Our forward-looking statement applies to roadmap projections.
Overview
Salesforce Data Cloud is a data platform built on Hyperforce that unifies Salesforce and external data into a clear, complete, and trusted 360-degree view of every customer or account.
Enterprises often operate multiple Salesforce orgs due to mergers and acquisitions, regional operations, functional separation, or for historical reasons. Architects must decide not only between a single Home Org versus multi-org configuration, but also whether to provision multiple independent Data Cloud instances, use Data Cloud One to unify orgs under a single instance, or collaborate between independent Data Cloud instances using data sharing between Data Clouds (Data Cloud-to-Data Cloud data sharing). These choices impact governance, compliance, cost, latency, and the organization’s ability to scale AI and cross-org platform features.
Data Cloud is provisioned automatically on any production org that receives a Data Cloud license.Data Cloud One is Salesforce’s multi-org connectivity architecture that allows a single Home Org to host the Data Cloud instance, while other Salesforce orgs connect as Companion Orgs. The choice of which org holds the Data Cloud license, and thus becomes a Data Cloud home org, is a critical architectural decision with long-term consequences.
How you provision Salesforce Data Cloud is a foundational architectural decision because it determines how the enterprise unifies customer data, enforces governance, and enables critical platform features especially AI, Agentforce, and analytics—across the organization. Anchoring a cluster of orgs to a single Data Cloud provides a unified data model, centralized governance, and enterprise-wide AI readiness, while enabling Companion Orgs to access shared metadata and features as if the data were local. By contrast, multiple independent Data Cloud instances are appropriate when regulatory, compliance, or autonomy requirements prevent centralization, with Data Cloud-to-Data Cloud data sharing enabling selective, zero-copy collaboration between these instances.
For architects, this decision is critical. It defines who controls data governance, where data resides, how platform features are enabled, and how smoothly future integrations and AI initiatives can scale. Even for orgs that don’t currently have Data Cloud, it can be important to future-proof your architecture by developing a strategy for adding Data Cloud access going forward. Salesforce features across Sales, Service, Marketing, Commerce, Industries, and Agentforce are increasingly built on Data Cloud. Orgs that want to use these platform features must provision their own Data Cloud or connect to a shared Data Cloud as companion orgs.
This guide helps architects design a provisioning strategy that balances simplicity, enterprise-wide consistency, compliance, and scalability, ensuring the organization can confidently leverage Data Cloud for customer 360, AI, and cross-platform innovation. It will help you decide how to select which orgs you provision Data Cloud on and how to choose between Data Cloud One and Data Cloud-to-Data Cloud data sharing, helping lay a firm groundwork that moves your business forward into a Data Cloud-centric future.
Provisioning Considerations
Every provisioning choice — whether about choosing between Data Cloud One and data sharing between Data Cloud orgs, or which org to designate as the Home Org — should be evaluated against these cross-cutting considerations:
| Consideration | Why It Matters | Example Scenarios |
|---|---|---|
| Data Residency & Compliance | Determines where data is stored and processed. Regulatory rules may require specific regions or multiple instances. | A global bank provisions a Data Cloud tenant on a Salesforce org geolocated in Frankfurt for GDPR compliance and another one on an org in Virginia for its US division. |
| Governance & Security | Who owns and administers Data Cloud? Should policies be managed centrally or delegated per business unit? | A multinational with strong central IT creates a dedicated Home Org managed by a Center of Excellence. |
| Autonomy vs. Centralization | Different leaders may want separate ownership of data. Autonomy favors multiple Data Clouds; centralization favors Data Cloud One. | A holding company with independent subsidiaries allows each BU to run its own Data Cloud. |
| Latency & Performance | Impacts query speed and experience, especially for Companion Orgs connected to a Data Cloud tenant across regions. | A sales team in London querying data from a Data Cloud tenant in the US may see higher latency. |
| Integration Complexity | More Data Cloud tenants = more pipelines, APIs, and middleware. Consolidation simplifies integration. | A retailer avoids building 10 ETL pipelines by consolidating into a Data Cloud One configuration. |
| Zero Copy Data Source Region | Zero Copy connectors may have cross-region access requirements that limit which regions your Data Cloud can be located in. | A company has a Snowflake instance in the AWS eu-west-1 region. They can use Zero Copy to federate data to a Data Cloud in their region, but can't use Zero Copy to federate to a Data Cloud in the US region. |
| Private Connect Cross-Region Compatibility | In some cases, Private Connect support depends on whether the data source is in the same region as the Data Cloud tenant. | A company has a Snowflake instance in the aws-east-1 region that they want to connect to via zero copy. They can only establish a Private Connect network connection if the Data Cloud Home Org is in the same region. |
| Cost & Licensing | Each Data Cloud tenant adds cost. Consolidating into fewer instances optimizes spend. | A healthcare provider reduces licensing costs by adopting Data Cloud One instead of multiple independent Data Cloud instances. |
| Future Scalability | Provisioning choices today set the foundation for growth. | A SaaS company starts with a single Data Cloud instance but plans to expand to Data Cloud One as it acquires subsidiaries with Salesforce orgs. |
| Enterprise-Wide AI Readiness | AI features and Agentforce require a connected Data Cloud tenant in every org. Provisioning decisions affect how AI models train and activate across the enterprise. | A financial services company unifies data in Data Cloud One so its Einstein AI models have access to enterprise-wide customer data. |
Important Considerations
- Provisioning is tied to licensing: Data Cloud is provisioned in the org where the Data Cloud license is purchased, and the region is determined by that org's location at the time of provisioning.
