Virksomheder lagrer ofte data i både Salesforce og andre eksterne datalager, f.eks. Snowflake, Google BigQuery, Databricks, Redshift eller cloudlagring som Amazon S3. Denne isolering af data i forskellige kildesystemer udgør en udfordring for firmaer, der ønsker at udnytte den fulde styrke af deres data.
Architekter, der arbejder på at samle data på tværs af flere datalager, står over for vigtige arkitektoniske beslutninger om, hvordan de bedst integrerer disse data. Data 360 tilbyder flere muligheder for dataintegration, hvor hver af dem tilbyder forskellige fordele og ulemper.
Denne vejledning leverer en struktur til at evaluere, hvilket mønster der bedst passer til dine krav til forsinkelse, omkostninger, skalerbarhed, styring og kompleksitet, når du integrerer data, hvilket hjælper dig med at vælge, hvornår du vil bruge dataoverførsel, Zero Copy-dataføderation eller en hybrid tilgang. Vejledningen vil også hjælpe dig med at vælge mellem forskellige metoder til dataoverførsel og dataforening, hvor hver af dem opfylder et forskelligt behov.
Integration af eksterne datalager med Data 360 kræver omhyggelig overvejelse af afvejninger mellem dataopdatering, styring og pipelineeffektivitet. Brug af f.eks. Zero Copy-dataforenings live-forespørgsler maksimerer opdateringen af dataene, men kan reducere pipelineeffektiviteten, når du flytter flere data over netværket. Derfor er en kombination af overførsel og federation i et multi-cloud lakehouse-økosystem den optimale sti for de fleste real-world-implementeringer. Denne hybrid tilgang sikrer en skalerbar, administreret, interoperabel arkitektur, der problemfrit understøtter både driftsmæssige arbejdsbelastninger med lav forsinkelse, f.eks. tilpasning i realtid og bedrageriregistrering, og analytiske arbejdsbelastninger som reguleringsrapportering og historiske tendensanalyser. Denne beslutningsvejledning hjælper dig med at forstå, hvordan du navigerer i disse afvejninger og vælger den rigtige strategi.
- Dataoverførsel: Kopierer data til Salesforce Data 360 og opretter administrerede, kanoniske datamodeller. Ideel, når du har brug for at:
- Opbyg en omfattende Customer 360: Foren og transformer uensartede kilder til en enkelt, betroet profil.
- Opfylder strenge lovgivning overholdelse: Opret en reviderbar, centraliseret kopi, hvor dataadgang og -afstamning kan kontrolleres nøje.
- Zero Copy Federation: Forespørger på eksterne kilder i realtid uden dubletter, og aktiverer tilpasning i realtid, live-dashboards og hurtig kildens introduktion. To primære indstillinger med afvejninger, du skal afbalancere:
- Live og cachelagring (Accelerated Query): Bedst til interaktive analyser og realtidsdashboards på data, der findes på eksterne dataplatforme som Snowflake, Google BigQuery, Redshift eller Databricks. Undgår langsom, dyr dataduplikering ved at overføre behandling ned til kildesystemet.
- Filforening: Bedst til batchbehandling i stor skala og AI-modeluddannelse på data i din cloud-data lake (S3, ADLS). Undgår dyr og langsom overførsel ved direkte at forespørge på filer i åbne tabelformater og låse op for massive datasæt for ETL og datavidenskabsarbejdsbelastninger.
- Hybrid Model: Blend-overførsel for forenede profiler med federation for friskhed, understøttelse af Omni-Channel-engagement, Agentforce handlinger og AI/ML-træning.
-
Hybrid arkitektur: Det er ofte nødvendigt at blande dataoverførsel og datafederation.
- Brug dataoverførsel på kritiske data til kanoniske datamodeller og kerneadministration.
- Føder alle andre data via Zero Copy for at minimere driftsmæssigt overhead af opbygning og vedligeholdelse af overførselsdatapipelines.
-
Frekvens for dataoverførsel betyder noget: Vælg frekvensen baseret på forretningsværdi, forsinkelsesbehov og driftsmæssig kompleksitet.
- Brug realtid til tidssensitive arbejdsflows (tilpasning, live-dashboards, Agentforce).
- Nær i realtid for moderat vigtige processer (kampagner, driftsmæssige rapporter).
- Batch for historiske datasæt eller datasæt med lav hastighed.
-
Match Federation-mønsteret til forsinkelse og ydeevne: Vælg den, der bedst matcher dine adgangsmønstre og kravene til opdatering, ydeevne og omkostninger.
- Brug Live-forespørgsel til driftsmæssige dashboards og tilpasning i realtid, hvor lav forsinkelse er vigtig.
- Brug cachelagring (Accelerated Query), når forespørgsler er hyppige, men lidt forældede resultater accepteres, hvilket afbalancerer ydeevne og omkostninger.
- Brug Filforening til store, højtydende analyser eller batcharbejdsbelastninger, som er ideelle til historiske eller mindre tidsfølsomme datasæt.
-
Brug styring i overensstemmelse med dataplaceringskrav:
- Brug overførsel, hvor centraliseret ledelse er vigtig.
- Brug federation, hvor decentraliseret ledelse er acceptabelt, mens du håndhæver streng ledelse ved den eksterne kilde. Zero Copy respekterer politikker på kildeniveau, f.eks. sikkerhed på rækkeniveau (RLS) og datamaskering.
-
Prioriter overførsel for arbejdsflows med høj værdi: Anvend overførsel selektivt på vigtige processer, f.eks. identitetsløsning, regulerende rapportering og operativ aktivering.
