 og konfigurer en enkel distributionspolitik (f.eks. CNAME), så det tomme domæne fortolkes til det private områdes standardværtsnavn.
For tilpassede domæner kan du bruge AWS Route 53 eller andre globale CDN-tjenester med distributionspolitikker. I diagrammet nedenfor bruges AWS Route 53 med "enkel" distributionspolitik. Når en forbruger fra et offentligt (eksternt) netværk anmoder om acme.com, distribuerer AWS Route 53 anmodningen til MuleSoft's private pladsoverførselscontroller.
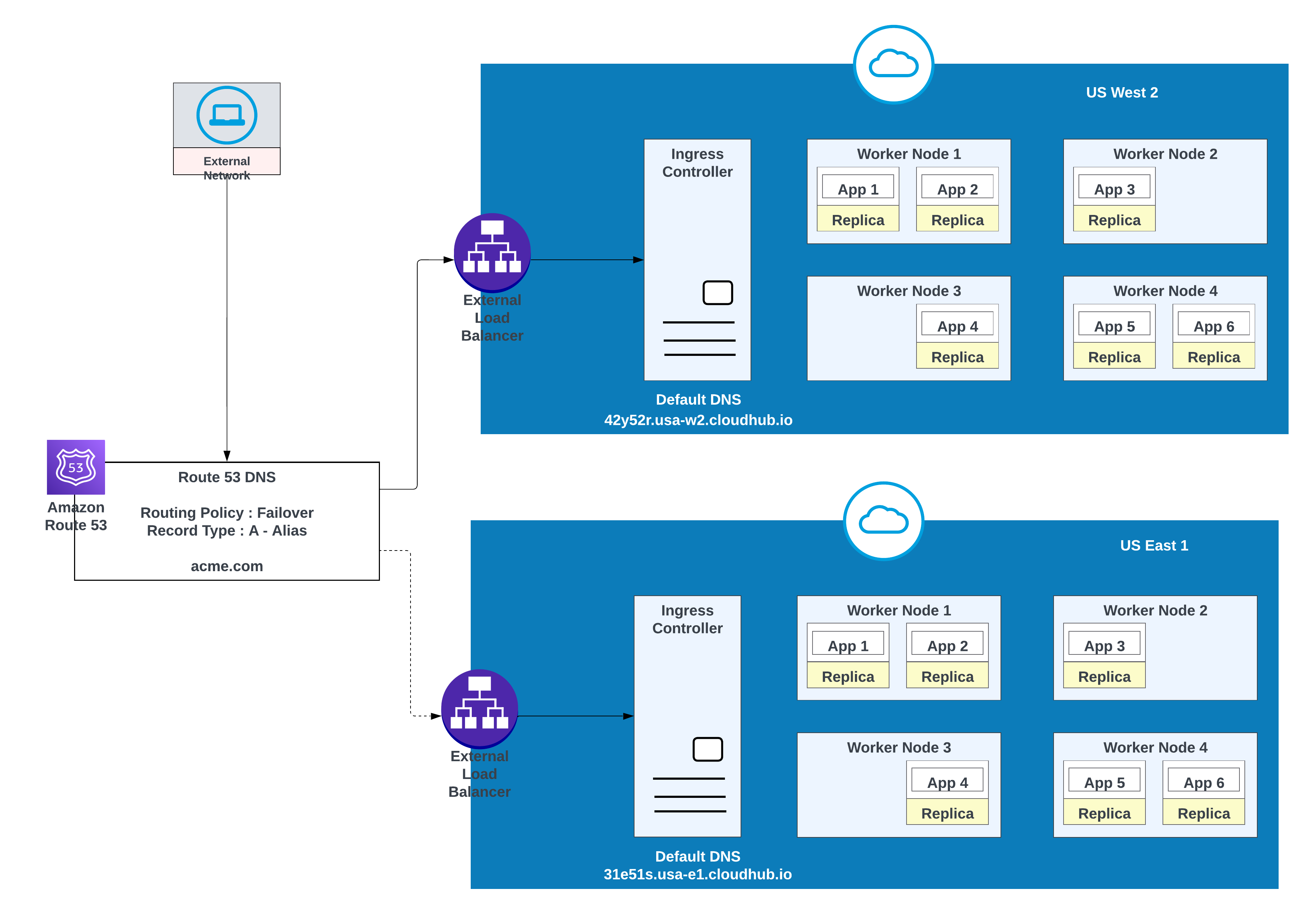
Brug denne indstilling, når applikationer kræver fejlover: implementer en forekomst i det primære område (f.eks. us-west-2) og en anden i et sekundært område (f.eks. us-east-1).
