Moderne Salesforce-arkitekturer styrkes i stigende grad af asynkron behandling. Ikke som en bekvemmelighed, men som et strategisk krav til skalering. I de seneste år har vi set flere og flere firmaer kæmpe med stigende datamængder, komplekse integrationer, der involverer flere kontaktpunkter, og stigningen i autonome systemer, der kører 24/7/365. Alle disse ting skubber arkitekter i retning af at designe systemer, der er asynkrone-først.
Asynkron behandling i Salesforce betyder ofte at designe omkring styringsbegrænsninger og kompleksitet. Disse grænser fungerer som guardrails og arkitektoniske begrænsninger, der hjælper med at oprette massesikre, skalerbare systemer. Selvom ingen platformsbegrænsninger direkte tjener til at håndtere kompleksitet, kan designmønstre hjælpe med at reducere risiko på den front. Intern overfører Salesforce ofte platformens grænser for at fremme test af nye funktioner og automatisere komplekse forretningsprocesser. Vi har opbygget en trinbaseret asynkron behandlingsstruktur til kørsel af asynkrone job med et vilkårligt antal trin. Hvert trin kan køres, forsøges og genstartes uafhængigt med delte styringskontroller og fuld operativ synlighed gennem centraliseret logføring. Dette dokument skitserer dets nøglearkitektoniske komponenter: Apex og Finalizers, Planlagt forløb, Apex, handlinger, der kan kaldes, og integrationer med Slack. Sammen giver disse komponenter en modulær, skalerbar og observabel arkitektur, der er egnet til udviklende virksomhedsbehov.
- Moderne Salesforce-arkitekturer bør omfavne en asynkron først-tilgang for at opnå skalering, fleksibilitet og driftsmæssig gennemsigtighed.
- Opdeling af komplekst arbejde i uafhængigt eksekverbare trin aktiverer forudsigelig ydeevne, sikrere forsøg, kontrolpunktering, tilbagerulning og moduludvikling uden omdesign af kernearbejdsflows.
- Strukturen leverer et skalerbart alternativ til monolitiske og aldrende batchjob, kæde-asynkrone kald og dybt indlejrede forløb og er bygget til højvolumen arbejdsbelastninger, der skal skaleres vandret i Salesforce uden orkestrering uden platform.
- Deterministisk og observabel kørsel sikrer statussporing, SLA-overvågning, fejldiagnosticering og gennemsigtighed på revisionsniveau gennem centraliseret logføring og styring.
- Designet til strenghed på virksomhedsniveau, herunder forenet styring, overholdelse og distribueret statskontrol på tværs af længe kørende forretningsprocesser.
Før du gennemser kravene, er her nogle fordele og mangler for, hvornår du skal bruge en struktur som denne. Overvej først og fremmest, hvilket system der er den eneste kilde til sandheden. Hvis din Salesforce-organisation er minimalt afhængig af eksterne data, men har brug for at skalere fra hundredvis til millioner af registreringer, kan du overveje en trinbaseret asynkron struktur.
Brug denne ramme, hvis:
- Det meste (eller alle) af de oplysninger, der skal handles på, findes allerede i dit CRM.
- Den indledende eller igangværende omkostning ved vedligeholdelse af et ETL-job (Extract Transform Load) til at harmonisere eksterne data er for høj.
- Du skal udsætte behandling af et stort antal Salesforce-registreringer efter en angivet tidsplan.
- Du kan opdele behandlingen i særskilte trin. Du kan f.eks. oprette et hierarkisk eller træbaseret sæt af registreringer, især hvis datamængden fanerer ned ad hierarkiet eller træet.
Brug ikke denne ramme, hvis:
- Oprettelse eller opdatering af registreringer kræver øjeblikkelig genberegning.
- Integration er udfordrende, fordi eksterne systemer er vært for primære data for registreringsopdateringer. (Overvej at overføre opdaterede data til Salesforce med masse-API).
Husk på disse fremgangsmåder, så lad os gennemse vores krav og begynde at bygge.
Overvej problemerklæringen:
Hvis der er et job, der skal køres dagligt, skal du kontrollere, om bestemte registreringer opfylder foruddefinerede kriterier for yderligere behandling. Hvis de gør, kan du starte disse behandlingsjob. Behandling af registreringer kan betyde at hente data fra flere eksterne systemer for at udføre beregninger. Trin i job skal advisere personer via Slack om, at behandlede registreringer er klar til gennemgang. Trin skal også eskalere adviseringer til managers og højere i rollehierarkiet baseret på en konfigurerbar forsinkelse efter den første runde af adviseringer.
