Our forward-looking statement applies to roadmap projections.
Roadmap corresponds to June 2024 projections.
Guide Overview
This guide provides tools recommendations for various triggered automation use cases along with the rationale for those recommendations. It also provides insight into how Flow automatically handles bulkification and recursion control on behalf of the customer, as well as some pointers on performance and automation design.
Here are the most important takeaways:
- Takeaway #1: Flow and Apex are the preferred no-code and pro-code solutions for triggered automation on the platform.
- Takeaway #2: Stop putting same-record field updates into Workflow Rules and Process Builder. Start putting same-record field updates into before-save flow triggers instead.
- Takeaway #3: Wherever possible, start implementing use cases in after-save flow triggers rather than in Process Builder and Workflow (except for same-record field updates, in which case see takeaway #2).
- Takeaway #4: If you have high performance batch processing needs or require highly sophisticated implementation logic, use Apex. (See Well-Architected - Data Handling for more information.)
- Takeaway #5: You don’t need to put all of your record-triggered automation into a single “mega flow” per object, but it’s worth thinking about how to organize and maintain your automation for the long-term. (See Well-Architected - Composable for more information.)
This doc focuses on record-triggered automation. For the same assessment on Salesforce form-building tools, check out Architect’s Guide to Building Forms on Salesforce.
| Low Code | --------------------------------------> | Pro Code | ||
|---|---|---|---|---|
| Before-Save Flow Trigger | After-Save Flow Trigger | After-Save Flow Trigger + Apex | Apex Triggers | |
| Same-Record Field Updates | Available | Not Ideal | Not Ideal | Available |
| High-Performance Batch Processing | Not Ideal | Not Ideal | Not Ideal | Available |
| Cross-Object CRUD | Not Available | Available | Available | Available |
| Asynchronous Processing | Not Available | Available | Available | Available |
| Complex List Processing | Not Available | Not Ideal | Available | Available |
| Custom Validation Errors | Not Available | Not Available | Not Available | Available |
- Available: Works fine with basic considerations.
- Not Ideal: Possible but consider an alternative tool.
- Roadmap: Estimated support within the next 12 months (June 2024). See Roadmap Explorer for details.
- Future: Estimated for support beyond our Summer '24 Release (June 2024).
- Not Available: No plans to support this capability within the next twelve months.
The table above shows the most common trigger use cases, and the tools we believe are well-suited for each.
In a case where multiple tools are available for a use case, we recommend choosing the tool that will allow you to implement and maintain the use case with the lowest cost. This will be highly dependent on the makeup of your team.
For example, if your team includes Apex developers, and it already has a well-established CI/CD pipeline along with a well-managed framework for handling Apex triggers, it will probably be cheaper to continue on that path. In this case, the cost of changing your organization’s operating models to adopt Flow development would be significant. On the other hand, if your team doesn’t have consistent access to developer resources, or a strong institutionalized culture of code quality, you’d likely be better served by triggered flows that more people can maintain, rather than by several lines of code that few people can maintain.
For a team with mixed skill sets or admin-heavy skill sets, flow triggers provide a compelling option that is more performant and easier to debug, maintain, and extend than any no-code offering of the past. If you have limited developer resources, using flow triggers to delegate the delivery of business process implementation, enables you to focus those resources on projects and tasks that will make the most of their skill sets.
So Long, Process Builder & Workflow Rules
While the road to retirement for Process Builder and Workflow Rules may be long, we recommend that you begin implementing all your go-forward low-code automation in Flow. Flow is better architected to meet the increasing functionality and extensibility requirements of Salesforce customers today.
- The vast majority of Workflow Rules are used to perform same-record field updates. While Workflow Rules have a reputation for being fast, they nevertheless cause a recursive save, and will always be considerably slower and more resource-hungry than a single, functionally equivalent before-save flow trigger.
- Additionally, Workflow Rules are just a completely different system than Flow, with different metadata and a different runtime. Any improvements Salesforce makes to Flow — not just performance improvements, but debugging improvements, manageability improvements, CI/CD improvements, and so on — will never benefit Workflow Rules, and vice versa.
- Process Builder will always be less performant and harder to debug than Flow. Also it has a difficult-to-read list view.
- Process Builder runs on top of the Flow runtime, but there is a significant difference between Process Builder’s user-facing design-time model and the Flow runtime’s metadata model. This abstraction results in the underlying metadata for a process resolving to a mangled, less performant, and often incomprehensible Flow definition. And a mangled Flow definition is much harder to debug than a non-mangled Flow definition.
- In addition to the shortcomings already cited, both Process Builder and Workflow Rules depend on a highly inefficient initialization phase that drives processing time up across every save-order execution that they are in. In practice, we've found that the majority of Process Builder and Workflow Rules resolve to a no-op at runtime (that is, criteria aren't met, so no operations are performed), and don't materially benefit from the initialization phase. Unfortunately, this part of the implementation occurs at a fundamental layer of the code, where making changes is extremely risky.
- This costly initialization phase has been eliminated in the new triggered Flow architecture.
For these reasons, moving forward Salesforce will be focusing investments on Flow. We recommend building in Flow where possible, and resorting to Process Builder or Workflow only when necessary.
At this point, Flow has closed all the major functional gaps we had identified between it and Workflow Rules and Process Builder. We continue to invest in closing remaining minor gaps, including enhanced formulas and entry conditions, as well as usability improvements to streamline areas where Flow is more complex.
A Note on Naming
Flow has introduced a new concept to the low-code automation space by separating its record triggers into before and after save within the trigger order of execution. This aligns with the corresponding functionality available in Apex and allows for significantly better performance when it comes to same-record field updates. However, this introduces additional complexity to the Flow user experience, and users unfamiliar with triggers found the terminology confusing. So throughout this guide, we will continue to refer to these two options as “before save” and “after save,” but in Flow Builder, they have been renamed to “fast field update” and “actions and related records.”
Use Case Considerations
Same-Record Field Updates
| Record-Changed Flow: Before Save | Record-Changed Flow: After Save | Record-Changed Flow: After Save + Apex | Apex Triggers | |
|---|---|---|---|---|
| Same-Record Updates | Available | Not Ideal | Not Ideal | Available |
Of all the recommendations in this guide, we most strongly recommend taking steps to minimize the number of same-record field updates that occur after the save. Or put more plainly, stop implementing same-record field update actions inside Workflow Rules or Process Builder processes! And don’t start implementing same-record field updates in after-save flow triggers, either! Instead, do start implementing same-record field update actions in before-save flow triggers or before-save Apex triggers. Before-save same-record field updates are significantly faster than after-save same-record field updates, by design. There are two primary reasons for this:
- The record’s field values are already loaded into memory and don’t need to be loaded again.
- The update is performed by changing the values of the record in memory, and relying on the original underlying DML operation to save the changes to the database. This avoids not only an expensive DML operation, but also the entire associated ensuing recursive save.
Well, that’s the theory anyways; what happens in practice?
Our tests (Performance Discussion: Same-Record Field Updates) provide some empirical flavor. In our experiments, bulk same-record updates performed anywhere between 10-20x faster when implemented using before-save triggers than when implemented using Workflow Rules or Process Builder. For this reason, while there are still some theoretical limits relative to Apex, we do not believe performance should be considered as a limitation for implementing on before-save flow triggers, except in perhaps the most extreme scenarios.
The main limitation of before-save flow triggers is that they are functionally sparse: you can query records, loop, evaluate formulas, assign variables, and perform decisions (for example, Switch statements) for logic, and can only make updates to the underlying record. You cannot extend a before-save flow trigger with Apex invocable actions or subflows. Meanwhile, you can do anything you want in a before-save Apex trigger (except explicit DML on the underlying record). We’ve scoped before-save flow triggers intentionally to support only those operations that will ensure the performance gains mentioned above.
We know that same-record field updates account for the lion’s share of Workflow Rule actions executed site-wide, and are also a large contributor to problematic Process Builder execution performance. Pulling any “recursive saves” out of the save order and implementing them before the save will lead to a lot of exciting performance improvements.
High-Performance Batch Processing
| Record-Changed Flow: Before Save | Record-Changed Flow: After Save | Record-Changed Flow: After Save + Apex | Apex Triggers | |
|---|---|---|---|---|
| High-Performance Batch Processing | Not Ideal | Not Ideal | Not Ideal | Available |
If you’re looking for highly performant evaluation of complex logic in batch scenarios, then the configurability of Apex and its rich debug and tooling capabilities are for you. Here are some examples of what we mean by “complex logic,” and why we recommend Apex.
- Defining and evaluating complicated logical expressions or formulas.
- Flow’s formula engine sporadically exhibits poor performance when resolving extremely complex formulas. This issue is exacerbated in batch use cases because formulas are currently both compiled and resolved serially during runtime. We’re actively assessing batch-friendly formula compilation options, but formula resolution will always be serial. We have not yet identified the root cause of the poor formula resolution performance.