Brug et eksisterende miljø i det sekundære område, når det er muligt. Oprettelse af et nyt miljø kræver yderligere indsats.
Eksempel på apps implementeret i et område (USA Vest 2) med en fejloverførsel til et andet område (USA Øst 1)
| Registreringsnavn | Værdi/Rute trafik til | Distribueringspolitik | Id for tilstandscheck |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Fejloverførsel | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Fejloverførsel | 43e131s131sq |
I denne konfiguration distribuerer AWS Route 53 trafik til indtastningscontrollere for de private områder i US West 2 og US East 1. En failover-distributionspolitik konfigureres med en tilstandscheck.
Hvis du ønsker en lavere forsinkelse sammen med høj tilgængelighed, skal du bruge implementeringsstrategien, der er beskrevet i diagrammet. Med denne strategi kan apps implementeres i to områder (us-west-2 og us-east-1 i dette eksempel).
Brug forsinkelsesdistributionspolitikken i AWS Route 53 til at distribuere anmodninger til det område, der tilbyder den laveste forsinkelse, mens du bevarer høj tilgængelighed. "forsinkelse"-distributionspolitik i AWS Route 53 til at distribuere anmodningen om lavere forsinkelse, der stadig har høj tilgængelighed.
Apps implementeret i begge regioner (USA Vest 2 og USA Øst 1) for lavere forsinkelse og høj tilgængelighed
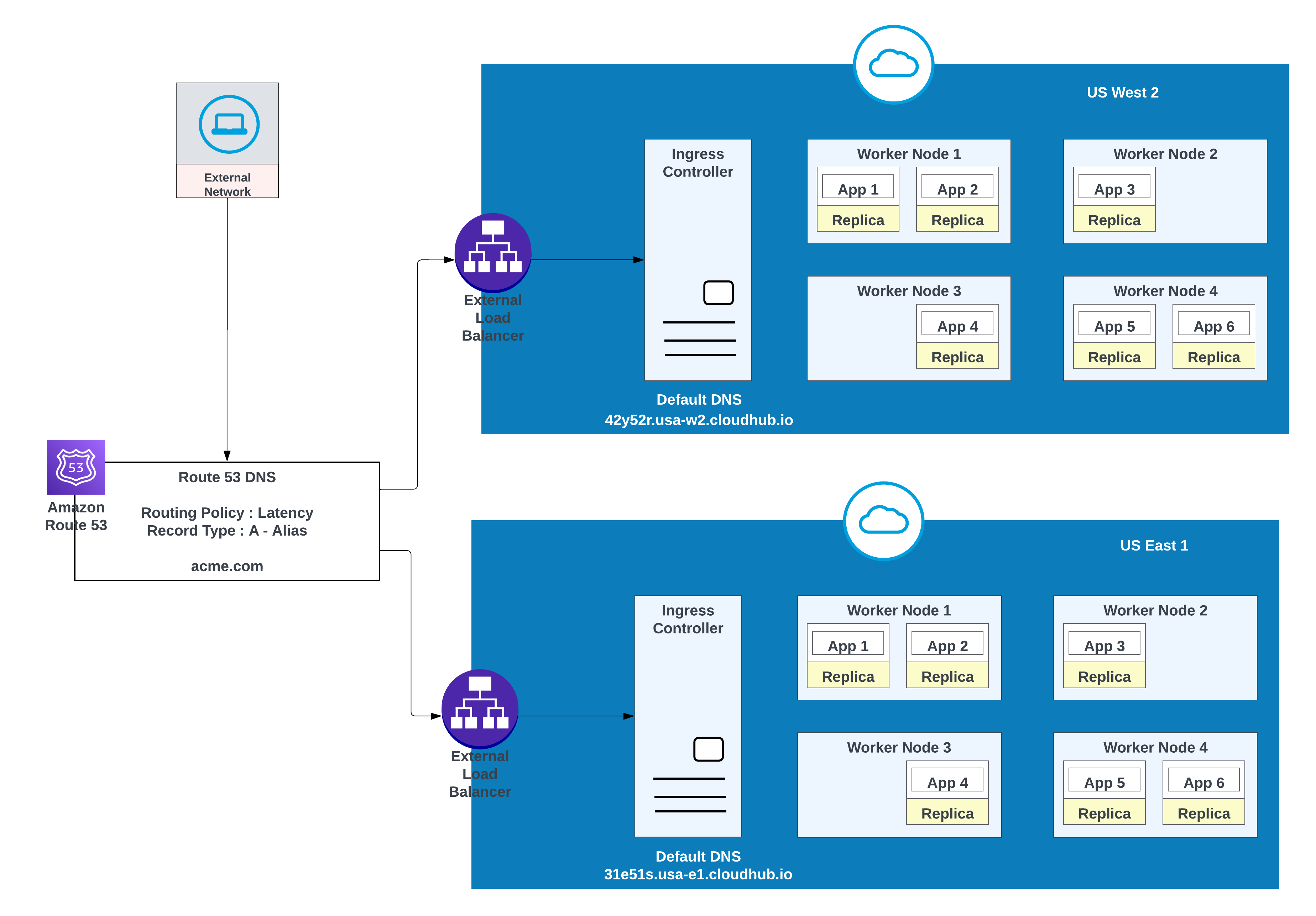
| Registreringsnavn | Værdi/ Distribuer trafik til | Distribueringspolitik | Id for tilstandscheck |
|---|---|---|---|
| acme.com | 42y52r.usa-w2.cloudhub.io | Forsinkelse | 31s3wseq121 |
| acme.com | 31e51s.usa-e1.cloudhub.io | Forsinkelse | 43e131s131sq |
MuleSoft CloudHub 2.0 giver et robust grundlag for fleksibilitet i området, primært ved at udnytte automatiseret replikeredundans og intelligent indlæsningsbalancering. Implementering af applikationer med flere repliker i et enkelt cloud-område sikrer, at hvis en forekomst mislykkes, kan andre straks overtage arbejdsbelastningen. Den integrerede belastningsbalancering distribuerer effektivt indgående trafik på tværs af disse sunde replikaer, hvilket minimerer nedetid og sikrer kontinuerlig tilgængelighed af service under normale driftsbetingelser.