Dette problem involverer flere forskellige trin, hvoraf nogle kan ske uafhængigt af hinanden. Der er mange måder at opdele arbejdet på. Her er en gruppering:
- Planlæggeren.
- Tringrænsefladen og konkrete implementeringer, der behandler registreringer (uanset behandlingstypen).
- Den procesor, der organiserer trin.
- Apex, der kan kaldes, kaldes af planlæggeren.
- adviseringselementet. Vi bruger Apex Slack SDK.
- Der er noget kompleksitet skjult i udtrykket "konfigurerbar forsinkelse". Vi gennemser denne kompleksitet senere i denne artikel.
Her er et meningsdiagram for den indbyggede struktur:
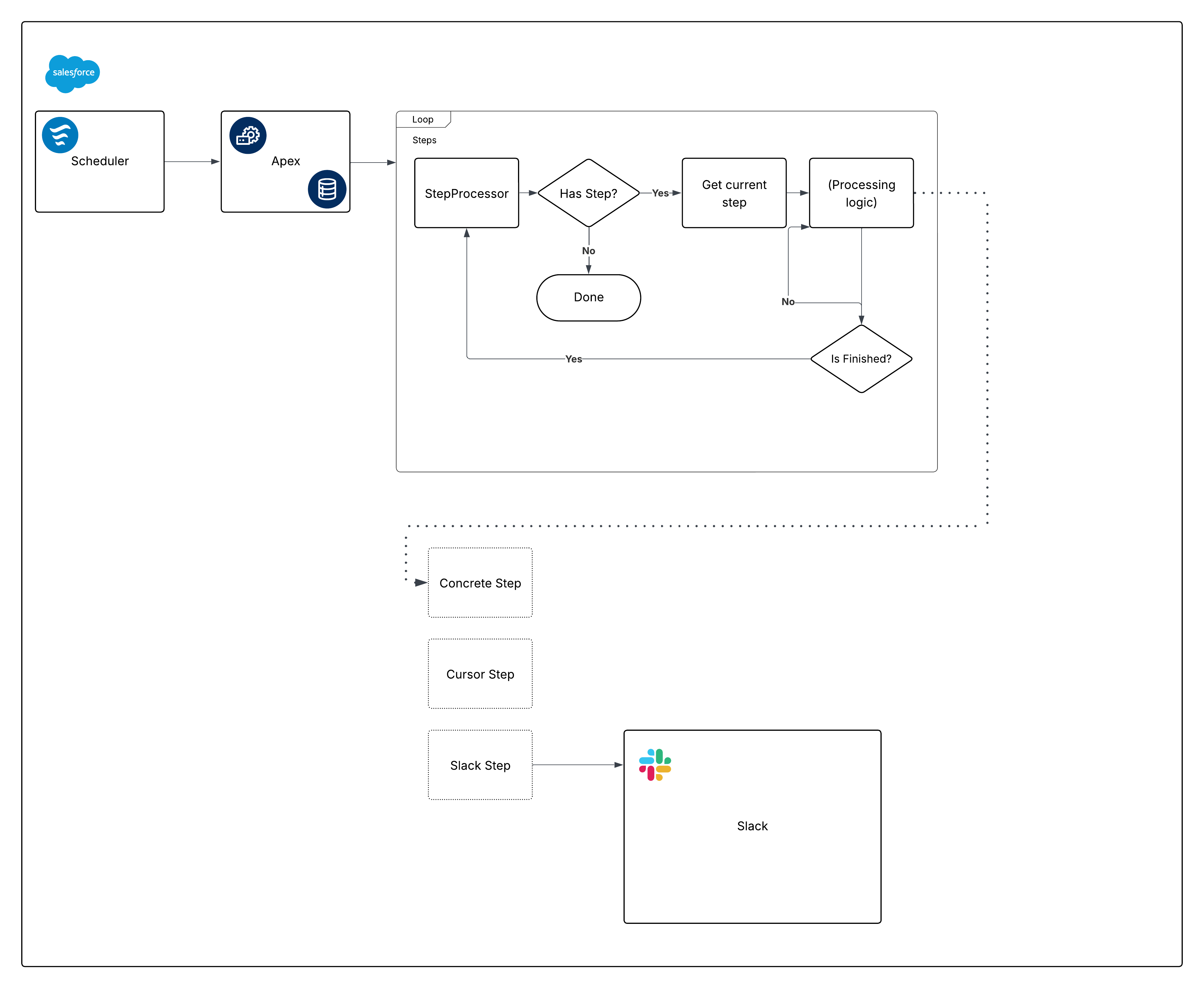 Opdel nu dette diagram, og start med at bygge delene.