- Complex list processing, loading and transforming data from large numbers of records, looping over loops of loops.
- See Complex List Processing for more on current limitations around directly working with lists in Flow.
- Anything requiring Map-like or Set-like functionalities.
- Flow does not support the Map datatype. Relatedly, if an Apex invocable action passes an Apex object into Flow, and the Apex object contains a member variable of type Map, then you will not be able to access that member variable in Flow. However, the member variable is retained during runtime, such that if Flow passes that Apex object into another Apex invocable action, then you will be able to access the member variable in the recipient Apex invocable action.
- Transaction savepoints
- Transaction savepoints are not supported in Flow triggers and will likely never be supported in Flow.
While before-save flow triggers are not quite as performant as before-save Apex triggers in barebones speed contests, the impact of the overhead is somewhat minimized when contextualized within the scope of the broader transaction. Before-save flow triggers should still be fast enough for the vast majority of non-complex (as enumerated above), same-record field update batch scenarios. As they are consistently more than 10x faster than Workflow Rules, it’s safe to use them anywhere you currently use Workflow Rules.
For batch processing that does not need to be triggered immediately during the initial transaction, Flow has some capabilities, though they continue to be more constrained and less feature-rich than Apex. Scheduled Flows can currently do a batch operation on up to 250,000 records per day and can be used for data sets that are unlikely to reach near that limit. Scheduled Paths in record-triggered flows also now support configurable batch sizes, so admins can change the batch size from the default (200) to a different amount, if needed. This can be used for scenarios like external callouts that cannot support the default batch size. (See Well-Architected - Data Handling for more information.)
Cross-Object CRUD
| Record-Changed Flow: Before Save | Record-Changed Flow: After Save | Record-Changed Flow: After Save + Apex | Apex Triggers | |
|---|---|---|---|---|
| Cross-Object CRUD | Not Available | Available | Available | Available |
Creating, updating, or deleting a different record (other than the original record that triggered the transaction) requires a database operation, no matter what tool you use. The only tool that doesn’t currently support cross-object “crupdeletes” (a portmanteau of the create, update, and delete operations) is the before-save flow trigger.
Currently, Apex outperforms Flow in raw database operation speed. That is, it takes less time for the Apex runtime to prepare, perform, and process the result of any specific database call (e.g. a call to create a case) than it takes the Flow runtime to do the same. In practice, however, if you are looking for major performance improvements, you will likely reap greater benefits by identifying inefficient user implementations, and fixing them first, before looking into optimizing for lower level operations. The execution of actual user logic on the app server generally consumes far more time than the handling of database operations.
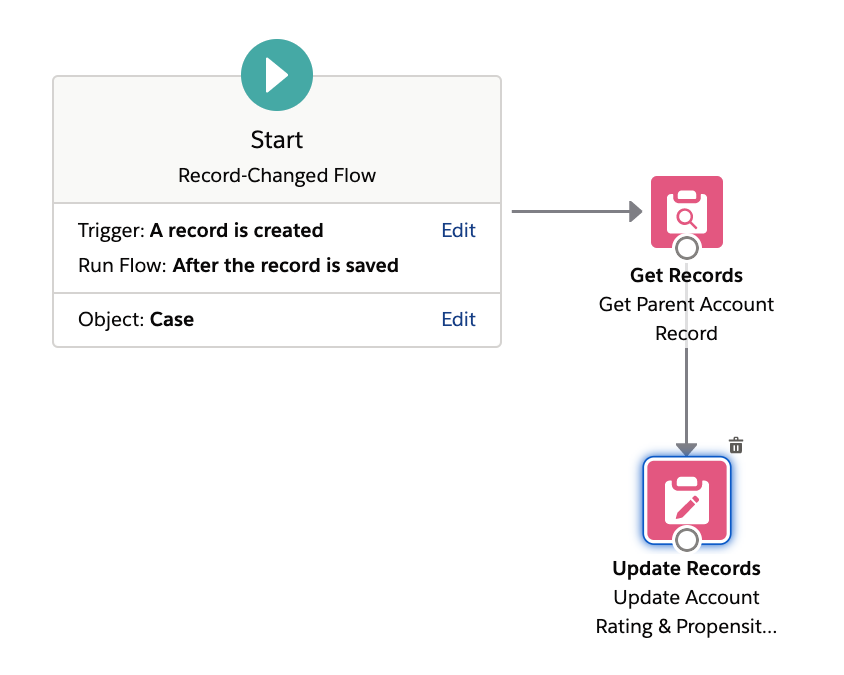
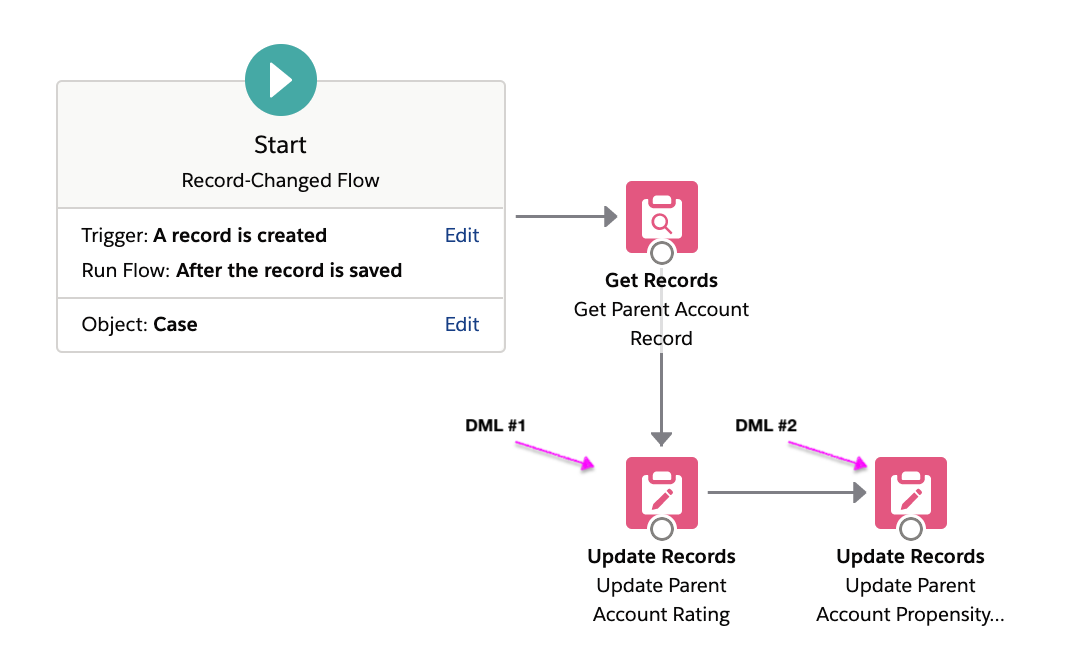
The most inefficient user implementations tend to issue multiple DML statements where fewer would suffice. For example, here is an implementation of a flow trigger that updates two fields on a case’s parent account record with two Update Records elements.
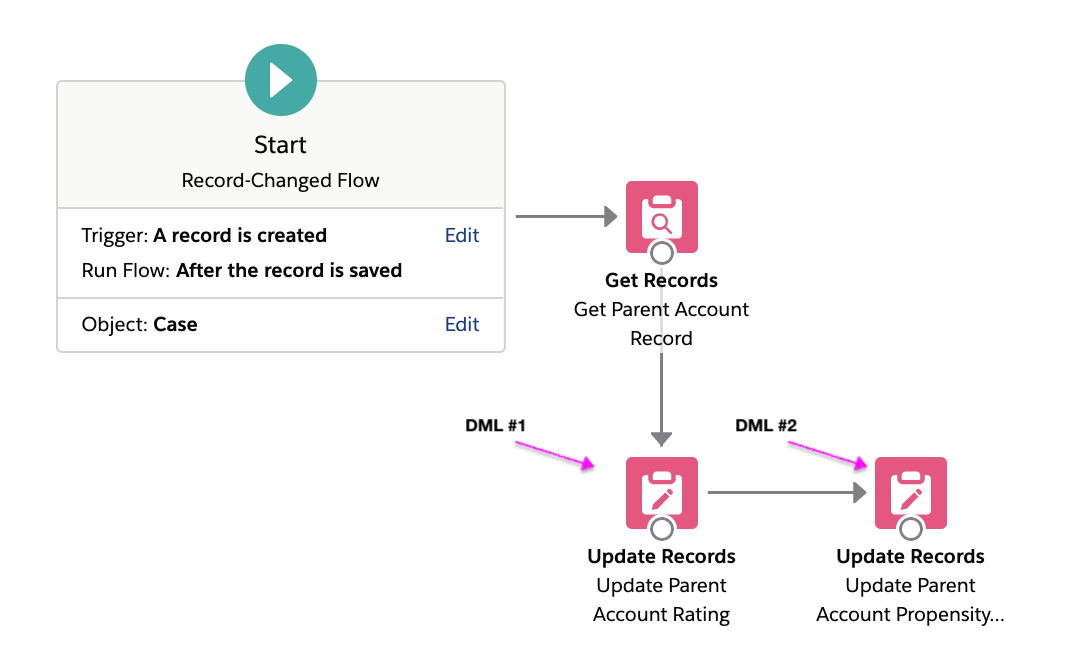
This is a suboptimal implementation as it causes two DML operations (and two save orders) to be executed at runtime. Combining the two field updates into a single Update Records element will result in only one DML operation being executed at runtime.