- Keep your options open by planning for Data Cloud even if you don't need it now. Decisions you make now can smooth your path if you implement Data Cloud to power platform features like Agentforce later.
- Single-org customers: Provision Data Cloud in your existing production org for fastest time-to-value.
- Multi-org customers: Minimize complexity by creating the least number of Data Cloud instances as possible, ideally using Data Cloud One configuration.
- Multiple Data Cloud instances should only be used when required by compliance, residency, or organizational autonomy. In those cases, use Data Cloud-to-Data Cloud data sharing to enable secure collaboration.
- Zero Copy Data Sources: Pay close attention to what regions are supported for various public clouds and Zero Copy data sources. Also, determine if Private Connect is required for your security posture to connect to those data sources and if in-region or cross-region connections are supported.
- Governance and autonomy are central concepts: decide whether Data Cloud should be managed centrally (Center of Excellence model) or whether individual lines of business need separately-managed Data Cloud instances.
Section 1: Provisioning Data Cloud – Choosing the Home Org
1.1 What is a Data Cloud Home Org?
When you purchase a Data Cloud license, the Data Cloud instance is provisioned in the Salesforce org associated with that license. This org is referred to as the Data Cloud Home Org.
 The Home Org is the anchor for your Data Cloud instance. It is where:
The Home Org is the anchor for your Data Cloud instance. It is where:
- Data Cloud storage and compute are managed (in the region selected at provisioning).
- Administration, governance, and security policies are applied.
- Data ingestion, harmonization, identity resolution, segmentation, and activation are performed.