Opdel nu dette diagram, og start med at bygge delene.
Planlagt forløb tilbyder flere fordele som en planlægningsmekanisme:
- Planlagte forløb kan pakkes og implementeres som metadata. Dette gælder ikke for job, der er planlagt via Apex (eller via siden Planlagte job).
- Ventelementet er vigtigt for strukturer, der kræver udkald. Ved at bruge det i forløb er udkald ikke nødvendige i den del, der kan kaldes i strukturen.
- Planlægningens detaljer opfylder kravene: det mindste interval for planlagte forløb er dagligt. Hvis du har brug for en højere frekvens (f.eks. pr. time), kan du genoverveje Planlagt forløb for dette krav.
En anden overvejelse, når du konfigurerer det planlagte forløb, er miljø gate. Før du kalder Apex-handlingen, skal du tilføje et beslutningselement, der evaluerer {!$Api.Enterprise_Server_URL_100}. Dette sikrer, at jobbet kun kører i de tilsigtede miljøer, f.eks. UAT og Produktion. Dette mønster er vigtigt, fordi sandboxes hyppigt opdateres eller netop oprettes under SDLC, og uden en eksplicit miljøkontrol kan et planlagt forløb utilsigtet blive afviklet i miljøer, hvor strukturen ikke er beregnet til at køre. Brug af contains-operatoren i beslutningselementet gør opsætningen fleksibel over for fremtidige sandbox-oprettelser eller URL-ændringer.
Overvej endelig, hvordan strukturen skal registrere fejl. Tilføj altid en fejlsti, når forløbet kalder en handling. Du kan f.eks. sende fejl til Nebula Loggers "Tilføj logpost"-handling. Nebula Logger skriver logfiler til tilpassede objekter, så kunderne skal være opmærksomme på, at logdata forbruger organisationslagring – som standard lagres logfiler i 14 dage i en organisation og renses derefter op. Denne bevarelsesperiode kan konfigureres. Nebula Logger bruger også Platformsbegivenheder til at udgive logfiler, så logoplysninger gemmes uafhængigt af hoveddatabehandlingstransaktionen – dette sikrer, at fejl registreres, selvom den primære forløbshandling eller Apex ruller tilbage. Kunder bør evaluere den forventede logvolumen og bevarelseskrav, når de overvejer tilføjelse af en logføringsstruktur.
Sådan ser forløbet ud:
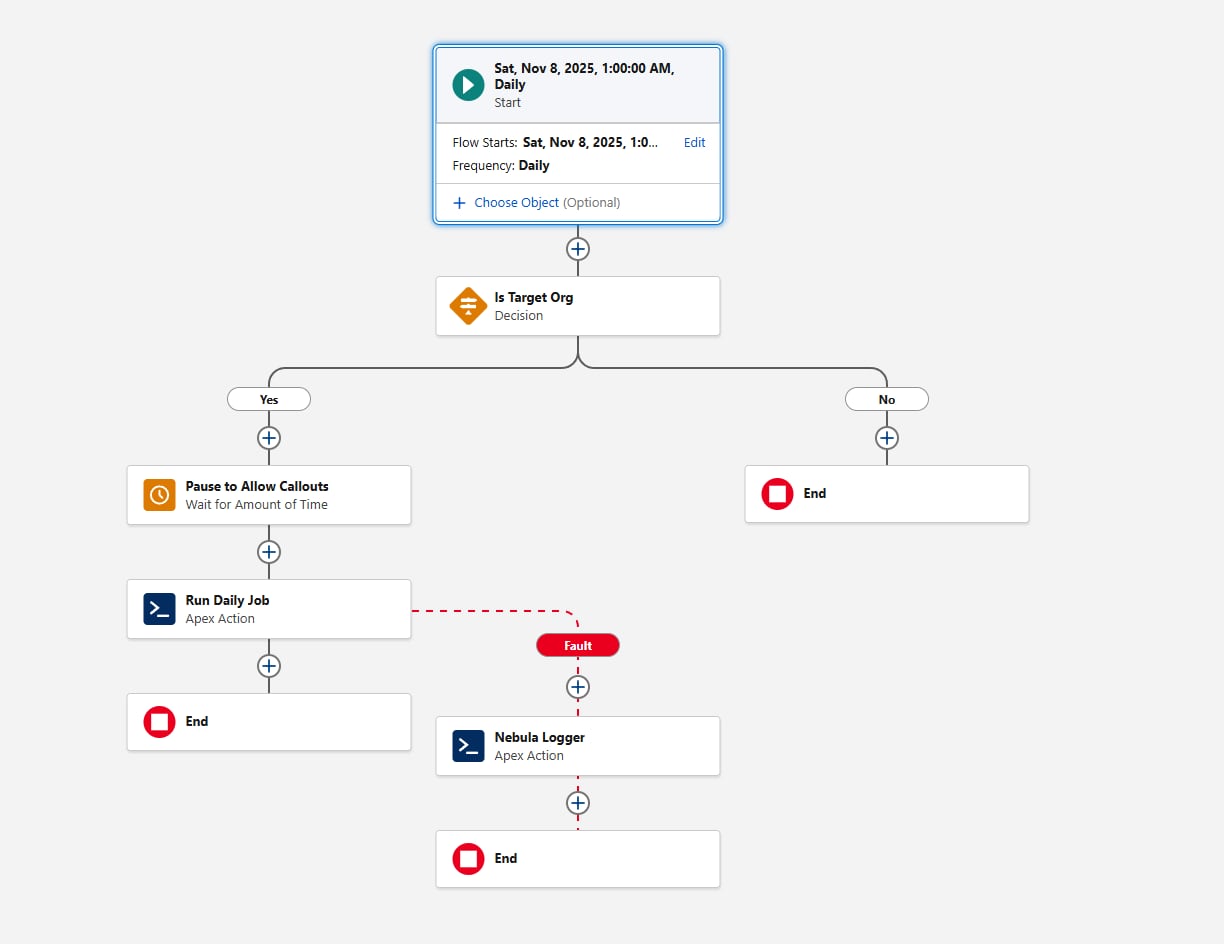
Lad os gå videre til de første dele af Apex med planlægningskravene nu opfyldt.
Definer en Step-grænseflade:
I denne artikel vises step-grænsefladen som en ydre klasse af hensyn til tydeligheden. Selve strukturen er fleksibel – teams kan organisere grænsefladen og dens implementeringer ved brug af ethvert Apex, de foretrækker, når blot alle trinklasser refererer til den samme grænseflade.
Der er nogle få ting, du bør bemærke om de metoder, der er defineret i vores grænseflade:
execute, om end uden argumenter på nuværende tidspunkt, forbedres, når vi overfører enStateklasse (eller grænseflade) til at orkestrere data mellem trin, når orden betyder noget.getNamekan returnere enSystem.Typei stedet for enString. Målet er at give orkestreringslaget en måde til at logføre trinnavne uden at vise andre egenskaber.
Her er den første konkrete implementering, der viser, hvordan disse dele passer sammen. Med en undtagelse senere anbefaler vi, at du bruger Apex i kø til at implementere asynkron behandling i Apex. Batch Apex er typisk unødvendigt (og @future metoder anbefales ikke). Købar Apex starter hurtigt og har med Apex Cursors mange fordele i forhold til batch Apex.
Apex-markører tilbyder et moderne alternativ til den traditionelle batch-Apex-model. I lighed med batchbehandling kan en markørimplementering hente registreringer i segmenter (op til 2.000 pr. batch). Men markører tillader flere hentninger i en enkelt transaktion, hvilket aktiverer en væsentligt højere gennemsnit for storvolumen handlinger.
Når du anvender markører som en del af denne struktur, bør teams være klar over de aktuelle test- og mockability-begrænsninger. Kursoradfærd i test kan være forskellig fra produktionsadfærd, så det er vigtigt at designe teststrategier, der undgår at være afhængige af kursorinterne og i stedet validere orkestreringslogik ved grænserne. Efterhånden som platformen udvikles, vil disse områder fortsætte med at blive forbedret, men kernevejledningen forbliver: Markører giver højere ydeevne og reduceret orkestreringsoverhead sammenlignet med Batch Apex for mange anvendelsessituationer.
