Pattern Overview
Heroku Connect can replicate data from an object in a connected Salesforce organization to a table in the PostgreSQL database. If the data changes on the PostgreSQL side, Heroku Connect can be prompted to replicate the change back to the Salesforce organization.
Replicating data between multiple Salesforce organizations can be orchestrated by combining Heroku Connect with an instance of Heroku Postgres.
Data Replication to a Shared Database

Data replication enabled with a shared database.
Heroku Connect replicates data between an object and a table. In order to replicate between multiple organizations, we need a way to take the change that was replicated to a Postgres table and apply that change to a corresponding downstream table. Then Heroku Connect can replicate the change to the corresponding downstream Salesforce org.
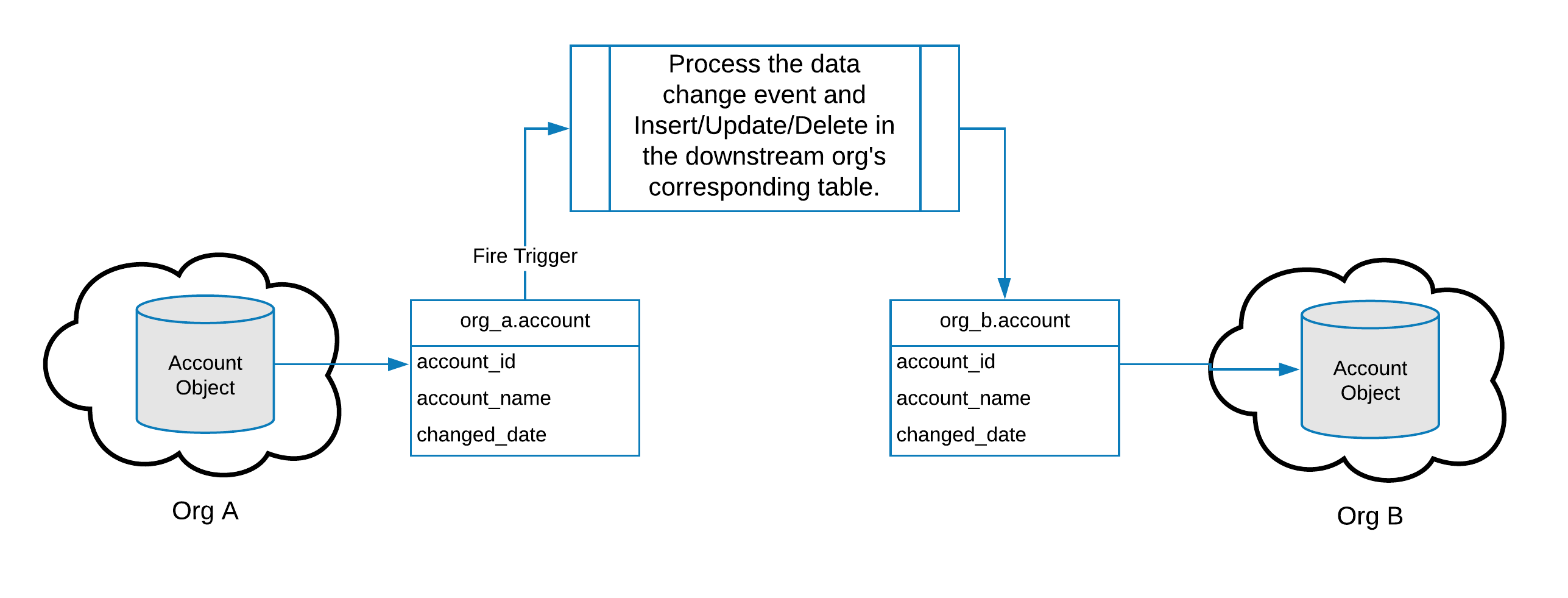
A PostgreSQL trigger can be used to migrate a change to a downstream table.
This approach can be used to enable direct replications between organizations. However, as the number of tables and organizations increase, having individual triggers manage the logic of replicating the data can become unwieldy. One strategy for dealing with this is to centralize the replication logic. This can be done by adding two tables:
-
Change Queue table*: A table that is responsible for tracking all the changes across all of the replication tables. To simplify the implementation, the change queue table can store a copy of the changed data as a serialized JSON string.
-
Replication Mapping table: A table that is responsible for housing the rules for how data should be replicated. For example, org_a.account replicates to org_b.account.
Organization to Organization

Organization to organization replication using a centralized change queue and replication rules.
Note: Any tables that don’t replicate back to a Salesforce org need to be in their own database schema.
While this approach can work, it has some limitations. The database must be able to process all of the inbound and outbound triggers as well as the replication logic. Maintaining the replication logic in a procedural language on the database is problematic; it is difficult to test, expand, and scale.
Replicating Via Application Server
We shifted the replication logic off of the database and onto an application server, that is, a worker dyno. The trade-off was a decrease in development friction at the cost of the additional complexity in communicating between tiers.
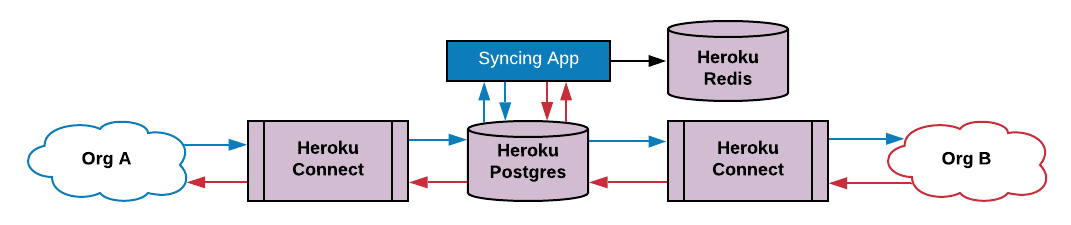
Shifting the replication logic to an application tier.
This approach offloads the responsibility of replication to the application tier. Because the replication rules rarely change, we can further reduce the burden on the Postgres database by relocating them to a Heroku Redis instance. The syncing app can be designed to replicate data either in batches or dynamically.
To enable an event driven replication model, the PostgreSQL pg_notify() function can be used to send messages to the syncing app. The change_queue table is basically a work queue for the syncing app.
About the Contributors
Steve Stearns is a Regional Success Architect Director at Salesforce on the Scale and Availability team. Scale and Availability architects apply the learnings from our large customer engagements to help influence product scale evolution and innovation.