Men at være udelukkende afhængig af denne enkelt-områdearkitektur, selv en med høj redundans, repræsenterer en væsentlig risiko for et omfattende, katastrofalt regionalt nedbrud. Historien har vist, at selv de mest pålidelige og teknologisk avancerede cloududbydere er modtagelige for forstyrrende hændelser, der kan påvirke et helt geografisk område. Selvom disse enkelte fejlpunkter er sjældne, kan de opstå fra forskellige begivenheder, herunder:
- Infrastrukturhændelser i stor skala
- Større strømfejl
- Udbredte netværksafbrydelser
Derfor skal en arkitektur designes til at overskride begrænsningerne i en enkelt områdemodel for at opnå ægte høj tilgængelighed (HA) og katastrofegendannelse (DR). Den anbefalede strategi er implementering på tværs af flere geografisk forskellige områder. Denne tværregionelle fleksibilitet sikrer, at hvis et helt cloudområde bliver utilgængeligt på grund af en uventet katastrofe, kan trafikken problemfrit overføres til en applikationsforekomst, der kører i et separat, upåvirket område, hvilket garanterer minimal serviceafbrydelse og opnåelse af maksimale oppetidsmål.
CloudHub 2.0-netværksarkitektur
Konfiguration af tværgående fejloverførsel for standardkøer
Objektlager V2-implementeringsområder
Din objektbutiks implementeringsområde
Gulal Kumar er Software Engineering Architect hos Salesforce med fokus på data- og integrationsarkitektur. Med over 20 års erfaring inden for integration og API'er, moderniseringsprogrammer, sikkerhed og AIML-initiativer giver han en lang række ekspertise. Gulal har været engageret i at fremme forretningstransformationsinitiativer, forbedre sikkerhed og modstandsdygtighed, fremme arkitektonisk ekspertise og føre AIML-initiativer på tværs af forskellige domæner.
Ajay Nagaraju er Enterprise Architect og Senior Director hos MuleSoft med over 28 års erfaring inden for virksomhedsarkitektur, systemintegration og digital transformation i stor skala. Han har ledet arkitektur og levering af komplekse, multimillion dollar-programmer på tværs af Fortune 100- og Fortune 500-organisationer med dyb ekspertise inden for API-ledet tilslutning, SOA, cloud-teknologier og virksomhedsintegrationsmønstre. Ajay har indgået tætte partnerskaber med ledelse for at modernisere forretningsprocesser, dataplatforme og integrationsøkosystemer og er passioneret for at opbygge skalerbare arkitekturer, mentorere teams og fremme målbare forretningsresultater gennem teknologi.