Workflow Rules has gained a reputation for being highly performant. Part of this can be attributed to how Workflow Rules constrains the amount of DML it performs during a save.
- All of the immediate, same-record field update actions, across all Workflow rules on an object, are automatically consolidated into a single DML statement at runtime (so long as their criteria are met).
- A similar runtime consolidation occurs for the immediate, detail-to-master cross-object field update actions across all the Workflow rules on an object.
- Cross-object DML support is very constrained in Workflow Rules in the first place.
Thus, when it comes to cross-object DML scenarios, the idea is to minimize unnecessary DML from the start.
- Before starting any optimization, it’s crucial to first know where all the DML is happening. This step is easier when you have logic spread across fewer triggers and have to look in fewer places (this is one reason for the commonly espoused one/two-trigger-per-object pattern), but you can also solve for this by institutionalizing strong documentation practices, by maintaining object-centric subflows, or by creating your own design standards that enable the efficient discovery of DML at design time.
- Once you know where all the DML is happening, try to consolidate any DML that targets the same record into the fewest number of Update Records elements necessary.
- When dealing with more complex use cases that require conditionally and/or sequentially editing multiple fields on a related record, consider creating a record variable to serve as a temporary, in-memory container for the data in the related record. Make updates to the temporary data in that variable during the flow’s logical sequence using the Assignment element, and perform a single, explicit Update Records operation to persist the temporary data to the database at the end of the flow.
Sometimes this is easier said than done — if you’re not actually experiencing performance issues, then you may just find that such optimization is not worth the investment.
Complex List Processing
| Record-Changed Flow: Before Save | Record-Changed Flow: After Save | Record-Changed Flow: After Save + Apex | Apex Triggers | |
|---|---|---|---|---|
| Complex List Processing | Not Available | Not Ideal | Available | Available |
There are a few major list processing limitations in Flow today.
- Flow offers a limited set of basic list processing operations out of the box.
- There’s no way to reference an item in a Flow collection, either by index or by using Flow’s Loop functionality (during runtime, for each iteration through a given collection, the Loop element simply assigns the next value in the collection to the Loop variable; this assignment is performed by value, and not by reference). Thus, you can’t do in Flow anything that you’d use
MyList[myIndexVariable]to do in Apex. - Loops are executed serially during runtime, even during batch processing. For this reason, any SOQL or DML operations which are enclosed within a loop are not bulkified, and add risk that the corresponding transaction Governor limits will be exceeded.
The combination of these limitations makes some common list-processing tasks, such as in-place data transforms, sorts, and filters, overly cumbersome to achieve in Flow while being much more straightforward (and more performant) to achieve in Apex.
This is where extending flows with invocable Apex can really shine. Apex developers can and have created efficient, modular, object-agnostic list processing methods in Apex. Since these methods are declared as invocable methods, they are automatically made available to Flow users. It’s a great way to keep business logic implementation in a tool that business-facing users can use, without forcing developers to implement functional logic in a tool that’s not as well-suited for functional logic implementation.
When building invocable Apex, take into account these considerations:
- Responsibility lies with the developer to ensure that their invocable Apex method is properly bulkified. Invocable methods can be invoked from a trigger context, such as a process or an after-save flow, so they need to be able to handle multiple invocations in a given batch. During runtime, flow invokes the method, passing in a list containing the inputs from each applicable Flow Interview in the batch.
- Apex invocable methods can now be declared to take generic sObject inputs. While more abstract, this functionality allows for the implementation and maintenance of a single invocable Apex method that can be reused for many triggers across multiple sObjects. Coupling the generic sObject pattern with dynamic Apex can allow for some very elegant and reusable implementations.
Since this guide was originally written, Flow has added more list processing capabilities, including filtering and sorting. However, it still does not have all the list processing capabilities of Apex, so the advice around using Apex or modularizing individual components still applies for more complex use cases.
Asynchronous Processing
| Record-Changed Flow: Before Save | Record-Changed Flow: After Save | Record-Changed Flow: After Save + Apex | Apex Triggers | |
|---|---|---|---|---|
| Fire & Forget Asynchronous Processing | Not Available | Available | Available | Available |
| Other Asynchronous Processing | Not Available | Available | Available | Available |
Asynchronous processing has many meanings in the world of programming, but when it comes to record-triggers, there are a couple topics that generally arise. It's often requested in opposition to the default option, which is to make changes synchronously during the trigger order of execution. Let's explore why you would or would not want to take action synchronously.
Benefits of Synchronous Processing
- Minimal Database Transactions: Record-change triggers are generally configured to run during the initial transaction in order to optimize database transactions. As seen in same-record field updates, you can optimize these because you already know that the triggering record will be updated, so you can combine the additional automated updates into a single database transaction using before-save.
- Consistent Rollbacks: Similarly, for updates to other records, compiling changes into the initial transaction means that the overall change to the database will be atomic from a data integrity standpoint, and rollbacks can be handled together. So if a record-triggered flow on an account updates all the related contacts, but then a separate piece of automation later in the transaction throws an error which voids the whole transaction, those contacts will not be updated if the original account update didn’t go through.
Downsides of Synchronous Processing
- Time Window: The record-trigger starts with an open transaction to the database that cannot be committed until all the steps in the trigger order of execution have happened. This means that there is a limited time window in which to do any additional synchronous automation, because the database cannot be held open indefinitely. And, in the case of a user-triggered record change, we do not want the user to sit through lengthy delays after making an edit.
- Governor Limits: Due to the time constraints detailed above, Apex and Flow have more permissive governor limits for asynchronous processing than for synchronous processing to ensure consistent performance.
- Support for External Objects and Callouts: In general, any access to an external system that needs to wait for a response (say, to then update the triggering record with a new value) will be too long to do within the original open transaction. Some invocable actions get around this limitation by implementing custom logic for queuing their own execution after the original transaction has completed. Email alerts and outbound messages do this, for example, which is why you are able to call an outbound message from an after-save flow but not an External Service action. However, this is not the case for the vast majority of callouts, and we recommend separating callouts into their own asynchronous processes whenever possible.
- Mixed DML: Occasionally, you may want to do cross-object CRUD on objects in Setup and non-Setup, like updating a user and an associated contact after a particular change. Due to security constraints, these cannot be done in a single transaction, so some use cases require a new separate transaction to be triggered via a second asynchronous process.
With these considerations in mind, both Flow and Apex offer solutions for executing logic asynchronously to meet use cases that require separate transactions, external callouts, or will just simply take too long. For Apex, we recommend implementing asynchronous processing inside a Queueable Apex class. For Flow, we recommend using the Run Asynchronously path in after-save flows to achieve a similar result in a low-code manner. (See Well-Architected - Throughput for more information about synchronous and asynchronus processing.)
When deciding between low- and pro-code, a key consideration is the amount of control Apex will give you around callouts. Flow offers a fixed amount of retries and some basic error handling via its fault path, but Apex offers more direct control. For a mixed use case, you can call System.enqueueJob against Queueable Apex from within an invocable Apex method, then invoke the method from Flow through the invocable action framework.
When testing on any solution, particularly one employing any kind of callouts, it’s important to think through the ramifications of what happens when any particular step has an error, a timeout, or sends back malformed data. In general, asynchronous processing has more power, but requires the designer to be more thoughtful about such edge cases, especially if that process is part of a larger solution that may be relying on a specific value. As an example, if your quoting automation requires a callout to a credit check bureau, what state will the quote be in if that credit check system is down for maintenance? What if it returns an invalid value? What state will your Opportunity or Lead be in during that interim, and what downstream automation is waiting on that result? Apex has more complex error handling customization than Flow, including the ability to intentionally trigger a failure case, and that may be a deciding factor between the two.
What About Other Solutions?
Previously, low-code admins have used various approaches (or “hacks”) for achieving asynchronous processing. One was to create a time-based workflow (in Workflow Rules), a scheduled action (in Process Builder), or a Scheduled Path (in Flow) that ran 0 minutes after the trigger executed. This effectively did the same thing as the Run Asynchronously path does today, but the new dedicated path has some advantages, including how quickly it will run. A 0-minute scheduled action could take a minute or more to fully instantiate, whereas Run Asynchronously is optimized to ensure it is enqueued and run as quickly as possible. Run Asynchronously will also potentially allow for more stateful capabilities in the future, like the ability to access the prior value of the triggering record, though it can’t do this today. It does some specialized caching to improve performance.