For at definere en tydelig grænse mellem den systemleverede cursor og din egen kode anbefaler vi, at du opretter en cursor-lignende repræsentation, når du implementerer Step-grænsefladen. Overvej denne kode:
Bemærk Cursor. Apex-markører er eksempler på Database.Cursor, men vores implementering af Cursor giver os fleksibilitet omkring markørernes mangler. Her er implementeringen:
I resten af denne artikel udelader vi sharing, når der henvises til Apex-klasser. I praksis skal du sørge for, at klasser på topniveau eksplicit bruges med eller uden deling, så de overholder din objektmodel og dine tilladelser.
Bemærk også, at vores Cursor implementering uddelegerer til platformens Database.Cursor, med yderligere fordele diskuteret herefter.
Først er her de tilsvarende test:
Ved at gøre Cursor virtuel kan konkrete CursorStep-implementeringer fungere uden et Database.Cursor, når de ikke behøver at gentage et stort registreringssæt – svarende til at returnere et System.Iterable<T> i stedet for et Database.QueryLocator i Batch Apex. Her er et eksempel:
Bemærk, at da denne klasse også er abstrakt, overlader den den konkrete implementering af innerExecute til underklasser.
Der er også et alternativ til den indvendige underklasse CursorLike. Hvis du ved, at konkrete versioner af et trin som dette ikke går gennem andre styringsbegrænsninger, kan du returnere this.records fra CursorLike.fetch og tilsidesætte det overordnede CursorStep.shouldRestart() for at returnere falsk. Dette giver dig mulighed for at gentage over en liste, der kun er begrænset af Apex på 12 MB pr. asynkron transaktion.
Vores markørbaserede implementering giver os masser af fleksibilitet, når du sideinddeler over store mængder data. I mellemtiden giver Step grænsefladen os fleksibilitet til at beskrive og indkapsle trin af alle slags.
Overvej et forløbsbaseret trin:
Da forløb ikke kan returnere outputparametre, der er i overensstemmelse med en Apex-defineret type, kontrollerer vi for en shouldRestart outputparameter, før vi bruger den.
Nogle trin kan være funktionsmarkerede. Du kan implementere logik for at beslutte, hvilke trin der skal inkluderes, eller du kan bruge et no-op-trin for en inaktiveret funktion. Nulobjektmønsteret er en almindelig måde at reducere kompleksiteten i orkestreringslaget:
Vi har nu nogle få byggeblokke at arbejde med. Lad os se på orkestreringslaget, der er ansvarlig for gentagelse over trin.
Processoren er et drejningspunkt i arkitekturen. Vi skal beslutte, hvem der definerer, hvilke trin der initialiseres, og hvor. Indstillingerne omfatter:
- Få processoren til at definere, hvilke trin der skal knyttes til forretningslogik. Denne indstilling er enkel, men den skaleres dårligt af hensyn til læsbarheden.
- Definer tilknytningen med tilpassede metadata (CMDT). Metadatarelationsfelter understøtter ikke
ApexClass, hvilket løst knytter stavemåde for klassenavne til din forretningsprocesopsætning. Du kan reducere administratorrisici ved at gøre feltet til en plukliste og validere typen findes (Type.forName()eller ved at forespørge påApexClass), men da CMDT-registreringer ikke understøtter udløsere, sker validering på kørselstidspunktet. Denne rute kan afprøves, men administratorer kan stadig kun oprette CMDT-registreringer i produktion – fortsæt omhyggeligt. - Definer tilknytningen med registreringer. Ikke-administratorer kan konfigurere trin, men implementeringer bliver vanskeligere, og miljøer kan afvige. Fortsæt med forsigtighed.
Der er et berømt citat fra Clean Code om, hvordan man håndterer denne særlige kompleksitet:
Løsningen på dette problem er at begrave
switcherklæring [for at lave objekter] i kælderen af en abstrakt fabrik, og aldrig lade nogen se det.