In multi-org scenarios, the Home Org manages the central Data Cloud instance for other Salesforce "Companion" orgs.
Why the Home Org matters:
- It determines the geographical location of your Data Cloud instance.
- It determines who owns and administers your Data Cloud instance. Admins in your Data Cloud Home Org can access all data ingested into Data Cloud.
- It controls Companion Org connections in a Data Cloud One configuration.
- It sets the foundation for your enterprise data strategy — changing it later is difficult and disruptive.
1.2 Decision: Existing Org or New Org as the Home Org?
The first major decision is whether to provision Data Cloud in an existing production org or to create a new, dedicated org to act as the Home Org.
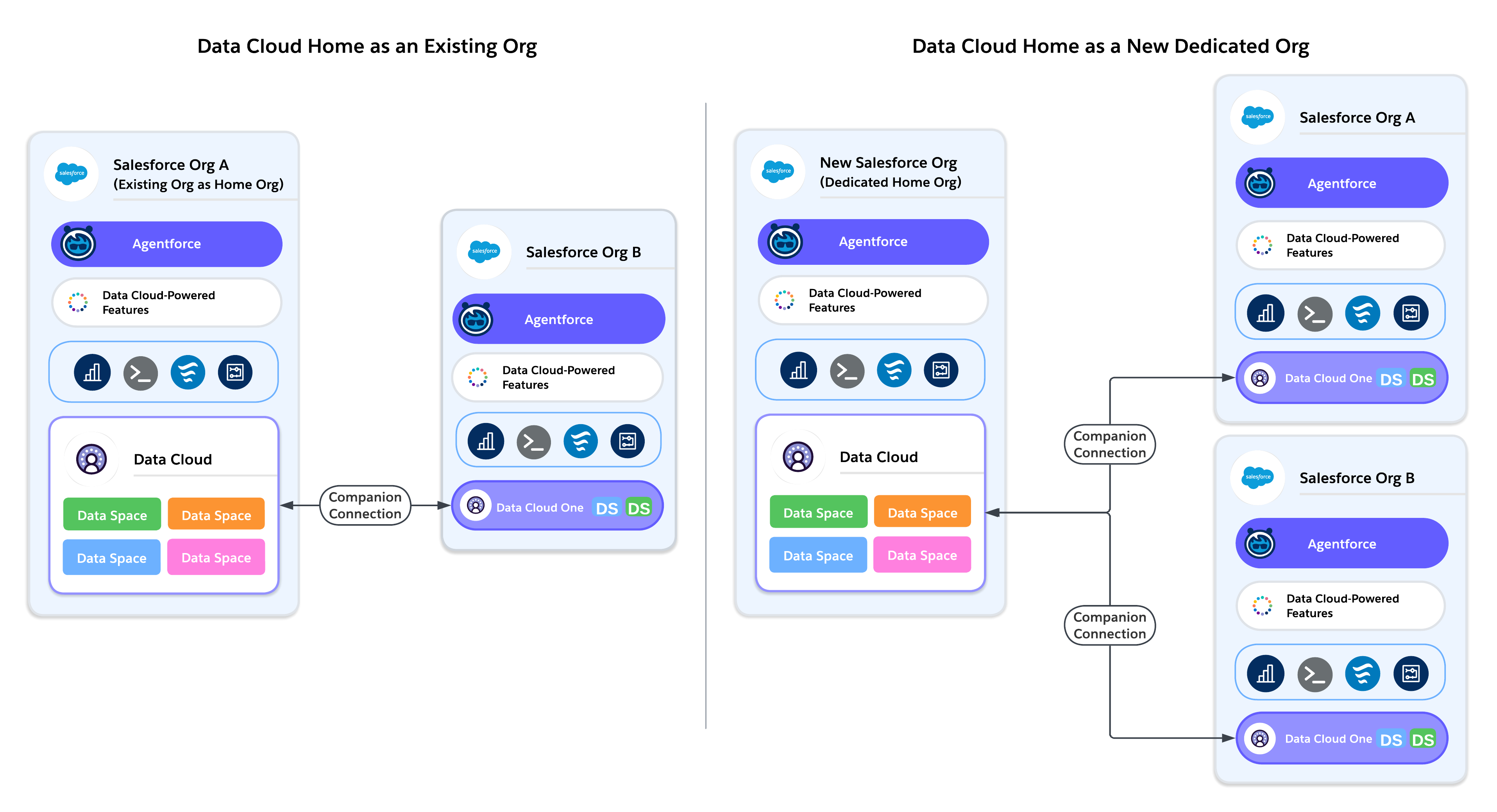
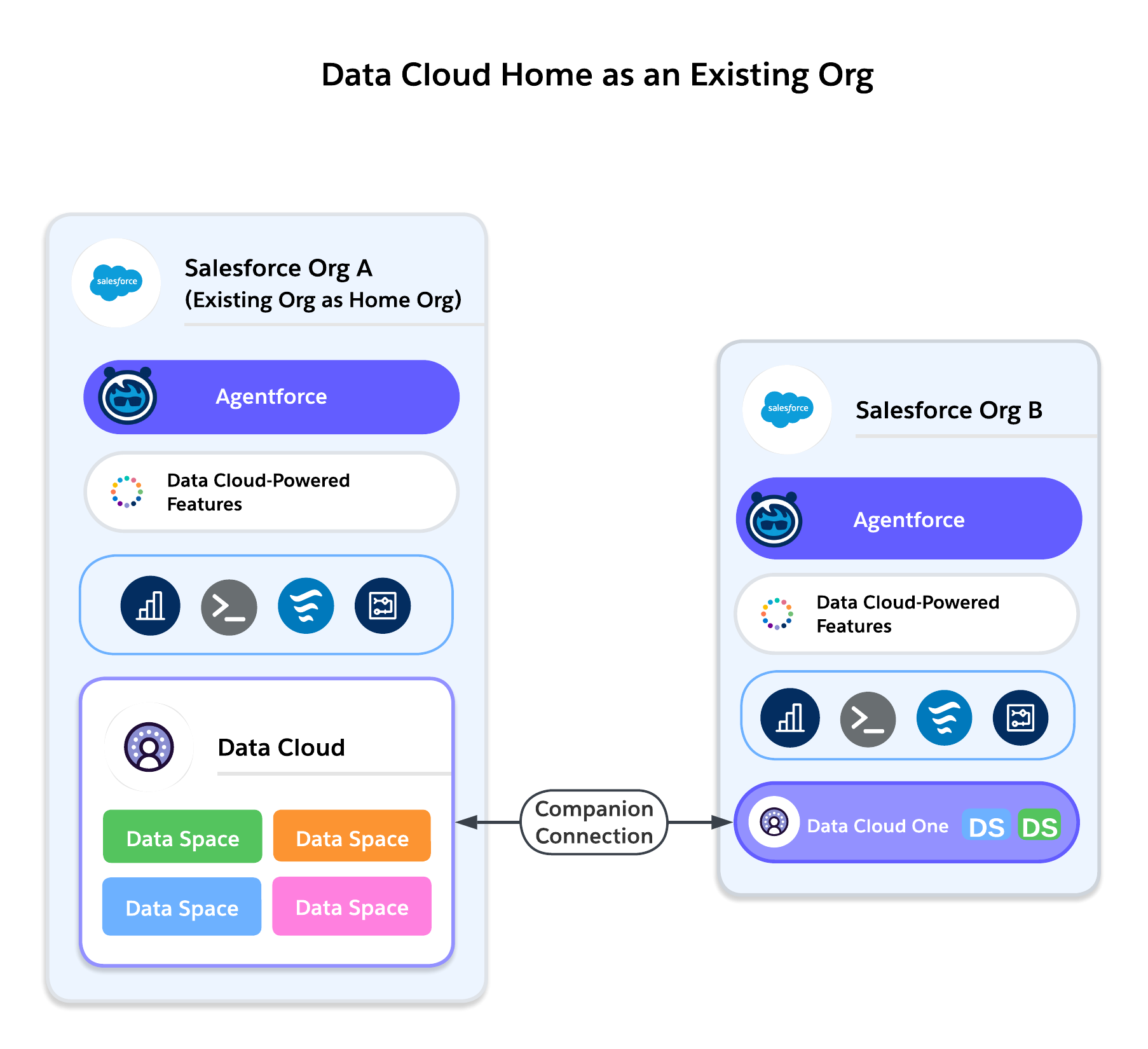
Option A: Provision Data Cloud in an Existing Org
Works Best For: Customers with a single Salesforce org, or multi-org customers who already have a major centralized org where most business runs.
-
Pros:
- Simplest path: Data Cloud is provisioned where your CRM data already lives.
- Immediate access to local Sales, Service, and Marketing data.
- No additional integration required.
- Fewer licenses and environments to manage.
- Accelerates early adoption, pilots, and production use cases.
-
Cons:
- May inherit existing org’s governance or technical debt.
- If no single “main org” exists, selecting one may create ownership debates.
- Performance tied to the org’s location; may not align with enterprise-wide residency needs.
- If multiple business units use different orgs, local provisioning can lead to fragmentation if not paired with Data Cloud One.
Example:
A SaaS company with one Salesforce org provisions Data Cloud in that org to unify customer subscription and support data.