The other “hack” that has been used was to add a Pause element using an autolaunched subflow that waited for zero minutes, and then call that flow from Process Builder. That “zero-wait pause” will effectively break the transaction and schedule the remaining automation to run in its own transaction, but the mechanisms it uses do not scale well, as they were not designed for this purpose. As a result, increased use will lead to performance problems and flow interview limits. Additionally, the flow becomes more brittle and difficult to debug. Customers who have used this approach have often had to abandon it after reaching scale. We do not recommend starting down that path (pun intended), which is why it’s not available for subflows called from record-triggered flows.
Transferring Data or State Between Processes
One of the appeals of the “zero-wait pause” is the perceived stateful relationship between the synchronous and asynchronous processing. A flow variable may persist before and after the pause in this particular hack, even if that pause waits for weeks or months. This can have an appeal from an initial design perspective, but it goes against the underlying programming principles that asynchronous processing is intended to model. Separating out processes to run asynchronously allows them more flexibility and control over performance, but the data they operate on generally needs to be self-contained. That data could change in the time between two different independent processes run, even if it’s only milliseconds between one and the next, and almost certainly if it’s for longer. Flow variables, like the ones in New Resource, are designed to only last as long as the individual process that is running. If that information is going to be needed by a separate process, even one set to run asynchronously as soon as it finishes, it should be saved into persistent storage. Most often this will take the form of a custom field on the object of the record that triggered the flow, as that will automatically be loaded as $Record in any path on a record-triggered flow. For example, if you use Get Records to get an associated name from a contact for a record, and you want to reuse that name in an asynchronous path, you will either need to invoke the Get Records again in the separate path, or save that associated name back to $Record. If you need sophisticated caching or alternative data stores beyond Salesforce objects and records, we recommend using Apex. (See Well-Architected - State Management for more information about state management.)
Summary
When it comes to asynchronous processing, it may take additional care and consideration to design your record-triggered automation, particularly if you require callouts to external systems or need to perpetuate state between processes. The Run Asynchronously path in Flow should meet many of your low-code needs, but some complex ones around custom errors or configurable retries will require Apex instead.
Custom Validation Errors
| Record-Changed Flow: Before Save | Record-Changed Flow: After Save | Record-Changed Flow: After Save + Apex | Apex Triggers | |
|---|---|---|---|---|
| Custom Validation Errors | Not Available | Not Available | Not Available | Available |
At this time, Flow provides no way to either prevent DML operations from committing, or to throw custom errors; the addError() Apex method is not supported when executed from Flow via Apex invocable method. Support for calling the addError() method directly from Flow as a new low-code element is expected to be included in an upcoming ‘24 release. In the meantime, Validation Rules can be used for simple use cases and Apex triggers can be used for complex ones.
Designing Your Record-Triggered Automation
There are countless debates in the community around best practices when it comes to designing record-triggered automation. You may have heard some of the following:
- Only use one tool or framework per object
- Put all your automation into a single Process Builder or parent flow and use subflows for all logic
- Don’t put all your automation in one place, split out your flows into the smallest possible chunks
- There is an ideal number of flows you should have per object (and that number is 1…or 2…or 5…or 1,000)
The fact is that there are kernels of truth in all of the advice, but that none of them address everyone’s challenges or specific needs. There will always be exceptions and rules that apply to some instances but not others. This section describes the specific problems that are addressed by various pieces of advice, to help you make your own determinations.
What Problem Are You Trying to Solve?
Performance
When it came to building automation in Process Builder, performance was a big reason to recommend building one process per object/trigger. Process Builder has a high initialization cost, so every time a Process Builder ran on a record edit, it would incur a performance hit, and since Process Builder didn’t come with any gating entry conditions, those hits would always be incurred on every edit. Flow functions differently than Process Builder, so it does not have nearly as high of an initialization cost, but it does have some. Raw speed tests between Flow and Apex for identical use cases will usually show Apex being at least theoretically ahead, since Flow’s low-code benefits add at least one layer of abstraction, but from a performance perspective, this small difference is not a major differentiator for most use cases.
Flow also provides entry conditions, which can help dramatically lower the performance impact if they are used to exclude a flow from a record-edit. The majority of changes to a record are unlikely to necessitate running automation that makes additional changes. So if a typo gets fixed in a description, for example, you don’t need to rerun your owner assignment automation. You can configure entry conditions so that automation runs only when a certain conditional state is achieved. Edits made on a record are tracked and the automation executes only when a defined change is made. So you can run an automation when an opportunity is closed or on the specific edit that changed its status from open to closed. Either of these options are more efficient than running an automation on every update to a closed opportunity.
Summary
Making your record-triggered automation performant is a multidimensional problem, and no design rule will encompass all the factors For Flow, there are two important points to remember when it comes to your design:
- Consolidating your automation into a single flow will not have a major impact on the performance compared to splitting it out into multiple flows.
- Entry conditions can lead to significant performance improvements for your record-triggered automation if they are used to exclude changes that do not impact a specific use case.
This guide covers a number of performance considerations and recommendations, including using before-save flows to make field updates and eliminating excess or repeat DML operations wherever possible. Those areas, which are often where we see performance problems materialize in real-world customer scenarios, should be addressed first.
Troubleshooting
As architects, we would love to never have to troubleshoot automation, but we do from time to time. While having your automation spread out among multiple tools can work during initial development, it often causes more headaches over time as changes are made in different places. This is where the advice to consolidate your automation on a single Object into either Apex or Flow comes from. There is currently no unified troubleshooting experience that spans all Salesforce tools, so depending on the complexity of your organization and your anticipated debugging and troubleshooting needs, you may want to make the decision to stick with just one tool for your automation. Some customers make this a hard-and-fast rule due to their environment or the skills of their admins and engineers. Others find it useful to split out their automation across Flow and Apex, for example, by using invocable actions for pieces of automation that are too complex or require careful handling and calling them from Flow for greater access among admins.
Summary
It may be prudent to consolidate an object’s automation in a single tool when maintenance, debugging, or conflicts (such as different people editing the same field) are likely to be a concern. Other approaches, like using invocable actions to implement more complex functionality from non-admins, can also be used.
Ordering & Orchestration
For many years, the biggest reason to consolidate automation into a single process or flow was to ensure ordering. The only way to keep two pieces of automation separate, but have them execute in a guaranteed sequential order, was to put them together. This quickly led to scaling problems. As orgs became more dynamic and needed to adapt to business changes, these “mega flows” became unwieldy and difficult to update, even for small changes.
With flow trigger ordering, introduced in Spring '22, admins can now assign a priority value to their flows and guarantee their execution order. This priority value is not an absolute value, so the values need not be sequentially numbered as 1, 2, 3, and so on. Instead, the flow will execute in the order described, with a tie-break applied to duplicate values (if there are two priority 1s, for example, they will execute alphabetically) in order to minimize disruption from other automation, managed packages, or movement between orgs. All flows that don’t have a trigger order (all legacy or active flows) will run between numbers 1000 and 1001 to allow for backwards compatibility. If you’d like to leave your active flows alone, you can start your ordering at 1001 for any new flows you’d like to run after them. As a best practice, leave space between flows that you number – use 10, 20, and 30 as values rather than 1, 2, and 3 for example. That way, if you add a flow in the future, you can number it 15 to put it between your first and second without having to deactivate and edit those flows that are already running.
For more advanced use cases, such as task lists for groups, or multi-step processes that interact with multiple users and multiple systems, or if you need an audit of the execution of your process, consider Flow Orchestration. An orchestration is a sequence of stages, comprised of one or more steps that can run synchronously or asynchronously. Each step in an orchestration is a flow, autolaunched flow for background processing and screen flow for user interaction. You can specify whether changes or creation of records in a given object will trigger or wake up an orchestration. Use Flow Orchestration to automate long running processes, and use Flow Trigger Explorer to order record-triggered flows.
Summary
In the past, the need for ordering has led to recommendations for consolidating all automation into a single flow. With flow trigger ordering, there is now no need to do that. (See Well-Architected - Data Handling for more data handling best practices.)
Organizational Issues
It is tempting to dissect the technical reasons underpinning various best practices, but it’s no less important to think about your organization and the people building and maintaining the automation. Some customers like to have their admins build all their automation in subflows, with only one key administrator tasked with consolidating all those into a single flow as a way of managing change control. Some only want to build in Apex because they have developers who can get it done faster that way. Others want more functionality to come in Flow entry conditions, so they can use record type, for example, to ensure multiple groups can build automation that won’t run into conflicts in production (we are working on that record type request!). We recommend that you organize around your business first and group flows functionally by what they are intended to automate and who is intended to own them, but that is going to look different for different orgs.