-
Omkostning og kompleksitet skaber beslutningen: Overførsel i realtid kan være dyrt og komplekst. Architekter bør veje omkostningerne ved introduktion, lagring og transformation af data op mod omkostningerne ved at forespørge på dem direkte via Zero Copy.
Valg af det rigtige integrationsmønster – Dataoverførsel, Nulkopiering eller en hybrid tilgang – påvirker direkte forsinkelse, styring, driftseffektivitet og omkostninger på tværs af multi-cloud-platforme. Denne beslutning formaterer, hvordan indsigter i realtid, AI-styret aktivering og personligt engagement kan leveres pålideligt og på en skala.
Denne tabel giver en teknisk sammenligning af dataoverførsels- og nulkopieringsmønstre i Salesforce Data 360 med fokus på funktioner, afvejninger og fordele sammen med anvendelsessituationer og resultater for virksomheden. Architekter kan bruge dette som en reference til at designe hybride, multi-cloud-dataplatforme, der afbalancerer ydeevne, omkostninger og compliance.
| Mønstertype | Tilstand/værktøj | Fordele | Overvejelser | Resultater |
|---|---|---|---|---|
| Dataoverførsel | Realtid: Under-sekunders forsinkelsesoverførsel via overførsels-API'er med CDC-understøttelse. Kontinuerlig streaming af pipelines. | - Øjeblikkelige indsigter - Ideel til anvendelsessituationer med lav forsinkelse og tilpasning - Understøtter begivenhedsstyrede arbejdsflows |
- Høje omkostninger - Kompleks arkitektur - Kræver kildesystemer med lav forsinkelse - Højvolumen kilder kan forårsage overdreven streaming, der fører til mættede pipelines - I/O intensiv - Overvej selektive felter og filtrering for at reducere overhead |
Agentforce: - Bedrageriadvarsler i realtid, detailtilpasning, driftsmæssige advarsler Analytics: - Under-sekundedashboards, KPI-overvågning Overensstemmelse: - Kontinuerlige opdateringer af kunderegistreringer for regulerede arbejdsflows |
| Streaming: Mikrobatchoverførsel hver 1-3 minutter via oprindelige forbindelser | - Afbalanceret udgift i forhold til friskhed - Enklere arkitektur end i realtid - Understøtter trinvise opdateringer |
- Lille forsinkelse - Kan ikke være egnet til vigtige under-sekundbeslutninger - Batchstørrelse påvirker hukommelse/beregning - I/O er moderat - Bedst til forudsigelige, gentagne opdateringsmønstre - Overvej aggregering i vinduer for at reducere behandlingsbelastning |
Agentforce: - Tidlige kampagneudløsere, næsten live-engagement Analytics: - Anbefalingssystemer, næsten live-dashboards Overensstemmelse: - Hyppige opdateringer med revisionsmulighed |
|
| Batch: Planlagte store indlæsninger via forbindelser eller API'er. Understøtter objektlager og ETL/ELT-pipelines. | - Omkostningseffektiv for massive datasæt - Nem at implementere - Pålideligt for historiske analyser |
- Dataforsinkelse - Ikke egnet til tidsfølsomme handlinger - I/O intensiv under indlæsningsvinduer - Netværksgennemstrømning kan blive en flaskehalse for store filer - Bedst til historisk aggregering eller regulerede rapporteringsarbejdsflows |
Agentforce: - It-supporttickets (Jira/ServiceNow), aggregerede arbejdsflows Analytics: - Historisk analyse, tendensevaluering Klage: - Bestemmelsesrapportering, aggregering af patient-/kravsdata |
|
| Nulkopier | Live-forespørgsel: Direkte forespørgsler på eksterne systemer; skema-på-læse; ingen dataduplikering | - Maksimal friskhed - Mindste lageroverhead, understøtter driftsmæssige indsigter i realtid |
- Afhængig af kildens ydeevne - Høj forespørgselsvolumen kan påvirke forsinkelse - Ideel til forespørgsler med prædikat-pushdown og aggregering for at minimere I/O - Undgå ufiltrerede forespørgsler på massive datasæt |
Agentforce: - Dynamiske arbejdsflows, der tilpasser sig live-aktivitet Analytics: - Driftsmæssige dashboards, live-rapportering Overensstemmelse: - Overholder sikkerhed på rækkeniveau og maskering ved kilde |
| Accelerated Query (Caching): Cachelagrede lokale kopier for forenede forespørgsler. Konfigurerbar fra 15 min. til 7 dage. Optimeret forespørgselsudførelse | - Reducerer forsinkelse - Lavere omkostninger end gentagne live-forespørgsler - Forbedrer ydeevnen for hyppige adgangsmønstre |
- Cachestyring kræves - Forældet afhænger af cacheinterval - Bedst til højfrekvente forespørgsler - Ikke egnet til under-second-beslutning |
Agentforce: - Forudaggregerede engagementsmetrikker til hurtig beslutningstagning Analytics: - BI-dashboards, segmentering, analytisk rapportering Overensstemmelse: - Ensartede regulerede dashboards med revisionslogfiler |
|
| Filforening: Direkte adgang til store historiske datasæt i objektbutikker eller søer (S3, Iceberg, Google BigQuery, Redshift). | - Håndterer datasæt i stor skala - Mindste lager i Data 360 - Understøtter AI/ML-arbejdsbelastninger |
- Skrivebeskyttet - Forespørgselsydeevne afhænger af ekstern systemgennemstrømning - Optimeret til batchtunge, gennemsnitskrævende job - Ikke egnet til dashboards i realtid |
Agentforce: - (Ikke typisk – batchtung) Analytics: - ML/AI-uddannelse, historiske analyser, petabyte-skala-rapportering Overensstemmelse: - Administreret adgang til eksterne datasæt uden duplikering |
Med dataoverførsel kopieres data fysisk til Data 360 og administreres fuldt, i modsætning til Zero Copy, hvor data forbliver ved kilden. Beregning af transformationer sker i Data 360, hvilket tillader centraliseret styring og revision.