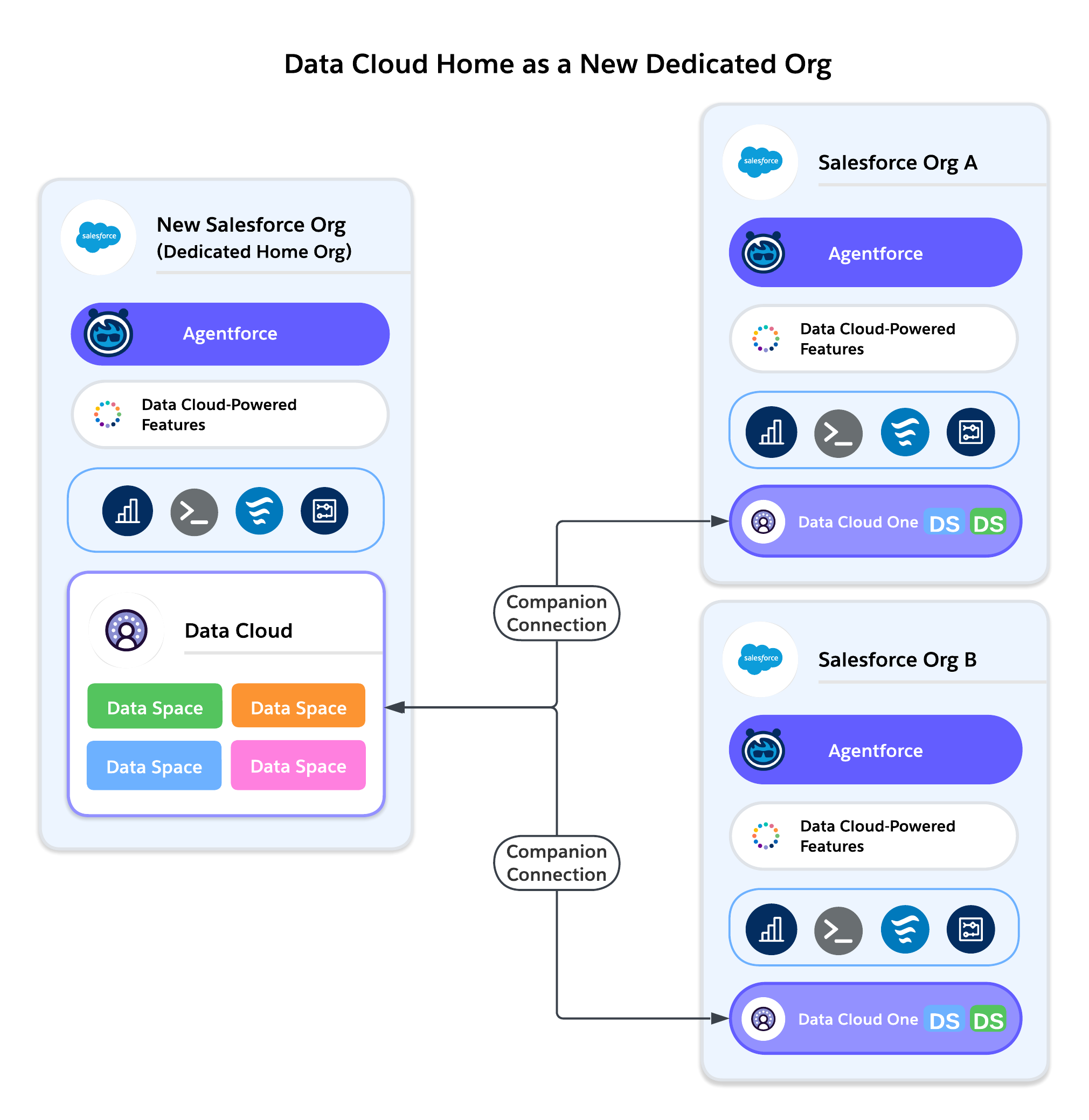
Option B: Provision Data Cloud in a New, Dedicated Org
Works Best For: Customers with multiple Salesforce orgs who cannot align on a single major org, or enterprises with a strong Center of Excellence (CoE) model.
-
Pros:
- Clean slate for governance, with no inherited org complexities.
- Centralized control across multiple lines of business.
- Flexibility to choose a region based on compliance needs.
- Acts as a neutral “shared service” org, not tied to one business unit.
- Set up for future Data Cloud One architecture (Home Org with multiple Companion Orgs).
-
Cons:
- Customers must license a new Salesforce org on which to provision Data Cloud.
- Additional integration required to connect the org to a Data Cloud via a Data Cloud One companion connection.
- May add administrative overhead (user management, security, identity).
- Slower time-to-value compared to provisioning in an existing production org.
Example:
A multinational financial services company creates a dedicated Home Org to provision Data Cloud. All business unit orgs (Retail, Wealth, Commercial Banking) connect as Companion Orgs through Data Cloud One.
Decision Criteria
| Consideration | Existing Org as Home Org (Preferred Default) | New Org as Home Org (Alternative) |
|---|---|---|
| Simplicity | Builds on existing user and data structure for faster setup; Data Cloud is integrated by default with the Home Org. | Requires licensing and setup of new Salesforce org, and additional administrative overhead to manage it. |
| Time-to-Value | Immediate use of local CRM data. | Slower ramp; integration required. |
| Governance | Inherits existing org's basic governance model--existing users and permission sets. This may be fine if org is already central. | Clean slate for governance; ideal for CoE-led models. |
| Compliance | Residency tied to existing org's region. | Flexibility to select a region independent of existing orgs. |
| Performance | Best performance for local CRM queries. | Dependent on Companion Org connectivity, whether it is same-region or cross-region to the other orgs. |
| Future Scalability | Works well if paired with Data Cloud One; harder to shift later if the wrong org is chosen. | Scales easily with Data Cloud One; designed for neutrality. |
| Cost | Lower incremental cost. | Higher overhead from additional environments. |
1.3 Recommendations
As a general principle, favor using an existing major org as your Home Org to minimize initial effort and accelerate adoption. Only create a new, dedicated Home Org if your long-term governance or compliance strategy requires it. Creating a new, dedicated Home Org is a common choice for larger enterprises with a COE.