It can be incredibly challenging to understand an org that has years of automation built by admins who are no longer on the product. Best practices and documented design standards for your organization that are implemented upfront can help with long-term maintenance. Salesforce continues to invest in this area, with new features like Flow Trigger Explorer to help you understand what triggered automation is already in place and running today. It’s always a good idea to consider what will benefit the long-term health and maintenance of any automation you build. If you’re still stuck, we recommend reaching out to your Trailblazer Community. Many Trailblazers who have gone down this path, and they can advise on the human side of building automation as well as on the technical details. Best practices come from everyone!
It’s important to remember that documentation is just as important as automation! As you document your work, write clear, unique names for things, and use the Description field on every element across Flow to explain your intent. Comment your code. Every architect who has been around long enough has rushed through this step to meet some deadline. Likewise experienced architects have also eventually been on the receiving end of this scenario, and wound up scratching their head at some undocumented rogue piece of automation.
Summary
Ultimately, the best approach is one that works well with your business and organization. If you feel a bit lost, the Trailblazer Community is full of advice on how to manage a complex organization, so dig in and ask questions as you learn how to better match your unique business and admin setup with the product. And remember: Write things down!
Triggered Flow Runtime Behavior
The rest of this document describes technical details about the Flow runtime.
Performance Discussion: Same-Record Field Updates
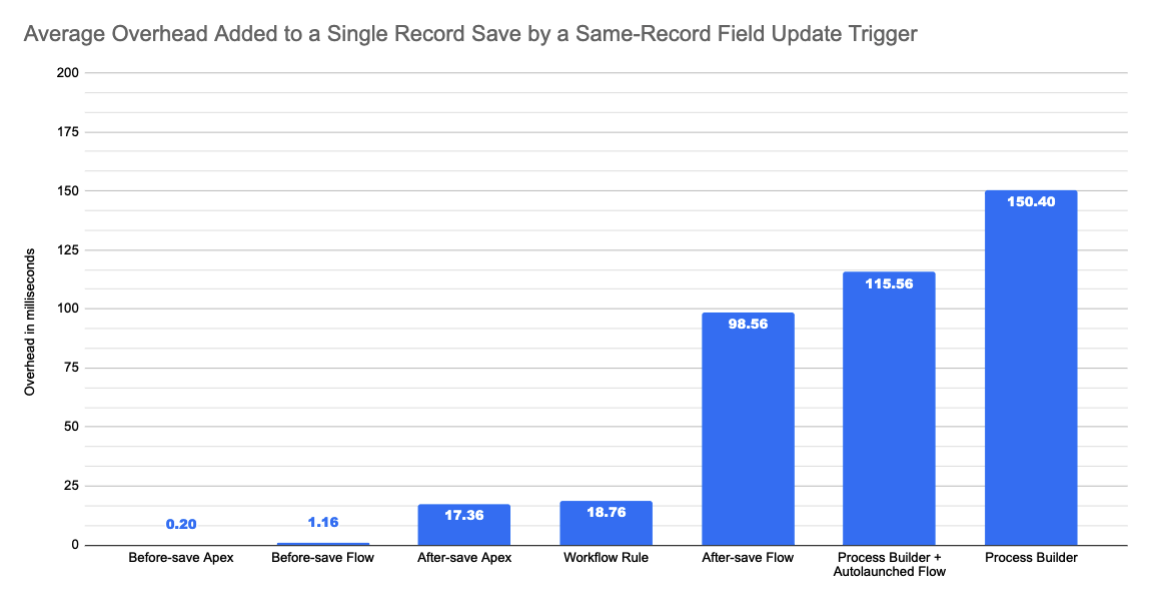
Approximately 150 billion actions were executed by Workflow, Process Builder, and Flow in April 2020, including record updates, email alerts, outbound messages, and invocable actions. Around 100 billion of those 150 billion actions were same-record field updates. Note that before-save flow triggers had only been launched the release before, so that means 100 billion after-save same-record field updates — or equivalently, 100 billion recursive saves — were executed in just one month. Imagine how much time could have been saved by before-save flow triggers
Caveat: Architects should view all performance claims with a critical eye, even when they come from Salesforce. Results in your org will likely be different than the results in our orgs.
Earlier in this guide, we noted that while Workflow Rules have a reputation for being fast, they will always be slower and more resource-hungry than a single, functionally equivalent before-save flow trigger. The theoretical side to this assertion is that, by design, before-save flow triggers neither cause DML operations nor the ensuing recursive firing of the save order, while Workflow Rules do (because they happen after the save).
But what happens in practice? We ran a few experiments to find out.
[Experiment 1] Single trigger; single record created from the UI; Apex debug log duration
How much longer does an end user have to wait for a record to save?
For each of the different automation tools that can be used to automate a same-record field update, we created a fresh org, + one more fresh org to serve as a baseline org.
Then for each org, we:
- Except for the baseline org, implemented the simplest version of a trigger on
Opportunity Createthat would setOpportunity.NextStep = Opportunity.Amount. - Enabled Apex debug logging, with all debug levels set to
NoneexceptWorkflow.InfoandApex Code.Debug - Manually created a new Opportunity record with a populated Amount value through the UI, 25 times.
- Calculated the average duration of the log across the 25 transactions.
- Subtracted from the average duration in #4, the average duration of the log in the baseline org.
This gave us the average overhead that each trigger added to the log duration.
[Experiment 2] 50 triggers; 50,000 records inserted via Bulk API (200 record batches); internal tooling
How about the other side of the spectrum: high-volume batch processing?
We borrowed some of our performance team’s internal environments to get a sense of how well the different trigger tools scale.
The configuration was:
- 1 org with 50 before-save flows on
Account Createwhich each updateAccount.ShippingPostalCode - 1 org with 50 before-save Apex triggers on
Account Createwhich each updateAccount.ShippingPostalCode - 1 org with 50 Workflow Rules on
Account Createwhich each updateAccount.ShippingPostalCode - 1 org with 50 after-save flow triggers on
Account Createwhich each updateAccount.ShippingPostalCode - 1 org with 50 Process Builder processes on
Account Createwhich each updateAccount.ShippingPostalCode
Then each Tuesday for the last 12 weeks, we uploaded 50,000 Accounts to each org through the Bulk API, with a 200-record batch size.
Fortunately, our internal environments can directly profile trigger execution time without requiring Apex debug logging or extrapolation from a baseline.
Because our internal environments are not representative of production, we’re sharing only the relative performance timings, and not the raw performance timings.
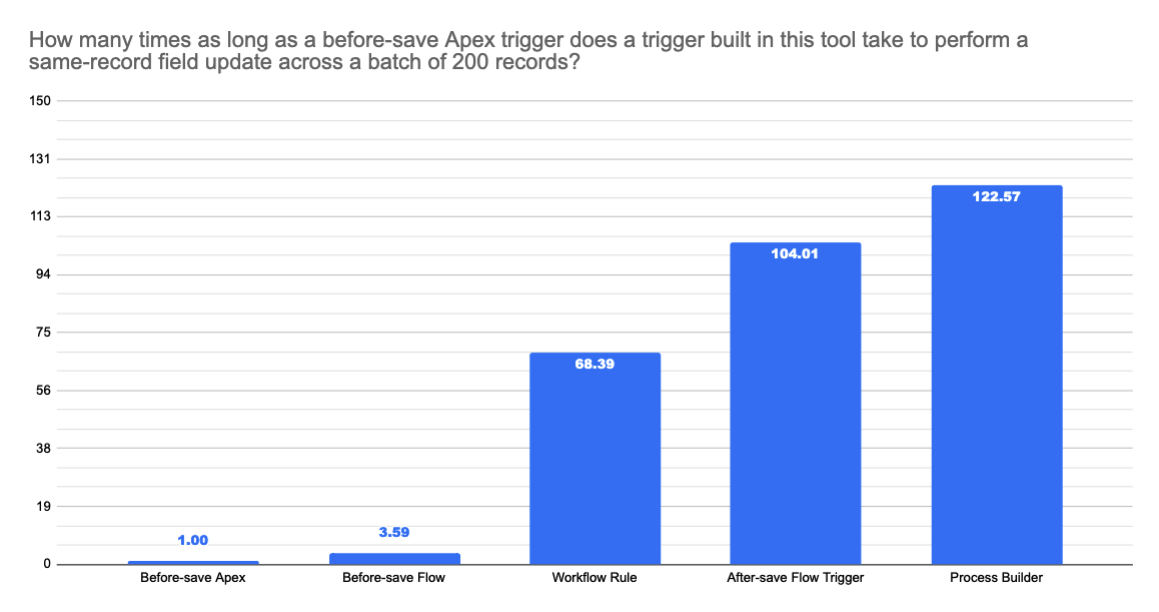
In both single-record and bulk use cases, the before-save Flow performs extremely well. As much as we’d like to take credit for the outcomes, however, most of the performance savings come simply due to the huge advantage of being before the save.