Brug dataoverførsel til at lagre kanoniske, administrerede datasæt i Salesforce Data 360 til overensstemmelse og driftskontrol. Brug overførsel, når der kræves fuld kontrol, revision og sporbarhed. Ideel til regulerede eller højværdiarbejdsflows, hvor centraliseret beregning og styring er afgørende.
Overførsel er bedst til opbygning af et betroet grundlag for identitetsløsning, regulerende rapportering og missionskritiske AI-styrede arbejdsflows og kundeengagement.

Dataoverførselsmetoder varierer, afhængigt af hvilken forbindelse du bruger til at overføre dine data. Nogle forbindelser tilbyder en række overførselsmetoder, mens andre kun fungerer i batchtilstand eller streamingtilstand. Se Data 360: Integrationer og forbindelser for en komplet liste over Data 360-forbindelser og deres tilgængelige metoder.
- Realtid
- Sub-sekund overførsel ved hjælp af streaming pipelines eller Change Dataregistrering (CDC).
- Bedst til tidsfølsomme arbejdsflows (snydregistrering, tilpasning, driftsmæssige dashboards).
- Overfør transformationer og aggregeringer i Data 360 for at reducere downstream-I/O og optimere beregningsanvendelse. Brug trinvis CDC til at minimere dataombrydning.
- Streaming
- Overførsel for hver 1-3 minutter i små trin.
- Afbalancerer friskhed og omkostninger, egnet til kampagneorkestrering, næsten live-engagement og driftsmæssig rapportering.
- Brug mikrobatches til at kontrollere I/O-spikes. Aggreger data ved kilden, hvis det er muligt, for at reducere overførselsmængder og optimere lagring.
- Batch (planlagte indlæsninger)
- Periodisk overførsel af store datasæt (time, dagligt, ugentligt).
- Omkostningseffektiv og pålidelig for historiske datasæt, regulerende rapportering og anvendelsessituationer med overensstemmelse.
- Sørg for beregningsplacering i samme område som kildelager for ydeevne og optimering af omkostninger.
- Anvendelsessituationer til dataoverførsel
- Generer Customer 360 forenede profiler: Opbygning af en enkelt kilde til sandhed for kundeidentitet og attributter.
- Vedligehold datasæt til overholdelse af bestemmelser: Håndhævelse af styring, afstamning og revisionsmulighed for følsomme data.
- Centraliser kampagneorkestrering: Sørg for, at marketing, salg og service alle fungerer fra ensartede, betroede datasæt.
- Design Practices
- Foretræk batchoverførsel for historiske eller lavt ventetolerante behov, f.eks. arkiveringsrapportering eller periodiske øjebliksbilleder.
- Brug CDC eller streaming-API'er til at bevare opdatering for driftsmæssige og tilpasningsarbejdsflows og sikre opdateringer i næsten realtid.
- Kontroller lager- og beregningsvækst ved at anvende trinvise indlæsninger i stedet for at genindlæse hele datasæt for at optimere omkostninger og effektivitet.
- Juster overførselspipelines med beregningsplacering og trinvis behandling for at reducere netværks-I/O. Anvend transformationer i Data 360 for at undgå at flytte rå data unødvendigt.
- Overvejelser i forbindelse med omkostninger
- Overførsel i realtid: Højeste beregnings- og pipelineomkostninger. Berettiget for højværdifulde, tidsfølsomme arbejdsflows, f.eks. tilpasning, driftsmæssige dashboards eller Agentforce handlinger.
- Streamingoverførsel: Moderer beregnings- og lagringsomkostninger. Velegnet til hyppige opdateringer, der kan tolerere små forsinkelser, f.eks. kampagneorkestrering eller driftsmæssig rapportering.
- Batchoverførsel: Lavere beregningsomkostninger, forudsigeligt lager, bedst til historiske datasæt eller opdateringer med lav frekvens. Overførsel af batchdata fra Salesforce-organisationer ved brug af bestemte forbindelser er gratis.
- Opdateringstilstand: Valg af Trinvis opdatering-tilstand reducerer de samlede overførsels- og beregningsomkostninger. Vi anbefaler brug af trinvis opdatering, hvor det er muligt, for at optimere effektiviteten på tværs af alle overførselstyper.
- Omkostninger påvirkes også af I/O-mængde fra kilde til Data 360. Optimering af batchstørrelser, partitioner og regional justering reducerer overførselsomkostninger og forbedrer ydeevnen.
- Branchescenarier
- Finance: Overfør datasæt, der er påkrævet for at kende din kunde (KYC), Anti Money Laundering (AML) og bedrageriregistrering, hvor der ikke kan forhandles om revision og overensstemmelse.
- Sundhedspleje: Brug overførsel til løsning af patientidentitet og HIPAA-kompatible registreringer, så du aktiverer sikre, forenede visninger.