Single Org Environment
Provision Data Cloud in your existing production org. This maximizes simplicity and immediate value. It avoids unnecessary integration overhead.
Multiple Org Environment
Prefer to select one of your major orgs — typically the one where most of your business runs, or the org that already serves as your centralized CRM — to act as the Home Org. This reduces complexity, minimizes setup work, and allows you to realize the value of Data Cloud quickly. Using an existing major org also avoids the cost and integration effort of managing a new environment.
When to Consider a New, Dedicated Home Org
If your organization has a strong Center of Excellence (CoE) and wants governance separate from business-unit orgs. If no single existing org is suitable due to compliance or organizational constraints. In those cases, creating a new Home Org provides flexibility and neutrality — but with slower time-to-value.
Section 2: Multi-Org Strategy and Data Cloud One
2.1 The Multi-Org Challenge
Enterprises often operate multiple Salesforce orgs — and this is not an edge case, but the norm. As of February 2024, approximately 19,000 Salesforce customers already ran more than one Salesforce org.
Why does this happen?
- Acquisitions and mergers: Newly acquired companies bring their own Salesforce instances.
- Regional operations: Separate orgs for EU, North America, Asia-Pacific, etc., often to satisfy data residency laws.
- Functional separation: Different business units (e.g., Retail Banking, Wealth Management, Insurance) maintain their own orgs for autonomy.
- Regulatory or security isolation: Certain industries mandate logically distinct orgs for compliance reasons.
- Historic/technical reasons: Over time, customers organically accumulate multiple orgs.
Each reason makes sense individually, but together they create fragmentation of data. Without a unifying layer, each org only has a partial view of the customer.
The architectural challenge: How do you unify data across orgs into a single source of truth while respecting compliance, governance, and autonomy requirements?
2.2 What Is Data Cloud One?
Data Cloud One is Salesforce’s multi-org connectivity architecture that allows multiple Salesforce orgs to share a single Data Cloud instance. It is the recommended pattern for enterprises with multiple Salesforce orgs.
In any Data Cloud One cluster, one Salesforce org is designated as the Home Org, which hosts the Data Cloud instance. Other Salesforce orgs connect as Companion Orgs, consuming the unified data and metadata from the Home Org’s Data Cloud.
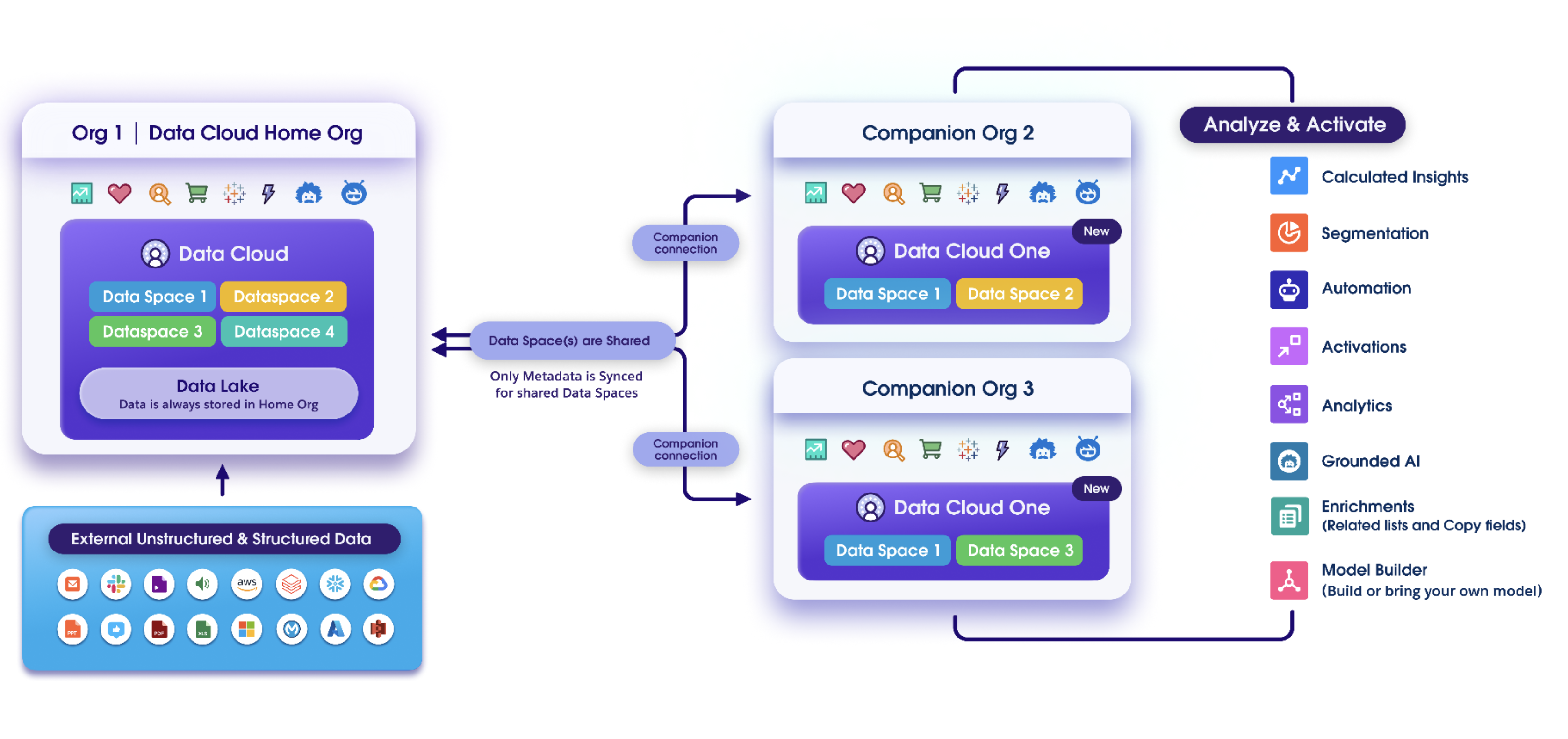
How Data Cloud One Works
- Data Ingestion & Unification (Home Org)
- All data ingestion configuration (Salesforce CRM, external sources, streaming, batch) happens from the Home Org only.