Med det i tankerne, og fordi vores aktuelle antal trin er veldefineret og sandsynligvis ikke vokser for stort, er det okay, at trinprocessoren også er fabrikken for trin. Dette kan bruge en omtale til at styre skiftserklæringen:
Og så til vores StepProcessor:
De viste fabriksmetoder, f.eks. addTypeOneSteps(), kan uddelegere bekymringer som funktionsmarkering. cleanSteps() foretager en engangskontrol af de indsamlede trin for at sikre, at der ikke er nogen "tomme" trin, før der går virkelig asynkroniseret. Det kan se sådan ud:
Vi har ikke diskuteret fejlhåndtering, siden vi omtalte Nebula Logger i afsnittet Planlagt forløb. Det skyldes, at System.Finalizer giver os mulighed for at registrere alle fejlforhold uden at tilføje specifik fejlhåndtering i hvert trin. Hver Step fokuserer på at køre, mens vi logfører og omrytter alle ulykkelige stier, så de dukker op i enhedstest. Dette understøtter sikker iteration og advarsel på produktionsniveau (brug af Slack Logger-plug-in'en til Nebula til alle WARN- og ERROR-logfiler).
En bemærkning om fejlregistrering: Overførsel af trinforekomsten til logmeddelelser antager et niveau af Trust i det, der bliver synligt i logfiler. Standard-toString() for Apex-klasser inkluderer alle statiske egenskaber og egenskaber på forekomstniveau i meddelelsen. Det kan være ønskeligt – eller det kan lække følsomme oplysninger. Selv om logning og sikkerhed ikke er fokus her, skal du bemærke, at overholdelse af en grænseflade som Step for nogle systemer også kan involvere tvunget tilsidesættelse af toString().
En sådan metode lægger byrden på hver objektopretter til at beslutte, hvad der er tilladt at udskrive, hvilket kan være ønskeligt.
På logføringsniveauer: På StepProcessor bruger vi INFO, det højeste fejlfri niveau. Efterhånden som du bliver mere detaljeret i applikationen, bør logføringsniveauerne reduceres tilsvarende. Individuelle trin kan bruge DEBUG til information på højt niveau, med FINE, FINER og FINEST reserveret til stadig mere detaljerede resultater. Logføring er lige så meget en kunst som en videnskab, men at følge disse principper hjælper med at bevare logfiler ensartede og nyttige.
Før vi går videre, skal vi kort tænke over beslutningen om, at vores trinprocessor skal være vært for den logik, som trin bruges til. I en stor kodebase kan du overveje at gøre StepProcessor virtuelle eller abstrakte, og få underklasser til at identificere specifikke trin for at etablere en korrekt adskillelse af bekymringer.
Planlæggeren kalder til sidst Apex. Når resten af opsætningen er fuldført, kan afsnittet Apex, der kan kaldes, beslutte, hvilke trin der skal køres og overføre List<StepType> til processoren:
Dette er en enkel del af ligningen – brug af registreringer, data eller logik til at bestemme, hvilke trintyper der skal køres. Handlingen, der kan kaldes, er enkel, fordi vi har indkapslet kompleksitet andre steder. Vi har også beskyttet mod uventede undtagelser og gjort hvert stykke nemt at teste isoleret.
Apex Slack SDK er uden for rammerne af denne artikel, men et potentielt snup fra kravene bør ses igen: Advisering af personer opad i rollehierarkiet baseret på en konfigurerbar forsinkelse. På papiret er dette enkelt, og du kan (korrekt) overveje System.enqueueJob(this) i StepProcessor. Med System.AsyncOptions, vores oprindelige tilbøjelighed var at bruge enqueueJob overbelastning for at opfylde dette krav.
Men for nu er den maksimale forsinkelse via System.AsyncOptions.MinimumQueueableDelayInMinutes 10 minutter. Da kravet er 120 minutter, er der nogle få muligheder tilbage. En naiv tilgang kan se sådan ud:
I praksis vil forsinkelsen blive overført til denne klasse, da forsinkelsen er konfigurationsstyret.
Vi anbefaler ikke denne tilgang, medmindre du er sikker på, at der kun nogensinde vil være en forsinket adviseringstype. Den brænder gennem 11 ekstra asynkrone job, før den starter (eller mere, hvis forsinkelsen øges). Denne omkostning kan være god for et job – ikke for mange. Du skal også føje en metode til Step-grænsefladen, så hvert trin kan fortælle processoren, hvor længe den skal vente, før den genstarter, hvilket tilføjer støj.