- Detail: Konsolider POS-, eCommerce- og loyalitetsprogramdata i forenede profiler til segmentering og tilpasning
- Telekom: Understøt afgangsforebyggelse og anvendelsesanalyser med kanoniske, administrerede abonnentdata.
| Funktion | Overførsel i realtid | Streamingoverførsel | Batchoverførsel |
|---|---|---|---|
| Latency og friskhed | Sub-sekunders forsinkelsesoverførsel via overførsels-API'er med understøttelse af CDC (Change Dataregistrering). Leverer kontinuerlige streaming-pipelines. Bedst til driftsmæssige anvendelsessituationer med lav forsinkelse. | Mikrobatchoverførsel for hver 1-3 minutter via oprindelige forbindelser. Understøtter trinvise opdateringer. Der forventes en lille forsinkelse. | Dataforsinkelse forventes. Planlagte store indlæsninger. Periodisk overførsel (time, dagligt, ugentligt). Ikke egnet til tidsfølsomme handlinger. |
| Primære anvendelsessituationer | Ideel til anvendelsessituationer med lav forsinkelse og tilpasning. Bruges til tidsfølsomme arbejdsflows. Understøtter begivenhedsstyrede arbejdsflows. Bruges til realtidsbedragerialarmer og driftsmæssige advarsler. | Velegnet til moderat vigtige processer. Bruges til kampagneorkestrering, næsten live-engagement og driftsmæssig rapportering. Bruges til rettidige kampagneudløsere. | Omkostningseffektiv for massive datasæt. Pålideligt for historiske analyser. Bruges til historisk aggregering eller regulerede rapporteringsarbejdsflows. Bedst til historiske datasæt eller datasæt med lav hastighed. |
| Arkitektonisk kompleksitet og I/O | Høj omkostning og kompleks arkitektur. Kræver kildesystemer med lav forsinkelse. I/O intensiv. Højvolumen kilder kan forårsage mættede pipelines. | Enklere arkitektur end i realtid. I/O er moderat. Bedst til forudsigelige, gentagne opdateringsmønstre. Batchstørrelse påvirker hukommelse/beregning. | Nem at implementere. I/O intensiv under indlæsningsvinduer. Netværksgennemstrømning kan blive en flaskehalse for store batches. |
| Overvejelser i forbindelse med omkostninger | Højeste beregnings- og pipelineomkostninger. Begrundet kun for arbejdsflows med høj værdi, hvor der skelnes mellem tid og værdi. | Moderer beregnings- og lagringsomkostninger. Giver en afbalanceret omkostnings- kontra-friskhed-tilgang. Velegnet til hyppige opdateringer, der kan tolerere små forsinkelser. | Lavere beregningsomkostninger og forudsigelig lagring. Anbefales til historiske datasæt eller opdateringer med lav frekvens. Overførsel via interne Salesforce-pipelines er gratis. |
| Design Practices | Brug trinvis CDC til at minimere dataombrydning. Filtrer og brug selektive felter til at reducere overhead. | Brug mikrobatches til at kontrollere I/O-spikes. Overvej vinduesaggregering for at reducere behandlingsbelastning. | Foretræk dette for arkiveringsrapportering eller periodiske øjebliksbilleder. Sørg for beregningsplacering i samme område som kildelager for optimering af omkostninger. |
Brug Zero Copy til forespørgsler i realtid på eksterne systemer uden dataduplikering, så du aktiverer smidighed, opdatering og skalerbar adgang til store eller midlertidige datasæt. Det er bedst til live-dashboards, udforskende analyser, AI/ML-modeluddannelse og kundeengagement i realtid direkte gennem Salesforce Data 360.