- The Data Cloud tenant tied to the Home Org performs identity resolution, harmonization, modeling, and unification into trusted Customer 360 profiles.
- Data Cloud administration, governance policies, tagging, and masking are applied centrally from the Home Org.
- Data Space Architecture
- From the Home Org, data is organized into Data Spaces, which act as logical containers for data, metadata, and processes.
- Enterprises can create Data Spaces for brands, regions, or lines of business.
- Data Space Sharing: From the Home Org, specific Data Spaces are selectively shared with Companion Orgs. This ensures that only the relevant data (and associated metadata) flows to the right orgs.
- Metadata Sharing
Companion Orgs receive metadata definitions from the Home Org, including data model objects (DMOs), unified profile schema, calculated insights, segments, and more. These appear natively inside the Companion Org as if they were local assets, but they are actually linked to the Home Org. - Jobs to Be Done in Home Org vs. Companion Orgs Feature access differs between Home and Companion Orgs. Companion Orgs can’t ingest or unify data, and rely on the Home Org for ingestion, modeling, and unification. Companion orgs can access Data Cloud data to power Data Cloud-powered platform features, and they can create local insights, segments, and flows on top of the shared, trusted data. In the future vision, they can also access activation features.
- Platform Feature Parity
From the perspective of users and builders, once the metadata is shared, there are some functional differences between Home and Companion Orgs in terms of using Salesforce platform features. List of supported features can be found in Data Cloud Features on Companion Orgs.
- Salesforce platform features — such as Flows, Reports, Prompt Builder, dashboards, and other platform-native tools — work in both Home and Companion Orgs once metadata is available.
- Data Cloud-powered features — such as Agentforce, Prospecting Center, Sales Cloud Einstein features, and Service Cloud AI features — also work seamlessly in both Home and Companion Orgs. Some features may be on their path to reach complete compatibility but the overall goal is to have feature parity between Home and Companion orgs for all Cross-Cloud features that depend on Data Cloud.
- Consumption Model
All Companion Org activity (queries, segment runs, Data Cloud-triggered flows, AI usage, Einstein Trust Layer logging, etc.) consumes Data Cloud credits from the Home Org. Consumption flows one way: credits are centralized, billed, and tracked against the Home Org's credit allocation. However, you can drill down to see how many credits each individual org used in Digital Wallet. - Design Principle: Horizontal Construct
Data Cloud One is designed as a horizontal construct of the Salesforce platform — much like Sandboxes. The goal is that every new feature Salesforce releases will work in both Home and Companion Orgs without additional setup. This ensures Data Cloud One is not just a data architecture choice but a foundational element of the Salesforce platform going forward.
| Capability | Home Org | Companion Org |
|---|---|---|
| Connect Configure connectors, create data streams, ingest or federate data | ✅ | ❌ |
| Harmonize & Unify Build and run data transforms and identity resolution | ✅ | ❌ |
| Govern Secure data with data space and permissions | ✅ | ✅ |
| Segment & Predict Build segments, insights and Einstein Studio models | ✅ | ✅ |
| Activate Everywhere Activations, data actions | ✅ | ✅ |
| Platform Features Prompt Builder, Flows, Reports, Enrichment, and more | ✅ | ✅ |
| Data Cloud-Powered Features Prospecting Center, Sales and Service Cloud features, Agentforce, and more | ✅ | ✅ |
2.3 Decision: Multiple Independent Data Clouds vs. One Shared Data Cloud (Data Cloud One)
Enterprises with multiple orgs must choose how and where to locate Data Cloud within their ecosystem. Do they want to provision independent Data Clouds in each org, or use Data Cloud One to unify orgs under a single Home Org?
Option A: Multiple Independent Data Clouds
Each Salesforce org provisions its own Data Cloud instance.
Pros:
- Autonomy: Each business unit or region controls its own Data Cloud.
- Simplicity within each org: Governance, security, and customizations are localized.
- Regulatory compliance: Useful when strict regulatory separation is required (e.g., data must not cross borders).
Cons:
- Data silos: Customer 360 cannot be achieved across orgs.
- Higher cost: Each instance requires licensing, administration, and integration. Customers end up ingesting the same source data multiple times to achieve a complete C360 view in multiple different orgs.
- Duplicate work: Identity resolution, segmentation, and enrichment must be repeated in each Data Cloud.
Option B: One Shared Data Cloud (Data Cloud One Cluster)
A single Data Cloud is provisioned in a Home Org, with other Salesforce orgs connected as Companion Orgs.
Pros:
- Single Source of Truth (SSOT): All orgs share the same unified data model.
- Cost efficiency: Only one Data Cloud license and infrastructure to manage.