Go forth and stop implementing same-record field updates in Workflow Rules and Process Builder!
Bulkification & Recursion Control
This section is intended to help you better better understand how & why Flow accrues against Governor limits the way it does. It contains technical discussion about Flow’s runtime bulkification & recursion control behaviors.
We’ll mainly be focusing on how Flow affects these Governor limits.
- Total number of SOQL queries issued (100)
- Total number of DML statements issued (150)
- Total number of records processed as a result of DML statements (10,000)
- Maximum CPU time on the Salesforce servers (10,000 ms)
We assume the reader possesses a prerequisite understanding of what these limits represent, and we recommend refreshing on the content and terminologies used in How DML Works and Triggers and Order of Execution.
Before diving into the specifics of triggered Flow runtime behavior, it’s extremely important to make sure we use the same common mental model of the save order for the purpose of further discussion. We believe a tree model provides a reasonably accurate abstraction.
- Each node Nodei in the save order tree corresponds to a single Salesforce record Rα and a timestamped DML operation DMLi that processed that record.
- It is possible for the same Salesforce record Rα to be processed by multiple timestamped DML operations {DMLi, DMLj, DMLk, ...} through the lifetime of a transaction.
- It is possible for a single timestamped DML operation DMLi to process multiple Salesforce records {Rα , Rβ, Rρ, ...} if the operation is a bulk DML operation.
- It is possible for a single non-timestamped DML operation to process the same Salesforce record(s) multiple times through a transaction, whether intentionally by design or unintentionally through recursion.
- The root node of the save order tree, Node0, is created when an end user performs a save. If a user creates a single record in the UI, then up to one save order tree is created; if a user submits a batch of 200 record updates through the API, then up to 200 independent save order trees are created -- one for each single record update in the batch. Save order trees can be skipped if the save is rejected by before-save validation rules.
- At runtime, the save order tree is populated according to the resolved save order. For a given node Nodei ( Rα , DMLi) in the save order tree,
- For each trigger that fired in response to the DML operation DMLi on Rα ,
- For each DML operation DMLp that was executed by the trigger during runtime:
- For each single Salesforce record Rβ that was processed by that DML operation DMLp,
- The trigger generates a child node Nodej ( Rβ, DMLp) to the original node Nodei ( Rα , DMLi).
- For each single Salesforce record Rβ that was processed by that DML operation DMLp,
- For each DML operation DMLp that was executed by the trigger during runtime:
- For each trigger that fired in response to the DML operation DMLi on Rα ,
- The subtree of a node Nodei represents the entire cumulative set of records that was processed by DML during runtime as a result of DMLi.
- The entire tree, which is the subtree rooted at the root node Node0, thus represents all the records that were processed by DML in response to a top-level single record DML operation DML0. In a batch of 200 records, the 200 corresponding trees would represent all of the records that were processed by DML in the transaction.
Since each node in a save order tree corresponds to a single processed DML record, and there is a limit of 10,000 on the number of processed DML records per transaction, there can be no more than 10,000 nodes total, across all of the save order trees in the transaction.
Additionally, there can be no more than 150 unique timestamped DML operations {DML0, DML1, ...* *, DML149} across all of the save order trees in the transaction.
Now, let’s revisit our earlier example of a suboptimal cross-object triggered flow implementation:
Suppose that there are no other triggers in the org, and a user creates a single new Case, Case005, against parent Account Acme Corp. The corresponding save order tree is fairly simple:
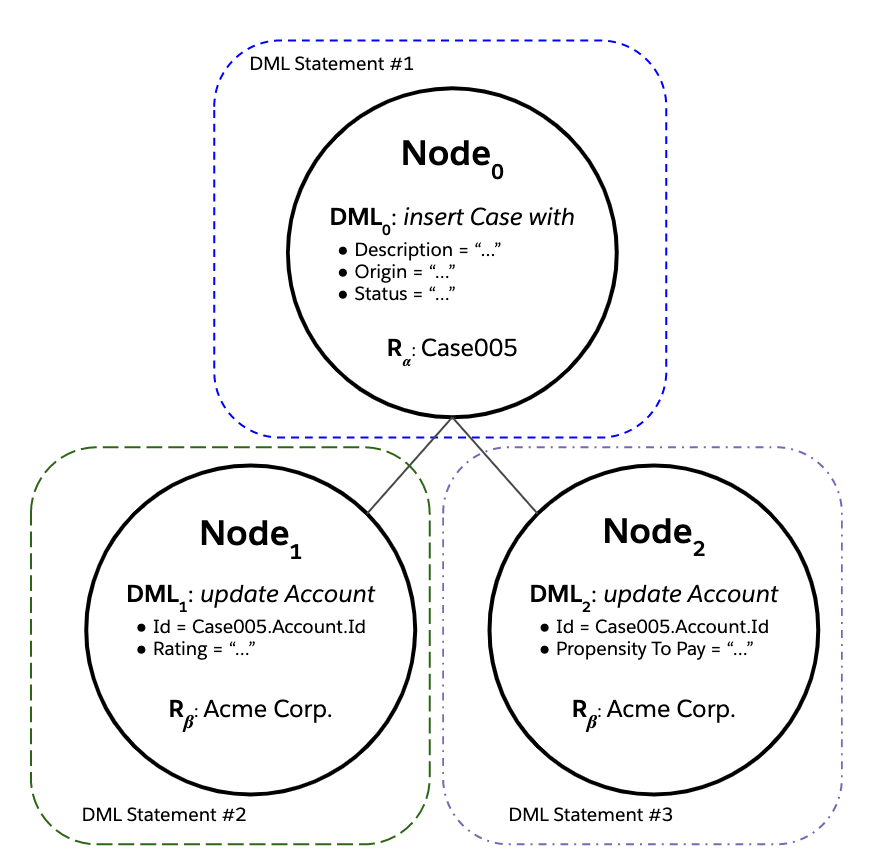
- There are a total of three records processed by DML.
- Each of the records was processed by its own dedicated DML statement, for a total of three DML statements issued.
Suppose that the user then creates two new cases, Case006 and Case007, in a single DML statement. You’d get two save order trees with three nodes each, for a total of six records processed by DML. However, thanks to Flow’s automatic cross-batch bulkification logic (Flow Bulkification), the six nodes would still be covered by a total of three issued DML statements:
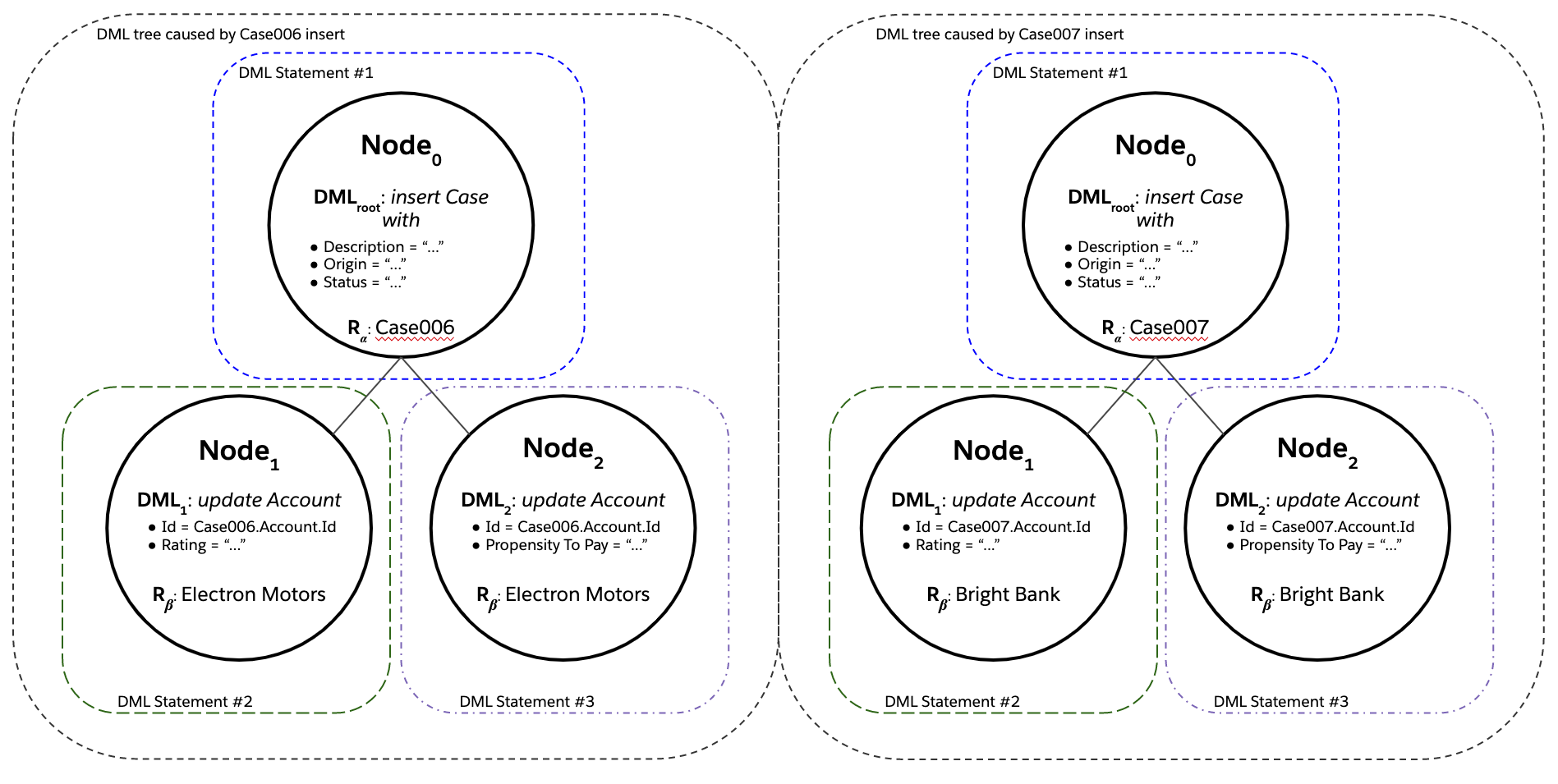
Still not bad, right? In real life, though, you’d probably expect there to be a host of triggers on Account update, such that any single save order tree would end up looking like this (for the sake of discussion let’s say there are 3 triggers on Account):
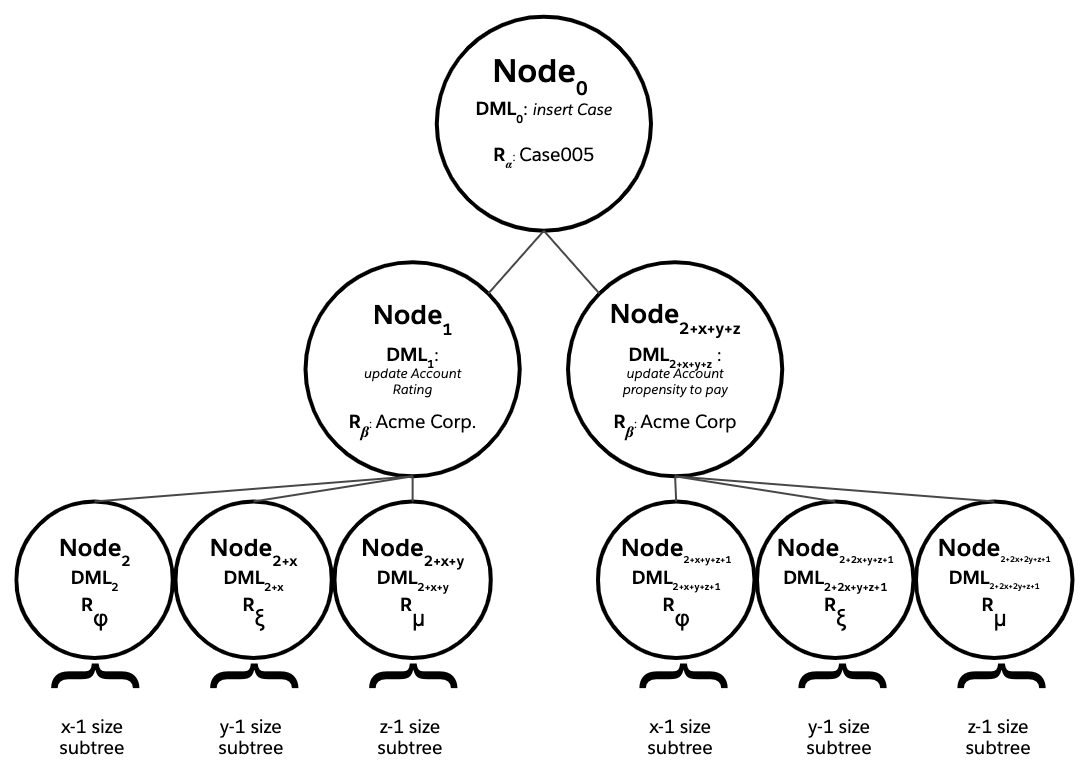
And in a scenario where you’ve batch-inserted 200 Cases, there would be 200 respective save order trees sharing a 10,000 total node limit and a 150 total issued DML statements limit. Bad news bears.
However, by combining the Flow’s two original Update Records elements into a single Update Records element, the entire right subtree of Node0 can be eliminated.
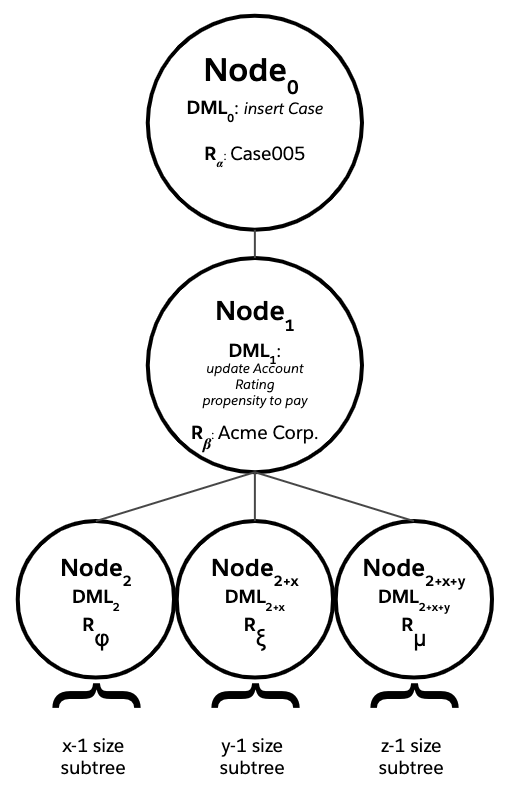
This is an example of what we’ll call functional bulkification, one of two types of bulkification practices that can reduce the number of DML statements needed to process all the DML rows in a batch.
-
Functional bulkification attempts to minimize the number of unique DML statements that are needed to process all of the records in a single save order tree.
The example above achieves functional bulkification by effectively merging two functionally distinct DML nodes, and their respective save order subtrees, on Acme Corp. into a single, functionally equivalent, merged DML node and save order subtree. Not only does this reduce the number of DML statements issued, but it also saves CPU time. All the non-DML trigger logic is run once and not twice.
-
Cross-batch bulkification attempts to maximize the number of DML statements that can be shared across all save order trees in a batch.
An example of perfect cross-batch bulkification is an implementation where, if one record’s save order tree requires 5 DML statements to be issued, then a 200 record batch still requires only 5 DML statements to be issued.
In the above example, cross-batch bulkification is handled automatically by the Flow runtime.
Recursion control, on the other hand, increases processing efficiency by pruning functionally redundant subtrees.
Flow Bulkification
The Flow runtime automatically performs cross-batch bulkification on behalf of the user. However, it does not perform any functional bulkification.
The following Flow elements can cause the consumption of DML & SOQL in a triggered flow.
- Create / Update / Delete Records: Each element consumes 1 DML for the entire batch, not including any downstream DML caused by triggers on the target object.
- Get Records: Each element consumes 1 SOQL for the entire batch.
- Action Calls: Depends on how the action is implemented. During runtime, the Flow runtime compiles a list of the inputs across all of the relevant Flow Interviews in the batch, then passes that list into a bulk action call. From that point, it’s up to the action developer to ensure the action is properly bulkified.
- Loop: Doesn’t consume DML or SOQL directly, but instead overrides rules #1-3 above by executing each contained element in the loop serially, for each Flow Interview in the batch, one-by-one.
- This essentially “escapes” Flow’s automatic cross-batch bulkification: no DML or SOQL in a loop is shared across the save order trees, so the number of records in a batch has a multiplicative effect on the amount of DML & SOQL consumed.
As an example, consider the following triggered Flow implementation, which, when an Account is updated, automatically updates all of its related Contracts, and attaches a Contract Amendment Log child record to each of those updated Contracts.