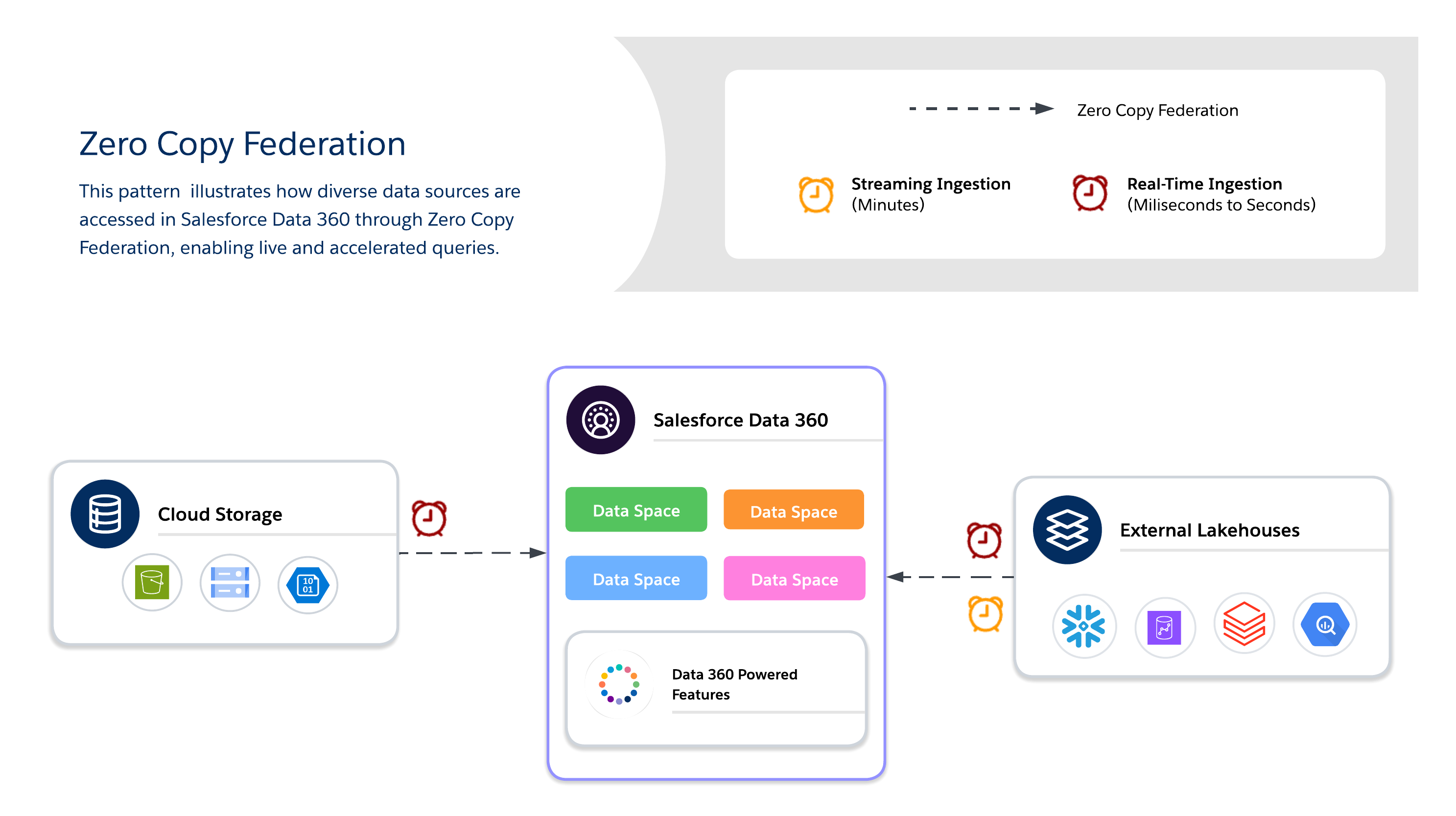
Når du bruger Zero Copy, skal arkitekter beslutte yderligere mellem tre tilgængelige dataforeningsmetoder, hvoraf hver tilbyder sine egne afvejninger mellem opdatering, ydeevne og omkostninger.
- Liveforespørgsel
- Kører forespørgsler direkte mod eksterne systemer (Snowflake, Google BigQuery, Redshift, Databricks osv.) uden dataduplikering.
- Optimal, når prædikater og aggregeringer kan skubbes ned, hvilket minimerer dataflytning over netværket og reducerer I/O på Salesforce Data 360-computeren.
- Bedst til realtidsindsigter og driftsmæssige dashboards med lav forsinkelse. Afhængig af det eksterne systems ydeevne.
- Cachelagring (Accelerated Query)
- Gemmer midlertidigt cachelagrede kopier af forenede data i Salesforce Data 360.
- Reducerer gentagne forespørgselsomkostninger og forsinkelse for hyppigt åbnede datasæt med konfigurerbar varighed (minutter til dage).
- Data kopieres ikke permanent eller administreres ikke fuldt ud. Opdatering administreres via planlagte opdateringer fra kilden.
- Filforening
- Giver direkte skrivebeskyttet adgang til datasæt i stor skala i objektbutikker (f.eks. S3, GCS med Iceberg).
- Bedst til AI/ML-arbejdsbelastninger, historiske analyser og petabyte-skalarapportering uden at flytte data.
- Forespørgselsydeevne afhænger i høj grad af objektformat, partitionering og netværks-I/O. Store scanninger kan generere væsentlig I/O, hvis de ikke optimeres.
- Brug sager
- Personliggørelse i realtid og adaptive arbejdsflows: Lever dynamiske tilbud, anbefalinger og Next-Best-handlinger, når kundeadfærden ændres.
- Live-dashboards og driftsanalyser: Sæt styr på forretningskritiske dashboards og KPI'er direkte fra eksterne lagerbygninger.
- AI/ML modeluddannelse med store eksterne datasæt: Udnyt data på petabyte-skala fra datalager og lagerbygninger ved brug af filforening uden at flytte den.
- Branchescenarier
- Detail/Media: Aktiver personlige anbefalinger og kundeengagement i realtid ved at forbinde clickstream- eller indholdsinteraktionsdata.
- Finance: Kør bedrageriregistrering og risikoscoring næsten i realtid ved at forespørge på eksterne lagerbygninger uden at duplikere følsomme data.
- Tech/Enterprise: Understøt cross-cloud-rapportering, it-servicedashboards og driftsanalyser, hvor datasæt findes i flere systemer.
- Design Practices
- Liveforespørgsel
- Bruges til forespørgsler med høj QPS og lav forsinkelse, når friskhed er vigtig.
- Overfør prædikater og aggregeringer til det eksterne system for at reducere dataskydning over netværket.
- Undgå forespørgsler, der scanner massive datamængder unødvendigt. Overvej at beskære partitioner og filtre.
- Filforening
- Få adgang til datasæt på petabyte-skala i objektbutikker uden overførsel.
- Bevar objektlager i det samme cloudområde som Salesforce Computing for at minimere forsinkelse og udgangsomkostninger.
- Brug partitionerede, kolonneformater (Parket/ORC) og push-down-filtre til at reducere I/O og netværksoverførsel.
- Anvend forespørgsel og prædikat-push-down for at filtrere og aggregere data ved kilden og reducere dataflytning.
- Undgå krydsområdedataadgang, medmindre det er nødvendigt, da det øger I/O, forsinkelse og omkostninger.