- Unified governance: Policies, security, and compliance controls are applied centrally.
- Cross-org enrichment: Companion Orgs can access harmonized profiles, insights, and segments.
- AI readiness: Enterprise-wide dataset enables better training and activation of AI models.
- Future proof: Adding new Companion Orgs is simple; no need for new Data Clouds.
Cons:
- Additional preparation: Requires planning for org-to-Home Org connectivity.
- Latency considerations: Companion Orgs in different regions may see slower queries.
- Complex governance: If each org has very different customization needs, fine-grained governance can be complex.
Option C: Multiple Data Cloud One Clusters
In some cases, governance, compliance, or other business requirements may make it impractical to cluster every org together. This may lead to a need to implement a hybrid solution in which the enterprise operates several Data Clouds, each of which is the Home Org for a different cluster of Companion Orgs.
Example:
A multinational corporation has Salesforce orgs in a variety of regions, including Europe, the US, and Asia. To comply with regional data residency regulations, the provision one Data Cloud for each separate region.
Decision Criteria
| Consideration | Multiple Independent Data Clouds | One Shared Data Cloud (Data Cloud One) |
|---|---|---|
| Autonomy | High autonomy for each org or business unit. | Centralized governance, less autonomy per org. |
| Compliance | Useful when strict separation is required (e.g., regional laws). | Works best when residency allows centralization. |
| Cost | Higher licensing and admin costs. | More cost-efficient; one license for many orgs. |
| Governance | Fragmented; policies differ per org. | Centralized, consistent policies across orgs. |
| Data Silos | Each org has its own view; no enterprise 360. | Unified dataset, no duplication. |
| AI/Analytics | Limited to each org's data. | Enterprise-wide models with better accuracy. |
| Complexity | More instances to manage, more integrations. | Simpler architecture, fewer moving parts. |
| Performance | Best for within-org use cases. | Companion Org access may introduce latency. |
2.4 Recommendations
Preferred Pattern: Data Cloud One
Default to a single Home Org with connected Companion Orgs for multi-org enterprises.
This creates an enterprise-wide Customer 360, simplifies governance, and optimizes cost.
When to use multiple Data Clouds:
Only if compliance, residency, or organizational autonomy strictly require it. For example, if European operations must remain fully separate from US operations due to regulation.
How to choose the Home Org in Data Cloud One:
Start by considering one of your major orgs — typically where most of the business runs. Provisioning Data Cloud there can minimize complexity and maximize early value.
Only if no existing org is suitable, consider creating a dedicated Home Org managed by a Center of Excellence Team.
General Principle:
In multi-org environments, minimize the number of Data Clouds. Favor Data Cloud One as the default pattern to reduce duplication, enable AI readiness, and simplify governance.
Section 3: Multiple Data Clouds and Data Sharing Between Data Clouds
3.1 What Is Data Sharing Between Data Clouds?
While Data Cloud One is the recommended approach for most enterprises, there are scenarios where customers may need to provision multiple Data Cloud instances. Once multiple Data Clouds exist, unification across isn’t automatic.
Data Cloud to Data Cloud data sharing enables customers to share specific objects between Data Cloud instances without duplication or custom pipelines. It is a zero-copy metadata sharing mechanism designed for collaboration across Data Clouds.
How It Works
- Each Data Cloud is provisioned in its own Home Org.
- Administrators can create a Data Share — a grouping of specific objects they want to share.
- Access to the selected data is shared with a target org’s Data Cloud, where the objects appear as if defined locally. The underlying data remains in the source Data Cloud; only access is shared.
- Tags are not shared. Only the raw objects are made available; the target org must reapply any governance, operational, or AI tags as needed.
Key Difference from Data Cloud One
- In Data Cloud One, multiple Companion Orgs share a single Data Cloud instance. Platform features (Agentforce, Prospecting Center, Tableau Next, etc.) all run on the same underlying data, ensuring consistency.
- In Data Cloud-to-Data Cloud data sharing, each org has its own Data Cloud. Features like Agentforce in Org A and Org B each operate independently on their local instance. No sharing occurs automatically — deliberate data shares must be created to collaborate on specific objects only.
3.2 Use Cases for Data Cloud-to-Data Cloud Sharing
Regional compliance:
A multinational retailer provisions one Data Cloud in the EU and another in the US. Data Cloud-to-Data Cloud data sharing allows the company to aggregate insights (e.g., loyalty KPIs) to be shared with US HQ while raw data remains local.
Business unit collaboration:
A conglomerate runs separate Data Clouds for Retail and Insurance. Data sharing between Data Clouds allows users to access a single, authoritative source of data without moving or copying. With Data Cloud-to-Data Cloud data sharing, the Insurance org receives Retail’s “High Value Customer” segment for targeted cross-sell campaigns.
Mergers and acquisitions:
A parent company acquires a subsidiary with its own Data Cloud. Maintaining data silos in the short term maintains data security and maintains separate SSOT systems while data sharing between Data Clouds allowing selective data collaboration and gives the company time to plan a careful transition.
Federated executive dashboards:
A multinational spread across continents provisions individual Data Clouds per region. Executives want a federated quarterly performance view. Each regional Data Cloud shares aggregated calculated insights with an “Executive Org,” enabling enterprise-wide reporting.