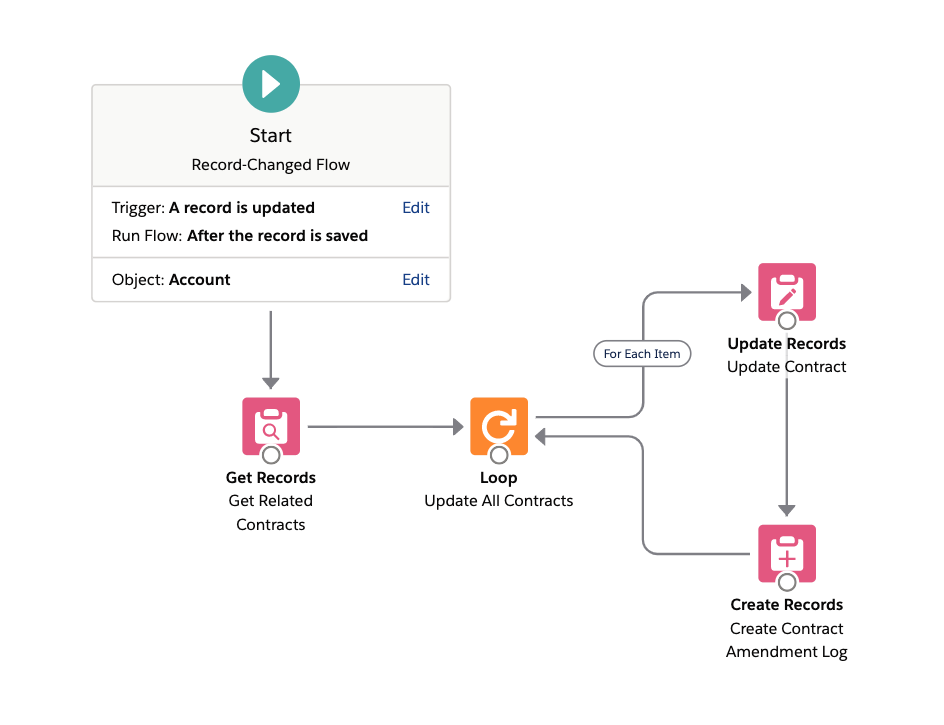
Suppose now that 200 Accounts are bulk updated. Then during runtime:
- The Get Related Contracts element will add + 1 SOQL for the entire batch of 200 Accounts.
- Then, for each Account in the 200 Accounts:
- For each Contract that is related to that Account:
- The Update Contract element will add + 1 DML to update the Contract, not including any downstream DML caused by triggers on Contract update.
- The Create Contract Amendment Log will add + 1 DML to create the corresponding Contract Amendment Log child record, not including any downstream DML caused by triggers on Contract Amendment Log create.
- For each Contract that is related to that Account:
We strongly recommend against including DML & SOQL in loops for this reason. This is very similar to best practice #2 in Apex Code Best Practices. Users will be warned if they attempt to do so while building in Lightning Flow Builder.
Flow Recursion Control
Triggered Flows are subject to the recursive save behavior outlined in the Apex Developer Guide’s Triggers and Order of Execution page.

What does this actually mean? Let’s go back to the tree model we established earlier, and revisit this specific property of the tree:
- At runtime, the save order tree is populated according to the resolved save order:For a given node Nodei ( Rα , DMLi) in the save order tree,
- For each trigger that fired in response to the DML operation DMLi on Rα ,
- For each DML operation DMLp that was executed by the trigger during runtime:
- For each single Salesforce record Rβ that was processed by that DML operation DMLp,
- The trigger generates a child node Nodej ( Rβ, DMLp) to the original node Nodei ( Rα , DMLi).
- For each single Salesforce record Rβ that was processed by that DML operation DMLp,
- For each DML operation DMLp that was executed by the trigger during runtime:
- For each trigger that fired in response to the DML operation DMLi on Rα ,
The guarantee, “During a recursive save, Salesforce skips ... ” adds an additional bit of magic:
- At runtime, the save order tree is populated according to the resolved save order:For a given node Nodei ( Rα , DMLi) in the save order tree,
- For each trigger that would normally fire in response to the DML operation DMLi on Rα ,
- If that trigger is included in the save order steps 9 - 18:
- If that trigger has already previously fired in response to a previous DML operation on Rα , and in doing so set off a chain of DML operations that has led to the current DML operation DMLi on Rα,
- The trigger doesn’t fire.
- If that trigger has already previously fired in response to a previous DML operation on Rα , and in doing so set off a chain of DML operations that has led to the current DML operation DMLi on Rα,
- Otherwise, the trigger fires.
- For each DML operation DMLp that was executed by the trigger during runtime:
- For each single Salesforce record Rβ that was processed by that DML operation DMLp,
- The trigger generates a child node Nodej ( Rβ, DMLp) to the original node Nodei ( Rα , DMLi).
- For each single Salesforce record Rβ that was processed by that DML operation DMLp,
- For each DML operation DMLp that was executed by the trigger during runtime:
- If that trigger is included in the save order steps 9 - 18:
- For each trigger that would normally fire in response to the DML operation DMLi on Rα ,
This has a few important implications:
[Consideration #1] A Flow trigger can fire multiple times on the same record during a transaction.
For example, suppose that in addition to the suboptimal Flow trigger on Case Create to the right, the org also has a Flow trigger on Account Update.
For simplicity’s sake, let’s assume the triggered Flow on Account Update is a no-op. Suppose we create a new Case, Case #007, with parent Account “Bond Brothers.”
Then the save order tree would look like this:
- Case #007 is created.
- Save order for
Case Createon Case #007 is entered.- Steps 1-16 in the save order execute. Since there are no other triggers on Case aside from the Flow trigger above, nothing happens.
- Step 17 executes: our public doc hasn’t been updated yet, but after-save Flow triggers will be the new step #17; the current step #17, roll-ups, and everything below it, is shifted 1 step lower.
- The Flow trigger on
Case Createfires.- The Flow trigger updates the Bond Brothers Account rating.
- Save order for
Account Updateon Bond Brothers is entered. - Steps 1-16 in the save order execute. No operations.
- Step 17 executes.
- The Flow trigger on
Account Updatefires. // First execution on Bond Brothers.- Since we defined the Flow trigger on
Account Updateto be a no-op, nothing happens.
- Since we defined the Flow trigger on
- Since there are no other Flow triggers on
Account Update, Step 17 concludes.
- The Flow trigger on
- Steps 18-22 execute. No operations.
- Save order for
Account Updateon Bond Brothers is exited.
- Save order for
- The Flow trigger updates the Bond Brothers Account propensity to pay.
- Save order for
Account Updateon Bond Brothers is entered. - Steps 1-16 in the save order execute. No operations.
- Step 17 executes.
- The Flow trigger on
Account Updatefires. // Second execution on Bond Brothers. // Not a recursive execution!- Since we defined the Flow trigger on
Account Updateto be a no-op, nothing happens.
- Since we defined the Flow trigger on
- Since there are no other Flow triggers on
Account Update, Step 17 concludes.
- The Flow trigger on
- Steps 18-22 execute. No operations.
- Save order for
Account Updateon Bond Brothers is exited.
- Save order for
- The Flow trigger updates the Bond Brothers Account rating.
- Since there are no other Flow triggers on
Case Create, Step 17 concludes.
- The Flow trigger on
- Steps 18-22 execute. No operations.
- Save order for
Case Createon Case #007 concludes.
- Transaction closes.
Had the two Update Records elements been merged into a single Update Records element, the resolved save order would have instead looked like this:
- Case #007 is created.
- Save order for
Case Createon Case #007 is entered.- Steps 1-16 in the save order execute. Since there are no other triggers on Case aside from the Flow trigger above, nothing happens.
- Step 17 executes: our public doc hasn’t been updated yet, but after-save Flow triggers will be the new step #17; the current step #17, roll-ups, and everything below it, is shifted 1 step lower.
- The Flow trigger on
Case Createfires.- The Flow trigger updates the Bond Brothers Account rating and propensity to pay.
- Save order for
Account Updateon Bond Brothers is entered. - Steps 1-16 in the save order execute. No operations.
- Step 17 executes.
- The Flow trigger on
Account Updatefires. // First execution on Bond Brothers.- Since we defined the Flow trigger on
Account Updateto be a no-op, nothing happens.
- Since we defined the Flow trigger on
- Since there are no other Flow triggers on
Account Update, Step 17 concludes.
- The Flow trigger on
- Steps 18-22 execute. No operations.
- Save order for
Account Updateon Bond Brothers is exited.
- Save order for
- The Flow trigger updates the Bond Brothers Account rating and propensity to pay.
- Since there are no other Flow triggers on
Case Create, Step 17 concludes.
- The Flow trigger on
- Steps 18-22 execute. No operations.
- Save order for
Case Createon Case #007 concludes.
- Transaction closes.
[Consideration #2] A Flow trigger will never cause itself to fire on the same record again.
[Consideration #3] Although Flow triggers (and all other triggers in the v48.0 save order steps 9-18) get this type of recursion control for free, Steps 1-8 and 19-21 do not. So, when an after-save Flow trigger performs a same-record update, a save order is entered, and Steps 1-8 and 19-21 all execute again. This behavior is why it’s so important to move same-record updates into before-save Flow triggers!
Closing Remarks
You’ve made it! Have a good day and thanks for the read. Hope you learned something you found valuable.
Tell us what you think
Help us make sure we're publishing what is most relevant to you: take our survey to provide feedback on this content and tell us what you’d like to see next.