- Cachelagring (Accelerated Query)
- Sæt hyppigt åbnede datasæt i cache for at afbalancere omkostninger og ydeevne.
- Konfigurer opdateringsintervaller for at afbalancere opdatering kontra forespørgselsomkostninger.
- Overensstemmelse: Håndhæv styring ved kilden ved at udnytte sikkerhed på rækkeniveau (RLS) og maskering af politikker direkte i forenede systemer. Nedenfor er de bedste fremgangsmåder for ensartet RLS og maskering på tværs af platforme.
- Brug et centraliseret virksomheds-id: Tilknyt brugere og enheder i Salesforce Data 360 til en entydig, centraliseret virksomhedsidentifikator, der svarer til identiteter i eksterne systemer.
- Align sikkerhedspolitikker: Sørg for, at sikkerhed på rækkeniveau og maskeringspolitikker i forenede systemer anvendes baseret på den tilknyttede identitet. Dette bevarer overensstemmelse, når der forespørges på eksterne data.
- Standardiser identitetsskemaer: Vedligehold ensartede identitetsattributter (mail, bruger-id, kunde-id osv.) på tværs af alle datakilder for at undgå uoverensstemmelser og adgangsovertrædelser.
- Liveforespørgsel
- Overvejelser i forbindelse med omkostninger
- Liveforespørgsel: Betalings-præ-forespørgselsmodel – omkostninger opkræves på eksternt lakehouse-databehandling og kan spidse med høj QPS. Bedst til anvendelsessituationer, hvor værdien er større end omkostningsvariation.
- Accelereret forespørgsel (cache): Sænker forespørgselsomkostninger sammenlignet med Live-forespørgsel ved at reducere hits til kildesystemet, men føjer til batchdataoverførselsomkostninger for udfyldning og opdatering af cachen. Bedst til hyppigt åbnede datasæt.
- Filforening: Den billigste lagringsindstilling som data i objektbutik, men forespørgselsomkostninger afhænger af filstørrelse, partitionering og beskæring. Bedst til historiske eller massedata på petabyte-skala.
| Beslutningspunkt | Live-forespørgsel | Cachelagring (Accelerated Query) | Filforening |
|---|---|---|---|
| Datakildeplacering | Eksterne datalager (Snowflake, Google BigQuery, Redshift, Databricks). | Eksterne datalager (Snowflake, Google BigQuery, Redshift, Databricks) | Objektbutikker eller clouddatalager (S3, ADLS, GCS), der ofte bruger åbne tabelformater som Iceberg. |
| Formål/anvendelsessituation | Ideel til interaktive analyser og realtidsdashboards. Bedst til tilpasning i realtid og dynamiske arbejdsflows. | Bedst til, når forespørgsler er hyppige, men lidt forældede resultater er acceptable. Velegnet til BI-dashboards og segmentering. | Bedst til batchbehandling i stor skala og AI/ML-modeluddannelse. Ideel til historiske analyser og petabyte-skalarapportering. |
| Freshness/Latency | Maksimal opdatering. Forespørgsler kører direkte i realtid. Understøtter under-second-beslutning. | Lidt forældede resultater er acceptable. Friskheden afhænger af cacheintervallet, der kan konfigureres fra 15 minutter til 7 dage. | Optimeret til batchtunge, gennemsnitskrævende job. Ikke egnet til dashboarding i realtid. |
| Adgangsmønster | Bedst til sjældne eller ad hoc-forespørgsler. Bruges til forespørgsler med høj QPS (forespørgsel pr. sekund), hvor forespørgsler med lav forsinkelse er vigtige. | Bedst til højfrekvent læsescenarier. Forbedrer ydeevnen for hyppige adgangsmønstre. | Skrivebeskyttet adgang. Velegnet til datasæt på petabyte-skala uden overførsel. |
| Ydeevnedrivere | Højt afhængig af det eksterne kildesystems ydeevne. Optimeres, når prædikater og aggregeringer kan overføres ned til kilden. | Reducerer forsinkelse sammenlignet med gentagne live-forespørgsler. Ydeevne afhænger af cachestyring og interval. | Ydeevne afhænger i høj grad af objektformat, partitionering og ekstern systemgennemstrømning. Brug partitionerede, kolonneformater (Parket/ORC). |
| Omkostninger | Betalingsforespørgselsmodel. Omkostninger opkræves på ekstern lakehouse-computer. Omkostningseffektiv for sjældne forespørgsler, men udgifter kan stige med høj forespørgselsvolumen pr. sekund (QPS). | Lavere omkostninger end gentagne live-forespørgsler. Reducerer behovet for gentaget at forespørge på den eksterne kilde. Tilføjer cachelagring og opdatering overhead. | Billigste lagerindstilling. Forespørgselsomkostninger afhænger af filstørrelse og partitionering. |
| Nøgleovervejelser | Undgå ufiltrerede forespørgsler, der scanner massive datamængder unødvendigt. | Kræver cachestyring. Ikke egnet til under-second-beslutning. | Forespørgselsydeevne er stærkt afhængig af optimering via partitionering og prædikat-push-down. |
Hybridarkitekturer gør det muligt for arkitekter at forankre kritiske datasæt i Data 360 for centraliseret styring, mens de udnytter forenede forespørgsler for at opnå opdatering, reduceret duplikering og skalerbar adgang til store eksterne datasæt. Denne tilgang afbalancerer I/O, beregningsplacering, omkostninger og compliancekrav.