Pros and Cons of Data Cloud-to-Data Cloud Data Sharing
| Factor | Pros | Cons |
|---|---|---|
| Data Residency | Supports regional separation while enabling collaboration. | Does not remove the need to manage multiple Data Clouds. |
| Data Duplication | Zero-copy; no duplication of objects. | Requires deliberate selection of objects for inclusion in each data share. |
| Governance | Sharing is explicit and deliberate (object-level). | No tags or policies flow; target org must reapply governance. |
| Complexity | Enables selective collaboration without centralization. | Requires management of multiple Data Clouds and data shares. |
| AI/Analytics | Regional AI/analytics possible; insights can be shared across orgs. | No enterprise-wide AI unless data is deliberately shared. |
| Platform Features | Each org's Data Cloud–powered features run independently. | No automatic sharing — duplication risk if not carefully designed. |
| Cost | May reduce the need for ETL pipelines. | Still incurs cost of multiple Data Clouds. Consumes credits for data queries and data sharing. |
Decision Criteria
| Consideration | Data Cloud One (Preferred for multi-org) | Data Cloud-to-Data Cloud Sharing |
|---|---|---|
| Single Source of Truth | ✅ Yes — all orgs share the same DC. | ❌ No — each Data Cloud has its own data model. |
| Compliance | Works only when residency allows centralization. | Needed when residency laws prevent centralization. |
| Governance | Centralized, consistent. | Federated; deliberate object-level shares. |
| Complexity | Fewer moving parts, simpler. | More complex — requires Data Shares and multiple Data Clouds. |
| AI/Analytics | Enterprise-wide AI models. | Regional AI; insights can be shared selectively. |
| Platform Features | Shared Data Cloud means all features work consistently across Home + Companions. | Features run independently in each Data Cloud; sharing must be explicit. |
3.3 Best Practices
If your enterprise has multiple Data Clouds:
- Use Data Cloud-to-Data Cloud Sharing to collaborate across them rather than building custom pipelines or duplicating data.
- Share specific objects (DMOs, Calculated Insights, Segments) by creating Data Shares and granting them to target orgs.
- Be aware that tags are not shared — the receiving org must reapply tags (e.g., governance, classification, AI enrichment).
When to use Data Cloud-to-Data Cloud Sharing:
- To meet regulatory requirements that prevent centralization.
- To maintain business unit autonomy while enabling selective collaboration.
- To provide federated executive dashboards across multiple regions.
- To bridge M&A scenarios where consolidation is not immediately possible.
Design carefully
Sharing must be deliberate and object-specific. Avoid “over-sharing” — align Data Shares with business and compliance needs. Treat Data Cloud-to-Data Cloud data sharing as a federation strategy, not as a replacement for Data Cloud One.
Summary
- Every org should plan for access to a Data Cloud
- Going forward, all Salesforce platform features — from Sales Cloud and Service Cloud to Agentforce — require Data Cloud connectivity. Each org must either host a Data Cloud Home Org or be a Companion Org connected via Data Cloud One.
- Think enterprise-wide, not org-by-org
- Avoid unilateral, line-of-business decisions made in isolation.
- Provisioning should be decided collectively, ideally by an enterprise architecture or data governance council. Always anticipate future AI and analytics needs, which depend on broad, unified datasets.
- Minimize Data Silos
- Favor provisioning Data Cloud in an existing major org for simplicity and speed.
- In multi-org environments, Data Cloud One is the default pattern to unify orgs under one Data Cloud.
- Provision multiple Data Clouds only if strictly required for compliance, residency, or organizational autonomy.
- Design deliberately if you must run multiple Data Clouds
- Use Data Cloud-to-Data Cloud data sharing for collaboration, not custom ETL pipelines.
- Share specific objects (DMOs, Calculated Insights, Segments) via data shares.
- Remember: tags are not shared, and consumption is billed to the source org.
- Plan governance and ownership early
- Decide whether Data Cloud will be managed centrally (Center of Excellence model) or delegated to lines of business. Define roles for administrators, security teams, and compliance leads.
- Avoid ambiguity: unclear ownership is a common source of friction.
- Avoid short-term shortcuts
- Do not spin up multiple Data Clouds for POCs without a long-term plan — this creates disruptive consolidation work later.
- Instead, align pilots and early deployments to your enterprise-wide provisioning strategy.
These provisioning choices are critical because the Salesforce platform is evolving toward a Data Cloud-first model, where every feature, from customer segmentation to AI agent grounding, will depend on it. The decisions you make today will set the foundation for how effectively your enterprise unifies customer data, how quickly you can adopt new Salesforce features, and how confidently you can scale AI across your business. To succeed, you must provision carefully, minimize duplication, align with compliance requirements, govern deliberately, and think long-term. Ultimately, provisioning Data Cloud is the first step in making data, AI, and CRM work together as one cohesive platform.
About the Authors
Kunal Goyal is a Director of Product Management at Salesforce, focused on advancing multi-org architecture and scalability within Data Cloud. Since 2017, he has led multiple initiatives and products centered on cross-org collaboration and multi-tenant system design. Kunal is one of the Data Cloud Best Practices Architecture Leads and the product owner for Data Cloud One, setup, provisioning, and admin experiences.
Erin Wagner Tidwell is a principal technical writer and content designer for Data Cloud. She’s been at Salesforce since 2013. She’s dedicated to making Data Cloud easier to understand and use though clear, consistent, and accurate technical documentation and in-app communication.
Yugandhar Bora is a Software Engineering Architect at Salesforce, specializing in data architecture within the Data & Intelligence Applications platform. He leads enterprise architecture review board (EARB) initiatives focused on data governance and unified data models, while contributing to automated platform provisioning solutions.
Samarpan Jain is a Principal Architect at Salesforce specializing in Commerce Cloud, platform integration, and cross-org architecture. One of Salesforce's longest-tenured employees, he leads key initiatives including data residency compliance for government customers and Data Cloud usage attribution systems.