Dette efterlader os med to interessante muligheder:
- Du kan opdele det forsinkede trin i din eksisterende jobstruktur, hvis du allerede har et pollingjob planlagt til et relevant interval. Du skal også være OK med den angivne forsinkelse, der når op til 15 minutter senere (15 minutter er det mindste opdateringsinterval for et Apex CRON-udtryk). Dette svarer groft til eksemplet på Apex, der kan kaldes. Planlægningen udføres i stedet via Apex. Med andre ord kan du genbruge den samme
Step-baserede arkitektur til at behandle registreringer baseret på et "Start efter"-tidsstempel og beslutte, hvilke trin der skal bruges baseret på en plukliste eller en plukliste med flere valg, der knyttes tilbage til de tidligere visteStepType-nummerværdier. - Alternativt kan du, hvis du har det godt med at definere en ekstra ekstern Apex-klasse, vende tilbage til Batch Apex (i modsætning til Apex i kø, der understøtter indvendige klasser, skal batch Apex-klasser være eksterne klasser) ved brug af
System.scheduleBatch().
Overvej Apex. Selvom vi generelt anbefaler Apex, der kan sættes i kø, for fleksibilitet og kontrol, er dette et tilfælde, hvor batch Apex stadig hersker:
Og forestil dig derefter i StepProcessor, at den tidligere viste addTypeOneSteps()-metode opdateres med dette forsinkede trin:
Selvom vi typisk ikke anbefaler at hoppe så meget, bliver denne trinforsinkelse til en anden genanvendelig byggeblok. Indtil længere forsinkelser er tilladt i Apex i kø, repræsenterer det også den nemmeste måde at opnå denne effekt (uden en afstemningsmekanisme, som diskuteret).
Vi har brugt objektorienteret design til at opfylde kravene og oprettet et system, der skaleres, mens det afbalancerer de langsigtede omkostninger ved opbygning og vedligeholdelse. Mens trindeklaration og oprettelse af forekomster i sidste ende kan vokse ud over deres plads i StepProcessor, er der ikke meget ekstra teknisk gæld her. Med FlowStep kan administratorer og udviklere sammen beslutte, hvornår no-code- eller pro-code-løsninger giver mest mening.
Ved at bruge System.Finalizer-grænsefladen i Apex Købar-strukturen har vi sammen med Nebula Logger opbygget et robust, testbart system, der advarer os om uforudsete fejl, selv hvis fremtidige trin mangler eksplicit logføring. For os er dette system lykkeligt at skære tal og reducere omkostninger og kompleksitet. Den har også givet os værdifuld indsigt i Apex Cursors' adfærd under virkelige arbejdsbelastninger, hvilket har hjulpet os med at finjustere vores tilgang og samtidig forbedre selve funktionen.
Ved at opdele komplekse, højvolumen arbejdsbelastninger i modulære kørselstrin transformerer den trinbaserede asynkrone behandlingsstruktur platformsbegrænsninger til tekniske fordele, hvilket aktiverer forudsigelig ydeevne, observabilitet og styring på virksomhedsskala. Trin kan opsættes af både administratorer og udviklere, og i begge tilfælde kan trinforfattere fokusere på at observere de grundlæggende grænser for platformsstyring (f.eks. DML-rækker og forespørgselsrækker, der hentes) uden at skulle bekymre sig om, hvordan de skalere hvert trin.
Hvis du vil implementere og indføre dette mønster på tværs af virksomhedsimplementeringer, skal arkitekter:
- Evaluer eksisterende automatiseringer for at identificere områder, hvor asynkron orkestrering kan bidrage til at forbedre ydeevnen og forbedre observationsevnen.
- Opdel store processer i diskrete, uafhængigt eksekverbare trin med tydelige behandlingsmål og diskrete opretterpunkter (som forløb eller Apex).
- Definer og grupper trintyper for at fremskynde tringenbrug og standardisering på tværs af forretningsenheder.
- Prøv løsningen med nye processer eller eksisterende automatiseringer. Du vil måske blive overrasket over, hvor mange kantsager du finder gratis inden for trin, pleje din indbyggede logning og observabilitet!
James Simone er chefsoftwareingeniør i Salesforce og har mere end ti års erfaring med at arbejde på platformen. Han var Salesforce-kunde – og produktejer – før han gik i udvikling, og har skrevet tekniske detaljer om Salesforce siden 2019 i The Joys Of Apex. Han har tidligere udgivet artikler på Salesforce Developer-bloggen og Salesforce Engineering-bloggen.