Brug en hybrid tilgang til afbalanceret styring, opdatering og driftseffektivitet ved at kombinere dataoverførsel og nulkopiering for at levere indsigter, der kan handles på, i realtid. Brug overførsel til højværdi, regulerede datasæt, hvor sporbarhed, RLS og maskering er påkrævet, og federation til midlertidige eller højvolumen datasæt, hvor opdatering og ydeevne er nøglen.
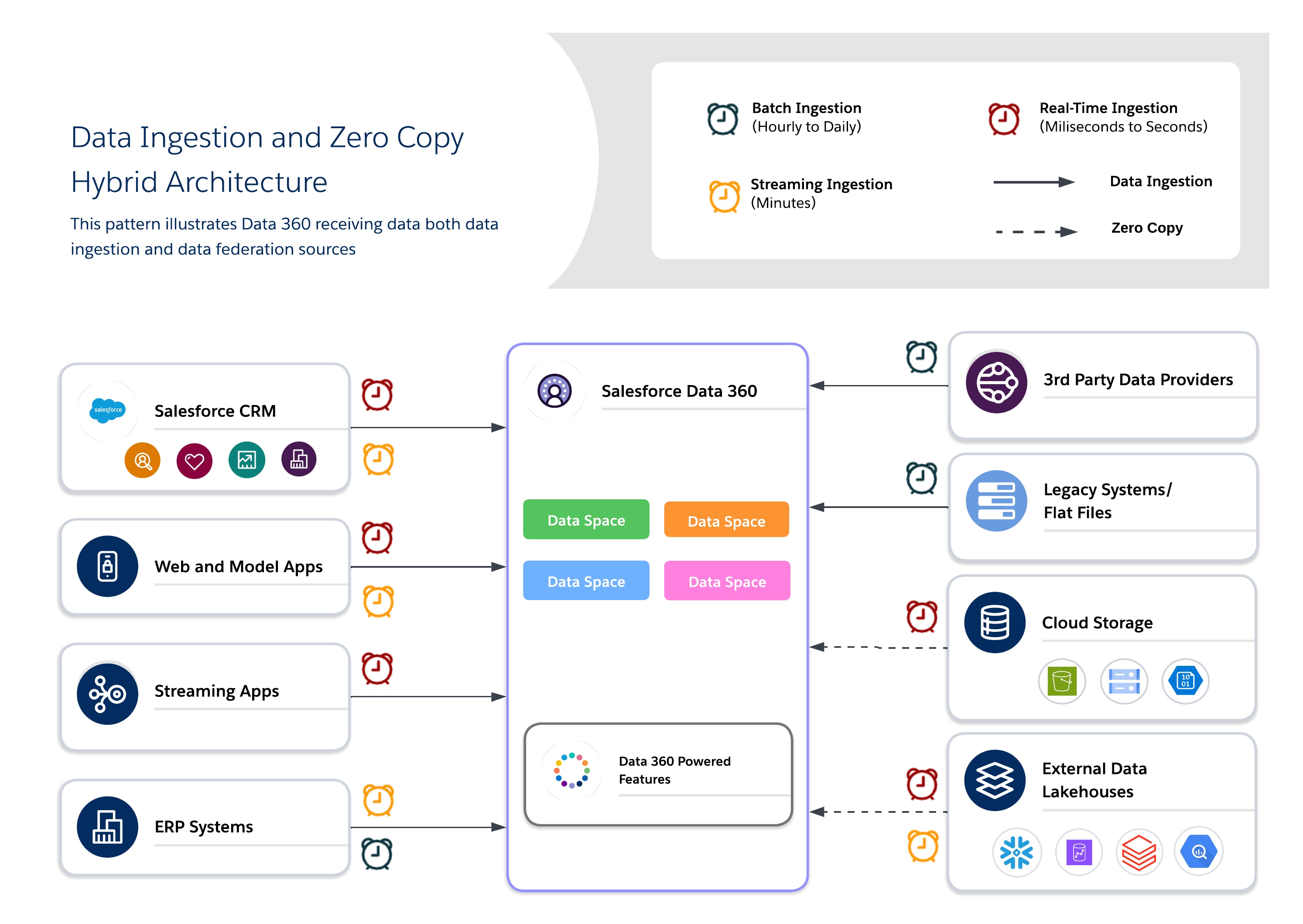
- Brug sager
- Omni-Channel-engagement: Blend historiske kundedata med realtidsadfærd for at levere ensartede kontekstbevidste oplevelser.
- AI/ML-rørledninger: Træn modeller på organiserede, kanoniske datasæt, mens du beriger dem med rå eller realtidssignaler fra eksterne kilder.
- Blandt behov for overensstemmelse og smidighed: Anvend streng styring for følsomme data, men forenet for driftsmæssig smidighed.
- Branchescenarier
- Detail: Brug overførsel til identitetsløsning og profilforening. Forenet for tilbud i realtid og tilpasning.
- Sundhedspleje: Vedligehold gyldne patientregistreringer via overførsel, mens du forener IoT-enhedsstreams og sensordata for øjeblikkelig kontekst.
- Finansielle tjenester: Overfør regulerede data i en overensstemmelsesstyret lake, mens du forener eksterne forespørgsler til bedrageriregistrering og risikovurdering.
- Design Practices
- Ankerstyring med overførsel: Overfør data af høj værdi eller regulerede data til kanoniske modeller for at sikre Trust og compliance.
- Brug Federation til friskhed: Lad eksterne lakehuse give adgang til data i realtid eller i stor skala uden duplikering.
- Saldoomkostninger vs. Ydeevne: Profilarbejdsbelastninger for at beslutte, hvad der skal overføres i forhold til forenet, så du minimerer unødvendige lagrings- eller forespørgselsomkostninger.
- Anvend lagdelt ledelse: Håndhæv centraliseret ledelse for overførte data, mens du anvender forenet systems egne sikkerhedskontroller (f.eks. RLS, maskering).
- Når du designer hybrid-pipelines, skal du sørge for trinvis overførsel for historiske datasæt og overføre aggregeringer eller filtre til forenede kilder for at optimere I/O og beregningsanvendelse.
- Overvejelser i forbindelse med omkostninger
- Optimer den samlede omkostning kontra ydeevne ved at kombinere overførsel for overensstemmelse eller kritiske data med federation, når der er behov for opdatering.
- Konto for I/O og beregningsdistribution, når der blandes overførsel og federation. Hvis du vil reducere beregningsomkostninger i kildesystemer for gentagne forespørgsler, skal du bruge cachelagring (Accelerated Query) for højt læste, hyppigt åbnede forenede datasæt.
Nedenfor er almindelige arketyper, der illustrerer, hvordan denne logik anvendes.
- Den "enkle kilde til sandhed" Archetype: Centraliser og styr
- Scenarie: Du skal opbygge kompatible, forenede Customer 360 for hele din globale virksomhed. Dataene kommer fra et dusin forskellige systemer, skal overholde strenge GDPR- og CCPA-bestemmelser og vil fungere som den betroede kilde for alle marketing- og serviceinteraktioner.
- Anbefalet mønster: Dataoverførsel. Prioriteten er styring, Trust og kontrol. Overførsel af dataene i Data 360 er den eneste måde at oprette en fuldt reviderbar kanonisk profil, der er isoleret fra kildesystemerne.
- Arketypen "Indsigter i realtid": Analyser uden at flytte
- Scenarie: Dit datavidenskabsteam skal køre udforskende forespørgsler på en massiv, konstant opdaterende transaktionstabel i Snowflake. Samtidig ønsker dit ledelsesteam et live BI-dashboard drevet af de samme data. Flytning af petabyte af data dagligt er for langsom og dyrt.
- Anbefalet mønster: Zero Copy Federation. Prioriteten er hastighed, smidighed og omkostningseffektivitet på skala. Zero Copy giver dig mulighed for at udnytte den enorme styrke i dit eksisterende datalager til forespørgsler i realtid uden overhead og forsinkelse af dataduplikering.
- Arketypen "Hybrid intelligens": Styr kerne, Føderer kanten
- Scenarie: Du ønsker at berige dine administrerede, overførte kundeprofiler med adfærdssignaler i realtid (f.eks. websiteklik) fra en datalake. Du skal have stabiliteten af kerneprofilen, men umiddelbarheden af live-dataene for at styrke tilpasningen i øjeblikket.
- Anbefalet mønster: A Hybrid Approach. Brug dataoverførsel til at oprette den stabile, administrerede kerne af dine kundedata. Brug derefter Zero Copy til at forene de flydende "kanten"-data i realtid og sammenføje dem på forespørgselstidspunktet for at få en komplet visning, der er opdateret i sekunden.
Virksomhedsdatastrategi handler ikke længere om at vælge et enkelt integrationsmønster – det handler om at arkitektere kontrolleret fleksibilitet i et interoperabelt dataøkosystem. Valg af den rigtige dataintegrationsmetode for hvert kildedatasystem baseret på forretningsbehov fører ofte til en hybrid tilgang, der blander styrken ved både dataoverførsel og dataføderation.:
- Overfør missionskritiske, administrerede datasæt til Salesforce Data 360 for overensstemmelse, identitetsløsning og driftsmæssige arbejdsflows.
- Forenet data via Zero Copy for live, udforskende og AI-styrede analyser uden dubletlagring.
Salesforce Data 360 på Hyperforce giver fleksibilitet og skalerbarhed i flere områder. et åbent søhus med Iceberg-tabeller muliggør separation og interoperabilitet med platforme som Snowflake, Databricks og S3 Iceberg – hvilket danner grundlaget for et virkelig interoperabelt datatilbud med flere skyer.
Efterhånden som dataøkosystemer udvikles, skal du kontinuerligt afbalancere opdatering, omkostninger, ydeevne og overensstemmelse for at bevare arkitektonisk smidighed. Fremtidssikret din platform ved at forene overførte, administrerede data med forenet adgang. Dette aktiverer realtidsdata, AI-aktivering og tilpasning på virksomhedsskala på tværs af clouds, områder og forretningsdomæner.
Løsninger, der passer til alle, passer ikke til de fleste forretninger. Den optimale strategi tilknytter det rigtige mønster til den rigtige forretningsdriver.
Yugandhar Bora er Software Engineering Architect hos Salesforce, der er specialiseret i dataarkitektur på platformen Data og intelligensapplikationer. Han fører EARB-initiativer (Enterprise Architecture Review Board), der er fokuseret på dataadministration og forenede datamodeller, mens han bidrager til automatiserede platformsprovisioneringsløsninger.
Jan Fernando er hovedarkitekt på kontoret for hovedarkitekten i Salesforce. Han tilsluttede sig Salesforce i 2012 og tog med sig et væld af erfaring fra sin tid i opstartsøkosystemet. Før han tilsluttede sig kontorets chefarkitekt, brugte han over et årti i platformsorganisationen, hvor han førte flere nøgleteknologitransformationer.